
code
stringlengths 30
403k
| size
int64 31
406k
| license
stringclasses 10
values |
|---|---|---|
# Testing
*Assumption: The <u>behavior of the program</u> with any other inputs is the <u>consistent</u> with the behavior shown with the tested input.*
## Pros and Cons
- Pros:
- Does not generate false positives
=> When testing generates a failure, it must be a failure.
- **Cons:**
- **Highly incomplete**
**Can only consider a tiny fraction of the input domain**
<br>
## Granularity Levels
### Developer's Testing
* Unit testing
* Integration testing (集成测试)
Test the <u>interaction among the differnet units/modules</u>
* System testing (系统测试)
Test the <u>system as a whole</u>
* Functional testing (功能测试)
Aims to verify the functionality provided by the system
* Non-functional testing (非功能测试)
Aims to verify the non-functional properties of the system
* Configuration testing (配置测试)
* Compatibility testing (兼容性测试)
* Performance testing (性能测试),
* Concurrency testing (并发测试)
* Load testing (负载测试)
* Robustness testing (稳健性测试)
* Security testing (安全测试)
* Reliability testing (可信赖度测试)
* Recovery testing (故障恢复测试)
* ...
<br>
### Alpha Testing
-> Distribute the software to a set of users that are <u>internal to the organization</u>
*内部人员测试 (内测)*
<br>
### Beta Testing
-> Distribute the software to a <u>selected set of users outside of the organization</u>
<br>
## Techniques
### Black-box Testing (黑箱测试) / Functional Testing
#### 1. Definition & Explanation
Consider the software as a closed box (black-box)
=> Based on the **specification of the software**, but **not look into the software and the code implementation**
#### 2. Pros & Cons
* Pros:
* Focus on the input domain
Make sure that we cover the input domain, i.e., the important behaviors of the software
* No need for the code
=> <u>Early test design</u> before implementation
* Applicable at <u>all granularity levels</u>
* Cons:
* Since we don't look into the implementation, we <u>cannot reveal failures due to implementation details</u>.
#### 3. Systematic Approach
*即根据功能描述 -> 找可独立测试的feature -> 确定相关input -> 写test cases*
*且由于一次性找出所有的可独立测试的features<u>太不现实</u>, 这应该是一个iterative的过程.*
1. Start from **functional specification (功能规格说明)**
2. Identify **independent testable features**
3. identify the **relevant inputs** for each one of the independent testable features
"Test data selection"
<img src="https://github.com/Ziang-Lu/Software-Development-and-Design/blob/master/1-Software%20Phases/test_data_selection.png?raw=true">
* Exaustive testing (穷举测试)?
-> Impossible in terms of time => 不现实
* Random testing (随机测试)?
-> 大海捞针 => 效果不好
* <u>Partition testing (分割测试)</u>
Due to the fact that though failures are <u>generally sparse</u>, they are <u>dense in some subdomains (partitions)</u>
* Identify partitions
* Select inputs from each partition
=> Errors tend to occur at the <u>boundary of the partitions</u>.
=> Select inputs at these boundaries
4. Derive **test case specifications (测试用例规格说明)**
-> Defines how the test input values should be put together when actually testing the system
* Simply combine the selected input values to actual test cases, and eliminate the meaningless and invalid ones
5. Generate **test cases** from the corresponding test case specifications
*Note that test cases are simply instantiations of test case specifications*
#### 4. Category-Partition Method (类别-分割方法) - A Specific Black-Box Testing Approach
1. Identify **independent testable features**
*Same as the systematic approach*
2. Identify **categories**
***
A <u>category</u> is the <u>characteristics of one input element</u>.
***
=> Identify characteristics that are meaningful and cover the main aspects of the input element
e.g.,
```java
public void split(String s, int size) {}
```
* Category 1: Characteristics of `String s`
* Characteristic: Length of the string
* Characteristic: Contents of the string
* Category 2: Characteristics of `int size`
* Characteristic: Value of the integer
3. **Partition categories into choices**
***
A <u>choice</u> is an <u>interesting case in a category</u>.
***
e.g.,
```java
public void split(String s, int size) {}
```
- Category 1: Characteristics of `String s`
- Characteristic: Length of the string
- `length = 0`
- `length = size - 1 `
- `length = size`
- `length = size + 1`
- `length = 2 * size - 1`
- ...
- Characteristic: Contents of the string
- Only whitespaces
- Only special characters, like non-printable characters
- ...
- Category 2: Characteristics of `int size`
- Characteristic: Value of the integer
- `size = Integer.MIN_VALUE`
- `size < 0`
- `size = 0`
- `size > 0`
- `size = Integer.MAX_VALUE`
4. Identify **constraints among choices**
=> To eliminate the meaningless and invalid combinations of inputs
*即识别出一些不合法的输入choice组合, 并排除掉他们*
5. Produce/Evaluate **test case specifications**
* Can be <u>automated</u>
i.e., Identify categories, then choices, and then add constraints => (Automate, 有脚本或应用程序来处理) Test frames
* Produce <u>test frames (测试框架)</u>
***
A test frame is a specification of a test. (Similar to test case specification).
***
| Test Frame #36 | |
| ---------------- | ----------------------------------------------- |
| Input "String s" | length: size - 1<br>content: special characters |
| Input "int size" | Value: > 0 |
6. Generate **test cases** from test case specifications
* Simply <u>instantiate test frames, producing concrete test cases</u>
| Test Case #36 | wvv |
| ------------- | ----------- |
| s | "ABCC!\n\t" |
| size | 9 |
*(满足之前的test frame #36)*
<br>
### White-box Testing (白箱测试) / Structural Testing (结构测试)
#### 1. Definition & Explanation
"Look inside the box"
***
*Assumption:*
* *Executing the faulty statement is a necessary condition for revealing a fault.*
*If there is a bug in the program, but if we don't execute the statement that contains the bug, we won't be able to find it.*
*=> Make sense*
***
=> Based on the **code implementation**, but **not look into the specification of the software**
#### 2. Pros & Cons
* Pros:
* White-box testing is based on the code.
* It <u>can be measured objectively</u>.
* It <u>can be measured automatically</u>.
* Allows for <u>covering the coded behavior</u> of the software
i.e., If there is some mistake in the code, and is not obvious by looking at the specification of the code, white-box testing might be able to catch it, because white-box testing tries to exercise the code implementation.
* <u>Can be used to compare test suites (测试套件)</u>
i.e., If you have two alternative sets of tests that you can use to assess the quality of your software, white-box testing techniques can tell you which one of these two test suites is likely to be more effective in testing your code.
* Cons: Since we don't look into the specification, we <u>cannot reveal the failures of parts of the software that haven't been implemented</u>.
=> Black-box and white-box testings are really **complementary** techniques.
#### 3. Classifications
* **Control-flow based ~ (基于控制流的白盒测试)** [讨论重点]
* Data-flow based ~ (基于数据流的白盒测试)
* Fault based ~ (基于错误的白盒测试)
#### 4. Coverage Criteria (覆盖标准)
* Defined in terms of <u>test requirements (测试需求)</u>
*Test requirement: Entities (interesting aspects) in the code that we need to execute in order to satisfy the criteria*
* Result in <u>test specifcations (测试规格说明)</u> and <u>test cases</u>
By exploring the test requirements, we get the corresponding test specifications; and by instantiating the test specifications, we get the corresponding test cases.
e.g.,
```java
public static void printSum(int a, int b) {
int result = a + b;
if (result > 0) {
printInColor("red", result); // TEST REQUIREMENT #1: Execution of this block
/*
* => Test Specification #1:
* a + b > 0
*
* => Test Case #1:
* a = 1
* b = 2
* Expected output: red 3
* ...
*/
} else if (result < 0) {
printInColor("blue", result); // TEST REQUIREMENT #2: Execution of this block
/*
* => Test Specification #2:
* a + b < 0
*
* => Test Case #2:
* a = -1
* b = -2
* Expected output: blue -3
* ...
*/
}
}
```
**Specific coverage criterions:**
1. **Statement Coverage (语句覆盖)**
Described by
* Test requirements:
<u>All the statements</u> in the program
* Coverage measure:
$\frac{\# \ of \ executed \ statements}{Total \ \# \ statementsl}$
*=> The higher this ratio, the better we execise our code.*
2. **Branch Coverage (分支覆盖)**
Described by
- Test requirements:
<u>All the branches</u> in the program
- Coverage measure:
$\frac{\# \ of \ executed \ branches}{Total \ \# \ branches}$
*=> The higher this ratio, the better we execise our code.*
```java
public static void printSum(int a, int b) {
int result = a + b;
if (result > 0) { // if-1
printInColor("red", result); // Branch-1
} else if (result < 0) { // Branch-2 & if-2
printInColor("blue", result); // Branch-2-1
} // Branch-2-2
}
// 4 branches => 4 test requirements
```
***
* <u>Branch coverage => (subsume)/(stronger) => Statement coverage</u>
Branch coverage 100% $\Rightarrow$ Statement coverage 100%
Branch coverage 100% $\nLeftarrow$ Statement coverage 100%
=> Achieving 100% branch coverage requires more test cases than statement coverage.
=> It is more expensive to achieve 100% branch coverage than statement coverage.
***
3. **Condition Coverage (条件覆盖)**
Described by
- Test requirements:
<u>Individual conditions</u> in the program
- Coverage measure:
$\frac{\# \ of \ executed \ conditions \ that \ are \ both \ true \ and \ false}{Total \ \# \ conditions}$
*=> The higher this ratio, the better we execise our code.*
***
* <u>就subsumption关系而言, condition coverage与statement coverage / branch coverage并无直接关联, 即没有subsumption关系.</u>
与branch coverage并无直接subsumption关系的原因是branch coverage关注于if statement的整个expression, 而condition coverage关注于individual condition (即if statement中boolean的sub-expression).
* 因此有可能一套test suite可以满足if statement的整个expression为`true`和`false` (100% branch coverage), 却不能满足每个if statement中每个boolean的sub-expression都为`true`和`false` ($\neq$ 100% condition coverage)
(100% branch coverage $\nRightarrow$ 100$ condition coverage)
* 也有可能一套test suite可以满足每个if statement中每个boolean的sub-expression都为`true`和`false` (100% condition coverage), 却有一些if statement的expression恒为`true`或`false` ($\neq$ 100% branch coverage)
(100% condition coverage $\nRightarrow$ 100$ branch coverage)
***
<br>
Combining branch and condition coverage => **Branch and Condition Coverage (分支与条件覆盖)**
***
* <u>Branch and condition coverage => (subsume)/(stronger) => Branch coverage</u>
Branch and condition coverage 100% $\Rightarrow$ Branch coverage 100%
Branch and condition coverage 100% $\nLeftarrow$ Branch coverage 100%
* <u>Branch and condition coverage => (subsume)/(stronger) => Condition coverage</u>
Branch and condition coverage 100% $\Rightarrow$ Condition coverage 100%
Branch and condition coverage 100% $\nLeftarrow$ Condition coverage 100%
* <u>Branch coverage => (subsume)/(stronger) => Statement coverage</u>
Branch coverage 100% $\Rightarrow$ Statement coverage 100%
Branch coverage 100% $\nLeftarrow$ Statement coverage 100%
=> Achieving 100% branch coverage requires more test cases than statement coverage.
=> It is more expensive to achieve 100% branch coverage than statement coverage.
*** | 12,289 | MIT |
---
layout: post
title: "Web App 相关技术"
date: 2015-06-17 14:06:05
categories: JavaScript
tags: JavaScript HTML CSS Sass 移动端 XSS AMD requireJS CommonJS 性能优化 WebApp
---
* content
{:toc}
> 往前推2到3年,前端工程师还在忧心忡忡地想,移动互联网时代下,前端是不是没有生存空间了。但今天一看,在我们团队,前端工程师超过一半的工作都是在做移动端的Web或者APP的开发。移动Web或者APP在技术本质上是和做桌面端Web没有本质区别,但是移动端的坑那是非常的多,通过学习这部分内容,让你成为一名桌面移动通吃的前端开发工程师。
## 概念
* 参考: [移动 Web 开发入门](http://junmer.github.io/mobile-dev-get-started/)
上面这个 slide 资料讲的非常好,算是一个入门的介绍吧。带我们建立基本的移动 web 开发知识体系和常见问题的实践。包含以下几个方面:
* 基本概念
* Native
本地应用 使用 Java \ Objective-C \ Swift 开发
* WebApp
网页应用 html5 开发
* Hybrid
混合应用 ooxx(native, web)
* 对比
* 视觉
* 设备的像素
* 文字单位使用 rem
* viewport 属性
* 横屏竖屏
* Flex 伸缩布局
* 响应式设计
* 软键盘
* 隐藏地址栏
* 苹果设备添加到主屏图标
* 交互
* Touch
* click 延迟
* Scroll
* Gestures(hammer --A javascript library for multi-touch gestures)
* 手指友好设计
* HTML5 APIS(图像,摇动,声音等)
* 实践
* 屏蔽点击元素时的阴影
* 图像(像素、矢量图标、base64 减少请求、lazyload)
* CSS3(合理使用渐变/圆角/阴影、代替 js 动画、translate3d、解决动画闪烁)
* localStorage
* 避免(iframe、fixed + input)
* SPA 或 Multi page
* can I use
* 压缩合并
* @G/3G 下建立连接时间
* 调试
* 浏览器自己的调试工具,模拟手机设备
* weinre
关于 weinre 我写了一篇博客介绍它。[Weinre --WebApp 调试工具](http://gaohaoyang.github.io/2015/06/18/weinre/)
---
## head 标签
参考:
* [移动前端不得不了解的html5 head 头标签](http://www.css88.com/archives/5480)
上面的链接详细的讲解了:
* DOCTYPE
* charset
* lang属性
* 优先使用 IE 最新版本和 Chrome
* 360 使用Google Chrome Frame
* SEO 优化部分:页面标题<title>标签(head 头部必须),页面关键词 keywords,页面描述内容 description,定义网页作者 author,网页搜索引擎索引方式
* 为移动设备添加 viewport
`viewport` 可以让布局在移动浏览器上显示的更好。 通常会写
```html
<meta name ="viewport" content ="initial-scale=1, maximum-scale=3, minimum-scale=1, user-scalable=no">
<!-- `width=device-width` 会导致 iPhone 5 添加到主屏后以 WebApp 全屏模式打开页面时出现黑边 http://bigc.at/ios-webapp-viewport-meta.orz -->
```
* content 参数:
* width viewport 宽度(数值/device-width)
* height viewport 高度(数值/device-height)
* initial-scale 初始缩放比例
* maximum-scale 最大缩放比例
* minimum-scale 最小缩放比例
* user-scalable 是否允许用户缩放(yes/no)
* ios 设备,iOS 图标,Android,Windows 8
**总结:**
```html
<!DOCTYPE html> <!-- 使用 HTML5 doctype,不区分大小写 -->
<html lang="zh-cmn-Hans"> <!-- 更加标准的 lang 属性写法 http://zhi.hu/XyIa -->
<head>
<!-- 声明文档使用的字符编码 -->
<meta charset='utf-8'>
<!-- 优先使用 IE 最新版本和 Chrome -->
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"/>
<!-- 页面描述 -->
<meta name="description" content="不超过150个字符"/>
<!-- 页面关键词 -->
<meta name="keywords" content=""/>
<!-- 网页作者 -->
<meta name="author" content="name, [email protected]"/>
<!-- 搜索引擎抓取 -->
<meta name="robots" content="index,follow"/>
<!-- 为移动设备添加 viewport -->
<meta name="viewport" content="initial-scale=1, maximum-scale=3, minimum-scale=1, user-scalable=no">
<!-- `width=device-width` 会导致 iPhone 5 添加到主屏后以 WebApp 全屏模式打开页面时出现黑边 http://bigc.at/ios-webapp-viewport-meta.orz -->
<!-- iOS 设备 begin -->
<meta name="apple-mobile-web-app-title" content="标题">
<!-- 添加到主屏后的标题(iOS 6 新增) -->
<meta name="apple-mobile-web-app-capable" content="yes"/>
<!-- 是否启用 WebApp 全屏模式,删除苹果默认的工具栏和菜单栏 -->
<meta name="apple-itunes-app" content="app-id=myAppStoreID, affiliate-data=myAffiliateData, app-argument=myURL">
<!-- 添加智能 App 广告条 Smart App Banner(iOS 6+ Safari) -->
<meta name="apple-mobile-web-app-status-bar-style" content="black"/>
<!-- 设置苹果工具栏颜色 -->
<meta name="format-detection" content="telphone=no, email=no"/>
<!-- 忽略页面中的数字识别为电话,忽略email识别 -->
<!-- 启用360浏览器的极速模式(webkit) -->
<meta name="renderer" content="webkit">
<!-- 避免IE使用兼容模式 -->
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<!-- 针对手持设备优化,主要是针对一些老的不识别viewport的浏览器,比如黑莓 -->
<meta name="HandheldFriendly" content="true">
<!-- 微软的老式浏览器 -->
<meta name="MobileOptimized" content="320">
<!-- uc强制竖屏 -->
<meta name="screen-orientation" content="portrait">
<!-- QQ强制竖屏 -->
<meta name="x5-orientation" content="portrait">
<!-- UC强制全屏 -->
<meta name="full-screen" content="yes">
<!-- QQ强制全屏 -->
<meta name="x5-fullscreen" content="true">
<!-- UC应用模式 -->
<meta name="browsermode" content="application">
<!-- QQ应用模式 -->
<meta name="x5-page-mode" content="app">
<!-- windows phone 点击无高光 -->
<meta name="msapplication-tap-highlight" content="no">
<!-- iOS 图标 begin -->
<link rel="apple-touch-icon-precomposed" href="/apple-touch-icon-57x57-precomposed.png"/>
<!-- iPhone 和 iTouch,默认 57x57 像素,必须有 -->
<link rel="apple-touch-icon-precomposed" sizes="114x114" href="/apple-touch-icon-114x114-precomposed.png"/>
<!-- Retina iPhone 和 Retina iTouch,114x114 像素,可以没有,但推荐有 -->
<link rel="apple-touch-icon-precomposed" sizes="144x144" href="/apple-touch-icon-144x144-precomposed.png"/>
<!-- Retina iPad,144x144 像素,可以没有,但推荐有 -->
<!-- iOS 图标 end -->
<!-- iOS 启动画面 begin -->
<link rel="apple-touch-startup-image" sizes="768x1004" href="/splash-screen-768x1004.png"/>
<!-- iPad 竖屏 768 x 1004(标准分辨率) -->
<link rel="apple-touch-startup-image" sizes="1536x2008" href="/splash-screen-1536x2008.png"/>
<!-- iPad 竖屏 1536x2008(Retina) -->
<link rel="apple-touch-startup-image" sizes="1024x748" href="/Default-Portrait-1024x748.png"/>
<!-- iPad 横屏 1024x748(标准分辨率) -->
<link rel="apple-touch-startup-image" sizes="2048x1496" href="/splash-screen-2048x1496.png"/>
<!-- iPad 横屏 2048x1496(Retina) -->
<link rel="apple-touch-startup-image" href="/splash-screen-320x480.png"/>
<!-- iPhone/iPod Touch 竖屏 320x480 (标准分辨率) -->
<link rel="apple-touch-startup-image" sizes="640x960" href="/splash-screen-640x960.png"/>
<!-- iPhone/iPod Touch 竖屏 640x960 (Retina) -->
<link rel="apple-touch-startup-image" sizes="640x1136" href="/splash-screen-640x1136.png"/>
<!-- iPhone 5/iPod Touch 5 竖屏 640x1136 (Retina) -->
<!-- iOS 启动画面 end -->
<!-- iOS 设备 end -->
<meta name="msapplication-TileColor" content="#000"/>
<!-- Windows 8 磁贴颜色 -->
<meta name="msapplication-TileImage" content="icon.png"/>
<!-- Windows 8 磁贴图标 -->
<link rel="alternate" type="application/rss+xml" title="RSS" href="/rss.xml"/>
<!-- 添加 RSS 订阅 -->
<link rel="shortcut icon" type="image/ico" href="/favicon.ico"/>
<!-- 添加 favicon icon -->
<title>标题</title>
</head>
<body>
</body>
</html>
```
## 页面切换动画
* [移动端重构系列13——页面切换](http://www.w3cplus.com/mobile/mobile-terminal-refactoring-slider.html)
* [CSS3 3D Transform](http://www.w3cplus.com/css3/css3-3d-transform.html)
关于 HammerJS 的一个中文文档
* [Hammer.js](http://www.cnblogs.com/iamlilinfeng/p/4239957.html)
---
## CSS Processing
> CSS语言由于其自身语言设计的问题,加上一些浏览器兼容性问题,往往会使得我们在写它的时候,要写很多冗余代码,或者为了兼容性对同一个样式设定写好几遍。针对这些问题,诞生了CSS预处理和后处理的概念及相关方法、工具。
>
> 这些工具和方法帮助我们能够更加高效地书写可维护性更强的CSS代码。
这里我尝试使用了 Sass,果然很好用。下面记录几个 sass 教程。
* [Sass入门-w3cplus](http://www.w3cplus.com/sassguide/)
* [SASS用法指南-阮一峰](http://www.ruanyifeng.com/blog/2012/06/sass.html)
### 安装
首先要有 ruby 环境。
由于国内网络原因(你懂的),导致 rubygems.org 存放在 Amazon S3 上面的资源文件间歇性连接失败。这时候我们可以通过gem sources命令来配置源,先移除默认的 https://rubygems.org 源,然后添加淘宝的源 https://ruby.taobao.org/,然后查看下当前使用的源是哪个,如果是淘宝的,则表示可以输入 sass 安装命令 `gem install sass` 了。
$ gem sources --remove https://rubygems.org/
$ gem sources -a https://ruby.taobao.org/
$ gem sources -l
*** CURRENT SOURCES ***
https://ruby.taobao.org
# 请确保只有 ruby.taobao.org
$ gem install sass
### 编译
sass --watch style.scss:style.css --style expanded
---
### 补充
**`rem`**
字体单位使用 rem,用户在手机上设置了字体大小时,不会打破布局,造成混乱。
* [CSS3的REM设置字体大小-w3cplus](http://www.w3cplus.com/css3/define-font-size-with-css3-rem)
* [响应式十日谈第一日:使用 rem 设置文字大小-一丝](http://www.iyunlu.com/view/css-xhtml/76.html)
---
## 安全
> 安全是大家经常容易忽视,但其实一旦出现影响会非常大的问题,尤其对于没有经历过企业开发,或者没有踩过坑的同学,如果等到公司工作,做实际项目后非常容易发生安全问题。
### 分类
WEB基本攻击大致可以分为三大类:“资源枚举”、“参数操纵” 和 “其它攻击”
* 资源枚举
* 参数操纵
* SQL注入
* XPath注入
* cgi命令执行
* XXS(cross-site scripting跨域脚本攻击)其重点是“跨域”和“客户端执行”
* Reflected XSS ——基于反射的XSS攻击。主要依靠站点服务端返回脚本,在客户端触发执行从而发起WEB攻击。
* DOM-based or local XSS——基于DOM或本地的XSS攻击
* Stored XSS——基于存储的XSS攻击
* 会话劫持
* 其它攻击
* CSRF(cross-site request forgery)跨站请求伪造
* 钓鱼攻击指的是网站的伪造,比如ta0bao.com,然后在其中应用XSS等方式发起攻击。
* 拒绝服务(DoS)指的是向网站发起洪水一样的请求(Traffic Floor),导致服务器超负荷并关闭,处理方法常规是采用QoS(Quality of Service)的软硬件解决方案。
### 关于 XSS
> **跨网站脚本**(Cross-site scripting,通常简称为XSS或跨站脚本或跨站脚本攻击)是一种网站应用程序的安全漏洞攻击,是代码注入的一种。它允许恶意用户将代码注入到网页上,其他用户在观看网页时就会受到影响。这类攻击通常包含了HTML以及用户端脚本语言。
>
> XSS攻击通常指的是通过利用网页开发时留下的漏洞,通过巧妙的方法注入恶意指令代码到网页,使用户加载并执行攻击者恶意制造的网页程序。这些恶意网页程序通常是JavaScript,但实际上也可以包括Java, VBScript, ActiveX, Flash 或者甚至是普通的HTML。攻击成功后,攻击者可能得到更高的权限(如执行一些操作)、私密网页内容、会话和cookie等各种内容。
>
> ——维基百科
### XSS 防护
1. 浏览器解析顺序:
HTML Parser >> CSS Parser >> JavaScript Parser
2. 浏览器解码顺序:
HTML Decoding >> URL Decoding >> JavaScript Decoding
3. 具体的防护方式:
* 验证输入并且基于语境和按照正确的顺序转义不可信数据
* HTML 中的字符串
* HTML 属性中的字符串
* 事件句柄属性和 JavaScript 中的字符串
* HTML 属性中的 URL 路径
* HTML 风格属性和 CSS 中的字符串
* JavaScript 中的 HTML
* 始终遵循白名单优于黑名单的做法
* 使用 UTF-8 为默认的字符编码以及设置 content 为 text/html
* 不要将用户可以控制的文本放在<meta>标签前。通过使用不同的字符集注射可以导致 XSS。
* 使用 <!DOCTYPE html>
* 使用推荐的 HTTP 响应头进行 XSS 防护
* 防止 CRLF 注入/HTTP 响应拆分
* 禁止 TRACE 和其他非必要方法
对于 innerHTML 的方式输出的,我们可以采用如下的方式转码
```js
/**
* 转码 XSS 防护
* @param {String} str 用户输入的字符串
* @return {String} 转码后的字符串
*/
function changeCode(str) {
str = str.replace(/&/g, "&")
.replace(/</g, "<")
.replace(/>/g, ">")
.replace(/"/g, """)
.replace(/'/g, "'")
.replace(/\//g, "/");
return str;
}
```
---
参考:
* [浅谈WEB安全性(前端向)](http://www.cnblogs.com/vajoy/p/4176908.html)
* [XSS的原理分析与解剖](http://www.freebuf.com/articles/web/40520.html)
* [原创翻译:给开发者的终极XSS防护备忘录](http://www.fooying.com/chinese-translationthe-ultimate-xss-protection-cheatsheet-for-developers/)
---
## 性能优化
> 在自己做一些小项目时,可能是学校的一些网站项目,流量可能日均都不超过500,而且大多是校园局域网内访问;或者是开发一些实验室的MIS系统,这辈子你都不会去使用你开发的这个系统。在这样一些项目中,性能优化往往会被你忽略。
>
> 但是如果你是做一个日均PV数万、数十万、甚至更大的量级,开发的页面会被全国各地,不同网络条件的用户来进行访问。这个时候,性能问题就无法忽视了。在当今的网络条件下,如果你的页面3秒都无法完成首屏渲染,一定会让你的网站流失很多用户。
>
> 整个网站的性能优化有很多的环节和工作,大多数时候,不是前端工程师单独就能完成的,尤其在职能划分明确的公司中,往往需要前后端、运维、DBA等多个职位协同完成。所以,在我们的课程中,主要让你了解整个性能优化都涉及哪些方面的工作,同时,我们会专注介绍一些在前端领域可以重点关注的技术点。
这里就是网页的打开速度,如果你的网页打开速度很慢,那么一定会有用户的流失。所以性能优化很重要。
* 网页内容
* 减少http请求次数
* 减少DNS查询次数
* 避免页面跳转
* 缓存Ajax
* 延迟加载
* 提前加载
* 减少DOM元素数量
* 根据域名划分内容
* 减少iframe数量
* 避免404
* 服务器
* 使用CDN
* 添加Expires 或Cache-Control报文头
* Gzip压缩传输文件
* 配置ETags
* 尽早flush输出
* 使用GET Ajax请求
* 避免空的图片src
* Cookie
* 减少Cookie大小
* 页面内容使用无cookie域名
* CSS
* 将样式表置顶
* 避免CSS表达式
* 用\<link\>代替@import
* 避免使用Filters
* Javascript
* 将脚本置底
* 使用外部Javascirpt和CSS文件
* 精简Javascript和CSS
* 去除重复脚本
* 减少DOM访问
* 使用智能事件处理
* 图片
* 优化图像
* 优化CSS Sprite
* 不要在HTML中缩放图片
* 使用小且可缓存的favicon.ico
* 移动客户端
* 保持单个内容小于25KB
* 打包组建成符合文档
具体细节参考文章:
* [毫秒必争,前端网页性能最佳实践](http://www.cnblogs.com/developersupport/p/webpage-performance-best-practices.html)
我在 ToDo 这个任务中主要使用了 CDN 来加载静态资源。比如我使用了 [百度静态资源公共库](http://cdn.code.baidu.com/)。引用了里面的 fontawesome,速度果然比在 GitHub 仓库里快很多。下一步是压缩我自己写的静态资源。
其他参考资料:
* [给网页设计师和前端开发者看的前端性能优化](http://www.oschina.net/translate/front-end-performance-for-web-designers-and-front-end-developers#section:maximising-parallelisation)
* [梳理:提高前端性能方面的处理以及不足](http://www.zhangxinxu.com/wordpress/?p=3152)
* [css sprite原理优缺点及使用](http://www.cnblogs.com/mofish/archive/2010/10/12/1849062.html)
* [CSS Sprites:鱼翅还是三鹿?](http://www.qianduan.net/css-sprites-useful-technique-or-potential-nuisance/)
* [大型网站的灵魂——性能](http://www.cnblogs.com/leefreeman/p/3998757.html)
* [编写高效的 CSS 选择器](http://web.jobbole.com/35339/)
---
## 模块化
> 对于一个复杂项目,特别是多人协作的复杂项目,如何合理划分模块,如何更加方便地进行模块加载,如何管理模块之间的依赖,是一个项目团队都会面临的问题,目前业界已经有了一些较为普遍的解决方案,如AMD。这个部分希望你能够通过学习JavaScript的模块化,学习如何合理地规划项目模块,合理使用模块化工具来优化你的项目代码结构。
一个模块就是实现特定功能的文件,有了模块,我们就可以更方便地使用别人的代码,想要什么功能,就加载什么模块。模块开发需要遵循一定的规范,否则就都乱套了。
根据AMD规范,我们可以使用 `define` 定义模块,使用 `require` 调用模块。
目前,通行的 js 模块规范主要有两种:`CommonJS` 和 `AMD`。
### AMD规范
AMD 即 Asynchronous Module Definition,中文名是“异步模块定义”的意思。它是一个在浏览器端模块化开发的规范,服务器端的规范是 CommonJS
模块将被异步加载,模块加载不影响后面语句的运行。所有依赖某些模块的语句均放置在回调函数中。
AMD 是 RequireJS 在推广过程中对模块定义的规范化的产出。
详细 API 如下:
* [AMD(中文版)](https://github.com/amdjs/amdjs-api/wiki/AMD-(%E4%B8%AD%E6%96%87%E7%89%88))
---
### CommonJS规范
CommonJS 是服务器端模块的规范,Node.js 采用了这个规范。Node.JS 首先采用了 js 模块化的概念。
根据 CommonJS 规范,一个单独的文件就是一个模块。每一个模块都是一个单独的作用域,也就是说,在该模块内部定义的变量,无法被其他模块读取,除非定义为 global 对象的属性。
输出模块变量的最好方法是使用 module.exports 对象。
---
### 为什么要用 requireJS
试想一下,如果一个网页有很多的js文件,那么浏览器在下载该页面的时候会先加载js文件,从而停止了网页的渲染,如果文件越多,浏览器可能失去响应。其次,要保证js文件的依赖性,依赖性最大的模块(文件)要放在最后加载,当依赖关系很复杂的时候,代码的编写和维护都会变得困难。
RequireJS就是为了解决这两个问题而诞生的:
> (1)实现js文件的异步加载,避免网页失去响应;
> (2)管理模块之间的依赖性,便于代码的编写和维护。
#### requireJS
* [requireJS 官网](http://requirejs.org/)
* [requireJS 中文网](http://www.requirejs.cn/)
---
### AMD和CMD
CMD(Common Module Definition) 通用模块定义。该规范明确了模块的基本书写格式和基本交互规则。该规范是在国内发展出来的。AMD是依赖关系前置,CMD是按需加载。
> AMD 是 RequireJS 在推广过程中对模块定义的规范化产出。
> CMD 是 SeaJS 在推广过程中对模块定义的规范化产出。
* [CMD 模块定义规范](https://github.com/seajs/seajs/issues/242)
对于依赖的模块,AMD 是提前执行,CMD 是延迟执行。
> AMD:提前执行(异步加载:依赖先执行)+延迟执行
> CMD:延迟执行(运行到需加载,根据顺序执行)
---
### 参考
* [Javascript模块化编程(一):模块的写法--阮一峰](http://www.ruanyifeng.com/blog/2012/10/javascript_module.html)
* [Javascript模块化编程(二):AMD规范](http://www.ruanyifeng.com/blog/2012/10/asynchronous_module_definition.html)
* [Javascript模块化编程(三):require.js的用法](http://www.ruanyifeng.com/blog/2012/11/require_js.html)
* [详解 JavaScript 模块开发](http://segmentfault.com/a/1190000000733959)
* [浅谈模块化的JavaScript](http://www.cnblogs.com/jinguangguo/archive/2013/04/06/3002515.html?utm_source=tuicool)
* [再谈 SeaJS 与 RequireJS 的差异](http://div.io/topic/430)
* 玩转AMD系列 by erik@EFE
* [玩转AMD - 写在前面](http://efe.baidu.com/blog/dissecting-amd-preface/)
* [玩转AMD - 设计思路](http://efe.baidu.com/blog/dissecting-amd-what/)
* [玩转AMD - 应用实践](http://efe.baidu.com/blog/dissecting-amd-how/)
* [玩转AMD - Loader](http://efe.baidu.com/blog/dissecting-amd-loader/)
---
## 前端工程化
> 业界目前有非常多的前端开发工具,完成一些开发过程中可以自动化完成的工作,提高研发效率,并且可以提高多人协作时的开发过程一致性,提高整个项目的运维效率。
>
> 在EFE日常工作中,我们是基于EDP,完成项目开发过程中的项目构建、包管理、调试、单测、静态检测、打包、压缩、优化、项目部署等一系列所有工作。
注:
如果网络不好,可以使用 [淘宝 NPM 镜像](http://npm.taobao.org/)。
### 参考
* [前端工程与模块化框架](http://div.io/topic/439)
* [手机百度前端工程化之路](http://mweb.baidu.com/p/baidusearch-front-end-road.html)
* [对话百度前端工程师张云龙:F.I.S与前端工业化](http://www.infoq.com/cn/articles/yunlong-on-fis)
* [EDP](https://github.com/ecomfe/edp)
* [Grunt教程——初涉Grunt](http://www.w3cplus.com/tools/grunt-tutorial-start-grunt.html)
* [gulp入门指南](http://www.open-open.com/lib/view/open1417068223049.html)
* [Gulp开发教程(翻译)](http://www.w3ctech.com/topic/134)
* [Gulp 中文网](http://www.gulpjs.com.cn/)
* [npm的package.json中文文档](https://github.com/ericdum/mujiang.info/issues/6)
---
## 最终作品
在任务三中,做了一个 PC 端的 ToDo 应用。任务四是将它优化,以适应移动端设备。
### ToDo WebApp Version
* [任务四要求](https://github.com/baidu-ife/ife/tree/master/task/task0004)
* [源代码](https://github.com/Gaohaoyang/ToDo-WebApp)
* [在线 demo](http://gaohaoyang.github.io/ToDo-WebApp/)
* 手机查看 ↓ 二维码 ↓

* [我的博客 HyG](http://gaohaoyang.github.io)
### Details
* **数据存储**
以 JSON 模拟数据表的形式存储于 LocalStorage 中
使用数据库的思想,构建3张表。
cateJson 分类
childCateJson 子分类
taskJson 任务
分类表 cate
----------------------
id* | name | child(FK)
----------------------
子分类表 childCate
--------------------------------
id* | pid(FK) | name | child(FK)
--------------------------------
任务表 task
----------------------------------------------
id* | pid(FK) | finish | name | date | content
----------------------------------------------
* **使用 `Sass` 重构了 CSS 代码**
使用分块、继承等方式,使得代码更加清晰明了。
* **响应式布局**
针对手机端细节做了很多调整,更符合手机上的视觉交互习惯。
* **加入页面切换效果**
使用 `translate3d()`,纯 CSS3 切换动画效果。
* **处理了 XSS 防护**
对可能造成破坏的字符进行转码。
* **性能优化**
使用 CDN 处理静态资源 fontAwesome,压缩静态资源等
* **模块化**
使用 requireJS 模块化 JavaScript 代码。重构 JavaScript 代码。优化之前写的耦合性高的绑定事件,重新绑定事件,降低耦合性。期间根据具体需求重写了事件代理的代码。
* **前端工程化**
使用 gulp,自动编译 Sass,压缩 CSS 和 JavaScript 代码。并且配置了自动流程。
---
## 其他
### `-webkit-tap-highlight-color` 属性
感谢 [fiona](https://github.com/fiona23) 指出。
safari移动端点击的时候会闪一下加上 `-webkit-tap-highlight-color: transparent;` 就不会闪了。
参考:
* [`-webkit-tap-highlight-color` css88](http://www.css88.com/webkit/-webkit-tap-highlight-color/)
* [`-webkit-tap-highlight-color` 属性](http://ued.ctrip.com/webkitcss/prop/tap-highlight-color.html)
---
### textarea 标签 disabled 颜色
* 为什么用 disabled 属性?
因为我发现仅仅使用 readonly 属性,在 IE 下是显示光标的。于是使用 disabled。
* 出现的问题
各家浏览器对于 disabled 属性有自己的样式设定,比如 IE 下是灰色的。苹果设备下也是。改变这些样式的方法也不是统一的。如果要兼容 Safari 必须加上
```
background: #fff;
-webkit-text-fill-color: rgba(0, 0, 0, 1);
-webkit-opacity: 1;
```
于是最终代码如下:
```css
textarea:disabled {
color:#000;
background: #fff;
-webkit-text-fill-color: rgba(0, 0, 0, 1);
-webkit-opacity: 1;
}
```
* 参考:[Disabled input text color 中的评论](http://stackoverflow.com/a/4648315) | 17,391 | MIT |
## spring-cloud-starter-netflix-zuul
#### 最简教程
##### 1. 添加注解
@EnableZuulProxy
##### 2. 添加路由配置
zuul.routes.user.path=/user/**
zuul.routes.user.url=http://localhost:8000/user
###### 即可完成一个最简单的网关
--
##### 四种过滤器类型
- pre
- route
- post
- error | 250 | MIT |
---
layout: zh-tw/layouts/about.njk
title: About
eleventyNavigation:
key: About
order: 3
---
[Cymetrics](https://cymetrics.io) 是一個全面的 SaaS 資訊安全評估平台,可提升資安曝險的可視性並以更敏捷及彈性化的方式管理資安風險。而這裡是 Cymetrics 團隊的技術部落格,工程團隊的前後端工程師與資安工程師都會在這邊發表文章。
如果想要持續追蹤我們的文章,可以追蹤 [Facebook](https://www.facebook.com/Cymetrics-100957872049641) 或是訂閱 [RSS](https://tech-blog.cymetrics.io/feed/feed.xml),若是你對於這樣的工程文化有興趣,歡迎[加入我們](https://www.yourator.co/companies/OneDegree)。
此部落格以 [eleventy-high-performance-blog](https://github.com/google/eleventy-high-performance-blog) 以及 [error-baker-blog](https://github.com/Lidemy/error-baker-blog) 為基底進行開發,程式原始碼在 [GitHub](https://github.com/cymetrics/blog)。
### 作者列表
<!-- 底下交給 layout 來自動渲染 --> | 710 | MIT |
---
layout: post
comments: true
title: "微信小程序的数据绑定"
categories: miniprogram
tags: miniprogram wechat
date: 2017/11/25 20:49:44
---
* content
{:toc}
微信小程序的数据绑定
[框架](https://mp.weixin.qq.com/debug/wxadoc/dev/framework/MINA.html)
小程序的视图 View 与 逻辑层 JavaScript ,与
Rails 视图 View 与 控制 Controller 可以近似看成一一对应。
## View
```
<!-- This is our View -->
<view> Hello {{name}}! </view>
<button bindtap="changeName"> Click me! </button>
```
## JS
```js
// This is our App Service.
// This is our data.
var helloData = {
name: 'WeChat'
}
// Register a Page.
Page({
data: helloData,
changeName: function(e) {
// sent data change to view
this.setData({
name: 'MINA'
})
}
})
```
* 在 `page` 中通过 `data` 将数据传到 View ,从而可以在 View 中使用 `{{ name }}` 来调用存储的数据
* 在 View 中通过 `bindtap` 绑定了按钮与单击按钮后的处理函数 `changeName`
* 当单击按钮后,View 会发送 `changeName` 事件给逻辑层,而逻辑层则找到对应的函数来处理
* 在逻辑层则通过 `setData` 这个方法来实现改变控件的文本。
## Links
* [框架](https://mp.weixin.qq.com/debug/wxadoc/dev/framework/MINA.html) | 1,002 | MIT |
---
layout: post
title: "「自由時報」- 專家:美中脫鉤大勢所趨,貿易協議只影響脫鉤速度與範圍"
date: 2019-12-13T18:43:34+08:00
author: 透視中國
from: https://tw.sinoinsider.com/2019/12/%e3%80%8c%e8%87%aa%e7%94%b1%e6%99%82%e5%a0%b1%e3%80%8d-%e5%b0%88%e5%ae%b6%ef%bc%9a%e7%be%8e%e4%b8%ad%e8%84%ab%e9%89%a4%e5%a4%a7%e5%8b%a2%e6%89%80%e8%b6%a8%ef%bc%8c%e8%b2%bf%e6%98%93%e5%8d%94%e8%ad%b0/
tags: [ 透視中國 ]
categories: [ 透視中國 ]
---
<article class="post-5816 post type-post status-publish format-standard has-post-thumbnail hentry category-media" id="post-5816" itemscope="" itemtype="https://schema.org/CreativeWork">
<div class="inside-article">
<div class="featured-image page-header-image-single">
<img alt="" class="attachment-full size-full" height="600" itemprop="image" sizes="(max-width: 900px) 100vw, 900px" src="https://tw.sinoinsider.com/wp-content/uploads/sites/2/2019/12/20191213_ec.ltn_.com_.tw_.jpg" srcset="https://tw.sinoinsider.com/wp-content/uploads/sites/2/2019/12/20191213_ec.ltn_.com_.tw_.jpg 900w, https://tw.sinoinsider.com/wp-content/uploads/sites/2/2019/12/20191213_ec.ltn_.com_.tw_-450x300.jpg 450w, https://tw.sinoinsider.com/wp-content/uploads/sites/2/2019/12/20191213_ec.ltn_.com_.tw_-768x512.jpg 768w, https://tw.sinoinsider.com/wp-content/uploads/sites/2/2019/12/20191213_ec.ltn_.com_.tw_-300x200.jpg 300w, https://tw.sinoinsider.com/wp-content/uploads/sites/2/2019/12/20191213_ec.ltn_.com_.tw_-600x400.jpg 600w" width="900"/>
</div>
<header class="entry-header">
<h1 class="entry-title" itemprop="headline">
「自由時報」- 專家:美中脫鉤大勢所趨,貿易協議只影響脫鉤速度與範圍
</h1>
<div class="entry-meta">
<span class="posted-on">
<a href="https://tw.sinoinsider.com/2019/12/%e3%80%8c%e8%87%aa%e7%94%b1%e6%99%82%e5%a0%b1%e3%80%8d-%e5%b0%88%e5%ae%b6%ef%bc%9a%e7%be%8e%e4%b8%ad%e8%84%ab%e9%89%a4%e5%a4%a7%e5%8b%a2%e6%89%80%e8%b6%a8%ef%bc%8c%e8%b2%bf%e6%98%93%e5%8d%94%e8%ad%b0/" rel="bookmark" title="18:43">
<time class="updated" datetime="2020-03-30T05:31:56+08:00" itemprop="dateModified">
2020-03-30
</time>
<time class="entry-date published" datetime="2019-12-13T18:43:34+08:00" itemprop="datePublished">
2019-12-13
</time>
</a>
</span>
</div>
<!-- .entry-meta -->
</header>
<!-- .entry-header -->
<div class="entry-content" itemprop="text">
<blockquote>
<p>
政治風險顧問公司「透視中國」(SinoInsider)資深分析家Larry Ong指出,貿易戰現在儼然成為「意識形態、價值體系與道德觀的關鍵戰役」。本週中國官媒新華社報導說,兩家中企已合作研發本國的作業系統,似乎旨在挑戰美國微軟視窗系統的優勢地位。當中一家公司的財務長說,「迫切需要研發本國獨立的作業系統,該系統有著統一的科技體系與生態系」。
</p>
</blockquote>
<p>
<a href="https://ec.ltn.com.tw/article/breakingnews/3008589" rel="noopener noreferrer" target="_blank">
原文
</a>
</p>
</div>
<!-- .entry-content -->
<footer class="entry-meta">
<span class="cat-links">
<span class="screen-reader-text">
分類
</span>
<a href="https://tw.sinoinsider.com/category/media/" rel="category tag">
媒體報導
</a>
</span>
<nav class="post-navigation" id="nav-below">
<span class="screen-reader-text">
文章導覽
</span>
</nav>
<!-- #nav-below -->
</footer>
<!-- .entry-meta -->
</div>
<!-- .inside-article -->
</article> | 3,141 | MIT |
# 条款7: 为多态基类声明virtual析构函数
这一条款是至关重要的,因此我打算不吝笔墨做详细介绍。
首先来复习一下C++的多态。用一个基类的指针(或引用)指向一个派生类的实例,并且我们希望藉由基类指针的调用表现的和派生类一致。`Base`类定义了方法`DoSth()`,继承了`Base`的派生类`Derived`对方法`DoSth()`有着和基类不同的实现。指向 `Derived`实例的`Base`指针`bPtr`应该调用`Derived`的`DoSth()`实现,而非`Base`的。
从内存模型来看,调用类方法和调用一般的函数没有区别,每一个类方法的定义对应了唯一的函数入口地址。如果`DoSth()`没有被声明为`virtual`,那么在执行`bPtr->Dosth()`时,编译器知道`Base`类的`DoSth()`定义,于是生成了call指令让程序跳转到它的入口地址,就和编译一般的函数调用的代码一模一样。唯一的区别是调用方法的实例的地址也会作为隐式地作为函数参数传递,这就是`this`指针。就如以下指令所示。
```
-> 0x100003a6d <+34>: movq -0x18(%rbp), %rax
0x100003a71 <+38>: movq %rax, %rdi
0x100003a74 <+41>: callq 0x100003b3a ; symbol stub for: Base::DoSth()
```
看起来,实现多态的任务是要让编译器知道执行`bPtr->Dosth()`时,实际执行的究竟是`Base`类的`DoSth()`定义还是`Derived`类的`DoSth()`定义。这需要提前知道指针指向的究竟是基类还是派生类,但这基本是一个不可能完成的事情,就连拥有人类智慧的程序员也无从下手。因此我们只能放弃在编译时就知道对应的函数入口地址并直接生成代码的想法,退而把这一工作在程序运行时完成。
通过vptr(virtual table pointer, 虚表指针)可以做到这一点。具有`virtual`方法(或者说,虚函数)的类实例自身会携带一个叫vptr的指针,它通常位于对象的头部,它指向了一个存储了虚函数地址的数组,即虚表。每一个具有虚函数的类都对应了这样一个虚表,`Base`类和`Derived`类都各自有一个不同的虚表,里面存储有各自的`DoSth()`实现的地址。编译器在处理虚函数的调用时会做特殊处理,不是直接生成调用某个函数的代码,而是先访问对象的vptr所指的虚表,再从中获得需要访问的函数的入口地址。在执行`bPtr->Dosth()`时,尽管`bPtr`是一个`Base`指针,但是因为它指向的实例是`Derived`的,因此vptr指向了`Derived`的虚表,于是程序运行了`Derived`对`DoSth()`的实现。下面的代码展示了一次调用虚函数`Dosth()`的过程,和上面的非虚函数调用不同的是,程序先取对象中的vptr访问虚表(+34和+38),再从虚表中取出函数入口地址放入寄存器rdx(+41),最后call指令的操作数正是寄存器rdx中的值。
```
-> 0x100003a67 <+34>: movq -0x18(%rbp), %rax
0x100003a6b <+38>: movq (%rax), %rax
0x100003a6e <+41>: movq (%rax), %rdx
0x100003a71 <+44>: movq -0x18(%rbp), %rax
0x100003a75 <+48>: movq %rax, %rdi
0x100003a78 <+51>: callq *%rdx
```
关于虚函数和vptr有一条关键规则:一个类的虚函数性质会延续到继承它的类。当一个类继承了基类时,它也从基类继承了一份虚表,里面是所有虚函数的入口地址。如果它自己实现了某个虚函数,那么就在虚表中用自己的实现替换掉基类的。如果有的虚函数没有实现,那么通过派生类实例访问到的仍然是基类的版本。同样的,派生类可以定义自己的而非继承自基类的虚函数,这将是基类的虚表中没有的条目。如果`Base`定义了方法`DoSth2()`但是没有声明为`virtual`,那么再在`Derived`中定义`DoSth2()`就是一个和基类完全无关的新的函数。我们可以把`Derived`中定义的`DoSth2()`声明为`virtual`,这样`Derived`和它的派生类们都会用虚函数的规则处理`DoSth2()`。但是用`Base`指针调用`DoSth2()`却永远不会进入`Derived`以及更之后的继承中的实现,因为对于`Base`来说`DoSth2()`是非虚的。
铺垫了这么多,现在终于可以步入正题了。析构函数较之其它类方法有一个特殊之处,即如果一个派生类的析构函数被调用,那么程序会自下而上依次调用所有祖先类的析构函数。可以这样概括,析构函数会沿着继承关系的反方向链式调用。实现这样的逻辑很简单,编译器只需要在每一个类的析构函数定义中调用它继承的类的析构函数即可。
有时候我们需要通过一个基类指针释放派生类实例的资源,这时`delete`基类指针应该有和`delete`派生类指针相同的表现,将析构函数声明为`virtual`可以确保这一点。考虑一条继承链,链头部的类具有虚析构函数,于是自它往下,所有的类指针在被`delete`时,都要从虚表中找到对应的析构函数入口地址。如果某一个派生类定义了自己的析构函数,那么它的入口地址会被装填到这个类的虚表中,同时这个析构函数中会隐含继承链上一级的析构函数的调用。于是无论是继承链上游的哪一级指针,都能正确地释放下游的类实例资源。下面的代码演示了一条继承链。值得注意的是被用来作为起点的`A`实际上还继承了没有虚析构函数的基类`Base`,因此通过`Base`的指针无法正确释放下游类实例的资源。这意味着我们应该尽量避免继承析构函数非虚的类,如果一定要这样做,那么不可用它的指针来释放资源。
还有一个需要注意的地方是,我们可以声明一个析构函数是纯虚的(pure virtual),但是仍然需要给出它的定义。因为析构函数会向上链式调用,而且不会因为遇到了纯虚析构函数就停止这样做。
```c++
class A : public Base /* Base的析构函数是非虚的 */ {
public:
virtual ~A(); // 声明为虚析构函数, 隐含了对~Base()的调用
};
class B : public A {
public:
~B(); // 隐含了对~A()的调用
};
class C : public B {
public:
~C(); // 隐含了对~B()的调用
};
A* ptrA = new C;
delete ptrA; // 找到~C()的入口地址,链式调用~C() -> ~B() -> ~A() -> ~Base()
ptrA = new B;
delete ptrA; // 找到~B()的入口地址,链式调用~B() -> ~A() -> ~Base()
Base* ptrBase = new C;
delete Base; // 只会调用~Base()
``` | 3,126 | MIT |
# validate-support
jquery表单验证插件,依赖validate插件特性,使用更加方便简单
依赖插件 http://plugins.jquery.com/validate
其中修改依赖插件代码 (用来支持keyup后的验证信息显示)
```javascript
原: if(describedby.length > 0 && event.type != 'keyup')
现: if(describedby.length > 0)
```
> 特性
1. 提供多个方法可直接使用
1. 支持自定义函数验证
1. 支持全局配置及局部覆盖配置,提示信息可定制化
1. 操作简单
1. 支持表单不通过时定位到指定元素位置
1. 在rules中添加配置后才会进行元素限制
> 使用方式
```javascript
$(form).validateSupport(options);
```
> demo演示 [地址](https://joker-pper.github.io/validate-support/example/)
> 覆盖默认语言/覆盖默认函数
```javascript
$.extend($.fn.validateSupport.defaults.language, {
});
$.extend($.fn.validateSupport.defaults.api, {
phone: function (val) {
return val == "";
}
});
```
> api
```javascript
clearAll() //清除提示样式
getRule(key) //获取指定key的rule
getField(key) //获取指定key的field对象
scrollErrorTo(key) //滚动到指定错误元素,key为null时是滚动到默认 根据error配置项执行,必须为error field才会执行
scrollTo(key, offset, duration) //滚动到指定元素 offset及duration同options中scrollToError的参数
```
> options 参数 (均可重写覆盖)
```javascript
/**{
sendForm: boolean, //默认值true,是否为表单的默认提交行为
eachValidField: fn(event), //元素验证成功时执行(this指当前元素的jquery对象)
eachInvalidField: fn(event), //元素验证失败时执行(this同上)
invalid: fn(event), //表单提交验证失败时执行(this指当前表单的jquery对象)
valid: fn(event), //表单提交验证通过时执行(this同上)
/**
* 用于清除验证提示样式的函数(this同上)
* @param $elements:
* {
* $el: object, // rule key所对应的表单元素jquery对象
* key: string, // rule key
* $description: object, // rule key所对应的提示元素jquery对象
* }
* @param rules: 所设置表单元素的rules
*/
clearAll: fn($elements, rules),
/**
* 默认不存在
* 函数存在时会在每次验证后执行(this指当前元素的jquery对象)
* @param key: rule key
* @param valid: boolean 验证通过或失败
* @param rules
*/
always: fn(key, valid, rules),
/**
* 默认不存在
* 存在时会在表单不通过滚动到当前表单首位错误元素的位置
*/
scrollToError: {
/**
*
* this指当前错误元素的jquery对象
* @param key: rule key
* @param rules
* @return number
*/
offset: number || fn(key, rules) //基于当前错误元素位置的offset值
duration: number //scroll duration 可选,默认值500
},
/**
*
* 用于全局设置元素是否required,默认值false
* 【局部rule中key的该参数可覆盖对应元素的属性】
* @param $el: 当前key对应元素的jquery对象
* @param key: rule key
* @param rule
* @return boolean
*/
required: boolean || fn($el, key, rule),
trim: boolean, //全局设置是否启用trim, 默认false 【局部rule中key的该参数可覆盖对应元素的属性】
/**
*
* 不存在时默认作为当前表单元素父级的兄弟元素
* 用于设置提示元素显示的位置(全局)【rule中key的该参数可覆盖全局,参数一致】
*
* @param $description: 当前key对应提示元素
* @param $el: 当前key对应元素的jquery对象
* @param key: rule key
* @param rule
*/
description: null || function($description, $el, key, rule),
/**
* 生成提示信息的元素id前缀,默认值为validate
* 最终名称: descriptionPrefix + key + "-description"
*/
descriptionPrefix: string,
/**
* 生成提示信息的元素所应用的class,默认值validate-description
*/
descriptionClass: string,
/**
*
* 用于设置提示元素显示的显示内容元素(全局)【rule中key的该参数可覆盖全局,参数一致】
* 提示类型总共分为四种 required(必填) pattern(正则不通过) valid(验证通过) conditional(自定义函数不通过)
* 主要介绍required,其他三种同理
*/
message: {
required: {
/**
*
* 提示元素的html内容
* 默认值: <span class="help-block">{content}</span>
* 【{content}作为提示文字的占位符】
* @param key: rule key
* @return string
*/
template: string || fn(key),
/**
* 提示文字
* 默认值: $.fn.validateSupport.defaults.language.required
* @param key: rule key
* @return string
*/
content: string || fn(key),
},
pattern: {
template: string || fn(key),
content: string || fn(key)
},
conditional: {
template: string || fn(key),
content: string || fn(key)
},
valid: {
template: string || fn(key),
content: string || fn(key)
}
},
rules: {
/**
* key是作为当前表单元素的标识
* 表单如何匹配元素(id > selector > key默认匹配):
* id (boolean) 当前key作为id选择器匹配
* 通过selector匹配对应元素(string||fn)
* selector不存在时根据name属性(key)在当前表单匹配
*
* rule key所支持函数属性将单独列出
*/
key: {
id: boolean, //是否以key作为id选择器
/**
* 正则表达式,用于验证是否满足条件,不通过时显示当前key所应用的pattern提示信息
*/
pattern: string,
/**
* 用于格式化元素值满足正则验证后应用
*/
mask: string,
/** 用于匹配当前key元素的jqery对象,string时直接作为选择器匹配对象
* @param $form: 当前表单jquery对象
* @return object: 当前key对应的表单元素jquery对象
*/
selector: string || fn($form),
/**
* 自定义函数验证当前元素是否满足条件
* 返回值为boolean: false时显示当前key所应用的conditional提示信息
* @param $el
* @param key
* @param rule
* @param rules
*
* @return boolean
* ||
* {
* status: boolean, //是否验证通过
* error: string //status为false时,用于作为当前key的提示信息(不存在时采用默认的conditional提示信息)
* }
*/
conditional: fn($el, key, rule, rules),
/*** 以下属性参数,可以覆盖对应的全局配置项 ***/
message: {
},
required: boolean || fn($el, key, rule),
trim: boolean,
description: null || function($description, $el, key, rule)
}
}
}*/
```
> rule key中支持函数配置
```javascript
range: [number, number] //验证值是否在指定区间范围
/**
* equalTo 验证元素值是否相等,
* 参数为string时为对应元素key(同对象参数key),
* 参数为对象时error值可覆盖默认equalTo函数提示文字
*/
equalTo: string || {key: string, error: string}
maxlength || minlength (会依赖trim参数值)
参数值 number || {}
默认转化为{}验证,参数值为number时作为长度
{
twoCharLinebreak: boolean, //默认值true
utf8: boolean, //默认值false
size: number //长度,整数
}
//其他函数
number(数字), url, email, digits(整数), idcard, phone, date, dateISO
参数值 boolean || 0 || 1
min(最小值) max(最大值)
参数值 number
```
> 代码示例 (demo中的示例二) [地址](https://joker-pper.github.io/validate-support/example/#form2)
```javascript
$("form").validateSupport({
eachValidField: function (event) {
//成功时添加的样式
var $this = this;
$this.parents('.form-group').removeClass('has-error').addClass('has-success has-feedback');
var $feedback = $this.next(".glyphicon");
if (!($feedback[0])) {
$feedback = $('<span class="glyphicon form-control-feedback" aria-hidden="true"></span>');
$feedback.insertAfter($this);
}
$feedback.removeClass('glyphicon-remove').addClass("glyphicon-ok");
},
eachInvalidField: function (event) {
//失败时
var $this = this;
$this.parents('.form-group').removeClass('has-success').addClass('has-error has-feedback');
var $feedback = $this.next(".glyphicon");
if (!($feedback[0])) {
$feedback = $('<span class="glyphicon form-control-feedback" aria-hidden="true"></span>');
$feedback.insertAfter($this);
}
$feedback.removeClass('glyphicon-ok').addClass("glyphicon-remove");
},
clearAll: function ($elements, rules) {
//用于清除提示的样式
for (var i in $elements) {
var $element = $elements[i];
$element.$description.children().remove();
var $el = $element.$el;
$el.parents('.form-group').removeClass("has-success has-error");
$el.next(".glyphicon").remove();
}
},
sendForm: false, //阻止表单的默认提交行为
message: {
valid: { //通过验证时的提示模板
content: function (key) {
return "通过验证";
}
},
pattern: {
content: function (key) {
return "验证失败";
}
},
conditional: {
content: "验证失败"
},
required: {
content: function (key) {
return "必填项";
}
}
},
description: function ($description, $el, key, rule) {
//全局设置提示元素显示的位置
$description.insertAfter($el);
},
required: true, //rules中配置的将会使用该属性,如果其存在将会进行覆盖
trim: true,
rules: {
name: {
minlength: {
size: 2
},
maxlength: {
size: 20
},
conditional: function ($el, key, rule, rules) {
//自定义函数验证
var value = $el.val();
if (value == "joker") {
//error将作为当前不通过的验证提示
return {status: false, error: "you are joker"};
} else if (value == "yyc") {
return {status: false};
} else {
return {status: true};
}
return true;
},
message: {
valid: { //覆盖验证通过时的提示
content: '名称通过验证'
}
}
},
email: {
email: true
},
idcard: {
required: false,
idcard: true
}
},
invalid: function (event, options) { //提交表单验证不通过时
//console.log(this)
},
valid: function (event, options) {
alert(this.serialize());
}
});
``` | 10,038 | Apache-2.0 |
# vuepress的主配置文件描述
```js vuepress配置说明
module.exports = { // 主配置文件
/* ------------- base ------------ */
// string,网页标题,它将显示在导航栏
title: '5102的技术文档',
// string,网站的描述,它将会以 <meta> 标签渲染到当前页面的 HTML 中
description: '欧里给!!!',
// string,站点基础路径
base: '/My_Growth/',
// Array,额外的需要被注入到当前页面的 HTML <head> 中的标签
// [tagName, { attrName: attrValue }, innerHTML?]
head: [],
// string,指定用于 dev server 的主机名
host: '0.0.0.0',
// number,指定 dev server 的端口
port: 8081,
// string,指定客户端文件的临时目录
temp: '/path/to/@vuepress/core/.temp',
// string,输出目录
dest: './docs/.vuepress/dist',
// { [path: string]: Object },提供多语言支持的语言配置
locales: undefined,
// Function,用来控制对于哪些文件,是需要生成 <link rel="prefetch"> 资源提示的
shouldPrefetch: () => true,
// boolean|string,VuePress 默认使用了 cache-loader 来大大地加快 webpack 的编译速度
// 指定 cache 的路径,设置为 false 来在每次构建之前删除 cache
cache: true,
// Array,指定额外的需要被监听的文件,文件变动将会触发 vuepress 重新构建
extraWatchFiles: [],
// Array,默认解析的文件
patterns: ['**/*.md', '**/*.vue'],
/* -------------- Styling -----------*/
// 定义一些变量,外部样式变量
palette: {
styl: '/'
},
// 一种添加额外样式的简便方法,外部样式
index: {
styl: '/'
},
/* -------------- theme -----------*/
// string,当你使用自定义主题的时候,需要指定它
theme: undefined,
// Object,为当前的主题提供一些配置,这些选项依赖于你正在使用的主题
themeConfig: {
nav: require('./nav'),
sidebar: require('./sidebar'),
},
/* -------------- Pluggable -----------*/
// Object|Array,使用插件
plugins: undefined,
/* -------------- Markdown -----------*/
markdown: {
// boolean=undefined是否在每个代码块的左侧显示行号
lineNumbers: true,
// Function,一个将标题文本转换为 slug 的函数
slugify:source,
// Object,markdown-it-anchor 的选项。
anchor: {
permalink: true,
permalinkBefore: true,
permalinkSymbol: '#'
},
// Object,这个键值对将会作为特性被增加到是外部链接的 <a> 标签上,默认的选项将会在新窗口中打开一个该外部链接
// 打开a外部链接会额外打开的选项
externalLinks: {
target: '_blank',
rel: 'noopener noreferrer'
},
// Object,markdown-it-table-of-contents 的选项
toc: {
includeLevel: [2, 3]
},
// Object|Array,配置 markdown-it插件
plugins:[],
// Function,一个用于修改当前的 markdown-it 实例的默认配置,或者应用额外的插件的函数
extendMarkdown: undefined,
// Array,提取到this.$page.headers中的元素
extractHeaders: ['h2', 'h3']
},
/* -------------- 构建流程 -----------*/
// Object,配置postcss-loader,指定这个值,将会覆盖内置的 autoprefixer
postcss: {
plugins: [require('autoprefixer')]
},
// Object,配置stylus-loader
stylus: {
preferPathResolver: 'webpack'
},
// Object,配置scss-loader,加载*.scss文件
scss: {},
// Object,配置sass-loader,加载*.sass文件
sass: {
indentedSyntax: true
},
// Object,less-loader配置
less: {},
// Object | Function,用于修改内部的 Webpack 配置,会合并到主配置
configureWebpack: { }
},
// Function,通过web-pack-chain,链式配置config
chainWebpack: undefined,
/* -------------- 浏览器兼容性 -----------*/
// boolean | Function,是否不开启polyfills,即不兼容低版本浏览器
evergreen: false,
}
``` | 2,920 | MIT |
---
layout: post
title: "种族主义又惹祸,美国国家书评人协会濒临解体"
date: 2020-06-24
author: 危幸龄
from: https://m.allnow.com/post/5ef23a0cfcd3560001551d93
tags: [ 燕京书评 ]
categories: [ 燕京书评 ]
---
<div class="main" data-v-7f77c10f="" data-v-c130297e="">
<div class="head-img-wrap" data-v-7f77c10f="">
<img class="head-img" data-v-7f77c10f="" src="//img.allhistory.com/5ef1850ad7f8a70001be8a06.png?imageView2/2/w/750"/>
<!-- -->
</div>
<div class="column-wrap" data-v-7f77c10f="">
<p class="column" data-v-7f77c10f="">
<a class="column-link" data-v-7f77c10f="" href="/column/199">
燕京书评
</a>
<!-- -->
</p>
<p class="title" data-v-7f77c10f="">
种族主义又惹祸,美国国家书评人协会濒临解体
</p>
</div>
<div class="author-wrap" data-v-7f77c10f="">
<div class="left" data-v-7f77c10f="">
<a class="single-avatar" data-v-7f77c10f="" href="/user/782354">
<img data-v-7f77c10f="" src="//pic.allhistory.com/T1VaZCBsZ51RCvBVdK.jpg?imageView2/2/w/64"/>
</a>
<a class="single-name" data-v-7f77c10f="" href="/user/782354">
危幸龄
</a>
<div class="icon" data-v-7f77c10f="">
</div>
</div>
<div class="time" data-v-7f77c10f="">
6-24
</div>
</div>
<div class="abstract-wrap" data-v-7f77c10f="">
<p class="abstract" data-v-7f77c10f="">
“不同意黑人关于种族问题的观点就是种族主义吗?”
</p>
</div>
<div data-v-7f77c10f="" id="article-content">
<p>
美国国家书评人协会(National Book Critics Circle,简称NBCC)的成员正动员起来,要求解除其理事会成员卡林·罗马诺(Carlin Romano)的职务,因为他抨击了该组织计划发布的一项反种族主义承诺条例,并威胁说要在随后的人事变动中起诉他在理事会的同事。目前,总共24位成员的理事会已有15位成员罢工,其中超过20位准备呼吁会议投票表决将他除名。
</p>
<figure class="image-box dls-image-block dls-media-image">
<img src="//img.allhistory.com/5ef2096bd7f8a70001be8ace.png?imageView2/2/w/800"/>
<figcaption class="dls-image-capture">
<p>
美国国家书评人协会奖是美国最权威的文学奖之一,由美国书评人协会(National Book Critics Circle)于1975年创办。NBCC拥有1000多名审阅者与图书编辑,最终候选人与获奖者由该组织的24人委员会选出;罗贝托·波拉尼奥、伊恩·麦克尤恩、爱丽丝·门罗、约翰·厄普代克、菲利浦·罗斯等著名作家均获得过该奖项。
</p>
</figcaption>
</figure>
<p>
NBCC内部分歧最早出现在6月10日晚上,当时NBCC计划通过一份概述其支持有色人种成员的声明来表明自己支持最近的反种族主义抗议活动。理事会主席、劳里·赫策尔(Laurie Hertzel)通过电子邮件向全体成员发送了这份声明,并要求他们参与修改或撰写。《高等教育纪事报》(The Chronicle of Higher Education)的自由评论家、NBCC前主席罗马诺表示,他不同意其中的一些说法,但不想“分散绝大多数成员的注意力,使他们无法完成自己的使命”。然而,他继续详细阐述了自己对其中一些说法的反对意见,并将该声明的基本前提斥为“完全一派胡言”。
</p>
<p>
</p>
<p>
作为一名白人评论家和前理事会主席,他对“白人至上和制度性种族主义(institutional racism)”,以及“在行业各个层面压制黑人”的观点提出了异议,就像声明中说的那样。他认为,这些主张相当于“对几代白人出版商和编辑的诽谤”,他们曾为出版有色人种作家的作品而斗争。他在邮件中写道:“有人认为,在图书出版和文学领域,白人是一股对立力量,需要被送入再教育集中营,我对此感到不满……在我四十多年文学和出版生涯中,我看到的更多是白人作家帮助黑人作家,而不是相反。”
</p>
<p>
</p>
<p>
为了平复他的情绪,赫策尔回复罗马诺称其“反对意见合理”。乌干达裔美国作家霍普·瓦布克(Hope Wabuke)最初建议撰写这份声明,但当她读到罗马诺和赫策尔之间的这段对话时,她感到非常愤怒。6月11日早上,她在推特上发布了该组织的电子邮件截图,并在一个附带的帖子中宣布了自己辞职的消息。她写道,作为理事会成员之一,罗马诺在决定谁获得该组织的年度奖以及哪些书要被评阅方面拥有强大的发言权,她指责赫策尔没有把他的名字指出来。在描述该组织根深蒂固的种族主义和反黑人文化时,她补充说,“从内部改变是不可能的。”
</p>
<p>
</p>
<p>
随之而来的是一波又一波的辞职浪潮,一些成员离开是为了抗议瓦布克在推特上发布理事会决定,因为他们觉得她没有准确地代表该组织,而另一些人是因为对NBCC摆脱困境的能力失去了信心。正如其中一位成员所言,整件事就像昆汀·塔伦蒂诺的电影一样,“怪异又血腥”。在强烈的反对声中,理事会在NBCC网站上发布了这份声明,并附上了一份承认高层辞职的通知。
</p>
<p>
</p>
<h4>
解体风波
</h4>
<p>
</p>
<p>
因抗议瓦布克推特帖子而辞职的成员还有现任主席赫策尔。她在接受采访时表示,“没有必要再在一个机密性遭到破坏的理事会任职。”不过,她还是后悔自己处理罗马诺邮件的方式。她说,理事会将一致投票支持该声明。她希望通过奉承罗马诺来防止他“扰乱讨论,破坏投票”。“其实我和他之间有一段很不好的记忆。”她补充道,在她竞选NBCC主席期间,罗马诺给NBCC理事会发了很多邮件,贬低她的人格,让她感到羞耻和不安,“从那以后,在他面前我都异常谨慎小心。”
</p>
<p>
</p>
<p>
自90年代中期以来,罗马诺断断续续在理事会任职。据十几名现任和前任成员说,他在该组织中一直表现出恃强凌弱的态度。其中一位成员伊斯梅尔·穆罕默德(Ismail Muhammad)说,在过去四年中,“他总是指责其他成员缺乏职业道德,还试图用他狭隘的观念告诉我们什么是文学叙事或文学批评。”
</p>
<p>
</p>
<p>
对于瓦布克口中关于他的种族主义和反黑人言论,罗马诺说,“几十年来,理事会一直致力于公正地评判各种带有政治色彩的书籍,但近年来,一些成员试图把它变成一个‘没有自由思想’的区域,一个意识形态上带有偏见的工具,用于他们自己的政治活动。在我看来,他们反对真正的批判性讨论。摆脱他们(指已辞职的成员)真是太好了。没有他们,NBCC会更健康。尽管有人一致反对,但我还是会努力留在组织,希望我能帮助NBCC回到过去的辉煌。”
</p>
<figure class="image-box dls-image-block dls-media-image">
<img src="//img.allhistory.com/5ef20bc2d7f8a70001be8ad3.png?imageView2/2/w/800"/>
<figcaption class="dls-image-capture">
<p>
2018年NBCC Awards获奖作家合影
</p>
</figcaption>
</figure>
<p>
随着理事会继续解体,一些成员希望通过撤掉罗马诺来挽救局面。但根据NBCC章程,任何一名理事会成员的罢免必须经过全员投票决定。6月12日,在得知有人讨论罢免他时,罗马诺通过电子邮件向理事会余下成员致信:
</p>
<blockquote>
<p>
如果你们继续试图投票让我退出理事会,我会以诽谤罪和其他诉讼理由起诉NBCC,也会以同样的理由对你们每个人提起诉讼。我将会一对一地发起诉讼,这将意味着没有人可以轻易帮你们支付个人法律费用。我有时间和精力,来吧,奉陪到底。
</p>
</blockquote>
<p>
之后,理事会一些成员还会见了律师,但律师称,根据伊利诺斯州501(c)(3)非营利组织的相关法律,仅凭他们自己的力量是无法将罗马诺移除组织的。
</p>
<p>
</p>
<p>
“罗马诺根本不可能被除名,”赫策尔补充道:“以前理事会也曾经尝试过(将他除名),每次他都威胁说要起诉整个组织和每一位成员。”针对这一说法,罗马诺依旧否认。
</p>
<p>
</p>
<h4>
一种新希望
</h4>
<p>
</p>
<p>
事实上,每一位辞职的黑人理事会成员都是出于不同的原因。哥伦比亚大学英语和比较文学副教授约翰·麦克沃特强调,他不支持瓦布克。和罗马诺一样,他也对出版业受到种族主义困扰的说法提出了质疑。麦克沃特说:“所有种族差异都不是由于偏见或结构性障碍造成的。”
</p>
<p>
</p>
<p>
他说,他离开是因为他觉得自己不再适应理事会文化,“不同意黑人关于种族问题的观点就是种族主义吗?我并不这么认为。”此前默罕默德决定离开,是因为对该组织的未来感到沮丧。但在上周一(6月15日)辞职后,他又感到些许乐观,“这让近一半成员加入到深刻的自我反省和实际改革中,也挺有意义的……改变是有途径的,也需要方法。他说,他期待着选举新的理事会成员,NBCC需要有新眼光的人。”
</p>
<p>
</p>
<p>
黑人作家、评论家亚当·以色列(Yahdon Israel)曾于2016年至2019年间在NBCC理事会任职,他说,在一个白人占多数的组织中,谈论有色人种作家的作品通常很困难,因为这个组织不愿公开将种族问题作为一本书的文学使命和价值的一部分来看待。他补充:“我的理解是,无论什么时候,一旦种族问题成为了一本书的核心,它也就成了最能削弱这本书完整性的东西”,“对我来说,为了谈论它,我必须用不那么真诚的语言来构建它。”
</p>
<p>
</p>
<p>
作为当时最年轻的成员,他还说,理事会在很大程度上也代表了出版和批评的一个新时代(a different era of publishing and criticism),“在这个时代,作为一名书评家意味着什么,这个组织并没有真正想清楚这个问题……罗马诺现在手上还抓着早已不存在的东西……组织刚成立的时候,书评业和现在还不太一样,书评文化约等于精英文化。有更多人拿着体面工资撰写书评,但这也是有代价的,做书评工作的很少是有色人种、女性和非白人男性。”
</p>
<p>
</p>
<p>
承诺条例指出,NBCC所处的行业中,代表人数过少一直是一个问题(Lee & Low Books在其2019年调查中指出,76%的出版员工是白人),但该承诺同时还指出,2019年BIPOC(Black, Indigenous, and People of Color)作家在NBCC获奖者和入围者中所占比例为30%,较2008年的22%有所上升。
</p>
<p>
</p>
<p>
“我们能够而且必须做得更好,”承诺中有一句话这样谈到,同时也代表着一种共同的希望。
</p>
<figure class="image-box dls-image-block dls-media-image">
<img src="//img.allhistory.com/5ef20c05a4188f0001a94119.png?imageView2/2/w/800"/>
<figcaption class="dls-image-capture">
<p>
</p>
</figcaption>
</figure>
<p>
<em>
参考来源:Lit Hub、Vulture、NPR
</em>
</p>
</div>
</div> | 5,885 | MIT |
# MCQRScan
一个轻量级的二维码扫描识别工具类,已解耦合,核心代码很少,容易理解,以及自定义自己的 界面的 UI样式。
## 一. 使用
简单的构建一个二维码扫描界面
```
// 添加扫描时显示摄像头画面的 view
_scanView = [[MCScanUIView alloc] initWithFrame:self.view.bounds];
_scanView.scanRect = CGRectMake(kX, kY, kW, kH);
[self.view addSubview:_scanView];
// 创建二维码扫描工具
_qrScaner = [[MCQRScaner alloc] init];
// 绑定摄像显示的 preview
[_qrScaner addPreview:preview];
// 打开相机识别二维码
[_qrScaner openCarmeraToScanQR:^(NSString * _Nonnull code) {
NSLog(@"code: %@", code);
}];
```
默认是二维码出现在屏幕里就开始识别,如果想要二维码进入边框后在识别,可以添加如下代码:
```
[_qrScaner setScanRetangleRect:CGRectMake(kX, kY, kW, kH)];
```
具体代码可见 Demo 代码。
## 二. 核心类
#### MCQRScaner
提供识别二维码的全部功能,包括打开相机识别二维码、 从图片中识别二维码、 检测当前相机环境的明暗度:
1.打开二维码识别:
```
/**
开启二维码扫描
@param complete 扫描到二维码的回调
*/
- (void)openCarmeraToScanQR:(MCQRScanerCompleteBlock )complete;
```
2.从图片识别二维码
```
/**
从图片中识别二维码
@param image 二维码图
*/
- (NSString *)scanQRFromImage:(UIImage *)image;
```
3.检测当前拍摄环境的明亮度,可用于在比较暗的环境下打开闪光灯
```
/**
开启亮度检测
@param monitorBlock 检测回调,可用于环境比较暗的时候开启闪光灯
*/
- (void)monitorBrightness:(MCQRScanerMonitorBrightnessBlock )monitorBlock;
```
#### MCScanUIView
提供了一个二维码扫描是界面方框绘制的一个样本代码,代码简单,容易理解,自己可以重新定义。
#### MCQRScanController
基于 `MCQRScaner` 与 `MCScanUIView` 写的一个简单的二维码扫描界面,通过它你能更好的理解 `MCQRScaner` 与 `MCScanUIView` 如何搭配来形成一个二维码扫描界面,当然你也可以直接使用 `MCQRScanController` 来实现效果。
#### Author
杭州魔厨科技-青芒小组- [email protected] | 1,392 | MIT |
# 编辑距离
给你两个单词 word1 和 word2,请你计算出将 word1 转换成 word2 所使用的最少操作数 。
你可以对一个单词进行如下三种操作:
- 插入一个字符
- 删除一个字符
- 替换一个字符
**示例1**
```
输入:word1 = "horse", word2 = "ros"
输出:3
解释:
horse -> rorse (将 'h' 替换为 'r')
rorse -> rose (删除 'r')
rose -> ros (删除 'e')
```
**示例2**
```
输入:word1 = "intention", word2 = "execution"
输出:5
解释:
intention -> inention (删除 't')
inention -> enention (将 'i' 替换为 'e')
enention -> exention (将 'n' 替换为 'x')
exention -> exection (将 'n' 替换为 'c')
exection -> execution (插入 'u')
```
## 动态规划
- 从`-1`位开始dp[0][0] = 0
- <img src="https://latex.codecogs.com/gif.latex?dp[i][j]&space;=&space;\left\{\begin{matrix}dp[i&space;-&space;1][j&space;-&space;1]&space;&&space;if(s[i&space;-&space;1]&space;===&space;p[j&space;-&space;1])&space;\\min\bigl(\begin{smallmatrix}dp[i&space;-&space;1][j&space;-&space;1]\\&space;dp[i&space;-&space;1][j]\\&space;dp[i][j&space;-&space;1]\end{smallmatrix}\bigr)&space;+&space;1&&space;else\end{matrix}\right." title="dp[i][j] = \left\{\begin{matrix}dp[i - 1][j - 1] & if(s[i - 1] === p[j - 1]) \\min\bigl(\begin{smallmatrix}dp[i - 1][j - 1]\\ dp[i - 1][j]\\ dp[i][j - 1]\end{smallmatrix}\bigr) + 1& else\end{matrix}\right." />
<div v-viewer>
<img style="width: 60%;position: relative;left: 20%;" :src="`${$cloudUrl}img/minDistance.png`"/>
</div>
```javascript
export const minDistance = (word1, word2) => {
const m = word1.length,
n = word2.length
const dp = []
for (let i = 0; i <= m; i++) {
dp[i] = [i]
}
for (let j = 0; j <= n; j++) {
dp[0][j] = j
}
/* dp[0][0] = 0
dp[1][0] = 1
dp[0][1] = 1 */
for (let i = 1; i <= m; i++) {
for (let j = 1; j <= n; j++) {
if (word1[i - 1] === word2[j - 1]) dp[i][j] = dp[i - 1][j - 1]
// index 从1开始, 所以比较[i - 1]与[j - 1]
else
dp[i][j] =
Math.min(
dp[i - 1][j - 1], // 替换
dp[i - 1][j], // 删除
dp[i][j - 1] // 增加
) + 1
}
}
return dp[m][n]
}
```
<CodeTest style="margin-top: 20px;" mode="minDistance" />
<vTalk /> | 2,026 | MIT |
!> new Set
ES6中新增了Set数据结构,类似于数组,但是它的成员都是唯一的,其构造函数可以接受一个数组作为参数
```js
let arr1 = [1,2,1,4,5,4];
let set = new Set(arr1);
console.log(set) // => Set(length) {1,2,4,5}
```
!> Array.from
ES6中Array新增了一个静态方法Array.from,可以把类似数组的对象转换为数组
```js
let arr1 = [1,2,1,4,5,4];
let set = new Set(arr1);
let arr2 = Array.from(set);
console.log(arr2) //=> [1,2,4,5]
```
### ES6方法
借用上面的例子可实现一行代码去重
```js
let array = Array.from(new Set([1,2,2,2,1,3]));
console.log(array) //[1,2,3]
```
### ES5方法
Es5实现数组去重(过滤NaN)
```js
//为了便于阅读,就多个var了
var arr1 = [0,'3',1,5,2,2,3,NaN,NaN,{}]
Array.prototype.uniq = function(){
var arr = [];
var flag = true;
this.forEach(function(item){
//排除NaN
if(item != item){
flag && arr.indexOf(item) === -1 ? arr.push(item) : '';
//阻止重复的NaN进入条件
flag = false;
}else{
arr.indexOf(item) === -1 ? arr.push(item) : '';
}
})
return arr;
}
arr1.uniq();
```
### ES6 数据对象去重
---
```javascript
//领取列表去重
let obj = {};
let arr = [{name:'male',id:1},{name:'lala',id:1},{name:'luce',id:0},{name:'lucced',id:5}];
let newarr = arr.reduce((cur, next) => {
obj[next.task_id] ? "" : (obj[next.task_id] = true && cur.push(next));
return cur;
}, []);
console.log(newarr, "去重后的数据");
```
<!-- ## 数组交集
---
### ES6
!> filter()方法创建一个新的数组,新数组中的元素是通过检查指定数组中符合条件的所有元素 true保留,false则不保留
```js
let a = new Set([1,1,12,0,3]);
let b = new Set([3,5,0,1]);
let result = [..a].filter(item=>b.has(item));
console.log(result); //[1,0,3]
``` --> | 1,551 | MIT |
---
layout: post
title: "Arduino & 溫度感測器"
date: 2019-11-24 18:09:11 +0800
categories: RaspberryPi LoRa
---
# Arduino & 溫度感測器
## 1. 將溫度感測器接上插上Arduino

[連接圖檔案]({{ "files/fz_sketch/2019-11-24_Arduino_DHT22.fzz" | relative_url }})
<!--[元件位置]({{ "files/fz_part/.fzpz" | relative_url }})-->
## 3. 程式碼
```cpp
#include "DHT.h"
#define DHTPIN 2
#define DHTTYPE DHT22
DHT dht(DHTPIN, DHTTYPE); // Initialize DHT sensor
void setup() {
Serial.begin(9600);
dht.begin();
}
void loop() {
delay(2000);
float h = dht.readHumidity();
float t = dht.readTemperature();
Serial.print("Humidity: ");
Serial.print(h);
Serial.println("%");
Serial.print("Temperature: ");
Serial.print(t);
Serial.println("*C");
}
```
## 4. 結果


 | 1,011 | CC-BY-4.0 |
---
layout: post
title: AsyncTask的缺陷和问题
date: 2016-09-21 19:23:11
---
### 1、first step
我们要在父类的FragmentActivity的onActivityResult中进行一步操作
```java
@Override
protected void onActivityResult(int requestCode, int resultCode, Intent data) {
super.onActivityResult(requestCode, resultCode, data);
/*在这里,我们通过碎片管理器中的Tag,就是每个碎片的名称,来获取对应的fragment*/
Fragment f = fragmentManager.findFragmentByTag(curFragmentTag);
/*然后在碎片中调用重写的onActivityResult方法*/
f.onActivityResult(requestCode, resultCode, data);
}
}
```
### 1、second step
在Fragment的onActivityResult获取返回值
```java
@Override
public void onActivityResult(int requestCode, int resultCode, Intent data) {
super.onActivityResult(requestCode, resultCode, data);
switch (requestCode) {
case1:
if (resultCode != Activity.RESULT_OK) {
return;
}
break;
default:
break;
}
}
``` | 1,001 | CC-BY-4.0 |
GCC和库文件
=========
## 前言
本文由 `xgfone` 整理!
**文档说明:**
本文大部分内容翻译自`GCC官方手册`(参考自`GCC4.6.1`手册),尤其是“`GCC命令行选项`”一节。如有翻译不当,请指明。
**本文参考书目:**
《Using the GNU Compiler Collection》(For GCC version 4.6.1)。
早期,GCC是“`GNU C Compiler`”之意,单指GNU生产的“`C语言编译器`”;现在,GCC是“`GNU Compiler Collection`”之意,指GNU生产的“`众多编程语言的编译器集合`”。
## 1、GCC所支持的常见后缀名
suffix | state
-------------------------------------|-----------------------------------------
.a | 静态库(文档)
.c | 需要预处理的C语言源代码
.h | C/C++语言源代码的头文件
.i | 经过预处理后的C语言源代码
.o | 目标文件(经过汇编产生的)
.s | 经过编译后产生的汇编语言代码(不需要再进行预处理)
.S .sx | 需要进程预处理的汇编语言代码
.so | 动态共享库
.C .c++ .cc .cpp .cp .cxx .CPP | 需要预处理的C++源代码
.hh .hpp .H .hp .hxx .HPP .h++ .tcc | C++头文件
## 2、GCC的编译流程
GCC的编译流程分为4个阶段:
### (1) 预处理(Preprocessing)
```shell
$ gcc -E file.c -o file.i
```
注:如果没有“`-o file.i`”,其结果只会输出到标准输出。
### (2) 编译(Compiling):生成汇编代码
```shell
$ gcc -S file.c
```
注:上述命令会自动生成`file.s`文件(不用添加“`-o`”选项)。如果编译多个源文件,会为每个源文件都生成一个汇编语言模块。
### (3) 汇编(Assembling):生成目标代码
```shell
$ gcc -c file.c
```
注:上述命令会自动生成`file.o`文件(不用添加“`-o`”选项)。
### (4) 链接(Linking):生成二进制可执行程序
```shell
$ gcc file.o // 生成a.out文件
$ gcc file.o -o file // 生成file文件
```
注:生成最终的可执行文件的命令如果没有用“`-o`”选项指定,则默认输出为`a.out`。
以上四步可以单独执行,也可以合并在一起形成一条命令执行(即,不添加任何“`-E`”、“`-S`”或“`-c`”选项)。
## 3、库文件的制作与使用
### (1) 创建静态库
静态库是一些`.o`文件的集合,它们是由编译程序按照通常的方式生成的。在编译链接时,链接器会把静态库文件的代码全部加入到可执行文件中,因此,生成的文件比较大,但在运行时也就不再需要库文件了,运行效率相对较快些。将程序连接到库中的目标文件和将程序连接到目录中的目标文件是一样的。静态库的另一个名字是文档(archive),而管理这些文档内容的工具叫做`ar`。
#### 制作静态库的一般步骤是
第一步,先生成目标文件(即.o文件): $ gcc -c file1.c file2.c
第二步,使用ar工具创建静态库: $ ar -r libfile.a file1.o file2.o
注:静态库的命名习惯以`lib`开头、以`.a`为后缀。
### (2) 静态库的使用
将程序和静态库链接起来的方式有两种:
**第一种:**在链接命令中指定静态库的名称:
```shell
$ gcc -o prog prog.c libdemo.a
```
**第二种:**将静态库放在链接器搜索的其中一个标准目录中,然后使用`-l`选项指定库名(即库的文件名去除了`lib`前缀和`.a`后缀):
```shell
$ gcc -o prog -ldemo
```
### (3) 创建动态共享库
与静态库相反,动态库在编译链接时并没有把库文件的代码加入到可执行文件中,而是在程序执行时由运行时链接文件加载动态库,这样可节省系统的开销。但相对静态库来说,效率会低一些。
动态库是目标文件的集合,但是这些目标文件是由编译程序按照特殊文件方式生成的。对象模块的每个地址(变量引用和函数调用等)都是相对地址,不是绝对地址。因此允许在运行程序时,可以动态地加载和执行共享库模块。
虽然共享库的代码是由多个进程共享的,但其中的变量却不是的。每个使用共享库的进程会拥有自己的库中定义的全局和静态变量的副本。
#### 制作动态库的一般步骤是
**第一步:**先生成目标文件(即.o文件,但要添加-fpic选项):
```shell
$ gcc -c -fpic file1.c file2.c
```
其中,`-c`指出编译器要生成`.o`目标文件,`-fpic`使得输出的对象模块是按照可重定位地址方式生成的,缩写`pic`代表`位置独立代码`(Position Independent Code)。
**第二步:**使用“`-shared`”选项生成动态库:
```shell
$ gcc -shared file1.o file2.o -o file.so
```
其中,`-shared`选项指出生成动态共享库。
说明:以上两条命令步骤可以合并成一个:
```shell
$ gcc -fpic -shared file1.c file2.c -o file.so
```
注:在生成最终的动态共享库(即上述的`file.so`)时,一定要使用“`-o`”选项,否则,默认生成`a.out`格式。
_以上是C语言的一般制作方法,但对于C++同样适用,只需要gcc换成g++,把其C文件换成C++文件即可。_
### (4) 共享库的使用
为了使用一个共享库就需要做两件事情(使用静态库的程序则无需完全这两件事情):
(1)将程序与共享库链接起来时自动会将库的名字嵌入可执行文件中;
(2)动态链接,即在运行时解析内嵌的库名(这个任务是由动态链接器来完成的)。
注:动态链接器本身也是一个共享库,共名称是 `/lib/ld-linux.so.2`。
注:GCC在链接时优先考虑共享库,其次才是静态库,如果希望GCC只考虑静态库,可以指定`-static`选项。
## 4、GCC命令行选项
### (1) 通用选项
#### -x language
为后面的输入文件显式地指定语言(而不是让编译器根据文件后缀挑选一个默认的)。
这个选项作用于下一个 -x 选项前的所有输入文件。该选项的有效值有:
c c-header cpp-output c++ c++-header c++-cpp-output
objective-c objective-c-header objective-c-cpp-output
objective-c++ objective-c++-header objective-c++-cpp-output
assembler assembler-with-cpp
ada
f77 f95 f77-cpp-input f95-cpp-input
go
java
#### -x none
关闭任何语言的指定,后序的文件将重新根据文件后缀来处理。
#### -c
编译或汇编源文件,但不链接,最终输出目标文件(.o)。
#### -S
在编译后停止,不进程汇编(即只编译、不汇编),其输出的是汇编源代码文件(.s,不需要再进行预处理)。
#### -E
在预处理后停止,不进行编译(即只预处理、不编译)。
其输出默认打印到标准输出,必须指定“-o”选项才能把预处理后的源代码输出到一个文件(.i或.ii)中。
#### -o file
把执行结果输出到file文件中,该选项可以用于任何阶段。
#### -v
把在编译阶段所要执行的命令打印到标准错误输出。
#### -###
同 -v 选项,但有区别,如:当前命令不会被执行。
#### --help
打印帮助信息到标准输出。
#### --version
打印GCC的版本号和版权。
### (2) C语言选项
#### -ansi
在C模式下,等价于 “-std=c90”;在C++模式下,等价于 “-std=c++98”。
该选项将关闭一些与ISO C90或C++标准不兼容的GCC特性。
#### -std=
决定语言的标准。该选项仅仅支持C/C++,其有效值有:
c90 c89 iso9899:1990 // ISO C90标准
iso9899:199409 // ISO C90修订案1
c99 c9x iso9899:1999 iso9899:199x // ISO C99标准,该标准没有完全被支持且“c9x”和“iso9899:199x”被废弃。
c1x // ISO C1x标准(下一个ISO C标准)
gnu90 gnu89 // ISO C90的GNU方言(包括一些C99特性),这是默认选项。
gnu99 gnu9x // ISO C99的GNU方言。当ISO C99完全被实现时,该选项将是默认选项,且“gnu9x”被废弃。
gnu1x // ISO C1x的GNU方言。
c++98 // ISO C++1998标准及其修订案(2003)。
gnu++98 // “-std=c++98”的GNU方言,这是C++的默认选项。
c++0x // 即将到来的ISO C++0x标准的工作草案。(译者注:2011年ISOC++标准委员会已经公布了C++11标准)。
gnu++0x // “-std=c++0x”的GNU方言。
#### -aux-info headerfilename
把定义或声明在一个翻译单元(即C语言源代码文件)中的所有函数的原型声明输出到headerfilename文件中。该选项仅用于C语言。
#### -traditional
兼容最原始的C语法检查。
### (3) 调试选项
#### -g
根据操作系统本地的格式产生调试信息到可执行文件中。GDB会使用这些信息。
#### -ggdb
同“-g”,但如果有可能,会包含一些GDB扩展。
#### -gcoff
同“-g”,但如果有可能,会产生COFF格式的信息。
#### -gxcoff
同“-g”,但如果有可能,会产生XCOFF格式的信息。
#### -gxcoff++
同“-gxcoff”,但会使用仅被GDB所理解的GNU扩展。
#### -gvms
同“-g”,但如果有可能,会产生VMS格式的信息。
#### -glevel
#### -ggdblevel
#### -gstabslevel
#### -gcofflevel
#### -gxcofflevel
#### -gvmslevel
要求调试信息,但也使用用来指定有多少调试信息的level等级。默认等级为2,有效的level值有0、1、2、3。
其中,0表示无调试信息,1表示最小的调试信息。
#### -gtoggle
关闭调试信息的产生,否则默认产生“-g2”。
### (4) 预处理选项
#### -D name
预定义name为一个宏,默认定义为1。
#### -D name=definition
预定义name为一个宏,真值为definition。
注:“-D”和“-U”的处理在“-imacros file”和“include file”之前。
#### -U name
取消名为name的宏定义。
#### -undef
不预定义任何由系统指定或GCC指定的宏。
#### -I dir
增加目录dir到头文件的搜索目录,并且dir优先于标准头文件库搜索。
#### -include file
如同源文件中的“#include “file””指令。
#### -imacros file
如同“-include file”选项,但file中被认为是宏定义。
### (5) 链接选项
#### -llibrary
#### -l library
当链接时搜索名为library的库。(注:第二个形式仅仅为POSIX相容。)
#### -s
从可执行文件中移除所有的符号表和重定位信息。
#### -static
在支持动态链接的系统上,该选项阻止编译器链接到动态共享库。在其他系统上,该选项无效。
#### -shared
产生一个能被链接到其它目标文件以产生一个可执行文件的共享库。注:并不是所有的系统都支持该选项。
#### -nostrtfiles
当链接时,不使用标准的系统启动文件,而标准系统库文件仍然能够正常被使用,
除非指定“-nostdlib”或“-nodefaultlibs”选项。
#### -nodefaultlibs
当链接时,不使用标准的系统库文件,而只有指定的库文件才被传递给链接器;
但是,标准的启动文件仍可正常使用,除非指定了“-nostartfiles”选项。
#### -nostdlib
等同于同时使用“-nostartfiles”和“-nodefaultlibs”两个选项,
即当链接时,不使用标准的系统启动文件和库文件,只有指定的启动文件和库文件才被传递给链接器。
#### -Wl,option
把option作为一个选项传递给链接器。如果option中包含逗号,它就在逗号处分隔多个选项
(译者注:即如果option中需要包含多个选项,可以用逗号隔开,而一次性传递,这在传递带参数的选项时非常有用)。
对于GNU链接器,可以把option中的逗号换成等号。
说明:W后面的l是字母L的小写,不是数字1。
#### -Xlinker option
把option作为一个选项传递给链接器。使用这个选项可以提供GCC无法识别的、待定系统上的链接选项。
如果传递一个带有参数的选项,必须使用两次“-Xlinker”,一次用于传递选项,另一次用于传递参数。
对于GNU链接器,可以使用“option=value”来传递带参数的选项,而不是使用两次“-Xlinker”。
#### -u symbol
假装取消symbol的符号定义,以强迫库模块间的链接去定义它。
可以多次使用带不同symbol的-u选项,以强迫额外的库模块的加载。
#### -T script
把script作为链接脚本来使用,该选项被大部分使用GNU链接器的系统所支持。
### (6) 目录搜索选项
#### -Idir
添加目录dir到头文件搜索目录,并且dir优先于系统头文件目录搜索,因此,dir中的头文件有可能被系统头文件覆盖。
#### -Ldir
添加目录dir到搜索“-l”的目录列表中(以搜索链接库)。
#### -Bprefix
指定在哪找到可执行文件、库文件、头文件(即include文件)、以及编译器自身的数据文件。
#### -iquotedir
添加目录dir到搜索头文件的目录列表中,它只适用于“#include “file””而不适用于“#include<file>”;
除此之外,它和“-I”一样。
#### -I-
被废弃,现在使用“-iquotedir”。
### (7) 警告选项
#### -w
关闭所有警告信息。
#### -Werror
把所有警告当作错误处理。
#### -pedantic
严格按照C/C++标准来提示警告信息。
#### -pedantic-errors
像“-pedantic”,但只产生错误信息而提示警告信息。
#### -Wall
打开所有的警告信息。
### (8) 优化选项
#### -O0
不优化。减少编译时间以及让调试产生所期望的结果。这是默认选项。
#### -O
#### -O1
对于大函数,该优化选项将占用较长的时间和相当大的内存。
使用该选项,编译器试图减少目标码的大小和执行时间,而不会执行任何将花费大量编译时间的优化。
说明:O后面的1是数字1,而不是字母L的小写。
#### -O2
除了-O指定的所有优化选项外,该选项还进行更多的优化。
除了涉及空间和速度交换的优化选项外,该选项将完成几乎所有的优化。
同-O选项相比,该选项虽然增加了编译时间,但也提高了生成代码的运行效果。
#### -O3
除了-O2指定的所有优化选项外,该选项还进行了更多的优化。
#### -Os
对代码尺寸大小的优化。该选项开启了-O2优化选项中不会增加代码尺寸大小的所有优化选项;
同时,它还完成了一些旨在减少代码大小的进一步的优化。
#### -Ofast
忽略应严格顺从的标准。
它不但开启了一些-O3指定的所有优化选项,还开启了一些对于所有顺从标准的程序并不是都有效的优化。
如果指定了多个“-O”选项,无论带不带表示优化等级的数字,有效的总是最后一个。
## 5、C++和C的混合编程
### (1) 在C++中调用C
在C++中调用C,就必须在C++文件中使用`extern`指令来声明 C函数 的头文件,而在C文件中则不需要这样的声明。一般使用`extern “C”`,其中的`“C”`并不是指`C语言`的意思,而是指`某种规则`,该规则命令为`“C”`。如:
```c++
/* c++.cpp */
extern “C” void csayhello(const char *str);
int main()
{
csayhello(“Hello from C++to C”);
return 0;
}
```
```c
/* csayhello.c */
#include <stdio.h>
void csayhello(const char *str)
{
printf(“%s\n”, str);
}
```
编译上面两个文件:
```shell
$ g++ -c c++.cpp -o c++.o
$ gcc -c csayhello.c -o csayhello.o
$ g++ c++.o csayhello.o -o program
```
### (2) 在C中调用C++
C++程序有责任为C程序提供C语言形式的接口。如:
```c++
/* c++sayhello.cpp */
#include <iostream>
extern “C” void c++sayhello(const char *str);
void c++sayhello(const char *str)
{
std::cout << str << endl;
}
```
```c
/* c.c */
void c++sayhello(const char *str);
int main(void)
{
c++sayhello(“Hello from C to C++”);
return 0;
}
```
编译上面两个文件:
```shell
$ g++ -c c++sayhello.cpp -o c++sayhello.o
$ gcc -c c.c -o c.o
$ gcc c++sayhello.o c.o -o program
```
## 6、共享库
### (1) 共享库版本和命名规则
共享库的每个不兼容版本是通过一个唯一的主要版本标识符来区分的,这个主要版本标识符是共享库的真实名称的一部分。根据惯例,主要版本标识符由一个数字构成,这个数字随着库的每个不兼容版本的发布而顺序递增。除了主要版本标识符之外,真实名称还包一个次要版本标识符,它用来区分库的主要版本中兼容的次要版本。真实名称的格式规范为 `libname.so.major-id.minor-id`。
与主要版本标识符一样,次要版本标识符可以是任意字符串。但根据惯例,它要么是一个数字,要么是两个由点分隔的数字,其中第一个数字标识出了次要版本,第二个数字表示该次要版本中的补丁号或修订号。
共享库的`soname`包括相应的真实名称中的主要版本标识符,但不包含次要版本标识符。因此,`soname`的形式为 `libname.so.major-id`。
通常会将 `soname` 创建为包含真实名称的目录中的一个相对符号链接。
除了真实名称和`soname`之外,通常还会为每个共享库定义第三个名称:`链接器名称`————将可执行文件与共享库链接起来时会用到这个名称。链接器名称是一个只包含库名同时不包含主要或次要版本标识符的符号链接,因此其形式为 `libname.so`。
### (2) 兼容与不兼容库比较
如果是兼容的话则意味着只需要修改库的真实名称的次要版本标识符即可,如果是不兼容的话则意味着必须要定义一个库的新主要版本。
当满足下列条件时表示修改过的库与既有库版本兼容:
A. 库中所有公共方法和变量的语义保持不变。
换句话说,每个函数的参数列表不变并且对全局变量和返回参数产生的影响不变,同时返回同样的结果值。
B. 没有删除库的公共API中的函数和变量,但向公共API中添加新函数和变量不会影响兼容性。
C. 在每个函数中分配的结构以及每个函数返回的结构保持不变。类似的,由库导出的公共结构保持不变。
这个规则的一个例外情况是在特定情况下,可能会向既有结构的结尾处添加新的字段,
但当调用程序在分配这个结构类型的数组时会产生问题。
如果所有这些条件都得到了满足,那么在更新新库名时就只需要调整既有名称中的次要版本号,否则就需要创建库的一个新主要版本。
### (3) 动态加载库
`dlopen API` 使得程序能够在运行时打开一个共享库,根据名字在库中搜索一个函数,然后调用这个函数。
在运行时采用这种方式加载的共享库通常被称为动态加载的库,它的创建方式与其他共享库的创建方式完全一样。
核心`dlopen API`由下列函数构成:
A. dlopen函数打开一个共享库,返回一个供后续调用使用的句柄;
B. dlsym函数在库中搜索一个符号(一个包含函数或变量的字符串)并返回其地址;
C. dlclose函数关闭之前由dlopen打开的库;
D. dlerror函数返回一个错误消息字符串,在调用上述函数中的某个函数发生错误时可以使用这个函数来获取错误消息。
要在Linux上使用 `dlopen API` 构建程序必须要指定 `-ldl` 选项以便与 `libdl` 库链接起来 。
如果 `dlopen` 会自动加载被依赖的库;如果有必要的话,这一过程会递归进行。
在同一个库文件中可以多次调用 `dlopen` 函数,但将库加载进内存的操作只会发生一次(第一次调用),所有的调用都返回同样的句柄值。
### (4) 初始化和终止函数
可以定义一个或多个在共享库被加载和卸载时自动执行的函数,这样在使用共享库时就能够完成一些初始化和终止工作了。不管库是自动被加载还使用 `dlopen` 接口加载的,初始化函数和终止函数都会被执行。
初始化和终止函数是使用 `GCC` 的 `constructor` 和 `destructor` 特性来定义折。在库被加载时需要执行的所有函数都应该定义成下面的形式:
```c
void __attribute__((constructor)) some_name_load(void)
{
/* Initialization code */
}
void __attribute__((destructor)) some_name_load(void)
{
/* Finalization code */
}
``` | 10,975 | MIT |
---
layout: post
category: swing
folder: MultipleButtonsInTableCell
title: JTableのセルに複数のJButtonを配置する
tags: [JTable, TableCellEditor, TableCellRenderer, JButton, JPanel, ActionListener]
author: aterai
pubdate: 2009-10-05T12:57:02+09:00
description: JTableのセル内にクリック可能な複数のJButtonを配置します。
image: https://lh4.googleusercontent.com/_9Z4BYR88imo/TQTQRygoYeI/AAAAAAAAAfU/-Sr9o7PsQkM/s800/MultipleButtonsInTableCell.png
hreflang:
href: https://java-swing-tips.blogspot.com/2009/10/multiple-jbuttons-in-jtable-cell.html
lang: en
comments: true
---
## 概要
`JTable`のセル内にクリック可能な複数の`JButton`を配置します。
{% download https://lh4.googleusercontent.com/_9Z4BYR88imo/TQTQRygoYeI/AAAAAAAAAfU/-Sr9o7PsQkM/s800/MultipleButtonsInTableCell.png %}
## サンプルコード
<pre class="prettyprint"><code>class ButtonsPanel extends JPanel {
public final List<JButton> buttons =
Arrays.asList(new JButton("view"), new JButton("edit"));
public ButtonsPanel() {
super();
setOpaque(true);
for (JButton b: buttons) {
b.setFocusable(false);
b.setRolloverEnabled(false);
add(b);
}
}
}
class ButtonsRenderer extends ButtonsPanel
implements TableCellRenderer {
public ButtonsRenderer() {
super();
setName("Table.cellRenderer");
}
@Override public Component getTableCellRendererComponent(JTable table,
Object value, boolean isSelected, boolean hasFocus, int row, int column) {
setBackground(isSelected?table.getSelectionBackground():table.getBackground());
return this;
}
}
class ButtonsEditor extends ButtonsPanel
implements TableCellEditor {
public ButtonsEditor(final JTable table) {
super();
// ---->
// DEBUG: view button click -> control key down + edit button(same cell) press
// -> remain selection color
MouseListener ml = new MouseAdapter() {
@Override public void mousePressed(MouseEvent e) {
ButtonModel m = ((JButton) e.getSource()).getModel();
if (m.isPressed() && table.isRowSelected(table.getEditingRow())
&& e.isControlDown()) {
setBackground(table.getBackground());
}
}
};
buttons.get(0).addMouseListener(ml);
buttons.get(1).addMouseListener(ml);
// <----
buttons.get(0).addActionListener(new ActionListener() {
@Override public void actionPerformed(ActionEvent e) {
fireEditingStopped();
JOptionPane.showMessageDialog(table, "Viewing");
}
});
buttons.get(1).addActionListener(new ActionListener() {
@Override public void actionPerformed(ActionEvent e) {
int row = table.convertRowIndexToModel(table.getEditingRow());
Object o = table.getModel().getValueAt(row, 0);
fireEditingStopped();
JOptionPane.showMessageDialog(table, "Editing: " + o);
}
});
addMouseListener(new MouseAdapter() {
@Override public void mousePressed(MouseEvent e) {
fireEditingStopped();
}
});
}
@Override public Component getTableCellEditorComponent(JTable table,
Object value, boolean isSelected, int row, int column) {
this.setBackground(table.getSelectionBackground());
return this;
}
@Override public Object getCellEditorValue() {
return "";
}
// Copied from AbstractCellEditor
// protected EventListenerList listenerList = new EventListenerList();
transient protected ChangeEvent changeEvent = null;
@Override public boolean isCellEditable(java.util.EventObject e) {
return true;
}
// ...
</code></pre>
## 解説
上記のサンプルでは、`CellRenderer`用と`CellEditor`用に`JButton`を`2`つ配置した`JPanel`をそれぞれ作成しています。`CellRenderer`用の`JButton`は表示のみに使用するため`Action`を設定するのは`CellEditor`用の`JButton`のみです。
- - - -
- `LookAndFeel`などが更新されたら`JTable#updateUI()`メソッド内で`SwingUtilities#updateRendererOrEditorUI()`メソッドを呼び出すなどして各セルレンダラーやセルエディタ(これらは`JTable`の子コンポーネントではないので)を更新
- `AbstractCellEditor`を継承するセルエディタは`Component`も`DefaultCellEditor`も継承していないので`LookAndFeel`を変更しても追従しない
- そのため`JTable#updateUI()`をオーバーライドしてセルエディタ自体を再作成するなどの対応が必要
- このサンプルでは、`Component`を継承(`TableCellEditor`を実装)するセルエディタを作成し、`AbstractCellEditor`から必要なメソッドをコピーして回避している
<!-- dummy comment line for breaking list -->
<pre class="prettyprint"><code>// SwingUtilities#updateRendererOrEditorUI()
static void updateRendererOrEditorUI(Object rendererOrEditor) {
if (rendererOrEditor == null) {
return;
}
Component component = null;
if (rendererOrEditor instanceof Component) {
component = (Component) rendererOrEditor;
}
if (rendererOrEditor instanceof DefaultCellEditor) {
component = ((DefaultCellEditor) rendererOrEditor).getComponent();
}
if (component != null) {
SwingUtilities.updateComponentTreeUI(component);
}
}
</code></pre>
- - - -
- `JSpinner`(`2`つの`JButton`と`JTextField`の組み合わせ)を`CellEditor`に使用する
- [JTableのCellEditorにJPanelを使用して複数コンポーネントを配置](https://ateraimemo.com/Swing/PanelCellEditorRenderer.html)に移動
<!-- dummy comment line for breaking list -->
## 参考リンク
- [JTableのセルにJButtonを追加して行削除](https://ateraimemo.com/Swing/DeleteButtonInCell.html)
- [JTableのセルにHyperlinkを表示](https://ateraimemo.com/Swing/HyperlinkInTableCell.html)
- [Table Button Column « Java Tips Weblog](https://tips4java.wordpress.com/2009/07/12/table-button-column/)
- [JTableのセル中にJRadioButtonを配置](https://ateraimemo.com/Swing/RadioButtonsInTableCell.html)
- [JTableのCellにJCheckBoxを複数配置する](https://ateraimemo.com/Swing/CheckBoxesInTableCell.html)
<!-- dummy comment line for breaking list -->
## コメント
- 第`0`列目が編集状態でボタンをクリックした場合、パネルが`2`度表示されるバグを修正。 -- *aterai* 2009-10-06 (火) 11:56:21
- [Table Button Column « Java Tips Weblog](https://tips4java.wordpress.com/2009/07/12/table-button-column/)を参考にして、`JTable#editCellAt`ではなく、逆に`TableCellEditor#stopCellEditing()`を使用してクリック直後に編集終了するように変更。 -- *aterai* 2009-11-03 (火) 04:36:55
- <kbd>Ctrl</kbd>キーを押しながら、`edit`ボタンをクリックすると異なる行(`table.getSelectedRow()`)の内容が表示されるバグを修正。 -- *aterai* 2011-03-10 (木) 02:35:35
- すごいと思いました! -- *いわく* 2013-05-24 (金) 11:57:26
- こんばんは。たしかに`JTable`の`TableCellRenderer`、`TableCellEditor`の仕組みは、すごい良くできているといつも感心してしまいます :) -- *aterai* 2013-05-24 (金) 23:59:16
<!-- dummy comment line for breaking list --> | 6,205 | MIT |
---
home: true
actionText: 起步 →
actionLink: /example/
features:
- title: 极简的思想
details: 面向对象, 参数集中处理, 以一个 table 对象来完成所有的操作
- title: 高度的灵活
details: 支持 element-ui table 组件的所有 api, slot, event,且不用担心版本升级问题
- title: 快捷的使用
details: 解决了 element-ui table 的潜在 bug, 集成了更方便好用的扩展功能
footer: MIT Licensed | Copyright ©agrss
---
<!-- <ClientOnly><test-table/></ClientOnly> -->
### 如此简单
```html
<template>
<agel-table v-model="table"></agel-table>
</template>
<script>
export default {
data() {
return {
table: {},
};
},
};
</script>
``` | 572 | MIT |
---
id: 239-max-sliding-window
title: 滑动窗口最大值
sidebar_label: 239. 滑动窗口最大值
keywords:
- Sliding Window
---
:::success Tips
题目类型: 滑动窗口
相关题目:
- [3. 无重复字符的最长子串](/leetcode/medium/3-length-of-longest-substring)
- [76. 最小覆盖子串](/leetcode/hard/76-min-window)
- [209. 长度最小的子数组](/leetcode/medium/209-min-sub-array-len)
- [424. 替换后的最长重复字符](/leetcode/medium/424-character-replacement)
- [438. 找到字符串中所有字母异位词](/leetcode/medium/438-find-anagrams)
- [567. 字符串的排列](/leetcode/medium/567-check-inclusion)
:::
## 题目
给你一个整数数组 nums, 有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧. 你只可以看到在滑动窗口内的 k 个数字. 滑动窗口每次只向右移动一位. 返回滑动窗口中的最大值.
:::info 示例
```ts
输入: nums = [1,3,-1,-3,5,3,6,7], k = 3
输出: [3,3,5,5,6,7]
滑动窗口的位置 最大值
--------------- -----
[1 3 -1] -3 5 3 6 7 3
1 [3 -1 -3] 5 3 6 7 3
1 3 [-1 -3 5] 3 6 7 5
1 3 -1 [-3 5 3] 6 7 5
1 3 -1 -3 [5 3 6] 7 6
1 3 -1 -3 5 [3 6 7] 7
```
:::
## 题解
### 直观解法
像我这种垃圾, 菜鸡, 废物一开始肯定会这么写, 心里还在嘲笑一道 hard 为什么简单, 直到提交的时候告诉我 Time Limit Exceeded.
```ts
/**
* @param {number[]} nums
* @param {number} k
* @return {number[]}
*/
var maxSlidingWindow = function (nums, k) {
let left = 0,
right = k
const res = []
while (right <= nums.length) {
const sub = nums.slice(left, right)
const max = Math.max(...sub)
res.push(max)
left++
right++
}
return res
}
```
### 优雅解法
使用双端队列, 队首始终保存窗口中最大的元素(滑进窗口的那个数要通过与队尾比较找到属于自己的位置, 比队尾大要不断弹出队尾, 把自己插进去; 比队尾小则让自己成为队尾), 在窗口滑动过程中检查最大值是否还在窗口内, 否则就弹出. 这样记录下每次滑动时的队首就行了.
```ts
/**
* @param {number[]} nums
* @param {number} k
* @return {number[]}
*/
var maxSlidingWindow = function (nums, k) {
// deque 中存储的是 nums 中每个元素的下标
const deque = []
const maxs = []
const len = nums.length
if (len === 0 && k <= 0) return maxs
for (let i = 0; i < len; i++)
// 如果队列不为空且队尾对应的元素小于当前遍历到的值,
// 则弹出当前队尾, 直到队尾没有小于 i 所对应的元素,
// 这样就确保了队首对应的元素始终是最大的.
while (deque.length !== 0 && nums[deque[deque.length - 1]] <= nums[i]) {
deque.pop()
}
// 队尾弹入 i
deque.push(i)
// 如果队首所对应的元素不在窗口内, 则弹出
if (deque[0] <= i - k) {
deque.shift()
}
// 只有当 i 大于等于窗口大小时才能写入窗口的最大值
if (i >= k - 1) {
maxs.push(nums[deque[0]])
}
}
return maxs
}
``` | 2,268 | MIT |
## codeLineCount
[](https://nodei.co/npm/code-rows-count/)
一个用来统计项目内代码行数的工具.
## Installation
```
$ npm install -g code-rows-count
```
or
```
$ yarn global add code-rows-count
```
## Usage
```
$ codeLineCount -h
Usage: codeLineCount [options]
Options:
-V, --version output the version number
-p, --filePath [filePath] 文件路径
-i, --ignoreFile [ignoreFile] 忽略文件
-h, --help output usage information
```
> -p: 需要统计代码行数项目的绝对路径
> -i: 不需要参与统计的项目内的文件名, 多个文件名使用逗号分割
example:
```
$ codeLineCount -p /home/silence/nodejs/test -i node_modules,yarn.lock,.git,package.json.lock
文件路径:/home/silence/nodejs/test/color.js, 文件行数:19
文件路径:/home/silence/nodejs/test/commander.js, 文件行数:14
文件路径:/home/silence/nodejs/test/http.js, 文件行数:6
文件路径:/home/silence/nodejs/test/package.json, 文件行数:6
文件路径:/home/silence/nodejs/test/aaa/color.js, 文件行数:19
------------------分割线start------------------
done, 总耗时: 5 ms
总文件数:5, 总代码行数: 64
------------------分割线end------------------
```
## License
[MIT](LICENSE)
<!-- ## 代码提交规范 -->
<!-- -->
<!-- 1. 安装 [Commitizen](https://github.com/commitizen/cz-cli) 工具 -->
<!-- -->
<!-- ``` -->
<!-- $ npm install -g commitizen -->
<!-- ``` -->
<!-- -->
<!-- 2. 替换 `git commit` 命令 -->
<!-- -->
<!-- ``` -->
<!-- $ git cz -->
<!-- ``` -->
<!-- 3. git cz以后会出现选项框用于选择本次提交的内容类型 -->
<!-- ``` -->
<!-- feat:新功能(feature) -->
<!-- fix:修补bug -->
<!-- docs:文档(documentation) -->
<!-- style: 格式(不影响代码运行的变动) -->
<!-- refactor:重构(即不是新增功能,也不是修改bug的代码变动) -->
<!-- perf: 提高性能的代码 -->
<!-- test:增加测试 -->
<!-- build: 影响构建系统或外部依赖项的更改 -->
<!-- ci: 修改ci配置文件或者脚本 -->
<!-- chore:构建过程或辅助工具的变动 -->
<!-- revert: 恢复之前的提交 -->
<!-- ``` -->
<!-- 4. 选择以后会出现Denote the scope of this change ($location, $browser, $compile, etc.) 用于输入本次提交改变的功能范围 -->
<!-- 5. 然后出现Write a short, imperative tense description of the change 用于输入本次提交内容的概要 -->
<!-- 6. Provide a longer description of the change,用于输入本次提交内容的详细 描述 -->
<!-- 7. List any breaking changes,用于输入本次提交的重要变更内容 -->
<!-- 8. List any issues closed by this change 用于输入本次提交解决的问题 --> | 2,194 | MIT |
---
layout: post
title: go 双向链表 DoublyLinkedList
category: Go
tags: centos,ftp,Apache,GPL,LGPL,MIT
description:
---
https://www.cnblogs.com/manji/p/4903990.html
```javascript
package main
/*
双向链表也叫双链表,是链表的一种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。所以,从双向链表中的任意一个结点开始,都可以很方便地访问它的前驱结点和后继结点。一般我们都构造双向循环链表。
*/
func main() {
}
type Node struct {
data int
next *Node
prev *Node
}
type LinkedList struct {
head *Node
tail *Node
}
func (list *LinkedList) InsertList(i int){
data := &Node{data:i}
if list.head != nil {
list.head.prev = data
data.next = list.head
}
list.head = data
}
func (list *LinkedList)InsertLast(i int){
data := &Node{data:i}
if list.head == nil {
list.head = data
list.tail = data
return
}
if list.tail != nil{
list.tail.next = data
data.prev = list.tail
}
list.tail = data
}
func (list *LinkedList) RemoveByValue(i int) bool{
if list.head == nil {
return false
}
if list.head.data == i {
list.head = list.head.next
list.head.prev = nil
return true
}
if list.tail.data == i {
list.tail = list.tail.prev
list.tail.next = nil
return true
}
current := list.head
for current.next != nil {
if current.next.data == i {
if current.next.next != nil {
current.next.next.prev = current
}
current.next = current.next.next
return true
}
current = current.next
}
return false
}
func (list *LinkedList)RemovedByIndex(i int) bool {
if list.head == nil {
return false
}
if i < 0 {
return false
}
if i == 0 {
list.head.prev = nil
list.head = list.head.next
return true
}
current := list.head
for u := 1; u < i;u ++ {
if current.next.next == nil {
return false
}
current = current.next
}
if current.next.next != nil {
current.next.next.prev = current
}
current.next = current.next.next
return true
}
func (list *LinkedList) SearchValue (i int) bool {
if list.head == nil {
return false
}
current := list.head
for current != nil {
if current.data == i {
return true
}
current = current.next
}
return false
}
func (list *LinkedList) GetFirst() (int,bool){
if list.head == nil {
return 0,false
}
return list.head.data,true
}
func (list *LinkedList)Getlast() (int,bool){
if list.head == nil {
return 0,false
}
current := list.head
for current.next != nil {
current = current.next
}
return current.data,true
}
func (list *LinkedList)GetSize() int {
count := 0
current := list.head
for current != nil {
count += 1
current = current.next
}
return count
}
func (list *LinkedList)GetItemsFromStart() []int {
var items []int
current := list.head
for current != nil{
items = append(items,current.data)
current = current.next
}
return items
}
func (list *LinkedList)GetItemsFromEnd() []int {
var items []int
current := list.tail
for current != nil{
items = append(items,current.data)
current = current.prev
}
return items
}
```
---
<script language="javascript" type="text/javascript" src="//js.users.51.la/19176892.js"></script>
<noscript><a href="//www.51.la/?19176892" target="_blank"><img alt="我要啦免费统计" src="//img.users.51.la/19176892.asp" style="border:none" /></a></noscript> | 3,045 | MIT |
---
title: "我的邻居爱丽丝在 Binance 上推出 NFT 销售"
date: 2021-07-30T21:57:40+08:00
lastmod: 2021-07-30T16:45:40+08:00
draft: false
authors: ["Zachariah"]
description: "以构建社区为基础的区块链游戏《爱丽丝邻居》正式上线币安NFT新商城独家NFT系列。他们将其称为 Midsummer with Alice,这是新玩家和现有玩家获取新 NFT 的绝佳方式。"
featuredImage: "my-neighbor-alice-launches-nft-sale-on-binance.png"
tags: ["Strategy Game","策略游戏","Play to Earn"]
categories: ["news"]
news: ["策略游戏"]
weight:
lightgallery: true
pinned: false
recommend: false
recommend1: false
---
以构建社区为基础的区块链游戏《爱丽丝邻居》正式上线币安NFT新商城独家NFT系列。他们将其称为 Midsummer with Alice,这是新玩家和现有玩家获取新 NFT 的绝佳方式。
<!--more--> | 594 | MIT |
---
layout: post
title: "【文明客厅读书会|巫一毛课堂 第4期 总第198期】Emily Wu Feather in the Storm Chapter 4 English Version"
date: 2021-08-06T01:00:20.000Z
author: 文明客厅周孝正
from: https://www.youtube.com/watch?v=hF90Fd4TvVs
tags: [ 文明客厅周孝正 ]
categories: [ 文明客厅周孝正 ]
---
<!--1628211620000-->
[【文明客厅读书会|巫一毛课堂 第4期 总第198期】Emily Wu Feather in the Storm Chapter 4 English Version](https://www.youtube.com/watch?v=hF90Fd4TvVs)
------
<div>
《暴风雨中一羽毛——动乱中失去的童年》巫一毛著Feather in the Storm--A Childhood Lost in Chaos by Emily Wu
</div> | 505 | MIT |
# [Leetcode-4/30][Array] #1 Two Sum
## #1 Two Sum
#### 題目難度:Easy :star:
#### 題目敘述:
```
Given an array of integers, return indices of the two numbers such that they add up to a specific target.
You may assume that each input would have exactly one solution.
Example:
Given nums = [2, 7, 11, 15], target = 9,
Because nums[0] + nums[1] = 2 + 7 = 9,
return [0, 1].
```
#### 題目解答:
```javascript
/**
* @param {number[]} nums
* @param {number} target
* @return {number[]}
*/
const twoSum = (nums, target) => {
let num_1, num_2;
let numbers = [];
for(let i = 0; i < nums.length; i++) {
num_1 = nums[i];
num_2 = target - num_1;
if(numbers.indexOf(num_2) !== -1) {
return [numbers.indexOf(num_2), i];
} else {
numbers[i] = num_1;
}
}
};
```
#### 題目連結:[1. Two Sum](https://leetcode.com/problems/two-sum/)
#### 解題說明:
今天是第四天啦~結束了字串 `String` 篇,接下來三天主題是陣列 `Array`!
既然是 `Array` 第一天,當然就要先從最簡單的題目開始囉,所以今天來解 `LeetCode` 題庫第一題 [1. Two Sum](https://leetcode.com/problems/two-sum/),
題目是給**一個陣列**和**一個數字**,數字會是這個陣列裡的某兩個數字的總和,答案就是**這兩個數字在陣列的位置**,看他給的範例就能秒懂了~
這題用到最基本的 `Array`,沒有什麼花俏的演算法,所以請輕鬆服用即可!
#### 解題步驟:
- 步驟 1.
宣告我們需要變數,
`num_1` 跟 `num_2` 分別代表**目前數字**跟**需求數字**,
什麼事**需求數字**呢?下一個步驟會說明~
`numbers[]` 則是用來存已經掃過的數字。
```javascript
let num_1, num_2;
let numbers = [];
```
- 步驟 2.
最外層的 `for` loop 就是一個一個掃過去陣列,
然後將 `num_1` 存目前的數字,`num_2` 是 `num_1` 跟 `target` 的差距,
因為題目要我們找兩個數字的總和,所以思路是:
**存一個目前的數字,找之前掃過的數字中有沒有剛好加起來是 `target` 的數字**,如果有的話那很好,直接 ```return [numbers.indexOf(num_2), i];``` ,就是答案需要的 **`[位置1, 位置2]`** !
但不幸如果找不到的話,也沒什麼,就存在 `numbers[]` 裡就好,以備未來不實之用!
完成!
備註:[`indexOf()`](http://www.w3schools.com/jsref/jsref_indexof.asp) 的用法,就是在 `Array` 中找出指定東西的位置,是不是非常好用呢~~
```javascript
for(let i = 0; i < nums.length; i++) {
num_1 = nums[i];
num_2 = target - num_1;
if(numbers.indexOf(num_2) !== -1) {
return [numbers.indexOf(num_2), i];
} else {
numbers[i] = num_1;
}
}
``` | 1,962 | MIT |
# AuthorizationPolicy
`AuthorizationPolicy`(授权策略)实现了对网格中工作负载的访问控制。
授权策略支持访问控制的 `CUSTOM`、`DENY` 和 `ALLOW` 操作。当 `CUSTOM`、`DENY` 和 `ALLOW` 动作同时用于一个工作负载时,首先评估 `CUSTOM` 动作,然后是 `DENY` 动作,最后是 `ALLOW` 动作。评估是按以下顺序进行:
1. 如果有任何 `CUSTOM` 策略与请求相匹配,如果评估结果为拒绝,则拒绝该请求。
2. 如果有任何 `DENY` 策略与请求相匹配,则拒绝该请求。
3. 如果没有适合该工作负载的 `ALLOW` 策略,允许该请求。
4. 如果有任何 `ALLOW` 策略与该请求相匹配,允许该请求。
5. 拒绝该请求。
Istio 授权策略还支持 `AUDIT` 动作,以决定是否记录请求。`AUDIT` 策略不影响请求是否被允许或拒绝到工作负载。请求将完全基于 `CUSTOM`、`DENY` 和 `ALLOW` 动作被允许或拒绝。
如果工作负载上有一个与请求相匹配的 AUDIT 策略,则请求将被内部标记为应该被审计。必须配置并启用一个单独的插件,以实际履行审计决策并完成审计行为。如果没有启用这样的支持插件,该请求将不会被审计。目前,唯一支持的插件是 [Stackdriver](https://preliminary.istio.io/latest/docs/reference/config/proxy_extensions/stackdriver/) 插件。
## 示例
下面是一个 Istio 授权策略的例子。
它将 `action` 设置为 `ALLOW` 来创建一个允许策略。默认动作是 `ALLOW`,但在策略中明确规定是很有用的。
它允许请求来自:
- 服务账户 `cluster.local/ns/default/sa/sleep` 或
- 命名空间 `test`
来访问以下工作负载:
- 在前缀为 `/info` 的路径上使用 `GET` 方法,或者
- 在路径 `/data` 上使用 `POST` 方法
且当请求具有由 `https://accounts.google.com` 发布的有效 JWT 令牌时。
任何其他请求将被拒绝。
```yaml
apiVersion: security.istio.io/v1beta1
kind: AuthorizationPolicy
metadata:
name: httpbin
namespace: foo
spec:
action: ALLOW
rules:
- from:
- source:
principals: ["cluster.local/ns/default/sa/sleep"]
- source:
namespaces: ["test"]
to:
- operation:
methods: ["GET"]
paths: ["/info*"]
- operation:
methods: ["POST"]
paths: ["/data"]
when:
- key: request.auth.claims[iss]
values: ["https://accounts.google.com"]
```
下面是另一个例子,它将 `action` 设置为 `DENY` 以创建一个拒绝策略。它拒绝来自 `dev` 命名空间对 `foo` 命名空间中所有工作负载的 `POST` 请求。
```yaml
apiVersion: security.istio.io/v1beta1
kind: AuthorizationPolicy
metadata:
name: httpbin
namespace: foo
spec:
action: DENY
rules:
- from:
- source:
namespaces: ["dev"]
to:
- operation:
methods: ["POST"]
```
下面的授权策略将 `action` 设置为 `AUDIT`。它将审核任何对前缀为 `/user/profile` 的路径的 GET 请求。
```yaml
apiVersion: security.istio.io/v1beta1
kind: AuthorizationPolicy
metadata:
namespace: ns1
name: anyname
spec:
selector:
matchLabels:
app: myapi
action: AUDIT
rules:
- to:
- operation:
methods: ["GET"]
paths: ["/user/profile/*"]
```
授权策略的范围(目标)由 `metadata`/`namespace` 和一个可选的 `selector` 决定。
- `metadata`/`namespace` 告诉策略适用于哪个命名空间。如果设置为根命名空间,该策略适用于网格中的所有命名空间。
- 工作负载 `selector` 可以用来进一步限制策略的适用范围。
例如,以下授权策略适用于 `bar` 命名空间中包含标签 `app: httpbin` 的工作负载。
```yaml
apiVersion: security.istio.io/v1beta1
kind: AuthorizationPolicy
metadata:
name: policy
namespace: bar
spec:
selector:
matchLabels:
app: httpbin
```
以下授权策略适用于命名空间 `foo` 中的所有工作负载。
```yaml
apiVersion: security.istio.io/v1beta1
kind: AuthorizationPolicy
metadata:
name: policy
namespace: foo
spec:
{}
```
以下授权策略适用于网格中所有命名空间中包含标签 `version: v1` 的工作负载(假设根命名空间被配置为 `istio-config`)。
```yaml
apiVersion: security.istio.io/v1beta1
kind: AuthorizationPolicy
metadata:
name: policy
namespace: istio-config
spec:
selector:
matchLabels:
version: v1
```
- 关于 `AuthorizationPolicy` 配置的详细用法请参考 [Istio 官方文档](https://istio.io/latest/docs/reference/config/security/authorization-policy/)。
- 关于认证策略条件的详细配置请参考 [Istio 官方文档](https://preliminary.istio.io/latest/docs/reference/config/security/conditions/)。
## 参考
- [Authorization Policy - istio.io](https://istio.io/latest/docs/reference/config/security/authorization-policy/)
- [Authorization Policy Conditions - istio.io](https://istio.io/latest/docs/reference/config/security/conditions/) | 3,488 | Apache-2.0 |
**策略模式(Strategy Pattern)——算法的封装与切换**
说明:设计模式系列文章是读`刘伟`所著`《设计模式的艺术之道(软件开发人员内功修炼之道)》`一书的阅读笔记。个人感觉这本书讲的不错,有兴趣推荐读一读。详细内容也可以看看此书作者的博客`https://blog.csdn.net/LoveLion/article/details/17517213`。
## 模式概述
俗话说:条条大路通罗马。在很多情况下,实现某个目标的途径不止一条,例如我们在外出旅游时可以选择多种不同的出行方式,如骑自行车、坐汽车、坐火车或者坐飞机。
这就是变化的地方,可根据实际情况(距离、预算、时间、舒适度等)来选择一种出行方式。
在软件开发中,也常会遇到类似的情况,实现某一个功能有多种算法,此时就可以使用一种设计模式来实现灵活地选择解决途径,也能够方便地增加新的解决途径。
下面介绍一种为了适应算法灵活性而产生的设计模式——策略模式。
### 模式定义
策略模式的主要目的是将算法的定义与使用分开,也就是将算法的行为和环境分开。
将算法的定义放在专门的策略类中,每一个策略类封装了一种实现算法,使用算法的环境类针对抽象策略类进行编程,符合`依赖倒转原则`。在出现新的算法时,只需要增加一个新的实现了抽象策略类的具体策略类即可。
策略模式定义如下:
> 策略模式(`Strategy Pattern`):定义一系列算法类,将每一个算法封装起来,并让它们可以相互替换,策略模式让算法独立于使用它的客户而变化,也称为政策模式(`Policy`)。策略模式是一种对象行为型模式。
### 模式结构图
策略模式结构并不复杂,但我们需要理解其中环境类`Context`的作用,其结构如下图所示:
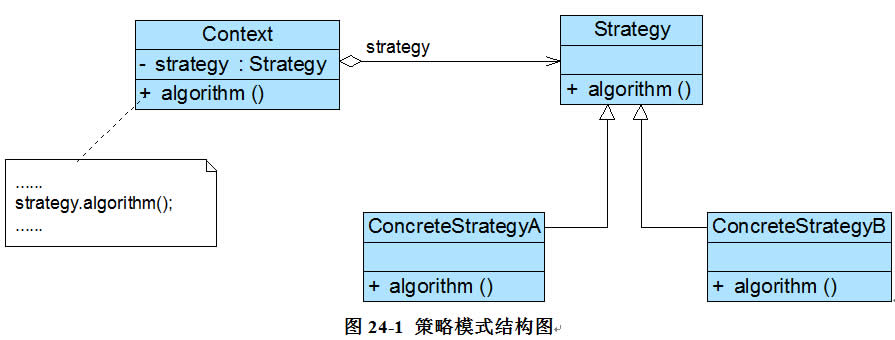
在策略模式结构图中包含如下几个角色:
- `Context`(环境类):环境类是使用算法的角色,它在解决某个问题(即实现某个方法)时可以采用多种策略。在环境类中维持一个对抽象策略类的引用实例,用于定义所采用的策略。
- `Strategy`(抽象策略类):它为所支持的算法声明了抽象方法,是所有策略类的父类,它可以是抽象类或具体类,也可以是接口。环境类通过抽象策略类中声明的方法在运行时调用具体策略类中实现的算法。
- `ConcreteStrategy`(具体策略类):它实现了在抽象策略类中声明的算法,在运行时,具体策略类将覆盖在环境类中定义的抽象策略类对象,使用一种具体的算法实现某个业务处理。
### 模式伪代码
抽象策略类(`Strategy`)典型代码如下:
```java
/**
* 定义抽象算法
*/
public interface Strategy {
void algorithm();
}
```
具体策略类(`ConcreteStrategy`)封装每一种具体的算法,典型代码如下:
```java
/**
* 一种具体的算法
*/
public class ConcreteStrategy implements Strategy {
@Override
public void algorithm() {
// 具体的算法实现
}
}
```
`Context`引用抽象策略,典型代码如下:
```java
public class Context {
// 抽象策略
private Strategy strategy;
/**
* 业务逻辑
*/
public void service() {
// ...
// 调用具体的算法实现
strategy.algorithm();
// ...
}
}
```
这样就将算法的定义和使用分离开来,可独立扩展新的算法。
## 模式应用
待完善。
## 模式总结
策略模式提供了一种可插拔式(`Pluggable`)算法的实现方案。
策略模式实用性强、扩展性好,在软件开发中得以广泛使用,是使用频率较高的设计模式之一。
### 主要优点
- 符合开闭原则,可以在不修改原有系统的基础上选择算法或行为,也可以灵活地增加新的算法或行为
- 将算法的定义和使用分离开来,符合单一职责原则,可最大程度地复用算法
### 主要缺点
系统可能会产生很多具体策略类。
### 适用场景
策略模式用于算法的自由切换和扩展。
策略模式对应于解决某一问题的一个算法族,允许用户从该算法族中任选一个算法来解决某一问题,同时可以方便地更换算法或者增加新的算法。
只要涉及到算法的封装、复用和切换都可以考虑使用策略模式。 | 2,111 | MIT |
---
layout: post
category: swing
folder: LeftScrollBar
title: JScrollBarをJScrollPaneの左と上に配置
tags: [JScrollBar, JScrollPane, BorderLayout]
author: aterai
pubdate: 2007-01-08T14:26:45+09:00
description: JScrollBarの配置位置を、JScrollPaneの左側、上側に変更します。
image: https://lh6.googleusercontent.com/_9Z4BYR88imo/TQTPG13yZbI/AAAAAAAAAdc/1a4aTgyblRo/s800/LeftScrollBar.png
comments: true
---
## 概要
`JScrollBar`の配置位置を、`JScrollPane`の左側、上側に変更します。
{% download https://lh6.googleusercontent.com/_9Z4BYR88imo/TQTPG13yZbI/AAAAAAAAAdc/1a4aTgyblRo/s800/LeftScrollBar.png %}
## サンプルコード
<pre class="prettyprint"><code>scroll.setComponentOrientation(ComponentOrientation.RIGHT_TO_LEFT);
JPanel panel = new JPanel(new BorderLayout());
int w = scroll.getVerticalScrollBar().getPreferredSize().width;
panel.add(Box.createHorizontalStrut(w), BorderLayout.WEST);
panel.add(scroll.getHorizontalScrollBar(), BorderLayout.CENTER);
add(panel, BorderLayout.NORTH);
add(scroll, BorderLayout.CENTER);
</code></pre>
## 解説
- 水平スクロールバーを右から左に移動
- パネルのレイアウトに`BorderLayout`を設定して`JScrollPane`をそのパネルの中央(`BorderLayout.CENTER`)に追加し、`JScrollPane#setComponentOrientation(...)`メソッドで`ComponentOrientation.RIGHT_TO_LEFT`を設定
- 垂直スクロールバーを下から上に移動
- `JScrollPane#getHorizontalScrollBar()`メソッドでスクロールバーを取得し、パネルレイアウトを使って`JScrollPane`の上部(`BorderLayout.NORTH`)に配置されているように表示
- 左上隅の余白は`Box.createHorizontalStrut(縦スクロールバーの幅)`で埋める
<!-- dummy comment line for breaking list -->
## 参考リンク
- [Swing - JScrollPane with scroll bar on the left](https://community.oracle.com/thread/1375964)
- [2000ピクセル以上のフリー写真素材集](http://sozai-free.com/)
- [JScrollBarのButtonの位置を変更](https://ateraimemo.com/Swing/ScrollBarButtonLayout.html)
<!-- dummy comment line for breaking list -->
## コメント
- グッド -- *a1* 2008-12-26 (金) 13:52:59
- どうもです。 -- [aterai](https://ateraimemo.com/aterai.html)
<!-- dummy comment line for breaking list --> | 1,866 | MIT |
---
layout: post
category: Leetcode
title: Maximum Subarray
tags: Algorithm Leetcode
---
  给定一个数组,找出其中和最大的子串长度。比如对于`[−2,1,−3,4,−1,2,1,−5,4]`,和最大的连续子串为`[4,−1,2,1]`,即最大的和为6.
<!--more-->
  比较简单的一个题目,但是开始做的时候,没考虑好,陷入了一个死胡同,一直纠结设定一个cur指针,如何调整cur指针的位置。事实上,遍历一遍是肯定的,在遍历的过程中,纪录tSum的值,更新mSum的值。比较关键的一点就是,当前元素的值比tSum的值大时,直接tSum=nums[i],相当于更新了cur指针的位置。
{% highlight C++ %}
//时间、空间复杂度都是O(n)
class Solution {
public:
int maxSubArray(vector<int>& nums) {
int mSum = INT_MIN, tSum = 0;
for (int i = 0; i < nums.size(); ++i) {
tSum += nums[i];
if (nums[i] > tSum)
tSum = nums[i];
mSum = tSum > mSum ? tSum : mSum;
}
return mSum;
}
};
{% endhighlight %} | 766 | MIT |
---
title: "Gamee 在 12 月停止第二次 G-Bots 销售"
date: 2021-11-15T21:57:40+08:00
lastmod: 2021-11-15T16:45:40+08:00
draft: false
authors: ["Justin"]
description: "Gamee 宣布他们将于 12 月 9 日出售第二批 G-Bots NFT。在即将到来的销售中,他们将售出 3800 包,在撰写本文时,最便宜的售价为 100 GMEE 或大约 32 美元。最昂贵的将花费 5000 GMEE 或 1580 美元。"
featuredImage: "gamee-dropping-second-g-bots-sale-in-december.png"
tags: ["Virtual World","虚拟世界","Play to Earn"]
categories: ["news"]
news: ["虚拟世界"]
weight:
lightgallery: true
pinned: false
recommend: false
recommend1: false
---
Gamee 宣布他们将于 12 月 9 日出售第二批 G-Bots NFT。在即将到来的销售中,他们将售出 3800 包,在撰写本文时,最便宜的售价为 100 GMEE 或大约 32 美元。最昂贵的将花费 5000 GMEE 或 1580 美元。
<!--more--> | 650 | MIT |
---
description: 使用安装者在 Microsoft Edge 中自动执行和测试
title: Puppeteer
author: MSEdgeTeam
ms.author: msedgedevrel
ms.date: 04/06/2021
ms.topic: article
ms.prod: microsoft-edge
ms.technology: devtools
keywords: microsoft edge, Web 开发, 开发人员, 工具, 自动化, 测试
ms.openlocfilehash: 89a4dad3319f8e61f27487973509a8ee5ac23b6a
ms.sourcegitcommit: 146072bf606b84e5145a48333abf9c6b892a12d8
ms.translationtype: MT
ms.contentlocale: zh-CN
ms.lasthandoff: 04/07/2021
ms.locfileid: "11480165"
---
# <a name="puppeteer-overview"></a>Puppeteer 概述
[部署程序是][|::ref1::|Main] 一个 [节点][NodejsMain] 库,它提供高级 API 以使用 [DevTools][GithubChromedevtoolsProtocol]协议控制 Microsoft Edge \ (Chromium\) 。 默认情况下,安装 [者启动无][WikiHeadlessBrowser] 头浏览器。 无头浏览器不显示 UI,因此您必须使用命令行。 还可以将安装工具配置为运行完整 \ (无头\) Microsoft Edge。
默认情况下,当你安装安装安装者时,安装程序会下载最新版本的 [Chromium,][ChromiumHome]这是 Microsoft Edge 也基于 构建 [的开放源代码浏览器][MicrosoftBlogsWindowsExperience20181206]。 如果已安装 Microsoft Edge \ (Chromium\) ,可以使用 [用户核心][PuppeteerApivscore]。 `puppeteer-core` 是启动现有浏览器安装的一个轻型版本,如 Microsoft Edge \ (Chromium\) 。 若要下载 Microsoft Edge \ (Chromium\) ,请导航到下载 [Microsoft Edge 预览体验成员频道][MicrosoftedgeinsiderDownload]。
## <a name="installing-puppeteer-core"></a>安装安装程序核心
可以使用以下 `puppeteer-core` 命令之一添加到网站或应用。
```shell
npm i puppeteer-core
```
```shell
yarn add puppeteer-core
```
## <a name="launch-microsoft-edge-with-puppeteer-core"></a>使用企业核心启动 Microsoft Edge
> [!NOTE]
> `puppeteer-core` 依赖于 Node v8.9.0 或更高版本。 下面的示例使用仅在 Node `async` / `await` v7.6.0 或更高版本中支持它。 从 `node -v` 命令行运行,以确保具有兼容的 Node.js。
`puppeteer-core` 其他浏览器测试框架(如 [WebDriver)的用户应该很熟悉][WebdriverChromiumMain]。 创建浏览器实例,打开一个页面,然后使用一个百年工具 API 对其进行操作。 在下面的代码示例中,启动 `puppeteer-core` Microsoft Edge \ (Chromium\) ,导航到 `https://www.microsoftedgeinsider.com` ,将屏幕截图保存为 `example.png` 。
复制以下代码段并将其另存为 `example.js` 。
```javascript
const puppeteer = require('puppeteer-core');
(async () => {
const browser = await puppeteer.launch({
executablePath: 'C:\\Program Files (x86)\\Microsoft\\Edge Dev\\Application\\msedge.exe'
});
const page = await browser.newPage();
await page.goto('https://www.microsoftedgeinsider.com');
await page.screenshot({path: 'example.png'});
await browser.close();
})();
```
更改为 `executablePath` 指向安装的 Microsoft Edge \ (Chromium\) 。 例如,在 macOS 上 `executablePath` ,Microsoft Edge Canary 的 应设置为 `/Applications/Microsoft\ Edge\ Canary.app/` 。 若要查找 ,请导航到 并复制该页面上的可执行路径,或者使用下列命令之一安装边缘 `executablePath` `edge://version` 路径包。 **** [][npmEdgePaths]
```shell
npm i edge-paths
```
```shell
yarn add edge-paths
```
下面的代码示例使用 [边缘][npmEdgePaths] 路径包以编程方式查找在操作系统上安装 Microsoft Edge \ (Chromium\) 的路径。
```javascript
const edgePaths = require("edge-paths");
const EDGE_PATH = edgePaths.getEdgePath();
```
最后,在 `executablePath: EDGE_PATH` 中设置 `example.js` 。 保存更改。
> [!NOTE]
> Microsoft Edge \ (EdgeHTML\) 不能与 一起工作 `puppeteer-core` 。 必须安装 [Microsoft Edge 预览体验成员频道][MicrosoftedgeinsiderDownload] ,以继续按照此示例操作。
现在, `example.js` 从命令行运行。
```shell
node example.js
```
`puppeteer-core` 启动 Microsoft Edge,导航到 `https://www.microsoftedgeinsider.com` ,并保存网页的屏幕截图。 使用[page.setViewport 自定义屏幕截图 () 。 ][PuppeteerApipagesetviewport]
:::image type="complex" source="./media/puppeteer-example.png" alt-text="由example.png生成的example.js" lightbox="./media/puppeteer-example.png":::
`example.png`生成的文件 `example.js`
:::image-end:::
这只是一个简单的示例,演示了由一个和 启用的自动化和测试方案 `puppeteer-core` 。 有关一览器及其工作原理的信息,请导航到 ["百分百][|::ref2::|Main]"。
## <a name="getting-in-touch-with-the-microsoft-edge-devtools-team"></a>与 Microsoft Edge 开发人员工具团队联系
Microsoft Edge 开发人员团队希望倾听你有关使用 Feedbackeer、和 `puppeteer-core` Microsoft Edge 的反馈。 使用**** Microsoft Edge 开发人员工具或推文或推文@EdgeDevTools[][TwitterIntentTweetEdgedevtools]发送反馈图标,让 Microsoft Edge 团队了解你的想法。
:::image type="complex" source="../devtools-guide-chromium/media/bing-devtools-send-feedback.msft.png" alt-text="Microsoft Edge DevTools 中的“发送反馈”图标" lightbox="../devtools-guide-chromium/media/bing-devtools-send-feedback.msft.png":::
Microsoft Edge DevTools 中的**发送反馈**图标
:::image-end:::
<!--## See also
* [WebDriver (Chromium)][WebdriverChromiumMain]
* [WebDriver (EdgeHTML)][ArchiveMicrosoftEdgeLegacyDeveloperWebdriverIndex]
* [Chrome DevTools Protocol Viewer on GitHub][GithubChromedevtoolsProtocol]
* [Microsoft Edge: Making the web better through more open source collaboration on Microsoft Experience Blog][MicrosoftBlogsWindowsExperience20181206]
* [Download Microsoft Edge Insider Channels][MicrosoftedgeinsiderDownload]
* [Chromium on The Chromium Projects][ChromiumHome]
* [Node.js][NodejsMain]
* [Puppeteer][PuppeteerMain]
* [puppeteer vs. puppeteer-core][PuppeteerApivscore]
* [page.setViewport() on Puppeteer][PuppeteerApipagesetviewport]
* [Headless browser on Wikipedia][WikiHeadlessBrowser] -->
<!-- links -->
[WebdriverChromiumMain]: ../webdriver-chromium/index.md "WebDriver (Chromium) |Microsoft Docs"
<!-- [ArchiveMicrosoftEdgeLegacyDeveloperWebdriverIndex]: /archive/microsoft-edge/legacy/developer/webdriver/index "WebDriver (EdgeHTML) | Microsoft Docs" -->
[GithubChromedevtoolsProtocol]: https://chromedevtools.github.io/devtools-protocol "Chrome DevTools 协议查看器|GitHub"
[MicrosoftBlogsWindowsExperience20181206]: https://blogs.windows.com/windowsexperience/2018/12/06/microsoft-edge-making-the-web-better-through-more-open-source-collaboration "Microsoft Edge:通过更多开放源代码协作功能改善|Microsoft 体验博客"
[MicrosoftedgeinsiderDownload]: https://www.microsoftedgeinsider.com/download "下载 Microsoft Edge 预览体验成员频道"
[ChromiumHome]: https://www.chromium.org/Home "Chromium |Chromium 项目"
[NodejsMain]: https://nodejs.org "Node.js"
[npmEdgePaths]: https://www.npmjs.com/package/edge-paths "边缘路径|npm"
[PuppeteerMain]: https://pptr.dev "木工"
[PuppeteerApivscore]: https://pptr.dev/#?product=Puppeteer&version=v2.0.0&show=api-puppeteer-vs-puppeteer-core "一|木工"
[PuppeteerApipagesetviewport]: https://pptr.dev/#?product=Puppeteer&version=v2.0.0&show=api-pagesetviewportviewport "page.setViewport (视口) |木工"
[TwitterIntentTweetEdgedevtools]: https://twitter.com/intent/tweet?text=@EdgeDevTools "@EdgeDevTools - 发布推文|Twitter"
[WikiHeadlessBrowser]: https://en.wikipedia.org/wiki/Headless_browser "无头浏览器|Wikipedia" | 6,297 | CC-BY-4.0 |
---
title: "守护者公会中突袭和制作的第一个细节"
date: 2021-10-25T21:57:40+08:00
lastmod: 2021-10-25T16:45:40+08:00
draft: false
authors: ["Brittany"]
description: "当《守护者公会》在 2022 年软启动时,该游戏将具有两个主要系统,突袭和制作。Immutable 和 Stepico 揭示了有关这些机制的第一个细节,这让我们感到兴奋。让我们首先深入研究突袭,然后我们可以更多地谈论制作。"
featuredImage: "first-details-on-raids-and-crafting-in-guild-of-guardians.png"
tags: ["Virtual World","虚拟世界","Play to Earn"]
categories: ["news"]
news: ["虚拟世界"]
weight:
lightgallery: true
pinned: false
recommend: false
recommend1: false
---
当《守护者公会》在 2022 年软启动时,该游戏将具有两个主要系统,突袭和制作。Immutable 和 Stepico 揭示了有关这些机制的第一个细节,这让我们感到兴奋。让我们首先深入研究突袭,然后我们可以更多地谈论制作。
<!--more--> | 630 | MIT |
---
title: 重大變更: SignalR: MessagePack Hub 通訊協定選項類型已變更
description: 瞭解 ASP.NET Core 5.0 的重大變更,標題為 SignalR: MessagePack 中樞通訊協定選項類型已變更
author: scottaddie
ms.author: scaddie
ms.date: 10/01/2020
ms.openlocfilehash: b75dbec834699472f18b3058052274476bd9751d
ms.sourcegitcommit: d8020797a6657d0fbbdff362b80300815f682f94
ms.translationtype: MT
ms.contentlocale: zh-TW
ms.lasthandoff: 11/24/2020
ms.locfileid: "95760786"
---
# <a name="signalr-messagepack-hub-protocol-options-type-changed"></a>SignalR: MessagePack Hub 通訊協定選項類型已變更
ASP.NET Core SignalR MessagePack Hub 通訊協定選項類型已從變更 `IList<MessagePack.IFormatterResolver>` 為 [MessagePack](https://www.nuget.org/packages/MessagePack) 程式庫的 `MessagePackSerializerOptions` 類型。
如需此變更的討論,請參閱 [dotnet/aspnetcore # 20506](https://github.com/dotnet/aspnetcore/issues/20506)。
## <a name="version-introduced"></a>引進的版本
5.0 Preview 4
## <a name="old-behavior"></a>舊的行為
您可以新增至選項,如下列範例所示:
```csharp
services.AddSignalR()
.AddMessagePackProtocol(options =>
{
options.FormatterResolvers.Add(MessagePack.Resolvers.StandardResolver.Instance);
});
```
並取代這些選項,如下所示:
```csharp
services.AddSignalR()
.AddMessagePackProtocol(options =>
{
options.FormatterResolvers = new List<MessagePack.IFormatterResolver>()
{
MessagePack.Resolvers.StandardResolver.Instance
};
});
```
## <a name="new-behavior"></a>新的行為
您可以新增至選項,如下列範例所示:
```csharp
services.AddSignalR()
.AddMessagePackProtocol(options =>
{
options.SerializerOptions =
options.SerializeOptions.WithResolver(MessagePack.Resolvers.StandardResolver.Instance);
});
```
並取代這些選項,如下所示:
```csharp
services.AddSignalR()
.AddMessagePackProtocol(options =>
{
options.SerializerOptions = MessagePackSerializerOptions
.Standard
.WithResolver(MessagePack.Resolvers.StandardResolver.Instance)
.WithSecurity(MessagePackSecurity.UntrustedData);
});
```
## <a name="reason-for-change"></a>變更的原因
這項變更是移至 MessagePack v2. x 的一部分,這是在 [aspnet/公告 # 404](https://github.com/aspnet/Announcements/issues/404)中宣告的。 V2 程式庫已新增更容易使用的選項 API,並提供比之前公開的清單更多的功能 `MessagePack.IFormatterResolver` 。
## <a name="recommended-action"></a>建議的動作
這項中斷性變更會影響正在設定值的任何人 <xref:Microsoft.AspNetCore.SignalR.MessagePackHubProtocolOptions> 。 如果您使用 ASP.NET Core SignalR MessagePack Hub 通訊協定和修改選項,請更新您的使用方式以使用新的 options API,如上所示。
## <a name="affected-apis"></a>受影響的 API
<xref:Microsoft.AspNetCore.SignalR.MessagePackHubProtocolOptions?displayProperty=nameWithType>
<!--
### Category
ASP.NET Core
### Affected APIs
`T:Microsoft.AspNetCore.SignalR.MessagePackHubProtocolOptions`
--> | 2,691 | CC-BY-4.0 |
---
layout: post
title: 使用Java实现单向链表,并完成链表反转。
date: 2018-10-26 21:30:07 +0800
categories: 数据结构
tag: [面试题, 单向链表, 链表反转]
---
* content
{:toc}
### 使用Java实现单向链表,并完成链表反转。
算法和数据结构是程序员逃不过的一个坎,所以趁着闲余时间,开始学习基础的算法和数据结构。这里记录下自己实现简单的单项链表的过程,如有错误,敬请指正。
#### 明确需求
在Java中,常用的数据容器里面,跟链表关系紧密的当属LinkedList了,它的底层实现为双向链表,这里就以它为参照物,实现自己的简单的单向链表。另外,还需要支持增删改查、获取大小等功能。
如下所示,先定义了增删改查方法支持的范围。
```
/**
* 增删改查方法
* add(index, E) index >= 0 && index <= size
* remove(index) index >= 0 && index < size
* set(index, E) index >= 0 && index < size
* get(index) index >= 0 && index < size
*/
```
#### 定义链表结点Node
结点的定义很简单,这里为了简单起见,不支持泛型,结点存储的数据类型固定为int。
```
private static class Node {
private int item;
private Node next;
public Node(int item, Node next) {
this.item = item;
this.next = next;
}
public void setItem(int item) {
this.item = item;
}
@Override
public String toString() {
return String.valueOf(this.item);
}
}
```
#### 定义辅助方法
既然是单向链表,容器中只需要持有first引用即可,不需要last引用。再需要定义一个size用来表示链表大小;另外,为了方便查看测试结果,我们重写toString方法。代码如下:
```
public class SingleLinkedList {
private int size = 0;
private Node first = null;
...
}
```
```
/**
* 返回当前容器大小。
* @return
*/
public int getSize() {
return size;
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append('[');
if (first != null) {
Node curr = first;
while (curr != null) {
sb.append(String.valueOf(curr));
if (curr.next != null) {
sb.append(",").append(" ");
}
curr = curr.next;
}
}
sb.append("]");
return sb.toString();
}
```
#### 定义查询方法get(index)
在已有数据中获取数据,这个最为简单,由于单向链表容器中只存储首个结点first引用,所以不能直接角标index获取,需要从first中根据角标依次遍历,代码如下:
```
/**
* 获取角标上的数据。
*
* @param index
* @return
*/
public Node get(int index) {
checkElementIndex(index);
Node x = first;
for (int i = 0; i < index; i++) {
x = x.next;
}
return x;
}
```
#### 定义增加方法add(index, value)
与另外三组方法(获取、修改、删除)均不同,增加方法不仅仅要支持链表现有的数据范围,而且还需要支持角标为size的位置。
在当前位置插入结点,需要获取到前一个结点,让前一个结点的next指向新增的结点,再让新增结点的next指向该位置原来的结点。需要注意一些特殊情况的处理,还有不要忘了size的数值增加。代码如下:
```
/**
* 在角标为index的位置插入数据
*
* @param index
* @param value
* @return
*/
public boolean add(int index, int value) {
checkPositionIndex(index);
if (index == 0) {
if (first == null) {
first = new Node(value, null);
} else {
Node next = get(0);
Node node = new Node(value, next);
first = node;
}
} else {
Node prev = get(index - 1);
Node node = new Node(value, prev.next);
prev.next = node;
}
size++;
return true;
}
```
#### 定义修改方法set(index, value)
修改方法也很简单,只需根据角标获取已经存在结点,然后将结点中存储的数据修改即可,代码如下:
```
public boolean set(int index, int value) {
checkElementIndex(index);
Node node = get(index);
node.setItem(value);
return true;
}
```
#### 定义删除方法remove(index)
删除当前位置的结点,核心是让上一个结点的next指向当前位置的下一个结点即可,与添加方法类似,需要做好极端情况的处理,代码如下:
```
public boolean remove(int index) {
checkElementIndex(index);
// size > 0
if (getSize() == 1) {//size == 1
first = null;
} else {// size > 1
if (index == 0) {// 删除第一个数据
first = first.next;
} else if (getSize() - 1 == index) {// 删除最后一个数据
Node prev = get(index - 1);
prev.next = null;
} else {// 删除中间的数据
get(index - 1).next = get(index).next;
}
}
size--;
return true;
}
```
#### 实现链表反转
为了实现单向链表的反转,在遍历的过程中,让每个节点的next指向上一个结点。代码如下:
```
/**
* 反转链表
*
* @return
*/
public Node reverseList() {
Node prev = null;
Node curr = first;
while (curr != null) {
Node temp = curr.next;
curr.next = prev;
prev = curr;
curr = temp;
}
logFromHead("reverseList", prev);
return prev;
}
```
#### 完整代码请查看
项目中搜索SingleLinkedList即可。
github传送门 [https://github.com/tinyvampirepudge/DataStructureDemo](https://github.com/tinyvampirepudge/DataStructureDemo)
gitee传送门 [https://gitee.com/tinytongtong/DataStructureDemo](https://gitee.com/tinytongtong/DataStructureDemo)
#### 参考
[https://leetcode.com/problems/reverse-linked-list/description/](https://leetcode.com/problems/reverse-linked-list/description/) | 4,865 | MIT |
---
layout: tutorial
title: IBM Cloud Private 中的日志记录和跟踪
breadcrumb_title: Logging and Tracing
relevantTo: [ios,android,windows,javascript]
weight: 2
---
<!-- NLS_CHARSET=UTF-8 -->
## 概述
{: #overview }
{{ site.data.keys.product_full }} 将错误、警告和参考消息记录到日志文件中。 日志记录的底层机制因应用程序服务器而异。 在 {{ site.data.keys.prod_icp }} 中,唯一支持的应用程序服务器
为 Liberty。
以下文档阐述如何为在 {{ site.data.keys.prod_icp }} 上的 Kubernetes 集群中运行的 {{ site.data.keys.mf_server }} 启用跟踪和收集日志。
#### 跳转至:
{: #jump-to }
* [先决条件](#prereqs)
* [配置日志记录和监视机制](#configure-log-monitor)
* [收集 *kubectl* 日志](#collect-kubectl-logs)
* [使用 IBM 提供的定制脚本收集日志](#collect-logs-custom-script)
## 先决条件
{: #prereqs}
安装并配置日志收集和故障诊断所需的以下工具:
* Docker (`docker`)
* Kubernetes CLI (`kubectl`)
要为在 {{ site.data.keys.prod_icp }} 上运行的集群配置 `kubectl` 客户机,请遵循[此处](https://www.ibm.com/support/knowledgecenter/en/SSBS6K_2.1.0/manage_cluster/cfc_cli.html)描述的步骤。
## 配置日志记录和监视机制
{: #configure-log-monitor}
缺省情况下,所有的 {{ site.data.keys.product }} 日志记录都将记入应用程序服务器日志文件。 Liberty 中提供的标准工具可用于控制 {{ site.data.keys.product }} 服务器日志记录。 从[配置日志记录和监视机制](https://www.ibm.com/support/knowledgecenter/en/SSHS8R_8.0.0/com.ibm.worklight.installconfig.doc/admin/r_logging_and_monitoring_mechanisms.html)上的文档了解更多信息。
[配置日志记录和监视机制](https://www.ibm.com/support/knowledgecenter/en/SSHS8R_8.0.0/com.ibm.worklight.installconfig.doc/admin/r_logging_and_monitoring_mechanisms.html)提供有关如何更新 `server.xml` 以配置日志记录的详细信息,并提供有关启用跟踪的信息。 使用过滤器 `com.ibm.ws.logging.trace.specification` 来选择性启用跟踪,[了解更多信息](https://www.ibm.com/support/knowledgecenter/en/SSEQTP_8.5.5/com.ibm.websphere.wlp.doc/ae/rwlp_logging.html)。 可通过 `jvm.option` 或在服务器实例的 `bootstrap.properties` 中指定此属性。
例如,在 `jvm.options` 中添加以下条目,将为以 `com.ibm.mfp` 开头的所有方法启用跟踪,并且跟踪级别将设置为 *all*。
```
-Dcom.ibm.ws.logging.trace.specification=com.ibm.mfp.*=all=enabled
```
您可以使用 JNDI 配置来设置此条目。 有关更多信息,请参阅[此处]({{ site.baseurl }}/tutorials/en/foundation/8.0/bluemix/mobilefirst-server-on-icp/#env-mf-server)。
## 收集 *kubectl* 日志
{: #collect-kubectl-logs}
`kubectl logs` 命令可用于获取有关 Kubernetes 集群上已部署容器的信息。 例如,以下命令检索在命令中提供其 *pod_name* 的 pod 的日志:
```bash
kubectl logs po/<pod_name>
```
有关 `kubectl logs` 命令的更多信息,请参阅 [Kubernetes 文档](https://kubernetes-v1-4.github.io/docs/user-guide/kubectl/kubectl_logs/)。
## 使用 IBM 提供的定制脚本来收集日志
{: #collect-logs-custom-script}
可以使用脚本 [get-icp-logs.sh](get-icp-logs.sh) 来收集 {{ site.data.keys.mf_server }} 日志和容器日志。 它将 *Helm 发行版名称*作为输入,并从部署的所有 pod 收集日志。
可如下所示执行脚本:
```bash
get-icp-logs <helm_release_name> [<output_directory>] [<name_space>]
```
下表描述定制脚本使用的每个参数。
| 选项 | 描述 | 备注 |
|--------|-------------|---------|
| helm_release_name | 各个 Helm Chart 安装的发行版名称 | **必需** |
| output_directory | 放置所收集日志的输出目录 | **可选**<br/>缺省值:当前工作目录下的 **mfp-icp-logs**。 |
| name_space | 安装各个 Helm Chart 的名称空间 | **可选**<br/>缺省值:**default** | | 2,854 | Apache-2.0 |
---
layout: post
title: 科赫曲线
date: 2013-03-25 12:00:00.000000000 +08:00
tags: Java
---
作者:杨振林 yangzhenlin.com
下面我分享一下我用递归绘制科赫曲线的基本过程。
绘制科赫曲线,我首先想到了从简到难的基本思路。最开始的时候,只有一条直线。然后中间三分之一的部分突起成为三角状。当我想到这里的时候,我在想如何把中间三分之一的横线擦除。但又想了一想,我发现一边画一边擦并不是非常好的方法。如果可以规划好各个折点,最后一起连接起来,应该比较方便。
因为这不是单纯的一条链的循环,而是一变四、四变十六的形式,所以我想到了递归的方法。因为在递归中,可以用递归的形式, KochPaint(x1, y1, x3, y3, level);KochPaint(x3, y3, x5, y5, level);KochPaint(x5, y5, x4, y4, level);KochPaint(x4, y4, x2, y2, level); 一步步地深入下去。
我将整个项目分为两个文件。一个是 Koch.java 主要用来实现窗体等。另一个是 KochListener.java 主要用来实现监听器。
在 Koch.java 中,我实现了窗体、设置了拉杆(用来调节层数)、获取了画布。并将拉杆和画布传入到了 KochListener.java 中的鼠标监听器中去。
在 KochListener.java 中,用 KochListener 类继承了 java.awt.event.MouseListener 接口,并在下面实现了全部方法。用 mouseClicked 点击获取到了起始的画点,并在类最后用 KochPaint(x1, y1, x2, y2, level); 使用自定义的递归方法。
关于递归方法,在一次使用的过程中,有五个点是最重要的,即层数是2的时候的五个折点(左点(1)、左三分之一点(3)、中间凸起点(5),右三分之一点(4),右点(2))。然后将五个点按顺序两两传到下一层中。这样就基本实现了递归方法绘制科赫曲线的功能。这时出现了一个问题,是关于中间凸起点的。我在绘制的过程中,有时这个点是凸起的,有时竟然凹陷下去了。经过分析我发现,1号点和2号点是有方向的,有时可能出现1号点在2号点的右侧,所以如果方法不得当,定义5号点的时候反向,就可能出现凹陷的情况。只要保证5号点在以1号点为圆心,1、2号点为半径的逆时针旋转小于90度的范围内就是正确的。所以,根据1、2号点的位置情况,用if-else写出了不同的定义5号点的方法。根据分析,1、2号点只可能出现六种不同的位置,具体见下方代码。
递归方法自身调用容易让人有一些疑惑。事实上,递归到最后一定要停下来的。所以,在每深入一层使用递归的时候,要有一些不同从而判断是否应该停止递归。用计数器是一个比较方便的方法。每深入一层,计数器减一,直到减到特定数值为止。
最后,实现了用递归绘制科赫曲线。
需要更深入学习的地方:
* 优化算法
* 绘制更复杂的科赫曲线
* 进一步学习拉杆JSlider的相关知识
代码如下
Koch.java
```
import java.awt.Color;
import java.awt.FlowLayout;
import java.awt.Graphics;
import java.awt.event.MouseListener;
import javax.swing.JFrame;
import javax.swing.JSlider;
/**
*
* @author yangzhenlin
*
*/
public class Koch extends JFrame {
/**
* 主函数
*
* @param args
*/
public static void main(String[] args) {
Koch koch = new Koch();
koch.initUI();
}
/**
* initUI
*/
public void initUI() {
this.setTitle("科赫曲线");
this.setSize(500, 500);
this.setDefaultCloseOperation(3);
this.setLocationRelativeTo(null);
this.setResizable(true);
this.setLayout(new FlowLayout());
/**
* 设置拉杆
*/
JSlider js = new JSlider(1, 7);
this.add(js);
this.setVisible(true);
/**
* 获取画布
*/
Graphics g = this.getGraphics();
/**
* 设置背景颜色
*/
this.getContentPane().setBackground(Color.BLACK);
MouseListener kl = new KochListener(g, js);
this.addMouseListener(kl);
}
}
```
KochListener.java
```
import java.awt.Color;
import java.awt.Graphics;
import java.awt.event.MouseEvent;
import java.awt.event.MouseListener;
import javax.swing.JSlider;
/**
*
* @author yangzhenlin
*
*/
public class KochListener implements MouseListener {
double x1, x2, y1, y2, x3, y3, x4, y4, x5, y5;
Graphics g;
JSlider js;
private int level;
public KochListener(Graphics g, JSlider js) {
this.g = g;
this.js = js;
/**
* 设置颜色
*/
g.setColor(Color.GREEN);
}
/**
* 点击
*/
public void mouseClicked(MouseEvent e) {
/**
* 设置层数
*/
level = this.js.getValue();
x1 = e.getX();
y1 = e.getY();
x2 = x1 + 400;
y2 = y1;
KochPaint(x1, y1, x2, y2, level);
}
public void KochPaint(double x1, double y1, double x2, double y2, int level) {
if (level == 1) {
g.drawLine((int) x1, (int) y1, (int) x2, (int) y2);
} else if (level > 1) {
level--;
double x3 = (2 * x1 + x2) / 3;
double y3 = (2 * y1 + y2) / 3;
double x4 = (2 * x2 + x1) / 3;
double y4 = (2 * y2 + y1) / 3;
double x5 = 0, y5 = 0;
/**
* 水平线中间凸起点位置是(x5,y5)
*/
/**
* 0度
*/
if ((x3<x4)&&(y3==y4)) {
x5 = (x3 + x4) / 2;
y5 = y3 - (x4 - x3) * Math.sqrt(3) / 2;
}
/**
* 60度
*/
else if ((x3<x4)&&(y3>y4)) {
x5 = x1;
y5 = y4;
}
/**
* 120度
*/
else if ((x3>x4)&&(y3>y4)) {
x5 = x2;
y5 = y3;
}
/**
* 180度
*/
else if ((x3>x4)&&(y3==y4)) {
x5 = (x3 + x4) / 2;
y5 = y3 + (x3 - x4) * Math.sqrt(3) / 2;
}
/**
* 240度
*/
else if ((x3>x4)&&(y3<y4)) {
x5 = x1;
y5 = y4;
}
/**
* 300度
*/
else if ((x3<x4)&&(y3<y4)) {
x5 = x2;
y5 = y3;
}
KochPaint(x1, y1, x3, y3, level);
KochPaint(x3, y3, x5, y5, level);
KochPaint(x5, y5, x4, y4, level);
KochPaint(x4, y4, x2, y2, level);
}
}
public void mousePressed(MouseEvent e) {
}
public void mouseReleased(MouseEvent e) {
}
public void mouseEntered(MouseEvent e) {
}
public void mouseExited(MouseEvent e) {
}
}
```
运行结果如下

附jar包
[koch.jar](//source.yangzhenlin.com/kochcurve/koch.jar) | 4,493 | CC-BY-4.0 |
# 初始化php
迄今为止, 你看到的PHP_EMBED_START_BLOCK()和 PHP_EMBED_END_BLOCK()宏都用于启动, 执行, 终止一个紧凑的原子的php请求。
这样 做的优点是任何导致php bailout的错误顶多影响到PHP_EMBED_END_BLOCK()宏之内 的当前作用域. 通过将你的代码执行放入到这两个宏之间的小块中, php的错误就不会影响到你的整个应用.
你刚才已经看到了, 这种短小精悍的方法主要的缺点在于每次你建立一个新的 START/END块的时候, 都需要创建⼀个新的请求, 新的符号表, 因此就失去了所有的持久性语义.
要想同时得到两种优点(持久化和错误处理), 就需要将START和END宏分解为它们各 自的组件(译注: 如果不明白可以参考这两个宏的定义). 下面是本章开始给出的embed2.c 程序, 这⼀次, 我们对它进行了分解:
````c
#include <sapi/embed/php_embed.h>
int main(int argc, char *argv[])
{
#ifdef ZTS
void ***tsrm_ls;
#endif
php_embed_init(argc, argv PTSRMLS_CC);
zend_first_try {
zend_eval_string("echo 'Hello World!';", NULL,"Embed 2 Eval'd string" TSRMLS_CC);
} zend_end_try();
php_embed_shutdown(TSRMLS_C);
return 0;
}
````
它执行和之前⼀样的代码, 只是这一次你可以看到打开和关闭的括号包裹了你的代码, 而不是无法分开的START和END块。
将php_embed_init()放到你应用的开始, 将php_embed_shutdown()放到末尾, 你的应用就得到了一个持久的单请求生命周期, 它还可 以使用zend_first_try {} zend_end_try(); 结构捕获所有可能导致你整个包装应用跳出末尾
的PHP_EMBED_END_BLOCK()宏的致命错误.
为了看看真实世界环境的这种方法的应用, 我们将本章前面⼀些的例子的启动和终止 处理进行了抽象:
````c
#include <sapi/embed/php_embed.h>
#ifdef ZTS
void ***tsrm_ls;
#endif
static void startup_php(void)
{
/* Create "dummy" argc/argv to hide the arguments
* meant for our actual application */
int argc = 1;
char *argv[2] = { "embed4", NULL };
php_embed_init(argc, argv PTSRMLS_CC);
}
static void shutdown_php(void)
{
php_embed_shutdown(TSRMLS_C);
}
static void execute_php(char *filename) {
zend_first_try {
char *include_script;
spprintf(&include_script, 0, "include '%s';", filename);
zend_eval_string(include_script, NULL, filename TSRMLS_CC);
efree(include_script);
} zend_end_try();
}
int main(int argc, char *argv[])
{
if (argc <= 1) {
printf("Usage: embed4 scriptfile");
return -1;
}
startup_php();
execute_php(argv[1]);
shutdown_php();
return 0;
}
````
类似的概念也可以应用到处理任意代码的执行以及其他任务. 只需要确认在最外部的 容器上使用zend_first_try, 则里面的每个容器上使用zend_try即可.
## links
* [目录](<preface.md>)
* 20.2 [错误处理](<20.2.md>)
* 20.4 [覆写INI_SYSTEM和INI_PERDIR选项](<20.4.md>) | 2,000 | Apache-2.0 |
---
layout: post
title: C语法
category: C
tags: [C]
excerpt: C语法
---
JNI的概念
Java Native Interface java本地接口
Native Native Language 本地语言 看操作系统使用什么语言开发的 那么这个语言就是本地语言
java c/c++ 通信的接口
Java 特点 一处编译到处运行 通过java虚拟机 把java代码和底层的操作系统隔离起来
c/c++ 平台相关性强
① java 想与硬件之间直接交互 不能直接交互 需要访问硬件的驱动 java需要调用C的代码
② java 运行的速度 比c要慢一些 高清视频回放 视频解码的库都是用c/c++去开发的
③ java 编译之后生成.class .class可以很容易的进行反编译 c编译之后生成机器码 机器码只能反汇编
金融软件
④ c语言有好多开源库 openCV ffmpeg vitamio
学习的目的 ①可以看懂android 所有的源码
② 有一些特定的需求 需要通过调用C去实现 需要使用JNI
Native c语言的基础 能看懂会调用
Interface NDK native develop kit
Java->C
c-> java
实际案例
printf("Hello World!\n");
c 基本数据类型
java的基本数据类型 C的基本数据类型
boolean 没有boolean 0 false 非0 true
byte 没有byte
printf("char类型占%d个字节\n", sizeof(char));
printf("short类型占%d个字节\n", sizeof(short));
printf("int类型占%d个字节\n", sizeof(int));
printf("long类型占%d个字节\n", sizeof(long));
printf("float类型占%d个字节\n", sizeof(float));
printf("double类型占%d个字节\n", sizeof(double));
int ii = 0;
unsigned char cc = 256;
printf("c = %d\n", cc);
signed和unsigned 可以用来修饰整形变量 short int long char
signed 有符号 默认情况下都是有符号的
unsigned 无符号 使用了unsigned 来修饰整形变量 这个整形变量的最高位就是数值位 不再是符号位
C 输出函数
00000000 10111100 01100001 01001110
01100001 01001110
使用占位符的时候 一定要注意 类型和占位符之间一定要一一对应 如果用错了可能会出现问题
C 数组的声明 [] 一定要放到变量名字的后面
char str[]
#include <stdlib.h> // include 包含 类似java 的import
#include <stdio.h> // .h head C的头文件 std standard 标准的 stdlib 标准函数库 stdio.h 标准输入输出流
/**
%d - int
%ld – long int
%lld - long long
%hd – 短整型 short
%c - char
%f - float
%lf – double
%u – 无符号数
%x – 十六进制输出 int 或者long int 或者short int
%o - 八进制输出
%s – 字符串
*/
#
char c = 'a';
short s = 1234;
int i = 12345678;
long l = 1234567890;
float f = 3.14;
double d = 3.1415926;
printf("c = %c\n", c);
printf("s = %hd\n", s);
printf("i = %d\n", i);
printf("l = %ld\n", l);
printf("f = %.2f\n", f);
printf("d = %.7lf\n", d);
printf("i = %#x\n", i);
printf("i = %#o\n", i);
char str[] = { 'a','b','c','d','e','\0' };
char str1[] = "你好";
printf("str =%s\n", str1);
//java 字符串 string c的字符串实际上就是字符的数组 字符数组结束的标记就是 '\0'
char str4[] = { 'a','b','c','d','e','\0' };
char str2[] = "abcde";
char *str3 = "你好";
printf("%s\n", str3);
printf("%#x\n", str3);
C 输入函数
int count;
printf("请输入班级的人数:");
scanf("%d", &count);
printf("班级的人数为: %d\n", count);
printf("count的地址:%d\n", &count);
char name[2];
printf("name的地址:%d\n", &name);
printf("请输入班级的名字:");
scanf("%s", &name);
printf("班级的人数是:%d\n班级的名字是:%s\n", count, name);
内存地址的概念
内存的最小单位 byte 8位二进制数
内存要使用的时候 一定得对每一个byte进行编号 只有编号之后才能使用
32位系统 xp /win7 地址线32位 4G的内存
64位系统
C 的指针 ☆☆☆☆☆
int i1 = 456;
int *p = &i1;
printf("p =%#x\n", p);
printf("i的地址:%#x\n", &i1);
printf("*p = %d\n", *p);
*p = 789;
printf("i = %d\n", i1);
C指针的常见错误
double *p2 = &i1;
printf("*p2 = %lf\n", *p2);
C 指针的练习
交换两个数的值
值传递 调用函数/方法的时候 传到方法中的是变量的值 值传递
引用传递 调用函数/方法的时候 传到方法中的也是数值 只不过这个值是一个地址值 引用传递
交换两个数
int i2 = 123;
int j2 = 456;
swap2(&i2, &j2);
printf("i = %d,j = %d\n", i2, j2);
返回多个值
function(&i2, &j2);
printf("i = %d,j = %d\n", i2, j2);
C 数组 和指针之间的关系
java的数组 是一块连续的内存空间
int array[] = { 1,2,3,4,15 };
printf("array[0]的地址%#x\n", &array[0]);
printf("array[1]的地址%#x\n", &array[1]);
printf("array[2]的地址%#x\n", &array[2]);
printf("array[3]的地址%#x\n", &array[3]);
printf("array[4]的地址%#x\n", &array[4]);
printf("array的地址%#x\n", &array);
double *p3 = &array;
printf("array[0]的地址%d\n", *(p3 + 0));
printf("array[1]的地址%d\n", *(p3 + 1));
printf("array[2]的地址%d\n", *(p3 + 2));
printf("array[3]的地址%d\n", *(p3 + 3));
printf("array[4]的地址%d\n", *(p3 + 4));
printf("p+0的地址%d\n", p3 + 0);
printf("p+1的地址%d\n", p3 + 1);
printf("p+2的地址%d\n", p3 + 2);
printf("p+3的地址%d\n", p3 + 3);
printf("p+4的地址%d\n", p3 + 4);
C的字符串的最常用的声明方式
char str4[] = { 'a','b','c','d','e','\0' };
char str2[] = "abcde";
char *str3 = "你好";
printf("%s\n", str3);
printf("%#x\n", str3);
C指针变量的长度
C 的多级指针
用2级指针保存1级指针的地址
用n级指针 保存 n-1级指针的地址
int *p7;
double *p8;
printf("int类型指针变量占%d个字节,double类型指针变量占%d个字节\n", sizeof(p7), sizeof(p8));
main函数中 获取子函数临时变量的地址
float *p9;
function2(&p9);
printf("p = %#x\n", p9);
静态内存分配和动态内存分配
静态内存分配 栈内存 大小固定 高地址向低地址扩展 栈内存的分配和回收是系统控制
int *p10 = function3();
function4();
printf("*(p+0) =%d,*(p+1) =%d,*(p+2) =%d,*(p+3) =%d,*(p+4) =%d\n", *(p + 0), *(p + 1), *(p + 2), *(p + 3), *(p + 4));
printf("*(p+0) =%d,*(p+1) =%d,*(p+2) =%d,*(p+3) =%d,*(p+4) =%d\n", *(p + 0), *(p + 1), *(p + 2), *(p + 3), *(p + 4));
C 的结构体☆☆☆☆☆
C 的联合体
C 的枚举
C 的自定义类型 | 4,885 | Apache-2.0 |
---
title: Go项目简单接入travis ci
layout: post
category: golang
author: 夏泽民
---
本文不讲述 Go 的单元测试如何编写,这里直接以filenamify(一个合法化文件路径的库)为例子。已为filenamify.go编写测试文件filenamify_test.go。只需要在tracis中执行go test -v即可。
# https://github.com/flytam/filenamify/blob/master/.travis.yml
language: go
go:
- 1.13.x
env:
- GO111MODULE=on
script: go test -v
复制代码然后给在项目中加上构建状态图标。搞定
<!-- more -->
这样,每次推送到远程,就会触发CI自动执行单元测试
发布 github release
有时候我们的 Go 项目是需要打包成可行文件直接发布到 github release 让别人下载执行的。这时候也可以使用travis实现,借助travis releases工具即可
1、新建一个.travis.yml文件,填入基本的 Go 配置环境
language: go
go:
- 1.13.x
env:
- GO111MODULE=on # 启用Go mod
install:
- go get -v
复制代码2、编写Makefile
在nodejs项目中,我们一般会配置一个npm run test的命令执行测试,但是 Go 是没有npm和package.json这两个东西,这时候就需要编写Makefile来实现了(可以把Makefile看作功能类型于package.json的东西,只是使用make xxx来执行),Makefile编写可以参考。
以blog-sync为例子,这里我是需要打包全平台的可行文件,于是Makefile如下
GOCMD=go
GOBUILD=$(GOCMD) build
BINARY_NAME=bin
NAME=blog-sync
#mac
build:
CGO_ENABLED=0 $(GOBUILD) -o $(BINARY_NAME)/$(NAME)-mac
# windows
build-linux:
CGO_ENABLED=0 GOOS=windows GOARCH=amd64 $(GOBUILD) -o $(BINARY_NAME)/$(NAME)-linux
# linux
build-win:
CGO_ENABLED=0 GOOS=linux GOARCH=amd64 $(GOBUILD) -o $(BINARY_NAME)/$(NAME)-win.exe
# 全平台
build-all:
make build
make build-win
make build-linux
复制代码执行make build-all即可在bin目录下生成 3 个平台的可执行文件。
language: go
go:
- 1.13.x
env:
- GO111MODULE=on # 启用Go mod
install:
- go get -v
before_deploy: make build-all
deploy:
provider: releases
api_key: 自动生成的github key
file_glob: true
file: bin/*
skip_cleanup: true
on:
repo: flytam/blog-sync
tags: true
复制代码3、使用setup初始化配置
# 已经安装travis cli
travis setup releases
# 按需填写,输入github账号密码,加密key,发布文件等
复制代码再简单定制化后,最终如下配置,releases配置可参考文档
# https://github.com/flytam/blog-sync/blob/master/.travis.yml
language: go
go:
- 1.13.x
env:
- GO111MODULE=on # 启用Go mod
install:
- go get -v
before_deploy: make build-all # 发布前执行生成二进制文件的命令
deploy:
provider: releases
api_key:
secure: xxxx
# 使用glob匹配发布bin目录下的文件
file_glob: true
file: bin/*
skip_cleanup: true
on:
repo: flytam/blog-sync
# tag才触发发布
tags: true
复制代码4、发布
每次打tag推送到仓库,就会触发自动发布可执行文件到github release
git tag 1.0.0
git push --tags
复制代码5、可以看到,我们的自动构建发布 release 成功了 | 2,268 | MIT |
---
title: "leetcode hashmap基本操作"
category: leetcode
layout: post
---
* content
{:toc}
# 705 & 706
这两个leetcode 题目基本是很简单的一个类型,只要你把key自动填充到对应的数组位置即可,
但是,这样太直接了,效率上来说应该会有问题。所以,这并不是最优解。
```c
#define NUM 1000010
typedef struct {
int *arr;
} MyHashMap;
/** Initialize your data structure here. */
MyHashMap* myHashMapCreate() {
MyHashMap *obj = malloc(sizeof(MyHashMap));
if(!obj)
return ;
obj->arr = (int *)malloc(sizeof(int) * NUM);
if(!obj->arr) // here may be a problem
return ;
memset(obj->arr, -1, NUM);
return obj;
}
/** value will always be non-negative. */
void myHashMapPut(MyHashMap* obj, int key, int value) {
obj->arr[key] = value;
}
/** Returns the value to which the specified key is mapped, or -1 if this map contains no mapping for the key */
int myHashMapGet(MyHashMap* obj, int key) {
if(obj->arr[key] != -1)
return obj->arr[key];
return -1;
}
/** Removes the mapping of the specified value key if this map contains a mapping for the key */
void myHashMapRemove(MyHashMap* obj, int key) {
if(obj->arr[key] == -1)
return;
obj->arr[key] = -1;
}
void myHashMapFree(MyHashMap* obj) {
free(obj);
}
/**
* Your MyHashMap struct will be instantiated and called as such:
* MyHashMap* obj = myHashMapCreate();
* myHashMapPut(obj, key, value);
* int param_2 = myHashMapGet(obj, key);
* myHashMapRemove(obj, key);
* myHashMapFree(obj);
*/
``` | 1,455 | MIT |
<properties
pageTitle="服務布料的轉印圖樣反向 Proxy |Microsoft Azure"
description="使用服務布料的轉印圖樣的反向 proxy microservices 從內部和外部叢集通訊"
services="service-fabric"
documentationCenter=".net"
authors="BharatNarasimman"
manager="timlt"
editor="vturecek"/>
<tags
ms.service="service-fabric"
ms.devlang="dotnet"
ms.topic="article"
ms.tgt_pltfrm="na"
ms.workload="required"
ms.date="10/04/2016"
ms.author="vturecek"/>
# <a name="service-fabric-reverse-proxy"></a>服務布料的轉印圖樣反向 Proxy
服務布料的轉印圖樣反向 proxy 是反向 proxy 內建到服務布料的轉印圖樣,可讓您處理 microservices 服務布料的轉印圖樣叢集公開 HTTP 端點。
## <a name="microservices-communication-model"></a>Microservices 通訊模型
在服務布料的轉印圖樣 Microservices 通常叢集 VM 的子集上執行,並可以將一個 VM 到另一個各種原因。 因此,可以動態變更 microservices 的結束點。 要傳達給 microservice 的一般模式是下,解決循環播放
1. 解決一開始透過命名服務的服務位置。
2. 連線至服務。
3. 決定連線失敗的原因,以及重新解決必要時的服務位置。
此程序通常涉及文繞圖的用戶端通訊文件庫中實作服務解析度和重試原則重試循環播放。
本主題的詳細資訊,請參閱[與服務通訊](service-fabric-connect-and-communicate-with-services.md)。
### <a name="communicating-via-sf-reverse-proxy"></a>透過 SF 反向 proxy 通訊
服務布料的轉印圖樣反向 proxy 執行叢集內的所有節點。 它代表用戶端上執行的整個服務解析度程序,然後再將轉寄用戶端的要求。 因此叢集上執行的用戶端只可以使用任何用戶端 HTTP 通訊文件庫,與目標服務,透過在本機上相同的節點執行 SF 反向 proxy。
![內部通訊][1]
## <a name="reaching-microservices-from-outside-the-cluster"></a>不讓其與 Microservices 從叢集外
Microservices 的預設外部通訊模型已**選擇加入的**位置預設的每個服務不能直接從外部用戶端存取。 [Azure 負載平衡器](../load-balancer/load-balancer-overview.md)是網路之間的邊界 microservices 和外部的用戶端,可以執行網路位址轉譯,將外部要求轉送內部**IP:port**結束點。 若要直接存取外部用戶端 microservice 的端點,請 Azure 負載平衡器必須先設定轉寄的流量到叢集服務使用的每個連接埠。 此外,大部分 microservices (esp.狀態 microservices) 不 live 叢集的所有節點,他們可以在容錯移轉,節點之間移動,在這種情況下,Azure 負載平衡器無法有效判斷目標節點的複本位於要轉寄至的流量。
### <a name="reaching-microservices-via-the-sf-reverse-proxy-from-outside-the-cluster"></a>透過 SF 反向 proxy 從叢集外達到 Microservices
而非設定個別服務的連接埠 azure 負載平衡器中,您可以設定 Azure 負載平衡器只 SF 反向 proxy 連接埠。 這個選項可讓叢集以外的用戶端達到透過額外的設定不反向 proxy 叢集內的服務。
![外部通訊][0]
>[AZURE.WARNING] 設定反向 proxy 的連接埠負載平衡器上,將公開 http 端點,為叢集外 addressible 叢集微的所有服務。
## <a name="uri-format-for-addressing-services-via-the-reverse-proxy"></a>URI 格式來處理透過反向 proxy 服務
反向 proxy 會用來識別傳入要求應該轉寄到哪一個服務磁碟分割特定 URI 格式︰
```
http(s)://<Cluster FQDN | internal IP>:Port/<ServiceInstanceName>/<Suffix path>?PartitionKey=<key>&PartitionKind=<partitionkind>&Timeout=<timeout_in_seconds>
```
- **http(s):**反向 proxy 可以設定為接受 HTTP 或 HTTPS 流量。 若 HTTPS 流量 SSL 終止時所發生的反向 proxy。 轉寄反向 proxy 叢集服務的要求是透過 http。
- **叢集 FQDN | 內部 IP:**針對外部用戶端,使其位於透過叢集網域 (例如 mycluster.eastus.cloudapp.azure.com) 可以設定反向 proxy。 預設反向 proxy 執行的每個節點,因此內部流量它可以存取任何內部節點 IP (例如 10.0.0.1) 或本機上。
- **連接埠︰**已指定為反向 proxy 連接埠。 例如︰ 19008。
- **ServiceInstanceName:**這是您嘗試連絡細的服務的完整部署的服務執行個體名稱 「 布料的轉印圖樣: / 」 配置。 例如,若要達到服務*布料的轉印圖樣: / myapp/myservice/*,您可以使用*myapp/myservice*。
- **尾碼路徑︰**這是您要連線至服務的實際 URL 路徑。 例如, *myapi/值/加入/3*
- **PartitionKey:**分割的服務,這是您要連絡的磁碟分割的計算的磁碟分割索引鍵。 請注意,這是**磁碟分割的識別碼 GUID。 這個參數不需要使用單一資料分割配置的服務。
- **PartitionKind:**服務的資料分割配置。 這可能是 「 Int64Range 」 或 「 名稱 」。 這個參數不需要使用單一資料分割配置的服務。
- **逾時︰** 指定 http 要求代表用戶端要求服務反向 proxy 所建立的逾時。 這樣的預設值為 60 秒。 這是選用的參數。
### <a name="example-usage"></a>使用範例
例如,讓我們來看服務**布料的轉印圖樣: / MyApp/MyService**開啟 HTTP 上的接聽程式將下列 URL:
```
http://10.0.05:10592/3f0d39ad-924b-4233-b4a7-02617c6308a6-130834621071472715/
```
使用下列資源︰
- `/index.html`
- `/api/users/<userId>`
如果服務使用的是單一分割配置, *PartitionKey*和*PartitionKind*查詢字串參數且並非必要,並且服務可以無法透過閘道器為︰
- 從外部︰`http://mycluster.eastus.cloudapp.azure.com:19008/MyApp/MyService`
- 在內部︰`http://localhost:19008/MyApp/MyService`
如果服務會使用一致的 Int64 分割配置,必須使用*PartitionKey*和*PartitionKind*查詢字串參數達到服務的一部分︰
- 從外部︰`http://mycluster.eastus.cloudapp.azure.com:19008/MyApp/MyService?PartitionKey=3&PartitionKind=Int64Range`
- 在內部︰`http://localhost:19008/MyApp/MyService?PartitionKey=3&PartitionKind=Int64Range`
若要達到服務所公開的資源,只要將 URL 中服務名稱後面的資源路徑︰
- 從外部︰`http://mycluster.eastus.cloudapp.azure.com:19008/MyApp/MyService/index.html?PartitionKey=3&PartitionKind=Int64Range`
- 在內部︰`http://localhost:19008/MyApp/MyService/api/users/6?PartitionKey=3&PartitionKind=Int64Range`
閘道器會再將這些要求轉寄給該服務的 URL:
- `http://10.0.05:10592/3f0d39ad-924b-4233-b4a7-02617c6308a6-130834621071472715/index.html`
- `http://10.0.05:10592/3f0d39ad-924b-4233-b4a7-02617c6308a6-130834621071472715/api/users/6`
## <a name="special-handling-for-port-sharing-services"></a>特殊的處理連接埠共用服務
若要重新解決服務的地址,並再試一次要求時無法存取服務,嘗試應用程式閘道器。 這是一個的主要優點閘道器,因為實作自己服務解析度並解決循環播放,並不需要用戶端程式碼。
通常時無法存取服務,表示服務執行個體或複本會移到不同的節點做為其標準的生命週期的一部分。 這種情況,閘道器可能會收到網路連線錯誤指出端點已不再原本址上開啟。
不過,複本或服務執行個體可以共用主機處理程序,以及可能也會共用連接埠時裝載 http.sys 型網頁伺服器,包括︰
- [System.Net.HttpListener](https://msdn.microsoft.com/library/system.net.httplistener%28v=vs.110%29.aspx)
- [ASP.NET 核心 WebListener](https://docs.asp.net/latest/fundamentals/servers.html#weblistener)
- [武士](https://www.nuget.org/packages/Microsoft.AspNet.WebApi.OwinSelfHost/)
在此情況下可能是網頁伺服器適用於主機處理程序和回應的要求,但解決的服務執行個體或複本已不再提供主機上。 在此情況下,閘道器會收到 HTTP 404 回應網頁伺服器。 如此一來,HTTP 404 具有兩個不同的意義︰
1. 服務地址正確無誤,但不是存在要求使用者的資源。
2. 服務地址不正確,並要求使用者的資源可能實際上存在上不同的節點。
在第一個的情況下,這是標準的 HTTP 404,其視為使用者錯誤。 不過,在第二個案例中,使用者已要求資源存在,但閘道器找不到它,因為已經移動本身的服務,在此情況下需要重新解析地址,並再試一次閘道器。
閘道器,因此需要區分這兩種情況的方式。 若要讓該差異,請從伺服器提示需要。
- 根據預設,應用程式閘道假設 #2 的大小寫,並嘗試重新解決並重新發行的要求。
- 若要將應用程式閘道的案例 #1,服務應傳回下列 HTTP 回應標頭︰
`X-ServiceFabric : ResourceNotFound`
此 HTTP 回應標頭表示標準的 HTTP 404 情況中不存在要求的資源,及閘道器不會嘗試重新解決服務地址。
## <a name="setup-and-configuration"></a>安裝和設定
您可以啟用透過[Azure 資源管理員範本](./service-fabric-cluster-creation-via-arm.md)叢集服務布料的轉印圖樣反向 proxy。
一旦您擁有您想要部署叢集的範本 (從 [範例範本或建立自訂的資源管理員範本) 反向 proxy 可以啟用範本中的下列步驟。
1. 反向 proxy 範本的[參數] 區段](../resource-group-authoring-templates.md)中定義的連接埠。
```json
"SFReverseProxyPort": {
"type": "int",
"defaultValue": 19008,
"metadata": {
"description": "Endpoint for Service Fabric Reverse proxy"
}
},
```
2. 節點類型物件**叢集**[資源類型] 區段](../resource-group-authoring-templates.md)中的每個指定的連接埠
為 apiVersion 的之前 ' 2016年-09-01 連接埠由參數名稱***httpApplicationGatewayEndpointPort***
```json
{
"apiVersion": "2016-03-01",
"type": "Microsoft.ServiceFabric/clusters",
"name": "[parameters('clusterName')]",
"location": "[parameters('clusterLocation')]",
...
"nodeTypes": [
{
...
"httpApplicationGatewayEndpointPort": "[parameters('SFReverseProxyPort')]",
...
},
...
],
...
}
```
針對 apiVersion 的在或之後 ' 2016年-09-01 連接埠由參數名稱***reverseProxyEndpointPort***
```json
{
"apiVersion": "2016-09-01",
"type": "Microsoft.ServiceFabric/clusters",
"name": "[parameters('clusterName')]",
"location": "[parameters('clusterLocation')]",
...
"nodeTypes": [
{
...
"reverseProxyEndpointPort": "[parameters('SFReverseProxyPort')]",
...
},
...
],
...
}
```
3. 若要解決反向 proxy 從 azure 叢集外的,設定的步驟 1 中指定的連接埠**azure 負載平衡器規則**。
```json
{
"apiVersion": "[variables('lbApiVersion')]",
"type": "Microsoft.Network/loadBalancers",
...
...
"loadBalancingRules": [
...
{
"name": "LBSFReverseProxyRule",
"properties": {
"backendAddressPool": {
"id": "[variables('lbPoolID0')]"
},
"backendPort": "[parameters('SFReverseProxyPort')]",
"enableFloatingIP": "false",
"frontendIPConfiguration": {
"id": "[variables('lbIPConfig0')]"
},
"frontendPort": "[parameters('SFReverseProxyPort')]",
"idleTimeoutInMinutes": "5",
"probe": {
"id": "[concat(variables('lbID0'),'/probes/SFReverseProxyProbe')]"
},
"protocol": "tcp"
}
}
],
"probes": [
...
{
"name": "SFReverseProxyProbe",
"properties": {
"intervalInSeconds": 5,
"numberOfProbes": 2,
"port": "[parameters('SFReverseProxyPort')]",
"protocol": "tcp"
}
}
]
}
```
4. 若要連接埠反向 proxy 設定的 SSL 憑證,請將憑證新增至**叢集**[資源類型] 區段](../resource-group-authoring-templates.md)中的 [httpApplicationGatewayCertificate] 屬性
為 apiVersion 的之前 ' 2016年-09-01 憑證由參數名稱***httpApplicationGatewayCertificate***
```json
{
"apiVersion": "2016-03-01",
"type": "Microsoft.ServiceFabric/clusters",
"name": "[parameters('clusterName')]",
"location": "[parameters('clusterLocation')]",
"dependsOn": [
"[concat('Microsoft.Storage/storageAccounts/', parameters('supportLogStorageAccountName'))]"
],
"properties": {
...
"httpApplicationGatewayCertificate": {
"thumbprint": "[parameters('sfReverseProxyCertificateThumbprint')]",
"x509StoreName": "[parameters('sfReverseProxyCertificateStoreName')]"
},
...
"clusterState": "Default",
}
}
```
針對 apiVersion 的在或之後 ' 2016年-09-01 憑證由參數名稱***reverseProxyCertificate***
```json
{
"apiVersion": "2016-09-01",
"type": "Microsoft.ServiceFabric/clusters",
"name": "[parameters('clusterName')]",
"location": "[parameters('clusterLocation')]",
"dependsOn": [
"[concat('Microsoft.Storage/storageAccounts/', parameters('supportLogStorageAccountName'))]"
],
"properties": {
...
"reverseProxyCertificate": {
"thumbprint": "[parameters('sfReverseProxyCertificateThumbprint')]",
"x509StoreName": "[parameters('sfReverseProxyCertificateStoreName')]"
},
...
"clusterState": "Default",
}
}
```
## <a name="next-steps"></a>後續步驟
- 請參閱[在 GitHUb 範例專案](https://github.com/Azure-Samples/service-fabric-dotnet-getting-started/tree/master/Services/WordCount)中的服務之間的 HTTP 通訊的範例。
- [使用可靠的服務遠端遠端程序呼叫](service-fabric-reliable-services-communication-remoting.md)
- [網路可靠的服務中使用 OWIN 的 API](service-fabric-reliable-services-communication-webapi.md)
- [使用可靠 Services WCF 通訊](service-fabric-reliable-services-communication-wcf.md)
[0]: ./media/service-fabric-reverseproxy/external-communication.png
[1]: ./media/service-fabric-reverseproxy/internal-communication.png | 10,571 | CC-BY-3.0 |
---
title: Cloud-Gateway 统一网关配置
date: 2021-01-17
sidebar: 'auto'
categories:
- spring-cloud
- 网关
tags:
- spring-cloud
- gateway
---
## Eureka
> 结合 eureka 的服务发现, 可以更好的做网关的负载均衡
## 配置
```yml
server:
port: 8080
eureka:
client:
serviceUrl:
defaultZone: http://v10-host:8088/eureka/
spring:
application:
name: service-gateway
profiles:
include: middleware
cloud:
gateway:
routes:
- id: url-proxy-oauth2
uri: lb://service-smart-sso
predicates:
- Path=/oauth2/**
filters:
# 去掉前缀 /oauth2
- StripPrefix=1
# 用户模块
- id: proxy-os-user
uri: lb://os-user
predicates:
- Path=/useros/**
filters:
# 去掉前缀 /useros
- StripPrefix=1
```
#### Predicate
> datetime
>
> ```yaml
> # ZonedDateTime.now() 与这个属性做比较
> - After= 2018-12-30T23:59:59.789+08:00[Asia/Shanghai]
> - Before= 2018-12-30T23:59:59.789+08:00[Asia/Shanghai]
> - Between= 2018-12-30T23:59:59.789+08:00[Asia/Shanghai],2019-12-30T23:59:59.789+08:00[Asia/Shanghai]
> ```
>
> ```
> AfterRoutePredicateFactory
> BeforeRoutePredicateFactory
> BetweenRoutePredicateFactory
> ```
> cookie
>
> ```yml
> # 正则匹配 CookieRoutePredicateFactory
> - Cookie=sessionId, regx
> ```
>
>
> header
>
> ```yml
> # 正则匹配 HeaderRoutePredicateFactory
> - Header=X-Request-Id, \d+
> ```
> host
>
> ```yml
> # 将匹配 www.somehost.org 和 sub.somehost.org HostRoutePredicateFactory
> - Host=**.somehost.org
> ```
> method
>
> ```yml
> # MethodRoutePredicateFactory
> - Method=GET, POST
> ```
> path
>
> ```yml
> # PathRoutePredicateFactory
> - Path=/foo/{segment}
> ```
> queryParam
>
> ```yml
> # 第一个是必须的参数名, 第二个是可选的正则参数值 QueryRoutePredicateFactory
> - Query=foo, ba.
> ```
> readBody
>
> ```yml
> # ReadBodyRoutePredicateFactory
> - ReadBody=
> ```
> remoteAddr
>
> ```yml
> # CIDR 表示法, /24 代表子网掩码 RemoteAddrRoutePredicateFactory
> - RemoteAddr=192.168.1.1/24
> ```
>weight: 路由权重
>
>```yml
># 多个同组的会根据权重分配 WeightRoutePredicateFactory
>- Weight=groupName, weightValue
>```
### 说明
> **Eureka**
>
> 配置 eureka, 便于之后的负载均衡
```yml
eureka:
client:
serviceUrl:
defaultZone: http://v10-host:8088/eureka/
spring:
application:
name: api-gateway
```
> **Oauth2.0**
>
> 统一认证服务入口, 申请 token 和验证 token
```yml
spring:
cloud:
gateway:
routes:
- id: url-proxy-oauth2
uri: lb://service-smart-sso
predicates:
- Path=/oauth2/**
filters:
# 去掉前缀 /oauth2
- StripPrefix=1
```
> **用户模块**
>
> 用户管理的统一入口
```yml
- id: proxy-os-user
uri: lb://os-user
predicates:
- Path=/useros/**
filters:
# 去掉前缀 /useros
- StripPrefix=1
``` | 2,773 | Apache-2.0 |
---
title: "ES 8新特性 - (2017)"
date: "2019-11-26"
featured: false
category: "js"
excerpt: "ES2018引入异步迭代器"
tag: ["js"]
status: "publish"
type: "post"
cover: "./cover-es.png"
---
- async/await
- `Object.values()`
- `Object.entries()`
- String padding: `padStart()`和`padEnd()`,填充字符串达到当前长度
- 函数参数列表结尾允许逗号
- `Object.getOwnPropertyDescriptors()`
- `ShareArrayBuffer`和`Atomics`对象,用于从共享内存位置读取和写入
##### 1.async/await
ES2018引入异步迭代器(asynchronous iterators),这就像常规迭代器,除了`next()`方法返回一个Promise。因此`await`可以和`for...of`循环一起使用,以串行的方式运行异步操作。例如:
```js
async function process(array) {
for await (let i of array) {
doSomething(i);
}
}
```
##### 2.Object.values()
`Object.values()`是一个与`Object.keys()`类似的新函数,但返回的是Object自身属性的所有值,不包括继承的值。
假设我们要遍历如下对象`obj`的所有值:
```js
const obj = {a: 1, b: 2, c: 3};
```
**不使用Object.values() :ES7**
```js
const vals=Object.keys(obj).map(key=>obj[key]);
console.log(vals);//[1, 2, 3]
```
**使用Object.values() :ES8**
```js
const values=Object.values(obj1);
console.log(values);//[1, 2, 3]
```
从上述代码中可以看出`Object.values()`为我们省去了遍历key,并根据这些key获取value的步骤。
##### 3.Object.entries()
`Object.entries()`函数返回一个给定对象自身可枚举属性的键值对的数组。
接下来我们来遍历上文中的`obj`对象的所有属性的key和value:
**不使用Object.entries() :ES7**
```js
Object.keys(obj).forEach(key=>{
console.log('key:'+key+' value:'+obj[key]);
})
//key:a value:1
//key:b value:2
//key:c value:3
```
**使用Object.entries() :ES8**
```js
for(let [key,value] of Object.entries(obj1)){
console.log(`key: ${key} value:${value}`)
}
//key:a value:1
//key:b value:2
//key:c value:3
```
##### 4.String padding
在ES8中String新增了两个实例函数`String.prototype.padStart`和`String.prototype.padEnd`,允许将空字符串或其他字符串添加到原始字符串的开头或结尾。
**String.padStart(targetLength,\[padString\])**
- targetLength:当前字符串需要填充到的目标长度。如果这个数值小于当前字符串的长度,则返回当前字符串本身。
- padString:(可选)填充字符串。如果字符串太长,使填充后的字符串长度超过了目标长度,则只保留最左侧的部分,其他部分会被截断,此参数的缺省值为 ” “。
```js
console.log('0.0'.padStart(4,'10')) //10.0
console.log('0.0'.padStart(20))// 0.00
```
**String.padEnd(targetLength,padString\])**
- targetLength:当前字符串需要填充到的目标长度。如果这个数值小于当前字符串的长度,则返回当前字符串本身。
- padString:(可选) 填充字符串。如果字符串太长,使填充后的字符串长度超过了目标长度,则只保留最左侧的部分,其他部分会被截断,此参数的缺省值为 ” “;
```js
console.log('0.0'.padEnd(4,'0')) //0.00
console.log('0.0'.padEnd(10,'0'))//0.00000000
```
##### 5.函数参数列表结尾允许逗号
主要作用是方便使用git进行多人协作开发时修改同一个函数减少不必要的行变更。
##### 6.Object.getOwnPropertyDescriptors()
`Object.getOwnPropertyDescriptors()`函数用来获取一个对象的所有自身属性的描述符,如果没有任何自身属性,则返回空对象。
**函数原型:**
```js
Object.getOwnPropertyDescriptors(obj)
```
返回`obj`对象的所有自身属性的描述符,如果没有任何自身属性,则返回空对象。
```js
const obj2 = {
name: 'Jine',
get age() { return '18' }
};
Object.getOwnPropertyDescriptors(obj2)
// {
// age: {
// configurable: true,
// enumerable: true,
// get: function age(){}, //the getter function
// set: undefined
// },
// name: {
// configurable: true,
// enumerable: true,
// value:"Jine",
// writable:true
// }
// }
```
##### 7.SharedArrayBuffer对象
SharedArrayBuffer 对象用来表示一个通用的,固定长度的原始二进制数据缓冲区,类似于 ArrayBuffer 对象,它们都可以用来在共享内存(shared memory)上创建视图。与 ArrayBuffer 不同的是,SharedArrayBuffer 不能被分离。
```js
/**
*
* @param {*} length 所创建的数组缓冲区的大小,以字节(byte)为单位。
* @returns {SharedArrayBuffer} 一个大小指定的新 SharedArrayBuffer 对象。其内容被初始化为 0。
*/
new SharedArrayBuffer(length)
```
##### 8.Atomics对象
Atomics 对象提供了一组静态方法用来对 SharedArrayBuffer 对象进行原子操作。
这些原子操作属于 Atomics 模块。与一般的全局对象不同,Atomics 不是构造函数,因此不能使用 new 操作符调用,也不能将其当作函数直接调用。Atomics 的所有属性和方法都是静态的(与 Math 对象一样)。
多个共享内存的线程能够同时读写同一位置上的数据。原子操作会确保正在读或写的数据的值是符合预期的,即下一个原子操作一定会在上一个原子操作结束后才会开始,其操作过程不会中断。
- **Atomics.add()**
将指定位置上的数组元素与给定的值相加,并返回相加前该元素的值。
- **Atomics.and()**
将指定位置上的数组元素与给定的值相与,并返回与操作前该元素的值。
- **Atomics.compareExchange()**
如果数组中指定的元素与给定的值相等,则将其更新为新的值,并返回该元素原先的值。
- **Atomics.exchange()**
将数组中指定的元素更新为给定的值,并返回该元素更新前的值。
- **Atomics.load()**
返回数组中指定元素的值。
- **Atomics.or()**
将指定位置上的数组元素与给定的值相或,并返回或操作前该元素的值。
- **Atomics.store()**
将数组中指定的元素设置为给定的值,并返回该值。
- **Atomics.sub()**
将指定位置上的数组元素与给定的值相减,并返回相减前该元素的值。
- **Atomics.xor()**
将指定位置上的数组元素与给定的值相异或,并返回异或操作前该元素的值。
wait() 和 wake() 方法采用的是 Linux 上的 futexes 模型(fast user-space mutex,快速用户空间互斥量),可以让进程一直等待直到某个特定的条件为真,主要用于实现阻塞。
- **Atomics.wait()**
检测数组中某个指定位置上的值是否仍然是给定值,是则保持挂起直到被唤醒或超时。返回值为 “ok”、”not-equal” 或 “time-out”。调用时,如果当前线程不允许阻塞,则会抛出异常(大多数浏览器都不允许在主线程中调用 wait())。
- **Atomics.wake()**
唤醒等待队列中正在数组指定位置的元素上等待的线程。返回值为成功唤醒的线程数量。
- **Atomics.isLockFree(size)**
可以用来检测当前系统是否支持硬件级的原子操作。对于指定大小的数组,如果当前系统支持硬件级的原子操作,则返回 true;否则就意味着对于该数组,Atomics 对象中的各原子操作都只能用锁来实现。此函数面向的是技术专家。 | 4,466 | MIT |
# 🥧Mycat1.6.7.3
> ## 💿安装环境:CentOS 7
> ## 🚬下载
> ## 📦解压
> ## 🛠配置(server.xml)
> ## 🛠配置(schema.xml)
> ## 🍟注意(autopartition-long.txt)
> ## ⚗测试
## 🥄下载Mycat1.6.7.3
### 🤝作者提供:[Mycat1.6.7.3](https://shushun.oss-cn-shenzhen.aliyuncs.com/software/Mycat-server-1.6.7.3-release-20190828135747-linux.tar.gz)
# 📦解压
tar -zxvf Mycat-server-1.6.7.3-release-20190828135747-linux.tar.gz -C /usr/local/
# 🛠配置(server.xml)
vim /usr/local/mycat/conf/server.xml
server.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
<property name="nonePasswordLogin">0</property> <!-- 0为需要密码登陆、1为不需要密码登陆 ,默认为0,设置为1则需要指定默认账户-->
<property name="useHandshakeV10">1</property>
<property name="useSqlStat">0</property> <!-- 1为开启实时统计、0为关闭 -->
<property name="useGlobleTableCheck">0</property> <!-- 1为开启全加班一致性检测、0为关闭 -->
<property name="sqlExecuteTimeout">300</property> <!-- SQL 执行超时 单位:秒-->
<property name="sequnceHandlerType">2</property>
<!--<property name="sequnceHandlerPattern">(?:(\s*next\s+value\s+for\s*MYCATSEQ_(\w+))(,|\)|\s)*)+</property>-->
<!--必须带有MYCATSEQ_或者 mycatseq_进入序列匹配流程 注意MYCATSEQ_有空格的情况-->
<property name="sequnceHandlerPattern">(?:(\s*next\s+value\s+for\s*MYCATSEQ_(\w+))(,|\)|\s)*)+</property>
<property name="subqueryRelationshipCheck">false</property> <!-- 子查询中存在关联查询的情况下,检查关联字段中是否有分片字段 .默认 false -->
<!-- <property name="useCompression">1</property>--> <!--1为开启mysql压缩协议-->
<!-- <property name="fakeMySQLVersion">5.6.20</property>--> <!--设置模拟的MySQL版本号-->
<!-- <property name="processorBufferChunk">40960</property> -->
<!--
<property name="processors">1</property>
<property name="processorExecutor">32</property>
-->
<!--默认为type 0: DirectByteBufferPool | type 1 ByteBufferArena | type 2 NettyBufferPool -->
<property name="processorBufferPoolType">0</property>
<!--默认是65535 64K 用于sql解析时最大文本长度 -->
<!--<property name="maxStringLiteralLength">65535</property>-->
<!--<property name="sequnceHandlerType">0</property>-->
<!--<property name="backSocketNoDelay">1</property>-->
<!--<property name="frontSocketNoDelay">1</property>-->
<!--<property name="processorExecutor">16</property>-->
<!--
<property name="serverPort">8066</property> <property name="managerPort">9066</property>
<property name="idleTimeout">300000</property> <property name="bindIp">0.0.0.0</property>
<property name="dataNodeIdleCheckPeriod">300000</property> 5 * 60 * 1000L; //连接空闲检查
<property name="frontWriteQueueSize">4096</property> <property name="processors">32</property> -->
<!--分布式事务开关,0为不过滤分布式事务,1为过滤分布式事务(如果分布式事务内只涉及全局表,则不过滤),2为不过滤分布式事务,但是记录分布式事务日志-->
<property name="handleDistributedTransactions">0</property>
<!--
off heap for merge/order/group/limit 1开启 0关闭
-->
<property name="useOffHeapForMerge">0</property>
<!--
单位为m
-->
<property name="memoryPageSize">64k</property>
<!--
单位为k
-->
<property name="spillsFileBufferSize">1k</property>
<property name="useStreamOutput">0</property>
<!--
单位为m
-->
<property name="systemReserveMemorySize">384m</property>
<!--是否采用zookeeper协调切换 -->
<property name="useZKSwitch">false</property>
<!-- XA Recovery Log日志路径 -->
<!--<property name="XARecoveryLogBaseDir">./</property>-->
<!-- XA Recovery Log日志名称 -->
<!--<property name="XARecoveryLogBaseName">tmlog</property>-->
<!--如果为 true的话 严格遵守隔离级别,不会在仅仅只有select语句的时候在事务中切换连接-->
<property name="strictTxIsolation">false</property>
<property name="useZKSwitch">true</property>
</system>
<!-- 全局SQL防火墙设置 -->
<!--白名单可以使用通配符%或着*-->
<!--例如<host host="127.0.0.*" user="root"/>-->
<!--例如<host host="127.0.*" user="root"/>-->
<!--例如<host host="127.*" user="root"/>-->
<!--例如<host host="1*7.*" user="root"/>-->
<!--这些配置情况下对于127.0.0.1都能以root账户登录-->
<!--
<firewall>
<whitehost>
<host host="1*7.0.0.*" user="root"/>
</whitehost>
<blacklist check="false">
</blacklist>
</firewall>
-->
<user name="root" defaultAccount="true">
<property name="password">ShuShun@1558</property>
<property name="schemas">user</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
<user name="user">
<property name="password">user</property>
<property name="schemas">user</property>
<property name="readOnly">true</property>
</user>
</mycat:server>
# 🛠配置(schema.xml)
vim /usr/local/mycat/conf/schema.xml
schema.xml:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="user" checkSQLschema="true" sqlMaxLimit="100">
<!-- auto sharding by id (long) -->
<table name="user" dataNode="dn154,dn155" rule="auto-sharding-long" />
</table>
<!-- <table name="oc_call" primaryKey="ID" dataNode="dn1$0-743" rule="latest-month-calldate"
/> -->
</schema>
<!-- <dataNode name="dn1$0-743" dataHost="localhost1" database="db$0-743"
/> -->
<dataNode name="dn154" dataHost="db154" database="user_154" />
<dataNode name="dn155" dataHost="db155" database="user_155" />
<!--<dataNode name="dn4" dataHost="sequoiadb1" database="SAMPLE" />
<dataNode name="jdbc_dn1" dataHost="jdbchost" database="db1" />
<dataNode name="jdbc_dn2" dataHost="jdbchost" database="db2" />
<dataNode name="jdbc_dn3" dataHost="jdbchost" database="db3" /> -->
<dataHost name="db154" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="M1" url="192.168.182.154:3306" user="root"
password="ShuShun@1558">
<!-- can have multi read hosts -->
<!--<readHost host="hostS2" url="192.168.1.200:3306" user="root" password="xxx" />-->
</writeHost>
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>
<dataHost name="db155" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="M1" url="192.168.182.155:3306" user="root"
password="ShuShun@1558">
<!-- can have multi read hosts -->
<!--<readHost host="hostS2" url="192.168.1.200:3306" user="root" password="xxx" />-->
</writeHost>
<!-- <writeHost host="hostM2" url="localhost:3316" user="root" password="123456"/> -->
</dataHost>
<!--
<dataHost name="sequoiadb1" maxCon="1000" minCon="1" balance="0" dbType="sequoiadb" dbDriver="jdbc">
<heartbeat> </heartbeat>
<writeHost host="hostM1" url="sequoiadb://1426587161.dbaas.sequoialab.net:11920/SAMPLE" user="jifeng" password="jifeng"></writeHost>
</dataHost>
<dataHost name="oracle1" maxCon="1000" minCon="1" balance="0" writeType="0" dbType="oracle" dbDriver="jdbc"> <heartbeat>select 1 from dual</heartbeat>
<connectionInitSql>alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss'</connectionInitSql>
<writeHost host="hostM1" url="jdbc:oracle:thin:@127.0.0.1:1521:nange" user="base" password="123456" > </writeHost> </dataHost>
<dataHost name="jdbchost" maxCon="1000" minCon="1" balance="0" writeType="0" dbType="mongodb" dbDriver="jdbc">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM" url="mongodb://192.168.0.99/test" user="admin" password="123456" ></writeHost> </dataHost>
<dataHost name="sparksql" maxCon="1000" minCon="1" balance="0" dbType="spark" dbDriver="jdbc">
<heartbeat> </heartbeat>
<writeHost host="hostM1" url="jdbc:hive2://feng01:10000" user="jifeng" password="jifeng"></writeHost> </dataHost> -->
<!-- <dataHost name="jdbchost" maxCon="1000" minCon="10" balance="0" dbType="mysql"
dbDriver="jdbc"> <heartbeat>select user()</heartbeat> <writeHost host="hostM1"
url="jdbc:mysql://localhost:3306" user="root" password="123456"> </writeHost>
</dataHost> -->
</mycat:schema>
# 🍟注意(autopartition-long.txt)
将1000M-1500M注释掉
# range start-end ,data node index
# K=1000,M=10000.
0-500M=0
500M-1000M=1
#1000M-1500M=2
# 👍特别注意
关于密码策略mysql设置密码的时候选择旧版本的加密方式:
ALTER USER 'root'@'%' IDENTIFIED WITH mysql_native_password BY 'ShuShun@1558';
mysql8cli连接mycat的时候选择旧版的加密策略:
mysql -uroot -p -P8066 --default-auth=mysql_native_password | 10,582 | MIT |
仮想ネットワークと複数のオンプレミスのサイト間の接続を構成できます。詳細については、下の表を参照してください。この表は、この構成について新しい記事、新しいデプロイメント モデル、追加のツールが利用できるようになったら更新されるものです。記事が利用できるようになったら、表から直接リンクできるようにします。
| | **クラシック デプロイメント** | **リソース マネージャーのデプロイメント** |
|-----------------------------------------|-------------|---------------------|
| **クラシック ポータル** | サポートされていません | サポートされていません |
| **Azure ポータル** | サポートされていません | サポートされていません |
| **PowerShell** | [記事](../articles/vpn-gateway/vpn-gateway-multi-site.md) | あり |
<!---HONumber=AcomDC_0224_2016--> | 494 | CC-BY-3.0 |
---
layout: post
title: "站点存在的意义"
header-img: "img/posts/new_year.jpg"
tags:
- Me
---
<!-- 嗯,新站点也渐渐稳定下来了w于是就把之前的第一篇挪回来了。 -->
<!--more-->
# 概览 / Overview
`jskyzero` `2020/08/04`
本博客为 jskyzero 所建,用来分享编程与计算机科学相关的内容。
```C++
otaku.change(world); // by jskyzero
```
## 结构 / Structure
```C++
+ 0.博客介绍 // 基础情况的介绍
+ 1.编程语言 // 编程语言的语法、最佳实践
+ 2.软件工具 // 辅助工具的使用、参考
+ 3.计算机科学 // 学科相关
+ 专题-UNITY // UNITY与游戏开发
+ 专题-UWP // WINDOWS与UWP
```
## 更新日志
+ 2020/08/04 Update:使用gitbook重新整理了博客。
+ 2019/08/01 Update:准备将一些放弃的梦想整理出来。
+ 2019/04/22 Update:重新分析应该把内容放在哪里。
+ README: 项目的简短介绍
+ GitHub Wiki:项目内相关的介绍
+ Blog:专题的概览介绍
+ 2019/01/03 Update:重新整理了已經有的文章。
+ 2018/11/11 Update:更新到了原來某個簡介美觀的主題。
+ 2018/10/13 Update:將頁面黑白化。
+ 2018/07/04 Update:本博客定位变成
+ Notes,各种需要记录下来的事情。
+ Program,编程与计算机相关的总结。
+ Books & Items,读书报告和物件。
+ 2018/05/09 Update:对文章目录进行了分类。
+ 2017/05/04 Update:计划移除ACGN/个人生活相关的内容
+ 2017/02/16 Update:想要多添加一些tag
+ 2017/02/09 Update:将之前的一些内容薄弱的随笔进行了整合,有些“post”的内容根本不能被称为一篇文章。
+ 2017/02/02 Update:关于建立该博客的原因:
1. Because I can.
2. 想要确实的记录点什么,知识也好,感触也罢。
+ 2016/12/30:会把很多markdown里面的东西归档过来吧...不过会慢慢来...
## ClariS
最后附上可爱的ClariS的近照~
 | 1,313 | MIT |
---
layout: post
title: "成长中的中产阶级:维护稳定还是催化变革?"
date: 2011-12-10
author: 刘岩川
from: http://cnpolitics.org/2011/12/chinas-middle-class/
tags: [ 政見 ]
categories: [ 政見 ]
---
<div class="post-block">
<h1 class="post-head">
成长中的中产阶级:维护稳定还是催化变革?
</h1>
<p class="post-subhead">
</p>
<p class="post-tag">
#中产阶级 #中国大陆 #政治参与 #社会 #美国
</p>
<p class="post-author">
<!--a href="http://cnpolitics.org/author/liuyanchuan/">刘岩川</a-->
<a href="http://cnpolitics.org/author/liuyanchuan/">
刘岩川
</a>
<span style="font-size:14px;color:#b9b9b9;">
|2011-12-10
</span>
</p>
<!--p class="post-lead">一个重要的课题正摆在中国学者和政府面前:中产阶级给这个国家带来的变化究竟会是什么?它是引导变革的催化剂,还是维护稳定的保险栓?</p-->
<div class="post-body">
<p>
<strong>
“政见”观察员 刘岩川
</strong>
</p>
<div class="wp-caption aligncenter" id="attachment_368" style="width: 610px">
<img alt="" class="size-full wp-image-368" height="300" sizes="(max-width: 600px) 100vw, 600px" src="http://cnpolitics.org/wp-content/uploads/2011/12/1126_mz_china.jpg" srcset="http://cnpolitics.org/wp-content/uploads/2011/12/1126_mz_china.jpg 600w, http://cnpolitics.org/wp-content/uploads/2011/12/1126_mz_china-300x150.jpg 300w" width="600">
<p class="wp-caption-text">
Source: BusinessWeek
</p>
</img>
</div>
<p>
无论在英国、美国还是日本,中产阶级的兴起都引发了政治、经济和文化的变革。中国的改革开放在造成贫富差距的同时,也缔造了一个日益显现的中间阶层。一个重要的课题正摆在中国学者和政府面前:中产阶级给这个国家带来的变化究竟会是什么?它是引导变革的催化剂,还是维护稳定的保险栓?
</p>
<p>
在《中国新兴的中产阶级》一书中,布鲁金斯学会的研究员李成总结了学术界有关中国中产阶级的研究成果。回顾中华人民共和国六十年左右的历史,不难发现中产是一个半新概念。1949年新中国成立以后,社会分层变得极为敏感。政府甚至宣布中国只有三个阶层,即工人、农民和主要由知识分子组成的中间层。根据马克思主义理论,该中间层将逐渐萎缩直到消失。时间推进到60年代,中国的阶级斗争登峰造极,阶级完全成为被消灭的对象。
</p>
<p>
1979年对于中国现有的中产阶级有着特殊的意义,因为邓小平的上台和改革开放的实施奠定了未来三十年经济发展的基础,同时也拉大了贫富差距。中产阶级应运而生,同时也慢慢成为学术界关注的对象。
</p>
<p>
李成发现,最早关注中产阶级的中国学者都认为它将是维护现有政策的稳定因素。例如,早期的中产阶级研究常常引用亚里士多德与孟子的论述。两位先贤虽然年代久远而且天各一方,却都警惕极端贫穷和极端富有所造成的社会矛盾,并且强调中间阶层的缓和作用。在改革开放后的中国,先富起来的阶层中自然有人拥护现存体制。
</p>
<p>
近年来,关注中产阶级的学者却得出了截然相反的结论:随着西方消费文化、自由思想的传播,中国的中产阶级比其他阶层更偏离主流意识,更倾向于质疑官员的承诺,更可能对时局表达不满。日益蔓延的腐败现象、政策实施过程中的错误,都是中产阶级批评的焦点。换言之,互联网与中西方交流所带来的权利意识加速了中间阶层的“转变”。
</p>
<p>
中产阶级的不满已经越来越明显,其影响也越发广泛。黯淡的大学生就业率似乎与中产阶层无关,但事实上,许多就业不顺利的毕业生都来自中产家庭。私营企业中的中产者也频繁抱怨国家政策对于国企的“偏爱”。在2007年至2009年间,厦门、上海和广州出现了由中产阶层领衔的抗议活动,分别冻结了当地政府建造化工厂、新地铁线和垃圾焚烧厂的计划。还有研究表明,大城市的中产阶级比其他阶层更乐于参与基层选举、更懂得用法律保护自己的权益。
</p>
<p>
李成援引国内学者李路路的研究指出,中产阶级会扮演催化变革还是巩固稳定的角色,也许关键并不在于他们自身,而是取决于他们身处的政治环境。在宽松自由的环境下,中产阶级很可能成为稳定的因素。在权力高度集中、中产阶层相对独立于统治阶层的国家,中产与政府发生利益冲突的可能性很大。胡鞍钢和胡联合两位学者干脆指出,如果要中国的中产阶级暂缓“思变”的趋势、起到稳定的作用,政府必须采取一系列措施,例如防止经济动荡、保护财产权、维护中产的社会地位、允许更多的政治参与。
</p>
<p>
与世界其他庞大经济体一样,逐渐变为经济强国的中国正在经历中产阶级的崛起。中产者对现有体制越来越响亮的质疑声表明,他们已经不再是当前政策的坚实维护者,而是对政府日渐挑剔的社会群体。如何将向往变革的中间阶层转化为拥护稳定的力量,已经成为政府的艰巨任务。
</p>
<p>
<span style="color: #888888;">
备注:布鲁金斯学会约翰.桑顿中国研究中心研究主任、布鲁金斯学会外交政策资深研究员李成是美中关系全国委员会董事,他的研究聚焦于中国政治领导人的转型、代际更迭和技术发展。文中提到的《中国新兴的中产阶级》(China’s Emerging Middle Class)由李成主编并且由布鲁金斯学会于2010年发行。
</span>
</p>
<p>
<span style="color: #888888;">
相关链接:
<a href="http://www.brookings.edu/events/2009/0922_china_middle_class.aspx" target="_blank">
<span style="color: #888888;">
http://www.brookings.edu/events/2009/0922_china_middle_class.aspx
</span>
</a>
</span>
</p>
<p>
【延伸阅读】
</p>
<p>
<a href="http://cnpolitics.org/2011/12/chinas-middleclass-boomthe-polarization-of-global-perspective/" target="_blank">
中国中产阶层:二元分化的国际观
</a>
</p>
</div>
<!-- icon list -->
<!--/div-->
<!-- social box -->
<div class="post-end-button back-to-top">
<p style="padding-top:20px;">
回到开头
</p>
</div>
<div id="display_bar">
<img src="http://cnpolitics.org/wp-content/themes/CNPolitics/images/shadow-post-end.png"/>
</div>
</div> | 3,667 | MIT |
---
layout: post
title: Swift4.1翻译
subtitle: 第二章 Strings and Characters
date: 2018-05-31
author: BeyoundCong
header-img: img/post-bg-rwd.jpg
catalog: true
tags:
- iOS
- 翻译
- Swift
---
## 字符串和字符
字符串就是由一系列的字符组成,例如:“hello,world”或者“albatross”。
Swift 中的字符串由 String 表示。字符串(包括 Character values )可以以多种方式访问。
Swift 的字符串和字符类型提供了一种快速、符合 Unicode 的方法,可以在代码中使用文本。字符串的语法创建和操作容易,可读性强。可以使用字符串将常量、变量、文字和表达式插入到更长的字符串,这样不论是显示、存储和打印一些特定的字符串值会更加容易。
注意:
Swift 的字符串类型与 Foundation 的 NSString 类连接。Foundation 还扩展了字符串,以暴露由 NSString 定义的方法。如果您导入 Foundation,您就可以在没有选择的情况下访问那些 NSString 方法。
```
let string:String = "hello";
let otherString:NSString = "world";
print(string + (otherString as String));
```
使用字符串字面量作为常量或变量的初始值:
```
let someString = "Some string literal value”
```
创建多行字符串:(不会以换行符开头或结尾)
```
let quotation = """
The White Rabbit put on his spectacles. "Where shall I begin,
please your Majesty?" he asked.
"Begin at the beginning," the King said gravely, "and go on
till you come to the end; then stop.
"""
```
多行字符串中如果想使用换行符让源码更容易阅读,并且不希望换行符是字符串值的一部分,可以在这些行的末尾加一个反斜杠(\):
```
let someString = """
“The White Rabbit put on his spectacles. "Where shall I begin, \
please your Majesty?" he asked.”
“Begin at the beginning," the King said gravely, "and go on \
till you come to the end; then stop.”
"""
```
让一个多行字符串字面意思开始或以一个行结束,写一个空行作为第一行或者最后一行:
```
let someString = """
“This string starts with a line break.
It also ends with a line break.”
"""
```
多行字符串可以缩进匹配周围的代码。在结束引号(“”)之前的空格会告诉Swift在所有其他行之前忽略哪些空白。以下俩份代码可以运行对比一下输出
```
let someString = """
“This string starts with a line break.
adada
It also ends with a line break.”
"""
```
```
let someString = """
“This string starts with a line break.
adada
It also ends with a line break.”
"""
```
### 字符串中的特殊字符
字符串值中可以包括以下特殊字符:
>转义符: 空字符\0、反斜杠 \\\ 、水平Tab \t、换行\n、回车\r、双引号\"和单引号\‘ 。一个任意的 Unicode 标量,写成\u{n},其中 n 是一个 1-8位十六进制数字,其值就等于一个有效的 Unicode 编码点。例如:
```
let wiseWords = "\"Imagination is more important than knowledge\" - Einstein"
let dollarSign = "\u{24}"
let blackHeart = "\u{2665}"
let sparklingHeart = "\u{1F496}"
```
多行字符串文本使用了三个双引号而不是一个,所以在多行字符串字面上包含双引号(“),不需要转义。如果要在多行字符串中包含文本"",至少要对其中一个引号做处理。例如:
```
let threeDoubleQuotationMarks = """
Escaping the first quotation mark \"""
Escaping all three quotation marks \"\"\"
"""
```
初始化一个空字符串:
```
var emptyString = ""
var anotherEmptyString = String()
```
检查字符串值以及 BOOL 属性是否为空
```
var name = ""
if name.isEmpty {
print("Nothing to see here")
}
```
字符串具有可变性:
可以指定一个字符串是否可以通过将其赋值给一个变量(可修改),或者是一个常量(不可修改)
```
var variableString = "Horse"
variableString += " and carriage"
// variableString is now "Horse and carriage
let constantString = "Highlander"
constantString += " and another Highlander"
//this reports a compile-time error - a constant string cannot be modified
```
可以通过 类型 NSString 和 NSMutableString 来定义字符串是否可以被修改。
#### 字符串值类型(Value Types):
当你创建一个新的字符串值,把它传给一个函数或方法时,或者当它被分配给一个常量或变量时,这个字符串会被复制。在以上情况下,都会创建一个现有字符串值的对象,并传递或分配新对象,而不是之前的对象。值类型在结构中描述,枚举类型为值类型。
Swift 默认字符串确保当一个函数或方法传递给你一个字符串值时,你可以确信这个值不会被修改,除了你自己去修改它。Swift 的编译器优化了字符串的使用,必要时进行深拷贝。这就保证在使用字符串作为值类型时,性能会更好一些。
#### 通过循环遍历字符串来输出单个字符的值:
```
for character in "Dog" {
print(character)
}
```
又或者单个字符串创建字符串常量或变量:
```
let exclamationMark: Character = "1"
```
传递一个字符值数组来当字符串值初始值的参数创建:
```
let catCharacters: [Character] = ["C", "a", "t", "!", "🐱"]
let catString = String(catCharacters)
```
可以将字符串值用” + “连接创建一个新的字符串值:
```
let string1 = "hello"
let string2 = " there"
var welcome = string1 + string2
```
或者利用 ”+=“ 来把值加到现有的字符串中:
```
var instruction = "look over"
instruction += string2
```
使用 String 类型的 append() 方法也可以将字符值追加到字符串变量:
```
let exclamationMark: Character = "!"
welcome.append(exclamationMark)
```
注意:不能将字符串或字符加到现有的字符变量中,因为字符值只包含一个字符 !!!
想让多行字符串文本构建更长的字符串行,并且希望符串中的每一行都以换行符结束,包括最后一行:
```
let badStart = """
one
two
"""
let end = """
three
"""
print(badStart + end)
/*
one
twothree
*/
let goodStart = """
one
two
"""
print(goodStart + end)
/*
one
two
three
*/
```
### 字符串插值
在单行或多行字符串文本中使用字符串插值,在其中插入的每一项都包在括号中,由反斜杠(\)前缀。这是一种从常量、变量、文字和表达式混合中构造一个新的字符串值的方法:
```
let multiplier = 3
let message = "\(multiplier) times 2.5 is \(Double(multiplier) * 2.5)"
```
注意:
被插入的字符串括号内不能包含未转义的反斜杠(\)、回车或换行,可以包含其他字符串文本。
#### Unicode
Unicode是一种国际标准,用于在不同的书写系统中编码、表示和处理文本。它使您能够从任何语言中以标准化的形式表示几乎任何字符,并从外部源(如文本文件或web页面)读取和写入这些字符。Swift的字符串和字符类型完全符合unicode。
#### Unicode标量
Swift 原生字符串类型是有 Unicode 标量值创建的。Unicode 标量是一个字符或修饰语的唯一21位“数字”,例如拉丁语小写字母A(“A”)的U+0061。Unicode 标量是在U+0000到U+D7FF的范围内的任何Unicode编码点
请注意,并不是所有的21位Unicode标量都被分配给一个字符,一些标量是为将来的赋值预留的。被分配给一个角色的标量通常也有一个名字,比如上面例子中的拉丁字母a或者表情。
#### 扩展字母集(Extended Grapheme Clusters)
Swift 的字符类型的每个实例都表示一个扩展的 字母集。可扩展的字母集是一个或多个 Unicode 标量的序列(当组合起来时)产生一个人可读的字符。比如:
```
let eAcute: Character = "\u{E9}"
let combinedEAcute: Character = "\u{65}\u{301}"
```
从输出可以看出来结果是一样的。第一种是单一的 Unicode 标量e (U+00E9)第二种是一对标量 小写字母e(U+0065) + 重音标量(U+0301)组合。
扩展字母集是一种灵活的方式,可将复杂的脚本字符表示为单个字符值。例如 韩语字母表中的韩语音节可以被表示成一个预先组成的或分解的序列。这两种表述都符合Swift的单个字符值:
```
let precomposed: Character = "\u{D55C}"
let decomposed: Character = "\u{1112}\u{1161}\u{11AB}"
```
扩展的字符集标量也可以用来封装标记,将其他 Unicode 标量作为单个字符值的一部分括起来:
```
let enclosedEAcute: Character = "\u{E9}\u{20DD}"
```
区域符号 Unicode 标量也可以组合成对出现组成单个字符值:
```
let regionalIndicatorForUS: Character = "\u{1F1FA}\u{1F1F8}"
```
### 计数字符
检索字符串中字符值的计算(count 属性)
```
let unusualMenagerie = "Koala 🐨, Snail 🐌, Penguin 🐧, Dromedary 🐪"
print("unusualMenagerie has \(unusualMenagerie.count) characters")
```
如果在字符值使用扩展字符集,字符串连接和修改可能并不会影响字符串的字符计算,例如下面将重音标量加到字符串末尾,字符计数并没有改变:
```
var word = "cafe"
print("the number of characters in \(word) is \(word.count)")
word += "\u{301}"
print("the number of characters in \(word) is \(word.count)")
```
注意:
count属性必须遍历整个字符串中的Unicode标量,以确定该字符串的字符。因为扩展的字符集可以由多个 Unicode 标量组成。不同的字符、相同字符的不同表示,可能需要不同的内存存储。count属性返回的字符的计数并不总是与包含相同字符的NSString的length属性相同。NSString的长度基于字符串中UTF-16表示的16位代码单元的数量,而不是字符串中Unicode扩展字符集的数量。
### 访问和修改字符串
通过方法、属性、下标语法访问和修改一个字符串。
每个字符串值都有一个关联的索引类型,字符串。索引,它对应于字符串中每个字符的位置。
不同的字符可以要求不同的内存存储,因此为了确定哪个字符处于特定的位置,您必须从该字符串的开始或结束迭代每个Unicode标量。由于这个原因,Swift字符串不能按整数值进行索引。
用startIndex属性访问字符串的第一个字符的位置。endIndex属性是字符串中最后一个字符后的位置。因此,endIndex属性对于字符串的下标不是有效的参数。如果一个字符串是空的,那么startIndex和endIndex是相等的。
```
let greeting = "Guten Tag!"
greeting[greeting.startIndex]
// G
print(greeting[greeting.startIndex])
greeting[greeting.index(before: greeting.endIndex)]
// !
print(greeting[greeting.index(before: greeting.endIndex)])
greeting[greeting.index(after: greeting.startIndex)]
// u
print(greeting[greeting.index(after: greeting.startIndex)])
let index = greeting.index(greeting.startIndex, offsetBy: 7)
greeting[index]
// a”
print(greeting[index])
```
访问字符串范围外的索引或在字符串范围外的索引访问一个字符或报错!
```
let greeting = ""
greeting[greeting.endIndex] // Error
greeting.index(after: greeting.endIndex) // Error”
```
使用索引访问字符串中单个字符的所有索引:
```
let greeting = "Dog is !"
for index in greeting.indices {
print("\(greeting[index]) ", terminator: "")
}
```
注意:
您可以使用startIndex和endIndex属性和索引(before:)、索引(after:)和索引(_:offsetBy:)方法对任何符合集合协议的类型的方法。(字符串、集合类型:数组、字典和集合)。
### 字符串插入及删除
将单个字符插入到指定位置的字符串中:insert(_:at:)
在指定的索引中插入另外一个字符串的内容:inset(contentsOf:at:)
```
var welcome:String = "hello"
welcome.insert("!", at: welcome.endIndex)
print(welcome)
// welcome now equals "hello!"
welcome.insert(contentsOf: " there", at: welcome.index(before: welcome.endIndex))
print(welcome)
// welcome now equals "hello there!”
```
从指定索引中的字符串删除单个字符,使用 remove(at:)
指定范围内删除子字符串,使用 removeSubrange(_:)
```
var welcome = "hello there!"
welcome.remove(at: welcome.index(before: welcome.endIndex))
// welcome now equals "hello there"
let range = welcome.index(welcome.endIndex, offsetBy: -6)..<welcome.endIndex
welcome.removeSubrange(range)
// welcome now equals "hello”
```
### 子字符串
从字符串获取子字符串的实例,然后用方法处理子字符串,可以短时间使用子字符串,如果想长时间使用就需要把子字符串转化为字符串实例。例如:
```
let greeting = "Hello, world!"
let index = greeting.index(of: ",") ?? greeting.endIndex
let beginning = greeting[..<index]
// beginning is "Hello"
print(beginning)
// Convert the result to a String for long-term storage.
let newString = String(beginning)
print(newString)
```
跟字符串一样,每个子字符串都有一个内存区域,组成子字符串的字符被存储其中。字符串和子字符串之间的区别是,作为性能优化,子字符串可以重用用于存储原始字符串的部分内存,或者用于存储另一个子字符串的部分内存。(字符串有类似的优化,但是如果两个字符串共享内存,它们是相等的。)意味着,在修改字符串或子字符串之前,不必担心会有复制内存的性能成本。子字符串不适合长期存储,因为它们重用原始字符串的存储,只要使用它的任何子字符串,就必须将整个原始字符串保存在内存中。
在上面的示例中,greeting是一个字符串,这意味着它有一个内存区域,其中组成字符串的字符被存储在其中。因为开始是一种问候的子串,它重新使用了问候使用的记忆。相反,newString是一个字符串,当它从子字符串创建时,它有自己的存储。下图显示了这些关系:

注意:
字符串和子字符串都符合StringProtocol协议,字符串处理函数通常接受StringProtocol值。您可以使用字符串或子字符串值调用这些函数。
### 字符串的比较
Swift 提供了三种方法比较:符串和字符相等、前缀相等和后缀相等。
字符串和字符串使用 相等(==) 和 不相等(!=)进行比较:
```
let quotation = "We're a lot alike, you and I."
let sameQuotation = "We're a lot alike, you and I."
if quotation == sameQuotation {
print("These two strings are considered equal")
}
// Prints "These two strings are considered equal
```
两个字符串值相等,如果他们的扩展字符集等同(具有相同的语言意义和外形),那么它们也是相等的。
```
// "Voulez-vous un café?" using LATIN SMALL LETTER E WITH ACUTE
let eAcuteQuestion = "Voulez-vous un caf\u{E9}?"
// "Voulez-vous un café?" using LATIN SMALL LETTER E and COMBINING ACUTE ACCENT
let combinedEAcuteQuestion = "Voulez-vous un caf\u{65}\u{301}?"
if eAcuteQuestion == combinedEAcuteQuestion {
print("These two strings are considered equal")
}
// Prints "These two strings are considered equal
```
但是、英语的字母A 并不等于西里尔字母A,尽管在视觉上相似,但是没有相同的语言含义:
```
let latinCapitalLetterA: Character = "\u{41}"
let cyrillicCapitalLetterA: Character = "\u{0410}"
if latinCapitalLetterA != cyrillicCapitalLetterA {
print("These two characters are not equivalent.")
}
// Prints "These two characters are not equivalent.
```
注意:
在 Swift 中,字符串和字符并不区分低于(not locale-sensitive)
### 检查前后缀是否相等
要检查字符串是否具有特定的字符串前缀或后缀,请调用字符串的hasPrefix(_:)和hasSuffix(_:)方法,这两种方法都接受一个字符串类型的参数并返回一个布尔值。
使用 hasPrefix(_:) 方法计算出第1幕场景的数量:
```
let romeoAndJuliet = [
"Act 1 Scene 1: Verona, A public place",
"Act 1 Scene 2: Capulet's mansion",
"Act 1 Scene 3: A room in Capulet's mansion",
"Act 1 Scene 4: A street outside Capulet's mansion",
"Act 1 Scene 5: The Great Hall in Capulet's mansion",
"Act 2 Scene 1: Outside Capulet's mansion",
"Act 2 Scene 2: Capulet's orchard",
"Act 2 Scene 3: Outside Friar Lawrence's cell",
"Act 2 Scene 4: A street in Verona",
"Act 2 Scene 5: Capulet's mansion",
"Act 2 Scene 6: Friar Lawrence's cell"
]
var act1SceneCount = 0
for scene in romeoAndJuliet {
if scene.hasPrefix("Act 1 ") {
act1SceneCount += 1
}
}
print("There are \(act1SceneCount) scenes in Act 1")
// Prints "There are 5 scenes in Act 1
```
使用hasSuffix(_:)方法计算 Capulet's mansion 和 Friar Lawrence's cell 数量
```
var mansionCount = 0
var cellCount = 0
for scene in romeoAndJuliet {
if scene.hasSuffix("Capulet's mansion") {
mansionCount += 1
} else if scene.hasSuffix("Friar Lawrence's cell") {
cellCount += 1
}
}
print("\(mansionCount) mansion scenes; \(cellCount) cell scenes")
// Prints "6 mansion scenes; 2 cell scenes
```
### Unicode 字符串展示
将 Unicode 字符串写入文本或存储时,该字符串中的 Unicode 标量会存在这个 Unicode 定义的编码表单中。字符串会被编码成小块,称为代码单元。UTF-8编码格式(它将字符串编码为8位代码单元)、UTF-16编码格式(将字符串编码为16位代码单元)和UTF-32编码表单(将字符串编码为32位代码单元)。
Swift 提供了几种方式来访问字符串的 Unicode。可以使用 for in 遍历字符串,访问它的单个字符值作为 Unicode 扩展字符集。
另外一种方法,在符合三个条件的 unicode 中,访问一个字符串值:
- UTF-8代码单元的集合(用字符串的utf8属性访问)
- UTF-16代码单元的集合(使用字符串的utf16属性访问)
- 一个21位的 Unicode标 量值集合,等价于字符串的UTF-32编码表单(使用字符串的unicodeScalars属性访问)
举个例子:
```
let dogString = "Dog‼🐶"
```
上面的字符串是由 Dog + 感叹号(Unicode 标量U+203C) + 🐶字符(Unicode 标量U+1F436)
#### UTF-8 展示
通过遍历 UTF-8 属性来访问字符串的 UTF-8 展示。属性是 String 类型,视图如下:

```
let dogString = "Dog‼🐶"
for codeUnit in dogString.utf8 {
print("\(codeUnit) ", terminator: "")
}
print("")
// Prints "68 111 103 226 128 188 240 159 144 182
```
解释:前三个十进制码单元值(68 111 103)表示字符D、o和g,它们的 UTF-8 表示与它们的 ASCII 表示相同。接下来的三个十进制代码单元值(226,128,188)是一个3字节的 UTF-8 表示双感叹号字符。最后四个 codeUnit 值(240、159、144、182)是 DOG FACE 字符的4字节 UTF-8 表示。
#### UTF-16 展示
通过遍历 UTF-16 属性来访问字符串的 UTF-16 展示。属性是 String 类型,视图如下:

```
let dogString = "Dog‼🐶"
for codeUnit in dogString.utf16 {
print("\(codeUnit) ", terminator: "")
}
print("")
// Prints "68 111 103 8252 55357 56374
```
同样,前三个codeUnit值(68、111、103)表示字符D、o和g,其UTF-16代码单元的值与字符串的UTF-8表示相同(因为这些Unicode标量表示ASCII字符)。
第四个codeUnit值(8252)是十六进制值203C的十进制等价物,它表示双感叹号字符的Unicode标量U+203C。该字符可以表示为UTF-16中的单个代码单元。
第五个和第6个codeUnit值(55357和56374)是一个UTF-16代理对狗脸字符的表示。这些值是U+D83D (decimal值55357)的高代理值,以及U+DC36 (decimal值56374)的一个低代理值。
#### Unicode 标量表示
遍历 unicodeScalars 属性,访问字符串值的 Unicode 标量。

```
let dogString = "Dog‼🐶"
for scalar in dogString.unicodeScalars {
print("\(scalar.value) ", terminator: "")
}
print("")
// Prints "68 111 103 8252 128054
```
前三个UnicodeScalar值(68、111、103)的值属性再次表示字符D、o和g。
第四个codeUnit值(8252)又相当于十六进制值203C,它表示双感叹号字符的Unicode标量U+203C。
第五个和最后一个UnicodeScalar(128054)的值属性是一个十进制等价的十六进制值1F436,它代表了狗脸字符的Unicode标量U+1F436。
除了查询其值属性之外,还可以使用每个UnicodeScalar值来构造一个新的字符串值,比如字符串插值:
```
let dogString = "Dog‼🐶"
for scalar in dogString.unicodeScalars {
print("\(scalar) ")
}
// D
// o
// g
// ‼
// 🐶
```
更多swift4.1翻译请查看[github](https://github.com/iOSDevelopShareTeam/SwiftTourv4.1)。
QQ技术交流群:214541576
微信公众号:shavekevin
开发者头条:
热爱生活,分享快乐。好记性不如烂笔头。多写,多记,多实践,多思考。
| 14,394 | MIT |
---
layout: post
category: "dl"
title: "hypergraph相关"
tags: [hypergraph, 超图, ]
---
目录
<!-- TOC -->
<!-- /TOC -->
[IJCAI 2019 论文解读 \| 基于超图网络模型的图网络进化算法](https://mp.weixin.qq.com/s/nGPUcDHTrG6KwAqDCkfA1w)
现实生活中很多的数据可以用图(graph)来建模,比如社交网络数据,paper 引用数据等。对于 AI 而言,一个常见的任务是半监督分类,即对图中的每一个点进行分类,在仅有部分点有标注的情况下。
处理理此类问题,比较经典的方法是 GCN,通过对相邻节点的特征聚合操作来对每个节点进行特征提取。GCN 等 GNN 模型对于节点之间的关系表征是二元的,即仅能表征两个节点 ```<e1,e2>``` 之间的关系,对于大于二元的关系组只能通过多个二元关系的方式去近似。
超图模型(Hypergraph)就是针对这种情况提出的一种网络结构。不同类型的数据中都存在着多元关系,超图模型的基本设定就是一个边可以包含大于 2 个点,去拟合多元关系。 | 530 | Apache-2.0 |
---
layout: post
title: "村级民主带来的改变"
date: 2012-08-17
author: 赵蒙旸
from: http://cnpolitics.org/2012/08/effects-of-village-level-elections/
tags: [ 政見 ]
categories: [ 政見 ]
---
<div class="post-block">
<h1 class="post-head">
村级民主带来的改变
</h1>
<p class="post-subhead">
</p>
<p class="post-tag">
#中国大陆 #政经 #治理 #美国
</p>
<p class="post-author">
<!--a href="http://cnpolitics.org/author/zhaomengyang/">赵蒙旸</a-->
<a href="http://cnpolitics.org/author/zhaomengyang/">
赵蒙旸
</a>
<span style="font-size:14px;color:#b9b9b9;">
|2012-08-17
</span>
</p>
<!--p class="post-lead">由伦敦政治经济学院、耶鲁大学、约翰霍普金斯大学与北京大学合作完成的研究报告《民主化对公共产品和再分配的影响——来自中国的证据》发现,中国的村级选举带来了乡村政治经济结构实质性的改变。村级选举不仅提升了当地公共产品的投入,而且促使改革前高收入家庭的财富向低收入家庭转移。</p-->
<div class="post-body">
<p>
<strong>
□“政见”观察员 赵蒙旸
</strong>
</p>
<p>
<a href="http://cnpolitics.org/wp-content/uploads/2012/08/china-voting.jpg">
<img alt="" class="aligncenter size-full wp-image-1754" height="324" sizes="(max-width: 465px) 100vw, 465px" src="http://cnpolitics.org/wp-content/uploads/2012/08/china-voting.jpg" srcset="http://cnpolitics.org/wp-content/uploads/2012/08/china-voting.jpg 465w, http://cnpolitics.org/wp-content/uploads/2012/08/china-voting-300x209.jpg 300w" width="465"/>
</a>
</p>
<p>
民主能够带来繁荣吗?在今年初出版的《国家为何失败》一书中,经济学者阿塞莫格鲁和政治学者罗宾逊以翔实的案例,指出国家繁荣最根本的动力仰赖于制度。新世纪以来的诸多民主化研究成果,也倾向于支持这个结论。然而,虽然理论层出不穷,大多数研究关注的对象都是国别层面的,没有对地区差异作进一步的探讨。
</p>
<p>
近日,由伦敦政治经济学院、耶鲁大学、约翰霍普金斯大学与北京大学组成的团队公布了有关中国乡村选举的研究报告
<strong>
《民主化对公共产品和再分配的影响——来自中国的证据》
</strong>
。该报告视角的创新之处有两点,一是关注面从宏观的民主与繁荣到相对微观的基层选举与发展;二是调查结合了异常丰富的历史数据与实证研究,规模也是有史以来最大的。这也是迄今为止最详细的有关中国乡村选举改革与政治经济结构的研究报告。
</p>
<p>
1982年,《宪法》正式赋予村民自治以合法地位,自那时起,中国的基层选举既遭遇到了坎坷和阻力,也在中央的允许与地方的争取下取得了一定的进展。这份基于经验调查的报告分析了1982年到2005年共23年间的数据,对象涵盖随机筛选的中国29省217个行政村。
</p>
<p>
本次调查的首要意义,在于发现
<strong>
民主选举的引入极大地提升了当地公共产品的投入和官员对于群众需求的回应。
</strong>
在对乡政府支出进行历史比较后发现,民主选举推行后,用于公共产品的投入比之前增长了大约27.2%,这些投入包括灌溉、小学、排污设备、村间小路、电力设施、周边环境等多个方面。
</p>
<p>
进一步的调查表明,这种支出的增长并不是因为官员的腐败,或是乡政府在政绩工程指引下的一厢情愿,而是村民集体意愿的反映。因为调查者发现,一些公共工程的实施并非自上而下实行,而是自下而上完成的。由于乡政府没有额外征税的权力,几乎所有的农户都会接受更高额度的专门收费,甚至参与募款,来保证乡政府顺利实施计划内的工程。这个事实也驳斥了一个关于民主的假设:即所有的民主化进程都会使得政府的征税能力下降。
</p>
<p>
第二个重要发现有关收入的再分配。
<strong>
民主选举的引入,促使改革前高收入家庭的财富向低收入家庭转移。
</strong>
在最主要的农业收入上,最贫困群体的收入上涨幅度最大,为28%。选举推行前收入低于样本中位数的家庭,多多少少都比之前富裕,而高于中位数的家庭,收入则有所减少。在占到总收入16%的工资收入上,也出现了这样一种类似的转移。农业收入和工资收入变化共同导致的结果是,最贫困的10%人口收入与最富裕的10%人口收入的比率,在选举引入后上升了21%。数字背后的原因是选举推动了农村耕地的再分配,继而缩小了收入间的差距。这其中,最明显的变化是乡政府直接控制的土地变少了,政府将分配剩余的土地租用给乡镇企业的情况变少了,乡村政治精英通过土地的获利因而也相应缩水。
</p>
<p>
选举的引进亦改变了乡村的政治格局,村委会的平均年龄下降了两岁,教育程度提高了将近一年。在开放提名的选举中,村民更容易选出自己中意的候选人,当选者是党员的可能性有所下降,换届时连任的可能性则增加了。以上种种数据和现象表明,
<strong>
村级选举带来了乡村政治经济结构实质性的改变。
</strong>
</p>
<p>
这份报告的数据来源包括两大块,一是通过查阅当地资料获得的地方政治改革与经济政策的历史、二是中国农业部提供的村级和家庭经济数据。对本次研究有利的一点是,虽然中国很多改革的导火索来自民间,但是基层改革的推行往往出于中央高层的授意,这就引发了两个结果,一是改革前与改革后出现了一条较为清晰的,有利于分析的界限,二是整个改革的进程中没有出现大的社会波动。这就使得分析中国基层选举时,避免了很多外在因素的干扰,研究结论对现实的指导意义也就更大。
</p>
<p>
虽然这份报告没有解释所有的问题,比如为何农村的收入差距比城市还要大,比如实行村级民主后,农村抗议为何不降反增等。但总的来说,报告呈现出的内容,不仅是对中国村级选举的历史和影响所进行的全面梳理,更验证和丰富了很多有关民主化的假说,兼具理论价值与现实意义。
</p>
<p>
【参考文献】
<br>
Monica Martinez-Bravo. Gerard Padró i Miquel. Nancy Qian. Yang Yao. The Effects of Democratization on Public Goods and Redistribution: Evidence from China[C]. NBER Working Paper No. 18101,2012
<br>
研究报告下载地址:http://www.nber.org/papers/w18101
</br>
</br>
</p>
</div>
<!-- icon list -->
<!--/div-->
<!-- social box -->
<div class="post-end-button back-to-top">
<p style="padding-top:20px;">
回到开头
</p>
</div>
<div id="display_bar">
<img src="http://cnpolitics.org/wp-content/themes/CNPolitics/images/shadow-post-end.png"/>
</div>
</div> | 3,731 | MIT |
---
author: 李喆
date: 2017-02-3 10:15:10
layout: post
title: Git基本概念介绍
description: Git介绍
tags: [git]
categories: [guide]
---
研发团队正很多人正在使用svn作为代码版本管理工具,本教程的目的是指导大家快速学习Git,文章可能有点长,但是看过本后大家的Git基本就算入门了,同时也应该具备了正确的Git观,接下来就是多多练习,完全熟练掌握Git。
<!-- more -->
#相关资源
[git官方网站](https://git-scm.com/)
[git官方电子书](https://git-scm.com/book/en/v2)
#源码版本控制系统的发展
##集中化的版本控制系统
在这个时期分为两个阶段,首先是单机文件版本管理系统,具体的例子有windows文件版本管理等等,这个阶段时间上是没有联网的,所有操作都在本机进行,如下图所示:
第二阶段是可以联网的文件版本管理系统,具体有CVS、SVN、VSS、Proforce等等,如下图所示:
这也是我们之前最常用的源码管理解决方案,所有人都想统一的代码管理服务器或者服务器集群提交代码,如果断网则无法提交代码。
##分布式版本控制系统
这个时候Git闪亮登场了,Git采用了与以往不同的版本管理体系,采用分布式方案,每个客户端都有整个代码库完整的信息,提交代码不需要联网,只需要本地提交,本地代码可以通过push操作推到远程服务器,参与团队协作。如下图所示:
经过几十年的发展,Git成为了目前最为优秀的源码管理方式,那么Git是如何产生的呢?我们来看看Git的历史。
#Git的历史
同生活中的许多伟大事件一样,Git诞生于一个极富纷争大举创新的年代。Linux内核开源项目有着为数众多的参与者。绝大多数的Linux内核维护 工作都花在了提交补丁和保存、归档的繁琐事务上(1991-2002年间)。到 2002年,整个项组开始启用分布式版本控制系统BitKeeper来管理和维护代码。
到2005年的时候,开发BitKeeper的商业公司同Linux内核开源社区的合作关系结束,他们收回了免费使用BitKeeper的权利。这就迫使Linux开源社区(特别是Linux的缔造者Linus Torvalds )不得不吸取教训,只有开发 一套属于自己的版本控制系统才不至于重蹈覆辙。他们对新的系统订了若干目标:
* 速度
* 简单的设计
* 对非线性开发模式的强力支持(允许上千个并行开发的分支)
* 完全分布式
* 有能高效管理类似Linux内核一样的超大规模项目(速度和数据量)
所以说是时代造就了Git。
#Git基础要点
##直接快照, 而非比较差异
我们来看下面的图,版本1创建了A、B、C三个文件,版本2修改了A、C两个文件,版本3修改了C文件,版本4修改了文件A、B,版本5修改了文件B、C

实际上每个版本只储存了变化量,我们继续看下面的图:

虽然每个版本都存储了全部的文件信息,但实际上,如果此版本有些文件没有改动,则只对这些文件做快照,相当于用指针指向这些文件,而不是真正的在磁盘上存储这些文件。理解起来应该不困难,我们就不在赘述了。
##近乎所有操作都可以本地执行
在 Git 中的绝大多数操作都只需要访问本地文件和资源,不用连网。但如果用SVN的话,差不多所有操作都需要连接网络。因为Git在本地磁盘上就保存着所有有关当前项目的历史更新,所以处理起来速度飞快。
##时刻保证数据完整性
在保存到Git之前,所有数据都要进行内容的校验和(checksum)计算,并将此结果作为数据的唯一标识和索引。换句话说,不可能在你修改了文件或目录之后,Git一无所知。这项特性作为Git的设计哲学,建在整体架构的最底层。所以如果文件在传输时变得不完整,或者磁盘损坏导致文件数据缺失,Git都能立即察觉。
##多数操作仅添加数据
常用的Git操作大多仅仅是把数据添加到数据库。因为任何一种不可逆的操作,比如删除数据,要回退或重现都会非常困难。在别的VCS中,若还未提交更新,就有可能丢失或者混淆一些修改的内容,但在Git里,一旦提交快照之后就完全不用担心丢失数据,特别是在养成了定期推送至其他镜像仓库的习惯的话。
##Git的三种状态
好,现在请注意,接下来要讲的概念非常重要。对于任何一个文件,在 Git 内都只有三种状态:已提交(committed),已修改(modified)和已暂存(staged)。已提交表示该 文件已经被安全地保存在本地数据库中了;已修改表示修改了某个文件,但还没有提交保存;已暂存表示把已修改的文件放在下次提交时要保存的清单中。
由此我们看到 Git 管理项目时,文件流转的三个工作区域:Git的本地数据目录,工作目录以及暂存区域。

每个项目都有一个git目录,它是Git用来保存元数据和对象数据库的地方。该目录非常重要,每次克隆镜像仓库的时候,实际拷贝的就是这个目录里面的数据。
从项目中取出某个版本的所有文件和目录,用以开始后续工作的叫做工作目录。这些文件实际上都是从git目录中的压缩对象数据库中提取出来的,接下来就可以在工作目录中对这些文件进行编辑。
所谓的暂存区域只不过是个简单的文件,一般都放在git目录中。有时候人们会把这个文件叫做索引文件,不过标准说法还是叫暂存区域。
* 基本的 Git 工作流程如下所示:
1. 在工作目录中修改某些文件。
2. 对这些修改了的文件作快照,并保存到暂存区域。
3. 提交更新,将保存在暂存区域的文件快照转储到 git 目录中。
所以,我们可以从文件所处的位置来判断状态:如果是git目录中保存着的特定版本文件,就属于已提交状态;如果作了修改并已放入暂存区域,就属于已暂存状态;如果自上次取出后,作了修改但还没有放到暂存区域,就是已修改状态。 | 2,917 | MIT |
# そぎぎボタン
<!-- prettier-ignore -->
[video](https://media.mstdn.plusminus.io/media_attachments/files/000/229/109/original/d6f2fc844a6772f6.mp4 ':include')
CWに`そぎぎ`を挿入するボタンを追加する。
一度作って壊れてたのを [@mohemohe](https://github.com/mohemohe) が直してくれた。 | 241 | MIT |
---
name: Bug report
about: 提交Bug反馈
---
<!-- 请确定这是一个Bug反馈,而不是一个需求反馈或问题求助,否则ISSUE可能被关闭 -->
<!-- 请提供可供复现Bug的必要条件,否则ISSUE可能被关闭 -->
## Bug report
#### 控制台错误输出?
<!-- (若无错误输出请忽略) -->
#### 期望情况?
#### 实际情况?
#### 其他相关信息
### 系统信息
<!-- 运行 vue info --> | 248 | MIT |
# 业务字段抽象
> 表单做的好,下班下的早
## 动态组件
动态组件作为具体实现,可以让两个实现(组件)之间不直接依赖。
> [Vue动态组件](https://cn.vuejs.org/v2/guide/components-dynamic-async.html) [JSX](https://zh-hans.reactjs.org/docs/introducing-jsx.html)
## 渲染模版
通过编写渲染模版,可以通过配置让对应映射渲染组件,只需传入配置和数据,模版渲染的表单即可自动和组件绑定
```js
const endTime = {
key: 'end_time', // 数据结构中的key
label: '结束时间', // 表单展示时的中文标签
type: 'datetime', // 表单渲染时,所渲染的对应类型
disabled: true, // 是否禁用此选项
placeholder: '2020-01-20', // 默认placeholder提示文字
required: true, // 该字段是否必填
editComponent: undefined, // 编辑型表单的动态组件
listComponent: undefined // 展示型表单(表格)的动态组件
}
```
```vue
<template>
<el-form>
<template v-for="{key, label, type, disabled, placeholder, required, editComponent} in configs">
<el-form-item :key="key" :label="label" :required="required">
<component v-if="editComponent" :is="editComponent" v-model="params[key]"></component>
<el-date-time-picker
v-else-if="type === 'datetime'"
v-model="params[key]"
:disabled="disabled" />
<!--省略其他-->
</el-form-item>
</template>
</el-form>
</template>
<script>
export default {
props: {
configs: {
type: Array,
required: true
},
params: {
type: Object,
required: true
}
}
}
</script>
``` | 1,476 | MIT |
---
title: "Gitの初心者向け入門資料を集めてみた"
path: "/entry/173"
date: "2019-11-30 14:51:36"
coverImage: "../../../images/thumbnail/git-logo.png"
author: "s-yoshiki"
tags: ["github","git","gitlab"]
---
## 概要
バージョン管理システムとして利用される事が多いGitですが、初心者には意外とハードルが高かったりするため、初心者向け入門資料を集めてみました。
Git入門資料
<!-- wp:embed {"url":"https://gist.github.com/s-yoshiki/3ef9bfde7c0b33816b4349f874364d05","type":"rich","providerNameSlug":"埋め込みハンドラー","className":""} -->
<figure class="wp-block-embed is-type-rich is-provider-埋め込みハンドラー"><div class="wp-block-embed__wrapper">
https://gist.github.com/s-yoshiki/3ef9bfde7c0b33816b4349f874364d05
</div></figure>
<!-- /wp:embed -->
<!-- wp:embed -->
<a href="https://gist.github.com/s-yoshiki/3ef9bfde7c0b33816b4349f874364d05">https://gist.github.com/s-yoshiki/3ef9bfde7c0b33816b4349f874364d05</a>
<!-- /wp:embed --> | 825 | MIT |
# 请求
如何设置请求超时执行的函数?
# 记录
```
/** * 保留当前页面,跳转到应用内的某个页面,使用wx.navigateBack可以返回到原页面。
* * 注意:为了不让用户在使用小程序时造成困扰,
* 我们规定页面路径只能是五层,请尽量避免多层级的交互方式。 */
function navigateTo(options: NavigateToOptions): void;
``` | 212 | Apache-2.0 |
### 題目
[2. Add Two Numbers](https://leetcode.com/problems/add-two-numbers/)
### 解題思路
這題想通就不難了,遍歷兩個鏈表相加即可。
進位的部分要多練習。
### 代碼
```go
/**
* Definition for singly-linked list.
* type ListNode struct {
* Val int
* Next *ListNode
* }
*/
func addTwoNumbers(l1 *ListNode, l2 *ListNode) *ListNode {
dummy := ListNode{}
head := &dummy
carry := 0
for l1 != nil || l2 != nil || carry != 0 {
sum := 0
if l1 != nil {
sum += l1.Val
l1 = l1.Next
}
if l2 != nil {
sum += l2.Val
l2 = l2.Next
}
sum += carry
// 取出進位值
carry = sum / 10
head.Next = &ListNode{Val: sum % 10}
head = head.Next
}
return dummy.Next
}
``` | 668 | MIT |
---
layout: post
title: "党史杂谈(315)—毛岸英受到特殊照顾,彭德怀的警卫员深陷“美人计”"
date: 2020-11-02T14:45:33.000Z
author: 温相说党史
from: https://www.youtube.com/watch?v=vaQEtSzyzoc
tags: [ 温相说党史 ]
categories: [ 温相说党史 ]
---
<!--1604328333000-->
[党史杂谈(315)—毛岸英受到特殊照顾,彭德怀的警卫员深陷“美人计”](https://www.youtube.com/watch?v=vaQEtSzyzoc)
------
<div>
成为此频道的会员即可获享以下福利:https://www.youtube.com/channel/UCGtvPQxpuRrXeryEWxQkAkA/join
</div> | 401 | MIT |
<properties
pageTitle="在 Logic Apps 中使用 Twilio 連接器 | Microsoft Azure App Service"
description="如何建立並設定 Twilio 連接器或 API 應用程式,並在 Azure App Service 的邏輯應用程式中使用它"
services="app-service\logic"
documentationCenter=".net,nodejs,java"
authors="anuragdalmia"
manager="erikre"
editor=""/>
<tags
ms.service="app-service-logic"
ms.devlang="multiple"
ms.topic="article"
ms.tgt_pltfrm="na"
ms.workload="integration"
ms.date="02/11/2016"
ms.author="sameerch"/>
# 開始使用 Twilio 連接器並將它加入您的邏輯應用程式
>[AZURE.NOTE] 這一版文章適用於邏輯應用程式 2014-12-01-preview 結構描述版本。若為 2015-08-01-preview 結構描述版本,請按一下 [Twilio API](../connectors/create-api-twilio.md)。
連線至您的 Twilio 帳戶以傳送和接收 SMS 訊息。您也可擷取電話號碼和使用量資料。邏輯應用程式可以根據各種資料來源觸發,並提供連接器以取得及處理屬於流程一部分的資料。您可以將 Twilio 連接器加入您的商務工作流程,就能在邏輯應用程式的該工作流程中處理資料。
## 建立邏輯應用程式的 Twilio 連接器 ##
連接器可以在邏輯應用程式內建立,或直接從 Azure Marketplace 建立。從 Marketplace 建立連接器:
1. 在 Azure 開始面板中,選取 [**Marketplace**]。
2. 搜尋「Twilio 連接器」,將其選取,然後選取 [建立]。
3. 設定 Twilio 連接器,如下所示:
![][1]
- **位置** - 選擇您要部署連接器的地理位置
- **訂閱** - 選擇您要建立此連接器的訂閱
- **資源群組** - 選取或建立連接器所在的資源群組
- **Web 裝載方**案 - 選取或建立 Web 裝載方案
- **定價層** - 選擇連接器的定價層
- **名稱** - 提供 Twilio 連接器的名稱
- **套裝設定**
- **帳戶 SID** - 帳戶的唯一識別碼。您可以從 <https://www.twilio.com/user/account/settings> 擷取帳戶的帳戶 SID
- **授權權杖** - 與帳戶關聯的授權權杖。您可以從 <https://www.twilio.com/user/account/settings> 擷取帳戶的授權權杖
4. 按一下 [建立]。將建立新的 Twilio 連接器。
5. 建立 API 應用程式執行個體後,您可以建立邏輯應用程式,以便使用 Twilio 連接器。
## 在邏輯應用程式中使用 Twilio 連接器 ##
建立 API 應用程式之後,您現在可以使用 Twilio 連接器做為邏輯應用程式的動作。若要這樣做,您需要:
1. 建立新的邏輯應用程式,並選擇具有 Twilio 連接器的相同資源群組:
![][2]
2. 開啟 [觸發程序和動作] 以開啟 Logic Apps 設計工具,並設定您的流程:
![][3]
3. Twilio 連接器就會出現在右側程式庫中的 [此資源群組中的 API Apps] 區段:
![][4]
4. 您可以在 [Twilio 連接器] 上按一下來將 Twilio 連接器 API 應用程式置入編輯器。
5. 您現在便可以在流程中使用 Twilio 連接器。您可以在流程中使用 [傳送訊息] 動作來傳送訊息。設定 [傳送訊息] 動作,如下所示:
- **傳自電話號碼** - 輸入支援您想要傳送之訊息類型的 Twilio 電話號碼。只有從 Twilio 購買的電話號碼或簡短程式碼能用於此連接器。
- **傳到電話號碼** - 目的地電話號碼。接受的格式為:加號 (+) 後面跟隨國碼 (地區碼),然後是電話號碼。例如, +16175551212。如果省略加號 (+),Twilio 會使用您在 [傳自] 號碼中輸入的國碼。
- **文字** - 您要傳送的訊息文字。
![][5]
![][6]
## 進一步運用您的連接器
現在已建立連接器,您可以將它加入到使用邏輯應用程式的商務工作流程。請參閱[什麼是邏輯應用程式?](app-service-logic-what-are-logic-apps.md)。
>[AZURE.NOTE] 如果您想在註冊 Azure 帳戶前開始使用 Azure Logic Apps,請移至[試用 Logic App](https://tryappservice.azure.com/?appservice=logic),即可在 App Service 中立即建立短期入門邏輯應用程式。不需要信用卡,無需承諾。
檢視位於[連接器和 API Apps 參考](http://go.microsoft.com/fwlink/p/?LinkId=529766)的 Swagger REST API 參考。
您也可以檢閱連接器的效能統計資料及控制安全性。請參閱[管理和監視內建 API Apps 和連接器](app-service-logic-monitor-your-connectors.md)。
<!--Image references-->
[1]: ./media/app-service-logic-connector-twilio/img1.PNG
[2]: ./media/app-service-logic-connector-twilio/img2.PNG
[3]: ./media/app-service-logic-connector-twilio/img3.png
[4]: ./media/app-service-logic-connector-twilio/img4.png
[5]: ./media/app-service-logic-connector-twilio/img5.PNG
[6]: ./media/app-service-logic-connector-twilio/img6.PNG
<!---HONumber=AcomDC_0224_2016--> | 2,906 | CC-BY-3.0 |
---
layout: post
title: go语言基础
tags: go
categories: backend
---
概述、变量、常量、运算符和函数、导包、指针、defer、数组、切片、map、type使用、面向对象、反射、chanel、协程、json操作、随机数、网络编程、读取文件、beego
**概述**
`1`特性:
- 自动垃圾回收
- 更丰富的内置类型
- 函数多返回值
- 错误处理
- 匿名函数和闭包
- 类型和接口
- 并发编程
- 反射
- 语言交互性
`2`编译
linux可执行文件
```
set GOARCH=amd64 set GOOS=linux go build
```
windows可执行文件
```
set GOARCH=386 set GOOS=windows go build
```
---
**变量**
相当于时一块数据存储空间的命名
1)变量声明
```go
var v1 int
var v2 string
var v3 [10]int // 数组
var v4 []int // 数组切片
var v5 struct {
f int
}
var v6 *int // 指针
var v7 map[string]int // map,key为string类型,value为int类型
var v8 func(a int) int
```
var关键字的另一种用法是可以将若干个需要声明的变量放置在一起
```go
var (
v1 int
v2 string
)
```
单行声明
```go
var a,b=1,2
```
2)变量初始化
```go
var v1 int = 10 // 正确的使用方式1
var v2 = 10 // 正确的使用方式2,编译器可以自动推导出v2的类型
v3 := 10 // 正确的使用方式3,编译器可以自动推导出v3的类型,这样的方式不可声明全局变量
```
变量一旦被声明后必须使用,否则无法编译
---
**常量**
`1`常量特点
- 常量的值不可被改变
- 常量不复制会自动赋值上一行的表达式
- 常量定义后不使用,编译器不会报错
```go
package main
import (
"fmt"
)
func main() {
const(
sping =10
summer
autumn = 20
winter
)
fmt.Println(sping,summer,autumn,winter)
}
```
`2`iota枚举
以一组相似规则初始化常量,且只可在const中使用
```go
package main
import "fmt"
func main(){
const (
a=iota
b
c
d
)
fmt.Printf("a=%d,b=%d,c=%d,d=%d",a,b,c,d)//a=0,b=1,c=2,d=3
}
```
```go
package main
import "fmt"
func main(){//方法后的大括号不可以换行
const (
a=iota
b,c=iota,iota//如果定义的枚举常量写在同一行值相同,换一行加一
d,e
)
fmt.Printf("a=%d,b=%d,c=%d,d=%d,e=%d",a,b,c,d,e)//a=0,b=1,c=1,d=2,e=2
}
```
```go
package main
import "fmt"
var z=1
func main() {
const(
a,b=iota+1,iota+2 //iota=0 1,2
c,d //iota=1 3,4
e,f=iota*2,iota*3 //iota=2 4,6
g,h //iota=3 6,9
)
fmt.Printf("a=%d,b=%d,c=%d,d=%d,e=%d,f=%d,g=%d,h=%d",a,b,c,d,e,f,g,h)
//a=1,b=2,c=2,d=3,e=4,f=6,g=6,h=9
}
```
---
**运算符和函数**
`1`算术运算符
| 算数符 | 含义 |
| ------ | -------------------------------------------- |
| + | 加 |
| - | 减 |
| * | 乘 |
| / | 除 |
| % | 取余 |
| ++ | 自增,仅后自增,不可运用在表达式中,如a:=b++ |
| -- | 自减,仅后自减,不可运用在表达式中,如a:=b-- |
`2`数据类型转换
```go
package main
import "fmt"
func main(){
var a int32 = 1;
var b int64 = 2;
c := int64(a) + b//将32位的int转换成64为的int
fmt.Print(c)
}
```
`3`有返回值的函数
```go
package main
import "fmt"
func main() {
a,b :=foo()
fmt.Printf("a=%d,b=%d",a,b)
}
func foo()(int,int){
return 1,2
}
```
```go
package main
import "fmt"
func main() {
var a int;
var b int;
a,b =foo()
fmt.Printf("a=%d,b=%d",a,b)
}
func foo()(a int,b int){
a = 1
b = 2
return
}
```
```go
package main
import "fmt"
func main() {
var a int;
var b int;
a,b =foo()
fmt.Printf("a=%d,b=%d",a,b)
}
func foo()(a ,b int){
a = 1
b = 2
return
}
```
---
**导包**
`1`导包基本过程
1)定义包
创建文件夹lib1,lib2
```go
package lib1
import "fmt"
func Foo1() {
fmt.Println("lib1")
}
```
```go
package lib2
import "fmt"
func Foo2() {
fmt.Println("lib2")
}
```
```go
package lib2
import "fmt"
func Foo3() {
fmt.Println("lib3")
}
```
2)导包调用
```go
package main
import (
"awesomeProject1/lib1"
"awesomeProject1/lib2"
)
func main() {
lib1.Foo1()
lib2.Foo2()
lib2.Foo3()
}
```
`2`导包方式
```go
import (
_ "awesomeProject1/lib1" //匿名导入,会执行包里的init()
lib "awesomeProject1/lib2" //为导入的包取别名,通过别名调用包内方法
. "awesomeProject1/lib2" //将包内方法导入当前路径,直接调用方法
)
```
---
**指针**
```go
import "fmt"
func main() {
a := 1
b := 2
swap(&a,&b)
fmt.Printf("a=%d,b=%d",a,b) //a=2,b=1
}
func swap(pa *int,pb *int) {
var temp int
temp = *pa //1
fmt.Println(temp)
*pa = *pb
*pb = temp
}
```
声明指针用\*,取某个对象的指针用&,通过指针获取该指针的对象用\*
```go
package main
import "fmt"
type student struct {
name string
age int
}
func main() {
m := make(map[string]*student)
stus := []student{
{name: "pprof.cn", age: 18},
{name: "测试", age: 23},
{name: "博客", age: 28},
}
for _, stu := range stus {
m[stu.name] = &stu
}
for k, v := range m {
fmt.Println(k,v)
fmt.Println(k, "=>", v.name)
}
/**
pprof.cn &{博客 28}
pprof.cn => 博客
测试 &{博客 28}
测试 => 博客
博客 &{博客 28}
博客 => 博客
*/
}
```
不要遍历对象时用指针,和预想的不一致
---
**defer**
```go
package main
func main() {
foo()
//aaaaaaaaaaaaaaa
//最后执行……
}
func foo()(int) {
defer println("最后执行……")
return foo1()
}
func foo1()(int) {
println("aaaaaaaaaaaaaaa")
return 1
}
```
---
**数组**
```go
package main
func main() {
//不定长度数组
array1 := []int{1,2,3}
//定长数组
array2 := [10]int{}
printArray(array1)
printArray1(array2)
}
func printArray(array []int) {
for _,value := range array{
println(value)
}
}
func printArray1(array [10]int) {
for _,value := range array{
println(value)
}
}
```
把数组作为参数在方法中传递,对于动态数组传递的是引用,对于固定长度的数组,通过值拷贝方式传递
---
**切片**
1)声明
```go
package main
import "fmt"
func main() {
//字面值方式
slice := []int{1,2}
var slice1 []int
//内置函数make
slice1 = make([]int,2)
slice2 := make([]int,2)
fmt.Printf("%v",slice)
fmt.Printf("%v",slice1)
fmt.Printf("%v",slice2)
// 创建一个整型切片
// 其长度为 3 个元素,容量为 5 个元素
slice := make([]int, 3, 5)
fmt.Println(slice)
//长度不可以大于容量
}
```
注意
// 注意和字符串数组区别([]和[...]), 下面是声明数组
arr := [...]string{"Red", "Blue", "Green", "Yellow", "Pink"}
2)扩容、截取、拷贝
```go
package main
import "fmt"
func main() {
slice := []int{1,2}
slice = append(slice, 3)//扩容
s3 := make([]int,2)
copy(s3,slice)//将slice中的数据拷贝到s3中
fmt.Printf("%v",slice)
fmt.Printf("%v",slice[1:])//截取
fmt.Printf("%v",s3)//拷贝
}
```
---
**Map**
1)声明
```go
package main
import "fmt"
func main() {
//第一种声明方式
var mymap1 map[string]string
mymap1 =make(map[string]string,10)
initmap(mymap1)
fmt.Printf("%v",mymap1)
//第二种声明方式
mymap2 := make(map[string]string,10)
initmap(mymap2)
fmt.Printf("%v",mymap2)
//第三种声明方式,字面值方式
mymap3 := map[string]string{
"1":"java",
"2":"python",
"3":"C++",
}
fmt.Printf("%v",mymap3)
}
func initmap(map1 map[string]string) {
//传递的是引用
map1["1"] = "java"
map1["2"] = "python"
map1["3"] = "C++"
}
```
2)使用
```go
package main
import "fmt"
func main() {
mymap3 := map[string]string{
"1":"java",
"2":"python",
"3":"C++",
}
fmt.Printf("%v",mymap3)
//新增
mymap3["4"] = "go"
//遍历
for key,value := range mymap3{
fmt.Println(key)
fmt.Println(value)
}
//删除
delete(mymap3,"4")
//修改
mymap3["4"] = "c"
}
```
---
**type使用**
1)给某个类型起别名
```go
package main
import "fmt"
type myint int
func main() {
var a myint
a =1
fmt.Println(a)
}
```
2)定义结构体
```go
import "fmt"
type Book struct {
name string
}
func main() {
book := Book{}
book.name = "111"
fmt.Println(book)
}
```
---
**面向对象**
1)对象的定义
```go
package main
import "fmt"
//定义对象
type Cat struct {
color string
}
//定义方法
func (this *Cat) getColor() string {
return this.color
}
func (this *Cat) setColor(color string) {
this.color = color
}
func (this *Cat) Show() {
fmt.Println("this cat's color is ",this.color)
}
func main() {
cat :=Cat{}
cat.setColor("red")
cat.Show()
}
```
对象的方法或属性大写表示在包外可以访问,小写表示仅在本包内可访问(封装)
2)继承
```go
package main
import "fmt"
type Cat struct {
color string
}
func (this *Cat) getColor() string {
return this.color
}
func (this *Cat) setColor(color string) {
this.color = color
}
func (this *Cat) Show() {
fmt.Println("this cat's color is ",this.color)
}
type tomCat struct {
Cat
}
func main() {
cat := tomCat{}
cat.setColor("red")
cat.Show()
}
```
3)多态
```go
package main
import "fmt"
type Animal interface {
getColor() string
setColor(color string)
Show()
}
type Cat struct {
color string
}
func (this *Cat) getColor() string {
return this.color
}
func (this *Cat) setColor(color string) {
this.color = color
}
func (this *Cat) Show() {
fmt.Println("this cat's color is ",this.color)
}
func main() {
var cat Animal
cat = &Cat{}
cat.setColor("red")
cat.Show()
}
```
类实现接口中的全部方法就可以用接口类型的指针指向子类型的对象
4)万能接口
```go
package main
import "fmt"
func test(a interface{}) {
fmt.Println(a)
}
func main() {
test(1)
test("aaaa")
}
```
```go
package main
import "fmt"
func test(a interface{}) {
//断言
value ,ok :=a.(string)
fmt.Println(value,ok)
}
func main() {
test(1) //false
test("aaaa")//aaa true
}
```
---
**反射**
`1`获取类型及属性
```go
package main
import (
"fmt"
"reflect"
)
type User struct {
Id int
Name string
Age int
}
func DofieldAndMethod(arg interface{}) {
argType := reflect.TypeOf(arg)
argValue :=reflect.ValueOf(arg)
fmt.Println("type:",argType)
fmt.Println("value:",argValue)
for i := 0;i<argType.NumField();i++{
field := argType.Field(i)
value := argValue.Field(i).Interface()
fmt.Println(field.Name," ",field.Type,"=",value)
}
}
func main(){
user := User{
1,
"zhang",
22,
}
DofieldAndMethod(user)
}
```
`2`标签
```go
package main
import (
"fmt"
"reflect"
)
type User struct {
Id int `info:"id" doc:"内码"`
Name string `info:"姓名" doc:"用户姓名"`
Age int `info:"年龄" doc:"用户年龄"`
}
func findTag(arg interface{}) {
t := reflect.TypeOf(arg).Elem()
for i :=0;i<t.NumField();i++{
taginfo := t.Field(i).Tag.Get("info")
tagdoc := t.Field(i).Tag.Get("doc")
fmt.Println("info =",taginfo)
fmt.Println("doc =",tagdoc)
}
}
func main(){
user := User{}
findTag(&user)
}
/**
info = id
doc = 内码
info = 姓名
doc = 用户姓名
info = 年龄
doc = 用户年龄
*/
```
---
**Channel**
`1`定义和取值
```go
package main
import (
"fmt"
"time"
)
func main(){
c := make(chan int)
go func() {
time.Sleep(time.Second)
c <- 666
c <- 111
}()
num := <-c //未拿到值,这里会阻塞
num1 := <-c
fmt.Println(num)//666
fmt.Println(num1)//111
}
```
```go
package main
import (
"fmt"
)
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
go func() {
for i := 0; i < 10; i++ {
ch1 <- i
}
close(ch1)
}()
go func(){
for{
i, ok := <-ch1 // 通道关闭后再取值ok=false
if !ok {
break
}
ch2 <- i * i
}
close(ch2)
}()
for i:=range ch2{
fmt.Println(i)
}
}
```
`2`Channel的关闭
```go
package main
import "fmt"
func main(){
c := make(chan int)
go func() {
for i :=0;i<5;i++{
c <-i
}
close(c)
}()
for{
if data,ok := <-c; ok{
fmt.Println(data)
}else{
break
}
}
fmt.Println("finished...")
/**
0
1
2
3
4
finished...
*/
}
```
关闭channel后无法向其发送数据,但可接受数据
```go
package main
import "fmt"
func main(){
c := make(chan int)
go func() {
for i :=0;i<5;i++{
c <-i
}
close(c)
}()
//和上面代码等效
for data := range c{
fmt.Println(data)
}
fmt.Println("finished...")
}
```
`3`只写和只读
```go
package main
import "fmt"
func main() {
//只写
ch1 := make(chan <- int)
ch1 <- 1
//只读
ch2 := make(<- chan int)
a := <-ch2 //会报错
fmt.Println(a)
}
```
---
**协程**
`1`协程定义
```go
package main
import (
"fmt"
"sync"
)
var wg sync.WaitGroup
func main() {
for i := 0; i < 10; i++ {
wg.Add(1) // 启动一个goroutine就登记+1
go hello(i)
}
wg.Wait() // 等待所有登记的goroutine都结束
}
func hello(i int) {
defer wg.Done() // goroutine结束就登记-1
fmt.Println("Hello Goroutine!", i)
}
```
`2`协程池
```go
package main
import (
"fmt"
"time"
)
func main() {
//创建一个Task
t := NewTask(func() error {
fmt.Println(time.Now())
time.Sleep(time.Second)
return nil
})
//创建一个协程池,最大开启3个协程worker
p := NewPool(1)
//开一个协程 不断的向 Pool 输送打印一条时间的task任务
go func() {
for i:=0;i<10;i++{
p.EntryChannel <- t
}
}()
//启动协程池p
p.Run()
}
/* 有关Task任务相关定义及操作 */
//定义任务Task类型,每一个任务Task都可以抽象成一个函数
type Task struct {
f func() error //一个无参的函数类型
}
//通过NewTask来创建一个Task
func NewTask(f func() error) *Task {
t := Task{
f: f,
}
return &t
}
//执行Task任务的方法
func (t *Task) Execute() {
t.f() //调用任务所绑定的函数
}
/* 有关协程池的定义及操作 */
//定义池类型
type Pool struct {
//对外接收Task的入口
EntryChannel chan *Task
//协程池最大worker数量,限定Goroutine的个数
worker_num int
//协程池内部的任务就绪队列
JobsChannel chan *Task
}
//创建一个协程池
func NewPool(cap int) *Pool {
p := Pool{
EntryChannel: make(chan *Task),
worker_num: cap,
JobsChannel: make(chan *Task),
}
return &p
}
//协程池创建一个worker并且开始工作
func (p *Pool) worker(work_ID int) {
//worker不断的从JobsChannel内部任务队列中拿任务
for {
select {
case task := <-p.JobsChannel:
task.Execute()
fmt.Println("worker ID ", work_ID, " 执行完毕任务")
default:
break
}
}
}
//让协程池Pool开始工作
func (p *Pool) Run() {
//1,首先根据协程池的worker数量限定,开启固定数量的Worker,
// 每一个Worker用一个Goroutine承载
for i := 0; i < p.worker_num; i++ {
go p.worker(i)
}
//2, 从EntryChannel协程池入口取外界传递过来的任务
// 并且将任务送进JobsChannel中
for{
select {
case task := <-p.EntryChannel:
p.JobsChannel <- task
default:
break
}
}
//3, 执行完毕需要关闭JobsChannel
close(p.JobsChannel)
//4, 执行完毕需要关闭EntryChannel
close(p.EntryChannel)
}
```
`3`select多路复用
```go
package main
import "fmt"
func fibna(c,quit chan int) {
x,y := 1,1
for{
select {
//c读取数据前触发
case c<-x:
y = x
x = x + y
//向quit中写数据触发
case <-quit:
fmt.Println("quit")
return
}
}
}
func main(){
c := make(chan int)
quit := make(chan int)
go func() {
for i :=0;i<5;i++{
fmt.Println(<-c)
}
quit <-0
}()
fibna(c,quit)
}
/**
1
2
4
8
16
quit
*/
```
`4`互斥锁
```go
package main
import (
"fmt"
"sync"
)
var x int64
var wg sync.WaitGroup
var lock sync.Mutex
func main() {
wg.Add(3)
go add()
go add()
go add()
wg.Wait()
fmt.Println(x)
}
func add() {
for i := 0; i < 10; i++ {
lock.Lock() // 加锁
x = x + 1
lock.Unlock() // 解锁
}
wg.Done()
}
```
`5`读写锁
```go
package main
import (
"fmt"
"sync"
"time"
)
var (
wg sync.WaitGroup
rwlock sync.RWMutex
)
func write() {
rwlock.Lock() // 加写锁
fmt.Println("正在写")
time.Sleep(2*time.Second) // 假设读操作耗时10毫秒
rwlock.Unlock() // 解写锁
wg.Done()
}
func read() {
rwlock.RLock() // 加读锁
fmt.Println("正在读")
time.Sleep(time.Second) // 假设读操作耗时1毫秒
rwlock.RUnlock() // 解读锁
wg.Done()
}
func main() {
start := time.Now()
for i := 0; i < 10; i++ {
wg.Add(1)
go write()
}
for i := 0; i < 10; i++ {
wg.Add(1)
go read()
}
wg.Wait()
end := time.Now()
fmt.Println(end.Sub(start))
}
```
`6`原子操作
```go
package main
import (
"fmt"
"sync"
"sync/atomic"
"time"
)
var x int64
var l sync.Mutex
var wg sync.WaitGroup
// 原子操作版加函数
func atomicAdd() {
atomic.AddInt64(&x, 1)
wg.Done()
}
func main() {
start := time.Now()
for i := 0; i < 10000; i++ {
wg.Add(1)
go atomicAdd() // 原子操作版add函数 是并发安全,性能优于加锁版
}
wg.Wait()
end := time.Now()
fmt.Println(x)
fmt.Println(end.Sub(start))
}
```
---
**json操作**
`1`结构体转json
```go
package main
import (
"encoding/json"
"fmt"
)
type User struct {
Id int `json:"id"`
Name string `json:"name"`
Age int `json:"age"`
}
func main(){
user := User{
1,
"zhang",
20,
}
jsonStr,err := json.Marshal(user)
if err != nil{
fmt.Println("json marshal error",err)
return
}
fmt.Printf("%s",jsonStr)
//{"id":1,"name":"zhang","age":20}
}
```
`2`json转结构体
```go
package main
import (
"encoding/json"
"fmt"
)
type User struct {
Id int `json:"id"`
Name string `json:"name"`
Age int `json:"age"`
}
func main(){
user := User{}
str := "{\"id\":1,\"name\":\"zhang\",\"age\":20}"
err := json.Unmarshal([]byte(str),&user)
if err != nil{
fmt.Println("json marshal error",err)
return
}
fmt.Println(user)
}
```
---
**随机数**
```go
package main
import (
"fmt"
"math/rand"
"time"
)
func main() {
rand.Seed(time.Now().Unix())
fmt.Println(rand.Intn(100))
}
```
new()和make()的区别
- new(T) 回一个指向类型为 T,值为 0 的地址的指针,它适用于值类型如数组和结构体
- make(T) 返回一个类型为 T 的初始值,它只适用于3种内建的引用类型:切片、map 和 channel
---
**网络编程**
```go
package main
import (
"fmt"
"net/http"
)
// handler函数
func myHandler(w http.ResponseWriter, r *http.Request) {
fmt.Println(r.RemoteAddr, "连接成功")
// 请求方式:GET POST DELETE PUT UPDATE
fmt.Println("method:", r.Method)
// /go
fmt.Println("url:", r.URL.Path)
fmt.Println("header:", r.Header)
fmt.Println("body:", r.Body)
// 回复
w.Write([]byte("www.5lmh.com"))
}
func main() {
http.HandleFunc("/go", myHandler)
// addr:监听的地址
// handler:回调函数
http.ListenAndServe("127.0.0.1:8000", nil)
}
```
---
**读取文件**
```go
package main
import (
"os"
)
func openfile(){
buf := make([]byte, 1024)
f, _ := os.Open("C:\\Users\\zhanghuan\\Desktop\\1.txt")
defer f.Close()
for {
n, _ := f.Read(buf)
if n == 0 {
break
}
os.Stdout.Write(buf[:n])
}
}
func main(){
openfile()
}
```
`1`基本操作
1)创建
```go
package main
import (
"log"
"os"
)
func checkErr(err error){
if err!=nil{
log.Fatal(err)
}
}
func main(){
var newFile,err=os.Create("C:\\Users\\zhanghuan\\Desktop\\text.txt")
checkErr(err)
log.Println(newFile)
newFile.Close()
}
```
2)重命名和移动
```go
package main
import (
"log"
"os"
)
func checkErr(err error){
if err!=nil{
log.Fatal(err)
}
}
func main(){
var err=os.Rename("C:\\Users\\zhanghuan\\Desktop\\text.txt","C:\\Users\\zhanghuan\\Desktop\\text1.txt")
checkErr(err)
}
```
3)文件信息
```go
package main
import (
"fmt"
"log"
"os"
)
func checkErr(err error){
if err!=nil{
log.Fatal(err)
}
}
func main(){
var fileInfo, err = os.Stat("C:\\Users\\zhanghuan\\Desktop\\text1.txt")
fmt.Printf("%v\n",fileInfo)
//&{text1.txt 32 {857397888 30901355} {857397888 30901355} {857397888 30901355} 0 0 0 0 {0 0} C:\Users\zhanghuan\Desktop\text1.txt 0 0 0 false}
checkErr(err)
}
```
如果文件不存在会打印出错误
4)删除文件
```go
package main
import (
"log"
"os"
)
func checkErr(err error){
if err!=nil{
log.Fatal(err)
}
}
func main(){
var err = os.Remove("C:\\Users\\zhanghuan\\Desktop\\text1.txt")
checkErr(err)
}
```
`2`检查读写权限
```go
package main
import (
"fmt"
"log"
"os"
)
func checkErr(err error){
if err!=nil{
log.Fatal(err)
}
}
func main(){
var info,err = os.OpenFile("C:\\Users\\zhanghuan\\Desktop\\text11.txt",os.O_WRONLY,0666)
if err!=nil{
if os.IsPermission(err){
fmt.Println("没有权限")
}
if os.IsNotExist(err){
fmt.Println("文件不存在")
}
}
println(info)
checkErr(err)
}
```
`3`改变权限、拥有者、时间戳
```go
package main
import (
"fmt"
"log"
"os"
"time"
)
func checkErr(err error){
if err!=nil{
log.Fatal(err)
}
}
func main(){
//授权
err := os.Chmod("C:\\Users\\zhanghuan\\Desktop\\text1.txt",0777)
checkErr(err)
//改变拥有者,仅支持linux
err = os.Chown("C:\\Users\\zhanghuan\\Desktop\\text1.txt",os.Geteuid(),os.Getegid())
//checkErr(err)
//修改文件日期
twoDaysFromNow:=time.Now().Add(48*time.Hour)
err = os.Chtimes("C:\\Users\\zhanghuan\\Desktop\\text1.txt",twoDaysFromNow,twoDaysFromNow)
checkErr(err)
a, _ := os.Stat("C:\\Users\\zhanghuan\\Desktop\\text1.txt")
fmt.Println(a.ModTime())
//2021-07-31 20:02:05.3058743 +0800 CST
}
```
`4`创建链接
```go
package main
import (
"log"
"os"
)
func main() {
// 创建硬链接
err := os.Link("C:\\Users\\zhanghuan\\Desktop\\text1.txt", "C:\\Users\\zhanghuan\\Desktop\\texta.txt")
if err != nil {
log.Fatal(err)
}
// 创建软链接
err = os.Symlink("C:\\Users\\zhanghuan\\Desktop\\text1.txt", "C:\\Users\\zhanghuan\\Desktop\\textb.txt")
if err != nil {
log.Fatal(err)
}
}
```
`5`文件复制
```go
package main
import (
"io"
"log"
"os"
)
func main() {
file,err := os.Open("C:\\Users\\zhanghuan\\Desktop\\text1.txt")
checkerror(err)
distfile ,err:= os.Create("C:\\Users\\zhanghuan\\Desktop\\text2.txt")
checkerror(err)
io.Copy(distfile,file)
}
func checkerror(err error){
if err!=nil{
log.Fatal(err)
}
}
```
`6`写入文件
1)普通方式
```go
package main
import (
"fmt"
"log"
"os"
)
func main() {
file,err := os.OpenFile("C:\\Users\\zhanghuan\\Desktop\\text1.txt",os.O_WRONLY|os.O_CREATE|os.O_APPEND,0666)
checkerror(err)
content := []byte("Bytes!\n")
bytesWritten, err := file.Write(content)
checkerror(err)
fmt.Println(bytesWritten)
}
func checkerror(err error){
if err!=nil{
log.Fatal(err)
}
}
```
2)快速写入
```go
package main
import (
"io/ioutil"
"log"
)
func main() {
//覆盖
err := ioutil.WriteFile("C:\\Users\\zhanghuan\\Desktop\\text1.txt",[]byte("Bytes!\n"),0666)
checkerror(err)
}
func checkerror(err error){
if err!=nil{
log.Fatal(err)
}
}
```
3)缓存写
```go
package main
import (
"bufio"
"fmt"
"log"
"os"
)
func main() {
file,err:=os.OpenFile("C:\\Users\\zhanghuan\\Desktop\\text1.txt",os.O_WRONLY,0666)
checkerror(err)
defer file.Close()
bufferdWriter:=bufio.NewWriter(file)
result,err:=bufferdWriter.Write([]byte{65,66,67})
checkerror(err)
bufferdWriter.Flush()
fmt.Println(result)
}
func checkerror(err error){
if err!=nil{
log.Fatal(err)
}
}
```
`7`压缩和解压
1)zip包
```go
package main
import (
"archive/zip"
"fmt"
"log"
"os"
)
//压缩
func main() {
file,err:=os.Create("C:\\Users\\zhanghuan\\Desktop\\1.zip")
checkerror(err)
defer file.Close()
zipwriter := zip.NewWriter(file)
for i:=0;i<10;i++{
//int转换成string
str := fmt.Sprintf("%d", i)
//zip包内放入文件
filewriter,err := zipwriter.Create(str)
//zip包放入的文件写入内容
filewriter.Write([]byte("aaaa"))
checkerror(err)
}
zipwriter.Close()
}
func checkerror(err error){
if err!=nil{
log.Fatal(err)
}
}
```
```go
package main
import (
"archive/zip"
"io"
"log"
"os"
"path/filepath"
)
func main() {
zipreader,err := zip.OpenReader("C:\\Users\\zhanghuan\\Desktop\\1.zip")
checkerror(err)
defer zipreader.Close()
for _,file := range zipreader.Reader.File{//遍历zip中的文件
//打开当前文件
zippedfile,err := file.Open()
checkerror(err)
//定义目标文件夹
path := filepath.Join("C:\\Users\\zhanghuan\\Desktop\\zip",file.Name)
if file.FileInfo().IsDir(){
os.MkdirAll("C:\\Users\\zhanghuan\\Desktop\\zip",file.Mode())
}else{
outputfile,err :=os.OpenFile(path,os.O_WRONLY|os.O_CREATE|os.O_TRUNC,file.Mode())
checkerror(err)
//将文件内容复制到目标文件
_, err = io.Copy(outputfile, zippedfile)
checkerror(err)
outputfile.Close()
}
}
}
func checkerror(err error){
if err!=nil{
log.Fatal(err)
}
}
```
2)gzip包
```go
package main
import (
"compress/gzip"
"log"
"os"
)
func main() {
outputfile,err := os.Create("C:\\Users\\zhanghuan\\Desktop\\2.gz")
checkerror(err)
defer outputfile.Close()
gzipwriter := gzip.NewWriter(outputfile)
_,err = gzipwriter.Write([]byte("Gophers rule!\n"))
checkerror(err)
}
func checkerror(err error){
if err!=nil{
log.Fatal(err)
}
}
```
```go
package main
import (
"compress/gzip"
"io"
"log"
"os"
)
func main() {
reader,err := os.Open("C:\\Users\\zhanghuan\\Desktop\\2.gz")
checkerror(err)
gzipreader,err := gzip.NewReader(reader)
defer gzipreader.Close()
dist,err := os.Create("C:\\Users\\zhanghuan\\Desktop\\2")
io.Copy(dist,gzipreader)
dist.Close()
}
func checkerror(err error){
if err!=nil{
log.Fatal(err)
}
}
```
`8`临时文件
```go
package main
import (
"io/ioutil"
"log"
"os"
)
func main() {
tempDirPath, err := ioutil.TempDir("C:\\Users\\zhanghuan\\Desktop\\","t")
checkerror(err)
tempFile, err := ioutil.TempFile(tempDirPath, "myTempFile.txt")
checkerror(err)
err = tempFile.Close()
//删除临时文件
err = os.Remove(tempFile.Name())
if err != nil {
log.Fatal(err)
}
//删除临时文件目录
err = os.Remove(tempDirPath)
if err != nil {
log.Fatal(err)
}
}
func checkerror(err error){
if err!=nil{
log.Fatal(err)
}
}
```
`9`哈希和摘要
```go
package main
import (
"crypto/md5"
"crypto/sha1"
"crypto/sha256"
"crypto/sha512"
"fmt"
"io/ioutil"
"log"
)
func main() {
data,err := ioutil.ReadFile("C:\\Users\\zhanghuan\\Desktop\\text1.txt")
checkerror(err)
fmt.Printf("Md5: %x\n\n", md5.Sum(data))
fmt.Printf("Sha1: %x\n\n", sha1.Sum(data))
fmt.Printf("Sha256: %x\n\n", sha256.Sum256(data))
fmt.Printf("Sha512: %x\n\n", sha512.Sum512(data))
}
func checkerror(err error){
if err!=nil{
log.Fatal(err)
}
}
```
`10`文件下载
```go
package main
import (
"io"
"log"
"net/http"
"os"
)
func main() {
newFile, err := os.Create("C:\\Users\\zhanghuan\\Desktop\\devdungeon.html")
checkerror(err)
defer newFile.Close()
url := "http://baidu.com"
response,err := http.Get(url)
defer response.Body.Close()
length,err := io.Copy(newFile,response.Body)
checkerror(err)
log.Print(length)
}
func checkerror(err error){
if err!=nil{
log.Fatal(err)
}
}
```
---
**beego**
安装bee工具
```
git config --global http.sslVerify false
go get -u github.com/beego/bee
```
github加速
```
C:\Windows\System32\drivers\etc\hosts
```
这个文件内新增
```
140.82.112.4 github.com
199.232.5.194 github.global.ssl.fastly.net
``` | 24,318 | MIT |
<properties
pageTitle="Azure Active Directory B2C 預覽:應用程式註冊 | Microsoft Azure"
description="如何向 Azure Active Directory B2C 註冊您的應用程式"
services="active-directory-b2c"
documentationCenter=""
authors="swkrish"
manager="mbaldwin"
editor="bryanla"/>
<tags
ms.service="active-directory-b2c"
ms.workload="identity"
ms.tgt_pltfrm="na"
ms.devlang="na"
ms.topic="get-started-article"
ms.date="02/25/2016"
ms.author="swkrish"/>
# Azure Active Directory B2C 預覽:註冊您的應用程式
[AZURE.INCLUDE [active-directory-b2c-preview-note](../../includes/active-directory-b2c-preview-note.md)]
## 必要條件
若要建置可接受取用者註冊與登入的應用程式,您必須先使用 Azure Active Directory B2C 租用戶註冊該應用程式。使用[建立 Azure AD B2C 租用戶](active-directory-b2c-get-started.md)中概述的步驟來建立您自己的租用戶。在您遵循該文章中的所有步驟之後,B2C 功能刀鋒視窗應會釘選至您的「開始面板」。
[AZURE.INCLUDE [active-directory-b2c-devquickstarts-v2-apps](../../includes/active-directory-b2c-devquickstarts-v2-apps.md)]
## 瀏覽至 B2C 功能刀鋒視窗
您可以從 Azure 入口網站或 Azure 傳統入口網站瀏覽至 B2C 功能刀鋒視窗。
### 1\.在 Azure 入口網站上進行存取
若您已將 B2C 功能刀鋒視窗釘選至「開始面板」,則在您以 B2C 租用戶的全域管理員身分登入 [Azure 入口網站](https://portal.azure.com/)時,即會看見該刀鋒視窗。
您也可以在 [Azure 入口網站](https://portal.azure.com/)的左側功能窗格中依序按一下 [瀏覽] 和 [Azure AD B2C],來存取刀鋒視窗。
您也可以瀏覽至 [https://portal.azure.com/{tenant}.onmicrosoft.com/?#blade/Microsoft\_AAD\_B2CAdmin/TenantManagementBlade/id/](https://portal.azure.com/{tenant}.onmicrosoft.com/?#blade/Microsoft_AAD_B2CAdmin/TenantManagementBlade/id/) (其中 **{tenant}** 是使用建立租用戶時所用的名稱來取代,例如 contosob2c),直接存取刀鋒視窗。您可將此連結加入書籤供日後使用。
> [AZURE.IMPORTANT]
You need to be a Global Administrator of the B2C tenant to be able to access the B2C features blade. A Global Administrator from any other tenant or a user from any tenant cannot access it.
### 2\.在 Azure 傳統入口網站上進行存取
以訂用帳戶管理員身分登入 [Azure 傳統入口網站](https://manage.windowsazure.com/)。(此為您註冊 Azure 時所用的相同工作或學校帳戶,或是相同的 Microsoft 帳戶)。 瀏覽至左側的 Active Directory 擴充,然後按一下 B2C 租用戶。在 [快速啟動] 索引標籤 (第一個開啟的索引標籤) 上,按一下 [管理] 下方的 [管理 B2C 設定]。此動作將會在新的瀏覽器視窗或索引標籤中,開啟 B2C 功能刀鋒視窗。
您也可以在 [設定] 索引標籤的 [B2C 管理] 區段中找到 [管理 B2C 設定] 連結。
## 註冊應用程式
1. 在 Azure 入口網站的 B2C 功能刀鋒視窗中,按一下 [應用程式]。
2. 按一下刀鋒視窗頂端的 [+新增]。
3. 輸入應用程式的**名稱**,此名稱將會為取用者說明您的應用程式。例如,您可以輸入「Contoso B2C app」。
4. 如果您正在撰寫 Web 應用程式,請將 [包含 Web 應用程式/Web API] 切換為 [是]。**回覆 URL** 是 Azure AD B2C 傳回您應用程式要求之任何權杖的所在端點。例如,輸入 `https://localhost:44321/`。若您的應用程式包含需要保護的伺服器端元件 (API),則您亦可按一下 [產生金鑰] 按鈕,以建立 (和複製) **應用程式密碼**。
> [AZURE.NOTE]
**應用程式密碼**是重要的安全性認證。
5. 如果您正在撰寫行動應用程式,請將 [包含原生用戶端] 切換為 [是]。複製系統自動為您建立的預設**重新導向 URI**。
6. 按一下 [建立] 以註冊您的應用程式。
7. 按一下您剛才建立的應用程式,並複製稍後要在程式碼中使用的全域唯一**應用程式識別碼**。
## 建置快速啟動應用程式
您現已在 Azure AD B2C 註冊應用程式,只需完成其中一個快速啟動教學課程,即可開始操作和執行。以下是一些建議:
[AZURE.INCLUDE [active-directory-v2-quickstart-table](../../includes/active-directory-b2c-quickstart-table.md)]
<!---HONumber=AcomDC_0302_2016--> | 2,765 | CC-BY-3.0 |
# 使用Thymeleaf模板引擎渲染web视图
Web应用的开发就绕不过渲染Web页面,Spring Boot 提供了很多默认配置的模板引擎;
主要是:`Thymeleaf ` 、 `FreeMarker` 、`Velocity` 、`Groovy` 、`Mustache`;
**Spring Boot建议使用这些模板引擎,避免使用JSP,若一定要使用JSP将无法实现Spring Boot的多种特性**;
后续重点学习几个模块引擎是如何使用的;
### Thymeleaf
[Thymeleaf](https://www.thymeleaf.org)是一个`XML/XHTML/HTML5`模板引擎,可用于`Web`与`非Web`环境中的应用开发。
它是一个开源的Java库,基于Apache License 2.0许可,由`Daniel Fernández`创建,该作者还是Java加密库`Jasypt`的作者。
Thymeleaf提供了一个用于整合`Spring MVC`的可选模块,在应用开发中,你可以使用Thymeleaf来完全代替JSP或其他模板引擎,如`Velocity`、`FreeMarker`等。
`Thymeleaf`的主要目标在于提供一种可被浏览器正确显示的、格式良好的模板创建方式,因此也可以用作`静态建模`。
你可以使用它创建经过验证的XML与HTML模板。`相对于编写逻辑或代码,开发者只需将标签属性添加到模板中即可`。
接下来,这些标签属性就会在DOM(文档对象模型)上执行预先制定好的逻辑。
### Spring Boot 项目资源说明及静态资源访问
在我们开发`Web`应用的时候,需要引用大量的`js`、`css`、`图片`等静态资源。
Spring Boot默认提供静态资源目录位置需置于classpath下,目录名需符合如下规则:
- `/static`
- `/public`
- `/resources`
- `/META-INF/resources`
例如:我们可以在`src/main/resources/`目录下创建`static`,在该位置放置一个`wlj.jpg`图片文件。启动程序后,尝试访问`http://localhost:8080/wlj.jpg`。如能显示图片,配置成功。
### Thymeleaf的配置及使用
**Thymeleaf的配置**
如有需要修改默认配置的时候,只需复制下面要修改的属性到`application.properties`中,并修改成需要的值,如修改模板文件的扩展名,修改默认的模板路径等。
```properties
#thymeleaf start
spring.thymeleaf.mode=HTML5
spring.thymeleaf.encoding=UTF-8
spring.thymeleaf.servlet.content-type=text/html
#开发时关闭缓存,不然没法看到实时页面
spring.thymeleaf.cache=false
#页面的存放路径就使用默认配置了
spring.thymeleaf.prefix=classpath:/templates/
spring.thymeleaf.check-template-location=true
spring.thymeleaf.suffix=.html
#thymeleaf end
#更多的配置信息,请去官网查看文档哦
```
**Thymeleaf的使用**
在当前项目的`pom.xml`文件内引入`Thymeleaf`模块:
```xml
<dependencies>
.....
.....
<!--引入Web模块-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--引入Thymeleaf模块-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
</dependencies>
```
在默认的模板路径`src/main/resources/templates`下编写模板文件即可;当然你可以自己改下配置信息,修改下模块的存放路径的;
**控制器**
```java
@Controller
public class HelloController {
/**
* 测试 thymeleaf
*
* @return
*/
@RequestMapping(value = "/hello", method = RequestMethod.GET)
public String thymeleaf(HttpServletRequest request,
//@RequestParam 设置请求参数 非必须,默认值为 wlj
@RequestParam(value = "name",
required = false,
defaultValue = "wlj") String name) {
// 加入一个属性,用来在模板中读取
request.setAttribute("name", name);
// return模板文件的名称,对应src/main/resources/templates/hello.html
return "hello";
}
}
```
**Tips: 注意是`@Controller` 不是`@RestController`**
这两个的区别是:
```java
@RestController注解相当于 @ResponseBody + @Controller合在一起的作用
使用@RestController注解Controller,则Controller中的方法无法返回jsp或者其他页面的
如果需要返回json,用于提供API,请使用@RestController
如果需要返回Web页面,用于展示页面,请使用@Controller
```
在默认目录`src/main/resources/templates/`下创建`hello.html`静态页面
```html
<!DOCTYPE HTML>
<html xmlns:th="http://www.thymeleaf.org">
<head>
<title>Hello Thymeleaf</title>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8"/>
</head>
<body>
<!--/*@thymesVar id="name" type="java.lang.String"*/-->
<p th:text="'Hello!, ' + ${name} + '!'">Spring Boot</p>
</body>
</html>
```
运行项目,并在浏览器内输入`http://localhost:8080/hello`;
或者你传参,在浏览器内输入`http://localhost:8080/hello?name=thymeleaf`;
**运行效果**

源代码就不提供了,因为真的很简单,如果还有运行疑问,给我提问题哦,我会耐心解答的;
具体更细节的使用及语法需要查看官方文档进行仔细研究,这里只做入门使用哦;后续专门学习一下`Thymeleaf`,然后写一篇更详尽的使用文档; | 3,649 | Apache-2.0 |
`zip` 是最广泛使用的归档文件, 除了linux,windows也是非常的广泛。,支持无损数据压缩。 zip 文件是包含一个或多个压缩文件或目录的数据容器。
接下来,我将解释如何使用 `unzip` 命令通过命令行解压缩 Linux 系统中的文件。
还有与之对应就是 zip。

## 安装unzip
在大多数 Linux 发行版中,unzip 不是默认安装的,但是您可以使用您的发行版的包管理器轻松地安装它。
- 在 Ubuntu 和 Debian 上
```
sudo apt install unzip
```
- Fedora 和 Fedora
```
sudo yum install unzip
```
## 如何解压 `ZIP` 文件
最简单的形式是,当不带任何选项使用时,unzip 命令将指定 `ZIP` 归档文件中的所有文件解压缩到工作目录文件夹中。
举个例子,假设你下载了 Wordpress 安装 `ZIP` 文件。 要将这个文件解压到工作目录文件夹,你只需运行以下命令:
```
unzip latest.zip
```
zip 文件不支持 linux 样式的所有权信息。提取的文件属于运行命令的用户。
您必须对解压压缩 `ZIP` 归档文件的目录具有写权限。
## 静默运行
默认情况下,解压缩将打印所提取的所有文件的名称,并在提取完成时打印一个摘要。
使用 -q 开关禁止打印这些消息。
```
unzip -q filename.zip
```
## 将 `ZIP` 文件解压缩到另一个目录
要将 `ZIP` 文件解压缩到与当前目录不同的目录,请使用 -d 开关:
```
unzip filename.zip -d /path/to/directory
```
例如,要将 WordPress 归档 latest.zip 解压缩到/var/www/目录,可以使用以下命令:
```
sudo unzip latest.zip -d /var/www
```
在上面的命令中,我使用 sudo 是因为我登录的用户通常没有对/var/www 目录的写权限。 当使用 sudo 对 `ZIP` 文件进行解压缩时,提取的文件和目录归用户根所有。
## 解压密码保护的 `ZIP` 文件
要解压缩受密码保护的文件,请调用 unzip 命令,并在 -P 选项后面加上密码:
```
unzip -P PasswOrd filename.zip
```
在命令行中键入密码是不安全的,应该避免。 一个更安全的选择是正常地提取文件而不提供密码。 如果 `ZIP` 文件是加密的,解压缩会提示你输入密码:
```
unzip filename.zip
archive: filename.zip
[filename.zip] file.txt password:
```
只要是正确的,unzip 将对所有加密文件使用相同的密码。
## 解压缩 `ZIP` 文件时排除文件
要排除特定的文件或目录进行解压缩,请使用-x 选项,然后使用空格分隔的存档文件列表排除解压缩:
```
unzip filename.zip -x file1-to-exclude file2-to-exclude
```
在下面的示例中,我将从 `ZIP` 归档文件中提取除. git 目录以外的所有文件和目录:
```
unzip filename.zip -x "*.git/*"
```
## 覆盖现有文件
假设您已经解压缩了一个 `ZIP` 文件,并且再次运行相同的命令:
```
unzip latest.zip
```
默认情况下,解压缩将询问您是否只覆盖当前文件、覆盖所有文件、跳过当前文件的提取、跳过所有文件的提取,或者重命名当前文件。
```
Archive: latest.zip
replace wordpress/xmlrpc.php? [y]es, [n]o, [A]ll, [N]one, [r]ename:
```
如果您想在没有提示的情况下覆盖现有文件,请使用-o 选项:
```
unzip -o filename.zip
```
谨慎使用此选项。如果对文件做了任何更改,更改将丢失。
## 解压 `ZIP` 文件而不改写现有文件
假设您已经解压缩了一个 `ZIP` 文件,并且对一些文件进行了更改,但是不小心删除了一些文件。 您希望保留更改并从 `ZIP` 归档文件中还原已删除的文件。
在这种情况下,使用-n 选项强制 unzip 跳过提取已经存在的文件:
```
unzip -n filename.zip
```
## 解压多个 `ZIP` 文件
您可以使用正则表达式来匹配多个归档文件。
例如,如果你当前的工作目录文件夹中有多个 `ZIP` 文件,你可以只用一个命令解压所有文件:
```
unzip '*.zip'
```
注意 * 旁边的单引号。 如果你忘记引用参数,shell 会展开通配符,你会得到一个错误。
## 列出 zip 文件的内容
若要列出 `ZIP` 文件的内容,请使用-l 选项:
```
unzip -l filename.zip
```
在下面的例子中,我列出了所有的 WordPress 安装文件:
```
unzip -l latest.zip
```
输出结果如下:
Archive: latest.zip
Length Date Time Name
--------- ---------- ----- ----
0 2019-08-02 22:39 test/
3065 2019-08-31 18:31 test/xmlrpc.php
364 2019-12-19 12:20 test/wp-blog-header.php
7415 2019-03-18 17:13 test/readme.html
...
...
21323 2019-03-09 01:15 test/wp-admin/themes.php
8353 2019-09-10 18:20 test/wp-admin/options-reading.php
4620 2019-10-24 00:12 test/wp-trackback.php
1889 2019-05-03 00:11 test/wp-comments-post.php
--------- -------
27271400 1648 files
## 小结
Unzip 是一个实用工具,可以帮助您列出、测试和解压缩 `ZIP` 文档。
要在 Linux 系统上创建 `ZIP` 归档文件,您需要使用 `ZIP` 命令。
 | 3,089 | Apache-2.0 |
---
author: ''
categories: [中國戰略分析]
date: 2018-01-01
from: http://zhanlve.org/?p=4279
layout: post
tags: [中國戰略分析]
title: '美国外交关系委员会(2017)CFR: 2018年度值得关注的八项主要威胁'
---
<div id="entry">
<div class="at-above-post addthis_tool" data-url="http://zhanlve.org/?p=4279">
</div>
<p>
2017年12月11日,美国外交关系委员会(CFR)发布第十个年度《值得关注的主要威胁》报告(Preventive Priorities Survey)。报告列出了美国在2018年应高度关注的八项潜在冲突危机,特别强调美国和朝鲜以及伊朗可能发生的武装冲突是关系国际社会的重大问题。
<br/>
本年度报告由CFR的预防行动中心(CPA)编写。中心邀请多名外交政策专家将三十项已经或可能出现的冲突事件按发生(或升级)概率以及对美国国家利益的潜在影响度进行排序,最后筛选出如下八项"一级"冲突威胁:
<br/>
朝鲜及其周边国家与美国发生军事冲突。
<br/>
因伊朗卷入地区冲突或支持武装代理人组织(包括也门胡塞武装和黎巴嫩真主党),而导致伊朗和美国或其盟国发生武装对峙。
<br/>
针对美国关键基础设施和网络的极具破坏性的网络攻击。
<br/>
俄罗斯与北约成员国之间因俄在东欧的武断行为发生有预谋或无预谋的军事对峙。
<br/>
因南海问题中国与一个或多个南亚国家和地区(文莱、马来西亚、菲律宾、台湾或越南)发生武装对峙。
<br/>
国外或国内恐怖分子对美国或其北约盟国发动大规模恐怖袭击。
<br/>
由于政府武装试图夺回领土导致叙利亚国内动乱加剧,美国、俄罗斯和伊朗等外部力量的介入使局势更加紧张。
<br/>
由于塔利班暴乱和可能发生的政府倒台加剧阿富汗国内的动荡不安。
<br/>
CPA负责人表示,随着全球武装冲突风险加大,美国应该有选择地加以关注或投放军力,年度《值得关注的主要威胁》报告正是针对这一目的撰写的。很多前些年的报告中所关注的威胁事项在2018年仍将是关注重点。今年报告中列出的三十项主要威胁中,有二十八项在去年的报告中就存在,而新出现的八项威胁主要来源于以色列和黎巴嫩真主党之间的冲突加剧,以及巴尔干地区紧张态势升级或极端主义暴力活动。有两项威胁今年升级为一级威胁:一项是伊朗和美国或其盟国之间发生武装对峙,另一项是中国与一个或多个南亚争议国家或地区就南海问题发生武装对峙。另有两项威胁被降级:一项是土耳其和其国内以及邻国库尔德武装组织之间的暴力冲突,另一项是利比亚的暴乱。
</p>
<p>
中文摘要转自:http://cn.uscnpm.org/model_item.html?action=view&table=article&id=14883
</p>
<p>
</p>
<h1 class="article-header__title">
Preventive Priorities Survey: 2018
</h1>
<p>
The Council on Foreign Relations'tenth annual
<a id="www_cfr_org_report_preventive_prior" name="www_cfr_org_report_preventive_prior">
</a>
Preventive Priorities Survey identified eight top conflict prevention priorities for the United States in the year ahead, highlighting armed confrontations between the United States and North Korea and Iran as serious international concerns.
</p>
<h3 class="interview-title">
<a href="http://www.cfr.org/global/global-conflict-tracker/p32137#!/">
The Global Conflict Tracker: Learn About the World's Top Hotspots
</a>
</h3>
<p>
The survey, conducted by CFR's
<a id="www_cfr_org_thinktank_cpa__utm_medi" name="www_cfr_org_thinktank_cpa__utm_medi">
</a>
<a href="http://links.cfr.mkt5175.com/ctt?kn=2&ms=NTU1MjU0OTMS1&r=MzExNTMzMTc0OTEzS0&b=0&j=MTMwMTIyNjAyOAS2&mt=1&rt=0" target="_blank" title="Center for Preventive Action">
Center for Preventive Action
</a>
(CPA) asked foreign policy experts to rank thirty ongoing or potential conflicts based on their likelihood of occurring or escalating in the next year and their potential impact on U.S. national interests.
</p>
<p>
<b>
This year, eight conflicts were considered "top tier" risks:
</b>
</p>
<ul>
<li>
military conflict involving the United States,
<b>
North Korea
</b>
, and its neighboring countries
</li>
<li>
an armed confrontation between
<b>
Iran
</b>
and the United States or one of its allies over Iran's involvement in regional conflicts and support of militant proxy groups, including the Yemeni Houthis and Lebanese Hezbollah
</li>
<li>
a highly disruptive
<b>
cyberattack
</b>
on U.S. critical infrastructure and networks
</li>
<li>
a deliberate or unintended military confrontation between
<b>
Russia
</b>
and
<b>
North Atlantic Treaty Organization
</b>
members, stemming from assertive Russian behavior in Eastern Europe
</li>
<li>
an armed confrontation over disputed maritime areas in the
<b>
South China Sea
</b>
between China and one or more Southeast Asian claimants—Brunei, Malaysia, the Philippines, Taiwan, or Vietnam
</li>
<li>
a mass casualty
<b>
terrorist attack
</b>
on the U.S. homeland or a treaty ally by either foreign or homegrown terrorist(s)
</li>
<li>
intensified violence in
<b>
Syria
</b>
as government forces attempt to regain control over territory, with heightened tensions among external parties to the conflict, including the United States, Russia, and Iran
</li>
<li>
increased violence and instability in
<b>
Afghanistan
</b>
resulting from the Taliban insurgency and potential government collapse
</li>
</ul>
<p>
"With the risk of armed conflict growing in the world, the United States needs to make smart choices about where to focus attention and resources to avert potentially costly military engagements. Our annual Preventive Priorities Survey is designed to help U.S. policymakers do just that," said
<a id="www_cfr_org_experts_conflict_preven" name="www_cfr_org_experts_conflict_preven">
</a>
<a href="http://links.cfr.mkt5175.com/ctt?kn=9&ms=NTU1Mjc3NjES1&r=MzExNTQ3ODcxMjY1S0&b=0&j=MTMwMTI2MzUyNQS2&mt=1&rt=0" target="_blank" title="Paul B. Stares">
<b>
Paul B. Stares
</b>
</a>
, General John W. Vessey senior fellow for conflict prevention, CPA director, and author of the new book
<a id="www_cfr_org_book_preventive_engagem" name="www_cfr_org_book_preventive_engagem">
</a>
<a href="http://links.cfr.mkt5175.com/ctt?kn=8&ms=NTU1Mjc3NjES1&r=MzExNTQ3ODcxMjY1S0&b=0&j=MTMwMTI2MzUyNQS2&mt=1&rt=0" target="_blank" title="Preventive Engagement: How America Can Avoid War, Stay Strong, and Keep the Peace">
<em>
Preventive Engagement: How America Can Avoid War, Stay Strong, and Keep the Peace
</em>
</a>
.
</p>
<p>
Many of the contingencies identified in previous surveys remain concerns for 2018. Of the thirty identified this year, twenty-two were considered risks last year. Among the eight new contingencies in this year's survey are the risks of intensified clashes between Israel and Hezbollah, increased violence and political instability in the Sahel region of Africa, and escalating tensions or extremist violence in the Balkans.
</p>
<p>
Two contingencies were upgraded to the top tier this year: an armed confrontation between Iran and the United States or one of its allies, and an armed confrontation over disputed maritime areas in the South China Sea between China and one or more Southeast Asian claimants.
</p>
<p>
The 2018 survey downgraded the priority rankings of two contingencies, compared to last year: the intensification of violence between Turkey and various Kurdish armed groups within Turkey and neighboring countries,and the probability of greater violence in Libya.
</p>
<p>
CPA's
<a id="www_cfr_org_global_global_conflict_" name="www_cfr_org_global_global_conflict_">
</a>
<a href="http://links.cfr.mkt5175.com/ctt?kn=10&ms=NTU1Mjc3NjES1&r=MzExNTQ3ODcxMjY1S0&b=0&j=MTMwMTI2MzUyNQS2&mt=1&rt=0" target="_blank" title="Global Conflict Tracker">
Global Conflict Tracker
</a>
plots ongoing conflicts on an interactive map paired with background information, CFR analysis, and news updates.
</p>
<p>
<em>
The Preventive Priorities Survey was made possible by a generous grant from Carnegie Corporation of New York. The statements made and views expressed are solely the responsibility of the Center for Preventive Action.
</em>
</p>
<p>
</p>
<p>
英文版出自:https://www.cfr.org/report/preventive-priorities-survey-2018
</p>
<p>
<img alt="" class="aligncenter size-large wp-image-4280" height="791" sizes="(max-width: 1024px) 100vw, 1024px" src="http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_01-1024x791.jpg" srcset="http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_01-1024x791.jpg 1024w, http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_01-300x232.jpg 300w, http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_01-768x593.jpg 768w, http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_01.jpg 1584w" width="1024"/>
<img alt="" class="aligncenter size-large wp-image-4281" height="791" sizes="(max-width: 1024px) 100vw, 1024px" src="http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_02-1024x791.jpg" srcset="http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_02-1024x791.jpg 1024w, http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_02-300x232.jpg 300w, http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_02-768x593.jpg 768w" width="1024"/>
<img alt="" class="aligncenter size-large wp-image-4282" height="791" sizes="(max-width: 1024px) 100vw, 1024px" src="http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_03-1024x791.jpg" srcset="http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_03-1024x791.jpg 1024w, http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_03-300x232.jpg 300w, http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_03-768x593.jpg 768w" width="1024"/>
<img alt="" class="aligncenter size-large wp-image-4283" height="791" sizes="(max-width: 1024px) 100vw, 1024px" src="http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_04-1024x791.jpg" srcset="http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_04-1024x791.jpg 1024w, http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_04-300x232.jpg 300w, http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_04-768x593.jpg 768w" width="1024"/>
<img alt="" class="aligncenter size-large wp-image-4284" height="791" sizes="(max-width: 1024px) 100vw, 1024px" src="http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_05-1024x791.jpg" srcset="http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_05-1024x791.jpg 1024w, http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_05-300x232.jpg 300w, http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_05-768x593.jpg 768w, http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_05.jpg 1584w" width="1024"/>
<img alt="" class="aligncenter size-large wp-image-4285" height="791" sizes="(max-width: 1024px) 100vw, 1024px" src="http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_06-1024x791.jpg" srcset="http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_06-1024x791.jpg 1024w, http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_06-300x232.jpg 300w, http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_06-768x593.jpg 768w, http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_06.jpg 1584w" width="1024"/>
<img alt="" class="aligncenter size-large wp-image-4286" height="791" sizes="(max-width: 1024px) 100vw, 1024px" src="http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_07-1024x791.jpg" srcset="http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_07-1024x791.jpg 1024w, http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_07-300x232.jpg 300w, http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_07-768x593.jpg 768w, http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_07.jpg 1584w" width="1024"/>
<img alt="" class="aligncenter size-large wp-image-4287" height="791" sizes="(max-width: 1024px) 100vw, 1024px" src="http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_08-1024x791.jpg" srcset="http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_08-1024x791.jpg 1024w, http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_08-300x232.jpg 300w, http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_08-768x593.jpg 768w" width="1024"/>
<img alt="" class="aligncenter size-large wp-image-4288" height="791" sizes="(max-width: 1024px) 100vw, 1024px" src="http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_09-1024x791.jpg" srcset="http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_09-1024x791.jpg 1024w, http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_09-300x232.jpg 300w, http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_09-768x593.jpg 768w" width="1024"/>
<img alt="" class="aligncenter size-large wp-image-4289" height="791" sizes="(max-width: 1024px) 100vw, 1024px" src="http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_10-1024x791.jpg" srcset="http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_10-1024x791.jpg 1024w, http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_10-300x232.jpg 300w, http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_10-768x593.jpg 768w" width="1024"/>
<img alt="" class="aligncenter size-large wp-image-4290" height="791" sizes="(max-width: 1024px) 100vw, 1024px" src="http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_11-1024x791.jpg" srcset="http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_11-1024x791.jpg 1024w, http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_11-300x232.jpg 300w, http://zhanlve.org/wp-content/uploads/2018/02/PPS_2018_Web_页面_11-768x593.jpg 768w" width="1024"/>
</p>
<!-- AddThis Advanced Settings above via filter on the_content -->
<!-- AddThis Advanced Settings below via filter on the_content -->
<!-- AddThis Advanced Settings generic via filter on the_content -->
<!-- AddThis Share Buttons above via filter on the_content -->
<!-- AddThis Share Buttons below via filter on the_content -->
<div class="at-below-post addthis_tool" data-url="http://zhanlve.org/?p=4279">
</div>
<!-- AddThis Share Buttons generic via filter on the_content -->
</div> | 13,115 | MIT |
# Spring Boot 配置文件加密
1.mavne导入依赖
```xml
<dependency>
<groupId>com.github.ulisesbocchio</groupId>
<artifactId>jasypt-spring-boot-starter</artifactId>
<version>3.0.4</version>
</dependency>
```
2.在配置文件中添加加密盐
```yaml
jasypt:
encryptor:
password: $2a$10$Wzamw5.YLzsW8a4S2Iey7.
```
3.获取需要加密字符串的密文
```java
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
public class PasswordCreate {
@Autowired
private StringEncryptor stringEncryptor;
/**
* 生成
*/
@Test
void contextLoads() {
String root = stringEncryptor.encrypt("root");
System.out.println(root);
}
}
```
4.在配置文件密文,密文需要 __ENC()__ 包起来
```yaml
server:
port: 8443
ssl:
enabled: false
key-store: classpath:admin.jks
key-store-password: ENC(yLT+TMQBFMTdC4PK4cIQwqyo/UFF1xyXQZ1ptND8n3TANYvl9WOnahNLcFitWFAO)
key-store-type: JKS
key-alias: admin
spring:
datasource:
druid:
db-type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.p6spy.engine.spy.P6SpyDriver
stat-view-servlet:
enabled: true
url-pattern: /druid/*
reset-enable: false
login-username: admin
login-password: ENC(yLT+TMQBFMTdC4PK4cIQwqyo/UFF1xyXQZ1ptND8n3TANYvl9WOnahNLcFitWFAO)
``` | 1,292 | Apache-2.0 |
---
title: 两数相加
tags:
- 两数相加
sidebar: auto
---
### 两数相加
::: tip 难度
中等
:::

## [题目:](https://leetcode-cn.com/problems/add-two-numbers/)
给出两个 非空 的链表用来表示两个非负的整数。其中,它们各自的位数是按照 逆序 的方式存储的,并且它们的每个节点只能存储 一位 数字。
如果,我们将这两个数相加起来,则会返回一个新的链表来表示它们的和。
您可以假设除了数字 0 之外,这两个数都不会以 0 开头
**示例 1:**
```
输入:(2 -> 4 -> 3) + (5 -> 6 -> 4)
输出:7 -> 0 -> 8
原因:342 + 465 = 807
```
## 抛砖引玉

**思路**
首先想到的是通过链表模拟累加得到和,再把和转换成链表,但是会发现求和时如果数组过大变量存贮数字时会溢出,
那么通过可以直接在累加时就顺便生成链表
**注意**
- 每个位上的和包括:l1、l2 指定位上的数字,和上一轮进位的数字
- 链表中数字计算完成还可能有进位的数字
- 衔接链表的 next 时需要通过中间变量衔接:
中间链表的指针根据 next 切换,避免结果链表指针变化后无法回溯的问题
### 递归
```javascript
/**
* Definition for singly-linked list.
* function ListNode(val, next) {
* this.val = (val===undefined ? 0 : val)
* this.next = (next===undefined ? null : next)
* }
*/
/**
* @param {ListNode} l1
* @param {ListNode} l2
* @return {ListNode}
*/
var addTwoNumbers = function(l1, l2) {
let sum = 0, // 每个位上的和
_result = null, // 结果链表
mid = null // 传递next的中间链表
function helper(a, b) {
if (a == undefined && b == undefined) return
let item = 0
if (a && a.val) item = a.val + item
if (b && b.val) item = b.val + item
sum = sum + item
if (_result) {
mid.next = new ListNode(sum % 10)
mid = mid.next
} else {
mid = new ListNode(sum % 10)
_result = mid
}
sum = Math.floor(sum / 10)
helper(a ? a.next : undefined, b ? b.next : undefined)
}
helper(l1, l2)
// 最后如果有剩余进位则继续追加
if (sum) {
mid.next = new ListNode(sum)
}
return _result
}
```
### 迭代
通过改变 l1、l2 指针指向的链表位置来迭代求和
```javascript
/**
* @param {ListNode} l1
* @param {ListNode} l2
* @return {ListNode}
*/
var addTwoNumbers = function(l1, l2) {
let sum = 0, // 每个位上的和
_result = null, // 结果链表
mid = null // 传递next的中间链表
while (l1 || l2) {
let item = 0
if (l1 && l1.val) item = l1.val + item
if (l2 && l2.val) item = l2.val + item
sum = sum + item
if (_result) {
mid.next = new ListNode(sum % 10)
mid = mid.next
} else {
mid = new ListNode(sum % 10)
_result = mid
}
sum = Math.floor(sum / 10)
if (l1) l1 = l1.next
if (l2) l2 = l2.next
}
if (sum) {
mid.next = new ListNode(sum)
}
return _result
}
``` | 2,383 | Unlicense |
# 断言 (Assert)
<!--introduced_in=v0.10.0-->
> 稳定性:2 - 稳定的
`assert`模块提供了一组简单的断言测试,可用来测试不变量。
有` strict `(严格)和 ` legacy `(老版本)模式, 建议只使用 [` strict 模式 `] []。
更多关于平等性的对比,可以参考 [MDN 上 JavaScript 中的相等性判断](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Equality_comparisons_and_sameness)。
## Strict 模式
<!-- YAML
added: V8.13.0
changes:
- version: V8.13.0
pr-url: https://github.com/nodejs/node/pull/17002
description: Added strict mode to the assert module.
-->
When using the `strict mode`, any `assert` function will use the equality used in the strict function mode. So [`assert.deepEqual()`][] will, for example, work the same as [`assert.deepStrictEqual()`][].
可以通过如下方式使用:
```js
const assert = require('assert').strict;
```
## Legacy 模式
> 稳定性:0 - 已弃用:改为使用Strict模式。
当直接访问 `assert`, 而不是通过 `strict` 属性访问时,[Abstract Equality Comparison(抽象等式比较)](https://tc39.github.io/ecma262/#sec-abstract-equality-comparison) 将被用于任何名称中没有“strict”的函数, 例如[`assert.deepEqual()`]。
可以通过如下方式使用:
```js
const assert = require('assert');
```
建议使用 [`strict 模式`], 而不使用 [Abstract Equality Comparison(抽象等式比较)](https://tc39.github.io/ecma262/#sec-abstract-equality-comparison) , 因为后者通常会产生意想不到的结果。 这尤其适用于在比较规则宽松的地方,例如 [`assert.deepEqual()`]:
```js
// WARNING: This does not throw an AssertionError!
assert.deepEqual(/a/gi, new Date());
```
## assert(value[, message])
<!-- YAML
added: v0.5.9
-->
* `value` {any}
* `message` {any}
[`assert.ok()`][]的别名。
## assert.deepEqual(actual, expected[, message])
<!-- YAML
added: v0.1.21
changes:
- version: v8.0.0
pr-url: https://github.com/nodejs/node/pull/12142
description: Set and Map content is also compared
- version: v6.4.0, v4.7.1
pr-url: https://github.com/nodejs/node/pull/8002
description: Typed array slices are handled correctly now.
- version: v6.1.0, v4.5.0
pr-url: https://github.com/nodejs/node/pull/6432
description: Objects with circular references can be used as inputs now.
- version: v5.10.1, v4.4.3
pr-url: https://github.com/nodejs/node/pull/5910
description: Handle non-`Uint8Array` typed arrays correctly.
-->
* `actual` {any}
* `expected` {any}
* `message` {any}
**Strict 模式**
[`assert.deepStrictEqual()`] 的别名。
**Legacy 模式**
> 稳定性:0 - 已弃用:改为使用 [`assert.deepStrictEqual()`][]。
测试 `actual` 和 `expected` 参数之间是否深度相等。 将原始值与 [Abstract Equality Comparison(抽象等式比较)](https://tc39.github.io/ecma262/#sec-abstract-equality-comparison) ( `==` ) 进行比较。
仅考虑 [可枚举的 “own” 属性](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Enumerability_and_ownership_of_properties)。 [`assert.deepEqual()`] 的实现不测试对象的 [`[[Prototype]]`](https://tc39.github.io/ecma262/#sec-ordinary-object-internal-methods-and-internal-slots),附加的符号,或不可枚举的属性 - 对这些类型的测试,考虑使用[`assert.deepStrictEqual()`][]。 这可能会导致不可预期的结果。 以下示例不会抛出 `AssertionError`, 因为 [`RegExp`] 对象上的属性是不可枚举的类型:
```js
// WARNING: This does not throw an AssertionError!
assert.deepEqual(/a/gi, new Date());
```
针对 [`Map`][] 和 [`Set`][] 的例外。 因为 Map 和 Set 也比较了它们包含的项目。
“深度”相等意味着子对象的可枚举的“own”属性也会被比较:
```js
const assert = require('assert');
const obj1 = {
a: {
b: 1
}
};
const obj2 = {
a: {
b: 2
}
};
const obj3 = {
a: {
b: 1
}
};
const obj4 = Object.create(obj1);
assert.deepEqual(obj1, obj1);
// OK, object is equal to itself
assert.deepEqual(obj1, obj2);
// AssertionError: { a: { b: 1 } } deepEqual { a: { b: 2 } }
// values of b are different
assert.deepEqual(obj1, obj3);
// OK, objects are equal
assert.deepEqual(obj1, obj4);
// AssertionError: { a: { b: 1 } } deepEqual {}
// Prototypes are ignored
```
如果两个值不相等,会抛出一个带有 `message` 属性的 `AssertionError`, 其中该属性的值等于传入的 `message` 参数的值。 如果 `message` 参数未定义,则赋予默认错误消息。
## assert.deepStrictEqual(actual, expected[, message])
<!-- YAML
added: v1.2.0
changes:
- version: v8.5.0
pr-url: https://github.com/nodejs/node/pull/15001
description: Error names and messages are now properly compared
- version: v8.0.0
pr-url: https://github.com/nodejs/node/pull/12142
description: Set and Map content is also compared
- version: v6.4.0, v4.7.1
pr-url: https://github.com/nodejs/node/pull/8002
description: Typed array slices are handled correctly now.
- version: v6.1.0
pr-url: https://github.com/nodejs/node/pull/6432
description: Objects with circular references can be used as inputs now.
- version: v5.10.1, v4.4.3
pr-url: https://github.com/nodejs/node/pull/5910
description: Handle non-`Uint8Array` typed arrays correctly.
-->
* `actual` {any}
* `expected` {any}
* `message` {any}
通常与`assert.deepEqual()`相同,但有一些例外:
### 比较的详细说明
* 使用 [严格相等比较法](https://tc39.github.io/ecma262/#sec-strict-equality-comparison) ( `===` ) 对原始值进行比较。
* 使用 [SameValueZero](https://tc39.github.io/ecma262/#sec-samevaluezero) 来比较Set值和Map键值。 (这意味着在比较它们时不会出现[警告](#assert_caveats))。
* 对象的 [类型标签](https://tc39.github.io/ecma262/#sec-object.prototype.tostring) 应该相同。
* 对象的 [`[[原型]]`](https://tc39.github.io/ecma262/#sec-ordinary-object-internal-methods-and-internal-slots) 使用 [严格相等比较法](https://tc39.github.io/ecma262/#sec-strict-equality-comparison) 进行比较。
* 仅考虑 [可枚举的 “own” 属性](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Enumerability_and_ownership_of_properties)。
* [`Error`][] messages are always compared, even though this property is non-enumerable.
* [对象包装器](https://developer.mozilla.org/en-US/docs/Glossary/Primitive#Primitive_wrapper_objects_in_JavaScript) 会分别以对象以及解包装后值的方式进行比较。
* Object properties are compared unordered.
* Map keys and Set items are compared unordered.
* 当两边的值不相同或遇到循环引用时,递归会停止。
```js
const assert = require('assert').strict;
assert.deepEqual({ a: 1 }, { a: '1' });
// OK, because 1 == '1'
assert.deepStrictEqual({ a: 1 }, { a: '1' });
// AssertionError: { a: 1 } deepStrictEqual { a: '1' }
// because 1 !== '1' using strict equality
// The following objects don't have own properties
const date = new Date();
const object = {};
const fakeDate = {};
Object.setPrototypeOf(fakeDate, Date.prototype);
assert.deepEqual(object, fakeDate);
// OK, doesn't check [[Prototype]]
assert.deepStrictEqual(object, fakeDate);
// AssertionError: {} deepStrictEqual Date {}
// Different [[Prototype]]
assert.deepEqual(date, fakeDate);
// OK, doesn't check type tags
assert.deepStrictEqual(date, fakeDate);
// AssertionError: 2017-03-11T14:25:31.849Z deepStrictEqual Date {}
// Different type tags
assert.deepStrictEqual(new Number(1), new Number(2));
// Fails because the wrapped number is unwrapped and compared as well.
assert.deepStrictEqual(new String('foo'), Object('foo'));
// OK because the object and the string are identical when unwrapped.
```
如果两个值不相等,会抛出一个带有 `message` 属性的 `AssertionError`, 其中该属性的值等于传入的 `message` 参数的值。 如果 `message` 参数未定义,则赋予默认错误消息。
## assert.doesNotReject(block\[, error\]\[, message\])
<!-- YAML
added: V8.13.0
-->
* `block` {Function}
* `error` {RegExp|Function}
* `message` {any}
Awaits for the promise returned by function `block` to complete and not be rejected. See [`assert.rejects()`][] for more details.
When `assert.doesNotReject()` is called, it will immediately call the `block` function, and awaits for completion.
Besides the async nature to await the completion behaves identical to [`assert.doesNotThrow()`][].
```js
(async () => {
await assert.doesNotReject(
async () => {
throw new TypeError('Wrong value');
},
SyntaxError
);
})();
```
```js
assert.doesNotReject(
() => Promise.reject(new TypeError('Wrong value')),
SyntaxError
).then(() => {
// ...
});
```
## assert.doesNotThrow(block\[, error\]\[, message\])
<!-- YAML
added: v0.1.21
changes:
- version: v5.11.0, v4.4.5
pr-url: https://github.com/nodejs/node/pull/2407
description: The `message` parameter is respected now.
- version: v4.2.0
pr-url: https://github.com/nodejs/node/pull/3276
description: The `error` parameter can now be an arrow function.
-->
* `block` {Function}
* `error` {RegExp|Function}
* `message` {any}
断言 `block` 函数不会抛出错误。 请参考 [`assert.throws()`][] 以获取更多详细信息。
请注意,使用 `assert.doesNotThrow()` 实际上没有用处,因为通过捕获一个错误并再抛出这个错误一次,并没有任何好处。 相反,考虑在不应抛出的特定代码路径旁边添加注释,并尽可能保持错误消息清晰的表达性。
当 `assert.doesNotThrow()` 被调用时,它会立即调用 `block` 函数。
如果一个错误被抛出,并且它与 `error` 参数所指定的类型相同,那么会抛出 `AssertionError`。 如果错误是不同的类型,或者 `error` 参数未定义,则将错误返回调用方。
下面这个示例会抛出 [`TypeError`][], 因为在断言部分没有可匹配的错误类型:
```js
assert.doesNotThrow(
() => {
throw new TypeError('Wrong value');
},
SyntaxError
);
```
然而,下面的示例会抛出带有错误信息 - “得到不想要的异常 (TypeError)...” 的 `AssertionError` :
```js
assert.doesNotThrow(
() => {
throw new TypeError('Wrong value');
},
TypeError
);
```
如果 `AssertionError` 被抛出,并且提供一个值给 `message` 参数,那么 `message` 的值会被添加在 `AssertionError` 信息中:
```js
assert.doesNotThrow(
() => {
throw new TypeError('Wrong value');
},
TypeError,
'Whoops'
);
// Throws: AssertionError: Got unwanted exception (TypeError). Whoops
```
## assert.equal(actual, expected[, message])
<!-- YAML
added: v0.1.21
-->
* `actual` {any}
* `expected` {any}
* `message` {any}
**Strict 模式**
[`assert.strictEqual()`][] 的别名。
**Legacy 模式**
> 稳定性:0 - 已弃用:改为使用 [`assert.strictEqual()`][]。
浅测试,使用 [抽象相等比较法](https://tc39.github.io/ecma262/#sec-abstract-equality-comparison) ( `==` ) 比较 `actual` 和 `expected` 之间的强制相等性。
```js
const assert = require('assert');
assert.equal(1, 1);
// OK, 1 == 1
assert.equal(1, '1');
// OK, 1 == '1'
assert.equal(1, 2);
// AssertionError: 1 == 2
assert.equal({ a: { b: 1 } }, { a: { b: 1 } });
//AssertionError: { a: { b: 1 } } == { a: { b: 1 } }
```
如果两个值不相等,会抛出一个带有 `message` 属性的 `AssertionError`, 其中该属性的值等于传入的 `message` 参数的值。 如果 `message` 参数未定义,则赋予默认错误消息。
## assert.fail(message)
## assert.fail(actual, expected[, message[, operator[, stackStartFunction]]])
<!-- YAML
added: v0.1.21
-->
* `actual` {any}
* `expected` {any}
* `message` {any}
* `operator` {string} **Default:** `'!='`
* `stackStartFunction` {Function} **Default:** `assert.fail`
抛出一个 `AssertionError` 错误. 如果 `message` 是虚值,错误消息被设置为由提供的 `operator` 分隔的 `actual` 和 `expected` 的值。 如果只提供了 `actual` 和 `expected` 两个参数,则 `operator` 的默认值是 `'!='`。 如果 `message` 是被提供的唯一参数,它将被作为错误消息,其它参数将作为属性存储在被抛出的对象上。 如果提供了 `stackStartFunction`, 所有在这个函数之上的栈帧将被从追溯栈中移除。(请参见 [`Error.captureStackTrace`] )。
```js
const assert = require('assert').strict;
assert.fail(1, 2, undefined, '>');
// AssertionError [ERR_ASSERTION]: 1 > 2
assert.fail(1, 2, 'fail');
// AssertionError [ERR_ASSERTION]: fail
assert.fail(1, 2, 'whoops', '>');
// AssertionError [ERR_ASSERTION]: whoops
```
*注意*:在后两种情况中,`actual`, `expected` 和 `operator` 对错误消息没有影响。
```js
assert.fail();
// AssertionError [ERR_ASSERTION]: Failed
assert.fail('boom');
// AssertionError [ERR_ASSERTION]: boom
assert.fail('a', 'b');
// AssertionError [ERR_ASSERTION]: 'a' != 'b'
```
使用 `stackStartFunction` 截断异常的追溯栈的示例:
```js
function suppressFrame() {
assert.fail('a', 'b', undefined, '!==', suppressFrame);
}
suppressFrame();
// AssertionError [ERR_ASSERTION]: 'a' !== 'b'
// at repl:1:1
// at ContextifyScript.Script.runInThisContext (vm.js:44:33)
// ...
```
## assert.ifError(value)
<!-- YAML
added: v0.1.97
-->
* `value` {any}
如果 `value` 为真值,抛出`value`。 当在回调函数中测试 `error` 参数时,这一点很有用。
```js
const assert = require('assert').strict;
assert.ifError(null);
// OK
assert.ifError(0);
// OK
assert.ifError(1);
// Throws 1
assert.ifError('error');
// Throws 'error'
assert.ifError(new Error());
// Throws Error
```
## assert.notDeepEqual(actual, expected[, message])
<!-- YAML
added: v0.1.21
-->
* `actual` {any}
* `expected` {any}
* `message` {any}
**Strict 模式**
[`assert.notDeepStrictEqual()`][] 的别名。
**Legacy 模式**
> 稳定性:0 - 已弃用:改为使用 [`assert.notDeepStrictEqual()`][]。
用于深度非相等测试。 与 [`assert.deepEqual()`][] 相反。
```js
const assert = require('assert');
const obj1 = {
a: {
b: 1
}
};
const obj2 = {
a: {
b: 2
}
};
const obj3 = {
a: {
b: 1
}
};
const obj4 = Object.create(obj1);
assert.notDeepEqual(obj1, obj1);
// AssertionError: { a: { b: 1 } } notDeepEqual { a: { b: 1 } }
assert.notDeepEqual(obj1, obj2);
// OK: obj1 and obj2 are not deeply equal
assert.notDeepEqual(obj1, obj3);
// AssertionError: { a: { b: 1 } } notDeepEqual { a: { b: 1 } }
assert.notDeepEqual(obj1, obj4);
// OK: obj1 and obj4 are not deeply equal
```
如果两个值深度相等,会抛出一个带有 `message` 属性的 `AssertionError`, 其中该属性的值等于传入的 `message` 参数的值。 如果 `message` 参数未定义,则赋予默认错误消息。
## assert.notDeepStrictEqual(actual, expected[, message])
<!-- YAML
added: v1.2.0
-->
* `actual` {any}
* `expected` {any}
* `message` {any}
测试深度严格不相等。 与 [`assert.deepStrictEqual()`][] 相反。
```js
const assert = require('assert').strict;
assert.notDeepEqual({ a: 1 }, { a: '1' });
// AssertionError: { a: 1 } notDeepEqual { a: '1' }
assert.notDeepStrictEqual({ a: 1 }, { a: '1' });
// OK
```
如果两个值深度严格相等,会抛出一个带有 `message` 属性的 `AssertionError`, 其中该属性的值等于传入的 `message` 参数的值。 如果 `message` 参数未定义,则赋予默认错误消息。
## assert.notEqual(actual, expected[, message])
<!-- YAML
added: v0.1.21
-->
* `actual` {any}
* `expected` {any}
* `message` {any}
**Strict 模式**
[`assert.notStrictEqual()`][] 的别名。
**Legacy 模式**
> 稳定性:0 - 已弃用:改为使用 [`assert.notStrictEqual()`][]。
浅测试,使用 [抽象相等比较法](https://tc39.github.io/ecma262/#sec-abstract-equality-comparison) ( `!=` ) 比较强制非相等性。
```js
const assert = require('assert');
assert.notEqual(1, 2);
// OK
assert.notEqual(1, 1);
// AssertionError: 1 != 1
assert.notEqual(1, '1');
// AssertionError: 1 != '1'
```
如果两个值相等,会抛出一个带有 `message` 属性的 `AssertionError`, 其中该属性的值等于传入的 `message` 参数的值。 如果 `message` 参数未定义,则赋予默认错误消息。
## assert.notStrictEqual(actual, expected[, message])
<!-- YAML
added: v0.1.21
-->
* `actual` {any}
* `expected` {any}
* `message` {any}
使用 [严格相等比较法](https://tc39.github.io/ecma262/#sec-strict-equality-comparison) ( `!==` ) 测试严格不相等性。
```js
const assert = require('assert').strict;
assert.notStrictEqual(1, 2);
// OK
assert.notStrictEqual(1, 1);
// AssertionError: 1 !== 1
assert.notStrictEqual(1, '1');
// OK
```
如果两个值严格相等,会抛出一个带有 `message` 属性的 `AssertionError`, 其中该属性的值等于传入的 `message` 参数值。 如果 `message` 参数未定义,则赋予默认错误消息。
## assert.ok(value[, message])
<!-- YAML
added: v0.1.21
-->
* `value` {any}
* `message` {any}
测试 `value` 是否为真值。 它和 `assert.equal(!!value, true, message)` 功能完全一样。
如果 `value` 不是真值,会抛出一个带有 `message` 属性的 `AssertionError`, 其中该属性的值等于传入的 `message` 参数的值。 如果 `message` 参数未定义,则赋予默认错误消息。
```js
const assert = require('assert').strict;
assert.ok(true);
// OK
assert.ok(1);
// OK
assert.ok(false);
// throws "AssertionError: false == true"
assert.ok(0);
// throws "AssertionError: 0 == true"
assert.ok(false, 'it\'s false');
// throws "AssertionError: it's false"
```
## assert.strictEqual(actual, expected[, message])
<!-- YAML
added: v0.1.21
-->
* `actual` {any}
* `expected` {any}
* `message` {any}
使用 [严格相等比较法](https://tc39.github.io/ecma262/#sec-strict-equality-comparison) ( `===` ) 测试严格相等性。
```js
const assert = require('assert').strict;
assert.strictEqual(1, 2);
// AssertionError: 1 === 2
assert.strictEqual(1, 1);
// OK
assert.strictEqual(1, '1');
// AssertionError: 1 === '1'
```
如果两个值不是严格相等,会抛出一个带有 `message` 属性的 `AssertionError`, 其中该属性的值等于传入的 `message` 参数的值。 如果 `message` 参数未定义,则赋予默认错误消息。
## assert.rejects(block\[, error\]\[, message\])
<!-- YAML
added: V8.13.0
-->
* `block` {Function}
* `error` {RegExp|Function|Object}
* `message` {any}
Awaits for promise returned by function `block` to be rejected.
When `assert.rejects()` is called, it will immediately call the `block` function, and awaits for completion.
Besides the async nature to await the completion behaves identical to [`assert.throws()`][].
If specified, `error` can be a constructor, [`RegExp`][], a validation function, or an object where each property will be tested for.
如果指定的话,假如block拒绝失败,`message` 会是由 `AssertionError` 提供的消息。
```js
(async () => {
await assert.rejects(
async () => {
throw new Error('Wrong value');
},
Error
);
})();
```
```js
assert.rejects(
() => Promise.reject(new Error('Wrong value')),
Error
).then(() => {
// ...
});
```
## assert.throws(block\[, error\]\[, message\])
<!-- YAML
added: v0.1.21
changes:
- version: V8.13.0
pr-url: https://github.com/nodejs/node/pull/23223
description: The `error` parameter can now be an object as well.
- version: v4.2.0
pr-url: https://github.com/nodejs/node/pull/3276
description: The `error` parameter can now be an arrow function.
-->
* `block` {Function}
* `error` {RegExp|Function|object}
* `message` {any}
期望 `block` 函数抛出一个错误。
If specified, `error` can be a constructor, [`RegExp`][], a validation function, or an object where each property will be tested for.
如果指定的话,假如block抛出失败,`message` 会是由 `AssertionError` 提供的消息。
使用构造函数验证instanceof:
```js
assert.throws(
() => {
throw new Error('Wrong value');
},
Error
);
```
使用 [`RegExp`][] 验证错误消息:
```js
assert.throws(
() => {
throw new Error('Wrong value');
},
/value/
);
```
自定义错误验证:
```js
assert.throws(
() => {
throw new Error('Wrong value');
},
function(err) {
if ((err instanceof Error) && /value/.test(err)) {
return true;
}
},
'unexpected error'
);
```
自定义error对象或error实例:
```js
assert.throws(
() => {
const err = new TypeError('Wrong value');
err.code = 404;
throw err;
},
{
name: 'TypeError',
message: 'Wrong value'
// Note that only properties on the error object will be tested!
}
);
```
注意, `error` 不能是一个字符串。 如果提供一个字符串作为第二个参数,那么会认为 `error` 被省略了,并且这个字符串会代替 `message`。 这会导致不容易被发现的错误。 Please read the example below carefully if using a string as the second argument gets considered:
<!-- eslint-disable no-restricted-syntax -->
```js
function throwingFirst() {
throw new Error('First');
}
function throwingSecond() {
throw new Error('Second');
}
function notThrowing() {}
// The second argument is a string and the input function threw an Error.
// In that case both cases do not throw as neither is going to try to
// match for the error message thrown by the input function!
assert.throws(throwingFirst, 'Second');
assert.throws(throwingSecond, 'Second');
// The string is only used (as message) in case the function does not throw:
assert.throws(notThrowing, 'Second');
// AssertionError [ERR_ASSERTION]: Missing expected exception: Second
// If it was intended to match for the error message do this instead:
assert.throws(throwingSecond, /Second$/);
// Does not throw because the error messages match.
assert.throws(throwingFirst, /Second$/);
// Throws a error:
// Error: First
// at throwingFirst (repl:2:9)
```
由于令人困惑的表示方法,建议不要使用字符串作为第二个参数。 这可能会导致难以发现的错误。
## 注意事项
在如下情况中,请考虑使用ES2015中的 [`Object.is()`][],它会使用[SameValueZero](https://tc39.github.io/ecma262/#sec-samevaluezero)来进行比较。
```js
const a = 0;
const b = -a;
assert.notStrictEqual(a, b);
// AssertionError: 0 !== -0
// Strict Equality Comparison doesn't distinguish between -0 and +0...
assert(!Object.is(a, b));
// but Object.is() does!
const str1 = 'foo';
const str2 = 'foo';
assert.strictEqual(str1 / 1, str2 / 1);
// AssertionError: NaN === NaN
// Strict Equality Comparison can't be used to check NaN...
assert(Object.is(str1 / 1, str2 / 1));
// but Object.is() can!
```
请参考[MDN上关于相等比较和等同性的指南](https://developer.mozilla.org/en-US/docs/Web/JavaScript/Equality_comparisons_and_sameness)以获取更多信息。 | 19,262 | MIT |
# mybatis-generator-ext-plugin
对mybatis-generator插件的扩展
## 使用
1. 下载项目并打包
```shell
git clone https://github.com/xiaozhaoosc/mybatis-generator-ext-plugin.git
cd mybatis-generator-ext-plugin/mybatis-generator-ext-plugin
mvn clean
mvn install
```
2. 在pom.xml中的<build>---><plugins>中添加包引用,再添加generatorConfig.xml配置;如
```xml
<build>
<plugins>
<plugin>
<groupId>org.mybatis.generator</groupId>
<artifactId>mybatis-generator-maven-plugin</artifactId>
<version>1.3.5</version>
<configuration>
<verbose>true</verbose>
<overwrite>false</overwrite>
</configuration>
<dependencies>
<dependency>
<groupId>com.ken.utils</groupId>
<artifactId>mybatis-generator-ext-plugin</artifactId>
<version>1.0.0-SNAPSHOT</version>
</dependency>
</dependencies>
</plugin>
</plugins>
</build>
```
## generatorConfig.xml示例
```xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE generatorConfiguration
PUBLIC "-//mybatis.org//DTD MyBatis Generator Configuration 1.0//EN"
"http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd">
<generatorConfiguration>
<!--导入属性配置-->
<!--<properties resource="jdbc.properties"></properties>-->
<classPathEntry location="xxx\ojdbc14.jar"/>
<context id="DB2Tables" targetRuntime="MyBatis3">
<!-- 分页相关 -->
<plugin type="org.mybatis.generator.plugins.RowBoundsPlugin" />
<!-- 带上序列化接口 -->
<plugin type="org.mybatis.generator.plugins.SerializablePlugin" />
<!-- 自定义的注释生成插件-->
<plugin type="com.ken.utils.mybatis.generator.plugins.RemarkPlugin">
<!-- 抑制警告 -->
<property name="suppressTypeWarnings" value="true" />
<!-- 是否去除自动生成的注释 true:是 : false:否 -->
<property name="suppressAllComments" value="true" />
<!-- 是否生成注释代时间戳-->
<property name="suppressDate" value="true" />
</plugin>
<!-- 整合lombok-->
<!--<plugin type="com.ken.utils.mybatis.generator.plugins.LombokPlugin" >-->
<!--<property name="hasLombok" value="true"/>-->
<!--</plugin>-->
<!-- 生成注释为false 不生成为true 【不生成注释时会被重复写入导致报错】 -->
<!--<commentGenerator>-->
<!--<property name="suppressAllComments" value="false"/>-->
<!--</commentGenerator>-->
<!--jdbc的数据库连接 -->
<jdbcConnection driverClass="oracle.jdbc.driver.OracleDriver"
connectionURL="jdbc:oracle:thin:@xxx:1521:orcl" userId="xxx"
password="xxx">
<property name="remarksReporting" value="true"></property>
</jdbcConnection>
<!-- 默认false,把JDBC DECIMAL 和 NUMERIC 类型解析为 Integer,为 true时把JDBC DECIMAL 和
NUMERIC 类型解析为java.math.BigDecimal -->
<javaTypeResolver >
<property name="forceBigDecimals" value="false" />
</javaTypeResolver>
<!-- Model模型生成器,用来生成含有主键key的类,记录类 以及查询Example类
targetPackage 指定生成的model生成所在的包名
targetProject 指定在该项目下所在的路径
-->
<!--<javaModelGenerator targetPackage="xxx.pojo" targetProject=".\src\main\java">-->
<javaModelGenerator targetPackage="xxx.generator.pojo" targetProject="./src/main/java">
<!-- 是否允许子包,即targetPackage.schemaName.tableName -->
<property name="enableSubPackages" value="false"/>
<!-- 是否对model添加 构造函数 -->
<property name="constructorBased" value="true"/>
<!-- 是否对类CHAR类型的列的数据进行trim操作 -->
<property name="trimStrings" value="true"/>
<!-- 建立的Model对象是否 不可改变 即生成的Model对象不会有 setter方法,只有构造方法 -->
<property name="immutable" value="false"/>
</javaModelGenerator>
<!--mapper映射文件生成所在的目录 为每一个数据库的表生成对应的SqlMap文件 -->
<sqlMapGenerator targetPackage="mappers" targetProject="./src/main/resources">
<!-- enableSubPackages:是否让schema作为包的后缀 -->
<property name="enableSubPackages" value="false"/>
</sqlMapGenerator>
<!-- targetPackage:mapper接口dao生成的位置 -->
<javaClientGenerator type="XMLMAPPER" targetPackage="xxx.generator.dao" targetProject="./src/main/java">
<!-- enableSubPackages:是否让schema作为包的后缀 -->
<property name="enableSubPackages" value="false" />
</javaClientGenerator>
<table schema="" tableName="xxx" enableCountByExample="false" enableUpdateByExample="false" enableDeleteByExample="false" enableSelectByExample="false" selectByExampleQueryId="false"></table>
</context>
</generatorConfiguration>
```
## 注意事项
- 编码问题
```xml
<!-- 指定生成的java文件的编码,没有直接生成到项目时中文可能会乱码 -->
<property name="javaFileEncoding" value="UTF-8"/>
```
- 无法获取注释问题,需要在<jdbcConnection>标签中添加属性
```xml
<!-- 针对oracle数据库 -->
<property name="remarksReporting" value="true"></property>
<!-- 针对mysql数据库 -->
<property name="useInformationSchema" value="true"></property>
```
- 生成的mappper.xml是否需要些基本的操作方法
```xml
<table schema="" tableName="xxx" domainObjectName="xxx"
enableCountByExample="false" enableUpdateByExample="false"
enableDeleteByExample="false" enableSelectByExample="false"
selectByExampleQueryId="false">
</table>
``` | 4,840 | Apache-2.0 |
---
layout: post
title: "ubuntu16.04 titan rtx 24g +显卡驱动+cuda10.1+cudnn环境配置"
subtitle: "CSDN博客搬家系列"
date: 2019-08-23 15:48:00
author: "He"
header-img: "img/post-bg-2015.jpg"
tags:
- cuda
- envs config
---
> “Yeah It's on. ”
## 前言
o(*////▽////*)q
## 链接地址
[传送门](https://blog.csdn.net/He_9520/article/details/99714635) | 349 | Apache-2.0 |
# spring-boot-quartz-cluster
> quartz 定时任务集群
之前[spring-boot-quartz](../spring-boot-quartz) 是内存级别的,不支持多JVM下的高可用。
[TOC]
## Quartz 两种存储器的对比
| 类型 | 优点 | 缺点 |
| ---- | ---- | ---- |
|RAMJobStore|不要外部数据库,配置容易,运行速度快|因为调度程序信息是存储在被分配给 JVM 的内存里面,所以,当应用程序停止运行时,所有调度信息将被丢失。另外因为存储到JVM内存里面,所以可以存储多少个 Job 和 Trigger 将会受到限制|
|JDBC 作业存储|支持集群,因为所有的任务信息都会保存到数据库中,可以控制事物,还有就是如果应用服务器关闭或者重启,任务信息都不会丢失,并且可以恢复因服务器关闭或者重启而导致执行失败的任务|运行速度的快慢取决与连接数据库的快慢|
## @DisallowConcurrentExecution
在job SayHelloJob上添加Quartz 的 @DisallowConcurrentExecution 注解,保证相同 JobDetail 在多个 JVM 进程中,有且仅有一个节点在执行。
## application.yml配置quartz
```yaml
spring:
datasource:
test:
url: jdbc:mysql://127.0.0.1:3306/test?useSSL=false&useUnicode=true&characterEncoding=UTF-8
driver-class-name: com.mysql.jdbc.Driver
username: root
password: Root123456
quartz:
url: jdbc:mysql://127.0.0.1:3306/quartz?useSSL=false&useUnicode=true&characterEncoding=UTF-8
driver-class-name: com.mysql.jdbc.Driver
username: root
password: Root123456
# Quartz 的配置,对应 QuartzProperties 配置类
quartz:
scheduler-name: clusteredScheduler # Scheduler 名字。默认为 schedulerName
job-store-type: jdbc # Job 存储器类型。默认为 memory 表示内存,可选 jdbc 使用数据库。
auto-startup: true # Quartz 是否自动启动
startup-delay: 0 # 延迟 N 秒启动
wait-for-jobs-to-complete-on-shutdown: true # 应用关闭时,是否等待定时任务执行完成。默认为 false ,建议设置为 true
overwrite-existing-jobs: false # 是否覆盖已有 Job 的配置
properties: # 添加 Quartz Scheduler 附加属性,更多可以看 http://www.quartz-scheduler.org/documentation/2.4.0-SNAPSHOT/configuration.html 文档
org:
quartz:
# JobStore 相关配置
jobStore:
# 数据源名称
dataSource: quartzDataSource # 使用的数据源
class: org.quartz.impl.jdbcjobstore.JobStoreTX # JobStore 实现类
driverDelegateClass: org.quartz.impl.jdbcjobstore.StdJDBCDelegate
tablePrefix: QRTZ_ # Quartz 表前缀
isClustered: true # 是集群模式
clusterCheckinInterval: 1000
useProperties: false
scheduler:
instanceName: Scheduler-Instance
instanceId: AUTO
# 线程池相关配置
threadPool:
threadCount: 25 # 线程池大小。默认为 10 。
threadPriority: 5 # 线程优先级
class: org.quartz.simpl.SimpleThreadPool # 线程池类型
jdbc: # 使用 JDBC 的 JobStore 的时候,JDBC 的配置
initialize-schema: never # 是否自动使用 SQL 初始化 Quartz 表结构。这里设置成 never ,我们手动创建表结构。
cron:
sayHelloJob: 0/5 * * * * ?
```
## DataSourceConfiguration
创建 DataSourceConfiguration 类,配置数据源
```java
@Configuration
public class DataSourceConfiguration {
private static HikariDataSource createHikariDataSource(final DataSourceProperties properties) {
// 创建 HikariDataSource 对象
final HikariDataSource dataSource = properties.initializeDataSourceBuilder().type(HikariDataSource.class).build();
// 设置线程池名
if (StringUtils.hasText(properties.getName())) {
dataSource.setPoolName(properties.getName());
}
return dataSource;
}
/**
* 创建 user 数据源的配置对象
*/
@Primary
@Bean(name = "userDataSourceProperties")
@ConfigurationProperties(prefix = "spring.datasource.test") // 读取 spring.datasource.test 配置到 DataSourceProperties 对象
public DataSourceProperties testDataSourceProperties() {
return new DataSourceProperties();
}
/**
* 创建 user 数据源
*/
@Primary
@Bean(name = "userDataSource")
@ConfigurationProperties(prefix = "spring.datasource.test.hikari")
// 读取 spring.datasource.user 配置到 HikariDataSource 对象
public DataSource testDataSource() {
// 获得 DataSourceProperties 对象
final DataSourceProperties properties = this.testDataSourceProperties();
// 创建 HikariDataSource 对象
return createHikariDataSource(properties);
}
/**
* 创建 quartz 数据源的配置对象
*/
@Bean(name = "quartzDataSourceProperties")
@ConfigurationProperties(prefix = "spring.datasource.quartz")
// 读取 spring.datasource.quartz 配置到 DataSourceProperties 对象
public DataSourceProperties quartzDataSourceProperties() {
return new DataSourceProperties();
}
/**
* 创建 quartz 数据源
*/
@Bean(name = "quartzDataSource")
@ConfigurationProperties(prefix = "spring.datasource.quartz.hikari")
@QuartzDataSource
public DataSource quartzDataSource() {
// 获得 DataSourceProperties 对象
final DataSourceProperties properties = this.quartzDataSourceProperties();
// 创建 HikariDataSource 对象
return createHikariDataSource(properties);
}
}
```
## 导入sql
在 [Quartz Download](http://www.quartz-scheduler.org/downloads/) 地址下载对应版本的发布包。解压后,在`src/org/quartz/impl/jdbcjobstore/`目录,执行对应数据库的脚本初始化。
[doc/tables_mysql_innodb.sql](doc/tables_mysql_innodb.sql)
## 启动项目,模拟集群
创建App.java和App2.java
```java
public class App {
public static void main(final String[] args) {
System.setProperty("server.port", "0");
SpringApplication.run(App.class, args);
}
}
```
```java
@SpringBootApplication
public class App2 {
public static void main(final String[] args) {
System.setProperty("server.port", "0");
SpringApplication.run(App2.class, args);
}
}
```
首先启动App,会看到定时任务开始执行,
然后再启动App2,定时任务并没有执行,当关闭App后,该App2应用的定时任务才开始执行。
## Try it
* MacOS/Linux
* ./mvnw spring-boot:run
* Windows
* mvnw spring-boot:run
## package
mvn clean package -Dmaven.test.skip=true
## run jar
java -jar xxx.jar | 5,485 | MIT |
# ScratchCanvas
一个基于canvas实现“刮刮卡”功能的js库。
## 安装
使用npm:
```bash
$ npm install scratch-canvas
```
直接引入<script>:
```html
<script src="//cdn.jsdelivr.net/npm/[email protected]/dist/scratch-canvas.min.js"></script>
```
## 示例
[查看demo页面](https://vilfredli.github.io/scratch-canvas)
## 快速开始
首先需要在html中放置一个容器:
```html
<div class="container"></div>
```
在js中引入ScratchCanvas并将容器元素传递给构造函数后调用实例的init方法即可:
```js
import ScratchCanvas from 'scratch-canvas'
const containerElm = document.querySelector('.container')
const scratchCanvas = new ScratchCanvas(containerElm)
scratchCanvas.init()
```
## 配置
在创建实例时通过向第二个参数传入一个对象进行配置:
```js
const scratchCanvas = new ScratchCanvas(elm, {/* 配置项... */})
scratchCanvas.init()
```
可用配置项:
选项名 | 类型 | 默认值 | 可选值 | 描述
:-: | :-: | :-: | - | -
bg | String | null | 有效的图片url | 若bg的值为有效的图片url,则会在蒙层下自动生成背景
mask | String | #ccc | 有效的颜色字符串或图片url | 蒙层的填充内容
pureMask | Boolean | true | - | 是否为纯色蒙层,当使用图片作为蒙层时,必须显式地将该属性设置为false
width | Number | null | 正整数 | 生成的canvas标签的width属性值,不设置该值时canvas的width将会是容器元素的实际宽度
height | Number | null | 正整数 | 生成的canvas标签的height属性值,不设置该值时canvas的height将会是容器元素的实际高度
brushSize | Number | 25 | 正整数 | 笔刷(半径)大小
brushPress | Number | 1 | 0~1之间任意数字 | 笔刷压强
onCreated | Function | null | - | 实例初始化完毕被插入到dom节点后的回调函数
onScratch | Function | null | - | "刮除"蒙层时的回调函数,接收一个参数,该参数值为已"刮除"面积与总面积的百分比(对于一个像素掉,"已刮除"的定义是该像素点透明度小于0.25,而不是该像素点必须被mousedown/mousemove等事件处理过)
throttleWait | Number | 0 | 正数 | 节流函数的间隔时间参数,如果在使用过程中发现明显卡顿(刮除不连续属于正常现象)可以尝试调高该参数值
## 实例API
API名 | 描述
-|-
init() | 初始化并将生成的canvas插入到创建实例时传入的容器元素节点中,插入后会触发回调函数onCreated
## License
[MIT](./LICENSE) | 1,613 | MIT |
# SubModule \(XML\)
## 字段描述
* `Name` - 模组的名称。
* `Id` - 模组的ID \(不要使用空格\)。
* `Version` - 模组的当前版本。
* `SinglePlayerModule` - 单人游戏中模组是否可用。
* `MultiPlayerModule` - 多人游戏中模组是否可用。
* `DependedModules` - 此模组正常工作需要的依赖模组。
* `SubModules` - 该模组由哪些子模组 \(DLLs\)组成。
* `Xmls` - 包含ModuleData文件夹中的XML文件路径。
## 重要提示
对于两个独立的mod,如果XML中的id相同,它们的内容将会合并 **而不是** 互相覆盖。然而,假如两个物体在XML文件中具有相同的id(例如:两个item),它们会按照启动器中Mod的排列顺序覆盖。了解这一点对于重写native中的内容非常有用。
`MPClassDivisions` 当前存在问题。
## 例子
```xml
<Module>
<Name value="My Module"/>
<Id value="MyModule"/>
<Version value="v1.0.0"/>
<SingleplayerModule value="true"/>
<MultiplayerModule value="false"/>
<DependedModules>
<DependedModule Id="Native"/>
<DependedModule Id="SandBoxCore"/>
<DependedModule Id="Sandbox"/>
<DependedModule Id="CustomBattle"/>
<DependedModule Id="StoryMode" />
</DependedModules>
<SubModules>
<!-- 以下的SubModule标签是可选的。如果你的模组不需要DLL外链,可用移除这部分内容。-->
<SubModule>
<Name value="MySubModule"/>
<!-- DLL文件的路径, 假如你的模组叫MyModule,写法会像下面这样 -->
<DLLName value="ExampleMod.dll"/>
<SubModuleClassType value="ExampleMod.MySubModule"/>
<Tags>
<Tag key="DedicatedServerType" value="none" />
<Tag key="IsNoRenderModeElement" value="false" />
</Tags>
</SubModule>
</SubModules>
<Xmls>
<XmlNode>
<XmlName type="1" id="Items" path="customitems"/>
</XmlNode>
<XmlNode>
<XmlName type="1" id="SPCultures" path="customcultures"/>
</XmlNode>
<XmlNode>
<XmlName type="1" id="NPCCharacters" path="customcharacters"/>
</XmlNode>
</Xmls>
</Module>
``` | 1,763 | MIT |
---
description: WebView2 ローダー ライブラリを静的にリンクする方法について説明します。
title: WebView2 ローダー ライブラリを静的にリンクする方法
author: MSEdgeTeam
ms.author: msedgedevrel
ms.date: 05/06/2021
ms.topic: how-to
ms.prod: microsoft-edge
ms.technology: webview
keywords: IWebView2、IWebView2WebView、Webview2、Webview、win32 アプリ、win32、edge、ICoreWebView2、ICoreWebView2Host、ブラウザー コントロール、エッジ html
ms.openlocfilehash: d6248058182189a5b734e60ecd0572518572295a
ms.sourcegitcommit: 97b32870897c702eed52d9fbbd13cfff2046ad87
ms.translationtype: MT
ms.contentlocale: ja-JP
ms.lasthandoff: 10/22/2021
ms.locfileid: "12107962"
---
# <a name="statically-link-the-webview2-loader-library"></a>WebView2 ローダー ライブラリを静的にリンクする
多くのファイルのパッケージではなく、1 つの実行可能ファイルでアプリケーションを配布できます。 単一の実行可能ファイルを作成したり、パッケージのサイズを小さくしたりするには、WebView2Loader ファイルを静的にリンクする必要があります。 WebView2 SDK には、ヘッダー ファイル、および `WebView2Loader.dll` ファイルが含 `IDL` まれています。 `WebView2Loader.dll` は、アプリがデバイス上で WebView2 ランタイムまたはプレビュー チャネルMicrosoft Edgeを見つけるのに役立つ小さなコンポーネントです。
出荷しないアプリの場合は、 `WebView2Loader.dll` 次の手順を実行します。
1. アプリの `.vcxproj` プロジェクト ファイルをテキスト エディター (テキスト エディターなど) で開Visual Studio Code。
> [!NOTE]
> プロジェクト `.vcproj` ファイルは非表示のファイルである可能性があります。つまり、プロジェクト ファイルは非表示Visual Studio。 コマンド ラインを使用して、隠しファイルを検索します。
1. パッケージ ターゲット ファイルに WebView2 ファイルを含めるコードNuGet探します。 コード内の場所は、次の図で強調表示されています。
:::image type="complex" source="./media/insert-here.png" alt-text="Projectファイル コード スニペット" lightbox="./media/insert-here.png":::
Projectファイル コード スニペット
:::image-end:::
1. 次のコード スニペットをコピーし、含まれる場所に `Microsoft.Web.WebView2.targets` 貼り付けます。
```xaml
<PropertyGroup>
<WebView2LoaderPreference>Static</WebView2LoaderPreference>
</PropertyGroup>
```
:::image type="complex" source="./media/static-lib.png" alt-text="挿入されたコード スニペット" lightbox="./media/static-lib.png":::
挿入されたコード スニペット
:::image-end:::
1. アプリをコンパイルして実行します。
<!-- ====================================================================== -->
## <a name="see-also"></a>関連項目
* [WebView2 はじめに ガイド][Webview2MainGetStarted]
* [WebView2Samples repo][GithubMicrosoftedgeWebview2samples] - WebView2 機能の包括的な例。
* [WebView2 API リファレンス][Webview2ApiReference]
* [「WebView2][Webview2MainNextSteps] _の概要」Microsoft Edge参照してください_。
<!-- ====================================================================== -->
<!-- links -->
[DevtoolsGuideChromiumMain]: ../index.md "Microsoft Edge開発者ツール |Microsoft Docs"
[Webview2ApiReference]: ../webview2-api-reference.md "Microsoft EdgeWebView2 API リファレンス |Microsoft Docs"
[Webview2MainNextSteps]: ../index.md#see-also "「WebView2 の概要」もMicrosoft Edge参照|Microsoft Docs"
[Webview2MainGetStarted]: ../index.md#get-started "はじめに - WebView2 Microsoft Edgeの概要|Microsoft Docs"
[GithubMicrosoftedgeWebviewfeedbackMain]: https://github.com/MicrosoftEdge/WebViewFeedback "WebView フィードバック-MicrosoftEdge/WebViewFeedback | GitHub"
[GithubMicrosoftedgeWebview2samples]: https://github.com/MicrosoftEdge/WebView2Samples "WebView2 サンプル-MicrosoftEdge/WebView2Samples | GitHub"
[GithubMicrosoftVscodeJSDebugWhatsNew]: https://github.com/microsoft/vscode-js-debug#whats-new "新機能- JavaScript デバッガー Visual Studio Code - microsoft/vscode-js-debug |GitHub"
[GithubMicrosoftVscodeEdgeDebug2ReadmeChromiumWebviewApplications]: https://github.com/microsoft/vscode-edge-debug2/blob/master/README.md#microsoft-edge-chromium-webview-applications "Microsoft EdgeWebView アプリケーション - Visual Studio Code - デバッガー Microsoft Edge - microsoft/vscode-edge-debug2 |GitHub" | 3,473 | CC-BY-4.0 |
# libra-common-log 说明
此组件主要实现了日志拦截,提供配置有:
1、提供日志记录开关`libra.log.enabled`默认开启,如果关闭则不处理相关逻辑
2、提供是否入库配置`libra.log.db`默认开启,如果开启了此模块需要依赖基础服务`libra-base-service`,需要在启动类添加@EnableFeignClients注解及扫描范围`@EnableFeignClients({TenantConstant.LIBRA_TENANT_PACKAGE})`
# libra-common-log 接入说明
1、在对应服务pom.xml文件引入对应依赖
```xml
<dependency>
<groupId>cn.hfbin</groupId>
<artifactId>libra-common-log</artifactId>
</dependency>
```
2、启动类添加注解`@EnableAspectJAutoProxy(proxyTargetClass = true)`
# libra-common-log 使用说明
在对应接口层类或者方法上添加注解和相关字段标识即可,比如`@Log(desc = "员工管理-分页查询", logType = LogTypeEnum.OPT_LOG, optBehavior = OptBehaviorEnum.SELECT)`
```java
@RestController
@RequestMapping("/identity/employee" )
@Api(tags = "员工身份信息管理")
public class IdentityEmployeeController implements IdentityEmployeeApiService {
@Autowired
private IdentityEmployeeService identityEmployeeService;
/**
* 分页查询
* @param pageNo 页码
* @param pageSize 页数
* @param employeeQueryParams 员工身份信息表
* @return ResponseData
*/
@Override
@PreAuthorize("emp:list")
@ApiOperation(value = "分页查询数据", notes = "分页查询数据")
@Log(desc = "员工管理-分页查询", logType = LogTypeEnum.OPT_LOG, optBehavior = OptBehaviorEnum.SELECT)
public ResponseData<Page<IdentityInfoVo>> page(Integer pageNo,
Integer pageSize,
EmployeeQueryParams employeeQueryParams) {
return ResponseData.ok(identityEmployeeService.page(pageNo, pageSize, employeeQueryParams));
}
}
``` | 1,554 | Apache-2.0 |
# LeetCode#1-两数之和
## 1. 问题
给定一个整数数组 `nums` 和一个目标值 `target`,请你在该数组中找出和为目标值的那 **两个** 整数,并返回他们的数组下标。
你可以假设每种输入只会对应一个答案。但是,数组中同一个元素不能使用两遍。
## 2. 思路
### 1. 简单粗暴的n^2双循环
> 这里没什么好讲的,从`index=0`开始遍历第`n`个数`number1`,然后遍历后面的`length-n`个数`number2`,然后找出符合要求的`number2`和`number1`
**时间复杂度:** O(n^2)
**空间复杂度:** O(1)
### 2. 哈希表做辅助
> 用“空间换时间”的方法,先做一个存储所有数值的哈希表,然后利用哈希索引取值的`O(1)`复杂度,降低空间复杂度
代码:
```javascript
/**
* @param {number[]} nums
* @param {number} target
* @return {number[]}
*/
var twoSum = function(nums, target) {
const map = {}
for (let i = 0; i < nums.length; i++) {
if (map[(target - nums[i])] !== undefined) {
return [map[(target - nums[i])], i]
break;
}
map[nums[i]] = i
}
};
```
### 3.排序+双指针
> LeetCode热评下的大佬用的方法,个人觉得很有趣:
1. 先将数组排列(从小到大、从大到小均可)。此过程的时间复杂度视你用的方法而定(JS的原生排序为O(NlogN))
2. 使用队首和队尾的双指针的辅助,如果双指针所在的两数之和过大/过小,则根据第`1`步排列的方式,将队首指针后移或将队尾指针前移,直到找到符合条件的2个位置
代码:
```javascript
/**
* @param {number[]} nums
* @param {number} target
* @return {number[]}
*/
var twoSum = function(nums, target) {
const sort = [...nums].sort((a, b) => (a - b)) // 结果为从小到大
let i = 0, j = nums.length - 1
while (i < j) {
if (sort[i] + sort[j] < target) {
i++
} else if (sort[i] + sort[j] > target) {
j--
} else{
return [nums.indexOf(sort[i]), nums.lastIndexOf(sort[j])]
}
}
};
``` | 1,417 | MIT |
# GlobalPage
封装小程序底部导航 GlobalPage
在页面最外层套上GlobalPage
> 有关底部导航配置 在`store/index.js`内配置
```vue
<template>
<GlobalPage>
<!--内容-->
<view>内容区域</view>
</GlobalPage>
</template>
```
 | 248 | MIT |
---
title: 常见 Power BI 工作区集合方案
description: 常见 Power BI Embedded 方案
services: power-bi-embedded
author: markingmyname
ROBOTS: NOINDEX
ms.assetid: 0bf9706c-11bd-432a-bab3-89c04bc4dd1f
ms.service: power-bi-embedded
ms.topic: article
ms.workload: powerbi
origin.date: 09/20/2017
ms.date: 09/26/2018
ms.author: v-junlch
ms.openlocfilehash: 86ae855bac438416758084b05b3afe3be2efe617
ms.sourcegitcommit: d75065296d301f0851f93d6175a508bdd9fd7afc
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 11/30/2018
ms.locfileid: "52657177"
---
# <a name="common-power-bi-workspace-collection-scenarios"></a>常见 Power BI 工作区集合方案
Power BI 工作区集合侧重于在 Azure 服务中提供大多数现有 Power BI API 功能,以用于开发应用。 此外,还可以编程方式预配、开发和部署所需的资源和 Power BI 内容。 若要了解详细信息,请参阅 [Power BI 工作区集合入门](get-started.md)。
> [!IMPORTANT]
> Power BI 工作区集合已弃用,到 2018 年 6 月 或合同指示时可用。 建议你规划到 Power BI Embedded 的迁移以避免应用程序中断。 若要了解如何将数据迁移到 Power BI Embedded,请参阅[如何将 Power BI 工作区集合内容迁移到 Power BI Embedded](https://powerbi.microsoft.com/documentation/powerbi-developer-migrate-from-powerbi-embedded/)。
下面介绍了几种在应用中使用 Power BI 工作区集合的方案。
- 可以使用新的应用令牌身份验证模型在自己的应用程序中嵌入在 Power BI Desktop 中创建的完整交互式报表。
- 如果独立软件供应商和客户生成面向客户的应用,可以使用 Power BI 工作区集合服务和 Power BI SDK,嵌入交互式报表。 若要了解如何执行操作,请参阅 [Power BI 工作区集合入门](get-started.md)。
- 开发人员可以使用 Power BI 可视化框架来创建自定义可视化元素,可以将这些可视化元素用于自己的应用中。 请参阅 [使用自定义视觉对象扩展 Power BI](https://powerbi.microsoft.com/custom-visuals/)。
### <a name="see-also"></a>另请参阅
- [Power BI 工作区集合入门](get-started.md)
- [示例入门](get-started-sample.md)
<!-- Update_Description: update metedata properties --> | 1,552 | CC-BY-4.0 |
``uni-app`` 在发布到H5时支持所有vue的语法;发布到App和小程序时,由于平台限制,无法实现全部vue语法,但``uni-app``仍是是对vue语法支持度最高的跨端框架。本文将详细讲解差异。
相比Web平台, ``Vue.js`` 在 ``uni-app`` 中使用差异主要集中在两个方面:
- 新增:uni-app除了支持Vue实例的生命周期,还支持应用启动、页面显示等生命周期
- 受限:相比web平台,在小程序和App端部分功能受限,具体见下。
## 生命周期
``uni-app`` 完整支持 ``Vue`` 实例的生命周期,同时还新增 [应用生命周期](/frame?id=应用生命周期) 及 [页面生命周期](/frame?id=页面生命周期)。
详见Vue官方文档:[生命周期钩子](https://cn.vuejs.org/v2/api/#%E9%80%89%E9%A1%B9-%E7%94%9F%E5%91%BD%E5%91%A8%E6%9C%9F%E9%92%A9%E5%AD%90)。
## 模板语法
``uni-app`` 完整支持 ``Vue`` 模板语法。
详见Vue官方文档:[模板语法](https://cn.vuejs.org/v2/guide/syntax.html)。
**注意**
如果使用**老版**的非自定义组件模式,即manifest中`"usingComponents":false`,部分模版语法不支持,但此模式已不再推荐使用,[详见](https://ask.dcloud.net.cn/article/35699)。
**老版**非自定义组件模式不支持情况(**新版自定义组件模式已不存在此情况**):
- 不支持部分复杂的 JavaScript 渲染表达式
- 不支持过滤器
## data 属性
``data`` 必须声明为返回一个初始数据对象的函数;否则页面关闭时,数据不会自动销毁,再次打开该页面时,会显示上次数据。
```javascript
//正确用法,使用函数返回对象
data() {
return {
title: 'Hello'
}
}
//错误写法,会导致再次打开页面时,显示上次数据
data: {
title: 'Hello'
}
```
## 全局变量
实现全局变量的方式需要遵循 Vue 单文件模式的开发规范。详细参考:[uni-app全局变量的几种实现方式](https://ask.dcloud.net.cn/article/35021)
## Class 与 Style 绑定
为节约性能,我们将 ``Class`` 与 ``Style`` 的表达式通过 ``compiler`` 硬编码到 ``uni-app`` 中,支持语法和转换效果如下:
class 支持的语法:
```html
<view :class="{ active: isActive }">111</view>
<view class="static" v-bind:class="{ active: isActive, 'text-danger': hasError }">222</view>
<view class="static" :class="[activeClass, errorClass]">333</view>
<view class="static" v-bind:class="[isActive ? activeClass : '', errorClass]">444</view>
<view class="static" v-bind:class="[{ active: isActive }, errorClass]">555</view>
```
style 支持的语法:
```html
<view v-bind:style="{ color: activeColor, fontSize: fontSize + 'px' }">666</view>
<view v-bind:style="[{ color: activeColor, fontSize: fontSize + 'px' }]">777</view>
```
非H5端不支持 [Vue官方文档:Class 与 Style 绑定](https://cn.vuejs.org/v2/guide/class-and-style.html) 中的 ``classObject`` 和 ``styleObject`` 语法。
不支持示例:
```html
<template>
<view :class="[activeClass]" :style="[baseStyles,overridingStyles]"></view>
</template>
<script>
export default {
data() {
return {
activeClass: {
'active': true,
'text-danger': false
},
baseStyles: {
color: 'green',
fontSize: '30px'
},
overridingStyles: {
'font-weight': 'bold'
}
}
}
}
</script>
```
**注意:以``:style=""``这样的方式设置px像素值,其值为实际像素,不会被编译器转换。**
此外还可以用 ``computed`` 方法生成 ``class`` 或者 ``style`` 字符串,插入到页面中,举例说明:
```html
<template>
<!-- 支持 -->
<view class="container" :class="computedClassStr"></view>
<view class="container" :class="{active: isActive}"></view>
<!-- 不支持 -->
<view class="container" :class="computedClassObject"></view>
</template>
<script>
export default {
data () {
return {
isActive: true
}
},
computed: {
computedClassStr () {
return this.isActive ? 'active' : ''
},
computedClassObject () {
return { active: this.isActive }
}
}
}
</script>
```
**用在组件上**
非H5端暂不支持在自定义组件上使用 ``Class`` 与 ``Style`` 绑定
## 计算属性
完整支持 [Vue官方文档:计算属性](https://cn.vuejs.org/v2/guide/computed.html)。
## 条件渲染
完整支持 [Vue官方文档:条件渲染](https://cn.vuejs.org/v2/guide/conditional.html)
## 列表渲染
完整vue列表渲染 [Vue官方文档:列表渲染](https://cn.vuejs.org/v2/guide/list.html)
### key
如果列表中项目的位置会动态改变或者有新的项目添加到列表中,并且希望列表中的项目保持自己的特征和状态(如 ``<input>`` 中的输入内容,``<switch>`` 的选中状态),需要使用 ``:key`` 来指定列表中项目的唯一的标识符。
``:key`` 的值以两种形式提供
- 使用 ``v-for`` 循环 ``array`` 中 ``item`` 的某个 ``property``,该 ``property`` 的值需要是列表中唯一的字符串或数字,且不能动态改变。
- 使用 ``v-for`` 循环中 ``item`` 本身,这时需要 ``item`` 本身是一个唯一的字符串或者数字
当数据改变触发渲染层重新渲染的时候,会校正带有 ``key`` 的组件,框架会确保他们被重新排序,而不是重新创建,以确保使组件保持自身的状态,并且提高列表渲染时的效率。
**如不提供 ``:key``,会报一个 ``warning``, 如果明确知道该列表是静态,或者不必关注其顺序,可以选择忽略。**
**示例:**
```html
<template>
<view>
<!-- array 中 item 的某个 property -->
<view v-for="(item,index) in objectArray" :key="item.id">
{{index +':'+ item.name}}
</view>
<!-- item 本身是一个唯一的字符串或者数字时,可以使用 item 本身 -->
<view v-for="(item,index) in stringArray" :key="item">
{{index +':'+ item}}
</view>
</view>
</template>
<script>
export default {
data () {
return {
objectArray:[{
id:0,
name:'li ming'
},{
id:1,
name:'wang peng'
}],
stringArray:['a','b','c']
}
}
}
</script>
```
### 注意事项
* 在H5平台 使用 v-for 循环整数时和其他平台存在差异,如 `v-for="(item, index) in 10"` 中,在H5平台 item 从 1 开始,其他平台 item 从 0 开始,可使用第二个参数 index 来保持一致。
* 在非H5平台 循环对象时不支持第三个参数,如 `v-for="(value, name, index) in object"` 中,index 参数是不支持的。
## 事件处理器
几乎全支持 [Vue官方文档:事件处理器](https://cn.vuejs.org/v2/guide/events.html)
```javascript
// 事件映射表,左侧为 WEB 事件,右侧为 ``uni-app`` 对应事件
{
click: 'tap',
touchstart: 'touchstart',
touchmove: 'touchmove',
touchcancel: 'touchcancel',
touchend: 'touchend',
tap: 'tap',
longtap: 'longtap',
input: 'input',
change: 'change',
submit: 'submit',
blur: 'blur',
focus: 'focus',
reset: 'reset',
confirm: 'confirm',
columnchange: 'columnchange',
linechange: 'linechange',
error: 'error',
scrolltoupper: 'scrolltoupper',
scrolltolower: 'scrolltolower',
scroll: 'scroll'
}
```
**注意:**
<!-- * 事件映射表中没有的原生事件也可以使用,例如``map``组件的``regionchange`` 事件直接在组件上写成 ``@regionchange``,同时这个事件也非常特殊,它的 ``event`` ``type`` 有 ``begin`` 和 ``end`` 两个,导致我们无法在``handleProxy`` 中区分到底是什么事件,所以你在监听此类事件的时候同时监听事件名和事件类型既
``<map @regionchange="functionName" @end="functionName" @begin="functionName"><map>``。 -->
* 为兼容各端,事件需使用 ``v-on`` 或 ``@`` 的方式绑定,请勿使用小程序端的``bind`` 和 ``catch`` 进行事件绑定。
* 事件修饰符
* ``.stop``:各平台均支持, 使用时会阻止事件冒泡,在非 H5 端同时也会阻止事件的默认行为
* ``.prevent`` 仅在 H5 平台支持
* ``.self``:仅在 H5 平台支持
* ``.once``:仅在 H5 平台支持
* ``.capture``:仅在 H5 平台支持
* ``.passive``:仅在 H5 平台支持
* 若需要禁止蒙版下的页面滚动,可使用 ``@touchmove.stop.prevent="moveHandle"``,moveHandle 可以用来处理 touchmove 的事件,也可以是一个空函数。
```html
<view class="mask" @touchmove.stop.prevent="moveHandle"></view>
```
* 按键修饰符:``uni-app``运行在手机端,没有键盘事件,所以不支持按键修饰符。
## 表单控件绑定
支持 [Vue官方文档:表单控件绑定](https://cn.vuejs.org/v2/guide/forms.html)。
建议开发过程中直接使用 [uni-app:表单组件](component/button)。用法示例:
H5 的select 标签用 picker 组件进行代替
```html
<template>
<view>
<picker @change="bindPickerChange" :value="index" :range="array">
<view class="picker">
当前选择:{{array[index]}}
</view>
</picker>
</view>
</template>
<script>
export default {
data () {
return {
index: 0,
array: ['A', 'B', 'C']
}
},
methods: {
bindPickerChange (e) {
console.log(e)
}
}
}
</script>
```
表单元素 radio 用 radio-group 组件进行代替
```html
<template>
<view>
<radio-group class="radio-group" @change="radioChange">
<label class="radio" v-for="(item, index) in items" :key="item.name">
<radio :value="item.name" :checked="item.checked"/> {{item.value}}
</label>
</radio-group>
</view>
</template>
<script>
export default {
data () {
return {
items: [
{name: 'USA', value: '美国'},
{name: 'CHN', value: '中国', checked: 'true'},
{name: 'BRA', value: '巴西'},
{name: 'JPN', value: '日本'},
{name: 'ENG', value: '英国'},
{name: 'TUR', value: '法国'}
]
}
},
methods: {
radioChange (e) {
console.log('radio发生change事件,携带value值为:', e.target.value)
}
}
}
</script>
```
## v-html指令
由于非H5端,不支持dom和普通html元素,所以自然非H5端也不支持v-html。
跨端的富文本处理方案详见:[https://ask.dcloud.net.cn/article/35772](https://ask.dcloud.net.cn/article/35772)
## 组件
### Vue 组件
组件是 ``vue`` 技术中非常重要的部分,组件使得与ui相关的轮子可以方便的制造和共享,进而使得vue使用者的开发效率大幅提升。
uni-app搭建了组件的插件市场,可大幅提升开发者的效率。[https://ext.dcloud.net.cn/](https://ext.dcloud.net.cn/)
在项目的/component目录下存放组件,在要显示组件的页面中则分为3步:导入、注册和使用。
可以这个[评分组件](https://ext.dcloud.net.cn/plugin?id=33)的使用为例,了解vue组件的使用方式。
```html
<template>
<view>
<uni-rate value="2"></uni-rate> <!-- 第三步,使用组件。并传值点亮2颗星 -->
</view>
</template>
<script>
import uniRate from "@/components/uni-rate/uni-rate.vue" //第一步,导入组件
export default {
components: {
uniRate //第二步,注册组件
}
}
</script>
```
**uni-app只支持vue单文件组件(.vue 组件)**。其他的诸如:动态组件,自定义 ``render``,和``<script type="text/x-template">`` 字符串模版等,在非H5端不支持。
详细的非H5端不支持列表:
* ``Slot``(``scoped`` 暂时还没做支持)
* 动态组件
* 异步组件
* ``inline-template``
* ``X-Templates``
* ``keep-alive``
* ``transition`` (可使用 [animation](/api/ui/animation) 或 CSS 动画替代)
* [老的非自定义组件编译模式](https://ask.dcloud.net.cn/article/35843)不支持在组件引用时,在组件上定义 ``click`` 等原生事件、``v-show``(可用 ``v-if`` 代替)和 ``class`` ``style`` 等样式属性(例:``<card class="class-name"> </card>`` 样式是不会生效的)。建议更新为自定义组件模式
* [老的非自定义组件编译模式](https://ask.dcloud.net.cn/article/35843)组件里使用 ``slot`` 嵌套的其他组件时不支持 ``v-for``。建议更新为自定义组件模式
[Vue官方文档参考:组件](https://cn.vuejs.org/v2/guide/components.html) 。
### uni-app内置基础组件
``uni-app`` 内置了小程序的所有[组件](component/),比如: ``picker``,``map`` 等,需要注意的是原生组件上的事件绑定,需要以 ``vue`` 的事件绑定语法来绑定,如 ``bindchange="eventName"`` 事件,需要写成 ``@change="eventName"``
**示例**
```html
<picker mode="date" :value="date" start="2015-09-01" end="2017-09-01" @change="bindDateChange">
<view class="picker">
当前选择: {{date}}
</view>
</picker>
```
### 全局组件
```uni-app``` 支持配置全局组件,需在 ``main.js`` 里进行全局注册,注册后就可在所有页面里使用该组件。
**注意**
- ``Vue.component`` 的第一个参数必须是静态的字符串。
- nvue页面暂不支持全局组件
**示例**
main.js 里进行全局导入和注册
```javascript
import Vue from 'vue'
import pageHead from './components/page-head.vue'
Vue.component('page-head',pageHead)
```
index.vue 里可直接使用组件
```html
<template>
<view>
<page-head></page-head>
</view>
</template>
```
### 命名限制
在 `uni-app` 中以下这些作为保留关键字,不可作为组件名。
- `a`
- `canvas`
- `cell`
- `content`
- `countdown`
- `datepicker`
- `div`
- `element`
- `embed`
- `header`
- `image`
- `img`
- `indicator`
- `input`
- `link`
- `list`
- `loading-indicator`
- `loading`
- `marquee`
- `meta`
- `refresh`
- `richtext`
- `script`
- `scrollable`
- `scroller`
- `select`
- `slider-neighbor`
- `slider`
- `slot`
- `span`
- `spinner`
- `style`
- `svg`
- `switch`
- `tabbar`
- `tabheader`
- `template`
- `text`
- `textarea`
- `timepicker`
- `trisition-group`
- `trisition`
- `video`
- `view`
- `web`
**Tips**
- 除以上列表中的名称外,标准的 HTML 及 SVG 标签名也不能作为组件名。
## 常见问题
**1. 如何获取上个页面传递的数据**
在 ``onLoad`` 里得到,``onLoad`` 的参数是其他页面打开当前页面所传递的数据。
**2. 如何设置全局的数据和全局的方法**
``uni-app`` 内置了 [vuex](https://vuex.vuejs.org/zh/guide/) ,在app里的使用,可参考``hello-uniapp`` ``store/index.js``。
```javascript
//store.js
import Vue from 'vue'
import Vuex from 'vuex'
Vue.use(Vuex)
const store = new Vuex.Store({
state: {...},
mutations: {...},
actions: {...}
})
export default store
//main.js
...
import store from './store'
Vue.prototype.$store = store
const app = new Vue({
store,...
})
...
//test.vue 使用时:
import {mapState,mapMutations} from 'vuex'
```
**3. 如何捕获 app 的 onError**
由于 ``onError`` 并不是完整意义的生命周期,所以只提供一个捕获错误的方法,在 ``app`` 的根组件上添加名为 ``onError`` 的回调函数即可。如下:
```javascript
export default {
// 只有 app 才会有 onLaunch 的生命周期
onLaunch () {
// ...
},
// 捕获 app error
onError (err) {
console.log(err)
}
}
```
**4. 组件属性设置不生效解决办法**
当重复设置某些属性为相同的值时,不会同步到view层。
例如:每次将scroll-view组件的scroll-top属性值设置为0,只有第一次能顺利返回顶部。
这和props的单向数据流特性有关,组件内部scroll-top的实际值改动后,其绑定的属性并不会一同变化。
解决办法有两种(以scroll-view组件为例):
* 监听scroll事件,记录组件内部变化的值,在设置新值之前先设置为记录的当前值
```html
<scroll-view :scroll-top="scrollTop" scroll-y="true" @scroll="scroll">
```
```js
export default {
data() {
return {
scrollTop: 0,
old: {
scrollTop: 0
}
}
},
methods: {
scroll: function(e) {
this.old.scrollTop = e.detail.scrollTop
},
goTop: function(e) {
this.scrollTop = this.old.scrollTop
this.$nextTick(function() {
this.scrollTop = 0
});
}
}
}
```
* 监听scroll事件,获取组件内部变化的值,实时更新其绑定值
```html
<scroll-view :scroll-top="scrollTop" scroll-y="true" @scroll="scroll">
```
```js
export default {
data() {
return {
scrollTop: 0,
}
},
methods: {
scroll: function(e) {
this.scrollTop = e.detail.scrollTop
},
goTop: function(e) {
this.scrollTop = 0
}
}
}
```
第二种解决方式在某些组件可能造成抖动,推荐第一种解决方式。 | 12,682 | Apache-2.0 |
---
title: 盒子模型
date: 2019-12-28
categories:
- FrontEnd
tags:
- CSS
---
## 1. 盒子模型
Box-Model 四大元素:Content、Padding、Border、Margin
:link:[ Box-Model ](https://developer.mozilla.org/zh-CN/docs/Web/CSS/CSS_Box_Model/Introduction_to_the_CSS_box_model)
### 1.1 W3C盒模型(标准)
+ 标准盒模型的大小:是由 `content + padding + border` 三部分组成
+ 标准盒模型占据的位置大小:是由 `content + padding + border + margin` 四部分组成
> 通俗理解就是 content-box 是在原有的宽高上在外面继续附上 padding + border ,相当于固定框,再给外面糊上 padding 和 border
举例:
```html
<style>
.div{
box-sizing: content-box;
width: 300px;
height: 300px;
background-color: #ff8c00;
padding: 10px;
border: #9932cc 10px solid;
margin: 10px;
}
</style>
<div>content-box</div>
<!--
逐次添加 padding: 10px; border: 10px; margin: 10px;
后会发现,盒子的最终宽高是 content + padding + border
-->
```


### 1.2 IE盒模型(怪异)
+ IE盒模型的大小: `(缩小的content) + padding + border` 三部分组成
+ IE盒模型所占据的位置大小: `(缩小的content) + padding + border + margin` 四部分组成
> 通俗理解就是 border-box 会在原来的宽高上压缩 content ,相当于固定框,然后挤压框里的content 然后在框和 content 之间的间隙塞进去 padding 和 border
```html
<style>
.div{
box-sizing: border-box;
width: 300px;
height: 300px;
background-color: #ff8c00;
padding: 10px;
border: #9932cc 10px solid;
margin: 10px;
}
</style>
<div>border-box</div>
<!--
逐次添加 padding: 10px; border: 10px; margin: 10px;
后会发现,盒子的最终宽高是 (content变小,260px)content + padding + border
-->
```


### 1.3 margin重叠
(margin collapse)
垂直方向的 margin 会发生重叠,都为正值时,取其中较大值,不全是正值时, ||marginA| - |marginB||,没有正值,则都取绝对值,然后用0减去最大值。
**怎么解决 margin collapse ?**
+ 兄弟元素
> 1. 在两个 div 之间再加一个块级元素,设置其高度为 1px,背景色透明即可,此时上下外边距是各自 margin 值加 1px ( :triangular_flag_on_post: 会多1px)
> 2. 下面的元素设置 float: left;
> 3. 底部元素的 position: absolute;
> 4. 在设置 margin-top/bottom 值时统一只设置上或下
+ 父子元素
> 1. 父元素 overflow: hidden;
> 2. 父元素透明边框 border: 1px solid transparent;
> 3. 父元素设置 padding
> 4. 子元素 position: absolute;
> 5. 子元素 float:left;
**另注:** 父子结构,若子元素的 margin-top 是负值,且其绝对值大于父元素的 margin-top,上述解决方案就又会发生很有意思的现象,可以手敲代码探索一下,但实际开发中没人这么布局,所以这里略过。
### 1.4 扩展
+ `inline` 元素设置 `margin` 和 `padding` 只有左右方向的外、内边距会发生改变,变垂直方向的布局不会改变,但需要注意的是上下 `padding` 会发生覆盖,上下 `margin` 则是不起作用。
`inline` 元素设置成 `inline-block` 时`margin` 和 `padding` 四个方向就都会起作用。
```html
<div>
<span>...<strong>...</strong>...</span>
</div>
```
图一:
```css
strong {
margin: 30px;
}
```

图二:
```css
strong {
padding: 30px;
opacity: 0.8;
}
```

图三:
```css
strong {
display: inline-block;
padding: 30px;
}
```

图四:
```css
strong {
display: inline-block;
padding: 30px;
}
```

图五:
```css
strong {
display: inline-block;
padding: 30px;
margin: 30px;
}
```
 | 3,446 | MIT |
# Route 路由跳转
## Route 路由跳转使用方法
```
/**
* @description: 跳转再封装,不支持复杂传参。
* @param {string} path 跳转地址
* @param {object} params 跳转携带对参数
* @param {number} type 跳转类型
0: "navigateTo", //保留当前页面,跳转到应用内的某个页面,使用uni.navigateBack可以返回到原页面。
1: "redirectTo", //关闭当前页面,跳转到应用内的某个页面。
2: "reLaunch", //关闭所有页面,打开到应用内的某个页面。
3: "switchTab", //跳转到 tabBar 页面,并关闭其他所有非 tabBar 页面。
*/
this.$uct.to(path, params = {}, type = 0)
```
## Route 路由跳转案例
```vue
<template>
<view class="px40">
<uct-nav>
<view slot="center">Route 路由跳转</view>
</uct-nav>
<uct-button class="mt40" @click="item.handler" v-for="(item, index) in router" :key="index">
<view slot="text" class="f14">{{ item.text }}</view>
</uct-button>
</view>
</template>
<script>
export default {
data() {
return {
router: [
{
text: "保留当前页面,跳转到应用内的某个页面",
handler: () => this.$uct.to("/pages/components/empty", {}, 0),
},
{
text: "关闭当前页面,跳转到应用内的某个页面",
handler: () => this.$uct.to("/pages/components/empty", {}, 1),
},
{
text: "关闭所有页面,打开到应用内的某个页面",
handler: () => this.$uct.to("/pages/components/empty", {}, 2),
},
{
text: "跳转到tabBar页面,并关闭其他所有非tabBar页面",
handler: () => this.$uct.to("/pages/components/empty", {}, 3),
},
{
text: "跳转外部链接。例如:百度",
handler: () => this.$uct.to("http://www.baidu.com"),
},
],
};
},
};
</script>
``` | 1,502 | MIT |
# LeetCode Problem Type
The topics are arranged in alphabetical order.
<!-- GFM-TOC -->
<!-- * [算法思想](#算法思想)
* [二分查找](#二分查找)
* [贪心思想](#贪心思想)
* [双指针](#双指针)
* [排序](#排序)
* [快速选择](#快速选择)
* [堆排序](#堆排序)
* [桶排序](#桶排序)
* [搜索](#搜索)
* [BFS](#bfs)
* [DFS](#dfs)
* [Backtracking](#backtracking)
* [分治](#分治)
* [动态规划](#动态规划)
* [斐波那契数列](#斐波那契数列)
* [最长递增子序列](#最长递增子序列)
* [最长公共子序列](#最长公共子序列)
* [0-1 背包](#0-1-背包)
* [数组区间](#数组区间)
* [字符串编辑](#字符串编辑)
* [分割整数](#分割整数)
* [矩阵路径](#矩阵路径)
* [其它问题](#其它问题)
* [数学](#数学)
* [素数](#素数)
* [最大公约数](#最大公约数)
* [进制转换](#进制转换)
* [阶乘](#阶乘)
* [字符串加法减法](#字符串加法减法)
* [相遇问题](#相遇问题)
* [多数投票问题](#多数投票问题)
* [其它](#其它)
* [数据结构相关](#数据结构相关)
* [栈和队列](#栈和队列)
* [哈希表](#哈希表)
* [字符串](#字符串)
* [数组与矩阵](#数组与矩阵)
* [链表](#链表)
* [树](#树)
* [递归](#递归)
* [层次遍历](#层次遍历)
* [前中后序遍历](#前中后序遍历)
* [BST](#bst)
* [Trie](#trie)
* [图](#图)
* [位运算](#位运算)
* [参考资料](#参考资料) -->
<!-- GFM-TOC -->
--------
## Backtracking
- General references:
- http://www.cnblogs.com/wuyuegb2312/p/3273337.html
- https://github.com/CyC2018/Interview-Notebook/blob/master/notes/Leetcode%20%E9%A2%98%E8%A7%A3.md#backtracking
### Combinations
- 77. Combinations
- 39. Combination Sum I
- 40. Combination Sum II
- 216. Combination Sum III
- 377. Combination Sum IV
- references:
- https://leetcode.com/problems/combination-sum-iv/discuss/85120/C++-template-for-ALL-Combination-Problem-Set
- https://leetcode.com/problems/combination-sum-iv/discuss/85106/A-summary-of-all-combination-sum-problem-in-LC-C++
### Permutations
- 31. Next Permutation
- 46. Permutations
- 47. Permutations II
- 60. Permutation Sequence
- 266. Palindrome Permutation
- 267. Palindrome Permutation II
- 784. Letter Case Permutation
### Subsets
- 78. Subsets
- 90. Subsets II
- references:
- https://zhuanlan.zhihu.com/p/34083013?group_id=952032396409843712
- https://zhuanlan.zhihu.com/p/34153380
- https://zhuanlan.zhihu.com/p/28340833
- https://zhuanlan.zhihu.com/p/24523433
### Word Search
- 79. Word Search [M]
- 212. Word Search II [H]
--------
## Binary Search
- 33. Search in Rotated Sorted Array [M]
- 81. Search in Rotated Sorted Array II [M]
- 153. Find Minimum in Rotated Sorted Array [M]
- 154. Find Minimum in Rotated Sorted Array II [H]
- 215. Kth Largest Element in an Array [M]
- 230. Kth Smallest Element in a BST [M]
- 378. Kth Smallest Element in a Sorted Matrix [M]
- 658. Find K Closest Elements [M]
- 744. Find Smallest Letter Greater Than Target [E]
--------
## Binary Tree/BST
### Binary Tree Traversal
- 144. Binary Tree Preorder Traversal [M]
- 94. Binary Tree Inorder Traversal [M]
- 145. Binary Tree Postorder Traversal [M]
- 102. Binary Tree Level Order Traversal [M]
- 107. Binary Tree Level Order Traversal II [E]
- 103. Binary Tree Zigzag Level Order Traversal [M]
- 314. Binary Tree Vertical Order Traversal [M]
- references:
- [[LeetCode] Binary Tree Inorder Traversal 二叉树的中序遍历](http://www.cnblogs.com/grandyang/p/4297300.html)
- [Morris Traversal方法遍历二叉树(非递归,不用栈,O(1)空间)](http://www.cnblogs.com/AnnieKim/archive/2013/06/15/morristraversal.html)
- [leetcode | 二叉树的前序遍历、中序遍历、后续遍历的非递归实现](https://blog.csdn.net/quzhongxin/article/details/46315251)
- [二叉树前序、中序、后序遍历非递归写法的透彻解析](https://blog.csdn.net/zhangxiangdavaid/article/details/37115355)
- [前中后序遍历](https://github.com/CyC2018/Interview-Notebook/blob/master/notes/Leetcode%20%E9%A2%98%E8%A7%A3.md#%E5%89%8D%E4%B8%AD%E5%90%8E%E5%BA%8F%E9%81%8D%E5%8E%86)
### Construct Binary Tree
- 105. Construct Binary Tree from Preorder and Inorder Traversal [M]
- 106. Construct Binary Tree from Inorder and Postorder Traversal [M]
### Iterator
- 173. Binary Search Tree Iterator [M]
- 281. Zigzag Iterator [M]
- 284. Peeking Iterator [M]
- 285. Inorder Successor in BST [M]
### Longest Consecutive Sequence
- 298. Binary Tree Longest Consecutive Sequence [M]
- 549. Binary Tree Longest Consecutive Sequence II [M]
- 128. Longest Consecutive Sequence (similar question) [H]
### 想法
- 处理树的问题,尤其是对BST的操作,如果一开始没有想法或者只能想到brute force,不妨与几种遍历方式联系想想或者是DFS、BFS之类的
--------
## Dynamic Programming
### Best Time to Buy and Sell Stock
- 121. Best Time to Buy and Sell Stock [E]
- 122. Best Time to Buy and Sell Stock II [E]
- 123. Best Time to Buy and Sell Stock III [H]
- 188. Best Time to Buy and Sell Stock IV [H]
- 309. Best Time to Buy and Sell Stock with Cooldown [M]
- 714. Best Time to Buy and Sell Stock with Transaction Fee [M]
- references: [Most consistent ways of dealing with the series of stock problems
](https://leetcode.com/problems/best-time-to-buy-and-sell-stock-with-transaction-fee/discuss/108870/most-consistent-ways-of-dealing-with-the-series-of-stock-problems)
### Regularization
- 10. Regular Expression Matching [H]
- 44. Wildcard Matching [H]
--------
## Finding Missing/Duplicate Number(s) in Vector
- 数组中找Missing,duplicate呀核心思想就是“环”,时间复杂度O(n):
- Three Main Methods: +n, -nums[i], relocate elements
- 268. Missing Number [E]
- 442. Find All Duplicates in an Array [M]
- 448. Find All Numbers Disappeared in an Array [E]
- 645. Set Mismatch [E]
- 287. Find the Duplicate Number [M]
- 565. Array Nesting [M]
- 41. First Missing Positive [H]
--------
## Graph
### Course Schedule (Directed graph)
- 207. Course Schedule [M]
- 210. Course Schedule II [H]
- 630. Course Schedule III [H]
### Indirected graph
- 133. Clone Graph [M]
--------
## K Elements
- 347. Top K Frequent Elements
- 692. Top K Frequent Words
- 373. Find K Pairs with Smallest Sums
- 658. Find K Closest Elements
## Kth Smallest Element
- 215. Kth Largest Element in an Array
- 230. Kth Smallest Element in a BST
- 378. Kth Smallest Element in a Sorted Matrix
- 440. K-th Smallest in Lexicographical Order
- 668. Kth Smallest Number in Multiplication Table
- 719. Find K-th Smallest Pair Distance
- 786. K-th Smallest Prime Fraction
--------
## Overlapping/Non-Overlapping Intervals
- 56. Merge Intervals
- 57. Insert Interval
- 252. Meeting Rooms
- 253. Meeting Rooms II
- 435. Non-overlapping Intervals
- 452. Minimum Number of Arrows to Burst Balloons
--------
## String/Stack/Recursion
### Calculator
- 224. Basic Calculator [H]
- 227. Basic Calculator II [M]
- 772. Basic Calculator III [H]
- [ ] 770. Basic Calculator IV [H]
### Palindrome
- 5. Longest Palindromic Substring
- 9. Palindrome Number
- 125. Valid Palindrome
- 680. Valid Palindrome II
- [ ] 131. Palindrome Partitioning
- [ ] 132. Palindrome Partitioning I
- [ ] 214. Shortest Palindrome
- 234. Palindrome Linked List
- 266. Palindrome Permutation
- [ ] 267. Palindrome Permutation II
- [ ] 336. Palindrome Pairs
- [ ] 409. Longest Palindrome
- 479. Largest Palindrome Product
- [ ] 564. Find the Closest Palindrome
### Serialize and Deserialize
- 271. Encode and Decode Strings [M]
- 297. Serialize and Deserialize Binary Tree [H]
- 449. Serialize and Deserialize BST [M]
- 536. Construct Binary Tree from String [M]
- 606. Construct String from Binary Tree [E]
--------
## Tree
### Serialize and Deserialize
- 297. Serialize and Deserialize Binary Tree [H]
- 449. Serialize and Deserialize BST [M]
- 536. Construct Binary Tree from String [M]
- 606. Construct String from Binary Tree [E]
--------
## Trie
- 208. Implement Trie (Prefix Tree) [M]
- 211. Add and Search Word - Data structure design [M]
- 212. Word Search II [H]
- 745. Prefix and Suffix Search [M] | 7,617 | MIT |
---
keywords: Experience Platform;ホーム;人気の高いトピック;API チュートリアル;ストリーミング宛先 API;Platform
solution: Experience Platform
title: Adobe Experience Platformのフローサービス API を使用して、ストリーミング宛先に接続し、データをアクティブ化する
description: このドキュメントでは、Adobe Experience Platform API を使用したストリーミング先の作成について説明します
topic-legacy: tutorial
type: Tutorial
exl-id: 3e8d2745-8b83-4332-9179-a84d8c0b4400
source-git-commit: 47a94b00e141b24203b01dc93834aee13aa6113c
workflow-type: tm+mt
source-wordcount: '2049'
ht-degree: 53%
---
# Flow Service API でストリーミング宛先に接続してデータを有効化する
>[!IMPORTANT]
>
>宛先に接続するには、 **[!UICONTROL 宛先の管理]** [アクセス制御権限](/help/access-control/home.md#permissions).
>
>データをアクティブ化するには、 **[!UICONTROL 宛先の管理]**, **[!UICONTROL 宛先のアクティブ化]**, **[!UICONTROL プロファイルの表示]**、および **[!UICONTROL セグメントを表示]** [アクセス制御権限](/help/access-control/home.md#permissions).
>
>詳しくは、 [アクセス制御の概要](/help/access-control/ui/overview.md) または製品管理者に問い合わせて、必要な権限を取得してください。
このチュートリアルでは、API 呼び出しを使用してAdobe Experience Platformデータに接続する方法、ストリーミングクラウドストレージの宛先 ([Amazon Kinesis](../catalog/cloud-storage/amazon-kinesis.md) または [Azure イベントハブ](../catalog/cloud-storage/azure-event-hubs.md))、新しく作成した宛先へのデータフローを作成し、新しく作成した宛先へのデータをアクティブ化します。
このチュートリアルでは、 [!DNL Amazon Kinesis] の宛先はすべての例で同じですが、手順は [!DNL Azure Event Hubs].

Platform のユーザーインターフェイスを使用して宛先に接続し、データをアクティブ化する場合は、 [宛先の接続](../ui/connect-destination.md) および [ストリーミングセグメントの書き出し先に対するオーディエンスデータのアクティブ化](../ui/activate-segment-streaming-destinations.md) チュートリアル
## はじめに
このガイドは、Adobe Experience Platform の次のコンポーネントを実際に利用および理解しているユーザーを対象としています。
* [[!DNL Experience Data Model (XDM) System]](../../xdm/home.md):Experience Platform が顧客体験データを整理するための標準的なフレームワーク。
* [[!DNL Catalog Service]](../../catalog/home.md): [!DNL Catalog] は、Experience Platform内のデータの場所と系列のレコードのシステムです。
* [サンドボックス](../../sandboxes/home.md):Experience Platform には、単一の Platform インスタンスを別々の仮想環境に分割し、デジタルエクスペリエンスアプリケーションの開発と発展に役立つ仮想サンドボックスが用意されています。
以下の節では、Platform でストリーミング宛先に対してデータをアクティブ化する際に知っておく必要がある追加情報を示します。
### 必要な資格情報の収集
このチュートリアルの手順を完了するには、接続してセグメントをアクティブ化する宛先の種類に応じて、次の資格情報を準備しておく必要があります。
* の場合 [!DNL Amazon Kinesis] 接続: `accessKeyId`, `secretKey`, `region` または `connectionUrl`
* の場合 [!DNL Azure Event Hubs] 接続: `sasKeyName`, `sasKey`, `namespace`
### API 呼び出し例の読み取り {#reading-sample-api-calls}
このチュートリアルでは、API 呼び出しの例を提供し、リクエストの形式を設定する方法を示します。この中には、パス、必須ヘッダー、適切な形式のリクエストペイロードが含まれます。また、API レスポンスで返されるサンプル JSON も示されています。ドキュメントで使用される API 呼び出し例の表記について詳しくは、Experience Platform トラブルシューテングガイドの[API 呼び出し例の読み方](../../landing/troubleshooting.md#how-do-i-format-an-api-request)に関する節を参照してください。
### 必須ヘッダーおよびオプションヘッダーの値の収集 {#gather-values}
Platform API への呼び出しを実行する前に、[認証に関するチュートリアル](https://experienceleague.adobe.com/docs/experience-platform/landing/platform-apis/api-authentication.html?lang=ja)を完了する必要があります。認証に関するチュートリアルを完了すると、すべての Experience Platform API 呼び出しで使用する、以下のような各必須ヘッダーの値が提供されます。
* Authorization: Bearer `{ACCESS_TOKEN}`
* x-api-key: `{API_KEY}`
* x-gw-ims-org-id: `{ORG_ID}`
Experience Platform のリソースは、特定の仮想サンドボックスに分離することができます。Platform API へのリクエストでは、操作を実行するサンドボックスの名前と ID を指定できます。次に、オプションのパラメーターを示します。
* x-sandbox-name: `{SANDBOX_NAME}`
>[!NOTE]
>
>Experience Platform のサンドボックスについて詳しくは、[サンドボックスの概要ドキュメ ント](../../sandboxes/home.md)を参照してください。
ペイロード(POST、PUT、PATCH)を含むすべてのリクエストには、メディアのタイプを指定する以下のような追加ヘッダーが必要です。
* Content-Type: `application/json`
### Swagger のドキュメント {#swagger-docs}
このチュートリアルに含まれるすべての API 呼び出しについての参照ドキュメンは、Swagger のホームページにあります。詳しくは、 [Adobe I/Oに関するフローサービス API ドキュメント](https://www.adobe.io/experience-platform-apis/references/flow-service/). このチュートリアルと Swagger のドキュメントページを並行して使用することをお勧めします。
## 使用可能なストリーミング先のリストを取得する {#get-the-list-of-available-streaming-destinations}

最初の手順として、データをアクティブ化するストリーミング先を決定する必要があります。 最初に、接続してセグメントをアクティブ化できる、使用可能な宛先のリストを要求する呼び出しを実行します。`connectionSpecs` エンドポイントに次の GET リクエストを実行すると、使用可能な宛先のリストが返されます。
**API 形式**
```http
GET /connectionSpecs
```
**リクエスト**
```shell
curl --location --request GET 'https://platform.adobe.io/data/foundation/flowservice/connectionSpecs' \
--header 'accept: application/json' \
--header 'x-gw-ims-org-id: {ORG_ID}' \
--header 'x-api-key: {API_KEY}' \
--header 'x-sandbox-name: {SANDBOX_NAME}' \
--header 'Authorization: Bearer {ACCESS_TOKEN}'
```
**応答**
リクエストが成功した場合、使用可能な宛先のリストと、その一意の ID(`id`)が返されます。使用する宛先の値を保存します。この値は、以降の手順で必要になります。例えば、に接続してセグメントを配信する場合は、 [!DNL Amazon Kinesis] または [!DNL Azure Event Hubs]の場合、応答内で次のスニペットを探します。
```json
{
"id": "86043421-563b-46ec-8e6c-e23184711bf6",
"name": "Amazon Kinesis",
...
...
}
{
"id": "bf9f5905-92b7-48bf-bf20-455bc6b60a4e",
"name": "Azure Event Hubs",
...
...
}
```
## Experience Platform データへの接続 {#connect-to-your-experience-platform-data}

次に、Experience Platform データに接続し、目的の宛先にプロファイルデータを書き出してアクティブ化できるようにする必要があります。そのためには、以下に示す 2 つの手順を実行します。
1. 最初に、Experience Platform のデータへのアクセスを認証する呼び出しを実行します。そのためには、ベース接続を設定します。
2. 次に、ベース接続 ID を使用して、ソース接続を作成する別の呼び出しを実行します。これで、Experience Platform データへの接続が確立されます。
### Experience Platform のデータへのアクセスを認証する
**API 形式**
```http
POST /connections
```
**リクエスト**
```shell
curl --location --request POST 'https://platform.adobe.io/data/foundation/flowservice/connections' \
--header 'Authorization: Bearer {ACCESS_TOKEN}' \
--header 'x-api-key: {API_KEY}' \
--header 'x-gw-ims-org-id: {ORG_ID}' \
--header 'x-sandbox-name: {SANDBOX_NAME}' \
--header 'Content-Type: application/json' \
--data-raw '{
"name": "Base connection to Experience Platform",
"description": "This call establishes the connection to Experience Platform data",
"connectionSpec": {
"id": "{CONNECTION_SPEC_ID}",
"version": "1.0"
}
}'
```
* `{CONNECTION_SPEC_ID}`:プロファイルサービスの接続仕様 ID を使用します。 `8a9c3494-9708-43d7-ae3f-cda01e5030e1`.
**応答**
リクエストが成功した場合、ベース接続の一意の ID(`id`)が返されます。この値は、次の手順でソース接続を作成する際に必要になるため保存します。
```json
{
"id": "1ed86558-59b5-42f7-9865-5859b552f7f4"
}
```
### Experience Platform データへの接続 {#connect-to-platform-data}
**API 形式**
```http
POST /sourceConnections
```
**リクエスト**
```shell
curl --location --request POST 'https://platform.adobe.io/data/foundation/flowservice/sourceConnections' \
--header 'Authorization: Bearer {ACCESS_TOKEN}' \
--header 'x-api-key: {API_KEY}' \
--header 'x-gw-ims-org-id: {ORG_ID}' \
--header 'x-sandbox-name: {SANDBOX_NAME}' \
--header 'Content-Type: application/json' \
--data-raw '{
"name": "Connecting to Profile Service",
"description": "Optional",
"connectionSpec": {
"id": "{CONNECTION_SPEC_ID}",
"version": "1.0"
},
"baseConnectionId": "{BASE_CONNECTION_ID}",
"data": {
"format": "json"
},
"params": {}
}'
```
* `{BASE_CONNECTION_ID}`:前述の手順で取得した ID を使用します。
* `{CONNECTION_SPEC_ID}`:プロファイルサービスの接続仕様 ID を使用します。 `8a9c3494-9708-43d7-ae3f-cda01e5030e1`.
**応答**
正常な応答は、一意の識別子 (`id`) をクリックします。 識別子が返された場合、Experience Platform データに正常に接続できています。この値は、後の手順で必要になるため保存します。
```json
{
"id": "ed48ae9b-c774-4b6e-88ae-9bc7748b6e97"
}
```
## ストリーミング先に接続 {#connect-to-streaming-destination}

この手順では、目的のストリーミング宛先への接続を設定します。 そのためには、以下に示す 2 つの手順を実行します。
1. まず、ベース接続を設定して、ストリーミング先へのアクセスを認証する呼び出しを実行する必要があります。
2. 次に、ベース接続 ID を使用して、ターゲット接続を作成する別の呼び出しを実行します。これで、書き出されたデータが送信されるストレージアカウント内の場所と、書き出されるデータの形式が指定されます。
### ストリーミング先へのアクセスを許可
**API 形式**
```http
POST /connections
```
**リクエスト**
>[!IMPORTANT]
>
>以下の例には、というプレフィックスが付いたコードコメントが含まれています。 `//`. これらのコメントは、異なるストリーミング先に異なる値を使用する必要がある場所を強調表示します。 スニペットを使用する前にコメントを削除してください。
```shell
curl --location --request POST 'https://platform.adobe.io/data/foundation/flowservice/connections' \
--header 'Authorization: Bearer {ACCESS_TOKEN}' \
--header 'x-api-key: {API_KEY}' \
--header 'x-gw-ims-org-id: {ORG_ID}' \
--header 'x-sandbox-name: {SANDBOX_NAME}' \
--header 'Content-Type: application/json' \
--data-raw '{
"name": "Connection for Amazon Kinesis/ Azure Event Hubs",
"description": "summer advertising campaign",
"connectionSpec": {
"id": "{_CONNECTION_SPEC_ID}",
"version": "1.0"
},
"auth": {
"specName": "{AUTHENTICATION_CREDENTIALS}",
"params": { // use these values for Amazon Kinesis connections
"accessKeyId": "{ACCESS_ID}",
"secretKey": "{SECRET_KEY}",
"region": "{REGION}"
},
"params": { // use these values for Azure Event Hubs connections
"sasKeyName": "{SAS_KEY_NAME}",
"sasKey": "{SAS_KEY}",
"namespace": "{EVENT_HUB_NAMESPACE}"
}
}
}'
```
* `{CONNECTION_SPEC_ID}`:手順「[使用可能な宛先のリストを取得する](#get-the-list-of-available-destinations)」で取得した接続仕様 ID を使用します。
* `{AUTHENTICATION_CREDENTIALS}`:ストリーミング先の名前を入力します。 `Aws Kinesis authentication credentials` または `Azure EventHub authentication credentials`.
* `{ACCESS_ID}`: *の場合 [!DNL Amazon Kinesis] 接続。* Amazon Kinesisストレージの場所のアクセス ID。
* `{SECRET_KEY}`: *の場合 [!DNL Amazon Kinesis] 接続。* Amazon Kinesisストレージの場所の秘密鍵。
* `{REGION}`: *の場合 [!DNL Amazon Kinesis] 接続。* の地域 [!DNL Amazon Kinesis] Platform がデータをストリーミングするアカウント。
* `{SAS_KEY_NAME}`: *の場合 [!DNL Azure Event Hubs] 接続。* SAS キー名を入力します。 認証の詳細 [!DNL Azure Event Hubs] に SAS キーを設定 [Microsoftドキュメント](https://docs.microsoft.com/en-us/azure/event-hubs/authenticate-shared-access-signature).
* `{SAS_KEY}`: *の場合 [!DNL Azure Event Hubs] 接続。* SAS キーを入力します。 認証の詳細 [!DNL Azure Event Hubs] に SAS キーを設定 [Microsoftドキュメント](https://docs.microsoft.com/en-us/azure/event-hubs/authenticate-shared-access-signature).
* `{EVENT_HUB_NAMESPACE}`: *の場合 [!DNL Azure Event Hubs] 接続。* 次の項目に入力: [!DNL Azure Event Hubs] namespace :Platform がデータをストリーミングする場所。 詳しくは、 [Event Hubs 名前空間の作成](https://docs.microsoft.com/en-us/azure/event-hubs/event-hubs-create#create-an-event-hubs-namespace) 内 [!DNL Microsoft] ドキュメント。
**応答**
リクエストが成功した場合、ベース接続の一意の ID(`id`)が返されます。この値は、次の手順でターゲット接続を作成する際に必要になるため保存します。
```json
{
"id": "1ed86558-59b5-42f7-9865-5859b552f7f4"
}
```
### ストレージの場所とデータ形式を指定する
**API 形式**
```http
POST /targetConnections
```
**リクエスト**
>[!IMPORTANT]
>
>以下の例には、というプレフィックスが付いたコードコメントが含まれています。 `//`. これらのコメントは、異なるストリーミング先に異なる値を使用する必要がある場所を強調表示します。 スニペットを使用する前にコメントを削除してください。
```shell
curl --location --request POST 'https://platform.adobe.io/data/foundation/flowservice/targetConnections' \
--header 'Authorization: Bearer {ACCESS_TOKEN}' \
--header 'x-api-key: {API_KEY}' \
--header 'x-gw-ims-org-id: {ORG_ID}' \
--header 'Content-Type: application/json' \
--data-raw '{
"name": "Amazon Kinesis/ Azure Event Hubs target connection",
"description": "Connection to Amazon Kinesis/ Azure Event Hubs",
"baseConnectionId": "{BASE_CONNECTION_ID}",
"connectionSpec": {
"id": "{CONNECTION_SPEC_ID}",
"version": "1.0"
},
"data": {
"format": "json"
},
"params": { // use these values for Amazon Kinesis connections
"stream": "{NAME_OF_DATA_STREAM}",
"region": "{REGION}"
},
"params": { // use these values for Azure Event Hubs connections
"eventHubName": "{EVENT_HUB_NAME}"
}
}'
```
* `{BASE_CONNECTION_ID}`:前述の手順で取得したベース接続 ID を使用します。
* `{CONNECTION_SPEC_ID}`:手順「[使用可能な宛先のリストを取得する](#get-the-list-of-available-destinations)」で取得した接続仕様 ID を使用します。
* `{NAME_OF_DATA_STREAM}`: *の場合 [!DNL Amazon Kinesis] 接続。* 既存のデータストリームの名前を [!DNL Amazon Kinesis] アカウント Platform はこのストリームにデータを書き出します。
* `{REGION}`: *の場合 [!DNL Amazon Kinesis] 接続。* Amazon Kinesisアカウント内の、Platform がデータをストリーミングする地域です。
* `{EVENT_HUB_NAME}`: *の場合 [!DNL Azure Event Hubs] 接続。* 次の項目に入力: [!DNL Azure Event Hub] 名前 Platform がデータをストリーミングする場所。 詳しくは、 [イベントハブの作成](https://docs.microsoft.com/en-us/azure/event-hubs/event-hubs-create#create-an-event-hub) 内 [!DNL Microsoft] ドキュメント。
**応答**
正常な応答は、一意の識別子 (`id`) を使用します。 この値は、後の手順で必要になるため保存します。
```json
{
"id": "12ab90c7-519c-4291-bd20-d64186b62da8"
}
```
## データフローの作成

前述の手順で取得した ID を使用して、Experience Platform データと、データをアクティブ化する宛先との間でデータフローを作成できます。これは、パイプラインを構築する手順と考えることができます。データは、このパイプラインを通って Experience Platform と目的の宛先の間を流れます。
データフローを作成するには、以下のような POST リクエストを実行します。このとき、ペイロード内で以下に示す値を指定します。
次の POST リクエストを実行して、データフローを作成します。
**API 形式**
```http
POST /flows
```
**リクエスト**
```shell
curl -X POST \
'https://platform.adobe.io/data/foundation/flowservice/flows' \
-H 'Authorization: Bearer {ACCESS_TOKEN}' \
-H 'x-api-key: {API_KEY}' \
-H 'x-gw-ims-org-id: {ORG_ID}' \
-H 'x-sandbox-name: {SANDBOX_NAME}' \
-H 'Content-Type: application/json' \
-d '{
"name": "Azure Event Hubs",
"description": "Azure Event Hubs",
"flowSpec": {
"id": "{FLOW_SPEC_ID}",
"version": "1.0"
},
"sourceConnectionIds": [
"{SOURCE_CONNECTION_ID}"
],
"targetConnectionIds": [
"{TARGET_CONNECTION_ID}"
],
"transformations": [
{
"name": "GeneralTransform",
"params": {
"profileSelectors": {
"selectors": [
]
},
"segmentSelectors": {
"selectors": [
]
}
}
}
]
}
```
* `{FLOW_SPEC_ID}`:プロファイルベースの宛先のフロー仕様 ID は、 `71471eba-b620-49e4-90fd-23f1fa0174d8`. 呼び出しでこの値を使用します。
* `{SOURCE_CONNECTION_ID}`:手順「[Experience Platform データへの接続](#connect-to-your-experience-platform-data)」で取得したソース接続 ID を使用します。
* `{TARGET_CONNECTION_ID}`:手順で取得したターゲット接続 ID を使用します [ストリーミング先に接続](#connect-to-streaming-destination).
**応答**
リクエストが成功した場合は、新しく作成したデータフローの ID(`id`)と `etag` が返されます。両方の値をメモしておきます。これらの値は、次の手順でセグメントをアクティブ化する際に使用します。
```json
{
"id": "8256cfb4-17e6-432c-a469-6aedafb16cd5",
"etag": "8256cfb4-17e6-432c-a469-6aedafb16cd5"
}
```
## 新しい宛先に対してデータをアクティブ化にする {#activate-data}

これで、すべての接続とデータフローを作成したので、ストリーミングプラットフォームに対してプロファイルデータをアクティブ化できます。 この手順では、宛先に送信するセグメントとプロファイル属性を選択し、スケジュールを設定して宛先にデータを送信します。
新しい宛先に対してセグメントをアクティブ化するには、次の例のような JSON パッチ操作を実行する必要があります。1 回の呼び出しで、複数のセグメントとプロファイル属性をアクティブ化できます。JSON パッチについて詳しくは、[RFC 仕様](https://tools.ietf.org/html/rfc6902)を参照してください。
**API 形式**
```http
PATCH /flows
```
**リクエスト**
```shell
curl --location --request PATCH 'https://platform.adobe.io/data/foundation/flowservice/flows/{DATAFLOW_ID}' \
--header 'Authorization: Bearer {ACCESS_TOKEN}' \
--header 'x-api-key: {API_KEY}' \
--header 'x-gw-ims-org-id: {ORG_ID}' \
--header 'Content-Type: application/json' \
--header 'x-sandbox-name: {SANDBOX_NAME}' \
--header 'If-Match: "{ETAG}"' \
--data-raw '[
{
"op": "add",
"path": "/transformations/0/params/segmentSelectors/selectors/-",
"value": {
"type": "PLATFORM_SEGMENT",
"value": {
"name": "Name of the segment that you are activating",
"description": "Description of the segment that you are activating",
"id": "{SEGMENT_ID}"
}
}
},
{
"op": "add",
"path": "/transformations/0/params/profileSelectors/selectors/-",
"value": {
"type": "JSON_PATH",
"value": {
"operator": "EXISTS",
"path": "{PROFILE_ATTRIBUTE}"
}
}
}
]
```
* `{DATAFLOW_ID}`:前述の手順で取得したデータフローを使用します。
* `{ETAG}`:前述の手順で取得した ETag を使用します。
* `{SEGMENT_ID}`:この宛先に書き出すセグメント ID を指定します。アクティブ化するセグメントのセグメント ID の取得方法については、を参照してください。 **https://www.adobe.io/apis/experienceplatform/home/api-reference.html#/**​を選択します。 **[!UICONTROL セグメント化サービス API]** 左側のナビゲーションメニューで、 `GET /segment/definitions` 操作 **[!UICONTROL セグメント定義]**.
* `{PROFILE_ATTRIBUTE}`:例: `personalEmail.address` または `person.lastName`
**応答**
202 OK レスポンスを探します。レスポンスの本文は返されません。リクエストが正しいことを検証する方法については、次の手順「データフローの検証」を参照してください。
## データフローの検証

このチュートリアルの最後の手順では、セグメントとプロファイル属性が実際にデータフローに正しくマッピングされたことを検証する必要があります。
検証するには、次の GET リクエストを実行します。
**API 形式**
```http
GET /flows
```
**リクエスト**
```shell
curl --location --request PATCH 'https://platform.adobe.io/data/foundation/flowservice/flows/{DATAFLOW_ID}' \
--header 'Authorization: Bearer {ACCESS_TOKEN}' \
--header 'x-api-key: {API_KEY}' \
--header 'x-gw-ims-org-id: {ORG_ID}' \
--header 'Content-Type: application/json' \
--header 'x-sandbox-name: prod' \
--header 'If-Match: "{ETAG}"'
```
* `{DATAFLOW_ID}`:前述の手順で作成したデータフローを使用します。
* `{ETAG}`:前述の手順で取得した Etag を使用します。
**応答**
返されたレスポンスの `transformations` パラメーターに、前述の手順で送信したセグメントとプロファイル属性が含まれています。レスポンス内のサンプル `transformations` パラメーターは次のようになります。
```json
"transformations": [
{
"name": "GeneralTransform",
"params": {
"profileSelectors": {
"selectors": [
{
"type": "JSON_PATH",
"value": {
"path": "personalEmail.address",
"operator": "EXISTS"
}
},
{
"type": "JSON_PATH",
"value": {
"path": "person.lastname",
"operator": "EXISTS"
}
}
]
},
"segmentSelectors": {
"selectors": [
{
"type": "PLATFORM_SEGMENT",
"value": {
"name": "Men over 50",
"description": "",
"id": "72ddd79b-6b0a-4e97-a8d2-112ccd81bd02"
}
}
]
}
}
}
],
```
**書き出されたデータ**
>[!IMPORTANT]
>
> 手順のプロファイル属性とセグメントに加えて [新しい宛先に対してデータをアクティブ化する](#activate-data)、で書き出されたデータ [!DNL AWS Kinesis] および [!DNL Azure Event Hubs] id マップに関する情報も含まれます。 これは、エクスポートされたプロファイルの ID を表します ( 例: [ECID](https://experienceleague.adobe.com/docs/id-service/using/intro/id-request.html?lang=ja)、モバイル ID、Google ID、電子メールアドレスなど )。 以下の例を参照してください。
```json
{
"person": {
"email": "[email protected]"
},
"segmentMembership": {
"ups": {
"72ddd79b-6b0a-4e97-a8d2-112ccd81bd02": {
"lastQualificationTime": "2020-03-03T21:24:39Z",
"status": "exited"
},
"7841ba61-23c1-4bb3-a495-00d695fe1e93": {
"lastQualificationTime": "2020-03-04T23:37:33Z",
"status": "existing"
}
}
},
"identityMap": {
"ecid": [
{
"id": "14575006536349286404619648085736425115"
},
{
"id": "66478888669296734530114754794777368480"
}
],
"email_lc_sha256": [
{
"id": "655332b5fa2aea4498bf7a290cff017cb4"
},
{
"id": "66baf76ef9de8b42df8903f00e0e3dc0b7"
}
]
}
}
```
## Postmanコレクションを使用したストリーミング宛先への接続 {#collections}
このチュートリアルで説明するストリーミング先により効率的に接続するには、 [[!DNL Postman]](https://www.postman.com/).
[!DNL Postman] は、API 呼び出しをおこなったり、事前に定義された呼び出しおよび環境のライブラリを管理したりするのに使用できるツールです。
この特定のチュートリアルでは、次の手順に従います [!DNL Postman] コレクションが添付されました:
* [!DNL AWS Kinesis] [!DNL Postman] collection
* [!DNL Azure Event Hubs] [!DNL Postman] コレクション
クリック [ここ](../assets/api/streaming-destination/DestinationPostmanCollection.zip) コレクションアーカイブをダウンロードします。
各コレクションには、 [!DNL AWS Kinesis]、および [!DNL Azure Event Hub]、それぞれ。
### Postmanコレクションの使用方法
接続されたを使用して宛先に正常に接続するには [!DNL Postman] コレクションを使用するには、次の手順に従います。
* ダウンロードとインストール [!DNL Postman];
* [ダウンロード](../assets/api/streaming-destination/DestinationPostmanCollection.zip) 添付されたコレクションを解凍します。
* 対応するフォルダーからPostmanにコレクションを読み込む。
* この記事の手順に従って、環境変数を入力します。
* を実行します。 [!DNL API] この記事の手順に基づいて、Postmanからのリクエストを送信します。
## 次の手順
このチュートリアルでは、Platform を目的のストリーミング宛先の 1 つに接続し、それぞれの宛先へのデータフローを設定しました。 これで、送信データを、顧客分析や他の実行が必要なデータ操作の宛先で使用できるようになりました。 詳しくは、以下のページを参照してください。
* [宛先の概要](../home.md)
* [宛先カタログの概要](../catalog/overview.md) | 20,108 | MIT |
# CMake 入门实战
你或许听过好几种 Make 工具,例如 GNU Make ,QT 的 qmake ,微软的 MS nmake,BSD Make(pmake),Makepp,等等。这些 Make 工具遵循着不同的规范和标准,所执行的 Makefile 格式也千差万别。这样就带来了一个严峻的问题:如果软件想跨平台,必须要保证能够在不同平台编译。而如果使用上面的 Make 工具,就得为每一种标准写一次 Makefile ,这将是一件让人抓狂的工作。
CMake就是针对上面问题所设计的工具:它首先允许开发者编写一种平台无关的 CMakeList.txt 文件来定制整个编译流程,然后再根据目标用户的平台进一步生成所需的本地化 Makefile 和工程文件,如 Unix 的 Makefile 或 Windows 的 Visual Studio 工程。从而做到“Write once, run everywhere”。显然,CMake 是一个比上述几种 make 更高级的编译配置工具。一些使用 CMake 作为项目架构系统的知名开源项目有 VTK、ITK、KDE、OpenCV、OSG 等.
在 linux 平台下使用 CMake 生成 Makefile 并编译的流程如下:
1. 编写 CMake 配置文件 CMakeLists.txt 。
2. 执行命令 `cmake PATH` 或者 `ccmake PATH` 生成 Makefile 。其中, `PATH` 是CMakeLists.txt 所在的目录。
3. 使用 `make` 命令进行编译。
本文将从实例入手,一步步讲解 CMake 的常见用法,文中所有的实例代码可以在这里找到。如果你读完仍觉得意犹未尽,可以继续学习我在文章末尾提供的其他资源。
## 入门案例:单个源文件
对于简单的项目,只需要写几行代码就可以了。例如,假设现在我们的项目中只有一个源文件 `main.cc` ,该程序的用途是计算一个数的指数幂。
```c
#include <stdio.h>
#include <stdlib.h>
/**
* power - Calculate the power of number.
* @param base: Base value.
* @param exponent: Exponent value.
*
* @return base raised to the power exponent.
*/
double power(double base, int exponent)
{
int result = base;
int i;
if (exponent == 0) {
return 1;
}
for(i = 1; i < exponent; ++i){
result = result * base;
}
return result;
}
int main(int argc, char *argv[])
{
if (argc < 3){
printf("Usage: %s base exponent \n", argv[0]);
return 1;
}
double base = atof(argv[1]);
int exponent = atoi(argv[2]);
double result = power(base, exponent);
printf("%g ^ %d is %g\n", base, exponent, result);
return 0;
}
```
### 编写 CMakeLists.txt
首先编写 CMakeLists.txt 文件,并保存在与 `main.cc` 源文件同个目录下:
```cmake
# CMake 最低版本号要求
cmake_minimum_required (VERSION 2.8)
# 项目信息
project (Demo1)
# 指定生成目标
add_executable(Demo main.cc)
```
CMakeLists.txt 的语法比较简单,由命令、注释和空格组成,其中**命令是不区分大小写的**。符号 `#` 后面的内容被认为是注释。`命令`由`命令名称`、`小括号`和`参数`组成,参数之间使用空格进行间隔。
对于上面的 CMakeLists.txt 文件,依次出现了几个命令:
1. `cmake_minimum_required`:指定运行此配置文件所需的 CMake 的最低版本;
2. `project`:参数值是 `Demo1`,该命令表示项目的名称是 `Demo1` 。
3. `add_executable`: 将名为 `main.cc` 的源文件编译成一个名称为 Demo 的可执行文件。
### 编译项目
之后,在当前目录执行 `cmake .` ,得到 Makefile 后再使用 `make` 命令编译得到 Demo1 可执行文件。
```shell
[andy@AI Demo1]$ cmake .
-- The C compiler identification is GNU 4.8.2
-- The CXX compiler identification is GNU 4.8.2
-- Check for working C compiler: /usr/sbin/cc
-- Check for working C compiler: /usr/sbin/cc -- works
-- Detecting C compiler ABI info
-- Detecting C compiler ABI info - done
-- Check for working CXX compiler: /usr/sbin/c++
-- Check for working CXX compiler: /usr/sbin/c++ -- works
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Configuring done
-- Generating done
-- Build files have been written to: /home/ehome/Documents/programming/C/power/Demo1
[ehome@xman Demo1]$ make
Scanning dependencies of target Demo
[100%] Building C object CMakeFiles/Demo.dir/main.cc.o
Linking C executable Demo
[100%] Built target Demo
[ehome@xman Demo1]$ ./Demo 5 4
5 ^ 4 is 625
[ehome@xman Demo1]$ ./Demo 7 3
7 ^ 3 is 343
[ehome@xman Demo1]$ ./Demo 2 10
2 ^ 10 is 1024
```
## 多个源文件
### 同一目录,多个源文件
上面的例子只有单个源文件。现在假如把 `power` 函数单独写进一个名为 `MathFunctions.c` 的源文件里,使得这个工程变成如下的形式:
```vim
./Demo2
|
+--- main.cc
|
+--- MathFunctions.cc
|
+--- MathFunctions.h
```
这个时候,CMakeLists.txt 可以改成如下的形式:
```cmake
# CMake 最低版本号要求
cmake_minimum_required (VERSION 2.8)
# 项目信息
project (Demo2)
# 指定生成目标
add_executable(Demo main.cc MathFunctions.cc)
```
唯一的改动只是在 `add_executable` 命令中增加了一个 `MathFunctions.cc` 源文件。这样写当然没什么问题,但是如果源文件很多,把所有源文件的名字都加进去将是一件烦人的工作。更省事的方法是使用 `aux_source_directory` 命令,该命令会查找指定目录下的所有源文件,然后将结果存进指定变量名。其语法如下:
```cmake
aux_source_directory(<dir> <variable>)
```
因此,可以修改 CMakeLists.txt 如下:
```cmake
# CMake 最低版本号要求
cmake_minimum_required (VERSION 2.8)
# 项目信息
project (Demo2)
# 查找当前目录下的所有源文件并将名称保存到 DIR_SRCS 变量
aux_source_directory(. DIR_SRCS)
# 指定生成目标
add_executable(Demo ${DIR_SRCS})
```
这样,CMake 会将当前目录所有源文件的文件名赋值给变量 `DIR_SRCS` ,再指示变量 `DIR_SRCS` 中的源文件需要编译成一个名称为 Demo 的可执行文件。
### 多个目录,多个源文件
现在进一步将 `MathFunctions.h` 和 `MathFunctions.cc` 文件移动到 math 目录下:
```vim
./Demo3
|
+--- main.cc
|
+--- math/
|
+--- MathFunctions.cc
|
+--- MathFunctions.h
```
对于这种情况,需要分别在项目根目录 Demo3 和 math 目录里各编写一个 CMakeLists.txt 文件。为了方便,我们可以先将 math 目录里的文件编译成静态库再由 main 函数调用。
根目录中的 CMakeLists.txt :
```cmake
# CMake 最低版本号要求
cmake_minimum_required (VERSION 2.8)
# 项目信息
project (Demo3)
# 查找当前目录下的所有源文件并将名称保存到 DIR_SRCS 变量
aux_source_directory(. DIR_SRCS)
# 添加 math 子目录
add_subdirectory(math)
# 指定生成目标
add_executable(Demo main.cc)
# 添加链接库
target_link_libraries(Demo3 MathFunctions)
```
该文件添加了下面的内容: 第3行,使用命令 `add_subdirectory` 指明本项目包含一个子目录 math,这样 math 目录下的 CMakeLists.txt 文件和源代码也会被处理 。第6行,使用命令 `target_link_libraries` 指明可执行文件 main 需要连接一个名为 MathFunctions 的链接库 。
子目录中的 CMakeLists.txt:
```cmake
# 查找当前目录下的所有源文件并将名称保存到 DIR_LIB_SRCS 变量
aux_source_directory(. DIR_LIB_SRCS)
# 生成链接库
add_library (MathFunctions ${DIR_LIB_SRCS})
```
在该文件中使用命令 add_library 将 src 目录中的源文件编译为静态链接库。
## 自定义编译选项
CMake 允许为项目增加编译选项,从而可以根据用户的环境和需求选择最合适的编译方案。
例如,可以将 MathFunctions 库设为一个可选的库,如果该选项为 `ON` ,就使用该库定义的数学函数来进行运算。否则就调用标准库中的数学函数库。
### 修改 CMakeLists 文件
我们要做的第一步是在顶层的 CMakeLists.txt 文件中添加该选项:
```cmake
# CMake 最低版本号要求
cmake_minimum_required (VERSION 2.8)
# 项目信息
project (Demo4)
# 加入一个配置头文件,用于处理 CMake 对源码的设置
configure_file (
"${PROJECT_SOURCE_DIR}/config.h.in"
"${PROJECT_BINARY_DIR}/config.h"
)
# 是否使用自己的 MathFunctions 库
option (USE_MYMATH
"Use provided math implementation" ON)
# 是否加入 MathFunctions 库
if (USE_MYMATH)
include_directories ("${PROJECT_SOURCE_DIR}/math")
add_subdirectory (math)
set (EXTRA_LIBS ${EXTRA_LIBS} MathFunctions)
endif (USE_MYMATH)
# 查找当前目录下的所有源文件并将名称保存到 DIR_SRCS 变量
aux_source_directory(. DIR_SRCS)
# 指定生成目标
add_executable(Demo ${DIR_SRCS})
target_link_libraries (Demo ${EXTRA_LIBS})
```
其中:
1. 第7行的 `configure_file` 命令用于加入一个配置头文件 config.h ,这个文件由 CMake 从 config.h.in 生成,通过这样的机制,将可以通过预定义一些参数和变量来控制代码的生成。
2. 第13行的 `option` 命令添加了一个 USE_MYMATH 选项,并且默认值为 `ON` 。
3. 第17行根据 `USE_MYMATH` 变量的值来决定是否使用我们自己编写的 MathFunctions 库。
### 修改 main.cc 文件
之后修改 main.cc 文件,让其根据 USE_MYMATH 的预定义值来决定是否调用标准库还是 MathFunctions 库:
```c
#include
#include
#include "config.h"
#ifdef USE_MYMATH
#include "math/MathFunctions.h"
#else
#include
#endif
int main(int argc, char *argv[])
{
if (argc < 3){
printf("Usage: %s base exponent \n", argv[0]);
return 1;
}
double base = atof(argv[1]);
int exponent = atoi(argv[2]);
#ifdef USE_MYMATH
printf("Now we use our own Math library. \n");
double result = power(base, exponent);
#else
printf("Now we use the standard library. \n");
double result = pow(base, exponent);
#endif
printf("%g ^ %d is %g\n", base, exponent, result);
return 0;
}
```
### 编写 config.h.in 文件
上面的程序值得注意的是第2行,这里引用了一个 config.h 文件,这个文件预定义了 `USE_MYMATH` 的值。但我们并不直接编写这个文件,为了方便从 CMakeLists.txt 中导入配置,我们编写一个 config.h.in 文件,内容如下:
```cmake
#cmakedefine USE_MYMATH
```
这样 CMake 会自动根据 CMakeLists 配置文件中的设置自动生成 config.h 文件。
### 编译项目
现在编译一下这个项目,为了便于交互式的选择该变量的值,可以使用 `ccmake` 命令:

从中可以找到刚刚定义的 `USE_MYMATH` 选项,按键盘的方向键可以在不同的选项窗口间跳转,按下 enter 键可以修改该选项。修改完成后可以按下 `c` 选项完成配置,之后再按 `g` 键确认生成 Makefile 。ccmake 的其他操作可以参考窗口下方给出的指令提示。
我们可以试试分别将 `USE_MYMATH` 设为 `ON` 和 `OFF` 得到的结果:
**USE_MYMATH 为 ON**
运行结果:
```shell
[andy@AI Demo4]$ ./Demo
Now we use our own MathFunctions library.
7 ^ 3 = 343.000000
10 ^ 5 = 100000.000000
2 ^ 10 = 1024.000000
```
此时 config.h 的内容为:
```c
#define USE_MYMATH
```
**USE_MYMATH 为 OFF**
运行结果:
```shell
[andy@AI Demo4]$ ./Demo
Now we use the standard library.
7 ^ 3 = 343.000000
10 ^ 5 = 100000.000000
2 ^ 10 = 1024.000000
```
此时 config.h 的内容为:
```c
/* #undef USE_MYMATH */
```
## 安装和测试
CMake 也可以指定安装规则,以及添加测试。这两个功能分别可以通过在产生 Makefile 后使用 `make install` 和 `make test` 来执行。在以前的 GNU Makefile 里,你可能需要为此编写 `install` 和 `test` 两个伪目标和相应的规则,但在 CMake 里,这样的工作同样只需要简单的调用几条命令。
### 定制安装规则
首先先在 math/CMakeLists.txt 文件里添加下面两行:
```cmake
# 指定 MathFunctions 库的安装路径
install (TARGETS MathFunctions DESTINATION bin)
install (FILES MathFunctions.h DESTINATION include)
```
指明 MathFunctions 库的安装路径。之后同样修改根目录的 CMakeLists 文件,在末尾添加下面几行:
```cmake
# 指定安装路径
install (TARGETS Demo DESTINATION bin)
install (FILES "${PROJECT_BINARY_DIR}/config.h"
DESTINATION include)
```
通过上面的定制,生成的 Demo 文件和 MathFunctions 函数库 libMathFunctions.o 文件将会被复制到 `/usr/local/bin` 中,而 MathFunctions.h 和生成的 config.h 文件则会被复制到 `/usr/local/include` 中。我们可以验证一下:
```shell
[andy@AI Demo5]$ sudo make install
[ 50%] Built target MathFunctions
[100%] Built target Demo
Install the project...
-- Install configuration: ""
-- Installing: /usr/local/bin/Demo
-- Installing: /usr/local/include/config.h
-- Installing: /usr/local/bin/libMathFunctions.a
-- Up-to-date: /usr/local/include/MathFunctions.h
[ehome@xman Demo5]$ ls /usr/local/bin
Demo libMathFunctions.a
[ehome@xman Demo5]$ ls /usr/local/include
config.h MathFunctions.h
```
### 为工程添加测试
添加测试同样很简单。CMake 提供了一个称为 CTest 的测试工具。我们要做的只是在项目根目录的 CMakeLists 文件中调用一系列的 `add_test` 命令。
```cmake
# 启用测试
enable_testing()
# 测试程序是否成功运行
add_test (test_run Demo 5 2)
# 测试帮助信息是否可以正常提示
add_test (test_usage Demo)
set_tests_properties (test_usage
PROPERTIES PASS_REGULAR_EXPRESSION "Usage: .* base exponent")
# 测试 5 的平方
add_test (test_5_2 Demo 5 2)
set_tests_properties (test_5_2
PROPERTIES PASS_REGULAR_EXPRESSION "is 25")
# 测试 10 的 5 次方
add_test (test_10_5 Demo 10 5)
set_tests_properties (test_10_5
PROPERTIES PASS_REGULAR_EXPRESSION "is 100000")
# 测试 2 的 10 次方
add_test (test_2_10 Demo 2 10)
set_tests_properties (test_2_10
PROPERTIES PASS_REGULAR_EXPRESSION "is 1024")
```
上面的代码包含了四个测试。第一个测试 `test_run` 用来测试程序是否成功运行并返回 0 值。剩下的三个测试分别用来测试 5 的 平方、10 的 5 次方、2 的 10 次方是否都能得到正确的结果。其中 `PASS_REGULAR_EXPRESSION` 用来测试输出是否包含后面跟着的字符串。
让我们看看测试的结果:
```shell
[andy@AI Demo5]$ make test
Running tests...
Test project /home/ehome/Documents/programming/C/power/Demo5
Start 1: test_run
1/4 Test #1: test_run ......................... Passed 0.00 sec
Start 2: test_5_2
2/4 Test #2: test_5_2 ......................... Passed 0.00 sec
Start 3: test_10_5
3/4 Test #3: test_10_5 ........................ Passed 0.00 sec
Start 4: test_2_10
4/4 Test #4: test_2_10 ........................ Passed 0.00 sec
100% tests passed, 0 tests failed out of 4
Total Test time (real) = 0.01 sec
```
如果要测试更多的输入数据,像上面那样一个个写测试用例未免太繁琐。这时可以通过编写宏来实现:
```cmake
# 定义一个宏,用来简化测试工作
macro (do_test arg1 arg2 result)
add_test (test_${arg1}_${arg2} Demo ${arg1} ${arg2})
set_tests_properties (test_${arg1}_${arg2}
PROPERTIES PASS_REGULAR_EXPRESSION ${result})
endmacro (do_test)
# 使用该宏进行一系列的数据测试
do_test (5 2 "is 25")
do_test (10 5 "is 100000")
do_test (2 10 "is 1024")
```
关于 CTest 的更详细的用法可以通过 `man 1 ctest` 参考 CTest 的文档。
## 支持 gdb
让 CMake 支持 gdb 的设置也很容易,只需要指定 `Debug` 模式下开启 `-g` 选项:
```cmake
set(CMAKE_BUILD_TYPE "Debug")
set(CMAKE_CXX_FLAGS_DEBUG "$ENV{CXXFLAGS} -O0 -Wall -g -ggdb")
set(CMAKE_CXX_FLAGS_RELEASE "$ENV{CXXFLAGS} -O3 -Wall")
```
之后可以直接对生成的程序使用 gdb 来调试。
## 添加环境检查
有时候可能要对系统环境做点检查,例如要使用一个平台相关的特性的时候。在这个例子中,我们检查系统是否自带 pow 函数。如果带有 pow 函数,就使用它;否则使用我们定义的 power 函数。
### 添加 CheckFunctionExists 宏
首先在顶层 CMakeLists 文件中添加 CheckFunctionExists.cmake 宏,并调用 `check_function_exists` 命令测试链接器是否能够在链接阶段找到 `pow` 函数。
```cmake
# 检查系统是否支持 pow 函数
include (${CMAKE_ROOT}/Modules/CheckFunctionExists.cmake)
check_function_exists (pow HAVE_POW)
```
将上面这段代码放在 `configure_file` 命令前。
### 预定义相关宏变量
接下来修改 config.h.in 文件,预定义相关的宏变量。
```c
// does the platform provide pow function?
#cmakedefine HAVE_POW
```
### 在代码中使用宏和函数
最后一步是修改 main.cc ,在代码中使用宏和函数:
```c
#ifdef HAVE_POW
printf("Now we use the standard library. \n");
double result = pow(base, exponent);
#else
printf("Now we use our own Math library. \n");
double result = power(base, exponent);
#endif
```
## 添加版本号
给项目添加和维护版本号是一个好习惯,这样有利于用户了解每个版本的维护情况,并及时了解当前所用的版本是否过时,或是否可能出现不兼容的情况。
首先修改顶层 CMakeLists 文件,在 `project` 命令之后加入如下两行:
```cmake
set (Demo_VERSION_MAJOR 1)
set (Demo_VERSION_MINOR 0)
```
分别指定当前的项目的主版本号和副版本号。
之后,为了在代码中获取版本信息,我们可以修改 config.h.in 文件,添加两个预定义变量:
```c
// the configured options and settings for Tutorial
#define Demo_VERSION_MAJOR @Demo_VERSION_MAJOR@
#define Demo_VERSION_MINOR @Demo_VERSION_MINOR@
```
这样就可以直接在代码中打印版本信息了
```c
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include "config.h"
#include "math/MathFunctions.h"
int main(int argc, char *argv[])
{
if (argc < 3){
// print version info
printf("%s Version %d.%d\n",
argv[0],
Demo_VERSION_MAJOR,
Demo_VERSION_MINOR);
printf("Usage: %s base exponent \n", argv[0]);
return 1;
}
double base = atof(argv[1]);
int exponent = atoi(argv[2]);
#if defined (HAVE_POW)
printf("Now we use the standard library. \n");
double result = pow(base, exponent);
#else
printf("Now we use our own Math library. \n");
double result = power(base, exponent);
#endif
printf("%g ^ %d is %g\n", base, exponent, result);
return 0;
}
```
## 生成安装包
本节将学习如何配置生成各种平台上的安装包,包括二进制安装包和源码安装包。为了完成这个任务,我们需要用到 CPack ,它同样也是由 CMake 提供的一个工具,专门用于打包。
首先在顶层的 CMakeLists.txt 文件尾部添加下面几行:
```cmake
# 构建一个 CPack 安装包
include (InstallRequiredSystemLibraries)
set (CPACK_RESOURCE_FILE_LICENSE
"${CMAKE_CURRENT_SOURCE_DIR}/License.txt")
set (CPACK_PACKAGE_VERSION_MAJOR "${Demo_VERSION_MAJOR}")
set (CPACK_PACKAGE_VERSION_MINOR "${Demo_VERSION_MINOR}")
include (CPack)
```
上面的代码做了以下几个工作:
1. 导入 InstallRequiredSystemLibraries 模块,以便之后导入 CPack 模块;
3. 设置一些 CPack 相关变量,包括版权信息和版本信息,其中版本信息用了上一节定义的版本号;
3. 导入 CPack 模块。
接下来的工作是像往常一样构建工程,并执行 `cpack` 命令。
- 生成二进制安装包:
```shell
cpack -C CPackConfig.cmake
```
- 生成源码安装包
```shell
cpack -C CPackSourceConfig.cmake
```
我们可以试一下。在生成项目后,执行 `cpack -C CPackConfig.cmake` 命令:
```shell
[andy@AI Demo8]$ cpack -C CPackSourceConfig.cmake
CPack: Create package using STGZ
CPack: Install projects
CPack: - Run preinstall target for: Demo8
CPack: - Install project: Demo8
CPack: Create package
CPack: - package: /home/ehome/Documents/programming/C/power/Demo8/Demo8-1.0.1-Linux.sh generated.
CPack: Create package using TGZ
CPack: Install projects
CPack: - Run preinstall target for: Demo8
CPack: - Install project: Demo8
CPack: Create package
CPack: - package: /home/ehome/Documents/programming/C/power/Demo8/Demo8-1.0.1-Linux.tar.gz generated.
CPack: Create package using TZ
CPack: Install projects
CPack: - Run preinstall target for: Demo8
CPack: - Install project: Demo8
CPack: Create package
CPack: - package: /home/ehome/Documents/programming/C/power/Demo8/Demo8-1.0.1-Linux.tar.Z generated.
```
此时会在该目录下创建 3 个不同格式的二进制包文件:
```shell
[andy@AI Demo8]$ ls Demo8-*
Demo8-1.0.1-Linux.sh Demo8-1.0.1-Linux.tar.gz Demo8-1.0.1-Linux.tar.Z
```
这 3 个二进制包文件所包含的内容是完全相同的。我们可以执行其中一个。此时会出现一个由 CPack 自动生成的交互式安装界面:
```shell
[andy@AI Demo8]$ sh Demo8-1.0.1-Linux.sh
Demo8 Installer Version: 1.0.1, Copyright (c) Humanity
This is a self-extracting archive.
The archive will be extracted to: /home/ehome/Documents/programming/C/power/Demo8
If you want to stop extracting, please press <ctrl-C>.
The MIT License (MIT)
Copyright (c) 2013 Joseph Pan(http://hahack.com)
Permission is hereby granted, free of charge, to any person obtaining a copy of
this software and associated documentation files (the "Software"), to deal in
the Software without restriction, including without limitation the rights to
use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of
the Software, and to permit persons to whom the Software is furnished to do so,
subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS
FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR
COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER
IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN
CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
Do you accept the license? [yN]:
y
By default the Demo8 will be installed in:
"/home/ehome/Documents/programming/C/power/Demo8/Demo8-1.0.1-Linux"
Do you want to include the subdirectory Demo8-1.0.1-Linux?
Saying no will install in: "/home/ehome/Documents/programming/C/power/Demo8" [Yn]:
y
Using target directory: /home/ehome/Documents/programming/C/power/Demo8/Demo8-1.0.1-Linux
Extracting, please wait...
Unpacking finished successfully
```
完成后提示安装到了 Demo8-1.0.1-Linux 子目录中,我们可以进去执行该程序:
```shell
[andy@AI Demo8]$ ./Demo8-1.0.1-Linux/bin/Demo 5 2
Now we use our own Math library.
5 ^ 2 is 25
```
关于 CPack 的更详细的用法可以通过 man 1 cpack 参考 CPack 的文档。 | 17,154 | MIT |
+++
title = "EP9: Let's Play Tennis"
description = "一起打網球"
date = 2020-05-13
slug = "ep9-lets-play-tennis"
template = "page.html"
[taxonomies]
[extra]
episode = 9
cover = "/ep9_cover.png"
duration = "2461"
length = "59112090"
+++
這集分享了我們彼此對網球的愛,以及我們對於"運動“的一些看法
除了網球之外我們前陣子也開始攀岩(Bouldering),我們覺得攀岩跟網球是個非常互補的運動,攀岩完後再去打網球打得更好!
運動除了讓身體變強壯之外,也可以藉此認識新朋友,更可以拿來挑戰自己,真的好處多多。
<!-- more -->
希望疫情趕快趨緩這樣我們才能早日重回網球及攀岩的懷抱
[iTunes](https://podcasts.apple.com/us/podcast/third-stream-podcast/id1503447781)
https://podcasts.apple.com/us/podcast/third-stream-podcast/id1503447781
[Spotify](https://open.spotify.com/show/4Lt3yXZrcOvZ7NgBn7iJLV)
https://open.spotify.com/show/4Lt3yXZrcOvZ7NgBn7iJLV
[Third Stream Website](https://thirdstream.life)
https://thirdstream.life
Music from https://tfbeats.com/ | 793 | MIT |
<p align="center">
<img src="FFRouter_logo.png" title="FFRouter logo" float=left>
</p>
<p align="center">
<a href="http://cocoapods.org/pods/FFRouter"><img src="https://img.shields.io/cocoapods/v/FFRouter.svg?style=flat"></a>
<a href="http://cocoapods.org/pods/FFRouter"><img src="https://img.shields.io/cocoapods/l/FFRouter.svg?style=flat"></a>
<a href="http://cocoapods.org/pods/FFRouter"><img src="https://img.shields.io/cocoapods/p/FFRouter.svg?style=flat"></a>
</p>
### [中文教程](https://github.com/imlifengfeng/FFRouter#中文使用说明)
FFRouter is a powerful and easy-to-use URL routing library in iOS that supports URL Rewrite, allowing the APP to dynamically modify the relevant routing logic after publishing. It is more efficient to find URLs based on matching rather than traversal. Integration and use are very simple!
### function
- [x] Have basic URL registration, Route, cancel registration, print Log, etc.
- [x] Support forward and reverse pass values
- [x] Support the use of wildcards (*) to register URL
- [x] Support URL Rewrite
- [x] Support get the original URL parameter or URLComponents when Rewrite, and can be URL Encode or Decode
- [x] Support get an Object by URL
- [x] Support get an Object by asynchronous callback when Route URL
- [x] Support Transferring unconventional objects when Route URL
- [x] Support Route an unregistered URL unified callback
### install
#### CocoaPods
```ruby
target 'MyApp' do
pod 'FFRouter'
end
```
run `pod install`
#### Manual install
Add the `FFRouter` folder to your project
### Usage
First
```objective-c
#import "FFRouter.h"
```
##### 1、Basic Usage
```objective-c
/**
Register URL,use it with 'routeURL:' and 'routeURL: withParameters:'.
@param routeURL Registered URL
@param handlerBlock Callback after route
*/
+ (void)registerRouteURL:(NSString *)routeURL handler:(FFRouterHandler)handlerBlock;
/**
Register URL,use it with 'routeObjectURL:' and ‘routeObjectURL: withParameters:’,can return a Object.
@param routeURL Registered URL
@param handlerBlock Callback after route, and you can get a Object in this callback.
*/
+ (void)registerObjectRouteURL:(NSString *)routeURL handler:(FFObjectRouterHandler)handlerBlock;
/**
Registered URL, use it with `routeCallbackURL: targetCallback:'and `routeCallback URL: withParameters: targetCallback:', calls back `targetCallback' asynchronously to return an Object
@param routeURL Registered URL
@param handlerBlock Callback after route,There is a `targetCallback' in `handlerBlock', which corresponds to the `targetCallback:' in `routeCallbackURL: targetCallback:'and `routeCallbackURL: withParameters: targetCallback:', which can be used for asynchronous callback to return an Object.
*/
+ (void)registerCallbackRouteURL:(NSString *)routeURL handler:(FFCallbackRouterHandler)handlerBlock;
/**
Determine whether URL can be Route (whether it has been registered).
@param URL URL to be verified
@return Can it be routed
*/
+ (BOOL)canRouteURL:(NSString *)URL;
/**
Route a URL
@param URL URL to be routed
*/
+ (void)routeURL:(NSString *)URL;
/**
Route a URL and bring additional parameters.
@param URL URL to be routed
@param parameters Additional parameters
*/
+ (void)routeURL:(NSString *)URL withParameters:(NSDictionary<NSString *, id> *)parameters;
/**
Route a URL and get the returned Object
@param URL URL to be routed
@return Returned Object
*/
+ (id)routeObjectURL:(NSString *)URL;
/**
Route a URL and bring additional parameters. get the returned Object
@param URL URL to be routed
@param parameters Additional parameters
@return Returned Object
*/
+ (id)routeObjectURL:(NSString *)URL withParameters:(NSDictionary<NSString *, id> *)parameters;
/**
Route a URL, 'targetCallBack' can asynchronously callback to return a Object.
@param URL URL to be routed
@param targetCallback asynchronous callback
*/
+ (void)routeCallbackURL:(NSString *)URL targetCallback:(FFRouterCallback)targetCallback;
/**
Route a URL with additional parameters, and 'targetCallBack' can asynchronously callback to return a Object.
@param URL URL to be routed
@param parameters Additional parameters
@param targetCallback asynchronous callback
*/
+ (void)routeCallbackURL:(NSString *)URL withParameters:(NSDictionary<NSString *, id> *)parameters targetCallback:(FFRouterCallback)targetCallback;
/**
Route callback for an unregistered URL
@param handler Callback
*/
+ (void)routeUnregisterURLHandler:(FFRouterUnregisterURLHandler)handler;
/**
Cancel registration of a URL
@param URL URL to be cancelled
*/
+ (void)unregisterRouteURL:(NSString *)URL;
/**
Unregister all URL
*/
+ (void)unregisterAllRoutes;
/**
Whether to display Log for debugging
@param enable YES or NO.The default is NO
*/
+ (void)setLogEnabled:(BOOL)enable;
```
###### 【Notes】
(1)Register URL
<br>Three types of URL:
```objective-c
[FFRouter registerRouteURL:@"protocol://page/routerDetails/:id" handler:^(NSDictionary *routerParameters) {
//Callbacks of Route's URL match with this registration URL
//routerParameters contains all the parameters that are passed
}];
[FFRouter registerRouteURL:@"wildcard://*" handler:^(NSDictionary *routerParameters) {
//Callbacks of Route's URL match with this registration URL
//routerParameters contains all the parameters that are passed
}];
[FFRouter registerRouteURL:@"protocol://page/routerObjectDetails" handler:^(NSDictionary *routerParameters) {
//Callbacks of Route's URL match with this registration URL
//routerParameters contains all the parameters that are passed
}];
```
The parameters in the URL can be obtained by `routerParameters`,`routerParameters[FFRouterParameterURLKey]`Is the full URL.
<br><br>Three ways of registration and Route:
```objective-c
//Way 1:
+ (void)registerRouteURL:(NSString *)routeURL handler:(FFRouterHandler)handlerBlock;
//Use the following two Route methods
+ (void)routeURL:(NSString *)URL;
+ (void)routeURL:(NSString *)URL withParameters:(NSDictionary<NSString *, id> *)parameters;
//Way 2:
+ (void)registerObjectRouteURL:(NSString *)routeURL handler:(FFObjectRouterHandler)handlerBlock;
//Use the following two Route methods
+ (id)routeObjectURL:(NSString *)URL;
+ (id)routeObjectURL:(NSString *)URL withParameters:(NSDictionary<NSString *, id> *)parameters;
//Way 3:
+ (void)registerCallbackRouteURL:(NSString *)routeURL handler:(FFCallbackRouterHandler)handlerBlock;
//Use the following two Route methods
+ (void)routeCallbackURL:(NSString *)URL targetCallback:(FFRouterCallback)targetCallback;
+ (void)routeCallbackURL:(NSString *)URL withParameters:(NSDictionary<NSString *, id> *)parameters targetCallback:(FFRouterCallback)targetCallback;
```
<br><br><br>(2)When you need to use the following methods:
```objective-c
+ (id)routeObjectURL:(NSString *)URL;
```
Route a URL and get the return value, you need to register URL with the following methods:
```objective-c
+ (void)registerObjectRouteURL:(NSString *)routeURL handler:(FFObjectRouterHandler)handlerBlock;
```
And return the corresponding Object in `handlerBlock`, for example:
```objective-c
//Register and return the necessary values
[FFRouter registerObjectRouteURL:@"protocol://page/routerObjectDetails" handler:^id(NSDictionary *routerParameters) {
NSString *str = @“According to the need to return the necessary Object”;
return str;
}];
//Gets the returned value
NSString *ret = [FFRouter routeObjectURL:@"protocol://page/routerObjectDetails"];
```
<br><br>(3)If you want to get the returned Object through an asynchronous callback after routeURL, you can register and Route URL using the following method:
```objective-c
//Register URL and return to Object by callback at the necessary time.
[FFRouter registerCallbackRouteURL:@"protocol://page/RouterCallbackDetails" handler:^(NSDictionary *routerParameters, FFRouterCallback targetCallBack) {
//When necessary, return to Object through'targetCallBack'callback.
targetCallBack(@"Any Object");
}];
//When Route URL, by 'targetCallback' callbacks to get Object returned
[FFRouter routeCallbackURL:@"protocol://page/RouterCallbackDetails?nickname=imlifengfeng" targetCallback:^(id callbackObjc) {
self.testLabel.text = [NSString stringWithFormat:@"%@",callbackObjc];
}];
```
<br><br>(4)If you need to transfer non conventional objects as parameters, such as `UIImage`,You can use the following ways
:
```objective-c
[FFRouter routeURL:@"protocol://page/routerDetails?nickname=imlifengfeng" withParameters:@{@"img":[UIImage imageNamed:@"router_test_img"]}];
```
If you only need to pass common parameters, you can splice parameters directly after URL:
```objective-c
[FFRouter routeURL:@"protocol://page/routerDetails?nickname=imlifengfeng&id=666¶meters......"];
```
Then get these parameters from `routerParameters`. for example:`routerParameters[@"nickname"]`
##### 2、URL Rewrite
```objective-c
/**
According to the set of Rules, go to rewrite URL.
@param url URL to be rewritten
@return URL after being rewritten
*/
+ (NSString *)rewriteURL:(NSString *)url;
/**
Add a RewriteRule
@param matchRule Regular matching rule
@param targetRule Conversion rules
*/
+ (void)addRewriteMatchRule:(NSString *)matchRule targetRule:(NSString *)targetRule;
/**
Add multiple RewriteRule at the same time, the format must be:@[@{@"matchRule":@"YourMatchRule",@"targetRule":@"YourTargetRule"},...]
@param rules RewriteRules
*/
+ (void)addRewriteRules:(NSArray<NSDictionary *> *)rules;
/**
Remove a RewriteRule
@param matchRule MatchRule to be removed
*/
+ (void)removeRewriteMatchRule:(NSString *)matchRule;
/**
Remove all RewriteRule
*/
+ (void)removeAllRewriteRules;
```
###### 【Notes】
(1)You can add a Rewrite rule using `regular`, for example:
you want to When URL:`https://www.amazon.com/search/Atomic_bomb` is opened, intercept it and use the locally registered URL:`protocol://page/routerDetails?product=Atomic_bomb` to open it.
First, add a Rewrite rule:
```objective-c
[FFRouterRewrite addRewriteMatchRule:@"(?:https://)?www.amazon.com/search/(.*)" targetRule:@"protocol://page/routerDetails?product=$1"];
```
After open URL:`https://www.amazon.com/search/Atomic_bomb`,Will Rewrite into URL:`protocol://page/routerDetails?product=Atomic_bomb`。
```objective-c
[FFRouter routeURL:@"https://www.amazon.com/search/Atomic_bomb"];
```
<br><br>(2)You can add multiple rules using the following methods:
```objective-c
+ (void)addRewriteRules:(NSArray<NSDictionary *> *)rules;
```
The rules format must be in the following format:
```objective-c
@[@{@"matchRule":@"YourMatchRule1",@"targetRule":@"YourTargetRule1"},
@{@"matchRule":@"YourMatchRule2",@"targetRule":@"YourTargetRule2"},
@{@"matchRule":@"YourMatchRule3",@"targetRule":@"YourTargetRule3"},]
```
<br><br>(3)Reserved words in Rewrite rules:
- Get the corresponding part of the standard URL via `$scheme`, `$host`, `$port`, `$path`, `$query`, `$fragment`. Get the full URL via `$url`
- Use `$1`, `$2`, `$3`... to get the parameters of the `matchRule` rule using parentheses
- `$`: the value of the original variable, `$$`: the value of the original variable URL Encode, `$#`: the value of the original variable URL Decode
<br>for example:
`https://www.taobao.com/search/原子弹`for the Rewrite rule`(?:https://)?www.taobao.com/search/(.*)`
```objective-c
$1=原子弹
$$1=%e5%8e%9f%e5%ad%90%e5%bc%b9
```
the same as,`https://www.taobao.com/search/%e5%8e%9f%e5%ad%90%e5%bc%b9`for the Rewrite rule`(?:https://)?www.taobao.com/search/(.*)`
```objective-c
$1=%e5%8e%9f%e5%ad%90%e5%bc%b9
$#1=原子弹
```
##### 2、FFRouterNavigation
Considering the frequent use of routing to configure the jump between `UIViewController`, an additional tool `FFRouterNavigation` has been added to make it easier to control jumps between `UIViewController`. Use as follows:
```objective-c
/**
Whether TabBar automatically hide when push
@param hide Whether to automatically hide, the default is NO
*/
+ (void)autoHidesBottomBarWhenPushed:(BOOL)hide;
/**
Get current ViewController
@return Current ViewController
*/
+ (UIViewController *)currentViewController;
/**
Get current NavigationViewController
@return return Current NavigationViewController
*/
+ (nullable UINavigationController *)currentNavigationViewController;
/**
Push ViewController
@param viewController Target ViewController
@param animated Whether to use animation
*/
+ (void)pushViewController:(UIViewController *)viewController animated:(BOOL)animated;
/**
Push ViewController,can set whether the current ViewController is still reserved.
@param viewController Target ViewController
@param replace whether the current ViewController is still reserved
@param animated Whether to use animation
*/
+ (void)pushViewController:(UIViewController *)viewController replace:(BOOL)replace animated:(BOOL)animated;
/**
Push multiple ViewController
@param viewControllers ViewController Array
@param animated Whether to use animation
*/
+ (void)pushViewControllerArray:(NSArray *)viewControllers animated:(BOOL)animated;
/**
present ViewController
@param viewController Target ViewController
@param animated Whether to use animation
@param completion Callback
*/
+ (void)presentViewController:(UIViewController *)viewController animated:(BOOL)animated completion:(void (^ __nullable)(void))completion;
/**
Close the current ViewController, push, present universal
@param animated Whether to use animation
*/
+ (void)closeViewControllerAnimated:(BOOL)animated;
```
## License
This project is used under the <a href="http://opensource.org/licenses/MIT" target="_blank">MIT</a> license agreement. For more information, see <a href="https://github.com/imlifengfeng/FFRouter/blob/master/LICENSE">LICENSE</a>.
# 中文使用说明
FFRouter 是 iOS 中一个强大且易用的 URL 路由库,支持 URL Rewrite,使 APP 在发布之后也可以动态修改相关路由逻辑。基于匹配查找 URL,效率高。集成和使用都非常简单!
### 功能
- [x] 具备基本的 URL 注册、Route、取消注册、打印 Log 等
- [x] 支持正向、反向传值
- [x] 支持使用通配符(*)注册 URL
- [x] 支持 URL Rewrite
- [x] 支持 Rewrite 时获取原 URL 参数或 URLComponents,并可对其进行URL Encode或 Decode
- [x] 支持通过 URL 获取 Object
- [x] 支持 Route URL 时通过异步回调的方式获取 Object
- [x] 支持 Route URL 时传递非常规对象
- [x] 支持 Route 一个未注册的 URL 时统一回调
### 安装
#### CocoaPods
```ruby
target 'MyApp' do
pod 'FFRouter'
end
```
运行 `pod install`
#### 手动安装
添加其中的 `FFRouter` 文件夹到自己项目
### 使用方法
首先
```objective-c
#import "FFRouter.h"
```
##### 1、基本使用
```objective-c
/**
注册 url,与 ‘routeURL:’ 和 ‘routeURL: withParameters:’ 配合使用
@param routeURL 要注册的 URL
@param handlerBlock URL 被 Route 后的回调
*/
+ (void)registerRouteURL:(NSString *)routeURL handler:(FFRouterHandler)handlerBlock;
/**
注册 URL,与 'routeObjectURL:' 和 ‘routeObjectURL: withParameters:’ 配合使用,可返回一个 Object
@param routeURL 要注册的 URL
@param handlerBlock URL 被 Route 后的回调,可在回调中返回一个 Object
*/
+ (void)registerObjectRouteURL:(NSString *)routeURL handler:(FFObjectRouterHandler)handlerBlock;
/**
注册 URL,与 ‘routeCallbackURL: targetCallBack:’ 和 ‘routeCallbackURL: withParameters: targetCallBack:’ 配合使用,可异步回调返回一个 Object
@param routeURL 要注册的 URL
@param handlerBlock URL 被 Route 后的回调,handlerBlock 中有一个 targetCallBack ,对应 ‘routeCallbackURL: targetCallBack:’ 和 ‘routeCallbackURL: withParameters: targetCallBack:’ 中的 targetCallBack,可用于异步回调返回一个 Object
*/
+ (void)registerCallbackRouteURL:(NSString *)routeURL handler:(FFCallbackRouterHandler)handlerBlock;
/**
判断 URL 是否可被 Route(是否已经注册)
@param URL 要判断的 URL
@return 是否可被 Route
*/
+ (BOOL)canRouteURL:(NSString *)URL;
/**
Route 一个 URL
@param URL 要 Route 的 URL
*/
+ (void)routeURL:(NSString *)URL;
/**
Route 一个 URL,并带上额外参数
@param URL 要 Route 的 URL
@param parameters 额外参数
*/
+ (void)routeURL:(NSString *)URL withParameters:(NSDictionary<NSString *, id> *)parameters;
/**
Route 一个 URL,可获得返回的 Object
@param URL 要 Route 的 URL
@return 返回的 Object
*/
+ (id)routeObjectURL:(NSString *)URL;
/**
Route 一个 URL,并带上额外参数,可获得返回的 Object
@param URL 要 Route 的 URL
@param parameters 额外参数
@return 返回的 Object
*/
+ (id)routeObjectURL:(NSString *)URL withParameters:(NSDictionary<NSString *, id> *)parameters;
/**
Route 一个 URL,targetCallBack 可异步回调以返回一个 Object
@param URL 要 Route 的 URL
@param targetCallback 异步回调
*/
+ (void)routeCallbackURL:(NSString *)URL targetCallback:(FFRouterCallback)targetCallback;
/**
Route 一个 URL,并带上额外参数,targetCallBack 可异步回调以返回一个 Object
@param URL 要 Route 的 URL
@param parameters 额外参数
@param targetCallback 异步回调
*/
+ (void)routeCallbackURL:(NSString *)URL withParameters:(NSDictionary<NSString *, id> *)parameters targetCallback:(FFRouterCallback)targetCallback;
/**
Route 一个未注册 URL 时回调
@param handler 回调
*/
+ (void)routeUnregisterURLHandler:(FFRouterUnregisterURLHandler)handler;
/**
取消注册某个 URL
@param URL 要被取消注册的 URL
*/
+ (void)unregisterRouteURL:(NSString *)URL;
/**
取消注册所有 URL
*/
+ (void)unregisterAllRoutes;
/**
是否显示 Log,用于调试
@param enable YES or NO,默认为 NO
*/
+ (void)setLogEnabled:(BOOL)enable;
```
###### 【备注】
(1)注册 URL
<br>三种 URL 类型:
```objective-c
[FFRouter registerRouteURL:@"protocol://page/routerDetails/:id" handler:^(NSDictionary *routerParameters) {
//Route的URL与本次注册URL匹配时的回调
//routerParameters中包含了传递过来的所有参数
}];
[FFRouter registerRouteURL:@"wildcard://*" handler:^(NSDictionary *routerParameters) {
//Route的URL与本次注册URL匹配时的回调
//routerParameters中包含了传递过来的所有参数
}];
[FFRouter registerRouteURL:@"protocol://page/routerObjectDetails" handler:^(NSDictionary *routerParameters) {
//Route的URL与本次注册URL匹配时的回调
//routerParameters中包含了传递过来的所有参数
}];
```
可通过`routerParameters`获取 URL 中的参数,`routerParameters[FFRouterParameterURLKey]`为完整的URL.
<br><br>三种注册及 Route 方式:
```objective-c
//注册方式1:
+ (void)registerRouteURL:(NSString *)routeURL handler:(FFRouterHandler)handlerBlock;
//与下面两个 Route 方法配合使用
+ (void)routeURL:(NSString *)URL;
+ (void)routeURL:(NSString *)URL withParameters:(NSDictionary<NSString *, id> *)parameters;
//注册方式2:
+ (void)registerObjectRouteURL:(NSString *)routeURL handler:(FFObjectRouterHandler)handlerBlock;
//与下面两个 Route 方法配合使用,可同步反向传值
+ (id)routeObjectURL:(NSString *)URL;
+ (id)routeObjectURL:(NSString *)URL withParameters:(NSDictionary<NSString *, id> *)parameters;
//注册方式3:
+ (void)registerCallbackRouteURL:(NSString *)routeURL handler:(FFCallbackRouterHandler)handlerBlock;
//与下面两个 Route 方法配合使用,可异步反向传值
+ (void)routeCallbackURL:(NSString *)URL targetCallback:(FFRouterCallback)targetCallback;
+ (void)routeCallbackURL:(NSString *)URL withParameters:(NSDictionary<NSString *, id> *)parameters targetCallback:(FFRouterCallback)targetCallback;
```
<br><br><br>(2)当需要通过以下方法:
```objective-c
+ (id)routeObjectURL:(NSString *)URL;
```
Route 一个 URL 并获取返回值时,需要使用如下方法注册 URL:
```objective-c
+ (void)registerObjectRouteURL:(NSString *)routeURL handler:(FFObjectRouterHandler)handlerBlock;
```
并在 handlerBlock 中返回需要返回的 Object,例如:
```objective-c
//注册并返回必要的值
[FFRouter registerObjectRouteURL:@"protocol://page/routerObjectDetails" handler:^id(NSDictionary *routerParameters) {
NSString *str = @“根据需要返回必要的Object”;
return str;
}];
//获取返回的值
NSString *ret = [FFRouter routeObjectURL:@"protocol://page/routerObjectDetails"];
```
<br><br>(3)如果想要 routeURL 后通过异步回调获取返回的 Object,可使用下面方法注册和 Route URL:
```objective-c
//注册并在必要时间通过回调返回对应 Object
[FFRouter registerCallbackRouteURL:@"protocol://page/RouterCallbackDetails" handler:^(NSDictionary *routerParameters, FFRouterCallback targetCallBack) {
//在必要时候通过 targetCallBack 回调去返回对应 Object
targetCallBack(@"任意Object");
}];
//Route 时通过 ‘targetCallback’ 回调获取返回的对应 Object
[FFRouter routeCallbackURL:@"protocol://page/RouterCallbackDetails?nickname=imlifengfeng" targetCallback:^(id callbackObjc) {
self.testLabel.text = [NSString stringWithFormat:@"%@",callbackObjc];
}];
```
<br><br>(4)如果需要传递非常规对象作为参数,如`UIImage`等,可使用如下方式:
```objective-c
[FFRouter routeURL:@"protocol://page/routerDetails?nickname=imlifengfeng" withParameters:@{@"img":[UIImage imageNamed:@"router_test_img"]}];
```
如果只需要传递普通参数,直接在URL后拼接参数即可:
```objective-c
[FFRouter routeURL:@"protocol://page/routerDetails?nickname=imlifengfeng&id=666¶meters......"];
```
之后从`routerParameters`中获取这些参数。例如:`routerParameters[@"nickname"]`
##### 2、URL Rewrite
```objective-c
/**
根据设置的 Rules 去 rewrite 一个 URL
@param url 将被 rewrite 的 URL
@return rewrite 后的 URL
*/
+ (NSString *)rewriteURL:(NSString *)url;
/**
添加一个 RewriteRule
@param matchRule 正则匹配规则
@param targetRule 转换规则
*/
+ (void)addRewriteMatchRule:(NSString *)matchRule targetRule:(NSString *)targetRule;
/**
同时添加多个 RewriteRule,格式必须为:@[@{@"matchRule":@"YourMatchRule",@"targetRule":@"YourTargetRule"},...]
@param rules RewriteRules
*/
+ (void)addRewriteRules:(NSArray<NSDictionary *> *)rules;
/**
移除一个 RewriteRule
@param matchRule 将被移除的 matchRule
*/
+ (void)removeRewriteMatchRule:(NSString *)matchRule;
/**
移除所有 RewriteRule
*/
+ (void)removeAllRewriteRules;
```
###### 【备注】
(1)可以使用`正则`添加一条 Rewrite 规则,例如:
要实现打开 URL:`https://www.taobao.com/search/原子弹`时,将其拦截,改用本地已注册的 URL:`protocol://page/routerDetails?product=原子弹`打开。
首先添加一条 Rewrite 规则:
```objective-c
[FFRouterRewrite addRewriteMatchRule:@"(?:https://)?www.taobao.com/search/(.*)" targetRule:@"protocol://page/routerDetails?product=$1"];
```
之后在打开URL:`https://www.taobao.com/search/原子弹`时,将会 Rewrite 到URL:`protocol://page/routerDetails?product=原子弹`。
```objective-c
[FFRouter routeURL:@"https://www.taobao.com/search/原子弹"];
```
<br><br>(2)可以通过以下方法同时增加多个规则:
```objective-c
+ (void)addRewriteRules:(NSArray<NSDictionary *> *)rules;
```
其中 rules 格式必须为以下格式:
```objective-c
@[@{@"matchRule":@"YourMatchRule1",@"targetRule":@"YourTargetRule1"},
@{@"matchRule":@"YourMatchRule2",@"targetRule":@"YourTargetRule2"},
@{@"matchRule":@"YourMatchRule3",@"targetRule":@"YourTargetRule3"},]
```
<br><br>(3)Rewrite 规则中的保留字:
- 通过 `$scheme`、`$host`、`$port`、`$path`、`$query`、`$fragment` 获取标准 URL 中的相应部分。通过`$url`获取完整 URL
- 通过 `$1`、`$2`、`$3`...获取`matchRule`的正则中使用圆括号取出的参数
- `$`:原变量的值、`$$`:原变量URL Encode后的值、`$#`:原变量URL Decode后的值
<br>例如:
`https://www.taobao.com/search/原子弹`对于Rewrite 规则`(?:https://)?www.taobao.com/search/(.*)`
```objective-c
$1=原子弹
$$1=%e5%8e%9f%e5%ad%90%e5%bc%b9
```
同样,`https://www.taobao.com/search/%e5%8e%9f%e5%ad%90%e5%bc%b9`对于Rewrite 规则`(?:https://)?www.taobao.com/search/(.*)`
```objective-c
$1=%e5%8e%9f%e5%ad%90%e5%bc%b9
$#1=原子弹
```
##### 2、FFRouterNavigation
考虑到经常用路由配置`UIViewController`之间的跳转,所以增加了额外的工具`FFRouterNavigation`来更方便地控制`UIViewController`之间的跳转。具体使用方法如下:
```objective-c
/**
push 时是否自动隐藏底部TabBar
@param hide 是否自动隐藏,默认为 NO
*/
+ (void)autoHidesBottomBarWhenPushed:(BOOL)hide;
/**
获取当前 ViewController
@return 当前 ViewController
*/
+ (UIViewController *)currentViewController;
/**
获取当前 NavigationViewController
@return return 当前 NavigationViewController
*/
+ (nullable UINavigationController *)currentNavigationViewController;
/**
Push ViewController
@param viewController 被 Push 的 ViewController
@param animated 是否使用动画
*/
+ (void)pushViewController:(UIViewController *)viewController animated:(BOOL)animated;
/**
Push ViewController,可设置当前 ViewController 是否还保留
@param viewController 被 Push 的 ViewController
@param replace 当前 ViewController 是否还保留
@param animated 是否使用动画
*/
+ (void)pushViewController:(UIViewController *)viewController replace:(BOOL)replace animated:(BOOL)animated;
/**
Push 多个 ViewController
@param viewControllers ViewController Array
@param animated 是否使用动画
*/
+ (void)pushViewControllerArray:(NSArray *)viewControllers animated:(BOOL)animated;
/**
present ViewController
@param viewController 被 present 的 ViewController
@param animated 是否使用动画
@param completion 回调
*/
+ (void)presentViewController:(UIViewController *)viewController animated:(BOOL)animated completion:(void (^ __nullable)(void))completion;
/**
关闭当前 ViewController,push、present 方式通用
@param animated 是否使用动画
*/
+ (void)closeViewControllerAnimated:(BOOL)animated;
```
### 感谢
`FFRouter`实现方案参考了以下文章,在此表示感谢!
- [天猫解耦神器 —— 统跳协议和Rewrite引擎](http://pingguohe.net/2015/11/24/Navigator-and-Rewrite.html)
- [蘑菇街 App 的组件化之路](http://limboy.me/tech/2016/03/10/mgj-components.html)
## 许可
该项目在 <a href="http://opensource.org/licenses/MIT" target="_blank">MIT</a> 许可协议下使用. 有关详细信息,请参阅 <a href="https://github.com/imlifengfeng/FFRouter/blob/master/LICENSE">LICENSE</a>. | 24,260 | MIT |
# TDD下的react测试
## 什么是TDD
**Test Driven Development**
测试驱动开发,这种开发方式是先写测试用例.因为完全没有代码,测试用例自然全部爆红,前端的任务就是不停的补齐完成测试用例的代码,一点点的全部跑绿.
TDD开发有一些优势:
1. **长期减少回归bug.** 这个自然不必说,只要测试能通过,我们就没有必要关注代码内部的实现,就算忘了当时怎么写的也无所谓.
2. **代码质量好.** 因为你在编写测试用例的时候,规范/模块化/功能函数等等的细分都规划好了,自然比写一步算一步强.
3. **测试覆盖率高.** 现有测试用例,后有代码.肯定是覆盖率高啊.
4. **错误的测试代码不容易出现.** 如果是先有代码,后有测试,那么测试有可能是有问题而导致通过了,这回会让我们误以为代码是ok额.但是先写测试就没这个问题,因为开始测试就是未通过的.
## react下配置jest
当我们用 `create-react-app` 脚手架去生成react项目的时候,在 src 目录下其实是有 App.test.js 文件的,说明react脚手架已经集成了jest工具.但是因为配置文件被隐藏了,我们无法进行自定义配置.需要释放(弹射)配置:
```sh
npm run eject
```
这样我们的项目多出了几个文件,像 package.json 文件, config 和 scripts 目录.但是我们发现没有前面我们章节用到的 jest.config.js 文件.
这是因为 jest 的配置不仅仅可以写在 js 文件中,也可以写在 package.json 中.我们查看这个文件,果然,有jest命令,包含了很多的内容.我们可以尝试在根目录下新建 jest.config.js 文件,把 jest 下面的内容全部移植过去:
```js
module.exports = {
......
}
```
运行`npm test`.发现没问题,jest配置还是没问题的.这里大概介绍下jest的每个配置项的内容:
```json
{
"collectCoverageForm": [ // collect 收集
"src/**/*.{js,jsx,ts,tsx}", // 我们在测试的过程中只测试src下的 js/jsx/ts/tsx 文件
"!src/**/*.d.ts" // ! 的意思是不是测试 .d.ts 文件,这类文件一般是ts里面的类型生命文件,不是业务代码,没必要测试.
],
"setupFiles": [ // setup 设置/组织/调整
"react-app-polyfill/jsdom" // 当我们进行测试之前,需要进行什么样的额外准备.这里需要一个jsdom的垫片用于解决兼容问题.
]
}
``` | 1,255 | Apache-2.0 |
---
layout: post
title: "数据描摹中国网络政治的极化"
date: 2014-04-02
author: 赵蒙旸
from: http://cnpolitics.org/2014/04/ideological-polarization-over-a-china-as-superpower-mindset/
tags: [ 政見 ]
categories: [ 政見 ]
---
<div class="post-block">
<h1 class="post-head">
数据描摹中国网络政治的极化
</h1>
<p class="post-subhead">
</p>
<p class="post-tag">
</p>
<p class="post-author">
<!--a href="http://cnpolitics.org/author/zhaomengyang/">赵蒙旸</a-->
<a href="http://cnpolitics.org/author/zhaomengyang/">
赵蒙旸
</a>
<span style="font-size:14px;color:#b9b9b9;">
|2014-04-02
</span>
</p>
<!--p class="post-lead">利用四年间的“政治坐标系测试”数据,研究者发现,在中国互联网中稳定存在两类明显不同的个体:第一类人有着高度系统化的政治信仰系统,他们又分为自由主义者和民族主义者;另一类人则在对各种社会政治议题的看法上缺乏自洽的逻辑。
</p-->
<div class="post-body">
<p>
□“政见”观察员 赵蒙旸
<br>
<img alt="unnamed" class="aligncenter size-full wp-image-4361" height="582" sizes="(max-width: 569px) 100vw, 569px" src="http://cnpolitics.org/wp-content/uploads/2014/04/unnamed.png" srcset="http://cnpolitics.org/wp-content/uploads/2014/04/unnamed.png 569w, http://cnpolitics.org/wp-content/uploads/2014/04/unnamed-293x300.png 293w" width="569">
<br>
中国思想界的左右之争随着社交媒体的出现日益草根化和白热化。然而,中国网民的政治态度和观点极化问题一直没有获得足够的关注,而审查的存在也导致数据获取受限,学者们往往很少去梳理各种混乱的价值标签,更遑论系统检测中国网民的政治光谱。美国西北大学博士生吴晓即将发表于《国际传播学刊》的研究,用扎实的经验数据和创新的研究方法弥补了这一领域的空白,描绘出中国网络意识形态的复杂与动态。
</br>
</img>
</br>
</p>
<p>
2007年,一套基于中国国情的
<a href="http://www.zuobiao.me/">
“政治坐标系测试”
</a>
在中国高校论坛和博客圈中开始流行。标准测试共50题,涉及政治、经济、文化诸多方面,比一般的政治态度测试更能反映一个人一以贯之的价值体系。2008年到2011年,有几十万人次参与了调查。巧合的是,这段时间也是网民数量增长极快的时期,互联网普及率从16%蹿升至34%。科学的测试方式,庞大的数据基础,关键的时间节点,这让研究者得以定量考察网民政治态度的分布和变迁。
</p>
<p>
研究者在2008到2011四年的测试数据中,每年随机抽取1000张答卷进行分析。与之前单独分析政治态度中某一具体方面的学者不同,本研究的重点在于考察人们的政治信仰系统(political belief system),即人们对不同问题所持态度之间的关系——这种关系既可以是一致的,也可以是矛盾的。每个人态度的统一和对立会形成一张“观点之网”,而很多张网络的聚合则形成了人们的诠释性社群(interpretive communities)。
</p>
<p>
初步的数据分析结果显示,网民对问卷的回答可以归类为五个宏观层面的抽象价值观,分别是“文化自由主义(政治和文化上支持自由多元)”、“国家主义(维护本国政治领土军事力量)”、“政治保守主义(反对西式民主)”、“传统主义(尊崇中国传统文化价值)”和“经济独立论(强调国家在经济领域的主权独立)”。作者同时设定了三个中观经济政策上的态度问题:“改革不满度(对改革时期收入分配不平等不满)”、“市场管制(国家干预市场价格)”和“农业补贴(国家高价收购农产品)”来进一步分析网民抽象和具体层面的观点一致性。
</p>
<p>
研究发现,在中国互联网中稳定存在两类明显不同的个体。第一类人有着高度系统化的政治信仰系统,根据公众舆论既有文献,这些人可被称作思想者(ideologues)。思想者的信仰体系发端于中国互联网内在割裂、二元对立的本土语境:一面是政治、文化上的自由多元主义,另一面是某种大国崛起的民族主义态度,包含具有扩张倾向的军事国家主义、对中国政治体制的包容、对传统文化的尊崇,以及对国家经济主权的强调。在这种交锋式的语境下,思想者内部自然发展出两派人马:对“大国崛起”不感冒的自由主义者,以及倡导“大国崛起”的民族主义者。
</p>
<p>
另一类人对各种社会政治议题的看法则似乎缺乏自洽的逻辑,他们给出的答案之间的相关性很弱或几乎为零。从分析结果来看,他们没有任何共同的政治信仰系统,依据文献,作者用不可知者(agnostics)来形容他们。 有趣的是,不管是思想者还是不可知者,在经济平等类议题上都缺乏系统认识,暗示了中国网民可能普遍缺乏对经济运作和政策的了解。
</p>
<p>
运用语义网分析方法,研究者进一步考察了网民的观点极化问题。如果两位作答者在30道问题中有20题以上答案类似,他们会被连接在一起。最终输出的网络图案和我们通常的认知一致:除了很多价值观点不一致的、处在意见模糊区域的不可知者,中国互联网上确实存在两个在许多层面互斥的价值共同体,也即上文所描述的自由主义者和民族主义者。与上一节的发现相吻合,这两派人的观点在经济平等议题上的分野最不明显。
</p>
<p>
考察几年间的变化趋势,发现则更加有趣:对比四年的图案,自由主义者和民族主义者在两极的政治态度对立分布很稳定,而处在观点中间地带的不可知者的网络形态却差异较大。年份越靠后,中间地带的网络密度和集中度越低。具体来说,这个群体一方面表现出对于国家主义、政治保守主义、经济独立论和传统主义的反感,另一方面,则在文化自由主义方面出现越来越多的内部分歧。换言之,国家主义在整个互联网语境下的影响力正在衰落,但同时,文化自由主义似乎也未能招募到更多的拥趸。
</p>
<p>
本研究不仅从分布上揭示了中国网络政治话语的现状,而且引入时间取向,绘制出这些政治话语在四年中的演变路径。此前,民族主义的研究往往定义不清晰,当民族主义被更细致地划分成军事层面的国家主义和政权支持度后,数据揭示:尽管很多网民支持中国强硬的外交手段和中国崛起的逻辑,但政权的支持度却在下降。
</p>
<p>
其次,自由主义者和民族主义者占据的两极阵营相对稳定,但不可知者的阵营却似乎在迅速萎缩,为今后的网络舆论增添了更多不确定性。
</p>
<p>
再者,正如数据已经呈现出的,中国网络的经济话语极其杂乱,网民的经济观点和其文化政治观点缺乏相关性,自由主义者和民族主义者虽然在“大国崛起”的方方面面都尖锐对立,在经济平等议题上却甚少存在争论。
</p>
<p>
最后,总体来看,虽然中国互联网的扩散是从年轻人向年长者,从高收入、高教育者向低收入、低文化水平人群转移,虽然政治极化的趋势普遍存在,但整个网络话语环境并没有走向娱乐和保守,而是进一步远离了国家倡导的意识形态。
</p>
<p>
值得注意的是,本研究的时间跨度仅仅为四年,但揭示出的整体意见走向却非常明显。可见,不同于有着稳定政党政治和宗教认同的民主社会,互联网对中国社会思潮的改造和形塑作用可能比我们想象的要剧烈。虽然无法推导出因果关系,但本文为观察网络思潮的大趋势提供了纪录起点。在宏观背景上,互联网让人们逐步挣脱国家意识形态的束缚,在微观机制上,网络提供了无限的可能,既让现实更加自由多元,也让人们目睹了社会在各个领域的撕裂。
</p>
<p>
注:感谢论文作者吴晓对译介提出的修改意见。
</p>
<p>
【参考文献】
<br>
Wu, A.X. (Forthcoming). Ideological polarization over a China-as-superpower mindset: An exploratory charting of belief systems among Chinese Internet users, 2008-2011. International Journal of Communication. Available at SSRN:
<a href="http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2408639">
http://papers.ssrn.com/sol3/papers.cfm?abstract_id=2408639
</a>
</br>
</p>
</div>
<!-- icon list -->
<!--/div-->
<!-- social box -->
<div class="post-end-button back-to-top">
<p style="padding-top:20px;">
回到开头
</p>
</div>
<div id="display_bar">
<img src="http://cnpolitics.org/wp-content/themes/CNPolitics/images/shadow-post-end.png"/>
</div>
</div> | 4,474 | MIT |
# HTTP Request Method
---
### 方法汇总一
方法 | 说明
--- | ---
GET | 从服务端获取指定的资源
POST | 发送特定类型的数据给服务端,进行资源的创建
PUT | 发送数据给服务端,新增资源或替换目标资源
DELETE | 告诉服务端删除指定的资源
--
### 方法汇总二
方法 | 说明
--- | ---
OPTIONS | 获取资源所支持的方法
HEAD | 获取资源的响应头部,与GET获取到的相同
PATCH | 发送数据给服务端,部分修改资源
TRACE | 回显服务器收到的请求,主要用于测试或诊断
CONNECT | HTTP/1.1协议中预留,将连接改为管道方式
---
### 方法的三个属性
- [安全(Safe)](https://developer.mozilla.org/zh-CN/docs/Glossary/safe),不改变服务端资源
- [幂等(Idempotent)](https://developer.mozilla.org/zh-CN/docs/Glossary/%E5%B9%82%E7%AD%89),多次调用效果相同
- [可缓存(Cacheable)](https://developer.mozilla.org/en-US/docs/Glossary/Cacheable),响应可以被客户端缓存
---
## GET
*从服务端获取指定的资源*
属性 | 值
--- | ---
请求是否有主体 | 否
成功的响应是否有主体 | 是
安全 | 是
幂等 | 是
可缓存 | 是
是否支持表单 | 是
--
### Ajax方式
```bash
//请求
GET /api/employees/zhangchunxin
```
<!-- .element: class="fragment visible"-->
```bash
//响应
HTTP/1.1 200
Host: 127.0.0.1
ETag: de08b7bc-82d9-40da-b1b9-8ee1b2aff19f
Content-Type: application/json
Content-Length: 67
Date: Tue, 09 Jan 2018 02:56:26 GMT
//响应主体
{"status":"success","data":{"name":"zhangchunxin","id":"00230635"}}
```
<!-- .element: class="fragment visible"-->
```bash
//另一种请求方式
GET /api/employees/api/employees?name=zhangchunxin
```
<!-- .element: class="fragment visible"-->
--
### 表单方式
```html
//表单请求
<form method="get" action="/api/employees">
<input name="name" value="zhangchunxin">
<input type="submit">
</form>
```
```bash
HTTP/1.1 200
Host: 127.0.0.1
ETag: de08b7bc-82d9-40da-b1b9-8ee1b2aff19f
Content-Type: application/json
Content-Length: 67
Date: Tue, 09 Jan 2018 02:57:46 GMT
//响应主体
{"status":"success","data":{"name":"zhangchunxin","id":"00230635"}}
```
<!-- .element: class="fragment visible"-->
---
## POST
*发送特定类型的数据给服务端,进行资源的创建*
属性 | 值
--- | ---
请求是否有主体 | 是
成功的响应是否有主体 | 是
安全 | 否
幂等 | 否
可缓存 | [看情况](https://stackoverflow.com/questions/626057/is-it-possible-to-cache-post-methods-in-http)
是否支持表单 | 是
--
### Ajax方式
```bash
//请求
POST /api/employees
Content-Type: application/json
{
"name": "luanzhuo",
"id": "00356107"
}
```
<!-- .element: class="fragment visible"-->
```bash
//响应
HTTP/1.1 201
ETag: f55a6fdc-1ac1-4ea2-9b43-f6517c93b3ac
Location: /api/employees/luanzhuo
Content-Type: application/json
Content-Length: 63
Date: Tue, 09 Jan 2018 02:59:45 GMT
//响应主体
{"status":"success","data":{"name":"luanzhuo","id":"00356107"}}
```
<!-- .element: class="fragment visible"-->
--
### 表单方式
```html
//表单请求
<form method="post" action="/api/employees">
<input name="name" value="luanzhuo">
<input name="id" value="00356107">
<input type="submit">
</form>
```
```bash
HTTP/1.1 201
ETag: 5c17d201-79c0-464d-bb6f-48fef959aa30
Location: /api/employees/luanzhuo
Content-Type: application/json
Content-Length: 63
Date: Tue, 09 Jan 2018 03:00:20 GMT
//响应主体
{"status":"success","data":{"name":"luanzhuo","id":"00356107"}}
```
<!-- .element: class="fragment visible"-->
---
## PUT
*发送数据给服务端,新增资源或替换目标资源*
属性 | 值
--- | ---
请求是否有主体 | 是
成功的响应是否有主体 | 都可以
安全 | 否
幂等 | 是
可缓存 | 否
是否支持表单 | 否
--
### 创建
```bash
//请求
PUT /api/employees/tiankai
Content-Type: application/json
{
"name": "tiankai",
"id": "00226034"
}
```
<!-- .element: class="fragment visible"-->
```bash
//响应
HTTP/1.1 201
ETag: 97e7e534-e5b2-4dbf-9aff-885db335581c
Content-Type: application/json
Content-Location: /api/employees/tiankai
Date: Tue, 09 Jan 2018 03:41:41 GMT
```
<!-- .element: class="fragment visible"-->
--
### 替换
```bash
//请求
PUT /api/employees/tiankai
Content-Type: application/json
{
"id": "00226034"
}
```
<!-- .element: class="fragment visible"-->
```bash
//响应
HTTP/1.1 204
Content-Type: application/json
ETag: b0307586-832f-46fc-bd97-9e1ba30f5f79
Content-Location: /api/employees/tiankai
Date: Tue, 09 Jan 2018 03:42:06 GMT
```
<!-- .element: class="fragment visible"-->
--
### 修改 OK
```bash
//请求
PUT /api/employees/tiankai
Content-Type: application/json
{
"id": "00226034"
}
```
<!-- .element: class="fragment visible"-->
```bash
//响应 修改
HTTP/1.1 200
ETag: 284b01cd-5e7b-4fd6-9cd8-d0263b8aaaa0
Content-Type: application/json
Content-Length: 62
Date: Tue, 09 Jan 2018 04:02:05 GMT
//响应主体
{"status":"success","data":{"name":"tiankai","id":"00226034"}}
```
<!-- .element: class="fragment visible"-->
--
### 修改 Not Found
```bash
//请求
PUT /api/employees/tiankai
Content-Type: application/json
{
"id": "00226034"
}
```
<!-- .element: class="fragment visible"-->
```bash
//响应 资源不存在
HTTP/1.1 404
Content-Type: application/json
Content-Length: 67
Date: Tue, 09 Jan 2018 04:01:10 GMT
//响应主体
{"status":"error","message":"employees named tiankai is not exist."}
```
<!-- .element: class="fragment visible"-->
---
## DELETE
*告诉服务端删除指定的资源*
属性 | 值
--- | ---
请求是否有主体 | 否
成功的响应是否有主体 | 否
安全 | 否
幂等 | 是
可缓存 | 否
是否支持表单 | 否
--
### 删除 OK
```bash
//请求
DELETE /api/employees/tiankai
```
<!-- .element: class="fragment visible"-->
```bash
//响应 删除
HTTP/1.1 200
Content-Length: 0
Date: Tue, 09 Jan 2018 04:05:27 GMT
```
<!-- .element: class="fragment visible"-->
```bash
//另一种请求方式
DELETE /api/employees?name=tiankai
```
<!-- .element: class="fragment visible"-->
--
### 删除 Not Found
```bash
//请求
DELETE /api/employees/tiankai
```
<!-- .element: class="fragment visible"-->
```bash
//响应 资源不存在
HTTP/1.1 404
Content-Length: 0
Date: Tue, 09 Jan 2018 04:09:57 GMT
```
<!-- .element: class="fragment visible"-->
```bash
//另一种请求方式
DELETE /api/employees?name=tiankai
```
<!-- .element: class="fragment visible"-->
---
## HEAD
*获取资源的响应头部,与GET获取到的相同*
属性 | 值
--- | ---
请求是否有主体 | 否
成功的响应是否有主体 | 否
安全 | 是
幂等 | 是
可缓存 | 是
是否支持表单 | 否
--
### 普通方式
```bash
//请求
HEAD /api/employees
```
<!-- .element: class="fragment visible"-->
```bash
//响应
HTTP/1.1 204
ETag: 6c919dba-2f90-4625-a13a-7ea3b0950a28
Host: 127.0.0.1
Content-Type: application/json
Date: Tue, 09 Jan 2018 07:12:40 GMT
```
<!-- .element: class="fragment visible"-->
--
### CORS方式
```bash
//请求
HEAD http://localhost:8080/api/employees
Access-Control-Request-Headers: X_API_employees, Content-Type
```
<!-- .element: class="fragment visible"-->
```bash
//响应
HTTP/1.1 204
Access-Control-Allow-Headers: X_API_employees, Content-Type
Access-Control-Allow-Origin: zhangchunxin.inhuawei.com
Access-Control-Max-Age: 86400
Content-Type: application/json
Date: Tue, 09 Jan 2018 07:23:55 GMT
```
<!-- .element: class="fragment visible"-->
---
## OPTIONS
*获取资源所支持的方法*
属性 | 值
--- | ---
请求是否有主体 | 否
成功的响应是否有主体 | 否
安全 | 是
幂等 | 是
可缓存 | 否
是否支持表单 | 否
--
### 普通方式
```bash
//请求
OPTIONS /api/employees
```
<!-- .element: class="fragment visible"-->
```bash
//响应
HTTP/1.1 204
Allow: HEAD,DELETE,POST,GET,OPTIONS,PUT
Date: Tue, 09 Jan 2018 06:35:14 GMT
```
<!-- .element: class="fragment visible"-->
--
### CORS方式
```bash
//请求
OPTIONS /api/employees
Access-Control-Request-Method: POST, GET
```
<!-- .element: class="fragment visible"-->
```bash
//响应
HTTP/1.1 204
Access-Control-Allow-Methods: GET
Access-Control-Allow-Origin: zhangchunxin.inhuawei.com
Access-Control-Max-Age: 86400
Date: Tue, 09 Jan 2018 07:27:14 GMT
```
<!-- .element: class="fragment visible"-->
---
## GET V.S. POST
GET —— 查询资源
POST —— 创建资源
--
### 属性对比一
属性 | GET | POST
--- | --- | ---
可缓存 | 支持 | 不支持
编码类型 | application/x-www-form-urlencoded | 多种
参数长度 | URL限制(2048) | 无限制
参数类型 | ASCII | 无限制
--
### 属性对比二
属性 | GET | POST
--- | --- | ---
安全性 | 数据保存在URL中 | 数据不保存
可见性 | 任何人可见 | 不可见
发送敏感信息 | 不可以 | 可以
刷新/后退(幂等) | 无影响 | 重新提交
书签收藏 | 支持 | 不支持
历史记录 | 包含参数 | 不包含参数
--
### 总结
#### GET
- 用于查询请求场景
- 用于安全性要求不高的情况
- 用于需要缓存的场景
- 需要保证幂等性
#### POST
- 用于创建请求场景
- 用于安全性要求较高的情况
- 扩展GET查询,支持更复杂的查询条件
---
## POST V.S. PUT
POST —— 创建资源
PUT —— 创建或替换资源
--
### 属性对比
属性 | POST | PUT
--- | --- | ---
请求是否有主体 | 是 | 是
成功的响应是否有主体 | 是 | 都可以
安全 | 否 | 否
幂等 | 否 | 是
可缓存 | [看情况](https://stackoverflow.com/questions/626057/is-it-possible-to-cache-post-methods-in-http) | 否
是否支持表单 | 是 | 否
--
POST创建请求
```bash
POST /api/employees
Content-Type: application/json
{
"name": "luanzhuo",
"id": "00356107"
}
```
PUT修改请求
```bash
PUT /api/employees/tiankai
Content-Type: application/json
{
"id": "00226034"
}
```
--
### 总结
- POST和PUT都可以用于创建或修改
- PUT需要保证幂等性
- 业界RESTful实践中,POST用作创建,PUT/PATCH用作修改
---
## 全文总结
介绍常见的HTTP方法,希望大家在后续开发中能够保证对应方法的正确性。
--
### 拓扑的HTTP方法规范
方法 | 说明
--- | ---
GET | 查询
POST | 创建
PUT | 修改
DELETE | 删除
---
### 附录
- [HTTP Protocol Specification - w3](https://www.w3.org/Protocols/rfc2616/rfc2616-sec9.html)
- [HTTP 请求方法 -MDN](https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Methods)
- [HTTP Methods: GET vs. POST - 3school](https://www.w3schools.com/tags/ref_httpmethods.asp)
- [PUT vs. POST in REST - Stack Overflow](https://stackoverflow.com/questions/630453/put-vs-post-in-rest)
- [源码](http://isource-xa.huawei.com/z00230635/java_practice/tree/master/Spring/aq-spring-demo/src/main/java/aq/springboot/demo/jersey/controller/http/MethodController.java) | 8,902 | MIT |
長這樣
-----
```css
html, body {
position: relative;
padding: 0; margin: 0;
overflow: hidden;
font-family: '文泉驛微米黑', 'LiHei Pro', '微軟正黑體', sans-serif;
font-weight: 200;
letter-spacing: -0.02em;
color: #eee; width: 100%; height: 100%;
min-height: 400px;
}
table {
border-collapse: collapse;
border-spacing: 0;
}
```
---
CSS Syntax
----------

<small>Source: [W3Schools](http://w3schools.com/css/css_syntax.asp)</small>
---
把 CSS 加進 HTML
---------------
### `<link>`
```html
<head>
...
<link rel="stylesheet" type="text/css" href="path/to/file.css">
...
</head>
```
---
把 CSS 加進 HTML (2)
---------------
### `<style>`
[[mrorz-css-styletag]]
`<style>` 可放在 `<head>` 或 `<body>` 均可。
---
Cascading Style Sheet
---------------------
<!-- https://developer.mozilla.org/en/CSS/Getting_Started/Cascading_and_inheritance -->
<div class="row">
<div class="span3">
<h3>Cascading</h3>
<p>元素的最後外觀,來自於多個樣式定義</p>
<ul>
<li>瀏覽器預設樣式</li>
<li>瀏覽器使用者樣式</li>
<li>網頁作者(你)所指定的樣式</li>
</ul>
<hr>
<p>後者蓋過前者。</p>
</div>
<div class="span3">
<h3>Inheritance</h3>
<p>某些外觀屬性(Ex: `color`)會透過 HTML 嵌套,繼承給裡面的元素</p>
[[mrorz-css-inheritence]]
</div>
</div>
---
CSS Reset
---------
[[mrorz-css-reset]]
拿掉瀏覽器預設的外觀定義
---
CSS Normalization
-----------------
[[comoyisiki/1]]
統一各瀏覽器的外觀定義 <small>[規則說明](https://github.com/necolas/normalize.css/wiki)</small>
---
大綱
----
<!-- CSS 屬性有交互作用,比較沒辦法用「課文」例子來講。 -->
* 常用外觀樣式
* 除錯工具介紹
* 數值 & 字型
* CSS Selectors & Specificity
* Box Model 與 Positioning
* CSS3
* 難懂的屬性:`vertical-align`, `z-index`
* Media Query | 1,675 | MIT |
---
categories:
- Linux 命令
date: '2020-09-25 08:00:00'
tags:
- Linux
- Linux Command
- Linux 命令
- ifcfg
title: 【Linux 命令】ifcfg
updated: '2020-09-25 09:40:30'
---
置Linux中的网络接口参数
## 补充说明
**ifcfg命令** 是一个Bash脚本程序,用来设置Linux中的网络接口参数。
### 语法
```shell
ifcfg(参数)
```
### 参数
```shell
网络接口:指定要操作的网络接口;
add/del:添加或删除网络接口上的地址;
ip地址:指定IP地址和子网掩码;
Stop:停用指定的网络接口的IP地址。
```
<!-- Linux命令行搜索引擎:https://jaywcjlove.github.io/linux-command/ --> | 433 | MIT |
# ngx-logger-icy
> angular9+以上的版本可以使用;继承console上的方法,可以根据环境变量控制log是否输出,解决开发环境需要打印一些log日志但是生产环境并不需要;[demo地址](https://ngx-library.now.sh/tools/logger)
## 1、开始使用
- <a href="#install">安装</a>
- <a href="#use">使用</a>
## 2、LoggerService中的方法
- <a href="#log">log()</a>
- <a href="#info">info()</a>
- <a href="#debug">debug()</a>
- <a href="#error">error()</a>
- <a href="#warn">warn()</a>
- <a href="#assert">assert()</a>
- <a href="#clear">clear()</a>
- <a href="#count">count()</a>
- <a href="#group">group()</a>
- <a href="#groupCollapsed">groupCollapsed()</a>
- <a href="#groupEnd">groupEnd()</a>
- <a href="#table">table()</a>
- <a href="#time">time()</a>
- <a href="#timeEnd">timeEnd()</a>
- <a href="#trace">trace()</a>
- <a href="#profile">profile()</a>
## <a name="install">安装</a>
```
npm i ngx-logger-icy
```
## <a name="use">使用</a>
``LoggerModule``应该在``AppModule``中使用``forRoot()``静态方法注册,在子模块中使用``forChild()``注册。这些方法也接受``enable``对象。将其保留为默认值为空是``true``。
```javascript
import { BrowserModule } from '@angular/platform-browser';
import { NgModule } from '@angular/core';
import { LoggerModule } from 'ngx-logger-icy';
import { AppRoutingModule } from './app-routing.module';
import { AppComponent } from './app.component';
import { environment } from '../environments/environment';
@NgModule({
declarations: [
AppComponent
],
imports: [
BrowserModule,
LoggerModule.forRoot(environment.enableConsole),// forRoot()如果为空,默认值为true
AppRoutingModule,
],
providers: [],
bootstrap: [AppComponent]
})
export class AppModule { }
```
```javascript
import { Component } from '@angular/core';
import { LoggerService } from 'ngx-logger-icy';
@Component({
selector: 'app-root',
templateUrl: './app.component.html',
styleUrls: ['./app.component.less']
})
export class AppComponent {
constructor(
private _logger: LoggerService
) {
this._logger.log('%c这就输出了。', 'color: green');
this._logger.debug();
this._logger.error('我是错误的输出。');
}
}
```
## <a name="log">log()</a>
```javascript
/**
* 输出信息
* @description 同console.log()
*/
log(): Function;
```
## <a name="info">info()</a>
```javascript
/**
* log别名,输出信息
* @description 同console.info()
*/
info(): Function;
```
## <a name="debug">debug()</a>
```javascript
/**
* @description 同console.debug()
*/
debug(): Function;
```
## <a name="error">error()</a>
```javascript
/**
* 输出信息时,在最前面加一个红色的叉,表示出错,同时会显示错误发生的堆栈。
* @description 同console.error()
*/
error(): Function;
```
## <a name="warn">warn()</a>
```javascript
/**
* 输出警告信息
* @description 同console.warn()
*/
warn(): Function;
```
## <a name="assert">assert()</a>
```javascript
/**
* @param boolean
* @param string
* @description 同console.assert(); 接受两个参数,只有当第一个参数为false,才会输出第二个参数,否则不输出任何东西
*/
assert(): Function;
```
## <a name="clear">clear()</a>
```javascript
/**
* 清除当前控制台的所有输出,将光标回置到第一行
* @description 同console.clear();此方法不分环境
*/
clear(): Function;
```
## <a name="count">count()</a>
```javascript
/**
* 用于计数,输出它被调用了多少次。
* @description 同console.count()
*/
count(): Function;
```
## <a name="group">group()</a>
```javascript
/**
* 用于将显示的信息分组,可以把信息进行折叠和展开。
* @description 同console.group()
*/
group(): Function;
```
## <a name="groupCollapsed">groupCollapsed()</a>
```javascript
/**
* 与group方法很类似,唯一的区别是该组的内容,在第一次显示时是收起的(collapsed),而不是展开的
* @description 同console.groupCollapsed()
*/
groupCollapsed(): Function;
```
## <a name="groupEnd">groupEnd()</a>
```javascript
/**
* 结束内联分组
* @description 同console.groupEnd()
*/
groupEnd(): Function;
```
## <a name="table">table()</a>
```javascript
/**
* 将复合类型的数据转为表格显示
* @description 同console.table()
*/
table(): Function;
```
## <a name="time">time()</a>
```javascript
/**
* 计时开始
* @description 同console.time()
*/
time(): Function;
```
## <a name="timeEnd">timeEnd()</a>
```javascript
/**
* 计时结束
* @description 同console.timeEnd()
*/
timeEnd(): Function;
```
## <a name="trace">trace()</a>
```javascript
/**
* 追踪函数的调用过程
* @description 同console.trace()
*/
trace(): Function;
```
## <a name="profile">profile()</a>
```javascript
/**
* 性能分析器
* @description 同console.profile()
*/
profile(): Function;
``` | 4,186 | MIT |
## tieba-crawler
<p>
<a href="https://www.npmjs.com/package/tieba-crawler"><img src="https://img.shields.io/npm/dm/tieba-crawler.svg" alt="Downloads"></a>
<a href="https://www.npmjs.com/package/tieba-crawler"><img src="https://img.shields.io/npm/v/tieba-crawler.svg" alt="Version"></a>
<a href="https://www.npmjs.com/package/tieba-crawler"><img src="https://img.shields.io/npm/l/tieba-crawler.svg" alt="License"></a>
</p>
## 介绍
:rocket: 原生nodejs对百度贴吧实现爬虫
## 操作说明
### 配置环境,安装node,官网下载 [node](https://nodejs.org/en/)
npm install tieba-crawler
### 操作
simple操作
创建simple.js,内容如下,然后执行node simple.js
```javascript
/* 下载单页某帖子的数据 */
const tieba = require('tieba-crawler');
const url = ''; // 你想要爬取的贴子网址
tieba(url, 'simple');
```
first操作
创建first.js,内容如下,然后执行node first.js
```javascript
/* 下载某贴吧首页的所有帖子的数据 */
const tieba = require('tieba-crawler');
const url = ''; // 你想要爬取的贴吧首页
tieba(url, 'first');
```
### 新操作
创建test.js,内容如下,执行npm install commander
执行node test s/simple/f/first (方式选一种,如 node test s)
```javascript
#!/usr/bin/env node
const program = require('commander');
const tieba = require('tieba-crawler');
program
.command('simple')
.description('crawler files from tieba')
.alias('s')
.action(function(type, name){
process.stdout.write('输入网址:');
process.stdin.on('data', function (chunk) {
let url = String(chunk);
process.stdin.end();
tieba(url, 'simple');
});
});
program
.command('first')
.description('crawler files from tieba')
.alias('f')
.action(function(type, name){
process.stdout.write('输入贴吧首页:');
process.stdin.on('data', function (chunk) {
let url = String(chunk);
process.stdin.end();
tieba(url, 'first');
});
});
program.parse(process.argv);
```
## 功能以及注意事项说明
### 功能
simple操作
1.收集帖子的每层楼回复的图片,层主的头像和id
2.帖子超过一页的可以自动翻页继续手机
3.帖子的标题,链接,每层楼回复内容和回复人id,保存在文本中
first操作
1.获取贴吧首页的所有帖子标题,发帖人,帖子链接
2.针对每个帖子执行simple操作
### 目录结构
下载后你的文件夹会出现
data文件夹/
帖吧名(内含首页的所有帖子信息).txt
贴吧名文件夹/
帖子名文件夹/
帖子名(内含帖子的详细信息).txt
帖子的所有用户头像.JPG
帖子的所有回复图片.JPG
## 函数说明
这里提供了一个函数,参数为(url, method, msg, page)。
url: 爬虫地址,需要带上协议名,完整的url
method:爬虫方式,'simple'和'first',默认为'simple'
msg: 初始消息,默认为 ''
page: 帖子爬取的初始页,默认为 1
最后两个参数可以不用设置
作者:微博 [@itagn][1] - Github [@itagn][2]
[1]: https://weibo.com/p/1005053782707172
[2]: https://github.com/itagn | 2,486 | MIT |
[iTranswarp](https://github.com/michaelliao/itranswarp) 是廖雪峰大神官方网站的开源 CMS,用来托管个人的网站,简洁够用。

# 1 技术架构
iTranswarp 主体上是使用了 Spring Boot 2.2.6 的一个单体应用,其页面模板引擎为 pebbletemplates,并且使用了 redis 缓存和全文检索 lucene,数据存储使用其自定义的简化数据持久框架 warpdb,其底层注入 JdbcTemplate 完成数据持久化。
数据库是常用的 MySQL,使用了 HikariCP 数据源连接池。
Markdown 解析器使用的是 commonmark-java:一个基于 [CommonMark](http://commonmark.org/) 规范解析和渲染 Markdown 文本的 Java 库,特点是小、快、灵活。后续需要通过这一块扩展 gitbook 内容直接导入(wiki)的功能。
使用了 JDK 11版本。
# 2 程序分析
## 2.1 数据持久化
iTranswarp 的数据持久化是通过其自定义的简化数据持久框架 warpdb 来完成的。
在 WarpDb 类里面使用了 Spring 的 JdbcTemplate 来完成最终的数据持久化操作。
```java
public class WarpDb {
final Log log = LogFactory.getLog(getClass());
JdbcTemplate jdbcTemplate;
```
warpdb 持久化框架最重要的一个类是范型化的 `Mapper<T>` 类:
```java
final class Mapper<T> {
final Class<T> entityClass;
final String tableName;
// @Id property:
final AccessibleProperty[] ids;
// @Version property:
final AccessibleProperty version;
// all properties including @Id, key is property name (NOT column name)
final List<AccessibleProperty> allProperties;
// lower-case property name -> AccessibleProperty
final Map<String, AccessibleProperty> allPropertiesMap;
final List<AccessibleProperty> insertableProperties;
final List<AccessibleProperty> updatableProperties;
// lower-case property name -> AccessibleProperty
final Map<String, AccessibleProperty> updatablePropertiesMap;
final BeanRowMapper<T> rowMapper;
final String selectSQL;
final String insertSQL;
final String insertIgnoreSQL;
final String updateSQL;
final String deleteSQL;
final String whereIdsEquals;
final Listener prePersist;
final Listener preUpdate;
final Listener preRemove;
final Listener postLoad;
final Listener postPersist;
final Listener postUpdate;
final Listener postRemove;
...
```
可以通过 ArticleService 文章服务类的 createArticle 方法看到清晰的数据操作过程。
```java
@Transactional
public Article createArticle(User user, ArticleBean bean) {
bean.validate(true);
getCategoryById(bean.categoryId);
Article article = new Article();
article.id = IdUtil.nextId();
article.userId = user.id;
article.categoryId = bean.categoryId;
article.name = bean.name;
article.description = bean.description;
article.publishAt = bean.publishAt;
article.tags = bean.tags;
AttachmentBean atta = new AttachmentBean();
atta.name = article.name;
atta.data = bean.image;
article.imageId = attachmentService.createAttachment(user, atta).id;
article.textId = textService.createText(bean.content).id;
this.db.insert(article);
return article;
}
```
- 创建实体 Article(使用 JPA 注解 @Entity、@Table、@Column 等进行标注),并设置各种属性;
- 调用 WarpDb 的 insert 方法,将实体 Article 存入数据库;
持久化框架通过传入的实体对象获取其类其 `Mapper<Article>`,构建对应的 sql,最终通过 jdbcTemplate 执行这段sql,将其存储到数据库中。
```java
private <T> boolean doInsert(boolean ignore, T bean) {
try {
int rows;
final Mapper<?> mapper = getMapper(bean.getClass());
final String sql = ignore ? mapper.insertIgnoreSQL : mapper.insertSQL;
...
rows = jdbcTemplate.update(sql, args);
...
}
```
## 2.2 视图模板
iTranswarp 的视图模板使用的是不太常见、但是效率较高的 Pebble Templates:简单高效,容易上手。
Pebble 官方提供了 Spring Boot 的 starter 集成,但是 iTranswarp 使用了原始的集成方式:在 MvcConfiguration 类中注册了 ViewResolver 为 Spring MVC 提供视图解析器。
```java
@Bean
public ViewResolver pebbleViewResolver(@Autowired Extension extension) {
// disable cache for native profile:
boolean cache = !"native".equals(activeProfile);
logger.info("set cache as {} for active profile is {}.", cache, activeProfile);
PebbleEngine engine = new PebbleEngine.Builder().autoEscaping(true).cacheActive(cache).extension(extension)
.loader(new ClasspathLoader()).build();
PebbleViewResolver viewResolver = new PebbleViewResolver();
viewResolver.setPrefix("templates/");
viewResolver.setSuffix("");
viewResolver.setPebbleEngine(engine);
return viewResolver;
}
```
- 视图解析前缀为 templates/;
- 视图解析后缀为空;
以 ManageController 控制器为例,看看其中的“新建文章” 服务的代码:
```java
@GetMapping("/article/article_create")
public ModelAndView articleCreate() {
return prepareModelAndView("manage/article/article_form.html", Map.of("id", 0, "action", "/api/articles"));
}
```
- 使用 "templates/manage/article/article_form.html" 这个模板。
模板文件 _base.html 是最基础的页面,可以在其上添加你需要的内容,例如网站备案信息。
> 为了简便起见(毕竟我只用一次),硬编码添加,没有扩展为“管理控制台”里面的设置属性。
```html
<div id="footer">
<div class="x-footer uk-container x-container">
<hr>
<div class="uk-grid">
<div class="x-footer-copyright uk-width-small-1-2 uk-width-medium-1-3">
<p>
<a href="/" title="version={{ __version__ }}">{{ __website__.name }}</a> {{ __website__.copyright|raw }}
<a href="http://www.beian.miit.gov.cn/" target="blank">蜀ICP备20013663号</a>
<br>
Powered by <a href="https://github.com/michaelliao/itranswarp" target="_blank">iTranswarp</a>
</p>
</div>
...
```
## 2.3 数据库表
数据库表命名清晰,自说明强。
系统配套数据库表19张,其作用分别如下:
| 序号 | 表名 | 用途 | 说明 |
| ---- | ------------ | ---------------- | ------------------------------------------------------------ |
| 1 | users | 用户表 | 需要线下添加用户,线上不需要注册用户 |
| 2 | local_auths | 本地用户认证信息 | 存放users中用户的密码 |
| 3 | oauths | 第三方认证 | |
| 4 | ad_slots | 广告位 | 在管理控制台中的“广告-广告位”功能中设置 |
| 5 | ad_periods | 广告期限 | 在管理控制台中的“广告-广告期限”功能中设置 |
| 6 | ad_materials | 广告素材 | 需要在有广告位和广告期限的前提下,使用sponsor用户登录,在管理控制台中的“广告-广告素材”功能中设置 |
| 7 | settings | 设置表 | 在管理控制台中的“设置”功能中配置 |
| 8 | wikis | 维基 | 创建书籍、教程用,在管理控制台中的“维基”功能中维护 |
| 9 | wiki_pages | 维基页面 | 存放维基页面,使用Markdown编辑,内容通过textId存入texts表中,需要扩展成通过gitbook批量导入一本书 |
| 10 | navigations | 导航 | 在管理控制台中的“导航”功能中配置,在首页的顶部导航栏显示。导航有5种类型:/category/xxx,文章类型(需要先创建文章类型,并在数据库中查询id进行配置导航);/single/xxx,页面(需要在管理控制台“页面”创建,并在数据库中查询id进行配置导航);/wiki/xxx,维基,就是教程了,也是先创建在配置导航;/discuss,论坛(系统内置);外部链接 |
| 11 | boards | 论坛 | 在管理控制台中的“讨论”功能中维护 |
| 12 | articles | 文章 | 在管理控制台中的“文章”功能中维护 |
| 13 | topics | 话题 | 文章中第一个评论,评论的答复在replies中。也是论坛的话题。文章评论和论坛话题混到一起,有点儿不清晰 |
| 14 | replies | 回复 | 文章中评论的回复,话题的回复 |
| 15 | attachments | 附件 | 例如文章中的图片,通过imageId指定到附件中的记录,附件记录中的resourceId,在resources表中以base64编码存储图片 |
| 16 | resources | 资源 | 资源存储表,比如存储文章、wiki中的图片,字段content需要将类型从mediumtext修改成LongText,支持高清的图片 |
| 17 | single_pages | 页面 | 在管理控制台中的“页面”功能中维护 |
| 18 | categories | 文章类型 | 是文章的分类,比如设置“程序人生”文章类别 |
| 19 | texts | 文本 | 存放文本,如文章(articles)通过textId将Markdown文本存储在这张表的一条记录中。每做一次修改保存就会在这里添加一条记录。content字段类型text需要修改为mediumtext以容纳更多的文字 |
这样 iTranswarp 就将所有的内容都存放到 MySQL 数据库中了,而不需要使用服务器文件系统,备份 CMS 网站就变成了备份数据库。在小型个人网站应用场景中,数据量不会特别大,这样的设计确实非常方便了。
## 2.4 系统角色
系统内有5种角色,由 Role 类来定义:
```java
package com.itranswarp.enums;
public enum Role {
ADMIN(0),
EDITOR(10),
CONTRIBUTOR(100),
SPONSOR(1_000),
SUBSCRIBER(10_000);
public final int value;
Role(int value) {
this.value = value;
}
}
```
# 3 使用说明
右上角地图图标是国际设定,支持英语和中文两种语言。
系统的设置、内容创作,都需要在系统内登录。
查看数据库 users 表,登录用户有5个,默认密码为 password:
| 用户名 | 用户邮箱 | 角色 | 密码 |
| ----------- | -------------------------- | ----------- | -------- |
| admin | [email protected] | ADMIN | password |
| editor | [email protected] | EDITOR | password |
| contributor | [email protected] | CONTRIBUTOR | password |
| sponsor | [email protected] | SPONSOR | password |
| subscriber | [email protected] | SUBSCRIBER | password |
系统的维护操作,都可以使用 admin 用户登录,使用管理控制台进行维护、内容创作。
管理控制台管理的内容,请参考“数据库表”小节中的“说明”列。
# 4 系统扩展
为了更好地维护网站内容,需要提供在线 api:
- 支持导入服务器本地指定目录下的 Markdown 文章(方便离线写作或其他网站备份下来的文章,并要将待导入文章中的图片下载解析并存入本 CMS 系统的数据库表中);
- 支持导入gitbook到 wiki 中(图片支持本地图片和网络图片的导入);
- 支持导出 wiki 到 gitbook 格式到服务器的某个目录并 zip 下载;
- 支持导出某一篇文章或某一些文章到服务器的某个目录并 zip 下载。
## 4.1 扩展工具类
对 iTranswarp 的工具类进行扩展或新增,以统一提供额外的功能。
### 4.1.1 图像处理类 ImageUtil
主要添加读取图像到字符数组的方法,供文章或wiki中的附件(图片)导入调用。
#### 4.1.1.1 readWebImageStream
对 ImageUtil 类进行扩展,添加 readWebImageStream 方法,使用apache HttpClients 组件,从网络上读取图片文件。
```java
/**
* 从网络链接获取图片
* @param imgUrl 网络图片地址Ø
* @param imgType 图片类型:jpeg|bmp|gif|png
* @return 存放图片的字节数组
* @throws Exception
*/
public static byte[] readWebImageStream(String imgUrl, String imgType) throws Exception {
byte[] bitImg;
CloseableHttpClient httpClient = HttpClients.createDefault();
CloseableHttpResponse response = null;
HttpGet httpGet = new HttpGet(imgUrl);
// 浏览器表示
httpGet.addHeader("User-Agent", "Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6)");
// 传输的类型
httpGet.addHeader("Content-Type", "image/" + imgType.toLowerCase());//有效类型为:image/jpeg image/bmp image/gif image/png
try {
// 执行请求
response = httpClient.execute(httpGet);
// 获得响应的实体对象
HttpEntity entity = response.getEntity();
// 包装成高效流
BufferedInputStream bis = new BufferedInputStream(entity.getContent());
ByteArrayOutputStream bos = new ByteArrayOutputStream();
byte[] byt = new byte[1024 * 8];
Integer len = -1;
while ((len = bis.read(byt)) != -1) {
bos.write(byt, 0, len);
}
bitImg = bos.toByteArray();
bos.close();
bis.close();
} finally {
// 释放连接
if (null != response) {
try {
response.close();
httpClient.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return bitImg;
}
```
#### 4.1.1.2 readLocalImageStream
从本地文件路径下读取文件,返回到字节数组中。
```java
/**
* 从本地文件中读取到字节数组
* @param fileName 文件路径
* @return
* @throws Exception
*/
public static byte[] readLocalImageStream(String fileName) throws Exception {
byte[] bitImg;
try (InputStream in = new FileInputStream(fileName)) {
ByteArrayOutputStream out = new ByteArrayOutputStream();
byte[] buffer = new byte[1024 * 8];
int n = 0;
while ((n = in.read(buffer)) != -1) {
out.write(buffer, 0, n);
}
bitImg = out.toByteArray();
}
return bitImg;
}
```
### 4.1.2 Markdown 文件处理类 MdFileUtil
这个类主要处理 Markdown 文件的操作。
#### 4.1.2.1 readLines(File file)
将文本文件(一般就是一个 Markdown 文件)按行读取文件到 List 中,后续需要提取其中的图片行,以供从网络上下载图片文件或读取本地图片文件,并以附件的形式导入到 iTranswarp 数据库中。
```java
/**
* 按行读取文件到List中
*
* @param file 待读取的文件
* @return 按行存储的list
* @throws FileNotFoundException
* @throws IOException
*/
public static List<String> readLines(File file) throws FileNotFoundException, IOException {
try (BufferedReader bf = new BufferedReader(new FileReader(file))) {
List<String> lines = new ArrayList<String>();
String line;
// 按行读取字符串
while ((line = bf.readLine()) != null) {
lines.add(line);
}
return lines;
}
}
```
#### 4.1.2.2 readLines(String content)
从文本 content(一般就是从网页维护传送到后台的一篇 Markdown 文本内容)读取内容到一个 List 中,后续需要提取其中的图片行,以供从网络上下载图片文件或读取本地图片文件,并以附件的形式导入到 iTranswarp 数据库中。
```java
/**
* 从文本中按行划分为List
*
* @param content
* @return
*/
public static List<String> readLines(String content) {
String[] strs = content.split(System.getProperty("line.separator"));
List<String> lines = Arrays.asList(strs);
return lines;
}
```
#### 4.1.2.3 readImageLines
从给定的 List(是按行存放的 Markdown 文本内容)中读取 image 标签的行到返回的 List 中,后续将从这个返回的图片 List 中获取 image 标签信息供从网络上下载图片文件或读取本地图片文件,并以附件的形式导入到 iTranswarp 数据库中。
```java
/**
* 获取图片标记行
*
* @param lines MD文件的所有行
* @return MD文件中的图片标记行
*/
public static Map<Integer, MdImageMarkBean> readImageLines(List<String> lines) {
Map<Integer, MdImageMarkBean> imgs = new HashMap<Integer, MdImageMarkBean>();
for (int i = 0; i < lines.size(); i++) {
String line = trimLeft(lines.get(i));
if (line.startsWith("
String imgUrl = line.substring(line.indexOf("](") + 2, line.lastIndexOf(")"));// 提取图片url地址
String imgTip = line.substring(line.indexOf("![") + 2, line.indexOf("]"));// 提取图片的描述信息
String imgType = "jpeg";// 提取图片的类型
if (line.indexOf(".png") != -1) {
imgType = "png";
} else if (line.indexOf(".jpg") != -1) {
imgType = "jpeg";
} else if (line.indexOf(".gif") != -1) {
imgType = "gif";
} else if (line.indexOf(".bpm") != -1) {
imgType = "bmp";
}
// 判断图片是否是web图片
String location = "local"; // 默认本地图片
if (line.indexOf("http://") != -1 || line.indexOf("https://") != -1) {
location = "web";
}
String imageMark = "";// 保存到当前文件的imges目录下
MdImageMarkBean imgBean = new MdImageMarkBean();// 创建这张图片的Map存储对象
imgBean.setLine(i);
imgBean.setUrl(imgUrl);
imgBean.setTip(imgTip);
imgBean.setType(imgType);
imgBean.setLocation(location);// 图片位置:本地local|网络web
imgBean.setImageMark(imageMark);// 更新过的图片标签
imgs.put(i, imgBean);
}
}
return imgs;
}
```
#### 4.1.2.4 writeFile(List\<String\> lines, File file)
将按行存储的 Markdown 内容(lines参数,这个时候,image 标签已经做了对应的替换,如从网络图片更换为本地文件)保存到文件中。
```java
/**
* 将按行存储的list写入文件
*
* @param lines
* @param file
* @throws IOException
*/
public static void writeFile(List<String> lines, File file) throws IOException {
try (FileWriter fw = new FileWriter(file)) {
for (int i = 0; i < lines.size(); i++) {
fw.write(lines.get(i));
fw.write(System.getProperty("line.separator"));
}
}
}
```
#### 4.1.2.5 writeFile(**byte**[] bytes, File file)
将字节数组(一般是从网络流中读取的网络图片)存储到本地文件,例如将简书文章中的网络图片下载保存到本地文件夹中。
```java
/**
* 将字节数组写入文件
*
* @param bytes
* @param file
* @throws IOException
*/
public static void writeFile(byte[] bytes, File file) throws IOException {
try (FileOutputStream fos = new FileOutputStream(file);
BufferedOutputStream bos = new BufferedOutputStream(fos)) {
bos.write(bytes);
}
}
```
## 4.2 扩展附件服务 AttachmentService 类
扩展 AttachmentService 类,添加2个方法向系统添加附件(也就导入MD文件中的图片)。
### 4.2.1 importWebAttachment
通过 url 导入 web 上的图片到附件中。
```java
/**
* 通过url导入网络图片创建附件
* @param user 当前登录用户
* @param url 图片的网络地址
* @param type 图片类型
* @param name 存入系统附件的名称
* @return
* @throws Exception
*/
@Transactional
public Attachment importWebAttachment(User user, String url, String type, String name) throws Exception {
AttachmentBean bean = new AttachmentBean();
byte[] img = ImageUtil.readWebImageStream(url, type);
bean.data = Base64.getEncoder().encodeToString(img);
bean.name = name;
return createAttachment(user, bean);
}
```
### 4.2.2 importLocalAttachment
通过文件路径,导入服务器本地指定文件路径下的图片到附件中。
```java
/**
* 导入本地文件(图片)创建附件
* @param user 当前登录用户
* @param url 服务器上文件绝对路径
* @param type 图片类型
* @param name 存入系统附件的名称
* @return
* @throws Exception
*/
@Transactional
public Attachment importLocalAttachment(User user, String url, String name) throws Exception {
AttachmentBean bean = new AttachmentBean();
byte[] img = ImageUtil.readLocalImageStream(url);
bean.data = Base64.getEncoder().encodeToString(img);
bean.name = name;
return createAttachment(user, bean);
}
```
## 4.3 导入文章
导入文章会根据文章的位置,分为本地文章和网络文章:
- 本地文章:Markdown文件及其以来的本地图片文件事先已经写好并上传到服务器的指定目录中;
- 网络文章:在网络上(CSDN或简书等)写好的文章,特点是图片都是上传在网络服务器上;
### 4.3.1 扩展文章服务 ArticleService 类
为其添加导入文章的服务方法 importArticle,在方法内部区分网络文章或本地文章的导入。
```java
/**
* 导入文章
*
* @param user 当前登录用户
* @param bean 从页面传递过来的文章值对象,其content做了区分复用(将就用了,不改了)
* @param source 源=local(本地导入)|web(网络导入)
* @return
* @throws Exception
*/
@Transactional
public Article importArticle(User user, ArticleBean bean, String source) throws Exception {
String hdImage = settingService.getWebsiteFromCache().hdImage;
boolean usingHD = false;
if (null != hdImage && hdImage.length() > 0) {
usingHD = hdImage.toLowerCase().equals("hd")? true: false;
}
Article article = new Article();
List<String> lines;
String fileDir = "";
if ("local".equals(source.trim().toLowerCase())) {// 将Markdown文件及其图片文件都上传到服务器了
File file = new File(bean.content);// bean.content 是借用来存储服务器上Markdown文件的绝对位置的,例如:/Users/kevin/temp/test.md
fileDir = file.getParent();// 服务器上存放Markdown文件的文件夹,供图片标签的相对路径用
lines = MarkdownFileUtil.readLines(file);// 读取MD源文件
} else {// 将Markdown文件内容复制到导入页面的文本块中上传到服务后台,值为web
lines = MarkdownFileUtil.readLines(bean.content);
}
Map<Integer, MarkdownImageBean> imgs = MarkdownFileUtil.readImageLines(lines);// 获取MD源文件中的图片标记
for (MarkdownImageBean img : imgs.values()) {
String url = img.getUrl();
String type = img.getType();
String tip = img.getTip();
String location = img.getLocation();
Attachment attachment = null;
if ("web".equals(location)) {// 如果是网络图片就导入到系统的附件中
attachment = attachmentService.importWebAttachment(user, url, type, tip);// 导入附件
} else {// 处理本地图片,图片标签一般是这样的: 
url = fileDir + System.getProperty("file.separator") + url; // 转换成服务器上的绝对文件路径
attachment = attachmentService.importLocalAttachment(user, url, tip);// 导入附件
}
long attachmentId = attachment.id;
img.setAttachmentId(attachmentId);
String articleImage;
if (usingHD) {
articleImage = "";//高清图
} else {
articleImage = "";
}
img.setImageMark(articleImage);// 替换图片标记为iTranswarp附件格式
if (article.imageId == 0) {// 导入的Article的封面图片使用文章的第一张图片
article.imageId = attachmentId;
}
}
// 更新原 MD 文件中的图片标记,并将所有的文章内容合并到一个字符串中
StringBuffer sb = new StringBuffer();
for (int i = 0; i < lines.size(); i++) {// 替换MD文件内容中的图片标签
if (imgs.containsKey(i)) {
lines.set(i, imgs.get(i).getImageMark());
}
sb.append(lines.get(i)).append(System.getProperty("line.separator"));// 合并更新了图片标记后的每一行
}
article.id = IdUtil.nextId();
article.userId = user.id;
article.categoryId = bean.categoryId;
article.name = bean.name;
article.description = bean.description;
article.publishAt = bean.publishAt;
article.tags = bean.tags;
article.textId = textService.createText(sb.toString()).id;
this.db.insert(article);
return article;
}
```
### 4.3.2 扩展 ApiController
为其添加方法 articleImportSource 和 articleImportLocal,供前端 ManageController 调用服务用。
```java
/**
* 从网络Markdown源文件导入
* @param bean
* @return
*/
@PostMapping("/articles/import/source")
@RoleWith(Role.CONTRIBUTOR)
public Article articleImportSource(@RequestBody ArticleBean bean) {
Article article = null;
try {
article = this.articleService.importArticle(HttpContext.getRequiredCurrentUser(), bean, "web");
} catch (Exception e) {
e.printStackTrace();
}
if (article != null) {
this.articleService.deleteArticlesFromCache(article.categoryId);
}
return article;
}
/**
* 从服务器本地 Markdown 文件导入,需要事先将 Markdown 文件scp到服务器上,用来维护现有离线文章的
* @param bean
* @return
*/
@PostMapping("/articles/import/local")
@RoleWith(Role.CONTRIBUTOR)
public Article articleImportLocal(@RequestBody ArticleBean bean) {
//bean.content 是借用来存储服务器上Markdown文件的绝对位置的,例如:/Users/kevin/temp/test.md
Article article = null;
try {
article = this.articleService.importArticle(HttpContext.getRequiredCurrentUser(), bean, "local");
} catch (Exception e) {
e.printStackTrace();
}
if (article != null) {
this.articleService.deleteArticlesFromCache(article.categoryId);
}
return article;
}
```
### 4.3.3 扩展 ManageController
提供两个方法 articleImportSource 和 articleImportLocal,连接前端页面和后端服务。
注意其中的 "action" 就是传递到页面供导入文章用的 rest 服务地址。
```java
/**
* 从网络 Markdown 源文件的导入,特点是文章中的图片存储在网络上
* @return
*/
@GetMapping("/article/article_import_source")
public ModelAndView articleImportSource() {
return prepareModelAndView("manage/article/article_import_source_form.html", Map.of("id", 0, "action", "/api/articles/import/source"));
}
/**
* 从服务器本地 Markdown 文件导入,特点是文章中的图片在本地
* @return
*/
@GetMapping("/article/article_import_local")
public ModelAndView articleImportLocal() {
return prepareModelAndView("manage/article/article_import_local_form.html", Map.of("id", 0, "action", "/api/articles/import/local"));
}
```
### 4.3.4 扩展页面
在文章列表页面,添加两个导入按钮,通过其 url 将其连接到两个导入页面:article_import_local_form.html 和 article_import_source_form.html。
```html
<div class="uk-margin">
<a href="javascript:refresh()" class="uk-button"><i class="uk-icon-refresh"></i> {{ _('Refresh') }}</a>
<a href="article_create" class="uk-button uk-button-primary uk-float-right"><i class="uk-icon-plus"></i>{{ _('New Article') }}</a>
<a href="article_import_source" class="uk-button uk-button-primary uk-float-right"><i class="uk-icon-plus"></i>{{ _('Import Article') }}</a>
<a href="article_import_local" class="uk-button uk-button-primary uk-float-right"><i class="uk-icon-plus"></i>{{ _('Import Local Article') }}</a>
</div>
```
新建的两个导入页面,拷贝自 article_form.html 并略做修改。
## 4.4 导入 wiki
一般而言,大型创作,比如一整套教程、一整本书,使用客户端本地创作还是相对更方便,比如使用 gitbook 管理书籍,使用 Typora 以 Markdown 格式书写内容,图片等处理都非常顺手。
所以就诞生了将 gitbook 写好的一整本书导入到 wiki 中来的需求:
1. 离线写好 gitbook;
2. 在系统内创建 wiki;
3. 将 gitbook 的所有文件上传到服务器某个目录下;
4. 系统提供界面,填写 gitbook 所在的文件路径,然后导入。
### 4.4.1 GitbookSummaryUtil 目录工具类
gitbook 使用 `SUMMARY.md` 文件来管理书籍目录,所以对 gitbook 的导入,主要就是处理这个目录文件内容。
首先创建目录行值对象类 `GitbookSummaryBean` ,存储目录行,并记录父目录信息。
```java
public class GitbookSummaryBean {
private String content;// 内容:“8个空格* [1.2.1 在路上](第01章 万事开头难/1.2.1onTheWay.md)”,3级内容
private String title;// 显示用的标题:“1.2.1 在路上”
private String markdownFile;// 文件地址:“第01章 万事开头难/1.2.1onTheWay.md”
private int level;// 当前页面所处的级别:3级
private int displayOrder;// 同层页面显示序号:0
private long id;// 当前页面的编码,导入wiki page后,就是数据库内的编码
private GitbookSummaryBean parent;// 当前这个目录文件的父文件,就是挂靠目录树用的
```
按顺序读取 `SUMMARY.md` 文件,将其存入 List 中,重点是同层序号 displayOrder 和目录的父目录的设定。
```java
/**
* 从Gitbook的summary文件中读取文章目录结构,不支持文件内页面锚点
*
* @param file
* @return
* @throws FileNotFoundException
* @throws IOException
*/
public static List<GitbookSummaryBean> readLines(File file) throws FileNotFoundException, IOException {
try (BufferedReader bf = new BufferedReader(new FileReader(file))) {
List<GitbookSummaryBean> summary = new ArrayList<GitbookSummaryBean>();
String line;
int[] displayOrders = new int[] { 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 };// 最多支持10级目录,第0级不用
GitbookSummaryBean[] parents = new GitbookSummaryBean[] { null, null, null, null, null, null, null, null, null, null, null };// 最多支持10级目录,第0级不用
int preLineLevel = 1;// 前一行的级别
int curLineLevel = 1;// 当前行的级别
// 按行读取字符串
while ((line = bf.readLine()) != null) {
String tempLine = line;
if (!tempLine.trim().startsWith("* [")) {// 跳过不是目录的行
continue;
}
GitbookSummaryBean bean = new GitbookSummaryBean();
bean.setContent(line);
bean.setTitle(line.substring(line.indexOf("* [") + 3, line.indexOf("](")));
bean.setMarkdownFile(line.substring(line.indexOf("](") + 2, line.lastIndexOf(")")));
// 解析line到bean:“8个空格* [1.2.1 在路上](第01章 万事开头难/1.2.1onTheWay.md)”
if (line.startsWith("* [")) {// 一级内容,如“* [第01章 万事开头难](第01章 万事开头难/Start.md)”
curLineLevel = 1;
} else {// 非一级内容,用空格解析
String s = line.substring(0, line.indexOf("* ["));// 左边的空格
curLineLevel = s.length() / 4 + 1;
}
bean.setLevel(curLineLevel);// 当前目录行级别
bean.setParent(parents[curLineLevel]);// 当前页面的父页面
parents[curLineLevel + 1] = bean; // 当前页面就是后续下级页面的父页面
if (curLineLevel == preLineLevel) {// 同级
bean.setDisplayOrder(displayOrders[curLineLevel]);
displayOrders[curLineLevel] = displayOrders[curLineLevel] + 1;// 当前编号+1,为下一行做准备
}
if (curLineLevel > preLineLevel) {// 向下降级
bean.setDisplayOrder(0);// 重新编号
displayOrders[curLineLevel] = displayOrders[curLineLevel] + 1;// 当前编号+1,为下一行做准备
}
if (curLineLevel < preLineLevel) {// 向上升级,沿用既有编号
for (int i = curLineLevel; i < displayOrders.length - 1; i++) {// 将当前级以下的全部置0,重新编号
displayOrders[i + 1] = 0;
parents[curLineLevel] = null;
}
bean.setDisplayOrder(displayOrders[curLineLevel]);
}
summary.add(bean);
preLineLevel = curLineLevel;// 下一行的前一行就是当前行
}
return summary;
}
}
```
### 4.4.2 扩展 WikiService 类
在 wiki 服务类中增加 `importWiki` 方法:创建带父子关系的 wiki page,并将 Markdown 文件内容导入page 中,其中的图片,导入系统附件。
```java
/**
* @throws Exception
* 从gitbook导入wiki
* @param user
* @param bean
* @return
* @throws IOException
* @throws
*/
@Transactional
public Wiki importWiki(User user, WikiImportBean bean) throws Exception {
String hdImage = settingService.getWebsiteFromCache().hdImage;
boolean usingHD = false;
if (null != hdImage && hdImage.length() > 0) {
usingHD = hdImage.toLowerCase().equals("hd")? true: false;
}
long wikiId = bean.wikiId;
Wiki wiki = this.getById(wikiId);
String fileName = bean.gitbookPath + System.getProperty("file.separator") + "SUMMARY.md";
List<GitbookSummaryBean> list = GitbookSummaryUtil.readLines(new File(fileName));
for (GitbookSummaryBean summary: list) {
long parentId;
if (summary.getParent() == null) { // 没有父节点的是“第1章”这样的,直接挂到wiki下
parentId = wikiId;
} else {
parentId = summary.getParent().getId();
}
//处理页面文件中的附件(图片)
String pageFile = bean.gitbookPath + System.getProperty("file.separator") + summary.getMarkdownFile();
List<String> lines = MarkdownFileUtil.readLines(new File(pageFile));//页面内容
Map<Integer, MarkdownImageBean> imgs = MarkdownFileUtil.readImageLines(lines);// 获取MD源文件中的图片标记
for (MarkdownImageBean img : imgs.values()) {
String url = img.getUrl();
String type = img.getType();
String tip = img.getTip();
String location = img.getLocation();
Attachment attachment = null;
if ("web".equals(location)) {// 如果是网络图片就导入到系统的附件中
attachment = attachmentService.importWebAttachment(user, url, type, tip);// 导入附件
} else {// 处理本地图片,图片标签一般是这样的: 
url = pageFile.subSequence(0, pageFile.lastIndexOf("/") + 1) + url; // 转换成服务器上的绝对文件路径
attachment = attachmentService.importLocalAttachment(user, url, tip);// 导入附件
}
long attachmentId = attachment.id;
img.setAttachmentId(attachmentId);
String imageMark;
if (usingHD) {
imageMark = "";//高清图
} else {
imageMark = "";
}
img.setImageMark(imageMark);// 替换图片标记为iTranswarp附件格式
}
// 更新页面文件中的图片标记,并将所有的页面内容合并到一个字符串中
StringBuffer sbPage = new StringBuffer();
for (int i = 0; i < lines.size(); i++) {// 替换MD文件内容中的图片标签
if (imgs.containsKey(i)) {
lines.set(i, imgs.get(i).getImageMark());
}
sbPage.append(lines.get(i)).append(System.getProperty("line.separator"));// 合并更新了图片标记后的每一行
}
WikiPage page = new WikiPage();
page.wikiId = wikiId;
page.parentId = parentId;
page.name = summary.getTitle();
page.publishAt = wiki.publishAt;//使用wiki的发布时间,一家人就是要整整齐齐嘛
page.textId = textService.createText(sbPage.toString()).id;
page.displayOrder = summary.getDisplayOrder();
this.db.insert(page);
summary.setId(page.id);//供后续获取父页面id用
}
return wiki;
}
```
### 4.4.3 扩展 ApiController 类
首先创建 WikiImportBean 值对象,用来存储从页面上传递回控制器的信息。
```java
public class WikiImportBean extends AbstractRequestBean {
public String gitbookPath;
public long wikiId;
public long publishAt;
public String content = "New wiki page content";//默认wiki页面的内容
@Override
public void validate(boolean createMode) {
}
}
```
在 ApiController 类中添加 wikiImport 方法,将 gitbook 导入系统。
```java
@PostMapping("/wikiImport")
@RoleWith(Role.EDITOR)
public Wiki wikiImport(@RequestBody WikiImportBean bean) {
Wiki wiki = wikiService.getById(bean.wikiId);
try {
wiki = this.wikiService.importWiki(HttpContext.getRequiredCurrentUser(), bean);
} catch (Exception e) {
e.printStackTrace();
}
this.wikiService.removeWikiFromCache(wiki.id);
return wiki;
}
```
### 4.4.3 修改 wiki_list.html 页面
在 wiki 行的操作列添加一个按钮,接收 gitbook 在服务器上的文件路径,然后调用后台方法,导入 wiki:
```javascript
importBook: function (w) {// 从gitbook导入wiki
var now = Date.now();
UIkit.modal.prompt("{{ _('Gitbook在服务器上的位置') }}:", "{{ _('/Users/kevin/temp/demobook') }}", function (path) {
postJSON('/api/wikiImport', {
wikiId: w.id,
gitbookPath: path,
publishAt: now,
content: 'New wiki page content'
}, function(err, result) {
if (err) {
showError(err);
return;
}
});
});
}
```
## 4.5 用户维护
个人网站,为了避免内容审核维护工作,初期不提供用户评论功能。
所以,需要增加本地用户维护功能:新增用户和用户密码修改(仅限管理员增加,不支持陌生人自行注册)。
用户通过页面登录时,传递到后端的密码不是明文,而是加密处理过的值,如下:
```html
<script src="/static/js/3rdparty/sha256.js"></script>
$('#hashPasswd').val(sha256.hmac(email, pwd));
```
新增 user_form.html 文件,提供用户注册功能,配套提供后台服务代码。
修改 user_list.html 文件,提供用户密码修改功能,同样修改后台服务代码。
## 4.6 图片显示
iTranswarp 中的 文章和wiki,在显示图片时,为了节约网络流量,对图片做了处理,导致图片显示不清晰。
FileController 这个类的 process 方法通过 `attachmentService.downloadAttachment(id, size);` 获取不同大小的图片,并输出到HttpServletResponse 中,供前端浏览器显示用。
```java
@GetMapping("/files/attachments/" + ID)
public void process(@PathVariable("id") long id, HttpServletResponse response) throws IOException {
process(id, '0', response);
}
@GetMapping("/files/attachments/" + ID + "/0")
public void process0(@PathVariable("id") long id, HttpServletResponse response) throws IOException {
process(id, '0', response);
}
@GetMapping("/files/attachments/" + ID + "/l")
public void processL(@PathVariable("id") long id, HttpServletResponse response) throws IOException {
process(id, 'l', response);
}
@GetMapping("/files/attachments/" + ID + "/m")
public void processM(@PathVariable("id") long id, HttpServletResponse response) throws IOException {
process(id, 'm', response);
}
@GetMapping("/files/attachments/" + ID + "/s")
public void processS(@PathVariable("id") long id, HttpServletResponse response) throws IOException {
process(id, 's', response);
}
void process(long id, char size, HttpServletResponse response) throws IOException {
DownloadBean bean = attachmentService.downloadAttachment(id, size);
response.setContentType(bean.mime);
response.setContentLength(bean.data.length);
response.setHeader("Cache-Control", maxAge);
@SuppressWarnings("resource")
ServletOutputStream output = response.getOutputStream();
output.write(bean.data);
output.flush();
}
```
可以在导入文章或 wiki 时,根据扩展后的 Website.hdImage 属性设置显示文章的大小,高清就使用这样的图片链接:``
> 系统上新建文章或 wiki(页面)时,暂不处理。
>
> 可以在新建/修改文章或 wiki 页面的 Markdown 文本中将图片标记的最后一个字符修改为 0 来显示高清图片。
## 4.7 小结
导入文章和导入 wiki 这两个功能使用频率不高,所以页面及后台代码并没有做太多的设计,够用就好。
经测试,一本 500+ 页的 gitbook 导入,在我的开发笔记本上导入时间小于30秒。
修改的版本在[这里](https://github.com/gyzhang/itranswarp),欢迎fork,欢迎star。
Kevin,2020年5月20日,成都。 | 31,330 | Apache-2.0 |
# PyPI に自作の python package を登録する方法
<!-- markdownlint-disable MD046 code-block-style -->
## 必要となる背景知識
以下の項目の解説は行わないのですが、検索すると直ぐに出てくると思いますので、必要に応じてご確認下さい。
- pyenv-virtualenv, pipenv などの python仮想環境の作成方法
- python package 作成方法の詳細
- PyPI サイトでのアカウント作成、登録方法
## 前準備
### 確認した version
```text
Python 3.8.5
pip 21.0.1
setuptools 50.3.2
twine 3.4.1
wheel 0.35.1
```
### フォルダ構成の例
. <--- 作業用フォルダ
├── README.md
├── build <-自動生成
├── dist <-自動生成
├── <package_name>
│ ├── __init__.py
│ └── __main__.py
├── <package_name>.egg-info <-自動生成
├── setup.cfg <-作成
└── setup.py <-作成
- 作業用フォルダを git で管理している場合には、`.gitignore` に以下を追加しておく。これらのフォルダ中のデータは作業後消去可能。
```.gitignore
build/
dist/
<package_name>.egg-info/
```
## 自作 python package 登録までの手順
1. `setup.py` に以下のみを記載
```python
from setuptools import setup
setup()
```
- 注記 [setup.cfg-only projects](https://setuptools.readthedocs.io/en/latest/setuptools.html#setup-cfg-only-projects) によると、"setuptools >= 40.9.0" においては、setup.py は後方互換性の確保とバグ対策のためのファイルとなっており、詳細は setup.cfg に記載する。
1. setup.cfg の作成
- setup.cfg 記載方法の詳細は検索すると出てきます。
- 動作確認に使用した setup.cfg を[こちら](https://github.com/KazKobara/ebcic/blob/master/setup.cfg)に置いてあります。
- 注意点や助言:
- install_requires, python_requires は以下のテストの段階で動作を確認しながら決める。
- install_requires で指定可能な `;` はその後ろの条件が True の場合にのみその前のパッケージが必要となるという意味。
- 例えば、以下は python_version が 2.6 の場合には importlib を求めるという意味。(version 2.6 の python を求めるという意味ではないことに注意!!)
```text
install_requires =
importlib; python_version == "2.6"
```
1. soft と binary の dist を作成しチェック
以下のコマンドを実行
```console
pip install twine wheel
python setup.py sdist bdist_wheel
twine check ./dist/*
```
以下のように `PASSED` が表示されれば次に進む。
```text
Checking dist/<package_name>-<version>*: PASSED
```
1. テスト環境を作り、そこに上記 dist 下につくられたローカルパッケージをインストールしテスト
- Pythonの仮想環境などを用いてテスト環境を作り、そこにテストする version の Python とデフォルトのパッケージのみが入った状態にする。
- 以下のコマンドにより <package_name> をインストール
```console
pip install --no-index --find-links=<上記でチェックしたdistへのPATH>/dist <package_name>
```
```text
ERROR: Could not find a version that satisfies the requirement scipy (from ebcic)
ERROR: No matching distribution found for scipy
```
- 上記のエラーメッセージのように他のパッケージの不足やインストールが求められたら、それらをインストールすると共に、それらのパッケージ名を setup.cfg の `install_requires =` の下に1行づつ入れる。
- (パッケージ間の依存関係により、パッケージのインストール順序を変えると上記に記述すべきパッケージの数は変わるため、なるべく規模の大きなパッケージからインストールするとよい。)
- なお、 `pip install --no-index --find-links=` によるローカルフォルダからのパッケージインストールでは、`install_requires =` に記載したパッケージは自動インストールされないため、インストールしたパッケージの動作確認が終われば次に進む。
- `pip list` により意図する version の <package_name> がインストールされていることが確認できれば、<package_name> の動作を確認する。
1. PyPI テストサイトおよび本番サイトへのユーザ登録
- [PyPI本番サイトのユーザ登録ページ](https://test.pypi.org/account/register/)および[PyPIテストサイトのユーザ登録ページ](https://pypi.org/account/register/)でそれぞれユーザ登録する。
- 登録情報は同じでも違ってもよい。
1. 登録コマンド省略するための設定
- 必要に応じ以下の内容を `~/.pypirc` に記載。
```text
[distutils]
index-servers =
pypi
testpypi
[pypi]
repository: https://upload.pypi.org/legacy/
username: <上記で登録したユーザ名>
# password: <パスワードは記載しない>
[testpypi]
repository: https://test.pypi.org/legacy/
username: <上記で登録したユーザ名>
# password: <パスワードは記載しない>
```
1. PyPI テストサイトへのアップロードとインストール
- PyPI 本番およびテストサイトでは、いずれも、登録したパッケージの削除は可能であるが、一度登録した version 番号に対してはそのパッケージを削除したとしても、**同じversion 番号で別のパッケージを登録することはできない**
- PyPI の本番およびテストサイトは独立しているため、それらに同じ version 番号で違う内容を登録することはできる。
- そのため、まずは PyPIのテストサイトを用いて登録のテストを行うこと。
- 以下のコマンドで PyPI テストサイトへアップロード
```console
twine upload -r testpypi dist/<package_name>-<version>*
```
- 初期状態に戻したテスト環境(Python仮想環境)へ移動し、パッケージをダウンロードし動作をテスト。
```console
pip install -i https://test.pypi.org/simple/ <package_name>==<version>
```
1. PyPI テストサイトへのアップロードとインストール
- 以下のコマンドで PyPI 本番サイトへアップロード
```console
twine upload -r pypi dist/<package_name>-<version>*
```
- 初期状態に戻したテスト環境(Python仮想環境)へ移動し、パッケージをダウンロードし動作をテスト。
```console
pip install ebcic==<version>
```
---
[homeに戻る](https://kazkobara.github.io/) | 4,435 | MIT |
---
title: Wierd JavaScript - 37:函式程式設計(二)
tags:
- Wierd JavaScript
date: 2019-09-05 16:44:45
---
透過資源庫培養函式程式設計的思維!
<!-- more -->
## 開源教育
---
**Underscore** 就像 jQuery 一樣,是一個知名的 JavaScript **資源庫(Library)**,內含許多處理陣列、物件以及函式的語法。
類似功能的資源庫還有後起之秀 **Lodash** ,它也包括處理陣列、物件以及陣列的語法,且效率更好,速度更快,逐漸取代 Underscore.js 成為主流。
相關連結:
* [Underscore](https://underscorejs.org/#)
* [Lodash](https://lodash.com/)
課程講師鼓勵我們透過閱讀、解析這些框架(Frame)、資源庫的原始碼,去深入理解函式程式設計的方法與原理,這個過程符合**開源教育(Open Source Education)**的精神。
我們可以點擊上方連結,到 Underscore 的官方網站,下載 Development(擁有註解) 的版本,並在 Visual Studio 中打開 `underscore.js` ,從中檢視原始碼撰寫的設計原理。
## Underscore.js
---
檢視 `underscore.js` 的原始碼,我們會發現所有程式碼都被包在一個 IIFE 裡面,保證我們載入這個 Library 後,其內容不會與我們撰寫的程式碼產生衝突。
載入 `underscore.js` :
```html
<html>
<head></head>
<body>
...
<script scr="underscore.js"></script>
<script scr="app.js"></script> // 我們自己撰寫的 JavaScript
</body>
</html>
```
使用 `underscore.js` 的語法:
```javascript
var arr1 = _.map([1, 2, 3, 4, 5], function(item){
return item * item ;
})
var arr2 = _.filter([1, 2, 3, 4, 5, 6], function(item){
return item % 2 === 0 ;
})
console.log(arr1) ;
console.log(arr2) ;
```
## 結論
---
* 找各式各樣的 JavaScript 框架或資源庫(Library)來玩,閱讀、理解它們的原始碼,培養程式設計的經驗與感覺。
## 參考資料
---
1. JavaScript 全攻略:克服 JS 奇怪的部分 4-52 | 1,279 | MIT |
---
title: 排查 Azure 专用终结点连接问题
description: 有关诊断专用终结点连接的分步指导
services: private-endpoint
documentationcenter: na
author: rockboyfor
manager: digimobile
editor: ''
ms.service: private-link
ms.devlang: na
ms.topic: troubleshooting
ms.tgt_pltfrm: na
ms.workload: infrastructure-services
origin.date: 01/31/2020
ms.date: 06/15/2020
ms.author: v-yeche
ms.openlocfilehash: 5b08e31995f186fe8cc8efd3b105d2099241f8f2
ms.sourcegitcommit: 3de7d92ac955272fd140ec47b3a0a7b1e287ca14
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 06/12/2020
ms.locfileid: "84723743"
---
# <a name="troubleshoot-azure-private-endpoint-connectivity-problems"></a>排查 Azure 专用终结点连接问题
本文提供了有关验证和诊断 Azure 专用终结点连接设置的分步指导。
Azure 专用终结点是一个网络接口,可以通过私密且安全的方式连接到专用链接服务。 此解决方案提供从虚拟网络到 Azure 服务资源的专用连接,帮助保护 Azure 中的工作负荷。 此解决方案可以有效地将这些服务接入虚拟网络。
下面是专用终结点可用的连接方案:
- 同一区域中的虚拟网络
- 区域对等互连的虚拟网络
- 全球对等互连的虚拟网络
- 基于 VPN 或 Azure ExpressRoute 线路的客户本地连接
## <a name="diagnose-connectivity-problems"></a>诊断连接问题
查看下面的步骤,确保所有一般配置都符合预期,以解决专用终结点的连接问题。
1. 通过浏览资源来查看专用终结点配置。
a. 转到“专用链接中心”****。

b. 在左侧窗格中,选择“专用终结点”。****

c. 筛选并选择要诊断的专用终结点。
d. 查看虚拟网络和 DNS 信息。
- 验证连接状态是否为“已批准”****。
- 确保 VM 已连接到托管专用终结点的虚拟网络。
- 检查是否分配了 FQDN 信息(复制)和专用 IP 地址。

1. 使用 [Azure Monitor](/azure-monitor/overview) 查看是否有数据在流动。
a. 在“专用终结点”资源中,选择“监视”****。
- 选择“传入数据”**** 或“传出数据”**** - 查看在尝试连接到专用终结点时是否有数据在流动。 预计延迟大约为 10 分钟。

1. 使用 Azure 网络观察程序中的“VM 连接故障排除”****。
a. 选择客户端 VM。
b. 选择“连接故障排除”****,然后选择“出站连接”**** 选项卡。

c. 选择“使用网络观察程序进行详细的连接跟踪”****。

d. 选择“按 FQDN 进行测试”****。
- 从专用终结点资源粘贴 FQDN。
- 提供一个端口。 通常,对于 Azure 存储或 Azure Cosmos DB,请使用 443;对于 SQL,请使用 1336。
e. 选择“测试”,验证测试结果****。

1. 测试结果中的 DNS 解析必须包含分配给专用终结点的同一专用 IP 地址。
a. 如果 DNS 设置不正确,请执行以下步骤:- 如果使用专用区域:- 请确保客户端 VM 虚拟网络与专用区域相关联。
- 检查是否存在专用 DNS 区域记录。 如果不存在,请创建它。
- 如果使用自定义 DNS:- 检查你的自定义 DNS 设置,并验证 DNS 配置是否正确。
有关指南,请参阅[专用终结点概述:DNS 配置](/private-link/private-endpoint-overview#dns-configuration)。
b. 如果连接由于网络安全组 (NSG) 或用户定义的路由而失败:- 请查看 NSG 出站规则,并创建合适的出站规则以允许流量。

1. 如果连接的验证结果符合预期,则连接问题可能与应用层的其他方面(例如机密、令牌和密码)相关。
- 在这种情况下,请检查与专用终结点关联的专用链接资源的配置。 有关详细信息,请参阅 [Azure 专用链接故障排除指南](troubleshoot-private-link-connectivity.md)。
1. 如果问题仍未解决,并且连接问题仍然存在,请联系 [Azure 支持](https://support.azure.cn/support/support-azure/)团队。
## <a name="next-steps"></a>后续步骤
* [在更新的子网上创建专用终结点(Azure 门户)](/private-link/create-private-endpoint-portal)
* [专用链接故障排除指南](troubleshoot-private-link-connectivity.md)
<!-- Update_Description: new article about troubleshoot private endpoint connectivity -->
<!--NEW.date: 02/24/2020--> | 3,445 | CC-BY-4.0 |
---
layout: post
Date: 2015-01-30 12:00:00 +0800
title: '使用 mitmproxy 代理 JAVA 应用 HTTPS 请求'
tags: [java, https, proxy]
last_modified_at: 2016-08-25 15:20:00 +0800
---
## 背景问题
设置 `-Dhttps.proxyHost=localhost -Dhttps.proxyPort=8080` 使 JAVA 应用所有 HTTPS 请求经过 [mitmproxy][mp] 代理发出. 结果得到下面的错误:
[mp]: http://mitmproxy.org
> Server access Error: sun.security.validator.ValidatorException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested ...
<!--more-->
### 环境
```
Mac OSX 10.10.2
java version "1.7.0_55"
Java(TM) SE Runtime Environment (build 1.7.0_55-b13)
Java HotSpot(TM) 64-Bit Server VM (build 24.55-b03, mixed mode)
```
## 解决方案
将 [mitmproxy][mp] 的证书导入到 JDK 默认的 keystore 中:
```
sudo keytool -importcert -alias mitmproxy \
-keystore <keystore_path> \
-storepass <password> \
-trustcacerts \
-file ~/.mitmproxy/mitmproxy-ca-cert.pem
```
> password 默认是 changeit
### 查明 keystore 路径
```
scala -e 'import java.net._; new URL("https://www.wacai.com").openConnection.asInstanceOf[HttpURLConnection].disconnect' -Djavax.net.debug=SSL | grep "trustStore is"
```
The end. | 1,163 | MIT |
---
layout: post
category: C++
title: Vector与String数组的转换
tags: C++
---
  读入一组 string 类型的数据,并将它们存储在 vector 中。接着,把该 vector 对象复制给一个字符指针数组。为 vector 中的 每个元素创建一个新的字符数组,并把该 vector 元素的数据复制到相应的字符 数组中,最后把指向该数组的指针插入字符指针数组。
<!--more-->
### Vector与String数组的转换
{% highlight C++ %}
#include <iostream>
#include <vector>
#include <string>
using namespace std;
int main() {
vector<string> svec;
string str;// 输入 vector 元素
cout << "Enter strings:(Ctrl+Z to end)" << endl;
while (cin >> str)
svec.push_back(str);
// 创建字符指针数组
char **parr = new char*[svec.size()];
// 处理 vector 元素
size_t ix = 0;
for (vector<string>::iterator iter = svec.begin(); iter != svec.end(); ++iter, ++ix) {
// 创建字符数组
char *p = new char[(*iter).size()+1];
// 复制 vector 元素的数据到字符数组
strcpy(p, (*iter).c_str());
// 将指向该字符数组的指针插入到字符指针数组
parr[ix] = p;
}
// 释放各个字符数组
for (ix =0; ix != svec.size(); ++ix)
delete [] parr[ix];
// 释放字符指针数组
delete [] parr;
return 0;
}
{% endhighlight %}
### 外层循环中不使用typedef定义的类型,遍历二维数组元素
{% highlight C++ %}
#include <iostream>
using namespace std;
int main() {
//3 个元素,每个元素是一个有4个 int 元素的数组
int ia[3][4] = \{\{1, 2, 3, 4\}, \{5, 6, 7, 8\}, \{9, 10, 11, 12 \}\};
int (*p)[4];
for (p = ia; p != ia + 3; ++p)
for (int *q = *p; q != *p + 4; ++q)
cout << *q << endl;
return 0;
}
{% endhighlight %} | 1,470 | MIT |
---
layout: post
title: "劳工|工伤不是意外"
date: 2021-02-05T11:59:06.000Z
author: 多数派Masses
from: https://matters.news/@masses2020/%25E5%258A%25B3%25E5%25B7%25A5-%25E5%25B7%25A5%25E4%25BC%25A4%25E4%25B8%258D%25E6%2598%25AF%25E6%2584%258F%25E5%25A4%2596-bafyreiggc2gstkuokpf6y2lpgkbvh4redhaiapqikmk7khaifz7ddzjzbm
tags: [ Matters ]
categories: [ Matters ]
---
<!--1612526346000-->
[劳工|工伤不是意外](https://matters.news/@masses2020/%25E5%258A%25B3%25E5%25B7%25A5-%25E5%25B7%25A5%25E4%25BC%25A4%25E4%25B8%258D%25E6%2598%25AF%25E6%2584%258F%25E5%25A4%2596-bafyreiggc2gstkuokpf6y2lpgkbvh4redhaiapqikmk7khaifz7ddzjzbm)
------
<div>
劳工|工伤不是意外
</div> | 632 | MIT |
# 进阶用法(@todo)
### 介绍
通过本章节你可以了解到一些进阶用法,比如多种浏览器适配方式。
## 浏览器适配
### Rem 布局适配
样式默认使用 `px` 作为单位,如果需要使用 `rem` 单位,推荐使用以下两个工具:
- [postcss-pxtorem](https://github.com/cuth/postcss-pxtorem) 是一款 postcss 插件,用于将单位转化为 rem
- [lib-flexible](https://github.com/amfe/lib-flexible) 用于设置 rem 基准值
#### PostCSS 配置
下面提供了一份基本的 postcss 配置,可以在此配置的基础上根据项目需求进行修改。
```js
module.exports = {
plugins: {
autoprefixer: {
browsers: ['Android >= 4.0', 'iOS >= 8'],
},
'postcss-pxtorem': {
rootValue: 37.5,
propList: ['*'],
},
},
};
```
> Tips: 在配置 postcss-loader 时,应避免 ignore node_modules 目录,否则将导致 react-vant 样式无法被编译。
### 触摸事件模拟
这是一个面向移动端的组件库,因此默认只适配了移动端设备,这意味着组件只监听了移动端的 `touch` 事件,没有监听桌面端的 `mouse` 事件。
如果你需要在桌面端使用,可以引入我们提供的 [@vant/touch-emulator](https://github.com/youzan/vant/tree/dev/packages/vant-touch-emulator),这个库会在桌面端自动将 `mouse` 事件转换成对应的 `touch` 事件,使得组件能够在桌面端使用。
```bash
# 安装模块
npm i vant/touch-emulator -S
```
```js
// 引入模块后自动生效
import '@vant/touch-emulator';
```
### 底部安全区适配
iPhone X 等机型底部存在底部指示条,指示条的操作区域与页面底部存在重合,容易导致用户误操作,因此我们需要针对这些机型进行安全区适配。部分组件提供了 `safe-area-inset-top` 或 `safe-area-inset-bottom` 属性,设置该属性后,即可在对应的机型上开启适配,如下示例:
```jsx
<!-- 在 head 标签中添加 meta 标签,并设置 viewport-fit=cover 值 -->
<meta
name="viewport"
content="width=device-width, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0, viewport-fit=cover"
/>
<!-- 开启顶部安全区适配 -->
<van-nav-bar safe-area-inset-top />
<!-- 开启底部安全区适配 -->
<van-number-keyboard safe-area-inset-bottom />
```
<img src="https://img.yzcdn.cn/vant/safearea.png"> | 1,541 | MIT |
# 通行证
* 组织管理
* 用户管理
* 权限管理
## 注册
1.邮箱+密码
2.手机号+验证码+密码
## 登录
1.邮箱+密码
2.手机号+验证码+密码
## 重置密码
1.邮箱+旧密码+密码
2.1 发验证邮件
2.2 验证邮件中的url
2.3 邮箱+新密码
3.1 发验证短信
3.2 手机号+验证码+新密码
## 找回密码
邀请码表
/**
* 注册激活码
*/
@Column
String activate_code | 251 | Apache-2.0 |