
code
stringlengths 30
403k
| size
int64 31
406k
| license
stringclasses 10
values |
|---|---|---|
---
layout: post
title: "LINUX系统epoll函数原理"
date: 2019-06-10 23:00:00 +0800
author: "simba"
header-img: "img/post-bg-miui6.jpg"
tags:
- linux
---
在介绍epoll之前,先来说一下select的不足之处,和epoll的改进:
* 一个进程内,select能打开的fd是有限制的,由宏FD_SETSIZE设置,默认值是1024.在某些时候,这个数值是远远不够用的.解决办法有两种,一是修改宏然后重新编译内核,但与此同时会引起网络效率的下降;二是使用多进程来解决,但是创建多个进程是有代价的,而且进程间数据同步没有多线程间方便.
而epoll没有这个限制,它所支持的最大FD上限远远大于1024,在1GB内存的机器上是10万左右(具体数目可以cat /proc/sys/fs/file-max查看).
* select函数每次都是当监听的套接组有事件产生时就会返回,但却不能将有事件产生的套接字筛选出来,而是改变其在套接组的标志量,所以每次监听到事件,都需要将套接组整个遍历一遍.时间复杂度是O(n).当FD数目增加时,效率会线性下降.
而epoll,每次会将监听套结字中产生事件的套接字加到一列表中,然后我们可以直接对此列表进行操作,而没有产生事件的套接字会被过滤掉,极大的提高了IO效率.这一点尤其在套接字监听数量巨大而活跃数量很少的时候很明显.
#### epoll的相关系统调用
epoll有epoll_create, epoll_ctl, epoll_wait 3个系统调用.
<br>
<br>
a. int epoll_create(int size);
创建一个epoll的句柄.自从linux2.6.8之后,size参数是被忽略的.需要注意的是,当创建好epoll句柄后,它就是会占用一个fd值,在linux下如果查看/proc/进程id/fd/,是能够看到这个fd的,所以在使用完epoll后,必须调用close()关闭,否则可能导致fd被耗尽.
<br>
<br>
b. int epoll_ctl(int epfd, int op, int fd, struct epoll_event \*event);
epoll的事件注册函数,它不同于select()是在监听事件时告诉内核要监听什么类型的事件,而是在这里先注册要监听的事件类型.<br>
  第一个参数是epoll_create()的返回值.<br>
  第二个参数表示动作,用三个宏来表示:
* EPOLL_CTL_ADD:注册新的fd到epfd中;
* EPOLL_CTL_MOD:修改已经注册的fd的监听事件;
* EPOLL_CTL_DEL:从epfd中删除一个fd;
  第三个参数是需要监听的fd.<br>
  第四个参数是告诉内核需要监听什么事,struct epoll_event结构如下:
```
//保存触发事件的某个文件描述符相关的数据(与具体使用方式有关)
typedef union epoll_data {
void *ptr;
int fd;
__uint32_t u32;
__uint64_t u64;
} epoll_data_t;
//感兴趣的事件和被触发的事件
struct epoll_event {
__uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
```
  events可以是以下几个宏的集合:
* EPOLLIN:表示对应的文件描述符可以读(包括对端SOCKET正常关闭);
* EPOLLOUT:表示对应的文件描述符可以写;
* EPOLLPRI:表示对应的文件描述符有紧急的数据可读(这里应该表示有带外数据到来);
* EPOLLERR:表示对应的文件描述符发生错误;
* EPOLLHUP:表示对应的文件描述符被挂断;
* EPOLLET:将EPOLL设为边缘触发(Edge Triggered)模式,这是相对于水平触发(Level Triggered)来说的.
* EPOLLONESHOT:只监听一次事件,当监听完这次事件之后,如果还需要继续监听这个socket的话,需要再次把这个socket加入到EPOLL队列里.
c. int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
收集在epoll监控的事件中已经发送的事件.参数events是分配好的epoll_event结构体数组,epoll将会把发生的事件赋值到events数组中(events不可以是空指针,内核只负责把数据复制到这个events数组中,不会去帮助我们在用户态中分配内存).maxevents告之内核这个events有多大,这个 maxevents的值不能大于创建epoll_create()时的size,参数timeout是超时时间(毫秒,0会立即返回,-1将不确定,也有说法说是永久阻塞).如果函数调用成功,返回对应I/O上已准备好的文件描述符数目,如返回0表示已超时.
#### LT和ET
LT(level triggered)是epoll缺省的工作方式,并且同时支持block和no-block socket.在这种做法中,内核告诉你一个文件描述符是否就绪了,然后你可以对这个就绪的fd进行IO操作.如果你不作任何操作,内核还是会继续通知你的,所以,这种模式编程出错误可能性要小一点.传统的select/poll都是这种模型的代表.
ET (edge-triggered)是高速工作方式,只支持no-block socket,它效率要比LT更高.ET与LT的区别在于,当一个新的事件到来时,ET模式下当然可以从epoll_wait调用中获取到这个事件,可是如果这次没有把这个事件对应的套接字缓冲区处理完,在这个套接字中没有新的事件再次到来时,在ET模式下是无法再次从epoll_wait调用中获取这个事件的.而LT模式正好相反,只要一个事件对应的套接字缓冲区还有数据,就总能从epoll_wait中获取这个事件.
因此,LT模式下开发基于epoll的应用要简单些,不太容易出错.而在ET模式下事件发生时,如果没有彻底地将缓冲区数据处理完,则会导致缓冲区中的用户请求得不到响应.
Nginx默认采用ET模式来使用epoll.
#### epoll工作原理
epoll只告知那些就绪的文件描述符,而且当我们调用epoll_wait()获得就绪文件描述符时,返回的不是实际的描述符,而是一个代表就绪描述符数量的值,只需要去epoll指定的一个数组中依次取得相应数量的文件描述符即可.<br>
另一个本质的改进在于epoll采用基于事件的就绪通知方式.在select/poll中,进程只有在调用一定的方法后(比如调用select方法),内核才对所有监视的文件描述符进行扫描,而epoll事先通过epoll_ctl()来注册一个文件描述符,一旦基于某个文件描述符就绪时,内核会采用类似callback的回调机制,迅速激活这个文件描述符,当进程调用epoll_wait()时便得到通知.
当一个进程调用epoll_create方法时,Linux内核会创建一个eventpoll结构体,这个结构体中有两个成员与epoll的使用方式密切相关:
```
/*
* This structure is stored inside the "private_data" member of the file
* structure and represents the main data structure for the eventpoll
* interface.
*/
struct eventpoll {
/* Protect the access to this structure */
spinlock_t lock;
/*
* This mutex is used to ensure that files are not removed
* while epoll is using them. This is held during the event
* collection loop, the file cleanup path, the epoll file exit
* code and the ctl operations.
*/
struct mutex mtx;
/* Wait queue used by sys_epoll_wait() */
wait_queue_head_t wq;
/* Wait queue used by file->poll() */
wait_queue_head_t poll_wait;
/* List of ready file descriptors */
struct list_head rdllist;
/* RB tree root used to store monitored fd structs */
struct rb_root rbr;//红黑树根节点,这棵树存储着所有添加到epoll中的事件,也就是这个epoll监控的fd
/*
* This is a single linked list that chains all the "struct epitem" that
* happened while transferring ready events to userspace w/out
* holding ->lock.
*/
struct epitem *ovflist;
/* wakeup_source used when ep_scan_ready_list is running */
struct wakeup_source *ws;
/* The user that created the eventpoll descriptor */
struct user_struct *user;
struct file *file;
/* used to optimize loop detection check */
int visited;
struct list_head visited_list_link;//双向链表中保存着将要通过epoll_wait返回给用户的、满足条件的事件
};
```
每一个epoll对象都有一个独立的eventpoll结构体,这个结构体会在内核空间中创造独立的内存,用于存储使用epoll_ctl方法向epoll对象中添加进来的事件.这样,重复的事件就可以通过红黑树而高效的识别出来.在epoll中,对于每一个事件都会建立一个epitem结构体:
```
/*
* Each file descriptor added to the eventpoll interface will
* have an entry of this type linked to the "rbr" RB tree.
* Avoid increasing the size of this struct, there can be many thousands
* of these on a server and we do not want this to take another cache line.
*/
struct epitem {
/* RB tree node used to link this structure to the eventpoll RB tree */
struct rb_node rbn;
/* List header used to link this structure to the eventpoll ready list */
struct list_head rdllink;
/*
* Works together "struct eventpoll"->ovflist in keeping the
* single linked chain of items.
*/
struct epitem *next;
/* The file descriptor information this item refers to */
struct epoll_filefd ffd;
/* Number of active wait queue attached to poll operations */
int nwait;
/* List containing poll wait queues */
struct list_head pwqlist;
/* The "container" of this item */
struct eventpoll *ep;
/* List header used to link this item to the "struct file" items list */
struct list_head fllink;
/* wakeup_source used when EPOLLWAKEUP is set */
struct wakeup_source __rcu *ws;
/* The structure that describe the interested events and the source fd */
struct epoll_event event;
};
```
epoll维护了一个双链表,用于存储发生的事件.当epoll_wait调用时,仅仅观察这个list链表里有没有数据即可.有数据就返回,没有数据就sleep,等到timeout时间到后即使链表没数据也返回.所以,epoll_wait非常高效.
通常情况下即使我们要监控百万计的句柄,大多一次也只返回很少量的准备就绪句柄而已,所以,epoll_wait仅需要从内核态copy少量的句柄到用户态而已,如何能不高效?
这个准备就绪list链表是怎么维护的呢?当我们执行epoll_ctl时,除了把socket放到epoll文件系统里file对象对应的红黑树上之外,还会给内核中断处理程序注册一个回调函数,告诉内核,如果这个句柄的中断到了,就把它放到准备就绪list链表里.所以,当一个socket上有数据到了,内核在把网卡上的数据copy到内核中后就把socket插入到准备就绪链表里了.
如此,一颗红黑树,一张准备就绪句柄链表,少量的内核cache,就帮我们解决了大并发下的socket处理问题.执行epoll_create时,创建了红黑树和就绪链表,执行epoll_ctl时,如果增加socket句柄,则检查在红黑树中是否存在,存在立即返回,不存在则添加到树干上,然后向内核注册回调函数,用于当中断事件来临时向准备就绪链表中插入数据.执行epoll_wait时立刻返回准备就绪链表里的数据即可.
<br>
<br>
参考文章:<br>
https://blog.csdn.net/xiajun07061225/article/details/9250579
https://blog.csdn.net/to_be_better/article/details/47349573 | 7,017 | Apache-2.0 |
---
title: Azure Container Instances に gitRepo ボリュームをマウントする
description: gitRepo ボリュームをマウントし、Git リポジトリの複製をコンテナー インスタンスに作成する方法について説明します。
services: container-instances
author: mmacy
manager: jeconnoc
ms.service: container-instances
ms.topic: article
ms.date: 04/16/2018
ms.author: marsma
ms.openlocfilehash: e40d841c07534c9c0074c038d1e3c6e435265564
ms.sourcegitcommit: e2adef58c03b0a780173df2d988907b5cb809c82
ms.translationtype: HT
ms.contentlocale: ja-JP
ms.lasthandoff: 04/28/2018
---
# <a name="mount-a-gitrepo-volume-in-azure-container-instances"></a>Azure Container Instances に gitRepo ボリュームをマウントする
*gitRepo ボリューム*をマウントし、Git リポジトリの複製をコンテナー インスタンスに作成する方法について説明します。
> [!NOTE]
> *gitRepo* ボリュームのマウントは現在、Linux コンテナーに限定されています。 すべての機能を Windows コンテナーにも採り入れることに取り組んでいますが、現在のプラットフォームの違いは、「[Quotas and region availability for Azure Container Instances](container-instances-quotas.md)」(Azure Container Instances のクォータとリージョンの可用性) で確認できます。
## <a name="gitrepo-volume"></a>gitRepo ボリューム
*gitRepo* ボリュームはディレクトリをマウントし、コンテナーの起動時、指定の Git リポジトリの複製をそのディレクトリに作成します。 コンテナー インスタンスで *gitRepo* ボリュームを使用することで、そのためのコードを自分のアプリケーションに追加する必要がなくなります。
*gitRepo* ボリュームをマウントするとき、次の 3 つのプロパティを設定し、ボリュームを構成できます。
| プロパティ | 必須 | [説明] |
| -------- | -------- | ----------- |
| `repository` | [はい] | 完全 URL。複製を作成する Git リポジトリの `http://` または `https://` も含まれます。|
| `directory` | いいえ | リポジトリの複製を作成するディレクトリ。 パスには "`..`" を含めることができません。 "`.`" を指定すると、リポジトリの複製がボリュームのディレクトリに作成されます。 指定しない場合、ボリューム ディレクトリ内の指定の下位ディレクトリに Git リポジトリの複製が作成されます。 |
| `revision` | いいえ | 複製を作成するリビジョンのコミット ハッシュ。 指定しない場合、`HEAD` リビジョンが複製されます。 |
## <a name="mount-gitrepo-volume-azure-cli"></a>gitRepo ボリュームのマウント: Azure CLI
[Azure CLI](/cli/azure)を使ってコンテナー インスタンスをデプロイするときに gitRepo ボリュームをマウントするには、[az container create][az-container-create] コマンドに `--gitrepo-url` および `--gitrepo-mount-path` パラメーターを指定します。 必要に応じて、複製先となるボリューム内のディレクトリ (`--gitrepo-dir`) と複製されるリビジョンのコミット ハッシュ (`--gitrepo-revision`) を指定することもできます。
この例のコマンドは、[aci-helloworld][aci-helloworld] サンプル アプリケーションをコンテナー インスタンス内の `/mnt/aci-helloworld`に複製しています。
```azurecli-interactive
az container create \
--resource-group myResourceGroup \
--name hellogitrepo \
--image microsoft/aci-helloworld \
--dns-name-label aci-demo \
--ports 80 \
--gitrepo-url https://github.com/Azure-Samples/aci-helloworld \
--gitrepo-mount-path /mnt/aci-helloworld
```
gitRepo ボリュームがマウントされたことを確認するには、[az container exec][az-container-exec] を使ってコンテナー内のシェルを起動し、ディレクトリを一覧表示します。
```console
$ az container exec --resource-group myResourceGroup --name hellogitrepo --exec-command /bin/sh
/usr/src/app # ls -l /mnt/aci-helloworld/
total 16
-rw-r--r-- 1 root root 144 Apr 16 16:35 Dockerfile
-rw-r--r-- 1 root root 1162 Apr 16 16:35 LICENSE
-rw-r--r-- 1 root root 1237 Apr 16 16:35 README.md
drwxr-xr-x 2 root root 4096 Apr 16 16:35 app
```
## <a name="mount-gitrepo-volume-resource-manager"></a>gitRepo ボリュームのマウント: Resource Manager
[Azure Resource Manager テンプレート](/azure/templates/microsoft.containerinstance/containergroups)を使ってコンテナー インスタンスをデプロイするときに gitRepo ボリュームをマウントするには、最初にテンプレートのコンテナー グループの `properties` セクションにある `volumes` 配列を設定します。 次に、*gitRepo* ボリュームをマウントするコンテナー グループ内の各コンテナーに対して、コンテナー定義の `properties` セクションで `volumeMounts` 配列を設定します。
たとえば、次の Resource Manager テンプレートでは、1 つのコンテナーから構成されるコンテナー グループが作成されます。 このコンテナーによって、*gitRepo* ボリューム ブロックにより指定される 2 つの GitHub リポジトリが複製されます。 2 つ目のボリュームには、複製先のディレクトリを指定する追加プロパティと複製する特定のリビジョンのコミット ハッシュが含まれています。
<!-- https://github.com/Azure/azure-docs-json-samples/blob/master/container-instances/aci-deploy-volume-gitrepo.json -->
[!code-json[volume-gitrepo](~/azure-docs-json-samples/container-instances/aci-deploy-volume-gitrepo.json)]
先のテンプレートに定義されていた 2 つの複製リポジトリのディレクトリ構造は結果的に次のようになります。
```
/mnt/repo1/aci-helloworld
/mnt/repo2/my-custom-clone-directory
```
Azure Resource Manager テンプレートによるコンテナー インスタンスのデプロイ例を見るには、[Azure Container Instances での複数コンテナーのデプロイ](container-instances-multi-container-group.md)に関するページを参照してください。
## <a name="next-steps"></a>次の手順
Azure Container Instances にその他の種類のボリュームをマウントする方法について学習してください。
* [Azure Container Instances に Azure ファイル共有をマウントする](container-instances-volume-azure-files.md)
* [Azure Container Instances に emptyDir ボリュームをマウントする](container-instances-volume-emptydir.md)
* [Azure Container Instances にシークレット ボリュームをマウントする](container-instances-volume-secret.md)
<!-- LINKS - External -->
[aci-helloworld]: https://github.com/Azure-Samples/aci-helloworld
<!-- LINKS - Internal -->
[az-container-create]: /cli/azure/container#az-container-create
[az-container-exec]: /cli/azure/container#az-container-exec | 4,651 | CC-BY-4.0 |
<!--
* @Author: 一尾流莺
* @Description:邮箱
* @Date: 2021-09-13 18:18:23
* @LastEditTime: 2021-10-14 09:28:36
* @FilePath: \warblerjs-guide\docs\guide\form\emailReg.md
-->
# 邮箱
验证邮箱。
## 语法
```js
import { emailReg } from 'warbler-js';
const result = emailReg(value);
```
## 参数
- `value` (**String**) : 待验证字符串。
## 返回值
**Boolean** : 是否通过验证,`true` 通过验证, `false` 没有通过验证。
## 源码
```js
const emailReg = (value) => {
const reg = /^(([^<>()[\]\\.,;:\s@"]+(\.[^<>()[\]\\.,;:\s@"]+)*)|(".+"))@((\[[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\])|(([a-zA-Z\-0-9]+\.)+[a-zA-Z]{2,}))$/;
return reg.test(value);
};
```
## 例子
```js
import { emailReg } from 'warbler-js';
const result1 = emailReg('[email protected]')
const result2 = emailReg('http://warbler.duwanyu.com/')
console.log(result1) // true
console.log(result2) // false
``` | 837 | Apache-2.0 |
---
layout: post
title: "安徽合肥一村莊夏天被洪水泡半個月,被判定為危房,整體拆遷轉移,當地村民卻無家可歸,只能租房子,不知道猴年馬月才能住上新房"
date: 2020-11-23T00:27:13.000Z
author: 圍城記
from: https://www.youtube.com/watch?v=IRcrQ7kJ70A
tags: [ 圍城記 ]
categories: [ 圍城記 ]
---
<!--1606091233000-->
[安徽合肥一村莊夏天被洪水泡半個月,被判定為危房,整體拆遷轉移,當地村民卻無家可歸,只能租房子,不知道猴年馬月才能住上新房](https://www.youtube.com/watch?v=IRcrQ7kJ70A)
------
<div>
#合肥洪水 #洪水後續 #拆遷
</div> | 384 | MIT |
# 推送通知
## 本地推送
- 本地推送通知


- iOS8需要进行注册
```objc
// iOS8进行本地通知的话,需要提前注册
if([[UIDevice currentDevice].systemVersion doubleValue] >= 8.0){
UIUserNotificationSettings *settings = [UIUserNotificationSettings settingsForTypes:UIUserNotificationTypeBadge | UIUserNotificationTypeAlert | UIUserNotificationTypeSound categories:nil];
// 注册
[application registerUserNotificationSettings:settings];
}
```



- 第一次运行程序时会弹出提醒用户是否接收通知

- iOS7会自己弹出
- alertView

- 其他属性

```objc
// 1.创建本地通知
UILocalNotification *localNote = [[UILocalNotification alloc] init];
// 2.设置本地通知的内容
// 2.1.设置通知发出的时间
localNote.fireDate = [NSDate dateWithTimeIntervalSinceNow:3.0];
// 2.2.设置通知的内容
localNote.alertBody = @"吃饭了吗?";
// 2.3.设置滑块的文字
localNote.alertAction = @"快点";
// 2.4.决定alertAction是否生效
localNote.hasAction = NO;
// 2.5.设置点击通知的启动图片
localNote.alertLaunchImage = @"3213432dasf";
// 2.6.设置alertTitle
localNote.alertTitle = @"3333333333";
// 2.7.设置有通知时的音效
localNote.soundName = @"buyao.wav";
// 2.8.设置应用程序图标右上角的数字
localNote.applicationIconBadgeNumber = 999;
// 2.9.设置额外信息
localNote.userInfo = @{@"type" : @1};
// 3.调用通知
[[UIApplication sharedApplication] scheduleLocalNotification:localNote];
}
```
- 在appDelegate里
- 如果是在程序杀死情况下,需要在didFinishLaunchingWithOptions里做判断
```objc
- (BOOL)application:(UIApplication *)application didFinishLaunchingWithOptions:(NSDictionary *)launchOptions {
// iOS8进行本地通知的话,需要提前注册
if([[UIDevice currentDevice].systemVersion doubleValue] >= 8.0){
UIUserNotificationSettings *settings = [UIUserNotificationSettings settingsForTypes:UIUserNotificationTypeBadge | UIUserNotificationTypeAlert | UIUserNotificationTypeSound categories:nil];
// 注册
[application registerUserNotificationSettings:settings];
}
// 设置消息数量位0
[application setApplicationIconBadgeNumber:0];
// 应用被杀死后,接收到通知会进入这个方法,然后根据通知做一些事情
if (launchOptions[UIApplicationLaunchOptionsLocalNotificationKey]) {
UILabel *lab = [[UILabel alloc] init];
lab.numberOfLines = 0;
lab.text = [NSString stringWithFormat:@"%@",launchOptions];
lab.frame = self.window.bounds;
[self.window.rootViewController.view addSubview:lab];
}
return YES;
}
```

- 在应用程序不死的情况话,在前台或者由后台进入前台都会进入这个方法
```objc
/**
* 在应用程序不死的情况话,在前台或者由后台进入前台都会进入这个方法
*/
- (void)application:(UIApplication *)application didReceiveLocalNotification:(UILocalNotification *)notification
{
if (application.applicationState == UIApplicationStateInactive) {
NSLog(@"由后台进入前台");
NSLog(@"%@",notification.userInfo);
}
else if(application.applicationState == UIApplicationStateActive)
{
NSLog(@"在前台");
}
else if(application.applicationState == UIApplicationStateBackground)
{
NSLog(@"在后台"); // 在后台接收通知,不会执行
}
}
```
#### 远程推送
- APNs
- deviceToken:获取必须有开发者账号,这个暂时没法测试了

`格式:{"aps":{"alert":"This is some fancy message.","badge":1,"sound":"default"}}`
```objc
if ([[UIDevice currentDevice].systemVersion doubleValue] >= 8.0) { //iOS8
UIUserNotificationSettings *settings = [UIUserNotificationSettings settingsForTypes:UIUserNotificationTypeAlert | UIUserNotificationTypeBadge | UIUserNotificationTypeSound categories:nil];
[application registerUserNotificationSettings:settings];
// iOS8注册远程通知
[application registerForRemoteNotifications];
}
// iOS7用这个方法注册
[application registerForRemoteNotificationTypes:UIUserNotificationTypeAlert | UIUserNotificationTypeBadge | UIUserNotificationTypeSound];
```

- 当得到苹果的APNs服务器返回的DeviceToken就会被调用
```objc
- (void)application:(UIApplication *)application didRegisterForRemoteNotificationsWithDeviceToken:(NSData *)deviceToken {
NSLog(@"deviceToken是:%@", deviceToken);
}
// 接收到远程通知,触发方法和本地通知一致
- (void)application:(UIApplication *)application didReceiveRemoteNotification:(NSDictionary *)userInfo {
NSLog(@"%@", userInfo);
}
```
- 使用后台的远程消息推送

```objc
1> 在Capabilities中打开远程推送通知
2> 实现代理方法
- (void)application:(UIApplication *)application didReceiveRemoteNotification:(NSDictionary *)userInfo fetchCompletionHandler:(void (^)(UIBackgroundFetchResult))completionHandler
远程消息数据格式:
{"aps" : {"content-available" : 1},"content-id" : 42}
执行completionHandler有两个目的
1> 系统会估量App消耗的电量,并根据传递的UIBackgroundFetchResult 参数记录新数据是否可用
2> 调用完成的处理代码时,应用的界面缩略图会自动更新
注意:接收到远程通知到执行完网络请求之间的时间不能超过30秒
if (userInfo) {
int contentId = [userInfo[@"content-id"] intValue];
ViewController *vc = (ViewController *)application.keyWindow.rootViewController;
[vc loadDataWithContentID:contentId completion:^(NSArray *dataList) {
vc.dataList = dataList;
NSLog(@"刷新数据结束");
completionHandler(UIBackgroundFetchResultNewData);
}];
} else {
completionHandler(UIBackgroundFetchResultNoData);
}
```
- deviceToken 转换字符串
```objc
- (void)application:(UIApplication *)application didRegisterForRemoteNotificationsWithDeviceToken:(NSData *)deviceToken
{
NSLog(@"%@",deviceToken.description);
NSString *receiveToken = [[deviceToken description] stringByTrimmingCharactersInSet:[NSCharacterSet characterSetWithCharactersInString:@"<>"]];
receiveToken = [receiveToken stringByReplacingOccurrencesOfString:@" " withString:@""];
NSString *localToken = [[NSUserDefaults standardUserDefaults] objectForKey:@"deviceToken"];
if (![localToken isEqualToString:receiveToken]) {
[[NSUserDefaults standardUserDefaults] setObject:receiveToken forKey:@"deviceToken"];
}
NSLog(@"%@",receiveToken);
}
```
- 在合适的时间,比如登陆成功后上传至自己的服务器
- 第三方apns
- JPush
- <https://www.jpush.cn> | 6,163 | MIT |
---
title: 二项逻辑斯蒂回归模型
layout: post
category: spark
author: 夏泽民
---
Logistic回归与多重线性回归实际上有很多相同之处,最大的区别就在于它们的因变量不同,其他的基本都差不多。正是因为如此,这两种回归可以归于同一个家族,即广义线性模型(generalizedlinear model)。
这一家族中的模型形式基本上都差不多,不同的就是因变量不同。
如果是连续的,就是多重线性回归;
如果是二项分布,就是Logistic回归;
如果是Poisson分布,就是Poisson回归;
如果是负二项分布,就是负二项回归。
Logistic回归的因变量可以是二分类的,也可以是多分类的,但是二分类的更为常用,也更加容易解释。所以实际中最常用的就是二分类的Logistic回归。
Logistic回归的主要用途:
寻找危险因素:寻找某一疾病的危险因素等;
预测:根据模型,预测在不同的自变量情况下,发生某病或某种情况的概率有多大;
判别:实际上跟预测有些类似,也是根据模型,判断某人属于某病或属于某种情况的概率有多大,也就是看一下这个人有多大的可能性是属于某病。
Logistic回归主要在流行病学中应用较多,比较常用的情形是探索某疾病的危险因素,根据危险因素预测某疾病发生的概率,等等。例如,想探讨胃癌发生的危险因素,可以选择两组人群,一组是胃癌组,一组是非胃癌组,两组人群肯定有不同的体征和生活方式等。这里的因变量就是是否胃癌,即“是”或“否”,自变量就可以包括很多了,例如年龄、性别、饮食习惯、幽门螺杆菌感染等。自变量既可以是连续的,也可以是分类的。
常规步骤
Regression问题的常规步骤为:
寻找h函数(即hypothesis);
构造J函数(损失函数);
想办法使得J函数最小并求得回归参数(θ)
http://blog.csdn.net/wjlucc/article/details/69264144
<!-- more -->
1. 二项逻辑斯蒂回归模型
二项逻辑斯蒂回归模型是如下的条件概率分布:
$P(Y=1|x)=\frac{\exp{(w \cdot x+b)}}{1+\exp(w\cdot x+b)}$
P(Y=0|x)=11+exp(w⋅x+b)
注意:P(Y=1|x)模型也经常写成hθ(x)=11+exp(−θT⋅x)。
事件的几率(odds)是指该事件发生的概率与该事件不发生的概率的比值。
如果事件发生的概率是p,那么该事件的几率是P1−P,该事件的对数几率(log odds)或logit函数是:logit(P)=logp1−p。
逻辑回归的对数几率是:
log(P(Y=1|x)1−P(Y=1|x))=w⋅x
意义:在逻辑斯蒂回归模型中,输出Y=1的对数几率是输入x的线性函数。或者说,输出Y=1的对数几率是由属于x的线性函数表示的模型,即逻辑斯蒂回归模型。(这里需要再理解下)
感知机只通过决策函数(w⋅x)的符号来判断属于哪一类。逻辑斯蒂回归需要再进一步,它要找到分类概率P(Y=1)与输入向量x的直接关系,再通过比较概率值来判断类别。
令决策函数(w⋅x)输出值等于概率值比值取对数,即:
logp1−p=w⋅x⟹p=exp(w⋅x+b)1+exp(w⋅x+b)
逻辑斯蒂回归模型的定义式P(Y=1|x)中可以将线性函数w⋅x转换为概率,这时,线性函数的值越接近正无穷,概率值就越接近1;线性函数的值越接近负无穷,概率值就接近0.
2. 模型参数估计
应用极大似然法进行参数估计,从而获得逻辑斯蒂回归模型。极大似然估计的数学原理参考这里。
设:P(Y=1|x)=π(x),P(Y=0|x)=1−π(x)
似然函数为:
∏i=1N[π(xi)]yi[1−π(xi)]1−yi
上式连乘符号内的两项中,每个样本都只会取到两项中的某一项。若该样本的实际标签yi=1,取样本计算为1的概率值π(xi);若该样本的实际标签yi=0,取样本计算的为0的概率值1−π(xi)。
对数似然函数为:
L(w)====∑i=1N[yilogπ(xi)+(1−yi)log(1−π(xi))]∑i=1N[yilogπ(xi)1−π(xi)+log(1−π(xi))]∑i=1N[yi(w⋅xi)+log11+exp(w⋅xi)]∑i=1N[yi(w⋅xi)−log(1+exp(w⋅xi))]
对上式中的L(w)求极大值,得到w的估计值。
问题转化成以对数似然函数为目标函数的无约束最优化问题,通常采用梯度下降法以及拟牛顿法求解w。
假设w的极大估计值是wˆ,那么学到的逻辑斯蒂回归模型为:
P(Y=1|x)=exp(wˆ⋅x)1+exp(wˆ⋅x)
P(Y=0|x)=11+exp(wˆ⋅x)
3. 多项逻辑斯蒂回归
多项逻辑斯蒂回归用于多分类问题,其模型为:
P(Y=k|x)=exp(wk⋅x)1+∑k=1K−1exp(wk⋅x),k=1,2,⋯,K−1
P(Y=K|x)=11+∑k=1K−1exp(wk⋅x)
上面的公式和二分类的类似,式中k的取值只能取到K−1。
4. 交叉熵损失函数的求导
逻辑回归的另一种理解是以交叉熵作为损失函数的目标最优化。交叉熵损失函数可以从上文最大似然推导出来。
交叉熵损失函数为:
y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))
则可以得到目标函数为:
J(θ)==−1m∑i=1my(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))−1m∑i=1m[y(i)θTx(i)−log(1+eθTx(i))]
计算J(θ)对第j个参数分量θj求偏导:
∂∂θjJ(θ)====∂∂θj(1m∑i=1m[log(1+eθTx(i))−y(i)θTx(i)])1m∑i=1m[∂∂θjlog(1+eθTx(i))−∂∂θj(y(i)θTx(i))]1m∑i=1m⎛⎝x(i)jeθTx(i)1+eθTx(i)−y(i)x(i)j⎞⎠1m∑i=1m(hθ(x(i))−y(i))x(i)j | 2,576 | MIT |
# 关于构造方法的那些事儿
1 前言
----
构造方法是一种特殊的方法,它是一个与类同名且没有返回值类型的方法。对象的创建就是通过构造方法来完成,其功能主要是完成对象的初始化。当类实例化一个对象时会自动调用构造方法。构造方法和其他方法一样也可以重载。在 Java 中,任何变量在被使用前都必须先设置初值,构造方法就是专门为类的成员变量赋初值的方法。
2 特殊性
-----
构造方法是一种特殊的成员方法,它的特殊性主要反映在如下几个方面:
- 构造方法的作用主要有两个,分别为构造出来一个类的实例和对构造出来的类的实例(对象)进行初始化;
- 构造方法的名字必须与定义他的类名完全相同,没有返回类型,甚至连 void 也没有;
- 主要完成对象的初始化工作,构造方法的调用是在创建一个对象时使用 new 操作完成的;
- 类中必定有构造方法,若不写,系统自动添加无参构造方法;
- 接口不允许被实例化,因此接口中没有构造方法;
- 不能被`static`、`final`、`synchronized`、`abstract`和`native`修饰;
- 构造方法在初始化对象时自动执行,一般不能显式地直接调用;
- 当同一个类存在多个构造方法时,java 编译系统会自动按照初始化时最后面括号的参数个数以及参数类型来自动的一一对应,完成构造函数的调用;
- 构造方法分为两种,分别为无参的构造方法和有参的构造方法;
- 构造方法可以被重载,没有参数的构造方法称为默认构造方法,与一般的方法一样,构造方法可以进行任何活动,但是经常将他设计为进行各种初始化活动,比如初始化对象的属性。
此外,咱们在介绍一下构造代码块,其作用也是给对象进行初始化,对象一建立就执行,而且优先于构造函数执行。构造代码块和构造函数的区别在于构造代码块是给所有不同对象的共性进行统一初始化,构造函数则是给对应的对象进行初始化。
3 代码示例
------
**第一步**:创建一个 Method 类
```
/**
* @author Charies Gavin
* @create 2017-07-26
*/
public class Method {
public Method(){
System.out.println("您调用了无参的构造函数!");
}
public Method(String mess){
System.out.println("您调用了有参的构造函数," + "参数内容为:" + mess);
}
}
```
**第二步**:创建一个 TestMethod 类
```
/**
* @author Charies Gavin
* @create 2017-07-26
*/
public class TestMethod {
public static void main(String[] args) {
//调用无参的构造函数
Method method_1 = new Method();
//调用有参的构造函数
Method method_2 = new Method("Hello World!");
}
}
```
运行程序后,结果如下图所示:

4 总结
----
构造方法是一个与类同名的方法,对象的创建就是通过构造方法来完成的,构造方法有两个特点:**一是没有返回值**;**二是与类同名**。如果在类中没有定义任何(无参或者有参)构造方法时,编译器会在该类中自动创建一个无参的构造方法,也就是我们常说的默认构造方法。
此外,还有一点需要特别注意:**如果类中定义了构造方法且都不是无参的,那么编译器也不会自动创建无参的构造方法,而是根据参数个数和类型,按顺序进行匹配,直到找到对应的构造方法;当我们调用了无参的构造方法实例化对象时,编译器就会报错啦,因为现在全是有参的构造方法,没有无参的构造方法。** | 1,785 | MIT |
## 题目地址(5. 最长回文子串)
https://leetcode-cn.com/problems/longest-palindromic-substring/
## 题目描述
给定一个字符串 s,找到 s 中最长的回文子串。你可以假设 s 的最大长度为 1000。
示例 1:
输入: "babad"
输出: "bab"
注意: "aba" 也是一个有效答案。
示例 2:
输入: "cbbd"
输出: "bb"
## 前置知识
- 回文
## 公司
- 阿里
- 百度
- 腾讯
## 思路
这是一道最长回文的题目,要我们求出给定字符串的最大回文子串。

解决这类问题的核心思想就是两个字“延伸”,具体来说**如果在一个不是回文字符串的字符串两端添加任何字符,或者在回文串左右分别加不同的字符,得到的一定不是回文串**

base case 就是一个字符(轴对称点是本身),或者两个字符(轴对称点是介于两者之间的虚拟点)。

事实上,上面的分析已经建立了大问题和小问题之间的关联,基于此,我们可以建立动态规划模型。
我们可以用 dp[i][j] 表示 s 中从 i 到 j(包括 i 和 j)是否可以形成回文,
状态转移方程只是将上面的描述转化为代码即可:
```js
if (s[i] === s[j] && dp[i + 1][j - 1]) {
dp[i][j] = true;
}
```
## 关键点
- ”延伸“(extend)
## 代码
代码支持:Python,JavaScript,CPP
Python Code:
```python
class Solution:
def longestPalindrome(self, s: str) -> str:
n = len(s)
if n == 0:
return ""
res = s[0]
def extend(i, j, s):
while(i >= 0 and j < len(s) and s[i] == s[j]):
i -= 1
j += 1
return s[i + 1:j]
for i in range(n - 1):
e1 = extend(i, i, s)
e2 = extend(i, i + 1, s)
if max(len(e1), len(e2)) > len(res):
res = e1 if len(e1) > len(e2) else e2
return res
```
JavaScript Code:
```js
/*
* @lc app=leetcode id=5 lang=javascript
*
* [5] Longest Palindromic Substring
*/
/**
* @param {string} s
* @return {string}
*/
var longestPalindrome = function (s) {
// babad
// tag : dp
if (!s || s.length === 0) return "";
let res = s[0];
const dp = [];
// 倒着遍历简化操作, 这么做的原因是dp[i][..]依赖于dp[i + 1][..]
for (let i = s.length - 1; i >= 0; i--) {
dp[i] = [];
for (let j = i; j < s.length; j++) {
if (j - i === 0) dp[i][j] = true;
// specail case 1
else if (j - i === 1 && s[i] === s[j]) dp[i][j] = true;
// specail case 2
else if (s[i] === s[j] && dp[i + 1][j - 1]) {
// state transition
dp[i][j] = true;
}
if (dp[i][j] && j - i + 1 > res.length) {
// update res
res = s.slice(i, j + 1);
}
}
}
return res;
};
```
CPP Code:
```cpp
class Solution {
private:
int expand(string &s, int L, int R) {
while (L >= 0 && R < s.size() && s[L] == s[R]) {
--L;
++R;
}
return R - L - 1;
}
public:
string longestPalindrome(string s) {
if (s.empty()) return s;
int start = 0, maxLen = 0;
for (int i = 0; i < s.size(); ++i) {
int len1 = expand(s, i, i);
int len2 = expand(s, i, i + 1);
int len = max(len1, len2);
if (len > maxLen) {
start = i - (len - 1) / 2;
maxLen = len;
}
}
return s.substr(start, maxLen);
}
};
```
**复杂度分析**
- 时间复杂度:$O(N^2)$
- 空间复杂度:$O(N^2)$
## 相关题目
- [516.longest-palindromic-subsequence](./516.longest-palindromic-subsequence.md)
大家对此有何看法,欢迎给我留言,我有时间都会一一查看回答。更多算法套路可以访问我的 LeetCode 题解仓库:https://github.com/azl397985856/leetcode 。 目前已经 37K star 啦。
大家也可以关注我的公众号《力扣加加》带你啃下算法这块硬骨头。
 | 3,459 | Apache-2.0 |
# SVG
参考 [w3c-svg教程](https://www.w3school.com.cn/svg/index.asp)
## 1 SVG 是使用 XML 来描述二维图形和绘图程序的语言
- SVG 指可伸缩矢量图形 (Scalable Vector Graphics)
- SVG 用来定义用于网络的基于矢量的图形
- SVG 使用 XML 格式定义图形
- SVG 图像在放大或改变尺寸的情况下其图形质量不会有所损失
- SVG 是万维网联盟的标准
- SVG 与诸如 DOM 和 XSL 之类的 W3C 标准是一个整体
## 2 SVG 的历史和优势
在 2003 年一月,SVG 1.1 被确立为 W3C 标准。
参与定义 SVG 的组织有:太阳微系统、Adobe、苹果公司、IBM 以及柯达。
与其他图像格式相比,使用 SVG 的优势在于:
- SVG 可被非常多的工具读取和修改(比如记事本)
- SVG 与 JPEG 和 GIF 图像比起来,尺寸更小,且可压缩性更强。
- SVG 是可伸缩的
- SVG 图像可在任何的分辨率下被高质量地打印
- SVG 可在图像质量不下降的情况下被放大
- SVG 图像中的文本是可选的,同时也是可搜索的(很适合制作地图)
- SVG 可以与 Java 技术一起运行
- SVG 是开放的标准
- SVG 文件是纯粹的 XML
SVG 的主要竞争者是 Flash。与 Flash 相比,SVG 最大的优势是与其他标准(比如 XSL 和 DOM)相兼容。而 Flash 则是未开源的私有技术。

## 3 SVG 文件说明
- 文件后缀名必须是.svg
- **第一行**必须包含 XML 声明 (<?xml ?>),不能是空行,也不能是注释性语言 <!-- -->
```xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<svg xmlns="http://www.w3.org/2000/svg" version="1.1" height="190">
<polygon points="100,10 40,180 190,60 10,60 160,180"
style="fill:lime;stroke:purple;stroke-width:5;fill-rule:evenodd;" />
</svg>
```
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>SVG</title>
<style>
body{
background: url(img.svg) no-repeat;
}
</style>
</head>
<body>
</body>
</html>
```
## 4 命令
以下所有命令均允许小写字母。大写表示绝对定位,小写表示相对定位。
| 命令 | 说明 |
| ---- | ------------------------------------------------------------ |
| M | moveto。移动到的点的x轴和y轴的坐标 |
| L | lineto。需要两个参数,分别是一个点的x轴和y轴坐标,L命令将会在当前位置和新位置<br />(L前面画笔所在的点)之间画一条线段 |
| H | horizontal lineto。绘制平行线 |
| V | vertical lineto。绘制垂直线 |
| C | curveto。三次贝塞尔曲线 |
| S | smooth curveto。简写的三次贝塞尔曲线命令 |
| Q | quadratic Belzier curve。二次贝塞尔曲线 |
| T | smooth quadratic Belzier curveto。简写的二次贝塞尔曲线命令 |
| A | elliptical Arc。弧形命令 |
| Z | closepath。从当前点画一条直线到路径的起点 | | 2,255 | MIT |
---
title: 常见问题 - 使用 Azure Site Recovery 进行 Hyper-V 到 Azure 的灾难恢复 | Azure
description: 本文汇总了有关使用 Azure Site Recovery 站点设置本地 Hyper-V VM 到 Azure 的灾难恢复的常见问题。
services: site-recovery
author: rockboyfor
manager: digimobile
ms.service: site-recovery
origin.date: 05/30/2019
ms.date: 07/08/2019
ms.topic: conceptual
ms.author: v-yeche
ms.openlocfilehash: 4766e857a90fc6ce4368baef174275d59c2abc59
ms.sourcegitcommit: e575142416298f4d88e3d12cca58b03c80694a32
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 07/12/2019
ms.locfileid: "67861705"
---
# <a name="common-questions---hyper-v-to-azure-disaster-recovery"></a>常见问题 - Hyper-V 到 Azure 的灾难恢复
本文提供将本地 Hyper-V VM 复制到 Azure 时可能遇到的常见问题的解答。
## <a name="general"></a>常规
### <a name="how-is-site-recovery-priced"></a>Site Recovery 如何计费?
请查看 [Azure Site Recovery 定价详细信息](https://www.azure.cn/pricing/details/site-recovery/)。
### <a name="how-do-i-pay-for-azure-vms"></a>Azure VM 如何计费?
在复制期间,数据将复制到 Azure 存储,因此,VM 不会产生任何费用。 故障转移到 Azure 时,Site Recovery 会自动创建 Azure IaaS 虚拟机。 然后,在 Azure 中使用的计算资源会产生费用。
## <a name="azure"></a>Azure
### <a name="what-do-i-need-in-hyper-v-to-orchestrate-replication-with-site-recovery"></a>在 Hyper-V 中,需要做好哪些准备才能使用 Site Recovery 来协调复制?
对于 Hyper-V 主机服务器,用户的所需取决于部署方案。 在以下内容中查看 Hyper-V 先决条件:
* [将 Hyper-V VM 复制(不使用 VMM)到 Azure](site-recovery-hyper-v-site-to-azure.md)
* [将 Hyper-V VM 复制(使用 VMM)到 Azure](site-recovery-vmm-to-azure.md)
* [将 Hyper-V VM 复制到辅助数据中心](site-recovery-vmm-to-vmm.md)
* 若要复制到辅助数据中心,请阅读 [Hyper-V 虚拟机的受支持的来宾操作系统](https://technet.microsoft.com/library/mt126277.aspx)。
* 若要复制到 Azure,Site Recovery 支持 [Azure 支持的](https://technet.microsoft.com/library/cc794868%28v=ws.10%29.aspx)所有来宾操作系统。
### <a name="can-i-protect-vms-when-hyper-v-is-running-on-a-client-operating-system"></a>当 Hyper-V 在客户端操作系统上运行时,我可以保护 VM 吗?
不可以。VM 必须位于在受支持的 Windows 服务器计算机上运行的 Hyper-V 主机服务器上。 如果需要保护客户端计算机,可以将其作为物理计算机复制到 [Azure](site-recovery-vmware-to-azure.md) 或[辅助数据中心](site-recovery-vmware-to-vmware.md)。
### <a name="do-hyper-v-hosts-need-to-be-in-vmm-clouds"></a>Hyper-V 主机是否需要位于 VMM 云中?
如果要复制到辅助数据中心,那么 Hyper-V VM 就必须位于 VMM 云中的 Hyper-V 主机服务器上。 如果想要复制到 Azure,那么可以复制 VM(无论是否使用 VMM 云)。 [详细了解](tutorial-hyper-v-to-azure.md)从 Hyper-V 复制到 Azure。
### <a name="can-i-replicate-hyper-v-generation-2-virtual-machines-to-azure"></a>可以将 Hyper-V 第 2 代虚拟机复制到 Azure 吗?
是的。 Site Recovery 在故障转移过程中将从第 2 代转换成第 1 代。 在故障回复时,计算机将转换回到第 2 代。 [了解详细信息](https://azure.microsoft.com/blog/2015/04/28/disaster-recovery-to-azure-enhanced-and-were-listening/)。
### <a name="can-i-deploy-site-recovery-with-vmm-if-i-only-have-one-vmm-server"></a>如果只有一个 VMM 服务器,可以部署带 VMM 的 Site Recovery 吗?
是的。 可以将 VMM 云中 Hyper-V 服务器上的 VM 复制到 Azure,或者在同一台服务器上的 VMM 云之间进行复制。 对于本地到本地复制,建议在主站点与辅助站点中都部署一个 VMM 服务器。
### <a name="what-do-i-need-in-azure"></a>需要在 Azure 中做好哪些准备?
需要一个 Azure 订阅、一个恢复服务保管库、一个存储帐户和一个虚拟网络。 保管库、存储帐户和网络必须位于同一区域。
### <a name="what-azure-storage-account-do-i-need"></a>需要哪个 Azure 存储帐户?
需要 LRS 或 GRS 存储帐户。 建议使用 GRS,以便在发生区域性故障或无法恢复主要区域时,能够复原数据。 支持高级存储。
### <a name="does-my-azure-account-need-permissions-to-create-vms"></a>我的 Azure 帐户是否需要拥有创建 VM 的权限?
如果你是订阅管理员,则已经获得了所需的复制权限。 否则,需要有权在配置 Site Recovery 时指定的资源组和虚拟网络中创建 Azure VM,并有权写入选定的存储帐户。 [了解详细信息](site-recovery-role-based-linked-access-control.md#permissions-required-to-enable-replication-for-new-virtual-machines)。
### <a name="is-replication-data-sent-to-site-recovery"></a>复制数据是否会发送到 Site Recovery?
不会。Site Recovery 不会拦截复制的数据,也不包含 VM 上运行的组件的任何相关信息。 复制数据在 Hyper-V 主机与 Azure 存储之间交换。 站点恢复并不具有拦截该数据的能力。 只有协调复制与故障转移所需的元数据会发送到站点恢复服务。
Site Recovery 已通过 ISO 27001:2013、27018、HIPAA、DPA 认证,目前正在接受 SOC2 和 FedRAMP JAB 评估。
### <a name="can-we-keep-on-premises-metadata-within-a-geographic-region"></a>是否可将本地元数据保留在某个地理区域中?
是的。 当你在某个区域中创建保管库时,我们会确保 Site Recovery 使用的所有元数据保留在该区域的地理边界内。
### <a name="does-site-recovery-encrypt-replication"></a>Site Recovery 是否将复制数据加密?
是的,传输中加密和 [Azure 中加密](/storage/storage-service-encryption)均受支持。
## <a name="deployment"></a>部署
### <a name="what-can-i-do-with-hyper-v-to-azure-replication"></a>可通过哪些方法实现 Hyper-V 到 Azure 的复制?
- **灾难恢复**:可以设置完整的灾难恢复。 在此场景中,可将本地 Hyper-V VM 复制到 Azure 存储:
- 可将 VM 复制到 Azure。 如果本地基础结构不可用,则可以故障转移到 Azure。
- 在故障转移时,将使用复制的数据创建 Azure VM。 可以访问 Azure VM 上的应用和工作负载。
- 本地数据中心重新可用时,可从 Azure 故障回复到本地站点。
- **迁移**:可以使用 Site Recovery 将本地 Hyper-V VM 迁移到 Azure 存储。 然后从本地故障转移到 Azure。 故障转移后,应用和工作负荷可供使用并在 Azure VM 上运行。
### <a name="what-do-i-need-on-premises"></a>需要在本地做好哪些准备?
需要一个或多个在一个或多个独立或群集 Hyper-V 主机上运行的 VM。 还可以复制 System Center Virtual Machine Manager (VMM) 托管的主机上运行的 VM。
- 如果不运行 VMM,则在 Site Recovery 部署期间,将 Hyper-V 主机和群集收集到 Hyper-V 站点中。 在每个 Hyper-V 主机上安装 Site Recovery 代理(Azure Site Recovery 提供程序和 Recovery Services 代理)。
- 如果 Hyper-V 主机位于 VMM 云中,则在 VMM 中协调复制。 在 VMM 服务器上安装 Site Recovery 提供程序,在每个 Hyper-V 主机上安装恢复服务代理。 在 VMM 逻辑/VM 网络和 Azure VNet 之间进行映射。
- [详细了解](hyper-v-azure-architecture.md) Hyper-V 到 Azure 的体系结构。
### <a name="can-i-replicate-vms-located-on-a-hyper-v-cluster"></a>是否可以复制 Hyper-V 群集上的 VM?
可以,Site Recovery 支持群集 Hyper-V 主机。 请注意:
- 群集的所有节点应注册到同一保管库。
- 如果不使用 VMM,则应将群集中的所有 Hyper-V 主机添加到同一 Hyper-V 站点。
- 在群集中每个 Hyper-V 主机上安装 Azure Site Recovery 提供程序和恢复服务代理,并将每个主机添加到 Hyper-V 站点。
- 无需在群集上执行任何特定步骤。
- 如果对 Hyper-V 运行部署规划器工具,此工具会从正在运行且其中运行此 VM 的节点收集配置文件数据。 该工具不会从已关闭的节点中收集任何数据,但会跟踪该节点。 该节点启用和运行后,此工具开始从其中收集 VM 配置文件数据(如果此 VM 是配置文件 VM 列表的一部分且在该节点上运行)。
- 如果 Site Recovery 保管库中的 Hyper-V 主机上的某个 VM 迁移到同一群集中的其他 Hyper-V 主机或迁移到独立主机,则该 VM 的复制不受影响。 Hyper-V 主机必须满足[先决条件](hyper-v-azure-support-matrix.md#on-premises-servers),且必须在 Site Recovery 保管库中进行配置。
### <a name="can-i-protect-vms-when-hyper-v-is-running-on-a-client-operating-system"></a>当 Hyper-V 在客户端操作系统上运行时,我可以保护 VM 吗?
不可以。VM 必须位于在支持的 Windows 服务器计算机上运行的 Hyper-V 主机服务器上。 如果需要保护客户端计算机,可以[将其作为物理计算机复制](physical-azure-disaster-recovery.md)到 Azure。
### <a name="can-i-replicate-hyper-v-generation-2-virtual-machines-to-azure"></a>可以将 Hyper-V 第 2 代虚拟机复制到 Azure 吗?
是的。 Site Recovery 在故障转移过程中将从第 2 代转换成第 1 代。 在故障回复时,计算机将转换回到第 2 代。
### <a name="can-i-automate-site-recovery-scenarios-with-an-sdk"></a>是否可以使用 SDK 自动执行 Site Recovery 方案?
是的。 可以使用 Rest API、PowerShell 或 Azure SDK 将 Site Recovery 工作流自动化。 以下为通过 PowerShell 将 Hyper-V 复制到 Azure 的当前支持方案:
- [使用 PowerShell 在无 VMM 的情况下复制 Hyper-V](hyper-v-azure-powershell-resource-manager.md)
- [使用 PowerShell 在有 VMM 的情况下复制 Hyper-V](hyper-v-vmm-powershell-resource-manager.md)
## <a name="replication"></a>复制
### <a name="where-do-on-premises-vms-replicate-to"></a>本地 VM 将复制到哪个位置?
数据将复制到 Azure 存储。 运行故障转移时,Site Recovery 会自动从存储帐户创建 Azure VM。
### <a name="what-apps-can-i-replicate"></a>可以复制哪些应用?
可以复制任何运行符合[复制要求](hyper-v-azure-support-matrix.md#replicated-vms)的 Hyper-V VM 的应用或工作负荷均。 Site Recovery 支持应用程序感知型复制,因此,应用可以故障转移或故障回复到智能状态。 Site Recovery 除了与 Microsoft 应用程序(例如 SharePoint、Exchange、Dynamics、SQL Server 及 Active Directory)集成之外,还能与行业领先的供应商(包括 Oracle、SAP、IBM 及 Red Hat)紧密配合。 [详细了解](site-recovery-workload.md)工作负荷保护。
### <a name="whats-the-replication-process"></a>复制过程是什么?
1. 当触发初始复制时,系统会拍摄 Hyper-V VM 快照。
2. VM 上的虚拟硬盘是逐一复制的,直至全部复制到 Azure 为止。 该过程可能需要一些时间,具体取决于 VM 大小和网络带宽。 了解如何增加网络带宽。
3. 如果在初始复制期间发生磁盘更改,Hyper-V 副本复制跟踪器将跟踪这些更改,并将其记录在 Hyper-V 复制日志 (.hrl) 中。 这些日志文件位于与磁盘相同的文件夹中。 每个磁盘都有一个关联的 .hrl 文件,该文件将发送到辅助存储器。 当初始复制正在进行时,快照和日志文件将占用磁盘资源。
4. 当初始复制完成时,会删除 VM 快照。
5. 日志中的任何磁盘更改会进行同步,并合并到父磁盘中。
6. 初始复制完成后,“在虚拟机上完成保护”作业将运行。 该作业会配置网络和其他复制后设置以便保护 VM。
7. 在此阶段,可以检查 VM 设置以确保它已为故障转移做好准备。 可针对 VM 运行灾难恢复钻取(测试故障转移)来检查它是否按预期进行故障转移。
8. 在完成初始复制后,根据复制策略开始增量复制同步。
9. 更改是所记录的 .hrl 文件。 为复制配置的每个磁盘都有一个关联的 .hrl 文件。
10. 此日志会发送到客户的存储帐户。 当日志正处于传输到 Azure 的过程中时,主磁盘中的变更会记录到同一文件夹的另一日志文件中。
11. 在初始复制和增量复制过程中,均可以在 Azure 门户中监视 VM。
[详细了解](hyper-v-azure-architecture.md#replication-process)复制过程。
### <a name="can-i-replicate-to-azure-with-a-site-to-site-vpn"></a>是否可以使用站点到站点 VPN 复制到 Azure?
Site Recovery 通过公共终结点或使用 ExpressRoute 公共对等互连将数据从本地复制到 Azure 存储。 不支持通过站点到站点 VPN 网络进行的复制。
### <a name="can-i-replicate-to-azure-with-expressroute"></a>是否可以使用 ExpressRoute 复制到 Azure?
可以使用 ExpressRoute 将 VM 复制到 Azure。 Site Recovery 通过公共终结点将数据复制到 Azure 存储帐户。需要设置[公共对等互连](../expressroute/expressroute-circuit-peerings.md#publicpeering)才能进行 Site Recovery 复制。 将 VM 故障转移到 Azure 虚拟网络后,可以使用[专用对等互连](../expressroute/expressroute-circuit-peerings.md#privatepeering)访问这些 VM。
<!--MOONCAKE Anchor is correct on public-peering-->
### <a name="why-cant-i-replicate-over-vpn"></a>为何不能通过 VPN 复制?
复制到 Azure 时,复制流量将到达 Azure 存储帐户的公共终结点。 因此,只能使用 ExpressRoute(公共对等互连)通过公共 Internet 进行复制,VPN 不起作用。
### <a name="what-are-the-replicated-vm-requirements"></a>复制的 VM 要满足哪些要求?
若要复制某个 Hyper-V VM,该 VM 必须运行受支持的操作系统。 此外,该 VM 必须满足 Azure VM 的要求。 在支持矩阵中[了解详细信息](hyper-v-azure-support-matrix.md#replicated-vms)。
### <a name="how-often-can-i-replicate-to-azure"></a>可以多久复制到 Azure 一次?
可以每隔 30 秒(高级存储除外)、5 分钟或 15 分钟复制一次 Hyper-V VM。
### <a name="can-i-extend-replication"></a>是否可以扩展复制?
不支持扩展扩展或链式复制。
<!--Not Available on Request this feature in [feedback forum](https://support.azure.cn/en-us/support/contact/)-->
### <a name="can-i-do-an-offline-initial-replication"></a>是否可以执行脱机初始复制?
不支持此操作。
<!--Not Available on Request this feature in the [feedback forum](https://support.azure.cn/en-us/support/contact/)-->
### <a name="can-i-exclude-disks"></a>是否可以排除磁盘?
可以从复制中排除磁盘。
### <a name="can-i-replicate-vms-with-dynamic-disks"></a>是否可以复制包含动态磁盘的 VM?
可以复制动态磁盘。 操作系统磁盘必须是基本磁盘。
## <a name="security"></a>安全性
### <a name="what-access-does-site-recovery-need-to-hyper-v-hosts"></a>Site Recovery 需要对 Hyper-V 主机拥有哪些访问权限?
Site Recovery 需要对 Hyper-V 主机具备访问权限才能复制所选的 VM。 Site Recovery 在 Hyper-V 主机上安装以下代理:
- 如果不运行 VMM,则在每个主机上安装 Azure Site Recovery 提供程序和恢复服务代理。
- 如果运行 VMM,则在每个主机上安装恢复服务代理。 此提供程序在 VMM 服务器上运行。
### <a name="what-does-site-recovery-install-on-hyper-v-vms"></a>Site Recovery 在 Hyper-V VM 上安装什么内容?
Site Recovery 不会在启用复制的 Hyper-V VM 上显式安装任何内容。
## <a name="failover-and-failback"></a>故障转移和故障回复
### <a name="how-do-i-fail-over-to-azure"></a>如何故障转移到 Azure?
可以运行从本地 Hyper-V VM 到 Azure 的计划内或计划外故障转移。
- 如果运行计划内故障转移,则源 VM 关闭以确保不会丢失数据。
- 如果无法访问主站点,可以运行计划外故障转移。
- 可以故障转移单个虚拟机,或者创建恢复计划来协调多个虚拟机的故障转移。
- 运行故障转移。 故障转移的第一阶段完成后,应该会在 Azure 中看到创建的副本 VM。 如果需要,可向 VM 分配公共 IP 地址。 然后,提交故障转移以开始从副本 Azure VM 访问工作负载。
### <a name="how-do-i-access-azure-vms-after-failover"></a>故障转移后如何访问 Azure VM?
故障转移后,可以通过安全的 Internet 连接、站点到站点 VPN 或 Azure ExpressRoute 来访问 Azure VM。 在连接之前需要做许多准备。 [了解详细信息](site-recovery-test-failover-to-azure.md#prepare-to-connect-to-azure-vms-after-failover)
### <a name="is-failed-over-data-resilient"></a>故障转移的数据是否有复原能力?
Azure 具有复原能力。 Site Recovery 能够根据 Azure SLA 故障转移到辅助 Azure 数据中心。 发生故障转移时,我们会确保元数据和保管库保留在为保管库选择的同一地理区域中。
### <a name="is-failover-automatic"></a>故障转移是自动发生的吗?
[故障转移](site-recovery-failover.md)不是自动的。 可以在门户中单击一下鼠标来启动故障转移,也可以使用 [PowerShell](https://docs.microsoft.com/powershell/module/az.recoveryservices) 来触发故障转移。
### <a name="how-do-i-fail-back"></a>如何故障回复?
在本地基础结构启动并再次运行后,即可进行故障回复。 故障回复会出现在以下三个阶段:
1. 可以使用以下不同选项启动从 Azure 到本地站点的计划内故障转移:
- 最大限度减少停机时间:如果使用此选项,Site Recovery 将在故障转移之前同步数据。 它会检查更改的数据块并将它们下载到本地站点,同时让 Azure VM 保持运行并最大限度减少停机时间。 当手动指定故障转移应完成时,Azure VM 会关闭,任何最终增量更改会被复制,而故障转移将启动。
- 完整下载:使用此选项可在故障转移期间同步数据。 此选项会下载整个磁盘。 该操作更快,因为不计算校验和,但停机时间会增加。 如果运行副本 Azure VM 已有一段时间,或者如果本地 VM 已删除,请使用此选项。
2. 可选择故障回复到同一 VM 或备用 VM。 如果 VM 尚不存在,可指定 Site Recovery 应创建 VM。
3. 初始数据同步完成后,选择完成故障转移。 该操作完成后,可以登录到本地 VM 验证一切是否按预期运行。 在 Azure 门户中,可以看到 Azure VM 均已停止。
4. 完成故障转移的提交,并重新开始从本地 VM 访问工作负载。
5. 在工作负载进行故障回复后,启用反向复制,以便本地 VM 重新复制到 Azure。
### <a name="can-i-fail-back-to-a-different-location"></a>是否可以故障回复到不同位置?
可以。故障转移到 Azure 后,如果原始位置不可用,可以故障回复到不同的位置。 [了解详细信息](hyper-v-azure-failback.md#failback-to-an-alternate-location-in-hyper-v-environment)。
<!-- Update_Description: update meta properties, wording update --> | 11,645 | CC-BY-4.0 |
# Spring Boot集成Swagger2
## 集成Swagger2
- 引入依赖
```xml
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger2</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>io.springfox</groupId>
<artifactId>springfox-swagger-ui</artifactId>
<version>2.9.2</version>
</dependency>
```
- 集成Swagger:增加Swagger配置并启用Swagger
```java
@SpringBootConfiguration
@EnableSwagger2 //开启Swagger2
public class SwaggerConfig {
}
```
此时Swagger已集成,启动项目可以通过`http://localhost:8080/swagger-ui.html`访问到Swagger页面了。
## 配置Swagger2
Swagger的bean实例:Docket
### 基本配置:
```java
//配置Swagger的Docket的Bean实例
@Bean
public Docket docket() {
return new Docket(DocumentationType.SWAGGER_2)
.apiInfo(apiInfo());
}
//配置Swagger信息
private ApiInfo apiInfo() {
Contact contact = new Contact(
"HUA",
"http://localhost",
"[email protected]");
return new ApiInfo(
"Swagger-Demo Api 文档",
"Api Documentation 描述",
"V1.0",//版本
"urn:tos",
contact,
"Apache 2.0",
"http://www.apache.org/licenses/LICENSE-2.0",
new ArrayList<VendorExtension>());
}
```
### 配置扫描接口
`Docket.select()`
```java
@Bean
public Docket docket() {
return new Docket(DocumentationType.SWAGGER_2)
.apiInfo(apiInfo())
.select()
//RequestHandlerSelectors.any() 扫描所有
//RequestHandlerSelectors.none() 不扫描
//RequestHandlerSelectors.basePackage() 基于包扫描
//RequestHandlerSelectors.withClassAnnotation(RestController.class) 扫描类上的注解
//RequestHandlerSelectors.withMethodAnnotation(GetMapping.class) 扫描方法上的注解
.apis(RequestHandlerSelectors.basePackage("my.hua.swagger"))
//paths 根据请求路径过滤
//PathSelectors.any()
//PathSelectors.none()
//PathSelectors.ant("/user/**") 匹配url中有 /user 的请求
//PathSelectors.regex() 正则匹配路径
.paths(PathSelectors.any())
.build();
}
```
### 配置是否启用Swagger
```java
@Bean
public Docket docket() {
return new Docket(DocumentationType.SWAGGER_2)
.apiInfo(apiInfo())
.enable(true) //配置是否启用Swagger
.select()
.apis(RequestHandlerSelectors.basePackage("my.hua.swagger"))
.paths(PathSelectors.any())
.build();
}
```
### 配置Swagger分组及配置多个分组
- 通过`groupName()`方法配置分组名称
```java
@Bean
public Docket goodsDocket(Environment environment) {
return new Docket(DocumentationType.SWAGGER_2)
.apiInfo(apiInfo())
.enable(true) //配置是否启用Swagger
.groupName("商品管理API")//配置分组名称
.select()
.apis(RequestHandlerSelectors.basePackage("my.hua.swagger"))
.paths(PathSelectors.ant("/goods/**"))
.build();
}
```
- 配置多个Docket实例来配置多个分组
```java
@Bean
public Docket aDocket(){
return new Docket(DocumentationType.SWAGGER_2).groupName("A");
}
@Bean
public Docket bDocket(){
return new Docket(DocumentationType.SWAGGER_2).groupName("B");
}
@Bean
public Docket cDocket(){
return new Docket(DocumentationType.SWAGGER_2).groupName("C");
}
```
### 其他
- 只要Controller中的方法返回值中存在实体类,就会被扫描到Swagger中,在Models中显示
## Swagger常用注解
整理了一些Swagger常用的注解,详细信息请看官方文档:
- [http://docs.swagger.io/swagger-core/v1.5.X/apidocs/](http://docs.swagger.io/swagger-core/v1.5.X/apidocs/)
- [https://github.com/swagger-api/swagger-core/wiki/Annotations-1.5.X](https://github.com/swagger-api/swagger-core/wiki/Annotations-1.5.X)
### `@Api`
用在类上,说明该类的作用,可标记一个Controller类为Swagger资源。
`@Api(value = "/user",tags = {"用户操作类"})`
|属性|备注|
|---|---|
|value |若未使用tags,该值会被用于设置标签,若使用tags,该值无效|
|tags |标签,设置多个,用于对资源进行逻辑分组|
|description |对api资源的描述(过时)|
|basePath |基本路径可以不配置(过时)|
|position |如果配置了多个Api,可用该注解改变显示顺序(过时)|
|produces |For example, "application/json, application/xml"|
|consumes |For example, "application/json, application/xml"|
|protocols |Possible values: http, https, ws, wss|
|authorizations |高级特性认证时配置|
|hidden |配置为true,将在文档中隐藏|
### `@ApiOperation`
用在Controller类的方法上,用来描述具体的API
```java
@ApiOperation(value = "通过id查询用户",
notes = "通过id查询用户信息,参数为int类型",
response = User.class,
tags = {"查询"})
```
|属性|备注|
|---|---|
|value |操作的简要描述|
|notes |操作的详细描述|
|tags |标记可用于根据资源或任何其他限定符对操作进行逻辑分组|
|response |操作的响应类型|
|responseContainer |声明一个容器,有效值是“List”、“Set”或“Map”。其他任何值都将被忽略|
|responseReference |指定对响应类型的引用,覆盖任何指定的response()类|
|httpMethod |指定一种请求方式|
|position |(过时)|
|nickname |第三方工具使用operationId来惟一地标识该操作|
|produces |对应于操作的“生成”字段,接受内容类型的逗号分隔值。例如,“application/json, application/xml”将建议此操作生成json和xml输出。|
|consumes |接受内容类型的逗号分隔值。例如,“application/json, application/xml”将建议此API资源接受json和xml输入|
|protocols |为该操作设置特定的协议(方案),可用协议的逗号分隔值。可能的值:http、https、ws、wss。|
|authorizations |获取此操作的授权(安全需求)列表|
|hidden |从操作列表中隐藏操作|
|responseHeaders |响应可能提供的响应头列表|
|code |响应状态码,默认200|
|extensions |可选的扩展数组|
### `@ApiParam`
用在Controller类的方法上,用来描述方法参数。
```java
public User selectUserById(@ApiParam(name = "id",value = "用户id",required = true,example = "123") @PathVariable(value = "id", required = true) int id) {
return new User(id, "Tom");
}
```
|属性|备注|
|---|---|
|name |参数名称|
|value |参数简要描述|
|defaultValue |参数的默认值|
|allowableValues |限制可接受参数|
|required |指定是否需要参数,默认false|
|access |允许从API文档中过滤参数|
|allowMultiple |指定参数是否可以通过多次出现来接受多个值|
|hidden |从参数列表中隐藏参数|
|example |参数示例|
|examples |参数示例。仅适用于body参数|
|type |添加覆盖检测到的类型的能力|
|format |添加提供自定义格式的功能|
|allowEmptyValue |添加将格式设置为empty的功能|
|readOnly |增加被指定为只读的能力|
|collectionFormat |添加使用' array '类型覆盖collectionFormat的功能|
### `@ApiImplicitParams` & `@ApiImplicitParam`
用在controller的方法上,对API操作中的单个参数进行描述。
```java
@ApiImplicitParams({
@ApiImplicitParam(name = "name", value = "User's name", required = true, dataType = "string", paramType = "query"),
@ApiImplicitParam(name = "email", value = "User's email", required = false, dataType = "string", paramType = "query"),
@ApiImplicitParam(name = "id", value = "User ID", required = true, dataType = "long", paramType = "query")
})
public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
}
```
|属性|备注|
|---|---|
|name |参数的名称|
|value |参数的简要描述|
|defaultValue |描述参数的默认值|
|allowableValues |限制此参数的可接受值|
|required |指定是否需要参数,默认false|
|access |允许从API文档中过滤参数|
|allowMultiple |指定参数是否可以接受多个逗号分隔的值|
|dataType |参数的数据类型,可以是类名或基元|
|dataTypeClass |url的路径位置|
|paramType |参数的参数类型,有效值是路径、查询、正文、标题或表单|
|example |非主体类型参数的一个示例|
|examples |参数示例。仅适用于body参数|
|type |添加覆盖检测到的类型的能力|
|format |添加提供自定义格式的功能|
|format |添加提供自定义格式的功能|
|allowEmptyValue |添加将格式设置为空的功能|
|collectionFormat |添加使用' array '类型覆盖collectionFormat的功能|
### `@ApiResponses` & `@ApiResponse`
描述服务器响应。
```
@ApiResponses(value = {
@ApiResponse(code = 400, message = "Invalid ID supplied",
responseHeaders = @ResponseHeader(name = "X-Rack-Cache", description = "Explains whether or not a cache was used", response = Boolean.class)),
@ApiResponse(code = 404, message = "User not found") })
```
|属性|备注|
|---|---|
|code |状态码,默认200|
|message |返回响应信息|
|response |可选的响应类来描述消息的有效负载|
|reference |指定对响应类型的引用,覆盖任何指定的response()类|
|responseHeaders |响应可能提供的响应头列表|
|responseContainer |声明一个响应容器,有效值是“List”、“Set”或“Map”。其他任何值都将被忽略|
### `@ResponseHeader`
响应头设置。响应可能提供的响应头列表
|属性|备注|
|---|---|
|name |响应头的名字|
|description |响应头的长描述|
|response |响应头的数据类型|
|responseContainer |声明一个响应容器,有效值是“List”、“Set”或“Map”。其他任何值都将被忽略|
### `@ApiModel`
用在Controller中方法返回的对象上,描述返回对象
```java
@ApiModel(value = "用户",description = "用户实体")
public class User {
private Integer id;
private String userName;
}
```
|属性|备注|
|---|---|
|value |为模型提供一个替代名称,默认使用类名|
|description |提供一个更长的类描述|
|parent |为模型提供一个超类以允许描述继承|
|discriminator |支持模型继承和多态性,这是用作鉴别器的字段的名称,基于这个字段,可以断言需要使用哪个子类型|
|subTypes |继承自此模型的子类型的数组|
|reference |指定对相应类型定义的引用,覆盖指定的任何其他元数据|
### `@ApiModelProperty`
用于描述Model的属性
```java
public class User {
@ApiModelProperty(value = "用户id", dataType = "Integer", example = "123")
private Integer id;
@ApiModelProperty(name = "userName", value = "姓名", dataType = "String", notes = "用户姓名")
private String userName
```
|属性|备注|
|---|---|
|value |属性的简要描述|
|name |允许重写属性的名称|
|access |允许从API文档中过滤参数|
|allowableValues |限制此属性的可接受值|
|notes |目前未使用|
|dataType |参数的数据类型,这可以是类名或基元。该值将覆盖从类属性读取的数据类型|
|required |指定是否需要参数,默认false|
|position |允许显式地对模型中的属性进行排序|
|hidden |允许模型属性隐藏在Swagger模型定义中|
|example |属性的示例值|
|readOnly |允许模型属性被指定为只读|
|reference |指定对相应类型定义的引用,覆盖指定的任何其他元数据|
|allowEmptyValue|允许传递空值|
### `@Authorization`
用在controller的方法上,声明要在资源或操作上使用的授权方案。
|属性|备注|
|---|---|
|value |用于此资源/操作的授权方案的名称|
|scopes |如果授权模式是OAuth2,则使用的作用域|
### `@AuthorizationScope`
用在controller的方法上,用于定义为已定义授权方案的操作所使用的授权范围。
```java
@ApiOperation(value = "Add a new pet to the store",
authorizations = {
@Authorization(
value="petoauth",
scopes = { @AuthorizationScope(scope = "add:pet") }
)
}
)
public Response addPet(...) {...}
```
|属性|备注|
|---|---|
|scope |使用OAuth2授权方案的范围,作用域应该在Swagger对象的securityDefinition部分中预先声明|
|description |用于遗留支持| | 9,243 | Apache-2.0 |
+++
title = "EP28: Job Titles"
description = "About job titles"
date = 2020-10-01
slug = "ep28-job-titles"
template = "page.html"
[taxonomies]
[extra]
episode = 28
cover = "/ep28_cover.png"
duration = "2086"
length = "50083183"
+++
這集我們在聊的是關於工作頭銜相關的事情,順便也稍微提及了一些議題像是:Pay Gap
between Product Designer and Visual Designer,Software Developer vs Software
Engineer。
<!-- more -->
---
歡迎註冊加入我們的論壇:
[https://forum.thirdstream.life/](https://forum.thirdstream.life/)
---
[iTunes](https://podcasts.apple.com/us/podcast/third-stream-podcast/id1503447781)
[Spotify](https://open.spotify.com/show/4Lt3yXZrcOvZ7NgBn7iJLV)
[Third Stream Website](https://thirdstream.life)
Music from [https://tfbeats.com/](https://tfbeats.com/) | 725 | MIT |
---
title: jQueryを使用する - declare使用例
description: 本来外部モジュールはnpm install hogehogeでインストールを行えばComponentで使用できるようになるが、CDNやインストールしないタイプのモジュールでは使用できない。
---
# jQueryを使用する - declare使用例
本来外部モジュールは`npm install hogehoge`でインストールを行えばComponentで使用できるようになるが、CDNやインストールしないタイプのモジュールでは使用できない。
<ClientOnly>
<CallInFeedAdsense />
</ClientOnly>
## インストール
Jquery本体と型のインストールを行う。
```bash
npm install jquery --save
npm install @types/jquery --save-dev
```
## angular.jsonの編集
scriptタグ(2箇所)にjquery.jsを読み込む設定を記述する。
```json
"scripts": [
"node_modules/jquery/dist/jquery.js"
]
```
## sample
画像animationサンプル。
HTMLに関してはjQueryの書き方がそのまま使える。
```html
<!-- app.component.ts -->
<button (click)="debug()">click me</button>
<svg
xmlns="http://www.w3.org/2000/svg"
enable-background="new 0 0 24 24"
height="24"
viewBox="0 0 24 24"
width="24"
id="book"
>
<g><rect fill="none" height="24" width="24" /></g>
<g>
<g>
<g>
<path
d="M8.5,14.5L4,19l1.5,1.5L9,17h2L8.5,14.5z M15,1c-1.1,0-2,0.9-2,2s0.9,2,2,2s2-0.9,2-2S16.1,1,15,1z M21,21.01L18,24 l-2.99-3.01V19.5l-7.1-7.09C7.6,12.46,7.3,12.48,7,12.48v-2.16c1.66,0.03,3.61-0.87,4.67-2.04l1.4-1.55 C13.42,6.34,14.06,6,14.72,6h0.03C15.99,6.01,17,7.02,17,8.26v5.75c0,0.84-0.35,1.61-0.92,2.16l-3.58-3.58v-2.27 c-0.63,0.52-1.43,1.02-2.29,1.39L16.5,18H18L21,21.01z"
/>
</g>
</g>
</g>
</svg>
```
component.tsでは
* `import * as jQuery from 'jquery'; `は型呼び出しのため
* `declare var $: typeof jQuery;` は`$`に型を定義する。
```ts
// app.component.ts
import { Component } from '@angular/core';
import * as jQuery from 'jquery'; // jqueryの読み込み
declare var $: typeof jQuery; // $の型を宣言する
@Component({
selector: 'app-root',
templateUrl: './app.component.html',
styleUrls: ['./app.component.scss'],
})
export class AppComponent {
title = 'jquery-test';
constructor() {}
debug(): void {
$('#book').animate( // jQeuryが型を見ながらコーディングできる。
{
opacity: 0.25,
right: '+=50',
height: 'toggle',
},
5000
);
}
}
```
`declare`はアンビエント宣言と呼ぶみたい。**componentソース上にはない変数(関数、Objectなどを含む)を定義済みとする**機能。angular.jsonにjquery.jsが読み込まれているためグローバル変数として`$`関数は存在しているが、app.component.tsには`$`が存在しないため`declare`宣言が存在しない場合、コンパイルエラーになる。`$`はコードに見えないけど存在していますよ!みたいな感じで使える。
ここの例はjQueryを使用しているがCDNなどによりindex.htmlの`<script>`により宣言したjsにも使える。 | 2,353 | MIT |
中文|[English](README.md)
**本样例为大家学习昇腾软件栈提供参考,非商业目的!**
**本样例适配20.0及以上版本,支持产品为Atlas200DK、Atlas300([ai1s](https://support.huaweicloud.com/productdesc-ecs/ecs_01_0047.html#ecs_01_0047__section78423209366))。**
**本README只提供命令行方式运行样例的指导,如需在Mindstudio下运行样例,请参考[Mindstudio运行视频样例wiki](https://github.com/Huawei-Ascend/samples/wikis/Mindstudio%E8%BF%90%E8%A1%8C%E5%9B%BE%E7%89%87%E6%A0%B7%E4%BE%8B?sort_id=3164874)。**
## vdecandvenc样例
功能:调用dvpp的venc和vdec接口,实现视频编码功能。
样例输入:原始mp4文件,h264或者h265文件。
样例输出:编码后的h264或者h265文件。
### 前提条件
部署此Sample前,需要准备好以下环境:
- 请确认已按照[环境准备和依赖安装](../../../environment)准备好环境。
- 已完成对应产品的开发环境和运行环境安装。
### 软件准备
1. 获取源码包。
可以使用以下两种方式下载,请选择其中一种进行源码准备。
- 命令行方式下载(下载时间较长,但步骤简单)。
开发环境,非root用户命令行中执行以下命令下载源码仓。
**cd $HOME**
**git clone https://github.com/Huawei-Ascend/samples.git**
- 压缩包方式下载(下载时间较短,但步骤稍微复杂)。
1. samples仓右上角选择 **克隆/下载** 下拉框并选择 **下载ZIP**。
2. 将ZIP包上传到开发环境中的普通用户家目录中,例如 **$HOME/ascend-samples-master.zip**。
3. 开发环境中,执行以下命令,解压zip包。
**cd $HOME**
**unzip ascend-samples-master.zip**
2. 获取此应用中所需要的原始网络模型。
参考下表获取此应用中所用到的原始网络模型及其对应的权重文件,并将其存放到开发环境普通用户下的任意目录,例如:$HOME/models/vdecandvenc。
| **模型名称** | **模型说明** | **模型下载路径** |
|---|---|---|
| face_detection| 图片分类推理模型。是基于Caffe的yolov3模型。 | 请参考[https://github.com/Huawei-Ascend/modelzoo/tree/master/contrib/TensorFlow/Research/cv/facedetection/ATC_resnet10-SSD_caffe_AE](https://github.com/Huawei-Ascend/modelzoo/tree/master/contrib/TensorFlow/Research/cv/facedetection/ATC_resnet10-SSD_caffe_AE)目录中README.md下载原始模型章节下载模型和权重文件。 |
 **说明:**
> - modelzoo中提供了转换好的om模型,但此模型不匹配当前样例,所以需要下载原始模型和权重文件后重新进行模型转换。
3. 将原始模型转换为Davinci模型。
**注:请确认环境变量已经在[环境准备和依赖安装](../../../environment)中配置完成**
1. 设置LD_LIBRARY_PATH环境变量。
由于LD_LIBRARY_PATH环境变量在转使用atc工具和运行样例时会产生冲突,所以需要在命令行单独设置此环境变量,方便修改。
**export install\_path=$HOME/Ascend/ascend-toolkit/latest**
**export LD_LIBRARY_PATH=\\${install_path}/atc/lib64**
2. 执行以下命令下载aipp配置文件并使用atc命令进行模型转换。
**cd $HOME/models/face_detection_camera**
**wget https://c7xcode.obs.cn-north-4.myhuaweicloud.com/models/face_detection_camera/insert_op.cfg**
**atc --output_type=FP32 --input_shape="data:1,3,300,300" --weight=./face_detection_fp32.caffemodel --input_format=NCHW --output=./face_detection --soc_version=Ascend310 --insert_op_conf=./insert_op.cfg --framework=0 --save_original_model=false --model=./face_detection.prototxt**
3. 执行以下命令将转换好的模型复制到样例中model文件夹中。
**cp ./face_detection.om $HOME/samples/cplusplus/level2_simple_inference/0_data_process/vdecandvenc/model/**
4. 获取样例需要的测试视频。
执行以下命令,进入样例的data文件夹中,下载对应的测试视频。
**cd $HOME/samples/cplusplus/level2_simple_inference/0_data_process/vdecandvenc/data**
**wget https://c7xcode.obs.cn-north-4.myhuaweicloud.com/models/vdecandvenc/out_video.h264**
**wget https://c7xcode.obs.cn-north-4.myhuaweicloud.com/models/vdecandvenc/person.mp4**
### 样例部署
1. 开发环境命令行中设置编译依赖的环境变量。
基于开发环境与运行环境CPU架构是否相同,请仔细看下面的步骤:
- 当开发环境与运行环境CPU架构相同时,执行以下命令导入环境变量。
**export DDK_PATH=$HOME/Ascend/ascend-toolkit/latest/x86_64-linux**
**export NPU_HOST_LIB=$DDK_PATH/acllib/lib64/stub**
 **说明:**
> - 如果是20.0版本,此处 **DDK_PATH** 环境变量中的 **x86_64-linux** 应修改为 **x86_64-linux_gcc7.3.0**。
> - 可以在命令行中执行 **uname -a**,查看开发环境和运行环境的cpu架构。如果回显为x86_64,则为x86架构。如果回显为arm64,则为Arm架构。
- 当开发环境与运行环境CPU架构不同时,执行以下命令导入环境变量。例如开发环境为X86架构,运行环境为Arm架构,由于开发环境上同时部署了X86和Arm架构的开发套件,后续编译应用时需要调用Arm架构开发套件的ACLlib库,所以此处需要导入环境变量为Arm架构的ACLlib库路径。
**export DDK_PATH=$HOME/Ascend/ascend-toolkit/latest/arm64-linux**
**export NPU_HOST_LIB=$DDK_PATH/acllib/lib64/stub**
 **说明:**
> - 如果是20.0版本,此处 **DDK_PATH** 环境变量中的 **arm64-liunx** 应修改为 **arm64-linux_gcc7.3.0**。
> - 可以在命令行中执行 **uname -a**,查看开发环境和运行环境的cpu架构。如果回显为x86_64,则为x86架构。如果回显为arm64,则为Arm架构。
2. 切换到vdecandvenc目录,创建目录用于存放编译文件,例如,本文中,创建的目录为 **build/intermediates/host**。
**cd $HOME/samples/cplusplus/level2_simple_inference/0_data_process/vdecandvenc**
**mkdir -p build/intermediates/host**
3. 切换到 **build/intermediates/host** 目录,执行cmake生成编译文件。
- 当开发环境与运行环境操作系统架构相同时,执行如下命令编译。
**cd build/intermediates/host**
**make clean**
**cmake \.\./\.\./\.\./src -DCMAKE_CXX_COMPILER=g++ -DCMAKE_SKIP_RPATH=TRUE**
- 当开发环境与运行环境操作系统架构不同时,需要使用交叉编译器编译。例如开发环境为X86架构,运行环境为Arm架构,执行以下命令进行交叉编译。
**cd build/intermediates/host**
**make clean**
**cmake \.\./\.\./\.\./src -DCMAKE_CXX_COMPILER=aarch64-linux-gnu-g++ -DCMAKE_SKIP_RPATH=TRUE**
4. 执行make命令,生成的可执行文件main在 **venc/out** 目录下。
**make**
### 样例运行
**注:开发环境与运行环境合一部署,请跳过步骤1,直接执行[步骤2](#step_2)即可。**
1. 执行以下命令,将开发环境的 **vdecandvenc** 目录上传到运行环境中,例如 **/home/HwHiAiUser**,并以HwHiAiUser(运行用户)登录运行环境(Host)。
**scp -r $HOME/samples/cplusplus/level2_simple_inference/0_data_process/vdecandvenc [email protected]:/home/HwHiAiUser**
**ssh [email protected]**
 **说明:**
> - **xxx.xxx.xxx.xxx**为运行环境ip,200DK在USB连接时一般为192.168.1.2,300(ai1s)为对应的公网ip。
2. <a name="step_2"></a>运行可执行文件。
- 如果是开发环境与运行环境合一部署,执行以下命令,设置运行环境变量,并切换目录。
**export LD_LIBRARY_PATH=**
**source ~/.bashrc**
**cd $HOME/samples/cplusplus/level2_simple_inference/0_data_process/vdecandvenc/out**
- 如果是开发环境与运行环境分离部署,执行以下命令切换目录。
**cd $HOME/vdecandvenc/out**
切换目录后,执行以下命令运行样例。
**mkdir output**
**./main ../data/out_video.h264**
### 查看结果
运行完成后,会在运行环境的命令行中打印出推理结果,并在$HOME/vdecandvenc/out/output目录下生成推理后的图片。 | 6,064 | Apache-2.0 |
# SpringBoot 中利用 Spring Task 使用定时任务
一个企业级应用中或多或少都会有使用定时任务(也称任务调度)的需求。比如,每天凌晨 3 点执行一次定时任务,删除系统中超过 60 天还未激活的用户。又或者,用户在图形化界面中手动开启一个 3 小时后需要执行的任务。
**按照使用角度划分,可以分为两类:(技术角度)**
- 按照固定的频率执行任务(比如,每个 3 天执行执行一次任务)(周期性任务)
- 按照指定的时间点执行任务(比如,12 小时后执行任务)(基于日历的单次任务)
**按照任务创建方式的角度划分,也可以分为两类:(业务角度)**
- **业务流程产生型:**任务的执行时间离任务的触发时间不长的情况下。比如 3 小时候执行的任务。
- **扫描线程产生型:**通过定期扫描线程根据扫描到的业务数据动态的去创建任务。比如扫描到 60 天内都没有激活的用户,然后创建一个再从线程池中获取一个线程去处理业务。
## 定时任务的几种解决方案
定时任务本身涉及多线程、运行时间规则制定及解析、运行线程保持与恢复(程序突然停止了,就需要持久化定时任务的存储)、线程池维护等多方便的工作。如果直接使用自定义线程这种原始方法,实现起来的难度会很大,而且程序的稳定性也不好。实际上 Java 领域提供了很多任务调度的解决方案(尽管它们底层也是直接使用的自定义线程的方式,但是它们内部做了很多其他的工作,使得这个任务调度的程序变得很可靠)供用户使用。
- Timer/TimerTask
- 这是 Java1.3 版本增加的用于实现定时任务的工具类,它只能够按照指定的频率执行任务,而不能够在指定的时间执行任务。
- 功能单一,实际工作中有更好的替代方式,所以,没有必要去了解它哦。
- Executor
- 这是 Java5.0 juc 包中新增的线程池相关的工具类,两种类型的定时任务都支持。
- **如果项目确定是一个单体应用,且不需要大量使用到定时任务,那么非常推荐使用它。**
- **基于日历的单次任务,直接使用它即可。对于周期性定时任务最好是直接使用 Spring Task (对 Java5.0 Executor 的一个封装)。**
- Spring Task
- 这是 Spring3.0 之后对于定时任务的一个基础性封装,它内部封装了 Timer、Executor 等。
- 它内部有一个 ThreadPoolTaskExecutor 类,是对于 java.util.concurrent.ThreadPoolExecutor 类的一个封装。对外暴露了一些属性,供开发人员进行配置。
- **对于单体应用中的固定频率的定时任务,推荐使用它。**
- Quartz
- 这是一个专业的任务调度框架,能够使用数据库做持久化,同时还能够支持分布式集群(但是使用起来麻烦)。
- **如果是单体应用,且有大量的定时任务需要使用,推荐使用它。**
- XXL-JOB
- 这是一个专业的分布式任务调度框架,早期是基于 Quartz 实现的,后期改为自己实现的定时任务引擎。
- **如果是分布式应用,且有大量的定时任务需要使用,那么推荐使用它。(使用广泛、简单、社区活跃度高)**
- Elastic-Job
- 这也是一个专业的分布式任务调度框架,它的作者同时还开源了 ShardingSphere ,目前已经是 Apache 的顶级项目了,未来应该也会有很大的发展吧。
- 如果是分布式应用,到底是应该使用 XXL-JOB 还是 Elastic-Job 呢?我也不知道啊,前者好像使用的多一点吧。
## Cron 表达式
Cron 表达式是一种使用字符串形式来描述周期性定时任务的语法,包括 6~7 个时间元素,元素之间使用空格隔开的。
### Cron 表达式的组成

### Cron 表达式各个通配符的含义

### Cron 表达式的各种使用示例

## Spring Task 的使用
### Spring Task 线程池配置
默认情况下 Spring Task 是使用单个线程来执行所有定时任务,如果系统中的定时任务很多,肯定是需要配置一个线程池的。Spring Task 提供了一个ThreadPoolTaskExecutor 类,是对于 java.util.concurrent.ThreadPoolExecutor 类的一个封装。对外暴露了一些属性,供开发人员进行配置。SpringBoot 中配置线程池的方式如下:
```java
/**
* 给 Spring Task 配置线程池
*/
@Configuration
@EnableScheduling // 必须加上此注解,否则定时任务不会开启
public class ScheduleConfiguration implements SchedulingConfigurer {
private static final Logger log = LoggerFactory.getLogger(ScheduleConfiguration.class);
// 给ScheduledTaskRegistrar对象注入一个ThreadPoolTaskScheduler对象,就拥有了使用线程池来执行定时任务的能力
@Override
public void configureTasks(ScheduledTaskRegistrar taskRegistrar) {
ThreadPoolTaskScheduler taskScheduler = new ThreadPoolTaskScheduler();
// ThreadPoolTaskScheduler对象核心配置
taskScheduler.setPoolSize(4);
taskScheduler.setWaitForTasksToCompleteOnShutdown(true);
taskScheduler.setThreadNamePrefix("schedule");
taskScheduler.setRemoveOnCancelPolicy(true);
taskScheduler.setErrorHandler(t -> log.error("Error occurs", t));
taskScheduler.initialize(); // 这行代码不能少
// 向 ScheduledTaskRegistrar 对象中注册 ThreadPoolTaskScheduler 对象
taskRegistrar.setTaskScheduler(taskScheduler);
}
}
```
### Spring Task 定时任务的配置
Spring Task 是专门用实现固定频率类型的定时任务的,只需要在一个 POJO 类的普通方法上使用 @Scheduled 注解即可。一共有 4 种方式来实现,分别是:
- 指定 cron 表达式
- 指定 fixedRate 属性
- 指定 fixedDelay 属性
- 指定 initialDelay 属性
```java
/**
* 测试 4 种定时执行任务的写法
*/
@Component
public class SpringTaskJob {
private static final Logger log = LoggerFactory.getLogger(SpringTaskJob.class);
private AtomicLong counter = new AtomicLong();
// 上一次 执行完毕时间点 之后 10 秒再执行。
@Scheduled(fixedDelay = 10 * 1000L)
public void scheduleWithFixedDelay() throws Exception {
try {
TimeUnit.MILLISECONDS.sleep(10 * 1000L);
} catch (InterruptedException e) {
log.error("Interrupted exception", e);
}
long count = counter.incrementAndGet();
log.info("Schedule executor {} times with fixed delay", count);
}
// 第一次延迟 2 秒后执行,之后按 fixedRate 的规则每 10 秒执行一次。
@Scheduled(initialDelay = 2000L, fixedDelay = 10 * 1000L)
public void scheduleWithinitialDelayAndFixedDelay() throws Exception {
try {
TimeUnit.MILLISECONDS.sleep(10 * 1000L);
} catch (InterruptedException e) {
log.error("Interrupted exception", e);
}
long count = counter.incrementAndGet();
log.info("Schedule executor {} times with fixed delay", count);
}
// 上一次 开始执行时间点 之后 10 秒再执行。
@Scheduled(fixedRate = 10 * 1000L)
public void scheduleAtFixedRate() throws Exception {
long count = counter.incrementAndGet();
log.info("Schedule executor {} times at fixed rate", count);
}
// 根据 cron 表达式定义,每隔 10 秒执行一次。
@Scheduled(cron = "0/10 * * * * *")
public void scheduleWithCronExpression() throws Exception {
long count = counter.incrementAndGet();
log.info("Schedule executor {} times with ", count);
}
}
```
## 注意事项
- 静态变量是 ClassLoader 级别的,如果 Web 应用程序停止,那么这些静态变量也会从 JVM 中清除。但是,线程池是 JVM 级别的。**这意味着如果用户在 Web 应用中启动了一个线程,那么这个线程的生命周期并不会和 Web 应用程序保持同步。这是个大坑,但是很多人显然不知道。所以,真正保险的方式是,在程序关闭的时候,手动的去关闭这些线程。**这时候,最好还是利用 Spring 已经实现好了的机制来实现这个功能,不要去自己实现。
## 参考链接
- 《精通Spring 4.x》第 16 章
- https://juejin.im/post/5d653f9ef265da03a31d4792
- https://medium.com/@guraycintir/task-scheduling-in-spring-boot-e70a1069a9f
- https://juejin.im/post/5b31b9eff265da598826c200#heading-1
- http://www.bejson.com/othertools/cron/
- https://www.pppet.net/ | 5,165 | Apache-2.0 |
---
layout: post
category: swing
folder: DividerFocus
title: JSplitPaneのDividerをマウスクリックで選択状態にする
tags: [JSplitPane]
author: aterai
pubdate: 2020-05-11T17:50:27+09:00
description: JSplitPaneのDividerをマウスでクリックしたとき選択状態になるよう設定します。
image: https://drive.google.com/uc?id=1KMTrAVDblIUSfTjTvu0s_fBYMckaaF9Z
comments: true
---
## 概要
`JSplitPane`の`Divider`をマウスでクリックしたとき選択状態になるよう設定します。
{% download https://drive.google.com/uc?id=1KMTrAVDblIUSfTjTvu0s_fBYMckaaF9Z %}
## サンプルコード
<pre class="prettyprint"><code>JSplitPane splitPane = new JSplitPane();
Container divider = ((BasicSplitPaneUI) splitPane.getUI()).getDivider();
divider.addMouseListener(new MouseAdapter() {
@Override public void mousePressed(MouseEvent e) {
super.mousePressed(e);
splitPane.requestFocusInWindow();
// or
// Action startResize = splitPane.getActionMap().get("startResize");
// startResize.actionPerformed(new ActionEvent(
// splitPane, ActionEvent.ACTION_PERFORMED, "startResize"));
}
});
</code></pre>
## 解説
- `Default`
- デフォルトの`JSplitPane`では`Divider`をクリックしてもフォーカス移動は発生しない
- <kbd>F8</kbd>キーを押して`startResize`アクションを実行しないと`Divider`は選択状態にならず、カーソルキーでの`Divider`移動は不可
- `JSplitPane`とその子コンポーネントがすべてフォーカス不可の場合、`Divider`を選択状態にすることはできない
- `JSplitPane#setFocusable(true)`を設定すれば<kbd>Tab</kbd>キーなどで`Divider`を選択状態にできる
- `Divider.addMouseListener`
- `BasicSplitPaneUI#getDivider()`で取得した`Divider`に`MouseListener`を設定して、クリックされたら親の`JSplitPane`にフォーカスを移動することで`Divider`を選択状態にする
- `Container`である`Divider`に`requestFocusInWindow()`を実行することは可能だが、これを実行しても`Divider`は選択状態にならない
- `JSplitPane`とその子コンポーネントがすべてフォーカス不可でも`Divider`を選択状態にできる
<!-- dummy comment line for breaking list -->
- - - -
- メモ: カーソルキーによる`Divider`の移動量を変更したい
- `BasicSplitPaneUI.KEYBOARD_DIVIDER_MOVE_OFFSET`が定義されているがどこからも使用されていない?
- `BasicSplitPaneUI#getKeyboardMoveIncrement()`メソッドが存在してマジックナンバーで`3`が返される
- これをオーバーライドして移動量を変更したいが、パッケージプライベートなので利用しづらい
<!-- dummy comment line for breaking list -->
## 参考リンク
- [JSplitPaneのDividerをマウスで移動できないように設定する](https://ateraimemo.com/Swing/FixedDividerSplitPane.html)
<!-- dummy comment line for breaking list -->
## コメント | 2,150 | MIT |
# 校园双创服务平台(基于SpringCloud的微服务架构及DevOps实践)
[](https://travis-ci.org/notobject/ccsu-micro-platform-projects)
[](http://www.apache.org/licenses/LICENSE-2.0.html)
## 一、介绍
### 逻辑架构

主要分为四层:
1. 负载均衡层:各终端通过域名访问云端,通过DNS服务器解析至负载均衡层,负载均衡层(采用了Nginx)负责通过特定的负载均衡算法将终端请求路由到网关层的某一具体实例。
2. 网关层:网关层是整个系统的唯一入口。负责建立、维护会话连接,并对请求进行多级过滤,确保到达服务后端的请求是确定的和安全的。
3. 微服务层:微服务层又可以细分为基础微服务和业务微服务,其中基础微服务作为整个后端系统的支撑结构,为所有业务微服务所依赖。微服务层主要处理来自终端的业务请求。
4. 数据访问层:Mysql集群,Redis集群和RabbitMQ集群。
### 物理架构

### 云控中心架构及模块组成


序号|名称|简述
--|--|--
1|服务上线|供开发者使用,提供服务上线前的配置工作,包括服务名配置,资源分配,配置文件定义及代码仓库。
2|服务构建|由系统自动执行,通过拉取预配置代码仓库的程序代码进行自动化构建的过程。
3|服务治理|提供给服务责任人的简单服务管理功能,包括服务的启动,停止,重启,扩容/缩容,回滚,服务降级,熔断等操作。
4|服务配置|针对指定服务的配置文件进行在线修改实时生效,并提供配置回滚能力。
4|状态监控|对服务状态及宿主服务器状态进行实时监控。
4|资源配置|提供给运维人员进行服务器资源配置功能,方便进行资源分配。
4|审计日志|记录持续集成系统内的全链路操作日志,方便故障溯源和排错。
### 目录结构
目录名 | 简述
-------|--
MP-Agent |控制代理,运行于宿主机,通过接收控制中心指令,在服务上执行相应的操作,Go语言实现。采用了RabbitMQ的topic模式用于接收指令,fanout模式用于实时上报执行过程和执行结果。
MP-UI|平台前端,采用微信小程序实现
control-center|控制中心Web端,负责展示系统状态,和用户交互。将命令下发给控制代理,并展示过程和结果。
common-script|一些Shell脚本,主要用于前期自动化部署测试,现已废弃。
common-code|项目公共代码
ccsu-register-server|注册中心,采用了eureka实现,负责服务的注册与发现。
ccsu-config-server| 配置中心,直接采用了Github作为配置仓库,并配置了WebHook和AMQP实现自动更新。 [配置仓库](https://github.com/notobject/config-center)
ccsu-proxy-server|API网关层,采用了Zuul实现。网关层主要做了请求的登录校验,请求头校验,权限校验,会话及用户信息统一管理功能。
ccsu-user-service|用户信息及会话服务,这个主要是为网关层服务。用了Redis进行分布式会话维护。用户信息直接落在Mysql。
ccsu-notify-service| 通知服务,直接提供一对一,一对多的用户提醒功能,包括邮件通知,短信通知,站内通知,基于Websocket做站内主动推送。并且采用了spring cloud stream对发送和接收解耦,该服务为通用服务。
ccsu-main-service| 首页聚合服务,主要聚合Banber推荐,功能菜单栏,Feed流等服务的数据,客户端只需要请求一次这个服务,就能取得首页所有需要渲染的数据。
ccsu-team-service| 团队页聚合服务,效果同上。
ccsu-socre-service|综测服务,统一综测管理,该服务为通用服务。
## 三、准备
### 服务器资源分配
为能够最大程度模拟集群部署,请至少准备4台云服务器 or 个人电脑 or 虚拟机:
序号|标签|用途|备注
--|--|--|--
1|ServerA|服务集群|模拟A地机房
2|ServerB|服务集群|模拟B地机房
3|ServerC|持久化集群| 这个非重点,用一台模拟集群环境
4|ServerD|服务治理平台| 这个可以选择在自己本地部署
### 系统&工具
### centos 配置
略
### maven 安装及配置
略
### git 安装及配置
略
### docker 安装及配置
略
### ningx 安装及配置
略
### mysql 安装及配置
略
### redis 安装及配置
略
### rabbitMQ 安装及配置
略
## 四、开始
### step 1. Control-Center
略
### step 2. MP-Agent
略
### step 3. Register-Server
#### 注册中心:ServiceA 120.78.82.47
首先拉取代码并执行编译
```shell
git clone https://github.com/notobject/ccsu-micro-platform-projects build
cd build/
cd ccsu-register-server/
mvn clean package -Dmaven.test.skip=true -Pprod
cp target/*.jar ./app.jar
vim Dockerfile
#-----------------------------下同
FROM java:openjdk-8-jre-alpine
COPY app.jar /app.jar
ENTRYPOINT ["java","-jar","/app.jar"]
#---------------------------------------
docker build -t notobject/mp-base:register-center .
docker run -d --name register-server -p 8761:8761 -t notobject/mp-base:register-center -v /var/log/:/var/log/ --restart=always --eureka.instance.ip-address=120.78.82.47 --eureka.client.service-url.defaultZone=http://39.106.96.220:8761/eureka/
#推送镜像到远程,
docker push notobject/mp-base:register-center
```
#### 注册中心:ServiceB 39.106.96.220
> 拉取远程镜像
docker pull notobject/mp-base:register-center
> 运行容器
docker run -d --name register-server -p 8761:8761 -t notobject/mp-base:register-center -v /var/log/:/var/log/ --restart=always --eureka.instance.ip-address=39.106.96.220 --eureka.client.service-url.defaultZone=http://120.78.82.47:8761/eureka/
### step 4. Config-Server
#### ServiceA 120.78.82.47
docker run -d --name config-server -p 8888:8888 -v /var/log/:/var/log/ -t notobject/mp-base:config-center --restart=always --eureka.instance.ip-address=120.78.82.47 --eureka.client.service-url.defaultZone=http://120.78.82.47:8761/eureka/,http://39.106.96.220:8761/eureka/
#### ServiceB 39.106.96.220
docker run -d --name config-server -p 8888:8888 -v /var/log/:/var/log/ -t notobject/mp-base:config-center --restart=always --eureka.instance.ip-address=39.106.96.220 --eureka.client.service-url.defaultZone=http://120.78.82.47:8761/eureka/,http://39.106.96.220:8761/eureka/
### step 5. Proxy-Server
#### ServiceA 120.78.82.47
docker run -d --name proxy-server -p 8000:8000 -v /var/log/:/var/log/ -t notobject/mp-base:proxy-center --restart=always --eureka.instance.ip-address=120.78.82.47 --eureka.client.service-url.defaultZone=http://120.78.82.47:8761/eureka/,http://39.106.96.220:8761/eureka/
#### ServiceB 39.106.96.220
docker run -d --name proxy-server -p 8000:8000 -v /var/log/:/var/log/ -t notobject/mp-base:proxy-center --restart=always --eureka.instance.ip-address=39.106.96.220 --eureka.client.service-url.defaultZone=http://120.78.82.47:8761/eureka/,http://39.106.96.220:8761/eureka/
### step 6. Business-Services
#### 以ccsu-user-service 为例
git clone https://github.com/notobject/ccsu-micro-platform-projects build
cd build/
cd ccsu-user-service
mvn clean package -Dmaven.test.skip=true -Pprod
cp target/*.jar ./app.jar
docker build -t notobject/mp-base:user-service .
- ServiceA:
docker run -d --name user-service -p 58080:58080 -v /var/log/:/var/log/ -t notobject/mp-base:user-service --restart=always --server.port=58080 --eureka.instance.ip-address=120.78.82.47 --eureka.client.service-url.defaultZone=http://120.78.82.47:8761/eureka/,http://39.106.96.220:8761/eureka/
- ServiceB:
docker run -d --name user-service -p 58080:58080 -v /var/log/:/var/log/ -t notobject/mp-base:user-service --restart=always --server.port=58080 --eureka.instance.ip-address=39.106.96.220 --eureka.client.service-url.defaultZone=http://120.78.82.47:8761/eureka/,http://39.106.96.220:8761/eureka/
### step 7. MP-UI (mini program)
参见微信小程序开发文档
## 五、FAQ
- Any issue or question is welcome, Please feel free to open github issues :)
## 六、Contributors
- [longduping](https://github.com/notobject/ccsu-micro-platform-projects/edit/master/README.md#六、Contributors)
- [zhanghang](https://github.com/notobject/ccsu-micro-platform-projects/edit/master/README.md#六、Contributors)
- [caoxiaoshuang](https://github.com/notobject/ccsu-micro-platform-projects/edit/master/README.md#六、Contributors)
- [hechong](https://github.com/notobject/ccsu-micro-platform-projects/edit/master/README.md#六、Contributors)
- [xiaohaoxiong](https://github.com/notobject/ccsu-micro-platform-projects/edit/master/README.md#六、Contributors) | 6,734 | Apache-2.0 |
---
title: template
layout: post
category: golang
author: 夏泽民
---
官方定义:
Package template implements data-driven templates for generating textual output.
template 包是数据驱动的文本输出模板,其实就是在写好的模板中填充数据。
模板
什么是模板?
下面是一个简单的模板示例:
// 模板定义
tepl := "My name is \{\{ . \}\}"
// 解析模板
tmpl, err := template.New("test").Parse(tepl)
// 数据驱动模板
data := "jack"
err = tmpl.Execute(os.Stdout, data)
复制代码\{\{ 和 \}\} 中间的句号 . 代表传入模板的数据,根据传入的数据不同渲染不同的内容。
. 可以代表 go 语言中的任何类型,如结构体、哈希等。
至于 \{\{ 和 \}\} 包裹的内容统称为 action,分为两种类型:
数据求值(data evaluations)
控制结构(control structures)
action 求值的结果会直接复制到模板中,控制结构和我们写 Go 程序差不多,也是条件语句、循环语句、变量、函数调用等等...
将模板成功解析(Parse)后,可以安全地在并发环境中使用,如果输出到同一个 io.Writer 数据可能会重叠(因为不能保证并发执行的先后顺序)。
<!-- more -->
Actions
模板中的 action 并不多,我们一个一个看。
注释
\{\{/* comment */\}\}
复制代码裁剪空格
// 裁剪 content 前后的空格
\{\{- content -\}\}
// 裁剪 content 前面的空格
\{\{- content \}\}
// 裁剪 content 后面的空格
\{\{ content -\}\}
复制代码文本输出
\{\{ pipeline \}\}
复制代码pipeline 代表的数据会产生与调用 fmt.Print 函数类似的输出,例如整数类型的 3 会转换成字符串 "3" 输出。
条件语句
\{\{ if pipeline \}\} T1 \{\{ end \}\}
\{\{ if pipeline \}\} T1 \{\{ else \}\} T0 \{\{ end \}\}
\{\{ if pipeline \}\} T1 \{\{ else if pipeline \}\} T0 \{\{ end \}\}
// 上面的语法其实是下面的简写
\{\{ if pipeline \}\} T1 \{\{ else \}\}\{\{ if pipeline \}\} T0 { {end \}\}\{\{ end \}\}
\{\{ if pipeline \}\} T1 \{\{ else if pipeline \}\} T2 \{\{ else \}\} T0 \{\{ end \}\}
复制代码如果 pipeline 的值为空,不会输出 T1,除此之外 T1 都会被输出。
空值有 false、0、任意 nil 指针、接口值、数组、切片、字典和空字符串 ""(长度为 0 的字符串)。
循环语句
\{\{ range pipeline \}\} T1 \{\{ end \}\}
// 这个 else 比较有意思,如果 pipeline 的长度为 0 则输出 else 中的内容
\{\{ range pipeline \}\} T1 \{\{ else \}\} T0 \{\{ end \}\}
// 获取容器的下标
\{\{ range $index, $value := pipeline \}\} T1 \{\{ end \}\}
复制代码pipeline 的值必须是数组、切片、字典和通道中的一种,即可迭代类型的值,根据值的长度输出多个 T1。
define
\{\{ define "name" \}\} T \{\{ end \}\}
复制代码定义命名为 name 的模板。
template
\{\{ template "name" \}\}
\{\{ template "name" pipeline \}\}
复制代码引用命名为 name 的模板。
block
\{\{ block "name" pipeline \}\} T1 \{\{ end \}\}
复制代码block 的语义是如果有命名为 name 的模板,就引用过来执行,如果没有命名为 name 的模板,就是执行自己定义的内容。
也就是多做了一步模板是否存在的判断,根据这个结果渲染不同的内容。
with
\{\{ with pipeline \}\} T1 \{\{ end \}\}
// 如果 pipeline 是空值则输出 T0
\{\{ with pipeline \}\} T1 \{\{ else \}\} T0 \{\{ end \}\}
\{\{ with arg \}\}
. // 此时 . 就是 arg
\{\{ end \}\}
复制代码with 创建一个新的上下文环境,在此环境中的 . 与外面的 . 无关。
参数
参数的值有多种表现形式,可以求值任何类型,包括函数、指针(指针会自动间接取值到原始的值):
布尔、字符串、字符、浮点数、复数的行为和 Go 类似
关键字 nil 代表 go 语言中的 nil
字符句号 . 代表值的结果
以 $ 字符开头的变量则为变量对应的值
结构体的字段表示为 .Field,结果是 Field 的值,支持链式调用 .Field1.Field2
字典的 key 表示为 .Key 结果是 Key 对应的值
如果是结构体的方法集中的方法 .Method 结果是方法调用后返回的值(The result is the value of invoking the method with dot as the receiver)**
方法要么只有一个任意类型的返回值要么第二个返回值为 error,不能再多了,如果 error 不为 nil,会直接报错,停止模板渲染
方法调用的结果可以继续链式调用 .Field1.Key1.Method1.Field2.Key2.Method2
声明变量方法集也可以调用 $x.Method1.Field
用括号将调用分组 print (.Func1 arg1) (.Func2 arg2) 或 (.StructValuedMethod "arg").Field
这里最难懂的可能就是函数被调用的方式,如果访问结构体方法集中的函数和字段中的函数,此时的行为有什么不同?
写个 demo 测一下:
type T struct {
Add func(int) int
}
func (t *T) Sub(i int) int {
log.Println("get argument i:", i)
return i - 1
}
func arguments() {
ts := &T{
Add: func(i int) int {
return i + 1
},
}
tpl := `
// 只能使用 call 调用
call field func Add: \{\{ call .ts.Add .y \}\}
// 直接传入 .y 调用
call method func Sub: \{\{ .ts.Sub .y \}\}
`
t, _ := template.New("test").Parse(tpl)
t.Execute(os.Stdout, map[string]interface{}{
"y": 3,
"ts": ts,
})
}
output:
call field func Add: 4
call method func Sub: 2
复制代码可以得出结论:如果函数是结构体中的函数字段,该函数不会自动调用,只能使用内置函数 call 调用。
如果函数是结构体方法集中的方法,会自动调用该方法,并且会将返回值赋值给 .,如果函数返回新的结构体、map,可以继续链式调用。
变量
action 中的 pipeline 可以初始化变量存储结果,语法也很简单:
$variable = pipeline
复制代码此时,这个 action 声明了一个变量而没有产生任何输出。
range 循环可以声明两个变量:
range $index, $element := pipeline
复制代码在 if、with 和 range 中,变量的作用域拓展到 \{\{ end \}\} 所在的位置。
如果不是控制结构,声明的变量的作用域会扩展到整个模板。
例如在模板开始时声明变量:
\{\{ $pages := .pagination.Pages \}\}
\{\{ $current := .pagination.Current \}\}
复制代码在渲染开始的时候,$ 变量会被替换成 . 开头的值,例如 $pages 会被替换成 .pagenation.Pages。所以在模板间的相互引用不会传递变量,变量只在某个特定的作用域中产生作用。
函数
模板渲染时会在两个地方查找函数:
自定义的函数 map
全局函数 map,这些函数是模板内置的
自定义函数使用 func (t *Template) Funcs(funcMap FuncMap) *Template 注册。
全局函数列表:
and
返回参数之间 and 布尔操作的结果,其实就是 JavaScript 中的逻辑操作符 &&,返回第一个能转换成 false 的值,在 Go 中就是零值,如果都为 true 返回最后一个值。
tpl := "\{\{ and .x .y .z \}\}"
t, _ := template.New("test").Parse(tpl)
t.Execute(os.Stdout, map[string]interface{}{
"x": 1,
"y": 0,
"z": 3,
})
output:
0
复制代码or
逻辑操作符 ||,返回第一个能转换成 true 的值,在 Go 中就是非零值,如果都为 false 返回最后一个值。
tpl := "\{\{ or .x .y .z \}\}"
t, _ := template.New("test").Parse(tpl)
t.Execute(os.Stdout, map[string]interface{}{
"x": 1,
"y": 0,
"z": 3,
})
output:
1
复制代码call
返回调用第一个函数参数的结果,函数必须有一个或两个回值(第二个返回值必须是 error,如果值不为 nil 会停止模板渲染)
tpl := "call: \{\{ call .x .y .z \}\} \n"
t, _ := template.New("test").Parse(tpl)
t.Execute(os.Stdout, map[string]interface{}{
"x": func(x, y int) int { return x+y},
"y": 2,
"z": 3,
})
output:
5
复制代码html
返回转义后的 HTML 字符串,这个函数不能在 html/template 中使用。
js
返回转义后的 JavaScript 字符串。
index
在第一个参数是 array、slice、map 时使用,返回对应下标的值。
index x 1 2 3 等于 x[1][2][3]。
len
返回复合类型的长度。
not
返回布尔类型参数的相反值。
print
等于 fmt.Sprint。
printf
等于 fmt.Sprintf。
println
等于 fmt.Sprintln。
urlquery
对字符串进行 url Query 转义,不能在 html/template 包中使用。
// URLQueryEscaper returns the escaped value of the textual representation of
// its arguments in a form suitable for embedding in a URL query.
func URLQueryEscaper(args ...interface{}) string {
return url.QueryEscape(evalArgs(args))
}
复制代码从源码可以看到这个函数直接调用 url.QueryEscape 对字符串进行转义,并没有什么神秘的。
比较函数
eq: ==
ge: >=
gt: >
le: <=
lt: <
ne: !=
分析两个源码:
// eq evaluates the comparison a == b || a == c || ...
func eq(arg1 reflect.Value, arg2 ...reflect.Value) (bool, error) {
v1 := indirectInterface(arg1)
k1, err := basicKind(v1)
if err != nil {
return false, err
}
if len(arg2) == 0 {
return false, errNoComparison
}
for _, arg := range arg2 {
v2 := indirectInterface(arg)
k2, err := basicKind(v2)
if err != nil {
return false, err
}
truth := false
if k1 != k2 {
// Special case: Can compare integer values regardless of type's sign.
switch {
case k1 == intKind && k2 == uintKind:
truth = v1.Int() >= 0 && uint64(v1.Int()) == v2.Uint()
case k1 == uintKind && k2 == intKind:
truth = v2.Int() >= 0 && v1.Uint() == uint64(v2.Int())
default:
return false, errBadComparison
}
} else {
switch k1 {
case boolKind:
truth = v1.Bool() == v2.Bool()
case complexKind:
truth = v1.Complex() == v2.Complex()
case floatKind:
truth = v1.Float() == v2.Float()
case intKind:
truth = v1.Int() == v2.Int()
case stringKind:
truth = v1.String() == v2.String()
case uintKind:
truth = v1.Uint() == v2.Uint()
default:
panic("invalid kind")
}
}
if truth {
return true, nil
}
}
return false, nil
}
// ne evaluates the comparison a != b.
func ne(arg1, arg2 reflect.Value) (bool, error) {
// != is the inverse of ==.
equal, err := eq(arg1, arg2)
return !equal, err
}
复制代码eq 先判断接口类型是否相等,然后判断值是否相等,没什么特殊的地方。
ne 更是简单的调用 eq,然后取反。
ge、gt、le、lt 与 eq 类似,先判断类型,然后判断大小。
嵌套模板
下面是一个更复杂的例子:
// 加载模板
template.ParseFiles("templates/")
// 加载多个模板到一个命名空间(同一个命名空间的模块可以互相引用)
template.ParseFiles("header.tmpl", "content.tmpl", "footer.tmpl")
// must 加载失败时 panic
tmpl := template.Must(template.ParseFiles("layout.html"))
// 执行加载后的模板文件,默认执行第一个
tmpl.Execute(w, "test")
// 如果 tmpl 中有很多个模板,可以指定要执行的模板名
tmpl.ExecuteTemplate(w, "layout", "Hello world")
复制代码ExecuteTemplate 指定的名字就是模板文件中 define "name" 的 name。
总结
Parse 系列函数初始化的 Template 类型实例。
Execute 系列函数则将数据传递给模板渲染最终的字符串。
模板本质上就是 Parse 函数加载多个文件到一个 Tempalte 类型实例中,解析文件中的 define 关键字注册命名模板,命名模板之间可以使用 template 互相引用,Execute 传入对应的数据渲染。
Go标准库提供了几个package可以产生输出结果,而text/template 提供了基于模板输出文本内容的功能。html/template则是产生 安全的HTML格式的输出。这两个包使用相同的接口,但是我下面的例子主要面向HTML应用。
解析和创建模板
命名模板
模板没有限定扩展名,最流行的后缀是.tmpl, vim-go提供了对它的支持,并且godoc的例子中也使用这个后缀。Atom 和 GoSublime 对.gohtml后缀的文件提供了语法高亮的支持。通过对代码库的分析统计发现.tpl后缀也被经常使用。当然后缀并不重要,在项目中保持清晰和一致即可。
创建模板
tpl, err := template.Parse(filename)得到文件名为名字的模板,并保存在tpl变量中。tpl可以被执行来显示模板。
解析多个模板
template.ParseFiles(filenames)可以解析一组模板,使用文件名作为模板的名字。template.ParseGlob(pattern)会根据pattern解析所有匹配的模板并保存。
解析字符串模板
t, err := template.New("foo").Parse(\{ {define "T"\}\}Hello, { {.\}\}!{ {end\}\}`)` 可以解析字符串模板,并设置它的名字。
执行模板
执行简单模板
又两种方式执行模板。简单的模板tpl可以通过tpl.Execute(io.Writer, data)去执行, 模板渲染后的内容写入到io.Writer中。Data是传给模板的动态数据。
执行命名的模板
tpl.ExecuteTemplate(io.Writer, name, data)和上面的简单模板类似,只不过传入了一个模板的名字,指定要渲染的模板(因为tpl可以包含多个模板)。
模板编码和HTML
上下文编码
html/template基于上下文信息进行编码,因此任何需要编码的字符都能被正确的进行编码。
例如"<h1>A header!</h1>"中的尖括号会被编码为<h1>A header!</h1>。
template.HTML可以告诉Go要处理的字符串是安全的,不需要编码。template.HTML("<h1>A Safe header</h1>")会输出<h1>A Safe header</h1>,注意这个方法处理用户的输入的时候比较危险。
html/template还可以根据模板中的属性进行不同的编码。(The go html/template package is aware of attributes within the template and will encode values differently based on the attribute.)
Go 模板也可以应用javascript。struct和map被展开为JSON 对象,引号会被增加到字符串中,,用做函数参数和变量的值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// Go
type Cat struct {
Name string
Age int
}
kitten := Cat{"Sam", 12}
// Template
<script>
var cat = { {.kitten\}\}
</script>
// Javascript
var cat = {"Name":"Sam", "Age" 12}
安全字符串和 HTML注释
默认情况下 html/template会删除模板中的所有注释,这会导致一些问题,因为有些注释是有用的,比如:
1
2
3
<!--[if IE]>
Place content here to target all Internet Explorer users.
<![endif]-->
我们可以使用自定义的方法创建一个可以返回注释的函数。在FuncMap中定义htmlSafe方法:
1
2
3
4
5
testTemplate, err = template.New("hello.gohtml").Funcs(template.FuncMap{
"htmlSafe": func(html string) template.HTML {
return template.HTML(html)
},
}).ParseFiles("hello.gohtml")
这个函数会产生一模一样的HTML代码,这个函数可以用在模板中保留前面的注释:
1
2
3
{ {htmlSafe "<!--[if IE 6]>" \}\}
<meta http-equiv="Content-Type" content="text/html; charset=Unicode">
{ { htmlSafe "<![endif]-->" \}\}
模板变量
. 字符
模板变量可以是boolean, string, character, integer, floating-point, imaginary 或者 complex constant。传给模板这样的数据就可以通过点号.来访问:
1
{ { . \}\}
如果数据是复杂类型的数据,可以通过{ { .FieldName \}\}来访问它的字段。
如果字段还是复杂类型,可以链式访问 { { .Struct.StructTwo.Field \}\}。
模板中的变量
传给模板的数据可以存在模板中的变量中,在整个模板中都能访问。 比如 { {$number := .\}\}, 我们使用$number作为变量,保存传入的数据,可以使用{ {$number\}\}来访问变量。
1
2
{ {$number := .\}\}
<h1> It is day number { {$number\}\} of the month </h1>
1
2
3
4
5
var tpl *template.Template
tpl = template.Must(template.ParseFiles("templateName"))
err := tpl.ExecuteTemplate(os.Stdout, "templateName", 23)
上面的例子我们把23传给模板,模板的变量$number的值是23,可以在模板中使用。
模板动作
if/else 语句
像其它语言,模板支持if/else语句。我们可以使用if检查数据,如果不满足可以执行else。空值是是false, 0、nil、空字符串或者长度为0的字符串都是false。
1
<h1>Hello, { {if .Name\}\} { {.Name\}\} { {else\}\} Anonymous { {end\}\}!</h1>
如果.Name存在,会输出Hello, Name,否则输出Hello, Anonymous。
模板也提供了{ {else if .Name2 \}\}处理多个分支。
移除空格
往模板中增加不同的值的时候可能会增加一定数量的空格。我们既可以改变我们的模板以便更好的处理它,忽略/最小化这种效果,或者我们还可以使用减号-:
1
<h1>Hello, { {if .Name\}\} { {.Name\}\} { {- else\}\} Anonymous { {- end\}\}!</h1>
上面的例子告诉模板移除 .Name变量之间的空格。我们在end关键字中也加入减号。这样做的好处是在模板中我们通过空格更方便编程调试,但是生产环境中我们不需要空格。
Range
模板提供range关键字来遍历数据。假如我们又下面的数据结构:
1
2
3
4
5
6
7
8
9
10
type Item struct {
Name string
Price int
}
type ViewData struct {
Name string
Items []Item
}
ViewData对象传给模板,模板如下:
1
2
3
4
5
6
{ {range .Items\}\}
<div class="item">
<h3 class="name">{ {.Name\}\}</h3>
<span class="price">${ {.Price\}\}</span>
</div>
{ {end\}\}
对于Items中的每个Item, 我们输出它的名称和价格。在range中当前的项目变成了{ {.\}\},它的属性是{ {.Name\}\}和{ {.Price\}\}。
模板函数
模板包提供了一组预定义的函数,下面介绍一些常用的函数。
获取索引值
如果传给模板的数据是map、slice、数组,那么我们就可以使用它的索引值。我们使用{ {index x number\}\}来访问x的第number个元素, index是关键字。比如{ {index names 2\}\}等价于names[2]。{ {index names 2 3 4\}\} 等价于 names[2][3][4]。
1
2
3
<body>
<h1> { {index .FavNums 2 \}\}</h1>
</body>
1
2
3
4
5
6
7
8
9
10
type person struct {
Name string
FavNums []int
}
func main() {
tpl := template.Must(template.ParseGlob("*.gohtml"))
tpl.Execute(os.Stdout, &person{"Curtis", []int{7, 11, 94\}\})
}
上面的例子传入一个person的数据结构,得到它的FavNums字段中的第三个值。
and 函数
and函数返回bool值,通过返回第一个空值或者最后一个值。and x y逻辑上相当于if x then y else x。考虑下面的代码:
1
2
3
4
5
6
7
type User struct {
Admin bool
}
type ViewData struct {
*User
}
传入一个Admin为true的ViewData对象给模板:
1
2
3
4
5
{ {if and .User .User.Admin\}\}
You are an admin user!
{ {else\}\}
Access denied!
{ {end\}\}
结果会显示You are an admin user!, 如果ViewData不包含一个User值,或者Admin为false,显示结果则会是Access denied!。
or 函数
类似 and 函数,但是只要遇到 true就返回。or x y 等价于 if x then x else y。 x 非空的情况下y不会被评估。
not 函数
not函数返回参数的相反值:
1
2
3
{ { if not .Authenticated\}\}
Access Denied!
{ { end \}\}
管道
函数调用可以链式调用,前一个函数的输出结果作为下一个函数调用的参数。html/template称之为管道,类似于linux shell命令中的管道一样,它采用|分隔。
注意前一个命令的输出结果是作为下一个命令的最后一个参数,最终命令的输出结果就是这个管道的结果。
模板比较函数
比较
html/template提供了一系列的函数用做数据的比较。数据的类型只能是基本类型和命名的基本类型,比如type Temp float3,格式是{ { function arg1 arg2 \}\}。
eq: arg1 == arg2
ne: arg1 != arg2
lt: arg1 < arg2
le: arg1 <= arg2
gt: arg1 > arg2
ge: arg1 >= arg2
eq函数比较特殊,可以拿多个参数和第一个参数进行比较。{ { eq arg1 arg2 arg3 arg4\}\}逻辑是arg1==arg2 || arg1==arg3 || arg1==arg4。
嵌套模板和布局
嵌套模板
嵌套模板可以用做跨模板的公共部分代码,比如 header或者 footer。使用嵌套模板我们就可以避免一点小小的改动就需要修改每个模板。嵌套模板定义如下:
1
2
3
4
5
{ {define "footer"\}\}
<footer>
<p>Here is the footer</p>
</footer>
{ {end\}\}
这里定义了一个名为footer的模板,可以在其他模板中使用:
1
{ {template "footer"\}\}
模板之间传递变量
模板action可以使用第二个参数传递数据给嵌套的模板:
1
2
3
4
5
6
7
8
9
10
11
12
// Define a nested template called header
{ {define "header"\}\}
<h1>{ {.\}\}</h1>
{ {end\}\}
// Call template and pass a name parameter
{ {range .Items\}\}
<div class="item">
{ {template "header" .Name\}\}
<span class="price">${ {.Price\}\}</span>
</div>
{ {end\}\}
这里我们使用和上面一样的range遍历items,但是我们会把每个name传给header模板。
创建布局
Glob模式通过通配符匹配一组文件名。template.ParseGlob(pattern string)会匹配所有符合模式的模板。template.ParseFiles(files...)也可以用来解析一组文件。
、
模板默认情况下会使用配置的参数文件名的base name作为模板名。这意味着views/layouts/hello.gohtml的文件名是hello.gohtml,如果模板中有{ {define “templateName”\}\}的话,那么templateName会用作这个模板的名字。
模板可以通过t.ExecuteTemplate(w, "templateName", nil)来执行, t是一个类型为Template的对象,w的类型是io.Writer,比如http.ResponseWriter,然后是要执行的模板的名称,以及要传入的数据:
main.go
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
// Omitted imports & package
var LayoutDir string = "views/layouts"
var bootstrap *template.Template
func main() {
var err error
bootstrap, err = template.ParseGlob(LayoutDir + "/*.gohtml")
if err != nil {
panic(err)
}
http.HandleFunc("/", handler)
http.ListenAndServe(":8080", nil)
}
func handler(w http.ResponseWriter, r *http.Request) {
bootstrap.ExecuteTemplate(w, "bootstrap", nil)
}
所有的.gohtml文件都被解析,然后当访问/的时候,bootstrap会被执行。
views/layouts/bootstrap.gohtml定义如下:
views/layouts/bootstrap.gohtml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
{ {define "bootstrap"\}\}
<!DOCTYPE html>
<html lang="en">
<head>
<title>Go Templates</title>
<link href="//maxcdn.bootstrapcdn.com/bootstrap/3.3.7/css/bootstrap.min.css"
rel="stylesheet">
</head>
<body>
<div class="container-fluid">
<h1>Filler header</h1>
<p>Filler paragraph</p>
</div>
<!-- jquery & Bootstrap JS -->
<script src="//ajax.googleapis.com/ajax/libs/jquery/1.11.3/jquery.min.js"
</script>
<script src="//maxcdn.bootstrapcdn.com/bootstrap/3.3.7/js/bootstrap.min.js">
</script>
</body>
</html>
{ {end\}\}
模板调用函数
函数变量 (调用结构体的方法)
我们可以调用模板中对象的方法返回数据,下面定义了User类型,以及一个方法:
1
2
3
4
5
6
7
8
9
10
11
12
type User struct {
ID int
Email string
}
func (u User) HasPermission(feature string) bool {
if feature == "feature-a" {
return true
} else {
return false
}
}
当User类型传给模板后,我们可以在模板中调用它的方法:
1
2
3
4
5
6
7
8
9
10
11
{ {if .User.HasPermission "feature-a"\}\}
<div class="feature">
<h3>Feature A</h3>
<p>Some other stuff here...</p>
</div>
{ {else\}\}
<div class="feature disabled">
<h3>Feature A</h3>
<p>To enable Feature A please upgrade your plan</p>
</div>
{ {end\}\}
模板会调用User的HasPermission方法做检查,并且根据这个返回结果渲染数据。
函数变量 (调用)
如果有时HasPermission方法的设计不得不需要更改,但是当前的函数方法有不满足要求,我们可以使用函数(func(string) bool)作为User类型的字段,这样在创建User的时候可以指派不同的函数实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
// Structs
type ViewData struct {
User User
}
type User struct {
ID int
Email string
HasPermission func(string) bool
}
// Example of creating a ViewData
vd := ViewData{
User: User{
ID: 1,
Email: "[email protected]",
// Create the HasPermission function
HasPermission: func(feature string) bool {
if feature == "feature-b" {
return true
}
return false
},
},
}
// Executing the ViewData with the template
err := testTemplate.Execute(w, vd)
我们需要告诉Go模板我们想调用这个函数,这里使用call关键字。把上面的例子修改如下:
1
2
3
4
5
6
7
8
9
10
11
{ {if (call .User.HasPermission "feature-b")\}\}
<div class="feature">
<h3>Feature B</h3>
<p>Some other stuff here...</p>
</div>
{ {else\}\}
<div class="feature disabled">
<h3>Feature B</h3>
<p>To enable Feature B please upgrade your plan</p>
</div>
{ {end\}\}
自定义函数
另外一种方式是使用template.FuncMap创建自定义的函数,它创建一个全局的函数,可以在整个应用中使用。FuncMap通过map[string]interface{}将函数名映射到函数上。注意映射的函数必须只有一个返回值,或者有两个返回值但是第二个是error类型。
1
2
3
4
5
6
7
8
9
// Creating a template with function hasPermission
testTemplate, err = template.New("hello.gohtml").Funcs(template.FuncMap{
"hasPermission": func(user User, feature string) bool {
if user.ID == 1 && feature == "feature-a" {
return true
}
return false
},
}).ParseFiles("hello.gohtml")
这个函数hasPermission检查用户是否有某个权限,它会被保存在FuncMap中。注意自定义的函数必须在调用ParseFiles()之前创建。
这个函数在模板中的使用如下:
1
{ { if hasPermission .User "feature-a" \}\}
需要传入.User和feature-a参数。
自定义函数 (全局)
我们前面实现的自定义方法需要依赖.User类型,很多情况下这种方式工作的很好,但是在一个大型的应用中传给模板太多的对象维护起来很困难。我们需要改变自定义的函数,让它无需依赖User对象。
和上面的实现类似,我们创建一个缺省的hasPermission函数,这样可以正常解析模板。
1
2
3
4
5
testTemplate, err = template.New("hello.gohtml").Funcs(template.FuncMap{
"hasPermission": func(feature string) bool {
return false
},
}).ParseFiles("hello.gohtml")
这个函数在main()中或者某处创建,并且保证在解析文件之前放入到 hello.gohtml 的function map中。这个缺省的函数总是返回false,但是不管怎样,函数是已定义的,而且不需要User,模板也可以正常解析。
下一个技巧就是重新定义hasPermission函数。这个函数可以使用User对象的数据,但是它是在Handler处理中使用的,而不是传给模板,这里采用的是闭包的方式。所以在模板执行之前你死有机会重新定义函数的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
func handler(w http.ResponseWriter, r *http.Request) {
w.Header().Set("Content-Type", "text/html")
user := User{
ID: 1,
Email: "[email protected]",
}
vd := ViewData{}
err := testTemplate.Funcs(template.FuncMap{
"hasPermission": func(feature string) bool {
if user.ID == 1 && feature == "feature-a" {
return true
}
return false
},
}).Execute(w, vd)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
}
}
在这个Handler中User被创建,ViewData使用这个User对象。hasPermission采用闭包的方式重新定义了函数。{ {if hasPermission "feature-a"\}\}的的确确没有传入User参数。
第三方自定义函数
除了官方的预定义的函数外,一些第三方也定义了一些函数,你可以使用这些库,避免重复造轮子。
比如sprig库,定义了很多的函数:
String Functions: trim, wrap, randAlpha, plural, etc.
String List Functions: splitList, sortAlpha, etc.
Math Functions: add, max, mul, etc.
Integer Slice Functions: until, untilStep
Date Functions: now, date, etc.
Defaults Functions: default, empty, coalesce, toJson, toPrettyJson, toRawJson, ternary
Encoding Functions: b64enc, b64dec, etc.
Lists and List Functions: list, first, uniq, etc.
Dictionaries and Dict Functions: get, set, dict, hasKey, pluck, deepCopy, etc.
Type Conversion Functions: atoi, int64, toString, etc.
File Path Functions: base, dir, ext, clean, isAbs
Flow Control Functions: fail
Advanced Functions
UUID Functions: uuidv4
OS Functions: env, expandenv
Version Comparison Functions: semver, semverCompare
Reflection: typeOf, kindIs, typeIsLike, etc.
Cryptographic and Security Functions: derivePassword, sha256sum, genPrivateKey, etc.
需要注意三点:
变量有作用域,只要出现end,则当前层次的作用域结束。内层可以访问外层变量,但外层不能访问内层变量。
有一个特殊变量$,它代表模板的最顶级作用域对象(通俗地理解,是以模板为全局作用域的全局变量),在Execute()执行的时候进行赋值,且一直不变。例如上面的示例中,$ = [11 22 33 44 55]。再例如,define定义了一个模板t1,则t1中的$作用域只属于这个t1。
变量不可在模板之间继承。普通变量可能比较容易理解,但对于特殊变量"."和"$",比较容易搞混。见下面的例子。
例如:
func main() {
t1 := template.New("test1")
tmpl, _ := t1.Parse(
`
\{\{- define "T1"\}\}ONE \{\{println .\}\}\{\{end\}\}
\{\{- define "T2"\}\}\{\{template "T1" $\}\}\{\{end\}\}
\{\{- template "T2" . -\}\}
`)
_ = tmpl.Execute(os.Stdout, "hello world")
}
上面使用define额外定义了T1和T2两个模板,T2中嵌套了T1。\{\{template "T2" .\}\}的点代表顶级作用域的"hello world"对象。在T2中使用了特殊变量$,这个$的范围是T2的,不会继承顶级作用域"hello world"。但因为执行T2的时候,传递的是".",所以这里的$的值仍然是"hello world"。
不仅$不会在模板之间继承,.也不会在模板之间继承(其它所有变量都不会继承)。实际上,template可以看作是一个函数,它的执行过程是template("T2",.)。如果把上面的$换成".",结果是一样的。如果换成\{\{template "T2"\}\},则$=nil | 20,384 | MIT |
## 块级元素和行内元素
* 块级元素是指单独撑满一行的元素,如 div、ul、li、table、p、h1 等元素。这些元素的 display 值默认是 `block`、`table`、`list-item` 等。
* 内联元素又叫行内元素,指只占据它对应标签的边框所包含的空间的元素,这些元素如果父元素宽度足够则并排在一行显示的,如 span、a、em、i、img、td 等。这些元素的 display 值默认是 `inline`、`inline-block`、`inline-table`、`table-cell` 等。
---
## CSS 样式表规则
CSS 样式表由大量样式规则组成。每条样式规则分成两个部分:选择器(selector)和声明块(declaration block)。
选择器指明本条规则对哪些网页元素生效,声明块描述样式规则的具体内容。
```
h1 {
color: red;
}
```
声明块的内容,放在一对大括号里面。大括号之中是一个或多个键值对,每个键值对用分号结尾。
声明块可以写成多行,也可以写成一行。缩进和换行只是为了增加可读性,CSS 引擎会忽略它们。
CSS 允许重复声明某个样式,这时最后声明的键值对会覆盖前面的键值对。
---
## 注释
CSS 使用 `/* ... */` 表示注释,可以是单行,也可以是多行。 | 598 | MIT |
<!-- _coverpage.md -->

# FireCat <small>1.0.8</small>
> 简洁至上的koa上层框架
- 简单、轻便、快速
- 基于装饰器来替代中间件
- 使用webpack打包部署
[GitHub](https://github.com/Jon-Millent/fire-cat)
[Get Started](#开始)
<!-- 背景色 -->
 | 255 | MIT |
# OA 用户模块 06
## 权限管理
### 展示角色
```htm
<tr>
<td>角色:</td>
<td>
<span th:each="item : ${session.account.roles}">
[[${item.name}]] ,
</span>
</td>
</tr>
```
### 认证
```java
// 已登录用户是否有权限访问当前页面
// if(!hasAuth(account.getPermissions(),uri)) {
//
// request.setAttribute("msg", "您无权访问当前页面:" + uri);
// request.getRequestDispatcher("/errorPage").forward(request, response);
// return;
// }
System.out.println("----filter----" + uri);
chain.doFilter(request, response);
}
private boolean hasAuth(List<Permission> list, String uri) {
for (Permission permission : list) {
if(uri.startsWith(permission.getUri())) {
return true;
}
}
return false;
}
```
### 角色-》权限
#### 多选
https://developer.snapappointments.com/bootstrap-select/examples/#basic-examples
https://harvesthq.github.io/chosen/
http://icheck.fronteed.com/
### thymeleaf 循环
```javascript
<script type="text/javascript" th:inline="javascript">
[# th:each="p :${role.permissions}"]
[# th:utext="'$(\\'#' + ${p.id} + '\\').iCheck(\\'check\\')'" /]
[/]
</script>
```
```javascript
$(document).ready(function(){
$('input').each(function(){
var self = $(this),
label = self.next(),
label_text = label.text();
label.remove();
self.iCheck({
checkboxClass: 'icheckbox_line-red',
radioClass: 'iradio_line-red',
insert: '<div class="icheck_line-icon"></div>' + label_text
});
});
});
```
### crud
```java
public interface AccountMapper extends BaseMapper<Account> {
}
public interface MenuMapper extends BaseMapper<Menu> {
}
public interface IAccountService extends IService<Account>{
}
```
permission
## 批量生成文件
### 导入依赖
pom.xml
``` xml
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.freemarker</groupId>
<artifactId>freemarker</artifactId>
<version>2.3.28</version>
</dependency>
```
### 官方示例
https://mp.baomidou.com/guide/generator.html
### 自定义注入
``` java
InjectionConfig cfg = new InjectionConfig() {
@Override
public void initMap() {
HashMap<String, Object> map = new HashMap<>();
map.put("xxoo", "yimingge");
this.setMap(map);
}
};
```
### 自定义模板
模板文件实际位置
src/main/resources/templates/entity.ftl
```java
// 配置模板
TemplateConfig templateConfig = new TemplateConfig();
templateConfig.setEntity("/templates/entity");
```
### 读取自定义注入内容
末班文件中加入
``` java
${cfg.xxoo}
```
## freemarker 模板
```
${"abc"?cap_first} //首字母大写
${entity} 实体类名
${table} 表
${table.controllerName} controller名称
${r'${itemStat.count}'} 转义
${table.entityName} 大写类名
${table.name} 小写
```
### 循环
```html
<#list table.fields as field>
<td th:text="${r'${item.'}${field.propertyName}}">${field.propertyName}</td>
</#list>
```
### 自定义输出
```java
// 添加前端页面
// 输入
String html_list_Path = "/templates/html_list.ftl";
//输出
focList.add(new FileOutConfig(html_list_Path) {
@Override
public String outputFile(TableInfo tableInfo) {
// 自定义输出文件名 , 如果你 Entity 设置了前后缀、此处注意 xml 的名称会跟着发生变化!!
return projectPath + "/src/main/resources/templates/" + pc.getModuleName()
+ "/" + tableInfo.getEntityName() + "List.html";
}
});
```
### entity模板
``` java
package ${package.Entity};
import java.io.Serializable;
/**
* <p>
${cfg.xxoo}
* ${table.comment!}
* </p>
*
* @author ${author}
* @since ${date}
*/
public class ${entity} implements Serializable {
<#if entitySerialVersionUID>
private static final long serialVersionUID = 1L;
</#if>
//TableInfo(importPackages=[java.io.Serializable], convert=false, name=menu, comment=, entityName=Menu, mapperName=MenuMapper, xmlName=MenuMapper, serviceName=IMenuService, serviceImplName=MenuServiceImpl, controllerName=MenuController, fields=[TableField(convert=false, keyFlag=false, keyIdentityFlag=false, name=name, type=varchar(45), propertyName=name, columnType=STRING, comment=, fill=null, customMap=null), TableField(convert=false, keyFlag=false, keyIdentityFlag=false, name=roles, type=varchar(45), propertyName=roles, columnType=STRING, comment=, fill=null, customMap=null), TableField(convert=false, keyFlag=false, keyIdentityFlag=false, name=index, type=varchar(45), propertyName=index, columnType=STRING, comment=, fill=null, customMap=null)], commonFields=[TableField(convert=false, keyFlag=true, keyIdentityFlag=true, name=id, type=int(11), propertyName=id, columnType=INTEGER, comment=, fill=null, customMap=null)], fieldNames=name, roles, index)
<#-- ---------- 主键 字段循环遍历 ---------->
<#list table.commonFields as field>
private ${field.propertyType} ${field.propertyName};
</#list>
<#-- ---------- BEGIN 字段循环遍历 ---------->
<#list table.fields as field>
private ${field.propertyType} ${field.propertyName};
</#list>
<#------------ END 字段循环遍历 ---------->
<#if !entityLombokModel>
<#list table.fields as field>
<#if field.propertyType == "boolean">
<#assign getprefix="is"/>
<#else>
<#assign getprefix="get"/>
</#if>
public ${field.propertyType} ${getprefix}${field.capitalName}() {
return ${field.propertyName};
}
<#if entityBuilderModel>
public ${entity} set${field.capitalName}(${field.propertyType} ${field.propertyName}) {
<#else>
public void set${field.capitalName}(${field.propertyType} ${field.propertyName}) {
</#if>
this.${field.propertyName} = ${field.propertyName};
<#if entityBuilderModel>
return this;
</#if>
}
</#list>
</#if>
<#if entityColumnConstant>
<#list table.fields as field>
public static final String ${field.name?upper_case} = "${field.name}";
</#list>
</#if>
<#if activeRecord>
@Override
protected Serializable pkVal() {
<#if keyPropertyName??>
return this.${keyPropertyName};
<#else>
return null;
</#if>
}
</#if>
<#list table.commonFields as field>
public void set${field.propertyName?cap_first}(${field.propertyType} ${field.propertyName}){
this.${field.propertyName} = ${field.propertyName};
};
public ${field.propertyType} get${field.propertyName?cap_first}(){
return ${field.propertyName};
};
</#list>
<#-- ---------- get set 字段循环遍历 ---------->
<#list table.fields as field>
public void set${field.propertyName?cap_first}(${field.propertyType} ${field.propertyName}){
this.${field.propertyName} = ${field.propertyName};
};
public ${field.propertyType} get${field.propertyName?cap_first}(){
return ${field.propertyName};
};
</#list>
<#------------ END 字段循环遍历 ---------->
}
```
``` java
/**
* <p>
* ${table.comment!} 前端控制器
* </p>
*${table}
* @author ${author}
* @since ${date}
*/
@Controller
@RequestMapping("<#if package.ModuleName??>/${package.ModuleName}</#if>/<#if controllerMappingHyphenStyle??>${controllerMappingHyphen}<#else>${table.entityPath}</#if>")
public class ${table.controllerName} {
@Autowired
${entity}Service ${table.name}Srv;
@RequestMapping("/delete${entity}")
@ResponseBody
public RespStat delete${table.controllerName}(int id) {
System.out.println("id:" + id);
RespStat stat = ${table.name}Srv.delete(id);
return stat;
}
@RequestMapping("/list")
public String list(@RequestParam(defaultValue = "1") int pageNum,@RequestParam(defaultValue = "1" ) int pageSize,Model model) {
PageInfo<${entity}>accountList = ${table.name}Srv.findByPage(pageNum,pageSize);
return "/${table.name}/list";
}
``` | 7,828 | Apache-2.0 |
---
layout: post
title: Flex 4.6 XML搜索、匹配示例
date: 2011-05-20 01:43
author: admin
comments: true
categories: [Flex]
---
效果见图
初始化界面
<img class="alignnone" alt="" src="http://a.hiphotos.bdimg.com/album/s%3D550%3Bq%3D90%3Bc%3Dxiangce%2C100%2C100/sign=512510f857fbb2fb302b58177f715199/3c6d55fbb2fb431665e962df22a4462308f7d3a4.jpg?referer=becb17663887e9501b00c75c1d7a&x=.jpg" width="258" height="385" />
输入“设置”,进行搜索、匹配后界面
<img class="alignnone" alt="" src="http://a.hiphotos.bdimg.com/album/s%3D550%3Bq%3D90%3Bc%3Dxiangce%2C100%2C100/sign=512510f857fbb2fb302b58177f715199/3c6d55fbb2fb431665e962df22a4462308f7d3a4.jpg?referer=becb17663887e9501b00c75c1d7a&x=.jpg" width="258" height="385" />
下面是代码
<?xml version="1.0" encoding="utf-8"?>
<s:Application xmlns:fx="http://ns.adobe.com/mxml/2009"
xmlns:s="library://ns.adobe.com/flex/spark"
xmlns:mx="library://ns.adobe.com/flex/mx"
minWidth="955" minHeight="600" creationComplete="init(event)">
<fx:Script>
<![CDATA[
import mx.events.FlexEvent;
import mx.utils.StringUtil;
import spark.events.TextOperationEvent;
public var rawList:XML =
<apps name="应用程序" >
<item name="关于"
icon="plugins/about_002/assets/icons/about_48.png"
iconSmall="plugins/about_002/assets/icons/about_24.png"
moduleUrl="plugins/about_002/Ahout_002.swf"
version="1.0" date="2013-5-13" author="way" type="plugin"
description="关于能源管理中心的一个说明" />
<item name="程序管理"
icon="plugins/appManager_001/assets/icons/apps_48.png"
iconSmall="plugins/appManager_001/assets/icons/apps_24.png"
moduleUrl="plugins/appManager_001/AppManager_001.swf"
version="1.0" date="2013-3-5" author="way" type="plugin" resizable="false"
description="对系统应用,及用户自定义应用进行管理"
shortCutCreated="true"/>
<item name="导航设置"
icon="plugins/navigatorSetting_001/assets/icons/gears_48.png"
iconSmall="plugins/navigatorSetting_001/assets/icons/gears_24.png"
moduleUrl="plugins/navigatorSetting_001/NavigatorSetting_001.swf"
version="1.0" date="2013-3-13" author="way" type="plugin" resizable="false"
description="对导航进行设置"/>
<item name="主题设置"
icon="plugins/themeSetting_001/assets/icons/icon_48.png"
iconSmall="plugins/themeSetting_001/assets/icons/icon_24.png"
moduleUrl="plugins/themeSetting_001/ThemeSetting_001.swf"
version="1.0" date="2013-3-5" author="way" type="plugin" resizable="false"
description="对系统的主题、样式进行设置"/>
</apps>
;
[Bindable]
public var rawListShow:XML = null; //搜索过滤后的数据
protected function init(event:FlexEvent):void
{
getData();
}
protected function textinput1_changeHandler(event:TextOperationEvent):void
{
getData();
}
//初始化数据
private function getData():void{
if(StringUtil.trim(textInput.text) == ""){
rawListShow = rawList ;
}else{
createNewXml(textInput.text,rawList);
}
/* 打开或关闭指定项目下的所有树项目。如果设置 dataProvider 之后立即调用 expandChildrenOf(),
则您可能看不到正确的行为。您应该等待对组件进行验证或调用 validateNow() 方法 */
tree1.validateNow();
expandtree();
}
//搜索过滤后,生产新的xml
private function createNewXml(searchString:String, xml:XML):void{
rawListShow =<apps name="应用程序" />;
for(var i:int = 0; i<xml.children().length(); i++)
{
var itemXml:XML = xml.child("item")[i];
if(isInStr(searchString,[email protected]())){
rawListShow.appendChild(itemXml);
}
}
}
//判断search_str是否在str内
public function isInStr(search_str:String , str:String):Boolean{
var num:int= str.indexOf(search_str);
if(num>-1){
return true;
}else{
return false;
}
}
//展开树
private function expandtree():void {
for each(var item:XML in this.tree1.dataProvider)
this.tree1.expandChildrenOf(item,true);
}
]]>
</fx:Script>
<fx:Declarations>
<!-- 该例子由waylau.com提供-->
</fx:Declarations>
<s:TextInput prompt="请输入要搜索的字段" x="10" y="10"
change="textinput1_changeHandler(event)" id="textInput"/>
<mx:Tree id="tree1" dataProvider="{rawListShow}"
labelField="@name" width="200" height="300" x="10" y="40">
</mx:Tree>
<s:Label text="更多例子 请关注 waylau.com" x="10" y="360"/>
</s:Application> | 4,443 | MIT |
---
date: 2016-12-31T11:33:21+08:00
title: "Go语言学习笔记(一)"
description: ""
disqus_identifier: 1485833601608649675
slug: "Goyu-yan-xue-xi-bi-ji-(yi-)"
source: "https://segmentfault.com/a/1190000006047562"
tags:
- go语言
- golang
categories:
- 编程语言与开发
---
> 主要是看[《the way to
> go》](https://github.com/Unknwon/the-way-to-go_ZH_CN/blob/master/eBook/preface.md)时的一些笔记,比较凌乱,内容也不全,以后慢慢补充。
标签(空格分隔): go 监控
------------------------------------------------------------------------
### 关键字
`break` `default` `func` `interface` `select` `case` `defer` `go` `map`
`struct` `chan` `else` `goto`\
`package` `switch` `const` `fallthrough` `if` `range` `type` `continue`
`for` `import` `return` `var`
### 基本类型,内置函数
`append` `bool` `byte` `cap` `close` `complex` `complex64` `complex128`
`uint16` `copy` `false` `float32` `float64`\
`imag` `int` `int8` `int16` `uint32` `int32` `int64` `iota` `len` `make`
`new` `nil` `panic` `uint64` `print` `println`\
`real` `recover` `string` `true` `uint` `uint8` `uintptr`
### 可见性
首字母大写相当于public,小写相当于pivate
### 包重命名
package main
import fm "fmt" // alias3
func main() {
fm.Println("hello, world")
}
### global virable
declare after package import
### func params and return values
func Sum(a, b int) int { return a + b }
func functionName(parameter_list) (return_value_list) {
…
}
//????????????
func (t T) Method1() {
//...
}
parameter\_list 的形式为 (param1 type1, param2 type2, …)\
return\_value\_list 的形式为 (ret1 type1, ret2 type2, …)
### 常量定义
可以是布尔型、数字型(整数型、浮点型和复数)和字符串型。常量的定义格式`const identifier [type] = value`
- 显式类型定义: `const b string = "abc"`
- 隐式类型定义: `const b = "abc"`
> 常量的值必须是能够在编译时就能够确定的,数字型的常量是没有大小和符号的,并且可以使用任何精度而不会导致溢出
### 变量
var a, b *int
var a int
var b bool
var str string
var (
a int
b bool
str string
)
> 变量被声明之后,系统自动赋予它该类型的零值:int 为 0,float 为
> 0.0,bool 为 false,string 为空字符串,指针为 nil。
编译时即可推断类型
var identifier [type] = value
var a int = 15
var i = 5
var b bool = false
var str string = "Go says hello to the world!"
//编译时推断类型
var a = 15
var b = false
var str = "Go says hello to the world!"
var (
a = 15
b = false
str = "Go says hello to the world!"
numShips = 50
city string
)
//运行时自动推断
var (
HOME = os.Getenv("HOME")
USER = os.Getenv("USER")
GOROOT = os.Getenv("GOROOT")
)
> 函数内部变量首字母大写全局or局部:**函数内部变量均为局部**
### 基本类型何运算符
### 数字类型
**整数**\
int8(-128 -> 127)\
int16(-32768 -> 32767)\
int32(-2,147,483,648 -> 2,147,483,647)\
int64(-9,223,372,036,854,775,808 -> 9,223,372,036,854,775,807)
**无符号整数**\
uint8(0 -> 255)\
uint16(0 -> 65,535)\
uint32(0 -> 4,294,967,295)\
uint64(0 -> 18,446,744,073,709,551,615)
**浮点型(IEEE-754 标准)**\
float32(+- 1e-45 -> +- 3.4 \* 1e38)\
float64(+- 5 *1e-324 -> 107* 1e308)
> float32 精确到小数点后 7 位,float64 精确到小数点后 15
> 位。通过增加前缀 0 来表示 8 进制数(如:077),增加前缀 0x 来表示 16
> 进制数(如:0xFF),以及使用 e 来表示 10 的连乘(如: 1e3 = 1000,或者
> 6.022e23 = 6.022 x 1e23)。
package main
import "fmt"
func main() {
var n int16 = 34
var m int32
// compiler error: cannot use n (type int16) as type int32 in assignment
//m = n
m = int32(n)
fmt.Printf("32 bit int is: %d\n", m)
fmt.Printf("16 bit int is: %d\n", n)
}
**格式化输出**\
`%d` 用于格式化整数(`%x` 和 `%X` 用于格式化 16 进制表示的数字),`%g`
用于格式化浮点型(`%f` 输出浮点数,`%e` 输出科学计数表示法),`%0d`
用于规定输出定长的整数,其中开头的数字 0 是必须的。`%n.mg` 用于表示数字
n 并精确到小数点后 m 位,除了使用 g 之外,还可以使用 e 或者
f,例如:使用格式化字符串 `%5.2e` 来输出 3.4 的结果为 `3.40e+00`。
**类型转换**
func IntFromFloat64(x float64) int {
if math.MinInt32 <= x && x <= math.MaxInt32 { // x lies in the integer range
whole, fraction := math.Modf(x)
if fraction >= 0.5 {
whole++
}
return int(whole)
}
panic(fmt.Sprintf("%g is out of the int32 range", x))
}
**运算符优先级**
优先级 运算符
7 ^ !
6 * / % << >> & &^
5 + - | ^
4 == != < <= >= >
3 <-
2 &&
1 ||
### 字符串
**解释字符串**\
该类字符串使用双引号括起来,其中的相关的转义字符将被替换,这些转义字符包括:
\n:换行符
\r:回车符
\t:tab 键
\u 或 \U:Unicode 字符
\\:反斜杠自身
**非解释字符串**\
该类字符串使用反引号括起来,支持换行,例如:\
`This is a raw string \n` 中的 `\n` 会被原样输出。
> 在循环中使用加号+拼接字符串并不是最高效的做法,更好的办法是使用函数
> strings.Join(),有没有更好地办法了?有!使用字节缓冲(bytes.Buffer)拼接更加给力!
**字符串操作**\
`strings和strconv包`
//前缀和后缀
strings.HasPrefix(s, prefix string) bool
strings.HasSuffix(s, suffix string) bool
//包含关系
strings.Contains(s, substr string) bool
strings.ContainsAny(s, chars string) bool
strings.ContainsRune(s string, r rune) bool
//索引
strings.Index(s, str string) int
strings.LastIndex(s, str string) int
strings.IndexRune(s string, r rune) int
//替换
strings.Replace(str, old, new, n) string
//次数统计
strings.Count(s, str string) int
//重复次数
strings.Repeat(s, count int) string
//大小写
strings.ToLower(s) string
strings.ToLower(s) string
//修剪字符串
func Trim(s string, cutset string) string
func TrimLeft(s string, cutset string) string
func TrimRight(s string, cutset string) string
func TrimSpace(s string) string
//分割字符串
strings.Fields(s) []string
strings.Split(s, sep string) []string
//拼接字符串
strings.Join(sl []string, sep string) string
**日期和时间**
func timeTest(){
t := time.Now()
fm.Println(t)
fm.Println(t.Day(), t.Hour(), t.Minute())
t = time.Now().UTC()
fm.Println(t)
fm.Println(t.Format(time.RFC822))
fm.Println(t.Format(time.ANSIC))
fm.Println(t.Format("02 Jan 2006 15:04"))
}
**指针**
//声明方式
var intP *int
//使用方式
intP = &i1
不允许指针运算`pointer+2`、`c=*p++`,空指针的反向引用是不合法。
**控制结构**
- if-esle语句
- switch语句\
不需要break,执行完分支自动退出switch,如果需要继续执行则使用fallthrough
<!-- -->
switch num1 {
case 98, 99:
fmt.Println("It's equal to 98")
case 100:
fmt.Println("It's equal to 100")
default:
fmt.Println("It's not equal to 98 or 100")
}
//多条件同行,fallthrough,return跳出
func switchStruct() int {
a := 4
switch a {
case 1,2,3: fmt.Println(a)
case 4: fallthrough
case 5:
fm.Println("break")
return 1
default:
fmt.Println("ALL")
}
return 0
}
//bool用法
switch {
case num1 < 0:
fmt.Println("Number is negative")
case num1 > 0 && num1 < 10:
fmt.Println("Number is between 0 and 10")
default:
fmt.Println("Number is 10 or greater")
}
//初始化用法
switch a, b := x[i], y[j]; {
case a < b: t = -1
case a == b: t = 0
case a > b: t = 1
}
- for语句
<!-- -->
func forStatement() {
for i := 1; i < 15; i++{
fm.Println(i)
}
j := 1
GO:
fm.Println(j)
j++
if j < 15{
goto GO
}
for k := 0; k < 5; k++ {
for m := 0; m < k; m++ {
fm.Printf("G")
}
fm.Println()
}
str := "GGGGGGGGGGGGGGGGGGGGGGGG"
for i := 0; i < 5; i++ {
fm.Println(str[0:i+1])
}
str1 := "G"
for i := 0; i < 5; i++ {
fm.Println(str1)
str1 += "G"
}
}
### 函数
Go 里面有三种类型的函数:
1. 普通的带有名字的函数
2. 匿名函数或者lambda函数
3. 方法(Methods)
**defer关键字**
> 在函数return之后执行相关语句,多个defer逆序执行
func a() {
i := 0
defer fmt.Println(i)
i++
return
}
//输出0,输出语句之前的值
- 关闭文件流:\
// open a file defer file.Close() (详见第 12.2 节)
- 解锁一个加锁的资源\
mu.Lock() defer mu.Unlock() (详见第 9.3 节)
- 打印最终报告\
printHeader() defer printFooter()
- 关闭数据库链接\
// open a database connection defer disconnectFromDB()
<!-- -->
func testDefer() {
fmt.Printf("In function1 at the top\n")
defer func2()
fmt.Printf("In function1 at the bottom!\n")
i := 0
i++
defer fmt.Println(i)
i++
for i := 0; i < 5; i++ {
defer fmt.Printf("%d", i)
}
defer deferC(deferA(), deferB())
fm.Println("Begin:\n")
return
}
func deferA() (rtn string) {
fm.Println("in A")
rtn = "AA"
tmp := "tmp1"
defer func() {
fm.Println(tmp)
}()
defer fm.Println(rtn)
tmp = "tmp2"
return "AAAA"
}
func deferB() string {
fm.Println("in B")
return "B"
}
func deferC(str1, str2 string) {
fm.Println("in C")
}
/*输出
In function1 at the top
In function1 at the bottom!
in A
AA
tmp2
in B
Begin:
in C
432101
function2: Deferred until the end of the calling function!
*/
> `defer`函数中的函数(`defer deferC(deferA(), deferB())`中的`A`和`B`)会先于return执行,`defer func()`可以`rentun`语句执行完变量的最新的值,无`func()`时则函数参数取对应`defer`语句执行完变量的最新值。
**内置函数**\
**递归函数**
**函数作参数**
func main() {
callback(1, Add)
}
func Add(a, b int) {
fmt.Printf("The sum of %d and %d is: %d\n", a, b, a+b)
}
func callback(y int, f func(int, int)) {
f(y, 2) // this becomes Add(1, 2)
}
**闭包**
func main() {
var f = Adder()
fmt.Print(f(1), " - ")
fmt.Print(f(20), " - ")
fmt.Print(f(300))
}
func Adder() func(int) int {
var x int
return func(delta int) int {
x += delta
return x
}
}
// 1,21,321
### 数组与切片
**数组**
Go 语言中的数组是一种**值类型**(不像 C/C++
中是指向首元素的指针),所以可以通过 new() 来创建: var arr1 =
new(\[5\]int)。**arr1 的类型是 \*\[5\]int,而 arr2的类型是
\[5\]int**。结果就是当把一个数组赋值给另一个时,需要在做一次数组内存的拷贝操作。例如:
arr2 := arr1
arr2[2] = 100
两个数组就有了不同的值,在赋值后修改 arr2 不会对 arr1 生效。
func f(a [3]int) { fmt.Println(a) }
func fp(a *[3]int) { fmt.Println(a) }
func main() {
var ar [3]int
f(ar) // passes a copy of ar
fp(&ar) // passes a pointer to ar
}
> 当数组赋值时,发生了数组内存拷贝。
**切片**\
切片是引用,所以它们不需要使用额外的内存并且比使用数组更有效率。
var identifier []type
var slice1 []type = arr1[start:end]
var slice1 []type = arr1[:] //全部
slice1 = &arr1 //全部
> 一个由数字 1、2、3
> 组成的切片可以这么生成:`s := [3]int{1,2,3} `甚至更简单的
> `s := []int{1,2,3}`。**数组区别:数组是切片的特例**
**buffer 串联字符串**\
创建一个 buffer,通过 `buffer.WriteString(s)` 方法将字符串 s
追加到后面,最后再通过 `buffer.String()` 方法转换为
string,这种实现方式比使用 `+=` 要更节省内存和 CPU。
var buffer bytes.Buffer
for {
if s, ok := getNextString(); ok { //method getNextString() not shown here
buffer.WriteString(s)
} else {
break
}
}
fmt.Print(buffer.String(), "\n")
func AppendByte(slice []byte, data ...byte) []byte {
m := len(slice)
n := m + len(data)
if n > cap(slice) { // if necessary, reallocate
// allocate double what's needed, for future growth.
newSlice := make([]byte, (n+1)*2)
copy(newSlice, slice)
slice = newSlice
}
slice = slice[0:n]
copy(slice[m:n], data)
return slice
}
**for-range**
seasons := []string{"Spring", "Summer", "Autumn", "Winter"}
//index&val
for ix, season := range seasons {
fmt.Printf("Season %d is: %s\n", ix, season)
}
//just val
var season string
for _, season = range seasons {
fmt.Printf("%s\n", season)
}
//just index
for ix := range seasons {
fmt.Printf("%d", ix)
}
**复制与追加**
func main() {
// count number of characters:
str1 := "asSASA ddd dsjkdsjs dk"
fmt.Printf("The number of bytes in string str1 is %d\n",len(str1))
fmt.Printf("The number of characters in string str1 is %d\n",utf8.RuneCountInString(str1))
str2 := "asSASA ddd dsjkdsjsこん dk"
fmt.Printf("The number of bytes in string str2 is %d\n",len(str2))
fmt.Printf("The number of characters in string str2 is %d",utf8.RuneCountInString(str2))
}
/* Output:
The number of bytes in string str1 is 22
The number of characters in string str1 is 22
The number of bytes in string str2 is 28
The number of characters in string str2 is 24
*/
//将一个字符串追加到某一个字符数组的尾部
var b []byte
var s string
b = append(b, s...)
> Go
> 语言中的字符串是不可变的,必须先将字符串转换成字节数组,然后再通过修改数组中的元素值来达到修改字符串的目的,最后将字节数组转换回字符串格式。
s := "hello"
c := []byte(s)
c[0] = ’c’
s2 := string(c) // s2 == "cello"
**append操作**
- 将切片 b 的元素追加到切片 a 之后:`a = append(a, b...)`
- 复制切片 a 的元素到新的切片 b 上:
<!-- -->
b = make([]T, len(a))
copy(b, a)
- 删除位于索引 i 的元素:\
`a = append(a[:i], a[i+1:]...)`
- 切除切片 a 中从索引 i 至 j 位置的元素:\
`a = append(a[:i], a[j:]...)`
- 为切片 a 扩展 j 个元素长度:\
`a = append(a, make([]T, j)...)`
- 在索引 i 的位置插入元素 x:\
`a = append(a[:i], append([]T{x}, a[i:]...)...)`
- 在索引 i 的位置插入长度为 j 的新切片:\
`a = append(a[:i], append(make([]T, j), a[i:]...)...)`
- 在索引 i 的位置插入切片 b 的所有元素:\
`a = append(a[:i], append(b, a[i:]...)...)`
- 取出位于切片 a 最末尾的元素 x:\
`x, a = a[len(a)-1], a[:len(a)-1]`
- 将元素 x 追加到切片 a:\
`a = append(a, x)`
**垃圾回收**
var digitRegexp = regexp.MustCompile("[0-9]+")
func FindDigits(filename string) []byte {
b, _ := ioutil.ReadFile(filename)
return digitRegexp.Find(b)
}
// 通过拷贝避免小切片占用大内存(整个文件)
func FindDigits(filename string) []byte {
b, _ := ioutil.ReadFile(filename)
b = digitRegexp.Find(b)
c := make([]byte, len(b))
copy(c, b)
return c
}
> `error: rune is not a Type`:代码中又于rune重名的函数
### Map
`var map1 map[keytype]valuetype`
> 不要使用 new,永远用 make 来构造 map
**map类型是非线程安全的,并行访问map数据会出错。并且为了性能map没有锁机制**
// map排序
var (
barVal = map[string]int{"alpha": 34, "bravo": 56, "charlie": 23,"delta": 87, "echo": 56, "foxtrot": 12,"golf": 34, "hotel": 16, "indio": 87,"juliet": 65, "kili": 43, "lima": 98}
)
func main() {
fmt.Println("unsorted:")
for k, v := range barVal {
fmt.Printf("Key: %v, Value: %v / ", k, v)
}
keys := make([]string, len(barVal))
i := 0
for k, _ := range barVal {
keys[i] = k
i++
}
sort.Strings(keys)
fmt.Println()
fmt.Println("sorted:")
for _, k := range keys {
fmt.Printf("Key: %v, Value: %v / ", k, barVal[k])
}
}
### 包(package)
**regexp包**\
**锁和sync包**\
**big包**
### struct和method
可以使用 make() 的三种类型:\
`slices / maps / channels(见第 14 章)`
> 在一个结构体中对于每一种数据类型只能有一个匿名字段。
**内嵌结构体**
package main
import "fmt"
type A struct {
ax, ay int
}
type B struct {
A
bx, by float32
}
func main() {
b := B{A{1, 2}, 3.0, 4.0}
fmt.Println(b.ax, b.ay, b.bx, b.by)
fmt.Println(b.A)
}
定义方法的一般格式:\
`func (recv receiver_type) methodName(parameter_list) (return_value_list) { ... }`
结构体方法
type TwoInts struct {
a int
b int
}
func main() {
two1 := new(TwoInts)
two1.a = 12
two1.b = 10
fmt.Printf("The sum is: %d\n", two1.AddThem())
fmt.Printf("Add them to the param: %d\n", two1.AddToParam(20))
two2 := TwoInts{3, 4}
fmt.Printf("The sum is: %d\n", two2.AddThem())
}
func (tn *TwoInts) AddThem() int {
return tn.a + tn.b
}
func (tn *TwoInts) AddToParam(param int) int {
return tn.a + tn.b + param
}
非结构体类型方法
type IntVector []int
func (v IntVector) Sum() (s int) {
for _, x := range v {
s += x
}
return
}
func main() {
fmt.Println(IntVector{1, 2, 3}.Sum()) // 输出是6
}
> 类型和作用在它上面定义的方法可以不同文件,但是必须在同一个包里定义,除非定义别名:
type myTime struct {
time.Time //anonymous field
}
func (t myTime) first3Chars() string {
return t.Time.String()[0:3]
}
func main() {
m := myTime{time.Now()}
// 调用匿名Time上的String方法
fmt.Println("Full time now:", m.String())
// 调用myTime.first3Chars
fmt.Println("First 3 chars:", m.first3Chars())
}
/* Output:
Full time now: Mon Oct 24 15:34:54 Romance Daylight Time 2011
First 3 chars: Mon
*/
指针方法和值方法都可以在指针或非指针上被调用
type List []int
func (l List) Len() int { return len(l) }
func (l *List) Append(val int) { *l = append(*l, val) }
func main() {
// 值
var lst List
lst.Append(1)
fmt.Printf("%v (len: %d)", lst, lst.Len()) // [1] (len: 1)
// 指针
plst := new(List)
plst.Append(2)
fmt.Printf("%v (len: %d)", plst, plst.Len()) // &[2] (len: 1)
}
**并发访问对象**
import “sync”
type Info struct {
mu sync.Mutex
// ... other fields, e.g.: Str string
}
func Update(info *Info) {
info.mu.Lock()
// critical section:
info.Str = // new value
// end critical section
info.mu.Unlock()
}
**内嵌方法**
//内嵌方法测试
func methodTest() {
point := &NamedPoint{Point{3, 4}, "name"}
fm.Println(point.Abs(), point.Point.Abs())
}
type Point struct {
x, y float64
}
func (p *Point)Abs() float64 {
return math.Sqrt(p.x*p.x + p.y*p.y)
}
type NamedPoint struct {
Point
name string
}
func (p *NamedPoint)Abs() float64 {
return p.Point.Abs() * p.Point.Abs()
}
**多重继承**
type Camera struct{}
func (c *Camera) TakeAPicture() string {
return "Click"
}
type Phone struct{}
func (p *Phone) Call() string {
return "Ring Ring"
}
type CameraPhone struct {
Camera
Phone
}
func main() {
cp := new(CameraPhone)
fmt.Println("Our new CameraPhone exhibits multiple behaviors...")
fmt.Println("It exhibits behavior of a Camera: ", cp.TakeAPicture())
fmt.Println("It works like a Phone too: ", cp.Call())
}
**垃圾回收和SetFinalizer**\
内存状态
// fmt.Printf("%d\n", runtime.MemStats.Alloc/1024)
// 此处代码在 Go 1.5.1下不再有效,更正为
var m runtime.MemStats
runtime.ReadMemStats(&m)
fmt.Printf("%d Kb\n", m.Alloc / 1024)
回收对象时,对象移除前操作:
runtime.SetFinalizer(obj, func(obj *typeObj))
### 接口和反射
不同的结构实现interface中定义的接口,通过接口变量自动识别对应结构来实现多态,所有类型必须完全实现interface中的所有函数
type Shaper interface {
Area() float32
}
type Square struct {
side float32
}
func (sq *Square) Area() float32 {
return sq.side * sq.side
}
type Rectangle struct {
length, width float32
}
func (r Rectangle) Area() float32 {
return r.length * r.width
}
func main() {
r := Rectangle{5, 3} // Area() of Rectangle needs a value
q := &Square{5} // Area() of Square needs a pointer
// shapes := []Shaper{Shaper(r), Shaper(q)}
// or shorter
shapes := []Shaper{r, q}
fmt.Println("Looping through shapes for area ...")
for n, _ := range shapes {
fmt.Println("Shape details: ", shapes[n])
fmt.Println("Area of this shape is: ", shapes[n].Area())
}
}
> 接口的实现通过指针则变量必须传入指针;接口可以嵌套。
**类型判断**
switch t := areaIntf.(type) {
case *Square:
fmt.Printf("Type Square %T with value %v\n", t, t)
case *Circle:
fmt.Printf("Type Circle %T with value %v\n", t, t)
case nil:
fmt.Printf("nil value: nothing to check?\n")
default:
fmt.Printf("Unexpected type %T\n", t)
}
//简洁版
switch areaIntf.(type) {
case *Square:
// TODO
case *Circle:
// TODO
...
default:
// TODO
}
> 也可用于测试变量是否实现某接口
type Stringer interface {
String() string
}
if sv, ok := v.(Stringer); ok {
fmt.Printf("v implements String(): %s\n", sv.String()) // note: sv, not v
}
**接口调用**
- 指针方法可以通过指针调用
- 值方法可以通过值调用
- 接收者是值的方法可以通过指针调用,因为指针会首先被解引用
- 接收者是指针的方法不可以通过值调用,因为存储在接口中的值没有地址
- 类型 *T 的可调用方法集包含接受者为* T 或 T 的所有方法集
- 类型 T 的可调用方法集包含接受者为 T 的所有方法
- 类型 T 的可调用方法集不包含接受者为 \*T 的方法
**自定义类型排序接口**
package sort
// 排序接口
type Sorter interface {
Len() int
Less(i, j int) bool
Swap(i, j int)
}
func Sort(data Sorter) {
len := data.Len()
for i := 1; i < len; i++{
for j := 0; j < len - i; j++ {
if data.Less(j+1, j) {
data.Swap(j+1, j)
}
}
}
}
func main(){
Sunday := day{0, "SUN", "Sunday"}
Monday := day{1, "MON", "Monday"}
Tuesday := day{2, "TUE", "Tuesday"}
Wednesday := day{3, "WED", "Wednesday"}
Thursday := day{4, "THU", "Thursday"}
Friday := day{5, "FRI", "Friday"}
Saturday := day{6, "SAT", "Saturday"}
data2 := []day{Tuesday, Thursday, Wednesday, Sunday, Monday, Friday, Saturday, Thursday}
array2 := dayArr(data2)
sort.Sort(array2)
for _, d := range data2 {
fmt.Printf("%v ", d)
}
fmt.Printf("\n")
fm.Println(array2)
fmt.Printf("\n")
}
// 自己想到的实现方式
type day struct {
num int
shortName string
longName string
}
type dayArr []day
func (p dayArr)Len() int {
return len(p)
}
func (p dayArr)Less(i, j int) bool {
return p[i].num < p[j].num
}
func (p dayArr)Swap(i, j int) {
p[i], p[j] = p[j], p[i]
}
func main(){
Sunday := day{0, "SUN", "Sunday"}
Monday := day{1, "MON", "Monday"}
Tuesday := day{2, "TUE", "Tuesday"}
Wednesday := day{3, "WED", "Wednesday"}
Thursday := day{4, "THU", "Thursday"}
Friday := day{5, "FRI", "Friday"}
Saturday := day{6, "SAT", "Saturday"}
data3 := []*day{&Tuesday, &Thursday, &Wednesday, &Sunday, &Monday, &Friday, &Saturday}
// 结构体初始化
array3 := dayArray{data3}
sort.Sort(&array3)
for _, d := range data3 {
fmt.Printf("%v ", d)
}
fmt.Printf("\n")
fm.Println(array3)
fmt.Printf("\n")
}
// 作者实现方式
type dayArray struct {
data []*day
}
func (p *dayArray)Len() int {
return len(p.data)
}
func (p *dayArray)Less(i, j int) bool {
return p.data[i].num < p.data[j].num
}
func (p *dayArray)Swap(i, j int) {
p.data[i], p.data[j]= p.data[j], p.data[i]
}
> 两种方式对比:
- 第一种方式使用struct数组(切片更恰当)和变量,都是通过值拷贝;第二种通过struct指针数组和数组的指针,通过引用。故内存占用和调用消耗有差别。
- 暂时没想到,以后补充
**构建通用类型或包含不同类型变量的数组**\
对于返回值未知的接口,可以通过返回空接口。
package min
type Miner interface {
Len() int
ElemIx(ix int) interface{}
Less(i, j int) bool
}
func Min(data Miner) interface{} {
min := data.ElemIx(0)
for i:=1; i < data.Len(); i++ {
if data.Less(i, i-1) {
min = data.ElemIx(i)
}
}
return min
}
type IntArray []int
func (p IntArray) Len() int { return len(p) }
func (p IntArray) ElemIx(ix int) interface{} { return p[ix] }
func (p IntArray) Less(i, j int) bool { return p[i] < p[j] }
type StringArray []string
func (p StringArray) Len() int { return len(p) }
func (p StringArray) ElemIx(ix int) interface{} { return p[ix] }
func (p StringArray) Less(i, j int) bool { return p[i] < p[j] }
**复制数据切片至空接口切片**\
内存布局不一样,需要一个个赋值
var dataSlice []myType = FuncReturnSlice()
var interfaceSlice []interface{} = make([]interface{}, len(dataSlice))
for ix, d := range dataSlice {
interfaceSlice[ix] = d
}
**通用节点数据结构**
type Node struct {
le *Node
data interface{}
ri *Node
}
func NewNode(left, right *Node) *Node {
return &Node{left, nil, right}
}
func (n *Node) SetData(data interface{}) {
n.data = data
}
**接口和动态类型**
**函数重载**\
通过函数参数`...T`实现,或空接口\
`fmt.Printf(format string, a ...interface{}) (n int, errno error)`
**接口继承**\
当一个类型包含(内嵌)另一个类型(实现了一个或多个接口)的指针时,这个类型就可以使用(另一个类型)所有的接口方法。
type Task struct {
Command string
*log.Logger
}
func NewTask(command string, logger *log.Logger) *Task {
return &Task{command, logger}
}
task.Log()
//多重继承
type ReaderWriter struct {
*io.Reader
*io.Writer
}
**类型转换问题**\
[对空接口interface{}进行强制类型转换报错](http://stackoverflow.com/questions/18041334/convert-interface-to-int-in-go-lang)
> Conversions are expressions of the form T(x) where T is a type and x
> is an expression that can be converted to type T.
A non-constant value x can be converted to type T in any of these cases:
1. x is assignable to T.
2. x's type and T have identical underlying types.
3. x's type and T are unnamed pointer types and their pointer base
types have identical underlying types.
4. x's type and T are both integer or floating point types.
5. x's type and T are both complex types.
6. x is an integer or a slice of bytes or runes and T is a string type.
7. x is a string and T is a slice of bytes or runes.
> 转换是形如`T(x)`的表达式,其中`T`是一种类型,而`x`是能转换为类型`T`的表达式
下面任何一种情况中非常量x都能转换为类型`T`
1. x可赋值给T
2. x的类型和T的底层类型一致
3. x的类型和T是匿名指针类型且它们的指针基类型的底层类型一致
4. x的类型和T都是整型或浮点型
5. x的类型和T都是复数类型
6. x是整数、bytes切片或runes,且T是string
7. x是string且T是bytes切片或runes
### GO中的OO
OO 语言最重要的三个方面分别是:封装,继承和多态,在 Go
中它们是怎样表现的呢?
1. 封装(数据隐藏):Go 把它从4层简化为了2层:
- 包范围内的:通过标识符首字母小写,对象只在它所在的包内可见
- 可导出的:通过标识符首字母大写,对象 对所在包以外也可见
1. 继承:用组合实现:内嵌一个(或多个)包含想要的行为(字段和方法)的类型;多重继承可以通过内嵌多个类型实现
2. 多态:用接口实现:某个类型的实例可以赋给它所实现的任意接口类型的变量。类型和接口是松耦合的,并且多重继承可以通过实现多个接口实现。
### 读写数据
**输入输出**\
**文件读写**
inputFile, inputError := os.Open("input.dat")
if inputError != nil {
fmt.Printf("An error occurred on opening the inputfile\n" +
"Does the file exist?\n" +
"Have you got acces to it?\n")
return // exit the function on error
}
defer inputFile.Close()
inputReader := bufio.NewReader(inputFile)
for {
inputString, readerError := inputReader.ReadString('\n')
if readerError == io.EOF {
return
}
fmt.Printf("The input was: %s", inputString)
}
**读到字符串**
func main() {
inputFile := "products.txt"
outputFile := "products_copy.txt"
buf, err := ioutil.ReadFile(inputFile)
if err != nil {
fmt.Fprintf(os.Stderr, "File Error: %s\n", err)
// panic(err.Error())
}
fmt.Printf("%s\n", string(buf))
err = ioutil.WriteFile(outputFile, buf, 0644) // oct, not hex
if err != nil {
panic(err. Error())
}
}
**缓冲读取**
buf := make([]byte, 1024)
...
n, err := inputReader.Read(buf)
if (n == 0) { break}
**按列读取**
func main() {
file, err := os.Open("products2.txt")
if err != nil {
panic(err)
}
defer file.Close()
var col1, col2, col3 []string
for {
var v1, v2, v3 string
_, err := fmt.Fscanln(file, &v1, &v2, &v3)
// scans until newline
if err != nil {
break
}
col1 = append(col1, v1)
col2 = append(col2, v2)
col3 = append(col3, v3)
}
fmt.Println(col1)
fmt.Println(col2)
fmt.Println(col3)
}
**写文件**
func main () {
outputFile, outputError := os.OpenFile("output.dat", os.O_WRONLY|os.O_CREATE, 0666)
if outputError != nil {
fmt.Printf("An error occurred with file opening or creation\n")
return
}
defer outputFile.Close()
outputWriter := bufio.NewWriter(outputFile)
outputString := "hello world!\n"
for i:=0; i<10; i++ {
outputWriter.WriteString(outputString)
}
outputWriter.Flush()
}
- os.O\_RDONLY:只读
- os.O\_WRONLY:只写
- os.O\_CREATE:创建:如果指定文件不存在,就创建该文件。
- os.O\_TRUNC:截断:如果指定文件已存在,就将该文件的长度截为0。
<!-- -->
// 非缓冲写入
func main() {
os.Stdout.WriteString("hello, world\n")
f, _ := os.OpenFile("test", os.O_CREATE|os.O_WRONLY, 0)
defer f.Close()
f.WriteString("hello, world in a file\n")
}
**文件拷贝**
func CopyFile(dstName, srcName string) (written int64, err error) {
src, err := os.Open(srcName)
if err != nil {
return
}
defer src.Close()
dst, err := os.OpenFile(dstName, os.O_WRONLY|os.O_CREATE, 0644)
if err != nil {
return
}
defer dst.Close()
return io.Copy(dst, src)
}
**读取参数**
func main() {
who := "Alice "
if len(os.Args) > 1 {
who += strings.Join(os.Args[1:], " ")
}
fmt.Println("Good Morning", who)
}
**JSON**
1. JSON 与 Go 类型对应如下
- bool 对应 JSON 的 booleans
- float64 对应 JSON 的 numbers
- string 对应 JSON 的 strings
- nil 对应 JSON 的 null
1. 不是所有的数据都可以编码为JSON类型:只有验证通过的数据结构才能被编码:
- JSON 对象只支持字符串类型的 key;要编码一个 Go map 类型,map 必须是
map\[string\]T(T是json包中支持的任何类型)
- Channel,复杂类型和函数类型不能被编码
- 不支持循环数据结构;它将引起序列化进入一个无限循环指针可以被编码,实际上是对指针指向的值进行编码(或者指针是
nil)
### 错误处理与测试
### 协程与通道
> 不要通过共享内存来通信,而通过通信来共享内存。
func main() {
runtime.GOMAXPROCS(2)
ch1 := make(chan int)
ch2 := make(chan int)
go pump1(ch1)
go pump2(ch2)
go suck(ch1, ch2)
time.Sleep(1e9)
}
func pump1(ch chan int) {
for i:=0; ; i++ {
ch <- i*2
}
}
func pump2(ch chan int) {
for i:=0; ; i++ {
ch <- i+5
}
}
func suck(ch1,ch2 chan int) {
for i := 0; ; i++ {
select {
case v := <- ch1:
fmt.Printf("%d - Received on channel 1: %d\n", i, v)
case v := <- ch2:
fmt.Printf("%d - Received on channel 2: %d\n", i, v)
}
}
}
**协程间通信**\
通道声明:
var identifier chan type
id := make(chan type)
// 缓冲通道
iden := make(chan type, len)
1. 流向通道(发送)\
`ch <- int1`表示:用通道 ch 发送变量int1(双目运算符,中缀 = 发送)
2. 从通道流出(接收),三种方式:
- `int2 = <- ch` 表示:变量 int2 从通道 ch(一元运算的前缀操作符,前缀
= 接收)接收数据(获取新值)
- 假设 int2 已经声明过了,如果没有的话可以写成:`int2 := <- ch`
- <- ch
可以单独调用获取通道的(下一个)值,当前值会被丢弃,但是可以用来验证,以下代码是合法的:
<!-- -->
if <- ch != 1000{
...
}
数据传输
func TestChan() {
ch := make(chan string)
go sendData(ch)
go recvData(ch)
time.Sleep(1e9)
}
func sendData(ch chan string) {
ch <- "hu"
ch <- "yuan"
ch <- "sky"
}
func recvData(ch chan string) {
recv := ""
for {
recv = <-ch
fmt.Println(recv)
}
}
**阻塞**
// 发送阻塞
func main() {
ch1 := make(chan int)
go pump(ch1) // pump hangs
time.Sleep(2*1e9)
fmt.Println("Recv", <-ch1) // prints only 0
time.Sleep(1e9)
}
func pump(ch chan int) {
for i := 1; ; i++ {
ch <- i
fmt.Println("Send ",i)
}
}
//发送阻塞
func main() {
c := make(chan int)
go func() {
time.Sleep(15 * 1e9)
x := <-c
fmt.Println("received", x)
}()
fmt.Println("sending", 10)
c <- 10
fmt.Println("sent", 10)
}
**信号量模式**\
循环并行执行
// 测试同步执行
type Empty interface {}
const N = 100000
func Compare() {
ch_buf := make(chan Empty, N)
data := make([]float64, N)
for i:=0; i < N; i++{
data[i] = float64(i)
}
s := time.Now()
TestChannal(data, ch_buf)
fmt.Println(time.Now().Sub(s))
//fmt.Println(data)
for i:=0; i < N; i++{
data[i] = float64(i)
}
s = time.Now()
TestNormal(data)
fmt.Println(time.Now().Sub(s))
//fmt.Println(data)
}
func TestChannal(data []float64, ch_buf chan Empty) {
var em Empty
for ix, val :=range data {
go func(ix int, val float64) {
for j := 0; j < N; j++ {
data[ix] += val
}
ch_buf <- em
}(ix, val)
}
for i := 0; i < N; i++ { <-ch_buf}
}
func TestNormal(data []float64){
for ix, val := range data {
for j := 0; j < N; j++ {
data[ix] += val
}
}
}
**通道的方向**
var send_only chan<- int // channel can only send data
var recv_only <-chan int // channel can onley recv data
> 只接收的通道(`<-chan T`)无法关闭,因为关闭通道是发送者用来表示不再给通道发送值了,所以对只接收通道是没有意义的。
### 网络、模板和网络应用
### 注意事项
- 所有的包名使用小写
- 如果对一个包进行更改或重新编译,所有引用了这个包的客户端程序都必须全部重新编译。
- must define main function in main package else you will get
error 'undefined'. main function has not params and return value
- init function execute before main
- production server must use function in package "fmt"
- 全局变量是允许声明但不使用 | 33,434 | MIT |
---
title: ES6
display: home
image: https://picsum.photos/1920/1080/?random&date=2019-11-1-19
date: 2019-10-11
tags:
- ES6
categories:
- 笔记
---
> ES6相关笔记
Label `ES6相关笔记`
### 一、ES6 let、const
`let`
let是更完美的var
{}形成域,let只能在域中获取。
1. let声明的变量拥有块级作用域,let声明仍然保留了提升的特性,但不会盲目提升。
2. let声明的全局变量不是全局对象的属性。不可以通过 `window.变量名` 的方式访问
3. 形如 `for (let x…)` 的循环在每次迭代时都为 `x` 创建新的绑定
4. let声明的变量直到控制流到达该变量被定义的代码行时才会被装载,所以在到达之前使用该变量会触发错误。
`const`
定义常量值,不可以重新赋值,但是如果值是一个对象,可以改变对象里的属性值
``` js
const OBJ = {"a":1, "b":2};
OBJ.a = 3;
OBJ = {};// 重新赋值,报错!
console.log(OBJ.a); // 3
```
### 二、模板字符串
``` js
/**
* 模板字符串
*/
let name = "Henry";
function makeUppercase(word){
return word.toUpperCase();
}
let template =
`
<h1>${makeUppercase('Hello')}, ${name}!</h1>
<p>感谢大家收看我们的视频, ES6为我们提供了很多遍历好用的方法和语法!</p>
<ul>
<li>1</li>
<li>2</li>
<li>3</li>
<li>4</li>
<li>5</li>
</ul>
`;
document.getElementById('template').innerHTML = template;
```
### 三、箭头函数
> 解决的问题
> 1. 缩减代码
> 2. 改变this指向
1. 缩减代码
``` js
const double1 = function(number){
return number * 2;
}
const double2 = (number) => {
return number * 2;
}
const double3 = (number) => number * 2;
const double4 = number => number * 2;
const double5 = (number => number * 2);
const double6 = (number,number2) => number + number2;
const double = (number,number2) => {
sum = number + number2
return sum;
}
// console.log(double(20,20));
// map一个数组,让数组中的值以double形式展现
const numbers = [1,2,3];
var newNumbers = numbers.map(function(number){
return number * 2;
})
var newNumbers = numbers.map(number => number * 2);
// console.log(newNumbers);
```
2. 改变this指向
``` js
const team1 = {
members:["Henry","Elyse"],
teamName:"es6",
teamSummary:function(){
let self = this;
return this.members.map(function(member){
// this不知道该指向谁了
return `${member}隶属于${self.teamName}小组`;
})
}
}
const team2 = {
members:["Henry","Elyse"],
teamName:"es6",
teamSummary:function(){
return this.members.map(function(member){
// this不知道该指向谁了
return `${member}隶属于${this.teamName}小组`;
}.bind(this))
}
}
const team = {
members:["Henry","Elyse"],
teamName:"es6",
teamSummary:function(){
return this.members.map((member) => {
// this指向的就是team对象
return `${member}隶属于${this.teamName}小组`;
})
}
}
console.log(team.teamSummary());
```
### 四、增强对象字面量
> 解决的问题
> 1. 缩减代码
``` js
function saveFile(url,data){
$.ajax({
method:"POST",
url,//==url:url,
data,//==data:data
});
}
const url = "http://fileupload.com";
const data = {color:"red"};
saveFile(url,data);
```
### 五、函数参数默认值
> 解决的问题
> 1. 优化代码
通过`method = "GET"`这种方式直接设置默认值
``` js
// function makeAjaxRequest(url,method){
// if(!method){
// method = "GET";
// }
// return method;
// }
// function makeAjaxRequest(url,method = "GET"){
// return method;
// }
// console.log(makeAjaxRequest("google.com"));
// console.log(makeAjaxRequest("google.com","POST"));
function User(id){
this.id = id;
}
// console.log(new User(1));
function randomId(){
return Math.random() * 99999999;
}
// console.log(new User(randomId()));
function createAdminUser(user = new User(randomId())){
user.admin = true;
return user;
}
const user = new User(2);
console.log(createAdminUser());
```
### 六、spread operator 展开运算符
> 更快,更便捷的操作数组,将一个数组转为用逗号分隔的参数序列
#### 合并数组
``` js
let a = [1,2,3];
let b = [4,5,6];
let c = [...a,...b]; // [1,2,3,4,5,6]
```
#### 替代apply
``` js
function f(a,b,c){
console.log(a,b,c)
}
let args = [1,2,3];
// 以下三种方法结果相同
f.apply(null,args)
f(...args)
f(1,2,3)
function f2(...args){
console.log(args)
}
f2(1,2,3) // [1,2,3]
function f3(){
console.log(Array.from(arguments))
}
f3(1,2,3) // [1,2,3]
```
#### 解构赋值
``` js
let a = [1,2,3,4,5,6]
let [c,...d] = a
console.log(c); // 1
console.log(d); // [2,3,4,5,6]
//展开运算符必须放在最后一位
```
#### 浅拷贝
``` js
//数组
var a = [1,2,4]
var b = [...a]
a.push(6)
console.log(b) // [1,2,4]
//对象
var a = {a:1}
var b = {...a}
a.a = 5
console.log(b.a) // 1
```
### 七、Calss
> 万事皆对象
### 八、Promise
> 更快,更便捷的操作数组
#### 三种状态:
1. unresolved 等待任务完成
2. resolved 任务完成并且没有任何问题 then 回调callback
3. rejected 任务完成,但是出现问题 catch 回调callback | 4,239 | MIT |
---
title: "产品系列"
description: 本小节主要介绍 MySQL Plus 版本规格。
keywords: mysql plus 版本规格, 版本应用场景
weight: 20
collapsible: false
draft: false
---
MySQL Plus 根据 AppCenter 功能特点定制了三个功能系列:基础版、高可用版、金融版。
## 系列介绍
|<span style="display:inline-block;width:60px">系列</span> |<span style="display:inline-block;width:320px">版本说明</span>|<span style="display:inline-block;width:240px">适应场景</span> |
|:----|:----|:----|
|基础版 |面向个人用户或中小型团队用户推出的单节点数据库版本,成本低,可实现极高的性价比。 |适用于个人学习、小型网站、开发测试等使用场景。|
|高可用版 |面向企业级生产环境推出的双节点数据库版本,采用一主两从的高可用架构,提供数据库的高可用保障。|适用于大中型企业生产库、互联网、电商零售、物流、游戏等行业应用。|
|金融版 |面向金融级生产环境推出的三节点数据库版本,采用多主单写的三主节点架构,保证数据的强一致性,提供金融级可靠性。|适用于对数据安全性要求非常高的金融、证券、保险等行业的核心数据库。|
<!--
## 系列规格
各系列实例规格如下。
|<span style="display:inline-block;width:60px">系列</span>|<span style="display:inline-block;width:60px">vCPU </span>|<span style="display:inline-block;width:80px">内存</span> |<span style="display:inline-block;width:100px">vCPU/内存比</span> |<span style="display:inline-block;width:100px">最大IOPS</span> |<span style="display:inline-block;width:220px">存储空间</span> |
|:----|:----|:----|:----|:----|:----|
|基础版 |1~8| 1GB~32GB| 1:1,1:2,1:4| 500~2500| 基础型:10G~2000G|
|高可用版| 2~32| 4GB~128GB| 1:2,1:4,1:8| 2000~30000 |SSD企业型:10G~2000G <br> NeonSAN:100G~10000G|
|金融版 |2~32 |8GB~256GB| 1:4,1:8 | 2000~30000| SSD企业型:10G~2000G <br> NeonSAN:100G~10000G|
--> | 1,334 | Apache-2.0 |
---
title: 在门户中为 Azure 应用创建标识 | Microsoft 文档
description: 介绍如何创建新的 Azure Active Directory 应用程序和服务主体,在 Azure Resource Manager 中将此服务主体与基于角色的访问控制配合使用可以管理对资源的访问权限。
services: active-directory
documentationcenter: na
author: rwike77
manager: CelesteDG
ms.service: active-directory
ms.subservice: develop
ms.devlang: na
ms.topic: conceptual
ms.tgt_pltfrm: na
ms.workload: na
origin.date: 05/17/2019
ms.date: 06/24/2019
ms.author: v-junlch
ms.reviewer: tomfitz
ms.custom: seoapril2019
ms.collection: M365-identity-device-management
ms.openlocfilehash: e6d4d0803a5e438df80d33dd638f0ca66381ee10
ms.sourcegitcommit: 5f85d6fe825db38579684ee1b621d19b22eeff57
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 07/05/2019
ms.locfileid: "67568501"
---
# <a name="how-to-use-the-portal-to-create-an-azure-ad-application-and-service-principal-that-can-access-resources"></a>如何:使用门户创建可访问资源的 Azure AD 应用程序和服务主体
本文介绍如何创建新的 Azure Active Directory (Azure AD) 应用程序和服务主体,后者可以与基于角色的访问控制配合使用。 如果有需要访问或修改资源的代码,则可以为应用创建标识。 此标识称为服务主体。 可以将所需权限分配给服务主体。 本文介绍如何使用门户创建服务主体。 重点介绍单租户应用程序,其中应用程序只应在一个组织内运行。 通常会将单租户应用程序作为在组织中运行的业务线应用程序使用。
> [!IMPORTANT]
> 请考虑使用 Azure 资源的托管标识作为应用程序标识,而不是创建服务主体。 如果代码在支持托管标识的服务上运行并访问支持 Azure AD 身份验证的资源,则托管标识是更好的选择。
## <a name="create-an-azure-active-directory-application"></a>创建 Azure Active Directory 应用程序
我们直接介绍如何创建标识。 如果遇到问题,请查看[所需权限](#required-permissions),确保帐户可以创建标识。
1. 通过 [Azure 门户](https://portal.azure.cn)登录到 Azure 帐户。
1. 选择“Azure Active Directory” 。
1. 选择“应用注册” 。

1. 选择“新注册”。

1. 提供应用程序的名称。 选择支持的帐户类型,它决定了谁可以使用应用程序。 在“重定向 URI” 下,选择“Web” 作为要创建的应用程序类型。 输入访问令牌将发送到的 URI。 该类型不能用于自动化应用程序。 设置这些值后,选择“注册” 。

现已创建了 Azure AD 应用程序和服务主体。
## <a name="assign-the-application-to-a-role"></a>将应用程序分配给角色
要访问订阅中的资源,必须将应用程序分配到角色。 判定哪个角色能为应用程序提供适当的权限。 若要了解有关可用角色的信息,请参阅 [RBAC:内置角色](../../role-based-access-control/built-in-roles.md)。
可将作用域设置为订阅、资源组或资源级别。 较低级别的作用域会继承权限。 例如,将某个应用程序添加到资源组的“读取者”角色意味着该应用程序可以读取该资源组及其包含的所有资源。
1. 导航到要将应用程序分配到的作用域级别。 例如,若要在订阅范围内分配角色,请依次选择“所有服务”和“订阅” 。

1. 选择要将应用程序分配到的特定订阅。

如果未看到所需订阅,请选择“全局订阅筛选器” 。 请确保已为该门户选择所需的订阅。
1. 选择“访问控制(IAM)” 。
1. 选择“添加角色分配” 。

1. 选择要分配到应用程序的角色。 若要允许应用程序执行诸如“重启”、“启动”和“停止”实例之类的操作,请选择“参与者”角色 。 默认情况下,可用选项中不显示 Azure AD 应用程序。 若要查找应用程序,请搜索其名称并选中它。

1. 选择“保存” 完成角色分配。 该应用程序会显示在分配到该范围角色的用户列表中。
服务主体已设置完毕。 可以开始使用它运行脚本或应用。 下一部分演示如何获取以编程方式登录时所需的值。
## <a name="get-values-for-signing-in"></a>获取用于登录的值
以编程方式登录时,需要随身份验证请求传递租户 ID。 还需要应用程序 ID 和身份验证密钥。 若要获取这些值,请使用以下步骤:
1. 选择“Azure Active Directory” 。
1. 从 Azure AD 中的“应用注册” ,选择应用程序。

1. 复制“目录(租户) ID”并将其存储在应用程序代码中。

1. 复制“应用程序 ID” 并将其存储在应用程序代码中。

## <a name="certificates-and-secrets"></a>证书和机密
守护程序应用程序可以使用两种形式的凭据来向 Azure AD 进行身份验证:证书和应用程序机密。 我们建议使用证书,但你也可以创建新的应用程序机密。
### <a name="upload-a-certificate"></a>上传证书
可以使用现有证书(如果有)。 (可选)可以创建自签名证书以进行测试。 打开 PowerShell 并使用以下参数运行 [New-SelfSignedCertificate](https://docs.microsoft.com/powershell/module/pkiclient/new-selfsignedcertificate),以在计算机上的用户证书存储中创建自签名证书:`$cert=New-SelfSignedCertificate -Subject "CN=DaemonConsoleCert" -CertStoreLocation "Cert:\CurrentUser\My" -KeyExportPolicy Exportable -KeySpec Signature`。 使用可从 Windows 控制面板访问的[管理用户证书](https://docs.microsoft.com/dotnet/framework/wcf/feature-details/how-to-view-certificates-with-the-mmc-snap-in) MMC 管理单元导出此证书。
若要上传证书,请执行以下操作:
1. 选择“证书和机密” 。

1. 单击“上传证书” 并选择证书(现有证书或导出的自签名证书)。

1. 单击“添加” 。
在门户中将证书注册到应用程序后,需要启用客户端应用程序代码才能使用该证书。
### <a name="create-a-new-application-secret"></a>创建新的应用程序机密
如果选择不使用证书,则可以创建新的应用程序机密。
1. 选择“证书和机密” 。

1. 选择“客户端机密”->“新建客户端机密” 。
1. 提供机密的说明和持续时间。 完成后,选择“添加” 。

保存客户端密码后,将显示客户端密码的值。 复制此值,因为稍后不能检索密钥。 提供密钥值及应用程序 ID,以该应用程序的身份登录。 将密钥值存储在应用程序可检索的位置。

## <a name="required-permissions"></a>所需的权限
必须具有足够的权限向 Azure AD 租户注册应用程序,并将应用程序分配到 Azure 订阅中的角色。
### <a name="check-azure-ad-permissions"></a>检查 Azure AD 权限
1. 选择“Azure Active Directory” 。
1. 记下你的角色。 如果角色为“用户”,则必须确保非管理员可以注册应用程序 。

1. 选择“用户设置” 。

1. 检查“应用注册” 设置。 只有管理员可设置此值。 如果设置为“是”,则 Active AD 租户中的任何用户都可以注册应用 。

如果应用注册设置设定为“否” ,则只有具有管理员角色的用户才能注册这些类型的应用程序。 请参阅[可用角色](../users-groups-roles/directory-assign-admin-roles.md#available-roles)和[角色权限](../users-groups-roles/directory-assign-admin-roles.md#role-permissions)来了解 Azure AD 中的可用管理员角色以及授予每个角色的具体权限。 如果将帐户分配到“用户”角色,但应用注册设置仅限于管理员用户,请要求管理员为你分配可以创建和管理应用注册的所有方面的管理员角色之一,或者让用户能够注册应用。
### <a name="check-azure-subscription-permissions"></a>检查 Azure 订阅权限
在 Azure 订阅中,帐户必须具有 `Microsoft.Authorization/*/Write` 访问权限才能向角色分配 AD 应用。 通过[所有者](../../role-based-access-control/built-in-roles.md#owner)角色或[用户访问管理员](../../role-based-access-control/built-in-roles.md#user-access-administrator)角色授权此操作。 如果将帐户分配到“参与者”角色,则没有足够权限 。 尝试将服务主体分配到角色时,将收到错误。
检查订阅权限的方法如下:
1. 在右上角选择自己的帐户,然后选择“...”->“我的权限”。

1. 从下拉列表中,选择要在其中创建服务主体的订阅。 然后,选择“单击此处查看此订阅的完整访问详细信息” 。

1. 选择“角色分配” 以查看分配到的角色,并确定你是否拥有足够的权限来向角色分配 AD 应用。 如果没有,请要求订阅管理员将你添加到用户访问管理员角色。 在下图中,用户分配到了“所有者”角色,这意味着该用户具有足够的权限。

## <a name="next-steps"></a>后续步骤
* 若要设置多租户应用程序,请参阅 [使用 Azure Resource Manager API 进行授权的开发人员指南](../../azure-resource-manager/resource-manager-api-authentication.md)。
* 若要了解如何指定安全策略,请参阅 [Azure 基于角色的访问控制](../../role-based-access-control/role-assignments-portal.md)。
* 有关可对用户授予或拒绝的可用操作的列表,请参阅 [Azure 资源管理器资源提供程序操作](../../role-based-access-control/resource-provider-operations.md)。
<!-- Update_Description: wording update --> | 6,955 | CC-BY-4.0 |
# in-array
> Return true if a value exists in an array. Faster than using indexOf and won't blow up on null values.
> npm: [in-array - npm](https://www.npmjs.com/package/in-array)
```javascript
/*!
* in-array <https://github.com/jonschlinkert/in-array>
*
* Copyright (c) 2014 Jon Schlinkert, contributors.
* Licensed under the MIT License
*/
'use strict';
module.exports = function inArray (arr, val) {
// 若是外部arr 不存在则使用空数组
arr = arr || [];
// 数组长度缓存和下标声明
var len = arr.length;
var i;
// 遍历查找
for (i = 0; i < len; i++) {
if (arr[i] === val) {
return true;
}
}
return false;
};
```
> 我感觉我的智商给碾压了,只是单纯的考虑了一些基础数据类型的比较和遍历 | 666 | MIT |
---
layout: post
title: Spring Boot(二四) - 安全
date: 2017-07-13 13:49:00 +0800
categories: Spring-Boot
tag: 教程
---
* content
{:toc}
安全
==================
Spring Boot提供三个层级的安全设置
+ Spring Security :用作WEB应用的登录
+ OAuth 2 :用作认证服务器
+ Actuator Security :用作Actuator的安全设置
> 本次只简单探索下Spring Security在Spring Boot中的应用。
Spring Security
------------------
Spring Boot针对Spring Security的自动配置在org.springframework.boot.autoconfigure.security包中。
如果添加了Spring Security的依赖,那么web应用默认对所有的HTTP路径(也称为终点,端点,表示API的具体网址)使用`basic`认证。为了给web应用添加方法级别(method-level)的保护,可以添加 `@EnableGlobalMethodSecurity` 并使用想要的设置,其他信息参考[Spring Security Reference](http://docs.spring.io/spring-security/site/docs/4.2.3.RELEASE/reference/htmlsingle#jc-method)。
默认的 `AuthenticationManager` 只有一个用户(用户名为`user`的用户名, 随机密码会在应用启动时以INFO日志级别打印出来)
默认的安全配置是通过 `SecurityAutoConfiguration` , `SpringBootWebSecurityConfiguration`(用于web安全), `AuthenticationManagerConfiguration` (可用于非web应用的认证配置)进行管理的。可以添加一个 `@EnableWebSecurity` bean来彻底关掉Spring Boot的默认配置。为了对它进行自定义,需要使用外部的属性配置和 `WebSecurityConfigurerAdapter` 类型的beans(比如,添加基于表单的登陆)。 想要关闭认证管理的配置,可以添加一个 `AuthenticationManager` 类型的bean,或在 `@Configuration` 类的某个方法里注入 `AuthenticationManagerBuilder` 来配置全局的 `AuthenticationManager` 。
这里有一些安全相关的[Spring Boot应用示例](https://github.com/spring-projects/spring-boot/tree/v1.5.4.RELEASE/spring-boot-samples/)可以拿来参考。
在web应用中能得到的开箱即用的基本特性如下:
1. 一个使用内存存储的 `AuthenticationManager` bean和一个用户(查看 `SecurityProperties.User` 获取user的属性)。
2. 忽略(不保护)常见的静态资源路径( `/css/**`, `/js/**`, `/images/**` , `/webjars/**` 和 `**/favicon.ico` )。
3. 对其他所有路径实施HTTP Basic安全保护。
4. 安全相关的事件会发布到Spring的 `ApplicationEventPublisher` (成功和失败的认证,拒绝访问)。
5. Spring Security提供的常见底层特性(HSTS, XSS, CSRF, 缓存)默认都被开启。
上述所有特性都能通过外部配置( `security.*` )打开,关闭,或修改。想要覆盖访问规则而不改变其他自动配置的特性,可以添加一个注解 `@Order(SecurityProperties.ACCESS_OVERRIDE_ORDER)` 的 `WebSecurityConfigurerAdapter` 类型的 @Bean 。当我们自己扩展的配置时,只需配置类基础呢个`WebSecurityConfigurerAdapter`就可以了。
{% highlight java %}
@Configuration
public class WebSecurityConfig extends WebSecurityConfigureAdapter {
}
{% endhighlight %}
SecurityProperties使用以`security`为前缀的属性配置Spring Security相关的配置,
{% highlight text %}
security.user.name=user #内存中的用户默认帐号为user
security.user.password= # 默认用户的密码
security.user.role=USER # 默认用户的角色
security.require-ssl=false # 是否需要SSL支持
security.enable-csrf=false # 是否开启"跨站请求伪造"支持,默认关闭
security.basic.enabled=
security.basic.realm=
security.basic.path= # /**
security.basicauthorize-mode=
security.filter-order=0
security.headers.xss=false
security.headers.cache=false
security.headers.frame=false
security.headers.content-type=false
security.headers.hsts=all
security.sessions=stateless
security.ignored= # 用逗号隔开的无需拦截的路径
{% endhighlight %}
实验
==================
> 本实验基于Spring Security, MYSQL和Thymeleaf实现。
创建数据库
------------------
{% highlight sql %}
DROP DATABASE IF EXISTS `security-test`;
CREATE DATABASE `security-test`;
{% endhighlight %}
创建一个Maven项目
------------------

pom.xml
------------------
{% highlight xml %}
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.freud.test</groupId>
<artifactId>spring-boot-24</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>spring-boot-24</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-security</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.thymeleaf.extras</groupId>
<artifactId>thymeleaf-extras-springsecurity4</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>1.5.4.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
</project>
{% endhighlight %}
application.yml
------------------
{% highlight yml %}
spring:
application:
name: test-24
jpa:
show-sql: true
hibernate:
ddl-auto: update
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/security-test?useSSL=false
username: root
password: root
thymeleaf:
cache: false
server:
port: 9090
{% endhighlight %}
index.html
------------------
{% highlight java %}
<!DOCTYPE html>
<html lang="en" xmlns:th="http://www.thymeleaf.org"
xmlns:sec="http://www.thymeleaf.org/thymeleaf-extras-springsecurity4">
<head>
<meta charset="UTF-8"/>
<title>首页展示</title>
<style type="text/css">
table {
border-spacing: 0px;
border-collapse: 0px;
border-width: 3px;
border-color: black;
}
</style>
</head>
<body>
<div>
<h2>权限展示</h2>
<table border="1">
<thead>
<tr>
<td>Names</td>
<td>Values</td>
</tr>
</thead>
<tbody>
<tr>
<td>Login User:</td>
<td sec:authentication="name"></td>
</tr>
<tr>
<td>Title:</td>
<td th:text="${content}"></td>
</tr>
<tr sec:authorize="hasRole('ROLE_ADMIN')">
<td>Admin Role Show:</td>
<td th:text="${adminMsg}"></td>
</tr>
<tr sec:authorize="hasRole('ROLE_USER')">
<td>User RoleShow:</td>
<td th:text="${userMsg}"></td>
</tr>
<tr>
<td>Logout:</td>
<td>
<form th:action="@{/logout}" method="post">
<input type="submit" class="btn btn-primary" value="注销"/>
</form>
</td>
</tr>
</tbody>
</table>
</div>
</body>
</html>
{% endhighlight %}
login.html
------------------
{% highlight java %}
<!DOCTYPE html>
<html lang="en" xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8"/>
<title>登录</title>
<style type="text/css">
.bg-warning {
color: pink;
}
.bg-danger {
color: red;
}
</style>
</head>
<body>
<div>
<div>
<h2>登录</h2>
<form th:action="@{/login}" action="/login" method="post">
<div>
<label>账号</label>
<input type="text" name="username" value="" placeholder="账号"/>
</div>
<div>
<label>密码</label>
<input type="password" name="password" placeholder="密码"/>
</div>
<input type="submit" id="login" value="Login"/>
</form>
<br />
<p th:if="${param.logout}" class="bg-warning">已注销</p>
<p th:if="${param.error}" class="bg-danger">有错误,请重试</p>
</div>
</div>
</body>
</html>
{% endhighlight %}
Role.java
------------------
{% highlight java %}
package com.freud.test.springboot.bean;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
/**
* @author Freud
*/
@Entity
public class Role {
@Id
@GeneratedValue
private long id;
@Column
private String name;
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
{% endhighlight %}
User.java
------------------
{% highlight java %}
package com.freud.test.springboot.bean;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
import javax.persistence.CascadeType;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.GeneratedValue;
import javax.persistence.Id;
import javax.persistence.ManyToMany;
import org.springframework.security.core.GrantedAuthority;
import org.springframework.security.core.authority.SimpleGrantedAuthority;
import org.springframework.security.core.userdetails.UserDetails;
/**
* @author Freud
*/
@Entity
public class User implements UserDetails {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue
private Long id;
@Column
private String username;
@Column
private String password;
@ManyToMany(cascade = { CascadeType.REFRESH }, fetch = FetchType.EAGER)
private List<Role> roles;
@Override
public Collection<? extends GrantedAuthority> getAuthorities() {
List<GrantedAuthority> auths = new ArrayList<GrantedAuthority>();
List<Role> roles = this.getRoles();
for (Role role : roles) {
auths.add(new SimpleGrantedAuthority(role.getName()));
}
return auths;
}
@Override
public String getPassword() {
return this.password;
}
@Override
public String getUsername() {
return this.username;
}
@Override
public boolean isAccountNonExpired() {
return true;
}
@Override
public boolean isAccountNonLocked() {
return true;
}
@Override
public boolean isCredentialsNonExpired() {
return true;
}
@Override
public boolean isEnabled() {
return true;
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public List<Role> getRoles() {
return roles;
}
public void setRoles(List<Role> roles) {
this.roles = roles;
}
public void setUsername(String username) {
this.username = username;
}
public void setPassword(String password) {
this.password = password;
}
}
{% endhighlight %}
CustomUserService.java
------------------
{% highlight java %}
package com.freud.test.springboot.config;
import java.text.MessageFormat;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.security.core.userdetails.UserDetails;
import org.springframework.security.core.userdetails.UserDetailsService;
import org.springframework.security.core.userdetails.UsernameNotFoundException;
import org.springframework.stereotype.Component;
import com.freud.test.springboot.bean.User;
import com.freud.test.springboot.repository.UserRepository;
/**
* @author Freud
*/
@Component
public class CustomUserService implements UserDetailsService {
@Autowired
private UserRepository userRepository;
@Override
public UserDetails loadUserByUsername(String username) throws UsernameNotFoundException {
User user = userRepository.findUserByUsername(username);
if (user == null) {
throw new UsernameNotFoundException(MessageFormat.format("用户名[{0}]不存在", username));
}
return user;
}
}
{% endhighlight %}
MyPermissionEvaluator.java
------------------
{% highlight java %}
package com.freud.test.springboot.config;
import java.io.Serializable;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.security.access.PermissionEvaluator;
import org.springframework.security.core.Authentication;
import org.springframework.stereotype.Component;
import org.springframework.util.CollectionUtils;
import com.freud.test.springboot.bean.User;
import com.freud.test.springboot.repository.UserRepository;
/**
* @author Freud
*/
@Component
public class MyPermissionEvaluator implements PermissionEvaluator {
@Autowired
private UserRepository userRepository;
@Override
public boolean hasPermission(Authentication authentication, Object targetDomainObject, Object permission) {
String username = authentication.getName();
User user = userRepository.findUserByUsername(username);
if (CollectionUtils.isEmpty(user.getRoles())) {
return false;
} else {
return true;
}
}
@Override
public boolean hasPermission(Authentication authentication, Serializable targetId, String targetType,
Object permission) {
// not supported
return false;
}
}
{% endhighlight %}
SecurityConfig.java
------------------
{% highlight java %}
package com.freud.test.springboot.config;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Configuration;
import org.springframework.security.authentication.encoding.Md5PasswordEncoder;
import org.springframework.security.config.annotation.authentication.builders.AuthenticationManagerBuilder;
import org.springframework.security.config.annotation.method.configuration.EnableGlobalMethodSecurity;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.config.annotation.web.builders.WebSecurity;
import org.springframework.security.config.annotation.web.configuration.WebSecurityConfigurerAdapter;
/**
* @author Freud
*/
@Configuration
@EnableGlobalMethodSecurity(prePostEnabled = true)
public class SecurityConfig extends WebSecurityConfigurerAdapter {
@Autowired
private CustomUserService customUserService;
@Override
protected void configure(HttpSecurity http) throws Exception {
http.authorizeRequests().anyRequest().authenticated()
.and().formLogin().loginPage("/login").failureUrl("/login?error").permitAll().defaultSuccessUrl("/", true)
.and().logout().logoutUrl("/logout").logoutSuccessUrl("/login?logout").permitAll()
.and().sessionManagement().maximumSessions(1).expiredUrl("/expired")
.and()
.and().exceptionHandling().accessDeniedPage("/accessDenied");
}
@Override
public void configure(WebSecurity web) throws Exception {
web.ignoring().antMatchers("/js/**", "/css/**", "/images/**", "/**/favicon.ico", "/resources/**");
}
@Override
protected void configure(AuthenticationManagerBuilder auth) throws Exception {
auth.userDetailsService(customUserService).passwordEncoder(new Md5PasswordEncoder());
}
}
{% endhighlight %}
HomeController.java
------------------
{% highlight java %}
package com.freud.test.springboot.controller;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.servlet.ModelAndView;
/**
* @author Freud
*/
@Controller
public class HomeController {
@RequestMapping("/login")
public String login() {
return "login";
}
@RequestMapping({ "", "/", "/index" })
public ModelAndView index() {
ModelAndView mav = new ModelAndView();
mav.setViewName("index");
mav.addObject("title", "Just for Spring Security Test");
mav.addObject("adminMsg", "Show only have ADMIN role.");
mav.addObject("userMsg", "Show only have USER role.");
return mav;
}
}
{% endhighlight %}
UserRepository.java
------------------
{% highlight java %}
package com.freud.test.springboot.repository;
import org.springframework.data.jpa.repository.JpaRepository;
import com.freud.test.springboot.bean.User;
/**
* @author Freud
*/
public interface UserRepository extends JpaRepository<User, Long> {
User findUserByUsername(String username);
}
{% endhighlight %}
App.java
------------------
{% highlight java %}
package com.freud.test.springboot;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* @author Freud
*/
@SpringBootApplication
public class App {
public static void main(String[] args) {
SpringApplication.run(App.class, args);
}
}
{% endhighlight %}
项目结构
------------------

运行及结果
==================
初始化数据库脚本
------------------
程序启动后会在数据库初始化相关的数据表如下:

然后在数据库执行如下脚本插入初始化数据:
{% highlight sql %}
DELETE FROM `user_roles`;
DELETE FROM `role`;
DELETE FROM `user`;
INSERT INTO `role`
(`id`,`name`)
VALUES
(1,'ROLE_ADMIN'),
(2,'ROLE_USER');
INSERT INTO `user`
(`id`,`username`,`password`)
VALUES
(1,'root','63a9f0ea7bb98050796b649e85481845'),
(2,'admin','21232f297a57a5a743894a0e4a801fc3');
INSERT INTO `user_roles`
(`user_id`,`roles_id`)
VALUES
(1,1),
(2,2);
{% endhighlight %}
访问登录界面
----------------
请求`http://localhost:9090/`, URL会重定向到`http://localhost:9090/login`

登录出错
----------------
输入错误的用户名和密码`aaa/aaa`

登录成功-ROLE_ADMIN
----------------
使用`root/root`用户登录之后,展示的是角色`ROLE_AMDIN`内容

登录成功-ROLE_USER
----------------
使用`admin/admin`用户登录之后,展示的是角色`ROLE_AMDIN`内容

注销
----------------
登录成功后点击注销

参考资料
==================
Spring Boot Reference Guide : [http://docs.spring.io/spring-boot/docs/current-SNAPSHOT/reference/htmlsingle/](http://docs.spring.io/spring-boot/docs/current-SNAPSHOT/reference/htmlsingle/)
《JavaEE开发的颠覆者 Spring Boot实战》 - 汪云飞
【Spring】关于Boot应用中集成Spring Security你必须了解的那些事 : [http://www.cnblogs.com/softidea/p/5991897.html](http://www.cnblogs.com/softidea/p/5991897.html)
在Spring Boot中使用Spring Security实现权限控制 : [http://blog.csdn.net/u012702547/article/details/54319508](http://blog.csdn.net/u012702547/article/details/54319508)
Test26-Security : [https://github.com/lenve/JavaEETest/tree/master/Test26-Security](https://github.com/lenve/JavaEETest/tree/master/Test26-Security) | 19,912 | Apache-2.0 |
# vue-mobile-calendar

[](https://nodei.co/npm/vue-mobile-calendar/)
> a vue component of calendar for mobile
> 移动端日期选择器(>=vue2.0)
[点击查看DEMO](https://lx544690189.github.io/vue-mobile-calendar/),或手机扫描下方二维码
<p>
<img src="https://github.com/lx544690189/vue-mobile-calendar/blob/master/screenshot/QRcode.png" width="200" float="left" style="border-radius: 6px" />
</p>
<p>
<img src="https://github.com/lx544690189/vue-mobile-calendar/blob/master/screenshot/single.png" width="200" float="left" style="border-radius: 6px" />
<img src="https://github.com/lx544690189/vue-mobile-calendar/blob/master/screenshot/multiple.png" width="200" float="left" style="border-radius: 6px" />
<img src="https://github.com/lx544690189/vue-mobile-calendar/blob/master/screenshot/single.png" width="200" float="left" style="border-radius: 6px" />
</p>
## 使用方法
### npm安装
```bash
npm install vue-mobile-calendar
```
```javascript
import Calendar from 'vue-mobile-calendar'
Vue.use(Calendar);
```
### 外部引用方式,引入目录文件`disk/Calendar.umd.min.js`
```javascript
<script src='/dist/Calendar.umd.min.js'></script>
```
### **注意**
**本次版本升级api与2.x版本不相同,2.x版本api[请点击查看](https://github.com/lx544690189/vue-mobile-calendar/blob/master/README-2.x.md)**
### 更新日志
- V3.2.1(2019-8-17)
- [ feat ] 新增日期中显示自定义内容`v-slot:day`,使用方法查看demo-9
- [ [PR](https://github.com/lx544690189/vue-mobile-calendar/pull/28) ] during 模式下,增加只能在当前展示的月份上进行选择的 prop
- [ [fix](https://github.com/lx544690189/vue-mobile-calendar/issues/25) ] changeDate 参数校验错误
- V3.2.0(2019-7-14)
- 新增`yearName`设置“年”的多语言;
- 新增`changeDate`方法,用于改变已选日期;
- 修复弹窗calendar未暴露组件的某些方法导致调用报错;
- 修复移动端滚动穿透问题;
- V3.1.1(2019-6-2) 新增minDate、maxDate设置最大、最小可选日期;新增changeDateView方法,用于重置置当前显示的日期
- V3.0.6(2019-3-26) [增加年月切换事件switch](https://github.com/lx544690189/vue-mobile-calendar/pull/11)
- V3.0.0(2019-3-16) 增加多选、时间段选择模式;增加日期内联显示方式;部分api与2.x不相同,升级请注意
### Quickstart
```javascript
<template>
<div id="demo">
<calendar @change="onChange"/>
<inlineCalendar />
</div>
</template>
<script>
// Vue.use(Calendar)后可直接使用`<calendar />`和`<inlineCalendar />`组件。calendar为底部弹窗显示,inlineCalendar为页面内联显示(可放置页面任意地方)
export default {
methods: {
onChange(date) {
console.log(date.format('YY-MM-DD'));
},
},
};
// 或者在.vue文件中单独引入注册
// import {calendar,inlineCalendar} from 'vue-mobile-calendar';
// export default {
// components: {
// calendar,
// },
// };
</script>
```
## 关于日期类型
组件中日期处理依赖[dayjs](https://github.com/iamkun/dayjs/blob/dev/docs/zh-cn/API-reference.md#api)(api和moment相同,大小仅2kb),如在设置`defaultDate`时,所支持类型如下:
> #### 当前时间
>
> 直接运行 `dayjs()`,得到包含当前时间和日期的 `Dayjs` 对象。
>
> ```js
> dayjs()
> ```
>
> ### 时间字符串
>
> 可以解析传入的一个标准的[ISO 8601](https://en.wikipedia.org/wiki/ISO_8601)时间字符串。
>
> ```js
> dayjs(String)
> dayjs('1995-12-25')
> ```
>
> ### Date 对象
>
> 可以解析传入的一个 Javascript Date 对象。
>
> ```js
> dayjs(Date)
> dayjs(new Date(2018, 8, 18))
> ```
>
> ### Unix 时间戳 (毫秒)
>
> 可以解析传入的一个 Unix 时间戳 (13 位数字)。
>
> ```js
> dayjs(Number)
> dayjs(1318781876406)
> ```
>
> ### Unix 时间戳 (秒)
>
> 可以解析传入的一个 Unix 时间戳 (10 位数字)。
>
> ```js
> dayjs.unix(Number)
> dayjs.unix(1318781876)
> ```
更多api查看[dayjs](https://github.com/iamkun/dayjs/blob/dev/docs/zh-cn/API-reference.md#api)
### 属性
名称 | 类型 | 默认值 | 说明
---|--- | --- | ---
`mode` | `String` | 'single' | 时间选择模式,`single`:单选模式;`multiple`:多选模式;`during`:时间段选择模式
`defaultDate` | `[Date, Number, Array, String]` | - | 默认已选时间,`mode`为单选模式时为`Dayjs`所支持的时间类型(见上面说明),如'1995-12-25';`mode`为多选模式为数组形式;`mode`为时间段选择模式为长度2的数组,如`[startDate,endDate]`
`disabledDate` | `Array` | [] | 不可选日期,仅`mode`为'single'和'multiple'下支持
`enableTouch` | `Boolean` | `true` | 允许手势滑动切换月份
`yearName` | `String` | `'年'` | “年”的文本
`monthNames` | `Array` | `['一月', '二月', '三月', '四月', '五月', '六月', '七月', '八月', '九月', '十月', '十一月', '十二月']` | 显示的月份文本
`weekNames` | `Array` | `['周一', '周二', '周三', '周四', '周五', '周六', '周日']` | 显示的星期文本
`show` | `Boolean` | `false` | 显示/关闭时间选择器弹窗(仅弹窗显示形式的calendar生效),可以使用sync修饰符`:show.sync="isShow"`来对此属性进行双向绑定,方便控制组件的显示隐藏
`closeByClickMask` | `Boolean` | `true` | 允许点击遮罩层关闭(仅弹窗显示形式的calendar生效)
`dayClick` | `Function` | - | 日期点击时的回调函数,回调参数为当前所点击的日期,`return false`将不会执行选中、取消选中的操作
`switch` | `Function` | - | 年月切换的回调,回调参数为当前显示的年月`{year,month}`
`minDate` | `[Date, Number, Array, String]` | - | (v-3.1.0新增)指定最小可选时间,为`Dayjs`所支持的类型数据,不能与`disabledDate`同时使用
`maxDate` | `[Date, Number, Array, String]` | - | (v-3.1.0新增)指定最大可选时间,为`Dayjs`所支持的类型数据,不能与`disabledDate`同时使用
### 事件
名称 | 说明 | 回调
---|--- | ---
change | 当前所选日期改变 | 回调参数为当前所选日期(dayjs类型,如获取时间字符串:`date.format('YYYY-MM-DD')`),`mode`为单选模式时为`date`;`mode`为多选模式为`[date1,date2]`;`mode`为时间段选择模式为`[startDate,endDate]`,当只选了开始时间时会为`[startDate]`
### 方法
名称 | 说明 | 默认值
---|--- | ---
changeDate | 通过`this.$refs.myCalendar.changeDateView(date)`改变当前已选日期,参数为`Dayjs`所支持的类型数据 | -
changeDateView | 通过`this.$refs.myCalendar.changeDateView(toDate)`改变当前显示的日期,如“回到今天” | `toDate`参数不传默认为当前日期
### slot
名称 | 说明 | 参数
---|--- | ---
date | 日期自定义内容 | 参数及使用见下说明
v-slot:day 使用:
```javascript
<template>
<inlineCalendar>
<!-- 自定义日期中内容 -->
<template v-slot:day="scope">
<!-- 如每月1号显示圆点 -->
<div v-if="scope.date.value === 1" class="point" />
</template>
</inlineCalendar>
</template>
<script>
// 可获取的scope对象如下
scope = {
date: {
value,//当前几号
dateTime,// 当前日期(dayjs类型)
isGrey,// 是否当前月的日期
isToday,// 是否今天
isSelect,// 是否被选中
isDisable,// 是否被禁止选择
isDuring,// 是否在已选日期段内
}
}
</script>
```
## Reference
- [framework7](https://github.com/nolimits4web/Framework7) | 5,685 | MIT |
# 编译 vs 链接
## 一、编译
编译又包含了:`预处理`、`编译`、`汇编`和`链接(二进制可重定位文件)`。
```mermaid
graph LR
A(hello.c) -- -E_预处理 -->B(hello.i)
B -- -S_编译 --> C[hello.s]
C -- -c_汇编 --> E[hello.o]
E -- 链接 --> F(可执行文件)
```
### 1. 预处理:
```sh
gcc -E hello.c -o hello.i
```
- 将所有的“#define”删除,并且展开所有的宏定义
- 处理所有的条件编译指令,比如`#if`、`#ifdef`、`#elif`、`#else`、`#endif`
- 处理`#include`预编译指令,将被包含的头文件插入到该编译指令的位置。(这个过程是递归进行的,因为被包含的文件可能还包含了其他文件)
- 删除所有的注释`//`和`/* */`。
- 添加行号和文件名标识,方便后边编译时编译器产生调试用的行号心意以及编译时产生编译错误或警告时能够显示行号。
- 保留所有的`#pragma`编译指令,因为编译器需要使用它们
### 2. 编译:
```sh
gcc -S hello.i -o hello.o
```
- 编译过程是整个程序构建的核心部分,编译成功,会将源代码由文本形式转换成机器语言,编译过程就是把预处理完的文件进行一系列词法分析、语法分析、语义分析以及优化后生成相应的汇编代码文件。
### 3. 链接:
```sh
gcc hello.o -o hello
```
## 二、xx
## 四、参考
1. [csdn - 编译和链接的过程](https://blog.csdn.net/guaiguaihenguai/article/details/81160310)
1. [csdn - 编译与链接详解](https://blog.csdn.net/Gamebot/article/details/78301714)
1. [简书 - 编译与链接过程的思考](https://www.jianshu.com/p/2310b61e687e) | 957 | MIT |
---
description: Microsoft Edge (Chromium) 扩展以及构建和发布浏览器扩展的概述。
title: Microsoft Edge (Chromium) 扩展
author: MSEdgeTeam
ms.author: msedgedevrel
ms.date: 05/28/2020
ms.topic: conceptual
ms.prod: microsoft-edge
keywords: 边缘、扩展开发、浏览器扩展、addons、合作伙伴中心、开发人员、chromium 扩展
ms.openlocfilehash: 85858fc7e1159db3175c3a67c3cfd5f6dfbb448f
ms.sourcegitcommit: 845a0d53a86bee3678f421adee26b3372cefce57
ms.translationtype: MT
ms.contentlocale: zh-CN
ms.lasthandoff: 10/08/2020
ms.locfileid: "11104698"
---
# Microsoft Edge (Chromium) 扩展
扩展是您 (开发人员的小程序 \ ) 可能会用来将新功能添加到 Microsoft Edge \ (Chromium \ ) 或修改现有功能。 扩展旨在通过提供对目标受众非常重要的小功能来改善用户的日常浏览体验。
如果你的想法或产品依赖于特定的 web 浏览器的可用性,或者补充你希望提供的功能扩展现有网站的浏览体验,则可以创建扩展。 附带体验的示例包括 adblockers 和密码管理器。
扩展的结构类似于常规 web 应用。 它至少包含应用清单 JSON 文件,该文件包含基本平台信息、用于定义功能的 JavaScript 文件以及 HTML 和 CSS 文件,以根据需要确定用户界面 \ (的外观 \ ) 。 若要直接处理部分浏览器(如窗口或选项卡),必须发送 API 请求,并且通常按名称引用浏览器。
:::image type="complex" source="./media/example-extension-screenshot.png" alt-text="Microsoft Edge (Chromium) 扩展":::
Microsoft Edge \ (Chromium \ ) 扩展名
:::image-end:::
## 基本指南
一些最热门的浏览器可用于包含 Safari、Firefox、Chrome、Opera、Brave 和 Microsoft Edge。 开始扩展开发教程和文档检索的好地方是由浏览器组织托管的网站。 下表不是明确的,请将其用作有用的起始点。
| Web 浏览器 | 基于 Chromium? | 扩展开发主页 |
|:--- |:--- |:--- |
| Safari | 否 | [developer.apple.com/documentation/safariservices/safari_app_extensions][AppleDeveloperSafariservicesAppExtensions] |
| Firefox | 否 | [developer.mozilla.org/docs/Mozilla/Add-ons/WebExtensions][MDNWebextensions] |
| 镶边 | 是 | [developer.chrome.com/extensions][ChromeDeveloperExtensions] |
| Opera | 是 | [dev.opera.com/extensions][OperaDevExtensions] |
| Brave | 是 | 使用 [Chrome Web Store][GoogleChromeWebstoreCategoryExtensions] |
| 新的 Microsoft Edge | 是 | [developer.microsoft.com/microsoft-edge/extensions][MicrosoftDeveloperEdgeExtensions] |
> [!IMPORTANT]
> 网站的许多教程都使用特定于浏览器的 Api,这些 Api 可能与你要开发的浏览器不匹配。 在大多数情况下,Chromium 扩展在不同的 Chromium 浏览器中工作,并且 Api 按预期工作。 只有一些较少的常见 Api 才能严格地特定于浏览器。 有关教程的链接,请参阅另 [请参阅](#see-also)。
## 为什么 Chromium?
如果你的目标是将扩展发布到尽可能多的浏览器扩展存储,则必须针对多个版本对其进行修改,以便在每个不同的浏览器环境中进行目标和运行。 与其他扩展类型不同, [Safari 扩展][AppleDeveloperSafariservicesAppExtensions]可以利用 web 和本机代码与对应的本机应用程序进行通信。 [Firefox 扩展][MDNWebextensions] 与其他扩展类型共享更多的内容,但也有一些 [差异][ExtensionworkshopPorting] 需要考虑。 但有一些好消息,上面的图表中的最后四个浏览器能够利用相同的代码程序包,并最大程度地减少更改和维护并行版本的要求。 这是因为浏览器基于 [Chromium 开放源代码项目][|::ref1::|Home]。
通过创建 Chromium 扩展,你可以写入最少的代码,以最大程度地增加目标扩展存储的数量,并且最终可以找到并获取你的扩展的用户数。
以下内容主要关注 Chromium 扩展。
## 浏览器兼容性和扩展测试
有时,Chromium 浏览器之间不存在 API 奇偶校验。 例如,标识和支付 Api 之间存在差异。 为确保您的扩展满足客户期望值,请通过官方浏览器文档(如 [Chrome api][ChromeDeveloperExtensionsApiIndex]、 [Opera 支持的扩展 Api][OperaDevExtensionsApis]和 [端口 CHROME (扩展][ExtensionsChromiumDeveloperGuidePortChrome])查看 API 状态,Chromium) Edge。
根据你所需的 Api,这些差异可能意味着你必须在每个应用商店的代码中创建稍有不同的代码包。
开发扩展时,在将扩展提交到浏览器存储之前,你可以在浏览器中旁加载,以在不同的环境中对其进行测试。
## 将扩展发布到浏览器存储
你可以在以下浏览器存储中提交和查找浏览器扩展。
* [Firefox 浏览器加载项][MozillaAddonsFirefoxExtensions]
* [Chrome Web Store][GoogleChromeWebstoreCategoryExtensions]
* [Opera addons][OperaAddonsExtensions]
* [Microsoft Edge 加载项][MicrosoftEdgeAddonsCategoryExtensions]
某些商店允许您从其他浏览器下载列出的扩展。 从另一个浏览器下载可能会将您 (开发人员 \ ) 的工作,如果用户能够导航到不同浏览器中的现有应用商店列表,则可以删除向其他商店提交的要求。 但是,浏览器存储不保证跨浏览器访问。 为了确保你的用户能够在不同的浏览器中找到你的扩展,你应该在每个浏览器扩展存储中维护一个列表。
扩展可能具有重叠的访问群体,这些受众经常使用多个浏览器,或者你可能会发现它应该面向的读者不是以前的浏览器。 若要实现此目的,现有的 Chromium 扩展可能会从一个浏览器迁移到另一个浏览器。
### 将现有扩展迁移到 Microsoft Edge
如果你已为另一个 Chromium 浏览器开发了扩展,并且想要提供它并确保它通过 Microsoft Edge 工作,则不必重写你的扩展。 只要你使用的 Api 在不同的浏览器上可用,或者存在提供所需功能的其他 Api,将现有的 Chromium 扩展迁移到其他 Chromium 浏览器就非常简单。
有关移植你的 Chrome 扩展的详细信息,请参阅 [向 Microsoft (Chromium) Edge 的端口 Chrome 扩展][ExtensionsChromiumDeveloperGuidePortChrome]。 将扩展移植到目标浏览器后,下一步是发布它。
### 发布到 Microsoft Edge 加载项网站
若要开始将扩展发布到 Microsoft Edge,您必须注册一个包含 MSA 电子邮件帐户的 [开发者帐户][MicrosoftDeveloperRegistration] \ ( @outlook .com、@live ) .com 等,以便在应用商店中提交您的扩展列表。 选择要注册的电子邮件地址时,请考虑是否必须与组织中的其他人一起转移或共享该扩展名的所有权。 注册完成后,您可以创建一个新的向应用商店提交的扩展。
若要将扩展提交到应用商店,必须满足以下要求。
* 存档 \ ( .zip \ ) 文件,其中包含你的代码文件。
* 所有所需的视觉资源,包括徽标和小型促销图块。
* 可选促销媒体,如屏幕截图、较大的促销图块、URL 或与您的分机的视频相结合的任意组合。
* 描述你的扩展的信息,如名称、简短说明、详细说明和指向隐私策略的链接。
> [!NOTE]
> 不同的存储可能具有不同的提交要求。 上面的列表总结了将扩展发布到 Microsoft Edge 的 [要求][ExtensionsChromiumPublish] 。
完成提交过程后,将审阅您的扩展,并通过或失败认证过程。 将通知所有者,并根据需要执行后续步骤。 如果你向应用商店提交更新的扩展名(包括对扩展列表详细信息的更新),则会启动新的审阅过程。
## 另请参阅
* [移植 Google Chrome 扩展][ExtensionworkshopPorting]
* [构建 Safari 应用扩展][AppleDeveloperSafariservicesAppExtensionsBuilding]
* [你的第一个扩展 (Firefox) ][MDNWebextensionsYourFirst]
* [入门教程 (Chrome) ][ChromeDeveloperExtensionsGetstarted]
* [ (Opera 入门) ][OperaDevExtensionsGettingStarted]
* [Microsoft Edge 入门 (Chromium) 扩展][ExtensionsChromiumGettingStartedIndex]
<!-- image links -->
<!-- links -->
[ExtensionsChromiumDeveloperGuidePortChrome]: ./developer-guide/port-chrome-extension.md "将端口 Chrome 扩展到 Microsoft (Chromium) Edge |Microsoft 文档"
[ExtensionsChromiumGettingStartedIndex]: ./getting-started/index.md "Microsoft Edge 入门 (Chromium) 扩展 |Microsoft 文档"
[ExtensionsChromiumPublish]: ./publish/publish-extension.md "发布扩展 |Microsoft 文档"
[MicrosoftDeveloperEdgeExtensions]: https://developer.microsoft.com/microsoft-edge/extensions "开发 Microsoft Edge 的扩展 |Microsoft 开发人员"
[MicrosoftDeveloperRegistration]: https://developer.microsoft.com/registration "合作伙伴中心 |Microsoft 开发人员"
[MicrosoftEdgeAddonsCategoryExtensions]: https://microsoftedge.microsoft.com/addons/category/Edge-Extensions "Microsoft Edge 的扩展 |Microsoft Edge"
[AppleDeveloperSafariservicesAppExtensions]: https://developer.apple.com/documentation/safariservices/safari_app_extensions "Safari 应用扩展 |Apple 开发人员"
[AppleDeveloperSafariservicesAppExtensionsBuilding]: https://developer.apple.com/documentation/safariservices/safari_app_extensions/building_a_safari_app_extension "构建 Safari 应用扩展 |Apple 开发人员"
[ChromeDeveloperExtensions]: https://developer.chrome.com/extensions "什么是扩展? |Chrome 开发人员"
[ChromeDeveloperExtensionsApiIndex]: https://developer.chrome.com/extensions/api_index "Chrome Api |Chrome 开发人员"
[ChromeDeveloperExtensionsGetstarted]: https://developer.chrome.com/extensions/getstarted "入门教程 |Chrome 开发人员"
[ChromiumHome]: https://www.chromium.org/Home "Chromium"
[ExtensionworkshopPorting]: https://extensionworkshop.com/documentation/develop/porting-a-google-chrome-extension "移植 Google Chrome 扩展 |延长研讨会"
[GoogleChromeWebstoreCategoryExtensions]: https://chrome.google.com/webstore/category/extensions "扩展名 |Chrome Web Store"
[MDNWebextensions]: https://developer.mozilla.org/docs/Mozilla/Add-ons/WebExtensions "浏览器扩展 |MDN"
[MDNWebextensionsYourFirst]: https://developer.mozilla.org/docs/Mozilla/Add-ons/WebExtensions/Your_first_WebExtension "您的第一个扩展 |MDN"
[MozillaAddonsFirefoxExtensions]: https://addons.mozilla.org/firefox/extensions "扩展名 |Firefox 的加载项"
[OperaAddonsExtensions]: https://addons.opera.com/extensions "扩展名 |Opera Addons"
[OperaDevExtensions]: https://dev.opera.com/extensions "扩展文档 |开发人员的 Opera"
[OperaDevExtensionsApis]: https://dev.opera.com/extensions/apis "Opera 中支持的扩展 Api |开发人员的 Opera"
[OperaDevExtensionsGettingStarted]: https://dev.opera.com/extensions/getting-started "入门 |开发人员的 Opera" | 7,441 | CC-BY-4.0 |
# SomeUIDemos
一些iOS小Demo,这里主要是UI层面的Demo,几个完整示例。基本基于 OC / Swift 双版本实现
当前 Swift 版本为 4.0 ,在我使用 Swift 4.0 写代码的时候依旧出现了很多不解之谜,浪费了很多时间也让我对 Swift 的体验印象很差!(当然有我自己的原因:对Swift 并不足够熟悉,对一些代码习惯不熟悉等) 不论如何我还是坚持写了几个小程序,并记录了下来我在使用 Swift 开发中遇到的“问题”,与有缘人共勉!
- **Swift 4.0 读取和解析 Plist 文件,读不到数据!同样的代码、逻辑正确,在 Swift 3.2 版本正常,4.0 版本读不到数据。太™坑了!**
``` Swift
fileprivate lazy var questions : [XYQuestion] = { [unowned self] in
/// Swift 4.0 打印读取到的数据为 nil
/// Swift 3.2 打印读取到的数据为 正常
var questions = [XYQuestion]()
let path : String = Bundle.main.path(forResource: "questions", ofType: "plist")!
let data = NSArray(contentsOfFile: path)!
for dict in data {
let question = XYQuestion(dict: dict as! [String : AnyObject])
questions.append(question)
}
return questions
}()
```
- **IB文件中使用AutoLayout创建的控件,在代码中修改frame无效.要么IB文件中取消使用AutoLayout,要么代码中使用AutoLayout修改Contraint**
``` objc
/// OC 中正确写法
[UIView animateWithDuration:0.25 animations:^{
//cover 透明度
self.cover.alpha = 0.7;
//icon大小修改
self.iconWidthCons.constant = ScreenW;
self.iconCenterYCons.constant = 0;
}];
```
``` Swift
/// 这个Swift动画很诡异---,如下方式能修改IB文件中通过AutoLayout创建的控件frame,也仅限于两个动画嵌套,OC中不行<Xcode 版本 9>
UIView.animate(withDuration: 0.1, animations: {
self.iconBtn.frame = self.defaultIconRect!
self.cover.alpha = 0.7
}) { (isComplete) in
UIView.animate(withDuration: 0.25, animations: {
self.iconBtn.frame = CGRect(x: 0, y: 0, width: self.view.bounds.size.width, height: self.view.bounds.size.width)
self.iconBtn.center = self.view.center
})
}
```
## 1. 超级猜图
一款看图猜文字的小游戏。
e.g:
<img src="images/superGuessPic.gif" width = "200" height = "355.7" alt="图片名称" align=center />
## 2. 通信录使用
一个简单的通信录应用,暂时荒废了
e.g:
<!-- // 注释一下,以后再补上
<img src="images/superGuessPic.gif" width = "200" height = "355.7" alt="图片名称" align=center />
-->
## 3. 时间选择控件
一个简单的时间选择控件,
应用场景之一:用户选择在网上预约商店的某项服务,选择时间
e.g:
<img src="images/timePicker.gif" width = "200" height = "355.7" alt="图片名称" align=center />
DEMO名称 | DEMO地址
------------ | -------------
超级猜图 | [超级猜图传送门](超级猜图)
通信录使用 | [通讯录传送门](通信录使用/README.md)
时间选择控件 | [时间选择传送门](时间选择) | 2,442 | MIT |
# PagingRecyclerView
[](https://jitpack.io/#dss886/PagingRecyclerView)
[For English Version, Click Me >>>](/README.md)
一个支持分页加载和错误重试的RecyclerView,提供可扩展的header和footer。



## 下载
在project的build.gradle中加入以下语句:
~~~
allprojects {
repositories {
jcenter()
maven { url "https://jitpack.io" }
}
}
~~~
在module的build.gradle中加入以下语句:
~~~
dependencies {
compile 'com.github.dss886:PagingRecyclerView:$(latest-version)'
}
~~~
## 使用方法
1\. 使用PagingRecyclerView替换原生的RecyclerView:
~~~xml
<com.dss886.pagingrecyclerview.PagingRecyclerView
android:id="@+id/recycler_view"
android:layout_width="match_parent"
android:layout_height="match_parent" />
~~~
2\. 添加OnPagingListener来设置分页加载时要执行的动作:
~~~java
recyclerView.setOnPagingListener(new PagingRecyclerView.OnPagingListener() {
@Override
public void onPaging(PagingRecyclerView view, int direction) {
if (direction == PagingRecyclerView.FOOT) {
// do your paging work
}
}
});
~~~
4\. 当加载完成或发生错误时更新header或footer的状态:
~~~java
recyclerView.onPaging(PagingRecyclerView.FOOT);
recyclerView.onFailure(PagingRecyclerView.FOOT);
recyclerView.onNoMoreData(PagingRecyclerView.FOOT);
~~~
## Header and Footer
默认情况下顶部的分页加载是关闭的,如果你希望启用它,使用:
~~~java
recyclerView.setPageEnable(boolean header, boolean footer);
~~~
如果想要自定义Header and Footer,继承PagingRecyclerView并覆写`createPagingViewHolder`方法:
~~~java
/**
* Override this method to custom your own paging item
*/
protected AbsPagingViewHolder createPagingViewHolder(LayoutInflater inflater, ViewGroup parent, int direction, PagingRecyclerView.OnPagingListener pagingListener) {
View view = inflater.inflate(R.layout.paging_recycler_view_default_item, parent, false);
return new DefaultPagingViewHolder(view, direction, this, pagingListener);
}
~~~
## 使用了自定义的LayoutManager
本项目支持三种默认的LayoutManager(Linear、Gird和Staggered)。但如果你使用了自定义的LayoutManager,默认的OnScrollListener就无法自动检测到是否滑到了顶部或底部,你需要自己实现OnScrollListener然后添加到PagingRecyclerView中。
更多信息请参考:[com/dss886/pagingrecyclerview/PagingScrollListener.java](https://github.com/dss886/PagingRecyclerView/blob/master/library/src/main/java/com/dss886/pagingrecyclerview/PagingScrollListener.java)
## 注意事项
1\. 因为PagingRecyclerView使用了一个装饰类来包装你的adapter,所以`adapter.notifyDataSetChanged()`可能会没有效果,需要用`PagingRecyclerView.notifyDataSetChanged()`方法来代替。
2\. 当顶部加载的item正在显示时,`ViewHolder.getAdapterPosition()`和`ViewHolder.getLayoutPosition()`的返回值是计算header了的,如果这不是你想要的,可以使用`PagingRecyclerView.getFixedPostion(int position)`来得到这个item在你的adatper中的真正位置。
## Thanks
1\. 本项目的基本思路源自于[nicolasjafelle的PagingListView](https://github.com/nicolasjafelle/PagingListView),但是遗憾的是作者不再进行维护了,也没有支持RecyclerView的打算,所以才有了这个项目。
2\. [cundong的HeaderAndFooterRecyclerView](https://github.com/cundong/HeaderAndFooterRecyclerView)在接口设计和实现上也给了本项目很大的灵感。
## License
~~~
Copyright 2018 dss886
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
~~~ | 3,473 | Apache-2.0 |
## 92. Reverse Linked List II
### Description
Reverse a linked list from position m to n. Do it in one-pass.
**Note**: 1 ≤ m ≤ n ≤ length of list.
**Example**:
```
Input: 1->2->3->4->5->NULL, m = 2, n = 4
Output: 1->4->3->2->5->NULL
```
反转从位置 m 到 n 的链表。请使用一趟扫描完成反转。
**说明**:1 ≤ m ≤ n ≤ 链表长度。
**示例**:
```
输入: 1->2->3->4->5->NULL, m = 2, n = 4
输出: 1->4->3->2->5->NULL
```
### Solution
和206没什么本质区别,参见
[206. Reverse Linked List【反转链表】](206.md)`Easy`
### Code
```
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* reverseBetween(ListNode* head, int m, int n) {
n -= m;
ListNode dummy(0);
dummy.next = head;
ListNode *p = &dummy;
while (--m) {
p = p->next;
}
ListNode *q = p->next;
while (n--) {
ListNode *temp = q->next;
q->next = q->next->next;
temp->next = p->next;
p->next = temp;
}
return dummy.next;
}
};
```
### Reference
- [Reverse Linked List II](https://leetcode.com/problems/reverse-linked-list-ii/description/)
- [反转链表 II](https://leetcode-cn.com/problems/reverse-linked-list-ii/description/) | 1,304 | MIT |
`````
物料平台
# 物料指南
快速了解 Arco 物料概念,创建你的第一个物料。
`````
[Arco 物料平台](https://arco.design/material) 服务于前端技术团队,致力于增强团队协作、促进资源共享、提升开发效率。我们基于来自 ArcoDesign 组件库的技术沉淀,提供了简单易学的物料开发方案。
## 何为物料
在中后台项目开发中,我们早已习惯了使用 UI 组件库提升开发效率。基础的 UI 组件库极大降低了界面开发成本,但此类组件通常都是一些与业务逻辑完全解耦的原子组件,不能完全满足复杂的业务场景。
实际项目中包含了大量的可以复用的业务逻辑强耦合的模块,例如站点导航条、员工选择器。如何在团队内部最大程度复用基础业务模块以提升效率、降低冗余?物料的概念就是为了解决这一问题,将基础业务模块从项目之中抽离,统一维护,它们便可以被称为「物料」。
## 物料分类
在 Arco 的物料体系中,我们将物料细分为了三个种类:组件、区块、页面。
### 组件
组件的概念与 Arco 提供的基础组件最为接近,它们是页面的基础元素构成,但是可能与业务逻辑产生了耦合。使用方式与组件库保持一致,通过引入 NPM 依赖来引用组件。
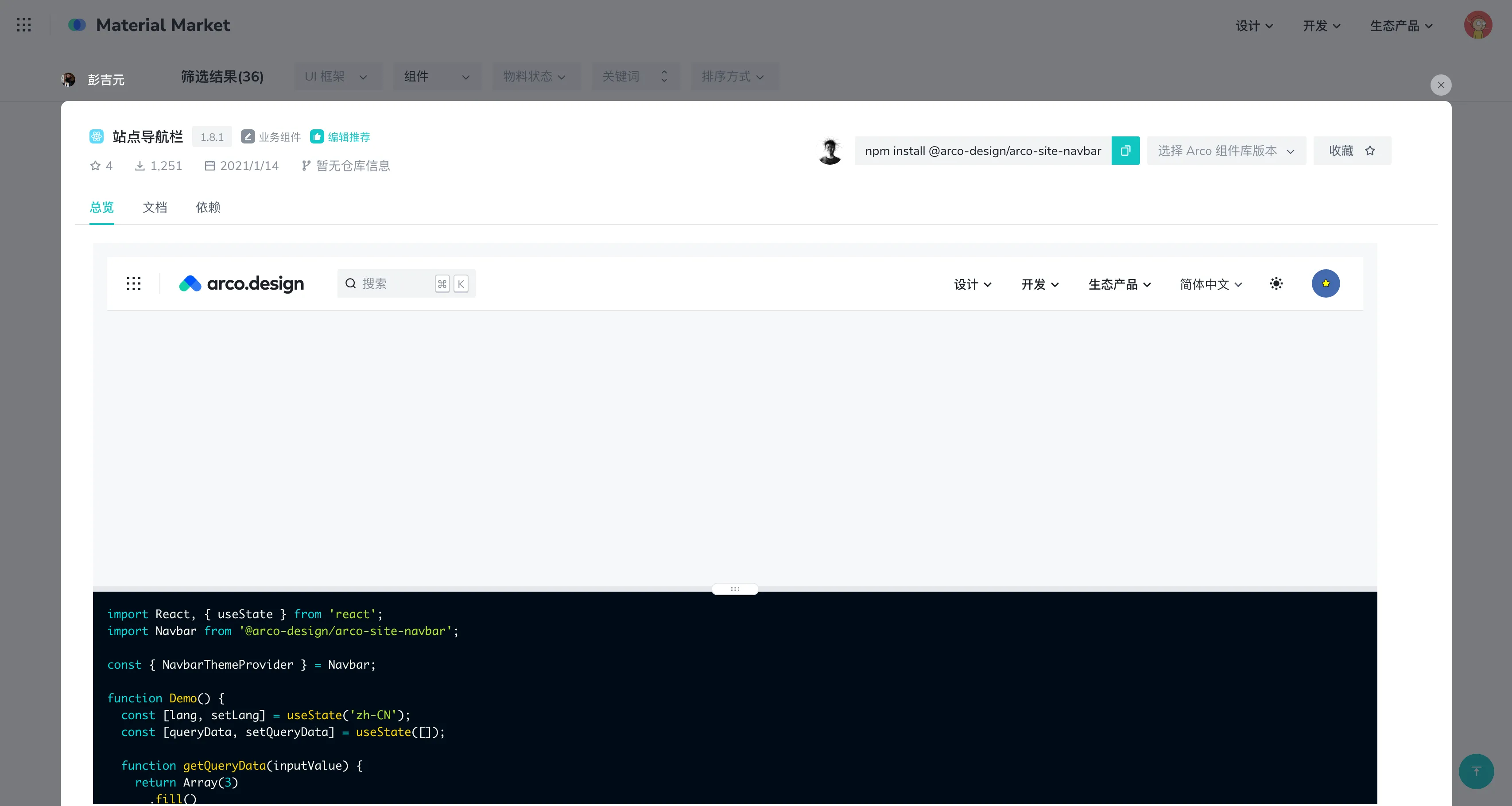
### 区块
区块相比组件更为复杂,可以理解为多个组件的集合。一个页面通常由若干个区块组成,开发者可以将区块添加到自己的页面进行二次开发。由于区块的复杂性和二次开发的需求存在,区块使用方式与组件不同,本质上是将区块的源码直接下载到本地项目之中。
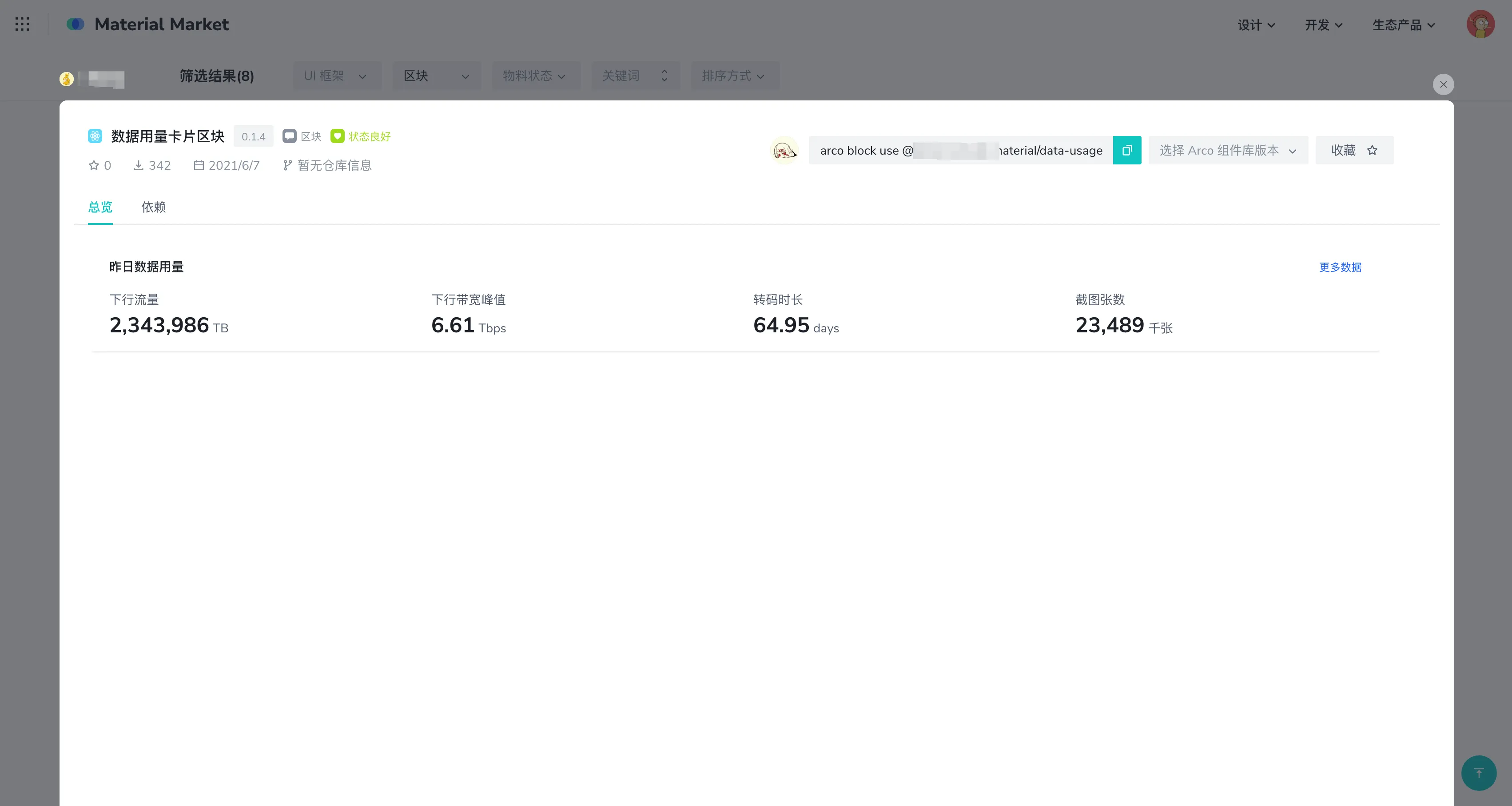
### 页面
页面即其字面意思,使用方式与区块类似。典型的例子为 [ArcoDesign Pro](https://arco.design/pro/) 所提供的页面。
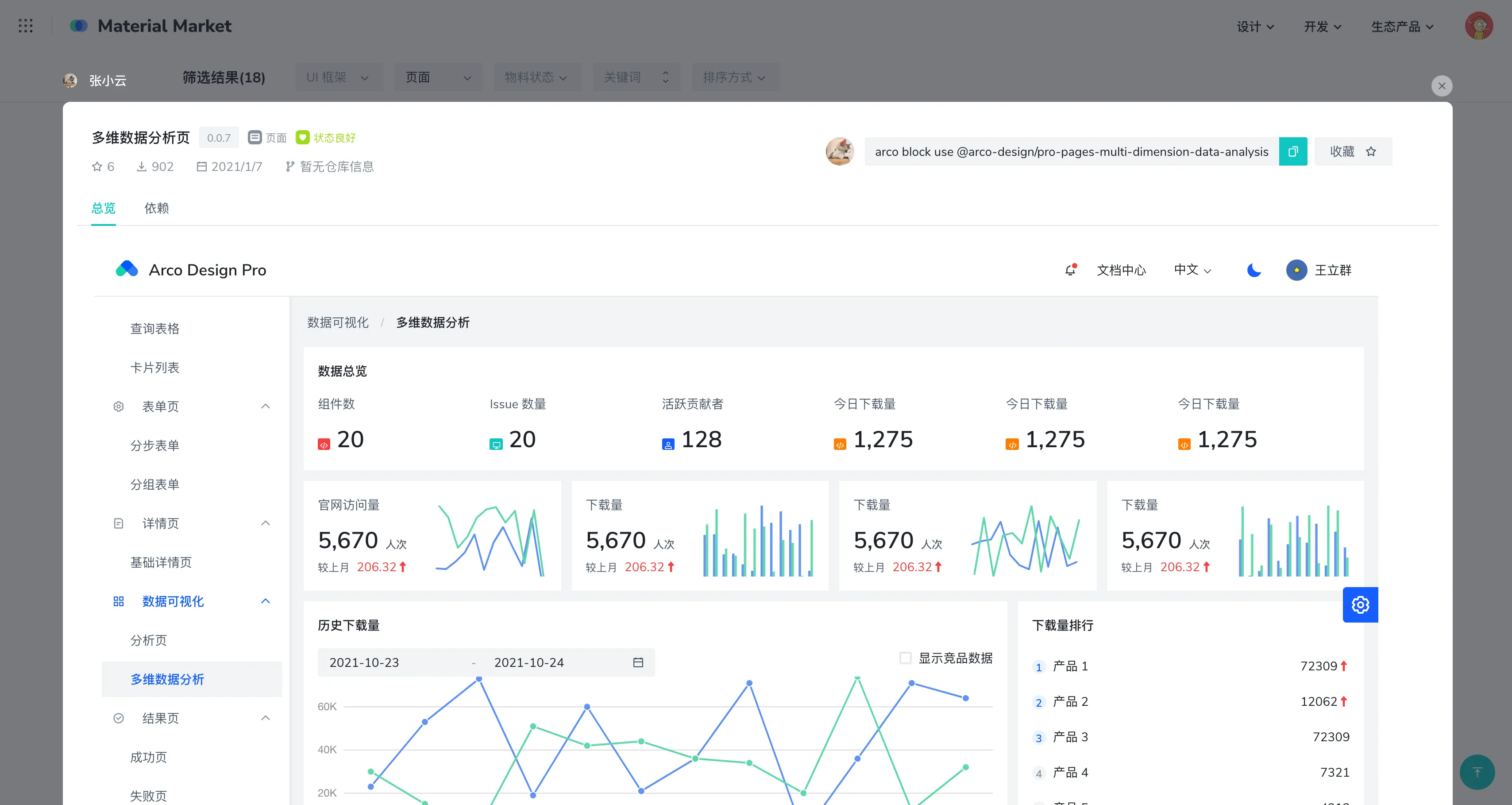
## Arco CLI
为了方便开发者快速搭建物料项目、管理使用物料。Arco 提供了基于 Node 的脚手架工具 arco-cli,它大致包含了以下的功能:
- 根据模板创建基于 ArcoDesign 的物料项目;
- 发布、管理、使用物料;
- 在项目中使用物料区块或者页面;
在开始进一步的流程体验之前,你需要通过 ` npm i arco-cli -g` 全局安装 Arco CLI。
## 新建项目
通过 Arco CLI,我们可以快速新建一个基于 ArcoDesign 的物料项目。使用 `arco init yourProjectName` 初始化项目:
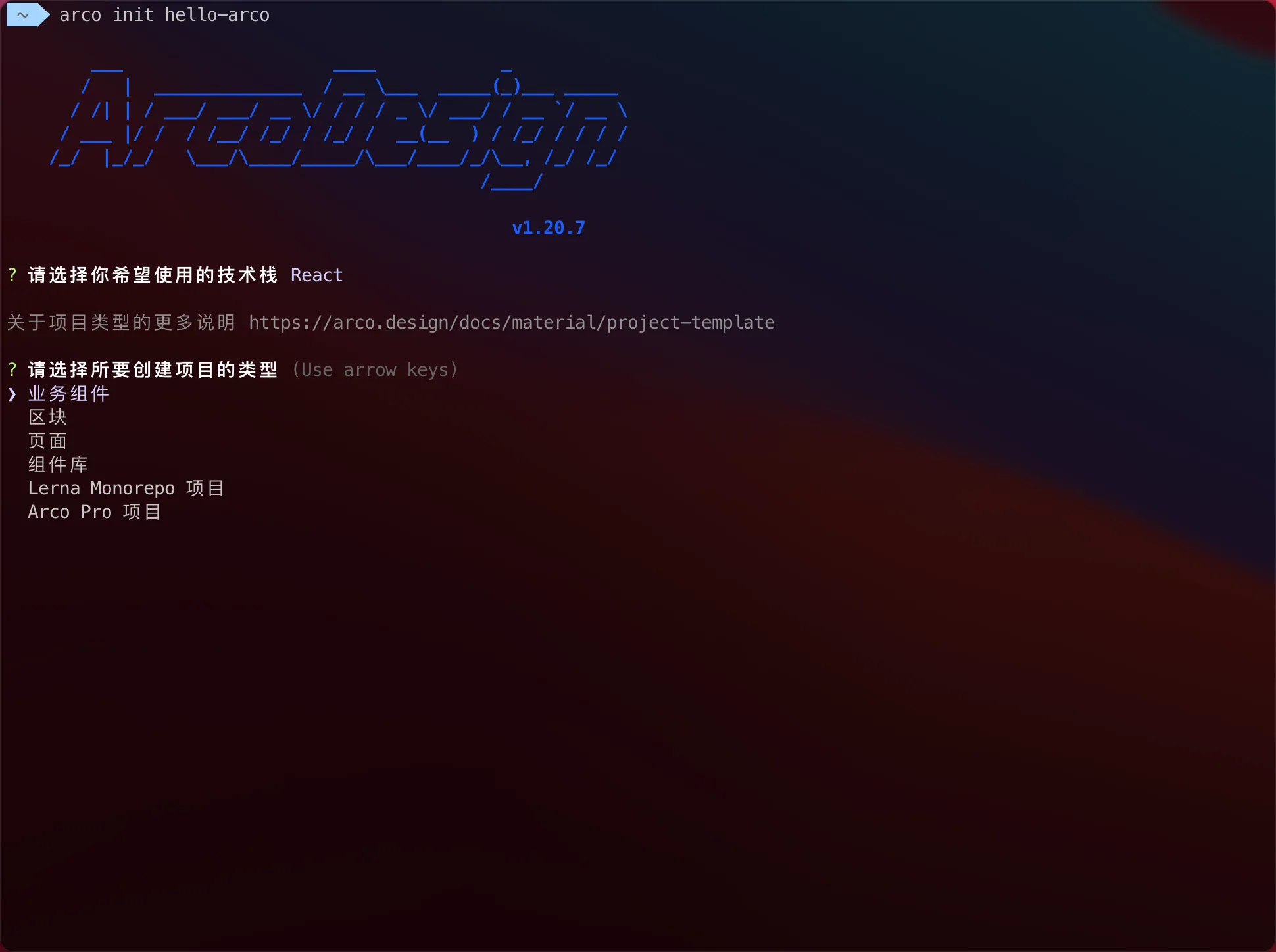
执行命令之后,我们需要选择所需创建的项目类型。我们前边介绍了物料分为「组件、区块、页面」三个类型,但 CLI 界面包含了 6 个选项,他们的具体含义如下:
- 组件:创建一个「组件物料」的「基础」项目;
- 区块:创建一个「区块物料」的「基础」项目;
- 页面:创建一个「页面物料」的「基础」项目;
- 组件库:创建一个「组件物料」的「library 库」项目;
- Lerna Monorepo:创建一个「组件物料」的基于 Lerna 管理的「monorepo 库」项目;
- ArcoDesign Pro 项目:创建一个基于 ArcoDesign Pro 的前端工程项目。
上述项目类型之间主要是物料组织形式的不同:
- 「基础」项目表示该项目包含一个 NPM 包,并且仅包含一个物料;
- 「library 库」项目表示该项目包含一个 NPM 包,但是包含了多个物料;
- 「monorepo 库」项目表示该项目包含多个 NPM 包,每个 NPM 包包含一个物料。
关于项目类型的选择,我们有以下的建议:
- 实际开发中请尽量避免使用「基础」项目,每个物料对应一个项目的组织形式将为后续的维护带来极大的不便;
- 物料仅供团队内部业务使用,优先选择「library 库」类型的项目,通过在项目中引入单个 NPM 包即可使用团队的所有物料;
- 物料提供给所有的团队使用,优先选择「monorepo 库」类型的项目,每个物料为单独的 NPM 包方便用户引入,多个 NPM 包由 Lerna 统一管理降低了开发者的维护成本。
这里我们选择「Lerna Monorepo」类型创建一个项目,等待项目初始化完成。
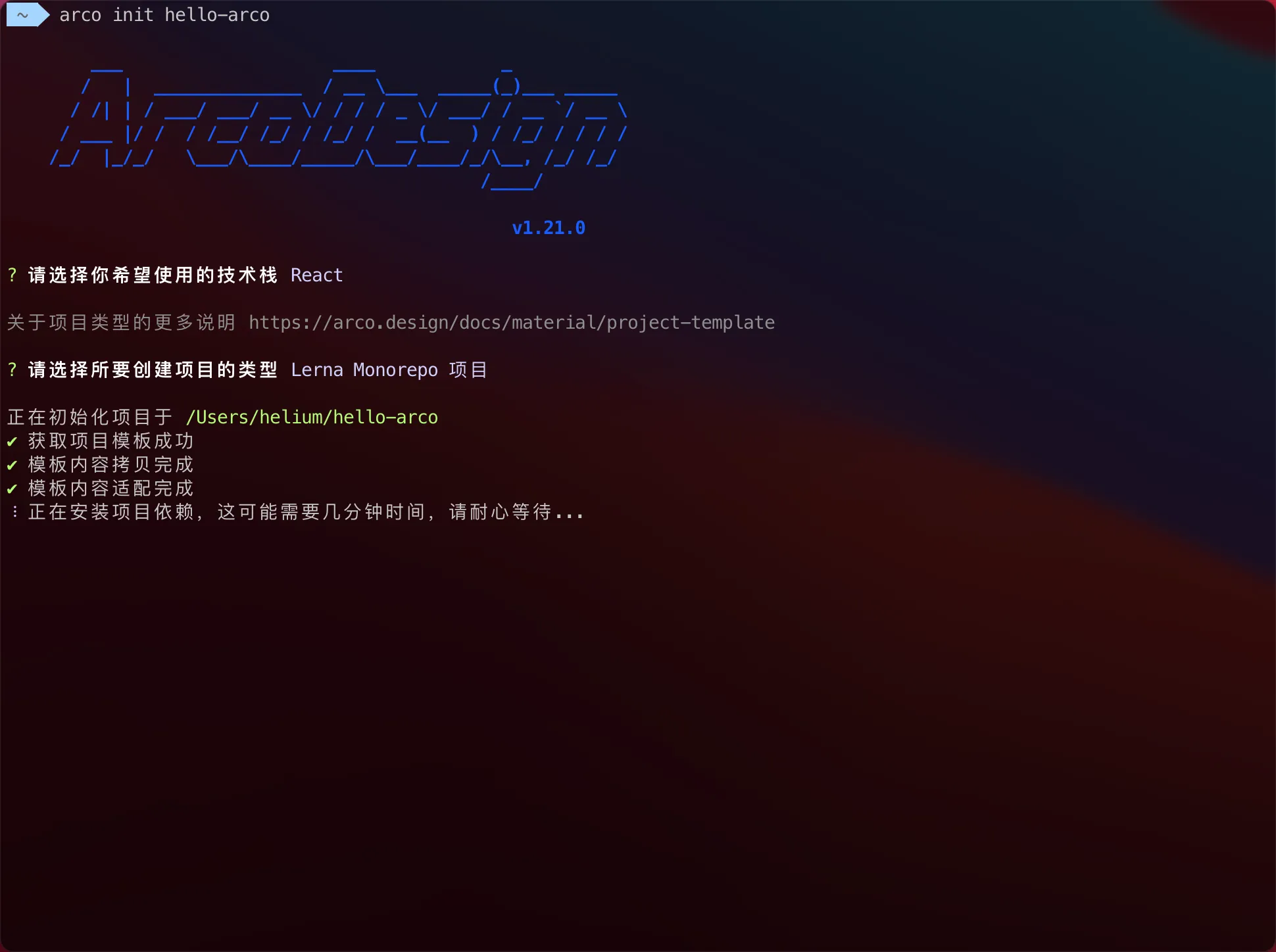
## 添加物料
依据 Arco CLI 的指引,运行 `yarn add:package myFirstMaterial` 添加我们的第一个物料,这里需要回答几个关于物料信息的问题。
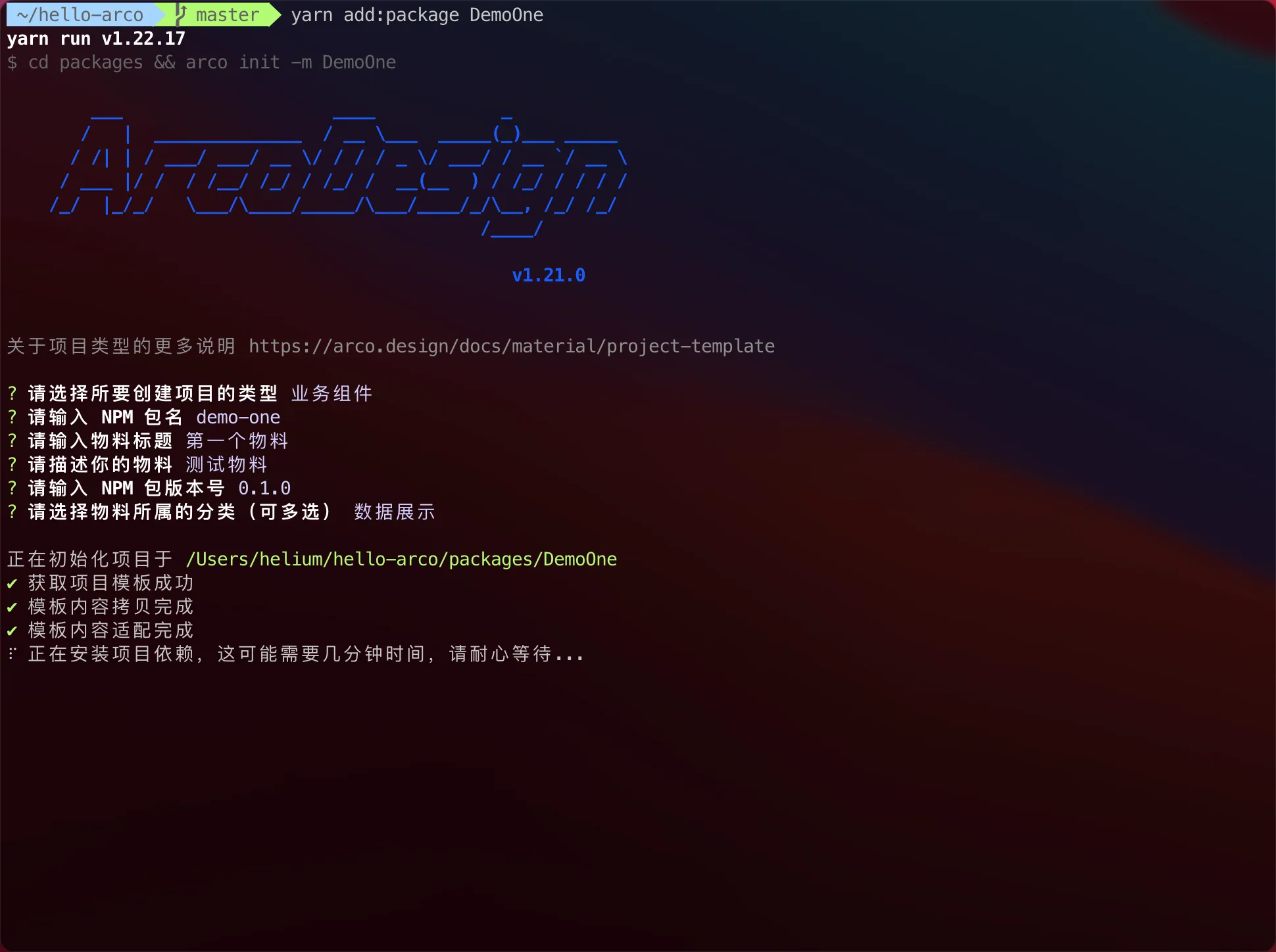
## 开发物料
依据 Arco CLI 的指引,运行 `yarn dev` 来开发预览物料。
### 代码开发
所有的物料项目都默认采用了 TypeScript 进行开发,在物料开发中我们建议遵循以下约束:
- 提供详细的 API 说明;
- 遵循 [semver](https://semver.org/lang/zh-CN/) 版本规范,避免主版本内的破坏式更新;
- 面向所有用户的物料尽量避免与业务逻辑耦合,避免接口调用;
- 尽量避免使用 CSS Modules。如果无法确定用户的技术选型,请保证你开发的物料不会导致意料之外的开发环境错误;
- 编写测试用例。项目内置了 Jest 单元测试,通过编写单元测试来提升物料的健壮性。
- 尽量使用 Arco 提供的 CSS 变量来定义颜色,可以让你的物料无缝支持 [暗色模式](https://arco.design/react/docs/dark)。
### Demo书写
请为你的物料提供尽可能详细的用法示例。
Demo 的书写位置位于 `/src/demo` 目录下,每个示例应对应一个单独的文件。在书写示例时,你需要注意以下事项:
- 在 `/src/demo/index.js` 中声明并导出 Demo,只有在这里声明并导出才可以在 Storybook 中预览到新添加的 Demo;
- 在 `/src/demo/index.js` 中添加组件和 Demo 的描述,这些描述将在构建时被提取,用于在物料平台的展示;
- Demo 默认不支持引用除 React 和 Arco 组件库相关的其他依赖包,如需引入请参考 [Demo 依赖](/docs/material/build#demo-依赖)。
```javascript
/**
* @file
* @name CloudIcon
* @memberOf 通用
* @description 字节云图标
*/
/**
* @name 基本应用
* @description `CloudIcon` 示例
*/
export { default as Basic } from './basic';
/**
* @name 所有的Icon
* @description `CloudIcon` 所包含的所有图标
*/
export { default as AllIcon } from './icon';
```
### 文档生成
物料文档包含了两个方面:组件 Props 参数和示例代码。物料的 `/src` 目录结构如下:
```
─ /src
├── __test__
├── TEMPLATE.md
├── demo
│ └── basic.jsx
├── index.tsx
└── style
```
你需要关注的有 `TEMPLATE.md` 和 `demo`,在使用 TypeScript 的项目中,arco-scripts 可以通过提取注释内容来快速生成组件接口文档。`TEMPLATE.md` 为文档生成的模板。其内容如下:
```
---
file: index
---
# TooltipButton
## 属性/Props
%%Props%%
## Demos
%%Demos%%
```
其中 `%%Props%%` 会在 `docgen` 命令之后组件的 `Props` 参数填充,`%%Demos%%` 会被 `/src/demo` 中的 Demo 代码填充。
```markdown
# TooltipButton
## 属性/Props
### `<TooltipButton>`
| 参数名 | 描述 | 类型 | 默认值 |
| ------ | :--------: | :---------: | -----: |
| title | 按钮的提示 | `ReactNode` | `-` |
## Demos
~~~jsx
import React from 'react';
import TooltipButton from '@arco-design/rc-xxx';
/**
* 基本用法
*/
export default () => {
return <TooltipButton title="tooltip title">Demo Basic</TooltipButton>;
};
~~~
```
在 Arco 官方物料模板所创建的项目中,你不必费心地去处理文档生成,我们会在 `npm publish` 之前生成一份最新的文档并将其上传至 NPM。
### 区块和页面
区块和页面的开发与组件略有不同,如果你不需要开发区块或者页面,可以暂时跳过此部分。
以区块项目为例,其 `/src` 的文件结构如下:
```
src
├── README.md
├── __test__
│ ├── __snapshots__
│ │ └── demo.test.tsx.snap
│ └── index.test.tsx
├── demo
│ ├── basic.jsx
│ └── index.js
├── index.tsx
└── lib
├── index.tsx
└── style
└── index.less
```
与组件相比,你需要注意以下几点不同:
- 在 `/src/lib` 下开发你的区块(页面为 `/src/page`),此目录将在用户使用此区块时被拷贝用户的项目中;
- 无需为区块、页面书写 Demo,仅关注其本身的开发即可,物料平台会默认展示 `/src/index` 所暴露出来的模块;
如果你需要自行书写物料平台所展示的区块预览,参考以下步骤:
- 修改区块 package.json 中的 `docgen` 命令为 `arco-scripts docgen`;
- 确保 arco-scripts >= 1.20.4;
- 确保 `/.config/docgen.config.js` 中配置了 `config.template = 'README.md'`;
- 为 `/src/README.md` 添加以下内容:
```markdown
## Demos
%%Demos%%
```
- 为物料书写 Demo;
- 本地开发完成后可以通过 `yarn prepublishOnly && arco preview` 来区块在预览物料平台的实际展示效果。
## 预览物料
为了保证所开发的物料在物料平台能够被正常预览,我们提供了 `arco preview` 命令来预览本地物料。在预览之前,保证物料已经被构建和生成文档,你可以通过以下命令快速实现:
```bash
# 构建以及生成文档
yarn prepublishOnly
# 如果未生成过物料信息,生成物料信息
yarn generate
# 预览物料
arco preview
```
## 发布物料
在确保物料功能正常、API 文档完整、物料平台预览正常之后,就可以发布我们的物料了。在 Lerna 项目中,可以通过 `lerna publish` 命令发布 NPM 版本。
NPM 发布完毕之后,我们需要将物料信息同步至物料平台。如果你是某一团队的成员,需要将项目中的所有物料发布在团队下,可以修改 项目根目录的 `arco.config.js` 中的默认 `group` 字段为你的团队 ID。这样,所有新物料在发布时都会默认发布到你的团队之下。
```javascript
module.exports = {
// globs to your packages
// e.g. [ 'packages/*' ]
packages: ['packages/*'],
// command you want to replace 'arco subCommand'
// e.g. publish: 'lerna publish'
alias: {
publish: 'lerna publish',
},
// initial meta for 'arco generate'
initialMeta: {
// 修改此处为你的团队 ID
group: 1,
},
// path of arco block insertion, relative to /src ('myPath' will be resolved as '/src/myPath')
// pathBlockInsert: 'pathRelativeToSrc',
};
```
通过以下命令,同步物料信息:
```bash
# 同步当前目录下的物料信息
arco sync --from-current-package
# 或者
yarn sync
# 同步当前项目下的所有物料信息
arco sync
```
至此,我们已经完成了一个物料的开发、发布流程。
## 团队站点
团队站点是一个更为集中的团队物料展示方案,它的形式基于 Arco 官方组件文档页面。创建团队站点之前,你需要至 [此页面](https://arco.design/material/createGroup/) 申请创建自己的物料团队。
关于团队站点的配置和使用方法,请移步 [团队站点](/docs/material/team-site) 。 | 6,849 | MIT |
# 第1章创建项目并集成LeanCloud SDK #
## 注册LeanCloud并创建项目 ##
- 访问[https://leancloud.cn/](https://leancloud.cn/) 并注册账号
- 登陆并进入控制台,选择【中国华东节点】节点,我的机器其他节点测试连接失败:

- 创建新应用【Instagram】

- 输入新应用名称

- 创建成功后显示应用列表

- 查看应用Key

## 新建 Instagram 项目
- 新建项目

- 项目信息

- 项目文件结构

## 将LeanCloud SDK 集成到 iOS 项目中
### 关闭项目
- 在工程文件夹下新增 Podfile内容如下
```
platform :ios, '12.1'
use_frameworks!
target 'Instagram' do
pod 'LeanCloud'
end
```
- 在终端中执行安装命令
```
pod install
```
- 安装结果
完成后会新建两个文件“Instagram.xcworkspace”和“Podfile.lock”,同时新建一个文件夹Pods,如图所示:

### 重新打开项目
- 点击“Instagram.xcworkspace”文件,打开项目

### 修改源代码
- 修改 AppDelegate.swfit 的 func application(_ application: UIApplication, didFinishLaunchingWithOptions launchOptions: [UIApplication.LaunchOptionsKey: Any]?) -> Bool 方法
```swift
func application(_ application: UIApplication, didFinishLaunchingWithOptions
launchOptions: [UIApplication.LaunchOptionsKey: Any]?) -> Bool {
// Override point for customization after application launch.
LeanCloud.initialize(applicationID: "Your App ID", applicationKey: "Your App Key")
/* Create an object. */
let object = LCObject(className: "Post")
object.set("words", value: "Hello World!")
/* Save the object to LeanCloud application. */
object.save { result in
switch result {
case .success: print("Success")
case .failure: print("Failure")
}
}
return true
}
```
- 运行结果

- 数据成功写入LeanCloud
 | 2,886 | MIT |
# es5-polyfill-ie78-jq
基于jq的,在ie7/8浏览器环境下,实现的es5方法垫片语法糖
## 项目缘由
由于公司的项目,还是要求兼容IE7/8,并且在项目中已经引入了jquery1.x版本,但是并没有引入es5-shim一类的es5兼容库(理由是es5-shim 库太大?)
所以,在完成公司任务的时候,不能愉快的使用es5的Array的相关方法,非常不爽,即使jq也提供了$.each,$.map一类的方法,我还是想要使用原生方法。
在考虑到体积一类的问题,最终决定,依赖jq这个库,自己动手写个语法糖,比如
```js
if (!Array.prototype.map) {
Array.prototype.map = function(callback, thisArg) {
var that = this;
return $.map(this, function(value, index) {
return callback.call(thisArg, value, index, that);
});
};
}
```
## 支持的API
+ Array
- Array.isArray
- Array.prototype.forEach
- Array.prototype.every
- Array.prototype.filter
- Array.prototype.indexOf
- Array.prototype.map
- Array.prototype.some
+ String
- String.prototype.trim
+ Date
- Date.now
+ Object
- Object.keys
## 引入的方法
```html
<head>
<script src="../lib/jquery.min.js"></script>
<!--[if lte IE 8]>
<script src="../dist/es5-polyfill-ie78-jq.min.js"></script>
<![endif]-->
</head>
<body>
</body>
```
> 请先引入`jquery`
## 注意
- 本兼容方案,是以在IE7/8环境中正常可用为标准,不关心是否和ES5完全一致,比如错误提示一致。
- 本兼容方案出于体积考虑,只放入常用方法。
- 本兼容方案依赖jq,请先引入jq,在引入本js。
- 如无特殊要求,建议引入`es5-shim`的兼容方案。
- 再次重申,本兼容方案,只适合于使用了jq,并且要兼容IE7/8时,可使用ES5的部分方法。
## 其它
github由于众所周知原因,特别慢,推荐使用 github.com.cnpmjs.org 代替github,比如本项目,原本
`https://github.com/fan19900404/es5-polyfill-ie78-jq` 改为 `https://github.com.cnpmjs.org/fan19900404/es5-polyfill-ie78-jq` | 1,386 | MIT |
<properties
pageTitle="ハイブリッド接続を使用して .NET バックエンド モバイル サービスからオンプレミスの SQL Server に接続する | Azure Mobile Services"
description="Azure ハイブリッド接続を使用して .NET バックエンド モバイル サービスからオンプレミスの SQL Server に接続する方法について説明します。"
services="mobile-services"
documentationCenter=""
authors="ggailey777"
manager="dwrede"
editor=""/>
<tags
ms.service="mobile-services"
ms.workload="mobile"
ms.tgt_pltfrm="na"
ms.devlang="multiple"
ms.topic="article"
ms.date="03/05/2016"
ms.author="glenga"/>
# ハイブリッド接続を使用して Azure Mobile Services からオンプレミスの SQL Server に接続する
[AZURE.INCLUDE [mobile-service-note-mobile-apps](../../includes/mobile-services-note-mobile-apps.md)]
> このトピックの Mobile Apps バージョンについては、「[Access on-premises resources using hybrid connections in Azure App Service (Azure App Service のハイブリッド接続を使用してオンプレミスのリソースにアクセスする)](../app-service-web/web-sites-hybrid-connection-get-started.md)」を参照してください。
企業がクラウドに移行するときに、すべての資産を Azure にすぐに移行できない場合があります。ハイブリッド接続を使用すると、Azure Mobile Services からオンプレミスの資産に安全に接続できます。この方法で、モバイル クライアントが Azure を使用することによってオンプレミスのデータにアクセスできるようにします。サポートされている資産には、Microsoft SQL Server、MySQL、HTTP Web APIs、およびほとんどのカスタム Web サービスなど、静的 TCP ポートで実行されるすべてのリソースが含まれます。ハイブリッド接続では、Shared Access Signature (SAS) 認証を使用して、モバイル サービスとオンプレミスの Hybrid Connection Manager からハイブリッド接続への接続を保護します。詳細については、[ハイブリッド接続の概要](../biztalk-services/integration-hybrid-connection-overview.md)を参照してください。
このチュートリアルでは、サービスでプロビジョニングされた既定の Azure SQL Database の代わりに、ローカルのオンプレミスの SQL Server データベースを使用するように .NET バックエンド モバイル サービスを変更する方法について説明します。ハイブリッド接続は JavaScript バックエンド モバイル サービスでもサポートされており、[この記事](http://blogs.msdn.com/b/azuremobile/archive/2014/05/12/connecting-to-an-external-database-with-node-js-backend-in-azure-mobile-services.aspx)でも説明されています。
##前提条件##
このチュートリアルを完了するには、次のものが必要です。
- **既存の .NET バックエンド モバイル サービス** <br/>[Mobile Services の使用]チュートリアルに従がって、新しい .NET バックエンド モバイル サービスを [Azure クラシック ポータル]から作成およびダウンロードします。
[AZURE.INCLUDE [hybrid-connections-prerequisites](../../includes/hybrid-connections-prerequisites.md)]
## SQL Server Express をインストールし、TCP/IP を有効にして、オンプレミスの SQL Server データベースを作成する
[AZURE.INCLUDE [hybrid-connections-create-on-premises-database](../../includes/hybrid-connections-create-on-premises-database.md)]
## ハイブリッド接続を作成する
[AZURE.INCLUDE [hybrid-connections-create-new](../../includes/hybrid-connections-create-new.md)]
## オンプレミスのハイブリッド接続マネージャーをインストールして接続を完了する
[AZURE.INCLUDE [hybrid-connections-install-connection-manager](../../includes/hybrid-connections-install-connection-manager.md)]
## SQL Server データベースに接続するモバイル サービス プロジェクトを構成する
このステップでは、オンプレミスのデータベースに接続するための接続文字列を定義し、この接続が使用されるようにモバイル サービスを変更します。
1. Visual Studio 2013 で、.NET バックエンドのモバイル サービスを定義するプロジェクトを開きます。
.NET バックエンド プロジェクトのダウンロード方法については、[Mobile Services の使用](mobile-services-dotnet-backend-windows-store-dotnet-get-started.md)を参照してください。
2. ソリューション エクスプローラーで、Web.config ファイルを開き、 **connectionStrings** セクションを探し、次のような新しい SqlClient エントリを追加します。このエントリはオンプレミスの SQL Server データベースを指しています。
<add name="OnPremisesDBConnection"
connectionString="Data Source=OnPremisesServer,1433;
Initial Catalog=OnPremisesDB;
User ID=HybridConnectionLogin;
Password=<**secure_password**>;
MultipleActiveResultSets=True"
providerName="System.Data.SqlClient" />
この文字列内の `<**secure_password**>` は、*HbyridConnectionLogin* 用に作成したパスワードに置き換えてください。
3. Visual Studio で **[保存]** をクリックして、Web.config ファイルを保存します。
> [AZURE.NOTE]この接続設定は、ローカル コンピューターで実行されるときに使用されます。Azure で実行される場合、この設定は、ポータルで定義された接続設定によってオーバーライドされます。
4. **Models** フォルダーを展開し、*Context.cs* で終わるデータ モデル ファイルを開きます。
6. **DbContext** を、値 `OnPremisesDBConnection` をベース **DbContext** コンストラクターに渡すように変更します。次のスニペットに似ています。
public class hybridService1Context : DbContext
{
public hybridService1Context()
: base("OnPremisesDBConnection")
{
}
}
これで、サービスは、SQL Server データベースへの新しい接続を使用するようになります。
##データベース接続をローカルでテストする
ハイブリッド接続を Azure に発行して使用する前に、ローカルで実行したときにデータベース接続が機能するかどうかを確認することをお勧めします。これによって、接続に関する問題を簡単に診断して修正した後、ハイブリッド接続を再発行して使用を開始できます。
[AZURE.INCLUDE [mobile-services-dotnet-backend-test-local-service-api-documentation](../../includes/mobile-services-dotnet-backend-test-local-service-api-documentation.md)]
## オンプレミスの接続文字列を使用するように Azure を更新する
データベース接続の確認が終わったら、この新しい接続文字列が Azure から使用できるようにアプリ設定を追加して、モバイル サービスを Azure に発行する必要があります。
1. [Azure クラシック ポータル]で、モバイル サービスを参照します。
1. [**構成**] タブをクリックして、[**接続文字列**] セクションを参照します。

2. `OnPremisesDBConnection` という名前の新しい接続 **SQL Server** 文字列に次のように値を入力して追加します。
Server=OnPremisesServer,1433;Database=OnPremisesDB;User ID=HybridConnectionsLogin;Password=<**secure_password**>
`<**secure_password**>` を *HybridConnectionLogin* のセキュリティ保護されたパスワードで置き換えます。
2. [**保存**] をクリックして、今作成したハイブリッド接続と接続文字列を保存します。
3. Visual Studio を使用して、更新済みのモバイル サービス プロジェクトを Azure に発行します。
サービスのスタート ページが表示されます。
4. これまでのようにスタート ページの [**今すぐ試す**] ボタン、またはモバイル サービスに接続されたクライアント アプリのいずれかを使用して、データベースの変更を生成するいくつかの操作を呼び出します。
>[AZURE.NOTE] [**今すぐ試す**] ボタンを使用して API のヘルプ ページを起動する場合は、アプリケーション キーをパスワードとして指定します (ユーザー名は空白にします)。
4. SQL Server Management Studio で、SQL Server インスタンスに接続し、オブジェクト エクスプローラーを開き、**OnPremisesDB** データベースを展開し、**[テーブル]** を展開します。
5. **hybridService1.TodoItems** テーブルを右クリックし、[**先頭の 1000 行を選択**] をクリックすると、結果が表示されます。
アプリで発生した変更が、モバイル サービスによって、ハイブリッド接続を介してオンプレミスのデータベースに保存されたことに注意してください。
##関連項目##
+ [ハイブリッド接続の Web サイト](https://azure.microsoft.com/services/biztalk-services/)
+ [ハイブリッド接続の概要](../biztalk-services/integration-hybrid-connection-overview.md)
+ [BizTalk Services: [ダッシュボード]、[監視]、[スケール]、[構成]、および [ハイブリッド接続] タブ](../biztalk-services/biztalk-dashboard-monitor-scale-tabs.md)
+ [データ モデルの変更を .NET バックエンド モバイル サービスに加える方法](mobile-services-dotnet-backend-how-to-use-code-first-migrations.md)
<!-- IMAGES -->
<!-- Links -->
[Azure クラシック ポータル]: http://manage.windowsazure.com
[Mobile Services の使用]: mobile-services-dotnet-backend-windows-store-dotnet-get-started.md
<!---HONumber=AcomDC_0504_2016--> | 6,073 | CC-BY-3.0 |
# egg-mongolass
[![NPM version][npm-image]][npm-url]
[![build status][travis-image]][travis-url]
[![Test coverage][codecov-image]][codecov-url]
[![David deps][david-image]][david-url]
[![Known Vulnerabilities][snyk-image]][snyk-url]
[![npm download][download-image]][download-url]
[npm-image]: https://img.shields.io/npm/v/egg-mongolass.svg?style=flat-square
[npm-url]: https://npmjs.org/package/egg-mongolass
[travis-image]: https://img.shields.io/travis/Sunshine168/egg-mongolass.svg?style=flat-square
[travis-url]: https://travis-ci.org/Sunshine168/egg-mongolass
[codecov-image]: https://img.shields.io/codecov/c/github/Sunshine168/egg-mongolass.svg?style=flat-square
[codecov-url]: https://codecov.io/github/Sunshine168/egg-mongolass?branch=master
[david-image]: https://img.shields.io/david/Sunshine168/egg-mongolass.svg?style=flat-square
[david-url]: https://david-dm.org/Sunshine168/egg-mongolass
[snyk-image]: https://snyk.io/test/npm/egg-mongolass/badge.svg?style=flat-square
[snyk-url]: https://snyk.io/test/npm/egg-mongolass
[download-image]: https://img.shields.io/npm/dm/egg-mongolass.svg?style=flat-square
[download-url]: https://npmjs.org/package/egg-mongolass
<!--
Description here.
-->
## 依赖说明
### 依赖的 egg 版本
egg-mongolass 版本 | egg 1.x
--- | ---
1.x | 😁
0.x | ❌
### 依赖的插件
<!--
如果有依赖其它插件,请在这里特别说明。如
- security
- multipart
-->
## API(!!!)
参照[mongolass](https://github.com/mongolass/mongolass)
更多 [node-mongodb-native](http://mongodb.github.io/node-mongodb-native/3.0/api/Collection.html)
请注意,不同连接mongodb的lib封装的api是不一样的,请参照文档。
## 开启插件
```js
// config/plugin.js
exports.mongolass = {
enable: true,
package: 'egg-mongolass',
};
```
## 详细配置
```js
// {app_root}/config/config.default.js
// use the config url (see https://docs.mongodb.com/manual/reference/connection-string/)
exports.mongolass = {
client{
url: 'mongodb://127.0.0.1/test',
}
};
// or
exports.mongolass = {
client: {
host: 'localhost',
port: '27017',
database: 'blog',
},
}
```
## Global plugin
project_root/lib/mongolass.js
```js
'use strict';
const moment = require('moment');
const objectIdToTimestamp = require('objectid-to-timestamp');
module.exports = {
addCreatedAt: {
afterFind(results) {
results.forEach(function(item) {
item.created_at = moment(objectIdToTimestamp(item._id)).format(
'YYYY-MM-DD HH:mm'
);
});
return results;
},
afterFindOne(result) {
if (result) {
result.created_at = moment(objectIdToTimestamp(result._id)).format(
'YYYY-MM-DD HH:mm'
);
}
return result;
},
},
};
// example in test suit
const testUser = await UserModal.findOne({
name: 'mai',
}).addCreatedAt().exec();
assert.ok(testUser.created_at);
```
## Example
```js
// app/model/user.js
module.exports = app =>{
const { mongolass } = app;
const User = mongolass
.model('User', {
account: { type: 'string' },
name: { type: 'string' },
})
User.index({ account: 1 }, { unique: true })
.exec();
return User
}
```
## 提问交流
请到 [egg issues](https://github.com/Sunshine168/egg-mongolass/issues) 异步交流。
## License
[MIT](LICENSE) | 3,211 | MIT |
---
title: Welcome
tags: qbycs
---
欢迎来到我的博客!
<!--more-->
---
If you like TeXt, don't forget to give me a star. :star2:
[](https://github.com/kitian616/jekyll-TeXt-theme/) | 290 | MIT |
# 版本日志
---
<!-- ### v1.0.1
::: tip 2020-03-25 首次发布
- **新增内容**
- **BUG修复**
- **下版计划**
::: -->
### v1.0.1
::: tip 2020-03-25 首次发布
- **新增内容**
- 新增动画、背景、边框、布局、文本内置css样式类
- 新增uxt-button按钮组件
- 新增uxt-bar-group单元格分组组件
- 新增uxt-bar单元格组件
- 新增uxt-icon图标组件
- 新增uxt-page页面容器组件
- 新增uxt-modal模态框组件
- 新增uxt-checkbox复选框组件
- 新增uxt-input输入组件
- 新增uxt-input-box输入框组件
- 新增uxt-radio单选框组件
- 新增uxt-switch开关组件
- 新增uxt-action-sheet上拉菜单组件
- 新增uxt-dialog对话框组件
- 新增uxt-loading加载组件
- 新增uxt-pulldown-refresh下拉刷新组件
- 新增uxt-swipe-action滑动操作组件
- 新增uxt-notify消息通知组件
- 新增uxt-toast轻提示组件
- 新增uxt-avatar头像组件
- 新增uxt-avatar-group头像组组件
- 新增uxt-divider分隔线组件
- 新增uxt-progress进度条组件
- 新增uxt-steps步骤条组件
- 新增uxt-tag标签组件
- 新增uxt-badge角标组件
- 新增uxt-timeline时间轴组件
- 新增uxt-fab浮动按钮组件
- 新增uxt-grid宫格组件
- 新增uxt-nav-bar导航栏组件
- 新增uxt-tab页签组件
- 新增uxt-tab-bar页签栏组件
- 新增uxt-title-bar标题栏组件
- **下版计划**
- 重新整理表单组件,拆分uxt-input输入组件
::: | 1,010 | Apache-2.0 |
line-chart
==========
供小程序内使用的简单折线图,使用步骤:
- clone或者复制js代码到自己项目中
- 在需要绘图的页面里放置一个canvas并指定id
- 在页面对应的js中onReady时初始化并绘制折线图
更多内容请参考[此文](https://amsimple.com/blog/article/84.html)。
code example:
-------------
### wxml
``` {.html}
<view class="wrap" style="width: 320px; height: 200px;">
<canvas canvas-id="chart" style="width: 320px; height: 200px;"></canvas>
<!-- 用于触摸提示,保持与上一个canvas大小与位置完全一致,不需要的话可以省略 -->
<canvas canvas-id="chart-tips" style="width: 320px; height: 200px;"
disable-scroll
bindtouchstart="tipsStart"
bindtouchmove="tipsMove"
bindtouchend="tipsEnd">
</canvas>
</view>
```
### css
``` {.css}
.wrap {
position: relative;
margin: 0 auto;
}
.wrap canvas {
position: absolute;
top: 0;
left: 0;
}
```
### js
``` {.javascript}
const lineChart = require('./line-chart/index.js');
let chart = null;
Page({
onReady: function() {
chart = lineChart.init('chart', {
tipsCtx: 'chart-tips',
width: 320,
height: 200,
margin: 10,
yUnit: 'h'
xAxis: ['10.1', '10.2', '10.3', '10.4', '10.5', '10.6', '10.7']
lines: [{
color: '#1296db',
points: [5, 6, 8, 6, 7, 4, 3]
}]
});
chart.draw();
},
tipsStart: function(e) {
let x = e.changedTouches[0].x;
this.chartTipsShowing = true;
chart.tipsByX(x);
},
tipsMove: function(e) {
let x = e.changedTouches[0].x;
if (this.chartTipsShowing) {
chart.tipsByX(x);
}
},
tipsEnd: function() {
this.chartTipsShowing = false;
chart.clearTips();
}
});
``` | 1,730 | MIT |
<!-- YAML
added: v10.0.0
-->
* `path` {string|Buffer|URL}
* `atime` {number|string|Date}
* `mtime` {number|string|Date}
* 返回: {Promise}
更改 `path` 指向的对象的文件系统时间戳,然后在成功时解决 `Promise` 且不带参数。
`atime` 和 `mtime` 参数遵循以下规则:
- 值可以是表示 Unix 纪元时间的数字、`Date` 对象、或类似 `'123456789.0'` 的数值字符串。
- 如果该值无法转换为数值、或值为 `NaN`、`Infinity` 或 `-Infinity`,则抛出 `Error`。 | 340 | CC-BY-4.0 |
---
layout: post
title: go json to struct
category: Go
tags: centos,ftp,Apache,GPL,LGPL,MIT
description:
---
```javascript
package main
import (
"encoding/json"
"fmt"
)
/*
{"name":"张三","Age":18,"HIgh":true,"class":{"Name":"1班","Grade":3}}
*/
type Stu struct {
Name string `json:"name"`
Age int
HIgh bool
sex string
Class *Class `json:"class"`
}
type Class struct {
Name string
Grade int
}
func main() {
//实例化一个数据结构,用于生成json字符串
stu := Stu{
Name: "张三",
Age: 18,
HIgh: true,
sex: "男",
}
//指针变量
cla := new(Class)
cla.Name = "1班"
cla.Grade = 3
stu.Class=cla
//Marshal失败时err!=nil
jsonStu, err := json.Marshal(stu)
if err != nil {
fmt.Println("生成json字符串错误")
}
//jsonStu是[]byte类型,转化成string类型便于查看
fmt.Println(string(jsonStu))
}
```
---
<script language="javascript" type="text/javascript" src="//js.users.51.la/19176892.js"></script>
<noscript><a href="//www.51.la/?19176892" target="_blank"><img alt="我要啦免费统计" src="//img.users.51.la/19176892.asp" style="border:none" /></a></noscript> | 1,055 | MIT |
# Jrequests - java端requests
## 简介:
在写这个项目之前本人已经对Python爬虫有了一些了解,也写过一些博客:[https://blog.csdn.net/qq_44700693](https://blog.csdn.net/qq_44700693) 。 <br>
后来在使用java编写一些web项目时,会用到一些网络上的实时信息,所以就有了这个小项目,目的在于在java原生类的基础上进行封装,写出一个java端的类 **requests** 插件。
## 更新记录:
| 日 期 | 更 新 摘 要 |
| ------ | ------ |
| **21-4-2** | 请求参数支持传JSONObject或String。<br>实际上都是调用的参数类型为JSONObject类型的方法,传入String类型时进行了类型转换。|
| **21-3-31** | 重构逻辑,实现对应接口,GET和POST都已经支持单独的请求体、单独的请求头或请求头和请求体一起传入。<br>创建了多参数的方法待用。|
| **21-3-29** | POST支持同时添加请求头和请求体 |
| **21-3-20** | 在实例化`Jrequests`对象时可以指定编码,默认 `UTF-8` |
| **21-3-11** | 新增响应头部信息的获取,返回的是一个 **JSON** 对象。 |
| **21-3-9** | GET请求更新带参数请求方式。中文自动编码。 |
| **21-3-8** | 完成最基本的 **GET** 和 **POST** 请求,并提交项目至仓库。|
## 项目依赖:
* **JLogger** : 自己编写的极简日志工具,用于日志输出。
> 仓库地址:[https://gitee.com/jackson-art/jlogger](https://gitee.com/jackson-art/jlogger)
* **fastjson-1.2.75** : 用于JSON数据操作。
## 方法定义:
> 不带参数:**`get(String sUrl)`** <br>
> 一个参数:**`get(String sUrl, JSONObject jsonObject)`**<br>
>> 同时接受 **headers** 或 **data** 或 **params** 。有判断去分别处理。<br>
> 带两个参数:**`get(String sUrl, JSONObject jsonObject, JSONObject jsonObject)`**
>> 参数不分先后,(headers, params/data)
> **POST** 请求类似
## 使用介绍:
需要导入编译好的jar包,或者自行下载源码编译。
* 1、首先需要创建 **Jrequests** 对象:<br>
`Jrequests jrequests = new Jrequests();`<br>
* 2、通过不同的请求方式来进行网页请求: 如:<br>
a、对网页 **url** 进行 **GET** 请求:<br>
`Jresponse jreponse = jrequests.get(String url);`<br>
b、对网页 **url** 进行 **POST** 请求:<br>
`Jresponse jreponse = jrequests.post(String url,String data);`
## 功能介绍:
目前已经支持的功能有:
| 方法 | 作用 |
| --- | --- |
| **`getURL()`** | 获取网页请求链接|
| **`getText()`** | 获取网页源码 |
| **`getJson()`** | 获取返回的JSON数据 |
| **`getStatusCode()`** | 获取网页请求状态 |
| **`getRequestsHeaders()`** | 获取请求头部信息 |
| **`getResponseHeaders()`** | 获取响应头部信息 |
## 代码示例:
```java
import com.alibaba.fastjson.JSONObject;
import hu.jspider.jrequests.Jrequests;
import hu.jspider.jrequests.Jresponse;
/**
* 发送GET请求
* @author Jackson-art
*/
public class JrequestsDemo1 {
public static void main(String[] args) {
Jrequests jrequests = new Jrequests();
// Get 不带参数
Jresponse jresponse = jrequests.get("http://******.com");
// 获取响应头部
JSONObject headers = jresponse.getResponseHeaders();
String set_cookies = headers.getString("Set-Cookie");
System.out.println(set_cookies);
// 获取网页源码
System.out.println(jresponse.getText());
// 获取请求状态码
System.out.println(jresponse.getStatusCode());
// 获取请求URL
System.out.println(jresponse.getUrl());
// Get 带参数
JSONObject params = JSONObject.parseObject("{\"wd\":\"Jrequests site:gitee.com\"}");
Jresponse jresponse = jrequests.get("http://www.baidu.com/s", params);
// 获取响应头部
JSONObject headers = jresponse.getResponseHeaders();
// 获取网页源码
System.out.println(jresponse.getText());
// 获取请求状态码
System.out.println(jresponse.getStatusCode());
// 获取请求URL
System.out.println(jresponse.getUrl());
}
}
```
```java
import com.alibaba.fastjson.JSONObject;
import hu.jspider.jrequests.Jrequests;
import hu.jspider.jrequests.Jresponse;
/**
* 发送POST请求
* @author Jackson-art
*/
public class JrequestsDemo2 {
public static void main(String[] args) {
Jrequests jrequests = new Jrequests("utf-8");
// Post --- 无请求体
Jresponse jresponse = jrequests.post("https://api.******.php");
// 获取响应头部
JSONObject headers = jresponse.getResponseHeaders();
// 获取网页源码
System.out.println(jresponse.getText());
// 获取请求状态码
System.out.println(jresponse.getStatusCode());
// 获取请求URL
System.out.println(jresponse.getUrl());
// Post --- 有请求体
JSONObject json = JSONObject.parseObject("{\"key\":\"value\"}");
Jresponse jresponse = jrequests.post("https://api.******.php", json);
// 获取响应头部
JSONObject headers = jresponse.getResponseHeaders();
// 获取网页源码
System.out.println(jresponse.getText());
// 获取请求状态码
System.out.println(jresponse.getStatusCode());
// 获取请求URL
System.out.println(jresponse.getUrl());
}
}
``` | 4,205 | MIT |
layout: art
title: jQuery的事件机制——事件对象、兼容、接口
subtitle: 闲来没事读源码系列——jQuery
tags:
- JavaScript
categories:
- JS技术
date: 2014/5/12
---
这篇主要介绍了jQuery中事件管理器的事件对象、兼容实现以及在jQuery对象上暴露的接口
<!-- more -->
接上一篇 [jQuery的事件机制——核心篇](http://lingyu.wang/#/art/blog/2014/05/12/read-jq-src-3)
##事件对象
jq中使用自己创立的对象传递给回调函数,这里解析一下这个事件对象:
###构造函数
jq的事件对象的构造函数如下:
```javascript
jQuery.Event = function( src, props ) {
//内部的代码
};
```
接下来接下下内部代码:
```javascript
/*兼容不使用new的情况*/
if ( !(this instanceof jQuery.Event) ) {
return new jQuery.Event( src, props );
}
```
用于防止出现没有使用new直接调用构造函数的情况
```javascript
if ( src && src.type ) {
this.originalEvent = src;
this.type = src.type;
// Events bubbling up the document may have been marked as prevented
// by a handler lower down the tree; reflect the correct value.
this.isDefaultPrevented = src.defaultPrevented ||
// Support: Android < 4.0
src.defaultPrevented === undefined &&
src.getPreventDefault && src.getPreventDefault() ?
returnTrue :
returnFalse;
// Event type
} else {
this.type = src;
}
```
这里根据传入的是事件对象还是事件名称分别进行处理,当传入原生事件对象时,使用originalEvent指向原生事件对象,并获取它的事件名称。另外还要判断事件是否已经屏蔽默认行为了。如果传入的是字符串,直接写入到事件名称中
```javascript
/*通过extend添加额外属性*/
if ( props ) {
jQuery.extend( this, props );
}
```
事件对象可以添加一些其他属性,这里添加的属性通过props传入,直接extend就好
```javascript
/*创建时间*/
this.timeStamp = src && src.timeStamp || jQuery.now();
/*jq事件对象标记*/
this[ jQuery.expando ] = true;
```
一个创建时的时间戳,不知道干嘛用的,至于版本号标记,主要是用来判断对象是原生事件对象还是jq自己的事件对象
###原型上的方法
事件对象实际上是jq新建的对象,对原生事件对象进行了一层包裹,那么应该提供一些方法操作原生事件对象。我们操作原生事件对象无外乎preventDefault和stopPropagation,这里就是做了一层封装
```javascript
isDefaultPrevented: returnFalse,
isPropagationStopped: returnFalse,
isImmediatePropagationStopped: returnFalse,
```
默认情况下,不会阻止默认行为,事件不会被终止。这里ImmediatePropagtaionStop其实和PropagationStop没什么区别
```javascript
preventDefault: function() {
var e = this.originalEvent;
this.isDefaultPrevented = returnTrue;
if ( e && e.preventDefault ) {
e.preventDefault();
}
},
```
阻止默认行为,先在jq的事件对象上做个标记,然后调用原生事件的preventDefault方法
```javascript
stopPropagation: function() {
var e = this.originalEvent;
this.isPropagationStopped = returnTrue;
if ( e && e.stopPropagation ) {
e.stopPropagation();
}
},
stopImmediatePropagation: function() {
this.isImmediatePropagationStopped = returnTrue;
this.stopPropagation();
}
```
终止事件执行,同样是先在事件对象上做个标记,然后调用原生事件的pstopPropagation方法,可以看到,两个方法没什么区别
##事件对象在事件机制中的使用
jq不嫌麻烦自己弄了个事件对象进行包装,就是为了屏蔽浏览器之间事件对象上的差异。这里jq事件对象需要根据事件的类型,来构建兼容的事件对象,同样是使用钩子的形式,调用这些钩子的地方,在事件管理器的fix方法
###fix方法
fix方法就是将原生事件对象加工为jq自己的事件对象,内部都是用钩子来加对不同类型的事件进行加工
```javascript
if ( event[ jQuery.expando ] ) {
return event;
}
```
jq事件对象上有jq版本标记,如果标记已存在,说明是jq时间爱你对象,没必要加工了
```javascript
var i, prop, copy,
/*获取事件的名称*/
type = event.type,
/*将原生事件对象缓存*/
originalEvent = event,
/*获取事件对象对应的钩子*/
fixHook = this.fixHooks[ type ];
/*如果没有钩子,需要判断这个对象类型是鼠标事件还是键盘事件*/
if ( !fixHook ) {
this.fixHooks[ type ] = fixHook =
rmouseEvent.test( type ) ? this.mouseHooks :
rkeyEvent.test( type ) ? this.keyHooks :
{};
}
```
这里会获取特殊事件的钩子,如果没有钩子,那需要判断事件是鼠标事件还是按键事件,这俩都需要特别处理。另外也会做缓存,获取到钩子后写入到fixHooks中,下次同样类型的事件就能直接获取钩子了
```javascript
/*获取鼠标事件或键盘事件应当拷贝的相关属性的列表*/
copy = fixHook.props ? this.props.concat( fixHook.props ) : this.props;
/*新建一个包装了原生事件对象的jq事件对象*/
event = new jQuery.Event( originalEvent );
/*将这些需要拷贝的属性全部拷贝到jq事件对象中*/
i = copy.length;
while ( i-- ) {
prop = copy[ i ];
event[ prop ] = originalEvent[ prop ];
}
```
鼠标类型事件和按键类型时间都有自己的一些属性,当然还有些公有属性,这里需要获取事件应当从原生事件中拷贝值名称的列表。获取到列表后新建一个jq事件对象进行拷贝。
```javascript
if ( !event.target ) {
event.target = document;
}
if ( event.target.nodeType === 3 ) {
event.target = event.target.parentNode;
}
```
这里修复了一些事件target不正确的问题
```javascript
return fixHook.filter ? fixHook.filter( event, originalEvent ) : event;
```
最后再通过filter钩子做一下最后的加工处理。处理完成之后,返回jq的事件对象
###鼠标事件和键盘事件的处理
fix中都是调用钩子来获得元素列表和filter最后处理,在事件管理器中定义了鼠标事件和键盘事件需要的属性
####公有属性
```javascript
props: "altKey bubbles cancelable ctrlKey currentTarget eventPhase metaKey relatedTarget shiftKey target timeStamp view which".split(" "),
```
这些是鼠标和键盘事件公有的属性
####键盘事件
```javascript
keyHooks: {
props: "char charCode key keyCode".split(" "),
filter: function( event, original ) {
// Add which for key events
if ( event.which == null ) {
event.which = original.charCode != null ? original.charCode : original.keyCode;
}
return event;
}
},
```
这里是键盘钩子,定义了键盘事件特有属性以及其filter,filter主要是将如charCode、keyCode等进行统一,创建出符合W3C标准的which
####鼠标事件
```javascript
mouseHooks: {
props: "button buttons clientX clientY offsetX offsetY pageX pageY screenX screenY toElement".split(" "),
filter: function( event, original ) {
var eventDoc, doc, body,
button = original.button;
if ( event.pageX == null && original.clientX != null ) {
eventDoc = event.target.ownerDocument || document;
doc = eventDoc.documentElement;
body = eventDoc.body;
event.pageX = original.clientX + ( doc && doc.scrollLeft || body && body.scrollLeft || 0 ) - ( doc && doc.clientLeft || body && body.clientLeft || 0 );
event.pageY = original.clientY + ( doc && doc.scrollTop || body && body.scrollTop || 0 ) - ( doc && doc.clientTop || body && body.clientTop || 0 );
}
if ( !event.which && button !== undefined ) {
event.which = ( button & 1 ? 1 : ( button & 2 ? 3 : ( button & 4 ? 2 : 0 ) ) );
}
return event;
}
},
```
同样的方式,定义了鼠标事件特有的属性,另外做了一个兼容,做出了pageX、pageY、which等属性
##特殊事件
上一篇讲了jq事件核心,可以看到针对特殊事件,基本上每个地方都需要通过钩子特殊处理,那么有哪些特殊事件呢?这些在事件管理器的special里都有:
###load
```javascript
load: {
// Prevent triggered image.load events from bubbling to window.load
noBubble: true
},
```
load事件不冒泡,需要注意
###focus和blur
```javascript
focus: {
// Fire native event if possible so blur/focus sequence is correct
trigger: function() {
if ( this !== safeActiveElement() && this.focus ) {
this.focus();
return false;
}
},
delegateType: "focusin"
},
blur: {
trigger: function() {
if ( this === safeActiveElement() && this.blur ) {
this.blur();
return false;
}
},
delegateType: "focusout"
},
```
focus和blur事件,这俩有自己的trigger钩子,另外其使用代理时名称也不同。事实上focus和blur除了trigger钩子,还有在事件注册和事件删除时的setup和teardown钩子,可以看到代码如下
```javascript
if ( !support.focusinBubbles ) {
jQuery.each({ focus: "focusin", blur: "focusout" }, function( orig, fix ) {
// Attach a single capturing handler on the document while someone wants focusin/focusout
var handler = function( event ) {
jQuery.event.simulate( fix, event.target, jQuery.event.fix( event ), true );
};
jQuery.event.special[ fix ] = {
setup: function() {
var doc = this.ownerDocument || this,
attaches = data_priv.access( doc, fix );
if ( !attaches ) {
doc.addEventListener( orig, handler, true );
}
data_priv.access( doc, fix, ( attaches || 0 ) + 1 );
},
teardown: function() {
var doc = this.ownerDocument || this,
attaches = data_priv.access( doc, fix ) - 1;
if ( !attaches ) {
doc.removeEventListener( orig, handler, true );
data_priv.remove( doc, fix );
} else {
data_priv.access( doc, fix, attaches );
}
}
};
});
}
```
###click
```javascript
click: {
// For checkbox, fire native event so checked state will be right
trigger: function() {
if ( this.type === "checkbox" && this.click && jQuery.nodeName( this, "input" ) ) {
this.click();
return false;
}
},
/*浏览器兼容,如果元素是a标签,那么不触发原生click事件*/
// For cross-browser consistency, don't fire native .click() on links
_default: function( event ) {
return jQuery.nodeName( event.target, "a" );
}
},
```
点击时间爱你,在checkbox上有钩子,调用其原生api。另外,当元素为a标签时,不触发原生click事件
###beforeunload
```javascript
beforeunload: {
postDispatch: function( event ) {
// Support: Firefox 20+
// Firefox doesn't alert if the returnValue field is not set.
if ( event.result !== undefined ) {
event.originalEvent.returnValue = event.result;
}
}
}
```
beforeunlaod事件在ff中最后结果可能不同,需要做兼容
###mouseenter和mouseleave
mouseover和mouseout的问题在于,他们只监听最外层的大容器,而大容器中是由很多子元素的。如果鼠标在子元素上,而离开了大容器,mouseout事件也会触发。
比如一个列式菜单,最上层菜单上有一些选项,鼠标悬停在选项上,右侧会出现该选项下的子选项。如果在菜单上使用mouseover和mouseout来绑定事件,当鼠标移动到子选项时,实际上移出了容器,会触发mouseout事件,菜单就被隐藏了...
jq通过新建两个事件mouseenter和mouseleave来防止这种情况发生
```javascript
jQuery.each({
mouseenter: "mouseover",
mouseleave: "mouseout"
}, function( orig, fix ) {
jQuery.event.special[ orig ] = {
delegateType: fix,
bindType: fix,
handle: function( event ) {
var ret,
target = this,
related = event.relatedTarget,
handleObj = event.handleObj;
// For mousenter/leave call the handler if related is outside the target.
// NB: No relatedTarget if the mouse left/entered the browser window
if ( !related || (related !== target && !jQuery.contains( target, related )) ) {
event.type = handleObj.origType;
ret = handleObj.handler.apply( this, arguments );
event.type = fix;
}
return ret;
}
};
});
```
可以看到,这里可以看到,使用contains判断当前元素是否被包含在容器中,如果包含将不会执行回调函数
##jQuery对象上的方法
我们需要一系列的方法将事件用于jQuery对象之上,依旧是在fn上扩展,有如下一些方法:
1. on: 绑定事件添加回调
2. one:绑定知识性一次的事件
3. off:移除事件
4. trigger:对每一个元素触发事件
5. triggerHandler:对jq对象中的第一个元素触发事件
###on (types, selector, data, fn, /\*内部使用\*/one)
jq使用on方法在元素时行绑定事件,这里types可以是一个`event1 event2`这样的字符串,同时绑定多个事件公用相同的回调函数fn。另外,当types为对象时,键为事件名称,值为回调函数,也可以一次绑定多个事件。这是一个多接口方法,需要根据传入的参数判断如何处理
```javascript
if ( typeof types === "object" ) {
// ( types-Object, selector, data )
if ( typeof selector !== "string" ) {
// ( types-Object, data )
data = data || selector;
selector = undefined;
}
/*一次绑定多个事件*/
for ( type in types ) {
this.on( type, selector, data, types[ type ], one );
}
return this;
}
```
可以看到,这里就是处理types为对象的情况,这里实际上根据types中的每个键值对,递归调用了on方法进行单个绑定
```javascript
/*可以不提供数据*/
if ( data == null && fn == null ) {
// ( types, fn )
//情况1
fn = selector;
data = selector = undefined;
} else if ( fn == null ) {
if ( typeof selector === "string" ) {
// ( types, selector, fn )
//情况2
fn = data;
data = undefined;
} else {
// ( types, data, fn )
//情况3
fn = data;
data = selector;
selector = undefined;
}
}
if ( fn === false ) {
fn = returnFalse;
} else if ( !fn ) {
return this;
}
```
这里处理了三种情况:
1. 只有事件名称和回调函数
2. 有事件名称,代理选择器和回调函数
3. 有事件名称,事件数据和回调函数
如果没有回调函数,需要给与一个默认的回调函数,这个默认回调函数直接`return false`
```javascript
if ( one === 1 ) {
origFn = fn;
fn = function( event ) {
// Can use an empty set, since event contains the info
jQuery().off( event );
return origFn.apply( this, arguments );
};
// Use same guid so caller can remove using origFn
fn.guid = origFn.guid || ( origFn.guid = jQuery.guid++ );
}
```
我们可以绑定一次性事件,实现骑士很简单,通过闭包对事件回调函数做一个包装,在其被运行之前,调用off移除掉事件就行了
```javascript
return this.each( function() {
jQuery.event.add( this, types, fn, data, selector );
});
```
最后,确定好了配置,最后在jq对象中的每个元素上调用通过事件管理器的add方法添加事件回调函数
###one ( types, selector, data, fn )
绑定一次性事件,上面的on已经做了实现,这里只不过是调用一下接口
```javascript
one: function( types, selector, data, fn ) {
return this.on( types, selector, data, fn, 1 );
},
```
###off ( types, selector, fn )
同样是个多接口函数,在只有事件名称时,直接删除整个事件。如果有确定回调函数,那么删除对应时间的对应回调函数。需要注意代理的情况
```javascript
if ( types && types.preventDefault && types.handleObj ) {
// ( event ) dispatched jQuery.Event
handleObj = types.handleObj;
jQuery( types.delegateTarget ).off(
handleObj.namespace ? handleObj.origType + "." + handleObj.namespace : handleObj.origType,
handleObj.selector,
handleObj.handler
);
return this;
}
```
这里处理的是参数是事件对象的情况,这种情况会在使用one绑定事件回调执行后自动删除时发生。获取事件对象其中的属性,递归调用off删除
```javascript
if ( typeof types === "object" ) {
// ( types-object [, selector] )
for ( type in types ) {
this.off( type, selector, types[ type ] );
}
return this;
}
```
如果typs是事件名称到回调函数的键值对,那么对其中的每个键和值,分别进行删除,递归调用off删除
```javascript
if ( selector === false || typeof selector === "function" ) {
// ( types [, fn] )
fn = selector;
selector = undefined;
}
if ( fn === false ) {
fn = returnFalse;
}
```
这里处理了只有事件名称和回调函数的接口情况
```javascript
return this.each(function() {
jQuery.event.remove( this, types, fn, selector );
});
```
最后,对jq对象中的每个元素移除事件中的回调函数就好
###trigger (type, data) 和 triggerHandler (type, data)
没啥说的,都是直接用的事件管理器的trigger方法。只不过前者对每个元素调用一次,后者只对第一个元素调用
```javascript
/*对jq对象中的每个元素触发事件*/
trigger: function( type, data ) {
return this.each(function() {
jQuery.event.trigger( type, data, this );
});
},
/*对jq对象中的第一个元素触发事件*/
triggerHandler: function( type, data ) {
var elem = this[0];
if ( elem ) {
return jQuery.event.trigger( type, data, elem, true );
}
}
```
##总结
这一篇直接看的话,肯定会不知所云...最好能结合上一篇一起看,上一篇介绍了事件机制的核心方法,这一篇主要是jq事件对象和一些兼容性问题的解决方法(主要是钩子)。jq的钩子方式很不错,在写框架对付兼容性问题时可以多多使用 | 13,699 | MIT |
# WebSocket
## 一、页面扩展
1、新增按钮
按钮相关样式调整如下:
```
.btn {
float: left;
min-width: 70px;
height: 30px;
color: #fff;
padding: 0 10px;
cursor: pointer;
font-size: 12px;
font-weight: bold;
line-height: 30px;
text-align: center;
margin-right: 20px;
background: #ec8e72;
}
.btn_wrap {
height: 30px;
overflow: hidden;
margin-bottom: 20px;
}
```
对应dom结构调整如下:
```
<div class="btn_wrap">
<div class="btn" data-type="file">新增文件映射</div>
<div class="btn" data-type="client">新增Client映射</div>
<div class="btn" data-type="server">新增Server映射</div>
</div>
```
2、列表扩展
main类的样式调整如下:
```
.main {
margin: auto;
width: 1100px;
padding-top: 24px;
}
```
列表区域新增type列,template区域新增一列用来表示类型,如下所示:
```
<th style="width: 100px;">类型</th>
<td>{type}</td>
```
3、交互调整
新增按钮事件逻辑调整如下:
```
$('#main .btn').on('click', function btnEvent() {
Page.showDialog(-1, $(this).data('type'));
});
```
新增配置弹框的显示逻辑如下:
```
if (type === 'file') {
$('#dialog').find('.title').html('文件映射').end()
.find('.row span').first().html('URL: ');
} else if (type === 'client') {
$('#dialog').find('.title').html('WebSocket-Client映射').end()
.find('.row span').first().html('传输内容: ');
} else if (type === 'server') {
$('#dialog').find('.title').html('WebSocket-Server映射').end()
.find('.row span').first().html('传输内容: ');
}
$('#dialog').removeClass('hide').find('.btn').data('index', index).data('type', type);
```
调整配置弹框确定按钮部分逻辑如下:
```
const result = {
type: $(this).data('type'),
url: $($('#dialog input')[0]).val(),
file: $($('#dialog input')[1]).val(),
};
```
调整渲染函数部分逻辑如下:
```
list.forEach((item) => {
$('tbody').append(tpl.replace('{type}', item.type).replace('{url}', item.url).replace('{file}', item.file));
});
```
4、预览


## 二、Websocket映射
1、追加相关依赖库
项目目录下执行npm install --save ws lodash安装依赖库,接着执行npm install --save-dev @types/ws @types/lodash
2、增加工具类
在src下添加shared文件夹,并增加WebSocketTool.ts文件,并增加后续需要的相关定义
```
// whistle提供的Websocket对象
type WhistleWebSocket = WebSocket;
// whistle提供的Request对象
interface WhistleRequest extends http.IncomingMessage {
originalReq: {
url: string;
headers: {
[key: string]: string;
};
};
curSendState: string;
curReceiveState: string;
wsReceiveClient: WhistleWebSocket;
}
// whistle提供的Options对象
interface Options {
storage: {
setProperty: Function;
getProperty: Function;
};
}
// websocket单配置对象
interface WebSocketItem {
rule: string;
file: string;
type: 'server' | 'client';
}
```
增加WebSocketTool类,并添加websocket转发逻辑:
```
// 库
import {
Server,
} from 'ws';
import * as http from 'http';
// WebSocket库
import WebSocket = require('ws');
/**
* WebSocket工具类
*/
export default class WebSocketTool {
/**
* 监听websocket请求
* @param server []
*/
static handleWebSockeListening(server: http.Server, options: Options): void {
const wss = new Server({
server,
verifyClient: WebSocketTool.verifyClient,
});
wss.on('connection', (ws: WhistleWebSocket, req: WhistleRequest) => {
const {
wsReceiveClient,
} = req;
// 监听服务端发送到客户端的数据
wsReceiveClient.on('message', (data) => {
const isIgnore = req.curReceiveState === 'ignore';
// 触发一下
req.emit('serverFrame', `Server: ${data}`, isIgnore);
// 转发请求,确保ws请求返回到真实的客户端
!isIgnore && ws.send(data);
});
// 监听客户端发送到服务端的数据
ws.on('message', (data) => {
const isIgnore = req.curSendState === 'ignore';
// 触发一下
req.emit('clientFrame', `Client: ${data}`, isIgnore);
// 转发请求,方便代码生成的客户端进行捕获
!isIgnore && wsReceiveClient.send(data);
});
});
}
/**
* 利用ws库生成Server中需要的参数
* @param info [信息对象,req为whistle提供的Request对象]
* @param callback [回调函数]
*/
private static verifyClient(info: {req: http.IncomingMessage}, callback: Function): void {
const req = info.req as WhistleRequest;
const {
url,
headers,
} = req.originalReq;
const protocols = [headers['sec-websocket-protocol'] || ''];
delete headers['sec-websocket-key'];
const client = new WebSocket(url, protocols, {
headers,
rejectUnauthorized: false,
});
let isDone = false;
const checkContinue = (error: Error): void => {
if (isDone) {
return;
}
isDone = true;
if (error) {
callback(false, 502, error.message);
} else {
callback(true);
}
};
client.on('error', checkContinue);
client.on('open', () => {
req.wsReceiveClient = client as WhistleWebSocket;
checkContinue(null);
});
}
}
```
3、添加映射逻辑
WebSocketTool类增加映射匹配逻辑:
```
private static getProxyDataFromType(data: WebSocket.Data, type: 'client' | 'server', options: Options): WebSocket.Data {
let filePath = '';
const content = data.toString();
const list: WebSocketItem[] = options.storage.getProperty('list') || [];
// 过滤对应类型的配置数据
list.filter((item) => item.type === type).some((item) => {
const reg = new RegExp(item.rule);
if (reg.test(content)) {
filePath = item.file;
return true;
}
return false;
});
// 没有匹配的映射规则,则直接返回
if (_.isEmpty(filePath)) {
return data;
}
// 如果对应文件不存在在,则直接返回
if (!fs.existsSync(filePath)) {
return data;
}
// 读取对应文件,并返回
return fs.readFileSync(filePath).toString();
}
```
调整websocket监听逻辑如下:
```
// 监听服务端发送到客户端的数据
wsReceiveClient.on('message', (data) => {
const isIgnore = req.curReceiveState === 'ignore';
// 触发一下
req.emit('serverFrame', `Server: ${data}`, isIgnore);
// 转发请求,确保ws请求返回到真实的客户端
if (!isIgnore) {
// 这里进行数据修改
const result = WebSocketTool.getProxyDataFromType(data, 'client', options);
ws.send(result);
}
});
// 监听客户端发送到服务端的数据
ws.on('message', (data) => {
const isIgnore = req.curSendState === 'ignore';
// 触发一下
req.emit('clientFrame', `Client: ${data}`, isIgnore);
// 转发请求,方便代码生成的客户端进行捕获
if (!isIgnore) {
// 这里进行数据修改
const result = WebSocketTool.getProxyDataFromType(data, 'server', options);
wsReceiveClient.send(result);
}
});
```
server.ts增加websocket处理逻辑:
```
import WebSocketTool from '../shared/WebSocketTool';
WebSocketTool.handleWebSockeListening(server, options);
```
4、预览

## 三、更新包
1、修改package.json中的version为1.0.1
2、命令行中执行npm publish进行包更新 | 7,171 | MIT |
# validate-js 0.0.1
一个用来进行输入验证的组件,基于[validator.js][validator-url]和[tooltip.js][tooltip-url],可在node和browser环境下使用。
无需更多的其他依赖。**同validator一致,所有验证的value需为str类型**。
### 模块化安装使用
通过github地址安装: `npm install git+https://[email protected]/Ysanwen/validate-js.git`。
在node环境下使用:
```javascript
var validate = require('validate-js');
validate.isInt('abc'); //=> false
```
支持的方法请参考:[validator.js][validator-url]
通过组件化引入浏览器端使用:
```javascript
import validate from 'validate-js'
validate.autoValidate() //对含有class="validate"的input元素进行验证,验证时机通过设置input的validate-trigger属性决定。默认为onchange
validate.validateAll() //对全部class="validate"的input元素进行验证。
validate.doValidate(el) //验证指定的input元素。
```
### 浏览器端直接引入
```html
<script type="text/javascript" src="validate-js.min.js"></script>
<script type="text/javascript">
validate.isEmail('[email protected]'); //=> true
validate.autoValidate();
</script>
```
### 验证规则
- 待验证的元素必须包含`validate`的class name
- 验证时机,validate.autoValidate的验证时机由`validate-trigger`指定,不指定则默认的为`onchange`时触发验证。
触发时机可以设定为`change`, `keypress`, `keydown`, `keyup`, `blur`之中的任意一种。
- 验证规则通过`validate-rule`指定,规则之间通过`|`分割,由左至右的顺序执行,遇到验证失败直接停止并提示信息。
例如:`validate-rule="doTrim|int:{min:1,max:10}"`
- 提示信息,`validate-success`自定义验证通过时显示信息,不设置则不显示。`validate-fail`自定义验证失败时的显示信息,不设置则显示默认信息。
- 提示信息位置`validate-tips-position`,默认位置为'bottom-start',即在被验证元素底部,左侧对齐位置显示验证结果。可接受的value为:
```
'top', 'top-start', 'top-end',
'right', 'right-start', 'right-end',
'bottom', 'bottom-start', 'bottom-end',
'left', 'left-start', 'left-end'
```

### 示例
```html
<input class="validate" validate-rule="int|len:{min:3,max:5}" validate-success="输入正确" validate-fail="请输入数字" placeholder="输入整数">
<script type="text/javascript">
validate.autoValidate();
</script>
```

支持自定义验证规则
```html
<input class="validate" validate-rule="myRule:{min:1,max:2}" placeholder="自定义规则">
<script type="text/javascript">
function myRuleFunction (inputValue, ruleParams) {
/*
** inputValue为input标签获取的value,自定义的rule函数需接受此参数,不可省略。
** ruleParams为验证规则的参数,即为示例中的{min:1,max:2},无需规则参数时可以省略
**
*/
}
// 此处进行相关验证或是其他处理逻辑
return true //必须返回true 或 false
}
validate.addRule('myRule', myRuleFunction) //增加规则到validate对象。'myRule'需与validate-rule中一致。
validate.autoValidate();
</script>
```
对于radio和checkbox可能存在的组合验证,可通过validate-group指定相同的名称进行组合,一组相同的validate-group只需
在其中的一个element中指定validate-rule,相关的验证结果会显示在具有validate-rule的element下面。
```html
<div><input type="radio" class="validate" name="radio" value="radio1" validate-group="group1"/> radio1</div>
<div><input type="radio" class="validate" name="radio" value="radio2" validate-group="group1" validate-rule="in:['radio2','radio3']"/> radio2</div>
```
### 支持的规则
同[validator.js][validator-url]一致,参数部分通过`:`分割,例如:`len:{min:6,max:50}`,`in:['a','b']`,`str|contains:"abc"`
```bash
contains, equals, afterDate, alpha, alphanumeric, ascii, base64, beforeDate, boolean, byteLen, creditCard,
currency, uri, decimal, divisibleBy, email, domain, float ,withFullWidth, withHalfWidth, hexColor, hexadecimal,
empty, ip, isbn, issn, isin, date, isrc, in, int, json, len, lowercase, macAdd, md5, mobile, mongoId, multiByte,
numeric, surrogatePair, url, uuid, uppercase, variableWidth, whiteList, matches,
doRemoveBlackList, doEscape, doUnescape, doTrimLeft, doTrimRight, doRemoveLowercase, doToBoolean, doToDate,
doToFloat, doToInt, doTrim, doToString, doKeepWhiteList, doNormalizeEmail
```
### 基于源文件开发
```bash
# git clone
npm install
npm run dev # 开启dev调试server,对src文件夹下的源文件作出修改后,可在http://localhost:8080/增加相应的规则进行检测
npm run build # 生成对应的dist模块文件以及validate-js.min.js文件
```
### License (MIT)
Code and documentation copyright 2017 Ysanwen. Code released under the [MIT license][mit-url]
[validator-url]: https://github.com/chriso/validator.js
[tooltip-url]: https://github.com/FezVrasta/popper.js
[mit-url]: https://github.com/FezVrasta/popper.js/blob/master/LICENSE.md | 3,965 | MIT |
---
date: 2016-01-05 16:17:02
layout: post
title: 2016.01.05 多面世界
categories: CheriShe
tags: [life, love, mood]
toc: true
---
好像,只有难听的话表达得才最为真实。
而其他的话,无论好坏,都可能会跟上转折。
比如,你真丑(我真的嫌弃你);
比如,你真胖(我真的嫌弃你);
比如,你真矮(我真的嫌弃你);
比如,……
<!-- more -->
比如,天很晚了(我不想见到你);
比如,我吃饱了(我不想见到你);
比如,你很忙啊(我不想见到你);
比如,……
比如,你是好人(但我不喜欢你);
比如,你很优秀(但我不喜欢你);
比如,你很体贴(但我不喜欢你);
比如,……
我一直不能明白,什么话像说出来的那么简单,什么话有更深的一层含义。
我也一直不能明白,为什么两个人能一个像夏天,一个像冬天。
有的人,在外面很坚强,总是努力保持着微笑,却总是对着屏幕哭得很伤心;
也有的人,内外都脆弱,总是轻易落下眼泪,却也总是对着屏幕开怀大笑。
有的人,想得很多,肩负起责任,想要无忧无虑却总是劳心劳累;
也有的人,不去想未来,依然不轻松,想没有烦恼却只能没心没肺。
有的人,充满了希望,总是想从黑暗中找寻出一丝光亮;
也有的人,躲在阴影下,即便是晴天也只注意到一片乌云。
这是一个多面的世界,有光照的地方,自然有阴暗。
我不愿从别人的表情里揣测到这个世界有多么美好,所以我学会了用耳倾听;
我不愿从别人的言语里听闻到这个世界有多么美好,所以我学会了用眼观察;
我不愿从别人的生活里目睹到这个世界有多么美好,所以我学会了用心体会。
这是一个不完美的世界,有人欢笑,自然有人哀伤。
悲伤的人那么多,不要再多一个两个你我。
每一场暴雨终究都会停歇,就像每一幕黑夜终究都会白昼。
每一段烦恼也终究都会消散。
一切都会好起来。
你要相信。 | 835 | Apache-2.0 |
---
title: Card 卡片
---
用于卡片化展示数据,为`ContentControl`的派生类
```cs
public class Card : ContentControl
```
# 基础属性
| 属性 | 用途 |
| ---------------------- | ------------------------------ |
| Header | 卡片头部内容,用于显示同步文本 |
| HeaderTemplate | 卡片头部模板 |
| HeaderTemplateSelector | 卡片模板样式选择器 |
| HeaderStringFormat | 卡片头部模板内容显示格式 |
| Footer | 卡片尾部内容 |
| FooterTemplate | 卡片尾部模板 |
| FooterTemplateSelector | 卡片尾部样式选择器 |
| FooterStringFormat | 卡片尾部内容显示格式 |
# 案例
## 单卡片使用
### `xaml`中使用
```xml
<hc:Card MaxWidth="240" BorderThickness="0" Effect="{DynamicResource EffectShadow2}" Margin="8">
<!--Card 的内容部分-->
<Border CornerRadius="4,4,0,0" Width="160" Height="160">
<TextBlock TextWrapping="Wrap" VerticalAlignment="Center" HorizontalAlignment="Center" Text="测试"/>
</Border>
<!--Card 的尾部部分-->
<hc:Card.Footer>
<StackPanel Margin="10" Width="160">
<!--Card 的一级内容-->
<TextBlock TextWrapping="NoWrap" Style="{DynamicResource TextBlockLargeBold}" TextTrimming="CharacterEllipsis"
Text="大标题"
HorizontalAlignment="Left"/>
<!--Card 的二级内容-->
<TextBlock TextWrapping="NoWrap" Style="{DynamicResource TextBlockDefault}" TextTrimming="CharacterEllipsis"
Text="描述信息" Margin="0,6,0,0"
HorizontalAlignment="Left"/>
</StackPanel>
</hc:Card.Footer>
</hc:Card>
```
### 效果
## 作为数据模板
### 数据类型
```c#
public class CardModel
{
public string Header { get; set; }
public string Content { get; set; }
public string Footer { get; set; }
}
```
### 视图实体
此实体并没有按照规范的`mvvm`方式进行设计,仅仅是作为普通数据源做展示使用
```c#
public class CardDemoViewModel
{
private IList<CardModel> _dataList;
public CardDemoViewModel()
{
DataList = GetCardDataList();
}
internal ObservableCollection<CardModel> GetCardDataList()
{
return new ObservableCollection<CardModel>
{
new CardModel
{
Header = "Atomic",
Content = "1.jpg",
Footer = "Stive Morgan"
},
new CardModel
{
Header = "Zinderlong",
Content = "2.jpg",
Footer = "Zonderling"
},
new CardModel
{
Header = "Busy Doin' Nothin'",
Content = "3.jpg",
Footer = "Ace Wilder"
},
new CardModel
{
Header = "Wrong",
Content = "4.jpg",
Footer = "Blaxy Girls"
},
new CardModel
{
Header = "The Lights",
Content = "5.jpg",
Footer = "Panda Eyes"
},
new CardModel
{
Header = "EA7-50-Cent Disco",
Content = "6.jpg",
Footer = "еяхат музыка"
},
new CardModel
{
Header = "Monsters",
Content = "7.jpg",
Footer = "Different Heaven"
},
new CardModel
{
Header = "Gangsta Walk",
Content = "8.jpg",
Footer = "Illusionize"
},
new CardModel
{
Header = "Won't Back Down",
Content = "9.jpg",
Footer = "Boehm"
},
new CardModel
{
Header = "Katchi",
Content = "10.jpg",
Footer = "Ofenbach"
}
};
}
public IList<CardModel> DataList { get => _dataList; set => _dataList = value; }
}
```
### `xaml`中的使用方式
`handycontrol`的命名空间和`DataContext`上下文需要自行引入
```xml
xmlns:hc="https://handyorg.github.io/handycontrol"
xmlns:data="CardModel所在命名空间"
xmlns:vm="CardDemoViewModel所在命名空间"
........
```
```xml
<!--在listbox的父级中使用-->
<listbox的父级.Resources>
<vm:CardDemoViewModel x:Key="Card"></vm:CardDemoViewModel>
</listbox的父级.Resources>
<listbox的父级.DataContext>
<Binding Source="{StaticResource Card}"/>
</listbox的父级.DataContext>
```
```xml
<ListBox Margin="32" BorderThickness="0" Style="{DynamicResource WrapPanelHorizontalListBox}" ItemsSource="{Binding DataList}">
<ListBox.ItemTemplate>
<DataTemplate DataType="data:CardModel">
<hc:Card MaxWidth="240" BorderThickness="0" Effect="{DynamicResource EffectShadow2}" Margin="8" Footer="{Binding Footer}">
<!--Card 的内容部分模板-->
<Border CornerRadius="4,4,0,0" Width="160" Height="160">
<TextBlock TextWrapping="Wrap" VerticalAlignment="Center" HorizontalAlignment="Center" Text="{Binding Content}"/>
</Border>
<!--Card 的尾部部分模板-->
<hc:Card.FooterTemplate>
<DataTemplate>
<StackPanel Margin="10" Width="160">
<!--Card 的一级内容-->
<TextBlock TextWrapping="NoWrap" Style="{DynamicResource TextBlockLargeBold}" TextTrimming="CharacterEllipsis"
Text="{Binding DataContext.Header,RelativeSource={RelativeSource AncestorType=hc:Card}}"
HorizontalAlignment="Left"/>
<!--Card 的二级内容-->
<TextBlock TextWrapping="NoWrap" Style="{DynamicResource TextBlockDefault}" TextTrimming="CharacterEllipsis"
Text="{Binding}" Margin="0,6,0,0"
HorizontalAlignment="Left"/>
</StackPanel>
</DataTemplate>
</hc:Card.FooterTemplate>
</hc:Card>
</DataTemplate>
</ListBox.ItemTemplate>
</ListBox>
```
### 效果
 | 6,957 | MIT |
Oauth2:
AuthorizationServerConfigurer
TokenGranter OAuth2授予令牌
AuthorizationCodeTokenGranter 授权码模式
RefreshTokenGranter 刷新 token 模式
ImplicitTokenGranter implicit 模式
ClientCredentialsTokenGranter 客户端模式
ResourceOwnerPasswordTokenGranter 密码模式
实现AbstractTokenGranter 自定义模式
TokenStore 令牌存储
AccessTokenConverter JwtAccessTokenConverter: Jwt Access Token转换实例
AuthenticationManager 授权管理者:用于整合oauth2的password授权模式
ClientDetailsService InMemoryClientDetailsService/JdbcClientDetailsService Oauth2存储客户端信息
TokenEnhancer
DefaultTokenServices
Security:
WebSecurity.IgnoredRequestConfigurer
CredentialsContainer
UserDetails
User
GrantedAuthority 已授予的权限
UserDetailsService 自定义用户信息: 实现它:代理掉loadUserByUsername()方法,由业务自己实现 参考:ApiBootUserDetailsService
AuthenticationEntryPoint 端点处理
AccessDeniedHandler 异常处理 实现它:认证异常自定义返回格式化内容到前端 参考:ApiBootDefaultAccessDeniedHandler
AuthenticationSuccessHandler
AuthenticationFailureHandler
@Autowired
private ObjectMapper mapper;
@Override
public void onAuthenticationFailure(HttpServletRequest request, HttpServletResponse response,
AuthenticationException exception) throws IOException {
String message;
if (exception instanceof UsernameNotFoundException) {
message = "用户不存在!";
} else if (exception instanceof BadCredentialsException) {
message = "用户名或密码错误!";
} else if (exception instanceof LockedException) {
message = "用户已被锁定!";
} else if (exception instanceof DisabledException) {
message = "用户不可用!";
} else if (exception instanceof AccountExpiredException) {
message = "账户已过期!";
} else if (exception instanceof CredentialsExpiredException) {
message = "用户密码已过期!";
} else if (exception instanceof ValidateCodeException || exception instanceof FebsCredentialExcetion) {
message = exception.getMessage();
} else {
message = "认证失败,请联系网站管理员!";
}
response.setContentType(FebsConstant.JSON_UTF8);
response.getWriter().write(mapper.writeValueAsString(ResponseBo.error(message)));
}
TODO 自定义Filter
参考:ApiBootOauthTokenGranter
在WebSecurityConfigurerAdapter的实现类中添加:Cors支持
@Bean
public UrlBasedCorsConfigurationSource corsConfigurationSource(){
CorsConfiguration corsConfiguration = new CorsConfiguration();
corsConfiguration.addAllowedMethod("*");
corsConfiguration.addAllowedOrigin("*");
corsConfiguration.addAllowedHeader("*");
corsConfiguration.setAllowCredentials(true);
UrlBasedCorsConfigurationSource corsConfigurationSource = new UrlBasedCorsConfigurationSource();
corsConfigurationSource.registerCorsConfiguration("/**",corsConfiguration);
return corsConfigurationSource;
}
配置自定义用户:
实现UserDetailsService类
提供UserDetails对象包括其权限:【AuthorityUtils.commaSeparatedStringToAuthorityList(permissions)】
认证
1. AbstractAuthenticationProcessingFilter 拦截请求的username和password
2. 将拦截到的username放入:AbstractAuthenticationToken 中,密码可以一起打包成string放进去
3. 将其他HttpServletRequest信息放入:AbstractAuthenticationToken的detail中
private void setDetails(HttpServletRequest request,
SmsCodeAuthenticationToken authRequest) {
authRequest.setDetails(authenticationDetailsSource.buildDetails(request));
}
4. 实现AuthenticationProvider的认证方法
验证用户是否存在
密码是否正确
最后给与当前userdetial和对应权限出去
SmsCodeAuthenticationToken(String mobile) {
super(null);
this.principal = mobile;
setAuthenticated(false);
}
SmsCodeAuthenticationToken(Object principal, Collection<? extends GrantedAuthority> authorities) {
super(authorities);
this.principal = principal;
super.setAuthenticated(true);
}
@Override
public Authentication authenticate(Authentication authentication) {
SmsCodeAuthenticationToken authenticationToken = (SmsCodeAuthenticationToken) authentication;
UserDetails userDetails = userDetailService.loadUserByUsername((String) authenticationToken.getPrincipal());
if (userDetails == null)
throw new InternalAuthenticationServiceException("没有该用户!");
SmsCodeAuthenticationToken authenticationResult = new SmsCodeAuthenticationToken(userDetails, userDetails.getAuthorities());
authenticationResult.setDetails(authenticationToken.getDetails());
return authenticationResult;
}
5. 实现handler
成功失败拒绝等
6. 实现SecurityConfigurerAdapter
配置拦截器
apply到 WebSecurityConfigurerAdapter | 5,352 | Apache-2.0 |
# laravel-admin iframe-tabs
## Installation
Run :
```
$ composer require ichynul/iframe-tabs
```
Then run:
```
$ php artisan vendor:publish --tag=iframe-tabs
$ php artisan admin:import iframe-tabs
```
## Update it
[2019-10-19] 修复左边菜单很多的时候上下滚动无效的bug#32#29#21.修改了dashboard.css样式,升级后记得`php artisan vendor:publish --tag=iframe-tabs --force`更新一下样式.
(本扩展依赖一些 js 和 css 文件,composer update 若版本号有变请强制发布资源,可能是更新了某些样式)
After `composer update` , if version of this extension changed :
Run
```
php artisan vendor:publish --tag=iframe-tabs --force
```
This will override css and js fiels to `/public/vendor/laravel-admin-ext/iframe-tabs/`
Or you can and a script in `composer.json` :
```json
"scripts": {
"post-update-cmd": "php artisan vendor:publish --tag=iframe-tabs --force",
}
```
## Config
Add a config in `config/admin.php`:
```php
'extensions' => [
'iframe-tabs' => [
// Set to `false` if you want to disable this extension
'enable' => true,
// The controller and action of dashboard page `/admin/dashboard`
'home_action' => App\Admin\Controllers\HomeController::class . '@index',
// Default page tab-title
'home_title' => 'Home',
// Default page tab-title icon
'home_icon' => 'fa-home',
// Whether show icon befor titles for all tab
'use_icon' => true,
// dashboard css
'tabs_css' =>'vendor/laravel-admin-ext/iframe-tabs/dashboard.css',
// layer.js path
'layer_path' => 'vendor/laravel-admin-ext/iframe-tabs/layer/layer.js',
/**
* href links do not open in tab .
* selecter : .sidebar-menu li a,.navbar-nav>li a,.sidebar .user-panel a,.sidebar-form .dropdown-menu li a
* if(href.indexOf(pass_urls[i]) > -1) //pass
*/
'pass_urls' => ['/auth/logout', '/auth/lock'],
// When login session state of a tab-page was expired , force top-level window goto login page .
'force_login_in_top' => true,
// tabs left offset
'tabs_left' => 42,
// bind click event of table actions [edit / view]
'bind_urls' => 'popup', //[ popup / new_tab / none]
//table actions dom selecter
'bind_selecter' => '.box-body table.table tbody a.grid-row-view,.box-body table.table tbody a.grid-row-edit,.box-header .pull-right .btn-success,.popup',
//table action links [view edit] and create button ,and any thing has class pupop : <a class="pupop" popw="400px" poph="200px" href="someurl">mylink</a>
]
],
```
If `bind_urls` set to `popup` or `new_tab` , recommend `disableView` and `disableList` in form
`/Admin/bootstrap.php` :
```php
Encore\Admin\Form::init(function ($form) {
$form->tools(function ($tools) {
$tools->disableDelete();
$tools->disableView();
$tools->disableList();
});
});
```
See https://laravel-admin.org/docs/zh/model-form-init
And `disableEdit` and `disableList` in show :
```php
$show->panel()
->tools(function ($tools) {
$tools->disableEdit();
$tools->disableList();
$tools->disableDelete();
});;
```
## Lang
Add a lang config in `resources/lang/{zh-CN}/admin.php`
```php
'iframe_tabs' => [
'oprations' => '页签操作',
'refresh_current' => '刷新当前',
'close_current' => '关闭当前',
'close_all' => '关闭全部',
'close_other' => '关闭其他',
'open_in_new' => '新窗口打开',
'open_in_pop' => '弹出窗打开',
'scroll_left' => '滚动到最左',
'scroll_right' => '滚动到最右',
'scroll_current' => '滚动到当前',
'goto_login' => '登录超时,正在跳转登录页面...'
],
```
## Usage
Open `http://your-host/admin`
Thanks to https://github.com/bswsfhcw/AdminLTE-With-Iframe
License
---
Licensed under [The MIT License (MIT)](LICENSE). | 3,895 | MIT |
---
title: 用phar-composer来构建基于composer的phar包
layout: post
category: php
author: 夏泽民
---
phar.readonly=off
本文成功执行的前提依然是php.ini中的phar.readonly=off。
如果您自己的项目,是基于composer的。并且需要打包成phar文件。那么本条内容,就是您所需要的。我们需要在当前项目根目录下面,执行如下语句。
phar-composer build
但是这条语句顺利生成一个phar文件的前提是:该目录使用composer进行管理。也就是说:根目录下面应该有个composer.json。这个文件,我们可以通过下面命令生成。
composer init
这样的话,我们就符合这个phar-compser工具的执行条件了。事实上,代码还是我们的代码,仅仅多了个没有什么用途的composer.json文件而已。这个就免得我们大家再写个构建脚本了。还是挺容易的,推荐使用。如果您还是需要依赖包的话,您还可能需要下列命令。
composer install
通过git地址打包phar
还是以上述需求为例,我们打包一下aliyun的oss库。
Bash
phar-composer build https://github.com/aliyun/aliyun-oss-php-sdk.git
通过命令行交互式打包
Bash
phar-composer
输入要打包的项目关键词,选择要打包的序号。
<!-- more -->
Git Clone代码到本地:复制
git clone http://www.github.com/clue/phar-composer
https://www.kutu66.com/GitHub/article_102438
https://github.com/clue/phar-composer
https://github.com/clue/phar-composer#phar-composer
{% raw %}
humbug/box 是一款快速的、零配置的 PHAR 打包工具。
还记得前些天的《SMProxy, 让你的数据库操作快三倍!》吗,该项目的 PHAR 便是使用 Box 打包完成的。
该项目是 box-project/box2 的 Fork 分支,原项目已经不再维护。新项目的作者呼吁我们支持该 Fork。
Box 的可配置项有很多,为了能够快速帮助大家了解用法,接下来我将使用 SMProxy 的 box.json 作为例子给大家做一个简单的介绍。
推荐一篇预备知识,可以帮你简单了解 PHAR 的部分用途:使用 phar 上线你的代码包。
首先,正如 Box 作者的描述:
Fast, zero config application bundler with PHARs.
我们默认无需任何配置,在你的 PHP 应用的根目录执行:
composer require humbug/box
vendor/bin/box compile
即可生成一个基本的 PHAR 包文件。
Box 的配置文件为应用根目录的 box.json,例如 SMProxy 项目的该文件内容为:
{
"main": "bin/SMProxy",
"output": "SMProxy.phar",
"directories": [
"bin",
"src"
],
"finder": [
{
"notName": "/LICENSE|.*\\.md|.*\\.dist|composer\\.json|composer\\.lock/",
"exclude": [
"doc",
"docs",
"test",
"test_old",
"tests",
"Tests",
"vendor-bin"
],
"in": "vendor"
},
{
"name": "composer.json",
"in": "."
}
],
"compression": "NONE",
"compactors": [
"KevinGH\\Box\\Compactor\\Json",
"KevinGH\\Box\\Compactor\\Php"
],
"git": "phar-version"
}
main 用于设定应用的入口文件,也就是打包 PHAR 后,直接运行该 PHAR 包所执行的代码,你可以在某种意义上理解为 index.php。
output 用于设定 PHAR 的输出文件,可以包含目录,相对路径或绝对路径。
directories 用于指定打包的 PHP 源码目录。
finder 配置相对比较复杂,底层是使用 Symfony/Finder 实现,与 PHP-CS-Fixer 的 Finder 规则类似。在以上例子中,包含两个 Finder;第一个定义在 vendor 文件夹内,排除指定名称的文件和目录;第二个表示包含应用根目录的 composer.json。
compression 用于设定 PHAR 文件打包时使用的压缩算法。可选值有:GZ(最常用) / BZ2 / NONE(默认)。但有一点需要注意:使用 GZ 要求运行 PHAR 的 PHP 环境已启用 Gzip 扩展,否则会造成报错。
compactors 用于设定压缩器,但此处的压缩器不同于上文所介绍的 compression;一个压缩器类实例可压缩特定文件类型,降低文件大小,例如以下 Box 自带的压缩器:
KevinGH\Box\Compactor\Json:压缩 JSON 文件,去除空格和缩进等。
KevinGH\Box\Compactor\Php:压缩 PHP 文件,去除注释和 PHPDoc 等。
KevinGH\Box\Compactor\PhpScoper:使用 humbug/php-scoper 隔离代码。
git 用于设定一个「占位符」,打包时将会扫描文件内是否含有此处定义的占位符,若存在将会替换为使用 Git 最新 Tag 和 Commit 生成的版本号(例如 2.0.0 或 2.0.0@e558e33)。你可以参考 这里 的代码来更加深入地理解该用法。
{% endraw %}
注意事(坑)项(点)
假如你打包的项目中,入口文件index.php 要引入(include or require)项目中的其他脚本,务必使用绝对路径,否则你打包成phar包之后,其他项目要引入这个phar就会路径出错!!,即如下:
<?php //这是index.php 入口文件
require __DIR__."/src/controller.php"; //要使用绝对路径
require "./lib/tools.php"; //不要使用相对路径
https://dawnki.github.io/2017/07/04/Phar/
https://newsn.net/say/php-phar-create.html
https://packagist.org/
https://m.yisu.com/zixun/39302.html
一个php应用程序往往是由多个文件构成的,如果能把他们集中为一个文件来分发和运行是很方便的,这样的列子有很多,比如在window操作系统上面的安装程序、一个jquery库等等,为了做到这点php采用了phar文档文件格式,这个概念源自java的jar,但是在设计时主要针对 PHP 的 Web 环境,与 JAR 归档不同的是Phar 归档可由 PHP 本身处理,因此不需要使用额外的工具来创建或使用,使用php脚本就能创建或提取它。phar是一个合成词,由PHP 和 Archive构成,可以看出它是php归档文件的意思。
关于phar的官网文档请见http://php.net/manual/en/book.phar.php,本文档可以看做和官网文档互为补充
phar归档文件有三种格式:tar归档、zip归档、phar归档,前两种执行需要php安装Phar 扩展支持,用的也比较少,这里主要讲phar归档格式。
phar格式归档文件可以直接执行,它的产生依赖于Phar扩展,由自己编写的php脚本产生。
Phar 扩展对 PHP 来说并不是一个新鲜的概念,在php5.3已经内建于php中,它最初使用 PHP 编写并被命名为 PHP_Archive,然后在 2005 年被添加到 PEAR 库。由于在实际中,解决这一问题的纯 PHP 解决方案非常缓慢,因此 2007 年重新编写为纯 C 语言扩展,同时添加了使用 SPL 的 ArrayAccess 对象遍历 Phar 归档的支持。自那时起,人们做了大量工作来改善 Phar 归档的性能。
Phar 扩展依赖于php流包装器,关于此可访问笔者的另外一篇帖子:
http://blog.csdn.net/u011474028/article/details/52814049
很多php应用都是以phar格式分发并运行的,著名的有依赖管理:composer、单元测试:phpunit,下面我们来看一看如何创建、运行、提取还原。
phar文件的创建:
首先在php.ini中修改phar.readonly这个选项,去掉前面的分号,并改值为off,由于安全原因该选项默认是on,如果在php.ini中是禁用的(值为0或off),那么在用户脚本中可以开启或关闭,如果在php.ini中是开启的,那么用户脚本是无法关闭的,所以这里设置为off来展示示例。
我们来建立一个项目,在服务器根目录中建立项目文件夹为project,目录内的结构如下:
复制代码
file
-yunek.js
-yunke.css
lib
-lib_a.php
template
-msg.html
index.php
Lib.php
复制代码
其中file文件夹有两个内容为空的js和css文件,仅仅演示phar可以包含多种文件格式
lib_a.php内容如下:
复制代码
<?php
/**
* Created by yunke.
* User: yunke
* Date: 2017/2/10
* Time: 9:23
*/
function show(){
echo "l am show()";
}
复制代码
msg.html内容如下:
复制代码
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>phar</title>
</head>
<body>
<?=$str; ?>
</body>
</html>
复制代码
index.php内容如下:
复制代码
<?php
/**
* Created by yunke.
* User: yunke
* Date: 2017/2/10
* Time: 9:17
*/
require "lib/lib_a.php";
show();
$str = isset($_GET["str"]) ? $_GET["str"] : "hello world";
include "template/msg.html";
复制代码
Lib.php内容如下:
复制代码
<?php
/**
* Created by yunke.
* User: yunke
* Date: 2017/2/10
* Time: 9:20
*/
function yunke()
{
echo "l am yunke()";
}
复制代码
项目文件准备好了,开始创建,现在在project文件夹同级目录建立一个yunkeBuild.php,用于产生phar格式文件,内容如下:
复制代码
<?php
/**
* Created by yunke.
* User: yunke
* Date: 2017/2/10
* Time: 9:36
*/
//产生一个yunke.phar文件
$phar = new Phar('yunke.phar', 0, 'yunke.phar');
// 添加project里面的所有文件到yunke.phar归档文件
$phar->buildFromDirectory(dirname(__FILE__) . '/project');
//设置执行时的入口文件,第一个用于命令行,第二个用于浏览器访问,这里都设置为index.php
$phar->setDefaultStub('index.php', 'index.php');
复制代码
然后在浏览器中访问这个yunkeBuild.php文件,将产生一个yunke.phar文件,此时服务器根目录结构如下:
project
yunkeBuild.php
yunke.phar
这就是产生一个phar归档文件最简单的过程了,更多内容请看官网,这里需要注意的是如果项目不具备单一执行入口则不宜使用phar归档文件
phar归档文件的使用:
我们在服务器根目录建立一个index.php文件来演示如何使用上面创建的phar文件,内容如下:
复制代码
<?php
/**
* Created by yunke.
* User: yunke
* Date: 2017/2/8
* Time: 9:33
*/
require "yunke.phar";
require "phar://yunke.phar/Lib.php";
yunke();
复制代码
如果index.php文件中只有第一行,那么和不使用归档文件时,添加如下代码完全相同:
require "project/index.php";
如果没有第二行,那么第三行的yunke()将提示未定义,所以可见require一个phar文件时并不是导入了里面所有的文件,而只是导入了入口执行文件而已,但在实际项目中往往在这个入口文件里导入其他需要使用的文件,在本例中入口执行文件为project/index.php
phar文件的提取还原:
我们有时候会好奇phar里面包含的文件源码,这个时候就需要将phar文件还原,如果只是看一看的话可以使用一些ide工具,比如phpstorm 10就能直接打开它,如果需要修改那么就需要提取操作了,为了演示,我们下载一个composer.phar放在服务器目录,在根目录建立一个get.php文件,内容如下:
复制代码
<?php
/**
* Created by yunke.
* User: yunke
* Date: 2017/2/9
* Time: 19:02
*/
$phar = new Phar('composer.phar');
$phar->extractTo('composer'); //提取一份原项目文件
$phar->convertToData(Phar::ZIP); //另外再提取一份,和上行二选一即可
复制代码
用浏览器访问这个文件,即可提取出来,以上列子展示了两种提取方式:第二行将建立一个composer目录,并将提取出来的内容放入,第三行将产生一个composer.zip文件,解压即可得到提取还原的项目文件。
补充:
1、在部署phar文件到生产服务器时需要调整服务器的配置,避免当访问时浏览器直接下载phar文件
2、可以为归档设置别名,别名保存在归档文件中永久保存,它可以用一个简短的名字引用归档,而不管归档文件在文件系统中存储在那里,设置别名:
$phar = new Phar('lib/yunke.phar', 0);
$phar->setAlias ( "yun.phar");
<?php
require "lib/yunke.phar";
require "phar://yun.phar/Lib.php"; //使用别名访问归档文件
require "phar://lib/yunke.phar/Lib.php"; //当然仍然可以使用这样的方式去引用
如果在制作phar文件时没有指定别名,也可以在存根文件里面使用Phar::mapPhar('yunke.phar');指定
3、归档文件中有一个存根文件,其实就是一段php执行代码,在制作归档时可以设置,直接执行归档文件时,其实就是执行它,所以它是启动文件;在脚本中包含归档文件时就像包含普通php文件一样包含它并运行,但直接以phar://的方式包含归档中某一个文件时不会执行存根代码, 往往在存根文件里面require包含要运行的其他文件,对存根文件的限制仅为以__HALT_COMPILER();结束,默认的存根设计是为在没有phar扩展时能够运行,它提取phar文件内容到一个临时目录再执行,不过从php5.3开始该扩展默认内置启用了
4、制作的phar文件不能被改动,因此配置文件之类的文件需要另外放置在归档文件外面
5、mapPhar函数:这个函数只应该在stub存根代码中调用,在没有设置归档别名的时候可以用来设置别名,打开一个引用映射到phar流
https://www.cnblogs.com/fps2tao/p/8717569.html | 7,763 | MIT |
---
layout: blog
title: AngularJS 路由:ng-route 与 ui-router
tags: AngularJS HTML JavaScript MVC 模板 路由
---
[AngularJS][angular]的[ng-route][ng-route]模块为控制器和视图提供了[Deep-Linking]URL。
通俗来讲,[ng-route][ng-route]模块中的`$route`Service监测`$location.url()`的变化,并将它映射到预先定义的控制器。也就是在客户端进行URL的路由。
下面首先给出`$route`的使用示例,然后引入一个更加强大的客户端路由框架[ui-router][ui-router]。
## Angular 路由
在APP中定义多个页面的控制器,并给出对应的模板。然后`$routeProvider`进行配置,即可将URL映射到这些控制器和视图。
首先定义一个基本的Angular APP,并引入`ngRoute`:
> Angular`$route`Service在`ngRoute`模块里。需要引入它对应的javascript文件,并在我们的APP里`ngRoute`添加为模块依赖([如何添加模块依赖?][module])。
```javascript
var app = angular.module('ngRouteExample', ['ngRoute'])
.controller('MainController', function($scope) {
})
.config(function($routeProvider, $locationProvider) {
$routeProvider
.when('/users', {
templateUrl: 'user-list.html',
controller: 'UserListCtrl'
})
.when('/users/:username', {
templateUrl: 'user.html',
controller: 'UserCtrl'
});
// configure html5
$locationProvider.html5Mode(true);
});
```
上述代码中,`$routeProvider`定义了两个URL的映射:`/users`使用`user-list.html`作为模板,`UserListCtrl`作为控制器;
`/users/:username`则会匹配类似`/users/alice`之类的URL,稍后你会看到如何获得`:username`匹配到的值。先看首页的模板:
> **HTML5Mode**: 服务器端路由和客户端路由的URL以`#`分隔。例如`/foo/bar#/users/alice`,Angular通过操作锚点来进行路由。
> 然而`html5Mode(true)`将会去除`#`,URL变成`/foo/bar/users/alice`(这需要浏览器支持HTML5的,因为此时Angular通过`pushState`来进行路由)。
> 此时服务器对所有的客户端路由的URL都需要返回首页(`/foo/bar`)视图,再交给Angular路由到`/foo/bar/users/alice`对应的视图。
```html
<div ng-controller="MainController">
Choose:
<a href="users">user list</a> |
<a href="users/alice">user: alice</a>
<div ng-view></div>
</div>
```
注意到模板文件中有一个`div[ng-view]`,子页面将会载入到这里。
<!--more-->
## 路由参数
接着我们定义上述路由配置的子页面控制器和视图模板。用户列表页面:
```javascript
app.controller('UserListCtrl', function($scope) {});
```
```html
<!--user-list.html-->
<h1>User List Page</h1>
```
用户页面:
```javascript
app.controller('UserCtrl', function($scope, $routeParams) {
$scope.params = $routeParams;
});
```
```html
<!--user.html-->
<h1>User Page</h1>
<span ng-bind="params.userName"></span>
```
我们点击首页的`/users/alice`时,将会载入`user.html`,`span`的值为`alice`。[$routeParams][route-params]提供了当前的路由参数,例如:
```javascript
// Given:
// URL: http://server.com/index.html#/Chapter/1/Section/2?search=moby
// Route: /Chapter/:chapterId/Section/:sectionId
//
// Then
$routeParams ==> {chapterId:'1', sectionId:'2', search:'moby'}
```
除了[$routeParams][route-params],Angular还提供了[$location][location]来获取和设置URL。
## UI-Router
[UI-Router][ui-router]是[Angular-UI][angular-ui]提供的客户端路由框架,它解决了原生的[ng-route][ng-route]的很多不足:
1. 视图不能嵌套。这意味着`$scope`会发生不必要的重新载入。这也是我们在[Onboard][onboard]中引入`ui-route`的原因。
2. 同一URL下不支持多个视图。这一需求也是常见的:我们希望导航栏用一个视图(和相应的控制器)、内容部分用另一个视图(和相应的控制器)。
[UI-Router][ui-router]提出了`$state`的概念。一个`$state`是一个当前导航和UI的状态,每个`$state`需要绑定一个URL Pattern。
在控制器和模板中,通过改变`$state`来进行URL的跳转和路由。这是一个简单的例子:
```html
<!-- in index.html -->
<body ng-controller="MainCtrl">
<section ui-view></section>
</body>
```
```javascript
// in app-states.js
$stateProvider
.state('contacts', {
url: '/contacts',
template: 'contacts.html',
controller: 'ContactCtrl'
})
.state('contacts.detail', {
url: "/contacts/:contactId",
templateUrl: 'contacts.detail.html',
controller: function ($stateParams) {
// If we got here from a url of /contacts/42
$stateParams.contactId === "42";
}
});
```
当访问`/contacts`时,`contacts` `$state`被激活,载入对应的控制器和视图。在[ui-router][ui-router]时,通常使用`$state`来完成页面跳转,
而不是直接操作URL。例如,在脚本使用[$state.go][go]:
```javascript
$state.go('contacts'); // 指定state名,相当于跳转到 /contacts
$state.go('contacts.detail', {contactId: 42}); // 相当于跳转到 /contacts/42
```
在模板中使用[ui-sref][sref](这是一个Directive):
```html
<a ui-sref="contacts">Contacts</a>
<a ui-sref="contacts.detail({contactId: 42})">Contact 42</a>
```
## 嵌套视图
不同于Angular原生的[ng-route][ng-route],[ui-router][ui-router]的视图可以嵌套,视图嵌套通常对应着[$state][state]的嵌套。
`contacts.detail`是`contacts`的子`$state`,`contacts.detail.html`也将作为`contacts.html`的子页面:
```html
<!-- contacts.html -->
<h1>My Contacts</h1>
<div ui-view></div>
```
```html
<!-- contacts.detail.html -->
<span ng-bind='contactId'></span>
```
> 上述`ui-view`的用法和`ng-view`看起来很相似,但不同的是`ui-view`可以配合`$state`进行任意层级的嵌套,
> 即`contacts.detail.html`中仍然可以包含一个`ui-view`,它的`$state`可能是`contacts.detail.hobbies`。
## 命名视图
在[ui-router][ui-router]中,一个`$state`下可以有多个视图,它们有各自的模板和控制器。这一点也是[ng-route][ng-route]所没有的,
给了前端路由极大的灵活性。来看例子:
```html
<!-- index.html -->
<body>
<div ui-view="filters"></div>
<div ui-view="tabledata"></div>
<div ui-view="graph"></div>
</body>
```
这一个模板包含了三个命名的`ui-view`,可以给它们分别设置模板和控制器:
```javascript
$stateProvider
.state('report',{
views: {
'filters': {
templateUrl: 'report-filters.html',
controller: function($scope){ ... controller stuff just for filters view ... }
},
'tabledata': {
templateUrl: 'report-table.html',
controller: function($scope){ ... controller stuff just for tabledata view ... }
},
'graph': {
templateUrl: 'report-graph.html',
controller: function($scope){ ... controller stuff just for graph view ... }
}
}
})
```
[state]: http://angular-ui.github.io/ui-router/site/#/api/ui.router.state.$state
[sref]: https://github.com/angular-ui/ui-router/wiki/Quick-Reference#ui-sref
[go]: https://github.com/angular-ui/ui-router/wiki/Quick-Reference#stategoto--toparams--options
[onboard]: https://onboard.cn
[angular-ui]: https://github.com/angular-ui
[route-params]: http://docs.angularjs.cn/api/ngRoute/service/$routeParams
[location]: http://docs.angularjs.cn/api/ng/service/$location
[ng-route]: http://docs.angularjs.cn/api/ngRoute/service/$route
[module]: /web/angular-module.html
[ui-router]: https://github.com/angular-ui/ui-router
[angular]: https://docs.angularjs.org
[dl]: http://en.wikipedia.org/wiki/Deep_linking | 5,990 | CC-BY-4.0 |
---
title: 片段
date: 2021-03-11
---
在 Vue 3 中,组件现在正式支持多根节点组件,即片段!
## Vue2
在2.0中 template中只能包装在一个div中
```html
<!-- Layout.vue -->
<template>
<div>
<header>...</header>
<main>...</main>
<footer>...</footer>
</div>
</template>
```
## Vue3
在3.0中template可以包裹多个根节点
```html
<!-- Layout.vue -->
<template>
<header>...</header>
<main v-bind="$attrs">...</main>
<footer>...</footer>
</template>
``` | 418 | MIT |
## springboot-mybatis-druid整合多数据源
> pom文件
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.0.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.9</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
> 配置文件
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driverClassName: com.mysql.cj.jdbc.Driver
druid:
# 主库数据源
master:
url: jdbc:mysql://localhost:3306/springboot?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false
username: root
password: root
# 从库数据源
slave:
url: jdbc:mysql://ip:3306/springboot?serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false
username: root
password: root
# 初始连接数
initial-size: 10
# 最大连接池数量
max-active: 100
# 最小连接池数量
min-idle: 10
# 配置获取连接等待超时的时间
max-wait: 60000
# 打开PSCache,并且指定每个连接上PSCache的大小
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 20
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
timeBetweenEvictionRunsMillis: 60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
min-evictable-idle-time-millis: 300000
validation-query: SELECT 1 FROM DUAL
test-while-idle: true
test-on-borrow: false
test-on-return: false
stat-view-servlet:
enabled: true
url-pattern: /monitor/druid/*
filter:
stat:
log-slow-sql: true
slow-sql-millis: 1000
merge-sql: false
wall:
config:
multi-statement-allow: true
> 主从数据源配置
MasterDataSourcesConfig,SlaveDataSourcesConfig配置类。
其他的和单独配置mybatis差不多,只不过无需在application文件中指定包路径和mapper.xml文件路径
## 事物问题
> 主数据库
直接使用@Transactional即可
@Override
@Transactional
public void update(SysUser sysUser) {
sysUserMapper.update(sysUser);
int i = 10 / 0;
}
> 从数据库
使用配置的事务管理器,即SlaveDataSourcesConfig类中的slaveTransactionManager
@Override
@Transactional(value = "slaveTransactionManager")
public void update(User user) {
userMapper.update(user);
int i = 10 / 0;
}
## 问题
1、druid的配置文件需放在application文件中,放在application-druid中没读取到 | 3,116 | MIT |
[Qiita記事へのリンク](https://qiita.com/takanassyi/items/f933cdadebae7ddf88bc)
AWS が提供するサービスを組み合わせて、Git で管理された Markdown を PDF に一括変換する CI/CD パイプラインを構築した。
# パイプライン構成図

# 処理フロー
1. Markdown を含むファイルを Git で CodeCommit のリポジトリにプッシュ
2. CodeBuild で CodeCommit から Markdown を含むソース一式を取得
3. ECR にある Pandoc の Docker イメージを利用して Markdown から PDF に変換
4. PDFをまとめて zip に圧縮し S3 へ転送
# パイプライン構築手順
**【注意】各種サービスのリージョンは同一リージョンに揃える必要がある**
## S3
生成したPDFを格納するS3バケットを構築する。特に注意点はなし。
## ECR
Pandoc の Docker イメージをプッシュするためのレジストリを予め作成しておき、Docker イメージをプッシュする。
### Pandoc Docker イメージ
k1low さん作成の Docker イメージを利用させていただきました。[^1]
[^1]: 参考資料 k1low/alpine-pandoc-ja | Docker Hub を参照
```dockerfile
FROM k1low/alpine-pandoc-ja
```
上記 Dockerfile をビルドしたイメージを ECR にプッシュする
### アクセス許可
CodeBuild から ECR の Docker イメージをプルできるようにアクセス許可を与える必要がある。
Pandoc が格納されているレジストリの Permissions を選択し、ポリシー JSON を下記のように編集する
```json
{
"Version": "2008-10-17",
"Statement": [
{
"Sid": "CodeBuildAccess",
"Effect": "Allow",
"Principal": {
"Service": "codebuild.amazonaws.com"
},
"Action": [
"ecr:BatchCheckLayerAvailability",
"ecr:BatchGetImage",
"ecr:GetDownloadUrlForLayer"
]
}
]
}
```

## CodeCommit
Git リポジトリを作成する。
### ディレクトリ構成
```
.
├── buildspec.yml
└── src
├── foo.md
└── bar.md
```
- CodeCommit 上のリポジトリに必要なファイル及びディレクトリ
- buildspec.yml : Codebuild で必要な YAMLファイル。次節で解説。
- src : PDF に変換したい Markdown 一式を格納するディレクトリ。
## CodeBuild
CodeCommit からソース一式と ECR からPandoc の Docker イメージを持ってきて、Markdown を PDF に変換する。
### ビルドプロジェクト作成
- 任意のプロジェクト名を入力
- ソースプロバイダは AWS CodeCommit を選択し、リポジトリは Markdownを含むリポジトリを選択

- 環境イメージはECRにプッシュしたPandocのDocker イメージを利用するため、カスタムイメージを選択
- 本稿のDockerfileを利用する場合、下記のように設定
- 環境タイプは Linux
- イメージレジストリは Amazon ECR
- ECR は自分の ECR アカウント
- レポジトリは Pandoc の Docker イメージをプッシュしたリポジトリ
- 特権付与にチェック
- サービスロールは既存のものがあれば選択、ない場合は新規で作成

- BuildSpec は buildspec.ymlを利用
- アーティファクト(生成した PDF)を任意のS3のバケットにアップロードするように設定

### サービスロールに割り当てるポリシー
今回のCI/CDパイプラインを動作させるために、CodeBuild のサービスロールに下記のポリシーを IAM から割り当てる。
```json
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"ecr:DescribeImageScanFindings",
"ecr:GetLifecyclePolicyPreview",
"ecr:GetDownloadUrlForLayer",
"ecr:GetAuthorizationToken",
"ecr:ListTagsForResource",
"ecr:UploadLayerPart",
"ecr:PutImage",
"ecr:BatchGetImage",
"ecr:CompleteLayerUpload",
"ecr:DescribeImages",
"ecr:InitiateLayerUpload",
"ecr:BatchCheckLayerAvailability",
"ecr:GetRepositoryPolicy",
"ecr:GetLifecyclePolicy"
],
"Resource": "*"
}
]
}
```

### buildspec.yml
実際に Markdown を PDF に変換する処理を buildspec.yml に記述する。
```yaml
version: 0.2
phases:
install:
commands:
- echo Nothing to do in the install phase...
build:
commands:
- echo Build started on `date`
- ls #for execution test on docker environment
- mkdir -p _build
- for file in `find src -type f -name "*.md"`;
do
out=`echo $file | (sed -e s/src/_build/ | sed -e s/\.md//)`;
echo $out.pdf;
pandoc $file -f markdown -o $out.pdf -V documentclass=ltjarticle -V classoption=a4j -V geometry:margin=1in --pdf-engine=lualatex;
done
- ls _build
post_build:
commands:
- echo Build completed on `date`
artifacts:
files:
- '_build/*'
```
上記 YAML の build フェーズの commands が Pandoc の Docker イメージで実行されるコマンド。
`src/` にある Markdown を `_build/` に PDF に変換したファイルを格納する。
artifacts で、 `_build/` にある全ての PDF をアップロードすることを記述している。
## CodePipeline
CodeCommit, CodeBuild をつなげる。デプロイステージは今回は省略した。




これまで構築したサービスが正しく設定されていれば、CodePipelineが成功するはず。

Markdown を編集して CodeCommit に push すると、CodePipeline が動作し、編集した内容を反映させてPDFを作成する。
作成した PDF は ログから保存先の S3 バケットにアクセスできる。zip で保存されているため、ダウンロードして展開すると生成した PDF が参照できる。

# サンプルソース
- GitHubに公開
- https://github.com/takanassyi/md2pdf-pipeline
# 参考資料
- [k1low/alpine-pandoc-ja | Docker Hub](https://hub.docker.com/r/k1low/alpine-pandoc-ja/)
- [GitHub - k1LoW/docker-alpine-pandoc-ja: Pandoc for Japanese based on Alpine Linux](https://github.com/k1LoW/docker-alpine-pandoc-ja)
- [MarkdownからWordやPDF生成ができるようにする (またはPandoc環境の構築方法) (2017/12版) - Copy/Cut/Paste/Hatena](https://k1low.hatenablog.com/entry/2017/12/22/083000)
- [CodeBuild の Docker サンプル - AWS CodeBuild](https://docs.aws.amazon.com/ja_jp/codebuild/latest/userguide/sample-docker.html#sample-docker-files)
- [CodeBuild の Amazon ECR サンプル - AWS CodeBuild](https://docs.aws.amazon.com/ja_jp/codebuild/latest/userguide/sample-ecr.html)
- [MarkdownをCircleCI上でPDFに変換してGoogleドライブにデプロイする \| QUARTETCOM TECH BLOG](https://tech.quartetcom.co.jp/2018/05/14/markdown-pdf-circleci-googledrive-deployment/) | 6,794 | MIT |
---
layout: post
title: react hooks学习
date: 2019-08-17 19:19:00
tags:
- react
---
react hooks 学习. [FAQ](https://zh-hans.reactjs.org/docs/hooks-faq.html#which-versions-of-react-include-hooks)
<!-- more -->
## useState代替state
```
function Example(){
const [ count , setCount ] = useState(0);
return (
<div>
<p>You clicked {count} times</p>
<button onClick={()=>{setCount(count+1)}}>click me</button>
</div>
)
}
```
## useEffect代替常用生命周期函数
实现类似componentWillUnmount的效果,useEffect的第二个参数,它是一个数组,数组中可以写入很多状态对应的变量,意思是当**状态值发生变化时,我们才进行解绑**。但是当传空数组[]时,就是当组件将被销毁时才进行解绑,这也就实现了componentWillUnmount的生命周期函数
```
useEffect(()=>{
// 初始化,更新时
return ()=>{
// 类似于销毁时
}
},[]) // [] 状态发生变化,在达到条件时才触发
```
## useContext 让父子组件传值更简单
`useContext`跨越组件层级直接传递变量,实现共享
```
const CountContext = createContext()
function Parent(){
const [ count , setCount ] = useState(0);
return (
<div>
<p>You clicked {count} times</p>
<button onClick={()=>{setCount(count+1)}}>click me</button>
<CountContext.Provider value={count}> //共享出去
<Child />
</CountContext.Provider>
</div>
)
}
function Child() {
// 接收
const count = useContext(CountContext)
return <h2>{count}</h2>
}
```
## useReducer完成类似的Redux
useReducer可以让代码具有更好的可读性和可维护性
```
function ReducerDemo(){
const [ count , dispatch ] =useReducer((state,action)=>{
switch(action){
case 'add':
return state+1
case 'sub':
return state-1
default:
return state
}
},0)
return (
<div>
<h2>现在的分数是{count}</h2>
<button onClick={()=>dispatch('add')}>Increment</button>
<button onClick={()=>dispatch('sub')}>Decrement</button>
</div>
)
}
```
待续
## useCallback
## useMemo
## useRef
## useImperativeHandle
## useLayoutEffect | 1,984 | Apache-2.0 |
# SOGuidePage
版本第一次安装引导图,支持gif,普通图片!
使用方式
pod 'SOGuidePage'
新建一个引导ViewController,把代码加入即可
/** 支持Gif和普通图片混合 **/
SOGuidePageView *guidePage = [[SOGuidePageView alloc] initWithImgsArray:@[@"1.gif", [UIImage imageNamed:@"img2"], @"img3", [UIImage imageNamed:@"img4"]] guidePageCurrentIdx:nil];
//设置滚动到最后一张图片,继续滚动可以跳转到主页,实现代理方法lastImageGoToMainVC
guidePage.isScrollLastImageToMainVC = YES;
//设置背景颜色
guidePage.guidePageBGColor = [UIColor blackColor];
//设置pageControl的Y位置
guidePage.pageY = 22;
//设置page未选中图片
guidePage.pageNormalImage = [UIImage imageNamed:@"dot_normal"];
//设置page选中时的图片
guidePage.pageCurrentImage = [UIImage imageNamed:@"dot_select"];
guidePage.delegate = self;
//加入开启按钮
UIButton *test = [[UIButton alloc] initWithFrame:CGRectMake(100, 500, 150, 50)];
test.backgroundColor = [UIColor yellowColor];
[test addTarget:self action:@selector(enterClick) forControlEvents:UIControlEventTouchUpInside];
[guidePage.imgs.lastObject addSubview:test];
[self.view addSubview:guidePage]; | 1,072 | MIT |
# 基本使用方法
* 1. 引入必要文件
```
//在使用的View中引入WxParse模块
var WxParse = require('../../wxParse/wxParse.js');
```
```
//在使用的Wxss中引入WxParse.css,可以在app.wxss
@import "/wxParse/wxParse.wxss";
```
* 2. 数据绑定
```
var article = '<div>我是HTML代码</div>';
/**
* WxParse.wxParse(bindName , type, data, target,imagePadding)
* 1.bindName绑定的数据名(必填)
* 2.type可以为html或者md(必填)
* 3.data为传入的具体数据(必填)
* 4.target为Page对象,一般为this(必填)
* 5.imagePadding为当图片自适应是左右的单一padding(默认为0,可选)
*/
var that = this;
WxParse.wxParse('article', 'html', article, that, 5);
```
* 3. 模版引用
```
// 引入模板
<import src="你的路径/wxParse/wxParse.wxml"/>
//这里data中article为bindName
<template is="wxParse" data="{{wxParseData:article.nodes}}"/>
```
* 4.详细方法参考:
https://github.com/icindy/wxParse/edit/master/README.md | 750 | MIT |
# 精尽 Spring MVC 面试题
以下面试题,基于网络整理,和自己编辑。具体参考的文章,会在文末给出所有的链接。
如果胖友有自己的疑问,欢迎在星球提问,我们一起整理吊吊的 Spring MVC 面试题的大保健。
而题目的难度,艿艿尽量按照从容易到困难的顺序,逐步下去。
当然,艿艿还是非常推荐胖友去撸一撸 Spring MVC 的源码,特别是如下两篇:
- [《精尽 Spring MVC 源码分析 —— 组件一览》](http://svip.iocoder.cn/Spring-MVC/Components-intro/)
- [《精尽 Spring MVC 源码分析 —— 请求处理一览》](http://svip.iocoder.cn/Spring-MVC/DispatcherServlet-process-request-intro/)
考虑到 Spring MVC 和 Rest 关系比较大,所以本文一共分成两大块:
- Spring MVC
- REST
# Spring MVC
## Spring MVC 框架有什么用?
Spring Web MVC 框架提供”模型-视图-控制器”( Model-View-Controller )架构和随时可用的组件,用于开发灵活且松散耦合的 Web 应用程序。
MVC 模式有助于分离应用程序的不同方面,如输入逻辑,业务逻辑和 UI 逻辑,同时在所有这些元素之间提供松散耦合。
## 介绍下 Spring MVC 的核心组件?
Spring MVC 一共有九大核心组件,分别是:
- MultipartResolver
- LocaleResolver
- ThemeResolver
- HandlerMapping
- HandlerAdapter
- HandlerExceptionResolver
- RequestToViewNameTranslator
- ViewResolver
- FlashMapManager
虽然很多,但是在前后端分离的架构中,在 [「描述一下 DispatcherServlet 的工作流程?」](http://svip.iocoder.cn/Spring-MVC/Interview/#) 问题中,我们会明白,最关键的只有 HandlerMapping + HandlerAdapter + HandlerExceptionResolver 。
关于每个组件的说明,直接看 [《精尽 Spring MVC 源码分析 —— 组件一览》](http://svip.iocoder.cn/Spring-MVC/Components-intro/) 。
## 描述一下 DispatcherServlet 的工作流程?
DispatcherServlet 的工作流程可以用一幅图来说明:

① **发送请求**
用户向服务器发送 HTTP 请求,请求被 Spring MVC 的调度控制器 DispatcherServlet 捕获。
② **映射处理器**
DispatcherServlet 根据请求 URL ,调用 HandlerMapping 获得该 Handler 配置的所有相关的对象(包括 **Handler** 对象以及 Handler 对象对应的**拦截器**),最后以 HandlerExecutionChain 对象的形式返回。
- 即 HandlerExecutionChain 中,包含对应的 **Handler** 对象和**拦截器**们。
> 此处,对应的方法如下:
>
> ```
> > // HandlerMapping.java
> >
> > @Nullable
> > HandlerExecutionChain getHandler(HttpServletRequest request) throws Exception;
> >
> ```
③ **处理器适配**
DispatcherServlet 根据获得的 Handler,选择一个合适的HandlerAdapter 。(附注:如果成功获得 HandlerAdapter 后,此时将开始执行拦截器的 `#preHandler(...)` 方法)。
提取请求 Request 中的模型数据,填充 Handler 入参,开始执行Handler(Controller)。 在填充Handler的入参过程中,根据你的配置,Spring 将帮你做一些额外的工作:
- HttpMessageConverter :会将请求消息(如 JSON、XML 等数据)转换成一个对象。
- 数据转换:对请求消息进行数据转换。如 String 转换成 Integer、Double 等。
- 数据格式化:对请求消息进行数据格式化。如将字符串转换成格式化数字或格式化日期等。
- 数据验证: 验证数据的有效性(长度、格式等),验证结果存储到 BindingResult 或 Error 中。
Handler(Controller) 执行完成后,向 DispatcherServlet 返回一个 ModelAndView 对象。
> 此处,对应的方法如下:
>
> ```
> > // HandlerAdapter.java
> >
> > @Nullable
> > ModelAndView handle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception;
> >
> ```
.
> 图中没有 ④ 。
⑤ **解析视图**
根据返回的 ModelAndView ,选择一个适合的 ViewResolver(必须是已经注册到 Spring 容器中的 ViewResolver),解析出 View 对象,然后返回给 DispatcherServlet。
> 此处,对应的方法如下:
>
> ```
> > // ViewResolver.java
> >
> > @Nullable
> > View resolveViewName(String viewName, Locale locale) throws Exception;
> >
> ```
⑥ ⑦ **渲染视图** + **响应请求**
ViewResolver 结合 Model 和 View,来渲染视图,并写回给用户( 浏览器 )。
> 此处,对应的方法如下:
>
> ```
> > // View.java
> >
> > void render(@Nullable Map<String, ?> model, HttpServletRequest request, HttpServletResponse response) throws Exception;
> >
> ```
------
这样一看,胖友可能有点懵逼,所以还是推荐看看:
- [《精尽 Spring MVC 源码分析 —— 组件一览》](http://svip.iocoder.cn/Spring-MVC/Components-intro/)
- [《精尽 Spring MVC 源码分析 —— 请求处理一览》](http://svip.iocoder.cn/Spring-MVC/DispatcherServlet-process-request-intro/)
**但是 Spring MVC 的流程真的一定是酱紫么**?
既然这么问,答案当然不是。对于目前主流的架构,前后端已经进行分离了,所以 Spring MVC 只负责 **M**odel 和 **C**ontroller 两块,而将 **V**iew 移交给了前端。所以,在上图中的步骤 ⑤ 和 ⑥ 两步,已经不在需要。
那么变成什么样了呢?在步骤 ③ 中,如果 Handler(Controller) 执行完后,如果判断方法有 `@ResponseBody` 注解,则直接将结果写回给用户( 浏览器 )。
但是 HTTP 是不支持返回 Java POJO 对象的,所以需要将结果使用 [HttpMessageConverter](http://svip.iocoder.cn/Spring-MVC/HandlerAdapter-5-HttpMessageConverter/) 进行转换后,才能返回。例如说,大家所熟悉的 [FastJsonHttpMessageConverter](https://github.com/alibaba/fastjson/wiki/在-Spring-中集成-Fastjson) ,将 POJO 转换成 JSON 字符串返回。
😈 是不是略微有点复杂,还是那句话,撸下源码,捅破这个窗口。当然,如果胖友精力有限,只要看整体流程的几篇即可。
------
嘻嘻,再来补充两个图,这真的是 Spring MVC 非常关键的问题,所以要用心理解。
> FROM [《SpringMVC - 运行流程图及原理分析》](https://blog.csdn.net/J080624/article/details/77990164)
>
> **流程示意图**:
>
> 
>
> **代码序列图**:
>
> 
>
> ------
>
> FROM [《看透 Spring MVC:源代码分析与实践》](https://item.jd.com/11807414.html) P123
>
> **流程示意图**:
>
> 
## @Controller 注解有什么用?
`@Controller` 注解,它将一个类标记为 Spring Web MVC **控制器** Controller 。
## @RestController 和 @Controller 有什么区别?
`@RestController` 注解,在 `@Controller` 基础上,增加了 `@ResponseBody` 注解,更加适合目前前后端分离的架构下,提供 Restful API ,返回例如 JSON 数据格式。当然,返回什么样的数据格式,根据客户端的 `"ACCEPT"` 请求头来决定。
## @RequestMapping 注解有什么用?
`@RequestMapping` 注解,用于将特定 HTTP 请求方法映射到将处理相应请求的控制器中的特定类/方法。此注释可应用于两个级别:
- 类级别:映射请求的 URL。
- 方法级别:映射 URL 以及 HTTP 请求方法。
## @RequestMapping 和 @GetMapping 注解的不同之处在哪里?
- `@RequestMapping` 可注解在类和方法上;`@GetMapping` 仅可注册在方法上。
- `@RequestMapping` 可进行 GET、POST、PUT、DELETE 等请求方法;`@GetMapping` 是 `@RequestMapping` 的 GET 请求方法的特例,目的是为了提高清晰度。
## 返回 JSON 格式使用什么注解?
可以使用 **`@ResponseBody`** 注解,或者使用包含 `@ResponseBody` 注解的 **`@RestController`** 注解。
当然,还是需要配合相应的支持 JSON 格式化的 HttpMessageConverter 实现类。例如,Spring MVC 默认使用 MappingJackson2HttpMessageConverter 。
## 介绍一下 WebApplicationContext ?
WebApplicationContext 是实现ApplicationContext接口的子类,专门为 WEB 应用准备的。
- 它允许从相对于 Web 根目录的路径中**加载配置文件**,**完成初始化 Spring MVC 组件的工作**。
- 从 WebApplicationContext 中,可以获取 ServletContext 引用,整个 Web 应用上下文对象将作为属性放置在 ServletContext 中,以便 Web 应用环境可以访问 Spring 上下文。
关于这一块,如果想要详细了解,可以看看如下两篇文章:
- [《精尽 Spring MVC 源码分析 —— 容器的初始化(一)之 Root WebApplicationContext 容器》](http://svip.iocoder.cn/Spring-MVC/context-init-Root-WebApplicationContext/)
- [《精尽 Spring MVC 源码分析 —— 容器的初始化(二)之 Servlet WebApplicationContext 容器》](http://svip.iocoder.cn/Spring-MVC/context-init-Servlet-WebApplicationContext/)
## Spring MVC 的异常处理?
Spring MVC 提供了异常解析器 HandlerExceptionResolver 接口,将处理器( `handler` )执行时发生的异常,解析( 转换 )成对应的 ModelAndView 结果。代码如下:
```
// HandlerExceptionResolver.java
public interface HandlerExceptionResolver {
/**
* 解析异常,转换成对应的 ModelAndView 结果
*/
@Nullable
ModelAndView resolveException(
HttpServletRequest request, HttpServletResponse response, @Nullable Object handler, Exception ex);
}
```
- 也就是说,如果异常被解析成功,则会返回 ModelAndView 对象。
- 详细的源码解析,见 [《精尽 Spring MVC 源码解析 —— HandlerExceptionResolver 组件》](http://svip.iocoder.cn/Spring-MVC/HandlerExceptionResolver/) 。
一般情况下,我们使用 `@ExceptionHandler` 注解来实现过异常的处理,可以先看看 [《Spring 异常处理 ExceptionHandler 的使用》](https://www.jianshu.com/p/12e1a752974d) 。
- 一般情况下,艿艿喜欢使用**第三种**。
## Spring MVC 有什么优点?
1. 使用真的真的真的非常**方便**,无论是添加 HTTP 请求方法映射的方法,还是不同数据格式的响应。
2. 提供**拦截器机制**,可以方便的对请求进行拦截处理。
3. 提供**异常机制**,可以方便的对异常做统一处理。
4. 可以任意使用各种**视图**技术,而不仅仅局限于 JSP ,例如 Freemarker、Thymeleaf 等等。
5. 不依赖于 Servlet API (目标虽是如此,但是在实现的时候确实是依赖于 Servlet 的,当然仅仅依赖 Servlet ,而不依赖 Filter、Listener )。
## Spring MVC 怎样设定重定向和转发 ?
- 结果转发:在返回值的前面加 `"forward:/"` 。
- 重定向:在返回值的前面加上 `"redirect:/"` 。
当然,目前前后端分离之后,我们作为后端开发,已经很少有机会用上这个功能了。
## Spring MVC 的 Controller 是不是单例?
绝绝绝大多数情况下,Controller 是**单例**。
那么,Controller 里一般不建议存在**共享的变量**。实际场景下,艿艿也没碰到需要使用共享变量的情况。
## Spring MVC 和 Struts2 的异同?
1. 入口
不同
- Spring MVC 的入门是一个 Servlet **控制器**。
- Struts2 入门是一个 Filter **过滤器**。
2. 配置映射
不同,
- Spring MVC 是基于**方法**开发,传递参数是通过**方法形参**,一般设置为**单例**。
- Struts2 是基于**类**开发,传递参数是通过**类的属性**,只能设计为**多例**。
- 视图
不同
- Spring MVC 通过参数解析器是将 Request 对象内容进行解析成方法形参,将响应数据和页面封装成 **ModelAndView** 对象,最后又将模型数据通过 **Request** 对象传输到页面。其中,如果视图使用 JSP 时,默认使用 **JSTL** 。
- Struts2 采用**值栈**存储请求和响应的数据,通过 **OGNL** 存取数据。
当然,更详细的也可以看看 [《面试题:Spring MVC 和 Struts2 的区别》](http://www.voidcn.com/article/p-ylualwcj-c.html) 一文。
## 详细介绍下 Spring MVC 拦截器?
`org.springframework.web.servlet.HandlerInterceptor` ,拦截器接口。代码如下:
```
// HandlerInterceptor.java
/**
* 拦截处理器,在 {@link HandlerAdapter#handle(HttpServletRequest, HttpServletResponse, Object)} 执行之前
*/
default boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler)
throws Exception {
return true;
}
/**
* 拦截处理器,在 {@link HandlerAdapter#handle(HttpServletRequest, HttpServletResponse, Object)} 执行成功之后
*/
default void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler,
@Nullable ModelAndView modelAndView) throws Exception {
}
/**
* 拦截处理器,在 {@link HandlerAdapter#handle(HttpServletRequest, HttpServletResponse, Object)} 执行完之后,无论成功还是失败
*
* 并且,只有该处理器 {@link #preHandle(HttpServletRequest, HttpServletResponse, Object)} 执行成功之后,才会被执行
*/
default void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler,
@Nullable Exception ex) throws Exception {
}
```
- 一共有三个方法,分别为:
- `#preHandle(...)` 方法,调用 Controller 方法之**前**执行。
- `#postHandle(...)` 方法,调用 Controller 方法之**后**执行。
- ```
#afterCompletion(...)
```
方法,处理完 Controller 方法返回结果之
后
执行。
- 例如,页面渲染后。
- **当然,要注意,无论调用 Controller 方法是否成功,都会执行**。
- 举个例子:
- 当俩个拦截器都实现放行操作时,执行顺序为 `preHandle[1] => preHandle[2] => postHandle[2] => postHandle[1] => afterCompletion[2] => afterCompletion[1]` 。
- 当第一个拦截器 `#preHandle(...)` 方法返回 `false` ,也就是对其进行拦截时,第二个拦截器是完全不执行的,第一个拦截器只执行 `#preHandle(...)` 部分。
- 当第一个拦截器 `#preHandle(...)` 方法返回 `true` ,第二个拦截器 `#preHandle(...)` 返回 `false` ,执行顺序为 `preHandle[1] => preHandle[2] => afterCompletion[1]` 。
- 总结来说:
- `#preHandle(...)` 方法,按拦截器定义**顺序**调用。若任一拦截器返回 `false` ,则 Controller 方法不再调用。
- `#postHandle(...)` 和 `#afterCompletion(...)` 方法,按拦截器定义**逆序**调用。
- `#postHandler(...)` 方法,在调用 Controller 方法之**后**执行。
- `#afterCompletion(...)` 方法,只有该拦截器在 `#preHandle(...)` 方法返回 `true` 时,才能够被调用,且一定会被调用。为什么“且一定会被调用”呢?即使 `#afterCompletion(...)` 方法,按拦截器定义**逆序**调用时,前面的拦截器发生异常,后面的拦截器还能够调用,**即无视异常**。
------
关于这块,可以看看如下两篇文章:
- [《Spring MVC 多个拦截器执行顺序及拦截器使用方法》](https://blog.csdn.net/amaxiaochen/article/details/77210880) 文章,通过**实践**更加理解。
- [《精尽 Spring MVC 源码分析 —— HandlerMapping 组件(二)之 HandlerInterceptor》](http://svip.iocoder.cn/Spring-MVC/HandlerMapping-2-HandlerInterceptor/) 文章,通过**源码**更加理解。
## Spring MVC 的拦截器可以做哪些事情?
拦截器能做的事情非常非常非常多,例如:
- 记录访问日志。
- 记录异常日志。
- 需要登陆的请求操作,拦截未登陆的用户。
- …
## Spring MVC 的拦截器和 Filter 过滤器有什么差别?
看了文章 [《过滤器( Filter )和拦截器( Interceptor )的区别》](https://blog.csdn.net/xiaodanjava/article/details/32125687) ,感觉对比的怪怪的。艿艿觉得主要几个点吧:
- **功能相同**:拦截器和 Filter都能实现相应的功能,谁也不比谁强。
- **容器不同**:拦截器构建在 Spring MVC 体系中;Filter 构建在 Servlet 容器之上。
- **使用便利性不同**:拦截器提供了三个方法,分别在不同的时机执行;过滤器仅提供一个方法,当然也能实现拦截器的执行时机的效果,就是麻烦一些。
另外,😈 再补充一点小知识。我们会发现,拓展性好的框架,都会提供相应的拦截器或过滤器机制,方便的我们做一些拓展。例如:
- Dubbo 的 Filter 机制。
- Spring Cloud Gateway 的 Filter 机制。
- Struts2 的拦截器机制。
# REST
本小节的内容,基本是基于 [《排名前 20 的 REST 和 Spring MVC 面试题》](http://www.spring4all.com/article/1445) 之上,做增补。
## REST 代表着什么?
REST 代表着抽象状态转移,它是根据 HTTP 协议从客户端发送数据到服务端,例如:服务端的一本书可以以 XML 或 JSON 格式传递到客户端。
然而,假如你不熟悉REST,我建议你先看看 [REST API design and development](http://bit.ly/2zIGzWK) 这篇文章来更好的了解它。不过对于大多数胖友的英语,可能不太好,所以也可以阅读知乎上的 [《怎样用通俗的语言解释 REST,以及 RESTful?》](https://www.zhihu.com/question/28557115) 讨论。
## 资源是什么?
资源是指数据在 REST 架构中如何显示的。将实体作为资源公开 ,它允许客户端通过 HTTP 方法如:[GET](http://javarevisited.blogspot.sg/2012/03/get-post-method-in-http-and-https.html), [POST](http://www.java67.com/2014/08/difference-between-post-and-get-request.html),[PUT](http://www.java67.com/2016/09/when-to-use-put-or-post-in-restful-web-services.html), DELETE 等读,写,修改和创建资源。
## 什么是安全的 REST 操作?
REST 接口是通过 HTTP 方法完成操作。
- 一些HTTP操作是安全的,如 GET 和 HEAD ,它不能在服务端修改资源
- 换句话说,PUT,POST 和 DELETE 是不安全的,因为他们能修改服务端的资源。
所以,是否安全的界限,在于**是否修改**服务端的资源。
## 什么是幂等操作? 为什么幂等操作如此重要?
有一些HTTP方法,如:GET,不管你使用多少次它都能产生相同的结果,在没有任何一边影响的情况下,发送多个 GET 请求到相同的[URI](http://www.java67.com/2013/01/difference-between-url-uri-and-urn.html) 将会产生相同的响应结果。因此,这就是所谓**幂等**操作。
换句话说,[POST方法不是幂等操作](http://javarevisited.blogspot.sg/2016/05/what-are-idempotent-and-safe-methods-of-HTTP-and-REST.html) ,因为如果发送多个 POST 请求,它将在服务端创建不同的资源。但是,假如你用PUT更新资源,它将是幂等操作。
甚至多个 PUT 请求被用来更新服务端资源,将得到相同的结果。你可以通过 Pluralsight 学习 [HTTP Fundamentals](http://pluralsight.pxf.io/c/1193463/424552/7490?u=https%3A%2F%2Fwww.pluralsight.com%2Fcourses%2Fxhttp-fund) 课程来了解 HTTP 协议和一般的 HTTP 的更多幂等操作。
## REST 是可扩展的或说是协同的吗?
是的,[REST](http://javarevisited.blogspot.sg/2015/08/difference-between-soap-and-restfull-webservice-java.html) 是可扩展的和可协作的。它既不托管一种特定的技术选择,也不定在客户端或者服务端。你可以用 [Java](http://javarevisited.blogspot.sg/2017/11/top-5-free-java-courses-for-beginners.html), [C++](http://www.java67.com/2018/02/5-free-cpp-courses-to-learn-programming.html), [Python](http://www.java67.com/2018/02/5-free-python-online-courses-for-beginners.html), 或 [JavaScript](http://www.java67.com/2018/04/top-5-free-javascript-courses-to-learn.html) 来创建 RESTful Web 服务,也可以在客户端使用它们。
我建议你读一本关于REST接口的书来了解更多,如:[RESTful Web Services](http://javarevisited.blogspot.sg/2017/02/top-5-books-to-learn-rest-and-restful-web-services-in-java.html) 。
> 艿艿:所以这里的“可拓展”、“协同”对应到我们平时常说的,“跨语言”、“语言无关”。
## REST 用哪种 HTTP 方法呢?
REST 能用任何的 HTTP 方法,但是,最受欢迎的是:
- 用 GET 来检索服务端资源
- 用 POST 来创建服务端资源
- [用 PUT 来更新服务端资源](http://javarevisited.blogspot.sg/2016/04/what-is-purpose-of-http-request-types-in-RESTful-web-service.html#axzz56WGunSwy)
- 用 DELETE 来删除服务端资源。
恰好,这四个操作,对上我们日常逻辑的 CRUD 操作。
> 艿艿:经常能听到胖友抱怨自己做的都是 CRUD 的功能。看了这个面试题,有没觉得原来 CRUD 也能玩的稍微高级一点?!
>
> 实际上,每个 CRUD 也是可以通过不断的打磨,玩的很高级。例如说 DDD 领域驱动,完整的单元测试,可扩展的设计。
## 删除的 HTTP 状态返回码是什么 ?
在删除成功之后,您的 REST API 应该返回什么状态代码,并没有严格的规则。它可以返回 200 或 204 没有内容。
- 一般来说,如果删除操作成功,响应主体为空,返回 [204](http://www.netingcn.com/http-status-204.html) 。
- 如果删除请求成功且响应体不是空的,则返回 200 。
## REST API 是无状态的吗?
**是的**,REST API 应该是无状态的,因为它是基于 HTTP 的,它也是无状态的。
REST API 中的请求应该包含处理它所需的所有细节。它**不应该**依赖于以前或下一个请求或服务器端维护的一些数据,例如会话。
**REST 规范为使其无状态设置了一个约束,在设计 REST API 时,您应该记住这一点**。
## REST安全吗? 你能做什么来保护它?
安全是一个宽泛的术语。它可能意味着消息的安全性,这是通过认证和授权提供的加密或访问限制提供的。
REST 通常不是安全的,但是您可以通过使用 Spring Security 来保护它。
- 至少,你可以通过在 Spring Security 配置文件中使用 HTTP 来启用 HTTP Basic Auth 基本认证。
- 类似地,如果底层服务器支持 HTTPS ,你可以使用 HTTPS 公开 REST API 。
## RestTemplate 的优势是什么?
在 Spring Framework 中,RestTemplate 类是 [模板方法模式](http://www.java67.com/2012/09/top-10-java-design-pattern-interview-question-answer.html) 的实现。跟其他主流的模板类相似,如 JdbcTemplate 或 JmsTempalte ,它将在客户端简化跟 RESTful Web 服务的集成。正如在 RestTemplate 例子中显示的一样,你能非常容易地用它来调用 RESTful Web 服务。
> 艿艿:当然,实际场景我还是更喜欢使用 [OkHttp](http://square.github.io/okhttp/) 作为 HTTP 库,因为更好的性能,使用也便捷,并且无需依赖 Spring 库。
## HttpMessageConverter 在 Spring REST 中代表什么?
HttpMessageConverter 是一种[策略接口](http://www.java67.com/2014/12/strategy-pattern-in-java-with-example.html) ,它指定了一个转换器,它可以转换 HTTP 请求和响应。Spring REST 用这个接口转换 HTTP 响应到多种格式,例如:JSON 或 XML 。
每个 HttpMessageConverter 实现都有一种或几种相关联的MIME协议。Spring 使用 `"Accept"` 的标头来确定客户端所期待的内容类型。
然后,它将尝试找到一个注册的 HTTPMessageConverter ,它能够处理特定的内容类型,并使用它将响应转换成这种格式,然后再将其发送给客户端。
如果胖友对 HttpMessageConverter 不了解,可以看看 [《Spring 中 HttpMessageConverter 详解》](https://leokongwq.github.io/2017/06/14/spring-MessageConverter.html) 。
## 如何创建 HttpMessageConverter 的自定义实现来支持一种新的请求/响应?
我们仅需要创建自定义的 AbstractHttpMessageConverter 的实现,并使用 WebMvcConfigurerAdapter 的 `#extendMessageConverters(List> converters)` 方法注中册它,该方法可以生成一种新的请求 / 响应类型。
具体的示例,可以学习 [《在 Spring 中集成 Fastjson》](https://github.com/alibaba/fastjson/wiki/在-Spring-中集成-Fastjson) 文章。
## @PathVariable 注解,在 Spring MVC 做了什么? 为什么 REST 在 Spring 中如此有用?
`@PathVariable` 注解,是 Spring MVC 中有用的注解之一,它允许您从 URI 读取值,比如查询参数。它在使用 Spring 创建 RESTful Web 服务时特别有用,因为在 REST 中,资源标识符是 URI 的一部分。
具体的使用示例,胖友如果不熟悉,可以看看 [《Spring MVC 的 @RequestParam 注解和 @PathVariable 注解的区别》](https://blog.csdn.net/cx361006796/article/details/52829759) 。
# 666. 彩蛋
文末的文末,艿艿还是那句话!!!!还是非常推荐胖友去撸一撸 Spring MVC 的源码,特别是如下两篇:
- [《精尽 Spring MVC 源码分析 —— 组件一览》](http://svip.iocoder.cn/Spring-MVC/Components-intro/)
- [《精尽 Spring MVC 源码分析 —— 请求处理一览》](http://svip.iocoder.cn/Spring-MVC/DispatcherServlet-process-request-intro/)
参考和推荐如下文章:
- [《排名前 20 的 REST 和 Spring MVC 面试题》](http://www.spring4all.com/article/1445)
- [《跟着 Github 学习 Restful HTTP API 的优雅设计》](http://www.iocoder.cn/Fight/Learn-Restful-HTTP-API-design-from-Github/) | 15,895 | MIT |
# 博客前端
## 环境
- nodejs
- yarn
## 部署方式
前端利用 yarn 作为包管理器,首先确保安装了 node 14 或以上版本,然后安装:
```bash
npm install -g yarn
yarn
```
由于网络问题,可能无法成功还原,此时可以解压doc仓库中的 node_modules 压缩包到项目目录中,然后对 `node_modules/.bin` 中的所有文件设置可执行权限:
```bash
chmod +x node_modules/.bin/*
```
最后运行前端项目:
```bash
yarn start
```
然后访问 `http://localhost:3000`即可。
## 编写指南
[Guide.md](Guide.md) | 354 | MIT |
# rollup开发依赖包(npm library)实战
> 本文涉及包版本:node 11.6.0 、npm 6.11.3、webpack 4.39.3;使用mac开发;
## 项目
[源码](https://github.com/jiaoyanlin/npm-library-demo) -> https://github.com/jiaoyanlin/npm-library-demo ,求star😄
```
npm i
npm start
```
建议开始动手实践前先浏览下本文的的 三、知识点
## 一、发布包基本流程
#### 1、使用nrm管理npm源:
> nrm:npm registry 管理工具,方便切换不同的源;我们开发的包要发布的源是https://registry.npmjs.org,更详细的安装可以参考[nrm —— 快速切换 NPM 源](https://segmentfault.com/a/1190000000473869)
```
// 安装
npm install -g nrm
// 查看
nrm ls
// 切换
nrm use taobao
// 增加源
nrm add <registry> <url> [home]
// 删除源
nrm del <registry>
```
#### 2、发布包:
> 记得先在 https://www.npmjs.com 注册账户并在邮箱激活账户
(1)编写包代码(npm init等操作,具体在下面会提及)
(2)切换registry到npm对应链接https://registry.npmjs.org/:nrm use npm
(3)登录:npm login
(4)发布、更新:npm publish
#### 3、关于为何选择rollup而不是webpack编写一个npm包
> 为了支持tree shaking,得导出一份符合es6模块规范的代码,但是webpack不支持导出为es6模块,所以使用rollup来开发我们的包
> [rollup和webpack使用场景分析](https://www.jianshu.com/p/60070a6d7631)中提到:Rollup偏向应用于js库,webpack偏向应用于前端工程,UI库;如果你的应用场景中只是js代码,希望做ES转换,模块解析,可以使用Rollup。如果你的场景中涉及到css、html,涉及到复杂的代码拆分合并,建议使用webpack。
> rollup可以直接构建出符合es6模块规范的代码(有利于tree shaking),但是webpack不能;因此为了更好地使用es6模块化来实现tree shaking,以及优化包代码体积等原因,选用rollup来开发npm包;
## 二、使用rollup构建npm包
> 以下内容引自[rollup中文网](https://www.rollupjs.com/guide/introduction/): 为了确保你的 ES6 模块可以直接与「运行在 CommonJS(例如 Node.js 和 webpack)中的工具(tool)」使用,你可以使用 Rollup 编译为 UMD 或 CommonJS 格式,然后在 package.json 文件的 main 属性中指向当前编译的版本。如果你的 package.json 也具有 module 字段,像 Rollup 和 webpack 2 这样的 ES6 感知工具(ES6-aware tools)将会直接导入 ES6 模块版本。
> 关于rollup更加详细的介绍及使用,可以参考以下文章:[Rollup:下一代ES模块打包工具](https://zhuanlan.zhihu.com/p/75717476) 、[rollup中文网](https://www.rollupjs.com/guide/introduction/) 、[Rollup.js 实战学习笔记](https://rollupjs.org/guide/zh/)、[webpack创建library](https://chenshenhai.github.io/rollupjs-note/)
#### 1、先来个简单的demo:[源码](https://github.com/jiaoyanlin/npm-library-demo/tree/master/demos/demo-1)
(1)新建一个文件夹npm-library-demo
初始化:
```
cd npm-library-demo
npm init -y // 初始化,生成package.json
npm i rollup -D // 安装rollup
```
根据以下目录结构新增文件夹及文件:
```
npm-library-demo
|--build
|--rollup.config.js
|--example
|--index.html
|--src
|--main.js
|--foo.js
```
(2)文件内容:
package.json中加入构建脚本命令:
```
"scripts": {
"build": "rollup -c ./build/rollup.config.js"
}
```
```javascript
// rollup.config.js
const path = require('path');
const resolve = function (filePath) {
return path.join(__dirname, '..', filePath)
}
export default {
input: resolve('src/main.js'), // 入口文件
output: { // 出口文件
file: resolve('dist/bundle.js'),
format: 'umd',
name: 'myLibrary'
}
};
```
```javascript
// main.js
import foo from './foo.js';
export default (function () {
console.log(foo);
})();
```
```javascript
// foo.js
export default 'hello world!';
```
index.html:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>example</title>
</head>
<body>
</body>
<script src="../dist/bundle.js"></script>
</html>
```
(3)执行`npm run build`,就可以生成打包文件/dist/bundle.js,打开example/index.html控制台可以查看打包文件是否生效
#### 2、使用插件,在1的基础上进行以下操作:[源码](https://github.com/jiaoyanlin/npm-library-demo/tree/master/demos/demo-2)
在rollup中如果要处理json,就要用到插件,比如rollup-plugin-json
`npm i rollup-plugin-json -D`
```javascript
// rollup.config.js
const path = require('path');
import json from 'rollup-plugin-json';
const resolve = function (filePath) {
return path.join(__dirname, '..', filePath)
}
export default {
input: resolve('src/main.js'),
output: {
file: resolve('dist/bundle.js'),
format: 'umd',
name: 'myLibrary'
},
plugins: [ // 在此处使用插件
json(),
],
};
```
```javascript
// main.js
import foo from './foo.js';
import { version } from '../package.json'; // 利用json插件可以获得package.json中的数据
console.log('version ' + version);
export default (function () {
console.log(foo);
})();
```
此时再次使用`npm run build`打包,打开index.html,在控制台可以看到相关结果
其他插件使用方式类似
#### 3、Rollup 与其他工具集成
##### (1)npm packages:添加配置让rollup知道如何处理你从npm安装到node_modules文件夹中的软件包
`npm install rollup-plugin-node-resolve rollup-plugin-commonjs -D`
* rollup-plugin-node-resolve: 告诉 Rollup 如何查找外部模块
* rollup-plugin-commonjs:将CommonJS模块转换为 ES2015 供 Rollup 处理,请注意,rollup-plugin-commonjs应该用在其他插件转换你的模块之前 - 这是为了防止其他插件的改变破坏CommonJS的检测
```javascript
// rollup.config.js
import resolve from 'rollup-plugin-node-resolve';
import commonjs from 'rollup-plugin-commonjs';
import json from 'rollup-plugin-json';
const path = require('path');
const resolveFile = function (filePath) {
return path.join(__dirname, '..', filePath)
}
export default {
input: resolveFile('src/main.js'),
output: {
file: resolveFile('dist/bundle.js'),
format: 'cjs',
},
plugins: [
commonjs(),
resolve({
// 将自定义选项传递给解析插件
customResolveOptions: {
moduleDirectory: 'node_modules'
}
}),
json(),
],
};
```
##### (2)external:有些包要处理成外部引用(例如lodash等),externals就是用来处理外部的引用,不要将这些包打包到输出文件中,减小打包文件体积
> external 接受一个模块名称的数组或一个接受模块名称的函数,如果它被视为外部引用(externals)则返回true
```javascript
// rollup.config.js
export default {
...,
// 作用:指出应将哪些模块视为外部模块,否则会被打包进最终的代码里
external: ['lodash']
// external: id => /lodash/.test(id) // 也可以使用这种方式
};
```
安装lodash:`npm i lodash -S`
```javascript
// main.js
...
import _ from 'lodash';
console.log('-------lodash:', _.defaults({ 'a': 1 }, { 'a': 3, 'b': 2 }));
```
可以打包试试external配置与否对打包文件的影响(直接查看dist/bundle.js)
由于此时打包生成的是cjs格式的js,可以直接在控制台执行`node ./dist/bundle.js`测试打包结果;此时index.html是没法成功加载bundle.js的,因为此时的文件是cjs的,无法直接在浏览器中使用
##### (3)babel7:
`npm i -D rollup-plugin-babel @babel/core @babel/plugin-transform-runtime @babel/preset-env`
`npm i -S @babel/runtime @babel/runtime-corejs2`
```javascript
// rollup.config.js
...
import babel from 'rollup-plugin-babel';
export default {
...
plugins: [
...,
babel({
exclude: 'node_modules/**', // 只编译我们的源代码
runtimeHelpers: true,
}),
],
external: id => {
return /@babel\/runtime/.test(id) || /lodash/.test(id);
}
}
```
根目录下新建文件.babelrc.js
```javascript
module.exports = {
presets: [
[
"@babel/preset-env",
{
// "debug": true, // debug,编译的时候 console
"useBuiltIns": false, // 是否开启自动支持 polyfill
"modules": false, // 模块使用 es modules ,不使用 commonJS 规范
// "targets": "> 0.25%, last 2 versions, iOS >= 8, Android >= 4.4, not dead"
}
]
],
plugins: [
[
"@babel/plugin-transform-runtime",
{
// useESModules:引入的helpers是否是es modules规范的;注意当打包成cjs时不能引入es modules下的代码,会报错
// "useESModules": true,
"corejs": 2 // 参考官方文档
}
],
]
}
```
可以自己在main.js中加入一些es6语法,看看打包后的文件是否将es6语法编译成了es5(如const、let等)
??????? babel还有一篇相关博文补充
##### (4)引入eslint:
`npm i -D babel-eslint rollup-plugin-eslint`
> eslint位置很重要,放在babel插件后面会导致定位问题的时候出错
```javascript
// rollup.config.js
...
import { eslint } from 'rollup-plugin-eslint';
module.exports = {
...,
plugins: [
...,
eslint({ // eslint插件必须放在babel插件之前,不然检测的是转换后的文件,导致检测有误
throwOnError: true,
throwOnWarning: true,
include: ['src/**'],
exclude: ['node_modules/**']
}),
...
]
}
```
根目录下新增文件.eslitrc.js
```javascript
module.exports = {
//一旦配置了root,ESlint停止在父级目录中查找配置文件
root: true,
parser: "babel-eslint", // 配置babel-eslint,避免在使用es6类属性时,eslint报Parsing error: Unexpected token
//想要支持的JS语言选项
parserOptions: {
//启用ES6语法支持(如果支持es6的全局变量{env: {es6: true}},则默认启用ES6语法支持)
//此处也可以使用年份命名的版本号:2015
ecmaVersion: 6,
//默认为script
sourceType: "module",
//支持其他的语言特性
ecmaFeatures: {}
},
//代码运行的环境,每个环境都会有一套预定义的全局对象,不同环境可以组合使用
env: {
amd: true, // 否则会出现'require' is not defined 提示
es6: true,
browser: true,
jquery: true
},
//访问当前源文件中未定义的变量时,no-undef会报警告。
//如果这些全局变量是合规的,可以在globals中配置,避免这些全局变量发出警告
globals: {
//配置给全局变量的布尔值,是用来控制该全局变量是否允许被重写
test_param: true,
window: true,
process: false,
},
//集成推荐的规则
extends: ["eslint:recommended"],
//启用额外的规则或者覆盖默认的规则
//规则级别分别:为"off"(0)关闭、"warn"(1)警告、"error"(2)错误--error触发时,程序退出
rules: {
//关闭“禁用console”规则
"no-console": "off",
//缩进不规范警告,要求缩进为2个空格,默认值为4个空格
"indent": ["warn", 4, {
//设置为1时强制switch语句中case的缩进为2个空格
"SwitchCase": 1,
}],
// 函数定义时括号前面要不要有空格
"space-before-function-paren": [0, "always"],
//定义字符串不规范错误,要求字符串使用双引号
// quotes: ["error", "double"],
//....
//更多规则可查看http://eslint.cn/docs/rules/
}
}
```
##### (5)一次编译,同时打包生成不同格式文件,如cjs、es、umd等
有两种方法:
首先,`npm i -D rollup-plugin-serve rollup-plugin-uglify`
修改packag.json
```json
{
...,
"module": "es/index.js",
"main": "lib/index.js",
"scripts": {
"build": "rollup -c ./build/rollup.config.js"
"clean": "rm -rf ./dist/ ./es/ ./lib/",
"easy": "npm run clean && NODE_ENV=development rollup -w -c ./build/easy.config.js",
"node:dev": "npm run clean && NODE_ENV=development node ./build/dev.js",
"node:build": "npm run clean && NODE_ENV=production node ./build/build.js",
"start": "npm run clean && NODE_ENV=development rollup -w -c ./build/rollup.config.js",
"build": "npm run clean && NODE_ENV=production rollup -c ./build/rollup.config.js"
},
"files": [
"dist",
"lib",
"es",
"types"
],
```
注意:mac可以直接使用NODE_ENV=development方式传递变量,window下不一定可以,如果失败请引入[cross-env](https://juejin.im/post/5c009b13f265da612e285d43)
(1)第一种方法:使用rollup命令打包
```javascript
// rollup.config.js
import json from 'rollup-plugin-json';
import resolve from 'rollup-plugin-node-resolve';
import commonjs from 'rollup-plugin-commonjs';
import babelPlugin from 'rollup-plugin-babel';
import serve from 'rollup-plugin-serve';
import { uglify } from 'rollup-plugin-uglify';
import { eslint } from 'rollup-plugin-eslint'
const path = require('path');
const resolveFile = function (filePath) {
return path.join(__dirname, '..', filePath)
}
const isDev = process.env.NODE_ENV !== 'production';
console.log('----------dev:', process.env.NODE_ENV, isDev)
// 通过控制outputs中对应的isExternal、isUglify值来决定打包的文件是否启用external和uglify
const outputs = [
{
file: resolveFile('lib/index.js'),
format: 'cjs',
isExternal: true,
},
{
file: resolveFile('es/index.js'),
format: 'es',
isExternal: true,
},
{
file: resolveFile('dist/index.js'),
format: 'umd',
name: 'npmLibraryDemo',
},
{
file: resolveFile('dist/index.min.js'),
format: 'umd',
name: 'npmLibraryDemo',
isUglify: true,
}
].map(i => {
i.sourcemap = isDev; // 开发模式:开启sourcemap文件的生成
return i;
});
const len = outputs.length;
const config = outputs.map((output, i) => {
const isUglify = output.isUglify || false;
const isExternal = output.isExternal || false;
console.log('------config:', isExternal)
return {
input: resolveFile('src/main.js'),
output,
plugins: [
// rollup-plugin-commonjs应该用在其他插件转换你的模块之前 - 这是为了防止其他插件的改变破坏CommonJS的检测
// 作用:将CommonJS模块转换为 ES2015 供 Rollup 处理
commonjs(),
// 作用:处理json格式文件
json(),
// 作用:告诉 Rollup 如何查找外部模块
resolve({
// 将自定义选项传递给解析插件
customResolveOptions: {
moduleDirectory: 'node_modules'
}
}),
eslint({
throwOnError: true,
throwOnWarning: true,
include: ['src/**'],
exclude: ['node_modules/**']
}),
babelPlugin({
exclude: 'node_modules/**', // 只编译我们的源代码
runtimeHelpers: true,
}),
...(
isDev && i === len - 1 ?
[
serve({ // 使用开发服务插件
port: 3001,
// 设置 exmaple的访问目录和dist的访问目录
contentBase: [resolveFile('example'), resolveFile('dist')]
})
] : isUglify ? [
uglify()
] : []
)
],
// 作用:指出应将哪些模块视为外部模块,否则会被打包进最终的代码里
external: id => {
return !isExternal ? false :
(/@babel\/runtime/.test(id) || /lodash/.test(id));
}
}
})
export default config;
```
使用`npm start`开启开发模式;使用`npm run build`可以打包出文件;总共导出三种格式文件:cjs、es、umd,umd格式的文件有压缩和未压缩
> start时如果报错“getaddrinfo ENOTFOUND localhost”,参考这篇[方法](https://segmentfault.com/a/1190000015274463)解决
(2)第二种方法:使用rollup api进行打包
build文件夹下新增文件:node.config.js、dev.js、build.js
```javascript
// node.config.js
const json = require('rollup-plugin-json');
const resolve = require('rollup-plugin-node-resolve');
const commonjs = require('rollup-plugin-commonjs');
const babelPlugin = require('rollup-plugin-babel');
const { uglify } = require('rollup-plugin-uglify');
const path = require('path');
const isDev = process.env.NODE_ENV !== 'production';
const resolveFile = function (filePath) {
return path.join(__dirname, '..', filePath)
}
module.exports.outputs = [
{
file: resolveFile('lib/index.js'),
format: 'cjs',
isExternal: true,
},
{
file: resolveFile('es/index.js'),
format: 'es',
isExternal: true,
},
{
file: resolveFile('dist/index.js'),
format: 'umd',
name: 'npmLibraryDemo',
},
{
file: resolveFile('dist/index.min.js'),
format: 'umd',
name: 'npmLibraryDemo',
isUglify: true,
}
].map(i => {
i.sourcemap = isDev; // 开发模式:开启sourcemap文件的生成
return i;
});
module.exports.configFun = function config({isUglify, isExternal} = {}) {
return {
input: resolveFile('src/main.js'),
plugins: [
// rollup-plugin-commonjs应该用在其他插件转换你的模块之前 - 这是为了防止其他插件的改变破坏CommonJS的检测
// 作用:将CommonJS模块转换为 ES2015 供 Rollup 处理
commonjs(),
// 作用:处理json格式文件
json(),
// 作用:告诉 Rollup 如何查找外部模块
resolve({
// 将自定义选项传递给解析插件
customResolveOptions: {
moduleDirectory: 'node_modules'
}
}),
babelPlugin({
exclude: 'node_modules/**', // 只编译我们的源代码
runtimeHelpers: true,
}),
...(
isUglify ? [ uglify() ] : []
)
],
// 作用:指出应将哪些模块视为外部模块,否则会被打包进最终的代码里
external: id => {
return !isExternal ? false :
(/@babel\/runtime/.test(id) || /lodash/.test(id));
},
}
};
```
```javascript
// dev.js
const path = require('path');
const serve = require('rollup-plugin-serve');
const rollup = require('rollup');
const { configFun, outputs } = require('./node.config.js');
const resolveFile = function (filePath) {
return path.join(__dirname, '..', filePath)
}
let watchOptions = [];
const len = outputs.length;
outputs.forEach((output, i) => {
let options = {
isUglify: output.isUglify,
isExternal: output.isExternal,
}
let config = {
output,
...configFun(options)
};
if (i === len - 1) {
config.plugins.push(
serve({ // 使用开发服务插件
port: 3001,
// 设置 exmaple的访问目录和dist的访问目录
contentBase: [resolveFile('example'), resolveFile('dist')]
})
);
}
watchOptions.push(config);
});
const watcher = rollup.watch(watchOptions);
watcher.on('event', event => {
// event.code 会是下面其中一个:
// START — 监听器正在启动(重启)
// BUNDLE_START — 构建单个文件束
// BUNDLE_END — 完成文件束构建
// END — 完成所有文件束构建
// ERROR — 构建时遇到错误
// FATAL — 遇到无可修复的错误
switch (event.code) {
case 'START':
console.log(`[info] 监听器正在启动(重启)`);
break;
case 'BUNDLE_START':
console.log(`[info] 开始构建 ${event.output}`);
break;
case 'BUNDLE_END':
console.log(`[info] 完成构建 ${event.output}`);
console.log(`[info] 构建时长 ${event.duration}`);
break;
case 'END':
console.log(`[info] 完成所有构建`);
break;
case 'ERROR':
case 'FATAL':
console.log(`[error] 构建发生错误`);
}
});
// 停止监听
// watcher.close();
```
```javascript
// build.js
const rollup = require('rollup');
const { configFun, outputs } = require('./node.config.js');
outputs.forEach(async (output) => {
const inputOptions = configFun({
isUglify: output.isUglify,
isExternal: output.isExternal,
});
build(inputOptions, output);
})
async function build(inputOptions, outputOptions) {
console.log(`[INFO] 开始编译 ${inputOptions.input}`);
// create a bundle
const bundle = await rollup.rollup(inputOptions);
// generate code and a sourcemap
const res = await bundle.generate(outputOptions);
console.log(`[INFO] ${res}`);
// or write the bundle to disk
await bundle.write(outputOptions);
console.log(`[SUCCESS] 编译结束 ${outputOptions.file}`);
}
```
使用`npm run node:dev`开启开发模式;使用`npm run node:build`可以打包出文件;
可以实现一个简单功能实验一下配置是否成功,比如这次提交[简单预加载图片](https://github.com/jiaoyanlin/npm-library-demo/commit/e7a48b6f0332cf68a3d888a73867dc565d63da8e)
注意:
1、examp/index.html中引入的js是umd形式的,如果我们的代码中引入了运行时需要使用到的第三方包(例如lodash等),并且没有在index.html手动将该包引入,会导致找不到该包而报错;因此我这里的配置中,输出文件如果是umd格式的,就不配置external,直接将第三方包的代码一起打包进最终的打包文件中;
2、当输出文件是cjs或者es时,配置external,即不将某些第三方包打包,减小最终的打包文件体积;由于我们把第三方包安装在“dependencies”中,当别人加载我们的这个包时,他们的项目会自动安装我们的“dependencies”中所有的包,所以可以加载到我们开发的包中涉及到的第三方包;
3、关于调试
我开发包的过程中用到了两种调试方式:
方法1:直接通过npm start启动时的http://localhost:3001来调试;由于开启了rollup的监听功能,因此当我们修改代码时,会自动构建打包出新代码,只要刷新浏览器就能看到最新的效果;
> 开启source map调试我只在方法1的调试方法中能正常使用
方法2:在项目中调试正在开发的包:
> npm link命令通过链接目录和可执行文件,实现任意位置的npm包命令的全局可执行。
在包目录下执行`npm link`(假设包名为pky-test);
在项目目录下执行`npm link pky-test`即可使用该包(执行`npm unlink pky-test`可以删除包链接);
在包目录下执行`npm start`可以实时打包出最新代码
#### 6、发布,增加命令实现自动打标签并根据提交记录生成changelog
`npm i -D conventional-changelog-cli`
package.json
```json
{
...,
"scripts": {
...,
"tag": "node ./build/version.js",
"x": "npm --no-git-tag-version version major",
"y": "npm --no-git-tag-version version minor",
"z": "npm --no-git-tag-version version patch",
"postversion": "npm run changelog && git add . && npm run tag",
"changelog": "conventional-changelog -p angular -i CHANGELOG.md -s -r 0",
"prepublishOnly": "npm run build",
"postpublish": "npm run clean"
}
}
```
新建文件build/version.js:根据packag.json中的version提交代码并且打标签
```javascript
const fs = require('fs');
const path = require('path');
const pathname = path.resolve(__dirname, '../package.json');
const pkg = JSON.parse(fs.readFileSync(pathname, 'utf-8'));
let version = pkg.version;
console.log('version:', version)
const exec = require('child_process').exec;
let cmdStr = `git commit -m "v${version}" && git push && git tag -a "v${version}" -m "${version}" && git push origin --tags`;
exec(cmdStr, function (err, stdout, stderr) {
console.log('exec:', err, stdout, stderr);
});
```
(1)执行`npm run x/y/z`可以改变package.json中的version,然后根据提交的commit信息自动生成changelog,最后会根据version提交代码并打标签;
(2)执行`npm run publish`发布代码
其他:
(1)我没有使用preversion钩子和
conventional-changelog-cli自动生成changelog,因为如果在改变版本号之前执行自动生成changelog,那么当前版本提交的commit信息不会被自动生成到changelog中(因为changelog只会生成当前版本之前的commit记录)
(2)必须遵循一定的commit规范,才能根据commit记录自动生成changelog,具体自行百度下conventional-changelog-cli的使用哦
因此,推荐的工作流:
1.改动代码
2.提交这些改动
3.改变package.json中的版本号
4.使用conventional-changelog工具
5.提交 package.json和CHANGELOG.md文件
6.打标签tag
7.push代码
可以参考[使用conventional-changelog生成版本日志](https://github.com/rayliao/blog/issues/4)
## 三、知识点
> 先学习下以下两篇文章:
> [如何开发和维护一个npm项目](https://juejin.im/post/5bd32ecff265da0ab33193b4)
> [你所需要的npm知识储备都在这了](https://juejin.im/post/5d08d3d3f265da1b7e103a4d)
#### 1、package.json中需要注意的点:
(1)version:
版本格式: [主版本号major.次版本号minor.修订号patch]
先行版本: 内部版本alpha、公测版本beta、Release candiate正式版本的候选版本rc,例如1.0.0-alpha、1.0.0-beta.1
使用npm version进行版本号管理:
```
npm version 1.0.1 # 显示设置版本号为 1.0.1
npm version major # major + 1,其余版本号归 0
npm version minor # minor + 1,patch 归 0
npm version patch # patch + 1
# 预发布版本
# 当前版本号为 1.2.3
npm version prepatch # 版本号变为 1.2.4-0,也就是 1.2.4 版本的第一个预发布版本
npm version preminor # 版本号变为 1.3.0-0,也就是 1.3.0 版本的第一个预发布版本
npm version premajor # 版本号变为 2.0.0-0,也就是 2.0.0 版本的第一个预发布版本
npm version prerelease # 版本号变为 2.0.0-1,也就是使预发布版本号加一
# 在git环境下npm version会默认执行git add->git commit->git tag
npm version minor -m "feat(version): upgrade to %s" # 可自定义commit message;%s 会自动替换为新版本号
# 模块 tag 管理
# 当前版本为1.0.1
npm version prerelease # 1.0.2-0
npm publish --tag beta # 发布包beta版本,打上beta tag
npm dist-tag ls xxx # 查看某个包的tag;beta: 1.0.2-0
npm install xxx@beta # 下载beta版本 1.0.2-0
# 当prerelease版本已经稳定了,可以将prerelease版本设置为稳定版本
npm dist-tag add [email protected] latest
npm dist-tag ls xxx # latest: 1.0.2-0
```
npm version 可以更新包版本,当仓库已经被git初始化了,那么运行npm version修改完版本号以后,还会运行git add 、git commit和git tag的命令,其中commit的信息默认是自改完的版本号
(2)main、module、sideEffect:
* main、module:用来指定npm包的入口文件
* main: npm自带,一般表示符合CommonJS规范的文件入口
* module: 符合ES模块规范的文件入口,使得代码可进行Tree Shaking;并且在webpack的默认配置中,module的优先级要高于main
> 因为一般项目配置babel时,为了加速项目编译过程,会忽略node_modules中的模块,所以module入口的文件最好是符合ESmodule规范的ES5的代码(说白了就是该文件只有导入导出是用的ES6模块化语法,其他都已经转成了es5),webpack最终会把ESmodule转换为它自己的commonjs规范的代码
* sideEffect:webpack4中新增特性,表示npm包的代码是否有副作用;
> sideEffect可设置为Boolean或者数组;当为false时,表明这个包是没有副作用的,可以进行按需引用;如果为数组时,数组的每一项表示的是有副作用的文件在组件库开发的时候,如果有样式文件,需要把样式文件的路径放到sideEffect的数组中,因为UglifyJs只能识别js文件,如果不设置的话,最后打包的时候会把样式文件忽略掉。
由于webpack4引入了sideEffect,因此当第三方包设置了sideEffect时,可以直接去除没有用到的代码,比如antd组件库设置sideEffect,那在webpack4时就不用再依赖babel-plugin-import进行按需加载了,webpack打包时直接就能把没用到的代码通过tree-shaking清除掉。
> 参考文章:
> [package.json 中的 Module 字段是干嘛的](https://github.com/sunyongjian/blog/issues/37)
> [聊聊 package.json 文件中的 module 字段](https://loveky.github.io/2018/02/26/tree-shaking-and-pkg.module/)
(3)tree shaking,用来剔除 JavaScript 中用不上的死代码
> 更多详情可参考[使用 Tree Shaking](http://www.xbhub.com/wiki/webpack/4%E4%BC%98%E5%8C%96/4-10%E4%BD%BF%E7%94%A8TreeShaking.html)
要让 Tree Shaking 正常工作的前提是交给 Webpack 的 JavaScript 代码必须是采用 ES6 模块化语法的。 因为 ES6 模块化语法是静态的(导入导出语句中的路径必须是静态的字符串,而且不能放入其它代码块中),这让 Webpack 可以简单的分析出哪些 export 的被 import 过了。 如果你采用 ES5 中的模块化,例如 module.export={...}、 require(x+y)、 if(x){require('./util')},Webpack 无法分析出哪些代码可以剔除。
基于以上说明,需要做一些配置让tree shaking生效:
第一种情况--针对项目:
* 把采用 ES6 模块化的代码直接交给 Webpack,需要配置 Babel 让其保留 ES6 模块化语句,修改 .babelrc 文件如下;要剔除用不上的代码还得经过 UglifyJS 去处理一遍,因此需要在项目中引入UglifyJSPlugin;
```
{
"presets": [
[
"env",
{
"modules": false
}
]
]
}
```
* 在package.json中根据实际情况设置sideEffects,详细解释请看上面的第(2)点
第二种情况--针对npm包开发:
* 提供两份代码,一份采用 CommonJS 模块化语法,一份采用 ES6 模块化语法,package.json 文件中有两个字段:
```
{
"main": "lib/index.js", // 指明采用 CommonJS 模块化的代码入口
"module": "es/index.js" // 指明采用 ES6 模块化的代码入口;当该代码存在时,webpack会优先加载这个代码
}
```
* 根据情况设置package.json中的sideEffects字段
> 关于tree shaking、sideEffects使用请查看:
> [Tree-Shaking性能优化实践 - 原理篇](https://juejin.im/post/5a4dc842518825698e7279a9)
> [你的Tree-Shaking并没什么卵用](https://juejin.im/post/5a5652d8f265da3e497ff3de)
> [深入浅出 sideEffects](https://www.lindongzhou.com/article/know-sideEffects)
> [Webpack 中的 sideEffects 到底该怎么用](https://zhuanlan.zhihu.com/p/40052192)
>
由文章可知sideEffects并不是在项目真的不存在副作用代码时才可以设置
#### 2、控制npm发布的包包含的文件有以下方式:
* package.json#files:数组,表示可以包含哪些文件,格式和.gitignore的写法一样
* .npmignore:表示哪些文件将被忽略,格式和.gitignore的写法一样
* .gitignore:表示要忽略哪些文件
优先级:files > .npmignore > .gitignore
#### 3、package-lock.json:
* package-lock.json把所有依赖按照顺序列出来,第一次出现的包名会提升到顶层,后面重复出现的将会放入被依赖包的node_modules当中,因此会引起不完全扁平化问题。
* 在开发应用时,建议把package-lock.json文件提交到代码仓库,从而让团队成员、运维部署人员或CI系统可以在执行npm install时安装的依赖版本都是一致的。
* 但在开发一个库时,则不应把package-lock.json文件提交到仓库中。实际上,npm也默认不会把package-lock.json文件发布出去。之所以这么做,是因为库项目一般是被其他项目依赖的,在不写死的情况下,就可以复用主项目已经加载过的包,而一旦库依赖的是精确的版本号那么可能会造成包的冗余。
#### 4、npm scripts 脚本、npx、path环境变量
package.json:
```
"scripts": {
"serve": "vue-cli-service serve",
...
}
```
原理: package.json 中的 bin 字段;字段 bin 表示一个可执行文件到指定文件源的映射。
例如在@vue/cli-service的package.json中:
```
"bin": {
"vue-cli-service": "bin/vue-cli-service.js"
}
```
npx:方便调用项目内部安装的模块
PATH环境变量:执行`env`可查看当前所有环境变量;`npm run env`可查看脚本运行时的环境变量;通过npm run可在不添加路径前缀的情况下直接访问当前项目node_modules/.bin目录里面的可执行文件
#### 5、其他
(1)
```
npm outdated # 查看当前项目中可升级的模块
npm audit [--json] # 安全漏洞检查;加上--json,以 JSON 格式生成漏洞报告
npm audit fix # 修复存在安全漏洞的依赖包(自动更新到兼容的安全版本)
npm audit fix --force # 将依赖包版本号升级到最新的大版本,而不是兼容的安全版本;尽量避免使用--force
```
(2)git提交可参考以下规范:
feat:新功能(feature)
fix:修补bug
docs:文档(documentation)
style: 格式(不影响代码运行的变动)
refactor:重构(即不是新增功能,也不是修改bug的代码变动)
test:增加测试
chore:构建过程或辅助工具的变动
(3)npm包发布流程:
[于Webpack和ES6构建NPM包](https://juejin.im/post/5ac4a4d85188255c4c107e42)
[从dist到es:发一个NPM库,我蜕了一层皮](https://segmentfault.com/a/1190000018242549)
[8102年底如何开发和维护一个npm项目](https://juejin.im/post/5bd32ecff265da0ab33193b4)
(4)几点心得:
1、对于webpack构建的项目或者包,在babel中设置`"modules": false`其实只是让项目中经过babel转化后的代码(已经是es5)仍然保留 ES6 模块化语句,也就是只有导入导出语句保留es6写法;此时webpack会自动再去转换这里的es6模块化语句;也就是ES6 模块化语句交给webpack自己去转换;
2、对于webpack构建生成的包,不支持导出为es6模块(最终都转成了es5,无法保留ES6 模块化语句不转换),因此如果开发的npm包希望导出多种格式,推荐使用rollup
3、为了加速项目编译过程,一般都会设置忽略编译node_modules中的模块,所以这就需要我们开发的npm包是编译过的;
> 一般来说,用于node环境的包,只要提供符合CMD规范的包,但用于web的包,就要提供更多的选项:
> * lib:符合commonjs规范的文件,一般放在lib这个文件夹里面,入口是mian
> * es:符合ES module规范的文件,一般放在es这个文件夹里面,入口是module
> * dist:经过压缩的文件,一般是可以通过script标签直接引用的文件 | 26,203 | Apache-2.0 |
---
layout: post
title: "ClassLoader"
categories: JVM
tags: JVM
author: 转载
---
* content
{:toc}
## 前言
深入理解Java类加载器(ClassLoader)
## 课程目录
本篇博文主要是探讨类加载器,同时在本篇中列举的源码都基于Java8版本,不同的版本可能有些许差异。主要内容如下:
1. 类加载的机制的层次结构
* 启动Bootstrap类加载器
* 扩展Extension类加载器
* 系统System类加载器
2. 理解双亲委派模式
* 双亲委派模式工作原理
* 双亲委派模式优势
* 类加载器间的关系
3. 类与类加载器
* 类与类加载器
* 了解class文件的显示加载与隐式加载的概念
4. 编写自己的类加载器
* 自定义File类加载器
* 自定义网络类加载器
* 热部署类加载器
5. 双亲委派模型的破坏者-线程上下文类加载器
## 类加载的机制的层次结构
每个编写的”.java”拓展名类文件都存储着需要执行的程序逻辑,这些”.java”文件经过Java编译器编译成拓展名为”.class”的文件,”.class”文件中保存着Java代码经转换后的虚拟机指令,当需要使用某个类时,虚拟机将会加载它的”.class”文件,并创建对应的class对象,将class文件加载到虚拟机的内存,这个过程称为类加载,这里我们需要了解一下类加载的过程,如下:

* 加载:类加载过程的一个阶段:通过一个类的完全限定查找此类字节码文件,并利用字节码文件创建一个Class对象
* 验证:目的在于确保Class文件的字节流中包含信息符合当前虚拟机要求,不会危害虚拟机自身安全。主要包括四种验证,文件格式验证,元数据验证,字节码验证,符号引用验证。
* 准备:为类变量(也叫静态变量,即static修饰的字段变量)分配内存并且设置该类变量的初始值即0(如static int i=5;这里只将i初始化为0,至于5的值将在初始化时赋值),这里不包含用final修饰的static,因为final在编译的时候就会分配了,注意这里不会为实例变量分配初始化,类变量会分配在方法区中,而实例变量是会随着对象一起分配到Java堆中。
* 解析:主要将常量池中的符号引用替换为直接引用的过程。符号引用就是一组符号来描述目标,可以是任何字面量,而直接引用就是直接指向目标的指针、相对偏移量或一个间接定位到目标的句柄。有类或接口的解析,字段解析,类方法解析,接口方法解析(这里涉及到字节码变量的引用,如需更详细了解,可参考《深入Java虚拟机》)。
* 初始化:类加载最后阶段,若该类具有超类,则对其进行初始化,执行静态初始化器和静态初始化成员变量(如前面只初始化了默认值的static变量将会在这个阶段赋值,成员变量也将被初始化)。
前面的类加载过程,除了在加载阶段用户应用程序可以通过自定义类加载器参与之外,其余动作完全由虚拟机主导和控制。到了初始化阶段,才真正开始执行类中定义的Java程序代码。
这便是类加载的5个过程,而类加载器的任务是根据一个类的全限定名来读取此类的二进制字节流到JVM中,然后转换为一个与目标类对应的java.lang.Class对象实例,在虚拟机提供了3种类加载器,引导(Bootstrap)类加载器、扩展(Extension)类加载器、系统(System)类加载器(也称应用类加载器),下面分别介绍。
### 启动(Bootstrap)类加载器
启动类加载器主要加载的是JVM自身需要的类,这个类加载使用C++语言实现的,是虚拟机自身的一部分,它负责将 `<JAVA_HOME>/lib`路径下的核心类库或`-Xbootclasspath`参数指定的路径下的jar包加载到内存中,注意必由于虚拟机是按照文件名识别加载jar包的,如rt.jar,如果文件名不被虚拟机识别,即使把jar包丢到lib目录下也是没有作用的(出于安全考虑,Bootstrap启动类加载器只加载包名为java、javax、sun等开头的类)。
### 扩展(Extension)类加载器
扩展类加载器是指Sun公司(已被Oracle收购)实现的`sun.misc.Launcher$ExtClassLoader`类,由Java语言实现的,是Launcher的静态内部类,它负责加载`<JAVA_HOME>/lib/ext`目录下或者由系统变量`-Djava.ext.dir`指定位路径中的类库,开发者可以直接使用标准扩展类加载器。
```java
//ExtClassLoader类中获取路径的代码
private static File[] getExtDirs() {
//加载<JAVA_HOME>/lib/ext目录中的类库
String s = System.getProperty("java.ext.dirs");
File[] dirs;
if (s != null) {
StringTokenizer st =
new StringTokenizer(s, File.pathSeparator);
int count = st.countTokens();
dirs = new File[count];
for (int i = 0; i < count; i++) {
dirs[i] = new File(st.nextToken());
}
} else {
dirs = new File[0];
}
return dirs;
}
```
### 系统(System)类加载器
也称应用程序加载器是指 Sun公司实现的`sun.misc.Launcher$AppClassLoader`。它负责加载系统类路径`java -classpath`或`-D java.class.path` 指定路径下的类库,也就是我们经常用到的classpath路径,开发者可以直接使用系统类加载器,一般情况下该类加载是程序中默认的类加载器,通过`ClassLoader#getSystemClassLoader()`方法可以获取到该类加载器。
>在Java的日常应用程序开发中,类的加载几乎是由上述3种类加载器相互配合执行的,在必要时,我们还可以自定义类加载器,需要注意的是,Java虚拟机对class文件采用的是按需加载的方式,也就是说当需要使用该类时才会将它的class文件加载到内存生成class对象,而且加载某个类的class文件时,Java虚拟机采用的是双亲委派模式即把请求交由父类处理,它一种任务委派模式,下面我们进一步了解它。
## 理解双亲委派模式
### 双亲委派模式工作原理
双亲委派模式要求除了顶层的启动类加载器外,其余的类加载器都应当有自己的父类加载器,请注意双亲委派模式中的父子关系并非通常所说的类继承关系,而是采用组合关系来复用父类加载器的相关代码,类加载器间的关系如下:

双亲委派模式是在Java 1.2后引入的,其工作原理的是,如果一个类加载器收到了类加载请求,它并不会自己先去加载,而是把这个请求委托给父类的加载器去执行,如果父类加载器还存在其父类加载器,则进一步向上委托,依次递归,请求最终将到达顶层的启动类加载器,如果父类加载器可以完成类加载任务,就成功返回,倘若父类加载器无法完成此加载任务,子加载器才会尝试自己去加载,这就是双亲委派模式,即每个儿子都很懒,每次有活就丢给父亲去干,直到父亲说这件事我也干不了时,儿子自己想办法去完成,这不就是传说中的实力坑爹啊?那么采用这种模式有啥用呢?
### 双亲委派模式优势
采用双亲委派模式的是好处是Java类随着它的类加载器一起具备了一种带有优先级的层次关系,通过这种层级关可以避免类的重复加载,当父亲已经加载了该类时,就没有必要子ClassLoader再加载一次。其次是考虑到安全因素,java核心api中定义类型不会被随意替换,假设通过网络传递一个名为java.lang.Integer的类,通过双亲委托模式传递到启动类加载器,而启动类加载器在核心Java API发现这个名字的类,发现该类已被加载,并不会重新加载网络传递的过来的java.lang.Integer,而直接返回已加载过的Integer.class,这样便可以防止核心API库被随意篡改。可能你会想,如果我们在classpath路径下自定义一个名为java.lang.SingleInterge类(该类是胡编的)呢?该类并不存在java.lang中,经过双亲委托模式,传递到启动类加载器中,由于父类加载器路径下并没有该类,所以不会加载,将反向委托给子类加载器加载,最终会通过系统类加载器加载该类。但是这样做是不允许,因为java.lang是核心API包,需要访问权限,强制加载将会报出如下异常:
>java.lang.SecurityException: Prohibited package name: java.lang
所以无论如何都无法加载成功的。下面我们从代码层面了解几个Java中定义的类加载器及其双亲委派模式的实现,它们类图关系如下:

图可以看出顶层的类加载器是ClassLoader类,它是一个抽象类,其后所有的类加载器都继承自ClassLoader(不包括启动类加载器),这里我们主要介绍ClassLoader中几个比较重要的方法。
* loadClass(String)
该方法加载指定名称(包括包名)的二进制类型,该方法在JDK1.2之后不再建议用户重写但用户可以直接调用该方法,`loadClass()方法是ClassLoader类自己实现的,该方法中的逻辑就是双亲委派模式的实现`,其源码如下,loadClass(String name, boolean resolve)是一个重载方法,resolve参数代表是否生成class对象的同时进行解析相关操作。
```java
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// 先从缓存查找该class对象,找到就不用重新加载
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
if (parent != null) {
//如果找不到,则委托给父类加载器去加载
c = parent.loadClass(name, false);
} else {
//如果没有父类,则委托给启动加载器去加载
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// If still not found, then invoke findClass in order
// 如果都没有找到,则通过自定义实现的findClass去查找并加载
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {//是否需要在加载时进行解析
resolveClass(c);
}
return c;
}
}
```
正如loadClass方法所展示的,当类加载请求到来时,先从缓存中查找该类对象,如果存在直接返回,如果不存在则交给该类加载去的父加载器去加载,倘若没有父加载则交给顶级启动类加载器去加载,最后倘若仍没有找到,则使用findClass()方法去加载(关于findClass()稍后会进一步介绍)。从loadClass实现也可以知道如果不想重新定义加载类的规则,也没有复杂的逻辑,只想在运行时加载自己指定的类,那么我们可以直接使用`this.getClass().getClassLoder.loadClass("className")`,这样就可以直接调用ClassLoader的loadClass方法获取到class对象。
* findClass(String)
在JDK1.2之前,在自定义类加载时,总会去继承ClassLoader类并重写loadClass方法,从而实现自定义的类加载类,但是在JDK1.2之后已不再建议用户去覆盖loadClass()方法,而是建议把自定义的类加载逻辑写在findClass()方法中,从前面的分析可知,findClass()方法是在loadClass()方法中被调用的,当loadClass()方法中父加载器加载失败后,则会调用自己的findClass()方法来完成类加载,这样就可以保证自定义的类加载器也符合双亲委托模式。需要注意的是ClassLoader类中并没有实现findClass()方法的具体代码逻辑,取而代之的是抛出ClassNotFoundException异常,同时应该知道的是findClass方法通常是和defineClass方法一起使用的(稍后会分析),ClassLoader类中findClass()方法源码如下:
```java
//直接抛出异常
protected Class<?> findClass(String name) throws ClassNotFoundException {
throw new ClassNotFoundException(name);
}
```
* defineClass(byte[] b, int off, int len)
defineClass()方法是用来将byte字节流解析成JVM能够识别的Class对象(ClassLoader中已实现该方法逻辑),通过这个方法不仅能够通过class文件实例化class对象,也可以通过其他方式实例化class对象,如通过网络接收一个类的字节码,然后转换为byte字节流创建对应的Class对象,defineClass()方法通常与findClass()方法一起使用,一般情况下,在自定义类加载器时,会直接覆盖ClassLoader的findClass()方法并编写加载规则,取得要加载类的字节码后转换成流,然后调用defineClass()方法生成类的Class对象,简单例子如下:
```java
protected Class<?> findClass(String name) throws ClassNotFoundException {
// 获取类的字节数组
byte[] classData = getClassData(name);
if (classData == null) {
throw new ClassNotFoundException();
} else {
//使用defineClass生成class对象
return defineClass(name, classData, 0, classData.length);
}
}
```
需要注意的是,如果直接调用defineClass()方法生成类的Class对象,这个类的Class对象并没有解析(也可以理解为链接阶段,毕竟解析是链接的最后一步),其解析操作需要等待初始化阶段进行。
* resolveClass(Class≺?≻ c)
使用该方法可以使用类的Class对象创建完成也同时被解析。前面我们说链接阶段主要是对字节码进行验证,为类变量分配内存并设置初始值同时将字节码文件中的符号引用转换为直接引用。
上述4个方法是ClassLoader类中的比较重要的方法,也是我们可能会经常用到的方法。接看SercureClassLoader扩展了 ClassLoader,新增了几个与使用相关的代码源(对代码源的位置及其证书的验证)和权限定义类验证(主要指对class源码的访问权限)的方法,一般我们不会直接跟这个类打交道,更多是与它的子类URLClassLoader有所关联,前面说过,ClassLoader是一个抽象类,很多方法是空的没有实现,比如 findClass()、findResource()等。而URLClassLoader这个实现类为这些方法提供了具体的实现,并新增了URLClassPath类协助取得Class字节码流等功能,在编写自定义类加载器时,如果没有太过于复杂的需求,可以直接继承URLClassLoader类,这样就可以避免自己去编写findClass()方法及其获取字节码流的方式,使自定义类加载器编写更加简洁,下面是URLClassLoader的类图(利用IDEA生成的类图)

类图结构看出URLClassLoader中存在一个URLClassPath类,通过这个类就可以找到要加载的字节码流,也就是说URLClassPath类负责找到要加载的字节码,再读取成字节流,最后通过defineClass()方法创建类的Class对象。从URLClassLoader类的结构图可以看出其构造方法都有一个必须传递的参数`URL[]`,该参数的元素是代表字节码文件的路径,换句话说在创建URLClassLoader对象时必须要指定这个类加载器的到那个目录下找class文件。同时也应该注意`URL[]`也是URLClassPath类的必传参数,在创建URLClassPath对象时,会根据传递过来的URL数组中的路径判断是文件还是jar包,然后根据不同的路径创建FileLoader或者JarLoader或默认Loader类去加载相应路径下的class文件,而当JVM调用findClass()方法时,就由这3个加载器中的一个将class文件的字节码流加载到内存中,最后利用字节码流创建类的class对象。请记住,如果我们在定义类加载器时选择继承ClassLoader类而非URLClassLoader,必须手动编写findclass()方法的加载逻辑以及获取字节码流的逻辑。了解完URLClassLoader后接着看看剩余的两个类加载器,即拓展类加载器ExtClassLoader和系统类加载器AppClassLoader,这两个类都继承自URLClassLoader,是sun.misc.Launcher的静态内部类。sun.misc.Launcher主要被系统用于启动主应用程序,ExtClassLoader和AppClassLoader都是由sun.misc.Launcher创建的,其类主要类结构如下:

他们间的关系正如前面所阐述的那样,同时我们发现ExtClassLoader并没有重写loadClass()方法,这足矣说明其遵循双亲委派模式,而AppClassLoader重载了loadCass()方法,但最终调用的还是父类loadClass()方法,因此依然遵守双亲委派模式,重载方法源码如下:
```java
/**
* Override loadClass 方法,新增包权限检测功能
*/
public Class loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
int i = name.lastIndexOf('.');
if (i != -1) {
SecurityManager sm = System.getSecurityManager();
if (sm != null) {
sm.checkPackageAccess(name.substring(0, i));
}
}
//依然调用父类的方法
return (super.loadClass(name, resolve));
}
```
其实无论是ExtClassLoader还是AppClassLoader都继承URLClassLoader类,因此它们都遵守双亲委托模型,这点是毋庸置疑的。ok~,到此我们对ClassLoader、URLClassLoader、ExtClassLoader、AppClassLoader以及Launcher类间的关系有了比较清晰的了解,同时对一些主要的方法也有一定的认识,这里并没有对这些类的源码进行详细的分析,毕竟没有那个必要,因为我们主要弄得类与类间的关系和常用的方法同时搞清楚双亲委托模式的实现过程,为编写自定义类加载器做铺垫就足够了。ok~,前面出现了很多父类加载器的说法,但每个类加载器的父类到底是谁,一直没有阐明,下面我们就通过代码验证的方式来阐明这答案。
### 类加载器间的关系
我们进一步了解类加载器间的关系(并非指继承关系),主要可以分为以下4点
* 启动类加载器,由C++实现,没有父类。
* 拓展类加载器(ExtClassLoader),由Java语言实现,父类加载器为null
* 系统类加载器(AppClassLoader),由Java语言实现,父类加载器为ExtClassLoader
* 自定义类加载器,父类加载器肯定为AppClassLoader。
下面我们通过程序来验证上述阐述的观点
```java
/**
* Created by zejian on 2017/6/18.
* Blog : http://blog.csdn.net/javazejian [原文地址,请尊重原创]
*/
//自定义ClassLoader,完整代码稍后分析
class FileClassLoader extends ClassLoader{
private String rootDir;
public FileClassLoader(String rootDir) {
this.rootDir = rootDir;
}
// 编写获取类的字节码并创建class对象的逻辑
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
//...省略逻辑代码
}
//编写读取字节流的方法
private byte[] getClassData(String className) {
// 读取类文件的字节
//省略代码....
}
}
public class ClassLoaderTest {
public static void main(String[] args) throws ClassNotFoundException {
FileClassLoader loader1 = new FileClassLoader(rootDir);
System.out.println("自定义类加载器的父加载器: "+loader1.getParent());
System.out.println("系统默认的AppClassLoader: "+ClassLoader.getSystemClassLoader());
System.out.println("AppClassLoader的父类加载器: "+ClassLoader.getSystemClassLoader().getParent());
System.out.println("ExtClassLoader的父类加载器: "+ClassLoader.getSystemClassLoader().getParent().getParent());
/**
输出结果:
自定义类加载器的父加载器: sun.misc.Launcher$AppClassLoader@29453f44
系统默认的AppClassLoader: sun.misc.Launcher$AppClassLoader@29453f44
AppClassLoader的父类加载器: sun.misc.Launcher$ExtClassLoader@6f94fa3e
ExtClassLoader的父类加载器: null
*/
}
}
```
代码中,我们自定义了一个FileClassLoader,这里我们继承了ClassLoader而非URLClassLoader,因此需要自己编写findClass()方法逻辑以及加载字节码的逻辑,关于自定义类加载器我们稍后会分析,这里仅需要知道FileClassLoader是自定义加载器即可,接着在main方法中,通过ClassLoader.getSystemClassLoader()获取到系统默认类加载器,通过获取其父类加载器及其父父类加载器,同时还获取了自定义类加载器的父类加载器,最终输出结果正如我们所预料的,AppClassLoader的父类加载器为ExtClassLoader,而ExtClassLoader没有父类加载器。如果我们实现自己的类加载器,它的父加载器都只会是AppClassLoader。这里我们不妨看看Lancher的构造器源码
```java
public Launcher() {
// 首先创建拓展类加载器
ClassLoader extcl;
try {
extcl = ExtClassLoader.getExtClassLoader();
} catch (IOException e) {
throw new InternalError(
"Could not create extension class loader");
}
// Now create the class loader to use to launch the application
try {
//再创建AppClassLoader并把extcl作为父加载器传递给AppClassLoader
loader = AppClassLoader.getAppClassLoader(extcl);
} catch (IOException e) {
throw new InternalError(
"Could not create application class loader");
}
//设置线程上下文类加载器,稍后分析
Thread.currentThread().setContextClassLoader(loader);
//省略其他没必要的代码......
}
```
显然Lancher初始化时首先会创建ExtClassLoader类加载器,然后再创建AppClassLoader并把ExtClassLoader传递给它作为父类加载器,这里还把AppClassLoader默认设置为线程上下文类加载器,关于线程上下文类加载器稍后会分析。那ExtClassLoader类加载器为什么是null呢?看下面的源码创建过程就明白,在创建ExtClassLoader强制设置了其父加载器为null。
```java
//Lancher中创建ExtClassLoader
extcl = ExtClassLoader.getExtClassLoader();
//getExtClassLoader()方法
public static ExtClassLoader getExtClassLoader() throws IOException{
//........省略其他代码
return new ExtClassLoader(dirs);
// .........
}
//构造方法
public ExtClassLoader(File[] dirs) throws IOException {
//调用父类构造URLClassLoader传递null作为parent
super(getExtURLs(dirs), null, factory);
}
//URLClassLoader构造
public URLClassLoader(URL[] urls, ClassLoader parent, URLStreamHandlerFactory factory) {
//...
}
```
显然ExtClassLoader的父类为null,而AppClassLoader的父加载器为ExtClassLoader,所有自定义的类加载器其父加载器只会是AppClassLoader,注意这里所指的父类并不是Java继承关系中的那种父子关系。
## 类与类加载器
### 类与类加载器
在JVM中表示两个class对象是否为同一个类对象存在两个必要条件:
* 类的完整类名必须一致,包括包名。
* 加载这个类的ClassLoader(指ClassLoader实例对象)必须相同。
也就是说,在JVM中,即使这个两个类对象(class对象)来源同一个Class文件,被同一个虚拟机所加载,但只要加载它们的ClassLoader实例对象不同,那么这两个类对象也是不相等的,这是因为不同的ClassLoader实例对象都拥有不同的独立的类名称空间,所以加载的class对象也会存在不同的类名空间中,但前提是覆写loadclass方法,从前面双亲委派模式对loadClass()方法的源码分析中可以知,在方法第一步会通过Class<?> c = findLoadedClass(name);从缓存查找,类名完整名称相同则不会再次被加载,因此我们必须绕过缓存查询才能重新加载class对象。当然也可直接调用findClass()方法,这样也避免从缓存查找,如下:
```java
String rootDir="/Users/zejian/Downloads/Java8_Action/src/main/java/";
//创建两个不同的自定义类加载器实例
FileClassLoader loader1 = new FileClassLoader(rootDir);
FileClassLoader loader2 = new FileClassLoader(rootDir);
//通过findClass创建类的Class对象
Class<?> object1=loader1.findClass("com.zejian.classloader.DemoObj");
Class<?> object2=loader2.findClass("com.zejian.classloader.DemoObj");
System.out.println("findClass->obj1:"+object1.hashCode());
System.out.println("findClass->obj2:"+object2.hashCode());
/**
* 直接调用findClass方法输出结果:
* findClass->obj1:723074861
findClass->obj2:895328852
生成不同的实例
*/
```
如果调用父类的loadClass方法,结果如下,除非重写loadClass()方法去掉缓存查找步骤,不过现在一般都不建议重写loadClass()方法。
```java
//直接调用父类的loadClass()方法
Class<?> obj1 =loader1.loadClass("com.zejian.classloader.DemoObj");
Class<?> obj2 =loader2.loadClass("com.zejian.classloader.DemoObj");
//不同实例对象的自定义类加载器
System.out.println("loadClass->obj1:"+obj1.hashCode());
System.out.println("loadClass->obj2:"+obj2.hashCode());
//系统类加载器
System.out.println("Class->obj3:"+DemoObj.class.hashCode());
/**
* 直接调用loadClass方法的输出结果,注意并没有重写loadClass方法
* loadClass->obj1:1872034366
loadClass->obj2:1872034366
Class-> obj3:1872034366
都是同一个实例
*/
```
所以如果不从缓存查询相同完全类名的class对象,那么只有ClassLoader的实例对象不同,同一字节码文件创建的class对象自然也不会相同。
### 了解class文件的显式加载与隐式加载的概念
所谓class文件的显式加载与隐式加载的方式是指JVM加载class文件到内存的方式,显式加载指的是在代码中通过调用ClassLoader加载class对象,如直接使用Class.forName(name)或this.getClass().getClassLoader().loadClass()加载class对象。而隐式加载则是不直接在代码中调用ClassLoader的方法加载class对象,而是通过虚拟机自动加载到内存中,如在加载某个类的class文件时,该类的class文件中引用了另外一个类的对象,此时额外引用的类将通过JVM自动加载到内存中。在日常开发以上两种方式一般会混合使用,这里我们知道有这么回事即可。
## 编写自己的类加载器
通过前面的分析可知,实现自定义类加载器需要继承ClassLoader或者URLClassLoader,继承ClassLoader则需要自己重写findClass()方法并编写加载逻辑,继承URLClassLoader则可以省去编写findClass()方法以及class文件加载转换成字节码流的代码。那么编写自定义类加载器的意义何在呢?
* 当class文件不在ClassPath路径下,默认系统类加载器无法找到该class文件,在这种情况下我们需要实现一个自定义的ClassLoader来加载特定路径下的class文件生成class对象。
* 当一个class文件是通过网络传输并且可能会进行相应的加密操作时,需要先对class文件进行相应的解密后再加载到JVM内存中,这种情况下也需要编写自定义的ClassLoader并实现相应的逻辑。
* 当需要实现热部署功能时(一个class文件通过不同的类加载器产生不同class对象从而实现热部署功能),需要实现自定义ClassLoader的逻辑。
### 自定义File类加载器
这里我们继承ClassLoader实现自定义的特定路径下的文件类加载器并加载编译后DemoObj.class,源码代码如下:
```java
public class DemoObj {
@Override
public String toString() {
return "I am DemoObj";
}
}
```
```java
import java.io.*;
/**
* Created by zejian on 2017/6/21.
* Blog : http://blog.csdn.net/javazejian [原文地址,请尊重原创]
*/
public class FileClassLoader extends ClassLoader {
private String rootDir;
public FileClassLoader(String rootDir) {
this.rootDir = rootDir;
}
/**
* 编写findClass方法的逻辑
* @param name
* @return
* @throws ClassNotFoundException
*/
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
// 获取类的class文件字节数组
byte[] classData = getClassData(name);
if (classData == null) {
throw new ClassNotFoundException();
} else {
//直接生成class对象
return defineClass(name, classData, 0, classData.length);
}
}
/**
* 编写获取class文件并转换为字节码流的逻辑
* @param className
* @return
*/
private byte[] getClassData(String className) {
// 读取类文件的字节
String path = classNameToPath(className);
try {
InputStream ins = new FileInputStream(path);
ByteArrayOutputStream baos = new ByteArrayOutputStream();
int bufferSize = 4096;
byte[] buffer = new byte[bufferSize];
int bytesNumRead = 0;
// 读取类文件的字节码
while ((bytesNumRead = ins.read(buffer)) != -1) {
baos.write(buffer, 0, bytesNumRead);
}
return baos.toByteArray();
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
/**
* 类文件的完全路径
* @param className
* @return
*/
private String classNameToPath(String className) {
return rootDir + File.separatorChar
+ className.replace('.', File.separatorChar) + ".class";
}
public static void main(String[] args) throws ClassNotFoundException {
String rootDir="/Users/zejian/Downloads/Java8_Action/src/main/java/";
//创建自定义文件类加载器
FileClassLoader loader = new FileClassLoader(rootDir);
try {
//加载指定的class文件
Class<?> object1=loader.loadClass("com.zejian.classloader.DemoObj");
System.out.println(object1.newInstance().toString());
//输出结果:I am DemoObj
} catch (Exception e) {
e.printStackTrace();
}
}
}
```
显然我们通过getClassData()方法找到class文件并转换为字节流,并重写findClass()方法,利用defineClass()方法创建了类的class对象。在main方法中调用了loadClass()方法加载指定路径下的class文件,由于启动类加载器、拓展类加载器以及系统类加载器都无法在其路径下找到该类,因此最终将有自定义类加载器加载,即调用findClass()方法进行加载。如果继承URLClassLoader实现,那代码就更简洁了,如下:
```java
/**
* Created by zejian on 2017/6/21.
* Blog : http://blog.csdn.net/javazejian [原文地址,请尊重原创]
*/
public class FileUrlClassLoader extends URLClassLoader {
public FileUrlClassLoader(URL[] urls, ClassLoader parent) {
super(urls, parent);
}
public FileUrlClassLoader(URL[] urls) {
super(urls);
}
public FileUrlClassLoader(URL[] urls, ClassLoader parent, URLStreamHandlerFactory factory) {
super(urls, parent, factory);
}
public static void main(String[] args) throws ClassNotFoundException, MalformedURLException {
String rootDir="/Users/zejian/Downloads/Java8_Action/src/main/java/";
//创建自定义文件类加载器
File file = new File(rootDir);
//File to URI
URI uri=file.toURI();
URL[] urls={uri.toURL()};
FileUrlClassLoader loader = new FileUrlClassLoader(urls);
try {
//加载指定的class文件
Class<?> object1=loader.loadClass("com.zejian.classloader.DemoObj");
System.out.println(object1.newInstance().toString());
//输出结果:I am DemoObj
} catch (Exception e) {
e.printStackTrace();
}
}
}
```
非常简洁除了需要重写构造器外无需编写findClass()方法及其class文件的字节流转换逻辑。
### 自定义网络类加载器
自定义网络类加载器,主要用于读取通过网络传递的class文件(在这里我们省略class文件的解密过程),并将其转换成字节流生成对应的class对象,如下:
```java
/**
* Created by zejian on 2017/6/21.
* Blog : http://blog.csdn.net/javazejian [原文地址,请尊重原创]
*/
public class NetClassLoader extends ClassLoader {
private String url;//class文件的URL
public NetClassLoader(String url) {
this.url = url;
}
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
byte[] classData = getClassDataFromNet(name);
if (classData == null) {
throw new ClassNotFoundException();
} else {
return defineClass(name, classData, 0, classData.length);
}
}
/**
* 从网络获取class文件
* @param className
* @return
*/
private byte[] getClassDataFromNet(String className) {
String path = classNameToPath(className);
try {
URL url = new URL(path);
InputStream ins = url.openStream();
ByteArrayOutputStream baos = new ByteArrayOutputStream();
int bufferSize = 4096;
byte[] buffer = new byte[bufferSize];
int bytesNumRead = 0;
// 读取类文件的字节
while ((bytesNumRead = ins.read(buffer)) != -1) {
baos.write(buffer, 0, bytesNumRead);
}
//这里省略解密的过程.......
return baos.toByteArray();
} catch (Exception e) {
e.printStackTrace();
}
return null;
}
private String classNameToPath(String className) {
// 得到类文件的URL
return url + "/" + className.replace('.', '/') + ".class";
}
}
```
比较简单,主要是在获取字节码流时的区别,从网络直接获取到字节流再转车字节数组然后利用defineClass方法创建class对象,如果继承URLClassLoader类则和前面文件路径的实现是类似的,无需担心路径是filePath还是Url,因为URLClassLoader内的URLClassPath对象会根据传递过来的URL数组中的路径判断是文件还是jar包,然后根据不同的路径创建FileLoader或者JarLoader或默认类Loader去读取对于的路径或者url下的class文件。
### 热部署类加载器
所谓的热部署就是利用同一个class文件不同的类加载器在内存创建出两个不同的class对象(关于这点的原因前面已分析过,即利用不同的类加载实例),由于JVM在加载类之前会检测请求的类是否已加载过(即在loadClass()方法中调用findLoadedClass()方法),如果被加载过,则直接从缓存获取,不会重新加载。注意同一个类加载器的实例和同一个class文件只能被加载器一次,多次加载将报错,因此我们实现的热部署必须让同一个class文件可以根据不同的类加载器重复加载,以实现所谓的热部署。实际上前面的实现的FileClassLoader和FileUrlClassLoader已具备这个功能,但前提是直接调用findClass()方法,而不是调用loadClass()方法,因为ClassLoader中loadClass()方法体中调用findLoadedClass()方法进行了检测是否已被加载,因此我们直接调用findClass()方法就可以绕过这个问题,当然也可以重新loadClass方法,但强烈不建议这么干。利用FileClassLoader类测试代码如下:
```java
public static void main(String[] args) throws ClassNotFoundException {
String rootDir="/Users/zejian/Downloads/Java8_Action/src/main/java/";
//创建自定义文件类加载器
FileClassLoader loader = new FileClassLoader(rootDir);
FileClassLoader loader2 = new FileClassLoader(rootDir);
try {
//加载指定的class文件,调用loadClass()
Class<?> object1=loader.loadClass("com.zejian.classloader.DemoObj");
Class<?> object2=loader2.loadClass("com.zejian.classloader.DemoObj");
System.out.println("loadClass->obj1:"+object1.hashCode());
System.out.println("loadClass->obj2:"+object2.hashCode());
//加载指定的class文件,直接调用findClass(),绕过检测机制,创建不同class对象。
Class<?> object3=loader.findClass("com.zejian.classloader.DemoObj");
Class<?> object4=loader2.findClass("com.zejian.classloader.DemoObj");
System.out.println("loadClass->obj3:"+object3.hashCode());
System.out.println("loadClass->obj4:"+object4.hashCode());
/**
* 输出结果:
* loadClass->obj1:644117698
loadClass->obj2:644117698
findClass->obj3:723074861
findClass->obj4:895328852
*/
} catch (Exception e) {
e.printStackTrace();
}
}
```
## 双亲委派模型的破坏者-线程上下文类加载器
在Java应用中存在着很多服务提供者接口(Service Provider Interface,SPI),这些接口允许第三方为它们提供实现,如常见的 SPI 有 JDBC、JNDI等,这些 SPI 的接口属于 Java 核心库,一般存在rt.jar包中,由Bootstrap类加载器加载,而 SPI 的第三方实现代码则是作为Java应用所依赖的 jar 包被存放在classpath路径下,由于SPI接口中的代码经常需要加载具体的第三方实现类并调用其相关方法,但SPI的核心接口类是由引导类加载器来加载的,而Bootstrap类加载器无法直接加载SPI的实现类,同时由于双亲委派模式的存在,Bootstrap类加载器也无法反向委托AppClassLoader加载器SPI的实现类。在这种情况下,我们就需要一种特殊的类加载器来加载第三方的类库,而线程上下文类加载器就是很好的选择。
线程上下文类加载器(contextClassLoader)是从 JDK 1.2 开始引入的,我们可以通过java.lang.Thread类中的getContextClassLoader()和 setContextClassLoader(ClassLoader cl)方法来获取和设置线程的上下文类加载器。如果没有手动设置上下文类加载器,线程将继承其父线程的上下文类加载器,初始线程的上下文类加载器是系统类加载器(AppClassLoader),在线程中运行的代码可以通过此类加载器来加载类和资源,如下图所示,以jdbc.jar加载为例:

由图可知rt.jar核心包是由Bootstrap类加载器加载的,其内包含SPI核心接口类,由于SPI中的类经常需要调用外部实现类的方法,而jdbc.jar包含外部实现类(jdbc.jar存在于classpath路径)无法通过Bootstrap类加载器加载,因此只能委派线程上下文类加载器把jdbc.jar中的实现类加载到内存以便SPI相关类使用。显然这种线程上下文类加载器的加载方式破坏了“双亲委派模型”,它在执行过程中抛弃双亲委派加载链模式,使程序可以逆向使用类加载器,当然这也使得Java类加载器变得更加灵活。为了进一步证实这种场景,不妨看看DriverManager类的源码,DriverManager是Java核心rt.jar包中的类,该类用来管理不同数据库的实现驱动即Driver,它们都实现了Java核心包中的java.sql.Driver接口,如mysql驱动包中的com.mysql.jdbc.Driver,这里主要看看如何加载外部实现类,在DriverManager初始化时会执行如下代码:
```java
//DriverManager是Java核心包rt.jar的类
public class DriverManager {
//省略不必要的代码
static {
loadInitialDrivers();//执行该方法
println("JDBC DriverManager initialized");
}
//loadInitialDrivers方法
private static void loadInitialDrivers() {
sun.misc.Providers()
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
//加载外部的Driver的实现类
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);
//省略不必要的代码......
}
});
}
```
在DriverManager类初始化时执行了loadInitialDrivers()方法,在该方法中通过ServiceLoader.load(Driver.class);去加载外部实现的驱动类,ServiceLoader类会去读取mysql的jdbc.jar下META-INF文件的内容,如下所示:

com.mysql.jdbc.Driver继承类如下:
```java
public class Driver extends com.mysql.cj.jdbc.Driver {
public Driver() throws SQLException {
super();
}
static {
System.err.println("Loading class `com.mysql.jdbc.Driver'. This is deprecated. The new driver class is `com.mysql.cj.jdbc.Driver'. "
+ "The driver is automatically registered via the SPI and manual loading of the driver class is generally unnecessary.");
}
}
```
从注释可以看出平常我们使用com.mysql.jdbc.Driver已被丢弃了,取而代之的是com.mysql.cj.jdbc.Driver,也就是说官方不再建议我们使用如下代码注册mysql驱动。
```java
//不建议使用该方式注册驱动类
Class.forName("com.mysql.jdbc.Driver");
String url = "jdbc:mysql://localhost:3306/cm-storylocker?characterEncoding=UTF-8";
//通过java库获取数据库连接
Connection conn = java.sql.DriverManager.getConnection(url, "root", "root@555");
```
而是直接去掉注册步骤,如下即可
```java
String url = "jdbc:mysql://localhost:3306/cm-storylocker?characterEncoding=UTF-8";
//通过java库获取数据库连接
Connection conn = java.sql.DriverManager.getConnection(url, "root", "root@555");
```
这样ServiceLoader会帮助我们处理一切,并最终通过load()方法加载,看看load()方法实现
```java
public static <S> ServiceLoader<S> load(Class<S> service) {
//通过线程上下文类加载器加载
ClassLoader cl = Thread.currentThread().getContextClassLoader();
return ServiceLoader.load(service, cl);
}
```
很明显了确实通过线程上下文类加载器加载的,实际上核心包的SPI类对外部实现类的加载都是基于线程上下文类加载器执行的,通过这种方式实现了Java核心代码内部去调用外部实现类。我们知道线程上下文类加载器默认情况下就是AppClassLoader,那为什么不直接通过getSystemClassLoader()获取类加载器来加载classpath路径下的类的呢?其实是可行的,但这种直接使用getSystemClassLoader()方法获取AppClassLoader加载类有一个缺点,那就是代码部署到不同服务时会出现问题,如把代码部署到Java Web应用服务或者EJB之类的服务将会出问题,因为这些服务使用的线程上下文类加载器并非AppClassLoader,而是Java Web应用服自家的类加载器,类加载器不同。所以我们应用该少用getSystemClassLoader()。总之不同的服务使用的可能默认ClassLoader是不同的,但使用线程上下文类加载器总能获取到与当前程序执行相同的ClassLoader,从而避免不必要的问题。ok~.关于线程上下文类加载器暂且聊到这,前面阐述的DriverManager类,大家可以自行看看源码,相信会有更多的体会,另外关于ServiceLoader本篇并没有过多的阐述,毕竟我们主题是类加载器,但ServiceLoader是个很不错的解耦机制,大家可以自行查阅其相关用法。
ok~,本篇到此告一段落,如有误处,欢迎留言,谢谢。
>参考资料:
http://blog.csdn.net/yangcheng33/article/details/52631940
http://ifeve.com/wp-content/uploads/2014/03/JSR133%E4%B8%AD%E6%96%87%E7%89%881.pdf
《深入理解JVM虚拟机》
《深入分析Java Web 技术内幕》
## 参考
[原文链接--深入理解Java类加载器(ClassLoader)](https://blog.csdn.net/javazejian/article/details/73413292) | 27,811 | MIT |
# 判断子序列
给定字符串 s 和 t ,判断 s 是否为 t 的子序列。
你可以认为 s 和 t 中仅包含英文小写字母。字符串 t 可能会很长(长度 ~= 500,000),而 s 是个短字符串(长度 <=100)。
字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,"ace"是"abcde"的一个子序列,而"aec"不是)。
```
示例1:
s = "abc", t = "ahbgdc"
返回true.
示例2:
s = "axc", t = "ahbgdc"
返回false.
```
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/is-subsequence
## 分析:
如示例1,利用双指针i和j,分别遍历s和t,先取s的首字符a和t的首字符a,判断相等,i++,j++,再取s和t的第二个字符b,h,发现不相等,j++,接着取t的第三个字符b,发现相等,i++,j++,直到s被遍历完,说明s是t的子序列,否则s不是t的子序列
## 解答:
```js
/**
* @param {string} s
* @param {string} t
* @return {boolean}
*/
var isSubsequence = function(s, t) {
let i = 0,j = 0;
while(i<s.length && j<t.length){
if(s[i] == t[j]){
i++;
j++
}else{
j++
}
}
return i === s.length;
};
``` | 774 | MIT |
# 高性能 高开发效率 功能全面 的数据库orm框架
* 中文
* [English](README-en.md)
[](https://goreportcard.com/report/github.com/zhuxiujia/GoMybatis)
[](https://travis-ci.com/zhuxiujia/GoMybatis)
[](https://godoc.org/github.com/zhuxiujia/GoMybatis)
[](https://coveralls.io/github/zhuxiujia/GoMybatis?branch=master)
[](https://codecov.io/gh/zhuxiujia/GoMybatis)

### 使用教程请仔细阅读文档网站 https://zhuxiujia.github.io/gomybatis.io/info.html
# 优势
* <a href="https://zhuxiujia.github.io/gomybatis.io/info.html">高性能</a>,单机每秒事务数最高可达456621Tps/s,总耗时0.22s (测试环境 返回模拟的sql数据,并发1000,总数100000,6核16GB win10)<br>
* <a href="https://zhuxiujia.github.io/gomybatis.io/info.html">事务</a>,session灵活插拔,兼容过渡期微服务<br>
* <a href="https://zhuxiujia.github.io/gomybatis.io/info.html">异步日志</a>异步消息队列日,框架内sql日志使用带缓存的channel实现 消息队列异步记录日志<br>
* <a href="https://zhuxiujia.github.io/gomybatis.io/info.html">动态SQL</a>,在xml中`<select>,<update>,<insert>,<delete>,<trim>,<if>,<set>,<where>,<foreach>,<resultMap>,<bind>,<choose><when><otherwise>,<sql><include>`等等java框架Mybatis包含的15种实用功能<br>
* <a href="https://zhuxiujia.github.io/gomybatis.io/info.html">多数据库</a>Mysql,Postgres,Tidb,SQLite,Oracle....等等更多<br>
* <a href="https://zhuxiujia.github.io/gomybatis.io/info.html">无依赖</a>基于反射动态代理,无需go generate生成*.go等中间代码,xml读取后可直接调用函数<br>
* <a href="https://zhuxiujia.github.io/gomybatis.io/info.html">智能表达式</a>`#{foo.Bar}``#{arg+1}``#{arg*1}``#{arg/1}``#{arg-1}`不但可以处理简单判断和计算任务,同时在取值时 假如foo.Bar 这个属性是指针,那么调用 foo.Bar 则取实际值,避免解引用操作,单个参数为结构体时默认展开它的属性,免去重复写a.b.c的深度取值<br>
* <a href="https://zhuxiujia.github.io/gomybatis.io/info.html">动态数据源</a>可以使用路由engine.SetDataSourceRouter自定义多数据源规则<br>
* <a href="https://zhuxiujia.github.io/gomybatis.io/info.html">模板标签(核心优势-兼顾开发效率/扩展性)</a>一行代码实现增删改查,逻辑删除,乐观锁(基于版本号更新)极大减轻CRUD操作的心智负担。除此之外,模板标签body体可以插入任意xml逻辑非常高的扩展性(和传统Orm框架最大区别,编写动态sql的同时代码行数骤减)<br>
* <a href="https://zhuxiujia.github.io/gomybatis.io/info.html">乐观锁</a>`<updateTemplete>`支持通过修改版本号实现的乐观锁<br>
* <a href="https://zhuxiujia.github.io/gomybatis.io/info.html">逻辑删除</a>`<insertTemplete>``<updateTemplete>``<deleteTemplete>``<selectTemplete>`均支持逻辑删除<br>
* <a href="https://zhuxiujia.github.io/gomybatis.io/info.html">8种事务传播行为</a>复刻Spring MVC的事务传播行为功能<br>
* <a href="https://zhuxiujia.github.io/gomybatis.io/info.html">定制easyrpc 基于rpc/jsonrpc</a>让服务完美支持RPC(减少参数限制),动态代理,事务订阅,易于微服务集成和扩展 详情请点击链接https://github.com/zhuxiujia/easyrpc<br>
## 使用教程
> 示例源码https://github.com/zhuxiujia/GoMybatis/tree/master/example
设置好GoPath,用go get 命令下载GoMybatis和对应的数据库驱动
```
go get github.com/zhuxiujia/GoMybatis
go get github.com/go-sql-driver/mysql
```
实际使用mapper
```
import (
_ "github.com/go-sql-driver/mysql" //导入mysql驱动
"GoMybatis"
"fmt"
"time"
)
//定义xml内容,建议以*Mapper.xml文件存于项目目录中,在编辑xml时就可享受GoLand等IDE渲染和智能提示。生产环境可以使用statikFS把xml文件打包进程序里
var xmlBytes = []byte(`
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"https://raw.githubusercontent.com/zhuxiujia/GoMybatis/master/mybatis-3-mapper.dtd">
<mapper namespace="ActivityMapperImpl">
<!--SelectAll(result *[]Activity)error-->
<select id="selectAll">
select * from biz_activity where delete_flag=1 order by create_time desc
</select>
</mapper>
`)
type ExampleActivityMapperImpl struct {
SelectAll func() ([]Activity, error)
}
func main() {
var engine = GoMybatis.GoMybatisEngine{}.New()
//Mysql链接格式 用户名:密码@(数据库链接地址:端口)/数据库名称,如root:123456@(***.com:3306)/test
err := engine.Open("mysql", "*?charset=utf8&parseTime=True&loc=Local")
if err != nil {
panic(err)
}
var exampleActivityMapperImpl ExampleActivityMapperImpl
//加载xml实现逻辑到ExampleActivityMapperImpl
engine.WriteMapperPtr(&exampleActivityMapperImpl, xmlBytes)
//使用mapper
result, err := exampleActivityMapperImpl.SelectAll(&result)
if err != nil {
panic(err)
}
fmt.Println(result)
}
```
## 动态数据源
```
//添加第二个mysql数据库,请把MysqlUri改成你的第二个数据源链接
GoMybatis.Open("mysql", MysqlUri)
//动态数据源路由
var router = GoMybatis.GoMybatisDataSourceRouter{}.New(func(mapperName string) *string {
//根据包名路由指向数据源
if strings.Contains(mapperName, "example.") {
var url = MysqlUri//第二个mysql数据库,请把MysqlUri改成你的第二个数据源链接
fmt.Println(url)
return &url
}
return nil
})
```
## 自定义日志输出
```
engine.SetLogEnable(true)
engine.SetLog(&GoMybatis.LogStandard{
PrintlnFunc: func(messages []byte) {
},
})
```
## 异步日志-基于消息队列日志
## 多数据库支持-驱动列表
```
//传统数据库
Mysql: github.com/go-sql-driver/mysql
MyMysql: github.com/ziutek/mymysql/godrv
Postgres: github.com/lib/pq
SQLite: github.com/mattn/go-sqlite3
MsSql: github.com/denisenkom/go-mssqldb
MsSql: github.com/lunny/godbc
Oracle: github.com/mattn/go-oci8
//分布式NewSql数据库
Tidb: github.com/pingcap/tidb
CockroachDB(也是Postgres驱动): github.com/lib/pq
```
## 嵌套事务-事务传播行为
<table>
<thead>
<tr><th>事务类型</th>
<th>说明</th>
</tr>
</thead>
<tbody><tr><td>PROPAGATION_REQUIRED</td><td>表示如果当前事务存在,则支持当前事务。否则,会启动一个新的事务。默认事务类型。</td></tr>
<tr><td>PROPAGATION_SUPPORTS</td><td>表示如果当前事务存在,则支持当前事务,如果当前没有事务,就以非事务方式执行。</td></tr>
<tr><td>PROPAGATION_MANDATORY</td><td>表示如果当前事务存在,则支持当前事务,如果当前没有事务,则返回事务嵌套错误。</td></tr>
<tr><td>PROPAGATION_REQUIRES_NEW</td><td>表示新建一个全新Session开启一个全新事务,如果当前存在事务,则把当前事务挂起。</td></tr>
<tr><td>PROPAGATION_NOT_SUPPORTED</td><td>表示以非事务方式执行操作,如果当前存在事务,则新建一个Session以非事务方式执行操作,把当前事务挂起。</td></tr>
<tr><td>PROPAGATION_NEVER</td><td>表示以非事务方式执行操作,如果当前存在事务,则返回事务嵌套错误。</td></tr>
<tr><td>PROPAGATION_NESTED</td><td>表示如果当前事务存在,则在嵌套事务内执行,如嵌套事务回滚,则只会在嵌套事务内回滚,不会影响当前事务。如果当前没有事务,则进行与PROPAGATION_REQUIRED类似的操作。</td></tr>
<tr><td>PROPAGATION_NOT_REQUIRED</td><td>表示如果当前没有事务,就新建一个事务,否则返回错误。</td></tr></tbody>
</table>
```
//嵌套事务的服务
type TestService struct {
exampleActivityMapper *ExampleActivityMapper //服务包含一个mapper操作数据库,类似java spring mvc
UpdateName func(id string, name string) error `tx:"" rollback:"error"`
UpdateRemark func(id string, remark string) error `tx:"" rollback:"error"`
}
func main() {
var testService TestService
testService = TestService{
exampleActivityMapper: &exampleActivityMapper,
UpdateRemark: func(id string, remark string) error {
testService.exampleActivityMapper.SelectByIds([]string{id})
panic(errors.New("业务异常")) // panic 触发事务回滚策略
return nil // rollback:"error"指定了返回error类型 且不为nil 就会触发事务回滚策略
},
UpdateName: func(id string, name string) error {
testService.exampleActivityMapper.SelectByIds([]string{id})
return nil
},
}
GoMybatis.AopProxyService(&testService, &engine)//必须使用AOP代理服务的func
testService.UpdateRemark("1","remark")
}
```
## 内置xml生成工具- 根据用户定义的struct结构体生成对应的 mapper.xml
```
//step1 定义你的数据库模型,必须包含 json注解(默认为数据库字段), gm:""注解指定 值是否为 id,version乐观锁,logic逻辑软删除
type UserAddress struct {
Id string `json:"id" gm:"id"`
UserId string `json:"user_id"`
RealName string `json:"real_name"`
Phone string `json:"phone"`
AddressDetail string `json:"address_detail"`
Version int `json:"version" gm:"version"`
CreateTime time.Time `json:"create_time"`
DeleteFlag int `json:"delete_flag" gm:"logic"`
}
//第二步,在你项目main 目录下建立一个 XmlCreateTool.go 内容如下
func main() {
var bean = UserAddress{} //此处只是举例,应该替换为你自己的数据库模型
GoMybatis.OutPutXml(reflect.TypeOf(bean).Name()+"Mapper.xml", GoMybatis.CreateXml("biz_"+GoMybatis.StructToSnakeString(bean), bean))
}
//第三步,执行命令,在当前目录下得到 UserAddressMapper.xml文件
go run XmlCreateTool.go
//以下是自动生成的xml文件内容
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"https://raw.githubusercontent.com/zhuxiujia/GoMybatis/master/mybatis-3-mapper.dtd">
<mapper>
<!--logic_enable 逻辑删除字段-->
<!--logic_deleted 逻辑删除已删除字段-->
<!--logic_undelete 逻辑删除 未删除字段-->
<!--version_enable 乐观锁版本字段,支持int,int8,int16,int32,int64-->
<resultMap id="BaseResultMap" tables="biz_user_address">
<id column="id" property="id"/>
<result column="id" property="id" langType="string" />
<result column="user_id" property="user_id" langType="string" />
<result column="real_name" property="real_name" langType="string" />
<result column="phone" property="phone" langType="string" />
<result column="address_detail" property="address_detail" langType="string" />
<result column="version" property="version" langType="int" version_enable="true" />
<result column="create_time" property="create_time" langType="Time" />
<result column="delete_flag" property="delete_flag" langType="int" logic_enable="true" logic_undelete="1" logic_deleted="0" />
</resultMap>
</mapper>
```
## 配套生态(RPC,JSONRPC,Consul)-搭配GoMybatis
* https://github.com/zhuxiujia/easy_mvc //mvc,极大简化开发流程
* https://github.com/zhuxiujia/easyrpc //easyrpc(基于标准库的RPC)吸收GoMybatis的概念,类似标准库的api,定义服务没有标准库的要求那么严格(可选不传参数,或者只有一个参数,只有一个返回值)
* https://github.com/zhuxiujia/easyrpc_discovery //基于easyrpc定制微服务发现,支持动态代理,支持GoMybatis事务,AOP代理,事务嵌套,tag定义事务,自带负载均衡算法(随机,加权轮询,源地址哈希法)
## 请及时关注版本,及时升级版本(新的功能,bug修复)
## TODO 未来新特性(可能会更改)
## 喜欢的老铁欢迎在右上角点下 star 关注和支持我们哈 | 9,590 | Apache-2.0 |
<properties
pageTitle="VirtualBox を使用した Docker ホストの構成 | Microsoft Azure"
description="Docker マシンと VirtualBox を使用して既定の Docker インスタンスを構成する詳細な手順"
services="visual-studio-online"
documentationCenter="na"
authors="allclark"
manager="douge"
editor="" />
<tags
ms.service="multiple"
ms.devlang="dotnet"
ms.topic="article"
ms.tgt_pltfrm="na"
ms.workload="multiple"
ms.date="06/08/2016"
ms.author="allclark" />
# VirtualBox を使用した Docker ホストの構成
## 概要
この記事では、Docker マシンと VirtualBox を使用して既定の Docker インスタンスを構成する方法を説明します。[Docker for Windows のベータ版](http://beta.docker.com/)を使用している場合、この構成は必要ありません。
## 前提条件
次のツールをインストールする必要があります。
- [Docker Toolbox](https://www.docker.com/products/overview#/docker_toolbox)
## Windows PowerShell を使用した Docker クライアントの構成
Docker クライアントを構成するには、Windows PowerShell を開き、次の手順を実行します。
1. 既定の Docker ホスト インスタンスを作成します。
```PowerShell
docker-machine create --driver virtualbox default
```
1. 既定のインスタンスが構成され、実行されていることを確認します。(通常は、"default" という名前のインスタンスが実行されていることがわかります)。
docker-machine ls
![][0]
1. 現在のホストを既定として設定し、シェルを構成します。
docker-machine env default | Invoke-Expression
1. アクティブな Docker コンテナーを表示します。リストは空にする必要があります。
docker ps
![][1]
> [AZURE.NOTE] 開発用コンピューターを再起動するたびに、ローカルの Docker ホストを再起動する必要があります。これを行うには、コマンド プロンプトで、次のコマンドを発行します。`docker-machine start default`
[0]: ./media/vs-azure-tools-docker-setup/docker-machine-ls.png
[1]: ./media/vs-azure-tools-docker-setup/docker-ps.png
<!---HONumber=AcomDC_0608_2016--> | 1,509 | CC-BY-3.0 |
---
layout: post
title: "中英“人质外交”往事"
date: 2013-02-01
author: 宿亮
from: http://cnpolitics.org/2013/02/sino-uk-diplomacy/
tags: [ 政見 ]
categories: [ 政見 ]
---
<div class="post-block">
<h1 class="post-head">
中英“人质外交”往事
</h1>
<p class="post-subhead">
</p>
<p class="post-tag">
#中国 #国际关系 #外交 #英国
</p>
<p class="post-author">
<!--a href="http://cnpolitics.org/author/suliang/">宿亮</a-->
<a href="http://cnpolitics.org/author/suliang/">
宿亮
</a>
<span style="font-size:14px;color:#b9b9b9;">
|2013-02-01
</span>
</p>
<!--p class="post-lead">上世纪60年代末,中英之间经历一段“人质外交”。中国最高领导层在特殊政治环境中,控制国内情绪、保证外交稳定;而英方奉行“沉默外交”,没有对中国严苛制裁,促使双方谈判团队在彼此准确理解对方想法的前提下开展外交解决,避免类似美国和伊朗1979年人质事件后外交关系不断恶化的状况。</p-->
<div class="post-body">
<p>
(本文已刊发于2013年1月30日出刊的《青年参考》)
</p>
<p>
<strong>
□“政见”观察员 宿亮
</strong>
</p>
<p>
<a href="http://cnpolitics.org/wp-content/uploads/2013/02/sino-uk.jpg">
<img alt="sino-uk" class="aligncenter size-full wp-image-2735" height="278" sizes="(max-width: 500px) 100vw, 500px" src="http://cnpolitics.org/wp-content/uploads/2013/02/sino-uk.jpg" srcset="http://cnpolitics.org/wp-content/uploads/2013/02/sino-uk.jpg 500w, http://cnpolitics.org/wp-content/uploads/2013/02/sino-uk-300x166.jpg 300w" width="500"/>
</a>
</p>
<p>
外交是妥协的艺术。外交技巧是制造平静的技巧。一旦平静被打破,一国政府外交部门的谈判技巧随即受到极大挑战。
</p>
<p>
在漫长的外交史中,1979年伊朗扣押美国使馆人员长达444天是经典事件,直至今天还有人指责美国政府外交团队的无能。而国际外交史上另一段互相扣押人员的经历却鲜为人知,这段经历的主角是英国政府和成立仅有二十年左右的新中国政府。
</p>
<p>
伦敦大学皇家霍洛威学院中英关系专家
<strong>
CHI-KWAN MARK
</strong>
在《外交与治国》杂志(Diplomacy & Statecraft)撰文,梳理了这段历史。
</p>
<p>
他认为,冷战之中,中英既非朋友,也不是敌人。两国之间有很多互不赞同的地方,但又有很多共同利益。面对外交危机,他们之间的互动体现了特殊时期的外交技巧,同时体现不同政治文化间外交互动的有效做法。
</p>
<p>
1967年夏天,受到中国国内政治局势影响,香港社会发生动荡,引发全球关注。在极左外交思想影响下,中国于5月18日关闭了在上海的英国代办处,将外交官集中到北京。7月,港英当局逮捕了中国驻香港官方新闻机构一名记者,以煽动罪名判处两年羁押。中方随即软禁英国路透社记者安东尼·格雷。
</p>
<p>
8月,形势急转直下,港英当局继续扣押中国新闻记者,而中国部分极左势力火烧英国驻京代办处。伦敦政府随即控制中国代办处,并派警力监视,导致中国外交人员与英国警方冲突。两国“人质外交”紧急展开。
</p>
<p>
当时,英国在国际上奉行“沉默外交”,并不希望卷入激烈冲突,而中英双方当时的贸易状况不错,所以英国没有孤注一掷与中国断交。
</p>
<p>
此时,中国问题专家、英方驻中国代表霍普森向伦敦发出建议,希望英国“示弱”。首先,霍普森建议伦敦做出善意姿态,争取中方信任。他强调中国人重“面子”,既然英国先在香港抓人,就应该先“服软”,这样中国也会相应让步。其次,霍普森和英国外交大臣都认为,这时以周恩来为代表的中国高层反对冲击英国使馆的行为并对此纠责,关系缓和的窗口已经打开。
</p>
<p>
英国随后放松中方人员在伦敦的活动范围限制;而中国也通知霍普森将解除对英方驻京人员限制。事实上,中方高层在8月份情况恶化时就希望缓和中英关系。周恩来将冲击代表处称为极左行为,毛泽东也表示这是“坏人”所为。
</p>
<p>
中方此时取消了所有英国外交人员签证,这种情况下,英国外交官无法出境,实质上成为“人质”,而中国驻英人员,包括外交官和新闻工作和也受到同样待遇,困在伦敦。
</p>
<p>
于是,谈判围绕两个问题展开,一个是外交官的签证;另一个是记者格雷获释。霍普森清楚地看到,格雷事件的原因是港英当局扣押中国记者,与另外两名中国记者在伦敦遭遇签证问题的情况性质不同。所以,签证和格雷两件事要分开解决。因此他建议解决中方人员,包括新闻记者和银行工作人员的签证问题,主张“一步一步来”。
</p>
<p>
但英国外交部负责远东事务的官员认为中国的主张没有考虑英国立场——换句话说,没给英国面子。英国外交部人员担心,解决了中国记者的签证,但格雷依旧受羁押的事实可能会引发公众和议会强烈反弹。所以,英方给予中国外交官签证,但没有取消新闻机构的签证限制,主张格雷事件与签证问题“相关联”。
</p>
<p>
正如霍普森所料,中国没有因为英方让步而解除对英国外交人员的签证限制。霍普森再次急电伦敦,建议在解决格雷事件前先“搞定”外交官们的签证。霍普森建议伦敦向公众表示,不会撤出代表团,只是替换人员,这样就可以避免民众认为政府“抛弃格雷”。
</p>
<p>
就在英国政府准备做出让步、港英政府也答应了中方探视被捕记者的要求时,中国政府却没有履行承诺,仅仅对6名低级别外交人员颁发签证,没有任何一个签证给到高级外交官头上。究其原因,美国航空母舰“企业号”此间访港,这一举动被中方视为利用香港作为基地侵略越南的行为。
</p>
<p>
英国政府走出一步“硬棋”,联合多达26个国家声明支持英国对外交官的权利要求;中方在压力之下让步,包括霍普森在内的高级外交官于8月份获得签证,合法离境。
</p>
<p>
英国外交官离开中国后,两国谈判桌上剩下的任务就是解决格雷事件。一些英国外交官认为要从中英大局考虑,不宜过于压迫中国政府,要给中国“台阶”,释放在押香港的中国记者,换取格雷自由。但反对者认定,香港殖民安全最为重要,不能随意释放。
</p>
<p>
在这期间,英国媒体舆论对格雷事件疯狂介入,他们认定格雷没有享受到合理生活待遇,担心他的健康。向港英当局施压,要求其在安全条件好转的情况下释放中国记者,以换取格雷的自由。最终,英方在内部达成妥协,港英政府放弃增加刑期的准备,而为了香港司法稳定,也不考虑提前释放中国记者。
</p>
<p>
1969年10月4日,随着最后一名中国记者即将在随后一天释放,格雷在北京恢复了自由,并在4天后离境。中英两国的“人质外交”宣告结束。格雷认定,自己被“两个无耻的政府当成了抵押物”。但分析师指出,无论如何,正是两国政府的努力才导致他获释。
</p>
<p>
这段“人质外交”将当时的中英关系带到了20世纪50年代以来的最低点,但值得注意的是,两国同期的经济联系没有受到政治影响,1969年是两国贸易额自1950年以来最好的一年。甚至在联合国中,英国还是投票支持了让中国易于夺回联合国席位的方案。
</p>
<p>
研究者认为,中英之间的“人质外交”之所以没有导致美国和伊朗最终不断恶化的双边关系,一方面是因为中国最高领导人在特殊的国内政治环境中,在很大程度上控制国内情绪,努力保证外交的稳定;另一方面则是因为英国奉行“沉默外交”,没有对中国施加相对严苛的制裁。谈判双方当时完全准确理解了彼此的想法,英国外交团队也充分利用了舆论作用给伦敦和香港当局施压,中英的谈判方案远比美国伊朗“高明”。
</p>
<p>
外交是一门“大艺术”,特别是在外交危机发生时,能否通过谈判妥善把问题的解决和阻止关系恶化结合在一起,决定着国际关系的“阴晴圆缺”。在现代外交错综复杂的现状下,或许回溯历史也能获得教益。
</p>
<p>
<strong>
【参考资料】
</strong>
</p>
<p>
Chi-Kwan Mark, Hostage Diplomacy: Britain, China, and the Politics of Negotiation, 1967–1969, Diplomacy & Statecraft, 20:473–493, 2009
</p>
</div>
<!-- icon list -->
<!--/div-->
<!-- social box -->
<div class="post-end-button back-to-top">
<p style="padding-top:20px;">
回到开头
</p>
</div>
<div id="display_bar">
<img src="http://cnpolitics.org/wp-content/themes/CNPolitics/images/shadow-post-end.png"/>
</div>
</div> | 4,495 | MIT |
# 链表中倒数第k个结点
输入一个链表,输出该链表中倒数第k个结点。
## 栈
- stack
```cpp
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
class Solution {
public:
ListNode* FindKthToTail(ListNode* pListHead, unsigned int k) {
ListNode *kNode = NULL;
if(pListHead==NULL || k<=0) return kNode;
stack<ListNode *> s;
unsigned int count = 0;
while(pListHead!=NULL)
{
++count;
s.push(pListHead);
pListHead = pListHead->next;
}
if(k>count) return kNode;
k -= 1;
while(k--) s.pop();
kNode = s.top();
return kNode;
}
};
```
- vector
```cpp
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
class Solution {
public:
ListNode* FindKthToTail(ListNode* pListHead, unsigned int k) {
ListNode *kNode = NULL;
if(pListHead==NULL || k<=0) return kNode;
vector<ListNode *> vec;
unsigned int count = 0;
while(pListHead!=NULL)
{
++count;
vec.push_back(pListHead);
pListHead = pListHead->next;
}
if(k>count) return kNode;
kNode = vec[count-k];
return kNode;
}
};
```
## 递归
- 链接:https://www.nowcoder.com/questionTerminal/529d3ae5a407492994ad2a246518148a
- 来源:牛客网
```cpp
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
class Solution {
public:
unsigned int cnt = 0;
ListNode* FindKthToTail(ListNode* pListHead, unsigned int k) {
if(pListHead==NULL)
return NULL;
ListNode* node=FindKthToTail(pListHead->next, k);
if(node!=NULL)
return node;
cnt++;
if(cnt==k)
return pListHead;
else
return NULL;
}
};
```
- 下面的递归代码不正确,还需要想想如何不需要全局变量情况下实现~!
```cpp
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
class Solution {
public:
ListNode* FindKthToTail(ListNode* pListHead, unsigned int k) {
ListNode *kNode = NULL;
if(pListHead==NULL || k<=0) return kNode;
unsigned int tail_flag = 0;
unsigned int count = 0;
kNode = helper(pListHead, &count, k, &tail_flag);
return kNode;
}
ListNode* helper(ListNode* pListHead, unsigned int *count, unsigned int k, unsigned int *tail_flag)
{
if(*tail_flag==0)
{
if(pListHead->next==NULL)
{
*tail_flag = 1;
*count += 1;
return pListHead;
}
else
{
return helper(pListHead->next, count, k, tail_flag);
}
}
if(*tail_flag==1)
{
if(*count==k)
return pListHead;
*count += 1;
return helper(pListHead->next, count, k, tail_flag);
}
}
};
```
- 下面代码基于第一个递归代码改的,也不正确
```cpp
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
class Solution {
public:
ListNode* FindKthToTail(ListNode* pListHead, unsigned int k)
{
if(pListHead==NULL || k<=0) return NULL;
unsigned int cnt = 0;
ListNode *kNode = FindKthToTail(pListHead, k, &cnt);
return kNode;
}
ListNode* FindKthToTail(ListNode* pListHead, unsigned int k, unsigned int *cnt) {
if(pListHead==NULL)
return NULL;
FindKthToTail(pListHead->next, k, cnt);
*cnt++;
if(*cnt==k)
return pListHead;
return NULL;
}
};
```
## 双指针
```cpp
/*
struct ListNode {
int val;
struct ListNode *next;
ListNode(int x) :
val(x), next(NULL) {
}
};*/
class Solution {
public:
ListNode* FindKthToTail(ListNode* pListHead, unsigned int k) {
if(pListHead==NULL || k<=0) return NULL;
int count = 0;
ListNode *kNode = pListHead;
while(pListHead)
{
count++;
if(count>k)
kNode = kNode->next;
pListHead = pListHead->next;
}
return count>=k ? kNode : NULL;
}
};
``` | 4,311 | Apache-2.0 |
<header><B>iOS使用自签名证书实现HTTPS请求</B></header><br/>
由于苹果规定2017年1月1日以后,所有APP都要使用HTTPS进行网络请求,否则无法上架,因此研究了一下在iOS中使用HTTPS请求的实现。相信大家对HTTPS都或多或少有些了解,这里我就不再介绍了,主要功能就是将传输的报文进行加密,提高安全性。
<B>1、证书准备</B>
证书分为两种,一种是花钱向认证的机构购买的证书,服务端如果使用的是这类证书的话,那一般客户端不需要做什么,用HTTPS进行请求就行了,苹果内置了那些受信任的根证书的。另一种是自己制作的证书,使用这类证书的话是不受信任的(当然也不用花钱买),因此需要我们在代码中将该证书设置为信任证书。
我这边使用的是xca来制作了根证书,制作流程请参考http://www.2cto.com/Article/201411/347512.html,由于xca无法导出.jsk的后缀,因此我们只要制作完根证书后以.p12的格式导出就行了,之后的证书制作由命令行来完成。自制一个批处理文件,添加如下命令:
<pre>
set ip=%1%
md %ip%
keytool -importkeystore -srckeystore ca.p12 -srcstoretype PKCS12 -srcstorepass 123456 -destkeystore ca.jks -deststoretype JKS -deststorepass 123456
keytool -genkeypair -alias server-%ip% -keyalg RSA -keystore ca.jks -storepass 123456 -keypass 123456 -validity 3650 -dname "CN=%ip%, OU=ly, O=hik, L=hz, ST=zj, C=cn"
keytool -certreq -alias server-%ip% -storepass 123456 -file %ip%\server-%ip%.certreq -keystore ca.jks
keytool -gencert -alias ca -storepass 123456 -infile %ip%\server-%ip%.certreq -outfile %ip%\server-%ip%.cer -validity 3650 -keystore ca.jks
keytool -importcert -trustcacerts -storepass 123456 -alias server-%ip% -file %ip%\server-%ip%.cer -keystore ca.jks
keytool -delete -keystore ca.jks -alias ca -storepass 123456
</pre>
将上面加粗的ca.p12改成你导出的.p12文件的名称,123456改为你创建证书的密码。
然后在文件夹空白处按住ctrl+shift点击右键,选择在此处打开命令窗口,在命令窗口中输入“start.bat ip/域名”来执行批处理文件,其中start.bat是添加了上述命令的批处理文件,ip/域名即你服务器的ip或者域名。执行成功后会生成一个.jks文件和一个以你的ip或域名命名的文件夹,文件夹中有一个.cer的证书,这边的.jks文件将在服务端使用.cer文件将在客户端使用,到这里证书的准备工作就完成了。
<B>2、服务端配置</B>
由于我不做服务端好多年,只会使用Tomcat,所以这边只讲下Tomcat的配置方法,使用其他服务器的同学请自行查找设置方法。
打开tomcat/conf目录下的server.xml文件将HTTPS的配置打开,并进行如下配置:
\<Connector URIEncoding="UTF-8" protocol="org.apache.coyote.http11.Http11NioProtocol" port="8443" maxThreads="200" scheme="https" secure="true" SSLEnabled="true" sslProtocol="TLSv1.2" sslEnabledProtocols="TLSv1.2" keystoreFile="${catalina.base}/ca/ca.jks" keystorePass="123456" clientAuth="false" SSLVerifyClient="off" netZone="你的ip或域名"/>
keystoreFile是你.jks文件放置的目录,keystorePass是你制作证书时设置的密码,netZone填写你的ip或域名。注意苹果要求协议要TLSv1.2以上。
<B>3、iOS端配置</B>
首先把前面生成的.cer文件添加到项目中,注意在添加的时候选择要添加的targets。
1.使用NSURLSession进行请求
代码如下:
<pre>NSString *urlString = @"https://xxxxxxx";
NSURL *url = [NSURL URLWithString:urlString];
NSMutableURLRequest *request = [NSMutableURLRequest requestWithURL:url cachePolicy:NSURLRequestReloadIgnoringCacheData timeoutInterval:10.0f];
NSURLSession *session = [NSURLSession sessionWithConfiguration:[NSURLSessionConfiguration defaultSessionConfiguration] delegate:self delegateQueue:[NSOperationQueue mainQueue]];
NSURLSessionDataTask *task = [session dataTaskWithRequest:request];
[task resume];</pre>
需要实现NSURLSessionDataDelegate中的URLSession:didReceiveChallenge:completionHandler:方法来进行证书的校验,代码如下:
<pre>- (void)URLSession:(NSURLSession *)session didReceiveChallenge:(NSURLAuthenticationChallenge *)challenge
completionHandler:(void (^)(NSURLSessionAuthChallengeDisposition disposition, NSURLCredential * _Nullable credential))completionHandler {
NSLog(@"证书认证");
if ([[[challenge protectionSpace] authenticationMethod] isEqualToString: NSURLAuthenticationMethodServerTrust]) {
do
{
SecTrustRef serverTrust = [[challenge protectionSpace] serverTrust];
NSCAssert(serverTrust != nil, @"serverTrust is nil");
if(nil == serverTrust)
break; /* failed */
/**
* 导入多张CA证书(Certification Authority,支持SSL证书以及自签名的CA),请替换掉你的证书名称
*/
NSString *cerPath = [[NSBundle mainBundle] pathForResource:@"ca" ofType:@"cer"];//自签名证书
NSData* caCert = [NSData dataWithContentsOfFile:cerPath];
NSCAssert(caCert != nil, @"caCert is nil");
if(nil == caCert)
break; /* failed */
SecCertificateRef caRef = SecCertificateCreateWithData(NULL, (__bridge CFDataRef)caCert);
NSCAssert(caRef != nil, @"caRef is nil");
if(nil == caRef)
break; /* failed */
//可以添加多张证书
NSArray *caArray = @[(__bridge id)(caRef)];
NSCAssert(caArray != nil, @"caArray is nil");
if(nil == caArray)
break; /* failed */
//将读取的证书设置为服务端帧数的根证书
OSStatus status = SecTrustSetAnchorCertificates(serverTrust, (__bridge CFArrayRef)caArray);
NSCAssert(errSecSuccess == status, @"SecTrustSetAnchorCertificates failed");
if(!(errSecSuccess == status))
break; /* failed */
SecTrustResultType result = -1;
//通过本地导入的证书来验证服务器的证书是否可信
status = SecTrustEvaluate(serverTrust, &result);
if(!(errSecSuccess == status))
break; /* failed */
NSLog(@"stutas:%d",(int)status);
NSLog(@"Result: %d", result);
BOOL allowConnect = (result == kSecTrustResultUnspecified) || (result == kSecTrustResultProceed);
if (allowConnect) {
NSLog(@"success");
}else {
NSLog(@"error");
}
/* kSecTrustResultUnspecified and kSecTrustResultProceed are success */
if(! allowConnect)
{
break; /* failed */
}
#if 0
/* Treat kSecTrustResultConfirm and kSecTrustResultRecoverableTrustFailure as success */
/* since the user will likely tap-through to see the dancing bunnies */
if(result == kSecTrustResultDeny || result == kSecTrustResultFatalTrustFailure || result == kSecTrustResultOtherError)
break; /* failed to trust cert (good in this case) */
#endif
// The only good exit point
NSLog(@"信任该证书");
NSURLCredential *credential = [NSURLCredential credentialForTrust:challenge.protectionSpace.serverTrust];
completionHandler(NSURLSessionAuthChallengeUseCredential,credential);
return [[challenge sender] useCredential: credential
forAuthenticationChallenge: challenge];
}
while(0);
}
// Bad dog
NSURLCredential *credential = [NSURLCredential credentialForTrust:challenge.protectionSpace.serverTrust];
completionHandler(NSURLSessionAuthChallengeCancelAuthenticationChallenge,credential);
return [[challenge sender] cancelAuthenticationChallenge: challenge];
}</pre>
此时即可成功请求到服务端。
<B>注:调用SecTrustSetAnchorCertificates设置可信任证书列表后就只会在设置的列表中进行验证,会屏蔽掉系统原本的信任列表,要使系统的继续起作用只要调用SecTrustSetAnchorCertificates方法,第二个参数设置成NO即可。</B>
2.使用AFNetworking进行请求
AFNetworking首先需要配置AFSecurityPolicy类,AFSecurityPolicy类封装了证书校验的过程。
<pre>
/**
AFSecurityPolicy分三种验证模式:
AFSSLPinningModeNone:只是验证证书是否在信任列表中
AFSSLPinningModeCertificate:该模式会验证证书是否在信任列表中,然后再对比服务端证书和客户端证书是否一致
AFSSLPinningModePublicKey:只验证服务端证书与客户端证书的公钥是否一致
*/
AFSecurityPolicy *securityPolicy = [AFSecurityPolicy policyWithPinningMode:AFSSLPinningModeCertificate];
securityPolicy.allowInvalidCertificates = YES;//是否允许使用自签名证书
securityPolicy.validatesDomainName = NO;//是否需要验证域名,默认YES
AFHTTPSessionManager *_manager = [AFHTTPSessionManager manager];
_manager.responseSerializer = [AFHTTPResponseSerializer serializer];
_manager.securityPolicy = securityPolicy;
//设置超时
[_manager.requestSerializer willChangeValueForKey:@"timeoutinterval"];
_manager.requestSerializer.timeoutInterval = 20.f;
[_manager.requestSerializer didChangeValueForKey:@"timeoutinterval"];
_manager.requestSerializer.cachePolicy = NSURLRequestReloadIgnoringCacheData;
_manager.responseSerializer.acceptableContentTypes = [NSSet setWithObjects:@"application/xml",@"text/xml",@"text/plain",@"application/json",nil];
__weak typeof(self) weakSelf = self;
[_manager setSessionDidReceiveAuthenticationChallengeBlock:^NSURLSessionAuthChallengeDisposition(NSURLSession *session, NSURLAuthenticationChallenge *challenge, NSURLCredential *__autoreleasing *_credential) {
SecTrustRef serverTrust = [[challenge protectionSpace] serverTrust];
/**
* 导入多张CA证书
*/
NSString *cerPath = [[NSBundle mainBundle] pathForResource:@"ca" ofType:@"cer"];//自签名证书
NSData* caCert = [NSData dataWithContentsOfFile:cerPath];
NSArray *cerArray = @[caCert];
weakSelf.manager.securityPolicy.pinnedCertificates = cerArray;
SecCertificateRef caRef = SecCertificateCreateWithData(NULL, (__bridge CFDataRef)caCert);
NSCAssert(caRef != nil, @"caRef is nil");
NSArray *caArray = @[(__bridge id)(caRef)];
NSCAssert(caArray != nil, @"caArray is nil");
OSStatus status = SecTrustSetAnchorCertificates(serverTrust, (__bridge CFArrayRef)caArray);
SecTrustSetAnchorCertificatesOnly(serverTrust,NO);
NSCAssert(errSecSuccess == status, @"SecTrustSetAnchorCertificates failed");
NSURLSessionAuthChallengeDisposition disposition = NSURLSessionAuthChallengePerformDefaultHandling;
__autoreleasing NSURLCredential *credential = nil;
if ([challenge.protectionSpace.authenticationMethod isEqualToString:NSURLAuthenticationMethodServerTrust]) {
if ([weakSelf.manager.securityPolicy evaluateServerTrust:challenge.protectionSpace.serverTrust forDomain:challenge.protectionSpace.host]) {
credential = [NSURLCredential credentialForTrust:challenge.protectionSpace.serverTrust];
if (credential) {
disposition = NSURLSessionAuthChallengeUseCredential;
} else {
disposition = NSURLSessionAuthChallengePerformDefaultHandling;
}
} else {
disposition = NSURLSessionAuthChallengeCancelAuthenticationChallenge;
}
} else {
disposition = NSURLSessionAuthChallengePerformDefaultHandling;
}
return disposition;
}];
</pre>
上述代码通过给AFHTTPSessionManager重新设置证书验证回调来自己验证证书,然后将自己的证书加入到可信任的证书列表中,即可通过证书的校验。
由于服务端使用.jks是一个证书库,客户端获取到的证书可能不止一本,我这边获取到了两本,具体获取到基本可通过SecTrustGetCertificateCount方法获取证书个数,AFNetworking在evaluateServerTrust:forDomain:方法中,AFSSLPinningMode的类型为AFSSLPinningModeCertificate和AFSSLPinningModePublicKey的时候都有校验服务端的证书个数与客户端信任的证书数量是否一样,如果不一样的话无法请求成功,所以这边我就修改他的源码,当有一个校验成功时即算成功。
当类型为AFSSLPinningModeCertificate时
<pre>return trustedCertificateCount == [serverCertificates count] - 1;</pre>
为AFSSLPinningModePublicKey时
<pre>return trustedPublicKeyCount > 0 && ((self.validatesCertificateChain) || (!self.validatesCertificateChain && trustedPublicKeyCount >= 1));</pre>
去掉了第二块中的trustedPublicKeyCount == [serverCertificates count]的条件。
这边使用的AFNetworking的版本为2.5.3,如果其他版本有不同之处请自行根据实际情况修改。 | 10,657 | MIT |
---
layout: post
title: Web进阶题-web2
excerpt: "攻防世界进阶Web题目-web2"
date: 2020-10-24 13:30:00
categories: [CTF]
comments: true
---
## 我的解题过程
1. 题目描述,"解密"
2. 访问目标网页,网页内容如下
```php
<?php
$miwen="a1zLbgQsCESEIqRLwuQAyMwLyq2L5VwBxqGA3RQAyumZ0tmMvSGM2ZwB4tws";
function encode($str){
$_o=strrev($str);
// echo $_o;
for($_0=0;$_0<strlen($_o);$_0++){
$_c=substr($_o,$_0,1);
$__=ord($_c)+1;
$_c=chr($__);
$_=$_.$_c;
}
return str_rot13(strrev(base64_encode($_)));
}
highlight_file(__FILE__);
/*
逆向加密算法,解密$miwen就是flag
*/
?>
```
3. 处理变量名,增大代码可读性
```php
<?php
$miwen="a1zLbgQsCESEIqRLwuQAyMwLyq2L5VwBxqGA3RQAyumZ0tmMvSGM2ZwB4tws";
function encode($str){
$input=strrev($str);
// echo $input;
for($i=0;$i<strlen($input);$i++){
$tool2=substr($input,$i,1);
$tool1=ord($tool2)+1;
$tool2=chr($tool1);
$output=$output.$tool2;
}
return str_rot13(strrev(base64_encode($output)));
}
highlight_file(__FILE__);
/*
逆向加密算法,解密$miwen就是flag
*/
?>
```
* strrev(),将字符串反转
* 凯撒加密向后移动一位:进入一个循环,循环次数为明文长度,每次循环将第i字符赋值给tool2,把tool2的ASCII数值+1之后转为字符重新赋值给tool2,拼接到输出
* 对输出字符串进行base64加密,反转
* 对输出字符串进行str_rot13编码,即把每一个字母在字母表中向前移动13个字母,数字和非字母字符保持不变,解码方式是再对它进行一次str_rot13
4. 编写解码脚本
```php
<?php
$miwen="a1zLbgQsCESEIqRLwuQAyMwLyq2L5VwBxqGA3RQAyumZ0tmMvSGM2ZwB4tws";
function decode($str){
$input=base64_decode(strrev(str_rot13($str)));
for($i=0;$i<strlen($input);$i++){
$tool2=substr($input,$i,1);
$tool1=ord($tool2)-1;
$tool2=chr($tool1);
$output=$output.$tool2;
}
return strrev($output);
}
echo decode($miwen);
?>
```
5. 使用浏览器访问本地PHP环境,得到flag,flag:{NSCTF_b73d5adfb819c64603d7237fa0d52977}
6. 提交,答案正确 | 2,004 | MIT |
---
title: epoll_event
layout: post
category: linux
author: 夏泽民
---
结构体epoll_event被用于注册所感兴趣的事件和回传所发生待处理的事件,定义如下:
typedef union epoll_data {
void *ptr;
int fd;
__uint32_t u32;
__uint64_t u64;
} epoll_data_t;//保存触发事件的某个文件描述符相关的数据
struct epoll_event {
__uint32_t events; /* epoll event */
epoll_data_t data; /* User data variable */
};
其中events表示感兴趣的事件和被触发的事件,可能的取值为:
EPOLLIN:表示对应的文件描述符可以读;
EPOLLOUT:表示对应的文件描述符可以写;
EPOLLPRI:表示对应的文件描述符有紧急的数可读;
EPOLLERR:表示对应的文件描述符发生错误;
EPOLLHUP:表示对应的文件描述符被挂断;
EPOLLET: ET的epoll工作模式;
<!-- more -->
1、epoll_create函数
函数声明:int epoll_create(int size)
功能:该函数生成一个epoll专用的文件描述符,其中的参数是指定生成描述符的最大范围;
2、epoll_ctl函数
函数声明:int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event)
功能:用于控制某个文件描述符上的事件,可以注册事件,修改事件,删除事件。
@epfd:由epoll_create生成的epoll专用的文件描述符;
@op:要进行的操作,EPOLL_CTL_ADD注册、EPOLL_CTL_MOD修改、EPOLL_CTL_DEL删除;
@fd:关联的文件描述符;
@event:指向epoll_event的指针;
成功:0;失败:-1
3、epoll_wait函数
函数声明:int epoll_wait(int epfd,struct epoll_event * events,int maxevents,int timeout)
功能:该函数用于轮询I/O事件的发生;
@epfd:由epoll_create生成的epoll专用的文件描述符;
@epoll_event:用于回传代处理事件的数组;
@maxevents:每次能处理的事件数;
@timeout:等待I/O事件发生的超时值;
成功:返回发生的事件数;失败:-1
Epoll的ET模式与LT模式
ET(Edge Triggered)与LT(Level Triggered)的主要区别可以从下面的例子看出
eg:
1. 标示管道读者的文件句柄注册到epoll中;
2. 管道写者向管道中写入2KB的数据;
3. 调用epoll_wait可以获得管道读者为已就绪的文件句柄;
4. 管道读者读取1KB的数据
5. 一次epoll_wait调用完成
如果是ET模式,管道中剩余的1KB被挂起,再次调用epoll_wait,得不到管道读者的文件句柄,除非有新的数据写入管道。如果是LT模式,只要管道中有数据可读,每次调用epoll_wait都会触发。
另一点区别就是设为ET模式的文件句柄必须是非阻塞的。
三、 Epoll的实现
Epoll 的源文件在/usr/src/linux/fs/eventpoll.c,在module_init时注册一个文件系统 eventpoll_fs_type,对该文件系统提供两种操作poll和release,所以epoll_create返回的文件句柄可以被poll、 select或者被其它epoll epoll_wait。对epoll的操作主要通过三个系统调用实现:
1. sys_epoll_create
2. sys_epoll_ctl
3. sys_epoll_wait
下面结合源码讲述这三个系统调用。
1.1 long sys_epoll_create (int size)
该系统调用主要分配文件句柄、inode以及file结构。在linux-2.4.32内核中,使用hash保存所有注册到该epoll的文件句柄,在该系统调用中根据size大小分配hash的大小。具体为不小于size,但小于2size的2的某次方。最小为2的9次方(512),最大为2的17次方(128 x 1024)。在linux-2.6.10内核中,使用红黑树保存所有注册到该epoll的文件句柄,size参数未使用。
1.2 long sys_epoll_ctl(int epfd, int op, int fd, struct epoll_event event)
1. 注册句柄 op = EPOLL_CTL_ADD
注册过程主要包括:
A.将fd插入到hash(或rbtree)中,如果原来已经存在返回-EEXIST,
B.给fd注册一个回调函数,该函数会在fd有事件时调用,在该函数中将fd加入到epoll的就绪队列中。
C.检查fd当前是否已经有期望的事件产生。如果有,将其加入到epoll的就绪队列中,唤醒epoll_wait。
2. 修改事件 op = EPOLL_CTL_MOD
修改事件只是将新的事件替换旧的事件,然后检查fd是否有期望的事件。如果有,将其加入到epoll的就绪队列中,唤醒epoll_wait。
3. 删除句柄 op = EPOLL_CTL_DEL
将fd从hash(rbtree)中清除。
1.3 long sys_epoll_wait(int epfd, struct epoll_event events, int maxevents,int timeout)
如果epoll的就绪队列为空,并且timeout非0,挂起当前进程,引起CPU调度。
如果epoll的就绪队列不空,遍历就绪队列。对队列中的每一个节点,获取该文件已触发的事件,判断其中是否有我们期待的事件,如果有,将其对应的epoll_event结构copy到用户events。
revents = epi->file->f_op->poll(epi->file, NULL);
epi->revents = revents & epi->event.events;
if (epi->revents) {
……
copy_to_user;
……
}
需要注意的是,在LT模式下,把符合条件的事件copy到用户空间后,还会把对应的文件重新挂接到就绪队列。所以在LT模式下,如果一次epoll_wait某个socket没有read/write完所有数据,下次epoll_wait还会返回该socket句柄。
epoll原理简述:epoll = 一颗红黑树 + 一张准备就绪句柄链表 + 少量的内核cache
select/poll 每次调用时都要传递你所要监控的所有socket给select/poll系统调用,这意味着需要将用户态的socket列表copy到内核态,如果以万计的句柄会导致每次都要copy几十几百KB的内存到内核态,非常低效。
调用epoll_create后,内核就已经在内核态开始准备帮你存储要监控的句柄了,每次调用epoll_ctl只是在往内核的数据结构里塞入新的socket句柄。
epoll向内核注册了一个文件系统,用于存储上述的被监控socket。当调用epoll_create时,就会在这个虚拟的epoll文件系统里创建一个file结点。当然这个file不是普通文件,它只服务于epoll。
epoll在被内核初始化时(操作系统启动),同时会开辟出epoll自己的内核高速cache区,用于安置每一个我们想监控的socket,这些socket会以红黑树的形式保存在内核cache里,以支持快速的查找、插入、删除。
这个内核高速cache区,就是建立连续的物理内存页,然后在之上建立slab层,简单的说,就是物理上分配好你想要的size的内存对象,每次使用时都是使用空闲的已分配好的对象。
调用epoll_create时,内核除了帮我们在epoll文件系统里建了个file结点,在内核cache里建了个红黑树用于存储以后epoll_ctl传来的socket外,还会再建立一个list链表,用于存储准备就绪的事件,当epoll_wait调用时,仅仅观察这个list链表里有没有数据即可。有数据就返回,没有数据就sleep,等到timeout时间到后即使链表没数据也返回。
通常情况下即使我们要监控百万计的句柄,大多一次也只返回很少量的准备就绪句柄而已,所以,epoll_wait仅需要从内核态copy少量的句柄到用户态而已
这个准备就绪list链表是怎么维护的呢?当我们执行epoll_ctl时,除了把socket放到epoll文件系统里file对象对应的红黑树上之外,还会给内核中断处理程序注册一个回调函数,告诉内核,如果这个句柄的中断到了,就把它放到准备就绪list链表里。
所以,当一个socket上有数据到了,内核在把网卡上的数据copy到内核中后就来把socket插入到准备就绪链表里了。
【转】epoll的两种工作模式:
Epoll的2种工作方式-水平触发(LT)和边缘触发(ET)
假如有这样一个例子:
我们已经把一个用来从管道中读取数据的文件句柄(RFD)添加到epoll描述符
这个时候从管道的另一端被写入了2KB的数据
调用epoll_wait(2),并且它会返回RFD,说明它已经准备好读取操作
然后我们读取了1KB的数据
调用epoll_wait(2)……
Edge Triggered 工作模式:
如果我们在第1步将RFD添加到epoll描述符的时候使用了EPOLLET标志,那么在第5步调用epoll_wait(2)之后将有可能会挂起,因为剩余的数据还存在于文件的输入缓冲区内,而且数据发出端还在等待一个针对已经发出数据的反馈信息。只有在监视的文件句柄上发生了某个事件的时候 ET 工作模式才会汇报事件。因此在第5步的时候,调用者可能会放弃等待仍在存在于文件输入缓冲区内的剩余数据。在上面的例子中,会有一个事件产生在RFD句柄上,因为在第2步执行了一个写操作,然后,事件将会在第3步被销毁。因为第4步的读取操作没有读空文件输入缓冲区内的数据,因此我们在第5步调用 epoll_wait(2)完成后,是否挂起是不确定的。epoll工作在ET模式的时候,必须使用非阻塞套接口,以避免由于一个文件句柄的阻塞读/阻塞写操作把处理多个文件描述符的任务饿死。最好以下面的方式调用ET模式的epoll接口,在后面会介绍避免可能的缺陷。
基于非阻塞文件句柄
只有当read(2)或者write(2)返回EAGAIN时才需要挂起,等待。但这并不是说每次read()时都需要循环读,直到读到产生一个EAGAIN才认为此次事件处理完成,当read()返回的读到的数据长度小于请求的数据长度时,就可以确定此时缓冲中已没有数据了,也就可以认为此事读事件已处理完成。
Level Triggered 工作模式:
相反的,以LT方式调用epoll接口的时候,它就相当于一个速度比较快的poll(2),并且无论后面的数据是否被使用,因此他们具有同样的职能。因为即使使用ET模式的epoll,在收到多个chunk的数据的时候仍然会产生多个事件。调用者可以设定EPOLLONESHOT标志,在 epoll_wait(2)收到事件后epoll会与事件关联的文件句柄从epoll描述符中禁止掉。因此当EPOLLONESHOT设定后,使用带有
EPOLL_CTL_MOD标志的epoll_ctl(2)处理文件句柄就成为调用者必须作的事情。
struct epoll_event
typedef union epoll_data {
void *ptr;
int fd;
__uint32_t u32;
__uint64_t u64;
} epoll_data_t;
//感兴趣的事件和被触发的事件
struct epoll_event {
__uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
注意epoll_data是个union而不是struct,两者的区别: http://www.gonglin91.com/cpp-struct-union/
所以当我们在epoll中为一个文件注册一个事件时,如果不需要什么额外的信息,只需要简单在epoll_data.fd = 当前文件的fd
(尽管这并不是必须的,在网上找到的几乎所有的博客都是这样写,呵呵)
但是当我们需要一些额外的数据的时候,就要用上void* ptr;
我们可以自定义一种类型,例如my_data,然后让ptr指向它,以后取出来的时候就能用了;
最后,记住union的特性,它只会保存最后一个被赋值的成员,所以不要data.fd,data.ptr都赋值;通用的做法就是给ptr赋值,fd只是有些时候为了演示或怎么样罢了
所以个人的想法是,其实epoll_data完全可以就是一个void*,不过可能为了一些简单的场景,才设计成union,包含了fd,u32,u64 | 5,784 | MIT |
# 2021-6-24
共50条
<!-- BEGIN -->
1. [如何看待欧洲宇航员正在紧锣密鼓地学习中文?中国的空间站还有哪些信息应当重点关注?](https://www.zhihu.com/question/466521697)
1. [如何看待收废品的大叔画上千幅油画火了,从专业的水平来看大叔画的怎么样?](https://www.zhihu.com/question/466839329)
1. [如何看待沈阳骑手为了反抗美团霸王条款,深夜接单直接强行点击 「已送达」的行为?美团可能如何处理?](https://www.zhihu.com/question/465982752)
1. [如何看待韩国渔民发现 32 条腿章鱼,专家「可能遭辐射变异」?](https://www.zhihu.com/question/466878537)
1. [「成人世界答辩会」里,近70% 的人认为填志愿,要选自己热爱的而不是热门的,你怎么看?](https://www.zhihu.com/question/466549049)
1. [如何看待四川开始清退加密货币挖矿?可能会带来哪些影响?](https://www.zhihu.com/question/466079044)
1. [如何看待快手宣布从 7 月 1 日起取消大小周?这么多互联网公司自行搞大小周合法吗?](https://www.zhihu.com/question/467143015)
1. [6 月 23 日俄军向英国军舰开火投弹示警,英军事后却称「以为俄军在射击演习」,该表态有何深意?](https://www.zhihu.com/question/466882658)
1. [江苏高考分数线揭晓,普通类本科:历史等科目类476,物理等科目类417。如何看待今年的分数线?](https://www.zhihu.com/question/467115094)
1. [什么名字可以拯救云这个姓?](https://www.zhihu.com/question/374976506)
1. [如何评价2021年江苏高考分数线?](https://www.zhihu.com/question/467116422)
1. [公司安装监控女子担心走光打伞上班被开除,索赔 33 万被驳回 ,如何看待这一审判结果?](https://www.zhihu.com/question/466782388)
1. [如何看待片仔癀被炒到一粒上千元,市值达 2584 亿?](https://www.zhihu.com/question/466984445)
1. [2021 年河南高考分数线公布,文理一本分数线分别为 558、518 分,如何看待今年的分数线?](https://www.zhihu.com/question/466845813)
1. [2021 中国医院薪酬报告公布,上海最高,平均年薪 35.1 万,你是否后悔学医?](https://www.zhihu.com/question/466745043)
1. [防晒衣是不是智商税?](https://www.zhihu.com/question/398086368)
1. [有哪些公办的二本院校推荐?](https://www.zhihu.com/question/407123693)
1. [台湾人来大陆后是什么样的体验?](https://www.zhihu.com/question/403879552)
1. [NBA 球员摔倒后为什么要别人拉才起?](https://www.zhihu.com/question/20245636)
1. [如何看待伦敦市长宣布:伦敦地铁 2024 年全面覆盖 4G 网络?](https://www.zhihu.com/question/466979963)
1. [如何看待字节跳动一实习生删除公司 GB 以下所有机器学习模型,事情经过是怎样的?事故影响有多大?](https://www.zhihu.com/question/466656197)
1. [黑小虎和虹猫出现在现实生活中,你会选择嫁给谁?](https://www.zhihu.com/question/403110937)
1. [计算机、医学、法律和金融是目前最强最好的四个专业吗?大学专业该怎么选?](https://www.zhihu.com/question/458947942)
1. [台湾地区新冠致死率已超4% ,远超全球平均水平,致死率为何这么高?](https://www.zhihu.com/question/466839287)
1. [为什么人到中年朋友就越来越少甚至没朋友?](https://www.zhihu.com/question/365256729)
1. [为什么连周冬雨都拯救不了古装偶像剧?《千古玦尘》是哪里出了问题?](https://www.zhihu.com/question/465674599)
1. [如何看待英国军舰闯入俄罗斯领海被投弹驱逐,英方拒不承认却遭BBC打脸?](https://www.zhihu.com/question/466996777)
1. [2021 年河北高考分数线公布,历史物理本科控制分数线分别为 454、412,如何看待今年的分数线?](https://www.zhihu.com/question/466845912)
1. [毕业三年,一事无成,被迫回老家,26岁却觉得自己干什么都晚了,我该怎么走出来?](https://www.zhihu.com/question/302335564)
1. [电竞圈的人怎么看《你微笑时很美》这部剧?](https://www.zhihu.com/question/466744188)
1. [女生选口腔医学专业好吗?](https://www.zhihu.com/question/375683427)
1. [CPU 的性能是不是快到天花板了?为什么?](https://www.zhihu.com/question/376567574)
1. [如何评价女性向手机游戏《光与夜之恋》?](https://www.zhihu.com/question/464964538)
1. [如何看待高考出分后,衡水中学、镇海中学等超级中学的学霸笔记成二手平台抢手货?](https://www.zhihu.com/question/467025412)
1. [有什么沐浴露可以把自己腌入味?](https://www.zhihu.com/question/48929487)
1. [为什么现在肺癌越来越多?](https://www.zhihu.com/question/454025025)
1. [如何看待元气森林创始人称「没有好产品靠炒出来,中国做消费要一点闲心」?](https://www.zhihu.com/question/467016021)
1. [请问什么专业适合理科女生?](https://www.zhihu.com/question/453285867)
1. [看完恋爱综艺《心动的信号》第四季第一期,你有什么感受?](https://www.zhihu.com/question/466811742)
1. [如何看待纯视觉自动驾驶方案(如 Apollo lite 和特斯拉),激光雷达是昙花一现还是必由之路?](https://www.zhihu.com/question/466297901)
1. [有什么免费的思维导图软件可以推荐?](https://www.zhihu.com/question/19610340)
1. [为什么《神话》易小川会同时有“自私无义”和“天真圣母”这两个相冲突的罪名?](https://www.zhihu.com/question/465013423)
1. [集成灶到底好还是不好?](https://www.zhihu.com/question/34441049)
1. [王源的新歌《流星也为你落下来了》好听吗?属于什么风格?](https://www.zhihu.com/question/465486549)
1. [对于一个即将步入高三的学生,你能给我一些建议吗?](https://www.zhihu.com/question/463306680)
1. [菲律宾前总统阿基诺三世去世,如何评价他的政治生涯?](https://www.zhihu.com/question/467004815)
1. [好像越来越多大学生转行互联网,真实情况如何?是出于哪些原因?](https://www.zhihu.com/question/459260995)
1. [怎样和喜欢的女生聊天?](https://www.zhihu.com/question/269469147)
1. [为什么外国人会对滇西小哥云南乡下的美食如此痴迷,这算是他们向往的东方传统文化吗?](https://www.zhihu.com/question/466627104)
1. [为了照顾缺失父母的侄子,老公和我吵架怎么办?](https://www.zhihu.com/question/466965270)
<!-- END --> | 3,905 | MIT |
---
title: 设置tabBar
header: develop
nav: api
sidebar: show_tabbar
---
setTabBarBadge
---
**解释:**为 tabBar 某一项的右上角添加文本
**参数:**Object
**Object 参数说明:**
|参数名 |类型 |必填 |说明|
|---- | ---- | ---- |---- |
|index |Number |是| tabBar的哪一项,从左边算起|
|text |String |是| 显示的文本,超过 4 个字符则显示成“…”|
|success| Function | 否 | 接口调用成功的回调函数|
|fail | Function | 否 | 接口调用失败的回调函数|
|complete | Function | 否 | 接口调用结束的回调函数(调用成功、失败都会执行)|
**示例:**
```js
swan.setTabBarBadge({
index: 0,
text: '文本'
});
```
<!-- #### 错误码
**Andriod**
|错误码|说明|
|--|--|
|1001|执行失败 |
**iOS**
|错误码|说明|
|--|--|
|202|解析失败,请检查参数是否正确。|
|1001|当前页面不含tabbar| -->
removeTabBarBadge
---
**解释:**移除tabBar某一项右上角的文本。
**Object 参数说明:**
|参数名 |类型 |必填 |说明|
|---- | ---- | ---- |---- |
|index |Number |是| tabBar的哪一项,从左边算起|
|success| Function | 否 | 接口调用成功的回调函数|
|fail | Function | 否 | 接口调用失败的回调函数|
|complete | Function | 否 | 接口调用结束的回调函数(调用成功、失败都会执行)|
**示例:**
```js
swan.removeTabBarBadge({
index: 0
});
```
<!-- #### 错误码
**Andriod**
|错误码|说明|
|--|--|
|1001|执行失败 |
**iOS**
|错误码|说明|
|--|--|
|202|解析失败,请检查参数是否正确。|
|1001|当前页面不含tabbar| -->
showTabBarRedDot
---
**解释:**显示 tabBar 某一项的右上角的红点
**参数:**Object
**Object 参数说明:**
|参数名 |类型 |必填 |说明|
|---- | ---- | ---- |---- |
|index |Number |是| tabBar的哪一项,从左边算起|
|success |Function | 否 | 接口调用成功的回调函数|
|fail | Function | 否 | 接口调用失败的回调函数|
|complete | Function | 否 | 接口调用结束的回调函数(调用成功、失败都会执行)|
**示例:**
```js
swan.showTabBarRedDot({
index: 0
});
```
<!-- #### 错误码
**Andriod**
|错误码|说明|
|--|--|
|1001|执行失败|
**iOS**
|错误码|说明|
|--|--|
|202|解析失败,请检查参数是否正确。|
|1001|当前页面不含tabbar| -->
hideTabBarRedDot
---
**解释:**隐藏 tabBar 某一项的右上角的红点
**参数:**Object
**Object 参数说明:**
|参数名 |类型 |必填 |说明|
|---- | ---- | ---- |---- |
|index |Number |是| tabBar的哪一项,从左边算起|
|success |Function | 否 | 接口调用成功的回调函数|
|fail | Function | 否 | 接口调用失败的回调函数|
|complete | Function | 否 | 接口调用结束的回调函数(调用成功、失败都会执行)|
**示例:**
```js
swan.hideTabBarRedDot({
index: 0
});
```
<!-- #### 错误码
**Andriod**
|错误码|说明|
|--|--|
|1001|执行失败 |
**iOS**
|错误码|说明|
|--|--|
|202|解析失败,请检查参数是否正确。|
|1001|当前页面不含tabbar| -->
setTabBarStyle
---
**解释:**动态设置 tabBar 的整体样式
**参数:**Object
**Object 参数说明:**
|参数名 |类型 |是否必填|说明|
|---- | ---- |---- |----|
|color |HexColor | 否|tab 上的文字默认颜色|
|selectedColor |HexColor | 否|tab 上的文字选中时的颜色|
|backgroundColor |HexColor | 否| tab 的背景色|
|borderStyle |String |否 | tabbar上边框的颜色, 仅支持 black/white|
|success| Function | 否 | 接口调用成功的回调函数|
|fail | Function | 否 |接口调用失败的回调函数|
|complete | Function | 否|接口调用结束的回调函数(调用成功、失败都会执行)|
**示例:**
```js
swan.setTabBarStyle({
color: '#FFFFBD',
selectedColor: '#FFFFBD',
backgroundColor: '#FFFFBD',
borderStyle: 'white'
});
```
<!-- #### 错误码
**Andriod**
|错误码|说明|
|--|--|
|1001|执行失败 |
**iOS**
|错误码|说明|
|--|--|
|1001|当前页面不含tabbar| -->
setTabBarItem
---
**解释:**动态设置 tabBar 某一项的内容
**参数:**Object
**Object 参数说明:**
|参数名 |类型 |必填 |说明|
|---- | ---- |---- |---- |
|index |Number |是| tabBar的哪一项,从左边算起。|
|text |String |否| tab 上按钮文字|
|iconPath |String |否| 图片绝对路径,icon 大小限制为 40KB,建议尺寸为 81px * 81px,当 position 为 top 时,此参数无效,不支持网络图片。|
|selectedIconPath |String |否| 选中时的图片的绝对路径,icon 大小限制为 40KB,建议尺寸为 81px * 81px ,当`position`为 top 时,此参数无效。|
|success| Function | 否 | 接口调用成功的回调函数|
|fail | Function | 否 | 接口调用失败的回调函数|
|complete | Function | 否 | 接口调用结束的回调函数(调用成功、失败都会执行)|
**示例:**
```js
swan.setTabBarItem({
index: 0,
text: '文本',
// 图片路径
iconPath: '/images/component_normal.png',
// 选中图片路径
selectedIconPath: '/images/component_selected.png',
});
```
<!-- #### 错误码
**Andriod**
|错误码|说明|
|--|--|
|1001|执行失败 |
**iOS**
|错误码|说明|
|--|--|
|202|解析失败,请检查参数是否正确。|
|1002|超过icon文件最大值| -->
showTabBar
---
**解释:**显示 tabBar
**参数:**Object
**Object 参数说明:**
|参数名 |类型 |必填 |说明|
|---- | ---- |---- |---- |
|animation | Boolean | 否 | 是否需要动画效果,默认无。|
|success| Function | 否 | 接口调用成功的回调函数|
|fail | Function | 否 | 接口调用失败的回调函数|
|complete | Function | 否 | 接口调用结束的回调函数(调用成功、失败都会执行)|
**示例:**
```js
swan.showTabBar({
success: function (res) {
console.log(res);
},
fail: function (err) {
console.log('错误码:' + err.errCode);
console.log('错误信息:' + err.errMsg);
}
});
```
<!-- #### 错误码
**Andriod**
|错误码|说明|
|--|--|
|1001|执行失败 |
**iOS**
|错误码|说明|
|--|--|
|1001|当前页面不含tabbar| -->
hideTabBar
---
**解释:**隐藏 tabBar
**参数:**Object
**Object 参数说明:**
|参数名 |类型 |必填 |说明|
|---- | ---- |---- |---- |
|animation | Boolean | 否 | 是否需要动画效果,默认无。|
|success| Function | 否 | 接口调用成功的回调函数|
|fail | Function | 否 | 接口调用失败的回调函数|
|complete | Function | 否 | 接口调用结束的回调函数(调用成功、失败都会执行)|
**示例:**
```js
swan.hideTabBar({
success: function (res) {
console.log(res);
},
fail: function (err) {
console.log('错误码:' + err.errCode);
console.log('错误信息:' + err.errMsg);
}
});
```
<!-- #### 错误码
**Andriod**
|错误码|说明|
|--|--|
|1001|执行失败 |
**iOS**
|错误码|说明|
|--|--|
|1001|当前页面不含tabba| --> | 4,947 | Apache-2.0 |
---
author: 杨帆
categories: [中國戰略分析]
date: 2020-07-05
from: http://zhanlve.org/?p=8189
layout: post
tags: [中國戰略分析]
title: 杨帆:关于文革研究的几个问题
---
<div id="entry">
<div class="at-above-post addthis_tool" data-url="http://zhanlve.org/?p=8189">
</div>
<p>
</p>
<p>
</p>
<p>
</p>
<p>
关于文革研究的几个问题 2020.5.18.
</p>
<p>
-----纪念《五一六通知》发表54周年
</p>
<p>
</p>
<p>
杨帆回忆录(五)
</p>
<p>
我的中学时代(二)
</p>
<p>
一.我再次要求党中央允许公开进行文革研究
</p>
<p>
我认识一些文革派, 没一个是吃铁饭碗的,都是民间学者,值得尊敬的是河南袁庾华。他原是大型国企管理人员,河南造反派“二七公社”负责人,相当于省级干部。后被作为“三种人”判15年刑,出狱后一直积极从事思想整合,在本地威信很高,他为人真诚,热心助人,也有许多人帮助他。
</p>
<p>
袁庾华在河南给我办过讲座, 也来北京访问过我,我请他吃饭,他再三说吃饭无所谓,借书最重要。我说你随便挑拿走就是,结果他抗走一大包。 他真诚信仰毛泽东的理想社会,一直和工人打成一片。我说我也一样真诚地奋斗10年,但大多数人不愿这样做。。
</p>
<p>
袁庾华感念于心的是1966—1967两年造反夺权经历,那是体现毛泽东五七指示的“真正文革”,至于前4年准备,后8年停滞,都不算文化革命。
</p>
<p>
我说,你这是偷换概念啊。不过可把这两年划出来作为核心阶段,你要承认文革是失败了。他们认为文革失败是四人帮的责任。还有年轻人武汉的田力为更有意思。他一边经商一边调查文革史,深入到许多地区,他说两派斗争是当权派挑起的,他们破坏文革。
</p>
<p>
我对袁庾华说:左派没逻辑,右派没良心。他觉得有意思,到处传播者两句话,我还要感谢他。
</p>
<p>
改革开放40年来,党中央秉承邓小平“不争论”的原则,只给文革扣上一顶:“历史浩劫,经济崩溃边缘”大帽子,严格控制学术研究和宣传教育。结果是“文革学”在美国成了一门学科:中国学者反要去美国和香港查材料。这不仅在学术上荒谬,且不能阻止文革派顽强发声甚至小成气候。 年轻人对文革一片空白,没记忆没感觉没免疫力,如文革再次出现,他们会不知不觉地卷入其中。
</p>
<p>
争论不可怕,抹去历史记忆才可怕。文革发生的关键是决策者发动。但其根源埋藏在人性和中国文化里,潜伏于社会矛盾中,在一定历史条件下可能再度出现。数十年来那么多人曾经捶胸顿足地保证:文革再不可能发生,现在他们不一定敢说了。
</p>
<p>
我已建议多次开放文革研究。法律规定档案30年解密,现文革开始从1966年算起是54年,从1976年结束算起是44年,一些优秀的专家如印红标,徐友渔,秦晖已七十有余,袁庾华已八十有余。老三届退休10年来写出大量回忆录,再不开放研究,文革史将失去最后一批见证人,这将是中国最大损失。
</p>
<p>
</p>
<p>
二.认识文革的本质特点
</p>
<p>
</p>
<p>
数十年来对于文革,主流是彻底否定,民间文革派是盲目肯定。但对“文革”概念和核心特点,并没彻底搞清。 依据1966年《五一六通知》的说法:
</p>
<ul>
<li>
遵循1962年毛泽东提出的“党的基本路
</li>
</ul>
<p>
线”, 以阶级斗争为纲,主要矛盾是人民群众和“走资本主义道路当权派”的矛盾。经4年舆论准备,形成了严重的个人崇拜,要在上层建筑领域里,无产阶级对资产阶级的实行全面专政。
</p>
<ul>
<li>
运动的重点是三种人:走资本主义道路的
</li>
</ul>
<p>
当权派,资产阶级反动学术权威,横扫一切牛鬼蛇神。这三个概念在法律上没有确切定义,不是以行为定罪,而是以身份定罪,从根本上破坏了依法治国。
</p>
<p>
具体做法是一斗二批三改,改革教育,改革文艺,改革一切不适应社会主义经济基础的上层建筑,文化革命准备三年完成。
</p>
<p>
第三,真正“史无前例”的是:文化革命不是依靠党和行政系统,不是依靠公检法和军队自上而下安排的,党和政府管理部门大部分停止了工作。检察院和法院一关门就是8年,基层党委瘫痪,刘少奇派工作组被撤销。刘少奇茫然,说我们是“老革命遇到了新问题”,“努力想跟毛主席就是跟不上”。
</p>
<p>
文革实行的机制是:
</p>
<p>
(1)神化的最高领袖直接发布语录,称为“最高指示”,直接通过《人民日报》通知全国人民;
</p>
<p>
(2)成立中央文化革命小组,取代党中央书记处, 成为决策和执行机构,凌驾于党中央政治局和中央委员会之上。
</p>
<p>
(3)发动群众“自己教育自己,自己解放自己”,好像1926年毛泽东《湖南农民运动考察报告》歌颂的农民造反运动。
</p>
<p>
1966年8月毛泽东给清华附中红卫兵写信,提出“造反有理”。 红卫兵冲上社会“破四旧”,使用了私人暴力,称为“红八月”;10月份中央文革又鼓动成立群众组织造反夺权。群众组织越过了中间管理层,直接与领袖沟通,搞“大鸣大放大字报大辩论”。
</p>
<p>
第四,自由派把文革归结为“专制”是不准确的。专制是最高领导一个人决策,通过中层(国家机器)来管理下层,而文革是把领袖神化,直接依靠群众打掉中层,这是民粹主义和法国大革命的路数,在中国民间亦有历史积淀,如墨家在农民起义中的影响。
</p>
<p>
自由派一直没抓住这点,把任何“左倾”简单类比为文革,成为一种帽子,降低了他们理论解释力。
</p>
<p>
第五,1967年1月1日以上海为起点,搞“三结合革命委员会”,军代表为一把手,有干部和群众代表参加;毛泽东认为这是无产阶级政权组织形式。
</p>
<p>
不搞“三权分立”,立法司法行政企业,在人民公社层面“四合一”; 并有基层单位的人民民主选举和监督,有“大鸣大放大字报”的舆论监督。1967年各单位都成立了革委会,毛泽东的目标在形式上已实现。
</p>
<p>
第六,文革派辩护的理由之一,说这是“人民群众的大民主”,是社会主义实质民主,比资本主义形式民主要真实。但他们不愿意承认这种大民主缺乏操作性,群众一旦发动起来,就控制不住:
</p>
<p>
(1)私人暴力盛行,大部分领导干部,许多知识分子和“有历史问题的人”遭受残酷的批判斗争,人生侮辱,死于非命;
</p>
<p>
(2)其次是大部分庙宇古迹被捣毁,古籍文物甚至私人日记,私人股权和房产证被焚毁;
</p>
<p>
(3) 全国性的派性武斗,群众组织分裂成为两派,一派支持书记,一派支持厂长,并非团结起来反对走资派,毛泽东说主要矛盾是人民群众和走资派的矛盾,这个判断是有误的。党中央多次呼吁大联合都不执行,直至1967年武汉事件激怒了毛泽东,下决心全面清理造反派。知识青年上山下乡,撤销“三支两军”,恢复了“党的一元化领导”。
</p>
<ul>
<li>
但“极左”理论和路线并未纠正:
</li>
<li>
张春桥姚文元提出“无产阶级专政下继续
</li>
</ul>
<p>
革命理论”,批判“资产阶级法权”,批儒评法三大基本任务;
</p>
<p>
(2)城市居民票证供应,工农业剪刀差,把消费压低到极点;取消奖金,依靠政治运动和思想教育多年,效果递减,人的劳动积极性越来越低;
</p>
<p>
(4)以基层组织的介绍信代替法律,剥夺了越来越多的个人选择,一切都需要单位盖公章,如结婚离婚,调动工作,迁居探亲,报考大学,住宿旅馆等。
</p>
<p>
经10年实践,文革终于受到大多数人反对。1976年发生“四五”群众运动,10月四人帮被抓,华国锋宣布结束文革。又经两年过渡至1978年12月共产党十一届三中全会,才确立改革开放路线。
</p>
<ul>
<li>
文革有两件“副产品”需要一提:
</li>
</ul>
<p>
(1)1966年下半年大串联,是在基础设施极端
</p>
<p>
落后条件下,上亿青少年全国性的免费旅游,促进了他们的社会化。
</p>
<ul>
<li>
上山下乡的“老三届”,青春有悔还是无悔。
</li>
</ul>
<p>
我认为不能开历史倒车去缩小三大差别,不能用牺牲一代人的办法去培养少数人。至于少数人在逆境中吸收了什么有益的东西,属于自己的造化,不是人人都能如此的。
</p>
<p>
</p>
<p>
</p>
<p>
</p>
<p>
</p>
<!-- AddThis Advanced Settings above via filter on the_content -->
<!-- AddThis Advanced Settings below via filter on the_content -->
<!-- AddThis Advanced Settings generic via filter on the_content -->
<!-- AddThis Share Buttons above via filter on the_content -->
<!-- AddThis Share Buttons below via filter on the_content -->
<div class="at-below-post addthis_tool" data-url="http://zhanlve.org/?p=8189">
</div>
<!-- AddThis Share Buttons generic via filter on the_content -->
</div> | 4,288 | MIT |
---
layout: post
title: Spring Boot(二三) - 使用JTA处理分布式事务
date: 2017-07-12 09:08:00 +0800
categories: Spring-Boot
tag: 教程
---
* content
{:toc}
使用JTA处理分布式事务
==================
Spring Boot通过[Atomkos](http://www.atomikos.com/)或[Bitronix](https://github.com/bitronix/btm)的内嵌事务管理器支持跨多个XA资源的分布式JTA事务,当部署到恰当的J2EE应用服务器时也会支持JTA事务。
当发现JTA环境时,Spring Boot将使用Spring的 `JtaTransactionManager` 来管理事务。自动配置的JMS,DataSource和JPAbeans将被升级以支持XA事务。可以使用标准的Spring idioms,比如 `@Transactional` ,来参与到一个分布式事务中。如果处于JTA环境,但仍想使用本地事务,你可以将 `spring.jta.enabled` 属性设置为 `false` 来禁用JTA自动配置功能。
使用Atomikos事务管理器
------------------
Atomikos是一个非常流行的开源事务管理器,并且可以嵌入到Spring Boot应用中。可以使用 `spring-boot-starter-jta-atomikos` Starter去获取正确的Atomikos库。Spring Boot会自动配置Atomikos,并将合适的 `depends-on` 应用到Spring Beans上,确保它们以正确的顺序启动和关闭。
默认情况下,Atomikos事务日志将被记录在应用home目录(应用jar文件放置的目录)下的 `transaction-logs` 文件夹中。可以在 `application.properties` 文件中通过设置 `spring.jta.log-dir` 属性来定义该目录,以 `spring.jta.atomikos.properties` 开头的属性能用来定义Atomikos的 `UserTransactionServiceIml` 实现,具体参考[AtomikosProperties javadoc](http://docs.spring.io/spring-boot/docs/1.5.4.RELEASE/api/org/springframework/boot/jta/atomikos/AtomikosProperties.html)。
> 注 为了确保多个事务管理器能够安全地和相应的资源管理器配合,每个Atomikos实例必须设置一个唯一的ID。默认情况下,该ID是Atomikos实例运行的机器上的IP地址。为了确保生产环境中该ID的唯一性,需要为应用的每个实例设置不同的 `spring.jta.transaction-manager-id` 属性值。
使用Bitronix事务管理器
------------------
Bitronix是一个流行的开源JTA事务管理器实现,可以使用 ·spring-bootstarter-jta-bitronix· starter为项目添加合适的Birtronix依赖。和Atomikos类似,Spring Boot将自动配置Bitronix,并对beans进行后处理(post-process)以确保它们以正确的顺序启动和关闭。
默认情况下,Bitronix事务日志( `part1.btm` 和 `part2.btm` )将被记录到应用home目录下的 `transaction-logs` 文件夹中,可以通过设置 `spring.jta.log-dir` 属性来自定义该目录。以 `spring.jta.bitronix.properties` 开头的属性将被绑定到 `bitronix.tm.Configuration` bean,可以通过这完成进一步的自定义,具体参考[Bitronix文档](https://github.com/bitronix/btm/wiki/Transaction-manager-configuration)。
> 注 为了确保多个事务管理器能够安全地和相应的资源管理器配合,每个Bitronix实例必须设置一个唯一的ID。默认情况下,该ID是Bitronix实例运行的机器上的IP地址。为了确保生产环境中该ID的唯一性,需要为应用的每个实例设置不同的 `spring.jta.transaction-manager-id` 属性值。
使用Narayana事务管理器
------------------
Narayana是一个流行的开源JTA事务管理器实现,目前只有JBoss支持。可以使用 `spring-boot-starter-jta-narayana` starter添加合适的Narayana依赖,像Atomikos和Bitronix那样,Spring Boot将自动配置Narayana,并对beans后处理(post-process)以确保正确启动和关闭。
Narayana事务日志默认记录到应用home目录(放置应用jar的目录)的 `transaction-logs` 目录下,可以通过设置 `application.properties` 中的 `spring.jta.log-dir` 属性自定义该目录。以 `spring.jta.narayana.properties` 开头的属性可用于自定义Narayana配置,具体参考[NarayanaProperties](http://docs.spring.io/spring-boot/docs/1.5.4.RELEASE/api/org/springframework/boot/jta/narayana/NarayanaProperties.html)。
> 注 为了确保多事务管理器能够安全配合相应资源管理器,每个Narayana实例必须配置唯一的ID,默认ID设为 1 。为确保生产环境中ID唯一性,可以为应用的每个实例配置不同的 `spring.jta.transaction-manager-id` 属性值。
使用J2EE管理的事务管理器
------------------
如果将Spring Boot应用打包为一个 `war` 或 `ear` 文件,并将它部署到一个J2EE的应用服务器中,那就能使用应用服务器内建的事务管理器。Spring Boot将尝试通过查找常见的JNDI路径( `java:comp/UserTransaction` ,`java:comp/TransactionManager` 等)来自动配置一个事务管理器。如果使用应用服务器提供的事务服务,通常需要确保所有的资源都被应用服务器管理,并通过JNDI暴露出去。Spring Boot通过查找JNDI路径 `java:/JmsXA` 或 `java:/XAConnectionFactory` 获取一个 `ConnectionFactory` 来自动配置JMS,并且可以使用 `spring.datasource.jndi-name` 属性配置 `DataSource` 。
混合XA和non-XA的JMS连接
------------------
当使用JTA时,primary JMS `ConnectionFactory` bean将能识别XA,并参与到分布式事务中。有些情况下,可能需要使用non-XA的 `ConnectionFactory` 去处理一些JMS消息。例如,JMS处理逻辑可能比XA超时时间长。
如果想使用一个non-XA的 `ConnectionFactory` ,可以注入 `nonXaJmsConnectionFactory` bean而不是 `@Primary``jmsConnectionFactory` bean。为了保持一致, `jmsConnectionFactory` bean将以别名 `xaJmsConnectionFactor` 来被使用。
示例如下:
{% highlight java %}
// Inject the primary (XA aware) ConnectionFactory
@Autowired
private ConnectionFactory defaultConnectionFactory;
// Inject the XA aware ConnectionFactory (uses the alias and injects the same as above)
@Autowired
@Qualifier("xaJmsConnectionFactory")
private ConnectionFactory xaConnectionFactory;
// Inject the non-XA aware ConnectionFactory
@Autowired
@Qualifier("nonXaJmsConnectionFactory")
private ConnectionFactory nonXaConnectionFactory;
{% endhighlight %}
支持可替代的内嵌事务管理器
------------------
[XAConnectionFactoryWrapper](https://github.com/spring-projects/spring-boot/tree/v1.5.4.RELEASE/spring-boot/src/main/java/org/springframework/boot/jta/XAConnectionFactoryWrapper.java)和[XADataSourceWrapper](https://github.com/spring-projects/spring-boot/tree/v1.5.4.RELEASE/spring-boot/src/main/java/org/springframework/boot/jta/XADataSourceWrapper.java)接口用于支持可替换的内嵌事务管理器。该接口用于包装 `XAConnectionFactory` 和 `XADataSource` beans,并将它们暴露为普通的 `ConnectionFactory` 和 `DataSource` beans,这样在分布式事务中可以透明使用。Spring Boot将使用注册到 `ApplicationContext` 的合适的XA包装器及 `JtaTransactionManager` bean自动配置DataSource和JMS。
[BitronixXAConnectionFactoryWrapper](https://github.com/spring-projects/spring-boot/tree/v1.5.4.RELEASE/spring-boot/src/main/java/org/springframework/boot/jta/bitronix/BitronixXAConnectionFactoryWrapper.java)和[BitronixXADataSourceWrapper](https://github.com/spring-projects/spring-boot/tree/v1.5.4.RELEASE/spring-boot/src/main/java/org/springframework/boot/jta/bitronix/BitronixXADataSourceWrapper.java)提供了很好
的示例用于演示怎么编写XA包装器。
实验
==================
> 本实验基于Atomikos事务管理器和MYSQL数据库实现。
创建数据库
------------------
{% highlight sql %}
DROP DATABASE IF EXISTS `jta-income`;
CREATE DATABASE `jta-income`;
USE `jta-income`;
DROP TABLE IF EXISTS `income`;
CREATE TABLE `income` (
`id` INT(20) NOT NULL AUTO_INCREMENT,
`userId` INT(20) NOT NULL,
`amount` FLOAT(8,2) NOT NULL,
`operateDate` DATETIME NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8;
DROP DATABASE IF EXISTS `jta-user`;
CREATE DATABASE `jta-user`;
USE `jta-user`;
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (
`id` INT(20) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(50) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8;
{% endhighlight %}
创建一个Maven项目
------------------

pom.xml
------------------
{% highlight xml %}
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.freud.test</groupId>
<artifactId>spring-boot-23</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>spring-boot-23</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jta-atomikos</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>1.0.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>1.5.4.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
</project>
{% endhighlight %}
application.yml
------------------
{% highlight yml %}
spring:
application:
name: test-23
jpa:
show-sql: true
jta:
enabled: true
atomikos:
datasource:
jta-user:
xa-properties.url: jdbc:mysql://localhost:3306/jta-user
xa-properties.user: root
xa-properties.password: root
xa-data-source-class-name: com.mysql.jdbc.jdbc2.optional.MysqlXADataSource
unique-resource-name: jta-user
max-pool-size: 25
min-pool-size: 3
max-lifetime: 20000
borrow-connection-timeout: 10000
jta-income:
xa-properties.url: jdbc:mysql://localhost:3306/jta-income
xa-properties.user: root
xa-properties.password: root
xa-data-source-class-name: com.mysql.jdbc.jdbc2.optional.MysqlXADataSource
unique-resource-name: jta-income
max-pool-size: 25
min-pool-size: 3
max-lifetime: 20000
borrow-connection-timeout: 10000
server:
port: 9090
{% endhighlight %}
UserMapper.xml
------------------
{% highlight xml %}
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//ibatis.apache.org//DTD Mapper 3.0//EN"
"http://ibatis.apache.org/dtd/ibatis-3-mapper.dtd">
<mapper namespace="com.freud.test.springboot.mapper.user.UserMapper">
<insert id="insert" useGeneratedKeys="true" keyProperty="id">
INSERT INTO USER
(
NAME
)
VALUES
(
#{name}
)
</insert>
</mapper>
{% endhighlight %}
User.java
------------------
{% highlight java %}
package com.freud.test.springboot.bean;
/**
* @author Freud
*/
public class User {
private long id;
private String name;
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
{% endhighlight %}
Income.java
------------------
{% highlight java %}
package com.freud.test.springboot.bean;
import java.sql.Timestamp;
/**
* @author Freud
*/
public class Income {
private long id;
private long userId;
private double amount;
private Timestamp operateDate;
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public long getUserId() {
return userId;
}
public void setUserId(long userId) {
this.userId = userId;
}
public double getAmount() {
return amount;
}
public void setAmount(double amount) {
this.amount = amount;
}
public Timestamp getOperateDate() {
return operateDate;
}
public void setOperateDate(Timestamp operateDate) {
this.operateDate = operateDate;
}
}
{% endhighlight %}
DataSourceJTAIncomeConfig.java
------------------
{% highlight java %}
package com.freud.test.springboot.config;
import javax.sql.DataSource;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.mybatis.spring.SqlSessionTemplate;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import com.atomikos.jdbc.AtomikosDataSourceBean;
/**
* @author Freud
*/
@Configuration
@EnableConfigurationProperties
@EnableAutoConfiguration
@MapperScan(basePackages = "com.freud.test.springboot.mapper.income", sqlSessionTemplateRef = "jtaIncomeSqlSessionTemplate")
public class DataSourceJTAIncomeConfig {
@Bean
@ConfigurationProperties(prefix = "spring.jta.atomikos.datasource.jta-income")
public DataSource dataSourceJTAIncome() {
return new AtomikosDataSourceBean();
}
@Bean
public SqlSessionFactory jtaIncomeSqlSessionFactory(@Qualifier("dataSourceJTAIncome") DataSource dataSource)
throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(dataSource);
bean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath:mapper/*.xml"));
bean.setTypeAliasesPackage("com.freud.test.springboot.mapper.income");
return bean.getObject();
}
@Bean
public SqlSessionTemplate jtaIncomeSqlSessionTemplate(
@Qualifier("jtaIncomeSqlSessionFactory") SqlSessionFactory sqlSessionFactory) throws Exception {
return new SqlSessionTemplate(sqlSessionFactory);
}
}
{% endhighlight %}
DataSourceJTAUserConfig.java
------------------
{% highlight java %}
package com.freud.test.springboot.config;
import javax.sql.DataSource;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.mybatis.spring.SqlSessionTemplate;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import com.atomikos.jdbc.AtomikosDataSourceBean;
@Configuration
@EnableConfigurationProperties
@EnableAutoConfiguration
@MapperScan(basePackages = "com.freud.test.springboot.mapper.user", sqlSessionTemplateRef = "jtaUserSqlSessionTemplate")
public class DataSourceJTAUserConfig {
@Bean
@ConfigurationProperties(prefix = "spring.jta.atomikos.datasource.jta-user")
@Primary
public DataSource dataSourceJTAUser() {
return new AtomikosDataSourceBean();
}
@Bean
@Primary
public SqlSessionFactory jtaUserSqlSessionFactory(@Qualifier("dataSourceJTAUser") DataSource dataSource)
throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(dataSource);
bean.setMapperLocations(new PathMatchingResourcePatternResolver().getResources("classpath:mapper/*.xml"));
bean.setTypeAliasesPackage("com.freud.test.springboot.mapper.user");
return bean.getObject();
}
@Bean
@Primary
public SqlSessionTemplate jtaUserSqlSessionTemplate(
@Qualifier("jtaUserSqlSessionFactory") SqlSessionFactory sqlSessionFactory) throws Exception {
return new SqlSessionTemplate(sqlSessionFactory);
}
}
{% endhighlight %}
IncomeController.java
------------------
{% highlight java %}
package com.freud.test.springboot.controller;
import java.sql.Timestamp;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.transaction.annotation.Transactional;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import com.freud.test.springboot.bean.Income;
import com.freud.test.springboot.bean.User;
import com.freud.test.springboot.mapper.income.IncomeMapper;
import com.freud.test.springboot.mapper.user.UserMapper;
/**
* @author Freud
*/
@RestController
@RequestMapping("/income")
public class IncomeController {
public static final String RESULT_SUCCESS = "success";
public static final String RESULT_FAILED = "failed";
@Autowired
private IncomeMapper incomeMapper;
@Autowired
private UserMapper userMapper;
@GetMapping("/addincome/1")
@Transactional
public String addIncome1(@RequestParam("name") String name, @RequestParam("amount") double amount) {
try {
User user = new User();
user.setName(name);
userMapper.insert(user);
Income income = new Income();
income.setUserId(user.getId());
income.setAmount(amount);
income.setOperateDate(new Timestamp(System.currentTimeMillis()));
incomeMapper.insert(income);
return RESULT_SUCCESS;
} catch (Exception e) {
e.printStackTrace();
return RESULT_FAILED + ":" + e.getMessage();
}
}
@GetMapping("/addincome/2")
@Transactional
public String addIncome2(@RequestParam("name") String name, @RequestParam("amount") double amount) {
try {
User user = new User();
user.setName(name);
userMapper.insert(user);
this.throwRuntimeException();
Income income = new Income();
income.setUserId(user.getId());
income.setAmount(amount);
income.setOperateDate(new Timestamp(System.currentTimeMillis()));
incomeMapper.insert(income);
return RESULT_SUCCESS;
} catch (Exception e) {
e.printStackTrace();
throw e;
// return RESULT_FAILED + ":" + e.getMessage();
}
}
public void throwRuntimeException() {
throw new RuntimeException("User defined exceptions");
}
}
{% endhighlight %}
IncomeMapper.java
------------------
{% highlight java %}
package com.freud.test.springboot.mapper.income;
import org.apache.ibatis.annotations.Insert;
import com.freud.test.springboot.bean.Income;
/**
* @author Freud
*/
public interface IncomeMapper {
@Insert("INSERT INTO INCOME(userId,amount,operateDate) VALUES(#{userId},#{amount},#{operateDate})")
public void insert(Income income);
}
{% endhighlight %}
UserMapper.java
------------------
{% highlight java %}
package com.freud.test.springboot.mapper.user;
import com.freud.test.springboot.bean.User;
/**
* @author Freud
*/
public interface UserMapper {
public void insert(User user);
}
{% endhighlight %}
App.java
------------------
{% highlight java %}
package com.freud.test.springboot;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* @author Freud
*/
@SpringBootApplication
public class App {
public static void main(String[] args) {
SpringApplication.run(App.class, args);
}
}
{% endhighlight %}
项目结构
------------------

运行及结果
==================
查看表中数据
------------------
首先先看下两个数据库中表的情况:

`user`库中user表的数据情况如下:

`income`库中income表的数据情况如下:

事务正常
------------------
访问`http://localhost:9090/income/addincome/1?name=freud&amount=10`,正常在两个数据库各插入一条数据。

`user`库中user表的数据情况如下:

`income`库中income表的数据情况如下:

事务失败
------------------
访问`http://localhost:9090/income/addincome/2?name=kkk&amount=10`,程序中会抛出一个运行时异常,事务失败,两个库都不会插入数据成功。

`user`库中user表的数据情况如下:

`income`库中income表的数据情况如下:

参考资料
==================
Spring Boot Reference Guide : [http://docs.spring.io/spring-boot/docs/current-SNAPSHOT/reference/htmlsingle/](http://docs.spring.io/spring-boot/docs/current-SNAPSHOT/reference/htmlsingle/)
Spring-boot下的mybatis多数据源JTA配置 : [http://blog.csdn.net/pichunhan/article/details/70846695](http://blog.csdn.net/pichunhan/article/details/70846695)
JTA 深度历险 - 原理与实现 : [https://www.ibm.com/developerworks/cn/java/j-lo-jta/](https://www.ibm.com/developerworks/cn/java/j-lo-jta/) | 21,728 | Apache-2.0 |
---
layout: post
category: "duilib"
title: "Duilib中list控件支持ctrl和shif多行选中的实现"
tags: [duilib,ui]
date: 2017-09-08
---
# 一、 由于diulib不支持list控件的多选修改。下面是修改的原理。
Ctrl+左键多选,按下Ctrl键点击,主要有三种情况:
- 选中一个
- 再点击,又选中一个
- 再点击前一个,前一个选中状态消失
总结分析:ctrl按下的情况,点击,不会使前一个(一部分)选中项失去选中状态,而只是让当前点击的项改变选中状态,并将焦点移到当前项。
shift+左键,主要有4中情况
- 点击选中一个(ID为2),向下选中一个(ID为5),则2-5被选中
- 再向下选中一个(ID为10),则2-10被选中
- 向上选中一个(ID为8),则2-8被选中
- 向上选中一个(ID为1),则1-2被选中。
总结分析:shift按下的情况,点击,是选中一个范围,起始项为焦点所在的项,shift点击的项为结束项。
# 二、代码修改
UIList.cpp将Select修改如下:
```c
bool CListElementUI::Select(bool bSelect, bool bCallback)
{
BOOL bShift = (GetKeyState(VK_SHIFT) & 0x8000);
BOOL bCtrl = (GetKeyState(VK_CONTROL) & 0x8000);
if (!IsEnabled()) return false;
//if( bSelect == m_bSelected ) return true;
if (bCtrl) {
m_bSelected = !m_bSelected;
}
else {
m_bSelected = bSelect;
}
if (m_bSelected == false) {
Hot(false);
}
else {
Hot(true);
}
if (bCallback && m_pOwner != NULL) {
if (bShift) {
m_pOwner->SelectRange(m_iIndex);
}
else {
m_pOwner->SelectItem(m_iIndex);
}
}
Invalidate();
return true;
}
```
添加hot函数:
```c
bool CListElementUI::Hot(bool bHot)
{
if (!IsEnabled()) return false;
if (bHot)
{
m_uButtonState |= UISTATE_HOT;
}
else {
if ((m_uButtonState & UISTATE_HOT) != 0) {
m_uButtonState &= ~UISTATE_HOT;
}
}
//m_pOwner->HotItem(m_iIndex, bHot);
Invalidate();
return true;
}
```
修改SelectItem函数的实现:
```c
bool CListUI::SelectItem(int iIndex, bool bTakeFocus)
{
BOOL bCtrl = (GetKeyState(VK_CONTROL) & 0x8000);
//if( iIndex == m_iCurSel ) return true;
//int iTempSel = -1;
// We should first unselect the currently selected item
if (!bCtrl) {
//if( m_iCurSel >= 0 ) {
for (int i = 0;i < GetCount();i++) {
if (i != iIndex) {
CControlUI* pControl = GetItemAt(i);
if (pControl != NULL) {
IListItemUI* pListItem = static_cast<IListItemUI*>(pControl->GetInterface(_T("ListItem")));
if (pListItem != NULL) {
if (pListItem->IsSelected()) {
pListItem->Select(false,false);
}
}
}
}
}
m_iCurSel = -1;
//}
}
if (iIndex == m_iCurSel) return true;
int iOldSel = m_iCurSel;
if (iIndex < 0) return false;
CControlUI* pControl = GetItemAt(iIndex);
if (pControl == NULL) return false;
if (!pControl->IsVisible()) return false;
if (!pControl->IsEnabled()) return false;
IListItemUI* pListItem = static_cast<IListItemUI*>(pControl->GetInterface(_T("ListItem")));
if (pListItem == NULL) return false;
m_iCurSel = iIndex;
/*if (!bCtrl) {
if (!pListItem->Select(true)) {
m_iCurSel = -1;
return false;
}
}*/
EnsureVisible(m_iCurSel);
if (bTakeFocus) pControl->SetFocus();
if (m_pManager != NULL) {
m_pManager->SendNotify(this, DUI_MSGTYPE_ITEMSELECT, m_iCurSel, iOldSel);
}
return true;
}
```
添加下面的函数:
```c
bool CListUI::SelectRange(int iIndex, bool bTakeFocus)
{
int i = 0;
int iFirst = m_iCurSel;
int iLast = iIndex;
int iCount = GetCount();
if (iFirst == iLast) return true;
CControlUI* pControl = GetItemAt(iIndex);
if (pControl == NULL) return false;
if (!pControl->IsVisible()) return false;
if (!pControl->IsEnabled()) return false;
IListItemUI* pListItem = static_cast<IListItemUI*>(pControl->GetInterface(_T("ListItem")));
if (pListItem == NULL) return false;
if (!pListItem->Select(true,false)) {
m_iCurSel = -1;
return false;
}
EnsureVisible(iIndex);
if (bTakeFocus) pControl->SetFocus();
if (m_pManager != NULL) {
m_pManager->SendNotify(this, DUI_MSGTYPE_ITEMSELECT, iIndex, m_iCurSel);
}
//locate (and select) either first or last
// (so order is arbitrary)
while (i < iCount) {
if (i == iFirst || i == iLast) {
i++;
break;
}
CControlUI* pControl = GetItemAt(i);
if (pControl != NULL) {
IListItemUI* pListItem = static_cast<IListItemUI*>(pControl->GetInterface(_T("ListItem")));
if (pListItem != NULL) pListItem->Select(false, false);
}
i++;
}
// select rest of range
while (i < iCount) {
CControlUI* pControl = GetItemAt(i);
if (pControl != NULL) {
IListItemUI* pListItem = static_cast<IListItemUI*>(pControl->GetInterface(_T("ListItem")));
if (pListItem != NULL) pListItem->Select(true, false);
}
if (i == iFirst || i == iLast) {
i++;
break;
}
i++;
}
// unselect rest of range
while (i < iCount) {
CControlUI* pControl = GetItemAt(i);
if (pControl != NULL) {
IListItemUI* pListItem = static_cast<IListItemUI*>(pControl->GetInterface(_T("ListItem")));
if (pListItem != NULL) pListItem->Select(false, false);
}
i++;
}
return true;
}
```
● UIList.h在class IListOwnerUI中添加虚函数:
```c
virtual bool SelectRange(int iIndex, bool bTakeFocus = false) = 0;//@xdrt81y@20140218@支持shift多选
```
在class IListItemUI中替换select函数的声明:
```c
virtual bool Select(bool bSelect = true, bool bCallback = true) = 0;
```
在class UILIB_API CListUI中添加函数声明:
```c
bool SelectRange(int iIndex, bool bTakeFocus = false);//@xdrt81y@20140218@支持shift多选
```
在class UILIB_API CListElementUI中修改函数声明:
```c
bool Select(bool bSelect = true, bool bCallback = true);
```
在class UILIB_API CListContainerElementUI中修改声明:
```c
bool Select(bool bSelect = true, bool bCallback = true);
```
● UICombo.cpp添加函数实现:
```c
bool CComboUI::SelectRange(int iIndex, bool bTakeFocus)
{
return true;
}
```
● UICombo.h添加函数声明:
```c
bool SelectRange(int iIndex, bool bTakeFocus = false);//@xdrt81y@20140218
``` | 6,120 | MIT |
```
================================================================================================
88888888ba, 88 88
88 `"8b "" 88
88 `8b 88
8b, ,d8 88 88 88 ,adPPYYba, 88 ,adPPYba, ,adPPYb,d8
`Y8, ,8P' 88 88 88 "" `Y8 88 a8" "8a a8" `Y88
)888( 88 8P 88 ,adPPPPP88 88 8b d8 8b 88
,d8" "8b, 88 .a8P 88 88, ,88 88 "8a, ,a8" "8a, ,d88
8P' `Y8 88888888Y"' 88 `"8bbdP"Y8 88 `"YbbdP"' `"YbbdP"Y8
aa, ,88
"Y8bbdP"
================================================================================================
```
# 优雅的 Android 对话框类库封装 xDialog
对 Android 开发而言,对话框是打交道比较频繁的 UI 控件之一。对话框对大部分程序员而言并不陌生。然而,当考虑到复杂的交互效果、组件复用、自定义和各种 UI 风格的时候,事情变得麻烦了起来。xDialog 就是我设计的用来整合以上多种情况的 UI 组件。相比于大部分开源库,它可自定义程度更高,能满足更多的应用场景。
<div style="display:flex;" id="target">
<img src="resources/Screenshot_2022-02-24-23-16-15-05_08de23611bf79886a74beffca0ad6bab.jpg" width="19%" />
<img src="resources/Screenshot_2022-02-24-23-16-23-42_08de23611bf79886a74beffca0ad6bab.jpg" style="margin-left:5px;" width="19%"/>
<img src="resources/Screenshot_2022-02-24-23-16-19-28_08de23611bf79886a74beffca0ad6bab.jpg" style="margin-left:5px;" width="19%"/>
<img src="resources/Screenshot_2022-02-24-23-16-21-50_08de23611bf79886a74beffca0ad6bab.jpg" style="margin-left:5px;" width="19%"/>
<img src="resources/Screenshot_2022-02-24-23-16-25-65_08de23611bf79886a74beffca0ad6bab.jpg" style="margin-left:5px;" width="19%"/>
</div>
## 1、整体设计
xDialog 基于 Kotlin 开发,也吸取了 KotlinDSL 的特性,提供了更加方便使用的 API. 该对话框基于 DialogFragment 开发,在复用性方面,分别将对话框的头部、内容和底部进行了抽象,提取了三个接口,所以,用户只需要实现这三个接口就可以拼凑出自己的对话框,真正实现了三个部分的随意组装,
```kotlin
class BeautyDialog : DialogFragment() {
private var iDialogTitle: IDialogTitle? = null
private var iDialogContent: IDialogContent? = null
private var iDialogFooter: IDialogFooter? = null
// ...
override fun onCreateDialog(savedInstanceState: Bundle?): Dialog {
// ...
}
@BeautyDialogDSL class Builder {
private var dialogTitle: IDialogTitle? = null
private var dialogContent: IDialogContent? = null
private var dialogFooter: IDialogFooter? = null
// ...
/** 为对话框指定头部 */
fun withTitle(iDialogTitle: IDialogTitle) {
this.dialogTitle = iDialogTitle
}
/** 为对话框指定内容 */
fun withContent(iDialogContent: IDialogContent) {
this.dialogContent = iDialogContent
}
/** 为对话框指定底部 */
fun withBottom(iDialogFooter: IDialogFooter) {
this.dialogFooter = iDialogFooter
}
fun build(): BeautyDialog {
val dialog = BeautyDialog()
// ...
return dialog
}
}
}
/** 提供了基于 kotlin DSL 风格的对话框构建器 */
inline fun createDialog(
init: BeautyDialog.Builder.() -> Unit
): BeautyDialog = BeautyDialog.Builder().apply(init).build()
```
如上代码所示,用户只需要将通过实现三个接口实现自己的各个部分,然后就可以做到指定的位置的 UI 的替换。
<div style="display:flex;" id="target">
<img src="resources/animation.gif" style="margin-left:5px;" width="19%"/>
</div>
## 2、兼容平板、手机和横屏
基于上述设计思路,我为构建者增加了几个参数用来满足在不同分辨率上使用的场景的需求。该库内置了四种不同大小的对话框,对于用户,只需要判断上述不同的情景之后根据情况传入指定的样式即可。然后在对话框内部会使用不同的 style 作为对话框的主题,
```kotlin
val theme = when(dialogStyle) {
STYLE_WRAP -> R.style.BeautyDialogWrap
STYLE_HALF -> R.style.BeautyDialogHalf
STYLE_TWO_THIRD -> R.style.BeautyDialogTwoThird
else -> R.style.BeautyDialog
}
val dialog = if (bottomSheet) {
BottomSheetDialog(requireContext(), theme)
} else {
AlertDialog.Builder(requireContext(), theme).create()
}
```
## 3、兼容 BottomSheet 和普通的对话框的场景
谷歌提供的 Material 库中提供了叫做 BottomSheetDialog 的对话框。相比于普通的对话框,这个类可以提供更好的交互效果。比如,比如自己的地图中就有类似的交互效果。底部弹出一部分,然后向上可以继续拖拽并展示全部内容。这种交互方式在许多情景下会非常有用,特别是,当我们需要提供的内容可能在普通的对话框装不下的情况而又不希望切换一个新的页面的时候。较少的切换页面,降低操作的层级,可以提供更好的用户交互体验。
<div style="display:flex;" id="target">
<img src="resources/animation0.gif" style="margin-left:5px;" width="19%"/>
</div>
在 xDialog 中,我增加了几个参数来支持这种应用场景,
```kotlin
val dialog = if (bottomSheet) {
BottomSheetDialog(requireContext(), theme).apply {
halfExpandedRatio?.let { this.behavior.halfExpandedRatio = it }
isFitToContents ?.let { this.behavior.isFitToContents = it }
peekHeight ?.let { this.behavior.peekHeight = it }
}
} else {
AlertDialog.Builder(requireContext(), theme).create()
}
```
所以,对于使用这个库的用户而言,只需要动态调整几个参数就可以随意在两种不同的交互方式之间切换。
## 4、提供对话框背景模糊效果
xDialog 为背景模糊效果提供了封装。为此 xDialog 提供了 BlurEngine 用来在 Dialog 显示的时候截取屏幕进行模糊并展示到对话框背部。用户启用的方式也非常简单,只需要传入一个参数就可以直接使用背景模糊的效果。
<div style="display:flex;" id="target">
<img src="resources/Screenshot_2022-02-24-23-16-19-28_08de23611bf79886a74beffca0ad6bab.jpg" style="margin-left:5px;" width="19%"/>
</div>
## 5、提供了默认的封装和多种实用 API
除了上述封装,xDialog 提供了几个默认的头部、内容和底部实现类。用户可以直接使用,也可以参照他们实现自己想要的效果,
此外,xDialog 还提供了其他的 API,比如自定义对话框显示的位置是头部、中间还是底部,自定义对话框是否可以撤销,自定义对话框的背景,监听对话框的的显示和隐藏事件等等。
<div style="display:flex;" id="target">
<img src="resources/Screenshot_2022-02-24-23-16-29-23_08de23611bf79886a74beffca0ad6bab.jpg" width="16%" />
<img src="resources/Screenshot_2022-02-24-23-16-32-17_08de23611bf79886a74beffca0ad6bab.jpg" style="margin-left:5px;" width="16%"/>
<img src="resources/Screenshot_2022-02-24-23-16-37-24_08de23611bf79886a74beffca0ad6bab.jpg" style="margin-left:5px;" width="16%"/>
<img src="resources/Screenshot_2022-02-24-23-16-40-25_08de23611bf79886a74beffca0ad6bab.jpg" style="margin-left:5px;" width="16%"/>
<img src="resources/Screenshot_2022-02-24-23-16-45-48_08de23611bf79886a74beffca0ad6bab.jpg" style="margin-left:5px;" width="16%"/>
<img src="resources/Screenshot_2022-02-24-23-16-56-55_08de23611bf79886a74beffca0ad6bab.jpg" style="margin-left:5px;" width="16%"/>
</div>
## 其他
上述是对该对话框封装的分析。对话框相关的开源库还是挺多的,这里我只是觉得这个设计可以拿出来分享一下。如果你需要做相关的工作的话,可以参考一下。最后源代码地址,
[源码地址:https://github.com/Shouheng88/xDialog](https://github.com/Shouheng88/xDialog) | 6,358 | Apache-2.0 |
# SnailPopupController


<a href="https://github.com/snail-z/OverlayController-Swift/blob/master/LICENSE"><img src="https://img.shields.io/badge/license-MIT-green.svg?style=flat"></a>
快速弹出自定义视图,支持自定义蒙版样式、过渡效果、手势拖动、弹性动画等等。简单快捷,方便使用!
#### _[Swift version is here.](https://github.com/snail-z/OverlayController-Swift) - [OverlayController-Swift](https://github.com/snail-z/OverlayController-Swift)_
## Installation
To install OverlayController using [CocoaPods](https://cocoapods.org "CocoaPods" ), please integrate it in your existing Podfile, or create a new Podfile:
```ruby
platform :ios, '7.0'
use_frameworks!
target 'You Project' do
pod 'SnailPopupController', '~> 2.0.5'
end
```
Then run pod install.
## Preview
<img src="https://github.com/snail-z/SnailPopupController/blob/master/preview/SnailPopupController_gif.gif?raw=true" width="204px" height="365px">
## Import
``` objc
#import "SnailPopupController.h"
```
## Update
* 增加视图弹出样式
```objc
// Controls how the popup will be presented.
typedef NS_ENUM(NSInteger, PopupTransitStyle) {
PopupTransitStyleSlightScale, // 轻微缩放效果
PopupTransitStyleShrinkInOut, // 从中心点扩大或收缩
PopupTransitStyleDefault // 默认淡入淡出效果
};
```
* 修改present接口,增加回弹动画等
```objc
/*
- parameter contentView: 需要弹出的视图 // This is the view that you want to appear in popup.
- parameter duration: 动画时间
- parameter isElasticAnimated: 是否使用弹性动画
- parameter sView: 在sView上显示
*/
- (void)presentContentView:(nullable UIView *)contentView
duration:(NSTimeInterval)duration
elasticAnimated:(BOOL)isElasticAnimated
inView:(nullable UIView *)sView;
```
#### 以下是修改后接口api,具体如下:
```objc
// Control mask view of style.
// 控制蒙版视图的样式
typedef NS_ENUM(NSUInteger, PopupMaskType) {
PopupMaskTypeBlackBlur = 0, // 黑色半透明模糊效果
PopupMaskTypeWhiteBlur, // 白色半透明模糊效果
PopupMaskTypeWhite, // 纯白色
PopupMaskTypeClear, // 全透明
PopupMaskTypeDefault, // 默认黑色半透明效果
};
// Control popup view display position.
// 控制弹出视图的显示位置
typedef NS_ENUM(NSUInteger, PopupLayoutType) {
PopupLayoutTypeTop = 0, // 在顶部显示
PopupLayoutTypeBottom,
PopupLayoutTypeLeft,
PopupLayoutTypeRight,
PopupLayoutTypeCenter // 默认居中显示
};
// Controls how the popup will be presented.
// 控制弹出视图将以哪种样式呈现
typedef NS_ENUM(NSInteger, PopupTransitStyle) {
PopupTransitStyleFromTop = 0, // 从上部滑出
PopupTransitStyleFromBottom, // 从底部滑出
PopupTransitStyleFromLeft, // 从左部滑出
PopupTransitStyleFromRight, // 从右部滑出
PopupTransitStyleSlightScale, // 轻微缩放效果
PopupTransitStyleShrinkInOut, // 从中心点扩大或收缩
PopupTransitStyleDefault // 默认淡入淡出效果
};
```
* 属性设置
```objc
@property (nonatomic, assign) PopupMaskType maskType; // 设置蒙版样式,default = PopupMaskTypeDefault
@property (nonatomic, assign) PopupLayoutType layoutType; // 视图显示位置,default = PopupLayoutTypeCenter
// Must set layoutType = PopupLayoutTypeCenter
@property (nonatomic, assign) PopupTransitStyle transitStyle; // 视图呈现方式,default = PopupTransitStyleDefault
// Must set maskType = PopupMaskTypeTranslucent
@property (nonatomic, assign) CGFloat maskAlpha; // 设置蒙版视图的透明度,default = 0.5
// Must set layoutType = PopupLayoutTypeCenter
@property (nonatomic, assign) BOOL dismissOppositeDirection; // 是否反方向消失,default = NO
@property (nonatomic, assign) BOOL dismissOnMaskTouched; // 点击蒙版视图是否响应dismiss事件,default = YES
@property (nonatomic, assign) BOOL allowPan; // 是否允许视图拖动,default = NO
@property (nonatomic, assign) BOOL dropTransitionAnimated; // 视图倾斜掉落动画,当transitStyle为PopupTransitStyleFromTop样式时可以设置为YES使用掉落动画,default = NO
@property (nonatomic, assign, readonly) BOOL isPresenting; // 视图是否正在显示中
```
* 相关事件block
```objc
// Block gets called when mask touched. 蒙版触摸事件block,主要用来自定义dismiss动画时间及弹性效果
@property (nonatomic, copy) void (^maskTouched)(SnailPopupController *popupController);
// Should implement this block before the presenting. 应该在present前实现的block
@property (nonatomic, copy) void (^willPresent)(SnailPopupController *popupController); // ContentView will present. 视图将要呈现
@property (nonatomic, copy) void (^didPresent)(SnailPopupController *popupController); // ContentView Did present. 视图已经呈现
@property (nonatomic, copy) void (^willDismiss)(SnailPopupController *popupController); // ContentView Will dismiss. 视图将要消失
@property (nonatomic, copy) void (^didDismiss)(SnailPopupController *popupController); // ContentView Did dismiss. 视图已经消失
```
* 弹出自定义视图方法等
```objc
/*
- parameter contentView: 需要弹出的视图 // This is the view that you want to appear in popup.
- parameter duration: 动画时间
- parameter isElasticAnimated: 是否使用弹性动画
- parameter sView: 在sView上显示
*/
- (void)presentContentView:(nullable UIView *)contentView
duration:(NSTimeInterval)duration
elasticAnimated:(BOOL)isElasticAnimated
inView:(nullable UIView *)sView;
// inView = nil, 在Window显示
- (void)presentContentView:(nullable UIView *)contentView duration:(NSTimeInterval)duration elasticAnimated:(BOOL)isElasticAnimated;
/*
- duration = 0.25
- isElasticAnimated = NO
- inView = nil, 在Window显示
*/
- (void)presentContentView:(nullable UIView *)contentView;
/*
- parameter duration: 动画时间
- parameter isElasticAnimated: 是否使用弹性动画
*/
- (void)dismissWithDuration:(NSTimeInterval)duration elasticAnimated:(BOOL)isElasticAnimated;
// - parameters等于present时对应设置的values
- (void)dismiss;
// Convenience method for creating popupController with custom values. 便利构造popupController并设置相应属性值
+ (instancetype)popupControllerWithLayoutType:(PopupLayoutType)layoutType
maskType:(PopupMaskType)maskType
dismissOnMaskTouched:(BOOL)isDismissOnMaskTouched
allowPan:(BOOL)isAllowPan;
// When layoutType = PopupLayoutTypeCenter // 若弹出视图想居中显示时,可以使用这个方法快速设置
+ (instancetype)popupControllerLayoutInCenterWithTransitStyle:(PopupTransitStyle)transitStyle
maskType:(PopupMaskType)maskType
dismissOnMaskTouched:(BOOL)isDismissOnMaskTouched
dismissOppositeDirection:(BOOL)isDismissOppositeDirection
allowPan:(BOOL)isAllowPan;
```
* block 对应的代理方法
``` objc
@protocol SnailPopupControllerDelegate <NSObject>
@optional
// - Block对应的Delegate方法,block优先
- (void)popupControllerWillPresent:(nonnull SnailPopupController *)popupController;
- (void)popupControllerDidPresent:(nonnull SnailPopupController *)popupController;
- (void)popupControllerWillDismiss:(nonnull SnailPopupController *)popupController;
- (void)popupControllerDidDismiss:(nonnull SnailPopupController *)popupController;
@end
```
* 为需要使用SnailPopupController的类增加属性sl_popupController
``` objc
@interface NSObject (SnailPopupController)
// 因为SnailPopupController内部子视图是默认添加在keyWindow上的,所以如果popupController是局部变量的话不会被任何引用,生命周期也只在这个方法内。为了使内部视图正常响应,所以应将popupController声明为全局属性,保证其生命周期,也可以直接使用sl_popupController
@property (nonatomic, strong) SnailPopupController *sl_popupController;
@end
```
## Usage
* 可以直接使用sl_popupController弹出视图
``` objc
[self.sl_popupController presentContentView:customView];
```
* 自定义sl_popupController
```objc
self.sl_popupController = [[SnailPopupController alloc] init];
self.sl_popupController.layoutType = PopupLayoutTypeLeft;
self.sl_popupController.allowPan = YES;
// ...
[self.sl_popupController presentContentView:customView];
```
#### 更多使用方法请参考Demo
## License
SnailPopupController is distributed under the MIT license. | 7,820 | MIT |
---
layout: article
title: "「CV」 ROC 和 PR 曲线"
date: 2020-10-23 14:06:40 +0800
key: cv-roc-pr
aside:
toc: true
category: [AI, CV, cv_foundation]
---
<span id='head'></span>
>ROC曲线和PR(Precision - Recall)曲线皆为类别不平衡问题中常用的评估方法
<!--more-->
# 1. 基础概念
| 缩写 | 术语 | 实际类别 | 说明 |
| TP | 真阳性 | 正样本 | |
| FP | 假阳性 | 负样本 | 一类错误,假报警 |
| TN | 真阴性 | 负样本 | |
| FN | 假阴性 | 正样本 | 二类错误,未命中 |
真阳性率: $$ TPR = \frac{TP}{P} = \frac{TP}{TP + FP}$$
假阳性率: $$ FPR = \frac{FP}{N} = \frac{FP}{FP + TN}$$
准确率: $$ Precision = \frac{TP}{Y} = \frac{TP}{FP + TP}$$
# 2 ROC
关于 TPR 和 FPR 的曲线 [详情](#TPR-FPR);
AUC (Area Under the Curve):反映的是将正样本判为负的概率比将负样本判为正的概率大多少;
## 2.1 优点
## 2.2 缺点
# 3 PR
以 recall 为横坐标,precision 为纵坐标绘制出 PR 曲线;
此处,正负样本形成对抗,使得曲线越靠近左上角(正例优先于负例),模型整体表现越好(可视化之后,正负样本之间 gap 很大);而处于随机线(主对角线)上的点则意味着,一个样本会被随机判断为正/负;
`这里,ROC 指标表现,等于模型泛化能力更好吗`{:.warning} 并不是,因为泛化说的是评测指标在训练集和测试集上表现的差异程度;而此处,说的是 ROC 在某个数据集上的表现好,说到泛化,还是要和训练集上的指标(ROC)相比才可以;
## 3.1 优点
- 兼顾正例(TPR)和负例(FPR);
- 指标不依赖于数据分布(类别间数量差异);`什么意思,有哪个指标依赖于具体类别吗`{:.warning}
FPR 依赖的是所有正样本,FPR 依赖所有负样本;当正负样本比例失调时,ROC 曲线也不会产生很大变化;但 Precision 同时依赖正负样本,就易受数据分布影响;
## 3.2 缺点
-------------------
[End](#head)
{:.warning}
# 附录
## A 参考资料
1. 张乐乐章. PR曲线 ROC曲线的 计算及绘制[EB/OL]. <https://www.cnblogs.com/zle1992/p/6825076.html>. 2017-05-08/2020-10-23.
ROC 的例子很好理解;
1. massquantity. 机器学习之类别不平衡问题 (2) —— ROC和PR曲线[EB/OL]. <https://developer.aliyun.com/article/620175>. 2018-03-20/2020-10-23.
## B 概念
<span id="TPR-FPR"> **1. ROC 曲线的形成**</span>
以二分类为例,此处 P 的定义是置信度>阈值为正,否则为负;那么设定一个阈值得到一个 TPR——FPR 点,(0, 1)的阈值就可以得到一组点,进而绘制成 ROC 曲线; ;我们通常使用的 softmax + argmax,其实是用的阈值 0.5; | 1,689 | MIT |
---
title: iOS开发需要掌握的知识点
date: 2015-10-29 15:35:49
tags:
- iOS
categories:
- 直播
---
任何一个方向,都需要基本功扎实。软件开发领域,数据结构与算法,操作系统,网络协议(tcp/ip协议族)是立足的基础。
下面列举iOS开发需要掌握的知识点:
<!-- more -->
## 一、数据结构与算法
### (一)数据结构
#### 1. 链表
#### 2. 队列
#### 3. 树(二叉树)
#### 4. 哈希表(即散列表)
### (二)算法
#### 1. 查找算法
#### 2. 排序算法
## 二、操作系统
### (一)缓存
### (二)分页
### (三)生产者与消费者
## 三、网络协议(tcp/ip协议族)
### (一)http协议(http/https)
### (二)tcp协议
### (三)udp协议
### (四)ip协议
## 四、Socket、Thread(套接字、线程)
### (一)Socket(套接字)
### (二)Thread(线程)
## 四、iOS方向知识点
### (一)AutoLayout / SizeClass
### (二)KVO/KVC
### (三)NSNotification
### (四)Block
### (五)Protocol/Delegate
### (六)Grand Central Dispatch
### (七)NSOperation Queue
### (八)NSRunloop
### (九)Runtime
### (十)HTTP Request:Post、Get
### (十一)Json、XML
### (十二)CoreData、Sqlite
### (十三)LLDB | 815 | Apache-2.0 |
[](https://www.npmjs.com/package/xcompress)
## XCOMPRESS
用于CSS文件,JS文件和HTML文件夹的批量压缩工具
## Usage
### 环境需求
```
Node.js 0.10.0+ (tested on CentOS, Ubuntu, OS X 10.6+, and Windows 7+)
```
### 安装
```
npm install xcompress
```
### 使用
```
node xcompress [options]
-h, --help 获得帮助
-v, --version 输出版本号
-c, --comment 输出的js和css文件将会保留源码的第一对/* ... */之间的注释
```
即可打包位于根目录下的项目文件
##### 例子
[](http://i1.tietuku.com/c4e9482e1c9ee3cc.png)
在当前目录执行`node xcompress`后,红框处文件夹内的所有后缀为css,js,html(or htm)的文件将被压缩引擎处理并发布到`./dest`目录中,图片以及其他静态文件将被原样输出。
##### 注意之处
* 当前版本不可全局使用,请等待更新。
* 对于js压缩,会在Uglifyjs的基础上使用JsPacker进行eval操作,压缩率大大提升,但是会对性能有非常微小的影响。倘若在eval后反而增大了体积则只进行Uglifyjs的步骤。
[1.1.44 / 2015-05-22]()
==================
* 修正了会被压缩器忽略的文件不会被保留的BUG
* 修正了保留注释功能中匹配原文注释不全的功能
* 也一并压缩了HTML中的script和style,html真正的变为一行了 | 933 | MIT |
+++
date = "2017-05-01T22:45:52+09:00"
tags = ["novels"]
title = "流れよ我が涙、と警官は言った"
comments = true
+++
今までは映像作品についてのみこのブログでは語ってきたけれど、今日からは「物語」であれば全てこちらのブログに買いて行こうと思う。例えばゲーム、例えばマンガ、例えば演劇[^1]。色々な物語に対する僕の「感想」を色々と書いていきたい。
[^1]: プロの舞台を見に行ったことないけれど。
ちなみに、今年度の目標として「SF小説を月に1冊くらい読む」を掲げているので、今回の『流れよ我が涙、と警官は言った』は進捗報告第1回でもあります。
<!--more-->
## 作品紹介
今回はタイトル買いした『流れよ我が涙、と警官は言った』。作者はP.K.ディック。『アンドロイドは電気羊の夢を見るか?』は過去に一応読んだことがある。
[Amazon へのリンク](https://www.amazon.co.jp/%E6%B5%81%E3%82%8C%E3%82%88%E3%82%8F%E3%81%8C%E6%B6%99%E3%80%81%E3%81%A8%E8%AD%A6%E5%AE%98%E3%81%AF%E8%A8%80%E3%81%A3%E3%81%9F-%E3%83%8F%E3%83%A4%E3%82%AB%E3%83%AF%E6%96%87%E5%BA%ABSF-%E3%83%95%E3%82%A3%E3%83%AA%E3%83%83%E3%83%97%E3%83%BBK%E3%83%BB%E3%83%87%E3%82%A3%E3%83%83%E3%82%AF/dp/415010807://www.amazon.co.jp/%E6%B5%81%E3%82%8C%E3%82%88%E3%82%8F%E3%81%8C%E6%B6%99%E3%80%81%E3%81%A8%E8%AD%A6%E5%AE%98%E3%81%AF%E8%A8%80%E3%81%A3%E3%81%9F-%E3%83%8F%E3%83%A4%E3%82%AB%E3%83%AF%E6%96%87%E5%BA%ABSF-%E3%83%95%E3%82%A3%E3%83%AA%E3%83%83%E3%83%97%E3%83%BBK%E3%83%BB%E3%83%87%E3%82%A3%E3%83%83%E3%82%AF/dp/4150108072)を貼るだけでは味気ないので、簡単な紹介をしよう。
主人公のジェイスン・タヴァナーはマルチタレント、毎週火曜日に3,000万人もの視聴者を誇る大人気番組の司会者だ。そのタヴァナーがある朝、ホテルで目覚めると、彼はIDカードを失っており、助けを求めようにも彼自身のことを知っている人間は居ない。警察から追われる身となったタヴァナーが世界の裏側を歩く物語である。
## 感想
その舞台設定や登場人物とタヴァナーとの様々な会話、そしてバックマン本部長の人間らしさに少し心打たれた。
この物語は、全く正反対の二人の男を描いている。当然タヴァナーとバックマンだが、どちらかも本人にとって最も大切なものを取り上げた話だ。タヴァナーはタレントとしての名声を、バックマンは最愛の人を。
タヴァナーは持ち前の魅力で女性たちを味方にしつつ、決して諦めず執着し続けられたのに対して、バックマンは強い感情の昂りを、最後までコントロールすることができない。彼は言うなれば諦めてしまうのだ、こんな風に季節外れに寒い夜は。
タヴァナーのようにありたいとは思うが、実際には僕はバックマンのように行動してしまう人である気がする。感情が続かない、途中で投げ出してしまうのだ。怒り疲れ、泣き疲れ、帰って寝よう、寝てから考えよう。そういう夜に限って寝れなかったりする。
それがきっと、人の「悲しみ」の表現の仕方な気がするし、少なくとも愛する誰かを失った夜には、僕にはそれしかできない気がする。 | 1,708 | MIT |
---
layout: post
title: "《javascript权威指南》读书笔记"
date: 2016-11-24
author: "赵祎鑫"
header-img: "img/post-bg-js-version.jpg"
tags:
- 笔记
---
#### 词法结构
区分大小写,HTML并不区分大小写。
注释://单行注释
/*多行注释
*/
{x:1,y:2} //对象
[1,2,3,4,5] //数组
#### 值和变量
整型直接量: 0,3,100……
浮点型直接量:3.1,5,5,6,02e23……
无穷大值,基于它们的加减乘除运算结果还是无穷大值(当然还保留它们的正负号)
被0整除在javascript中不报错,它只是简单的返回Infinity或-Infinity。
0除以0是没有意义的,返回NaN。
无穷大除以无穷大,给任意负数作开方运算或者算术运算符不是数字或无法转换为数字的操作数一起使用时都将返回NaN。
下面这些值会被转换成false:undefined,null,0,-0,NaN,空字符串
typeof null //object
undefined是预定义的全局变量,不是关键字,它的值就是“未定义”
typeof undefined //undefined
null == undefined //true
null === undefined //false
null和undefined都是假值,都不包含任何的属性和方法
undefined“系统级”,出乎意料的或类似错误的值
null“程序级”,正常的或在意料之中的值,通常赋值给变量或者属性,或者将它们作为参数传入函数
当javascript解释器启动时,它将创建一个新的全局对象,并给它一组定义的初始属性:
- 全局属性,undefined、Infinity、NaN
- 全局函数,isNaN() parseInt() parseFloat() eval()
- 构造函数,Date() RegExp() String() Object() Array()
- 全局对象,Math JSON
null == undefined
'0' == 0 //比较之前字符串转换成数字
0 == false //比较之前布尔值转换成数字
'0' == false //比较之前字符串和布尔值转换成数字
所有的对象继承了两个转换方法。一个是toString(),它的作用是返回一个反映这个对象的字符串
({x;1,y;2}).toString() //[object object]
转换对象的函数:toString() valueOf()
javascript函数里声明的所有变量(但不涉及赋值)都被“提前”至函数体的顶部
当声明一个javascript全局变量时,实际上是定义了一个全局对象的一个属性。当使用var声明一个变量时,创建的这个属性是不可配置的,也就是说这个变量是不能通过delete运算符删除。
```
var a = 1;
delete a //false
```
如果没有使用严格模式并给一个未声明的变量赋值的话,javascript会自动创建一个全局变量。以这种方式创建的变量是全局对象的正常的可配置属性,可以删除。
```
b = 2;
delete b; //true
```
#### 表达式和运算符
函数定义表达式:var square = function(x){return x*x;} //返回传入参数值的平方
```
var i=1; j=++i //i和j的值都是2,对操作符进行增量计算,并返回计算后的值
var i=1; j=i++ //i是2,j是1,对操作符进行增量计算,并返回未做增量计算的值
```
in运算符希望它的左操作数是字符串或可以转换为字符串,希望它的右侧操作数是一个对象。如果右侧的对象拥有一个名为左操作数值的属性名,则表达式返回true
```
var point = {x:1,y:2};
'x' in point; //true
'z' in point; //false
```
instanceof操作符希望左操作数是一个对象,右操作数标识对象的类。如果左侧的对象是右侧类的实例,则表达式返回true,否则返回false。
```
var d = new Date();
d instanceof Date; //true
d instanceof Object; //true
d instanceof Number; //false
```
如果instanceof的左操作数不是对象,instanceof会返回false,如果右操作数不是函数,则抛出一个类型错误异常。
typeof是一元运算符,放在单个操作数的前面,操作数可以是任意类型。返回值为表示操作数类型的一个字符串。
delete是一元操作符,它用来删除对象属性或者数组元素。
#### 语句
全局变量是全局对象的属性,然而和其他全局对象属性不同的是,var声明的变量是无法通过delete删除的
两种函数定义写法:
- var f = function(x){return x+1;} //将表达式赋值给一个变量
- function f(x){return x+1;} //含有变量名的语句
函数声明的语句语法如下:
```
function funcname([arg1[,arg2[.../argn]]]){
statements
}
```
break语句是跳转到循环或者其他语句的结束
continue语句是终止本次循环的执行并开始下一次循环的执行
return语句只能出现在函数体内,如果不是得话会报语法错误
#### 对象
对象是javascript的基本数据类型
除了包含属性之外,每个对象还拥有三个相关的对象特性:
- 对象的原型指向另外一个对象,本对象的属性继承自它的原型对象
- 对象的类是一个标识对象类型的字符串
- 对象的拓展标记指明了是否可以向该对象添加新属性
javascript中,只有在查询属性时才会体会到继承的存在,而设置属性则和继承无关
访问不存在的属性不会报错,会返回undefined
如果对象不存在,试图查询这个不存在的对象的属性就会报错
```
//内置构造函数的原型是只读的
Object.prototype = o; //赋值失败,但没报错,Object.prototype没有修改
```
#### 函数
return语句导致函数停止执行,并返回它的表达式(如果有的话)的值给调用者
如果return语句没有一个与之相关的表达式,则返回undefined值给调用者
构成函数主体的javascript代码在定义之时并不会执行,只有在调用该函数时,它们才会执行。有四种方法来调用javascript函数:
- 作为函数
- 作为方法
- 作为构造函数
- 通过它们的call()和apply()方法间接调用
在一个调用中,每个参数表达式(圆括号之间的部分)都会计算出一个值,计算的结果作为参数传递给另外一个函数
这些值作为实参传递给声明函数时定义的形参
在函数体中存在一个形参的引用,指向当前传入的实参列表,通过它可以获得参数的值 | 3,221 | Apache-2.0 |
---
layout: post # 使用的布局(不需要改)
title: Linux基础命令 # 标题
subtitle: 常见、高级命令 #副标题
date: 2020-01-03 # 时间
author: 新宇 # 作者
header-img: img/post-bg-2015.jpg #这篇文章标题背景图片
catalog: true # 是否归档
tags: #标签
- Linux
---
# 一、基础简介
## 1. 虚拟机
1. 虚拟机就是一款软件,运行在windows macos上
2. 虚拟机作用:在当前系统上虚拟出一个或多个操作系统,
3. 虚拟机的优点:各个虚拟机之间相互独立,互不影响
4. docker容器
5. anaconda:python环境管理工具,不同容器中可以选择不同的python版本
## 2. ubuntu系统
1. 根目录: /
2. 当前用户目录: /home/用户名
## 3. Linux内核与发行版本
1. linux内核(非常小):Linux控制和操作硬件的核心部分
2. 发行版本:Linux内核 + 常用软件
3. 常见发行版本:
- ubuntu
- centOS
- redhat
# 二、常见命令介绍
## 1.Linux基础命令
### 1. 系统版本
```
# 处理器架构
arch
# 内核版本
uname -r
# cpu info
cat /proc/cpuinfo
# Linux 版本
cat /proc/version
```
### 2. 目录操作
```
# 展示当前目录所有文件
ls
# 以树的方式展示目录结构(两层)
tree -L 2
# 展示当前路径
pwd
# 清屏
clear(或者通过 ctrl + l / ctrl + k)
```
### 3. 切换目录
```
# 切换到上一级目录
cd ..
# 切换到用户目录
cd ~
# 当前目录
cd .
# 切换到上次的目录
cd -
```
### 4. 绝对路径和相对路径
```
pwd
# 当前目录 /home/python/aaa
# 切换到Desktop:
# 1.使用绝对路径
cd /home/python/Desktop
# 2.使用相对路径
cd ../Desktop
```
### 5. 文件操作相关命令
```
# 创建文件
touch 文件名
# 删除文件
rm 文件名
# 删除文件夹(及文件夹中所有文件)
rm -r 文件夹
# 删除空文件夹
rmdir 文件夹
```
### 6. 复制、移动文件和目录
```
# 复制文件和目录(也可修改文件名)
cp 文件 目录 (或文件名)
# 复制文件夹(递归)
cp -r 文件夹 目录
# 移动(重命名)文件和目录(不需要 -r)
mv 源文件 新文件
```
### 7. 终端命令格式组成
```
格式:
命令 [可选项] [参数]
命令:必须
可选项:预定义好
参数:不确定
```
### 8. 查看命令格式
```
# 建议此方式
命令 --help
man 命令
```
### 9. ls常用可选项
```
# 列表方式
-l
# 智能显示(文件大小已 K M G 量级显示)
-lh
# 展示所有文件(包括隐藏文件)
-a
# 展示所有文件详情(包括隐藏文件)
-al
# 智能展示所有文件详情(包括隐藏文件)
-alh
```
### 10. 创建文件夹、删除文件或文件夹可选项
```
# 把父文件夹一并创建
mkdir -p 文件夹
# 递归删除文件夹下的所有文件和文件夹
rm -r
# 强制删除,没有提示
rm -f
# 交互式提醒
rm -i
# 强制递归删除
rm -rf
```
### 11. 拷贝或移动文件
```
拷贝 cp
-i: 交互式提示(拷贝文件防止覆盖)
-v: 显示拷贝后的路径描述
-r: 拷贝文件目录
–a: 拷贝文件夹并且文件权限不丢失
移动 mv
-i: 交互式提示(移动文件防止覆盖)
-v: 显示拷贝后的路径描述
```
## 2.Linux高级命令
### 1. 重定向
- 作用: 将命令输出,放到其他地方(比如写入文件)
- 分类: 1.覆盖添加 > 2. 追加 >>
### 2. echo 回显
```
echo 字符串(控制台上显示字符串)
echo "hello world" > d.txt
创建文件并初始化内容
```
### 3. 查看文件内容 cat more
```
# 把文件名显示到终端上,适合小文件
cat 文件名
# 通过分页方式展示,适合大文件
# 快捷键 f:下一页 b:上一页 回车:下一行
more 文件名
# |:管道,把上个命令的输出作为下个命令的输入
# 命令|命令
ll | more
```
### 4. 链接 ln
- 软连接:相当于快捷方式
```
# 尽量使用绝对路径,相对路径容易失效!!!
ln -s 需要链接的文件/文件夹 软连接名称
```
- 硬连接:类比于指向同一个对象的两个不同指针
```
# 硬连接和源文件共用同一块内存
# 修改硬连接,源文件也会变化
# 一般用来保存非常重要的文件
# 删除硬连接,不会影响源文件
ln 需要链接的文件 硬连接名称
# cp:拷贝,复制出一样的文件
```
### 5. 查找特定内容 grep
```
grep [可选项] 字符串/正则 文件
可选项
-n 显示行号
-v 取反
-i 忽略大小写
正则:
^a 以a开头
a$ 以a结尾
. 匹配任意一个字符
# 与管道连用
ll / | grep 字符串/正则
ps -aux | grep ssh
```
### 6. 查找文件 find which
```
# find 路径 [可选项目] 文件名/通配符
find . -name "a.txt"
find . -name "a*.txt"
find . -name "a?.txt"
通配符:
? 匹配一个字符
* 匹配一个或多个字符
# which 可执行程序
which python3
```
### 7. 压缩和解压缩 tar zip unzip
```
# tar本身是归档操作
# tar包不会压缩
tar -cvf a.tar *.txt/或多个文件,以空格分割
tar -xvf a.tar
# gz压缩包稍大,比较快
tar -zcvf a.tar.gz *.txt/或多个文件
tar -zxvf a.tar.gz
# bz2压缩包更小,比较慢
tar -jcvf a.tar.bz2 *.txt/或多个文件
tar -jxvf a.tar.bz2
tar -jxvf a.tar.bz2 -C 解压目录
可选项:
-c: 创建打包文件
-x: 解压缩
-z: 压缩成gz
-j: 压缩成bz2
-v: 显示详细信息
-f: 指定文件名称,放在所有选项后
-C: 指定解压目录
# zip和gz区别:
# linux下一般都使用gz,因为zip压缩效率比较低
zip a.zip 文件名
unzip a.zip
```
### 8. 文件权限管理
windows只能控制只读权限
Linux可以精确控制文件权限
- 角色:
- 文件创建者 u
- 用户组组 g
- 其他用户 o
- 所有 a
- 文件类型
- d:文件夹
- -:普通文件
- l:软连接
- b:块文件
- 权限控制:
- r: 可读 4
- w: 可写 2
- x: 可执行 1

### 9. 修改权限 chmod
注意:在非用户目录下,需要获取管理员权限才可以执行;
```
# 1.字母法 chmod u/g/o/a/+/-/=/rwx- 文件名
# eg:
chmod a=rwx a.py
chmod o=- a.py
# 将py文件改成可执行程序:
# 在py环境最上方添加 #!/usr/local/bin/python3
# 2.数字法
chmod 777 a.py
```
### 10. 用户和管理员权限
```
# 切换到用户
sudo -s
# 获取一次管理员权限
sudo 指令
# 获取当前用户
whoami
# 获取所有登陆用户
who
# 关机和重启
shutdown -r now
reboot
# 创建用户
sudo useradd -m tt
# 自定密码
sudo passwd tt
# 切换用户到tt
su tt
# 退出当前用户
exit
# 删除tt用户
userdel -r tt
```
### 11. 远程拷贝和登陆
```
# 远程登陆 ssh 用户@
sudo apt install openssh-server
sudo apt install openssh-client
ssh [email protected]
# 远程拷贝
# 拷贝文件到远程
scp [-r(拷贝目录)] [-p 端口号] local_file remote_username@remote_ip:remote_folder
# 拷贝远程文件到本地
scp [-r(拷贝目录)] [-p 端口号] remote_username@remote_ip:remote_file local_folder
# 使用FileZille拷贝,图形化界面
```
### 12. 软件安装
- deb离线方式:先下载软件,然后通过命令安装 sudo dpkg -i 安装包 卸载:sudo dpkg -r 软件
- apt-get在线安装: 从镜像仓库安装 sudo apt-get install 软件 卸载:sudo apt remove 软件
- 第三方安装
### 13. vim
- 命令模式: vim a.txt 直接进入命令模式,i 进入编辑模式,: 进入命令模式
- 编辑模式: 编辑文本,esc 进入命令模式
- 末行模式: q/q!/wq/x/ZZ , esc 进入命令模式

```
常用命令:
行首:shift 6
行尾:shift 4
文件末尾:G
文件开始:gg
到第N行:number + G
撤销:U
反撤销:ctrl + r
复制:yy
粘贴:P
删除/剪贴:dd
按行选中:v
查找: :/xxx 从头查找 , :?xxx 从尾查找
看下一个: n
看上一个: N
左下上右:h j k l
显示行号::set number
```


```shell
如何多行插入?
按Esc进入“命令模式”
使用Ctrl + V进入可视块模式
向上 / 向下移动在你要评论的行选择文本的列。
然后按Shift + i,然后输入要插入的文本。
然后按Esc键 ,等待1秒钟,插入的文本将出现在每一行上。
```
注意:快捷键参考 https://linux.cn/article-8144-1.html
## 14. 查看进程信息 ps
```
# 获取进程信息
ps -ef | grep python
ps -aux | grep python
# 杀死进程
kill -9 进程号
```

## 15.查看硬件配置
```shell
# 查看内存
free -h
# 查看硬盘
df -h
# 查看CPU
lscpu
# 查看文件大小
du -sh ./*
```
## 16. 查看python路径
```shell
whereis python
``` | 5,451 | MIT |
---
title: Python-BeautifulSoup
date: 2018-11-16 14:50:41
tags: Python BeautifulSoup
categories: Python lib
---
# Python-BeautifulSoup的使用
BeautiSoup,是借助网页的结构和属性等特性来解析网页的工具,有了它我们不用再去写一些复杂的正则,只需要简单的几条语句就可以完成网页中某个元素的提取。
## BeautifulSoup简介
官方解释如下:
BeautifulSoup提供一些简单的、Python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。 BeautifulSoup 自动将输入文档转换为 Unicode 编码,输出文档转换为 utf-8 编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时你仅仅需要说明一下原始编码方式就可以了。 BeautifulSoup 已成为和 lxml、html6lib 一样出色的 Python 解释器,为用户灵活地提供不同的解析策略或强劲的速度。
## 解析器
BeautifulSoup 在解析的时候实际上是依赖于解析器的,它除了支持 Python 标准库中的 HTML 解析器,还支持一些第三方的解析器比如 LXML,下面我们对 BeautifulSoup 支持的解析器及它们的一些优缺点做一个简单的对比。
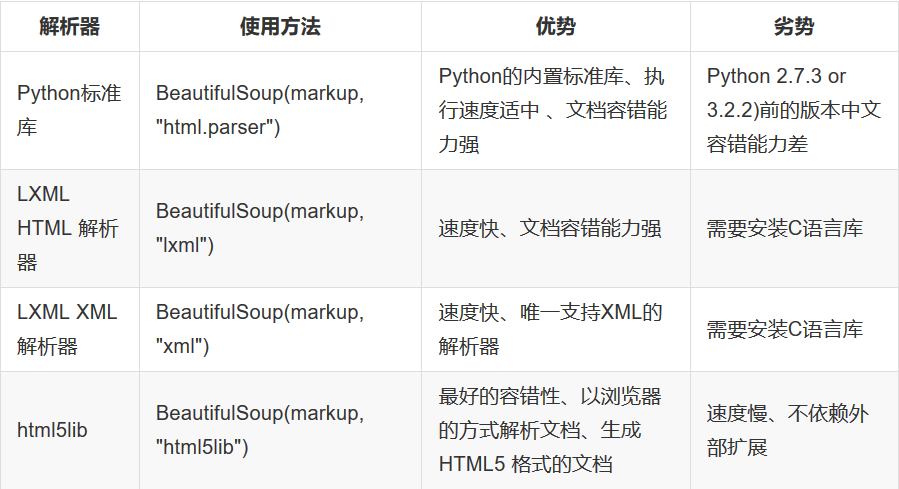
## 基本使用
``` python
from bs4 import BeautifulSoup
html = '''
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
'''
soup = BeautifulSoup(html, 'lxml')
print(soup.prettify()) # 把要解析的字符串以标准的缩进格式输出(自动更正格式)
print(soup.title.string)
# 输出
<html>
<head>
<title>
The Dormouse's story
</title>
</head>
<body>
<p class="title" name="dromouse">
<b>
The Dormouse's story
</b>
</p>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1">
<!-- Elsie -->
</a>
,
<a class="sister" href="http://example.com/lacie" id="link2">
Lacie
</a>
and
<a class="sister" href="http://example.com/tillie" id="link3">
Tillie
</a>
;
and they lived at the bottom of a well.
</p>
<p class="story">
...
</p>
</body>
</html>
The Dormouse's story
```
## 节点选择器
### 选择元素
``` python
soup = BeautifulSoup(html, 'lxml')
print(soup.title)
print(type(soup.title.string))
print(soup.title.string)
print(soup.head)
print(soup.p) # 只选择第一个出现的p标签
# 输出
<title>The Dormouse's story</title>
<class 'bs4.element.NavigableString'>
The Dormouse's story
<head><title>The Dormouse's story</title></head>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
```
## 提取信息
#### 获取名称
可以利用 name 属性来获取节点的名称。还是以上面的文本为例,我们选取 title 节点,然后调用 name 属性就可以得到节点名称。
``` python
print(soup.title.name)
# 输出
title
```
#### 获取属性
每个节点可能有多个属性,比如 id,class 等等,我们选择到这个节点元素之后,可以调用 attrs 获取所有属性。
``` python
print(soup.p.attrs)
print(soup.p.attrs['name'])
#更加简便的写法
print(soup.p['name'])
print(soup.p['class'])
# 输出
{'class': ['title'], 'name': 'dromouse'}
dromouse
dromouse
['title']
```
#### 获取内容
可以利用 string 属性获取节点元素包含的文本内容。
``` python
print(soup.p.string)
# 输出
The Dormouse's story
```
### 嵌套选择
在上面的例子中我们知道每一个返回结果都是 bs4.element.Tag 类型,它同样可以继续调用节点进行下一步的选择,比如我们获取了 head 节点元素,我们可以继续调用 head 来选取其内部的 head 节点元素。
``` python
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.head.title)
print(type(soup.head.title))
print(soup.head.title.string)
# 输出
<title>The Dormouse's story</title>
<class 'bs4.element.Tag'>
The Dormouse's story
```
### 关联选择
我们在做选择的时候有时候不能做到一步就可以选择到想要的节点元素,有时候在选择的时候需要先选中某一个节点元素,然后以它为基准再选择它的子节点、父节点、兄弟节点等等。
#### 子节点和子孙节点
选取到了一个节点元素之后,如果想要获取它的**直接子节点**可以调用 contents 属性。 contents 返回的是列表类型, children 返回的是生成器类型。
``` python
print(soup.p.contents)
print(soup.p.children)
print(soup.p.contents)
print(soup.p.children)
for i, child in enumerate(soup.p.children):
print(i, child)
# 输出
['Once upon a time there were three little sisters; and their names were\n', <a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, ',\n', <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, ' and\n', <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>, ';\nand they lived at the bottom of a well.']
0 Once upon a time there were three little sisters; and their names were
1 <a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>
2 ,
3 <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>
4 and
5 <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
6 ;
and they lived at the bottom of a well.
```
#### 父节点和祖先节点
如果要获取某个节点元素的直接父节点,可以调用 parent 属性,要想获取所有的祖先节点,可以调用 parents 。
``` python
print(soup.a.parent)
print(soup.a.parents)
# 输出
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
[(0, <p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>), (1, <body>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body>), (2, <html><head><title>The Dormouse's story</title></head>
<body>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html>), (3, <html><head><title>The Dormouse's story</title></head>
<body>
<p class="story">Once upon a time there were three little sisters; and their names were
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>,
<a class="sister" href="http://example.com/lacie" id="link2">Lacie</a> and
<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
</body></html>)]
```
#### 兄弟节点
``` python
from bs4 import BeautifulSoup
html = """
<html>
<body>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
Hello
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
and they lived at the bottom of a well.
</p>
"""
soup = BeautifulSoup(html, 'lxml')
print('next_sibling', soup.a.next_sibling)
print('prev_sibling', soup.a.previous_sibling)
print('next_siblings', list(enumerate(soup.a.next_sibling)))
print('prev_siblings', list(enumerate(soup.a.previous_sibling)))
# 输出
next_sibling
Hello
prev_sibling
Once upon a time there were three little sisters; and their names were
next_siblings [(0, '\n Hello\n '), (1, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>), (2, ' \n and\n '), (3, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>), (4, '\n and they lived at the bottom of a well.\n ')]
prev_siblings [(0, '\n Once upon a time there were three little sisters; and their names were\n ')]
```
## 方法选择器
前面讲的选择方法都是通过属性来选择元素的,这种选择方法非常快,但是如果要进行比较复杂的选择的话则会比较繁琐,不够灵活。所以 BeautifulSoup 还提供了一些查询的方法,比如 find_all()、find() 等方法,我们可以调用方法然后传入相应等参数就可以灵活地进行查询。
### find_all--查找所有符合条件的元素
``` python
from bs4 import BeautifulSoup
html='''
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
'''
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all(name = 'ul'))
for ul in soup.find_all(name = 'ul'):
print(ul.find_all(name = 'li'))
for li in ul.find_all(name = 'li'):
print(li.string)
# 输出
[<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>, <ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>]
[<li class="element">Foo</li>, <li class="element">Bar</li>, <li class="element">Jay</li>]
Foo
Bar
Jay
[<li class="element">Foo</li>, <li class="element">Bar</li>]
Foo
Bar
```
### attrs
根据属性进行查询
``` python
print(soup.find_all(attrs = {'id': 'list-1'}))
# 输出
[<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>]
```
### text
text 参数可以用来匹配节点的文本,传入的形式可以是字符串,可以是正则表达式对象。
``` python
import re
html='''
<div class="panel">
<div class="panel-body">
<a>Hello, this is a link</a>
<a>Hello, this is a link, too</a>
</div>
</div>
'''
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.find_all(text=re.compile('link')))
# 输出
['Hello, this is a link', 'Hello, this is a link, too']
```
### find()
find方法和find_all类似,只是返回的是第一个匹配的元素
### othres API
- find_parents() find_parent()
find_parents() 返回所有祖先节点,find_parent() 返回直接父节点。
- find_next_siblings() find_next_sibling()
find_next_siblings() 返回后面所有兄弟节点,find_next_sibling() 返回后面第一个兄弟节点。
- find_previous_siblings() find_previous_sibling()
find_previous_siblings() 返回前面所有兄弟节点,find_previous_sibling() 返回前面第一个兄弟节点。
- find_all_next() find_next()
find_all_next() 返回节点后所有符合条件的节点, find_next() 返回第一个符合条件的节点。
- find_all_previous() 和 find_previous()
find_all_previous() 返回节点后所有符合条件的节点, find_previous() 返回第一个符合条件的节点
## CSS选择器
BeautifulSoup 还提供了另外一种选择器,那就是 CSS 选择器。使用 CSS 选择器,只需要调用 select() 方法,传入相应的 CSS 选择器即可。
``` python
from bs4 import BeautifulSoup
html='''
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
'''
soup = BeautifulSoup(html, 'lxml')
print(soup.select('.panel .panel-heading'))
print(soup.select('ul li'))
print(soup.select('#list-2 .element'))
print(type(soup.select('ul')[0]))
# 输出
[<div class="panel-heading">
<h4>Hello</h4>
</div>]
[<li class="element">Foo</li>, <li class="element">Bar</li>, <li class="element">Jay</li>, <li class="element">Foo</li>, <li class="element">Bar</li>]
[<li class="element">Foo</li>, <li class="element">Bar</li>]
<class 'bs4.element.Tag'>
```
### 嵌套选择
select() 方法同样支持嵌套选择,例如我们先选择所有 ul 节点,再遍历每个 ul 节点选择其 li 节点。
``` python
for ul in soup.select('ul'):
print(ul.select('li'))
# 输出
[<li class="element">Foo</li>, <li class="element">Bar</li>, <li class="element">Jay</li>]
[<li class="element">Foo</li>, <li class="element">Bar</li>]
```
### 获取属性
``` python
for ul in soup.select('ul'):
print(ul['id'])
print(ul.attrs['id'])
# 输出
list-1
list-1
list-2
list-2
```
### 获取文本
获取文本可以用前面所讲的 string 属性,还有一个方法那就是 get_text()。
``` python
for li in soup.select('li'):
print('Get Text:', li.get_text())
print('String:', li.string)
# 输出
Get Text: Foo
String: Foo
Get Text: Bar
String: Bar
Get Text: Jay
String: Jay
Get Text: Foo
String: Foo
Get Text: Bar
String: Bar
``` | 12,551 | MIT |
# IO
<!--ts-->
- [IO](#io)
- [IO模型简介](#io模型简介)
- [IO分类](#io分类)
- [java中为什么有了字节流还要有字符流?](#java中为什么有了字节流还要有字符流)
- [五种IO模型](#五种io模型)
- [输入操作两个阶段](#输入操作两个阶段)
- [套接字输入操作](#套接字输入操作)
- [BIO](#bio)
- [NIO](#nio)
- [NIO的特性、NIO与IO的区别](#nio的特性nio与io的区别)
- [AIO](#aio)
- [阻塞/非阻塞 异步/同步](#阻塞非阻塞-异步同步)
- [NIO](#nio-1)
- [流与块](#流与块)
- [通道与缓冲区](#通道与缓冲区)
- [选择器](#选择器)
- [多路IO复用](#多路io复用)
- [Reactor模型](#reactor模型)
- [零拷贝](#零拷贝)
- [select、poll、epoll](#selectpollepoll)
- [select](#select)
- [poll](#poll)
- [epoll](#epoll)
- [select、poll、epoll的区别](#selectpollepoll的区别)
<!-- Added by: hanzhigang, at: 2021年 8月17日 星期二 13时51分20秒 CST -->
<!--te-->
## IO模型简介
### IO分类
- 磁盘操作:file
- 字节操作:InputStream和OutputStream
- 字符操作:Reader和Writer
- 对象操作:Serializable
- 网络操作:Socket
#### java中为什么有了字节流还要有字符流?
字节流是java虚拟机将字节转换得到的,这个过程还算是非常耗时,并且如果我们不知道编码类型,就很容易出现乱码问题。所以IO流就直接提供了一个直接操作字符的接口,方便我们平时对字符进行流操作。如果音频文件、图片等媒体文件用字节流比较好,如果涉及到字符的话用字符会比较好。
### 五种IO模型
- 阻塞式IO(BIO)
- 非阻塞式IO(NIO)
- IO复用(select和poll)
- 信号驱动式IO
- 异步IO(AIO)
### 输入操作两个阶段
- 等待数据准备好
- 从内核向进程复制数据
### 套接字输入操作
- 等待数据从网络中达到,当所等待分组到达时,它被复制到内核中的某个缓冲区。
- 把数据从内核缓冲区复制到进程缓冲区。
### BIO
- 同步阻塞IO模式,数据的读取写入必须阻塞在一个线程内等待完成。应用程序被阻塞,直到数据复制到应用程序缓冲区中才返回。
- 这里阻塞过程中,其他程序还可以继续执行。
- 对于十万甚至百万级连接时,传统的BIO模型是无能为力的。
- 一请求一应答通信模型
### NIO
- 同步非阻塞IO模式,在java1.4中引入了NIO框架,对于java.nio包,提供了Channel、Selector、Buffer等抽象。
- 支持面向缓冲区,基于通道的I/O操作方法。
- 提供了`SocketChannel`和`ServerSocketChannel`两种不同的套接字通道实现,也支持阻塞模式,相对于BIO中的`Socket`和`ServerSocket`。
- 非阻塞模式对于低负载、低并发的应用程序,可以使用同步阻塞I/O来提升开发效率和更好的维护性。对于高负载和高并发的应用,使用NIO的非阻塞模式来开发。
#### NIO的特性、NIO与IO的区别
- **IO流是阻塞的,NIO是非阻塞的**
1. 单线程中从通道读取数据到buffer,同时可以继续做别的事情,当在通道中读取到buffer的时候,线程再继续处理数据。
2. 非阻塞写,一个线程写一些数据到通道中,不需要等待它完全写入,就可以去做别的事情。
- **Buffer(缓冲区)**
1. IO是面向流的,NIO是面向缓冲区的
2. Buffer是一个对象,它包含一些要写入或读出的数据。NIO引入了Buffer这个对象,这是和IO一个重要的区别。
3. IO是Stream oriented,虽然Stream也有Buffer开头的扩展类,但是只是流的包装类,最终还是从流到缓冲区。
4. Buffer是直接将数据读到缓冲区中进行处理的。
- **Channel(通道)**
1. 通道是双向的,可读可写,但流的读写是单向的。无论读写,通道都是和Buffer交互。因为Buffer,通道可以异步的读写。
- **Selector(选择器)**
1. NIO有选择器,IO没有选择器
2. 选择器用于单线程处理多个通道。对于操作系统来说,线程之间的切换是比较昂贵的,所以需要使用较少的线程来处理多个通道,所以使用选择器对于提高操作系统的效率是比较有用的。
### AIO
- 异步非阻塞的I/O模型,基于事件和回调机制实现的。
### 阻塞/非阻塞 异步/同步
- 同步和异步是通信机制,阻塞和非阻塞是调用状态。
- 阻塞是在调用revfrom的时候,因为还没有数据准备好,线程阻塞,直到数据准备好再返回。非阻塞是在调用revfrom的时候,不论数据有没有准备好,都返回一个状态码。
- 同步是在数据准备好后,调用revfrom的线程发起系统调用,将数据从内核复制到用户空间。异步是当数据返回好后,主动将数据从内核复制到用户空间。然后返回一个状态码给相应的线程。
### NIO
#### 流与块
- IO与NIO最重要的区别就是数据打包方式和传输方式。IO以流的方式处理数据,而NIO以块的方式处理数据。
- 面向流的IO一次处理一个字节数据:一个输入流产生一个字节数据,一个输出流产生一个字节数据。
- 面向块的IO一次处理一个数据块,按块处理数据比流处理数据要快得多。
#### 通道与缓冲区
- **通道**
通道Channel是对原IO包中流的模拟,可以通过它读取和写入数据。通道和流的不同之处在于通道是双向的,可以用于读或写或者同时读写。流是单向的。
- **缓冲区**
发送给一个通道的所有数据必须先放到缓冲区中,同样的,从通道中读取的任何数据都要先读到缓冲区中,也就是说不会直接对通道进行读写数据,而是要先经过缓冲区。
缓冲状态变量:capacity 最大容量,position 已经读写的字节数,limit 还可以读写的字节数。
缓冲区实际上是一个数组,但它不仅仅是一个数组,缓冲区提供了对数据的结构化访问,而且还可以跟踪系统的读/写进程。
#### 选择器
- **选择器** NIO实现了IO多路复用中的Reactor模型,一个线程Thread使用一个选择器Selector通过轮询的方式监听多个通道Channel上的事件,从而让一个线程就可以处理多个事件。
通过配置监听的通道Channel为非阻塞,那么当Channel上的IO事件还未到达时,就不会进入阻塞状态一直等待,而是继续轮询其他Channel,直到IO事件已经到达的Channel执行。
### 多路IO复用
#### Reactor模型
- 并发读写
Reactor分为mainReactor和subReactor,mainReactor主要进行客户端的连接的处理,处理完成之后将该连接交由sunReactor以处理客户端的网络读写。这里的subReactor则是使用一个线程池来支撑的,其读写能力将会随着线程数的增多而大大增加。对于业务操作,则是使用一个线程池,每个业务请求都只需要进行编解码和业务计算。
### 零拷贝
1. mmap + write(两次次系统调用+三次拷贝)
mmap()系统调用函数会直接把内核缓冲区里的数据`映射`到用户空间,这样,操作系统内核与用户空间就不需要再进行任何的数据拷贝操作。
具体过程如下:
- 应用程序调用了mmap()后,DMA会把磁盘的数据拷贝到内核的缓冲区里。接着,应用程序和操作系统`共享`这个缓冲区。
- 应用程序再调用write(),操作系统直接把内核缓冲区的数据拷贝到socket缓冲区中,这一切都发生在内核态,由CPU来搬运数据。
- 最后把内核的socket缓冲区里的数据,拷贝到网卡的缓冲区里,这个过程是由DMA搬运的。
仍需要通过CPU把内核缓冲区的数据拷贝到socket缓冲区里,仍然需要4次上下文切换,因为系统调用还是2次。
2. sendfile(一次系统调用+三次拷贝)
```c++
#include <sys/socket.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
```
前两个参数是目的端和源端的文件描述符,后两个参数是源端的偏移量和复制数据的长度,返回值是实际复制数据的长度。
它可以替代前面的read()和write()这两个系统调用,这样就可以减少一次系统调用,也就减少了两次上下文切换的开销。
该系统调用可以直接把内核缓冲区里的数据拷贝到socket缓冲区里,不再拷贝到用户态,这样就只有2次上下文切换和3次数据拷贝。
(一次系统调用+两次拷贝)
如果网卡支持SG-DMA技术,可以进一步减少通过CPU把内核缓冲区里的数据拷贝到socket缓冲区的过程。
在linux内核2.4版本开始,对于支持网卡支持SG—DMA技术的情况下,sendfile()系统调用的过程具体如下:
- 第一步:通过DMA将磁盘上的数据拷贝到内核缓冲区里。
- 第二步:缓冲区描述符和数据长度传到socket缓冲区,这样网卡的SG-DMA控制器就可以直接将内核缓冲中的数据拷贝到网卡的缓冲区里,此过程不需要将数据从操作系统内核缓冲区拷贝到socket缓冲区中,这样就减少了一次数据拷贝。
3. 大文件使用异步 + 直接IO,不使用零拷贝,因为零拷贝会用到PageCache(磁盘高速缓存),PageCache主要用来就IO的数据进行合并以及预读。将大文件放到PageCache中会造成大文件很快填满PageCache,造成很多小的热点文件不能被读到。(将数据拷贝到内核缓冲区中,这个内核缓冲区说的就是磁盘高速缓存)。
### select、poll、epoll
#### select
```c++
int select(int maxfdp, fd_set *readset, fd_set *writeset,
fd_set *exceptset, struct timeval *timeout);
```
- 基本原理:select函数监视的文件描述符分为三类,writefds,readfds和exceptfds。调用select时会被阻塞,直到有fd就绪或者超时,函数返回一个大于0的值,遍历文件描述符fd_set,来找到就绪的描述符。
- maxfdp是一个整数值,是指集合中所有文件描述符的范围,即所有最大文件描述符+1。fd_set是以位图的形式存储这些文件描述符,maxfdp定义了位图中有效的位的个数。
- 时间复杂度O(n),n为文件描述符fd_set的大小。文件描述符最大限制1024。
#### poll
```c++
int poll ( struct pollfd * fds, unsigned int nfds, int timeout);
```
- poll定义了一个pollfd结构的数组,用于存放需要检测其状态的所有文件描述符,调用poll的时候不会清空这个数组,特别对于文件描述符比较多的情况,在一定程度上提高了查询的效率。这和select有很大的不同,在每次调用select之后,都会清空它检测的文件描述符集合,导致每次调用select都必须把文件描述符重新加入到待检测的文件描述符集合中。因此select适合只检测一个文件描述符的情况,而poll适合检测大量文件描述符的情况。
- 时间复杂度:O(n),n是文件描述符集合的大小。文件描述符没有最大限制。
#### epoll
- 将所有文件描述符存储在共享内存中(用户空间和内核空间可以直接访问)。调用epoll_create函数创建epoll对象,并以红黑树的结构存储在内核空间,epoll_ctl函数用来在红黑树中添加或注销监视文件描述符,最后调用epoll_wait函数直到有就绪的文件描述符,立即返回给用户态进程。
- 时间复杂度O(1),文件描述符最大限制能打开的fd的上限远大于1024。
- epoll的两种工作方式:LT:水平触发,若就绪事件一次没有处理完所有要做的事件,就会一直处理,即就会把没有处理完的事件继续放回就绪队列中,一直进行处理。ET:边缘触发,就绪处理事件只处理一次,若没有处理完,会在下次事件就绪时继续处理。如果后续没有就绪的事件,那么剩余的那部分数据也会随之而丢失。
### select、poll、epoll的区别
1. select 应用场景 select 的 timeout 参数精度为 1ns,而 poll 和 epoll 为 1ms,因此 select 更加适用于实时要求更高的场景,比如核反应堆的控制。 select 可移植性更好,几乎被所有主流平台所支持。
2. poll 应用场景 poll 没有最大描述符数量的限制,如果平台支持并且对实时性要求不高,应该使用 poll 而不是 select。 需要同时监控小于 1000 个描述符,就没有必要使用 epoll,因为这个应用场景下并不能体现 epoll 的优势。 需要监控的描述符状态变化多,而且都是非常短暂的,也没有必要使用 epoll。因为 epoll 中的所有描述符都存储在内核中,造成每次需要对描述符的状态改变都需要通过 epoll_ctl() 进行系统调用,频繁系统调用降低效率。并且epoll 的描述符存储在内核,不容易调试。
3. epoll 应用场景 只需要运行在 Linux 平台上,并且有非常大量的描述符需要同时轮询,而且这些连接最好是长连接。
4. 传递方式:select和poll都是内核到用户,epoll则是共享内存。
5. 在select和poll中,进程只有在调用方法后,内核才对所有监视的文件描述符进行扫描,发现有任何一个文件描述符就绪或者超时,就会立即返回。而epoll则是基于事件的就绪通知方式,事先通过epoll_ctl来注册一个文件描述符,一旦基于某个文件描述符就绪时,内核会采用callback的回调机制,迅速激活这个文件描述符,当进程调用epoll_wait时就会得到通知。 | 6,217 | Apache-2.0 |
---
layout: post
title: "最高法院多数意见:为什么要承认同性婚姻权利"
date: 2015-06-30
author: 政见
from: http://cnpolitics.org/2015/06/kennedy/
tags: [ 政見 ]
categories: [ 政見 ]
---
<div class="post-block">
<h1 class="post-head">
最高法院多数意见:为什么要承认同性婚姻权利
</h1>
<p class="post-subhead">
</p>
<p class="post-tag">
</p>
<p class="post-author">
<!--a href="http://cnpolitics.org/author/cnpolitics/">政见</a-->
<a href="http://cnpolitics.org/author/cnpolitics/">
政见
</a>
<span style="font-size:14px;color:#b9b9b9;">
|2015-06-30
</span>
</p>
<!--p class="post-lead">认为追求同性婚姻的男女缺乏对婚姻的尊重,这是对其意图的误解。他们的抗辩内容彰显着对婚姻的尊重,而恰恰是这份强烈尊重,激励他们追寻亲身实现婚姻的价值。他们不愿茕茕孑立,终身孤立于人类文明最为悠久的习俗之外。他们在法律面前寻求平等的尊严。</p-->
<div class="post-body">
<figure>
<img alt="kennedy" src="http://cnpolitics.org/wp-content/uploads/2015/06/0630-1.jpg" width="566"/>
</figure>
<div class="post-lead">
翻译:
<a href="http://cnpolitics.org/author/caoqitong/">
曹起曈
</a>
、
<a href="http://cnpolitics.org/author/zhangyueran/">
张跃然
</a>
、
<a href="http://cnpolitics.org/author/suliang/">
宿亮
</a>
、
<a href="http://cnpolitics.org/author/taoyu/">
陶郁
</a>
、
<a href="http://cnpolitics.org/author/guisu/">
归宿
</a>
、
<a href="http://cnpolitics.org/author/admin/">
方可成
</a>
</div>
</div>
</div> | 1,319 | MIT |
Otoi - Simple Contact Form
==========================
**Otoi**とはPHP詳しくない方でも使いやすい、シンプルな、お問い合わせフォームのシステムです
**Otoi** is a simple contact form app, designed to be easy to set
up and configure with minimal PHP knowledge
English documentation can be found below.
### Requirements 必要条件
PHP >= 5.6
## 使用法
Otoiを使用する最も簡単な方法はOtoiのフォルダーを実行したい場所におくことです。
Otoiの別のディレクトリで実行したい場合、自分の作ったindex.phpのファイルにbootstrap.phpをインコルードもできます。 \
より高度なユーザだと、OtoiがComposerで実装されたものなのでautoload.phpをインクルードすると自由に
`Otoi\Otoi`のインスタンスを作成で始め、または`Otoi\Otoi::start()`の静的のメソッドを使用ください。
### 例
```php
<?php
// /contact/index.php
require "/var/www/lib/Otoi/bootstrap.php";
// OR
require "/var/www/lib/Otoi/autoload.php";
Otoi\Otoi::start();
```
_セキュリティーに関しては、通常に設定ファイルとテンプレートをドキュメントルートの外側におくか、.htaccessの「Deny
from all」を含めることがおすすめです_
### 書き換え
OtoiはURL書き換えを使用しているために、下記のような.htaccessファイルが必要です。
```apacheconfig
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteRule . index.php [L]
</IfModule>
```
---
## 設定
**Otoi** attempts to keep configuration simple and easy.
### 基本
重要な設定は.envファイルに設定されています。 \
その.envファイルは順序でディレクトリ内で検索されます。
1. Otoiが実行されていたディレクトリ
2. Otoiが実行されていたディレクトリのconfigというディレクトリ
3. Otoiの最上位フォルダ
4. Otoiのsrcフォルダ
```dotenv
# App Configuration
BASE_URL=/ # フォームのURL
CONFIG=config # configディレクトリ
LOGS=logs # ログディレクトリ(書き込み可能である必要)
TEMPLATES=templates # テンプレートディレクトリ
DEBUG=false # デバッグモードで実行
HONEYPOT=true # スパムを減らすためにハニーポットを使う
# Mail Configuration
MAIL_DRIVER=mail # メール用ドライバ(mail、sendmail、smtp)
MAIL_LANG=jp # メールコンテンツの言語設定
SMTP_HOST=smtp.example.com # SMTPホスト (smtpドライバを使用している場合)
SMTP_USER=user # 必要に応じてSMTPのユーザー名
SMTP_PASS=password # 必要に応じてSMTPのパスワード
SMTP_PORT=25 # SMTP用ポート(SSLを使用している場合は設定が必要な場合があります)
```
configディレクトリの中には2つのファイルがあります。
- forms.php
- mail.php
### フォーム
forms.phpファイルの中には、それぞれの設定を書き込みます。ファイルは「`{form-name} => {configuration}`」の
連想配列を返さなければなりません。\
高度なユーザではない場合、アプリケーションのルートで実行される「default」というフォームを含めるべきです。
```php
<?php
return [
"default" => [/** ...configuration */],
"reserve" => [/** ...configuration */]
];
```
フォームのURLはフォーム名キーから自動的に生成されます。
例えば:
`reservation`キー名は以下のURLを生成します:
- `GET reservation/`
- `POST reservation/confirm`
- `POST reservation/mail`
これらのURLは、env変数に設定されているBASE_URLに追加されます。
そうしてBASE_URLが`/contact`だとフォームの完全なURLがこの通り:
- `/contact/reservation/`
- `/contact/reservation/confirm`
- `/contact/reservation/mail`
`default`キー名configから生成されたフォームは` / contact`にあります。
#### 設定構造
フォーム設定のスキーマは簡単です。 \
キーは内部的にフォームを識別するためと、URLのスラグのために使用されます。
(例外はデフォルトで、ルートで実行されますので、URLスラッグはありません)
**以下のフィールドはすべて必須です**
`"validation"`
入力名と検証文字列の設定の `name => validation`配列。 \
可能な検証オプションについては、 [下記](#validation)の検証セクションを参照してください。
`"templates"`
`"index "=> {string}`と `" confirm "=> {string}`を含める**必要**があります。
文字列は、テンプレートフォルダ内のテンプレートファイルへのパスです。
`"final-location"`
フォームの完成時にユーザーが転送されるURL。
`"mail"`
フォームの完成時に送信されるEメールの配列。これらはmail.phpに設定されるメール設定の名前です
##### 例
```php
<?php
return [
"default" => [
"validation" => [
"name" => "required",
"email" => "email|required",
"file" => ""
],
"templates" => ["index" => "index", "confirm" => "confirm"],
"final-location" => "/",
"mail" => ["admin", "customer"]
]
];
```
### メール
mail.phpというファイル内には、各フォームの設定を書き込みます。
ファイルは `{mail-name} => {configuration}`の連想配列を返さなければなりません。
```php
<?php
return [
"customer-response" => [/** ...configuration */],
"admin" => [/** ...configuration */]
];
```
#### 設定構造
メール設定は少なくとも `" to "`、 `" from "`、 `" subject "`キーが**必須**です。
`"cc"`, `"bcc"`, `"files"`, `"template"`は任意です。
`" to "`、 `" from "`、 `" cc "`、`" bcc "`はすべて以下のいずれかです。
- メールアドレスの文字列 e.g `"[email protected]"`
- メールアドレスの文字列の配列 e.g `["[email protected]", "[email protected]"]`
- メールアドレス・名のペア e.g `["[email protected]", "name1"]`
- メールアドレスと名前のペアの配列 e.g `[["[email protected]", "name1"], ["[email protected]", "name2"]]`
`"files"`は、メールの添付ファイルとして送信されるファイルアップロード入力に関連する入力名の文字列または配列です。
`"tempate"`はテンプレートディレクトリを基準とした、電子メールの本文を作成するために使われるテンプレートのパスです。
##### 例
```php
<?php
return [
"admin" => [
"subject" => "SUBJECT",
"to" => "[email protected]",
"from" => ["[email protected]", "Test Server"],
"template" => "mail/default",
"files" => "file",
"cc" => ["[email protected]", "[email protected]"]
],
"customer" => [
"subject" => "CUSTOMER SUBJECT",
"to" => ["@email", "@name"],
"from" => ["[email protected]", "Test Server"],
"template" => "mail/default"
]
];
```
このメール設定を各フォーム設定に名前で追加します。
### 検証
検証設定は文字列の形式です。 \
ルールはパイプ `|`で区切ります。ルールが引数を取る場合、引数はコロン `:`で区切られ、各引数はカンマ `、`で区切られます。
e.g:
- `email`
- `required|email`
- `blacklist:not,this,or,this|required`
利用可能なルール:
- required
- whitelist
- blacklist
- email
- phone
- ext
- pdf
- regex
### テンプレート
テンプレートは単にphpファイルです。そのように他のファイルを要求など、通常PHPで実行できます。ただし、
ファイルはテンプレートクラスで実行されるため、あなたがOtoiを他のPHPファイル変数に埋め込んでいるなら、
親ファイルは範囲外になります。\
CSRFトークンとHoneytrapを簡単に含めるために、これらをレンダリングするためのヘルパーがあります。`$csrf()`と
`$honeypot()`。 CSRFトークンは、クロスサイトリクエストフォージェリ攻撃に対抗するために常に必要です。
ハニーポットは.envファイルで無効にできます。ハニーポットは、埋められた場合にフォームが拒否される原因となる隠し入力
を含めることによって、ボットからのスパムの量を減らすためのシンプルで効果的な手法です。\
ボットが自動的にそれを記入している間、人間はこの入力を見て記入しないでしょう。
入力値はインデックステンプレートと確認テンプレートにある`$data`配列を通して利用可能です。 これらは項目の`name`
でインデックスされています(検証設定で登録されている必要あります)。入力に対して値が送信されていない場合は、
空の文字列になります (`""`)。 \
エラーはインデックステンプレートのみにある`$errors`配列で利用できます。\
`$errors`配列はname =\> errors[]の配列です。入力が有効な場合、これは空の配列になります。 エラーの値は失敗した
ルールの名前になります。\
e.g `required|email`の検証の項目に`test&test.com`を入力すると、エラー配列が`['email']`になります。\
もっと有用なエラーメッセージが表示されます。\
`$ action`変数はフォームの次の段階のために生成されたURLを取得するために使うことができます。
#### Example Template
```php
<html>
<head>
<meta http-equiv="Content-Type" content="text/html;charset=UTF-8">
</head>
<div>
<ul>
<?php foreach($errors as $name => $errs) ?>
<?php foreach ($errs as $err) ?>
<li><?= $err ?></li>
<?php endforeach ?>
<?php endforeach ?>
</ul>
</div>
<form enctype="multipart/form-data" action="<?= $action ?>" method="post">
<?php $csrf() ?>
<label>Name: <input type="text" name="name" value="<?= $data["name"] ?>"></label><br>
<label>Email: <input type="text" name="email" id="<?= $data["email"] ?>"></label><br>
<label>File: <input type="file" name="file"></label><br>
<input type="submit" value="Submit">
<?php $honeypot() ?>
</form>
</html>
```
---
# English
## Usage
The simplest way of using Otoi is to just drop the folder into the
location you want it to run at. You can also include bootstrap file
if you want Otoi to run in a different directory. \
For more advanced users, Otoi is build with composer so it can also
be started by including its autoload and either creating an instance
of `Otoi\Otoi()` or using the `Otoi\Otoi::start()` static method.
### Example
```php
<?php
// /contact/index.php
require "/var/www/lib/Otoi/bootstrap.php";
// OR
require "/var/www/lib/Otoi/autoload.php";
Otoi\Otoi::start();
```
_With regards to security it is usually better to keep config files and_
_templates outside of the document root or include a "Deny from all" .htaccess_
### Rewrites
Otoi uses URL routing so the following, or similar, .htaccess file is necessary.
```apacheconfig
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteRule . index.php [L]
</IfModule>
```
---
## Configuration
**Otoi** uses naming conventions to make configuration simple and easy. \
Inside your config directory there should be two files:
- forms.php
- mail.php
### App
The apps key configuration is set in a .env file. \
The file is searched for in directories in the following order:
1. The directory in which Otoi was run
2. A directory named config in the director in which Otoi was run
3. The top level folder of Otoi
4. The src folder of Otoi
```dotenv
# App Configuration
BASE_URL=/ # The base url of the contact forms
CONFIG=config # Location of the config directory
LOGS=logs # Locaiton of the log directory (Must be writable)
TEMPLATES=templates # Location of the template directory
DEBUG=false # Run in debug mode
HONEYPOT=true # Uses honeypot method for reducing spam
# Mail Configuration
MAIL_DRIVER=mail # Driver for mail (mail, sendmail, smtp)
MAIL_LANG=jp # Language setting for mail content
SMTP_HOST=smtp.example.com # SMTP host if using smtp driver
SMTP_USER=user # Username for SMTP if required
SMTP_PASS=password # Password for SMTP if required
SMTP_PORT=25 # Port for SMTP (May need setting if using SSL)
```
### Forms
Inside the forms file is where you will write the configuration for each
form. The file **MUST** return an associative array of `{form-name} => {configuration}`.
It **SHOULD** include a "default" form that will be run at the root of the application.
```php
<?php
return [
"default" => [/** ...configuration */],
"reserve" => [/** ...configuration */]
];
```
URLs for the forms are generated automatically from the form name key.
For example:
`reservation` name key will generate the following URLs:
- `GET reservation/`
- `POST reservation/confirm`
- `POST reservation/mail`
These URLs are then appended to the base url set in env variables.
So if your base url is `/contact` then the full URL of your form will be:
- `/contact/reservation/`
- `/contact/reservation/confirm`
- `/contact/reservation/mail`
The form generated from `default` key name config will then be found at `/contact`
#### Configuration Schema
The schema for Form configuration is simple. \
The key will be used to identify the form internally as well as for the
slug for the url. (The exception being default, which runs at the root
of the app and so has no url slug)
**The following four fields are required**
`"validation"`
A `name => validation` array of input names and the validation string configuration. \
For possible validation options so Validation section [below](#validation).
`"templates"`
**MUST** contain `"index" => {string}` and `"confirm" => {string}` where \
the string is a path to a template file inside the template folder.
`"final-location"`
A URL to which users will be redirected upon completion of a form.
`"mail"`
An array of emails to be sent upon completion of the form. These are names
of mail configurations that will be set in `mail.php`
##### Example Configuration
```php
<?php
return [
"default" => [
"validation" => [
"name" => "required",
"email" => "email|required",
"file" => ""
],
"templates" => ["index" => "index", "confirm" => "confirm"],
"final-location" => "/",
"mail" => ["admin", "customer"]
]
];
```
### Mail
Inside the mail file is where you will write the configuration for each form.
The file must return an associative array of `{mail-name} => {configuration}`.
The mail-name key is used to identify the each mail configuration when configuring forms.
```php
<?php
return [
"customer-response" => [/** ...configuration */],
"admin" => [/** ...configuration */]
];
```
#### Configuration Schema
A mail configuration **MUST** have at least a `"to"`, `"from"` and `"subject"` key.
`"cc"`, `"bcc"`, `"files"`, `"template"` are optional.
`"to"`, `"from"`, `"cc"` and `"bcc"` can all be either:
- Single string email address e.g `"[email protected]"`
- Array of string email addresses e.g `["[email protected]", "[email protected]"]`
- Email address-name e.g `["[email protected]", "name1"]`
- Array of email address-name pairs e.g `[["[email protected]", "name1"], ["[email protected]", "name2"]]`
`"files"` is an string or array of input names that relate to a file upload input to be sent as
an attachment on the email.
`"tempate"` is the path, relative to the template directory, of the template to be used to
construct the body of the email.
##### Example Configuration
```php
<?php
return [
"admin" => [
"subject" => "SUBJECT",
"to" => "[email protected]",
"from" => ["[email protected]", "Test Server"],
"template" => "mail/default",
"files" => "file",
"cc" => ["[email protected]", "[email protected]"]
],
"customer" => [
"subject" => "CUSTOMER SUBJECT",
"to" => ["@email", "@name"],
"from" => ["[email protected]", "Test Server"],
"template" => "mail/default"
]
];
```
Add these mail configurations by name to each form configuration.
### Validation
The validation configuration takes the form of a string. \
Rules are separated by a pipe `|`, if a rule takes arguments they are delineated with a colon
`:` and each argument separated by a comma `,`.
e.g:
- `email`
- `required|email`
- `blacklist:not,this,or,that|required`
Available rules include
- required
- whitelist
- blacklist
- email
- phone
- ext
- pdf
- regex
### Templates
Templates are simply php files. As such you are free to require other files and do anything
else you can usually in PHP. However, as the file is executed in the templating classes
context, if you are for some reason embedding Otoi in another PHP file variables from the
parent file will be out of scope. \
To make including a CSRF token and a Honeytrap easier there are helpers to render these.
`$csrf()` and `$honeypot()`. CSRF token is always necessary to combat cross site request
forgery attacks. Honeypot can be disabled via the .env file. The honeypot is
a simple and effective technique to reduce the amount of spam from bots by including a hidden
input which if filled will cause the form to be rejected. Humans will not see and not fill
in this input while bots will automatically fill it in.
Input values are available through the `$data` array which is present in both the index
template and the confirm template. These are indexed by the name keys in the validation
configuration. If no value has been submitted for an input it will be an empty string (`""`). \
Errors are available through the `$errors` array, present ONLY in the index template. \
The errors array is an array of name =\> errors[]. Each input will have an an array of error,
empty if valid. The value of the errors will be the name of the failed rule. \
e.g input of `test&test.com` for a validation of `required|email` will have an errors array of
`['email']` \
More useful error messages are left to you to display. It is recommended to make an easy to use
function that can be imported into the template to handle all the possible validation errors. \
The `$action` variable can be used to get the generated url for the next stage of the form.
#### Example Template
```php
<html>
<head>
<meta http-equiv="Content-Type" content="text/html;charset=UTF-8">
</head>
<div>
<ul>
<?php foreach($errors as $name => $errs) ?>
<?php foreach ($errs as $err) ?>
<li><?= $err ?></li>
<?php endforeach ?>
<?php endforeach ?>
</ul>
</div>
<form enctype="multipart/form-data" action="<?= $action ?>" method="post">
<?php $csrf() ?>
<label>Name: <input type="text" name="name" value="<?= $data["name"] ?>"></label><br>
<label>Email: <input type="text" name="email" id="<?= $data["email"] ?>"></label><br>
<label>File: <input type="file" name="file"></label><br>
<input type="submit" value="Submit">
<?php $honeypot() ?>
</form>
</html>
```
---
©2019 Simon Leigh | 15,620 | MIT |
# Dquora
[](https://www.python.org/downloads/release/python-378/)
[](https://www.djangoproject.com/)
[](https://getbootstrap.com/docs/4.1/getting-started/introduction/)
> #### 基于 Python 和 Django 的知识问答平台。
## 概览
+ 使用Supervisor进行部署
+ 前端使用DTL,后端模块化编程,前后端不分离
+ 支持动态、问答、发表文章
+ 支持点赞、评论、消息通知
+ 支持Markdown及预览
+ 支持用户间私信
## 安装部署
### Linux 环境
1. 安装必要的依赖及服务
```bash
yum install -y python-devel zlib-devel mysql-devel libffi-devel bzip2-devel openssl-devel java gcc wget
yum install -y nginx redis supervisor git
systemctl enable redis nginx supervisord
```
2. mysql服务
```bash
systemctl enable mysqld
create database dquora charset utf8;
create user 'dquora'@'%' identified by 'dquora123';
use dquora;
grant all on dquora to 'dquora'@'%';
flush privileges;
```
3. 包安装
```bash
cd /root/myproject/dquora
pipenv shell
mkdir logs
pip3 install -r deploy/requirements.txt
python manage.py collectstatic
python manage.py makemigrations
python manage.py migrate
```
4. 启动服务
```bash
/usr/local/python3/bin/gunicorn --env DJANGO_SETTINGS_MODULE=config.settings.local -b 127.0.0.1:9000 --chdir /root/myproject/dquora config.wsgi
/usr/local/python3/bin/daphne -p 8000 config.asgi:application
/usr/local/python3/bin/celery --work=/root/myproject/dquora -A dquora.taskapp worker -l info
cp deploy/nginx.conf /etc/nginx/nginx.conf
systemctl restart nginx
cp deploy/*.ini /etc/supervisord.d/
systemctl start supervisord
supervisorctl update
supervisorctl reload
```
## 浏览器支持
Modern browsers(chrome, firefox) 和 Internet Explorer 10+.
## 特别感谢
+ [Echo1996](https://github.com/Ehco1996/django-sspanel)
+ [Dusai](https://github.com/stacklens/django_blog_tutorial)
## 许可
The [MIT](http://opensource.org/licenses/MIT) License | 2,079 | MIT |
---
layout: post
title: "光阴是酒,醉了来人"
date: 2017-06-08
categories: poetry
permalink: /archivers/2017-06-08/2
description: "这首诗,两年了,读起来还是那么的有味道。"
---
这首诗,两年了,读起来还是那么的有味道。
<!--more-->
季节一茬茬地来了又去了,像人,一批批地走来,又一批批地融化。时间的水,冲刷春夏秋冬,阳春白雪,也让许多人的影子沉溺消逝。尽管寒来暑往是一种经难,而人,也还是在出世入世间醉了自己,醉了时空。
是谁把光阴酿成了甘醇,一滴酒里就论了乾坤。点点清亮的水液,容纳了大唐的雄风,装进了汉王的豪气。究竟是时光醉了人,还是人醉了时光。
日子不等人,不管你是柴禾背夫,还是皇室王子,气数的极限就等候在眼前,无论你看见还是看见,抑或装作没看见,它都有足够的耐心蹲守在那里。孟婆碗里的汤,从不分高贵与贫贱,人生命的季节末端,总有奈何桥上大一统的公平与平等。
那是一座怎样美妙的彩虹桥啊!谁走在上面,都是天堂的等待。因为这里废弃了等级观念,人人都是光阴酒缸里的裸浴者。王冠和草帽一样的散香,赤裸的身躯同样的云中飞,雾中驰。
在世上,人人都想活出个光彩照人,个个都拼出老命也要把红尘间的锦囊扑抓。本想优雅转身时,却撞上了华丽的黑暗。
时光把四季熏得年年旋,月月转,怎么也跨不出春花秋果的轮回圈。人是日子的背包,让年月一遍遍地装入,随着岁数的递增,包底的沉重一次次地拖压,终成漏兜的一个滴落。
小时候,总盼望着花儿快快的开,把轻快的脚步向往成光阴里的一枚枚敬拜。于是,对着月下星空,遥想长大后的种种美好。那时,一秒钟的憧憬,就温暖了几个世纪的来生。
日落日升不醉人,人自醉。一落入尘埃,黎明的第一缕曙光,就是一坛迷人的酒,你饮与不饮,由不得心的首造。
时辰很慈悲,从不索求什么。只要人一落世,对谁都平等相待。
锦上添花是人的本性嗜好,在苦难中挣扎的生命需要手的救援,但常常碰到的是袖手旁观的姿势。黑色的脚印墨化了人性的良善,而狼性的生吞活剥在人世得到了最大程度的释放。生存中,人学会了残暴,冷酷,狞笑,势利,三五九等成为惯常的衡量思维,祭祀的飘带上,有神的遗嘱在猎猎飞扬。
人时常赞美大自然的公正,岂不知,自然界是一个最没有情商的怪物,它和政治的心律一样,只跳荡在适者生存的理念上。一条生物链,把弱肉强食的经转念到了地老天荒。
一代豪杰,总想活出个千年黑,万年白,炼丹炉里的熊熊火光,忽闪出嘲讽的烈焰,映红了永世不泯的野心。世事不会有尽头,而人总想扒住时光的岩石,做一朵永不凋谢的石茶花。
宇宙间,除了时间是不可争论的公平君子外,一切皆是虚晃的游戏。所有主义的,只能代表政治的某种主张,不能代替文化。政治的潜规则,是人玩出来的。文化是酿酒师,把人酿成了哲学。
易经,是物质运行轨迹的学说;佛学,是因果的学说。人神共舞,这个世界因此精彩无限。在世上,人人都想当主角,生活中,实则大部分都只能是配角。
芸芸众生是现实的本来面目,众多星星里一盘月亮才是合乎天规的所在。人想通了,则一通百通。闷头曳犁的牛,常常会在收割的季节里咀嚼出生命最本真的滋味。
一枚草叶的清香,就到达了幸福的彼岸。
境界是文化的酒香,悲剧是历史的命题。回光返照让一个时代疯狂得烫手,谁在持念一把剑的血刃上,玷污了一个民族的良知。
等候的灯盏照不出人前行后尘的路,官僚阶级的产生,让众生瞠目结舌。于是,畸形的意识腐蚀了经世的流年。世界不变的规律就是不停地在变,海不会枯,石不会烂,只有人的誓言才会在利己的环境下溃散如沙。
在排除异己,消除后患的现实面前,翻寻先人业力里的残忍,使人返祖的记忆呈现一派黑色瑰丽,亮了自己的眼,暗了神坛上的的灯。
尘垢在肉身上结成了一件厚厚的外衣,人活不出自我,就被沉重的衣服拖向黑夜的深渊里。思想的灾难导致凡俗间的不了情,为求得一地生存,早已忘却了天堂和地狱两扇迥异的门。
斟一杯时光的酒,你来我往的路上,皆是醉汉,踉跄的身影,婀娜的梦想,飘逸出岁月的醇香。
尘世一缘,相遇相逢,你在我的眼里,我在你的眸上,光阴的酒豪迈了来者的醉意,盘腿一坐,便嗅出了年轮的禅味…… | 1,909 | MIT |
# 2022-03-28
共 0 条
<!-- BEGIN WEIBO -->
<!-- 最后更新时间 Mon Mar 28 2022 23:23:03 GMT+0800 (China Standard Time) -->
<!-- END WEIBO --> | 134 | MIT |
---
title: vue
date: 2017-01-19 15:19:03
tags: vue eventloop js
---
### js
1. 这里对该vm注册一个Watcher实例,Watcher的getter为updateComponent函数,用于触发所有渲染所需要用到的数据的getter,进行依赖收集,就是在mounted的时候进行依赖收集。
用户的自定义 watcher 要优先于渲染 watcher 执行;因为用户自定义 watcher 是在渲染 watcher 之前创建的。Vm._watcher.update()
1. 对于渲染 watcher 而言,它在执行 this.get() 方法求值的时候,会执行 getter 方法: updateComponent = () => {
updateComponent = () => { vm._update(vm._render(), hydrating)
1. vue diff 算法
```text
//相同的话进行patch
patchVnode (oldVnode, vnode) {
const el = vnode.el = oldVnode.el
let i, oldCh = oldVnode.children, ch = vnode.children
if (oldVnode === vnode) return
if (oldVnode.text !== null && vnode.text !== null && oldVnode.text !== vnode.text) {
api.setTextContent(el, vnode.text)
}else {
updateEle(el, vnode, oldVnode)
if (oldCh && ch && oldCh !== ch) {
updateChildren(el, oldCh, ch)
}else if (ch){
createEle(vnode) //create el's children dom
}else if (oldCh){
api.removeChildren(el)
}
}
}
```
1. 提高性能
```text
压缩代码
提取页面公共资源 基础包cdn\splitchunks
Tree shaking
scope hoisting
图片压缩
动态polyfill
```
1. 事件代理:1. 减少事件注册,节省内存。 2. 简化了dom更新时,上面的事件off与on 操作。focus,blur之类的,本身就没用冒泡的特性
2. 函数式组件与普通组件的区别
函数式组件需要在声明组件是指定functional
函数式组件不需要实例化,所以没有this,this通过render函数的第二个参数来代替
函数式组件没有生命周期钩子函数,不能使用计算属性,watch等等
函数式组件不能通过$emit对外暴露事件,调用事件只能通过context.listeners.click的方式调用外部传入的事件
因为函数式组件是没有实例化的,所以在外部通过ref去引用组件时,实际引用的是HTMLElement
函数式组件的props可以不用显示声明,所以没有在props里面声明的属性都会被自动隐式解析为prop,而普通组件所有未声明的属性都被解析到$attrs里面,并自动挂载到组件根元素上面(可以通过inheritAttrs属性禁止)
3. 「适合引入自动化测试的场景:」
公共库类的开发维护
中长期项目的迭代/重构
引用了不可控的第三方依赖
1. Observer 是一个类,它的作用是给对象的属性添加 getter 和 setter,用于依赖收集和派发更新。Render 时通过getter 进行依赖收集。
2. Dep 是一个 Class,它定义了一些属性和方法,这里需要特别注意的是它有一个静态属性 target,这是一个全局唯一 Watcher,这是一个非常巧妙的设计,
因为在同一时间只能有一个全局的 Watcher 被计算,另外它的自身属性 subs 也是 Watcher 的数组。
3. vue array 拦截
```js
/*取得原生数组的原型*/
const arrayProto = Array.prototype
/*创建一个新的数组对象,修改该对象上的数组的七个方法,防止污染原生数组方法*/
export const arrayMethods = Object.create(arrayProto)
```
1. 首先通过 Vue.options = Object.create(null) 创建一个空对象,然后遍历 ASSET_TYPES:
Vue.options.components = {}
Vue.options.directives = {}
Vue.options.filters = {}
3. vue 父子组件:
加载渲染过程
父beforeCreate->父created->父beforeMount->子beforeCreate->子created->子beforeMount->子mounted->父mounted
父beforeUpdate->子beforeUpdate->子updated->父updated
父组件更新过程
父beforeUpdate->父updated
销毁过程
父beforeDestroy->子beforeDestroy->子destroyed->父destroyed
1. for await...of循环,则是用于遍历异步的 Iterator 接口。
```javascript
function main(inputFilePath) {
const readStream = fs.createReadStream(
inputFilePath,
{ encoding: 'utf8', highWaterMark: 1024 }
);
readStream.on('data', (chunk) => {
console.log('>>> '+chunk);
});
readStream.on('end', () => {
console.log('### DONE ###');
});
}
// 异步遍历器写法
async function main(inputFilePath) {
const readStream = fs.createReadStream(
inputFilePath,
{ encoding: 'utf8', highWaterMark: 1024 }
);
for await (const chunk of readStream) {
console.log('>>> '+chunk);
}
console.log('### DONE ###');
}
```
1. Vm.$watch this._data.$$state 的值,/* 检测store中的_committing的值,如果是true代表不是通过mutation的方法修改的 */
2. /* 这里new了一个Vue对象,运用Vue内部的响应式实现注册state以及computed*/
store._vm = new Vue({ data: {$$state: state }, computed })
3. this.$on('hook:updated', () => {})
1. Vue.config.optionMergeStrategies
1. 在Vue2.5之前,使用函数式组件只能通过JSX的方式,在之后,可以通过模板语法来生命函数式组件
```html
<!--在template 上面添加 functional属性-->
<template functional>
<img :src="avatar ? avatar : 'default-avatar.png'" />
</template>
<!--根据上一节第六条,可以省略声明props-->
```
1. Vue beforecreated:data vue 实例化、init events
1. 作用域插槽 this.$scopedSlots.header({ text: this.headerText })
2. 全局的components ,通过vue 的options merge 到组件上。 最后通过 extend(Vue.options.components, builtInComponents) 把一些内置组件扩展到 Vue.options.components 上,
Vue 的内置组件目前有 <keep-alive>、<transition> 和 <transition-group> 组件,这也就是为什么我们在其它组件中使用 <keep-alive> 组件不需要注册的原因
11. components,filters,directives
两个对象合并的时候,不会相互覆盖,而是 权重小的 被放到 权重大 的 的原型上
13. 数组叠加 包括生命周期函数和watch
14. 函数合并叠加 包括选项:data,provide,权重大的优先
1. 最主要最关键的原因是函数式组件不需要实例化,无状态,没有生命周期,所以渲染性能要好于普通组件
函数式组件结构比较简单,代码结构更清晰
4. inject 用法:
```javastript
inject: {
// 注入的属性名称 parentForm: {
// 通过 from 指定从哪个属性注入
from: 'customForm',
default: () => ({ size: 'default' }) } },
```
1. redirective
```text
binding:一个对象,包含以下 property:
name:指令名,不包括 v- 前缀。
value:指令的绑定值,例如:v-my-directive="1 + 1" 中,绑定值为 2。
oldValue:指令绑定的前一个值,仅在 update 和 componentUpdated 钩子中可用。无论值是否改变都可用。
expression:字符串形式的指令表达式。例如 v-my-directive="1 + 1" 中,表达式为 "1 + 1"。
arg:传给指令的参数,可选。例如 v-my-directive:foo 中,参数为 "foo"。
modifiers:一个包含修饰符的对象。例如:v-my-directive.foo.bar 中,修饰符对象为 { foo: true, bar: true }。
```
1. Async validator
```javascript
asyncValidator: (rule, value) => {
return new Promise((resolve, reject) => {
if (value < 18) {
reject("too young"); // reject with error message
} else {
resolve();
}
});
}
```
1. ref用创建一个包装对象,只具备一个响应式属性value,如果将对象指定为ref的值,该对象将被reactive方法深度遍历。如果传入 ref 的是一个对象,将调用 reactive 方法进行深层响应转换。所以ref 可以解构
1. history 模式:
```text
通过 history.pushState() 方法改变地址栏
监听 popstate 事件
根据当前路由地址找到对应组件重新渲染
```
1. `<input type="text" v-on="{ input:onInput,focus:onFocus,blur:onBlur, }">` 同样 v-bind
1. keepalive mouted 只会执行一次,vnode上关联的component intance,在patch 阶段会转换为真实的dom.
1.
```javascript
/*parse解析得到ast树*/
const ast = parse(template.trim(), options)
/*
将AST树进行优化
优化的目标:生成模板AST树,检测不需要进行DOM改变的静态子树。
一旦检测到这些静态树,我们就能做以下这些事情:
1.把它们变成常数,这样我们就再也不需要每次重新渲染时创建新的节点了。
2.在patch的过程中直接跳过。
*/
optimize(ast, options)
```
optimize的主要作用是标记static静态节点,这是Vue在编译过程中的一处优化,后面当update更新界面时,会有一个patch的过程,diff算法会直接跳过静态节点,从而减少了比较的过程,优化了patch的性能。
1. Render
// resolve template/el and convert to render function 。mounted 方法中
在此方法中调用 vm._render 方法先生成虚拟 Node(render 函数返回的就是vnode),最终调用 vm._update 更新 DOM。
Update 调用的时机:1.首次渲染 2.数据更新
1.
1. Vue 通过在内存中实现文档结构的虚拟表示来解决此问题,其中虚拟节点(VNode)表示 DOM 树中的节点。当需要操纵时,可以在虚拟 DOM的 内存中执行计算和操作,而不是在真实 DOM 上进行操纵。这自然会更快,并且允许虚拟 DOM 算法计算出最优化的方式来更新实际 DOM 结构。
1.
Vue 不会对 provide 中的变量进行响应式处理。所以,要想 inject 接受的变量是响应式的,provide 提供的变量本身就需要是响应式的。单项数据流
inheritAttrs: false, // 可以关闭自动挂载到组件根元素上的没有在props声明的属性
1. 子组件不需要任何处理,只需要在父组件引用的时候通过@hook来监听即可,代码重写如下:<Child @hook:mounted="doSomething”/>
1. 数据动态变化:
export const store = Vue.observable({ count: 0 });
1. vue life cycle
```
parse阶段:使用正在表达式将template进行字符串解析,得到指令、class、style等数据,生成抽象语法树 AST。
optimize阶段:寻找 AST 中的静态节点进行标记,为后面 VNode 的 patch 过程中对比做优化。被标记为 static 的节点在后面的 diff 算法中会被直接忽略,不做详细的比较。
generate阶段:根据 AST 结构拼接生成 render 函数的字符串。
```
[life cycle](https://user-gold-cdn.xitu.io/2019/12/26/16f40a08cac6d3cb?imageView2/0/w/1280/h/960/format/webp/ignore-error/1)
1. 每个逻辑关注点的代码现在都在复合函数中并置在一起。 这大大减少了在处理大型组件时需要不断“跳转”的情况。 组合函数也可以在编辑器中折叠,使组件更容易扫描:
1. js 链接 defer 和 async
1. keep-alive 的实现正是用到了 LRU 策略,将最近访问的组件 push 到 this.keys 最后面,this.keys[0]也就是最久没被访问的组件,当缓存实例超过 max 设置值,删除 this.keys[0]
```text
defer 和 async 都是并行加载的,主要区别在于下载后何时执行。
每一个 async 属性的脚本都在它下载结束之后立刻执行,所以就有可能出现脚本执行顺序被打乱的情况
每一个 defer 属性的脚本会在 HTML 解析完成后, DOMContentLoaded 之前,按照 DOM 中的顺序执行(ie>=10)
defer 和 async 都只适用于外部脚本文件,对与内联的 script 标签是不起作用
```
1. preload 用 “as” 或者用 “type” 属性来表示他们请求资源的优先级(比如说 preload 使用 as="style" 属性将获得最高的优先级)。没有 “as” 属性的将被看作异步请求,“Early”意味着在所有未被预加载的图片请求之前被请求(“late”意味着之后)
2. Vue.config.errorHandler
3. v-pre 场景:vue 是响应式系统,但是有些静态的标签不需要多次编译,这样可以节省性能
4. v-loader transformAssetUrls
在模板编译过程中,编译器可以将某些特性转换为 require 调用,例如 src 中的 URL。因此这些目标资源可以被 webpack 处理。例如 <img src="./foo.png"> 会找到你文件系统中的 ./foo.png 并将其作为一个依赖包含在你的包里
1. view router加key 场景:由于 Vue 会复用相同组件, 即 /page/1 => /page/2 或者 /page?id=1 => /page?id=2 这类链接跳转时, 将不在执行created, mounted之类的钩子
1.
1. 生命周期
```text
beforeCreate阶段:vue实例的挂载元素el和数据对象data都是undefined,还没有初始化。
created阶段:vue实例的数据对象data有了,可以访问里面的数据和方法,未挂载到DOM,el还没有
beforeMount阶段:vue实例的el和data都初始化了,但是挂载之前为虚拟的dom节点
mounted阶段:vue实例挂载到真实DOM上,就可以通过DOM获取DOM节点
beforeUpdate阶段:响应式数据更新时调用,发生在虚拟DOM打补丁之前,适合在更新之前访问现有的DOM,比如手动移除已添加的事件监听器
updated阶段:虚拟DOM重新渲染和打补丁之后调用,组成新的DOM已经更新,避免在这个钩子函数中操作数据,防止死循环
beforeDestroy阶段:实例销毁前调用,实例还可以用,this能获取到实例,常用于销毁定时器,解绑事件
destroyed阶段:实例销毁后调用,调用后所有事件监听器会被移除,所有的子实例都会被销毁
```
1. __proto__ 属性,这是历史遗留的非标准的语法,但在现代浏览器中广泛实现。获得原型的更可靠方法是使用 Object.getPrototypeOf(new Object());例如:
```javascript
const car = {}
const list = []
console.log(Object.getPrototypeOf(car));
console.log(Object.getPrototypeOf(list));
```
### 内部机制
vue-loader
compiler 目录包含 Vue.js 所有编译相关的代码。它包括把模板解析成 ast 语法树,ast 语法树优化,代码生成等功能。
微任务的例子:micortask
process.nextTick
promise
Object.observe
宏任务的例子:
setTimeout
setInterval
setImmediate
I/O
需要注意的是node 和 浏览器的 event loop 是有区别的(需要注意的是node v12.0 之后和浏览器处理事一致的):
```text
浏览器的事件循环:
执行全局Script同步代码,这些同步代码有一些是同步语句,有一些是异步语句(比如setTimeout等);
全局Script代码执行完毕后,调用栈Stack会清空;
从微队列microtask queue中取出位于队首的回调任务,放入调用栈Stack中执行,执行完后microtask queue长度减1;
继续取出位于队首的任务,放入调用栈Stack中执行,以此类推,直到直到把microtask queue中的所有任务都执行完毕。注意,如果在执行microtask的过程中,又产生了microtask,那么会加入到队列的末尾,也会在这个周期被调用执行;
microtask queue中的所有任务都执行完毕,此时microtask queue为空队列,调用栈Stack也为空;
取出宏队列macrotask queue中位于队首的任务,放入Stack中执行;
执行完毕后,调用栈Stack为空;
重复第3-7个步骤;
重复第3-7个步骤;
……
NodeJS中微队列主要有2个:
Next Tick Queue:是放置process.nextTick(callback)的回调任务的
Other Micro Queue:放置其他microtask,比如Promise等
具体参见: https://segmentfault.com/a/1190000016278115
```
```
timers 阶段:这个阶段执行timer(setTimeout、setInterval)的回调
I/O callbacks 阶段:执行一些系统调用错误,比如网络通信的错误回调
idle, prepare 阶段:仅node内部使用
poll 阶段:获取新的I/O事件, 适当的条件下node将阻塞在这里
check 阶段:执行 setImmediate() 的回调
close callbacks 阶段:执行 socket 的 close 事件回调
timers 是事件循环的第一个阶段,Node 会去检查有无已过期的timer,如果有则把它的回调压入timer的任务队列中等待执行,事实上,Node 并不能保证timer在预设时间到了就会立即执行,因为Node对timer的过期检查不一定靠谱,它会受机器上其它运行程序影响,或者那个时间点主线程不空闲。比如下面的代码,setTimeout() 和 setImmediate() 的执行顺序是不确定的。
poll 阶段
poll 阶段主要有2个功能:
处理 poll 队列的事件
当有已超时的 timer,执行它的回调函数
even loop将同步执行poll队列里的回调,直到队列为空或执行的回调达到系统上限(上限具体多少未详),接下来even loop会去检查有无预设的setImmediate(),分两种情况:
若有预设的setImmediate(), event loop将结束poll阶段进入check阶段,并执行check阶段的任务队列
若没有预设的setImmediate(),event loop将阻塞在该阶段等待
注意一个细节,没有setImmediate()会导致event loop阻塞在poll阶段,这样之前设置的timer岂不是执行不了了?所以咧,在poll阶段event loop会有一个检查机制,检查timer队列是否为空,如果timer队列非空,event loop就开始下一轮事件循环,即重新进入到timer阶段。
check 阶段
setImmediate()的回调会被加入check队列中,从event loop的阶段图可以知道,check阶段的执行顺序在poll阶段之后。
回顾上一篇,浏览器环境下,microtask的任务队列是每个macrotask执行完之后执行。而在Node.js中,microtask会在事件循环的各个阶段之间执行,也就是一个阶段执行完毕,就会去执行microtask队列的任务。详见:http://lynnelv.github.io/js-event-loop-nodejs
process.nextTick() 会在各个事件阶段之间执行,一旦执行,要直到nextTick队列被清空,才会进入到下一个事件阶段,所以如果递归调用 process.nextTick(),会导致出现I/O starving(饥饿)的问题
官方文档:https://nodejs.org/en/docs/guides/event-loop-timers-and-nexttick/
```
###vitual dom
VD 最大的特点是将页面的状态抽象为 JS 对象的形式,配合不同的渲染工具,使跨平台渲染成为可能。如 React 就借助 VD 实现了服务端渲染、浏览器渲染和移动端渲染等功能。
js计算-》生成渲染树-》渲染页面
通过VD的比较,我们可以将多个操作合并成一个批量的操作,从而减少dom重排的次数,进而缩短了生成渲染树和绘制所花的时间。
在mounted 方法中会将template 编译成为render 方法。这是一个编译过程,render中会调用createElement 创建vnode。
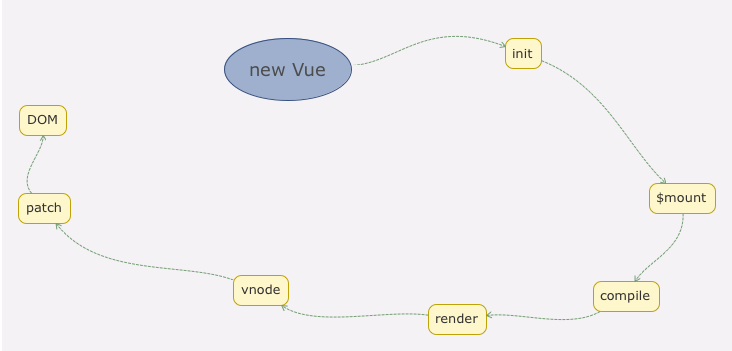
回到 mountComponent 函数的过程,我们已经知道 createElement 是如何创建了一个 VNode,接下来就是要把这个 VNode 渲染成一个真实的 DOM 并渲染出来,这个过程是通过 vm._update 完成的
Vue 的 _update 是实例的一个私有方法,它被调用的时机有 2 个,一个是首次渲染,一个是数据更新的时候;由于我们这一章节只分析首次渲染部分,数据更新部分会在之后分析响应式原理的时候涉及。_update 方法的作用是把 VNode 渲染成真实的 DOM
在我们之前对 setter 的分析过程知道,当响应式数据发送变化后,触发了 watcher.update(),只是把这个 watcher 推送到一个队列中,在 nextTick 后才会真正执行 watcher 的回调函数。而一旦我们设置了 sync,就可以在当前 Tick 中同步执行 watcher 的回调函数。
##### 修饰符(Modifiers)是以半角句号 . 指明的特殊后缀,用于指出一个指定应该以特殊方式绑定。例如,.prevent 修饰符告诉 v-on 指令对于触发的事件调用 event.preventDefault()
```
<!-- 阻止单击事件冒泡 -->
<a v-on:click.stop="doThis"></a>
<!-- 提交事件不再重载页面 -->
<form v-on:submit.prevent="onSubmit"></form>
<!-- 修饰符可以串联 -->
<a v-on:click.stop.prevent="doThat"></a>
<!-- 只有修饰符 -->
<form v-on:submit.prevent></form>
<!-- 添加事件侦听器时使用事件捕获模式 -->
<div v-on:click.capture="doThis">...</div>
<!-- 只当事件在该元素本身(而不是子元素)触发时触发回调 -->
<div v-on:click.self="doThat">...</div>
<a v-on:click.once="doThis"></a>
```
##### 按键修饰符
记住所有的 keyCode 比较困难,组合键 所以 Vue 为最常用的按键提供了别名:
```
<!-- Alt + C -->
<input v-on:keyup.alt.67="clear">
<!-- Ctrl + Click -->
<div v-on:click.ctrl="doSomething">Do something</div>
<!-- 同上 -->
<input v-on:keyup.enter="submit">
<!-- 缩写语法 -->
<input @keyup.enter="submit">
全部的按键别名:
.enter
.tab
.delete (捕获 “删除” 和 “退格” 键)
.esc
.space
.up
.down
.left
.right
```
#### mock vuex
```
setup() {
useLoginStatusProvide()
return {}
},
import { provide, inject, ref } from '@vue/composition-api'
const StatusSymbol = Symbol('status')
export const useLoginStatusProvide = () => {
const loginStatus = ref(false)
const setLoginStatus = val => (loginStatus.value = val)
provide(StatusSymbol, { loginStatus, setLoginStatus })
}
export const useLoginStatusInject = () => {
const context = inject(StatusSymbol)
if (!context) throw new Error('useLoginStatusInject must be used after useLoginStatusProvide')
return context
}
``` | 12,987 | MIT |
## js简答题
1. ##### js中的单行和多行注释如何表示?
单行注释为 // 注释
多行注释为 `/*注释*/`
2. ##### 什么是变量,声明变量有哪几种方式?
值可以改变的量,用来保存数据时使用
声明变量的两种方式:
1. 定义变量不赋值
2. 定义变量并赋值
3. 同时定义多个变量
`var 变量名1, 变量名2`
4. 同时定义多个变量并赋值
3. ##### 变量名命名可以包含什么?其中不能以什么开头?
变量命名可以包含数字,下划线,`$`,大小写字母
不能以数字开头
4. ##### 变量名命名为什么区分大小写?不能拿什么用来命名?
大小写不同,相当于不同的变量。
不能用关键字命名,而且不推荐使用关键字
## js编程题
1. ##### 根据题意注释下面的内容
```
( 使用单行注释注释小括号的内容 )
【 使用
多行注释
注释大括号的
内容 】
···不要注释我···
```
2. ##### 使用一个var同时定义:变量名为age变量值为18;变量名为name变量值无;变量名为num变量值为NaN
```js
var age=18,
name,
num=NAN
```
3. ##### 作为一名程序员,请指出下面错误的变量命名方式,并说明原因
```js
var ABC = "A123";
var name1 = "杨";
var _age$ = 3;
var 6Bu = 6; // 不能以数字开头
var this = "that"; // 不能使用关键字命名
var is_Na& = "NO" // 符号只能用$和_
var 呵呵 = 233 //不推荐使用中文命名
```
4. ##### 指出下面代码的错误及原因,并给出你认为正确的修正
```js
var num, age, name;
const num1; // 声明常量必须赋值
const name = "杨"; // name已经被用来定义变量,不能再用来定义常量
const age1 = 3;
age = age1 = 18; // 不可以改变常量的值
console.log(age);
``` | 1,106 | MIT |
# swooleCrawler
### 基于swoole框架agileSwoole开发的一个爬虫框架
#### 方便进行二次开发
#### 目前基础功能有:
1. 远程发起爬虫任务
2. 远程关闭爬虫任务
### demo
route中定义
```
'post' => [
[
'path' => '/crawler',
'dispatch' => [\Controller\Crawler::class, 'run'],
'before' => [\Controller\Crawler::class, 'before'],
'after' => [\Controller\Crawler::class, 'after'],
'type' => \Component\Producer\Producer::PRODUCER_PROCESS
],
],
'put' => [
//put
],
'delete'=> [
[
'path' => '/crawler',
'dispatch' => [\Controller\Crawler::class, 'stop'],
'type' => \Component\Producer\Producer::PRODUCER_SYNC
]
]
```
cd public
php index.php
打开 http://localhost:9550 即可看到宣传首页
使用curl 请求即可
提交数据示例:
{"action":"crawler","interval":"500","task_en_name":"csdn","target":"http:\/\/blog.csdn.net\/","number_count":2250,"channel_rule":"http:\/\/blog.csdn.net\/*\/article\/details\/*"}
```
<?php
$curl = curl_init();
curl_setopt_array($curl, array(
CURLOPT_PORT => "9550",
CURLOPT_URL => "http://localhost:9550/crawler",
CURLOPT_RETURNTRANSFER => true,
CURLOPT_ENCODING => "",
CURLOPT_MAXREDIRS => 10,
CURLOPT_TIMEOUT => 30,
CURLOPT_HTTP_VERSION => CURL_HTTP_VERSION_1_1,
CURLOPT_CUSTOMREQUEST => "POST",
CURLOPT_POSTFIELDS => "{\"action\":\"crawler\",\"interval\":\"500\",\"task_en_name\":\"csdn\",\"target\":\"http:\\/\\/blog.csdn.net\\/\",\"number_count\":2250,\"channel_rule\":\"http:\\/\\/blog.csdn.net\\/*\\/article\\/details\\/*\"}",
CURLOPT_HTTPHEADER => array(
"cache-control: no-cache",
),
));
$response = curl_exec($curl);
$err = curl_error($curl);
curl_close($curl);
if ($err) {
echo "cURL Error #:" . $err;
} else {
echo $response;
}
``` | 2,177 | MIT |
---
title: "Windows PowerShell ISE スクリプト オブジェクト モデル"
ms.date: 2016-05-11
keywords: "PowerShell, コマンドレット"
description:
ms.topic: article
author: jpjofre
manager: dongill
ms.prod: powershell
ms.assetid: 69b047d0-da79-413e-b948-8e45d05d1f85
translationtype: Human Translation
ms.sourcegitcommit: a656ec981dc03fd95c5e70e2d1a2c741ee1adc9b
ms.openlocfilehash: e1c4da3865f8c9dd7d2f73b243ac0b0216bd9631
---
# Windows PowerShell ISE スクリプト オブジェクト モデル
[Windows PowerShell® Integrated Scripting Environment (ISE) は、ユーザーの Windows PowerShell ISE の外観および機能のさまざまな側面を操作する Windows PowerShell スクリプトを記述できるようにする、基になるスクリプト オブジェクト モデルによってその機能を公開します。 スクリプティング オブジェクト、スクリプティング オブジェクトのプロパティ、およびそのメソッドは、この用途専用で定義されます。
## このドキュメントの内容
- [Windows PowerShell ISE のスクリプト オブジェクト モデルの目的](Purpose-of-the-Windows-PowerShell-ISE-Scripting-Object-Model.md)
- [ISE オブジェクト モデル階層](The-ISE-Object-Model-Hierarchy.md)
- [Windows PowerShell ISE オブジェクト モデル リファレンス](Windows-PowerShell-ISE-Object-Model-Reference.md)
- [その他の有用なスクリプティング オブジェクト](../../getting-started/cookbooks/Other-Useful-Scripting-Objects.md)
## 参照
[Windows PowerShell スクリプトの環境と #40; ISE ) の統合](../../getting-started/fundamental/Windows-PowerShell-Integrated-Scripting-Environment--ISE-.md)
<!--HONumber=Oct16_HO1--> | 1,288 | CC-BY-4.0 |
---
layout: post
title: "用影子数组 ( Shadow Array )加速数组扩容"
date: 2018-04-18 18:53
comments: true
categories: 计算机
---
## 起源
这学期学习数据结构,其中一个概念想了很久,就是影子数组的问题。
<!--more-->
## Shadow Array
影子数组主要的作用是帮助实现在扩增的时候,实现快速的迭代。因为比较难以用语言形容,这里我直接用纸币来解释问题了。
影子数组其实就是就是在每一个数组实现中都同时实现一个两倍于当前数组的数组。这样在实现的时候,每一步都同步拷贝新的元素到影子数组,当当前数组满了的时候直接切换到影子数组,这样实现原来数组满了之后会出现的 O(N) 时间到常数时间。
用下图表示:

## 1. 创建 current 和 shadow 两个数组
我选择 2 作为初始的大小吗,所以 current 的长度是 2 , shadow 的长度是 4。
## 2. 填充元素
分别在每一步同时拷贝新元素(1,2)进入 current 和 shadow 两个数组。
## 3. 切换数组并建立新数组
可以看到当当前数组满了之后,我们切换 current 到 shadow,然后重新建立一个两倍大小的心 shadow。原来的 current 会有JVM回收,不用担心。
但是这个时候一个自然的问题,需要拷贝原始元素到新的 shadow 吗?
很显然,新的 shadow 是空的,我们需要拷贝,但是不应该选择一次性到位。因为这样又需要把原数组遍历一边,时间复杂度还是 N (对于添加新元素这步操作而言)。
## 4. 添加新元素 并 一次拷贝一个老元素
可以看到,当添加新元素 3 的时候,除了把 3 拷贝到它所在的位置上,同时我们拷贝了current 数组的第一个元素 1 来填补 shadow 数组缺少的第一个元素。
相应的做操作添加新元素 4。
这时候发现 current 又满了,需要切换了。同时我们发现,因为新的数组始终是两倍扩大,所以其实当空的一般填满了,多复制的旧元素也把新 shadow 补足了。
## 5. 切换数组并建立新数组
这步其实就是说明这个操作的可行性,可以看到当 current 满了,需要切换的时候,每次 shadow 也正好补满。
同时因为每步拷贝做一个添加新元素加上拷贝旧元素的操作,时间复杂度不变还是 O(1) 量级。
## 思考
其实这里最重要的思想就是,不要一曝十寒,要细水长流,把一个宏大的任务分解掉。其实总的操作数不变,但是每一步的 workload 就比较均衡了。
但是,实现这个前提是,你的数据结构比较精巧。
可以看到每次都扩大两倍是最好的选择,如果每次扩大三倍,就不能保证这个操作的完整性和方便性。
## 实际工程
当然上面的结果都是理论的推到,实际中用的每次扩大 2.5 倍而不是 2 倍。
具体
* In Java, ArrayList uses x = 3/2.
* In C++, the GCC STL implementation uses x = 2.
这个呢,其实没什么道理,只是某种工程实践指导下的选择,因为这样可以降低 resize 的次数。
可以看下下面两篇文章的讲解。
[Why Java grows ArrayList by 3/2?](https://stackoverflow.com/questions/21624515/why-java-grows-arraylist-by-3-2?lq=1)
[How ArrayList Works Internally in Java](http://www.codenuclear.com/how-arraylist-works-internally-java/)
[How fast should your dynamic arrays grow?](https://lemire.me/blog/2013/02/06/how-fast-should-your-dynamic-arrays-grow/) | 1,802 | MIT |
#[](http://www.kymjs.com/works/)
CJFrameForAndroid简介
CJFrame不再更新,推荐大家使用360的黑科技[DroidPlugin](https://github.com/Qihoo360/DroidPlugin) 四大组件均可支持插件化。
---
## CJFrameForAndroid 相关链接
* blog:http://blog.kymjs.com<br>
* QQ群:[257053751](http://jq.qq.com/?_wv=1027&k=WoM2Aa)(开发者群1),[201055521](http://jq.qq.com/?_wv=1027&k=MBVdpK)(开发者群2)
# 原理描述
CJFrameForAndroid的实现原理是通过类加载器,动态加载存在于SD卡上的apk包中的Activity。通过使用一个托管所,插件Activity全部事务(包括声明周期与交互事件)将交由托管所来处理,间接实现插件的运行。更多介绍:[CJFrameForAndroid原理介绍](http://blog.kymjs.com/code/2014/10/15/01/)<br>
一句话概括:CJFrameForAndroid中的托管所,复制了插件中的Activity,来替代插件中的Activity与用户交互。<br>
# 框架使用
1. 需要注意的是,插件中所涉及的权限,都需要在宿主中加以声明。宿主Manifest文件写法请参考:[AndroidManifest.xml](https://github.com/kymjs/CJFrameForAndroid/blob/master/AndroidManifest.xml)
2. 你只需要在你项目想要启动插件的任意位置(UI线程中),例如Button的Onclick事件中加入如下代码即可。
```java
/**
* @param context 上下文对象
* @param path 插件所在的绝对路径
*/
CJActivityUtils.startPlugin(context,path);
```
## 许可
Copyright (c) 2014, Zhang Tao.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. | 1,571 | Apache-2.0 |
#### Condition
##### Condition 接口
```java
// ========== 阻塞 ==========
// 造成当前线程在接到信号或被中断之前一直处于等待状态。
void await() throws InterruptedException;
// 造成当前线程在接到信号之前一直处于等待状态。【注意:该方法对中断不敏感】。
void awaitUninterruptibly();
// 造成当前线程在接到信号、被中断或到达指定等待时间之前一直处于等待状态。
// 返回值表示剩余时间,如果在`nanosTimeout` 之前唤醒,那么返回值 `= nanosTimeout - 消耗时间` ,如果返回值 `<= 0` ,则可以认定它已经超时了。
long awaitNanos(long nanosTimeout) throws InterruptedException;
// 造成当前线程在接到信号、被中断或到达指定等待时间之前一直处于等待状态。
// 如果没有到指定时间就被通知,则返回 true ,否则表示到了指定时间,返回返回 false 。
boolean await(long time, TimeUnit unit) throws InterruptedException;
// 造成当前线程在接到信号、被中断或到达指定最后期限之前一直处于等待状态。
// 如果没有到指定时间就被通知,则返回 true ,否则表示到了指定时间,返回返回 false 。
boolean awaitUntil(Date deadline) throws InterruptedException;
// ========== 唤醒 ==========
// 唤醒一个等待线程。该线程从等待方法返回前必须获得与Condition相关的锁。
void signal();
// 唤醒所有等待线程。能够从等待方法返回的线程必须获得与Condition相关的锁。
void signalAll();
```
和 synchronized 的 await / notify 对比
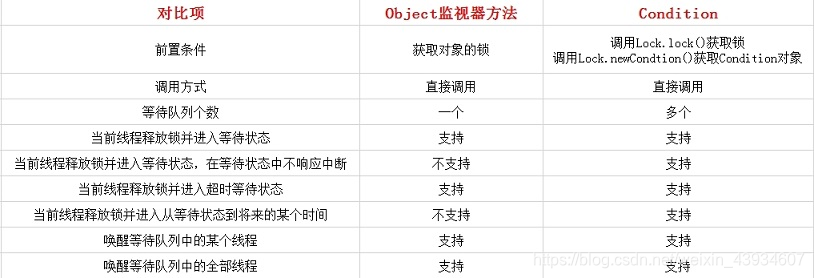
##### ConditionObject
是 AQS 的内部类,因为需要使用到 AQS 的 CHL 队列 与相关操作
* `#await()` 就是在当前线程持有锁的基础上释放锁资源,并新建 Condition 节点加入到 Condition 的队列尾部,阻塞当前线程 。
* `#signal()` 就是将 Condition 的头节点移动到 AQS 等待节点尾部,让其等待再次获取锁。
* 和 CHL 队列异同
* Node 定义与 AQS 的 CLH 同步队列的节点使用的都是同一个类(AbstractQueuedSynchronized#Node 静态内部类)。
* Node 的 Mode 都是 Node.CONDITION
* 是单向链表,通过 nextWaiter 属性连接下一个节点。
```java
// 注意:不是静态的,所以有 AQS 的引用
public class ConditionObject implements Condition, java.io.Serializable {
/** First node of condition queue. */
private transient Node firstWaiter; // 头节点
/** Last node of condition queue. */
private transient Node lastWaiter; // 尾节点
public ConditionObject() {
}
// ... 省略内部代码
}
```
###### await
注意:中断敏感
```java
/**
* 使当前线程进入等待状态,同时会加入到 Condition 等待队列,并且同时释放锁。
* 当从 #await() 方法结束时,当前线程一定是重新在 CLH 队列排队,然后获得了同步状态
*/
public final void await() throws InterruptedException {
// 当前线程中断
if (Thread.interrupted())
throw new InterruptedException();
//当前线程加入等待队列
Node node = addConditionWaiter();
//释放锁
long savedState = fullyRelease(node);
int interruptMode = 0;
/**
* 检测此节点的线程是否在同步队上,如果不在,则说明该线程还不具备竞争锁的资格,则继续等待直到检测到此节点在同步队列上。
* 放在 while 循环主要是防止意外唤醒。
*/
while (!isOnSyncQueue(node)) {
//线程挂起,等待 unpark 后继续执行。
// unpark 会发生在重新入队 CLH 后,排队轮到它后,被头节点唤醒
LockSupport.park(this);
//如果已经中断了,则退出
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
}
//竞争同步状态
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
// 清理下条件队列中的不是在等待条件的节点
if (node.nextWaiter != null) // clean up if cancelled
unlinkCancelledWaiters();
if (interruptMode != 0)
// 中断敏感,抛异常
reportInterruptAfterWait(interruptMode);
}
/**
* 加入 condition 队列
*/
private Node addConditionWaiter() {
Node t = lastWaiter; //尾节点
// Node 的节点状态如果不为 CONDITION ,则表示该节点不处于等待状态,需要清除节点
if (t != null && t.waitStatus != Node.CONDITION) {
//清除条件队列中所有状态不为Condition的节点
unlinkCancelledWaiters();
t = lastWaiter;
}
// 为当前线程新建节点,状态 CONDITION
Node node = new Node(Thread.currentThread(), Node.CONDITION);
if (t == null)
firstWaiter = node;
else
// 注意:使用的 nextWaiter 属性进行连接
t.nextWaiter = node;
// 将该节点加入到条件队列中最后一个位置
lastWaiter = node;
return node;
}
/**
* 完全释放该线程持有的锁,重入的也要释放完,不然tryRelease() 返回 false 的话就没法从 CLH 队列移除
* 这里重入的指的 ReentrantLock 和 WriteLock,因为 ReadLock 不支持 Condition
*/
final long fullyRelease(Node node) {
boolean failed = true;
try {
// 节点状态--其实就是持有锁的数量
long savedState = getState();
// 释放锁(把重入的次数全部释放掉,然后从 CLH 队列移除)
if (release(savedState)) {
failed = false;
return savedState;
} else {
throw new IllegalMonitorStateException();
}
} finally {
if (failed)
// 状态变为 CANCLE 之后会被其后面的节点移除,或者被前面的节点唤醒了其后的节点导致 cancle 节点移除
node.waitStatus = Node.CANCELLED;
}
}
/**
* 如果一个节点回到同步队列上了,那么返回 true
*/
final boolean isOnSyncQueue(Node node) {
// 状态为 Condition,或者前驱节点为 null(因为 clh 队列的每个节点的 prev 肯定不为 null) ,返回 false
if (node.waitStatus == Node.CONDITION || node.prev == null)
return false;
// 后继节点不为 null,肯定在 CLH 同步队列中
if (node.next != null)
return true;
// 遍历 CLH 队列
return findNodeFromTail(node);
}
private boolean findNodeFromTail(Node node) {
Node t = tail;
for (;;) {
if (t == node)
return true;
if (t == null)
return false;
// 遍历 clh 队列
// 用 prev 指针遍历是为了防止 cancelAcquire() 中的 node.next = node.
t = t.prev;
}
}
/**
* 将条件队列中状态不为 Condition 的节点删除(单链表删除操作)
*/
private void unlinkCancelledWaiters() {
Node t = firstWaiter;
Node trail = null; // 用于中间不需要跳过时,记录上一个 Node 节点
while (t != null) {
Node next = t.nextWaiter;
// 如果节点的状态不是 Node.CONDITION 的话,这个节点就是被取消的
if (t.waitStatus != Node.CONDITION) {
t.nextWaiter = null;
if (trail == null)
firstWaiter = next;
else
trail.nextWaiter = next;
if (next == null)
lastWaiter = trail;
}
else
trail = t;
t = next;
}
}
```
###### signal
```java
/**
* 唤醒在等待队列中等待最长时间的节点(条件队列里的首节点),在唤醒节点前,会将节点移到CLH同步队列中。
*/
public final void signal() {
// 检查要去执行唤醒操作的线程是否是占有锁的线程(lock 自己实现)
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
//头节点,唤醒条件队列中的第一个节点
Node first = firstWaiter;
if (first != null)
doSignal(first); //唤醒
}
private void doSignal(Node first) {
do {
//修改头结点,完成旧头结点的移出工作
if ( (firstWaiter = first.nextWaiter) == null)
lastWaiter = null;
first.nextWaiter = null;
// 如果加入CLH 队列失败,那么继续尝试下一个节点
// 失败是因为节点不是 Node.CONDITION 状态了,那肯定是 cancle 状态,因为 conditionObject 只在 fullyRelease 把是失败的节点修改为 cancle
} while (!transferForSignal(first) &&
(first = firstWaiter) != null);
}
/**
* 将节点移动到 CLH 同步队列中
*/
final boolean transferForSignal(Node node) {
// 将该节点从状态 CONDITION 改变为初始状态 0,
if (!compareAndSetWaitStatus(node, Node.CONDITION, 0))
return false;
// 将节点加入到 syn 队列中去,返回的是 syn 队列中 node 节点前面的一个节点
Node p = enq(node);
int ws = p.waitStatus;
// 如果结点p的状态为 cancel 或者修改 waitStatus 失败,则直接唤醒
// 如果在这唤醒,那么被唤醒线程已经在 clh 队列了,会继续在 await 方法执行 aquireQueue(),在这个方法会继续其修改前面节点的状态
if (ws > 0 || !compareAndSetWaitStatus(p, ws, Node.SIGNAL))
LockSupport.unpark(node.thread);
return true;
}
```
##### 示例
```java
public class ConditionTest {
private LinkedList<String> buffer; //容器
private int maxSize ; //容器最大
private Lock lock;
private Condition notFull;
private Condition notEmpty;
ConditionTest(int maxSize){
this.maxSize = maxSize;
buffer = new LinkedList<String>();
lock = new ReentrantLock();
notFull = lock.newCondition();
notEmpty = lock.newCondition();
}
public void set(String string) throws InterruptedException {
lock.lock(); //获取锁
try {
while (maxSize == buffer.size()){
notFull.await(); //满了,添加的线程进入等待状态
}
buffer.add(string);
notEmpty.signal();
} finally {
lock.unlock(); //释放锁
}
}
public String get() throws InterruptedException {
String string;
lock.lock();
try {
while (buffer.size() == 0){
notEmpty.await();
}
string = buffer.poll();
notFull.signal();
} finally {
lock.unlock();
}
return string;
}
} | 8,024 | Apache-2.0 |
title: Autolayout和Masrony的使用
date: 2017-02-15 16:04:29
tags:
- autolayout
categories: UI
---
#iOS界面布局
目前来说iOS目前几种主流的UI布局:
- Frame布局
- AutoLayout
- 使用代码实现AutoLayout
- 使用xib或者StoryBoard
在代码可读性上 frame > 使用代码实现AutoLayout > 使用xib或者StoryBoard
在开发效率上 使用xib或者StoryBoard > 使用代码实现AutoLayout > Frame布局
`AutoLayout`是通常是通过定义一系列的约束(constrains)来进行定的。和Frame定位一样,它同样需要你提供位置和尺寸信息,但是和Frame不同的是,它不是让你直接提供x,y,width,height,而是通过你给的约束来推断出相应的尺寸和位置。
## AutoLayout本质
一次函数:
> y = ax + b
>
> item1.attribute1 = multiplier × item2.attribute2 + constant
看一段原生的代码实现AutoLayout(NSLayoutConstraint)
VFL是这么写的:
```objectivec
NSDictionary *viewsDictionary = [NSDictionary dictionaryWithObjectsAndKeys:label1,@"label1",label2,@"label2",label3,@"label3",label4,@"label4", nil];
NSDictionary *metrics = [NSDictionary dictionaryWithObject:@(88) forKey:@"labelHeight"];
NSArray *constraints = [NSLayoutConstraint constraintsWithVisualFormat:@"V:|[label1(labelHeight)]-[label2(labelHeight)]-[label3(labelHeight)]-[label4(labelHeight)]-(>=10)-|" options:NSLayoutFormatAlignAllLeft metrics:metrics views:viewsDictionary];
[view addConstraints:constraints];
```
还有一种写法:
```objectivec
view.translatesAutoresizingMaskIntoConstraints = NO;
NSLayoutConstraint * constraint = [NSLayoutConstraint
constraintWithItem:view
attribute:NSLayoutAttributeTop
relatedBy:NSLayoutRelationEqual
toItem:view
attribute:NSLayoutAttributeTop
multiplier:1.0
constant:10];
[view addConstraint:constraint];
```
苹果好像也发现这样写有点尴尬,于是在iOS8和iOS9中对autolayout的api进行改动:
```objectivec
//iOS8
[NSLayoutConstraint constraintWithItem:view1 attribute:NSLayoutAttributeCenterX relatedBy:NSLayoutRelationEqual toItem:view2 attribute:NSLayoutAttributeCenterX multiplier:1 constant:10];
//iOS9
view.translatesAutoresizingMaskIntoConstraints = NO;
[view.widthAnchor constraintEqualToConstant:100];
[view.heightAnchor constraintEqualToConstant:100];
[view.centerXAnchor constraintEqualToAnchor:view1.centerXAnchor];
[view.centerYAnchor constraintEqualToAnchor:view1.centerYAnchor];
```
一个view的位置确定,正常情况下需要来自内部或者外部的4条约束才能确定其位置。所以使用原生代码实现起来太过繁琐,所以为了解决这个问题,将NSLayoutConstraint简化封装使用就非常有必要了,开源项目中有很多项目已经很成熟了,比如Masonry和purelayout等,下面简单介绍Masonry。
## Masonry的介绍
Masonry是iOS在控件布局中经常使用的一个轻量级框架,Masonry让NSLayoutConstraint使用起来更为简洁。Masonry简化了NSLayoutConstraint的使用方式,让我们可以以链式的方式为我们的控件指定约束。
**使用Masonry完成上面的代码**
```objectivec
[view mas_makeConstraints:^(MASConstraintMaker *make) {
make.top.equalTo(@(10));
}];
```
当然一条约束什么都干不了,完成一个View的布局,至少有4个来自内部或者外部的约束,比如:
```objectivec
[view mas_makeConstraints:^(MASConstraintMaker *make) {
make.top.equalTo(@(10));
make.left.equalTo(@(10));
make.bottom.equalTo(@(-10));
make.right.equalTo(@(-10));
}];
```
Masonry最重要的4个方法
```objectivec
/**
* Finds the closest common superview between this view and another view
*
* @param view other view
*
* @return returns nil if common superview could not be found
*/
- (instancetype)mas_closestCommonSuperview:(MAS_VIEW *)view;
/**
* Creates a MASConstraintMaker with the callee view.
* Any constraints defined are added to the view or the appropriate superview once the block has finished executing
*
* @param block scope within which you can build up the constraints which you wish to apply to the view.
*
* @return Array of created MASConstraints
*/
- (NSArray *)mas_makeConstraints:(MASConstraintMakerConfigBlock)block;
/**
* Creates a MASConstraintMaker with the callee view.
* Any constraints defined are added to the view or the appropriate superview once the block has finished executing.
* If an existing constraint exists then it will be updated instead.
*
* @param block scope within which you can build up the constraints which you wish to apply to the view.
*
* @return Array of created/updated MASConstraints
*/
- (NSArray *)mas_updateConstraints:(MASConstraintMakerConfigBlock)block;
/**
* Creates a MASConstraintMaker with the callee view.
* Any constraints defined are added to the view or the appropriate superview once the block has finished executing.
* All constraints previously installed for the view will be removed.
*
* @param block scope within which you can build up the constraints which you wish to apply to the view.
*
* @return Array of created/updated MASConstraints
*/
- (NSArray *)mas_remakeConstraints:(MASConstraintMakerConfigBlock)block;
```
### MASViewConstraint的对象链式调用
如何实现链式调用
Masonry中大量的使用了链式调用的,比如
```objectivec
view.top.left.equalTo(superView).offset(10);
```
上面的这种方式就是链式调用,而且像equalTo(superView)这种形式也不是Objective-C中函数调用的方式,在Objective-C中是通过[]来调用函数的,而此处使用了()。接下来讲分析这种链式的调用是如何实现的。
```objectivec
class ClassB;
interface ClassA : NSObject
// 1. 定义一些 block 属性
property(nonatomic, readonly) ClassA *(^aaa)(BOOL enable);
property(nonatomic, readonly) ClassA *(^bbb)(NSString* str);
@property(nonatomic, readonly) ClassB *(^ccc)(NSString* str);
@implement ClassA
// 2. 实现这些 block 方法,block 返回值类型很关键,影响着下一个链式
- (ClassA *(^)(BOOL))aaa
{
return ^(BOOL enable) {
//code
if (enable) {
NSLog(@"ClassA yes");
} else {
NSLog(@"ClassA no");
}
return self;
}
}
- (ClassA *(^)(NSString *))bbb
{
return ^(NSString *str)) {
//code
NSLog(@"%@", str);
return self;
}
}
// 这里返回了ClassB的一个实例,于是后面就可以继续链式 ClassB 的 block 方法
// 见下面例子 .ccc(@"Objective-C").ddd(NO)
- (ClassB * (^)(NSString *))ccc
{
return ^(NSString *str) {
//code
NSLog(@"%@", str);
ClassB* b = [[ClassB alloc] initWithString:ccc];
return b;
}
}
//------------------------------------------
@interface ClassB : NSObject
@property(nonatomic, readonly) ClassB *(^ddd)(BOOL enable);
- (id)initWithString:(NSString *)str;
@implement ClassB
- (ClassB *(^)(BOOL))ddd
{
return ^(BOOL enable) {
//code
if (enable) {
NSLog(@"ClassB yes");
} else {
NSLog(@"ClassB no");
}
return self;
}
}
// 最后我们可以这样做
id a = [ClassA new];
a.aaa(YES).bbb(@"HelloWorld!").ccc(@"Objective-C").ddd(NO)
```
offset(10)这种调用方式是如何实现的呢?
```objectivec
- (MASConstraint * (^)(CGFloat))offset {
return ^id(CGFloat offset){
self.offset = offset;
return self;
};
}
```
不难发现,offset是一个getter方法的名,offset函数的返回值是一个匿名Block, 也就是offset后边的()。这个匿名闭包有一个CGFloat的参数,为了支持链式调用该匿名闭包返回一个MASConstraint的对象。
优化UITableViewCell高度计算的那些事:
https://github.com/forkingdog/UITableView-FDTemplateLayoutCell
http://blog.sunnyxx.com/2015/05/17/cell-height-calculation/ | 6,908 | MIT |