
code
stringlengths 30
403k
| size
int64 31
406k
| license
stringclasses 10
values |
|---|---|---|
---
layout: post
title: 企业微信定时提醒机器人🤖️
categories: [plugin]
description: 通过云函数及企业微信机器人,创建定时任务,定时发送消息提醒
keywords: 云函数, serverless、企业微信
---
## 前期准备
- 需要有一个企业微信的群(3人以上),主要用于拿到WebHook;
- 腾讯云 or 阿里云的账号,此处主要以腾讯云进行说明~
## 创建企业微信机器人🤖️
步骤如下:
- 在PC版本的企业微信,鼠标右键出现「添加群机器人」
- 出现弹窗,可以选择使用已有机器人or新建机器人,点击最上方「新创建一个机器人」

- 最后在群里会出现一个机器人,显示WebHook地址为`https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=XXXX-XXXX`(PS:此处为key为安全用X简单示意,非真实,WebHook比较关键,不要随意泄露)

## 配置云函数
### 1.登录[腾讯云](https://cloud.tencent.com/)
此处默认大家已有腾讯云账号(若无,直接使用微信登录+实名认证+服务分配即可)
### 2.创建一个函数服务
进入[云函数模块](https://serverless.cloud.tencent.com/start?c=scf),选择一个函数模板,创建一个函数服务。

### 3.函数服务配置
基础配置可按照提示进行修改,点击完成,函数创建成果,此时会默认部署默认的HelloWorld代码,并跳转到工作台。
### 4.函数服务-添加代码
点击左侧的【函数管理】,选择函数代码tab选项卡,里面出现了代码编辑区域,可以看到之前默认的代码为“已部署”状态。

在代码编辑区域添加如下代码
```javascript
'use strict'
/**************************************************
demo-show 说明
postData里的content需要修改为自己需要的
request里的url需要填写之前创建的机器人对应的WebHook
***************************************************/
const request = require('request')
exports.main_handler = async (event, context, callback) => {
return new Promise((resolve, reject) => {
const date = dateFormat({
time: +new Date(),
format: 'yyyymmdd'
})
const postData = {
"msgtype": "text",
"text": {
"content": "又是学习知识的一天\n大家可以访问链接:https://shineasyr.github.io/:",
"mentioned_list":["@all"]
}
}
request({
url: '创建的机器人的WebHook',
method: 'POST',
headers: {
"content-type": "application/json",
},
body: JSON.stringify(postData)
}, function(err, res) {
if (!err && res.statusCode == 200) {
resolve('success')
} else {
reject(err)
}
});
})
}
function dateFormat (options) {
// options支持两个参数
// format,返回字符串的格式,"yyyy/mm/dd hh:ii",
// 除了其中的字母之外,标点,分隔符等,可以随意修改
// time为一个有效的时间,可以是字符串,可以是对象
// 如果只传入一个参数,那么该参数为format的值
const format = options.format
const t = new Date(options.time)
const tf = num => (num < 10 ? '0' : '') + num
return format.replace(/yyyy|mm|dd|hh|ii|ss/g, function (a) {
switch (a) {
case 'yyyy':
return tf(t.getFullYear())
case 'mm':
return tf(t.getMonth() + 1)
case 'dd':
return tf(t.getDate())
case 'hh':
return tf(t.getHours())
case 'ii':
return tf(t.getMinutes())
case 'ss':
return tf(t.getSeconds())
}
})
}
```
添加后点击部署,代码即可部署成功,可以点击测试按钮,此时群里会有一个消息提示。
### 5.函数服务创建触发器。
点击左侧的【触发管理】-【创建触发器】,在弹出框里修改相应设定,一般触发周期选择「自定义触发周期」,填写「Cron表达式」

#### Cron表达式举例
- `0 30 15 * * WED *`为每周三的15:30点触发,其中第一位0代表秒,30代表分钟,15代表时(24时计时法),WED为周三
- `*/5 * * * * * *` 表示每5秒触发一次
- `0 0 2 1 * * *` 表示在每月的1日的凌晨2点触发
- `0 0 10,14,16 * * * *` 表示在每天上午10点,下午2点,4点触发
更多关于Cron的说明,可以查看[文档](https://cloud.tencent.com/document/product/583/9708#cron-.E8.A1.A8.E8.BE.BE.E5.BC.8F) | 3,188 | MIT |
---
layout: post
title: springboot整合常见三方框架
categories: [springboot]
description: springboot整合dubbo,mybatis等,如何打包运行等
keywords: springboot
typora-root-url: ../../
---
SpringBoot可以帮助我们快速开发一个应用服务。下面整理了如何整合常见的三方框架~
## 整合dubbo
### 引入dubbo依赖
```xml
<!-- Dubbo Spring Boot Starter -->
<dependency>
<groupId>org.apache.dubbo</groupId>
<artifactId>dubbo-spring-boot-starter</artifactId>
<version>2.7.5</version>
</dependency>
<!-- zk curator的依赖 -->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.2.0</version>
</dependency>
```
### 配置dubbo属性
```properties
# Spring boot application
spring.application.name=qz-springboot-dubbo-provider
# 扫描dubbo的@Service注解, 或者在启动类上加@EnableDubbo,2者效果一样
dubbo.scan.base-packages=com.qz.springboot.dubbo.provider
# Dubbo Application
dubbo.application.name=${spring.application.name}
# Dubbo Protocol
dubbo.protocol.name=dubbo
dubbo.protocol.port=20880
## 注册中心zookeeper地址
dubbo.registry.address=zookeeper://127.0.0.1:2181
```
### 服务提供方
在接口实现类上添加**dubbo**的注解`@Service`
```java
@Service(version = "1.0.0") //dubbo的注解
public class DemoServiceImpl implements DemoService {
private Logger logger = LoggerFactory.getLogger(DemoServiceImpl.class);
/**
* The default value of ${dubbo.application.name} is ${spring.application.name}
*/
@Value("${dubbo.application.name}")
private String serviceName;
@Override
public String sayHello(String name) {
logger.info("sayHello param {}", name);
return String.format("[%s] : Hello, %s", serviceName, name);
}
}
```
### 服务消费者
配置dubbo相关属性
```yaml
spring:
application:
name: qz-springboot-dubbo-consumer
dubbo:
registry:
address: zookeeper://127.0.0.1:2181
protocol:
name: dubbo
consumer:
check: false
```
用`@Reference`注解来注入接口
```java
@SpringBootApplication
public class Consumer {
Logger logger = LoggerFactory.getLogger(getClass());
public static void main(String[] args) {
SpringApplication.run(Consumer.class, args);
}
@Reference(check = false, version = "1.0.0")
private DemoService demoService;
@Bean
public ApplicationRunner runner() {
return args -> {
logger.info(demoService.sayHello("cxyxq"));
};
}
}
```
## SpringBoot整合Mybatis
### 引入mybatis,mysql依赖
```xml
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.1.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
```
### 配置datasource,mybatis
在`application.yml`中添加datasource、mybatis的配置
```yaml
spring:
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/my_dev
username: root
password: root
mybatis:
mapper-locations: classpath:/mybatis/mapper/*.xml
```
### 编写mapper接口
创建`UserMapper.java`,示例中采用注解,xml2种方式:
```
public interface UserMapper {
/**
* 采用注解方式
*/
@Select("select * from user where id = #{uid}")
User getUserById(@Param("uid") Integer id);
/**
* 采用xml方式
*/
List<User> getUserByName(@Param("name") String name);
}
```
### 编写mapper.xml文件
在`resource/mybaits/mapper/`下创建`UserMapper.xml`:
```
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.xq.springboot.edu.mapper.UserMapper">
<select id="getUserByName" resultType="com.xq.springboot.edu.api.User">
select * from user where name like concat('%',#{name,jdbcType=VARCHAR},'%')
</select>
</mapper>
```
### 新建UserController
在UserController中注入UserMapper:
```java
@RestController
public class UserController {
@Autowired
private UserMapper userMapper;
@RequestMapping("/id/{id}")
public User getUserById(@PathVariable("id") Integer id) {
User user = userMapper.getUserById(id);
return user;
}
@RequestMapping("/name/{name}")
public List<User> getUserByName(@PathVariable String name) {
List<User> userList = userMapper.getUserByName(name);
return userList;
}
}
```
### 配置Mapper接口扫描
在`ApplicationBoot.java`中,添加注解`@MapperScan`:
```java
import org.mybatis.spring.annotation.MapperScan;
@SpringBootApplication
@MapperScan(value = {"com.xq.springboot.edu.mapper"}) //用来生成mapper接口的代理类
public class ApplicationBoot {
```
### 测试mybatis整合
访问地址[http://127.0.0.1:8080/id/1](http://127.0.0.1:8080/id/1),[http://127.0.0.1:8080/name/a](http://127.0.0.1:8080/name/a)进行2个接口的测试。
## 整合freemarker模板引擎
### 引入freemarker依赖
```xml
<!--引入模板引擎freemarker-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-freemarker</artifactId>
</dependency>
```
### 编写后台controller
新建`FreemarkerController`类,内容如下:
```java
/**
* 此处应该用 @Controller表示,因为要返回页面
**/
@Controller
public class FreemarkerController {
@RequestMapping("/freemarkerDemo")
public String freemarkerDemo(ModelMap modelMap) {
modelMap.addAttribute("title", "我从后台来");
return "hello";
}
}
```
### 添加`application.yml`
在`resources`目录下创建配置文件`application.yml`.
```yaml
spring:
freemarker:
suffix: .ftl
template-loader-path: "classpath:/templates/"
```
### 添加.ftl文件
freemarker文件默认存放的目录为:`resources/templates`, 文件以`.ftl`结尾。
我们创建`hello.ftl`内容如下:
```html
<html>
<head>
<title>spring boot freemarker example</title>
</head>
<body>
<h1>Spring Boot Freemarker 示例</h1>
<table>
<#list users as user>
<tr>
<td>${user.id}</td>
<td>${user.name}</td>
</tr>
</#list>
</table>
</body>
</html>
```
访问[http://127.0.0.1:8080/freemarkerDemo](http://127.0.0.1:8080/freemarkerDemo)后,即可看到页面输出:
```
Spring Boot Freemarker 示例
我从后台来
```
### 如何访问静态资源
在`resources/`目录下创建目录`static`,新建`hello.js`:
```
function hello() {
//do something
}
```
如何访问呢?
答案是: [http://127.0.0.1:8080/hello.js](http://127.0.0.1:8080/hello.js),可以看到路径并不需要加:`/static/`。
### 整合jsp的注意事项
项目类型得是`war`包类型,否则无法访问到页面.
## 应用监控
添加依赖:
```xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
<version>2.2.4.RELEASE</version>
</dependency>
```
## 整合定时任务
### 注解说明(`@Scheduled`,`@EnableScheduling`)
查看Spring文档[注解方式支持定时任务](https://docs.spring.io/spring/docs/current/spring-framework-reference/integration.html#scheduling-annotation-support),所以需要2个注解:`@Scheduled`和`@EnableScheduling`,其中`@EnableScheduling`需要加到`@Configuration`标注的类上面。
### 添加注解`@EnableScheduling`
在`ApplicationBoot`类上加注解`@EnableScheduling`:
```
@EnableScheduling
public class ApplicationBoot {}
```
### 创建定时任务
创建`ScheduleDemo`类,每隔5s打印当前时间:
```
@Component
public class ScheduleDemo {
private SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
@Scheduled(fixedRate = 5000)
public void printTime() {
System.out.println("Time Now: " + sdf.format(new Date()));
}
}
```
重新运行当前应用,查看控制台日志输出: `Time Now: 2019-10-13 18:07:15`
## SpringBoot整合多数据源
## 多数据源事务
## SpringBoot全局异常
### 返回自定义的Json体
主要是用`ControllerAdvice`、`ExceptionHandler`来返回自定义异常.
```
@ControllerAdvice
public class WebExceptionHandler {
@ExceptionHandler(Exception.class)
@ResponseBody
public Map<String, Object> globalExceptionHandler(Exception ex) {
Map<String, Object> map = new HashMap<>();
map.put("ret", 0);
map.put("message", "oops,出错啦! " + ex.getMessage());
return map;
}
}
```
### 404,500页面的自定义
在`resource/templates/error/`目录下创建:`[HTTP_STATUS].ftl`,比如:404.ftl,500.ftl即可。
## 多环境配置文件
### spring.profiles.active方式
1. 配置文件制定profiles.同时创建多个`application-[env].yml`,例如:`application-dev.yml`,`application-test.yml`:
```
spring:
profiles:
active: dev
```
### Maven Profiles方式
我们可以根据maven的profile来控制,很方便:
#### resource配置
```xml
<build>
<finalName>springboot-edu</finalName>
<resources>
<resource> <!-- 定义哪个目录下的文件中的变量,将被profiles替换 -->
<directory>src/main/resources</directory>
<filtering>true</filtering>
</resource>
</resources>
</build>
```
#### profiles 多环境配置
```xml
<profiles>
<profile>
<id>dev</id>
<activation>
<activeByDefault>true</activeByDefault>
</activation>
<properties>
<mvn.cxyxq.custom.title>title from maven dev</mvn.cxyxq.custom.title>
<mvn.cxyxq.custom.message>message from maven dev</mvn.cxyxq.custom.message>
</properties>
</profile>
<profile>
<id>test</id>
<properties>
<mvn.cxyxq.custom.title>title from maven test</mvn.cxyxq.custom.title>
<mvn.cxyxq.custom.message>message from maven 测试环境</mvn.cxyxq.custom.message>
</properties>
</profile>
</profiles>
```
#### application.yml变量配置
```yml
cxyxq:
custom:
title: ${mvn.cxyxq.custom.title}
message: ${mvn.cxyxq.custom.message}
````
#### Maven 打包
执行maven命令时,可以加`-P`选项来控制用哪个maven profile.
`mvn -Pdev clean package`
`mvn -Ptest clean package`
#### 参考文档
[https://portofino.manydesigns.com/en/docs/portofino3/tutorials/using-maven-profiles-and-resource-filtering](https://portofino.manydesigns.com/en/docs/portofino3/tutorials/using-maven-profiles-and-resource-filtering)
[https://maven.apache.org/plugins/maven-resources-plugin/examples/filter.html](https://maven.apache.org/plugins/maven-resources-plugin/examples/filter.html)
## 如何打包运行
### springboot-maven插件打包
1. 进入代码根目录,执行maven命令`mvn clean package`进行打包
2. 执行完后,进入target目录,执行`java -jar xxx-1.0-SNAPSHOT.jar`
3. 2.1 发现会报错:`xxx-1.0-SNAPSHOT.jar中没有主清单属性`,表示没有main class.
2.2 在`pom.xml`中添加如下内容,然后重新执行步骤1.
```xml
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<!-- 如果不指定mainClass,插件会自动搜索带有main方法的类 -->
<mainClass>xxxx.Application</mainClass>
</configuration>
</plugin>
</plugins>
</build>
```
4. 重新打包后,再次运行,即可看到正确输出
### Maven assembly 打包
使用assembly自定义打包
```xml
<!-- 添加plugin -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>2.4</version>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptors>
<descriptor>src/main/maven/assembly-package.xml</descriptor>
</descriptors>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
```
自定义描述符文件,将文件放到目录:`src/main/maven/assembly-package.xml`
```xml
<assembly>
<id>package</id>
<formats>
<format>zip</format>
</formats>
<includeBaseDirectory>false</includeBaseDirectory>
<fileSets>
<fileSet>
<directory>src/main/bin</directory>
<outputDirectory>bin</outputDirectory>
</fileSet>
<fileSet>
<directory>src/main/resources</directory>
<outputDirectory>/conf</outputDirectory>
<filtered>true</filtered>
</fileSet>
<fileSet>
<directory>lib</directory>
<outputDirectory>lib</outputDirectory>
</fileSet>
</fileSets>
<dependencySets>
<dependencySet>
<outputDirectory>lib</outputDirectory>
</dependencySet>
</dependencySets>
</assembly>
```
执行:`mvn clean package`,会在target目录zip包
## 自定义Starter
## SpringBoot启动流程简要说明 | 11,946 | MIT |
---
layout: post
title: 将存在父子级关系的数据转化为树状结构
categories: data
description: 将存在父子级关系的数据转化为树状结构
keywords: data
---
自己将element-ui的tree组件修改了一下,二次封装成了一个[简单的树状表格组件](http://gaofangshang.com//2018/08/01/vue-tree-table/),
但是组件需要树状结构的数据,所以需要转换。
源数据:
let arr = [
{deviceId: '1',parentId: ''},
{deviceId: '2',parentId: ''},
{deviceId: '1-1',parentId: '1'},
{deviceId: '1-1-1',parentId: '1-1'},
{deviceId: '1-1-2',parentId: '1-1'},
]
目标数据结构:
[
{
"deviceId": "1",
"parentId": "",
"children": [
{
"deviceId": "1-1",
"parentId": "1",
"children": [
{
"deviceId": "1-1-1",
"parentId": "1-1"
},
{
"deviceId": "1-1-2",
"parentId": "1-1"
}
]
}
]
},
{
"deviceId": "2",
"parentId": ""
}
]
下面贴上转换函数:
dataToTree.js中
import {deepCopy} from "./copy";
/**
* Mr.Gao
* @param data 源数组
* @param id 唯一键名
* @param parentId 父级id键名
* @param children 子集键名
* @param copy 是否开启copy模式。 默认为false,会修改原来的数组。 为true时,会进行深拷贝再转换,不影响原来的数组。
* 区别在于性能差异, 如果源数组没有在使用,则建议设置为false
* @returns {Array} 转换后的属性结构
*/
export const dataToTree = (data, {id='id', parentId='parentId', children='children'}, copy= false) =>{
copy && ( data = deepCopy(data) )
let tree = [];
data.forEach(item=>{
function run(arr) {
return arr.some(val=>{
if(val[id] === item[parentId]){
val[children] ? val[children].push(item) : val[children] = [item];
return true
}else{
return val[children] && run(val[children])
}
})
}
if(!run(tree)){
tree.push(item)
for(let i=tree.length -1;i>=0;i--){
let val = tree[i];
if(item[id] === val[parentId]){
item[children] ? item[children].push(val) : item[children] = [val];
tree.splice(i,1)
}
}
}
})
return tree
}
copy.js中
/**
* 深拷贝对象或者数组
* @param obj 对象或数组
* @returns {*} 返回一个同样的对象/数组,但是与原对象/数组没有关联
*/
export const deepCopy = (obj) => {
let objClone = Array.isArray(obj) ? [] : {}
if (obj && typeof obj === 'object') {
for (let key in obj) {
if (obj.hasOwnProperty(key)) {
// 判断ojb子元素是否为对象,如果是,递归复制
if (obj[key] && typeof obj[key] === 'object') {
objClone[key] = deepCopy(obj[key])
} else {
// 如果不是,简单复制
objClone[key] = obj[key]
}
}
}
}
return objClone
}
**以上就是最终封装好的代码**。
其实,在一开始转换的时候,为了稳妥起见,思路没那么清晰,也没有那么骚的去使用那么多关键字。
原始的代码也贴一下:
function dataToTreeOrigin(data){
let tree = [];
data.forEach(item=>{
let flag = false
find(tree)
function find(arr) {
for(let i=0;i<arr.length;i++){
let val = arr[i]
if(val.deviceId === item.parentId){
val.children ? val.children.push(item) : val.children = [item];
flag = true
break;
}else{
val.children && find(val.children)
}
}
}
if(!flag){
tree.push(item)
}
})
return tree
}
很多代码一开始并没有那么骚气。功力不足的话,都是从很土的代码开始尝试,功能完成后再开始简化封装,自然就变得高级了。
等简化的次数多了,自然功力就增长了,代码的整理和封装也算是个人成长的一大养料。๑乛◡乛๑ | 3,747 | MIT |
---
layout: post
title: Linux常用命令
date: 2019-08-31
categories: 技术
tags: linux
---
**转载自:[https://www.cnblogs.com/alqscool/p/8397788.html](https://www.cnblogs.com/alqscool/p/8397788.html)**
<div class="postBody">
<div id="cnblogs_post_body" class="blogpost-body ">
查看软件xxx安装内容
**#dpkg -L xxx**
查找软件
**#apt-cache search 正则表达式**
查找文件属于哪个包
**#dpkg -S filename apt-file search filename**
查询软件xxx依赖哪些包
**#apt-cache depends xxx**
查询软件xxx被哪些包依赖
**#apt-cache rdepends xxx**
增加一个光盘源
**#sudo apt-cdrom add**
系统升级
**#sudo apt-get update
#sudo apt-get upgrade
#sudo apt-get dist-upgrade**
清除所以删除包的残余配置文件
**#dpkg -l 'grep ^rc'awk '{print $2}' 'tr [""n"] [" "]'sudo xargs dpkg -P -**
编译时缺少h文件的自动处理
**#sudo auto-apt run ./configure**
查看安装软件时下载包的临时存放目录
**#ls /var/cache/apt/archives**
备份当前系统安装的所有包的列表
**#dpkg -get-selections ' grep -v deinstall > ~/somefile**
从上面备份的安装包的列表文件恢复所有包
**#dpkg -set-selections < ~/somefile sudo dselect**
清理旧版本的软件缓存
**#sudo apt-get autoclean**
清理所有软件缓存
**#sudo apt-get clean**
删除系统不再使用的孤立软件
**#sudo apt-get autoremove**
查看包在服务器上面的地址
**#apt-get -qq -print-uris install ssh ' cut -d"' -f2**
### **系统**
查看内核
**#uname -a**
查看Ubuntu版本
**#cat /etc/issue**
查看内核加载的模块
**#lsmod**
查看PCI设备
**#lspci**
查看USB设备
**#lsusb**
查看网卡状态
**#sudo ethtool eth0**
查看CPU信息
**#cat /proc/cpuinfo**
显示当前硬件信息
**#lshw**
### **硬盘**
查看硬盘的分区
**#sudo fdisk -l**
查看IDE硬盘信息
**#sudo hdparm -i /dev/hda**
查看STAT硬盘信息
**#sudo hdparm -I /dev/sda
**或 **
#sudo apt-get install blktool
#sudo blktool /dev/sda id**
查看硬盘剩余空间
**#df -h
#df -H**
查看目录占用空间
**#du -hs 目录名**
优盘没法卸载
**#sync fuser -km /media/usbdisk**
### **内存**
查看当前的内存使用情况
**#free -m**
### **进程**
### 查看当前有哪些进程
**#ps -A**
中止一个进程
**#kill 进程号(就是ps -A中的第一列的数字) 或者 killall 进程名**
强制中止一个进程(在上面进程中止不成功的时候使用)
**#kill -9 进程号 或者 killall -9 进程名**
图形方式中止一个程序
**#xkill 出现骷髅标志的鼠标,点击需要中止的程序即可**
查看当前进程的实时状况
**#top**
查看进程打开的文件
**#lsof -p**
ADSL 配置 ADSL
**#sudo pppoeconf**
ADSL手工拨号
**#sudo pon dsl-provider**
激活 ADSL
**#sudo /etc/ppp/pppoe_on_boot**
断开 ADSL
**#sudo poff**
查看拨号日志
**#sudo plog**
如何设置动态域名
#首先去http://www.3322.org申请一个动态域名
#然后修改 /etc/ppp/ip-up 增加拨号时更新域名指令** sudo vim /etc/ppp/ip-up**
#在最后增加如下行 w3m -no-cookie -dump
### **网络**
根据IP查网卡地址
**#arping IP地址**
查看当前IP地址
**#ifconfig eth0 'awk '/inet/ {split($2,x,":");print x[2]}'**
查看当前外网的IP地址
**#w3m -no-cookie -dumpwww.edu.cn'grep-o****'[0-9]"{1,3"}".[0-9]"{1,3"}".[0-9]"{1,3"}".[0-9]"{1,3"}'
#w3m -no-cookie** **-dumpwww.xju.edu.cn'grep-o'[0-9]"{1,3"}".[0-9]"{1,3"}".[0-9]"{1,3"}".[0-9]"{1,3"}'** **
#w3m -no-cookie -dump ip.loveroot.com'grep -o'[0-9]"{1,3"}".[0-9]"{1,3"}".[0-9]"{1,3"}".[0-9]"{1,3"}'**
查看当前监听80端口的程序
**#lsof -i :80**
查看当前网卡的物理地址
**#arp -a ' awk '{print $4}' ifconfig eth0 ' head -1 ' awk '{print $5}'**
立即让网络支持nat
**#sudo echo 1 > /proc/sys/net/ipv4/ip_forward
#sudo iptables -t nat -I POSTROUTING -j MASQUERADE**
查看路由信息
**#netstat -rn sudo route -n**
手工增加删除一条路由
**#sudo route add -net 192.168.0.0 netmask 255.255.255.0 gw 172.16.0.1
#sudo route del -net 192.168.0.0 netmask 255.255.255.0 gw 172.16.0.1**
修改网卡MAC地址的方法
**#sudo ifconfig eth0 down **关闭网卡**
#sudo ifconfig eth0 hw ether 00:AA:BB:CC:DD:EE** 然后改地址
#**sudo ifconfig eth0 up** 然后启动网卡
统计当前IP连接的个数
**#netstat -na'grep ESTABLISHED'awk '{print $5}''awk -F: '{print $1}''sort'uniq -c'sort -r -n
#netstat -na'grep SYN'awk '{print $5}''awk -F: '{print $1}''sort'uniq -c'sort -r -n**
统计当前20000个IP包中大于100个IP包的IP地址
**#tcpdump -tnn -c 20000 -i eth0 ' awk -F "." '{print $1″."$2″."$3″."$4}' ' sort ' uniq -c ' sort -nr ' awk ' $1 > 100 '**
屏蔽IPV6
**#echo "blacklist ipv6″ ' sudo tee /etc/modprobe.d/blacklist-ipv6**
### **服务**
添加一个服务
**#sudo update-rc.d 服务名 defaults 99**
删除一个服务
**#sudo update-rc.d 服务名 remove**
临时重启一个服务
**#/etc/init.d/服务名 restart**
临时关闭一个服务
**#/etc/init.d/服务名 stop**
临时启动一个服务
**#/etc/init.d/服务名 start**
### **设置**
配置默认Java使用哪个
**#sudo update-alternatives -config java**
修改用户资料
**#sudo chfn userid**
给apt设置代理
**#export http_proxy=http://xx.xx.xx.xx:xxx**
修改系统登录信息
**#sudo vim /etc/motd**
### **中文**
转换文件名由GBK为UTF8
**#sudo apt-get install convmv convmv -r -f cp936 -t utf8 -notest -nosmart ***
批量转换src目录下的所有文件内容由GBK到UTF8
**#find src -type d -exec mkdir -p utf8/{} "; find src -type f -exec iconv -f GBK -t UTF-8 {} -o utf8/{} "; mv utf8/* src rm -fr utf8**
转换文件内容由GBK到UTF8
**#iconv -f gbk -t utf8 $i > newfile**
转换 mp3 标签编码
**#sudo apt-get install python-mutagen find . -iname "*.mp3" -execdir mid3iconv -e GBK {} ";**
控制台下显示中文
**#sudo apt-get install zhcon 使用时,输入zhcon即可**
### **文件**
快速查找某个文件
**#whereis filename**
**#find 目录 -name 文件名**
查看文件类型
**#file filename**
显示xxx文件倒数6行的内容
**#tail -n 6 xxx**
让tail不停地读地最新的内容
**#tail -n 10 -f /var/log/apache2/access.log**
查看文件中间的第五行(含)到第10行(含)的内容
**#sed -n '5,10p' /var/log/apache2/access.log**
查找包含xxx字符串的文件
**#grep -l -r xxx .**
全盘搜索文件(桌面可视化)
**gnome-search-tool**
查找关于xxx的命令
**#apropos xxx man -k xxx**
通过ssh传输文件
**#scp -rp /path/filenameusername@remoteIP:/path**
#将本地文件拷贝到服务器上
**#scp -rpusername@remoteIP:/path/filename/path**
#将远程文件从服务器下载到本地
查看某个文件被哪些应用程序读写
**#lsof 文件名**
把所有文件的后辍由rm改为rmvb
**#rename 's/.rm$/.rmvb/' ***
把所有文件名中的大写改为小写
**#rename 'tr/A-Z/a-z/' ***
删除特殊文件名的文件,如文件名:-help.txt
**#rm - -help.txt 或者 rm ./-help.txt**
查看当前目录的子目录
**#ls -d */. 或 echo */.**
将当前目录下最近30天访问过的文件移动到上级back目录
**#find . -type f -atime -30 -exec mv {} ../back ";**
将当前目录下最近2小时到8小时之内的文件显示出来
**#find . -mmin +120 -mmin -480 -exec more {} ";**
删除修改时间在30天之前的所有文件
**#find . -type f -mtime +30 -mtime -3600 -exec rm {} ";**
查找guest用户的以avi或者rm结尾的文件并删除掉
**#find . -name '*.avi' -o -name '*.rm' -user 'guest' -exec rm {} ";**
查找的不以java和xml结尾,并7天没有使用的文件删除掉
**#find . ! -name *.java ! -name '*.xml' -atime +7 -exec rm {} ";**
统计当前文件个数
**#ls /usr/bin'wc -w**
统计当前目录个数
**#ls -l /usr/bin'grep ^d'wc -l**
显示当前目录下2006-01-01的文件名
**#ls -l 'grep 2006-01-01 'awk '{print $8}'**
### **FTP**
上传下载文件工具-filezilla
**#sudo apt-get install filezilla
**
filezilla无法列出中文目录?**
站点->字符集->自定义->输入:GBK**
本地中文界面
**1)**下载filezilla中文包到本地目录,**如~/**
**2)#unrar x Filezilla3_zhCN.rar**
**3) **如果你没有unrar的话,请先**安装rar和unrar**
**#sudo apt-get install rar unrar**
**#sudo ln -f /usr/bin/rar /usr/bin/unrar**
**4)**先**备份**原来的语言包,再安装;实际就是拷贝一个语言包。
**#sudo cp /usr/share/locale/zh_CN/filezilla.mo /usr/share/locale/zh_CN/filezilla.mo.bak**
**#sudo cp ~/locale/zh_CN/filezilla.mo /usr/share/locale/zh_CN/filezilla.mo**
**5)重启**filezilla,即可!
### **解压缩**
解压缩 xxx.tar.gz
**#tar -zxvf xxx.tar.gz**
解压缩 xxx.tar.bz2
**#tar -jxvf xxx.tar.bz2**
压缩aaa bbb目录为xxx.tar.gz
**#tar -zcvf xxx.tar.gz aaa bbb**
压缩aaa bbb目录为xxx.tar.bz2
**#tar -jcvf xxx.tar.bz2 aaa bbb**
解压缩 RAR 文件
**1) **先安装
**#sudo apt-get install rar unrar
#sudo ln -f /usr/bin/rar /usr/bin/unrar
2)** 解压
**#unrar x aaaa.rar**
解压缩 ZIP 文件
**1) **先安装
**#sudo apt-get install zip unzip
#sudo ln -f /usr/bin/zip /usr/bin/unzip
2)** 解压
**#unzip x aaaa.zip**
### **Nautilus**
显示隐藏文件
**Ctrl+h**
显示地址栏
**Ctrl+l**
特殊 URI 地址
*** computer:/// **- 全部挂载的设备和网络
*** network:///** - 浏览可用的网络
*** burn:///** - 一个刻录 CDs/DVDs 的数据虚拟目录
*** smb:///** - 可用的 windows/samba 网络资源
*** x-nautilus-desktop:///** - 桌面项目和图标
***file:///**- 本地文件
*** trash:///** - 本地回收站目录
*** ftp://** - FTP 文件夹
*** ssh:// **- SSH 文件夹
*** fonts:/// **- 字体文件夹,可将字体文件拖到此处以完成安装
*** themes:///** - 系统主题文件夹
查看已安装字体
**在nautilus的地址栏里输入"fonts:///",就可以查看本机所有的fonts**
### **程序**
详细显示程序的运行信息
**#strace -f -F -o outfile**
**日期和时间**
设置日期
**#date -s mm/dd/yy**
设置时间
**#date -s HH:MM**
将时间写入CMOS
**#hwclock -systohc**
读取CMOS时间
**#hwclock -hctosys**
从服务器上同步时间
**#sudo ntpdate time.nist.gov
#sudo ntpdate time.windows.com**
**控制台**
不同控制台间切换
**Ctrl + ALT + ← Ctrl + ALT + →**
指定控制台切换
**Ctrl + ALT + Fn(n:1~7)**
控制台下滚屏
**SHIFT + pageUp/pageDown**
控制台抓图
**#setterm -dump n(n:1~7)**
### **数据库**
mysql的数据库存放在地方
**#/var/lib/mysql**
从mysql中导出和导入数据**
#mysqldump 数据库名 > 文件名 **#导出数据库
**#mysqladmin create 数据库名 **#建立数据库
**#mysql 数据库名 < 文件名 **#导入数据库
忘了mysql的root口令怎么办
**#sudo /etc/init.d/mysql stop**
**#sudo mysqld_safe -skip-grant-tables **
**#sudo mysqladmin -u user password 'newpassword"
#sudo mysqladmin flush-privileges**
修改mysql的root口令
**#sudo mysqladmin -uroot -p password '你的新密码'**
### **其它**
**下载网站文档**
**#wget -r -p -np -khttp://www.21cn.com**
· r:在本机建立服务器端目录结构;
· -p: 下载显示HTML文件的所有图片;
· -np:只下载目标站点指定目录及其子目录的内容;
· -k: 转换非相对链接为相对链接。
如何删除Totem电影播放机的播放历史记录
**#rm ~/.recently-used**
如何更换gnome程序的快捷键
点击菜单,鼠标停留在某条菜单上,键盘输入任意你所需要的键,可以是组合键,会立即生效; 如果要清除该快捷键,请使用backspace
vim 如何显示彩色字符
**#sudo cp /usr/share/vim/vimcurrent/vimrc_example.vim /usr/share/vim/vimrc**
如何在命令行删除在会话设置的启动程序
**#cd ~/.config/autostart rm 需要删除启动程序**
如何提高wine的反应速度
**#sudo sed -ie '/GBK/,/^}/d' /usr/share/X11/locale/zh_CN.UTF-8/XLC_LOCALE**
**#chgrp**
[语法]: chgrp [-R] 文件组 文件...
[说明]: 文件的GID表示文件的文件组,文件组可用数字表示, 也可用一个有效的组名表示,此命令改变一个文件的GID,可参看chown。
-R 递归地改变所有子目录下所有文件的存取模式
[例子]:
**#chgrp group file **将文件 file 的文件组改为 group
**#chmod**
[语法]: chmod [-R] 模式 文件...
或 chmod [ugoa] {+'-'=} [rwxst] 文件...
[说明]: 改变文件的存取模式,存取模式可表示为数字或符号串,例如:
**#chmod nnnn file** , n为0-7的数字,意义如下:
4000 运行时可改变UID
2000 运行时可改变GID
1000 置粘着位
0400 文件主可读
0200 文件主可写
0100 文件主可执行
0040 同组用户可读
0020 同组用户可写
0010 同组用户可执行
0004 其他用户可读
0002 其他用户可写
0001 其他用户可执行
nnnn 就是上列数字相加得到的,例如 chmod 0777 file 是指将文件 file 存取权限置为所有用户可读可写可执行。
-R 递归地改变所有子目录下所有文件的存取模式
u 文件主
g 同组用户
o 其他用户
a 所有用户
+ 增加后列权限
- 取消后列权限
= 置成后列权限
r 可读
w 可写
x 可执行
s 运行时可置UID
t 运行时可置GID
[例子]:
**#chmod 0666** file1 file2 将文件 file1 及 file2 置为所有用户可读可写
**#chmod u+x file** 对文件 file 增加文件主可执行权限
**#chmod o-rwx** 对文件file 取消其他用户的所有权限
**#chown**
[语法]: chown [-R] 文件主 文件...
[说明]: 文件的UID表示文件的文件主,文件主可用数字表示, 也可用一个有效的用户名表示,此命令改变一个文件的UID,仅当此文件的文件主或超级用户可使用。
-R 递归地改变所有子目录下所有文件的存取模式
[例子]:
**#chown mary file **将文件 file 的文件主改为 mary
**#chown 150 file** 将文件 file 的UID改为150
### Ubuntu命令行下修改网络配置
**以eth0为例**
**1. 以DHCP方式配置网卡**
编辑文件/etc/network/interfaces:
**#sudo vi /etc/network/interfaces**
并用下面的行来替换有关eth0的行:
# The primary network interface - use DHCP to find our address
auto eth0
iface eth0 inet dhcp
用下面的命令使网络设置生效:
**#sudo /etc/init.d/networking restart**
当然,也可以在命令行下直接输入下面的命令来获取地址**
#sudo dhclient eth0**
**2. 为网卡配置静态IP地址**
编辑文件/etc/network/interfaces:
**#sudo vi /etc/network/interfaces**
并用下面的行来替换有关eth0的行:
# The primary network interface
auto eth0
iface eth0 inet static
address 192.168.3.90
gateway 192.168.3.1
netmask 255.255.255.0
network 192.168.3.0
broadcast 192.168.3.255
将上面的ip地址等信息换成你自己就可以了.
用下面的命令使网络设置生效:
**#sudo /etc/init.d/networking restart**
**3. 设定第二个IP地址(虚拟IP地址)**
编辑文件/etc/network/interfaces:
**#sudo vi /etc/network/interfaces**
在该文件中添加如下的行:
auto eth0:1
iface eth0:1 inet static
address 192.168.1.60
netmask 255.255.255.0
network x.x.x.x
broadcast x.x.x.x
gateway x.x.x.x
根据你的情况填上所有诸如address,netmask,network,broadcast和gateways等信息.
用下面的命令使网络设置生效:
**#sudo /etc/init.d/networking restart**
**4. 设置主机名称(hostname)**
使用下面的命令来查看当前主机的主机名称:
**#sudo /bin/hostname**
使用下面的命令来设置当前主机的主机名称:
**#sudo /bin/hostname newname**
系统启动时,它会从/etc/hostname来读取主机的名称.
**5. 配置DNS**
首先,你可以在/etc/hosts中加入一些主机名称和这些主机名称对应的IP地址,这是简单使用本机的静态查询.
要访问DNS 服务器来进行查询,需要设置/etc/resolv.conf文件.
假设DNS服务器的IP地址是192.168.3.2, 那么/etc/resolv.conf文件的内容应为:
search test.com
nameserver 192.168.3.2
### **安装AMP服务**
如果采用Ubuntu Server CD开始安装时,可以选择安装,这系统会自动装上apache2,php5和mysql5。下面主要说明一下如果不是安装的Ubuntu server时的安装方法。
用命令在Ubuntu下架设Lamp其实很简单,用一条命令就完成。在终端输入以下命令:
**#sudo apt-get install apache2 mysql-server php5 php5-mysql php5-gd #phpmyadmin**
装好后,**mysql管理员是root,无密码**,通过http://localhost/phpmyadmin就可以访问mysql了
**修改 MySql 密码**
终端下输入:
**#mysql -u root**
**#mysql> GRANT ALL PRIVILEGES ON *.* TO root@localhost IDENTIFIED BY "123456″;**
'123456'是root的密码,可以自由设置,但最好是设个安全点的。
**#mysql> quit; **退出mysql
**apache2的操作命令**
启动:**#sudo /etc/init.d/apache2 start**
重启:**#sudo /etc/init.d/apache2 restart**
关闭:**#sudo /etc/init.d/apache2 stop**
**apache2的默认主目录:/var/www/**
</div>
<div id="MySignature"></div>
<div class="clear"></div>
</div> | 11,813 | MIT |
---
layout : post
title : 使用 supervisor 来监控 django celery
category : supervisor
date : 2016-01-19
tags : [supervisor, django, celery]
---
之前启动celery时,使用nohup 方式启动。这种方式是不安全的,今天使者使用supervisor来管理监控celery,记录如下,备查。
### 0x00 安装 supervisor
pip install supervisor
### 0x01 配置文件
echo_supervisord_conf > /etc/supervisord.conf
在配置文件最后添加如下配置:
[program:celeryd]
command=python manage.py celery worker -l info #此处可使用绝对路径
stdout_logfile=/path/to/your/logs/celeryd.log
stderr_logfile=/path/to/your/logs/celeryd.log
autostart=true
autorestart=true
startsecs=10
stopwaitsecs=600
<!-- more -->
配置文件其他配置详解:
```conf
[unix_http_server]
file=/tmp/supervisor.sock ; socket文件的路径,supervisorctl用XML_RPC和supervisord通信就是通过它进行
的。如果不设置的话,supervisorctl也就不能用了
不设置的话,默认为none。 非必须设置
;chmod=0700 ; 这个简单,就是修改上面的那个socket文件的权限为0700
不设置的话,默认为0700。 非必须设置
;chown=nobody:nogroup ; 这个一样,修改上面的那个socket文件的属组为user.group
不设置的话,默认为启动supervisord进程的用户及属组。非必须设置
;username=user ; 使用supervisorctl连接的时候,认证的用户
不设置的话,默认为不需要用户。 非必须设置
;password=123 ; 和上面的用户名对应的密码,可以直接使用明码,也可以使用SHA加密
如:{SHA}82ab876d1387bfafe46cc1c8a2ef074eae50cb1d
默认不设置。。。非必须设置
;[inet_http_server] ; 侦听在TCP上的socket,Web Server和远程的supervisorctl都要用到他
不设置的话,默认为不开启。非必须设置
;port=127.0.0.1:9001 ; 这个是侦听的IP和端口,侦听所有IP用 :9001或*:9001。
这个必须设置,只要上面的[inet_http_server]开启了,就必须设置它
;username=user ; 这个和上面的uinx_http_server一个样。非必须设置
;password=123 ; 这个也一个样。非必须设置
[supervisord] ;这个主要是定义supervisord这个服务端进程的一些参数的
这个必须设置,不设置,supervisor就不用干活了
logfile=/tmp/supervisord.log ; 这个是supervisord这个主进程的日志路径,注意和子进程的日志不搭嘎。
默认路径$CWD/supervisord.log,$CWD是当前目录。。非必须设置
logfile_maxbytes=50MB ; 这个是上面那个日志文件的最大的大小,当超过50M的时候,会生成一个新的日
志文件。当设置为0时,表示不限制文件大小
默认值是50M,非必须设置。
logfile_backups=10 ; 日志文件保持的数量,上面的日志文件大于50M时,就会生成一个新文件。文件
数量大于10时,最初的老文件被新文件覆盖,文件数量将保持为10
当设置为0时,表示不限制文件的数量。
默认情况下为10。。。非必须设置
loglevel=info ; 日志级别,有critical, error, warn, info, debug, trace, or blather等
默认为info。。。非必须设置项
pidfile=/tmp/supervisord.pid ; supervisord的pid文件路径。
默认为$CWD/supervisord.pid。。。非必须设置
nodaemon=false ; 如果是true,supervisord进程将在前台运行
默认为false,也就是后台以守护进程运行。。。非必须设置
minfds=1024 ; 这个是最少系统空闲的文件描述符,低于这个值supervisor将不会启动。
系统的文件描述符在这里设置cat /proc/sys/fs/file-max
默认情况下为1024。。。非必须设置
minprocs=200 ; 最小可用的进程描述符,低于这个值supervisor也将不会正常启动。
ulimit -u这个命令,可以查看linux下面用户的最大进程数
默认为200。。。非必须设置
;umask=022 ; 进程创建文件的掩码
默认为022。。非必须设置项
;user=chrism ; 这个参数可以设置一个非root用户,当我们以root用户启动supervisord之后。
我这里面设置的这个用户,也可以对supervisord进行管理
默认情况是不设置。。。非必须设置项
;identifier=supervisor ; 这个参数是supervisord的标识符,主要是给XML_RPC用的。当你有多个
supervisor的时候,而且想调用XML_RPC统一管理,就需要为每个
supervisor设置不同的标识符了
默认是supervisord。。。非必需设置
;directory=/tmp ; 这个参数是当supervisord作为守护进程运行的时候,设置这个参数的话,启动
supervisord进程之前,会先切换到这个目录
默认不设置。。。非必须设置
;nocleanup=true ; 这个参数当为false的时候,会在supervisord进程启动的时候,把以前子进程
产生的日志文件(路径为AUTO的情况下)清除掉。有时候咱们想要看历史日志,当
然不想日志被清除了。所以可以设置为true
默认是false,有调试需求的同学可以设置为true。。。非必须设置
;childlogdir=/tmp ; 当子进程日志路径为AUTO的时候,子进程日志文件的存放路径。
默认路径是这个东西,执行下面的这个命令看看就OK了,处理的东西就默认路径
python -c "import tempfile;print tempfile.gettempdir()"
非必须设置
;environment=KEY="value" ; 这个是用来设置环境变量的,supervisord在linux中启动默认继承了linux的
环境变量,在这里可以设置supervisord进程特有的其他环境变量。
supervisord启动子进程时,子进程会拷贝父进程的内存空间内容。 所以设置的
这些环境变量也会被子进程继承。
小例子:environment=name="haha",age="hehe"
默认为不设置。。。非必须设置
;strip_ansi=false ; 这个选项如果设置为true,会清除子进程日志中的所有ANSI 序列。什么是ANSI
序列呢?就是我们的\n,\t这些东西。
默认为false。。。非必须设置
; the below section must remain in the config file for RPC
; (supervisorctl/web interface) to work, additional interfaces may be
; added by defining them in separate rpcinterface: sections
[rpcinterface:supervisor] ;这个选项是给XML_RPC用的,当然你如果想使用supervisord或者web server 这
个选项必须要开启的
supervisor.rpcinterface_factory = supervisor.rpcinterface:make_main_rpcinterface
[supervisorctl] ;这个主要是针对supervisorctl的一些配置
serverurl=unix:///tmp/supervisor.sock ; 这个是supervisorctl本地连接supervisord的时候,本地UNIX socket
路径,注意这个是和前面的[unix_http_server]对应的
默认值就是unix:///tmp/supervisor.sock。。非必须设置
;serverurl=http://127.0.0.1:9001 ; 这个是supervisorctl远程连接supervisord的时候,用到的TCP socket路径
注意这个和前面的[inet_http_server]对应
默认就是http://127.0.0.1:9001。。。非必须项
;username=chris ; 用户名
默认空。。非必须设置
;password=123 ; 密码
默认空。。非必须设置
;prompt=mysupervisor ; 输入用户名密码时候的提示符
默认supervisor。。非必须设置
;history_file=~/.sc_history ; 这个参数和shell中的history类似,我们可以用上下键来查找前面执行过的命令
默认是no file的。。所以我们想要有这种功能,必须指定一个文件。。。非
必须设置
; The below sample program section shows all possible program subsection values,
; create one or more 'real' program: sections to be able to control them under
; supervisor.
;[program:theprogramname] ;这个就是咱们要管理的子进程了,":"后面的是名字,最好别乱写和实际进程
有点关联最好。这样的program我们可以设置一个或多个,一个program就是
要被管理的一个进程
;command=/bin/cat ; 这个就是我们的要启动进程的命令路径了,可以带参数
例子:/home/test.py -a 'hehe'
有一点需要注意的是,我们的command只能是那种在终端运行的进程,不能是
守护进程。这个想想也知道了,比如说command=service httpd start。
httpd这个进程被linux的service管理了,我们的supervisor再去启动这个命令
这已经不是严格意义的子进程了。
这个是个必须设置的项
;process_name=%(program_name)s ; 这个是进程名,如果我们下面的numprocs参数为1的话,就不用管这个参数
了,它默认值%(program_name)s也就是上面的那个program冒号后面的名字,
但是如果numprocs为多个的话,那就不能这么干了。想想也知道,不可能每个
进程都用同一个进程名吧。
;numprocs=1 ; 启动进程的数目。当不为1时,就是进程池的概念,注意process_name的设置
默认为1 。。非必须设置
;directory=/tmp ; 进程运行前,会前切换到这个目录
默认不设置。。。非必须设置
;umask=022 ; 进程掩码,默认none,非必须
;priority=999 ; 子进程启动关闭优先级,优先级低的,最先启动,关闭的时候最后关闭
默认值为999 。。非必须设置
;autostart=true ; 如果是true的话,子进程将在supervisord启动后被自动启动
默认就是true 。。非必须设置
;autorestart=unexpected ; 这个是设置子进程挂掉后自动重启的情况,有三个选项,false,unexpected
和true。如果为false的时候,无论什么情况下,都不会被重新启动,
如果为unexpected,只有当进程的退出码不在下面的exitcodes里面定义的退
出码的时候,才会被自动重启。当为true的时候,只要子进程挂掉,将会被无
条件的重启
;startsecs=1 ; 这个选项是子进程启动多少秒之后,此时状态如果是running,则我们认为启
动成功了
默认值为1 。。非必须设置
;startretries=3 ; 当进程启动失败后,最大尝试启动的次数。。当超过3次后,supervisor将把
此进程的状态置为FAIL
默认值为3 。。非必须设置
;exitcodes=0,2 ; 注意和上面的的autorestart=unexpected对应。。exitcodes里面的定义的
退出码是expected的。
;stopsignal=QUIT ; 进程停止信号,可以为TERM, HUP, INT, QUIT, KILL, USR1, or USR2等信号
默认为TERM 。。当用设定的信号去干掉进程,退出码会被认为是expected
非必须设置
;stopwaitsecs=10 ; 这个是当我们向子进程发送stopsignal信号后,到系统返回信息
给supervisord,所等待的最大时间。 超过这个时间,supervisord会向该
子进程发送一个强制kill的信号。
默认为10秒。。非必须设置
;stopasgroup=false ; 这个东西主要用于,supervisord管理的子进程,这个子进程本身还有
子进程。那么我们如果仅仅干掉supervisord的子进程的话,子进程的子进程
有可能会变成孤儿进程。所以咱们可以设置可个选项,把整个该子进程的
整个进程组都干掉。 设置为true的话,一般killasgroup也会被设置为true。
需要注意的是,该选项发送的是stop信号
默认为false。。非必须设置。。
;killasgroup=false ; 这个和上面的stopasgroup类似,不过发送的是kill信号
;user=chrism ; 如果supervisord是root启动,我们在这里设置这个非root用户,可以用来
管理该program
默认不设置。。。非必须设置项
;redirect_stderr=true ; 如果为true,则stderr的日志会被写入stdout日志文件中
默认为false,非必须设置
;stdout_logfile=/a/path ; 子进程的stdout的日志路径,可以指定路径,AUTO,none等三个选项。
设置为none的话,将没有日志产生。设置为AUTO的话,将随机找一个地方
生成日志文件,而且当supervisord重新启动的时候,以前的日志文件会被
清空。当 redirect_stderr=true的时候,sterr也会写进这个日志文件
;stdout_logfile_maxbytes=1MB ; 日志文件最大大小,和[supervisord]中定义的一样。默认为50
;stdout_logfile_backups=10 ; 和[supervisord]定义的一样。默认10
;stdout_capture_maxbytes=1MB ; 这个东西是设定capture管道的大小,当值不为0的时候,子进程可以从stdout
发送信息,而supervisor可以根据信息,发送相应的event。
默认为0,为0的时候表达关闭管道。。。非必须项
;stdout_events_enabled=false ; 当设置为ture的时候,当子进程由stdout向文件描述符中写日志的时候,将
触发supervisord发送PROCESS_LOG_STDOUT类型的event
默认为false。。。非必须设置
;stderr_logfile=/a/path ; 这个东西是设置stderr写的日志路径,当redirect_stderr=true。这个就不用
设置了,设置了也是白搭。因为它会被写入stdout_logfile的同一个文件中
默认为AUTO,也就是随便找个地存,supervisord重启被清空。。非必须设置
;stderr_logfile_maxbytes=1MB ; 这个出现好几次了,就不重复了
;stderr_logfile_backups=10 ; 这个也是
;stderr_capture_maxbytes=1MB ; 这个一样,和stdout_capture一样。 默认为0,关闭状态
;stderr_events_enabled=false ; 这个也是一样,默认为false
;environment=A="1",B="2" ; 这个是该子进程的环境变量,和别的子进程是不共享的
;serverurl=AUTO ;
; The below sample eventlistener section shows all possible
; eventlistener subsection values, create one or more 'real'
; eventlistener: sections to be able to handle event notifications
; sent by supervisor.
;[eventlistener:theeventlistenername] ;这个东西其实和program的地位是一样的,也是suopervisor启动的子进
程,不过它干的活是订阅supervisord发送的event。他的名字就叫
listener了。我们可以在listener里面做一系列处理,比如报警等等
楼主这两天干的活,就是弄的这玩意
;command=/bin/eventlistener ; 这个和上面的program一样,表示listener的可执行文件的路径
;process_name=%(program_name)s ; 这个也一样,进程名,当下面的numprocs为多个的时候,才需要。否则默认就
OK了
;numprocs=1 ; 相同的listener启动的个数
;events=EVENT ; event事件的类型,也就是说,只有写在这个地方的事件类型。才会被发送
;buffer_size=10 ; 这个是event队列缓存大小,单位不太清楚,楼主猜测应该是个吧。当buffer
超过10的时候,最旧的event将会被清除,并把新的event放进去。
默认值为10。。非必须选项
;directory=/tmp ; 进程执行前,会切换到这个目录下执行
默认为不切换。。。非必须
;umask=022 ; 淹没,默认为none,不说了
;priority=-1 ; 启动优先级,默认-1,也不扯了
;autostart=true ; 是否随supervisord启动一起启动,默认true
;autorestart=unexpected ; 是否自动重启,和program一个样,分true,false,unexpected等,注意
unexpected和exitcodes的关系
;startsecs=1 ; 也是一样,进程启动后跑了几秒钟,才被认定为成功启动,默认1
;startretries=3 ; 失败最大尝试次数,默认3
;exitcodes=0,2 ; 期望或者说预料中的进程退出码,
;stopsignal=QUIT ; 干掉进程的信号,默认为TERM,比如设置为QUIT,那么如果QUIT来干这个进程
那么会被认为是正常维护,退出码也被认为是expected中的
;stopwaitsecs=10 ; max num secs to wait b4 SIGKILL (default 10)
;stopasgroup=false ; send stop signal to the UNIX process group (default false)
;killasgroup=false ; SIGKILL the UNIX process group (def false)
;user=chrism ;设置普通用户,可以用来管理该listener进程。
默认为空。。非必须设置
;redirect_stderr=true ; 为true的话,stderr的log会并入stdout的log里面
默认为false。。。非必须设置
;stdout_logfile=/a/path ; 这个不说了,好几遍了
;stdout_logfile_maxbytes=1MB ; 这个也是
;stdout_logfile_backups=10 ; 这个也是
;stdout_events_enabled=false ; 这个其实是错的,listener是不能发送event
;stderr_logfile=/a/path ; 这个也是
;stderr_logfile_maxbytes=1MB ; 这个也是
;stderr_logfile_backups ; 这个不说了
;stderr_events_enabled=false ; 这个也是错的,listener不能发送event
;environment=A="1",B="2" ; 这个是该子进程的环境变量
默认为空。。。非必须设置
;serverurl=AUTO ; override serverurl computation (childutils)
; The below sample group section shows all possible group values,
; create one or more 'real' group: sections to create "heterogeneous"
; process groups.
;[group:thegroupname] ;这个东西就是给programs分组,划分到组里面的program。我们就不用一个一个去操作了
我们可以对组名进行统一的操作。 注意:program被划分到组里面之后,就相当于原来
的配置从supervisor的配置文件里消失了。。。supervisor只会对组进行管理,而不再
会对组里面的单个program进行管理了
;programs=progname1,progname2 ; 组成员,用逗号分开
这个是个必须的设置项
;priority=999 ; 优先级,相对于组和组之间说的
默认999。。非必须选项
; The [include] section can just contain the "files" setting. This
; setting can list multiple files (separated by whitespace or
; newlines). It can also contain wildcards. The filenames are
; interpreted as relative to this file. Included files *cannot*
; include files themselves.
;[include] ;这个东西挺有用的,当我们要管理的进程很多的时候,写在一个文件里面
就有点大了。我们可以把配置信息写到多个文件中,然后include过来
;files = relative/directory/*.ini
```
### 0x02 启动关闭supervisor
# 启动
supervisord
# 进入supervisor命令行
supervisorctl
# 直接执行启动
supervisorctl start celery
# 关闭没有发现好的方法只能kill了
kill your-supervisor-pid
### 0x03 配置启停脚本
启停脚本地址:https://github.com/Supervisor/initscripts
- 使用redhat-init-mingalevme,将脚本保存为 /etc/init.d/supervisord
- 设置自启动
```bash
chkconfig --add supervisord
chkconfig supervisord on
```
- 启停命令
```bash
service supervisord start
#supervisorctl 命令
supervisorctl start xxx
supervisorctl stop xxx
#重新加载配置文件
supervisorctl reload
```
### QA
1、FATAL Exited too quickly (process log may have details
原因:配置文件命令行问题,错误前配置:python manage.py celery worker -l info >celery.log
改正:python manage.py celery worker -l info
2、问题:
```bash
[root@localhost ~]# echo_supervisord_conf > /etc/supervisord.conf
Traceback (most recent call last):
File "/usr/local/bin/echo_supervisord_conf", line 5, in <module>
from pkg_resources import load_entry_point
File "/usr/local/lib/python2.7/site-packages/setuptools-0.6c11-py2.7.egg/pkg_resources.py", line 2603, in <module>
File "/usr/local/lib/python2.7/site-packages/setuptools-0.6c11-py2.7.egg/pkg_resources.py", line 666, in require
File "/usr/local/lib/python2.7/site-packages/setuptools-0.6c11-py2.7.egg/pkg_resources.py", line 565, in resolve
pkg_resources.DistributionNotFound: meld3>=0.6.5
```
解决方法:
注释掉 `/usr/local/lib/python2.7/site-packages/setuptools-0.6c11-py2.7.egg/require.txt` 文件中的 `meld3>=0.6.5`
### 参考:
- [https://micropyramid.com/blog/celery-with-supervisor/](https://micropyramid.com/blog/celery-with-supervisor/)
- [http://www.marswj.com/post/45/Installation-and-configuration-of-supervisor-in-CentOS](http://www.marswj.com/post/45/Installation-and-configuration-of-supervisor-in-CentOS) | 16,898 | MIT |
## 1.VSCode 创建Maven-Web项目
* `Ctrl + Shift + P` 输入Maven Generate Web Project
## 2.pom.xml中加入依赖,其余依赖自动下载
```
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>${org.springframework.version}</version>
</dependency
```
## 3.在Web.xml配置DispatcherServlet拦截所有请求,交给SpringMVC处理
```
<!-- 配置DispatcherServlet -->
<servlet>
<servlet-name>springDispatcherServlet</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<load-on-startup>1</load-on-startup>
<!-- 配置初始化参数,配置SpringMVC文件的位置和名称 -->
<!-- 实际上也可以不通过contextConfigLocation来配置SpringMVC的配置文件,而使用
默认的配置文件: /WEB-INF/<servlet-name>-servlet.mxl-->
<init-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:spring-mvc.xml</param-value>
</init-param>
</servlet>
<servlet-mapping>
<servlet-name>springDispatcherServlet</servlet-name>
<url-pattern>/</url-pattern>
</servlet-mapping>
```
## 4.编写Java代码控制器
```
@Controller
public class HelloWorld {
/**
* 1. 使用@RequestMapping 注解来映射请求的URL
* 2. 返回值会通过视图解析器为实际的物理视图,
* 3. 对InternalResourceViewResolver视图解析器,会做如下解析:
* 通过 prefix + returnVal + 后缀 这样的方式得到实际的物理视图,然后做转发操作
* WEB-INF/views/success.jsp
* @return
*/
@RequestMapping("/helloword")
public String hello() {
System.out.println("hello world, spirngmvc");
return "success";
}
}
```
## 5.配置beans.xml或者springDispatcherServlet-servlet.xml
```
<!-- 配置视图解析器 -->
<bean class="org.springframework.web.servlet.view.InternalResourceViewResolver">
<property name="prefix" value="/WEB-INF/views/"></property>
<property name="suffix" value=".jsp"></property>
</bean>
```
## 6. mvn compile编译代码
## 7. mvn package生成war包 | 1,881 | MIT |
---
title: L1-020 帅到没朋友
author: saltycat
date: 2022-04-13 17:16:12 +0800
categories: [题解,PAT]
tags: [格式化输出]
math: true
comments: true
mermaid: true
typora-root-url: ../../sa1tycat.github.io
---
# [L1-020 帅到没朋友](https://pintia.cn/problem-sets/994805046380707840/problems/994805117167976448)
## Description
当芸芸众生忙着在朋友圈中发照片的时候,总有一些人因为太帅而没有朋友。本题就要求你找出那些帅到没有朋友的人。
## Input
输入第一行给出一个正整数 $N(≤100)$,是已知朋友圈的个数;随后 $N$ 行,每行首先给出一个正整数 $K(≤1000)$,为朋友圈中的人数,然后列出一个朋友圈内的所有人——为方便起见,每人对应一个ID号,为 $5$ 位数字(从 $00000$ 到 $99999$ ),ID间以空格分隔;之后给出一个正整数 $M(≤10000)$,为待查询的人数;随后一行中列出 $M$ 个待查询的ID,以空格分隔。
注意:没有朋友的人可以是根本没安装“朋友圈”,也可以是只有自己一个人在朋友圈的人。虽然有个别自恋狂会自己把自己反复加进朋友圈,但题目保证所有K超过1的朋友圈里都至少有2个不同的人。
## Output
按输入的顺序输出那些帅到没朋友的人。ID间用1个空格分隔,行的首尾不得有多余空格。如果没有人太帅,则输出`No one is handsome`。
注意:同一个人可以被查询多次,但只输出一次。
## Sample Input 1
```
3
3 11111 22222 55555
2 33333 44444
4 55555 66666 99999 77777
8
55555 44444 10000 88888 22222 11111 23333 88888
```
## Sample Output 1
```
10000 88888 23333
```
## Sample Input 2
```
3
3 11111 22222 55555
2 33333 44444
4 55555 66666 99999 77777
4
55555 44444 22222 11111
```
## Sample Output 2
```
No one is handsome
```
## 分析
根据题意,只需找出帅到没朋友的人满足以下:
- 没有在任何朋友圈中出现过
- 朋友圈仅有他一人(本来可以是朋友圈有多人且全是他自己,但根据题目保证所有K超过1的朋友圈里都至少有2个不同的人,因此这种情况下就是 $k=1$)
但是要注意 ID 的编号方式,如 0 应该输出为 `00000`。
### 实现方法1
数组模拟实现,用数组 `f[]` 来储存是否出现过,没有出现过或朋友圈仅一人,值为 0,否则为 1。
注意输出时候,首先要格式化输出五位数字,即 `"%05d"`,其次避免重复输出。
### 实现方法2
利用set避免重复输出(set 只能储存一个相同元素)。定义两个集合 s,s1,前者用于储存有朋友的人的 id,后者用于储存已输出的 id。
`cout<<setw(5)<<setfill('0')<<id` 保证了是五位数输出。
## 代码
### 数组模拟
```c++
#include<cstdio>
#include<cstring>
#define MAXN 99999+6
using namespace std;
bool f[MAXN],v[MAXN];
int main(){
int n,k,m,id;
memset(f,0,sizeof(f));
memset(v,0,sizeof(v));
scanf("%d",&n);
while(n--){
scanf("%d",&k);
for(int i=1;i<=k;i++){
scanf("%d",&id);
if(k==1&&!f[id]){
break;
}
f[id]=1;
}
}
scanf("%d",&k);
bool start=1;
while(k--){
scanf("%d",&id);
if(!f[id]&&!v[id]){
v[id]=1;
if(start){
printf("%05d",id);
start=0;
}
else{
printf(" %05d",id);
}
}
}
if(start){
printf("No one is handsome");
}
return 0;
}
```
### set实现
```c++
/*
author: This is pioneer
source: https://blog.csdn.net/mizifor666/article/details/107218013
*/
#include <iostream>
#include <set>
#include <iomanip>
using namespace std;
int main()
{
int n;//n个朋友圈
cin>>n;
int k;//某朋友圈的好友个数
int id;//好友id
int m;//查询人数
int num=0;//handsome人数
set<int> s,s1;//s存储朋友圈id,s1存储答案id
for(int i=0;i<n;i++)
{
cin>>k;
if(k>=2)//2人以上
{
for(int j=0;j<k;j++)
{
cin>>id;
s.insert(id);
}
}
else//单个人不加入set,因为查询到他时他直接为帅到没朋友
cin>>id;
}
cin>>m;
for(int i=0;i<m;i++)
{
cin>>id;
if(s.find(id)==s.end()&&s1.find(id)==s1.end())//有朋友的id和已输出的id中无该id
{
if(num!=0)
cout<<' ';
s1.insert(id);
cout<<setw(5)<<setfill('0')<<id;//保证id为五位
num++;
}
}
if(num==0)
cout<<"No one is handsome";
return 0;
}
``` | 3,150 | MIT |
##### `RACSignalSequence`作为`RACSequence`的子类,提供了一个方法通过`RACSignal`初始化一个`RACSequence`。
完整测试用例[在这里](https://github.com/jianghui1/TestRACSignalSequence)。
查看`.m`中的方法:
+ (RACSequence *)sequenceWithSignal:(RACSignal *)signal {
RACSignalSequence *seq = [[self alloc] init];
RACReplaySubject *subject = [RACReplaySubject subject];
[signal subscribeNext:^(id value) {
[subject sendNext:value];
} error:^(NSError *error) {
[subject sendError:error];
} completed:^{
[subject sendCompleted];
}];
seq->_subject = subject;
return seq;
}
方法中初始化`RACSignalSequence` `RACReplaySubject`对象,并对参数`signal`完成了订阅,此时通过`RACReplaySubject`保存信号的信息。所以,通过`seq`可以获取`signal`的所有信息。
测试用例:
- (void)test_sequenceWithSignal
{
RACSignal *signal = [RACSignal createSignal:^RACDisposable *(id<RACSubscriber> subscriber) {
[subscriber sendNext:@"1"];
[subscriber sendCompleted];
return nil;
}];
RACSequence *sequence = [RACSignalSequence sequenceWithSignal:signal];
NSLog(@"sequenceWithSignal -- %@", sequence);
// 打印日志:
/*
2018-08-17 17:08:33.093062+0800 TestRACSignalSequence[50146:18295650] sequenceWithSignal -- <RACSignalSequence: 0x60400023fe80>{ name = , values = (
1
) … }
*/
}
***
- (id)head {
id value = [self.subject firstOrDefault:self];
if (value == self) {
return nil;
} else {
return value ?: NSNull.null;
}
}
通过`firstOrDefault:`获取`subject`的第一个值,作为`head`值。
测试用例:
- (void)test_head
{
RACSignal *signal = [RACSignal createSignal:^RACDisposable *(id<RACSubscriber> subscriber) {
[subscriber sendNext:@"1"];
[subscriber sendCompleted];
return nil;
}];
RACSequence *sequence = [RACSignalSequence sequenceWithSignal:signal];
NSLog(@"head -- %@", sequence.head);
// 打印日志:
/*
2018-08-17 17:10:39.537477+0800 TestRACSignalSequence[50245:18302711] head -- 1
*/
}
***
- (RACSequence *)tail {
RACSequence *sequence = [self.class sequenceWithSignal:[self.subject skip:1]];
sequence.name = self.name;
return sequence;
}
通过`skip:1`获取信号除去第一个值之后的信号,并通过`sequenceWithSignal:`生成一个`RACSequence`对象作为`tail`值。
测试用例:
- (void)test_tail
{
RACSignal *signal = [RACSignal createSignal:^RACDisposable *(id<RACSubscriber> subscriber) {
[subscriber sendNext:@"1"];
[subscriber sendNext:@"2"];
[subscriber sendCompleted];
return nil;
}];
RACSequence *sequence = [RACSignalSequence sequenceWithSignal:signal];
NSLog(@"tail -- %@", sequence.tail);
// 打印日志:
/*
2018-08-17 17:12:54.839794+0800 TestRACSignalSequence[50350:18310055] tail -- <RACSignalSequence: 0x60400023c820>{ name = , values = (
2
) … }
*/
}
***
- (NSArray *)array {
return self.subject.toArray;
}
通过`toArray`获取到信号值组成的数组。
测试用例:
- (void)test_array
{
RACSignal *signal = [RACSignal createSignal:^RACDisposable *(id<RACSubscriber> subscriber) {
[subscriber sendNext:@"1"];
[subscriber sendNext:@"2"];
[subscriber sendCompleted];
return nil;
}];
RACSequence *sequence = [RACSignalSequence sequenceWithSignal:signal];
NSLog(@"array -- %@", sequence.array);
// 打印日志:
/*
2018-08-17 17:17:30.637284+0800 TestRACSignalSequence[50521:18323552] array -- (
1,
2
)
*/
}
***
格式化日志方法不再分析。
##### 所以,这个类的功能就是将一个信号转换成一个序列,通过序列的方法获取信号的值。 | 3,947 | MIT |
---
layout: post
title: "NFS安装"
date: 2019-04-24 17:38:32
categories: [linux,ubuntu]
excerpt_separator: <!--more-->
---
NFS(Network File System)即网络文件系统,是FreeBSD支持的文件系统中的一种,它允许网络中的计算机之间通过TCP/IP网络共享资源。在NFS的应用中,本地NFS的客户端应用可以透明地读写位于远端NFS服务器上的文件,就像访问本地文件一样。
<!--more-->
<!-- @import "[TOC]" {cmd="toc" depthFrom=1 depthTo=6 orderedList=false} -->
<!-- code_chunk_output -->
* [nfs服务安装s](#nfs服务安装s)
* [1. 概述](#1-概述)
* [2. CentOS/RHEL安装NFS](#2-centosrhel安装nfs)
* [3. Ubuntu/Debian安装NFS](#3-ubuntudebian安装nfs)
<!-- /code_chunk_output -->
## 1. 概述
NFS(Network File System)即网络文件系统,是FreeBSD支持的文件系统中的一种,它允许网络中的计算机之间通过TCP/IP网络共享资源。在NFS的应用中,本地NFS的客户端应用可以透明地读写位于远端NFS服务器上的文件,就像访问本地文件一样。
k8s可以使用nfs进行持久化存储。
## 2. CentOS/RHEL安装NFS
* 安装NFS服务
服务器端:
```bash
yum install rpcbind nfs-utils -y
```
客户端:
```shell
yum install nfs-common -y
```
* 编辑NFS配置
```bash
vim /etc/exports
```
```text
/home/storage *(rw,sync,no_root_squash,no_subtree_check)
```
* 启动NFS服务
```bash
systemctl start rpcbind nfs
```
* 确认NFS成功运行
```bash
rpcinfo -p | grep nfs
```
* NFS客户端查看服务
```bash
showmount -e 192.168.1.192
```
## 3. Ubuntu/Debian安装NFS
* 安装NFS服务
服务器端:
```shell
sudo apt install nfs-kernel-server rpcbind -y
```
客户端:
```shell
sudo apt install nfs-common
```
* 编辑NFS配置
```bash
vim /etc/exports
```
```text
/home/storage *(rw,sync,no_root_squash,no_subtree_check)
```
* 重启NFS服务
```bash
systemctl restart nfs-kernel-server
```
* 启动NFS客户端
```bash
systemctl start rpcbind
```
* 确认NFS成功运行
```bash
rpcinfo -p | grep nfs
```
* NFS客户端查看服务
```bash
showmount -e 192.168.1.192
``` | 1,583 | MIT |
---
layout: post
title: OpenResty Api - req api
category: NGINX
tags: NGINX,OpenResty,C,Lua
keywords: NGINX,OpenResty,C,Lua
description:
---
## 一 概述
`ngx.req` 主要围绕对请求头、请求 `uri`、请求参数、请求包体、请求连接 `socket`、请求方法等进行操作。
## 二 请求头相关
包含 `ngx.req.http_version`、 `ngx.req.raw_header`、 `ngx.req.clear_header`、 `ngx.req.set_header`、 `ngx.req.get_headers` 操作函数。
### 1. `ngx.req.http_version`
功能:获得请求使用的 `HTTP` 协议版本号,返回数值类型(`0.9`、`1.0`、`1.1`、`2.0`),客户端发起请求时会将协议版本号放在请求行中。出错会返回 `nil`。
### 2. `ngx.req.raw_header`
```lua
str = ngx.req.raw_header(no_request_line?)
```
功能:用来获取 `NGINX` 收到的原始请求头,返回字符串。可选布尔类型参数 `no_request_line` 用来控制是否返回请求行。
介入阶段: set_by_lua*, rewrite_by_lua*, access_by_lua*, content_by_lua*, header_filter_by_lua
示例:
```lua
ngx.print(ngx.req.raw_header())
```
输出如下:
```
GET /t HTTP/1.1
Host: localhost
Connection: close
Foo: bar
```
如果 `no_request_line` 为 `true` 时输出如下:
```
Host: localhost
Connection: close
Foo: bar
```
### 3. `ngx.req.clear_header`
```lua
ngx.req.clear_header(header_name)
```
清除请求头中名为 `header_name` 的头。`clear_header` 的实现与 `set_header` 方法实现相同,只不过 `clear_header` 设置的值为 `nil`。`clear_header` 实现:
```c
static int
ngx_http_lua_ngx_req_header_clear(lua_State *L)
{
// 参数检查,只有一个参数(header_name)
if (lua_gettop(L) != 1) {
return luaL_error(L, "expecting one arguments, but seen %d",
lua_gettop(L));
}
// 向栈中压入 nil
lua_pushnil(L);
return ngx_http_lua_ngx_req_header_set_helper(L);
}
// 函数主要功能是将 header 的 key、value 获取出来,再调用最终保存函数
static int
ngx_http_lua_ngx_req_header_set_helper(lua_State *L)
{
// ... 参数检查
// http 0.9 无 header
if (r->http_version < NGX_HTTP_VERSION_10) {
return 0;
}
// 获得 header 名
p = (u_char *) luaL_checklstring(L, 1, &len);
key.data = ngx_palloc(r->pool, len + 1);
if (key.data == NULL) {
return luaL_error(L, "no memory");
}
ngx_memcpy(key.data, p, len);
key.data[len] = '\0';
key.len = len;
// 获得 header 值
if (lua_type(L, 2) == LUA_TNIL) {
ngx_str_null(&value);
} else if (lua_type(L, 2) == LUA_TTABLE) {
n = luaL_getn(L, 2);
if (n == 0) {
ngx_str_null(&value);
} else {
// 使用数组设置 header
for (i = 1; i <= n; i++) {
dd("header value table index %d, top: %d", (int) i,
lua_gettop(L));
// 取出数组中的元素放在栈顶
lua_rawgeti(L, 2, i);
// 从栈顶取 header 值
p = (u_char *) luaL_checklstring(L, -1, &len);
/*
* we also copy the trailling '\0' char here because nginx
* header values must be null-terminated
* */
value.data = ngx_palloc(r->pool, len + 1);
if (value.data == NULL) {
return luaL_error(L, "no memory");
}
ngx_memcpy(value.data, p, len + 1);
value.len = len;
rc = ngx_http_lua_set_input_header(r, key, value,
i == 1 /* override */);
if (rc == NGX_ERROR) {
return luaL_error(L,
"failed to set header %s (error: %d)",
key.data, (int) rc);
}
}
return 0;
}
} else {
/*
* we also copy the trailling '\0' char here because nginx
* header values must be null-terminated
* */
p = (u_char *) luaL_checklstring(L, 2, &len);
value.data = ngx_palloc(r->pool, len + 1);
if (value.data == NULL) {
return luaL_error(L, "no memory");
}
ngx_memcpy(value.data, p, len + 1);
value.len = len;
}
dd("key: %.*s, value: %.*s",
(int) key.len, key.data, (int) value.len, value.data);
// 保存 header 到请求中
rc = ngx_http_lua_set_input_header(r, key, value, 1 /* override */);
if (rc == NGX_ERROR) {
return luaL_error(L, "failed to set header %s (error: %d)",
key.data, (int) rc);
}
return 0;
}
```
上面两个函数做了 `header` 保存的准备工作,将 `header` 的 `key`、`value` 提取出来,调用 `ngx_http_lua_set_input_header` 对 `header` 进行操作。`lua-nginx` 模块对常见或特殊 `header` 有特殊操作(因为这些 `header` 保存位置或者同时需要更新其他信息),将其保存在一张操作表中(`ngx_http_lua_set_handlers`),表中最后一个元素是通用的 `header` 处理。实现:
```c
static ngx_http_lua_set_header_t ngx_http_lua_set_handlers[] = {
{ ngx_string("Host"),
offsetof(ngx_http_headers_in_t, host),
ngx_http_set_host_header },
// ... 省略其他常见或特殊 header
{ ngx_null_string, 0, ngx_http_set_header }
};
ngx_int_t
ngx_http_lua_set_input_header(ngx_http_request_t *r, ngx_str_t key,
ngx_str_t value, unsigned override)
{
ngx_http_lua_header_val_t hv;
ngx_http_lua_set_header_t *handlers = ngx_http_lua_set_handlers;
ngx_uint_t i;
dd("set header value: %.*s", (int) value.len, value.data);
hv.hash = ngx_hash_key_lc(key.data, key.len);
hv.key = key;
hv.offset = 0;
hv.no_override = !override;
hv.handler = NULL;
// 遍历 ngx_http_lua_set_handlers 数组,查找是否是设置预定义 header
for (i = 0; handlers[i].name.len; i++) {
if (hv.key.len != handlers[i].name.len
|| ngx_strncasecmp(hv.key.data, handlers[i].name.data,
handlers[i].name.len) != 0)
{
dd("hv key comparison: %s <> %s", handlers[i].name.data,
hv.key.data);
continue;
}
dd("Matched handler: %s %s", handlers[i].name.data, hv.key.data);
hv.offset = handlers[i].offset;
hv.handler = handlers[i].handler;
break;
}
// 未找到,使用 ngx_http_lua_set_handlers 数组末尾元素进行存储调用
if (handlers[i].name.len == 0 && handlers[i].handler) {
hv.offset = handlers[i].offset; // 0
hv.handler = handlers[i].handler; // ngx_http_set_header
}
#if 1
if (hv.handler == NULL) {
return NGX_ERROR;
}
#endif
return hv.handler(r, &hv, &value);
}
```
### 4. `ngx.req.set_headr`
```lua
ngx.req.set_header(header_name, header_value)
```
将当前请求中名为 `header_name` 的头设置为 `header_value`,如果 `header_name` 已经存在则覆盖原有值。如果 `header_value` 为 `nil` 功能与 `clear_header` 相同。`header_value` 可以为 `array table`。
`set_header` 的实现与 `clear_header` 相似,只是其检查函数不同。
### 5. `ngx.req.get_headers`
```lua
headers, err = ngx.req.get_headers(max_headers?, raw?)
```
返回一个包含所有 `header` 的 `table`,可选数值参数 `max_headers` 用来控制获取的 `header` 数量(其实是 `header_value` 的数量,因为在请求中每个 `header_value` 是一 `header`),默认 100。可选布尔类型参数 `raw` 用来控制返回 `table` 是否有元方法,默认 `false`。
实现函数:
```c
static int
ngx_http_lua_ngx_req_get_headers(lua_State *L)
{
// ... 忽略参数定义
// 获得调用参数梳理
n = lua_gettop(L);
// 取调用参数 max、raw
if (n >= 1) {
if (lua_isnil(L, 1)) {
max = NGX_HTTP_LUA_MAX_HEADERS;
} else {
max = luaL_checkinteger(L, 1);
}
if (n >= 2) {
raw = lua_toboolean(L, 2);
}
} else {
max = NGX_HTTP_LUA_MAX_HEADERS;
}
r = ngx_http_lua_get_req(L);
if (r == NULL) {
return luaL_error(L, "no request object found");
}
ngx_http_lua_check_fake_request(L, r);
// 计算 header 总数
part = &r->headers_in.headers.part;
count = part->nelts;
while (part->next) {
part = part->next;
count += part->nelts;
}
if (max > 0 && count > max) {
count = max;
ngx_log_debug1(NGX_LOG_DEBUG_HTTP, r->connection->log, 0,
"lua exceeding request header limit %d", max);
}
// 创建返回 table,根据 raw 参数设置 table 的元表(有 index 元方法)
lua_createtable(L, 0, count);
if (!raw) {
lua_pushlightuserdata(L, &ngx_http_lua_headers_metatable_key);
lua_rawget(L, LUA_REGISTRYINDEX);
lua_setmetatable(L, -2);
}
// 遍历 header,将其保存到新创建的 table 中
part = &r->headers_in.headers.part;
header = part->elts;
for (i = 0; /* void */; i++) {
dd("stack top: %d", lua_gettop(L));
if (i >= part->nelts) {
if (part->next == NULL) {
break;
}
part = part->next;
header = part->elts;
i = 0;
}
if (raw) {
lua_pushlstring(L, (char *) header[i].key.data, header[i].key.len);
} else {
lua_pushlstring(L, (char *) header[i].lowcase_key,
header[i].key.len);
}
/* stack: table key */
lua_pushlstring(L, (char *) header[i].value.data,
header[i].value.len); /* stack: table key value */
ngx_http_lua_set_multi_value_table(L, -3);
ngx_log_debug2(NGX_LOG_DEBUG_HTTP, r->connection->log, 0,
"lua request header: \"%V: %V\"",
&header[i].key, &header[i].value);
if (--count == 0) {
return 1;
}
}
return 1;
}
```
## 三 请求 `uri`
### 1. `ngx.req.set_uri`
```lua
ngx.req.set_uri(uri, jump?)
```
使用字符串参数 `uri` 重写请求的 `uri`,`uri` 如果非字符串或者字符串长度为零会触发错误。可选布尔参数 `jump` 控制是否进行内部跳转(重新在当前 `server{}` 内进行 `location` 查找)。**`set_uri` 无法修改 `uri` 参数,需要使用 `ngx.req.set_uri_args` 修改参数**。
函数 `ngx_http_lua_ngx_req_set_uri` 是 `set_uri` 的实现函数,在其中修改了请求的 `uri` 以及 `uri_changed` 状态变量,实际的跳转功能是在协程处理循环中实现。
```c
static int
ngx_http_lua_ngx_req_set_uri(lua_State *L)
{
// ... 省略无关代码
// 参数数量获取
n = lua_gettop(L);
if (n != 1 && n != 2) {
return luaL_error(L, "expecting 1 or 2 arguments but seen %d", n);
}
// 获取 uri
p = (u_char *) luaL_checklstring(L, 1, &len);
if (len == 0) {
return luaL_error(L, "attempt to use zero-length uri");
}
// 是否跳转标识
if (n == 2) {
luaL_checktype(L, 2, LUA_TBOOLEAN);
jump = lua_toboolean(L, 2);
if (jump) {
ctx = ngx_http_get_module_ctx(r, ngx_http_lua_module);
if (ctx == NULL) {
return luaL_error(L, "no ctx found");
}
// 阶段检查
ngx_http_lua_check_context(L, ctx, NGX_HTTP_LUA_CONTEXT_REWRITE);
ngx_http_lua_check_if_abortable(L, ctx);
}
}
// uri 更新
r->uri.data = ngx_palloc(r->pool, len);
if (r->uri.data == NULL) {
return luaL_error(L, "no memory");
}
ngx_memcpy(r->uri.data, p, len);
r->uri.len = len;
r->internal = 1;
r->valid_unparsed_uri = 0;
ngx_http_set_exten(r);
// 跳转标识,在协程处理循环中会使用
if (jump) {
r->uri_changed = 1;
return lua_yield(L, 0);
}
r->valid_location = 0;
r->uri_changed = 0;
return 0;
}
```
## 四 请求参数
### 1. `ngx.req.set_uri_args`
```lua
ngx.req.set_uri_args(args)
```
使用 `args` 参数重写当前请求的 `uri` 查询参数,`args` 可以是字符串也可以是 `table`。如果使用 `table` 会将参数进行 `uri_encode`(其实是调用 `ngx.encode_args` 将 `args` 编码为字符串)。`set_uri_args` 实现函数:
```c
static int
ngx_http_lua_ngx_req_set_uri_args(lua_State *L)
{
// ... 省略其他代码
// 参数检查
if (lua_gettop(L) != 1) {
return luaL_error(L, "expecting 1 argument but seen %d", lua_gettop(L));
}
r = ngx_http_lua_get_req(L);
if (r == NULL) {
return luaL_error(L, "no request object found");
}
ngx_http_lua_check_fake_request(L, r);
// 获取 args
switch (lua_type(L, 1)) {
case LUA_TNUMBER:
case LUA_TSTRING:
p = (u_char *) lua_tolstring(L, 1, &len);
args.data = ngx_palloc(r->pool, len);
if (args.data == NULL) {
return luaL_error(L, "no memory");
}
ngx_memcpy(args.data, p, len);
args.len = len;
break;
case LUA_TTABLE:
ngx_http_lua_process_args_option(r, L, 1, &args);
dd("args: %.*s", (int) args.len, args.data);
break;
default:
msg = lua_pushfstring(L, "string, number, or table expected, "
"but got %s", luaL_typename(L, 2));
return luaL_argerror(L, 1, msg);
}
dd("args: %.*s", (int) args.len, args.data);
// 更新 args
r->args.data = args.data;
r->args.len = args.len;
r->valid_unparsed_uri = 0;
return 0;
}
```
### 2. `ngx.req.get_uri_args`
```lua
args, err = ngx.req.get_uri_args(max_args?)
```
返回一个包含当前请求 `URL` 参数的 `table`。可选数值参数 `max_args` 用来控制返回参数个数,默认为 100,修改为 0 则无限制。
当请求行为 `GET /test?foo=bar&bar=baz&bar=blah` 时,获得的 `table` 为:
```lua
{foo="bar", bar={"baz", "blah"}}
```
当请求行为 `GET /test?foo&bar` 时,获得的 `table` 为:
```lua
{foo=true, bar=true}
```
当请求行为 `GET /test?foo=&bar=` 时,获得的 `table` 为:
```lua
{foo="", bar=""}
```
实现函数:
```c
static int
ngx_http_lua_ngx_req_get_uri_args(lua_State *L)
{
// ... 省略无关代码
// 获得调用参数数量
n = lua_gettop(L);
if (n != 0 && n != 1) {
return luaL_error(L, "expecting 0 or 1 arguments but seen %d", n);
}
if (n == 1) {
max = luaL_checkinteger(L, 1);
lua_pop(L, 1);
} else {
max = NGX_HTTP_LUA_MAX_ARGS;
}
r = ngx_http_lua_get_req(L);
if (r == NULL) {
return luaL_error(L, "no request object found");
}
ngx_http_lua_check_fake_request(L, r);
if (r->args.len == 0) {
lua_createtable(L, 0, 0);
return 1;
}
/* we copy r->args over to buf to simplify
* unescaping query arg keys and values */
// 获得请求参数
buf = ngx_palloc(r->pool, r->args.len);
if (buf == NULL) {
return luaL_error(L, "no memory");
}
// 保存 args 的 table
lua_createtable(L, 0, 4);
ngx_memcpy(buf, r->args.data, r->args.len);
last = buf + r->args.len;
// 将请求参数进行解析并保存到 table 中
// 会对参数名和参数值进行 url decode
retval = ngx_http_lua_parse_args(L, buf, last, max);
ngx_pfree(r->pool, buf);
return retval;
}
```
### 3. `ngx.req.get_post_args`
```lua
args, err = ngx.req.get_post_args(max_args?)
```
返回包含当前请求 POST 查询参数的 `table`,调用前需要调用 `ngx.req.read_body` 函数或者通过 `lua_need_request_body` 读取请求包体。可选数值参数 `max_args` 用来控制返回参数个数,默认为 100,修改为 0 则无限制。实现:
```c
static int
ngx_http_lua_ngx_req_get_post_args(lua_State *L)
{
// ... 忽略无关代码
// 获得调用参数个数
n = lua_gettop(L);
if (n != 0 && n != 1) {
return luaL_error(L, "expecting 0 or 1 arguments but seen %d", n);
}
// 参数检查
if (n == 1) {
max = luaL_checkinteger(L, 1);
lua_pop(L, 1);
} else {
max = NGX_HTTP_LUA_MAX_ARGS;
}
r = ngx_http_lua_get_req(L);
if (r == NULL) {
return luaL_error(L, "no request object found");
}
ngx_http_lua_check_fake_request(L, r);
// 已经丢弃请求包体
if (r->discard_body) {
lua_createtable(L, 0, 0);
return 1;
}
if (r->request_body == NULL) {
return luaL_error(L, "no request body found; "
"maybe you should turn on lua_need_request_body?");
}
// 请求包体存储在临时文件中,不能使用 get_post_args
if (r->request_body->temp_file) {
lua_pushnil(L);
lua_pushliteral(L, "requesty body in temp file not supported");
return 2;
}
if (r->request_body->bufs == NULL) {
lua_createtable(L, 0, 0);
return 1;
}
/* we copy r->request_body->bufs over to buf to simplify
* unescaping query arg keys and values */
// 读取请求包体
len = 0;
for (cl = r->request_body->bufs; cl; cl = cl->next) {
len += cl->buf->last - cl->buf->pos;
}
if (len == 0) {
lua_createtable(L, 0, 0);
return 1;
}
buf = ngx_palloc(r->pool, len);
if (buf == NULL) {
return luaL_error(L, "no memory");
}
lua_createtable(L, 0, 4);
p = buf;
for (cl = r->request_body->bufs; cl; cl = cl->next) {
p = ngx_copy(p, cl->buf->pos, cl->buf->last - cl->buf->pos);
}
dd("post body: %.*s", (int) len, buf);
last = buf + len;
// 解析请求包体
retval = ngx_http_lua_parse_args(L, buf, last, max);
ngx_pfree(r->pool, buf);
return retval;
}
```
如果在 `NGINX` 配置中将请求包体保存在临时文件中,不能使用 `get_post_args` 函数。同时,`get_post_args` 会对参数名、参数值进行 `url` 解码处理。
## 五 请求体
### 1. `ngx.req.read_body`
```lua
ngx.req.read_body()
```
同步非阻塞的读取请求体,同步的意思是请求头读取完毕后返回,非阻塞的意思是不会将整个处理进程 `hang` 住,当无可读数据时会处理其他协程。实现:
```c
static int
ngx_http_lua_ngx_req_read_body(lua_State *L)
{
// ... 忽略无关代码
// 参数检查
n = lua_gettop(L);
if (n != 0) {
return luaL_error(L, "expecting 0 arguments but seen %d", n);
}
r = ngx_http_lua_get_req(L);
if (r == NULL) {
return luaL_error(L, "request object not found");
}
r->request_body_in_single_buf = 1;
r->request_body_in_persistent_file = 1;
r->request_body_in_clean_file = 1;
#if 1
if (r->request_body_in_file_only) {
r->request_body_file_log_level = 0;
}
#endif
ctx = ngx_http_get_module_ctx(r, ngx_http_lua_module);
if (ctx == NULL) {
return luaL_error(L, "no ctx found");
}
ngx_http_lua_check_context(L, ctx, NGX_HTTP_LUA_CONTEXT_REWRITE
| NGX_HTTP_LUA_CONTEXT_ACCESS
| NGX_HTTP_LUA_CONTEXT_CONTENT);
coctx = ctx->cur_co_ctx;
if (coctx == NULL) {
return luaL_error(L, "no co ctx found");
}
ngx_log_debug0(NGX_LOG_DEBUG_HTTP, r->connection->log, 0,
"lua start to read buffered request body");
// 读请求包体
rc = ngx_http_read_client_request_body(r, ngx_http_lua_req_body_post_read);
#if (nginx_version < 1002006) || \
(nginx_version >= 1003000 && nginx_version < 1003009)
r->main->count--;
#endif
if (rc >= NGX_HTTP_SPECIAL_RESPONSE) {
ctx->exit_code = rc;
ctx->exited = 1;
ngx_log_debug1(NGX_LOG_DEBUG_HTTP, r->connection->log, 0,
"http read client request body returned error code %i, "
"exitting now", rc);
return lua_yield(L, 0);
}
#if (nginx_version >= 1002006 && nginx_version < 1003000) || \
nginx_version >= 1003009
r->main->count--;
dd("decrement r->main->count: %d", (int) r->main->count);
#endif
if (rc == NGX_AGAIN) {
ngx_log_debug0(NGX_LOG_DEBUG_HTTP, r->connection->log, 0,
"lua read buffered request body requires I/O "
"interruptions");
ctx->waiting_more_body = 1;
ctx->downstream = coctx;
ngx_http_lua_cleanup_pending_operation(coctx);
coctx->cleanup = ngx_http_lua_req_body_cleanup;
coctx->data = r;
return lua_yield(L, 0);
}
/* rc == NGX_OK */
ngx_log_debug0(NGX_LOG_DEBUG_HTTP, r->connection->log, 0,
"lua has read buffered request body in a single run");
return 0;
}
```
### 2. `ngx.req.discard_body`
```lua
ngx.req.discard_body()
```
丢弃请求包体,读取连接上的请求数据,并立即丢弃。函数是异步调用,立即返回。如果已经读取请求包体,函数无影响立即返回。实现:
```c
static int
ngx_http_lua_ngx_req_discard_body(lua_State *L)
{
// ... 忽略无关代码
// 参数判断
n = lua_gettop(L);
if (n != 0) {
return luaL_error(L, "expecting 0 arguments but seen %d", n);
}
r = ngx_http_lua_get_req(L);
if (r == NULL) {
return luaL_error(L, "request object not found");
}
ngx_http_lua_check_fake_request(L, r);
// 丢弃处理
rc = ngx_http_discard_request_body(r);
if (rc == NGX_ERROR || rc >= NGX_HTTP_SPECIAL_RESPONSE) {
return luaL_error(L, "failed to discard request body");
}
return 0;
}
ngx_int_t
ngx_http_discard_request_body(ngx_http_request_t *r)
{
// ... 忽略无关代码
#if (NGX_HTTP_V2)
if (r->stream) {
r->stream->skip_data = 1;
return NGX_OK;
}
#endif
if (ngx_http_test_expect(r) != NGX_OK) {
return NGX_HTTP_INTERNAL_SERVER_ERROR;
}
rev = r->connection->read;
ngx_log_debug0(NGX_LOG_DEBUG_HTTP, rev->log, 0, "http set discard body");
if (rev->timer_set) {
ngx_del_timer(rev);
}
if (r->headers_in.content_length_n <= 0 && !r->headers_in.chunked) {
return NGX_OK;
}
size = r->header_in->last - r->header_in->pos;
if (size || r->headers_in.chunked) {
rc = ngx_http_discard_request_body_filter(r, r->header_in);
if (rc != NGX_OK) {
return rc;
}
if (r->headers_in.content_length_n == 0) {
return NGX_OK;
}
}
rc = ngx_http_read_discarded_request_body(r);
if (rc == NGX_OK) {
r->lingering_close = 0;
return NGX_OK;
}
if (rc >= NGX_HTTP_SPECIAL_RESPONSE) {
return rc;
}
/* rc == NGX_AGAIN */
// 设置处理函数为丢弃请求数据
r->read_event_handler = ngx_http_discarded_request_body_handler;
if (ngx_handle_read_event(rev, 0) != NGX_OK) {
return NGX_HTTP_INTERNAL_SERVER_ERROR;
}
r->count++;
r->discard_body = 1;
return NGX_OK;
}
```
### 3. `ngx.req.get_body_data`
```lua
data = ngx.req.get_body_data()
```
获取存储在内存中的请求体数据,返回字符串。为了正确使用函数的功能,需要保证调用前已经使用 `ngx.req.read_body` 或者通过配置 `lua_need_request_body` 读取请求包体;同时,请求包体使用内存存储而非存储在临时文件中(通过配置实现)。
在 `NGINX` 配置指令中,`client_body_buffer_size` 配置指令用来控制接收包体内存缓冲区的大小,`client_max_body_size` 用来控制可以接收的最大包体限制。如果两者相同,接收的请求包体必定在内存中,使用 `ngx.req.get_body_data` 可以将请求数据读取出来。
```c
static int
ngx_http_lua_ngx_req_get_body_data(lua_State *L)
{
// ... 忽略无关代码
// 参数判断
n = lua_gettop(L);
if (n != 0) {
return luaL_error(L, "expecting 0 arguments but seen %d", n);
}
r = ngx_http_lua_get_req(L);
if (r == NULL) {
return luaL_error(L, "request object not found");
}
ngx_http_lua_check_fake_request(L, r);
// 无请求包体、请求包体存储在临时文件中,返回 nil
if (r->request_body == NULL
|| r->request_body->temp_file
|| r->request_body->bufs == NULL)
{
lua_pushnil(L);
return 1;
}
// 请求包体在一个 buf 中存储,直接使用 buf 生成 lua string
cl = r->request_body->bufs;
if (cl->next == NULL) {
len = cl->buf->last - cl->buf->pos;
if (len == 0) {
lua_pushnil(L);
return 1;
}
lua_pushlstring(L, (char *) cl->buf->pos, len);
return 1;
}
/* found multi-buffer body */
// 需要遍历 chain,计算长度、并分配缓冲区,将所有的 buf 拷贝在一起,返回 string
len = 0;
for (; cl; cl = cl->next) {
dd("body chunk len: %d", (int) ngx_buf_size(cl->buf));
len += cl->buf->last - cl->buf->pos;
}
if (len == 0) {
lua_pushnil(L);
return 1;
}
buf = (u_char *) lua_newuserdata(L, len);
p = buf;
for (cl = r->request_body->bufs; cl; cl = cl->next) {
p = ngx_copy(p, cl->buf->pos, cl->buf->last - cl->buf->pos);
}
lua_pushlstring(L, (char *) buf, len);
return 1;
}
```
### 4. `ngx.req.get_body_file`
```lua
file_name = ngx.req.get_body_file()
```
获得使用临时文件存储请求体的文件名。与 `ngx.req.get_body_data` 函数相似,需要使用 `ngx.req.read_body` 或 `lua_need_request_body` 配置读取包体。
使用 `NGINX` 配置指令 `client_body_in_file_only` 可以将请求包体保存在临时文件中。
```c
static int
ngx_http_lua_ngx_req_get_body_file(lua_State *L)
{
// 参数判断
n = lua_gettop(L);
if (n != 0) {
return luaL_error(L, "expecting 0 arguments but seen %d", n);
}
r = ngx_http_lua_get_req(L);
if (r == NULL) {
return luaL_error(L, "request object not found");
}
ngx_http_lua_check_fake_request(L, r);
if (r->request_body == NULL || r->request_body->temp_file == NULL) {
lua_pushnil(L);
return 1;
}
// 返回文件名
lua_pushlstring(L, (char *) r->request_body->temp_file->file.name.data,
r->request_body->temp_file->file.name.len);
return 1;
}
```
### 5. `ngx.req.set_body_data`
```lua
ngx.set_body_data(data)
```
使用 `data` 参数指定当前请求的请求体。函数调用前需要读取请求包体(包体存储在内存或者文件无所谓),函数会将原始请求清理(释放内存、请求临时文件设置清理回调函数)。
```c
static int
ngx_http_lua_ngx_req_set_body_data(lua_State *L)
{
// 参数判断
n = lua_gettop(L);
if (n != 1) {
return luaL_error(L, "expecting 1 arguments but seen %d", n);
}
// 要设置的包体
body.data = (u_char *) luaL_checklstring(L, 1, &body.len);
r = ngx_http_lua_get_req(L);
if (r == NULL) {
return luaL_error(L, "request object not found");
}
ngx_http_lua_check_fake_request(L, r);
// 已经执行 discard_body
if (r->discard_body) {
return luaL_error(L, "request body already discarded asynchronously");
}
// 未读入请求体
if (r->request_body == NULL) {
return luaL_error(L, "request body not read yet");
}
rb = r->request_body;
tag = (ngx_buf_tag_t) &ngx_http_lua_module;
// 临时文件清理函数
tf = rb->temp_file;
if (tf) {
if (tf->file.fd != NGX_INVALID_FILE) {
dd("cleaning temp file %.*s", (int) tf->file.name.len,
tf->file.name.data);
ngx_http_lua_pool_cleanup_file(r->pool, tf->file.fd);
tf->file.fd = NGX_INVALID_FILE;
dd("temp file cleaned: %.*s", (int) tf->file.name.len,
tf->file.name.data);
}
rb->temp_file = NULL;
}
if (body.len == 0) {
// 释放原始 buf 缓冲区
if (rb->bufs) {
for (cl = rb->bufs; cl; cl = cl->next) {
if (cl->buf->tag == tag && cl->buf->temporary) {
dd("free old request body buffer: size:%d",
(int) ngx_buf_size(cl->buf));
ngx_pfree(r->pool, cl->buf->start);
cl->buf->tag = (ngx_buf_tag_t) NULL;
cl->buf->temporary = 0;
}
}
}
rb->bufs = NULL;
rb->buf = NULL;
dd("request body is set to empty string");
goto set_header;
}
if (rb->bufs) {
// 释放原始缓冲区
for (cl = rb->bufs; cl; cl = cl->next) {
if (cl->buf->tag == tag && cl->buf->temporary) {
dd("free old request body buffer: size:%d",
(int) ngx_buf_size(cl->buf));
ngx_pfree(r->pool, cl->buf->start);
cl->buf->tag = (ngx_buf_tag_t) NULL;
cl->buf->temporary = 0;
}
}
// 创建一块新的缓冲区,用来存储新设置的包体
rb->bufs->next = NULL;
b = rb->bufs->buf;
ngx_memzero(b, sizeof(ngx_buf_t));
b->temporary = 1;
b->tag = tag;
b->start = ngx_palloc(r->pool, body.len);
if (b->start == NULL) {
return luaL_error(L, "no memory");
}
b->end = b->start + body.len;
b->pos = b->start;
b->last = ngx_copy(b->pos, body.data, body.len);
} else {
// 创建缓冲区存储新设置的包体
rb->bufs = ngx_alloc_chain_link(r->pool);
if (rb->bufs == NULL) {
return luaL_error(L, "no memory");
}
rb->bufs->next = NULL;
b = ngx_create_temp_buf(r->pool, body.len);
if (b == NULL) {
return luaL_error(L, "no memory");
}
b->tag = tag;
b->last = ngx_copy(b->pos, body.data, body.len);
rb->bufs->buf = b;
rb->buf = b;
}
set_header:
// 更新 content-length 头
/* override input header Content-Length (value must be null terminated) */
value.data = ngx_palloc(r->pool, NGX_SIZE_T_LEN + 1);
if (value.data == NULL) {
return luaL_error(L, "no memory");
}
value.len = ngx_sprintf(value.data, "%uz", body.len) - value.data;
value.data[value.len] = '\0';
dd("setting request Content-Length to %.*s (%d)",
(int) value.len, value.data, (int) body.len);
r->headers_in.content_length_n = body.len;
if (r->headers_in.content_length) {
r->headers_in.content_length->value.data = value.data;
r->headers_in.content_length->value.len = value.len;
} else {
ngx_str_set(&key, "Content-Length");
rc = ngx_http_lua_set_input_header(r, key, value, 1 /* override */);
if (rc != NGX_OK) {
return luaL_error(L, "failed to reset the Content-Length "
"input header");
}
}
return 0;
}
```
### 6. `ngx.req.set_body_file`
```lua
ngx.req.set_body_file(file_name, auto_clean?)
```
使用 `file_name` 参数指定的文件作为请求体,可选布尔类型参数 `auto_clean` 用来控制释放需要自动清理文件(默认为 `false`)。函数调用前需要读取请求包体(包体存储在内存或者文件无所谓),函数会将原始请求清理(释放内存、请求临时文件设置清理回调函数)。
```c
static int
ngx_http_lua_ngx_req_set_body_file(lua_State *L)
{
// ... 省略无关代码
// 参数检查
n = lua_gettop(L);
if (n != 1 && n != 2) {
return luaL_error(L, "expecting 1 or 2 arguments but seen %d", n);
}
// 文件名
p = (u_char *) luaL_checklstring(L, 1, &name.len);
r = ngx_http_lua_get_req(L);
if (r == NULL) {
return luaL_error(L, "no request found");
}
ngx_http_lua_check_fake_request(L, r);
// 是否丢弃了请求体
if (r->discard_body) {
return luaL_error(L, "request body already discarded asynchronously");
}
// 是否未读取请求体
if (r->request_body == NULL) {
return luaL_error(L, "request body not read yet");
}
// 文件名
name.data = ngx_palloc(r->pool, name.len + 1);
if (name.data == NULL) {
return luaL_error(L, "no memory");
}
ngx_memcpy(name.data, p, name.len);
name.data[name.len] = '\0';
// 自动清理
if (n == 2) {
luaL_checktype(L, 2, LUA_TBOOLEAN);
clean = lua_toboolean(L, 2);
} else {
clean = 0;
}
dd("clean: %d", (int) clean);
rb = r->request_body;
/* clean up existing r->request_body->bufs (if any) */
tag = (ngx_buf_tag_t) &ngx_http_lua_module;
if (rb->bufs) {
dd("XXX reusing buf");
// 释放缓冲区
for (cl = rb->bufs; cl; cl = cl->next) {
if (cl->buf->tag == tag && cl->buf->temporary) {
dd("free old request body buffer: size:%d",
(int) ngx_buf_size(cl->buf));
ngx_pfree(r->pool, cl->buf->start);
cl->buf->tag = (ngx_buf_tag_t) NULL;
cl->buf->temporary = 0;
}
}
rb->bufs->next = NULL;
b = rb->bufs->buf;
ngx_memzero(b, sizeof(ngx_buf_t));
b->tag = tag;
rb->buf = NULL;
} else {
dd("XXX creating new buf");
rb->bufs = ngx_alloc_chain_link(r->pool);
if (rb->bufs == NULL) {
return luaL_error(L, "no memory");
}
rb->bufs->next = NULL;
b = ngx_calloc_buf(r->pool);
if (b == NULL) {
return luaL_error(L, "no memory");
}
b->tag = tag;
rb->bufs->buf = b;
rb->buf = NULL;
}
b->last_in_chain = 1;
/* just make r->request_body->temp_file a bare stub */
tf = rb->temp_file;
if (tf) {
// 原始的临时文件清理
if (tf->file.fd != NGX_INVALID_FILE) {
dd("cleaning temp file %.*s", (int) tf->file.name.len,
tf->file.name.data);
ngx_http_lua_pool_cleanup_file(r->pool, tf->file.fd);
ngx_memzero(tf, sizeof(ngx_temp_file_t));
tf->file.fd = NGX_INVALID_FILE;
dd("temp file cleaned: %.*s", (int) tf->file.name.len,
tf->file.name.data);
}
} else {
tf = ngx_pcalloc(r->pool, sizeof(ngx_temp_file_t));
if (tf == NULL) {
return luaL_error(L, "no memory");
}
tf->file.fd = NGX_INVALID_FILE;
rb->temp_file = tf;
}
/* read the file info and construct an in-file buf */
// 打开新的文件
ngx_memzero(&of, sizeof(ngx_open_file_info_t));
of.directio = NGX_OPEN_FILE_DIRECTIO_OFF;
if (ngx_http_lua_open_and_stat_file(name.data, &of, r->connection->log)
!= NGX_OK)
{
return luaL_error(L, "%s \"%s\" failed", of.failed, name.data);
}
dd("XXX new body file fd: %d", of.fd);
tf->file.fd = of.fd;
tf->file.name = name;
tf->file.log = r->connection->log;
tf->file.directio = 0;
if (of.size == 0) {
// 设置自动清理,在此处已经删除了文件,
// 只不过进程持有文件描述符,文件的 inode 被删除,但是文件内容还在。
if (clean) {
if (ngx_delete_file(name.data) == NGX_FILE_ERROR) {
err = ngx_errno;
if (err != NGX_ENOENT) {
ngx_log_error(NGX_LOG_CRIT, r->connection->log, err,
ngx_delete_file_n " \"%s\" failed",
name.data);
}
}
}
if (ngx_close_file(of.fd) == NGX_FILE_ERROR) {
ngx_log_error(NGX_LOG_ALERT, r->connection->log, ngx_errno,
ngx_close_file_n " \"%s\" failed", name.data);
}
r->request_body->bufs = NULL;
r->request_body->buf = NULL;
goto set_header;
}
/* register file cleanup hook */
cln = ngx_pool_cleanup_add(r->pool,
sizeof(ngx_pool_cleanup_file_t));
if (cln == NULL) {
return luaL_error(L, "no memory");
}
cln->handler = clean ? ngx_pool_delete_file : ngx_pool_cleanup_file;
clnf = cln->data;
clnf->fd = of.fd;
clnf->name = name.data;
clnf->log = r->pool->log;
b->file = &tf->file;
if (b->file == NULL) {
return NGX_HTTP_INTERNAL_SERVER_ERROR;
}
dd("XXX file size: %d", (int) of.size);
b->file_pos = 0;
b->file_last = of.size;
b->in_file = 1;
dd("buf file: %p, f:%u", b->file, b->in_file);
set_header:
/* override input header Content-Length (value must be null terminated) */
// 设置 content-length 头
value.data = ngx_palloc(r->pool, NGX_OFF_T_LEN + 1);
if (value.data == NULL) {
return luaL_error(L, "no memory");
}
value.len = ngx_sprintf(value.data, "%O", of.size) - value.data;
value.data[value.len] = '\0';
r->headers_in.content_length_n = of.size;
if (r->headers_in.content_length) {
r->headers_in.content_length->value.data = value.data;
r->headers_in.content_length->value.len = value.len;
} else {
ngx_str_set(&key, "Content-Length");
rc = ngx_http_lua_set_input_header(r, key, value, 1 /* override */);
if (rc != NGX_OK) {
return luaL_error(L, "failed to reset the Content-Length "
"input header");
}
}
return 0;
}
```
### 7. `ngx.req.init_body`
```lua
ngx.req.init_body(buffer_size?)
```
为当前请求创建一个新的空白请求体,后续可以通过 `ngx.req.append_body`、 `ngx.req.finish_body` 向缓冲区写数据。可选参数 `buffer_size` 用来控制初始化缓冲区的大小,其默认值为 `client_body_buffer_size` 指令设置的大小。
在使用 `ngx.req.append_body` 写请求数据上,如果缓冲区超过了 `buffer_size` 大小,会将请求数据完整的写到临时文件中。
```c
static int
ngx_http_lua_ngx_req_init_body(lua_State *L)
{
// check arg number
n = lua_gettop(L);
if (n != 1 && n != 0) {
return luaL_error(L, "expecting 0 or 1 argument but seen %d", n);
}
r = ngx_http_lua_get_req(L);
if (r == NULL) {
return luaL_error(L, "no request found");
}
ngx_http_lua_check_fake_request(L, r);
// should not discard body
if (r->discard_body) {
return luaL_error(L, "request body already discarded asynchronously");
}
// should read in body data
if (r->request_body == NULL) {
return luaL_error(L, "request body not read yet");
}
// has buffer_size param
if (n == 1) {
num = luaL_checkinteger(L, 1);
if (num < 0) {
return luaL_error(L, "bad size argument: %d", (int) num);
}
size = (size_t) num;
} else {
// get location's client_body_buffer_size conf size
clcf = ngx_http_get_module_loc_conf(r, ngx_http_core_module);
size = clcf->client_body_buffer_size;
}
// save request data in temp file
if (size == 0) {
r->request_body_in_file_only = 1;
}
rb = r->request_body;
#if 1
tf = rb->temp_file;
if (tf) {
// add indenpent clean up handler original request body temp file
if (tf->file.fd != NGX_INVALID_FILE) {
dd("cleaning temp file %.*s", (int) tf->file.name.len,
tf->file.name.data);
ngx_http_lua_pool_cleanup_file(r->pool, tf->file.fd);
ngx_memzero(tf, sizeof(ngx_temp_file_t));
tf->file.fd = NGX_INVALID_FILE;
dd("temp file cleaned: %.*s", (int) tf->file.name.len,
tf->file.name.data);
}
rb->temp_file = NULL;
}
#endif
r->request_body_in_clean_file = 1;
r->headers_in.content_length_n = 0;
// alloc new body data buf size
rb->buf = ngx_create_temp_buf(r->pool, size);
if (rb->buf == NULL) {
return luaL_error(L, "no memory");
}
rb->bufs = ngx_alloc_chain_link(r->pool);
if (rb->bufs == NULL) {
return luaL_error(L, "no memory");
}
rb->bufs->buf = rb->buf;
rb->bufs->next = NULL;
return 0;
}
```
### 8. `ngx.req.append_body`
```lua
ngx.req.append_body(data_chunk)
```
将 `data_chunk` 参数指定的新数据块添加到当前请求的请求包体中,请求包体必须要由 `ngx.req.init_body` 创建(使用 `ngx.req.get_body_data` 虽然获取了请求包体,但是包体缓冲区链表最后指向的是 `NULL` 无法直接使用)。
```c
static int
ngx_http_lua_ngx_req_append_body(lua_State *L)
{
ngx_http_request_t *r;
int n;
ngx_http_request_body_t *rb;
ngx_str_t body;
size_t size, rest;
size_t offset = 0;
ngx_chain_t chain;
ngx_buf_t buf;
// check arg number
n = lua_gettop(L);
if (n != 1) {
return luaL_error(L, "expecting 1 arguments but seen %d", n);
}
// data chunk param
body.data = (u_char *) luaL_checklstring(L, 1, &body.len);
r = ngx_http_lua_get_req(L);
if (r == NULL) {
return luaL_error(L, "no request found");
}
ngx_http_lua_check_fake_request(L, r);
// must have request_body
// and requst_body_buf has buf
if (r->request_body == NULL
|| r->request_body->buf == NULL
|| r->request_body->bufs == NULL)
{
return luaL_error(L, "request_body not initialized");
}
// write into temp file
if (r->request_body_in_file_only) {
buf.start = body.data;
buf.pos = buf.start;
buf.last = buf.start + body.len;
buf.end = buf.last;
buf.temporary = 1;
chain.buf = &buf;
chain.next = NULL;
if (ngx_http_lua_write_request_body(r, &chain) != NGX_OK) {
return luaL_error(L, "fail to write file");
}
r->headers_in.content_length_n += body.len;
return 0;
}
// write into memory buf
rb = r->request_body;
rest = body.len;
while (rest > 0) {
if (rb->buf->last == rb->buf->end) {
if (ngx_http_lua_write_request_body(r, rb->bufs) != NGX_OK) {
return luaL_error(L, "fail to write file");
}
rb->buf->last = rb->buf->start;
}
size = rb->buf->end - rb->buf->last;
if (size > rest) {
size = rest;
}
ngx_memcpy(rb->buf->last, body.data + offset, size);
rb->buf->last += size;
rest -= size;
offset += size;
r->headers_in.content_length_n += size;
}
return 0;
}
```
### 9. `ngx.req.finish_body`
```lua
ngx.req.finish_body()
```
构建请求包体完成操作,如果使用临时文件存储请求数据,将缓冲区中数据写入临时文件,更新 `content-length` 头。
```c
static int
ngx_http_lua_ngx_req_body_finish(lua_State *L)
{
// ... omit
n = lua_gettop(L);
if (n != 0) {
return luaL_error(L, "expecting 0 argument but seen %d", n);
}
r = ngx_http_lua_get_req(L);
if (r == NULL) {
return luaL_error(L, "no request found");
}
ngx_http_lua_check_fake_request(L, r);
if (r->request_body == NULL
|| r->request_body->buf == NULL
|| r->request_body->bufs == NULL)
{
return luaL_error(L, "request_body not initialized");
}
rb = r->request_body;
if (rb->temp_file) {
/* save the last part */
if (ngx_http_lua_write_request_body(r, rb->bufs) != NGX_OK) {
return luaL_error(L, "fail to write file");
}
b = ngx_calloc_buf(r->pool);
if (b == NULL) {
return luaL_error(L, "no memory");
}
b->in_file = 1;
b->file_pos = 0;
b->file_last = rb->temp_file->file.offset;
b->file = &rb->temp_file->file;
if (rb->bufs->next) {
rb->bufs->next->buf = b;
} else {
rb->bufs->buf = b;
}
}
/* override input header Content-Length (value must be null terminated) */
// update content-length header
value.data = ngx_palloc(r->pool, NGX_SIZE_T_LEN + 1);
if (value.data == NULL) {
return luaL_error(L, "no memory");
}
size = (size_t) r->headers_in.content_length_n;
value.len = ngx_sprintf(value.data, "%uz", size) - value.data;
value.data[value.len] = '\0';
dd("setting request Content-Length to %.*s (%d)", (int) value.len,
value.data, (int) size);
if (r->headers_in.content_length) {
r->headers_in.content_length->value.data = value.data;
r->headers_in.content_length->value.len = value.len;
} else {
ngx_str_set(&key, "Content-Length");
rc = ngx_http_lua_set_input_header(r, key, value, 1 /* override */);
if (rc != NGX_OK) {
return luaL_error(L, "failed to reset the Content-Length "
"input header");
}
}
return 0;
}
```
## 六 请求套接字
### 1. `ngx.req.socket`
```lua
tcpsock, err = ngx.req.socket(raw)
```
返回与客户端之间只读的 `cosocket`,只支持 `receive` 和 `receiveuntil` 函数。出错返回 `nil`,以及错误描述字符串。
使用 `cosocket` 可以使用流方式读取请求包体,不过不能与 `ngx.req.read_body`、`ngx.req.discard_body` 混用(`lua_need_request_body` 指令同样不能使用)。**不支持 `chunked` 传输编码**。
可选布尔参数 `raw` 用来控制是否返回原始套接字,如果为 `true` 将返回全双工的套接字,支持 `receive`、`receiveuntil`、`send` 函数。全双工的套接字需要保证无输出缓存数据(由 `ngx.say`、`ngx.print` 产生),可以在调用 `ngx.req.socket` 前调用 `ngx.flush(true)` 刷出待输出数据。
**不支持 `HTTP2`、`SPDY` 协议**。
```c
static int
ngx_http_lua_req_socket(lua_State *L)
{
// ... omit other code
n = lua_gettop(L);
if (n == 0) {
raw = 0;
} else if (n == 1) {
raw = lua_toboolean(L, 1);
lua_pop(L, 1);
} else {
return luaL_error(L, "expecting zero arguments, but got %d",
lua_gettop(L));
}
r = ngx_http_lua_get_req(L);
if (r != r->main) {
return luaL_error(L, "attempt to read the request body in a "
"subrequest");
}
#if nginx_version >= 1003009
if (!raw && r->headers_in.chunked) {
lua_pushnil(L);
lua_pushliteral(L, "chunked request bodies not supported yet");
return 2;
}
#endif
ctx = ngx_http_get_module_ctx(r, ngx_http_lua_module);
if (ctx == NULL) {
return luaL_error(L, "no ctx found");
}
ngx_http_lua_check_context(L, ctx, NGX_HTTP_LUA_CONTEXT_REWRITE
| NGX_HTTP_LUA_CONTEXT_ACCESS
| NGX_HTTP_LUA_CONTEXT_CONTENT);
c = r->connection;
if (raw) {
#if !defined(nginx_version) || nginx_version < 1003013
lua_pushnil(L);
lua_pushliteral(L, "nginx version too old");
return 2;
#else
if (r->request_body) {
if (r->request_body->rest > 0) {
lua_pushnil(L);
lua_pushliteral(L, "pending request body reading in some "
"other thread");
return 2;
}
} else {
rb = ngx_pcalloc(r->pool, sizeof(ngx_http_request_body_t));
if (rb == NULL) {
return luaL_error(L, "no memory");
}
r->request_body = rb;
}
if (c->buffered & NGX_HTTP_LOWLEVEL_BUFFERED) {
lua_pushnil(L);
lua_pushliteral(L, "pending data to write");
return 2;
}
if (ctx->buffering) {
lua_pushnil(L);
lua_pushliteral(L, "http 1.0 buffering");
return 2;
}
if (!r->header_sent) {
/* prevent other parts of nginx from sending out
* the response header */
r->header_sent = 1;
}
ctx->header_sent = 1;
dd("ctx acquired raw req socket: %d", ctx->acquired_raw_req_socket);
if (ctx->acquired_raw_req_socket) {
lua_pushnil(L);
lua_pushliteral(L, "duplicate call");
return 2;
}
ctx->acquired_raw_req_socket = 1;
r->keepalive = 0;
r->lingering_close = 1;
#endif
} else {
/* request body reader */
if (r->request_body) {
lua_pushnil(L);
lua_pushliteral(L, "request body already exists");
return 2;
}
if (r->discard_body) {
lua_pushnil(L);
lua_pushliteral(L, "request body discarded");
return 2;
}
dd("req content length: %d", (int) r->headers_in.content_length_n);
if (r->headers_in.content_length_n <= 0) {
lua_pushnil(L);
lua_pushliteral(L, "no body");
return 2;
}
// 对 except 请求头处理
if (ngx_http_lua_test_expect(r) != NGX_OK) {
lua_pushnil(L);
lua_pushliteral(L, "test expect failed");
return 2;
}
/* prevent other request body reader from running */
rb = ngx_pcalloc(r->pool, sizeof(ngx_http_request_body_t));
if (rb == NULL) {
return luaL_error(L, "no memory");
}
rb->rest = r->headers_in.content_length_n;
r->request_body = rb;
}
// 元表: receive、receiveuntil、send、send 元表
lua_createtable(L, 3 /* narr */, 1 /* nrec */); /* the object */
if (raw) {
lua_pushlightuserdata(L, &ngx_http_lua_raw_req_socket_metatable_key);
} else {
lua_pushlightuserdata(L, &ngx_http_lua_req_socket_metatable_key);
}
lua_rawget(L, LUA_REGISTRYINDEX);
lua_setmetatable(L, -2);
// 创建 cosocket
u = lua_newuserdata(L, sizeof(ngx_http_lua_socket_tcp_upstream_t));
if (u == NULL) {
return luaL_error(L, "no memory");
}
#if 1
lua_pushlightuserdata(L, &ngx_http_lua_downstream_udata_metatable_key);
lua_rawget(L, LUA_REGISTRYINDEX);
lua_setmetatable(L, -2);
#endif
lua_rawseti(L, 1, SOCKET_CTX_INDEX);
ngx_memzero(u, sizeof(ngx_http_lua_socket_tcp_upstream_t));
if (raw) {
u->raw_downstream = 1;
} else {
u->body_downstream = 1;
}
coctx = ctx->cur_co_ctx;
u->request = r;
llcf = ngx_http_get_module_loc_conf(r, ngx_http_lua_module);
u->conf = llcf;
// 超时时间
u->read_timeout = u->conf->read_timeout;
u->connect_timeout = u->conf->connect_timeout;
u->send_timeout = u->conf->send_timeout;
// 清理函数
cln = ngx_http_lua_cleanup_add(r, 0);
if (cln == NULL) {
u->ft_type |= NGX_HTTP_LUA_SOCKET_FT_ERROR;
lua_pushnil(L);
lua_pushliteral(L, "no memory");
return 2;
}
cln->handler = ngx_http_lua_socket_tcp_cleanup;
cln->data = u;
u->cleanup = &cln->handler;
// 与客户端的网络连接
pc = &u->peer;
pc->log = c->log;
pc->log_error = NGX_ERROR_ERR;
pc->connection = c;
dd("setting data to %p", u);
coctx->data = u;
ctx->downstream = u;
// 删除读超时定时器
if (c->read->timer_set) {
ngx_del_timer(c->read);
}
if (raw) {
if (c->write->timer_set) {
// 删除写超时定时器
ngx_del_timer(c->write);
}
}
lua_settop(L, 1);
return 1;
}
```
## 七 请求方法
### 1. `ngx.req.get_method`
```lua
method_name = ngx.req.get_method()
```
获得当前请求的请求方法,返回值为字符串类型,子请求会返回相应子请求的方法。
### 2. `ngx.req.set_method`
```lua
ngx.req.set_method(method_id)
```
设置当前请求的请求方法,参数为数值类型。可选参数:
```lua
ngx.HTTP_GET
ngx.HTTP_HEAD
ngx.HTTP_PUT
ngx.HTTP_POST
ngx.HTTP_DELETE
ngx.HTTP_OPTIONS (added in the v0.5.0rc24 release)
ngx.HTTP_MKCOL (added in the v0.8.2 release)
ngx.HTTP_COPY (added in the v0.8.2 release)
ngx.HTTP_MOVE (added in the v0.8.2 release)
ngx.HTTP_PROPFIND (added in the v0.8.2 release)
ngx.HTTP_PROPPATCH (added in the v0.8.2 release)
ngx.HTTP_LOCK (added in the v0.8.2 release)
ngx.HTTP_UNLOCK (added in the v0.8.2 release)
ngx.HTTP_PATCH (added in the v0.8.2 release)
ngx.HTTP_TRACE (added in the v0.8.2 release)
```
## 八 请求时间
### 1. `ngx.req.start_time`
```lua
secs = ngx.req.start_time()
```
返回当前请求创建的时间戳,浮点类型数值,精确到毫秒级。
## 九 内部请求判断
### 1. `ngx.req.is_internal`
```lua
is_internal = ngx.req.is_internal()
```
判断当前请求是否是内部请求。 | 48,610 | MIT |
<!--
@author: harold.duan
@date: 18-06-01
@memo: Notes logging
-->
# Mac Notes
``` Comments
Ctrl + Left/Right : 左右切换屏幕
Ctrl + Up/Down : 开启/关闭 屏幕管理器
```
# iTerm2 Notes
``` Comments
Command + Enter : 切换全屏
Alt + Command + Up/Down/Left/Right : 切换分屏
```
# Xcode Notes
``` Comments
Command + / : (取消)注释
Command + Option + / : 标柱
Command + Left/Right : 行首/尾
Command + Up/Down : 文首/末
Ctrl + I : 格式化代码
Command + Option + Left/Right : 折叠/展开代码
Shift + Command + Option + Left/Right : 全局折叠/展开代码
Ctrl + Shift + Command + Left/Right : 折叠/展开代码(/**/之间的代码)
``` | 550 | MIT |
---
layout: post
title: "危机关头,政治关系很值钱"
date: 2014-11-28
author: 张跃然
from: http://cnpolitics.org/2014/11/value-of-connections-in-turbulent-times/
tags: [ 政見 ]
categories: [ 政見 ]
---
<div class="post-block">
<h1 class="post-head">
危机关头,政治关系很值钱
</h1>
<p class="post-subhead">
</p>
<p class="post-tag">
</p>
<p class="post-author">
<!--a href="http://cnpolitics.org/author/zhangyueran/">张跃然</a-->
<a href="http://cnpolitics.org/author/zhangyueran/">
张跃然
</a>
<span style="font-size:14px;color:#b9b9b9;">
|2014-11-28
</span>
</p>
<!--p class="post-lead">在经济危机爆发、政府官员权力暂时变大的时候,即使在美国,政治关系也依然能带来显著的经济回报。</p-->
<div class="post-body">
<figure>
<img alt="Pakistan B" src="http://cnpolitics.org/wp-content/uploads/2014/11/unnamed-19.jpg" width="566"/>
</figure>
<p>
政治关系能否为市场中的个体带来经济回报?政见团队的《
<a href="http://cnpolitics.org/2014/10/political-connection/">
“搞关系”究竟是不是全世界的通病?
</a>
》一文曾经指出,在美国这样制度体系完善的国家,政治关系不具经济价值。然而麻省理工学院经济学教授
<strong>
Daron Acemoglu
</strong>
及合作者新近的一篇论文表明,至少在经济危机爆发、政府官员权力暂时变大的时候,即使在美国,政治关系也依然能带来显著的经济回报。
</p>
<p>
2008年下半年,正是美国经济前景最为暗淡的时候。11月21日,坊间流出传闻,新当选的总统奥巴马拟提名盖特纳为新一任财政部长。11月24日,奥巴马确认了对盖特纳的提名。在这一消息传出之后,市场是否对那些和盖特纳有联系的金融企业做出了格外积极的回应?
</p>
<p>
回答这一问题的关键,自然是对那些与盖特纳有联系的金融企业和其他企业进行比较,观察它们在提名消息传出后一段时间内的股票收益率是否有显著不同。但其中的难点在于,与盖特纳有联系的企业和那些没有联系的企业相比,很可能是两类具有本质性不同的公司——这其中的本质差异,多半无法体现在公司规模、投资偏好、盈利状况等可观测的指标上。在这种情况下,即使我们发现了两类公司在盖特纳获得提名后的股票收益率存在差异,也不能断定这就是“和盖特纳有没有私下关系”这一因素——而非其他不可观测的“本质”差异——导致的。从数据分析技术上说,无论是回归分析还是倾向分数匹配,都无法很好地解决这个问题。
</p>
<p>
因此,研究者采用了一种叫做synthetic matching(虚构匹配)的方法。这其中的基本逻辑是,不将“实验组”(和盖特纳有联系的公司)和“对照组”(和盖特纳没联系的公司)进行直接对比,而是对于实验组中的每一个公司个体,都通过将对照组中全部公司进行加权平均的方式构造出一个“虚拟”的“对照公司”,使得实验个体和虚拟的对照个体在过去的各方面市场行为、趋势上达到最大程度的相似性。当我们为每一个实验个体都构造了这么一个虚拟的对照个体后,我们就获得了一个新的对照组,从而可以和实验组比较,看两组公司在盖特纳提名后的股票收益率是否有区别。这一方法的目的,是通过让被互相比较的公司在过往市场行为、趋势上尽可能相似,从而在一定程度上排除影响这些行为、趋势的不可观测因素的干扰。
</p>
<p>
运用这一方法,研究者发现,在盖特纳提名消息传出后的一个交易日内,和盖特纳有联系的金融企业在股市上的累积超额收益率整体为6%,在十个交易日内,这个数字达到了12%。换句话说,和盖特纳有联系的公司确实从提名消息中显著获益。而在2009年1月份,当盖特纳传出逃税丑闻、为其提名被参议院批准的前景蒙上阴影之时,这些公司的股票表现出了短暂而明显的疲软。在改换变量的测量方式、剔除极端样本、以及进行若干证伪检验(falsification tests)后,研究者的数据分析结果依然和上述发现吻合。
</p>
<p>
那么,导致上述发现成立的具体机制是什么呢?需要注意的是,这些公司的股市起伏都发生在盖特纳正式就任美国财长之前,因此和盖特纳本人的施政行为没有关系。换句话说,是市场预期盖特纳就任财长后其施政行为会额外惠及和他有联系的公司。这又是为何?市场根据什么这样认为?
</p>
<p>
研究者认为,市场之所以产生这样的预期,并不是因为美国制度体系长期存在漏洞或者认定盖特纳一定会贪污腐败,而是危机时期的特殊表现。在严峻的金融危机面前,美国国会通过的救市法案使得财政部在执行救市计划时获得空前的自由裁量权。而与此同时,在危机面前,盖特纳对于应该如何施政的不确定性也会增加。在这种情况下,盖特纳必然会一方面依赖于关系熟络的“智囊团”的建议,一方面从其信任的旧友中聘任若干人员助其行政——两方面一结合,就为那些和盖特纳有故交的公司影响政策执行、多为自身争取利益提供了渠道。危机关头,行动要紧,速度第一,因此财政部的行为难免缺少制衡和监督,而这些行为在危机环境中又恰恰具备不同往常的巨大影响力。因此,政治联系此时展现出的显著经济价值,源自市场对“危机时期财政部权力暂时大增”这一事实的判断。
</p>
<p>
因此,这一研究的发现并不和之前的许多研究发现冲突——它恰恰说明了,在制度相对完善的国家,政治关系有没有经济价值并不能一概而论,而要看具体的经济社会环境。在政局稳定、没有危机的情况下,制度限制确实能比较好的杜绝权钱互惠的情况。然而,在严重危机面前,某些部门和官员自由裁量权变大,制衡监督机制变弱,政治关系的价值就显现了出来。
</p>
<p>
虽然中国和美国的政治制度环境天差地别,但这一研究发现对于认识中国当下的政治经济生态似乎也有一定借鉴意义。每当经济运行出现危机时,政治权力对于资源分配的作用和市场活动的干预程度提升,与权力的关系也就更可能转化为经济利益。这一视角,尤其有助于我们理解中国在2008-2009救市时期“四万亿”金融资源分配过程中出现的一些乱象。
</p>
<div class="post-endnote">
<h4>
参考文献
</h4>
<ul>
<li>
Acemoglu, D., Johnson, S., Kermani, A., Kwak, J., & Mitton, T. (2013). The Value of connections in turbulent times: Evidence from the United States. NBER Working Paper No. 19701.
</li>
</ul>
</div>
</div>
<!-- icon list -->
<!--/div-->
<!-- social box -->
<div class="post-end-button back-to-top">
<p style="padding-top:20px;">
回到开头
</p>
</div>
<div id="display_bar">
<img src="http://cnpolitics.org/wp-content/themes/CNPolitics/images/shadow-post-end.png"/>
</div>
</div> | 3,584 | MIT |
# UIImage
## 功能
- 颜色转图片、根据Url获取image信息、制作Pod库引用内容资源等
## 方法
```objective-c
/**
不对外使用
@param imageName 图片名
@param className 类名
@return image
*/
+ (UIImage *)loadBundleImage:(NSString *)imageName ClassName:(NSString *)className;
/**
返回一张不超过屏幕尺寸的 image
@param image 图片
@return 图片
*/
+ (UIImage *)wya_ImageSizeWithScreenImage:(UIImage *)image;
/**
将颜色转化为图片
@param color UIColor对象
@return Image对象
*/
+ (UIImage *)wya_createImageWithColor:(UIColor * _Nonnull)color;
/**
根据url获取图片信息
like this :{
ColorModel = RGB;
DPIHeight = 72;
DPIWidth = 72;
Depth = 8;
PixelHeight = 795;
PixelWidth = 1200;
"{JFIF}" = {
DensityUnit = 1;
JFIFVersion = (
1,
0,
1
);
XDensity = 72;
YDensity = 72;
};
@param urlString url
@return 信息
*/
+ (NSDictionary *)wya_imageInfoWithUrl:(NSString *)urlString;
- (nonnull UIImage *)croppedImageWithFrame:(CGRect)frame angle:(NSInteger)angle circularClip:(BOOL)circular;
/// 返回一张可拉伸的图片
+ (UIImage *)wya_resizeImageNamed:(NSString *)name;
/**
颜色生成图片是否需要切圆角
@param color 颜色
@param size 图片尺寸
@param rate 圆角系数为0不切圆角
@return 图片
*/
+ (UIImage *)wya_imageWithColor:(UIColor *)color size:(CGSize)size rate:(CGFloat)rate;
``` | 1,254 | MIT |
---
layout: post
title: Spring
tags: java
categories: backends
---
简介、耦合、控制反转、依赖注入、注解方式反转控制和依赖注入、Spring整合Junit、银行转账案例、代理、AOP面向切面编程、JDBCTemplate
**简介**
`1`核心内容
IOC反向控制、AOP面向切面编程
`2`优势
方便解耦,简化编程
AOP编程支持
声明式事务支持
方便程序的测试
方便集成各种优秀的框架
降低JAVAEE API的使用难度
JAVA源码是经典的学习范例
`3`四大核心容器
Beans、Core、Context、SpEL
---
**耦合**
程序间的依赖关系称为耦合。解耦就是降低程序间的依赖关系。
`1`解耦案例一
```java
DriverManager,registeDriver(new com.mysql.jdbc.Driver());
//编译依赖
class.forName("com.mysql.jdbc.Driver")
//运行依赖
//分析:如果删除掉com.mysql.jdbc.Driver文件,前者在编译时报错,后者在运行时报错
```
避免使用new关键字,通过读取配置文件来获取要创建对象的全类名,再使用反射来创建对象
`2`Bean的概念
Bean表示可重复使用的组件
JavaBean表示java语言编写的重复使用的组件
`3`工厂模式案例
1)Bean.properties
```
service1=services.service1
```
2)BeanFactory.java
```java
package client;
import java.io.IOException;
import java.io.InputStream;
import java.util.Enumeration;
import java.util.HashMap;
import java.util.Properties;
public class BeanFactory {
static private Properties properties;
static private HashMap<String,Object> map;
static {
try {
//读取配置文件
InputStream in=BeanFactory.class.getClassLoader ().getResourceAsStream ("Bean.properties");
properties=new Properties ();
properties.load (in);
//创建实例并放入容器中
Enumeration keys=properties.keys ();
map=new HashMap<String, Object> ();
while (keys.hasMoreElements ()){
String key=keys.nextElement ().toString ();
Object obj=Class.forName (properties.getProperty (key)).newInstance ();
map.put (key,obj);
}
} catch (IOException e) {
e.printStackTrace ( );
} catch (IllegalAccessException e) {
e.printStackTrace ( );
} catch (InstantiationException e) {
e.printStackTrace ( );
} catch (ClassNotFoundException e) {
e.printStackTrace ( );
}
}
public static Object getBean(String beanname){
return map.get (beanname);
}
}
```
3)clientMain
```java
package client;
import services.service1;
public class clientMain {
public static void main(String[] args) {
for (int i = 0; i <5 ; i++) {
service1 s=(service1) BeanFactory.getBean ("service1");
System.out.println (s);
s.service ();
}
}
}
//执行的是同一个实例的方法
```
---
**控制反转**
把创建对象的权力交给框架,此过程称为控制反转,是框架的重要特性,包括依赖注入、依赖查找
`1`Spring IOC的基本使用
1)pom文件
```xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.zhanghuan</groupId>
<artifactId>sprignioc</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<dependencies>
<dependency><!--导入相关依赖-->
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>5.2.5.RELEASE</version>
</dependency>
</dependencies>
</project>
```
2)beans配置文件
```xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<bean id="service1" class="services.service1"></bean>
</beans>
```
3)client.java
```java
package client;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import services.service1;
public class clientMain {
public static void main(String[] args) {
ApplicationContext ac=new ClassPathXmlApplicationContext ("beans.xml");
//创建Bean对象方式一
service1 s=(service1)ac.getBean ("service1");
//创建Bean对象方式二
service1 s1=ac.getBean ("service1",service1.class);
//总之,通过xml文件配置的id获取bean
s.service ();
s1.service ();
}
}
```
`2`ApplicationContext接口的3种实现类
| 实现类 | 传入配置文件特点 |
| ---------------------------------- | -------------------------------- |
| ClassPathXmlApplicationContext | 配置文件在类路径下 |
| FileSystemXmlApplicationContext | 配置文件在磁盘任意未知 |
| AnnotationConfigApplicationContext | 无配置文件,配置信息通过注解设置 |
`3`核心容器的接口
| 接口名 | 特点 |
| ------------------ | ---------------------------- |
| ApplicationContext | 读取完配置文件,立即创建对象 |
| BeanFactory | 读取完配置文件,延迟创建对象 |
常用的是ApplicationContext,可自动根据不同情况实现单例或多例模式
`4`创建Bean的三种方式
1)默认构造函数创建
```xml
<!--省略部分代码-->
<bean id="service1" class="services.service1"></bean>
```
如果对象无默认构造函数,则无法创建实例
2)使用工厂普通方法创建
```java
package services;
//这是工厂类
public class serviceFactory {
service1 build_service(){
return new service1 ();
}
}
```
```xml
<!--省略部分代码-->
<bean id="serviceFactory" class="services.serviceFactory"></bean>
<bean id="service_from_factory1" factory-bean="serviceFactory" factory-method="build_service"></bean>
```
3)使用工厂静态方法创建
```java
package services;
//这是工厂类
public class serviceStaticFactory {
static service1 build_service(){
return new service1 ();
}
}
```
```xml
<!--省略部分代码-->
<bean id="serviceStaticFactory" class="services.serviceStaticFactory" factory-method="build_service"></bean>
```
`5`bean标签的scope属性
| 属性名 | 说明 |
| -------------- | ------------------------ |
| singleton | 单例 |
| prototype | 多例 |
| request | 作用于web应用的请求范围 |
| session | 作用于会话的请求范围 |
| global-session | 作用于集群会话的请求范围 |
---
**依赖注入**
依赖关系的维护交给spring来做,此过程称为依赖注入。(创建对象的过程中,将参数传入,参数可能是其他对象,使得对象间产生依赖)
`1`可注入的类
基本类型和String类型
其他bean(配置文件中配置过的或注解配置过的bean)
复合类型/集合类型
> 注意
>
> 经常变化的不要注入
`2`注入方式
1)构造方法注入
```xml
<bean id="student" class="doMain.Student">
<constructor-arg name="id" value="1"></constructor-arg>
<constructor-arg name="male" value="男"></constructor-arg>
<constructor-arg name="name" value="zhanghuan"></constructor-arg>
<constructor-arg name="math" value="95"></constructor-arg>
<constructor-arg name="english" value="100"></constructor-arg>
</bean>
```
需要注意的是,doMain.Student类里必须要有对应参数的构造方法,否则无法注入,其本质是调用构造方法注入
constructor-arg标签的属性
| 属性 | 解释 |
| ----- | ------------------------------------------ |
| type | 要注入的参数的类型 |
| index | 要注入的参数的下标 |
| name | 要注入的参数的参数名 |
| value | 要注入的参数的值,支持字符串和数字 |
| ref | 要注入的参数的值,支持配置文件中的其他bean |
2)setter方法注入
```xml
<bean id="student" class="doMain.Student">
<property name="id" value="1"></property>
<property name="male" value="男"></property>
<property name="name" value="zhanghuan"></property>
<property name="math" value="95"></property>
<property name="english" value="100"></property>
</bean>
```
property 标签的属性
| 属性 | 解释 |
| ----- | ------------------------------------------ |
| name | 要注入的参数的参数名 |
| value | 要注入的参数的值,支持字符串和数字 |
| ref | 要注入的参数的值,支持配置文件中的其他bean |
复杂类型通过setter方法注入
```java
package doMain;
import java.util.List;
import java.util.Map;
//目标bean
public class LoveYou {
private List<Student> students;
private Map<String,String> map;
public List<Student> getStudents() {
return students;
}
public void setStudents(List<Student> students) {
this.students = students;
}
public Map<String, String> getMap() {
return map;
}
public void setMap(Map<String, String> map) {
this.map = map;
}
@Override
public String toString() {
return "LoveYou{" +
"students=" + students +
", map=" + map +
'}';
}
}
```
```xml
<bean id="loveyou" class="doMain.LoveYou">
<property name="students">
<list>
<ref bean="student"/>
<ref bean="student"/>
</list>
</property>
<property name="map">
<map>
<entry key="name" value="zhanghuan"></entry>
</map>
</property>
</bean>
```
列表类型数据可选标签:list,array,set
键值对数据可选标签:map,props
---
**注解方式反转控制和依赖注入**
`1`xml方式和注解方式对比
| 功能 | xml配置文件 | 注解 |
| -------------- | ------------------ | --------------------------------------- |
| 创建对象 | bean标签 | Component,Controller,Service,Repository |
| 注入依赖(数据) | property标签 | Autowired,Quqlifier,Resource,Value |
| 改变作用范围 | scope属性 | Scope |
| 生命周期相关 | init-method属性 | Postconstruct |
| | destroy-method属性 | PreDestroy |
`2`各注解功能
1)Component注解
用于把当前类对象存入spring容器中,属性value设置该bean的id,如果不设置默认为该类的小写名。Controller,Service,Repository和该注解的功能一样。
使用前需要在配置xml文件中进行如下配置
```xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<context:component-scan base-package="doMain"></context:component-scan>
<!--扫描文件夹,将里的类实例化后放入容器-->
</beans>
```
2)注入bean
(1)Autowired注解
指定注入依赖,可配置在类的变量上,也可配置在类的方法上。在变量上配置该注解后,该变量的setter方法可省去。注入的前提是,容器中有唯一一个bean对象和要注入的变量类型匹配,否则导致注入失败而报错。
(2)Qualifier注解
不可以单独使用,必须和Autowored合用,value属性值设置注入bean的id
(3)Resource注解
可单独使用,name属性值设置注入bean的id
> 注意
>
> 以上3中方式只可注入bean类型,无法注入基本类型和String类型,集合类型只能通过xml方式注入
3)注入基本类型和String类型
Value注解
其value属性值为要注入的基本类型和String类型数据,可以使用spring中的SpEl表达式
4)Scope注解
其value属性值为singleton和prototype,控制类的使用方式是单例还是多例
5)生命周期相关注解
Postconstruct注解和PreDestroy注解,主要在单例模式下使用,value值为指定的类的构造方法和析构方法
`3`数据库增删改查案例
1)pom.xml
```xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.zhanghuan</groupId>
<artifactId>annotationspring</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<dependencies>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>5.0.2.RELEASE</version>
</dependency>
<dependency>
<groupId>commons-dbutils</groupId>
<artifactId>commons-dbutils</artifactId>
<version>1.4</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
<dependency>
<groupId>c3p0</groupId>
<artifactId>c3p0</artifactId>
<version>0.9.1.2</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
</dependency>
</dependencies>
</project>
```
2)StudentDaoImpl.java
```java
package com.rootpackage.dao;
import com.rootpackage.doMain.Student;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.BeanHandler;
import org.apache.commons.dbutils.handlers.BeanListHandler;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Repository;
import java.sql.SQLException;
import java.util.List;
@Repository("studentdao")
public class StudentDaoImpl implements StudentDao {
@Autowired
private QueryRunner runner;
public void setRunner(QueryRunner runner) {
this.runner = runner;
}
public void insertOne(Student student) {
try {
runner.update ("insert into student (male,name,math,english) values(?,?,?,?)",student.getMale (),student.getName (),student.getMath (),student.getEnglish ());
} catch (SQLException e) {
e.printStackTrace ( );
}
}
public void deleteOne(int id) {
try {
runner.update ("delete from student where id=?",id);
} catch (SQLException e) {
e.printStackTrace ( );
}
}
public void updateOne(Student student) {
try {
runner.update ("update student set male=?,name=?,math=?,english=? where id=?",student.getMale (),student.getName (),student.getMath (),student.getEnglish (),student.getId ());
} catch (SQLException e) {
e.printStackTrace ( );
}
}
public Student findOne(int id) {
try {
return runner.query ("select * from student where id=?",new BeanHandler<Student> (Student.class),id);
} catch (SQLException e) {
throw new RuntimeException ();
}
}
public List<Student> findAll() {
try {
return runner.query ("select * from student",new BeanListHandler<Student> (Student.class));
} catch (SQLException e) {
throw new RuntimeException ();
}
}
}
```
3)StudentServiceImpl.java
```java
package com.rootpackage.services;
import com.rootpackage.dao.StudentDao;
import com.rootpackage.doMain.Student;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Repository;
import java.util.List;
@Repository("studentserviceimpl")
public class StudentServiceImpl implements StudentService {
@Autowired
private StudentDao dao;
public void insertOne(Student student) {
dao.insertOne (student);
}
public void deleteOne(int id) {
dao.deleteOne (id);
}
public void updateOne(Student student) {
dao.updateOne (student);
}
public Student findOne(int id) {
return dao.findOne (id);
}
public List<Student> findAll() {
return dao.findAll ();
}
}
```
4)beans.xml
```xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd">
<context:component-scan base-package="com.rootpackage"></context:component-scan>
<bean id="runner" class="org.apache.commons.dbutils.QueryRunner" scope="prototype">
<constructor-arg name="ds" ref="datasource"></constructor-arg>
</bean>
<bean id="datasource" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="com.mysql.jdbc.Driver"></property>
<property name="jdbcUrl" value="jdbc:mysql://127.0.0.1:3306/test1?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF-8"></property>
<property name="user" value="root"></property>
<property name="password" value=""></property>
</bean>
</beans>
```
5)test01.java
```java
import com.rootpackage.doMain.Student;
import org.junit.Before;
import org.junit.Test;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import com.rootpackage.services.StudentServiceImpl;
import java.util.List;
public class test01 {
private StudentServiceImpl s=null;
@Before
public void init(){
ApplicationContext ac=new ClassPathXmlApplicationContext ("beans.xml");
s=ac.getBean ("studentserviceimpl",StudentServiceImpl.class);
}
@Test
public void findal(){
List<Student> list=s.findAll ();
for (Student i:
list) {
System.out.println (i);
}
}
@Test
public void insertone(){
Student student=new Student ();
student.setMale ("男");
student.setName ("sylvester");
student.setMath (85);
student.setEnglish (90);
s.insertOne (student);
}
@Test
public void deleteone(){
s.deleteOne (13);
}
@Test
public void updateone(){
Student student=new Student ();
student.setId (15);
student.setMale ("男");
student.setName ("sylvester1");
student.setMath (85);
student.setEnglish (90);
s.updateOne (student);
}
@Test
public void findone(){
Student student=s.findOne (15);
System.out.println (student);
}
}
```
`4`配置类
1)Configuration注解
该注解标志的类表示是一个配置类
2)ComponentScan注解
指定创建容器扫描的包,value值为要扫描的包的位置
3)Bean注解
修饰方法,该方法的返回值将会被存入spring的ioc容器中
```java
//注解配置方式创建容器
ApplicationContext ac=new AnnotationConfigApplicationContext (springConfig.class,jdbcConfig.class);//这里可传入多个字节码文件,传入的字节码文件对应的类的Configuration注解可省略
s=ac.getBean ("studentserviceimpl",StudentServiceImpl.class);
```
```java
package config;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
@Configuration
@ComponentScan("com.rootpackage")
public class springConfig {
}
```
```java
package config;
import com.mchange.v2.c3p0.ComboPooledDataSource;
import org.apache.commons.dbutils.QueryRunner;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
import java.beans.PropertyVetoException;
@Configuration
public class jdbcConfig {
@Bean
public DataSource createDataSource(){
try {
ComboPooledDataSource ds=new ComboPooledDataSource();
ds.setDriverClass ("com.mysql.jdbc.Driver");
ds.setJdbcUrl ("jdbc:mysql://127.0.0.1:3306/test1?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF-8");
ds.setUser ("root");
ds.setPassword ("");
return ds;
} catch (PropertyVetoException e) {
throw new RuntimeException (e);
}
}
@Bean
public QueryRunner createQueryRunner(DataSource ds){
return new QueryRunner (ds);
}
}
```
4)Import注解
在一个配置类中,导入另一个配置类,一般是父配置类v导入子配置类。value值为目标配置类的字节码文件
```java
package config;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
@Configuration
@ComponentScan("com.rootpackage")
@Import (jdbcConfig.class)//这里将子配置文件导入
public class springConfig {
}
```
```java
ApplicationContext ac=new AnnotationConfigApplicationContext (springConfig.class);//创建容器时只需将父配置文件的字节码文件导入即可
```
5)Scope注解
value值标记实例是单例的还是多例的
6)PropertySource注解
将xxx.properties文件读取到spring的环境变量中,在变量上用@Value("${变量名}")可取到变量值
```
#duid.properties
# 注意:用户这里的变量是user,不可用username,username默认是admin无法使用
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql://127.0.0.1:3306/test1?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF-8
user=root
password=
```
```java
package config;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
import org.springframework.context.annotation.PropertySource;
@Configuration
@ComponentScan("com.rootpackage")
@Import (jdbcConfig.class)
@PropertySource("classpath:druid.properties")//将properties文件读取到spring的环境中
public class springConfig {
}
```
```java
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
import java.beans.PropertyVetoException;
@Configuration
public class jdbcConfig {
@Value ("${driverClassName}")//spEl表达式将变量读取到这里,并注入给变量
private String driverClassName;
@Value ("${url}")
private String url;
@Value ("${user}")
private String user;
@Value ("${password}")
private String password;
@Bean
public DataSource createDataSource(){
try {
ComboPooledDataSource ds=new ComboPooledDataSource();
ds.setDriverClass (driverClassName);
ds.setJdbcUrl (url);
ds.setUser (user);
ds.setPassword (password);
return ds;
} catch (PropertyVetoException e) {
throw new RuntimeException (e);
}
}
@Bean
public QueryRunner createQueryRunner(DataSource ds){
return new QueryRunner (ds);
}
}
```
7)Qualifier注解的另一种用法
```java
package config;
import com.mchange.v2.c3p0.ComboPooledDataSource;
import org.apache.commons.dbutils.QueryRunner;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
import java.beans.PropertyVetoException;
@Configuration
public class jdbcConfig {
@Value ("${driverClassName}")
private String driverClassName;
@Value ("${url}")
private String url;
@Value ("${user}")
private String user;
@Value ("${password}")
private String password;
@Bean("ds1")
public DataSource createDataSource(){
try {
ComboPooledDataSource ds=new ComboPooledDataSource();
ds.setDriverClass (driverClassName);
ds.setJdbcUrl (url);
ds.setUser (user);
ds.setPassword (password);
return ds;
} catch (PropertyVetoException e) {
throw new RuntimeException (e);
}
}
@Bean("ds2")
public DataSource createDataSource1(){
try {
ComboPooledDataSource ds=new ComboPooledDataSource();
ds.setDriverClass (driverClassName);
ds.setJdbcUrl (url);
ds.setUser (user);
ds.setPassword (password);
return ds;
} catch (PropertyVetoException e) {
throw new RuntimeException (e);
}
}
//这里有两个datasource分别是ds1和ds2,默认情况下会无法注入而报错
@Bean
public QueryRunner createQueryRunner(@Qualifier("ds1") DataSource ds){
//此处的@Qualifier指定将ds1注入,就不会报错了
return new QueryRunner (ds);
}
}
```
---
**Spring整合Junit**
默认情况,测试时需要创建容器,获取容器中要测试的对象。为了方便,我们想在测试时,也想让程序自动创建容器且自动注入对象,需要使用Spring的整合Junit的依赖
1)pom.xml中导入依赖
```
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>5.0.2.RELEASE</version>
</dependency>
```
注意两个依赖的版本,这里版本不对会报错
2)测试类上使用注解创建容器和自动注入
```java
import com.rootpackage.doMain.Student;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import com.rootpackage.services.StudentServiceImpl;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;;
import java.util.List;
@RunWith (SpringJUnit4ClassRunner.class)//这个注解表示这个测试类是整合spring的
//@ContextConfiguration(classes=springConfig.class)
@ContextConfiguration(locations = "classpath:beans.xml")//创建容器,将配置文件导入,支持两种配置文件
public class test01 {
@Autowired
private StudentServiceImpl s=null;
@Test
public void findal(){
List<Student> list=s.findAll ();
for (Student i:
list) {
System.out.println (i);
}
}
@Test
public void insertone(){
Student student=new Student ();
student.setMale ("男");
student.setName ("sylvester");
student.setMath (85);
student.setEnglish (90);
s.insertOne (student);
}
@Test
public void deleteone(){
s.deleteOne (13);
}
@Test
public void updateone(){
Student student=new Student ();
student.setId (15);
student.setMale ("男");
student.setName ("sylvester1");
student.setMath (85);
student.setEnglish (90);
s.updateOne (student);
}
@Test
public void findone(){
Student student=s.findOne (15);
System.out.println (student);
}
}
```
---
**银行转账案例**
分析:转账过程中涉及事务操作,业务层包含持久层的多个操作,而者多个操作默认情况是多个事务,转账过程执行中报错易导致总数据量发生变化。为解决这个问题,我们使用Threadlocal将数据库的Connection存放进去,在业务层运行时,直接通过业务层的Threadlocal获取出Connection,开启事务进行一些列操作。
`1`目录结构
```
-main
-java
-com
-rootpackage
-dao
--accountDao
--accountDaoImpl
-doMain
--Account
-service
--AccountService
--AccountServiceImpl
-utils
--ConnectionUtils
--TransactionManager
-config
--jdbcConfig
--SpringConfig
-resources
--druid.properties
-test
-java
--test1
```
`2`文件代码
```java
package com.rootpackage.dao;
import com.rootpackage.doMain.Account;
import java.util.List;
public interface accountDao {
List<Account> findAll();
void addOme(Account account);
void deleteOne(int id);
void updateOne(Account account);
Account findOne(int id);
}
```
```java
package com.rootpackage.dao;
import com.rootpackage.doMain.Account;
import com.rootpackage.utils.ConnectionUtils;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.handlers.BeanHandler;
import org.apache.commons.dbutils.handlers.BeanListHandler;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.sql.SQLException;
import java.util.List;
@Component
public class accountDaoImpl implements accountDao {
@Autowired
private QueryRunner runner;
@Autowired
private ConnectionUtils connectionUtils;
public List<Account> findAll() {
try {
return runner.query (connectionUtils.getThreadConnection (),"select * from account",new BeanListHandler<Account> (Account.class));
} catch (SQLException e) {
throw new RuntimeException (e);
}
}
public void addOme(Account account) {
try {
runner.update (connectionUtils.getThreadConnection (),"insert into account (name,money) values (?,?)",account.getName (),account.getMoney ());
} catch (SQLException e) {
throw new RuntimeException (e);
}
}
public void deleteOne(int id) {
try {
runner.update (connectionUtils.getThreadConnection (),"delete from account where id=?",id);
} catch (SQLException e) {
throw new RuntimeException (e);
}
}
public void updateOne(Account account) {
try {
runner.update (connectionUtils.getThreadConnection (),"update account set name=?,money=? where id=?",account.getName (),account.getMoney (),account.getId ());
} catch (SQLException e) {
throw new RuntimeException (e);
}
}
public Account findOne(int id) {
try {
return runner.query (connectionUtils.getThreadConnection (),"select * from account where id=?",new BeanHandler<Account> (Account.class),id);
} catch (SQLException e) {
throw new RuntimeException (e);
}
}
}
```
```java
package com.rootpackage.doMain;
public class Account {
private int id;
private String name;
private int money;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getMoney() {
return money;
}
public void setMoney(int money) {
this.money = money;
}
@Override
public String toString() {
return "Account{" +
"id=" + id +
", name='" + name + '\'' +
", money=" + money +
'}';
}
}
```
```java
package com.rootpackage.service;
import com.rootpackage.doMain.Account;
import java.util.List;
public interface AccountService {
List<Account> findAll();
void addOme(Account account);
void deleteOne(int id);
void updateOne(Account account);
Account findOne(int id);
void transfer(int id1,int id2,int money);
}
```
```java
package com.rootpackage.service;
import com.rootpackage.doMain.Account;
import com.rootpackage.utils.TransactionManager;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.util.List;
import com.rootpackage.dao.accountDaoImpl;
@Component
public class AccountServiceImpl implements AccountService {
@Autowired
private accountDaoImpl dao;
@Autowired
private TransactionManager manager;
public List<Account> findAll() {
try {
manager.beginTransaction ();
List<Account> list=dao.findAll ();
manager.commit ();
return list;
} catch (Exception e) {
manager.rollback ();
throw new RuntimeException (e);
} finally {
manager.release ();
}
}
public void addOme(Account account) {
try {
manager.beginTransaction ();
dao.addOme (account);
manager.commit ();
} catch (Exception e) {
manager.rollback ();
throw new RuntimeException (e);
} finally {
manager.release ();
}
}
public void deleteOne(int id) {
try {
manager.beginTransaction ();
dao.deleteOne (id);
manager.commit ();
} catch (Exception e) {
manager.rollback ();
throw new RuntimeException (e);
} finally {
manager.release ();
}
}
public void updateOne(Account account) {
try {
manager.beginTransaction ();
dao.updateOne (account);
manager.commit ();
} catch (Exception e) {
manager.rollback ();
throw new RuntimeException (e);
} finally {
manager.release ();
}
}
public Account findOne(int id) {
try {
manager.beginTransaction ();
Account a=dao.findOne (id);
manager.commit ();
return a;
} catch (Exception e) {
manager.rollback ();
throw new RuntimeException (e);
} finally {
manager.release ();
}
}
public void transfer(int id1, int id2, int money) {
try {
manager.beginTransaction ();
Account a1=dao.findOne (id1);
Account a2=dao.findOne (id2);
a1.setMoney (a1.getMoney ()-money);
a2.setMoney (a2.getMoney ()+money);
dao.updateOne (a1);
int a=10/0;//这里会报错,但是会进行回滚,数据总量不会发生改变
dao.updateOne (a2);
manager.commit ();
} catch (Exception e) {
manager.rollback ();
throw new RuntimeException (e);
} finally {
manager.release ();
}
}
}
```
```java
package com.rootpackage.utils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import javax.sql.DataSource;
import java.sql.Connection;
import java.sql.SQLException;
@Component
public class ConnectionUtils {
private ThreadLocal<Connection> t1=new ThreadLocal<Connection> ();
//一个线程内部的存储类,可以在指定线程内存储数据,数据存储以后,只有指定线程可以得到存储数据
@Autowired
private DataSource dataSource;
public Connection getThreadConnection(){
try {
Connection con=t1.get ();
if(con==null){
con=dataSource.getConnection ();
t1.set (con);
}
return con;
} catch (SQLException e) {
throw new RuntimeException (e);
}
}
public void removeConnection(){
t1.remove ();
}
}
```
```java
package com.rootpackage.utils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.sql.SQLException;
@Component
public class TransactionManager {
@Autowired
private ConnectionUtils connectionUtils;
public void beginTransaction(){
try {
connectionUtils.getThreadConnection ().setAutoCommit (false);
} catch (SQLException e) {
e.printStackTrace ( );
}
}
public void commit(){
try {
connectionUtils.getThreadConnection ().commit ();
} catch (SQLException e) {
e.printStackTrace ( );
}
}
public void rollback(){
try {
connectionUtils.getThreadConnection ().rollback ();
} catch (SQLException e) {
e.printStackTrace ( );
}
}
public void release(){
connectionUtils.removeConnection ();
}
}
```
```jade
package config;
import com.mchange.v2.c3p0.ComboPooledDataSource;
import org.apache.commons.dbutils.QueryRunner;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
import java.beans.PropertyVetoException;
@Configuration
public class jdbcConfig {
@Value ("${driverClassName}")
private String driverClassName;
@Value ("${url}")
private String url;
@Value ("${user}")
private String user;
@Value ("${password}")
private String password;
@Bean
public DataSource createdatasource(){
try {
ComboPooledDataSource ds=new ComboPooledDataSource();
ds.setDriverClass (driverClassName);
ds.setJdbcUrl (url);
ds.setUser (user);
ds.setPassword (password);
return ds;
} catch (PropertyVetoException e) {
throw new RuntimeException (e);
}
}
@Bean
public QueryRunner createqueryrunner(DataSource ds){
return new QueryRunner (ds);
}
}
```
```java
package config;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
import org.springframework.context.annotation.PropertySource;
@Configuration
@ComponentScan("com.rootpackage")
@PropertySource("classpath:druid.properties")
@Import (jdbcConfig.class)
public class SpringConfig {
}
```
```
#duid.properties
# 注意:用户这里的变量是user,不可用username,username默认是admin无法使用
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql://127.0.0.1:3306/test2?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF-8
user=root
password=
```
```java
import com.rootpackage.doMain.Account;
import com.rootpackage.service.AccountServiceImpl;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import config.SpringConfig;
import java.util.List;
@RunWith (SpringJUnit4ClassRunner.class)
@ContextConfiguration(classes = SpringConfig.class)
public class test1 {
@Autowired
private AccountServiceImpl service;
@Test
public void findall(){
List<Account> list=service.findAll ();
for (Account a:
list) {
System.out.println (a);
}
}
@Test
public void transfer(){
service.transfer (1,2,500);
}
}
```
---
**代理**
`1`jdk中的代理类
java在JDK1.5之后提供了一个"java.lang.reflect.Proxy"类,通过"Proxy"类提供的一个newProxyInstance方法用来创建一个对象的代理对象
```java
//部分代码
final computermaker m=new computermaker ();//该被代理对象必须实现一个接口,并且final关键字修饰
saler n=(saler) Proxy.newProxyInstance (m.getClass ( ).getClassLoader ( ), m.getClass ().getInterfaces (), new InvocationHandler ( ) {
/*
ClassLoader 类加载器,让代理对象和被代理对象使用相同的类加载器
Class[] 字节码数组,让代理对象和被代理对象有相同的方法
InvocationHandler 需要创建一个该接口的匿名内部类,并重写invoke方法以增强
*/
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
return method.invoke (m,args);//注意:第一个参数是被代理对象,最后一个参数是该方法传过来的参数
}
});
n.sale ();
```
`2`第三方代理类
由于jdk提供的代理要求被代理对象必须实现接口,对于没有实现接口的被代理对象可使用第三方代理类
1)pom.xml导入依赖
```xml
<dependency>
<groupId>cglib</groupId>
<artifactId>cglib</artifactId>
<version>3.3.0</version>
</dependency>
```
2)部分代码
```java
final computermaker m=new computermaker ();
computermaker n=(computermaker)Enhancer.create (m.getClass ( ), new MethodInterceptor ( ) {
public Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {
return method.invoke (m,objects);
}
});
n.sale ();
```
`3`转账案例改用代理
1)AccountServiceImpl修改简化
```java
package com.rootpackage.service;
import com.rootpackage.doMain.Account;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.util.List;
import com.rootpackage.dao.accountDaoImpl;
@Component("accountservice")
public class AccountServiceImpl implements AccountService {
@Autowired
private accountDaoImpl dao;
public List<Account> findAll() {
List<Account> list=dao.findAll ();
return list;
}
public void addOme(Account account) {
dao.addOme (account);
}
public void deleteOne(int id) {
dao.deleteOne (id);
}
public void updateOne(Account account) {
dao.updateOne (account);
}
public Account findOne(int id) {
Account a=dao.findOne (id);
return a;
}
public void transfer(int id1, int id2, int money) {
Account a1=dao.findOne (id1);
Account a2=dao.findOne (id2);
a1.setMoney (a1.getMoney ()-money);
a2.setMoney (a2.getMoney ()+money);
dao.updateOne (a1);
int a=9/0;
dao.updateOne (a2);
}
}
```
2)新建代理工厂
```java
package com.rootpackage.factory;
import com.rootpackage.service.AccountService;
import com.rootpackage.utils.TransactionManager;
import net.sf.cglib.proxy.Enhancer;
import net.sf.cglib.proxy.MethodInterceptor;
import net.sf.cglib.proxy.MethodProxy;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Component;
import java.lang.reflect.Method;
@Component
public class BeanFactory {
@Autowired
@Qualifier("accountservice")
private AccountService accountService;
@Autowired
private TransactionManager manager;
public AccountService getAccountService(){
return (AccountService)Enhancer.create (accountService.getClass ( ), new MethodInterceptor ( ) {
public Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable {
Object result=null;
try {
manager.beginTransaction ();
result=method.invoke (accountService,objects);
manager.commit ();
return result;
} catch (Exception e) {
manager.rollback ();
throw new RuntimeException (e);
} finally {
manager.release ();
}
}
});
}
}
```
3)测试类
```java
import com.rootpackage.doMain.Account;
import com.rootpackage.factory.BeanFactory;
import com.rootpackage.service.AccountServiceImpl;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import config.SpringConfig;
import java.util.List;
@RunWith (SpringJUnit4ClassRunner.class)
@ContextConfiguration(classes = SpringConfig.class)
public class test1 {
@Autowired
private BeanFactory factory;
@Test
public void findall(){
List<Account> list=factory.getAccountService ().findAll ();//通过代理工厂获取AccountService对象
for (Account a:
list) {
System.out.println (a);
}
}
@Test
public void transfer(){
factory.getAccountService ().transfer (1,2,500);
}
}
```
---
**AOP面向切面编程**
Aspect Oriented Programming,是spring框架中一个重要内容,是函数式编程的一种衍生范型。利用AOP可对业务逻辑各个部分进行隔离,从而使业务逻辑各个部分间耦合度降低。
特点:在程序运行期间,不改变源码对已有方法进行增强
优势:减少重复代码,提高开发效率,维护方便
`1`常用名词
| 名词 | 英文 | 解释 |
| -------- | ------------ | ------------------------------------------ |
| 连接点 | joinpoint | 已经被增强的挂载点,如增强的方法 |
| 切入点 | pointcut | 所有可以被拦截的点(方法) |
| 通知 | advice | 拦截到切入点后要做的事情 |
| 映入 | introduction | 运行期动态添加的方法或Field |
| 目标对象 | target | 代理的目标对象 |
| 织入 | weaving | 增强应用到目标对象来创建新的代理对象的过程 |
| 代理 | proxy | 一个类被aop增强后的一个结果类 |
| 切面 | aspect | 切入点和通知的结合 |
`2`快速开始
1)pom.xml导入依赖
```
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
<version>1.8.7</version>
</dependency>
```
2)定义一个服务类
```java
package com.rootpackage.services;
public class service1 {
public void doservice(){
System.out.println ("开始服务……");
}
}
```
3)定义一个日志类
```java
package com.rootpackage.mout;
public class log {
public void dolog1(){
System.out.println ("打印日志1");
}
public void dolog2(){
System.out.println ("打印日志2");
}
public void dolog3(){
System.out.println ("打印日志3");
}
public void dolog4(){
System.out.println ("打印日志4");
}
}
```
4)beans.xml配置文件
```xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop.xsd">
<bean id="service1" class="com.rootpackage.services.service1"></bean>
<bean id="log" class="com.rootpackage.mout.log"></bean>
<aop:config>
<aop:aspect id="asp1" ref="log">
<!--id是给这个切面的id,ref指向通知类(放入切入点的方法所属的类)-->
<aop:before method="dolog1" pointcut="execution(* *..*.doservice(..))"></aop:before>
<!--method是通知方法的方法名,pointcut切入点-->
<aop:after-returning method="dolog2" pointcut="execution(* *..*.doservice(..))"></aop:after-returning>
<aop:after-throwing method="dolog3" pointcut="execution(* *..*.doservice(..))"></aop:after-throwing>
<aop:after method="dolog4" pointcut="execution(* *..*.doservice(..))"></aop:after>
</aop:aspect>
</aop:config>
</beans>
```
5)测试类
```java
import com.rootpackage.services.service1;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations ="classpath:beans.xml" )
public class test1 {
@Autowired
service1 sv1;
@Test
public void test1(){
sv1.doservice ();
}
}
```
`3`execution指定切点的格式
```
访问修饰符 返回值 包名 类名 .方法名(参数类型)
```
| 格式 | 通配符 | 说明 |
| ---------- | ------ | ---------------------------------------------------------- |
| 访问修饰符 | * | |
| 返回值 | * | |
| 包名 | *,.. | |
| 类名 | * | |
| 方法名 | * | |
| 参数类型 | *,.. | 直接写数据类型如int,java.lang.String,可有参数,也可无参数 |
全通配`* *..*.*(..)`,但通常情况都不用全同配。切入到业务实现类的所有方法,会有一个问题就是通知内容会多执行一次,是由于构造方法导致的。
`4`四种通知类型
| 关键字 | 类型 |
| --------------- | ---- |
| before | 前置 |
| after-returning | 后置 |
| after-throwing | 异常 |
| after | 最终 |
`5`配置共用切入点
```xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop.xsd">
<bean id="service1" class="com.rootpackage.services.service1"></bean>
<bean id="log" class="com.rootpackage.mout.log"></bean>
<aop:config>
<aop:pointcut id="s1" expression="execution(* * ..*.doservice(..))"></aop:pointcut>
<aop:aspect id="asp1" ref="log">
<aop:before method="dolog1" pointcut-ref="s1"></aop:before>
<aop:after-returning method="dolog2" pointcut-ref="s1"></aop:after-returning>
<aop:after-throwing method="dolog3" pointcut-ref="s1"></aop:after-throwing>
<aop:after method="dolog4" pointcut-ref="s1"></aop:after>
</aop:aspect>
</aop:config>
</beans>
```
`6`环绕通知
```xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop.xsd">
<bean id="service1" class="com.rootpackage.services.service1"></bean>
<bean id="log" class="com.rootpackage.mout.log"></bean>
<aop:config>
<aop:pointcut id="s1" expression="execution(* * ..*.doservice(..))"></aop:pointcut>
<aop:aspect id="asp1" ref="log">
<aop:around method="doarround" pointcut-ref="s1"></aop:around>
</aop:aspect>
</aop:config>
</beans>
```
配置环绕通知后,只有通知方法执行,切入点原方法未执行。此时需要在通知方法中传入ProceedingJoinPoint的实现类(定义该接口的参数,spring自动传入实现类),再通过该实现类调用切入点方法
```java
package com.rootpackage.mout;
import org.aspectj.lang.ProceedingJoinPoint;
public class log {
public void doarround(ProceedingJoinPoint pjp){
try {
System.out.println ("打印日志1");
Object[] args=pjp.getArgs ();//获取切入点参数
pjp.proceed (args);//调用切入点方法
System.out.println ("打印日志2");
} catch (Throwable throwable) {
throwable.printStackTrace ( );
System.out.println ("打印日志3");
} finally {
System.out.println ("打印日志4");
}
}
}
```
---
`7`注解
1)Aspect注解
表示该类是一个切面内
2)Before注解
表示该方法是一个前置通知
3)After注解
表示该方法是一个最终通知
4)AfterReturning注解
表示该方法是一个后置通知
5)AfterThrowing注解
表示该方法是一个异常通知
6)Arround注解
表示该方法是一个环绕通知
7)Point注解
定义一个切点,定义在一个方法上,参数是“execution(...)”,引用切面是需要调用该方法
在定义切面、通知前需要在配置文件中配置
```xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop.xsd">
<bean id="service1" class="com.rootpackage.services.service1"></bean>
<bean id="log" class="com.rootpackage.mout.log"></bean>
<aop:aspectj-autoproxy></aop:aspectj-autoproxy><!--需要配置这一句-->
</beans>
```
```java
package com.rootpackage.mout;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.*;
@Aspect//标识该类是一个切面类
public class log {
@Pointcut("execution(* *..*.doservice(..))")//定义切点
public void pf(){}
@Before ("pf()")//定义前置通知
public void dolog1(){
System.out.println ("打印日志1");
}
@AfterReturning("pf()")
public void dolog2(){
System.out.println ("打印日志2");
}
@AfterThrowing("pf()")
public void dolog3(){
System.out.println ("打印日志3");
}
@After ("pf()")
public void dolog4(){
System.out.println ("打印日志4");
}
}
```
执行后发现最终通知在后置通知之前执行,不合理。所以建议使用环绕通知
```java
package com.rootpackage.mout;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.*;
@Aspect//标识该类是一个切面类
public class log {
@Pointcut("execution(* *..*.doservice(..))")//定义切点
public void pf(){}
@Around ("pf()")
public void doarround(ProceedingJoinPoint pjp){
try {
System.out.println ("打印日志1");
Object[] args=pjp.getArgs ();
pjp.proceed (args);
System.out.println ("打印日志2");
} catch (Throwable throwable) {
throwable.printStackTrace ( );
System.out.println ("打印日志3");
} finally {
System.out.println ("打印日志4");
}
}
}
```
9)不使用xml配置
此时应该在配置类上加一行注解`@EnableAspectJAutoProxy`
`8`转账案例使用切面新增事务
```xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop.xsd">
<context:component-scan base-package="org.zhanghuan"></context:component-scan>
<bean id="ds" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="com.mysql.jdbc.Driver"></property>
<property name="jdbcUrl" value="jdbc:mysql://127.0.0.1:3306/test2?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF-8"></property>
<property name="user" value="root"></property>
<property name="password" value=""></property>
</bean>
<bean class="org.apache.commons.dbutils.QueryRunner">
<constructor-arg name="ds" ref="ds"></constructor-arg>
</bean>
<aop:config><!--将事务通过切面织入-->
<aop:pointcut id="p1" expression="execution(* org.zhanghuan.service.AccountServiceImpl.*(..))"></aop:pointcut>
<aop:aspect id="isp1" ref="transaction">
<aop:before method="beginTransaction" pointcut-ref="p1"></aop:before>
<aop:after method="release" pointcut-ref="p1"></aop:after>
<aop:after-returning method="commit" pointcut-ref="p1"></aop:after-returning>
<aop:after-throwing method="rollback" pointcut-ref="p1"></aop:after-throwing>
</aop:aspect>
</aop:config>
</beans>
```
`9`DataSourceTransactionManager的使用
Spring的事务处理中,通用的事务处理流程是由抽象事务管理器AbstractPlatformTransactionManager来提供的,而具体的底层事务处理实现,由PlatformTransactionManager的具体实现类来实现
1)配置文件方式
```xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:context="http://www.springframework.org/schema/context" xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx.xsd">
<context:component-scan base-package="org.zhanghuan"></context:component-scan>
<bean id="ds" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="com.mysql.jdbc.Driver"></property>
<property name="jdbcUrl" value="jdbc:mysql://127.0.0.1:3306/test2?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF-8"></property>
<property name="user" value="root"></property>
<property name="password" value=""></property>
</bean>
<bean class="org.apache.commons.dbutils.QueryRunner">
<constructor-arg name="ds" ref="ds"></constructor-arg>
</bean>
<!--导入事务管理器-->
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"><!--这个包在spring-jdbc中,需在maven中导入-->
<property name="dataSource" ref="ds"></property>
</bean>
<!--配置事务通知-->
<tx:advice id="manager" transaction-manager="transactionManager">
<tx:attributes>
<tx:method name="*" propagation="REQUIRED" read-only="false"></tx:method>
<tx:method name="*find*" propagation="SUPPORTS" read-only="true"></tx:method><!--表示包含find关键字的方法,只读,不一定包含事务-->
</tx:attributes>
</tx:advice>
<!--配置aop,将事务通知织入-->
<aop:config>
<aop:pointcut id="p1" expression="execution(* org.zhanghuan.service.AccountServiceImpl.*(..))"></aop:pointcut>
<aop:advisor advice-ref="manager" pointcut-ref="p1"></aop:advisor>
</aop:config>
</beans>
```
事务通知里方法的属性
| 属性名 | 含义 |
| --------------- | ------------------------------------------------------------ |
| isolation | 事务隔离级别 |
| propagation | 指定事务传播形式,默认REQUIRED,表示必有事务。对于查询的方法,使用SUPPORTS |
| read-only | 指定事务是否只读,默认false,查询方法设置未true |
| timeout | 指定事务超时时间,默认未-1,表示永不超时。如果设置值,以秒未单位 |
| rollback-for | 指定一个异常,该异常发生,则回滚;其他异常发生,不回滚。无默认值,未设置表示出现任何异常都回滚 |
| no-rollback-for | 指定一个异常,该异常发生,不回滚;其他异常发生,回滚。无默认值,未设置表示出现任何异常都回滚 |
2)注解配置方式
```xml
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:context="http://www.springframework.org/schema/context" xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx.xsd">
<context:component-scan base-package="org.zhanghuan"></context:component-scan>
<bean id="ds" class="com.mchange.v2.c3p0.ComboPooledDataSource">
<property name="driverClass" value="com.mysql.jdbc.Driver"></property>
<property name="jdbcUrl" value="jdbc:mysql://127.0.0.1:3306/test2?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF-8"></property>
<property name="user" value="root"></property>
<property name="password" value=""></property>
</bean>
<bean class="org.apache.commons.dbutils.QueryRunner">
<constructor-arg name="ds" ref="ds"></constructor-arg>
</bean>
<!--导入事务管理器-->
<bean id="transactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"><!--这个包在spring-jdbc中,需在maven中导入-->
<property name="dataSource" ref="ds"></property>
</bean>
<!--开启spring对注解事务的支持-->
<tx:annotation-driven transaction-manager="transactionManager"></tx:annotation-driven>
<!--在需要开启事务的地方表上注解@Transactional-->
</beans>
```
在配置文件中完成以上配置后,在需要开启事务的地方表上注解@Transactional
3)无xml方式
```java
//配置文件
package org.zhanghuan.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import org.springframework.transaction.annotation.EnableTransactionManagement;
import javax.sql.DataSource;
@Configuration
@Import (jdbcConfig.class)
@ComponentScan("org.zhanghuan")
@EnableTransactionManagement//相当于xml中的tx:annotation-driven标签+@Transactional注解
public class springConfig {
@Bean//导入事务管理器
public DataSourceTransactionManager getDataSourceTransactionManager(DataSource ds){
return new DataSourceTransactionManager(ds);
}
}
```
找到事务实现类,并开启事务
---
**JDBCTemplate**
`1`pom.xml导入依赖
```
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>5.2.5.RELEASE</version>
</dependency>
```
`2`快速使用
```java
//部分代码
//创建数据源
DriverManagerDataSource ds=new DriverManagerDataSource ();
ds.setDriverClass ("com.mysql.jdbc.Driver");
ds.setJdbcUrl ("jdbc:mysql://127.0.0.1:3306/test2?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF-8");
ds.setUser ("root");
ds.setPassword ("");
JdbcTemplate template=new JdbcTemplate (ds);
List<Map<String,Object>> list=template.queryForList ("select * from account");
for (Map<String,Object> m:
list) {
System.out.println ("id:"+m.get ("id"));
}
```
`3`query方法
```java
query(String sql,Objectp[] args,RowMapper<T> rowmapper);//所有版本可用
query(String sql,RowMapper<T> rowmapper,Object.. args);//jdk1.5之后可用
```
--- | 59,668 | MIT |
# 開発者用README
## 役割分担
- Local [@raylicola](https://github.com/raylicola)
- フロントエンド
- Server [@mhrwh](https://github.com/mhrwh)
- サーバーサイド(水検出処理除く)
- Detection [@hiro6260000](https://github.com/hiro6260000) [@mikiya1130](https://github.com/mikiya1130)
- 水検出
## タスクと流れ
1. [画像取得、serverへ渡す](post.md) @Local
1. [clientから画像受け取り、水検出処理ファイルへ渡す](controller.md) @Server
1. [水検出・割り箸検出](detect.md) @Detection
1. [計算、結果をclientへ返す](calc.md) @Server
1. [serverから水の容量取得、ブラウザ表示](print.md) @Local
## 運用方針
### ブランチ
- `master`
- リリースできるもの
- 直接pushはNG
- `develop`からのmergeのみ
- `develop`
- 各々このブランチを基準にcheckout、pull req
- `<user id>/***`
- 作業ブランチ
### コミット時のコメント
- 特に統一はしないけど、こだわりなければ[このサイト](https://www.tam-tam.co.jp/tipsnote/program/post16686.html)のスタイルを参考に(個人的にはprefixの末尾に:付けないけど)
- この前会話してたときの人のリポジトリも参考に
- 2行目を空行は推奨
### 自動フォーマット
- black使用
- ~~vscode使うなら特に気にせんでいいように設定したはず(保存すると勝手に走るはず)~~
- 環境によって`.vscode`フォルダをGit管理するとまずかったので、各自`.vscode/settings.json`に[ここ](https://github.com/mikiya1130/Amazon/blob/0231e0cb09/.vscode/settings.json)の内容をコピペ推奨
## 推奨環境
- VSCode
- Python 3.7.x
- モジュールは[requirements.txt](../requirements.txt)参照
開発環境が絶対このバージョンでなくてはならないわけではないけど、この環境でテストしてmergeすることにします
## チートシート
- [環境構築](build.md)
- [チートシート](cheatsheet.md) | 1,272 | MIT |
条款 01: 视 c++ 为一个语言联邦
========
c++ 是一个多重泛型编程语言, 同时支持: 面向过程, 面向对象, 函数式编程, 泛型编程, 元编程. 这些无与伦比的能力和弹性给了程序员更加丰富的选择. 这自然也引发了一些迷惑: 在使用 c++ 编程的过程中, 怎样的方式是 "适当用法".
<br>
c++ 可以看作是四种语言组成的联邦:
# 1. c 语言
这一点无需多言, c++ 的设计初衷是对 c 编程语言的改进, 向前兼容 c 语言. 这为 c++ 提供了强大的生命力, 但也为其留下了些历史包袱: 比如 c++ 中, 对象以默认参数初始化时, 和 c 中的函数定义相冲突等. 但是瑕不掩瑜, c++ 在 c 之外提供了更加高级的用法.
# 2. 面向对象的 c++
面向对象编程提供了封装, 继承, 多态等用法, 将面向过程中机械地初始化和释放资源等环节形象地等价到了对象的生命周期管理中. 使得 c++ 的表达方式站在了一个更高的层次, 允许程序员更方便地做自顶向下的程序构建. 当然面向对象同样带来了一些问题: 如内存管理, 将对象以参数方式进行传递时, 会涉及大量的内存拷贝, 由此 c++ 引入了对象的拷贝构造, 赋值构造, 甚至引入了引用和 std::move 的方式来减少对象的拷贝.
<br>
> 这里笔者要说一下自己的看法 ( 哈哈, 我也有一天能够自称为 "笔者" 了 ) :
> <br>
> 我是一个强烈推崇 rust 的程序员, 至于为什么不去搞个 learning_rust 项目, 我只能说, 那才是我的终极目标. 如果我不把 c++ 学到一定深度, 我怎么会有底气地说 rust 才是永远滴神呢.
> <br>
> c++ 中对内存的管理过于豪放, 默认的值传递就是拷贝所有成员变量, "隐式地" 进行一些开销较大的操作, 这使得 c++ 程序员不得不为了效率而使用 std::move 和引用. 而 rust 在这方面做得足够严谨: rust 中, 需要进行结构体拷贝的操作一定要 "显式地" 指出, 否则默认将所有权转移. 可以说, rust 是将 c++ 的最佳实践固化到基本语法中的编程语言.
# 3. 泛型编程 c++
泛型编程打开了又一个新世界的大门: 它允许程序员以一种独立于任何特定类型的方式编写代码, 并且编译后生成的代码仍然保持最高的执行效率, 无需在执行时产生额外的动态绑定等开销.
# 4. STL
STL (标准模板库) 是一套功能强大的 c++ 模板类,提供了通用的模板类和函数,这些模板类和函数可以实现多种流行和常用的算法和数据结构. STL 避免了程序员在基本数据结构上 "重复造轮子". 当然, 使用 STL 时, 请注意严格遵守它的规约: 工程中常用的 std::map, 你真的完全知道它的用法吗?
```c++
#include <iostream>
#include <map>
#include <string_view>
void print_map(std::string_view comment, const std::map<std::string, int>& m)
{
std::cout << comment;
for (const auto& [key, value] : m) {
std::cout << key << " = " << value << "; ";
}
std::cout << "\n";
}
int main()
{
// Create a map (that map to integers)
std::map<std::string, int> m;
print_map("Initial map: ", m);
if (m["key0"]) {
std::cout << "contains key0" << std::endl;
}
print_map("Updated map: ", m);
/*
* Initial map:
* Updated map: key0 = 0;
*/
}
```
非常遗憾的是, 真的有人用上面这种方式判断 map 中元素是否存在, 而且更加遗憾的是, 如果 map 中没有 key0 这个元素, if 条件中的代码的确不会执行. 但这个程序会向 map 中添加一个元素. 这样一个 bug 我们在实际项目中, 三个人排查了一整天.
<br>
如果你说上面这个错误你绝对不会犯, 那你一定要看看下面这个操作:
```c++
int main()
{
// Create a map (that map to integers)
std::map<std::string, int> m;
print_map("Initial map: ", m);
m["key0"] = 1;
m.emplace(std::make_pair("key0", 2));
print_map("Updated map: ", m);
/*
* Initial map:
* Updated map: key0 = 1;
*/
}
```
没错, map 中的元素没有被更新, 这个 bug 我们也用了至少两个小时才排查出来.
<br>
总之, 在使用 STL 时, 一定注意仔细阅读接口文档, 严格遵守规约才能够做到准确和高效.
<br>
回到我们的主题, c++ 是上面四种子语言的联合. 当你从某个子语言切换到另一个时, 你需要遵守的高效编程规范可能会发生变化: 比如当你使用 c 语言内置类型时, 直接使用值传递会比引用传递更高效, 毕竟引用的本质是加了语法糖的指针 (有兴趣的话, 可以查看一下汇编结果); 而当你传递一个自定义的对象类型时, 使用引用或指针就是一个非常高效的方式了, 这样能够避免构造临时对象和成员变量的拷贝; 而如果你在使用 STL 的话, 迭代器和函数对象都是在 c 指针上塑造出来的, 所以值传递的效率更高.
<br>
记住下面这句话
========
# c++ 高效编程守则视状况而变化, 取决于你使用 c++ 的哪一部分 | 2,712 | MIT |
# PowerShell リポジトリの登録
内部リポジトリに対して動作するように PowerShellGet を構成できます。 これは、次の追加コマンドレットを使用して行います。
- Register-PSRepository: 現在のユーザーのリポジトリを登録します。
- Unregister-PSRepository: 現在のユーザーの登録済みリポジトリを削除します。
- Set-PSRepository: 登録されたリポジトリの値を設定します。
- Get-PSRepository: 現在のユーザーのすべての登録済みリポジトリを取得します。
リポジトリを登録した後、Find-Module および Install-Module を使用して操作できます。
```powershell
\#Register a default repository
Register-PSRepository –Name DemoRepo –SourceLocation “https://www.myget.org/F/powershellgetdemo/api/v2” –PublishLocation “<https://www.myget.org/F/powershellgetdemo/api/v2>/package” –InstallationPolicy –Trusted
\#Get all of the registered repositories
Get-PSRepository
Name SourceLocation
---- --------------
PSGallery https://msconfiggallery.cloudapp...
DemoRepo https://www.myget.org/F/powershe...
\#Search only the new repository for modules
Find-Module -Repository DemoRepo
Repository Version Name
---------- ------- ----
DemoRepo 1.0.1 xActiveDirectory
DemoRepo 1.1.1 SomeModule
\#By default, PowerShellGet operates against all registered repositories when none is specified. In this example, the “SomeModule” module is installed from the DemoRepo.
Install-Module SomeModule
\#Removing a repository
Unregister-PSRepository DemoRepo
```
<!--HONumber=Oct16_HO1--> | 1,256 | CC-BY-4.0 |
---
title: Kubernetes 博客
linkTitle: 博客
menu:
main:
title: "博客"
weight: 40
post: >
<p>阅读关于 kubernetes 和容器规范的最新信息,以及获取最新的技术。</p>
---
{{< comment >}}
<!-- For information about contributing to the blog, see
https://kubernetes.io/docs/contribute/new-content/blogs-case-studies/#write-a-blog-post -->
有关为博客提供内容的信息,请参见
https://kubernetes.io/zh/docs/contribute/new-content/blogs-case-studies/#write-a-blog-post
{{< /comment >}} | 445 | CC-BY-4.0 |
# Tag 标签
用于对内容的分类标记
---
### 特点
+ 支持标签的增加及和删除
+ 支持标签的选择
### 基础样式
最基本的标签样式,可以通过添加 `closable` 变为可关闭标签。同时要调用 `tag.init` 方法初始化即可。页面中所有tag标签自己需要调用一次 `tag.init` 即可。
```html
<span class="nv-tag-normal">普通标签</span>
<span class="nv-tag-closable">
可删除标签 <i class="nvicon-close"></i>
</span>
<!--javascript代码-->
Nv.use("tag",function(nv,tag){
//如果只是nv-tag-normal 普通标签,无需加载tag 组件。tag 组件用于可删除和可编辑的标签。
tag.init();
})
```
<br/>
### 动态编辑标签
支持显示图片、字符和icon,其中字符和icon可以更换背景色
```html
<span class="nv-tag">
<span class="nv-tag-addable">
<i class="nvicon-add"></i> 可添加标签
</span>
<input type="text" class="nv-tag-input"/>
</span>
<!--javascript代码-->
Nv.use("tag",function(nv,tag){
//如果只是nv-tag-normal 普通标签,无需加载tag 组件。tag 组件用于可删除和可编辑的标签。
tag.init();
})
```
<br/>
### 五颜六色标签
支持显示图片、字符和icon,其中字符和icon可以更换背景色
```html
<!--HTML代码-->
<span class="nv-tag-normal nv-tag-red">Tag red</span>
<span class="nv-tag-normal nv-tag-orange">Tag orange</span>
<span class="nv-tag-normal nv-tag-yellow">Tag yellow</span>
<span class="nv-tag-normal nv-tag-green">Tag green</span>
<span class="nv-tag-normal nv-tag-cyan">Tag cyan</span>
<span class="nv-tag-normal nv-tag-geekblue">Tag geekblue</span>
<span class="nv-tag-normal nv-tag-blue">Tag blue</span>
<span class="nv-tag-normal nv-tag-purple">Tag purple</span>
<!--javascript代码-->
Nv.ready(function () {
Nv.use("tag", function (nv,tag) {
tag.init();
})
})
```
<br/>
[Demo展示](http://www.nv-js.com/api?type=tag)
[留言和讨论](https://github.com/Nv-js/nv-source/issues/33) | 1,696 | MIT |
```html
<template>
<tyh-button simple @click="open3 = true">点我打开第一层</tyh-button>
<tyh-dialog v-model="open3" title="这是标题" width="50%">
欢迎使用 tyh-ui 的 dialog 对话框!
<tyh-button type="success" @click="open4 = true">打开第二层</tyh-button>
<tyh-dialog v-model="open4" title="这是标题" top="10vh">
hi~我是第二层的 dialog 对话框
</tyh-dialog>
</tyh-dialog>
</template>
<script setup>
import { ref } from 'vue'
const open3 = ref(false)
const open4 = ref(false)
</script>
```
## Attributes
| 参数 | 说明 | 类型 | 可选值 | 默认值 |
| ------------ | ---------------------- | ------- | ------ | ------ |
| v-model | 绑定值 | boolean | —— | false |
| width | 宽度 | string | —— | 30% |
| top | 顶部距离 | string | —— | 15vh |
| title | 标题 | string | —— | —— |
| appendToBody | 是否镶嵌到 body 上 | boolean | —— | false |
| modal | 是否显示遮罩层 | boolean | —— | true |
| modalClose | 点击遮罩层是否可以关闭 | boolean | —— | true |
| showClose | 是否显示关闭按钮 | boolean | —— | true |
| showHeader | 是否显示头部信息 | boolean | —— | true |
| zIndex | z-index 属性 | number | —— | 3500 |
## Events
| 事件名称 | 说明 | 回调参数 |
| -------- | -------------------- | -------- |
| open | 打开时的回调 | —— |
| onOpen | 打开动画结束时的回调 | —— |
| close | 关闭时的回调 | —— |
| onClose | 关闭动画结束时的回调 | —— |
## Slots
| 插槽名称 | 说明说明 |
| -------- | ------------ |
| title | 自定义标题 |
| footer | 自定义操作区 |
| default | 内容 |
<tyh-turn-page style="margin: 50px 0">
<tyh-turn-page-item direction="left" url="/component/drawer">
Drawer 抽屉
</tyh-turn-page-item>
<!-- <tyh-turn-page-item direction="right" url="/component/rate">
Rate 评分
</tyh-turn-page-item> -->
</tyh-turn-page> | 1,924 | MIT |
<!-- TOC -->
- [CDH](#cdh)
- [资源下载](#资源下载)
- [网络配置](#网络配置)
- [时间同步及JDK](#时间同步及jdk)
- [更改yum源](#更改yum源)
- [时钟同步](#时钟同步)
- [JDK安装](#jdk安装)
- [mysql tar包离线安装](#mysql-tar包离线安装)
- [创建用户](#创建用户)
- [mysql.tar上传和解包](#mysqltar上传和解包)
- [更改mysql所属用户和组](#更改mysql所属用户和组)
- [修改my.cnf配置](#修改mycnf配置)
- [安装和初始化](#安装和初始化)
- [环境变量](#环境变量)
- [修改密码](#修改密码)
- [远程访问](#远程访问)
- [开机启动](#开机启动)
- [其他节点](#其他节点)
- [免密登录](#免密登录)
- [httpd服务](#httpd服务)
- [安装httpd服务](#安装httpd服务)
- [配置parcels](#配置parcels)
- [安装CM的server和daemons](#安装cm的server和daemons)
- [元数据库的创建](#元数据库的创建)
- [创建与授权](#创建与授权)
- [上传mysql-connector-java](#上传mysql-connector-java)
- [启动cloudera-scm-server服务并查看日志](#启动cloudera-scm-server服务并查看日志)
- [ClouderaManager管理](#clouderamanager管理)
- [cm-web界面](#cm-web界面)
- [CDH集群配置](#cdh集群配置)
- [FAQ](#faq)
- [HDFS副本不足](#hdfs副本不足)
- [Navigator数据治理](#navigator数据治理)
- [navigator元数据库](#navigator元数据库)
- [mysql-connector-java](#mysql-connector-java)
- [navigator配置](#navigator配置)
- [虚拟机脚本备份](#虚拟机脚本备份)
<!-- /TOC -->
<a id="markdown-cdh" name="cdh"></a>
# CDH
<a id="markdown-资源下载" name="资源下载"></a>
## 资源下载
```
http://archive.cloudera.com/cm5/repo-as-tarball/5.16.1/cm5.16.1-centos7.tar.gz
http://archive.cloudera.com/cdh5/parcels/5.16.1/CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel
http://archive.cloudera.com/cdh5/parcels/5.16.1/CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel.sha1
http://archive.cloudera.com/cdh5/parcels/5.16.1/manifest.json
```
注意【CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel.sha1】下载完成后需要将扩展名修改为【sha】
浏览器直接下载的话会很慢,可以采用百度云离线下载或者直接迅雷下载。
<a id="markdown-网络配置" name="网络配置"></a>
## 网络配置
参考 [网络配置](基础环境.md#网络配置)
<a id="markdown-时间同步及jdk" name="时间同步及jdk"></a>
## 时间同步及JDK
<a id="markdown-更改yum源" name="更改yum源"></a>
### 更改yum源
如果是centos最小安装,则需要通过yum安装wget
```shell
yum isntall -y wget
```
```shell
#备份原镜像
[root@master ~]# mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
[root@master ~]# cd /etc/yum.repos.d/
#centos 7
[root@localhost yum.repos.d]# wget http://mirrors.163.com/.help/CentOS7-Base-163.repo
#centos 6
[root@localhost yum.repos.d]# wget http://mirrors.163.com/.help/CentOS6-Base-163.repo
#------------------------#
[root@localhost yum.repos.d]# yum clean all
[root@localhost yum.repos.d]# yum makecache
```
<a id="markdown-时钟同步" name="时钟同步"></a>
### 时钟同步
```shell
# 安装同步服务
[root@master ~] yum install -y ntp
# centos6 设置开机启动
[root@master ~] chkconfig ntpd on
# centos7 查看服务是否已运行
[root@master ~] systemctl | grep ntpd
[root@master ~] systemctl is-enabled ntpd
[root@master ~] systemctl enable ntpd
[root@master ~] systemctl start ntpd
```
<a id="markdown-jdk安装" name="jdk安装"></a>
### JDK安装
**JDK的安装目录一定是/usr/java,否则CDH启动失败!!!!!!**
```shell
[root@master ~]# cd /usr/java/
# 上传文件 jdk-8u202-linux-x64.tar.gz
[root@master ~]# rz
[root@master ~]# tar -zxvf jdk-8u202-linux-x64.tar.gz
```
配置jdk环境变量
```shell
[root@master jdk8]# vi /etc/profile
# java环境变量
export JAVA_HOME=/usr/java/jdk1.8.0_202
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin
```
<a id="markdown-mysql-tar包离线安装" name="mysql-tar包离线安装"></a>
## mysql tar包离线安装
<a id="markdown-创建用户" name="创建用户"></a>
### 创建用户
创建用户组:【mysql】,用户名:【mysql】
```shell
[root@master ~]# groupadd mysql
[root@master ~]# useradd -g mysql mysql
[root@master ~]# passwd mysql
更改用户 mysql 的密码 。
新的 密码:
无效的密码: 密码未通过字典检查 - 它基于字典单词
重新输入新的 密码:
passwd:所有的身份验证令牌已经成功更新。
```
<a id="markdown-mysqltar上传和解包" name="mysqltar上传和解包"></a>
### mysql.tar上传和解包
MySQL Community Server (Archived Versions),版本选择 5.7.xx
https://downloads.mysql.com/archives/community/
将下载好的tar包上传至服务器指定位置:【/usr/local/】目录
```shell
[root@master ~]# service vsftpd start
Redirecting to /bin/systemctl start vsftpd.service
[root@master ~]# cd /var/ftp/pub/
[root@master pub]# ll
总用量 372068
-rw------- 1 ftp ftp 376537503 12月 7 10:25 mysql-5.7.31-linux-glibc2.12-x86_64.tar.gz
-rw------- 1 ftp ftp 4456335 12月 7 10:25 mysql-connector-java-5.1.48.tar.gz
[root@master pub]# mv mysql-5.7.31-linux-glibc2.12-x86_64.tar.gz /usr/local/
```
解压并重命名:
```shell
[root@master pub]# cd /usr/local
[root@master local]# ll
总用量 367716
drwxr-xr-x. 2 root root 6 4月 11 2018 bin
drwxr-xr-x. 2 root root 6 4月 11 2018 etc
drwxr-xr-x. 2 root root 6 4月 11 2018 games
drwxr-xr-x. 2 root root 6 4月 11 2018 include
drwxr-xr-x. 2 root root 6 4月 11 2018 lib
drwxr-xr-x. 2 root root 6 4月 11 2018 lib64
drwxr-xr-x. 2 root root 6 4月 11 2018 libexec
-rw------- 1 ftp ftp 376537503 12月 7 10:25 mysql-5.7.31-linux-glibc2.12-x86_64.tar.gz
drwxr-xr-x. 2 root root 6 4月 11 2018 sbin
drwxr-xr-x. 5 root root 49 12月 4 15:54 share
drwxr-xr-x. 2 root root 6 4月 11 2018 src
[root@master local]# tar -zxvf mysql-5.7.31-linux-glibc2.12-x86_64.tar.gz
[root@master local]# mv mysql-5.7.31-linux-glibc2.12-x86_64 mysql/
[root@master local]# ll
总用量 367716
drwxr-xr-x. 2 root root 6 4月 11 2018 bin
drwxr-xr-x. 2 root root 6 4月 11 2018 etc
drwxr-xr-x. 2 root root 6 4月 11 2018 games
drwxr-xr-x. 2 root root 6 4月 11 2018 include
drwxr-xr-x. 2 root root 6 4月 11 2018 lib
drwxr-xr-x. 2 root root 6 4月 11 2018 lib64
drwxr-xr-x. 2 root root 6 4月 11 2018 libexec
drwxr-xr-x 9 7161 31415 129 6月 2 2020 mysql
-rw------- 1 ftp ftp 376537503 12月 7 10:25 mysql-5.7.31-linux-glibc2.12-x86_64.tar.gz
drwxr-xr-x. 2 root root 6 4月 11 2018 sbin
drwxr-xr-x. 5 root root 49 12月 4 15:54 share
drwxr-xr-x. 2 root root 6 4月 11 2018 src
```
<a id="markdown-更改mysql所属用户和组" name="更改mysql所属用户和组"></a>
### 更改mysql所属用户和组
```shell
[root@master local]# chown -R mysql mysql/
[root@master local]# chgrp -R mysql mysql/
[root@master local]# cd mysql
[root@master mysql]# mkdir data
[root@master mysql]# chown -R mysql:mysql data
```
<a id="markdown-修改mycnf配置" name="修改mycnf配置"></a>
### 修改my.cnf配置
```shell
[root@master mysql]# cd /etc/
[root@master etc]# vi my.cnf
```
替换掉【/etc/my.cnf】文件内容如下:
```
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8
[mysqld]
skip-name-resolve
#设置3306端口
port = 3306
# 设置mysql的安装目录
basedir=/usr/local/mysql
# 设置mysql数据库的数据的存放目录
datadir=/usr/local/mysql/data
# 允许最大连接数
max_connections=200
# 服务端使用的字符集默认为utf8编码
character-set-server=utf8
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB
lower_case_table_names=1
max_allowed_packet=16M
```
<a id="markdown-安装和初始化" name="安装和初始化"></a>
### 安装和初始化
```shell
[root@master etc]# cd /usr/local/mysql
[root@master mysql]# bin/mysql_install_db --user=mysql --basedir=/usr/local/mysql --datadir=/usr/local/mysql/data
2020-12-07 13:33:58 [WARNING] mysql_install_db is deprecated. Please consider switching to mysqld --initialize
2020-12-07 13:34:01 [WARNING] The bootstrap log isn't empty:
2020-12-07 13:34:01 [WARNING] 2020-12-07T05:33:58.553062Z 0 [Warning] --bootstrap is deprecated. Please consider using --initialize instead
2020-12-07T05:33:58.554576Z 0 [Warning] Changed limits: max_open_files: 1024 (requested 5000)
2020-12-07T05:33:58.554599Z 0 [Warning] Changed limits: table_open_cache: 407 (requested 2000)
```
```shell
[root@master mysql]# cp ./support-files/mysql.server /etc/init.d/mysqld
[root@master mysql]# chown 777 /etc/my.cnf
[root@master mysql]# chmod +x /etc/init.d/mysqld
[root@master mysql]# service mysqld start
Starting MySQL. SUCCESS!
```
<a id="markdown-环境变量" name="环境变量"></a>
### 环境变量
`vi /etc/profile` 编辑追加以下内容:
```
# MYSQL
export MYSQL_HOME="/usr/local/mysql/"
export PATH="$PATH:$MYSQL_HOME/bin"
```
使修改生效
```shell
[root@master ~]# source /etc/profile
```
<a id="markdown-修改密码" name="修改密码"></a>
### 修改密码
修改【/etc/my.cnf】文件,添加一行配置:
```
[mysql]
# 设置mysql客户端默认字符集
default-character-set=utf8
[mysqld]
skip-name-resolve
#设置3306端口
port = 3306
# 设置mysql的安装目录
basedir=/usr/local/mysql
# 设置mysql数据库的数据的存放目录
datadir=/usr/local/mysql/data
# 允许最大连接数
max_connections=200
# 服务端使用的字符集默认为8比特编码的latin1字符集
character-set-server=utf8
# 创建新表时将使用的默认存储引擎
default-storage-engine=INNODB
lower_case_table_names=1
max_allowed_packet=16M
# 添加下面这行配置,不启动授权表,即不需要登录即可访问数据库
skip-grant-tables
```
重启mysql服务:
```shell
service mysqld restart
```
登录并使用update语句更新密码:
```sql
update user set authentication_string=PASSWORD('123456') where User='root';
```
```shell
[root@master ~]# mysql -u root
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.7.31 MySQL Community Server (GPL)
Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> use mysql
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> update user set authentication_string=PASSWORD('123456') where User='root';
Query OK, 1 row affected, 1 warning (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 1
mysql> exit
Bye
```
注释或删掉【/etc/my.cnf】中【skip-grant-tables】,然后重启mysql服务,使用密码进行登录
上面修改的密码相当于在mysql安装的时候的初始化的密码变成了我们修改的密码。所以在登录系统后mysql数据库要你修改原始密码:
```sql
SET PASSWORD = PASSWORD('123456'); --这个密码和上面一样也可以是其他的
```
```shell
[root@master ~]# mysql -uroot -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 2
Server version: 5.7.31
Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show databases;
ERROR 1820 (HY000): You must reset your password using ALTER USER statement before executing this statement.
mysql> SET PASSWORD = PASSWORD('123456');
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.00 sec)
```
<a id="markdown-远程访问" name="远程访问"></a>
### 远程访问
```sql
select host,user from user;
create user 'root'@'%' identified by '123456';
```
```shell
[root@master ~]# mysql -uroot -p
Enter password:
mysql> use mysql
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> select host,user from user;
+-----------+---------------+
| host | user |
+-----------+---------------+
| localhost | mysql.session |
| localhost | mysql.sys |
| localhost | root |
+-----------+---------------+
3 rows in set (0.00 sec)
mysql> create user 'root'@'%' identified by '123456';
Query OK, 0 rows affected (0.00 sec)
mysql> select host,user from user;
+-----------+---------------+
| host | user |
+-----------+---------------+
| % | root |
| localhost | mysql.session |
| localhost | mysql.sys |
| localhost | root |
+-----------+---------------+
4 rows in set (0.00 sec)
```
<a id="markdown-开机启动" name="开机启动"></a>
### 开机启动
```shell
[root@master ~]# chkconfig --level 35 mysqld on
[root@master ~]# chmod +x /etc/rc.d/init.d/mysqld
[root@master ~]# chkconfig --add mysqld
[root@master ~]# chkconfig --list mysqld
注:该输出结果只显示 SysV 服务,并不包含
原生 systemd 服务。SysV 配置数据
可能被原生 systemd 配置覆盖。
要列出 systemd 服务,请执行 'systemctl list-unit-files'。
查看在具体 target 启用的服务请执行
'systemctl list-dependencies [target]'。
mysqld 0:关 1:关 2:开 3:开 4:开 5:开 6:关
```
<a id="markdown-其他节点" name="其他节点"></a>
## 其他节点
机器名 | IP | 备注
----|----|---
master | 192.168.217.150 | 主节点 centos 7.6
node001 | 192.168.217.151 | 子节点 centos 7.6
node002 | 192.168.217.152 | 子节点 centos 7.6
使用vmware克隆两个虚拟机重新生成mac地址,并修改ip和network相关配置。
```shell
hostnamectl set-hostname node001
hostname node001
```
修改ip地址:
```shell
vi /etc/sysconfig/network-scripts/ifcfg-ens33
# 修改为151
# IPADDR=192.168.217.151
# 注释掉UUID,克隆主机防止重复
#UUID=fc598c8e-a7c7-4a13-a9ca-xxxxxxxxxxx
```
```shell
[root@master ~]# vi /etc/sysconfig/network
```
修改主机名称:
```shell
NETWORKING=yes
HOSTNAME=node001
```
更新hosts文件
```shell
vi /etc/hosts
```
```
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.217.150 master
192.168.217.151 node001
192.168.217.152 node002
```
<a id="markdown-免密登录" name="免密登录"></a>
## 免密登录
在master主机上生成密钥
参考 [免密登录](基础环境.md#免密登录)
<a id="markdown-httpd服务" name="httpd服务"></a>
## httpd服务
<a id="markdown-安装httpd服务" name="安装httpd服务"></a>
### 安装httpd服务
master主机节点安装httpd服务
```shell
# 安装 httpd 服务
[root@master ~]# yum install -y httpd
# 启动 httpd 服务
[root@master ~]# service httpd start
# 设置开机启动
[root@master ~]# chkconfig httpd on
```
<a id="markdown-配置parcels" name="配置parcels"></a>
### 配置parcels
```shell
[root@master ~]# cd /var/www/html
[root@master html]# mkdir parcels
[root@master html]# cd /var/ftp/pub/
[root@master pub]# ll
总用量 3094320
-rw------- 1 ftp ftp 2127506677 12月 7 16:37 CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel
-rw------- 1 ftp ftp 41 12月 7 16:37 CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel.sha
-rw------- 1 ftp ftp 1041013234 12月 7 16:37 cm5.16.1-centos7.tar.gz
-rw------- 1 ftp ftp 56892 12月 7 16:37 manifest.json
[root@master pub]# mv CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel /var/www/html/parcels/
[root@master pub]# mv CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel.sha /var/www/html/parcels/
[root@master pub]# mv manifest.json /var/www/html/parcels/
```
创建cm文件
```shell
[root@master parcels]# cd /var/www/html/
# 在/var/www/html创建cm5/redhat/7/x86_64/文件夹(和官网一样的路径)
[root@master html]# mkdir -p cm5/redhat/7/x86_64/
[root@master html]# mv /var/ftp/pub/cm5.16.1-centos7.tar.gz /var/www/html/
[root@master html]# ll
总用量 1016616
drwxr-xr-x 3 root root 20 12月 7 16:49 cm5
-rw------- 1 ftp ftp 1041013234 12月 7 16:37 cm5.16.1-centos7.tar.gz
drwxr-xr-x 2 root root 126 12月 7 16:48 parcels
[root@master html]# tar -zxvf cm5.16.1-centos7.tar.gz
[root@master html]# ll
总用量 1016616
drwxrwxr-x 3 1106 592 121 11月 21 2018 cm
drwxr-xr-x 3 root root 20 12月 7 16:49 cm5
-rw------- 1 ftp ftp 1041013234 12月 7 16:37 cm5.16.1-centos7.tar.gz
drwxr-xr-x 2 root root 126 12月 7 16:48 parcels
# 将解压好的文件夹移动到上述创建的文件夹下
[root@master html]# mv cm /var/www/html/cm5/redhat/7/x86_64/
# 配置本地的yum源,cdh集群在安装时会就从本地down包,不会从官网了,所有节点都要执行
[root@master html]# vi /etc/yum.repos.d/cloudera-manager.repo
```
```
[cloudera-manager]
name = Cloudera Manager, Version 5.16.1
baseurl = http://192.168.217.150/cm5/redhat/7/x86_64/cm/5/
gpgcheck = 0
```
```shell
# 重新建立缓存
[root@master ~]# yum makecache
# 推送至其他节点
[root@master yum.repos.d]# scp /etc/yum.repos.d/cloudera-manager.repo node001:/etc/yum.repos.d/
[root@master yum.repos.d]# scp /etc/yum.repos.d/cloudera-manager.repo node002:/etc/yum.repos.d/
```
<a id="markdown-安装cm的server和daemons" name="安装cm的server和daemons"></a>
## 安装CM的server和daemons
```shell
# 进入上述创建的CM的文件目录下
[root@master ~]# cd /var/www/html/cm5/redhat/7/x86_64/cm/5.16.1/RPMS/x86_64/
# 安装cloudera-manager-daemons
[root@master x86_64]# yum install -y cloudera-manager-daemons-5.16.1-1.cm5161.p0.1.el7.x86_64.rpm
# 安装cloudera-manager-server-,不用安装db版本的,生产环境中是使用MySQL数据库的
[root@master x86_64]# yum install -y cloudera-manager-server-5.16.1-1.cm5161.p0.1.el7.x86_64.rpm
```
<a id="markdown-元数据库的创建" name="元数据库的创建"></a>
## 元数据库的创建
<a id="markdown-创建与授权" name="创建与授权"></a>
### 创建与授权
在master节点通过命令行创建mysql数据库:
```shell
[root@master ~]# mysql -uroot -p
Enter password:
mysql> use mysql
```
```sql
-- 创建cmf用户,并创建cmf数据库,此数据库需在CDH的数据库配置文件中配置
create database cmf DEFAULT CHARACTER SET utf8;
grant all on cmf.* TO 'cmf'@'%' IDENTIFIED BY '123456';
flush privileges;
-- 创建其他数据库,并授权
create database amon DEFAULT CHARACTER SET utf8;
grant all on amon.* TO 'amon'@'%' IDENTIFIED BY '123456';
flush privileges;
create database hive DEFAULT CHARACTER SET utf8;
grant all on hive.* TO 'hive'@'%' IDENTIFIED BY '123456';
flush privileges;
create database oozie DEFAULT CHARACTER SET utf8;
grant all on oozie.* TO 'oozie'@'%' IDENTIFIED BY '123456';
flush privileges;
create database hue DEFAULT CHARACTER SET utf8;
grant all on hue.* TO 'hue'@'%' IDENTIFIED BY '123456';
flush privileges;
```
如果需要root用户可访问所有数据库,执行下面的命令:
```sql
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%';
flush privileges;
```
修改CDH关于数据库的配置文件:
```shell
vi /etc/cloudera-scm-server/db.properties
```
新增以下配置,注意ip地址和数据库的密码同步更新:
```
com.cloudera.cmf.db.setupType=EXTERNAL
com.cloudera.cmf.db.host=192.168.217.150:3306
com.cloudera.cmf.db.name=cmf
com.cloudera.cmf.db.user=cmf
com.cloudera.cmf.db.password=123456
```
<a id="markdown-上传mysql-connector-java" name="上传mysql-connector-java"></a>
### 上传mysql-connector-java
在所有节点上执行上传操作,将jar包上传至【/usr/share/java】,并统一名称为:【mysql-connector-java.jar】
```shell
[root@master ~]# mkdir -p /usr/share/java
[root@master ~]# cd /usr/share/java
# 上传 mysql-connector-java-5.1.48.tar.gz 文件
[root@master ~]# rz
[root@master java]# tar -zxvf mysql-connector-java-5.1.48.tar.gz
[root@master java]# mv mysql-connector-java-5.1.48/mysql-connector-java-5.1.48.jar ./mysql-connector-java.jar
[root@master java]# mv mysql-connector-java-5.1.48.jar mysql-connector-java.jar
[root@master java]# ssh node001 mkdir -p /usr/share/java
[root@master java]# ssh node002 mkdir -p /usr/share/java
[root@master java]# scp mysql-connector-java.jar node001:/usr/share/java/
[root@master java]# scp mysql-connector-java.jar node002:/usr/share/java/
```
<a id="markdown-启动cloudera-scm-server服务并查看日志" name="启动cloudera-scm-server服务并查看日志"></a>
## 启动cloudera-scm-server服务并查看日志
```shell
# 启动
service cloudera-scm-server start
service cloudera-scm-server status
# 重新启动
service cloudera-scm-server restart
#在启动时有可能碰到The server time zone value 'EDT' is unrecognized异常,这是mysql的时区和系统的时区不匹配,可以参考如下网站解决
#https://blog.csdn.net/u010003835/article/details/88974898
#查看日志
cd /var/log/cloudera-scm-server/
tail -f cloudera-scm-server.log
# 出现如下7180即证明启动成功
#WebServerImpl:org.mortbay.log: Started [email protected]:7180
```
检查cmf下自动创建的表:

<a id="markdown-clouderamanager管理" name="clouderamanager管理"></a>
## ClouderaManager管理
<a id="markdown-cm-web界面" name="cm-web界面"></a>
### cm-web界面
浏览器中登录管理页面:http://192.168.217.150:7180/cmf/login
默认用户名和密码均为:admin
神奇的事情,chrome竟然无法看到【许可条款和条件】页面,从而导致无法点击【继续】
换其他浏览器跳过此步骤,选择免费【ClouderaExpress】版本测试:

为 CDH 群集安装指定主机:

<a id="markdown-cdh集群配置" name="cdh集群配置"></a>
### CDH集群配置
1. 将parcels文件拷贝至【/opt/cloudera/parcel-repo】
```shell
cp /var/www/html/parcels/CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel /opt/cloudera/parcel-repo
cp /var/www/html/parcels/CDH-5.16.1-1.cdh5.16.1.p0.3-el7.parcel.sha /opt/cloudera/parcel-repo
# 修改权限
chown -R cloudera-scm:cloudera-scm /opt/cloudera/parcel-repo/*
# 重启服务
service cloudera-scm-server restart
```
选择存储库:


2. JDK 安装选项,以之前安装好的默认JDK即可,无需重复安装。
3. 单用户模式,默认即可
4. 提供 SSH 登录凭据,可以自由选择,这里直接使用root用户和密码登录
5. 集群安装

6. 安装选定Parcel,先前配置的Parcel就作用于此处,否则从线上下载会很慢。
7. 检查主机正确性,一般来说此步会存在swap设置和大页面2个问题,可以使用如下代码在每个主机上进行配置,然后重新检测即可:
```shell
# 关闭大页面
echo never > /sys/kernel/mm/transparent_hugepage/defrag
echo never > /sys/kernel/mm/transparent_hugepage/enabled
echo 'echo never > /sys/kernel/mm/transparent_hugepage/defrag'>> /etc/rc.local
echo 'echo never > /sys/kernel/mm/transparent_hugepage/enabled'>> /etc/rc.local
# 设置swap
echo 'vm.swappiness = 10' >> /etc/sysctl.conf
sysctl -p
```
<a id="markdown-faq" name="faq"></a>
## FAQ
<a id="markdown-hdfs副本不足" name="hdfs副本不足"></a>
### HDFS副本不足
HDFS-副本不足的块,报错信息:
测试 HDFS 是否具有过多副本不足块。
不良 : 群集中有 8 个 副本不足的块 块。群集中共有 11 个块。百分比 副本不足的块: 72.73%。 临界阈值:40.00%。
原因:设置的副本备份数与DataNode的个数不同。
点击集群-HDFS-配置,搜索 dfs.replication ,设置为2后保存更改。
dfs.replication这个参数其实只在文件被写入dfs时起作用,虽然更改了配置文件,但是不会改变之前写入的文件的备份数。
所以我们还需要步骤2,在cm0中通过命令更改备份数:
这里的-R 2的数字2就对应我们的DataNode个数。
```shell
[root@master /]# su hdfs
[hdfs@master /]$ hadoop fs -setrep -R 2 /
```
<a id="markdown-navigator数据治理" name="navigator数据治理"></a>
## Navigator数据治理
需要升级至 Enterprise Edition ,基本版Express不支持。
<a id="markdown-navigator元数据库" name="navigator元数据库"></a>
### navigator元数据库
```shell
[root@master ~]# mysql -uroot -p
Enter password:
mysql> use mysql
```
```sql
create database nms default character set utf8;
CREATE USER 'nms'@'%' IDENTIFIED BY '123456';
GRANT ALL PRIVILEGES ON nms. * TO 'nms'@'%';
FLUSH PRIVILEGES;
create database nas default character set utf8;
CREATE USER 'nas'@'%' IDENTIFIED BY '123456';
GRANT ALL PRIVILEGES ON nas. * TO 'nas'@'%';
FLUSH PRIVILEGES;
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%';
FLUSH PRIVILEGES;
```
<a id="markdown-mysql-connector-java" name="mysql-connector-java"></a>
### mysql-connector-java
通过软链接方式或者修改文件名称存放 【/usr/share/java/mysql-connector-java.jar】
```shell
cd /usr/share/java/
ln -s mysql-connector-java-5.1.34.jar mysql-connector-java.jar
```
使用管理员登录Cloudera Manager的WEB界面,进入Cloudera Management Service服务
进入实例界面,添加角色实例,选择“Navigator Metadata Server”和“Navigator Audit Server”角色部署的节点
安装完成后,选择“Navigator Audit Server”和“Navigator Metadata Server”服务启动角色。
<a id="markdown-navigator配置" name="navigator配置"></a>
### navigator配置
参考此内容进行配置 :[Navigator的使用](https://cloud.tencent.com/developer/article/1079092)
<a id="markdown-虚拟机脚本备份" name="虚拟机脚本备份"></a>
## 虚拟机脚本备份
三台虚拟机:
ip | host-name | RAM
---|------|----
10.2.14.226 | KG-FMS-226 | 16G
10.2.14.227 | KG-FMS-227 | 8G
10.2.14.228 | KG-FMS-228 | 8G
```shell
vi /etc/hosts
10.2.14.226 KG-FMS-226
10.2.14.227 KG-FMS-227
10.2.14.228 KG-FMS-228
```
```shell
vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=KG-FMS-226
NETWORKING=yes
HOSTNAME=KG-FMS-227
NETWORKING=yes
HOSTNAME=KG-FMS-228
```
rpm 离线安装 ntp
```
# 检查是否已安装有ntp
rpm -qa|grep ntp
```
---
参考引用:
[CentOS7安装CDH 第五章:CDH的安装和部署-CDH5.7.0](https://www.cnblogs.com/yangshibiao/p/10862656.html)
[手把手部署CDH(5.12.1)完全离线模式安装超级详细攻略](https://www.jianshu.com/p/f25b81772142)
[CDH5与CDH6对比](https://cloud.tencent.com/developer/article/1419293)
[Cloudera Manager安装部署](https://blog.csdn.net/lukabruce/article/details/80805929)
[CDH搭建大数据集群(5.10.0)](https://www.cnblogs.com/rmxd/p/11343704.html)
[大数据之CM+CDH5.16.1(二)](https://www.jianshu.com/p/8bbd2603b6bd)
[Cloudera Manager安装 & 搭建CDH集群](https://blog.csdn.net/oschina_41140683/article/details/81211635)
[centos7 无法启动网络(service network restart)错误解决办法](https://www.cnblogs.com/spmt/p/10662243.html)
[Cloudera Navigator介绍与安装](https://cloud.tencent.com/developer/article/1078927)
[Navigator的使用](https://cloud.tencent.com/developer/article/1079092) | 23,060 | Apache-2.0 |
# Start Development
项目创建好后,在项目目录下运行 `npm i` 安装好依赖,然后再运行 `feflow dev` 就能启动本地服务,服务默认运行在 http://127.0.0.1:8001。
After creating project, run `npm i` in the project to install dependencies. And run `feflow dev` to start local server. The service's location is http://127.0.0.1:8001.
打开 http://127.0.0.1:8001 ,你会看到初始态的一个页面。如果你想修改这个页面,则需要先大概了解一下项目的目录结构,知道去哪改。
Open http://127.0.0.1:8001, you can see a pure page. If you want to change the page, you should know the folder tree.
<!-- 项目的目录结构是由你所选择的脚手架决定的,以本教程所使用的脚手架为例,生成的项目主要结构如下: -->
The project's directory structure is determined by the scaffolding of your choice. Take the scaffolding used in this tutorial as an example. The main structure of the generated project is as follows:
```sh
|- src
|- assets # 公共的 JS、CSS、Images 目录
|- middleware # 公共的 Redux 中间件 目录
|- modules # 公共模块
|- pages # 页面目录
|- index # 首页
|- actions # 页面级的 actions 目录
|- components # 页面级的公共组件目录
|- reducers # 页面级的 reducers 目录
|- index.html # HTML 入口
|- index.js # 页面 Class
|- index.less # pageComponent.js 中元素的样式,或者全局样式
|- init.js # JS 入口
|- pageComponent.js # React 根组件
|- reducers # 公共的 reducers 目录
|- feflow.json # Feflow 配置文件
```
```sh
|- src
|- assets # common JS、CSS、Images directory
|- middleware # common Redux middleware directory
|- modules # common module directory
|- pages # pages directory
|- index # home page
|- actions # common actions directory in home page
|- components # common components directory in home page
|- reducers # common reducers directory in home page
|- index.html # home page html
|- index.js # home page Class
|- index.less # pageComponent.js 中元素的样式,或者全局样式
|- init.js # JS 入口
|- pageComponent.js # React 根组件
|- reducers # 公共的 reducers 目录
|- feflow.json # Feflow 配置文件
```
其中,`src/pages/index/index.html` 就是 `http://127.0.0.1:8001` 展示的页面。你可以打开 `src/pages/index/pageComponent.js` 文件进行修改。 | 2,103 | MIT |
---
title: プログレッシブ Web アプリでファイルを処理する
description: オペレーティング システムにファイル をPWAするファイル ハンドラーとして登録する方法について説明します。
author: MSEdgeTeam
ms.author: msedgedevrel
ms.date: 09/01/2021
ms.topic: conceptual
ms.prod: microsoft-edge
ms.technology: pwa
keywords: プログレッシブ Web アプリ、PWA、Edge、JavaScript、ファイル
ms.openlocfilehash: 2d0fafb37d5da49f84797a3a41e77bb985dd0f15
ms.sourcegitcommit: 242e9611f73507f587d1669af24d0e3423f722dc
ms.translationtype: MT
ms.contentlocale: ja-JP
ms.lasthandoff: 10/11/2021
ms.locfileid: "12087435"
---
# <a name="handle-files-in-progressive-web-apps"></a>プログレッシブ Web アプリでファイルを処理する
ファイルを処理できるプログレッシブ Web アプリは、ユーザーのネイティブ性が高く、オペレーティング システムとの統合性が向上します。
Web サイトでは、ユーザーがドラッグ [ `<input type="file">` ](https://developer.mozilla.org/docs/Web/API/File/Using_files_from_web_applications)アンド ドロップを使用してファイルをアップロードできますが、PWA はさらに一歩進み、オペレーティング システムでファイル ハンドラーとして登録できます。
特定のPWAのファイル ハンドラーとして登録されている場合、オペレーティング システムは、これらのファイルをユーザーが開いた場合に、Microsoft Word がファイルを処理する方法と同様に、アプリを自動的に起動できます。 `.docx`
<!-- ====================================================================== -->
## <a name="enable-the-file-handling-api"></a>ファイル処理 API を有効にする
ファイル処理機能は実験的です。
ファイル処理機能を有効にするには、次の操作を行います。
1. [次へ `edge://flags` ] をクリックMicrosoft Edge。
1. [検索 **フラグ] を** 選択し、「ファイル処理 API」と入力します。
1. [既定**の有効** > **な再起動]** > **を選択します**。
:::image type="content" source="../media/enable-file-handling-experiment.png" alt-text="'ファイル処理 API' 実験を有効にする。" lightbox="../media/enable-file-handling-experiment.png":::
<!-- ====================================================================== -->
## <a name="define-which-files-your-app-handles"></a>アプリで処理するファイルを定義する
まず、アプリで処理するファイルの種類を宣言します。 これは、配列メンバーを使用 [して、アプリ](./web-app-manifests.md)マニフェスト ファイルで `file_handlers` 行われます。
配列内の各エントリ `file_handlers` には、次の 2 つのプロパティが必要です。
* `action`: オペレーティング システムを起動するときに、オペレーティング システムが移動する必要PWA。
* `accept`: 受け入れ可能なファイルの種類のオブジェクト。 キーは MIME 型 (部分型、ワイルドカード 記号を使用) であり、値は受け入れられるファイル拡張子 `*` の配列です。
次の例を検討してください。
```json
{
"file_handlers": [
{
"action": "/openFile",
"accept": {
"text/*": [
".txt"
]
}
}
]
}
```
この例では、アプリはテキスト ファイルを受け入れる単一のファイル ハンドラーを登録します。 たとえば、デスクトップ上のアイコンをダブルクリックしてユーザーがファイルを開いた場合、オペレーティング システムは URL を使用して `.txt` アプリを起動 `/openFile` します。
<!-- ====================================================================== -->
## <a name="detect-whether-the-file-handling-api-is-available"></a>ファイル処理 API が使用可能かどうかを検出する
ファイルを処理する前に、アプリは、ファイル処理 API がデバイスとブラウザーで使用できるかどうかを確認する必要があります。
ファイル処理 API が使用可能かどうかを確認するには、次のようにオブジェクト `launchQueue` が存在するかどうかをテストします。
```javascript
if ('launchQueue' in window) {
console.log('File Handling API is supported!');
} else {
console.error('File Handling API is not supported!');
}
```
<!-- ====================================================================== -->
## <a name="handle-files-on-launch"></a>起動時にファイルを処理する
ファイルを開いた後に OS によってアプリを起動すると、オブジェクトを使用してファイル `launchQueue` コンテンツにアクセスできます。
テキスト コンテンツを処理するには、次の JavaScript コードを使用します。
```javascript
if ('launchQueue' in window) {
console.log('File handling API is supported!');
launchQueue.setConsumer(launchParams => {
handleFiles(launchParams.files);
});
} else {
console.error('File handling API is not supported!');
}
async function handleFiles(files) {
for (const file of files) {
const blob = await file.getFile();
blob.handle = file;
const text = await blob.text();
console.log(`${file.name} handled, content: ${text}`);
}
}
```
オブジェクト `launchQueue` は、コンシューマーがで設定されるまで、起動されたファイルのキューに入れられます `setConsumer` 。 オブジェクトとオブジェクトの詳細 `launchQueue` については `launchParams` 、「ファイル処理」の説明 [を参照してください](https://github.com/WICG/file-handling/blob/main/explainer.md#launch)。
<!-- ====================================================================== -->
## <a name="demo"></a>デモ
マイ トラックは、PWA処理機能を使用してファイルを処理するデモ アプリ `.gpx` です。 このデモ アプリで機能を試す方法は次の方法です。
* [[アプリ] で機能](#enable-the-file-handling-api)を有効Microsoft Edge。
* [マイ トラック [] に移動し][MyTracksDemoApp] 、アプリをインストールします。
* コンピューターに GPX ファイルをダウンロードします。 このテスト [GPX ファイルを使用できます][TestGPXFile]。
* ダウンロードした GPX ファイルを開きます。
アプリが自動的に起動し、Microsoft Edgeを処理するためのアクセス許可が要求されます。
:::image type="content" source="../media/my-tracks-allow-file-handling.png" alt-text="'Open file? アクセス許可要求ダイアログ。" lightbox="../media/my-tracks-allow-file-handling.png":::
アプリでファイルの処理を許可すると、アプリのサイドバーに新しいエントリが表示され、その横にあるチェック ボックスをクリックして、対応する GPS トラックを視覚化できます。
:::image type="content" source="../media/my-tracks-new-file.png" alt-text="My Tracks アプリで処理される新しい GPS トラック。" lightbox="../media/my-tracks-new-file.png":::
このアプリのソース コードは、My Tracks リポジトリ[GitHubできます][MyTracksDemoAppGitHub]。
* [manifest.json ソース ファイル][MyTracksDemoAppManifestJsonFile]は、配列を `file_handlers` 使用してファイルの処理を要求 `.gpx` します。
* ソース [file.js][MyTracksDemoAppFileJsFile] は、オブジェクトを `launchQueue` 使用して受信ファイルを処理します。
<!-- ====================================================================== -->
<!-- links -->
[MyTracksDemoApp]: https://captainbrosset.github.io/mytracks/ "マイ トラック"
[MyTracksDemoAppGitHub]: https://github.com/captainbrosset/mytracks "サンプル Web アプリを使用して、PWA機能の|GitHub"
[TestGPXFile]: https://www.visugpx.com/download.php?id=okB1eM4fzj
[MyTracksDemoAppManifestJsonFile]: https://github.com/captainbrosset/mytracks/blob/main/mytracks/manifest.json
[MyTracksDemoAppFileJsFile]: https://github.com/captainbrosset/mytracks/blob/main/src/file.js | 5,482 | CC-BY-4.0 |
---
layout: post
title: 前端单元测试之 Karma 环境搭建
date: 2016-09-13
excerpt_separator: <!--end_excerpt-->
---
在前端开发中,测试常常是被忽略的一环。因此最近在研究前端自动化测试框架Karma,把个人的学习过程分享出来,希望对大家有帮助。
<!--end_excerpt-->
## 什么是Karma?
Karma是由Google团队开发的一套前端测试运行框架。它不同于测试框架(例如jasmine,mocha等),运行在这些测试框架之上。主要完成一下工作:
1. Karma启动一个web服务器,生成包含js源代码和js测试脚本的页面;
2. 运行浏览器加载页面,并显示测试的结果;
3. 如果开启检测,则当文件有修改时,执行继续执行以上过程。
## Karma的安装配置
### 初始项目结构
karma-example
├── src
├── index.js
├── test
├── package.json
index.js的内容如下
```javascript
function isNum(num) {
if (typeof num === 'number') {
return true
} else {
return false
}
}
```
### 安装Karma环境
为了方便搭建Karma环境,我们可以全局安装`karma-cli`来帮我们初始化测试环境:
npm i -g karma-cli
然后在项目中安装karma包
npm i --save-dev karma
接下来在工程目录中运行`karma init`来进行测试环境初始化,并按照指示一步步完成。
![Karma Config Example][1]
上图是选项的示例,这里使用jasmine测试框架,PhantomJS作为代码运行的环境(也可以选择其他浏览器作为运行环境,比如Chrome,IE等)。最后在项目中生成karma.conf.js文件。
至此就搭建好了基本的Karma运行环境。
### 运行Karma
在test目录里编写一个简单的测试脚本,我们使用的是jasmine测试框架,具体的api可以参考[jasmine api](http://jasmine.github.io/2.5/introduction.html),内容如下
```javascritp
describe('index.js: ', function() {
it('isNum() should work fine.', function() {
expect(isNum(1)).toBe(true)
expect(isNum('1')).toBe(false)
})
})
```
然后在项目根目录下运行`karma start`命令,我们可以看到运行的结果如下
![Karma Running Result][2]
可以看到,运行的结果显示测试成功。
同时,因为我们之前设置了监控文件的修改,所以当我们修改源文件或者测试脚本的时候,Karma会自动帮我们再次运行,无需我们手动操作。
### Coverage
如何衡量测试脚本的质量呢?其中一个参考指标就是代码覆盖率(coverage)。
什么是代码覆盖率?简而言之就是测试中运行到的代码占所有代码的比率。其中又可以分为行数覆盖率,分支覆盖率等。具体的含义不再细说,有兴趣的可以自行查阅资料。
虽然并不是说代码覆盖率越高,测试的脚本写得越好(可以看看参考文献4),但是代码覆盖率对撰写测试脚本还是有一定的指导意义的。因此接下来我们在Karma环境中添加Coverage。
首先安装好Karma覆盖率工具
npm i --save-dev karma-coverage
然后修改配置文件karma.conf.js,
module.exports = function(config) {
config.set({
basePath: '',
frameworks: ['jasmine'],
files: [
'src/**/*.js',
'test/**/*.js'
],
exclude: [],
// modified
preprocessors: {
'src/**/*.js': ['coverage']
},
//modified
reporters: ['progress', 'coverage'],
// add
coverageReporter: {
type : 'html',
dir : 'coverage/'
},
port: 9876,
colors: true,
logLevel: config.LOG_INFO,
autoWatch: true,
browsers: ['PhantomJS'],
singleRun: false,
concurrency: Infinity
})
}
再运行`karma start`后,会在目录下生成coverage目录,里面有本次测试的覆盖报告。打开后的结果如下
![Coverage][3]
### 使用Webpack+Babel
在实际项目中,有事会需要用到Webpack和ES6,所以接下来将Webpack和Babel集成进Karma环境中。
安装karma-webpack
npm i --save-dev karma-webpack
安装babel
npm i --save-dev babel-loader babel-core babel-preset-es2015
然后文件进行改造,`src/index.js`文件修改为
function isNum(num) {
if (typeof num === 'number') {
return true
} else {
return false
}
}
exports.isNum = isNum
`text/index.js`文件修改为
const Util = require('../src/index')
describe('index.js: ', () => {
it('isNum() should work fine.', () => {
expect(Util.isNum(1)).toBe(true)
expect(Util.isNum('1')).toBe(false)
})
})
接下来修改配置文件karma.conf.js
module.exports = function(config) {
config.set({
basePath: '',
frameworks: ['jasmine'],
files: [
'test/**/*.js'
],
exclude: [],
preprocessors: {
'test/**/*.js': ['webpack', 'coverage']
},
reporters: ['progress', 'coverage'],
coverageReporter: {
type: 'html',
dir: 'coverage/'
},
port: 9876,
colors: true,
logLevel: config.LOG_INFO,
autoWatch: true,
browsers: ['PhantomJS'],
singleRun: false,
concurrency: Infinity,
webpack: {
module: {
loaders: [{
test: /\.js$/,
loader: 'babel',
exclude: /node_modules/,
query: {
presets: ['es2015']
}
}]
}
}
})
}
注意这里的修改:
1. files只留下test文件。因为webpack会自动把需要的其它文件都打包进来,所以只需要留下入口文件。
2. preprocessors也修改为test文件,并加入webpack域处理器
3. 加入webpack配置选项。可以自己定制配置项,但是不需要entry和output。这里加上babel-loader来编译ES6代码
运行`karma start`,成功了~
再看看Coverage,卧槽。。居然不是百分之百了。。。
原因很简单,webpack会加入一些代码,影响了代码的Coverage。如果我们引入了一些其它的库,比如jquery之类的,将源代码和库代码打包在一起后,覆盖率会更难看。。这样的Coverage就没有了参考的价值。
还好有大神给我们提供了解决方案,需要安装插件
npm i --save-dev babel-plugin-istanbul
修改webpack中babel-loader的配置
{
test: /\.js$/,
loader: 'babel',
exclude: /node_modules/,
query: {
presets: ['es2015'],
plugins: ['istanbul']
}
}
因为这里引入了istanbul插件来检测Coverage,所以要把preprocessors里的`coverage`去掉。
搞定以后,运行`karma start`。当当当当~一切OK啦,尽情编写测试脚本把~
最后附上示例项目地址:[karma-example](https://github.com/xiaojimao18/karma-example)
## References
1. [Karma](https://karma-runner.github.io)
2. [Karma using ES6](http://www.syntaxsuccess.com/viewarticle/writing-jasmine-unit-tests-in-es6)
3. [Jasmine API](http://jasmine.github.io/2.5/introduction.html)
4. [测试覆盖(率)到底有什么用?](http://www.infoq.com/cn/articles/test-coverage-rate-role)
5. [Just Say No to More End-to-End Tests](https://testing.googleblog.com/2015/04/just-say-no-to-more-end-to-end-tests.html)
[1]: /assets/images/10007/init.png
[2]: /assets/images/10007/start.png
[3]: /assets/images/10007/coverage.png | 5,420 | MIT |
<!--
* @Description: 1011 analyse
* @Author: Yihao Wang
* @Date: 2020-01-06 17:03:41
* @LastEditors : Yihao Wang
* @LastEditTime : 2020-01-06 18:07:03
-->
# 1011题解
本题在我看discuss板块之前, 我都没有想到这是一个二分算法的题目, 所以就导致了我无法在时限里面完成该题. 那么问题来了, 为什么这个题是一个二分算法题?
首先要明确这个解的范围在一开始就可以知道, 因为每天货物的重量我们知道, 设总货物重量为sum_goods, 最大日载重量为max_goods, 最小日载重量为min_goods, 天数D也知道, 则 sum_goods/D <= result =< sum_goods, 即所设定的载重量的范围我们是在一开始就可以求得. (公式解释: 载重量若是小于sum_goods/D, 那么必不可能在规定时日内运载完, 载重量若大于sum_goods, 那么肯定不是最小值, 因为一天就可以全部运完而且会有剩余)
若先设定好载重量, 再去看看当前载重量需要多少天数, 则本题就从已知天数求载重量变成了已知载重量求天数, 而且已知载重量求天数又十分好求, 仅需要每日尽可能多载货物即可求出, 所以便可以使用二分算法了:
若是求得得天数比D小, 说明可以缩减载重量(载得太快了, 还有缩减空间); 若是求得得天数大于D, 或说明必须增加载重量(载重量过低无法在规定时日内完成) | 690 | MIT |
# microservice-zuul-demo
路由网关`zuul`的练习
## microservice-eureka
`Eureka`服务注册中心
访问地址:`http://localhost:8761/`
## microservice-provider
服务提供者
`hello`服务:请求地址:`http://localhost:8081/provider/hello` 或者 `http://localhost:8081/provider/hello?name=tom`
`hi`服务:请求地址:`http://localhost:8081/provider/hi?name=tom`
当请求`hi`服务时,不携带`name`参数,会自动默认参数`provider`此时服务内部直接抛出一个运行异常,出现运行异常后,将由`hystrix`全局异常方法进行处理
当请求`hello`服务时,该服务出现奔溃时,此时会有`hystrix`自定义异常方法进行处理
## microservice-consumer
服务消费者,提供`Hello`、`hi`和`getName`服务,其中`Hello`、`hi`是通过`openFeign`调用服务提供者`microservice-provider`的服务
`hello`服务:请求地址:`http://localhost:8080/consumer/hello?name=tom` 或者 `http://localhost:8080/consumer/hello`
`hi`服务:请求地址:`http://localhost:8080/consumer/hi?name=tom`
`getName`服务:请求地址:`http://localhost:8080/consumer/getName`
当请求`Hello`和`hi`服务时,若是服务提供者已经宕机,则会触发熔断,防止服务雪崩。
## microservice-turbine
微服务集群监控服务
地址:`http://localhost:8764/hystrix` 在地址栏中填写`http://localhost:8764/turbine.stream` 可以查看所有服务监控,
TIPS:若是一直时加载中得状态,请刷新几次请求接口即可
## microservice-zuul
路由网关服务
我们不想暴露服务消费者,或者对消费者服务做负载,以及授权访问时,我们使用`zuul`组件进行路由网关配置
启动消费者服务时,复制一份模板,启动一个`8085`的消费者与`8080`消费者进行负载均衡
```yaml
#配置路由规则
# 路径中包含 provider 的都转发到 MICROSERVICE-PROVIDER 服务
# 路径中包含 consumer 的都转发到 MICROSERVICE-CONSUMER 服务
zuul:
routes:
provider:
path: /provider/**
serviceId: MICROSERVICE-PROVIDER
consumer:
path: /consumer/**
serviceId: MICROSERVICE-CONSUMER
#对服务配置负载均衡
MICROSERVICE-CONSUMER:
ribben:
listOfServers: http://localhost:8080,http://localhost:8085 #需要再启动一个端口为8085的服务消费方
```
当调用时,真是的地址就是:`http://localhost:8760/consumer/consumer/hello?token=111` 其中token为授权码,不能为空的即可 | 1,638 | Apache-2.0 |
---
categories:
- Linux 命令
date: '2020-09-25 08:00:00'
tags:
- Linux
- Linux Command
- Linux 命令
- fuser
title: 【Linux 命令】fuser
updated: '2020-09-25 09:21:30'
---
使用文件或文件结构识别进程
## 补充说明
**fuser命令** 用于报告进程使用的文件和网络套接字。fuser命令列出了本地进程的进程号,那些本地进程使用file,参数指定的本地或远程文件。对于阻塞特别设备,此命令列出了使用该设备上任何文件的进程。
每个进程号后面都跟随一个字母,该字母指示进程如何使用文件。
* `c` :指示进程的工作目录。
* `e` :指示该文件为进程的可执行文件(即进程由该文件拉起)。
* `f` :指示该文件被进程打开,默认情况下f字符不显示。
* `F` :指示该文件被进程打开进行写入,默认情况下F字符不显示。
* `r` :指示该目录为进程的根目录。
* `m` :指示进程使用该文件进行内存映射,抑或该文件为共享库文件,被进程映射进内存。
### 语法
```shell
fuser(选项)(参数)
```
### 选项
```shell
-a:显示命令行中指定的所有文件;
-k:杀死访问指定文件的所有进程;
-i:杀死进程前需要用户进行确认;
-l:列出所有已知信号名;
-m:指定一个被加载的文件系统或一个被加载的块设备;
-n:选择不同的名称空间;
-u:在每个进程后显示所属的用户名。
```
### 参数
文件:可以是文件名或者TCP、UDP端口号。
### 实例
要列出使用`/etc/passwd`文件的本地进程的进程号,请输入:
```shell
fuser /etc/passwd
```
要列出使用`/etc/filesystems`文件的进程的进程号和用户登录名,请输入:
```shell
fuser -u /etc/filesystems
```
要终止使用给定文件系统的所有进程,请输入:
```shell
fuser -k -x -u -c /dev/hd1 或者 fuser -kxuc /home
```
任一命令都列出了进程号和用户名,然后终止每个正在使用`/dev/hd1 (/home)`文件系统的进程。仅有root用户能终止属于另一用户的进程。如果您正在试图卸下`/dev/hd1`文件系统,而一个正在访问`/dev/hd1`文件系统的进程不允许这样,您可能希望使用此命令。
要列出正在使用已从给定文件系统删除的文件的全部进程,请输入:
```shell
fuser -d /usr文件
```
`/dev/kmem` 用于系统映像。
`/dev/mem` 也用于系统映像。
<!-- Linux命令行搜索引擎:https://jaywcjlove.github.io/linux-command/ --> | 1,291 | MIT |
Ubuntu/Debian/Linux Mint 系统中使用 Tor
================================================================================
**Tor**, **T**he **O**nion **R**outer (洋葱路由),是一种虚拟通道网络,它可使用户安全以及匿名的进行互联网通信。Tor 可以让组织及个人通过公共网络分享信息而不用担心隐私会泄露。我们可以用 Tor 来避免网站追踪我们及我们家人的信息,也可以用来连接新闻网站、即时通讯服务或者那些被网络提供商和网络管理员封锁的网站。
Tor 最初是当做第三代[美国海军研究实验室的洋葱路由项目][1]而设计、实现及发展起来的。在美国海军心中,最初设计Tor的目的是为了政府的通信安全,但到了今天,出于各种各样的目的,Tor正在供普通人、军队、记者、执法人员、活动家以及其他更多的人每天使用。
这篇快速教程中,我们会学到怎么在浏览器上使用 Tor。下面所示的操作步骤是 Ubuntu 13.04 桌面系统中测试的,但它在所有的 Debian/Ubuntu 系统及它们的衍生系统中应该也适用。
### 在 Ubuntu / Debian / Linux Mint 上安装 Tor 和 Vidalia ###
Tor 在 Debian/Ubuntu 系统的默认源库中已经存在,但它们有点过时了。所以得把 Tor 源库加入你发行版的源列表中。
编辑 **/etc/apt/sources.list** 文件,
$ sudo nano /etc/apt/sources.list
根据你系统的发行版本添加如下的一行。因为在我的 Ubuntu 13.04 桌面系统上做测试,所以我添加了如下的一行。
[...]
deb http://deb.torproject.org/torproject.org raring main
保存并关闭文件。如果你使用的是 buntu 13.10 系统,添加行应该是,
deb http://deb.torproject.org/torproject.org saucy main
Debian 7 Wheezy 如下:
deb http://deb.torproject.org/torproject.org wheezy main
用如下命令添加 gpg 密钥:
$ gpg --keyserver keys.gnupg.net --recv 886DDD89
$ gpg --export A3C4F0F979CAA22CDBA8F512EE8CBC9E886DDD89 | sudo apt-key add -
用下面命令更新源库列表及安装 vidalia:
$ sudo apt-get update
$ sudo apt-get install tor vidalia deb.torproject.org-keyring
在安装期间,你会被问到要用哪一个用户来负责 Tor 服务,选择一个用户然后点击 OK。

现在 Vidalia 已经安装运行了。
### 配置火狐浏览器 ###
打开浏览器。进入 **编辑 -> 首选项 -> 高级 -> 网络 ->设置**。如下截图所示,选择手动配置代理,在 SOCKS Host 一栏,输入 **localhost** 或者 **127.0.0.1**,在端口一栏输入 **9050**。

现在,在浏览器上输入网址 **https://check.torproject.org/**。你会看到一个绿色的讯息:“**恭喜。这个浏览器配置为可以使用Tor**“。红色的消息表明 Tor 还没有设置。请参考下面的截图。

相同的设置适用于所有浏览器,只要打开浏览器设置/首选项窗口,找到网络设置,在代理服务器栏中输入 **127.0.0.1**,在端口选项框中输入**9050**。要禁用 Tor,在浏览器设置中选择**使用系统代理设置**。
**注意**: 如果你想使用 Tor 匿名浏览网页,请阅读我们有关[Tor浏览器套件][2]的文章,它提供了易于配置的Tor以及浏览器补丁包,以使匿名访问更方便。要直接使用SOCKS(即时通讯,Jabber,IRC等),你可以直接在 Tor(本地端口9050)配置里指向你的应用程序,但需要先看看[这些FAQ条目] [3]来了解这么做的风险。
就这么多。好运吧!保持安全!
--------------------------------------------------------------------------------
via: http://www.unixmen.com/configure-browser-use-tor-ubuntu-debian-linux-mint/
译者:[runningwater](https://github.com/runningwater) 校对:[Mr小眼儿](http://blog.csdn.net/tinyeyeser)
本文由 [LCTT](https://github.com/LCTT/TranslateProject) 原创翻译,[Linux中国](http://linux.cn/) 荣誉推出
[1]:http://www.onion-router.net/
[2]:http://www.unixmen.com/protect-your-online-privacy-with-tor-browser/
[3]:https://trac.torproject.org/projects/tor/wiki/doc/TorFAQ#SOCKSAndDNS | 2,776 | Apache-2.0 |
# ファイルアップロード設定
[[toc]]
## 概要
GROWI ページへのファイルアップロードに関する設定について紹介します。
## 添付ファイル保存先の指定
GROWI ページの添付ファイルの保存先は以下を利用できます。詳細は[こちら](/ja/admin-guide/management-cookbook/app-settings.html#ファイルアップロード設定)を参照してください。
- Amazon S3
- Google Cloud Storage
- MongoDB
- ローカルファイルシステム
### 環境変数による添付ファイル保存先の固定
::: danger
ファイル保存先を途中で変更すると、これまでにアップロードしたファイル等へのアクセスができなくなりますのでご注意ください。
:::
<!-- textlint-disable weseek/sentence-length -->
添付ファイルの保存先を環境変数によって固定したい場合は、環境変数 `FILE_UPLOAD_USES_ONLY_ENV_VAR_FOR_FILE_UPLOAD_TYPE` を `true` にし、以下の表を参考に環境変数 `FILE_UPLOAD` の値を設定してください。
<!-- textlint-enable weseek/sentence-length -->
| 保存先 | `FILE_UPLOAD` |
| --- | --- |
| Amazon S3 | `aws` |
| Google Cloud Storage | `gcs` |
| MongoDB | `mongodb` |
| ローカルファイルシステム | `local` |
環境変数 `FILE_UPLOAD_USES_ONLY_ENV_VAR_FOR_FILE_UPLOAD_TYPE` によって保存先が固定されている場合、管理画面で設定した保存先は無効となります。
### 環境変数による Google Cloud Storage 設定
ファイルアップロード設定内の GCS 設定のフォームで値を指定していない場合は、以下のデフォルト値を利用します。
- API Key Json Path: `GCS_API_KEY_JSON_PATH`
- バケット名: `GCS_BUCKET`
- Name Space: `GCS_UPLOAD_NAMESPACE`
#### 環境変数による GCS 設定の固定
GCS 設定を環境変数によって固定したい場合は、環境変数 `GCS_USES_ONLY_ENV_VARS_FOR_SOME_OPTIONS` を `true` にし、上記の環境変数に値を入れてください。未設定の場合は、null が入ります。
<!-- textlint-disable weseek/sentence-length -->
環境変数 `GCS_USES_ONLY_ENV_VARS_FOR_SOME_OPTIONS` による GCS 設定の固定が有効な場合、ファイルアップロード設定での GCS 設定のフォームの値は無効となり、変更もできなくなります。
<!-- textlint-enable weseek/sentence-length -->
## 添付ファイルのサイズ制限
以下の環境変数により、一度にアップロードできるファイルのサイズ上限と全ページに添付されているファイルの累計サイズの上限を設定できます。いずれも単位は `bytes` です。デフォルトではいずれの値も `Infinity` となっており、ファイルサイズは制限されません。
- `MAX_FILE_SIZE` : [アップロード可能なファイルのサイズ上限(bytes)]
- `FILE_UPLOAD_TOTAL_LIMIT` : [アップロードされたファイルの累計サイズ上限(bytes)]
## 添付ファイル参照方法
v4.2.3 より 添付ファイル参照方法に変更が加わりました。
Amazon S3, Google Cloud Storage を利用する場合、下記の2種類の方法から選択できます。
なお、v4.2.3 以降はデフォルトが Redirect Mode になります。
完全なセキュリティーが必要な場合のみ、
[管理画面のアプリ設定](/ja/admin-guide/management-cookbook/app-settings.html#ファイルアップロード設定)から
Relay Mode に変更してください。
### Relay Mode (オプショナル / v4.2.2 以前のデフォルト仕様)
<!-- https://dev.growi.org/5fd8424f2271ae00481ed2e8 -->

Relay Mode では GROWI サーバーが Cloud Service との通信を中継し、クライアントにデータをリレー配信します。
クライアントは GROWI サーバーとの通信しか行わないため、
ファイル参照に関してはセキュリティー的には最も安全な手段となります。
ただしリレーの特性上、画像の数や容量、リクエスト数に応じて GROWI サーバーと Cloud Service との間のトラフィックが増大するというデメリットがあります。
### Redirect Mode (v4.2.3 以降のデフォルト仕様)
<!-- https://dev.growi.org/5fd8424f2271ae00481ed2e8 -->

Redirect Mode では Cloud Service にファイル参照用の署名付きURLの発行を依頼し、
それをクライアントに知らせ、リダイレクトを促します。
クライアントは受け取った署名付きURLにアクセスし、Cloud Service から画像を直接取得します。
GROWI サーバーはトラフィックを中継せず、各クライアントが直接 Cloud Service から画像を受け取ります。
そのため、画像の数や容量、リクエスト数によって GROWI サーバーに負荷がかからず、全体的に優れたパフォーマンスを発揮できます。
また署名付きURLの発行時は十分に短い失効期間が設定されるため、セキュリティ上もバランスの取れた仕様となっています。
GROWI サーバーは失効期間と同じ長さだけ署名付きURLをキャッシュします(デフォルトでは120秒)。
キャッシュを保持する秒数は[環境変数](/ja/admin-guide/admin-cookbook/env-vars.html)で設定できます。
- AWS(S3)
- `S3_LIFETIME_SEC_FOR_TEMPORARY_URL`
- GCP(GCS)
- `GCS_LIFETIME_SEC_FOR_TEMPORARY_URL` | 3,064 | MIT |
QQ交流群 微信交流群
====

### 重点集群配置推荐,太低会导致安装异常
**
- - node节点最低4gb
- - Master节点最低8gb**
* Q群名称:K8s自动化部署交流
* Q群 号:893480182
### - 实测单机版支持腾讯云服务器
### - 实测集群版支持天翼云服务器
### - 实测集群版支持阿里云服务器(需要预先设置中文字符集否则菜单界面乱码不显示中文,后续我会修复这个问题到脚本里面 暂时没有阿里云服务器调试)
特点: 完全离线,不依赖互联网(系统新装配置好ip开机即可!其他都什么都不用安装)
====
1. 真正原生centos7.3.-7.6Minimal新装系统(只需要统一集群的root密码即可)一键搭建k8s集群
1. 单机/集群任意服务器数量一键安装(目前一个节点对应一个etcd节点后续会分离可自定义)
1. 一键批量增删node节点(新增的服务器系统环境必须干净密码统一)
1. ipvs负载均衡,内网yum源共享页面端口42344
1. 单机版或集群版默认集成prometheus+grafan监控环境,默认端口30000,账号密码admin admin
1. 图形化向导菜单安装,web管理页面dashboar端口42345
1. Heketi+GlusterFS(分布式存储集群)+helm完全一键离线部署
1. 默认版本v1.15.7,可执行替换各版本软件包,集群版目前已测安装数量在1-30台一键安装正常
1. 集群数量超过4台及以上默认开启k8s数据持久化方案:glusterfs+Heketi 最低3台分布式存储 \n (全自动自动安装,启用k8s集群持久化方案务必保证存储节点均有一块空盘(例如/deb/sdb无需分区(默认40%用于k8s集群持久化60%挂载到本机的/data目录)))
如启用Heketi+GlusterFS,默认会创建一个pvc验证动态存储效果
一键安装
===
#### 一键安装介绍任选通道进行安装
一键安装命令(要求centos7系统为新装系统无任何软件环境可联网)
不推荐git下来仓库大概1.5gb左右比较大,可以直接下载离线包
##一键安装通道01(默认走家庭宽带普通通道---不稳定不推荐)
``` shell
while [ true ]; do rm -f K8s_1.2.tar*;curl -o K8s_1.2.tar http://www.linuxtools.cn:42344/K8s_1.2.tar && break 1 ||sleep 5;echo 网络错误正在重试下载 ;done && tar -xzvf K8s_1.2.tar && cd K8s/ && sh install.sh
```
##一键安装通道02(走群友无私赞助电信机房专线服务器--高速稳定下载----强烈推荐)
``` shell
while [ true ]; do rm -f K8s_1.2.tar*;curl -o K8s_1.2.tar http://www.linuxtools.cn:42344/K8s_1.2.tar && break 1 ||sleep 5;echo 网络错误正在重试下载 ;done && tar -xzvf K8s_1.2.tar && cd K8s/ && sh install.sh
```
```
[root@k8s-master-db2 ~]#
[root@mubanji49 ~]# sh K8s/shell_01/Check02.sh
==============master节点健康检测 kube-apiserver kube-controller-manager kube-scheduler etcd kubelet kube-proxy docker==================
192.168.123.69 | CHANGED | rc=0 >>
active active active active active active active
===============================================note节点监控检测 etcd kubelet kube-proxy docker===============================================
192.168.123.25 | CHANGED | rc=0 >>
active active active active
192.168.123.23 | CHANGED | rc=0 >>
active active active active
192.168.123.24 | CHANGED | rc=0 >>
active active active active
192.168.123.22 | CHANGED | rc=0 >>
active active active active
===============================================监测csr,cs,pvc,pv,storageclasses===============================================
NAME AGE REQUESTOR CONDITION
certificatesigningrequest.certificates.k8s.io/node-csr-BhGxRilO9l04KxPRB8xvyyLfJWXbj9uBWaeSKz3PoB4 3m1s kubelet-bootstrap Approved,Issued
certificatesigningrequest.certificates.k8s.io/node-csr-Fp2t03YNTTPFKQf_ljIZvuYAGOyuv3SbJ97Dhm5DIzQ 2m59s kubelet-bootstrap Approved,Issued
certificatesigningrequest.certificates.k8s.io/node-csr-RapTjQ_XBKSG8vrNX8_WO8szy39WE5hUN8lXMIHCIZM 2m59s kubelet-bootstrap Approved,Issued
certificatesigningrequest.certificates.k8s.io/node-csr-eMBnkUV4nUFXDhxTXiCc7ZjpkBL6UhRf56N_qpVMnVM 2m59s kubelet-bootstrap Approved,Issued
certificatesigningrequest.certificates.k8s.io/node-csr-uVc1At65pHTwPmRTEZ584h2AWnGeopEfaKSuu-pbi7I 2m59s kubelet-bootstrap Approved,Issued
NAME STATUS MESSAGE ERROR
componentstatus/scheduler Healthy ok
componentstatus/controller-manager Healthy ok
componentstatus/etcd-3 Healthy {"health":"true"}
componentstatus/etcd-2 Healthy {"health":"true"}
componentstatus/etcd-0 Healthy {"health":"true"}
componentstatus/etcd-1 Healthy {"health":"true"}
componentstatus/etcd-4 Healthy {"health":"true"}
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/gluster1-test Bound pvc-c02684ba-ff23-11e9-ae0a-000c29ed75cf 1Gi RWX gluster-heketi 50s
persistentvolumeclaim/my-grafana Bound pvc-c5734aaf-ff23-11e9-ae0a-000c29ed75cf 10Gi RWO gluster-heketi 41s
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/pvc-c02684ba-ff23-11e9-ae0a-000c29ed75cf 1Gi RWX Delete Bound default/gluster1-test gluster-heketi 45s
persistentvolume/pvc-c5734aaf-ff23-11e9-ae0a-000c29ed75cf 10Gi RWO Delete Bound default/my-grafana gluster-heketi 23s
NAME PROVISIONER AGE
storageclass.storage.k8s.io/gluster-heketi kubernetes.io/glusterfs 50s
===============================================监测node节点labels===============================================
NAME STATUS ROLES AGE VERSION LABELS
192.168.123.22 Ready node 2m38s v1.15.7 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=192.168.123.22,kubernetes.io/os=linux,node-role.kubernetes.io/node=node,storagenode=glusterfs
192.168.123.23 Ready node 2m37s v1.15.7 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=192.168.123.23,kubernetes.io/os=linux,node-role.kubernetes.io/node=node,storagenode=glusterfs
192.168.123.24 Ready node 2m38s v1.15.7 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=192.168.123.24,kubernetes.io/os=linux,node-role.kubernetes.io/node=node,storagenode=glusterfs
192.168.123.25 Ready node 2m37s v1.15.7 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=192.168.123.25,kubernetes.io/os=linux,node-role.kubernetes.io/node=node,storagenode=glusterfs
192.168.123.69 Ready master 2m38s v1.15.7 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,dashboard=master,kubernetes.io/arch=amd64,kubernetes.io/hostname=192.168.123.69,kubernetes.io/os=linux,node-role.kubernetes.io/master=master,storagenode=glusterfs
===============================================监测coredns是否正常工作===============================================
coredns-57656b67bb-nzzlw 1/1 Running 0 2m15s
Server: 10.0.0.2
Address 1: 10.0.0.2 kube-dns.kube-system.svc.cluster.local
Name: kubernetes
Address 1: 10.0.0.1 kubernetes.default.svc.cluster.local
pod "dns-test" deleted
===============================================监测,pods状态===============================================
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
default my-grafana-766fb5978b-tq6l8 0/1 Running 0 43s 172.17.1.3 192.168.123.69
kube-system coredns-57656b67bb-nzzlw 1/1 Running 0 2m17s 172.17.23.2 192.168.123.24
kube-system kubernetes-dashboard-5b5697d4-khqqd 1/1 Running 0 2m14s 172.17.1.2 192.168.123.69
kube-system tiller-deploy-7dd4495c74-nzz74 1/1 Running 0 2m33s 172.17.14.2 192.168.123.22
===============================================监测node节点状态===============================================
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
192.168.123.22 Ready node 2m40s v1.15.7 192.168.123.22 CentOS Linux 7 (Core) 3.10.0-514.el7.x86_64 docker://19.3.4
192.168.123.23 Ready node 2m39s v1.15.7 192.168.123.23 CentOS Linux 7 (Core) 3.10.0-514.el7.x86_64 docker://19.3.4
192.168.123.24 Ready node 2m40s v1.15.7 192.168.123.24 CentOS Linux 7 (Core) 3.10.0-693.el7.x86_64 docker://19.3.4
192.168.123.25 Ready node 2m39s v1.15.7 192.168.123.25 CentOS Linux 7 (Core) 3.10.0-693.el7.x86_64 docker://19.3.4
192.168.123.69 Ready master 2m40s v1.15.7 192.168.123.69 CentOS Linux 7 (Core) 3.10.0-957.el7.x86_64 docker://19.3.4
================================================监测helm版本================================================
Client: &version.Version{SemVer:"v2.15.2", GitCommit:"8dce272473e5f2a7bf58ce79bb5c3691db54c96b", GitTreeState:"clean"}
Server: &version.Version{SemVer:"v2.15.2", GitCommit:"8dce272473e5f2a7bf58ce79bb5c3691db54c96b", GitTreeState:"clean"}
[root@mubanji49 ~]#
[root@mubanji49 ~]# ansible all -m shell -a "cat /etc/redhat-release "
192.168.123.23 | CHANGED | rc=0 >>
CentOS Linux release 7.3.1611 (Core)
192.168.123.22 | CHANGED | rc=0 >>
CentOS Linux release 7.3.1611 (Core)
192.168.123.24 | CHANGED | rc=0 >>
CentOS Linux release 7.4.1708 (Core)
192.168.123.25 | CHANGED | rc=0 >>
CentOS Linux release 7.4.1708 (Core)
192.168.123.69 | CHANGED | rc=0 >>
CentOS Linux release 7.6.1810 (Core)
[root@mubanji49 ~]#
```
* ps:目前是单master,后期会上多master高可用
* ps:近期提交代码过于频繁有时候可能会有=一些bug,欢迎到群随时提出
====
### [高能警告] 系统只能存在一个固定ip地址 一个网卡一个ip 切记美分系统不能多个ip多个网卡
### [高能警告] 暂仅支持centos7.3-centos7.7, “不支持Centos7.2及其以下版本”
### [高能警告] 系统ip不能使用 10.0.0.0网段,尽量避开系统使用172.17.x.x 10.0.0.x网段(否则安装会有问题)
**
# K8s升级替换v1.14.0 v1.15.0
#如果不需要使用v1.14.0 v1.15.0直接默认一键安装即可。master分支默认的是v1.15.7
## 默认版本为v1.15.7,提供升级软件包v14 v15自行下载后放到 K8s/Software_package 目录即可(务必删除原有的)
链接:[http://linuxtools.cn:42344/K8s_list/](http://linuxtools.cn:42344/K8s_list/)
放入前务必执行以下操作
``` shell
rm -fv K8s/Software_package/kubernetes-server-linux-amd64.tar.a*
```
``` shell
#可选执行-----替换第三方yum源
rm -fv rm -f /etc/yum.repos.d/*
while [ true ]; do curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo && break 1 ;done
while [ true ]; do curl -o /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo && break 1 ;done
```
华丽分界线。。。。。。。。。。。。。。
一键安装
===
#### 一键安装介绍任选通道进行安装
一键安装命令(要求centos7系统为新装系统无任何软件环境可联网)
不推荐git下来仓库大概1.5gb左右比较大,可以直接下载离线包
##一键安装通道01(走私有服务器高速通道)
``` shell
while [ true ]; do rm -f K8s_1.2.tar*;curl -o K8s_1.2.tar http://www.linuxtools.cn:42344/K8s_1.2.tar && break 1 ||sleep 5;echo 网络错误正在重试下载 ;done && tar -xzvf K8s_1.2.tar && cd K8s/ && sh install.sh
```
##一键安装通道02(走码云服务器)
``` shell
#零时弃用
```
视频演示地址
===
https://www.bilibili.com/video/av57242055?from=search&seid=4003077921686184728
#### 测试环境
* VMware15虚拟化平台,所有服务器节点2核2G
* 已测1-50节点安装正常
* 建议新装centos7.6系统,环境干净(不需要提前安装任何软件不需要提前安装docker).集群功能至少2台服务器节点
网络 | 系统 | 内核版本 | IP获取方式 | docker版本 | Kubernetes版本 |K8s集群安装方式 |
---- | ----- | ------ | ---- | ---- | ---- | ---- |
桥接模式 | 新装CentOS7.6.1810 (Core) | 3.10.0-957.el7.x86_64 | 手动设置固定IP(不能dhcp获取所有节点) | 18.06.1-ce | v1.15.7 | 二进制包安装 |
#### 安装教程
``` shell
rm -f K8s_1.2.tar*
```
#下载通道01 走普通家庭宽带下载点
``` shell
curl -o K8s_1.2.tar http://www.linuxtools.cn:42344/K8s_1.2.tar
```
#下载通道02 走群友无私赞助电信机房专线服务器--高速稳定下载----强烈推荐
``` shell
curl -o K8s_1.2.tar http://www.linuxtools.cn:42344/K8s_1.2.tar
```
``` shell
tar -xzvf K8s_1.2.tar
cd K8s/ && sh install.sh
```
#### 使用说明
1. xxxx
2. xxxx
3. xxxx
#### 参与贡献
#### 使用截图
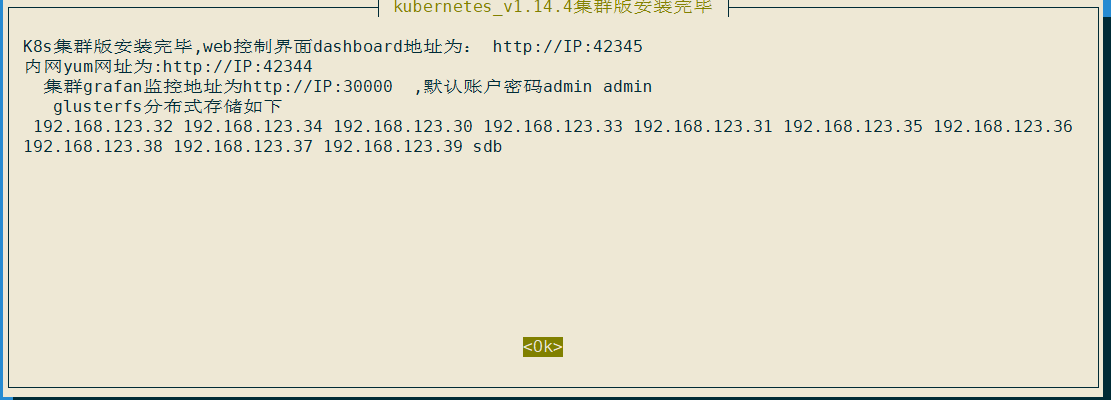
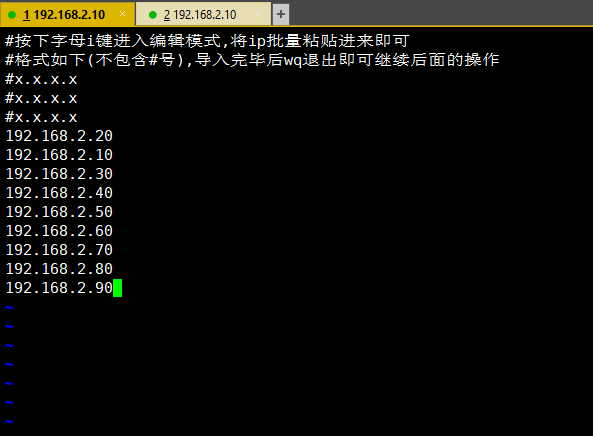
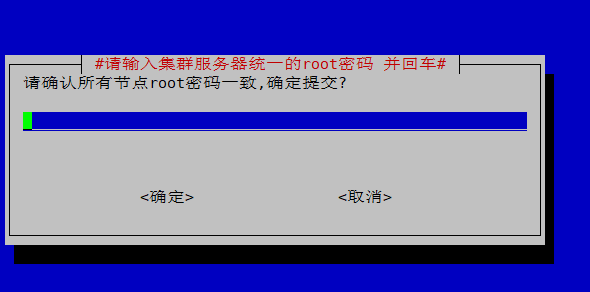
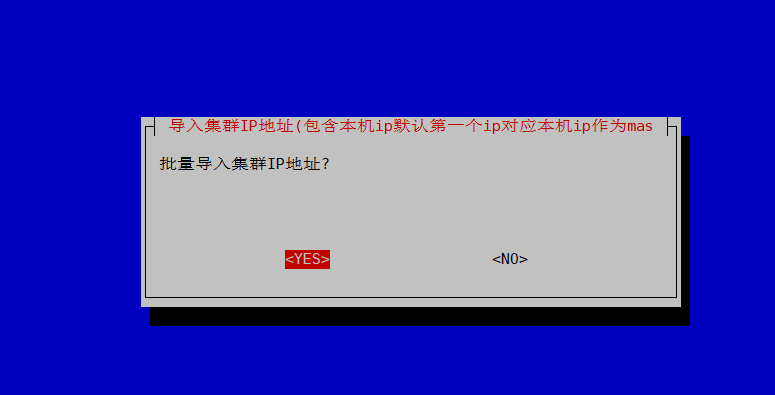
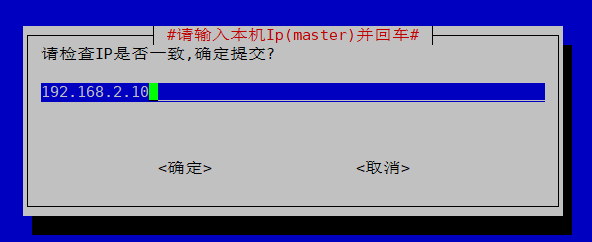
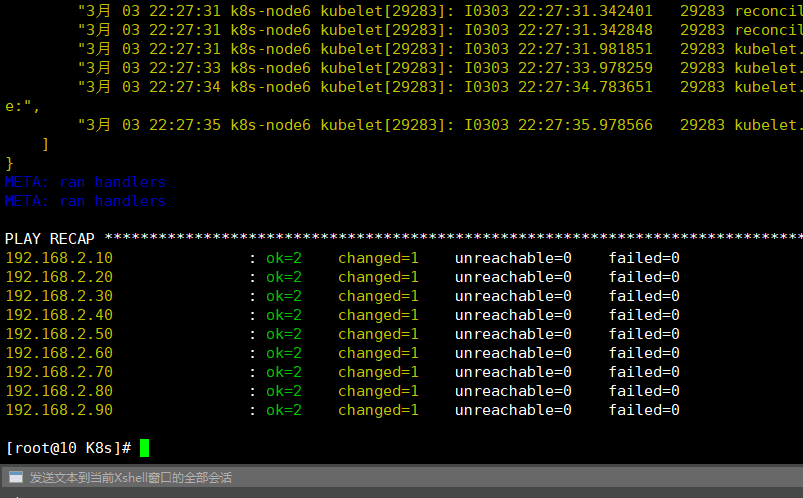
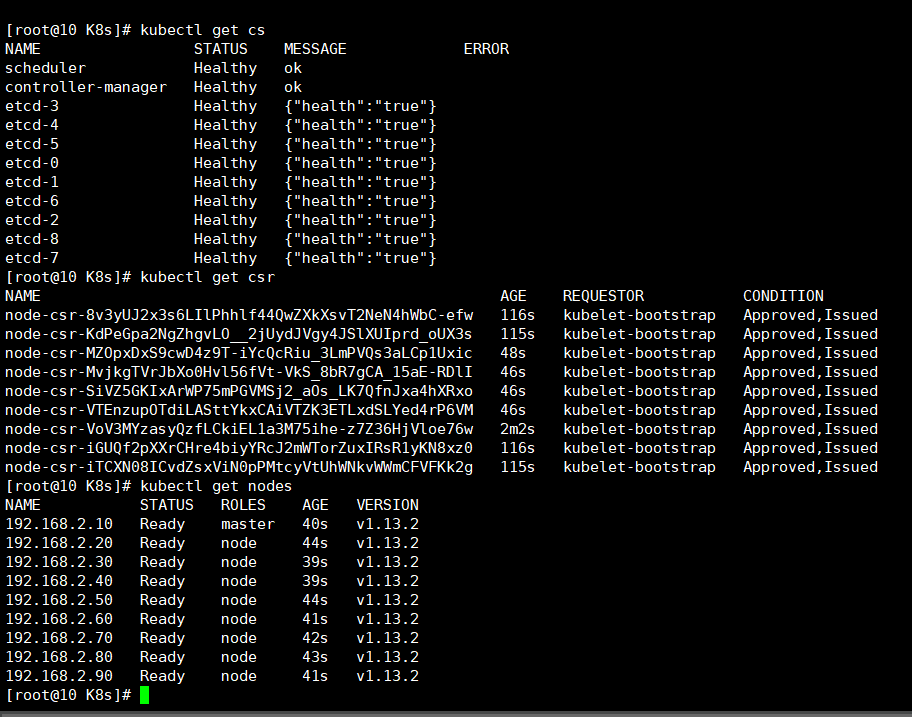
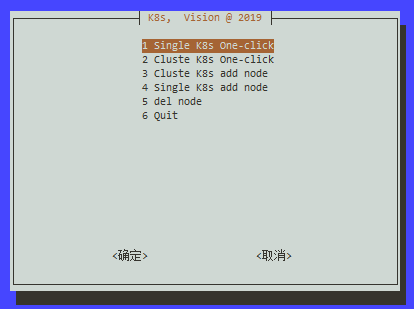
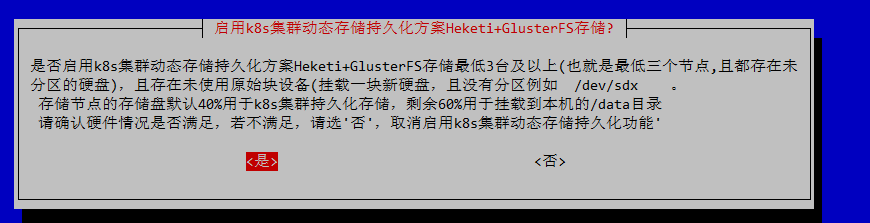
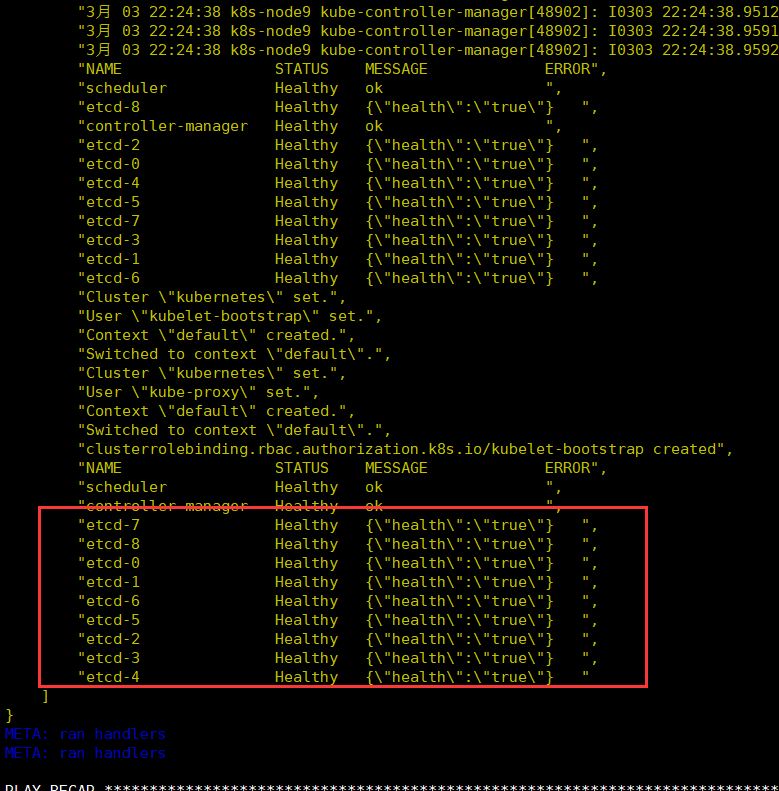
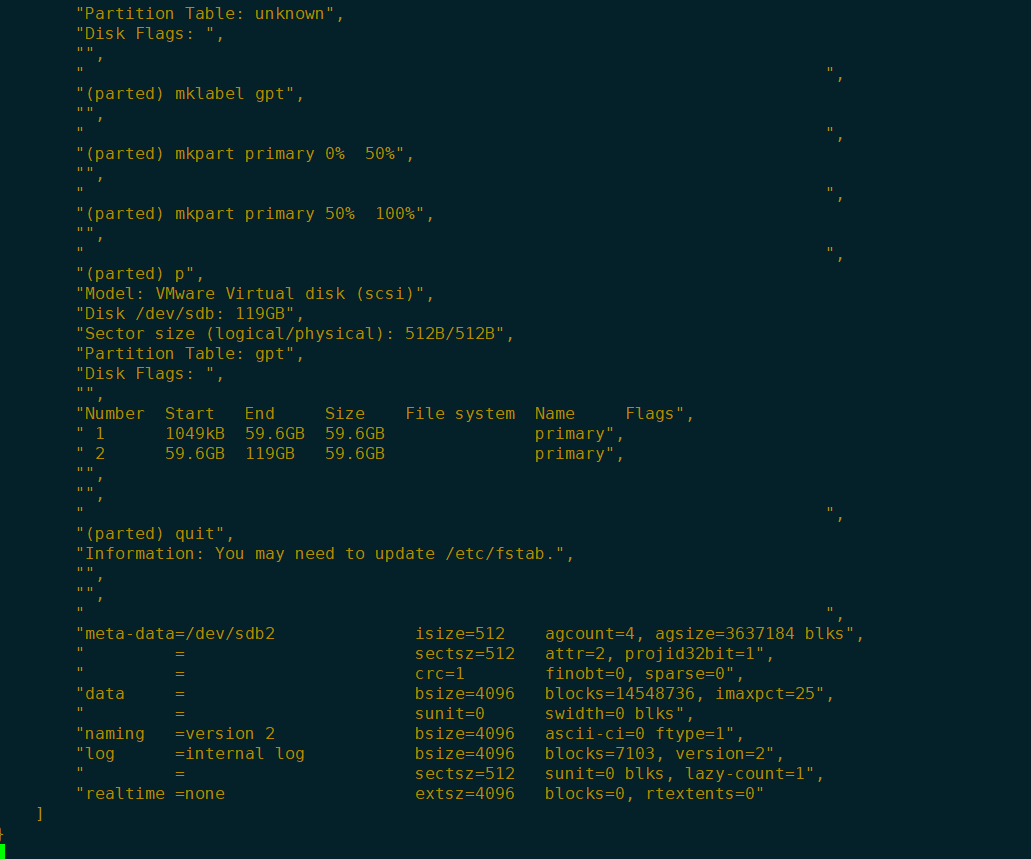
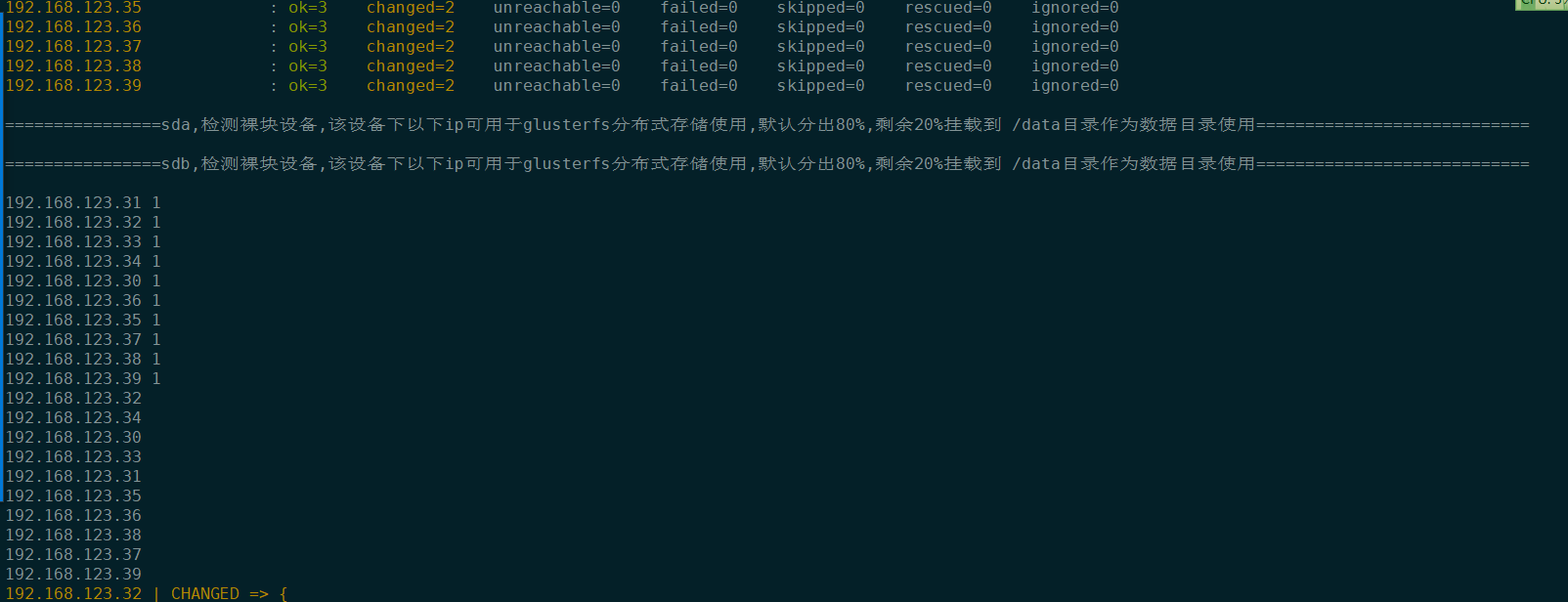
监控图片一揽
===
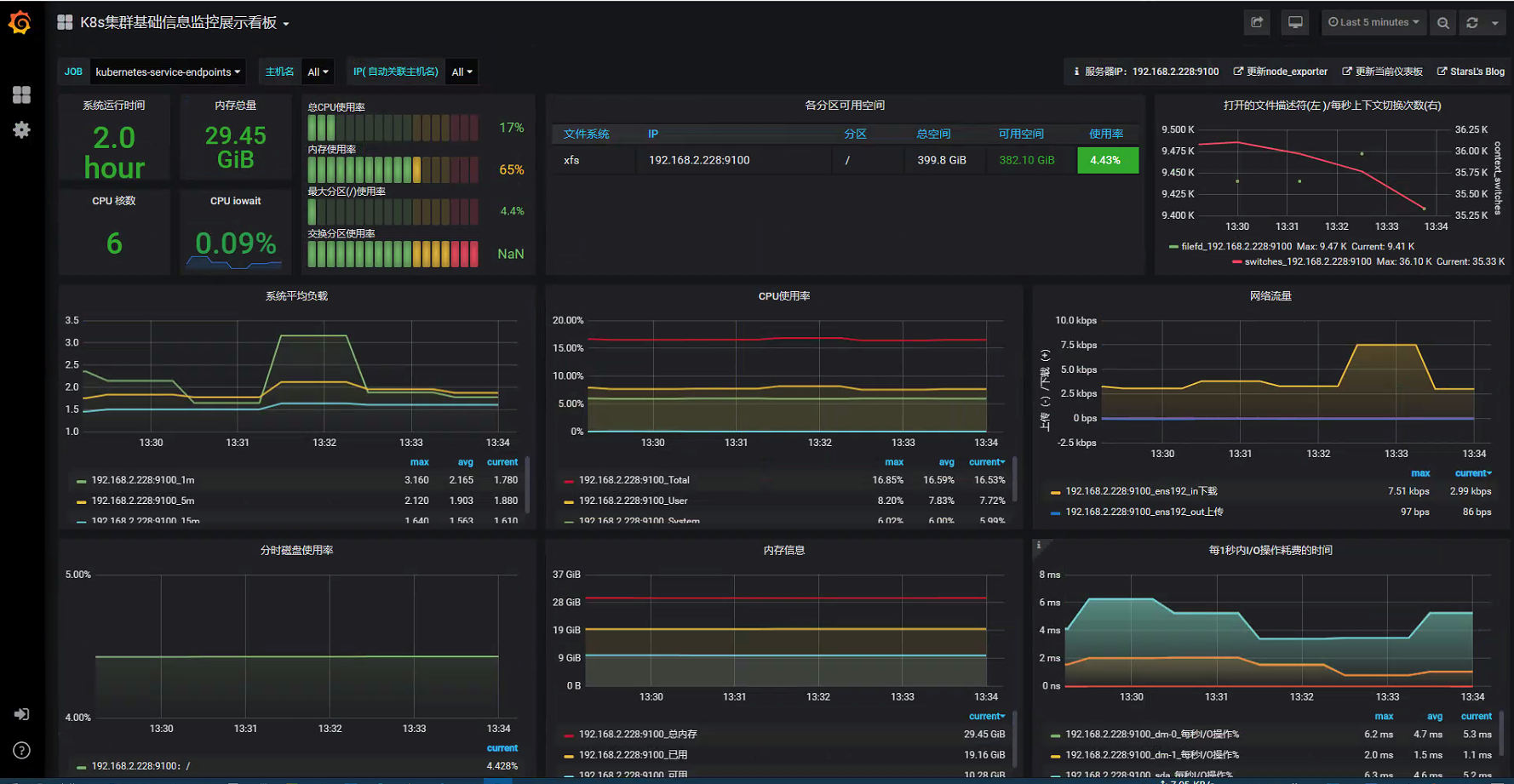
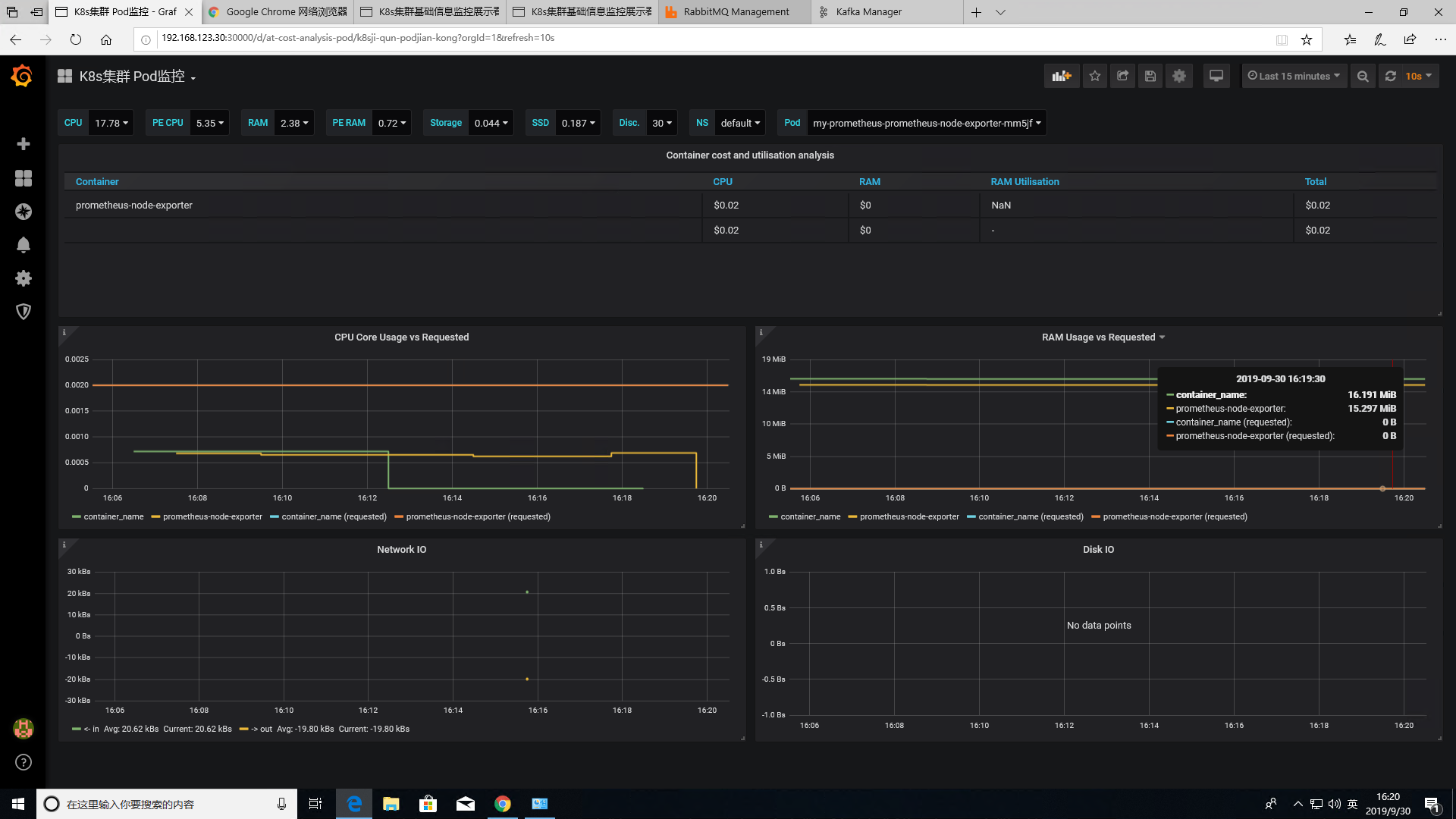
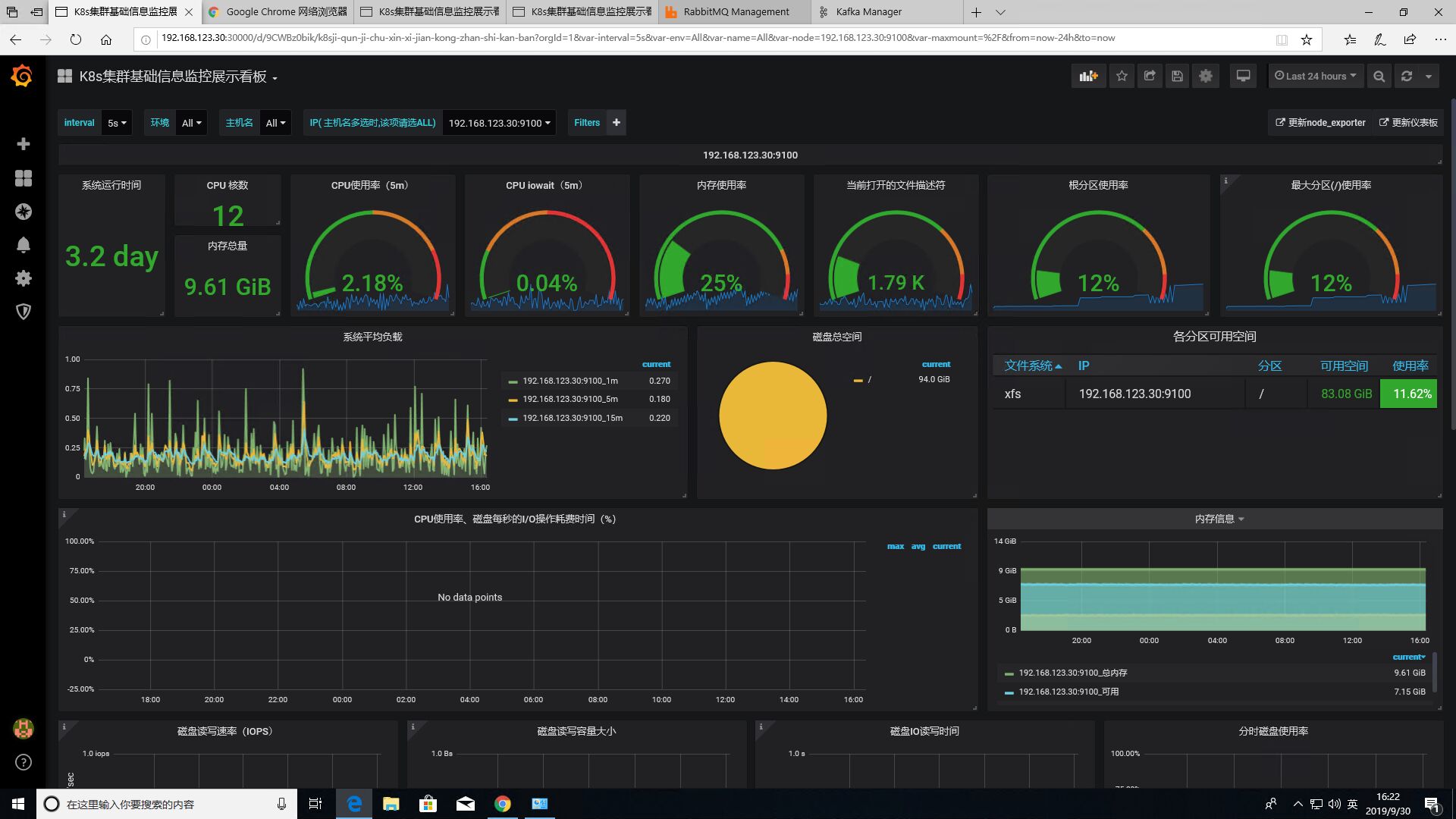
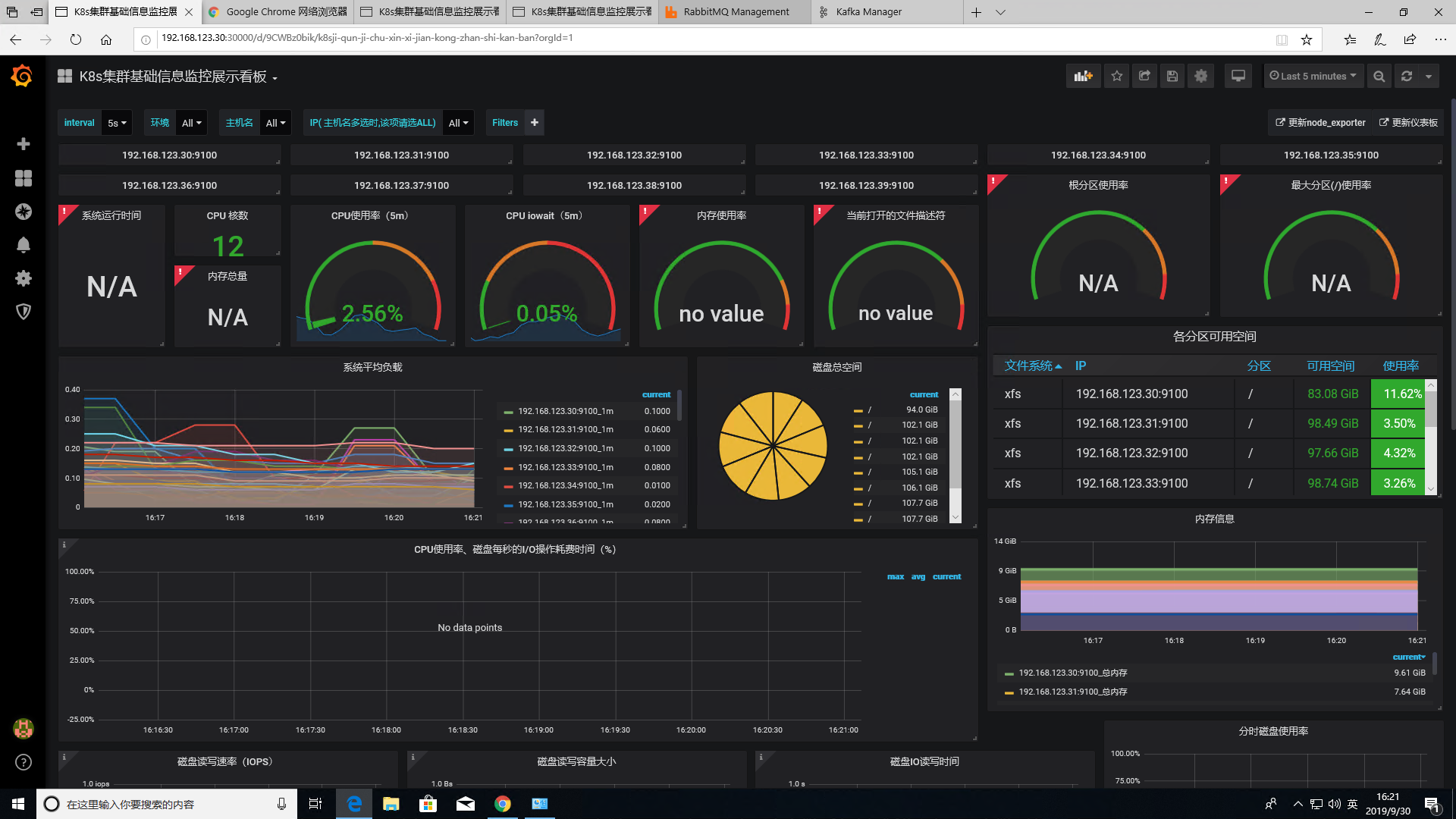
Dashboard图片
===
更新日志
===
===
### -----------------
2020-2-8
新增卸载功能,优化部署脚本
修复一些bug+内核优化
### -----------------
### -----------------
2019-10-19
修复一些bug+内核优化
### -----------------
### -----------------
2019-10-10
修复时区问题,所有pod默认中国上海时区
### -----------------
### -----------------
2019-9-16
1. 集群版新增prometheus +grafan集群监控环境(被监控端根据集群数量自动弹性扩展) 默认端口30000,默认账户密码admin admin
1. 必须在启用数据持久化功能的基础上才会开启
1. grafana已内置了k8s集群pod监控模板,集群基础信息监控模板,已内置饼图插件,开箱即可用
### -----------------
2019-9-27
1. 单机版新增nfs_k8s动态存储,单机版k8s也能愉快的玩helm了,后续增加集群版nfs云端存储/本地存储持久化方案。
1. 单机版新增prometheus+grafan监控环境
1. 单机版默认storageclasses均为gluster-heketi
### -----------------
### -----------------
2019-9-25
1. 优化一些参数,集群版持久化功能支持最低2个节点起
1. 单机版新增helm
1. 修复一些bug
### -----------------
2019-9-13
1. 集群版新增coredns 感谢群内dockercore大佬的指导
1. 优化集群版部署脚本,新增集群重要功能监测脚本
1. 新增内置busybox镜像测试dns功能
### -----------------
2019-8-26
1 新增node节点批量增删
2 新增glusterfs分布式复制卷---持久化存储(集群版4台及以上自动内置部署)
### -----------------
2019-7-11
修复部分环境IP取值不精确导致etcd安装失败的问题
### -----------------
2019-7-10
1. 新增集群版 web图形化控制台dashboard
2. 更新docker-ce版本为 Version: 18.09.7
K8s集群版安装完毕,web控制界面dashboard地址为 http://IP:42345
### -----------------
2019-7-1
新增单机版 web图形化控制台dashboard
K8s单机版安装完毕,web控制界面dashboard地址为 http://IP:42345
# 良心友情链接
[腾讯QQ群快速检索](http://u.720life.cn/s/8cf73f7c)
[软件免费开发论坛](http://u.720life.cn/s/bbb01dc0) | 14,668 | Apache-2.0 |
---
layout: post
title: "工廠打工妹一天生活費只花5块钱省吃俭用,到底是因為什麼原因。"
date: 2021-09-27T09:00:11.000Z
author: 打工妹四妹
from: https://www.youtube.com/watch?v=SudT1KjHD9g
tags: [ 打工妹四妹 ]
categories: [ 打工妹四妹 ]
---
<!--1632733211000-->
[工廠打工妹一天生活費只花5块钱省吃俭用,到底是因為什麼原因。](https://www.youtube.com/watch?v=SudT1KjHD9g)
------
<div>
歡迎訂閱
</div> | 319 | MIT |
---
layout: post
date: 2012-11-12 16:00:00 +0800
title: '一个系统过载的案例及其解决办法'
tags: [system, recovery]
last_modified_at: 2016-08-25 15:20:00 +0800
---
系统出现过载现象(或问题)的原因和场景有很多, 这里并不试图归纳总结; 而是如题, 就一个特定的案例, 分享一些过载保护的实践办法.
## 案例
> 系统R需要通过轮询(读取)数据库中存储的记录状态, 进行一些业务补偿的操作, 而后再对数据库的状态进行更新.
>
> 轮询机制实现并未采用定时周期的方式, 而是采用 **请求 - 响应 - 再请求** 的事件驱动方式.
>
> 在压测的时候发现, 数据库访问(无论读写)大量失败, 错误日志狂刷.
<!--more-->
## 分析
经排查, 由于数据库被多个系统公用, 其它系统的一些SQL执行耗时超长, 资源占用过多, 导致系统R的数据库访问请求超时失败, 而失败后的不断重试, 变本加厉, 最终数据库撑不住挂了.
类似的典型场景, 如 **秒杀** :
> 海量并发请求下, 系统已经出现过载, 请求响应过缓, 而用户耐不住, 则不断尝试刷新页面, 寄期望于请求被响应. 可事与愿违, 系统在没有保护的情况下, 将持续超过载的状态, 直到 **宕机**.
## 解决
面对过载, 可能最容易被想到的是 **扩容**. 是的, 它是一种不降低服务质量的必不可少的预防方案, 但我们不得不接受一个事实:
> 系统的容量(或处理能力)始终是有限的, 即使不考虑成本的扩容, 也只能应付你可以预见程度, 一旦有个"万一", 系统仍将崩溃.
若服务可以降级, 则 **限流** 是能够应对"万一"的良方, 下面就 **限流** 这个思路, 分享几个办法.
### 定时
将轮询改用定时来实现, 就可以保证稳定的访问节奏, 加之一旦支持动态修改定时周期时间, 便可以根据实际情况灵活调整节奏了.
不仅做到了 **限流** , 更是做到了 **流控**, 不错.
可以实际应用中会发现, 初始的定时周期很难找到合适的值, 需要在处理实时性和请求量之间平衡.
> 个人不太喜欢用定时方案, 它不仅让单元测试结果不稳定, 还浪费线程.
### 休息
**请求 - 响应 - 再请求** 的事件驱动的轮询方式, 有个好处: 就是在正常情况下, 让访问节奏由数据库说了算, 即数据库响应快, 轮询则快, 反之则放缓. 只可惜异常的情况下, 就如案例中那样.
休息很好理解:
> 若人累了, 就不要继续强撑, 让身体休息一会(踹口气), 再恢复工作.
同理, 当数据库访问失败后, 优雅地拒绝掉随后若干次请求, 让数据库休息一会.
如何做到优雅? 就本案例而言则是, 读取失败后的若干次请求迅速返回空集合. 总之, 拒绝可以是除抛异常外, 任何对处理逻辑有意义的默认`NULL`结果.
若干次到底是多少次? 这与选择定时时间一样是需要平衡的.
### 补偿
本案例中轮询的读取失败返回空集合是个好的休息办法, 可要是状态更新失败呢? 没法返回结果, 只能抛异常, 但异常又会导致重试, 这不仅没让数据库休息, 且可能导致大量`ERROR Stacktrace`日志输出.
不抛异常, 而将异常转换为一次失败记录(日志), 这些记录可以用来对数据库状态的不一致进行补偿操作, 具体如何补偿, 什么时机开始补偿, 这里就不展开细说了, 它们都需要由业务场景来决定.
---
写在最后, 上述三种办法都不是银弹, 也并非互斥, 完全可以根据情况结合使用的.
The end. | 1,578 | MIT |
---
layout: post
title: 'Docker指南-2021(冯兄话吉 [译])'
subtitle: '从基本的概念到Docker中级,带你从零到一学习Docker。通过本指南你应该学习到:几乎基于所有平台的容器化工具的安装;上传一个自定义的Docker镜像(Image)到镜像仓库(registry);使用docker-compose协作多个容器。'
background: '/img/posts/docker-handbook-2021-fxhj-trans.jpg'
comment: false
---
# 目录
- [0. 前言](#0)
- [1. 准备](#1)
- [2. 容器化(Containerization)和Docker简介](#2)
- [3. 怎么样安装Docker](#3)
- [3.1 怎么在macOS系统上安装Docker](#3.1)
- [3.2 怎么在Windows系统上安装Docker](#3.2)
- [3.3 怎么在Linux系统上安装Docker](#3.3)
- [4. Docker运行Hello World - Docker基本介绍](#4)
- [4.1 什么是容器?](#4.1)
- [4.2 什么是镜像?](#4.2)
- [4.3 什么是Docker仓库(Docker Registry)?](#4.3)
- [4.4. Docker架构](#4.4)
- [4.5. 完整的Docker工作过程](#4.5)
- [5. Docker容器基本操作](#5)
- [5.1 怎样运行一个容器?](#5.1)
- [5.2 怎样发布一个端口?](#5.2)
- [5.3 怎样使用后台模式?](#5.3)
- [5.4 怎样查看容器?](#5.4)
- [5.5 怎样命名或者重命名一个容器?](#5.5)
- [5.6 怎样停止或者杀死一个运行中的容器?](#5.6)
- [5.7 怎样重启一个容器?](#5.7)
- [5.8 怎样不启动容器的情况下创建一个容器?](#5.8)
- [5.9 怎样移除一个不用的容器?](#5.9)
- [5.10 怎样使用命令行交互的方式启动一个容器?](#5.10)
- [5.11 怎样在容器内执行命令?](#5.11)
- [5.12 怎样操作可执行镜像?](#5.12)
- [6. Docker镜像基本操作](#6)
- [6.1 怎样创建一个Docker镜像?](#6.1)
- [6.2 怎样给镜像打标签?](#6.2)
- [6.3 怎样展示和删除镜像?](#6.3)
- [6.4 怎样理解多层镜像?](#6.4)
- [6.5 怎样从源代码构建NGINX?](#6.5)
- [6.6 怎样优化一个Docker镜像?](#6.6)
- [6.7 拥抱Alpine Linxu](#6.7)
- [6.8 怎样创建一个可执行Docker镜像?](#6.8)
- [6.9 怎样在线共享你的镜像?](#6.9)
- [7. 怎样容器化一个Javascript应用?](#7)
- [7.1 怎么写Dockerfile?](#7.1)
- [7.2 怎么在Docker中进行Bind Mounts(绑定挂载)?](#7.2)
- [7.3 怎么使用Docker的匿名卷?](#7.3)
- [7.4 怎么在Docker中执行多阶段构建(Multi-Staged Builds)?](#7.4)
- [7.5 怎么忽略掉不必要的文件?](#7.5)
- [8. Docker中的网络操作](#8)
- [8.1 Docker网络基础](#8.1)
- [8.2 怎样在Docker中自定义一个桥接网络?](#8.2)
- [8.3 怎样在Docker中附接一个容器到网络中?](#8.3)
- [8.4 怎样在Docker中将容器从网络中断开连接?](#8.4)
- [8.5 怎样在Docker中删除网络?](#8.5)
- [9. 怎样容器化配置一个多容器JavaScript应用?](#9)
- [9.1 怎样运行一个数据库服务?](#9.1)
- [9.2 怎样在Docker中使用实名卷?](#9.2)
- [9.3 怎样在Docker中查看容器的日志?](#9.3)
- [9.4 怎样在Docker中创建一个网络并且将数据库容器附接到网络中?](#9.4)
- [9.5 怎样写Dockerfile?](#9.5)
- [9.6 怎样在运行的容器中执行命令?](#9.6)
- [9.7 怎样写管理Docker的脚本?](#9.7)
- [10. 怎样使用Docker-Compose?](#10)
- [10.1 Docker Compose基础](#10.1)
- [10.2 Docker Compose中如何启动服务?](#10.2)
- [10.3 Docker Compose如何展示服务?](#10.3)
- [10.4 怎样在Docker Compose运行的服务中执行命令?](#10.4)
- [10.5 怎样在Docker Compose中查看运行的服务的日志?](#10.5)
- [10.6 怎样在Docker Compose中停止运行的服务?](#10.6)
- [10.7 怎样Compose一个全栈应用?](#10.7)
- [11. 结论](#11)
- [12. 译者注](#12)
---
<h2 id="0">0. 前言</h2>
容器化是一个相当古老的技术,2013年[Docker Engine](https://docs.docker.com/get-started/overview/#docker-engine)的出现让一个应用容器化变得更加简单。
根据[Stack Overflow开发者调查](https://insights.stackoverflow.com/survey/2020#overview),2020年[Docker](https://docker.com/)是[最被需要](https://insights.stackoverflow.com/survey/2020#technology-most-loved-dreaded-and-wanted-platforms-wanted5)、[最受喜爱](https://insights.stackoverflow.com/survey/2020#technology-most-loved-dreaded-and-wanted-platforms-loved5)和[最流行](https://insights.stackoverflow.com/survey/2020#technology-platforms)的平台。
Docker技术如此流行,似乎我们不得不学习它。因此,本指南囊括有从基本到中级的容器化技术。通过本指南你应该学习到:几乎基于所有平台的容器化;上传一个自定义的Docker镜像(Image)到在线仓库(registry);使用docker-compose协作多个容器。
---
<h2 id="1">1. 准备</h2>
- 熟悉Linux命令行操作
- 熟悉JavaScript语言(后续的项目中使用到了JavaScript)
<h2 id="2">2. 容器化(Containerization)和Docker简介</h2>
[IBM](https://www.ibm.com/cloud/learn/containerization#toc-what-is-co-r25Smlqq)指出:容器化技术就是将软件代码和其所有的依赖打包或者封装,使其统一能够在任何平台上持续运行的技术。
换句话说,容器技术就是能够让你把软件和其依赖打包在一个自包含的包中,这样软件运行的时候就不必解决启动依赖的一些问题。
让我们考虑一个实际的生活场景,假设你开发了一个神奇的图书管理系统,你也可以向你的朋友提供书籍的借阅功能。如果把这个系统的依赖都列出来,可能是这样的:
- Node.js
- Express.js
- SQLite3
理论上来讲,应该就是这些依赖了,但是实际上并不止这些。我们知道[Node.js](https://nodejs.org/)使用一个叫做`node-gyp`的构建工具用来构建本地插件,并且根据[官方仓库](https://github.com/nodejs/node-gyp)的[安装文档](https://github.com/nodejs/node-gyp#installation),这个构建工具需要`Python`2或者3和一个合适的c/c++编译器。
这样说来,最终的依赖列表可能是这样的:
- Node.js
- Express.js
- SQLite3
- Pytho2 or 3
- c/c++ 编译器
在任何平台安装`Python`2或者3都比较简单。在Linux平台上安装c/c++编译器比较容易,但是在Windows和Mac系统上安装就是一个痛苦的过程了。
在Windows中,C++编译器有超过1G的大小,需要花费不少的时间安装。在Mac系统中,你需要安装[Xcode](https://developer.apple.com/xcode/)或者体量小的[Xcode命令行工具](https://developer.apple.com/downloads/)。
尽管你安装好了依赖,在OS更新后,你的依赖可能被破坏。事实上,在macOS系统上,这个问题如此常见,以至于在官方的仓库中记录着[安装日志](https://github.com/nodejs/node-gyp/blob/master/macOS_Catalina.md)。
让我们假设你克服了重重困难安装好了开发应用的所有依赖,你认为现在就万事大吉了吗?还没有。
如果你的同事使用的Windows系统开发,而你使用的是macOS系统,你需要考虑两个操作系统对文件路径的差异处理。再或者说[Nginx](https://nginx.org/)并没有很好的针对Windows系统做优化。一些技术例如[Redis](https://redis.io/)甚至没有Windows系统的预编译包。
即使项目已经开发完成,如果部署人员不清楚部署的流程呢?
如果采用下面的办法,所有上面的问题都能够被解决:
- 在和你最终部署环境匹配的隔离环境(所谓的容器)中开发(部署)并运行系统。
- 把你的应用和其所有的依赖及配置打包为一个单文件(所谓的镜像)。
- 通过一个中央服务器(所谓的仓库)分享应用给有合适权限的人。
你的同事们可以从中央仓库中下载镜像,启动应用时不用担心环境的不一致的问题,甚至可以直接启动应用,因为镜像中可能已经做好了相关配置。
这就是容器化的概念:将你的应用(和依赖)打包在一个自包含的镜像中,这个镜像是轻量级的并且可以在不同的环境中复制。
那么,现在的问题是:**Docker 到底是做什么的?**
就像我上面说的,容器化技术就是通过将应用的环境、依赖和配置封装在一个黑盒子中,来解决应用部署时千千万万的问题。
容器化技术已经有一些实现,[Docker](https://www.docker.com/)是其中的一种。它是一个开源的容器平台,能够将你的应用容器化,通过私有或者公共仓库分享,并且还可以让这些[容器协作起来](https://docs.docker.com/get-started/orchestration/)。
如今,Docker不是市面上唯一的容器化工具,但它是最流行的一个。另一个我喜爱的容器化平台是红帽公司开发的[Podman](https://podman.io/)。其他的容器化工具像Google的[Kaniko](https://github.com/GoogleContainerTools/kaniko),CoreOS的[rkt](https://coreos.com/rkt/)也很优秀,但是暂时还不是Docker的可替代的工具。
如果你想了解容器化的历史,你可以读一下[A Brief History of Containers:From the 1970s Till Now](https://blog.aquasec.com/a-brief-history-of-containers-from-1970s-chroot-to-docker-2016)这个经典介绍,里面介绍了容器化技术的重要演变过程。
---
<h2 id="3">3.怎么样安装Docker</h2>
根据操作系统的不同,安装的Docker的方法也不相同,但是总体来说,安装过程是比较简单的。
Docker能够运行在不同的主流操作系统macOS、Windows和Linux上,在这三个平台上,macOS系统上安装最容易,所以我们就从macOS系统开始。
<h3 id="3.1">3.1 怎么在macOS系统上安装Docker</h3>
在macOS上,你首先要做的就是找到官网的[下载地址](https://www.docker.com/products/docker-desktop)并下载一个mac平台的稳定版本。
你将会得到一个macOS系统的安装包并将它拖拽一个应用程序文件夹中。

你可以双击安装包,一旦应用启动成功,你会在菜单栏中看到Docker的图标。

现在,打开命令行终端并且执行`docker --version`和`docker-compose --version`命令来验证Docker的安装是否成功。
<h3 id="3.2">3.2 怎么在Windows系统上安装Docker</h3>
在Windows系统上除了额外的步骤要执行以外,其他的步骤和在macOS系统上大体一致。安装的步骤如下:
1. 访问[该网址](https://docs.microsoft.com/en-us/windows/wsl/install-win10),并且按照指示在Windows10系统上安装WSL2。
2. 找到官方网站[下载页](https://www.docker.com/products/docker-desktop),下载Windows平台的稳定版本。
3. 双击安装包,根据引导默认完成安装。
安装完成后,你可以从桌面或者开始菜单中打开Docker,你的Docker就会出现在任务栏中。

现在,可以打开你从Microsoft Store中安装的Ubuntu或者任何发行版,执行`docker --version`和`docker-compose --version`命令来验证Docker的安装是否成功。

你也可以打开cmd或者Power shell命令行终端来验证,只是在Windows上我喜欢WSL2命令行工具。
<h3 id="3.3">3.3 怎么在Linux系统上安装Docker</h3>
在Linux系统上安装Docker和上面两个系统完全不同,并且你使用Linux发行版不同,安装方式也不相同。但实际上,安装过程也很简单。
在Windows或者macOS系统上的Docker桌面安装包是包含像Docker Engine, Docker Compose, Docker Dashboard, Kubernetes等工具的集合包。然而在Linux操作系统上,没有这样捆绑一起的包,你需要手动安装你需要的工具包。不同平台的安装过程如下:
- 如果你是Ubuntu系统,你可以按照[Ubuntu官网文档指示安装Docker Engine](https://docs.docker.com/engine/install/ubuntu/)。
- 其他不同的Linux发行版,你也能从官方文档中获取安装指示。
- [Debian系统上安装Docker](https://docs.docker.com/engine/install/debian/)
- [Fedora系统上安装Docker](https://docs.docker.com/engine/install/fedora/)
- [Centos系统上安装Docker](https://docs.docker.com/engine/install/centos/)
- 如果官方文档中没有你使用发行版的说明,你需要按照[二进制编译安装的指示](https://docs.docker.com/engine/install/binaries/)进行安装。
- 无论你怎么样安装,一些针对[Linux系统安装后必须执行的步骤](https://docs.docker.com/engine/install/linux-postinstall/)是很重要的。
- 在你完成了Docker的安装,你还需要安装Docker Composed,你可以从官方文档中获取[安装Docker Composed的说明](https://docs.docker.com/compose/install/)。
安装完成后,打开命令行终端并且执行`docker --version`和`docker-compose --version`命令来验证Docker的安装是否成功。

尽管Docker能够在不同的平台上使用,我还是更倾向于在Linux上使用,本书中我将使用[Ubuntu20.04](https://releases.ubuntu.com/20.04/)和[Fedora33](https://fedoramagazine.org/announcing-fedora-33/)。
另外一件事我想现在就说明的是:我没有使用任何GUI工具操作Docker。
尽管不同平台有一些很好用的GUI工具,但是学习基本命令行Docker命令是本书的主要目标之一。
---
<h2 id="4">4. Docker运行Hello World - Docker基本介绍</h2>
现在在你的机器上有一个运行中的Docker,是时候运行你的第一个容器了,打开命令行,输入如下命令:
```shell
docker run hello-world
Unable to find image 'hello-world:latest' locally
latest: Pulling from library/hello-world
2db29710123e: Pull complete
Digest: sha256:9ade9cc2e26189a19c2e8854b9c8f1e14829b51c55a630ee675a5a9540ef6ccf
Status: Downloaded newer image for hello-world:latest
Hello from Docker!
This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps:
1. The Docker client contacted the Docker daemon.
2. The Docker daemon pulled the "hello-world" image from the Docker Hub.
(amd64)
3. The Docker daemon created a new container from that image which runs the
executable that produces the output you are currently reading.
4. The Docker daemon streamed that output to the Docker client, which sent it
to your terminal.
To try something more ambitious, you can run an Ubuntu container with:
$ docker run -it ubuntu bash
Share images, automate workflows, and more with a free Docker ID:
https://hub.docker.com/
For more examples and ideas, visit:
https://docs.docker.com/get-started/
```
[hello-world](https://hub.docker.com/_/hello-world)镜像是Docker提供的一个很小的容器化程序,它是很简单的[hello.c](https://github.com/docker-library/hello-world/blob/master/hello.c)程序,在终端打印出Hello World字符串。
在终端中,你可以执行使用`docker ps -a`命令来查看目前或者历史运行的Docker容器
```
docker ps -a
# CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
# 128ec8ceab71 hello-world "/hello" 14 seconds ago Exited (0) 13 seconds ago exciting_chebyshev
```
输出结果中,镜像hello-world对应有一个命名为`exciting_chebyshev`的容器,容器的ID为`128ec8ceab71`,还有一个`Exited(0)13 seconds ago`的状态表示容器运行的过程中没有产生错误。
为了能够理解刚才屏幕中输出的内容,必须要了解Docker的架构和容器化技术的三个基本概念,如下:
- [容器](https://www.freecodecamp.org/news/@fhsinchy/s/the-docker-handbook/~/drafts/-MS1b3opwENd_9qH1jTO/hello-world-in-docker#container)
- [镜像](https://www.freecodecamp.org/news/@fhsinchy/s/the-docker-handbook/~/drafts/-MS1b3opwENd_9qH1jTO/hello-world-in-docker#image)
- [仓库](https://www.freecodecamp.org/news/@fhsinchy/s/the-docker-handbook/~/drafts/-MS1b3opwENd_9qH1jTO/hello-world-in-docker#registry)
我按照字母表的顺序开始第一个重要概念的讲解:
<h3 id="4.1">4.1 什么是容器?</h3>
在容器化技术中,没有比容器更基本的概念了。
[Docker官方文档](https://www.docker.com/resources/what-container)中是这样说的:
> 容器是可以将应用和其依赖打包在一起的应用层的一种抽象。与虚拟化整个硬件不同,容器仅仅将宿主操作系统虚拟化。
你可以认为容器化技术是下一代的虚拟化技术。
就像虚拟机一样,容器之间以及容器和宿主机之间环境都是彼此隔离的。相比较虚拟机,容器也更加轻量级,因此同一个宿主机上可以同时跑多个容器,并且不影响宿主机的性能。
容器和虚拟机使用不同的方法进行虚拟化,两者的主要不同是虚拟化方法的不同。
虚拟机通常被一个叫做Hypervisor的程序创建并管理,例如[Oracle VM VirtualBox](https://www.virtualbox.org/)、[VMware](https://www.vmware.com/)、[KVM](https://www.linux-kvm.org/)和微软[Hyper-V](https://docs.microsoft.com/en-us/virtualization/hyper-v-on-windows/about/)等等。这个Hypervisor程序处在宿主机操作系统和虚拟机之间,承担中间通信的职责。

在虚拟机中运行的程序和本地操作系统(gust operating system)通信,本地操作系统和Hypervisor程序通信,Hypervisor程序再向宿主机操作系统从硬件中申请必要的资源来运行程序。
从上面可以看出,虚拟机中运行的程序和宿主基础硬件之间有一个长长的通信链,即使是虚拟机中程序申请很小的资源,由于本地操作系统的存在也增加了明显的性能消耗。
和虚拟机使用的虚拟方法不一样,容器使用更加聪明的方式。容器没有完整的本地操作系统,它通过运行时的容器服务使用宿主机操作系统,同时又像虚拟机那样保持环境的隔离性。

运行时的容器服务,也就是Docker,处在宿主机操作系统和容器之间,容器通过Docker和宿主机操作系统进行通信,从基础物理硬件获取程序运行的资源。
容器由于取消了完整的本地操作系统,相比虚拟机更加轻量级和资源少消耗。
为了验证这一点,执行下面的代码:
```
uname -a
# Linux DESKTOP-N5K2GI1 5.10.16.3-microsoft-standard-WSL2 #1 SMP Fri Apr 2 22:23:49 UTC 2021 x86_64 x86_64 x86_64 GNU/Linux
docker run alpine uname -a
# Linux 9c2c71a183ee 5.10.16.3-microsoft-standard-WSL2 #1 SMP Fri Apr 2 22:23:49 UTC 2021 x86_64 Linux
```
上面的代码中,我先在宿主机上执行了`uname -a`命令,获取宿主机操作系统的内核详情。然后第二行运行了一个[Alpine Linux](https://alpinelinux.org/)容器执行了同样的命令。
从输出的结果可以看出来,容器实际上使用了宿主机操作系统的内核,这也证明了容器虚拟化了宿主机的操作系统而不是自身也拥有一个。
如果你使用Windows机器,你会发现所有的容器都是使用WSL2内核,这是因为WSL2提供Windows上Docker的后台服务。在macOS系统上,默认的后台服务是一个基于[HiperKit](https://github.com/moby/hyperkit) Hypervisor的VM。
> 冯兄话吉:冯兄(译者)的操作环境正是WSL2。
<h3 id="4.2">4.2 什么是镜像?</h3>
镜像是分层的,自包含的,用来创建容器的模版源文件。它们可以通过镜像仓库共享。
过去,不同的容器引擎需要不同的镜像格式。后来,[Open Container Initiative(OCI)](https://opencontainers.org/)定义了标准的容器镜像规范,大部分的主流容器化平台都遵循这一规范,这也意味着在Docker上构建的镜像在没有任何修改的情况下可以直接在Podman容器平台上使用。
容器其实就是运行时的镜像,当你从互联网上获取一个镜像并且运行这个镜像的时候,你实际上基于只读镜像层新创建了一个临时可写入层。
镜像的概念会随着本书的深入会越来越清晰,现在需要记住的是,镜像是一个多层次的、只读的,将你的应用打包为指定某一状态的文件。
<h3 id="4.3">4.3 什么是Docker仓库(Docker Registry)?</h3>
我们已经学习了两个非常重要的概念,容器和镜像,剩下的就是Docker仓库的概念了。
镜像仓库是一个你能够上传并且下载别人上传镜像的中央镜像管理处。[Docker Hub](https://hub.docker.com/)是Docker官方默认的镜像仓库,另外一个流行的镜像仓库是Red Hat的[Quay](https://quay.io/)。
本书中,我们使用Docker Hub作为我们的镜像仓库。

你可以免费在Docker Hub上分享你的公开镜像,互联网上的人们可以从那里免费下载它们。我上传的镜像可以在我的主页([fhsinchy](https://hub.docker.com/u/fhsinchy))中找到。

除了Docker Hub和Quay,你也可以创建私有的镜像仓库。实际你本地也运行着一个私有仓库,用来存储从远端仓库拉下来的镜像。
<h3 id="4.4">4.4 Docker架构</h3>
现在你已经学习了容器化技术和Docker的基本概念,是时候学习Docker是怎么工作的。
Docker引擎包含三个主要部分:
1. **Docker Daemon**:daemon进程(`dockerd`)在后台运行并且监听客户端的请求,它能够管理各种各样的Docker对像。
2. **Docker Client**:客户端(`docker`)是一个命令行接口程序,主要负责传递用户的请求。
3. **REST API**:REST接口是Docker后台程序和客户端之间的桥梁,用户输入的任务命令行请求都会通过接口传递到后台Docker Daemon那里。
根据官方[文档](https://docs.docker.com/get-started/overview/#docker-architecture):
> Docker使用C/S的架构,客户端向服务端通信,服务端处理构建、运行和分发容器的工作。
你作为用户使用Docker客户端输入命令,客户端使用REST API将命令转发给后台守护进程dockerd,并由后台进程完成工作。
<h3 id="4.5">4.5 完整的Docker工作过程</h3>
好的,基础的概念已经了解了,我们开始把所学习的一切串起来,看看它们合在一起是怎么工作的。在我们详细讲解`docker run hello-world`命令背后到底发生什么之前,先看看我画的一张图:

这张图基于Docker官方网站的一张稍微作出改动,当你执行命令的时候,发生的事情如下:
1. 你执行`docker run hello-world`命令,这里的hello-world是Docker镜像的名字。
2. Docker客户端转发命令到Docker后台进程,说要获取hello-world镜像并创建一个容器。
3. Docker后台进程从本地仓库中寻找镜像,但是没有找到,日记中会打印出:`Unable to find image 'hello-world':latest`。
4. Docker后台进程会去默认的Docker Hub仓库中下载最新的镜像,日志中会打印出:`latest: pulling from library/hello-world`。
5. Docker后台进程基于下载的镜像创建一个容器。
6. 最后,Docker后台进程运行这个容器,并输出结果到命令行终端上。
Docker在本地找不到拉取镜像的时候,默认会去Docker Hub仓库下载。一旦镜像被下载,就会缓存到本地仓库。所以,你重新执行命令,就看不到如下的日志输出:
```
Unable to find image 'hello-world:latest' locally
latest: Pulling from library/hello-world
2db29710123e: Pull complete
Digest: sha256:9ade9cc2e26189a19c2e8854b9c8f1e14829b51c55a630ee675a5a9540ef6ccf
Status: Downloaded newer image for hello-world:latest
```
如果在公共的Docker仓库有一个新的镜像版本,Docker后台程序会重新获取镜像,这里的`:latest`是一个标签。Docker镜像会有一个有意义标签表示版本或者构建。关于标签我们在后续会做详细介绍。
---
<h2 id="5">5. Docker容器基本操作</h2>
在前面的章节中,你学习了Docker的基础概念并且使用docker run命令运行了一个Docker容器。
在这一部分中,你们将会学习到详细的Docker容器操作。容器操作是你每天必须执行的基本任务,所以正确的理解各种命令很关键。
要知道的是,这里列出来的Docker命令不是全部的,而是一些最基本的命令。如果想要学习更多Docker支持的命令,可以访问官方文档的[命令行说明](https://docs.docker.com/engine/reference/commandline/container/)。
<h3 id="5.1">5.1 怎样运行一个容器?</h3>
之前的章节我们基于hello-world镜像,使用docker run命令启动了一个容器。基本的命令行语法是这样的:
```shell
docker run <image-name>
```
尽管这是一个很有效命令,Docker提供了更好的方式,可以将客户端命令传递给Docker后台进程。
在Docker1.13之前,Docker只支持上面语法的命令。后来,Docker[重构](https://www.docker.com/blog/whats-new-in-docker-1-13/)了命令行语法:
```shell
docker <object> <command> <options>
```
在这个语法中:
- object表示你要操作的Docker对象,可以是container、image、network和volume对象。
- command表示Docker后台进程要执行的内容,比如说run。
- options可以是任何有效的覆盖默认行为的参数,例如`--publish`参数表示端口映射。
参照上面的语法,run命令可以写成:
```shell
docker container run <image-name>
```
image name可以是任何本地或者远程仓库上的镜像名称。例如,你也可以使用[fhsinchy/hello-dock](https://hub.docker.com/r/fhsinchy/hello-dock)这个镜像名称,这个镜像包含了一个简单的[vue.js](https://vuejs.org/)应用,运行容器内应用启动并监听80端口。想要运行这个镜像的容器,执行下面的命令:
```
docker container run --publish 8080:80 fhsinchy/hello-dock
Unable to find image 'fhsinchy/hello-dock:latest' locally
latest: Pulling from fhsinchy/hello-dock
0a6724ff3fcd: Pull complete
1d7c87af3754: Pull complete
9668ffa91d19: Pull complete
e81a2f5037c1: Pull complete
991b5ddb4d9e: Pull complete
9f4fab0aaa1b: Pull complete
Digest: sha256:852a90695e942a8aefe5883cb9681a3fbedfdf89f64468e22fa30e04766e5f2e
Status: Downloaded newer image for fhsinchy/hello-dock:latest
/docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration
/docker-entrypoint.sh: Looking for shell scripts in /docker-entrypoint.d/
/docker-entrypoint.sh: Launching /docker-entrypoint.d/10-listen-on-ipv6-by-default.sh
10-listen-on-ipv6-by-default.sh: Getting the checksum of /etc/nginx/conf.d/default.conf
10-listen-on-ipv6-by-default.sh: Enabled listen on IPv6 in /etc/nginx/conf.d/default.conf
/docker-entrypoint.sh: Launching /docker-entrypoint.d/20-envsubst-on-templates.sh
/docker-entrypoint.sh: Configuration complete; ready for start up
```
命令行很好理解,需要解释的`--publish 8080:80`参数会在下一部分内容中解释。
<h3 id="5.2">5.2 怎样发布一个端口?</h3>
容器是隔离的环境。容器的宿主机并不知道容器内发生的一切。因此,容器外部是不能直接访问容器内部的。
如果想要容器外部访问容器,需要将容器内部的端口发布到容器宿主机的网路上,语法`--publish`和`-p`如下:
```shell
--publish <host port>:<container port>
```
当你像刚才命令中那样指定`--publish 8080:80`参数,意味着任何访问宿主机8080端口的请求都会被转发到容器内到80端口。
现在可以在浏览器中访问http://127.0.0.1:8080。

> 冯兄话吉:这里127.0.0.1代表启动docker服务的宿主机IP,如果你在宿主机上启动的虚拟机或者WSL,需要替换为VM的IP。后续文章中给出的`http://127.0.0.1`访问页面都要注意IP地址替换的问题。
你可以使用ctrl + c命令停止容器,命令行终端将会停止进程或者关闭整个终端。
<h3 id="5.3">5.3 怎样使用后台模式?</h3>
另外一个`run`命令常用的命令行参数是`--detach`或者`-d`。在上面的操作中,容器如果想保持运行状态,必须要保持命令行窗口打开的状态。关闭命令行窗口,容器就会被停掉。
这是因为,默认容器在前台启动,并且会像其他程序一样绑定在调用方终端上。
我们可以通过`--detach`参数让容器在后台启动,命令如下:
```shell
docker container run --detach --publish 8080:80 fhsinchy/hello-dock
# 9f21cb77705810797c4b847dbd330d9c732ffddba14fb435470567a7a3f46cdc
```
和之前不一样,你的命令行终端上打印出了容器的ID。
参数的顺序先后没有关系,如果你把`--publish`参数放在了`--detach`参数之前,容器依然可以正常启动。对于`docker run`命令,只要记住镜像的名字是放在最后的就可以,如果镜像的名字后面还有内容,会被作为容器entry-point(见[在一个容器中执行命令](https://fengmengzhao.github.io/2021/06/25/docker-handbook-2021.html#executing-commands-inside-a-container)模块)的参数传递,可能会得到意想不到的结果。
<h3 id="5.4">5.4 怎样查看容器?</h3>
`container ls`命令可以展示出正在运行中的容器,命令如下:
```
docker container ls
# CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
# 9f21cb777058 fhsinchy/hello-dock "/docker-entrypoint.…" 5 seconds ago Up 5 seconds 0.0.0.0:8080->80/tcp gifted_sammet
```
一个名称为`gifted_sammet`的容器在运行中,它在5秒钟之前被创建,并且已经正常启动了5秒钟。
容器的ID是`9f21cb777058`,这个ID是完整容器ID的前12个字符,完整的ID是`9f21cb77705810797c4b847dbd330d9c732ffddba14fb435470567a7a3f46cdc`,含有64个字符。当前面使用`docker container run`运行容器的时候,完整的容器ID就输出在了控制台。
`port`列表示宿主机8080端口指向容器的80端口。`gifted_sammet`名字是docker生成的,根据平台不同,这个名字可能也不同。
`container ls`命令仅仅展示出了目前正在运行的容器,如果想列出来历史运行过的容器,使用`--all`或者`-a`参数。
```
docker container ls --all
# CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
# 9f21cb777058 fhsinchy/hello-dock "/docker-entrypoint.…" 2 minutes ago Up 2 minutes 0.0.0.0:8080->80/tcp gifted_sammet
# 6cf52771dde1 fhsinchy/hello-dock "/docker-entrypoint.…" 3 minutes ago Exited (0) 3 minutes ago reverent_torvalds
# 128ec8ceab71 hello-world "/hello" 4 minutes ago Exited (0) 4 minutes ago exciting_chebyshev
```
可以看出来,第二个名字为`reverent_torvalds`的容器早些时候运行过,退出时候exit code为0,标识容器运行的时候没有产生错误。
<h3 id="5.5">5.5 怎样命名或者重命名一个容器?</h3>
每一个容器默认都有两个标识,它们是:
- 容器ID - 64位长度的字符串。
- 容器名称 - 用下划线连接的两个随机单词。
使用随机生成的容器名称来指代容器很不方便,我们也可以自定义容器的名称。
通过参数`--name`可以定义容器名称,基于镜像`fhsinchy/hello-dock`启动另外一个名称为`hello-dock-container`的容器,使用如下命令:
```
docker container run --detach --publish 8888:80 --name hello-dock-container fhsinchy/hello-dock
# b1db06e400c4c5e81a93a64d30acc1bf821bed63af36cab5cdb95d25e114f5fb
```
8080的本地端口被我们之前启动的容器占用着,因此我们使用了一个新的端口8888。可以查看下启动的容器:
```
docker container ls
# CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
# b1db06e400c4 fhsinchy/hello-dock "/docker-entrypoint.…" 28 seconds ago Up 26 seconds 0.0.0.0:8888->80/tcp hello-dock-container
# 9f21cb777058 fhsinchy/hello-dock "/docker-entrypoint.…" 4 minutes ago Up 4 minutes 0.0.0.0:8080->80/tcp gifted_sammet
```
名称为`hello-dock-container`的容器处于运行中状态。
你也可以使用`docker container rename`命令重命名一个容器,语法如下:
```shell
docker container rename <container identifier> <new name>
```
重命名之前的名称为gifted_sammet的容器为hello-dock-container-2,命令如下:
```shell
docker container rename gifted_sammet hello-dock-container-2
```
这个命令执行没有任何输出结果,不过你可以通过查看容器列表`container ls`确实是否修改成功
无论容器在运行态或者停止态,`rename`命令都可以使用。
<h3 id="5.6">5.6 怎样停止或者杀死一个运行中的容器?</h3>
前台运行的容器可以通过关闭终端命令行或者按键ctrl + c来停止运行。后台运行的容器需要使用不同的方法。
有两个命令可以停止容器,第一个是`container stop`命令,基本的语法是:
```shell
docker container stop <container identifier>
```
这里的container identifier可以是容器的名称或者ID。
应该还记得我们之前启动的容器还在后台运行着,通过container ls查看容器的标识(这里我们以hello-dock-container作为示例)。执行下面的命令来停止容器运行:
```
docker container stop hello-dock-container
# hello-dock-container
```
如果你使用容器的名称作为标识,容器停止后控制台会将名字输出。stop命令通过发送`SIGTERM`信号优雅的关闭掉了容器。如果容器在一段时间内没有停掉,则会发送一个`SIGKILL`信号,立即停止容器。
如果你想发送`SIGKILL`而不是`SIGTERM`信号,你可以使用container kill命令,命令的语法如下:
```
docker container kill hello-dock-container-2
# hello-dock-container-2
```
<h3 id="5.7">5.7 怎样重启一个容器?</h3>
这里说的重启,有两种场景:
- 重启之前已经停掉或者被杀死的容器
- 重启一个运行中的容器
在上面的章节中,我们系统中有停掉的容器,可以使用`container start`命令来启动停掉或者被杀死的容器,语法如下:
```shell
docker container start <container identifier>
```
可以使用`container ls --all`命令列出来所有的容器,找到状态是`Exited`的。
```
docker container ls --all
# CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
# b1db06e400c4 fhsinchy/hello-dock "/docker-entrypoint.…" 3 minutes ago Exited (0) 47 seconds ago hello-dock-container
# 9f21cb777058 fhsinchy/hello-dock "/docker-entrypoint.…" 7 minutes ago Exited (137) 17 seconds ago hello-dock-container-2
# 6cf52771dde1 fhsinchy/hello-dock "/docker-entrypoint.…" 7 minutes ago Exited (0) 7 minutes ago reverent_torvalds
# 128ec8ceab71 hello-world "/hello" 9 minutes ago Exited (0) 9 minutes ago exciting_chebyshev
```
现在可以重启`hello-dock-container`容器,执行以下命令:
```
docker container start hello-dock-container
# hello-dock-container
```
可以通过`container ls`命令展示运行中的容器,验证容器是否启动成功。
`container start`命令默认情况下,保留之前的端口配置启动任何后台容器,所以如果你现在访问`http://127.0.0.1:8080`,就能够像之前那样访问到`hello-dock`应用。

现在说下重启运行中容器的场景,要用到`container restart`命令,语法和`container start`命令类似。
```
docker container restart hello-dock-container-2
# hello-dock-container-2
```
二者不同的地方在于,重启容器(restart)是先停掉容器再启动,而启动(start)容器就直接启动。
对于停止状态的容器,二者都可以使用。但是对于运行中的容器,只能使用`docker restart`命令。
<h3 id="5.8">5.8 怎样不启动容器的情况下创建一个容器?</h3>
目前,我们学习用`docker run`命令启动一个容器。实际上,这个命令包含两部分:
- `container create`命令,基于一个镜像创建一个容器。
- `container start`命令,启动刚刚创建的容器。
我们可以像[怎样运行一个容器](#7.1)章节那样,分两个步骤,启动一个容器:
```
docker container create --publish 8080:80 fhsinchy/hello-dock
# 2e7ef5098bab92f4536eb9a372d9b99ed852a9a816c341127399f51a6d053856
docker container ls --all
# CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
# 2e7ef5098bab fhsinchy/hello-dock "/docker-entrypoint.…" 30 seconds ago Created hello-dock
```
通过上面`container ls --all`命令展示所有容器,我们看到一个基于镜像`fhsinchy/hello-dock`的名称是`hello-dock`的容器。目前容器的状态是`Created`,说明这个容器没有运行,使用参数`--all`容器也不会展示出来。
容器创建后,我们可以用`container start`命令来启动它:
```
docker container start hello-dock
# hello-dock
docker container ls
# CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
# 2e7ef5098bab fhsinchy/hello-dock "/docker-entrypoint.…" About a minute ago Up 29 seconds 0.0.0.0:8080->80/tcp hello-dock
```
容器的状态从`Created`变为了`Up 29 seconds`,表明容器现在是运行的状态。之前空着的PORTS列也有了数据。
<h3 id="5.9">5.9 怎样移除一个不用的容器?</h3>
一个被停掉或者杀死的容器还会停留在系统中,这些不用的容器会占用空间并且可能会很新的容器冲突。
可以是`container rm`移除停掉的容器,语法如下:
```shell
docker container rm <container-identifier>
```
想找出来哪些容器不是运行的状态,可以使用`container ls --all`命令并寻找`Exited`状态的容器。
```
docker container ls --all
# CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
# b1db06e400c4 fhsinchy/hello-dock "/docker-entrypoint.…" 6 minutes ago Up About a minute 0.0.0.0:8888->80/tcp hello-dock-container
# 9f21cb777058 fhsinchy/hello-dock "/docker-entrypoint.…" 10 minutes ago Up About a minute 0.0.0.0:8080->80/tcp hello-dock-container-2
# 6cf52771dde1 fhsinchy/hello-dock "/docker-entrypoint.…" 10 minutes ago Exited (0) 10 minutes ago reverent_torvalds
# 128ec8ceab71 hello-world "/hello" 12 minutes ago Exited (0) 12 minutes ago exciting_chebyshev
```
从上面我们能找出来,容器ID是`6cf52771dde1`和`128ec8ceab71`的容器不是运行的状态,移除容器ID`6cf52771dde1`的容器,执行命令:
```
docker container rm 6cf52771dde1
# 6cf52771dde1
```
可以使用`container ls --all`来验证容器是否被移除。如果要批量移除容器,可以一次性将容器的标识用空格隔开传递给命令。
或者,你可以不用单个的移除容器,使用`container prune`命令可以一次性移除所有停掉或者退出的容器。
使用`container ls --all`命令验证容器是否被移除:
```
docker container ls --all
# CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
# b1db06e400c4 fhsinchy/hello-dock "/docker-entrypoint.…" 8 minutes ago Up 3 minutes 0.0.0.0:8888->80/tcp hello-dock-container
# 9f21cb777058 fhsinchy/hello-dock "/docker-entrypoint.…" 12 minutes ago Up 3 minutes 0.0.0.0:8080->80/tcp hello-dock-container-2
```
如果严格按照本书的执行,执行到了这里,应该能够看到列表中的另个容器:`hello-dock-container`和`hello-dock-container-2`。建议进行下面的内容之前将这两个容器移除。
`container run`命令和`container start`命令也有一个参数`--rm`,表示一旦容器停掉就删除容器。可以使用`--rm`参数启动另一个`hello-dock`容器。
```
docker container run --rm --detach --publish 8888:80 --name hello-dock-volatile fhsinchy/hello-dock
# 0d74e14091dc6262732bee226d95702c21894678efb4043663f7911c53fb79f3
```
使用`container ls`命令查看容器是否启动:
```shell
docker container ls
# CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
# 0d74e14091dc fhsinchy/hello-dock "/docker-entrypoint.…" About a minute ago Up About a minute 0.0.0.0:8888->80/tcp hello-dock-volatile
```
现在可以停掉这个容器并使用`container ls --all`名称查看确认:
```shell
docker container stop hello-dock-volatile
# hello-dock-volatile
docker container ls --all
# CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
```
可以看见容器被自动删除了。后面我们基本上都会用上`--rm`参数,不需要的地方会特殊说明。
<h3 id="5.10">5.10 怎样使用命令行交互的方式启动一个容器?</h3>
目前我们基于[hello-world](https://hub.docker.com/_/hello-world)和[fhsinchy/hello-dock](https://hub.docker.com/r/fhsinchy/hello-dock)镜像创建并运行容器,这些都是简单程序的镜像,不需要命令行交互。
镜像不都是这么简单的,它可以封装进去整个Linux的发行版。
流行的Linux发型版,例如[Ubuntu](https://ubuntu.com/)、[Fedora](https://fedora.org/)和[Debian](https://debian.org/)在官方的仓库中都有Docker镜像。编程语言,像[python](https://hub.docker.com/_/python)、[php](https://hub.docker.com/_/php)、[go](https://hub.docker.com/_/golang),或者运行时环境[node](https://hub.docker.com/_/node)和[deno](https://hub.docker.com/r/hayd/deno)都有自己的官方镜像。
这些镜像不仅仅是做了提前的一些配置,还默认会配置执行一个shell。对于操作系统镜像来说,可能是一个`sh`或者`bash`,对于一个编程语言或者运行时环境,可能是语言自身的shell。
我们都知道,shell是命令行交互式程序。如果一个镜像配置执行这样一个程序,这样的镜像称之为交互式的镜像。他们在启动容器`docker run`的时候需要一个`-it`参数。
举一个例子,如果你使用`docker container run ubuntu`启动一个ubuntu镜像的容器,命令行上你会看不到任何输出。但是如果你加上`-it`参数,你就能够直接在命令行中操作这个Ubuntu容器。
```shell
docker container run --rm -it ubuntu
root@573b5a48e7a8:/# cat /etc/os-release
NAME="Ubuntu"
VERSION="20.04.3 LTS (Focal Fossa)"
ID=ubuntu
ID_LIKE=debian
PRETTY_NAME="Ubuntu 20.04.3 LTS"
VERSION_ID="20.04"
HOME_URL="https://www.ubuntu.com/"
SUPPORT_URL="https://help.ubuntu.com/"
BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
VERSION_CODENAME=focal
UBUNTU_CODENAME=focal
root@573b5a48e7a8:/#
```
上面,我们执行命令`cat /etc/os-release`得到相应的输出,说明我们确实是和Ubuntu容器在进行交互。
`-it`参数能够让你和容器内的交互式程序进行交互。这个参数实际上是有两部分组成在一起。
- `-i`参数或者`--interactive`绑定连接终端到容器的输入流中,因此你可以在终端中输入。
- `-t`或者`--tty`参数保证输出的内容格式化,并且通过分配一个伪tty让你有一个很好的终端体验。
当你像以命令行交互的方式运行一个容器的时候,你需要使用`-it`。你可以这样启动node容器:
```shell
docker container run -it node
# Welcome to Node.js v15.0.0.
# Type ".help" for more information.
# > ['farhan', 'hasin', 'chowdhury'].map(name => name.toUpperCase())
# [ 'FARHAN', 'HASIN', 'CHOWDHURY' ]
```
任何有效的JavaScript代码都可以在这个终端中运行。`-it`是缩写,我们也分别可以写成`--interactive --tty`。
<h3 id="5.11">5.11 怎样在容器内执行命令?</h3>
在[Docker运行Hello World - Docker基本介绍](#4)章节,我们运行了一个Alpine Linux容器,并且执行了一个命令:
```
docker run alpine uname -a
# Linux 9c2c71a183ee 5.10.16.3-microsoft-standard-WSL2 #1 SMP Fri Apr 2 22:23:49 UTC 2021 x86_64 Linux
```
在上面的命令中,我在容器Alpine Linux容器中执行了`uname -a`命令。像这种的场景(启动一个容器的时候,需要在容器内执行一个命令)很常见。
假设你想base64一个字符串,这在Linux或者Unix系统中很容易做到(不包括Windows系统)。
你可以快速的启动一个基于[busybox](https://hub.docker.com/_/busybox)的镜像的容器,让这个容器做base64的工作。
把一个字符串base64的基本语法是:
```
echo -n my-secret | base64
# bXktc2VjcmV0
```
将命令传递给没有在运行的容器的基本语法是:
```shell
docker container run <image name> <command>
```
使用`busybox`镜像运行容器,并让容器执行base64命令,可以这样启动:
```
docker container run --rm busybox echo -n my-secret | base64
# bXktc2VjcmV0
```
这里的处理逻辑上,`docker run`命令任何在image name后面的内容都作为参数传递给容器的默认`entry point`。
所谓的`entry point`就是一个镜像的入口。除了可执行镜像(在下面[怎样操作可执行镜像](#5.12)章节说明)外,大部分镜像使用`shell`或者`sh`作为默认的`entry point`。因此任何有效的shell命令都可以作为参数传递。
<h3 id="5.12">5.12 怎样操作可执行镜像?</h3>
之前我们有简单提到可执行容器,这些容器的目的是像程序一样可执行。
看一看我的[rmbyext](https://github.com/fhsinchy/rmbyext)项目,这是一个简单的Python脚本,能够递归删除给定扩展名的文件。可以访问仓库了解更详细的信息:
[](https://github.com/fhsinchy/rmbyext)
如果你已经安装了Git和Python,可以执行下面的命令安装这个脚本:
```shell
pip install git+https://github.com/fhsinchy/rmbyext.git#egg=rmbyext
```
如果你已经配置好了Python环境命令,在任意的命令行中,都可以使用一下命令:
```shell
rmbyext <file extension>
```
为了测试,在一个空目录中打开命令行并以不同的扩展创建多个文件。你可以使用touch命令来这样做,现在我们有了一个目录,目录中有如下文件:
```
touch a.pdf b.pdf c.txt d.pdf e.txt
ls
# a.pdf b.pdf c.txt d.pdf e.txt
```
要删除所有的pdf文件,可以执行如下的命令:
`rmbyext pdf`
> 冯兄话吉:如果你不想安装`pip`,只要有Python环境就可以了。克隆项目`git clone https://github.com/fhsinchy/rmbyext.git`,找到对应的`rmbyext.py`用Python执行即可。在冯兄译者的操作环境中先进入测试文件目录,执行:`sudo python3 ../rmbyext.py pdf`。
一个可执行的镜像也应该像`rmbyext`脚本文件一样,接收一个文件后缀的参数,能够删除后缀结尾的文件。
[fhsinchy/rmbyext](https://hub.docker.com/r/fhsinchy/rmbyext)镜像和上面的程序类似,它包含了`rmbyext`脚本,并且配置了执行脚本时删除容器内`/zone`目录下的文件。
现在问题是容器和宿主机环境之间是隔离的,因此容器内运行的`rmbyext`程序不能够访问到宿主机的文件系统。如果我们能够将宿主机的目录映射到容器内的`/zone`目录,本地的文件就可以被宿主机访问到了。
使容器能够访问到宿主机文件系统的一种方法是绑定挂载点(bind mount)。
bind mount能够实现容器宿主机(源端)目录和容器(目标端)目录的内容保持一致,源端和目标端目录内和和的修改都会彼此同步。
我们来使用一下bind mount,不直接使用脚本删除文件,使用镜像来进行操作:
```shell
docker container run --rm -v $(pwd):/zone fhsinchy/rmbyext pdf
# Removing: PDF
# b.pdf
# a.pdf
# d.pdf
```
你可能已经猜到,我们在命令中使用了`-v $(pwd):/zone`参数。`-v`或者`--volume`参数用来为容器绑定一个挂载点,这个参数可以用冒号隔开的三部分组成,基本的语法是:
```shell
--volume <local file system directory absolute path>:<container file system directory path>:<read write access>
```
参数中前两部分是必选的,第三部分可选。
我们例子中的源端目录是`/home/fhsinchy/the-zone`,这个目录在命令行中是打开的,`$(pwd)`表示了之前提到的包含.pdf和.txt文件的当前工作目录。
你可以在[这里](https://www.gnu.org/software/bash/manual/html_node/Command-Substitution.html)学习到更多的命令行替换的用法。
`-v`或者`--volume`参数对于`container run`命令是有效的,同样对于`container create`也是有效的。我们将在接下来的章节中详细研究volume这个概念,所以现在如果不太理解,不用太担心。
可执行的镜像和常规镜像不同的地方是,可执行镜像的入口是执行一个程序而不是shell。在`rmbyext`示例中,我们之前也说过,任何在镜像名称后面的内容都会作为参数传递给容器的入口。
因此最后我们的`docker container run --rm -v $(pwd):/zone fhsinchy/rmbyext pdf`命令将`rmbyext pdf`程序转化了可执行镜像在容器内运行。可执行镜像实际上并不常见,但是有时候会非常有用。
---
<h2 id="6">6. Docker镜像基本操作</h2>
目前为止,我么学会了怎样启动一个镜像。接下来学习怎样创建你自己的镜像。
这部分中,我们将会学习基本的创建一个镜像,运行这个镜像和在线分享镜像。
我建议你下载[Visual Studio Code](https://code.visualstudio.com/)的[Docker官方插件](https://marketplace.visualstudio.com/items?itemName=ms-azuretools.vscode-docker),这样能极大有利于你的开发。
<h3 id="6.1">6.1 怎样创建一个Docker镜像?</h3>
在[hello-world章节](#4)我们有解释过,Docker镜像是多层次的、自包含的文件,是可以用来创建Docker容器的模版,就像是静态的容器的一份克隆。
在把你的程序创建成一个镜像之前,你必须要清楚定义这个镜像的版本。例如,基于[Nginx的官方镜像](https://hub.docker.com/_/nginx),你可以通过如下命令启动容器:
```shell
docker container run --rm --detach --name default-nginx --publish 8080:80 nginx
Unable to find image 'nginx:latest' locally
latest: Pulling from library/nginx
07aded7c29c6: Pull complete
bbe0b7acc89c: Pull complete
44ac32b0bba8: Pull complete
91d6e3e593db: Pull complete
8700267f2376: Pull complete
4ce73aa6e9b0: Pull complete
Digest: sha256:06e4235e95299b1d6d595c5ef4c41a9b12641f6683136c18394b858967cd1506
Status: Downloaded newer image for nginx:latest
5451c55a1b74be3f97445b8254526cc0e01da65c923d6fa5da5f8ab9af1ce2ea
# CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
# 5451c55a1b74 nginx "/docker-entrypoint.…" 8 seconds ago Up 8 seconds 0.0.0.0:8080->80/tcp default-nginx
```
现在,你可以在浏览器中访问`http://127.0.0.1:8080`,你会得到一个默认的响应界面。

这很好,但是如果你想自定义制作一个像官方那样的Nginx镜像呢?坦白来说,这种场景是会遇到的。我们来学习怎么制作它。
为了制作一个自定的Nginx镜像,必须要清楚镜像的最终状态是什么样的,在我看来应该是这样的:
- 镜像中的Nginx一定是安装好的,可以通过包管理命令行或者源代码编译的方式完成。
- 镜像启动的时候,Nginx应该自动启动。
很简单的,如果你克隆了书中链接的仓库,可以进入克隆的项目目录,找到一个`custom-nginx`的目录。
现在,在那个目录中创建一个名称为Dockerfile的文件,文件中定义的命令会执行怎样创建一个容器。Dockerfile的内容是:
```shell
FROM ubuntu:latest
EXPOSE 80
RUN apt-get update && \
apt-get install nginx -y && \
apt-get clean && rm -rf /var/lib/apt/lists/*
CMD ["nginx", "-g", "daemon off;"]
```
镜像是多层的文件系统,在Dockerfile文件中,你写的每一行(称之为instructions)为镜像创建了一层。
- 每一个有效的Dockerfile都以`FROM`命令开头,该命令设定了你目标镜像的基础镜像。通过设置`ubuntu:latest`基础镜像,你可以在自定义的镜像中获取ubuntu系统的完美功能,你可以使用`apt-get`命令方便的进行包的安装。
- `EXPOSE`命令表示端口需要被发布。使用该指标后你仍然需要使用`--publish`命令发布端口,它仅仅起到了一个文档的作用来指示运行你镜像的人。它还有其他的作用,在这里就不讨论了。
- Dockerfile中的`RUN`命令在容器的shell中执行命令。`apt-get update && apt-get install nginx -y`命令首先更新包版本然后安装nginx。`apt-get clean && rm -rf /var/lib/apt/list/*`命令用来清理包缓存,因为你不需要在镜像中有不必要的垃圾。这两个命令在Ubuntu系统中是两个常见的操作,没什么特殊的。这里的`RUN`命令写成了`shell`的形式,它也可以写成`exec`的形式,你可以访问[官方的文档](https://docs.docker.com/engine/reference/builder/#run)获取更多的信息。
- 最后`CMD`命令设置镜像默认执行的命令。命令以`exec`的形式包含了三个部分。`nginx`表示可执行的nginx程序,`-g`和`daemon off`是nginx程序的可选参数表示让nginx以单进程的方式在容器内运行,`CMD`也可以用`shell`的形式来写,你可以[官方文档](https://docs.docker.com/engine/reference/builder/#cmd)获取更多信息。
现在,你有一个有效的Dockerfile可以用来创建镜像。和容器相关的命令一样,镜像相关的命令语法如下:
```shell
docker image <command> <options>
```
想要创建你刚刚写的Dockerfile的镜像,在`custom-nginx`目录中打开终端,执行如下命令:
```shell
docker image build .
# Sending build context to Docker daemon 3.584kB
# Step 1/4 : FROM ubuntu:latest
# ---> d70eaf7277ea
# Step 2/4 : EXPOSE 80
# ---> Running in 9eae86582ec7
# Removing intermediate container 9eae86582ec7
# ---> 8235bd799a56
# Step 3/4 : RUN apt-get update && apt-get install nginx -y && apt-get clean && rm -rf /var/lib/apt/lists/*
# ---> Running in a44725cbb3fa
### LONG INSTALLATION STUFF GOES HERE ###
# Removing intermediate container a44725cbb3fa
# ---> 3066bd20292d
# Step 4/4 : CMD ["nginx", "-g", "daemon off;"]
# ---> Running in 4792e4691660
# Removing intermediate container 4792e4691660
# ---> 3199372aa3fc
# Successfully built 3199372aa3fc
```
为了执行镜像的构建,后台进程需要知道特定的信息,比如Dockerfile的名称和执行的上下文,命令的含义是:
- `docker image build`是构建镜像的命令,后台进程会在上下中寻找名称为Dockerfile的文件。
- 命令末尾的`.`设置build的上下文,也就是后台进程在构建过程中能访问的目录。
现在,你可以运行你刚刚构建的镜像。你可以使用`container run`命令和刚才构建镜像时得到的构建进程返回的镜像ID一起使用。我执行返回的ID是`3199372aa3fc`,表示镜像成功构建。
```shell
docker container run --rm --detach --name custom-nginx-packaged --publish 8080:80 3199372aa3fc
# ec09d4e1f70c903c3b954c8d7958421cdd1ae3d079b57f929e44131fbf8069a0
docker container ls
# CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
# ec09d4e1f70c 3199372aa3fc "nginx -g 'daemon of…" 23 seconds ago Up 22 seconds 0.0.0.0:8080->80/tcp custom-nginx-packaged
```
> 冯兄话吉:上面命令中最后的镜像ID要改为你刚刚构建的镜像ID。
你可以访问`http://127.0.0.1:8000`验证容器是否启动成功。

<h3 id="6.2">6.2 怎样给镜像打标签?</h3>
和容器一样,你可以不使用随机生成的ID而给镜像设置自定义的标识。对于一个镜像来说,这叫做打标签而不是重命名。`--tag`或者`-t`参数可以用来打标签。
通用的语法如下:
```shell
--tag <image repository>:<image tag>
```
repository是镜像的名称,image tag表示一个特定的构建或者版本。
拿[官方镜像mysql](https://hub.docker.com/_/mysql)为例,如果你想让运行特定版本,例如5.7的mysql容器,你可以执行`docker container run mysql:5.7`,这里`mysql`就是镜像名称,`5.7`是对应的标签。
如果你想定义custom-nginx:packaged这样自定义的标签,你可以在执行构建命令的时候这样:
```shell
docker image build --tag custom-nginx:packaged .
Sending build context to Docker daemon 1.052MB
Step 1/4 : FROM ubuntu:latest
---> 597ce1600cf4
Step 2/4 : EXPOSE 80
---> Using cache
---> 5c8cabcce264
Step 3/4 : RUN apt-get update && apt-get install nginx -y && apt-get clean && rm -rf /var/lib/apt/lists/*
---> Using cache
---> 46f355762489
Step 4/4 : CMD ["nginx", "-g", "daemon off;"]
---> Using cache
---> e1b5f20aceb8
Successfully built e1b5f20aceb8
Successfully tagged custom-nginx:packaged
```
现在你可以使用custom-nginx标识代替随机的串来引用你的镜像。
如果你在构建的时候忘记给镜像打标签,可以使用`image tag`命令重打标签:
```shell
docker image tag <image id> <image repository>:<image tag>
```
或者使用
```shell
docker image tag <image repository>:<image tag> <new image repository>:<new image tag>
```
<h3 id="6.3">6.3 怎样展示和删除镜像?</h3>
和`container ls`命令一样,你可以使用`image ls`命令展示出你本地的所有镜像:
```shell
docker image ls
# REPOSITORY TAG IMAGE ID CREATED SIZE
# <none> <none> 3199372aa3fc 7 seconds ago 132MB
# custom-nginx packaged f8837621b99d 4 minutes ago 132MB
```
这里展示的镜像可以使用`image rm`命令删除,基本的语法如下:
```shell
docker image rm <image identifier>
```
这里镜像的标识可以镜像ID,也可以是镜像名称,如果是名称的话必须带上标签。例如要删除custom-nginx:package镜像,你可以执行如下命令:
```shell
docker image rm custom-nginx:packaged
Untagged: custom-nginx:packaged
Deleted: sha256:e1b5f20aceb8a56a683f23fc57d46d14d1e473a5c45ac57e05f6c55aa6282229
Deleted: sha256:46f355762489b70eb78ee04c46cdc20797343388320c90d2a2a61a381d740f27
Deleted: sha256:6be04f9858cd868a92ca44b1a51b42843b726c6093b8a4d88d9ae90631135841
Deleted: sha256:5c8cabcce264e95c534f7e906c62631b4f95d0c663fde83b67e0d838195629ae
```
你也可以使用`image prune`命令来清理所有未打标签的未使用的镜像。
```shell
docker image prune --force
# Deleted Images:
# deleted: sha256:ba9558bdf2beda81b9acc652ce4931a85f0fc7f69dbc91b4efc4561ef7378aff
# deleted: sha256:ad9cc3ff27f0d192f8fa5fadebf813537e02e6ad472f6536847c4de183c02c81
# deleted: sha256:f1e9b82068d43c1bb04ff3e4f0085b9f8903a12b27196df7f1145aa9296c85e7
# deleted: sha256:ec16024aa036172544908ec4e5f842627d04ef99ee9b8d9aaa26b9c2a4b52baa
# Total reclaimed space: 59.19MB
```
`--force`或者`-f`参数可以让你跳过是否确认的问题。你也可以使用`--all`或者`-a`命令删除本地所有缓存的镜像。
<h3 id="6.4">6.4 怎样理解多层镜像?</h3>
从这本书的一开始,我就说容器是一个多层的文件。在这一部分中,我将证明镜像的不同层和它们在镜像的构建中起到的重要作用。
我们将使用上一章节中的custom-nginx:packaged镜像来进行说明。
你可以使用`image history`命令来展示一个镜像的不同层次,custom-nginx镜像的不同层可以使用如下命令展示:
```shell
docker image history custom-nginx:packaged
# IMAGE CREATED CREATED BY SIZE COMMENT
# 7f16387f7307 5 minutes ago /bin/sh -c #(nop) CMD ["nginx" "-g" "daemon… 0B
# 587c805fe8df 5 minutes ago /bin/sh -c apt-get update && apt-get ins… 60MB
# 6fe4e51e35c1 6 minutes ago /bin/sh -c #(nop) EXPOSE 80 0B
# d70eaf7277ea 17 hours ago /bin/sh -c #(nop) CMD ["/bin/bash"] 0B
# <missing> 17 hours ago /bin/sh -c mkdir -p /run/systemd && echo 'do… 7B
# <missing> 17 hours ago /bin/sh -c [ -z "$(apt-get indextargets)" ] 0B
# <missing> 17 hours ago /bin/sh -c set -xe && echo '#!/bin/sh' > /… 811B
# <missing> 17 hours ago /bin/sh -c #(nop) ADD file:435d9776fdd3a1834… 72.9MB
```
这个镜像一共有8个层,最上面的是最新的层,越往下是越基础的层。最上面的层也就是你用来运行容器的层。
我们来进一步看看从镜像`d70eaf7277ea`到`7f16387f7307`,最后四个IMAG是`<missing>`的层我们忽略不看。
- `d70eaf7277ea`是由`/bin/sh -c #(nop) CMD ["/bin/bash"]`创建的,表示Ubuntu系统默认的shell加载成功。
- `6fe4e51e35c1`是由`/bin/sh -c #(nop) EXPOSE 80`创建的,代表Dockerfile中的第二行语句。
- `587c805fe8df`是由`/bin/sh -c apt-get update && apt-get install nginx -y && apt-get clean && rm -rf /var/lib/apt/lists/*`创建的,代表Dockerfile中的第三行语句。你也可以在镜像创建的执行中该镜像安装所有的包后有60M的大小。
- 最后最上层的镜像`7f16387f7307`是由`/bin/sh -c #(nop) CMD ["nginx", "-g", "daemon off;"]`创建,设置该镜像默认执行的命令。
我们可以看到,镜像实际上是由很多只读层组成的,每一层记录着由特定的指令所触发的改变。当你运行一个镜像为容器时,实际上是基于最上层创建了一个可写入层。
这种分层模型的实现是由一个叫做联合文件系统(Union File System)的技术实现的,这里的联合指的是集合理论中的联合,根据[维基百科](https://en.wikipedia.org/wiki/UnionFS):
> 它允许不同文件系统的文件或者目录,也称之为分支,覆盖重叠在一起形成统一的单个文件系统。相同目录的文件合并后会都出现新的虚拟文件系统合并分支的同一个目录中。
利用这个技术,Docker能够避免数据重复并且能够利用前一个创建的层作为cache构建下一个层。这样就会形成小巧的、有效的镜像,你可以在任何地方使用。
<h3 id="6.5">6.5 怎样从源代码构建NGINX?</h3>
在上一部分中,我们学习了`FROM,EXPOSE,RUN,CMD`等命令,接下来我们学习更多的命令。
这一部分中我们还是创建一个自定义的NGINX镜像,但是不是用`apt-get`包管理的方式进行安装,而是从源代码构建一个NGINX。
为了从源代码构建NGINX,你首先需要拿到NGINX的源代码。如果你克隆了我的项目,在custom-nginx目录中你就会找到nginx-1.19.2.tar.gz包,我们将使用这个nginx源代码包进行构建NGINX。
在写代码之前,我们首先理一下构建的过程。这次镜像的构建步骤有这些:
- 获取一个正确的基础镜像进行构建。例如[ubuntu](https://hub.docker.com/_/ubuntu)。
- 在基础镜像中安装必要的依赖。
- 将`nginx-1.19.2.tar.gz`包复制到基础镜像中。
- 解压源代码压缩包并删除压缩包。
- 配置构建参数,使用`make`命令编译并安装程序。
- 删除解压后的源代码。
- 运行可执行`nginx`。
这些步骤清楚之后,我们打开之前到Dockerfile,更新为:
```shell
FROM ubuntu:latest
RUN apt-get update && \
apt-get install build-essential\
libpcre3 \
libpcre3-dev \
zlib1g \
zlib1g-dev \
libssl1.1 \
libssl-dev \
-y && \
apt-get clean && rm -rf /var/lib/apt/lists/*
COPY nginx-1.19.2.tar.gz .
RUN tar -xvf nginx-1.19.2.tar.gz && rm nginx-1.19.2.tar.gz
RUN cd nginx-1.19.2 && \
./configure \
--sbin-path=/usr/bin/nginx \
--conf-path=/etc/nginx/nginx.conf \
--error-log-path=/var/log/nginx/error.log \
--http-log-path=/var/log/nginx/access.log \
--with-pcre \
--pid-path=/var/run/nginx.pid \
--with-http_ssl_module && \
make && make install
RUN rm -rf /nginx-1.19.2
CMD ["nginx", "-g", "daemon off;"]
```
你可以看到,Dockerfile中的命令就是我们上面写的几个步骤。
- `FROM`命令把Ubuntu作为构建任何应用的合适基础镜像。
- `RUN`命令安装源码构建NGINX依赖的基础包。
- `COPY`是一个新的命令。这个命令表示将nginx-1.19.2.tar.gz压缩包复制到镜像中。基本的语法是`COPY <source> <destination>`,这里的source是本地文件系统,destination是镜像。`.`表示复制的目的地,也就是镜像中的工作目录,如果没有特殊制定,默认该目录是根目录`/`。
- 第二个`run`命令从压缩包解压文件并且删除压缩包。
- 压缩包中是一个目录nginx-1.19.2包含着nginx源代码。因此下一步你需要`cd`到这个目录再执行构建的程序。你可以阅读[怎么在Linux系统基于源代码上安装并卸载软件](https://itsfoss.com/install-software-from-source-code/)这篇文章了解关于这个主题的更多内容。
- 一旦你构建并且安装成功,你可以使用`rm`命令删除nginx-1.19.2这个目录。
- 最后一步你像之前以一样用单进程的方式启动NGINX。
现在你可以使用下面的命令构建镜像:
```shell
docker image build --tag custom-nginx:built .
# Step 1/7 : FROM ubuntu:latest
# ---> d70eaf7277ea
# Step 2/7 : RUN apt-get update && apt-get install build-essential libpcre3 libpcre3-dev zlib1g zlib1g-dev libssl-dev -y && apt-get clean && rm -rf /var/lib/apt/lists/*
# ---> Running in 2d0aa912ea47
### LONG INSTALLATION STUFF GOES HERE ###
# Removing intermediate container 2d0aa912ea47
# ---> cbe1ced3da11
# Step 3/7 : COPY nginx-1.19.2.tar.gz .
# ---> 7202902edf3f
# Step 4/7 : RUN tar -xvf nginx-1.19.2.tar.gz && rm nginx-1.19.2.tar.gz
---> Running in 4a4a95643020
### LONG EXTRACTION STUFF GOES HERE ###
# Removing intermediate container 4a4a95643020
# ---> f9dec072d6d6
# Step 5/7 : RUN cd nginx-1.19.2 && ./configure --sbin-path=/usr/bin/nginx --conf-path=/etc/nginx/nginx.conf --error-log-path=/var/log/nginx/error.log --http-log-path=/var/log/nginx/access.log --with-pcre --pid-path=/var/run/nginx.pid --with-http_ssl_module && make && make install
# ---> Running in b07ba12f921e
### LONG CONFIGURATION AND BUILD STUFF GOES HERE ###
# Removing intermediate container b07ba12f921e
# ---> 5a877edafd8b
# Step 6/7 : RUN rm -rf /nginx-1.19.2
# ---> Running in 947e1d9ba828
# Removing intermediate container 947e1d9ba828
# ---> a7702dc7abb7
# Step 7/7 : CMD ["nginx", "-g", "daemon off;"]
# ---> Running in 3110c7fdbd57
# Removing intermediate container 3110c7fdbd57
# ---> eae55f7369d3
# Successfully built eae55f7369d3
# Successfully tagged custom-nginx:built
```
代码没有问题,但是我们有一些地方可以改进。
- 不要将文件名称写死为nginx-1.19.2.tar.gz,你可以用ARG命令创建一个参数,这样就可以通过改变参数来改变文件的名称或者版本。
- 不要手动下载源文件,你可以让后台进程下载文件。`ADD`命令能够做到从网络上加载资源到镜像中。
打开之前到Dockerfile并更新内容:
```shell
FROM ubuntu:latest
RUN apt-get update && \
apt-get install build-essential\
libpcre3 \
libpcre3-dev \
zlib1g \
zlib1g-dev \
libssl1.1 \
libssl-dev \
-y && \
apt-get clean && rm -rf /var/lib/apt/lists/*
ARG FILENAME="nginx-1.19.2"
ARG EXTENSION="tar.gz"
ADD https://nginx.org/download/${FILENAME}.${EXTENSION} .
RUN tar -xvf ${FILENAME}.${EXTENSION} && rm ${FILENAME}.${EXTENSION}
RUN cd ${FILENAME} && \
./configure \
--sbin-path=/usr/bin/nginx \
--conf-path=/etc/nginx/nginx.conf \
--error-log-path=/var/log/nginx/error.log \
--http-log-path=/var/log/nginx/access.log \
--with-pcre \
--pid-path=/var/run/nginx.pid \
--with-http_ssl_module && \
make && make install
RUN rm -rf /${FILENAME}}
CMD ["nginx", "-g", "daemon off;"]
```
除了13、14行使用的`ARG`命令和16行使用的`ADD`命令外,新的的代码和之前的几乎一样。更新的内容如下:
- `ARG`命令让可以像其他语言一样声明一个变量,其他地方可以像使用`${argumentname}`这样使用。这里我把文件名nginx-1.19.2和文件扩展名tar.gz定义为两个变量,这样如果改变了nginx的版本或者改变了压缩方式就只有一个地方改变。代码中我给变量设置了默认值,变量的值可以通过`image build`命令的参数传递,你可以在[官方文档](https://docs.docker.com/engine/reference/builder/#arg)中了解更多。
- `ADD`命令中,我使用变量动态构建了一个URL。`https://nginx.org/download/${FILENAME}.${EXTENSION}`构建镜像的时候会替换为`https://nginx.org/download/nginx-1.19.2.tar.gz`这样。使用`ARG`命令只改变一个地方就可以改变文件的版本或者后缀名。
- `ADD`命令默认并不会解压网络中获取的资源,所以18行中使用了`tar`命令。
其余的代码几乎没有改变,现在你应该懂得了参数的使用。你可以使用更新后的代码重新构建镜像:
```shell
docker image build --tag custom-nginx:built .
# Step 1/9 : FROM ubuntu:latest
# ---> d70eaf7277ea
# Step 2/9 : RUN apt-get update && apt-get install build-essential libpcre3 libpcre3-dev zlib1g zlib1g-dev libssl-dev -y && apt-get clean && rm -rf /var/lib/apt/lists/*
# ---> cbe1ced3da11
### LONG INSTALLATION STUFF GOES HERE ###
# Step 3/9 : ARG FILENAME="nginx-1.19.2"
# ---> Running in 33b62a0e9ffb
# Removing intermediate container 33b62a0e9ffb
# ---> fafc0aceb9c8
# Step 4/9 : ARG EXTENSION="tar.gz"
# ---> Running in 5c32eeb1bb11
# Removing intermediate container 5c32eeb1bb11
# ---> 36efdf6efacc
# Step 5/9 : ADD https://nginx.org/download/${FILENAME}.${EXTENSION} .
# Downloading [==================================================>] 1.049MB/1.049MB
# ---> dba252f8d609
# Step 6/9 : RUN tar -xvf ${FILENAME}.${EXTENSION} && rm ${FILENAME}.${EXTENSION}
# ---> Running in 2f5b091b2125
### LONG EXTRACTION STUFF GOES HERE ###
# Removing intermediate container 2f5b091b2125
# ---> 2c9a325d74f1
# Step 7/9 : RUN cd ${FILENAME} && ./configure --sbin-path=/usr/bin/nginx --conf-path=/etc/nginx/nginx.conf --error-log-path=/var/log/nginx/error.log --http-log-path=/var/log/nginx/access.log --with-pcre --pid-path=/var/run/nginx.pid --with-http_ssl_module && make && make install
# ---> Running in 11cc82dd5186
### LONG CONFIGURATION AND BUILD STUFF GOES HERE ###
# Removing intermediate container 11cc82dd5186
# ---> 6c122e485ec8
# Step 8/9 : RUN rm -rf /${FILENAME}}
# ---> Running in 04102366960b
# Removing intermediate container 04102366960b
# ---> 6bfa35420a73
# Step 9/9 : CMD ["nginx", "-g", "daemon off;"]
# ---> Running in 63ee44b571bb
# Removing intermediate container 63ee44b571bb
# ---> 4ce79556db1b
# Successfully built 4ce79556db1b
# Successfully tagged custom-nginx:built
```
现在,你可以使用custom-nginx:build镜像来运行一个容器。
```shell
docker container run --rm --detach --name custom-nginx-built --publish 8080:80 custom-nginx:built
# 90ccdbc0b598dddc4199451b2f30a942249d85a8ed21da3c8d14612f17eed0aa
docker container ls
# CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
# 90ccdbc0b598 custom-nginx:built "nginx -g 'daemon of…" 2 minutes ago Up 2 minutes 0.0.0.0:8080->80/tcp custom-nginx-built
```
新的容器运行起来了,通过`http://127.0.0.1:8080`应该能够访问这个容器。

这里NGINX默认返回了一个页面,你可以访问[官方文档](https://docs.docker.com/engine/reference/builder/)来学习更多的指令。
<h3 id="6.6">6.6 怎样优化一个Docker镜像?</h3>
我们上一部分中构建的镜像是能够运行的,但是不是最优的。我们可以通过`image ls`命令来看一看镜像的大小:
```shell
docker image ls
# REPOSITORY TAG IMAGE ID CREATED SIZE
# custom-nginx built 1f3aaf40bb54 16 minutes ago 343MB
```
对于一个只包含NGINX的镜像太大了。如果你拉去官方的NGINX镜像查看大小,你会发现要小的多:
```shell
docker image pull nginx:stable
# stable: Pulling from library/nginx
# a076a628af6f: Pull complete
# 45d7b5d3927d: Pull complete
# 5e326fece82e: Pull complete
# 30c386181b68: Pull complete
# b15158e9ebbe: Pull complete
# Digest: sha256:ebd0fd56eb30543a9195280eb81af2a9a8e6143496accd6a217c14b06acd1419
# Status: Downloaded newer image for nginx:stable
# docker.io/library/nginx:stable
docker image ls
# REPOSITORY TAG IMAGE ID CREATED SIZE
# custom-nginx built 1f3aaf40bb54 25 minutes ago 343MB
# nginx stable b9e1dc12387a 11 days ago 133MB
```
为了找到根本原因,我们首先看看Dockerfile:
```shell
FROM ubuntu:latest
RUN apt-get update && \
apt-get install build-essential\
libpcre3 \
libpcre3-dev \
zlib1g \
zlib1g-dev \
libssl1.1 \
libssl-dev \
-y && \
apt-get clean && rm -rf /var/lib/apt/lists/*
ARG FILENAME="nginx-1.19.2"
ARG EXTENSION="tar.gz"
ADD https://nginx.org/download/${FILENAME}.${EXTENSION} .
RUN tar -xvf ${FILENAME}.${EXTENSION} && rm ${FILENAME}.${EXTENSION}
RUN cd ${FILENAME} && \
./configure \
--sbin-path=/usr/bin/nginx \
--conf-path=/etc/nginx/nginx.conf \
--error-log-path=/var/log/nginx/error.log \
--http-log-path=/var/log/nginx/access.log \
--with-pcre \
--pid-path=/var/run/nginx.pid \
--with-http_ssl_module && \
make && make install
RUN rm -rf /${FILENAME}}
CMD ["nginx", "-g", "daemon off;"]
```
第三行中我们看到`RUN`命令安装了很多东西,尽管这些东西对于构建NGINX是必要的,但是对于运行NGINX就不全是的了。
在我们安装的6个包中,仅仅有两个是运行NGINX必须的。它们是`libpcre3`和`zlib1g`。因此我们的想法是构建完成后卸载运行时不必要的包。
你可以更新Dockerfile为:
```shell
FROM ubuntu:latest
EXPOSE 80
ARG FILENAME="nginx-1.19.2"
ARG EXTENSION="tar.gz"
ADD https://nginx.org/download/${FILENAME}.${EXTENSION} .
RUN apt-get update && \
apt-get install build-essential \
libpcre3 \
libpcre3-dev \
zlib1g \
zlib1g-dev \
libssl1.1 \
libssl-dev \
-y && \
tar -xvf ${FILENAME}.${EXTENSION} && rm ${FILENAME}.${EXTENSION} && \
cd ${FILENAME} && \
./configure \
--sbin-path=/usr/bin/nginx \
--conf-path=/etc/nginx/nginx.conf \
--error-log-path=/var/log/nginx/error.log \
--http-log-path=/var/log/nginx/access.log \
--with-pcre \
--pid-path=/var/run/nginx.pid \
--with-http_ssl_module && \
make && make install && \
cd / && rm -rfv /${FILENAME} && \
apt-get remove build-essential \
libpcre3-dev \
zlib1g-dev \
libssl-dev \
-y && \
apt-get autoremove -y && \
apt-get clean && rm -rf /var/lib/apt/lists/*
CMD ["nginx", "-g", "daemon off;"]
```
你可以看到,第10一整行做了所有必要的工作。实际的流程是这样的:
- 从第10到17行,所有必要的依赖包都安装了。
- 第18行,下载源代码包并解压后删除。
- 从第19行到28行,NGINX被配置、构建并安装在系统中。
- 第29行,从下载的压缩包中解压出来的文件被删除。
- 从第30行到36行,所有不必要的依赖包被卸载并清理的缓存。`libpcre3`和`zlib1g`包作为NGINX运行时依赖被保留。
你可能会问为什么在这一个`RUN`命令中要做这么多的操作,而不是像之前那样分为多个`RUN`命令,因为分开是错误的。
如果你安装包和删除包在分开的`RUN`命令中,它们将存在于镜像的不同层中。尽管最终的镜像也不会有删除的包,但是包含安装的镜像层也会反应到最终镜像的大小上。因此,要确保这些改变发生在同一个镜像层中。
我们重新构建优化后的Dockerfile。
```shell
docker image build --tag custom-nginx:built .
# Sending build context to Docker daemon 1.057MB
# Step 1/7 : FROM ubuntu:latest
# ---> f63181f19b2f
# Step 2/7 : EXPOSE 80
# ---> Running in 006f39b75964
# Removing intermediate container 006f39b75964
# ---> 6943f7ef9376
# Step 3/7 : ARG FILENAME="nginx-1.19.2"
# ---> Running in ffaf89078594
# Removing intermediate container ffaf89078594
# ---> 91b5cdb6dabe
# Step 4/7 : ARG EXTENSION="tar.gz"
# ---> Running in d0f5188444b6
# Removing intermediate container d0f5188444b6
# ---> 9626f941ccb2
# Step 5/7 : ADD https://nginx.org/download/${FILENAME}.${EXTENSION} .
# Downloading [==================================================>] 1.049MB/1.049MB
# ---> a8e8dcca1be8
# Step 6/7 : RUN apt-get update && apt-get install build-essential libpcre3 libpcre3-dev zlib1g zlib1g-dev libssl-dev -y && tar -xvf ${FILENAME}.${EXTENSION} && rm ${FILENAME}.${EXTENSION} && cd ${FILENAME} && ./configure --sbin-path=/usr/bin/nginx --conf-path=/etc/nginx/nginx.conf --error-log-path=/var/log/nginx/error.log --http-log-path=/var/log/nginx/access.log --with-pcre --pid-path=/var/run/nginx.pid --with-http_ssl_module && make && make install && cd / && rm -rfv /${FILENAME} && apt-get remove build-essential libpcre3-dev zlib1g-dev libssl-dev -y && apt-get autoremove -y && apt-get clean && rm -rf /var/lib/apt/lists/*
# ---> Running in e5675cad1260
### LONG INSTALLATION AND BUILD STUFF GOES HERE ###
# Removing intermediate container e5675cad1260
# ---> dc7e4161f975
# Step 7/7 : CMD ["nginx", "-g", "daemon off;"]
# ---> Running in b579e4600247
# Removing intermediate container b579e4600247
# ---> 512aa6a95a93
# Successfully built 512aa6a95a93
# Successfully tagged custom-nginx:built
docker image ls
# REPOSITORY TAG IMAGE ID CREATED SIZE
# custom-nginx built 512aa6a95a93 About a minute ago 81.6MB
# nginx stable b9e1dc12387a 11 days ago 133MB
```
你可以看到镜像的大小从343MB下降到了81.6MB。官方的镜像大小为133MB。这已经是很大的优化了,我们在下一部分中会更进一步。
<h3 id="6.7">6.7 拥抱Alpine Linxu</h3>
如果你已经了解容器一段时间了,你应该遇到过叫做[Alpine Linux](https://alpinelinux.org/)的东西,它是一个类似于[Ubuntu](https://ubuntu.com/)、[Debian](https://ubuntu.com/)或者[Fedora](https://getfedora.org/)的[Linux发行版](https://en.wikipedia.org/wiki/Linux)。
Alpine的优点是基于`musl libc`和`busybox`并且非常轻量级。最新版本的[Ubuntu镜像](https://hub.docker.com/_/ubuntu)大小是28MB,而[alpine](https://hub.docker.com/_/ubuntu)只有2.8MB。
除了轻量级之外,Alpine也具有安全性并且相比较其他Linux发行版非常适合作为容器的基础镜像。
和其他商业发行版相比较Alpine使用上没有那个友好,但是(对于构建镜像来说)它的优势也非常明显。在这个章节中,我们学习使用Alpine基础镜像重新构建custom-nginx镜像。
更新Dockerfile如下:
```shell
FROM alpine:latest
EXPOSE 80
ARG FILENAME="nginx-1.19.2"
ARG EXTENSION="tar.gz"
ADD https://nginx.org/download/${FILENAME}.${EXTENSION} .
RUN apk add --no-cache pcre zlib && \
apk add --no-cache \
--virtual .build-deps \
build-base \
pcre-dev \
zlib-dev \
openssl-dev && \
tar -xvf ${FILENAME}.${EXTENSION} && rm ${FILENAME}.${EXTENSION} && \
cd ${FILENAME} && \
./configure \
--sbin-path=/usr/bin/nginx \
--conf-path=/etc/nginx/nginx.conf \
--error-log-path=/var/log/nginx/error.log \
--http-log-path=/var/log/nginx/access.log \
--with-pcre \
--pid-path=/var/run/nginx.pid \
--with-http_ssl_module && \
make && make install && \
cd / && rm -rfv /${FILENAME} && \
apk del .build-deps
CMD ["nginx", "-g", "daemon off;"]
```
代码和之前的没有什么差异,有差异的地方列出来如下:
- 使用`apk add`而不是`apt-get install`命令安装依赖包。`--no-cache`参数表示下载的依赖包不会被缓存。同样使用了`apk del`而不是`apt-get remove`来卸载依赖包。
- `apk add`命令的`--virtual`参数表示将多个包捆扎成单个包便于管理。那些仅仅是构建时候依赖的包被打上`.build-deps`的标签,后续可以通过`apk del .build-deps`命令删除。你可以在官方文档中了解更多关于[virtuals](https://docs.alpinelinux.org/user-handbook/0.1a/Working/apk.html#_virtuals)参数的内容。
- 这里包的名称可能有些不同。一般每一个Linux发行版都有自己的包仓库开放给大家寻找包。如果你知道你任务要依赖的包,你可以直接到目的发行版的仓库中还搜索它。你可以在[这里](https://pkgs.alpinelinux.org/packages)寻找Alpine Linux的包。
现在使用新的Dockerfile构建镜像,看看镜像的大小:
```shell
docker image build --tag custom-nginx:built .
# Sending build context to Docker daemon 1.055MB
# Step 1/7 : FROM alpine:latest
# ---> 7731472c3f2a
# Step 2/7 : EXPOSE 80
# ---> Running in 8336cfaaa48d
# Removing intermediate container 8336cfaaa48d
# ---> d448a9049d01
# Step 3/7 : ARG FILENAME="nginx-1.19.2"
# ---> Running in bb8b2eae9d74
# Removing intermediate container bb8b2eae9d74
# ---> 87ca74f32fbe
# Step 4/7 : ARG EXTENSION="tar.gz"
# ---> Running in aa09627fe48c
# Removing intermediate container aa09627fe48c
# ---> 70cb557adb10
# Step 5/7 : ADD https://nginx.org/download/${FILENAME}.${EXTENSION} .
# Downloading [==================================================>] 1.049MB/1.049MB
# ---> b9790ce0c4d6
# Step 6/7 : RUN apk add --no-cache pcre zlib && apk add --no-cache --virtual .build-deps build-base pcre-dev zlib-dev openssl-dev && tar -xvf ${FILENAME}.${EXTENSION} && rm ${FILENAME}.${EXTENSION} && cd ${FILENAME} && ./configure --sbin-path=/usr/bin/nginx --conf-path=/etc/nginx/nginx.conf --error-log-path=/var/log/nginx/error.log --http-log-path=/var/log/nginx/access.log --with-pcre --pid-path=/var/run/nginx.pid --with-http_ssl_module && make && make install && cd / && rm -rfv /${FILENAME} && apk del .build-deps
# ---> Running in 0b301f64ffc1
### LONG INSTALLATION AND BUILD STUFF GOES HERE ###
# Removing intermediate container 0b301f64ffc1
# ---> dc7e4161f975
# Step 7/7 : CMD ["nginx", "-g", "daemon off;"]
# ---> Running in b579e4600247
# Removing intermediate container b579e4600247
# ---> 3e186a3c6830
# Successfully built 3e186a3c6830
# Successfully tagged custom-nginx:built
docker image ls
# REPOSITORY TAG IMAGE ID CREATED SIZE
# custom-nginx built 3e186a3c6830 8 seconds ago 12.8MB
```
之前Ubuntu版本的大小是81.6MB,Alpine版本的大小下降到12.8MB,小了很多。Alpine和Ubuntu不同的地方出来`apk`包管理不一样之外还有一些其他的内容,但是并不重要。如果你使用遇到困难可以在网上寻找答案。
<h3 id="6.8">6.8 怎样创建一个可执行Docker镜像?</h3>
在之前的章节中你使用过了[fhsinchy/rmbyext镜像](https://hub.docker.com/r/fhsinchy/rmbyext),这一部分中你会学习怎样制作一个可执行的镜像。
首先打开之前在本书中克隆的仓库,rmbyext应用的代码就在同名的目录中。
在开始写Dockerfile之前,思考一下最终的输出应该是什么样的,在我看来应该是这样的:
- 镜像应该要提前安装好[Python](https://hub.docker.com/_/python)。
- 应该包含rmbyext脚本。
- 应该设置一个脚本运行的工作目录。
- rmbyext脚本应该设置为镜像的入口,这样镜像可以把文件扩展名作为参数传递。
为了制作上面描述的镜像,可以按照下面的步骤操作:
- 获取一个支持pytho运行的基础镜像,例如pytohn。
- 设置一个容易访问的工作目录。
- 安装Git以便从Github仓库上安装脚本。
- 使用Git和pip安装脚本。
- 删除运行时不必要依赖的的构建时依赖包。
- 设置rmbyext脚本作为镜像的入口。
现在,在rmbyext目录中创建一个Dockerfile文件,写入如下代码:
```shell
FROM python:3-alpine
WORKDIR /zone
RUN apk add --no-cache git && \
pip install git+https://github.com/fhsinchy/rmbyext.git#egg=rmbyext && \
apk del git
ENTRYPOINT [ "rmbyext" ]
```
解释如下:
- `FROM`命令设置[python](https://hub.docker.com/_/python)作为基础镜像,提供python脚本运行的环境。`3-alpine`标签表示你使用Alpine的Python3版本。
- `WORKDIR`命令设置`/zone`作为工作目录,这里工作目录的选择完全是随机的,我使用的是`/zone`,你可以自己设定目录。
- rmbyext是从Github中安装的,git是安装时的依赖。第5行的`RUN`命令安装了git并且用git和pip装了rmbyext脚本,随后git被删除。
- 最后在第9行设置rmbyext脚本为镜像入口。
在整个文件中,第9行将普通的镜像转化为了可执行镜像。现在你可以通过下面的命令构建镜像:
```shell
docker image build --tag rmbyext .
# Sending build context to Docker daemon 2.048kB
# Step 1/4 : FROM python:3-alpine
# 3-alpine: Pulling from library/python
# 801bfaa63ef2: Already exists
# 8723b2b92bec: Already exists
# 4e07029ccd64: Already exists
# 594990504179: Already exists
# 140d7fec7322: Already exists
# Digest: sha256:7492c1f615e3651629bd6c61777e9660caa3819cf3561a47d1d526dfeee02cf6
# Status: Downloaded newer image for python:3-alpine
# ---> d4d4f50f871a
# Step 2/4 : WORKDIR /zone
# ---> Running in 454374612a91
# Removing intermediate container 454374612a91
# ---> 7f7e49bc98d2
# Step 3/4 : RUN apk add --no-cache git && pip install git+https://github.com/fhsinchy/rmbyext.git#egg=rmbyext && apk del git
# ---> Running in 27e2e96dc95a
### LONG INSTALLATION STUFF GOES HERE ###
# Removing intermediate container 27e2e96dc95a
# ---> 3c7389432e36
# Step 4/4 : ENTRYPOINT [ "rmbyext" ]
# ---> Running in f239bbea1ca6
# Removing intermediate container f239bbea1ca6
# ---> 1746b0cedbc7
# Successfully built 1746b0cedbc7
# Successfully tagged rmbyext:latest
docker image ls
# REPOSITORY TAG IMAGE ID CREATED SIZE
# rmbyext latest 1746b0cedbc7 4 minutes ago 50.9MB
```
这里我没有提供给镜像提供任何tag,所以默认的tag是latest。你可以像之前章节那样运行这个镜像,记得引用你设置的镜像名字而不是这里的fhsinchy/rmbyext。
<h3 id="6.9">6.9 怎样在线共享你的镜像?</h3>
现在你知道了怎么制作一个镜像,是时候分享给这个世界了。分享镜像很简单,你只需要具有一个在线镜像仓库的账户,这里我们使用[Docker Hub](https://hub.docker.com/)。
导航到注册页并[注册](https://hub.docker.com/signup)一个免费用户。免费用户可以上传不限制的公共仓库和一个私有仓库。
创建用户之后,你需要使用docker CLI登陆,打开终端执行如下命令:
```shell
docker login
# Login with your Docker ID to push and pull images from Docker Hub. If you don't have a Docker ID, head over to https://hub.docker.com to create one.
# Username: fhsinchy
# Password:
# WARNING! Your password will be stored unencrypted in /home/fhsinchy/.docker/config.json.
# Configure a credential helper to remove this warning. See
# https://docs.docker.com/engine/reference/commandline/login/#credentials-store
#
# Login Succeeded
```
弹出框中要求你输入用户名和密码,如果输入正确,你就能够成功登陆你的账户。
为了能够在线分享镜像,镜像必要要打标签,你已经在上面的章节中学习了打tag,回想一下,基本的语法是:
```shell
--tag <image repository>:<image tag>
```
我们以共享custom-nginx镜像为例,在custom-nginx项目目录中打开一个新的命令行终端。
为了上传镜像,你必须遵照`<docker hub username>/<image name>:<image tag>`语法。我的用户名是fhsinchy,因此命令如下:
```shell
docker image build --tag fhsinchy/custom-nginx:latest --file Dockerfile.built .
# Step 1/9 : FROM ubuntu:latest
# ---> d70eaf7277ea
# Step 2/9 : RUN apt-get update && apt-get install build-essential libpcre3 libpcre3-dev zlib1g zlib1g-dev libssl-dev -y && apt-get clean && rm -rf /var/lib/apt/lists/*
# ---> cbe1ced3da11
### LONG INSTALLATION STUFF GOES HERE ###
# Step 3/9 : ARG FILENAME="nginx-1.19.2"
# ---> Running in 33b62a0e9ffb
# Removing intermediate container 33b62a0e9ffb
# ---> fafc0aceb9c8
# Step 4/9 : ARG EXTENSION="tar.gz"
# ---> Running in 5c32eeb1bb11
# Removing intermediate container 5c32eeb1bb11
# ---> 36efdf6efacc
# Step 5/9 : ADD https://nginx.org/download/${FILENAME}.${EXTENSION} .
# Downloading [==================================================>] 1.049MB/1.049MB
# ---> dba252f8d609
# Step 6/9 : RUN tar -xvf ${FILENAME}.${EXTENSION} && rm ${FILENAME}.${EXTENSION}
# ---> Running in 2f5b091b2125
### LONG EXTRACTION STUFF GOES HERE ###
# Removing intermediate container 2f5b091b2125
# ---> 2c9a325d74f1
# Step 7/9 : RUN cd ${FILENAME} && ./configure --sbin-path=/usr/bin/nginx --conf-path=/etc/nginx/nginx.conf --error-log-path=/var/log/nginx/error.log --http-log-path=/var/log/nginx/access.log --with-pcre --pid-path=/var/run/nginx.pid --with-http_ssl_module && make && make install
# ---> Running in 11cc82dd5186
### LONG CONFIGURATION AND BUILD STUFF GOES HERE ###
# Removing intermediate container 11cc82dd5186
# ---> 6c122e485ec8
# Step 8/9 : RUN rm -rf /${FILENAME}}
# ---> Running in 04102366960b
# Removing intermediate container 04102366960b
# ---> 6bfa35420a73
# Step 9/9 : CMD ["nginx", "-g", "daemon off;"]
# ---> Running in 63ee44b571bb
# Removing intermediate container 63ee44b571bb
# ---> 4ce79556db1b
# Successfully built 4ce79556db1b
# Successfully tagged fhsinchy/custom-nginx:latest
```
在命令中,fhsinchy/custom-nginx是镜像仓库,latest是标签,镜像名称可以根据你的喜欢设定并且一旦镜像上传就不能更改。tag你可以随时修改,一般表示应用的版本或者不同的构建。
以`node`镜像为例,`node:lts`镜像表示长期支持的版本,而`node:lts-alpine`版本表示在Alpine Linux上构建的版本,这个版本比其他版本会更小一些。
如果你没有给镜像设置标签,默认的标签是latest,但这并不意味着就是最新的版本,如果你不小心设置一个老的版本为latest,Docker不会校验是否是最新的版本。
镜像创建之后,你就可以通过下面的命令上传它:
```shell
docker image push <image repository>:<image tag>
```
具体到这个例子,你可以使用如下命令:
```shell
docker image push fhsinchy/custom-nginx:latest
# The push refers to repository [docker.io/fhsinchy/custom-nginx]
# 4352b1b1d9f5: Pushed
# a4518dd720bd: Pushed
# 1d756dc4e694: Pushed
# d7a7e2b6321a: Pushed
# f6253634dc78: Mounted from library/ubuntu
# 9069f84dbbe9: Mounted from library/ubuntu
# bacd3af13903: Mounted from library/ubuntu
# latest: digest: sha256:ffe93440256c9edb2ed67bf3bba3c204fec3a46a36ac53358899ce1a9eee497a size: 1788
```
根据镜像的大小,上传的过程可能要花费一点时间。一旦镜像上传成功,你就可以在你的仓库主页中找到它。
> 冯兄话吉:如果要上传镜像到远程仓库,给镜像重新打包时候必须遵照`<docker hub username>/<image name>:<image tag>`语法,也就是镜像名必须以你`https://hub.docker.com/`上注册的用户名最为开头。比如之前你打的`nginx`镜像是`nginx-custom:built`,你需要执行`docker tag custom-nginx:built arefmzhao/custom-nginx:built_Alpine`(这里tag由built改为built_Alpine,tag可以随意修改),然后`docker login`正确登录后就可以使用命令`docker push arefmzhao/custom-nginx:built_Alpine`推送到`arefmzhao`这个用户下面。上传后访问[主页](https://hub.docker.com/u/arefmzhao)如图:

---
<h2 id="7">7. 怎样容器化一个Javascript应用?</h2>
现在你学习了怎样创建一个镜像,接下来做一些更相关的内容。
在接下来的章节你将会编写之前用过的[fhsinchy/hello-dock](https://hub.docker.com/r/fhsinchy/hello-dock)镜像的源代码。在容器化这个简单应用的过程中,你将会了解卷(`volume`)和多步构建(`multi stage builds`)这两个Docker重要的概念。
<h3 id="7.1">7.1 怎么写Dockerfile?</h3>
打开你克隆本书的仓库目录,`hello-dock`应用的代码就在同名的子目录中。
这是一个使用[vitejs/vite](https://github.com/vitejs/vite)的非常简单的JavaScript项目,要了解接下来的内容你不需要懂`JavaScript`或者`vite`,只要对[Node.js](https://nodejs.org/)和[npm](https://nodejs.org/)有简单的了解就足够了。
就像之前章节的其他项目一样,你首先要对应用怎么运行有一个规划,在我看来,规划应该是:
- 获取一个运行JavaScript的基础镜像,例如[node](https://hub.docker.com/_/node)。
- 在镜像中设置默认的工作目录。
- 复制`package.json`文件到镜像中。
- 安装必要的依赖。
- 复制其他的项目文件。
- 通过执行`npm run dev`启动vite development服务。
这样的规划通常来自于应用的开发人员,如果你本身是一个开发人员,你应该已经对应用怎么运行有很好的理解了。
如果将上述的规划放在`Dockerfile.dev`中,内容应该是这样的:
```shell
FROM node:lts-alpine
EXPOSE 3000
USER node
RUN mkdir -p /home/node/app
WORKDIR /home/node/app
COPY ./package.json .
RUN npm install
COPY . .
CMD [ "npm", "run", "dev" ]
```
上述命令的解释如下:
- `FROM`命令表示指定Node.js镜像作为基础镜像,该镜像中你可以运行任何的JavaScript应用。`lts-alpine`标签表示你使用的是Alpine的镜像版本,这是一个支持长久维护的镜像版本。所有的tag和文档都可以在[node](https://hub.docker.com/_/node)的hub页面找到。
- `USER`命令设置该镜像默认的user为`node`。默认情况Docker以root用户运行容器,但是根据[Docker和Node.js的最佳实践](https://github.com/nodejs/docker-node/blob/master/docs/BestPractices.md)所示,这样会带来安全上的问题,所以最好尽可能用非root用户。这样node镜像拥有了一个非root的用户叫做`node`,你可以使用`USER`命令来设置默认的用户。
- `RUN mkdir -p /home/node/app/`命令使用node用户在家目录中创建了一个叫`app`的目录。Linux中一般非root用户的家目录默认是`/home/<username>`。
- `WORKDIR`命令设置默认的工作目录为新创建的`/home/node/app`目录。镜像默认的工作目录是root,你也不想一些不必要的文件散落在root目录是吧?因此你改变了默认的工作目录为更有意义的目录`/home/node/app`或者其他你喜欢的目录。接下来的`COPY`、`ADD`和`CMD`等命令都是在该工作目录下执行的。
- `COPY`指令复制`package.json`文件,该文件中包含了应用必要的依赖信息。`RUN`命令执行`npm install`命令,该命令是node项目中使用package.json来安装依赖包的默认命令。`.`代表工作目录。
- 第二个`COPY`命令表示复制文件系统中当前目录(`.`)剩余的内容到Docker镜像的工作目录(`.`)中。
- 最后`CMD`命令用`exec`的格式设置该镜像默认的运行命令为`npm run dev`。
- `vite` development服务默认运行的端口是`3000,`因此用`EXPOSE`命令加以说明是一个很好的选择。
现在使用该Dockerfile.dev文件来构建一个镜像,你可以执行如下指令:
```shell
docker image build --file Dockerfile.dev --tag hello-dock:dev .
Sending build context to Docker daemon 30.21kB
Step 1/9 : FROM node:lts-alpine
lts-alpine: Pulling from library/node
6a428f9f83b0: Pull complete
117b1bf70a74: Pull complete
a19603468f90: Pull complete
1d2672489abb: Pull complete
Digest: sha256:6e52e0b3bedfb494496488514d18bee7fd503fd4e44289ea012ad02f8f41a312
Status: Downloaded newer image for node:lts-alpine
---> ee0f6dca428d
Step 2/9 : EXPOSE 3000
---> Running in b84f92345310
Removing intermediate container b84f92345310
---> 62bad2323eb1
Step 3/9 : USER node
---> Running in 8b2a2f5c2cf4
Removing intermediate container 8b2a2f5c2cf4
---> ce491fc872e7
Step 4/9 : RUN mkdir -p /home/node/app
---> Running in ef00a4c8e5ba
Removing intermediate container ef00a4c8e5ba
---> 4704a2a978b5
Step 5/9 : WORKDIR /home/node/app
---> Running in 3ce3646c769e
Removing intermediate container 3ce3646c769e
---> ec9d8664d283
Step 6/9 : COPY ./package.json .
---> 44c0db178033
Step 7/9 : RUN npm install
---> Running in 8a475cd9eccf
> [email protected] postinstall /home/node/app/node_modules/esbuild
> node install.js
npm notice created a lockfile as package-lock.json. You should commit this file.
npm WARN optional SKIPPING OPTIONAL DEPENDENCY: fsevents@~2.3.2 (node_modules/chokidar/node_modules/fsevents):
npm WARN notsup SKIPPING OPTIONAL DEPENDENCY: Unsupported platform for [email protected]: wanted {"os":"darwin","arch":"any"} (current: {"os":"linux","arch":"x64"})
npm WARN [email protected] No description
npm WARN [email protected] No repository field.
npm WARN [email protected] No license field.
added 281 packages from 277 contributors and audited 283 packages in 115.576s
31 packages are looking for funding
run `npm fund` for details
found 0 vulnerabilities
Removing intermediate container 8a475cd9eccf
---> 917dbe53bca4
Step 8/9 : COPY . .
---> 1249c2a1115e
Step 9/9 : CMD [ "npm", "run", "dev" ]
---> Running in 034f6aa8f2dc
Removing intermediate container 034f6aa8f2dc
---> 0fcff97a7e2f
Successfully built 0fcff97a7e2f
Successfully tagged hello-dock:dev
```
因为`Dockerfile`文件名不是默认的Dockerfile,因此你需要使用`--file`参数来手动指定文件。你可以使用下面的命令来运行一个容器:
```shell
docker container run \
--rm \
--detach \
--publish 3000:3000 \
--name hello-dock-dev \
hello-dock:dev
# 21b9b1499d195d85e81f0e8bce08f43a64b63d589c5f15cbbd0b9c0cb07ae268
```
现在可以通过`http://127.0.0.1:3000`来访问hello-dock应用了。

恭喜你成功运行了第一个容器化的应用。你的代码没有问题,但是一些地方还有很大提高的空间,我们首先来看第一个问题。
<h3 id="7.2">7.2 怎么在Docker中进行Bind Mounts(绑定挂载)?</h3>
如果你之前有接触过前端的一些框架,你应该了解这些框架的development服务都有热部署的功能。那就是如果你源代码有所改变,服务端就会reload,任何修改都能够自动的立刻完成重新部署显现出来。
但是如果你现在改变你的源代码,启动的服务不会有任何改变。这是因为你的修改发生在本地文件系统上,而你看到的页面的后台服务的代码是在容器内的文件系统上。

为来解决这个问题,你可以使用[bind mount](https://docs.docker.com/storage/bind-mounts/),能很容易的实现将本地文件系统的一个目录挂载到容器上。bind mount不是复制了一份本地文件系统中的内容,而是让容器可以直接引用本地文件系统上的内容。

这样在你本地文件系统中改变的内容就会立马体现在容器中,触发vite development服务的热部署。容器中的任何改变也会反映在本地文件系统中。
在[怎样操作可执行镜像](#7.12)章节中我们学习了可以使用`container run`或者`container start`命令的`--volume|-v`参数来创建bind mount,提醒一下,基本的语法是这样的:
```shell
--volume <local file system directory absolute paty>:<container file system directory absolute path>:<read write access>
```
停掉你之前启动的hello-dock-dev容器,使用下面的命令启动一个新的容器:
```shell
docker container run \
--rm \
--publish 3000:3000 \
--name hello-dock-dev \
--volume $(pwd):/home/node/app \
hello-dock:dev
# sh: 1: vite: not found
# npm ERR! code ELIFECYCLE
# npm ERR! syscall spawn
# npm ERR! file sh
# npm ERR! errno ENOENT
# npm ERR! [email protected] dev: `vite`
# npm ERR! spawn ENOENT
# npm ERR!
# npm ERR! Failed at the [email protected] dev script.
# npm ERR! This is probably not a problem with npm. There is likely additional logging output above.
# npm WARN Local package.json exists, but node_modules missing, did you mean to install?
```
请注意,我省略了`--detach`参数是为了证明一个重要的内容,终端中可以看出,应用没有运行起来。
这是因为尽管`volume`的使用解决了热部署的问题,它带来了一个新的问题。如果你有node.js的经验,你会知道Node项目的依赖都在根目录下一个`node_modules`目录中。
如今,你将整个Node项目的挂载到本地文件系统的目录上,容器内的`node_modules`目录也被替换了,这样应用就不能正常启动了。
<h3 id="7.3">7.3 怎么使用Docker的匿名卷?</h3>
这个问题可以通过Docker匿名卷的方式解决,匿名卷除了不需要指定一个源目录之外和`bind mount`一样,通用的语法是:
```shell
--volume <container file system directory absolute path>:<read write access>
```
因此基于匿名卷最终运行容器hello-dock的命令是:
```shell
docker container run \
--rm \
--detach \
--publish 3000:3000 \
--name hello-dock-dev \
--volume $(pwd):/home/node/app \
--volume /home/node/app/node_modules \
hello-dock:dev
# 53d1cfdb3ef148eb6370e338749836160f75f076d0fbec3c2a9b059a8992de8b
```
在这里,Docker将容器内`node_modules`整个目录和由Docker daemon管理的匿名卷目录绑定。
<h3 id="7.4">7.4 怎么在Docker中执行多阶段构建(Multi-Staged Builds)?</h3>
目前为止,我们已经在开发环境下可以构建JavaScript应用镜像。如果你要在生产环境中构建一个镜像,新的挑战就出来了。
在生产环境中,`npm run build`编译了所有的JavaScript代码为HTML、CSS和JavaScript文件。运行这些文件,你不在需要node或者其他运行时的依赖。你所需要的是一个像nginx的http服务器。
为了创建在生产环境中运行应用的镜像,你可以按照按照以下步骤:
- 使用node作为基础镜像构建应用。
- 在node镜像中安装nginx并且使用它提供http服务。
上面的办法是可行的,但是问题是node镜像很大并且镜像中的很多东西对于http服务来说都不是必须的,这种情况更好的办法是:
- 使用node作为基础镜像构建应用。
- 复制node镜像中产生的文件到一个nginx镜像中。
- 抛弃node所有相关的东西,基于nginx创建最终的镜像。
这样制作的镜像仅仅包含需要的文件,镜像也会很小。
这种方法是多阶段构建,为了执行这样的构建,在你的hello-dock目录中创建一个新的Dockerfile,写入如下内容:
```shell
FROM node:lts-alpine as builder
WORKDIR /app
COPY ./package.json ./
RUN npm install
COPY . .
RUN npm run build
FROM nginx:stable-alpine
EXPOSE 80
COPY --from=builder /app/dist /usr/share/nginx/html
```
这个Dockefile除了新增的一些行外和之前的很类似,命令解释如下:
- 第1行,开始第一阶段的构建,使用`node-alpine`作为基础镜像,`as builder`语法指定了该阶段的一个名称,以便后续能够引用到。
- 第3到9行,这是我们之前看到过多次标准的命令。`RUN npm run build`命令是将整个项目编译并将结果输出到`/app/disk`目录,app目录是指定的工作目录,disk目录是vite默认的文件输出目录。
- 第11行,开启了一个新的bulid阶段,使用`nginx:stable-alpine`作为基础了nginx镜像。
- nginx服务默认监听80端口,因此加上`EXPOSE 80`。
- 最后一行是一个`COPY`命令,`--from=builder`参数表明你想要从builder阶段copy一些东西。那之后是一个标准的copy命令,`/app/dist`是源端、`/usr/share/nginx/html`是目标端。目标端路径使用的是nginx的默认配置路径,该路径下的文件会自动被nginx server读取。
从上面可以看到,生成的镜像以nginx为基础镜像,镜像中仅仅包含运行应用的必要文件。可以通过下面的命令构建镜像:
```shell
docker image build --tag hello-dock:prod .
Sending build context to Docker daemon 30.21kB
Step 1/9 : FROM node:lts-alpine as builder
---> ee0f6dca428d
Step 2/9 : WORKDIR /app
---> Running in 080b01d9e2d8
Removing intermediate container 080b01d9e2d8
---> 15bb688eb4c4
Step 3/9 : COPY ./package.json ./
---> 5fd5b06115ea
Step 4/9 : RUN npm install
---> Running in 18572629426e
> [email protected] postinstall /app/node_modules/esbuild
> node install.js
npm notice created a lockfile as package-lock.json. You should commit this file.
npm WARN optional SKIPPING OPTIONAL DEPENDENCY: fsevents@~2.3.2 (node_modules/chokidar/node_modules/fsevents):
npm WARN notsup SKIPPING OPTIONAL DEPENDENCY: Unsupported platform for [email protected]: wanted {"os":"darwin","arch":"any"} (current: {"os":"linux","arch":"x64"})
npm WARN [email protected] No description
npm WARN [email protected] No repository field.
npm WARN [email protected] No license field.
added 281 packages from 277 contributors and audited 283 packages in 74.227s
31 packages are looking for funding
run `npm fund` for details
found 0 vulnerabilities
Removing intermediate container 18572629426e
---> 878ba2ac11bc
Step 5/9 : COPY . .
---> 58d5a0ee61a6
Step 6/9 : RUN npm run build
---> Running in a2822f75d72a
> [email protected] build /app
> vite build
- Building production bundle...
[write] dist/index.html 0.39kb, brotli: 0.15kb
[write] dist/_assets/docker-handbook-github.3adb4865.webp 12.32kb
[write] dist/_assets/index.8504976b.js 46.40kb, brotli: 16.66kb
- Building production bundle...
[write] dist/_assets/style.0637ccc5.css 0.16kb, brotli: 0.10kb
Build completed in 2.57s.
Removing intermediate container a2822f75d72a
---> fb55c941aa54
Step 7/9 : FROM nginx:stable-alpine
stable-alpine: Pulling from library/nginx
4e9f2cdf4387: Pull complete
6cac039d45af: Pull complete
7bbb5e46b36d: Pull complete
39f6d17c9d38: Pull complete
a5f9fd374d3b: Pull complete
7d84628ff318: Pull complete
Digest: sha256:2012644549052fa07c43b0d19f320c871a25e105d0b23e33645e4f1bcf8fcd97
Status: Downloaded newer image for nginx:stable-alpine
---> 4146b18ae794
Step 8/9 : EXPOSE 80
---> Running in 01b01b69c2a9
Removing intermediate container 01b01b69c2a9
---> f8d96c5e9afa
Step 9/9 : COPY --from=builder /app/dist /usr/share/nginx/html
---> b9d79b0c84b7
Successfully built b9d79b0c84b7
Successfully tagged hello-dock:prod
```
镜像创建后,你可以通过执行下面的命令来运行容器:
```shell
docker container run \
--rm \
--detach \
--name hello-dock-prod \
--publish 8080:80 \
hello-dock:prod
# a2f7cd2244eddf7cb139e223c87fbf35c5d07026ba299f1f6523d00c46e56334
```
可用通过`http://127.0.0.1`来访问启动的服务。

这里你可以看到hello-dock应用。多阶段构建在构建有许多依赖的大项目的时候非常有用,如果能够很好的配置,多阶段构建的镜像非常的小并且优化。
<h3 id="7.5">7.5 怎么忽略掉不必要的文件?</h3>
如果你了解过git,你可能会知道.gitignore文件,该文件中包含的一系列文件和目录将会从git仓库中忽略掉。
同样,Docker也有一个类似概念,`.dockerignore`文件中包含一系列的文件和目录会在镜像构建时候忽略,你可以在hello-dock目录中找到`.dockerignore`。
```shell
.git
*Dockerfile*
*docker-compose*
node_modules
```
这个`.dockerignore`只适用在`build`阶段,`.dockerignore`中的文件和目录在`COPY`命令时会被忽略,但是如果你要进行目录挂载,`.dockerignore`就没有任何作用。我会在有必要的项目中添加`.dockerignore`文件。
---
<h2 id="8">8. Docker中的网络操作</h2>
目前为止本书中你只接触到了单个的容器,但是在实际的工作中,你要处理的大部分项目都超过一个容器。事实上,如果你不了解容器隔离的细微差别,就很难协作好多个容器。
因此本书的这一部分你会熟悉Docker网络并能够协作一个小的多容器项目。
从之前的章节中你会了解到容器时一个隔离的环境。现在假设你有一个基于[Express.js](https://expressjs.com/)的notes-api应用和一个[PostgreSQL](https://www.postgresql.org/)数据库服务分别在两个容器上运行。
这两个容器彼此间时完全隔离的并且彼此意识不到对方的存在。**那么两个容器之间如何能够连接起来,是不是很困难?**
你可能会想到这个问题的两个解决方案,它们是:
- 通过暴露的端口访问数据库服务。
- 通过数据库服务器的IP和默认端口访问数据库服务。
第一个方案需要`postgres`容器暴露一个端口,`notes-api`通过这个暴露的端口例如`5432`进行连接。如果你在`notes-api`容器中使用`127.0.0.1:5432`来连接数据库服务,你会发现`note-api`无法找到数据库服务。
原因是当你在`note-api`容器中使用`127.0.0.1`时,你实际上在访问当前容器的`localhost`,`postgres`服务在`notes-api`容器中并不存在,这样也就连接不上。
第二种方案你可能会想用`container inspect`命令找到`postgres`数据库容器的实际IP地址并且使用IP和端口进行连接。假设`postgres`数据库服务容器的名称是`notes-api-db-server`,你可以通过下面的命令,很方便的获得容器的IP地址:
```shell
docker container inspect --format='{{range .NetworkSettings.Networks}} {{.IPAddress}} {{end}}' notes-api-db-server
# 172.17.0.2
```
现在已知`postgres`默认的端口是`5432`,`notes-api`容器可以方便的通过`172.17.0.2:5432`连接到数据库服务。
这种办法也存在问题,实际上使用容器的IP来连接容器是不被推荐的。并且,假设容器被销毁或者被重新创建,容器的IP是会发生改变的,跟踪这些变化的IP是一件很繁琐的事情。
现在否定了原始问题的所有答案,我们给出正确的答案:**将要互联的容器放在一个用户自定义的桥接网络中。**
<h3 id="8.1">8.1 Docker网络基础</h3>
像`container`和`image`一样,`network`是Docker中的另外一个逻辑对象,同样有`docker network`开头的很多命令来管理网络。
列出系统中的所有网络,执行下面的命令:
```shell
docker network ls
# NETWORK ID NAME DRIVER SCOPE
# c2e59f2b96bd bridge bridge local
# 124dccee067f host host local
# 506e3822bf1f none null local
```
你能够看到系统中有三个网络,现在看下表格中的`DRIVER`列,该列表示网络的类型。
默认,Docker有5种网络drivers,它们是:
- 桥接(`bridge`)-Docker中的默认网络类型,这种类型适合使用在独立运行的容器并且容器间需要相互通信。
- 主机(`host`)-完全移除了网络的隔离。只要在主机网络下的任何容器都连接到了宿主机网络下。
- 无(`none`)-这种类型容器之间的网络连接,我还没有发现该中类型的任何用处。
- `overlay`-这种类型跨主机连接多个Docker daemon,不在本书的讨论范围之内。
- `macvlan`-它允许给容器分配MAC地址,是容器模拟一个物理设备。
也有第三方的插件允许你整合Docker和特殊的网络栈。在上面5中网络类型中,在本书中你只需要了解桥接网络类型。
<h3 id="8.2">8.2 怎样在Docker中自定义一个桥接网络?</h3>
在创建自定义网络之前,最好花一些时间认识一个Docker默认的桥接网络。从列出系统上的所有网络开始:
```shell
docker network ls
# NETWORK ID NAME DRIVER SCOPE
# c2e59f2b96bd bridge bridge local
# 124dccee067f host host local
# 506e3822bf1f none null local
```
可以看到,Docker有一个默认的桥接网络名字叫做`bridge`,你运行的容器都会自动附接在这个桥接网络下:
```shell
docker container run --rm --detach --name hello-dock --publish 8080:80 fhsinchy/hello-dock
# a37f723dad3ae793ce40f97eb6bb236761baa92d72a2c27c24fc7fda0756657d
docker network inspect --format='{{range .Containers}} {{.Name}} {{end}}' bridge #原文中是连在一起的,更好的格式化输出,分开
# hello-dock
```
之前有讲到过,附接在这个默认桥接网络下的所有容器相互间可以通过IP通信。
一个自定义的桥接网络相比较默认桥接有一些额外的功能,根据[官方文档](https://docs.docker.com/network/bridge/#differences-between-user-defined-bridges-and-the-default-bridge),额外的功能如下:
- **自定义桥接网络提供容器间自动DNS解析功能。**这意味着在同一个自定义桥接网络下的容器间可以通过容器名称通信。因此如果你有两个容器分别是`notes-api`和`notes-db`,那么API容器就可以通过note-db容器名字来连接数据库容器。
- **自定义桥接网络提供更好的容器间的隔离。**所有附接在默认桥接网络下的容器可能会彼此冲突,自定义桥接网络下的容器能确保更好的隔离。
- **容器能够随时附接在或者从自定义桥接中断开连接。**在容器的生命周期中你可以随时附接在或者断开于自定义桥接网络中,从自定义桥接网络中断开容器连接的方法是,首先要停掉容器,然后重新运行容器并指定网络参数。
现在你了解了足够多自定义桥接网络的内容,是时候自己动手创建一个了,可以使用`network create`命令来创建网络,基本的语法如下:
```shell
docker network create <network name>
```
创建一个名称为skynet的网络,命令如下:
```shell
docker network create skynet
# 7bd5f351aa892ac6ec15fed8619fc3bbb95a7dcdd58980c28304627c8f7eb070
docker network ls
# NETWORK ID NAME DRIVER SCOPE
# be0cab667c4b bridge bridge local
# 124dccee067f host host local
# 506e3822bf1f none null local
# 7bd5f351aa89 skynet bridge local
```
上面可以看到一个指定名称的网络被创建,目前没有容器附连在这个网络下面,下一部分你会学习如何附接一个容器到一个网络。
<h3 id="8.3">8.3 怎样在Docker中附接一个容器到网络中?</h3>
基本上有两个办法将一个容器附接在一个网络上。首先,你可以使用network的命令来附接容器,基本的语法如下:
```shell
docker network connect <network identifier> <container identifier>
```
为了能够将`hello-dock`容器附接在`skynet`网络下,你可以执行下面的命令:
```shell
docker network connect skynet hello-dock
docker network inspect --format='{{range .Containers}} {{.Name}} {{end}}' skynet
# hello-dock
docker network inspect --format='{{range .Containers}} {{.Name}} {{end}}' bridge
# hello-dock
```
从上面我们执行两条`network inspect`的输出中可以看到,`hello-dock`容器已经附接在`skynet`和默认`bridge`桥接网络下了。
第二种附接容器在网络下的方法是使用命令`container run|create`命令的`--network`参数,基本的语法如下:
```shell
--network <network identifier>
```
运行另外一个alpine-box容器并附接在同样的网络下,可以执行:
```shell
docker container run --network skynet --rm --name alpine-box -it alpine sh
docker container run --network skynet --rm --name alpine-box -it alpine sh
/ # ping hello-dock
PING hello-dock (172.18.0.2): 56 data bytes
64 bytes from 172.18.0.2: seq=0 ttl=64 time=0.055 ms
64 bytes from 172.18.0.2: seq=1 ttl=64 time=0.052 ms
64 bytes from 172.18.0.2: seq=2 ttl=64 time=0.065 ms
64 bytes from 172.18.0.2: seq=3 ttl=64 time=0.050 ms
64 bytes from 172.18.0.2: seq=4 ttl=64 time=0.076 ms
64 bytes from 172.18.0.2: seq=5 ttl=64 time=0.054 ms
64 bytes from 172.18.0.2: seq=6 ttl=64 time=0.064 ms
^C
--- hello-dock ping statistics ---
7 packets transmitted, 7 packets received, 0% packet loss
round-trip min/avg/max = 0.050/0.059/0.076 ms
```
你可以看到,在`alpine-box`容器中运行`ping hello-dock`能成功联通,因为二容器同在自定义的桥接网络中且具备自动DNS解析的功能。
需要注意的是,要想让自定义DNS解析功能成功,你必须给容器设定自定的名称,用自动生成的容器名称在DNS解析时是无效的。
<h3 id="8.4">8.4 怎样在Docker中将容器从网络中断开连接?</h3>
上面你学习了将一个容器附接在一个网络中,这一节你会学习到如何将一个容器从网络中断开连接。你可以使用`network disconnect`命令来完成,基本的语法如下:
```shell
docker network disconnect <network identifier> <container identifier>
```
将hello-dock容器从skynet网络中断开连接,你可以执行下面的命令:
```shell
docker network disconnect skynet hello-dock
```
和network connect命令一样,network disconnect命令也没有任何输出
<h3 id="8.5">8.5 怎样在Docker中删除网络?</h3>
和其他Docker中的逻辑对象一样,网络可以使用`network rm`命令删除,基本的语法是:
```shell
docker network rm <network identifier>
```
将skynet网络从系统中删除,可以执行如下命令:
```shell
docker network rm skynet
```
你也可以使用`network prune`命令来删除任何系统中没有使用的网络,该命令也具有`-f|--force`和`-a|--all`参数。
---
<h2 id="9">9. 怎样容器化配置一个多容器JavaScript应用?</h2>
现在你学习了足够多的Docker网络知识,在这一部分中,你会学习到如何容器化配置一个完整的多容器项目,该项目包括一个基于Express.js的`notes-api`和PostgreSQL。
在这个项目当中,一共有两个容器需要你用网络将它们连在一起。此外,你将会学习到如环境变量和实名卷(named volume)的概念,我们开始吧。
<h3 id="9.1">9.1 怎样运行一个数据库服务?</h3>
该项目的数据库服务是PostgreSQL,使用的是[官方镜像](https://hub.docker.com/_/postgres)。
根据官方文档,如果运行官方镜像,你必须提供`POSTGRES_PASSWORD`环境变量,我还同时使用`POSTGRES_DB`环境变量作为默认的数据库名称。PostgreSQL默认使用的端口是5432,因此你也需要发布该端口。
运行数据库容器,你可以执行下面的命令:
```shell
docker container run \
--detach \
--name=notes-db \
--env POSTGRES_DB=notesdb \
--env POSTGRES_PASSWORD=secret \
--network=notes-api-network \
postgres:12
# a7b287d34d96c8e81a63949c57b83d7c1d71b5660c87f5172f074bd1606196dc
docker container ls
# CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
# a7b287d34d96 postgres:12 "docker-entrypoint.s…" About a minute ago Up About a minute 5432/tcp notes-db
```
> 冯兄话吉:`container run`命令中的`--network`参数不会自动创建网络,因此要用命令`docker network create notes-api-network`手动创建指定的网络参数。
`--env`参数用在`container run`和`container create`命令中为运行的容器设置环境变量。上面可以看到数据库容器创建成功并且在运行中。
尽管容器成功运行中,还有一个问题。像PostgreSQL、MongoDB和MySQL持久化数据在一个数据目录中。PostgreSQL使用容器内的`/var/lib/postgresql/data`目录持久化数据。那如果由于某种原因容器被删除了,你将失去你所有的数据,为了解决这个问题,需要用到实名卷。
<h3 id="9.2">9.2 怎样在Docker中使用实名卷?</h3>
在之前我们学习了绑定挂载(bind mounts)和匿名卷,所谓的实名卷和匿名卷类似,但是实名卷可以通过名字来引用它。
卷(volume)在Docker中也是一个逻辑对象,可以通过命令行来进行管理。`volume create`命令可以用来创建实名卷。
基本的语法如下:
```shell
docker volume create <volume name>
```
创建一个名称为`notes-db-data`的实名卷,可以执行以下命令:
```shell
docker volume create notes-db-data
# notes-db-data
docker volume ls
# DRIVER VOLUME NAME
# local notes-db-data
```
实名卷可以挂载到`notes-db`容器的目录`/var/lib/postgresql/data`目录上,要进行挂载,首先停止并删除`notes-db`容器:
```shell
docker container stop notes-db
# notes-db
docker container rm notes-db
# notes-db
```
现在运行一个新的容器,用--volume或者-v参数进行挂载:
```shell
docker container run \
--detach \
--volume notes-db-data:/var/lib/postgresql/data \
--name=notes-db \
--env POSTGRES_DB=notesdb \
--env POSTGRES_PASSWORD=secret \
--network=notes-api-network \
postgres:12
935b934076402f2f62b1f885d90026cba58137a1a333c370d1a1a86524f6fb30
```
现在使用`inspect`命令查看`notes-db`容器的挂载是否成功:
```shell
docker container inspect --format='{{range .Mounts}} {{ .Name }} {{end}}' notes-db
# notes-db-data
```
现在`notes-db-data`的数据将会安全的持久化到卷中并且后面可以复用。这里也可以使用绑定挂载来代替实名卷,只是这种场景我更喜欢使用实名卷。
<h3 id="9.3">9.3 怎样在Docker中查看容器的日志?</h3>
为了查看一个容器的日志,你可以使用`contaier logs`命令,基本的语法是:
```shell
docker container logs <container identifier>
```
获取`notes-db`容器的日志,你可以执行下面的命令:
```shell
docker container logs notes-db
The files belonging to this database system will be owned by user "postgres".
This user must also own the server process.
The database cluster will be initialized with locale "en_US.utf8".
The default database encoding has accordingly been set to "UTF8".
The default text search configuration will be set to "english".
Data page checksums are disabled.
fixing permissions on existing directory /var/lib/postgresql/data ... ok
creating subdirectories ... ok
selecting dynamic shared memory implementation ... posix
selecting default max_connections ... 100
selecting default shared_buffers ... 128MB
selecting default time zone ... Etc/UTC
creating configuration files ... ok
running bootstrap script ... ok
performing post-bootstrap initialization ... ok
syncing data to disk ... ok
Success. You can now start the database server using:
pg_ctl -D /var/lib/postgresql/data -l logfile start
initdb: warning: enabling "trust" authentication for local connections
You can change this by editing pg_hba.conf or using the option -A, or
--auth-local and --auth-host, the next time you run initdb.
waiting for server to start....2021-10-12 09:05:44.718 UTC [48] LOG: starting PostgreSQL 12.8 (Debian 12.8-1.pgdg110+1) on x86_64-pc-linux-gnu, compiled by gcc (Debian 10.2.1-6) 10.2.1 20210110, 64-bit
2021-10-12 09:05:44.768 UTC [48] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
2021-10-12 09:05:44.994 UTC [49] LOG: database system was shut down at 2021-10-12 09:05:43 UTC
2021-10-12 09:05:45.046 UTC [48] LOG: database system is ready to accept connections
done
server started
CREATE DATABASE
/usr/local/bin/docker-entrypoint.sh: ignoring /docker-entrypoint-initdb.d/*
waiting for server to shut down...2021-10-12 09:05:46.331 UTC [48] LOG: received fast shutdown request
.2021-10-12 09:05:46.379 UTC [48] LOG: aborting any active transactions
2021-10-12 09:05:46.381 UTC [48] LOG: background worker "logical replication launcher" (PID 55) exited with exit code 1
2021-10-12 09:05:46.381 UTC [50] LOG: shutting down
2021-10-12 09:05:46.750 UTC [48] LOG: database system is shut down
done
server stopped
PostgreSQL init process complete; ready for start up.
2021-10-12 09:05:46.888 UTC [1] LOG: starting PostgreSQL 12.8 (Debian 12.8-1.pgdg110+1) on x86_64-pc-linux-gnu, compiled by gcc (Debian 10.2.1-6) 10.2.1 20210110, 64-bit
2021-10-12 09:05:46.888 UTC [1] LOG: listening on IPv4 address "0.0.0.0", port 5432
2021-10-12 09:05:46.888 UTC [1] LOG: listening on IPv6 address "::", port 5432
2021-10-12 09:05:47.019 UTC [1] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
2021-10-12 09:05:47.203 UTC [76] LOG: database system was shut down at 2021-10-12 09:05:46 UTC
2021-10-12 09:05:47.255 UTC [1] LOG: database system is ready to accept connections
```
从57行的日志可以看出来数据库服务已经启动并且等待外部的连接。有参数`--follow|-f`可以让你把终端的输出重定向到日志文件中,得到一个持续输出的文档。
<h3 id="9.4">9.4 怎样在Docker中创建一个网络并且将数据库容器附接到网络中?</h3>
之前我们有学过,为了容器之间能够通信,需要创建一个自定义的网络并且将容器附接到网络中。首先在系统中创建一个名称为notes-api-network的网络:
```shell
docker network create notes-api-network
```
现在将notes-db容器附接在这个网络下,执行下面的命令:
```shell
docker network connect notes-api-network notes-db
```
<h3 id="9.5">9.5 怎样写Dockerfile?</h3>
进入你下载的项目目录,进入`notes-api/api`目录,创建一个新的Dockerfile文件,copy下面的内容进去:
```shell
# stage one
FROM node:lts-alpine as builder
# install dependencies for node-gyp
RUN apk add --no-cache python make g++
WORKDIR /app
COPY ./package.json .
RUN npm install --only=prod
# stage two
FROM node:lts-alpine
EXPOSE 3000
ENV NODE_ENV=production
USER node
RUN mkdir -p /home/node/app
WORKDIR /home/node/app
COPY . .
COPY --from=builder /app/node_modules /home/node/app/node_modules
CMD [ "node", "bin/www" ]
```
这是一个多阶段的构建,第1阶段使用`node-gyp`进行构建和安装依赖,第2阶段用来运行应用。我简单介绍下相关步骤:
- 阶段1,使用`node:lts-alpine`作为基础镜像并且使用`builder`最为阶段1的阶段名称。
- 第5行,我们安装`python`、`make`和`g++`,`node-gyp`工具运行需要这3个依赖包。
- 第7行,设置`/app`作为工作目录。
- 第9和10行,我们复制`package.json`文件到工作目录中并且安装所有的依赖。
- 阶段2,仍然使用`node:lts-alpine`最为基础镜像。
- 第16行,我们设置`NODE_ENV`环境变量为`production`,要让API正常运行,这个设置相当重要。
- 第18到20行,我们设置默认的用户为node,创建`/home/node/app`目录并且设置该目录为工作目录。
- 第22行,我们复制所有的项目文件,第23行,我们从`builder`阶段复制了`node_modules`目录,该目录中包含所有运行依赖的构建阶段的包。
- 第25行,我们设置了默认的启动命令。
根据Dockerfile构建镜像,执行下面的命令:
```shell
docker image build --tag notes-api .
Sending build context to Docker daemon 37.38kB
Step 1/14 : FROM node:lts-alpine as builder
---> ee0f6dca428d
Step 2/14 : RUN apk add --no-cache python make g++
---> Running in 68e2bb1a2f38
fetch http://dl-cdn.alpinelinux.org/alpine/v3.11/main/x86_64/APKINDEX.tar.gz
fetch http://dl-cdn.alpinelinux.org/alpine/v3.11/community/x86_64/APKINDEX.tar.gz
(1/21) Installing binutils (2.33.1-r1)
(2/21) Installing gmp (6.1.2-r1)
(3/21) Installing isl (0.18-r0)
(4/21) Installing libgomp (9.3.0-r0)
(5/21) Installing libatomic (9.3.0-r0)
(6/21) Installing mpfr4 (4.0.2-r1)
(7/21) Installing mpc1 (1.1.0-r1)
(8/21) Installing gcc (9.3.0-r0)
(9/21) Installing musl-dev (1.1.24-r3)
(10/21) Installing libc-dev (0.7.2-r0)
(11/21) Installing g++ (9.3.0-r0)
(12/21) Installing make (4.2.1-r2)
(13/21) Installing libbz2 (1.0.8-r1)
(14/21) Installing expat (2.2.9-r1)
(15/21) Installing libffi (3.2.1-r6)
(16/21) Installing gdbm (1.13-r1)
(17/21) Installing ncurses-terminfo-base (6.1_p20200118-r4)
(18/21) Installing ncurses-libs (6.1_p20200118-r4)
(19/21) Installing readline (8.0.1-r0)
(20/21) Installing sqlite-libs (3.30.1-r2)
(21/21) Installing python2 (2.7.18-r0)
Executing busybox-1.31.1-r10.trigger
OK: 212 MiB in 37 packages
Removing intermediate container 68e2bb1a2f38
---> 986e49e94c73
Step 3/14 : WORKDIR /app
---> Running in f0f0f4656ace
Removing intermediate container f0f0f4656ace
---> 851dfc6767fc
Step 4/14 : COPY ./package.json .
---> 1e545000fd96
Step 5/14 : RUN npm install --only=prod
---> Running in 6647d1ff3261
npm WARN deprecated @hapi/[email protected]: Switch to 'npm install joi'
npm WARN deprecated @hapi/[email protected]: Moved to 'npm install @sideway/formula'
npm WARN deprecated @hapi/[email protected]: Moved to 'npm install @sideway/address'
npm WARN deprecated @hapi/[email protected]: Moved to 'npm install @sideway/pinpoint'
npm WARN deprecated [email protected]: Please upgrade to @mapbox/node-pre-gyp: the non-scoped node-pre-gyp package is deprecated and only the @mapbox scoped package will recieve updates in the future
npm WARN deprecated [email protected]: some dependency vulnerabilities fixed, support for node < 10 dropped, and newer ECMAScript syntax/features added
npm WARN deprecated [email protected]: request-promise-native has been deprecated because it extends the now deprecated request package, see https://github.com/request/request/issues/3142
npm WARN deprecated [email protected]: request has been deprecated, see https://github.com/request/request/issues/3142
npm WARN deprecated [email protected]: this library is no longer supported
npm WARN deprecated [email protected]: Please upgrade to version 7 or higher. Older versions may use Math.random() in certain circumstances, which is known to be problematic. See https://v8.dev/blog/math-random for details.
npm WARN deprecated [email protected]: https://github.com/lydell/resolve-url#deprecated
npm WARN deprecated [email protected]: Please see https://github.com/lydell/urix#deprecated
npm notice created a lockfile as package-lock.json. You should commit this file.
npm WARN optional SKIPPING OPTIONAL DEPENDENCY: fsevents@^2.1.2 (node_modules/jest-haste-map/node_modules/fsevents):
npm WARN notsup SKIPPING OPTIONAL DEPENDENCY: Unsupported platform for [email protected]: wanted {"os":"darwin","arch":"any"} (current: {"os":"linux","arch":"x64"})
npm WARN notes-api@ No description
npm WARN notes-api@ No repository field.
npm WARN notes-api@ No license field.
added 270 packages from 220 contributors and audited 1159 packages in 97.357s
4 packages are looking for funding
run `npm fund` for details
found 20 vulnerabilities (7 moderate, 13 high)
run `npm audit fix` to fix them, or `npm audit` for details
Removing intermediate container 6647d1ff3261
---> bd0ec09c1fe5
Step 6/14 : FROM node:lts-alpine
---> ee0f6dca428d
Step 7/14 : EXPOSE 3000
---> Using cache
---> 62bad2323eb1
Step 8/14 : ENV NODE_ENV=production
---> Running in 815df9f36de5
Removing intermediate container 815df9f36de5
---> 8b8f5bb002c4
Step 9/14 : USER node
---> Running in 0192718e8951
Removing intermediate container 0192718e8951
---> 1ca7806f6ccf
Step 10/14 : RUN mkdir -p /home/node/app
---> Running in 2e60b90beda2
Removing intermediate container 2e60b90beda2
---> ca808882bd72
Step 11/14 : WORKDIR /home/node/app
---> Running in d6c16b514ffb
Removing intermediate container d6c16b514ffb
---> 23efd3c64dbe
Step 12/14 : COPY . .
---> e9a07ac8e9c8
Step 13/14 : COPY --from=builder /app/node_modules /home/node/app/node_modules
---> 641798a416af
Step 14/14 : CMD [ "node", "bin/www" ]
---> Running in a5ccf9b8c68c
Removing intermediate container a5ccf9b8c68c
---> 23749f0a35c9
Successfully built 23749f0a35c9
Successfully tagged notes-api:latest
```
在使用构建出来的镜像运行容器之前,确保数据库容器是运行的并且已经附接在notes-api-network网络下。
```shell
docker container inspect notes-db
# [
# {
# ...
# "State": {
# "Status": "running",
# "Running": true,
# "Paused": false,
# "Restarting": false,
# "OOMKilled": false,
# "Dead": false,
# "Pid": 11521,
# "ExitCode": 0,
# "Error": "",
# "StartedAt": "2021-01-26T06:55:44.928510218Z",
# "FinishedAt": "2021-01-25T14:19:31.316854657Z"
# },
# ...
# "Mounts": [
# {
# "Type": "volume",
# "Name": "notes-db-data",
# "Source": "/var/lib/docker/volumes/notes-db-data/_data",
# "Destination": "/var/lib/postgresql/data",
# "Driver": "local",
# "Mode": "z",
# "RW": true,
# "Propagation": ""
# }
# ],
# ...
# "NetworkSettings": {
# ...
# "Networks": {
# "bridge": {
# "IPAMConfig": null,
# "Links": null,
# "Aliases": null,
# "NetworkID": "e4c7ce50a5a2a49672155ff498597db336ecc2e3bbb6ee8baeebcf9fcfa0e1ab",
# "EndpointID": "2a2587f8285fa020878dd38bdc630cdfca0d769f76fc143d1b554237ce907371",
# "Gateway": "172.17.0.1",
# "IPAddress": "172.17.0.2",
# "IPPrefixLen": 16,
# "IPv6Gateway": "",
# "GlobalIPv6Address": "",
# "GlobalIPv6PrefixLen": 0,
# "MacAddress": "02:42:ac:11:00:02",
# "DriverOpts": null
# },
# "notes-api-network": {
# "IPAMConfig": {},
# "Links": null,
# "Aliases": [
# "37755e86d627"
# ],
# "NetworkID": "06579ad9f93d59fc3866ac628ed258dfac2ed7bc1a9cd6fe6e67220b15d203ea",
# "EndpointID": "5b8f8718ec9a5ec53e7a13cce3cb540fdf3556fb34242362a8da4cc08d37223c",
# "Gateway": "172.18.0.1",
# "IPAddress": "172.18.0.2",
# "IPPrefixLen": 16,
# "IPv6Gateway": "",
# "GlobalIPv6Address": "",
# "GlobalIPv6PrefixLen": 0,
# "MacAddress": "02:42:ac:12:00:02",
# "DriverOpts": {}
# }
# }
# }
# }
# ]
```
为了方便展示,这里我省略了一些信息。在我的系统中,`notes-db`容器是运行的,该容器挂载了`notes-db-data`卷并且附接在桥接网络`notes-api-network`下。
确保所有的都正确后,你可以用下面的命令运行一个新的容器:
```shell
docker container run \
--detach \
--name=notes-api \
--env DB_HOST=notes-db \
--env DB_DATABASE=notesdb \
--env DB_PASSWORD=secret \
--publish=3000:3000 \
--network=notes-api-network \
notes-api
# a037399446fe41362cf3e485478585f20e0d3f702b2fcda62fdfb01b63ed5e0a
```
你应该能够自己能够理解这个长长的命令,因此我只对环境变量做简单的说明。
notes-api容器需要设置三个环境变量,它们是:
- `DB_HOST`-这个是数据库服务的主机名。由于数据库服务和API都附接在同一个自定义的桥接网络下,数据库服务可以使用容器名称`notes-db`来进行引用。
- `DB_DATABASE`-API使用的数据库。在[运行数据库服务](#9.1)部分,我们通过环境变量`POSTGRES_DB`设置了默认的数据库名称为`notesdb`,正是我们使用的这个。
- `DB_PASSWORD`-连接数据库的密码。这个变量也是通过[之前](#9.1)的环境变量`POSTGRES_PASSWORD`设置过。
查看应用是否正常启动,可以使用下面的命令:
```shell
docker container ls
# CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
# f9ece420872d notes-api "docker-entrypoint.s…" 12 minutes ago Up 12 minutes 0.0.0.0:3000->3000/tcp notes-api
# 37755e86d627 postgres:12 "docker-entrypoint.s…" 17 hours ago Up 14 minutes 5432/tcp notes-db
```
现在,容器在运行中,你可以通过`http://127.0.0.1:3000/`来访问一下API。

> 冯兄话吉:上图所示服务不能正常访问,需执行后续的数据初始化工作才能正常,上面看到的页面是正常的(基于上面执行的命令)。
该API共有5个路由,你可以在`/notes-api/api/api/routes/notes.js`查看。
尽管容器在运行中,在正式使用之前仍然有最后一件事情要做。你必要要进行必要的数据库迁移来设置数据库中的表,在容器中执行`npm run db:migrate`来完成。
<h3 id="9.6">9.6 怎样在运行的容器中执行命令?</h3>
在运行中的容器内执行命令,你需要用到`exec`命令,基本的语法是:
```shell
docker container exec <container identifier> <command>
```
在notes-api容器中执行`rpm run db:migrate`命令,你需要执行下面的命令:
```shell
docker container exec notes-api npm run db:migrate
COPY
```
如果你想用命令行交互的方式在容器内执行命令,必须要使用`-it`参数。例如你想在运行中的`notes-api`容器中启动交互式`shell`,你可以执行下面的命令:
```shell
docker container exec -it notes-api sh
# / # uname -a
# Linux a037399446fe 5.10.16.3-microsoft-standard-WSL2 #1 SMP Fri Apr 2 22:23:49 UTC 2021 x86_64 Linux
```
<h3 id="9.7">9.7 怎样写管理Docker的脚本?</h3>
管理一个带有卷和网络的多容器项目意味着有很多命令,为了简化这个过程,我通常用简单的`shell scripts`和`Makefile`。
你可以在`notes-api`目录中找打4个shell scripts,它们分别是:
- `boot.sh`-用来启动已经存在的容器。
- `build.sh`-用来创建并运行容器,如果必要的话也会创建卷和网络。
- `destroy.js`-删除该项目所有容器、卷及网络。
- `stop.js`-停掉所有的容器。
有一个`Makefile`包含了4个目标叫做`start`、`stop`、`build`和`destory`,每一个目标都是调用上面4个shell scripts。
如果系统中容器处于运行态,执行`make stop`命令应该停掉所有的容器。执行`make destory`应该停掉所有的容器并且删除所有的相关内容。确保你在`notes-api`目录中:
```shell
make destroy
# ./shutdown.sh
# stopping api container --->
# notes-api
# api container stopped --->
# stopping db container --->
# notes-db
# db container stopped --->
# shutdown script finished
# ./destroy.sh
# removing api container --->
# notes-api
# api container removed --->
# removing db container --->
# notes-db
# db container removed --->
# removing db data volume --->
# notes-db-data
# db data volume removed --->
# removing network --->
# notes-api-network
# network removed --->
# destroy script finished
```
如果你遇到了permission denied的错误,你需要在脚本上执行`sudo chmod +x *.sh`:
```shell
chmod +x boot.sh build.sh destroy.sh shutdown.sh
```
在这里不再解释这些脚本,因为它们都是一些`if-else`指令加上见过很多次的`Docker`命令。如果你有了解Linux Shell,你应该能够理解脚本中的内容。
---
<h2 id="10">10. 怎样使用Docker-Compose?</h2>
在上一章节,你学习了如何管理一个多容器的项目和解决相关的问题。存在有一个不用写那么多命令并且能够更方便管理多容器的工具,它叫做[Docker Compose](https://docs.docker.com/compose/)。
根据Docker[官方文档](https://docs.docker.com/compose/),Docker Compose是一个定义并运行多容器的工具。使用Compose你可以用一个YAML文件配置相关应用服务,使用一行命令就可以做到创建并启动配置的所有的服务。
尽管Docker Compose可以运行在各种环境中,但是它更适合用在开发和测试环境中,不推荐在生产环境中使用。
<h3 id="10.1">10.1 Docker Compose基础</h3>
进入你复制本项目的目录,进入`notes-api/api`目录,创建一个命名为Dockerfile.dev的文件,将下面的代码复制进去:
```shell
# stage one
FROM node:lts-alpine as builder
# install dependencies for node-gyp
RUN apk add --no-cache python make g++
WORKDIR /app
COPY ./package.json .
RUN npm install
# stage two
FROM node:lts-alpine
ENV NODE_ENV=development
USER node
RUN mkdir -p /home/node/app
WORKDIR /home/node/app
COPY . .
COPY --from=builder /app/node_modules /home/node/app/node_modules
CMD [ "./node_modules/.bin/nodemon", "--config", "nodemon.json", "bin/www" ]
```
这里的代码基本上和上一章节的`Dockerfile`的代码一致,不同的地方在于:
- 第10行,不使用`npm run install --only=prod`而是是哟个你`npm install`,因为我们也需要开发时的依赖。
- 第15行,我们设置环境变量`NODE_ENV`为`development`而不是`production`。
- 第24行,我们使用一个[nodemon](https://nodemon.io/)的工具进行API的热部署。
你已经知道这个项目共包含两个容器:
- `notes-db`,一个PostgreSQL数据库服务。
- `notes-api`,基于Express.js的REST API。
在compose这里,应用中的每一个容器被定义为一个service,compose应用第一步是要定义这些service。
就像Docker后台使用Dockerfile来构建镜像一样,Docker Compose使用一个`docker-compose.yaml`文件定义service。
进入notes-api目录并创建一个新的docker-compose.yaml文件,复制下面的代码到文件中:
```shell
version: "3.8"
services:
db:
image: postgres:12
container_name: notes-db-dev
volumes:
- notes-db-dev-data:/var/lib/postgresql/data
environment:
POSTGRES_DB: notesdb
POSTGRES_PASSWORD: secret
api:
build:
context: ./api
dockerfile: Dockerfile.dev
image: notes-api:dev
container_name: notes-api-dev
environment:
DB_HOST: db ## same as the database service name
DB_DATABASE: notesdb
DB_PASSWORD: secret
volumes:
- /home/node/app/node_modules
- ./api:/home/node/app
ports:
- 3000:3000
volumes:
notes-db-dev-data:
name: notes-db-dev-data
```
每一个有效的`docker-compose.yaml`文件在开头都会定义个一个版本,写作时最新的版本是`3.8`,你可以在[这里](https://docs.docker.com/compose/compose-file/)找到最新的版本。
`YAML`文件是用缩进定义不同的块,我将讲解每一个块的内容:
- `services`块定义应用的每一个容器或者服务,该项目中的两个services分别是api和db。
- `db`块定义了应用的db服务并且包含了启动容器的所有信息。每一个服务需要一个提前构建好的镜像或者一个`Dockerfile`来运行容器。对于该`db`服务使用的是官方的`PostgreSQL`镜像。
- 和`db`服务不同,`api`服务没有预编译的镜像使用,因此我们使用`Dockerfile.dev`。
- `volumes`块定义你需要的任何的卷。这里仅仅定义了db服务需要的`notes-db-dev-data`卷。
现在你对docker-compose.yaml有一个整体的认识,我们进一步仔细看下单个服务。
db服务的定义如下:
```shell
db:
image: postgres:12
container_name: notes-db-dev
volumes:
- db-data:/var/lib/postgresql/data
environment:
POSTGRES_DB: notesdb
POSTGRES_PASSWORD: secret
```
- `image`内容定义了该容器的镜像仓库和tag,我们使用的是运行数据库容器的`postgres:12`镜像。
- `container_name`内容定义了容器的名称,默认情况下容器名称定义为`<project directory name>_<service name>`语法格式。你可以用容器的名称`<container name>`进行覆写。
- `volumes`数组内容定义了服务的卷映射,支持实名卷、匿名卷和挂载绑定。语法`<source>:<destination>`和你之前看到的一样。
- `environment`内容定义的服务运行需要的不同环境变量。
`api`服务的定义代码如下:
```shell
api:
build:
context: ./api
dockerfile: Dockerfile.dev
image: notes-api:dev
container_name: notes-api-dev
environment:
DB_HOST: db ## same as the database service name
DB_DATABASE: notesdb
DB_PASSWORD: secret
volumes:
- /home/node/app/node_modules
- ./api:/home/node/app
ports:
- 3000:3000
```
- `api`服务没有一个预构建好的镜像,因此这里设置构建的参数。在`build`块下我们定义了上下文和用于构建镜像的Dockerfile,你现在应该能够理解上下文和Dockerfile,因为我们不做过多的解释了。
- `image`内容代表要构建的镜像的名称。如果没有指定默认将会遵照`<project directory name>_<service name>`的语法格式。
- 在`environment`映射中,`DB_HOST`变量证实了compose的一个功能,那就是你可以在同一项目下引用另外一个服务的名称,在这里就是`db`,它将会在容器中被替换为`api`服务的IP地址。`DB_DATABASE`和`DB_PASSWORD`变量和`db`服务中的`POSTGRE_DB`和`POSTGRE_PASSWORD`相对应。
- 在`volumes`映射中,你可以看到有一个匿名卷和绑定挂载被定义。其语法和之前看到的一样。
- `ports`映射定义了端口的映射。语法`<host port>:<container port>`和之前用的`--publish`语法一样。
最后`volumes`的代码如下:
```shell
volumes:
db-data:
name: notes-db-dev-data
```
任何实名卷都可以在这里定义,如果你没有给卷定义一个名称,卷名将遵照`<project directory name>_<volume_key>`的语法格式,这里的key是`db-data`。
你可以在[这里](https://docs.docker.com/compose/compose-file/compose-file-v3/#volumes)了解更多卷相关的配置。
<h3 id="10.2">10.2 Docker Compose中如何启动服务?</h3>
有多种方法可以启动应以在YAML文件中的服务,首先要学习的是`up`命令,`up`命令会一口气构建缺失的镜像、创建并启动容器。
在你执行命令之前,确保你打开终端的目录中有`docker-compose.yaml`文件,这对于你要执行的`docker-compose`命令来说很重要。
```shell
docker-compose --file docker-compose.yaml up --detach
# Creating network "notes-api_default" with the default driver
# Creating volume "notes-db-dev-data" with default driver
# Building api
# Sending build context to Docker daemon 37.38kB
#
# Step 1/13 : FROM node:lts-alpine as builder
# ---> 471e8b4eb0b2
# Step 2/13 : RUN apk add --no-cache python make g++
# ---> Running in 197056ec1964
### LONG INSTALLATION STUFF GOES HERE ###
# Removing intermediate container 197056ec1964
# ---> 6609935fe50b
# Step 3/13 : WORKDIR /app
# ---> Running in 17010f65c5e7
# Removing intermediate container 17010f65c5e7
# ---> b10d12e676ad
# Step 4/13 : COPY ./package.json .
# ---> 600d31d9362e
# Step 5/13 : RUN npm install
# ---> Running in a14afc8c0743
### LONG INSTALLATION STUFF GOES HERE ###
# Removing intermediate container a14afc8c0743
# ---> 952d5d86e361
# Step 6/13 : FROM node:lts-alpine
# ---> 471e8b4eb0b2
# Step 7/13 : ENV NODE_ENV=development
# ---> Running in 0d5376a9e78a
# Removing intermediate container 0d5376a9e78a
# ---> 910c081ce5f5
# Step 8/13 : USER node
# ---> Running in cfaefceb1eff
# Removing intermediate container cfaefceb1eff
# ---> 1480176a1058
# Step 9/13 : RUN mkdir -p /home/node/app
# ---> Running in 3ae30e6fb8b8
# Removing intermediate container 3ae30e6fb8b8
# ---> c391cee4b92c
# Step 10/13 : WORKDIR /home/node/app
# ---> Running in 6aa27f6b50c1
# Removing intermediate container 6aa27f6b50c1
# ---> 761a7435dbca
# Step 11/13 : COPY . .
# ---> b5d5c5bdf3a6
# Step 12/13 : COPY --from=builder /app/node_modules /home/node/app/node_modules
# ---> 9e1a19960420
# Step 13/13 : CMD [ "./node_modules/.bin/nodemon", "--config", "nodemon.json", "bin/www" ]
# ---> Running in 5bdd62236994
# Removing intermediate container 5bdd62236994
# ---> 548e178f1386
# Successfully built 548e178f1386
# Successfully tagged notes-api:dev
# Creating notes-api-dev ... done
# Creating notes-db-dev ... done
```
这里的`--detach|-d`参数和之前看到的参数功能一致,`--file|-f`参数当你需要指定命名非`docker-compose.yaml`文件时使用(这里用`-f`指定文件名是为了证明这个功能)。
除了`up`命令之外还有`start`命令可以启动,二者的区别在于`start`命令不会创建缺失的容器,仅仅会启动已经存在的容器,和`container start`命令是一样的。
`up`命令的`--build`参数强制重新构建镜像,还有其他的一些参数,可以查看[官方文档](https://docs.docker.com/compose/reference/up/)
<h3 id="10.3">10.3 Docker Compose如何展示服务?</h3>
尽管Compose启动的容器也可以通过`container ls`命令来展示,有一个`ps`命令可以只展示出YAML文件中定义的容器。
```shell
docker-compose ps
Name Command State Ports
-------------------------------------------------------------------------------------------------
notes-api-dev docker-entrypoint.sh ./nod ... Up 0.0.0.0:3000->3000/tcp,:::3000->3000/tcp
notes-db-dev docker-entrypoint.sh postgres Up 5432/tcp
```
展示的内容没有`container ls`那么详尽,但是如果你同时运行很多的容器,这个语法还是很有用的。
<h3 id="10.4">10.4 怎样在Docker Compose运行的服务中执行命令?</h3>
你应该记得在之前的章节使用命令执行过迁移脚本的工作来创建API服务的数据库表。
就像`container exec`命令一样,`docker-compose`命令也可以使用`exec`,基本的语法如下:
```shell
docker-compose exec <service name> <command>
```
在`api`服务中执行`npm run db:migrate`命令,你可以做如下操作:
```shell
docker-compose exec api npm run db:migrate
# > notes-api@ db:migrate /home/node/app
# > knex migrate:latest
#
# Using environment: development
# Batch 1 run: 1 migrations
```
> 冯兄话吉:这里`exec`后面的参数是`<service name`而不是容器的标识。
和`container exec`不同,你不需要`-it`参数来进行命令行交互,`docker-compose`自动给你做了。
<h3 id="10.5">10.5 怎样在Docker Compose中查看运行的服务的日志?</h3>
你可以使用`logs`命令来获取运行中服务的日志,基本的语法是:
```shell
docker-compose logs <service name>
```
从`api`服务中获取日志,执行如下命令:
```shell
docker-compose logs api
Attaching to notes-api-dev
notes-api-dev | [nodemon] 2.0.13
notes-api-dev | [nodemon] reading config ./nodemon.json
notes-api-dev | [nodemon] to restart at any time, enter `rs`
notes-api-dev | [nodemon] or send SIGHUP to 1 to restart
notes-api-dev | [nodemon] ignoring: *.test.js
notes-api-dev | [nodemon] watching path(s): *.*
notes-api-dev | [nodemon] watching extensions: js,mjs,json
notes-api-dev | [nodemon] starting `node bin/www`
notes-api-dev | [nodemon] forking
notes-api-dev | [nodemon] child pid: 21
notes-api-dev | [nodemon] watching 19 files
notes-api-dev | app running -> http://127.0.0.1:3000
```
这只是部分日志,你可以通过`-f|--follow`参数将日志流重定向到文件中,运行中服务后续的日志将持续不断输出到文件中直到你按下`ctrl + c`键或者关闭窗口,关闭或者退出日志窗口不会影响容器的运行。
<h3 id="10.6">10.6 怎样在Docker Compose中停止运行的服务?</h3>
你有两种办法来停掉服务,第一个是使用`down`命令,该命令会停掉所有的容器并且从系统中删除,它也会删除所有的网络:
```shell
docker-compose down --volumes
Stopping notes-db-dev ... done
Stopping notes-api-dev ... done
Removing notes-db-dev ... done
Removing notes-api-dev ... done
Removing network notes-api_default
Removing volume notes-db-dev-data
```
`--volumes`参数表示你想删除所有定义在`volumes`块中的实名卷,你可以在[官方文档](https://docs.docker.com/compose/reference/down/)中了解更多`down`命令的参数。
另外一个停掉服务的办法是用`stop`命令,功能和`container stop`命令一样。它会停掉应用的所有容器,这些容器会在后续`start`或者`up`命令中启动。
<h3 id="10.7">10.7 怎样Compose一个全栈应用?</h3>
在这一章节总我们将给notes API增加一个前端并且将之转化为一个全栈的应用。这里不会再解释`Dockerfile.dev`(除了nginx服务外),因为它们在之前的章节已经出现过多次。
如果你克隆过项目仓库,进入`fullstack-notes-application`目录,项目根目录下的每一个目录都包含代码和服务及其相关的`Dockerfile`。
在我们使用`docker-compose.yaml`文件启动项目之前,先让我们看一下该应用是如何工作的:

不像我们之前那样直接请求,该应用所有的请求先会到NGINX(让我们称之为路由)服务那里。
路由将会查看是否请求中包含`/api`内容,如果是,路由将会请求到后端服务,如果不是,路由将会请求到前端服务。
这样做的原因是,前端的应用不是在容器中运行的,而是在浏览器中,容器只提供服务。这样,Compose网络就会失效,前端应用找不到`api`服务。
NGINX,在容器中运行,能够和整个应用中的不同服务进行通信。
我不会在这里深入的解释NGINX的配置,该内容超出了本书的范围。如果你想看具体配置,查看文件`/fullstack-notes-application/nginx/development.conf`和`/fullstack-notes-application/nginx/production.conf`。`/fullstack-notes-application/nginx/Dockerfile.dev`代码如下:
> 冯兄话吉:上述路径原文指向有误。
```shell
FROM nginx:stable-alpine
COPY ./development.conf /etc/nginx/conf.d/default.conf
```
它所做的是将配置文件copy到容器内的`/etc/nginx/conf.d/default.conf`中。
我们开始书写`docker-compose.yaml`文件,除了`api`和`db`服务外,还有`client`和`nginx`服务,还有一些网络的定义稍定会做出说明:
```shell
version: "3.8"
services:
db:
image: postgres:12
container_name: notes-db-dev
volumes:
- db-data:/var/lib/postgresql/data
environment:
POSTGRES_DB: notesdb
POSTGRES_PASSWORD: secret
networks:
- backend
api:
build:
context: ./api
dockerfile: Dockerfile.dev
image: notes-api:dev
container_name: notes-api-dev
volumes:
- /home/node/app/node_modules
- ./api:/home/node/app
environment:
DB_HOST: db ## same as the database service name
DB_PORT: 5432
DB_USER: postgres
DB_DATABASE: notesdb
DB_PASSWORD: secret
networks:
- backend
client:
build:
context: ./client
dockerfile: Dockerfile.dev
image: notes-client:dev
container_name: notes-client-dev
volumes:
- /home/node/app/node_modules
- ./client:/home/node/app
networks:
- frontend
nginx:
build:
context: ./nginx
dockerfile: Dockerfile.dev
image: notes-router:dev
container_name: notes-router-dev
restart: unless-stopped
ports:
- 8080:80
networks:
- backend
- frontend
volumes:
db-data:
name: notes-db-dev-data
networks:
frontend:
name: fullstack-notes-application-network-frontend
driver: bridge
backend:
name: fullstack-notes-application-network-backend
driver: bridge
```
该文件几乎和我们之前见到的一样,需要做出解释的是`network`块,代码如下:
```shell
networks:
frontend:
name: fullstack-notes-application-network-frontend
driver: bridge
backend:
name: fullstack-notes-application-network-backend
driver: bridge
```
这里我定义了两个网络,默认情况下,Compose会定义一个桥接网络将所有的容器都附接在这个网络下。这个项目中我想要更好的网络隔离,因此定义了两个网络,一个是给前端用一个给后端用。
在每一个服务的定义里我也加入了`networks`块,这样`api`和`db`服务将在一个网络下,`client`将在一个分开的网络下。但是`nginx`服务将都是附接在两个网络下,这样才能够路由到前端和后端的服务。
执行下面的命令启动所有的服务:
```shell
docker-compose --file docker-compose.yaml up --detach
# Creating network "fullstack-notes-application-network-backend" with driver "bridge"
# Creating network "fullstack-notes-application-network-frontend" with driver "bridge"
# Creating volume "notes-db-dev-data" with default driver
# Building api
# Sending build context to Docker daemon 37.38kB
#
# Step 1/13 : FROM node:lts-alpine as builder
# ---> 471e8b4eb0b2
# Step 2/13 : RUN apk add --no-cache python make g++
# ---> Running in 8a4485388fd3
### LONG INSTALLATION STUFF GOES HERE ###
# Removing intermediate container 8a4485388fd3
# ---> 47fb1ab07cc0
# Step 3/13 : WORKDIR /app
# ---> Running in bc76cc41f1da
# Removing intermediate container bc76cc41f1da
# ---> 8c03fdb920f9
# Step 4/13 : COPY ./package.json .
# ---> a1d5715db999
# Step 5/13 : RUN npm install
# ---> Running in fabd33cc0986
### LONG INSTALLATION STUFF GOES HERE ###
# Removing intermediate container fabd33cc0986
# ---> e09913debbd1
# Step 6/13 : FROM node:lts-alpine
# ---> 471e8b4eb0b2
# Step 7/13 : ENV NODE_ENV=development
# ---> Using cache
# ---> b7c12361b3e5
# Step 8/13 : USER node
# ---> Using cache
# ---> f5ac66ca07a4
# Step 9/13 : RUN mkdir -p /home/node/app
# ---> Using cache
# ---> 60094b9a6183
# Step 10/13 : WORKDIR /home/node/app
# ---> Using cache
# ---> 316a252e6e3e
# Step 11/13 : COPY . .
# ---> Using cache
# ---> 3a083622b753
# Step 12/13 : COPY --from=builder /app/node_modules /home/node/app/node_modules
# ---> Using cache
# ---> 707979b3371c
# Step 13/13 : CMD [ "./node_modules/.bin/nodemon", "--config", "nodemon.json", "bin/www" ]
# ---> Using cache
# ---> f2da08a5f59b
# Successfully built f2da08a5f59b
# Successfully tagged notes-api:dev
# Building client
# Sending build context to Docker daemon 43.01kB
#
# Step 1/7 : FROM node:lts-alpine
# ---> 471e8b4eb0b2
# Step 2/7 : USER node
# ---> Using cache
# ---> 4be5fb31f862
# Step 3/7 : RUN mkdir -p /home/node/app
# ---> Using cache
# ---> 1fefc7412723
# Step 4/7 : WORKDIR /home/node/app
# ---> Using cache
# ---> d1470d878aa7
# Step 5/7 : COPY ./package.json .
# ---> Using cache
# ---> bbcc49475077
# Step 6/7 : RUN npm install
# ---> Using cache
# ---> 860a4a2af447
# Step 7/7 : CMD [ "npm", "run", "serve" ]
# ---> Using cache
# ---> 11db51d5bee7
# Successfully built 11db51d5bee7
# Successfully tagged notes-client:dev
# Building nginx
# Sending build context to Docker daemon 5.12kB
#
# Step 1/2 : FROM nginx:stable-alpine
# ---> f2343e2e2507
# Step 2/2 : COPY ./development.conf /etc/nginx/conf.d/default.conf
# ---> Using cache
# ---> 02a55d005a98
# Successfully built 02a55d005a98
# Successfully tagged notes-router:dev
# Creating notes-client-dev ... done
# Creating notes-api-dev ... done
# Creating notes-router-dev ... done
# Creating notes-db-dev ... done
```
现在访问`http://localhost:8080`并验证。

尝试增加或者删除notes验证应用是否能正常工作。这个项目也可以用shell scripts和Makefile完成,可以尝试像之前章节那样不使用Docker Compose来运行项目。
> 冯兄话吉:访问页面操作创建notes功能不能正常保存日记,是因为数据库没有执行初始化建表操作,使用命令`docker-compose exec api npm run db:migrate`即可完成初始化,重新保存日记,功能正常。
---
<h2 id="11">11. 结论</h2>
十分感谢您的时间阅读本书,希望你喜欢他并且学会的Docker的所有基础知识。
除了这一篇,我还写了关于其他主题的长篇指导性手册,可以在[freeCodeCamp](https://www.freecodecamp.org/news/the-docker-handbook/freecodecamp.org/news/author/farhanhasin/)中看到。
这些手册都是我秉承着努力简化每个人对技术的理解的热情写的,每一本都花费了大量的时间和精力。
如果你喜欢我的写作并且鼓励支持我,可以在我的[Github](https://github.com/fhsinchy/)给我点赞,或者在[LinkedIn])(https://www.linkedin.com/in/farhanhasin/)界面认可我的相关技能。我也欢迎您赞助我[一杯咖啡的钱](https://www.buymeacoffee.com/farhanhasin)。
您有任何意见或者建议可以在[这些平台](https://linktr.ee/farhanhasin)留言,也可以在[Twitter](https://twitter.com/frhnhsin)或者[LinkedIn](https://www.linkedin.com/in/farhanhasin/)上关注我,直接给我留言。
最后,建议将好东西分享给其他人,因为:
> 知识分享是最基本的友谊,因为它能够让你在不失去任何东西的情况下赠人玫瑰。 -- Richard Stallman
---
<h2 id="12">12. 译者注</h2>
- 本书翻译原文:[https://www.freecodecamp.org/news/the-docker-handbook/](https://www.freecodecamp.org/news/the-docker-handbook/)
- 原作者:`Farhan Hasin Chowdhury`
- 原项目仓库:[https://github.com/fhsinchy/docker-handbook-projects/](https://github.com/fhsinchy/docker-handbook-projects/)
- 译者:`冯兄话吉`
- 译者项目克隆仓库:[https://github.com/FengMengZhao/the-docker-handbook/](https://github.com/FengMengZhao/the-docker-handbook/)
- 译者gitee项目同步仓库(GitHub访问异常使用):[https://gitee.com/fengmengzhao/the-docker-handbook/](https://gitee.com/fengmengzhao/the-docker-handbook/)
---
<p align="center" style="color: red">本书完</p> | 119,208 | Apache-2.0 |
---
layout: post
title: " 匿名内部类练习题 "
subtitle:
cover-img:
thumbnail-img:
share-img:
date: 2022-01-02 22:57:26 +0800
tags: [Java, 练习题]
---
#### 匿名内部类练习题:
```java
public class exercisefour {
public static void main(String[] args) {
Cellphone cellphone = new Cellphone();
//调用testWork方法时,直接传入一个实现了Computer接口的匿名内部类即可
//该匿名内部类可以灵活的实现work,完成不同的计算任务
cellphone.testWork(new Computer() {
@Override
public double work(double n1, double n2) {
return n1 + n2;
}
}, 10, 15);
}
}
class Cellphone {
public void testWork(Computer computer, double n1, double n2) {
double result = computer.work(n1, n2);
System.out.println("计算后的结果为:" + result);
}
}
interface Computer {
double work(double n1, double n2);
}
```
以上练习题的匿名内部类是:
```java
new Computer() {
@Override
public double work(double n1, double n2) {
return n1 + n2;
}
}, //10,15 是两个传入的参数
```
同时也是一个对象,编译类型是Computer
```java
public class exerciser {
public static void main(String[] args) {
new A().f1();
}
}
class A {
private final String NAME = "clyde";
public void f1() {
class B {
private static final String NAME = "belle";
public void show() {
System.out.println("B name:" + NAME);
System.out.println("A name:" + A.this.NAME);
}
}
B b = new B();
b.show();
}
}
```
以上代码应注意:内部类应写在方法里边,同时在外部创建对象调用这个方法,就可以访问内部类
```java
package com.cuilo.Annotationc;
/**
* @author clyde
* @version 1.0
*/
public class exerciseSix {
public static void main(String[] args) {
Person person = new Person("唐僧", new Horse());
person.common();
person.passRiver();
}
}
class Person extends Factory {
private String name;
private Vehicles vehicles;
public Person(String name, Vehicles vehicles) {
this.name = name;
this.vehicles = vehicles;
}
public void passRiver() {
if (!(vehicles instanceof Boat)) {
vehicles = Factory.getBoat();
}
vehicles.work();
}
public void common() {
//判断当前属性是什么,不存在就获取一匹马
if (!(vehicles instanceof Horse)) {
vehicles = Factory.getHorse();
}
vehicles.work();
}
}
class Factory {
public static Horse getHorse() {
return new Horse();
}
public static Boat getBoat() {
return new Boat();
}
}
class Horse implements Vehicles {
@Override
public void work() {
System.out.println("一般情况,骑马行走");
}
}
class Boat implements Vehicles {
@Override
public void work() {
System.out.println("遇到河流,坐船行走");
}
}
interface Vehicles {
void work();
}
``` | 2,861 | MIT |
## 关于推送
### 开关
```ini
[notify]
enable = false
filter_words =
```
### 推送单元
> 以下数据为示例(e.g.),需要根据实际需求配置
**钉钉**
> 文档: https://developers.dingtalk.com/文档ument/robots/custom-robot-access
> 说明: 钉钉推送的密钥
```ini
; Dingtalk机器人|token|依赖USE_NOTIFY
[notify.dingtalk]
token = 566cc69da782ec****
```
**Telegram**
> 文档: https://core.telegram.org/bots/api#sendmessage
> 说明: 如果开启 TGbot API 反代,填写url,否则为空使用默认api。
> 说明: TG 推送的Token, xxx/bot{这是token部分}/xxxx
> 说明: TG 推送的用户/群组/频道 ID
```ini
; Tele机器人|url(可选)|token|chatid|依赖USE_NOTIFY
[notify.telegram]
url = https://*.*.workers.dev/bot
bottoken = 1640****:AAGlV3****_FscZ-****
chatid = 390****
```
**PUSH PLUS**
> 文档: http://www.pushplus.plus/doc/
> 说明: push plus++ 推送的 `token`
```ini
; Pushplus酱|token|依赖USE_NOTIFY
[notify.pushplus]
token = 566cc69da782ec****
```
**Sever酱(原版)**
> 文档: https://sc.ftqq.com/
> 说明: Server 酱老版本 key,SCU 开头的
```ini
; Sever酱(原版)|令牌Key|依赖USE_NOTIFY
[notify.sc]
sckey = SCU566cc69da782ec****
```
**Server酱(Turbo版)**
> 文档: https://sct.ftqq.com/
> 说明: Server 酱 Turbo 版本 key,SCT 开头的
```ini
; Server酱(Turbo版)|令牌Key|依赖USE_NOTIFY
[notify.sct]
sctkey = SCT566cc69da782ec****
```
**GoCqhttp**
> 文档: https://docs.go-cqhttp.org/api/
> 说明: 推送的完整api, 包含`/send_private_msg`、`/send_group_msg` 等等完整后缀
> 说明: 推送的AccessToken
> 说明: 目标QQ号或者QQ群号,根据API调整
```ini
; GoCqhttp|url|token|目标qq|依赖USE_NOTIFY
[notify.gocqhttp]
url = "http://127.0.0.1:5700/send_private_msg"
token = 566cc69da782ec****
target_qq = 10086
```
**Debug(个人用)**
> 文档: https://localhost:8921/doc
```ini
; Debug|个人调试推送|url|token|
[notify.debug]
url = "https://localhost:8921/notify"
token = 566cc69da782ec****
```
**企业微信群机器人**
> 文档: https://open.work.weixin.qq.com/api/doc/90000/90136/91770 | https://weibanzhushou.com/blog/330
> 说明: 推送的AccessToken
```ini
; 企业微信群机器人|token
[notify.we_com]
token = ec971f1d-****-4700-****-d9461e76****
```
**企业微信应用**
> 文档: https://open.work.weixin.qq.com/wwopen/devtool/interface?doc_id=10167
> 说明: 企业 id
> 说明: 应用的凭证密钥
> 说明: 企业应用的 id
> 说明: 指定接收消息的成员,成员 ID 列表 默认为@all
```ini
; 企业微信应用消息|corp_id|corp_secret|agent_id|to_user
[notify.we_com_app]
corp_id = ****
corp_secret = ****
agent_id = ****
to_user = UserId1|UserId2|UserId3
```
### 调试
https://github.com/lkeme/BiliHelper-personal/blob/eb06f55fa0fa6cb07bbeffc7e85c6ac0bfaa67b3/data/latest_version.json#L8
改成与线上不同的版本即可,检查新版本就会推送一次。 | 2,377 | MIT |
# leetcode 141 环形链表
```
给定一个链表,判断链表中是否有环。
为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。
示例 1:
输入:head = [3,2,0,-4], pos = 1
输出:true
解释:链表中有一个环,其尾部连接到第二个节点。
```
* 快慢指针解法
```c
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
bool hasCycle(struct ListNode *head) {
struct ListNode *fast=head;
struct ListNode *slow=head;
while(fast!=NULL && fast->next!=NULL){
fast=fast->next->next;
slow=slow->next;
if(fast==slow){
return true;
}
}
return false;
}
``` | 607 | Apache-2.0 |
# 利用 gitlab webhooks 实现代码同步到 Web 服务器
## 原理
基本原理就是只要你在 gitlab 上操作了某个动作,就会触发 `webhooks`
`webhooks` 就会请求你设定好的 URL,可以通过这个 URL 作为接口触发 web 服务器操作 `git pull`
## 踩过的坑
因为 `webhooks` 请求你的接口,是模拟 `http` 请求,所以这里涉及到服务器要设置好权限
而服务器上的 apache 用户跟你登录的又不一样,所以以下设置会涉及 `apache` 用户,目前以 `www` 为例
### SSH KEY
`git pull` 是 `apache` 用户操作的,我们直接在服务器上用 ssh-keygen 命令是给你登录的当前用户创建的
所以在生成 `SSH KEY` 的命令就是
```
sudo -u www ssh-keygen -t rsa
```
然后在服务器上 `clone` 也是需要用 `apache` 用户操作,这里以 `github` 的为例。**要使用 ssh 的地址**
```
sudo -u www git clone [email protected]:docrud/notebook.git
```
### git 操作权限
基本上 `apache` 用户是不会有 git 使用权限,所以我们设定一下,命令如下:
```
vim /etc/sudoers
// 在用户 root 下方加上以下,git 的地址可以通过 which git 命令查看
www localhost=(ALL) NOPASSWD:/usr/bin/git
```
该文档是只读的,所以得强制保存
### PHP 是否开放 exec shell_exec 等函数
可以先用 `phpinfo()` 查看以下 `disable_functions`
如果被禁用了,就得通过 `php.ini` 找到 `disable_functions`,删除相对应函数名称
### webhooks
登录 gitlab,切换到项目下,`setting - Integrations` 就可以新增 `webhooks`
点 `edit` 可以查看 `Recent Deliveries`
点 `View details` 就可以查看到请求详情(用于接口的接收)
### 接口代码 demo
因为框架用的是 `thinkPHP 5.1`,所以直接在框架里写了个控制器
需求相对简单,所以代码也写得简单
```php
<?php
namespace app\git\controller;
use app\common\controller\BaseController;
use email\Email;
/**
* Gitlab Webhooks
*
* chao@DoCRUD
*/
class Index extends BaseController
{
// 在 gitlab webhooks 设定好的 Secret Token
private const ACCESS_TOKEN = 'xxxxxxxxxxxxxxxxxxxx';
// 在 gitlab webhooks 里设定好的操作
private const ACCESS_EVENT = 'Merge Request Hook';
public function index()
{
// 获取到 gitlab webhooks 请求头部
$token = $this->request->header('X_GITLAB_TOKEN');
$event = $this->request->header('X_GITLAB_EVENT');
// 邮件通知
$mail = new Email();
$mail->sendTo('[email protected]');
$body = 'Request on [' . date('Y-m-d H:i:s') . '] from [' . $this->request->ip() . ']';
// Token 验证
if ($token !== self::ACCESS_TOKEN) {
$subject = 'Invalid token [' . $token . ']';
$mail->sendText($subject, $body);
return $this->buildFailed('401', 'Invalid token');
}
// 触发事件验证
if ($event !== self::ACCESS_EVENT) {
$subject = 'Invalid event [' . $event . ']';
$mail->sendText($subject, $body);
return $this->buildFailed('403', 'Invalid event');
}
// 操作限定,只在 merge 操作才触发 git pull
$attributes = $this->request->param('object_attributes');
$mergeStatus = $attributes['merge_status'];
// 判断操作状态
if ($mergeStatus != 'can_be_merged') {
$subject = 'Invalid merge status [' . $mergeStatus . ']';
$mail->sendText($subject, $body);
return $this->buildFailed('403', 'Invalid merge status');
}
// 先切换到项目目录下
exec("cd /home/wwwroot/docrud");
// 执行 git pull
exec("git pull origin master 2>&1", $output, $status);
$subject = 'Merge status: ' . $mergeStatus;
$body .= '<br>Pull result: ' . json_encode($output);
$mail->sendText($subject, $body);
return $this->buildSuccess();
}
}
``` | 3,114 | MIT |
---
layout: post
title: 注册表修改项名
subtitle: c++
date: 2019-12-3
author: YiMiTuMi
header-img:
catalog: true
tags:
- windows
---
# 注册表修改项名
windows中并没有提供修改注册表项名的接口(可能有我没找到),就手动写了一下。
思路:
  1)利用注册表的备份功能先备份出要改名的文件。
  2)删除要改名的文件。
  3)建一个要改的新名的项。
  4)将当前备份还原到新项中。
## 导出导入注册表权限获取函数
BOOL GetPrivilege()
{
BOOL bFlag = TRUE;
do
{
//设置权限导入导出注册表
HANDLE hToken,hToken1,hToken2;
TOKEN_PRIVILEGES tkp,tkp1,tkp2;
if(!OpenProcessToken (GetCurrentProcess(),TOKEN_ALL_ACCESS,&hToken))
{
bFlag = FALSE;
break;
}
if(!LookupPrivilegeValue( NULL, SE_BACKUP_NAME, &tkp.Privileges[0].Luid))
{
bFlag = FALSE;
break;
}
tkp.PrivilegeCount = 1;
tkp.Privileges[0].Attributes = SE_PRIVILEGE_ENABLED;
if(!AdjustTokenPrivileges( hToken, FALSE, &tkp, sizeof(TOKEN_PRIVILEGES),
(PTOKEN_PRIVILEGES)NULL, PDWORD(NULL)))
{
bFlag = FALSE;
break;
}
if(GetLastError () == ERROR_NOT_ALL_ASSIGNED || GetLastError () != ERROR_SUCCESS )
{
bFlag = FALSE;
break;
}
if(!OpenProcessToken (GetCurrentProcess(), TOKEN_ALL_ACCESS, &hToken1))
{
bFlag = FALSE;
break;
}
if(!LookupPrivilegeValue( NULL, SE_RESTORE_NAME, &tkp1.Privileges[0].Luid))
{
bFlag = FALSE;
break;
}
tkp1.PrivilegeCount = 1;
tkp1.Privileges[0].Attributes = SE_PRIVILEGE_ENABLED;
if(!AdjustTokenPrivileges( hToken1, FALSE, &tkp1, sizeof(TOKEN_PRIVILEGES), (PTOKEN_PRIVILEGES)NULL, PDWORD(NULL)))
{
bFlag = FALSE;
break;
}
if(GetLastError () == ERROR_NOT_ALL_ASSIGNED || GetLastError () != ERROR_SUCCESS )
{
bFlag = FALSE;
break;
}
if(!OpenProcessToken (GetCurrentProcess(), TOKEN_ALL_ACCESS, &hToken2))
{
bFlag = FALSE;
break;
}
if(!LookupPrivilegeValue( NULL, SE_DEBUG_NAME, &tkp2.Privileges[0].Luid))
{
bFlag = FALSE;
break;
}
tkp2.PrivilegeCount = 1;
tkp2.Privileges[0].Attributes = SE_PRIVILEGE_ENABLED;
if(!AdjustTokenPrivileges( hToken2, FALSE, &tkp2, sizeof(TOKEN_PRIVILEGES), (PTOKEN_PRIVILEGES)NULL, PDWORD(NULL)))
{
bFlag = FALSE;
break;
}
if(GetLastError () == ERROR_NOT_ALL_ASSIGNED || GetLastError () != ERROR_SUCCESS )
{
bFlag = FALSE;
break;
}
} while (FALSE);
return bFlag;
}
## 删除注册表项
删除注册表项我写了很多方法。
[RegDeleteKey](https://docs.microsoft.com/zh-cn/windows/win32/api/winreg/nf-winreg-regdeletekeya?redirectedfrom=MSDN) 函数删除的时候,删除的项下面不能有子项,所以要递归去删除。
BOOL DeleteReg(HKEY hPrimaryKey, wstring wstrRegPath)
{
BOOL bFlag = TRUE;
HKEY hKey = NULL;
long longReg = 0;
DWORD dwDisposition;
do
{
EnablePriviledge(SE_BACKUP_NAME); //最后会给出EnablePriviledge函数实现
EnablePriviledge(SE_RESTORE_NAME);
//这个是重点,传入这个参数可以直接忽视KEY_ALL_ACCESS这个参数的作用,直接以备份/还原的特权去操作注册表
longReg = RegCreateKeyExW(hPrimaryKey,
wstrRegPath.c_str(),
0,
NULL,
REG_OPTION_BACKUP_RESTORE,
KEY_ALL_ACCESS,
NULL,
&hKey,
&dwDisposition);
int b = GetLastError();
if (longReg != ERROR_SUCCESS)
{
bFlag = FALSE;
break;
}
/*
//打开注册表,这个也可以 上面那个测试权限用的
longReg = RegOpenKeyEx(hPrimaryKey, wstrRegPath.c_str(), 0, KEY_ALL_ACCESS | KEY_WOW64_64KEY, &hKey);
if (longReg != ERROR_SUCCESS)
{
bFlag = FALSE;
break;
}
*/
//获取注册表子键信息,判断是否有子键
TCHAR szSubKey[240]; //子键名称
DWORD dwName = 240; //名称大小
//是否有子键,如果有则递归查找,这里要注意,index不能自增,因为一旦删除了一个键,其余键的序号就会自己减一,所以不断删除0就可以了
int index = 0;
while (ERROR_SUCCESS == RegEnumKey(hKey, index, szSubKey, dwName))
{
wstring tmp = wstrRegPath + L"\\" + szSubKey;
bFlag = DeleteReg(hPrimaryKey, tmp);
}
//递归结束条件
if (!bFlag)
{
break;
}
//删除当前项
longReg = RegDeleteKey(hPrimaryKey, wstrRegPath.c_str());
int a = GetLastError();
if (longReg != ERROR_SUCCESS)
{
bFlag = FALSE;
break;
}
} while (FALSE);
RegCloseKey(hKey);
return bFlag;
}
也可以用[RegDeleteTree](https://docs.microsoft.com/zh-cn/windows/win32/api/winreg/nf-winreg-regdeletetreea?redirectedfrom=MSDN)去删除。
# 删除函数
当时写的是测试参数传的也比较随意。
注册表的HKEY,注册表修改项的上一项的路径,需要修改项的名字,新名字,修改项的全路径(其实传3项就可以解决,但懒得去截字符串了)
BOOL RenameRegItem(HKEY hPrimaryKey, wstring wstrRegPath, wstring wstrOldName,wstring wstrNewName, wstring FullPath)
{
BOOL bFlag = TRUE;
HKEY hKey = NULL;
long longReg = 0;
wstring wstrFilePath = L"";
do
{
if (wstrRegPath.empty() || wstrNewName.empty() || wstrOldName.empty() || hPrimaryKey == NULL)
{
break;
bFlag = FALSE;
}
if (!GetPrivilege())
{
bFlag = FALSE;
break;
}
wstring wstrOldPath = wstrRegPath + L"\\" + wstrOldName;
//打开注册表
longReg = RegOpenKeyEx(hPrimaryKey, wstrOldPath.c_str(), 0, KEY_ALL_ACCESS | KEY_WOW64_64KEY, &hKey);
if (longReg != ERROR_SUCCESS)
{
bFlag = FALSE;
break;
}
//重命名
wstrFilePath = L"C:\\Old_Name";
//备份注册表键值
longReg = RegSaveKey(hKey, wstrFilePath.c_str(), NULL);
int a = GetLastError();
if (longReg != ERROR_SUCCESS)
{
bFlag = FALSE;
break;
}
//递归删除旧项
if (0)
{
FullPath = L"cmd.exe /c reg delete " + FullPath + L" /F";
ExeCmd(FullPath);
}
wstring wsrtOldPath = wstrRegPath + L"\\" + wstrOldName;
if (!DeleteReg(hPrimaryKey, wsrtOldPath))
{
break;
}
//RegDeleteTree(hPrimaryKey, wsrtOldPath.c_str());
//关闭旧主键
RegCloseKey(hKey);
//新主键
//wstring wstrNewPath = wstrRegPath;
//打开新注册表
longReg = RegOpenKeyEx(hPrimaryKey, wstrRegPath.c_str(), 0, KEY_ALL_ACCESS | KEY_WOW64_64KEY, &hKey);
if (longReg != ERROR_SUCCESS)
{
bFlag = FALSE;
break;
}
HKEY newKey;
//创建新项
longReg = RegCreateKey(hKey, wstrNewName.c_str(), &newKey);
if (longReg != ERROR_SUCCESS)
{
bFlag = FALSE;
break;
}
//从文件中加载注册表键值
RegRestoreKey(newKey, wstrFilePath.c_str(), REG_FORCE_RESTORE);
if (longReg != ERROR_SUCCESS)
{
bFlag = FALSE;
break;
}
RegCloseKey(newKey);
} while (FALSE);
//删除保存注册表的文件
DeleteFile(wstrFilePath.c_str());
RegCloseKey(hKey);
return bFlag;
}
# 调用
int main()
{
RenameRegItem(HKEY_LOCAL_MACHINE, L"SYSTEM\\CurrentControlSet\\Control\\SafeBoot", L"999", L"321", L"HKEY_CURRENT_USER\\System\\999");
return 0;
}
# EnablePriviledge函数
BOOL EnablePriviledge(LPCTSTR lpSystemName)
{
HANDLE hToken;
TOKEN_PRIVILEGES tkp = {1};
if (OpenProcessToken(GetCurrentProcess(),TOKEN_ADJUST_PRIVILEGES | TOKEN_QUERY,&hToken))
{
if(LookupPrivilegeValue(NULL, lpSystemName, &tkp.Privileges[0].Luid))
{
tkp.PrivilegeCount = 1;
tkp.Privileges[0].Attributes = SE_PRIVILEGE_ENABLED;
AdjustTokenPrivileges(hToken, FALSE, &tkp, 0,(PTOKEN_PRIVILEGES) NULL, 0);
if (GetLastError() != ERROR_SUCCESS)
{
CloseHandle(hToken);
return false;
}
}
CloseHandle(hToken);
}
return true;
}
## 兔尾草 -- 尊贵杰出(被强烈科普,原来真有这个) | 7,456 | MIT |
# iframeTab plug-in for jQuery 2.3.7
jQuery iframeTab是一個模擬瀏覽器多窗口 + 標籤開啟頁面的插件,在標籤過多情況下將自動折疊成一行,還可右鍵關閉所有標籤。
除了樣式可以自由配置,還可配置事件回調函數。為了能更好更方便地操作本插件,iframeTab提供了API去對已初始化的對象進行操作。
#### 給我提供主機的離老闆最近忙於工作和公眾號,並沒有時間給我更新主頁。插件的更新日誌和使用說明請在 `example` 分支裡查看。
## DEMO演示 & API文檔
[示例](http://henrie.pursuitus.com/adminTemplate/)
## 最近更新
ver 2.3.7
1. **重要整改:**html結構修改,原本在 `<iframe>` 上的 `data-num` 和 `data-iframe` 屬性放到 `div.tab-panel` 上,參數不變;
2. 修復標籤爛展開狀態下,刪除標籤後,折疊按鈕無法再次出現bug;
3. 左側菜單寬度默認值從230改為0,如需設定,可將菜單欄 `id` 設為 `leftMenu` ,或自行在初始化時通過option設定數值;
4. 部分jQuery的代碼替換成JavaScript;
ver 2.3.6.1 on 04.01.2017
1. 更新教程文件和README,增加了關於樣式的說明;
ver 2.3.6.1 on 03.31.2017
1. 修復IE8以下,resize多次執行bug;
## 使用
### JS
初始化iframeTab並返回實例:
```js
var tab = iframeTab.init();
```
但我想你們會有自己的配置:
```js
var tab = iframeTab.init({
closesBtnClass: 'fa fa-close',
callback: {
beforeChange: function () {
$('.tab-panel.active iframe').hide();
},
onChange: function () {
$('.tab-panel.active iframe').hide();
},
afterChange: function () {
$('.tab-panel.active iframe').hide();
}
}
});
```
### HTML
#### 超鏈接
這是最簡單的超鏈接,`data-num=0` 是必須包含的,否則會作為一般鏈接在瀏覽器窗口打開:
```html
<a href="iframeTab-demo.html" data-num="0">主頁</a>
```
標籤欄上每個頁面的名字默認是超鏈接上的文字,如果你希望有所不同的話,你可以使用 `data-name`,例如:
```html
<a href="iframeTab-demo.html" data-num="0" data-name="我才不是主頁">主頁</a>
```
#### 標籤欄結構
```html
<div id="tabHeader">
<ul>
<li class="active tab-keep" data-tab="my-desktop.html" data-num="0">首頁</li>
<li data-tab="tabPage.html">標籤頁 <i data-btn="close"></i></li>
</ul>
</div>>
```
`<li>` 中的 `data-tab` 應與對應的iframe頁 `<iframe>` 中的 `src` 和 `data-iframe` 保持一致,內容應為iframe的 `src` 屬性。同時也必須包含 `data-num="0"` 。
`li.active` 表示當前標籤已激活,`li.tab-keep` 表示右鍵刪除所有標籤時將保留當前標籤。
若需添加 `data-btn="close"` 為刪除標籤按鈕。
#### iframe結構
```html
<div id="tabBody">
<div class="tab-panel tab-keep active" data-iframe="my-desktop.html" data-num="0">
<!-- 包裹iFrame的外部元素,可按自己需求更改,如需設置,應同時在option中配置iframeBox -->
<div class="right_col" role="main">
<iframe src="my-desktop.html" marginheight="0" marginwidth="0" frameborder="0" scrolling="no" onload="iframeTab.iframeHeight()" height="188"></iframe>
</div>
</div>
</div>
```
`<iframe>` 中的 `src` 和 `data-iframe` 應與對應的標籤 `<li>` 中的 `data-tab` 保持一致,內容應為iframe的 `src` 屬性。同時也必須包含 `data-num="0"` 。
`.tab-panel.active` 表示當前iframe已激活,`.tab-panel.tab-keep` 表示右鍵刪除所有標籤時將保留當前iframe頁。
```html
<div class="right_col" role="main">
```
為 `div.tab-panel` 和 `<iframe>` 間的容器,並非必要,若需自行配置或不需要該容器,可在option中配置 `iframeBox` 參數。
### CSS
雖然css都是自由搭配,但有幾個影響功能的樣式是必須要加上的(以下代碼摘自本demo未經過編譯的iframeTab.scss文件,僅供參考,選擇器請按需自行搭配):
```scss
.tabs-body {
.tab-panel {
display: none; /*隱藏窗口*/
&.active {
display: block; /*顯示窗口*/
}
iframe {
width: 100%; /*iframe寬度*/
}
}
}
.tab-contextmenu {
position: absolute; /*右鍵菜單位置*/
}
.tabs-header {
ul {
li {
&.active {
/*激活狀態標籤樣式*/
}
}
&.hide-tab {
height: 90px; /*標籤欄折疊高度*/
}
}
}
```
#### 重要提示
1. 標籤激活狀態和窗口的顯隱務必通過 `.active` 控制;
2. 標籤關閉圖標和標籤欄折疊圖標都是自行設計的,若非項目已有使用,不建議按照本demo引用文件。兩個圖標的樣式可通過初始化時傳遞參數設置,詳情請參看教程頁面;
## gulp
因為本插件涉及iframe操作,在本地直接打開將報錯,你需要在服務器上調試,本插件提供 `gulp` 調試方式,你可以以此進行插件模擬和代碼編譯。
可用的 `gulp` 命令如下:
* `gulp` 運行服務器并編譯所有代碼
* `gulp browser-sync` 運行服務器
* `gulp watch` 進入watch模式
* `gulp sass-to-css` 將sass編譯成css
* `gulp minify-css` 壓縮css
* `gulp jscompress` 壓縮js
## 分支說明
* `build` 開發分支
* `dist` 包含全部編譯後代碼的分支
* `example` 示例頁面分支
* `vendor` 其他插件分支
## 聯繫與討論
QQ:3088680950
如果發現八阿哥了或者有功能上的建議,推薦通過 `issue` 發起討論。
## License
[MIT license](https://opensource.org/licenses/MIT). 有好的想法歡迎提供。 | 3,691 | MIT |
<!-- DON'T EDIT THIS SECTION, INSTEAD RE-RUN sunsta TO UPDATE -->
**Table of Contents** *generated with [sunsta](https://zhihu.com/people/qydq)*
- [android快速集成基础框架 - Livery```1.1.111```](#android%E5%BF%AB%E9%80%9F%E9%9B%86%E6%88%90%E5%9F%BA%E7%A1%80%E6%A1%86%E6%9E%B6---livery1124)
- [情景能力# Ability](#%E6%83%85%E6%99%AF%E8%83%BD%E5%8A%9B-ability)
- [1:主要能力](#1%E4%B8%BB%E8%A6%81%E8%83%BD%E5%8A%9B)
- [2:最新版本能力](#2%E6%9C%80%E6%96%B0%E7%89%88%E6%9C%AC%E8%83%BD%E5%8A%9B)
- [集成方式# Binaries](#%E9%9B%86%E6%88%90%E6%96%B9%E5%BC%8F-binaries)
- [模块介绍# Details Module](#%E6%A8%A1%E5%9D%97%E4%BB%8B%E7%BB%8D-details-module)
- [部分情景能力演示](#%E9%83%A8%E5%88%86%E6%83%85%E6%99%AF%E8%83%BD%E5%8A%9B%E6%BC%94%E7%A4%BA)
- [an情景系列(material-ux)](#an%E6%83%85%E6%99%AF%E7%B3%BB%E5%88%97material-ux)
- [an情景系列(scene-mode)](#an%E6%83%85%E6%99%AF%E7%B3%BB%E5%88%97scene-mode)
- [弹幕控制](#%E5%BC%B9%E5%B9%95%E6%8E%A7%E5%88%B6)
- [混淆配置# proguard-rules](#%E6%B7%B7%E6%B7%86%E9%85%8D%E7%BD%AE-proguard-rules)
- [常见错误# Easy Mistake](#%E5%B8%B8%E8%A7%81%E9%94%99%E8%AF%AF-easy-mistake)
- [非常重要1:1.1.x版本用androidx,替换掉所有的support-v4,v7包](#%E9%9D%9E%E5%B8%B8%E9%87%8D%E8%A6%81111x%E7%89%88%E6%9C%AC%E7%94%A8androidx%E6%9B%BF%E6%8D%A2%E6%8E%89%E6%89%80%E6%9C%89%E7%9A%84support-v4v7%E5%8C%85)
- [非常重要2: Manifest merger failed : Attribute meta-data#android.support.FILE_PROVIDER_PATHS](#%E9%9D%9E%E5%B8%B8%E9%87%8D%E8%A6%812-manifest-merger-failed--attribute-meta-dataandroidsupportfile_provider_paths)
- [非常重要3:This project uses AndroidX dependencies, but the 'android.useAndroidX' property is not enabled. Set this property to true in the gradle.properties file and retry.](#%E9%9D%9E%E5%B8%B8%E9%87%8D%E8%A6%813this-project-uses-androidx-dependencies-but-the-androiduseandroidx-property-is-not-enabled-set-this-property-to-true-in-the-gradleproperties-file-and-retry)
- [注意事项2: More than one file was found with OS independent path 'META-INF/rxjava.properties'](#%E6%B3%A8%E6%84%8F%E4%BA%8B%E9%A1%B92-more-than-one-file-was-found-with-os-independent-path-meta-infrxjavaproperties)
- [更多:其它android中常见错误解决方法点击这里查看。](#%E6%9B%B4%E5%A4%9A%E5%85%B6%E5%AE%83android%E4%B8%AD%E5%B8%B8%E8%A7%81%E9%94%99%E8%AF%AF%E8%A7%A3%E5%86%B3%E6%96%B9%E6%B3%95%E7%82%B9%E5%87%BB%E8%BF%99%E9%87%8C%E6%9F%A5%E7%9C%8B)
- [版本日志# Version LOG](#%E7%89%88%E6%9C%AC%E6%97%A5%E5%BF%97-version-log)
- [apk下载及其说明](#apk%E4%B8%8B%E8%BD%BD%E5%8F%8A%E5%85%B6%E8%AF%B4%E6%98%8E)
- [1.0.x版本总述](#10x%E7%89%88%E6%9C%AC%E6%80%BB%E8%BF%B0)
- [1.1.x](#11x)
- [其它说明](#%E5%85%B6%E5%AE%83%E8%AF%B4%E6%98%8E)
- [关于自定义apk名说明](#%E5%85%B3%E4%BA%8E%E8%87%AA%E5%AE%9A%E4%B9%89apk%E5%90%8D%E8%AF%B4%E6%98%8E)
- [关于应用内apk自动安装说明](#%E5%85%B3%E4%BA%8E%E5%BA%94%E7%94%A8%E5%86%85apk%E8%87%AA%E5%8A%A8%E5%AE%89%E8%A3%85%E8%AF%B4%E6%98%8E)
- [致谢](#%E8%87%B4%E8%B0%A2)
- [LICENSE](#license)
<!-- END doctoc generated TOC please keep comment here to allow auto update -->
# android快速集成基础框架 - Livery```1.1.111```
[](https://github.com/qydq/alidd-sample/blob/master/LICENSE)
[](https://bintray.com/qydq/maven/livery/_latestVersion)
[](https://bintray.com/qydq/maven/livery/_latestVersion)

[](https://android-arsenal.com/api?level=21)
[](https://github.com/qydq/small-video-record/releases)
[](https://www.zhihu.com/people/qydq)
[***中文API帮助文档1.1下载`密码:xeq0`)***](https://pan.baidu.com/s/1yczO3lh4p8Njc_rdb9Fe5g) 一款针对Android平台下快速集成**便捷开发**框架,```an情景```系列```livery框架```部分基于基础的an-base项目[#原an框架](https://github.com/qydq/an-aw-base)仓库优化而来,其目的1是为小团子fang升级一款音乐聊天软件```[hong]3.0版本```,现在开放出来,当前优化后最新体积仅有603KB.

>20190609再次确定命名image*Internet.
>livery一直维护,周1-5工作,有bug提[issues]([https://github.com/qydq/alidd-samples/issues](https://github.com/qydq/livery-sample/issues))(或在知乎上给我留言,**问题描述清楚**就行],一般修复好周7当晚更新.
专注于物联网领域,世界的通信标准从今开始改变,手机也可以是路由器,成功于视频直播,标准并不一定是Http/s,也可以是Bluetooth.
[**我的唯一知乎地址.**](https://www.zhihu.com/people/qydq/columns)       (感谢关注🙏)
## 情景能力# Ability
```livery```一路走来经历了很多版本,现在是一个非常成熟的稳定版本;它包含一些非常实用的能力和一些技巧, 用简洁友好的方式,助力便捷开发;以下列举当前支持的**部分**功能<br/>
**⚠️注意**
>`1.1.10`之前的版本差异较大,建议使用最新版本. [(点击这里查看老版本日志记录)](https://github.com/qydq/alidd-samples/blob/master/alidd_old_1.0.x.md)
>`1.2.0`Livery已经启动了1.2.0国际化版本的任务,敬请期待!
### 1:主要能力
- [x] 符合Google Material Design的基类,如:AliActivity、AliFragment、BasePresenter、BaseView==.
- [x] 两种夜间模式.
- [x] 网络1请求基于xutils3模块的封装,http实现XHttps.** (⚠️因控制大小移除xutils,替代为Retrofit+RxJava)
- [x] INA系列控件相关,如标题栏,弹幕,tab.
- [x] 拉```La```情景实用能力集,如MD5加密,数据校验,尺寸,图片处理,网络,模糊算法,更新软件==.
- [x] StrictMode API 禁权限便捷申请.
### 2:最新版本能力
- [x] 网络2请求InternetClient基于Retrofit封装;RxJava,RxAndroid实现InternetAsyncManager.
- [x] GIF图片更友好便捷使用,提供GifImageView可以更快的加载Gif,效率可对比之前INAPowerImageView.
- [x] Glide加载图片会出现抖动的修复,请使用LaImageLoader.
- [x] 拍照相册选择能力,集成[PictureSelector](https://github.com/LuckSiege/_PictureSelector_);整合原TakePhoto模块,视频预览图MediaHelper.
- [x] 快速集成实现你的导航栏工具
- [ ] 正在开发ing...智能语音唤醒监听能力(世界上最美的就是声音Voice ).
     [**最新体验扫描二维码下载hong1.1.111.apk**](https://github.com/qydq/alidd-samples/raw/master/apk/demo_livery1.1.111.apk)    
## 集成方式# Binaries
集成方式有以下两种:
### 1.(建议)通过JCenter集成
第1步骤: 在你项目(app module)的build.gradle中添加(致谢JitPack和Jcenter).
```Groovy
dependencies {
implementation'com.sunsta.livery:livery:1.1.111'
}
```
第2步骤(可选):如果使用`网络2请求`,最好在你的`XxxApplication`中继承`AnApplication`,然后在`onCreate()`方法中调用如下代码
```java
public class AliddApplication extends AnApplication {
@Override
public void onCreate() {
super.onCreate();
Livery.instance().initialze("BASE_URL");
Livery.instance().enableLog(DEBUG,"LOGFILTER);//当配置该内容时候,会打印Livery关键建议信息
}
```
说明:`BASE_URL`是符合Retrofit的网络请求地址,如:`https://github.com/qydq/`,需要以`/`结尾,最后把`XxxApplication`添加到`AndroidManifest.xml`中.
### 2.(可选)手动集成:
第1步骤: 在链接:https://pan.baidu.com/s/1_NtHc-AlTaw3ka2aoeqQ_A 密码:16f2;下载Livery最新版本文件livery1.1.111.aar
然后将文件拷贝到libs目录中添加引用关系:
```Groovy
dependencies {
implementation(name:'livery1.1.111', ext:'aar')
}
```
## 模块介绍# Details Module
```hong1.x.x.apk```为提供的安装包(可以扫描前面的二维码下载),```kaiyan.apk```为livery结合MVVM开发的安装包,已共享到```玩安卓```网站,这里也可以下载;```hong1.x.xx_picture.apk```为PictureSelector二次编译以后的图片选择框架。
尽量少的依赖其它库来完成这个demo,使用原生的系统的组件和本livery框架提供的部分
包含4个tab:```1.Livery```提供,```2.通用业务```框架的使用,```3.视频```和```4.关于```
>```1和2模块```中控件符合material design但是具体需要注意只有标注为:☀️ 表示这个模块的功能为发行版本,其它的示例代码仅供参考.
>```3和4模块```类似该功能不做参考,个人当前测试的一些逻辑性,功能性代码,如视频编解码,这部分代码仅供参考.
关于```livery情景```更多的api可以查看帮助文档.

下面是部份```Details Module```的介绍,更多内容可以从本人知乎an情景专栏中获取.
### 部分情景能力演示
说明:效果图包含了部分livery情景能力,关注我的知乎获取更多实用的技巧.
| 主页Home | 动画Gif |
|:-----------:|:-----------:|
|
||
| 导航栏 | 导航栏1 | 导航栏2 |
|:-----------:|:--------:|:---------:|
|
 |||
### an情景系列(material-ux)
1.Gif图片加载方法
```XML
<com.sunsta.bear.engine.gif.GifImageView
android:id="@+id/gif_iamge_view"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:src="@mipmap/gif"/>
```
循环播放
GifImageView默认播放一次就停止了,我们可以通过GifImageView获取GifDrawable,然后再通过GifDrawable设置循环播放的次数,或者设置无限循环播放
```JAVA
GifImageView gifImageView = findViewById(R.id.gif_iamge_view);
GifDrawable gifDrawable = (GifDrawable) gifImageView.getDrawable();
gifDrawable.setLoopCount(5); //设置具体播放次数
gifDrawable.setLoopCount(0); //设置无限循环播放
```
### an情景系列(scene-mode)
#### 弹幕控制
barrage_rowNum //设置弹幕有多少行 , 默认1行弹幕
barrage_rowHeight //设置弹幕的高度 ,默认10dp
注意:当覆盖布局文件中的高度时,会使用xml中的布局高度
barrage_speed //设置弹幕的滚动的速度 ,默认8000秒
barrage_itemGap //设置弹幕与弹幕之间的间距,默认10dp
barrage_RowGap //设置弹幕与弹幕之间的行距,默认2dp
barrage_mode //设置弹幕的布局方式,默认正常(default)平均
barrage_isFly //设置弹幕是否可以漫天飞羽,默认true
barrage_keepSequence //当漫天飞羽时,设置是否保持先后顺序,默认false表示弹幕在布局INABarrageView内随机没有顺序的,不分先后出现,true表示弹幕每次显示一行,当第一行显示完再显示第二行
注意:当设置弹幕行数大于1(超过默认行数),则漫天飞羽关闭
barrage_interreptor //设置差值器,(保留字段)
barrage_gravity //设置弹幕内容,相对于布局INABarrageView的方向, 默认default,则有可能从上到下显示
barrage_duration // 保留字段,不可用,无效,
动画持续的时间,不同宽度的物体,划过同一个窗口,规定了总时间,以此获取对应的速度
barrage_repeatCount //设置动画重复的次数,默认0,设置为:ValueAnimator.INFINITE 则该弹幕会无限循环播放
## 混淆配置# proguard-rules
混淆规则一定要看:[**Android App代码混淆解决方案click**](https://zhuanlan.zhihu.com/p/34559807)
```BASH
#---------------------------4.(反射实体)个人指令区-qy晴雨(请关注知乎Bgwan)---------------------
# livery 1.1.xx
-keep class com.sunsta.bear.view.activity.**{*;}
-keep class androidx.support.widget.helper.**{*;}
-keep class com.sunsta.bear.**{*;}
-keep class com.sunsta.livery.**{*;}
-keep class com.sunsta.bear.view.**{*;}
-keep class com.sunsta.bear.view.recyclerview.**{*;}
-keep class com.sunsta.bear.view.activity.**{*;}
-dontwarn com.sunsta.bear.**
-keep class com.sunsta.bear.layout.** { *; }
-dontwarn com.sunsta.bear.layout.ucrop**
-keep class com.sunsta.bear.layout.ucrop** { *; }
-keep interface com.sunsta.bear.layout.ucrop** { *; }
#内部内
-keepclasseswithmembers class com.sunsta.bear.AnConstants$URL {
<methods>;}
-keepclasseswithmembers class com.sunsta.bear.AnConstants$KEY {
<methods>;}
-keep public class com.sunsta.bear.engine.gif.GifIOException{<init>(int);}
-keep class com.sunsta.bear.engine.gif.GifInfoHandle{<init>(long,int,int,int);}
```
## 常见错误# Easy Mistake
./gradlew processDebugManifest --stacktrace
### 非常重要1:1.1.x版本用androidx,替换掉所有的support-v4,v7包
由于```livery```基于```an-aw-base```,在版本```1.1.x```以后用```androidx```替换了所有的```support-v4,v7```等;如果你的项目已经包含了```v4,v7,```建议删除跟```v4,v7```的依赖,如不能删除,如下参考配置.
项目的根目录的build.gradle中添加,这样就可以忽略support相关的包引用问题
```Groovy
configurations {
all*.exclude group :'com.android.support',module:'support-compat'
all*.exclude group :'com.android.support',module:'support-v4'
all*.exclude group :'com.android.support',module:'support-annotations'
all*.exclude group :'com.android.support',module:'support-fragment'
all*.exclude group :'com.android.support',module:'support-core-utils'
all*.exclude group :'com.android.support',module:'support-core-ui'
}
```
或参考:
```Groovy
implementation('me.imid.swipebacklayout.lib:library:1.1.0') {
exclude group: 'com.android.support'
}
```
### 非常重要2: Manifest merger failed : Attribute meta-data#android.support.FILE_PROVIDER_PATHS
这是File_provider冲突,修改AndroidManifest.xml文件.[参考](https://blog.csdn.net/lbqcsdn/article/details/84795775)
```XML
<provider
android:name="android.support.v4.content.FileProvider"
android:authorities="${applicationId}.fileprovider"
android:exported="false"
android:grantUriPermissions="true">
<meta-data
android:name="android.support.FILE_PROVIDER_PATHS"
android:resource="@xml/gdt_file_path" />
</provider>
<provider
android:name=".utils.BuglyFileProvider"
android:authorities="${applicationId}.fileProvider"
android:exported="false"
android:grantUriPermissions="true"
tools:replace="name,authorities,exported,grantUriPermissions">
<meta-data
android:name="android.support.FILE_PROVIDER_PATHS"
android:resource="@xml/bugly_file_paths"
tools:replace="name,resource" />
</provider>
```
### 非常重要3:This project uses AndroidX dependencies, but the 'android.useAndroidX' property is not enabled. Set this property to true in the gradle.properties file and retry.
在你的gradle.properties中加入:
>android.useAndroidX=true
如下参考配置:
```Groovy
org.gradle.jvmargs=-Xmx1536m
# org.gradle.parallel=true
android.useAndroidX=true
# Automatically convert third-party libraries to use AndroidX
android.enableJetifier=true
android.useDeprecatedNdk=true
```
### 注意事项1:Attribute application@theme value=(@style/AppTheme) from AndroidManifest.xml:11:9-40 is also present at [com.sunsta.livery:livery:1.1.13] AndroidManifest.xml
这是livery资源冲突,在你的AndroidManifest.xml application标签中添加(根据需要添加):
>tools:replace="android:icon,android:theme,android:label,android:allowBackup,android:name"
也可以把application标签中的重复的删除
### 注意事项2: More than one file was found with OS independent path 'META-INF/rxjava.properties'
这是rxJava冲突,在app目录的build.gradle下添加
```Groovy
packagingOptions {
exclude 'META-INF/rxjava.properties'
}
```
### [更多:其它android中常见错误解决方法点击这里查看。](https://github.com/qydq/alidd-samples/blob/master/error.md)
## 版本日志# Version LOG
[**an-aw-base0.x.x版本log.**](https://github.com/qydq/an-aw-base/releases)
**⚠️注意**
>代码提交严格跟随日志内容,方便日后查阅相关记录,为控制字数;这里只记录1.0.x版本日志总述([了解详细1.0.x版本日志点击这里](https://github.com/qydq/alidd-samples/blob/master/alidd_old_1.0.x.md))和1.1.8之后的重要版本记录
### apk下载及其说明
  [最新版本(demo_livery1.1.13.apk)](https://github.com/qydq/alidd-samples/raw/master/apk/demo_livery1.1.13.apk)
alidd-samples项目(project)概况:
| **livery版本** *`(日期)`* |项目大小|apk大小 |livery发布release大小 |备注(版本大小变化说明) |
| -------- | ----:|-----: |-----: | :---- |
|**v1.0.10** *`(2019/12/31)`*| 180M | 7.5M | 6.4M |INATabLayout为例,推广引入`livery`首发-使用案例 |
|**v1.0.19** *`(2020/01/02)`*| 255M | 13.4M |12.2M |1.包含了视频2个情景系列 和Gif加载动画<br/>2.引入了几张大 的资源gif图, 这是apk Size变大的原因 |
|**v1.1.10** *`(2020/03/26)`*| 259M | 16M | 2M |1.包含了视频滤镜的module videobeauty<br/>2.包含导航栏,新增md设计 |
|**v1.1.13** *`(2020/05/20)`*| 240M | 16.9M | 1.2M |1.针对资源文件进一步优化,移除大量的布局资源,进行统一分类,视频模块测试代码放开 |
|**v1.1.51** *`(2020/06/03)`*| 240M | 17.1M | 603M | 1.1.51再次移除了一些非必须的资源文件,增加优化了已知问题,继承的体积再此压缩到566KB|
|**v1.1.111** *`(2020/06/03)`*| 230M | 17.1M | 603M | 1.1.111优化了一些已知问题|
说明:alidd-samples项目,是为了方便开发者快速集成livery提供的源代码;demo_livery1.1.11.apk,后面的版本是属于livery情景框架的版本号,非demo版本号(当前demo_apk版本暂时只为1.0).
另:1.1.100以后的版本,交替执行,偶数表示优化当前1.1.x版本, 1.2.x版本为基数如101版本(beta=1.2.x)
### 1.0.x版本总述
livery的初始版本,从an-aw-base重构而来,livery框架1.0.x(及以下的版本)支持的android最低版本为,minSdkVersion=19,总共发布了20个实际版本,具体依赖方法如下:
```Groovy
implementation 'com.sunsta:livery:1.0.x'
```
1.0.x包含包含了support系列的库
```Groovy
appcompat : 'com.android.support:appcompat-v7:27.0.2',
constraint: 'com.android.support.constraint:constraint-layout:1.0.2',
design : 'com.android.support:design:27.0.2',
recyclerview : 'com.android.support:recyclerview-v7:27.0.2',
retrofit : 'com.squareup.retrofit2:retrofit:2.3.0',
gson: 'com.squareup.retrofit2:converter-gson:2.1.0',
rxjava2: 'com.squareup.retrofit2:adapter-rxjava2:2.3.0',
okhttp : 'com.squareup.okhttp3:okhttp:3.8.1',
glide : 'com.github.bumptech.glide:glide:4.3.1',
xutils : 'org.xutils:xutils:3.5.0',
glidecompiler: 'com.github.bumptech.glide:compiler:4.3.1',
multipleimageselect: 'com.darsh.multipleimageselect:multipleimageselect:1.0.4',
crop: 'com.soundcloud.android.crop:lib_crop:1.0.0',
advancedluban: 'me.shaohui.advancedluban:library:1.3.2',
nineoldandroids : 'com.nineoldandroids:library:2.4.0',
```
### 1.1.x
**⚠️特别注意**
**:`1.1.x`相比`1.0.x`版本,不再支持`support包`,并且最低版本升级到api=21,也就是说,为了控制性能,`livery`不再支持`android5.0`以下的系统**
**记录内容:**
* 1.1.x版本主要是添加androidx,移除升级修复减小体积,相关第三方库bug,完善稳定网络2请求,修改最低支持版本为21,也就是说livery在以后不再支持android5.0以下的手机.
* 所有的控件使用均不支持support.v4,v7这样的包(包含如RecyclerView等等),代替的是androidx最新的库.
* 优化和移除takePhoto模块依赖的编译库,因为一些第三方库长久不更新,会导致一些问题,严重的可能出现崩溃,(如multipleimageselect 该库的作者未更新,导致更新glide后,在android8.0 ,9.0上存在兼容性问题).
* 引入androidx.camera的测试版本,(此版本存在兼容性问题,如需引用androidx.camera特性,需要依赖1.1.1版本:并同时修改minSdkVersion=21)优化并且统一框架中的资源命名规范问题,涉及到字符串,颜色资源,属性定义,布局文件,类文件标准命名等等.
```
api "androidx.concurrent:concurrent-futures:1.0.0-rc01"
api "androidx.camera:camera-lifecycle:1.0.0-alpha01"
api "androidx.camera:camera-core:1.0.0-alpha08"
api "androidx.camera:camera-camera2:1.0.0-alpha05"
```
**具体依赖方法如下类似:**
```Groovy
implementation 'com.sunsta:livery:1.1.x'
```
## 其它说明
### 关于自定义apk名说明
```Groovy
#---------------------------3.(自定义apk)个人其它说明区-sunst(请关注知乎Bgwan)---------------------
// 便利所有的Variants,all是迭代遍历操作符,相当于for
applicationVariants.all { variant ->// 遍历得出所有的variant
variant.outputs.all {// 遍历所有的输出类型,一般是debug和replease
// 定义apk的名字,拼接variant的版本号
def apkName = "app_${variant.versionName}"
// 判断是否为空
if (!variant.flavorName.isEmpty()) {
apkName += "_${variant.flavorName}"
}
// 赋值属性
String time = new Date().format("_YYYYMMddHH")
if (variant.buildType.name.equals("release")){
outputFileName = apkName + "_Replease" + time + ".apk"
}else {
outputFileName = apkName + "_Debug" +time + ".apk"
}
}
}
```
### 关于应用内apk自动安装说明
```Groovy
#---------------------------4.(应用内apk安装)个人其它说明区-sunst(请关注知乎Bgwan)---------------------
private Intent getInstallIntent() {
String fileName = savePath + appName + ".apk";
Uri uri = null;
Intent intent = new Intent(Intent.ACTION_VIEW);
try {
if (Build.VERSION.SDK_INT >= 24) {//7.0 Android N
//com.xxx.xxx.fileprovider为上述manifest中provider所配置相同
uri = FileProvider.getUriForFile(mContext, "你自己的包名.fileprovider", new File(fileName));
intent.setAction(Intent.ACTION_INSTALL_PACKAGE);
intent.addFlags(Intent.FLAG_GRANT_READ_URI_PERMISSION);//7.0以后,系统要求授予临时uri读取权限,安装完毕以后,系统会自动收回权限,该过程没有用户交互
} else {//7.0以下
uri = Uri.fromFile(new File(fileName));
intent.setAction(Intent.ACTION_VIEW);
intent.setFlags(Intent.FLAG_ACTIVITY_NEW_TASK);
}
intent.setDataAndType(uri, "application/vnd.android.package-archive");
startActivity(intent);
return intent;
} catch (IllegalArgumentException e) {
e.printStackTrace();
} catch (ActivityNotFoundException e) {
e.printStackTrace();
} catch (Exception e) {
e.printStackTrace();
}
return intent;
}
```
## 致谢
非常感谢以下前辈(or开源组织机构org)的开源精神,当代互联网的发展离不开前辈们的分享,Livery的成功发布也是.
再次感谢🙏。<br/> 最后感谢[github](https://github.com)优秀的代码管理平台(排名不分先后)
- [x] [致敬与缅怀-雷霄骅前辈](https://blog.csdn.net/leixiaohua1020 "雷霄骅")
- [x] [yalantis](https://www.runoob.com/w3cnote/android-ui-framework.html)
- [ ] [darsh2](https://github.com/darsh2/MultipleImageSelect)
- [x] [LuckSiege](https://github.com/LuckSiege/PictureSelector)
- [ ] [crazycodeboy](https://github.com/crazycodeboy/TakePhoto)
- [x] [ReactiveX RxAndroid](https://github.com/ReactiveX/RxAndroid)
- [x] [ReactiveX RxJava](https://github.com/ReactiveX/RxJava)
- [x] [squareup retrofit](//20191128)
- [x] [squareup gson](//20191128)
- [x] [squareup retrofit2 adapter-rxjava2](//20191128)
- [x] [bumptech glide](https://github.com/bumptech/glide)
- [x] [罗升阳](https://blog.csdn.net/Luoshengyang "罗升阳")
- [x] [**郭霖**](https://blog.csdn.net/sinyu890807 "guolin")
- [x] [严振杰](https://blog.csdn.net/yanzhenjie1003 "严振杰")
- [x] [张鸿洋_](https://blog.csdn.net/lmj623565791 "鸿洋_")
- [ ] [一片枫叶](https://blog.csdn.net/qq_23547831 "一片枫叶_刘超")
## LICENSE
***[版权声明©️](https://zhuanlan.zhihu.com/p/80668416)***
```java
/*
* Copyright (C) 2016 The Android Developer sunst
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
*http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
``` | 19,798 | Apache-2.0 |
# tars2php
## tars2php(自动生成php类工具)使用说明
### 简介
tars2php主要功能是通过tars协议文件,自动生成client端和server端php代码,方法大家使用。(server端主要为框架代码,实际业务逻辑需要自己补充实现)
### 基本类型的映射
如下是我们对基本类型的映射:
```text
bool => \TARS::BOOL
char => \TARS::CHAR
uint8 => \TARS::UINT8
short => \TARS::SHORT
uint16 => \TARS::UINT16
float => \TARS::FLOAT
double => \TARS::DOUBLE
int32 => \TARS::INT32
uint32 => \TARS::UINT32
int64 => \TARS::INT64
string => \TARS::STRING
vector => \TARS::VECTOR
map => \TARS::MAP
struct => \TARS::STRUCT
```
当我们需要标识具体的变量类型的时候,就需要用到这些基本的类型了,这些类型都是常量,从1-14。
### 复杂类型的映射
针对vector、map、struct三种基本的类型,有一些特殊的打包解包的机制,因此需要引入特别的数据类型: vector:
```text
vector => \TARS_VECTOR
它同时具有两个成员函数pushBack()和push_back()
入参为取决于vector本身是包含什么类型的数组
例如:
$shorts = ["test1","test2"];
$vector = new \TARS_VECTOR(\TARS::STRING); //定义一个string类型的vector
foreach ($shorts as $short) {
$vector->pushBack($short); //依次吧test1,test2两个元素,压入vector中
}
```
map:
```text
map => \TARS_MAP
它同时具有两个成员函数pushBack()和push_back()
入参为取决于map本身包含什么类型
例如:
$strings = [["test1"=>1],["test2"=>2]];
$map = new \TARS_MAP(\TARS::STRING,\TARS::INT64); //定义一个key为string,value是int64的map
foreach ($strings as $string) {
$map->pushBack($string); //依次把两个元素压入map中,注意pushBack接收一个array,且array只有一个元素
}
```
struct:
```text
struct => \TARS_Struct
struct的构造函数比较特殊,接收classname和classfields两个参数
第一个描述名称,第二个描述struct内的变量的信息
例如:
class SimpleStruct extends \TARS_Struct {
const ID = 0; //TARS文件中每个struct的tag
const COUNT = 1;
public $id; //strcut中每个元素的值保存在这里
public $count;
protected static $fields = array(
self::ID => array(
'name'=>'id',//struct中每个元素的名称
'required'=>true,//struct中每个元素是否必须,对应tars文件中的require和optional
'type'=>\TARS::INT64,//struct中每个元素的类型
),
self::COUNT => array(
'name'=>'count',
'required'=>true,
'type'=>\TARS::UINT8,
),
);
public function __construct() {
parent::__construct('App_Server_Servant.SimpleStruct', self::$fields);
}
}
```
### tars2php使用方法
如果用户只有使用打包解包需求的,那么使用流程如下:
1. 准备一份tars协议文件,例如example.tars
2. 编写一个tars.proto.php文件,这是用来生成代码的配置文件。
```text
//本范例的servant name为PHPTest.PHPServer.obj
return array(
'appName' => 'PHPTest', //tars服务servant name 的第一部分
'serverName' => 'PHPServer', //tars服务servant name 的第二部分
'objName' => 'obj', //tars服务servant name 的第三部分
'withServant' => true,//决定是服务端,还是客户端的自动生成
'tarsFiles' => array(
'./example.tars' //tars文件的地址
),
'dstPath' => './server/', //生成php文件的位置
'namespacePrefix' => 'Server\servant', //生成php文件的命名空间前缀
);
```
1. 执行php ./tars2php.php ./tars.proto.php
2. 工具会根据servant name自动生成三级目录结构,demo中会在./server目录下生成PHPTest/PHPServer/obj/目录,obj目录下的classers是struct对应的php对象,tars目录是tars协议文件本身 。
如example.tars中的struct:
```text
struct SimpleStruct {
0 require long id=0;
1 require unsigned int count=0;
2 require short page=0;
};
```
转变成classes/SimpleStruct.php
```text
<?php
namespace Server\servant\PHPTest\PHPServer\obj\classes;
class SimpleStruct extends \TARS_Struct {
const ID = 0; //tars协议中的tag
const COUNT = 1;
const PAGE = 2;
public $id; //元素的实际值
public $count;
public $page;
protected static $_fields = array(
self::ID => array(
'name'=>'id', //tars协议中没个元素的name
'required'=>true, //tars协议中是require或者optional
'type'=>\TARS::INT64, //类型
),
self::COUNT => array(
'name'=>'count',
'required'=>true,
'type'=>\TARS::UINT32,
),
self::PAGE => array(
'name'=>'page',
'required'=>true,
'type'=>\TARS::SHORT,
),
);
public function __construct() {
parent::__construct('PHPTest_PHPServer_obj_SimpleStruct', self::$_fields);
}
}
```
1. 以example.tars中的interface部分会自动生成单独的已interface命名的php文件。 例如`int testLofofTags(LotofTags tags, out LotofTags outtags);`接口生成的方法如下
server部分
```text
<?php
//注意生成文件中的注释部分会在server启动的时候转换为php代码,如非必要,请勿修改.
//server部分具体实现需要自己继承完成,注释说明依次如下
//参数为struct类型,对应$tags变量,对应的php对象在\Server\servant\PHPTest\PHPServer\obj\classes\LotofTags
//参数为struct类型,对应$outtags变量,对应的php对象在\Server\servant\PHPTest\PHPServer\obj\classes\LotofTags,是输出参数
//接口防止为int
/**
* @param struct $tags \Server\servant\PHPTest\PHPServer\obj\classes\LotofTags
* @param struct $outtags \Server\servant\PHPTest\PHPServer\obj\classes\LotofTags =out=
* @return int
*/
public function testLofofTags(LotofTags $tags,LotofTags &$outtags);
```
client部分
```text
<?php
try {
$requestPacket = new RequestPacket(); //构建请求包需要的参数
$requestPacket->_iVersion = $this->_iVersion;
$requestPacket->_funcName = __FUNCTION__;
$requestPacket->_servantName = $this->_servantName;
$encodeBufs = [];
$__buffer = TUPAPIWrapper::putStruct("tags",1,$tags,$this->_iVersion); //打包第一个参数tags
$encodeBufs['tags'] = $__buffer;
$requestPacket->_encodeBufs = $encodeBufs; //在请求包中设置请求bufs
$sBuffer = $this->_communicator->invoke($requestPacket,$this->_iTimeout); //发送请求包,接收返回包
$ret = TUPAPIWrapper::getStruct("outtags",2,$outtags,$sBuffer,$this->_iVersion); //从返回包中解出第一个输出参数outtags
return TUPAPIWrapper::getInt32("",0,$sBuffer,$this->_iVersion); //解出返回参数 返回参数 name是空,tag为0
}
catch (\Exception $e) {
throw $e;
}
``` | 5,242 | BSD-3-Clause |
---
title: "Windows 通用 SDK 整合"
description: "適用於 Azure Mobile Engagement 的 Windows 通用 SDK 整合"
services: mobile-engagement
documentationcenter: mobile
author: piyushjo
manager: dwrede
editor:
ms.assetid: 9ded187d-5c07-4377-a41c-ce205dd38b50
ms.service: mobile-engagement
ms.workload: mobile
ms.tgt_pltfrm: mobile-windows-store
ms.devlang: dotnet
ms.topic: article
ms.date: 08/12/2016
ms.author: piyushjo;ricksal
translationtype: Human Translation
ms.sourcegitcommit: 2ea002938d69ad34aff421fa0eb753e449724a8f
ms.openlocfilehash: acf599588de4dac04d51a66348ea9336fe6ce2f7
---
# <a name="windows-universal-sdk-integration-for-azure-mobile-engagement"></a>適用於 Azure Mobile Engagement 的 Windows 通用 SDK 整合
此文件說明適用於 Azure Mobile Engagement Windows 通用 SDK 的所有整合及組態選項。
## <a name="prerequisites"></a>必要條件
開始本教學課程之前,您必須先完成 [15 分鐘教學課程](mobile-engagement-windows-store-dotnet-get-started.md)。
## <a name="advanced-features"></a>進階功能
### <a name="reporting-features"></a>報告功能
您可以新增這些功能:
1. [進階報告選項](mobile-engagement-windows-store-advanced-reporting.md)
2. [進階組態選項](mobile-engagement-windows-store-advanced-configuration.md)
### <a name="notifications"></a>通知
[如何在您的 Windows 通用 App 整合 Reach (通知)](mobile-engagement-windows-store-integrate-engagement-reach.md)
### <a name="tag-plan-implementation"></a>標記計畫實作:
[如何在您的 Windows 通用 App 使用進階的 Mobile Engagement 標記 API](mobile-engagement-windows-store-use-engagement-api.md)
## <a name="release-notes"></a>版本資訊
### <a name="340-04192016"></a>3.4.0 (04/19/2016)
* Reach 重疊增強功能。
* 已加入 "TestLogLevel" API 來啟用/停用/篩選 SDK 所發出的主控台記錄檔。
* 已修正活動中通知目標設定為應用程式啟動時未顯示的第一個活動。
如需較早版本,請參閱 [完整版本資訊](mobile-engagement-windows-store-release-notes.md)
## <a name="upgrade-procedures"></a>升級程序
如果您已經整合舊版 Engagement 到您的應用程式,在升級 SDK 時您必須考慮以下幾點。
如果您錯過了幾個版本的 SDK,您必須遵循幾個程序。 請參閱完整的 [升級程序](mobile-engagement-windows-store-upgrade-procedure.md)。 例如,如果您要從 0.10.1 移轉到 0.11.0,必須先遵循「從 0.9.0 到 0.10.1」的程序,然後「從 0.10.1 到 0.11.0」的程序。
### <a name="from-330-to-340"></a>從 3.3.0 到 3.4.0
#### <a name="test-logs"></a>測試記錄檔
SDK 所產生的主控台記錄檔現在可以啟用/停用/篩選。 若要自訂,請將屬性 `EngagementAgent.Instance.TestLogEnabled` 更新為 `EngagementTestLogLevel` 列舉的其中一個可用值,例如︰
EngagementAgent.Instance.TestLogLevel = EngagementTestLogLevel.Verbose;
EngagementAgent.Instance.Init();
#### <a name="resources"></a>資源
已改善 Reach 重疊。 它是 SDK NuGet 封裝資源的一部分。
當您升級到新版的 SDK,可以選擇是否要保留資源之重疊資料夾中的現有檔案︰
* 如果先前的重疊對您而言可以運作,或是您要手動整合 `WebView` 元素,則您可以決定保留現有檔案,這樣仍然可以運作。
* 若要更新為新的重疊,請將資源的整個 `overlay` 資料夾取代為來自 SDK 封裝的新資料夾 (UWP 應用程式︰升級後,您可以從 %USERPROFILE%\\.nuget\packages\MicrosoftAzure.MobileEngagement\3.4.0\content\win81\Resources 取得新的重疊資料夾)。
> [!WARNING]
> 使用新的重疊會覆寫先前版本上所做的任何自訂。
>
>
### <a name="upgrade-from-older-versions"></a>從舊版升級
請參閱 [升級程序](mobile-engagement-windows-store-upgrade-procedure.md)
<!--HONumber=Nov16_HO3--> | 2,844 | CC-BY-3.0 |
---
title: 你需掌握的CSS知识都在这了
type: reprint
date: 2020-04-04 16:36:35
tags:
- CSS
categories:
- 编程
- 前端
- CSS
---
> 这篇文章基本涵盖了CSS主要的技术要点,内容比较丰富,可以作为参考看看自己还有哪些没掌握,有哪些需要进一步理解。
<!-- more -->
原文排版有点乱,有些内容也不是很全,本文对其进行了部分补充和调整。
{% note info %}
## CSS盒模型
> CSS盒模型,在不同浏览器的差异
{% endnote %}
### CSS标准盒子模型
css盒子模型又称为框模型(Box Model),包含了元素内容(content)、内边距(padding)、边框(border)、外边距(margin)几个要素。如下图:

图中的最内层是content,然后依次是padding、border、margin。通常我们设置背景时就是内容、内边距、边框这三部分,如果border设置颜色的时候会显示boder颜色,当boder颜色是透明时会显示background-color的颜色。该元素的子元素的是从content开始的,而外边距是透明的,不会遮挡其他元素。
元素框的总宽度=width + padding_left + padding_right + border_left + border_right + margin_left + margin_right;
元素框的总高度=height + padding_top + padding_bottom + border_top + border_bottom + margin_top + margin_bottom;
### IE盒子模型
IE盒子模型如下图:

图中的最内层是content,然后依次是padding、border。通常我们设置背景时就是内容、内边距、边框这三部分。而外边距是透明的,不会遮挡其他元素。
元素框的总宽度=width(padding_left + padding_right + border_left + border_right);
元素框的总高度=height(padding_top + padding_bottom + border_top + border_bottom);
**两个模型宽度和高度的计算(是不一样的)**
w3c中的盒子模型的宽:包括margin + border + padding + width; width:margin×2 + border×2 + padding×2 + width; height:margin×2 + border×2 + padding×2 + height;
IE中的盒子模型的width:包括border + padding + width;
上面的两个宽度相加的属性是一样的。因此我们应该选择标准盒子模型,在网页的顶部加上`DOCTYPE`声明。
{% note info %}
## CSS选择器
> CSS所有选择器及其优先级、使用场景,哪些可以继承,如何运用at规则
{% endnote %}
### CSS选择器种类
* 通用选择器:*
* id选择器:#header{}
* class选择器:.header{}
* 元素选择器:div{}
* 子选择器:ul > li{}
* 后代选择器:div p{}
* 伪类选择器::hover、::selection、.action、:first-child、:last-child、:first-of-type、:last-of-type、:nth-of-type(n)、:nth-of-last-type(n)等,例如a:hover{}
* 伪元素选择器: :after、:before等,例如:li:after
* 属性选择器: input[type="text"]
* 组合选择器:E,F/E F(后代选择器)/E>F(子元素选择器)/E+F(直接相邻元素选择器----匹配之后的相邻同级元素)/E~F(普通相邻元素选择器----匹配之后的同级元素)
* 层次选择器:p~ul(选择前面有p元素的每个ul元素)
### CSS选择器优先级
选择器优先级由高到低分别为:!important > 作为style属性写在元素标签上的内联样式 > id选择器 > 类选择器 > 伪类选择器 > 属性选择器 > 标签选择器 > 通配符选择器(* 应少用)> 浏览器自定义;
当比较多个相同级别的CSS选择器优先级时,它们定义的位置将决定一切。下面从位置上将CSS优先级由高到低分为六级:
1. 位于<head/>标签里的<style/>中所定义的CSS拥有最高级的优先权。
2. 第二级的优先属性由位于<style/>标签中的 @import引入样式表所定义。
3. 第三级的优先属性由<link/>标签所引入的样式表定义。
4. 第四级的优先属性由<link/>标签所引入的样式表内的 @import导入样式表定义。
5. 第五级优先的样式有用户设定。
6. 最低级的优先权由浏览器默认。
### 使用场景
* class使用场景:需要某些特定样式的标签则放在同一个class中,需要此样式的标签可再添加此类。(class不可被javascript中的GetElementByID函数所调用)
* id使用场景:
1. 根据提供的唯一id号快速获取标签对象,如:document.getElementById(id) ;
2. 用于充当label标签for属性的值:示例:<label for='userid'>用户名:</label>,表示单击此label标签时,id为userid的标签获得焦点
### CSS哪些属性可以继承
css继承特性主要是指文本方面的继承(比如字体、颜色、字体大小等),盒模型相关的属性基本没有继承特性。
* 不可继承的:display、margin、border、padding、background、height、min-height、max-height、width、min-width、max-width、overflow、position、top、bottom、left、right、z-index、float、clear、 table-layout、vertical-align、page-break-after、page-bread-before和unicode-bidi
* 所有元素可继承的:visibility和cursor
* 终极块级元素可继承的:text-indent和text-align
* 内联元素可继承的:letter-spacing、word-spacing、white-space、line-height、color、font、font-family、font-size、font-style、font-variant、font-weight、text-decoration、text-transform、direction
* 列表元素可继承的:list-style、list-style-type、list-style-position、list-style-image
### 常用`@`规则及使用示例
常用`@`规则有:@charset、@import、@namespace、@document、@font-face、@keyframes、@media、@page、@supports
```css
/*定义字符集*/
@charset "utf-8"
/*导入css文件*/
@import "base.css"
/*自定义字体*/
@font-face {}
/*声明CSS3 animation动画关键帧*/
@keyframes fadeIn {}
/*媒体查询*/
@media{}
```
{% note info %}
## CSS伪类和伪元素
> CSS伪类和伪元素有哪些,它们的区别和实际应用
{% endnote %}
### 举例和区别
常见伪类:`:hover`、`:active`、`first-child`、`:visited`
常见伪元素:`:first-line`、`:first-letter`、`:after`、`:before`
伪类和伪元素的根本区别在于**它们是否创造了新的元素(抽象)**。从我们模仿其意义的角度来看,如果需要添加新元素加以标识的,就是伪元素;如果只需要在既有元素上添加类别的,就是伪类。
伪元素在一个选择器里只能出现一次,并且只能出现在末尾;
伪类则是像真正的类一样发挥着类的作用,没有数量上的限制,只要不是相互排斥的伪类,也可以同时使用在相同的元素上。
### 实际使用
* 伪类用一个冒号表示:`:first-child`
* 伪元素则使用两个冒号表示:`::first-line`
{% note info %}
## CSS定位
> CSS几种定位的规则、定位参照物、对文档流的影响,如何选择最好的定位方式,雪碧图实现原理
{% endnote %}
### 定位方式
1)static定位(普通流定位)——默认定位
2)float定位(浮动定位) 例:float:left;
有两个取值:left(左浮动)和right(右浮动)。浮动元素会在没有浮动元素的上方,效果上看是遮挡住了没有浮动的元素,有float样式规则的元素是脱离文档流的,它的父元素的高度并不能有它撑开。
3)relative定位(相对定位) position:relative;
相对本元素的左上角进行定位,top,left,bottom,right都可以有值。虽然经过定位后,位置可能会移动,但是本元素并没有脱离文档流,还占有原来的页面空间。可以设置z-index。使本元素相对于文档流中的元素,或者脱离文档流但是z-index的值比本元素的值要小的元素更加靠近用户的视线。
相对定位最大的作用是为了实现某个元素相对于本元素的左上角绝对定位,本元素需要设置position为relative。
4)absolute定位(绝对定位) position:absolute;
相对于祖代中有relative(相对定位)并且离本元素层级关系上是最近的元素的左上角进行定位,如果在祖代元素中没有有relative定位的,就默认相对于body进行定位。
绝对定位是脱离文档流的,与浮动定位是一样的效果,会压在非定位元素的上方。可以设置z-index属性。
### 雪碧图实现原理
CSS雪碧的基本原理是把你的网站上用到的一些图片整合到一张单独的图片中,从而减少你的网站的HTTP请求数量。该图片使用CSS background和background-position属性渲染,这也就意味着你的标签变得更加复杂了,图片是在CSS中定义,而非<img>标签。
{% note info %}
## 居中方案
> 写出尽可能多的水平垂直居中的方案并对比它们的优缺点
{% endnote %}
### 行内元素水平居中
首先看它的父元素是不是块级元素,如果是,则直接给父元素设置`text-align: center;`
如果不是,则先将其父元素设置为块级元素,再给父元素设置`text-align: center;`
### 块级元素水平居中(定宽度)
1)需要谁居中,给其设置`margin: 0 auto;`(作用:使盒子自己居中)
2)首先设置父元素为相对定位,再设置子元素为绝对定位:
* 设置子元素的`left:50%`,即让子元素的左上角水平居中;
* 设置子元素的`margin-left: 元素宽度的一半px;`
* 设置子元素的`transform: translateX(-50%);`
### 块级元素水平居中(不定宽度)
1) 默认子元素的宽度和父元素一样,这时需要设置子元素为`display: inline-block;`或`display: inline;`即将其转换成行内块级/行内元素,给父元素设置`text-align: center;`
2) 首先设置父元素为相对定位,再设置子元素为绝对定位:
* 设置子元素的`left:50%`,即让子元素的左上角水平居中;
* 利用css3新增属性`transform: translateX(-50%);`
### 块级元素水平居中(宽度定不定都可以)
使用flexbox布局,只需要给待处理的块状元素的父元素添加属性`display: flex; justify-content: center;`
### 单行的行内元素垂直居中
只需要设置单行行内元素的"行高等于盒子的高"即可;
### 多行的行内元素垂直居中
使用给父元素设置`display:table-cell;`和`vertical-align: middle;`即可。
### 块级元素垂直居中
方法一:使用定位
首先设置父元素为相对定位,再设置子元素为绝对定位,设置子元素的`top: 50%`,即让子元素的左上角垂直居中;
**定高度**:设置绝对子元素的`margin-top: -元素高度的一半px;` 或者设置`transform: translateY(-50%);`
**不定高度**:利用css3新增属性`transform: translateY(-50%);`
方法二:使用flexbox布局实现(高度定不定都可以)
使用flexbox布局,只需要给待处理的块状元素的父元素添加属性`display: flex; align-items: center;`
### 水平垂直居中-已知高度和宽度的元素
方法一:
设置父元素为相对定位,给子元素设置绝对定位,`top: 0; right: 0; bottom: 0; left: 0; margin: auto;`
方法二:
设置父元素为相对定位,给子元素设置绝对定位,`left: 50%; top: 50%; margin-left: 元素宽度的一半px; margin-top: 元素高度的一半px;`
### 水平垂直居中-未知高度和宽度的元素
方法一:使用定位属性
设置父元素为相对定位,给子元素设置绝对定位:`left: 50%; top: 50%; transform: translateX(-50%) translateY(-50%);`
方案二:使用flex布局实现
设置父元素为flex定位:`justify-content: center; align-items: center;`
{% note info %}
## BFC
> BFC的布局规则,实现原理,可以解决的问题
{% endnote %}
BFC直译为**块级格式化上下文**,它是一个独立的渲染区域,只有Block-level box参与,它规定了**内部的Block-level Box**如何布局,并且与外部毫不相干。
**注意**:可以把BFC理解为一个大的盒子,其内部是由Block-level box组成的。
### BFC布局规则
1. 内部的Box会在垂直方向,一个接一个地放置。
2. Box垂直方向的距离由margin决定。属于同一个BFC的两个相邻Box的margin会发生重叠
3. 每个元素的margin box的左边, 与包含块border box的左边相接触(对于从左往右的格式化,否则相反)。即使存在浮动也是如此。
4. BFC的区域不会与float box重叠。
5. BFC就是页面上的一个隔离的独立容器,容器里面的子元素不会影响到外面的元素。反之也如此。
6. 计算BFC的高度时,浮动元素也参与计算
### BFC的作用及原理
1. 自适应两栏布局
2. 清除内部浮动
3. 防止垂直margin重叠
`BFC`内部的元素和外部的元素绝对不会互相影响,因此, 当`BFC`外部存在浮动时,它不应该影响`BFC`内部Box的布局,`BFC`会通过变窄,而不与浮动有重叠。同样的,当`BFC`内部有浮动时,为了不影响外部元素的布局,`BFC`计算高度时会包括浮动的高度。避免margin重叠也是这样的一个道理。
{% note info %}
## CSS函数
{% endnote %}
根据w3cplus中可以划分为以下几类:
* 属性函数:attr();
* 背景图片函数:linear-gradient()、radial-gradient()、conic-gradient()、repeating-linear-gradient()、repeating-radial-gradient()、repeating-conic-gradient()、image-set()、image()、url()、element();
* 颜色函数:rgb()、rgba()、hsl()、hsla()、hwb()、color-mod();
* 图形函数:circle()、ellipse()、inset()、polygon()、path()
* 滤镜函数:blur()、brightness()、contrast()、drop-shadow()、grayscale()、hue-rotate()、invert()、opacity()、saturate()、sepia();
* 转换函数:matrix()、matrix3d()、perspective()、rotate()、rotate3d()、rotateX()、rotateY()、rotateZ()、scale()、scale3d()、scaleX()、scaleY()、scaleZ()、skew()、skewX()、skewY()、translate()、translateX()、translateY()、translateZ()、translate3d();
* 数学函数:calc()、min()、max()、mixmax()、repeat();
* 缓动函数:cubic-bezier()、steps();
* 其他函数:counter()、counters()、toggle()、var()、 symbols()。
{% note info %}
## PostCSS、Sass与Less
> PostCSS、Sass、Less的异同,以及使用配置,至少掌握一种
{% endnote %}
### 比较
* 编译环境不一样,Sass的安装需要Ruby环境,是在服务端处理的,而Less是需要引入less.js来处理Less代码输出css到浏览器,也可以在开发环节使用Less,然后编译成css文件,直接放到项目中;
* 变量符号不一样,Less是@,而Scss是$;
* 输出设置,Less没有输出设置,Sass提供4中输出选项:nested, compact, compressed 和 expanded;
* 处理条件语句,Sass支持条件语句,可以使用if{}else{},for{}循环等等。 LESS的条件语句使用有些另类,他不是我们常见的关键词if和else if之类,而其实现方式是利用关键词"when";
* 引用外部文件,文件名如果以下划线_开头的话,Sass会认为该文件是一个引用文件,不会将其编译为css文件,ess引用外部文件和css中的@import没什么差异;
* 工具库的不同,Sass有工具库Compass, 简单说,Sass和Compass的关系有点像Javascript和jQuery的关系,Compass在Sass的基础上,封装了一系列有用的模块和模板,补充强化了Sass的功能。Less有UI组件库Bootstrap,Bootstrap是web前端开发中一个比较有名的前端UI组件库,Bootstrap的样式文件部分源码就是采用Less语法编写。
### PostCSS
#### 介绍
PostCSS 的主要功能只有两个:第一个就是前面提到的把CSS解析成JavaScript可以操作的 AST,第二个就是调用插件来处理 AST 并得到结果。因此,不能简单的把 PostCSS 归类成 CSS 预处理或后处理工具。PostCSS 所能执行的任务非常多,同时涵盖了传统意义上的预处理和后处理。
#### 使用
PostCSS 一般不单独使用,而是与已有的构建工具进行集成。PostCSS 与主流的构建工具,如 Webpack、Grunt 和 Gulp 都可以进行集成。完成集成之后,选择满足功能需求的 PostCSS 插件并进行配置。现在经常用到的是基于PostCSS的Autoprefixer插件,使用方式可以在官网的插件库进行查询。下面是官网地址:
[PostCSS官网地址](https://www.postcss.com.cn/)
{% note info %}
## CSS模块化方案
{% endnote %}
css的模块化方案可能和js一样有很多,下面简单介绍几种主要的模块方案。
### OOCSS
面向对象的CSS,面对对象的规则,主要的原则是两种:分离结构和外观,分离容器和内容。
#### 名词解释
分离结构和外观:增加可重复的设计单元,同时去推进产品和ui对这方面的思考,比如下面的css使用时对象模式的命名和模块化规则。
分离容器和内容:指的是样式的使用不以元素位置唯一匹配,在任何位置你都可以使用这个样式,如果你不适用这个样式,会保持默认的样式。
#### 案例
```html
// dom结构
<div id="toogle" class="toogle simple">
<div class="toogle-control open">
<div class="toogle-tittle">标题</div>
</div>
<div class="toogle-details "></div>
</div>
```
```css
/* 模块的标记 */
toogle.toggle{
}
/* 皮肤样式的写法,如果基本结构是一样的,你可以用complex的一个辅助样式 */
.toggle .simple{
}
/* 是否做嵌套写法 相信很多预处理器的部分会支持嵌套 然后很多人会像下面这样写 */
.toogle{
.toogle-control{
}
.toogle-details{
}
}
/* 其实你会这样组织么?不是很建议,这样会降低查询效率,如果能确认唯一性的时候其实直接写即可 */
.toogle{
}
.toogle-control{
}
.toogle-details{
}
```
### SMACSS
SMACSS通过一个灵活的思维过程来检查你的设计过程和方式是否符合你的架构,更像一种规范。设计的主要规范有三点:
* Categorizing CSS Rules(为css分类)
* Naming Rules(命名规范)
* Minimizing the Depth of Applicability(最小化适配深度)
SMA和OOCSS有很多类似之处,但区分的地方有很多,主要是对样式的分类。分别是:基础、布局、模块、状态、主题
#### 基础
可以适用于任何位置,我也称全局样式
#### 布局
主要是用来实现不同的特色布局,提高布局的复用率,
#### 模块
设计中的模块化,可重复使用的一个单元,一般是dom+css的耦合绑定。
#### 状态
描述在特定状态下的布局或者模块的特殊化表现,这里我觉得要推荐下《css禅意花园》,在dom结构不变的情况下,可以通过css的皮肤化实现样式的改版。
#### 主题
与状态相比更加定制的是,我们会针对有些特殊的模块,进行主题的设置,包括一系列的颜色、尺寸、交互等进行重度设计,参数化设计。
#### 案例
```html
// dom结构
<div class="toogle toogle-simple">
<div class="toogle-control is-active">
<div class="toogle-tittle">标题</div>
</div>
<div class="toogle-details "></div>
</div>
```
与oocss相比,其实大部分设计思路是一样的,以一个类作为css的作用域(作用域就是两个限制,1、不符合场景时限制禁止使用 ;2、符合场景时要正确的使用),另外的区别就是针对皮肤和状态的不同书写规则。
### BEM
BEM分别代表着:Block(块)、Element(元素)、Modifier(修饰符),是一种组件化的 CSS 命名方法和规范,由俄罗斯 Yandex 团队所提出。它不涉及具体的css结构,只是建议你如何命名css。
#### 案例
```html
// dom结构
<div class="toogle toogle--simple">
<div class="toogle_control toogle_control--active">
<div class="toogle_tittle">标题</div>
</div>
<div class="toogle_details "></div>
</div>
```
#### 解释
块级:所属组件的名称
元素:元素在组件里的名称
修饰符:任何与元素修饰相关的类
### style-components
彻底抛弃 CSS,用 JavaScript 写 CSS 规则,点击[style-components](https://github.com/styled-components/styled-components)进入github的主页。
### CSS Modules
使用JS编译原生的CSS文件,使其具备模块化的能力,点击[CSS Modules](https://github.com/css-modules/css-modules)进入github主页。
这些模块化方案都是各有优缺点,如命名约定:命名复杂、缺乏扩展、 CSS Modules当然也有一些缺点(你得先学会它再去谈优劣)。在众多解决方案中,没有绝对的优劣。还是要结合自己的场景来决定。
{% note info %}
## CSS如何配置按需加载
{% endnote %}
* 使用require.js按需加载CSS
```js
//模块test.js
define(['css!../css/test.css'], function() { //先加载依赖样式
var test = {};
return test;
});
//配置
require.config({
map: { //map告诉RequireJS在任何模块之前,都先载入这个模块
'*': {
css: 'lib/css'
}
},
paths: {
test: 'lib/test',
}
});
//调用
require(['test'])
```
* webpack配置CSS的按需加载
这里以ant desgin css 为例:
```js
{
test: /\.(js|mjs|jsx|ts|tsx)$/,
include: paths.appSrc,
loader: require.resolve('babel-loader'),
options: {
customize: require.resolve(
'babel-preset-react-app/webpack-overrides'
),
plugins: [
["import",{libraryName: "antd", style: 'css'}], //只需加一行,手动划重点antd按需加载
[
require.resolve('babel-plugin-named-asset-import'),
{
loaderMap: {
svg: {
ReactComponent: '@svgr/webpack?-svgo,+ref![path]',
},
},
},
],
],
cacheDirectory: true,
cacheCompression: isEnvProduction,
compact: isEnvProduction,
},
}
```
{% note info %}
## 如何防止CSS阻塞渲染
{% endnote %}
默认情况下,CSS 被视为阻塞渲染的资源,这意味着浏览器将不会渲染任何已处理的内容,直至 CSSOM 构建完毕。请务必精简您的 CSS,并利用媒体类型和查询来解除对渲染的阻塞。
我们可以通过 CSS"媒体类型"和"媒体查询"来解决这类用例:
```html
<link href="style.css" rel="stylesheet">
<link href="print.css" rel="stylesheet" media="print">
<link href="other.css" rel="stylesheet" media="(min-width: 40em)">
```
媒体查询由媒体类型以及零个或多个检查特定媒体特征状况的表达式组成。
例如,上面的第一个样式表声明未提供任何媒体类型或查询,因此它适用于所有情况,也就是说,它始终会阻塞渲染。第二个样式表则不然,它只在打印内容时适用——或许您想重新安排布局、更改字体等等,因此在网页首次加载时,该样式表不需要阻塞渲染。最后,最后一个样式表声明提供由浏览器执行的"媒体查询":符合条件时,浏览器将阻塞渲染,直至样式表下载并处理完毕。
{% note info %}
## CSS(3)实现常见动画
> 熟练使用CSS(3)实现常见动画,如渐变、移动、旋转、缩放等等
{% endnote %}
我把一些常用的CSS动画效果代码上传到github了,有需要的同学可以点击下载,[CSS常用动画](https://github.com/qappleh/Web-Daily-Question/blob/master/CSS/css%E5%B8%B8%E7%94%A8%E5%8A%A8%E7%94%BB.css);
另外还有一些CSS动画库,比如:[animate.css](https://daneden.github.io/animate.css/)、[magic.css](https://github.com/miniMAC/magic)、[Hover.css](http://ianlunn.github.io/Hover/)。
{% note info %}
## CSS浏览器兼容性写法
{% endnote %}
### 浏览器CSS样式初始化
由于每个浏览器的css默认样式不尽相同,所以最简单有效的方式就是对其进行初始化,相信很多朋友都写过这样的代码,在所有CSS开始前,先把marin和padding都设为0,以防不同浏览器的显示效果不一样。
```css
* {
margin: 0;
padding: 0;
}
```
关于浏览器CSS样式初始化,经验不丰富的话,可能也不知道该初始化什么,这里给大家推荐一个库,Normalize.css,github star数量接近3.4万,选取展示其中几个样式设置,如下:
```css
html {
line-height: 1.15; /* Correct the line height in all browsers */
-webkit-text-size-adjust: 100%; /* Prevent adjustments of font size after orientation changes in iOS. */
}
body {
margin: 0;
}
a {
background-color: transparent; /* Remove the gray background on active links in IE 10. */
}
img {
border-style: none; /* Remove the border on images inside links in IE 10. */
}
```
通过CSS样式初始化,相信能解决不少常规的兼容性问题,接下来再看看浏览器的私有属性。
### 浏览器私有属性
我们经常会在某个CSS的属性前添加一些前缀,比如-webkit-,-moz- ,-ms-,这些就是浏览器的私有属性。
为什么会出现私有属性呢?这是因为制定HTML和CSS标准的组织W3C动作是很慢的。
通常,有W3C组织成员提出一个新属性,比如说圆角border-radius,大家都觉得好,但W3C制定标准,要走很复杂的程序,审查等。而浏览器商市场推广时间紧,如果一个属性已经够成熟了,就会在浏览器中加入支持。
但是为避免日后W3C公布标准时有所变更,会加入一个私有前缀,比如-webkit-border-radius,通过这种方式来提前支持新属性。等到日后W3C公布了标准,border-radius的标准写法确立之后,再让新版的浏览器支持border-radius这种写法。常用的前缀有:
* -moz代表firefox浏览器私有属性
* -ms代表IE浏览器私有属性
* -webkit代表chrome、safari私有属性
* -o代表opera私有属性
对于私有属性的顺序要注意,把标准写法放到最后,兼容性写法放到前面
```css
-webkit-transform:rotate(-3deg); /*为Chrome/Safari*/
-moz-transform:rotate(-3deg); /*为Firefox*/
-ms-transform:rotate(-3deg); /*为IE*/
-o-transform:rotate(-3deg); /*为Opera*/
transform:rotate(-3deg);
```
每个CSS属性写这么一堆兼容性代码,无疑是对生命最大的浪费,后面我们会讲一下通过自动化插件来处理这块。
### CSS hack
有时我们需要针对不同的浏览器或不同版本写特定的CSS样式,这种针对不同的浏览器/不同版本写相应的CSS code的过程,叫做CSS hack!
CSS hack的写法大致归纳为3种:条件hack、属性级hack、选择符级hack。
各游览器常用兼容标记一览表:
| 标记 | IE6 | IE7 |IE8 | FF | Opera | Sarari |
|:---|:---:|:---:|:---:|:---:|:---:|:---:|
| [*+><] | √ | √ | X | X | X | X |
| _ | √ | X | X | X | X | X |
| \9 | √ | √ | √ | X | X | X |
| \0 | X | X | √ | X | √ | X |
| @media screen and (-webkit-min-device-pixel-ratio:0){.bb {}} | X | X | X | X | X | √ |
| .bb , x:-moz-any-link, x:default | X | √ | X | √(ff3.5及以下) | X | X |
| @-moz-document url-prefix(){.bb{}} | X | X | X | √ | X | X |
| @media all and (min-width: 0px){.bb {}} | X | X | X | √ | √ | √ |
| * +html .bb {} | X | √ | X | X | X | X |
| 游览器内核 | Trident | Trident | Trident | Gecko | Presto | WebKit |
注:以上`.bb` 可更换为其它样式名
### 自动化插件
Autoprefixer是一款自动管理浏览器前缀的插件,它可以解析CSS文件并且添加浏览器前缀到CSS内容里,使用Can I Use(caniuse网站)的数据来决定哪些前缀是需要的。
把Autoprefixer添加到资源构建工具(例如Grunt)后,可以完全忘记有关CSS前缀的东西,只需按照最新的W3C规范来正常书写CSS即可。如果项目需要支持旧版浏览器,可修改browsers参数设置 。
```css
//我们编写的代码
div {
transform: rotate(30deg);
}
// 自动补全的代码,具体补全哪些由要兼容的浏览器版本决定,可以自行设置
div {
-ms-transform: rotate(30deg);
-webkit-transform: rotate(30deg);
-o-transform: rotate(30deg);
-moz-transform: rotate(30deg);
transform: rotate(30deg);
}
```
目前webpack、gulp、grunt都有相应的插件,如果还没有使用,那就赶紧应用到我们的项目中吧,别再让CSS兼容性浪费你的时间!
{% note info %}
## 响应式布局方案
{% endnote %}
比较常用的布局方式有float,position,display,table,flex,grid等。
全屏布局相关方案的兼容性、性能和自适应一览表:
| 方案 | 兼容性 | 性能 | 是否自适应 |
|:---:|:---:|:---:|:---:|
|Position|好|好|部分自适应|
|Flex|较差|差|可自适应|
|Grid|差|较好|可自适应|
实际项目使用中一般是根据具体场景去选择相应的布局方式。
{% note info %}
## CSS知识图谱
{% endnote %}


---
本文整理自https://juejin.im/post/5d8336d2f265da03df5f4a06。 | 16,808 | MIT |
scroll-top
==========
仿照[coding.net冒泡页]() 一键飞到顶部

### 使用
1. 插入猴子图片
```html
<body>
<!-- sidebar -->
<div class="sidebar">
.....
</div>
<!-- main -->
<div class="main" id="main">
</div>
<!-- extension: scroll top-->
<div class="btn-scrolltop" style="display: none">
<img src="./vendor/extension/scroll-top/images/stay.gif" alt="">
</div>
</body>
```
2. 加入css/js到扩展区域
```html
<!-- extensions START-->
<!-- scroll top -->
<link rel="stylesheet" href="vendor/extension/scroll-top/main.css">
<script src="vendor/extension/scroll-top/main.js"></script>
<!-- extensions END-->
``` | 660 | Apache-2.0 |
## 剑指Offer38:二叉树的深度
题目描述:
输入一棵二叉树,求该树的深度。从根结点到叶结点依次经过的结点(含根、叶结点)形成树的一条路径,最长路径的长度为树的深度。
思路:
深度遍历,返回左右子树中的最大高度+1。
```
/* function TreeNode(x) {
this.val = x;
this.left = null;
this.right = null;
} */
function TreeDepth(pRoot)
{
if(!pRoot) return 0;
let leftDepth = TreeDepth(pRoot.left);
let rightDepth = TreeDepth(pRoot.right);
return Math.max(leftDepth,rightDepth)+1;
}
``` | 414 | MIT |
<!-- 如果你是在使用过程中遇到了技术问题, 请按照下面的模板提交 issue -->
<!-- 如果你是想请求新的功能, 请无视下面的模板 -->
**问题描述**:
**系统信息**:
- OS版本(带版本号): macOS/Windows/Linux
- TeX 发行版(带版本号): TeX Live/MiKTeX/MacTeX
**日志信息**:
<!-- 请在 https://pastebin.ubuntu.com/ 中的 Content 处粘贴上 `thesis.log` 内全部内容, 并将生成的链接附在此处, 如 https://pastebin.ubuntu.com/26345571/ --> | 316 | Apache-2.0 |
---
layout: post
title: "杨佳案二审刑事裁定书"
date: 2008-10-21
author: 爱德布克
from: http://www.ideobook.com/638/yangjia-case-judgment-final/
tags: [ 智识 ]
categories: [ 智识 ]
---
<article class="post-entry clearfix post-638 post type-post status-publish format-standard has-post-thumbnail hentry category-miscellaneous">
<div class="post-entry-thumbnail">
<img alt="杨佳案二审刑事裁定书" src="http://www.ideobook.com/img/yangjia.jpg"/>
</div>
<!-- /blog-entry-thumbnail -->
<div class="post-entry-text clearfix">
<header>
<h1>
杨佳案二审刑事裁定书
</h1>
<ul class="post-entry-meta">
<li>
By:
<a href="http://www.ideobook.com/about-ideobook/" title="查看 爱德布克 的作者主页">
爱德布克
</a>
. 2008-10-21.
<a href="http://www.ideobook.com/372/post-views-count/" title="统计说明">
5,662
</a>
</li>
</ul>
</header>
<div class="post-entry-content">
<p>
<strong>
上海市高级人民法院刑事裁定书
</strong>
(2008)沪高刑终字第131号
</p>
<p>
原公诉机关上海市人民检察院第二分院。
</p>
<p>
上诉人(原审被告人)杨佳,男,1980年8月27日出生于北京市,汉族,中专文化程度,无业。因涉嫌犯故意杀人罪于2008年7月1日被刑事拘留,同年7月7日被逮捕。现羁押于上海市看守所。
</p>
<p>
辩护人翟建,上海市翟建律师事务所律师。
<br/>
辩护人吉剑青,北京市大成律师事务所上海分所律师。
</p>
<p>
上海市第二中级人民法院审理上海市人民检察院第二分院指控原审被告人杨佳犯故意杀人罪一案,于二○○八年九月一日作出(2008)沪二中刑初字第99 号刑事判决。原审被告人杨佳不服,提出上诉。本院依法组成合议庭,公开开庭审理了本案。上海市人民检察院指派检察员季刚、郭菲力、代理检察员金为群出庭履行职务。上诉人杨佳及其委托的辩护人翟建、吉剑青,鉴定人管唯到庭参加诉讼。现已审理终结。
<br/>
<span id="more-638">
</span>
<br/>
上海市第二中级人民法院判决认定:
</p>
<p>
被告人杨佳于2007年10月5日晚骑一辆无牌照自行车途经上海市芷江西路、普善路路口时,受到上海市公安局闸北分局(以下简称闸北公安分局)芷江西路派出所巡逻民警依法盘查,由于杨佳不配合,被带至该所询问,以查明其所骑自行车的来源。杨佳因对公安民警的盘查不满,通过电子邮件、电话等方式多次向公安机关投诉。闸北公安分局派员对杨佳进行了释明和劝导。杨在所提要求未被公安机关接受后,又提出补偿人民币一万元。杨因投诉要求未获满足,遂起意行凶报复。
</p>
<p>
2008年6月26日,杨佳来沪后购买了单刃尖刀、防毒面具、催泪喷射器等工具,并制作了若干个汽油燃烧瓶。
</p>
<p>
同年7月1日上午9时40分许,杨佳携带上述作案工具至上海市天目中路578号闸北公安分局北大门前投掷燃烧瓶,并戴防毒面具,持尖刀闯入该分局底楼接待大厅,朝在门内东侧办公桌前打电话的保安员顾建明头部砍击。随后,杨佳闯入大厅东侧的治安支队值班室,持尖刀分别朝方福新、倪景荣、张义阶、张建平等四名民警的头面、颈项、胸、腹等部位捅刺、砍击。接着,杨佳沿大楼北侧消防楼梯至第9层,在消防通道电梯口处遇见民警徐维亚,持尖刀朝徐的头、颈、胸、腹等部位捅刺。后杨佳继续沿大楼北侧消防楼梯上楼,在第9至10层楼梯处遇见民警王凌云,持尖刀朝王的右肩背、右胸等部位捅刺。杨佳至第11层后,在 1101室门外,持尖刀朝民警李珂的头、胸等部位捅刺。此后,杨佳沿大楼北侧消防楼梯至第21层,在大楼北侧电梯口,持尖刀朝民警吴钰骅胸部捅刺。吴钰骅被刺后退回2113室。杨佳闯入该室,持尖刀继续对民警实施加害,室内的李伟、林玮、吴钰骅等民警遂与杨佳搏斗,并与闻讯赶来的容侃敏、孔中卫、陈伟、黄兆泉等民警将杨佳制服。其间,民警李伟右侧面部被刺伤。
</p>
<p>
被害人方福新、张义阶、李珂、张建平被锐器戳刺胸部伤及肺等致失血性休克;被害人倪景荣被锐器戳刺颈部伤及血管、气管等致失血性休克;被害人徐维亚被锐器戳刺胸腹部伤及肺、肝脏等致失血性休克,上述六名被害人经抢救无效而相继死亡。被害人李伟外伤致面部遗留两处缝创,长度累计达9.9厘米,并伤及右侧腮腺;被害人王凌云外伤致躯干部遗留缝创,长度累计大于15厘米,右手食指与中指皮肤裂伤伴伸指肌腱断裂,李、王二人均构成轻伤。被害人吴钰骅外伤致右上胸部软组织裂创长为3厘米;被害人顾建明外伤致头皮裂创长为5.1厘米,吴、顾二人均构成轻微伤。
</p>
<p>
以上事实,由公诉人、辩护人当庭举证并经法庭质证,予以确认的下列证据证实:
</p>
<p>
第一、证实被告人杨佳故意杀人的证据有:查获的尖刀、防毒面具、催泪喷射器等作案工具;上海市公安局(2008)沪公刑技痕勘字第0069 号、(2008)沪公闸刑技勘字第1841号《现场勘查笔录》;上海市公安局物证鉴定中心沪公刑技物字(2008)0091号《检验报告》;上海市公安局沪公刑技法检字(2008)00293号《尸体检验报告》;上海市公安局损伤伤残鉴定中心沪公刑技伤字(2008)01899号、01900号、 01901号、01902号《鉴定书》;上海市公安局4008930号、4008932号《扣押物品、文件清单》;闸北公安分局北大门口、底楼接待大厅、治安支队值班室的监控录像;被害人顾建明、王凌云、吴钰骅、李伟的陈述,证人童佳骏、佘长富、石金根、惠立生、陶文瑾、黄骏远、柯?、乔军、孔中卫、黄兆泉、容侃敏、陈伟、李秀英、李金英、江玉英、陈舟等人的证言和相关辨认笔录,证人林玮的当庭陈述以及被告人杨佳的相关供述。
</p>
<p>
第二、证实被告人杨佳作案动机的证据有:芷江西路派出所民警在对杨佳依法盘查过程中形成的相关录音及监控录像;证人薛耀、陈银桥、陈红彬等人的证言,证人顾海奇的当庭陈述;被告人杨佳的相关供述以及杨佳发送给本市公安机关的《投诉信》。
</p>
<p>
第三、证实被告人杨佳具有完全刑事责任能力的证据有:司法鉴定科学技术研究所司法鉴定中心出具的司鉴中心[2008]精鉴字第205号《鉴定意见书》。
</p>
<p>
上海市第二中级人民法院认为,被告人杨佳为泄愤报复,持尖刀朝数名公安民警及保安人员连续捅刺,造成六人死亡,二人轻伤,二人轻微伤的严重后果,其行为已构成故意杀人罪,应依法惩处。据此,依照《中华人民共和国刑法》第二百三十二条、第五十七条第一款和第六十四条之规定,以故意杀人罪判处被告人杨佳死刑,剥夺政治权利终身;作案工具予以没收。
</p>
<p>
杨佳上诉辩称:其闯入闸北公安分局大楼时无杀人故意,造成多名民警死亡,实属意外;在芷江西路派出所接受盘查时,被数名民警按倒在地殴打;要求相关民警出庭未获准许,一审审判程序不公正。
</p>
<p>
辩护人认为:公安机关未能提供杨佳在芷江西路派出所接受盘查时的完整录像,不能排除杨佳曾遭公安民警殴打;司法鉴定科学技术研究所司法鉴定中心不具备鉴定资质,该中心对杨佳所作的鉴定结论不具有法律效力;杨佳可能存在精神异常情况,建议对杨佳重新进行精神病司法医学鉴定。
</p>
<p>
上海市人民检察院认为:一审判决认定杨佳犯故意杀人罪事实清楚,证据确实、充分,定性准确;杨佳犯罪动机清楚,杀人行为系在其意志支配、控制下实施,经依法鉴定具有完全刑事责任能力;民警对杨佳的盘查依法有据,杨佳所称遭民警殴打,没有证据支持;一审开庭符合公开审判的原则,所有证人证言均经当庭质证,未准许杨佳申请的证人出庭于法有据,法庭保障了其质证权利,杨佳在一审庭审中不回答法庭提问,不影响对案件事实的认定,一审审判程序合法;杨佳故意杀人,罪行极其严重,社会危害极大,且无法定从轻、减轻情节,一审判决量刑恰当。综上,杨佳的上诉理由缺乏事实和法律依据,不能成立。建议二审法院驳回杨佳的上诉,维持原判,依法报请最高人民法院核准。
</p>
<p>
本院在开庭审理时,检察员就上诉人杨佳的作案动机和刑事责任能力宣读和出示了相关证据,并申请对杨佳进行精神病司法医学鉴定的鉴定人之一管唯出庭作证。
</p>
<p>
关于杨佳的作案动机,检察员宣读和出示了下列证据:
</p>
<p>
1、司法鉴定科学技术研究所司法鉴定中心出具的司鉴中心[2008]技鉴字第504号《鉴定意见书》的结论为,未发现芷江西路派出所民警现场执法的录音经过剪辑处理。
</p>
<p>
2、上海市公安局物证鉴定中心沪公刑技文鉴字[2008]第0687号《鉴定书》的结论为,杨佳笔记本中的“20:30左右芷江西路.由东向西.遇一警察拦车,检查,停车(车上有东西,不能下车),警:你的身份证,答:在旅店里.为什么要查身份证,J:把身份证拿出来,靠边停车”字迹是杨佳本人所写。
</p>
<p>
3、证人寿绪光(芷江西路派出所副所长)2008年9月24日陈述:2007年10月5日晚,因杨佳骑一辆无牌照自行车,且不配合民警盘查,民警将杨口头传唤至派出所,派出所民警在盘查过程中未殴打过杨佳。
</p>
<p>
证人高铁军(芷江西路派出所民警)2008年9月24日陈述:2007年10月5日晚,民警将杨佳带进派出所工作区域后未殴打过杨佳。
</p>
<p>
证人吴钰骅(闸北公安分局督察支队民警)2008年9月28日陈述:2007年10月5日晚,其先后接到上海市公安局警务督察处和芷江西路派出所的电话,遂赶至芷江西路派出所,听取了杨佳的意见,向所内民警了解了情况,审查了当晚的执法录音和监控录像,没有发现民警殴打杨佳的证据,并将调查结果告知了杨佳,同时做了说服工作。
</p>
<p>
关于杨佳的刑事责任能力,鉴定人管唯当庭对杨佳进行精神病司法医学鉴定的程序、鉴定结论的依据向法庭作了说明。检察员还宣读和出示了下列证据:
</p>
<p>
1、《司法鉴定许可证》记载:上海市司法局颁发给司法鉴定科学技术研究所司法鉴定中心的《司法鉴定许可证》的有效期限为2006年9月28日至2011年9月28日,鉴定业务范围包括法医精神病鉴定等。
</p>
<p>
2、《司法部关于撤消“司法部司法鉴定中心”的批复》记载:根据全国人大常委会《关于司法鉴定管理问题的决定》,司法部于2005年9月22日同意撤消“司法部司法鉴定中心”。
</p>
<p>
3、《事业单位法人证书》记载:司法鉴定科学技术研究所系事业单位法人,业务范围包括司法鉴定与检验等。
</p>
<p>
4、证人朱广友(司法鉴定科学技术研究所司法鉴定中心机构负责人)2008年9月27日陈述:司法鉴定中心系由公益性事业单位司法鉴定科学技术研究所设立的机构,经上海市司法局审核,编入司法鉴定机构名册并予公告。
</p>
<p>
原判确认的证据及检察员提供的证据,均经二审当庭质证,查证属实,本院予以确认。本院审理查明的事实与原判相同。
</p>
<p>
针对上诉人的上诉理由、辩护人和检察机关的意见,结合本案的事实和证据,本院综合评判如下:
</p>
<p>
关于杨佳上诉称其没有杀人故意,且在本院开庭审理时,对其行凶杀人的事实辩称记不清或不是事实。经查,杨佳在闸北公安分局持刀行凶杀人的事实,有查获的作案工具、《现场勘查笔录》、《尸体检验报告》、相关《鉴定书》和闸北公安分局大楼监控录像、被害人的陈述、目击证人的证言等大量证据证实,杨佳到案后亦曾供认在案。根据杨佳持刀行凶过程及捅刺被害人身体的部位、力度和结果,已充分证实杨佳具有明显的杀人故意。因此,杨佳的相关辩解,与事实不符。
</p>
<p>
关于杨佳上诉称在芷江西路派出所接受盘查时,被数名民警按倒在地殴打。经查,现场执法录音以及相关证人证言证实,芷江西路派出所巡逻民警依法盘查杨佳时,由于杨佳不配合,即将杨带至派出所询问;芷江西路派出所的监控录像中未反映出民警对杨佳实施殴打;杨佳本人笔记本记载及给本市公安机关的《投诉信》中均未提及被数名民警按倒在地殴打;相关民警陈述,在芷江西路派出所内对杨佳进行盘查时没有殴打过杨佳。因此,杨佳上诉称其在芷江西路派出所被数名民警按倒在地殴打,没有证据证实。
</p>
<p>
关于杨佳上诉称部分证人未出庭作证,一审审判程序不公正。经查,上海市第二中级人民法院开庭审理时,针对本案的起因,公诉人宣读了相关民警的证言,出示了杨佳的《投诉信》;法庭还根据辩护人的申请,通知证人顾海奇到庭作证,播放了芷江西路派出所的现场执法录音和监控录像,上述证据均经当庭质证,查证属实,作为定案根据。本院认为,根据《最高人民法院关于执行< 中华人民共和国刑事诉讼法>若干问题的解释》第五十八条规定,“未出庭证人的证言宣读后经当庭查证属实的,可以作为定案的根据”,一审法院的审判程序,符合我国刑事诉讼法和相关司法解释的规定。
</p>
<p>
关于辩护人提出司法鉴定科学技术研究所司法鉴定中心不具备鉴定资质,建议对杨佳重新进行精神病司法医学鉴定的意见。
</p>
<p>
经查,《司法鉴定许可证》和证人朱广友的证言等证据证实,司法鉴定科学技术研究所司法鉴定中心根据《全国人民代表大会常务委员会关于司法鉴定管理问题的决定》的规定,经司法行政部门审核后予以登记并公告,取得了包括法医精神病鉴定等业务范围的《司法鉴定许可证》。因此,该鉴定中心依法具备鉴定资质。
</p>
<p>
司法鉴定科学技术研究所司法鉴定中心的《鉴定意见书》及鉴定人管唯的当庭说明反映,该鉴定中心接受公安机关的委托后,鉴定人审查了本案的有关材料,结合送检材料及精神检查所见,杨佳有现实的作案动机,对作案行为的性质、后果有客观的认识,根据有关诊断标准,杨佳无精神病,作案时对自己的行为存在完整的辨认和控制能力,按照有关技术规范,应评定为完全刑事责任能力。
</p>
<p>
现有证据表明,本案对杨佳进行司法鉴定的鉴定机构及鉴定人均有资质,鉴定人除对杨佳进行检查性谈话外,还审查了本案相关材料,鉴定程序规范、合法,鉴定依据的材料客观,鉴定结论符合杨佳的作案实际情况。本案无证据证实存在鉴定人不具备相关鉴定资格、鉴定程序不符合法律规定、鉴定材料有虚假、鉴定方法有缺陷、鉴定结论与其他证据相矛盾或者鉴定人应当回避而没有回避等情形。杨佳具有完全刑事责任能力的鉴定结论,符合刑事证据合法性、客观性、关联性的基本特征,应予采信。辩护人申请对杨佳重新进行精神病司法医学鉴定的理由不充分,本院不予准许。
</p>
<p>
本院认为,上诉人杨佳因对公安民警就其所骑无牌照自行车依法进行盘查及对公安机关就其投诉的处理不满,蓄意行凶报复,经充分准备,携带尖刀等作案工具闯入公安机关,连续捅刺、砍击数名民警及保安人员,造成六人死亡、二人轻伤、二人轻微伤的严重后果,其行为已构成故意杀人罪,犯罪手段极其残忍,罪行极其严重,社会危害极大,且无法定从轻情节,应依法惩处。原判认定被告人杨佳故意杀人的犯罪事实清楚,证据确实、充分,适用法律正确,量刑适当,审判程序合法。杨佳的上诉理由不能成立。辩护人的辩护意见,本院不予采纳。上海市人民检察院建议驳回上诉,维持原判的意见正确,应予支持。现依照《中华人民共和国刑事诉讼法》第一百八十九条第(一)项的规定,裁定如下:
</p>
<p>
驳回上诉,维持原判。
</p>
<p>
依照《中华人民共和国刑事诉讼法》第一百九十九条的规定,本裁定依法报请最高人民法院核准。
</p>
<p>
审 判 长 徐伟
<br/>
代理审判员 瞿崎
<br/>
代理审判员 孟猛
</p>
<p>
二〇〇八年十月二十日
</p>
<p>
书记员 费琦
</p>
</div>
<!-- /post-entry-content -->
<footer class="post-entry-footer">
<p>
Categorized:
<a href="http://www.ideobook.com/category/miscellaneous/" rel="category tag">
万象通讯 · MISCELLANEOUS
</a>
</p>
</footer>
<!-- /post-entry-footer -->
<footer class="post-entry-footer">
<p>
如果您喜欢本站文章,
<a href="http://www.ideobook.com/subscription/">
请订阅我们的电子邮件
</a>
,以便及时获取更新通知。
</p>
<p>
好书推荐:
<a href="https://amzn.to/2BLHdBY">
脱销多年新近重印的四卷本奥威尔文集 The Collected Essays, Journalism, and Letters of George Orwell: Volume 1
</a>
,
<a href="https://amzn.to/32VpT9o">
2
</a>
,
<a href="https://amzn.to/2pk1FHp">
3
</a>
,
<a href="https://amzn.to/32WV0RW">
4
</a>
.
</p>
</footer>
<div class="boxframe" id="commentsbox">
<div class="comments-area clearfix" id="comments">
<h3 class="comments-title comment-scroll">
<a class="comments-link" href="http://www.ideobook.com/638/yangjia-case-judgment-final/#comments">
2 Comments
</a>
</h3>
<ol class="commentlist">
<li class="comment even thread-even depth-1" id="li-comment-61856">
<div class="comment-body clearfix" id="comment-61856">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://0.gravatar.com/avatar/04de842369699be43a8fac8de28da782?s=45&d=mm&r=g" srcset="http://0.gravatar.com/avatar/04de842369699be43a8fac8de28da782?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
Totentanz
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/638/yangjia-case-judgment-final/#comment-61856">
· 2008-10-22
</a>
</span>
<span class="reply">
<a aria-label="Reply to Totentanz" class="comment-reply-link" data-belowelement="comment-61856" data-commentid="61856" data-postid="638" data-replyto="Reply to Totentanz" data-respondelement="respond" href="http://www.ideobook.com/638/yangjia-case-judgment-final/?replytocom=61856#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
虽然支持判决死刑
<br/>
只是对于杨佳被殴打,请还原真相,公布录音带。
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
<li class="comment odd alt thread-odd thread-alt depth-1" id="li-comment-61867">
<div class="comment-body clearfix" id="comment-61867">
<div class="comment-details">
<div class="comment-avatar">
<img alt="" class="avatar avatar-45 photo" height="45" loading="lazy" src="http://2.gravatar.com/avatar/ec9b946c43b7d3502f478614e0d605cd?s=45&d=mm&r=g" srcset="http://2.gravatar.com/avatar/ec9b946c43b7d3502f478614e0d605cd?s=90&d=mm&r=g 2x" width="45"/>
</div>
<!-- /comment-avatar -->
<section class="comment-author vcard">
<cite class="author">
<a class="url" href="http://www.148cn.rog/bbs" rel="external nofollow ugc">
xumz
</a>
</cite>
<span class="comment-date">
<a href="http://www.ideobook.com/638/yangjia-case-judgment-final/#comment-61867">
· 2008-11-1
</a>
</span>
<span class="reply">
<a aria-label="Reply to xumz" class="comment-reply-link" data-belowelement="comment-61867" data-commentid="61867" data-postid="638" data-replyto="Reply to xumz" data-respondelement="respond" href="http://www.ideobook.com/638/yangjia-case-judgment-final/?replytocom=61867#respond" rel="nofollow">
Reply
</a>
</span>
</section>
<!-- /comment-meta -->
<section class="comment-content">
<div class="comment-text">
<p>
判决量刑适当,无可争辩
<br/>
至于杨佳是否被殴打一事,恐难查明
</p>
</div>
<!-- /comment-text -->
</section>
<!-- /comment-content -->
</div>
<!-- /comment-details -->
</div>
<!-- /comment -->
</li>
<!-- #comment-## -->
</ol>
<!-- /commentlist -->
<div class="comment-respond" id="respond">
<h3 class="comment-reply-title" id="reply-title">
Leave a Reply
<small>
<a href="/638/yangjia-case-judgment-final/#respond" id="cancel-comment-reply-link" rel="nofollow" style="display:none;">
<span class="wpex-icon-remove-sign">
</span>
</a>
</small>
</h3>
</div>
<!-- #respond -->
</div>
<!-- /comments -->
</div>
<!-- /commentsbox -->
</div>
<!-- /post-entry-text -->
</article> | 12,531 | MIT |
#game
一辺1の正20面体の展開図から、一辺2と1の正四面体2つの展開図を切りだす方法。

* 太線に沿って切ります。 - matto
<!-- -->
[](storage:20面体→四面体x2/icosa-tetra.pdf)
[](storage:20面体→四面体x2/icosa-tetra.png)
[](storage:20面体→四面体x2/icosa-tetra.png) | 247 | MIT |
# STM32 HAL库FATFS文件系统W25Q64 FLASH
## 1.前期准备
安装好`STM32CubeMX`
安装好`Clion`
上一章已经掌握了如何读写`FLASH`,如果一直采用直接操作`FLASH`的方法会非常的繁琐,需要自行记住哪些地方用了,哪些没用以及哪些地方具体放了哪些内容,显然不适合管理。这章我们引进文件管理系统`FATFS`,由她来直接操作`FLASH`,我们只需要调用她提供的方法实现文件管理即可,解放生产力。
## 2.创建项目
**在上一章《`W24Q64 FLASH`》基础上新增配置如下:**

重新生成代码,项目将自动添加`FATFS`相关代码。
## 3.编辑代码
重新生成代码之后,别忘记在`main.c`的`SPI`对象声明前添加`extern`关键字,如下所示:
```c
extern SPI_HandleTypeDef hspi1;
```
给`FATFS`添加`FLASH`驱动,让她可以直接操作`FLASH`。我们只需更改`user_diskio.c`文件中相关函数,实现对`FLASH`的初始化、擦除、读、写等操作。包括:`USER_ioctl()`、`USER_initialize()`、`USER_status()`、`USER_read()`、`USER_write()`,下面逐一介绍:
**step1 添加`FLASH`头文件**
```c
//user_diskio.c文件中添加
#include "bsp_spi_flash.h"//添加FLASH驱动
```
**step2 `USER_ioctl()`修改**
`FATFS`调用该函数获取`FLASH`的器件信息,函数中添加扇区大小、扇区数量信息等,代码如下:
```c
DRESULT USER_ioctl (
BYTE pdrv, /* Physical drive nmuber (0..) */
BYTE cmd, /* Control code */
void *buff /* Buffer to send/receive control data */
)
{
/* USER CODE BEGIN IOCTL */
DRESULT res = RES_ERROR;
//获取FLASH参数
if(pdrv==0) {
switch (cmd) {
case CTRL_SYNC:
res = RES_OK;
break;
case GET_SECTOR_SIZE:
*(DWORD *) buff = 4096;//W25Q64每扇区为4096Byte
res = RES_OK;
break;
case GET_SECTOR_COUNT:
*(DWORD *) buff = 2048;//W25Q64容量为8MB,共计2048个扇区
res = RES_OK;
break;
case GET_BLOCK_SIZE:
*(DWORD *) buff = 1;//单次读写操作擦除扇区个数
res = RES_OK;
break;
default:
res = RES_PARERR;
}
}
else
{
res = RES_PARERR;
}
return res;
/* USER CODE END IOCTL */
}
```
**step3 `USER_initialize()`修改**
`FATFS`调用该函数实现`FLASH`的初始化,我们在`main.c`中已经完成了,只需要返回`OK`即可,代码如下:
```c
/**
* @brief Initializes a Drive
* @param pdrv: Physical drive number (0..)
* @retval DSTATUS: Operation status
*/
DSTATUS USER_initialize (
BYTE pdrv /* Physical drive nmuber to identify the drive */
)
{
/* USER CODE BEGIN INIT */
Stat = STA_NOINIT;
//添加代码
switch (pdrv)
{
case 1://SD
Stat = RES_PARERR;
break;
case 0://Flash,工程中使用驱动器0
//main函数中自动生成了W25Q64的初始化代码,直接返回成功。
Stat = RES_OK;
break;
default:
Stat = RES_PARERR;
}
return Stat;
/* USER CODE END INIT */
}
```
**step4 `USER_status()`修改**
`FATFS`调用该函数获取`FLASH`状态,已经准备好了,同样返回`OK`即可,代码如下:
```c
/**
* @brief Gets Disk Status
* @param pdrv: Physical drive number (0..)
* @retval DSTATUS: Operation status
*/
DSTATUS USER_status (
BYTE pdrv /* Physical drive number to identify the drive */
)
{
/* USER CODE BEGIN STATUS */
Stat = STA_NOINIT;
//返回启动器的状态,工程中使用了驱动器0
if(pdrv==0) Stat = RES_OK;//main函数中自动生成了FLASH初始化代码,直接返回成功。
return Stat;
/* USER CODE END STATUS */
}
```
**step5 `USER_read()`修改**
`FATFS`调用该函数读取`FLASH`数据,添加读取函数即可,代码如下:
```c
/**
* @brief Reads Sector(s)
* @param pdrv: Physical drive number (0..)
* @param *buff: Data buffer to store read data
* @param sector: Sector address (LBA)
* @param count: Number of sectors to read (1..128)
* @retval DRESULT: Operation result
*/
DRESULT USER_read (
BYTE pdrv, /* Physical drive nmuber to identify the drive */
BYTE *buff, /* Data buffer to store read data */
DWORD sector, /* Sector address in LBA */
UINT count /* Number of sectors to read */
)
{
/* USER CODE BEGIN READ */
//添加FLASH读函数
if(pdrv==0)
{
//调用读数据函数,值得注意的是sector指的是0-2047,即哪一个扇区,与W25Q64实际扇区地址不是一个概念
//一个扇区对应4096个字节,因此,输入地址为sector*4096,count同理。
SPI_FLASH_BufferRead((u8 *)buff,sector*4096,count*4096);
return RES_OK;
}
else
{
return RES_PARERR;
}
/* USER CODE END READ */
}
```
**step6 `USER_write()`修改**
`FATFS`调用该函数实现对`FLASH`写操作,添加写函数即可,代码如下:
```c
/**
* @brief Writes Sector(s)
* @param pdrv: Physical drive number (0..)
* @param *buff: Data to be written
* @param sector: Sector address (LBA)
* @param count: Number of sectors to write (1..128)
* @retval DRESULT: Operation result
*/
#if _USE_WRITE == 1
DRESULT USER_write (
BYTE pdrv, /* Physical drive nmuber to identify the drive */
const BYTE *buff, /* Data to be written */
DWORD sector, /* Sector address in LBA */
UINT count /* Number of sectors to write */
)
{
/* USER CODE BEGIN WRITE */
if(pdrv==0)
{
//添加写函数
//FLASH写操作前需要进行扇区擦除,需要擦除count个扇区,在USER_ioctl函数中
//设置了GET_BLOCK_SIZE为1,即单次读写操作擦除扇区个数为1,所以count值
//始终为1,因此只需要调用一次扇区擦除即可。
SPI_FLASH_SectorErase(sector*4096);
SPI_FLASH_BufferWrite((u8 *)buff,sector*4096,count*4096);
/* USER CODE HERE */
return RES_OK;
}
else
{
return RES_PARERR;
}
/* USER CODE END WRITE */
}
#endif /* _USE_WRITE == 1 */
```
**step7 准备就绪**
至此,已经完成了`FATFS`所有驱动的修改,添加上层代码便可实现文件管理了。
## 4.FATFS文件系统示例
在`main.c`中添加代码实现文件的创建、写入、读取功能!实现功能为:在`FLASH`上创建`RY.txt`文件,并写入、读出数据。`mian.c`文件中添加代码如下:
```c
//FATFS测试
void FATFS_FLASH_Test(void)
{
FATFS fs;//文件系统对象
static FIL fnew;//文件对象
BYTE FATFS_Wr_Buff[128] ="hello,嵌入式知识开源社区RYMCU欢迎你!\r\n";// 写缓冲区
BYTE FATFS_Rd_Buff[128] ={0};// 读缓冲区
UINT fnum;//成功读写数量
FRESULT res;//返回值
printf("\r\n\r\n------------------FLASH FATFS文件系统测试------------------\r\n\r\n");
res = f_mount(&fs,"0:",1);
if(res == FR_NO_FILESYSTEM)
{
printf("FLASH上没有建立文件系统,开始格式化!\r\n");
res = f_mkfs("0:",0,0);//格式化
if(res == FR_OK)
{
printf("FLASH文件系统格式化成功!\r\n");
//格式化成功后先取消,再重新挂载!
res = f_mount(NULL,"0:",1);
printf("取消挂载成功!: %d\r\n",res);
res = f_mount(&fs,"0:",1);
printf("重新挂载成功!: %d\r\n",res);
}
else
{
printf("FLASH文件系统格式化失败!\r\n");
}
}
printf("\r\n\r\n-------------------FATFS系统测试:写文件-------------------\r\n");
//打开文件,文件不存在则创建并打开
res = f_open(&fnew,"RY.txt",FA_CREATE_ALWAYS | FA_WRITE);
if(res == FR_OK) printf("打开或创建RY.txt成功!\r\n");
else printf("打开或创建RY.txt失败!\r\n");
//写测试
res = f_write(&fnew,FATFS_Wr_Buff, sizeof(FATFS_Wr_Buff),&fnum);
if(res == FR_OK) printf("往RY.txt写入数据:\r\n%s",FATFS_Wr_Buff);
else printf("往RY.txt写入数据失败,code: %d!\r\n",res);
//完成写操作后,关闭文件
f_close(&fnew);
printf("\r\n-------------------FATFS系统测试:读文件-------------------\r\n\r\n");
//打开文件,读方式打开已创建的文件
res = f_open(&fnew,"RY.txt",FA_OPEN_EXISTING | FA_READ);
if(res != FR_OK){printf("打开文件失败!\r\n");return;}
//读测试
res = f_read(&fnew,FATFS_Rd_Buff, sizeof(FATFS_Rd_Buff),&fnum);
if(res != FR_OK){printf("读取文件失败!\r\n");return;}
printf("读取文件数据:\r\n%s\r\n",FATFS_Rd_Buff);
f_close(&fnew);//读取完毕,关闭文件。
}
```
## 5.编译下载
将程序编译下载至开发板,并将开发板连接至`PC`,打开串口调试助手`RYCOM`,并设置为:`115200+8+N+1`,接收结果如下。

## 6.小节
本章学习了通过`FATFS`系统,实现了简单的文件操作。 | 7,090 | Apache-2.0 |
## 开始
**注意**:在后面的所有例子,我们都会以`Typescript`来编写,所以需要你具备一点基础的`Typescript`知识。
### 一个简单的例子
```typescript
class Count extends Tms {
value: number = 0;
$plus() {
this.value++;
}
}
const count = new Count();
```
通过Tms提供的Dep对象,监听每一个`Commit`方法执行完成
```typescript
count.dep.addSub((event) => {
console.log(event);
/** 输出:
{
type: '$plus',
payload: undefined,
payloads: [],
target: Count { value: 1 }
}
*/
});
```
执行一个`Commit`方法,更新实例状态
```typescript
count.$plus();
```
输出实例状态
```
console.log(count.value) // => 1
```
**注意**:`Tms的Commit方法`和`Vuex的Mutation方法`以及`Redux的Reducer方法`是类似的,所有更新实例的状态都必须通过`Commit`,这样才能实现对实例的历史状态进行追踪。 | 711 | MIT |
---
title: リレーションシップ - EF Core
author: rowanmiller
ms.date: 10/27/2016
ms.assetid: 0ff736a3-f1b0-4b58-a49c-4a7094bd6935
uid: core/modeling/relationships
ms.openlocfilehash: a53a862cc2443a1c4461aa287def100284635f26
ms.sourcegitcommit: dadee5905ada9ecdbae28363a682950383ce3e10
ms.translationtype: MT
ms.contentlocale: ja-JP
ms.lasthandoff: 08/27/2018
ms.locfileid: "42994943"
---
# <a name="relationships"></a>リレーションシップ
2 つのエンティティを定義するリレーションシップを互いに関連します。 リレーショナル データベースで外部キー制約によって表されます。
> [!NOTE]
> この記事のサンプルのほとんどは、概念を説明するのに一対多リレーションシップを使用します。 一対一および多対多のリレーションシップの例については、[リレーションシップの他のパターン](#other-relationship-patterns)記事の最後のセクション。
## <a name="definition-of-terms"></a>用語の定義
リレーションシップの記述に使用される用語のいくつか
* **依存エンティティ:** これは、外部キー プロパティを含むエンティティ。 リレーションシップの「子」とも呼ばれます。
* **プリンシパル エンティティ:** これは、プライマリ/代替キー プロパティを含むエンティティ。 リレーションシップの「親」と呼ばれるにあります。
* **外部キー:** エンティティに関連するプリンシパルのキー プロパティの値の格納に使用される依存エンティティのプロパティ。
* **プリンシパルのキー:** プリンシパル エンティティを一意に識別するプロパティ。 主キーや代替キーがあります。
* **ナビゲーション プロパティ:** 関連会計主体にへの参照を格納しているプリンシパルや依存エンティティで定義されたプロパティ。
* **コレクション ナビゲーション プロパティ:** 多くの関連エンティティへの参照を含むナビゲーション プロパティ。
* **参照ナビゲーション プロパティ:** 1 つの関連エンティティへの参照を保持するナビゲーション プロパティ。
* **逆のナビゲーション プロパティ:** 特定のナビゲーション プロパティを説明しながら、リレーションシップの他方の end のナビゲーション プロパティに関係する用語です。
次のコード リストは、一対多の関係を示しています`Blog`と。 `Post`
* `Post` 依存エンティティは、します。
* `Blog` プリンシパル エンティティには
* `Post.BlogId` 外部キーです。
* `Blog.BlogId` プリンシパルのキー (この例では、代替キーではなく、主キー)
* `Post.Blog` 参照ナビゲーション プロパティは、します。
* `Blog.Posts` コレクション ナビゲーション プロパティは、します。
* `Post.Blog` 逆のナビゲーション プロパティは、 `Blog.Posts` (その逆)
[!code-csharp[Main](../../../samples/core/Modeling/Conventions/Samples/Relationships/Full.cs#Entities)]
## <a name="conventions"></a>規約
慣例によりは、型上で検出されたナビゲーション プロパティがある場合に、リレーションシップが作成されます。 現在のデータベース プロバイダーによってスカラー型として指す型がマップしないことができる場合、プロパティはナビゲーション プロパティと見なされます。
> [!NOTE]
> 規則によって検出されたリレーションシップは、プリンシパル エンティティの主キーを常に対象とします。 代替キーを対象とは、Fluent API を使用して追加の構成を実行する必要があります。
### <a name="fully-defined-relationships"></a>完全に定義されたリレーションシップ
リレーションシップの最も一般的なパターンでは、リレーションシップと依存エンティティ クラスで定義されている外部キー プロパティの両方の end で定義されているナビゲーション プロパティがあります。
* 2 つの型の間のナビゲーション プロパティのペアが見つかった場合同じリレーションシップの逆のナビゲーション プロパティとして構成されます。
* 依存エンティティには、という名前のプロパティが含まれている場合`<primary key property name>`、 `<navigation property name><primary key property name>`、または`<principal entity name><primary key property name>`し、外部キーとして構成されます。
[!code-csharp[Main](../../../samples/core/Modeling/Conventions/Samples/Relationships/Full.cs?name=Entities&highlight=6,15,16)]
> [!WARNING]
> 2 つの型の間で定義されている複数のナビゲーション プロパティがあるかどうか (つまり、互いを指すナビゲーションの 1 つ以上の個別のペア)、し、リレーションシップは作成されません慣例および識別するためにそれらを手動で構成する必要がある方法ナビゲーション プロパティを組み合わせます。
### <a name="no-foreign-key-property"></a>外部キー プロパティ
依存エンティティ クラスで定義されている外部キー プロパティを持つことをお勧めしますが、これは必要ありません。 名前でシャドウの外部キー プロパティが導入される外部キー プロパティが見つからない場合`<navigation property name><principal key property name>`(を参照してください[プロパティをシャドウ](shadow-properties.md)詳細については)。
[!code-csharp[Main](../../../samples/core/Modeling/Conventions/Samples/Relationships/NoForeignKey.cs?name=Entities&highlight=6,15)]
### <a name="single-navigation-property"></a>単一のナビゲーション プロパティ
(ありません逆のナビゲーションと外部キー プロパティ) の 1 つだけのナビゲーション プロパティを含めると、規則で定義されたリレーションシップを持つだけです。 単一のナビゲーション プロパティと外部キー プロパティすることもできます。
[!code-csharp[Main](../../../samples/core/Modeling/Conventions/Samples/Relationships/OneNavigation.cs?name=Entities&highlight=6)]
### <a name="cascade-delete"></a>連鎖削除
設定される連鎖削除規則により、 *Cascade*に必要なリレーションシップと*ClientSetNull*の省略可能なリレーションシップです。 *Cascade*依存エンティティも削除されることを意味します。 *ClientSetNull*メモリに読み込まれていない依存するエンティティが存在することを意味変更なしとする必要があります手動で削除、または有効なプリンシパル エンティティをポイントするように更新します。 メモリに読み込まれるエンティティの場合は、EF Core を外部キー プロパティを null に設定を試みます。
参照してください、[必須および省略可能リレーションシップ](#required-and-optional-relationships)必須および省略可能なリレーションシップの違い」セクション。
参照してください[連鎖削除](../saving/cascade-delete.md)の詳細について、さまざまな動作と規約によって使用される既定値を削除しています。
## <a name="data-annotations"></a>データの注釈
リレーションシップを構成するのに使用できる 2 つのデータ注釈がある`[ForeignKey]`と`[InverseProperty]`します。
### <a name="foreignkey"></a>[不変]
データ注釈を使用すると、構成プロパティは、特定のリレーションシップの外部キー プロパティとして使用する必要があります。 外部キー プロパティが規則によって検出されないときにこれは通常です。
[!code-csharp[Main](../../../samples/core/Modeling/DataAnnotations/Samples/Relationships/ForeignKey.cs?name=Entities&highlight=17)]
> [!TIP]
> `[ForeignKey]`リレーションシップのいずれかのナビゲーション プロパティに注釈を配置できます。 依存エンティティ クラスでナビゲーション プロパティに移動する必要はありません。
### <a name="inverseproperty"></a>[InverseProperty]
依存とプリンシパル エンティティのナビゲーション プロパティを組み合わせる方法を構成するのには、データ注釈を使用できます。 2 つのエンティティ型の間のナビゲーション プロパティの 1 つ以上のペアがある場合にこれは通常です。
[!code-csharp[Main](../../../samples/core/Modeling/DataAnnotations/Samples/Relationships/InverseProperty.cs?name=Entities&highlight=20,23)]
## <a name="fluent-api"></a>Fluent API
Fluent API でのリレーションシップを構成するには、まず、リレーションシップを作成するナビゲーション プロパティを識別します。 `HasOne` または`HasMany`の構成を開始するエンティティ型にナビゲーション プロパティを識別します。 呼び出しをチェーンする`WithOne`または`WithMany`逆ナビゲーションを識別するためにします。 `HasOne`/`WithOne` 参照ナビゲーション プロパティに対して使用し、 `HasMany` / `WithMany`コレクション ナビゲーション プロパティに対して使用します。
[!code-csharp[Main](../../../samples/core/Modeling/FluentAPI/Samples/Relationships/NoForeignKey.cs?name=Model&highlight=8,9,10)]
### <a name="single-navigation-property"></a>単一のナビゲーション プロパティ
1 つのナビゲーション プロパティのみがある場合のパラメーターなしのオーバー ロードがあります`WithOne`と`WithMany`します。 これは、参照またはコレクションがリレーションシップのもう一方の端に概念的にが、エンティティ クラスに含まれるナビゲーション プロパティがないことを示します。
[!code-csharp[Main](../../../samples/core/Modeling/FluentAPI/Samples/Relationships/OneNavigation.cs?name=Model&highlight=10)]
### <a name="foreign-key"></a>外部キー
Fluent API を使用すると、構成プロパティは、特定のリレーションシップの外部キー プロパティとして使用する必要があります。
[!code-csharp[Main](../../../samples/core/Modeling/FluentAPI/Samples/Relationships/ForeignKey.cs?name=Model&highlight=11)]
次のコード リストは、複合外部キーを構成する方法を示します。
[!code-csharp[Main](../../../samples/core/Modeling/FluentAPI/Samples/Relationships/CompositeForeignKey.cs?name=Model&highlight=13)]
文字列のオーバー ロードを使用する`HasForeignKey(...)`外部キーとしてシャドウ プロパティを構成する (を参照してください[プロパティをシャドウ](shadow-properties.md)詳細については)。 (下図参照)、外部キーとして使用する前に、モデルを明示的にシャドウ プロパティを追加することをお勧めします。
[!code-csharp[Main](../../../samples/core/Modeling/FluentAPI/Samples/Relationships/ShadowForeignKey.cs#Sample)]
### <a name="principal-key"></a>プリンシパル キー
主キー以外のプロパティを参照する外部キーを設定する場合は、リレーションシップのプリンシパルのキー プロパティを構成する Fluent API を使用できます。 プリンシパルは、キーとして自動的に構成されているプロパティである代替キーとしてのセットアップ (を参照してください[代替キー](alternate-keys.md)詳細については)。
<!-- [!code-csharp[Main](samples/core/Modeling/FluentAPI/Samples/Relationships/PrincipalKey.cs?highlight=11)] -->
``` csharp
class MyContext : DbContext
{
public DbSet<Car> Cars { get; set; }
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Entity<RecordOfSale>()
.HasOne(s => s.Car)
.WithMany(c => c.SaleHistory)
.HasForeignKey(s => s.CarLicensePlate)
.HasPrincipalKey(c => c.LicensePlate);
}
}
public class Car
{
public int CarId { get; set; }
public string LicensePlate { get; set; }
public string Make { get; set; }
public string Model { get; set; }
public List<RecordOfSale> SaleHistory { get; set; }
}
public class RecordOfSale
{
public int RecordOfSaleId { get; set; }
public DateTime DateSold { get; set; }
public decimal Price { get; set; }
public string CarLicensePlate { get; set; }
public Car Car { get; set; }
}
```
次のコード リストは、複合主キーを構成する方法を示します。
<!-- [!code-csharp[Main](samples/core/Modeling/FluentAPI/Samples/Relationships/CompositePrincipalKey.cs?highlight=11)] -->
``` csharp
class MyContext : DbContext
{
public DbSet<Car> Cars { get; set; }
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Entity<RecordOfSale>()
.HasOne(s => s.Car)
.WithMany(c => c.SaleHistory)
.HasForeignKey(s => new { s.CarState, s.CarLicensePlate })
.HasPrincipalKey(c => new { c.State, c.LicensePlate });
}
}
public class Car
{
public int CarId { get; set; }
public string State { get; set; }
public string LicensePlate { get; set; }
public string Make { get; set; }
public string Model { get; set; }
public List<RecordOfSale> SaleHistory { get; set; }
}
public class RecordOfSale
{
public int RecordOfSaleId { get; set; }
public DateTime DateSold { get; set; }
public decimal Price { get; set; }
public string CarState { get; set; }
public string CarLicensePlate { get; set; }
public Car Car { get; set; }
}
```
> [!WARNING]
> プリンシパルのキー プロパティを指定した順序は、外部キーの指定された順序と一致する必要があります。
### <a name="required-and-optional-relationships"></a>必須およびオプションの関係
Fluent API を使用して、リレーションシップが必須か省略可能かどうかを構成することができます。 最終的に外部キー プロパティが必須または省略可能なのかどうかを制御します。 これは、シャドウ状態の外部キーを使用しているときに最も役立ちます。 外部キー プロパティがエンティティ クラスであるかどうかは、リレーションシップの requiredness が外部キー プロパティが必須または省略可能なのかどうかに基づいて決定されます (を参照してください[必須および省略可能なプロパティ](required-optional.md)詳細情報)。
<!-- [!code-csharp[Main](../../../samples/core/Modeling/FluentAPI/Samples/Relationships/Required.cs?highlight=11)] -->
``` csharp
class MyContext : DbContext
{
public DbSet<Blog> Blogs { get; set; }
public DbSet<Post> Posts { get; set; }
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Entity<Post>()
.HasOne(p => p.Blog)
.WithMany(b => b.Posts)
.IsRequired();
}
}
public class Blog
{
public int BlogId { get; set; }
public string Url { get; set; }
public List<Post> Posts { get; set; }
}
public class Post
{
public int PostId { get; set; }
public string Title { get; set; }
public string Content { get; set; }
public Blog Blog { get; set; }
}
```
### <a name="cascade-delete"></a>連鎖削除
Fluent API を使用して、明示的に指定したリレーションシップの連鎖削除の動作を構成することができます。
参照してください[連鎖削除](../saving/cascade-delete.md)各オプションの詳細についてはデータの保存 セクションでします。
<!-- [!code-csharp[Main](samples/core/Modeling/FluentAPI/Samples/Relationships/CascadeDelete.cs?highlight=11)] -->
``` csharp
class MyContext : DbContext
{
public DbSet<Blog> Blogs { get; set; }
public DbSet<Post> Posts { get; set; }
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Entity<Post>()
.HasOne(p => p.Blog)
.WithMany(b => b.Posts)
.OnDelete(DeleteBehavior.Cascade);
}
}
public class Blog
{
public int BlogId { get; set; }
public string Url { get; set; }
public List<Post> Posts { get; set; }
}
public class Post
{
public int PostId { get; set; }
public string Title { get; set; }
public string Content { get; set; }
public int? BlogId { get; set; }
public Blog Blog { get; set; }
}
```
## <a name="other-relationship-patterns"></a>その他のリレーションシップのパターン
### <a name="one-to-one"></a>一対一
一対一のリレーションシップでは、両方の側での参照ナビゲーション プロパティがあります。 一対多のリレーションシップと同じ規則に従ってがプリンシパルごとに 1 つだけの依存が関連することを確認する場合は、外部キー プロパティに一意のインデックスが導入されています。
<!-- [!code-csharp[Main](samples/core/Modeling/Conventions/Samples/Relationships/OneToOne.cs?highlight=6,15,16)] -->
``` csharp
public class Blog
{
public int BlogId { get; set; }
public string Url { get; set; }
public BlogImage BlogImage { get; set; }
}
public class BlogImage
{
public int BlogImageId { get; set; }
public byte[] Image { get; set; }
public string Caption { get; set; }
public int BlogId { get; set; }
public Blog Blog { get; set; }
}
```
> [!NOTE]
> EF はベースの外部キー プロパティを検出する機能に依存するエンティティのいずれかを選択します。 依存として間違ったエンティティを選択した場合は、これを修正する Fluent API を使用できます。
使用する Fluent API を使用した、リレーションシップを構成するときに、`HasOne`と`WithOne`メソッド。
-依存エンティティ型を指定する必要がある外部キーを構成するときに提供されるジェネリック パラメーターに注意してください`HasForeignKey`で以下のリスト。 一対多リレーションシップでは、参照ナビゲーションを使用したエンティティは、の依存しており、コレクションを使用して 1 つは、プリンシパルには明らかです。 はありませんが、一対一リレーションシップのためを明示的に定義する必要があります。
<!-- [!code-csharp[Main](samples/core/Modeling/FluentAPI/Samples/Relationships/OneToOne.cs?highlight=11)] -->
``` csharp
class MyContext : DbContext
{
public DbSet<Blog> Blogs { get; set; }
public DbSet<BlogImage> BlogImages { get; set; }
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Entity<Blog>()
.HasOne(p => p.BlogImage)
.WithOne(i => i.Blog)
.HasForeignKey<BlogImage>(b => b.BlogForeignKey);
}
}
public class Blog
{
public int BlogId { get; set; }
public string Url { get; set; }
public BlogImage BlogImage { get; set; }
}
public class BlogImage
{
public int BlogImageId { get; set; }
public byte[] Image { get; set; }
public string Caption { get; set; }
public int BlogForeignKey { get; set; }
public Blog Blog { get; set; }
}
```
### <a name="many-to-many"></a>多対多
結合テーブルを表すエンティティ クラスを持たない多対多リレーションシップはまだサポートされていません。 ただし、結合テーブルとのマッピングで独立した 2 つの一対多リレーションシップのエンティティ クラスを含めることによって、多対多リレーションシップを表すことができます。
<!-- [!code-csharp[Main](samples/core/Modeling/FluentAPI/Samples/Relationships/ManyToMany.cs?highlight=11,12,13,14,16,17,18,19,39,40,41,42,43,44,45,46)] -->
``` csharp
class MyContext : DbContext
{
public DbSet<Post> Posts { get; set; }
public DbSet<Tag> Tags { get; set; }
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
modelBuilder.Entity<PostTag>()
.HasKey(t => new { t.PostId, t.TagId });
modelBuilder.Entity<PostTag>()
.HasOne(pt => pt.Post)
.WithMany(p => p.PostTags)
.HasForeignKey(pt => pt.PostId);
modelBuilder.Entity<PostTag>()
.HasOne(pt => pt.Tag)
.WithMany(t => t.PostTags)
.HasForeignKey(pt => pt.TagId);
}
}
public class Post
{
public int PostId { get; set; }
public string Title { get; set; }
public string Content { get; set; }
public List<PostTag> PostTags { get; set; }
}
public class Tag
{
public string TagId { get; set; }
public List<PostTag> PostTags { get; set; }
}
public class PostTag
{
public int PostId { get; set; }
public Post Post { get; set; }
public string TagId { get; set; }
public Tag Tag { get; set; }
}
``` | 14,049 | MIT |
---
layout: post
title: "方舟子时评:川普的“政绩”和拜登面临的挑战"
date: 2021-01-21T11:13:54.000Z
author: 方舟子官方频道 Fang Zhouzi - Official Channel
from: https://www.youtube.com/watch?v=4m198IQUtUI
tags: [ 方舟子 ]
categories: [ 方舟子 ]
---
<!--1611227634000-->
[方舟子时评:川普的“政绩”和拜登面临的挑战](https://www.youtube.com/watch?v=4m198IQUtUI)
------
<div>
川普终于下台,拜登正式就职。如何评价川普的“政绩”?他会有什么的历史地位?拜登面临着什么样的挑战?
</div> | 375 | MIT |
---
title: CSS 陷阱
date: 2019-06-27 18:32:55
updated: 2020-02-03 18:32:55
tags:
- 学习
- 笔记
- CSS
categories:
- 云游的小笔记
---
CSS 的奇妙 Bug
<!-- more -->
<!-- for codepen -->
<script async src="https://static.codepen.io/assets/embed/ei.js"></script>
## FAQ
### Margin 塌陷
DEMO: [Margin Collapse](https://codepen.io/YunYouJun/pen/WqXGpo)
<p class="codepen" data-height="304" data-theme-id="0" data-default-tab="css,result" data-user="YunYouJun" data-slug-hash="WqXGpo" style="height: 304px; box-sizing: border-box; display: flex; align-items: center; justify-content: center; border: 2px solid; margin: 1em 0; padding: 1em;" data-pen-title="Margin Collapse">
<span>See the Pen <a href="https://codepen.io/YunYouJun/pen/WqXGpo/">
Margin Collapse</a> by YunYouJun (<a href="https://codepen.io/YunYouJun">@YunYouJun</a>)
on <a href="https://codepen.io">CodePen</a>.</span>
</p>
#### 父子间
添加 `overflow: hidden;`
#### 兄弟间
添加 `float:left;`
### transform 后 z-index 属性失效
Demo:
<p class="codepen" data-height="265" data-theme-id="default" data-default-tab="css,result" data-user="YunYouJun" data-slug-hash="PowMQjP" style="height: 265px; box-sizing: border-box; display: flex; align-items: center; justify-content: center; border: 2px solid; margin: 1em 0; padding: 1em;" data-pen-title="transform vs z-index">
<span>See the Pen <a href="https://codepen.io/YunYouJun/pen/PowMQjP">
transform vs z-index</a> by YunYouJun (<a href="https://codepen.io/YunYouJun">@YunYouJun</a>)
on <a href="https://codepen.io">CodePen</a>.</span>
</p>
原因主要是 `transform` 新创建了层叠上下文,影响了正常的 `z-index`。
**解决方案**:添加 `transform-style: preserve-3d;`,使之变成 3d 显示方式。再通过 `transform: translateZ(-1px);` 来控制层级顺序。
- [张鑫旭博文:深入理解 css 中的层叠上下文和层叠顺序](https://link.jianshu.com/?t=http://www.zhangxinxu.com/wordpress/2016/01/understand-css-stacking-context-order-z-index/)
- [Segmentfault 回答:Transform 引起的 z-index "失效"](https://link.jianshu.com/?t=https://segmentfault.com/q/1010000002480824)
### img 与父级元素下边框存在空隙
Demo:
<p class="codepen" data-height="265" data-theme-id="default" data-default-tab="html,result" data-user="YunYouJun" data-slug-hash="dyPxmGY" style="height: 265px; box-sizing: border-box; display: flex; align-items: center; justify-content: center; border: 2px solid; margin: 1em 0; padding: 1em;" data-pen-title="img space with father">
<span>See the Pen <a href="https://codepen.io/YunYouJun/pen/dyPxmGY">
img space with father</a> by YunYouJun (<a href="https://codepen.io/YunYouJun">@YunYouJun</a>)
on <a href="https://codepen.io">CodePen</a>.</span>
</p>
可以看到在底部,背景的红色透了出来。
其主要原因是文字默认的行高所产生的问题。(参见 demo)
**解决方案**:默认的 `vertical-align` 属性为 `baseline`,我们只需要为 `img` 添加 `vertical-align: bottom` (`middle | top | bottom` 都可以)。
> [CSS 深入理解 vertical-align 和 line-height 的基友关系](https://www.zhangxinxu.com/wordpress/2015/08/css-deep-understand-vertical-align-and-line-height/)
---
To Be Continued. | 2,899 | CC-BY-4.0 |
php标准注释
===========
### 文件头部模板
/**
*这是一个什么文件
*
*此文件程序用来做什么的(详细说明,可选。)。
* @author xxx<[email protected]>
* @version $Id$
* @since 1.0
*/
### 函数头部注释
/**
* some_func
* 函数的含义说明
*
* @access public
* @param mixed $arg1 参数一的说明
* @param mixed $arg2 参数二的说明
* @param mixed $mixed 这是一个混合类型
* @since 1.0
* @return array
*/
public function thisIsFunction($string, $integer, $mixed) {return array();}
### 类的注释
/**
* 类的介绍
*
* 类的详细介绍(可选。)。
* @author xxx<[email protected]>
* @since 1.0
*/
class Test
{
}
### 程序代码注释
1. 注释的原则是将问题解释清楚,并不是越多越好。
2. 若干语句作为一个逻辑代码块,这个块的注释可以使用/* */方式。
3. 具体到某一个语句的注释,可以使用行尾注释://。
/* 生成配置文件、数据文件。*/
$this->setConfig();
$this->createConfigFile(); //创建配置文件
$this->clearCache(); // 清除缓存文件
$this->createDataFiles(); // 生成数据文件
$this->prepareProxys();
$this->restart(); | 1,057 | MIT |
---
name: "🐛 Bug Report (缺陷反馈)"
about: '报告错误以帮助我们改进'
labels: '🐛 Bug'
---
<!--
感谢您为开源做出贡献!
感谢您向我们反馈问题,为了高效的解决问题,我们期望你能提供以下信息:
-->
### 以前的Issues
<!-- 如果已存在相关Issues和PR请列举 -->
### 问题描述
<!-- 请描述您的问题 -->
### 复现步骤
<!--
请提供BUG的复现步骤。
--> | 237 | MIT |
# 单页面脚手架
## node脚手架
### 1、全局安装脚手架
```
npm install -g wlg-cli-ff
```
### 2、ff list
- init 初始化项目
- add 初始化增删改查文件
- temp 初始化基础文件
- sentry 接入sentry
- qiankun 接入微前端
### 3、ff init 初始化命令
```
ff init <name>
```
直接会运行打开项目
以下命令需要到当前项目跟目录下使用
### 4、ff add
```
ff add <name>
```
- 在autoRouter文件中建立文件(FileName/FileName.vue) 增删改查模板
### 5、ff temp
```
ff temp <name>
```
- 基础模板
### 6、ff sentry
- npm install @sentry/browser
npm install @sentry/integrations
- 在main.js中注册
- 在src/services/server.js 写入sentry监听报错
- (注意:插入位置---// sentry预留位置1 ---- 请不要删除)
### 7、ff qiankun
- npm install qiankun
- 在main.js中注册
- src/router/modules 写入文件qiankun.js
- src/views 创建文件qiankun 写入qiankun.vue
- src/layout/components/AppMain.vue 处理展示的界面
## 单页面架构
### 1、layout配置
- logo: 'component', // 配置logo 只处理了svg的
- title: 'Vue Admin FF', // 配置title
- tagsView: true, // 配置导航标签
- IsSearch: false, // 配置菜单搜索
- breadcrumb: false, // 配置面包屑
- Layout: false, // 配置布局 true 左右结果 false 上下结构
- fixedHeader: true, // 是否固定头部导航栏
- sidebarLogo: true, // 是否显示Logo和title
- navbarBackground: '#324151', // 头部导航栏背景颜色
- navbarColor: '#fff', // 头部导航栏字体和图标颜色
- isUnifiedLogin: true, // 是否统一登入
- isGameShow: true, // 是否展示游戏平台
- isSwitchEnvironment: process.env.NODE_ENV.indexOf('development') > -1 // 是否切换环境
- isAPIRouter: true // 是否异步请求接口返回router
### 2、环境配置
```
"dev": "vue-cli-service serve", // 对应文件.env.development
"dev:sw": "vue-cli-service serve --mode developmentsw", // 对应文件.env.developmentsw
"dev:new": "vue-cli-service serve --mode developmentnew", // 对应文件.env.developmentnew
"build:prod": "vue-cli-service build", // 对应文件.env.production
"build:sw": "vue-cli-service build --mode prodsw", // 对应文件.env. prodsw
"build:new": "vue-cli-service build --mode prodnew", // 对应文件.env. prod new
```
- 注意:环境配置文件,主要需要NODE_ENV 和 VUE_APP_BASE_API,在请求服务文件apiURL中必须要和VUE_APP_BASE_API设置的一致,切换环境的时候需要用到 。 NODE_ENV 在打包正式环境关闭打印输出和判断正式和测试用到(只支持3种模式:development,production,test)
### 3、请求服务
serversapiUrl.js 按服务域名划分模块(注意:文件导出的变量需要和环境文件变量VUE_APP_BASE_API一致)
api.js 按模块写接口url
注意:myserver.postData('user', user)前面的‘user’必须要和apiUrl 的模块接口(user)对应上。
使用接口:对应页面引入api.js
```
import api from '@/services/api'
const { gamelist } = api.user
```
### 4、router 自动路由配置
- autoRouter文件生成路由
- 模块文件统一写在views/autoRouter 下面,包含文件夹的是嵌套路由(二级路由),不包含的一级路由。建议使用文件夹来包含,可创建子文件夹,即使是一级路由也不会影响。目前最多只支持二级路由的生成,所以在autoRouter中可以根据自己的需要,将文件按子模块新增文件夹(建立3级文件夹),是没有问题的。
- 如果需要3级路由,就自行配置路由文件就可以了,在router/modules下配置,该文件夹下的js文件会自动加载到router中
- router 配置文件
```
export default {
/**
* key:{} autoRouter文件名
* name 左侧菜单中文名
* icon 左侧菜单图标
* index 左侧菜单排序
* permission 左侧菜单权限
* newTime 左侧菜单New!展示到期时间
* isID: 动态id 可以配置任意参数
*/
system: {
name: '系统管理',
icon: 'form',
index: 2,
permission: [1, 2, 3],
newTime: '2021-06-20',
children: {
menu: {
name: '菜单管理',
icon: 'form',
index: 1,
permission: [1, 2, 3],
isID: '/:id'
},
user: {
name: '用户管理',
icon: 'form',
index: 2,
permission: [1, 2, 3],
newTime: '2021-06-20'
}
}
}
}
```
- 菜单排序
- 菜单排序是在生成菜单路由的时候处理,利用sort 排序。filterAsyncRoutes本身就是一个递归方法,所以可在这里调用,处理树形结构的排序
- 注意:排序序号,父菜单只管父菜单兄弟之间的排序,子菜单只管子菜单兄弟之间的排序。所以这里会建议父菜单和子菜单的分开,子菜单配置按模块划分。
- 菜单New!标志
- 这里处理的方式是在配置文件中配置newTime,传入时间字符串,比如’2021-05-20‘,这个时间与当前系统时间对比,如果时间未到就展示,过了隐藏。
- 注意:1、时间要字符串标准格式(2021-05-20),匹配时间是在该时间的0点,而非24点。
- 2、子菜单配置的newTime,父菜单也需要配置,并且要等于子菜单中最大的newTime。这样才能保持一致。
- 3、权限配置也类似。
- 配置 isID、动态id 可以配置任意参数
- 动态isID只能配置在子路由中,父路由是不生效的。配置的参数格式必须是’/:‘+任意字符串。意思就是传的参数不局限于id,可任意。
- 注意:如果使用动态路由,在路由拦截的地方进行跳转传参,那在左侧菜单的时候就不能使用path来做唯一值,这样选中效果就不生效。可以使用name来做唯一值
- 异步请求路由配置
- 映射服务器返回菜单与本地component
- 接口返回的数据格式
- 对应配置的router文件路径
- 注意:异步请求路由,权限,排序都由后台完成。请求接口得到的数据就是已经经过权限过滤,排序之后的数据。如果是异步请求路由,则无需在配置routerName文件。这个相对本地配置router来说是简单的,后台替我们分担了一部分工作。
### 5、utils公共方法文件
- index.js 写公共方法
- Reg 表单的校验
- auth 本地存储文件
### 6、filters 过滤器文件
- 全局注册过滤器 main.js
```
import * as filters from './filters'
Object.keys(filters).forEach(key => {
Vue.filter(key, filters[key])
})
```
### | 4,181 | MIT |
SVG VUEJS
---
[](https://www.npmjs.com/package/svg-vuejs)
[](https://www.npmjs.com/package/svg-vuejs)
[](https://github.com/og-liu/svg-vuejs/stargazers)

一套为 Vuejs 开发者准备的基于 Vue 2.0 的轻量的多色动态 SVG 组件。
Made with ❤️ by <a href="https://github.com/og-liu">og-liu</a>
## Links
📙 [中文文档](http://svg.ogliu.com)
## Installation
```bash
npm install svg-vuejs
```
```js
// main.js
import Vue from 'vue';
import vueSvg from 'svg-vuejs'
import App from './App.vue';
Vue.use(vueSvg);
new Vue({
el: '#app',
render: h => h(App)
});
```
```html
<!-- template -->
<vue-svg name="wechat" path="icon/"></vue-svg>
```
> 需要在项目根目录中的 src 文件夹下创建名为 svg 的文件夹,所有的 svg 文件都应该存放在 /src/svg/ 下,也可以在 svg 文件夹下继续创建文件夹用于区分管理图片。
```
├── build
├── config
├── src
│ │── assets
│ │── components
│ │── router
│ │── svg 手动创建 (必须)
│ │ ├── 可选创建
│ │ └── ... 可选创建
│ │── App.vue
│ └── main.js
│
├── static
├── .babelrc
├── .editorconfig
├── .eslintignore
├── .eslintrc.js
├── .gitignore
├── .postcssrc.js
├── index.html
├── package.json
└── README.md
```
## Liscense
MIT | 1,340 | MIT |
---
layout: post
title: "ant 自定义 task"
category: java
tags: [ant, notes]
keywords: ant, ant task, ant 自定义task, 自动化构建
description: ant 使用创建自定义task
---
###ant custom task: hello###
最简单的 task, 只需要一个对象, 其中有一个 execute 方法, 之后在 build.xml 通过 deskdef 定义 task, 指定 task 名字, task 对象路径, 以及 task 对象的完整名称
task对象:
public class Hello {
public void execute() {
System.out.println("hello");
}
}
ant 配置:
<!-- build.xml 配置 -->
<target name="hello" description="hello">
<taskdef name="hello" classname="com.test.tools.ant.Hello" classpath="${classes.dir}" />
<hello />
</target>
输出:
hello:
[hello] hello
###ant custom task: attr###
带属性的 ant task, 在 task 对象中添加与 task 对应的属性字段, 并提供 set 方法
task 对象:
/*
* ant custom, 带有两人个属性的 Ant task
*/
public class SplicerAttr {
private String hello;
private String world;
public void setHello(String hello) {
this.hello = hello;
}
public void setWorld(String world) {
this.world = world;
}
public void execute() {
System.out.println(hello + world);
}
}
ant 配置:
<!-- 现在想给 task 加上两个属性, hello, world -->
<target name="splicerAtr">
<taskdef name="splicerAttr" classname="com.test.tools.ant.SplicerAttr" classpath="${classes.dir}" />
<splicerAttr hello="hello" world="world" />
</target>
输出:
splicerAtr:
[splicerAttr] helloworld
###ant custom task: text###
跟 ant 有 echo 一样, 可以标签中使用文本<echo>hello world</echo>
task 对象:
/**
* 可以带文本的 ant task
*/
public class SplicerText {
private String hello;
private String world;
private String text;
public void addText(String text){
this.text = text;
}
public void setHello(String hello) {
this.hello = hello;
}
public void setWorld(String world) {
this.world = world;
}
public void execute() {
System.out.println(hello + world + text);
}
}
ant 配置:
<taskdef name="splicerText" classname="com.test.tools.ant.SplicerText" classpath="${classes.dir}" />
<!-- 给 task 加上 test -->
<target name="splicerText">
<splicerText hello="hello" world="world" >text</splicerText>
</target>
<!-- ${classes.dir} 在这里只是被当做了一个普通文本去处理 -->
<target name="splicerText2">
<splicerText hello="hello" world="world" >${classes.dir}</splicerText>
</target>
输出:
splicerText:
[splicerText] helloworldtext
splicerText2:
[splicerText] helloworld${classes.dir}
上面对 text 的输出并不会去处理 ${} 点位符, 需要改进一下,使用 project.replaceProperties() 方法对占位符进行处理
task 对象:
public class SplicerTextHold {
private String hello;
private String world;
private String text;
private Project project;
public void setProject(Project project) {
this.project = project;
}
public void addText(String text){
this.text = project.replaceProperties(text);
}
public void setHello(String hello) {
this.hello = hello;
}
public void setWorld(String world) {
this.world = world;
}
public void execute() {
System.out.println(hello + world + text);
}
}
ant 配置:
<!-- ${classes.dir} 在这里只是被当做了占位符去处理 -->
<target name="splicerTextHold">
<taskdef name="splicerTextHold" classname="com.test.tools.ant.SplicerTextHold" classpath="${classes.dir}" />
<splicerTextHold hello="hello" world="world" >${classes.dir}</splicerTextHold>
</target>
输出:
splicerTextHold:
[splicerTextHold] helloworldbin
note:
上面的 Project 为 org.apache.tools.ant.Project 对象, 如果 task 继承了 ant 对象可以不需要 setProject 方法, 显示是因为 Ant 对象已经实现了 set 方法
###ant custom: NestedElemetn###
带元素的 task, 下面一个 task 带有带有一个 <Message msg="msg"></message> 的内嵌元素. 实现的关键在于,在 task 对象中需要有 create, add, addConfigured + NestedElement 方法中一个方法或者多个都可以, 如果这三个方法都存在 ant 实际会调用哪一个并不确定, 这取决于 java 虚拟机.
task 对象:
public class WithNestedElement extends Ant {
@Override
public void execute() {
System.out.println(messages.size());
for (Iterator it = messages.iterator(); it.hasNext();) { // 4
Message msg = (Message) it.next();
log(msg.getMsg());
}
}
Vector<Message> messages = new Vector<Message>();
//使用createElement() 方法
public Message createMessage() {
Message m = new Message();
messages.add(m);
return m;
}
//使用 addMessage 方法
public void addMessage(Message message){
messages.add(message);
}
//使用 addConfiguredMessage 方法
public void addConfiguredMessage(Message anInner){
messages.add(anInner);
}
}
/**
* 内嵌元素
*/
public class Message {
public Message() {
}
String msg;
public void setMsg(String msg) {
this.msg = msg;
}
public String getMsg() {
return msg;
}
}
ant 配置:
<!-- 定义一个 task 这个 task 可以内嵌多个 message 的元素 -->
<target name="withNestedElement" description="user my task">
<taskdef name="withNestedElement" classname="com.test.tools.ant.WithNestedElement" classpath="${classes.dir}" />
<withNestedElement>
<message msg="aaaa"/>
<message msg="bbbb"/>
</withNestedElement>
</target>
输出:
withNestedElement:
[withNestedElement] aaaa
[withNestedElement] bbbb
###ant custom task: type###
带自定义类型的 task
task 对象:
public class WithNestedConditions extends Ant {
private List<Condition> conditions = new ArrayList<Condition>();
@Override
public void execute() {
Iterator<Condition> iter = conditions.iterator();
while(iter.hasNext()){
Condition c = iter.next();
log(String.valueOf(c.eval()));
}
}
public void add(Condition c) {
conditions.add(c);
}
}
ant 配置:
<!-- 定义类型 -->
<typedef name="condition.equals" classname="org.apache.tools.ant.taskdefs.condition.Equals"/>
<target name="withNestedConditions" description="user my task">
<taskdef name="withNestedConditions" classname="com.test.tools.ant.WithNestedConditions" classpath="${classes.dir}" />
<withNestedConditions>
<condition.equals arg1="false" arg2="true"/>
<condition.equals arg1="true" arg2="true"/>
</withNestedConditions>
</target>
输出:
[withNestedConditions] false
[withNestedConditions] true
###总结:###
ant 自定义 task 还是使用简单:
1. 创建一个 task 对象, 一个普通的 java 对象, 你也可以继承 ant 对象. 但是不必须的(继承 ant 会带来一些方便)
2. 给 task 的属性, 文本创建 set 方法
3. 给 task 添加内嵌元素添加一个 create 或者 add , addConfigured + NestedElement 方法
4. 给 task 添加自定义 type , 使用 add 方法
5. 使用 public void execute 方法处理任务
当然这只是一些玩具代码, 要处理实际问题, 还是要在 execute 方法中做复杂的逻辑处理.
参考:
<a href="http://ant.apache.org/manual/index.html">http://ant.apache.org/manual/index.html</a>
<a href="http://ant.apache.org/manual/develop.html#writingowntask">http://ant.apache.org/manual/develop.html#writingowntask</a> | 6,851 | MIT |
---
id: 587d824f367417b2b2512c5b
title: 使用 Chai-HTTP 测试 API 响应结果 (4)—PUT 方法
challengeType: 2
forumTopicId: 301591
dashedName: run-functional-tests-on-an-api-response-using-chai-http-iv---put-method
---
# --description--
请注意,本项目在 [这个 Repl.it 项目](https://repl.it/github/freeCodeCamp/boilerplate-mochachai) 的基础上进行开发。你也可以从 [GitHub](https://repl.it/github/freeCodeCamp/boilerplate-mochachai) 上克隆。
这个练习与上一个类似,我们详细看看。
# --instructions--
发送
```json
{
"surname": "da Verrazzano"
}
```
替换 assert.fail(),使测试通过。 分别测试 1) `status`,2) `type`,3) `body.name`,4) `body.surname` 请按照以上顺序书写断言,顺序错误会影响此挑战的判定。
# --hints--
不应有未通过的测试
```js
(getUserInput) =>
$.get(getUserInput('url') + '/_api/get-tests?type=functional&n=3').then(
(data) => {
assert.equal(data.state, 'passed');
},
(xhr) => {
throw new Error(xhr.responseText);
}
);
```
你需要测试 'res.status' 是否为 200
```js
(getUserInput) =>
$.get(getUserInput('url') + '/_api/get-tests?type=functional&n=3').then(
(data) => {
assert.equal(data.assertions[0].method, 'equal');
assert.equal(data.assertions[0].args[0], 'res.status');
assert.equal(data.assertions[0].args[1], '200');
},
(xhr) => {
throw new Error(xhr.responseText);
}
);
```
你需要测试 'res.type' 是否为 'application/json'
```js
(getUserInput) =>
$.get(getUserInput('url') + '/_api/get-tests?type=functional&n=3').then(
(data) => {
assert.equal(data.assertions[1].method, 'equal');
assert.equal(data.assertions[1].args[0], 'res.type');
assert.match(data.assertions[1].args[1], /('|")application\/json\1/);
},
(xhr) => {
throw new Error(xhr.responseText);
}
);
```
你需要测试 'res.body.name' 是否为 'Giovanni'
```js
(getUserInput) =>
$.get(getUserInput('url') + '/_api/get-tests?type=functional&n=3').then(
(data) => {
assert.equal(data.assertions[2].method, 'equal');
assert.equal(data.assertions[2].args[0], 'res.body.name');
assert.match(data.assertions[2].args[1], /('|")Giovanni\1/);
},
(xhr) => {
throw new Error(xhr.responseText);
}
);
```
你需要测试 'res.body.surname' 是否为 'da Verrazzano'
```js
(getUserInput) =>
$.get(getUserInput('url') + '/_api/get-tests?type=functional&n=3').then(
(data) => {
assert.equal(data.assertions[3].method, 'equal');
assert.equal(data.assertions[3].args[0], 'res.body.surname');
assert.match(data.assertions[3].args[1], /('|")da Verrazzano\1/);
},
(xhr) => {
throw new Error(xhr.responseText);
}
);
```
# --solutions--
```js
/**
Backend challenges don't need solutions,
because they would need to be tested against a full working project.
Please check our contributing guidelines to learn more.
*/
``` | 2,743 | BSD-3-Clause |
#雑記
## 燃料電池車の時代は来ないII
日経のECO JAPANという特集記事に清水和夫氏が燃料電池車について寄稿しているのだが・・・
* http://www.nikkeibp.co.jp/style/eco/column/shimizu/080916_fchv/
水素自動車は走りはじめるかでも紹介したが、彼は主観で提灯記事を書いているだけで、全く説得力がない。こんな記事を一面トップに掲載するECO JAPANの見識自体を疑ってしまう。言葉の端々の揚げ足を取るのは気がすすまないが、いきなり車のデザインのよしあしから議論が始まる点や、「エンジンブレーキ」のくだりや、700気圧の妥当性についての議論、燃料電池車とEVとの棲み分けに関する憶測だけの記述、自動車のエネルギー効率の悪さを知らずにエコを語る姿勢、燃料電池車に魅力を感じた理由が「ほとんど同じ時期にトヨタとメルセデスが燃料電池車こそ未来の自動車という強いメッセージを出し始めたから」というくだり。トヨタの公式発表以外の情報がない上に、清水氏の直感と思いこみだけの記述ばかりで、書かないほうが清水氏のためにも良いと思える。
バッテリーが改良されれば回生ブレーキが効くようになるというが、バッテリーが改良されれば燃料電池を車載する必要はないのではないか? バッテリーに回収しなくても放電したらブレーキとしての機能は持たせられるはずだがなぜそうしないのか? 水素を700気圧に圧縮するためのエネルギーはどこから得るのか? 金属に吸収されやすい水素をそんなに高圧にして、耐久性は大丈夫か? 実現までに越えるべきハードルのうち何割を越え、あと何割が残っているのか? つっこみどころはたくさんある。そういったことが明らかでないのに、なぜ燃料電池車の明るい未来が期待できるのかさっぱりわからない。
清水氏の好きな、大排気量自動車の趣味と、燃料電池車をはじめとするecoカーのめざす方向は全く逆である、また、前者は感性の世界だが、後者は、厳密に数値化できる科学技術のテリトリーにある。技術を感性や直感で語れば語るほど、空疎に聞こえる。客観的な批評ができないなら、ecoファンあるいは燃料電池応援団を自称したほうが良い。
燃料電池車の未来を(感性ではなく論理で)語るなら、安井氏のhttp://www.yasuienv.net/HydrogenTerminated.htm に反論できるだけの客観的データを示してからにしてほしい。清水氏が未来の車の方向性を語るなら、燃料電池よりも車体軽量化の技術のほうが向いていると私は思っている。
<!-- --> | 1,122 | MIT |
# MQTTX Project
 
中文 | [English](./readme_en.md)
- [1 介绍](#1-介绍)
- [1.1 快速开始](#11-快速开始)
- [1.2 项目依赖](#12-项目依赖)
- [1.3 线上实例](#13-线上实例)
- [2 架构](#2-架构)
- [2.1 目录结构](#21-目录结构)
- [3 容器化部署](#3-容器化部署)
- [4 功能说明](#4-功能说明)
- [4.1 qos 支持](#41-qos-支持)
- [4.2 topicFilter 支持](#42-topicfilter-支持)
- [4.3 集群支持](#43-集群支持)
- [4.4 ssl 支持](#44-ssl-支持)
- [4.5 topic 安全支持](#45-topic-安全支持)
- [4.6 共享主题支持](#46-共享主题支持)
- [4.7 websocket 支持](#47-websocket-支持)
- [4.8 系统主题](#48-系统主题)
- [4.9 消息桥接支持](#49-消息桥接支持)
- [5 开发者说](#5-开发者说)
- [6 附表](#6-附表)
- [6.1 配置项](#61-配置项)
- [6.2 版本说明](#62-版本说明)
- [6.2.1 v1.0](#621-v10)
- [6.2.2 v1.1](#622-v11)
- [6.3 Benchmark](#63-benchmark)
- [6.3.1 CleanSessionTrue](#631-cleansessiontrue)
- [6.3.2 CleanSessionFalse](#632-cleansessionfalse)
## 1 介绍
`Mqttx` 基于 [MQTT v3.1.1](http://docs.oasis-open.org/mqtt/mqtt/v3.1.1/os/mqtt-v3.1.1-os.html) 协议开发,旨在提供 ***易于使用*** 且 ***性能优越*** 的 **mqtt broker**。
### 1.1 快速开始
1. 打包
- 测试模式:运行 `mvnw -P test -DskipTests=true clean package`
- 开发模式:
1. 启动 `redis` 实例
2. 运行 `mvnw -P dev -DskipTests=true clean package`
2. 运行
1. 运行命令:`java -jar mqttx-1.0.5.BETA.jar`
*快速开始-测试模式* 图例:
<img src="https://s1.ax1x.com/2020/09/27/0kJp3F.gif" alt="快速开始" style="zoom: 80%;" />
- 测试模式
1. 集群功能被强制关闭
2. 消息保存在内存而不是 `redis`
- 开发模式
1. 消息会持久化到 `redis`, 默认连接 `localhost:6376` 无密码
所谓**测试模式**、**开发模式**只是方便同学们快速启动项目,方便测试功能测试。熟悉项目后,同学们可通过修改 ***[6.1 配置项](#61-配置项)*** 开启或关闭 `mqttx` 提供的各项功能。
> `mqttx` 依赖 `redis` 实现消息持久化、集群等功能,使用其它中间件(`mysql`, `mongodb`, `kafka` 等)同样能够实现,而 `springboot` 具备 `spring-boot-starter-***` 等各种可插拔组件,方便大家修改默认的实现
### 1.2 项目依赖
- [x] redis: 集群消息、消息持久化
- [x] kafka:桥接消息支持
其它说明:
1. 项目使用了 lombok,使用 ide 请安装对应的插件
> 开发工具建议使用 [Intellij IDEA](https://www.jetbrains.com/idea/) :blush:
>
> 举例:`idea` 需要安装插件 `Lombok`, `settings > Build,Execution,Deployment > Compiler > Annotation Processor` 开启 `Enable annotation processing`
### 1.3 线上实例
云端部署了一个 `mqttx` 单例服务,可供功能测试:
1. 不支持 ssl
2. 开启了 websocket, 可通过 http://tools.emqx.io/ 测试,仅需将域名修改为:`119.45.158.51`(端口、地址不变)
3. 支持共享订阅功能
4. 部署版本 `v1.0.5.BETA`

## 2 架构
`mqttx`支持客户端认证、topic 发布/订阅鉴权功能,如果需要配套使用,建议的架构如下图:
> 客户认证服务由使用者自行实现
内部实现框架关系(仅列出关键项):
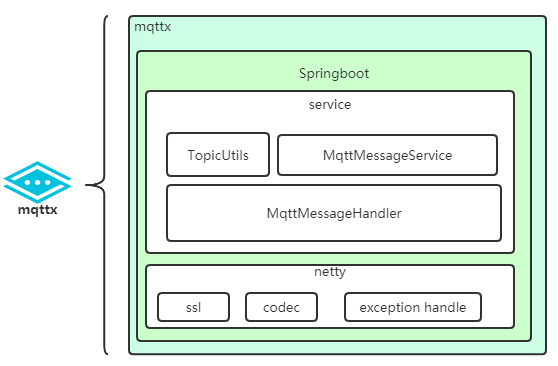
### 2.1 目录结构
```
├─java
│ └─com
│ └─jun
│ └─mqttx
│ ├─broker # mqtt 协议实现及处理包
│ │ ├─codec # 编解码
│ │ └─handler # 消息处理器(pub, sub, connn, etc)
│ ├─config # 配置,主要是 bean 声明
│ ├─constants # 常量
│ ├─consumer # 集群消息消费者
│ ├─entity # 实体类
│ ├─exception # 异常类
│ ├─service # 业务服务(用户认证, 消息存储等)接口
│ │ └─impl # 默认实现
│ └─utils # 工具类
└─resources # 资源文件(application.yml 在此文件夹)
└─tls # ca 存放地址
```
## 3 容器化部署
为了方便项目快速的部署,引进 docker
> 1. 执行本地部署动作前,需要先下载 docker。
> 2. docker-compose 文件中写死了端口映射(`1883, 8083`), 如果你修改了 `mqttx` 的端口配置,则 `docker-compose.yml` 中也应修改
1. 通过IDE提供的打包功能将项目打包为 target/*.jar
2. 进入 `dockerfile` 同级目录,执行 `docker build -t mqttx:v1.0.4.RELEASE .`
3. 执行 `docker-compose up`
## 4 功能说明
#### 4.1 qos 支持
| qos0 | qos1 | qos2 |
| ---- | ---- | ---- |
| 支持 | 支持 | 支持 |
为支持 qos1、qos2,引入 `redis` 作为持久层,这部分已经封装成接口,可自行替换实现(比如采用 `mysql`)。
#### 4.2 topicFilter 支持
1. 支持多级通配符 `#`与单级通配符 `+`
2. 不支持以 `/`结尾的topic,比如 `a/b/`,请改为 `a/b`。
3. 其它规则见 ***[mqtt v3.1.1](http://docs.oasis-open.org/mqtt/mqtt/v3.1.1/os/mqtt-v3.1.1-os.html) 4.7 Topic Names and Topic Filters***
> **mqttx** 仅对订阅 topicFilter 进行校验,publish 的 topic 是没有做合法性检查的,可通过开启 [4.5 topic 安全支持](#45-topic-安全支持) 限制客户端可发布的 topic。
举例:
| topicFilter | match topics |
| ----------- | ----------------------- |
| /a/b/+ | /a/b/abc, /a/b/test |
| a/b/# | a/b, a/b/abc, a/b/c/def |
| a/+/b/# | a/nani/b/abc |
| /+/a/b/+/c | /aaa/a/b/test/c |
校验工具类为:`com.jun.mqttx.utils.TopicUtils`
#### 4.3 集群支持
项目引入 `redis pub/sub ` 分发消息以支持集群功能。如果需要修改为 `kafka` 或其它 `mq` ,需要修改配置类 `ClusterConfig` 及替换实现类 `InternalMessageServiceImpl`。
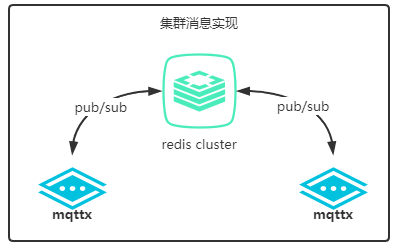
1. `mqttx.cluster.enable`:功能开关,默认 `false`
> `v1.0.5.RELEASE` 之前的版本集群消息处理存在 bug,无法使用.
#### 4.4 ssl 支持
开启 ssl 你首先应该有了 *ca*(自签名或购买),然后修改 `application.yml` 文件中几个配置:
1. `mqttx.ssl.enable`:功能开关,默认 `false`,同时控制 `websocket` 与 `socket`
2. `mqttx.ssl.key-store-location`:证书地址,基于 `classpath`
3. `mqttx.ssl.key-store-password`:证书密码
4. `mqttx.ssl.key-store-type`:keystore 类别,如 `PKCS12`
5. `mqttx.ssl.client-auth`:服务端是否需要校验客户端证书,默认 `false`
> `resources/tls` 目录中的 `mqttx.keystore` 仅供测试使用, 密码: `123456`.
>
> 证书加载工具类:`com/jun/mqttx/utils/SslUtils.java`
#### 4.5 topic 安全支持
为了对 client 订阅 topic 进行限制,加入 topic 订阅&发布鉴权机制:
1. `mqttx.enable-topic-sub-pub-secure`: 功能开关,默认 `false`
2. 使用时需要实现接口 `AuhenticationService` ,该接口返回对象中含有 `authorizedSub,authorizedPub` 存储 client 被授权订阅及发布的 `topic` 列表。
3. broker 在消息订阅及发布都会校验客户端权限
支持的主题类型:
- [x] 普通主题
- [x] 共享主题
- [x] 系统主题
#### 4.6 共享主题支持
共享订阅是 `mqtt5` 协议规定的内容,很多 mq(例如 `kafka`) 都有实现。
1. `mqttx.share-topic.enable`: 功能开关,默认 `true`
2. 格式: `$share/{ShareName}/{filter}`, `$share` 为前缀, `ShareName` 为共享订阅名, `filter` 就是非共享订阅主题过滤器。
3. 目前支持 `hash`, `random`, `round` 三种规则
下图展示了共享主题与常规主题之间的差异:
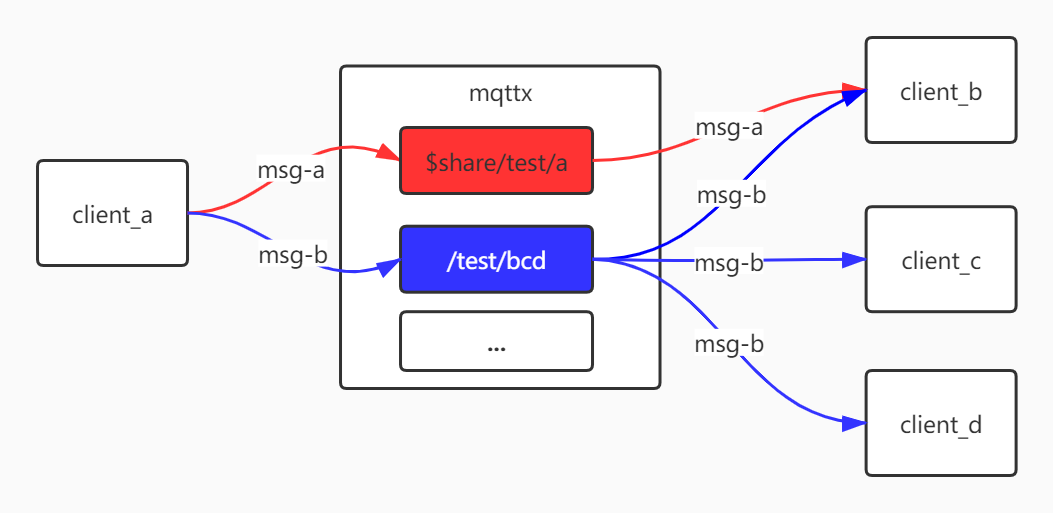
`msg-a` 消息分发策略取决于配置项 `mqttx.share-topic.share-sub-strategy`
可以配合 `cleanSession = 1` 的会话,共享主题的客户端断开连接后会被服务端移除订阅,这样共享主题的消息只会分发给在线的客户端。
***CleanSession*** 介绍:`mqtt3.1.1` 协议规定当 `cleanSession = 1` 时,连接断开后与会话相关联的所有状态(不含 retained 消息)都会被删除(`mqtt5` 增加了会话超时设置,感兴趣的同学可以了解一下)。
`mqttx v1.0.5.BETA` 版本后(含),`cleanSession = 1` 的会话消息保存在内存中,具备极高的性能.
> If CleanSession is set to 1, the Client and Server **MUST** discard any previous Session and start a new one. This Session lasts as long as the Network Connection. State data associated with this Session **MUST NOT** be reused in any subsequent Session [MQTT-3.1.2-6].
>
> The Session state in the Client consists of:
>
> - QoS 1 and QoS 2 messages which have been sent to the Server, but have not been completely acknowledged.
> - QoS 2 messages which have been received from the Server, but have not been completely acknowledged.
>
> The Session state in the Server consists of:
>
> - The existence of a Session, even if the rest of the Session state is empty.
> - The Client’s subscriptions.
> - QoS 1 and QoS 2 messages which have been sent to the Client, but have not been completely acknowledged.
> - QoS 1 and QoS 2 messages pending transmission to the Client.
> - QoS 2 messages which have been received from the Client, but have not been completely acknowledged.
> - Optionally, QoS 0 messages pending transmission to the Client.
#### 4.7 websocket 支持
支持
#### 4.8 系统主题
客户端可通过订阅系统主题获取 broker 状态,目前系统支持如下主题:
| topic | repeat | comment |
| ----------------------------------- | ------- | ------------------------------------------------------------ |
| `$SYS/broker/status` | `false` | 订阅此主题的客户端会定期(`mqttx.sys-topic.interval`)收到 broker 的状态,该状态涵盖下面所有主题的状态值. <br/>**注意:客户端连接断开后,订阅取消** |
| `$SYS/broker/activeConnectCount` | `true` | 立即返回当前的活动连接数量 |
| `$SYS/broker/time` | `true` | 立即返回当前时间戳 |
| `$SYS/broker/version` | `true` | 立即返回 `broker` 版本 |
| `$SYS/broker/receivedMsg` | `true` | 立即返回 `broker` 启动到现在收到的 `MqttMessage`, 不含 `ping` |
| `$SYS/broker/sendMsg` | `true` | 立即返回 `broker` 启动到现在发送的 `MqttMessage`, 不含 `pingAck` |
| `$SYS/broker/uptime` | `true` | 立即返回 `broker` 运行时长,单位***秒*** |
| `$SYS/broker/maxActiveConnectCount` | `true` | 立即返回 `broker` 运行至今的最大 `tcp` 连接数 |
> `repeat`:
>
> - `repeat = false` : 只需订阅一次,broker 会定时发布数据到此主题.
> - `repeat = true` : 订阅一次,broker 发布一次,可多次订阅.
>
> 注意:
>
> 1. *topic 安全机制* 同样会影响客户端订阅系统主题, 未授权客户端将无法订阅系统主题
> 2. 系统主题订阅不会持久化
响应对象格式为 `json` 字符串:
```json
{
"activeConnectCount": 2,
"timestamp": "2020-09-18 15:13:46",
"version": "1.0.5.ALPHA"
}
```
| field | 说明 |
| -------------------- | ------------------------------- |
| `activeConnectCount` | 当前活跃连接数量 |
| `timestamp` | 时间戳;(`yyyy-MM-dd HH:mm:ss`) |
| `version` | `mqttx` 版本 |
#### 4.9 消息桥接支持
支持消息中间件:
- [x] kafka
消息桥接功能可方便的对接消息队列中间。
1. `mqttx.message-bridge.enable`:开启消息桥接功能
2. `mqttx.bridge-topics`:需要桥接消息的主题
`mqttx` 收到客户端 ***发布*** 的消息后,先判断桥接功能是否开启,然后再判断主题是否是需要桥接消息的主题,最后发布消息到 ***MQ***。
**仅支持单向桥接:device(client) => mqttx => MQ**
## 5 开发者说
1. 集群态考虑整合服务注册的功能,便于管理集群状态,可能会使用 `consul`,做不做看我后面的想法吧
> 其实我想引入 `SpringCloud` ,但又觉得 `springcloud` 有点重了,可能会开一个分支去实现。
2. bug fix and optimization,这个会一直继续的,不过主要靠使用和学习 `mqttx` 的同学反馈问题给我(没反馈我就当没有呗~摊手.jpg)
> 这个其实非常重要的,但截至到目前也少有同学找我反馈问题,我一个人终究力量有限。
3. 目前正在开发基于 `vue2.0`, `element-ui` 的 [mqttx-admin](https://github.com/Amazingwujun/mqttx-admin) 管理平台,`mqttx` 的功能更新会暂停一段时间~~(最近在看 [mqtt5](http://docs.oasis-open.org/mqtt/mqtt/v5.0/csprd02/mqtt-v5.0-csprd02.html))~~。项目开发过程中发现需要对 `mqttx` 做一些改动,但这些改动不应该 push 给 mqttx master(比如 topic 安全认证这个功能需要配合 `mqttx-platform`,我可能会引入 [Retrofit](https://square.github.io/retrofit/) 处理接口调用,其实可以用 `feign`,我觉的这两个都差不多),我应该会开一个业务 branch 处理这个事情。话说 `javascript` 写项目可太爽了,以前怎么不觉得?
> 本来说要放一部分精力到 `mqttx-admin` 这个衍生项目的,但后来发现 `mqttx` 还有太多事情需要做,只能变更计划了。
4. [benchmark](#63-benchmark) 表明 mqttx 性能还有提升的可能,我将在 `v1.1.0.RELEASE` 改造 `pub/sub` 处理逻辑
> 主要是 `StringRedisTemplate` => `ReactiveStringRedisTemplate`,改**同步**为**异步**
5. 开发方向介绍
~~`v1.0.5.RELEASE` 成为 `mqttx` 第一个 **LTS** 版本,`v1.0` 将基于它维护和更新。 为提升单机性能, `v1.1` 版本将全面异步化。后续 [mqtt5](http://docs.oasis-open.org/mqtt/mqtt/v5.0/csprd02/mqtt-v5.0-csprd02.html) 协议支持可能会率先从 `v1.0` 开始。~~
`mqttx` 建立两个分支:
- v1.0:`com.jun.mqttx.service.impl` 同步接口
- v1.1:`com.jun.mqttx.service.impl` 改为异步接口
[mqtt5](http://docs.oasis-open.org/mqtt/mqtt/v5.0/csprd02/mqtt-v5.0-csprd02.html) 由 `v1.0` 开始支持。
6. 交流群
<img src="https://s1.ax1x.com/2020/10/10/0ytoSx.jpg" alt="群二维码" height="300" />
## 6 附表
### 6.1 配置项
`src/main/resources` 目录下有三个配置文件:
1. `application.yml`
2. `application-dev.yml`
3. `application-prod.yml`
后两个配置文件目的是区分不同环境下的配置,便于管理。
配置项说明:
| 配置 | 默认值 | 说明 |
| ---------------------------------------- | ----------------------------- | ------------------------------------------------------------ |
| `mqttx.version` | 取自 `pom.xml` | 版本 |
| `mqttx.brokerId` | `1` | 应用标志, 唯一 |
| `mqttx.heartbeat` | `60s` | 初始心跳,会被 conn 消息中的 keepalive 重置 |
| `mqttx.host` | `0.0.0.0` | 监听地址 |
| `mqttx.soBacklog` | `512` | tcp 连接处理队列 |
| `mqttx.enableTopicSubPubSecure` | `false` | 客户订阅/发布主题安全功能,开启后将限制客户端发布/订阅的主题 |
| `mqttx.enableInnerCache` | `true` | 发布消息每次都需要查询 redis 来获取订阅的客户端列表。开启此功能后,将在内存中建立一个主题-客户端关系映射, 应用直接访问内存中的数据即可 |
| `mqttx.enableTestMode` | `false` | 测试模式开关,开启后系统进入测试模式 |
| `mqttx.redis.clusterSessionHashKey` | `mqttx.session.key` | redis map key;用于集群的会话存储 |
| `mqttx.redis.topicPrefix` | `mqttx:topic:` | 主题前缀; topic <==> client 映射关系保存 |
| `mqttx.redis.retainMessagePrefix` | `mqttx:retain:` | 保留消息前缀, 保存 retain 消息 |
| `mqttx.redis.pubMsgSetPrefix` | `mqttx:client:pubmsg:` | client pub消息 redis set 前缀; 保存 pubmsg,当收到 puback 获取 pubrec 后删除 |
| `mqttx.redis.pubRelMsgSetPrefix` | `mqttx:client:pubrelmsg:` | client pubRel 消息 redis set 前缀;保存 pubrel 消息,收到 pubcom 消息删除 |
| `mqttx.redis.topicSetKey` | `mqttx:alltopic` | topic 集合,redis set key 值;保存所有的主题 |
| `mqttx.cluster.enable` | `false` | 集群开关 |
| `mqttx.cluster.innerCacheConsistancyKey` | `mqttx:cache_consistence` | 应用启动后,先查询 redis 中无此 key 值,然后在检查一致性 |
| `mqttx.ssl.enable` | `false` | ssl 开关 |
| `mqttx.ssl.client-auth` | `false` | 客户端证书校验 |
| `mqttx.ssl.keyStoreLocation` | `classpath: tls/mqttx.keystore` | keyStore 位置 |
| `mqttx.ssl.keyStorePassword` | `123456` | keyStore 密码 |
| `mqttx.ssl.keyStoreType` | `pkcs12` | keyStore 类别 |
| `mqttx.socket.enable` | `true` | socket 开关 |
| `mqttx.socket.port` | `1883` | socket 监听端口 |
| `mqttx.websocket.enable` | `false` | websocket 开关 |
| `mqttx.websocket.port` | `8083` | websocket 监听端口 |
| `mqttx.websocket.path` | `/mqtt` | websocket path |
| `mqttx.share-topic.enable` | `true` | 共享主题功能开关 |
| `mqttx.share-topic.share-sub-strategy` | `round` | 负载均衡策略, 目前支持随机、轮询、哈希 |
| `mqttx.sys-topic.enable` | `false` | 系统主题功能开关 |
| `mqttx.sys-topic.interval` | `60s` | 定时发布间隔 |
| `mqttx.sys-topic.qos` | `0` | 主题 qos |
| `mqttx.message-bridge.enable` | `false` | 消息桥接功能开关 |
| `mqttx.message-bridge.topics` | `null` | 需要桥接消息的主题列表 |
### 6.2 版本说明
#### 6.2.1 v1.0
- **v1.0.7.RELEASE(开发中)**
- [x] [mqtt5](http://docs.oasis-open.org/mqtt/mqtt/v5.0/csprd02/mqtt-v5.0-csprd02.html) 支持
- [x] bug 修复及优化
- **v1.0.6.RELEASE**
- [x] `netty 4.1.52.Final` 这个版本的 MqttEncoder.java 处理 UnsubAck 响应消息会导致 NPE,直接影响功能,不得不提前结束此版本的开发
- [x] bug 修复
- **v1.0.5.RELEASE**
- [x] 测试模式支持
- [x] `epoll` 支持,见 [https://netty.io/wiki/native-transports.html](https://netty.io/wiki/native-transports.html)
- [x] 优化 `cleanSession` 消息处理机制
- [x] 消息桥接
- [x] bug 修复及优化
- **v1.0.4.RELEASE**
- [x] websocket 支持
- [x] 集群状态自检
- [x] bug 修复及优化
- **v1.0.3.RELEASE**
- [x] bug 修复
- **v1.0.2.RELEASE**
- [x] 共享主题加入轮询策略
- [x] bug 修复及优化
- **v1.0.1.RELEASE**
- [x] 基于 `redis` 的集群功能支持
- [x] 共享主题支持
- [x] 主题权限功能
- [x] bug 修复及优化
- **v1.0.0.RELEASE**
- [x] `mqttv3.1.1` 完整协议实现
#### 6.2.2 v1.1
- ***v1.1.0.RELEASE(开发中)***
- [x] `redis` 同步转异步实现,提升性能
### 6.3 Benchmark
测试条件简陋,结果仅供参考。
版本: ***MQTTX v1.0.5.BETA***
工具: ***[mqtt-bench](https://github.com/takanorig/mqtt-bench)***
机器:
| 系统 | cpu | 内存 |
| ------- | --------- | ----- |
| `win10` | `i5-4460` | `16G` |
#### 6.3.1 CleanSessionTrue
1. 启用 `redis`
2. `cleanSession` : ***true***
> **实际上 `pub` 消息存储并未走 redis, 原因见 [共享主题](#46-共享主题支持) 中关于 `cleanSession` 的介绍**
执行 `java -jar -Xmx1g -Xms1g mqttx-1.0.5.BETA.jar`
- ***qos0***
```
C:\Users\Jun\go\windows_amd64>mqtt-bench.exe -broker=tcp://localhost:1883 -action=pub -clients=1000 -qos=0 -count=1000
2020-09-30 15:33:54.462089 +0800 CST Start benchmark
2020-09-30 15:34:33.6010217 +0800 CST End benchmark
Result : broker=tcp://localhost:1883, clients=1000, totalCount=1000000, duration=39134ms, throughput=25553.23messages/sec
```
- ***qos1***
```
C:\Users\Jun\go\windows_amd64>mqtt-bench.exe -broker=tcp://localhost:1883 -action=pub -clients=1000 -qos=1 -count=1000
2020-09-30 15:29:17.9027515 +0800 CST Start benchmark
2020-09-30 15:30:25.0316915 +0800 CST End benchmark
Result : broker=tcp://localhost:1883, clients=1000, totalCount=1000000, duration=67124ms, throughput=14897.80messages/sec
```
- ***qos2***
```
C:\Users\Jun\go\windows_amd64>mqtt-bench.exe -broker=tcp://localhost:1883 -action=pub -clients=1000 -qos=2 -count=1000
2020-09-30 15:37:00.0678207 +0800 CST Start benchmark
2020-09-30 15:38:55.4419847 +0800 CST End benchmark
Result : broker=tcp://localhost:1883, clients=1000, totalCount=1000000, duration=115369ms, throughput=8667.84messages/sec
```
| 并发连接数量 | 行为 | 单个消息大小 | 单连接消息数量 | 报文总数 | qos | 耗时 | qps |
| ------------ | -------- | ------------ | -------------- | -------- | ---- | -------- | ------- |
| `1000` | 发布消息 | `1024byte` | `1000` | 一百万 | `0` | `39.1s` | `25553` |
| `1000` | 发布消息 | `1024byte` | `1000` | 一百万 | `1` | `67.1s` | `14897` |
| `1000` | 发布消息 | `1024byte` | `1000` | 一百万 | `2` | `115.3s` | `8667` |
**资源消耗:`cpu: 25%`, `mem 440 MB`**
#### 6.3.2 CleanSessionFalse
1. 启用 `redis`
2. `cleanSession`: ***false***
执行 `java -jar -Xmx1g -Xms1g mqttx-1.0.5.BETA.jar`
- **qos0**
```
C:\Users\Jun\go\windows_amd64>mqtt-bench.exe -broker=tcp://localhost:1883 -action=pub -clients=1000 -qos=0 -count=1000
2020-09-30 17:03:55.7560928 +0800 CST Start benchmark
2020-09-30 17:04:36.2080909 +0800 CST End benchmark
Result : broker=tcp://localhost:1883, clients=1000, totalCount=1000000, duration=40447ms, throughput=24723.71messages/sec
```
- **qos1**
```
C:\Users\Jun\go\windows_amd64>mqtt-bench.exe -broker=tcp://localhost:1883 -action=pub -clients=1000 -qos=1 -count=1000
2020-09-30 17:06:18.9136484 +0800 CST Start benchmark
2020-09-30 17:08:20.9072865 +0800 CST End benchmark
Result : broker=tcp://localhost:1883, clients=1000, totalCount=1000000, duration=121992ms, throughput=8197.26messages/sec
```
- **qos2**
```
C:\Users\Jun\go\windows_amd64>mqtt-bench.exe -broker=tcp://localhost:1883 -action=pub -clients=1000 -qos=2 -count=1000
2020-09-30 17:09:35.1314262 +0800 CST Start benchmark
2020-09-30 17:13:10.7914125 +0800 CST End benchmark
Result : broker=tcp://localhost:1883, clients=1000, totalCount=1000000, duration=215656ms, throughput=4637.01messages/sec
```
| 并发连接数量 | 行为 | 单个消息大小 | 单连接消息数量 | 报文总数 | qos | 耗时 | qps |
| ------------ | -------- | ------------ | -------------- | -------- | ---- | -------- | ------- |
| `1000` | 发布消息 | `1024byte` | `1000` | 一百万 | `0` | `40.4s` | `24723` |
| `1000` | 发布消息 | `1024byte` | `1000` | 一百万 | `1` | `121.9s` | `8197` |
| `1000` | 发布消息 | `1024byte` | `1000` | 一百万 | `2` | `215.6s` | `4637` |
**资源消耗:`cpu: 45%`, `mem 440 MB`** | 19,521 | Apache-2.0 |
# 工作中遇到的问题
## 名称为纯英文数字等不换行问题
```
.wrap {
width: 100px;
word-wrap: break-word;
word-break: break-all;
}
```
这里存在高度会超出问题
## 各浏览器关于渐变色的适配
```
.main {
background: linear-gradient(left, #055798, #01b1f8);
background: -webkit-linear-gradient(left, #055798, #01b1f8);
background: -ms-linear-gradient(left, #055798, #01b1f8);
background: -moz--linear-gradient(left, #055798, #01b1f8);
background: -0--linear-gradient(left, #055798, #01b1f8);
filter: progid:DXImageTransform.Microsoft.gradient( startColorstr='#055798', endColorstr='#01b1f8',GradientType=1 );//默认值,水平
/*filter: progid:DXImageTransform.Microsoft.gradient( startColorstr='#055798', endColorstr='#01b1f8',GradientType=0 );//垂直*/
}
```
## 内容太多需一行显示,显示不全的省略
```
span {
display: block;
height: 17px;
overflow: hidden;
white-space: nowrap;//一行显示
text-overflow: ellipsis;//显示不全就省略
}
```
## js的日期时间格式化
```
//日期格式化
'2016-06-17'.replace(/(\d{4})-(\d{2})-(\d{2})/g,'$1年$2月$3日')
"2016年06月17日";
//日期时间格式化
/**方法1**/
// 对Date的扩展,将 Date 转化为指定格式的String
// 月(M)、日(d)、小时(h)、分(m)、秒(s)、季度(q) 可以用 1-2 个占位符,
// 年(y)可以用 1-4 个占位符,毫秒(S)只能用 1 个占位符(是 1-3 位的数字)
// 例子:
interface Io {
[key: string]: any
}
function format(fmt: string): string {
let myDate = new Date()
let o: Io = {
"M+": myDate.getMonth() + 1,
"d+": myDate.getDate(),
"h+": myDate.getHours(),
"m+": myDate.getMinutes(),
"s+": myDate.getSeconds(),
"q+": Math.floor((myDate.getMonth() + 3) / 3),
"S": myDate.getMilliseconds()
}
if (/(y+)/.test(fmt)){
fmt = fmt.replace(RegExp.$1, (myDate.getFullYear() + "").substr(4 - RegExp.$1.length));
}
let k: string
for (k in o) {
if (new RegExp("(" + k + ")").test(fmt)) {
fmt = fmt.replace(RegExp.$1, (RegExp.$1.length === 1) ?
(o[k]) :
(("00" + o[k]).substr(("" + o[k]).length)));
}
}
return fmt
}
let time1 = format("yyyy-MM-dd");
let time2 = format("yyyy-MM-dd hh:mm:ss");
console.log(time1)
console.log(time2)
```
## 在html的头部加入meta使得所有的资源请求由http请求转成https请求
```
<meta http-equiv="Content-Security-Policy" content="upgrade-insecure-requests">
``` | 2,219 | MIT |
<h1>用户信息管理</h1>
## 概述
+ 开发者应用的用户,通过username / password 注册到 JMessage后,SDK 侧可以发起注册,服务器端也可发起批量注册。
+ 用户登录 App,也同时登录 JMessage。登录后可以向其他 username 发聊天消息,也可以收到来自其他 username 或者群组的消息。
+ 用户 A 是否有权限向用户 B 发消息,需由开发者的App 自己控制。
+ 开发者可选择将用户头像等用户信息同步更新到 JMessage。
### 获取用户信息
异步从后台获取用户信息,此接口可用来获取不同[appkey](../../guideline/faq/#getappkey)下用户的信息,如果appKey为空,则默认获取当前[appkey](../../guideline/faq/#getappkey)下的用户信息。
```
JMessageClient.getUserInfo(String username, String appKey, GetUserInfoCallback callback);
```
参数说明
+ String username 用户名
+ String appKey 指定的appKey
+ GetUserInfoCallback callback 结果回调
### 获取当前登录账号的用户信息
此接口会直接从本地返回当前已经登录的用户的信息。
```
JMessageClient.getMyInfo();
```
参数说明
+ 无
返回
+ UserInfo 当前登录用户的用户信息。
### 更新用户信息
更新当前已登录用户的用户信息
```
JMessageClient.updateMyInfo(UserInfo.Field updateField, UserInfo info, BasicCallback callback);
```
参数说明
+ UserInfo.Field updateField 枚举类型,表示需要更新的用户信息字段。包括:
- nickname 昵称
- birthday 生日
- signature 签名
- gender 性别
- region 地区
- address 地址
- all 以上全部
+ UserInfo userInfo 待更新的用户信息(对象)。SDK将根据field参数来判断需要将哪个属性更新到服务器上去。
+ BasicCallback callback 结果回调
### 更新用户密码
更新当前已登录用户的密码
```
JMessageClient.updateUserPassword(String oldPassword, String newPassword, BasicCallback callback);
```
参数说明
+ String oldPassword 更新前密码
+ String newPassword 更新后密码
+ BasicCallback callback 结果回调
### 更新用户头像
更新当前已登录用户的头像
```
JMessageClient.updateUserAvatar(File avatar, BasicCallback callback);
```
参数说明
+ File avatar 用户头像文件
+ BasicCallback callback 结果回调
### 黑名单管理
可以将对方用户加入到“黑名单”列表中,加入之后,我方依然能给对方发消息,但是对方给我发消息时会返回指定错误码,发送消息失败。
#### 将用户加入黑名单
```
JMessageClient.addUsersToBlacklist(List<String> usernames, BasicCallback callback)
```
参数说明
+ List<String> usernames 被加入黑名单的用户username列表
+ BasicCallback callback 回调接口
#### 将用户移出黑名单
```
JMessageClient.delUsersFromBlacklist(List<String> usernames, BasicCallback callback)
```
参数说明
+ List<String> usernames 被移出黑名单的用户username列表
+ BasicCallback callback 回调接口
#### 获取被当前用户加入黑名单的用户列表
```
JMessageClient.getBlacklist(GetBlacklistCallback callback)
```
参数说明
+ GetBlacklistCallback 获取黑名单回调接口
回调
```
public abstract void gotResult(int responseCode,
String responseMessage, List<UserInfo> userInfos);
```
+ `List<UserInfo>` userInfos 被拉入黑名单的用户的UserInfo
### 通知栏管理
#### 设置通知展示类型
```
JMessageClient.setNotificationFlag(int flag);
```
参数说明
+ int flag 显示通知的模式,包括[FLAG_NOTIFY_WITH_SOUND](../im_android_api_docs/cn/jpush/im/android/api/JMessageClient.html#FLAG_NOTIFY_WITH_SOUND)、[FLAG_NOTIFY_WITH_VIBRATE](../im_android_api_docs/cn/jpush/im/android/api/JMessageClient.html#FLAG_NOTIFY_WITH_VIBRATE)、[FLAG_NOTIFY_WITH_LED](../im_android_api_docs/cn/jpush/im/android/api/JMessageClient.html#FLAG_NOTIFY_WITH_LED)等类型,支持使用 '|' 符号联结各个参数
#### 获取通知栏展示类型
***Since 2.2.0***
```
JMessageClient.getNotificationFlag();
```
返回
+ int 当前设置的通知栏的展示类型。
#### 通知栏点击事件监听
用户可以通过接受通知栏点击事件NotificationClickEvent,来实现自定义跳转,该事件如果没有接收者,点击通知栏时SDK将默认跳转到程序主界面。
事件接收方法见[事件处理](./event)一节
#### 进入单聊会话
UI层在进入聊天会话界面时调用,设置当前正在聊天的对象,调用此接口之后,收到对应用户发来的消息时,sdk不会弹出通知栏提示。
同时还会清掉与该聊天对象会话的未读消息数,以及通知栏通知。
此接口传入的数据采用覆盖逻辑,后面传入的参数会覆盖掉之前的设置。
```
JMessageClient.enterSingleConversation(String username,String appKey)
```
参数定义
+ String username 单聊聊天对象的username
+ String appKey 聊天对象所属appKey,若appkey为空则默认填充本应用的appkey
#### 进入群聊会话
UI层在进入聊天会话界面时调用,设置当前正在聊天的对象,调用此接口之后,收到对应群组中发来的消息时,sdk不会弹出通知栏提示。
同时还会清掉与该聊天对象会话的未读消息数,以及通知栏通知。
此接口传入的数据采用覆盖逻辑,后面传入的参数会覆盖掉之前的设置。
```
JMessageClient.enterGroupConversation(long groupID)
```
参数定义
+ long groupID 群聊聊天对象的群ID
#### 退出会话
退出会话。UI层在退出聊天会话界面时调用,清除当前正在聊天的对象,之后收到对应的用户或群组发来的消息时,会正常展示通知栏通知。
```
JMessageClient.exitConversation();
```
### <span id="Nodisturb">免打扰设置</span>
可以将用户/群组添加到“免打扰”列表中,收到免打扰用户/群组发过来的消息时,sdk不会弹出默认的通知提示,但[消息事件](../im_android_api_docs/cn/jpush/im/android/api/event/MessageEvent.html)照常下发。
#### 获取免打扰列表
```
JMessageClient.getNoDisturblist(GetNoDisurbListCallback callback)
```
参数定义
+ GetNoDisurbListCallback callback 回调接口。
#### 设置普通免打扰
```
/**
* 将此用户设置为免打扰。
*
* @param noDisturb 1 -- 免打扰,其他 -- 非免打扰
* @param callback 回调接口
*/
public abstract void setNoDisturb(int noDisturb, BasicCallback callback);
```
具体见api doc中[UserInfo](../im_android_api_docs/cn/jpush/im/android/api/model/UserInfo.html)和[GroupInfo](../im_android_api_docs/cn/jpush/im/android/api/model/GroupInfo.html)相关接口
#### 设置全局免打扰
设置全局免打扰之后,收到所有消息都将不会有通知栏通知,效果类似<br> `JMessageClient.setNotificationFlag(JMessageClient.FLAG_NOTIFY_DISABLE)`,但是此设置在用户换设备之后也会生效。
```
JMessageClient.setNoDisturbGlobal(int noDisturbGlobal, BasicCallback callback)
```
参数定义
+ int noDisturbGlobal 全局免打扰标志,1表示设置,其他表示取消设置。
+ BasicCallback callback 回调接口
#### 获取全局免打扰标识
```
JMessageClient.getNoDisturbGlobal(IntegerCallback callback)
```
参数定义
+ IntegerCallback callback 回调接口。 | 4,776 | MIT |
---
layout: post
title: " 网页制作中的图片"
date: 2018-03-22 23:06:05
categories: 前端知识
tags: 前端知识
excerpt: 总有人问我为什么他在html展示的时候图片变形了,或者部分没展示出来,图片尺寸应该怎么弄,因此,我觉得还是有必要在这里对网页中的图片做一下说明
mathjax: true
author: 闵超
---
* content
{:toc}
# 网页制作中的图片
图片:jpg,png,gif
## jpg图片
我们最常见的。
jpg:可压缩的,有损图片质量的格式。虽然可压缩,它的色彩还是比较丰富。
特点:文件小、色彩丰富。
在网页中常用。
劣势:不能保存透明背景图片。
用途:插入图,大篇幅的整个的背景图。本身不要求太清晰,文件加载够快。
IE6图片边框
如果在img标签外面套了一个a标签,在IE6里会给图片加一个边框。我们需要清除这个边框。
img{
border:none;
}
## png图片
png:不可压缩的,可以保存图层。
质量比较大,真正使用的时候保存的是png32格式。
png特点:支持透明和半透明。
用途:精灵图、背景图。
问题:IE6不支持它的透明和半透明。
高级浏览器支持透明和半透明。
解决办法:引入一段js语句
<!--[if IE 6]>
<script type="text/javascript" src="js/png.js"></script>
<script type="text/javascript">
DD_belatedPNG.fix("div,ul,img,li,input,span,b,h1,h2,h3,h4");
</script>
<![endif]-->
## gif图片
gif:本身跟压缩无关,颜色色值较少,256种、128种、2种。
特点:可以保存透明,不支持半透明。可以保存动图。
在IE6里,透明效果没有兼容性问题。
用途:背景透明,动图。 | 913 | MIT |
<!-- TOC -->
- [ES6练习](#es6练习)
- [对象结构赋值](#对象结构赋值)
- [模板字符串](#模板字符串)
- [数组求平方](#数组求平方)
- [类定义](#类定义)
<!-- /TOC -->
<a id="markdown-es6练习" name="es6练习"></a>
# ES6练习
<a id="markdown-对象结构赋值" name="对象结构赋值"></a>
## 对象结构赋值
使用结构赋值,实现两个变量的值的交换(编程题)。
```js
let a = 1;
let b = 2;
let temp = a;
a = b;
b = temp;
```
等价于下面写法
```js
let a = 1;
let b = 2;
// 实现a,b变量的交换
[a,b] = [b,a];
```
<a id="markdown-模板字符串" name="模板字符串"></a>
## 模板字符串
以下代码改用模板字符串方式表达:
```js
let im = "我是";
let name = "王富贵";
let str = "大家好," + im + name + ",多指教。";
```
等价于
```js
let im = "我是";
let name = "王富贵";
let str = `大家好,${im}${name},多指教。`;
```
<a id="markdown-数组求平方" name="数组求平方"></a>
## 数组求平方
计算出数组 [1,2,3,4] 每一个元素的平方并组成新的数组
```js
var arr = [1, 2, 3, 4];
var newArr = [];
for (let i = 0; i < arr.length; i++) {
newArr.push(Math.pow(arr[i], 2));
}
console.log(newArr);
```
等价于
```js
var arr = [1, 2, 3, 4];
// js map和箭头函数
var newArr = arr.map((x) => { return Math.pow(x, 2); });
console.log(newArr);
```
<a id="markdown-类定义" name="类定义"></a>
## 类定义
定义一个类Animal,通过传参初始化它的类型,如:“猫科类”。
它有一个实例方法:run,run函数体内容可自行定义。
```js
var Animal = function (type) {
this.type = type;
this.run = function () {
console.log(`${this.type} can run fast`);
}
}
var a1 = new Animal('小猫');
a1.run();
```
等价于
```js
class Animal {
constructor(type) {
this.type = type;
}
run() {
console.log(`${this.type} can run fast`);
}
}
var a1 = new Animal('小猫');
a1.run();
```
定义一个子类Cat并继承Animal类。初始化Cat类的昵称name和年龄age。
并拥有实例方法eat,eat函数体内容可自行定义。
```js
class Animal {
constructor(type) {
this.type = type;
}
run() {
console.log(`${this.type} can run fast`);
}
}
class Cat extends Animal {
constructor(name, age) {
super('小猫');
this.name = name;
this.age = age;
}
eat() {
console.log(`${this.name}喜欢吃鱼`);
}
}
var a1 = new Cat('小花', 2);
a1.run();
a1.eat();
``` | 1,961 | Apache-2.0 |
---
layout: post # 使用的布局(不需要改)
title: SpringDataJPA几种sql方式 # 标题
subtitle: 👣 #副标题
date: 2018-04-07 # 时间
author: Ian # 作者
header-img: img/post-bg-universe.jpg #这篇文章标题背景图片
catalog: true # 是否归档
iscopyright: true # 是否版权
tags: #标签
- 编程之路
- 自我总结
- DB
---
```java
/**
* SpringDataJPA 几种sql方式。
*/
public boolean login(String name,String password){
// User user = userDao.findByNameAndPassword(name,password);
/** User user = userDao.findOne(new Specifiaction<User>() {
public Predicate toPredicate(Root<User> root, CrieriaQuery<?> cq, CriteriaBuilder cb){
return cb.and(
cb.equal(
root.get("name").as(String.class),
name
),
cb.equal(
root.get("password").as(Stirng.class),
password
)
);
}
});
return user != null;
*/
@Modifying
@Query("delete User u where u.id =: id")
@Transactional
void delByUserId(@Param("id") Long id);
// select * from user where name =? and password =?
/**
* JPA 运行原生 sql 语句进行删除 一个user
*/
@Modifying
@Query(value="DELETE FORM user WHERE id=:id",nativeQuery = true)
@Transactional
void delUserByNativeSql(@Param("id")Long id);
}
```
1. @Component 加到类路径自动扫描
2. @Controller 一个web的控制层,在Spring MVC中使用
3. @Repository 数据管理/存储,企业级应用使用(Dao, DDD)
4. @Service 提供一个商业逻辑 - 一个无状态的切面
`Page<AcquisitionResults> AcquisitionResultsPage = acquisitionResultsService.findAll((root, cq, cb) -> {`
> root 路径相关 <https://www.objectdb.com/api/java/jpa/criteria/Root>
> cq 查询相关 <https://docs.oracle.com/javaee/6/api/javax/persistence/criteria/CriteriaQuery.html>
> cb 创建相关 <https://docs.oracle.com/javaee/7/api/javax/persistence/criteria/CriteriaBuilder.html>
条件对象<br>
equal 等价于 and<br>
大于 gn<br>
小于 le<br>
#### springDataJpa 需要注意的注解
1. @Modifying
2. @Query(value="DELETE from user where id=:id",nativeQuery = true 这个里面的sql语句 前面是 类名 不是表名) 加nativeQuery = true 表示使用原生sql
3. @Transactional
#### shiro生命周期
生命周期:
- spring 把shiro 注入进去
- 例子:
* 登录请求会转发给shiro 里面
* controller servlet 让shiro 来管理servlet
* 用aop的方式去管理所有的controller,然后定义用shiro来代理它
- 白名单:
* `spring-shiro.xml:` anon 当前所有请求登录都可以处理
* logout 登出
* /** = authc 指定哪个请求 验证器
* /** = user 除了上面的,其它的都要登录以后才能访问。
- redirect:/admin/index redirect转发。 | 2,629 | MIT |
---
bg: "13/13-13.jpg"
layout: post
title: "山陰の旅Part2"
crawlertitle:
summary: ""
date: 2019-07-13 13:40:00 +9
categories: posts
tags: '旅行記'
author: mencha
---
part1は[こちら](https://menchan.github.io/posts/saninn1/)
昼食後、松江城へ向かいます。
<!--more-->
歩いて10分程で松江城着きました。堀を渡り中を歩いてみます。

まず最初に見えてきたのがこの洋館。明治天皇の山陰巡幸のために建てられたそうです。ですが、結果的にそれは実現せず、皇太子(後の大正天皇)が山陰を訪れたときに迎賓館として使われたみたい。その後いろいろ使われ、現在は公開となっています。ちなみに入館料はいりません。

中はこんな感じ。木造です。この時代の洋風建物、好きです。特に窓のあたりが。
では、天守閣の方へ向かいましょう。天守閣に登るには、670円必要です。

全体的に黒っぽい、外観は4層の天守閣。内部は5階+地下1階となっています。この日は快晴だったので、写りがとても良いです。やっぱり写真は晴れに限ります。
松江城は1935年、国宝に指定されましたが、その後国宝指定が一度外れ、2015年にまた国宝に指定されたということです。

天守閣の中は現存の建物ということで、建物自身を見せるようになっています。




最上階に来ました。南側は宍道湖が見えて、眺めは良かったです。
松江城を後にして、周辺を歩いてみます。

こちら、塩見縄手という通りです。武家屋敷などの古い町並みが残っているところで、片側はお堀になっていてなかなかいい雰囲気の道でした。日本の道100選のうちの一つだそう。
その通りに面している一つの建物に行ってみました。小泉八雲(ラフカディオ・ハーン)の旧居です。小泉八雲といえば「怪談」で有名な人です。松江の人と結婚した後、一時期松江に住んでいたことがあり、その時の家です。


建物の中からは日本庭園が見えるようになっています。三方が庭園となっているなんて、好きだったんでしょうね、日本風の庭が。こういう景色の見える縁側でのんびりと、なんていいでしょうね。「怪談」、読んでみようかなぁ…
そろそろ16:00、いい時間になってきました。松江といえば宍道湖に沈む夕日です。まだ日没までは少しあるので、湖畔まで歩いていきます。

空が赤くなってきました。

島根県立美術館前での一枚。AIによる処理の恩恵を受けたような写真になりましたが、これが見た景色に近いんです。手前に広がる歩道と美術館のモニュメント、夕日を眺める人がうまく一枚に収まった、お気に入りの写真です!

こちらは人気の夕日スポット。なんとか島が目の前に見えます。ここにはたくさんの人がいました。
宍道湖に沈む夕日、今まで見た中でいちばん美しい夕日だったと思います。この景色を見ただけで来たかいがあったとも言えるほど、良いものでした。
そして時間は夕食時。日本海の美味しい魚でも食べたいと思うも…なんでだよ!居酒屋しかないじゃないか…仕方がないので居酒屋で海鮮丼だけを注文。魚のみでとても美味しかったんだけど、不思議な顔されたように思います。今度から食事処はしっかり探しておこう…でも、地でとれた魚って居酒屋ぐらいにしかないんだよなぁ

それにしても、美味しかった。新鮮な魚という感じ。肉の味の違いはあんまりわからんが、魚はすぐわかります。
明日は出雲方面へ。 | 2,875 | MIT |
<properties
pageTitle="Azure SQL Database のリソース制限"
description="このページでは、Azure SQL Database に対するいくつかの一般的なリソース制限について説明します。"
services="sql-database"
documentationCenter="na"
authors="carlrabeler"
manager="jhubbard"
editor="monicar" />
<tags
ms.service="sql-database"
ms.devlang="na"
ms.topic="article"
ms.tgt_pltfrm="na"
ms.workload="data-management"
ms.date="05/02/2016"
ms.author="carlrab" />
# Azure SQL Database のリソース制限
## 概要
Azure SQL Database では、**リソース ガバナンス**と**制限の適用**という 2 つの異なるメカニズムを使用して、データベースで使用できるリソースを管理します。このトピックでは、リソース管理のこれら 2 つの主な領域について説明します。
## リソース ガバナンス
Basic、Standard、および Premium サービス プランの設計目標の 1 つは、Azure SQL Database の動作を、データベースが他のデータベースから完全に分離された専用のコンピューターで稼働しているかのようにすることです。リソース ガバナンスは、この動作をエミュレートします。集計されたリソース使用率が、データベースに割り当てられた利用可能な CPU、メモリ、ログ I/O、データ I/O のリソースの最大値に達すると、リソース ガバナンスは、実行中のクエリをキューに配置し、リソースが解放されると、キューに配置されたクエリにそのリソースを割り当てます。
専用のコンピューターの場合と同様、利用可能なリソースをすべて利用すると、現在実行中のクエリの実行時間が長くなり、コマンドがクライアントでタイムアウトする可能性があります。積極的な再試行ロジックを使用するアプリケーションやデータベースに対して高い頻度でクエリを実行するアプリケーションでは、同時要求の制限に達したときに新しいクエリを実行しようとするとエラー メッセージが表示される場合があります。
### 推奨事項:
データベースの最大使用率に近づいてきたら、リソース使用率に加えて、クエリの平均応答時間も監視します。クエリの待機時間が長くなる場合、一般的には 3 つのオプションがあります。
1. データベースへの着信要求を少なくして、タイムアウトと大量の要求を防ぎます。
2. データベースにより高いパフォーマンス レベルを割り当てます。
3. クエリを最適化して、各クエリのリソース使用率を引き下げます。詳細については、Azure SQL Database パフォーマンス ガイダンスのクエリのチューニングとヒント設定に関するセクションを参照してください。
## 制限の適用
制限に達すると、新しい要求を拒否することによって CPU、メモリ、ログ I/O、およびデータ I/O 以外のリソースが適用されます。達した制限に応じて、クライアントは[エラー メッセージ](sql-database-develop-error-messages.md)を受け取ります。
たとえば、SQL Database への接続数と処理可能な同時要求の数が制限されます。SQL Database では、接続プールをサポートするために、データベースへの接続数が同時要求の数を上回ることを許可します。利用可能な接続数はアプリケーションで簡単に制御できるのに対し、並列要求の数の見積もりや制御は困難であることがよくあります。特に、負荷のピーク時に、アプリケーションから送信される要求が多すぎる場合や、データベースがそのリソースの制限に達し、クエリの実行時間が長くなることが原因でワーカー スレッドが蓄積され始める場合に、エラーが発生することがあります。
## サービス プランとパフォーマンス レベル
単一のデータベースの場合、データベースの制限はデータベース サービス階層とパフォーマンス レベルによって決まります。次の表では、パフォーマンス レベルごとの Basic、Standard、Premium の各データベースの特性について説明します。
[AZURE.INCLUDE [SQL DB のサービス階層表](../../includes/sql-database-service-tiers-table.md)]
[エラスティック データベース プール](sql-database-elastic-pool.md)は、プール内のデータベース全体のリソースを共有します。次の表では、Basic、Standard、および Premium のエラスティック データベース プールの特性について説明します。
[AZURE.INCLUDE [エラスティック データベースの SQL DB サービス階層を示す表](../../includes/sql-database-service-tiers-table-elastic-db-pools.md)]
前の表に示されている各リソースの詳細な定義いついては、「[サービス レベルの機能と制限](sql-database-performance-guidance.md#service-tier-capabilities-and-limits)」の説明を参照してください。サービス階層の概要については、[Azure SQL Database のサービス階層とパフォーマンス レベル](sql-database-service-tiers.md)に関するページを参照してください。
## その他の SQL Database の制限
| 領域 | 制限 | 説明 |
|---|---|---|
| サブスクリプションあたりの自動エクスポートを使用するデータベース | 10 | 自動エクスポートを使用すると、カスタム スケジュールを作成して、SQL Database をバックアップできます。詳細については、「[SQL Database: 自動 SQL Databaseエクスポートのサポート](http://weblogs.asp.net/scottgu/windows-azure-july-updates-sql-database-traffic-manager-autoscale-virtual-machines)」を参照してください。|
| サーバーあたりのデータベース | 最大 5000 | V12 サーバーでは、サーバーあたり最大 5000 個のデータベースが許可されています。サーバー上のすべてのデータベースに対するログイン アクティビティと master データベース内のシステム ビューに対するクエリの使用状況に応じて、実際には適用される上限は低くなる場合があります。サーバー上のデータベースの数を大幅に増加する場合は、問題が発生していないかどうかについてデータベース接続を監視することをお勧めします。 |
| サーバーあたりの DTU | 45000 | データベース、エラスティック プール、データ ウェアハウスをプロビジョニングする場合、V12 サーバーではサーバーあたり 45000 DTU を使用できます。 |
## Resources
[Azure サブスクリプションとサービスの制限、クォータ、制約](../azure-subscription-service-limits.md)
[Azure SQL Database のサービス階層とパフォーマンス レベル](sql-database-service-tiers.md)
[SQL Database クライアント プログラムのエラー メッセージ](sql-database-develop-error-messages.md)
<!---HONumber=AcomDC_0504_2016--> | 3,511 | CC-BY-3.0 |
---
layout: post
title: 无损压缩算法:deflate
tags: ['deflate']
published: true
---
本文目标是搞清楚zlib库的deflate算法实现。
<!--more-->
## 名词解释
[deflate](https://en.wikipedia.org/wiki/DEFLATE):最常见的无损压缩算法,非常关键。
[.zip]( https://en.wikipedia.org/wiki/Zip_(file_format) ):archive format,使用了deflate压缩算法
[.gz](https://en.wikipedia.org/wiki/Gzip)(或gzip格式): single file compress format,也是使用了deflate压缩算法
[.tar.gz]( https://en.wikipedia.org/wiki/Tar_(computing) )或.tgz:archive format,可认为.gz文件的集合,但又不止是多个.gz的集合,因为tgz利用了文件之间的关联信息,提升了压缩率。
[zlib](https://zlib.net/):一个通用库,只有源代码,不提供可执行文件,支持gzip。linux内核、libpng、git等等都用了它。
[gzip](https://www.gnu.org/software/gzip/manual/gzip.html):GNU Gzip,开源,提供了gzip和gunzip可执行文件,直接可以用来压缩、解压缩。内部也是实现了deflate算法。
7-Zip:类似gzip,也是工具。
经过了解,gzip的源码相对
## Huffman Coding 和 LZ77
### LZ77(Lempel–Ziv Coding)
LZ77是基于**字典**的算法。思路是,把数据中的重复(冗余)部分,用更短的metadata元信息代替。
wiki:[LZ77 and LZ78](https://en.wikipedia.org/wiki/LZ77_and_LZ78#LZ77)
根据wiki所说,作者是发明了2个算法LZ77和LZ78。这2个算法是其他LZ算法变种的基础(LZW、LZSS、LZMA)。
下面重点介绍LZ77。
#### LZ77关键词:
- input stream:待压缩的字节序列串
- byte:字节,是input stream的基本元素
- coding position:相当于一个指针,指向当前编码位置;也是lookahead buffer的起始位置
- lookahead buffer:就是指coding position为起点,input stream末端为终点的这段字节序列
- window:最大长度为W的滑动窗口,也是以coding position为起点,但是窗口方向是**反向往左**;窗口初始长度为0,随着编码的进行,长度会增长到W,然后就开始往右滑动
- match:当前匹配串
- pointer:当前匹配串的信息,一般用(B,L)表示,B表示Go **B**ack多少个字节(从coding position往左),因为也叫starting offset;L指匹配串从starting offset往右延伸的长度。 pointer为(0,0)时,表示匹配失败。
#### LZ77要注意的点:
- pointer的L是可能比B还大的,即匹配串从window区域,延伸进了lookahead buffer区域,又因为匹配串的起点就是lookahead buffer的起点,所以此时出现了**repeat**现象。这个repeat是没问题的,甚至是有用的,可以对不断重复的数据大大压缩。
- pointer有匹配成功和匹配失败2种情况,所以把pointer信息输出时,还得在pointer前用一个bit表示是哪种pointer。
- pointer里2个信息:B和L,它们的位数一般是固定的。位数大小可以是任意的N bits,但显然,位数太少的话,说明最大匹配长度就受限,即对于超长串是无法高度压缩的。
- **重点**:有的文章会把pointer表示成(B,L,C)。C就是一个byte数据,这是因为任意一个byte第一次出现时,肯定是找不到匹配串的,所以会输出(0,0,byte);并且,为了输出缓冲区的结构一致性,当匹配成功时,也得输出(B,L,C),C相当于一个空的占位符,有点浪费,所以有的LZ77算法会再成功匹配后,把下一个byte存到占位符里,因此encoding position要移动L+1。(注意下文讲解的实例占位符是留空的)
- B和L耗用的位数不需要一样。
- 既然固定了B和L的位数大小,那么最大窗口大小W也是可以固定的,例如当W为32KB时,那么15 bits就可以表达32KB的任意一个值。
- window的最大长度W影响到压缩比率和压缩效率。显然W越大,匹配得越充分,但也越慢。
- 需要定一个**最小匹配长度**,只有当当前匹配串大于最小匹配长度时,这个匹配才成立。例如B用15位,L用8位,差不多就用了3个字节,如果当前匹配串不足3个字节,例如1个字节,那就导致encoding后长度反而更长了。
- 显然LZ77的compress做的工作量要比decompress多得多,因为做了大量的匹配查找。所以LZ77特别适合于**一次压缩,多次解压缩**的情景。
#### 实例:
这种算法用实例来理解是最快的。微软[这篇文章](
https://msdn.microsoft.com/en-us/library/ee916854.aspx
)就给出了一个例子,这里拿来用一下。
([另外这篇文章](https://www.cnblogs.com/junyuhuang/p/4138376.html)给出了这个例子的示意图,建议同时参照下,本文就不做图了)
待压缩字节串(流):AABCBBABC
字节串中每个字节记一个位置标记position(上面的encoding position也是指这个),从1开始数,不是从0哦:
<pre>
Position 1 2 3 4 5 6 7 8 9
Byte A A B C B B A B C
</pre>
开始LZ77编码:

LZ77编码后,就输出了最右边一列,注意,这里只是方便理解,实际上不会存成文本形式,没有( ),这些字符。
这里重点要搞懂output这一列是怎么来的,用人话来描述下:
0. 初始时,滑动窗口window是空的:【】
1. 第1次遇到A,然后在window里match一下,必然找不到A,match失败,于是输出(0,0)A。window更新为【A】
2. 第2次遇到A,window里match一下,此时要注意,match的方向是右到左(反向)。在window右起第1个位置就找到了A,所以输出(1, 1),window更新为【AA】
3. 第1次遇到B,同步骤1,输出(0,0)B,window更新为【AAB】
4. 同步骤3,输出(0,0)C,window更新为【AABC】
5. 第2次遇到B,在window第2个位置找到B,于是starting position为2,同时发现下一个字节不匹配(左C和右B),所以长度为1,输出(2,1),window更新为【AABCB】
6. 第3次遇到B,在window第1个位置就找到B,同时发现下一个字节不匹配(左B和右C),所以长度为1,输出(1,1),window更新为【AABCBB】
7. 第3次遇到A,在window第5个位置找到A,然后迭代匹配,发现后面的BC也匹配上,所以长度为3,输出(5,3),window更新为【AABCBBABC】
接下来,看看如何把这一列output再解码回原文:

0. 输入(0,0)A,表示直接往输出缓冲区push一个A字符。 【A】
1. 输入(1,1),只有meta信息,(1,1)意思是它的位置等于1,长度为1,**注意,位置是反向数,长度是正向数**。显然,(1,1)等于缓冲区的字符A,于是push了一个一样的A。【AA】
2. (0,0)B,和步骤1一样,直接push一个B。【AAB】
3. (0,0)C,同上。【AABC】
4. (2,1),又是meta信息,位置为2,长度为1,倒着数当前缓冲区,发现起点是B字符,长度为1,所以push一个B。【AABCB】
5. (1,1),参考步骤5,也是push一个B。【AABCBB】
6. (5,3),长度终于不为1了,首先在缓冲区倒着数5下,发现是左起第二个A,然后长度3,于是往右再获取2个字符,得到ABC,push到缓冲区,得到【AABCBBABC】
上面的内容搞得懂的话,就差不多了,要继续深入就是看源码。但不急,先看完Huffman Coding。
### Huffman Coding
待续。
## zlib 和 deflate
想直接看zlib的deflate代码是很难的。我发现一个入手方式是看doc/algorithm.txt 和 [rfc1951](http://tools.ietf.org/html/rfc1951)还有deflate.c里的注释。
### zlib
zlib自带CMakeLists.txt,在Mac上可以直接生成一个Xcode project,不仅可以方便地编译zlib,还可以用来学习zlib(本文的重心):
```
cd build/
cmake .. -G 'Xcode'
```
然后打开zlib.xcodeproj,构建All,并选择运行example。能运行成功的话打开example.c,会发现有完整的zlib使用教程。
我们重点放在deflate的最简单的使用实例:
```c
test_deflate(compr, comprLen);
test_inflate(compr, comprLen, uncompr, uncomprLen);
```
第1行压缩,第2行解压。看懂了这两个函数代码,是理解deflate算法的第一步。
```c
// 该函数用到的外部代码片段,我搬运到这里,方便浏览
// 压缩强度级别
#define Z_NO_COMPRESSION 0
#define Z_BEST_SPEED 1
#define Z_BEST_COMPRESSION 9
#define Z_DEFAULT_COMPRESSION (-1)
// 这个结构大概相当于一个压缩控制器
typedef struct z_stream_s {
z_const Bytef *next_in; /* 指向待压缩数据的第一个字节 */
uInt avail_in; /* 待压缩数据next_in的长度 */
uLong total_in; /* 当前已读取多少输入字节 */
Bytef *next_out; /* 指向输出缓冲区,只需要在一开始赋值一次 */
uInt avail_out; /* 输出缓冲区next_out的剩余空间 */
uLong total_out; /* 当前已输出多少输入字节*/
z_const char *msg; /* 错误信息 */
struct internal_state FAR *state; /* 暂时不用管这个 */
alloc_func zalloc; /* 压缩过程会分配新内存(internal state),用户可以设置自己的alloc函数给z_stream */
free_func zfree; /* 释放内存 */
voidpf opaque; /* zalloc、zfree的第一个参数,默认设0即可 */
int data_type; /* 数据的类型的猜测:Z_BINARY 或者 Z_TEXT,即保存了detect_data_type的返回值 */
uLong adler; /* 未压缩数据的检验和 (Adler-32 or CRC-32) */
uLong reserved;
} z_stream;
//待压缩的字节串
static z_const char hello[] = "hello, hello!";
void test_deflate(compr, comprLen)
Byte *compr;
uLong comprLen;
{
z_stream c_stream;
int err;
uLong len = (uLong)strlen(hello)+1; // 待压缩数据大小
c_stream.zalloc = zalloc;
c_stream.zfree = zfree;
c_stream.opaque = (voidpf)0;
err = deflateInit(&c_stream, Z_DEFAULT_COMPRESSION);
CHECK_ERR(err, "deflateInit");
c_stream.next_in = (z_const unsigned char *)hello;
c_stream.next_out = compr;
// 如果不使用1字节buffer模式的话,要执行这2行
// c_stream.avail_in = len;
// c_stream.avail_out = comprLen;
// 开始压缩
while (c_stream.total_in != len && c_stream.total_out < comprLen) {
c_stream.avail_in = c_stream.avail_out = 1; /* 每次只处理1个字节,故意的*/
err = deflate(&c_stream, Z_NO_FLUSH);
CHECK_ERR(err, "deflate");
}
// 压缩末端的处理
for (;;) {
c_stream.avail_out = 1; // 依然每次只输出一个字节
err = deflate(&c_stream, Z_FINISH);
if (err == Z_STREAM_END) break; // 结束标记
CHECK_ERR(err, "deflate");
}
err = deflateEnd(&c_stream);
CHECK_ERR(err, "deflateEnd");
}
```
纵观整个压缩流程,其实就是1个变量和3个函数:
- 定义z_stream局部变量c_stream
- deflateInit(&c_stream, Z_DEFAULT_COMPRESSION),初始化c_stream
- deflate(&c_stream, Z_NO_FLUSH)和deflate(&c_stream, Z_FINISH),压缩数据
- deflateEnd(&c_stream),结束
这个example故意让缓冲区每次迭代都只有1个字节可用,可以去掉那2行代码,并在开始压缩之前执行:
```c
c_stream.avail_in = len;
c_stream.avail_out = comprLen;
```
接下来是解压缩:
```c
void test_inflate(compr, comprLen, uncompr, uncomprLen)
Byte *compr, *uncompr;
uLong comprLen, uncomprLen;
{
int err;
z_stream d_stream;
strcpy((char*)uncompr, "garbage");
d_stream.zalloc = zalloc;
d_stream.zfree = zfree;
d_stream.opaque = (voidpf)0;
d_stream.next_in = compr;
d_stream.avail_in = 0;
d_stream.next_out = uncompr;
// 如果不使用1字节buffer模式的话,要执行这2行
// d_stream.avail_in = (uInt)comprLen;
// d_stream.avail_out = (uInt)uncomprLen;
err = inflateInit(&d_stream);
CHECK_ERR(err, "inflateInit");
while (d_stream.total_out < uncomprLen && d_stream.total_in < comprLen) {
d_stream.avail_in = d_stream.avail_out = 1;
err = inflate(&d_stream, Z_NO_FLUSH);
if (err == Z_STREAM_END) break;
CHECK_ERR(err, "inflate");
}
err = inflateEnd(&d_stream);
CHECK_ERR(err, "inflateEnd");
if (strcmp((char*)uncompr, mytest)) {
fprintf(stderr, "bad inflate\n");
exit(1);
} else {
printf("inflate(): %s\n", (char *)uncompr);
}
}
```
deflate和inflate函数的源码,非常恐怖,单个函数几百行。这里就不贴出来分析了。
### deflate
待续。
## adler32 和 CRC32
都是checksum,adler32速度比CRC32快,可靠性比CRC32逊色一点。zlib是为了兼容gzip,才保留了crc32。
checksum函数类似hash函数,但定位却很不一样。checksum函数主要针对**错误检测和校正**,而hash函数没有校正需求,且对hash值的碰撞容忍度,checksum要比hash高,有的hash甚至要求加密,如HMAC。
如果不考虑错误校正,确实可以用hash函数如MD5/SHA1来计算校验值,就是有点杀鸡用牛刀(overkill)。性能也比CRC32差,毕竟计算复杂。另外长度差距也很大,CRC32仅需要4个字节。
adler32对短消息处理得不好,因为短消息不能很好地覆盖到32bits,没有充分利用32bits。
## 历史
一位答主写了压缩算法的演变史,很值得一看:
https://stackoverflow.com/questions/20762094/how-are-zlib-gzip-and-zip-related-what-do-they-have-in-common-and-how-are-they
简单来说,就是早期unix系统上面只有compress指令,compress使用了一个有版权的LZW算法,作者Phil Katz对LZW的免费使用有所争议。
并且,zip format也是这个作者设计的,但庆幸zip format是无版权的,于是就有个叫Info-ZIP group的组织开发了同样可以压缩&解压缩zip的程序,开源免费跨平台,这个东西导致zip format被大范围使用。
然后到了90年代早期,出现了新的压缩格式:gzip format(或.gz)以及对应的程序gzip。gzip的代码继承自Info-ZIP,gzip是打算用来取代unix的compress的。
gzip单个文件时,会给该文件加上.gz后缀。
然后又到了90年代中期,又遇到了版权问题,这次是关于gif格式的,gif用了带版权的LZW算法。于是又有人站出来开发了替代品:png。这是一种无损压缩图片的技术,同样使用了deflate作为内部格式。为了扩大png的使用范围,就弄出了libpng和zlib两个网站。libpng是用来处理png有关的所有事情,而zlib是作为libpng背后的支撑:提供了压缩和解压缩算法(当然现在也被用于别的软件)。注意,zlib的代码继承自gzip。
小结2点:**gzip是zlib之父;以上说的版权问题现在都已过期了**。
zlib兼容gzip,且提供了比gzip更多的功能选项。一是wrapping模式可选:无wrapping、zlib wrapping、gzip wrapping。无wrapping就是仅使用deflate内部格式;png使用的就是zlib wrapping。
zlib wrapping和gzip wrapping的主要区别是:zlib wrapping更紧凑并且新增了Adler-32算法,比gzip用的CRC32更快。
所以zlib源码会显得比较复杂,需要兼容gzip格式和CRC32,且新增了zlib格式和Adler32;gzip就显得比较原始,只有deflate和CRC32代码。
可以通过定义NO_GZIP宏,来关闭对gzip的兼容。默认是不定义的。如果定义了NO_GZIP,就只会使用alder32,没有crc32。
zlib是目前最广泛使用的压缩库。
再后来,就出现了新的基于deflate压缩库:7-Zip和google的zopfli。zopfli的压缩率比zlib的最高压缩率还高,压榨了最后的一些空间,但也花费了更多的CPU时间。当然这个最高压缩level是可选的。注意,zopfli只提供了压缩功能,解压缩依然得用zlib或gzip(大概是因为解压缩本来就足够优秀了);zopfli虽然有3-8%的压缩率提升,但耗时增长得更厉害,觉得zopfli还是显得鸡肋。
以上说的都是基于deflate算法的压缩库。实际上还存在别的算法:bzip2、LZMA等,他们有的甚至是完胜deflate。但很可惜,在互联网中要更替一种标准是非常困难的。deflate已经广泛运用到web的方方面面,难以取代。
所以还是学习deflate先吧。并且,阅读zlib库最佳。
## 资料
[A Universal Algorithm for Sequential Data Compression](https://www2.cs.duke.edu/courses/spring03/cps296.5/papers/ziv_lempel_1977_universal_algorithm.pdf)
[RFC1951 : DEFLATE Compressed Data Format Specification version 1.3](https://tools.ietf.org/html/rfc1951)
http://qianwenjie.net/?p=17
http://marknelson.us/1997/01/01/zlib-engine/
http://www.zlib.net/feldspar.html | 10,204 | MIT |
## 割圆术计算π
参考:[割圆术计算π|Java](../java/01.md)
由于Python有`decimal`这个库,我们可以用Python进行大数运算,而且效率比Java的`java.math.BigDecimal`更高,开方的计算也更直接,所以我把之前用Java计算圆周率的代码用Python写了一遍:
```python3
#!/usr/bin/python3
# -*- coding: utf-8 -*-
from decimal import *
#叮当里好像没有decimal库,请将该代码复制到本地库运行
getcontext().prec=256 #数字长度
print('='*40+'''
本程序将计算半径为1的正 3×2^n 边形的面积,从而近似算得π。
n越大,计算结果越精确。
参考: https://rainbowc0.gitee.io/java/01.html
'''+'='*40)
n,i,c,s=input('请输入n: '),0,Decimal('0.5'),Decimal('1')
if n.isdigit():
n=int(n)
while i<n:
c=((c+1)/2)**Decimal('0.5')
s*=c
i+=1
print('π约为: '+str(Decimal('1.5')*(Decimal('3')**Decimal('0.5'))/s))
else:
print('这不是数字!')
```
精确到了小数点后253位(当然还可以更多位):
```
========================================
本程序将计算半径为1的正 3×2^n 边形的面积,从而近似算得π。
n越大,计算结果越精确。
参考: https://rainbowc0.gitee.io/java/01.html
========================================
请输入n: 1024
π约为: 3.1415926535897932384626433832795028841971693993751058209749445923078164062862089986280348253421170679821480865132823066470938446095505822317253594081284811174502841027019385211055596446229489549303819644288109756659334461284756482337867831652712019091456/*第253位*/50
``` | 1,136 | Apache-2.0 |
---
layout: post
title: "颱風煙花和疫情雙重影響南京,江寧商業步行街異常冷冷清清"
date: 2021-07-27T12:44:41.000Z
author: 圍城記
from: https://www.youtube.com/watch?v=3rb-kx8tJu8
tags: [ 圍城記 ]
categories: [ 圍城記 ]
---
<!--1627389881000-->
[颱風煙花和疫情雙重影響南京,江寧商業步行街異常冷冷清清](https://www.youtube.com/watch?v=3rb-kx8tJu8)
------
<div>
#南京現狀 #南京最新情況 #颱風煙花
</div> | 322 | MIT |
---
title: 威胁资源管理器和实时检测
f1.keywords:
- NOCSH
ms.author: tracyp
author: msfttracyp
manager: dansimp
audience: ITPro
ms.topic: article
ms.localizationpriority: medium
search.appverid:
- MET150
- MOE150
ms.assetid: 82ac9922-939c-41be-9c8a-7c75b0a4e27d
ms.collection:
- M365-security-compliance
- m365initiative-defender-office365
description: 使用浏览器门户中的资源管理器Microsoft 365 Defender实时检测,以有效地调查和响应威胁。
ms.custom: seo-marvel-apr2020
ms.technology: mdo
ms.prod: m365-security
ms.openlocfilehash: 96004add9efe4fac033518f32b357044bdb7588f
ms.sourcegitcommit: d4b867e37bf741528ded7fb289e4f6847228d2c5
ms.translationtype: MT
ms.contentlocale: zh-CN
ms.lasthandoff: 10/06/2021
ms.locfileid: "60196509"
---
# <a name="threat-explorer-and-real-time-detections"></a>威胁资源管理器和实时检测
**适用对象**
- [Microsoft Defender for Office 365 计划 1 和计划 2](defender-for-office-365.md)
- [Microsoft 365 Defender](../defender/microsoft-365-defender.md)
如果你的组织拥有适用于 Office 365 的 [Microsoft Defender,](defender-for-office-365.md)并且你拥有必要的权限,则你拥有资源管理器或实时检测 (以前是实时报告 *—请参阅* 新增功能 [!) 。](#new-features-in-threat-explorer-and-real-time-detections) [](#required-licenses-and-permissions) 在安全&中心,转到"**威胁** 管理",然后选择"**资源管理器**"_或_**"实时检测"。**
<br>
****
|借助 Microsoft Defender for Office 365计划 2,你将看到:|借助 Microsoft Defender for Office 365 计划 1,可以看到:|
|---|---|
|||
|
资源管理器或实时检测可帮助安全运营团队高效地调查和响应威胁。 报告类似于下图:

通过此报告,您可以:
- [查看由安全Microsoft 365检测到的恶意软件](#see-malware-detected-in-email-by-technology)
- [查看网络钓鱼 URL 并单击裁定数据](#view-phishing-url-and-click-verdict-data)
- [仅从 Explorer (](#start-automated-investigation-and-response) Defender for Office 365 计划 2 中的视图启动自动调查和响应)
- [调查恶意电子邮件等](#more-ways-to-use-explorer-and-real-time-detections)
## <a name="improvements-to-threat-hunting-experience"></a>威胁搜寻体验改进
### <a name="introduction-of-alert-id-for-defender-for-office-365-alerts-within-explorerreal-time-detections"></a>在资源管理器/实时Office 365中引入适用于实时警报的 Defender 警报 ID
今天,如果你从警报导航到威胁资源管理器,它将在资源管理器中打开一个筛选视图,其中由警报策略 ID (策略 ID 筛选的视图是警报策略 id 的唯一标识符) 。
我们正在通过引入警报 ID (在威胁资源管理器和实时检测中查看) 下方的警报 ID 示例,以便查看与特定警报相关的消息以及电子邮件数量,从而使此集成更具相关性。 您还可以查看邮件是否属于警报,以及从该邮件导航到特定警报。
查看单个警报时,警报 ID 在 URL 中可用;示例为 `https://protection.office.com/viewalerts?id=372c9b5b-a6c3-5847-fa00-08d8abb04ef1` 。
> [!div class="mx-imgBorder"]
> 
> [!div class="mx-imgBorder"]
> 
### <a name="extending-the-explorer-and-real-time-detections-data-retention-and-search-limit-for-trial-tenants-from-7-to-30-days"></a>将 Explorer (和实时检测) 试用租户的数据保留和搜索限制从 7 天扩展到 30 天
作为此更改的一部分,你将能够在威胁资源管理器/实时检测中搜索并筛选 (过去 7 天) 针对 Office P1 和 P2 试用租户的 Defender 的电子邮件数据。
这不会影响 P1 和 P2/E5 客户的任何生产租户,这已具有 30 天的数据保留和搜索功能。
### <a name="updated-limits-for-export-of-records-for-threat-explorer"></a>更新了威胁资源管理器的记录导出限制
作为此更新的一部分,可以从威胁资源管理器导出的电子邮件记录的行数从 9990 增加到 200,000 条记录。 当前可以导出的列集将保持不变,但行数将自当前限制开始增加。
### <a name="tags-in-threat-explorer"></a>威胁资源管理器中的标记
> [!NOTE]
> 用户标记功能在 *预览版* 中,并非对所有人都可用,并且可能会更改。 有关发布计划的信息,请查看Microsoft 365路线图。
用户标记标识 Microsoft Defender for Office 365 中的特定用户组。 有关标记(包括许可和配置)的信息,请参阅 [用户标记](user-tags.md)。
在威胁资源管理器中,可以在以下体验中查看有关用户标记的信息。
#### <a name="email-grid-view"></a>电子邮件网格视图
电子邮件 **网格** 中的"标记"列包含已应用于发件人或收件人邮箱的所有标记。 默认情况下,优先显示优先帐户等系统标记。
> [!div class="mx-imgBorder"]
> 
#### <a name="filtering"></a>筛选
可以使用标记作为筛选器。 仅跨优先级帐户或特定用户标记方案进行智能寻线。 还可以排除具有特定标记的结果。 将此功能与其他筛选器相结合,以缩小调查范围。
[](../../media/tags-filter-normal.png#lightbox)
> [!div class="mx-imgBorder"]
> 
#### <a name="email-detail-flyout"></a>电子邮件详细信息飞出
若要查看发件人和收件人的单个标记,请选择主题以打开邮件详细信息飞出。 在 **"摘要"** 选项卡上,如果电子邮件存在发件人和收件人标记,则分别显示它们。
有关发件人和收件人的单个标记的信息还扩展到导出的 CSV 数据,您可以在两个单独的列中查看这些详细信息。
> [!div class="mx-imgBorder"]
> 
URL 单击飞出也显示标记信息。 若要查看它,请转到网络钓鱼或所有电子邮件视图,然后转到 **URL** 或 **URL 单击** 选项卡。选择单个 URL 飞出视图有关该 URL 的单击的其他详细信息,包括与该单击关联的标记。
### <a name="updated-timeline-view"></a>更新的时间线视图
> [!div class="mx-imgBorder"]
> 
>
观看[此视频](https://www.youtube.com/watch?v=UoVzN0lYbfY&list=PL3ZTgFEc7LystRja2GnDeUFqk44k7-KXf&index=4)了解更多信息。
## <a name="improvements-to-the-threat-hunting-experience-upcoming"></a>威胁搜寻体验的改进 (即将推出的)
### <a name="updated-threat-information-for-emails"></a>更新了电子邮件的威胁信息
我们专注于改进平台和数据质量,以提高电子邮件记录的数据准确性和一致性。 改进包括将传递前和传递后信息(如作为 ZAP 过程的一部分对电子邮件执行的操作)合并到单个记录中。 还包括垃圾邮件裁定、实体级别威胁 (,例如,哪些 URL 是恶意) ,以及最新的送达位置。
这些更新后,你将看到每封邮件的单个条目,而不管影响邮件的不同传递后事件如何。 操作可以包括 ZAP、手动修正 (这意味着管理员) 操作、动态传递等。
除了显示恶意软件和网络钓鱼威胁之外,您还可以看到与电子邮件关联的垃圾邮件裁定。 在电子邮件中,查看与电子邮件关联的所有威胁以及相应的检测技术。 电子邮件可以具有零个、一个或多个威胁。 你将在电子邮件飞出 **的详细信息部分看到** 当前威胁。 对于恶意软件 (网络钓鱼等多个威胁) ,检测技术字段显示威胁检测映射,这是识别威胁的检测技术。
检测技术集现在包括新的检测方法以及垃圾邮件检测技术。 您可以使用同一组检测技术跨恶意软件、网络钓鱼、所有电子邮件 (不同的电子邮件视图筛选) 。
> [!NOTE]
> 裁定分析不一定与实体关联。 例如,电子邮件可能分类为网络钓鱼或垃圾邮件,但没有标记有网络钓鱼/垃圾邮件裁定的 URL。 这是因为在分配裁定之前,筛选器还会评估电子邮件的内容和其他详细信息。
#### <a name="threats-in-urls"></a>URL 中的威胁
现在,可以在"电子邮件"飞出"详细信息"选项卡上看到 URL **的特定** 威胁。威胁可以是 *恶意软件*、 *网络钓鱼*、 *垃圾邮件* 或 *无*。)
> [!div class="mx-imgBorder"]
> 
### <a name="updated-timeline-view-upcoming"></a>更新了日程表视图 (即将推出的)
> [!div class="mx-imgBorder"]
> 
时间线视图标识所有传递和传递后事件。 它包括有关在这些事件的子集时确定的威胁的信息。 时间线视图还提供有关对项目执行 (操作(如 ZAP 或手动修正) )的信息,以及该操作的结果。 时间线视图信息包括:
- **源:** 事件的源。 它可以是管理员/系统/用户。
- **事件:** 包括顶级事件,如原始传递、手动修正、ZAP、提交和动态传递。
- **操作:** 作为 ZAP 或管理员操作一部分执行的特定 (例如,软删除) 。
- **威胁:** 涵盖 (识别的恶意软件、网络钓鱼) 垃圾邮件威胁。
- **结果/详细信息:** 有关操作结果的信息,例如它是否作为 ZAP/admin 操作一部分执行。
### <a name="original-and-latest-delivery-location"></a>原始和最新的送达位置
目前,我们在电子邮件网格和电子邮件浮出控件中显示传递位置。 The **Delivery location** field is getting renamed Original delivery **_location_*_.我们将引入另一个字段 _*_最新送达位置_**。
**原始送达** 位置将提供有关电子邮件最初送达位置的更多信息。 **最新的送达位置** 将说明电子邮件在系统操作(如 *ZAP)* 或管理员操作(如 *移动到已删除项目)之后登录的位置*。 最新送达位置旨在告知管理员邮件的上次已知位置传递后或任何系统/管理员操作。 它不包括对电子邮件的任何最终用户操作。 例如,如果用户删除了邮件或将邮件移动到 archive/pst,则邮件"传递"位置将不会更新。 但是,如果系统操作更新了位置 (例如,ZAP 导致电子邮件移动到隔离邮箱) ,最新送达位置将显示为"隔离"。
> [!div class="mx-imgBorder"]
> 
> [!NOTE]
> 在某些情况下,传递位置 **和****传递操作** 可能显示为"未知":
>
> - 如果邮件已送达,您可能会看到"送达位置"和"送达位置"为"未知",但收件箱规则将邮件移动到默认文件夹 (如草稿或存档) 而不是"收件箱"或"垃圾邮件"文件夹。
>
> - **如果已尝试** 执行管理/系统操作( (ZAP) ,但未找到邮件,则最新的传递位置可能未知。 通常,该操作发生在用户移动或删除邮件之后。 在这种情况下,请验证 **日程表视图中的"结果/** 详细信息"列。 查找"用户移动或删除的邮件"语句。
> [!div class="mx-imgBorder"]
> 
### <a name="additional-actions"></a>其他操作
*在电子邮件* 传递后应用了其他操作。 它们可以包括 *ZAP、 (* 管理员采取的操作(如软删除) 、动态传递和重新处理 *()* 针对被反向检测为) 。
> [!NOTE]
> 作为挂起更改的一部分,当前在"传递操作"筛选器中显示"由 ZAP 删除"值将消失。 你将有一种方法通过"其他操作"通过 ZAP 尝试搜索 **所有电子邮件**。
> [!div class="mx-imgBorder"]
> 
### <a name="system-overrides"></a>系统覆盖
*系统覆盖* 使您能够对邮件的预定传递位置进行例外。 根据筛选堆栈确定的威胁和其他检测,你可以覆盖系统提供的传递位置。 可以通过租户或用户策略设置系统覆盖,以根据策略的建议传递邮件。 替代可以标识由于配置差异(例如,用户设置的发件人策略范围过宽保险箱发送恶意邮件的意外传递。 这些替代值可以是:
- 用户策略允许:用户在邮箱级别创建策略以允许域或发件人。
- 被用户策略阻止:用户在邮件框级别创建策略以阻止域或发件人。
- 组织策略允许:组织的安全团队设置策略或 Exchange 邮件流规则 (也称为传输规则) ,以允许组织中的用户使用发件人和域。 这适用于一组用户或整个组织。
- 被组织策略阻止:组织的安全团队设置策略或邮件流规则,以阻止组织中用户的发件人、域、邮件语言或源 IP。 这可应用于一组用户或整个组织。
- 组织策略阻止的文件扩展名:组织的安全团队通过反恶意软件策略设置阻止文件扩展名。 这些值现在将显示在电子邮件详细信息中,以帮助进行调查。 Secops 团队还可使用丰富的筛选功能筛选阻止的文件扩展名。
[](../../media/System_Overrides.png#lightbox)
> [!div class="mx-imgBorder"]
> 
### <a name="improvements-for-the-url-and-clicks-experience"></a>URL 和单击体验的改进
这些改进包括:
- 显示完整单击的 URL (包括作为 URL 链接的一) **单击部分的任何** 查询参数。 目前,URL 域和路径显示在标题栏中。 我们将扩展该信息以显示完整 URL。
- 跨 URL 筛选器 (*URL* 与 *URL* 域与 *URL* 域和路径) 修复:更新会影响对包含 URL/单击裁定的邮件的搜索。 我们启用了协议不可知搜索支持,因此无需使用 ,即可搜索 `http` URL。 默认情况下,除非明确指定了其他值,否则 URL 搜索将映射到 http。 例如:
- 在"URL"、"URL 域"和"URL 域"和"路径"筛选器字段中使用 和 `http://` **不带前缀进行** 搜索。 搜索应显示相同的结果。
- 在 URL `https://` 中搜索 **前缀**。 未指定任何值时, `http://` 将假定前缀。
- `/`在 URL 路径、URL 域 **、URL** 域和路径字段的开头和 **结尾忽略**。 `/` 将忽略 **URL** 字段的末尾。
### <a name="phish-confidence-level"></a>网络钓鱼可信度
网络钓鱼可信度有助于确定电子邮件被分类为"网络钓鱼"的可信度。 两个可能的值是 *High* 和 *Normal*。 在初始阶段,此筛选器将仅在威胁资源管理器的网络钓鱼视图中可用。
[](../../media/Phish_Confidence_Level.png#lightbox)
### <a name="zap-url-signal"></a>ZAP URL 信号
ZAP URL 信号通常用于 ZAP 网络钓鱼警报方案,其中电子邮件被标识为钓鱼邮件,在传递后被删除。 此信号将警报与资源管理器中的相应结果连接。 它是警报的 IIC 之一。
为了改进搜寻过程,我们更新了威胁资源管理器和实时检测,使搜寻体验更加一致。 此处概述了这些更改:
- [时区改进](#timezone-improvements)
- [刷新过程中的更新](#update-in-the-refresh-process)
- [要添加到筛选器的图表深化](#chart-drilldown-to-add-to-filters)
- [在产品信息更新中](#in-product-information-updates)
### <a name="filter-by-user-tags"></a>按用户标记筛选
现在,你可以对系统或自定义用户标记进行排序和筛选,以快速了解威胁的范围。 若要了解更多信息,请参阅 [用户标记](user-tags.md)。
> [!IMPORTANT]
> 按用户标记进行筛选和排序目前处于公共预览阶段。 此功能在商业发行之前可能会进行重大修改。 Microsoft 对提供的信息不做出明示或暗示的担保。
> [!div class="mx-imgBorder"]
> 
### <a name="timezone-improvements"></a>时区改进
你将在门户和导出的数据中查看电子邮件记录的时区。 它将在电子邮件网格、详细信息飞出控件、电子邮件时间线和类似电子邮件等体验中可见,因此电子邮件结果集清晰。
> [!div class="mx-imgBorder"]
> 
### <a name="update-in-the-refresh-process"></a>刷新过程中的更新
一些用户已评论过与自动刷新 (混淆,例如,一旦更改日期,页面就会为其他筛选器) 刷新 (刷新) 。 同样,删除筛选器也会导致自动刷新。 在修改查询时更改筛选器可能会导致搜索体验不一致。 为了解决这些问题,我们将迁移到手动筛选机制。
从体验的角度来看,用户可以从筛选器集和日期 (应用和删除不同范围的筛选器) 并选择刷新按钮,以在定义查询后筛选结果。 屏幕上现在也强调刷新按钮。 我们还更新了相关工具提示和产品内文档。
> [!div class="mx-imgBorder"]
> 
### <a name="chart-drilldown-to-add-to-filters"></a>要添加到筛选器的图表深化
现在,你可以绘制图例值图表以将它们添加为筛选器。 选择" **刷新"** 按钮以筛选结果。
> [!div class="mx-imgBorder"]
> 
### <a name="in-product-information-updates"></a>产品内信息更新
产品内现在提供了其他详细信息,例如网格内搜索结果的总数 (请参阅下面的) 。 我们改进了标签、错误消息和工具提示,以提供有关筛选器、搜索体验和搜索结果集。
> [!div class="mx-imgBorder"]
> 
## <a name="extended-capabilities-in-threat-explorer"></a>威胁资源管理器中的扩展功能
### <a name="top-targeted-users"></a>主要目标用户
今天,我们在电子邮件的"恶意软件"视图中的"主要恶意软件系列"部分公开了主要目标 **用户** 列表。 我们还将在"钓鱼邮件"和"所有电子邮件"视图中扩展此视图。 你将能够看到前五个目标用户,以及每个用户针对相应视图的尝试次数。 例如,对于网络钓鱼视图,你将看到网络钓鱼尝试次数。
你将能够导出目标用户列表(最多 3,000 个)以及每个电子邮件视图的脱机分析尝试次数。 此外,选择尝试次数 (例如,在) 下的图像中尝试 13 次将在威胁资源管理器中打开筛选视图,以便你可以查看有关该用户的电子邮件和威胁的更多详细信息。
> [!div class="mx-imgBorder"]
> 
### <a name="exchange-transport-rules"></a>Exchange传输规则
作为数据扩充的一部分,你将能够看到应用于邮件的所有Exchange ETR () 传输规则。 此信息将在电子邮件网格视图中提供。 若要查看它,请选择网格 **中的列** 选项,然后从Exchange **添加** 传输规则。 它还将在电子邮件的" **详细信息** "飞出内容上可见。
您将能够查看已应用于邮件的传输规则的 GUID 和名称。 您将能够使用传输规则的名称搜索邮件。 这是一个"包含"搜索,这意味着您也可以执行部分搜索。
> [!IMPORTANT]
> ETR 搜索和名称可用性取决于分配给您的特定角色。 您需要具有以下角色/权限之一才能查看 ETR 名称和搜索。 如果没有分配任何这些角色,则看不到传输规则的名称,也看不到使用 ETR 名称搜索邮件。 但是,您可以在电子邮件详细信息中查看 ETR 标签和 GUID 信息。 电子邮件网格、电子邮件飞出、筛选器和导出中的其他记录查看体验不受影响。
>
> - 仅 EXO - 数据丢失防护:全部
> - 仅 EXO - O365SupportViewConfig:全部
> - Microsoft Azure Active Directory或 EXO - 安全管理员:全部
> - AAD 或 EXO - 安全读者:全部
> - 仅 EXO - 传输规则:全部
> - 仅 EXO - View-Only配置:全部
>
> 在电子邮件网格、"详细信息"飞出控件和导出的 CSV 中,ETR 将显示一个名称/GUID,如下所示。
>
> > [!div class="mx-imgBorder"]
> > 
### <a name="inbound-connectors"></a>入站连接器
连接器是一组说明,用于自定义电子邮件在组织或组织Microsoft 365 Office 365流。 它们使您能够应用任何安全限制或控件。 在威胁资源管理器中,你现在可以查看与电子邮件相关的连接器,然后使用连接器名称搜索电子邮件。
连接器的搜索本质上是"包含"的,这意味着部分关键字搜索也应正常工作。 在主网格视图、"详细信息"飞出控件和导出的 CSV 中,连接器以名称/GUID 格式显示,如下所示:
> [!div class="mx-imgBorder"]
> 
## <a name="new-features-in-threat-explorer-and-real-time-detections"></a>威胁资源管理器和实时检测中的新功能
- [查看发送给模拟用户和域的网络钓鱼电子邮件](#view-phishing-emails-sent-to-impersonated-users-and-domains)
- [预览电子邮件头并下载电子邮件正文](#preview-email-header-and-download-email-body)
- [电子邮件时间线](#email-timeline)
- [导出 URL 单击数据](#export-url-click-data)
### <a name="view-phishing-emails-sent-to-impersonated-users-and-domains"></a>查看发送给模拟用户和域的网络钓鱼电子邮件
若要识别针对被模拟用户的用户和域的网络钓鱼尝试,必须添加到用户 *列表中以保护*。 对于域,管理员必须启用 *"组织* 域",或向"域"添加域名 *才能保护*。 要保护的域位于"模拟"部分中的" *防* 钓鱼 *策略"* 页面上。
若要查看网络钓鱼邮件并搜索模拟的用户或域,请使用资源管理器> [电子邮件和网络钓鱼](threat-explorer-views.md) "视图。
此示例使用威胁资源管理器。
1. 在安全 [&合规 (](https://protection.office.com) 中,选择"威胁>资源管理器 (或实时检测 https://protection.office.com)) 。
2. 在"视图"菜单中,选择"电子邮件>钓鱼邮件"。
可以在此处选择 **模拟域或****模拟用户**。
3. **选择****"模拟域",** 然后在文本框中键入受保护的域。
例如,搜索 *contoso、contoso.com* 或 *contoso.com.au**等受保护的域名*。
4. Select the Subject of any message under the Email tab > Details tab to see additional impersonation information like Impersonated Domain / Detected location.
**OR**
选择 **"模拟用户** ",在文本框中键入受保护的用户的电子邮件地址。
> [!TIP]
> **为了获得最佳结果**,请使用 *完整电子邮件地址* 来搜索受保护的用户。 例如,在调查用户模拟时,如果搜索 *[email protected],您将* 更快、更成功地找到受保护的用户。 在搜索受保护的域时,搜索将 (contoso.com 根域(例如) )和域名 (*contoso*) 。 搜索根域 contoso.com将同时返回 contoso.com 和域名 *contoso 的模拟*。
5. 在"**电子邮件"****选项卡"详细信息**"选项卡下选择任何邮件的主题,以查看有关用户或域的其他模拟信息和 > 检测到 *的位置*。
:::image type="content" source="../../media/threat-ex-views-impersonated-user-image.png" alt-text="显示检测位置和检测到的威胁的受保护用户的"威胁资源管理器"详细信息窗格 (冒充用户或) 。":::
> [!NOTE]
> 在步骤 3 或 5 中,如果分别选择"检测技术"并选择"模拟域"或"模拟用户","电子邮件"选项卡"详细信息"选项卡中有关用户或域的信息以及"检测到的位置"将只显示在与"反网络钓鱼策略"页中列出的用户或域相关的邮件上。 >
### <a name="preview-email-header-and-download-email-body"></a>预览电子邮件头并下载电子邮件正文
你现在可以在威胁资源管理器中预览电子邮件头并下载电子邮件正文。 管理员可以分析下载的邮件头/电子邮件中的威胁。 因为下载电子邮件可能会暴露信息的风险,所以此过程由基于角色的访问控制 (RBAC) 。 必须将新角色 *Preview* 添加到另一个角色组 (如安全操作或安全管理员) ,以授予在全电子邮件视图中下载邮件的能力。 但是,查看电子邮件头不需要任何其他角色 (在威胁资源管理器中查看邮件所需的角色) 。
资源管理器和实时检测还将获得新字段,这些字段提供电子邮件到达位置的更完整图片。 这些更改使搜寻安全操作变得更加简单。 但主要结果是你可以一目了然地知道问题电子邮件的位置。
如何完成此操作? 传递状态现在分为两列:
- **传递操作** - 电子邮件的状态。
- **传递位置** - 电子邮件的路由位置。
*传递* 操作是对现有策略或检测对电子邮件采取的操作。 以下是电子邮件的可能操作:
<br>
****
|已传递|垃圾邮件|Blocked|已替换|
|---|---|---|---|
|电子邮件已传递到用户的收件箱或文件夹,用户可以访问它。|电子邮件已发送到用户的"垃圾邮件"或"已删除"文件夹,用户可以访问它。|被隔离、失败或已丢弃的电子邮件。 用户无法访问这些邮件。|电子邮件的恶意附件替换为.txt附件是恶意附件的附件。|
|
下面是用户可以看到和看不到的:
<br>
****
|最终用户可访问|最终用户无法访问|
|---|---|
|已传递|Blocked|
|垃圾邮件|已替换|
|
**传递** 位置显示运行传递后的策略和检测的结果。 它链接到传递 **_操作_**。 可能的值包括:
- *收件箱或文件夹*:电子邮件位于收件箱或文件夹中 (电子邮件规则) 。
- *本地或外部*:邮箱在云中不存在,但位于本地。
- *垃圾邮件* 文件夹:电子邮件位于用户的"垃圾邮件"文件夹中。
- *"已删除邮件"文件夹*:用户的"已删除邮件"文件夹中的电子邮件。
- *隔离*:电子邮件被隔离,不在用户邮箱中。
- *失败*:电子邮件无法到达邮箱。
- *已* 丢弃:电子邮件在邮件流中的某处丢失。
### <a name="email-timeline"></a>电子邮件时间线
电子邮件 **时间线** 是一种新的资源管理器功能,可改善管理员的搜寻体验。 它减少检查不同位置以尝试了解事件所花的时间。 当在电子邮件到达的同一时间或接近同一时间发生多个事件时,这些事件将显示在时间线视图中。 在"特殊操作"列中捕获在电子邮件传递后发生的一 **些** 事件。 管理员可以将时间线的信息与对邮件传递后执行的特殊操作相结合,以深入了解其策略如何工作、邮件最终路由在何处,在某些情况下,最终评估是什么。
有关详细信息,请参阅调查和修正在 Office 365[中传递的恶意Office 365。](investigate-malicious-email-that-was-delivered.md)
### <a name="export-url-click-data"></a>导出 URL 单击数据
现在,可以将 URL 单击报告导出到Microsoft Excel查看其网络消息 **ID** 并单击 **裁定**,这有助于说明 URL 单击流量的来源。 它的工作原理如下:在快速启动Office 365上的威胁管理中,按照以下链操作:
**资源管理器** \>**查看钓鱼邮件** \>**单击** \>**顶部 URL 或** **URL 顶部单击** \> 选择任意记录以打开 URL 飞出。
在列表中选择 URL 时,你将在飞出面板上看到一个新的"导出"按钮。 使用此按钮将数据移动到 Excel 电子表格,以便更轻松地报告。
按照此路径到达实时检测报告中的相同位置:
**资源管理器** \>**实时检测** \>**查看钓鱼邮件** \>**URL** \>**顶部 URL** 或 **顶部单击** \> 选择任意记录以打开 URL 飞出控件 \> 导航到"**单击"** 选项卡。
> [!TIP]
> 当您通过资源管理器或关联的第三方工具搜索 ID 时,网络消息 ID 将单击映射回特定邮件。 此类搜索可标识与单击结果关联的电子邮件。 通过关联网络消息 ID,可以更快速、更强大的分析。
> [!div class="mx-imgBorder"]
> 
## <a name="see-malware-detected-in-email-by-technology"></a>查看通过电子邮件技术检测到的恶意软件
假设您希望查看在按技术排序的电子邮件Microsoft 365恶意软件。 为此,请使用资源管理器>或 [实时检测的](threat-explorer-views.md#email--malware) "电子邮件 (恶意软件") 。
1. 在安全&合规 () 中,选择"威胁管理资源管理器 (或实时检测 <https://protection.office.com> \> ) 。 (此示例使用 Explorer.)
2. 在"**视图"** 菜单中,选择"**电子邮件恶意软件** \> **"。**
> [!div class="mx-imgBorder"]
> 
3. 单击 **"发件人**",然后选择"**基本** \> **检测技术"。**
你的检测技术现在用作报告的筛选器。
> [!div class="mx-imgBorder"]
> 
4. 选择一个选项。 然后选择" **刷新"** 按钮以应用该筛选器。
> [!div class="mx-imgBorder"]
> 
报告将刷新,以使用所选的技术选项显示电子邮件中检测到的恶意软件的结果。 在这里,你可以进行进一步分析。
## <a name="view-phishing-url-and-click-verdict-data"></a>查看网络钓鱼 URL 并单击裁定数据
假设你想要查看通过电子邮件中的 URL 的网络钓鱼尝试,包括允许、阻止和覆盖的 URL 列表。 若要标识单击的[URL,保险箱链接](safe-links.md)。 请确保为单击保险箱和单击[](set-up-safe-links-policies.md)裁定记录设置"链接"策略保险箱策略。
若要查看邮件中的网络钓鱼 URL 并单击网络钓鱼邮件中的 URL,请使用资源管理器的电子邮件[ > ](threat-explorer-views.md#email--phish)网络钓鱼视图或实时检测。
1. 在安全&合规 () 中,选择"威胁管理资源管理器 (或实时检测 <https://protection.office.com> \> ) 。 (此示例使用 Explorer.)
2. 在"**视图"** 菜单中,选择"**电子邮件钓鱼** \> **邮件"。**
> [!div class="mx-imgBorder"]
> 
3. 单击 **"发件人**",然后选择 **"URL""** \> **单击裁定"。**
4. 选择一个或多个选项,如"阻止"和"阻止 **覆盖**",然后选择与应用该筛选器的选项位于同一行上的"刷新"按钮。 (请勿刷新浏览器窗口。)
> [!div class="mx-imgBorder"]
> 
报告将刷新,以在报告下的"URL"选项卡上显示两个不同的 URL 表:
- **顶部 URL** 是筛选到的邮件中的 URL,每个 URL 的电子邮件传递操作计数。 在网络钓鱼电子邮件视图中,此列表通常包含合法 URL。 攻击者在邮件中混合了好 URL 和坏 URL,以尝试传递这些 URL,但它们会使恶意链接看起来更有趣。 URL 表按总电子邮件计数排序,但隐藏此列以简化视图。
- **点击量** 最高是保险箱链接包装的 URL,按总点击数排序。 此列也不显示,以简化视图。 按列的总计数指示每个保险箱 URL 的链接单击裁定计数。 在网络钓鱼电子邮件视图中,这些 URL 通常是可疑或恶意 URL。 但是,该视图可能包含不是威胁但包含钓鱼邮件中的 URL。 此处不会显示未包链接上的 URL 单击。
这两个 URL 表按传递操作和位置显示网络钓鱼电子邮件中的顶部 URL。 这些表显示了尽管出现警告仍被阻止或访问的 URL 单击,因此你可以看到向用户显示哪些潜在的错误链接以及用户点击了哪些链接。 在这里,你可以进行进一步分析。 例如,在图表下方,可以看到在组织环境中被阻止的电子邮件中的顶部 URL。
> [!div class="mx-imgBorder"]
> 
选择 URL 以查看更多详细信息。
> [!NOTE]
> 在"URL"弹出对话框中,将删除对电子邮件的筛选,以显示环境中 URL 曝光的完整视图。 这样,你可以筛选资源管理器中关注的电子邮件,查找潜在威胁的特定 URL,然后通过"URL 详细信息"对话框 (扩展对环境中 URL 曝光的了解) 而无需将 URL 筛选器添加到资源管理器视图本身。
### <a name="interpretation-of-click-verdicts"></a>单击裁定的解释
在"电子邮件"或"URL"飞出、"热门单击"以及我们的筛选体验中,你将看到不同的单击裁定值:
- **无:** 无法捕获 URL 裁定。 用户可能通过 URL 单击过。
- **允许:** 允许用户导航到 URL。
- **已阻止:** 阻止用户导航到 URL。
- **待定裁定:** 向用户显示等待触发的页面。
- **被阻止覆盖:** 阻止用户直接导航到 URL。 但用户过度控制块以导航到 URL。
- **已绕过待定裁定:** 向用户显示触发页面。 但是,用户为了访问 URL 而过度使用邮件。
- **错误:** 向用户显示错误页面,或捕获裁定时出错。
- **失败:** 捕获裁定时发生未知异常。 用户可能通过 URL 单击过。
## <a name="review-email-messages-reported-by-users"></a>查看用户报告的电子邮件
假设您希望查看您组织中用户通过报告邮件外接程序或报告网络钓鱼外接程序报告为垃圾邮件、非垃圾邮件或网络钓鱼[的电子邮件](enable-the-report-phish-add-in.md)。 [](enable-the-report-message-add-in.md) 若要查看它们,请使用资源管理器的"电子邮件[ > 提交" (](threat-explorer-views.md#email--submissions)或实时检测) 。
1. 在安全&合规 () 中,选择"威胁管理资源管理器 (或实时检测 <https://protection.office.com> \> ) 。 (此示例使用 Explorer.)
2. 在"**视图"** 菜单中,选择"**电子邮件** \> **提交"。**
> [!div class="mx-imgBorder"]
> 
3. 单击 **"发件人**",然后选择"**基本** \> **报告类型"。**
4. 选择一个选项(如 **钓鱼邮件**)然后选择" **刷新"** 按钮。
> [!div class="mx-imgBorder"]
> 
报告将刷新以显示有关组织中人员报告为网络钓鱼尝试的电子邮件的数据。 可以使用此信息进行进一步分析,如有必要,在 Microsoft Defender 中调整反网络钓鱼策略[,Office 365。](configure-mdo-anti-phishing-policies.md)
## <a name="start-automated-investigation-and-response"></a>启动自动调查和响应
> [!NOTE]
> Microsoft Defender for *Office 365 Plan 2* 和 Office 365 E5 *中提供了自动调查和响应Office 365 E5。*
[自动调查和响应](automated-investigation-response-office.md) 可以节省安全运营团队在调查和缓解网络攻击上花费的时间和精力。 除了配置可触发安全手册的警报之外,还可以从资源管理器中的视图启动自动调查和响应过程。 有关详细信息,请参阅 [示例:安全管理员从资源管理器触发调查](automated-investigation-response-office.md#example-a-security-administrator-triggers-an-investigation-from-threat-explorer)。
## <a name="more-ways-to-use-explorer-and-real-time-detections"></a>使用资源管理器和实时检测的更多方法
除了本文中概述的方案之外,资源管理器或实时检测功能中还提供了更多报告 (或实时) 。 另请参阅以下文章:
- [查找和调查投递的恶意电子邮件](investigate-malicious-email-that-was-delivered.md)
- [查看在 SharePoint Online、OneDrive 和 Microsoft Teams 中检测到的恶意Microsoft Teams](./mdo-for-spo-odb-and-teams.md)
- [大致了解威胁资源管理器中的视图 (实时检测) ](threat-explorer-views.md)
- [威胁防护状态报告](view-email-security-reports.md#threat-protection-status-report)
- [Microsoft 365 Defender 中的自动调查和响应](../defender/m365d-autoir.md)
## <a name="required-licenses-and-permissions"></a>所需的许可证和权限
你必须拥有[Microsoft Defender Office 365](defender-for-office-365.md)使用资源管理器或实时检测。
- 资源管理器包含在计划 2 Office 365 Defender 中。
- 实时检测报告包含在计划 1 的 Defender Office 365中。
- 计划为应受 Defender for Office 365 保护的所有用户分配Office 365。 资源管理器和实时检测显示许可用户的检测数据。
若要查看和使用资源管理器或实时检测,您必须具有适当的权限,例如授予安全管理员或安全读者的权限。
- 对于安全&合规中心,必须分配以下角色之一:
- 组织管理
- 安全 (可以在管理中心管理中心Azure Active Directory分配 <https://aad.portal.azure.com> ()
- 安全信息读取者
- 对于Exchange Online,必须在 Exchange 管理中心 () 或 PowerShell 中分配Exchange Online角色 <https://admin.protection.outlook.com/ecp/> [之一](/powershell/exchange/exchange-online-powershell):
- 组织管理
- 仅查看组织管理
- 仅查看收件人
- 合规性管理
若要详细了解角色和权限,请参阅以下资源:
- [Microsoft 365 Defender 门户中的权限](permissions-microsoft-365-security-center.md)
- [Exchange Online 中的功能权限](/exchange/permissions-exo/feature-permissions)
## <a name="differences-between-threat-explorer-and-real-time-detections"></a>威胁资源管理器和实时检测之间的差异
- 实时 *检测报告在* Defender for Office 365计划 1 中提供。 *威胁资源管理器* 在计划 2 的 Defender Office 365可用。
- 实时检测报告允许你实时查看检测。 威胁资源管理器也这样做,但它还提供了给定攻击的其他详细信息。
- " *所有电子邮件* "视图在威胁资源管理器中可用,但在实时检测报告中不可用。
- 威胁资源管理器中包含更多筛选功能和可用操作。 有关详细信息,请参阅[Microsoft Defender for Office 365 Service Description: Feature availability across Defender for Office 365 plans](/office365/servicedescriptions/office-365-advanced-threat-protection-service-description#feature-availability-across-advanced-threat-protection-atp-plans)。
## <a name="other-articles"></a>其他文章
[使用"电子邮件实体"页调查电子邮件](mdo-email-entity-page.md) | 21,619 | CC-BY-4.0 |
# Servlet 进阶
## 一、HttpServletRequest
只要有请求进入Tomcat服务器,Tomcat服务器就会把Http协议信息解析好封装到Request对象中,然后传递到Service方法中(doGet(),doPost()),我们可以通过HtttpServletRequest 对象获取到所有请求的信息;
### 1.1 常用方法
```java
//1、获取请求资源路径
System.out.println("请求资源路径为" + request.getRequestURI());
//2、获取统一资源定位符
System.out.println("统一资源定位符"+request.getRequestURL());
// 3、获取客户端IP地址
System.out.println("客户端IP地址"+request.getRemoteHost());
//4、获取请求头
System.out.println("请求头"+request.getHeader("User-Agent"));
//5、获取方法
System.out.println("请求方法"+request.getMethod());
```
### 1.2 获取页面发送过来的数据
```java
request.setCharacterEncoding("UTF-8"); // 处理中文字符乱码问题,设置字符编码
String username = request.getParameter("username");
String password = request.getParameter("password");
String box = request.getParameter("username");
String[] boxes = request.getParameterValues("box");
System.out.println(box);
```
### 1.3 请求转发
什么是请求转发,请求转发是指,服务器收到请求后,从一个资源跳转到,另一个资源的操作;

**请求转发的特点:**
1、浏览器地址栏没有变化
2、请求转发,只有一次请求;
3、多个请求,可以共享一个request数据;
4、可以映射到WEB-INF下的数据;
5、不能访问当前工程以外的资源;
### 1.4 WEB.中的绝对路径和相对路径
```java
/**
相对路径
. 表示当前目录
.. 表示上一级目录
资源名 表示当前目录/资源名
绝对路径
http://ip:port/工程路径/资源名
*/
```
## 二、HttpServletResopnse
HttpServletResponse 和HttpServletRequese,每次请求进来,服务器都会创建一个Response对象传递给Servlet程序去使用,H ttpServletRequest 表示请求信息,HttpServletResopnse 表示响应的相关信息。 若是我们需要设置返回给客户端的相关信息我们可以通过HttpServletResponse 来设置;
```java
protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
response.setCharacterEncoding("UTF-8");
//方式一:通过响应头也设置utf-8字符
response.setCharacterEncoding("UTF-8");
response.setHeader("content-Type", "text/html;charset=UTF-8");
// 方式二:setContenttype
response.setContentType("text/html;charset=UTF-8");
PrintWriter writer = response.getWriter();
writer.write("this is Response ");
}
```
### 2.1 请求重定向
请求重定向,指客户端给服务器发送请求,然后服务器告诉客户端给到他一个新地址,你去新的地址访问吧;

**特点:**
1、浏览器地址栏有变化,
2、两次请求;
3、不共享request 域中的数据;
4、不能访问 web-inf下的资源;
5、可以访问工程外的资源
```java
response.sendRedirect("http://localhost:8080");
```
## 三、Java EE三层架构
 | 2,480 | MIT |
# 附录-乙 测试平台vagrant部署
# 制作基于centos6.7和xampp7.0.1的vagrant box
已制作下载地址:http://pan.baidu.com/s/1o6Zq5zc
参考网页:
+ http://thornelabs.net/2013/11/11/create-a-centos-6-vagrant-base-box-from-scratch-using-virtualbox.html
+ http://my.oschina.net/bubifengyun/blog/550066
+ http://www.vagrantbox.es/
+ https://atlas.hashicorp.com/boxes/search?utm_source=vagrantcloud.com&vagrantcloud=1
已有较多的制作教程,本例讲述在 Ubuntu 麒麟下的制作过程。
# 一、软件准备
+ centos6.7 安装包,本次安装采用的是DVD1包,http://www.centoscn.com/CentosSoft/iso/2015/0813/6001.html
+ virtualbox 5.0.12及其扩展包,https://www.virtualbox.org/wiki/Downloads,
+ vagrant 安装包,https://www.vagrantup.com/downloads.html
+ xampp 7.0.1,https://www.apachefriends.org/download.html
# 二、准备工作
## 1、virtualbox 安装
本文下载的是deb文件,下面主要讲述命令行安装方式。
```
sudo dpkg -i /path/to/virtualbox.deb
```
安装完成后,应该可以在终端输入`virtualbox`启动virtualbox软件。
关闭virtualbox后,双击下载的virtualbox扩展包,可以直接安装成功。
## 2、vagrant 安装
下载最新包安装即可。
```
sudo dpkg -i /path/to/vagrant.deb
```
上面两步也可以跳过,直接使用命令行如下安装。
```
sudo apt-get install vagrant virtualbox -y
```
切记给virtualbox安装扩展支持。
# 三、安装centos
## 1、预备安装
+ 打开虚拟机virtualbox,New新建主机命名centos,
+ Type类型选择Linux,
+ Version版本选择Red Hat(64bit),
+ Memory size内存大小可以设置为512MB或者更多,
+ Hard drive 硬盘选择Create a virtual hard drive now新建硬盘,点击创建,
+ File Location硬盘文件地址选择默认,或者其他位置,看你磁盘空间而定,
+ File size硬盘大小默认8G足够,如有更多需求,你可以调大;
+ Hard Drive file type硬盘类型,选择VDI
+ Storage on physical hard drive 驱动存储方式, 选择 Dynamically allocated动态方式, 点击Create创建;
+ 现在打开Settings 设置,在存储里找到Controller:IDE,选择你下载的centos-6.7-x86-64-bin-DVD1.iso
+ 在声音和端口内关闭声音和USB驱动。
+ 点击确定
## 2、安装系统
选择virtualbox的centos,点击启动即可。
+ 建议安装过程中语言之类的选择English,如果需要可以选择中文简体。
+ root密码设置为vagrant
+ 时区选择Asia/Shanghai,时间不选UTC。
+ 最后安装类型选择最小化安装。
+ 其他选择默认。
安装完毕后重启。
## 3、配置系统(手动版)
本小节为配置的手动版,下面还有自动版(Kickstart Profile Installation)。两者选择其一即可。
下面非特殊说明,用户均为root。登录系统。用户名和密码为root,vagrant
### 3.1 启动网卡
系统默认不启动网卡的,所以要先启动他。
```
ifup eth0
```
### 3.2 安装必须的一些软件包
```
yum install -y openssh-clients man git vim wget curl ntp gcc
```
其中`vim`自认为不需要,`gcc`是为后续安装虚拟机系统guest os内部的virtualbox扩展包所用。
如果不可以上网,确认你虚拟机网络借口的配置方式是否正确,试试桥接或NAT方式,如果实在不行,请避免选用最小安装包的.iso文件,选择正确的安装包。
### 3.3 配置一些启动默认项
+ 启动ntpd服务
```
chkconfig ntpd on
```
+ 启动sshd服务
```
chkconfig sshd on
```
+ 设置SELinux允许
```
sed -i -e 's/^SELINUX=.*/SELINUX=permissive/' /etc/selinux/config
```
### 3.4 创建vagrant用户及其相关内容
```
useradd vagrant
mkdir -m 0700 -p /home/vagrant/.ssh
curl https://raw.githubusercontent.com/mitchellh/vagrant/master/keys/vagrant.pub >> /home/vagrant/.ssh/authorized_keys
chmod 600 /home/vagrant/.ssh/authorized_keys
chown -R vagrant:vagrant /home/vagrant/.ssh
sed -i 's/^\(Defaults.*requiretty\)/#\1/' /etc/sudoers
echo "vagrant ALL=(ALL) NOPASSWD: ALL" >> /etc/sudoers
```
考虑到一般不会对vagrant做太多改动,故采用默认的做法。
上述命令详细解释及说明见:http://thornelabs.net/2013/11/11/create-a-centos-6-vagrant-base-box-from-scratch-using-virtualbox.html
### 3.5 配置网卡参数
编辑`/etc/sysconfig/network-scripts/ifcfg-eth0`,部分参数如下:
```
DEVICE=eth0
TYPE=Ethernet
ONBOOT=yes
NM_CONTROLLED=no
BOOTPROTO=dhcp
```
重启电脑进入 4、安装虚拟机操作系统centos的virtualbox扩展。
## 3、配置系统(自动版)
详见参考文献:http://thornelabs.net/2013/11/11/create-a-centos-6-vagrant-base-box-from-scratch-using-virtualbox.html
<table>
Kickstart Profile Installation
I used this Kickstart Profile to automate the build.
When the CentOS boot menu appears, highlight Install or upgrade an existing system, hit the Tab key to bring up the anaconda boot line, and append the following:
```
noverifyssl ks=https://raw.githubusercontent.com/jameswthorne/kickstart-profiles/master/centos-6-x86_64-vagrant-box.txt
```
Hit the Enter key and wait for the installation to finish.
</table>
说人话就是:
在centos系统启动菜单里,选择Install or upgrade an existing system,点击Tab键,在后面添加如下内容。
```
noverifyssl ks=https://raw.githubusercontent.com/jameswthorne/kickstart-profiles/master/centos-6-x86_64-vagrant-box.txt
```
回车,等待安装完成。
重启电脑进入 4、安装虚拟机操作系统centos的virtualbox扩展。
## 4、安装虚拟机操作系统centos的virtualbox扩展
打开virtualbox某个虚拟机时,最上面菜单栏有个`设备`>`安装增强功能`。如果你电脑联网,virtualbox一般会自动帮你下载好该光盘并挂载在你的虚拟机上。
下面假设该光盘已经在你电脑上了。实在无法解决的,可以自行百度下载。
root用户进入到虚拟机centos中
在/root文件夹下新建一个文件cdromtmp
```
mkdir /root/cdromtmp
```
把光盘挂载到/root/cdromtmp下
```
mount /dev/cdrom /root/cdromtmp
```
注意,上面有可能是`/dev/cdrom1`或者其他,可以使用命令`ls /dev/cdrom*`查看,确实是否存在。
执行安装该扩展功能。
```
/root/cdromtmp/VBoxLinuxAdditions.run
```
找到类似的VBoxLinuxAdditions.run.run文件即可。有时候会出现缺少 `kernel-devel-xxx`的问题,按照提示安装。
最后可能会有opengGL的相关东西安装失败,不影响操作,可以继续。
这样就安装成功了。建议重启电脑。
# 四、安装xampp
centos系统一般默认是开通ssh,22端口的。如果可以查看centos的IP地址,不妨设为192.168.1.201,可以采用ssh或者sftp跟centos联通。
下面假设可以访问该虚拟机。
```
ssh [email protected]
```
## 1、开通8080,80,22端口
**下面如果没有特别说明,均为root用户在ssh里操作。**
centos 6.7依旧采用的是iptables管理端口。跟centos7不同。
编辑文件,
```bash
vi /etc/sysconfig/iptables
```
加入如下内容,一般22端口默认开通了,其他端口可以类似添加开通。
```
-A INPUT -m state –state NEW -m tcp -p tcp –dport 22 -j ACCEPT
-A INPUT -m state –state NEW -m tcp -p tcp –dport 80 -j ACCEPT
-A INPUT -m state –state NEW -m tcp -p tcp –dport 8080 -j ACCEPT
```
保存退出,重启查看iptables
```bash
/etc/init.d/iptables restart
/etc/init.d/iptables status
```
## 2、安装xampp
通过sftp把其他电脑上的xampp.run文件复制过来。
```bash
sftp [email protected]
#跳过代码部分
sftp put /path/to/xampp.run ./
```
这样把xampp.run文件复制到/root文件夹下了。
如果xampp.run没有执行权限,需要添加可以执行权限。
```bash
chmod u+x ./xampp.run
```
下面安装xampp.run文件。
```bash
./xampp.run
```
记住选择非开发模式。默认安装在/opt/lampp文件夹。
可以顺利安装完成。
可以在/opt/lampp/htdocs/下新建一个文件夹www,并让所有人对该文件夹操作。
```
mkdir /opt/lampp/htdocs/www
chmod -m 0777 -p /opt/lampp/htdocs/www
```
## 3、xampp加入开机自启动
首先在/etc/init.d下添加一个xampp启动脚本
```bash
vi /etc/init.d/xampp.sh
```
添加以下内容
```bash
#!/bin/sh
/opt/lampp/lampp start
```
保存退出,添加自启动
```bash
vi /etc/rc.d/rc.local
```
加入以下代码
```bash
sh /etc/init.d/xampp.sh
```
保存退出
注意要给上面两个文件加上执行权限。
```bash
chmod u+x /etc/init.d/xampp.sh
chmod u+x /etc/rc.d/rc.local
```
## 4、配置xampp可以在同局域网下使用phpmyadmin
编辑文件,
```bash
vi /opt/lampp/etc/extra/httpd-xampp.conf
```
修改为如下情况
```
<LocationMatch "^/(?i:(?:xampp|security|licenses|phpmyadmin|webalizer|server-status|server-info))">
# Require local
Require all granted
ErrorDocument 403 /error/XAMPP_FORBIDDEN.html.var
</LocationMatch>
```
注释掉只能本地访问功能,增加外网访问能力。
保存退出。
## 5、编辑文件`/opt/lampp/etc/httpd.conf`
```
vi /opt/lampp/etc/httpd.conf
```
在文中搜索`httpd-vhost.conf`,会找到
```bash
#Include etc/extra/httpd-vhosts.conf
```
取消该行注释。
在文中搜索`80`,会找到
```bash
Listen 80
```
改为
```bash
Listen 80
Listen 8080
```
### 6、编辑/opt/lampp/etc/extra/httpd-vhosts.conf
```bash
vi /opt/lampp/etc/extra/httpd-vhosts.conf
```
加入如下内容,可以类似修改。
```
<VirtualHost *:80>
ServerAdmin [email protected]
DocumentRoot "/opt/lampp/htdocs/www"
ServerName personshakehand.lxfive.com
ServerAlias www.personshakehand.lxfive.com
ErrorLog "logs/personshakehand-error_log"
CustomLog "logs/personshakehand-access_log" common
</VirtualHost>
<VirtualHost *:8080>
ServerAdmin [email protected]
DocumentRoot "/opt/lampp/htdocs"
ServerName backend.personshakehand.lxfive.com
ServerAlias www.backend.personshakehand.lxfive.com
ErrorLog "logs/backend-personshakehand-error_log"
CustomLog "logs/backend-personshakehand-access_log" common
</VirtualHost>
```
# 五、清理现场
在虚拟机中,去除一些不需要的日志信息等。
```
rm -f /etc/udev/rules.d/70-persistent-net.rules
yum clean all
rm -rf /tmp/*
rm -f /var/log/wtmp /var/log/btmp
history -c
shutdown -h now
```
删掉虚拟机的光盘驱动。
打开存储,可以看到有光盘标志的地方,选中他,在下面有删除按钮,选择删除他。
# 六、创建 create vagrant box
退出到主机,非虚拟机。
```
vagrant package --output centos-6.7-x64.box --base centos
```
添加vagrant box
```
vagrant box add centos-6.7-x64 centos-6.7-x64.box
```
跳转到工作文件夹
```
cd /opt/lampp/htdocs/www
```
初始化vagrant
```
vagrant init centos-6.7-x64
```
修改Vagrantfile,这时会在当前文件夹下看到Vagrantfile文件,其中部分内容如下。
```
config.vm.network "public_network", ip: "192.168.1.201"
config.vm.synced_folder "./", "/opt/lampp/htdocs/www/"
```
确保在局域网其他电脑也可以访问测试。并让当前工作文件夹和虚拟机服务器centos对应的文件夹可以访问。
启动vagrant,默认在当前文件夹下,
```
vagrant up
```
会弹出选择网卡等信息,如果不出意外,应该是可以正常启动了。
# 七、备注
+ 本文制作的centos-6.7-x64.box在百度云盘提供下载。
+ 在制作过程中对MySQL的用户和密码都进行了修改,分别为test,test
# 使用说明:
+ 假设你已经安装好了virtualbox,vagrant,且你的virtualbox支持64位操作系统。
+ 下载好centos-6.7-x64.box
+ 进入到你的工作项目根目录,不妨设为/opt/lampp/htdocs/www
+ 安装该虚拟机
```
vagrant box add <your-webserver-name> /path/to/centos-6.7-x64.box
vagrant init <your-webserver-name>
vagrant up
```
+ 如果你的虚拟机允许正常,关闭vagrant
```
vagrant halt
```
+ 可以编辑当前目录下的`Vagrantfile`文件,类似如下修改。
```
config.vm.network "public_network", ip: "192.168.1.201"
config.vm.synced_folder "./", "/opt/lampp/htdocs/www/"
```
+ 使用xampp,在/opt/lampp/htdocs/www下新建项目文件夹,
+ 在同一局域网其他电脑上,查看虚拟机IP地址对应的网站。
有问题欢迎在下面留言,或者发送邮件到[email protected] | 8,634 | BSD-3-Clause |
---
id: 1156
title: Google网站管理员的数据标注工具
date: 2013-02-20T20:48:35+08:00
author: chonghua
layout: post
guid: http://hechonghua.com/?p=1156
permalink: /google-data-highlighter/
categories:
- wordpress技巧
tags:
- Google网站管理员工具
- 微数据
- 微格式
- 数据标注工具
---
我们知道,Google会在搜索结果中显示网页的相关的微格式、微数据,这在一定程度上会提高用户的搜索体验,另一方面,在搜索结果中显示作者的头像或者评分,也在一定程度上会增加网站的流量。
<!--more-->
如果要显示此类数据,通常我们会选择安装此类的插件,然后等待Google的抓取。但是现在Google在管理员工具中添加了**数据标注工具**,使得添加这些数据更为方便。
<img style="display: block; float: none; margin-left: auto; margin-right: auto" src="http://chonghua-1251666171.cos.ap-shanghai.myqcloud.com/webmasters_99170_rsreview_en_zpsd6f008ed.png" alt="Google网站管理员的数据标注工具" />
登陆Google管理员后台,就在左边栏得下方
<img style="display: block; float: none; margin-left: auto; margin-right: auto" src="http://chonghua-1251666171.cos.ap-shanghai.myqcloud.com/richdate3_zpsefe6a967.png" width="520" height="326" alt="Google网站管理员的数据标注工具" />
点击开始标注按钮
会让你提供一个通用性的页面地址,我们可以随便选择一个文章页面开始。
<img style="display: block; float: none; margin-left: auto; margin-right: auto" src="http://chonghua-1251666171.cos.ap-shanghai.myqcloud.com/richdata_zps8dfb5e0d.png" width="520" height="327" alt="Google网站管理员的数据标注工具" /> </p>
在左边的预览窗口,可以用鼠标点击需要标注的文本或者图片,按上下文的菜单进行标注。比如说:日期,位置,作者等等。
需要注意的是:添加标注的网页必须是Google已经索引的网页。
然后,Google会自动列出其它的相似网页创建一个网页集,您也可以自己定义网页集的网页。
<img style="display: block; float: none; margin-left: auto; margin-right: auto" src="http://chonghua-1251666171.cos.ap-shanghai.myqcloud.com/richdate2_zps14607082.png" width="520" height="365" alt="Google网站管理员的数据标注工具" />
然后,向导会一步一步一个一个网页让你标注,更改错误的地方。
最后,点击发布就等待Google的更新了。 | 1,603 | MIT |
---
layout: post
title: "mybatis 学习笔记(4)——mybatis的参数传递和自定义结果集"
date: 2020-06-29 21:25:55 +0800
categories: notes
tags: mybatis
img: https://s1.ax1x.com/2020/06/29/Nfjd8f.png
---
MyBatis的注解使用方式;mybatis的参数传递;自定义结果集<resultMap></resultMap>
# MyBatis的注解使用方式(了解,主要使用xml)
还是使用t_user表,来实现CRUD操作。
public interface UserMapper {
@Select("select id,last_name lastName,sex from t_user where id = #{id}")
public User queryUserById(Integer id);
@Select("select id,last_name lastName,sex from t_user")
public List<User> queryUsers();
@Update(value="update t_user set last_name=#{lastName},sex=#{sex} where id = #{id}")
public int updateUser(User user);
@SelectKey(statement="select last_insert_id()",before=false,keyProperty="id",resultType=Integer.class)
@Insert(value="insert into t_user(`last_name`,`sex`) values(#{lastName},#{sex})")
public int saveUser(User user);
@Delete("delete from t_user where id = #{id}")
public int deleteUserById(Integer id);
}
因为有时项目的sql语句会比较多,而写在注解中不现实,我们将可以采用一种注解和xml方式共用配置sql语句,在注解中书写简单的sql语句,将复杂的sql语句写在mapper中。
UserMapper接口修改:
// @Select("select id,last_name lastName,sex from t_user where id = #{id}")
public User queryUserById(Integer id);
UserMapper.xml配置文件内容:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.atguigu.mapper.UserMapper">
<!-- public User queryUserById(Integer id); -->
<select id="queryUserById" resultType="com.atguigu.pojo.User" >
select id,last_name lastName,sex from t_user where id = #{id}
</select>
</mapper>
需要注意的是,对于同一个函数只能出现一次,要么使用注解方式要么就使用mapper接口的方式。
# mybatis的参数传递
## 一个普通数据类型
public interface UserMapper {
public User queryUserById(Integer id);
}
UserMapper.xml配置文件:
<!--
public User queryUserById(Integer id);
当方法的参数类型是一个普通数据类型的时候,
那么sql语句中配置的占位符里,可以写上参数名:#{id}
-->
<select id="queryUserById" resultType="com.atguigu.pojo.User">
select id,last_name lastName,sex from t_user where id = #{id}
</select>
## 多个普通数据类型
UserMapper接口:
/**
* 根据用户名和性别查询用户信息
*/
public List<User> queryUsersByNameOrSex(String name, Integer sex);
UserMapper.xml配置文件:
<!-- public List<User> queryUsersByNameOrSex(String name, Integer sex);
当方法参数是多个普通类型的时候。我们需要在占位符中写入的可用值是:0,1,param1,param2
0 表示第一个参数(不推荐使用)
1 表示第二个参数 (不推荐使用)
param1 表示第一个参数(推荐使用)
param2 表示第二个参数(推荐使用)
paramN 表示第n个参数(推荐使用)
-->
<select id="queryUsersByNameOrSex" resultType="com.atguigu.pojo.User">
select id,last_name lastName,sex from t_user where last_name = #{param1} or sex = #{param2}
</select>
## @Param注解命名参数
UserMapper接口
/**
* 根据用户名和性别查询用户信息
*/
public List<User> queryUsersByNameOrSex(@Param("name") String name,
@Param("sex") Integer sex);
UserMapper.xml配置文件:
<!--
public List<User> queryUsersByNameOrSex(@Param("name") String name,
@Param("sex") Integer sex);
当方法有多个参数的时候,我们可以使用mybatis提供的注解@Param来对方法的参数进行命名。
全名之后的使用。如下:
@Param("name") String name ====使用>>>> #{name}
@Param("sex") Integer sex ====使用>>>> #{sex}
使用了@Param之后,原来的0,1就不能再使用了。
但是Param1,和param2,可以使用。
-->
<select id="queryUsersByNameOrSex" resultType="com.atguigu.pojo.User">
select id,last_name lastName,sex from t_user where last_name = #{name} or sex = #{sex}
</select>
## 传递一个Map对象作为参数
UserMapper接口:
/**
* 希望Map中传入姓名和性别信息,以做为查询条件。
*/
public List<User> queryUsersByMap(Map<String, Object> paramMap);
UserMapper.xml配置文件:
<!-- public List<User> queryUsersByMap(Map<String, Object> paramMap);
当我们方法的参数类型是Map类型的时候,注意。
在配置的sql语句的占位符中写的参数名一定要和Map的key一致对应。
last_name = #{name} <<<<========>>> paramMap.put("name","bbb");
sex = #{sex} <<<<========>>> paramMap.put("sex",1);
-->
<select id="queryUsersByMap" resultType="com.atguigu.pojo.User">
select id,last_name lastName,sex from t_user where last_name = #{name} or sex = #{sex}
</select>
UserMapperTest.java中添加:
@Test
public void queryUserByMap() {
SqlSession session = sqlSessionFactory.openSession();
try{
UserMapper mapper = session.getMapper(UserMapper.class);
Map<String,Object> paraMap = new HashMap<String,Object>();
paraMap.put("name", "wjw");
paraMap.put("sex", 2);
mapper.queryUserByMap(paraMap).forEach(System.out::println);
}finally{
session.close();
}
fail("Not yet implemented");
}
## 一个javaBean数据类型
UserMapper接口
public int updateUser(User user);
UserMapper.xml配置文件:
<!-- public int updateUser(User user)
如果传入的参数是一个javaBean的时候,占位符中,要写上javaBean的属性名。
JavaBean属性 sql中的占位符
private Integer id; #{id}
private String lastName; #{lastName}
private Integer sex; #{sex}
-->
<update id="updateUser" parameterType="com.atguigu.pojo.User">
update
t_user
set
last_name=#{lastName},
sex=#{sex}
where
id=#{id}
</update>
## 多个Pojo数据类型
UserMapper接口
/**
* 要求使用第一个User对象的lastName属性,和第二个User对象的sex属性来查询用户信息。
*/
public List<User> queryUsersByTwoUsers(User name,User sex);
UserMapper.xml配置文件:
<!-- public List<User> queryUsersByTwoUsers(User name,User sex);
如果你是多个JavaBean类型的时候,第一个参数是param1,第二个参数是param2.以此类推第n个参数就是paramN
当然你也可以使用@Param来规定参数名。
如果你想要的只是参数对象中的属性,而需要写成为如下格式:
#{参数.属性名}
示例:
last_name ======== #{param1.lastName}
sex ========= #{param2.sex}
-->
<select id="queryUsersByTwoUsers" resultType="com.atguigu.pojo.User">
select id,last_name lastName,sex from t_user where last_name = #{param1.lastName} or sex = #{param2.sex}
</select>
## 模糊查询
需求:现在要根据用户名查询用户对象。 也就是希望查询如下: select * from t_user where user_name like '%张%'
UserMapper接口:
/**
* 根据给定的名称做用户名的模糊查询
*/
public List<User> queryUsersLikeName(String name);
UserMapper.xml配置文件:
<!-- /** -->
<!-- * 根据给定的名称做用户名的模糊查询 -->
<!-- */ -->
<!-- public List<User> queryUsersLikeName(String name); -->
<select id="queryUsersLikeName" resultType="com.atguigu.pojo.User">
select id,last_name lastName,sex from t_user where last_name like #{name}
</select>
测试的代码是:
@Test
public void testQueryUsersLikeName() {
SqlSession session = sqlSessionFactory.openSession();
try {
UserMapper mapper = session.getMapper(UserMapper.class);
String name = "bb";
String temp = "%"+name+"%";
mapper.queryUsersLikeName(temp).forEach(System.out::println);
} finally {
session.close();
}
}
UserMapper.xml中另一种写法:
<!-- /** -->
<!-- * 根据给定的名称做用户名的模糊查询 -->
<!-- */ -->
<!-- public List<User> queryUsersLikeName(String name);
\#{} 是占位符
${} 是把参数的值原样输出到sql语句中,然后做字符串的拼接操作
-->
<select id="queryUsersLikeName" resultType="com.atguigu.pojo.User">
select id,last_name lastName,sex from t_user where last_name like '%${value}%'
</select>
## {}和${}的区别
\#{} 它是占位符 ===>>> ?
${} 它是把表示的参数值原样输出,然后和sql语句的字符串做拼接操作。
### concat函数
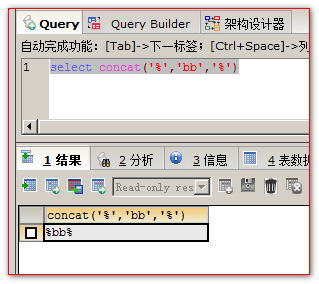
可以使用concat很好的解决 模糊查询的问题
<select id="queryUsersLikeName" resultType="com.atguigu.pojo.User">
select id,last_name lastName,sex from t_user where last_name like concat('%',#{name},'%')
</select>
## 自定义结果集<resultMap></resultMap>
resultMap标签,是自定义结果集标签。
resultMap标签可以把查询回来的结果集封装为复杂的javaBean对象。
原来的resultType属性它只能把查询到的结果集转换成为简单的JavaBean对象。
所谓简单的JavaBean对象,是指它的属性里没有JavaBean或集合类型的对象,反之亦然。
复杂的JavaBean对象,属性里有JavaBean类型或集合类型的属性的对象叫复杂的javaBean。
### 创建一对一数据库表
## 一对一数据表
## 创建锁表
create table t_lock(
`id` int primary key auto_increment,
`name` varchar(50)
);
## 创建钥匙表
create table t_key(
`id` int primary key auto_increment,
`name` varchar(50),
`lock_id` int ,
foreign key(`lock_id`) references t_lock(`id`)
);
## 插入初始化数据
insert into t_lock(`name`) values('阿里巴巴');
insert into t_lock(`name`) values('华为');
insert into t_lock(`name`) values('联想');
insert into t_key(`name`,`lock_id`) values('马云',1);
insert into t_key(`name`,`lock_id`) values('任正非',2);
insert into t_key(`name`,`lock_id`) values('柳传志',3);
### 创建实体对象
锁对象
public class Lock {
private Integer id;
private String name;
钥匙对象
public class Key {
private Integer id;
private String name;
private Lock lock;
### 一对一级联属性使用
#### KeyMapper接口
public interface KeyMapper {
public Key queryByIdSampler(Integer id);
}
#### 测试的代码:
public class KeyMapperTest {
@Test
public void testQueryByIdSampler() throws IOException {
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(Resources.getResourceAsStream("com/ncu/zte/mybatis6_29/mybatis-config.xml"));
SqlSession session = sqlSessionFactory.openSession();
try{
KeyMapper mapper = session.getMapper(KeyMapper.class);
System.out.println(mapper.queryByIdSampler(2));
}finally{
session.close();
}
fail("Not yet implemented");
}
#### KeyMapper.xml配置文件:
**普通查询:**
<select id="queryByIdSampler" resultType="key">
select
t_key.*,t_lock.name lock_name
from
t_key left join t_lock
on
t_key.lock_id = t_lock.id
where
t_key.id = #{id}
</select>
**运行结果:**

**修改后的配置文件**:
<!--
resultMap 标签可以把查询到的resultSet结果集转换成为复杂的JavaBean对象
type 属性 设置resultMap需要转换出来的Bean对象的全类名<br/>
id 属性 设置一个唯一的标识,给别人引用
-->
<resultMap type="key" id="queryKeyByIdForSample_resultMap">
<!-- id标签负责将主键列转换到bean对象的属性
column 设置将哪个主键列转换到指定的对象属性
property 属性设置将值注入到哪个对象的属性
-->
<id column="id" property="id"/>
<!-- result标签负责将非主键列转换到bean对象的属性 -->
<result column="name" property="name"/>
<!-- 将lock_id列注入到lock对象的id属性中
子对象.属性名 这种写法叫级联属性映射
-->
<result column="lock_id" property="lock.id"/>
<result column="lock_name" property="lock.name"/>
</resultMap>
<!-- public Key queryKeyByIdForSample(Integer id); -->
<select id="queryByIdSampler" resultMap="queryKeyByIdForSample_resultMap">
select
t_key.*,t_lock.name lock_name
from
t_key left join t_lock
on
t_key.lock_id = t_lock.id
where
t_key.id = #{id}
</select>
**运行结果:**

### <association /> 嵌套结果集映射配置
<association /> 可以配置映射一个子对象
<resultMap type="key" id="queryKeyByIdForSample_resultMap">
<!-- id标签负责将主键列转换到bean对象的属性
column 设置将哪个主键列转换到指定的对象属性
property 属性设置将值注入到哪个对象的属性
-->
<id column="id" property="id"/>
<!-- result标签负责将非主键列转换到bean对象的属性 -->
<result column="name" property="name"/>
<!--
association 标签映射子对象
property 属性设置association配置哪个子对象
javaType 属性设置lock具体的全类名
-->
<association property="lock" javaType="lock">
<id column="lock_id" property="id"/>
<result column="lock_name" property="name"/>
</association>
<!-- 将lock_id列注入到lock对象的id属性中
子对象.属性名 这种写法叫级联属性映射
<result column="lock_id" property="lock.id"/>
<result column="lock_name" property="lock.name"/>
-->
</resultMap>
### <association /> 定义分步查询
association标签还可以通过调用一个查询,得到子对象
#### KeyMapper接口
/**
* 这个方法只查key的信息
*/
public Key queryKeyByIdForTwoStep(Integer id);
#### LockMapper接口
public interface LockMapper {
/**
* 只查lock
* @param id
* @return
*/
public Lock queryLockById(Integer id);
}
#### LockMapper.xml配置文件:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.ncu.zte.mybatis6_29.mapper.LockMapper">
<select id="queryLockById" resultType="lock">
select id,name from t_lock where id = #{id}
</select>
</mapper>
#### KeyMapper.xml配置文件:
<resultMap type="key" id="queryKeyByIdForTwoStep_resultMap">
<id column="id" property="id"/>
<result column="name" property="name"/>
<!--
association 用来配置子对象
property属性设置你要配置哪个子对象
select 属性配置你要执行哪个查询得到这个子对象
column 属性配置你要将哪个列做为参数传递给查询用
-->
<association property="lock" column="lock_id"
select="com.ncu.zte.mybatis6_29.mapper.LockMapper.queryLockById" />
</resultMap>
### 延迟加载(懒加载)
延迟加载在一定程序上可以减少很多没有必要的查询。给数据库服务器提升性能上的优化。
要启用延迟加载,需要在mybatis-config.xml配置文件中,添加如下两个全局的settings配置。
<!-- 打开延迟加载的开关 -->
<setting name="lazyLoadingEnabled" value="true" />
<!-- 将积极加载改为消极加载 按需加载 -->
<setting name="aggressiveLazyLoading" value="false"/>
测试代码:
@Test
public void testQueryByIdSampler() throws IOException, InterruptedException {
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(Resources.getResourceAsStream("com/ncu/zte/mybatis6_29/mybatis-config.xml"));
SqlSession session = sqlSessionFactory.openSession();
try{
KeyMapper mapper = session.getMapper(KeyMapper.class);
Key key = mapper.queryKeyByIdForTwoStep(1);
System.out.println( key.getName() );
}finally{
session.close();
}
fail("Not yet implemented");
}
运行结果:

测试代码:
@Test
public void testQueryByIdSampler() throws IOException, InterruptedException {
SqlSessionFactory sqlSessionFactory = new SqlSessionFactoryBuilder().build(Resources.getResourceAsStream("com/ncu/zte/mybatis6_29/mybatis-config.xml"));
SqlSession session = sqlSessionFactory.openSession();
try{
KeyMapper mapper = session.getMapper(KeyMapper.class);
Key key = mapper.queryKeyByIdForTwoStep(1);
System.out.println( key.getName() );
Thread.sleep(5000);
System.out.println( key.getLock() );
}finally{
session.close();
}
fail("Not yet implemented");
}
运行结果:
 | 14,061 | MIT |
---
title: 洛谷P3063MilkRouting
tags:
- ACM
- 算法竞赛
- 图论
- dij
- C++
---
# 洛谷P3063MilkRouting
传送门:https://www.luogu.com.cn/problem/P3063
分析:首先想的就是最短路,然后发现需要一些判断条件,你每次选择管道后,都需要更新当前路径的最小容量。那么,我们只需要限制最小的容量,多做几次dij就可以了。
要点:dij的灵活运用
代码:
```c++
/*
* @Descripttion:
* @version:
* @Author: JODEHRK
* @Date: 2020-07-06 10:46:02
* @LastEditors: JODEHRK
* @LastEditTime: 2020-07-07 21:20:28
*/
#include <bits/stdc++.h>
using namespace std;
struct Edge
{
int nxt, to, w, dis;
} edge[1001];
int n, m, k, tot = 0, s, t;
int head[1001], dis[1001], c[1001], b[1001], minn = 0x7fffffff;
inline void add_edge(int from, int to, int w, int dis)
{
edge[++tot].nxt = head[from];
edge[tot].to = to;
edge[tot].w = w;
edge[tot].dis = dis;
head[from] = tot;
}
inline void add(int from, int to, int w, int dis)
{
add_edge(from, to, w, dis);
add_edge(to, from, w, dis);
}
void dij(int x)
{
queue<int> q;
memset(dis, 50, sizeof(dis));
memset(b, 0, sizeof(b));
q.push(s);
dis[s] = 0;
b[s] = 1;
while (!q.empty())
{
int u = q.front();
q.pop();
b[u] = 0;
for (int i = head[u]; i; i = edge[i].nxt)
{
int v = edge[i].to;
if (dis[v] > dis[u] + edge[i].dis && edge[i].w >= x)
{
dis[v] = dis[u] + edge[i].dis;
if (!b[v])
{
q.push(v);
b[v] = 1;
}
}
}
}
}
int main()
{
cin >> n >> m >> k;
for (int i = 1; i <= m; i++)
{
int x, y, d, l;
cin >> x >> y >> d >> l;
add(x, y, l, d);
c[i] = l;
}
sort(c + 1, c + m + 1);
s = 1, t = n;
for (int i = 1; i <= m; i++)
{
dij(c[i]);
minn = min(minn, dis[t] + k / c[i]);
}
cout << minn;
return 0;
}
``` | 1,883 | MIT |
# 2021-3-30
共50条
<!-- BEGIN -->
1. [小米集团官宣造车,首期投资 100 亿人民币,对市场将有何影响?你看好小米的汽车业务吗?](https://www.zhihu.com/question/452056573)
1. [如何评价华晨宇的无字歌《癌》?](https://www.zhihu.com/question/29680247)
1. [包钢通报职工跳入高炉钢水称「系自杀,疑因炒股亏损」,还有哪些信息值得关注?](https://www.zhihu.com/question/451976204)
1. [如何评价2021年3月30日发布的小米MIX Fold手机?有哪些亮点和槽点?](https://www.zhihu.com/question/451834265)
1. [最危险入侵物种之一红火蚁已传播至我国 12 省 435 个县市区,将对生态环境产生哪些危害?如何应对?](https://www.zhihu.com/question/451972493)
1. [如何评价 2021 年春季发布会小米新 logo?](https://www.zhihu.com/question/452081395)
1. [贵州将逐步取消少数民族高考加分,会对少数民族聚集地考生有什么影响?](https://www.zhihu.com/question/452011028)
1. [如何评价 2021 年 3 月 30 日发布的全新小米笔记本Pro?有哪些惊喜和不足?](https://www.zhihu.com/question/451548753)
1. [上海的房子动辄都是上千万的,那么到底买得起上千万房子的人真的有这么多吗?](https://www.zhihu.com/question/441231437)
1. [3 月 29 日美国宣布暂停与缅甸所有贸易往来,将带来哪些影响?](https://www.zhihu.com/question/451934393)
1. [你为什么想当公务员?](https://www.zhihu.com/question/300645894)
1. [如何看待艾回公司官网以及学员后期处境?](https://www.zhihu.com/question/452091118)
1. [如何看待艾滋病男子强奸 15 岁少女一审获刑 5 年,经网络发酵调卷审查,撤销原审判决改判 10 年?](https://www.zhihu.com/question/451895284)
1. [一个是新晋骨科医生,一个是消防中队长,我该选择哪一个做男朋友?](https://www.zhihu.com/question/451952869)
1. [如何看待俄罗斯总统新闻秘书称「普京不允许美国自称从实力的角度同俄罗斯谈话」?](https://www.zhihu.com/question/452047266)
1. [老公是 996 的 IT 男,身体不好,我要照顾老人小孩和老公,家务很多干不完,该咋办?](https://www.zhihu.com/question/451570365)
1. [如何评价原研哉设计的小米新logo?](https://www.zhihu.com/question/452081261)
1. [柴犬遭男子铁钳拔牙虐待,男子称狗咬人剪掉它尖牙,警方已介入,男子行为是否犯法?还有哪些值得关注的信息?](https://www.zhihu.com/question/451825502)
1. [白展堂把从小玩到大的兄弟姓姬那俩哥俩出卖了,一个炸成傻子送大牢另一个联合秀才致死,符合正面人物形象吗?](https://www.zhihu.com/question/49158428)
1. [如何看待美国总统拜登将发表3万亿经济复苏计划法案,重点解决美国基础设施建设、医疗补贴等问题?](https://www.zhihu.com/question/451818810)
1. [如何看待日本前首相安倍晋三渲染称「包括日本在内的亚洲地区已成中美对立最前线」?](https://www.zhihu.com/question/451818485)
1. [面试最后,HR 最后会说“我的问题问完了,你有什么要问我的吗?”如何理解和回答这句话?](https://www.zhihu.com/question/29904997)
1. [日本人在中国没有敬语可用会不会时常感到很焦虑?](https://www.zhihu.com/question/451533588)
1. [如何评价 2021 年 3 月 30日联想拯救者春季新品发布会?有哪些亮点和不足?](https://www.zhihu.com/question/451428493)
1. [杭州女子生三孩哺乳期被解除劳动合同,仲裁被驳回,你怎么看?](https://www.zhihu.com/question/451962098)
1. [中国气象卫星云海一号 02 星在轨道发生碎裂,形成 21 块碎片,原因可能是什么?有哪些影响?](https://www.zhihu.com/question/450861777)
1. [在校大学生学校免费接种新冠疫苗,要不要去打?你接种新冠疫苗了吗?](https://www.zhihu.com/question/447174102)
1. [请问在灭霸被打翻在地时,把雷神之锤放他肚子上他还能起来吗?](https://www.zhihu.com/question/451094415)
1. [南大碎尸案 25 年未破,被害人家属正式起诉学校,家属能获得赔偿吗?学校在其中应该承担哪些责任?](https://www.zhihu.com/question/451940236)
1. [人类攻克了核聚变的大关之后,世界会发生什么变化?](https://www.zhihu.com/question/450192407)
1. [外媒称,美国一儿童频道以「内容极其敏感」为由删除两集「海绵宝宝」,你怎么看?](https://www.zhihu.com/question/451976864)
1. [如果不生孩子,老了真的会很可怜吗?](https://www.zhihu.com/question/444313202)
1. [什么样的女生会让男生特别难忘?](https://www.zhihu.com/question/445195620)
1. [买房时要避开哪些楼层?](https://www.zhihu.com/question/447920355)
1. [Kindle 是不是小众又过时?](https://www.zhihu.com/question/448654996)
1. [如何看待成都一顾客要求旁桌室内不抽烟反被泼不明液体?你认为公共场所抽烟的行为应如何杜绝?](https://www.zhihu.com/question/452048135)
1. [如果一个17.8岁的孩子死了,父母知道后会发生什么,会对家庭,对身边朋友有什么影响?](https://www.zhihu.com/question/449971478)
1. [网友质疑微信监听用户,腾讯回应称「微信是绝不会做的」,目前市面上的软件真的有监听行为吗?](https://www.zhihu.com/question/451864673)
1. [空气炸锅做出来的东西和原始油炸食物一样吗?](https://www.zhihu.com/question/329986513)
1. [跑步伪科学前十名有哪些?](https://www.zhihu.com/question/436833457)
1. [有哪些让人看一眼就感到惊艳的连衣裙?](https://www.zhihu.com/question/383661922)
1. [如何看待秦霄贤获得《欢乐喜剧人》第七季总冠军?](https://www.zhihu.com/question/451765135)
1. [大学生在豆瓣给书打差评,被举报到学校,差评和诋毁的界限在哪里?](https://www.zhihu.com/question/451807889)
1. [有什么不起眼的却赚钱的小生意?](https://www.zhihu.com/question/325432814)
1. [如何解读小米的全新 LOGO 和品牌升级,有哪些含义?](https://www.zhihu.com/question/452084269)
1. [2021 年 3 月,日本动画《咒术回战》第一季 24 集完结撒花,如何评价这部新番?](https://www.zhihu.com/question/451501679)
1. [被长辈看见打 ARMA 3 是一种什么样的体验?](https://www.zhihu.com/question/264872112)
1. [有什么让你觉得意难平的句子?](https://www.zhihu.com/question/450750902)
1. [如何评价2021年3月29日发布的小米11Ultra手机?有哪些亮点和槽点?](https://www.zhihu.com/question/451833643)
1. [如何看待特斯拉副总裁陶琳称:车辆失控是小概率事件?](https://www.zhihu.com/question/452057557)
<!-- END --> | 4,032 | MIT |
# 2022-04-21
共 0 条
<!-- BEGIN WEIBO -->
<!-- 最后更新时间 Thu Apr 21 2022 23:25:53 GMT+0800 (China Standard Time) -->
<!-- END WEIBO --> | 134 | MIT |
# 适配器模式(Adapter Pattern)——不兼容结构的协调
说明:设计模式系列文章是读`刘伟`所著`《设计模式的艺术之道(软件开发人员内功修炼之道)》`一书的阅读笔记。个人感觉这本书讲的不错,有兴趣推荐读一读。详细内容也可以看看此书作者的博客`https://blog.csdn.net/LoveLion/article/details/17517213`。
## 模式概述
### 模式定义
与电源适配器相似,在适配器模式中引入了一个被称为适配器(`Adapter`)的包装类,而它所包装的对象称为适配者(`Adaptee`),即被适配的类。适配器的实现就是把客户类的请求转化为对适配者的相应接口的调用。也就是说:当客户类调用适配器的方法时,在适配器类的内部将调用适配者类的方法,而这个过程对客户类是透明的,客户类并不直接访问适配者类。因此,适配器让那些由于接口不兼容而不能交互的类可以一起工作。
> 适配器模式(`Adapter Pattern`): 将一个接口转换成期望的另一个接口,使接口不兼容的那些类可以一起工作,其别名为包装器(`Wrapper`)。适配器模式既可以作为类结构型模式,也可以作为对象结构型模式。
*注意:在适配器模式定义中所提及的接口是指广义的接口,它可以表示一个方法或者方法的集合。*
### 模式结构图
在适配器模式中,我们通过增加一个新的适配器类来解决接口不兼容的问题,使得原本没有任何关系的类可以协同工作。根据适配器类与适配者类的关系不同,适配器模式可分为`对象适配器`和`类适配器`两种,在`对象适配器`模式中,适配器与适配者之间是`关联关系`;在`类适配器`模式中,适配器与适配者之间是`继承`关系。在实际开发中,对象适配器的使用频率更高,对象适配器模式结构如图所示
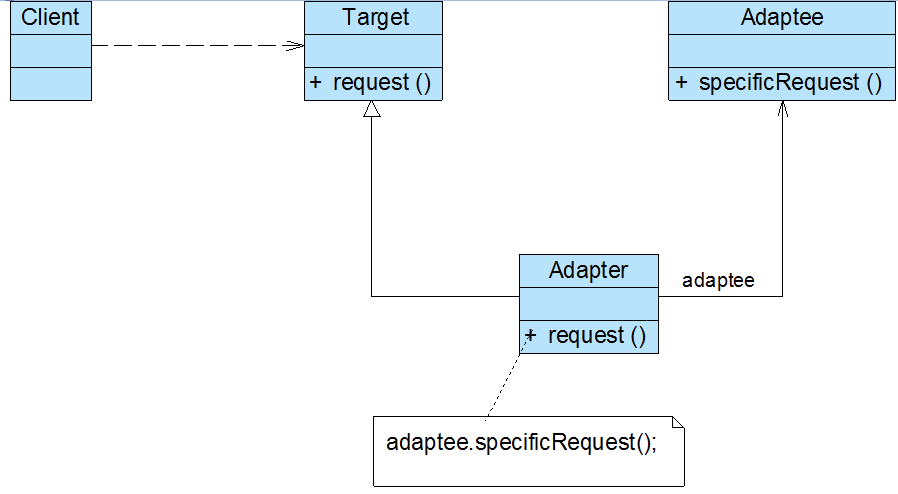
在对象适配器模式结构图中包含如下几个角色:
- `Target(目标抽象类)`:目标抽象类定义客户所需接口,可以是一个抽象类或接口,也可以是具体类。
- `Adapter(适配器类)`:适配器可以调用另一个接口,作为一个转换器,对`Adaptee`和`Target`进行适配,适配器类是适配器模式的核心,在对象适配器中,它通过继承(或者实现)`Target`并关联一个`Adaptee`对象使二者产生联系。
- `Adaptee(适配者类)`:适配者即被适配的角色,它定义了一个已经存在的接口,这个接口需要适配,适配者类一般是一个具体类,包含了客户希望使用的业务方法,在某些情况下可能没有适配者类的源代码。
### 模式伪代码
在`对象适配器`中,客户端需要调用`request()`方法,而适配者类`Adaptee`没有该方法,但是它所提供的`specificRequest()`方法却是客户端所需要的。为了使客户端能够使用适配者类,需要提供一个包装类`Adapter`,即适配器类。这个包装类包装了一个适配者的实例,从而将客户端与适配者衔接起来,在适配器的`request()`方法中调用适配者的`specificRequest()`方法。因为适配器类与适配者类是`关联关系`(也可称之为委派关系),所以这种适配器模式称为`对象适配器模式`。典型的对象适配器代码如下所示:
```java
public class Adapter implements Target {
// 维持一个对适配者对象的引用
private Adaptee adaptee;
// 构造注入适配者
public Adapter(Adaptee adaptee) {
this.adaptee = adaptee;
}
@Override
public void request() {
// 转发调用
adaptee.specificRequest();
}
}
```
### 类适配器,双向适配器,缺省适配器
#### 类适配器
`类适配器`模式和`对象适配器`模式最大的区别在于适配器和适配者之间的关系不同,对象适配器模式中适配器和适配者之间是`关联关系`,而类适配器模式中适配器和适配者是`继承关系`
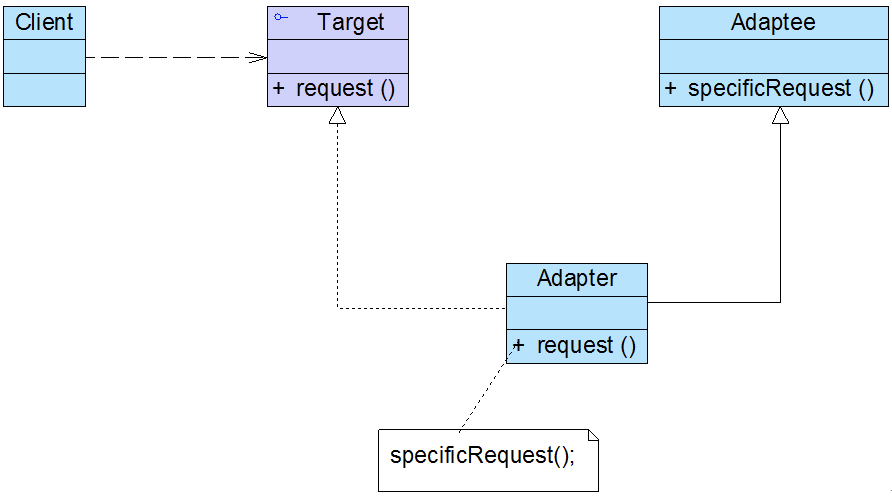
适配器类实现了抽象目标类接口`Target`,并继承了适配者类,在适配器类的`request()`方法中调用所继承的适配者类的`specificRequest()`方法,实现了适配。
典型代码实现如下:
```java
public class Adapter extends Adaptee implements Target {
@Override
public void request() {
specificRequest();
}
}
```
由于`Java`、`C#`等语言不支持多重类继承,因此`类适配器`的使用受到很多限制,例如如果目标抽象类`Target`不是接口,而是一个类,就无法使用类适配器;此外,如果适配者`Adaptee`为最终(`final`)类,也无法使用类适配器。在Java等面向对象编程语言中,大部分情况下我们使用的是对象适配器,`类适配器`较少使用。
#### 双向适配器
`双向适配器`: 在`对象适配器`的使用过程中,如果在适配器中同时包含对目标类和适配者类的引用,适配者可以通过它调用目标类中的方法,目标类也可以通过它调用适配者类中的方法,那么该适配器就是一个双向适配器。
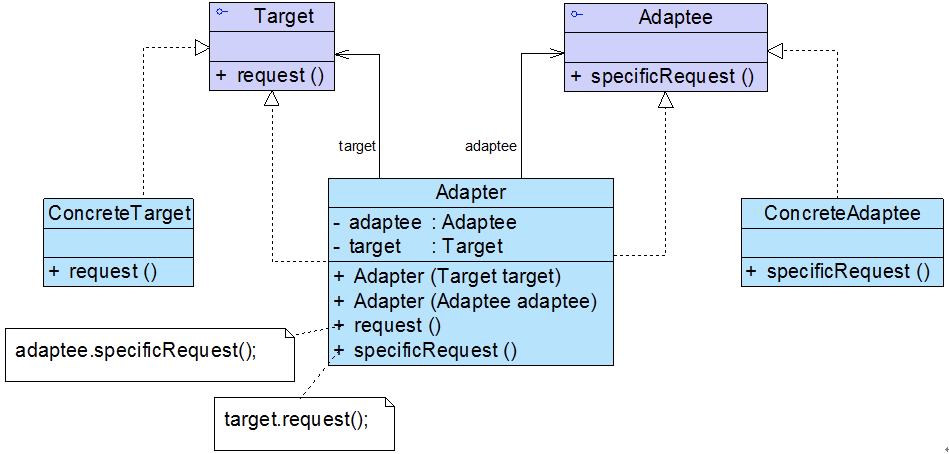
典型代码实现如下:
```java
public class Adapter implements Target, Adaptee {
//同时维持对抽象目标类和适配者的引用
private Target target;
private Adaptee adaptee;
public Adapter(Target target) {
this.target = target;
}
public Adapter(Adaptee adaptee) {
this.adaptee = adaptee;
}
@Override
public void request() {
adaptee.specificRequest();
}
@Override
public void specificRequest() {
target.request();
}
}
```
在实际开发中,我们很少使用`双向适配器`。违背了`单一职责`原则,相当于一个适配器承担了两个适配器的职责。
#### 缺省适配器
`缺省适配器`模式是适配器模式的一种变体,其应用也较为广泛。
> `缺省适配器模式(Default Adapter Pattern)`:当不需要实现一个接口所提供的所有方法时,可先设计一个抽象类实现该接口,并为接口中每个方法提供一个默认实现(空方法),那么该抽象类的子类可以选择性地覆盖父类的某些方法来实现需求,它适用于不想使用一个接口中的所有方法的情况,又称为`单接口适配器模式`。
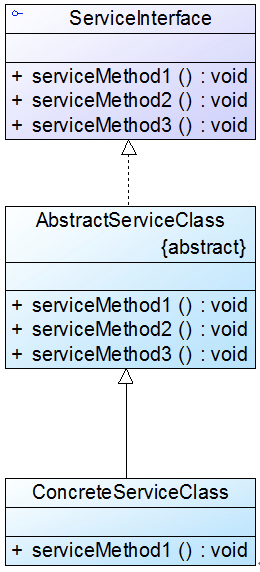
典型代码实现如下:
```java
public abstract class Adapter implements Target {
@Override
public void request1() {
// 空实现,让具体实现类去有选择地实现
}
@Override
public void request2() {
// 空实现,让具体实现类去有选择地实现
}
@Override
public void request3() {
// 空实现,让具体实现类去有选择地实现
}
}
public class ConcreteAdapter extends Adapter {
// 维持一个对适配者对象的引用
private Adaptee adaptee;
// 构造注入适配者
public Adapter(Adaptee adaptee) {
this.adaptee = adaptee;
}
@Override
public void request1() {
// 只实现request1
adaptee.specificRequest();
}
}
```
## 模式应用
### 模式在JDK中的应用
在JDK中,`IO`类中也大量使用到了适配器模式。比如说`StringReader`将`String`适配到`Reader`,`InputStreamReader`将`InputStream`适配到`Reader`等等。
这里用`StringReader`来说明。这里的`StringReader`相当于上述的`Adapter`,`Reader`相当于上述的`Target`,`String`相当于上述的`Adaptee`
```java
public class StringReader extends Reader {
// 维持对adaptee对象的引用
private String str;
private int length;
private int next = 0;
private int mark = 0;
/**
* 构造注入一个String用于之后的read操作
*/
public StringReader(String s) {
this.str = s;
this.length = s.length();
}
// 这里相当于是在做适配操作,转为目标对象所期望的请求
public int read() throws IOException {
synchronized (lock) {
ensureOpen();
if (next >= length)
return -1;
return str.charAt(next++);
}
}
}
```
### 模式在开源项目中的应用
其实不只是开源项目,我们自己写的项目很多地方都是隐含着适配器模式,只是有时候这种特性表现的不是很明显(因为我们很自然去使用),以至于我们都没有给类名命成`XxxAdapter`,比如说我们使用第三方库,第三方库某方法名太长或者参数过多,或者调用过于复杂了,我们可能会对第三方库再次做个封装,把适合自己项目当前业务逻辑的默认参数,默认实现补充完整,让其他地方很方便调用,举个具体例子,项目中可能经常会用到`HttpClient`,大多数情况下,对现有的`HttpClient`再次封装(比如client的创建、http响应结果的统一处理等等),封装成方便自己项目使用的`SpecialHttpClient`,如果你还想切换不同的底层`HttpClient`实现,还可以对`SpecialHttpClient`抽出来一个接口,通过不同的`Adapter`来注入不同的`HttpClient`(比如apache的`HttpClient`、`OkHttpClient`、Spring的`RestTemplate`以及`WebClient`等等)来实现,这种很自然的思想 个人觉得本质上也用到了`适配器模式`,相当于是把第三方的`HttpClient`适配成了自己的`SpecialHttpClient`。
当转换的源不是单一的时候,这种`适配器`思想就凸显出来了(对应上面的例子就是说 项目中需要同时用到apache的`HttpClient`、Spring的`RestTemplate`以及`WebClient`等)。
这里举个`Spring`中的例子。在`Spring`的`AOP`中,由于`Advisor`需要的是`MethodInterceptor`对象,所以每一个`Advisor`中的`Advice`都要适配成对应的`MethodInterceptor`对象
```java
public interface AdvisorAdapter {
boolean supportsAdvice(Advice advice);
MethodInterceptor getInterceptor(Advisor advisor);
}
class ThrowsAdviceAdapter implements AdvisorAdapter, Serializable{
@Override
public boolean supportsAdvice(Advice advice) {
return (advice instanceof ThrowsAdvice);
}
@Override
public MethodInterceptor getInterceptor(Advisor advisor) {
return new ThrowsAdviceInterceptor(advisor.getAdvice());
}
}
```
## 模式总结
适配器模式将现有接口转化为客户类所期望的接口,实现了对现有类的复用,它是一种使用频率非常高的设计模式,在软件开发中得以广泛应用。
### 主要优点
无论是对象适配器模式还是类适配器模式都具有如下优点:
(1) 将目标类和适配者类解耦,通过引入一个适配器类来重用现有的适配者类,无须修改原有结构,提高了扩展性,符合“开闭原则”
(2) 增加了类的透明性和复用性,将具体的业务实现过程封装在适配者类中,对于客户端类而言是透明的,而且提高了适配者的复用性,同一个适配者类可以在多个不同的系统中复用。
具体来说,`类适配器`模式还有如下优点:
由于适配器类是适配者类的子类,因此可以在适配器类中置换一些适配者的方法,使得适配器的灵活性更强。
`对象适配器`模式还有如下优点:
(1) 一个对象适配器可以把多个不同的适配者适配到同一个目标;
(2) 可以适配一个适配者的子类,由于适配器和适配者之间是关联关系,根据“里氏代换原则”,适配者的子类也可通过该适配器进行适配。
### 主要缺点
`类适配器`模式的缺点如下:
(1) 对于Java、C#等不支持多重类继承的语言,一次最多只能适配一个适配者类,不能同时适配多个适配者;
(2) 适配者类不能为最终类,如在Java中不能为final类,C#中不能为sealed类;
(3) 在Java、C#等语言中,类适配器模式中的目标抽象类只能为接口,不能为类,其使用有一定的局限性。
对象适配器模式的缺点如下:
与类适配器模式相比,要在适配器中置换适配者类的某些方法比较麻烦(比如说适配者类中的某些方法是`protected`,而我们做适配的时候刚好需要用到)。如果一定要置换掉适配者类的一个或多个方法,可以先做一个适配者类的子类,将适配者类的方法置换掉,然后再把适配者类的子类当做真正的适配者进行适配,实现过程较为复杂。
### 适用场景
在以下情况下可以考虑使用适配器模式:
系统需要使用(复用)一些现有的类,而这些类的接口(如方法名)不符合系统的需要,甚至没有这些类的源代码等等,可使用适配器模式协调诸多不兼容结构的场景。 | 7,051 | MIT |
### NIML示例
原始的template.niml:
```html
<html>
<head>
<ni:var name="$title">My First NIML Template</ni:var>
<title><ni:echo name="$title" /></title>
<head>
<body>
<h1>My Heading</h1>
<ul>
<ni:loop index="$index" steps="10" stepvalue="1">
<li><p>Paragraph <ni:echo name="$index" /></p></li>
</ni:loop>
</ul>
</body>
</html>
```
以上写法为原生标准写法,实际编写中,存在各种不同的简写方案。具体请参考[NIML标签参考手册]()
编译后的template.php:
```php
<?php
/*
* PHP CODE COMPILED FROM NIML
* CODE START
*/
echo '<html><head><title>';
$title = 'My First NIML Template';
echo $title;
echo '</title></head><body><h1>My Heading</h1><ul>';
for( $index=0; $index<10; $index++ ){
echo '<li><p>Paragraph ';
echo $index;
echo '</p></li>';
}
echo '</ul></body></html>';
/*
* CODE END
*/
```
最终输出的HTML文件:
```html
<html>
<head>
<title>My First NIML Template</title>
<head>
<body>
<h1>My Heading</h1>
<ul>
<li><p>Paragraph 0</p></li>
<li><p>Paragraph 1</p></li>
<li><p>Paragraph 2</p></li>
<li><p>Paragraph 3</p></li>
<li><p>Paragraph 4</p></li>
<li><p>Paragraph 5</p></li>
<li><p>Paragraph 6</p></li>
<li><p>Paragraph 7</p></li>
<li><p>Paragraph 8</p></li>
<li><p>Paragraph 9</p></li>
</ul>
</body>
</html>
```
[点击查看更多实例]()
##### NIML编译器使用
[点击学习NIML编译器接口规范]()
##### NIML标签
[点击查看NIML标签参考手册]() | 1,264 | Apache-2.0 |
# Hooks
<!-- {docsify-ignore} -->
**以下 hooks 继承自 vad**
## patchSchema : patchFn (内部)
执行方式: call
用于扩充 config 的验证 schema. 传递一个 patch 函数
## addDefaultOption : defaulter (内部)
执行方式: call
用于加工用户配置文件信息. 比如定义默认值等等. 传递一个 defaulter 对象.
## installPlugin : runner (内部)
执行方式: call
安装第三方插件前夕执行.
## afterPluginRun : runner
执行方式: call
所有第三方插件安装完毕
## defineEntry : entryContainer (内部)
执行方式: call
vad 独有
定义 entry 的容器. entry 阶段的 entries 在此时填充
entryContainer: 一个空数组, 往里面填充基础的 chunkBlock 实例.
## entry : entries, runnerConfig, webpackConfigAPI
执行方式: call
此时可以修改程序入口.
传递以下参数:
- entries: [chunkBlock,...], 数组, 元素为 chunkBlock 实例
- runnerConfig
- webpackConfigAPI: 一个可以操作 webpack 的 对象
## emitFile : addAppFileFn, tempDir
执行方式: call
此时可以添加需要输出的文件.
传递以下参数:
- addAppFileFn: 指定输出内容和路径
- tempDir: adf 提供的临时目录
## webpack : webpackConfigAPI
执行方式: call
可以对 webpack 进行修改.
传递以下参数:
- webpackConfigAPI: 一个可以操作 webpack 的 对象
## watch : addWatchFn
可以添加要 watch 的文件以及指定行为. 传递一个 addWatchFn 函数
比如某些文件变更后, 需要进入 restart/reemit 的生命周期.
## restart (第三方无需实现)
重新启动
## reemitApp
重新生成入口.
如果某些 watch 的文件变化了, 需要重新生成入口文件. 此时可以在这这个生命周期做一些清理工作, 因为和入口生成的相关 hook 会重新触发. | 1,145 | MIT |
# vue
## 虚拟DOM
## 生命周期
参考 [1](https://juejin.im/post/5afd7eb16fb9a07ac5605bb3)
## 常见问题及技巧
### data必须是一个函数
因为组件可能被用来创建多个实例。如果 data 仍然是一个纯粹的对象,则所有的实例将共享引用同一个数据对象!通过提供 data 函数,每次创建一个新实例后,我们能够调用 data 函数,从而返回初始数据的一个全新副本数据对象。
### props 要比 data 先完成初始化,所以我们可以利用这一点给 data 初始化一些数据进去
```js
export default {
data () {
return {
buttonSize: this.size
}
},
props: {
size: String
}
}
```
### this.$set() 使用
a.数组的下标去修改数组的值,数据已经被修改了,但是不触发updated函数,视图不更新。
b.vue中检测不到对象属性的添加和删除
### 生命周期函数/methods/watch里面不应该使用箭头函数
箭头函数的this指向外层,即函数所在的所用域,普通函数的this指向函数的调用者
### delete 与 Vue.delete ($delete)
- 都用于数组和对象
- delete 删除数组后,被删除的元素还占据原来的位置,变成empty或undefined,其他元素的简直不发生变化
- Vue.delete 直接删除了数组 改变了数组的键值。
### watch 的 immediate 属性
```js
created() {
this.fetchPostList()
},
watch: {
searchInputValue() {
this.fetchPostList()
}
}
```
可直接写成这样:
```js
watch: {
searchInputValue: {
handler: 'fetchPostList',
immediate: true
}
}
```
### 注销 watch
使用app.$watch()时,不用的时候须要注销掉,不然会引起内存泄露。该方法返回的就是一个注销方法,只要调用一下就可以了。
```js
//注册watch
const unWatch = app.$watch('text', (newVal, oldVal) => {
console.log(`${newVal} : ${oldVal}`);
});
// 手动注销watch
unWatch();
```
### 可以在同一个挂载点动态切换多个组件:
```js
var vm = new Vue({
el: '#example',
data: {
currentView: 'home'
},
components: {
home: { /* ... */ },
posts: { /* ... */ },
archive: { /* ... */ }
}
})
<component v-bind:is="currentView">
<!-- 组件在 vm.currentview 变化时改变! -->
</component>
```
### 异步组件
不需要首屏加载的组件都使用异步组件的方式来加载(如多tab),包括需要触发条件的动作也使用异步组件(如弹窗)
使用方式为:v-if来控制显示时机,引入组件的Promise即可。
```html
<template>
<div>
<HellowWorld v-if="showHello" />
</div>
</template>
<script>
export default {
components: { HellowWorld: () => import('../components/HelloWorld.vue') },
data() {
return {
showHello: false
}
},
methods: {
initAsync() {
addEventListener('scroll', (e) => {
if (scrollY > 100) {
this.showHello = true
}
});
}
}
}
</script>
```
### 深层组件通信 provide/inject
```html
//父组件 parent.vu
<template>
<div>
<child></child>
</div>
</template>
<script>
export default {
name: 'parent',
provide: {
data: 'I am parent.vue'
},
components: {
Child
}
}
</script>
```
```html
//子组件 child.vue
<template>
<div>
<grand-child></grand-child>
</div>
</template>
<script>
export default {
name: 'child',
components: {
GrandChild
}
}
</script>
```
```html
//孙组件 grandchild.vue
<script>
export default {
name: 'grandchild',
inject: ['data'],
mounted() {
// 控制台输出:
// grandchild:inject: I am parent.vue
console.log('grandchild:inject:',this.data);
}
}
</script>
```
provide 选项应该是一个对象或返回一个对象的函数。该对象包含可注入其子孙的属性。
inject 选项应该是一个字符串数组或一个对象,该对象的 key 代表了本地绑定的名称,value 就为provide中要取值的key。
参考
[1](https://juejin.im/post/5c204c98e51d454637699e33)
### slot-scope
父组件从子组件获取数据的方法,相当于函数中的回调
参考elementUI里的table
```html
<el-table-column
fixed="right"
label="操作"
width="100">
<template slot-scope="scope">
<el-button @click="handleClick(scope.row)" type="text">查看</el-button>
</template>
</el-table-column>
```
参考
[1](https://segmentfault.com/a/1190000015884505)
### sync修饰符
父组件
```html
<child :isShow.sync="isShow" v-show="isShow"/>
//是下面写法的语法糖
<child @update:isShow="e => isShow = e;" v-show="isShow"/>
```
子组件
```html
<input type="button" value="点我隐身" @click="upIsShow">
<script>
export default {
methods:{
upIsShow(){
this.$emit("update:isShow",false);
}
}
}
</script>
```
### 监听子组件(包括第三方子组件)的生命周期钩子
只需要这样:
```html
<Child @hook:mounted="childMounted"/>
```
```js
methods: {
childMounted() {
console.log("Child was mounted");
}
}
```
见[这里](https://codesandbox.io/s/18r05pkmn7)
### 用 Object.freeze 优化长列表性能
### Vue中的错误、警告捕获
全局捕获:
```js
//捕获错误
Vue.config.errorHandler = function(err, vm, info) {
console.log(`Error: ${err.toString()}\nInfo: ${info}`);
}
//捕获浸膏
Vue.config.warnHandler = function(msg, vm, trace) {
console.log(`Warn: ${msg}\nTrace: ${trace}`);
}
```
组件级捕获:
- 生命周期钩子 errorCaptured
```js
errorCaptured(err, vm, info) {
console.log(`cat EC: ${err.toString()}\ninfo: ${info}`);
return false;
}
```
- renderError 只在开发者环境下工作。
```js
new Vue({
render (h) {
throw new Error('oops');
},
renderError (h, err) {
return h('pre', { style: { color: 'red' }}, err.stack);
}
}).$mount('#app');
```
参考
[1](https://www.jianshu.com/p/d42c508ea9de)
[2](https://juejin.im/post/5be01d0ce51d450700084925)
[3](https://www.haorooms.com/post/vue_7secret)
[4](https://juejin.im/post/5b174de8f265da6e410e0b4e)
[5](https://www.haorooms.com/post/vue_project_cg)
[6](https://juejin.im/post/5c204c98e51d454637699e33)
[7](https://juejin.im/post/5ce3b519f265da1bb31c0d5f)
### $on 或 $once 代替 beforeDestroy 或 destroyed 生命周期来销毁事件或定时器
before:
```js
export default {
mounted() {
this.timer = setInterval(() => {
console.log(Date.now())
}, 1000)
},
beforeDestroy() {
clearInterval(this.timer)
}
}
```
after:
```js
export default {
mounted() {
this.creatInterval('hello')
this.creatInterval('world')
},
creatInterval(msg) {
let timer = setInterval(() => {
console.log(msg)
},
1000)
this.$once('hook:beforeDestroy', function() {
clearInterval(timer)
})
}
}
```
### Vue 的父组件和子组件生命周期钩子执行顺序
- 加载渲染过程:
父beforeCreate->父created->父beforeMount->子beforeCreate->子created->子beforeMount->子mounted->父mounted
- 子组件更新过程:
父beforeUpdate->子beforeUpdate->子updated->父updated
- 父组件更新过程:
父beforeUpdate->父updated
- 销毁过程:
父beforeDestroy->子beforeDestroy->子destroyed->父destroyed | 5,928 | MIT |
# 连载《Chrome V8 原理讲解》第九篇 Builtin源码分析

# 1 摘要
上一篇文章中,Builtin作为先导知识,我们做了宏观概括和介绍。Builtin(Built-in function)是编译好的内置代码块(chunk),存储在`snapshot_blob.bin`文件中,V8启动时以反序列化方式加载,运行时可以直接调用。Builtins功能共计600多个,细分为多个子类型,涵盖了解释器、字节码、执行单元等多个V8核心功能,本文从微观角度剖析Builtins功能的源码,在不使用`snapshot_blob.bin`文件的情况下,详细说明Builtin创建和运行过程。
本文内容组织结构:Bultin初始化过程(章节2),Builtin子类型讲解(章节3)。
# 2 Builtin初始化
下面是`code`类,它负责管理所有`Builtin`功能,是`builtin table`的数据类型。
```c++
1. class Code : public HeapObject {
2. public:
3. NEVER_READ_ONLY_SPACE
4. // Opaque data type for encapsulating code flags like kind, inline
5. // cache state, and arguments count.
6. using Flags = uint32_t;
7. #define CODE_KIND_LIST(V) \
8. V(OPTIMIZED_FUNCTION) \
9. V(BYTECODE_HANDLER) \
10. V(STUB) \
11. V(BUILTIN) \
12. V(REGEXP) \
13. V(WASM_FUNCTION) \
14. V(WASM_TO_CAPI_FUNCTION) \
15. V(WASM_TO_JS_FUNCTION) \
16. V(JS_TO_WASM_FUNCTION) \
17. V(JS_TO_JS_FUNCTION) \
18. V(WASM_INTERPRETER_ENTRY) \
19. V(C_WASM_ENTRY)
20. enum Kind {
21. #define DEFINE_CODE_KIND_ENUM(name) name,
22. CODE_KIND_LIST(DEFINE_CODE_KIND_ENUM)
23. #undef DEFINE_CODE_KIND_ENUM
24. NUMBER_OF_KINDS
25. };
26. static const char* Kind2String(Kind kind);
27. // Layout description.
28. #define CODE_FIELDS(V) \
29. V(kRelocationInfoOffset, kTaggedSize) \
30. V(kDeoptimizationDataOffset, kTaggedSize) \
31. V(kSourcePositionTableOffset, kTaggedSize) \
32. V(kCodeDataContainerOffset, kTaggedSize) \
33. /* Data or code not directly visited by GC directly starts here. */ \
34. /* The serializer needs to copy bytes starting from here verbatim. */ \
35. /* Objects embedded into code is visited via reloc info. */ \
36. V(kDataStart, 0) \
37. V(kInstructionSizeOffset, kIntSize) \
38. V(kFlagsOffset, kIntSize) \
39. V(kSafepointTableOffsetOffset, kIntSize) \
40. V(kHandlerTableOffsetOffset, kIntSize) \
41. V(kConstantPoolOffsetOffset, \
42. FLAG_enable_embedded_constant_pool ? kIntSize : 0) \
43. V(kCodeCommentsOffsetOffset, kIntSize) \
44. V(kBuiltinIndexOffset, kIntSize) \
45. V(kUnalignedHeaderSize, 0) \
46. /* Add padding to align the instruction start following right after */ \
47. /* the Code object header. */ \
48. V(kOptionalPaddingOffset, CODE_POINTER_PADDING(kOptionalPaddingOffset)) \
49. V(kHeaderSize, 0)
50. DEFINE_FIELD_OFFSET_CONSTANTS(HeapObject::kHeaderSize, CODE_FIELDS)
51. #undef CODE_FIELDS
52. STATIC_ASSERT(FIELD_SIZE(kOptionalPaddingOffset) == kHeaderPaddingSize);
53. inline int GetUnwindingInfoSizeOffset() const;
54. class BodyDescriptor;
55. // Flags layout. BitField<type, shift, size>.
56. #define CODE_FLAGS_BIT_FIELDS(V, _) \
57. V(HasUnwindingInfoField, bool, 1, _) \
58. V(KindField, Kind, 5, _) \
59. V(IsTurbofannedField, bool, 1, _) \
60. V(StackSlotsField, int, 24, _) \
61. V(IsOffHeapTrampoline, bool, 1, _)
62. DEFINE_BIT_FIELDS(CODE_FLAGS_BIT_FIELDS)
63. #undef CODE_FLAGS_BIT_FIELDS
64. static_assert(NUMBER_OF_KINDS <= KindField::kMax, "Code::KindField size");
65. static_assert(IsOffHeapTrampoline::kLastUsedBit < 32,
66. "Code::flags field exhausted");
67. // KindSpecificFlags layout (STUB, BUILTIN and OPTIMIZED_FUNCTION)
68. #define CODE_KIND_SPECIFIC_FLAGS_BIT_FIELDS(V, _) \
69. V(MarkedForDeoptimizationField, bool, 1, _) \
70. V(EmbeddedObjectsClearedField, bool, 1, _) \
71. V(DeoptAlreadyCountedField, bool, 1, _) \
72. V(CanHaveWeakObjectsField, bool, 1, _) \
73. V(IsPromiseRejectionField, bool, 1, _) \
74. V(IsExceptionCaughtField, bool, 1, _)
75. DEFINE_BIT_FIELDS(CODE_KIND_SPECIFIC_FLAGS_BIT_FIELDS)
76. #undef CODE_KIND_SPECIFIC_FLAGS_BIT_FIELDS
77. private:
78. friend class RelocIterator;
79. bool is_promise_rejection() const;
80. bool is_exception_caught() const;
81. OBJECT_CONSTRUCTORS(Code, HeapObject);
82. };
//........................代码太长,省略很多.....................
//.............................................................
```
上述代码中,`CODE_KIND_LIST`从code角度定义了类型,在`Builtin`类中也定义了`Builtin`一共有七种子类型,这是两种不同的定义方式,但说的都是Builtin。`Builtin`的初始化工作由方法`void Isolate::Initialize(Isolate* isolate,const v8::Isolate::CreateParams& params)`统一完成,下面给出这个方法的部分代码。
```c++
1. void Isolate::Initialize(Isolate* isolate,
2. const v8::Isolate::CreateParams& params) {
3. i::Isolate* i_isolate = reinterpret_cast<i::Isolate*>(isolate);
4. CHECK_NOT_NULL(params.array_buffer_allocator);
5. i_isolate->set_array_buffer_allocator(params.array_buffer_allocator);
6. if (params.snapshot_blob != nullptr) {
7. i_isolate->set_snapshot_blob(params.snapshot_blob);
8. } else {
9. i_isolate->set_snapshot_blob(i::Snapshot::DefaultSnapshotBlob());
10. }
11. auto code_event_handler = params.code_event_handler;
12. //........................代码太长,省略很多.....................
13. if (!i::Snapshot::Initialize(i_isolate)) {
14. // If snapshot data was provided and we failed to deserialize it must
15. // have been corrupted.
16. if (i_isolate->snapshot_blob() != nullptr) {
17. FATAL(
18. "Failed to deserialize the V8 snapshot blob. This can mean that the "
19. "snapshot blob file is corrupted or missing.");
20. }
21. base::ElapsedTimer timer;
22. if (i::FLAG_profile_deserialization) timer.Start();
23. i_isolate->InitWithoutSnapshot();
24. if (i::FLAG_profile_deserialization) {
25. double ms = timer.Elapsed().InMillisecondsF();
26. i::PrintF("[Initializing isolate from scratch took %0.3f ms]\n", ms);
27. }
28. }
29. i_isolate->set_only_terminate_in_safe_scope(
30. params.only_terminate_in_safe_scope);
31. }
```
上述方面中进入第22行,最终进入下面的Builtin初始化方法。
```c++
1. void SetupIsolateDelegate::SetupBuiltinsInternal(Isolate* isolate) {
2. //...................删除部分代码,留下最核心功能
3. //...................删除部分代码,留下最核心功能
4. int index = 0;
5. Code code;
6. #define BUILD_CPP(Name) \
7. code = BuildAdaptor(isolate, index, FUNCTION_ADDR(Builtin_##Name), #Name); \
8. AddBuiltin(builtins, index++, code);
9. #define BUILD_TFJ(Name, Argc, ...) \
10. code = BuildWithCodeStubAssemblerJS( \
11. isolate, index, &Builtins::Generate_##Name, Argc, #Name); \
12. AddBuiltin(builtins, index++, code);
13. #define BUILD_TFC(Name, InterfaceDescriptor) \
14. /* Return size is from the provided CallInterfaceDescriptor. */ \
15. code = BuildWithCodeStubAssemblerCS( \
16. isolate, index, &Builtins::Generate_##Name, \
17. CallDescriptors::InterfaceDescriptor, #Name); \
18. AddBuiltin(builtins, index++, code);
19. #define BUILD_TFS(Name, ...) \
20. /* Return size for generic TF builtins (stub linkage) is always 1. */ \
21. code = \
22. BuildWithCodeStubAssemblerCS(isolate, index, &Builtins::Generate_##Name, \
23. CallDescriptors::Name, #Name); \
24. AddBuiltin(builtins, index++, code);
25. #define BUILD_TFH(Name, InterfaceDescriptor) \
26. /* Return size for IC builtins/handlers is always 1. */ \
27. code = BuildWithCodeStubAssemblerCS( \
28. isolate, index, &Builtins::Generate_##Name, \
29. CallDescriptors::InterfaceDescriptor, #Name); \
30. AddBuiltin(builtins, index++, code);
31. #define BUILD_BCH(Name, OperandScale, Bytecode) \
32. code = GenerateBytecodeHandler(isolate, index, OperandScale, Bytecode); \
33. AddBuiltin(builtins, index++, code);
34. #define BUILD_ASM(Name, InterfaceDescriptor) \
35. code = BuildWithMacroAssembler(isolate, index, Builtins::Generate_##Name, \
36. #Name); \
37. AddBuiltin(builtins, index++, code);
38. BUILTIN_LIST(BUILD_CPP, BUILD_TFJ, BUILD_TFC, BUILD_TFS, BUILD_TFH, BUILD_BCH,
39. BUILD_ASM);
40. //...................删除部分代码,留下最核心功能
41. //...................删除部分代码,留下最核心功能
42. }
```
上述代码只保留了最核心的Builtin初始化功能,初始化工作的主要是生成并编译Builtin代码,并以独立功能的形式挂载到`isolate`上,以`BuildWithCodeStubAssemblerCS()`详细描述该过程。
见下面代码,第一个参数是`isolate`,用于保存初化完成的`Builtin`;第二个参数全局变量`index`,`Builtin`存储在`isolate`的数组成员中,`index`是数组下标;第三个参数`generator`是函数指针,该函数用于生成`Builtin`;第四个参数是call描述符;最后一个是函数名字。
```c++
1. // Builder for builtins implemented in TurboFan with CallStub linkage.
2. Code BuildWithCodeStubAssemblerCS(Isolate* isolate, int32_t builtin_index,
3. CodeAssemblerGenerator generator,
4. CallDescriptors::Key interface_descriptor,
5. const char* name) {
6. HandleScope scope(isolate);
7. // Canonicalize handles, so that we can share constant pool entries pointing
8. // to code targets without dereferencing their handles.
9. CanonicalHandleScope canonical(isolate);
10. Zone zone(isolate->allocator(), ZONE_NAME);
11. // The interface descriptor with given key must be initialized at this point
12. // and this construction just queries the details from the descriptors table.
13. CallInterfaceDescriptor descriptor(interface_descriptor);
14. // Ensure descriptor is already initialized.
15. DCHECK_LE(0, descriptor.GetRegisterParameterCount());
16. compiler::CodeAssemblerState state(
17. isolate, &zone, descriptor, Code::BUILTIN, name,
18. PoisoningMitigationLevel::kDontPoison, builtin_index);
19. generator(&state);
20. Handle<Code> code = compiler::CodeAssembler::GenerateCode(
21. &state, BuiltinAssemblerOptions(isolate, builtin_index));
22. return *code;
23. }
```
在代码中,第19行代码生成Builtin源码,以第一个Builtin为例说明`generator(&state)`的功能,此时`generator`指针代表的函数是`TF_BUILTIN(RecordWrite, RecordWriteCodeStubAssembler) `,下面是代码:
```c++
1. TF_BUILTIN(RecordWrite, RecordWriteCodeStubAssembler) {
2. Label generational_wb(this);
3. Label incremental_wb(this);
4. Label exit(this);
5. Node* remembered_set = Parameter(Descriptor::kRememberedSet);
6. Branch(ShouldEmitRememberSet(remembered_set), &generational_wb,
7. &incremental_wb);
8. BIND(&generational_wb);
9. {
10. Label test_old_to_young_flags(this);
11. Label store_buffer_exit(this), store_buffer_incremental_wb(this);
12. TNode<IntPtrT> slot = UncheckedCast<IntPtrT>(Parameter(Descriptor::kSlot));
13. Branch(IsMarking(), &test_old_to_young_flags, &store_buffer_exit);
14. BIND(&test_old_to_young_flags);
15. {
16. TNode<IntPtrT> value =
17. BitcastTaggedToWord(Load(MachineType::TaggedPointer(), slot));
18. TNode<BoolT> value_is_young =
19. IsPageFlagSet(value, MemoryChunk::kIsInYoungGenerationMask);
20. GotoIfNot(value_is_young, &incremental_wb);
21. TNode<IntPtrT> object =
22. BitcastTaggedToWord(Parameter(Descriptor::kObject));
23. TNode<BoolT> object_is_young =
24. IsPageFlagSet(object, MemoryChunk::kIsInYoungGenerationMask);
25. Branch(object_is_young, &incremental_wb, &store_buffer_incremental_wb);
26. }
27. BIND(&store_buffer_exit);
28. {
29. TNode<ExternalReference> isolate_constant =
30. ExternalConstant(ExternalReference::isolate_address(isolate()));
31. Node* fp_mode = Parameter(Descriptor::kFPMode);
32. InsertToStoreBufferAndGoto(isolate_constant, slot, fp_mode, &exit);
33. }
34. BIND(&store_buffer_incremental_wb);
35. {
36. TNode<ExternalReference> isolate_constant =
37. ExternalConstant(ExternalReference::isolate_address(isolate()));
38. Node* fp_mode = Parameter(Descriptor::kFPMode);
39. InsertToStoreBufferAndGoto(isolate_constant, slot, fp_mode,
40. &incremental_wb);
41. }
42. } //........................省略代码......................................
43. BIND(&exit);
44. IncrementCounter(isolate()->counters()->write_barriers(), 1);
45. Return(TrueConstant());
46. }
```
这个函数`TF_BUILTIN(RecordWrite, RecordWriteCodeStubAssembler)`是生成器,它的作用是生成写记录功能的源代码,`TF_BUILTIN`是宏模板,展开后可以看到它的类成员`CodeAssemblerState* state`保存了生成之后的源码。“用平台无关的生成器为特定平台生成源代码”是`Builtin`的常用做法,这样减少了工作量。函数执行完成后返回到`BuildWithCodeStubAssemblerCS`,生成的源代码经过处理后,最终由`code`表示,下面是`code`的数据类型。
```c++
class Code : public HeapObject {
public:
NEVER_READ_ONLY_SPACE
// Opaque data type for encapsulating code flags like kind, inline
// cache state, and arguments count.
using Flags = uint32_t;
#define CODE_KIND_LIST(V) \
V(OPTIMIZED_FUNCTION) \
V(BYTECODE_HANDLER) \
V(STUB) \
V(BUILTIN) \
V(REGEXP) \
V(WASM_FUNCTION) \
V(WASM_TO_CAPI_FUNCTION) \
V(WASM_TO_JS_FUNCTION) \
V(JS_TO_WASM_FUNCTION) \
V(JS_TO_JS_FUNCTION) \
V(WASM_INTERPRETER_ENTRY) \
V(C_WASM_ENTRY)
enum Kind {
#define DEFINE_CODE_KIND_ENUM(name) name,
CODE_KIND_LIST(DEFINE_CODE_KIND_ENUM)
#undef DEFINE_CODE_KIND_ENUM
NUMBER_OF_KINDS
};
//..................省略........................
//.............................................
```
上述代码中,可以看到从`code`的角度对`Builtin`进行了更详细的分类。另外`code`是堆对象,也就是说`Builtin`是由V8的堆栈进行管理,后续讲到堆栈时再详细说明这部分知识。图2给出函数调用堆栈,供读者自行复现。

在`SetupBuiltinsInternal()`中可以看到`AddBuiltin()`将生成的`code`代码添加到`isolate`中,代码如下。
```c++
void SetupIsolateDelegate::AddBuiltin(Builtins* builtins, int index,
Code code) {
DCHECK_EQ(index, code.builtin_index());
builtins->set_builtin(index, code);
}
//..............分隔线......................
void Builtins::set_builtin(int index, Code builtin) {
isolate_->heap()->set_builtin(index, builtin);
}
```
所有`Builtin`功能生成后保存在`Address builtins_[Builtins::builtin_count]`中,初始化方法`SetupBuiltinsInternal`按照`BUILTIN_LIST`的定义顺序依次完成所有Builtin的源码生成、编译和挂载到isolate。
# 2 Builtin子类型
从`Builtins`的功能看,它包括了:Ignition实现、字节码实现、以及ECMA规范实现等众多V8的核心功能,在`BUILTIN_LIST`定义中有详细注释,请读者自行查阅。前面讲过,从`BUILTIN`的实现角度分为七种类型,见下面代码:
```c++
#define BUILD_CPP(Name)
#define BUILD_TFJ(Name, Argc, ...)
#define BUILD_TFC(Name, InterfaceDescriptor)
#define BUILD_TFS(Name, ...)
#define BUILD_TFH(Name, InterfaceDescriptor)
#define BUILD_BCH(Name, OperandScale, Bytecode)
#define BUILD_ASM(Name, InterfaceDescriptor)
```
以子类型`BUILD_CPP`举例说明,下面是完整源代码。
```c++
1. Code BuildAdaptor(Isolate* isolate, int32_t builtin_index,
2. Address builtin_address, const char* name) {
3. HandleScope scope(isolate);
4. // Canonicalize handles, so that we can share constant pool entries pointing
5. // to code targets without dereferencing their handles.
6. CanonicalHandleScope canonical(isolate);
7. constexpr int kBufferSize = 32 * KB;
8. byte buffer[kBufferSize];
9. MacroAssembler masm(isolate, BuiltinAssemblerOptions(isolate, builtin_index),
10. CodeObjectRequired::kYes,
11. ExternalAssemblerBuffer(buffer, kBufferSize));
12. masm.set_builtin_index(builtin_index);
13. DCHECK(!masm.has_frame());
14. Builtins::Generate_Adaptor(&masm, builtin_address);
15. CodeDesc desc;
16. masm.GetCode(isolate, &desc);
17. Handle<Code> code = Factory::CodeBuilder(isolate, desc, Code::BUILTIN)
18. .set_self_reference(masm.CodeObject())
19. .set_builtin_index(builtin_index)
20. .Build();
21. return *code;
22. }
```
`BuildAdaptor`的生成功能由第13行代码实现,最终该代码的实现如下:
```c++
void Builtins::Generate_Adaptor(MacroAssembler* masm, Address address) {
__ LoadAddress(kJavaScriptCallExtraArg1Register,
ExternalReference::Create(address));
__ Jump(BUILTIN_CODE(masm->isolate(), AdaptorWithBuiltinExitFrame),
RelocInfo::CODE_TARGET);
}
}
```
上面两部分代码实现了第77号`Builtin`功能,名字是`HandleApiCall`,图2以`char`类型展示了生成的源代码。

总结:学习Builtin时,涉及很多系统结构相关的知识,本文讲解采用的是x64架构。每种`Builtin`的生成方式虽不相同,但分析源码的思路相同,有问题可以联系我。
好了,今天到这里,下次见。
**恳请读者批评指正、提出宝贵意见**
**微信:qq9123013 备注:v8交流 邮箱:[email protected]** | 17,647 | Apache-2.0 |
---
layout: article
title: 位图-go实现
tags: 数据结构 bitmap
key: data-structure-bitmap
mathajx: false
---
<!--more-->
```go
/**
位图
*/
type BitMap struct {
length int // 已存储元素个数
words []uint64 // 位图数组
}
func Construct() *BitMap {
return &BitMap{}
}
func (this *BitMap) Has(num int) bool {
word, bit := num/64, uint(num%64)
return word < len(this.words) && this.words[word]&(1<<bit) != 0
}
func (this *BitMap) Add(num int) {
word, bit := num/64, uint(num%64) // word:对应uint64的个数;bit:word内的位置
for i := len(this.words); i <= word; i++ {
this.words = append(this.words, 0)
}
this.words[word] |= (1 << bit) // 位或
this.length++
}
func (this *BitMap) Len() int {
return this.length
}
func (this *BitMap) Print() {
for i, j := 0, 0; i < this.length; i++ {
for ; ; j++ {
word, bit := j/64, uint(j%64)
if this.words[word]&(1<<bit) != 0 {
fmt.Println(j)
j++
break
}
}
}
}
``` | 1,030 | MIT |
---
layout: post
title: "scss文件编译错误及配置scsslint忽略检查项"
date: 2018-07-09
excerpt: "scss文件编译错误及配置scsslint忽略检查项"
tag:
- scss
- css
---
### scss文件编译时出现错误
* sass将scss文件编译成css文件的时候,scss文件路径不能有中文字符,否则会报错:`Encoding::CompatibilityError: incompatible character encodings: GBK and UTF-8 Use --trace for backtrace.`。
* scss文件注释文字中如果有中文,要在文件头部加个`@charset "utf-8";`,否则会报编码错误:` error 1.scss (Line 11: Invalid GBK character "\xE6")`。
### 配置忽略检查项
scsslint可在scss文件注释中直接配置需要忽略的检查项,如:
@charset "utf-8";
/* scss-lint:disable Indentation PropertySortOrder IdSelector*/ | 563 | MIT |
---
sidebarDepth: 3
---
# mdpress-types <GitHubLink repo="mdpress/mdpress-community"/>
目前 MdPress 并没有支持 typescript ,并且没有提供类型定义。
<!--
[mdpress-plugin-typescript](../plugins/typescript.md) 提供了在 VuePress 中使用 typescript 的部分能力。如果你想获取到正确的类型定义,你可以配合 `mdpress-types` 一起使用。
-->
::: warning 实验中
`mdpress-types` 作为 MdPress 的类型定义包,还处于实验阶段。如果你在使用时发现任何问题,欢迎提出 Issue 。
:::
## 安装
```sh
npm install -D mdpress-types
```
## 使用
你可以选择下列 **一种** 方式使用它:
### 手动引入
你可以手动在 `.ts` 文件中引入
### 添加到 tsconfig
你可以把它添加到 `tsconfig.json` 的 `compilerOptions.types` 中:
> 参考 [`tsconfig.json` 文档](https://www.typescriptlang.org/docs/handbook/tsconfig-json.html#types-typeroots-and-types)
```json {3}
{
"compilerOptions": {
"types": ["mdpress-types"]
}
}
``` | 739 | MIT |
<!-- # Echo server -->
# エコーサーバー
<!--
Let's merge transmission and reception into a single program and write an echo server. An echo
server sends back to the client the same text it sent. For this application, the microcontroller
will be the server and you and your laptop will be the client.
-->
送信と受信を1つのプログラムにまとめて、エコーサーバーを書いてみましょう。
エコーサーバーは、クライアントに送信されたものと同じテキストを送り返します。
このアプリケーションでは、マイクロコントローラがサーバーで、ノートPCがクライアントになります。
<!-- This should be straightforward to implement. (hint: do it byte by byte) -->
これは、素直な実装になるはずです。(ヒント:1バイトごとに処理します) | 546 | Apache-2.0 |
# excel
## 导出excel
添加依赖
```
<dependency>
<groupId>io.github.tobetwo</groupId>
<artifactId>tobetwo.excel</artifactId>
<version>1.0.1-SNAPSHOT</version>
</dependency>
```
使用
```
Excel e = new Excel();
XSheet sheet;
sheet = e.newSheet().name("基本信息");
sheet.getSchema().add("学号").add("姓名");
sheet.newRecord().add("2010000000").add("Foo");
sheet.newRecord().add("2010000001").add("Bar");
sheet = e.newSheet();
sheet.getSchema().add("foo").add("bar");
sheet.newRecord().add("0").add("1");
sheet.newRecord().add("2").add("4");
export(e.getBytes());
```
## 导入excel
```
byte[] bytes = import2Bytes();
Excel excel = Excel.fromBytes(bytes);
// sheet row cell
log(excel.get(0).get(1).get(1));
excel.forEach(sheet -> {
log("----------------------");
log(sheet.getName());
log(sheet.getSchema());
sheet.forEach(this::log);
});
/**
* 输出:
* Bar
* ----------------------
* 基本信息
* [学号, 姓名]
* [2010000000, Foo]
* [2010000001, Bar]
* ----------------------
* sheet-1
* [foo, bar]
* [0, 1]
* [2, 4]
``` | 1,027 | MIT |
# 删除链表中的节点
> 难度:简单
>
> https://leetcode-cn.com/problems/delete-node-in-a-linked-list/
## 题目
请编写一个函数,用于 **删除单链表中某个特定节点** 。在设计函数时需要注意,你无法访问链表的头节点`head` ,只能直接访问 **要被删除的节点** 。
题目数据保证需要删除的节点 **不是末尾节点** 。
### 示例 1:

```
输入:head = [4,5,1,9], node = 5
输出:[4,1,9]
解释:指定链表中值为5的第二个节点,那么在调用了你的函数之后,该链表应变为 4 -> 1 -> 9
```
### 示例 2:

```
输入:head = [4,5,1,9], node = 1
输出:[4,5,9]
解释:指定链表中值为1的第三个节点,那么在调用了你的函数之后,该链表应变为 4 -> 5 -> 9
```
## 解题
```ts
/**
* 和下一个节点交换
* @desc 时间复杂度 O(1) 空间复杂度 O(1)
* @param root
*/
export function deleteNode(root: ListNode | null): void {
if (root !== null) {
root.val = root.next!.val
root.next = root.next!.next
}
}
``` | 890 | MIT |
---
layout: post
title: "空拍广东东莞客家第一村,清溪镇铁场围古村,围龙屋建筑依水傍水个个风水宝地,客家祖先的聪明智慧真是牛!"
date: 2019-08-23T04:59:15.000Z
author: HEYFLY嘿飛人
from: https://www.youtube.com/watch?v=3ETv6_h_QRM
tags: [ HEYFLY嘿飛人 ]
categories: [ HEYFLY嘿飛人 ]
---
<!--1566536355000-->
[空拍广东东莞客家第一村,清溪镇铁场围古村,围龙屋建筑依水傍水个个风水宝地,客家祖先的聪明智慧真是牛!](https://www.youtube.com/watch?v=3ETv6_h_QRM)
------
<div>
空拍广东东莞客家第一村,清溪镇铁场围古村,围龙屋建筑依水傍水个个风水宝地,客家祖先的聪明智慧真是牛!
</div> | 417 | MIT |
---
title: '组装复合组件'
tocTitle: '合成组件'
description: '使用更简单的组件组装复合组件'
commit: 'ef6a2ed'
---
我们在上一章构建了我们的第一个组件;这一章我们继续扩展所学并构建一个 TaskList,即一组 Task。让我们组合组件并看看当引入更多的复杂性时会发生什么。
## Tasklist
Taskbox 通过将固定 task(pinned tasks)置于其他默认 task 之上来强调固定 task。这就需要您针对两种类型的`TaskList`创建对应的 story:默认的以及默认并固定的。

因为`Task`的数据可以是非同步的,我们**还**需要一个当连接不存在时需要提供的 loading 状态。此外我们还需要一个空状态来对应没有 task 的情况。

## 配置
合成组件相比基本组件并没有太大区别。创建一个`TaskList`组件和其伴随 story 文件:`src/components/TaskList.vue` 和 `src/components/TaskList.stories.js`.
先简单实现以下`TaskList`。您需要先导入`Task`组件并将属性作为输入传入。
```html:title=src/components/TaskList.vue
<template>
<div class="list-items">
<template v-if="loading">
loading
</template>
<template v-else-if="isEmpty">
empty
</template>
<template v-else>
<Task
v-for="task in tasks"
:key="task.id"
:task="task"
@archive-task="onArchiveTask"
@pin-task="onPinTask"
/>
</template>
</div>
</template>
<script>
import Task from './Task';
import { reactive, computed } from 'vue';
export default {
name: 'TaskList',
components: { Task },
props: {
tasks: { type: Array, required: true, default: () => [] },
loading: { type: Boolean, default: false },
},
emits: ['archive-task', 'pin-task'],
setup(props, { emit }) {
props = reactive(props);
return {
isEmpty: computed(() => props.tasks.length === 0),
/**
* Event handler for archiving tasks
*/
onArchiveTask(taskId) {
emit('archive-task', taskId);
},
/**
* Event handler for pinning tasks
*/
onPinTask(taskId) {
emit('pin-task', taskId);
},
};
},
};
</script>
```
下一步我们在 story 文件中创建`Tasklist`的测试状态。
```js:title=src/components/TaskList.stories.js
import TaskList from './TaskList.vue';
import * as TaskStories from './Task.stories';
export default {
component: TaskList,
title: 'TaskList',
decorators: [() => ({ template: '<div style="margin: 3em;"><story/></div>' })],
argTypes: {
onPinTask: {},
onArchiveTask: {},
},
};
const Template = args => ({
components: { TaskList },
setup() {
return { args, ...TaskStories.actionsData };
},
template: '<TaskList v-bind="args" />',
});
export const Default = Template.bind({});
Default.args = {
// Shaping the stories through args composition.
// The data was inherited from the Default story in task.stories.js.
tasks: [
{ ...TaskStories.Default.args.task, id: '1', title: 'Task 1' },
{ ...TaskStories.Default.args.task, id: '2', title: 'Task 2' },
{ ...TaskStories.Default.args.task, id: '3', title: 'Task 3' },
{ ...TaskStories.Default.args.task, id: '4', title: 'Task 4' },
{ ...TaskStories.Default.args.task, id: '5', title: 'Task 5' },
{ ...TaskStories.Default.args.task, id: '6', title: 'Task 6' },
],
};
export const WithPinnedTasks = Template.bind({});
WithPinnedTasks.args = {
// Shaping the stories through args composition.
// Inherited data coming from the Default story.
tasks: [
...Default.args.tasks.slice(0, 5),
{ id: '6', title: 'Task 6 (pinned)', state: 'TASK_PINNED' },
],
};
export const Loading = Template.bind({});
Loading.args = {
tasks: [],
loading: true,
};
export const Empty = Template.bind({});
Empty.args = {
// Shaping the stories through args composition.
// Inherited data coming from the Loading story.
...Loading.args,
loading: false,
};
```
<div class="aside">
<a href="https://storybook.js.org/docs/vue/writing-stories/decorators"><b>装饰器</b></a> 提供了一种任意包装story的方法。上述例子中我们在default export中使用decorator关键字来添加样式。装饰器也可以给组件添加其他上下文,详见下文。
</div>
通过导入`TaskStories`,我们能够以最小的代价[合成](https://storybook.js.org/docs/vue/writing-stories/args#args-composition)story 中的参数(argument)。这样就为每个组件保留了其所需的数据和 action(模拟回调)。
现在在 Storybook 中查看新的`TaskList` story 吧。
<video autoPlay muted playsInline loop>
<source
src="/intro-to-storybook/inprogress-tasklist-states-6-0.mp4"
type="video/mp4"
/>
</video>
## 创建状态
我们的组件仍然很粗糙但我们已经有了该如何构建 story 的方向。您可能觉得`.list-items`太过简单了。您是对的 - 大多数情况下我们不会仅仅为了增加一层包装就创建一个新组件。但是`WithPinnedTasks`,`loading`和 `empty`这些边界情况却揭示了`TaskList`**真正的复杂性**。
```diff:title=src/components/TaskList.vue
<template>
<div class="list-items">
<template v-if="loading">
+ <div v-for="n in 6" :key="n" class="loading-item">
+ <span class="glow-checkbox" />
+ <span class="glow-text"> <span>Loading</span> <span>cool</span> <span>state</span> </span>
+ </div>
</template>
<div v-else-if="isEmpty" class="list-items">
+ <div class="wrapper-message">
+ <span class="icon-check" />
+ <div class="title-message">You have no tasks</div>
+ <div class="subtitle-message">Sit back and relax</div>
+ </div>
</div>
<template v-else>
+ <Task v-for="task in tasksInOrder"
+ :key="task.id"
+ :task="task"
+ @archive-task="onArchiveTask
+ @pin-task="onPinTask"/>
</template>
</div>
</template>
<script>
import Task from './Task';
import { reactive, computed } from 'vue';
export default {
name: 'TaskList',
components: { Task },
props: {
tasks: { type: Array, required: true, default: () => [] },
loading: { type: Boolean, default: false },
},
emits: ["archive-task", "pin-task"],
setup(props, { emit }) {
props = reactive(props);
return {
isEmpty: computed(() => props.tasks.length === 0),
+ tasksInOrder:computed(()=>{
+ return [
+ ...props.tasks.filter(t => t.state === 'TASK_PINNED'),
+ ...props.tasks.filter(t => t.state !== 'TASK_PINNED'),
+ ]
+ }),
/**
* Event handler for archiving tasks
*/
onArchiveTask(taskId) {
emit('archive-task',taskId);
},
/**
* Event handler for pinning tasks
*/
onPinTask(taskId) {
emit('pin-task', taskId);
},
};
},
};
</script>
```
通过上述代码我们生成了如下 UI:
<video autoPlay muted playsInline loop>
<source
src="/intro-to-storybook/finished-tasklist-states-6-0.mp4"
type="video/mp4"
/>
</video>
注意固定项目出现在列表中的位置。我们希望固定项目可以出现在列表的顶端以提示用户其优先度。
## 自动化测试
在上一章中我们学习了如何使用 Storyshots 来进行快照测试。`Task`没有太多的复杂性,所以已经够用了。对于`TaskList`来说其增加了另一层复杂性,这就需要我们寻找一个合适的自动化测试方法来验证特定的输入可以产生特定的输出。我们使用[Jest](https://facebook.github.io/jest/)加测试渲染器来创建单元测试。

### 使用 Jest 进行单元测试
Storybook 使用手动检查和快照测试的方式来防止 UI 的 bug。看起来好像只要我们覆盖了足够多的场景,并且使用一些工具保证可以人为检查 story 的变化后,错误将会大大减少。
但是,魔鬼存在于细节中。我们还需要一个测试框架来显示的实现上述需求。也就是单元测试。
在我们的例子中,我们希望`TastList`可以将`tasks`属性中的固定 task 渲染在非固定 task 的**上面**。尽管我们已经有一个 story (`WithPinnedTasks`)来对应此场景;但对于任何人为的检查来说仍然过于含糊了,因此当组件**停止**按上述那样排序时 bug 就产生了。很显然这样的测试并不会大声告诉您**你错了!**。
所以为了防止这样的问题发生,我们可以使用 Jest 将 story 渲染成 DOM,然后跑一些 DOM 查询代码来验证输出中重要的部分。story 的 format 非常棒的一点在于,我们只需要简单的导入 story 到我们的测试中就可以渲染它了!
创建一个测试文件`tests/unit/TaskList.spec.js`。我们创建测试来判断输出结果。
```js:title=tests/unit/TaskList.spec.js
import { mount } from '@vue/test-utils';
import TaskList from '../../src/components/TaskList.vue';
//👇 Our story imported here
import { WithPinnedTasks } from '../../src/components/TaskList.stories';
test('renders pinned tasks at the start of the list', () => {
const wrapper = mount(TaskList, {
//👇 Story's args used with our test
propsData: WithPinnedTasks.args,
});
const firstPinnedTask = wrapper.find('.list-item:nth-child(1).TASK_PINNED');
expect(firstPinnedTask).not.toBe(null);
});
```

注意我们可以在 story 和单元测试中重用`withPinnedTasksData`;这样我们就可以继续以越来越多的方式运用现有资源(代表组件各种有趣配置的示例)。
请注意这个测试仍然十分脆弱。随着项目逐渐成熟,以及`Task`的实现改变时 -- 也许使用了另一个类名 -- 那测试很可能失败,这需要我们去更新它。这不一定是个问题,但是在 UI 中使用单元测试仍需十分小心。它们的维护工作并不容易。除了依靠肉眼,快照和视觉回归(visual regression)(参见[测试章节](/intro-to-storybook/vue/zh-CN/test/))。
<div class="aside">
别忘记提交您的代码到git!
</div> | 8,028 | MIT |
# [1010]总持续时间可被 60 整除的歌曲
> [总持续时间可被 60 整除的歌曲](https://leetcode-cn.com/problems/pairs-of-songs-with-total-durations-divisible-by-60/description/)
在歌曲列表中,第`i`首歌曲的持续时间为`time[i]`秒。
返回其总持续时间(以秒为单位)可被`60`整除的歌曲对的数量。形式上,我们希望索引的数字`i < j`且有`(time[i] + time[j]) % 60 == 0`。
**示例 1:**
```
输入:[30,20,150,100,40]
输出:3
解释:这三对的总持续时间可被 60 整数:
(time[0] = 30, time[2] = 150): 总持续时间 180
(time[1] = 20, time[3] = 100): 总持续时间 120
(time[1] = 20, time[4] = 40): 总持续时间 60
```
**示例 2:**
```
输入:[60,60,60]
输出:3
解释:所有三对的总持续时间都是 120,可以被 60 整数。
```
**提示:**
1. `1 <= time.length <= 60000`
2. `1 <= time[i] <= 500`
## 思考
如果一个数对 60 的余数为 20,则与它配对的数对 60 的余数必然为 40。故只需查看余数为 40 的数的个数,即为配对数目,同时记录余数为 20 的数的数目。最后统计配对数目总和即可
## 代码
```java
/*
* @lc app=leetcode.cn id=1010 lang=java
*
* [1010] 总持续时间可被 60 整除的歌曲
*/
// @lc code=start
class Solution {
public int numPairsDivisibleBy60(int[] time) {
int[] map = new int[60];
for (int t : time) {
map[t % 60]++;
}
int count = map[0] * (map[0] - 1) / 2 + map[30] * (map[30] - 1) / 2;
for (int i = 1; i < 30; i++) {
count += map[i] * map[60 - i];
}
return count;
}
}
// @lc code=end
``` | 1,154 | MIT |
# gulp-oss-manager
基于阿里云 OSS SDK开发的文件上传助手
### 安装
```shell
npm install -D gulp-oss-manager
```
### 使用
示例文件目录
---
|
|---- src
| |
| |---- App.vue
| |
| |---- OSS/ // 需要上传的目录
| | |
| 略 |---- logo.png
| |
| |---- max.png
| |
| 略 ( 同 main 结构)
|
|----
略
配置文件
```javascript
// gulpfile.js
const {src} = require("gulp");
const ossManager = require("gulp-oss-manager");
function upload () {
return src("src/OSS/**/**.*").pipe(
new ossManager({
accessKeyId: '阿里云 accessKeyId',
accessKeySecret: "阿里云 accessKeySecret",
region: "阿里云 region",
bucket: "阿里云 bucket",
customPath: "自定义的路径,非必填",
timeout: "超时时间,默认为60000ms,非必填"
}),
);
}
module.exports.default = upload;
``` | 852 | MIT |
---
id: Home
title: r0zh 生活分享&个人知识库
sidebar_label: 主页
slug: /
---
<!-- 一个不会讲故事的攻城狮,算不上一个很酷的产品汪~-->
Hi there~
这是我的知识库。
为了避免遗忘、便于分享,我在这里收录知识。
请随意浏览~
[](https://vercel.com/r0zh94/wblog/deployments)
[](https://github.com/r0zh94/wblog)
[](ContactMe)
<h6>luo zhenhua | 2022 | Built with Docusaurus</h6> | 637 | MIT |
---
title: 动态规划之背包问题
tags: [algorithm, dp]
---
动态规划是对解最优化问题的一种途径、一种方法,而不是一种特殊算法。动态规划往往是针对一种最优化问题,由于各种问题的性质不同,确定最优解的条件也互不相同,因而动态规划的设计方法对不同的问题,有各具特色的解题方法,而不存在一种万能的动态规划算法,可以解决各类最优化问题。
### 动态规划
#### 基本概念
动态规划过程是:每次决策依赖于当前状态,又随即引起状态的转移。一个决策序列就是在变化的状态中产生出来的,所以,这种多阶段最优化决策解决问题的过程就称为动态规划。
#### 基本思想与策略
基本思想与分治法类似,也是将待求解的问题分解为若干个子问题(阶段),按顺序求解子阶段,前一子问题的解,为后一子问题的求解提供了有用的信息。在求解任一子问题时,列出各种可能的局部解,通过决策保留那些有可能达到最优的局部解,丢弃其他局部解。依次解决各子问题,最后一个子问题就是初始问题的解。
由于动态规划解决的问题多数有重叠子问题这个特点,为减少重复计算,对每一个子问题只解一次,将其不同阶段的不同状态保存在一个二维数组中。
**与分治法最大的差别是:适合于用动态规划法求解的问题,经分解后得到的子问题往往不是互相独立的(即下一个子阶段的求解是建立在上一个子阶段的解的基础上,进行进一步的求解)。**
#### 适用的情况
能采用动态规划求解的问题的一般要具有 3 个性质:
- 最优化原理:如果问题的最优解所包含的子问题的解也是最优的,就称该问题具有最优子结构,即满足最优化原理。
- 无后效性:即某阶段状态一旦确定,就不受这个状态以后决策的影响。也就是说,某状态以后的过程不会影响以前的状态,只与当前状态有关。
- 有重叠子问题:即子问题之间是不独立的,一个子问题在下一阶段决策中可能被多次使用到。(**该性质并不是动态规划适用的必要条件,但是如果没有这条性质,动态规划算法同其他算法相比就不具备优势**)
#### 求解基本步骤
动态规划所处理的问题是一个多阶段决策问题,一般由初始状态开始,通过对中间阶段决策的选择,达到结束状态;或倒过来,从结束状态开始,通过对中间阶段决策的选择,达到初始状态。
动态规划的设计都有着一定的模式,一般要经历以下几个步骤:
- 划分阶段:按照问题的时间或空间特征,把问题分为若干个阶段。在划分阶段时,**注意划分后的阶段一定要是有序的或者是可排序的,否则问题就无法求解。**
- 确定状态和状态变量:将问题发展到各个阶段时所处于的各种客观情况用不同的状态表示出来。当然,状态的选择要满足无后效性。
- 确定决策并写出状态转移方程:因为决策和状态转移有着天然的联系,状态转移就是根据上一阶段的状态和决策来导出本阶段的状态。所以如果确定了决策,状态转移方程也就可写出。但事实上常常是反过来做,根据相邻两个阶段的状态之间的关系来确定决策方法和状态转移方程。
- 寻找边界条件:给出的状态转移方程是一个递推式,需要一个递推的终止条件或边界条件。
一般,只要解决问题的阶段、状态和状态转移决策确定了,就可以写出状态转移方程(包括边界条件)。
实际应用中可以按以下几个简化的步骤进行设计:
1. 分析最优解的性质,并刻画其结构特征。
2. 递归的定义最优解。
3. 以自底向上或自顶向下的记忆化方式(备忘录法)计算出最优值。
4. 根据计算最优值时得到的信息,构造问题的最优解。
#### 一个简单的动态规划
> 问题:10 节楼梯,每次只能上 1 节或者 2 节,恰好上到第 10 节有多少种上法?
可以从后往前推,上法总数 = 最后一步走 1 节的方法数 + 最后一步走 2 节的方法数。
我们定义 `f[10]` 为上到第 10 节的方法数,
那么显然 `f[10] = f[10-1] + f[10-2] = f[9] + f[8]`,
继续递推则有 `f[9] = f[8] + f[7]`,`f[8] = f[7] + f[6]`,
推广到一般形式即为 `f[n] = f[n-1] + f[n-2]`,
其中 `2<=n<=10`,初始条件为 `f[0] = 1`、`f[1] = 1`。
代码如下:
```c++
int climbStairs(int n) {
if(n <= 1) return 1;
int f[n+1];
f[0] = 1;
f[1] = 1;
for(int i=2; i<=n; i++){
f[i] = f[i-1] + f[i-2];
}
return f[n];
}
```
### 背包问题
#### 01 背包问题-1
> 有 n 个物品,每个物品体积为正整数 `A[i](1<=i<=n)`,一个背包容量为正整数 m,问这个背包最多能装多少体积?
>
> Sample Input: n = 4, A = [2, 3, 5, 7], m = 11
首先考虑最后一个体积为 7 的物品放不放?
不放:前三个物品 [2, 3, 5] 放到体积为 11 的包里,最多能放多少?
放:前三个物品 [2, 3, 5] 放到体积为(11-7=4)的包里,最多能放多少?
我们定义 `f[4][11]` 表示前 4 个物品放到体积为 11 的背包里,最多放的体积,
则有 `f[4][11] = max(f[3][11], f[3][11-7] + 7)`,
推广到一般形式即为 `f[i][j] = max(f[i-1][j], f[i-1][j-A[i]] + A[i])`,
其中 1<=i<=n、0<=j<=m,初始条件为 `f[0][0] = 0,f[0][1] = 0, ... ,f[0][m] = 0`,
时间复杂度为 O(n\*m)。
若A = [3, 4, 5, 8] m = 10,其动态规划过程如下表:
| 背包大小 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| ----- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ---- | ----- |
| 前0个物品 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 前1个物品 | 0 | 0 | 0 | 3 | 3 | 3 | 3 | 3 | 3 | 3 | 3 |
| 前2个物品 | 0 | 0 | 0 | 3 | 4 | 4 | 4 | 7 | 7 | 7 | 7 |
| 前3个物品 | 0 | 0 | 0 | 3 | 4 | 4 | 4 | 7 | 7 | 7 | 7 |
| 前4个物品 | 0 | 0 | 0 | 3 | 4 | 4 | 4 | 7 | 8 | 9 | **9** |
代码如下:
```java
/**
* @param m: An integer m denotes the size of a backpack
* @param A: Given n items with size A[i]
* @return: The maximum size
*/
public int backPack(int m, int[] A) {
int n = A.length;
int[][] f = new int[n + 1][m + 1];
for (int i = 1; i <= n; i++) {
for (int j = 0; j <= m; j++) {
f[i][j] = f[i - 1][j];
if (j - A[i - 1] >= 0) {
f[i][j] = max(f[i - 1][j], f[i - 1][j - A[i - 1]] + A[i - 1]);
}
}
}
return f[n][m];
}
public int max(int a, int b){
return a > b ? a : b;
}
```
#### 01 背包问题-2
> 有 n 个物品,每个物品体积为正整数 `A[i](1<=i<=n)`,价值为 `V[i]`,一个背包容量为正整数 m,问这个背包最多能装多少价值?
>
> Sample Input: n = 4, A = [2, 3, 5, 7], V = [1, 5, 2, 4], m = 11
**这个问题跟前一个背包问题差不多,只是把体积换成价值而已。**
首先考虑最后一个体积为 7,价值为 4 的物品放不放?
不放:前三个物品 [2, 3, 5] 放到体积为 11 的包里,最多能放多少?
放:前三个物品 [2, 3, 5] 放到体积为(11-7=4)的包里,最多能放多少?
我们定义 `f[4][11]` 表示前 4 个物品放到体积为 11 的背包里,最多放的价值,
则有 `f[4][11] = max(f[3][11], f[3][11-7] + 4)`,
推广到一般形式即为 `f[i][j] = max(f[i-1][j], f[i-1][j-A[i]] + V[i])`,
其中 1<=i<=n、0<=j<=m,初始条件为 `f[0][0] = 0,f[0][1] = 0, ... ,f[0][m] = 0`,
时间复杂度为 O(n\*m)。
代码跟上题几乎完全相同,只需把 `A` 替换成 `V` 即可:
```java
/**
* @param m: An integer m denotes the size of a backpack
* @param A & V: Given n items with size A[i] and value V[i]
* @return: The maximum value
*/
public int backPackII(int m, int[] A, int V[]) {
int n = A.length;
int[][] f = new int[n + 1][m + 1];
for (int i = 1; i <= n; i++) {
for (int j = 0; j <= m; j++) {
f[i][j] = f[i - 1][j];
if (j - A[i - 1] >= 0) {
f[i][j] = max(f[i - 1][j], f[i - 1][j - A[i - 1]] + V[i - 1]);
}
}
}
return f[n][m];
}
public int max(int a, int b){
return a > b ? a : b;
}
```
#### 背包计数问题
> 有 n 个物品,每个物品体积为正整数 `A[i](1<=i<=n)`,一个背包容量为正整数 m,问有多少种方法可以把它装满?
>
> Sample Input: n = 4, A = [2, 3, 5, 7], m = 11
首先考虑最后一个体积为 7 的物品放不放?
不放:前三个物品 [2, 3, 5] 放到体积为 11 的包里,有多少种方法装满?
放:前三个物品 [2, 3, 5] 放到体积为(11-7=4)的包里,有多少种方法装满?
我们定义 `f[4][11]` 表示前 4 个物品放到体积为 11 的背包里的方法总数,
则有 `f[4][11] = f[3][11] +f[3][11-7]`,
推广到一般形式即为 `f[i][j] = f[i-1][j] + f[i-1][j-A[i]]`,
其中 1<=i<=n、0<=j<=m,初始条件为 `f[0][0] = 0,f[0][1] = 0, ... ,f[0][m] = 0`,
时间复杂度为 O(n\*m)。
代码如下:
```java
/**
* @param m: An integer m denotes the size of a backpack
* @param A: Given n items with size A[i]
* @return: The maximum size
*/
public int backPack(int m, int[] A) {
int n = A.length;
int[][] f = new int[n + 1][m + 1];
for (int i = 1; i <= n; i++) {
for (int j = 0; j <= m; j++) {
f[i][j] = f[i - 1][j];
if (j - A[i - 1] >= 0) {
f[i][j] = f[i - 1][j] + f[i - 1][j - A[i - 1]];
}
}
}
return f[n][m];
}
```
#### 无限背包问题
> 有 n 个物品,每个物品体积为正整数 `A[i](1<=i<=n)`,价值为 `V[i]`,一个背包容量为正整数 m,问这个背包最多能装多少价值?**(每个物品可以有无限多个)**,
>
> Sample Input: n = 4, A = [2, 3, 5, 7], V = [1, 5, 2, 4], m = 11
首先考虑最后一个体积为 7,价值为 4 的物品放不放,放的话放多少个?
不放:前三个物品 [2, 3, 5] 放到体积为 11 的包里,最多能放多少?
放:放 k 个,前三个物品 [2, 3, 5] 放到体积为(11-k\*7)的包里,最多能放多少?
我们定义 `f[4][11]` 表示前 4 个物品放到体积为 11 的背包里,最多放的价值,
则有 `f[4][11] = max(f[3][11], f[3][11-k*7] + k*4)`,其中 1<=k<=11/7,k 为整数,
推广到一般形式即为 `f[i][j] = max(f[i-1][j], f[i-1][j-k*A[i]] + k*V[i])`,
其中 1<=i<=n、0<=j<=m,初始条件为 `f[0][0] = 0,f[0][1] = 0, ... ,f[0][m] = 0`,
时间复杂度为 O(n\*m^2)。
**本题还有一种 O(n\*m) 解法。**
同样的思路,考虑首先考虑最后一个体积为 7,价值为 4 的物品放不放?
不放:前三个物品 [2, 3, 5] 放到体积为 11 的包里,最多能放多少?
放:前**四**个物品 [2, 3, 5, **7**] 放到体积为(11-7=4)的包里,最多能放多少?
我们定义 `f[4][11]` 表示前 4 个物品放到体积为 11 的背包里,最多放的价值,
则有 `f[4][11] = max(f[3][11], f[4][11-7] + 4)`,
推广到一般形式即为 `f[i][j] = max(f[i-1][j], f[i][j-A[i]] + V[i])`,
其中 1<=i<=n、0<=j<=m,初始条件为 `f[0][0] = 0,f[0][1] = 0, ... ,f[0][m] = 0`,
时间复杂度为 O(n\*m)。
---
### 参考资料
- [五大常用算法之二:动态规划算法](http://www.cnblogs.com/steven_oyj/archive/2010/05/22/1741374.html)
- [九章算法](http://www.jiuzhang.com/) | 7,033 | MIT |
---
template: post
title: "工人维权的可能结局:被维稳、被反恐、被审判、被名录"
date: 2020-05-21
tags: shiping
image:
teaser: /202005/weiquanjieju1.jpg
excerpt_separator: <!--more-->
---
<div style="width:98%;padding:10px;background-color:black;color:white;margin:0;"><strong>摘要:</strong>他们不擅长解决问题,却很擅长解决提出问题的人!<br><br>
</div><br>
本来嘛,天下之大,无奇不有。不过见得事情多了,却也明白,当官的终究还是当官的,有钱的还终究是有钱的,劳动的人才是最穷的。不仅穷,而且今天要被资本家剥削,明天还会被当官的抓起来,无时无刻不生活在惶恐之中。
<div style="text-align:center"><h3>民工讨薪结局一:被公审</h3></div><br>
<div style="text-align:center;color:grey"><img src="/images/202005/weiquanjieju1.jpg" width="90%"></div>
2016年3月16日,四川阆中一起公审的案件引起关注。原来,受审的是讨薪民工。一时间舆论哗然,都在指责当地法院审“讨”不审“欠”。尽管后来有披露,受审的都是包工头,他们带着农民工讨要工程款,他们拒绝垫资先支付工资。
但这并没有影响人们对这件事情的看法。因为建筑工地的分包制度下,经常不是包工头卷钱跑路而是上头的大老板(还有政府)没付钱。事实上,倘若不是走投无路,包工头也不会选择和更底层的民工联合讨薪。如今讨薪反被判刑,可真是天下奇闻了。事后更有包工头爆料,四川阆中有几十个工队被欠薪,金额涉及几千万。
几年来政府向维权农民工武力镇压,对违法企业不闻不问,<span style="color:red"><strong>甚至欠薪最严重的一类工程,恰恰是政府的项目</strong></span>,政府成了头号老赖!
<div style="text-align:center"><h3>民工讨薪结局二:被镇压</h3></div>
2019年8月6日,广东省公安厅统一部署下,深圳公安集结在宝安海滨广场举行“广东公安夏季大练兵‘深圳亮剑’行动”,共计1.2万警力参加。明眼人都知道,那个时候是做给一河之隔的香港看的。但有意思的是,**现场竟然出现了“违法欠农民工工资,良心何在”“还我血汗钱”等横幅。**讨薪再次成为公安练兵对象,深圳公安就是这么维护“国家政治安全和社会平安稳定”的?
<div style="text-align:center;color:grey"><img src="/images/202005/weiquanjieju2.jpg" width="90%"></div>
<div style="text-align:center;color:grey"><img src="/images/202005/weiquanjieju3.jpg" width="90%"></div>
无独有偶,2009年,广州反恐演习多次以“工人为讨欠薪造成群体性事件”为对象。当时的人大代表、广州总工会副主席刘小钢对公安部门表示“抗议”,称这种做法“不太好”、“看了有点不舒服”。多家媒体也发表评论对此批评。
2011年,深圳大运会前夕。深圳为了维稳,设立了拖欠农民工工资的“严肃处理期”。住房和建设局发布文件规定,5月1日至9月30日,严禁农民工通过群体性上访等非正常手段讨要工资,否则造成严重后果或恶劣影响的,追究其刑事责任。且不是一个住建部门是不是管的太宽,这个规定本身就够让人愤慨的了。不久之后,深圳道歉,并撤回了这项规定。
看起来,把咱工人当作维稳对象,似乎是以广州、深圳为代表的广东政府的一贯传统。**作为中国资本主义最前沿,广东政府在拥有最完善的劳动争议法律手段外,似乎还有这最完善的针对工人的暴力镇压手段**,可真是,<span style="color:red"><strong>双管齐下搞维稳</strong></span>,把工人的反抗扼杀在萌芽里。
只是10年前,广州工会还花花心思维持自己“娘家人”的形象,轻描淡写说句“不舒服”;10年后,谁又会说一个不字呢?
<div style="text-align:center"><h3>小资产阶级维权?蹲牢房251天</h3></div><br>
<div style="text-align:center;color:grey"><img src="/images/202005/weiquanjieju4.jpg" width="90%"></div>
俗话说,有钱能使鬼推磨,现实中有钱能使警听话。2019年底,华为离职员工李洪元声称自己因离职赔偿一事,被拘留了251天。华为先后更改了三次对该员工的指控罪名,分别是涉嫌职务侵占、侵犯商业秘密、敲诈勒索。但最终因证据不足,该员工被无罪释放。
一个劳动争议,让员工蒙冤入狱251天。一个所谓民族品牌,就这样对待自己的员工。值得注意的是,办案警方为华为总部所在的深圳龙岗警方。比起劳动者维权被踢皮球、各种门槛和刁难,企业想动用警力折磨员工也太容易了不是?
前有鸿茅药酒跨省追捕,今有华为251。<strong>李宏元作为月入过万的技术白领,比咱们工人的生活好得多,社会地位也高得多,属于<span style="color:red">小资产阶级</span>,他尚且遭遇这样的待遇,底层工人又该当如何?</strong>我们倒想问一问,带国徽的究竟在为谁服务?
<div style="text-align:center"><h3>乖乖走法律途径维权?上黑名单</h3></div>
2020年4月30日,浙江省湖州南太湖新区人民法院联合湖州劳动人事争议仲裁院、湖州市劳动保障监察支队共同出台《关于建立“劳动者维权异常名录”的实施意见》,率先发布全国首个“劳动者维权异常名录”。纳入“劳动者维权异常名录”的劳动者,将被通报到辖区内各劳动中介、人才市场、**行业协会等相关单位,法院对所涉案件从严审查,通过关联案件检索,强化法律关系甄别,一旦发生不诚信诉讼、恶意诉讼行为,从严惩处,涉嫌刑事犯罪的,移送公安处理。**
<div style="text-align:center;color:grey"><img src="/images/202005/weiquanjieju5.jpg" width="90%"></div>
这可真是太为难劳动者了,找工作当心被坑,维权还要担心被纳入维权异常名录。须知,如果老板遵法守法,又有多少劳动者会闲着蛋疼,吃错了药一样频繁维权呢?如今,老板违法未被解决,劳动者维权先要被解决了。在此之前,类似名单只是一些公司或行业自己做,如今却变成了司法部门帮着做?那么,有没有谁做一份黑心老板名录,告诉每一位劳动者呢?
<span style="color:red"><strong>劳动者还没联合起来?当官的和资本家都已经开始联合了??</strong></span>
没错,他们早就联合起来了,**国家用法律、劳动监察大队和警察保护资本家,把维权的工人送进监狱折磨。**在资本主义国家,法律和各个国家机构的本质本来就是如此,只不过最近几年,连掩饰都不掩饰一下了。
为什么我们要和政府、和官僚警察斗?<span style="color:red"><strong>因为他们是资本家在政治上的代理人,利用手中权力一刻都没有停止对我们的镇压!</strong></span>只要我们不想被压榨得只剩下骨头渣,就必然会面临来自官方的阻拦。
整个资产阶级已经组织起来和我们斗争了,我们难道还不赶紧组织起来,和他们死磕到底? | 3,429 | MIT |
<p align="center">
<img src="docs/docs/.vuepress/public/images/logo.png" alt="PluginCore">
</p>
<h1 align="center">PluginCore</h1>
[English](README.md) | 中文
> 适用于 ASP.NET Core 的轻量级插件框架
[]()
[](https://github.com/yiyungent/PluginCore/blob/master/LICENSE)
[](https://www.codefactor.io/repository/github/yiyungent/plugincore)
[](https://www.nuget.org/packages/PluginCore/)
[](https://jq.qq.com/?_wv=1027&k=q5R82fYN)
## 介绍
适用于 ASP.NET Core 的轻量级插件框架
- **简单** - 约定优于配置, 以最少的配置帮助你专注于业务
- **开箱即用** - 前后端自动集成, 两行代码完成集成
- **动态 WebAPI** - 每个插件都可新增 Controller, 拥有自己的路由
- **插件前后端分离** - 可在插件 `wwwroot` 文件夹下放置前端文件 (index.html,...), 然后访问 `/plugins/pluginId/index.html`
- **热插拔** - 上传、安装、启用、禁用、卸载、删除 均无需重启站点; 甚至可通过插件在运行时添加 `HTTP request pipeline middleware`, 也无需重启站点
- **依赖注入** - 可在 实现 `IPlugin` 的插件类的构造方法上申请依赖注入项, 当然 `Controller` 构造方法上也可依赖注入
- **易扩展** - 你可以编写你自己的插件sdk, 然后引用插件sdk, 编写扩展插件 - 自定义插件钩子, 并应用
- **无需数据库** - 无数据库依赖
- **0侵入** - 近乎0侵入, 不影响你的现有系统
- **极少依赖** - 只依赖于一个第三方包 ( 用于解压的 `SharpZipLib` )
## 在线演示
- http://plugincore.moeci.com/PluginCore/Admin
- 用户名: admin 密码: ABC12345
- 在线演示, 功能大部分受限, 完整体验, 请自行搭建, 可使用下方 Docker 快速体验
- 非最新版本
## 截图




## 一分钟集成
推荐使用 [NuGet](https://www.nuget.org/packages/PluginCore), 在你项目的根目录 执行下方的命令, 如果你使用 Visual Studio, 这时依次点击 **Tools** -> **NuGet Package Manager** -> **Package Manager Console** , 确保 "Default project" 是你想要安装的项目, 输入下方的命令进行安装.
```bash
PM> Install-Package PluginCore
```
> 在你的 ASP.NET Core 应用程序中修改代码
>
> Startup.cs
```C#
using PluginCore.Extensions;
// This method gets called by the runtime. Use this method to add services to the container.
public void ConfigureServices(IServiceCollection services)
{
services.AddControllers();
// 1. 添加 PluginCore
services.AddPluginCore();
}
// This method gets called by the runtime. Use this method to configure the HTTP request pipeline.
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
}
app.UseHttpsRedirection();
app.UseRouting();
// 2. 使用 PluginCore
app.UsePluginCore();
app.UseAuthorization();
app.UseEndpoints(endpoints =>
{
endpoints.MapControllers();
});
}
```
> 现在访问 https://localhost:5001/PluginCore/Admin 即可进入 PluginCore Admin
> https://localhost:5001 需改为你的地址
### 注意
请登录 `PluginCore Admin` 后,为了安全,及时修改默认用户名,密码:
`App_Data/PluginCore.Config.json`
```json
{
"Admin": {
"UserName": "admin",
"Password": "ABC12345"
},
"FrontendMode": "LocalEmbedded",
"RemoteFrontend": "https://cdn.jsdelivr.net/gh/yiyungent/[email protected]/dist-cdn"
}
```
修改后,立即生效,无需重启站点,需重新登录 `PluginCore Admin`
## Docker 体验
如果你需要在本地体验 PluginCore, 那么这里有一个 [例子(/examples)](https://github.com/yiyungent/PluginCore/tree/main/examples)
```bash
docker run -d -p 5004:80 -e ASPNETCORE_URLS="http://*:80" --name plugincore-aspnetcore3-1 yiyungent/plugincore-aspnetcore3-1
```
现在你可以访问 http://localhost:5004/PluginCore/Admin
> 补充:
> 若使用 `Docker Compose`, 可参考仓库根目录下的 `docker-compose.yml`
> 补充:
> 使用 `ghcr.io`
>
> ```bash
> docker run -d -p 5004:80 -e ASPNETCORE_URLS="http://*:80" --name plugincore-aspnetcore3-1 ghcr.io/yiyungent/plugincore-aspnetcore3-1
> ```
## 使用
- [详细文档(/docs)](https://moeci.com/PluginCore "在线文档") 文档构建中
- [见示例(/examples)](https://github.com/yiyungent/PluginCore/tree/main/examples)
### 添加插件钩子, 并应用
> 1.例如,自定义插件钩子: `ITestPlugin`
```C#
using PluginCore.IPlugins;
namespace PluginCore.IPlugins
{
public interface ITestPlugin : IPlugin
{
string Say();
}
}
```
> 2.在需要激活的地方,应用钩子,这样所有启用的插件中,实现了 `ITestPlugin` 的插件,都将调用 `Say()`
```C#
using PluginCore;
using PluginCore.IPlugins;
namespace WebApi.Controllers
{
[Route("api/[controller]")]
[ApiController]
public class TestController : ControllerBase
{
private readonly PluginFinder _pluginFinder;
public TestController(PluginFinder pluginFinder)
{
_pluginFinder = pluginFinder;
}
public ActionResult Get()
{
//var plugins = PluginFinder.EnablePlugins<BasePlugin>().ToList();
// 所有实现了 ITestPlugin 的已启用插件
var plugins2 = _pluginFinder.EnablePlugins<ITestPlugin>().ToList();
foreach (var item in plugins2)
{
// 调用
string words = item.Say();
Console.WriteLine(words);
}
return Ok("");
}
}
}
```
### 自定义前端
PluginCore 支持3种前端文件加载方式
> 配置文件 `App_Data/PluginCore.Config.json` 中 `FrontendMode`
1. LocalEmbedded
- 默认, 嵌入式资源,前端文件打包进dll, 此模式下, 不容易自定义前端文件,需要修改 `PluginCore` 源代码,重新编译,不建议
2. LocalFolder
- 在集成了 `PluginCore` 的 ASP.NET Core 项目中, 新建 `PluginCoreAdmin`, 将前端文件放入此文件夹
3. RemoteCDN
- 使用远程cdn资源, 可通过 配置文件中 `RemoteFrontend` 指定url
> **注意:**
> 更新 `FrontendMode`, 需重启站点后, 才能生效
### 补充
> **补充**
>
> 开发插件只需要, 添加对 `PluginCore.IPlugins` 包 (插件sdk) 的引用即可,
>
> 当然如果你需要 `PluginCore` , 也可以添加引用
> **规范**
>
> 1. 插件sdk
>
> 插件接口应当位于 `PluginCore.IPlugins` 命名空间,这是规范,不强求,但建议这么做,
>
> 程序集名不一定要与命名空间名相同,你完全在你的插件sdk程序集中,使用 `PluginCore.IPlugins` 命名空间。
>
> 2. 插件
>
> 插件程序集名(一般=项目(Project)名) 与 插件 `info.json` 中 `PluginId` 一致, 例如: Project: `HelloWorldPlugin`, PluginId: `HelloWorldPlugin`, 此项必须,否则插件无法加载
> `PluginId` 为插件唯一标识
## 版本依赖
| PluginCore.IPlugins | 0.1.0 | 0.1.0 | 0.2.0 | 0.2.0 | 0.2.0 | 0.3.0 | 0.3.0 | 0.4.0 | 0.5.0 | 0.6.0 | 0.6.0 | 0.6.0 | 0.6.0 | 0.6.1 | 0.6.1 |
| :-----------------------: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| PluginCore | 0.1.0 | 0.2.0 | 0.3.0 | 0.3.1 | 0.4.0 | 0.5.0 | 0.5.1 | 0.6.0 | 0.7.0 | 0.8.0 | 0.8.1 | 0.8.2 | 0.8.3 | 0.8.4 | 0.8.5 |
| plugincore-admin-frontend | 0.1.0 | 0.1.2 | 0.1.2 | 0.1.3 | 0.1.3 | 0.2.0 | 0.2.0 | 0.2.0 | 0.2.0 | 0.2.0 | 0.2.3 | 0.2.3 | 0.2.3 | 0.2.3 | 0.3.0 |
| PluginCore.IPlugins | [](https://www.nuget.org/packages/PluginCore.IPlugins/) | [](https://www.nuget.org/packages/PluginCore.IPlugins/) |
| :-----------------: | :----------------------------------------------------------: | :----------------------------------------------------------: |
| PluginCore | [](https://www.nuget.org/packages/PluginCore/) | [](https://www.nuget.org/packages/PluginCore/) |
| PluginCore.Template | [](https://www.nuget.org/packages/PluginCore.Template/) | [](https://www.nuget.org/packages/PluginCore.Template/) |
## 环境
- 运行环境: .NET Core 3.1 (+)
- 开发环境: Visual Studio Community 2019
## 相关项目
- [plugincore-admin-frontend](https://github.com/yiyungent/plugincore-admin-frontend) PluginCore Admin 前端实现
- [Remember.Core](https://github.com/yiyungent/Remember.Core) 插件框架提取处
## 赞助者
TODO:
## 鸣谢
- 插件系统设计参考自 <a href="https://github.com/lamondlu/CoolCat" target="_blank">CoolCat</a>,感谢作者 lamondlu 的贡献
- 设计参考自 <a href="https://github.com/nopSolutions/nopCommerce" target="_blank">nopCommerce</a>,感谢作者 nopSolutions 的贡献
## Donate
PluginCore is an Apache-2.0 licensed open source project and completely free to use. However, the amount of effort needed to maintain and develop new features for the project is not sustainable without proper financial backing.
We accept donations through these channels:
- <a href="https://afdian.net/@yiyun" target="_blank">爱发电</a> (¥5.00 起)
- <a href="https://dun.mianbaoduo.com/@yiyun" target="_blank">面包多</a> (¥1.00 起)
## Author
**PluginCore** © [yiyun](https://github.com/yiyungent), Released under the [Apache-2.0](./LICENSE) License.<br>
Authored and maintained by yiyun with help from contributors ([list](https://github.com/yiyungent/PluginCore/contributors)).
> GitHub [@yiyungent](https://github.com/yiyungent) Gitee [@yiyungent](https://gitee.com/yiyungent) | 8,745 | Apache-2.0 |
layout: post
title: "Java1"
subtitle: " 假前小充电 "
date: 2017-06-09 12:00:00
author: "Oven"
header-img: "img/post-bg-2015.jpg"
catalog: true
tags:
- java
---
## SID假前小充电
Java 基础常识补点
---
- Java 的跨平台是通过什么实现的?
实现关键在Java虚拟机(JVM)。*.Java文件编译生成*.class文件,是字节码文件,与平台无关。所有平台上的JVM向编译器提供相同接口,而编译器只需面对JVM,生成与平台无关的字节码,然后由JVM来解释执行。
- JDK、JRE、JVM 的全称是什么?
JDK:Java SE Development 即Java标准版开发包
JRE:Java Runtime Environment,即Java运行时环境
JVM:Java Virtual Machine ,即Java虚拟机
JDK包含JRE,JRE包含JVM。
- public class 的类名必须跟文件名保持一致吗?
是。但在我个人理解看来,倒不如说是文件名和 public class 的类名保持一致。一个文件里只能有一个public 类,当文件中没有public 类的时候可以随意命名。
- 一个 Java 源文件可以写多个 Class 吗?编译后会不会生成多个 Class 文件?
可以。会,每个类会生成一个.class文件。
####在实际用命令行编译的时候,我们用Javac似乎是在对Java文件名不带拓展名,实际上是对类名 即Javac 类名
- 编程时,为什么需要注释?Java 中注释的类型有哪些?
整理思路,增加可读性。基本分为单行注释,多行注释,文档注释。
// 单行注释
/*多行
注释
*/
/**
*文档注释
*/
文档注释可利用javadoc提取出来生成API文档
利用javadoc标记如@author,@param,@return等
##面向对象(一)
- 简述面向对象和面向过程的区别和联系?
* 区别:
> 面向过程就是分析出解决问题所需要的步骤,然后用函数把这些步骤一步一步实现,使用的时候一个一个依次调用就可以了;面向对象是把构成问题事务分解成各个对象,建立对象的目的不是为了完成一个步骤,而是为了描叙某个事物在整个解决问题的步骤中的行为。
> 可以拿生活中的实例来理解面向过程与面向对象,例如五子棋,面向过程的设计思路就是首先分析问题的步骤:1、开始游戏,2、黑子先走,3、绘制画面,4、判断输赢,5、轮到白子,6、绘制画面,7、判断输赢,8、返回步骤2,9、输出最后结果。把上面每个步骤用不同的方法来实现。
> 如果是面向对象的设计思想来解决问题。面向对象的设计则是从另外的思路来解决问题。整个五子棋可以分为1、黑白双方,这两方的行为是一模一样的,2、棋盘系统,负责绘制画面,3、规则系统,负责判定诸如犯规、输赢等。第一类对象(玩家对象)负责接受用户输入,并告知第二类对象(棋盘对象)棋子布局的变化,棋盘对象接收到了棋子的变化就要负责在屏幕上面显示出这种变化,同时利用第三类对象(规则系统)来对棋局进行判定。
> 可以明显地看出,面向对象是以功能来划分问题,而不是步骤。同样是绘制棋局,这样的行为在面向过程的设计中分散在了多个步骤中,很可能出现不同的绘制版本,因为通常设计人员会考虑到实际情况进行各种各样的简化。而面向对象的设计中,绘图只可能在棋盘对象中出现,从而保证了绘图的统一。
——《C#编程词典》
* 联系:都存在调用函数(方法)解决某个问题的思想,所以面向对象也是建立在函数的基础上。
- 对象和类的关系时?
类(class)是某一批对象(object)的抽象,而对象是类的实例。对于一个类而言,可以包含三种最常见的成员:构造器,成员变量,方法。
成员变量用于定义该类的实例包含的状态数据,方法用于定义该类或该类实例的行为特征及功能实现。构造器用于构造该类的实例,通过new来调用得到对象。
构造器不是必须写的,不写,Java会自动为该类提供一个构造器,
static 多译为静态,真正的作用其实是用于区别成员变量,方法,内部类和初始化块到底属于类还是属于实例。有,属于类,没有,属于实例。静态成员不能直接访问非静态成员,可见 Java之面向对象
* 堆和栈的特点是什么?分别存放什么内容?
栈内存:放方法的局部变量,在方法调用结束以后,会消失
堆内存:放new出来的对象,没有引用的对象,会Java垃圾回收机制处理
* 局部变量使用之前,需要手动初始化吗?
系统不会对局部变量初始化,必须由程序员显式初始化
* Java 中如果不手动指定成员变量的值,系统会自动初始化,那么初始化的规则是?
|类型|默认值|
| -------- | :-----: |
|Boolean | false|
|Char| '\u0000'(null)|
|byte| (byte)0|
|short | (short)0|
|int| 0|
|long | 0L|
|float |0.0f|
|double | 0.0d|
注意,final修饰的成员变量必须被赋初值。
* 构造方法如何被调用?
构造方法,或译作构造器,其实是一种特殊的方法,不需要返回值,返回的是一个对象。用new来调用,构造出一个新对象。
e.g.
```java
person p = new person();
```
* 系统一定会给我们添加无参数的构造方法吗?请详细解释。
不一定,只有在我们没有定义构造方法的时候,系统自动
* 构造方法能不能重载?
能,和普通方法一样用。同名不同参数列表。
* this 在普通方法中,指的是哪个对象?在构造方法中,指的是?
指的是调用该方法的对象,构造方法中指的是该构造方法正在初始化的对象,利用this可在一个构造方法中,调用另一个构造方法,从而提高代码的重用性
* 静态初始化块和 main 方法哪个先被执行?
静态初始化块。它的执行是类的初始化的一部分。只有类初始化完了,才能用。而普通初始化块在构造器之前执行
* 一个构造方法调用另一个构造方法怎么调用?this() 这样的调用方式必须位于第一句吗?
e.g.
```java
public person(Sting name,String age){
this.name =name;
this.age =age;
}
public person (String name,String age,String height){
this(name,age);//直接使用另一个构造器的代码
this.height = height;
}
```
必须在第一句且只能在构造器里用。
- package 的两个作用是什么?
* 提供多重命名空间,解决类名冲突
* 划分功能相近的类,形成逻辑上的类库单元
* import static 叫做静态导入,那么其作用是什么?
导入指定类某个或全部静态成员变量或方法
* 请详细快速的说明 private、default、protected、public 的区别。
##### 访问控制
| 修饰符 |所在类内部| 包 |所在类的子类|任何|
| -------- | :-----: | :----: |
| private |O|X|X|X|
| default |O|O|X|X|
| protected |O|O|O|X|
| public |O|O|O|O|
####对于外部类的权限修饰只可以用public和default
因为没有处在任何一个类里,也就没有所在类里,所在类的子类这两个范围
-public类可以在任意地方被访问
default类只可以被同一个包内部的类访问
* javabean 就是只包含属性和相关 getter/setter 方法,不包含业务逻辑处理的被,这种说法对吗?
不对。JavaBean可以说是一种封装良好的规范。
必须满足:
每个成员变量都被private修饰,对应public修饰的setter和getter方法
它重点不在于含不含业务逻辑处理,而在于是否被良好封装。 | 3,525 | Apache-2.0 |
# 标签页关闭事件监听
```js
/**
* 直接关闭浏览器不触发
* 关闭标签页
* chrome、火狐下不显示自定义文字, 1:直接关闭不触发, 2:刷新操作提示:重新加载此网站?再关闭会提示:离开此网站?
* IE下会显示自定义文字:1:直接关闭会触发:确认退出, 2: 刷新会触发:确认退出, 选择离开后会触发:谢谢光临
**/
window.onbeforeunload = onbeforeunload_handler;
window.onunload = onunload_handler;
function onbeforeunload_handler(){
var warning="确认退出?";
return warning;
}
function onunload_handler(){
var warning="谢谢光临";
alert(warning);
}
``` | 415 | MIT |