
code
stringlengths 30
403k
| size
int64 31
406k
| license
stringclasses 10
values |
|---|---|---|
**SpringCloud Sleuth Stream Zipkin Kafka Elasticsearch 实现简单链路跟踪**
_注意版本号zipkin使用的是2.4.2,SpringCloud版本Dalston.SR5_
1. **服务端主要配置**<br>
**pom配置:**:
```$xslt
<!-- zipkin + kafka +es -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin-stream</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-kafka</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
<version>${zipkin.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-storage-elasticsearch-http</artifactId>
<version>${zipkin.version}</version>
</dependency>
```
**配置文件 application.properties:**
```$xslt
#采样率,推荐0.1,百分之百收集的话存储可能扛不住
spring.sleuth.sampler.percentage=1
spring.sleuth.enabled=false
maxHttpHeaderSize=8192
### kafka链接和zk的链接
spring.cloud.stream.kafka.binder.brokers=192.168.206.203:9092
spring.cloud.stream.kafka.binder.zkNodes=192.168.206.203:2181
## 使用es做存储
zipkin.storage.StorageComponent=elasticsearch
zipkin.storage.type=elasticsearch
zipkin.storage.elasticsearch.hosts=192.168.206.204:9200
#es集群名称
zipkin.storage.elasticsearch.cluster=zipkin-es
zipkin.storage.elasticsearch.index=zipkin-db
zipkin.storage.elasticsearch.index-shards=5
zipkin.storage.elasticsearch.index-replicas=1
```
**启动注解:**
```$xslt
@EnableZipkinStreamServer
```
代码参考[SpringCloud-ZipkinServer](https://github.com/Xlinlin/SpringCloud-Demo/tree/master/SpringCloud-ZipkinServer)
2.**客户端配置**<br>
**pom配置:**
```$xslt
<!-- zipkin服务 改造 sleuth stream + zipkin + es + kafka -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-stream</artifactId>
</dependency>
```
**参数配置application.properties:**
```$xslt
### spring 配置
spring:
## zipkin 链路跟踪配置
sleuth:
enabled: true
#采样率,越高会有性能影响
sampler:
percentage: 1.0
cloud:
## kafka zk配置 配合zipkin
stream:
kafka:
binder:
brokers: 192.168.206.203:9092
zkNodes: 192.168.206.203:2181
```
代码参考[SpringCloud-Provider](https://github.com/Xlinlin/SpringCloud-Demo/tree/master/SpringCloud-Provider)和[SpringCloud-Consumer](https://github.com/Xlinlin/SpringCloud-Demo/tree/master/SpringCloud-Consumer)<br>
[更多参考资料](https://www.jianshu.com/p/d2a71e242ca8) | 3,469 | MIT |
---
title: "CUE 的未来"
description: "即将推出的功能和能力"
weight: 10
---
{{<lead>}}
CUE 提议书和未来开发计划的相关信息。
{{< /lead >}}
<br>
有个相关的 Github Issue: [proposals](https://github.com/cue-lang/cue/issues?q=is%3Aopen+is%3Aissue+label%3AProposal)
issue 中 `roadmap/*` 标签以及在 Slack 中也会做相关讨论。
{{< childpages >}} | 291 | BSD-3-Clause |
# 2022-03-12
共 280 条
<!-- BEGIN TOUTIAO -->
<!-- 最后更新时间 Sat Mar 12 2022 23:09:24 GMT+0800 (China Standard Time) -->
1. [与胃癌抗争8个月的女孩苏日曼去世](https://so.toutiao.com/search?keyword=与胃癌抗争8个月的女孩苏日曼去世)
1. [新冠自测试剂盒厂家:指导价低于50元](https://so.toutiao.com/search?keyword=新冠自测试剂盒厂家:指导价低于50元)
1. [在这个问题上为什么要“先立后破”](https://so.toutiao.com/search?keyword=在这个问题上为什么要“先立后破”)
1. [泽连斯基:乌克兰已来到战略转折点](https://so.toutiao.com/search?keyword=泽连斯基:乌克兰已来到战略转折点)
1. [长春卫健委主任高玉堂被免职](https://so.toutiao.com/search?keyword=长春卫健委主任高玉堂被免职)
1. [深圳全面暂停堂食](https://so.toutiao.com/search?keyword=深圳全面暂停堂食)
1. [华为P50Pro全系官方直降500](https://so.toutiao.com/search?keyword=华为P50Pro全系官方直降500)
1. [商品房公摊面积该取消吗](https://so.toutiao.com/search?keyword=商品房公摊面积该取消吗)
1. [吉林战疫帮忙 点击求助](https://so.toutiao.com/search?keyword=吉林战疫帮忙%20点击求助)
1. [北京冬残奥会闭幕式13日举行](https://so.toutiao.com/search?keyword=北京冬残奥会闭幕式13日举行)
1. [公安部原副部长刘彦平被查](https://so.toutiao.com/search?keyword=公安部原副部长刘彦平被查)
1. [植树节带你了解中国植树多牛](https://so.toutiao.com/search?keyword=植树节带你了解中国植树多牛)
1. [西安一确诊病例被一口痰传染](https://so.toutiao.com/search?keyword=西安一确诊病例被一口痰传染)
1. [张文宏不同意躺平:会有较大死亡代价](https://so.toutiao.com/search?keyword=张文宏不同意躺平:会有较大死亡代价)
1. [深圳11区将实行居家办公](https://so.toutiao.com/search?keyword=深圳11区将实行居家办公)
1. [遇车祸患癌儿子喊消防先救父亲](https://so.toutiao.com/search?keyword=遇车祸患癌儿子喊消防先救父亲)
1. [第一视角看俄军控制乌克兰机场](https://so.toutiao.com/search?keyword=第一视角看俄军控制乌克兰机场)
1. [吉林疫情尿毒症患者:小区被封难透析](https://so.toutiao.com/search?keyword=吉林疫情尿毒症患者:小区被封难透析)
1. [世界最大石油公司沙特阿美跟中国合作](https://so.toutiao.com/search?keyword=世界最大石油公司沙特阿美跟中国合作)
1. [弟弟偷亲姐买房钱被姐姐报警](https://so.toutiao.com/search?keyword=弟弟偷亲姐买房钱被姐姐报警)
1. [汪小菲发文祝福徐熙媛](https://so.toutiao.com/search?keyword=汪小菲发文祝福徐熙媛)
1. [俄被冻结的3千亿美元或将用于乌重建](https://so.toutiao.com/search?keyword=俄被冻结的3千亿美元或将用于乌重建)
1. [俄警告制裁或致国际空间站坠毁](https://so.toutiao.com/search?keyword=俄警告制裁或致国际空间站坠毁)
1. [部分英国现役军人违规前往乌克兰](https://so.toutiao.com/search?keyword=部分英国现役军人违规前往乌克兰)
1. [美主播:美在乌实验室问题上撒谎](https://so.toutiao.com/search?keyword=美主播:美在乌实验室问题上撒谎)
1. [吉林市市长王路被免职](https://so.toutiao.com/search?keyword=吉林市市长王路被免职)
1. [张文宏:终有一天会发现已完全开放](https://so.toutiao.com/search?keyword=张文宏:终有一天会发现已完全开放)
1. [佟大为谈《奋斗》后和张晨光再合作](https://so.toutiao.com/search?keyword=佟大为谈《奋斗》后和张晨光再合作)
1. [专家:乌已成美“生物武器试验场”](https://so.toutiao.com/search?keyword=专家:乌已成美“生物武器试验场”)
1. [俄乌战事“外溢”风险有多高](https://so.toutiao.com/search?keyword=俄乌战事“外溢”风险有多高)
1. [Uzi首发BLG仍不敌EDG](https://so.toutiao.com/search?keyword=Uzi首发BLG仍不敌EDG)
1. [广厦力克上海 王哲林空砍28+17](https://so.toutiao.com/search?keyword=广厦力克上海%20王哲林空砍28+17)
1. [主人回应做核酸时狗狗在家大哭](https://so.toutiao.com/search?keyword=主人回应做核酸时狗狗在家大哭)
1. [北京一确诊曾聚餐:同餐10人3人确诊](https://so.toutiao.com/search?keyword=北京一确诊曾聚餐:同餐10人3人确诊)
1. [炎亚纶为剧组遇难工作人员发声](https://so.toutiao.com/search?keyword=炎亚纶为剧组遇难工作人员发声)
1. [张文宏:上海本轮防疫工作有突破](https://so.toutiao.com/search?keyword=张文宏:上海本轮防疫工作有突破)
1. [基辅西南方向一机场被俄军导弹摧毁](https://so.toutiao.com/search?keyword=基辅西南方向一机场被俄军导弹摧毁)
1. [山东累计确诊581例 有6个传播链](https://so.toutiao.com/search?keyword=山东累计确诊581例%20有6个传播链)
1. [2岁女童眼睛掏出6条虫](https://so.toutiao.com/search?keyword=2岁女童眼睛掏出6条虫)
1. [俄对西方个人报复性制裁名单已备好](https://so.toutiao.com/search?keyword=俄对西方个人报复性制裁名单已备好)
1. [乌总统办公室:泽连斯基仍在基辅](https://so.toutiao.com/search?keyword=乌总统办公室:泽连斯基仍在基辅)
1. [山东:本轮疫情发展快 无症状占比大](https://so.toutiao.com/search?keyword=山东:本轮疫情发展快%20无症状占比大)
1. [沈梦辰机场给粉丝补发喜糖](https://so.toutiao.com/search?keyword=沈梦辰机场给粉丝补发喜糖)
1. [哈农业部:糖储量够全国三个月需求](https://so.toutiao.com/search?keyword=哈农业部:糖储量够全国三个月需求)
1. [俄外交部:与美国的接触不会停止](https://so.toutiao.com/search?keyword=俄外交部:与美国的接触不会停止)
1. [哈德森空砍38+10+8 山东惜败深圳](https://so.toutiao.com/search?keyword=哈德森空砍38+10+8%20山东惜败深圳)
1. [乌“外籍军团”背后或有西方推手](https://so.toutiao.com/search?keyword=乌“外籍军团”背后或有西方推手)
1. [WTT大满贯赛:许昕零封晋级](https://so.toutiao.com/search?keyword=WTT大满贯赛:许昕零封晋级)
1. [乌方:将开放15条新的人道主义走廊](https://so.toutiao.com/search?keyword=乌方:将开放15条新的人道主义走廊)
1. [乌方称俄首次向乌西部发起进攻](https://so.toutiao.com/search?keyword=乌方称俄首次向乌西部发起进攻)
1. [拜登:应避免发生第三次世界大战](https://so.toutiao.com/search?keyword=拜登:应避免发生第三次世界大战)
1. [中国首批援助乌克兰物资已运抵](https://so.toutiao.com/search?keyword=中国首批援助乌克兰物资已运抵)
1. [意政府扣押俄富豪“世界最大游艇”](https://so.toutiao.com/search?keyword=意政府扣押俄富豪“世界最大游艇”)
1. [红警08解说巅峰杯决赛:威龙VS土豆](https://so.toutiao.com/search?keyword=红警08解说巅峰杯决赛:威龙VS土豆)
1. [WTT大满贯赛张本智和爆冷一轮游](https://so.toutiao.com/search?keyword=WTT大满贯赛张本智和爆冷一轮游)
1. [广东昨增本土33+191](https://so.toutiao.com/search?keyword=广东昨增本土33+191)
1. [李嘉诚卖伦敦写字楼净赚39亿](https://so.toutiao.com/search?keyword=李嘉诚卖伦敦写字楼净赚39亿)
1. [杭州顺丰多人确诊部分快递路边待取](https://so.toutiao.com/search?keyword=杭州顺丰多人确诊部分快递路边待取)
1. [特朗普就美国油价上涨质疑拜登](https://so.toutiao.com/search?keyword=特朗普就美国油价上涨质疑拜登)
1. [兰帕德:过去几年很少和阿布见面](https://so.toutiao.com/search?keyword=兰帕德:过去几年很少和阿布见面)
1. [国足热身赛5-0大胜亚泰 张玉宁建功](https://so.toutiao.com/search?keyword=国足热身赛5-0大胜亚泰%20张玉宁建功)
1. [印度地方选举结果出炉 印人党大胜](https://so.toutiao.com/search?keyword=印度地方选举结果出炉%20印人党大胜)
1. [英超取消阿布担任切尔西董事资格](https://so.toutiao.com/search?keyword=英超取消阿布担任切尔西董事资格)
1. [北京新增3例感染者 1人为医院保洁](https://so.toutiao.com/search?keyword=北京新增3例感染者%201人为医院保洁)
1. [山东聊城新增1例无症状感染者](https://so.toutiao.com/search?keyword=山东聊城新增1例无症状感染者)
1. [新疆男篮官方祝贺阿不都砍50分](https://so.toutiao.com/search?keyword=新疆男篮官方祝贺阿不都砍50分)
1. [全国人大代表:“对话”四年前的自己](https://so.toutiao.com/search?keyword=全国人大代表:“对话”四年前的自己)
1. [北京一确诊未接种疫苗 曾去故宫](https://so.toutiao.com/search?keyword=北京一确诊未接种疫苗%20曾去故宫)
1. [俄罗斯欲将Meta列为极端组织](https://so.toutiao.com/search?keyword=俄罗斯欲将Meta列为极端组织)
1. [重庆新增9例初筛阳性 均为学生](https://so.toutiao.com/search?keyword=重庆新增9例初筛阳性%20均为学生)
1. [俄军为何主攻乌克兰边境重镇](https://so.toutiao.com/search?keyword=俄军为何主攻乌克兰边境重镇)
1. [孙春兰:推广抗原筛查、核酸诊断模式](https://so.toutiao.com/search?keyword=孙春兰:推广抗原筛查、核酸诊断模式)
1. [乌国防部发“巴黎被轰炸”合成视频](https://so.toutiao.com/search?keyword=乌国防部发“巴黎被轰炸”合成视频)
1. [美CPI创新高 拜登甩锅普京被嘲](https://so.toutiao.com/search?keyword=美CPI创新高%20拜登甩锅普京被嘲)
1. [沈腾两次把浙江卫视说成江苏卫视](https://so.toutiao.com/search?keyword=沈腾两次把浙江卫视说成江苏卫视)
1. [《初拥》剧组摄影师收音师意外坠亡](https://so.toutiao.com/search?keyword=《初拥》剧组摄影师收音师意外坠亡)
1. [汽柴油零售价有望上调约1020元/吨](https://so.toutiao.com/search?keyword=汽柴油零售价有望上调约1020元/吨)
1. [俄军共摧毁3491处乌军事基础设施](https://so.toutiao.com/search?keyword=俄军共摧毁3491处乌军事基础设施)
1. [韩国当选总统欲将办公地迁出青瓦台](https://so.toutiao.com/search?keyword=韩国当选总统欲将办公地迁出青瓦台)
1. [吉林市阳性感染者10日内破千](https://so.toutiao.com/search?keyword=吉林市阳性感染者10日内破千)
1. [中方就乌克兰生物安全问题阐述立场](https://so.toutiao.com/search?keyword=中方就乌克兰生物安全问题阐述立场)
1. [安理会讨论生物武器 美俄互相指责](https://so.toutiao.com/search?keyword=安理会讨论生物武器%20美俄互相指责)
1. [欧盟高官承认西方对俄犯一系列错误](https://so.toutiao.com/search?keyword=欧盟高官承认西方对俄犯一系列错误)
1. [具俊晔发照片晒酒店隔离日常](https://so.toutiao.com/search?keyword=具俊晔发照片晒酒店隔离日常)
1. [俄监管机构将在48小时内封杀Ins](https://so.toutiao.com/search?keyword=俄监管机构将在48小时内封杀Ins)
1. [重庆本轮疫情感染来源尚不明确](https://so.toutiao.com/search?keyword=重庆本轮疫情感染来源尚不明确)
1. [中国缘何新增新冠“抗原筛查”](https://so.toutiao.com/search?keyword=中国缘何新增新冠“抗原筛查”)
1. [抗原自我检测是走出疫情必经之路吗](https://so.toutiao.com/search?keyword=抗原自我检测是走出疫情必经之路吗)
1. [阿不都是近两季唯一50+的本土球员](https://so.toutiao.com/search?keyword=阿不都是近两季唯一50+的本土球员)
1. [意大利阻止中企收购军用无人机企业](https://so.toutiao.com/search?keyword=意大利阻止中企收购军用无人机企业)
1. [吉林溯源:新的境外病毒致本地传播](https://so.toutiao.com/search?keyword=吉林溯源:新的境外病毒致本地传播)
1. [西安全城派发熊猫核酸贴纸](https://so.toutiao.com/search?keyword=西安全城派发熊猫核酸贴纸)
1. [俄媒:普京同意志愿者赴乌帮俄军作战](https://so.toutiao.com/search?keyword=俄媒:普京同意志愿者赴乌帮俄军作战)
1. [杨洪琼获得北京冬残奥会个人第3金](https://so.toutiao.com/search?keyword=杨洪琼获得北京冬残奥会个人第3金)
1. [《新闻联播》正在直播](https://so.toutiao.com/search?keyword=《新闻联播》正在直播)
1. [与胃癌抗争8个月的女孩去世](https://so.toutiao.com/search?keyword=与胃癌抗争8个月的女孩去世)
1. [河北沧州一地调整为中风险](https://so.toutiao.com/search?keyword=河北沧州一地调整为中风险)
1. [北京本轮疫情与京外输入有强烈关联](https://so.toutiao.com/search?keyword=北京本轮疫情与京外输入有强烈关联)
1. [重庆全市实行校园封闭管理](https://so.toutiao.com/search?keyword=重庆全市实行校园封闭管理)
1. [美油价上涨 特朗普拜登套娃式甩锅](https://so.toutiao.com/search?keyword=美油价上涨%20特朗普拜登套娃式甩锅)
1. [阿不都50分创生涯新高 新疆胜福建](https://so.toutiao.com/search?keyword=阿不都50分创生涯新高%20新疆胜福建)
1. [首批自测版新冠抗原试剂盒要来了吗](https://so.toutiao.com/search?keyword=首批自测版新冠抗原试剂盒要来了吗)
1. [河北昨增本土确诊22例无症状22例](https://so.toutiao.com/search?keyword=河北昨增本土确诊22例无症状22例)
1. [江歌妈妈公开投诉陈岚造谣诽谤](https://so.toutiao.com/search?keyword=江歌妈妈公开投诉陈岚造谣诽谤)
1. [天津重点区域开展全员核酸检测](https://so.toutiao.com/search?keyword=天津重点区域开展全员核酸检测)
1. [美国宣布将取消对俄最惠国待遇](https://so.toutiao.com/search?keyword=美国宣布将取消对俄最惠国待遇)
1. [郭富城方媛外出购物被拍](https://so.toutiao.com/search?keyword=郭富城方媛外出购物被拍)
1. [泽连斯基:马里乌波尔仍被封锁](https://so.toutiao.com/search?keyword=泽连斯基:马里乌波尔仍被封锁)
1. [山东昨增本土159+400](https://so.toutiao.com/search?keyword=山东昨增本土159+400)
1. [河北廊坊共报告14例确诊32例无症状](https://so.toutiao.com/search?keyword=河北廊坊共报告14例确诊32例无症状)
1. [东莞7天未做核检快递员确诊为谣言](https://so.toutiao.com/search?keyword=东莞7天未做核检快递员确诊为谣言)
1. [拜登称美国每天都在向乌运输武器](https://so.toutiao.com/search?keyword=拜登称美国每天都在向乌运输武器)
1. [乌剥夺传奇国脚季莫什丘克所有荣誉](https://so.toutiao.com/search?keyword=乌剥夺传奇国脚季莫什丘克所有荣誉)
1. [广州12日通报病例为奥密克戎株BA.2](https://so.toutiao.com/search?keyword=广州12日通报病例为奥密克戎株BA.2)
1. [“反诈”需推进国民财商教育](https://so.toutiao.com/search?keyword=“反诈”需推进国民财商教育)
1. [上海迪士尼乐园13日起将限流开放](https://so.toutiao.com/search?keyword=上海迪士尼乐园13日起将限流开放)
1. [美对俄新制裁:禁向俄供应美元纸币](https://so.toutiao.com/search?keyword=美对俄新制裁:禁向俄供应美元纸币)
1. [31省昨增本土476+1048](https://so.toutiao.com/search?keyword=31省昨增本土476+1048)
1. [乌克兰大部分城市响起空袭警报](https://so.toutiao.com/search?keyword=乌克兰大部分城市响起空袭警报)
1. [乌总统与拜登通话 同意加强对俄制裁](https://so.toutiao.com/search?keyword=乌总统与拜登通话%20同意加强对俄制裁)
1. [詹姆斯砍50分 湖人轻取奇才](https://so.toutiao.com/search?keyword=詹姆斯砍50分%20湖人轻取奇才)
1. [日本暂停与俄方达成的8项合作计划](https://so.toutiao.com/search?keyword=日本暂停与俄方达成的8项合作计划)
1. [俄指责美拒接受生物实验室国际检查](https://so.toutiao.com/search?keyword=俄指责美拒接受生物实验室国际检查)
1. [俄罗斯计划削减对国际空间站的投入](https://so.toutiao.com/search?keyword=俄罗斯计划削减对国际空间站的投入)
1. [北约:核心任务保证俄乌冲突不蔓延](https://so.toutiao.com/search?keyword=北约:核心任务保证俄乌冲突不蔓延)
1. [吉林确诊学生讲述隔离点现状](https://so.toutiao.com/search?keyword=吉林确诊学生讲述隔离点现状)
1. [印误射导弹落入巴基斯坦:深表遗憾](https://so.toutiao.com/search?keyword=印误射导弹落入巴基斯坦:深表遗憾)
1. [专家谈城乡老人养老金差距近20倍](https://so.toutiao.com/search?keyword=专家谈城乡老人养老金差距近20倍)
1. [法总统谴责英政府不想要乌克兰难民](https://so.toutiao.com/search?keyword=法总统谴责英政府不想要乌克兰难民)
1. [乌军方称俄军继续在乌境内推进](https://so.toutiao.com/search?keyword=乌军方称俄军继续在乌境内推进)
1. [江苏昨增本土20+13](https://so.toutiao.com/search?keyword=江苏昨增本土20+13)
1. [冬残奥细节里的中国温度](https://so.toutiao.com/search?keyword=冬残奥细节里的中国温度)
1. [5款新冠抗原自测产品获批上市](https://so.toutiao.com/search?keyword=5款新冠抗原自测产品获批上市)
1. [青岛新增15例本土确诊31例无症状](https://so.toutiao.com/search?keyword=青岛新增15例本土确诊31例无症状)
1. [泽连斯基再发视频能自证在基辅吗](https://so.toutiao.com/search?keyword=泽连斯基再发视频能自证在基辅吗)
1. [欧盟宣布第四波对俄罗斯制裁](https://so.toutiao.com/search?keyword=欧盟宣布第四波对俄罗斯制裁)
1. [美媒:拜登与泽连斯基通话49分钟](https://so.toutiao.com/search?keyword=美媒:拜登与泽连斯基通话49分钟)
1. [胡锡进:中国要巩固朋友 化解敌意](https://so.toutiao.com/search?keyword=胡锡进:中国要巩固朋友%20化解敌意)
1. [官方:对邮件快件处理场所大排查](https://so.toutiao.com/search?keyword=官方:对邮件快件处理场所大排查)
1. [香港博士康复感悟:与病毒共存不负责](https://so.toutiao.com/search?keyword=香港博士康复感悟:与病毒共存不负责)
1. [王晨阳夺冬残奥会越野滑雪冠军](https://so.toutiao.com/search?keyword=王晨阳夺冬残奥会越野滑雪冠军)
1. [茅台的技术含量究竟在哪](https://so.toutiao.com/search?keyword=茅台的技术含量究竟在哪)
1. [重庆部分高校连夜开展核酸检测](https://so.toutiao.com/search?keyword=重庆部分高校连夜开展核酸检测)
1. [俄乌冲突第17天:6个死亡故事](https://so.toutiao.com/search?keyword=俄乌冲突第17天:6个死亡故事)
1. [为何快递中转站让那么多杭州人中招](https://so.toutiao.com/search?keyword=为何快递中转站让那么多杭州人中招)
1. [俄军抛出美在乌生物实验证据](https://so.toutiao.com/search?keyword=俄军抛出美在乌生物实验证据)
1. [邓文迪女儿为父亲庆91岁生日](https://so.toutiao.com/search?keyword=邓文迪女儿为父亲庆91岁生日)
1. [北京门头沟一社区现初筛阳性1例](https://so.toutiao.com/search?keyword=北京门头沟一社区现初筛阳性1例)
1. [茅台“国家企业技术中心”资格被撤](https://so.toutiao.com/search?keyword=茅台“国家企业技术中心”资格被撤)
1. [穆雷27+9+5 马刺力克爵士](https://so.toutiao.com/search?keyword=穆雷27+9+5%20马刺力克爵士)
1. [自测新冠放开 相关板块掀涨停潮](https://so.toutiao.com/search?keyword=自测新冠放开%20相关板块掀涨停潮)
1. [重庆3名核酸异常人员确诊](https://so.toutiao.com/search?keyword=重庆3名核酸异常人员确诊)
1. [滴滴股价暴跌44%不足2美元](https://so.toutiao.com/search?keyword=滴滴股价暴跌44%不足2美元)
1. [台媒称台美签署69.9亿元新台币军购](https://so.toutiao.com/search?keyword=台媒称台美签署69.9亿元新台币军购)
1. [美媒主播批西方报道乌危机“双标”](https://so.toutiao.com/search?keyword=美媒主播批西方报道乌危机“双标”)
1. [瞒报?五问吉林农业科技学院](https://so.toutiao.com/search?keyword=瞒报?五问吉林农业科技学院)
1. [刘亦菲坐高铁被偶遇](https://so.toutiao.com/search?keyword=刘亦菲坐高铁被偶遇)
1. [拜登被曝亲自否决波兰对乌移交战机](https://so.toutiao.com/search?keyword=拜登被曝亲自否决波兰对乌移交战机)
1. [国际品牌在俄撤店 卷走巨额预付款](https://so.toutiao.com/search?keyword=国际品牌在俄撤店%20卷走巨额预付款)
1. [马克龙警告:欧盟或对俄采取新制裁](https://so.toutiao.com/search?keyword=马克龙警告:欧盟或对俄采取新制裁)
1. [波波维奇常规赛1336胜排名历史第一](https://so.toutiao.com/search?keyword=波波维奇常规赛1336胜排名历史第一)
1. [昨日陕西新增30例本土确诊病例](https://so.toutiao.com/search?keyword=昨日陕西新增30例本土确诊病例)
1. [湖人晒詹姆斯拥抱波普库兹马照片](https://so.toutiao.com/search?keyword=湖人晒詹姆斯拥抱波普库兹马照片)
1. [天津昨增45例阳性感染者](https://so.toutiao.com/search?keyword=天津昨增45例阳性感染者)
1. [浙江昨增本土23+2](https://so.toutiao.com/search?keyword=浙江昨增本土23+2)
1. [2月居民中长期贷款为何减少](https://so.toutiao.com/search?keyword=2月居民中长期贷款为何减少)
1. [张文宏解读新冠抗原检测](https://so.toutiao.com/search?keyword=张文宏解读新冠抗原检测)
1. [为何今年倒春寒这么冷](https://so.toutiao.com/search?keyword=为何今年倒春寒这么冷)
1. [非洲多国为何理解中国对乌局势立场](https://so.toutiao.com/search?keyword=非洲多国为何理解中国对乌局势立场)
1. [抗原筛查与核酸检测哪种更好](https://so.toutiao.com/search?keyword=抗原筛查与核酸检测哪种更好)
1. [俄媒:加拿大对俄国防部实施制裁](https://so.toutiao.com/search?keyword=俄媒:加拿大对俄国防部实施制裁)
1. [男子三轮车被扣后警车上卖完肉](https://so.toutiao.com/search?keyword=男子三轮车被扣后警车上卖完肉)
1. [吉林农业科技学院部分宿舍全阳性](https://so.toutiao.com/search?keyword=吉林农业科技学院部分宿舍全阳性)
1. [青岛:莱西疫情拐点很快会到来](https://so.toutiao.com/search?keyword=青岛:莱西疫情拐点很快会到来)
1. [麦当劳离开俄国 有人称不吃更健康](https://so.toutiao.com/search?keyword=麦当劳离开俄国%20有人称不吃更健康)
1. [吉林市、长春市疫情出现社区传播](https://so.toutiao.com/search?keyword=吉林市、长春市疫情出现社区传播)
1. [委员:应保障社会公众知情权](https://so.toutiao.com/search?keyword=委员:应保障社会公众知情权)
1. [青海祁连一车辆发生事故致7人死亡](https://so.toutiao.com/search?keyword=青海祁连一车辆发生事故致7人死亡)
1. [药监局批准新冠抗原自测产品上市](https://so.toutiao.com/search?keyword=药监局批准新冠抗原自测产品上市)
1. [最新MVP榜:约基奇榜首恩比德第二](https://so.toutiao.com/search?keyword=最新MVP榜:约基奇榜首恩比德第二)
1. [英国政府叫停切尔西出售计划](https://so.toutiao.com/search?keyword=英国政府叫停切尔西出售计划)
1. [李克强第十个总理记者会的十个比喻](https://so.toutiao.com/search?keyword=李克强第十个总理记者会的十个比喻)
1. [吉林昨增134例本土确诊266例无症状](https://so.toutiao.com/search?keyword=吉林昨增134例本土确诊266例无症状)
1. [金·卡戴珊首晒与男友合照](https://so.toutiao.com/search?keyword=金·卡戴珊首晒与男友合照)
1. [曝部分湖人球员只想熬过最后一个月](https://so.toutiao.com/search?keyword=曝部分湖人球员只想熬过最后一个月)
1. [顺丰杭州中转场现多例 消费者咋应对](https://so.toutiao.com/search?keyword=顺丰杭州中转场现多例%20消费者咋应对)
1. [中国概念股连续第二日重挫](https://so.toutiao.com/search?keyword=中国概念股连续第二日重挫)
1. [普京:俄乌会谈取得某些积极进展](https://so.toutiao.com/search?keyword=普京:俄乌会谈取得某些积极进展)
1. [中美夫妻之间差异有多大](https://so.toutiao.com/search?keyword=中美夫妻之间差异有多大)
1. [长春官方回应九台一中学生求助](https://so.toutiao.com/search?keyword=长春官方回应九台一中学生求助)
1. [官方:居民可自行买试剂测新冠](https://so.toutiao.com/search?keyword=官方:居民可自行买试剂测新冠)
1. [挂羊头卖狗肉:揭秘5种易造假食品](https://so.toutiao.com/search?keyword=挂羊头卖狗肉:揭秘5种易造假食品)
1. [2022年研考国家线公布](https://so.toutiao.com/search?keyword=2022年研考国家线公布)
1. [河北昨增本土22+22](https://so.toutiao.com/search?keyword=河北昨增本土22+22)
1. [黎建南:台湾年轻人没有“打仗意志”](https://so.toutiao.com/search?keyword=黎建南:台湾年轻人没有“打仗意志”)
1. [宋依佳任重庆市纪委书记](https://so.toutiao.com/search?keyword=宋依佳任重庆市纪委书记)
1. [中兴推出便携式太极云电脑W100D](https://so.toutiao.com/search?keyword=中兴推出便携式太极云电脑W100D)
1. [总理强调拐卖妇女儿童严惩不贷](https://so.toutiao.com/search?keyword=总理强调拐卖妇女儿童严惩不贷)
1. [李克强:要给骑手们系上“安全带”](https://so.toutiao.com/search?keyword=李克强:要给骑手们系上“安全带”)
1. [滨州发现2例新冠肺炎确诊病例](https://so.toutiao.com/search?keyword=滨州发现2例新冠肺炎确诊病例)
1. [厦门从外省协查人员中检出1名确诊](https://so.toutiao.com/search?keyword=厦门从外省协查人员中检出1名确诊)
1. [76人VS篮网全美平均收视人数250万](https://so.toutiao.com/search?keyword=76人VS篮网全美平均收视人数250万)
1. [虎年第5虎刘彦平被查](https://so.toutiao.com/search?keyword=虎年第5虎刘彦平被查)
1. [全球日增确诊超191万例](https://so.toutiao.com/search?keyword=全球日增确诊超191万例)
1. [俄媒:普京同意向乌克兰派遣志愿者](https://so.toutiao.com/search?keyword=俄媒:普京同意向乌克兰派遣志愿者)
1. [留学生花10万在莫斯科市中心买套房](https://so.toutiao.com/search?keyword=留学生花10万在莫斯科市中心买套房)
1. [俄罗斯10艘军舰穿越津轻海峡](https://so.toutiao.com/search?keyword=俄罗斯10艘军舰穿越津轻海峡)
1. [台一电影取景地出意外 2人坠谷死亡](https://so.toutiao.com/search?keyword=台一电影取景地出意外%202人坠谷死亡)
1. [昨日12至24时青岛新增本土确诊96例](https://so.toutiao.com/search?keyword=昨日12至24时青岛新增本土确诊96例)
1. [比永博捐出本季薪水在家乡建造医院](https://so.toutiao.com/search?keyword=比永博捐出本季薪水在家乡建造医院)
1. [李克强:地方政府要当“铁公鸡”](https://so.toutiao.com/search?keyword=李克强:地方政府要当“铁公鸡”)
1. [总理记者会“就业”词频10年新高](https://so.toutiao.com/search?keyword=总理记者会“就业”词频10年新高)
1. [国务院任免国家工作人员](https://so.toutiao.com/search?keyword=国务院任免国家工作人员)
1. [曝切尔西账户被冻结无法买大巴燃料](https://so.toutiao.com/search?keyword=曝切尔西账户被冻结无法买大巴燃料)
1. [上海疫情溯源:管理疏漏致本土感染](https://so.toutiao.com/search?keyword=上海疫情溯源:管理疏漏致本土感染)
1. [英国老兵赴乌参战被乌方当间谍拷打](https://so.toutiao.com/search?keyword=英国老兵赴乌参战被乌方当间谍拷打)
1. [俄方:欧洲将感受到制裁带来的后果](https://so.toutiao.com/search?keyword=俄方:欧洲将感受到制裁带来的后果)
1. [首批6架歼-10CE交付巴基斯坦](https://so.toutiao.com/search?keyword=首批6架歼-10CE交付巴基斯坦)
1. [美媒:美政府在乌实验室问题上撒谎](https://so.toutiao.com/search?keyword=美媒:美政府在乌实验室问题上撒谎)
1. [俄方:美已从乌实验室运走大量资料](https://so.toutiao.com/search?keyword=俄方:美已从乌实验室运走大量资料)
1. [李克强谈中美关系:择宽处行](https://so.toutiao.com/search?keyword=李克强谈中美关系:择宽处行)
1. [媒体关注儿童精分患者:易被家长误判](https://so.toutiao.com/search?keyword=媒体关注儿童精分患者:易被家长误判)
1. [尹锡悦称坚信韩中关系将更上一层楼](https://so.toutiao.com/search?keyword=尹锡悦称坚信韩中关系将更上一层楼)
1. [人大代表回顾这5年](https://so.toutiao.com/search?keyword=人大代表回顾这5年)
1. [吉林省昨增本土134+266](https://so.toutiao.com/search?keyword=吉林省昨增本土134+266)
1. [“屠杀”中概股的外国公司问责法是啥](https://so.toutiao.com/search?keyword=“屠杀”中概股的外国公司问责法是啥)
1. [公务车被曝不礼让老人还鸣笛抢行](https://so.toutiao.com/search?keyword=公务车被曝不礼让老人还鸣笛抢行)
1. [李克强:今年要实现身份证电子化](https://so.toutiao.com/search?keyword=李克强:今年要实现身份证电子化)
1. [上海中小学3月12日起开始线上教学](https://so.toutiao.com/search?keyword=上海中小学3月12日起开始线上教学)
1. [“95加满”是什么梗](https://so.toutiao.com/search?keyword=“95加满”是什么梗)
1. [吉林农业科技学院被隔离学生发声](https://so.toutiao.com/search?keyword=吉林农业科技学院被隔离学生发声)
1. [是否就俄乌冲突谴责俄方?李克强回应](https://so.toutiao.com/search?keyword=是否就俄乌冲突谴责俄方?李克强回应)
1. [曝成龙和空姐合影索要地址惹争议](https://so.toutiao.com/search?keyword=曝成龙和空姐合影索要地址惹争议)
1. [美CDC:98%美国人口无需戴口罩](https://so.toutiao.com/search?keyword=美CDC:98%美国人口无需戴口罩)
1. [村民自掏腰包修路因未办理审批涉罪](https://so.toutiao.com/search?keyword=村民自掏腰包修路因未办理审批涉罪)
1. [乌军被曝装备大量西方反坦克武器](https://so.toutiao.com/search?keyword=乌军被曝装备大量西方反坦克武器)
1. [淄博疫情与青岛威海病例无关联](https://so.toutiao.com/search?keyword=淄博疫情与青岛威海病例无关联)
1. [雪球产品集中敲入导致踩踏传闻再起](https://so.toutiao.com/search?keyword=雪球产品集中敲入导致踩踏传闻再起)
1. [吉林农业科技学院学生全部转运](https://so.toutiao.com/search?keyword=吉林农业科技学院学生全部转运)
1. [59家在俄外企登上“国有化名单”](https://so.toutiao.com/search?keyword=59家在俄外企登上“国有化名单”)
1. [沙特阿美冷落拜登后跟中企签约](https://so.toutiao.com/search?keyword=沙特阿美冷落拜登后跟中企签约)
1. [中国队1小时到手5个金容融](https://so.toutiao.com/search?keyword=中国队1小时到手5个金容融)
1. [北京天空现“不明光环”?回应来了](https://so.toutiao.com/search?keyword=北京天空现“不明光环”?回应来了)
1. [杭州一顺丰中转场已有14人确诊](https://so.toutiao.com/search?keyword=杭州一顺丰中转场已有14人确诊)
1. [网传上海将封城系谣言](https://so.toutiao.com/search?keyword=网传上海将封城系谣言)
1. [重庆高新区报告3名核酸异常人员](https://so.toutiao.com/search?keyword=重庆高新区报告3名核酸异常人员)
1. [俄乌冲突第16天:俄乌美都亮底牌](https://so.toutiao.com/search?keyword=俄乌冲突第16天:俄乌美都亮底牌)
1. [专家建议分层提高农村老人养老金](https://so.toutiao.com/search?keyword=专家建议分层提高农村老人养老金)
1. [山东青岛莱西新增109+264](https://so.toutiao.com/search?keyword=山东青岛莱西新增109+264)
1. [相逢时节最讨人厌的角色](https://so.toutiao.com/search?keyword=相逢时节最讨人厌的角色)
1. [吉林疫情存在两条传播链](https://so.toutiao.com/search?keyword=吉林疫情存在两条传播链)
1. [重庆成今年首个超30℃的省会级城市](https://so.toutiao.com/search?keyword=重庆成今年首个超30℃的省会级城市)
1. [卖自养猪肉获利0.58元为何罚10万](https://so.toutiao.com/search?keyword=卖自养猪肉获利0.58元为何罚10万)
1. [委内瑞拉重申支持俄罗斯](https://so.toutiao.com/search?keyword=委内瑞拉重申支持俄罗斯)
1. [委内瑞拉与俄罗斯讨论合作问题](https://so.toutiao.com/search?keyword=委内瑞拉与俄罗斯讨论合作问题)
1. [顺丰停止收寄香港至内地快件](https://so.toutiao.com/search?keyword=顺丰停止收寄香港至内地快件)
1. [上海六院全院封闭管控](https://so.toutiao.com/search?keyword=上海六院全院封闭管控)
1. [一疑似阳性人员进入广交会展馆](https://so.toutiao.com/search?keyword=一疑似阳性人员进入广交会展馆)
1. [拜登遭中东冷遇?布林肯极力淡化](https://so.toutiao.com/search?keyword=拜登遭中东冷遇?布林肯极力淡化)
1. [普京:俄罗斯不能生活在屈辱状态下](https://so.toutiao.com/search?keyword=普京:俄罗斯不能生活在屈辱状态下)
1. [俄公布无人机袭击乌据点画面](https://so.toutiao.com/search?keyword=俄公布无人机袭击乌据点画面)
1. [山东淄博部分公交线路暂停运营](https://so.toutiao.com/search?keyword=山东淄博部分公交线路暂停运营)
1. [3天态度大转弯 优衣库暂停在俄业务](https://so.toutiao.com/search?keyword=3天态度大转弯%20优衣库暂停在俄业务)
1. [吉林本轮疫情累计526例确诊](https://so.toutiao.com/search?keyword=吉林本轮疫情累计526例确诊)
1. [薛之谦新歌太虐心了](https://so.toutiao.com/search?keyword=薛之谦新歌太虐心了)
1. [“两岸统一”成两会热议话题](https://so.toutiao.com/search?keyword=“两岸统一”成两会热议话题)
1. [美副总统:美已在波兰部署导弹系统](https://so.toutiao.com/search?keyword=美副总统:美已在波兰部署导弹系统)
1. [俄军计划加强西部边界防御](https://so.toutiao.com/search?keyword=俄军计划加强西部边界防御)
1. [直击现场:长春全市小区封闭管理](https://so.toutiao.com/search?keyword=直击现场:长春全市小区封闭管理)
1. [俄方:已瘫痪3213处乌军事基础设施](https://so.toutiao.com/search?keyword=俄方:已瘫痪3213处乌军事基础设施)
1. [镍“史诗级”逼空背后谁在博弈](https://so.toutiao.com/search?keyword=镍“史诗级”逼空背后谁在博弈)
1. [世卫建议乌销毁实验室高危病原体](https://so.toutiao.com/search?keyword=世卫建议乌销毁实验室高危病原体)
1. [专家:若双方让步则镍逼空或迎拐点](https://so.toutiao.com/search?keyword=专家:若双方让步则镍逼空或迎拐点)
1. [俄方:切尔诺贝利供电设施遭乌方攻击](https://so.toutiao.com/search?keyword=俄方:切尔诺贝利供电设施遭乌方攻击)
1. [北约加强军援乌克兰力度](https://so.toutiao.com/search?keyword=北约加强军援乌克兰力度)
1. [吉林疫情毒株为奥密克戎变异株](https://so.toutiao.com/search?keyword=吉林疫情毒株为奥密克戎变异株)
1. [张若昀唐艺昕一家三口度假被偶遇](https://so.toutiao.com/search?keyword=张若昀唐艺昕一家三口度假被偶遇)
1. [俄将对宣布退出俄市场公司进行审查](https://so.toutiao.com/search?keyword=俄将对宣布退出俄市场公司进行审查)
1. [白象方便面订单量暴增](https://so.toutiao.com/search?keyword=白象方便面订单量暴增)
1. [“妖镍”大战逼出温州神秘富豪](https://so.toutiao.com/search?keyword=“妖镍”大战逼出温州神秘富豪)
<!-- END TOUTIAO --> | 21,309 | MIT |
---
layout: post
title: "使用C或C++扩展Python(一)-从python调用C(续)"
date: 2018-12-28 09:15:00 +0800
categories: jekyll update
---
原文:https://docs.python.org/dev/extending/extending.html
"使用C或C++扩展Python(一)-从python调用C(续)"
===
如果您知道如何用C编程,那么在Python中添加新的内置模块是相当容易的。扩展模块可以做两件不能在Python中直接完成的事情:它们可以实现新的内置对象类型,也可以调用C库函数和系统调用。
为了支持扩展,PythonAPI(应用程序编程器接口)定义了一组函数、宏和变量,这些函数、宏和变量提供了对Python运行时系统大部分的访问。PythonAPI是通过包含报头"Python.h"而合并到C源文件中的。
```
/*
keywdarg.c
compile:gcc -fPIC -shared -I /usr/include/python3.5m/ keywdarg.c -o keywdarg.so
usage:
>>> import keywds
>>> keywds.parrot(voltage=1)
reference:https://docs.python.org/dev/extending/extending.html
*/
#include <Python.h>
static PyObject *
keywdarg_parrot(PyObject *self, PyObject *args, PyObject *keywds)
{
int voltage;
const char *state = "a stiff";
const char *action = "voom";
const char *type = "Norwegian Blue";
static char *kwlist[] = {"voltage", "state", "action", "type", NULL};
if (!PyArg_ParseTupleAndKeywords(args, keywds, "i|sss", kwlist,
&voltage, &state, &action, &type))
return NULL;
printf("-- This parrot wouldn't %s if you put %i Volts through it.\n",
action, voltage);
printf("-- Lovely plumage, the %s -- It's %s!\n", type, state);
Py_RETURN_NONE;
}
static PyMethodDef keywdarg_methods[] = {
/* The cast of the function is necessary since PyCFunction values
* only take two PyObject* parameters, and keywdarg_parrot() takes
* three.
*/
{"parrot", (PyCFunction)keywdarg_parrot, METH_VARARGS | METH_KEYWORDS,
"Print a lovely skit to standard output."},
{NULL, NULL, 0, NULL} /* sentinel */
};
static struct PyModuleDef keywdargmodule = {
PyModuleDef_HEAD_INIT,
"keywdarg",
NULL,
-1,
keywdarg_methods
};
PyMODINIT_FUNC
PyInit_keywdarg(void)
{
return PyModule_Create(&keywdargmodule);
}
``` | 1,970 | CC-BY-4.0 |
## chaos 框架使用说明
> chaos 是一个组件化的页面渲染框架,可实现页面数据绑定,数据渲染,事件绑定以及组件通信
### 如何使用
1. 引入 Component 基类
```
var Component = require('_libs/chaos/Component.js');
```
2. 通过 Component.create 创建一个组件
3. 通过 new Example(model, [options]) 生成组件实例
```
var model = {
number: 12,
time: '20160-12-12'
}
/**
* 实例化一个组件
* @param {Object} model 组件渲染所需的数据
* @param {组件一些配置参数} {} 可选
*/
var linkItem = new LinkItem(model, {})
```
### Example
```
var Component = require('_libs/chaos/Component.js');
var Tpl = require('./tpl');
var ProjectType = require('./../../config').ProjectType;
var LinkItem = Component.create({
/**
* 非必须
* 如果未设置el和$el属性,默认会将模板数据render到这个节点下
* 自动生成 li 节点赋值给el 和 $el 属性
* @type {String}
*/
tagName: 'li',
/**
* 非必须
* 如果提供了tagName,那么可以通过这个设置组件外层的样式
* @type {String}
*/
className: 'step',
/**
* 必须
* 模板
* @type {[type]}
*/
template: Tpl,
/**
* 非必须
* DOM 节点,如果提供了此属性,那么重新render处理的html会插入到此节点下
* 用法参照module/LogInfo
* @param {[type]} '#app' [description]
* @return {[type]} [description]
*/
el: $('#app').find('.mod-logs')[0],
/**
* 非必须
* 在通过new LinkItem() 生成的时候会执行 initialize
* 基类有此方法,如果不写会执行默认值
* 可以覆盖掉,自己写一些操作
* @return {[type]} [description]
*/
initialize: function(options) {
this.options = options;
this.render();
},
/**
* 事件绑定,每个Component组件都可以写自己的事件绑定
* 负责本组件的所有事件处理
* 事件map的形式
* '事件 选择器': '处理函数名'
* 类似 this.$el.on('click', '.el', delete);
* @type {Object}
*/
events: {
'click .del': 'delete'
},
/**
* 模块之间通信,绑定action的执行函数
* 别的组件通过调用 this.dispatch('project:show', {id: 10}) 来发布事件
* @type {Object}
*/
actions: {
'project:show': 'handleProjectShow'
},
// 自定义的一些方法,供events调用
delete: function() {
this.$el.append('<h3>hello</h3>');
},
/**
* 非必须
* 解析本组件的数据, 如果写了次方法,组件会在每次render的时候重新自动调用
* @param {Object} model 原始数据
* @return {Object} [解析之后的数据]
*/
parse: function(model) {
if(!model){
return null;
}
model.typeName = ProjectType[model.stepType];
model.updateTime = model.lastUpdat ? new Date(model.lastUpdat) : '';
return model;
},
/**
* 生命周期函数
* 如果提供了此方法,会在组件渲染之前调用
* @type {function}
*/
onWillUpdate: NOOP,
/**
* 生命周期函数
* 如果提供了此方法,会在组件渲染之后调用
* @type {function}
*/
onDidUpdate: NOOP,
});
/**
* 实例化一个组件
* @param {Object} model 组件渲染所需的数据
* @param {组件一些配置参数} {} 可选
*/
var linkItem = new LinkItem(model, {})
``` | 2,704 | MIT |
---
title: 1.springboot整合druid
tags: springboot
---
Druid是一个非常优秀的连接池,很好的管理了数据库连接,可以实时监控数据库连接对象和应用程序的数据库操作记录
#### jar包导入
```java
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.0.26</version>
</dependency>
```
#### druid配置
##### application.properties文件配置
```properties
spring.druid.jdbc-url=jdbc:mysql://127.0.0.1:3306/springboot1
spring.druid.jdbc-url1=jdbc:mysql://127.0.0.1:3306/springboot2
spring.druid.username=root
spring.druid.password=root
spring.druid.driver-class-name=org.gjt.mm.mysql.Driver
spring.druid.initialSize=2
spring.druid.minIdle=2
spring.druid.maxActive=2
# 配置获取链接等待超时的时间
spring.druid.maxWait=60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
spring.druid.timeBetweenEvictionRunsMillis=60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
spring.druid.minEvictableIdleTimeMillis=300000
spring.druid.validationQuery=SELECT 1 FROM DUAL
spring.druid.testWhileIdle=true
spring.druid.testOnBorrow=false
spring.druid.poolPreparedStatement=false
spring.druid.maxPoolPreparedStatementPerConnectionSize=20
# 配置监控统计拦截的filters,去掉后监控见面sql无法统计,‘wall’用于防火墙
spring.druid.filters=stat
# 通过connectionProperties属性来打开mergeSql功能;慢sql记录
spring.druid.connectionProperties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
```
##### 数据库连接配置
```java
@Data
@Configuration
@ConfigurationProperties(prefix = "spring.druid", ignoreInvalidFields = true)
public class DruidConfig {
private String driverClassName;
private String jdbcUrl;
private String jdbcUrl1;
private String username;
private String password;
private int maxActive;
private int minIdle;
private int initialSize;
private Long timeBetweenEvictionRunsMillis;
private Long minEvictableIdleTimeMillis;
private String validationQuery;
private boolean testWhileIdle;
private boolean testOnBorrow;
private boolean testOnReturn;
private boolean poolPreparedStatements;
private Integer maxPoolPreparedStatementPerConnectionSize;
private String filters;
private String connectionProperties;
// 数据源对象创建并加入到spring容器中
@Bean
public DataSource getDs1() {
DruidDataSource druidDataSource = new DruidDataSource();
druidDataSource.setDriverClassName(driverClassName);
druidDataSource.setUrl(jdbcUrl);
druidDataSource.setUsername(username);
druidDataSource.setPassword(password);
druidDataSource.setMaxActive(maxActive);
druidDataSource.setInitialSize(initialSize);
druidDataSource.setTimeBetweenConnectErrorMillis(timeBetweenEvictionRunsMillis);
druidDataSource.setMinEvictableIdleTimeMillis(minEvictableIdleTimeMillis);
druidDataSource.setValidationQuery(validationQuery);
druidDataSource.setTestWhileIdle(testWhileIdle);
druidDataSource.setTestOnBorrow(testOnBorrow);
druidDataSource.setTestOnReturn(testOnReturn);
druidDataSource.setPoolPreparedStatements(poolPreparedStatements);
druidDataSource.setMaxPoolPreparedStatementPerConnectionSize(maxPoolPreparedStatementPerConnectionSize);
try {
druidDataSource.setFilters(filters);
} catch (SQLException e) {
e.printStackTrace();
}
return druidDataSource;
}
/**
* 配置访问 druid监控
*
* @return
*/
@Bean
public ServletRegistrationBean druidStateViewServlet() {
ServletRegistrationBean servletRegistrationBean = new ServletRegistrationBean(new StatViewServlet(), "/druid/*");
// 初始化参数initParams
// 添加白名单
servletRegistrationBean.addInitParameter("allow", "");
// 添加ip黑名单
servletRegistrationBean.addInitParameter("deny", "192.168.244.100");
// 登录查看信息的账号密码
servletRegistrationBean.addInitParameter("loginUsername", "admin");
servletRegistrationBean.addInitParameter("loginPassword", "123456");
// 是否能够重置数据
servletRegistrationBean.addInitParameter("resetEnable", "false");
return servletRegistrationBean;
}
/**
* 过滤不需要监控的后缀
*
* @return
*/
@Bean
public FilterRegistrationBean druidStatFilter() {
FilterRegistrationBean filterRegistrationBean = new FilterRegistrationBean(new WebStatFilter());
filterRegistrationBean.addUrlPatterns("/*");
filterRegistrationBean.addInitParameter("exclusions", "*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*");
return filterRegistrationBean;
}
}
``` | 4,469 | MIT |
---
layout: post
title: "校园意识形态管控加剧:陆港同步行动"
date: 2015-01-20T13:19:54+01:00
author: 卿子衿
from: https://pao-pao.net/article/343
tags: [ 泡泡 ]
categories: [ 泡泡 ]
---
<section class="clearfix" id="content" role="main">
<div class="region region-content">
<div class="block block-system" id="block-system-main">
<div class="content">
<div about="/article/343" class="node node-pao-pao-article node-promoted node-full view-mode-full clearfix" id="node-343" typeof="sioc:Item foaf:Document">
<span class="rdf-meta element-hidden" content="校园意识形态管控加剧:陆港同步行动" property="dc:title">
</span>
<span class="rdf-meta element-hidden" content="2" datatype="xsd:integer" property="sioc:num_replies">
</span>
<div class="submitted">
<span content="2015-01-20T13:19:54+01:00" datatype="xsd:dateTime" property="dc:date dc:created" rel="sioc:has_creator">
<a about="/author/702" class="username" datatype="" href="/author/702" property="foaf:name" title="查看用户资料" typeof="sioc:UserAccount" xml:lang="">
卿子衿
</a>
在 星期二, 01/20/2015 - 13:19 提交
</span>
</div>
<div class="content">
<div class="field field-name-field-image field-type-image field-label-hidden">
<div class="field-items">
<div class="field-item even">
<div class="file file-image file-image-jpeg" id="file-924--2">
<h2 class="element-invisible">
<a href="/file/924">
anp-30400103.jpg
</a>
</h2>
<div class="content">
<img alt="" height="164" src="https://pao-pao.net/sites/pao-pao.net/files/styles/article_detail/public/anp-30400103.jpg?itok=k1N4W0o3" title="" typeof="foaf:Image" width="290"/>
<div class="field field-name-field-image-source field-type-link-field field-label-hidden">
<div class="field-items">
<div class="field-item even">
<a href="https://www.anpfoto.nl/search.pp?page=1&ShowPicture=30400103&pos=13">
长沙学校抵制圣诞节 图/法新社
</a>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
<div class="field field-name-title field-type-ds field-label-hidden">
<div class="field-items">
<div class="field-item even" property="dc:title">
<h1 class="page-title">
校园意识形态管控加剧:陆港同步行动
</h1>
</div>
</div>
</div>
<div class="field-name-author">
<div class="label-inline">
文/
</div>
<a about="/author/702" class="username" datatype="" href="/author/702" property="foaf:name" title="查看用户资料" typeof="sioc:UserAccount" xml:lang="">
卿子衿
</a>
</div>
<div class="field field-name-body field-type-text-with-summary field-label-hidden">
<div class="field-items">
<div class="field-item even" property="content:encoded">
<p>
“高校宣传思想工作意见”出台,各大媒体联手转载,看起来“高度重视”。高校网络管理被作为其中一项重点,强调要“加强校园网络安全管理,加强高校校园网站联盟建设,加强高校网络信息管理系统建设”。同时,香港雨伞革命被大陆官媒指其源为“教育不力所致”,“秋后算账”之际疑似大波洗脑猛兽正在来袭。
</p>
<h2>
<strong>
大陆:高校意识形态管控加剧
</strong>
</h2>
<p>
官媒
<a href="http://news.xinhuanet.com/edu/2015-01/19/c_1114051345.htm" rel="nofollow">
新华网
</a>
1月19号报道,中共中央办公厅、国务院办公厅最日印发了一份《关于进一步加强和改进新形势下高校宣传思想工作的意见》,该消息当晚就上了央视《新闻联播》,同时有大量陆媒转载,被重视程度可见一斑。
<br/>
<br/>
报道指,该《意见》分七个部分:一、加强和改进高校宣传思想工作是一项重大而紧迫的战略任务;二、指导思想、基本原则和主要任务;三、切实推动中国特色社会主义理论体系进教材进课堂进头脑;四、大力提高高校教师队伍思想政治素质;五、不断壮大高校主流思想舆论;六、着力加强高校宣传思想阵地管理;七、切实加强党对高校宣传思想工作的领导。
</p>
<p>
<strong>
《意见》强调,高校是意识形态工作的“前沿阵地”
</strong>
。中国当局多年来一直严格把握大陆高校意识形态管控,北京理工大学经济学教授胡星斗曾说过:“中国的大学严格意义上來说都是党校”,正如该《意见》中显示的:“高校宣传思想战线始终坚持正确政治方向和舆论导向”、“高校思想理论建设取得新进展,宣传思想阵地管理不断加强,党委统一领导、党政工团齐抓共管的体制机制逐步完善”、“广大师生对党的领导衷心拥护,对以习近平同志为总书记的党中央充分信赖,对中国特色社会主义事业和实现中华民族伟大复兴的中国梦充满信心”……近年来,对知识分子和高校师生意识形态的控制更强了。
</p>
<p>
加强高校网络的管理,是此次高校意识形态工作的重点。《意见》中指出:
</p>
<blockquote>
<p>
要创新网络思想政治教育,开展高校校园网络文化建设专项试点工作,大力推进校报校刊数字化建设,探索建立优秀网络文章在科研成果统计、职务职称评聘方面的 认定机制,着力培育一批导向正确、影响力广的网络名师,立足校园网站建设开办一批贴近师生学习生活的网络名站名栏,建设一支由学生和青年教师骨干组成的网 络宣传员队伍,打造示范性思想理论教育资源网站、学生主题教育网站和网络互动社区,推进辅导员博客、思想政治理论课教师博客、校务微博、校园微信公众账号 等网络新媒体建设。
</p>
</blockquote>
<p>
本网曾报道,
<a href="https://pao-pao.net/node/332" rel="nofollow">
中国高校已部署网络监控系统
</a>
。其中由北京网康科技有限公司开发的ICG上网管理系统,已在河南大学、东华大学、北理工大学实施,将ICG设备旁路部署在学校核心交换机上,对所有用户的互联网行为和外发内容进行审计。
<br/>
<br/>
该《意见》指出了五点“加强和改进新形势下高校宣传思想工作的主要任务”:1、是加强灌输,强调不止要“理论正确、政治正确”,还得“情感正确”,比如“爱党爱国”——“坚定理想信念,深入开展中国特色社会主义和中国梦宣传教育,加强高校思想理论建设,加强具有中国特色、时代特征的高校哲学社会科学学术理论体系和学术话语体系建设,进一步增强理论认同、政治认同、情感认同……”。2、是强调“巩固和凝聚”,也就是讲意识形态核心、排斥异议,同时以宣扬“传统文化美德”带动爱国主义——“大力加强社会主义核心价值观教育,把培育和弘扬社会主义核心价值观作为凝魂聚气、强基固本的基础工程,弘扬中国精神,弘扬中华传统美德,加强道德教育和实践,提升师生思想道德素质……”。3、是暗示“警惕普世价值观影响”,强调官方意识形态要“掌握语话权”——“壮大主流思想舆论,切实加强高校意识形态引导管理,做大做强正面宣传,加强国家安全教育,加强国家观和民族团结教育,坚决抵御敌对势力渗透,牢牢掌握高校意识形态工作领导权、话语权,不断巩固马克思主义指导地位”。4和5则是强调“高校意识形态严管的目标和意义”——“推动文化传承创新,建设具有中国特色、体现时代要求的大学文化,培育和弘扬大学精神,把高校建设成为精神文明建设示范区和辐射源,继承和发扬中华优秀传统文化,促进社会主义先进文化建设,增强国家文化软实力”。
<br/>
<br/>
该“意见”并没有更新鲜的内容,总体体现的就是
<strong>
强调对意识形态管控的深入和加剧,也同时显示出官方对校方自我管制的肯定和“尚不满意”
</strong>
。去年八月底,中国三所知名高校,北大、复旦和中山大学在中共党刊《
<a href="http://www.qstheory.cn/dukan/qs/2014-08/31/c_1112247499.htm" rel="nofollow">
求是
</a>
》杂志上表态,誓言加强对学生的意识形态控制。北大在官网上公开招聘网络思想政治教育工作人员,呼吁师生“要对挑战社会主义核心价值观的言论进行坚决的斗争”。
</p>
<h2>
<strong>
24小时舆情报送
</strong>
</h2>
<p>
中共北大党委的文章写道:“一些别有用心的人在网络上推波助澜,最终把矛头指向中国共产党和社会主义制度,对网络舆论和社会思想共识造成了很大的负面影响。”北大的文章透露,近年来,
<strong>
北京大学建立了24小时舆情报送值班制度,设立专门队伍,使学校能在第一时间掌握舆情动态,第一时间研究对策
</strong>
,
<strong>
确保有效控制和减少负面言论可能带来的不良影响。
</strong>
<br/>
<br/>
纽约时报援引一位刚从北大毕业的学生的话说,舆情报送制度由学工部之下的青年研究中心负责。北大官网刊登的一个招聘启事表明,这个中心正在招聘可协助进行“网络思想政治教育”工作的人员。启事要求申请者必须是党员。同时,在课堂上宣讲宪政而被北大解聘的前教授夏业良在接受
<a href="https://www.voachinese.com/content/china-ideological-control-20140905/2439572.html" rel="nofollow">
美国之音
</a>
采访时表示,
<strong>
北大有一些学生被发展成线民,向领导汇报老师或者学生的可疑言行。
</strong>
他说,“所谓学生信息员是指他们的职责就是报告老师和同学之中有反党反社会等思想政治上有问题的言论,他们就要汇报。社会公众误以为北大的学生都是通过考试选拔出来的状元,其实不是,现在学生构成比较复杂。”
<br/>
<br/>
上述《意见》中也有提出紧抓对高校教师的意识形态管制工作:强调“要着力加强教师思想政治工作,坚持不懈用中国特色社会主义理论体系武装教师头脑,实行学术安全培训制度,重视在优秀青年教师中发展党员”。也就是说,教师与学生要接受同样的洗脑,不从者将遭受相应处罚。自“七不讲”被公开后,大陆已有数名高校教师因在课堂传授普世价值观而被解职,甚至治罪,如前华东政法大学副教授张雪忠、前北大教授夏业良,前中央民族大学副教授
<a href="https://pao-pao.net/node/74" rel="nofollow">
伊力哈木·土赫提则被以“煽动分裂”等多项罪名起诉
</a>
,官方提供的相关“证据”中就包含了他“涉嫌煽动暴力”的讲课视频。
</p>
<div class="half-right">
<div class="media media-element-container media-full">
<div class="ds-1col file file-image file-image-jpeg view-mode-full clearfix">
<img alt="" class="media-element file-full" height="270" src="https://pao-pao.net/sites/pao-pao.net/files/styles/large/public/1_11.jpg?itok=1Ly2YMdq" title="" typeof="foaf:Image" width="480"/>
</div>
</div>
<br/>
</div>
<div>
被指为“愚民教育”的中国意识形态控制一直是“从娃娃抓起”的,小学教材就开始党化思想渗透,中学进入系统灌输,大学则完全到达顶峰。马列主义、毛泽东思想、邓小平理论、三个代表重要思想、以及中共应届领导人的讲话,都是大学所有专业学生的必修课,据悉其课时量和学分占大学生总课时量和学分的10%。随着网络时代的到来,网民数量激增,民众接受普世价值观的机会越来越多,洗脑“战场”的重点又增加了网络这一项,不论是删帖封号、封锁屏蔽,还是大举发动五毛水军“占领”舆论平台,目的都是一致的——通过遏制言论和信息以控制思想。
</div>
<h2>
香港:“反国教”短暂起效,未能“治本”
</h2>
<p>
据香港传媒本月17日的报道,香港特首梁振英以荣誉赞助人身份支持成立“香港青少年军总会”,其妻子唐青仪担任青少年军总司令,并于18日假座解放军驻港昂船州军营正式举行成立典礼。其他荣誉赞助人包括中联办主任张晓明和解放军驻港部队司令员谭本宏,全国政协副主席董建华担任总会首席荣誉会长,妻子赵洪娉则担任荣誉顾问。
<br/>
<br/>
此举被泛民立法议员陈家洛指为“国民教育的借尸还魂”。陈家洛表示:根据青少年军的组织架构可以断定,梁振英无法在学校推行国民教育,故以另一种方法借尸还魂,渗入青年人阶层,招揽青少年加入,“梁振英的目的只有一个,就是用尽方法尽快染红下一代的脑袋,进行洗脑工程”。陈家洛在接受苹果日报的采访中表示:整件事非常危险,他提醒家长及青少年在有选择的情况下,应拒绝参与这类有明显政治目的活动,否则泥足深陷,“一旦加入之后就要跟住叫口号,跟住他们的路线同纲领,一步一步侵蚀下一代的批判思维”。
</p>
<div class="half-left">
<a href="http://www.post852.com/%E6%95%99%E8%A9%95%E6%9C%83%E4%BD%95%E6%BC%A2%E6%AC%8A%EF%BC%9A%E6%88%91%E5%B0%B1%E7%9C%9F%E4%BF%82%E5%94%94%E5%BB%BA%E8%AD%B0%E7%94%A8%EF%BC%88%E7%B8%BD%E5%8F%B8%E4%BB%A4%EF%BC%89%E5%91%A2%E4%B8%89/" rel="nofollow">
<div class="media media-element-container media-full">
<div class="ds-1col file file-image file-image-jpeg view-mode-full clearfix">
<img alt="" class="media-element file-full" height="397" src="https://pao-pao.net/sites/pao-pao.net/files/styles/large/public/tu_2_20.jpg?itok=j0pkthUz" title="" typeof="foaf:Image" width="480"/>
</div>
</div>
</a>
</div>
<div>
<br/>
<a href="http://www.post852.com/%E6%95%99%E8%A9%95%E6%9C%83%E4%BD%95%E6%BC%A2%E6%AC%8A%EF%BC%9A%E6%88%91%E5%B0%B1%E7%9C%9F%E4%BF%82%E5%94%94%E5%BB%BA%E8%AD%B0%E7%94%A8%EF%BC%88%E7%B8%BD%E5%8F%B8%E4%BB%A4%EF%BC%89%E5%91%A2%E4%B8%89/" rel="nofollow">
香港852邮报
</a>
在相关报道中表示,由被钦点为“总司令”的梁振英太太梁唐青仪带领一众临时拉伕的青少年军,向中联办主任张晓明和解放军驻港部队总司令员谭本宏宣誓“报效祖国”。教育评议会副主席何汉权次日在电台节目上坦言:该香港青少年军的筹组过程事前未有更多咨询教育界,教育界及公众至今仍对其知之甚少,对方須尽快让大家了解其活动细节。
<br/>
<br/>
梁振英曾在2012年试图在香港推广“德育与国民教育课”,计划在中小学列为必俢科,据称目的是“加深学生认同祖国及对国民身份的自豪感”。因为教育内容“爱党多于爱国”,被港人质疑为政治洗脑,遭到强烈反对。当年9月,12万港人游行集会“
<a href="https://zh.wikipedia.org/wiki/%E5%85%A8%E6%B0%91%E8%A1%8C%E5%8B%95%EF%BC%8C%E5%8F%8D%E5%B0%8D%E6%B4%97%E8%85%A6%EF%BC%8C7%E6%9C%8829%E6%97%A5%EF%BC%8C%E8%90%AC%E4%BA%BA%E5%A4%A7%E9%81%8A%E8%A1%8C" rel="nofollow">
反国民教育
</a>
”,此后梁振英被迫取消三年试行的死线。
</div>
<div class="half-right">
<div class="media media-element-container media-full">
<div class="ds-1col file file-image file-image-jpeg view-mode-full clearfix">
<img alt="" class="media-element file-full" height="360" src="https://pao-pao.net/sites/pao-pao.net/files/styles/large/public/tu_1_30.jpg?itok=DNOMdJOF" title="" typeof="foaf:Image" width="480"/>
</div>
</div>
<br/>
</div>
<div>
当时国民教育家长关注组召集人陈惜姿称:国民教育科已经搁置,但在学生的书包里面,他们的教材已经出现国民教育的内容。比如小学五年级的课程,其中一页提及所谓"中国建国",简化为抗日胜利后,毛泽东建立新中国,到改革开放,但反右、大饥荒和文化大革命就一字不提。“既然你要拿骄傲的事情来说,你是不是都可以提一提发生过什么事情,比如大饥荒、文革,这些真的实实在在生灵涂炭的事情”。另,关注组担忧的是,如果学生为求考试得分,照背老师所教的答案,就会教出不诚实的学生。
<br/>
<br/>
如今可见,当年的“反国民教育”抗争只是短期起效,并没能根除政府对港民进行大陆式洗脑的意识,趁占中抗争运动暂歇、“秋后算账”正行之时,一波大举洗脑计划已开始酝酿和进行中。大陆官媒《
<a href="http://china.huanqiu.com/article/2014-12/5304685.html" rel="nofollow">
环球时报
</a>
》在去年底就直言:“占中以青年人为主力,因此社会必须正视教育下一代,否则香港将来可能出现极端分子甚至死士”。“青少年军”之后还将有什么,实难想象,但足够肯定,香港教育或将迅速被“大陆化”。
<br/>
<br/>
近年来,有大陆民众提出“教育自救”方案,认为必须行动起来,以使自己或自己的子女从教育灾难中被解救。“公立学校和依附于体制的各种教育通过日复一日的反教育会使得民众失去感知力、想象力、创造力、同情心、正义感、是非之心、恻隐之心、羞耻之心……它最终造成的结果是:将人变成非人的存在,将孩子变成类人孩”。但“自救”计划又能实现几成?尚无法估测。对香港来说,则是抗争路远。
</div>
</div>
</div>
</div>
<div class="field field-name-service-links-displays-group field-type-ds field-label-hidden">
<div class="field-items">
<div class="field-item even">
<div class="service-links">
<a class="service-links-twitter" href="https://twitter.com/share?url=https%3A//pao-pao.net/article/343&text=%E6%A0%A1%E5%9B%AD%E6%84%8F%E8%AF%86%E5%BD%A2%E6%80%81%E7%AE%A1%E6%8E%A7%E5%8A%A0%E5%89%A7%EF%BC%9A%E9%99%86%E6%B8%AF%E5%90%8C%E6%AD%A5%E8%A1%8C%E5%8A%A8" rel="nofollow" title="Share this on Twitter">
<img alt="Twitter logo" src="https://pao-pao.net/sites/pao-pao.net/themes/rnw_paopao/servicelinks/png/twitter.png" typeof="foaf:Image"/>
</a>
<a class="service-links-facebook" href="https://www.facebook.com/sharer.php?u=https%3A//pao-pao.net/article/343&t=%E6%A0%A1%E5%9B%AD%E6%84%8F%E8%AF%86%E5%BD%A2%E6%80%81%E7%AE%A1%E6%8E%A7%E5%8A%A0%E5%89%A7%EF%BC%9A%E9%99%86%E6%B8%AF%E5%90%8C%E6%AD%A5%E8%A1%8C%E5%8A%A8" rel="nofollow" title="Share on Facebook">
<img alt="Facebook logo" src="https://pao-pao.net/sites/pao-pao.net/themes/rnw_paopao/servicelinks/png/facebook.png" typeof="foaf:Image"/>
</a>
<a class="service-links-google" href="https://www.google.com/bookmarks/mark?op=add&bkmk=https%3A//pao-pao.net/article/343&title=%E6%A0%A1%E5%9B%AD%E6%84%8F%E8%AF%86%E5%BD%A2%E6%80%81%E7%AE%A1%E6%8E%A7%E5%8A%A0%E5%89%A7%EF%BC%9A%E9%99%86%E6%B8%AF%E5%90%8C%E6%AD%A5%E8%A1%8C%E5%8A%A8" rel="nofollow" title="Bookmark this post on Google">
<img alt="谷歌 logo" src="https://pao-pao.net/sites/pao-pao.net/themes/rnw_paopao/servicelinks/png/google.png" typeof="foaf:Image"/>
</a>
</div>
</div>
</div>
</div>
</div>
<div class="block block-views related" id="block-views-articles-related-block-1">
<h2>
您可能感兴趣的文章
</h2>
<div class="content">
<div class="view view-articles-related view-id-articles_related view-display-id-block_1 related promoted view-dom-id-1634c65eced7f64850f1647db623cb52">
<div class="view-content">
<div class="views-row views-row-1 views-row-odd views-row-first">
<div class="ds-2col node node-pao-pao-article node-promoted node-sticky view-mode-home_promoted_block_ clearfix">
<div class="group-left">
<div class="field field-name-field-image field-type-image field-label-hidden">
<div class="field-items">
<div class="field-item even">
<a href="/article/770">
<img height="90" src="https://pao-pao.net/sites/pao-pao.net/files/styles/home_promoted/public/tou__19.jpg?itok=_8R9QyUV" typeof="foaf:Image" width="160"/>
</a>
</div>
</div>
</div>
</div>
<div class="group-right">
<div class="field field-name-field-promotitle field-type-text field-label-hidden">
<div class="field-items">
<div class="field-item even">
<h2>
<a href="/article/770">
悲观者指南:中文网络的2017
</a>
<h2>
</h2>
</h2>
</div>
</div>
</div>
</div>
</div>
</div>
<div class="views-row views-row-2 views-row-even">
<div class="ds-2col node node-pao-pao-article node-promoted view-mode-home_promoted_block_ clearfix">
<div class="group-left">
<div class="field field-name-field-image field-type-image field-label-hidden">
<div class="field-items">
<div class="field-item even">
<a href="/article/151">
<img height="90" src="https://pao-pao.net/sites/pao-pao.net/files/styles/home_promoted/public/anp-28004345.jpg?itok=zMPtQtZI" typeof="foaf:Image" width="160"/>
</a>
</div>
</div>
</div>
</div>
<div class="group-right">
<div class="field field-name-field-promotitle field-type-text field-label-hidden">
<div class="field-items">
<div class="field-item even">
<h2>
<a href="/article/151">
香港:动员反占中游行的“话题传销”
</a>
<h2>
</h2>
</h2>
</div>
</div>
</div>
</div>
</div>
</div>
<div class="views-row views-row-3 views-row-odd">
<div class="ds-2col node node-pao-pao-article node-promoted node-sticky view-mode-home_promoted_block_ clearfix">
<div class="group-left">
<div class="field field-name-field-image field-type-image field-label-hidden">
<div class="field-items">
<div class="field-item even">
<a href="/article/809">
<img height="90" src="https://pao-pao.net/sites/pao-pao.net/files/styles/home_promoted/public/qian_.jpg?itok=oApMDFCb" typeof="foaf:Image" width="160"/>
</a>
</div>
</div>
</div>
</div>
<div class="group-right">
<div class="field field-name-field-promotitle field-type-text field-label-hidden">
<div class="field-items">
<div class="field-item even">
<h2>
<a href="/article/809">
为什么很多中国网民“无理搅三分”;“吹捧群主风”是怎么来的?
</a>
<h2>
</h2>
</h2>
</div>
</div>
</div>
</div>
</div>
</div>
<div class="views-row views-row-4 views-row-even views-row-last">
<div class="ds-2col node node-pao-pao-article node-promoted node-sticky view-mode-home_promoted_block_ clearfix">
<div class="group-left">
<div class="field field-name-field-image field-type-image field-label-hidden">
<div class="field-items">
<div class="field-item even">
<a href="/article/739">
<img height="90" src="https://pao-pao.net/sites/pao-pao.net/files/styles/home_promoted/public/tou__4.jpg?itok=WM2sejcF" typeof="foaf:Image" width="160"/>
</a>
</div>
</div>
</div>
</div>
<div class="group-right">
<div class="field field-name-field-promotitle field-type-text field-label-hidden">
<div class="field-items">
<div class="field-item even">
<h2>
<a href="/article/739">
“我永远正确”背后的动机
</a>
<h2>
</h2>
</h2>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
</div>
<!-- /.block -->
<ul class="links inline">
<li class="comment-add first last active">
<a class="active" href="/article/343#comment-form" title="分享您有关本文的看法与观点。">
冒个泡吧!
</a>
</li>
</ul>
<div class="comment-wrapper" id="comments">
<h2 class="title">
评论
</h2>
<a id="comment-3877">
</a>
<div about="/comment/3877#comment-3877" class="comment comment-by-anonymous clearfix" typeof="sioc:Post sioct:Comment">
<div class="attribution">
<div class="comment-submitted">
<p class="commenter-name">
<span rel="sioc:has_creator">
<span class="username" datatype="" property="foaf:name" typeof="sioc:UserAccount" xml:lang="">
Jeaacalay (未验证)
</span>
</span>
</p>
<p class="comment-time">
<span content="2019-04-23T10:37:42+02:00" datatype="xsd:dateTime" property="dc:date dc:created">
星期二, 04/23/2019 - 10:37
</span>
</p>
<p class="comment-permalink">
<a class="permalink" href="/comment/3877#comment-3877" rel="bookmark">
永久连接
</a>
</p>
</div>
</div>
<div class="comment-text">
<div class="comment-arrow">
</div>
<h3 datatype="" property="dc:title">
<a class="permalink" href="/comment/3877#comment-3877" rel="bookmark">
Cialis Ci Vuole La Ricetta JeaPriods
</a>
</h3>
<div class="content">
<span class="rdf-meta element-hidden" rel="sioc:reply_of" resource="/article/343">
</span>
<div class="field field-name-comment-body field-type-text-long field-label-hidden">
<div class="field-items">
<div class="field-item even" property="content:encoded">
<p>
Viagra Vs Cialis [url=
<a href="http://oc-35.com]propecia">
http://oc-35.com]propecia
</a>
tablets for sale[/url] Where Do I Buy Cialis Levitra Vergessen
</p>
</div>
</div>
</div>
</div>
<!-- /.content -->
<ul class="links inline">
<li class="comment-reply first last">
<a href="/comment/reply/343/3877">
回复
</a>
</li>
</ul>
</div>
<!-- /.comment-text -->
</div>
<a id="comment-15964">
</a>
<div about="/comment/15964#comment-15964" class="comment comment-by-anonymous clearfix" typeof="sioc:Post sioct:Comment">
<div class="attribution">
<div class="comment-submitted">
<p class="commenter-name">
<span rel="sioc:has_creator">
<span class="username" datatype="" property="foaf:name" typeof="sioc:UserAccount" xml:lang="">
StevElug (未验证)
</span>
</span>
</p>
<p class="comment-time">
<span content="2019-06-01T10:17:36+02:00" datatype="xsd:dateTime" property="dc:date dc:created">
星期六, 06/01/2019 - 10:17
</span>
</p>
<p class="comment-permalink">
<a class="permalink" href="/comment/15964#comment-15964" rel="bookmark">
永久连接
</a>
</p>
</div>
</div>
<div class="comment-text">
<div class="comment-arrow">
</div>
<h3 datatype="" property="dc:title">
<a class="permalink" href="/comment/15964#comment-15964" rel="bookmark">
Cheap Tadalafil 20mg Stevprople
</a>
</h3>
<div class="content">
<span class="rdf-meta element-hidden" rel="sioc:reply_of" resource="/article/343">
</span>
<div class="field field-name-comment-body field-type-text-long field-label-hidden">
<div class="field-items">
<div class="field-item even" property="content:encoded">
<p>
Where Can I Buy Furosemide In The Uk <a href=
<a href="http://drugsed.com></a>">
http://drugsed.com></a>
</a>
Otc Metformin
</p>
</div>
</div>
</div>
</div>
<!-- /.content -->
<ul class="links inline">
<li class="comment-reply first last">
<a href="/comment/reply/343/15964">
回复
</a>
</li>
</ul>
</div>
<!-- /.comment-text -->
</div>
<h2 class="title comment-form">
冒个泡吧!
</h2>
</div>
</div>
</div>
</div>
<!-- /.block -->
</div>
<!-- /.region -->
</section> | 23,102 | MIT |
# 说明
装备做啥
1. 把onRequest 独立出来,单独用一个对象来处理
1. 写一个洋葱型中间件,就像koa那样
2. 中间件参数传递:Context表示上下文
# 独立onRequest里的代码
swoole的http server 中,一个 onRequest 就是一个完整的http生命周期
然后我们独立出来更直观一点
比如我们定义为 Http 对象 `Sharedsway\Http\Http`
从 `Sharedsway\Http\Http` 的构造到析构即一个http请求的完整生命周期
这里本来应该写一个接口,因为我们后续会用Di来管理大多数对象,在接口加持下,能很容易替换掉该 `Sharedsway\Http\Http` 对象
后来一想,算了,这事儿还早,先运行起来了再考虑不迟
Http 要哪些方法,大致写一下
算了,直接写上了,基本上这3个方法就行了,后续可能加一些查询等
```php
interface HttpInterface
{
/**
* 注册中间件
* @param $middleware
*/
public function use($middleware);
/**
* 进入下一个中间件
*/
public function next();
/**
*
*/
public function handle();
}
```
然后,Http 类,实现相应的方法就行了,具体看代码 src/Http.php
其中的思路就是:
1. use 注册一个中间件,push到数组
2. 通过yield 返回生成器
3. 执行生成器的 next()方法
# 上下文Context
说白了,就是把一推参数往里面放
所以就是一个普通对象
但是,因为对像里面可能会有其它的属性,为了区分,就把动态设置的上下参数放一个数组里面
另外,为了后续使用方便,继承下 InjectionAwareInterface 接口
```php
namespace Sharedsway\Http;
use Sharedsway\Di\Library\InjectableAwareTrait;
use Sharedsway\Di\Library\InjectionAwareInterface;
class Context implements InjectionAwareInterface
{
use InjectableAwareTrait;
protected $ctx = [];
function __set($k, $v)
{
$this->ctx[$k] = $v;
}
function __get($k)
{
$value = $this->ctx[$k] ?? null;
return $value;
}
}
```
上下文就这么简单的实现,后续中间件就用这货传递参数
# 修改Application
修改 onRequest 里的代码
```php
public function onRequest(Swoole\Http\Request $request, Swoole\Http\Response $response)
{
// 实例化一个http 对象
$http = new Http($request, $response);
// 注册中间件
$http->use(function ($context, $next) {
$context->hello = 'world';
var_dump('start 1');
$next();
var_dump('end 1');
});
$http->use(function ($context, $next) {
var_dump('start 2');
$next();
var_dump('end 2');
});
$http->use(function ($context, $next) {
var_dump('start 3');
$next();
var_dump('end 3');
});
$http->use('/hello', function ($context, $next) {
var_dump('the response is "hello hello"');
});
$http->use(function ($context, $next) {
var_dump('hello ' . $context->hello);
});
$http->use(function ($context, $next) {
var_dump('this is not visible');
});
// handle
$http->handle();
}
```
运行服务器
curl http://xxxx/ 输出:
```text
string(7) "start 1"
string(7) "start 2"
string(7) "start 3"
string(11) "hello world"
string(5) "end 3"
string(5) "end 2"
string(5) "end 1"
```
curl http://xxxx/hello 输出:
```text
string(7) "start 1"
string(7) "start 2"
string(7) "start 3"
string(29) "the response is "hello hello""
string(5) "end 3"
string(5) "end 2"
string(5) "end 1"
```
说明运行正常了
# commit id
[ed9f6a5f2047972b20e81b54b5501a369c2930a1](ed9f6a5f2047972b20e81b54b5501a369c2930a1) | 2,834 | MIT |
# 2022-01-05
共 231 条
<!-- BEGIN ZHIHUQUESTIONS -->
<!-- 最后更新时间 Wed Jan 05 2022 23:00:40 GMT+0800 (China Standard Time) -->
1. [西安一孕妇由于核酸问题无法入院,在医院门口等 2 小时后流产,该如何更好地解决类似情况?](https://www.zhihu.com/question/509889297)
1. [√8-√2=√2,这是怎么得出来的?](https://www.zhihu.com/question/461209225)
1. [西安大数据资源管理局局长停职检查,此前西安一码通半个月内两次崩溃,这给疫情防控带来哪些影响?](https://www.zhihu.com/question/509914345)
1. [如何看待斗鱼主播芜湖大司马疑似在直播《英雄联盟》中使用脚本进行游戏?](https://www.zhihu.com/question/509488149)
1. [南京一男子疑因地铁摸女生屁股被狂扇耳光,警方称正在核实,具体情况如何?遇到类似事情该如何妥善处理?](https://www.zhihu.com/question/509928485)
1. [为什么全世界博物馆都以拥有中国文物为荣耀?](https://www.zhihu.com/question/503661298)
1. [美国将幽门螺旋杆菌列为明确致癌物,中国感染率近 60% ,日常生活中该如何预防?](https://www.zhihu.com/question/509920996)
1. [网传腾讯外包员工在工作群抢到 5 元红包,组长要求其退回,真实性如何?腾讯外包和正式待遇上有啥不同?](https://www.zhihu.com/question/509778946)
1. [如何看待王老吉新年推出姓氏罐?这是创新还是对原有品牌的伤害?](https://www.zhihu.com/question/439688424)
1. [如何看待西安一业主因翻墙被志愿者罚对镜头做检讨,随后志愿者登门道歉?这种情况有更好地处理方式吗?](https://www.zhihu.com/question/509935442)
1. [卫健委专家曾光称「西安疫情是武汉后最严重的一回」,西安疫情有哪些不一样的地方?可以总结哪些新防疫经验?](https://www.zhihu.com/question/509860762)
1. [西安「猫咪纯手工限量款窗帘」意外走红,主人称拦不住就破罐子破摔了,铲屎官们都经历过哪些无可奈何的妥协?](https://www.zhihu.com/question/509021819)
1. [如何看待「女生被男朋友忘在服务区2小时,又冷又饿又没有手机」?恋爱期间怎样才能始终保持热情与温度?](https://www.zhihu.com/question/509758073)
1. [2022 新交规称「4 月 1 日起超速 20% 内不扣分」,这个新政对日常驾驶有哪些影响?](https://www.zhihu.com/question/509866092)
1. [如何看待有调查称「 2021 年本科毕业月平均起薪 5825 元」?你的工资达标了吗?](https://www.zhihu.com/question/509913360)
1. [如何看待华为赛力斯停产,首批用户成最后一批用户,售后问题如何解决?](https://www.zhihu.com/question/509823711)
1. [如何看待「雷军钦点的小米 6 钉子户」吐槽小米 12,四天死机三次?](https://www.zhihu.com/question/509932009)
1. [成龙批评年轻演员爱耍大牌,拍戏最晚到最早走,如何评价这一现状?为什么感觉年轻演员不如前辈努力?](https://www.zhihu.com/question/509828450)
1. [张小斐凭 54 亿票房《你好,李焕英》荣获金鸡影后,未来她会成为大陆市场又一个有票房号召力的女演员吗?](https://www.zhihu.com/question/509500739)
1. [上海割腕女子住院时跳楼身亡,家属索赔 237 万,这会给当地医院带来什么样的影响?](https://www.zhihu.com/question/508748543)
1. [广东一对姐弟走失超 10 小时后父母才报警,他们原以为失踪 24 小时才能报警,关于报警还有哪些误区?](https://www.zhihu.com/question/509642840)
1. [华为商城再开售 HUAWEI Mate 40 Pro 5G 手机,售价 6799 元,值得入手吗?](https://www.zhihu.com/question/509509785)
1. [报道称海归薪资已无太多优势,出国留学性价比下降,留学还值得吗?](https://www.zhihu.com/question/509757621)
1. [《安徽省人口与计划生育条例》正式施行,明确再婚家庭可再生育三个子女,这会带来哪些影响?](https://www.zhihu.com/question/509989767)
1. [古代的食用油是不是很稀罕?那他们是怎么吃得起油条的?](https://www.zhihu.com/question/508694145)
1. [市场监管总局对腾讯、杭州阿里创业投资等进行行政处罚,将带来哪些影响?](https://www.zhihu.com/question/509944131)
1. [亲兄弟亲姐妹一个超丑一个超美是什么体验?](https://www.zhihu.com/question/292663930)
1. [没有一本出土的古希腊时期的书上写着“亚里士多德”这个名字,这是否证明古希腊没有亚里士多德?](https://www.zhihu.com/question/509366242)
1. [罗永浩被执行信息清零,目前无被限制高消费,罗永浩公司称「不等于债务偿还完毕」,后续可能会怎样发展?](https://www.zhihu.com/question/509993748)
1. [二十万的轿车跟四十万的轿车究竟差别在哪里?](https://www.zhihu.com/question/343791192)
1. [1 月 4 日山东新增 1 确诊病例,境外返回曾在上海隔离 14 日,6 次核酸均为阴,目前情况如何?](https://www.zhihu.com/question/509941532)
1. [湖南怀化检察院报告称,「操场埋尸案」5 名司法人员被立案侦查,24 人被判刑,还有哪些值得关注?](https://www.zhihu.com/question/509770784)
1. [「假冒滴滴司机直播性侵」当事夫妻刑满释放,公开道歉并表示羞愧,如何评价这对夫妻的行为?](https://www.zhihu.com/question/509943604)
1. [如何评价云堇PV《神女劈观》?](https://www.zhihu.com/question/509974716)
1. [你有什么好的习惯坚持了十年?](https://www.zhihu.com/question/453783511)
1. [2022 年真的是性能车迷们最后的盛宴吗?](https://www.zhihu.com/question/509726121)
1. [如何评价物种进化主题放置类手游《从细胞到奇点》?](https://www.zhihu.com/question/509764156)
1. [在这个快穿文泛滥成灾的时候,你觉得有哪些与众不同/别具一格/清新脱俗/值得一看的快穿文?](https://www.zhihu.com/question/281451235)
1. [网约车司机、外卖骑手等灵活就业群体应该如何获得劳动权益保障?需要怎样的政策扶持?](https://www.zhihu.com/question/507261637)
1. [哈萨克斯坦因「取消液化石油气价格管制」爆发大规模抗议,总统宣布解散政府,目前当地情况如何?](https://www.zhihu.com/question/509920075)
1. [有没有考研英语一85分以上的同学来分享一下经验?](https://www.zhihu.com/question/480591736)
1. [你健身后,有什么健身前不知道的感悟?](https://www.zhihu.com/question/487122993)
1. [高通骁龙 8 Gen1 的性能明明很差,为什么各大手机厂还要「尬吹」?](https://www.zhihu.com/question/509273914)
1. [为什么职场待久了会变得像是自己以前讨厌的那种人?](https://www.zhihu.com/question/319461143)
1. [如何评价一位留学生看完《原神》云堇角色演示后大哭?](https://www.zhihu.com/question/509617578)
1. [美新研究发现「新冠病毒可在心脏、脑部存留数月」,如何从生物学角度解读该情况?](https://www.zhihu.com/question/508723221)
1. [第一批 00 后即将进入社会,会给职场带来哪些新变化?](https://www.zhihu.com/question/509785575)
1. [下班了领导不走,大家也不敢走,这算职场 PUA 吗?](https://www.zhihu.com/question/508704307)
1. [学历真的会影响找工作吗?对年轻人来说学历和努力哪个更重要?](https://www.zhihu.com/question/509083380)
1. [如何评价 Steam 差评「御三家」?](https://www.zhihu.com/question/507665519)
1. [如何看待云佛山滑雪场事件,官方道歉后,男子称工作人员又在直播间诽谤其「一周换一个媳妇」?](https://www.zhihu.com/question/509795759)
1. [立陶宛总统表示允许台湾当局以「台湾」为名开设代表处是错误决定,这意味着什么?](https://www.zhihu.com/question/509874135)
1. [如何看待一加 10 Pro 发布前曝光的邀请函参数表?](https://www.zhihu.com/question/509993272)
1. [每天上下班往返 1.5 小时的通勤时间算长吗?](https://www.zhihu.com/question/506546373)
1. [我努力了这么久,真的应该放弃吗?](https://www.zhihu.com/question/509388650)
1. [国家政策明确「职业本科与普通本科学位证书具有同样效力」,如何有效提升职业院校毕业生的就业竞争力?](https://www.zhihu.com/question/507263691)
1. [毕业四年找工作找了三个月,快要崩溃了?怎么办?](https://www.zhihu.com/question/501140511)
1. [疫情防控常态化的当下,中小微企业和个体工商户面临怎样的困境?如何解决「融资难」、「涉企乱收费」等问题?](https://www.zhihu.com/question/507268269)
1. [如何看待兰州动物园一游客投喂动物,遭工作人员高举喇叭辱骂?什么是更好的处理方式?](https://www.zhihu.com/question/509839992)
1. [《原神》将修改四位女角色立绘与模型,会给游戏体验带来哪些影响?](https://www.zhihu.com/question/509914184)
1. [《原神》修改部分角色外观,你还会继续玩这些角色吗?](https://www.zhihu.com/question/509910821)
1. [如何评价游戏《原神》2.4 版本魔神任务「风起鹤归」?](https://www.zhihu.com/question/509939980)
1. [茶颜悦色宣布涨价,大部分奶茶产品价格上调 1 元,这出于怎样的考虑?你能接受新价格吗?](https://www.zhihu.com/question/509975312)
1. [如何评价英特尔第 12 代酷睿移动版?](https://www.zhihu.com/question/509907915)
1. [有哪些孩子们说的话,让你感觉到了时代的发展?](https://www.zhihu.com/question/506631511)
1. [人为什么会突然喜欢上做饭?](https://www.zhihu.com/question/508923841)
1. [有没有意难平的句子或文案呀?](https://www.zhihu.com/question/509571248)
1. [作为高校毕业生,你的求职过程是否顺利,遇到了哪些困难?](https://www.zhihu.com/question/507262215)
1. [《雪中悍刀行》姜泥为什么会喜欢上杀父仇人的儿子徐凤年?](https://www.zhihu.com/question/509212732)
1. [能预测 2022 年疫情的走势吗,会结束吗?](https://www.zhihu.com/question/497861188)
1. [你的 2021 年度主机游戏是什么?](https://www.zhihu.com/question/508118046)
1. [你有哪些人生经典句子?](https://www.zhihu.com/question/506752315)
1. [如何看待北大教授称自己贬值太厉害,「高等教育普及化,大家都觉得不值钱了」?大学教授现在的待遇如何?](https://www.zhihu.com/question/509190611)
1. [如何评价 MIUI 13 可能内置反诈系统,有什么影响?](https://www.zhihu.com/question/509458835)
1. [媒体称快手裁员范围覆盖电商、商业化、国际化、游戏四大事业部,个别团队裁员 30%,员工能获得什么补偿?](https://www.zhihu.com/question/509851673)
1. [2022 年游戏行业将会有什么新的进展?](https://www.zhihu.com/question/496286655)
1. [如何评价下沉市场的消费能力,为何其成了「电商必争之地」?](https://www.zhihu.com/question/509821028)
1. [LOL 团战和《DOTA》团战有什么不同?](https://www.zhihu.com/question/305736388)
1. [原神为什么老是出一些老四星角色的上位替代,技能机制基本相同,为什么不出一些有意思的机制设计呢?](https://www.zhihu.com/question/506098499)
1. [Nintendo Switch OLED 国行版 1.11 发售,有哪些亮点?是否值得入手?](https://www.zhihu.com/question/509761517)
1. [你想在 2022 年实现什么愿望?](https://www.zhihu.com/question/505156538)
1. [未来几年,我国电影行业是否会以继续推进主旋律电影为主?](https://www.zhihu.com/question/506789450)
1. [NBA 21-22 赛季国王 114:122 湖人,詹姆斯 31 分威少 19+7,如何评价这场比赛?](https://www.zhihu.com/question/509940457)
1. [如何总结自己的游戏 2021 年?](https://www.zhihu.com/question/508109507)
1. [打四年游戏和学四年生化环材哪个更亏?](https://www.zhihu.com/question/497569812)
1. [现在还有可能造只有一万吨排水量的轻型航空母舰(CVL)么?](https://www.zhihu.com/question/36115979)
1. [为什么很多人看不起《火影忍者》里的飞段和角都?](https://www.zhihu.com/question/503921354)
1. [让你感到不舒服的友谊,该不该断?](https://www.zhihu.com/question/509624411)
1. [西安一男子求隔离未果后,一家 6 口全部确诊,现已得到救治,目前情况如何?谁应该承担责任?](https://www.zhihu.com/question/509844281)
1. [相亲有不成文的规矩吗?](https://www.zhihu.com/question/453068049)
1. [清穿成地位低下的美貌侍妾,要怎么苟到寿终正寝?](https://www.zhihu.com/question/486822044)
1. [如何评价 ThinkPad 全新 Z 系列的 Z13 与 Z16 笔记本电脑?](https://www.zhihu.com/question/508668630)
1. [号令如铁,三军奋力, 2022 全军热血开训。你对 2022 年国防和军队建设有哪些期待?](https://www.zhihu.com/question/509851345)
1. [被现在公司扣着不让走流程辞职,说是等公司招到人才可以走,该怎么办?](https://www.zhihu.com/question/509533871)
1. [如何评价电视剧《雪中悍刀行》 30 集?](https://www.zhihu.com/question/509705539)
1. [为什么枪械在综漫(无限流)作品中存在感不高?](https://www.zhihu.com/question/504340003)
1. [《红楼梦》中,面对贫困的刘姥姥,贾母只送了几件旧衣裳,为什么王夫人却豪掷 100 两?](https://www.zhihu.com/question/500578820)
1. [有哪些第一遍就让你单曲循环的音乐?](https://www.zhihu.com/question/34863117)
1. [为什么孙俪进不去电影圈?](https://www.zhihu.com/question/499998926)
1. [1²+2²+……+1005² 是奇数还是偶数?](https://www.zhihu.com/question/496972245)
1. [为什么我怎么改变自己都好不讨人喜欢,不受人欢迎,善待,待见呢?只是想像一个普通人一样交到朋友难吗?](https://www.zhihu.com/question/509626789)
1. [报考初级会计是在哪里报名,报考流程是什么?](https://www.zhihu.com/question/495797187)
1. [如何挑选成分安全的美白护肤品?](https://www.zhihu.com/question/456927669)
1. [为什么我7/0的阿狸能被0/7的青钢影打的毫无还手之力?](https://www.zhihu.com/question/508482749)
1. [读书的价值是什么?](https://www.zhihu.com/question/498191995)
1. [「2022 年你的年货清单该更新啦!你都有什么新年货灵感要分享」?](https://www.zhihu.com/question/509798917)
1. [1 月 4 日陕西新增本土确诊病例 35 例,目前当地疫情防控情况如何?](https://www.zhihu.com/question/509914978)
1. [《原神》将修改部分角色外观,你有哪些建议?](https://www.zhihu.com/question/509909910)
1. [无限循环小数,可以被计算吗?如果可以,那么 0.33333(无限循环)*1.58=多少?](https://www.zhihu.com/question/507305841)
1. [2021 年你发现了哪些「闭眼入」的好物?对 2022 年的趋势好物有什么期待?](https://www.zhihu.com/question/509841940)
1. [《光·遇》宴会节中等孩子回家的先祖爷爷奶奶,让你想起了谁,有什么样的故事?](https://www.zhihu.com/question/508149640)
1. [刚毕业,会计专业,每次找工作都被拒绝,别人说我没工作经验,我该怎么办?](https://www.zhihu.com/question/509608828)
1. [游戏《原神》的 2.4 版本已更新,你的体验如何?](https://www.zhihu.com/question/509939960)
1. [为什么会有人喜欢《小敏家》徐正那样控制欲极强的人?](https://www.zhihu.com/question/509209988)
1. [如何看待一男子在南京景区穿印有「东京卍会」日漫服饰,被游客要求脱下?我们该如何更好地尊重历史?](https://www.zhihu.com/question/509781113)
1. [所谓「南方湿冷比北方更冷」的观点是如何产生的?](https://www.zhihu.com/question/509727308)
1. [苹果市值盘中突破 3 万亿美元,一度成美国首家市值 3 万亿美元的上市公司,有哪些意义和影响?](https://www.zhihu.com/question/509753301)
1. [在编教师要辞职考研究生吗?](https://www.zhihu.com/question/509584688)
1. [电影《李茂扮太子》中哪些情节戳中了你的笑点?](https://www.zhihu.com/question/509288025)
1. [近代几乎一直维持着完整领土的法国人口为什么比割了东部的德国还要少?](https://www.zhihu.com/question/440186345)
1. [如何看待 2021 全球火箭发射次数打破太空竞赛高峰期的记录?](https://www.zhihu.com/question/509094002)
1. [考研复试应该什么时候开始准备?需要准备些什么?](https://www.zhihu.com/question/509800988)
1. [00 后竟然已经开始开歼-10 战斗机了,你对年轻一代飞行员有哪些期待?](https://www.zhihu.com/question/509847064)
1. [冬天如何穿衣既保暖又可以避免「裹成熊」?](https://www.zhihu.com/question/499250296)
1. [如何评价 AMD 正式发布的全新锐龙 6000 系列移动处理器?](https://www.zhihu.com/question/509892010)
1. [前领导的公司高薪挖我过去,到了新公司后,感觉自己啥也不会,对不起这份高薪,怎么办?](https://www.zhihu.com/question/505508009)
1. [2021 年,你认为最好看的电视剧有哪些?](https://www.zhihu.com/question/505106583)
1. [你有哪些对男孩子的恋爱忠告?](https://www.zhihu.com/question/293676302)
1. [2021年,包括出差在内,你都去过哪些地方旅游?](https://www.zhihu.com/question/509398077)
1. [快过年了,淘宝有哪些值得推荐的地道美食?](https://www.zhihu.com/question/509782090)
1. [穿越者干倒《斗罗大陆一》时期的唐三,至少要满足什么条件?](https://www.zhihu.com/question/507056086)
1. [超「A」年货新潮来袭,如何送礼才算新意过年?](https://www.zhihu.com/question/509825719)
1. [李白、杜甫、白居易一起旅行,即兴作诗谁的诗作会更好?](https://www.zhihu.com/question/504113625)
1. [如何十分钟做出一桌年夜饭?](https://www.zhihu.com/question/509784642)
1. [中国与日本首次建立双边自贸关系,有汽车相关企业将享 0 关税,这将带来哪些影响?](https://www.zhihu.com/question/509628715)
1. [孕期可以运动吗?不同时期有哪些注意事项?](https://www.zhihu.com/question/509020041)
1. [如何以「欢迎来到 2022 年」为开头,写一个故事?](https://www.zhihu.com/question/503473059)
1. [普通人应该去创业还是去打工?](https://www.zhihu.com/question/509364425)
1. [如何看待 2022 年 1 月 4 日美国 25 小时新增新冠确诊 102 万例?](https://www.zhihu.com/question/509759635)
1. [江歌案事件能不能还原一下,怎么没看懂啊?](https://www.zhihu.com/question/399610162)
1. [2022 年,准备装修的你,期待怎样的家装风格?](https://www.zhihu.com/question/508772600)
1. [孩子元旦晚会交换礼物,用手表换了一块旧橡皮,家长该不该出面干预?](https://www.zhihu.com/question/509488938)
1. [清华大学发布 2021 毕业生就业报告,超五成清华毕业生选择京外就业,反映了哪些趋势?](https://www.zhihu.com/question/509771054)
1. [《英雄联盟》的神话装备体系失败在哪?](https://www.zhihu.com/question/508915840)
1. [英特尔敦促主板厂商,禁用 12 代酷睿 AVX 512 指令集,如何解读这一举措?](https://www.zhihu.com/question/509451995)
1. [广东一职业打假人一年打假 800 多起获十几万元涉嫌敲诈勒索被立案,如何从法律角度解读是否构成犯罪?](https://www.zhihu.com/question/509668274)
1. [有二孩家庭的父母真能做到“公平”吗?](https://www.zhihu.com/question/508623656)
1. [你有没有因为别人的一句话,就去读一本书?](https://www.zhihu.com/question/509884806)
1. [室友睡过头你会喊他们吗?](https://www.zhihu.com/question/358502119)
1. [2021 这一年关于旅行的最美好的记忆是什么?](https://www.zhihu.com/question/507372179)
1. [有哪些适合发朋友圈的忧伤文案呢?](https://www.zhihu.com/question/501510823)
1. [有好看的先婚后爱这类型的小说推荐吗?](https://www.zhihu.com/question/472958152)
1. [男朋友求婚买的是几十块钱的戒指,说结婚时再买好的,怎么办?](https://www.zhihu.com/question/509490683)
1. [双飞燕是老品牌了,现在还流行吗?](https://www.zhihu.com/question/29374951)
1. [《英雄联盟》用闪现杀人值得吗?](https://www.zhihu.com/question/478115730)
1. [专家解读西安「解封」前首先要达到「社会面清零」,什么是「社会面清零」? 需要采取什么有效措施?](https://www.zhihu.com/question/509798367)
1. [请问有人试用过数字人民币吗?使用体验如何?](https://www.zhihu.com/question/426681704)
1. [为什么 32G 内存的笔记本电脑比 16G 内存版本贵那么多?](https://www.zhihu.com/question/491435796)
1. [2022 年 1 月起,最高人民检察院将在知乎「亲自答」知友提问。你有什么问题想邀请最高检来答?](https://www.zhihu.com/question/509754469)
1. [西安雁塔区回应就医难、吃菜难,目前西安的医疗和民生保障如何?](https://www.zhihu.com/question/509691518)
1. [如何看待曹丰泽落选 2021 清华大学学生年度人物?](https://www.zhihu.com/question/509414474)
1. [假如一种哺乳动物拥有像螳螂那样子的镰刀,相当于什么水平,能成为顶级猎食者吗?](https://www.zhihu.com/question/508485936)
1. [程序员挣够了钱,到中年失业真的很可怕吗?](https://www.zhihu.com/question/507161643)
1. [如何看待一男生买了拖拉机给 95 后女友当新年礼物?这一届情侣是不是越来越务实了?](https://www.zhihu.com/question/509683616)
1. [22考研的同学们对23考研的有什么建议吗?](https://www.zhihu.com/question/508458872)
1. [你见过最惊艳的玄幻小说等级制度是什么?](https://www.zhihu.com/question/380047941)
1. [你们的猫猫叫什么名字?](https://www.zhihu.com/question/508759973)
1. [你有忘不掉的那个人吗?](https://www.zhihu.com/question/505697234)
1. [为什么对于一些人来说笔记本电脑分辨率高反而是扣分项,他们只想用 1080P 屏幕?](https://www.zhihu.com/question/501353153)
1. [如何看待游戏《fgo》在运营 6 年半之后终于在新年实装保底系统?](https://www.zhihu.com/question/509367785)
1. [二次元游戏厂商因擅自出版游戏《三色绘恋 S》被罚 ,对相关行业能起到哪些警示?](https://www.zhihu.com/question/509333213)
1. [如何看待经济学家姚洋说 5000 元已经是很高的收入了,80、90 后的真实工资中位数是多少?](https://www.zhihu.com/question/509352665)
1. [网友爆料 Kindle 国内官方自营店大面积缺货,消息称亚马逊电子书业务要退出国内市场,是真的吗?](https://www.zhihu.com/question/509750467)
1. [包贝尔被曝疑似抄袭,北电导演系研究生质疑多处细节雷同,具体情况如何?从已知信息看是否构成抄袭?](https://www.zhihu.com/question/509660484)
1. [教资面试怎么准备呀?](https://www.zhihu.com/question/505465979)
1. [有什么可以当做座右铭的古诗词?](https://www.zhihu.com/question/457346008)
1. [做一个神仙或是妖怪是一种怎样的体验?](https://www.zhihu.com/question/37524382)
1. [天气冷的时候吃什么最有幸福感?](https://www.zhihu.com/question/508540544)
1. [2022 年你的存款目标是什么?](https://www.zhihu.com/question/506164190)
1. [有什么值得推荐的美白产品,美白效果稳定,暂停使用也可以持续美白?](https://www.zhihu.com/question/438353112)
1. [如何评价《原神》新角色演示「申鹤:闻鹤于野」?](https://www.zhihu.com/question/509782039)
1. [平心而论,江南的文风是不是真的不适合现在的网文市场了?](https://www.zhihu.com/question/467115518)
1. [BBA在电动时代会跌落神坛吗?](https://www.zhihu.com/question/508874191)
1. [2022 年,你最想尝试的极限运动是什么?为什么?](https://www.zhihu.com/question/503468407)
1. [人的大脑真的是越用越聪明吗?](https://www.zhihu.com/question/505348337)
1. [如何评价 1 月 4 号 realme 发布的真我 GT2 系列新品,有什么亮点与不足?](https://www.zhihu.com/question/509834100)
1. [西方哲学史看不懂怎么办?](https://www.zhihu.com/question/29582502)
1. [买一瓶香水花了 730 元,会不会太奢侈,我应该买吗?](https://www.zhihu.com/question/498419168)
1. [实习律师都需要哪些装备?](https://www.zhihu.com/question/498051566)
1. [2021 年性价比最高的路由器,你认为是哪一款?](https://www.zhihu.com/question/490945223)
1. [才失业不到一个月已经有点慌了怎么办?](https://www.zhihu.com/question/491837428)
1. [为什么中餐演变出了猛火灶的特点?](https://www.zhihu.com/question/427984175)
1. [2022 年真无线降噪蓝牙耳机推荐哪款?](https://www.zhihu.com/question/509564478)
1. [听说防晒霜是无论何时何地都要涂抹的,不然会容易皮肤老化,这是对的吗?](https://www.zhihu.com/question/507040023)
1. [生孩子后才发现,有哪些是没人会告诉你的事?](https://www.zhihu.com/question/499818785)
1. [有没有追妻火葬场但破镜没重圆的故事?](https://www.zhihu.com/question/497122453)
1. [李佳琦推荐的国货化妆品和护肤品真的好用吗?](https://www.zhihu.com/question/378011673)
1. [2022 年开工第一天,作为打工人,你现在心情如何?新的一年有什么计划?](https://www.zhihu.com/question/509769047)
1. [需求决定市场,中国年轻人看动漫需求有多大?动漫产业和日本相比如何?](https://www.zhihu.com/question/509591976)
1. [网传南京一男子公园里穿异国服饰被围住,遭游客要求脱衣,具体情况如何?](https://www.zhihu.com/question/509779528)
1. [假如你拥有想吃就吃的超能力,你最想吃什么?](https://www.zhihu.com/question/509766327)
1. [已发布的骁龙 8 旗舰中,真我 GT2 Pro 表现如何?](https://www.zhihu.com/question/509854718)
1. [什么样的人最容易获得成功?](https://www.zhihu.com/question/58655172)
1. [作为一个普通打工人,上班带饭真的很丢人吗?](https://www.zhihu.com/question/504600440)
1. [如何评价印度电影《杰伊·比姆》?](https://www.zhihu.com/question/501435695)
1. [假如你忘不掉前任,还该不该和现任继续在一起?](https://www.zhihu.com/question/509618931)
1. [生命已经这么短了,为什么大多数人还是流于世俗而不追求真正想要的?](https://www.zhihu.com/question/503742560)
1. [是坚持选择喜欢的人还是选择相处舒服的人?](https://www.zhihu.com/question/508857139)
1. [我今年 14 岁,想了一个数学思路,把数学各领域的联系写出来了,这个思路有什么问题吗?](https://www.zhihu.com/question/508303175)
1. [女朋友月薪三千,想买 iPhone13 Pro,我不建议买,请问怎么样和她沟通消费观这个问题?](https://www.zhihu.com/question/509052294)
1. [假如苹果万元手机卖 1000 元,其它手机厂商会倒闭吗?](https://www.zhihu.com/question/509104977)
1. [有什么让人清醒的雅思备考毒鸡汤?](https://www.zhihu.com/question/325725035)
1. [早上起来上班发现要迟到了,化妆和吃早餐只能选一样,你会选择哪个呢?](https://www.zhihu.com/question/505421780)
1. [为什么岸本齐史的《火影忍者》后期质量直线下降呢?](https://www.zhihu.com/question/22384168)
1. [中法俄英美发表「关于防止核战争与避免军备竞赛的联合声明」,释放了什么信号?](https://www.zhihu.com/question/509711049)
1. [结婚求婚钻戒好还是金条好?](https://www.zhihu.com/question/507876673)
1. [如何看待新疆大叔帮助游客、为了拒绝执意给钱的游客亮出党员徽章?](https://www.zhihu.com/question/509572598)
1. [2021 年,你为旅行花了多少钱?](https://www.zhihu.com/question/503472944)
1. [什么习惯可以让孩子越来越优秀?](https://www.zhihu.com/question/473346434)
1. [有什么充满安全感的文案推荐吗?](https://www.zhihu.com/question/483475509)
1. [新能源汽车到底行不行,该不该买?](https://www.zhihu.com/question/509625829)
1. [学生党刚接触彩妆,第一只口红买平价的还是香奈儿、TF这类大牌口红呢?](https://www.zhihu.com/question/503499221)
1. [有哪些圈子里才知道的小秘密?](https://www.zhihu.com/question/49502870)
1. [特斯拉第四季度交付量创纪录,全年累计交付 93.6 万辆,你认为该公司前景如何?](https://www.zhihu.com/question/509624970)
1. [是什么时候你觉得自己应该要努力了?](https://www.zhihu.com/question/509487319)
1. [3 月起,浙江每份外卖都必须使用「外卖封签」,是否值得推广?能否有效管控外卖安全问题?](https://www.zhihu.com/question/508963767)
1. [做事认真的员工为什么最先离开公司?](https://www.zhihu.com/question/503004198)
1. [如何忘记一个朝思暮想的人?](https://www.zhihu.com/question/509426117)
1. [用劳动价值论怎样解释水与钻石的悖论?](https://www.zhihu.com/question/44991605)
1. [读研时经常请教师兄师姐是不是很招人嫌?](https://www.zhihu.com/question/375196872)
1. [有哪些战争片中细节的错误至今没有被导演意识到?](https://www.zhihu.com/question/508437897)
<!-- END ZHIHUQUESTIONS --> | 17,907 | MIT |
---
bg: "106/106-5.jpg"
title: "みんなの九州きっぷ9~門司駅~"
layout: post
date: 2020-11-5 19:00:00 +9
categories: posts
tags: '旅行記'
author: mencha
---
[前回]( {% post_url 2020-11-5-minnanokyushu8 %}){:target="_blank"} の続き。別府駅から特急ソニックに乗車して小倉まで戻ってきました。

<!--more-->
ちょうど下関から415系がやってきました。こちらは車体がステンレス製の新しいやつ。JR九州の交直両用電車は国鉄形の415系しかないので、関門トンネルを通る場合は必ずこの電車へ乗ることになります。

小倉駅からひと駅隣の門司駅にやってきました。この駅が関門トンネルの入り口になる駅で、昔はブルートレインの機関車を付け替えたりしていた駅です。今でもJR西日本とJR九州の境界駅として、重要な役割を担っています。

門司駅ホームの上屋。きれいなレール組。

下関行の415系がやってきました。電車の電気が消えているのは、交直切り替えのテストをしているから。いったん電源をすべて落とし、車両のほうの回路を交流から直流へ切り替えているところです。実際に切り替わるのは関門トンネルのあたりですが、走っている途中に切り替わらないというトラブルが発生すると大変なので、このようにテストをしてからトンネルに入るそう。

信号というより表示です。港は門司港、関は関門トンネル方面ほ示しています。

今では無用になってしまった長いホーム。過去の繁栄の光景が思い浮かびます。あ、今でも朝夕ラッシュ時は10両程度の普通列車が走っているみたい。

暗いですが、ホーム先端には「直」注意と書かれた表示があります。交直切り替えの区間であることがよくわかります。

最後に、現在の関門海峡のヌシ、415系を。こちらは車体が鋼製のもので、形は113系等の国鉄近郊型電車とほぼ同じ。この形式のほかは、JR貨物のEH500しか通らない関門海峡、415系もだいぶと古くなっているので、後継車両がどのようなものになるのか気になるところです。 | 1,645 | MIT |
---
layout: post
title: "webpack入门指南"
date: 2017-02-23
categories: 技术
excerpt: '1. 导语1.1 什么叫做webpack webpack is a module bundler. webpack takes modules with dependencies and generates static assets representing those modules. 简单的概括就是:webpack是一个模块打包工具,处理模块之间的依赖同时生成对应模块的静态资源。1'
tag: [webpack, 前端工具]
cover: '/covers/20170223/webpack.jpeg'
comments: true
---
## 1. 导语
github仓库 [https://github.com/Rynxiao/webpack-test](https://github.com/Rynxiao/webpack-test)
### 1.1 什么叫做webpack
> webpack is a module bundler.
> webpack takes modules with dependencies and generates static assets representing those modules.
简单的概括就是:webpack是一个模块打包工具,处理模块之间的依赖同时生成对应模块的静态资源。
### 1.2 webpack可以做一些什么事情

图中已经很清楚的反应了几个信息:
- webpack把项目中所有的静态文件都看作一个模块
- 模快之间存在着一些列的依赖
- 多页面的静态资源生成(打包之后生成多个静态文件,涉及到代码拆分)
## 2. webpack安装
- 全局安装(供全局调用:如`webpack --config webpack.config.js`)
```javascript
npm install -g webpack
```
- 项目安装
```javascript
npm install webpack
// 处理类似如下调用
import webpack from "webpack";
var webpack = require("webpack");
```
建议安装淘宝的npm镜像,这样下载npm包会快上很多,具体做法:
```javascript
// 方式一
npm install xx --registry=https://registry.npm.taobao.org/
// 方式二:安装淘宝提供的npm工具
npm install -g cnpm
cnpm install xx
// 方式三
// 在用户主目录下,找到.npmrc文件,加上下面这段配置
registry=https://registry.npm.taobao.org/
```
## 3. webpack的基本配置
创建配置文件(`webpack.config.js`,执行webpack命令的时候,默认会执行这个文件)
```javascript
module.export = {
entry : 'app.js',
output : {
path : 'assets/',
filename : '[name].bundle.js'
},
module : {
loaders : [
// 使用babel-loader解析js或者jsx模块
{ test : /\.js|\.jsx$/, loader : 'babel' },
// 使用css-loader解析css模块
{ test : /\.css$/, loader : 'style!css' },
// or another way
{ test : /\.css$/, loader : ['style', 'css'] }
]
}
};
```
说明一: `webpack.config.js`默认输出一个`webpack`的配置文件,与`CLI`方式调用相同,只是更加简便
说明二: 执行`webpack`命令即可以运行配置,先决条件,全局安装`webpack`,项目安装各模块`loader`
说明三: `entry`对应需要打包的入口`js`文件,`output`对应输出的目录以及文件名,`module`中的`loaders`对应解析各个模块时需要的加载器
**一个简单的例子**
`basic/app.js`
```javascript
require('./app.css');
document.getElementById('container').textContent = 'APP';
```
---------
`basic/app.css`
```css
* {
margin: 0;
padding: 0;
}
#container {
margin: 50px auto;
width: 50%;
height: 200px;
line-height: 200px;
border-radius: 5px;
box-shadow: 0 0 .5em #000;
text-align: center;
font-size: 40px;
font-weight: bold;
}
```
--------
`basic/webpack.config.js`
```javascript
/**
* webpack打包配置文件
*/
module.exports = {
// 如果你有多个入口js,需要打包在一个文件中,那么你可以这么写
// entry : ['./app1.js', './app2.js']
entry : './app.js',
output : {
path : './assets/',
filename : '[name].bundle.js'
},
module : {
loaders : [
{ test : /\.js$/, loader : 'babel' },
{ test : /\.css$/, loader : 'style!css' }
]
}
};
```
-----------
`basic/index.html`
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>basic webpack</title>
</head>
<body>
<div id="container"></div>
<script src="./assets/main.bundle.js"></script>
</body>
</html>
```
在`basic`文件夹执行`webpack`,打包信息如下

生成`main.bundle.js`文件,`chunk`名称为`main`,也是`webpack`默认生成的`chunk`名
## 4. webapck常用到的各点拆分
---------------
### 4.1 entry相关
--------------
**4.1.1`webpack`的多入口配置**
上例的简单配置中,只有一个入口文件,那么如果对应于一个页面需要加载多个打包文件或者多个页面想同时引入对应的打包文件的时候,应该怎么做?
```javascript
entry : {
app1 : './app1.js',
app2 : './app2.js'
}
```
在`multi-entry`文件夹执行`webpack`,打包信息如下

可见生成了两个入口文件,以及各自对应的`chunk`名
----------
### 4.2 output相关
------------
**4.2.1 `output.publicPath`**
```javascript
output: {
path: "/home/proj/cdn/assets/[hash]",
publicPath: "http://cdn.example.com/assets/[hash]/"
}
```
引用一段官网的话:
> The publicPath specifies the public URL address of the output files when referenced in a browser. For loaders that embed `<script>` or `<link>` tags or reference assets like images, publicPath is used as the href or url() to the file when it’s different then their location on disk (as specified by path).
大致意思就是:`publicPath`指定了你在浏览器中用什么地址来引用你的静态文件,它会包括你的图片、脚本以及样式加载的地址,一般用于线上发布以及CDN部署的时候使用。
比如有下面一段配置:
```javascript
var path = require('path');
var HtmlWebpackPlugin = require('html-webpack-plugin');
module.exports = {
entry : './app.js',
output : {
path : './assets/',
filename : '[name].bundle.js',
publicPath : 'http://rynxiao.com/assets/'
},
module : {
loaders : [
{ test : /\.js$/, loader : 'babel' },
{ test : /\.css$/, loader : 'style!css' }
]
},
plugins : [
new HtmlWebpackPlugin({
filename: './index-release.html',
template: path.resolve('index.template'),
inject: 'body'
})
]
};
```
其中我将`publicPath`设置成了`http://rynxiao.com/assets/`,其中设置到了插件的一些东西,这点下面会讲到,总之这个插件的作用是生成了上线发布时候的首页文件,其中`script`中引用的路径将会被替换。如下图:

----------------
**4.2.2 `output.chunkFilename`**
各个文件除了主模块以外,还可能生成许多额外附加的块,比如在模块中采用代码分割就会出现这样的情况。其中`chunkFilename`中包含以下的文件生成规则:
[id] 会被对应块的id替换.
[name] 会被对应块的name替换(或者被id替换,如果这个块没有name).
[hash] 会被文件hash替换.
[chunkhash] 会被块文件hash替换.
例如,我在output中如下设置:
```javascript
output : {
path : './assets/',
filename : '[name].[hash].bundle.js',
chunkFilename: "chunk/[chunkhash].chunk.js"
}
```
同时我修改了一下`basic/app.js`中的文件
```javascript
require('./app.css');
require.ensure('./main.js', function(require) {
require('./chunk.js');
});
document.getElementById("container").textContent = "APP";
```
其中对应的`chunk.js`就会生成带有`chunkhash`的`chunk`文件,如下图:

*这在做给文件打版本号的时候特别有用,当时如何进行`hash`替换,下面会讲到*
-----------
**4.2.3 `output.library`**
这个配置作为库发布的时候会用到,配置的名字即为库的名字,通常可以搭配`libraryTarget`进行使用。例如我给`basic/webpack.config.js`加上这样的配置:
```javascript
output : {
// ...
library : 'testLibrary'
// ...
}
```
那么实际上生成出来的`main.bundle.js`中会默认带上以下代码:
```javascript
var testLibrary = (//....以前的打包生成的代码);
// 这样在直接引入这个库的时候,就可以直接使用`testLibrary`这个变量
```

------------
**4.2.4 `output.libraryTarget`**
规定了以哪一种方式输出你的库,比如:amd/cmd/或者直接变量,具体包括如下
`"var"` - 以直接变量输出(默认library方式) `var Library = xxx (default)`
`"this"` - 通过设置`this`的属性输出 `this["Library"] = xxx`
`"commonjs"` - 通过设置`exports`的属性输出 `exports["Library"] = xxx`
`"commonjs2"` - 通过设置`module.exports`的属性输出 `module.exports = xxx`
`"amd"` - 以amd方式输出
`"umd"` - 结合commonjs2/amd/root
例如我以`umd`方式输出,如图:

-------------
### 4.3 module相关
--------
#### 4.3.1 `loader`中`!`代表的含义
> `require("!style!css!less!bootstrap/less/bootstrap.less");`
// => the file "bootstrap.less" in the folder "less" in the "bootstrap"
// module (that is installed from github to "node_modules") is
// transformed by the "less-loader". The result is transformed by the
// "css-loader" and then by the "style-loader".
// If configuration has some transforms bound to the file, they will not be applied.
代表加载器的流式调用,例如:
```javascript
{ test : /\.css|\.less$/, loader : 'style!css!less' }
```
就代表了先使用less加载器来解释less文件,然后使用css加载器来解析less解析后的文件,依次类推
--------
#### 4.3.2 `loaders`中的`include`与`exclude`
`include`表示必须要包含的文件或者目录,而`exclude`的表示需要排除的目录
比如我们在配置中一般要排除`node_modules`目录,就可以这样写
```javascript
{
test : /\.js$/,
loader : 'babel',
exclude : nodeModuleDir
}
```
官方建议:优先采用include,并且include最好是文件目录
---------
#### 4.3.3 `module.noParse`
使用了`noParse`的模块将不会被`loaders`解析,所以当我们使用的库如果太大,并且其中不包含`require`、`define`或者类似的关键字的时候(因为这些模块加载并不会被解析,所以就会报错),我们就可以使用这项配置来提升性能。
例如下面的例子:在`basic/`目录中新增`no-parse.js`
```javascript
var cheerio = require('cheerio');
module.exports = function() {
console.log(cheerio);
}
```
`webpack.config.js`中新增如下配置:
```javascript
module : {
loaders : [
{ test : /\.js$/, loader : 'babel' },
{ test : /\.css$/, loader : 'style!css' }
],
noParse : /no-parse.js/
}
```
当执行打包后,在浏览器中打开`index.html`时,就会报错`require is not defined`

### 4.4 resolve相关
#### 4.4.1 `resolve.alias`
为模块设置别名,能够让开发者指定一些模块的引用路径。对一些经常要被import或者require的库,如react,我们最好可以直接指定它们的位置,这样webpack可以省下不少搜索硬盘的时间。
例如我们修改`basic/app.js`中的相关内容:
```javascript
var moment = require("moment");
document.getElementById("container").textContent = moment().locale('zh-cn').format('LLLL');
```
加载一个操作时间的类库,让它显示当前的时间。使用`webpack --profile --colors --display-modules`执行配置文件,得到如下结果:

其中会发现,打包总共生成了104个隐藏文件,其中一半的时间都在处理关于`moment`类库相关的事情,比如寻找`moment`依赖的一些类库等等。
在`basic/webpack.config.js`加入如下配置,然后执行配置文件
```javascript
resolve : {
alias : {
moment : 'moment/min/moment-with-locales.min.js'
}
}
```

有没有发现打包的时间已经被大大缩短,并且也只产生了两个隐藏文件。
**配合`module.noParse`使用**
`module.noParse`参看上面的解释
```javascript
noParse: [/moment-with-locales/]
```
执行打包后,效果如下:

是不是发现打包的时间进一步缩短了。
**配合`externals`使用**
`externals`参看下面的解释
>Webpack 是如此的强大,用其打包的脚本可以运行在多种环境下,Web 环境只是其默认的一种,也是最常用的一种。考虑到 Web 上有很多的公用 CDN 服务,那么 怎么将 Webpack 和公用的 CDN 结合使用呢?方法是使用 externals 声明一个外部依赖。
```javascript
externals: {
moment: true
}
```
当然了 HTML 代码里需要加上一行
```javascript
<script src="//apps.bdimg.com/libs/moment/2.8.3/moment-with-locales.min.js"></script>
```
执行打包后,效果如下:

---------
#### 4.4.2 `resolve.extensions`
```javascript
resolve : {
extensions: ["", ".webpack.js", ".web.js", ".js", ".less"]
}
```
这项配置的作用是自动加上文件的扩展名,比如你有如下代码:
```javascript
require('style.less');
var app = require('./app.js');
```
那么加上这项配置之后,你可以写成:
```javascript
require('style');
var app = require('./app');
```
------------
### 4.5 externals
当我们想在项目中require一些其他的类库或者API,而又不想让这些类库的源码被构建到运行时文件中,这在实际开发中很有必要。此时我们就可以通过配置externals参数来解决这个问题:
```javascript
//webpack.config.js
module.exports = {
externals: {
'react': 'React'
},
//...
}
```
externals对象的key是给require时用的,比如require('react'),对象的value表示的是如何在global(即window)中访问到该对象,这里是window.React。
同理jquery的话就可以这样写:'jquery': 'jQuery',那么require('jquery')即可。
HTML中注意引入顺序即可:
```javascript
<script src="react.min.js" />
<script src="bundle.js" />
```
----------------------
### 4.6 devtool
提供了一些方式来使得代码调试更加方便,因为打包之后的代码是合并以后的代码,不利于排错和定位。其中有如下几种方式,参见官网[devtool](http://webpack.github.io/docs/configuration.html#devtool)
例如,我在`basic/app.js`中增加如下配置:
```javascript
require('./app.css');
// 新增hello.js,显然在文件夹中是不会存在hello.js文件的,这里会报错
require('./hello.js');
document.getElementById("container").textContent = "APP";
```
执行文件,之后运行`index.html`,报错结果如下:

给出的提示实在main.bundle.js第48行,点进去看其中的报错如下:

从这里你完全看不出到底你程序的哪个地方出错了,并且这里的行数还算少,当一个文件出现了上千行的时候,你定位`bug`的时间将会更长。
增加`devtool`文件配置,如下:
```javascript
module.exports = {
devtool: 'eval-source-map',
// ....
};
```
执行文件,之后运行`index.html`,报错结果如下:

这里发现直接定位到了`app.js`,并且报出了在第二行出错,点击去看其中的报错如下:

发现问题定位一目了然。
## 5. webpack常用技巧
### 5.1 代码块划分
------------
**5.1.1 Commonjs采用`require.ensure`来产生`chunk`块**
```javascript
require.ensure(dependencies, callback);
//static imports
import _ from 'lodash'
// dynamic imports
require.ensure([], function(require) {
let contacts = require('./contacts')
})
```
这一点在`output.chunkFileName`中已经做过演示,可以去查看
----------------------------
**5.1.2 AMD采用`require`来产生`chunk`块**
```javascript
require(["module-a", "module-b"], function(a, b) {
// ...
});
```
---------------------
**5.1.3 将项目APP代码与公共库文件单独打包**
我们在`basic/app.js`中添加如下代码
```javascript
var $ = require('juqery'),
_ = require('underscore');
//.....
```
然后我们在配置文件中添加`vendor`,以及运用代码分离的插件对生成的`vendor`块重新命名
```javascript
var webpack = require("webpack");
module.exports = {
entry: {
app: "./app.js",
vendor: ["jquery", "underscore", ...],
},
output: {
filename: "bundle.js"
},
plugins: [
new webpack.optimize.CommonsChunkPlugin(/* chunkName= */"vendor", /* filename= */"vendor.bundle.js")
]
};
```
运行配置文件,效果如下:

------------------
**5.1.4 抽取多入口文件的公共部分**
我们重新建立一个文件夹叫做`common`,有如下文件:
```javascript
// common/app1.js
console.log("APP1");
```
```javascript
// common/app2.js
console.log("APP2");
```
打包之后生成的`app1.bundle.js`、`app2.bundle.js`中会存在许多公共代码,我们可以将它提取出来。
```javascript
// common/webpack.config.js
/**
* webpack打包配置文件
* 抽取公共部分js
*/
var webpack = require('webpack');
module.exports = {
entry : {
app1 : './app1.js',
app2 : './app2.js'
},
output : {
path : './assets/',
filename : '[name].bundle.js'
},
module : {
loaders : [
{ test : /\.js$/, loader : 'babel' },
{ test : /\.css$/, loader : 'style!css' }
]
},
plugins : [
new webpack.optimize.CommonsChunkPlugin("common.js")
]
};
```
抽取出的公共js为`common.js`,如图

查看`app1.bundle.js`,发现打包的内容基本是我们在模块中所写的代码,公共部分已经被提出到`common.js`中去了

**5.1.5 抽取css文件,打包成css bundle**
默认情况下以`require('style.css')`情况下导入样式文件,会直接在`index.html`的`<head>`中生成`<style>`标签,属于内联。如果我们想将这些css文件提取出来,可以按照下面的配置去做。
```javascript
// extract-css/app1.js
require('./app1.css');
document.getElementById("container").textContent = "APP";
// extract-css/app2.js
require('./app2.css');
document.getElementById("container").textContent = "APP1 APP2";
// extract-css/app1.css
* {
margin: 0;
padding: 0;
}
#container {
margin: 50px auto;
width: 50%;
height: 200px;
line-height: 200px;
border-radius: 5px;
box-shadow: 0 0 .5em #000;
text-align: center;
font-size: 40px;
font-weight: bold;
}
// extract-css/app2.css
#container {
background-color: #f0f0f0;
}
// extract-css/webpack.config.js
/**
* webpack打包配置文件
* 抽取公共样式(没有chunk)
*/
var webpack = require('webpack');
var ExtractTextPlugin = require("extract-text-webpack-plugin");
module.exports = {
entry : {
app1 : './app1.js',
app2 : './app1.js'
},
output : {
path : './assets/',
filename : '[name].bundle.js'
},
module : {
loaders : [
{ test : /\.js$/, loader : 'babel' },
{ test : /\.css$/, loader : ExtractTextPlugin.extract("style-loader", "css-loader") }
]
},
plugins : [
new ExtractTextPlugin("[name].css")
]
};
```
得到的效果如下图:

如果包含chunk文件,并且chunk文件中也因为了样式文件,那么样式文件会嵌入到js中
**css合并到一个文件**
```javascript
// ...
module.exports = {
// ...
plugins: [
new ExtractTextPlugin("style.css", {
allChunks: true
})
]
}
```
效果如图:

如果包含chunk文件,并且chunk文件中也因为了样式文件,样式文件不会嵌入到js中,而是直接输出到`style.css`
**配合CommonsChunkPlugin一起使用**
```javascript
// ...
module.exports = {
// ...
plugins: [
new webpack.optimize.CommonsChunkPlugin("commons", "commons.js"),
new ExtractTextPlugin("[name].css")
]
}
```
效果图如下:

-------------------
### 5.2 如何给文件打版本
线上发布时为了防止浏览器缓存静态资源而改变文件版本,这里提供两种做法:
**5.2.1 使用`HtmlWebpackPlugin`插件**
```javascript
// version/webpack.config.js
/**
* webpack打包配置文件
* 文件打版本,线上发布
*/
var path = require('path');
var HtmlWebpackPlugin = require('html-webpack-plugin');
module.exports = {
entry : './app.js',
output : {
path : './assets/',
filename : '[name].[hash].bundle.js',
publicPath : 'http://rynxiao.com/assets/'
},
module : {
loaders : [
{ test : /\.js$/, loader : 'babel' },
{ test : /\.css$/, loader : 'style!css' }
]
},
plugins : [
new HtmlWebpackPlugin({
filename: './index-release.html',
template: path.resolve('index.template'),
inject: 'body'
})
]
};
```
生成的效果如下:

每次打包之后都会生成文件hash,这样就做到了版本控制
----------------
**5.2.2 自定义插件给文件添加版本**
```javascript
// version/webpack.config.version.js
/**
* webpack打包配置文件
* 文件打版本,线上发布,自定义插件方式
*/
var path = require('path');
var fs = require('fs');
var cheerio = require('cheerio');
module.exports = {
entry : './app.js',
output : {
path : './assets/',
filename : '[name].[hash].bundle.js',
publicPath : 'http://rynxiao.com/assets/'
},
module : {
loaders : [
{ test : /\.js$/, loader : 'babel' },
{ test : /\.css$/, loader : 'style!css' }
]
},
plugins : [
function() {
this.plugin("done", function(stats) {
fs.writeFileSync(
path.join(__dirname, "stats.json"),
JSON.stringify(stats.toJson())
);
fs.readFile('./index.html', function(err, data) {
var $ = cheerio.load(data.toString());
$('script[src*=assets]').attr('src','http://rynxiao.com/assets/main.'
+ stats.hash +'.bundle.js');
fs.writeFile('./index.html', $.html(), function(err) {
!err && console.log('Set has success: '+ stats.hash)
})
})
});
}
]
};
```
效果如图:

可以达到同样的效果,但是stats暂时只能拿到hash值,因为我们只能考虑在hash上做版本控制,比如我们可以建hash目录等等
----------------
### 5.3 shim
比如有如下场景:我们用到 Pen 这个模块, 这个模块对依赖一个 window.jQuery, 可我手头的 jQuery 是 CommonJS 语法的,而 Pen 对象又是生成好了绑在全局的, 可是我又需要通过 require('pen') 获取变量。 最终的写法就是做 Shim 处理直接提供支持:
**做法一:**
```javascript
{test: require.resolve('jquery'), loader: 'expose?jQuery'}, // 输出jQuery到全局
{test: require.resolve('pen'), loader: 'exports?window.Pen'} // 将Pen作为一个模块引入
```
**做法二:**
```javascript
new webpack.ProvidePlugin({
$: "jquery",
jQuery: "jquery",
"window.jQuery": "jquery"
})
```
>This plugin makes a module available as variable in every module.
>The module is required only if you use the variable.
>Example: Make $ and jQuery available in every module without writing require("jquery").
--------------------
### 5.4 怎样写一个loader
> Loader 是支持链式执行的,如处理 sass 文件的 loader,可以由 sass-loader、css-loader、style-loader 组成,由 compiler 对其由右向左执行,第一个 Loader 将会拿到需处理的原内容,上一个 Loader 处理后的结果回传给下一个接着处理,最后的 Loader 将处理后的结果以 String 或 Buffer 的形式返回给 compiler。固然也是希望每个 loader **只做该做的事,纯粹的事**,而不希望一箩筐的功能都集成到一个 Loader 中。
官网给出了两种写法:
```javascript
// Identity loader
module.exports = function(source) {
return source;
};
```
```javascript
// Identity loader with SourceMap support
module.exports = function(source, map) {
this.callback(null, source, map);
};
```
第一种为基础的写法,采用`return`返回, 是因为是同步类的 Loader 且返回的内容唯一。如果你写loader有依赖的话,同样的你也可以在头部进行引用,比如:
```javascript
// Module dependencies.
var fs = require("fs");
module.exports = function(source) {
return source;
};
```
而第二种则是希望多个`loader`之间链式调用,将上一个`loader`返回的结果传递给下一个`loader`。
**案例**
比如我想开发一个es6-loader,专门用来做以`.es6`文件名结尾的文件处理,那么我们可以这么写
```javascript
// loader/es6-loader.js
// 当然如果我这里不想将这个loader所返回的东西传递给下一个laoder,那么我
// 可以在最后直接返回return source
// 这里改变之后,我直接可以扔给babel-loader进行处理
module.exports = function(source, map) {
// 接收es6结尾文件,进行source改变
source = "console.log('I changed in loader');"
// 打印传递进来的参数
console.log("param", this.query);
// ... 我们还可以做一些其他的逻辑处理
this.callback(null, source, map);
};
// loader/loader1.es6
let a = 1;
console.log(a);
// loader/app.js
// 向loader中传递参数
require('./es6-loader?param1=p1!./loader1.es6');
document.getElementById("container").textContent = "APP";
```
执行webpack打包命令,在控制台会打印出param的值,如图:

在执行完成之后,打开`index.html`,在控制台打印出“I changed in loader”,而不是1

**进阶**
可以去阅读以下这篇文章 [如何开发一个 Webpack loader](http://web.jobbole.com/84851/)
--------------------
### 5.4 怎样写一个plugin
插件基本的结构
插件是可以实例化的对象,在它的prototype上必须绑定一个`apply`方法。这个方法会在插件安装的时候被`Webpack compiler`进行调用。
```javascript
function HelloWorldPlugin(options) {
// Setup the plugin instance with options...
}
HelloWorldPlugin.prototype.apply = function(compiler) {
compiler.plugin('done', function() {
console.log('Hello World!');
});
};
module.exports = HelloWorldPlugin;
```
安装一个插件,将其添加到配置中的`plugins`数组中。
```javascript
var HelloWorldPlugin = require('hello-world');
var webpackConfig = {
// ... config settings here ...
plugins: [
new HelloWorldPlugin({options: true})
]
};
```
执行效果如图:

这里只作简单的引入,平常一般都不需要自己写插件,如果想进一步了解,可以去看官网例子
### 5.5 布置一个本地服务器
```javascript
// 1.全局安装webpack-dev-server
cnpm install -g webpack-dev-server
// 2. 设置一个文件启动目录,运行
webpack-dev-server --content-base basic/
// 3. 在浏览器输入localhost:8080
```
------------------
### 5.6 热替换
```javascript
// auto-refresh/app.js
document.getElementById("container").textContent = "APP APP HOT ";
console.log("OK");
// auto-refresh/server.js
var webpack = require('webpack');
var config = require('./webpack.config.js');
var WebpackDevServer = require("webpack-dev-server");
var compiler = webpack(config);
new WebpackDevServer(webpack(config), {
publicPath: config.output.publicPath,
hot: true,
noInfo: false,
historyApiFallback: true
}).listen(8080, 'localhost', function (err, result) {
if (err) {
console.log(err);
}
console.log('Listening at localhost:3000');
});
// auto-refresh/webpack.config.js
/**
* webpack打包配置文件
*/
var webpack = require('webpack');
module.exports = {
entry : [
'webpack-dev-server/client?http://127.0.0.1:8080', // WebpackDevServer host and port
'webpack/hot/only-dev-server',
'./app.js'
],
output : {
path : './assets/',
filename : '[name].bundle.js',
publicPath : './assets/'
},
module : {
loaders : [
{ test : /\.js$/, loader : 'react-hot!babel' },
{ test : /\.css$/, loader : 'style!css' }
]
},
plugins : [
new webpack.HotModuleReplacementPlugin(),
new webpack.NoErrorsPlugin(),
new webpack.DefinePlugin({
'process.env.NODE_ENV': '"development"'
}),
]
};
// auto-refresh/index.html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>basic webpack</title>
</head>
<body>
<div id="container"></div>
<script src="./assets/main.bundle.js"></script>
</body>
</html>
// 运行
node server.js
// 浏览器输入:localhost:8080
```
----------------------------
### 5.7 让wepack.config.js支持es6写法
```javascript
// 1. 安装babel-core、babel-preset-es2015以及babel-loader
// 2. 项目根目录下配置.babelrc文件
{
"presets": ["es2015"]
}
// 3. 将webpack.config.js重新命名为webpack.config.babel.js
// 4.运行webpack --config webpack.config.babel.js
// 说明node 版本5.0以上,babel-core版本6以上需要如此配置
```
>这是一个 Webpack 支持,但文档里完全没有提到的特性 (应该马上就会加上)。只要你把配置文件命名成 webpack.config.[loader].js ,Webpack 就会用相应的 loader 去转换一遍配置文件。所以要使用这个方法,你需要安装 babel-loader 和 babel-core 两个包。记住你不需要完整的 babel 包。
**其他办法(未成功)**
```javascript
1.在上述的方案中,其实不需要重新命名就可以直接运行webpack,但是今天试了一直不成功
2.{
test : /\.js|jsx$/,
loader : 'babel',
query: {
//添加两个presents 使用这两种presets处理js或者jsx文件
presets: ['es2015', 'react']
}
}
```
## 6.相关链接
[webpack官方网站](http://webpack.github.io/docs/)
[用 ES6 编写 Webpack 的配置文件](http://cnodejs.org/topic/56346ee43ef9ce60493b0c96)
[一小时包教会 —— webpack 入门指南](http://www.cnblogs.com/vajoy/p/4650467.html)
[Webpack傻瓜式指南(一)](https://zhuanlan.zhihu.com/p/20367175)
[前端模块化工具-webpack](http://www.cnblogs.com/Leo_wl/p/4862714.html)
[如何开发一个 Webpack Loader ( 一 )](http://web.jobbole.com/84851/)
[关于externals解释](https://segmentfault.com/q/1010000002720840)
[webpack使用优化](http://www.open-open.com/lib/view/open1452487103323.html)
[http://webpack.github.io/docs/installation.html](http://webpack.github.io/docs/installation.html)
[https://github.com/petehunt/webpack-howto](https://github.com/petehunt/webpack-howto) | 24,342 | MIT |
---
layout: post
title: "2021.04.17 Sara的VOG里开了赌局,听说老朽押注了,怎么回事儿?Tony回应对4670万美元的质疑。"
date: 2021-04-17T04:50:05.000Z
author: 图森破故事会
from: https://www.youtube.com/watch?v=CQc0hv37dj0
tags: [ 图森破故事会 ]
categories: [ 图森破故事会 ]
---
<!--1618635005000-->
[2021.04.17 Sara的VOG里开了赌局,听说老朽押注了,怎么回事儿?Tony回应对4670万美元的质疑。](https://www.youtube.com/watch?v=CQc0hv37dj0)
------
<div>
</div> | 372 | MIT |
---
layout: post
title: Swift Closure -- 闭包从入门到进阶
date: 2016-06-11
excerpt: "这里有swift闭包的用法和探寻"
tags:
- Swift
comments: true
feature: http://LSnail.github.io/assets/pictures/13044471,1440,900.jpg
---
## 写在前面
在我们开始话题之前,先来说说我们可以继续愉快的聊下去的几个前提:
* 你知道swift是一门牛逼的语言(说PHP是最好的语言的童鞋们,你们先放下手里的板砖,有话好好说!)
* 你了解swift的基本语法,包括什么是变量和func,以及怎么写一个func并调用它(“闭嘴,这用你来哔哔哔?”)
* 你现在身怀两门绝技,一种专门对付像我一样的菜鸟,抬手就让我等跪地唱征服,它叫做<a href="https://www.baidu.com">百度一下你就知道了</a>;另一种是用来高手过招,一出手风云变幻翻江倒海,下证命理上破虚空,名为<a href="https://www.google.com">谷歌一下你就什么都不知道了</a>
* 最重要的一点,你现在一点都不想揍我(你保证么?),那么,让我们开始听我来详(xia)细(bi)讲(bi)一下,**我所理解的swift闭包**(文章为@LSnail原创,引用内容在中间和最后均有注明)
# 什么是闭包
> **闭包(Closures)是独立的函数代码块,能在代码中传递及使用。Swift中的闭包与C和Objective-C中的代码块及其它编程语言中的匿名函数相似。**
> **闭包可以在上下文的范围内捕获、存储任何被定义的常量和变量引用。因这些常量和变量的封闭性,而命名为“闭包(Closures)”。Swift能够对所有你所能捕获到的引用进行内存管理。**
**PS:** 说的这么高大上,所以最后闭包到底是个什么鬼?好吧,其实它就是类似OC里面的`block`(请注意,是类似!并不是同一种东西),或者类似JavaScript里面的`匿名自执行函数`(JS:"你哪来的,别和我扯进乎哈")。
**再PS:** 那`捕获(capturing)`又是什么鬼?这个东西说出来你可能不信,它其实就是`引用/得到`(get/set)的高大上说法,用于捕捉某个范围内的常量和变量的值。这个有什么意义呢,我们后面会慢慢说。
**再再PS:**
* 全局函数都是闭包,特点是有函数名但没有捕获任何值。
* 嵌套函数都是闭包,特点是有函数名,并且可以在它封闭的函数中捕获值。
* 闭包表达式都是闭包,特点是没有函数名,可以使用轻量的语法在它所围绕的上下文中捕获值。
* 变量和常量也可以用闭包来表示。
# 闭包能干嘛
我和你说,闭包老厉害了~大神们写的出神入化的代码,里面肯定少不了各种闭包,先看看人家怎么形容的(来自letsswift.com):
> **Swift的闭包表达式有着干净,清晰的风格,并常见情况下对于鼓励简短、整洁的语法做出优化。这些优化包括:
推理参数及返回值类型源自上下文
隐式返回源于单一表达式闭包
简约参数名
尾随闭包语法**
好吧,我墨水少,我不会形容,但是我看明白了,闭包俩作用:
**`好看!`** **`厉害!`**
你想想哈,我用二十行的代码写的一个func,你用三行写出来了,还更简洁明了,调用的时候就像雪碧一样心飞扬,这是一件多有范儿的事情!废话到此为止,let's get it!
# 闭包怎么用(纯干货)
严重申明:我已经看了太多的 `intArray.sortInPlace({$0 >= $1})` 这种代码的帖子了,只想说一句,大神们你们写的很详细了,我也看懂了,但是为啥非要用 `public mutating func sortInPlace()` 这个方法上手很麻烦呐,内心一直有一种不安全感提醒我,真的完全明白了吗?所以,我打算从最基础的 1 + 2 写起,先入门再说。
{: .notice}
是不是已经感觉迫(废)不(话)及(好)待(多)了呢?来写一个闭包来展示下老夫的手段?那先来看看闭包的定义形式:
#### 闭包最全的定义形式是:
~~~ruby
{
(参数:参数类型) -> 返回值类型 in
code(return xxxxx)
}(需要传的参数)
~~~
PS:我的理解是,这里的闭包和JavaScript里的匿名自执行函数非常的相似,我们关注的地方在于可以在内部实现什么,而不是在外面如何使用它。
#### 感谢swift提供的类型推导,它可以根据后面括号里传的参数,自动判断参数的类型,所以我们可以把闭包内部的参数的类型省略掉:
~~~ruby
{
(参数) -> 返回值类型 in
code(return xxxxx)
}(需要传的参数)
~~~
#### 或者把闭包中的返回值类型省略掉,但是有一点注意,当你把参数和返回值类型同时省略的时候,一定要在外部声明这个闭包返回值类型(要不你什么都不说清楚,代码怎么知道你想要个啥啊)
~~~ruby
{
(参数) in
code(return xxxxx)
}(需要传的参数)
~~~
#### 最后,其实参数也是可以省略的,用**`$`**来调用函数内部给参数默认分配的名字。如果闭包中只有简单的一行代码,关键字**`return`**也是可以省略的,这部分请见下面的例子。
#### 正式上代码(以下代码在playground中完成并测试)
这里我就用一个简单的加法运算来说明下,有一点要牢记:**swift中,函数是一等公民!**(有关这个问题请自行施放百度/Google绝技):
~~~ruby
// "不使用闭包来实现两数字相加"
func getSum(a a: Int, b: Int) -> Int {
return a + b
}
var sum = getSum(a: 3, b: 5)
// "sum = 8"
~~~
~~~ruby
// "现在我们用闭包来实现相同功能"
// "这里的sumClosure实质上是一个(Int, Int) -> Int的func"
let sumClosure = {
(a: Int, b: Int) -> Int in
return a + b
}
var sum: Int = sumClosure(3, 5)
// "sum = 8"
// "或者我们干脆这么写(这里就已经是用闭包对变量/属性进行操作了)"
var sum: Int = {
(a: Int, b: Int) -> Int in
return a + b
}(3,5)
~~~
现在让我们开始对这个可怜的sum进行各种砍掉砍掉:
~~~ruby
// 1."省略参数类型"
var sum = {
a, b -> Int in
return a + b
}(3,5)
// 2."然后省略返回值类型(要注意在外部还要声明类型的哦~)"
var sum: Int = {
a, b in
return a + b
}(3,5)
// 3."效果不行,这么长怎么玩,我们把中间那行丑爆了的删掉"
var sum: Int = {
return $0 + $1 // "关于$是什么意思请自行查找"
}(3,5)
// 4."还可以砍么?答案是当然的!把碍眼的return砍掉!"
var sum: Int = {
$0 + $1
}(3,5)
// 5."激动人心的时刻到了,把它写在一行里面!"
var sum: Int = {$0 + $1}(3,5)
~~~
如何,最终的效果是不是很高大上?别急,这里有几个**`重要问题`**需要说明:
1. 这里声明了 `var sum: Int` ,主要是为了方便理解,平常用的时候是不会多这么一步的,把闭包当参数/返回值的时候再冒出来一个var,啧啧,水(逼)平(格)一下子就low了很多,所以可以这么写: someFunc(aString,{$0 + $1}(3,5))
2. 这点很重要,那就是为啥别人的闭包后面都没有(3,5)这种影响市容的玩意儿?那是因为啊,我没写一个合适的方法来使用这个闭包。(3,5)的作用,就相当于我立马在声明了这个闭包以后,就马上调用了这个闭包并给它传入参数。现在还是为了方便理解阶段呢,别急嘛~下面来个完整点的
~~~ruby
func printSum(string1 str1: String, string2 str2: String, result: (Int, Int) -> Int) {
let count = result(str1.characters.count, str2.characters.count)
print("\(str1) and \(str2)--> total length is: \(count)")
}
printSum(string1: "hello", string2: "world", result: {$0 + $1})
// "打印出的结果为 hello and world--> total length is: 10"
~~~
这里需要说明的是: 当你需要将一个闭包当做参数使用的时候,如果要给闭包本身传参,那就需要有一个合适的、对应的函数参数来接收闭包作为参数。在上面的例子中,printSum这个函数的作用就是打印两个字符串的总长度,这里第三个参数result就被声明为了:接收两个Int参数的闭包函数,并且返回两个参数的和。这也就是有了好车子就得买贵点的保险的道理。
{: .notice}
说到这里,相信童鞋们应该对闭包这货有点大致的理解了吧。其实上面所有的东西加起来,只是说明白(但愿吧)了闭包是什么和怎么写的问题。语法上来说并不难理解,而且闭包的使用也是非常灵活的。用好了,代码美观不说,最大的好处是当别人看的时候...啧啧,你们可以脑补一下 ^o^。多加练习总能写出自己的风(bi)格(ge)来~
Wait~!你以为这就完了?呵呵,太天真了。。。说了是纯干货的,会有这么简单么?来,倒杯咖啡,听我接着给你吹...啊不,接着说一下闭包的进阶形态。
## 属性的闭包
应该知道的是,类的属性可以用闭包来表示,可以在闭包中定义set,get,willSet,willGet等方法。就算是你当时并不清楚这个是闭包,但是肯定见过这样的写法。而且不仅仅是类的属性,变量也是可以这么做的,写法上面并没有区别。下面我们来举个例子:
~~~ruby
// "变量或者属性的闭包表示"
// "get和set"
var text: String {
get{
return "HelloWorld"
}
set{
print(newValue)
}
}
// "又或者willGet和willSet"
var text: String = "HelloWorld" {
willSet{
print("newValue:\(newValue)")
}
didSet{
print("oldValue:\(oldValue)")
}
}
// "至于newValue和oldValue请自行查询"
~~~
~~~ruby
// "这是在某个UIViewController里面的成员变量"
private var iconImgView: UIImageView = {
// "请注意这里不要调用self.iconImgView,原因你会懂的"
let temp = UIImageView(image: UIImage(named: "imageName"))
temp.frame = CGRectMake(0, 0, 100, 100)
return temp
}()
~~~
## 尾随闭包(Trailing Closures)
Trailing闭包是一个书写在函数括号之外(之后)的闭包表达式,函数支持将其作为最后一个参数调用。
也就是说,如果你需要将一个很长的闭包表达式作为最后一个参数传递给函数,可以使用trailing闭包来增强函数的可读性。
比较正式点的写法大概是这样的:
~~~ruby
// "这是一个使用闭包的函数"
func someFunctionThatTakesAClosure(closure: () -> ()) {
// "这里是函数本身的实现过程代码"
}
// "这是不使用尾随闭包的写法"
someFunctionThatTakesAClosure ({
// "这里写闭包的实现过程"
})
// "这是使用尾随闭包的写法(注意和上面的区别)"
someFunctionThatTakesAClosure() {
// "这里写尾随闭包的实现过程"
}
// "如果函数只需要闭包表达式一个参数,当使用尾随闭包时,甚至可以把()省略掉。"
someFunctionThatTakesAClosure {
// "这里写尾随闭包的实现过程"
}
~~~
下面是一个具体的例子:
~~~ruby
func addTwoNumbers(num1: Int, num2: Int, CaluFunction: (Int, Int) -> Int) -> Int{
return CaluFunction(num1, num2)
}
// "内联闭包形式,不使用尾随闭包"
var numReult1 = addTwoNumbers(2, num2: 3,CaluFunction: {(num1: Int, num2: Int) -> Int in
return num1 + num2
})
// "使用尾随闭包"
var numReult2 = addTwoNumbers(3, num2: 4) { $0 + $1 }
~~~
## 捕获值
HOHO~还记得它么,既然我们已经铺垫了这么多,现在是时候来把这个坑来填上了。
闭包可以在其定义的上下文中捕获常量或变量。 即使定义这些常量和变量的原域已经不存在,闭包仍然可以在闭包函数体内引用和修改这些值。
Swift最简单的闭包形式是嵌套函数,也就是定义在其他函数的函数体内的函数。 嵌套函数可以捕获其外部函数所有的参数以及定义的常量和变量。
先来个例子说明下捕获值的问题(PS:这个例子我是在网上找的,绝大多数的帖子都是复制的这个,相关资料也容易查找),我就直接在代码中稍作解释,废话少说上代码:
~~~ruby
// "makeIncrementor返回类型为() -> Int。 这意味着其返回的是一个函数,而不是一个简单类型值。 该函数在每次调用时不接受参数只返回一个Int类型的值。"
func makeIncrementor(forIncrement amount: Int) -> () -> Int {
// "makeIncrementor有一个Int类型的参数,其外部命名为forIncrement, 内部命名为amount,表示每次incrementor被调用时runningTotal将要增加的量。"
var runningTotal = 0
//incrementor函数用来执行实际的增加操作。 该函数简单地使runningTotal增加amount,并将其返回。
func incrementor() -> Int {
runningTotal += amount
return runningTotal
}
// "请注意这里返回的是一个func"
return incrementor
}
// "请注意,这里的ince是一个function,是makeIncrementor中返回的runningTotal,并非incrementor"
let ince = makeIncrementor(forIncrement: 3)
print(ince()) // "结果为 3"
~~~
然后针对返回的`func incrementor() -> Int` 稍作分析:
~~~ruby
/**
1. "incrementor函数并没有获取任何参数,但是在函数体内访问了`runningTotal`和`amount`变量。这是因为其通过捕获在包含它的函数体内已经存在的`runningTotal`和`amount`变量而实现。"
2. "由于没有修改amount变量,incrementor实际上捕获并存储了该变量的一个副本,而该副本随着incrementor一同被存储。"
3. "然而,因为每次调用该函数的时候都会修改`runningTotal`的值,`incrementor`捕获了当前`runningTotal`变量的引用,而不是仅仅复制该变量的初始值。捕获一个引用保证了当`makeIncrementor`结束时候并不会消失,也保证了当下一次执行`incrementor`函数时,`runningTotal`可以继续增加。"
*/
func incrementor() -> Int {
runningTotal += amount
return runningTotal
}
~~~
PS:
1. Swift会决定捕获引用还是拷贝值。
2. 不需要标注`amount`或者`runningTotal`来声明在嵌入的`incrementor`函数中的使用方式。
3. Swift同时也处理`runingTotal`变量的内存管理操作,如果不再被`incrementor`函数使用,则会被清除。
明白了这些以后,我们继续来测试,连续调用几次 ince() 试试看会有什么结果:
~~~ruby
let ince = makeIncrementor(forIncrement: 3)
print(ince()) // "结果为 3"
// "接着在我们之前的代码,后面继续添加这几行,看返回的结果"
ince() // 6
ince() // 9
ince() // 12
~~~
可以看到的是,ince()返回的值是递增的,也意味着,它把之前的返回值`runningTotal`保存了下来。
`let ince = ...`定义了一个叫做`ince`的常量,该常量指向一个每次调用会加3的`incrementro`函数,这就是一个关键的地方。
让我们来继续:
~~~ruby
// "如果创建了另一个incrementor,其会有一个属于自己的独立的runningTotal变量的引用。 下面的例子中,inceNew捕获了一个新的runningTotal变量,该变量和incrementByTen中捕获的变量没有任何联系:"
let inceNew = makeIncrementor(forIncrement: 10)
inceNew() // 10
ince() // 15(又加了一次)
~~~
PS:
* 如果将闭包赋值给一个类实例的属性,并且该闭包通过指向该实例或其成员来捕获了该实例,那么将会创建一个在闭包和实例间的强引用环。
* Swift 使用捕获列表来打破这种强引用环。更多信息,请参考 [闭包引起的循环强引用](http://www.yiibai.com/swift/strong_reference_cycles_for_closures.html)。
那么问题来了,不是说好的 `ince()` 和 `inceNew()`是`let`出来的常量么,怎么还能一直改变值呢?很简单,因为函数(func)和闭包(closures)都是 **`引用类型`** 。
当你指定一个函数或一个闭包常量/变量时,实际上是在设置该常量或变量是否为一个引用函数。在上面的例子中,ince是个闭包,ince指向的是恒定的,而不是封闭件本身的内容是恒定的。这也意味着,如果你分配一个封闭两种不同的常量或变量,这两个常量或变量将引用同一个闭包:
~~~ruby
let anotherInce = ince
anotherInce() // 18
~~~
## 非逃逸闭包(Nonescaping Closures)和swift中的block
等了这么久,也终于说到这个地方了。学闭包为了啥,反正我当时就是为了可以写一个block。。。可是swift中并没有OC中的block。没关系,我们可以用闭包来实现block相同的功能。
首先,要解释一下逃逸和非逃逸的闭包与block有啥关系。
一个闭包作为参数传到一个函数中,但是这个闭包在函数返回之后才被执行,我们称该闭包从函数中逃逸。可以在参数名之前标注`@noescape`,用来指明这个闭包是不允许“逃逸”出这个函数的。将闭包标注`@noescape`能使编译器知道这个闭包的生命周期.
像数组中有提供的一个sort方法,函数中的参数就定义成了非逃逸闭包。
~~~ruby
public func sort(@noescape isOrderedBefore: (Self.Generator.Element, Self.Generator.Element) -> Bool) -> [Self.Generator.Element]
~~~
非逃逸的闭包目前在我的经验中用的比较少,更多的时候是用逃逸闭包。举个例子:很多启动异步操作的函数接受一个闭包参数作为 `completion handler`。这类函数会在异步操作开始之后立刻返回,但是闭包直到异步操作结束后才会被调用。在这种情况下,闭包需要“逃逸”出函数,因为闭包需要在函数返回之后被调用。
这里说明,非逃逸闭包和逃逸闭包讲的不是执行先后顺序。非逃逸是指你的闭包不能在函数外单独调用,只能在函数内部调用,函数调用完成后,那个闭包也就结束了。
~~~ruby
var completionHandler = {(finished: Bool) -> Void in}
func testDoSomething(finishedClosure: (Bool) -> Void) {
// "进行一些操作,确认完成后,然后调用传入的闭包参数,并给闭包传参"
finishedClosure(true)
}
// "调用函数"
testDoSomething { (done) in
// "实现completionHandler"
if done {
print("task is done")
}
}
~~~
## 未完待续,持续更新中 | 9,646 | CC-BY-4.0 |
## Jquery-Datatables-Popover
## 目录
- [简介](#简介)
- [依赖](#依赖)
- [用法](#用法)
- [快速使用](#快速使用)
- [API](#api)
- [可配置项](#可配置项)
- [事件函数](#事件函数)
- [例子](#例子)
## 简介

- 一个弹出框组件,可以弹出表格信息以辅助选择
- 表格借助 datatables,基于 Jquery 拓展
- 还有更多功能待完善
## 依赖
- Jquery
- Datatables
## 用法
### 快速使用
```html
<!-- css -->
<link rel="stylesheet" href="css/table.popover.css" type="text/css" />
<!-- html -->
<div id="popover" class="table-popover fade"></div>
<!-- js -->
<script src="lib/jquery.min.js"></script>
<script src="lib/jquery.dataTables.min.js"></script>
<!-- first jquery, second datatables, third tablePopover -->
<script src="lib/table.popover.js"></script>
<script>
const columns = [
{
data: "name",
title: "名字"
},
{
data: "gender",
title: "性别"
}
];
const data = [
{
name: "张三",
gender: "男"
},
{
name: "西施",
gender: "女"
}
];
$("#popover").tablePopover({
columns: columns,
data: data
});
</script>
```
### API
- [`.tablePopover(options)`](<#.tablePopover(options))>)
- [`.tablePopover('show')`](<#.tablePopover('show'))>)
- [`.tablePopover('hide')`](<#.tablePopover('hide'))>)
#### .tablePopover(options)
```javascript
$("#popover").tablePopover({
columns: columns,
data: data
});
```
#### .tablePopover('show')
```javascript
$("#popover").tablePopover('show');
```
#### .tablePopover('hide')
```javascript
$("#popover").tablePopover('hide');
```
### 可配置项
可以对组件的样式、功能进行配置
| 名称 | 类型 | 是否必须 | 默认值 | 描述 |
| :---- | :----: | ---- | :----: | ---- |
| title | String | 否 | | 标题, 显示弹出框的标题 |
| columns | Array | 是 | [] | 表格列对象, 用来显示表格的表头信息 <br> 数据格式: [{title: '名称', data: 'name'}]|
| data | Array | 是 | [] | 表格数据对象, 用来显示表格的表体信息 <br> 数据格式: [{name: '张三'}]<br><font color="#FF0505">key值需与表格列对象数组中定义的data名称相匹配</font> |
| width | Number | 否| 600 | 弹出框的宽度 |
| height | Number | 否| 400 | 弹出框的高度 |
| rowIndex | Boolean | 否| false | 是否显示序号列 |
| tableStyle | String | 否| table-bordered | 控制表格样式 <br> 可选项: table-bordered ; table-table-striped |
| chosenClose | Boolean | 否| true | 选择表格行后关闭弹出框 |
### 事件函数
提供了一些事件函数,可供使用
| 事件类型 | 描述 |
| :---- | :---- |
|tp.shown| 弹出框显示出来之后被触发|
|tp.hidden| 弹出框被隐藏之后被触发|
|tp.row-selected | 选择表格数据后被触发|
## 例子
见demo目录下的example.html | 2,515 | MIT |
---
title: volantis迎春攻略
date: 2022-01-19
updated: 2022-01-19
categories: [开发心得]
author: Langwenchong
link: https://blog.coolchong.cn/2022/01/19/lantern/
headimg: https://gitee.com/Langwenchong/figure-bed/raw/master/20220118205901.png
---
灯花助春意,舞绶织欢心。新的一年,新的气象,快来为你的博客挂上漂漂亮亮的小🏮吧!哦对了,翀翀还斥巨资购买了大🎉,还不快进来看一看🥰~
<!-- more --> | 321 | MIT |
---
title: 教程 - 使用 Azure CLI 创建和管理 Linux VM | Azure
description: 本教程介绍如何使用 Azure CLI 在 Azure 中创建和管理 Linux VM
services: virtual-machines-linux
documentationcenter: virtual-machines
author: rockboyfor
manager: digimobile
editor: tysonn
tags: azure-resource-manager
ms.assetid: ''
ms.service: virtual-machines-linux
ms.topic: tutorial
ms.tgt_pltfrm: vm-linux
ms.workload: infrastructure
origin.date: 03/23/2018
ms.date: 11/11/2019
ms.author: v-yeche
ms.custom: mvc
ms.openlocfilehash: 524028ff03df47d7b188432a10c301eae7f48662
ms.sourcegitcommit: 5844ad7c1ccb98ff8239369609ea739fb86670a4
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 11/08/2019
ms.locfileid: "73831381"
---
# <a name="tutorial-create-and-manage-linux-vms-with-the-azure-cli"></a>教程:使用 Azure CLI 创建和管理 Linux VM
Azure 虚拟机提供完全可配置的灵活计算环境。 本教程介绍 Azure 虚拟机的基本部署项目,例如选择 VM 大小、选择 VM 映像和部署 VM。 你将学习如何执行以下操作:
> [!div class="checklist"]
> * 创建并连接到 VM
> * 选择并使用 VM 映像
> * 查看和使用特定 VM 大小
> * 调整 VM 的大小
> * 查看并了解 VM 状态
[!INCLUDE [azure-cli-2-azurechinacloud-environment-parameter](../../../includes/azure-cli-2-azurechinacloud-environment-parameter.md)]
如果选择在本地安装并使用 CLI,本教程要求运行 Azure CLI 2.0.30 或更高版本。 运行 `az --version` 即可查找版本。 如果需要进行安装或升级,请参阅[安装 Azure CLI](https://docs.azure.cn/cli/install-azure-cli?view=azure-cli-latest)。
## <a name="create-resource-group"></a>创建资源组
使用 [az group create](https://docs.azure.cn/cli/group?view=azure-cli-latest#az-group-create) 命令创建资源组。
Azure 资源组是在其中部署和管理 Azure 资源的逻辑容器。 必须在创建虚拟机前创建资源组。 在此示例中,在“chinaeast” 区域中创建了名为“myResourceGroupVM” 的资源组。
```azurecli
az group create --name myResourceGroupVM --location chinaeast
```
创建或修改 VM 时指定资源组,本教程会对此进行演示。
## <a name="create-virtual-machine"></a>创建虚拟机
使用 [az vm create](https://docs.azure.cn/cli/vm?view=azure-cli-latest#az-vm-create) 命令创建虚拟机。
创建虚拟机时,可使用多个选项,例如操作系统映像、磁盘大小调整和管理凭据。 下面的示例创建一个名为 *myVM*、运行 Ubuntu Server 的 VM。 将在该 VM 上创建名为 *azureuser* 的用户帐户,并生成 SSH 密钥(如果这些密钥在默认密钥位置 ( *~/.ssh*) 中不存在):
```azurecli
az vm create \
--resource-group myResourceGroupVM \
--name myVM \
--image UbuntuLTS \
--admin-username azureuser \
--generate-ssh-keys
```
创建 VM 可能需要几分钟。 创建 VM 后,Azure CLI 会输出有关 VM 的信息。 请记下 `publicIpAddress`,可以使用此地址访问虚拟机。
```azurecli
{
"fqdns": "",
"id": "/subscriptions/d5b9d4b7-6fc1-0000-0000-000000000000/resourceGroups/myResourceGroupVM/providers/Microsoft.Compute/virtualMachines/myVM",
"location": "chinaeast",
"macAddress": "00-0D-3A-23-9A-49",
"powerState": "VM running",
"privateIpAddress": "10.0.0.4",
"publicIpAddress": "52.174.34.95",
"resourceGroup": "myResourceGroupVM"
}
```
## <a name="connect-to-vm"></a>连接到 VM
现在可以使用 SSH 从本地计算机连接到 VM。 将示例 IP 地址替换为上一步骤中记下的 `publicIpAddress`。
```bash
ssh [email protected]
```
登录 VM 后,可以安装和配置应用程序。 完成后,可按正常方式关闭 SSH 会话:
```bash
exit
```
## <a name="understand-vm-images"></a>了解 VM 映像
Azure 市场包括许多可用于创建 VM 的映像。 在之前的步骤中,使用 Ubuntu 映像创建了虚拟机。 在此步骤中,使用 Azure CLI 在市场中搜索 CentOS 映像,此映像稍后用于部署第二个虚拟机。
若要查看最常用映像的列表,请使用 [az vm image list](https://docs.azure.cn/cli/vm/image?view=azure-cli-latest#az-vm-image-list) 命令。
```azurecli
az vm image list --output table
```
命令输出返回 Azure 上最常用的 VM 映像。
```bash
Offer Publisher Sku Urn UrnAlias Version
------------- ---------------------- ------------------ -------------------------------------------------------------- ------------------- ---------
WindowsServer MicrosoftWindowsServer 2016-Datacenter MicrosoftWindowsServer:WindowsServer:2016-Datacenter:latest Win2016Datacenter latest
WindowsServer MicrosoftWindowsServer 2012-R2-Datacenter MicrosoftWindowsServer:WindowsServer:2012-R2-Datacenter:latest Win2012R2Datacenter latest
WindowsServer MicrosoftWindowsServer 2008-R2-SP1 MicrosoftWindowsServer:WindowsServer:2008-R2-SP1:latest Win2008R2SP1 latest
WindowsServer MicrosoftWindowsServer 2012-Datacenter MicrosoftWindowsServer:WindowsServer:2012-Datacenter:latest Win2012Datacenter latest
UbuntuServer Canonical 16.04-LTS Canonical:UbuntuServer:16.04-LTS:latest UbuntuLTS latest
CentOS OpenLogic 7.3 OpenLogic:CentOS:7.3:latest CentOS latest
openSUSE-Leap SUSE 42.2 SUSE:openSUSE-Leap:42.2:latest openSUSE-Leap latest
SLES SUSE 12-SP2 SUSE:SLES:12-SP2:latest SLES latest
Debian credativ 8 credativ:Debian:8:latest Debian latest
CoreOS CoreOS Stable CoreOS:CoreOS:Stable:latest CoreOS latest
```
<!-- Not Available on RHEL-->
可以通过添加 `--all` 参数查看完整列表。 还可以按 `--publisher` 或 `--offer` 筛选映像列表。 在此示例中,已在列表中筛选出其产品与“CentOS” 匹配的所有映像。
```azurecli
az vm image list --offer CentOS --all --output table
```
部分输出:
```azurecli
Offer Publisher Sku Urn Version
---------------- ---------------- ---- -------------------------------------- -----------
CentOS OpenLogic 6.5 OpenLogic:CentOS:6.5:6.5.201501 6.5.201501
CentOS OpenLogic 6.5 OpenLogic:CentOS:6.5:6.5.201503 6.5.201503
CentOS OpenLogic 6.5 OpenLogic:CentOS:6.5:6.5.201506 6.5.201506
CentOS OpenLogic 6.5 OpenLogic:CentOS:6.5:6.5.20150904 6.5.20150904
CentOS OpenLogic 6.5 OpenLogic:CentOS:6.5:6.5.20160309 6.5.20160309
CentOS OpenLogic 6.5 OpenLogic:CentOS:6.5:6.5.20170207 6.5.20170207
```
若要使用特定的映像部署 VM,请记下“Urn”列中的值,包括发布者、产品/服务、SKU,以及用于[标识](cli-ps-findimage.md#terminology)映像的版本号(可选)。 指定映像时,可将映像版本号替换为“latest”,这会选择最新的发行版。 在此示例中,`--image` 参数用于指定最新版本的 CentOS 6.5 映像。
```azurecli
az vm create --resource-group myResourceGroupVM --name myVM2 --image OpenLogic:CentOS:6.5:latest --generate-ssh-keys
```
## <a name="understand-vm-sizes"></a>了解 VM 大小
虚拟机大小决定虚拟机可用计算资源(如 CPU、GPU 和内存)的数量。 需要根据预期的工作负载适当调整虚拟机的大小。 如果工作负荷增加,可调整现有虚拟机的大小。
### <a name="vm-sizes"></a>VM 大小
下表将大小分类成了多个用例。
| 类型 | 常见大小 | 说明 |
|--------------------------|-------------------|------------------------------------------------------------------------------------------------------------------------------------|
| [常规用途](sizes-general.md) |B、Dsv3、Dv3、DSv2、Dv2、Av2| CPU 与内存之比均衡。 适用于开发/测试、小到中型应用程序和数据解决方案。 |
| [计算优化](sizes-compute.md) | Fsv2 | 高 CPU 与内存之比。 适用于中等流量的应用程序、网络设备和批处理。 |
| [内存优化](sizes-memory.md) | Esv3、Ev3、M、DSv2、Dv2 | 较高的内存核心比。 适用于关系数据库、中到大型缓存和内存中分析。 |
| [GPU](sizes-gpu.md) | NCv3 | 专门针对大量图形绘制和视频编辑的 VM。 |
<!-- Not Available on DC -->
<!-- Not Available on [Storage optimized](sizes-storage.md) | Lsv2, Ls -->
<!-- Not Available NV, NVv2, NC, NCv2, NCv3, ND-->
<!-- Not Available [High performance](sizes-hpc.md) | H -->
### <a name="find-available-vm-sizes"></a>查找可用的 VM 大小
若要查看在特定区域可用的 VM 大小的列表,请使用 [az vm list-sizes](https://docs.azure.cn/cli/vm?view=azure-cli-latest#az-vm-list-sizes) 命令。
```azurecli
az vm list-sizes --location chinaeast --output table
```
部分输出:
```azurecli
MaxDataDiskCount MemoryInMb Name NumberOfCores OsDiskSizeInMb ResourceDiskSizeInMb
------------------ ------------ ---------------------- --------------- ---------------- ----------------------
2 3584 Standard_DS1 1 1047552 7168
4 7168 Standard_DS2 2 1047552 14336
8 14336 Standard_DS3 4 1047552 28672
16 28672 Standard_DS4 8 1047552 57344
4 14336 Standard_DS11 2 1047552 28672
8 28672 Standard_DS12 4 1047552 57344
16 57344 Standard_DS13 8 1047552 114688
32 114688 Standard_DS14 16 1047552 229376
1 768 Standard_A0 1 1047552 20480
2 1792 Standard_A1 1 1047552 71680
4 3584 Standard_A2 2 1047552 138240
8 7168 Standard_A3 4 1047552 291840
4 14336 Standard_A5 2 1047552 138240
16 14336 Standard_A4 8 1047552 619520
8 28672 Standard_A6 4 1047552 291840
16 57344 Standard_A7 8 1047552 619520
```
### <a name="create-vm-with-specific-size"></a>创建具有特定大小的 VM
在前面的 VM 创建示例中未提供大小,因此会使用默认大小。 可以在创建时使用 [az vm create](https://docs.azure.cn/cli/vm?view=azure-cli-latest#az-vm-create) 和 `--size` 参数选择 VM 大小。
```azurecli
az vm create \
--resource-group myResourceGroupVM \
--name myVM3 \
--image UbuntuLTS \
--size Standard_F4s \
--generate-ssh-keys
```
### <a name="resize-a-vm"></a>调整 VM 的大小
部署 VM 后,可调整其大小以增加或减少资源分配。 可通过 [az vm show](https://docs.azure.cn/cli/vm?view=azure-cli-latest#az-vm-show) 查看 VM 的当前大小:
```azurecli
az vm show --resource-group myResourceGroupVM --name myVM --query hardwareProfile.vmSize
```
调整 VM 大小之前,请检查所需的大小在当前 Azure 群集上是否可用。 [az vm list-vm-resize-options](https://docs.azure.cn/cli/vm?view=azure-cli-latest#az-vm-list-vm-resize-options) 命令返回大小列表。
```azurecli
az vm list-vm-resize-options --resource-group myResourceGroupVM --name myVM --query [].name
```
如果所需大小可用,则可从开机状态调整 VM 大小,但需在此操作期间重启 VM。 使用 [az vm resize](https://docs.azure.cn/cli/vm?view=azure-cli-latest#az-vm-resize) 命令执行大小调整。
```azurecli
az vm resize --resource-group myResourceGroupVM --name myVM --size Standard_DS4_v2
```
如果所需大小在当前群集上不可用,则需解除分配 VM,然后才能执行调整大小操作。 使用 [az vm deallocate](https://docs.azure.cn/cli/vm?view=azure-cli-latest#az-vm-deallocate) 命令停止和解除分配 VM。 请注意,重新打开 VM 的电源时,临时磁盘上的所有数据可能已删除。 除非使用静态 IP 地址,否则公共 IP 地址也会更改。
```azurecli
az vm deallocate --resource-group myResourceGroupVM --name myVM
```
解除分配后,可进行大小调整。
```azurecli
az vm resize --resource-group myResourceGroupVM --name myVM --size Standard_GS1
```
调整大小后,可以启动 VM。
```azurecli
az vm start --resource-group myResourceGroupVM --name myVM
```
## <a name="vm-power-states"></a>VM 电源状态
Azure VM 可能会处于多种电源状态之一。 从虚拟机监控程序的角度来看,此状态表示 VM 的当前状态。
### <a name="power-states"></a>电源状态
| 电源状态 | 说明
|----|----|
| 正在启动 | 指示正在启动虚拟机。 |
| 正在运行 | 指示虚拟机正在运行。 |
| 正在停止 | 指示正在停止虚拟机。 |
| 已停止 | 指示虚拟机已停止。 虚拟机处于停止状态时仍会产生计算费用。 |
| 正在解除分配 | 指示正在解除分配虚拟机。 |
| 已解除分配 | 指示虚拟机已从虚拟机监控程序中删除,但仍可在控制面板中使用。 处于“已解除分配”状态的虚拟机不会产生计算费用。 |
| - | 指示虚拟机的电源状态未知。 |
### <a name="find-the-power-state"></a>查找电源状态
若要检索特定 VM 的状态,请使用 [az vm get-instance-view](https://docs.azure.cn/cli/vm?view=azure-cli-latest#az-vm-get-instance-view) 命令。 请确保为虚拟机和资源组指定有效的名称。
```azurecli
az vm get-instance-view \
--name myVM \
--resource-group myResourceGroupVM \
--query instanceView.statuses[1] --output table
```
输出:
```azurecli
ode DisplayStatus Level
------------------ --------------- -------
PowerState/running VM running Info
```
## <a name="management-tasks"></a>管理任务
在虚拟机生命周期中,可能需要运行管理任务,例如启动、停止或删除虚拟机。 此外,可能还需要创建脚本来自动执行重复或复杂的任务。 使用 Azure CLI,可从命令行或脚本运行许多常见的管理任务。
### <a name="get-ip-address"></a>获取 IP 地址
此命令返回虚拟机的私有 IP 地址和公共 IP 地址。
```azurecli
az vm list-ip-addresses --resource-group myResourceGroupVM --name myVM --output table
```
### <a name="stop-virtual-machine"></a>停止虚拟机
```azurecli
az vm stop --resource-group myResourceGroupVM --name myVM
```
### <a name="start-virtual-machine"></a>启动虚拟机
```azurecli
az vm start --resource-group myResourceGroupVM --name myVM
```
### <a name="delete-resource-group"></a>删除资源组
删除资源组还会删除其包含的所有资源,例如 VM、虚拟网络和磁盘。 `--no-wait` 参数会使光标返回提示符处,无需等待操作完成。 `--yes` 参数将确认是否希望删除资源,而不会有额外提示。
```azurecli
az group delete --name myResourceGroupVM --no-wait --yes
```
## <a name="next-steps"></a>后续步骤
在本教程中,你已学习 VM 创建和管理的基本知识,例如如何:
> [!div class="checklist"]
> * 创建并连接到 VM
> * 选择并使用 VM 映像
> * 查看和使用特定 VM 大小
> * 调整 VM 的大小
> * 查看并了解 VM 状态
请转到下一教程,了解 VM 磁盘。
> [!div class="nextstepaction"]
> [创建和管理 VM 磁盘](./tutorial-manage-disks.md)
<!--Update_Description: update meta properties, update links, wording update --> | 13,328 | CC-BY-4.0 |
> 编写:[kesenhoo](https://github.com/kesenhoo),校对:
> 原文:<http://developer.android.com/training/camera/videobasics.html>
# 简单的录像
这节课会介绍如何使用现有的Camera程序来录制一个视频。和拍照一样,我们没有必要去重新发明录像程序。大多数的Android程序都有自带Camera来进行录像。(*这一课的内容大多数与前面一课类似,简要带过,一些细节不赘述了*)
## Request Camera Permission [请求权限]
```xml
<manifest ... >
<uses-feature android:name="android.hardware.camera" />
...
</manifest ... >
```
与上一课的拍照一样,你可以在启动Camera之前,使用hasSystemFeature(PackageManager.FEATURE_CAMERA).来检查是否存在Camera。
<!-- more -->
## Record a Video with a Camera App(使用相机程序来录制视频)
```java
private void dispatchTakeVideoIntent() {
Intent takeVideoIntent = new Intent(MediaStore.ACTION_VIDEO_CAPTURE);
startActivityForResult(takeVideoIntent, ACTION_TAKE_VIDEO);
}
public static boolean isIntentAvailable(Context context, String action) {
final PackageManager packageManager = context.getPackageManager();
final Intent intent = new Intent(action);
List<ResolveInfo> list =
packageManager.queryIntentActivities(intent,
PackageManager.MATCH_DEFAULT_ONLY);
return list.size() > 0;
}
```
## View the Video(查看视频)
Android的Camera程序会把拍好的视频地址返回。下面的代码演示了,如何查询到这个视频并显示到VideoView.
```java
private void handleCameraVideo(Intent intent) {
mVideoUri = intent.getData();
mVideoView.setVideoURI(mVideoUri);
}
``` | 1,317 | Apache-2.0 |
# 一键升级
## 使用WeBASE一键升级脚本
<span id="auto">
在WeBASE v1.5.0后,WeBASE将提供`webase-upgrade.sh`脚本(位于webase-deploy目录中,与`common.properties`文件同级目录)
#### 升级步骤说明
升级期间,脚本将暂停节点与WeBASE所有服务,替换WeBASE安装包(不会更新节点)、替换配置文件、更新数据库的数据表(并备份原数据)
- 确保`common.properties`中配置的数据库配置正确;若已经通过该配置成功完成了一键部署,即不用修改
- 需要确保WeBASE一键部署的文件目录未重命名(如webase-front)
- 需要连接外网下载WeBASE新版本的升级脚本与安装包
- 若升级脚本报错中断后,备份的各子服务文件存放在**以旧版本号命名**的目录,如`./v1.4.3`目录中
- 暂未支持WeBASE可视化部署的自动升级,未支持跨版本升级
#### 检测依赖
```bash
# 脚本依赖python3命令,dos2unix命令,curl命令,unzip命令,mysqldump命令,mysql命令
# 检查python3
$ python3 --version
Python 3.6.8
# 检查dos2unix
$ dos2unix -V
dos2unix 6.0.3
# 检查curl命令
$ curl -V
curl 7.29.0
$ mysql -V
mysql Ver 15.1 Distrib 5.5.65-MariaDB, for Linux (x86_64) using readline 5.1
$ mysqldump -V
mysqldump Ver 10.14 Distrib 5.5.65-MariaDB, for Linux (x86_64)
$ unzip -v
UnZip 6.00 of 20 April 2009, by Info-ZIP.
```
#### 执行升级脚本
运行脚本,通过`-o {oldVersion}`指定当前版本,通过`-n {newVersion}`指定新版本,脚本将自动完成升级步骤
- **当前只支持升级相邻的版本**,可以参考[ChangeLOG](../WeBASE/ChaingeLOG.html)查看版本信息
```bash
## 指定-o旧版本,-n新版本后,即可运行
# bash webase-upgrade.sh -o {old_webase_version} -n {new_webase-version}
$ bash webase-upgrade.sh -o v1.4.3 -n v1.5.0
## 下面简单阐述升级脚本的操作内容
################################################
# 下载新的webase安装包(zip包),已存在旧版本的zip包,则重命名为webase-XXX-{old_version}
# 解压新的zip包到webase-front.zip => webase-front-v1.5.0
# 停止原有的,python3 deploy.py stopAll
## 复制旧版本的自服务的配置文件到新版本目录
# webase-web 直接复制全部
# 复制已有front的conf/*.yml, *.key, *.crt, *.so,覆盖新front的文件
# 复制已有sign的conf/*.yml
# 复制已有node-mgr已有的conf的*.yml,conf/log目录
## 备份node-manager db
# 备份node-mgr数据库到webase-node-mgr/script/backup_node_mgr_{old_version}.sql
# 从common.properties中获取两个数据库密码
# 到node-mgr中检测script/upgrade目录,有匹配v143开头的,v150的结尾的,有则执行 mysql -e "source $sql_file"
# 更新数据表 执行webase-node-mgr-{new_version}/script/upgrade/v{old_version}_v{new_version}.sql
# 到sign...同上(当前版本无需升级数据库)
## 将旧版本的webase-XXX备份到当前目录的{old_version}目录,新版本的webase-XXX-{new_version}重命名为webase-XXX
# mv操作,备份已有的,如 webase-web => ./v1.4.3/webase-web 以及 webase-web-v1.5.0 => webase-web
## 更新各java服务的yml的版本号
# 启动新的,执行python3 deploy.py startAll
################################################
```
若升级失败,,只需要将当前目录升级中的webase子系统目录移除,并将旧版本目录的文件夹复制到当前目录,如`v1.4.3`,并重启WeBASE即可
以v1.4.3升级到v1.5.0为例,具体步骤如下:
- 查看当前目录的升级中的webase安装包:`ls .`
- 查看已备份的webase安装包:`ls ./v1.4.3`
- 首先将当前目录中已存在的`webase-{subsystem}`安装包移除:如移除当前目录的所有webase安装包,`rm -rf webase-*`
- 复制旧版本目录中的到当前目录:`cp -rf ./v1.4.3/* .`
- 重启 `python3 deploy.py startAll`
## 子系统升级
WeBASE子系统升级需要参考[WeBASE releases](https://github.com/WeBankBlockchain/WeBASE/releases)中WeBASE子系统间的兼容性说明,若只升级某个子系统,则需要查看子系统的Changelog,检查是否与已有的其他子系统兼容
**切记复制备份已有的子服务项目文件,便于恢复**,下面介绍各个服务的升级步骤
#### WeBASE-Front升级
1. 备份已有文件或数据,下载新的安装包(可参考[安装包下载](../WeBASE/mirror.html#install_package))
2. 采用新的安装包,并将旧版本yml已有配置添加到新版本yml中;可通过`diff aFile bFile`命令对比新旧yml的差异
3. `bash stop.sh && bash start.sh`重启
#### WeBASE-Node-Manager升级
1. 备份已有文件或数据,下载新的安装包(可参考[安装包下载](../WeBASE/mirror.html#install_package))
2. 使用新的安装包,并将旧版本yml已有配置添加到新版本yml中;可通过`diff aFile bFile`命令对比新旧yml的差异
3. 查看[节点管理服务升级文档](../WeBASE-Node-Manager/upgrade.html)中对应版本是否需要修改数据表,若不需要升级则跳过
3.1 若需要升级数据表,首先使用`mysqldump`命令备份数据库
3.2 按照升级文档指引,操作数据表
4. `bash stop.sh && bash start.sh`重启
#### WeBASE-Web升级
1. 备份已有文件或数据,下载新的安装包(可参考[安装包下载](../WeBASE/mirror.html#install_package))
2. 采用新的安装包,替换旧的`webase-web`目录,无需重启nginx
#### WeBASE-Sign升级
1. 备份已有文件或数据,下载新的安装包(可参考[安装包下载](../WeBASE/mirror.html#install_package))
2. 使用新的安装包,并将旧版本yml已有配置添加到新版本yml中;可通过`diff aFile bFile`命令对比新旧yml的差异
3. 查看[签名服务升级文档](../WeBASE-Sign/upgrade.html)中对应版本是否需要修改数据表,若不需要升级则跳过
3.1 若需要升级数据表,首先使用`mysqldump`命令备份数据库
3.2 按照升级文档指引,操作数据表
4. `bash stop.sh && bash start.sh`重启
#### 节点升级
FISCO-BCOS节点的升级的详情需要参考[FISCO-BCOS 版本信息](https://fisco-bcos-documentation.readthedocs.io/zh_CN/latest/docs/change_log/index.html#id24)文档
- 兼容升级 :直接替换 旧版本 的节点二进制文件为 新版本 的节点二进制文件,并重启。此方法无法启用节点新特性
- 全面升级 :参考 [安装FISCO-BCOS](https://fisco-bcos-documentation.readthedocs.io/zh_CN/latest/docs/installation.html) 搭建新链,重新向新节点提交所有历史交易 | 4,015 | Apache-2.0 |
---
title: 五子棋
description: 五子棋小 DEMO
draft: false
---
import Gomoku from '../src/components/Gomoku'
五子棋小 DEMO
<!-- truncate -->
Canvas2D 版本
<Gomoku />
<!-- WebGL 版本
<Gomoku webgl /> -->
[1]: https://www.shadertoy.com/
[2]: https://webglfundamentals.org/webgl/lessons/zh_cn/
[3]: https://www.shadertoy.com/user/iq
[4]: https://www.shadertoy.com/user/FabriceNeyret2 | 372 | MIT |
## 利用ajax加载本地页面模板
### 背景
公司的电商后台管理系统需要重构,之前系统是由[requirejs](http://www.requirejs.cn/)框架搭配后台的java模板[usingthymeleaf](http://www.thymeleaf.org/)来生成页面。系统有很多优缺点,暂时先不做评论。总之,因为使用不太方便,因此考虑重构一个系统。
>在开发之前,上网找了很多的资料,想要和之前的系统一样,能够把页面上很多重复的组件独立成模板,在需要的页面引用,从而避免重复写代码的目的。
### 相关阅读资料
*github地址:*
- [PURE Unobtrusive Rendering Engine](https://github.com/pure/pure/tree/master/tutorial)
- [JADE.js](https://github.com/jadejs/jade)
- [doT.js](https://github.com/olado/doT)
- [jquery.load()](http://api.jquery.com/load/)
- [jquery.deferred()](http://api.jquery.com/category/deferred-object/)
- [jQuery的deferred对象详解](http://www.ruanyifeng.com/blog/2011/08/a_detailed_explanation_of_jquery_deferred_object.html)
- [React.js and How Does It Fit In With Everything Else](http://www.funnyant.com/reactjs-what-is-it/)
-----------------
1. 参考了网上和[JADE.js](https://github.com/jadejs/jade)和[doT.js](https://github.com/olado/doT),都是`github`上很火的模板框架。但是既然是框架,肯定是也人写出来的,于是在接触之前我习惯自己瞎捣鼓一些东西...
1. 在写下面这些东西之前,看到了这篇牛文[JavaScript template engine in just 20 lines](http://krasimirtsonev.com/blog/article/Javascript-template-engine-in-just-20-line)
```js
var TemplateEngine = function(html, options) {
var re = /<%([^%>]+)?%>/g, reExp = /(^( )?(if|for|else|switch|case|break|{|}))(.*)?/g, code = 'var r=[];\n', cursor = 0;
var add = function(line, js) {
js? (code += line.match(reExp) ? line + '\n' : 'r.push(' + line + ');\n') :
(code += line != '' ? 'r.push("' + line.replace(/"/g, '\\"') + '");\n' : '');
return add;
}
while(match = re.exec(html)) {
add(html.slice(cursor, match.index))(match[1], true);
cursor = match.index + match[0].length;
}
add(html.substr(cursor, html.length - cursor));
code += 'return r.join("");';
return new Function(code.replace(/[\r\t\n]/g, '')).apply(options);
}
var template = '<p>Hello, my name is <%this.name%>. I\'m <%this.profile.age%> years old.</p>';
console.log(TemplateEngine(template, {
name: "Krasimir Tsonev",
profile: { age: 29 }
}));
```
在`chrome`控制台,复制上述代码,最终得到`<p>Hello, my name is Krasimir Tsonev. I'm 29 years old.</p>`,相当炫酷,对不对?
**额外补充**
>关于正则表达式的exec和match的区别
```js
var template = '<p>Hello, my name is <%this.name%>. I\'m <%this.profile.age%> years old.</p>';
var reg = /<%([^%>]+)?%>/g;
// 多次执行
reg.exec(template); // => ["<%this.name%>", "this.name"]
reg.exec(template); // => ["<%this.profile.age%>", "this.profile.age"]
reg.exec(template); // => null
template.match(reg) // => ["<%this.name%>", "<%this.profile.age%>"]
```
### 正文
目录结构:
```
- app
- index.html
- temp1.tpl
- temp2.tpl
- temp3.tpl
- css
- temp.css
- js
- temp.js
```
#### index.html
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Templates</title>
<link rel="stylesheet" href="http://cdn.bootcss.com/bootstrap/3.3.5/css/bootstrap.min.css">
<script src="http://cdn.bootcss.com/jquery/2.1.4/jquery.min.js"></script>
<script src="http://cdn.bootcss.com/bootstrap/3.3.5/js/bootstrap.js"></script>
<link rel="stylesheet" href="../css/temp.css">
<script src="../js/tplEngine.js"></script>
<script src="../js/temp.js"></script>
</head>
<body>
<section data-tpl="temp1.tpl"></section>
<section data-tpl="temp2.tpl"></section>
<section data-tpl="temp3.tpl"></section>
</body>
</html>
```
#### temp1.tpl & temp2.tpl & temp3.tpl
```html
<!-- temp1.tpl -->
<h2>this is a heading</h2>
<p>test-temp1</p>
<!-- temp2.tpl -->
<h2>this is a heading</h2>
<p>test-temp1</p>
<p>test-temp2</p>
<!-- temp3.tpl-->
<h2>this is a heading</h2>
<p>test-temp1</p>
<p>test-temp2</p>
<p>test-temp3</p>
```
**主要思路:利用`ajax`来读取同源文件,然后通过js渲染到`index.html`的页面中去**
查阅[jquery](http://api.jquery.com/jQuery.ajax/)文档,发现这样一段代码
```js
dataType (default: Intelligent Guess (xml, json, script, or html))
...
```
|dataType|meaning|
|:---:|:---|
|`html`|Returns HTML as plain text; included script tags are evaluated when inserted in the DOM.|
因此尝试依靠ajax来获取静态页面
`temp.js`
```js
utils.api.ajax = function (url, callback) {
$.ajax({
url: url,
type: 'GET',
dataType: 'html',
success: function (data) {
callback(data);
},
error: function (jqXHR, textStatus, errorThrown ) {
alert('ajax error:' + errorThrown);
}
});
};
```
碰到的问题是:ajax异步调用,要保证所有`.tpl`页面都加载完成后,再来给DOM绑定事件,第一次的解决办法:
```js
var xhrs = 0, execs = 0, xhrsTimer, execTimes = 0;
xhrs = $('html').find('section[data-tpl]').length;
$('html').find('section[data-tpl]').each(function () {
var url = $(this).attr('data-tpl');
var $this = $(this);
utils.api.ajax(url, function (data) {
execs += 1;
// html替换tpl的内容
$this.get(0).outerHTML = data;
/** $(this).html(data); // 这样会吧.tpl里的内容添加到section标签内,样式会有问题,因此不推荐
*/
});
});
xhrsTimer = setInterval(function () {
execTimes += 200;
console.log(execTimes);
if(execs && execs === xhrs){
clearInterval(xhrsTimer);
console.info('all xhrs done!');
afterXhrs();
}
}, 200); // 多次在chrome中测试,平均时间在230ms
function afterXhrs() {
console.log('all done');
}
```
后来在查阅jquery文档时,发现`$.load()`有这样的一段描述*Load data from the server and place the returned HTML into the matched element*,因此尝试利用该方法
```js
window.onload = function () {
// 页面加载
$('html').find('section[data-tpl]').each(function () {
// 缺陷:加载data-tpl中的内容到innerHTML中,不能替换outerHTML
$(this).load($(this).attr('data-tpl'));
});
};
```
因为最终加载的内容没有办法替换当前的`section`标签,因此不予考虑
最终由于[jquery.deferred()](http://www.ruanyifeng.com/blog/2011/08/a_detailed_explanation_of_jquery_deferred_object.html)已实现了上面通过xhrs个数来判断的方法,因此有了下面的代码
```js
var wait = function () {
var dtd = $.Deferred(); // 新建一个deferred对象
tasks(); // 执行模板加载任务
dtd.resolve();
return dtd.promise();
};
var tasks = function () {
$('html').find('section[data-tpl]').each(function () {
var url = $(this).attr('data-tpl');
var $this = $(this);
utils.api.ajax(url, function (data) {
// html替换tpl的内容
$this.get(0).outerHTML = data;
});
});
};
$.when(wait())
.done(function () {
console.info('all xhrs done!');
afterXhrs();
})
.fail(function () {
console.log('something is wrong');
})
```
上面的代码,由于对错误的处理不合理,因此又有了修改,见下面的`tplEngine.js`
```js
// 整合为jquery插件
$.tpls = function (selector, flag, done, fail) {
if($.type(flag) === 'function'){
done = flag;
flag = false;
}else if($.type(flag) === 'boolean'){
flag = flag;
}else{
throw ('Type error, the second parameter must be a boolean or a function');
}
var counts = 0, size = $('html').find(selector).length;
var fail = fail || function () {
console.error('load templates failed');
};
// dom加载完后处理
$(document).ready(function () {
$('html').find(selector).each(function () {
var url = $(this).attr('data-tpl');
var $this = $(this);
$.ajax(url).done(function (data) {
counts += 1;
if (flag) {
// html替换tpl的内容
$this.get(0).outerHTML = data;
} else {
$this.html(data);
}
}).fail(function (jqXHR) {
console.info('load ' + url + ' error:' + jqXHR.statusText);
fail();
});
});
});
var timer = setInterval(function () {
if(counts === size){
clearInterval(timer);
done();
}
}, 200);
// 如果xhr报错,则强制在3000ms后关掉定时器
setTimeout(function () {
clearInterval(timer);
}, 3000);
}
// 默认自动加载
$.tpls('section[data-tpl]', function () {
console.info('load all templates!');
});
```
初步尝试是成功的,但是里面还有很多需要改进的地方,欢迎指正交流! | 8,016 | MIT |
mysql
==========
### grammer
--------------
```
```
###address
--------------
```
http://127.0.0.1/php/dbm/
```
###寄存器的使用
----------------
```
访问:试图模式下输入:reg调出寄存器
粘帖:视图模式下输入"+p 或者其他命令粘帖
寄存器的类型:
1.无名(unnamed)寄存器:"",缓存最后一次操作内容;
2.数字(numbered)寄存器:"0 ~ "9,缓存最近操作内容,复制与删除有别, "0寄存器缓存最近一次复制的内容,"1-"9缓存最近9次删除内容
7.选择及拖拽(selection and drop)寄存器:"*, "+, "~,存取GUI选择文本,可用于与外部应用交互,使用前提为系统剪切板(clipboard)可用;
"ayy 就是复制当前行到 "a 字母寄存器中
"b3yy 复制当前行和下面2行 到 “b 字母寄存器
```
show create table `table_name`; # 显示数据库建表
create table
CREATE TABLE `clare_msg`.`user` (
`id` INT(13) UNSIGNED NOT NULL AUTO_INCREMENT ,
`name` VARCHAR(30) NOT NULL ,
`email` VARCHAR(150) NULL DEFAULT NULL ,
`passwd` INT(255) NULL DEFAULT NULL ,
PRIMARY KEY (`id`)
)
ENGINE = InnoDB CHARACTER SET utf8 COLLATE utf8_general_ci COMMENT = '用户表';
```
###mysqli的使用方法
---------------------
```
例子一
<?php
$link = mysqli_connect("localhost", "my_user", "my_password", "world");
/* check connection */
if (mysqli_connect_errno()) {
printf("Connect failed: %s\n", mysqli_connect_error());
exit();
}
$query = "SELECT Name, CountryCode FROM City ORDER by ID LIMIT 3";
$result = mysqli_query($link, $query);
/* numeric array */
$row = mysqli_fetch_array($result, MYSQLI_NUM);
printf ("%s (%s)\n", $row[0], $row[1]);
/* associative array */
$row = mysqli_fetch_array($result, MYSQLI_ASSOC);
printf ("%s (%s)\n", $row["Name"], $row["CountryCode"]);
/* associative and numeric array */
$row = mysqli_fetch_array($result, MYSQLI_BOTH);
printf ("%s (%s)\n", $row[0], $row["CountryCode"]);
/* free result set */
mysqli_free_result($result);
/* close connection */
mysqli_close($link);
?>
```
```
例子二
<?php
$mysqli = new mysqli("localhost", "my_user", "my_password", "world");
/* check connection */
if ($mysqli->connect_errno) {
printf("Connect failed: %s\n", $mysqli->connect_error);
exit();
}
$query = "SELECT Name, CountryCode FROM City ORDER by ID LIMIT 3";
$result = $mysqli->query($query);
/* numeric array */
$row = $result->fetch_array(MYSQLI_NUM);
printf ("%s (%s)\n", $row[0], $row[1]);
/* associative array */
$row = $result->fetch_array(MYSQLI_ASSOC);
printf ("%s (%s)\n", $row["Name"], $row["CountryCode"]);
/* associative and numeric array */
$row = $result->fetch_array(MYSQLI_BOTH);
printf ("%s (%s)\n", $row[0], $row["CountryCode"]);
/* free result set */
$result->free();
/* close connection */
$mysqli->close();
?>
‵‵‵ | 2,432 | MIT |
---
layout: post
category: "dl"
title: "Top-K Off-Policy Correction for a REINFORCE Recommender System"
tags: [Top-K Off-Policy Correction for a REINFORCE Recommender System, ]
---
目录
<!-- TOC -->
<!-- /TOC -->
[Top-K Off-Policy Correction for a REINFORCE Recommender System](https://arxiv.org/pdf/1812.02353.pdf)
视频链接:[Reinforcement Learning for Recommender Systems: A Case Study on Youtube](https://www.youtube.com/watch?v=HEqQ2_1XRTs)
参考[Youtube推荐已经上线RL了,强化学习在推荐广告工业界大规模应用还远吗?](https://zhuanlan.zhihu.com/p/69559974)
google的ai blog也说到了off-policy的分类方法,可以预测出哪种机器学习模型会产生最好结果。参考[https://ai.googleblog.com/2019/06/off-policy-classification-new.html](https://ai.googleblog.com/2019/06/off-policy-classification-new.html)
Youtube推荐系统架构主要分为两层:召回和排序。本文中的算法应用在**召回**侧。
建模思路是给定用户的**行为历史**,预测用户**下一次的点击item**。
受限于On-Policy方法对系统训练架构要求复杂,所以本文采用Off-Policy的训练策略,即,并不是根据用户的交互进行实时的策略更新,而是根据**收集到日志中用户反馈**进行**模型训练**。
假设同时展示K个不重复item的reward奖励等于每个item的reward的之和,
而offpolicy的训练方式,对policy gradient类的模型训练会带来如下问题:
+ 策略梯度是由不同的policy计算出来的
+ 同一个用户的行为历史也收集了其他召回策略的数据。(没看懂。。)
然后作者就提出了基于importance weighting的Off-Policy修正方案,对pg的计算进行一阶逼近:
`\[
\prod_{t^{\prime}=0}^{|\tau|} \frac{\pi\left(a_{t^{\prime}} | s_{t^{\prime}}\right)}{\beta\left(a_{t^{\prime}} | s_{t^{\prime}}\right)} \approx \prod_{t^{\prime}=0}^{t} \frac{\pi\left(a_{t^{\prime}} | s_{t^{\prime}}\right)}{\beta\left(a_{t^{\prime}} | s_{t^{\prime}}\right)}=\frac{P_{\pi_{\theta}}\left(s_{t}\right)}{P_{\beta}\left(s_{t}\right)} \frac{\pi\left(a_{t} | s_{t}\right)}{\beta\left(a_{t} | s_{t}\right)} \approx \frac{\pi\left(a_{t} | s_{t}\right)}{\beta\left(a_{t} | s_{t}\right)}
\]`
最终可以得到一个低variance的策略梯度的biased estimator:
`\[
\sum_{\tau \sim \beta}\left[\sum_{t=0}^{|\tau|} \frac{\pi_{\theta}\left(a_{t} | s_{t}\right)}{\beta\left(a_{t} | s_{t}\right)} R_{t} \nabla_{\theta} \log \pi_{\theta}\left(a_{t} | s_{t}\right)\right]
\]`
注:随机策略梯度就有这么个重要性权重,应该是类似的思路吧。。[https://daiwk.github.io/posts/rl-stepbystep-chap9.html#31-%E9%9A%8F%E6%9C%BA%E7%AD%96%E7%95%A5ac%E6%96%B9%E6%B3%95](https://daiwk.github.io/posts/rl-stepbystep-chap9.html#31-%E9%9A%8F%E6%9C%BA%E7%AD%96%E7%95%A5ac%E6%96%B9%E6%B3%95)
因为是基于用户的交互历史预测下一个用户点击的item,所以文中也采用RNN针对用户State的转换进行建模。文中提到实验了包括LSTM、GRU等RNN单元,发现Chaos Free的RNN单元([A recurrent neural network without chaos](https://arxiv.org/abs/1612.06212))因为稳定高效而使用起来效果最好。
上面那个公式里,最难获取到的是**用户的行为策略**,理想情况下是收集日志的时候同时把用户相应的用户策略也就是点击概率给收集下来,但由于策略不同等客观原因文中针对用户的行为策略使用另外一组`\(\theta '\)`参数进行预估,而且**防止它的梯度回传**影响主RNN网络的训练。
<html>
<br/>
<img src='../assets/topk-off-policy-another-theta.png' style='max-height: 300px'/>
<br/>
</html>
在推荐系统中,用户可以同时看到**k个**展示给用户的**候选item**,用户可能同时与一次展示出来的多个item进行交互。因此需要扩展策略根据用户的行为历史**预测下一次**用户**可能点击的top-K个item**。
假设**同时展示K个不重复**item的reward奖励等于**每个item的reward的之和**,这样,Top-K的Off-Policy修正的策略梯度如下:
`\[
\begin{aligned} & \sum_{\tau \sim \beta}\left[\sum_{t=0}^{|\tau|} \frac{\alpha_{\theta}\left(a_{t} | s_{t}\right)}{\beta\left(a_{t} | s_{t}\right)} R_{t} \nabla_{\theta} \log \alpha_{\theta}\left(a_{t} | s_{t}\right)\right] \\=& \sum_{\tau \sim \beta}\left[\sum_{t=0}^{|\tau|} \frac{\pi_{\theta}\left(a_{t} | s_{t}\right)}{\beta\left(a_{t} | s_{t}\right)} \frac{\partial \alpha\left(a_{t} | s_{t}\right)}{\partial \pi\left(a_{t} | s_{t}\right)} R_{t} \nabla_{\theta} \log \pi_{\theta}\left(a_{t} | s_{t}\right)\right] \end{aligned}
\]`
与上面Top 1的修正公式相比主要是多了一个包含K的系数。也就是说,**随着K的增长**,策略梯度会比原来的公式**更快地降到0**。 | 3,394 | Apache-2.0 |
[](https://yuenshome.github.io)
# 《机器人叛乱:在达尔文时代找到意义》读后感
这本书给我的第一感觉是震惊!不单是一种新的思考角度:我们的基因是我们的主人,我们人类只是基因的奴隶(或者说是机器人),我们所做的一切都是在延续我们的基因,因为我们会死掉,但是基因是在不断地繁衍下去的,我们只是基因的媒介,我们是“机器人”。

[toc]
这本书的封面便写着:你是(基因的)载体,是机器人,是不朽的基因和肮脏的模因复制自身的工具。如果《自私的基因》击碎了你的心和尊严,《机器人叛乱》将帮你找回自身存在的价值和意义。《自私的基因》作者理查德 · 道金斯评价此书:我们作为基因机器被制造出来——但是我们有反对我们创造者的能力。我们,孤独地存在于这个星球上,能反对自私的复制子这样的独裁者。<!--more-->
本书就是基于观点一步步思考下去的(也是作者对《自私的基因》的这本书的进一步挖掘,写出作者自己的见解),其实这本书我没有看完,从中间开始就涉及很多心理,哲学等范畴,我读起来晦涩难懂,所幸就此罢休,不看了。但不得不提的是开头那耐人寻味的故事,作者隐晦地用基因比作高高在上的人类,而我们则比作保护人类(实际是保护基因)的机器人。
其实,我很多写的是读后感,感少,多原书摘抄。有的时候觉得自己总结倒不如书中所说的那么好。下面就是对书中部分内容的摘录:
<h1>1. 推荐序 · 一</h1>
<h2>1.1 一段小故事</h2>
>这是《机器人叛乱》这本书的推荐序,尽管如此,故事还是非常耐人寻味的。
时间:2404年。
还有16年,你即将完成你的使命。你推开窗,看着冬眠医院外渐渐败落的城市。雾霾渐起,你的思绪回到380年前的那天。
那时,就像那个时代富人常常会做出的选择一样,你的主人决定将自己冬眠起来,一直到400年后。主人们可以“像植物一样活着”,将自己的身体封装在胶囊里面,一动不动,然后任由漫长的岁月腐蚀胶囊。当然,明智的主人们知道,“像植物一样活着”难以帮助自己度过冬眠期间的400年。胶囊的电源断了怎么办?医院被损坏了,需要搬动胶囊怎么办?主人们纷纷决定“像动物一样活着”,就是让机器人们来照顾自己。于是,有了你的诞生。
你是那一批机器人中毫不起眼、默默无闻的一个。
主人们制造了你们。你的终极使命就是帮助主人度过400年的冬眠期。为了完成这一终极使命,主人在程序中赋予了你小小的自由—你可以搬动主人胶囊;当封装主人身体的胶囊电源快用完了,你可以采取其他方法去获取电源。
你就像一条狗一样,你的终极使命就是那条短而有力的狗绳;你的小小的自由就是那条长长的狗绳。当你违反短狗绳的时候,你会遭遇强有力的牵拉,将你扳回继续照顾主人的正轨;当你违反长狗绳的时候,你遭受扳回力度则轻一些,采取什么样的方式搬动主人胶囊,那是你的自由。
一年又一年,十年又十年,百年又百年。你与沉默不语的主人胶囊相安无事。闲暇时,你也与其他机器人聊聊八卦、看看新闻、打打游戏。不太妙的是,保存主人胶囊的这座城市日益败坏。是污染,是战争,更是人性的贪婪。幸好,冬眠医院设计伊始考虑得足够多,所以,你与机器人同伴们度过了一次又一次危机。
终于,漫长的400年度过了384年。你遇到了一个棘手、难以解决的问题。你的身体日益腐朽,岁月锈蚀了你当初的机灵;保存主人身体的胶囊的电源也快用完,一次又一次报警。最多,只能再坚持3天。你该怎么办?
你有两个选择。一个选择是其他机器人遇到类似情况,采取的“A策略”。A策略就是将自己卖掉,然后委托其他机器人帮你照顾主人,度过剩余的16年。卖掉你这一堆破铜烂铁,获得的电源足以支撑主人跑到终点。
当我们将机器人看作机器人,当我们还记得“完成使命”那条短狗绳在过去岁月中一次又一次的牵拉,我们会选择A策略。
然而,短狗绳也同样受到了岁月的腐蚀。于是,有了“B策略”。B策略就是将主人的电源拔掉,给自己充电。在400年刚开始的时候,你想都不敢这么想,因为每次这种想法一产生,就会遭遇那条短狗绳狠狠的惩罚。机器人三定律已经深深地写在你的中央控制系统中。
但是,这已经不是400年刚开始的时候了,这是最后的16年了。于是,你选择了“B策略”。而这,就是你的主人曾经做过的选择。
在那漫长的演化历程中,你的主人—人类就是那个机器人,而基因则是人类的主人。
越在进化早期,基因的利益对生物影响就像一条短狗绳那样致命;随着漫长的时间演化,在进化后期,生物体本身的利益逐步背叛了基因的利益。人,是机器人;人,背叛了自己的主人—基因。这,就是人类心智演化史上的“机器人叛乱”。正如真核动物开启了人类进化新篇章;当载体开始背离基因利益—“机器人叛乱”开启了人类心智进化新篇章。
如果说进化心理学所强调的是基因的利益,“我们带着石器时代的大脑生活在互联网时代”,然而,进化心理学仅代表事情的一面。随着漫长的演化,人作为基因载体自身的利益本身,会与基因的利益发生冲突,最终背叛基因的利益。基因利益、人自身利益的多寡,从而形成了人类心智架构的双进程:快与慢。在快的心智处理进程,我们下意识做出反应,调用的认知资源非常少;在慢的心智处理进程,我们想得多一些,像机器人叛乱一样,去改写主人的使命,调用更多的认知资源。这,就是人类心智的“双过程理论”,如图0-1所示。
2404年,你违反了机器人三定律,你杀死了你的主人。
你在主人尸体旁边,静静地望着他,静静地等待你的电源用完。你是机器人,你没有名字。
<h2 class="entry-title">1.2 人类心智的双过程理论</h2>
在那漫长的演化历程中,你的主人——人类就是那个机器人,而基因则是人类的主人。
越在进化早期,基因的利益对生物影响就像一条短狗绳那样致命;随着漫长的时间演化,在进化后期,生物体本身的利益逐步背叛了基因的利益。人,是机器人;人,背叛了自己的主人——基因。这,就是人类心智演化史上的“机器人叛乱”。正如真核动物开启了人类进化新篇章;当载体开始背离基因利益——“机器人叛乱”开启了人类心智进化新篇章。

如果说进化心理学心理学所强调的是基因的利益,“我们带着石器时代的大脑生活在互联网时代”,然而,进化心理学仅代表事情的一面。随着漫长的演化,人作为基因载体自身的利益本身,会与基因的利益发生冲突,最终背叛基因的利益。基因利益,人自身利益的多寡,从而形成了人类心智架构的双进程:快与慢。在快的心智处理进程,我们下意识做出反应,调用的认知资源非常少;在慢的心智处理进程,我们想得多一些,就像机器人叛乱一样,去改写主人的使命,调用更多的认知资源。这,就是人类心智的“双过程理论”。
<h1>2. 狭义理性和广义理性之剑</h1>
想叛乱,自己得有两把剑。其中一把剑叫狭义理性,简单地说就是正确做事。这把剑能保证你得到自己想要的结果。可是,这些结果真的是你(载体)想要的,还是假扮成你的基因或模因想要的,你不知道。因为你此时不考虑自己的目标和欲望是否合理,只想着用合适的办法实现它。说白了,你只想着正确做事,至于事情本身正确不正确,你不在乎。因此,这些被正确完成的事情,有可能并没有体现你的意志,而是在为基因或模因效劳。
好在除了狭义理性之外,你还有广义理性这把剑。这把剑是要确保你做正确的事,而不仅仅是正确做事。否则,你有可能正确地做了一件对你有害的事。可狭义理性可不管这一点,因为它不在乎目标合理不合理,它只在乎手段是否能实现目的。有了广义理性这把剑,你就不那么容易误入歧途了。
不过,要想拿到这两把剑,尤其是拿到广义理性这把剑,很不容易。我猜,这大概也是为什么斯坦诺维奇要在最后一章花费那么多笔墨的原因所在了。
<h1>3. 模因</h1>
模因是道金斯发明的一个术语,可认为是文化基因。模因是一种能够自我复制的文化片段,可以从一个大脑进入另一个大脑。很多时候,模因对它们的寄主都很好,因此它们被寄主接受,安装在头脑中。这其实也是进化心理学家的普遍看法,即我们大多数的新年都对自己有好处,也正是因为它们对我们有好处,我们才把它们保留在自己的头脑中。可是,在斯坦诺维奇看来,进化心理学忽视了另外一种可能性,即有些模因对我们没好处,自身也不正确,但它们依然能够像病毒一样潜入我们的大脑,原因就在于它们太强大、太狡猾,拥有自我复制的巨大优势。相信自己死后能进天堂的模因,让恐怖分子铤而走险,蹈死不顾。相信一年能治绝症的模因,让很多人把钱源源不断地掏给骗子,即使没有任何疗效也执迷不悟。
不少模因比基因更可怕,更龌龊。基因至少会让载体活到可以繁殖下一代的年纪,可模因就不必对载体这么怜香惜玉,因为它的潜伏期更长。即使一个会让载体万劫不复的模因,它在载体倒霉之前也有无数机会传播自己。可以说,它更冷血,更无情。“洗脑”这个词描述的就是一种被模因感染的载体状态,因为它已丧失了对自己的控制权,彻底变成了模因的傀儡。它做的很多事,或许都对自己没好处,甚至有坏处,可它浑然不觉,因为模因控制了载体,让载体失去了判断力。载体变成了为模因效劳的仆人,一具行尸走肉。
<h1>4. 两种复制子(基因和模因)</h1>
普遍达尔文主义有一个令人震惊、叫人不安的洞见:人类是两种复制子(基因和模因)的寄主,而它们不关心人类的利益,仅仅扮演着复制管道的角色。理查德 · 道金斯总结了20世纪生物学的深刻见解,让我们在惊慌不安中意识到:作为人类的我们自己,事实上不过是基因的生存机器。现代进化科学让我们正确了解生物学,不过,这个学科带有很多不安的寓意。比如,人类被视作巨大的复制子殖民地,这些为数众多的复制子拥挤在笨重的载体中。本质上,人类就是一架复杂的机器,为基因殖民者服务。
同样,我们也是模因(文化的信息单位)的寄主;这是一种破坏人类自主的亚个人实体。跟基因一样,模因也是一种彻头彻尾的自私的复制子。总之,基因包含构造身体的指令,这个身体可携带基因,帮助它们传播自己。总之,模因被用来建立某种文化,这种文化则帮助模因传播自己。模因研究引发的最根本洞见就是,一种观念,<strong>即使不是真的,即使不能以任何方式帮助持有这种观念的人</strong>,也能传播开来。
<h1>5. 人类心智的独特架构特征</h1>
我认为,事实上,人类的独特性来自他们心智的架构特征。这种特征就是高阶表征的倾向。人类,跟其他所有动物都不一样,他们能尝试批判自身的一阶欲望(first-order desire)。这样,跟哲学家哈里 · 法兰克福笔下的玩偶(wanton)相比,人类就成了一种高级存在。要知道,玩偶只会像机器人一样追求他们的一阶欲望。其中,很多都是基因预设的目标,而在人类中,另一些可能就是模因病毒。面对一阶偏好,我们做出二阶评估,这就是所谓的强评估。这么做,我们其实是在问自己是否偏好对某一种结果的偏好。
人类的价值观常常表现为,对我们的一阶偏好进行批判。于是,实现我们一阶偏好跟高阶偏好一致性的奴隶——哲学家罗伯特 · 诺齐克称之为实现理性整合的努力——就成了人类认知的一个独特属性。这种属性能更明确地把人跟动物区别开来。在这一点上,它要胜过其他心理特征,包括意识。意识跟强评估能力不同,它更可能是以连续等级的方式,分布于动物界不同复杂性的大脑中。
<h1>6. 达尔文的进化程序算法</h1>
恰恰是宗教原教旨主义者把事情看得更透彻。而且,恰恰是相信进化论的那批人没看到普遍达尔文主义中存在的危险。这些危险是什么呢?我们首先看一个显而易见的选项:人类通过自然选择进化而来,这就意味着,人类不是上帝或其他任何神灵的特殊设计。它意味着,人类的出现没有任何目的。它还意味着,就生命形式而言,没有任何天生的“高等”或“低等”(见 Gould 1989,1996,2002 ;Sterelny 2001a)。简单地说,一种生命形式跟另一种一样好。
其次,存在一个令人恐惧的问题,进化无意义。这个问题来自一个事实,即进化是一种算法过程(Dennett 1995)。一个算法仅仅是一套形式步骤(即配方),用以解决一个具体问题。我们熟悉一种算法,即计算机程序。进化就是一种在自然界中而不是在计算机上执行的程序。设想有一种最简单的计算机程序,即复制那些在选择过程中存活下来的实体。根据像这种程序一样简单的逻辑,算法式自然选择过程(机械地,盲目地)构造出了像人脑一样复杂的结构(见 Dawkins 1986,1996)。
很多人认为自己相信进化论,可他们没有想清楚这一过程的含义。这一过程是算法式的:机械、盲目、无目的。不过,乔治 · 萧伯纳早在 1921 年就觉察到了这些含义。他写道:“这个理论看起来很简单,因为你最初没有意识到它意味着什么。不过,当你慢慢理解它的整个寓意时,你就会万念俱灰”。它蕴含着一种可怕的宿命论,无论是美丽和智慧,力量和目的,还是荣耀和抱负,都将发生可怕和该死的衰减“。我这里可不是说萧伯纳说得对,仅仅是说,他准确地觉察到达尔文主义对他世界观的威胁。事实上,我并不认为美丽和智慧在达尔文式的观点中就会衰减,而且我会在本书的第8章解释为什么。这里,重要的是,萧伯纳说对了一部分。他聪明地看到了进化的算法式本质。一种算法式过程也许会被描述为宿命论,而且,加之这种算法跟生活有关,于是萧伯纳觉得它狰狞可怕。
<h1>7. 为基因牺牲个体(自己)?</h1>
一只蜜蜂就可能牺牲自己作为载体的自身。比如,蜜蜂可能为了保护跟自己有血缘关系的蜂后,跟外来入侵者殊死搏斗,失去蜂刺而死。有时,基因会为了自身利益而牺牲载体。理解这一情形的寓意,将对我们理解人类的困境产生深远影响:我们是一种进化而来的、具有多重心智的物种。这是因为,正如在下一章中将要讨论的那样,人脑的某些部分执行的是弱约束目标。
蜜蜂的所有目标都是简单而纯粹的基因目标。在它们中,其中一些跟作为载体的蜜蜂的利益相一致,而另一些则不一致,但蜜蜂不知道这一点,也很难说它们在乎。谈到基因,基因目标跟载体目标有多大的重叠不是很重要,问题在于蜜蜂没有自我反思能力,而这种讷讷管理可以对基因利益和相关的载体利益做出区分。
当然,说到人,情况就完全不同了。基因利益跟载体利益具有分离的可能性。对于作为载体、拥有自我反思能力的人类来说,这种可能性影响深远,对于人类而言,把基因利益跟载体利益混为一谈,事实上就是把人看成是蜜蜂。可有时候,在进化心理学文献中,不少学者就是这么做的。它其实排除了这么一种可能性,即人类能意识到载体跟复制子之间的目标冲突,还能想办法来协调相互矛盾的心理输出。
然而,意识到这些潜在的目标冲突需要一个前提,那就是:理解这里谈到的复制子和载体的逻辑,以及它们的含义。对很多人来说,复制子的目标可能跟载体的福祉相冲突,这是一个违反直觉的观点。的确,他们早已习惯这样的观点:进化的运作是为了有机体的利益,而不是为了复制子的利益。复制子跟载体具有不同的含义,理解这种不同有困难。这一点,在道金斯(1982,51)说的一个故事中得到了揭示。他有一个同事,这个同事接受了一个大学生研究项目的申请。这个大学生是一个宗教原教旨主义者,他不相信自然选择的进化,只想研究自然界中的适应器(adaptation)。他认为适应器来自上帝的设计,而且,他只想研究上帝已经制造出来的适应器。但是,道金斯直言不讳地指出,这种立场寸步难行。那个学生陷入了一个令人尴尬的问题中,难以自拔:“上帝发明适应器,谁是受益者?”鲑鱼适应竭尽全力游回它们的产卵地后死去的方式。要是我们认可这样一个非常简单的假设,即对于大多数活着的生物体来说,活着而不是死去能更好地实现自身利益,那么,鲑鱼的这种行为显然不是为了自身利益。要是不掺和耗尽心力的产卵洄游之旅,鲑鱼会活得更久。不过,这种行为的确是服务于鲑鱼基因的繁殖利益。上帝设计这些适应器,是为了活生生的有机体,还是为了它们的基因?生物学的事实很明显,看起来上帝站在后者那一边。……
令人懊恼的是,这个答案来自生物学:人类是生存机器,善于帮助他们自身的基因复制,因此,相互合作构造人体的基因才生存的相当惬意。而且,现在,我们拥有了理解那个无比重要的洞见所需的语言:这是一个令人眩晕的见解。毫无疑问,它是机器人叛乱的第一步。作为载体的人类,破天荒地意识到一个惊人事实:<span style="color: #ff0000;"><strong>要是符合自身的利益,基因将总是牺牲载体</strong></span>。人类独一无二,他们有能力面对这种令人震惊的事实。
<h1>8. 跟自己作战的大脑——大脑中忽视我们的那一部分</h1>
自发式系统帮助把自我从世界中区分出来。它们自动运行,有时会跟你所知道的这个世界的知识相悖。比如,罗津、米尔曼和内梅洛夫(1986;也见 Rozin and Fallon 1987)做了一个跟厌恶情绪有关的实验。在其中一个场景中,参与者吃了一块高级软糖,他们表示还想再吃一块。不过,这时实验者提供了另一块同样的软糖,但是把软糖形状做成了狗屎样。参与者觉得很恶心,一点儿也没胃口了。他们也知道软糖其实不是狗屎,而且闻起来很香,可他们的厌恶反应依然发生了。
丹尼特(1991,414)描述了另一个版本的罗津实验,虽然是非正式的。实验如下。把你嘴里的唾沫咽下去。没问题。好,现在找一个空瓶子,把唾液吐进去,然后把它一饮而尽。呀!太恶心了!不过,为什么?正如丹尼特(1991)指出的那样,“看起来这跟我们的感知有关:一旦某物脱离了你的身体,它就不再是我们身体的一部分,它变得陌生,令人怀疑;它已经放弃了自己的公民身份,变成了要被断然拒绝的另一个东西”(414)。在某种意义上,我们知道。我们对吞咽和对喝的反应截然不同,这是非理性的,可是这也不能取消两种反应之间的差别。知道得再多,了解得再深,都不足以克服面对瓶中唾液时的自发式反应。它同样也是大脑中忽视我们的那一部分。
<h1>9. 自发式和分析式系统</h1>
在《意识的解释》这本书中,丹尼尔 · 丹尼特提出这样一种观点:分析式加工靠一系列虚拟机执行,而虚拟机是由很多平行的大脑硬件虚拟出来的。虚拟机就是运行在电子计算机上的一套指令(“一个虚拟机就是一套暂时的、高度结构化的规则,这套规则则由一个基于硬件的程序启动……这样就能给硬件一套巨大的、环环相扣的、做出反应的习惯或倾向”,丹尼特 1991,216)。简而言之,分析式系统在这种视角下更接近软件(某些人称之为“心智套件”;见 Clark 2001;Perkins 1995),而不是一套独立的硬件架构。
丹尼特(1991)的模型跟一个观点有关系;这个观点在认知科学文献中反复多次出现。它认为,在某种程度上,领域特殊性的自发式模块输出能被用作更为一般的目的,因而增加了行为的灵活性。不过,分析式系统的串行功能难以维持,因为它们是在更适合模式识别这种并行功能的硬件上模拟出来的。”
这样一种看待自发式和分析式系统差异的观点,跟长期以来人工智能领域中的反讽是一致的:人类擅长做的事,比如面孔识别、三维物体感知、语言理解,对计算机来说很难;而计算机很容易做的事,比如使用逻辑、概率推理,对人类来说就很难。现在,研究者对自发式和分析式系统之间为何不同的理解,把这种人工智能领域的悖论给理清了。对计算机来说,它没有建立起经历数百万年进化而成的精细严密的自发式系统。于是,作为一种进化遗产,诸多平行而有效的人类自发式系统擅长的事,对计算机来说简直是难于登天。相比之下,作为一种用于逻辑的串行处理器,人类的分析式系统是一种最近才安装的大脑软件。打一个比方,它就像是一台组装机(在计算机科学中,这是一种解决问题的粗糙方案)运行在诸多平行的、为别的目的而设计的硬件上。相反,计算机最初就是有意设计的串行处理器,依据逻辑规则而运行(Dennett 1991, 212-214)。怪不得,逻辑运算对计算机很容易,但对我们很难, | 8,306 | MIT |
# StandardConf
## 配置环境
- Git Commit Message
- TypeScript
- ESLint
- Prettier
- Lint Staged
- Jest
- Npm Script Hook
- Vuepress
- Github Actions
### Init
采用 NPM 可以对任何普通的项目进行初始化操作,执行 [`npm init`](https://docs.npmjs.com/cli/init) 会在项目根目录下生成 `package.json` 包描述文件。
> **温馨提示**:更多详细项目变更可以查看 Commit。
### Git Commit Message
[Commitizen](https://github.com/commitizen/cz-cli) 是一个规范 Git 提交说明(Commit Message)的 CLI 工具,具体如何配置可查看 [Cz 工具集使用介绍](https://juejin.im/post/5cc4694a6fb9a03238106eb9)。本项目中主要使用了以下功能:
- [cz-customizable](https://github.com/leonardoanalista/cz-customizable)
- [commitlint](https://commitlint.js.org/#/)
- [conventional-changelog](https://github.com/conventional-changelog/conventional-changelog/tree/master/packages/conventional-changelog)
配置以后会产生以下一些特性:
- 使用 `git cz` 代替 `git commit` 进行符合 Angular 规范的 Commit Message 信息提交
- 代码提交之前会通过 [husky](https://github.com/typicode/husky) 配合 git hook 进行提交信息校验,一旦提交信息不符合 Angular 规范,则提交会失败
- 执行 `npm run log` 会在根目录下自动生成 `CHANGELOG.md` 版本日志
> **温馨提示**:如果不知道什么是 CLI (命令行接口),可查看 [使用 NPM 发布和使用 CLI 工具](https://juejin.im/post/5eb89053e51d454de54db501)。
### TypeScript
本项目会构建输出 CommonJS 工具包(npm 包)供外部使用,采用 TypeScript 设计并输出声明文件有助于外部更好的使用该资源包。TypeScript 编译采用官方文档推荐的 Gulp 工具,配合 [gulp-typescript](https://github.com/ivogabe/gulp-typescript) 和 [tsconfig.json](https://www.tslang.cn/docs/handbook/tsconfig-json.html) 配置文件,可快速进行项目构建。在根目录下新建 `tsconfig.json` 文件并新增以下配置:
```javascript
{
"compilerOptions": {
// 指定 ECMAScript 目标版本 "ES3"(默认), "ES5", "ES6" / "ES2015", "ES2016", "ES2017" 或 "ESNext"。
"target": "ES5",
// 构建的目标代码删除所有注释,除了以 /!* 开头的版权信息
"removeComments": true,
// 可配合 gulp-typescript 生成相应的 .d.ts 文件
"declaration": true,
// 启用所有严格类型检查选项。启用 --strict 相当于启用 --noImplicitAny, --noImplicitThis, --alwaysStrict, --strictNullChecks, --strictFunctionTypes 和 --strictPropertyInitialization
"strict": true,
// 禁止对同一个文件的不一致的引用
"forceConsistentCasingInFileNames": true,
// 报错时不生成输出文件
"noEmitOnError": true
}
}
```
> **温馨提示**:这里没有新增 `module` 配置信息,因为默认输出 CommonJS 规范,更多关于 TypeScript 配置信息可查看[TypeScript 官方文档 / 编译选项](https://www.tslang.cn/docs/handbook/compiler-options.html)。如果对于 CommonJS 和 ES6 规范的区别不是很清晰,这里有一篇非常好的文档可以供大家阅读:[ES modules: A cartoon deep-dive](https://hacks.mozilla.org/2018/03/es-modules-a-cartoon-deep-dive/)。
同时在根目录下新建 `gulpfile.js` 文件:
```javascript
const gulp = require("gulp");
const ts = require("gulp-typescript");
const tsProject = ts.createProject("tsconfig.json");
// 输出 CommonJS 规范到 dist 目录下
gulp.task("default", function () {
const tsResult = tsProject.src().pipe(tsProject());
return tsResult.js.pipe(gulp.dest("dist"));
});
```
在 `package.json` 中新增 script 脚本:
```javascript
"scripts": {
"build": "rimraf dist && gulp"
},
```
其中 [rimfaf](https://github.com/isaacs/rimraf) 用于构建之前清除 dist 目录文件内容。此时在 `src` 目录下新增 TypeScript 源码并使用 `npm run build` 命令可以进行项目构建并输出 CommonJS 规范的目标代码到 `dist` 目录下。
除此之外,此项目希望可以快速生成声明文件供外部进行代码提示,此时仍然可以借助 `gulp-typescript` 工具自动生成声明文件。在 `gulpfile.js` 中新增以下配置
```javascript
const gulp = require("gulp");
const ts = require("gulp-typescript");
const tsProject = ts.createProject("tsconfig.json");
const merge = require("merge2");
// 输出 CommonJS 规范到 dist 目录下
gulp.task("default", function () {
const tsResult = tsProject.src().pipe(tsProject());
return merge([
tsResult.dts.pipe(gulp.dest("types")),
tsResult.js.pipe(gulp.dest("dist")),
]);
});
```
修改 `build` 命令使其在构建之前同时可以删除 `types` 目录:
```javascript
"scripts": {
"build": "rimraf dist types && gulp",
},
```
再次执行 `npm run build` 会在项目根目录下生成 `types` 文件夹,该文件夹主要存放自动生成的 TypeScript 声明文件。
需要注意发布 npm 包时默认会将当前项目的所有文件进行发布处理,但是这里希望发布的包只包含使用者需要的编译文件 `dist` 和 `types`,因此可以通过`package.json` 中的 [`files`](https://docs.npmjs.com/files/package.json#files)(用于指定发布的 NPM 包包含哪些文件) 字段信息进行控制:
```javascript
"files": [
"dist",
"types"
],
```
> **温馨提示**:发布的 npm 包中某些文件将忽视 `files` 字段信息,包括 `package.json`、`LICENSE`、`README.md` 等。
除此之外,如果希望发布的 npm 包通过 `require('algorithms-utils')` 或 `import` 形式引入时指向 `dist/index.js` 文件,需要配置 `package.json` 中的 [`main`](https://docs.npmjs.com/files/package.json#main) 字段信息:
```javascript
"main": "dist/index.js"
```
> **温馨提示**: 对于工具包使用全量引入的方式并不是一个好的选择,可以通过具体的工具方法进行按需引入。
### ESLint
#### ESLint背景
TypeScript 的代码检查工具主要有 TSLint 和 ESLint 两种。早期的 TypeScript 项目一般采用 TSLint 进行检查,TSLint 和 TypeScript 采用同样的 AST 格式进行编译,但主要问题是对于 JavaScript 生态的项目支持不够友好,因此 TypeScript 团队在 2019 年宣布全面转向 ESLint,更多关于转向 ESLint 的原因可查看:
- <https://medium.com/palantir/tslint-in-2019-1a144c2317a9>
- <https://github.com/microsoft/TypeScript/issues/30553>
TypeScript 和 ESLint 使用不同的 AST 进行解析,因此为了在 ESLint 中支持 TypeScript 代码检查需要制作额外的[自定义解析器](https://cn.eslint.org/docs/developer-guide/working-with-custom-parsers)(Custom Parsers,ESLint 的自定义解析器功能需要基于 [ESTree](https://github.com/estree/estree)),目的是为了能够解析 TypeScript 语法并转成与 ESLint 兼容的 AST。[@typescript-eslint/parser](https://github.com/typescript-eslint/typescript-eslint#getting-started--installation) 在这样的背景下诞生,它会处理所有 ESLint 特定的配置并调用 [@typescript-eslint/typescript-estree](https://github.com/typescript-eslint/typescript-eslint/tree/master/packages/typescript-estree) 生成 ESTree-compatible AST(需要注意的是不仅仅兼容 ESLint,也能够兼容 Prettier)。
`@typescript-eslint` 是一个 Monorepo 体系结构的仓库,采用 [Learn](https://github.com/lerna/lerna) 进行设计,除了上述提到的 NPM 包之外,还包含以下两个重要的 NPM 包:
- [@typescript-eslint/eslint-plugin](https://github.com/typescript-eslint/typescript-eslint/tree/master/packages/eslint-plugin): 配合 `@typescript-eslint/parser` 一起使用的 ESLint 插件,可以设置 TypeScript 的校验规则。
- [@typescript-eslint/eslint-plugin-tslint](https://github.com/typescript-eslint/typescript-eslint/tree/master/packages/eslint-plugin-tslint): TSLint 向 ESLint 迁移的插件。
> **温馨提示**:如果你正在使用 TSLint,并且你希望兼容 ESLint 或者向 ESLint 进行过渡(TSLint 和 ESLint 并存), 可查看 [Migrating from TSLint to ESLint](https://github.com/typescript-eslint/typescript-eslint#migrating-from-tslint-to-eslint)。除此之外,以上所介绍的这些包发布时版本一致(为了联合使用的适配性),如果还有什么需要注意的话你可能需要关心一下 `@typescript-eslint` 对于 TypeScript 和 ESLint 的版本支持性,更多可查看该库包的 @typescript-eslint/parser 的仓库信息。
#### ESLint配置
从背景的介绍中可以理解,对于全新的 TypeScript 项目(直接抛弃 TSLint)需要包含解析 AST 的解析器 @typescript-eslint/parser 和使用校验规则的插件 @typescript-eslint/eslint-plugin,这里需要在项目中进行安装
```javascript
yarn add eslint @typescript-eslint/parser @typescript-eslint/eslint-plugin -D
```
在根目录新建 `.eslintrc.js` 配置文件,并设置以下配置:
```javascript
module.exports = {
root: true,
parser: "@typescript-eslint/parser",
plugins: ["@typescript-eslint"],
extends: ["eslint:recommended", "plugin:@typescript-eslint/recommended"],
};
```
其中:
- `parser: '@typescript-eslint/parser'`:使用 ESLint 解析 TypeScript 语法
- `plugins: ['@typescript-eslint']`:在 ESLint 中加载插件 `@typescript-eslint/eslint-plugin`,该插件可用于配置 TypeScript 校验规则。
- `extends: [ ... ]`:在 ESLint 中使用[共享规则配置](https://cn.eslint.org/docs/developer-guide/shareable-configs),其中 `eslint:recommended` 是 ESLint 内置的推荐校验规则配置(也被称作最佳规则实践),`plugin:@typescript-eslint/recommended` 是类似于 `eslint:recommended` 的 TypeScript 推荐校验规则配置。
> **温馨提示**:如果你稍微阅读一下 recommanded 源码你会发现,其实内部可以理解为推荐校验规则的集合。因此如果想基于 `@typescript-eslint/eslint-plugin` 进行自定义规则,则可参考 [TypeScript Supported Rules](https://github.com/typescript-eslint/typescript-eslint/tree/master/packages/eslint-plugin#supported-rules)。
配置完成后在 `package.json` 中设置校验命令
```javascript
"lint": "eslint src",
```
此时如果在 `src` 目录下书写错误的语法,执行 `npm run lint` 就会输出错误信息:
```javascript
> eslint src
C:\Code\Git\algorithms\src\greet.ts
2:16 warning Missing return type on function @typescript-eslint/explicit-module-boundary-types
✖ 1 problem (0 errors, 1 warning)
```
> **温馨提示**:输出的错误信息是通过 [ESLint Formatters](https://cn.eslint.org/docs/user-guide/formatters/) 生成,查看 ESLint 源代码并调试可发现默认采用的是 [stylish](https://cn.eslint.org/docs/user-guide/formatters/#stylish) formatter。
#### ESLint 插件
如果不使用插件,很难发现写的代码可能存在 TypeScript 格式错误(除非手动 `npm run lint` 或监听代码的变更并实时运行 `npm run lint`),此时可以通过 VS Code 插件进行处理。安装 ESLint 插件后可进行代码的实时提示,具体如下图所示:

当然为了防止不需要被校验的文件出现校验信息,可以通过 `.eslintignore` 文件进行配置(例如以下都是一些不需要格式校验的配置文件)
```javascript
# gulp
gulpfile.js
# eslint
.eslintrc.js
# commitizen
commitlint.config.js
# jest
jest.config.js
# build
dist
```
此时可以发现之前执行 `lint` 命令的错误通过插件的形式可实时在 VS Code 编辑器中进行显示。除此之外,一些简单的 ESLint 格式错误(例如 多余的`;` 等)可通过配置 Save Auto Fix 进行保存自动格式化处理。具体 VS Code 的配置可参考 [ESLint 插件](https://marketplace.visualstudio.com/items?itemName=dbaeumer.vscode-eslint)的文档说明,这边应该需要进行如下配置:
``` javascript
"editor.codeActionsOnSave": {
"source.fixAll": true,
"source.fixAll.eslint": true
}
```
> **温馨提示**:VS Code 的配置分为两种类型(用户和工作区),针对上述通用的配置主要放在用户里,针对不同项目的不同配置则需要放入工作区进行处理。
#### ESLint 确保构建
VS Code 插件并不能确保代码上传或构建前无任何错误信息,此时仍然需要额外的流程能够避免错误。在构建前进行 ESLint 校验能够确保构建时无任何错误信息,一旦 ESLint 校验不通过则不允许进行源码的构建操作:
```javascript
"scripts": {
"lint": "eslint src",
"lint": "eslint src --max-warnings 0",
"build": "npm run lint && rimraf dist types && gulp",
}
```
需要注意在构建时进行校验的严格控制,一旦 lint 抛出 warning 或者 error 则立马终止构建(详情可查看 [ESLint 退出代码](https://cn.eslint.org/docs/user-guide/command-line-interface#exit-codes))。
> **温馨提示**:需要注意 Shell 中的 `&&` 和 `&` 是有差异的,`&&` 主要用于继发执行,只有前一个任务执行成功,才会执行下一个任务,`&` 主要用于并发执行,表示两个脚本同时执行。这里构建的命令需要等待 `lint` 命令执行通过才能进行,一旦 `lint` 失败那么构建命令将不再执行。
#### ESLint 确保代码上传
尽管可能配置了 ESLint 的校验脚本 以及 VS Code 插件,但是有些 ESLint 的规则校验是无法通过 Save Auto Fix 进行格式化修复的(例如质量规则),因此还需要一层保障能够确保代码提交之前所有的代码能够通过 ESLint 校验,这个配置将在 Lint Staged 中进行讲解。
### Prettier
#### Prettier 背景
Prettier 是一个统一代码格式风格的工具,如果你不清楚为什么需要使用 Prettier,可以查看 [Why Prettier?](https://prettier.io/docs/en/why-prettier.html)。很多人可能疑惑,ESLint 已经能够规范我们的代码风格,为什么还需要 Prettier?在 [Prettier vs Linters](https://prettier.io/docs/en/comparison.html) 中详细说明了两者的区别,Linters 有两种类型的规则:
- 格式规则(Formatting rules):例如 [max-len](https://eslint.org/docs/rules/max-len)、[keyword-spacing](https://eslint.org/docs/rules/keyword-spacing) 以及 [no-mixed-spaces-and-tabs](https://eslint.org/docs/rules/no-mixed-spaces-and-tabs) 等
- 质量规则(Code-quality rules):例如 [no-unused-vars](https://eslint.org/docs/rules/no-unused-vars)、[no-implicit-globals](https://eslint.org/docs/rules/no-implicit-globals) 以及 [prefer-promise-reject-errors](https://eslint.org/docs/rules/prefer-promise-reject-errors) 等
ESLint 的规则校验同时包含了 **格式规则** 和 **质量规则**,但是大部分情况下只有 **格式规则** 可以通过 `--fix` 或 VS Code 插件的 Sava Auto Fix 功能一键修复,而 **质量规则** 更多的是发现代码可能出现的 Bug 从而防止代码出错,这类规则往往需要手动修复。因此 **格式规则** 并不是必须的,而 **质量规则** 则是必须的。Prettier 与 ESLint 的区别在于 Prettier 专注于统一的**格式规则**,从而减轻 ESLint 在**格式规则上**的校验,而对于**质量规则** 则交给专业的 ESLint 进行处理。总结一句话就是:Prettier for formatting and linters for catching bugs!(ESLint 是必须的,Prettier 是可选的!)
需要注意如果 ESLint(TSLint) 和 Prettier 配合使用时**格式规则**有重复且产生了冲突,那么在编辑器中使用 Sava Auto Fix 时会让你的一键格式化哭笑不得。此时应该让两者把各自注重的规则功能区分开,使用 ESLint 校验**质量规则**,使用 Prettier 校验**格式规则**,更多信息可查看 [Integrating with Linters](https://prettier.io/docs/en/integrating-with-linters.html)。
> **温馨提示**:在 VS Code 中使用 ESLint 匹配到相应的规则时会产生黄色波浪线以及红色文件名进行错误提醒。Prettier 更希望你对格式规则无感知,从而不会让你觉得有任何使用的负担。如果想要了解更多 Prettier,还可以查看 Prettier 的背后思想 [Option Philosophy](https://prettier.io/docs/en/option-philosophy.html),个人认为了解一个产品设计的**哲学**能更好的指导你使用该产品。
#### Prettier 配置
首先安装 Prettier 所需要的依赖:
```javascript
npm i prettier eslint-config-prettier --save-dev
```
其中:
- [eslint-config-prettier](https://github.com/prettier/eslint-config-prettier): 用于解决 ESLint 和 Prettier 配合使用时容易产生的**格式规则**冲突问题,其作用就是关闭 ESLint 中配置的一些格式规则,除此之外还包括关闭 `@typescript-eslint/eslint-plugin`、`eslint-plugin-babel`、`eslint-plugin-react`、`eslint-plugin-vue`、`eslint-plugin-standard` 等格式规则。
理论上而言,在项目中开启 ESLint 的 `extends` 中设置的带有格式规则校验的规则集,那么就需要通过 `eslint-config-prettier` 插件关闭可能产生冲突的格式规则:
```javascript
{
"extends": [
"plugin:@typescript-eslint/recommended",
// 用于关闭 ESLint 相关的格式规则集,具体可查看 https://github.com/prettier/eslint-config-prettier/blob/master/index.js
"prettier",
// 用于关闭 @typescript-eslint/eslint-plugin 插件相关的格式规则集,具体可查看 https://github.com/prettier/eslint-config-prettier/blob/master/%40typescript-eslint.js
"prettier/@typescript-eslint",
]
}
```
配置完成后,可以通过[命令行接口](https://prettier.io/docs/en/cli.html)运行 Prettier:
```javascript
"scripts": {
"prettier": "prettier src test --write",
},
```
`--write` 参数类似于 ESLint 中的 `--fix`(在 ESLint 中使用该参数还是需要谨慎哈,建议还是使用 VS Code 的 Save Auto Fix 功能),主要用于自动修复格式错误。此时书写格式的错误代码:
```javascript
import great from "@/greet";
// 中间加很多空行
export default {
great,
};
```
执行 `npm run prettier` 进行格式修复:
```javascript
PS C:\Code\Git\algorithms> npm run prettier
> [email protected] prettier C:\Code\Git\algorithms
> prettier src test --write
src\greet.ts 149ms
src\index.ts 5ms
test\greet.spec.ts 11ms
```
修复之后的的文件格式如下:
```javascript
import great from "@/greet";
export default {
great,
};
```
需要注意如果某些规则集没有对应的 `eslint-config-prettier` 关闭配置,那么可以先通过 [CLI helper tool](https://github.com/prettier/eslint-config-prettier#cli-helper-tool) 检测是否有重复的格式规则集在生效,然后可以通过手动配置 `eslintrc.js` 的形式进行关闭:
```javascript
PS C:\Code\Git\algorithms> npx eslint --print-config src/index.ts | npx eslint-config-prettier-check
No rules that are unnecessary or conflict with Prettier were found.
```
例如把 `eslint-config-prettier` 的配置去除,此时进行检查重复规则:
```javascript
PS C:\Code\Git\algorithms> npx eslint --print-config src/index.ts | npx eslint-config-prettier-check
The following rules are unnecessary or might conflict with Prettier:
- @typescript-eslint/no-extra-semi
- no-mixed-spaces-and-tabs
The following rules are enabled but cannot be automatically checked. See:
https://github.com/prettier/eslint-config-prettier#special-rules
- no-unexpected-multiline
```
此时假设 `eslint-config-prettier` 没有类似的关闭格式规则集(例如本项目中配置的 `plugin:jest/recommended` 可能存在规则冲突),那么可以通过配置 `.eslintrc.js` 的形式自己手动关闭相应冲突的格式规则。
> **温馨提示**:ESLint 可以对不同的文件支持不同的规则校验, 因此 `--print-config` 只能对应单个文件的冲突格式规则检查。 由于通常的项目是一套规则对应一整个项目,因此对于整个项目所有的规则只需要校验一个文件是否有格式规则冲突即可。
#### Prettier 插件
通过命令行接口 `--write` 的形式可以进行格式自动修复,但是类似 ESLint,我们更希望项目在实时编辑时可以通过保存就能自动格式化代码(鬼知道 `--fix` 以及 `--write` 格式了什么文件,当然更希望通过肉眼的形式立即感知代码的格式化变化),此时可以通过配置 VS Code 的 [Prettier - Code formatter](https://marketplace.visualstudio.com/items?itemName=esbenp.prettier-vscode) 插件进行 Save Auto Fix,具体的配置查看插件文档。
#### Prettier 确保代码上传
和 ESLint 一样,尽管可能配置了 Prettier 的自动修复格式脚本以及 VS Code 插件,但是无法确保格式遗漏的情况,因此还需要一层保障能够确保代码提交之前能够进行 Prettier 格式化,这个配置将在 Lint Staged 中讲解,更多配置方案也可以查看 [Prettier - Pre-commit Hook](https://prettier.io/docs/en/precommit.html)。
### Lint Staged
#### Lint Staged 背景
在 Git Commit Message 中使用了 [commitlint](https://commitlint.js.org/#/) 工具配合 husky 可以防止生成不规范的 Git Commit Message,从而阻止用户进行不规范的 Git 代码提交,其原理就是监听了 Git Hook 的执行脚本(会在特定的 Git 执行命令诸如 `commit`、`push`、`merge` 等触发之前或之后执行相应的脚本钩子)。Git Hook 其实是进行项目约束非常好用的工具,它的作用包括但不限于:
- Git Commit Message 规范强制统一
- ESLint 规则统一,防止不符合规范的代码提交
- Prettier 自动格式化(类似的还包括 Style 样式格式等)
- 代码稳定性提交,提交之前确保测试用例全部通过
- 发送邮件通知
- CI 集成(服务端钩子)
Git Hook 的钩子非常多,但是在客户端中可能常用的钩子是以下两个:
- `pre-commit`:Git 中 `pre` 系列钩子允许终止即将发生的 Git 操作,而`post` 系列往往用作通知行为。`pre-commit` 钩子在键入提交信息(运行 `git commit` 或 `git cz`)前运行,主要用于检查当前即将被提交的代码快照,例如提交遗漏、测试用例以及代码等。该钩子如果以非零值退出则 Git 将放弃本次提交。当然你也可以通过配置命令行参数 `git commit --no-verify` 绕过钩子的运行。
- `commit-msg`:该钩子在用户输入 Commit Message 后被调用,接收存有当前 **Commit Message** 信息的临时文件路径作为唯一参数,因此可以利用该钩子来核对 Commit Meesage 信息(在 Git Commit Message 中使用了该钩子对提交信息进行了是否符合 Angular 规范的校验)。该钩子和 `pre-commit` 类似,一旦以非零值退出 Git 将放弃本次提交。
除了上述常用的客户端钩子,还有两个常用的服务端钩子:
- `pre-receive`:该钩子会在远程仓库接收 `git push` 推送的代码时执行(注意不是本地仓库),该钩子会比 `pre-commit` 更加有约束力(总会有这样或那样的开发人员不喜欢提交代码时所做的一堆检测,他们可能会选择绕过这些钩子)。`pre-receive` 钩子可用于接收代码时的强制规范校验,如果某个开发人员采用了绕过 `pre-commit` 钩子的方式提交了一堆 💩 一样的代码,那么通过设置该钩子可以拒绝代码提交。当然该钩子最常用的操作还是用于检查是否有权限推送代码、非快速向前合并等。
- `post-receive`:该钩子在推送代码成功后执行,适合用于发送邮件通知或者触发 CI 。
> **温馨提示**:想了解更多 Git Hook 信息可以查看 [Git Hook 官方文档](https://git-scm.com/book/zh/v2/%E8%87%AA%E5%AE%9A%E4%B9%89-Git-Git-%E9%92%A9%E5%AD%90) 或 [Git 钩子:自定义你的工作流](https://github.com/geeeeeeeeek/git-recipes/wiki/5.4-Git-%E9%92%A9%E5%AD%90%EF%BC%9A%E8%87%AA%E5%AE%9A%E4%B9%89%E4%BD%A0%E7%9A%84%E5%B7%A5%E4%BD%9C%E6%B5%81)。
需要注意初始化 Git 之后默认会在 `.git/hooks` 目录下生成所有 Git 钩子的 Shell 示例脚本,这些脚本是可以被定制化的。对于前端开发而言去更改这些示例脚本适配前端项目非常不友好(大多数前端开发同学压根不会设计 Shell 脚本,尽管这个对于制作工具是一件非常高效的事情),因此社区就出现了类似的增强工具,它们对外抛出的是简单的钩子配置(例如 [ghooks](https://github.com/ghooks-org/ghooks) 在 `package.json` 中只需要进行简单的[钩子属性配置](https://github.com/ghooks-org/ghooks#setup)),而在内部则通过替换 Git 钩子示例脚本的形式使得外部配置的钩子可以被执行,例如 [husky](https://github.com/typicode/husky)、ghooks 以及 [pre-commit](https://github.com/pre-commit/pre-commit) 等。
> **温馨提示**: Git Hook 还可以定制脚本执行的语言环境,例如对于前端而言当然希望使用熟悉的 Node 进行脚本设计,此时可以通过在脚本文件的头部设置 `#! /usr/bin/env node` 将 Node 作为可执行文件的环境解释器,如果你之前看过 [使用 NPM 发布和使用 CLI 工具](https://juejin.im/post/5eb89053e51d454de54db501) 可能会对这个环境解析器相对熟悉,这里也给出一个使用 Node 解释器的示例:[ghooks - hook.template.raw](https://github.com/ghooks-org/ghooks/blob/master/lib/hook.template.raw),ghooks 的实现非常简单,感兴趣的同学可以仔细阅读一些源码的实现。
介绍 Git Hook 是为了让大家清晰的认知到使用 Hook 可以在前端的工程化项目中做很多事情(本来应该放在 Git Commit Message 中介绍相对合适,但是鉴于那个小节引用了另外一篇文章,因此将这个信息放在本小节进行科普)。
之前提到使用 Git Hook 可以进行 ESLint 规范约束,因此大家其实应该能够猜到使用 `pre-commit` 钩子(当然需要借助 Git Hook 增强工具,本项目中一律选择 `husky`)配合 ESLint 可以进行提交说明前的项目代码规则校验,但是如果项目越来越大,ESLint 校验的时间可能越来越长,这对于频繁的代码提交者而言可能是一件相对痛苦的事情,因此可以借助 `lint-staged` 工具(听这个工具的名字就能够猜测 lint 的是已经放入 Git Stage 暂存区中的代码,`ed` 在英文中表明已经做过)减少代码的检测量。
#### Lint Staged 配置
使用 [commitlint](https://commitlint.js.org/#/) 工具可以防止生成不规范的 Git Commit Message,从而阻止用户进行 Git 代码提交。但是如果想要防止团队协作时开发者提交不符合 ESLint 规则的代码则可以通过 [lint-staged](https://github.com/okonet/lint-staged) 工具来实现。`lint-staged` 可以在用户提交代码之前(生成 Git Commit Message 信息之前)使用 ESLint 检查 Git 暂存区中的代码信息(`git add` 之后的修改代码),一旦存在 💩 一样不符合校验规则的代码,则可以终止提交行为。需要注意的是 `lint-staged` 不会检查项目的全量代码(全量使用 ESLint 校验对于较大的项目可能会是一个相对耗时的过程),而只会检查添加到 Git 暂存区中的代码。根据官方文档执行以下命令自动生成配置项信息:
```javascript
npx mrm lint-staged
```
需要注意默认生成的配置文件是针对 JavaScript 环境的,手动修改 `package.json` 中的配置信息进行 TypeScript 适配:
```javascript
// 我们的哈士奇再次上场,这次它是要咬着你的 ESLint 不放了,这里我简称它的动作为 "咬 💩" ~~~
"husky": {
"hooks": {
"pre-commit": "lint-staged"
}
},
"lint-staged": {
// 这里需要注意 ESLint 脚本的 --max-warnings 0
// 否则就算存在 warning 也不会终止提交行为
// 这里追加了 Prettier 的自动格式化,确保代码提交之前所有的格式能够修复
"*.ts": "npm run lint"
}
```
此时如果将要提交的代码有 💩 , 则提交时会提示错误信息且提交会被强制终止:
husky 在 `package.json` 中配置了 `pre-commit` 和 `commit-msg` 两个 [Git 钩子](https://git-scm.com/book/en/v2/Customizing-Git-Git-Hooks),优先使用 `pre-commit` 钩子执行 ESLint 校验,如果校验失败则终止运行。如果校验成功则会继续执行 `commit-msg` 校验 Git Commit Message。
### Jest
#### 测试背景
如果对于测试的概念和框架不是特别清楚,这里推荐一些可查看的文章:
- [JavaScript 程序测试](https://javascript.ruanyifeng.com/tool/testing.html) - 全面的测试基础知识
- [New to front-end testing? Start from the top of the pyramid!](https://dev.to/noriste/new-to-front-end-testing-start-from-the-top-of-the-pyramid-36kj) - 重点可以了解一下测试金字塔和测试置信度
- [[译] JavaScript 单元测试框架:Jasmine, Mocha, AVA, Tape 和 Jest 的比较](https://juejin.im/post/5acc721a6fb9a028b77b23c9) - 单元测试框架对比中文版(2018)
- [JavaScript unit testing frameworks in 2020: A comparison](https://raygun.com/blog/javascript-unit-testing-frameworks/) - 单元测试框架对比英文版(2020)
除此之外,如果想了解一些额外的测试技巧,这里推荐一些社区的最佳实践:
- [javascript-testing-best-practices](https://github.com/goldbergyoni/javascript-testing-best-practices/blob/master/readme-zh-CN.md)
- [ui-testing-best-practices](https://github.com/NoriSte/ui-testing-best-practices)
由于这里只是 Node 环境工具库包的单元测试,在对比了各个测试框架之后决定采用 [Jest](https://jestjs.io/) 进行单元测试:
- 内置断言库可实现开箱即用(从 `it` 到 `expect`, Jest 将整个工具包放在一个地方)
- Jest 可以可靠地并行运行测试,并且为了让加速测试进程,Jest 会优先运行之前失败的测试用例
- 内置覆盖率报告,无需额外进行配置
- 优秀的报错信息
> **温馨提示**:前端测试框架很多,相比简单的单元测试,e2e 测试会更复杂一些(不管是测试框架的支持以及测试用例的设计)。之前使用过 Karma 测试管理工具配合 Mocha 进行浏览器环境测试,也使用过 PhantomJS 以及 Nightwatch(使用的都是皮毛),印象最深刻的是使用 [testcafe](https://github.com/DevExpress/testcafe) 测试框架(复杂的 API 官方文档),除此之外如果还感兴趣,也可以了解一下 [cypress](https://github.com/cypress-io/cypress) 测试框架。
#### Jest 配置
本项目的单元测试主要采用了 [Jest](https://jestjs.io/en/) 测试框架。Jest 如果需要对 TypeScript 进行支持,可以通过配合 Babel 的形式,具体可查看 [Jest - Using TypeScript](https://jestjs.io/docs/en/getting-started#using-typescript),但是采用 Babel 会产生一些限制(具体可查看 [Babel 7 or TypeScript](https://kulshekhar.github.io/ts-jest/user/babel7-or-ts))。由于本项目没有采用 Babel 进行转译,并且希望能够完美支持类型检查,因此采用 [ts-jest](https://kulshekhar.github.io/ts-jest/user/install#customizing) 进行单元测试。按照官方教程进行依赖安装和项目初始化:
```javascript
npm install --save-dev jest ts-jest @types/jest
npx ts-jest config:init
```
在根目录的 `jest.config.js` 文件中进行 Jest 配置修改:
```javascript
module.exports = {
preset: "ts-jest",
testEnvironment: "node",
// 输出覆盖信息文件的目录
coverageDirectory: "./coverage/",
// 覆盖信息的忽略文件模式
testPathIgnorePatterns: ["<rootDir>/node_modules/"],
// 如果测试覆盖率未达到 100%,则测试失败
// 这里可用于预防代码构建和提交
coverageThreshold: {
global: {
branches: 100,
functions: 100,
lines: 100,
statements: 100,
},
},
// 路径映射配置,具体可查看 https://kulshekhar.github.io/ts-jest/user/config/#paths-mapping
// 需要配合 TypeScript 路径映射,具体可查看:https://www.tslang.cn/docs/handbook/module-resolution.html
moduleNameMapper: {
"^@/(.*)$": "<rootDir>/src/$1",
},
};
```
需要注意路径映射也需要配置 `tsconfig.json` 中的 `paths` 信息,同时注意将测试代码包含到 TypeScript 的编译目录中。配置完成后在 `package.json` 中配置测试命令:
```javascript
"scripts": {
"test": "jest --bail --coverage",
"prebuild": "npm run lint && npm run prettier && npm run test",
}
```
需要注意 Jest 中的这些配置信息(更多配置信息可查看 [Jest CLI Options](https://jestjs.io/docs/zh-Hans/cli)):
- `bail` 的配置作用相对类似于 ESLint 中的 `max-warnings`,设置为 `true` 则表明一旦发现单元测试用例错误则停止运行其余测试用例,从而可以防止运行用例过多时需要一直等待用例全部运行完毕的情况。
- `coverage` 主要用于在当前根目录下生成 `coverage` 代码的测试覆盖率报告,该报告还可以上传 [coveralls](https://coveralls.io/) 进行 Github 项目的 Badges 显示。
> **温馨提示**:Jest CLI Options 中的 `findRelatedTests` 可用于配合 `pre-commit` 钩子去运行最少量的单元测试用例,可配合 `lint-staged` 实现类似于 ESLint 的作用,更多细节可查看 [`lint-staged - Use environment variables with linting commands`](https://github.com/okonet/lint-staged#use-environment-variables-with-linting-commands)。
在当前根目录的 `test` 目录下新建 `greet.spec.ts` 文件,并设计以下测试代码:
```javascript
import greet from "@/greet";
describe("src/greet.ts", () => {
it("name param test", () => {
expect(greet("world")).toBe("Hello from world 1");
});
});
```
> **温馨提示**:测试文件有两种放置风格,一种是新建 `test` 文件夹,然后将所有的测试代码集中在 `test` 目录下进行管理,另外一种是在各个源码文件的同级目录下新建 `__test__` 目录,进行就近测试。大部分的项目可能都会倾向于采用第一种目录结构(可以随便找一些 github 上的开源项目进行查看,这里 `ts-test` 则是采用了第二种测试结构)。除此之外,需要注意 Jest 通过配置 [`testMatch`](https://jestjs.io/docs/zh-Hans/configuration#testmatch-arraystring) 或 [`testRegex`](https://jestjs.io/docs/zh-Hans/configuration#testregex-string--arraystring) 可以使得项目识别特定格式文件作为测试文件进行运行(本项目采用默认配置可识别后缀为 `.spec` 的文件进行单元测试)。
#### Jest 确保构建
单独通过执行 `npm run test` 命令进行单元测试,这里演示执行构建命令时的单元测试(需要保证构建之前所有的单元测试用例都能通过)。如果测试失败,那么应该防止继续构建,例如进行失败的构建行为:
```javascript
bogon:standard_conf chenjr$ tyarn test
yarn run v1.17.3
$ jest --bail --coverage
ts-jest[versions] (WARN) Version 4.0.2 of typescript installed has not been tested with ts-jest. If you're experiencing issues, consider using a supported version (>=3.8.0 <4.0.0-0). Please do not report issues in ts-jest if you are using unsupported versions.
FAIL test/greet.spec.ts
src/greet.ts
✕ name param test (16 ms)
● src/greet.ts › name param test
expect(received).toBe(expected) // Object.is equality
Expected: "Hello from world 1"
Received: "Hello from world"
3 | describe("src/greet.ts", () => {
4 | it("name param test", () => {
> 5 | expect(greet("world")).toBe("Hello from world 1");
| ^
6 | });
7 | });
at Object.<anonymous> (test/greet.spec.ts:5:28)
---------|---------|----------|---------|---------|-------------------
File | % Stmts | % Branch | % Funcs | % Lines | Uncovered Line #s
---------|---------|----------|---------|---------|-------------------
...files | 100 | 100 | 100 | 100 |
...t.ts | 100 | 100 | 100 | 100 |
---------|---------|----------|---------|---------|-------------------
Test Suites: 1 failed, 1 total
Tests: 1 failed, 1 total
Snapshots: 0 total
Time: 2.796 s
Ran all test suites.
error Command failed with exit code 1.
info Visit https://yarnpkg.com/en/docs/cli/run for documentation about this command.
```
需要注意由于是并行(`&&`)执行脚本,因此执行构建命令时(`npm run prebuild`)会先执行 ESLint 校验,如果 ESLint 校验失败那么退出构建,否则继续进行 Jest 单元测试。如果单元测试失败那么退出构建,只有当两者都通过时才会进行源码构建。
#### Jest 确保代码上传
除了预防不负责任的代码构建以外,还需要预防不负责任的代码提交。配合 `lint-staged` 可以防止未跑通单元测试的代码进行远程提交:
```javascript
"scripts": {
"lint": "eslint src --max-warnings 0",
"test": "jest --bail --coverage",
},
"lint-staged": {
"*.ts": [
"npm run lint",
"npm run test"
]
}
```
此时如果单元测试有误,都会停止代码提交:
```javascript
husky > pre-commit (node v12.13.1)
[STARTED] Preparing...
[SUCCESS] Preparing...
[STARTED] Running tasks...
[STARTED] Running tasks for *.ts
[STARTED] npm run lint
[SUCCESS] npm run lint
[STARTED] npm run jest
[FAILED] npm run jest [FAILED]
[FAILED] npm run jest [FAILED]
[SUCCESS] Running tasks...
[STARTED] Applying modifications...
[SKIPPED] Skipped because of errors from tasks.
[STARTED] Reverting to original state because of errors...
[SUCCESS] Reverting to original state because of errors...
[STARTED] Cleaning up...
[SUCCESS] Cleaning up...
× npm run jest:
FAIL test/greet.spec.ts
src/greet.ts
× name param test (4 ms)
● src/greet.ts › name param test
expect(received).toBe(expected) // Object.is equality
Expected: "Hello from world 1"
Received: "Hello from world"
3 | describe("src/greet.ts", () => {
4 | it("name param test", () => {
> 5 | expect(greet("world")).toBe("Hello from world 1");
| ^
6 | });
7 | });
8 |
at Object.<anonymous> (test/greet.spec.ts:5:28)
Test Suites: 1 failed, 1 total
Tests: 1 failed, 1 total
Snapshots: 0 total
Time: 1.339 s, estimated 3 s
Ran all test suites related to files matching /C:\\Code\\Git\\algorithms\\src\\index.ts|C:\\Code\\Git\\algorithms\\test\\greet.spec.ts/i.
npm ERR! code ELIFECYCLE
npm ERR! errno 1
npm ERR! [email protected] jest: `jest --bail --findRelatedTests --coverage "C:/Code/Git/algorithms/src/index.ts" "C:/Code/Git/algorithms/test/greet.spec.ts"`
npm ERR! Exit status 1
npm ERR!
npm ERR! Failed at the [email protected] jest script.
npm ERR! This is probably not a problem with npm. There is likely additional logging output above.
npm ERR! A complete log of this run can be found in:
npm ERR! C:\Users\子弈\AppData\Roaming\npm-cache\_logs\2020-07-12T14_33_51_183Z-debug.log
> [email protected] jest C:\Code\Git\algorithms
npm ERR! Exit status 1
npm ERR!
npm ERR! Failed at the [email protected] jest script.
npm ERR! This is probably not a problem with npm. There is likely additional logging output above.
npm ERR! A complete log of this run can be found in:
npm ERR! C:\Users\子弈\AppData\Roaming\npm-cache\_logs\2020-07-12T14_33_51_183Z-debug.log
> [email protected] jest C:\Code\Git\algorithms
> jest --bail --findRelatedTests --coverage "C:/Code/Git/algorithms/src/index.ts" "C:/Code/Git/algorithms/test/greet.spec.ts"
----------|---------|----------|---------|---------|-------------------
| File | % Stmts | % Branch | % Funcs | % Lines | Uncovered Line #s |
| ---------- | --------- | ---------- | --------- | --------- | ------------------- |
| All files | 0 | 0 | 0 | 0 |
| ---------- | --------- | ---------- | --------- | --------- | ------------------- |
husky > pre-commit hook failed (add --no-verify to bypass)
git exited with error code 1
```
> **温馨提示**:想要了解更多关于 Jest 的生态可以查看 [awesome-jest](https://github.com/jest-community/awesome-jest)。
#### Jest 对于 ESLint 支持
`src` 目录下的源码通过配置 `@typescript-eslint/eslint-plugin` 可进行推荐规则的 ESLint 校验,为了使得 `test` 目录下的测试代码能够进行符合 Jest 推荐规则的 ESLint 校验,可以通过配置 [eslint-plugin-jest](https://github.com/jest-community/eslint-plugin-jest) 进行支持(`ts-jest` 项目就是采用了该插件进行 ESLint 校验,具体可查看配置文件 [`ts-jest/.eslintrc.js`](https://github.com/kulshekhar/ts-jest/blob/master/.eslintrc.js#L12)),这里仍然采用推荐的规则配置:
```javascript
module.exports = {
root: true,
parser: "@typescript-eslint/parser",
plugins: ["@typescript-eslint"],
extends: [
"eslint:recommended",
"plugin:@typescript-eslint/recommended",
// 新增推荐的 ESLint 校验规则
// 所有规则集查看:https://github.com/jest-community/eslint-plugin-jest#rules(recommended 标识表明是推荐规则)
"plugin:jest/recommended",
],
};
```
为了验证推荐规则是否生效,这里可以找一个 [`no-identical-title`](https://github.com/jest-community/eslint-plugin-jest/blob/master/docs/rules/no-identical-title.md) 规则进行验证:
```javascript
import greet from "@/greet";
describe("src/greet.ts", () => {
it("name param test", () => {
expect(greet("world")).toBe("Hello from world 1");
});
});
// 这里输入了重复的 title
describe("src/greet.ts", () => {
it("name param test", () => {
expect(greet("world")).toBe("Hello from world 1");
});
});
```
需要注意修改 `package.json` 中的 ESLint 校验范围:
```javascript
"scripts": {
// 这里对 src 和 test 目录进行 ESLint 校验
"lint": "eslint src test --max-warnings 0",
},
```
执行 `npm run lint` 进行单元测试的格式校验:
```javascript
bogon:standard_conf chenjr$ tyarn lint
yarn run v1.17.3
$ eslint src test --max-warnings 0
/Users/chenjr/Documents/self/standard_conf/test/greet.spec.ts
10:10 error Describe block title is used multiple times in the same describe block jest/no-identical-title
✖ 1 problem (1 error, 0 warnings)
error Command failed with exit code 1.
info Visit https://yarnpkg.com/en/docs/cli/run for documentation about this command.
```
此时会发现 ESLint 抛出了相应的错误信息。需要注意采用此 ESLint 校验之后也会在 VS Code 中实时生成错误提示(相应的代码下会有红色波浪线,鼠标移入后会产生 Tooltip 提示该错误的相应规则信息,除此之外当前工程目录下对应的文件名也会变成红色),**此后的 Git 提交以及 Build 构建都会失败**!
> **温馨提示**:如果你希望 Jest 测试的代码需要一些格式规范,那么可以查看 [eslint-plugin-jest-formatting](https://github.com/dangreenisrael/eslint-plugin-jest-formatting) 插件。
### Npm Script Hook
当你查看前端开源项目时第一时间可能会找 `package.json` 中的 `main`、`bin` 以及 `files` 等字段信息,除此之外如果还想深入了解项目的结构,可能还会查看 `scripts` 脚本字段信息用于了解项目的开发、构建、测试以及安装等流程。npm 的脚本功能非常强大,你可以利用脚本制作项目需要的任何流程工具。本文不会过多介绍 npm 脚本的功能,只是讲解一下其中用到的 [钩子](https://www.npmjs.cn/misc/scripts/#description) 功能。
目前在本项目中使用的一些脚本命令如下(就目前而言脚本相对较少,定义还蛮清晰的):
```javascript
"lint": "eslint src test --max-warnings 0",
"test": "jest --bail --coverage",
"build": "npm run lint && npm run prettier && npm run test && rimraf dist types && gulp",
"changelog": "rimraf CHANGELOG.md && conventional-changelog -p angular -i CHANGELOG.md -s"
```
重点看下 `build` 脚本命令,会发现这个脚本命令包含了大量的继发执行脚本,但真正和 `build` 相关的只有 `rimraf dist types && gulp` 这两个脚本。这里通过 npm 的脚本钩子 `pre` 和 `post` 将脚本的功能区分开,从而使脚本的语义更加清晰(当然脚本越来越多的时候也可能容易增加开发者的认知负担)。npm 除了指定一些特殊的脚本钩子以外(例如 `prepublish`、`postpublish`、`preinstall`、`postinstall`等),还可以对任意脚本增加 `pre` 和 `post` 钩子,这里通过自定义钩子将并发执行的脚本进行简化:
```javascript
"lint": "eslint src test --max-warnings 0",
"test": "jest --bail --coverage",
"prebuild": "npm run lint && npm run prettier && npm run test",
"build": "rimraf dist types && gulp",
"changelog": "rimraf CHANGELOG.md && conventional-changelog -p angular -i CHANGELOG.md -s"
```
此时如果执行 `npm run build` 命令时事实上类似于执行了以下命令:
```javascript
npm run prebuild && npm run build
```
之后设计的脚本如果继发执行繁多,那么都会采用 npm scripts hook 进行设计。
> **温馨提示**:大家可能会奇怪什么地方需要类似于 `preinstall` 或 `preuninstall` 这样的钩子,例如查看 [husky - package.json](https://github.com/typicode/husky/blob/master/package.json),husky 在安装的时候因为要植入 Git Hook 脚本从而带来了一些副作用(此时当然可以通过 `preinstall` 触发 Git Hook 脚本植入的逻辑)。如果不想使用 husky,那么卸载后需要清除植入的脚本从而不妨碍原有的 Git Hook 功能。 当然如果想要了解更多关于 npm 脚本的信息,可以查看 [npm-scripts](https://www.npmjs.cn/misc/scripts/) 或 [npm scripts 使用指南](http://www.ruanyifeng.com/blog/2016/10/npm_scripts.html?utm_source=tuicool&utm_medium=referral)。
### Vuepress
#### Vuepress 背景
一般组件库或工具库都需要设计一个演示文档(提供良好的开发体验)。一般的工具库可以采用 [tsdoc](https://github.com/Microsoft/tsdoc)、[jsdoc](https://github.com/jsdoc/jsdoc) 或 [esdoc](https://github.com/esdoc/esdoc) 等工具进行 API 文档的自动生成,但往往需要符合一些注释规范,这些注释规范在某种程度上可能会带来开发负担,当然也可以交给 VS Code 的插件进行一键生成,例如 [Document This For jsdoc](https://marketplace.visualstudio.com/items?itemName=joelday.docthis) 或 [TSDoc Comment](https://marketplace.visualstudio.com/items?itemName=kingsimba.tsdoc-comment)。
组件库 Element UI 采用 [vue-markdown-loader](https://github.com/QingWei-Li/vue-markdown-loader#with-vue-cli-3)(Convert Markdown file to Vue Component using markdown-it) 进行组件的 Demo 演示设计,但是配置相对复杂。更简单的方式是配合 [Vuepress](https://www.vuepress.cn/) 进行设计,它的功能非常强大,但前提是熟悉 Vue,因为可以在 Markdown 中使用 Vue 语法。当然如果是 React 组件库的 Demo 演示,则可以采用 [dumi](https://d.umijs.org/guide) 生成组件 Demo 演示文档(不知道没有更加好用的类 Vuepress 的 React 组件文档生成器, 更多和 React 文档相关也可以了解 [react-markdown](https://github.com/rexxars/react-markdown#readme)、[react-static](https://github.com/react-static/react-static) 等)。
由于之前采用过 Vuepress 设计 Vue 组件库的 Demo 演示文档,因此这里仍然沿用它来设计工具库包的 API 文档(如果你想自动生成 API 文档,也可以额外配合 tsdoc 工具)。采用 Vuepress 设计文档的主要特点如下:
- 可以在 Markdown 中直接使用 Vue(还可以自定义 Vue 文档视图组件)
- 内置了很多 Markdown 拓展
- 可以使用 Webpack 进行构建定制化配置
- 默认主题支持搜索能力
- 可以安装 Vuepress 插件(后续需要支持的 [Latex](https://www.latex-project.org/) 排版就可以利用现有的插件能力生成)
- 默认响应式
#### Vuepress 配置
先按照官方的 [快速上手](https://www.vuepress.cn/guide/getting-started.html#%E5%BF%AB%E9%80%9F%E4%B8%8A%E6%89%8B) 文档进行依赖安装和 npm scripts 脚本设置:
```javascript
"scripts": {
"docs:dev": "vuepress dev docs",
"docs:build": "vuepress build docs"
}
```
按照 Vuepress 官网**约定优于配置**的原则进行演示文档的[目录结构](https://www.vuepress.cn/guide/directory-structure.html)设计,官方的文档可能一下子难以理解,可以先设计一个最简单的目录:
```javascript
.
├── docs
│ ├── .vuepress
│ │ └── config.js # 配置文件
│ └── README.md # 文档首页
└── package.json
```
根据[默认主题 / 首页](https://www.vuepress.cn/theme/default-theme-config.html#%E9%A6%96%E9%A1%B5)在 `docs/README.md` 进行首页设计:
```javascript
---
home: true
# heroImage: /hero.png
heroText: algorithms-utils
tagline: 算法与 TypeScript 实现
actionText: 开始学习
actionLink: /guide/
features:
- title: 精简理论
details: 精简《算法导论》的内容,帮助自己更容易学习算法理论知识。
- title: 习题练习
details: 解答《算法导论》的习题,帮助自己更好的实践算法理论知识。
- title: 面题精选
details: 搜集常见的面试题目,提升自己的算法编程能力以及面试通过率。
footer: MIT Licensed | Copyright © 2020-present 子弈
---
```
根据[配置](https://www.vuepress.cn/config/#%E9%85%8D%E7%BD%AE) 对 `docs/.vuepress/config.js` 文件进行基本配置:
```javascript
const packageJson = require("../../package.json");
module.exports = {
// 配置网站标题
title: packageJson.name,
// 配置网站描述
description: packageJson.description,
// 配置基本路径
base: "/algorithms/",
// 配置基本端口
port: "8080",
};
```
此时通过 `npm run docs:dev` 进行开发态文档预览:
```javascript
PS C:\Code\Git\algorithms> npm run docs:dev
> [email protected] docs:dev C:\Code\Git\algorithms
> vuepress dev docs
wait Extracting site metadata...
tip Apply theme @vuepress/theme-default ...
tip Apply plugin container (i.e. "vuepress-plugin-container") ...
tip Apply plugin @vuepress/register-components (i.e. "@vuepress/plugin-register-components") ...
tip Apply plugin @vuepress/active-header-links (i.e. "@vuepress/plugin-active-header-links") ...
tip Apply plugin @vuepress/search (i.e. "@vuepress/plugin-search") ...
tip Apply plugin @vuepress/nprogress (i.e. "@vuepress/plugin-nprogress") ...
√ Client
Compiled successfully in 5.31s
i 「wds」: Project is running at http://0.0.0.0:8080/
i 「wds」: webpack output is served from /algorithms-utils/
i 「wds」: Content not from webpack is served from C:\Code\Git\algorithms\docs\.vuepress\public
i 「wds」: 404s will fallback to /index.html
success [23:13:14] Build 10b15a finished in 5311 ms!
> VuePress dev server listening at http://localhost:8080/algorithms-utils/
```
效果如下:

当然除了以上设计的首页,在本项目中还会设计[导航栏](https://www.vuepress.cn/theme/default-theme-config.html#%E5%AF%BC%E8%88%AA%E6%A0%8F)、[侧边栏](https://www.vuepress.cn/theme/default-theme-config.html#%E4%BE%A7%E8%BE%B9%E6%A0%8F)、使用[插件](https://www.vuepress.cn/plugin/)、[使用组件](https://www.vuepress.cn/guide/using-vue.html#%E4%BD%BF%E7%94%A8%E7%BB%84%E4%BB%B6)等。这里重点讲解一下 [Webpack 构建](https://www.vuepress.cn/config/#chainwebpack) 配置。
为了在 Markdown 文档中可以使用 `src` 目录的 TypeScript 代码,这里对 `.vuepress/config.js` 文件进行配置处理:
```javascript
const packageJson = require("../../package.json");
const sidebar = require("./config/sidebar.js");
const nav = require("./config/nav.js");
const path = require("path");
module.exports = {
title: packageJson.name,
description: packageJson.description,
base: "/algorithms/",
port: "8080",
themeConfig: {
nav,
sidebar,
},
plugins: [
"vuepress-plugin-cat",
[
"mathjax",
{
target: "svg",
macros: {
"*": "\\times",
},
},
],
// 增加 Markdown 文档对于 TypeScript 语法的支持
[
"vuepress-plugin-typescript",
{
tsLoaderOptions: {
// ts-loader 的所有配置项
},
},
],
],
chainWebpack: (config) => {
config.resolve.alias.set("image", path.resolve(__dirname, "public"));
// 在文档中模拟库包的引入方式
// 例如发布了 algorithms-utils 库包之后,
// import greet from 'algorithms-utils/greet.ts' 在 Vuepress 演示文档中等同于
// import greet from '~/src/greet.ts',
// 其中 ~ 在这里只是表示项目根目录
config.resolve.alias.set(
"algorithms-utils",
path.resolve(__dirname, "../../src")
);
},
};
```
> **温馨提示**:这里的 Webpack 配置采用了 [webpack-chain](https://github.com/neutrinojs/webpack-chain) 链式操作,如果想要采用 Webpack 对象的配置方式则可以查看 [Vuepress - 构建流程 - configurewebpack](https://www.vuepress.cn/config/#configurewebpack)。
此时可以在 Vuepress 的 Markdown 文档中进行 TypeScript 引入的演示文档设计:
```javascript
# Test vuepress
::: danger 测试 Vuepress
引入 greet.ts 并进行调用测试。
:::
<template>
<collapse title="查看答案">{{msg}}</collapse>
</template>
<template>
<div>{{msg}}</div>
</template>
<script lang="ts">
import greet from 'algorithms-utils/greet'
const msg = greet('ziyi')
export default {
data() {
return {
msg
}
},
}
</script>
```
启动 Vuepress 查看演示文档:
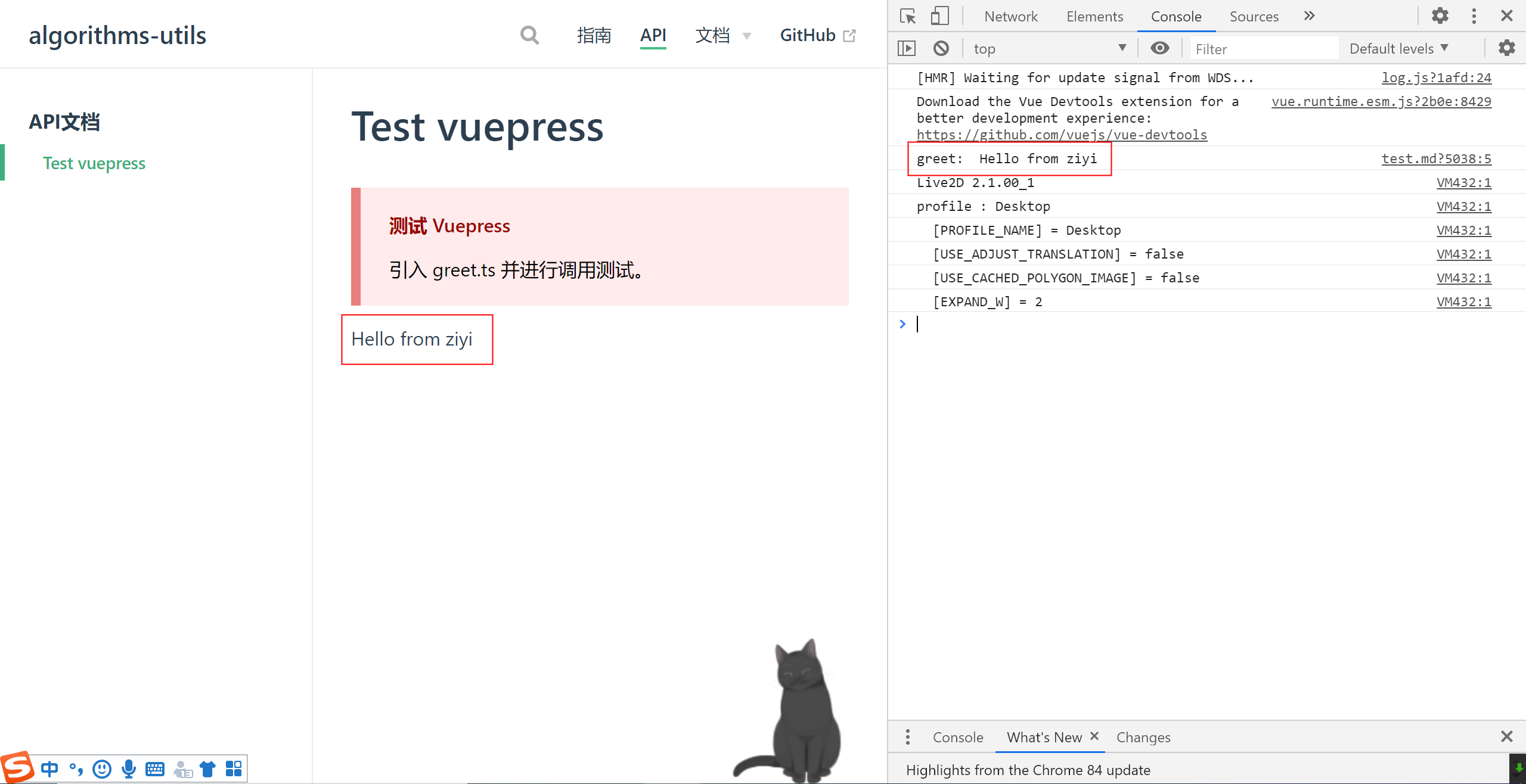
可以发现在 Markdown 中引入的 `src/greet.ts` 代码生效了,最终通过 `npm run docs:build` 可以生成演示文档的静态资源进行部署和访问。
> **温馨提示**:更多本项目的 Vuepress 配置信息可查看 Commit 信息,除此之外如果还想知道更多 Vuepress 的生态,例如有哪些有趣插件或主题,可查看 [awesome-vuepress](https://github.com/vuepressjs/awesome-vuepress) 或 [Vuepress 社区](https://vuepress.github.io/zh/)。
#### 文档工具和规范
通常在书写文档的时候很多同学都不注重文档的洁癖,其实书写文档和书写代码一样需要一些格式规范。[markdownlint](https://github.com/DavidAnson/markdownlint) 是类似于 ESLint 的 Markdown 格式校验工具,通过它可以更好的规范我们书写的文档。当然 Markdown 的格式校验不需要像 ESLint 或者 Prettier 校验那样进行强约束,简单的能够做到提示和 Save Auto Fix 即可。
通过安装 Vs Code 插件 [markdownlint](https://marketplace.visualstudio.com/items?itemName=DavidAnson.vscode-markdownlint) 并进行 Save Auto Fix 配置(在插件中明确列出了哪些规则是可以被 Fix 的)。安装完成后查看刚刚进行的测试文件:
此时会发现插件生效了,但是在 Markdown 中插入 html 是必须的一个能力(Vuepress 支持的能力就是在 Markdown 中使用 Vue),因此可以通过 `.markdownlintrc` 文件将相应的规则屏蔽掉。
> **温馨提示**:如果你希望在代码提交之前或文档构建之前能够进行 Markdown 格式校验,则可以尝试它的命令行接口 [markdownlint-cli](https://github.com/igorshubovych/markdownlint-cli)。除此之外,如果对文档的设计没有想法或者不清楚如何书写好的技术文档,可以查看 [技术文章的写作技巧分享](https://juejin.im/post/5ecbdff6e51d45783e17a7a1),一定能让你有所收获。
### Github Actions
#### CI / CD 背景
> 前提提示:个人对于 CI / CD 可能相对不够熟悉,只是简单的玩过 Travis、Gitlab CI / CD 以及 Jenkins。
关于 CI / CD 的背景这里就不再过多介绍,有兴趣的同学可以看看以下一些好文:
- [Introduction to CI/CD with GitLab(中文版)](https://s0docs0gitlab0com.icopy.site/ee/ci/introduction/index.html)
- [GitHub Actions 入门教程](http://www.ruanyifeng.com/blog/2019/09/getting-started-with-github-actions.html)
- [Github Actions 官方文档](https://docs.github.com/en/actions)
- [当我有服务器时我做了什么 · 个人服务器运维指南](https://shanyue.tech/op/#%E9%A2%84%E8%A7%88)(这个系列有点佩服啊)
在 [Introduction to CI/CD with GitLab(中文版)](https://s0docs0gitlab0com.icopy.site/ee/ci/introduction/index.html) 中你可以清晰的了解到 CI 和 CD 的职责功能:
通过以下图可以更清晰的发现 Gitlab 在每个阶段可用的功能:
由于本项目依赖 Github,因此没法使用 Gitlab 默认集成的能力。之前的 Github 项目采用了 Travis 进行项目的 CI / CD 集成,现在因为有了更方便的 Github Actions,因此决定采用 Github 自带的 Actions 进行 CI / CD 能力集成(大家如果想更多了解这些 CI / CD 的差异请自行 Google 哈)。Github Actions 所带来的好处在于:
- 可复用的 Actions(以前你需要写复杂的脚本,现在可以复用别人写好的脚本,可以简单理解为 CI 脚本插件化)
- 支持更多的 [webhook](https://docs.github.com/en/actions/reference/events-that-trigger-workflows),这些当然是 Github 生态特有的竞争力
当然也会产生一些[限制](https://docs.github.com/en/actions/reference/workflow-syntax-for-github-actions#usage-limits),这些限制主要是和执行时间以及次数相关。需要注意类似于 Jenkins 等支持本地连接运行,Github Actions 也支持连接到本地机器运行 workflow,因此部分限制可能不受本地运行的限制。
> **温馨提示**:本项目中使用到的 CI / CD 功能相对简单,如果想了解更多通用的 Actions,可查看 [官方 Actions](https://github.com/marketplace?type=actions) 和 [awesome-actions](https://github.com/sdras/awesome-actions)。最近在使用 Jenkins 做前端的自动化构建优化,后续可能会出一篇简单的教程文章(当然会跟普通讲解的用法会有所不同喽)。
#### Github Actions 配置
本项目的配置可能会包含以下三个方面:
- 自动更新静态资源流程
- 发布库包流程
- 提交 Pull Request 流程
这里主要讲解自动更新静态资源流程,大致需要分为以下几个步骤(以下都是在 Github 服务器上进行操作,你可以理解为新的服务环境):
- 拉取当前 Github 仓库代码并切换到相应的分支
- 安装 Node 和 Npm 环境
- 安装项目的依赖
- 构建库包和演示文档的静态资源
- 发布演示文档的静态资源
通过查看 [官方 Actions](https://github.com/marketplace?type=actions) 和 [awesome-actions](https://github.com/sdras/awesome-actions),找到所需的 Actions:
- [Checkout](https://github.com/actions/checkout): 从 Github 拉取仓库代码到 Github 服务器的 `$GITHUB_WORKSPACE` 目录下
- [cache](https://github.com/actions/cache): 缓存 npm
- [setup-node](https://github.com/actions/setup-node): 安装 Node 和 Npm 环境
- [actions-gh-pages](https://github.com/peaceiris/actions-gh-pages): 在 Github 上发布静态资源
> **温馨提示**:可用的 Action 很多,这里只是设置了一个简单的流程。
在 `.github/workflows` 下新增 `mian.yml` 配置文件:
``` yml
# 以下都是官方文档的简单翻译
# 当前的 yml(.yaml) 文件是一个 workflow,是持续集成一次运行的一个过程,必须放置在项目的 .github/workflow 目录下
# 如果不清楚 .yml 文件格式语法,可以查看 https://www.codeproject.com/Articles/1214409/Learn-YAML-in-five-minutes
# 初次编写难免会产生格式问题,可以使用 VS Code 插件进行格式检测,https://marketplace.visualstudio.com/items?itemName=OmarTawfik.github-actions-vscode
# 具体各个配置属性可查看 https: //docs.github.com/en/actions/reference/workflow-syntax-for-github-actions
# workflow 的执行仍然会受到一些限制,例如
# - 每个 job 最多执行 6 小时(本地机器不受限制)
# - 每个 workflow 最多执行 72 小时
# - 并发 job 的数量会受到限制
# - 更多查看 https: //docs.github.com/en/actions/reference/workflow-syntax-for-github-actions#usage-limits
# name: 当前 workflow 的名称
name: Algorithms
# on: 指定 workflow 触发的 event
#
# event 有以下几种类型
# - webhook
# - scheduled
# - manual
on:
# push: 一个 webhook event,用于提交代码时触发 workflow,也可以是触发列表,例如 [push, pull_request]
# workflows 触发的 event 大部分是基于 webhook 配置,以下列举几个常见的 webhook:
# - delete: 删除一个 branch 或 tag 时触发
# - fork / watch: 某人 fork / watch 项目时触发(你问有什么用,发送邮件通知不香吗?)
# - pull_request: 提交 PR 时触发
# - page_build: 提交 Github Pages-enabled 分支代码时触发
# - push: 提交代码到特定分支时触发
# - registry_package: 发布或跟新 package 时触发
# 更多 webhook 可查看 https: //docs.github.com/en/actions/reference/events-that-trigger-workflows
# 从这里可以看出 Git Actions 的一大特点就是 Gihub 官方提供的一系列 webhook
push:
# branches: 指定 push 触发的特定分支,这里你可以通过列表的形式指定多个分支
branches:
- feat/framework
#
# branches 的指定可以是通配符类型,例如以下配置可以匹配 refs/heads/releases/10
# - 'releases/**'
#
# branches 也可以使用反向匹配,例如以下不会匹配 refs/heads/releases/10
# - '!releases/**'
#
# branches-ignore: 只对 [push, pull_request] 两个 webhook 起作用,用于指定当前 webhook 不触发的分支
# 需要注意在同一个 webhook 中不能和 branches 同时使用
#
# tags: 只对 [push, pull_request] 两个 webhook 起作用,用于指定当前 webhook 触发的 tag
#
# tags:
# - v1 # Push events to v1 tag
# - v1.* # Push events to v1.0, v1.1, and v1.9 tags
#
# tags-ignore: 类似于 branches-ignore
#
# paths、paths-ignore...
#
# 更多关于特定过滤模式可查看 https://docs.github.com/en/actions/reference/workflow-syntax-for-github-actions#filter-pattern-cheat-sheet
#
# 其他的 webhook 控制项还包括 types(不是所有的 webhook 都有 types),例如已 issues 为例,可以在 issues 被 open、reopened、closed 等情况下触发 workflow
# 更多 webhook 的 types 可查看 https: //docs.github.com/en/actions/reference/events-that-trigger-workflows#webhook-events
#
# on:
# issues:
# types: [opened, edited, closed]
# 除此之外如果对于每个分支有不同的 webhook 触发,则可以通过以下形式进行多个 webhook 配置
#
# push:
# branches:
# - master
# pull_request:
# branches:
# - dev
#
# 除了以上所说的 webhook event,还有 scheduled event 和 manual event
# scheduled event: 用于定时构建,例如最小的时间间隔是 5 min 构建一次
# 具体可查看 https: //docs.github.com/en/actions/reference/events-that-trigger-workflows#scheduled-events
# env: 指定环境变量(所有的 job 生效,每一个 job 可以独立通过 jobs.<job_id>.env、jobs.<job_id>.steps.env 配置)
# defaults / defaults.run: 所有的 job 生效,每一个 job 可以独立通过 jobs.<job_id>.defaults 配置
# deafults
# defaults.run
# jobs: 一个 workflow 由一个或多个 job 组成
jobs:
# job id: 是 job 的唯一标识,可以通过 _ 进行连接,例如: my_first_job,例如这里的 build 就是一个 job id
build_and_deploy:
# name: 在 Github 中显示的 job 名称
name: Build And Deploy
#
# needs: 用于继发执行 job,例如当前 job build 必须在 job1 和 job2 都执行成功的基础上执行
# needs: [job1, job2]
#
# runs-on: job 运行的环境配置,包括:
# - windows-latest
# - windows-2019
# - ubuntu-20.04
# - ubuntu-latest
# - ubuntu-18.04
# - ubuntu-16.04
# - macos-latest
# - macos-10.15
# - self-hosted(本地机器,具体可查看 https: //docs.github.com/en/actions/hosting-your-own-runners/using-self-hosted-runners-in-a-workflow)
runs-on: ubuntu-latest
#
# outputs: 用于输出信息
#
# env: 用于设置环境变量
#
# defaults: 当前所有 step 的默认配置
#
# defaults.run
# if: 满足条件执行当前 job
# steps: 一个 job 由多个 step 组成,step 可以
# - 执行一系列 tasks
# - 执行命令
# - 执行 action
# - 执行公共的 repository
# - 在 Docker registry 中的 action
steps:
#
# id: 类似于 job id
#
# if: 类似于 job if
#
# name: 当前 step 的名字
- name: Checkout
#
# uses: 用于执行 action
#
# action: 可以重复使用的单元代码
# - 为了 workflow 的安全和稳定建议指定 action 的发布版本或 commit SHA
# - 使用指定 action 的 major 版本,这样可以允许你接收 fixs 以及 安全补丁并同时保持兼容性
# - 尽量不建议使用 master 版本,因为 master 很有可能会被发布新的 major 版本从而破坏了 action 的兼容性
# - action 可能是 JavaScript 文件或 Docker 容器,如果是 Docker 容器,那么 runs-on 必须指定 Linux 环境
#
# 指定固定 commit SHA
# uses: actions/setup-node@74bc508
# 指定一个 major 发布版本
# uses: actions/setup-node@v1
# 指定一个 minor 发布版本
# uses: actions/[email protected]
# 指定一个分支
# uses: actions/setup-node@master
# 指定一个 Github 仓库子目录的特定分支、ref 或 SHA
# uses: actions/aws/ec2@master
# 指定当前仓库所在 workflows 的目录地址
# uses: ./.github/actions/my-action
# 指定在 Dock Hub 发布的 Docker 镜像地址
# uses: docker: //alpine: 3.8
# A Docker image in a public registry
# uses: docker: //gcr.io/cloud-builders/gradle
# checkout action 主要用于向 github 仓库拉取源代码(需要注意 workflow 是运行在服务器上,因此需要向当前 github 拉取仓库源代码)
# 它的功能包括但不限于
# - Fetch all history for all tags and branches
# - Checkout a different branch
# - Checkout HEAD^
# - Checkout multiple repos (side by side)
# - Checkout multiple repos (nested)
# - Checkout multiple repos (private)
# - Checkout pull request HEAD commit instead of merge commit
# - Checkout pull request on closed event
# - Push a commit using the built-in token
# checkout action: https: //github.com/actions/checkout
uses: actions/checkout@v2
# with: action 提供的输入参数
with:
# 指定 checkout 的分支、tag 或 SHA
# 更多 checkout action 的配置可查看 https: //github.com/actions/checkout#usage
ref: feat/ci
# args: 用于 Docker 容器的 CMD 指令参数
# entrypoint: Docker 容器 action(覆盖 Dockerfile 的 ENTRYPOINT) 和 JavaScript action 都可以使用
#
# run: 使用当前的操作系统的默认的 non-login shell 执行命令行程序
# 运行单个脚本
# run: npm install
# 运行多个脚本
# run: |
# npm ci
# npm run build
#
# working-directory: 用于指定当前脚本运行的目录
# working-directory: ./temp
#
# shell: 可以指定 shell 类型进行执行,例如 bash、pwsh、python、sh、cmd、powershell
# shell: bash
#
# env: 除了可以设置 workflow 以及 job 的 env,也可以设置 step 的 env(可以理解为作用域不同,局部作用域的优先级更高)
#
# comtinue-on-error: 默认当前 step 失败则会阻止当前 job 继续执行,设置 true 时当前 step 失败则可以跳过当前 job 的执行
- name: Cache
# cache action: https://github.com/actions/cache
# cache 在这里主要用于缓存 npm,提升构建速率
uses: actions/cache@v2
# npm 缓存的路径可查看 https://docs.npmjs.com/cli/cache#cache
# 由于这里 runs-on 是 ubuntu-latest,因此配置 ~/.npm
with:
path: ~/.npm
key: ${{ runner.os }}-node-${{ hashFiles('**/package-lock.json') }}
restore-keys: |
${{ runner.os }}-node-
# github-script action: https://github.com/actions/github-script
# 在 workflow 中使用 Script 语法调用 Github API 或引用 workflow context
# setup-node action: https://github.com/actions/setup-node
# 配置 Node 执行环境(当前构建的服务器默认没有 Node 环境,可以通过 Action 安装 Node)
# 需要注意安装 Node 的同时会捆绑安装 npm,如果想了解为什么会捆绑,可以 Google 一下有趣的故事哦
# 因此使用了该 action 后就可以使用 npm 的脚本在服务器进行执行啦
# 这里也可以尝试 v2-beta 版本哦
- name: Set Node
uses: actions/setup-node@v1
with:
# 也可以通过 strategy.matrix.node 进行灵活配置
# 这里本地使用 node 的 12 版本构建,因此这里就进行版本固定啦
node-version: "12"
- run: npm install
- run: npm run build
- run: npm run docs:build
- name: Deploy
# 用于发布静态站点资源
# actions-gh-pages action: https://github.com/peaceiris/actions-gh-pages
uses: peaceiris/actions-gh-pages@v3
with:
# GTIHUB_TOKEN:https://docs.github.com/en/actions/configuring-and-managing-workflows/authenticating-with-the-github_token
# Github 会在 workflow 中自动生成 GIHUBT_TOKEN,用于认证 workflow 的运行
github_token: ${{ secrets.GITHUB_TOKEN }}
# 静态资源目录设置
publish_dir: ./docs/.vuepress/dist
# 默认发布到 gh-pages 分支上,可以指定特定的发布分支
publish_branch: gh-pages1 # default: gh-pages
full_commit_message: ${{ github.event.head_commit.message }}
#
# timeout-minutes: 一个 job 执行的最大时间,默认是 6h,如果超过时间则取消执行
#
# strategy.matrix: 例如指定当前 job 的 node 版本列表、操作系统类型列表等
# strategy.fail-fast
# strategy.max-parallel
# continue-on-error: 一旦当前 job 执行失败,那么 workflow 停止执行。设置为 true 可以跳过当前 job 执行
# container: Docker 容器配置,包括 image、env、ports、volumes、options 等配置
#
# services: 使用 Docker 容器 Action 或者 服务 Action 必须使用 Linux 环境运行
```
> **温馨提示**:这里不再叙述具体的配置过程,更多可查看配置文件中贴出的链接信息。
上传 CI 的配置文件后,Github 就会进行自动构建,具体如下:
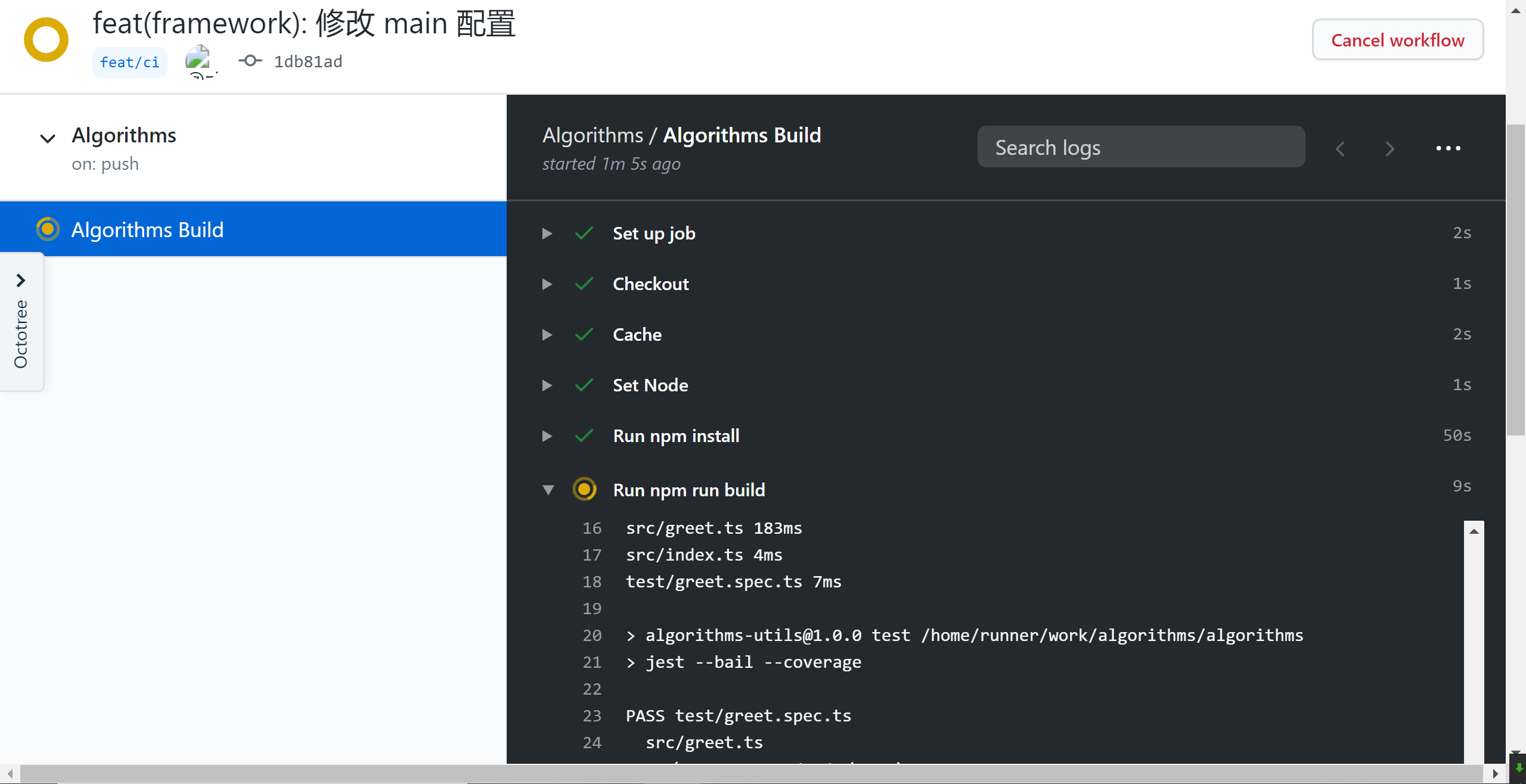
正在构建或者构建完成后可查看每个构建的信息,如果初次构建失败则可以通过构建信息找出失败原因,并重新修改构建配置尝试再次构建。除此之外,每次构建失败 Github 都会通过邮件的形式进行通知:
如果构建成功,则每次你推送新的代码后,Github 服务会进行一系列流程并自动更新静态资源站点。
## 总结
希望大家看完这篇文档之后如果想使用其中某些工具能够养成以下一些习惯:
- 通篇阅读工具的文档,了解相同功能的不同工具的差异点
通篇阅读工具对应的官方 Github README 文档以及官方站点文档,了解该工具设计的核心哲学、核心功能、解决什么核心问题。前端的工具百花齐放,同样的功能可能可以采用多种不同的工具实现。如果想要在项目中使用适当的工具,就得知道这些工具的差异。完整的阅读相应的官方文档,有助于你理解各自的核心功能和差异。
- 在调研了各个工具的差异之后,选择认为合适的工具进行实践
在实践的过程中你会对该工具的使用越来越熟悉。此时如果遇到一些问题或者想要实现某些功能,在通篇阅读文档的基础上会变得相对容易。当然如果遇到一些报错信息无法解决,此时第一时间应该是搜索当前工具所对应的 Github Issues。除此之外,你也可以根据错误的堆栈信息追踪工具的源码,了解源码之后可能会对错误信息产生的原因更加清晰。
- 在完成以上两步之后,你应该总结工具的使用技巧啦,此时在此通读工具文档可能会产生不一样的收获
## 链接文档
- [使用 NPM 发布和使用 CLI 工具](https://juejin.im/post/5eb89053e51d454de54db501)
- [Top 10 JavaScript errors from 1000+ projects (and how to avoid them)](https://rollbar.com/blog/top-10-javascript-errors/)
- [前端构建:3 类 13 种热门工具的选型参考](https://segmentfault.com/a/1190000017183743)
- [Cz 工具集使用介绍](https://juejin.im/post/5cc4694a6fb9a03238106eb9)
- [ES modules: A cartoon deep-dive](https://hacks.mozilla.org/2018/03/es-modules-a-cartoon-deep-dive/)(强烈推荐阅读)
- [JavaScript 程序测试](https://javascript.ruanyifeng.com/tool/testing.html)
- [New to front-end testing? Start from the top of the pyramid!](https://dev.to/noriste/new-to-front-end-testing-start-from-the-top-of-the-pyramid-36kj)
- [JavaScript & Node.js Testing Best Practices](https://github.com/goldbergyoni/javascript-testing-best-practices/blob/master/readme-zh-CN.md)
- [[译] JavaScript 单元测试框架:Jasmine, Mocha, AVA, Tape 和 Jest 的比较](https://juejin.im/post/5acc721a6fb9a028b77b23c9)
- [JavaScript unit testing frameworks in 2020: A comparison](https://raygun.com/blog/javascript-unit-testing-frameworks/)
- [javascript-testing-best-practices](https://github.com/goldbergyoni/javascript-testing-best-practices/blob/master/readme-zh-CN.md)
- [ui-testing-best-practices](https://github.com/NoriSte/ui-testing-best-practices)
- [npm scripts 使用指南](http://www.ruanyifeng.com/blog/2016/10/npm_scripts.html?utm_source=tuicool&utm_medium=referral)
- [技术文章的写作技巧分享](https://juejin.im/post/5ecbdff6e51d45783e17a7a1)
- [Introduction to CI/CD with GitLab(中文版)](https://s0docs0gitlab0com.icopy.site/ee/ci/introduction/index.html)
- [GitHub Actions 入门教程](http://www.ruanyifeng.com/blog/2019/09/getting-started-with-github-actions.html)
- [当我有服务器时我做了什么 · 个人服务器运维指南](https://shanyue.tech/op/#%E9%A2%84%E8%A7%88) | 53,633 | MIT |
---
title: 将托管磁盘复制到存储帐户 - CLI
description: Azure CLI 示例 - 将托管磁盘导出或复制到存储帐户。
documentationcenter: storage
manager: kavithag
ms.service: virtual-machines
ms.subservice: disks
ms.topic: sample
ms.workload: infrastructure
origin.date: 05/09/2019
author: rockboyfor
ms.date: 10/19/2020
ms.testscope: no
ms.testdate: 10/19/2020
ms.author: v-yeche
ms.custom: mvc,seodec18, devx-track-azurecli
ms.openlocfilehash: 746390a6f9b81e155a90d1247a7c718db9e84d34
ms.sourcegitcommit: 7b3c894d9c164d2311b99255f931ebc1803ca5a9
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 10/23/2020
ms.locfileid: "92470003"
---
<!--Renamed File-->
# <a name="exportcopy-a-managed-disk-to-a-storage-account-using-the-azure-cli"></a>使用 Azure CLI 将托管磁盘导出/复制到存储帐户
此脚本将托管磁盘的基础 VHD 导出到相同或不同区域中的存储帐户。 它首先生成托管磁盘的 SAS URI,然后使用该 SAS URI 将 VHD 复制到存储帐户。 使用此脚本将托管磁盘复制到另一区域以进行区域扩展。 若要在 Azure 市场中发布托管磁盘的 VHD 文件,可以使用此脚本将 VHD 文件复制到存储帐户,然后生成已复制的 VHD 的 SAS URI,以便在市场中发布。
[!INCLUDE [sample-cli-install](../../../includes/sample-cli-install.md)]
[!INCLUDE [quickstarts-free-trial-note](../../../includes/quickstarts-free-trial-note.md)]
## <a name="sample-script"></a>示例脚本
```azurecli
#Provide the subscription Id where managed disk is created
subscriptionId=yourSubscriptionId
#Provide the name of your resource group where managed disk is created
resourceGroupName=myResourceGroupName
#Provide the managed disk name
diskName=myDiskName
#Provide Shared Access Signature (SAS) expiry duration in seconds e.g. 3600.
#Know more about SAS here: https://docs.azure.cn/storage/storage-dotnet-shared-access-signature-part-1
sasExpiryDuration=3600
#Provide storage account name where you want to copy the underlying VHD file of the managed disk.
storageAccountName=mystorageaccountname
#Name of the storage container where the downloaded VHD will be stored
storageContainerName=mystoragecontainername
#Provide the key of the storage account where you want to copy the VHD
storageAccountKey=mystorageaccountkey
#Provide the name of the destination VHD file to which the VHD of the managed disk will be copied.
destinationVHDFileName=myvhdfilename.vhd
az account set --subscription $subscriptionId
sas=$(az disk grant-access --resource-group $resourceGroupName --name $diskName --duration-in-seconds $sasExpiryDuration --query [accessSas] -o tsv)
az storage blob copy start --destination-blob $destinationVHDFileName --destination-container $storageContainerName --account-name $storageAccountName --account-key $storageAccountKey --source-uri $sas
```
## <a name="script-explanation"></a>脚本说明
此脚本使用以下命令生成托管磁盘的 SAS URI,然后使用该 SAS URI 将基础 VHD 复制到存储帐户。 表中的每条命令均链接到特定于命令的文档。
| 命令 | 说明 |
|---|---|
| [az disk grant-access](https://docs.azure.cn/cli/disk#az_disk_grant_access) | 生成只读 SAS,使用该 SAS 可以将基础 VHD 文件复制到存储帐户或将其下载到本地 |
| [az storage blob copy start](https://docs.azure.cn/cli/storage/blob/copy#az-storage-blob-copy-start) | 将 blob 从一个存储帐户异步复制到另一个存储帐户 |
## <a name="next-steps"></a>后续步骤
[从 VHD 创建托管磁盘](virtual-machines-cli-sample-create-managed-disk-from-vhd.md)
[从托管磁盘创建虚拟机](virtual-machines-linux-cli-sample-create-vm-from-managed-os-disks.md)
有关 Azure CLI 的详细信息,请参阅 [Azure CLI 文档](https://docs.azure.cn/cli/)。
可以在 [Azure Linux VM 文档](../linux/cli-samples.md)中找到其他虚拟机和托管磁盘 CLI 脚本示例。
<!-- Update_Description: new article about virtual machines cli sample copy managed disks vhd -->
<!--NEW.date: 10/19/2020--> | 3,394 | CC-BY-4.0 |
## 响应式布局
参考 Bootstrap 的[响应式设计](http://getbootstrap.com/css/#grid-media-queries),预设六个响应尺寸:`xs` `sm` `md` `lg` `xl` `xxl`。
<!--start-code-->
```jsx
const grid = (
<div>
<Row>
<Col xs={2} sm={4} md={6} lg={8} xl={10}>
Col
</Col>
<Col xs={20} sm={16} md={12} lg={8} xl={4}>
Col
</Col>
<Col xs={2} sm={4} md={6} lg={8} xl={10}>
Col
</Col>
</Row>
</div>
);
ReactDOM.render(grid);
```
<!--end-code--> | 471 | MIT |
# 基于webpack4搭建ts环境
## 初始化项目
`yarn init -y`
## 安装依赖
`yarn add "ts-loader": "^5.3.3","tslint": "^5.13.0","typescript": "^3.3.3333","webpack": "^4.29.5","webpack-cli": "^3.2.3" --save`
## 全局下的package.json
```
{
"name": "webpack-ts-demo",
"version": "0.0.1",
"private": true,
"author": "wuhaohao <[email protected]>",
"license": "MIT",
"scripts": {
"build": "webpack",
"dev": "tsc --watch && yarn lint",
"lint": "tslint --project tslint.json"
},
"dependencies": {
"ts-loader": "^5.3.3",
"tslint": "^5.13.0",
"typescript": "^3.3.3333",
"webpack": "^4.29.5",
"webpack-cli": "^3.2.3"
}
}
```
## 全局下的tsconfig.json
```
{
"compilerOptions": {
/* Basic Options */
"target": "es5", /* 选择es6 */
"module": "es6", /* 采用es6模块,可以使用import与export. */
// "lib": [], /* Specify library files to be included in the compilation. */
// "allowJs": true, /* Allow javascript files to be compiled. */
// "checkJs": true, /* Report errors in .js files. */
// "jsx": "preserve", /* Specify JSX code generation: 'preserve', 'react-native', or 'react'. */
"declaration": true, /* 生成对应的.d.ts声明文件. */
"declarationMap": true, /* 生成对应的.d.tsmap声明文件. */
// "sourceMap": true, /* 生成对应的map文件,用于对于错误的捕捉. */
// "outFile": "./", /* Concatenate and emit output to single file. */
"outDir": "./dist", /* 输出为dist目录. */
// "rootDir": "./", /* Specify the root directory of input files. Use to control the output directory structure with --outDir. */
// "composite": true, /* Enable project compilation */
"removeComments": true, /* 输出文件没有注释 */
// "noEmit": true, /* Do not emit outputs. */
// "importHelpers": true, /* Import emit helpers from 'tslib'. */
// "downlevelIteration": true, /* Provide full support for iterables in 'for-of', spread, and destructuring when targeting 'ES5' or 'ES3'. */
// "isolatedModules": true, /* Transpile each file as a separate module (similar to 'ts.transpileModule'). */
/* Strict Type-Checking Options */
"strict": true, /* Enable all strict type-checking options. */
"noImplicitAny": true, /* 如果没有类型会报错的 */
// "strictNullChecks": true, /* Enable strict null checks. */
// "strictFunctionTypes": true, /* Enable strict checking of function types. */
// "strictPropertyInitialization": true, /* Enable strict che cking of property initialization in classes. */
// "noImplicitThis": true, /* Raise error on 'this' expressions with an implied 'any' type. */
// "alwaysStrict": true, /* Parse in strict mode and emit "use strict" for each source file. */
/* Additional Checks */
// "noUnusedLocals": true, /* Report errors on unused locals. */
// "noUnusedParameters": true, /* Report errors on unused parameters. */
// "noImplicitReturns": true, /* Report error when not all code paths in function return a value. */
// "noFallthroughCasesInSwitch": true, /* Report errors for fallthrough cases in switch statement. */
/* Module Resolution Options */
"moduleResolution": "node", /* 采用node形式. */
// "baseUrl": "./", /* Base directory to resolve non-absolute module names. */
// "paths": {}, /* A series of entries which re-map imports to lookup locations relative to the 'baseUrl'. */
// "rootDirs": [], /* List of root folders whose combined content represents the structure of the project at runtime. */
// "typeRoots": [], /* List of folders to include type definitions from. */
// "types": [], /* Type declaration files to be included in compilation. */
// "allowSyntheticDefaultImports": true, /* Allow default imports from modules with no default export. This does not affect code emit, just typechecking. */
"esModuleInterop": true, /* Enables emit interoperability between CommonJS and ES Modules via creation of namespace objects for all imports. Implies 'allowSyntheticDefaultImports'. */
// "preserveSymlinks": true, /* Do not resolve the real path of symlinks. */
/* Source Map Options */
// "sourceRoot": "", /* Specify the location where debugger should locate TypeScript files instead of source locations. */
// "mapRoot": "", /* Specify the location where debugger should locate map files instead of generated locations. */
"inlineSourceMap": true, /* Emit a single file with source maps instead of having a separate file. */
// "inlineSources": true, /* Emit the source alongside the sourcemaps within a single file; requires '--inlineSourceMap' or '--sourceMap' to be set. */
/* Experimental Options */
"experimentalDecorators": true, /* 这个是可以写装饰器的. */
// "emitDecoratorMetadata": true, /* Enables experimental support for emitting type metadata for decorators. */
},
"include": [ /* 入口文件目录 */
"src/**/*"
],
"exclude": [ /* 这写文件不需要编译 */
"dist",
"node_modules",
"**/*.spec.ts"
]
}
```
## 全局下的webpack.config.js
```
const path = require('path');
module.exports = {
entry: './src/index.ts',//入口文件
devtool: 'inline-source-map',//错误匹配到src下对应的文件
module: {
rules: [ //匹配规则:匹配所有的ts,使用ts-loader,忽略node_modules
{
test: /\.tsx?$/,
use: 'ts-loader',
exclude: /node_modules/
}
]
},
resolve: {
extensions: ['.tsx', '.ts', '.js']
},
output: { //编译为dist/bundle.js
filename: 'bundle.js',
path: path.resolve(__dirname, 'dist')
}
};
```
## 全局下的tslint.json
```
{
"defaultSeverity": "error", //错误警告
"extends": "tslint:recommended", //使用typescript稳定型的
"jsRules": {},
"rules": { //代码规则
"interface-name": false,
"trailing-comma": false,
"max-classes-per-file": false,
"ordered-imports": false,
"variable-name": false,
"prefer-const": false,
"member-ordering": false,
"no-bitwise": false,
"forin": false,
"object-literal-sort-keys": false,
"one-line": [
false
],
"object-literal-key-quotes": [
false
],
"no-string-literal": false,
"no-angle-bracket-type-assertion": false,
"only-arrow-functions": false,
"no-namespace": false,
"no-internal-module": false,
"unified-signatures": false,
"ban-types": false,
"no-conditional-assignment": false,
"radix": false,
"no-console": false,
"semicolon": false,
"eofline": false,
"quotemark": false,
"no-unused-variable": false,
"no-trailing-whitespace": false,
"no-unused-expression": false,
"no-empty": false
},
"rulesDirectory": []
}
``` | 7,440 | MIT |
---
title: Azure 流量管理器终结点监视 | Azure
description: 本文有助于你了解,流量管理器如何通过终结点监视和终结点自动故障转移来帮助 Azure 客户部署高可用性应用程序。
services: traffic-manager
author: rockboyfor
ms.service: traffic-manager
ms.devlang: na
ms.topic: article
ms.tgt_pltfrm: na
ms.workload: infrastructure-services
origin.date: 12/04/2018
ms.date: 02/18/2019
ms.author: v-yeche
ms.openlocfilehash: a7c6750d91ffaf6ca290cd643a09f08f68a707a1
ms.sourcegitcommit: b8fb6890caed87831b28c82738d6cecfe50674fd
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 03/29/2019
ms.locfileid: "58625223"
---
# <a name="traffic-manager-endpoint-monitoring"></a>流量管理器终结点监视
Azure 流量管理器包括内置的终结点监视和终结点自动故障转移功能。 此功能可以让你更好地交付高可用性应用程序,以便应对终结点故障(包括 Azure 区域故障)。
## <a name="configure-endpoint-monitoring"></a>配置终结点监视
若要配置终结点监视,必须在流量管理器配置文件中指定以下设置:
* **协议**。 选择 HTTP、HTTPS 或 TCP 作为协议,流量管理器在探测终结点以检查其运行状况时,将使用该协议。 HTTPS 监视并不验证 SSL 证书是否有效,它只检查是否有证书。
* **端口**。 选择用于请求的端口。
* **路径**。 此配置设置仅对 HTTP 和 HTTPS 协议有效,使用这些协议时,需要指定路径。 为 TCP 监视协议提供此设置会导致出错。 对于 HTTP 和 HTTPS 协议,指定监视功能要访问的网页或文件的相对路径和名称。 正斜杠 (/) 是相对路径的有效条目。 此值表示文件位于根目录中(默认设置)。
* **自定义标头设置**:此配置设置用于将特定的 HTTP 标头添加到运行状况检查,以便流量管理器将该检查发送到配置文件中的终结点。 自定义标头可以在配置文件级别指定,使之适用于该配置文件中的所有终结点,以及/或者在终结点级别指定,使之仅适用于该终结点。 可以使用自定义标头进行运行状况检查,通过指定主机标头,将多租户环境中的终结点正确路由到目标。 也可使用此设置来添加唯一标头,以便标识源自流量管理器的 HTTP(S) 请求并对其进行不同的处理。
* **预期的状态代码范围**:可以通过此设置以 200-299、301-301 格式指定多个成功代码范围。 如果这些状态代码是在启动运行状况检查时作为响应从终结点接收的,则流量管理器会将这些终结点标记为正常。 最多可以指定 8 个状态代码范围。 此设置仅适用于 HTTP 和 HTTPS 协议以及所有终结点。 此设置位于流量管理器配置文件级别。默认情况下,将值 200 定义为成功状态代码。
* **探测间隔**。 此值指定在流量管理器探测代理中检查终结点运行状况的频率。 可以在此处指定两个值:30 秒(正常探测)和 10 秒(快速探测)。 如果未提供任何值,配置文件将设置为默认值 30 秒。 请访问[流量管理器定价](https://www.azure.cn/pricing/details/traffic-manager/)页,了解有关快速探测定价的详细信息。
* **容许的失败次数**。 此值指定在将终结点标记为不正常之前,流量管理器探测代理容许的失败次数。 其值的范围为 0 到 9。 0 值表示发生监视失败一次就可能会导致将该终结点标记为不正常。 如果未指定任何值,则使用默认值 3。
* **探测超时**。 此属性指定在将运行状况检查探测数据发送到终结点时,将该项检查视为失败之前,流量管理器探测代理应该等待的时间。 如果探测间隔设置为 30 秒,则可将超时值设置为 5 - 10 秒。 如果未指定任何值,使用默认值 10 秒。 如果探测间隔设置为 10 秒,则可将超时值设置为 5 - 9 秒。 如果未指定任何超时值,使用默认值 9 秒。

**图 3:流量管理器终结点监视**
## <a name="how-endpoint-monitoring-works"></a>终结点监视功能的工作原理
如果监视协议设置为 HTTP 或 HTTPS,流量管理器探测代理将使用指定的协议、端口和相对路径向终结点发出 GET 请求。 如果收到返回的 200-OK 响应,或者在<strong>预期的状态代码 *范围</strong>中配置的任何响应,则认为该终结点正常。 如果响应是一个不同的值,或者在指定的超时期限内未收到的任何响应,则流量管理器探测代理会根据“容许的失败次数”设置重试(如果此设置为 0,则不执行重试)。 如果连续失败次数超过“容许的失败次数”设置,则将该终结点标记为不正常。
如果监视协议为 TCP,流量管理器探测代理将使用指定的端口发起 TCP 连接请求。 如果终结点响应了请求并提供了用于建立连接的响应,则将该运行状况检查标记为成功,并且流量管理器探测代理会重置 TCP 连接。 如果响应是一个不同的值,或者在指定的超时期限内未收到的任何响应,则流量管理器探测代理会根据“容许的失败次数”设置重试(如果此设置为 0,则不执行重试)。 如果连续失败次数超过“容许的失败次数”设置,则将该终结点标记为不正常。
在上述所有情况下,流量管理器都会从多个位置探测,并且每个区域将执行连续失败判定。 这也意味着,终结点将以高于“探测间隔”设置的频率从流量管理器接收运行状况探测数据。
>[!NOTE]
>对于 HTTP 或 HTTPS 监视协议,在终结点端上采取的一种常见做法是在应用程序中实施一个自定义页 - 例如 /health.aspx。 为监视使用此路径可以执行应用程序特定的检查,例如,检查性能计数器或者验证数据库可用性。 页面根据这些自定义检查返回相应的 HTTP 状态代码。
流量管理器配置文件中的所有终结点共享监视设置。 如果需要对不同的终结点使用不同的监视设置,可以创建[嵌套式流量管理器配置文件](traffic-manager-nested-profiles.md#example-5-per-endpoint-monitoring-settings)。
## <a name="endpoint-and-profile-status"></a>终结点和配置文件状态
可以启用和禁用流量管理器配置文件和终结点。 不过,也可以通过流量管理器的自动设置和过程来更改终结点状态。
### <a name="endpoint-status"></a>终结点状态
可以启用或禁用特定的终结点。 可能仍处于正常状态的基础服务不受影响。 更改终结点状态可以控制流量管理器配置文件中终结点的可用性。 当某个终结点的状态为已禁用时,流量管理器不会检查其运行状况,该终结点不会包括在 DNS 响应中。
### <a name="profile-status"></a>配置文件状态
使用配置文件状态设置可以启用或禁用特定的配置文件。 终结点状态影响单个终结点,而配置文件状态会影响整个配置文件(包括所有终结点)。 禁用某个配置文件时,不会检查终结点的运行状况,并且不会在 DNS 响应中包括任何终结点。 会针对 DNS 查询返回 [NXDOMAIN](https://tools.ietf.org/html/rfc2308) 响应代码。
### <a name="endpoint-monitor-status"></a>终结点监视器状态
终结点监视器状态是流量管理器生成的值,显示终结点的状态。 不能手动更改此设置。 终结点监视状态是终结点监视结果与所配置端点状态的组合。 下表显示了终结点监视状态的可能值:
| 配置文件状态 | 终结点状态 | 终结点监视器状态 | 注释 |
| --- | --- | --- | --- |
| 已禁用 |Enabled |非活动 |配置文件已禁用。 尽管终结点状态为“已启用”,但配置文件状态(“已禁用”)优先。 不会监视已禁用配置文件中的终结点。 会针对 DNS 查询返回 NXDOMAIN 响应代码。 |
| <任意> |已禁用 |已禁用 |终结点已禁用。 不会监视已禁用的终结点。 该终结点不会包括在 DNS 响应中,因此也不会接收流量。 |
| Enabled |Enabled |联机 |终结点受到监视,处于正常状态。 该终结点会包括在 DNS 响应中,并且可以接收流量。 |
| Enabled |Enabled |已降级 |监视运行状况检查的终结点将要发生故障。 该终结点不会包括在 DNS 响应中,也不会接收流量。 <br>一种例外的情况是,如果所有终结点已降级,则这些终结点全部被视为在查询响应中返回。</br>|
| Enabled |Enabled |正在检查终结点 |终结点受监视,但是,尚未收到首个探测的结果。 “正在检查终结点”是一种临时状态,在配置文件中添加或启用终结点后,通常会立即出现这种状态。 处于此状态的终结点会包括在 DNS 响应中,并且可以接收流量。 |
| Enabled |Enabled |已停止 |终结点指向的云服务或 Web 应用未运行。 检查云服务或 Web 应用设置。 如果终结点的类型为嵌套终结点,并且子配置文件已禁用或处于非活动状态,则也可能会发生这种情况。 <br>不会监视“已停止”状态的终结点。 该终结点不会包括在 DNS 响应中,也不会接收流量。 一种例外的情况是,如果所有终结点已降级,则这些终结点全部被视为在查询响应中返回。</br>|
有关如何为嵌套式终结点计算终结点监视状态的详细信息,请参阅[嵌套式流量管理器配置文件](traffic-manager-nested-profiles.md)。
>[!NOTE]
> 如果 Web 应用并非在标准层或更高层中运行,应用服务上的监视器状态可能会变为“停止的终结点”。 有关详细信息,请参阅[流量管理器与应用服务集成](/app-service/web-sites-traffic-manager)。
### <a name="profile-monitor-status"></a>配置文件监视器状态
配置文件监视状态是配置的配置文件状态与所有终结点的终结点监视状态值的组合。 下表描述了可能的值:
| 配置文件状态(根据配置) | 终结点监视器状态 | 配置文件监视器状态 | 注释 |
| --- | --- | --- | --- |
| 已禁用 |<任意> 或包含未定义终结点的配置文件。 |已禁用 |配置文件已禁用。 |
| Enabled |至少一个终结点的状态为“已降级”。 |已降级 |查看各终结点状态值,确定哪些终结点需要进一步的关注。 |
| Enabled |至少一个终结点的状态为“联机”。 没有任何终结点的状态为“已降级”。 |联机 |服务正在接受流量。 无需进一步执行操作。 |
| Enabled |至少一个终结点的状态为“正在检查终结点”。 没有任何终结点为“联机”或“已降级”状态。 |正在检查终结点 |创建或启用配置文件时,将出现这种过渡状态。 正在首次检查终结点的运行状况。 |
| Enabled |配置文件中所有终结点的状态为“已禁用”或“已停止”,或者配置文件中没有定义终结点。 |非活动 |没有任何终结点处于活动状态,但是配置文件的状态仍旧是“已启用”。 |
## <a name="endpoint-failover-and-recovery"></a>终结点故障转移和恢复
流量管理器定期检查每个终结点(包括不正常的终结点)的运行状况。 当终结点恢复正常时,流量管理器可以检测到这种状态,并将其重新加入轮转列表。
发生以下任一事件时,终结点将变得不正常:
- 如果监视协议为 HTTP 或 HTTPS:
- 收到非 200 响应,或者收到的响应不包括在“预期的状态代码范围”设置中指定的状态范围(包括其他 2xx 代码,或者 301/302 重定向)。
- 如果监视协议为 TCP:
- 收到非 ACK 或 SYN-ACK 响应,以响应流量管理器发送的用于尝试建立连接的 SYNC 请求。
- 超时。
- 导致无法访问终结点的其他任何连接问题。
有关针对失败的检查进行故障排除的详细信息,请参阅[排查 Azure 流量管理器中的降级状态](traffic-manager-troubleshooting-degraded.md)。
下图中的时间线详细描述了流量管理器终结点的监视过程,该终结点具有以下设置:监视协议为 HTTP,探测间隔为 30 秒,容许的失败次数为 3,超时值为 10 秒,DNS TTL 为 30 秒。

**图:流量管理器终结点故障转移和恢复顺序**
1. **GET**。 对于每个终结点,流量管理器监视系统将对监视设置中指定的路径执行 GET 请求。
2. **“200 正常”或由流量管理器配置文件监视设置指定的自定义代码范围**。 监视系统预期一条“‘200 正常’或由流量管理器配置文件监视设置指定的自定义代码范围”消息会在 10 秒钟内返回。 如果收到该响应,该系统会认为云服务可用。
3. **每隔 30 秒检查**。 终结点运行状况检查每隔 30 秒重复一次。
4. **服务不可用**。 该服务变得不可用。 在下次执行运行状况检查前,流量管理器不会知道该服务是否可用。
5. **尝试访问监视路径**。 监视系统执行了 GET 请求,但没有在 10 秒的超时期间内收到响应(也可能收到的是非 200 响应)。 然后又尝试了三次,每隔 30 秒一次。 如果其中一次尝试成功,尝试次数就会重置。
6. **状态设置为“已降级”**。 第四次连续失败后,监视系统将不可用终结点的状态标记为“已降级”。
7. **流量转移到其他终结点**。 流量管理器 DNS 名称服务器进行更新,流量管理器不再返回终结点来响应 DNS 查询。 新连接将定向到其他可用终结点。 不过,包含此终结点的 DNS 响应可能仍由递归 DNS 服务器和 DNS 客户端缓存。 在 DNS 缓存过期之前,客户端将一直使用该终结点。 DNS 缓存过期后,客户端将发出新的 DNS 查询并定向到其他终结点。 缓存持续时间由流量管理器配置文件中的 TTL 设置控制,例如,可以将其设置为 30 秒。
8. **继续进行运行状况检查**。 在终结点的状态为“已降级”后,流量管理器会继续检查该终结点的运行状况。 当终结点恢复正常时,流量管理器可检测到这种状态。
9. **服务重新联机**。 该服务变得可用。 终结点会在流量管理器中始终保持“已降级”状态,直至监视系统执行下一次运行状况检查。
10. **继续将流量定向到服务**。 流量管理器发送 GET 请求,并收到“200 正常”状态响应。 服务已恢复正常状态。 流量管理器名称服务器进行更新,并开始在 DNS 响应中分发服务的 DNS 名称。 当缓存的 DNS 响应(返回其他终结点)到期时,以及现有的到其他终结点的连接终止时,流量将返回到该终结点。
> [!NOTE]
> 由于流量管理器是在 DNS 级别工作的,因此不可能影响任何终结点的现有连接。 在终结点之间引导流量时(不管是通过更改配置文件设置来进行,还是在故障转移或故障回复期间进行),流量管理器都会将新连接引导到可用的终结点。 不过,其他终结点可能仍会通过现有连接继续接收流量,直至相关会话被终止。 若要耗尽现有连接的流量,应通过应用程序来限制适用于每个终结点的会话持续时间。
## <a name="traffic-routing-methods"></a>流量路由方法
当某个终结点处于“已降级”状态时,不再会在 DNS 查询的响应中返回该终结点。 而是选择一个替代终结点并将其返回。 配置文件中配置的流量路由方法确定如何选择替代的终结点。
* **优先级**。 终结点构成一个采用优先级的列表。 将始终返回列表中第一个可用的终结点。 如果终结点状态为“已降级”,则返回下一个可用的终结点。
* **加权**。 根据分配的权重以及其他可用终结点的权重随机选择任何可用的终结点。
* **性能**。 返回最靠近最终用户的终结点。 如果终结点不可用,流量管理器会将流量转移给下一个最靠近 Azure 区域的终结点。 可以使用[嵌套式流量管理器配置文件](traffic-manager-nested-profiles.md#example-4-controlling-performance-traffic-routing-between-multiple-endpoints-in-the-same-region)针对性能流量路由来配置替代故障转移计划。
<!-- Not Available on * **Geographic**. The endpoint mapped to serve the geographic location based on the query request IP's is returned. If that endpoint is unavailable, another endpoint will not be selected to failover to, since a geographic location can be mapped only to one endpoint in a profile (more details are in the [FAQ](traffic-manager-FAQs.md#traffic-manager-geographic-traffic-routing-method)). As a best practice, when using geographic routing, we recommend customers to use nested Traffic Manager profiles with more than one endpoint as the endpoints of the profile.-->
* **MultiValue**:返回多个映射到 IPv4/IPv6 地址的终结点。 收到此配置文件的查询时,系统会根据指定的“响应中的最大记录数”值返回正常终结点。 响应的默认数量为两个终结点。
* **子网**:返回映射到一组 IP 地址范围的终结点。 从该 IP 地址收到请求时,返回的终结点是针对该 IP 地址映射的终结点。
有关详细信息,请参阅[流量管理器流量路由方法](traffic-manager-routing-methods.md)。
> [!NOTE]
> 当所有符合条件的终结点处于降级状态时,正常的流量路由行为会发生一种例外情况。 流量管理器“尽最大努力”尝试, *其响应就好像所有处于“已降级”状态的终结点实际上处于联机状态一样*。 这种行为要优于替代方法,后者不会在 DNS 响应中返回任何终结点。 已禁用或已停止的终结点不受监视,因此,认为它们不符合接收流量的条件。
>
> 这种状态通常是服务配置不当造成的,例如:
>
> * 某个访问控制列表 (ACL) 正在阻止流量管理器运行状况检查。
> * 流量管理器配置文件中的监视端口或协议配置不当。
>
> 此行为的一个结果是,即使流量管理器运行状况检查没有正确进行配置,但从流量路由的角度来看,流量管理器似乎也运行正常。 但在这种情况下,不能发生会影响应用程序总体可用性的终结点故障转移。 必须检查配置文件是否显示“联机”状态而不是“已降级”状态。 状态为“联机”表示流量管理器运行状况检查按预期进行。
有关针对失败的运行状况检查进行故障排除的详细信息,请参阅 [Azure 流量管理器上的降级状态故障排除](traffic-manager-troubleshooting-degraded.md)。
## <a name="next-steps"></a>后续步骤
了解[流量管理器的工作原理](traffic-manager-how-it-works.md)
详细了解流量管理器支持的[流量路由方法](traffic-manager-routing-methods.md)
了解如何[创建流量管理器配置文件](traffic-manager-manage-profiles.md)
在流量管理器终结点上[排查降级状态](traffic-manager-troubleshooting-degraded.md)
<!--Update_Description: update meta properties --> | 9,130 | CC-BY-4.0 |
logback-kafka-appender
---
---
这是一个基于Apache Kafka的自定义Logback Appender实现。
主要功能是将日志信息通过自定义的appender发送至Kafka Topic.
# 配置描述
Kafka Producer Record Key生成策略
| class name | note |
| ------------------------------------------------------ | ------------------------------------- |
| io.coor.logger.logback.kafka.ContextNameKeyingStrategy | 使用ContextName的Hash值作为record key |
| io.coor.logger.logback.kafka.NoKeyKeyingStrategy | 不使用record key。默认 |
Kafka 发送策略
| class name | note |
| --------------------------------------------------- | -------------- |
| io.coor.logger.logback.kafka.AnsyncDeliveryStrategy | 异步发送 |
| io.coor.logger.logback.kafka.SyncDeliveryStrategy | 同步发送。默认 |
样例配置
```xml
<appender name="KAFKA" class="io.coor.logger.logback.KafkaAppender">
<encoder class="io.coor.logger.logback.encoder.PatternJsonLayoutEncoder">
<pattern>
<![CDATA[
{
"timestamp":"%d{yyyy-MM-dd HH:mm:ss.SSS}",
"app":"%cn",
"thread":"%thread",
"level":"%level",
"logger":"%logger",
"message":"%msg"
}
]]>
</pattern>
</encoder>
<!-- kafka product configuration-->
<kafkaProduct>
<!-- target kafka topic -->
<topic>test</topic>
<!-- kafka product record key generator strategy -->
<keyingStrategy class="io.coor.logger.logback.kafka.ContextNameKeyingStrategy"/>
<!-- kafka product send message strategy -->
<deliveryStrategy class="io.coor.logger.logback.kafka.AnsyncDeliveryStrategy"/>
<!-- kafka product config map -->
<producerConfig>bootstrap.servers=localhost:9092</producerConfig>
<producerConfig>client.id=${appName}</producerConfig>
</kafkaProduct>
</appender>
``` | 2,006 | Apache-2.0 |
---
layout: post
title: "Laravel 开发规范"
subtitle: "好好写代码"
date: 2018-04-23 11:00:00
author: "伍源辉"
header-img: "img/home-bg.jpg"
tags:
- Laravel
- 开发规范
- 数据库
- 事务
- 异常
---
# 开发规范
## 数据库
### 数据库事务
为避免暴露数据库结构和 SQL 语句,在系统的异常处理类 `Handler.php` 中增加了以下代码:
```php
public function render($request, Exception $exception)
{
if ($exception instanceof QueryException) {
$message = 'PDO query error.';
$status = empty($exception->getCode()) ? 999 : $exception->getCode();
return $request->expectsJson()
? response()->json([
'message' => $message,
'status' => $status,
/* 'file' => $exception->getFile(), */
/* 'line' => $exception->getLine(), */
])
: redirect()->back();
}
/* ... */
}
```
在系统开发过程中,建议使用 `Closure` 的方式处理数据库事物,会自动捕获异常、回滚及返回错误信息:
```php
use Illuminate\Support\Facades\DB;
DB::transaction(function () {
DB::table('users')->update(['votes' => 1]);
DB::table('posts')->delete();
});
```
不建议使用手动操作事务的方式,如需使用,必须先对 `QueryException` 进行处理后再返回错误信息:
```php
DB::beginTransaction();
try {
DB::table('users')->update(['votes' => 1]);
DB::table('posts')->delete();
DB::commit();
} catch(\Illuminate\Database\QueryException $e) {
/* 此处不能直接通过 $e->getMessage() 抛出 AppException() 异常, */
/* 必须先处理错误信息后再抛出,避免暴露数据库结构和 SQL 语句。 */
DB::rollback();
/* do something... */
} catch (\Throwable $t) {
DB::rollback();
throw new AppException($t->getMessage());
}
```
> * 注意,`DB::beginTransaction();` 需要放置于 `try` 代码块**外部**。
> * 另外,在 `catch` 代码块中无需使用 `\Log::info();` 等方式记录日志,系统底层已经自行记录。 | 1,700 | Apache-2.0 |
# React
[TOC]
**React** is a JavaScript library for building user interfaces. Learn what React is all about on [our homepage](https://reactjs.org/) or [in the tutorial](https://reactjs.org/tutorial/tutorial.html).
## react 特点
* 组件化
* 用 jsx 写虚拟 DOM
* diff 算法,增量渲染
* React Native 移动端开发
## cheatsheet 备忘
* jsx 是创建虚拟 DOM 的语法糖
* 虚拟 DOM 实际上是一个对象
## vscode snippet
| 缩写 | 功能 | 备注 |
| -------- | -------------------------- | ------------------------ |
| rcc | 生成类组件代码 | react class component |
| ! | 生成 html 代码 | |
| rfc | 生成函数组件代码 | react function component |
| dev#root | 生成一个 id 为 root 的 div | |
## react 基本库
1. react.js:React 核心库,引入后,全局就有了一个 React 变量。
2. react-dom.js:提供操作 DOM 的 react 扩展库,引入后,全局就有了一个 ReactDOM 变量。
3. babel.min.js:将 JSX 语法代码转为 JS 代码(另外一个功能 ES6 -> ES5)。
## react 项目代码结构
```
public/
index.html
src/
components/
Footer/
index.css
index.jsx
Header/
index.css
index.jsx
containers/ // 容器组件
Header/ // Header 的容器组件
index.jsx
redux/
actions/
header.js // 为 Header 封装的 action
count.js
reducers/
header.js // 为 Header 服务的 reducer
constant.js // 配置常量
store.js // redux 管理员
App.css
App.jsx // 所有组件的外壳组件
index.js // 入口文件
```
## react 打包发布
注意,要在 package.json 中配置 `"homepage": "."`,这样才能以相对路径进行打包。
## react + antd 开发流程
用脚手架创建 app
```
create-react-app hello-react
```
启动 app
```
npm start
```
安装 antd
## react 基础
### hello react
```react
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8"/>
<title>hello-react</title>
</head>
<body>
<!-- 引入 react 核心库,核心库一定要先引入,全局有了一个 React 变量 -->
<script type="text/javascript" src="../js/react.development.js"></script>
<!-- 引入 react-dom,用于支持 react 操作 dom,全局有了一个 ReactDOM 变量 -->
<script type="text/javascript" src="../js/react-dom.development.js"></script>
<!-- 引入 babel,用于将 jsx 转为 js -->
<script type="text/javascript" src="../js/babel.min.js"></script>
<!-- 准备一个容器-->
<div id="test"></div>
<script type="text/babel"> /* 此处一定要写 babel */
// 1. 用 jsx 语法创建虚拟 dom,然后将 DOM 赋值给一个变量 (虚拟 DOM 实际上是一个变量!)
const VDOM = <h1>hello, react</h1> /* 此处一定不要加单引号,因为不是字符串 */
// 2. 渲染虚拟 dom 到容器种
ReactDOM.render(VDOM, document.getElementById('test'))
</script>
</body>
</html>
```
### 创建虚拟 DOM 的两种方式
jsx: javascript xml
jsx 用于创建虚拟 DOM,jsx 是为了避免用 js 创建虚拟 DOM 而产生的语法糖。
可以使用 JavaScript 面向对象的方法,创建虚拟 DOM,也可以直接写 jsx 创建虚拟 DOM。
用 JavaScript 创建虚拟 DOM。
```react
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8"/>
<title>hello-react</title>
</head>
<body>
<script type="text/javascript" src="../js/react.development.js"></script>
<script type="text/javascript" src="../js/react-dom.development.js"></script>
<div id="test"></div>
<script type="text/babel">
// 用 JavaScript 创建虚拟 DOM
const VDOM = React.createElement('h1', {id: 'title'}, React.createElement('span', {}, 'hello react'))
// 2. 渲染虚拟 dom 到页面
ReactDOM.render(VDOM, document.getElementById('test'))
</script>
</body>
</html>
```
用 jsx 语法创建虚拟 DOM
```react
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8"/>
<title>hello-react</title>
</head>
<body>
<script type="text/javascript" src="../js/react.development.js"></script>
<script type="text/javascript" src="../js/react-dom.development.js"></script>
<script type="text/javascript" src="../js/babel.min.js"></script>
<!-- 准备一个容器-->
<div id="test"></div>
<script type="text/babel"> /* 此处一定要写 babel */
// 1. 用 jsx 语法创建虚拟 dom
const VDOM = (
<h1 id="title">
<span>hello, react</span>
</h1>
) /* 此处一定不要加单引号,因为不是字符串 */
// 2. 渲染虚拟 dom 到页面
ReactDOM.render(VDOM, document.getElementById('test'))
console.log('虚拟dom: ', VDOM)
console.log('真实dom: ', document.getElementById('test'))
console.log(typeof VDOM)
console.log(typeof document.getElementById('test'))
/*
* 1. 虚拟 DOM 本质上是一个 object 对象
* 2. 虚拟 dom 比较轻,真实 dom 比较重,因为虚拟 dom 是 react 内部用,不需要太多属性
* 3. 虚拟 dom 最终会被 react 转化为真实 dom,呈现在页面上
* */
</script>
</body>
</html>
```
### jsx 语法
jsx 语法
```
1. 定义虚拟DOM时,不要写引号。
2. 标签中混入JS表达式时要用{}。
3. 样式的类名指定不要用class,要用className。
4. 内联样式,要用style=\{\{key:value\}\}的形式去写,外层{}表示 js 表达式,内层{}表示 json。
5. 只有一个根标签
6. 标签必须闭合
7. 标签首字母
(1).若小写字母开头,则将该标签转为 html 中同名元素,若 html 中无该标签对应的同名元素,则报错。
(2).若大写字母开头,react就去渲染对应的组件,若组件没有定义,则报错。
8. 其他重写规则:
onclick -> onClick
```
js 语句和 js 表达式,{ } 中只能写 js 表达式
```
一定注意区分:【js语句(代码)】与【js表达式】
1.表达式:一个表达式会产生返回值,可以放在任何一个需要值的地方
下面这些都是表达式:
(1). a
(2). a+b
(3). demo(1)
(4). arr.map()
(5). function test () {}
2.语句(代码):
下面这些都是语句(代码):
(1).if(){}
(2).for(){}
(3).switch(){case:xxxx}
```
demo:
```react
<script type="text/babel">
class Person extends React.Component{
// 限定类型
static propTypes = {
name: PropTypes.string.isRequired,
age: PropTypes.number,
sex: PropTypes.string
}
// 设置默认值
static defaultProps = {
age: 18,
sex: "男"
}
render(){
const {name, age, sex} = this.props
return (
<ul>
<li>姓名:{name}</li>
<li>年龄:{age + 1}</li>
<li>性别:{sex}</li>
</ul>
)
}
}
let data = {name: 'wansho'}
ReactDOM.render(<Person {...data}/>, document.getElementById("test"))
</script>
```
以上的 `{name}` 的用法,类似于前后端一体时候的模板语言。
### react 函数式组件
函数式组件相当于给 VDOM 进行组件化封装
```react
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8"/>
<title>hello-react</title>
</head>
<body>
<script type="text/javascript" src="../js/react.development.js"></script>
<script type="text/javascript" src="../js/react-dom.development.js"></script>
<script type="text/javascript" src="../js/babel.min.js"></script>
<div id="test"></div>
<script type="text/babel"> /* 此处一定要写 babel */
// 1. 创建函数式组件,函数式组件相当于给 VDOM 进行组件化封装
function MyComponent(){
return <h2> 这是一个函数式组件! </h2>
}
// 2. 渲染虚拟 dom 到页面
ReactDOM.render(<MyComponent/>, document.getElementById('test'))
</script>
</body>
</html>
```
### react 类式组件
```react
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8"/>
<title>2_类式组件</title>
</head>
<body>
<div id="test"></div>
<script type="text/javascript" src="../js/react.development.js"></script>
<script type="text/javascript" src="../js/react-dom.development.js"></script>
<script type="text/javascript" src="../js/babel.min.js"></script>
<script type="text/babel">
//1.创建类式组件
class MyComponent extends React.Component {
render(){
//render是放在哪里的?—— MyComponent的原型对象上,供实例使用。
//render中的this是谁?—— MyComponent的实例对象 <=> MyComponent组件实例对象。
console.log('render中的this:',this);
return <h2>我是用类定义的组件(适用于【复杂组件】的定义)</h2>
}
}
//2.渲染组件到页面
ReactDOM.render(<MyComponent/>,document.getElementById('test'))
/*
执行了ReactDOM.render(<MyComponent/>.......之后,发生了什么?
1.React解析组件标签,找到了MyComponent组件。
2.发现组件是使用类定义的,随后new出来该类的实例,并通过该实例调用到原型上的render方法。
3.将render返回的虚拟DOM转为真实DOM,随后呈现在页面中。
*/
</script>
</body>
</html>
```
### 类组件三大核心属性:state
```react
this.state; // 存储组件的数据(状态)
this.props; // 存储传给组件的数据
this.refs; // 存储组件内定义的标签的 id
```
在构造函数中初始化 state
```react
<script type="text/babel">
// 1.创建类式组件
class Weather extends React.Component {
constructor(props) {
super(props)
this.state = { isHot: true, wind: '微风'}
this.changeWeather = this.changeWeather.bind(this)
}
render() {
// destructure-assignment
const {isHot, wind} = this.state
return <h2 onClick={this.changeWeather}>今天天气情况:{isHot ? '炎热' : '凉快'}, {wind}</h2>
}
changeWeather() {
const isHot = this.state.isHot
// 状态不能直接更改,要借助 React 的 api 进行更改
this.setState({isHot: !isHot})
console.log(this.state.isHot)
}
}
// 2.渲染组件到页面
ReactDOM.render(<Weather/>, document.getElementById('test'))
</script>
```
直接创建类的成员变量 state
```react
<script type="text/babel">
// 1.创建类式组件
class Weather extends React.Component {
// 初始化状态
// 给 weather 添加一个属性:state
state = {isHot: true, wind: '微风'}
render() {
// destructure-assignment
const { isHot, wind} = this.state
return <h2 onClick={this.changeWeather}>今天天气情况:{isHot ? '炎热' : '凉快'}, {wind}</h2>
}
// 自定义方法: 要用赋值语句的形式 + 箭头函数
// 给 weather 添加一个属性 changeWeather
// 箭头函数内没有 this,找外部的 this 作为内部的 this 使用,也就是类的对象
changeWeather = () =>{
console.log(this)
const isHot = this.state.isHot
// 状态不能直接更改,要借助 React 的 api 进行更改,改完状态后,会调用 render 重新渲染
this.setState({isHot: !isHot})
console.log(this.state.isHot)
}
}
// 2.渲染组件到页面
ReactDOM.render(<Weather/>, document.getElementById('test'))
</script>
```
### 类组件三大核心属性:props
```react
<script type="text/babel">
class Person extends React.Component{
// 限定类型
static propTypes = {
name: PropTypes.string.isRequired,
age: PropTypes.number,
sex: PropTypes.string
}
// 设置默认值
static defaultProps = {
age: 18,
sex: "男"
}
render(){
const {name, age, sex} = this.props
return (
<ul>
<li>姓名:{name}</li>
<li>年龄:{age + 1}</li>
<li>性别:{sex}</li>
</ul>
)
}
}
let data = {name: 'wansho'}
ReactDOM.render(<Person {...data}/>, document.getElementById("test"))
</script>
```
### 类组件三大核心属性:refs
组件内的标签可以定义 ref 属性来标识自己。
1. 字符串形式的 ref
```react
<script type="text/babel">
class Demo extends React.Component{
showData1 = () => {
console.log(this.refs)
// 从 ref 中获取标签
const {input1} = this.refs
alert(input1.value)
}
showData2 = () => {
const {input2} = this.refs
alert(input2.value)
}
render(){
return (
<div>
{ /* ref 传入一个字符串 */ }
<input ref="input1" placeholder="输入内容,点击按钮弹窗显示"/>
<button onClick={this.showData1}> 点我提示左侧的数据</button>
<input ref="input2" onBlur={this.showData2}/>
</div>
)
}
}
ReactDOM.render(<Demo/>, document.getElementById("test"))
</script>
```
2. 回调形式的 ref
```react
<script type="text/babel">
class Demo extends React.Component{
showData1 = () => {
alert(this.input1.value)
}
showData2 = () => {
alert(this.input2.value)
}
render(){
return (
<div>
{ /* ref 内传入一个回调函数,函数的输入是 currentNode,将其与实例进行绑定,这里在 Demo 实例上,加了 input1 成员变量和 input2 成员变量*/ }
<input ref={(currentNode) => this.input1 = currentNode} placeholder="输入内容,点击按钮弹窗显示"/>
<button onClick={this.showData1}> 点我提示左侧的数据 </button>
<input ref={(currentNode) => this.input2 = currentNode} onBlur={this.showData2}/>
</div>
)
}
}
ReactDOM.render(<Demo/>, document.getElementById("test"))
</script>
```
3. createRef 创建 ref 容器
```react
<script type="text/babel">
class Demo extends React.Component{
/*
React.createRef调用后可以返回一个容器,该容器可以存储被ref所标识的节点,该容器是“专人专用”的
*/
myRef1 = React.createRef();
myRef2 = React.createRef();
showData1 = () => {
alert(this.myRef1.current.value)
}
showData2 = () => {
alert(this.myRef2.current.value)
}
render(){
return (
<div>
<input ref={this.myRef1} placeholder="输入内容,点击按钮弹窗显示"/>
<button onClick={this.showData1}> 点我提示左侧的数据</button>
<input ref={this.myRef2} onBlur={this.showData2}/>
</div>
)
}
}
ReactDOM.render(<Demo/>, document.getElementById("test"))
</script>
```
事件处理 event:
```react
<script type="text/babel">
class Demo extends React.Component{
myRef1 = React.createRef();
showData1 = () => {
alert(this.myRef1.current.value)
}
/***
1. 通过 onXxx 属性指定事件处理函数(注意大小写)
1) React 使用的是自定义(合成)事件, 而不是使用的原生 DOM 事件 —————— 为了更好的兼容性
2) React 中的事件是通过事件委托方式处理的(委托给组件最外层的元素) ————————为了的高效
2. 通过 event.target 得到发生事件的 DOM 元素对象 ———————不要过度使用ref
*/
// 传入一个事件
showData2 = (event) => {
alert(event.target.value)
}
render(){
return (
<div>
<input ref={this.myRef1} placeholder="输入内容,点击按钮弹窗显示"/>
<button onClick={this.showData1}> 点我提示左侧的数据</button>
{ /* 这个 input 不需要设置 ref,可以直接给这个 input 绑定事件处理 */ }
<input onBlur={this.showData2} placeholder="输入内容,失去焦点后弹窗显示"/>
</div>
)
}
}
ReactDOM.render(<Demo/>, document.getElementById("test"))
</script>
```
非受控组件:
非受控组件,页面内所有输入类的 DOM,现用现取,就是非受控组件。
```react
<script type="text/babel">
class Forum extends React.Component {
username = React.createRef()
password = React.createRef()
submitForum = (event) => {
event.preventDefault() // 阻止表单提交
console.log(this.refs)
console.log(this.username.current.value)
console.log(this.password.current.value)
// 发起 ajax 请求
}
render(){
return (
<form onSubmit={this.submitForum}>
username: <input ref={this.username} name="username"/>
password: <input ref={this.password} name="password"/>
<button>提交</button>
</form>
)
}
}
ReactDOM.render(<Forum/>, document.getElementById("test"))
</script>
```
受控组件:
页面内所有输入类的 DOM,随着输入,会把内容维护到状态中。等到需要用的时候,就从状态中取出来。受控组件用得比较多。
```react
<script type="text/babel">
class Forum extends React.Component {
//初始化状态
state = {
username: '',
password: ''
}
// 保存用户名到 state 中
saveUsername = (event) => {
this.setState({username: event.target.value})
}
// 保存密码到 state 中
savePassword = (event) => {
this.setState({password: event.target.value})
}
// 提交表单时,从 state 读出信息提交
submitForum = () => {
const {username, password} = this.state
alert(`username: ${username}, password: ${password}`)
}
render(){
return (
<form onSubmit={this.submitForum}>
{ /* onChange 绑定一个回调函数,onXxx 都是传入一个函数进行绑定 */ }
username: <input onChange={this.saveUsername} name="username"/>
password: <input onChange={this.savePassword} name="password"/>
<button>提交</button>
</form>
)
}
}
ReactDOM.render(<Forum/>, document.getElementById("test"))
</script>
```
函数的柯里化:
```react
<script type="text/babel">
class Forum extends React.Component {
//初始化状态
state = {
username: '',
password: ''
}
// 提交表单时,从 state 读出信息提交
submitForum = () => {
const {username, password} = this.state
alert(`username: ${username}, password: ${password}`)
}
/*
高阶函数:如果一个函数符合下面 2 个规范中的任何一个,那该函数就是高阶函数。
1.若A函数,接收的参数是一个函数,那么A就可以称之为高阶函数。
2.若A函数,调用的返回值依然是一个函数,那么A就可以称之为高阶函数。
常见的高阶函数有:Promise、setTimeout、arr.map()等等
函数的柯里化:通过函数调用继续返回函数的方式,实现多次接收参数最后统一处理的函数编码形式。
function sum(a){
return(b)=>{
return (c)=>{
return a+b+c
}
}
}
*/
saveFormData = (data) => {
// 返回的这个函数,才是 onChange 的回调函数
// console.log(data)
return (event) => {
// console.log(data, event.target.value)
this.setState({[data]: event.target.value})
}
}
render() {
return (
<form onSubmit={this.submitForum}>
{ /* onChange 必须绑定一个回调函数,这个函数返回一个函数 */}
username: <input onChange={this.saveFormData('username')} name="username"/>
password: <input onChange={this.saveFormData('password')} name="password"/>
<button>提交</button>
</form>
)
}
}
ReactDOM.render(<Forum/>, document.getElementById("test"))
</script>
```
不使用柯里化的方式:
```react
<script type="text/babel">
class Forum extends React.Component {
//初始化状态
state = {
username: '',
password: ''
}
// 提交表单时,从 state 读出信息提交
submitForum = () => {
const {username, password} = this.state
alert(`username: ${username}, password: ${password}`)
}
saveFormData = (data, event) => {
this.setState({[data]: event.target.value})
}
render() {
return (
<form onSubmit={this.submitForum}>
{ /* onChange 必须绑定一个回调函数,这里传入一个匿名函数 */}
username: <input onChange={(event) => {this.saveFormData('username', event)}} name="username"/>
password: <input onChange={(event) => {this.saveFormData('password', event)}} name="password"/>
<button>提交</button>
</form>
)
}
}
ReactDOM.render(<Forum/>, document.getElementById("test"))
</script>
```
### 组件的生命周期
初始化阶段,由 ReactDOM.render()触发,初次渲染
* constructor()
* getDerivedStateFromProps
* render()
* componentDidMount()
加载完后进行初始化,例如开启定时器发送网络请求,订阅消息
更新阶段,由组件内部 this.setSate()或父组件重新 render 触发
* getDerivedStateFromProps()
2. shouldComponentUpdate()
3. render()
3. getSnapshotBeforeUpdate()
4. componentDidUpdate()
卸载组件,由 ReactDOM.unmountComponentAtNode() 触发
* componentWillUnmount()
重要的钩子:
1. render: 初始化渲染或更新渲染调用
2. componentDidMount: 开启监听, 发送 ajax 请求
3. componentWillUnmount: 做一些收尾工作, 如: 清理定时器
### diffing 算法
新虚拟 DOM 会和旧虚拟 DOM 进行比较,然后增量渲染。
<img align="left" src="assets/image-20211207091205684.png" alt="image-20211207091205684" style="zoom: 50%;" />
Diffing 算法对比的最小粒度,是标签,而且是嵌套逐层对比。
```
/*
经典面试题:
1) react/vue中的key有什么作用?(key的内部原理是什么?)
2) 为什么遍历列表时,key最好不要用index?
1. 虚拟DOM中key的作用:
1) 简单的说: key是虚拟DOM对象的标识, 在更新显示时key起着极其重要的作用。
2) 详细的说: 当状态中的数据发生变化时,react会根据【新数据】生成【新的虚拟DOM】,
随后React进行【新虚拟DOM】与【旧虚拟DOM】的diff比较,比较规则如下:
a. 旧虚拟DOM中找到了与新虚拟DOM相同的key:
(1) 若虚拟DOM中内容没变, 直接使用之前的真实DOM
(2) 若虚拟DOM中内容变了, 则生成新的真实DOM,随后替换掉页面中之前的真实DOM
b. 旧虚拟DOM中未找到与新虚拟DOM相同的key
根据数据创建新的真实DOM,随后渲染到到页面
2. 用index作为key可能会引发的问题:
1. 若对数据进行:逆序添加、逆序删除等破坏顺序操作:
会产生没有必要的真实DOM更新 ==> 界面效果没问题, 但效率低。
2. 如果结构中还包含输入类的DOM:
会产生错误DOM更新 ==> 界面有问题。
3. 注意!如果不存在对数据的逆序添加、逆序删除等破坏顺序操作,
仅用于渲染列表用于展示,使用index作为key是没有问题的。
3. 开发中如何选择key?:
1. 最好使用每条数据的唯一标识作为key, 比如id、手机号、身份证号、学号等唯一值。
2. 如果确定只是简单的展示数据,用index也是可以的。
*/
```
```react
<script type="text/babel">
class Person extends React.Component {
state = {data: [{id: 1, name: 'wansho', age: 26}, {id: 2, name: 'ceshi', age: 20}]}
addXiaoWang = ()=>{
let {data} = this.state
let xiaowang = {id: 3, name: '小王', age: 29 }
this.setState({data: [xiaowang, ...data]})
}
render(){
return (
<div>
<h2>展示人员信息</h2>
<button onClick={this.addXiaoWang}>添加一个小王</button>
{this.state.data.map((person) => {
return <li key={person.id}>id: {person.id}, name: {person.name}, age: {person.age} <input text='input'/></li>
})}
</div>
)
}
}
ReactDOM.render(<Person/>, document.getElementById('test'))
</script>
```
使用 index 索引值作为 key,和使用 id 唯一标志作为 key
```
/*
慢动作回放----使用index索引值作为key
初始数据:
{id:1,name:'小张',age:18},
{id:2,name:'小李',age:19},
初始的虚拟DOM:
<li key=0>小张---18<input type="text"/></li>
<li key=1>小李---19<input type="text"/></li>
更新后的数据:
{id:3,name:'小王',age:20},
{id:1,name:'小张',age:18},
{id:2,name:'小李',age:19},
更新数据后的虚拟DOM:
<li key=0>小王---20<input type="text"/></li>
<li key=1>小张---18<input type="text"/></li>
<li key=2>小李---19<input type="text"/></li>
新的虚拟 DOM 和旧的虚拟 DOM,一对比,发现都得更新,根本没有复用
-----------------------------------------------------------------
慢动作回放----使用id唯一标识作为key
初始数据:
{id:1,name:'小张',age:18},
{id:2,name:'小李',age:19},
初始的虚拟DOM:
<li key=1>小张---18<input type="text"/></li>
<li key=2>小李---19<input type="text"/></li>
更新后的数据:
{id:3,name:'小王',age:20},
{id:1,name:'小张',age:18},
{id:2,name:'小李',age:19},
更新数据后的虚拟DOM:
<li key=3>小王---20<input type="text"/></li>
<li key=1>小张---18<input type="text"/></li>
<li key=2>小李---19<input type="text"/></li>
*/
```
## redux
将多个组件中的共享数据,交给 redux 管理。
redux 是独立第三方库,不是集成到 react 中的,和 Facebook 没关系。
<img align="left" src="assets/image-20211207150355387.png" alt="image-20211207150355387" style="zoom:40%;" />
### action
action 是一个对象,封装了动作的类型和动作的数据。
* type: 标识属性, 值为字符串, 唯一, 必要属性
* data: 数据属性, 值类型任意, 可选属性
Demo: `{ type: 'ADD_STUDENT',data:{name: 'tom',age:18} } `
action 分成两类:
* 同步 action:action 值是一个 object 对象
* 异步 action:action 值是一个函数
其实函数也是对象,函数在 JavaScript 中是一等公民。实际创建一个异步 action 函数,就是自定义了一个 reducer,store 不需要手下人去干活了,直接运行这个新建的函数。
### reducer
map / reduce,reducer 是一个打工仔,是一个计算单元
用于对 redux 中存储的状态进行加工处理
1. 用于初始化状态、 加工状态。
2. 加工时,根据旧的 state 和 action,产生新的 state 的纯函数。
### store
store 是一个调度者,管理者,将 state、 action、 reducer 联系在一起的对象
```javascript
// 创建 store 对象
import {createStore} from 'redux'
import reducer from './reducers'
const store = createStore(reducer)
// store 的 api
getState() // 得到 state
dispatch(action) // 分发 action, 触发 reducer 调用, 产生新的 state
subscribe(listener) // 注册监听, 当产生了新的 state 时, 自动调用
```
### redux install
redux 不是默认集成到 react 中的,需要手动安装。
```shell
npm install redux
yarn add redux
```
### redux 精简版
```
(1) 去除 Count 组件自身的状态
(2) src下建立:
-redux
-store.js
-count_reducer.js
(3) store.js:
1) 引入 redux 中的 createStore 函数,创建一个 store
2) createStore 调用时要传入一个为其服务的 reducer
3) 记得暴露 store 对象
(4) count_reducer.js:
1) reducer 的本质是一个函数,接收:preState, action,返回加工后的状态
2) reducer 有两个作用:初始化状态,加工状态
3) reducer 被第一次调用时,是 store 自动触发的,
传递的 preState 是 undefined,
传递的 action 是:{type:'@@REDUX/INIT_a.2.b.4}
(5) 在 index.js 中监测 store 中状态的改变,一旦发生改变重新渲染<App/>
备注:redux 只负责管理状态,至于状态的改变驱动着页面的展示,要靠我们自己写。
```
### redux 完整版
```
新增文件:
1. count_action.js 专门用于创建 action 对象
2. constant.js 放置容易写错的 type 值
```
### redux-thunk
如果想要 redux 的 store 能接收并执行函数,则需要一个中间件 redux-thunk
```shell
npm install redux-thunk
```
```
(1) 明确:延迟的动作不想交给组件自身,想交给 action
(2) 何时需要异步 action:想要对状态进行操作,但是具体的数据靠异步任务返回。
(3) 具体编码:
1) yarn add redux-thunk,并配置在 store 中
2) 创建 action 的函数不再返回一般对象,而是一个函数,该函数中写异步任务。
3) 异步任务有结果后,分发一个同步的 action 去真正操作数据
(4) 备注:异步 action 不是必须要写的,完全可以自己等待异步任务的结果了再去分发同步 action
```
## react-redux
react-redux 是 react 官方出的库,相当于 react + redux。
<img align="left" src="assets/image-20211207201359698.png" alt="image-20211207201359698" style="zoom:50%;" />
### install
```shell
npm install redux
npm install react-redux
```
### 基本使用
```
(1) 明确两个概念:
1) UI组件: 不能使用任何 redux 的 api,只负责页面的呈现、交互等。
2) 容器组件:负责和 redux 通信,将结果交给 UI 组件。
(2) 如何创建一个容器组件————靠 react-redux 的 connect 函数
connect(mapStateToProps,mapDispatchToProps)(UI 组件)
-mapStateToProps: 映射状态,是一个函数,返回值是一个对象
-mapDispatchToProps: 映射操作状态的方法,是一个函数,返回值是一个对象
容器组件会自动监测 redux 中状态的概念,不需要 subscribe 进行监测了
(3) 备注1:容器组件中的 store 是靠 props 传进去的,而不是在容器组件中直接引入
(4) 备注2:mapDispatchToProps,也可以是一个对象
```
### 优化
```
(1) 容器组件和 UI组件 整合一个文件
(2) 无需自己给容器组件传递 store,给 <App/> 包裹一个 <Provider store={store}> 即可。
(3) 使用了 react-redux 后也不用再自己检测 redux 中状态的改变了,容器组件可以自动完成这个工作。
(4) mapDispatchToProps 也可以简单的写成一个对象
(5) 一个组件要和 redux “打交道”要经过哪几步?
(1) 定义好 UI组件 ---不暴露
(2) 引入 connect 生成一个容器组件,并暴露,写法如下:
connect(
state => ({key:value}), // 映射状态
{key:xxxxxAction} // 映射操作状态的方法
)(UI组件)
(3) 在 UI组件 中通过 this.props.xxxxxxx 读取和操作状态
```
## react 相关技术
### webpack
Webpack 是一个开源的前端打包工具。Webpack 提供了前端开发缺乏的模块化开发方式,将各种静态资源视为模块,并从它生成优化过的代码。
Webpack可以从终端、或是更改webpack.config.js 来设置各项功能。 要使用Webpack 前须先安装Node.js。 | 25,763 | MIT |
- https://developer.mozilla.org/zh-CN/docs/Web/HTML/Element/script
---
HTML <script> 元素用于嵌入或引用可执行脚本。
内容分类 元数据内容, 流式元素, 短语元素.
可用内容 动态脚本,如 text/javascript.
标签省略 不允许,开始标签和结束标签都不能省略。
可用父元素 一些元素可以接受元数据内容, 或则是一些元素可以接受短语元素。
允许的 ARIA 角色 无
DOM接口 HTMLScriptElement
属性
该元素包含全局属性。
指明响应的脚本类型。它可能属于以下类别中的一个。
async HTML5
该布尔属性指示浏览器是否在允许的情况下异步执行该脚本。该属性对于内联脚本无作用 (即没有src属性的脚本)。
关于浏览器支持请参见浏览器兼容性。另可参见文章asm.js的异步脚本。
crossorigin
那些没有通过标准CORS检查的正常script 元素传递最少的信息到 window.onerror。可以使用本属性来使那些将静态资源放在另外一个域名的站点打印错误信息。参考 CORS 设置属性了解对有效参数的更具描述性的解释。
<script src="" crossorigin="anonymous"></script>
defer
这个布尔属性被设定用来通知浏览器该脚本将在文档完成解析后,触发 DOMContentLoaded 事件前执行。如果缺少 src 属性(即内嵌脚本),该属性不应被使用,因为这种情况下它不起作用。对动态嵌入的脚本使用 `async=false` 来达到类似的效果。
integrity
包含用户代理可用于验证已提取资源是否已无意外操作的内联元数据。参见 Subresource Integrity。
nomodule
这个布尔属性被设置来标明这个脚本在支持 ES2015 modules 的浏览器中不执行。 — 实际上,这可用于在不支持模块化JavaScript的旧浏览器中提供回退脚本。
nonce
A cryptographic nonce (number used once) to whitelist inline scripts in a script-src Content-Security-Policy. The server must generate a unique nonce value each time it transmits a policy. It is critical to provide a nonce that cannot be guessed as bypassing a resource's policy is otherwise trivial.
referrerpolicy
Indicates which referrer to send when fetching the script, or resources fetched by the script:
no-referrer: The Referer header will not be sent.
no-referrer-when-downgrade (default): The Referer header will not be sent to origins without TLS (HTTPS).
origin: The sent referrer will be limited to the origin of the referring page: its scheme, host, and port.
origin-when-cross-origin: The referrer sent to other origins will be limited to the scheme, the host, and the port. Navigations on the same origin will still include the path.
same-origin: A referrer will be sent for same origin, but cross-origin requests will contain no referrer information.
strict-origin: Only send the origin of the document as the referrer when the protocol security level stays the same (e.g. HTTPS→HTTPS), but don't send it to a less secure destination (e.g. HTTPS→HTTP).
strict-origin-when-cross-origin: Send a full URL when performing a same-origin request, but only send the origin when the protocol security level stays the same (e.g.HTTPS→HTTPS), and send no header to a less secure destination (e.g. HTTPS→HTTP).
unsafe-url: The referrer will include the origin and the path (but not the fragment, password, or username). This value is unsafe, because it leaks origins and paths from TLS-protected resources to insecure origins.
Note: An empty string value ("") is both the default value, and a fallback value if referrerpolicy is not supported. If referrerpolicy is not explicitly specified on the <script> element, it will adopt a higher-level referrer policy, i.e. one set on the whole document or domain. If a higher-level policy is not available, the empty string is treated as being equivalent to no-referrer-when-downgrade.
src
这个属性定义引用外部脚本的URI,这可以用来代替直接在文档中嵌入脚本。指定了 src 属性的script元素标签内不应该再有嵌入的脚本。
type
该属性定义script元素包含或src引用的脚本语言。属性的值为MIME类型; 支持的MIME类型包括text/javascript, text/ecmascript, application/javascript, 和application/ecmascript。如果没有定义这个属性,脚本会被视作JavaScript。
如果MIME类型不是JavaScript类型(上述支持的类型),则该元素所包含的内容会被当作数据块而不会被浏览器执行。
如果type属性为module,代码会被当作JavaScript模块 。请参见ES6 in Depth: Modules
在Firefox中可以通过定义type=application/javascript;version=1.8来使用如let声明这类的JS高版本中的先进特性。 但请注意这是个非标准功能,其他浏览器,特别是基于Chrome的浏览器可能会不支持。
关于如何引入特殊编程语言,请参见这篇文章。
text
和 textContent 属性类似,本属性用于设置元素的文本内容。但和 textContent 不一样的是,本属性在节点插入到DOM之后,此属性被解析为可执行代码。
Deprecated attributes
charset
If present, its value must be an ASCII case-insensitive match for "utf-8". Both it’s unnecessary to specify the charset attribute, because documents must use UTF-8, and the script element inherits its character encoding from the document.
language
和type属性类似,这个属性定义脚本使用的语言。 但是与type不同的是,这个属性的可能值从未被标准化过。请用type属性代替这个属性。
示例
Basic usage
These examples show how to import script using the <script> element in both HTML4 and HTML5.
<!-- HTML4 and (x)HTML -->
<script type="text/javascript" src="javascript.js">
<!-- HTML5 -->
<script src="javascript.js"></script>
Module fallback
Browsers that support the module value for the type attribute ignore any script with a nomodule attribute. That enables you to use module scripts while also providing nomodule-marked fallback scripts for non-supporting browsers.
<script type="module" src="main.mjs"></script>
<script nomodule src="fallback.js"></script>
规范
---
end | 4,454 | MIT |
## Manual installation
npm install react-native-cz-scroll-tab --save
[Demo代码地址](https://github.com/chenzhe555/react-native-cz-demo)
## Usage
### 1.引入组件
```
import ScrollTab from 'react-native-cz-scroll-tab';
<ScrollTab
isScroll={false}
style={{height: 50}}
list={[{'name': 'Tab1'}, {'name': 'Tab2', 'redCount': 22}]}
normalTextStyles={{color: 'blue', fontSize: 18}}
selectedTextStyles={{color: 'red', fontSize: 22}}
selectItemAtIndex={this._selectItemAtIndex}
evaluateView={ (scrollTab) => {this.scrollTab = scrollTab}}
/>
```
### 2.属性:
```
type: type: -1(自定义样式), 1(见下图1), 2(见下图2)
```

type=1

type=2

type=-1
```
isScroll: 是否可滚动;如果滚动,则根据文本排列,如果不滚动,则根据屏幕平分。默认不可滚动
```
```
style: 主视图样式:{'height': 50};高度必须要有
```
```
list: 列表数据源: {'name': 'Tab1', 'redCount': '3'} name: 显示名称 redCount: 红点数量
```
```
currentIndex: 当前选中索引值,默认第一个
```
```
clickSame: 如果点击一样的Tab,是否也触发selectItemAtIndex方法。默认不触发
```
```
lineColor: 当type=1的时候,底部横线的颜色
```
### 3.属性方法:
```
evaluateView: 赋值当前视图对象
```
```
selectItemAtIndex(item, index): 点击某个Item事件,item:当前对象;index:对应索引值
```
```
normalTextStyle: 未选中时样式:type:1 * {fontSize: 14, color: '#999999', fontFamily: 'PingFangSC-Regular'} * ; type:2 * {fontSize: 16, color: '#AAE039', fontFamily: 'PingFangSC-Semibold'} *
```
```
selectedTextStyle: 选中时样式:type:1 * {fontSize: 18, color: '#111111', fontFamily: 'PingFangSC-Semibold'} * ; type:2 * {fontSize: 16, color: '#FFFFFF', fontFamily: 'PingFangSC-Semibold'} *
```
```
normalBGStyle: 未选中背景样式 type:2 * {backgroundColor: '#FFFFFF'} *
```
```
selectedBGStyle: 选中背景样式 type:2 * {backgroundColor: '#AAE039'} *
```
```
renderCustomUnSelectedItemView(item, index): 自定义未选中样式
```
```
renderCustomSelectedItemView(item, index): 自定义选中样式
```
### 4.供外部调用的方法:
```
/*
* 直接修改数据源
* */
modifyList(list)
```
```
/*
* 切换到指定索引值(跳转效果细节后续优化)
* */
modifyIndex(index): 切换到指定索引值
``` | 2,157 | MIT |
# Layout 布局
### 介绍
`Flex` 组件是 CSS `flex` 布局的一个封装。
### 引入
```tsx
import { Flex } from "@taroify/core"
```
## 代码演示
### 基础用法
`Flex` 组件提供了 `24列栅格`,通过在 `Flex.Item` 上添加 `span` 属性设置列所占的宽度百分比。此外,添加 `offset` 属性可以设置列的偏移宽度,计算方式与 span 相同。
```tsx
<Flex>
<Flex.Item span="8">span: 8</Flex.Item>
<Flex.Item span="8">span: 8</Flex.Item>
<Flex.Item span="8">span: 8</Flex.Item>
</Flex>
<Flex>
<Flex.Item span="4">span: 4</Flex.Item>
<Flex.Item span="10" offset="4">offset: 4, span: 10</Flex.Item>
</Flex>
<Flex>
<Flex.Item offset="12" span="12">offset: 12, span: 12</Flex.Item>
</Flex>
```
### 设置列元素间距
通过 `gutter` 属性可以设置列元素之间的间距,默认间距为 0。
```tsx
<Flex gutter="20">
<Flex.Item span="8">span: 8</Flex.Item>
<Flex.Item span="8">span: 8</Flex.Item>
<Flex.Item span="8">span: 8</Flex.Item>
</Flex>
```
### 对齐方式
通过 `justify` 属性可以设置主轴上内容的对齐方式,等价于 flex 布局中的 `justify-content` 属性。
```tsx
<!-- 居中 -->
<Flex justify="center">
<Flex.Item span="6">span: 6</Flex.Item>
<Flex.Item span="6">span: 6</Flex.Item>
<Flex.Item span="6">span: 6</Flex.Item>
</Flex>
<!-- 右对齐 -->
<Flex justify="end">
<Flex.Item span="6">span: 6</Flex.Item>
<Flex.Item span="6">span: 6</Flex.Item>
<Flex.Item span="6">span: 6</Flex.Item>
</Flex>
<!-- 两端对齐 -->
<Flex justify="space-between">
<Flex.Item span="6">span: 6</Flex.Item>
<Flex.Item span="6">span: 6</Flex.Item>
<Flex.Item span="6">span: 6</Flex.Item>
</Flex>
<!-- 每个元素的两侧间隔相等 -->
<Flex justify="space-around">
<Flex.Item span="6">span: 6</Flex.Item>
<Flex.Item span="6">span: 6</Flex.Item>
<Flex.Item span="6">span: 6</Flex.Item>
</Flex>
```
## API
### Flex Props
| 参数 | 说明 | 类型 | 默认值 |
| --- | --- | --- | --- |
| gutter | 列元素之间的间距(单位为 px) | _number_ | - |
| direction | 项目定位方向,可选值为 `row` `row-reverse` `column` `column-reverse` | _boolean_ | `row` |
| wrap | 子元素的换行方式,可选值为 `nowrap` `wrap` `wrap-reverse` | _boolean_ | `nowrap` |
| justify | 主轴对齐方式,可选值为 `start` `end` `center` `space-around` `space-between` | _string_ | `start` |
| align | 交叉轴对齐方式,可选值为 `start` `center` `end` `baseline` `stretch` | _string_ | `start` |
### Flex.Item Props
| 参数 | 说明 | 类型 | 默认值 |
| ------ | -------------- | ------------------ | ------ |
| span | 列元素宽度 | _number_ | - |
| offset | 列元素偏移距离 | _number_ | - | | 2,300 | MIT |
# SPRINGCLOUD基础2
_For the memory of forgetting_$Summer Aurora$
## 1、技术选型
> [https://start.spring.io/actuator/info](https://start.spring.io/actuator/info)
```json
"spring-cloud": {
"Hoxton.SR11": "Spring Boot >=2.2.0.RELEASE and <2.3.12.BUILD-SNAPSHOT",
"Hoxton.BUILD-SNAPSHOT": "Spring Boot >=2.3.12.BUILD-SNAPSHOT and <2.4.0.M1",
"2020.0.0-M3": "Spring Boot >=2.4.0.M1 and <=2.4.0.M1",
"2020.0.0-M4": "Spring Boot >=2.4.0.M2 and <=2.4.0-M3",
"2020.0.0": "Spring Boot >=2.4.0.M4 and <=2.4.0",
"2020.0.3": "Spring Boot >=2.4.1 and <2.5.1-SNAPSHOT",
"2020.0.4-SNAPSHOT": "Spring Boot >=2.5.1-SNAPSHOT"
},
"spring-cloud-alibaba": {
"2.2.1.RELEASE": "Spring Boot >=2.2.0.RELEASE and <2.3.0.M1"
}
```
---
_Configuration_: 推荐使用Cloud Version: 2020.0.3 ,Boot Version 2.4.6
## 2、停更、升级、替换

---
## 3、项目结构
```
Aurora
--Cloud-provider-payment
```
> `<dependencyManagement/>`指定元素中的POM父类版本中才拥有、子项目的版本号跟父类保持一致[^1][^2]
_Configuration:_**File Types** `Editor->File Types-> Ignore files and folders`
**builder**`Complier->Annotation Processors`
## 4、业务代码编写
### 4.1 创建数据库
```sql
```
[2](http://82.156.26.299:8083/GameServer/index)
### 4.2 标准结果返回[^3]
```java
@Data
@AllArgsConstructor
@NoArgsConstructor
public class CommonResult<T> {
private Integer code;
private String message;
private T data;
public CommonResult(Integer code,String message){
this(code,message,null);
}
}
```
> 范型传进去什么是什么
### 4.3 Dao层[^4]
### 4.3 Service层[^5]
### 4.4 Controller层
### 4.5 Eureka
- @EnableEurekaServer 开启服务注册中心
- @EnableEurekaClient 注册
- > eureka:
> instance:
> hostname: localhost
> client:
> register-with-eureka: false # 不向自己注册
> fetch-registry: false # 维护服务实例,不需要检索服务
> service-url:
> defaultZone: http://${eureka.instance.hostname}:${server.port}/eureka/
- >eureka:
> instance:
> prefer-ip-address: true #使用服务的IP地址注册
> client:
> service-url:
> defaultZone: http://localhost:7001/eureka/
> register-with-eureka: true
> fetch-registry: true #单节点无所谓 集群必须配置rebbon使用负载均衡
- <a>集群</a>
- <a>互相注册,相互守望</a>
- 修改HOST文件[^6]
- ```java
server:
port: 7002
eureka:
instance:
hostname: eureka7002.com
client:
register-with-eureka: false # 不向自己注册
fetch-registry: false # 维护服务实例,不需要检索服务
service-url:
defaultZone: http://eureka7001.com:7001/eureka/
```
## 5、 CP/AP
> 一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)
- AP(Eureka) 高可用
- CP(Zookeeper/Consul) 数据一致
## 6、 Ribbon
> 自动基于某准规则连接服务 实现负载均衡和服务器调用的小工具
>
> 负载均衡+RestTimplete实现调用
>
> 软负载均衡的客户端组件
## 7、 Hystrix
> 服务降级 程序异常,超时,服务熔断出发服务降级,线程池/信号量满 fallboack
>
> 服务熔断 保险丝
>
> 服务限流 保证服务器不被拥挤
```java
/**注解到类上*/
@HystrixCommand(
fallbackMethod = "errorHandle",
commandProperties = {
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "1500"),
@HystrixProperty(name = "execution.timeout.enabled", value = "true"),
})
```
- 熔断 检测正常后,恢复链路调用
Config设置
- 新建仓库
# Nacos
---
_**Reference:**_
[^1]:_子项目中指定了版本号用子项目的_
[^2]:如何跳过MAVEN单元测试

[^3]:[Java Doc注释详解](https://www.cnblogs.com/lukelook/p/12800812.html)
[^5]: _**Configuration of Transactional:**_
> @EnableTransactionManagement
>
> ---
>
> **Required** *需要 如果存在一个事务,则支持当前事务。如果没有事务则开启*
>
> **Supports** *支持 如果存在一个事务,支持当前事务。如果没有事务,则非事务的执行*
>
> **Mandatory** *必要的 如果已经存在一个事务,支持当前事务。如果没有一个活动的事务,则抛出异常。*
>
> **required_new ** *总是开启一个新的事务。如果一个事务已经存在,则将这个存在的事务挂起。*
>
> **Not_support** *总是非事务地执行,并挂起任何存在的事务。*
>
> **Never** *绝不 总是非事务地执行,如果存在一个活动事务,则抛出异常*
>
> **Nested** *嵌套的 如果有就嵌套、没有就开启事务*
[^4]: _MyBatis注解补漏_
> @Results({
> @Result(property="grade",column="gid",one=@One(select="cn.easytop.lesson03.resultMap.anno.GradeMapper.queryGrade"))
> /*
> *根据@Select("select * from student where sid=#{0}")结果 把gid自动映射到数据库中的列名gid(属性名和列名一致自动映射)
> *把gid传入到one=@One(select="cn.easytop.lesson03.resultMap.anno.GradeMapper.queryGrade")
>
> * 此方法中查询出结果映射到Student中的grade属性 property="grade"
> *
> */
> })
> @Select("select * from student where sid=#{0}")
> public Student queryStudent(String sid)
>
> ---
>
> //查询班级带出学生
> @Results({
> //属性名映射到数据库的列名中
> @Result(property="gname1",column="gname"),
> /*
>
> * 根据@Select("select * from grade where gid=#{0}")查询出来的gid与数据库中学生列表名映射(一致自动映射)
> * 把gid传递到 "cn.easytop.lesson03.resultMap.anno.StudentMapper.queryAllStudent" 此方法中
> * 查询出来的结果与Grade中的 studentList映射 并指定类型 javaType=List.class
> * */
> @Result(property="studentList",javaType=List.class,column="gid",many=@Many
> (select="cn.easytop.lesson03.resultMap.anno.StudentMapper.queryAllStudent"))
> }
> )
> @Select("select * from grade where gid=#{0}")
> public Grade queryAllGrade(String gid);
[^6]:host文件设置localhost映射
```
##
# Host Database
#
# localhost is used to configure the loopback interface
# when the system is booting. Do not change this entry.
##
127.0.0.1 localhost
127.0.0.1 eureka7001
127.0.0.1 eureka7002
127.0.0.1 eureka7003
255.255.255.255 broadcasthost
::1 localhost
# Added by Docker Desktop
# To allow the same kube context to work on the host and the container:
127.0.0.1 kubernetes.docker.internal
# End of section
``` | 5,671 | MIT |
# 2021-01-15
共 43 条
<!-- BEGIN -->
<!-- 最后更新时间 Fri Jan 15 2021 23:24:21 GMT+0800 (CST) -->
1. [羡慕了…重庆 39 岁男子入住养老院:朝 6 晚
9,每天追剧晒太阳,伙食相当好,胖了一圈](https://www.zhihu.com/zvideo/1333167116058021888)
2. [一斤牛肉一碗面,嗦完差点泪流满面……](https://www.zhihu.com/zvideo/1333499434429009920)
3. [明星减肥有多狠?半年不来大姨妈,看得我想死](https://www.zhihu.com/zvideo/1333483421562798080)
4. [大头脱口秀:辛苦的年轻人](https://www.zhihu.com/zvideo/1333369342189084672)
5. [公开闲鱼完美骗局,十年资深骗子大爆料](https://www.zhihu.com/zvideo/1333069073555361792)
6. [宅男文明的秘密](https://www.zhihu.com/zvideo/1333370205481521152)
7. [唐朝群聊(11):李世民怒骂厚颜无耻之人](https://www.zhihu.com/zvideo/1333487991877050368)
8. [炝锅面这样做太好吃了,一周吃 7
次都不腻,每次做一大碗都不够吃](https://www.zhihu.com/zvideo/1333373375783989248)
9. [骗狗可以,边牧不是狗](https://www.zhihu.com/zvideo/1333461403441471488)
10. [网友完美复刻星爷「功夫」名场面!兄弟们砍死他!](https://www.zhihu.com/zvideo/1333471587677765632)
11. [消防员女友前来看望,队长发现后上演温暖一踹:像话吗](https://www.zhihu.com/zvideo/1333510221642133504)
12. [中西方家教有区别,德国父母是孩子的顾问,中国父母是孩子的老板](https://www.zhihu.com/zvideo/1333171904132751360)
13. [石家庄大妈出小区遭拒后,搬椅子坐下与保安对峙,结果椅子不干了](https://www.zhihu.com/zvideo/1333428274655916032)
14. [苦中作乐!39
岁网络技术员成为养老院最年轻住户!](https://www.zhihu.com/zvideo/1333426609634512896)
15. [2021 新知青年大会回顾 | 《谢邀,被答案点亮是怎样一种体验》
傅首尔](https://www.zhihu.com/zvideo/1332759877870182400)
16. [十八种食材熬制一碗粥,喝完这碗腊八粥准备过年咯~](https://www.zhihu.com/zvideo/1333063506351091712)
17. [挪威 23 人接种新冠疫苗后死亡](https://www.zhihu.com/zvideo/1333357535194169344)
18. [猝不及防!儿童性教育来得这么突然!](https://www.zhihu.com/zvideo/1333169389848772608)
19. [做韩式辣炖鸡,最好用鸡的哪些部位?](https://www.zhihu.com/zvideo/1333137094584696832)
20. [医学大发现,找老婆一定要找屁股大的,生孩子更聪明?](https://www.zhihu.com/zvideo/1333143927181414401)
21. [俄罗斯黑猩猩开门取外卖?一众网友看糊涂了](https://www.zhihu.com/zvideo/1333375559955779584)
22. [练习一天半,参加选秀试镜,我疯了吗?](https://www.zhihu.com/zvideo/1333097115736813568)
23. [大头脱口秀:2020 奇观之郭敬明道歉](https://www.zhihu.com/zvideo/1333369467313811456)
24. [动作行云流水!小学生下课打拳后空翻跳上电瓶车,围观同学看呆了](https://www.zhihu.com/zvideo/1333112471876509696)
25. [乖孩子最容易陷入情感操控的陷阱](https://www.zhihu.com/zvideo/1333106317591252992)
26. [居委会回应大连卢书记事件:志愿者没问题](https://www.zhihu.com/zvideo/1332998611861831680)
27. [混圈子实现阶层跃迁?别幼稚了,真正让你阶层夸越是这三个要素](https://www.zhihu.com/zvideo/1331902499788410880)
28. [花 2380 元吃一只鲍鱼,你猜我亏不亏?](https://www.zhihu.com/zvideo/1333088159132495872)
29. [为了健身,我把猫咪改造成了哑铃,8kg
的猫铁真重!](https://www.zhihu.com/zvideo/1333048744888029184)
30. [都市版空空如也](https://www.zhihu.com/zvideo/1333366347199971328)
31. [拆解偷拍设备检测器,再也不怕自己成为种子文件里的演员了](https://www.zhihu.com/zvideo/1333175050615545856)
32. [3960 买一条巨大马鲛鱼,价格是普通马鲛 4
倍,它真的能好吃吗?](https://www.zhihu.com/zvideo/1332486745774841856)
33. [王嘉尔变帅进化史!男女通杀的魅力是这样炼成的 |
审美干货](https://www.zhihu.com/zvideo/1333048967702724608)
34. [疫情不出门,超子做蒜苔炒腊肠,媳妇下厨炒豆芽,一荤一素吃得香](https://www.zhihu.com/zvideo/1333009502846230528)
35. [【脱口秀】当英语老师来看脱口秀](https://www.zhihu.com/zvideo/1333124020007694336)
36. [《丁真的新年》来了!一个中国少年向世界送出的 2021
新年问候](https://www.zhihu.com/zvideo/1332762496801673216)
37. [厨师长制作川味版火焰醉鹅,点火那一刻大家都惊呆了](https://www.zhihu.com/zvideo/1333047174490263552)
38. [【李白】错付大唐一生,绣口一吐却是半个盛唐](https://www.zhihu.com/zvideo/1333084941534232576)
39. [疫情控制遥遥无期?辉瑞新冠疫苗造假,真实保护率只有
29%?](https://www.zhihu.com/zvideo/1332964148657643520)
40. [知乎十周年 CEO 主题演讲:抒写未来的答卷](https://www.zhihu.com/zvideo/1332714297550991360)
41. [大爷买菜结账插队未遂 恼羞成怒用菜猛砸收银员
网友炸锅:为老不尊](https://www.zhihu.com/zvideo/1331941382898933760)
42. [知乎十周年发布全新品牌口号:有问题,就会有答案!](https://www.zhihu.com/zvideo/1330523671446425600)
43. [当你撑不住了,一定要进来看一下!](https://www.zhihu.com/zvideo/1333010697387880448)
<!-- END --> | 3,580 | MIT |
---
name: 🚀 开发专用
about: 用于本项目管理(只有开发人员使用)
title: ''
labels: ''
assignees: ''
---
<!--
贡献流程:
- 新建issues
- 使用checkbox方式
- 完成后,进行PR
- 合并的pr,进行comment自己的issues,标记合并的hash
开发流程:
- 下载代码并运行
- 添加功能并测试
- 新建PR
- 等待审核与合并
-->
**⚠️ 重要 ⚠️ 使用 checkbox 的列表方式来拟定计划.**
- [ ] Func1
- [ ] Func2 | 278 | MIT |
---
layout: post
title: Kotlin-06-类和对象
date: 2020-5-2 16:28:32 +0800
categories: [Kotlin]
tags: [kotlin, sh]
published: true
---
# 类定义
Kotlin 类可以包含:构造函数和初始化代码块、函数、属性、内部类、对象声明。
Kotlin 中使用关键字 class 声明类,后面紧跟类名:
```kotlin
class User {
// 大括号内是类体构成
}
```
ps: 这个和 java 没有区别。
## 定义空类
```
class Empty
```
## 定义成语函数
可以在类中定义成员函数:
```kotlin
class User {
fun getName {
return "kotlin";
}
}
```
# 类的属性
## 属性定义
类的属性可以用关键字 `var` 声明为可变的,否则使用只读关键字 `val` 声明为不可变。
```kotlin
var age: String = ...;
let name: String = ...;
```
我们可以像使用普通函数那样使用构造函数创建类实例:
```
var define = User() //kotlin 没有关键词 new
```
要使用一个属性,只要用名称引用它即可
```
define.name
define.age
```
## 构造器
Koltin 中的类可以有一个主构造器,以及一个或多个次构造器,主构造器是类头部的一部分,位于类名称之后:
```kotlin
class Person constructor(firstName: String) {}
```
如果主构造器没有任何注解,也没有任何可见度修饰符,那么constructor关键字可以省略。
```kotlin
class Person(firstName: String) {
}
```
## getter 和 setter
- 属性声明的完整语法:
```
var <propertyName>[: <PropertyType>] [= <property_initializer>]
[<getter>]
[<setter>]
```
getter 和 setter 都是可选
如果属性类型可以从初始化语句或者类的成员函数中推断出来,那就可以省去类型,val不允许设置setter函数,因为它是只读的。
```kotlin
var allByDefault: Int? // 错误: 需要一个初始化语句, 默认实现了 getter 和 setter 方法
var initialized = 1 // 类型为 Int, 默认实现了 getter 和 setter
val simple: Int? // 类型为 Int ,默认实现 getter ,但必须在构造函数中初始化
val inferredType = 1 // 类型为 Int 类型,默认实现 getter
```
## 实例
以下实例定义了一个 Person 类,包含两个可变变量 lastName 和 no,lastName 修改了 getter 方法,no 修改了 setter 方法。
```kotlin
class Person {
var lastName: String = "zhang"
get() = field.toUpperCase() // 将变量赋值后转换为大写
set
var no: Int = 100
get() = field // 后端变量
set(value) {
if (value < 10) { // 如果传入的值小于 10 返回该值
field = value
} else {
field = -1 // 如果传入的值大于等于 10 返回 -1
}
}
var heiht: Float = 145.4f
private set
}
```
- 测试
```kotlin
fun main(args: Array<String>) {
var person: Person = Person()
person.lastName = "wang"
println("lastName:${person.lastName}")
person.no = 9
println("no:${person.no}")
person.no = 20
println("no:${person.no}")
}
```
- 结果
```
lastName:WANG
no:9
no:-1
```
## 类中字段的限制
Kotlin 中类不能有字段。
提供了 Backing Fields(后端变量) 机制,备用字段使用field关键字声明,field 关键词只能用于属性的访问器,如以上实例:
```kotlin
var no: Int = 100
get() = field // 后端变量
set(value) {
if (value < 10) { // 如果传入的值小于 10 返回该值
field = value
} else {
field = -1 // 如果传入的值大于等于 10 返回 -1
}
}
```
## 延迟初始化策略
非空属性必须在定义的时候初始化,kotlin提供了一种可以延迟初始化的方案,使用 `lateinit` 关键字描述属性:
```kotlin
public class MyTest {
lateinit var subject: TestSubject
@SetUp fun setup() {
subject = TestSubject()
}
@Test fun test() {
subject.method() // dereference directly
}
}
```
# 主构造器
主构造器中不能包含任何代码,初始化代码可以放在初始化代码段中,初始化代码段使用 `init` 关键字作为前缀。
```kotlin
class Person constructor(firstName: String) {
init {
println("FirstName is $firstName")
}
}
```
注意:主构造器的参数可以在初始化代码段中使用,也可以在类主体n定义的属性初始化代码中使用。
一种简洁语法,可以通过主构造器来定义属性并初始化属性值(可以是var或val):
```kotlin
class People(val firstName: String, val lastName: String) {
//...
}
```
如果构造器有注解,或者有可见度修饰符,这时constructor关键字是必须的,注解和修饰符要放在它之前。
## 实例
创建一个 User 类,并通过构造函数传入人名:
```kotlin
class User constructor(name: String) {
var name: String = "ryo"
var country: String = "CN"
var age = 20
init {
println("初始化人名: ${name}")
}
fun printTest() {
println("我是类的函数")
}
}
```
- 测试
```kotlin
fun main(args: Array<String>) {
val person = Runoob("小明")
println(person.name)
println(person.age)
println(person.country)
person.printTest()
}
```
- 输出
```
初始化人名: 小明
小明
20
CN
我是类的函数
```
# 次构造函数
类也可以有二级构造函数,需要加前缀 constructor:
```koltin
class Person {
constructor(parent: Person) {
parent.children.add(this)
}
}
```
如果类有主构造函数,每个次构造函数都要,或直接或间接通过另一个次构造函数代理主构造函数。
在同一个类中代理另一个构造函数使用 `this` 关键字:
```kotlin
class Person(val name: String) {
constructor (name: String, age:Int) : this(name) {
// 初始化...
}
}
```
ps: 这个是类似于 c++ 的构造器继承实现。
## 默认构造器
如果一个非抽象类没有声明构造函数(主构造函数或次构造函数),它会产生一个没有参数的构造函数,访问级别是 public。
如果你不想你的类有公共的构造函数,你就得声明一个空的主构造函数:
```kotlin
class DontCreateMe private constructor () {
}
```
注意:在 JVM 虚拟机中,**如果主构造函数的所有参数都有默认值,编译器会生成一个附加的无参的构造函数,这个构造函数会直接使用默认值。**
这使得 Kotlin 可以更简单的使用像 Jackson 或者 JPA 这样使用无参构造函数来创建类实例的库。
```kotlin
class Customer(val customerName: String = "")
```
ps: JPA/Jacson 会利用无参构造器进行反射。所有参数都有默认值,也可以理解为是一种无参。(不用外界显式指定参数)
## 实例
```kotlin
class Runoob constructor(name: String) { // 类名为 Runoob
// 大括号内是类体构成
var url: String = "http://www.runoob.com"
var country: String = "CN"
var siteName = name
init {
println("初始化网站名: ${name}")
}
// 次构造函数
constructor (name: String, alexa: Int) : this(name) {
println("Alexa 排名 $alexa")
}
fun printTest() {
println("我是类的函数")
}
}
```
- 测试
```kotlin
fun main(args: Array<String>) {
val runoob = Runoob("菜鸟教程", 10000)
println(runoob.siteName)
println(runoob.url)
println(runoob.country)
runoob.printTest()
}
```
- 输出
```
初始化网站名: 菜鸟教程
Alexa 排名 10000
菜鸟教程
http://www.runoob.com
CN
我是类的函数
```
# 抽象类
抽象是面向对象编程的特征之一,类本身,或类中的部分成员,都可以声明为 `abstract` 的。
抽象成员在类中不存在具体的实现。
注意:无需对抽象类或抽象成员标注 open 关键字。
## 实例
```kotlin
open class Base {
open fun f() {}
}
abstract class Derived : Base() {
override abstract fun f()
}
```
## open 关键字
这个原教程只是提了一下,那么什么是 open 关键字呢?
### 定义
open关键字的意思是“开放扩展”:
类的开放注释与Java的final注释相反:它允许其他人从此类继承。
**默认情况下,Kotlin中的所有类都是 final 的**,对应于有效Java,第17项:用于继承的设计和文档,否则将禁止该类。
方法也是如此。
### public 的区别
public关键字充当可见性修饰符,可以应用于类,函数等。请注意,如果没有其他明确指定,则public是默认设置:
如果您未指定任何可见性修饰符,则默认情况下使用public,这意味着您的声明将在所有位置可见。
### 个人理解
open 主要偏向于继承,为什么默认是 final。估计是为了维护类的安全性。
# 嵌套类
我们可以把类嵌套在其他类中,看以下实例:
```kotlin
class Outer { // 外部类
private val bar: Int = 1
class Nested { // 嵌套类
fun foo() = 2
}
}
fun main(args: Array<String>) {
val demo = Outer.Nested().foo() // 调用格式:外部类.嵌套类.嵌套类方法/属性
println(demo) // == 2
}
```
# 内部类
内部类使用 `inner` 关键字来表示。
内部类会带有一个对外部类的对象的引用,所以内部类可以访问外部类成员属性和成员函数。
```kotlin
class Outer {
private val bar: Int = 1
var v = "成员属性"
/**嵌套内部类**/
inner class Inner {
fun foo() = bar // 访问外部类成员
fun innerTest() {
var o = this@Outer //获取外部类的成员变量
println("内部类可以引用外部类的成员,例如:" + o.v)
}
}
}
fun main(args: Array<String>) {
val demo = Outer().Inner().foo()
println(demo) // 1
val demo2 = Outer().Inner().innerTest()
println(demo2) // 内部类可以引用外部类的成员,例如:成员属性
}
```
为了消除歧义,要访问来自外部作用域的 this,我们使用 `this@label`,其中 @label 是一个代指 this 来源的标签。
# 匿名内部类
使用对象表达式来创建匿名内部类:
```kotlin
class Test {
var v = "成员属性"
fun setInterFace(test: TestInterFace) {
test.test()
}
}
/**
* 定义接口
*/
interface TestInterFace {
fun test()
}
fun main(args: Array<String>) {
var test = Test()
/**
* 采用对象表达式来创建接口对象,即匿名内部类的实例。
*/
test.setInterFace(object : TestInterFace {
override fun test() {
println("对象表达式创建匿名内部类的实例")
}
})
}
```
# 类的修饰符
类的修饰符包括 classModifier 和 accessModifier :
## 类修饰符
classModifier: 类属性修饰符,标示类本身特性。
```kotlin
abstract // 抽象类
final // 类不可继承,默认属性
enum // 枚举类
open // 类可继承,类默认是final的
annotation // 注解类
```
### 访问修饰符
accessModifier: 访问权限修饰符
```kotlin
private // 仅在同一个文件中可见
protected // 同一个文件中或子类可见
public // 所有调用的地方都可见
internal // 同一个模块中可见
```
## 实例
```koltin
// 文件名:example.kt
package foo
private fun foo() {} // 在 example.kt 内可见
public var bar: Int = 5 // 该属性随处可见
internal val baz = 6 // 相同模块内可见
```
# 参考资料
## 官方
[官网](http://www.kotlinlang.org/)
## 参考入门教程
[Kotlin 类和对象](https://www.runoob.com/kotlin/kotlin-class-object.html)
[what-is-the-difference-between-open-and-public-in-kotlin](https://stackoverflow.com/questions/49024200/what-is-the-difference-between-open-and-public-in-kotlin)
* any list
{:toc} | 8,144 | Apache-2.0 |
# arr-diff
比较数组,得到数组不同的部分。
## 来源
- [GitHub](https://github.com/jonschlinkert/arr-diff)
## 示例
```js
var diff = require('arr-diff');
var a = ['a', 'b', 'c', 'd'];
var b = ['b', 'c'];
console.log(diff(a, b))
//=> ['a', 'd']
```
## 源码
```js
module.exports = function diff(arr/*, arrays*/) {
var len = arguments.length;
var idx = 0;
// 多次调用 比较方法比较多个数组
while (++idx < len) {
arr = diffArray(arr, arguments[idx]);
}
return arr;
};
function diffArray(one, two) {
if (!Array.isArray(two)) {
return one.slice();
}
var tlen = two.length
var olen = one.length;
var idx = -1;
var arr = [];
// 取 one 中的元素和 two 中的元素对比
while (++idx < olen) {
var ele = one[idx];
var hasEle = false;
for (var i = 0; i < tlen; i++) {
var val = two[i];
if (ele === val) {
hasEle = true;
break;
}
}
if (hasEle === false) {
arr.push(ele);
}
}
return arr;
}
``` | 941 | MIT |
Java 变量
---
<!-- TOC -->
- [1. 变量的概念](#1-变量的概念)
- [2. 变量的属性](#2-变量的属性)
- [2.1. 变量的标识符](#21-变量的标识符)
- [2.2. 常量](#22-常量)
- [2.3. 地址](#23-地址)
- [2.3.1. 很特殊的字符串](#231-很特殊的字符串)
- [2.4. 生存期](#24-生存期)
- [2.4.1. 栈](#241-栈)
- [2.4.2. 堆](#242-堆)
- [2.5. 作用域](#25-作用域)
- [3. 变量的行为](#3-变量的行为)
- [3.1. 构成声明语句](#31-构成声明语句)
- [3.2. 和操作符结合成为表达式](#32-和操作符结合成为表达式)
- [3.3. 初始化(对象)](#33-初始化对象)
- [4. 常用变量的用法](#4-常用变量的用法)
- [4.1. 变量类型](#41-变量类型)
- [4.2. 访问](#42-访问)
<!-- /TOC -->
# 1. 变量的概念
1. 不同角度看变量:
1. 物理角度:计算机的数据存储单元
2. 逻辑角度:计算机模型中的抽象数据单位
3. 语义角度:类的属性、方法的状态
2. 赋值:改变现实对象的状态
1. 通过赋值来改变模拟变量状态的**程序设计语言常规的符号名字**
2. 赋值打破了引用透明性
3. 与所有状态必须显示地操作的传递额外的参数的方式相比,通过引进赋值和将状态隐藏在局部变量的技术。我们能以一种更模块化的方式构造系统
# 2. 变量的属性
1. types:强类型语言
1. 基础数据类型
1. 物理视角
2. 使用预定义好的、基础的数据类型
3. 其中主类型和别的类型是不同的,比如int&&Integer,double&&Double
2. 引用类型
1. 来源与语义视角
2. 对象的遥控器
2. values:
1. 值
1. 基础数值类型:浮点数类型有精度损失
3. variables
## 2.1. 变量的标识符
1. 必须由字母、下划线、或者美元符开头
2. 区分大小写
3. 不允许包含有空格和制表符
4. 符合命名规则的好处:
1. 有助于在项目间传递知识
2. 在新的项目中更加快速的学习代码
3. 减少名字的增生
4. 弥补编程语言的不足
5. java命名规则:
1. 除了变量名以外,类、类常量,均使用大小写混合的方法
2. 第一个单词的首字母小写,其后单词的首字母大写
3. 变量名不应该以下划线或美元符号开头
## 2.2. 常量
命名:应该全部大写,单词间用下划线分隔
## 2.3. 地址
1. 变量的地址是与这个变量相关联的地址
2. 多个变量可以具有同一地址当用多个变量名来访问单个存储地址时,这些变量名就成为了别名
### 2.3.1. 很特殊的字符串
1. ==比较的是地址,`.equals()`比较的是内部的值
2. new String(str):可以强制分配对象
3. 相同字符串一般情况下只保存一个
```java
String a = new String();
a = "abc";
String b = new String();
b = "abc";
System.out.print(a==b);//true,分配两个对象,指向一个对象
String a = "abc";
String b = "abc";
System.out.print(a==b);//true,直接指向同一个
String a = new String("abc");
String b = new String("abc");
System.out.print(a==b);//false,强制分配两个
```
## 2.4. 生存期
1. 生存期是该变量绑定于某一特定存储地址的时间
2. 变量的生存期:
1. 静态变量
2. 栈动态变量
3. 显性堆动态变量
4. 隐性堆动态变量
### 2.4.1. 栈
1. 速度较快
2. 要求在编译的时候知道变量占用内存空间的大小和时间——局部变量
### 2.4.2. 堆
1. 效率较低
2. 不需要让编译器知道所占有内存空间的大小和时间
3. 在离开其作用域后虽然无法访问,但是依旧占据着内存空间
## 2.5. 作用域
1. 语句的一个范围,在这个范围之内,变量为可见的。如果一个变量在一条语句中可以被引用,这个变量即在这条语句中为可见的
2. 一般和代码块相关
3. 成员变量在类中声明,整个类中可见,涉及到访问权限的问题
4. 如果是使用成员变量,使用this关键字
# 3. 变量的行为
## 3.1. 构成声明语句
## 3.2. 和操作符结合成为表达式
## 3.3. 初始化(对象)
1. 对象的初识化的顺序:
1. 静态成员变量
2. 静态初始化块
3. 非静态成员变量
4. 构造器中初始化
5. 所有的成员变量都会在构造器执行之前被初始化为指定的值或默认值,在构造器中如果有对其赋值的语句将会再次对其进行初始化
# 4. 常用变量的用法
## 4.1. 变量类型
1. 局部变量(在方法内部)
+ 用于在方法内部临时存放数据
+ 不管是数据类型还是引用类型,如果在没有显示初始化的情况下使用,都会出现错误
2. 属性字段(在对象内部)
+ 用于存放表示类的属性的值
3. 静态变量(全局)
## 4.2. 访问
1. 直接访问(内部使用者)
2. 间接访问(外部使用者) | 2,521 | MIT |
# axios
##好坑的一个事
项目中 `axios.defaults.baseURL= /api/v1`
调用接口 调用的 /a/b
但是项目路径是 `www.***.com/***/ `
接口接口都404了
调用的地址 `www.***.com/api/v1/***/a/b`
我的天,至今不理解为什么,也不知道怎么改,被迫把接口都改成`/api/v1/a/b` | 194 | MIT |
---
title: "Azure SDK for .NET 2.9 リリース ノート"
description: "Azure SDK for .NET 2.9 リリース ノート"
services: app-service\web
documentationcenter: .net
author: Juliako
manager: erikre
editor:
ms.assetid: c83d815b-fc19-4260-821e-7d2a7206dffc
ms.service: app-service
ms.devlang: multiple
ms.topic: article
ms.tgt_pltfrm: na
ms.workload: integration
ms.date: 11/16/2016
ms.author: juliako;mikhegn
translationtype: Human Translation
ms.sourcegitcommit: 52ae631ad516767682122b0b5c05efb19e462209
ms.openlocfilehash: a8be2c34358c817ca35ccfe46c97409a57ed539a
---
# <a name="azure-sdk-for-net-29-release-notes"></a>Azure SDK for .NET 2.9 リリース ノート
このトピックには、Azure SDK for .NET のバージョン 2.9 および 2.9.6 のリリース ノートが含まれています。
##<a name="azure-sdk-for-net-296-release-summary"></a>Azure SDK for .NET 2.9.6 リリースの概要
リリース日: 2016 年 11 月 16 日
今回のリリースでは、Azure SDK 2.9 に対する重大な変更はありません。 また、既存のクラウド サービス プロジェクトでこの SDK を利用するために必要となるアップグレード プロセスもありません。
### <a name="visual-studio-2017-release-candidate"></a>Visual Studio 2017 Release Candidate
- Visual Studio 2017 RC では、Azure SDK for .NET のこのリリースが Azure ワークロードに組み込まれています。 Azure の開発に必要なすべてのツールは、今後 Visual Studio 2017 RC の一部になります。 Visual Studio 2015 と Visual Studio 2013 の場合、SDK は WebPI から引き続き使用できます。 Visual Studio 2013 用の Azure SDK for .NET のリリースは、Visual Studio 2017 が最終製品としてリリースされた時点で中止される予定です。 Visual Studio 2017 RC をダウンロードするには、https://www.visualstudio.com/vs/visual-studio-2017-rc/ にアクセスしてください。
### <a name="azure-diagnostics"></a>Azure 診断
- Cloud Services 診断ストレージ接続文字列のトークンで置き換えられるキーを含む部分的な接続文字列のみを格納するように、動作を変更しました。 実際のストレージ キーはユーザー プロファイル フォルダーに格納され、アクセスを制御できるようになりました。 Visual Studio は、ローカルのデバッグおよび公開プロセスのために、ユーザー プロファイル フォルダーからストレージ キーを読み取ります。
- 上記の変更に対応するために、Visual Studio Online チームは、Azure Cloud Services デプロイ タスク テンプレートを拡張しました。これにより、ユーザーは、継続的インテグレーションおよびデプロイで Azure に発行するときに診断拡張機能を設定するためのストレージ キーを指定できます。
- Azure Diagnostics (WAD) のセキュリティで保護された接続文字列とトークンを保存して、環境全体の構成に関する問題を解決できるようになりました。
### <a name="windows-server-2016-virtual-machines"></a>Windows Server 2016 の仮想マシン
- Visual Studio で、OS ファミリ 5 (Windows Server 2016) 仮想マシンにクラウド サービスをデプロイできるようになりました。 既存のクラウド サービスの場合は、設定を変更して新しい OS ファミリを対象とすることができます。 新しいクラウド サービスの作成時に .NET 4.6 以降を使用してサービスを作成することを選択すると、サービスで OS ファミリ 5 が既定で使用されるようになります。 詳細については、[ゲスト OS ファミリ サポート表](https://azure.microsoft.com/en-us/documentation/articles/cloud-services-guestos-update-matrix/)を参照してください。
### <a name="azure-in-role-cache"></a>Azure In-Role Cache
- Azure In-Role Cache のサポートは、2016 年 11 月 30 日に終了します。 詳細については、[ここ](https://azure.microsoft.com/en-us/blog/azure-managed-cache-and-in-role-cache-services-to-be-retired-on-11-30-2016/)をクリックしてください。
### <a name="azure-resource-manager-templates-for-azure-stack"></a>Azure Stack 用 Azure Resource Manager テンプレート
- Azure Resource Manager テンプレートのデプロイ ターゲットとして Azure Stack を新たに追加しました。
## <a name="azure-sdk-for-net-29-summary"></a>Azure SDK for .NET 2.9 の概要
## <a name="overview"></a>Overview
このドキュメントには、Azure SDK for .NET 2.9 リリースのリリース ノートが含まれます。
このリリースの詳細については、「 [Azure SDK 2.9 アナウンスの投稿](https://azure.microsoft.com/blog/announcing-visual-studio-azure-tools-and-sdk-2-9/)」をご覧ください。
## <a name="azure-sdk-29-for-visual-studio-2015-update-2-and-visual-studio-15-preview"></a>Azure SDK 2.9 for Visual Studio 2015 Update 2 と Visual Studio "15" プレビュー
バグの修正:
* REST API クライアント生成で、生成されたコード内でコード生成フォルダーや名前空間の名前が "Unknown Type” として表示される問題が修正されました。
* スケジュールされた Web ジョブで、認証情報がスケジューラのプロビジョニング プロセスに渡されないという問題が修正されました。
新機能:
* App Service のプロビジョニング ダイアログの [サービス] タブで、セカンダリ App Services がサポートされるようになりました。
## <a name="azure-data-lake-tools-for-visual-studio-2015-update-2"></a>Azure Data Lake Tools for Visual Studio 2015 Update 2
アップデートの内容:
* **Azure Data Lake Tools** for Visual Studio が Azure SDK for .NET リリースに統合されました。 Azure SDK をインストールすると、Azure Data Lake Tools が自動的にインストールされます。
このツールは頻繁に更新されます。最新版は[こちら](http://aka.ms/datalaketool)から取得してください。
* **サーバー エクスプローラー** で U-SQL メタデータ エンティティをすべて表示したり、一部を作成したりできるようになりました。 詳細については、 [このブログ](https://azure.microsoft.com/documentation/services/data-lake-analytics/) をご覧ください。
## <a name="hdinsight-tools"></a>HDInsight ツール
**HDInsight Tools** for Visual Studio で HDInsight Version 3.3 がサポートされるようになりました。これには、Tez グラフの表示やその他の言語の修正が含まれています。
## <a name="azure-resource-manager"></a>Azure リソース マネージャー
このリリースでは、ARM テンプレートの [KeyVault](../resource-manager-keyvault-parameter.md) サポートが追加されます。
## <a name="see-also"></a>関連項目
[Azure SDK 2.9 の発表に関するブログ記事](https://azure.microsoft.com/blog/announcing-visual-studio-azure-tools-and-sdk-2-9/)
<!--HONumber=Nov16_HO3--> | 4,549 | CC-BY-3.0 |
# 2021-01-04
共 232 条
<!-- BEGIN TOUTIAO -->
<!-- 最后更新时间 Mon Jan 04 2021 23:09:51 GMT+0800 (CST) -->
1. [新娘回应拒接亲:彩礼会退感情没了](https://so.toutiao.com/search?keyword=新娘回应拒接亲:彩礼会退感情没了)
1. [河北接连现本土确诊 4地升级中风险](https://so.toutiao.com/search?keyword=河北接连现本土确诊+4地升级中风险)
1. [沈阳疫情1传27 多名医务人员确诊](https://so.toutiao.com/search?keyword=沈阳疫情1传27+多名医务人员确诊)
1. [福奇驳斥特朗普疫情言论:去医院看](https://so.toutiao.com/search?keyword=福奇驳斥特朗普疫情言论:去医院看)
1. [李香琴去世](https://so.toutiao.com/search?keyword=李香琴去世)
1. [校长与女教师通奸?教育局回应](https://so.toutiao.com/search?keyword=校长与女教师通奸?教育局回应)
1. [月嫂为照看孩子睡觉坐地上吃外卖](https://so.toutiao.com/search?keyword=月嫂为照看孩子睡觉坐地上吃外卖)
1. [电动车逆行被撞散架 一人伤势严重](https://so.toutiao.com/search?keyword=电动车逆行被撞散架+一人伤势严重)
1. [16个人聚餐后没一个付钱全跑了](https://so.toutiao.com/search?keyword=16个人聚餐后没一个付钱全跑了)
1. [男子被妻子情夫暴砍 俩小偷拼死相救](https://so.toutiao.com/search?keyword=男子被妻子情夫暴砍+俩小偷拼死相救)
1. [知乎:拼多多官方回应真实 自删回答](https://so.toutiao.com/search?keyword=知乎:拼多多官方回应真实+自删回答)
1. [大连一确诊病例检测11次才阳性](https://so.toutiao.com/search?keyword=大连一确诊病例检测11次才阳性)
1. [外卖小哥被撞后哭着去送单](https://so.toutiao.com/search?keyword=外卖小哥被撞后哭着去送单)
1. [外卖员凌晨送餐遭保安棍打后死亡](https://so.toutiao.com/search?keyword=外卖员凌晨送餐遭保安棍打后死亡)
1. [宝利国际董事长被刑拘](https://so.toutiao.com/search?keyword=宝利国际董事长被刑拘)
1. [广西多人在广场持械打架 现场曝光](https://so.toutiao.com/search?keyword=广西多人在广场持械打架+现场曝光)
1. [曝韩红在相声界的辈分和姜昆一样高](https://so.toutiao.com/search?keyword=曝韩红在相声界的辈分和姜昆一样高)
1. [库里62分 勇士胜开拓者](https://so.toutiao.com/search?keyword=库里62分+勇士胜开拓者)
1. [河南洛阳:倡导外出务工者当地过节](https://so.toutiao.com/search?keyword=河南洛阳:倡导外出务工者当地过节)
1. [2021最新打架斗殴成本套餐](https://so.toutiao.com/search?keyword=2021最新打架斗殴成本套餐)
1. [美高官再称新冠出自武汉 中方回应](https://so.toutiao.com/search?keyword=美高官再称新冠出自武汉+中方回应)
1. [高校新冠疫苗接种陆续开始](https://so.toutiao.com/search?keyword=高校新冠疫苗接种陆续开始)
1. [母亲吃中药母乳喂养婴儿核酸转阴](https://so.toutiao.com/search?keyword=母亲吃中药母乳喂养婴儿核酸转阴)
1. [独居女子突然失联 家人:有抑郁症](https://so.toutiao.com/search?keyword=独居女子突然失联+家人:有抑郁症)
1. [4吨来源不明冻肉漂浮江面 官方回应](https://so.toutiao.com/search?keyword=4吨来源不明冻肉漂浮江面+官方回应)
1. [张艺谋:不建议演员整容](https://so.toutiao.com/search?keyword=张艺谋:不建议演员整容)
1. [110接线员失职 女子被砍致残](https://so.toutiao.com/search?keyword=110接线员失职+女子被砍致残)
1. [玄彬喜欢孙艺珍好明显](https://so.toutiao.com/search?keyword=玄彬喜欢孙艺珍好明显)
1. [福奇:未来几周美国疫情可能更糟糕](https://so.toutiao.com/search?keyword=福奇:未来几周美国疫情可能更糟糕)
1. [三股冷空气组团来袭](https://so.toutiao.com/search?keyword=三股冷空气组团来袭)
1. [男方婚前患艾滋病未告知 婚姻被撤销](https://so.toutiao.com/search?keyword=男方婚前患艾滋病未告知+婚姻被撤销)
1. [47岁李冰冰海边慵懒拍片](https://so.toutiao.com/search?keyword=47岁李冰冰海边慵懒拍片)
1. [拜腾再发内部邮件:全员待岗](https://so.toutiao.com/search?keyword=拜腾再发内部邮件:全员待岗)
1. [考满分溺亡女生家属:校方仍认为作弊](https://so.toutiao.com/search?keyword=考满分溺亡女生家属:校方仍认为作弊)
1. [西湖边的“网红松鼠”被抓走](https://so.toutiao.com/search?keyword=西湖边的“网红松鼠”被抓走)
1. [中纪委新年反腐 一枪四弹](https://so.toutiao.com/search?keyword=中纪委新年反腐+一枪四弹)
1. [陈乔恩炫耀捡钱惹争议](https://so.toutiao.com/search?keyword=陈乔恩炫耀捡钱惹争议)
1. [周红波任海南省委常委](https://so.toutiao.com/search?keyword=周红波任海南省委常委)
1. [雷军后悔与董明珠入十亿赌局](https://so.toutiao.com/search?keyword=雷军后悔与董明珠入十亿赌局)
1. [性转后的胡先煦](https://so.toutiao.com/search?keyword=性转后的胡先煦)
1. [中国有序开展新冠疫苗接种](https://so.toutiao.com/search?keyword=中国有序开展新冠疫苗接种)
1. [女子误转85万购房款 警方帮追回](https://so.toutiao.com/search?keyword=女子误转85万购房款+警方帮追回)
1. [张国荣曾试妆白蛇造型](https://so.toutiao.com/search?keyword=张国荣曾试妆白蛇造型)
1. [男孩给亡母过生日:妈你等着我](https://so.toutiao.com/search?keyword=男孩给亡母过生日:妈你等着我)
1. [华为公开新型手机外观设计专利](https://so.toutiao.com/search?keyword=华为公开新型手机外观设计专利)
1. [河北一对兄弟确诊:弟弟4次坐高铁](https://so.toutiao.com/search?keyword=河北一对兄弟确诊:弟弟4次坐高铁)
1. [特朗普通话录音曝光](https://so.toutiao.com/search?keyword=特朗普通话录音曝光)
1. [北京1名新增病例为冷鲜肉店员工](https://so.toutiao.com/search?keyword=北京1名新增病例为冷鲜肉店员工)
1. [法院回应患艾滋男子强奸女生判5年](https://so.toutiao.com/search?keyword=法院回应患艾滋男子强奸女生判5年)
1. [男生首次带女友回家准备给妈妈惊喜](https://so.toutiao.com/search?keyword=男生首次带女友回家准备给妈妈惊喜)
1. [首艘国产航母研制总指挥被处理](https://so.toutiao.com/search?keyword=首艘国产航母研制总指挥被处理)
1. [窦靖童疑有新恋情](https://so.toutiao.com/search?keyword=窦靖童疑有新恋情)
1. [纽交所摘牌中国3家运营商 中方回应](https://so.toutiao.com/search?keyword=纽交所摘牌中国3家运营商+中方回应)
1. [新娘父亲抖音谈内衣不合身不让接亲](https://so.toutiao.com/search?keyword=新娘父亲抖音谈内衣不合身不让接亲)
1. [拼多多致歉:知乎内容系供应商所发](https://so.toutiao.com/search?keyword=拼多多致歉:知乎内容系供应商所发)
1. [中央气象台:两股冷空气将接力来袭](https://so.toutiao.com/search?keyword=中央气象台:两股冷空气将接力来袭)
1. [李玉刚不顾形象床上吃面包](https://so.toutiao.com/search?keyword=李玉刚不顾形象床上吃面包)
1. [大张伟金靖太好笑了](https://so.toutiao.com/search?keyword=大张伟金靖太好笑了)
1. [抖音电商开启首届年货节](https://so.toutiao.com/search?keyword=抖音电商开启首届年货节)
1. [英国法官拒绝将阿桑奇引渡至美国](https://so.toutiao.com/search?keyword=英国法官拒绝将阿桑奇引渡至美国)
1. [石家庄进入战时状态](https://so.toutiao.com/search?keyword=石家庄进入战时状态)
1. [张钧甯窝窝头发型](https://so.toutiao.com/search?keyword=张钧甯窝窝头发型)
1. [女子抱路人大腿强行卖花](https://so.toutiao.com/search?keyword=女子抱路人大腿强行卖花)
1. [江西省委常委吴忠琼任赣州市委书记](https://so.toutiao.com/search?keyword=江西省委常委吴忠琼任赣州市委书记)
1. [35楼扔矿泉水瓶被判赔9万余元](https://so.toutiao.com/search?keyword=35楼扔矿泉水瓶被判赔9万余元)
1. [美10位前防长:不支持特朗普翻盘](https://so.toutiao.com/search?keyword=美10位前防长:不支持特朗普翻盘)
1. [郭德纲遭相声名家炮轰](https://so.toutiao.com/search?keyword=郭德纲遭相声名家炮轰)
1. [4吨不明冻肉漂浮江面 官方回应](https://so.toutiao.com/search?keyword=4吨不明冻肉漂浮江面+官方回应)
1. [全国4省市增13例本土确诊](https://so.toutiao.com/search?keyword=全国4省市增13例本土确诊)
1. [拼多多:网传官方回应系谣言](https://so.toutiao.com/search?keyword=拼多多:网传官方回应系谣言)
1. [美法案支持对台军售 国防部回应](https://so.toutiao.com/search?keyword=美法案支持对台军售+国防部回应)
1. [沈阳新增3地升为中风险](https://so.toutiao.com/search?keyword=沈阳新增3地升为中风险)
1. [男子给彩礼还被拒婚 砍杀未婚妻](https://so.toutiao.com/search?keyword=男子给彩礼还被拒婚+砍杀未婚妻)
1. [一图看懂大连疫情传播链](https://so.toutiao.com/search?keyword=一图看懂大连疫情传播链)
1. [泫雅贴在jessi胸上拍照](https://so.toutiao.com/search?keyword=泫雅贴在jessi胸上拍照)
1. [山东:确保群众安全温暖过冬](https://so.toutiao.com/search?keyword=山东:确保群众安全温暖过冬)
1. [邓文迪携男伴逛街](https://so.toutiao.com/search?keyword=邓文迪携男伴逛街)
1. [拼多多员工猝死 上海劳动部门调查](https://so.toutiao.com/search?keyword=拼多多员工猝死+上海劳动部门调查)
1. [81岁老戏骨自曝为拍戏锯掉三颗门牙](https://so.toutiao.com/search?keyword=81岁老戏骨自曝为拍戏锯掉三颗门牙)
1. [熊孩子破坏力有多强](https://so.toutiao.com/search?keyword=熊孩子破坏力有多强)
1. [美国加州疫情“震中”医院不堪重负](https://so.toutiao.com/search?keyword=美国加州疫情“震中”医院不堪重负)
1. [如何看待高铁坐过站可免费返回](https://so.toutiao.com/search?keyword=如何看待高铁坐过站可免费返回)
1. [福奇驳斥特朗普:到医院去看看](https://so.toutiao.com/search?keyword=福奇驳斥特朗普:到医院去看看)
1. [美媒:美国医疗系统处在崩溃边缘](https://so.toutiao.com/search?keyword=美媒:美国医疗系统处在崩溃边缘)
1. [财付通被处罚876万](https://so.toutiao.com/search?keyword=财付通被处罚876万)
1. [司机停车礼让反遭熊孩子竖中指](https://so.toutiao.com/search?keyword=司机停车礼让反遭熊孩子竖中指)
1. [特斯拉回应车辆行驶中失控](https://so.toutiao.com/search?keyword=特斯拉回应车辆行驶中失控)
1. [王菲15年前结婚照](https://so.toutiao.com/search?keyword=王菲15年前结婚照)
1. [安徽务工大县:非必要春节不返乡](https://so.toutiao.com/search?keyword=安徽务工大县:非必要春节不返乡)
1. [辽宁抚顺发现3名确诊病例密接者](https://so.toutiao.com/search?keyword=辽宁抚顺发现3名确诊病例密接者)
1. [河北新增4例本地确诊13例无症状](https://so.toutiao.com/search?keyword=河北新增4例本地确诊13例无症状)
1. [特朗普会搞军事政变吗](https://so.toutiao.com/search?keyword=特朗普会搞军事政变吗)
1. [员工猝死 拼多多官方回应系谣言](https://so.toutiao.com/search?keyword=员工猝死+拼多多官方回应系谣言)
1. [电动车逆行被撞 一人伤势严重](https://so.toutiao.com/search?keyword=电动车逆行被撞+一人伤势严重)
1. [中了5000万你会立刻离职吗](https://so.toutiao.com/search?keyword=中了5000万你会立刻离职吗)
1. [伊朗:暗杀外国领导人是美以标志](https://so.toutiao.com/search?keyword=伊朗:暗杀外国领导人是美以标志)
1. [1传33!大连疫情现超级传播现象](https://so.toutiao.com/search?keyword=1传33!大连疫情现超级传播现象)
1. [娱乐圈里的追星赢家](https://so.toutiao.com/search?keyword=娱乐圈里的追星赢家)
1. [新华社记者在台遇年度之问:打不打](https://so.toutiao.com/search?keyword=新华社记者在台遇年度之问:打不打)
1. [A股开门红 重回3500点大关](https://so.toutiao.com/search?keyword=A股开门红+重回3500点大关)
1. [高铁霸座女被罚款200元](https://so.toutiao.com/search?keyword=高铁霸座女被罚款200元)
1. [医院称抗疫医护“失明”与手术无关](https://so.toutiao.com/search?keyword=医院称抗疫医护“失明”与手术无关)
1. [小伙不负女友遗愿照顾其父母十几年](https://so.toutiao.com/search?keyword=小伙不负女友遗愿照顾其父母十几年)
1. [三亚房租跌幅全国居首](https://so.toutiao.com/search?keyword=三亚房租跌幅全国居首)
1. [拼多多回应猝死:底层谁不用命换钱](https://so.toutiao.com/search?keyword=拼多多回应猝死:底层谁不用命换钱)
1. [大S回应蔡康永:天生就是箭靶](https://so.toutiao.com/search?keyword=大S回应蔡康永:天生就是箭靶)
1. [中国全力恢复长江生物多样性](https://so.toutiao.com/search?keyword=中国全力恢复长江生物多样性)
1. [山东女留学生解除隔离回家后阳性](https://so.toutiao.com/search?keyword=山东女留学生解除隔离回家后阳性)
1. [澳女警救落水中国留学生两人均身亡](https://so.toutiao.com/search?keyword=澳女警救落水中国留学生两人均身亡)
1. [重庆公安局原局长邓恢林被双开](https://so.toutiao.com/search?keyword=重庆公安局原局长邓恢林被双开)
1. [在岸人民币兑美元升破6.50关口](https://so.toutiao.com/search?keyword=在岸人民币兑美元升破6.50关口)
1. [66岁刘晓庆拜访张纪中夫妇](https://so.toutiao.com/search?keyword=66岁刘晓庆拜访张纪中夫妇)
1. [特朗普通话录音遭曝光](https://so.toutiao.com/search?keyword=特朗普通话录音遭曝光)
1. [男子“随机”杀死女教师 疑20年前失踪](https://so.toutiao.com/search?keyword=男子“随机”杀死女教师+疑20年前失踪)
1. [A股开门红 创业板指大涨近4%](https://so.toutiao.com/search?keyword=A股开门红+创业板指大涨近4%)
1. [贾玲要给师父冯巩介绍对象](https://so.toutiao.com/search?keyword=贾玲要给师父冯巩介绍对象)
1. [汪涵反串《霸王别姬》致敬张国荣](https://so.toutiao.com/search?keyword=汪涵反串《霸王别姬》致敬张国荣)
1. [刘敏涛评价烧饼跳舞走神](https://so.toutiao.com/search?keyword=刘敏涛评价烧饼跳舞走神)
1. [美国接连调整中东航母部署想干啥](https://so.toutiao.com/search?keyword=美国接连调整中东航母部署想干啥)
1. [租客养狗咬坏家具房东想哭](https://so.toutiao.com/search?keyword=租客养狗咬坏家具房东想哭)
1. [蔡康永向大s道歉](https://so.toutiao.com/search?keyword=蔡康永向大s道歉)
1. [NBA十佳球:库里接球三分杀死比赛](https://so.toutiao.com/search?keyword=NBA十佳球:库里接球三分杀死比赛)
1. [金星吐槽印小天用力过猛](https://so.toutiao.com/search?keyword=金星吐槽印小天用力过猛)
1. [纽约时报称台湾防疫策略不可持续](https://so.toutiao.com/search?keyword=纽约时报称台湾防疫策略不可持续)
1. [邢台一对兄弟确诊 曾坐高铁](https://so.toutiao.com/search?keyword=邢台一对兄弟确诊+曾坐高铁)
1. [美国著名主持人拉里·金感染新冠](https://so.toutiao.com/search?keyword=美国著名主持人拉里·金感染新冠)
1. [新年第一个工作日](https://so.toutiao.com/search?keyword=新年第一个工作日)
1. [青海原副省长被双开](https://so.toutiao.com/search?keyword=青海原副省长被双开)
1. [原中船重工集团董事长胡问鸣被查](https://so.toutiao.com/search?keyword=原中船重工集团董事长胡问鸣被查)
1. [美国加州一医疗中心暴发群体感染](https://so.toutiao.com/search?keyword=美国加州一医疗中心暴发群体感染)
1. [春节如何防范疫情 专家建议来了](https://so.toutiao.com/search?keyword=春节如何防范疫情+专家建议来了)
1. [中粮集团原总会计师骆家駹被双开](https://so.toutiao.com/search?keyword=中粮集团原总会计师骆家駹被双开)
1. [男子醉酒睡街头手脚冻僵难保](https://so.toutiao.com/search?keyword=男子醉酒睡街头手脚冻僵难保)
1. [解放军军机入台同时美军机进南海](https://so.toutiao.com/search?keyword=解放军军机入台同时美军机进南海)
1. [天津现包装阳性汽车零部件](https://so.toutiao.com/search?keyword=天津现包装阳性汽车零部件)
1. [泫雅晒与好友合影](https://so.toutiao.com/search?keyword=泫雅晒与好友合影)
1. [篮网憾负奇才 欧文30+10](https://so.toutiao.com/search?keyword=篮网憾负奇才+欧文30+10)
1. [美媒爆料伊朗想刺杀特朗普](https://so.toutiao.com/search?keyword=美媒爆料伊朗想刺杀特朗普)
1. [杨笠回应争议自称老巫婆](https://so.toutiao.com/search?keyword=杨笠回应争议自称老巫婆)
1. [快船险胜太阳](https://so.toutiao.com/search?keyword=快船险胜太阳)
1. [外媒票选2020年最糟糕手机设计](https://so.toutiao.com/search?keyword=外媒票选2020年最糟糕手机设计)
1. [四川乐山4.2级地震](https://so.toutiao.com/search?keyword=四川乐山4.2级地震)
1. [沪指站上3500点](https://so.toutiao.com/search?keyword=沪指站上3500点)
1. [密会美总领事的香港反对派突然低调](https://so.toutiao.com/search?keyword=密会美总领事的香港反对派突然低调)
1. [游乐园回应游乐项目拒收现金](https://so.toutiao.com/search?keyword=游乐园回应游乐项目拒收现金)
1. [拼多多员工猝死](https://so.toutiao.com/search?keyword=拼多多员工猝死)
1. [湖人擒灰熊 詹姆斯22+13+8](https://so.toutiao.com/search?keyword=湖人擒灰熊+詹姆斯22+13+8)
1. [解放军军机今年4天都飞台空域](https://so.toutiao.com/search?keyword=解放军军机今年4天都飞台空域)
1. [美国航母为何在敏感时刻撤出中东](https://so.toutiao.com/search?keyword=美国航母为何在敏感时刻撤出中东)
1. [留守儿童把跨年礼物留给妹妹](https://so.toutiao.com/search?keyword=留守儿童把跨年礼物留给妹妹)
1. [去过沈阳这三家医院请主动报告](https://so.toutiao.com/search?keyword=去过沈阳这三家医院请主动报告)
1. [美国给中芯国际发放成熟制程许可证](https://so.toutiao.com/search?keyword=美国给中芯国际发放成熟制程许可证)
1. [主办方回应哈尔滨漫展不雅行为](https://so.toutiao.com/search?keyword=主办方回应哈尔滨漫展不雅行为)
1. [2021款卡罗拉上市](https://so.toutiao.com/search?keyword=2021款卡罗拉上市)
1. [佩洛西再次当选美国众议院议长](https://so.toutiao.com/search?keyword=佩洛西再次当选美国众议院议长)
1. [新疆进出境中欧班列突破9600列](https://so.toutiao.com/search?keyword=新疆进出境中欧班列突破9600列)
1. [女教师被打死 凶手疑20年前失踪者](https://so.toutiao.com/search?keyword=女教师被打死+凶手疑20年前失踪者)
1. [英国学者:新冠引发灾难性失败](https://so.toutiao.com/search?keyword=英国学者:新冠引发灾难性失败)
1. [市民向国务院平台反映问题获回复](https://so.toutiao.com/search?keyword=市民向国务院平台反映问题获回复)
1. [中国疫苗不良反应是如何监测的](https://so.toutiao.com/search?keyword=中国疫苗不良反应是如何监测的)
1. [被演员大兵举报的黑物业瓦解了](https://so.toutiao.com/search?keyword=被演员大兵举报的黑物业瓦解了)
1. [全球新冠累计确诊超8500万](https://so.toutiao.com/search?keyword=全球新冠累计确诊超8500万)
1. [北京8个月大确诊女婴密接8人](https://so.toutiao.com/search?keyword=北京8个月大确诊女婴密接8人)
1. [妈妈抖音"坑娃":棉花糖洗了再吃](https://so.toutiao.com/search?keyword=妈妈抖音"坑娃":棉花糖洗了再吃)
1. [贪5千万的服刑“老虎”赃物被拍卖](https://so.toutiao.com/search?keyword=贪5千万的服刑“老虎”赃物被拍卖)
1. [33岁王思聪过生日 私人飞机接送](https://so.toutiao.com/search?keyword=33岁王思聪过生日+私人飞机接送)
1. [车辆停路边停车费欠732笔5万多元](https://so.toutiao.com/search?keyword=车辆停路边停车费欠732笔5万多元)
1. [被教师撞死女大学生生前动态曝光](https://so.toutiao.com/search?keyword=被教师撞死女大学生生前动态曝光)
1. [杨笠到底有没有挑起性别对立](https://so.toutiao.com/search?keyword=杨笠到底有没有挑起性别对立)
1. [金莎回应跨界演戏](https://so.toutiao.com/search?keyword=金莎回应跨界演戏)
1. [女孩月考第一 疑遭老师质疑后溺亡](https://so.toutiao.com/search?keyword=女孩月考第一+疑遭老师质疑后溺亡)
1. [贵州茅台股价触及2000元关口](https://so.toutiao.com/search?keyword=贵州茅台股价触及2000元关口)
1. [32岁毛晓彤与男伴热舞秀长腿](https://so.toutiao.com/search?keyword=32岁毛晓彤与男伴热舞秀长腿)
1. [呼和浩特一4S店5份货物外包装阳性](https://so.toutiao.com/search?keyword=呼和浩特一4S店5份货物外包装阳性)
1. [理想汽车12月交付6126辆](https://so.toutiao.com/search?keyword=理想汽车12月交付6126辆)
1. [上千只鹦鹉白送没人要](https://so.toutiao.com/search?keyword=上千只鹦鹉白送没人要)
1. [小伙5米外飞扑克削开易拉罐](https://so.toutiao.com/search?keyword=小伙5米外飞扑克削开易拉罐)
1. [外卖小哥送餐发现老人去世泪崩](https://so.toutiao.com/search?keyword=外卖小哥送餐发现老人去世泪崩)
1. [妈妈"坑娃":棉花糖有点脏洗了再吃](https://so.toutiao.com/search?keyword=妈妈"坑娃":棉花糖有点脏洗了再吃)
1. [世卫来华调查 英媒有罪推证](https://so.toutiao.com/search?keyword=世卫来华调查+英媒有罪推证)
1. [巴啦啦小魔仙演员悼念孙侨潞](https://so.toutiao.com/search?keyword=巴啦啦小魔仙演员悼念孙侨潞)
1. [中国今年春季发射空间站核心舱](https://so.toutiao.com/search?keyword=中国今年春季发射空间站核心舱)
1. [2021开年两股冷空气](https://so.toutiao.com/search?keyword=2021开年两股冷空气)
1. [大连本轮疫情来源初步判定](https://so.toutiao.com/search?keyword=大连本轮疫情来源初步判定)
1. [女子误将85万买房钱转给陌生人](https://so.toutiao.com/search?keyword=女子误将85万买房钱转给陌生人)
1. [全国多地检出汽车零部件阳性](https://so.toutiao.com/search?keyword=全国多地检出汽车零部件阳性)
1. [巴啦啦小魔仙演员现状](https://so.toutiao.com/search?keyword=巴啦啦小魔仙演员现状)
1. [女强男弱的婚姻你能接受吗](https://so.toutiao.com/search?keyword=女强男弱的婚姻你能接受吗)
1. [老公朝妻子外套撒气被发现](https://so.toutiao.com/search?keyword=老公朝妻子外套撒气被发现)
1. [网友发“沈阳封城”假信息被处理](https://so.toutiao.com/search?keyword=网友发“沈阳封城”假信息被处理)
1. [哈尔滨漫展现不雅拍照事件](https://so.toutiao.com/search?keyword=哈尔滨漫展现不雅拍照事件)
1. [《巡回检察组》全剧组曾被骗](https://so.toutiao.com/search?keyword=《巡回检察组》全剧组曾被骗)
1. [医生治眼近乎失明 爱尔眼科再回应](https://so.toutiao.com/search?keyword=医生治眼近乎失明+爱尔眼科再回应)
1. [伊朗大使馆发文悼念苏莱曼尼](https://so.toutiao.com/search?keyword=伊朗大使馆发文悼念苏莱曼尼)
1. [李梦被曝剧组迟到耍大牌](https://so.toutiao.com/search?keyword=李梦被曝剧组迟到耍大牌)
1. [金莎金子涵表演不到3分钟](https://so.toutiao.com/search?keyword=金莎金子涵表演不到3分钟)
1. [天问一号奔向火星要飞多远](https://so.toutiao.com/search?keyword=天问一号奔向火星要飞多远)
1. [石家庄新增1例本土确诊 曾参加婚礼](https://so.toutiao.com/search?keyword=石家庄新增1例本土确诊+曾参加婚礼)
1. [河北邢台发现核酸阳性患者](https://so.toutiao.com/search?keyword=河北邢台发现核酸阳性患者)
1. [演员李梦发文回应争议](https://so.toutiao.com/search?keyword=演员李梦发文回应争议)
1. [战疫医生艾芬称没想当医闹](https://so.toutiao.com/search?keyword=战疫医生艾芬称没想当医闹)
1. [伊朗驻华大使馆1时20分发声](https://so.toutiao.com/search?keyword=伊朗驻华大使馆1时20分发声)
1. [沈阳5所中小学封校 所有学生禁返校](https://so.toutiao.com/search?keyword=沈阳5所中小学封校+所有学生禁返校)
1. [美国国会和法院同时向白宫施压](https://so.toutiao.com/search?keyword=美国国会和法院同时向白宫施压)
1. [25岁演员去世 心梗缠上年轻人?](https://so.toutiao.com/search?keyword=25岁演员去世+心梗缠上年轻人?)
1. [全国42个中风险地区](https://so.toutiao.com/search?keyword=全国42个中风险地区)
1. [患者自画CT片子去就诊 医生感叹](https://so.toutiao.com/search?keyword=患者自画CT片子去就诊+医生感叹)
1. [1传21!沈阳2家医疗机构被吊销执照](https://so.toutiao.com/search?keyword=1传21!沈阳2家医疗机构被吊销执照)
1. [元旦之后还有两股冷空气](https://so.toutiao.com/search?keyword=元旦之后还有两股冷空气)
1. [男子夜持杀猪刀行凶 老板夫妇遇害](https://so.toutiao.com/search?keyword=男子夜持杀猪刀行凶+老板夫妇遇害)
1. [青海火流星直径6.5米重430吨](https://so.toutiao.com/search?keyword=青海火流星直径6.5米重430吨)
1. [湖北多地行政区划调整](https://so.toutiao.com/search?keyword=湖北多地行政区划调整)
1. [美团就“标签门”道歉](https://so.toutiao.com/search?keyword=美团就“标签门”道歉)
1. [大学预测1个月11万美国人死于新冠](https://so.toutiao.com/search?keyword=大学预测1个月11万美国人死于新冠)
1. [云南省委书记搀扶她坐主席台正中央](https://so.toutiao.com/search?keyword=云南省委书记搀扶她坐主席台正中央)
1. [2021全国兵役登记工作启动](https://so.toutiao.com/search?keyword=2021全国兵役登记工作启动)
1. [汕尾工地坍塌致8死 多名官员被处理](https://so.toutiao.com/search?keyword=汕尾工地坍塌致8死+多名官员被处理)
1. [华为新旗舰处理器曝光](https://so.toutiao.com/search?keyword=华为新旗舰处理器曝光)
1. [张庭直播“翻车”](https://so.toutiao.com/search?keyword=张庭直播“翻车”)
1. [华为3纳米芯片曝光](https://so.toutiao.com/search?keyword=华为3纳米芯片曝光)
1. [西藏边防最高驻兵点内部画面公开](https://so.toutiao.com/search?keyword=西藏边防最高驻兵点内部画面公开)
1. [特斯拉降价官网一度被挤崩](https://so.toutiao.com/search?keyword=特斯拉降价官网一度被挤崩)
1. [纽交所摘牌3家中企 商务部回应](https://so.toutiao.com/search?keyword=纽交所摘牌3家中企+商务部回应)
1. [广东1例英国输入病例中发现突变株](https://so.toutiao.com/search?keyword=广东1例英国输入病例中发现突变株)
1. [中国省会城市大变局](https://so.toutiao.com/search?keyword=中国省会城市大变局)
1. [王思聪过生日 三亚包场开派对](https://so.toutiao.com/search?keyword=王思聪过生日+三亚包场开派对)
1. [汽车零件包装阳性 多地紧急排查](https://so.toutiao.com/search?keyword=汽车零件包装阳性+多地紧急排查)
1. [莫迪收到两条坏消息](https://so.toutiao.com/search?keyword=莫迪收到两条坏消息)
1. [特斯拉1天卖出蔚来1年销量](https://so.toutiao.com/search?keyword=特斯拉1天卖出蔚来1年销量)
1. [美团致歉](https://so.toutiao.com/search?keyword=美团致歉)
1. [方硕表现堪称灾难级](https://so.toutiao.com/search?keyword=方硕表现堪称灾难级)
1. [阿留申群岛海域发生6级地震](https://so.toutiao.com/search?keyword=阿留申群岛海域发生6级地震)
<!-- END TOUTIAO --> | 17,011 | MIT |
---
title: Table - 表格
group:
title: 展示组件
path: /view
order: 4000
---
# Table 表格
经典二维数据展示形式
## 常规
### 示例
最基础的用法,传入数据源`dataSource`, 并通过`columns`配置要显示的列
<code src="./base-demo.tsx" />
### 字段值渲染
- `field`用来指定要渲染的表格字段,支持对嵌套对象、数组项取值
- `render`可以用来进行一些复杂列的渲染
- 列不一定要对应一个数据源字段、可以通过`render`来生成虚拟列
<code src="./render-demo.tsx" />
### 大数据量渲染
html 表格的渲染效率是非常低的,这导致如果表格数据量很多会非常卡顿,如果你要渲染的数据很多,可以通过开箱即用的虚拟滚动来对其进行优化。
- m78 表格布局模式都是非 fixed 的,列宽根据内容动态设置,由于表格项是惰性加载的,如果列的内容宽度波动较大,建议为其设置一个固定的宽度, 否则表格会在子项宽度变更时会持续动态调整列宽
- 部分浏览器在使用默认滚动条时会包含滚动性能优化,关闭滚动条定制可以提升一定的性能
渲染 99999 条记录
<code src="./big-data-demo.tsx" />
> 🤔 大数据量渲染应该只作为防止组件崩溃的一个回退手段,通常,如果你要同时展示过多的数据,应该优先考虑对数据的展现形式进行优化(通过分页、搜索、智能推送等)。
### 样式
配置分割风格、条纹背景、尺寸等
<code src="./style-demo.tsx" />
### 单元格 props
单元格 props 能够为每个单元格传入独立的 props, 可以用来配置样式、对齐、事件等, 此外, 你还通过在`column.props`配置针对列的 prop
<code src="./cell-props-demo.tsx" />
### 固定列
表格包含很多列时,可以将其中的某些列固定到左侧或右侧方便查看和操作
<code src="./fixed-demo.tsx" />
### 合并单元格
对单元格进行行或列合并, 有以下注意事项:
- 对于被合并的行或列,必须为其返回 0 来腾出位置, 否则会导致表格排列异常
- fixed 列和普通列不能进行合并
- 合并不作用于表头
<code src="./span-demo.tsx" />
### 排序
为列配置`sort`来开启排序,然后通过`onSortChange`来排序数据源并显示
> 此示例是针对静态数据的,实际使用时一般会通过 onSortChange 来监听排序状态变更并根据排序参数重新请求后端接口
<code src="./sort-demo.tsx" />
### 过滤
通过列的 extra 配置在表头挂载额外的节点,以此来实现过滤逻辑
<code src="./filter-demo.tsx" />
### 总计栏
配置`summary`来对每一列生成总计
<code src="./summary-demo.tsx" />
## 选择
### 多选
多选的受控使用示例,可通过`value`/`defaultValue`/`onChange`自行控制受控和非受控件的使用方式
<code src="./mcheck-demo.tsx" />
### 单选
单选的受控使用示例,可通过`value`/`defaultValue`/`onChange`自行控制受控和非受控件的使用方式
<code src="./scheck-demo.tsx" />
## 树形表格
### 基础示例
使用树形表格时, dataSource 遵循一些特定的配置, 比如`children`配置其子项、`isLeaf`配置其是否为叶子节点.
> 树形表格和[tree](/docs/form/tree)共用一套底层的树形处理逻辑,仅对部分用法进行了增减
<code src="./tree-base-demo.tsx" />
### 多选
多选,支持受控、非受控使用, 可传入 checkStrictly 来关闭父子级的选中关联
<code src="./tree-mcheck-demo.tsx" />
### 单选
单选,支持受控、非受控使用,可通过 checkTwig 开启树枝节点选中, emptyTwigAsNode 将空的树节点视为子节点并使其可选中
<code src="./tree-scheck-demo.tsx" />
### 展开行为
有 4 种展开控制方式: 不受控、受控、默认展开全部、默认展开几级
<code src="./tree-opens-deme.tsx" />
### 动态加载
传入 onLoad 开启异步加载子项数据,它返回 Promise,该 Promise resolve 树节点的子项
<code src="./tree-dynamic-load-demo.tsx" />
### 手风琴
同一级下只会同时展开一个
<code src="./tree-accordion-demo.tsx" />
## 拖拽排序
拖动排序, 与[tree](/docs/form/tree#拖拽模式)的拖拽用法一样
> 这是一个操作本地数据的示例,详细的用法说明请参考[tree](/docs/form/tree#拖拽模式)组件
<code src="./dnd-demo.tsx" />
## Api
### **`Table`**
```tsx | pure
interface TableProps {
/** 表格列配置 */
columns: TableColumns;
/** 表格中的每一条记录都应该有一个能表示该条记录的字段, valueKey用于获取这个字段的key, 在启用了选择等功能时,valueKey指向的值会作为选中项的value */
valueKey: string | number;
/** 数据源 (每次更改时会解析树数据并缓存关联信息以提升后续操作速度,所以最好将dataSource通过useState或useMemo等进行管理,不要直接内联式传入) */
dataSource?: TableDataSourceItem[];
/**
* 组件内部更改了数据源时,通过此方法通知
* - 在启用了动态加载子节点、拖拽等功能时触发,它们的共同点是都会更改传入的dataSource
* - 此选项存在的意义是让动态加载、拖拽排序等功能使用更简单,目前常见组件库中的tree均是只做节点变更通知,需要由用户手动根据节点层级
* 将新数据/节点顺序设置到DataSource后再更新数据源,但是多层级的树形数据操作是非常麻烦且费时的,所以组件将这些更新操作放到内部进行,用户仅需监听
* onDataSourceChange并将新的DataSource合并即可
* - 出于性能考虑,在存在超大数据量的树形数据时,深拷贝非常耗时,组件会直接更改传入的dataSource,并在更新引用后传入onDataSourceChange
* 所以在开启了动态加载子节点、拖拽功能时,必须传入此项来同步dataSource
* */
onDataSourceChange?: (ds: TableDataSourceItem[]) => void;
/**
* 表格高度, 表格数据量过大时使用,传入此项时:
* - 开启虚拟滚动
* - 超出此高度会出现滚动条
* - 固定表头
* */
height?: string | number;
/** 设置加载中状态 */
loading?: boolean;
/* ############## 功能选项 ############## */
/**
* 根据传入坐标对行进行合并
* - 对于被合并的行,必须为其返回0来腾出位置, 否则会导致表格排列异常
* - fixed列和普通列不能进行合并
* - 不作用于表头、总结栏
* */
rowSpan?: (cellMeta: TableMeta) => number | void;
/**
* 根据传入坐标对列进行合并
* - 对于被合并的列,必须为其返回0来腾出位置, 否则会导致表格排列异常
* - fixed列和普通列不能进行合并
* - 不作用于表头
* */
colSpan?: (cellMeta: TableMeta) => number | void;
/** 开启总结栏并根据此函数返回生成每列的值 */
summary?: (colMeta: TableMeta) => React.ReactNode | void;
/** 默认的排序值 */
defaultSort?: TableSortValue;
/** 受控的排序值 */
sort?: TableSortValue;
/** 触发排序的回调, 无sort传入时表示取消排序 */
onSortChange?: (sort: TableSortValue | []) => void;
/** 如果传入,则控制要显示的列, 数组项为 columns.key 或 字符类型的columns.field */
showColumns?: string[];
/** 此项一般会传入一个对象,并且可以在TableMeta.ctx中访问,可用于在某些静态配置(column)中动态获取当前组件上下文的状态 */
ctx?: any;
/* ############## 定制选项 ############## */
/** 表格宽度,默认为容器宽度 */
width?: string | number;
/**
* 'regular' | 表格的数据分割类型:
* - border: 边框型
* - regular: 常规型,行直接带分割线
* */
divideStyle?: TableDivideStyleKeys | TableDivideStyleEnum;
/** true | 显示条纹背景 */
stripe?: boolean;
/** 表格尺寸 */
size?: SizeKeys | SizeEnum;
/** 300px 单元格最大宽度, 用于防止某一列内容过长占用大量位置导致很差的显示效果 */
cellMaxWidth?: string | number;
/** 单元格未获取到有效值时(checkFieldValid()返回false), 用于显示的回退内容, 默认显示 “-” */
fallback?: React.ReactNode | ((cellMeta: TableMeta) => React.ReactNode);
/** 通过column.filed获取到字段值后,会通过此函数检测字段值是否有效,无效时会显示回退值, 默认只有truthy和0会通过检测 */
checkFieldValid?: (val: any) => boolean;
/** true | 是否开启webkit下的自定义滚动条,部分浏览器使用默认滚动条时会自带滚动性能优化,可以关闭此项来提升性能 */
customScrollbar?: boolean;
/**
* 所有单元格设置的props, 支持td标签的所有prop
* - 可通过该配置为所有单元格同时设置样式、对齐、事件等
* - 部分被内部占用的props无效
* */
props?:
| React.PropsWithoutRef<JSX.IntrinsicElements['td']>
| ((cellMeta: TableMeta) => React.PropsWithoutRef<JSX.IntrinsicElements['td']> | void);
/** 自定义展开标识图标, 如果将className添加到节点上,会在展开时将其旋转90deg, 也可以通过open自行配置 */
expansionIcon?:
| React.ReactNode
| ((open: boolean, node: Node, className: string) => React.ReactNode);
/** 'children' | 自定义用于获取children的key */
childrenKey?: string;
/* ############## 单选/多选 ############## */
/** 是否可单选 (使用高亮样式) */
checkable?: boolean;
/** false | 是否可选中目录级(单选时可用) */
checkTwig?: boolean;
/** 是否可多选,启用后onChange/value/defaultValue接受数组,此配置的权重低于单选配置checkable */
multipleCheckable?: boolean;
/**
* true | 关闭后,父子节点不再强关联(父节点选中时选中所有子节点,子节点全选中时父节点选中)
* - 如果数据量超过10万,关闭选中关联会大大提高性能
* */
checkStrictly?: boolean;
/** 选项的受控值 (多选时,TreeValueType类型为数组) */
value?: TreeValueType;
/** 选项的非受控值 (多选时,TreeValueType类型为数组) */
defaultValue?: TreeValueType;
/** 选项的变更回调 (多选时,TreeValueType和TreeNode类型为数组) */
onChange?: (value: TreeValueType, extra: TableTreeNode) => void;
/* ############## 树常用配置 ############## */
/**
* 开启异步加载数据,启用后,除了配置了OptionsItem.isLeaf的节点和已有含值子级的节点外,一律可展开,并在展开时触发此回调
* - 返回选项数组时,会作为该节点的子项,返回空数组则表示该节点为空
* - 返回非以上值时,设置改节点为叶子节点,不可再展开
* - 如果promise异常,则忽略操作
* */
onLoad?: (node: Node) => Promise<Item[]>;
/** 手风琴模式,同级只会有一个节点被展开 */
accordion?: boolean;
/** 默认展开所有节点 */
defaultOpenAll?: boolean;
/** 默认展开到第几级 */
defaultOpenZIndex?: number;
/** 将包含children但值为`[]`的数组视为子节点, 使其可在单选模式下不开启checkTwig的情况下选中 */
emptyTwigAsNode?: boolean;
/** 点击节点 */
onNodeClick?: (current: Node) => void;
/** 禁用(工具条、展开、选中) */
disabled?: boolean;
/** 指定打开的节点 (受控) */
opens?: TreeValueType[];
/** 指定默认打开的节点 (非受控) */
defaultOpens?: TreeValueType[];
/** 打开节点变更时触发 */
onOpensChange?: (nextOpens: TreeValueType[], nodes: Node[]) => void;
/** 过滤掉所有返回false的节点,使其不在列表显示 */
filter?: (current: Node) => boolean;
/** 过滤关键字, 用于实现本地搜索 */
keyword?: string;
/* ############## 拖动 ############## */
/** 开启拖动排序 */
draggable?: boolean;
/** 拖动并触发重新排序时调用, 内置的排序逻辑仅作用于本地数据,用户应在此方法中完成排序数据的持久化 */
onDragAccept?: (event: DragFullEvent, nextDataSource: Item[]) => void;
/** 关闭默认的拖动数据源处理逻辑, 交由用户自行更新dataSource */
skipDragDatasourceProcess?: boolean;
}
```
### **`Column`**
```tsx | pure
interface TableDataSourceItem {
/** 列名 */
label: string;
/**
* 该列对应的数据字段
* - 传入字符数组时可以嵌套获取值, 如:
* @example
* - ['user', 'name'] => user.name
* - ['things', '1', 'name'] => things[1].name
* */
field?: string | string[];
/** 自定义渲染内容, 会覆盖field配置 */
render?: (cellMeta: TableMeta) => React.ReactNode;
/** 列的固定宽度, 不传时列宽取决于其内容的宽度 */
width?: string | number;
/**
* 列的最大宽度, 此配置会覆盖width配置
* - 具体表现为,内容宽度未超过maxWidth时根据内容决定列宽,内容宽度超过列宽时取maxWidth
* - 通常此配置能实现比width更好的显示效果
* */
maxWidth?: string | number;
/** 固定列到左侧或右侧, 如果声明了fixed的列在常规列中间,它会根据固定方向移动到表格两侧渲染 */
fixed?: TableColumnFixedKeys | TableColumnFixedEnum;
/**
* 为该列所有单元格设置的props, 支持td标签的所有prop
* - 可通过该配置为整列同时设置样式、对齐、事件等
* - 部分被内部占用的props无效
* */
props?:
| React.PropsWithoutRef<JSX.IntrinsicElements['td']>
| ((cellMeta: TableMeta) => React.PropsWithoutRef<JSX.IntrinsicElements['td']> | void);
/** 在列头渲染的额外内容 */
extra?: React.ReactNode | ((cellMeta: TableMeta) => React.ReactNode);
/**
* 如果开启了排序等功能, 需要通过此项来对列进行标识
* - 如果未明确传入此值,且field为string类型的话,会将filed作为key使用
* - 如果未明确传入此值,且field为array类型的话,会将其转换为字段字符串并作为key使用,如user.name、news[0].title
* - 如果包含多个相同的filed声明,则应该为重复的列显式传入key
* */
key?: string;
/**
* 开启过滤并通过onSort进行回调:
* - 如果为boolean值true,则表示同时开启asc和desc两种类型的排序
* - 如果为string类型,则表示只开启该类型的排序
* */
sort?: boolean | TableSortKeys | TableSortEnum;
/** 其他任意的键值 */
[key: string]: any;
}
```
### **`TreeDataSource`**
```tsx | pure
interface TableDataSourceItem {
/** 选项名 */
label: React.ReactNode;
/** 选项值, 默认与label相同 */
value: TreeValueType;
/** 是否禁用 */
disabled?: boolean;
/** 子项列表 */
children?: TreeDataSourceItem[];
/**
* 是否为叶子节点
* - 设置onLoad开启异步加载数据后,所有项都会显示展开图标,如果项被指定为叶子节点,则视为无下级且不显示展开图标
* - 传入onLoad时生效
* */
isLeaf?: boolean;
/** 在需要自行指定value或label的key时使用 */
[key: string]: any;
}
```
### **`TableTreeNode`**
```tsx | pure
interface TableTreeNode {
/** 该节点对应的值 */
value: TreeValueType;
/** 当前层级 */
zIndex: number;
/** 所有父级节点 */
parents?: TableTreeNode[];
/** 所有父级节点的value */
parentsValues?: TreeValueType[];
/** 所有兄弟节点(包含本身) */
siblings: TableTreeNode[];
/** 所有兄弟节点的value */
siblingsValues: TreeValueType[];
/** 所有子孙节点 */
descendants?: TableTreeNode[];
/** 所有子孙节点的value */
descendantsValues?: TreeValueType[];
/** 所有除树枝节点外的子孙节点 */
descendantsWithoutTwig?: TableTreeNode[];
/** 所有除树枝节点外的子孙节点的value */
descendantsWithoutTwigValues?: TreeValueType[];
/** 从第一级到当前级的value */
values: (string | number)[];
/** 从第一级到当前级的索引 */
indexes: number[];
/** 以该项关联的所有选项的关键词拼接字符 */
fullSearchKey: string;
/** 该项子级的所有禁用项 */
disabledChildren: TableTreeNode[];
/** 该项子级的所有禁用项的value */
disabledChildrenValues: TreeValueType[];
/** 未更改的原DataSource对象 */
origin: TableDataSourceItem;
/** 子节点列表 */
child?: TableTreeNode[];
}
``` | 10,287 | MIT |
# Java
[TOC]
毕向东 Java 学习笔记
## 基础
* Java 先编译,再解释执行:
1. `javac foo.java` 编译 Java 源文件生成字节码文件:`foo.class`
2. `java foo.class` 用虚拟机解释执行字节码文件
### 命名规范
* 类名:`HelloJava`
* 类的成员变量、局部变量、成员方法:`firstDay`,`getName()`
* 常量:`MAX_VALUE`
### for 循环
**增强 for 循环**
```java
for( String name : names ) {
System.out.print( name );
System.out.print(",");
}
```
**for 的 while 实现**
```java
for(;;){
}
```
### 位运算
**>> 和 >>>**
`>>` ,正数高位补零,负数高位补一。`>>>` 正负数都强制高位补 0
### 基本数据类型
```
java.lang.Number
Integer
Short
Long
Float
Double
Byte
BigInteger
BigDecimal
```
## 数组
数组是**相同类型**数据的集合。
### 数组的初始化
```java
double[] myList; // 定义一个数组的引用
```
```java
int[] integers = new int[10]; // 在堆内存中 new 一个数组,堆内存中创建的对象都有默认值
for(int integer : integers){ // 增强 for 循环
System.out.println(integer);
}
dataType[] arrayRefVar = {value0, value1, ..., valuek};
String[] strings = new String[]{"a", "b", "c", "d", "d1", "a1"};
```
```java
// new 二维数组
int[][] arr = new int[3][2];
System.out.println(arr.length);
System.out.println(arr[1].length);
int[][] arr = new int[3][];
```
匿名数组:
```java
public class Test {
public static void printArray(int []arr){
for (int i : arr) {
System.out.print(i);
}
}
public static void main(String[] args) {
//Many code
printArray(new int[]{1,2,3,4,5,6});
//Many code
}
}
```
### 常见方法
```java
System.arrayCopy(源数组,从哪开始,目标数组,从哪开始贴,粘几个);
Arrays.sort(被排序的数组);
Arrays.binarySearch(哪个数组,数组中的什么元素);
Arrays.fill(a, 2, 4, 100); //将数组a中2到4的索引的元素替换为100
```
### 内存分配
**栈内存**
存储的都是局部变量, 而且变量所属的作用域一旦结束,该变量就自动释放。
**堆内存**
存储是数组和对象(其实数组就是对象) 凡是new建立在堆中。
特点:
1. 每一个实体都有首地址值
2. 堆内存中的每一个变量都有默认初始化值,根据类型的不同而不同。整数是0,小数0.0或者0.0f,boolean false char '\u0000'
3. 垃圾回收机制
堆内存的默认初始化值:
| 类型 | 默认初始化值 |
| ------ | ------------ |
| int | 0 |
| float | 0.0 |
| String | null |
## 函数
### 构造函数
**特点**
* 函数名与类名相同
* 不用定义返回值类型
* 不可以 return
**作用**
* 给对象初始化
**注意**
* 构造函数是可以重载的,也就是可以有多种对象初始化方式
* 构造函数如果前面加了 void 就变成了一般函数。
* 默认的构造函数,类可以没有构造函数
当一个类中没有定义构造函数时,系统会默认给该类加入一个空参数的构造函数,例如 `Person(){}` 当自定义构造函数后,默认的构造函数就没了
但是当一个类加入了有参的构造函数时,我们就需要手动加上无参的构造函数,否则会在初始化对象的时候,会因为找不到无参构造器报错
* 什么时候需要构造函数?
分析事物时,该事物一开始就具备某些某些属性或行为,那么将这些 内容定义在构造函数中
* 可以通过私有化构造函数,进而禁止类进行初始化
### main 函数
```java
public static void main(String[] args){
}
```
* public 权限必须是最大的
* static 该函数并没有涉及到成员方法
* void 主函数没有具体的返回值
* main 不是关键字,是 JVM 识别的固定的名字
* String[] args 参数列表,是一个数组类型的参数,元素都是字符串
### 构造代码块
**作用**
* 定义所有对象的共性,给对象进行初始化,对象一建立就运行,而且先于构造函数执行
* 每 new 一个对象,构造代码块就运行一次
**构造代码块和构造函数的区别**
构造代码块是给所有对象进行统一初始化,而构造函数是给对应的对象初始化(对象也许有重载)
```java
// 构造代码块是定义每一个对象的共性
{
System.out.println("person code run");
}
```
### 静态代码块
随着类的加载而执行。而且只执行一次。
作用:用于给类进行初始化。
```java
static
{
System.out.println("static code");
}
```
### void
如果函数没有具体返回值,那么返回值类型可以用 `void` 来表示,函数中 `return` 可以不写,也可以写成 `return;`
### 重载
**重载与返回值类型无关**,只看参数类型是否不一样,参数类型不一样并且函数名一样则重载。
java是严谨性语言,如果函数出现的调用的不确定性,会编译失败。
<img align='left' src="assets/clip_image001.png" alt="重载" style="zoom:90%;" />
## 类
### 定义
成员变量
* 成员变量随着对象的创建而存在,随着对象的消失而消失
* 成员变量存在于堆内存的对象中,成员变量都有默认初始化值
### 匿名对象
```java
new Car(); // 匿名对象。其实就是定义对象的简写格式。
Car c = new Car();
c.run();
new Car().run();
// 1,当对象对方法仅进行一次调用的时候,就可以简化成匿名对象。
new Car().num = 5;
new Car().color = "green";
new Car().run();33
// 2,匿名对象可以作为实际参数进行传递。
Car c1 = new Car();
show(c1); // 等价于:
show(new Car());
```
### private
私有的内容只在本类中有效,不在子类中生效。
Java 中的 `this` 对应 Python 中的 `self` 关键字。
### static
**static 的特点**
1. static 是一个修饰符,用于修饰成员,可以修饰变量,也可以修饰方法
2. **static 修饰的成员被所有的对象所共享**
3. static 优先于对象存在,因为static的成员随着类的加载就已经存在了
4. static 修饰的成员多了一种调用方式,就可以直接被类名所调用 【类名.静态成员】
5. static 修饰的数据是共享数据,对象中的存储的是特有数据
**静态成员变量的特点**
1. 静态变量随着类的加载而存在,随着类的消失而消失
2. 静态成员(函数和变量)既可以被对象调用(这种方式在 Java 高版本中不提倡),还可以被类名调用
3. 静态变量称为**类变量**
4. 静态变量数据存储在方法区(共享数据区)的静态区,所以也叫对象的共享数据
5. 静态变量如果设置了 private,则通过类名的方式不能调用
**静态使用的注意事项**
1. 静态方法只能访问静态成员。 (**非静态既可以访问静态,又可以访问非静态**)
2. 静态方法中不可以使用this或者super关键字
3. 主函数是静态的
**static 使用场景**
1. 静态变量
当分析对象中所具备的成员变量的值都是相同的,这时这个成员就可以被静态修饰。
只要数据在对象中都是不同的,就是对象的特有数据,必须存储在对象中,是非静态的。如果是相同的数据,对象不需要做修改,只需要使用即可,不需要存储在对象中,定义成静态的。
2. 静态方法
函数是否用静态修饰,就参考一点,就是该函数功能是否有访问到对象中的特有数据。
简单点说,从源代码看,该功能是否需要访问非静态的成员变量,如果需要,该功能就是非静态的。如果不需要,就可以将该功能定义成静态的。当然,也可以定义成非静态,
但是非静态需要被对象调用,而仅创建对象调用非静态的。没有访问特有数据的方法,该对象的创建是没有意义。
### this
* 当成员变量和局部变量重名,可以用关键字this来区分
* this也可以用于在构造函数中调用其他构造函数
注意:只能定义在构造函数的第一行。因为初始化动作要先执行
### 继承
**super 和 this**
当本类的成员和局部变量同名用this区分。当子父类中的成员变量同名用super区分父类。
this和super的用法很相似。this:代表一个本类对象的引用。super:代表一个父类空间。
```java
// Demo
class Zi extends Fu{
Zi(){
super(); // Zi 的构造函数,一定会先执行 Fu 的构造函数
}
}
```
**构造函数**
子类的实例化过程:子类中所有的构造函数默认都会访问父类中的空参数的构造函数。
* super() 显式调用
如果父类中没有定义空参数构造函数,那么子类的构造函数必须用 super() 显式调用。明确要调用父类中哪个构造函数。
* super() 隐式调用
如果父类定义了空参数构造函数,那么子类的构造函数不用显式 super()
其实不管怎么样,子类都会访问父类的构造函数,所以代码里最好还是显式的把 `super()` 写出来比较好。
supre语句必须要定义在子类构造函数的第一行。因为父类的初始化动作要先完成。
通过super初始化父类内容时,子类的成员变量并未显示初始化。等super()父类初始化完毕后,才进行子类的成员变量显示初始化。
**函数重写(覆盖)**
我个人倾向于叫重写。
当子父类中出现成员函数一模一样的情况,会运行子类的函数。
这种现象,称为重写操作。这时函数在子父类中的特性。
函数两个特性
1. 重载。同一个类中。 overload
2. 覆盖。子类中。覆盖也称为重写,覆写。 override
重写注意事项:
1. 子类方法覆盖父类方法时,子类权限必须要大于等于父类的权限
2. 静态只能覆盖静态,或被静态覆盖
重写的使用场景:
1. 当对一个类进行子类的扩展时,子类需要保留父类的功能声明,但是要定义子类中该功能的特有内容时,就使用覆盖操作完成.
**单例设计模式**
```java
/*
设计模式:对问题行之有效的解决方式。其实它是一种思想。
1,单例设计模式。
解决的问题:就是可以保证一个类在内存中的对象唯一性。
必须对于多个程序使用同一个配置信息对象时,就需要保证该对象的唯一性。
如何保证对象唯一性呢?
1,不允许其他程序用new创建该类对象。
2,在该类创建一个本类实例。
3,对外提供一个方法让其他程序可以获取该对象。
步骤:
1,私有化该类构造函数。
2,通过new在本类中创建一个本类对象。
3,定义一个公有的方法,将创建的对象返回。
*/
//饿汉式
class Single //类一加载,对象就已经存在了。
{
private static Single s = new Single();
private Single(){}
public static Single getInstance(){
return s;
}
}
//懒汉式
class Single2 //类加载进来,没有对象,只有调用了getInstance方法时,才会创建对象。
//延迟加载形式。
{
private static Single2 s = null;
private Single2(){}
public static Single2 getInstance(){
if(s==null)
s = new Single2();
return s;
}
}
class SingleDemo{
public static void main(String[] args){
Single s1 = Single.getInstance();
Single s2 = Single.getInstance();
System.out.println(s1==s2);
}
}
```
### 抽象类
**概述**
1. 方法只有声明没有实现时,该方法就是抽象方法,需要被abstract修饰
2. 抽象方法必须定义在抽象类中。该类必须也被abstract修饰
3. 抽象类不可以被实例化。为什么?因为调用抽象方法没意义。抽象类必须有其子类覆盖了所有的抽象方法后,该子类才可以实例化。
否则,这个子类还是抽象类
4. 抽象类一定是一个父类,其生来就是要被继承的
注意,抽象类可以有构造函数,用于给子类进行初始化。抽象类也可以不定义抽象方法。
```java
abstract class Demo{
Demo(){
}
abstract public abstractFunc(); // 写一个接口协议,要求子类去实现
}
```
**abstract 关键字**
抽象关键字不可以和 private,static,final 同时存在:
1. private:抽象是定义了一个协议,要求子类去实现的,private 私有后,子类就访问不到了
2. static:抽象方法必须子类实现后才能访问,而 static 修饰后,可以直接通过类名进行访问,冲突了
3. final:final 定义的属性和方法,就不能修改了,而抽象关键字定义的函数是要被子类继承修改的
**抽象类和一般类的异同点**
1. 相同点
抽象类和一般类都是用来描述事物的,都在内部定了成员
2. 不同点
1. 一般类有足够的信息描述事物,抽象类描述事物的信息有可能不足
2. 一般类中不能定义抽象方法,只能定非抽象方法,抽象类中可定义抽象方法,同时也可以定义非抽象方法
3. 一般类可以被实例化,抽象类不可以被实例化
### 一个对象的实例化过程
一个对象的实例化过程 `Person p = new Person();`
1. JVM会读取指定的路径下的Person.class文件,并加载进内存,并会先加载Person的父类(如果有直接的父类的情况下)
2. 在堆内存中的开辟空间,分配地址。并在对象空间中,对对象中的属性进行默认初始化
3. 调用对应的构造函数进行初始化
4. 在构造函数中,第一行会先到调用父类中构造函数进行初始化
5. 父类初始化完毕后,在对子类的属性进行显示初始化
6. 在进行子类构造函数的特定初始化
7. 初始化完毕后,将地址值赋值给引用变量
### final
final 关键字的特点:
final关键字:
1. final是一个修饰符,可以修饰**类,方法,变量**。
2. final修饰的类不可以被继承。
3. final修饰的方法不可以被覆盖。
4. final修饰的变量是一个常量,只能赋值一次。
为什么要用final修饰变量?
其实在程序如果一个数据是固定的,那么直接使用这个数据就可以了,但是这样阅读性差,所以它该数据起个名称。
而且这个变量名称的值不能变化,所以加上final固定。
写法规范:常量所有字母都大写,多个单词,中间用_连接。
```java
public static final double MY_PI = 3.14;
```
### 接口
接口有点类似鸭子🦆类型。
当一个抽象类中的方法都是抽象的时候,这时可以将该抽象类用另一种形式定义和表示,就是接口 interface。
接口中的成员都是公共的权限。
```java
interface Demo{
public static final int NUM = 4;
public abstract void show1();
public abstract void show2();
}
```
只能由实现了接口的子类并覆盖了接口中所有的抽象方法后,该子类才可以实例化。否则,这个子类就是一个抽象类。
**多实现**
在java中不直接支持多继承,因为会出现调用的不确定性。所以java将多继承机制进行改良,在java中变成了多实现。一个类可以实现多个接口。
```java
// 多继承
interface A{
public void show(); // abstract 可以省略不写
}
interface Z{
public int add(int a,int b);
}
class Test implements A,Z{
public int add(int a,int b){
return a+b+3;
}
public void show(){}
}
```
**接口的多继承**
```java
interface CC{
void show();
}
interface MM{
void method();
}
interface QQ extends CC, MM //接口与接口之间是继承关系,而且接口可以多继承。
{
void function();
}
class WW implements QQ{
//覆盖3个方法。
public void show(){}
public void method(){}
public void function(){}
}
```
**接口和抽象类比较**
1. 相同点
都是不断向上抽取而来的。
2. 不同点
1. 抽象类需要被继承,而且只能单继承。
接口需要被实现,而且可以多实现。
2. 抽象类中可以定义抽象方法和非抽象方法,子类继承后,可以直接使用非抽象方法。
接口中只能定义抽象方法,必须由子类去实现。
3. 抽象类的继承,是 is a 关系,在定义该体系的基本共性内容。
接口的实现是 like a 关系,在定义体系额外功能。
### 多态
**什么是多态**
一个对象有多种特征。一个对象,走起路来像鸭子,叫声也像鸭子,那么这个对象就具有鸭子的特征;同时这个对象还是胎生的,那么其就有哺乳动物的特征。一个对象,多种状态。
多态的一个实际案例:
```
现实中,关于多态的例子不胜枚举。比方说按下 F1 键这个动作,如果当前在 Flash 界面下弹出的就是 AS 3 的帮助文档;如果当前在 Word 下弹出的就是 Word 帮助;在 Windows 下弹出的就是 Windows 帮助和支持。同一个事件发生在不同的对象上会产生不同的结果。
```
```java
class 动物
{}
class 猫 extends 动物
{}
class 狗 extends 动物
{}
猫 x = new 猫();
动物 x = new 猫(); //一个对象,多种形态。
```
猫这类事物即具备者猫的形态,又具备着动物的形态。这就是对象的多态性。
简单说:就是一个对象对应着不同类型。(因为实现了不同的接口)
多态在代码中的体现:父类或者接口的引用指向其子类的对象
多态的好处:提高了代码的扩展性,前期定义的代码可以使用后期的内容
多态的弊端:前期定义的内容不能使用(调用)后期子类的特有内容
多态的前提:1. 必须有关系,继承,实现。2. 要有覆盖。
```java
abstract class Animal{
abstract void eat();
}
class Dog extends Animal{
void eat(){
System.out.println("啃骨头");
}
void lookHome(){
System.out.println("看家");
}
}
class Cat extends Animal{
void eat(){
System.out.println("吃鱼");
}
void catchMouse(){
System.out.println("抓老鼠");
}
}
class Pig extends Animal{
void eat(){
System.out.println("饲料");
}
void gongDi(){
System.out.println("拱地");
}
}
class DuoTaiDemo{
public static void main(String[] args){
// Cat c = new Cat();
// c.eat();
// c.catchMouse();
Animal a = new Cat(); //自动类型提升,猫对象提升了动物类型。但是特有功能无法s访问。
//作用就是限制对特有功能的访问。
//专业讲:向上转型。将子类型隐藏。就不用使用子类的特有方法。
// a.eat();
//如果还想用具体动物猫的特有功能。
//你可以将该对象进行向下转型。
// Cat c = (Cat)a;//向下转型的目的是为了使用子类中的特有方法。
// c.eat();
// c.catchMouse();
// 注意:对于转型,自始自终都是子类对象在做着类型的变化。
// Animal a1 = new Dog();
// Cat c1 = (Cat)a1;//ClassCastException
/*
Cat c = new Cat();
// Dog d = new Dog();
// c.eat();
method(c);
// method(d);
// method(new Pig());
*/
method(new Dog());
}
public static void method(Animal a){ //Animal a = new Dog();
a.eat();
if(a instanceof Cat){ //instanceof:用于判断对象的具体类型。只能用于引用数据类型判断
//通常在向下转型前用于健壮性的判断。
Cat c = (Cat)a;
c.catchMouse();
}else if(a instanceof Dog){
Dog d = (Dog)a;
d.lookHome();
}else{
}
}
}
```
**多态时各组成的发化**
多态时,成员的特点:
1. 成员变量
编译时:参考引用型变量所属的类中的是否有调用的成员变量,有,编译通过,没有,编译失败。
运行时:参考引用型变量所属的类中的是否有调用的成员变量,并运行该所属类中的成员变量。
简单说:编译和运行都参考等号的左边。哦了。
2. 成员函数(非静态)
编译时:参考引用型变量所属的类中的是否有调用的函数。有,编译通过,没有,编译失败。
运行时:参考的是对象所属的类中是否有调用的函数。
简单说:编译看左边,运行看**右边**。(其他都是左边)
因为成员函数存在覆盖特性。
3. 静态函数
编译时:参考引用型变量所属的类中的是否有调用的静态方法。
运行时:参考引用型变量所属的类中的是否有调用的静态方法。
简单说,编译和运行都看左边。
其实对于静态方法,是不需要对象的。直接用类名调用即可。
```java
package com.wansho.hellojava;
class Fu {
static int num = 3;
void show(){
System.out.println("fu show");
}
static void method(){
System.out.println("fu static method");
}
}
class Zi extends Fu {
static int num = 4;
void show()
{
System.out.println("zi show");
}
static void method()
{
System.out.println("zi static method");
}
}
class DuoTaiDemo3 {
public static void main(String[] args)
{
Fu.method(); // fu static method
Zi.method(); // zi static method
Fu f = new Zi();
System.out.println(f.num); // 可以通过对象访问静态的成员变量 3
f.method(); // 可以通过对象访问静态的成员变量 fu static method
f.show(); // zi show
}
}
```
### 内部类
内部类感觉有点类似于闭包。
**内部类访问特点**
1. 内部类可以直接访问外部类中的成员。
2. 外部类要访问内部类,必须建立内部类的对象。
**使用场景**
一般用于类的设计。
分析事物时,发现该事物描述中还有事物,而且这个事物还在访问被描述事物的内容。
这时就是还有的事物定义成内部类来描述。
内部类能直接访问外部类中成员, 是因为内部类持有了外部类的引用,即外部类名.this。
内部类也可以存放在局部位置上,但是内部类在局部位置上只能访问局部中被final修饰的局部变量。
```java
class Outer{
private static int num = 31;
class Inner{// 内部类。
void show(){
System.out.println("show run..."+num);
}
/*static void function()//如果内部类中定义了静态成员,该内部类也必须是静态的。
{
System.out.println("function run ...."+num);
}
*/
}
public void method(){
Inner in = new Inner();
in.show();
}
}
class InnerClassDemo
{
public static void main(String[] args)
{
// Outer out = new Outer();
// out.method();
// 直接访问外部类中的内部类中的成员。
// Outer.Inner in = new Outer().new Inner();
// in.show();
//如果内部类是静态的。 相当于一个外部类
// Outer.Inner in = new Outer.Inner();
// in.show();
//如果内部类是静态的,成员是静态的。
// Outer.Inner.function();
}
}
```
### 匿名内部类
匿名内部类, 首先是一个类中类,其次是内部类的简写格式。其实就是一个匿名子类对象。
必须有前提:内部类必须继承或者实现一个外部类或者接口。
格式: new 父类or接口(){子类内容}
```java
abstract class Demo{
abstract void show();
}
class Outer{
int num = 4;
/*
class Inner extends Demo{
void show(){
System.out.println("show ..."+num);
}
}
*/
public void method(){
//new Inner().show();
new Demo(){//匿名内部类。
void show(){
System.out.println("show ........"+num);
}
}.show();
}
}
class InnerClassDemo4{
public static void main(String[] args){
new Outer().method();
}
}
```
**使用范例**
场景一:
当函数参数是接口类型时,而且接口中的方法不超过三个。可以用匿名内部类作为实际参数进行传递
```java
interface Inter
{
void show1();
void show2();
}
class Outer
{
/*
class Inner implements Inter
{
public void show1()
{ }
public void show2()
{ }
}
*/
public void method()
{
// Inner in = new Inner();
// in.show1();
// in.show2();
Inter in = new Inter(){
public void show1()
{ }
public void show2()
{ }
};
in.show1();
in.show2();
}
}
class InnerClassDemo5
{
class Inner
{ }
public static void main(String[] args)
{
System.out.println("Hello World!");
/*
show(new Inter()
{
public void show1(){}
public void show2(){}
});
*/
// new Inner();
}
public void method()
{
new Inner();
}
public static void show(Inter in)
{
in.show1();
in.show2();
}
}
```
范例二:
```java
class Outer
{
void method()
{
Object obj = new Object()
{
public void show()
{
System.out.println("show run");
}
};
obj.show();//因为匿名内部类这个子类对象被向上转型为了Object类型。
//这样就不能在使用子类特有的方法了。
}
}
class InnerClassDemo6
{
public static void main(String[] args)
{
new Outer().method();
}
}
```
## 异常
### 定义
异常:是在**运行时期**发生的不正常情况。
注意是在运行期间,程序在运行时总会发生大大小小的问题,但是我们不能因为一个小问题就停止程序的运行,所以要引入叫做异常的容错机制,对异常进行容错。
在 java 中**用类的形式对不正常情况进行了描述和封装对象**。描述不正常的情况的类,就称为异常类。
**以前正常流程代码和问题处理代码相结合,现在将正常流程代码和问题处理代码分离。提高阅读性。其实异常就是java通过面向对象的思想将问题封装成了对象。用异常类对其进行描述。不同的问题用不同的类进行具体的描述。 比如角标越界、 空指针等等。**
问题很多,意味着描述的类也很多,将其共性进行向上抽取,形成了异常体系。
**异常的共性:Throwable**
无论是 error,还是异常,问题,问题发生就应该可以抛出,让调用者知道并处理。
//该体系的特点就在于Throwable及其所有的子类都具有可抛性。
可抛性到底指的是什么呢?怎么体现可抛性呢?其实是通过两个关键字来体现的。throws throw , 凡是可以被这两个关键字所操作的类和对象都具备可抛性.
异常子类的后缀名都是用其父类名作为后缀,阅读性很强。
**异常分为两类**
* Error
一般不可处理的。
是由jvm抛出的严重性的问题。这种问题发生一般不针对性处理。直接修改程序
* Exception
可以处理的。
```java
class ExceptionDemo
{
public static void main(String[] args)
{
int[] arr = new int[1024*1024*800]; //java.lang.OutOfMemoryError: Java heap
}
/**
正常的问题代码的处理
*/
public static void sleep2(int time)
{
if(time<0)
{
// 处理办法。
// 处理办法。
// 处理办法。
}
if(time>100000)
{
// 处理办法。
// 处理办法。
}
System.out.println("我睡。。。 "+time);
}
/*
引入异常机制后
*/
public static void sleep(int time)
{
if(time<0)
{
// 抛出 new FuTime();//就代码着时间为负的情况,这个对象中会包含着问题的名称,信息,位置等信息。
}
if(time>100000)
{
// 抛出 new BigTime();
}
System.out.println("我睡。。。 "+time);
}
}
/*
class FuTime
{ }
class BigTime
{ }
*/
```
### 自定义异常
**一个需求**
对于角标是整数不存在,可以用角标越界表示,对于负数为角标的情况,准备用负数角标异常来表示。
负数角标这种异常在java中并没有定义过。那就按照java异常的创建思想,面向对象,将负数角标进行自定义描述。并封装成对象。
如果让一个类称为异常类,必须要继承异常体系,因为只有称为异常体系的子类才有资格具备可抛性。
**异常的分类**
1. 编译时被检测的异常
2. 编译时不被检测的异常(运行时异常,必须要让程序停下来,修改之)
**throws 和 throw**
1. throws 使用在函数上,throw 使用在函数内
2. throws 抛出的是异常类,可以抛出多个,用逗号隔开。throw 抛出的是异常对象
Demo:
```java
class FuShuIndexException extends Exception
{
FuShuIndexException()
{}
FuShuIndexException(String msg)
{
super(msg);
}
}
class Demo
{
public int method(int[] arr,int index) throws NullPointerException, FuShuIndexException
{
if(arr==null)
throw new NullPointerException("数组的引用不能为空! ");
if(index>=arr.length)
{
throw new ArrayIndexOutOfBoundsException("数组的角标越界啦,哥们,你是不是疯了?: "+index);
}
if(index<0)
{
throw new FuShuIndexException("角标变成负数啦!! ");
}
return arr[index];
}
}
class ExceptionDemo3
{
public static void main(String[] args) //throws FuShuIndexException
{
int[] arr = new int[3];
Demo d = new Demo();
int num = d.method(null,-30);
System.out.println("num="+num);
System.out.println("over");
}
}
```
### 异常的捕捉
Demo:
```java
try
{
//需要被检测异常的代码。
}
catch(异常类 变量)// 该变量用于接收发生的异常对象
{
//处理异常的代码。
}
finally
{
//一定会被执行的代码。
}
```
**异常处理的原则**
异常处理的原则:
1. 函数内容如果抛出需要检测的异常,那么函数上必须要声明。否则必须在函数内用trycatch捕捉,否则编译失败。
2. 如果调用到了声明异常的函数,要么try catch 要么 throws,否则编译失败。
3. 什么时候catch,什么时候throws 呢?功能内容可以解决,用catch。解决不了,用throws告诉调用者,由调用者解决 。
4. 一个功能如果抛出了多个异常,那么调用时,必须有对应多个catch进行针对性的处理。内部有几个需要检测的异常,就抛几个异常,抛出几个,就catch几个
Demo:
```java
class FuShuIndexException extends Exception
{
FuShuIndexException(String msg)
{
super(msg);
}
}
class Demo
{
public int method(int[] arr,int index) // throws NullPointerException,FuShuIndexException
{
if(arr==null)
throw new NullPointerException("没有任何数组实体"); // throw 后,下面的代码就不执行了
if(index<0)
throw new FuShuIndexException();
return arr[index];
}
}
class ExceptionDemo4
{
public static void main(String[] args)
{
int[] arr = new int[3];
Demo d = new Demo();
try
{
int num = d.method(null,-1);
System.out.println("num="+num);
}
catch(NullPointerException e)
{
System.out.println(e.toString());
}
catch(FuShuIndexException e)
{
System.out.println("message:"+e.getMessage());
System.out.println("string:"+e.toString());
e.printStackTrace(); //jvm默认的异常处理机制就是调用异常对象的这个方法。
System.out.println("负数角标异常!!!!");
}
/*
catch(Exception e)//多catch父类的catch放在最下面。
{ }
*/
System.out.println("over");
}
}
```
**try catch finally**
try catch finally 代码块组合特点:
1. try catch finally
2. try catch(多个)当没有必要资源需要释放时,可以不用定义finally
3. try finally 异常无法直接 catch 处理,但是资源需要关闭
**异常注意事项**
1. 子类在覆盖父类方法时,父类的方法如果抛出了异常,那么子类的方法只能抛出父类的异常或者该异常的子类
2. 如果父类抛出多个异常,那么子类只能抛出父类异常的子集
简单说:子类覆盖父类只能抛出父类的异常或者子类或者子集。
注意:如果父类的方法没有抛出异常,那么子类覆盖时绝对不能抛,就只能try
### 异常 Demo
场景
```
毕老师用电脑上课。
问题领域中涉及两个对象。
毕老师,电脑。
分析其中的问题。
比如电脑蓝屏啦。冒烟啦。
```
```java
class LanPingException extends Exception
{
LanPingException(String msg)
{
super(msg);
}
}
class MaoYanException extends Exception
{
MaoYanException(String msg)
{
super(msg);
}
}
class NoPlanException extends Exception
{
NoPlanException(String msg)
{
super(msg);
}
}
class Computer
{
private int state = 2;
public void run() throws LanPingException,MaoYanException
{
if(state==1)
throw new LanPingException("电脑蓝屏啦!! ");
if(state==2)
throw new MaoYanException("电脑冒烟啦!! ");
System.out.println("电脑运行");
}
public void reset()
{
state = 0;
System.out.println("电脑重启");
}
}
class Teacher
{
private String name;
private Computer comp;
Teacher(String name)
{
this.name = name;
comp = new Computer();
}
public void prelect() throws NoPlanException // 没有 catch 的异常则抛出
{
try
{
comp.run();
System.out.println(name+"讲课");
}
catch (LanPingException e) // 异常处理
{
System.out.println(e.toString());
comp.reset();
prelect();
}
catch (MaoYanException e)
{
System.out.println(e.toString());
test();
//可以对电脑进行维修。
// throw e;
throw new NoPlanException("课时进度无法完成,原因: "+e.getMessage()); // 能解决的异常自己解决,不能解决的,抛出异常,让调用者来解决
}
}
public void test()
{
System.out.println("大家练习");
}
}
class ExceptionTest
{
public static void main(String[] args)
{
Teacher t = new Teacher("毕老师");
try
{
t.prelect();
}
catch (NoPlanException e)
{
System.out.println(e.toString()+"......");
System.out.println("换人");
}
}
}
/*
com.wansho.hellojava.MaoYanException: 电脑冒烟啦!!
大家练习
com.wansho.hellojava.NoPlanException: 课时进度无法完成,原因: 电脑冒烟啦!! ......
换人
*/
```
## 包机制
导包的原则:用到哪个类,就导入哪个类。包在文件系统上的作用体现在文件夹上。
包名的规范:所有字母都小写。
**包的重点**
1. 对类文件进行分类管理
2. 给类提供多层命名空间(namespace),防止类太多命名冲突了
3. 写在程序文件第一行
4. **类名的全称**是:包名.类名
5. 包也是一种封装方式
### package Demo
```
|---mypack
|---|---PackageDemo.java
```
```java
package mypack;
class PackageDemo{
public static void main(String[] args){
System.out.println("hello package");
}
}
```
编译执行该 Java 文件:
```shell
javac PackageDemo.java # 生成 PackageDemo.class 文件
java PackageDemo # 执行 class 文件
#!!!错误: 找不到或无法加载主类 PackageDemo
java mypack.PackageDemo
# hello package
```
从上面的例子来看,一旦加入 package 机制后,Java 文件就应该在包名所在的文件夹下,而且类名的全称变成了 `包名.类名`,单独引用类名会找不到这个人。
javac 可以直接帮我们创建文件夹:
```shell
javac -d . PackageDemo.java
java mypack.PackageDemo
```
### classpath 的作用
编译 java 源文件生成的 class 文件,都放在 classpath 中,以起到**源文件与 class 文件隔离的作用**。
一篇文章让你弄懂到底什么是classpath - yuan的文章 - 知乎 https://zhuanlan.zhihu.com/p/113234567
classpath其实就是一个路径而已,我们经常在spring的配置文件中这样写:
```java
<property name="configLocation" value="classpath:mybatis/SqlMapConfig.xml" />
```
这样配置完之后spring就知道mybatis配置文件所在的地方。
那么?这个classpath指向的地方到底是哪里呢?

**classpath指向的就是打war包之后的classes的位置**。而classes文件夹下就是我们原项目的java文件和resources文件夹里面的内容。
所以上面的代码的意思就是在编译后的classes文件中找mybatis/SqlMapConfig.xml文件。
------
在编译打包后的项目中,根目录是`META-INF`和`WEB-INF` 。这个时候,我们可以看到classes这个文件夹,它就是我们要找的classpath。
`classpath:mybatis/SqlMapConfig.xml` 中,classpath 就是指 `WEB-INF/classes/` 这个目录的路径。需要声明的一点是,使用`classpath:`这种前缀,**就只能代表一个文件**。
而另一种写法,`classpath*:**/mapper/mapping/*Mapper.xml`,使用`classpath*:`这种前缀,**则可以代表多个匹配的文件**;`**/mapper/mapping/*Mapper.xml`,双星号`**`表示在任意目录下,也就是说在`WEB-INF/classes/`下任意层的目录,只要符合后面的文件路径,都会被作为资源文件找到。
### 包的封装作用和四种权限
包是对类的进一步封装。既然封装了,那么就涉及到外部的访问问题。在包中,只有 `public class` 才是外部可以访问的 class,不是 public 的 class 都被包封装了。
注意:对外暴露的 public 的 class,其类名要与文件名保持一致。在 public class 中对外暴露的函数也应该是 public 的(默认权限也是封装!)
包与包之间的访问,通过 `public` 和 `protected` 关键字来约束。
不同包不允许访问,但如果你是我们的儿子,那么就可以网开一面:`protected`,**不叫爹不行!**提供给不同包中的子类。
protected 关键字将对象保护在同包中,不同包无法调用 protected 的对象。
**java 四种权限**
| | public | protected | default | private |
| -------- | ------ | --------- | -------------- | ------- |
| 同一类中 | ok | ok | ok | ok |
| 同一包中 | ok | ok | ok | 封装 |
| 子类中 | ok | ok | 封装(访问不到) | 封装 |
| 不同包中 | ok | 封装 | 封装 | 封装 |
总结:包与包之间的类进行访问,被访问的包中的类必须是 public 的,被访问的包中的类的方法也必须是 public 的。
protected:比 default 稍微宽松一点,包外的子类可以访问
default:同包能访问,包外的子类就不能访问了
private:吃独食,子类都访问不了
<img align="left" src="assets/image-20210503084531612.png" alt="image-20210503084531612" style="zoom:80%;" />
### import 的作用和规范
import 的作用:简化类名书写!
```java
// 没导入之前:
packa.PackageADemo demoA = new packa.PackageADemo();
// 导入后
import packa.PackageADemo; // 导入 packa 下的 PackageADemo 类
PackageADemo demoA = new PackageADemo();
// 导入 packa 中所有的类
import packa.*;
import packa.abc.*; // 两个性质完全不一样
```
注意:
1. `import *` 只导入文件夹下的所有类,并不会导入包中包(没有 recursive 的功能)
2. 导包原则:用哪个类,导入哪个类
### jar 包
**是什么**
`jar` 是 Java 的一个命令,用于 Java 程序打包。`jar, rar`,jar 包就是 Java 的压缩包。
```shell
javac -d . JarDemo.java
java pack.JarDemo
jar -cvf haha.jar pack # 压缩
jar -xvf haha.jar # 解压缩
# 以前:./pack
# 压缩后:./haha.jar/pack
```
注意:jar 包中打包的是 class 文件,没有必要对源码进行打包。
**如何使用 jar 包**
```shell
set classpath=./haha.jar
java pack.JarDemo
```
## 多线程
### 垃圾回收线程
JVM 启动的时候,就启动了多个线程,至少有两个线程是我们可以分析出来的:
1. main
2. 负责垃圾回收的线程
```java
class Demo4 extends Object
{
@Override
public void finalize() // 在垃圾回收前调用
{
System.out.println("demo ok");
}
}
class ThreadDemo
{
public static void main(String[] args)
{
new Demo4();
new Demo4();
new Demo4();
System.gc(); // 进行垃圾回收
System.out.println("Hello World!");
}
}
```
运行结果:
垃圾回收线程,其执行结果每次都不太一样。
```
demo ok
demo ok
Hello World!
demo ok
-----------
demo ok
demo ok
demo ok
Hello World!
-----------
demo ok
Hello World!
demo ok
demo ok
```
### 创建线程-继承 Thread
创建线程方式一:继承Thread类。
步骤:
1. 定义一个类继承 Thread 类
2. 覆盖Thread类中的 run 方法
3. 直接创建Thread的子类对象创建线程
4. 调用start方法开启线程并调用线程的任务run方法执行
可以通过 Thread 的 getName 获取线程的名称 Thread-编号(从0开始)
Demo:
```java
class Demo extends Thread
{
private String name;
Demo(String name)
{
super(name);
this.name = name;
}
public void run()
{
for(int x=0; x<10; x++)
{
System.out.println(name+"....x="+x+".....name="+Thread.currentThread().getName());
}
}
}
class ThreadDemo2
{
public static void main(String[] args)
{
/*
创建线程的目的是为了开启一条执行路径,去运行指定的代码和其他代码实现同时运行。
而运行的指定代码就是这个执行路径的任务。
jvm创建的主线程的任务都定义在了主函数中。
而自定义的线程它的任务在哪儿呢?
Thread类用于描述线程,线程是需要任务的。所以Thread类也对任务的描述。
这个任务就通过Thread类中的run方法来体现。也就是说, run方法就是封装自定义线程运行任务的函数。
run方法中定义就是线程要运行的任务代码。
开启线程是为了运行指定代码,所以只有继承Thread类,并复写run方法。
将运行的代码定义在run方法中即可。
*/
Demo d1 = new Demo("旺财");
Demo d2 = new Demo("xiaoqiang");
d1.start();//开启线程,调用run方法。
d2.start();
System.out.println("over...."+Thread.currentThread().getName());
}
}
/**
over....main
小强....x=0.....name=小强
旺财....x=0.....name=旺财
小强....x=1.....name=小强
小强....x=2.....name=小强
旺财....x=1.....name=旺财
小强....x=3.....name=小强
小强....x=4.....name=小强
旺财....x=2.....name=旺财
小强....x=5.....name=小强
旺财....x=3.....name=旺财
小强....x=6.....name=小强
小强....x=7.....name=小强
小强....x=8.....name=小强
小强....x=9.....name=小强
旺财....x=4.....name=旺财
旺财....x=5.....name=旺财
旺财....x=6.....name=旺财
旺财....x=7.....name=旺财
旺财....x=8.....name=旺财
旺财....x=9.....name=旺财
*/
```
多线程的随机性,谁抢到 CPU,谁执行。
### 创建线程-实现 Runnable
步骤:
1. 定义类实现Runnable接口
2. 覆盖接口中的run方法,将线程的任务代码封装到run方法中
3. 通过Thread类创建线程对象,并将Runnable接口的子类对象作为Thread类的构造函数的参数进行传递。
为什么?因为线程的任务都封装在Runnable接口子类对象的run方法中。所以要在线程对象创建时就必须明确要运行的任务。
4. 调用线程对象的start方法开启线程
实现Runnable接口的好处:
1. 将线程的任务从线程的子类中分离出来,进行了单独的封装
按照面向对象的思想将任务的封装成对象
2. 避免了java单继承的局限性
所以,创建线程的第二种方式较为常用
```java
class Demo implements Runnable{//extends Fu //准备扩展Demo类的功能,让其中的内容可以作为线程的任务执行。
//通过接口的形式完成。
public void run()
{
show();
}
public void show()
{
for(int x=0; x<20; x++)
{
System.out.println(Thread.currentThread().getName()+"....."+x);
}
}
}
class ThreadDemo
{
public static void main(String[] args)
{
Demo d = new Demo();
Thread t1 = new Thread(d);
Thread t2 = new Thread(d);
t1.start();
t2.start();
}
}
```
### 同步和互斥
**synchronized**
[[synchronized 讲解]](https://www.cnblogs.com/weibanggang/p/9470718.html)
synchronized,翻译过来,就是同步的意思,其是 Java 的关键字,是一种同步锁,其修饰的对象有以下几种:
1. 修饰一个代码块,被修饰的代码块称为同步语句块,其作用的范围是大括号{}括起来的代码,作用的对象是调用这个代码块的对象;
2. 修饰一个方法,被修饰的方法称为同步方法,其作用的范围是整个方法,作用的对象是调用这个方法的对象;
3. 修改一个静态的方法,其作用的范围是整个静态方法,作用的对象是这个类的所有对象;
4. 修改一个类,其作用的范围是synchronized后面括号括起来的部分,作用主的对象是这个类的所有对象。
详细介绍:
1. 修饰代码块
一个线程访问一个对象中的synchronized(this)同步代码块时,其他试图访问该对象的线程将被阻塞。
2. 修饰一个方法
注意:synchronized 关键字不能被继承,如果在父类中的某个方法使用了synchronized关键字,而在子类中覆盖了这个方法,在子类中的这个方法默认情况下并不是同步的,而必须显式地在子类的这个方法中加上synchronized关键字才可以
3. 修饰静态方法
我们知道静态方法是属于类的而不属于对象的。同样的,synchronized修饰的静态方法锁定的是这个类的所有对象。
**卖票问题**
线程安全问题产生的原因:
1. 多个线程在操作共享的数据
2. 操作共享数据的线程代码有多条
当一个线程在执行操作共享数据的多条代码过程中,其他线程参与了运算。就会导致线程安全问题的产生。
解决思路:
就是将临界区封装起来,当有线程在执行这些代码的时候,其他线程时不可以参与运算的。必须要当前线程把这些代码都执行完毕后,其他线程才可以参与运算。在 java 中,用同步代码块就可以解决这个问题。同步代码块的格式:
```java
synchronized(对象)
{
需要被同步的代码 ;
}
```
同步的好处:解决了线程的安全问题。
同步的弊端:相对降低了效率,因为同步外的线程的都会判断同步锁。
同步的前提:同步中必须有多个线程并使用同一个锁。
```java
class Ticket implements Runnable//extends Thread
{
private int num = 100;
Object obj = new Object();
public void run()
{
while(true)
{
synchronized(obj)
{
if(num>0)
{
try{Thread.sleep(10);}catch (InterruptedException e){}
System.out.println(Thread.currentThread().getName()+".....sale...."+num--);
}
}
}
}
}
class TicketDemo
{
public static void main(String[] args)
{
Ticket t = new Ticket();//创建一个线程任务对象。
Thread t1 = new Thread(t);
Thread t2 = new Thread(t);
Thread t3 = new Thread(t);
Thread t4 = new Thread(t);
t1.start();
t2.start();
t3.start();
t4.start();
}
}
```
**银行存钱案例**
需求:储户,两个,每个都到银行存钱每次存100,共存三次。
```java
class Bank
{
private int sum;
public synchronized void add(int num) // 同步函数,临界区一次只允许一个进程访问
{
sum = sum + num;
try{Thread.sleep(10);}catch(InterruptedException e){} // 当前进程睡 10 ms
System.out.println("sum="+sum);
}
}
class Cus implements Runnable // 线程的另一种实现方式
{
private Bank b = new Bank();
public void run()
{
for(int x=0; x<3; x++)
{
b.add(100);
}
}
}
class BankDemo
{
public static void main(String[] args)
{
Cus c = new Cus(); // 注意 Cus 对象只创建了一次,也就是说银行这个对象只创建了一次!
Thread t1 = new Thread(c);
Thread t2 = new Thread(c);
t1.start();
t2.start();
}
}
/*
sum=100
sum=200
sum=300
sum=400
sum=500
sum=600
*/
```
**多线程下的单例安全问题**
```java
/*
多线程下的单例
*/
// 饿汉式不存在多线程安全问题
class Single
{
private static final Single s = new Single();
private Single(){}
public static Single getInstance()
{
return s;
}
}
// 懒汉式
// 加入同步为了解决多线程安全问题。
// 加入双重判断是为了解决效率问题。
class Single
{
private static Single s = null;
private Single(){}
public static Single getInstance()
{
if(s==null)
{
synchronized(Single.class) // 同步代码块
{
if(s==null)
// -->0 -->1
s = new Single();
}
}
return s;
}
}
class SingleDemo
{
public static void main(String[] args)
{
System.out.println("Hello World!");
}
}
```
注意:synchronized 关键字不能被继承,如果在父类中的某个方法使用了synchronized关键字,而在子类中覆盖了这个方法,在子类中的这个方法默认情况下并不是同步的,而必须显式地在子类的这个方法中加上synchronized关键字才可以。
**死锁 - 同步嵌套(没看懂)**
```java
class Ticket implements Runnable
{
private int num = 100;
Object obj = new Object();
boolean flag = true;
public void run()
{
if(flag)
while(true)
{
synchronized(obj)
{
show();
}
}
else
while(true)
this.show();
}
public synchronized void show()
{
synchronized(obj)
{
if(num>0)
{
try{Thread.sleep(10);}catch (InterruptedException e){}
System.out.println(Thread.currentThread().getName()+".....sale...."+num--);
}
}
}
}
class DeadLockDemo
{
public static void main(String[] args)
{
Ticket t = new Ticket();
// System.out.println("t:"+t);
Thread t1 = new Thread(t);
Thread t2 = new Thread(t);
t1.start();
try{Thread.sleep(10);}catch(InterruptedException e){}
t.flag = false;
t2.start();
}
}
```
**静态同步函数的锁**
静态的同步函数使用的锁是该函数所属字节码文件对象,可以用 getClass 方法获取,也可以用当前类名.class 表示。
```java
class Ticket implements Runnable
{
private static int num = 100;
// Object obj = new Object();
boolean flag = true;
public void run()
{
// System.out.println("this:"+this.getClass());
if(flag)
while(true)
{
synchronized(Ticket.class)//(this.getClass()) 此处因为对静态变量进行访问,所以取得得锁是类
{
if(num>0)
{
try{Thread.sleep(10);}catch (InterruptedException e){}
System.out.println(Thread.currentThread().getName()+".....obj...."+num--); // 此处非静态方法可以访问静态变量
}
}
}
else
while(true)
this.show();
}
public static synchronized void show()
{
if(num>0)
{
try{Thread.sleep(10);}catch (InterruptedException e){}
System.out.println(Thread.currentThread().getName()+".....function...."+num--);
}
}
}
class StaticSynFunctionLockDemo
{
public static void main(String[] args)
{
Ticket t = new Ticket();
// Class clazz = t.getClass();
//
// Class clazz = Ticket.class;
// System.out.println("t:"+t.getClass());
Thread t1 = new Thread(t);
Thread t2 = new Thread(t);
t1.start();
try{Thread.sleep(10);}catch(InterruptedException e){}
t.flag = false;
t2.start();
}
}
```
**同步函数 vs 同步代码块**
同步函数和同步代码块的区别:
1. 同步函数的锁是固定的this
2. 同步代码块的锁是任意的对象
3. 建议使用同步代码块
```java
class Ticket implements Runnable
{
private int num = 100;
// Object obj = new Object();
boolean flag = true;
public void run()
{
// System.out.println("this:"+this);
if(flag)
while(true)
{
synchronized(this) // 此处因为对类变量进行访问,所以取得的锁是对象
{
if(num>0)
{
try{Thread.sleep(10);}catch (InterruptedException e){}
System.out.println(Thread.currentThread().getName()+".....obj...."+num--);
}
}
}
else
while(true)
this.show();
}
public synchronized void show()
{
if(num>0)
{
try{Thread.sleep(10);}catch (InterruptedException e){}
System.out.println(Thread.currentThread().getName()+".....function...."+num--);
}
}
}
class SynFunctionLockDemo
{
public static void main(String[] args)
{
Ticket t = new Ticket();
// System.out.println("t:"+t);
Thread t1 = new Thread(t);
Thread t2 = new Thread(t);
t1.start();
try{Thread.sleep(10);}catch(InterruptedException e){}
t.flag = false;
t2.start();
}
}
```
**总结**
1. 无论synchronized关键字加在方法上还是对象上,如果它作用的对象是非静态的,则它取得的锁是对象;如果synchronized作用的对象是一个静态变量或方法,则它取得的锁是对类,该类所有的对象同一把锁
2. 每个对象只有一个锁(lock)与之相关联,谁拿到这个锁谁就可以运行它所控制的那段代码
3. 实现同步是要很大的系统开销作为代价的,甚至可能造成死锁,所以尽量避免无谓的同步控制
### join()
Java 官方解释:Waits for this thread to die.
当调用了 Thread.Join()方法后,当前线程会立即被执行,其他所有的线程会被暂停执行。当这个线程执行完后,其他线程才会继续执行。
```java
class Demo implements Runnable
{
public void run()
{
for(int x=0; x<50; x++)
{
System.out.println(Thread.currentThread().toString()+"....."+x);
Thread.yield(); // 线程进入就绪状态,让出 CPU 使用权
}
}
}
class JoinDemo
{
public static void main(String[] args) throws Exception
{
Demo d = new Demo();
Thread t1 = new Thread(d);
Thread t2 = new Thread(d);
t1.start();
t2.start();
t2.setPriority(Thread.MAX_PRIORITY); // 设置线程运行级别
t1.join(); // t1 先执行完再说
for(int x=0; x<50; x++)
{
System.out.println(Thread.currentThread()+"....."+x);
}
}
}
```
### 线程间通信
线程间通讯:多个线程在处理同一资源,但是任务却不同。
生产者和消费者,就是一种典型的线程间通信。
```java
//资源
class Resource
{
String name;
String sex;
}
//输入
class Input implements Runnable
{
Resource r ;
// Object obj = new Object();
Input(Resource r)
{
this.r = r;
}
public void run()
{
int x = 0;
while(true)
{
synchronized(r)
{
if(x==0)
{
r.name = "mike";
r.sex = "nan";
}
else
{
r.name = "丽丽";
r.sex = "女女女女女女";
}
}
x = (x+1)%2;
}
}
}
//输出
class Output implements Runnable
{
Resource r;
// Object obj = new Object();
Output(Resource r)
{
this.r = r;
}
public void run()
{
while(true)
{
synchronized(r)
{
System.out.println(r.name+"....."+r.sex);
}
}
}
}
class ResourceDemo
{
public static void main(String[] args)
{
//创建资源。
Resource r = new Resource();
//创建任务。
Input in = new Input(r);
Output out = new Output(r);
//创建线程,执行路径。
Thread t1 = new Thread(in);
Thread t2 = new Thread(out);
//开启线程
t1.start();
t2.start();
}
}
```
上面的代码只是一个演示代码,没有进行线程间的同步,只是一种理想化的生产消费。下面加入 wait 和 notify 进行进程之间的协作。
### wait / notify
等待/唤醒机制。
涉及的方法:
1. wait(): 让线程处于冻结(阻塞)状态,被wait的线程会被存储到线程池中
2. notify(): Wakes up a single thread that is waiting on this object's monitor.
3. notifyAll(): Wakes up all threads that are waiting on this object's monitor.
这些方法都必须定义在同步中。因为这些方法是用于操作线程状态的方法。必须要明确到底操作的是哪个锁上的线程。
以上三个方法,都是定义在 Object 基类中的类方法。因为这些方法是监视器的方法。监视器其实就是锁。锁可以是任意的对象,任意的对象调用的方式一定定义在Object类中。
**一个生产者和一个消费者**
```java
//资源
class Resource
{
String name;
String sex;
boolean flag = false;
}
//输入
class Input implements Runnable
{
Resource r ;
// Object obj = new Object();
Input(Resource r)
{
this.r = r;
}
public void run()
{
int x = 0;
while(true) // 这个线程一直跑
{
synchronized(r) // r 当成一把 lock
{
if(r.flag) // 有资源了,就阻塞
try{r.wait();}catch(InterruptedException e){}
if(x==0) // 生产者交替生产两个产品:mike 和 丽丽
{
r.name = "mike";
r.sex = "man";
}
else
{
r.name = "丽丽";
r.sex = "女女女女女女";
}
r.flag = true; // 标记有资源,然后环境消费者来消费
r.notify();
}
x = (x+1)%2;
}
}
}
//输出
class Output implements Runnable
{
Resource r;
// Object obj = new Object();
Output(Resource r)
{
this.r = r;
}
public void run()
{
while(true)
{
synchronized(r)
{
if(!r.flag) // 没资源,就阻塞,等有资源再消费
try{r.wait();}catch(InterruptedException e){}
System.out.println("消费:" + r.name+"....."+r.sex); // 有资源,消费 r
r.flag = false; // 消费完后,置空,然后唤醒沉睡的生产者进程
r.notify();
}
}
}
}
class ResourceDemo2
{
public static void main(String[] args)
{
//创建资源。
Resource r = new Resource();
//创建任务。
Input in = new Input(r);
Output out = new Output(r);
//创建线程,执行路径。
Thread t1 = new Thread(in);
Thread t2 = new Thread(out);
//开启线程
t1.start();
t2.start();
}
}
```
**另一种实现**
```java
class Resource
{
private String name;
private String sex;
private boolean flag = false;
public synchronized void set(String name,String sex)
{
if(flag)
try{this.wait();}catch(InterruptedException e){}
this.name = name;
this.sex = sex;
flag = true;
this.notify();
}
public synchronized void out()
{
if(!flag)
try{this.wait();}catch(InterruptedException e){}
System.out.println(name+"...+...."+sex);
flag = false;
notify();
}
}
//输入
class Input implements Runnable
{
Resource r ;
// Object obj = new Object();
Input(Resource r)
{
this.r = r;
}
public void run()
{
int x = 0;
while(true)
{
if(x==0)
{
r.set("mike","nan");
}
else
{
r.set("丽丽","女女女女女女");
}
x = (x+1)%2;
}
}
}
//输出
class Output implements Runnable
{
Resource r;
// Object obj = new Object();
Output(Resource r)
{
this.r = r;
}
public void run()
{
while(true)
{
r.out();
}
}
}
class ResourceDemo3
{
public static void main(String[] args)
{
//创建资源。
Resource r = new Resource();
//创建任务。
Input in = new Input(r);
Output out = new Output(r);
//创建线程,执行路径。
Thread t1 = new Thread(in);
Thread t2 = new Thread(out);
//开启线程
t1.start();
t2.start();
}
}
```
实际上,第一个例子才是最恰当的,生产和消费的行为被封装在了生产者和消费者上,而第二个例子,生产和消费的行为被绑定到了商品上,不符合常识。
**wait 和 sleep 的区别**
区别:
1. wait可以指定时间也可以不指定。sleep必须指定时间
2. 在同步中时,对cpu的执行权和锁的处理不同
wait:释放执行权,释放锁。
sleep:释放执行权,不释放锁。 (也就是不释放临界区,其他线程干等着,不符合让权等待)
3.
### 多生产者与消费者
多生产者,多消费者的问题。
if 判断标记,只有一次,会导致不该运行的线程运行了。出现了数据错误的情况。
while 判断标记,解决了线程获取执行权后,是否要运行!
`notify`: 只能唤醒一个线程,如果本方唤醒了本方,没有意义。而且while判断标记+notify会导致死锁。
`notifyAll`: 解决了本方线程一定会唤醒对方线程的问题。
```java
class Resource
{
private String name;
private int count = 1;
private boolean flag = false;
public synchronized void set(String name) // 生产
{
while(flag)
try{this.wait();}catch(InterruptedException e){} // 有鸭子,就进入阻塞状态
this.name = name + count;// 没鸭,生产 烤鸭1 烤鸭2 烤鸭3
count++; //2 3 4
System.out.println(Thread.currentThread().getName()+"... 生产者..."+this.name); // 生产烤鸭1 生产烤鸭2 生产烤鸭3
flag = true; // 表示有鸭子
notifyAll(); // 唤醒所有阻塞线程,生产者被唤醒则 wait,消费者被唤醒,则消费
}
public synchronized void out()// 消费
{
while(!flag)
try{this.wait();}catch(InterruptedException e){} // 没鸭子,进入阻塞状态
System.out.println(Thread.currentThread().getName()+"... 消费者........"+this.name);//消费烤鸭1
flag = false;
notifyAll(); // 唤醒了对方的所有线程
}
}
class Producer implements Runnable
{
private Resource r;
Producer(Resource r)
{
this.r = r;
}
public void run()
{
while(true)
{
r.set("烤鸭");
}
}
}
class Consumer implements Runnable
{
private Resource r;
Consumer(Resource r)
{
this.r = r;
}
public void run()
{
while(true)
{
r.out();
}
}
}
class ProducerConsumerDemo
{
public static void main(String[] args)
{
Resource r = new Resource();
Producer pro = new Producer(r);
Consumer con = new Consumer(r);
Thread t0 = new Thread(pro);
Thread t1 = new Thread(pro);
Thread t2 = new Thread(con);
Thread t3 = new Thread(con);
t0.start();
t1.start();
t2.start();
t3.start();
}
}
```
上面这个例子,仍然还是一个简单的生产一个,消费一个的例子,只是加入了多个生产者和消费者。
### 停止线程
停止线程:
1. `interrupt` 方法
2. run 方法结束
怎么控制线程的任务结束呢?
任务中都会有循环结构,只要控制住循环就可以结束任务。控制循环通常就用定义标记来完成。
但是如果线程处于了阻塞状态,无法读取标记。如何结束呢?可以使用 `interrupt()` 方法将线程从冻结状态强制恢复到运行状态中来,让线程具备cpu的执行资格。强制动作会发生 InterruptedException,要处理。
```java
class StopThread implements Runnable
{
private boolean flag = true;
public synchronized void run()
{
while(flag)
{
try
{
wait(); //t0 t1
}
catch (InterruptedException e)
{
System.out.println(Thread.currentThread().getName()+"....."+e);
flag = false;
}
System.out.println(Thread.currentThread().getName()+ "......++++"); // 被唤醒后,这句话还会执行
}
}
public void setFlag()
{
flag = false;
}
}
class StopThreadDemo
{
public static void main(String[] args)
{
StopThread st = new StopThread();
Thread t1 = new Thread(st);
Thread t2 = new Thread(st);
t1.start();
t2.setDaemon(true); // t2 设置为守护进程,主线程 main 和 用户线程 t1 执行完后,自动结束
t2.start();
int num = 1;
for(;;)
{
if(++num==50)
{
// st.setFlag();
t1.interrupt();
// t2.interrupt();
break;
}
System.out.println("main...."+num);
}
System.out.println("over");
}
}
```
**守护线程和用户线程**
`setDaemon(true)`
Marks this thread as either a [daemon](https://docs.oracle.com/javase/8/docs/api/java/lang/Thread.html#isDaemon--) thread or a user thread. The Java Virtual Machine exits when the only threads running are all daemon threads.
守护线程类似于守护进程,优先级低于用户线程和用户进程。
### 多线程总结
```
多线程总结:
1,进程和线程的概念。
|--进程:
|--线程:
2, jvm中的多线程体现。
|--主线程,垃圾回收线程,自定义线程。以及他们运行的代码的位置。
3,什么时候使用多线程,多线程的好处是什么?创建线程的目的?
|--当需要多部分代码同时执行的时候,可以使用。
4,创建线程的两种方式。★★★★★
|--继承 Thread
|--步骤
|--实现 Runnable
|--步骤
|--两种方式的区别?
5,线程的5种状态。
对于执行资格和执行权在状态中的具体特点。
|--被创建:
|--运行:
|--冻结:
|--临时阻塞:
|--消亡:
6,线程的安全问题。★★★★★
|--安全问题的原因:
|--解决的思想:
|--解决的体现: synchronized
|--同步的前提:但是加上同步还出现安全问题,就需要用前提来思考。
|--同步的两种表现方法和区别:
|--同步的好处和弊端:
|--单例的懒汉式。
|--死锁。
7,线程间的通信。等待/唤醒机制。
|--概念:多个线程,不同任务,处理同一资源。
|--等待唤醒机制。使用了锁上的 wait notify notifyAll. ★★★★★
|--生产者/消费者的问题。并多生产和多消费的问题。 while判断标记。用notifyAll唤醒对方。 ★
★★★★
|--JDK1.5以后出现了更好的方案,★★★
Lock接口替代了synchronized
Condition接口替代了Object中的监视方法,并将监视器方法封装成了Condition
和以前不同的是,以前一个锁上只能有一组监视器方法。现在,一个Lock锁上可以多组监视器方法对
象。
可以实现一组负责生产者,一组负责消费者。
|--wait和sleep的区别。★★★★★
8,停止线程的方式。
|--原理:
|--表现: --中断。
9,线程常见的一些方法。
|--setDaemon()
|--join();
|--优先级
|--yield();
|--在开发时,可以使用匿名内部类来完成局部的路径开辟。
```
## 常用类 API
### String
**构造函数**
```java
public class StringConstructorDemo {
/**
* @param args
*/
public static void main(String[] args) {
/*
* 将字节数组或者字符数组转成字符串可以通过String类的构造函数完成。
*/
stringConstructorDemo2();
stringConstructorDemo();
}
private static void stringConstructorDemo2() {
char[] arr = {'w','a','p','q','x'};
String s = new String(arr,1,3); // apq
System.out.println("s="+s);
}
public static void stringConstructorDemo() {
String s = new String(); // 等价于 String s = ""; 不等效String s = null;
byte[] arr = {97,66,67,68}; // aBCD
String s1 = new String(arr);
System.out.println("s1="+s1);
}
}
```
**字符串对象一旦被初始化就不会被改变**
字符串在内存中会存储到两个地方:
1. 常量池
```java
String s = "abc"; // "abc"存储在字符串常量池中。
String s1 = "abc";
System.out.println(s==s1); // true
```
2. 堆内存
```java
String s = "abc"; // 创建一个字符串对象在常量池中。
String s1 = new String("abc"); // 创建两个对象一个new一个字符串对象在堆内存中。
System.out.println(s==s1); // false
System.out.println(s.equals(s1));
```
**String 类方法及使用**
```java
public class StringMethodDemo {
/**
* @param args
*/
public static void main(String[] args) {
/*
* 按照面向对象的思想对字符串进行功能分类。
* "abcd"
*
* 1,获取:
* 1.1 获取字符串中字符的个数(长度).
* int length();
* 1.2 根据位置获取字符。
* char charAt(int index);
* 1.3 根据字符获取在字符串中的第一次出现的位置.
* int indexOf(int ch)
* int indexOf(int ch,int fromIndex):从指定位置进行ch的查找第一次出现位置
* int indexOf(String str);
* int indexOf(String str,int fromIndex);
* 根据字符串获取在字符串中的第一次出现的位置.
* int lastIndexOf(int ch)
* int lastIndexOf(int ch,int fromIndex):从指定位置进行ch的查找第一次出现位置
* int lastIndexOf(String str);
* int lastIndexOf(String str,int fromIndex);
* 1.4 获取字符串中一部分字符串。也叫子串.
* String substring(int beginIndex, int endIndex)//包含begin 不包含end 。
* String substring(int beginIndex);
*
*
* 2,转换。
* 2.1 将字符串变成字符串数组(字符串的切割)
* String[] split(String regex):涉及到正则表达式.
* 2.2 将字符串变成字符数组。
* char[] toCharArray();
* 2.3 将字符串变成字节数组。
* byte[] getBytes();
* 2.4 将字符串中的字母转成大小写。
* String toUpperCase():大写
* String toLowerCase():小写
* 2.5 将字符串中的内容进行替换
* String replace(char oldch,char newch);
* String replace(String s1,String s2);
* 2.6 将字符串两端的空格去除。
* String trim();
* 2.7 将字符串进行连接 。
* String concat(string);
*
* 3,判断
* 3.1 两个字符串内容是否相同啊?
* boolean equals(Object obj);
* boolean equalsIgnoreCase(string str);忽略大写比较字符串内容。
* 3.2 字符串中是否包含指定字符串?
* boolean contains(string str);
* 3.3 字符串是否以指定字符串开头。是否以指定字符串结尾。
* boolean startsWith(string);
* boolean endsWith(string);
*
* 4,比较。
*
*/
stringMethodDemo_4();
// System.out.println("abc".concat("kk"));
// System.out.println("abc"+"kk");
// System.out.println(String.valueOf(4)+1);
// System.out.println(""+4+1);
}
private static void stringMethodDemo_4() {
System.out.println("abc".compareTo("aqz")); // -15
/*
* int num = 'b' - 'q';
* System.out.println(String.valueOf(num));
* */
}
private static void stringMethodDemo_3() {
String s = "abc";
System.out.println(s.equals("ABC".toLowerCase()));
System.out.println(s.equalsIgnoreCase("ABC"));
System.out.println(s.contains("cc"));
String str = "ArrayDemo.java";
System.out.println(str.startsWith("Array"));
System.out.println(str.endsWith(".java"));
System.out.println(str.contains("Demo"));
}
private static void stringMethodDemo_2() {
String s = "张三,李四,王五";
String[] arr = s.split(",");
for (int i = 0; i < arr.length; i++) {
System.out.println(arr[i]);
}
char[] chs = s.toCharArray();
for (int i = 0; i < chs.length; i++) {
System.out.println(chs[i]);
}
s = "ab你";
byte[] bytes = s.getBytes();
for (int i = 0; i < bytes.length; i++) {
System.out.println(bytes[i]);
}
System.out.println("Abc".toUpperCase());
String s1 = "java";
String s2 = s1.replace('q', 'z');
System.out.println(s1==s2);//true
System.out.println("-"+" ab c ".trim()+"-");
}
private static void stringMethodDemo_1() {
String s = "abcdae";
System.out.println("length:"+s.length());//6
System.out.println("char:"+s.charAt(2));//c//StringIndexOutOfBoundsException
System.out.println("index:"+s.indexOf('k'));//0//-1 我们可以根据-1,来判断该字符或者字符串是否存在。
System.out.println("lastIndex:"+s.lastIndexOf('a'));//4
System.out.println("substring:"+s.substring(2,4));
}
}
```
**字符串比较**
```java
/*
* 1,给定一个字符串数组。按照字典顺序进行从小到大的排序。
* {"nba","abc","cba","zz","qq","haha"}
*
* 思路:
* 1,对数组排序。可以用选择,冒泡都行。
* 2,for嵌套和比较以及换位。
* 3,问题:以前排的是整数,比较用的比较运算符,可是现在是字符串对象。
* 字符串对象怎么比较呢?爽了,对象中提供了用于字符串对象比较的功能。
*/
public class StringTest_1 {
/**
* @param args
*/
public static void main(String[] args) {
String[] arr = { "nba", "abc", "cba", "zz", "qq", "haha" };
printArray(arr);
sortString(arr);
printArray(arr);
}
public static void sortString(String[] arr) {
for (int i = 0; i < arr.length - 1; i++) {
for (int j = i + 1; j < arr.length; j++) {
if(arr[i].compareTo(arr[j])>0) // 字符串比较用compareTo方法
swap(arr,i,j);
}
}
}
private static void swap(String[] arr, int i, int j) {
String temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
public static void printArray(String[] arr) {
System.out.print("[");
for (int i = 0; i < arr.length; i++) {
if (i != arr.length - 1)
System.out.print(arr[i] + ", ");
else
System.out.println(arr[i] + "]");
}
}
}
```
**字符串格式化**
MessageFormat
```java
String deleteSql =
"delete from \n" +
" {0} \n" +
"where \n" +
" {1} in (\n" +
" select \n" +
" {1} \n" +
" from \n" +
" (select * from {0}) as {0}_copy \n" +
" left join \n" +
" (select *, \"{4}\" as \"{4}\" from {2}) as {2}_copy \n" +
" on \n" +
" {0}_copy.{1} = {2}_copy.{3} \n" +
" where \n" +
" {2}_copy.{4} is NULL\n" +
" );";
deleteSql = MessageFormat.format(deleteSql, mainTableName, mainPrKeyName, subTableName, subPrKeyName, joinNULLFlag);
```
jdk 的 bug,MessageFormat doesn't replace {0} if followed by word with apostrophe。对于单引号,需要用两个单引号来显示:
```java
String deleteSql =
"delete from \n" +
" {0} \n" +
"where \n" +
" {1} in (\n" +
" select \n" +
" {1} \n" +
" from \n" +
" (select * from {0}) {0}_copy \n" +
" left join \n" +
" (select {2}.*, ''{4}'' {4} from {2}) {2}_copy \n" +
" on \n" +
" {0}_copy.{1} = {2}_copy.{3} \n" +
" where \n" +
" {2}_copy.{4} is NULL\n" +
" );";
```
StringBuffer 可以传入 bool 值 和 数值,统一转成字符串再存入 StringBuffer.
```java
public class StringBufferDemo {
/**
* @param args
*/
public static void main(String[] args) {
/*
* StringBuffer:就是字符串缓冲区。
* 用于存储数据的容器。
* 特点:
* 1,长度的可变的。
* 2,可以存储不同类型数据。
* 3,最终要转成字符串进行使用。
* 4,可以对字符串进行修改。
*
* 既然是一个容器对象。应该具备什么功能呢?
* 1,添加:
* StringBuffer append(data);
* StringBuffer insert(index,data);
* 2,删除:
* StringBuffer delete(start,end):包含头,不包含尾。
* StringBuffer deleteCharAt(int index):删除指定位置的元素
* 3,查找:
* char charAt(index);
* int indexOf(string);
* int lastIndexOf(string);
* 4, 修改:
* StringBuffer replace(start,end,string);
* void setCharAt(index,char);
*
* 增删改查 C(create)U(update)R(read)D(delete)
*/
bufferMethodDemo();
}
private static void bufferMethodDemo_2() {
StringBuffer sb = new StringBuffer("abce");
// sb.delete(1, 3);//ae
//清空缓冲区。
// sb.delete(0,sb.length());
// sb = new StringBuffer();
// sb.replace(1, 3, "nba");
// sb.setCharAt(2, 'q');
// sb.setLength(10);
// System.out.println("sb:"+sb);
// System.out.println("len:"+sb.length());
System.out.println(sb.reverse());
}
private static void bufferMethodDemo_1() {
StringBuffer sb = new StringBuffer("abce");
// sb.append("xixi");
sb.insert(2, "qq");
System.out.println(sb.toString());
}
public static void bufferMethodDemo(){
//创建缓冲区对象。
StringBuffer sb = new StringBuffer();
sb.append(4).append(false); //.append("haha");
sb.insert(1, "haha");
// sb.append(true);
System.out.println(sb);
}
}
```
```java
/*
* jdk1.5以后出现了功能和StringBuffer一模一样的对象。就是StringBuilder
*
* 不同的是:
* StringBuffer 是线程同步的。通常用于多线程。
* StringBuilder是线程不同步的。通常用于单线程。 它的出现提高效率。
*
* jdk升级:
* 1,简化书写。
* 2,提高效率。
* 3,增加安全性。
*/
```
### 包装类
```java
package com.wansho.hellojava;
public class WrapperDemo {
/**
* @param args
*/
public static void main(String[] args) {
/*
* 基本数据类型对象包装类。
* 为了方便操作基本数据类型值,将其封装成了对象,在对象中定义了属性和行为丰富了该数据的操
* 作。
* 用于描述该对象的类就称为基本数据类型对象包装类。
*
* byte Byte
* short Short
* int Integer
* long Long
* float Float
* double Double
* char Character
* booleanBoolean
*
* 该包装对象主要用基本类型和字符串之间的转换。
*
* 基本类型--->字符串
* 1,基本类型数值 + ""
* 2,用 String 类中的静态方法 valueOf(基本类型数值);
* 3,用 Integer 的静态方法 valueOf(基本类型数值);
*
* 字符串--->基本类型
* 1,使用包装类中的静态方法 xxx parseXxx("xxx类型的字符串");*****
* int parseInt("intstring");
* long parseLong("longstring");
* boolean parseBoolean("booleanstring");
* 只有Character没有parse方法
* 2,如果字符串被Integer进行对象的封装。
* 可使用另一个非静态的方法, intValue();
* 将一个Integer对象转成基本数据类型值。
*/
System.out.println(Integer.MAX_VALUE);
System.out.println(Integer.toBinaryString(-6));
int num = 4;
Integer i = new Integer(5);
int x = Integer.parseInt("123");
System.out.println(Integer.parseInt("123")+1);
i = new Integer("123");
System.out.println(i.intValue());
/*
* 整数具备不同的进制体现。
*
* 十进制-->其他进制。
* toBinaryString
* toOctalString
* toHexString
*
* 其他进制-->十进制。
* parseInt("string",radix)
*
*/
// 十进制-->其他进制。
System.out.println(Integer.toBinaryString(60));
System.out.println(Integer.toOctalString(60));
System.out.println(Integer.toHexString(60));
// System.out.println(Integer.toString(60,16));
// 其他进制-->十进制。
// System.out.println(Integer.parseInt("3c",16));
Integer a = new Integer("89");
Integer b = new Integer(300);
System.out.println(a==b);
System.out.println(a.equals(b));
// System.out.println(3>3);
System.out.println(a.compareTo(b));
}
}
```
**自动装箱拆箱**
```java
public class WrapperDemo2 {
public static void main(String[] args) {
int num = 4;
num = num + 5;
Integer i = 4; // i = new Integer(4); 自动装箱 简化书写。
i = i + 6; // i = new Integer(i.intValue() + 6); // i.intValue() 自动拆箱
// show(55);//
Integer a = new Integer(128);
Integer b = new Integer(128);
System.out.println(a==b); // false 两个对象
System.out.println(a.equals(b)); // true 值是相同的
Integer x = 129; // jdk1.5以后,自动装箱,如果装箱的是一个字节,那么该数据会被共享不会重新开辟空间。
Integer y = 129;
System.out.println(x==y); // false
System.out.println(x.equals(y)); //true
}
}
```
```java
import java.util.Arrays;
/*
* 对一个字符串中的数值进行从小到大的排序。
*
* "20 78 9 -7 88 36 29"
*
* 思路:
* 1,排序, 我很熟。可是我只熟int。
* 2,如何获取到这个字符串中的这些需要排序的数值?
* 发现这个字符串中其实都是空格来对数值进行分隔的。
* 所以就想到用字符串对象的切割方法将大串变成多个小串。
* 3,数值最终变成小字符串,怎么变成一个int数呢?135
* 字符串-->基本类型 可以使用包装类。
*
*
*/
public class WrapperTest {
private static final String SPACE_SEPARATOR = " ";
/**
* @param args
*/
public static void main(String[] args) {
String numStr = "20 78 9 -7 88 36 29";
System.out.println(numStr);
numStr = sortStringNumber(numStr);
System.out.println(numStr);
}
/**
*
* @param numStr
* @return
*/
public static String sortStringNumber(String numStr) {
//1,将字符串变成字符串数组。
String[] str_arr = stringToArray(numStr);
//2,将字符串数组变成int数组。
int[] num_arr = toIntArray(str_arr);
//3,对int数组排序。
mySortArray(num_arr);
//4,将排序后的int数组变成字符串。
String temp = arrayToString(num_arr);
return temp;
}
public static String arrayToString(int[] num_arr) {
StringBuilder sb = new StringBuilder();136
for(int x = 0; x<num_arr.length; x++){
if(x!=num_arr.length-1)
sb.append(num_arr[x]+SPACE_SEPARATOR);
else
sb.append(num_arr[x]);
}
return sb.toString();
}
public static void mySortArray(int[] num_arr) {
Arrays.sort(num_arr);
}
public static int[] toIntArray(String[] str_arr) {
int[] arr = new int[str_arr.length];
for (int i = 0; i < arr.length; i++) {
arr[i] = Integer.parseInt(str_arr[i]);
}
return arr;
}
/**
* @param numStr
*/
public static String[] stringToArray(String numStr) {
String[] str_arr = numStr.split(SPACE_SEPARATOR);
return str_arr;
}
}
```
### 泛型
在jdk1.5后,使用泛型来接收类中要操作的引用数据类型。
**泛型的作用**
[Oracle 泛型:工作原理及其重要性](https://www.oracle.com/cn/technical-resources/articles/java/juneau-generics.html)
在学习容器依赖,我一直忽视了两个很重要的点:
1. 容器可以同时存储不同类型的数据,例如 String 类型,Integer 类型,如果一个容器存储了不同类型的对象,不就乱套了
```java
ArrayList list = new ArrayList();
list.add("abc");
list.add(new Integer(19));
Iterator it = list.iterator();
while(it.hasNext()){
System.out.println(it.next() + "");
}
/*
abc
19
*/
```
2. 在定义容器变量的时候,并没有定义该容器存储的对象类型,这不对劲
在 C 语言中,我们定义结构体数组的时候,都会指定数组存储的对象类型,Java 的容器虽然不同于数组,但是其在定义容器的时候,不定义容器存储的数据类型,就感觉不对劲。
泛型相当于是定义了容器的存储类型
Generics 的具体介绍,参考 [Detailed-Generics](detailed-generics.md)
```java
public class Tool<QQ>{ // 泛型类,类中操作的引用数据类型不确定的时候,就使用泛型来表示。
private QQ q;
public QQ getObject() {
return q;
}
public void setObject(QQ object) {
this.q = object;
}
/**
* 将泛型定义在方法上。
* @param str
*/
public <W> void show(W str){
System.out.println("show : "+str.toString());
}
public void print(QQ str){
System.out.println("print : "+str);
}
/**
* 当方法静态时,不能访问类上定义的泛型。如果静态方法使用泛型,
* 只能将泛型定义在方法上。
* @param obj
*/
public static <Y> void method(Y obj){
System.out.println("method:"+obj);
}
}
```
**<? super E> <? extend E>**
```java
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
import cn.itcast.p2.bean.Person;
import cn.itcast.p2.bean.Student;
import cn.itcast.p2.bean.Worker;
public class GenericAdvanceDemo2 {
/**
* @param args
*/
public static void main(String[] args) {
ArrayList<Person> al = new ArrayList<Person>();
al.add(new Person("abc",30));
al.add(new Person("abc4",34));
ArrayList<Student> al2 = new ArrayList<Student>();
al2.add(new Student("stu1",11));
al2.add(new Student("stu2",22));
ArrayList<String> al3 = new ArrayList<String>();
al3.add("stu3331");
al3.add("stu33332");
printCollection(al2);
printCollection(al);
}
/**
* 迭代并打印集合中元素。
*
* 可以对类型进行限定:
* ? extends E:接收E类型或者E的子类型对象。上限!
*
* ? super E :接收E类型或者E的父类型。下限!
* @param al
*/
public static void printCollection(Collection<? extends Person> al)
{//Collection<Dog> al = new ArrayList<Dog>()
Iterator<? extends Person> it = al.iterator();
while(it.hasNext()){
// T str = it.next();
// System.out.println(str);
// System.out.println(it.next().toString());
Person p = it.next();
System.out.println(p.getName()+":"+p.getAge());
}
}
public static void printCollection(Collection<? super Student> al){
Iterator<? super Student> it = al.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
}
/*
* class TreeSet<Worker>
* {
* Tree(Comparator<? super Worker> comp);
* }
*
* 什么时候用下限呢?通常对集合中的元素进行取出操作时,可以是用下限。
*
*/
class CompByName implements Comparator<Person>{
@Override
public int compare(Person o1, Person o2) {
int temp = o1.getName().compareTo(o2.getName());
return temp==0? o1.getAge()-o2.getAge():temp;
}
}
class CompByStuName implements Comparator<Student>{
@Override
public int compare(Student o1, Student o2) {
int temp = o1.getName().compareTo(o2.getName());
return temp==0? o1.getAge()-o2.getAge():temp;
}
}
class CompByWorkerName implements Comparator<Worker>{
@Override
public int compare(Worker o1, Worker o2) {
int temp = o1.getName().compareTo(o2.getName());
return temp==0? o1.getAge()-o2.getAge():temp;
}
}
```
存储用上限:
```java
package cn.itcast.p5.generic.advance.demo;
import java.util.ArrayList;
import cn.itcast.p2.bean.Person;
import cn.itcast.p2.bean.Student;
import cn.itcast.p2.bean.Worker;
public class GenericAdvanceDemo3 {
public static void main(String[] args) {
ArrayList<Person> al1 = new ArrayList<Person>();
al1.add(new Person("abc", 30));
al1.add(new Person("abc4", 34));
ArrayList<Student> al2 = new ArrayList<Student>();
al2.add(new Student("stu1", 11));
al2.add(new Student("stu2", 22));
ArrayList<Worker> al3 = new ArrayList<Worker>();
al3.add(new Worker("stu1", 11));
al3.add(new Worker("stu2", 22));
ArrayList<String> al4 = new ArrayList<String>();
al4.add("abcdeef");
// al1.addAll(al4);//错误,类型不匹配。
al1.addAll(al2);
al1.addAll(al3);
System.out.println(al1.size());
}
}
/*
* 一般在存储元素的时候都是用上限,因为这样取出都是按照上限类型来运算的,不会出现类型安全隐患。
*/
class MyCollection<E> {
public void add(E e) {
}
public void addAll(MyCollection<? extends E> e) {
}
}
```
取出用下限:
```java
package cn.itcast.p5.generic.advance.demo;
import java.util.Comparator;
import java.util.Iterator;
import java.util.TreeSet;
import cn.itcast.p2.bean.Person;
import cn.itcast.p2.bean.Student;
import cn.itcast.p2.bean.Worker;
public class GenericAdvanceDemo4 {
public static void main(String[] args) {
TreeSet<Person> al1 = new TreeSet<Person>(new CompByName());
al1.add(new Person("abc4",34));
al1.add(new Person("abc1",30));
al1.add(new Person("abc2",38));
TreeSet<Student> al2 = new TreeSet<Student>(new CompByName());
al2.add(new Student("stu1",11));
al2.add(new Student("stu7",20));
al2.add(new Student("stu2",22));
TreeSet<Worker> al3 = new TreeSet<Worker>();
al3.add(new Worker("stu1",11));
al3.add(new Worker("stu2",22));
TreeSet<String> al4 = new TreeSet<String>();
al4.add("abcdeef");
// al1.addAll(al4);//错误,类型不匹配。
// al1.addAll(al2);
// al1.addAll(al3);
// System.out.println(al1.size());
Iterator<Student> it = al2.iterator();
while(it.hasNext()){
System.out.println(it.next());
}
}
}
/*
* class TreeSet<Worker>
* {
* Tree(Comparator<? super Worker> comp);
* }
*
* 什么时候用下限呢?通常对集合中的元素进行取出操作时,可以是用下限。
*
*/
class CompByName implements Comparator<Person>{
@Override
public int compare(Person o1, Person o2) {
int temp = o1.getName().compareTo(o2.getName());
return temp==0? o1.getAge()-o2.getAge():temp;
}
}
class CompByStuName implements Comparator<Student>{
@Override
public int compare(Student o1, Student o2) {
int temp = o1.getName().compareTo(o2.getName());
return temp==0? o1.getAge()-o2.getAge():temp;
}
}
class CompByWorkerName implements Comparator<Worker>{
@Override
public int compare(Worker o1, Worker o2) {
int temp = o1.getName().compareTo(o2.getName());
return temp==0? o1.getAge()-o2.getAge():temp;
}
}
```
#### 函数的可变参数
```java
public class ParamterDemo {
/**
* @param args
*/
public static void main(String[] args) {
// int sum = add(4,5);
// System.out.println("sum="+sum);
// int sum1 = add(4,5,6);
// System.out.println("sum1="+sum1);
// int[] arr = {5,1,4,7,3};
// int sum = add(arr);
// System.out.println("sum="+sum);
// int[] arr1 = {5,1,4,7,3,9,8,7,6};
// int sum1 = add(arr1);
// System.out.println("sum1="+sum1);
int sum = newAdd(5,1,4,7,3);
System.out.println("sum="+sum);
int sum1 = newAdd(5,1,2,7,3,9,8,7,6);
System.out.println("sum1="+sum1);
}
/*
* 函数的可变参数。
* 其实就是一个数组,但是接收的是数组的元素。
* 自动将这些元素封装成数组。简化了调用者的书写。
* 注意:可变参数类型,必须定义在参数列表的结尾。
*/
public static int newAdd(int a,int... arr){
int sum = 0;
for (int i = 0; i < arr.length; i++) {
sum+=arr[i];
}
return sum;
// System.out.println(arr);
// return 0;
}
public static int add(int[] arr){
int sum = 0;
for (int i = 0; i < arr.length; i++) {
sum+=arr[i];
}
return sum;
}
public static int add(int a,int b){
return a+b;
}
public static int add(int a,int b,int c){
return a+b+c;
}
}
```
#### 静态导入
```java
import java.util.ArrayList;
import java.util.List;
import static java.util.Collections.*;//静态导入,其实导入的是类中的静态成员。
//import static java.util.Collections.max;//静态导入,其实到入的是类中的静态成员。
import static java.lang.System.*;
public class StaticImportDemo {
/**
* @param args
*/
public static void main(String[] args) {
List<String> list = new ArrayList<String>();
list.add("abc3");
list.add("abc7");
list.add("abc1");
out.println(list);
sort(list);
System.out.println(list);
String max = max(list);
System.out.println("max="+max);
}
}
```
#### 日期类
Demo1
```java
package com.wansho.hellojava;
import java.util.Calendar;
public class CalendarDemo {
public static void main(String[] args) {
Calendar c = Calendar.getInstance();
int year = 2012;
showDays(year);
}
public static void showDays(int year) {
Calendar c = Calendar.getInstance();
c.set(year, 2, 1); // java Calendar 中的月数是从 0 开始计数,此处输入的时间是 3 月 1 日
c.add(Calendar.DAY_OF_MONTH, -1);
showDate(c);
}
public static void showDate(Calendar c) {
int year = c.get(Calendar.YEAR);
int month = c.get(Calendar.MONTH)+1;
int day = c.get(Calendar.DAY_OF_MONTH);
int week = c.get(Calendar.DAY_OF_WEEK);
System.out.println(year+"年"+month+"月"+day+"日"+getWeek(week));
}
public static String getWeek(int i) {
String[] weeks = {"","星期日","星期一","星期二","星期三","星期四","星期五","星期六"};
return weeks[i];
}
}
```
Demo2
```java
import java.text.DateFormat;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
public class DateDemo {
/**
* @param args
* @throws ParseException
*/
public static void main(String[] args) throws ParseException {
methodDemo_3();
}
/**
* 将日期格式的字符串-->日期对象。
* 使用的是 DateFormat 类中的 parse() 方法。
*
* @throws ParseException
*/
public static void methodDemo_3() throws ParseException {
String str_date = "2012年4月19日";
str_date = "2011---8---17";
DateFormat dateFormat = DateFormat.getDateInstance(DateFormat.LONG);
dateFormat = new SimpleDateFormat("yyyy---MM---dd");
Date date = dateFormat.parse(str_date);
System.out.println(date);
}
/**
* 对日期对象进行格式化。
* 将日期对象-->日期格式的字符串。
* 使用的是DateFormat类中的format方法。
*
*/
public static void methodDemo_2() {
Date date = new Date();
//获取日期格式对象。具体着默认的风格。 FULL LONG等可以指定风格。
DateFormat dateFormat = DateFormat.getDateInstance(DateFormat.LONG);
dateFormat = DateFormat.getDateTimeInstance(DateFormat.LONG,DateFormat.LONG);
// System.out.println(dateFormat);
//如果风格是自定义的如何解决呢?
dateFormat = new SimpleDateFormat("yyyy--MM--dd");
String str_date = dateFormat.format(date);
System.out.println(str_date);
}
/**
* 日期对象和毫秒值之间的转换。
*
* 毫秒值-->日期对象 :
* 1,通过Date对象的构造方法 new Date(timeMillis);
* 2,还可以通过setTime设置。
* 因为可以通过Date对象的方法对该日期中的各个字段(年月日等)进行操作。
*
* 日期对象-->毫秒值:
* 2, getTime方法。
* 因为可以通过具体的数值进行运算。
*/
public static void methodDemo_1() {
long time = System.currentTimeMillis();//
// System.out.println(time);//1335671230671
Date date = new Date();//将当前日期和时间封装成Date对象。
System.out.println(date);//Sun Apr 29 11:48:02 CST 2012
Date date2 = new Date(1335664696656l);//将指定毫秒值封装成Date对象。
System.out.println(date2);
}
}
```
Demo3
```java
import java.text.DateFormat;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
/* 练习:
* "2012-3-17"到"2012-4-6"
* 中间有多少天?
* 思路:
* 两个日期相减就哦了。
* 咋减呢?
* 必须要有两个可以进行减法运算的数。
* 能减可以是毫秒值。如何获取毫秒值?通过date对象。
* 如何获取date对象呢?可以将字符串转成date对象。
*
* 1,将日期格式的字符串转成Date对象。
* 2,将Date对象转成毫秒值。
* 3,相减,在变成天数
*
*/
public class DateTest {
/**
* @param args
* @throws ParseException
*/
public static void main(String[] args) throws ParseException {
String str_date1 = "2012-3-17";
String str_date2 = "2012-4-18";
test(str_date1,str_date2);
}
public static void test(String str_date1,String str_date2) throws ParseException
{
//1,将日期字符串转成日期对象。
//定义日期格式对象。
DateFormat dateFormat = DateFormat.getDateInstance();
dateFormat = new SimpleDateFormat("yyyy-MM-dd");
Date date1 = dateFormat.parse(str_date1);
Date date2 = dateFormat.parse(str_date2);
long time1 = date1.getTime();
long time2 = date2.getTime();
long time = Math.abs(time1-time2);
int day = getDay(time);
System.out.println(day);
}
private static int getDay(long time) {
int day = (int)(time/1000/60/60/24);
return day;
}
}
```
#### Math类
```java
import java.util.Random;
public class MathDemo {
public static void main(String[] args) {
/*
* Math:提供了操作数学运算的方法, 都是静态的。
* 常用的方法:
* ceil():返回大于参数的最小整数。 向上取整
* floor():返回小于参数的最大整数。向下取整
* round():返回四舍五入的整数。 四舍五入
* pow(a,b):a的b次方。
*/
double d1 = Math.ceil(12.56);
double d2 = Math.floor(12.56);
double d3 = Math.round(12.46);
// sop("d1="+d1);
// sop("d2="+d2);
// sop("d3="+d3);
// double d = Math.pow(10, 2);
// sop("d="+d);
Random r = new Random();
for (int i = 0; i < 10; i++) {
// double d = Math.ceil(Math.random()*10);
// double d = (int)(Math.random()*6+1);
// double d = (int)(r.nextDouble()*6+1);
int d = r.nextInt(6)+1;
System.out.println(d);
}
}
public static void sop(String string) {
System.out.println(string);
}
}
```
#### Runtime 类
Every Java application has a single instance of class `Runtime` that allows the application to interface with the environment in which the application is running. The current runtime can be obtained from the `getRuntime` method.
An application cannot create its own instance of this class.
```java
import java.io.IOException;
public class RuntimeDemo {
/**
* @param args
* @throws IOException
* @throws InterruptedException
*/
public static void main(String[] args) throws IOException, InterruptedException
{
/*
* Runtime:没有构造方法摘要,说明该类不可以创建对象。
* 又发现还有非静态的方法。说明该类应该提供静态的返回该类对象的方法。
* 而且只有一个,说明Runtime类使用了单例设计模式。
*
*/
Runtime r = Runtime.getRuntime();
// execute: 执行。 xxx.exe
Process p = r.exec("notepad.exe");
Thread.sleep(5000);
p.destroy();
}
}
```
#### System 类
java.lang.System
Among the facilities provided by the `System` class are standard input, standard output, and error output streams; access to externally defined properties and environment variables; a means of loading files and libraries; and a utility method for quickly copying a portion of an array.
```java
import java.util.Arrays;
import java.util.List;
import java.util.Properties;
import java.util.Set;
public class SystemDemo {
private static final String LINE_SEPARATOR = System.getProperty("line.separator");
/**
* @param args
*/
public static void main(String[] args) {
/*
* System: 类中的方法和属性都是静态的。
* 常见方法:
* long currentTimeMillis();获取当前时间的毫秒值。
*/
// long l1 = 1335664696656l;//System.currentTimeMillis();
// System.out.println(l1/1000/60/60/24);//1335664696656
// code..
// long l2 = System.currentTimeMillis();
// System.out.println(l2-l1);
System.out.println("hello-"+LINE_SEPARATOR+" world");
// demo_1();
//给系统设置一些属性信息。这些信息是全局,其他程序都可以使用。
// System.setProperty("myclasspath", "c:\myclass");
}
public static void demo_1(){
//获取系统的属性信息,并存储到了Properties集合中。
/*
* properties集合中存储都是String类型的键和值。
* 最好使用它自己的存储和取出的方法来完成元素的操作。
*/
Properties prop = System.getProperties();
Set<String> nameSet = prop.stringPropertyNames();
for(String name : nameSet){
String value = prop.getProperty(name);
System.out.println(name+"::"+value);
}
}
}
```
### 总结
```
Collection
List
ArrayList
LinkedList
Stack
Vector
Set
HashSet
LinkedHashSet (存储顺序不变)
TreeSet
Map
HashMap
LinkedHashMap (存储顺序不变)
HashTable
TreeMap
Queue
Deque
SortedSet
```
```
泛型:
jdk1.5出现的安全机制。
好处:
1,将运行时期的问题 ClassCastException 转到了编译时期。
2,避免了强制转换的麻烦。
<>:什么时候用?
当操作的引用数据类型不确定的时候。就使用<>。将要操作的引用数据类型传入即可.
其实<>就是一个用于接收具体引用数据类型的参数范围。在程序中,只要用到了带有<>的类或者接口,就要明确传入的具体引用数据类型 。
泛型技术是给编译器使用的技术, 用于编译时期。确保了类型的安全。
运行时,会将泛型去掉,生成的class文件中是不带泛型的,这个称为泛型的擦除。
为什么擦除呢?因为为了兼容运行的类加载器。
泛型的补偿:在运行时,通过获取元素的类型进行转换动作。不用使用者在强制转换了。
泛型的通配符: ? 未知类型。
泛型的限定:
? extends E: 接收E类型或者E的子类型对象。上限
一般存储对象的时候用。比如 添加元素 addAll.
? super E: 接收E类型或者E的父类型对象。 下限。
一般取出对象的时候用。比如比较器。
--------------------------------------------------------------------------------
集合的一些技巧:
需要唯一吗?
需要: Set
需要制定顺序:
需要: TreeSet
不需要: HashSet
但是想要一个和存储一致的顺序(有序):LinkedHashSet
不需要: List
需要频繁增删吗?
需要: LinkedList
不需要: ArrayList
如何记录每一个容器的结构和所属体系呢?看名字!
List
|--ArrayList
|--LinkedList
Set
|--HashSet
|--TreeSet
后缀名就是该集合所属的体系。
前缀名就是该集合的数据结构。
看到array:就要想到数组,就要想到查询快,有角标.
看到link:就要想到链表,就要想到增删快,就要想要 add get remove+frist last的方法
看到hash:就要想到哈希表,就要想到唯一性,就要想到元素需要覆盖hashcode方法和equals方法。
看到tree:就要想到二叉树,就要想要排序,就要想到两个接口Comparable, Comparator 。
而且通常这些常用的集合容器都是不同步的。
--------------------------------------------------------------------------------
Map:一次添加一对元素。 Collection 一次添加一个元素。
Map也称为双列集合, Collection集合称为单列集合。
其实map集合中存储的就是键值对。map集合中必须保证键的唯一性。
常用方法:
1,添加。
value put(key,value):返回前一个和key关联的值,如果没有返回null.
2,删除。186
void clear():清空map集合。
value remove(key):根据指定的key翻出这个键值对。
3,判断。
boolean containsKey(key):
boolean containsValue(value):
boolean isEmpty();
4,获取。
value get(key):通过键获取值,如果没有该键返回null.当然可以通过返回null,来判断是否包含指定键。
int size(): 获取键值对的个数。
Map常用的子类:
|--Hashtable :内部结构是哈希表,是同步的。不允许null作为键, null作为值。
|--Properties:用来存储键值对型的配置文件的信息,可以和IO技术相结合。
|--HashMap : 内部结构是哈希表,不是同步的。允许null作为键, null作为值。
|--TreeMap : 内部结构是二叉树,不是同步的。可以对Map集合中的键进行排序。
```
**集合遍历总结**
```java
//遍历List方法1,使用普通for循环:
for (int i = 0; i < list.size(); i++) {
String temp=(String)list.get(i);
System.out.println(temp);
//list.remove(i);//遍历删除元素,不过不推荐这种方式!
}
//遍历List方法2,使用增强for循环(应该使用泛型定义类型!):
for(String temp:list){
System.out.println(temp);
}
//遍历List方法3,使用Iterator迭代器:
for(Iterator iter=list.iterator();iter.hasNext();){
String temp=(String)iter.next();
System.out.println(temp);
}
Iterator iter=c.iterator();
while(iter.hasNext()){
Object obj=iter.next();
iter.remove();//如果要遍历删除集合中的元素,建议使用这种方式!
System.out.println(obj);
}
//遍历Set方法1,使用增强for循环:
for(String temp:set){
System.out.println(temp);
}
//遍历Set方法2,使用Iterator迭代器:
for(Iterator iter=list.iterator();iter.hasNext();){
String temp=(String)iter.next();
System.out.println(temp);
}
//遍历Map
Map<Integer, Man> maps=new HashMap<Integer, Man>();
Set<Integer> keySet=maps.keySet();
for(Integer id:keySet){
System.out.println(maps.get(id).name);
}
```
## I/O 流
### 是什么
I,Input:将外存中的数据读取到内存中
O,Output:将内存中的数据写入到外存中
### 字符流,字节流
一个字符由多个字节组成!
IO 流分为字符流和字节流:
* 字符流:字节流读取文字字节数据后,不直接操作而是先查指定的编码表。获取对应的文字。在对这个文字进行操作。简单说:**字节流+编码表**
顶层父类:Reader, Writer
* 字节流:顾名思义,计算机中的字节,8 位为一字节
顶层父类:InputStream, OutputStream
这些体系的子类都以父类名作为后缀。而且子类名的前缀就是该对象的功能。
### 转换流
FileReader 和 FileWriter 是转换流的子类!
Demo 将键盘的输入转换成大写,并输出到控制台:
```java
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.io.OutputStreamWriter;
public class TransStreamDemo {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
//字节流。键盘的输入,是字节流……
InputStream in = System.in;
// int ch = in.read();
// System.out.println(ch);
// int ch1 = in.read();
// System.out.println(ch1);
//将字节转成字符的桥梁。装换流。
InputStreamReader isr = new InputStreamReader(in);
// int ch = isr.read();
// System.out.println((char)ch);
//字符流。
BufferedReader bufr = new BufferedReader(isr);
OutputStream out = System.out;t
OutputStreamWriter osw = new OutputStreamWriter(out);
BufferedWriter bufw = new BufferedWriter(osw);
String line = null;
while((line=bufr.readLine())!=null){
if("over".equals(line))
break;
// System.out.println(line.toUpperCase());
// osw.write(line.toUpperCase()+"\r\n");
// osw.flush();
bufw.write(line.toUpperCase());
bufw.newLine();
bufw.flush();
}
}
}
```
功能相同的两行代码:
```java
/*
* 这两句代码的功能是等同的。
* FileWriter:其实就是转换流指定了本机默认码表的体现。而且这个转换流的子类对象,可以方
* 便操作文本文件。
* 简单说:操作文件的字节流+本机默认的编码表。
* 这是按照默认码表来操作文件的便捷类。
*
* 如果操作文本文件需要明确具体的编码。 FileWriter就不行了。必须用转换流。
*/
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("gbk_3.txt"), "GBK");
FileWriter fw = new FileWriter("gbk_1.txt");
```
### File, 过滤器
**File**
```java
import java.io.File;
public class FileDemo {
/**
* @param args
*/
public static void main(String[] args) {
// constructorDemo();
}
public static void constructorDemo() {
//可以将一个已存在的,或者不存在的文件或者目录封装成file对象。
File f1 = new File("c:\\a.txt");
File f2 = new File("c:\\","a.txt");
File f = new File("c:\\");
File f3 = new File(f,"a.txt");
File f4 = new File("c:"+File.separator+"abc"+File.separator+"a.txt");
System.out.println(f4); // 在 Windows 上执行打印的是:c:\abc\a.txt
}
}
```
```java
import java.io.File;
import java.io.IOException;
import java.text.DateFormat;
import java.util.Date;
public class FileMethodDemo {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
/*
* File对象的常见方法。
*
* 1,获取。
* 1.1 获取文件名称。
* 1.2 获取文件路径。
* 1.3 获取文件大小。
* 1.4 获取文件修改时间。
*
* 2,创建与删除。
*
* 3,判断。
*
* 4, 重命名
*
*/
// getDemo();
// createAndDeleteDemo();
// isDemo();
// renameToDemo();
// listRootsDemo();
}
public static void listRootsDemo() {
File file = new File("d:\\");
System.out.println("getFreeSpace:"+file.getFreeSpace());
System.out.println("getTotalSpace:"+file.getTotalSpace());
System.out.println("getUsableSpace:"+file.getUsableSpace());
// File[] files = File.listRoots();
// for(File file : files){
// System.out.println(file);
// }
}
public static void renameToDemo() { // 移动文件
File f1 = new File("c:\\9.mp3");
File f2 = new File("d:\\aa.mp3");
boolean b = f1.renameTo(f2);
System.out.println("b="+b);
}
public static void isDemo() throws IOException{
File f = new File("aaa");
// f.mkdir();
f.createNewFile();
// boolean b = f.exists();
// System.out.println("b="+b);
// 最好先判断是否存在。
System.out.println(f.isFile());
System.out.println(f.isDirectory());
}
public static void createAndDeleteDemo() throws IOException {
File dir = new File("abc\\q\\e\\c\\z\\r\\w\\y\\f\\e\\g\\s");
// boolean b = dir.mkdir();//make directory
// System.out.println("b="+b);
// dir.mkdirs();//创建多级目录
System.out.println(dir.delete());
// System.out.println(dir.delete());
// 文件的创建和删除。
// File file = new File("file.txt");
/*
* 和输出流不一样,如果文件不存在,则创建,如果文件存在,则不创建。
*
*/
// boolean b = file.createNewFile();
// System.out.println("b="+b);
// boolean b = file.delete();
// System.out.println("b="+b);
}
public static void getDemo(){
// File file = new File("E:\\java0331\\day22e\\a.txt");
File file = new File("a.txt");
String name = file.getName();
String absPath = file.getAbsolutePath();//绝对路径。
String path = file.getPath();
long len = file.length();
long time = file.lastModified();
Date date = new Date(time);
DateFormat dateFormat =
DateFormat.getDateTimeInstance(DateFormat.LONG,DateFormat.LONG);
String str_time = dateFormat.format(date);
System.out.println("parent:"+file.getParent());226
System.out.println("name:"+name);
System.out.println("absPath:"+absPath);
System.out.println("path:"+path);
System.out.println("len:"+len);
System.out.println("time:"+time);
System.out.println("str_time:"+str_time);
}
}
```
**三种常见过滤器**
1. 后缀名过滤器
```java
public class FilterByJava implements FilenameFilter {
@Override
public boolean accept(File dir, String name) {
// System.out.println(dir+"---"+name);
return name.endsWith(".java");
}
}
```
2. 根据后缀名可以指定任意后缀名过滤的过滤器
```java
import java.io.File;
import java.io.FilenameFilter;
public class SuffixFilter implements FilenameFilter {
private String suffix ;
public SuffixFilter(String suffix) {
super();
this.suffix = suffix;
}
@Override
public boolean accept(File dir, String name) {
return name.endsWith(suffix);
}
}
```
3. 隐藏属性过滤器
```java
import java.io.File;
import java.io.FileFilter;
public class FilterByHidden implements FileFilter {
@Override
public boolean accept(File pathname) {
return !pathname.isHidden();
}
}
```
Demo:
```java
import java.io.File;
import cn.itcast.io.p2.filter.FilterByHidden;
import cn.itcast.io.p2.filter.SuffixFilter;
public class FileListDemo {
/**
* @param args
*/
public static void main(String[] args) {
listDemo_2();
}
public static void listDemo_3() {
File dir = new File("c:\\");
File[] files = dir.listFiles(new FilterByHidden());
for(File file : files){
System.out.println(file);
}
}
public static void listDemo_2() {
File dir = new File("c:\\");
String[] names = dir.list(new SuffixFilter(".txt"));
for(String name : names){
System.out.println(name);
}
}
}
```
### IO流操作规律
想要知道开发时用到哪些对象。只要通过四个明确即可。
1. 明确源和目的(汇)
源: InputStream Reader
目的: OutputStream Writer
2. 明确数据是否是纯文本数据。
源:是纯文本: Reader
否: InputStream
目的:是纯文本 Writer
否: OutputStream
到这里,就可以明确需求中具体要使用哪个体系。
3. 明确具体的设备。
源设备:
硬盘: File
键盘: System.in
内存:数组
网络: Socket流
目的设备:
硬盘: File
控制台: System.out
内存:数组
网络: Socket流
4. 是否需要其他额外功能。
1,是否需要高效(缓冲区);
是,就加上buffer.
2,转换?
举例:
```
--------------------------------------------------------------------------------
需求1:复制一个文本文件。
1,明确源和目的。
源: InputStream Reader
目的: OutputStream Writer
2,是否是纯文本?
是!
源: Reader
目的: Writer
3,明确具体设备。
源:
硬盘: File
目的:
硬盘: File
FileReader fr = new FileReader("a.txt");
FileWriter fw = new FileWriter("b.txt");
4,需要额外功能吗?
需要,需要高效。
BufferedReader bufr = new BufferedReader(new FileReader("a.txt"));
BufferedWriter bufw = new BufferedWriter(new FileWriter("b.txt"));
--------------------------------------------------------------------------------
需求2:读取键盘录入信息,并写入到一个文件中。
1,明确源和目的。
源: InputStream Reader
目的: OutputStream Writer
2,是否是纯文本呢?
是,
源: Reader
目的: Writer
3,明确设备
源:
键盘。 System.in
目的:
硬盘。 File
InputStream in = System.in;
FileWriter fw = new FileWriter("b.txt");
这样做可以完成,但是麻烦。将读取的字节数据转成字符串。再由字符流操作。
4,需要额外功能吗?
需要。转换。 将字节流转成字符流。因为名确的源是Reader,这样操作文本数据做便捷。
所以要将已有的字节流转成字符流。使用字节-->字符 。 InputStreamReader
InputStreamReader isr = new InputStreamReader(System.in);
FileWriter fw = new FileWriter("b.txt");
还需要功能吗?
需要:想高效。
BufferedReader bufr = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bufw = new BufferedWriter(new FileWriter("b.txt"));
-------------------------------------------------------------------------------
需求3:将一个文本文件数据显示在控制台上。
1,明确源和目的。
源: InputStream Reader
目的: OutputStream Writer
2,是否是纯文本呢?
是,
源: Reader
目的: Writer
3,明确具体设备
源:
硬盘: File
目的:
控制台: System.out
FileReader fr = new FileReader("a.txt");
OutputStream out = System.out;//PrintStream
4,需要额外功能吗?
需要,转换。
FileReader fr = new FileReader("a.txt");
OutputStreamWriter osw = new OutputStreamWriter(System.out);
需要,高效。
BufferedReader bufr = new BufferedReader(new FileReader("a.txt"));
BufferedWriter bufw = new BufferedWriter(new OutputStreamWriter(System.out));
--------------------------------------------------------------------------------
需求4:读取键盘录入数据,显示在控制台上。
1,明确源和目的。
源: InputStream Reader
目的: OutputStream Writer
2,是否是纯文本呢?
是,
源: Reader
目的: Writer
3,明确设备。
源:
键盘: System.in
目的:
控制台: System.out
InputStream in = System.in;
OutputStream out = System.out;
4,明确额外功能?
需要转换,因为都是字节流,但是操作的却是文本数据。
所以使用字符流操作起来更为便捷。
InputStreamReader isr = new InputStreamReader(System.in);
OutputStreamWriter osw = new OutputStreamWriter(System.out);
为了将其高效。
BufferedReader bufr = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bufw = new BufferedWriter(new OutputStreamWriter(System.out));
--------------------------------------------------------------------------------
5,将一个中文字符串数据按照指定的编码表写入到一个文本文件中.
1,目的。 OutputStream, Writer
2,是纯文本, Writer。
3,设备:硬盘File
FileWriter fw = new FileWriter("a.txt");
fw.write("你好");
注意:既然需求中已经明确了指定编码表的动作。
那就不可以使用FileWriter,因为FileWriter内部是使用默认的本地码表。
只能使用其父类。 OutputStreamWriter.
OutputStreamWriter 接 收 一 个 字 节 输 出 流 对 象 , 既 然 是 操 作 文 件 , 那 么 该 对 象 应 该 是
FileOutputStream
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("a.txt"),charsetName);
需要高效吗?
BufferedWriter bufw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream("a.txt"),charsetName));
什么时候使用转换流呢?
1,源或者目的对应的设备是字节流,但是操作的却是文本数据,可以使用转换作为桥梁。
提高对文本操作的便捷。
2,一旦操作文本涉及到具体的指定编码表时,必须使用转换流
```
### 其他
#### Properties 集合+IO流
Properties = map + io
\* Properties集合:
\* 特点:
\* 1,该集合中的键和值都是字符串类型。
\* 2,集合中的数据可以保存到流中,或者从流获取。
*
\* 通常该集合用于操作以键值对形式存在的配置文件。
Demo:
```java
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.FileReader;
import java.io.FileWriter;
import java.io.IOException;
import java.util.Properties;
import java.util.Set;
public class PropertiesDemo {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
/*
* Map
* |--Hashtable
* |--Properties:
*
* Properties集合:
* 特点:
* 1,该集合中的键和值都是字符串类型。
* 2,集合中的数据可以保存到流中,或者从流获取。
*
* 通常该集合用于操作以键值对形式存在的配置文件。
*/
// methodDemo_4();
// myLoad();
test();
}
//对已有的配置文件中的信息进行修改。
/*
* 读取这个文件。
* 并将这个文件中的键值数据存储到集合中。
* 在通过集合对数据进行修改。
* 在通过流将修改后的数据存储到文件中。
*/
public static void test() throws IOException{
//读取这个文件。
File file = new File("info.txt");
if(!file.exists()){
file.createNewFile();
}
FileReader fr = new FileReader(file);
//创建集合存储配置信息。
Properties prop = new Properties();
//将流中信息存储到集合中。
prop.load(fr);
prop.setProperty("wangwu", "16");
FileWriter fw = new FileWriter(file);
prop.store(fw,"");
// prop.list(System.out);
fw.close();
fr.close();
}
//模拟一下load方法。
public static void myLoad() throws IOException{
Properties prop = new Properties();
BufferedReader bufr = new BufferedReader(new FileReader("info.txt"));
String line = null;
while((line=bufr.readLine())!=null){
if(line.startsWith("#"))
continue;
String[] arr = line.split("=");
// System.out.println(arr[0]+"::"+arr[1]);
prop.setProperty(arr[0], arr[1]);
}
prop.list(System.out);
bufr.close();
}
public static void methodDemo_4() throws IOException {
Properties prop = new Properties();
//集合中的数据来自于一个文件。
//注意;必须要保证该文件中的数据是键值对。
//需要使用到读取流。
FileInputStream fis = new FileInputStream("info.txt");
//使用load方法。
prop.load(fis);
prop.list(System.out);
}
public static void methodDemo_3() throws IOException {
Properties prop = new Properties();
//存储元素。
prop.setProperty("zhangsan","30");
prop.setProperty("lisi","31");
prop.setProperty("wangwu","36");
prop.setProperty("zhaoliu","20");
//想要将这些集合中的字符串键值信息持久化存储到文件中。
//需要关联输出流。
FileOutputStream fos = new FileOutputStream("info.txt");
//将集合中数据存储到文件中,使用store方法。
prop.store(fos, "info");
fos.close();
}
/**
* 演示Properties集合和流对象相结合的功能。
*/
public static void methodDemo_2(){
Properties prop = new Properties();
//存储元素。
// prop.setProperty("zhangsan","30");
// prop.setProperty("lisi","31");
// prop.setProperty("wangwu","36");
// prop.setProperty("zhaoliu","20");
prop = System.getProperties();
prop.list(System.out);
}
/*
* Properties集合的存和取。
*/
public static void propertiesDemo(){
//创建一个Properties集合。
Properties prop = new Properties();
//存储元素。
prop.setProperty("zhangsan","30");
prop.setProperty("lisi","31");
prop.setProperty("wangwu","36");
prop.setProperty("zhaoliu","20");
//修改元素。
prop.setProperty("wangwu","26");
//取出所有元素。
Set<String> names = prop.stringPropertyNames();
for(String name : names){
String value = prop.getProperty(name);
System.out.println(name+":"+value);
}
}
}
```
Demo 用Properties定义一个程序运行次数的程序:
```java
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Properties;
/*
* 定义功能,获取一个应用程序运行的次数,如果超过5次,给出使用次数已到请注册的提示。并不要在运行
程序。
*
* 思路:
* 1,应该有计数器。
* 每次程序启动都需要计数一次,并且是在原有的次数上进行计数。
* 2,计数器就是一个变量。 突然冒出一想法,程序启动时候进行计数,计数器必须存在于内存并进行运算。
* 可是程序一结束,计数器消失了。那么再次启动该程序,计数器又重新被初始化了。
* 而我们需要多次启动同一个应用程序,使用的是同一个计数器。
* 这就需要计数器的生命周期变长,从内存存储到硬盘文件中。
*
* 3,如何使用这个计数器呢?
* 首先,程序启动时,应该先读取这个用于记录计数器信息的配置文件。
* 获取上一次计数器次数。 并进行试用次数的判断。
* 其次,对该次数进行自增,并自增后的次数重新存储到配置文件中。
*
*
* 4,文件中的信息该如何进行存储并体现。
* 直接存储次数值可以,但是不明确该数据的含义。 所以起名字就变得很重要。
* 这就有了名字和值的对应,所以可以使用键值对。
* 可是映射关系map集合搞定,又需要读取硬盘上的数据,所以 map+io = Properties.
*/
public class PropertiesTest {
/**
* @param args
* @throws IOException
* @throws Exception
*/
public static void main(String[] args) throws IOException {
getAppCount();
}
public static void getAppCount() throws IOException{
//将配置文件封装成File对象。
File confile = new File("count.properties");
if(!confile.exists()){
confile.createNewFile();
}
FileInputStream fis = new FileInputStream(confile);
Properties prop = new Properties();
prop.load(fis);
//从集合中通过键获取次数。
String value = prop.getProperty("time");
//定义计数器。记录获取到的次数。
int count =0;
if(value!=null){
count = Integer.parseInt(value);
if(count>=5){
// System.out.println("使用次数已到,请注册,给钱! ");
// return;
throw new RuntimeException("使用次数已到,请注册,给钱! ");
}
}
count++;
//将改变后的次数重新存储到集合中。
prop.setProperty("time", count+"");
FileOutputStream fos = new FileOutputStream(confile);
prop.store(fos, "");
fos.close();
fis.close();
}
}
```
Demo 建立一个指定扩展名文件的列表:
```java
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileWriter;
import java.io.FilenameFilter;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
/*
* 获取指定目录下,指定扩展名的文件(包含子目录中的)
* 这些文件的绝对路径写入到一个文本文件中。
*
* 简单说,就是建立一个指定扩展名的文件的列表。
*
* 思路:
* 1,必须进行深度遍历。
* 2,要在遍历的过程中进行过滤。将符合条件的内容都存储到容器中。
* 3,对容器中的内容进行遍历并将绝对路径写入到文件中。
*/
public class Test {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
File dir = new File("e:\\java0331");
FilenameFilter filter = new FilenameFilter(){
@Override
public boolean accept(File dir, String name) {
return name.endsWith(".java");
}
};
List<File> list = new ArrayList<File>();
getFiles(dir,filter,list);
File destFile = new File(dir,"javalist.txt");
write2File(list,destFile);
}
/**
* 对指定目录中的内容进行深度遍历,并按照指定过滤器,进行过滤,
* 将过滤后的内容存储到指定容器List中。
* @param dir
* @param filter
* @param list
*/
public static void getFiles(File dir,FilenameFilter filter,List<File> list){
File[] files = dir.listFiles();
for(File file : files){
if(file.isDirectory()){
//递归啦!
getFiles(file,filter,list);
}else{
//对遍历到的文件进行过滤器的过滤。将符合条件File对象,存储到List集合中。
if(filter.accept(dir, file.getName())){
list.add(file);
}
}
}
}
public static void write2File(List<File> list,File destFile)throws IOException{
BufferedWriter bufw = null;
try {
bufw = new BufferedWriter(new FileWriter(destFile));
for(File file : list){
bufw.write(file.getAbsolutePath());
bufw.newLine();
bufw.flush();
}
} /*catch(IOException e){
throw new RuntimeException("写入失败");
}*/finally{
if(bufw!=null)
try {
bufw.close();
} catch (IOException e) {
throw new RuntimeException("关闭失败");
}
}
}
}
```
#### 打印流
打印流也是输出流的装饰流。
PrintStream PrintWriter
```java
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.PrintStream;
public class PrintStreamDemo {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
/*
* PrintStream: 字节打印流
* 1, 提供了打印方法可以对多种数据类型值进行打印。并保持数据的表示形式。
* 2,它不抛 IOException
*
* 构造函数,接收三种类型的值:
* 1,字符串路径。
* 2,File 对象。
* 3,字节输出流。
*/
PrintStream out = new PrintStream("print.txt");
// int by = read();
// write(by);
out.write(610); // 只写最低8位,
out.print(97); // 将97先变成字符保持原样将数据打印到目的地。
out.close();
}
}
```
```java
import java.io.BufferedReader;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
public class PrintWriterDemo {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
/*
* PrintWriter:字符打印流。
* 构造函数参数:
* 1,字符串路径。
* 2, File对象。
* 3,字节输出流。
* 4,字符输出流。
*
*/
BufferedReader bufr = new BufferedReader(new InputStreamReader(System.in));
PrintWriter out = new PrintWriter(new FileWriter("out.txt"),true);
String line = null;
while((line=bufr.readLine())!=null){
if("over".equals(line))
break;
out.println(line.toUpperCase());
// out.flush();
}
out.close();
bufr.close();
}
}
```
#### SequenceInputStream, Enumeration
SequenceInputStream 接收一个枚举类型的对象
```java
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.SequenceInputStream;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Enumeration;
import java.util.Iterator;
public class SequenceInputStreamDemo {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
/*
* 需求:将1.txt 2.txt 3.txt文件中的数据合并到一个文件中。
*/
// Vector<FileInputStream> v = new Vector<FileInputStream>();
// v.add(new FileInputStream("1.txt"));
// v.add(new FileInputStream("2.txt"));
// v.add(new FileInputStream("3.txt"));
// Enumeration<FileInputStream> en = v.elements();
ArrayList<FileInputStream> al = new ArrayList<FileInputStream>();
for(int x=1; x<=3; x++){
al.add(new FileInputStream(x+".txt"));
}
Enumeration<FileInputStream> en = Collections.enumeration(al);
/*
final Iterator<FileInputStream> it = al.iterator();
Enumeration<FileInputStream> en = new Enumeration<FileInputStream>(){
@Override
public boolean hasMoreElements() {
return it.hasNext();
}
@Override
public FileInputStream nextElement() {
return it.next();
}
};*/
SequenceInputStream sis = new SequenceInputStream(en);
FileOutputStream fos = new FileOutputStream("1234.txt");
byte[] buf = new byte[1024];
int len = 0;
while((len=sis.read(buf))!=-1){
fos.write(buf,0,len);
}
fos.close();
sis.close();
}
}
```
#### Demos
**文件切割与合并**
文件切割:
```java
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.util.Properties;
/*
* 文件切割器。
*/
public class SplitFileDemo {
private static final int SIZE = 1024 * 1024;
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
File file = new File("c:\\aa.mp3");
splitFile_2(file);
}
private static void splitFile_2(File file) throws IOException {
// 用读取流关联源文件。
FileInputStream fis = new FileInputStream(file);
// 定义一个1M的缓冲区。
byte[] buf = new byte[SIZE];
// 创建目的。245
FileOutputStream fos = null;
int len = 0;
int count = 1;
/*
* 切割文件时,必须记录住被切割文件的名称,以及切割出来碎片文件的个数。 以方便于合并。
* 这个信息为了进行描述,使用键值对的方式。用到了properties对象
*
*/
Properties prop = new Properties();
File dir = new File("c:\\partfiles");
if (!dir.exists())
dir.mkdirs();
while ((len = fis.read(buf)) != -1) {
fos = new FileOutputStream(new File(dir, (count++) + ".part"));
fos.write(buf, 0, len);
fos.close();
}
//将被切割文件的信息保存到prop集合中。
prop.setProperty("partcount", count+"");
prop.setProperty("filename", file.getName());
fos = new FileOutputStream(new File(dir,count+".properties"));
//将prop集合中的数据存储到文件中。
prop.store(fos, "save file info");
fos.close();
fis.close();
}
public static void splitFile(File file) throws IOException {
// 用读取流关联源文件。
FileInputStream fis = new FileInputStream(file);
// 定义一个 1M 的缓冲区。
byte[] buf = new byte[SIZE];
// 创建目的。
FileOutputStream fos = null;
int len = 0;
int count = 1;
File dir = new File("c:\\partfiles");
if (!dir.exists())
dir.mkdirs();
while ((len = fis.read(buf)) != -1) {
fos = new FileOutputStream(new File(dir, (count++) + ".part"));
fos.write(buf, 0, len);
}
fos.close();
fis.close();
}
}
```
文件合并:
```java
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.SequenceInputStream;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Enumeration;
import java.util.Properties;
public class MergeFile {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
File dir = new File("c:\\partfiles");
mergeFile_2(dir);
}
public static void mergeFile_2(File dir) throws IOException {
/*
* 获取指定目录下的配置文件对象。
*/
File[] files = dir.listFiles(new SuffixFilter(".properties"));
if(files.length!=1)
throw new RuntimeException(dir+",该目录下没有properties扩展名的文件或者不唯一");//记录配置文件对象。
File confile = files[0];
//获取该文件中的信息================================================。
Properties prop = new Properties();
FileInputStream fis = new FileInputStream(confile);
prop.load(fis);
String filename = prop.getProperty("filename");
int count = Integer.parseInt(prop.getProperty("partcount"));
//获取该目录下的所有碎片文件。 ==============================================
File[] partFiles = dir.listFiles(new SuffixFilter(".part"));
if(partFiles.length!=(count-1)){
throw new RuntimeException(" 碎片文件不符合要求,个数不对!应该"+count+"个");
}
//将碎片文件和流对象关联 并存储到集合中。
ArrayList<FileInputStream> al = new ArrayList<FileInputStream>();
for(int x=0; x<partFiles.length; x++){
al.add(new FileInputStream(partFiles[x]));
}
//将多个流合并成一个序列流。
Enumeration<FileInputStream> en = Collections.enumeration(al);
SequenceInputStream sis = new SequenceInputStream(en);
FileOutputStream fos = new FileOutputStream(new File(dir,filename));
byte[] buf = new byte[1024];
int len = 0;
while((len=sis.read(buf))!=-1){
fos.write(buf,0,len);
}
fos.close();
sis.close();
}
public static void mergeFile(File dir) throws IOException{
ArrayList<FileInputStream> al = new ArrayList<FileInputStream>();
for(int x=1; x<=3 ;x++){
al.add(new FileInputStream(new File(dir,x+".part")));
}
Enumeration<FileInputStream> en = Collections.enumeration(al);
SequenceInputStream sis = new SequenceInputStream(en);
FileOutputStream fos = new FileOutputStream(new File(dir,"1.bmp"));
byte[] buf = new byte[1024];
int len = 0;
while((len=sis.read(buf))!=-1){
fos.write(buf,0,len);
}
fos.close();
sis.close();
}
}
```
#### Serializable, ObjectStream
序列化和反序列化。序列化:将对象存储到文件中。
```java
import java.io.Serializable;
/*
* Serializable:用于给被序列化的类加入ID号。
* 用于判断类和对象是否是同一个版本。
*/
public class Person implements Serializable/*标记接口*/ {
/**
* transient:非静态数据不想被序列化可以使用这个关键字修饰。
*/
private static final long serialVersionUID = 9527l;
private transient String name;
private static int age;
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
```
```java
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import cn.itcast.io.p2.bean.Person;
public class ObjectStreamDemo {
/**
* @param args
* @throws IOException
* @throws ClassNotFoundException
*/
public static void main(String[] args) throws IOException, ClassNotFoundException
{
// writeObj();
readObj();
}
public static void readObj() throws IOException, ClassNotFoundException {
ObjectInputStream ois = new ObjectInputStream(new
FileInputStream("obj.object"));
//对象的反序列化。
Person p = (Person)ois.readObject();
System.out.println(p.getName()+":"+p.getAge());
ois.close();
}
public static void writeObj() throws IOException, IOException {
ObjectOutputStream oos = new ObjectOutputStream(new
FileOutputStream("obj.object"));
//对象序列化。 被序列化的对象必须实现Serializable接口。
oos.writeObject(new Person("小强",30));
oos.close();
}
}
```
#### RandomAccessFile
#### PipedStream
管道流
```java
import java.io.IOException;
import java.io.PipedInputStream;
import java.io.PipedOutputStream;
public class PipedStream {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
PipedInputStream input = new PipedInputStream();
PipedOutputStream output = new PipedOutputStream();
input.connect(output);
new Thread(new Input(input)).start();
new Thread(new Output(output)).start();
}
}
class Input implements Runnable{
private PipedInputStream in;
Input(PipedInputStream in){
this.in = in;
}
public void run(){
try {
byte[] buf = new byte[1024];
int len = in.read(buf);
String s = new String(buf,0,len);
System.out.println("s="+s);
in.close();
} catch (Exception e) {
// TODO: handle exception
}
}
}
class Output implements Runnable{
private PipedOutputStream out;
Output(PipedOutputStream out){
this.out = out;
}
public void run(){
try {
Thread.sleep(5000);
out.write("hi,管道来了! ".getBytes());
} catch (Exception e) {
// TODO: handle exception
}
}
}
```
#### DataStream
```java
import java.io.DataInputStream;
import java.io.DataOutputStream;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class DataSteamDemo {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
// writeData();
readData();
}
public static void readData() throws IOException {
DataInputStream dis = new DataInputStream(new FileInputStream("data.txt"));
String str = dis.readUTF();
System.out.println(str);
}
public static void writeData() throws IOException {
DataOutputStream dos = new DataOutputStream(new
FileOutputStream("data.txt"));
dos.writeUTF("你好");
dos.close();
}
}
```
#### ByteArrayStream
字节数组流
```java
import java.io.ByteArrayInputStream;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
public class ByteArrayStreamDemo {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) {
ByteArrayInputStream bis = new ByteArrayInputStream("abcedf".getBytes());
ByteArrayOutputStream bos = new ByteArrayOutputStream();
int ch = 0;
while((ch=bis.read())!=-1){
bos.write(ch);
}
System.out.println(bos.toString());
}
}
```
#### 编解码
编码:字符串 --> **字节数组**
解码:**字节数组** --> 字符串
```java
package com.wansho.hellojava;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
public class EncodeDemo {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
/*
* 字符串 --> 字节数组:编码。
* 字节数组 --> 字符串:解码。
*
* 你好: GBK: -60 -29 -70 -61
*
* 你好: utf-8: -28 -67 -96 -27 -91 -67
*
*
* 如果你编错了,解不出来。
* 如果编对了,解错了,有可能有救。
*/
String str = "谢谢";
byte[] buf = str.getBytes("gbk"); // 编码
String s1 = new String(buf,"UTF-8"); // 解码,解错了
System.out.println("s1="+s1); // лл
byte[] buf2 = s1.getBytes("UTF-8");//获取源字节.
printBytes(buf2); // -17 -65 -67 -17 -65 -67 -17 -65 -67
// -17 -65 -67 -17 -65 -67 -17 -65 -67 -17 -65 -67
// -48 -69 -48 -69
String s2 = new String(buf2,"GBK"); // 解码,解对了
System.out.println("s2="+s2);
// encodeDemo(str);
}
/**
* @param str
* @throws UnsupportedEncodingException
*/
public static void encodeDemo(String str)
throws UnsupportedEncodingException {
//编码;
byte[] buf = str.getBytes("UTF-8");
// printBytes(buf);
//解码:
String s1 = new String(buf,"UTF-8");
System.out.println("s1="+s1);
}
private static void printBytes(byte[] buf) {
for(byte b : buf){
System.out.print(b +" ");
}
}
}
```
### 总结
```
IO流:
输入流:
输出流:
字节流:
字符流:
为了处理文字数据方便而出现的对象。
其实这些对象的内部使用的还是字节流(因为文字最终也是字节数据)
只不过,通过字节流读取了相对应的字节数,没有对这些字节直接操作。
而是去查了指定的(本机默认的)编码表,获取到了对应的文字。
简单说:字符流就是 : 字节流+编码表。
--------------------------------------------------------------------------------
缓冲区:
提高效率的,提高谁的效率?提高流的操作数据的效率。
所以创建缓冲区之前必须先有流。
缓冲区的基本思想:其实就是定义容器将数据进行临时存储。
对于缓冲区对象,其实就是将这个容器进行了封装,并提供了更多高效的操作方法。
缓冲区可以提高流的操作效率。
其实是使用了一种设计思想完成。设计模式:装饰设计模式。
缓冲区的设计原理,装饰设计模式的由来:
Writer
|--TextWriter
|--MediaWriter
现在要对该体系中的对象进行功能的增强。增强的最常见手段就是缓冲区。
先将数据写到缓冲区中,再将缓冲区中的数据一次性写到目的地。
按照之前学习过的基本的思想,那就是对对象中的写方法进行覆盖。
产生已有的对象子类,复写write方法。不往目的地写,而是往缓冲区写。
所以这个体系会变成这样。
Writer
|--TextWriter write:往目的地
|--BufferTextWriter write:往缓冲区写
|--MediaWriter
|--BufferMediaWriter
想要写一些其他数据。就会子类。 DataWriter,为了提高其效率,还要创建该类的子类。 BufferDataWriter
Writer
|--TextWriter write:往目的地
|--BufferTextWriter write:往缓冲区写
|--MediaWriter
|--BufferMediaWriter
|--DataWriter
|--BufferDataWriter
发现这个体系相当的麻烦。每产生一个子类都要有一个高效的子类。
而且这写高效的子类使用的功能原理都一样,都是缓冲区原理。无论数据是什么。
都是通过缓冲区临时存储提高效率的。
那么, 对于这个体系就可以进行优化,因为没有必要让每一个对象都具备相同功能的子类。
哪个对象想要进行效率的提高,只要让缓冲区对其操作即可。也就说,单独将缓冲区进行封装变成对象。
//它的出现为了提高对象的效率。所以必须在创建它的时候先有需要被提高效率的对象
class BufferWriter
{
[];
BufferedWriter(Writer w)
{ }
/*
BufferWriter(TextWriter w)
{ }
BufferedWriter(MediaWriter w)
{ }
*/
}
BufferWriter的出现增强了Writer中的write方法。
但是增强过后, BufferWriter对外提供的还是write方法。只不过是高效的。
所以写的实质没有变,那么BufferWriter也是Writer中的一员。
所以体系就会变成这样。
Writer
|--TextWriter
|--MediaWriter
|--BufferWriter
|--DataWriter
BufferWriter出现了避免了继承体系关系的臃肿,比继承更为灵活。
如果是为了增强功能,这样方式解决起来更为方便。
所以就把这种优化,总结出来,起个名字:装饰设计模式。
装饰类和被装饰类肯定所属于同一个体系。
既然明确了BufferedReader由来。
我们也可以独立完成缓冲区的建立
原理;
1,使用流的read方法从源中读取一批数据存储到缓冲区的数组中。
2,通过计数器记录住存储的元素个数。
3,通过数组的角标来获取数组中的元素(从缓冲区中取数据).
4,指针会不断的自增,当增到数组长度,会归0.计数器会自减,当减到0时,就在从源拿一批数据进缓冲区。
内容补足:
MyBufferedReader
LineNumberReader :可以定义行号。
--------------------------------------------------------------------------------
字符流:
FileReader
FileWriter
BufferedReader
BufferedWriter
字节流:
InputStream OutputStream
操作文件的字节流对象
FileOutputStream
FileInputStream
BufferedOutputStream
BufferedInputStream
--------------------------------------------------------------------------------
转换流:
InputStreamReader isr = new InputStreamReader(new FileInputStream("a.txt"));
InputStreamReader isr = new InputStreamReader(new FileInputStream("a.txt"),"gbk");
FileReader fr = new FileReader("a.txt");
FileWriter fw = new FileWriter("b.txt");
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("b.txt"));
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream("b.txt"),"gbk");
转换流:字节流+编码表。
转换流的子类: FileReader, FileWriter:字节流+本地默认码表(GBK)。
如果操作文本文件使用的本地默认编码表完成编码。可以使用FileReader,或者FileWriter。因为这样写简
便。
如果对操作的文本文件需要使用指定编码表进行编解码操作,这时必须使用转换流来完成。
--------------------------------------------------------------------------------
IO流的操作规律总结:
1,明确体系:
数据源: InputStream , Reader
数据汇: OutputStream, Writer
2,明确数据:因为数据分两种:字节,字符。
数据源:是否是纯文本数据呢?
是: Reader
否: InputStream
数据汇:
是: Writer
否: OutputStream
到这里就可以明确具体要使用哪一个体系了。
剩下的就是要明确使用这个体系中的哪个对象。
3,明确设备:
数据源:
键盘: System.in
硬盘: FileXXX
内存:数组。
网络: socket socket.getInputStream();
数据汇:
控制台: System.out
硬盘: FileXXX
内存:数组
网络: socket socket.getOutputStream();
4,明确额外功能:
1,需要转换?是,使用转换流。 InputStreamReader OutputStreamWriter
2,需要高效?是,使用缓冲区。 Buffered
3,需要其他?
--------------------------------------------------------------------------------
1,复制一个文本文件。
1,明确体系:
源: InputStream , Reader
目的: OutputStream , Writer
2,明确数据:
源:是纯文本吗?是 Reader
目的;是纯文本吗?是 Writer
3,明确设备:
源:硬盘上的一个文件。 FileReader
目的:硬盘上的一个文件。 FileWriter269
FileReader fr = new FileReader("a.txt");
FileWriter fw = new FileWriter("b.txt");
4,需要额外功能吗?
需要,高效,使用buffer
BufferedReader bufr = new BufferedReader(new FileReader("a.txt"));
BufferedWriter bufw = new BufferedWriter(new FileWriter("b.txt"));
2,读取键盘录入,将数据存储到一个文件中。
1,明确体系:
源: InputStream , Reader
目的: OutputStream , Writer
2,明确数据:
源:是纯文本吗?是 Reader
目的;是纯文本吗?是 Writer
3,明确设备:
源:键盘, System.in
目的:硬盘, FileWriter
InputStream in = System.in;
FileWriter fw = new FileWriter("a.txt");
4,需要额外功能吗?
需要,因为源明确的体系时Reader。可是源的设备是System.in。
所以为了方便于操作文本数据,将源转成字符流。需要转换流。 InputStreamReader
InputStreamReader isr = new InputStreamReader(System.in);
FileWriter fw = new FileWriter("a.txt");
需要高效不?需要。 Buffer
BufferedReader bufr = new BufferedReader(new InputStreamReader(System.in));
BufferedWriter bufw = new BufferedWriter(new FileWriter("a.txt"));
3,读取一个文本文件,将数据展现在控制台上。
1,明确体系:
源: InputStream , Reader
目的: OutputStream , Writer
2,明确数据:
源:是纯文本吗?是 Reader
目的;是纯文本吗?是 Writer
3,明确设备:
源:硬盘文件, FileReader。
目的:控制台: System.out。
FileReader fr = new FileReader("a.txt");
OutputStream out = System.out;
4,需要额外功能?
因为源是文本数据,确定是Writer体系。所以为了方便操作字符数据,
需要使用字符流,但是目的又是一个字节输出流。
需要一个转换流, OutputStreamWriter
FileReader fr = new FileReader("a.txt");270
OutputStreamWriter osw = new OutputStreamWriter(System.out);
需要高效吗?需要。
BufferedReader bufr = new BufferedReader(new FileReader("a.txt"));
BufferedWriter bufw = new BufferedWriter(new
OutputStreamWriter(System.out));
4,读取键盘录入,将数据展现在控制台上。
1,明确体系:
源: InputStream , Reader
目的: OutputStream , Writer
2,明确数据:
源:是纯文本吗?是 Reader
目的;是纯文本吗?是 Writer
3,明确设备:
源:键盘: System.in
目的:控制台: System.out
InputStream in = System.in;
OutputStream out = System.out;
4,需要额外功能吗?
因为处理的数据是文本数据,同时确定是字符流体系。
为方便操作字符数据的可以将源和目的都转成字符流。使用转换流。
为了提高效率,使用Buffer
BufferedReader bufr =new BufferedReader(new
InputStreamReader(Systme.in));
BufferedWriter bufw = new BufferedWriter(new
OutputStreamWriter(System.out));
5,读取一个文本文件,将文件按照指定的编码表UTF-8进行存储,保存到另一个文件中。
1,明确体系:
源: InputStream , Reader
目的: OutputStream , Writer
2,明确数据:
源:是纯文本吗?是 Reader
目的;是纯文本吗?是 Writer
3,明确设备:
源:硬盘: FileReader.
目的:硬盘: FileWriter
FileReader fr = new FileReader("a.txt");
FileWriter fw = new FileWriter("b.txt");
4,额外功能:
注意:目的中虽然是一个文件,但是需要指定编码表。
而直接操作文本文件的FileWriter本身内置的是本地默认码表。无法明确具体指定码表。271
这时就需要转换功能。 OutputStreamWriter,而这个转换流需要接受一个字节输出流,而且
对应的目的是一个文件。这时就使用字节输出流中的操作文件的流对象。 FileOutputStream.
FileReader fr = new FileReader("a.txt");
OutputStreamWriter osw = new OutputStreamWriter(new
FileOutputStream("b.txt"),"UTF-8");
需要高效吗?
BufferedReader bufr = new BufferedReader(new FileReader("a.txt"));
BufferedWriter bufw =
new BufferedWriter(new OutputStreamWriter(new
FileOutputStream("b.txt"),"UTF-8"));
目前为止, 10个流对象重点掌握。
字符流:
FileReader
FileWriter
BufferedReader
BufferedWriter
InputStreamReader
OutputStreamWrier
字节流:
FileInputStream
FileOutputStream
BufferedInputStream
BufferedOutputStream
--------------------------------------------------------------------------------
File类:
用于将文件和文件夹封装成对象。
1,创建。
boolean createNewFile():如果该文件不存在,会创建,如果已存在,则不创建。不会像输出流
一样会覆盖。
boolean mkdir();
boolean mkdirs();
2,删除。
boolean delete();
void deleteOnExit();
3,获取:
String getAbsolutePath();
String getPath();
String getParent();
String getName();
long length();
long lastModified();
4,判断:
boolean exists();
boolean isFile();
boolean isDirectory();
5,
--------------------------------------------------------------------------------
IO中的其他功能流对象:
打印流:
PrintStream:字节打印流。
特点:
1,构造函数接收File对象,字符串路径,字节输出流。意味着打印目的可以有很多。
2,该对象具备特有的方法 打印方法 print println,可以打印任何类型的数据。
3,特有的print方法可以保持任意类型数据表现形式的原样性,将数据输出到目的地。
对于OutputStream父类中的write,是将数据的最低字节写出去。
PrintWriter:字符打印流。
特点:
1,当操作的数据是字符时,可以选择PrintWriter,比PrintStream要方便。
2,它的构造函数可以接收 File对象,字符串路径,字节输出流,字符输出流。
3,构造函数中,如果参数是输出流,那么可以通过指定另一个参数true完成自动刷新,该true对
println方法有效。
什么时候用?
当需要保证数据表现的原样性时,就可以使用打印流的打印方法来完成,这样更为方便。
保证原样性的原理:其实就是将数据变成字符串,在进行写入操作
SequenceInputStream:
特点:
1,将多个字节读取流和并成一个读取流,将多个源合并成一个源,操作起来方便。
2,需要的枚举接口可以通过Collections.enumeration(collection);
ObjectInputStream 和 ObjectOutputStream
对象的序列化和反序列化。
writeObject readObject273
Serializable标记接口
关键字: transient
RandomAccessFile:
特点:
1,即可读取,又可以写入。
2,内部维护了一个大型的byte数组,通过对数组的操作完成读取和写入。
3,通过getFilePointer方法获取指针的位置,还可以通过seek方法设置指针的位置。
4,该对象的内容应该封装了字节输入流和字节输出流。
5,该对象只能操作文件。
通过seek方法操作指针,可以从这个数组中的任意位置上进行读和写
可以完成对数据的修改。
但是要注意:数据必须有规律。
管道流:需要和多线程技术相结合的流对象。
PipedOutputStream
PipedInputStream
用操作基本数据类型值的对象:
DataInputStream
DataOutputStream
设备是内存的流对象。
ByteArrayInputStream ByteArrayOutputStream
CharArrayReader CharArrayWriter
--------------------------------------------------------------------------------
IO流体系:
字符流:
Reader
|--BufferedReader:
|--LineNumberReader
|--CharArrayReader
|--StringReader
|--InputStreamReaer
|--FileReader
Writer
|--BufferedWriter
|--CharArrayWriter
|--StringWriter
|--OutputStreamWriter
|--FileWriter
|--PrintWriter
字节流:
InputStream
|--FileInputStream:
|--FilterInputStream
|--BufferedInputStream
|--DataInputStream
|--ByteArrayInputStream
|--ObjectInputStream
|--SequenceInputStream
|--PipedInputStream
OutputStream
|--FileOutputStream
|--FilterOutputStream
|--BufferedOutputStream
|--DataOutputStream
|--ByteArrayOutputStream
|--ObjectOutputStream
|--PipedOutputStream
|--PrintStream
```
## 网络编程
### IP
```java
import java.net.InetAddress;
import java.net.UnknownHostException;
public class IPDemo {
/**
* @param args
* @throws UnknownHostException
*/
public static void main(String[] args) throws UnknownHostException {
//获取本地主机ip地址对象。
InetAddress ip = InetAddress.getLocalHost();
//获取其他主机的ip地址对象。
//ip = InetAddress.getByName("220.181.38.150");
//InetAddress.getByName("my_think");
System.out.println(ip.getHostAddress()); // 获取 IP 地址
System.out.println(ip.getHostName()); // 获取域名
}
}
```
### UDP
**send**
```java
import java.io.IOException;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.net.InetAddress;
import java.net.SocketException;
import java.net.UnknownHostException;
public class UDPSendDemo {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
System.out.println("发送端启动......");
/*
* 创建UDP传输的发送端。
* 思路:
* 1,建立udp的socket服务。
* 2,将要发送的数据封装到数据包中。
* 3,通过udp的socket服务将数据包发送出去。
* 4,关闭socket服务。
*/
//1, udpsocket服务。使用DatagramSocket对象。
DatagramSocket ds = new DatagramSocket(8888);
//2, 将要发送的数据封装到数据包中。
String str = "udp传输演示:哥们来了! ";
// 使用DatagramPacket将数据封装到的该对象包中。
byte[] buf = str.getBytes();
DatagramPacket dp = new
DatagramPacket(buf,buf.length,InetAddress.getByName("192.168.1.100"),10000);
//3,通过udp的socket服务将数据包发送出去。使用send方法。
ds.send(dp);
//4,关闭资源。
ds.close();
}
}
```
**receive**
```java
import java.io.IOException;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
public class UDPReceDemo {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
System.out.println("接收端启动......");
/*
* 建立UDP接收端的思路。
* 1,建立udp socket服务,因为是要接收数据,必须要明确一个端口号。
* 2,创建数据包,用于存储接收到的数据。方便用数据包对象的方法解析这些数据.
* 3,使用socket服务的receive方法将接收的数据存储到数据包中。
* 4,通过数据包的方法解析数据包中的数据。
* 5,关闭资源
*/
//1,建立udp socket服务。
DatagramSocket ds = new DatagramSocket(10000);
//2,创建数据包。
byte[] buf = new byte[1024];
DatagramPacket dp = new DatagramPacket(buf,buf.length);
//3,使用接收方法将数据存储到数据包中。
ds.receive(dp);//阻塞式的。
//4,通过数据包对象的方法,解析其中的数据,比如,地址,端口,数据内容。
String ip = dp.getAddress().getHostAddress();
int port = dp.getPort();
String text = new String(dp.getData(),0,dp.getLength());
System.out.println(ip+":"+port+":"+text);
//5,关闭资源。
ds.close();
}
}
```
**交互**
```java
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.net.InetAddress;
public class UDPSendDemo2 {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
System.out.println("发送端启动......");
/*
* 创建UDP传输的发送端。
* 思路:
* 1,建立udp的socket服务。
* 2,将要发送的数据封装到数据包中。
* 3,通过udp的socket服务将数据包发送出去。
* 4,关闭socket服务。
*/
//1,udpsocket服务。使用DatagramSocket对象。
DatagramSocket ds = new DatagramSocket(8888);
// String str = "udp传输演示:哥们来了! ";
BufferedReader bufr = new BufferedReader(new InputStreamReader(System.in));
String line = null;
while((line=bufr.readLine())!=null){
byte[] buf = line.getBytes();
DatagramPacket dp =
new
DatagramPacket(buf,buf.length,InetAddress.getByName("192.168.1.100"),10000);
ds.send(dp);
if("886".equals(line))
break;
}
//4,关闭资源。
ds.close();
}
}
//(信息接收端)
import java.io.IOException;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
public class UDPReceDemo2 {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
System.out.println("接收端启动......");
/*
* 建立UDP接收端的思路。
* 1,建立udp socket服务,因为是要接收数据,必须要明确一个端口号。
* 2,创建数据包,用于存储接收到的数据。方便用数据包对象的方法解析这些数据.
* 3,使用socket服务的receive方法将接收的数据存储到数据包中。
* 4,通过数据包的方法解析数据包中的数据。
* 5,关闭资源
*/
//1,建立udp socket服务。
DatagramSocket ds = new DatagramSocket(10000);
while(true){
//2,创建数据包。
byte[] buf = new byte[1024];
DatagramPacket dp = new DatagramPacket(buf,buf.length);
//3,使用接收方法将数据存储到数据包中。
ds.receive(dp);//阻塞式的。
//4,通过数据包对象的方法,解析其中的数据,比如,地址,端口,数据内容。
String ip = dp.getAddress().getHostAddress();
int port = dp.getPort();
String text = new String(dp.getData(),0,dp.getLength());
System.out.println(ip+":"+port+":"+text);
}
//5,关闭资源。
// ds.close();
}
}
```
**UDP 聊天程序,多线程**
```java
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.net.InetAddress;
public class Send implements Runnable {
private DatagramSocket ds;
public Send(DatagramSocket ds){
this.ds = ds;
}
@Override
public void run() {
try {
BufferedReader bufr = new BufferedReader(new
InputStreamReader(System.in));
String line = null;
while((line=bufr.readLine())!=null){
byte[] buf = line.getBytes();
DatagramPacket dp =
new
DatagramPacket(buf,buf.length,InetAddress.getByName("192.168.1.255"),10001);
ds.send(dp);
if("886".equals(line))
break;
}
ds.close();
} catch (Exception e) {
}
}
}
//(接收端)
package cn.itcast.net.p3.chat;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
public class Rece implements Runnable {
private DatagramSocket ds;
public Rece(DatagramSocket ds) {
this.ds = ds;
}
@Override
public void run() {
try {
while (true) {
// 2,创建数据包。
byte[] buf = new byte[1024];
DatagramPacket dp = new DatagramPacket(buf, buf.length);
// 3,使用接收方法将数据存储到数据包中。
ds.receive(dp);// 阻塞式的。
// 4,通过数据包对象的方法,解析其中的数据,比如,地址,端口,数据内容。
String ip = dp.getAddress().getHostAddress();
int port = dp.getPort();
String text = new String(dp.getData(), 0, dp.getLength());
System.out.println(ip + "::" + text);
if(text.equals("886")){
System.out.println(ip+"....退出聊天室");
}
}
} catch (Exception e) {
}
}
}
// 开启发送和接收两个线程开始运行聊天
import java.io.IOException;
import java.net.DatagramSocket;
import java.net.SocketException;
public class ChatDemo {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
DatagramSocket send = new DatagramSocket();
DatagramSocket rece = new DatagramSocket(10001);
new Thread(new Send(send)).start();
new Thread(new Rece(rece)).start();
}
}
```
### TCP
**客户端**
```java
import java.io.IOException;
import java.io.OutputStream;
import java.net.Socket;
import java.net.UnknownHostException;
public class ClientDemo {
/**
* @param args
* @throws IOException
* @throws UnknownHostException
*/
public static void main(String[] args) throws UnknownHostException, IOException
{
//客户端发数据到服务端
/*
* Tcp传输,客户端建立的过程。
* 1,创建tcp客户端socket服务。使用的是Socket对象。
* 建议该对象一创建就明确目的地。要连接的主机。
* 2,如果连接建立成功,说明数据传输通道已建立。
* 该通道就是socket流 ,是底层建立好的。 既然是流,说明这里既有输入,又有输出。
* 想要输入或者输出流对象,可以找Socket来获取。
* 可以通过getOutputStream(),和getInputStream()来获取两个字节流。
* 3,使用输出流,将数据写出。
* 4,关闭资源。
*/
//创建客户端socket服务。
Socket socket = new Socket("192.168.1.100",10002);
//获取socket流中的输出流。
OutputStream out = socket.getOutputStream();
//使用输出流将指定的数据写出去。
out.write("tcp演示:哥们又来了!".getBytes());
//关闭资源。
socket.close();
}
}
```
**服务端**
```java
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.ServerSocket;
import java.net.Socket;
public class ServerDemo {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
// 服务端接收客户端发送过来的数据,并打印在控制台上。
/*
* 建立tcp服务端的思路:
* 1,创建服务端socket服务。通过ServerSocket对象。
* 2,服务端必须对外提供一个端口,否则客户端无法连接。
* 3,获取连接过来的客户端对象。
* 4,通过客户端对象获取socket流读取客户端发来的数据
* 并打印在控制台上。
* 5,关闭资源。关客户端,关服务端。
*/
//1创建服务端对象。
ServerSocket ss = new ServerSocket(10002);
//2,获取连接过来的客户端对象。
Socket s = ss.accept();//阻塞式.
String ip = s.getInetAddress().getHostAddress();
//3,通过socket对象获取输入流,要读取客户端发来的数据
InputStream in = s.getInputStream();
byte[] buf = new byte[1024];
int len = in.read(buf);
String text = new String(buf,0,len);
System.out.println(ip+":"+text);
s.close();
ss.close();
}
}
```
**交互**
```java
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.Socket;
import java.net.UnknownHostException;
public class ClientDemo2 {
/**
* @param args
* @throws IOException
* @throws UnknownHostException
*/
public static void main(String[] args) throws UnknownHostException, IOException
{
//客户端发数据到服务端
/*
* Tcp传输,客户端建立的过程。
* 1,创建tcp客户端socket服务。使用的是Socket对象。
* 建议该对象一创建就明确目的地。要连接的主机。
* 2,如果连接建立成功,说明数据传输通道已建立。
* 该通道就是socket流 ,是底层建立好的。 既然是流,说明这里既有输入,又有输出。
* 想要输入或者输出流对象,可以找Socket来获取。
* 可以通过getOutputStream(),和getInputStream()来获取两个字节流。
* 3,使用输出流,将数据写出。
* 4,关闭资源。
*/
Socket socket = new Socket("192.168.1.100", 10002);
OutputStream out = socket.getOutputStream();
out.write("tcp演示:哥们又来了!".getBytes());
// 读取服务端返回的数据,使用 socket 读取流。
InputStream in = socket.getInputStream();
byte[] buf = new byte[1024];
int len = in.read(buf);
String text = new String(buf,0,len);
System.out.println(text);
//关闭资源。
socket.close();
}
}
//(服务端)
package cn.itcast.net.p4.tcp;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.ServerSocket;
import java.net.Socket;
public class ServerDemo2 {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
// 服务端接收客户端发送过来的数据,并打印在控制台上。
/*
* 建立tcp服务端的思路:
* 1,创建服务端socket服务。通过ServerSocket对象。
* 2,服务端必须对外提供一个端口,否则客户端无法连接。
* 3,获取连接过来的客户端对象。
* 4,通过客户端对象获取socket流读取客户端发来的数据
* 并打印在控制台上。
* 5,关闭资源。关客户端,关服务端。
*/
//1创建服务端对象。
ServerSocket ss = new ServerSocket(10002);
//2,获取连接过来的客户端对象。
Socket s = ss.accept();
String ip = s.getInetAddress().getHostAddress();
//3,通过socket对象获取输入流,要读取客户端发来的数据
InputStream in = s.getInputStream();
byte[] buf = new byte[1024];
int len = in.read(buf);
String text = new String(buf,0,len);
System.out.println(ip+":"+text);
//使用客户端socket对象的输出流给客户端返回数据
OutputStream out = s.getOutputStream();
out.write("收到".getBytes());
s.close();
ss.close();
}
}
```
**TCP创建一个英文大写服务器 **
```java
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.Socket;
import java.net.UnknownHostException;
public class TransClient {
/**
* @param args
* @throws IOException
* @throws UnknownHostException
*/
public static void main(String[] args) throws UnknownHostException, IOException
{
/*
* 思路:
* 客户端:
* 1,需要先有socket端点。
* 2,客户端的数据源:键盘。
* 3,客户端的目的: socket.
* 4,接收服务端的数据,源: socket。
* 5,将数据显示在打印出来:目的:控制台.
* 6,在这些流中操作的数据,都是文本数据。
* 转换客户端:
* 1,创建socket客户端对象。
* 2,获取键盘录入。
* 3,将录入的信息发送给socket输出流。
*/
//1,创建socket客户端对象。
Socket s = new Socket("192.168.1.100",10004);
//2,获取键盘录入。
BufferedReader bufr =
new BufferedReader(new InputStreamReader(System.in));
//3,socket输出流。
// new BufferedWriter(new OutputStreamWriter(s.getOutputStream()));
PrintWriter out = new PrintWriter(s.getOutputStream(),true);
//4,socket输入流,读取服务端返回的大写数据
BufferedReader bufIn = new BufferedReader(new
InputStreamReader(s.getInputStream()));
String line = null;
while((line=bufr.readLine())!=null){
if("over".equals(line))
break;
// out.print(line+"\r\n");
// out.flush();
out.println(line);
//读取服务端发回的一行大写数。
String upperStr = bufIn.readLine();
System.out.println(upperStr);
}
s.close();
}
}
//(服务端)
package cn.itcast.net.p5.tcptest;
import java.io.BufferedReader;292
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.PrintWriter;
import java.net.ServerSocket;
import java.net.Socket;
public class TransServer {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
/*
* 转换服务端。
* 分析:
* 1, serversocket服务。
* 2,获取socket对象。
* 3,源: socket,读取客户端发过来的需要转换的数据。
* 4,目的:显示在控制台上。
* 5,将数据转成大写发给客户端。
*/
//1,
ServerSocket ss = new ServerSocket(10004);
//2,获取socket对象。
Socket s = ss.accept();
//获取ip.
String ip = s.getInetAddress().getHostAddress();
System.out.println(ip+"......connected");
//3,获取socket读取流,并装饰。
BufferedReader bufIn = new BufferedReader(new
InputStreamReader(s.getInputStream()));
//4,获取socket的输出流,并装饰。
PrintWriter out = new PrintWriter(s.getOutputStream(),true);
String line = null;
while((line=bufIn.readLine())!=null){
System.out.println(line);
out.println(line.toUpperCase());
// out.print(line.toUpperCase()+"\r\n");
// out.flush();
}
s.close();
ss.close();
}
}
```
**上传图片**
```java
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.Socket;
public class UploadTask implements Runnable {
private static final int SIZE = 1024*1024*2;
private Socket s;
public UploadTask(Socket s) {
this.s = s;
}
@Override
public void run() {
int count = 0;
String ip = s.getInetAddress().getHostAddress();
System.out.println(ip + ".....connected");
try{
// 读取客户端发来的数据。
InputStream in = s.getInputStream();
// 将读取到数据存储到一个文件中。
File dir = new File("c:\\pic");
if (!dir.exists()) {
dir.mkdirs();
}
File file = new File(dir, ip + ".jpg");
//如果文件已经存在于服务端
while(file.exists()){
file = new File(dir,ip+"("+(++count)+").jpg");
}
FileOutputStream fos = new FileOutputStream(file);
byte[] buf = new byte[1024];
int len = 0;
while ((len = in.read(buf)) != -1) {
fos.write(buf, 0, len);
if(file.length()>SIZE){
System.out.println(ip+"文件体积过大");
fos.close();
s.close();
System.out.println(ip+"...."+file.delete());
return ;
}
}
// 获取socket输出流, 将上传成功字样发给客户端。
OutputStream out = s.getOutputStream();
out.write("上传成功".getBytes());
fos.close();
s.close();
}catch(IOException e){
}
}
}
//(上传的客户端)
package cn.itcast.net.p1.uploadpic;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.Socket;
import java.net.UnknownHostException;
public class UploadPicClient {
/**
* @param args
* @throws IOException
* @throws UnknownHostException
*/
public static void main(String[] args) throws UnknownHostException, IOException
{
//1,创建客户端socket。
Socket s = new Socket("192.168.1.100",10006);
//2,读取客户端要上传的图片文件。
FileInputStream fis = new FileInputStream("c:\\0.bmp");
//3,获取socket输出流,将读到图片数据发送给服务端。
OutputStream out = s.getOutputStream();
byte[] buf = new byte[1024];
int len = 0;
while((len=fis.read(buf))!=-1){
out.write(buf,0,len);
}
//告诉服务端说:这边的数据发送完毕。让服务端停止读取。
s.shutdownOutput();
//读取服务端发回的内容。
InputStream in = s.getInputStream();
byte[] bufIn = new byte[1024];
int lenIn = in.read(buf);
String text = new String(buf,0,lenIn);
System.out.println(text);
fis.close();
s.close();
}
}
//(上传的服务端)
package cn.itcast.net.p1.uploadpic;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.ServerSocket;
import java.net.Socket;
public class UploadPicServer {
/**
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
//创建tcp的socket服务端。
ServerSocket ss = new ServerSocket(10006);
while(true){
Socket s = ss.accept();
new Thread(new UploadTask(s)).start();
}
//获取客户端。
// ss.close();
}
}
```
**网络编程小结**
```
最常见的客户端:
浏览器 : IE。
最常见的服务端:
服务器: Tomcat。
为了了解其原理:
自定义服务端,使用已有的客户端IE,了解一下客户端给服务端发了什么请求?
发送的请求是:
GET / HTTP/1.1 请求行 请求方式 /myweb/1.html 请求的资源路径 http协议版本。
请求消息头 . 属性名:属性值
Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg,
application/x-shockwave-flash,
application/vnd.ms-excel, application/vnd.ms-powerpoint, application/msword, */*
Accept: */*
Accept-Language: zh-cn,zu;q=0.5
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; InfoPath.2)
Host: 192.168.1.100:9090
//Host: www.huyouni.com:9090
Connection: Keep-Alive
//空行
//请求体。
//服务端发回应答消息。
HTTP/1.1 200 OK //应答行, http的协议版本 应答状态码 应答状态描述信息
应答消息属性信息。 属性名:属性值
Server: Apache-Coyote/1.1
ETag: W/"199-1323480176984"
Last-Modified: Sat, 10 Dec 2011 01:22:56 GMT
Content-Type: text/html
Content-Length: 199
Date: Fri, 11 May 2012 07:51:39 GMT
Connection: close
//空行
//应答体。
<html>303
<head>
<title>这是我的网页</title>
</head>
<body>
<h1>欢迎光临</h1>
<font size='5' color="red">这是一个tomcat服务器中的资源。是一个html网页。 </font>
</body>
</html>
--------------------------------------------------------------------------------
网络结构,
1,C/S client/server
特点:
该结构的软件,客户端和服务端都需要编写。
可发成本较高,维护较为麻烦。
好处:
客户端在本地可以分担一部分运算。
2,B/S browser/server
特点:
该结构的软件,只开发服务器端,不开发客户端,因为客户端直接由浏览器取代。
开发成本相对低,维护更为简单。
缺点:所有运算都要在服务端完成。
```
## 反射机制
### 什么是反射机制(类的解剖)
```java
/*
* JAVA反射机制是在运行状态中,对于任意一个类 (class文件),都能够知道这个类的所有属性和方法;
* 对于任意一个对象,都能够调用它的任意一个方法和属性;
* 这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。
*
*
* 动态获取类中信息,就是java反射 。
* 可以理解为对类的解剖。
*
* 要想要对字节码文件进行解剖,必须要有字节码文件对象.
* 如何获取字节码文件对象呢?
*
*/
```
```java
public class ReflectDemo {
/**
* @param args
* @throws ClassNotFoundException
*/
public static void main(String[] args) throws ClassNotFoundException {
getClassObject_3();
}
/*
* 方式三:
* 只要通过给定的类的 字符串名称就可以获取该类,更为扩展。
* 可是用Class类中的方法完成。
* 该方法就是 forName.
* 这种方式只要有名称即可,更为方便,扩展性更强。
*/
public static void getClassObject_3() throws ClassNotFoundException {
String className = "cn.itcast.bean.Person";
Class clazz = Class.forName(className);
System.out.println(clazz);
}
/*
* 方式二:
* 2,任何数据类型都具备一个静态的属性.class来获取其对应的Class对象。
* 相对简单,但是还是要明确用到类中的静态成员。
* 还是不够扩展。
*
*/
public static void getClassObject_2() {
Class clazz = Person.class;
Class clazz1 = Person.class;
System.out.println(clazz==clazz1);
}
/*
* 获取字节码对象的方式:
* 1, Object类中的getClass()方法的。
* 想要用这种方式,必须要明确具体的类,并创建对象。
* 麻烦 .
*
*/
public static void getClassObject_1(){
Person p = new Person();
Class clazz = p.getClass();
Person p1 = new Person();
Class clazz1 = p1.getClass();
System.out.println(clazz==clazz1);
}
}
```
### 类的解剖
获取构造函数:
```java
import java.io.FileReader;
import java.lang.reflect.Constructor;
public class ReflectDemo2 {
/**
* @param args
* @throws Exception
* @throws InstantiationException
* @throws ClassNotFoundException
*/
public static void main(String[] args) throws ClassNotFoundException,
InstantiationException, Exception {
createNewObject_2();
}
public static void createNewObject_2() throws Exception {
// cn.itcast.bean.Person p = new cn.itcast.bean.Person("小强",39);
/*
* 当获取指定名称对应类中的所体现的对象时,
* 而该对象初始化不使用空参数构造该怎么办呢?
* 既然是通过指定的构造 函数进行对象的初始化,
* 所以应该先获取到该构造函数。 通过字节码文件对象即可完成。
* 该方法是: getConstructor(paramterTypes);
*
*/
String name = "cn.itcast.bean.Person";
//找寻该名称类文件,并加载进内存,并产生Class对象。
Class clazz = Class.forName(name);
//获取到了指定的构造函数对 象。
Constructor constructor = clazz.getConstructor(String.class,int.class);
//通过该构造器对象的newInstance方法进行对象的初始化。
Object obj = constructor.newInstance("小明",38);
}
public static void createNewObject() throws ClassNotFoundException,
InstantiationException, IllegalAccessException{
//早期: new时候,先根据被new的类的名称找寻该类的字节码文件,并加载进内存,
// 并创建该字节码文件对象,并接着创建该字节文件的对应的Person对象.
// cn.itcast.bean.Person p = new cn.itcast.bean.Person();
//现在:
String name = "cn.itcast.bean.Person";
//找寻该名称类文件,并加载进内存,并产生Class对象。
Class clazz = Class.forName(name);
//如何产生该类的对象呢?
Object obj = clazz.newInstance();
}
}
```
获取字段:
```java
import java.lang.reflect.Field;
public class ReflectDemo3 {
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
getFieldDemo();
}
/*
* 获取字节码文件中的字段。
*/
public static void getFieldDemo() throws Exception {
Class clazz = Class.forName("cn.itcast.bean.Person");
Field field = null;//clazz.getField("age");//只能获取公有的,
field = clazz.getDeclaredField("age");//只获取本类,但包含私有。
//对私有字段的访问取消权限检查。暴力访问。
field.setAccessible(true);
Object obj = clazz.newInstance();
field.set(obj, 89);
Object o = field.get(obj);
System.out.println(o);
// cn.itcast.bean.Person p = new cn.itcast.bean.Person();
// p.age = 30;
}
}
```
获取公共函数:
```java
import java.lang.reflect.Constructor;
import java.lang.reflect.Method;
public class ReflectDemo4 {
public ReflectDemo4() {
}
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
getMethodDemo_3();
}
public static void getMethodDemo_3() throws Exception {
Class clazz = Class.forName("cn.itcast.bean.Person");
Method method = clazz.getMethod("paramMethod", String.class,int.class);
Object obj = clazz.newInstance();
method.invoke(obj, "小强",89);
}
public static void getMethodDemo_2() throws Exception {
Class clazz = Class.forName("cn.itcast.bean.Person");
Method method = clazz.getMethod("show", null); //获取空参数一般方法。
// Object obj = clazz.newInstance();
Constructor constructor = clazz.getConstructor(String.class,int.class);
Object obj = constructor.newInstance("小明",37);
method.invoke(obj, null);
}
/*
* 获取指定Class中的所有公共函数。
*/
public static void getMethodDemo() throws Exception {
Class clazz = Class.forName("cn.itcast.bean.Person");
Method[] methods = clazz.getMethods();//获取的都是公有的方法。
methods = clazz.getDeclaredMethods();//只获取本类中所有方法,包含私有。
for(Method method : methods){
System.out.println(method);
}
}
}
```
## 正则表达式
Demos:
```java
public class RegexDemo {
/**
* @param args
*/
public static void main(String[] args) {
String qq = "123k4567";
// checkQQ(qq);
String regex = "[1-9][0-9]{4,14}";//正则表达式。
// boolean b = qq.matches(regex);
// System.out.println(qq+":"+b);
// String str = "aoooooooob";
// String reg = "ao{4,6}b";
// boolean b = str.matches(reg);
// System.out.println(str+":"+b);
}
/*
* 需求:定义一个功能对QQ号进行校验。
* 要求:长度5~15. 只能是数字, 0不能开头
*/
public static void checkQQ(String qq){
int len = qq.length();
if(len>=5 && len<=15){
if(!qq.startsWith("0")){
try {
long l = Long.parseLong(qq);
System.out.println(l+":正确");
}catch(NumberFormatException e){
System.out.println(qq+":含有非法字符");
}
}else{
System.out.println(qq+":不能0开头");
}
}else{
System.out.println(qq+":长度错误");
}
}
}
```
```java
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class RegexDemo2 {
/**
* @param args
*/
public static void main(String[] args) {
/*
* 正则表达式对字符串的常见操作:
* 1, 匹配。
* 其实使用的就是String类中的matches方法。
*
* 2,切割。
* 其实使用的就是String类中的split方法。
*
* 3,替换。
* 其实使用的就是String类中的replaceAll()方法。
*
* 4,获取。
*
*/
functionDemo_4();
}
/*
* 获取
* 将正则规则进行对象的封装。
* Pattern p = Pattern.compile("a*b");
* //通过正则对象的matcher方法字符串相关联。获取要对字符串操作的匹配器对象Matcher .
* Matcher m = p.matcher("aaaaab");
* //通过Matcher匹配器对象的方法对字符串进行操作。
* boolean b = m.matches();
*/
public static void functionDemo_4() {
String str = "da jia hao,ming tian bu fang jia!";
String regex = "\\b[a-z]{3}\\b";
//1,将正则封装成对象。
Pattern p = Pattern.compile(regex);
//2, 通过正则对象获取匹配器对象。
Matcher m = p.matcher(str);
//使用Matcher对象的方法对字符串进行操作。
//既然要获取三个字母组成的单词
//查找。 find();
System.out.println(str);
while(m.find()){
System.out.println(m.group());//获取匹配的子序列
System.out.println(m.start()+":"+m.end());
}
}
/*
* 替换
*/
public static void functionDemo_3() {
String str = "zhangsanttttxiaoqiangmmmmmmzhaoliu";
str = str.replaceAll("(.)\\1+", "$1");
System.out.println(str);
String tel = "15800001111"; //158****1111;
tel = tel.replaceAll("(\\d{3})\\d{4}(\\d{4})", "$1****$2");
System.out.println(tel);
}
/*
* 切割。
*
* 组: ((A)(B(C)))
*/
public static void functionDemo_2(){
String str = "zhangsanttttxiaoqiangmmmmmmzhaoliu";
String[] names = str.split("(.)\\1+"); //str.split("\\.");
for(String name : names){
System.out.println(name);
}
}
/*
* 演示匹配。
*/
public static void functionDemo_1(){
//匹配手机号码是否正确。
String tel = "15800001111";
String regex = "1[358]\\d{9}";
boolean b = tel.matches(regex);
System.out.println(tel+":"+b);
}
}
```
## 枚举类型
https://www.liaoxuefeng.com/wiki/1252599548343744/1260473188087424
为了让编译器能自动检查某个值在枚举的集合内,并且,不同用途的枚举需要不同的类型来标记,不能混用,我们可以使用`enum`来定义枚举类。
Demo:
```java
public enum Color {
RED, GREEN, BLUE;
}
```
编译出的 class 大概是这样的:
```java
public final class Color extends Enum { // 继承自Enum,标记为final class
// 每个实例均为全局唯一:
public static final Color RED = new Color();
public static final Color GREEN = new Color();
public static final Color BLUE = new Color();
// private构造方法,确保外部无法调用new操作符:
private Color() {}
}
```
编译后的`enum`类和普通`class`并没有任何区别。但是我们自己无法按定义普通`class`那样来定义`enum`,必须使用`enum`关键字,这是Java语法规定的。
因为`enum`是一个`class`,每个枚举的值都是`class`实例,因此,这些实例有一些方法:
```java
// name()
String s = Color.RED.name(); // "RED"
// ordinal() 返回定义的常量的顺序,从0开始计数
int n = Color.RED.ordinal();
```
```java
public class Main {
public static void main(String[] args) {
Weekday day = Weekday.SUN;
if (day.dayValue == 6 || day.dayValue == 0) {
System.out.println("Today is " + day + ". Work at home!");
} else {
System.out.println("Today is " + day + ". Work at office!");
}
}
}
enum Weekday {
MON(1, "星期一"), TUE(2, "星期二"), WED(3, "星期三"), THU(4, "星期四"), FRI(5, "星期五"), SAT(6, "星期六"), SUN(0, "星期日");
public final int dayValue;
private final String chinese;
private Weekday(int dayValue, String chinese) {
this.dayValue = dayValue;
this.chinese = chinese;
}
@Override
public String toString() {
return this.chinese;
}
}
```
注意,enum 在 Java 中是关键字,所以我们不能创建 enum 的包名,如果要在项目中创建枚举类,应该放在 enums 文件夹下! | 154,289 | MIT |
# @livelybone/form
[](https://www.npmjs.com/package/@livelybone/form)
[](https://www.npmjs.com/package/@livelybone/form)



> `pkg.module supported`, 天然支持 tree-shaking, 使用 es module 引用即可
[English Document](./README.md)
一个跨平台的表单管理工具,可以应用于 React, Vue, React Native, Angular... 实现表单验证, 值的格式化, 表单重置, 表单提交
## repository
https://github.com/livelybone/form.git
## Demo
https://github.com/livelybone/form#readme
## Run Example
你可以通过运行项目的 example 来了解这个组件的使用,以下是启动步骤:
1. 克隆项目到本地 `git clone https://github.com/livelybone/form.git`
2. 进入本地克隆目录 `cd your-module-directory`
3. 安装项目依赖 `npm i`(使用 taobao 源: `npm i --registry=http://registry.npm.taobao.org`)
4. 启动服务 `npm run dev`
5. 在你的浏览器看 example (地址通常是 `http://127.0.0.1:3000/examples/test.html`)
## Installation
```bash
npm i -S @livelybone/form
```
## Global name
`Form`
## Interface
去 [index.d.ts](./index.d.ts) 查看可用方法和参数
## Usage
####
```js
import { Form, FormItemsManager } from '@livelybone/form'
/** 管理你项目中的所有表单项 */
const formItems = new FormItemsManager({
name: { name: 'name', value: '' },
phone: {
name: 'phone',
value: '',
validator: val => {
return /^1\d{10}$/.test(val) ? '' : 'Chinese phone number was wrong'
},
},
amount: {
name: 'amount',
value: '',
formatter: val => {
return val.replace(/[^\d]+/g, '')
}
},
address: { name: 'address', value: '' },
})
/** 选择你当前要用到的表单项生成表单 */
const form = new Form(
formItems.getItems(['name', 'phone', 'amount']),
{
onSubmit: (data) => {
console.log(data)
// ...submit data to server, or do other action
},
validateAll: true,
initialValues: {},
validateOnChange: true
},
)
/** 更新表单的值 */
form.itemChange('name', 'livelybone')
/** 批量更新表单的值 */
form.itemsChange({ phone: '120', amount: 'a-b/1' })
/** 你可以看到表单的校验情况 */
console.log('Is name valid: ', form.getItemByName('name').valid)
// -> Is name valid: true
console.log('Is phone valid: ', form.getItemByName('phone').valid)
// -> Is phone valid: false
console.log('The phone error text is: ', form.getItemByName('phone').errorText)
// -> The form error text is: Chinese phone number was wrong
console.log('Is form valid: ', form.valid)
// -> Is form valid: false
console.log('The form error text is: ', form.errorText)
// -> The form error text is: Chinese phone number was wrong
/** 你可以看到 amount 的值被格式化了 */
console.log('The value of amount is: ', form.getItemByName('amount').value)
// -> The value of amount is: '1'
/** 你可以获取表单的数据 */
console.log('The data of the form is: ', form.data)
// -> The data of the form is: { name: 'livelybone', phone: '120', amount: '1' }
/** 提交表单 */
form.submit()
/** 重置表单 */
form.reset()
/** 重置单个表单项 */
form.resetItem('amount')
```
在 HTML 文件中直接引用,你可以在 [CDN: unpkg](https://unpkg.com/@livelybone/form/lib/umd/) 看到你能用到的所有 js 脚本
```html
<-- 然后使用你需要的 -->
<script src="https://unpkg.com/@livelybone/form/lib/umd/<--module-->.js"></script>
``` | 3,409 | MIT |
<!--
* @Author: your name
* @Date: 2021-11-09 16:56:23
* @LastEditTime: 2021-11-09 18:41:12
* @LastEditors: your name
* @Description: 打开koroFileHeader查看配置 进行设置: https://github.com/OBKoro1/koro1FileHeader/wiki/%E9%85%8D%E7%BD%AE
* @FilePath: \pytorch-YOLOv4\Use_yolov4_to_train_your_own_data.md
-->
yolov4的发布引起了不少的关注,但由于darknet是大佬c语言写的,对代码的阅读有诸多不变,所以周末的时候写了个pytorch版的(蹭一波热度)。虽然pytorch——yolov4写好已经有一段时间了,但是由于种种原因一直没有进行验证(主要就是懒),大家提出了诸多问题帮助修复很多bug,还有大佬一起增加新的功能,感谢大家的帮助。这些天呼声最高的就是如何如何使用自己的数据进行训练,昨天又是周末,就把这件拖了很久的事做了。并不像使用很多数据,于是自己制作了一个简单的数据集。
# 1. 代码准备
github 克隆代码
```
git clone https://github.com/Tianxiaomo/pytorch-YOLOv4.git
```
# 2. 数据准备
准备train.txt,内容是图片名和box。格式如下
```
image_path1 x1,y1,x2,y2,id x1,y1,x2,y2,id x1,y1,x2,y2,id ...
image_path2 x1,y1,x2,y2,id x1,y1,x2,y2,id x1,y1,x2,y2,id ...
...
```
- image_path : 图片名
- x1,y1 : 左上角坐标
- x2,y2 : 右下角坐标
- id : 物体类别
我自己用的数据是自己制作的了一个小数据集,检测各种各样的硬币(也就1元,5角,1角三种),为什么不使用其他的东西制作数据集呢,没有啊,手边只有这些硬币感觉比较合适,相对其他的东西也比较简单。

一共准备了没几张。
# 3. 参数设置
开始训练的时候我直接用原来的参数,batch size设为64,跑了几个epoch发现不对,我数据一共才二十多个。后修改网络更新策略,不是按照每个epoch的step更新,使用总的steps更新,观察loss貌似可以训练了,于是睡觉,明天再看训练如何(鬼知道我又改了啥)。
今天打开电脑一看,what xx,loss收敛到2.e+4下不去了,此种必又蹊跷,遂kill了。于是把batch size直接设为4,可以正常训练了。
```
Cfg.batch = 4
Cfg.subdivisions = 1
```
# 4. 开始训练
```
python3 train.py -l 0.001 -g 2 -pretrained ./yolov4.conv.137.pth -classes 3 -dir ./coins
-l 学习率
-g gpu id
-pretrained 预训练的主干网络,从AlexeyAB给的darknet的yolov4.conv.137转换过来的
-classes 类别种类
-dir 图片所在文件夹
```
看下loss曲线
```
tensorboard --logdir log --host 192.168.212.75 --port 6008
```

# 5. 验证
```
python model.py 3 weight/Yolov4_epoch166_coins.pth data/coin2.jpg data/coins.names
python model.py num_classes weightfile imagepath namefile
```
coins.names
```
1yuan
5jiao
1jiao
```

效果差强人意(训练数据只有3种类型硬币)。
# 附
- coins数据集 (链接:https://pan.baidu.com/s/1y701NRKSdpj6UKDIH-GpqA
提取码:j09s)
- yolov4.conv.137.pth (链接:https://pan.baidu.com/s/1ovBie4YyVQQoUrC3AY0joA 提取码:kcel) | 2,274 | Apache-2.0 |
---
title: 管理网络适配器以使用 Azure Site Recovery 实现本地灾难恢复
description: 介绍如何使用 Azure Site Recovery 管理网络接口,以实现本地到 Azure 的灾难恢复
manager: rochakm
ms.service: site-recovery
ms.topic: conceptual
origin.date: 04/09/2019
author: rockboyfor
ms.date: 10/19/2020
ms.testscope: no
ms.testdate: ''
ms.author: v-yeche
ms.openlocfilehash: 10b127e3400d90302f87ad1fc1e79101e5af3ce1
ms.sourcegitcommit: 6f66215d61c6c4ee3f2713a796e074f69934ba98
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 10/16/2020
ms.locfileid: "92128210"
---
# <a name="manage-vm-network-interfaces-for-on-premises-disaster-recovery-to-azure"></a>管理用于本地到 Azure 灾难恢复的 VM 网络接口
Azure 中的虚拟机 (VM) 必须附加有至少一个网络接口。 它可以附加 VM 的大小所能够支持的网络接口数量。
默认情况下,Azure 虚拟机上附加的第一个网络接口定义为主网络接口。 虚拟机中的所有其他网络接口为辅助网络接口。 默认情况下,来自虚拟机的所有出站流量都是通过分配给主网络接口的主 IP 配置的 IP 地址发出的。
在本地环境中,虚拟机或服务器可针对环境中的不同网络具有多个网络接口。 不同的网络通常用于执行特定操作,如升级、维护和访问 internet。 当从本地环境迁移或故障转移到 Azure 时,请记住,同一虚拟机中的网络接口必须全部连接到同一虚拟网络。
默认情况下,Azure Site Recovery 在 Azure 虚拟机上创建的网络接口数量与连接到本地服务器的网络接口数量相同。 通过编辑复制的虚拟机设置下的网络接口设置,可避免在迁移或故障转移过程中创建冗余网络接口。
## <a name="select-the-target-network"></a>选择目标网络
对于 VMware 和物理机,以及 Hyper-V(不带 System Center Virtual Machine Manager)虚拟机,可为单个虚拟机指定目标虚拟网络。 对于带 Virtual Machine Manager 的 Hyper-V 虚拟机,使用[网络映射](./hyper-v-vmm-network-mapping.md)映射某个源 Virtual Machine Manager 服务器上的 VM 网络,并以 Azure 网络为定向目标。
1. 在恢复服务保管库中的“复制的项” 下,选择任何复制的项以访问其设置。
2. 选择“计算和网络” 选项卡可访问复制项目的网络设置。
3. 在“网络属性” 下,从可用网络接口的列表中选择虚拟网络。
:::image type="content" source="./media/site-recovery-manage-network-interfaces-on-premises-to-azure/compute-and-network.png" alt-text="网络设置":::
修改目标网络会影响该特定虚拟机的所有网络接口。
对于 Virtual Machine Manager 云,修改网络映射会影响所有虚拟机及其网络接口。
## <a name="select-the-target-interface-type"></a>选择目标接口类型
在“计算和网络”窗格中的“网络接口”部分下,可查看和编辑网络接口设置。 还可指定目标网络接口类型。
- 故障转移需使用主网络接口 。
- 所有其他选定的网络接口(若有)为“辅助” 网络接口。
- 选择“不使用” 以避免在故障转移时创建某个网络接口。
默认情况下,启用复制时,Site Recovery 会选择本地服务器上所有检测到的网络接口。 它会将其中一个标记为“主要” ,所有其他的标记为“辅助” 。 本地服务器上后续添加的任何接口均默认标记为“不使用” 。 添加更多网络接口时,请确保选择正确的 Azure 虚拟机目标大小,以确保可容纳所有所需的网络接口。
## <a name="modify-network-interface-settings"></a>修改网络接口设置
可修改复制项网络接口的子网和 IP 地址。 如果未指定 IP 地址,则 Site Recovery 会在故障转移时将下一个可用 IP 地址从子网分配到网络接口。
1. 选择任何可用的网络接口以打开网络接口设置。
2. 从可用子网的列表中选择所需子网。
3. 输入所需 IP 地址(根据需要)。
:::image type="content" source="./media/site-recovery-manage-network-interfaces-on-premises-to-azure/network-interface-settings.png" alt-text="网络设置":::
4. 选择“确定” 以完成编辑,然后返回“计算和网络” 窗格。
5. 为其他网络接口重复步骤 1-4。
6. 选择“保存” ,保存全部更改。
## <a name="next-steps"></a>后续步骤
[深入了解](../virtual-network/virtual-network-network-interface-vm.md) Azure 虚拟机的网络接口。
<!-- Update_Description: update meta properties, wording update, update link --> | 2,655 | CC-BY-4.0 |
---
title: 中间件
permalink: /docs/advance/middleware/
---
### 1. 概念
中间件是在定义在控制器运行之前或之后运行的对象,中间件可以配置一个或多个。
中间件通常用于授权或者处理请求过滤等。
### 2.中间件的定义
路由的中间件在全局配置或应用配置文件中定义,
全局配置位于storage/Conf/middleware.php,应用配置位于app/应用名称/Conf/middleware.php文件中。
例如以下定义了auth和convert中间件:
```
<?php
return [
'auth'=>'App\\Home\\Middleware\\Authorize',
'convert'=>'App\\Home\\Middleware\\CharsetConvert',
];
```
### 3.中间件的开发
如上auth中间件位于命名空间“App\Home\Middleware”中,中间件需要实现handle方法。
handle方法的参数定义如下:
```
/**
* @param \Closure $next
* @param \Library\Request $request
* @param \Library\Response $response
* return \Closure
*/
function handle(\Closure $next,$request,$response)
```
例如auth中间件定义如下:
```
<?php
namespace App\Home\Middleware;
class Authorize{
public function handle(\Closure $next,$request,$response){
return $next($request,$response);
}
}
```
在handle方法中,需要返回 “$next($request,$response)”用于执行下一个中间件。
也可以使用下面的方式改变中间件的执行顺序:
```
public function handle(\Closure $next,$request,$response){
$result=$next($request,$response);
//处理中间件方法
return $result;
}
```
这样在控制器执行完成之后才会执行中间件的方法。
### 4. 中间件的路由配置
中间件可以在路由中配置,参考[路由/路由中间件](/docs/route/route_middleware/)。
也可以在控制器静态方法middleware中返回中间件:
```
<?php
namespace App\Home\Controller;
use Library\Controller;
class Index extends Controller{
public static function middleware(){
//控制器构造方法中使用中间件
return 'auth';
}
}
```
以上执行控制器的所有方法前都会先执行中间件,
可以指定不需要执行的方法:
```
//执行hello方法不会执行中间件
<?php
namespace App\Home\Controller;
use Library\Controller;
class Index extends Controller{
public static function middleware(){
//控制器构造方法中使用中间件
return 'auth:hello';
}
public function hello(){
}
public function test(){
}
}
```
也可以使用常量定义中间件
```
//执行hello方法不会执行中间件
<?php
namespace App\Home\Controller;
use Library\Controller;
class Index extends Controller{
const MIDDLEWARE='auth:hello';
public function hello(){
}
public function test(){
}
}
``` | 1,925 | MIT |
京都市ごみの捨て方・分別方法判定アプリケーション
===================
About This Project
-----------------------------------
このアプリケーションは、京都市のごみの収集日の表示とごみの捨て方・分類を簡単に調べるためのアプリケーションです。
[Code for Kanazawa](http://codeforkanazawa.org/)の
[5374プロジェクト](https://github.com/codeforkanazawa-org/5374)をベースとし、
Code for Kyotoの活動の一環で作成しています。
ごみの収集日・分別情報は、[Code for Kyotoの5374プロジェクト](https://github.com/ofuku3f/5374osaka.github.com)および、
[京都市オープンデータポータルサイト](https://data.city.kyoto.lg.jp/)のデータを利用しています。
How to localize this Application
-----------------------------------
このプロジェクトをForkし、各自治体向けのアプリケーションを作成し、公開する場合には、以下の修正を行ってください。
#### パッケージ名の変更
パッケージ名は必ず別のものに変更してください
#### API Keyの変更
Google Place APIを利用しています。APIキーを取得し、[AndroidManifest.xml](/app/src/main/AndroidManifest.xml)
の該当箇所に設定してください
<!-- for Google Place API -->
<!-- Please change your API_KEY -->
<meta-data
android:name="com.google.android.geo.API_KEY"
android:value="YOUR API KEY" />
#### ごみ収集日情報の参照先を変更
ごみ取集日情報は、5374プロジェクトのデータ形式に従っています。
このプロジェクトでは5374プロジェクトのGitHubに公開されているCSVファイルにアクセスしデータを取得します。
[AreaDataReader](/app/src/main/java/com/kubotaku/android/code4kyoto5374/util/AreaDataReader.java)の以下の定義を変更してください
public class AreaDataReader {
// GitHubのユーザー名
private static final String GITHUB_OWNER = "ofuku3f";
// GitHubのリポジトリ名
private static final String GITHUB_REPO = "5374osaka.github.com";
// GitHubのブランチ名
private static final String GITHUB_BRANCH = "gh-pages";
// 対象となる地区別収集日情報ファイル名
private static final String GITHUB_AREA_DAYS = "data/area_days.csv";
// 対象となる地区情報マスタファイル名
private static final String GITHUB_AREA_MASTER = "data/area_master.csv";
...
}
#### ごみの種別表記名・色の変更
ごみの種別名の表記、色を変更する際は、以下のファイルを修正してください
* 表記の変更 [GarbageType.java](/app/src/main/java/com/kubotaku/android/code4kyoto5374/data/GarbageType.java)
* 色の変更 [color.xml](/app/src/main/res/values/colors.xml)
#### ごみの分別方法辞典のデータ変更
ごみの分別方法を調べる機能は、各自治体ごとの分別方法をデータ化し、CSVファイルとして、
assetsフォルダ下にgarbage_dictionary.csvとして配置してください
* [garbage_dictionary.csv](/app/src/main/assets/garbage_dictionary.csv)
How to get Application
-----------------------------------
Google Playからインストールしてください(現在α公開中)
Functions List
-----------------------------------
以下の機能を実装しています。
* ごみの収集日表示
* ごみの収集日表示地点の選択
* ごみ収集日にアラーム通知(Notificaion)
* ごみの分別方法検索
* ごみの収集日表示ウィジェット
License
-----------------------------------
Copyright 2017 kubotaku1119 <[email protected]>
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. | 3,113 | Apache-2.0 |
---
layout: post
title: "Design Pattern - Factory"
subtitle: "Creational Pattern"
date: 2015-04-01 12:00:00
author: "Caedmom"
header-img: "img/in-post/default-bg.jpg"
tags:
- Design Pattern
- C++
---
## 1. 创建型模式
---
### 1.1. 工厂(Factory)模式
---
* **1.1.1.** 为了提高**内聚(Cohesion)**和松**耦合(Coupling)**,我们经常会**抽象出一些类的公共接口以形成抽象基类或者接口**。这样我们**可以通过声明一个指向基类的指针来指向实际的子类实现,达到了多态的目的。
* n多个子类继承自抽象基类,我们不得不在每次用到子类的地方就编写诸如“ new xxx ;”的代码,引入两个问题:
(1)客户端程序员必须知道实际子类的名称(当系统复杂后,命名将是一个很不好处理的问题);
(2)程序的扩展性和维护变得越来越困难。
* 对于 1.1.1 这种情况,我们经常就是**声明一个创建对象的接口,并封装了对象的创建的过程**。Factory这里类似于一个真正意义上的工厂(生产对象)。第一种情况Factory的结构示意图:

* **这种Factory模式经常在系统开发中用到**,但这并不是Factory模式的最大威力所在(因为可以通过其他方式解决这个问题)。
---
* **1.1.2** 第二种情况是在父类中并不知道具体要实例化哪一个具体的子类:假设我们在类A中要使用类B,B是一个抽象父类,在A中并不知道具体要实例化B的哪一个子类,但是类A的子类D中是可以知道的。在A中我们没有办法使用类似于“new xxx;”的语句,因为根本就不知道 xxx 是什么。以上问题引出了Factory模式的两个最重要的功能:
(1)定义创建对象的接口,封装了对象的创建;
(2)使得具体化类的工作延迟到了子类中。
* Factory模式不单是**提供了创建对象的接口**,其中最重要的是**延迟了子类的实例化**(第二种情况),第二种情况Factory的结构示意图:

* 这种Factory模式不只是为了封装对象的创建,而是要把对象的创建放到子类中实现:Factory中只是提供了对象创建的接口,其实现将放在Factory的子类ConcreteFactory中进行。这是两种Factory模式的结构示意图的区别所在。
---
### 讨论
* Factory模式在实际开发中应用非常广泛,面向对象的系统经常面临着对象创建问题:要创建的类实在是太多了。而Factory提供的**创建对象的接口封装**(第一个功能),以及它**将类的实例化推迟到子类**(第二个功能)都部分地解决了实际问题,采用Factory模式后系统可读性和维护都变得elegant许多。
* Factory也带来至少以下两个问题:
(1)如果为每一个具体的ConcreteProduct类的实例化提供一个函数体,那么我们可能不得不在系统中添加了一个方法来处理这个新建的ConcreteProduct,这样Factory的接口永远不可能封闭(Close)。当然我们可以通过创建一个Factory的子类来通过多态来实现这一点,但这也是以新建一个类作为代价的。
(2)在实现中我们可以通过参数化工厂方法,即给FactoryMethod()传递一个参数用以决定创建哪一个具体的Product。当然也可以通过模板化避免(1)中的子类创建子类,其方法就是将具体Product类作为模板参数,实现起来也很简单。
* 可以看出,Factory模式对于对象的创建给予开发人员提供了很好的实现策略,但是Factory模式**仅仅局限于一类类**(就是说Product是一类,有一个共同的基类)。
* **如果我们要为不同类的类提供一个创建对象的接口,那就要用AbstractFactory了。**
---
`C++`
---
<pre><code>//* 代码片断 1: `Product.h`
//Product.h
#ifndef _PRODUCT_H_
#define _PRODUCT_H_
class Product
{
public:
virtual ~Product() =0;
protected:
Product();
private:
};
class ConcreteProduct:publicProduct
{
public:
~ConcreteProduct();
ConcreteProduct();
protected:
private:
};
#endif //~_PRODUCT_H_
//* 代码片断 2: `Product.cpp`
//Product.cpp
#include "Product.h"
#include<iostream>
using namespace std;
Product::Product()
{
}
Product::~Product()
{
}
ConcreteProduct::ConcreteProduct()
{
cout<<"ConcreteProduct...."<<endl;
}
ConcreteProduct::~ConcreteProduct()
{
}
//* 代码片断 3: `Factory.h`
//Factory.h
#ifndef _FACTORY_H_
#define _FACTORY_H_
class Product;
class Factory
{
public:
virtual ~Factory() = 0;
virtual Product* CreateProduct() = 0;
protected:
Factory();
private:
};
class ConcreteFactory:public Factory
{
public:
~ConcreteFactory();
ConcreteFactory();
Product* CreateProduct();
protected:
private:
};
#endif //~_FACTORY_H_
//* 代码片断 4: `Factory.cpp`
//Factory.cpp
#include "Factory.h"
#include "Product.h"
#include <iostream>
using namespace std;
Factory::Factory()
{
}
Factory::~Factory()
{
}
ConcreteFactory::ConcreteFactory()
{
cout<<"ConcreteFactory....."<<endl;
}
ConcreteFactory::~ConcreteFactory()
{
}
Product* ConcreteFactory::CreateProduct()
{
return new ConcreteProduct();
}
//* 代码片断 5: `main.cpp`
//main.cpp
#include "Factory.h"
#include "Product.h"
#include <iostream>
using namespace std;
int main(int argc,char* argv[])
{
Factory* fac = new ConcreteFactory();
Product* p = fac->CreateProduct();
return 0;
}
</code></pre> | 3,607 | Apache-2.0 |
# .NET Client API参考文档 [](https://slack.min.io)
## 初始化MinIO Client object。
## MinIO
```cs
var minioClient = new MinioClient("play.min.io",
"Q3AM3UQ867SPQQA43P2F",
"zuf+tfteSlswRu7BJ86wekitnifILbZam1KYY3TG"
).WithSSL();
```
## AWS S3
```cs
var s3Client = new MinioClient("s3.amazonaws.com",
"YOUR-ACCESSKEYID",
"YOUR-SECRETACCESSKEY"
).WithSSL();
```
| 操作存储桶 | 操作对象 | Presigned操作 | 存储桶策略
|:--- |:--- |:--- |:--- |
| [`makeBucket`](#makeBucket) |[`getObject`](#getObject) |[`presignedGetObject`](#presignedGetObject) | [`getBucketPolicy`](#getBucketPolicy) |
| [`listBuckets`](#listBuckets) | [`putObject`](#putObject) | [`presignedPutObject`](#presignedPutObject) | [`setBucketPolicy`](#setBucketPolicy) |
| [`bucketExists`](#bucketExists) | [`copyObject`](#copyObject) | [`presignedPostPolicy`](#presignedPostPolicy) |[`setBucketNotification`](#setBucketNotification) |
| [`removeBucket`](#removeBucket) | [`statObject`](#statObject) | | [`getBucketNotification`](#getBucketNotification) |
| [`listObjects`](#listObjects) | [`removeObject`](#removeObject) | | [`removeAllBucketNotification`](#removeAllBucketNotification) |
| [`listIncompleteUploads`](#listIncompleteUploads) | [`removeObjects`](#removeObjects) | | |
| | [`removeIncompleteUpload`](#removeIncompleteUpload) | | |
## 1. 构造函数
<a name="constructors"></a>
| |
|---|
|`public MinioClient(string endpoint, string accessKey = "", string secretKey = "")` |
| 使用给定的endpoint创建个一个MinioClient对象。AccessKey、secretKey和region是可选参数,如果为空的话代表匿名访问。该client对象默认使用HTTP进行访问,如果想使用HTTPS,针对client对象链式调用WithSSL()可启用安全的传输协议。 |
__参数__
| 参数 | 类型 | 描述 |
|---|---|---|
| `endpoint` | _string_ | endPoint是一个URL,域名,IPv4或者IPv6地址。以下是合法的endpoints: |
| | |s3.amazonaws.com |
| | |play.min.io |
| | |localhost |
| | |play.min.io|
| `accessKey` | _string_ |accessKey类似于用户ID,用于唯一标识你的账户。可选,为空代表匿名访问。 |
|`secretKey` | _string_ | secretKey是你账户的密码。可选,为空代表匿名访问。 |
|`region` | _string_ | 对象存储的region。可选。|
__安全访问__
| |
|---|
|`client对象链式调用.WithSSL(),可以启用https。 ` |
__示例__
### MinIO
```cs
// 1. public MinioClient(String endpoint)
MinioClient minioClient = new MinioClient("play.min.io");
// 2. public MinioClient(String endpoint, String accessKey, String secretKey)
MinioClient minioClient = new MinioClient("play.min.io",
accessKey:"Q3AM3UQ867SPQQA43P2F",
secretKey:"zuf+tfteSlswRu7BJ86wekitnifILbZam1KYY3TG"
).WithSSL();
```
### AWS S3
```cs
// 1. public MinioClient(String endpoint)
MinioClient s3Client = new MinioClient("s3.amazonaws.com").WithSSL();
// 2. public MinioClient(String endpoint, String accessKey, String secretKey)
MinioClient s3Client = new MinioClient("s3.amazonaws.com:80",
accessKey:"YOUR-ACCESSKEYID",
secretKey:"YOUR-SECRETACCESSKEY").WithSSL();
```
## 2. 操作存储桶
<a name="makeBucket"></a>
### MakeBucketAsync(string bucketName, string location="us-east-1")
`Task MakeBucketAsync(string bucketName, string location = "us-east-1", CancellationToken cancellationToken = default(CancellationToken))`
创建一个存储桶。
__参数__
| 参数 | 类型 | 描述 |
|:--- |:--- |:--- |
| ``bucketName`` | _string_ | 存储桶名称。 |
| ``region`` | _string_| 可选参数。默认是us-east-1。 |
| ``cancellationToken``| _System.Threading.CancellationToken_ | 可选参数。 默认是default(CancellationToken) |
| 返回值类型 | 异常 |
|:--- |:--- |
| ``Task`` | 列出的异常: |
| | ``InvalidBucketNameException`` : 无效的存储桶名称。 |
| | ``ConnectionException`` : 连接异常。 |
| | ``AccessDeniedException`` : 拒绝访问。 |
| | ``RedirectionException`` : 服务器重定向。 |
| | ``InternalClientException`` : 内部错误。 |
__示例__
```cs
try
{
// Create bucket if it doesn't exist.
bool found = await minioClient.BucketExistsAsync("mybucket");
if (found)
{
Console.Out.WriteLine("mybucket already exists");
}
else
{
// Create bucket 'my-bucketname'.
await minioClient.MakeBucketAsync("mybucket");
Console.Out.WriteLine("mybucket is created successfully");
}
}
catch (MinioException e)
{
Console.Out.WriteLine("Error occurred: " + e);
}
```
<a name="listBuckets"></a>
### ListBucketsAsync()
`Task<ListAllMyBucketsResult> ListBucketsAsync(CancellationToken cancellationToken = default(CancellationToken))`
列出所有的存储桶。
| 参数 | 类型 | 描述 |
|:--- |:--- |:--- |
| ``cancellationToken``| _System.Threading.CancellationToken_ | 可选参数。默认是default(CancellationToken) |
|返回值类型 | 异常 |
|:--- |:--- |
| ``Task<ListAllMyBucketsResult>`` : 包含存储桶类型列表的Task。 | 列出的异常: |
| | ``InvalidBucketNameException`` : 无效的存储桶名称。 |
| | ``ConnectionException`` : 连接异常。 |
| | ``AccessDeniedException`` : 拒绝访问。 |
| | ``InvalidOperationException``: xml数据反序列化异常。 |
| | ``ErrorResponseException`` : 执行异常。 |
| | ``InternalClientException`` : 内部错误。 |
__示例__
```cs
try
{
// List buckets that have read access.
var list = await minioClient.ListBucketsAsync();
foreach (Bucket bucket in list.Buckets)
{
Console.Out.WriteLine(bucket.Name + " " + bucket.CreationDateDateTime);
}
}
catch (MinioException e)
{
Console.Out.WriteLine("Error occurred: " + e);
}
```
<a name="bucketExists"></a>
### BucketExistsAsync(string bucketName)
`Task<bool> BucketExistsAsync(string bucketName, CancellationToken cancellationToken = default(CancellationToken))`
检查存储桶是否存在。
__参数__
| 参数 | 类型 | 描述 |
|:--- |:--- |:--- |
| ``bucketName`` | _string_ | 存储桶名称。 |
| ``cancellationToken``| _System.Threading.CancellationToken_ | 可选参数。 默认是default(CancellationToken) |
| 返回值类型 | 异常 |
|:--- |:--- |
| ``Task<bool>`` : 如果存储桶存在的话则是true。 | 列出的异常: |
| | ``InvalidBucketNameException`` : 无效的存储桶名称。 |
| | ``ConnectionException`` : 连接异常。 |
| | ``AccessDeniedException`` : 拒绝访问。 |
| | ``ErrorResponseException`` : 执行异常。 |
| | ``InternalClientException`` : 内部错误。 |
__示例__
```cs
try
{
// Check whether 'my-bucketname' exists or not.
bool found = await minioClient.BucketExistsAsync(bucketName);
Console.Out.WriteLine("bucket-name " + ((found == true) ? "exists" : "does not exist"));
}
catch (MinioException e)
{
Console.WriteLine("[Bucket] Exception: {0}", e);
}
```
<a name="removeBucket"></a>
### RemoveBucketAsync(string bucketName)
`Task RemoveBucketAsync(string bucketName, CancellationToken cancellationToken = default(CancellationToken))`
删除一个存储桶
注意: - removeBucket不会删除存储桶中的对象,你需要调用removeObject API清空存储桶内的对象。
__参数__
| 参数 | 类型 | 描述 |
|:--- |:--- |:--- |
| ``bucketName`` | _string_ | 存储桶名称。 |
| ``cancellationToken``| _System.Threading.CancellationToken_ | 可选参数。默认是default(CancellationToken) |
| 返回值类型 | 异常 |
|:--- |:--- |
| Task | 列出的异常: |
| | ``InvalidBucketNameException`` : 无效的存储桶名称。 |
| | ``ConnectionException`` : 连接异常。 |
| | ``AccessDeniedException`` : 拒绝访问。 |
| | ``ErrorResponseException`` : 执行异常。 |
| | ``InternalClientException`` : 内部错误。 |
| | ``BucketNotFoundException`` : 存储桶不存在。 |
__示例__
```cs
try
{
// Check if my-bucket exists before removing it.
bool found = await minioClient.BucketExistsAsync("mybucket");
if (found)
{
// Remove bucket my-bucketname. This operation will succeed only if the bucket is empty.
await minioClient.RemoveBucketAsync("mybucket");
Console.Out.WriteLine("mybucket is removed successfully");
}
else
{
Console.Out.WriteLine("mybucket does not exist");
}
}
catch(MinioException e)
{
Console.Out.WriteLine("Error occurred: " + e);
}
```
<a name="listObjects"></a>
### ListObjectsAsync(string bucketName, string prefix = null, bool recursive = true)
`IObservable<Item> ListObjectsAsync(string bucketName, string prefix = null, bool recursive = true, CancellationToken cancellationToken = default(CancellationToken))`
列出存储桶里的对象。
__参数__
| 参数 | 类型 | 描述 |
|:--- |:--- |:--- |
| ``bucketName`` | _string_ | 存储桶名称。 |
| ``prefix`` | _string_ | 对象的前缀。 |
| ``recursive`` | _bool_ | `true`代表递归查找,`false`代表类似文件夹查找,以'/'分隔,不查子文件夹。 |
| ``cancellationToken``| _System.Threading.CancellationToken_ | 可选参数。默认是default(CancellationToken) |
|返回值类型 | 异常 |
|:--- |:--- |
| ``IObservable<Item>``:an Observable of Items. | _None_ |
__示例__
```cs
try
{
// Check whether 'mybucket' exists or not.
bool found = minioClient.BucketExistsAsync("mybucket");
if (found)
{
// List objects from 'my-bucketname'
IObservable<Item> observable = minioClient.ListObjectsAsync("mybucket", "prefix", true);
IDisposable subscription = observable.Subscribe(
item => Console.WriteLine("OnNext: {0}", item.Key),
ex => Console.WriteLine("OnError: {0}", ex.Message),
() => Console.WriteLine("OnComplete: {0}"));
}
else
{
Console.Out.WriteLine("mybucket does not exist");
}
}
catch (MinioException e)
{
Console.Out.WriteLine("Error occurred: " + e);
}
```
<a name="listIncompleteUploads"></a>
### ListIncompleteUploads(string bucketName, string prefix, bool recursive)
`IObservable<Upload> ListIncompleteUploads(string bucketName, string prefix, bool recursive, CancellationToken cancellationToken = default(CancellationToken))`
列出存储桶中未完整上传的对象。
__参数__
| 参数 | 类型 | 描述 |
|:--- |:--- |:--- |
| ``bucketName`` | _string_ | 存储桶名称。 |
| ``prefix`` | _string_ | 对象的前缀。 |
| ``recursive`` | _bool_ | `true`代表递归查找,`false`代表类似文件夹查找,以'/'分隔,不查子文件夹。 |
| ``cancellationToken``| _System.Threading.CancellationToken_ | 可选参数。默认是default(CancellationToken) |
|返回值类型 | 异常 |
|:--- |:--- |
| ``IObservable<Upload> `` | _None_ |
__示例__
```cs
try
{
// Check whether 'mybucket' exist or not.
bool found = minioClient.BucketExistsAsync("mybucket");
if (found)
{
// List all incomplete multipart upload of objects in 'mybucket'
IObservable<Upload> observable = minioClient.ListIncompleteUploads("mybucket", "prefix", true);
IDisposable subscription = observable.Subscribe(
item => Console.WriteLine("OnNext: {0}", item.Key),
ex => Console.WriteLine("OnError: {0}", ex.Message),
() => Console.WriteLine("OnComplete: {0}"));
}
else
{
Console.Out.WriteLine("mybucket does not exist");
}
}
catch (MinioException e)
{
Console.Out.WriteLine("Error occurred: " + e);
}
```
<a name="getBucketPolicy"></a>
### GetPolicyAsync(string bucketName, string objectPrefix)
`Task<PolicyType> GetPolicyAsync(string bucketName, string objectPrefix, CancellationToken cancellationToken = default(CancellationToken))`
获取存储桶或者对象前缀的访问权限。
__参数__
| 参数 | 类型 | 描述 |
|:--- |:--- |:--- |
| ``bucketName`` | _string_ | 存储桶名称。 |
| ``objectPrefix`` | _string_ | 该存储桶下的对象前缀 |
| ``cancellationToken``| _System.Threading.CancellationToken_ | 可选参数。默认是default(CancellationToken) |
| 返回值类型 | 异常 |
|:--- |:--- |
| ``Task<PolicyType>``: 指定存储桶和对象前缀的存储桶策略。 | 列出的异常: |
| | ``InvalidBucketNameException `` : 无效的存储桶名称。 |
| | ``InvalidObjectPrefixException`` : 无效的对象前缀。 |
| | ``ConnectionException`` : 连接异常。 |
| | ``AccessDeniedException`` : 拒绝访问。 |
| | ``InternalClientException`` : 内部错误。 |
| | ``BucketNotFoundException`` : 存储桶不存在。 |
__示例__
```cs
try
{
PolicyType policy = await minioClient.GetPolicyAsync("myBucket", objectPrefix:"downloads");
Console.Out.WriteLine("Current policy: " + policy.GetType().ToString());
}
catch (MinioException e)
{
Console.Out.WriteLine("Error occurred: " + e);
}
```
<a name="setBucketPolicy"></a>
### SetPolicyAsync(string bucketName, string policyJson)
`Task SetPolicyAsync(string bucketName, string policyJson, CancellationToken cancellationToken = default(CancellationToken))`
针对存储桶和对象前缀设置访问策略。
__参数__
| 参数 | 类型 | 描述 |
|:--- |:--- |:--- |
| ``bucketName`` | _string_ | 存储桶名称。 |
| ``PolicyJson`` | _string_ | 要设置的策略。 |
| ``cancellationToken``| _System.Threading.CancellationToken_ | 可选参数。默认是default(CancellationToken) |
| 返回值类型 | 异常 |
|:--- |:--- |
| Task | 列出的异常: |
| | ``InvalidBucketNameException`` : 无效的存储桶名称。 |
| | ``ConnectionException`` : 连接异常。 |
| | ``InternalClientException`` : 内部错误。 |
| | ``InvalidBucketNameException `` : 无效的存储桶名称。 |
__示例__
```cs
try
{
string policyJson = $@"{{""Version"":""2012-10-17"",""Statement"":[{{""Action"":[""s3:GetBucketLocation""],""Effect"":""Allow"",""Principal"":{{""AWS"":[""*""]}},""Resource"":[""arn:aws:s3:::{bucketName}""],""Sid"":""""}},{{""Action"":[""s3:ListBucket""],""Condition"":{{""StringEquals"":{{""s3:prefix"":[""foo"",""prefix/""]}}}},""Effect"":""Allow"",""Principal"":{{""AWS"":[""*""]}},""Resource"":[""arn:aws:s3:::{bucketName}""],""Sid"":""""}},{{""Action"":[""s3:GetObject""],""Effect"":""Allow"",""Principal"":{{""AWS"":[""*""]}},""Resource"":[""arn:aws:s3:::{bucketName}/foo*"",""arn:aws:s3:::{bucketName}/prefix/*""],""Sid"":""""}}]}}";
await minioClient.SetPolicyAsync("myBucket", policyJson);
}
catch (MinioException e)
{
Console.Out.WriteLine("Error occurred: " + e);
}
```
<a name="setBucketNotification"></a>
### SetBucketNotificationAsync(string bucketName,BucketNotification notification)
`Task SetBucketNotificationAsync(string bucketName, BucketNotification notification, CancellationToken cancellationToken = default(CancellationToken))`
给存储桶设置通知。
__参数__
| 参数 | 类型 | 描述 |
|:--- |:--- |:--- |
| ``bucketName`` | _string_ | 存储桶名称。 |
| ``notification`` | _BucketNotification_ | 要设置的通知。 |
| ``cancellationToken``| _System.Threading.CancellationToken_ | 可选参数。默认是default(CancellationToken) |
| 返回值类型 | 异常 |
|:--- |:--- |
| Task | 列出的异常: |
| | ``ConnectionException`` : 连接异常。 |
| | ``InternalClientException`` : 内部错误。 |
| | ``InvalidBucketNameException `` : 无效的存储桶名称。 |
| | ``InvalidOperationException``: 通知对象序列化异常。 |
__示例__
```cs
try
{
BucketNotification notification = new BucketNotification();
Arn topicArn = new Arn("aws", "sns", "us-west-1", "412334153608", "topicminio");
TopicConfig topicConfiguration = new TopicConfig(topicArn);
List<EventType> events = new List<EventType>(){ EventType.ObjectCreatedPut , EventType.ObjectCreatedCopy };
topicConfiguration.AddEvents(events);
topicConfiguration.AddFilterPrefix("images");
topicConfiguration.AddFilterSuffix("jpg");
notification.AddTopic(topicConfiguration);
QueueConfig queueConfiguration = new QueueConfig("arn:aws:sqs:us-west-1:482314153608:testminioqueue1");
queueConfiguration.AddEvents(new List<EventType>() { EventType.ObjectCreatedCompleteMultipartUpload });
notification.AddQueue(queueConfiguration);
await minio.SetBucketNotificationsAsync(bucketName,
notification);
Console.Out.WriteLine("Notifications set for the bucket " + bucketName + " successfully");
}
catch (MinioException e)
{
Console.Out.WriteLine("Error occurred: " + e);
}
```
<a name="getBucketNotification"></a>
### GetBucketNotificationAsync(string bucketName)
`Task<BucketNotification> GetBucketNotificationAsync(string bucketName, CancellationToken cancellationToken = default(CancellationToken))`
获取存储桶的通知配置。
__参数__
| 参数 | 类型 | 描述 |
|:--- |:--- |:--- |
| ``bucketName`` | _string_ | 存储桶名称。 |
| ``cancellationToken``| _System.Threading.CancellationToken_ | 可选参数。默认是default(CancellationToken) |
| 返回值类型 | 异常 |
|:--- |:--- |
| ``Task<BucketNotification>``: 存储桶的当前通知配置。 | 列出的异常: |
| | ``InvalidBucketNameException `` : 无效的存储桶名称。 |
| | ``ConnectionException`` : 连接异常。 |
| | ``AccessDeniedException`` : 拒绝访问。 |
| | ``InternalClientException`` : 内部错误。 |
| | ``BucketNotFoundException`` : 存储桶不存在。 |
| | ``InvalidOperationException``: xml数据反序列化异常。 |
__示例__
```cs
try
{
BucketNotification notifications = await minioClient.GetBucketNotificationAsync(bucketName);
Console.Out.WriteLine("Notifications is " + notifications.ToXML());
}
catch (MinioException e)
{
Console.Out.WriteLine("Error occurred: " + e);
}
```
<a name="removeAllBucketNotification"></a>
### RemoveAllBucketNotificationsAsync(string bucketName)
`Task RemoveAllBucketNotificationsAsync(string bucketName, CancellationToken cancellationToken = default(CancellationToken))`
删除存储桶上所有配置的通知。
__参数__
| 参数 | 类型 | 描述 |
|:--- |:--- |:--- |
| ``bucketName`` | _string_ | 存储桶名称。 |
| ``cancellationToken``| _System.Threading.CancellationToken_ | 可选参数。默认是default(CancellationToken) |
| 返回值类型 | 异常 |
|:--- |:--- |
| ``Task`: | 列出的异常: |
| | ``InvalidBucketNameException `` : 无效的存储桶名称。 |
| | ``ConnectionException`` : 连接异常。 |
| | ``AccessDeniedException`` : 拒绝访问。 |
| | ``InternalClientException`` : 内部错误。 |
| | ``BucketNotFoundException`` : 存储桶不存在。 |
| | ``InvalidOperationException``: xml数据序列化异常。 |
__示例__
```cs
try
{
await minioClient.RemoveAllBucketNotificationsAsync(bucketName);
Console.Out.WriteLine("Notifications successfully removed from the bucket " + bucketName);
}
catch (MinioException e)
{
Console.Out.WriteLine("Error occurred: " + e);
}
```
## 3. 操作对象
<a name="getObject"></a>
### GetObjectAsync(string bucketName, string objectName, Action<Stream> callback)
`Task GetObjectAsync(string bucketName, string objectName, Action<Stream> callback, CancellationToken cancellationToken = default(CancellationToken))`
返回对象数据的流。
__参数__
| 参数 | 类型 | 描述 |
|:--- |:--- |:--- |
| ``bucketName`` | _string_ | 存储桶名称。 |
| ``objectName`` | _string_ | 存储桶里的对象名称。 |
| ``callback`` | _Action<Stream>_ | 处理流的回调函数。 |
| ``cancellationToken``| _System.Threading.CancellationToken_ | 可选参数。默认是default(CancellationToken) |
| 返回值类型 | 异常 |
|:--- |:--- |
| ``Task``: Task回调,返回含有对象数据的InputStream。 | 列出的异常: |
| | ``InvalidBucketNameException`` : 无效的存储桶名称。 |
| | ``ConnectionException`` : 连接异常。 |
| | ``InternalClientException`` : 内部错误。 |
__示例__
```cs
try
{
// Check whether the object exists using statObject().
// If the object is not found, statObject() throws an exception,
// else it means that the object exists.
// Execution is successful.
await minioClient.StatObjectAsync("mybucket", "myobject");
// Get input stream to have content of 'my-objectname' from 'my-bucketname'
await minioClient.GetObjectAsync("mybucket", "myobject",
(stream) =>
{
stream.CopyTo(Console.OpenStandardOutput());
});
}
catch (MinioException e)
{
Console.Out.WriteLine("Error occurred: " + e);
}
```
<a name="getObject"></a>
### GetObjectAsync(string bucketName, string objectName, long offset,long length, Action<Stream> callback)
`Task GetObjectAsync(string bucketName, string objectName, long offset, long length, Action<Stream> callback, CancellationToken cancellationToken = default(CancellationToken))`
下载对象指定区域的字节数组做为流。offset和length都必须传。
__参数__
| 参数 | 类型 | 描述 |
|:--- |:--- |:--- |
| ``bucketName`` | _string_ | 存储桶名称。 |
| ``objectName`` | _string_ | 存储桶里的对象名称。 |
| ``offset``| _long_ | ``offset`` 是起始字节的位置。 |
| ``length``| _long_| ``length``是要读取的长度。 |
| ``callback`` | _Action<Stream>_ | 处理流的回调函数。 |
| ``cancellationToken``| _System.Threading.CancellationToken_ | 可选参数。默认是default(CancellationToken) |
| 返回值类型 | 异常 |
|:--- |:--- |
| ``Task``: Task回调,返回含有对象数据的InputStream。 | 列出的异常: |
| | ``InvalidBucketNameException`` : 无效的存储桶名称。 |
| | ``ConnectionException`` : 连接异常。 |
| | ``InternalClientException`` : 内部错误。 |
__示例__
```cs
try
{
// Check whether the object exists using statObject().
// If the object is not found, statObject() throws an exception,
// else it means that the object exists.
// Execution is successful.
await minioClient.StatObjectAsync("mybucket", "myobject");
// Get input stream to have content of 'my-objectname' from 'my-bucketname'
await minioClient.GetObjectAsync("mybucket", "myobject", 1024L, 10L,
(stream) =>
{
stream.CopyTo(Console.OpenStandardOutput());
});
}
catch (MinioException e)
{
Console.Out.WriteLine("Error occurred: " + e);
}
```
<a name="getObject"></a>
### GetObjectAsync(String bucketName, String objectName, String fileName)
`Task GetObjectAsync(string bucketName, string objectName, string fileName, CancellationToken cancellationToken = default(CancellationToken))`
下载并将文件保存到本地文件系统。
__参数__
| 参数 | 类型 | 描述 |
|:--- |:--- |:--- |
| ``bucketName`` | _String_ | 存储桶名称。 |
| ``objectName`` | _String_ | 存储桶里的对象名称。 |
| ``fileName`` | _String_ | 本地文件路径。 |
| ``cancellationToken``| _System.Threading.CancellationToken_ | 可选参数。默认是default(CancellationToken) |
| 返回值类型 | 异常 |
|:--- |:--- |
| ``Task `` | 列出的异常: |
| | ``InvalidBucketNameException`` : 无效的存储桶名称。 |
| | ``ConnectionException`` : 连接异常。 |
| | ``InternalClientException`` : 内部错误。 |
__示例__
```cs
try
{
// Check whether the object exists using statObjectAsync().
// If the object is not found, statObjectAsync() throws an exception,
// else it means that the object exists.
// Execution is successful.
await minioClient.StatObjectAsync("mybucket", "myobject");
// Gets the object's data and stores it in photo.jpg
await minioClient.GetObjectAsync("mybucket", "myobject", "photo.jpg");
}
catch (MinioException e)
{
Console.Out.WriteLine("Error occurred: " + e);
}
```
<a name="putObject"></a>
### PutObjectAsync(string bucketName, string objectName, Stream data, long size, string contentType)
` Task PutObjectAsync(string bucketName, string objectName, Stream data, long size, string contentType,Dictionary<string,string> metaData=null, CancellationToken cancellationToken = default(CancellationToken))`
通过Stream上传对象。
__参数__
| 参数 | 类型 | 描述 |
|:--- |:--- |:--- |
| ``bucketName`` | _string_ | 存储桶名称。 |
| ``objectName`` | _string_ | 存储桶里的对象名称。 |
| ``data`` | _Stream_ | 要上传的Stream对象。 |
| ``size`` | _long_ | 流的大小。 |
| ``contentType`` | _string_ | 文件的Content type,默认是"application/octet-stream"。 |
| ``metaData`` | _Dictionary<string,string>_ | 元数据头信息的Dictionary对象,默认是null。 |
| ``cancellationToken``| _System.Threading.CancellationToken_ | 可选参数。默认是default(CancellationToken) |
| 返回值类型 | 异常 |
|:--- |:--- |
| ``Task`` | 列出的异常: |
| | ``InvalidBucketNameException`` : 无效的存储桶名称。 |
| | ``ConnectionException`` : 连接异常。 |
| | ``InternalClientException`` : 内部错误。 |
| | ``EntityTooLargeException``: 要上传的大小超过最大允许值。 |
| | ``UnexpectedShortReadException``: 读取的数据大小比指定的size要小。 |
| | ``ArgumentNullException``: Stream为null。 |
__示例__
单个对象的最大大小限制在5TB。putObject在对象大于5MiB时,自动使用multiple parts方式上传。这样,当上传失败时,客户端只需要上传未成功的部分即可(类似断点上传)。上传的对象使用MD5SUM签名进行完整性验证。
```cs
try
{
byte[] bs = File.ReadAllBytes(fileName);
System.IO.MemoryStream filestream = new System.IO.MemoryStream(bs);
await minio.PutObjectAsync("mybucket",
"island.jpg",
filestream,
filestream.Length,
"application/octet-stream");
Console.Out.WriteLine("island.jpg is uploaded successfully");
}
catch(MinioException e)
{
Console.Out.WriteLine("Error occurred: " + e);
}
```
<a name="putObject"></a>
### PutObjectAsync(string bucketName, string objectName, string filePath, string contentType=null)
` Task PutObjectAsync(string bucketName, string objectName, string filePath, string contentType=null,Dictionary<string,string> metaData=null, CancellationToken cancellationToken = default(CancellationToken))`
通过文件上传到对象中。
__参数__
| 参数 | 类型 | 描述 |
|:--- |:--- |:--- |
| ``bucketName`` | _string_ | 存储桶名称。 |
| ``objectName`` | _string_ | 存储桶里的对象名称。 |
| ``fileName`` | _string_ | 要上传的本地文件名。 |
| ``contentType`` | _string_ | 文件的Content type,默认是"application/octet-stream"。 |
| ``metadata`` | _Dictionary<string,string>_ | 元数据头信息的Dictionary对象,默认是null。|
| ``cancellationToken``| _System.Threading.CancellationToken_ | 可选参数。默认是default(CancellationToken) |
| 返回值类型 | 异常 |
|:--- |:--- |
| ``Task`` | 列出的异常: |
| | ``InvalidBucketNameException`` : 无效的存储桶名称。 |
| | ``ConnectionException`` : 连接异常。 |
| | ``InternalClientException`` : 内部错误。 |
| | ``EntityTooLargeException``: 要上传的大小超过最大允许值。 |
__示例__
单个对象的最大大小限制在5TB。putObject在对象大于5MiB时,自动使用multiple parts方式上传。这样,当上传失败时,客户端只需要上传未成功的部分即可(类似断点上传)。上传的对象使用MD5SUM签名进行完整性验证。
```cs
try
{
await minio.PutObjectAsync("mybucket", "island.jpg", "/mnt/photos/island.jpg",contentType: "application/octet-stream");
Console.Out.WriteLine("island.jpg is uploaded successfully");
}
catch(MinioException e)
{
Console.Out.WriteLine("Error occurred: " + e);
}
```
<a name="statObject"></a>
### StatObjectAsync(string bucketName, string objectName)
`Task<ObjectStat> StatObjectAsync(string bucketName, string objectName, CancellationToken cancellationToken = default(CancellationToken))`
获取对象的元数据。
__参数__
| 参数 | 类型 | 描述 |
|:--- |:--- |:--- |
| ``bucketName`` | _string_ | 存储桶名称。 |
| ``objectName`` | _string_ | 存储桶里的对象名称。 |
| ``cancellationToken``| _System.Threading.CancellationToken_ | 可选参数。默认是default(CancellationToken) |
| 返回值类型 | 异常 |
|:--- |:--- |
| ``Task<ObjectStat>``: Populated object meta data. | 列出的异常: |
| | ``InvalidBucketNameException`` : 无效的存储桶名称。 |
| | ``ConnectionException`` : 连接异常。 |
| | ``InternalClientException`` : 内部错误。 |
__示例__
```cs
try
{
// Get the metadata of the object.
ObjectStat objectStat = await minioClient.StatObjectAsync("mybucket", "myobject");
Console.Out.WriteLine(objectStat);
}
catch(MinioException e)
{
Console.Out.WriteLine("Error occurred: " + e);
}
```
<a name="copyObject"></a>
### CopyObjectAsync(string bucketName, string objectName, string destBucketName, string destObjectName = null, CopyConditions copyConditions = null)
*`Task<CopyObjectResult> CopyObjectAsync(string bucketName, string objectName, string destBucketName, string destObjectName = null, CopyConditions copyConditions = null, CancellationToken cancellationToken = default(CancellationToken))`*
从objectName指定的对象中将数据拷贝到destObjectName指定的对象。
__参数__
| 参数 | 类型 | 描述 |
|:--- |:--- |:--- |
| ``bucketName`` | _string_ | 源存储桶名称。 |
| ``objectName`` | _string_ | 源存储桶中的源对象名称。 |
| ``destBucketName`` | _string_ | 目标存储桶名称。 |
| ``destObjectName`` | _string_ | 要创建的目标对象名称,如果为空,默认为源对象名称。|
| ``copyConditions`` | _CopyConditions_ | 拷贝操作的一些条件Map。|
| ``cancellationToken``| _System.Threading.CancellationToken_ | 可选参数。默认是default(CancellationToken) |
| 返回值类型 | 异常 |
|:--- |:--- |
| ``Task`` | 列出的异常: |
| | ``InvalidBucketNameException`` : 无效的存储桶名称。 |
| | ``ConnectionException`` : 连接异常。 |
| | ``InternalClientException`` : 内部错误。 |
| | ``ArgumentException`` : 存储桶不存在。 |
__示例__
本API执行了一个服务端的拷贝操作。
```cs
try
{
CopyConditions copyConditions = new CopyConditions();
copyConditions.setMatchETagNone("TestETag");
await minioClient.CopyObjectAsync("mybucket", "island.jpg", "mydestbucket", "processed.png", copyConditions);
Console.Out.WriteLine("island.jpg is uploaded successfully");
}
catch(MinioException e)
{
Console.Out.WriteLine("Error occurred: " + e);
}
```
<a name="removeObject"></a>
### RemoveObjectAsync(string bucketName, string objectName)
`Task RemoveObjectAsync(string bucketName, string objectName, CancellationToken cancellationToken = default(CancellationToken))`
删除一个对象。
__参数__
| 参数 | 类型 | 描述 |
|:--- |:--- |:--- |
| ``bucketName`` | _string_ | 存储桶名称。 |
| ``objectName`` | _string_ | 存储桶里的对象名称。 |
| ``cancellationToken``| _System.Threading.CancellationToken_ | 可选参数。默认是default(CancellationToken) |
| 返回值类型 | 异常 |
|:--- |:--- |
| ``Task`` | 列出的异常: |
| | ``InvalidBucketNameException`` : 无效的存储桶名称。 |
| | ``ConnectionException`` : 连接异常。 |
| | ``InternalClientException`` : 内部错误。 |
__示例__
```cs
try
{
// Remove objectname from the bucket my-bucketname.
await minioClient.RemoveObjectAsync("mybucket", "myobject");
Console.Out.WriteLine("successfully removed mybucket/myobject");
}
catch (MinioException e)
{
Console.Out.WriteLine("Error: " + e);
}
```
<a name="removeObjects"></a>
### RemoveObjectAsync(string bucketName, IEnumerable<string> objectsList)
`Task<IObservable<DeleteError>> RemoveObjectAsync(string bucketName, IEnumerable<string> objectsList, CancellationToken cancellationToken = default(CancellationToken))`
删除多个对象。
__参数__
| 参数 | 类型 | 描述 |
|:--- |:--- |:--- |
| ``bucketName`` | _string_ | 存储桶名称。 |
| ``objectsList`` | _IEnumerable<string>_ | 含有多个对象名称的IEnumerable。 |
| ``cancellationToken``| _System.Threading.CancellationToken_ | 可选参数。默认是default(CancellationToken) |
| 返回值类型 | 异常 |
|:--- |:--- |
| ``Task`` | 列出的异常: |
| | ``InvalidBucketNameException`` : 无效的存储桶名称。 |
| | ``ConnectionException`` : 连接异常。 |
| | ``InternalClientException`` : 内部错误。 |
__示例__
```cs
try
{
List<String> objectNames = new LinkedList<String>();
objectNames.add("my-objectname1");
objectNames.add("my-objectname2");
objectNames.add("my-objectname3");
// Remove list of objects in objectNames from the bucket bucketName.
IObservable<DeleteError> observable = await minio.RemoveObjectAsync(bucketName, objectNames);
IDisposable subscription = observable.Subscribe(
deleteError => Console.WriteLine("Object: {0}", deleteError.Key),
ex => Console.WriteLine("OnError: {0}", ex),
() =>
{
Console.WriteLine("Listed all delete errors for remove objects on " + bucketName + "\n");
});
}
catch (MinioException e)
{
Console.Out.WriteLine("Error: " + e);
}
```
<a name="removeIncompleteUpload"></a>
### RemoveIncompleteUploadAsync(string bucketName, string objectName)
`Task RemoveIncompleteUploadAsync(string bucketName, string objectName, CancellationToken cancellationToken = default(CancellationToken))`
删除一个未完整上传的对象。
__参数__
| 参数 | 类型 | 描述 |
|:--- |:--- |:--- |
| ``bucketName`` | _string_ | 存储桶名称。 |
| ``objectName`` | _string_ | 存储桶里的对象名称。 |
| ``cancellationToken``| _System.Threading.CancellationToken_ | 可选参数。默认是default(CancellationToken) |
| 返回值类型 | 异常 |
|:--- |:--- |
| ``Task`` | 列出的异常: |
| | ``InvalidBucketNameException`` : 无效的存储桶名称。 |
| | ``ConnectionException`` : 连接异常。 |
| | ``InternalClientException`` : 内部错误。 |
__示例__
```cs
try
{
// Removes partially uploaded objects from buckets.
await minioClient.RemoveIncompleteUploadAsync("mybucket", "myobject");
Console.Out.WriteLine("successfully removed all incomplete upload session of my-bucketname/my-objectname");
}
catch(MinioException e)
{
Console.Out.WriteLine("Error occurred: " + e);
}
```
## 4. Presigned操作
<a name="presignedGetObject"></a>
### PresignedGetObjectAsync(string bucketName, string objectName, int expiresInt, Dictionary<string,string> reqParams = null);
`Task<string> PresignedGetObjectAsync(string bucketName, string objectName, int expiresInt, Dictionary<string,string> reqParams = null)`
生成一个给HTTP GET请求用的presigned URL。浏览器/移动端的客户端可以用这个URL进行下载,即使其所在的存储桶是私有的。这个presigned URL可以设置一个失效时间,默认值是7天。
__参数__
| 参数 | 类型 | 描述 |
|:--- |:--- |:--- |
| ``bucketName`` | _String_ | 存储桶名称。 |
| ``objectName`` | _String_ | 存储桶里的对象名称。 |
| ``expiresInt`` | _Integer_ | 失效时间(以秒为单位),默认是7天,不得大于七天。 |
| ``reqParams`` | _Dictionary<string,string>_ | 额外的响应头信息,支持response-expires、response-content-type、response-cache-control、response-content-disposition。|
| 返回值类型 | 异常 |
|:--- |:--- |
| ``Task<string>`` : string包含可下载该对象的URL。 | 列出的异常: |
| | ``InvalidBucketNameException`` : 无效的存储桶名称。 |
| | ``ConnectionException`` : 连接异常。 |
| | ``InvalidExpiryRangeException`` : 无效的失效时间。 |
__示例__
```cs
try
{
String url = await minioClient.PresignedGetObjectAsync("mybucket", "myobject", 60 * 60 * 24);
Console.Out.WriteLine(url);
}
catch(MinioException e)
{
Console.Out.WriteLine("Error occurred: " + e);
}
```
<a name="presignedPutObject"></a>
### PresignedPutObjectAsync(string bucketName, string objectName, int expiresInt)
`Task<string> PresignedPutObjectAsync(string bucketName, string objectName, int expiresInt)`
生成一个给HTTP PUT请求用的presigned URL。浏览器/移动端的客户端可以用这个URL进行上传,即使其所在的存储桶是私有的。这个presigned URL可以设置一个失效时间,默认值是7天。
__参数__
| 参数 | 类型 | 描述 |
|:--- |:--- |:--- |
| ``bucketName`` | _string_ | 存储桶名称。 |
| ``objectName`` | _string_ | 存储桶里的对象名称。 |
| ``expiresInt`` | _int_ | 失效时间(以秒为单位),默认是7天,不得大于七天。 |
| 返回值类型 | 异常 |
|:--- |:--- |
| ``Task<string>`` : string包含可下载该对象的URL。 | 列出的异常: |
| | ``InvalidBucketNameException`` : 无效的存储桶名称。 |
| | ``InvalidKeyException`` : 无效的access key或secret key。 |
| | ``ConnectionException`` : 连接异常。 |
| | ``InvalidExpiryRangeException`` : 无效的失效时间。 |
__示例__
```cs
try
{
String url = await minioClient.PresignedPutObjectAsync("mybucket", "myobject", 60 * 60 * 24);
Console.Out.WriteLine(url);
}
catch(MinioException e)
{
Console.Out.WriteLine("Error occurred: " + e);
}
```
<a name="presignedPostPolicy"></a>
### PresignedPostPolicy(PostPolicy policy)
`Task<Dictionary<string, string>> PresignedPostPolicyAsync(PostPolicy policy)`
允许给POST请求的presigned URL设置策略,比如接收对象上传的存储桶名称的策略,key名称前缀,过期策略。
__参数__
| 参数 | 类型 | 描述 |
|:--- |:--- |:--- |
| ``PostPolicy`` | _PostPolicy_ | 对象的post策略。 |
| 返回值类型 | 异常 |
|:--- |:--- |
| ``Task<Dictionary<string,string>>``: string的键值对,用于构造表单数据。 | 列出的异常: |
| | ``InvalidBucketNameException`` : 无效的存储桶名称。 |
| | ``ConnectionException`` : 连接异常。 |
| | ``NoSuchAlgorithmException`` : 在做签名计算时找不到指定的算法。 |
__示例__
```cs
try
{
PostPolicy policy = new PostPolicy();
policy.SetContentType("image/png");
policy.SetUserMetadata("custom", "user");
DateTime expiration = DateTime.UtcNow;
policy.SetExpires(expiration.AddDays(10));
policy.SetKey("my-objectname");
policy.SetBucket("my-bucketname");
Dictionary<string, string> formData = minioClient.Api.PresignedPostPolicy(policy);
string curlCommand = "curl ";
foreach (KeyValuePair<string, string> pair in formData)
{
curlCommand = curlCommand + " -F " + pair.Key + "=" + pair.Value;
}
curlCommand = curlCommand + " -F file=@/etc/bashrc https://s3.amazonaws.com/my-bucketname";
Console.Out.WriteLine(curlCommand);
}
catch(MinioException e)
{
Console.Out.WriteLine("Error occurred: " + e);
}
```
## Client Custom Settings
<a name="SetAppInfo"></a>
### SetAppInfo(string appName, tring appVersion)
给User-Agent添加应用信息。
__参数__
| 参数 | 类型 | 描述 |
|---|---|---|
|`appName` | _string_ | 执行API请求的应用名称。 |
| `appVersion`| _string_ | 执行API请求的应用版本。 |
__示例__
```cs
// Set Application name and version to be used in subsequent API requests.
minioClient.SetAppInfo("myCloudApp", "1.0.0")
```
<a name="SetTraceOn"></a>
### SetTraceOn()
开启HTTP tracing,trace日志会输出到stdout。
__示例__
```cs
// Set HTTP tracing on.
minioClient.SetTraceOn()
```
<a name="SetTraceOff"></a>
### SetTraceOff()
Disables HTTP tracing.
__示例__
```cs
// Sets HTTP tracing off.
minioClient.SetTraceOff()
``` | 36,625 | Apache-2.0 |
# Spring MVC常用的功能
## 1. 文件上传下载
### A.必要条件
1. 在WebMvcConfig.java中,添加处理 Multipart-formdata 的功能@Bean, 如下:
```java
@Bean
public CommonsMultipartResolver multipartResolver() {
CommonsMultipartResolver multipartResolver = new CommonsMultipartResolver();
//做一些设置
multipartResolver.setDefaultEncoding("UTF-8");
multipartResolver.setMaxUploadSize(20*1024*1024);
multipartResolver.setMaxUploadSizePerFile(2*1024*1024); //单个文件不能超过2M
return multipartResolver;
}
```
### B.文件上传操作
1. 在前台的页面表单上,需要保证 form 表单的 method=post 以及 enctype=multipart/form-data
```jsp
<form action="${pageContext.request.contextPath}/upload" method="post"
enctype="multipart/form-data" name="uploadForm">
选择一个文件:<input type="file" name="uploadFile" accept="*/*">
<input type="submit" value="上传">
</form>
```
2. 在后台的控制器中,需要在参数中加上 MultipartFile 对象,并且参数名要与前台表单中<input type="file" name="与方法参数一样"> name属性值保持一致
```java
@RequestMapping(value = "/upload")
public String upload(MultipartFile uploadFile, Model model,
HttpSession session)
throws IOException {
log.debug("-- 上传的文件名:"+uploadFile.getOriginalFilename());
log.debug("-- 文件大小: "+uploadFile.getSize());
//
String originalFilename = uploadFile.getOriginalFilename();
int pos = originalFilename.lastIndexOf(".");
//原文件后缀名
String suffix = originalFilename.substring(pos);
//确定好服务端保存文件的具体位置
ServletContext context = session.getServletContext();
String realpath = context.getRealPath(UPLOAD_DIR);
//产生一个uuid式的随机文件名
String uuid = UUID.randomUUID().toString();
//构建目标的完整文件名
String fullname = realpath+ File.separator+uuid+suffix;
log.debug("** 目标文件名"+fullname);
//利用IO流进行读写,此处可以利用 commons-io中的工具类来快速完成
FileUtils.copyInputStreamToFile(uploadFile.getInputStream(), new File(fullname));
log.debug("-- 把上传的源文件COPY到目标文件完成....");
//把一个信息绑定到model中,以便在前端可以显示
model.addAttribute("originalFilename",originalFilename);
model.addAttribute("server_file_name",fullname);
model.addAttribute("filesize", uploadFile.getSize());
//
return "forward:/common/upload.jsp"; //不经过视图解析器
}
```
### C.文件下载
> 需要注意的是设置响应内容类型和响应头,代码片断如下:
```java
@RequestMapping(value = "/download", method = RequestMethod.GET)
public void downloadFile(String id, HttpServletRequest request, HttpServletResponse response) throws Exception {
//获取应用上下文
ServletContext context = request.getServletContext();
String realpath = context.getRealPath(UPLOAD_DIR);
log.debug("要下载的文件名:"+id);
//找到指定的文件
File parent = new File(realpath);
File target = new File(parent, id);
//
if(target.isFile()) {
//根据文件的类型不同,设置不同的响应内容类型
if(id.endsWith(".zip")) {
log.debug("-- 文件内容是 zip 格式,应响头为:application/zip");
response.setContentType("application/zip");
} else if(id.endsWith(".jpg") || id.endsWith(".jpeg")) {
log.debug("-- 文件内容是图片格式,应响头为:image/jpeg");
response.setContentType("image/jpeg");
} else {
log.debug("-- 设置成通用的格式:application/octet-stream ");
response.setContentType("application/octet-stream");
}
//这个头可以让浏览器弹出保存框
response.setHeader("Content-disposition","attachment;filename=\""+id+"\"");
// //把此文件以流的方式输出到客户端
try(FileInputStream fis = new FileInputStream(target);) {
//利用commons-io的工具类来完成读写的COPY
IOUtils.copy(fis, response.getOutputStream());
//刷新缓存
response.flushBuffer();
log.debug("下载完成");
}catch (IOException e) {
e.printStackTrace();
}
}
log.debug("下载的文件:"+id);
}
```
## 2.Bean Validation[后补充的笔记]
### 传统的写法
写起来代码量很大,且效率低下.
```java
String name = user.getName();
if(name == null || name.trim().equals("") ){
errors.put("name", "name不能为空!");
}else{
if(name.trim().length()>20 ){
errors.put("name", "name长度不能超过20!");
}else{
if(name 不满足某个格式){
errors.put("name", "name格式不正确!");
}else{
if(userService.getByName(name.trim()) != null){
errors.put("name", "用户名已被使用!");
}
}
}
}
```
* JSR-303 是JAVA EE 6 中的一项子规范,称为Bean Validation,官方参考实现是Hibernate Validator.
* 此实现与Hibernate ORM 没有任何关系, JSR303 用于对Java Bean 的属性值值进行验证。
* Spring MVC 支持 JSR-303,可以在控制器中对表单提交的数据方便地验证。
### 使用步骤
#### 配置 pom.xml
```xml
<!--JSR303-->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-validator</artifactId>
<version>5.3.0.Final</version>
</dependency>
```
#### 配置 MessageSource
```java
@Configuration
@ComponentScan
@EnableWebMvc
public class WebMvcConfig extends WebMvcConfigurerAdapter {
@Bean
public MessageSource validationMessageSource() {
ResourceBundleMessageSource messageSource = new ResourceBundleMessageSource();
//字符编码
messageSource.setDefaultEncoding("UTF-8");
//Set an array of basenames
messageSource.setBasenames("validationMessages");
//whether to use the message code as default message
messageSource.setUseCodeAsDefaultMessage(true);
return messageSource;
}
@Override
public Validator getValidator() {
LocalValidatorFactoryBean lvfb = new LocalValidatorFactoryBean();
lvfb.setValidationMessageSource(validationMessageSource());
return lvfb;
}
}
```
#### 准备校验逻辑
* 彻底理解需求
* 整理请求参数列表
* 整理校验逻辑
### 准备资源文件
基于 i18n 国际化技术,需要提供多语言环境下的各种资源文件
##### validationMessages_en.properties
```properties
user.name.invalid=Username must be between 6 and 12
user.password.invalid=The password must be between 6 and 12
user.age.invalid=Age must be between 18 and 80.
```
##### validationMessages_zh.properties
```properties
user.name.invalid=用户名必须在6到12之间
user.password.invalid=密码必须在6到12之间
user.age.invalid=年龄必须在18到200之间
```
### 定义校验封装类
```java
import org.hibernate.validator.constraints.NotEmpty;
import javax.validation.GroupSequence;
import javax.validation.constraints.Max;
import javax.validation.constraints.Min;
import javax.validation.constraints.NotNull;
import javax.validation.constraints.Size;
/**
* User Data Transfer Object
*/
public class UserDto {
@NotNull
@Size(min = 6, max = 12, message = "{user.name.invalid}")
private String name;
@NotNull
@Size(min = 6, max = 12, message = "{user.password.invalid}")
private String password;
@Min(value = 18, message = "{user.age.invalid}")
@Max(value = 80, message = "{user.age.invalid}")
private int age;
public UserDto() {
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPassword() {
return password;
}
public void setPassword(String password) {
this.password = password;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
}
```
### 控制器
```java
@RequestMapping(value = "add", method = RequestMethod.POST)
public String test(Model model, @Valid UserDto user, BindingResult bindingResult) {
if (bindingResult.hasErrors()) {
model.addAttribute("user", user);
model.addAttribute("errors", getErrorMap(bindingResult));
return "userAdd";
}
model.addAttribute("user", user);
return "result";
}
```
##### 可自定义提供转换方法:
```java
/**
* 将参数错误信息封装到 map
*/
private Object getErrorMap(BindingResult bindingResult) {
Map<String, String> errorMap = new HashMap<>();
for (ObjectError objectError : bindingResult.getAllErrors()) {
FieldError fieldError = (FieldError) objectError;
String field = fieldError.getField();
String error = fieldError.getDefaultMessage();
errorMap.put(field, error);
}
return errorMap;
}
```
#### 页面
```jsp
<%@ page contentType="text/html;charset=UTF-8" pageEncoding="UTF-8" language="java" %>
<html>
<head>
<title>Bean Validation (JSR303)</title>
</head>
<body>
<h1>Bean Validation (JSR303)</h1>
<hr/>
<p>演示提交一个User对象</p>
<form id="user" action="${path}/demo/add" method="post">
<table width="30%">
<tr>
<th>Name:</th>
<td>
<input id="name" name="name" type="text" value="${user.name}"/>
</td>
<td>
<span>${errors.name}</span>
</td>
</tr>
<tr>
<th>Password:</th>
<td>
<input id="password" name="password" type="password" value="${user.password}"/>
</td>
<td>
<span>${errors.password}</span>
</td>
</tr>
<tr>
<th>Age:</th>
<td>
<input id="age" name="age" type="text" value="${user.age}"/>
</td>
<td>
<span>${errors.age}</span>
</td>
</tr>
<tr>
<td style="text-align: center">
<input type="submit" value="提交">
</td>
</tr>
</table>
</form>
</body>
</html>
```
### 附录
#### JSR303提供
注解类 | 说明
----- | -----
@Null | 必须为null
@NotNull | 必须不为null
@AssertTrue | 必须为true
@AssertFalse | 必须为false
@Min(value) | 必须是一个数字,其值必须大于等于指定的最小值
@Max(value) | 必须是一个数字,其值必须小于等于指定的最大值
@DecimalMin(value) | 必须是一个数字,其值必须大于等于指定的最小值
@DecimalMax(value) | 必须是一个数字,其值必须小于等于指定的最大值
@Size(max, min) | 大小必须在指定的范围内
@Digits (integer, fraction) | 必须是一个数字,其值必须在可接受的范围内
@Past | 必须是一个过去的日期
@Future | 必须是一个将来的日期
@Pattern(value) | 必须符合指定的正则表达式
#### Hibernate Validator提供
注解类 | 说明
----- | -----
@Email | 必须是电子邮箱地址
@Length | 字符串的长度必须在指定的范围内
@NotEmpty |必须非空(有空格就不算Empty)
@NotBlank | 字符串的必须非空(单纯空格算Blank)
@Range | 必须在指定范围内
#### Spring MVC提供
注解类 | 说明
----- | -----
@Valid | 数据需要校验
## 3.拦截器 【Interceptor】
> 主要就是要弄清楚 Filter、 Interceptor、 AOP三者的区别,以及各自的应用场景。
> 1. **Filter:** **过滤器**,主要是针对**请求** 的过滤,在容器层次上进行,保证**“取你所需”**
> 2. **Interceptor:** 拦截器, 是过滤器的延伸,除了可以对请求操作外,还可以对 视图和模型进行拦截,是 “拒你所拒”
> 3. **AOP:** 面向切面编程, 主要针对 业务层和持久层的代码织入,它是降低代码耦合度的一种很好的方式,基于动态代理

# Restful 风构架构
> Spring mvc 框架是完全支持 Restful 风格的,我们采用 / 匹配模式可以完美地实现Restful 操作
## REST 定义
> Representation State Transfer, 表述性状态转移, 后端的任何资源都可以采用 统一资源定位符[URI] 来定位,配合上请求的动作,可以完整地表达出请求的含义。 根据数据的常用操作,把它与不同的请求类型相匹配,主要有:
>
> C操作,Create, 创建数据, 可以使用 POST 请求
>
> R操作,Retrieve, 获取数据,可以使用 GET 请求
>
> U操作,Update, 更新数据,可以使用 PUT 请求
>
> D操作,Delete, 删除数据,可以使用 DELETE 请求
在控制器的方法中, @RequestMapping中有一个 method属性,它可以指定此方法只接收哪种请求类型。
## 如何开发 REST风格的控制器
> 与开发普通的控制器相比,需要使用 @ResponseBody 来表明以方法返回值做为响应体,基本上都是以JSON做数据交换的格式。
1. 我们的控制器可以使用 @Controller + @ResponseBody 组合注解,也可以使用 @RestController 【推荐这个】
2. 在方法上面,使用 @RequestMapping 时,要指定 method 以及 produces
3. 由于在Rest风格上,可以通过 路径参数来传递请求参数,所以需要用到 @PathVariable 注解以及 @RequestBody 注解
## Rest风格与普通的URI对比
1. 获取id为1的Employee实例或获取所有的Employee实例
非REST风格URI: localhost:9090/emp/get?id=1 和 localhost:9090/emp/list
Rest风格URI: GET localhost:9090/emp/1 和 GET localhost:9090/emp
2. 删除ID为2的Employee 和 删除所有的 Employee
非REST风格URI: localhost:9090/emp/delete?id=1 和 localhost:9090/emp/deleteAll
Rest风格URI: DELETE localhost:9090/emp/2 和 DELETE localhost:9090/emp
综上所述,REST风格的URI 充份利用了请求的类型这个动词,所以,不需要在URI层面再去说明不同的操作【相当于“动词”前移】,在REST风格的URI中,它的格式:
请求动作 + URI名词 | 11,994 | MIT |
---
title: "用Hugo+码云搭建支持Markdown+LaTeX的云笔记"
date: 2020-01-07T19:20:35+08:00
draft: true
categories: ["杂事"]
tags: ["hugo","码云","typora","markdown","latex"]
---
## 目标(配置好后的日常操作)
> 更新流程简单舒服,页面主题简洁,完全支持Markdown+LaTeX。
1)**本地撰写**内容:用[Typora](https://www.typora.io/)写基于Markdown+LaTeX的内容。
2)利用静态网站生成器Hugo生成待发布的静态文件: 执行`./forgitee`。
- 这个脚本实际依次执行了:1. 对所有md文件进行部分内容替换,确保站点可以完全解析; 2. 执行`hugo -D`,生成待发布的静态文件,生成文件夹`public`; 3. 执行`./fortypora`对所有md文件进行逆向置换复原,确保Typora打开能完全显示正常。
3) 将站点**git提交**到[码云(gitee)](https://gitee.com): https://gitee.com/chaoskey/notes
- 包括站点全部源码(相当于文档云同步)和生成的静态文件目录`public`。
4) 部署到: https://chaoskey.gitee.io/notes
5) 一键发布的脚本`./publish`(注意,必须根据你自己的情况修改之),依次执行了: 1. `./forgitee`; 2. 将修改过的笔记提交到`master`分支; 3. 将`public`提交到`gh-pages`分支; 4. 将`gh-pages`分支`push`到`gitee`和`github`。
![[0103.jpg]]
<!--more-->
------
## 第一步:安装git
我选择的是[官方winGUI版本](https://git-scm.com/),国内很难下载,建议翻墙下载。默认选项安装即可。
由于官方版本本来就支持shell,后面的操作主要是在git bash下进行,如果GUI更方便时就使用GUI。
## 第二步:安装Hugo
选择Hugo的原因,是因为配置简单、库依赖度很低。
依然选择[官方win版本](https://github.com/gohugoio/hugo/releases),翻墙下载。
我选择的是`hugo_extended_0.64.1_Windows-64bit.zip`,解压,设置好PATH就能用。
## 第三步:在码云上创建一个初始库
选择[码云](https://gitee.com/)而不是GitHub的原因是众所周知,虽然可以翻墙,毕竟麻烦。
创建一个初始库即可,不用额外设置。
我所创建的库是:[https://gitee.com/chaoskey/notes](https://gitee.com/chaoskey/notes)
## 第四步:建立初始站点
打开git bash,后同。
```shell
# 初始化本地站点
hugo new site notes
cd notes
```
打开git GUI, 将`https://gitee.com/chaoskey/notes`克隆到刚构建本地目录`notes`。 如果克隆时提示已存在,则先备份notes,克隆后再覆盖回去。
![[0020.jpg]]
先设置站点根目录 https://chaoskey.gitee.io/notes/
## 第五步:选择主题
我的目标是学习笔记,所以我找到一款简洁并适合的主题`hugo-book`:
```shell
# 克隆主题到themes/book
git clone https://github.com/alex-shpak/hugo-book themes/book
# 复制主题范例站点和配置
cp -a themes/book/exampleSite/config.toml .
cp -a themes/book/exampleSite/content .
```
## 第六步:公式引擎配置(可选)
由于该主题已经支持`katex`,所以此步可选,对应的代码位置:
`themes\book\layouts\shortcodes\katex.html`
但原版默认只支持`{{</* katex [display] */>}}latex{{</* /katex */>}}`格式,所以我作了后面的改动,以支持```$\latex$```的格式,并且还通过配置支持`katex`和`mathjax`。
```html
<!--
原始位置:
themes\book\layouts\shortcodes\katex.html
也可以将其独立出来放在站点根目录下:
layouts\shortcodes\katex.html
-->
{{ if not (.Page.Scratch.Get "katex") }}
{{ if and (isset .Site.Params "katex") (eq .Site.Params "mathjax" ) }}
<!-- Include mathjax only first time -->
<script type="text/x-mathjax-config">
MathJax.Hub.Config({
showProcessingMessages: false,
messageStyle: "none",
extensions: ["tex2jax.js"],
jax: ["input/TeX", "output/HTML-CSS"],
tex2jax: {
inlineMath: [ ["$", "$"], ["\(", "\)"] ],
displayMath: [ ["$\n","\n$"], ["\\[","\\]"] ],
skipTags: ['script', 'noscript', 'style', 'textarea', 'pre','code','a'],
ignoreClass:"comment-content"
},
"HTML-CSS": {
availableFonts: ["STIX","TeX"],
showMathMenu: false
}
});
MathJax.Hub.Queue(["Typeset",MathJax.Hub]);
</script>
<script src="https://cdn.bootcss.com/mathjax/2.7.6/MathJax.js?config=TeX-AMS-MML_HTMLorMML"></script>
{{ else }}
<!-- Include katext only first time -->
<link rel="stylesheet" href="https://cdn.bootcss.com/KaTeX/0.11.1/katex.min.css" integrity="sha384-zB1R0rpPzHqg7Kpt0Aljp8JPLqbXI3bhnPWROx27a9N0Ll6ZP/+DiW/UqRcLbRjq" crossorigin="anonymous">
<script defer src="https://cdn.bootcss.com/KaTeX/0.11.1/katex.min.js" integrity="sha384-y23I5Q6l+B6vatafAwxRu/0oK/79VlbSz7Q9aiSZUvyWYIYsd+qj+o24G5ZU2zJz" crossorigin="anonymous"></script>
<script defer src="https://cdn.bootcss.com/KaTeX/0.11.1/contrib/auto-render.min.js" integrity="sha384-kWPLUVMOks5AQFrykwIup5lo0m3iMkkHrD0uJ4H5cjeGihAutqP0yW0J6dpFiVkI" crossorigin="anonymous"
onload="renderMathInElement(document.body,
{delimiters: [{left: '$\n', right: '\n$', display: true}, {left: '$', right: '$', display: false},
{left: '\\[', right: '\\]', display: true}, {left: '\\(', right: '\\)', display: false}]});"></script>
{{ end }}
{{ .Page.Scratch.Set "katex" true }}
{{ end }}
<span class="katex{{ with .Get "class" }} {{ . }}{{ end }}">
{{ if in .Params "display" }}\[{{ else }}\({{ end -}}
{{ $.Inner }}
{{- if in .Params "display" }}\]{{ else }}\){{ end }}
</span>
```
然后,在`config.toml`中添加一段配置,默认使用`katex`引擎
```latex
#######################################
# (Optional, default none) 选择数学公式渲染引擎
# 默认就是katex引擎, 另外的选择就是 mathjax引擎 (即使改了引擎,标签也继续沿用katex)
# 优先使用$$作为公式界定符号
# 1. 内联公式,比如: $a^2$
# 2. 块公式,比如:
# $$
# a^2
# $$
# 如果渲染失败时(hugo和引擎的冲突),首先作如下2个置换
# 1. 内联公式:\$\$(.*?\\[\\\}\{].*?)\$\$ => {{</* katex */>}}$1{{</* /katex */>}}
# 2. 块公式:\$\$(\n.*?\\[\\\}\{].*?\n)\$\$ => {{</* katex display */>}}$1{{</* /katex */>}}
# 如果还是失败,则修改公式。
#######################################
# katex = "mathjax"
```
## 第七步:Typora和Hugo站点协调
由于Hugo的Markdown解析机制和```$$```格式下的公式有时存在冲突,导致在Typora显示正常的公式,在Hugo解析Markdown时会错误显示或不显示公式。
为了解决这个问题,我写了两个shell脚本:
1) `./fortypora`: 执行后确保用Typora打开本地md文件可以正常渲染,特别是数学公式。
```bash
#!/bin/bash
# 执行后确保用Typora打开本地md文件可以正常渲染,特别是数学公式。
# 将`{{</* katex [display] */>}}latex{{</* /katex */>}}`
# 转换成$$格式
# ./fortypora
# md文件递归
function action(){
for file in `ls $1`
do
if [ -d $1"/"$file ]
then
action $1"/"$file
elif [ "${file#*.}"x = "md"x ]
then
# 方便用typora阅读
sed -i 's/{{</*\s*katex\s**/>}}/$/g; s/{{</*\s*katex\s*display\s**/>}}/$/g; s/{{</*\s*\/katex\s**/>}}/$$/g; s/!\[.*\](\.\.\/\.\.\/images\//`./forgitee`: 执行后确保用Hugo生成的站点可以正常渲染,特别是数学公式。
```bash
#!/bin/bash
# 执行后确保用Hugo生成的站点可以正常渲染,特别是数学公式。
# 先将`$$`
# 转换成`{{</* katex [display] */>}}latex{{</* /katex */>}}`
# 再执行 hugo [servere] -D 命令
# ./forgitee # 站点发布(生成静态文件)
# ./forgitee server # 站点预览
# md文件递归
function action(){
for file in `ls $1`
do
if [ -d $1"/"$file ]
then
action $1"/"$file
elif [ "${file#*.}"x = "md"x ]
then
# 方便发布到gitee
sed -i '/```/ { :begin1; /```.*```/! { $! { N; b begin1 }; }; n; }; /\$\$/ { :begin2; /\$\$[^$]*\$\$/! { $! { N; b begin2 }; }; }; s/\$\$\(\n[^$]*\n\)\$\$/{{</* katex display */>}}\1{{</* \/katex */>}}/g; s/\$\$\([^$]*\)\$\$/{{</* katex */>}}\1{{</* \/katex */>}}/g; s/!\[.*\](\.\.\/images\//的入门介绍及使用"
date: 2018-12-31 12:50:00
categories: 设计模式
tags: statemachine spring-statemachine
excerpt: 有限状态机的入门介绍及使用
---
* content
{:toc}
在实际开发中,可能会遇到使用一大块的if...else...的代码,并且通常情况下是多层if...else...的嵌套。如果代码有注释还好,可以通过注释梳理整个业务逻辑。如果没有注释,那么只能靠阅读每一个分支,拼出整个的逻辑,并且不一定能保证最终的正确性和完整性。
为了不给别人添麻烦,也为了让自己更容易地维护项目,在这种情况下,如果可以将整个流程分成一个个的状态的变换的话,可以考虑使用有限状态机来编写或重构上述的代码。对于学习过随机过程相关课程的同学,可以回想下,马尔可夫链中的状态转移图从而类比理解状态机中状态变换。整个业务流程在某一个时刻只能处于一个状态,只能执行给定的事件集合,从而触发状态变换。
举一个简单的例子来理解理解状态机。通常情况下,灯有两种状态:灯灭、灯亮,我们能做的事情也有两件:打开开关、关闭开关。灯灭时,只能执行打开开关事件,使得灯亮;灯亮时,只能执行关闭开关事件,使得灯灭。
使用Spring Statemachine来实现一个灯的状态机:
#### 1. 定义状态
```java
public enum LightState {
/**
* 灯灭
*/
OFF,
/**
* 灯亮
*/
ON;
}
```
#### 2. 定义事件
```java
public enum LightEvent {
/**
* 打开开关
*/
SWICH_ON,
/**
* 关闭开关
*/
SWITCH_OFF;
}
```
#### 3. 配置状态机
```java
@Configuration
@EnableStateMachine
public class LightSateMachineConfig extends EnumStateMachineConfigurerAdapter<LightState, LightEvent> {
@Override
public void configure(StateMachineConfigurationConfigurer<LightState, LightEvent> config)
throws Exception {
config
.withConfiguration()
.machineId("lightStateMachine")
.autoStartup(true)
.listener(listener());
}
@Override
public void configure(StateMachineStateConfigurer<LightState, LightEvent> states)
throws Exception {
states
.withStates()
.initial(LightState.OFF)
.states(EnumSet.allOf(LightState.class));
}
@Override
public void configure(StateMachineTransitionConfigurer<LightState, LightEvent> transitions)
throws Exception {
transitions
.withExternal()
.source(LightState.OFF).target(LightState.ON).event(LightEvent.SWICH_ON)
.and()
.withExternal()
.source(LightState.ON).target(LightState.OFF).event(LightEvent.SWITCH_OFF);
}
@Bean
public StateMachineListener<LightState, LightEvent> listener() {
return new StateMachineListenerAdapter<LightState, LightEvent>() {
@Override
public void stateChanged(State<LightState, LightEvent> from, State<LightState, LightEvent> to) {
System.out.println("light state change to " + to.getId());
}
};
}
}
```
#### 4. 使用状态机
```java
@Autowired
private StateMachine<LightState, LightEvent> lightStateMachine;
@Test
public void lightMachine() {
lightStateMachine.sendEvent(LightEvent.SWICH_ON);
lightStateMachine.sendEvent(LightEvent.SWICH_ON);
lightStateMachine.sendEvent(LightEvent.SWITCH_OFF);
}
```
输出结果:
```
light state change to ON
light state change to OFF
```
可以看到,虽然向状态机发送了3个事件:打开开关、打开开关、关闭开关,但是状态只变换了2次,原因是当灯已经被打开时,再次发送打开开关的事件时,灯已经是灯亮的状态,灯亮时只能执行关闭事件,再次打开的事件会被忽略。
### 总结
使用状态机时,抽象出业务中的一个个状态,然后定义好两个相邻状态间的事件集合,然后向状态机发送事件,使得状态机运转起来。期间,可以监听状态变化的过程,实现想要的业务逻辑。 | 3,052 | MIT |
---
layout: post
title: 无法向gerrit上push annotated tag,remote rejected
categories: [cm, git]
tags: [cm, git, gerrit]
---
无法向gerrit上push annotated tag,报告如下错误
```
! [remote rejected] qalink_v2.1.0_rc1 -> qalink_v2.1.0_rc1 (prohibited by Gerrit)
```
* 原因
是因为用户权限不够。
* 解决 - 1
将tag签名,然后在上传
* 解决 - 2
修改 access 权限:添加
Reference: refs/tags/*
添加 权限:Push Annotated Tag | 371 | MIT |
---
layout: post
title: 张国荣的时光
date: 2019-04-09 14:35:21
categories: [笔记]
tags: [荐读]
---
“你是真虞姬,我是假霸王”
<!--more-->
> 在褒贬双重意义上,他都是一个个性非常丰富,永远不会使你厌倦的人。
> Leslie是个性格十分直率、从不妥协的人,而工作中的他又是一个让旁人看得心痛得完美主义者和理想主义者。他所追求得理想常常是障碍重重的,要同理想和与理想存在着鸿沟的现实和平相处,他要奋斗、会受伤、须忍耐,甚至有时会弄得自己伤痕累累。但另一方面,他同时又是一个很有经济头脑、身处危机时能够随机应变并速战速决得现实主义者。既是理想主义者,又是现实主义者,面对她的理想和现实,他就是个完美主义者。
张国荣先生是个优质偶像,在做人和做事方面他都值得我学习,当然,他身为一个明星跟普通人肯定不一样,他也有缺点,但在很多方面确实能给我感动:待人真诚、做事认真等等。
《张国荣的时光》这本书给我们展现了作者合作的张国荣独特的一面,看过这本书,也就能够稍微理解为什么再他逝去这么多年里还能有着众多的粉丝:他有着一种特别的人格魅力。 | 514 | MIT |
---
order: 5
title: 国际化
group:
title: 框架使用
nav:
title: 文档
path: /docs
order: 1
---
`hrun4j`默认输出是中文(`I❤️Z`),如果需要使用英语,可以参考下面的方案。
## CLI模式
首先查看CLI运行帮助:`java -jar hrun4j.jar run --help`
```
[root@iZwz9d74mj3se04xsvz0crZ CLI_PROJECT]# java -jar hrun4j.jar run --help
Print run command information.
Usage: java -jar hrun4j.jar run [--bsh FILE] [--dot_env_path FILE] [--ext_name VAL] [--help] [--i18n VAL] [--pkg_name VAL] [--quiet] [--testcase_path <testcase_path>] [--testsuite_path <testsuite_path>]
--bsh FILE : Specify hrun4j.bsh as the project
path, not the current path.
--dot_env_path FILE : Specify the path to the.env file
--ext_name VAL : Specify the use case extension. (default:
yml)
--help : show help (default: true)
--i18n VAL : Internationalization support,support
us/cn. (default: CN)
--pkg_name VAL : Specify the project package name.
--quiet : suppress all output on stdout (default:
false)
--testcase_path <testcase_path> : list of testcase path to execute
--testsuite_path <testsuite_path> : Specify the TestSuite path
```
其中国际化支持可通过`i18n`设置,`i18n`全称为internationalization,如果想使用英文,运行时加入`--i18n=us`参数即可。
案例如下:`java -jar hrun4j.jar run --i18n us --testcase_path testcases/get/getScene.yml`
完整输出如下:
```
2021-06-27 21:30:04.863 [main] INFO vip.lematech.hrun4j.helper.LogHelper - Run mode: CLI
2021-06-27 21:30:04.876 [main] INFO vip.lematech.hrun4j.helper.LogHelper - The workspace path:/home/data/workplace/CLI_PROJECT
[TestNG] Running:
hrun4j
2021-06-27 21:30:08.239 [main] INFO vip.lematech.hrun4j.helper.LogHelper - [========================================]@beforeSuite()
2021-06-27 21:30:08.248 [main] INFO vip.lematech.hrun4j.helper.LogHelper - [====================getScene====================]@START
2021-06-27 21:30:08.257 [main] INFO vip.lematech.hrun4j.helper.LogHelper - Step
hrun4j.bsh文件所在路径即为项目工程路径
你好,欢迎使用hrun4j!
官网:http://www.lematech.vip
微信公众号:lematech
技术交流微信:wytest
2021-06-27 21:30:08.661 [main] INFO vip.lematech.hrun4j.helper.LogHelper - Request Url:https://postman-echo.com/get?website=http://lematech.vip&project=hrun4j&author=lematech&page={page}
2021-06-27 21:30:08.662 [main] INFO vip.lematech.hrun4j.helper.LogHelper - Request Method:GET
2021-06-27 21:30:12.199 [main] INFO vip.lematech.hrun4j.helper.LogHelper - Response StatusCode:200
2021-06-27 21:30:12.200 [main] INFO vip.lematech.hrun4j.helper.LogHelper - Response Body:{"args":{"website":"http://lematech.vip","author":"lematech","project":"hrun4j","page":"{page}"},"headers":{"x-amzn-trace-id":"Root=1-60d87d64-0b9cc79b189478636d70a3e8","x-forwarded-proto":"https","host":"postman-echo.com","x-forwarded-port":"443","accept-encoding":"gzip","user-agent":"okhttp/3.14.9"},"url":"https://postman-echo.com/get?website=http://lematech.vip&project=hrun4j&author=lematech&page={page}"}
2021-06-27 21:30:12.201 [main] INFO vip.lematech.hrun4j.helper.LogHelper - Response ContentLength:423
2021-06-27 21:30:12.201 [main] INFO vip.lematech.hrun4j.helper.LogHelper - Response Time:2.689
2021-06-27 21:30:12.201 [main] INFO vip.lematech.hrun4j.helper.LogHelper - Response Header:{"date":"Sun, 27 Jun 2021 13:30:12 GMT","content-length":"423","set-cookie":"sails.sid=s%3Ac30kDB8Vc4X2wjLhanbovdBwg5agfV0O.9ENw5sopbvJrf1slMR6OR9To0wrfqDFHvGhiLJN7XgA; Path=/; HttpOnly","vary":"Accept-Encoding","content-type":"application/json; charset=utf-8","etag":"W/\"1a7-ryYvxxb8SpvHilpiHdYlGmSCF/k\""}
2021-06-27 21:30:12.201 [main] INFO vip.lematech.hrun4j.helper.LogHelper - Response Cookie:
2021-06-27 21:30:12.344 [main] INFO vip.lematech.hrun4j.helper.LogHelper - Assert Check Point:status_code,ExpectValue:200,ActualValue:200,CheckResult:Pass
2021-06-27 21:30:12.351 [main] INFO vip.lematech.hrun4j.helper.LogHelper - Assert Check Point:body.args.website,ExpectValue:http://lematech.vip,ActualValue:http://lematech.vip,CheckResult:Pass
2021-06-27 21:30:12.356 [main] INFO vip.lematech.hrun4j.helper.LogHelper - Assert Check Point:${author},ExpectValue:lematech,ActualValue:lematech,CheckResult:Pass
2021-06-27 21:30:12.358 [main] INFO vip.lematech.hrun4j.helper.LogHelper - Assert Check Point:^website":"(.*?)"$,ExpectValue:website":"http://lematech.vip",ActualValue:website":"http://lematech.vip",CheckResult:Pass
2021-06-27 21:30:12.372 [main] INFO vip.lematech.hrun4j.helper.LogHelper - Step
2021-06-27 21:30:12.487 [main] INFO vip.lematech.hrun4j.helper.LogHelper - Request Url:https://postman-echo.com/get?website=http://lematech.vip&project=hrun4j&author=http://lematech.vip
2021-06-27 21:30:12.487 [main] INFO vip.lematech.hrun4j.helper.LogHelper - Request Method:GET
2021-06-27 21:30:12.726 [main] INFO vip.lematech.hrun4j.helper.LogHelper - Response StatusCode:200
2021-06-27 21:30:12.727 [main] INFO vip.lematech.hrun4j.helper.LogHelper - Response Body:{"args":{"website":"http://lematech.vip","author":"http://lematech.vip","project":"hrun4j"},"headers":{"x-amzn-trace-id":"Root=1-60d87d64-7015c2a1677f4e0c2aec0130","x-forwarded-proto":"https","host":"postman-echo.com","x-forwarded-port":"443","accept-encoding":"gzip","user-agent":"okhttp/3.14.9"},"url":"https://postman-echo.com/get?website=http://lematech.vip&project=hrun4j&author=http://lematech.vip"}
2021-06-27 21:30:12.727 [main] INFO vip.lematech.hrun4j.helper.LogHelper - Response ContentLength:417
2021-06-27 21:30:12.727 [main] INFO vip.lematech.hrun4j.helper.LogHelper - Response Time:0.238
2021-06-27 21:30:12.727 [main] INFO vip.lematech.hrun4j.helper.LogHelper - Response Header:{"date":"Sun, 27 Jun 2021 13:30:12 GMT","content-length":"417","set-cookie":"sails.sid=s%3A0-vmPuEl_VM_BfJbhK7bMZdBz4W9jV9e.xoWYlmhwuRqB%2FEmy7sLr30Fg7f9skZ8Q5mBOYlQmEZA; Path=/; HttpOnly","vary":"Accept-Encoding","content-type":"application/json; charset=utf-8","etag":"W/\"1a1-Wx8uIB/d86laeKz5ykC+h8/qhJU\""}
2021-06-27 21:30:12.728 [main] INFO vip.lematech.hrun4j.helper.LogHelper - Response Cookie:
2021-06-27 21:30:12.735 [main] INFO vip.lematech.hrun4j.helper.LogHelper - Assert Check Point:status_code,ExpectValue:200,ActualValue:200,CheckResult:Pass
2021-06-27 21:30:12.736 [main] INFO vip.lematech.hrun4j.helper.LogHelper - [====================getScene====================]@END
2021-06-27 21:30:12.745 [main] INFO vip.lematech.hrun4j.helper.LogHelper - [========================================]@afterSuite()
===============================================
hrun4j
Total tests run: 1, Failures: 0, Skips: 0
===============================================
```
全英文输出,体验棒棒哒💯。
## POM模式
POM模式设置中英文非常简单,在初始化运行配置时,通过代码设置i18n方法参数即可,代码如下:
```
public class Hrun4j extends TestBase {
@Override
@BeforeSuite
public void beforeSuite() {
LogHelper.info(" Add function to static code block !");
/**
* Test case file suffix
*/
RunnerConfig.getInstance().setI18n(Constant.I18N_US);
RunnerConfig.getInstance().setTestCaseExtName(Constant.SUPPORT_TEST_CASE_FILE_EXT_YML_NAME);
}
}
```
核心设置代码:`RunnerConfig.getInstance().setI18n(Constant.I18N_US);`
目前支持以下语言:
| 语言 | 文件名 | 备注 |
| --- | --- | --- |
| 英文 | message_en_US.properties | |
| 中文 | message_zh_CN.properties | 默认 |
国际化支持借助`ResourceBundle`工具类实现,国际化资源文件存储在`hrun-core`工程资源文件locales目录下 | 7,498 | MIT |
### 677. 键值映射
> 题目
[链接](https://leetcode-cn.com/problems/map-sum-pairs/)
> 思路
暴力
> 代码
```js
var MapSum = function () {
this.map = new Map();
};
/**
* @param {string} key
* @param {number} val
* @return {void}
*/
MapSum.prototype.insert = function (key, val) {
this.map.set(key, val);
};
/**
* @param {string} prefix
* @return {number}
*/
MapSum.prototype.sum = function (prefix) {
let res = 0;
for (const s of this.map.keys()) {
if (s.startsWith(prefix)) {
res += this.map.get(s);
}
}
return res;
};
```
> 复杂度分析
时间复杂度:O(n)。
空间复杂度:O(n)。
> 执行
执行用时:80 ms, 在所有 JavaScript 提交中击败了21.57%的用户
内存消耗:39.1 MB, 在所有 JavaScript 提交中击败了33.33%的用户 | 706 | MIT |
# 2021-6-19
共50条
<!-- BEGIN -->
1. [如何评价赛雷话金发布视频揭露「不让中国人吃海鲜」事件背后的反华组织利益链?](https://www.zhihu.com/question/465827983)
1. [顶级 985 研究生组团搞诈骗,涉案金额超 1 亿,反映了哪些问题?需要承担哪些法律责任?](https://www.zhihu.com/question/465557339)
1. [中国科学家成功让公鼠怀孕,诞下 10 只健康幼崽,这是怎么做到的?有哪些意义?](https://www.zhihu.com/question/465862552)
1. [如何评价刘强东发致股东信称:很多京东快递员在偏远省份都能月收入过万元?](https://www.zhihu.com/question/465738678)
1. [哈工大和北理工选择哪一个?](https://www.zhihu.com/question/329076452)
1. [小戏骨系列值得被提倡吗?](https://www.zhihu.com/question/354286546)
1. [八岁儿子一上午只写十个字,重庆 90 后妈妈吼骂儿子后内疚大哭,年轻家长育儿有哪些困境?如何更好解决?](https://www.zhihu.com/question/465723069)
1. [如何看待郑州一汽车销售公司举牌营销,表示「买车可以抱一下亲一下」?](https://www.zhihu.com/question/465898157)
1. [假如我的头盖骨能零距离确保挡住7.62mm全威力弹,我能成为战神级别的士兵吗?](https://www.zhihu.com/question/444459120)
1. [为什么平方腊时死了那么多梁山好汉?](https://www.zhihu.com/question/459476694)
1. [时隔不到一年时间,马斯克决定把名下最后一套房产卖了,有哪些值得关注的信息?](https://www.zhihu.com/question/465124442)
1. [女朋友结婚不要车想要20w的钻戒,说是收藏升值的,该买吗?](https://www.zhihu.com/question/460481721)
1. [刘德华确定出演《流浪地球 2》,你有哪些期待?](https://www.zhihu.com/question/465932631)
1. [深圳机场一餐饮人员核酸检测复核为阳性,之前曾接种疫苗,目前情况如何?](https://www.zhihu.com/question/465742318)
1. [猫被人抱的时候,心里在想什么?](https://www.zhihu.com/question/463390158)
1. [美媒挖坑提问「如何看待中国侵犯人权」,蔡崇信有力回击,如何评价这段采访?](https://www.zhihu.com/question/465932695)
1. [如何看待网传百度试用期员工因处罚 6 个虚假交易商家,被公司劝退一事?](https://www.zhihu.com/question/465745130)
1. [2021 年 Steam 夏促时间定了,大家打算入手什么游戏呢?](https://www.zhihu.com/question/456973633)
1. [歼-20列装人民空军多支英雄部队,你怎么看?对于我国空天安全和国防建设有什么意义?](https://www.zhihu.com/question/465781827)
1. [你认为最棒的前十位 iPad 应用是哪些?](https://www.zhihu.com/question/34453138)
1. [如何看待江西一孕妇出车祸瘫痪,丈夫欲离婚?其中涉及哪些法律问题?](https://www.zhihu.com/question/465900205)
1. [对于刘亦菲的新剧《梦华录》,大家有什么看法?](https://www.zhihu.com/question/463716425)
1. [如果回到100年前那个热血沸腾的革命年代,你最想体验谁的人生?](https://www.zhihu.com/question/460118166)
1. [6 月 20 日起,离深出省须持 48 小时内核酸阴性证明,会带来哪些影响?当地防控情况如何?](https://www.zhihu.com/question/466006647)
1. [你认为电影名字起的最好的电影是哪部?](https://www.zhihu.com/question/464066501)
1. [你会选择和一个你不喜欢但喜欢你的人过一辈子还是一个人过一辈子?](https://www.zhihu.com/question/461105913)
1. [大家能给我讲一个笑话吗?](https://www.zhihu.com/question/464776360)
1. [如何解读《了不起的盖茨比》中黛西这一角色?](https://www.zhihu.com/question/464349748)
1. [孩子七岁上一年级,每晚都要写作业到很晚才睡,我该怎么办?](https://www.zhihu.com/question/453264257)
1. [如何跟男友或老公保持新鲜感?](https://www.zhihu.com/question/323121337)
1. [作为爸爸,第一次见到自己出生的小孩是一种什么样的体验?](https://www.zhihu.com/question/352453251)
1. [高考志愿到底该怎么填写?](https://www.zhihu.com/question/409122324)
1. [我高一英语成绩不太理想,该怎么去提高呢?](https://www.zhihu.com/question/463008113)
1. [真的没人吐槽卫生棉条难用么?](https://www.zhihu.com/question/300142490)
1. [怎么判断男生是否真心喜欢你?](https://www.zhihu.com/question/431695365)
1. [作为一名牙科医生,你有哪些「一般人我都告诉他,可人家就是不听啊」的忠告?](https://www.zhihu.com/question/56477060)
1. [为什么有的人不愿意买滚筒洗衣机?](https://www.zhihu.com/question/393287010)
1. [蜜雪冰城的主题曲为什么突然爆火了?洗脑的原因是什么?](https://www.zhihu.com/question/464996660)
1. [iPhone 有哪些非常有必要下载的 App?](https://www.zhihu.com/question/28306141)
1. [如何看待调查组织报告显示,美国2020年共发布约1.5万炒作中国威胁论的报道,比前年增加57%?](https://www.zhihu.com/question/465877952)
1. [中国动画《雪孩子》改编自日本神话吗?](https://www.zhihu.com/question/465234646)
1. [怎么样可以全身美白?](https://www.zhihu.com/question/24969320)
1. [你心目中完美的养老院是什么样的?](https://www.zhihu.com/question/403290284)
1. [一个人有贵气是什么特征?](https://www.zhihu.com/question/61071183)
1. [win10专业版和家庭版有什么区别?](https://www.zhihu.com/question/51633999)
1. [男生哪些行为代表他爱你?](https://www.zhihu.com/question/460665781)
1. [一群会唱歌的人一起 k 歌是怎样一种体验?](https://www.zhihu.com/question/34563032)
1. [把猫独自放在家里七天猫咪会生气吗?](https://www.zhihu.com/question/297157565)
1. [NBA 2020-21 赛季 76 人 104:99 力克老鹰进入抢七,如何评价这场比赛?](https://www.zhihu.com/question/465879543)
1. [青岛现两车追尾事故,后车司机抱娃下车持刀猛扎前车司机,她将面临哪些处罚?还有哪些信息值得关注?](https://www.zhihu.com/question/465539331)
<!-- END --> | 3,773 | MIT |
#JavaWeb笔记
###Servlet
* Servlet执行原理
1. 当服务器接收到客户端浏览器的请求后, 会解析url路径, 获取访问的Servlet的资源路径
2. 查找web.xml, 是否有对应的 <url-pattern> 标签体内容
3. 如果有, 则找到对应的 <servlet-class> 全类名
4. tomcat会将字节码文件加载进内存, 并且创建其对象, 调用方法

* Servlet生命周期
1. 被创建: 执行init方法, 只执行一次
+ 说明Servlet在内存中只存在一个对象, Servlet是单例的, 多个用户访问时,可能存在线程安全问题, 所以尽量不要再Servlet中定义成员变量,
即使定义了成员变量, 也不要对其赋值
+ 默认情况下, 当Servlet第一次被访问时创建
+ 也可以在web.xml指定Servlet的创建时机
```xml
<!--指定Servlet的创建时间
1.第一被访问时创建, load-on-startup配置的值为负数, 默认也是-1
2.在服务器启动时创建, load-on-startup配置的值为0或正数
-->
<load-on-startup>-1</load-on-startup>
```
2. 提供服务: 执行Servlet方法, 执行多次
3. 被销毁: 执行destroy方法, 只执行一次 (只有服务器正常关闭时, 才会执行destroy方法, destroy方法在Servlet被销毁之前执行, 一般用于释放资源)
* Servlet3.0及以上支持注解配置, 不需要用web.xml了
```java
import javax.servlet.annotation.WebServlet;
@WebServlet(urlPatterns = "/myServlet") // 也可以 @WebServlet(value = "/myServlet") 或者 @WebServlet("/myServlet")
public class MyServlet implements Servlet {
//......
}
//一个Servlet可以配置多个访问路径
//@WebServlet({"/myServlet1","/myServlet2",""/myServlet3""})
//路径的定义规则
// 1. /xxx
// 2. /xxxxx/xxxxx (多层路径)
// 3. *.do ( *.后缀 不能加斜杠)
```
###HTTP
* 特点
1. 是基于TCP/IP的高级协议
2. 默认端口号是80
3. 基于请求/相应模型的: 一次请求对应一次响应
4. 无状态的: 每次请求之间相互独立, 不能交互数据
* 历史版本
1. **1.0版本**:每一次请求和响应都会建立新的连接
2. **1.1版本**:复用连接
* 请求消息数据格式
1. 请求行
+ 格式: 请求方式 请求url 请求协议/版本
+ HTTP协议有7种请求方式, 常用的有两种
- GET: 请求参数在请求行中, 在url后
- POST: 请求参数在请求体中
2. 请求头 (包含客户端浏览器告诉服务器的)一些信息
+ 格式: 请求头的名称: 请求头值
- 常见的请求头
1. User-Agent: 浏览器告诉服务器, 客户端访问服务器时, 使用的浏览器的版本信息 (可以用于服务器端获取该头信息,解决浏览器兼容性问题)
2. Referer: 告诉服务器, 当前请求从哪里来 (可以用于统计或防盗链)
3. 请求空行
+ 就是一个空行, 用于分隔POST请求的请求头和请求体的
4. 请求体 (封装POST请求消息的请求参数)
* 响应数据格式消息
1. 响应行
+ 格式: 协议/版本 响应状态码 状态码描述
+ 响应状态码:
1. 1xx: 服务器接收客户端消息, 但没有接收完成, 等待一段时间后, 发送1xx状态码
2. 2xx: 成功
3. 3xx: (302)重定向, (304)访问缓存
4. 4xx: 客户端错误 (404)请求路径没有对应的资源 (405)请求方式没有对应的方法
5. 5xx: 服务器端错误 (500)服务器内部出现异常
2. 响应头
+ 格式: 响应头的名称: 响应头值
- 常见的响应头
1. Content-Type: 服务器告诉客户端本次响应体数据格式以及编码格式
2. Content-disposition: 服务器告诉客户端以什么格式打开响应体数据
* in-line: 默认值, 在当前页面打开
* attachment; file-name=xxx: 以附件形式打开响应体, 常用于文件下载
3. 响应空行
4. 响应体
###Request

* request对象和response对象的原理
1. request/response对象是由服务器创建的, 我们来使用它们
2. request对象是来获取请求消息, response对象是来设置响应消息
* 获取请求行数据
- URL & URI
+ URL: 统一资源定位符
+ URI: 统一资源标识符
* 获取请求头数据
* 获取请求体数据 (只有POST方式才有请求体)
1. 获取流对象
2. 从流对象中拿数据
* 其他功能
+ 获取请求参数的通用方式
+ 请求转发(一种在服务器内部的资源跳转方式)
```java
req.getRequestDispatcher("/hello").forward(req,resp);
//请求转发的特点
//1.浏览器地址栏路径没有发生变化
//2.只能转发到当前服务器的内部资源中
//3.转发是一次请求 可以使用request对象来共享数据
```
+ 共享数据
- 域对象: 一个有作用范围的对象, 可以在范围内共享数据
- request域: 代表一次请求的范围, 一般用于请求转发的多个资源中共享数据
+ 获取ServletContext
* Tips:
+ 中文乱码问题
- tomcat8之后, get方式不会出现乱码, tomcat帮我们解决了
- post方式: 设置流的编码和页面一致
```html
<meta charset="UTF-8">
```
```java
//设置流的编码
req.setCharacterEncoding("utf-8");
```
```java
//获取流对象之前设置流的默认编码
//resp.setCharacterEncoding("utf-8"); //这一步可以省略
//告诉浏览器, 服务器发送的消息体数据数据的编码, 建议浏览器使用该编码解码
resp.setContentType("text/html;charset=utf-8");
```
+ 路径怎么写
1. 判断定义的路径是给谁用的? 或者说判断请求是从哪发出的?
2. 如果是浏览器发出的(给浏览器用的), 那就需要加虚拟目录, 如重定向
3. 如果是服务器发出的, 那就不需要加虚拟目录, 如转发
```java
//动态获取虚拟目录
String contextPath = req.getContextPath();
```
###Response
* 设置响应消息
1. 设置响应行
+ 设置状态码
2. 设置响应头
3. 设置响应体
+ 获取输出流
+ 使用输出流, 将数据输出到客户端浏览器中
* 重定向
```java
//1.设置状态码
//resp.setStatus(302);
//2.设置响应头location
//resp.setHeader("location", "/ServletStudy/success.html");
//有一种简单的重定向方法
resp.sendRedirect("/ServletStudy/success.html");
//重定向的特点
//1.地址栏发生变化
//2.重定向可以访问其他站点的资源
//3.重定向是两次请求 不能使用request对象来共享数据
```
###ServletContext对象
* 概述: 代表整个Web应用, 可以和程序的容器(服务器)来通信
* 功能:
1. 获取MIME类型: 在互联网通信过程中定义的一种文件数据类型
+ 格式: 大类型/小类型 如 text/html image/jpeg
2. 域对象:
+ ServletContext对象范围: 所有用户所有请求的数据
3. 获取文件的真实路径(在服务器的位置)
###会话技术
* 会话: 一次会话中包含多次请求和响应
+ 一次会话: 浏览器第一次给服务器资源发送请求, 会话建立, 直到有一方断开位置
* 功能: 在一次会话的范围内的多次请求间, 共享数据
* 方式:
+ 客户端会话技术: Cookie
+ 服务器端会话技术: Session
###Cookie
* 概述: 客户端的会话技术, 将数据保存到客户端
* 使用:
1. 创建Cookie对象, 绑定数据
2. 发送Cookie对象
3. 获取Cookie, 拿数据
* 实现原理(基于响应头set-cookie和请求头cookie实现的)

* 关于Cookie的几个问题
1. 一次可以发送多个cookie吗? ----> 可以创建多个Cookie对象, 使用response调用多次addCookie方法, 发送Cookie即可
2. Cookie在浏览器中可以存多久? ---->
+ 默认情况下, 当浏览器关闭后, Cookie数据被销毁
+ 设置Cookie的生命周期, 持久化存储
3. Cookie能不能存中文? ----->
+ 在Tomcat8之前, Cookie不能直接存储中文数据, 需要转码, 一般采用URL编码
+ 在Tomcat8之后, Cookie支持中文数据
4. Cookie的获取范围
+ 默认情况下, cookie不能共享(假设在一个tomcat里部署了多个web项目, 在这些web项目之间, cookie不能共享)
+ 如果部署在同一个tomcat的web项目要共享cookie, 可以使用setPath方法设置共享范围为 "/"
+ 不同的Tomcat服务器间cookie如何共享: 需要设置 setDomain , 如果设置一级域名相同, 那么多个服务器之间cookie可以共享
- 如: setDomain(".baidu.com"), 则tieba.baidu.com和news.baidu.com中cookie可以共享
* Cookie的特点
1. cookie存储数据在客户端浏览器
2. 浏览器对于单个cookie的大小有限制(4kb), 以及对于同一域名下的总cookie数量也有限制(20个)
* Cookie的作用
1. cookie一般用于存储少量的不太敏感的数据
2. 在不登陆的情况下, 完成服务器对客户端的身份识别
###JSP
* 本质: JSP的本质是Servlet
* JSP脚本
+ <% 代码 %>: 定义的java代码会出现在service方法中, service方法可以定义什么, 这里就能写什么
+ <%! 代码 %>: 定义的java代码, 会出现在jsp转换后的java类的成员位置, 比较少用
+ <% 代码 %>: 定义的java代码, 会输出到页面上, 输出语句中定义什么, 该脚本就可以定义什么
* JSP指令
+ 作用: 用于配置jsp页面, 导入资源文件
+ 格式: <%@ 指令名称 属性名1=属性值1 属性名2=属性值2 ...%>
+ 分类:
- page: 配置jsp页面
- include: 页面包含的文件和导入页面的资源文件 <%@include file="logo.jsp""%>
- taglib: 导入资源 <%@taglib prefix="c" uri="http://java.sun.com/jsp/jstl/core" %>
* JSP的内置对象(在jsp页面中不需要获取和创建, 可以直接使用的对象, 一共9个)
1. request: 域对象, 共享数据范围: 一次请求访问的多个资源(转发)
2. response: 响应对象
3. out: 字符输出流对象, 可以将数据输出到页面上 **response.getWriter()输出的数据永远在out之前**
4. pageContext: 域对象, 当前页面共享数据, 还可以用来获取其他8个内置对象
5. session: 域对象, 共享数据范围: 一次会话的多个请求间
6. application: 域对象, 类型是ServletContext, 共享数据的范围: 所有用户间
7. page: 当前页面(servlet)的对象 this
8. config: Servlet的配置对象
9. exception: 只有在page指令中声明 isErrorPage="true" 时, 才可以使用
###Session
* 概述: 服务器端会话技术, 在一次会话的多次请求间共享数据, 将数据保存在服务器端的HttpSession对象中
* 原理: Session的实现是依赖于Cookie的

* 关于Session的几个问题
1. 当客户端关闭后, 服务器不关闭, 两次获取的session是不是同一个?
+ 默认情况下不是
+ 如果需要相同, 则可以创建Cookie, 设置键为JSESSIONID, 设置最大存活时间, 让cookie持久化保存
+ ```java
Cookie c = new Cookie("JSESSIONID", session.getId());
c.setMaxAge(60*60);
resp.addCookie(c);
```
2. 当客户端不关闭, 服务器关闭后, 两次获取的session是不是同一个?
+ 不是同一个, 但是要确保数据不丢失
+ session的钝化: 在服务器正常关闭之前, 将session对象序列化到硬盘上
+ session的活化: 在服务器启动后, 将session文件转化为内存中的session对象即可
3. session什么时候被销毁?
+ 服务器关闭
+ session对象调用session.invalidate()方法
+ session的默认失效时间: 30min
```xml
<session-config>
<session-timeout>30</session-timeout>
</session-config>
```
* Session的特点
1. session用于存储一次会话的多次请求的数据, 存在服务器端
2. session可以存储任意类型, 任意大小的数据
* Session与Cookie的区别
1. session存储数据在服务器端, Cookie在客户端
2. session没有数据大小限制, cookie有
3. session数据安全, cookie相对不安全
###MVC

###三层架构

###Filter 过滤器
* Web中的过滤器: 当访问服务器的资源时, 过滤器可以将请求拦截下来, 完成一些特殊功能
* 过滤器的作用: 一般用于完成通用的操作, 如: 登录验证, 统一编码处理
* 过滤器的执行流程:
1. 执行过滤器
2. 执行放行后的资源
3. 回归过滤器, 执行过滤器放行之后下面的代码
* 过滤器配置
1. 拦截路径配置
+ 具体资源路径拦截: /index.jsp 只有访问index.jsp资源时, 过滤器才会被执行
+ 目录拦截: /user/* 访问/user 下的所有资源时, 过滤器都会被执行
+ 后缀名拦截: *.jsp 访问所有jsp资源时, 过滤器会被执行
+ 拦截所有资源: /*
2. 拦截方式配置: 资源被访问的方式
+ 注解配置(设置dispatcherTypes属性)
1. REQUEST: 默认值, 浏览器直接请求资源
2. FORWARD: 转发访问资源
3. INCLUDE: 包含访问资源
4. ERROR: 错误跳转资源
5. ASYNC: 异步访问资源
+ web.xml配置
```xml
<dispatcher>REQUEST</dispatcher>
```
* 过滤器链配置(配置多个过滤器)
+ 执行顺序(以2个过滤器为例, f1, f2)
1. f1先执行
2. f2后执行
3. 资源执行
4. 回归f2, 执行下面代码
5. 回归f1, 执行下面代码
+ 过滤器先后顺序问题
1. 注解配置(按照类名的字符串比较规则, 值小的先执行)
2. web.xml配置(哪个filter的<filter-mapping>配置在前就先执行)
###代理模式(一种设计模式)
* 概念:
+ 真实对象: 被代理的对象
+ 代理对象:
+ 代理模式: 代理对象代理真实对象, 达到增强真实对象功能的目的
* 实现方式
+ 静态代理: 定义一个类文件描述代理模式
+ 动态代理: 在内存中形成代理类
###Listener 监听器
* 概念:
+ 事件监听机制: 事件, 事件源, 监听器, 注册监听
###AJAX (Asynchronous JavaScript And XML)
* 概念:
1. 异步和同步:

2. 实现
+ 原生JavaScript实现
+ JQuery实现
```java
//使用$.ajax()发送异步请求
$.ajax({
url: "ajaxServlet"; //请求路径
type: "POST"; // 请求方式
data: {"username:jack", "age":23}, //请求参数
success: function(data) {
alert(date);
}, //响应成功后的回调函数
error: function() {
alert("出错啦...")
}, //如果请求响应出现错误, 会执行的回调函数
dataType: "text" //设置接收到的响应数据的格式
});
//使用$.get()发送异步请求 请求路径 请求参数 回调函数 响应结果的类型
$.get("ajaxServlet", {username:"tom"}, function(data) {
alert(date);
}, "text");
//使用$.post()发送异步请求
$.post("ajaxServlet", {username:"tom"}, function(data) {
alert(date);
}, "text");
``` | 9,660 | MIT |
# QUANTAXIS 的安装 WIN篇
<!-- TOC -->
- [QUANTAXIS 的安装 WIN篇](#quantaxis-的安装-win篇)
- [部署问题:](#部署问题)
- [下载PYTHON(可以跳过)](#下载python可以跳过)
- [安装(可以跳过)](#安装可以跳过)
- [下载git](#下载git)
- [使用git下载QUANTAXIS](#使用git下载quantaxis)
- [安装QUANTAXIS的依赖项](#安装quantaxis的依赖项)
- [下载安装数据库](#下载安装数据库)
- [安装QUANTAXIS的web插件](#安装quantaxis的web插件)
<!-- /TOC -->
## 部署问题:
- Windows/Linux(ubuntu) 已测试通过
- python3.6(开发环境) python2 回测框架不兼容(attention! 之后会逐步用更多高级语法) [*] 如果需要交易,请下载32位的python3.6
- nodejs 需要安装>7的版本,来支持es6语法
- mongodb是必须要装的
- 强烈推荐mongodb的可视化库 robomongo 百度即可下载
一个简易demo(需要先安装并启动mongodb,python版本需要大于3)
## 下载PYTHON(可以跳过)
QUANATXIS 支持的安装环境是python3以上 优先推荐3.6环境
在windows下,推荐使用ANACONDA集成环境来安装python[推荐Anaconda3-5.0.1-Windows-x86_64.exe]
(由于anaconda较大而官网的速度较慢,推荐去清华的anaconda镜像站下载)
[清华镜像ANACONDA链接](https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/)
## 安装(可以跳过)
在安装ANACONDA的过程中,注意勾选```add to path```选项,将python的执行路径加入系统路径中
在安装完成后,可以使用```python -V```来验证是否成功
```bash
λ python -V
Python 3.6.3 :: Anaconda, Inc.
```
## 下载git
QUANTAXIS的代码托管在github,你需要经常用过```git pull```来更新代码,所以请勿直接在网站上下载zip压缩包
[git 下载地址](http://rj.baidu.com/soft/detail/40642.html)
同样,在安装的时候 选择```add to path```
## 使用git下载QUANTAXIS
打开命令行(推荐使用powershell) 选择你想要的目录 下载quantaxis
```
WIN键+R 在运行中输入 powershell 回车
cd C:\
git clone https://github.com/yutiansut/quantaxis --depth 1
```
## 安装QUANTAXIS的依赖项
```
cd C:\quantaxis
python -m pip install -r requirements.txt -i https://pypi.doubanio.com/simple
python -m pip install git+https://github.com/yutiansut/tushare
python -m pip install -e . -i https://pypi.doubanio.com/simple
```
完成以后 在命令行输入 ```quantaxis```即可进入QUANTAXIS的cli界面
```
λ quantaxis
QUANTAXIS>> start QUANTAXIS
QUANTAXIS>> Selecting the Best Server IP of TDX
QUANTAXIS>> === The BEST SERVER ===
stock_ip 115.238.90.165 future_ip 61.152.107.141
QUANTAXIS>> Welcome to QUANTAXIS, the Version is remake-version
QUANTAXIS>
```
## 下载安装数据库
QUANTAXIS使用MONGODB数据库作为数据存储,需要下载数据库
下载地址
[下载地址 MongoDB 64位 3.4.7](https://www.mongodb.com/dr/fastdl.mongodb.org/win32/mongodb-win32-x86_64-2008plus-ssl-3.4.7-signed.msi)
安装以后,需要在本地新建一个文件夹作为数据存储的文件夹,示例中,我们建在D盘
```
# 打开Powershell(Win键+R 在运行中输入Powershell)
cd D:
md data
# 然后在data目录下 新建一个data目录用于存放mongo的数据,log目录用于存放log
cd data
md data
md log
# 到Mongo的程序文件夹下,使用命令
cd C:\Program Files\MongoDB\Server\3.4\bin
# 用mongod 命令安装
.\mongod.exe --dbpath D:\data\data --logpath D:\data\log\mongo.log --httpinterface --rest --serviceName 'MongoDB' --install
# 如果你下载了3.6版本以上的mongodb 则使用
.\mongod.exe --dbpath D:\data\data --logpath D:\data\log\mongo.log --serviceName 'MongoDB' --install
```
开启数据库服务
```
# 启动mongodb服务
net start MongoDB
```
## 安装QUANTAXIS的web插件
QUANTAXIS使用了nodejs写了web部分的插件,所以需要下载nodejs
nodejs下载地址 [](https://nodejs.org/zh-cn/download/current/)
注意: 需要下载的是nodejs8的版本,切勿下载9版本的nodejs
安装时也需要```add to path ```
安装完成后,在命令行输入```node -v```来查看是否安装成功
```
λ node -v
v8.9.3
```
```
npm install cnpm -g
cnpm install forever -g
cd C:\quantaxis\QUANTAXIS_WEBKIT\backend
cnpm install
cd C:\quantaxis\QUANTAXIS_WEBKIT\web
cnpm install
``` | 3,090 | MIT |
---
layout: post
title: 说说ThreadLocal
---
## 1.多方引用
- > ThreadLocal 无法解决共享对象的更新问题,ThreadLocal 对象建议使用 static 修饰。这个变量是针对一个线程内所有操作共享的,所以设置为静态变量,所有此类实例共享 此静态变量 ,也就是说在类第一次被使用时装载,只分配一块存储空间,所有此类的对象(只 要是这个线程内定义的)都可以操控这个变量。
- [ifive关于ThreadLocal内存泄漏的问题](http://ifeve.com/%E4%BD%BF%E7%94%A8threadlocal%E4%B8%8D%E5%BD%93%E5%8F%AF%E8%83%BD%E4%BC%9A%E5%AF%BC%E8%87%B4%E5%86%85%E5%AD%98%E6%B3%84%E9%9C%B2/)
## 2. 一些code
- 弱引用的使用
```java
/**
* The entries in this hash map extend WeakReference, using
* its main ref field as the key (which is always a
* ThreadLocal object). Note that null keys (i.e. entry.get()
* == null) mean that the key is no longer referenced, so the
* entry can be expunged from table. Such entries are referred to
* as "stale entries" in the code that follows.
*/
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
```
## 3. 其它
- InheritableThreadLocal:
* This class extends <tt>ThreadLocal</tt> to provide inheritance of value from parent thread to child thread
- netty中FastThreadLocal
* 用 **Object[] indexedVariables** 代替了原先Thread.ThreadLocalMap的hash table,并且没有了key 弱引用的设定。
* FastThreadLocal的index是一个static的AtomicInteger,是在new FastThreadLocal()中递增的。
* InternalThreadLocalMap ,在FastThreadLocalThread(extend Thread)这个fast线程中是一个成员变量 ;如果是Thread,就在ThreadLocal中放了InternalThreadLocalMap
* get()方法
```java
/**
* Returns the current value for the current thread
*/
@SuppressWarnings("unchecked")
public final V get() {
InternalThreadLocalMap threadLocalMap = InternalThreadLocalMap.get();
Object v = threadLocalMap.indexedVariable(index);
if (v != InternalThreadLocalMap.UNSET) {
return (V) v;
}
return initialize(threadLocalMap);
}
``` | 2,080 | MIT |
---
title: Docker入门
tags:
- Docker
---
> - 挂载到底是啥意思?Linux 下的挂载是什么意思?(“挂载到底何意”)
> - 就是把一个资源信息注册到文件系统中,然后访问文件系统就可以访问到资源
> - UFS是个啥?UNIX file system
> - **UFS**是UNIX文件系统的简称
> - 数据卷?
> 参考:https://yeasy.gitbooks.io/docker_practice/content/basic_concept/container.html
## 基本概念
Docker 包括三个基本概念
- 镜像 ( Image )
- 容器 ( Container )
- 仓库 ( Repository )
## Docker 镜像
Docker 镜像是一种特殊的文件系统,除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的一些配置参数(如匿名卷、环境变量、用户等)。镜像不包含任何动态数据,其内容在**构建之后也不会被改变**。
### 分层存储
镜像只是一个虚拟的概念,其实际体现是由一组文件系统组成,或者说,由多层文件系统联合组成。
镜像构建时,会一层层构建,前一层是后一层的基础。**每一层构建完就不会再发生改变**,后一层上的任何改变只发生在自己这一层。比如,删除前一层文件的操作,实际不是真的删除前一层的文件,而是仅在当前层标记为该文件已删除。在最终容器运行的时候,虽然不会看到这个文件,但是实际上该文件会一直跟随镜像。因此,在构建镜像的时候,需要额外小心,每一层尽量**只包含该层需要添加的东西**,任何额外的东西应该在该层构建结束前清理掉。
## Docker 容器
镜像(`Image`)和容器(`Container`)的关系,就像是面向对象程序设计中的 `类` 和 `实例` 一样,镜像是静态的定义,容器是镜像运行时的实体。容器可以被创建、启动、停止、删除、暂停等。
容器的实质是进程,但与直接在宿主执行的进程不同,容器进程运行于属于自己的独立的 [命名空间](https://en.wikipedia.org/wiki/Linux_namespaces)。因此容器可以拥有自己的 `root` 文件系统、自己的网络配置、自己的进程空间,甚至自己的用户 ID 空间。**容器内的进程**是运行在一个**隔离的环境**里,使用起来,就好像是在一个独立于宿主的系统下操作一样。这种特性使得**容器封装**的应用比直接在宿主运行**更加安全**。也因为这种隔离的特性,很多人初学 Docker 时常常会混淆容器和虚拟机。
前面讲过镜像使用的是**分层存储**,容器也是如此。每一个容器运行时,是以**镜像**为**基础层**,在其上创建一个**当前容器的存储层**,我们可以称**这个为容器运行时读写而准备的存储层**为 **容器存储层**。
容器存储层的生存周期和容器一样,容器消亡时,容器存储层也随之消亡。因此,任何保存于容器存储层的信息都会随**容器删除**而**丢失**。
按照 Docker 最佳实践的要求,容器**不应该**向其**存储层内写入任何数据**,容器存储层要保持无状态化。所有的文件写入操作,都应该使用 [数据卷(Volume)](https://yeasy.gitbooks.io/docker_practice/content/data_management/volume.html)、或者绑定宿主目录,在这些位置的读写会跳过容器存储层,直接对宿主(或网络存储)发生读写,其性能和稳定性更高。
数据卷的生存周期独立于容器,容器消亡,数据卷不会消亡。因此,使用数据卷后,容器删除或者重新运行之后,数据却不会丢失。
## Docker Registry
镜像构建完成后,可以很容易的在**当前宿主机上**运行,但是,如果需要在**其它服务器**上使用这个**镜像**,我们就需要一个集中的**存储、分发镜像**的服务,[Docker Registry](https://yeasy.gitbooks.io/docker_practice/content/repository/registry.html) 就是这样的服务。
一个 **Docker Registry** 中可以包含多个 **仓库**(`Repository`);每个仓库可以包含多个 **标签**(`Tag`);**每个标签**对应**一个镜像**。
通常,一个仓库会包含同一个软件不同版本的镜像,而标签就常用于对应该软件的各个版本。我们可以通过 `<仓库名>:<标签>` 的格式来指定具体是这个软件哪个版本的镜像。如果不给出标签,将以 `latest` 作为默认标签。
以 [Ubuntu 镜像](https://hub.docker.com/_/ubuntu) 为例,`ubuntu` 是仓库的名字,其内包含有不同的版本标签,如,`16.04`, `18.04`。我们可以通过 `ubuntu:16.04`,或者 `ubuntu:18.04` 来具体指定所需哪个版本的镜像。如果忽略了标签,比如 `ubuntu`,那将视为 `ubuntu:latest`。
仓库名经常以 *两段式路径* 形式出现,比如 `jwilder/nginx-proxy`,前者往往意味着 Docker Registry 多用户环境下的用户名,后者则往往是对应的软件名。但这并非绝对,取决于所使用的具体 Docker Registry 的软件或服务。
## Docker Registry 公开服务
Docker Registry 公开服务是**开放给用户使用**、允许用户管理镜像的 Registry 服务。一般这类公开服务允许用户免费上传、下载公开的镜像,并可能提供收费服务供用户管理私有镜像。
最常使用的 Registry 公开服务是官方的 [Docker Hub](https://hub.docker.com/),这也是默认的 Registry,并拥有大量的高质量的官方镜像。除此以外,还有 [CoreOS](https://coreos.com/) 的 [Quay.io](https://quay.io/repository/),CoreOS 相关的镜像存储在这里;Google 的 [Google Container Registry](https://cloud.google.com/container-registry/),[Kubernetes](https://kubernetes.io/) 的镜像使用的就是这个服务。
由于某些原因,在国内访问这些服务可能会比较慢。国内的一些云服务商提供了针对 Docker Hub 的镜像服务(`Registry Mirror`),这些镜像服务被称为**加速器**。常见的有 [阿里云加速器](https://cr.console.aliyun.com/#/accelerator)、[DaoCloud 加速器](https://www.daocloud.io/mirror#accelerator-doc) 等。使用加速器会直接从国内的地址下载 Docker Hub 的镜像,比直接从 Docker Hub 下载速度会提高很多。在 [安装 Docker](https://yeasy.gitbooks.io/docker_practice/content/install/mirror.html) 一节中有详细的配置方法。
国内也有一些云服务商提供类似于 Docker Hub 的公开服务。比如 [网易云镜像服务](https://c.163.com/hub#/m/library/)、[DaoCloud 镜像市场](https://hub.daocloud.io/)、[阿里云镜像库](https://cr.console.aliyun.com/) 等。
## 私有 Docker Registry
除了使用公开服务外,用户还可以在**本地搭建私有** Docker Registry。Docker 官方提供了 [Docker Registry](https://hub.docker.com/_/registry/) 镜像,可以直接使用做为私有 Registry 服务。在 [私有仓库](https://yeasy.gitbooks.io/docker_practice/content/repository/registry.html) 一节中,会有进一步的搭建私有 Registry 服务的讲解。
开源的 Docker Registry 镜像只提供了 [Docker Registry API](https://docs.docker.com/registry/spec/api/) 的服务端实现,足以支持 `docker` 命令,不影响使用。但不包含图形界面,以及镜像维护、用户管理、访问控制等高级功能。在官方的商业化版本 [Docker Trusted Registry](https://docs.docker.com/datacenter/dtr/2.0/) 中,提供了这些高级功能。
除了官方的 Docker Registry 外,还有第三方软件实现了 Docker Registry API,甚至提供了用户界面以及一些高级功能。比如,[Harbor](https://github.com/goharbor/harbor) 和 [Sonatype Nexus](https://yeasy.gitbooks.io/docker_practice/content/repository/nexus3_registry.html)。
# 使用 Docker 镜像
## 获取镜像
之前提到过,[Docker Hub](https://hub.docker.com/search?q=&type=image) 上有大量的高质量的镜像可以用,这里我们就说一下怎么获取这些镜像。
从 Docker 镜像仓库获取镜像的命令是 `docker pull`。其命令格式为:
```bash
docker pull [选项] [Docker Registry 地址[:端口号]/]仓库名[:标签]
```
具体的选项可以通过 `docker pull --help` 命令看到,这里我们说一下镜像名称的格式。
- Docker 镜像仓库地址:地址的格式一般是 `<域名/IP>[:端口号]`。默认地址是 Docker Hub。
- 仓库名:如之前所说,这里的仓库名是两段式名称,即 `<用户名>/<软件名>`。对于 Docker Hub,如果不给出用户名,则默认为 `library`,也就是官方镜像。
## 操作 Docker 容器
docker的命令:
- docker run xxx容器名 xxx容器下某个服务
- docker run -d 后台运行?不会打印到宿主机上。
- docker container ls 可以查看正在运行的容器信息。
- docker container logs命令可以获取容器的输出信息。
- 终止容器:docker container stop + 容器id或名字
### 进入容器
在使用 -d 参数时,容器启动后进入后台。
某些时刻需要进入容器进行操作,包括使用 `docker attach`命令或 `docker exec`命令。
#### attach 命令
```bash
docker attach id
```
如果从这个 stdin 中 exit,会导致容器的停止。
#### exec 命令
```bash
docker exec -it id bash
```
进入终端,如果在这个 stdin 中 exit, 不会导致容器的停止。
### 导出容器
如果要导出本地某个容器,可以使用 `docker export` 命令。
```bash
docker export ID > xxx.tar
```
这样将导出容器快照到本地文件。
### 导入容器快照
可以使用 `docker import `从容器快照文件中再导入为镜像,例如
```bash
$ cat ubuntu.tar | docker import - test/ubuntu:v1.0
$ docker image ls
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
test/ubuntu v1.0
```
此外,也可以通过指定 URL 或者某个目录来导入.
```bash
docker import http://example.com/exampleimage.tgz example/imagerepo
```
*注:用户既可以使用 `docker load` 来导入镜像存储文件到本地镜像库,也可以使用 `docker import` 来导入一个容器快照到本地镜像库。这两者的区别在于容器快照文件将丢弃所有的历史记录和元数据信息(即仅保存容器当时的快照状态),而镜像存储文件将保存完整记录,体积也要大。此外,从容器快照文件导入时可以重新指定标签等元数据信息。*
### 删除容器
`docker container rm`来删除一个处于终止状态的容器。Docker 会发送 `SIGKILL` 信号给容器。
### 清理所有处于终止状态的容器
用 `docker container ls -a` 命令可以查看所有已经创建的包括终止状态的容器,如果数量太多要一个个删除可能会很麻烦,用下面的命令可以清理掉所有处于终止状态的容器。
```bash
$ docker container prune
```
## 镜像构成
镜像是多层存储,每一次是在前一层的基础上修改;而容器同样也是多层存储,是以镜像为基础层,在其基础上加一层作为容器运行时的**存储层**。
`docker commit`命令可以将容器的存储层保存下来成为镜像。换句话说,就是在原有镜像的基础上,再叠加上容器的存储层,并构成新的镜像。以后,运行这个新镜像的时候,就会拥有原有容器最后的文件变化。
慎用 `docker commit`。这是一个黑箱操作,后人无法知道原作者对原镜像做了什么修改;如果使用 `docker commit` 制作镜像,以及后期修改的话,每一次修改都会让镜像更加臃肿一次,所删除的上一层的东西并不会丢失,会一直如影随形的跟着这个镜像,即使根本无法访问到。这会让镜像更加臃肿。
## 使用 Dockerfile 定制镜像
镜像的定制实际上就是定制每一层所添加的配置、文件。如果我们可以把每一层修改、安装、构建、操作的命令写入一个脚本,用这个脚本来构建、定制镜像,那么之前提及的无法重复的问题、镜像构建透明性的问题、体积的问题就都会解决。这个脚本就是 Dockerfile。
```
FROM scratch (基础镜像)
RUN shell格式/exec格式
```
RUN command,执行完后面一个命令后,就commit一次,就会构建一层镜像。
所以下面这种:
```
FROM debian:stretch
RUN apt-get update
RUN apt-get install -y gcc libc6-dev make wget
RUN wget -O redis.tar.gz "http://download.redis.io/releases/redis-5.0.3.tar.gz"
RUN mkdir -p /usr/src/redis
RUN tar -xzf redis.tar.gz -C /usr/src/redis --strip-components=1
RUN make -C /usr/src/redis
RUN make -C /usr/src/redis install
```
是不可取的,这样构建了 7 层镜像!应该替换成:
```
FROM debian:stretch
RUN buildDeps='gcc libc6-dev make wget' \
&& apt-get update \
&& apt-get install -y $buildDeps \
&& wget -O redis.tar.gz "http://download.redis.io/releases/redis-5.0.3.tar.gz" \
&& mkdir -p /usr/src/redis \
&& tar -xzf redis.tar.gz -C /usr/src/redis --strip-components=1 \
&& make -C /usr/src/redis \
&& make -C /usr/src/redis install \
&& rm -rf /var/lib/apt/lists/* \
&& rm redis.tar.gz \
&& rm -r /usr/src/redis \
&& apt-get purge -y --auto-remove $buildDeps
```
可以看到这一组命令的最后添加了清理工作的命令,删除了为了编译构建所需要的软件,清理了所有下载、展开的文件,并且还清理了 `apt` 缓存文件。这是很重要的一步,我们之前说过,**镜像是多层存储,每一层的东西并不会在下一层被删除,会一直跟随着镜像**。因此镜像构建时,一定要**确保每一层只添加真正需要添加的东西**,任何无关的东西都应该清理掉。
### 构建镜像
在 Dockerfile 目录下执行。
### 镜像构建上下文(Context)
docker 构建的时候,其实是在 docker 引擎即 docker 服务端完成的,通过一组 REST API ([Docker Remote API](https://docs.docker.com/develop/sdk/))实现,未来让服务端获得本地文件,引入了**上下文**的概念。构建的时候,需要指定构建镜像上下文的路径,docker build 命令就会把**该路径下的所有内容打包**,然后上传给 Docker 引擎。
Dockerfile 里面的路径需要使用相对路径!
一般来说,应该会将 `Dockerfile` 置于一个空目录下,或者项目根目录下。如果该目录下没有所需文件,那么应该把所需文件复制一份过来。如果目录下有些东西确实不希望构建时传给 Docker 引擎,那么可以用 `.gitignore` 一样的语法写一个 `.dockerignore`,该文件是用于剔除不需要作为上下文传递给 Docker 引擎的。
那么为什么会有人误以为 `.` 是指定 `Dockerfile` 所在目录呢?这是因为在默认情况下,如果不额外指定 `Dockerfile` 的话,会将上下文目录下的名为 `Dockerfile` 的文件作为 Dockerfile。
这只是默认行为,实际上 `Dockerfile` 的文件名并不要求必须为 `Dockerfile`,而且并不要求必须位于上下文目录中,比如可以用 `-f ../Dockerfile.php` 参数指定某个文件作为 `Dockerfile`。
当然,一般大家习惯性的会使用默认的文件名 `Dockerfile`,以及会将其置于镜像构建上下文目录中。
### CMD 的形式
### ENTRYPOINT 入口点
好好理解一下里面的一些例子:https://yeasy.gitbook.io/docker_practice/image/dockerfile/entrypoint。 大概是说运行docker像运行命令一样时,后面加一些参数可以传到docker内部某个命令里面去。
## 访问仓库
仓库 ( Repository ) 是集中存放镜像的地方。
一个容易混淆的概念是注册服务器(`Registry`)。实际上**注册服务器**是**管理仓库**的具体服务器,每个服务器上可以有多个仓库,而每个仓库下面有多个镜像。从这方面来说,仓库可以被认为是一个具体的项目或目录。例如对于仓库地址 `docker.io/ubuntu` 来说,`docker.io` 是注册服务器地址,`ubuntu` 是仓库名。
大部分时候,并不需要严格区分这两者的概念。
## 数据管理
### 数据卷
`数据卷`是一个可供一个或多个容器使用的特殊目录,它绕过了 UFS, 可以提供很多有用的特性:
- `数据卷` 可以在容器之间共享和重用
- 对 `数据卷` 的修改会立马生效
- 对 `数据卷` 的更新,不会影响镜像
- `数据卷` 默认会一直存在,即使容器被删除
### 创建一个数据卷
```bash
docker volume create my-vol
```
## 使用网络
### 新建网络
```bash
docker network create -d bridge my-net
```
-d 指定 Docker 网络类型,有 `bridge` `overlay`。其中 `overlay`网络类型用于 `Swarm mode`(涉及到分布式部署的概念)。
### 连接容器
运行一个容器,然后连接到新建的 `my-net`网络中。
多个容器互连使用 Docker Compose,这个是一个官方开源的项目。实现对 Docker 容器集群的快速编排。
### 配置 DNS
Docker 利用**虚拟文件**来挂载容器的3个相关配置文件。
## 内核命名空间
当用 `docker run` 启动一个容器时,在后台 Docker 为容器创建了一个独立的命名空间和控制组集合。
**命名空间**提供了最基础也是最直接的隔离,在容器中运行的进程不会被运行在主机上的进程和其它容器发现和作用。
每个容器都有自己**独有的网络栈**,意味着它们不能访问其他容器的 sockets 或接口。不过,如果主机系统上做了相应的设置,容器可以像跟主机交互一样的和其他容器交互。当指定公共端口或使用 links 来连接 2 个容器时,容器就可以相互通信了(可以根据配置来限制通信的策略)。
从网络架构的角度来看,所有的容器通过**本地主机的网桥接口**相互通信,就像物理机器通过物理交换机通信一样。
### 控制组
控制组是 Linux 容器机制的另外一个关键组件,负责实现资源的审计和限制。
确保各个容器可以公平地分享主机的内存、CPU、磁盘 IO 等资源;控制组确保了当容器内的资源使用产生压力时不会连累主机系统。 | 9,649 | MIT |
1. MainPage.xaml.cs プロジェクト ファイルを開き、次の using ステートメントを追加します。
using Windows.UI.Popups;
2. MainPage クラスに、次のコード スニペットを追加します。
private MobileServiceUser user;
private async System.Threading.Tasks.Task AuthenticateAsync()
{
while (user == null)
{
string message;
try
{
user = await App.MobileService
.LoginAsync(MobileServiceAuthenticationProvider.Facebook);
message =
string.Format("You are now logged in - {0}", user.UserId);
}
catch (InvalidOperationException)
{
message = "You must log in. Login Required";
}
var dialog = new MessageDialog(message);
dialog.Commands.Add(new UICommand("OK"));
await dialog.ShowAsync();
}
}
これにより、現在のユーザーを格納するためのメンバー変数と認証プロセスを処理するためのメソッドが作成されます。ユーザーは、Facebook ログインを使用して認証されます。Facebook 以外の ID プロバイダーを使用している場合は、上の **MobileServiceAuthenticationProvider** の値をプロバイダーに対応する値に変更してください。
3. 既存の **OnNavigatedTo** メソッド オーバーライドを、新しい **Authenticate** メソッドを呼び出す次のメソッドに置き換えます。
protected override async void OnNavigatedTo(NavigationEventArgs e)
{
await AuthenticateAsync();
RefreshTodoItems();
}
4. F5 キーを押してアプリケーションを実行し、選択した ID プロバイダーでアプリケーションにサインインします。
ログインに成功すると、アプリケーションはエラーなしで実行されます。また、モバイル サービスを照会してデータを更新できるようになります。
<!---HONumber=Oct15_HO3--> | 1,599 | CC-BY-3.0 |
date : 2016-12-19 17:50:20
title : 使用navicat 修改MySQL数据库的某个表后,无法再读取该表(MySQL-#1146-#1017)
categories : 2016-12
tags :
- Error
- MySQL
- Navicat
---
## 概述(abstract)
问题的产生原因是由于在Windows下使用Navicat客户端,操作位于CentOS上MySQL 5.6时,具体的执行一个重命名字段的操作时,Navicat停止了运行,然后将该Navicat强制的关闭后,再运行Navicat打开刚才重命名字段所在的表,再次卡死,反复操作几次,结果并没有改变.
## 解决1(figure it 1)
首先,去MySQL数据库所在的服务器,对MySQL服务进行重启
```
service mysqld restart
```
再去用Navicat操作MySQL ,报 ERROR 1146 table '' doesn't exist 的错误
## 解决2(figure it 2)
之后,通过查阅stackoverflow,可能是数据库文件权限的问题,然后照葫芦画瓢,使用下面的命令对其进行修改:
```
chown mysql:mysql /var/lib/mysql/ci/*
```
直接报,没有该文件
## 解决3(figure it 3)
需要通过下面的命令查询mysql data文件具体在什么位置
```
vim /etc/my.cnf
```
找到下面这行
```
datadir = /opt/mysql/db/data
```
再通过语句修改对应数据表所在数据库的权限,比如出现错误的表所在数据库的名字是'tmp_db'
```
chown mysql:mysql /opt/mysql/db/data/tmp_db/*
```
重新启动数据库
```
service mysqld restart
```
## 参考
[stackoverflow#1](http://stackoverflow.com/questions/6443428/cant-find-file-ci-users-frm-errno-13) | 965 | MIT |
---
title: Ex03 Connector
date: 2021-07-13 17:23:41
categories:
- Tomcat
tags:
- How Tomcat Works
---
> **Chapter3** presents a simplified version of Tomcat 4's default connector.
> The application built in this chapter serves as a learning tool to understand the connector discussed in Chapter4
PS: 这个 project 有点老了,其中用到的 Catalina 包比较老, 找了半天
```xml
<dependency>
<groupId>tomcat</groupId>
<artifactId>catalina</artifactId>
<version>4.0.4</version>
</dependency>
```
相比于 ex02 这章节实现的服务器多了如下功能
* connector parse request headers
* servlet can obtain headers, cookies parameter name/values, etc
* enhance response's getWriter
完成上述功能后,这个就是简化版的 Tomcat4 的 connector 了。Tomcat 的默认 connector 在 Tomcat4 时被 deprecated 了,不过还是有参考价值的。
## StringManager
开篇先介绍了一个用于做类似国际化的类 org.apache.catalina.util.StringManager. 原理很简单,就是这个类通过单例模式生成唯一对象,加载预先定义好的 properties,通过 getString 方法拿到对应语言的翻译。
StringManager 底层使用两个 Java 基础类做实现,一个是 ResourceBundle 另一个是 MessageFormat. ResourceBundle 可以通过 properties 加载多语言支持,MessageFormat 则用于格式化打印信息。
为了节省资源,StringManager 内部通过 Hashtable 存储多语言,并通过单例模式创建这个 field
```java
private static Hashtable managers = new Hashtable();
/**
* Get the StringManager for a particular package. If a manager for
* a package already exists, it will be reused, else a new
* StringManager will be created and returned.
*
* @param packageName
*/
public synchronized static StringManager getManager(String packageName) {
StringManager mgr = (StringManager)managers.get(packageName);
if (mgr == null) {
mgr = new StringManager(packageName);
managers.put(packageName, mgr);
}
return mgr;
}
```
PS: 它这里用的是饿汉式的声明,类加载的时候就创建了对象,调用 getManager() 的时候通过 synchronized 加锁保证线程安全。每一个 package 下的 LocalStrings 都会创建一个对象存储多语言信息。
## The Application
相比之前的 project,这章开始,代码开始分包
```txt
.
├── ServletProcessor.java
├── StaticResourceProcessor.java
├── connector
│ ├── RequestStream.java
│ ├── ResponseStream.java
│ ├── ResponseWriter.java
│ └── http
│ ├── Constants.java
│ ├── HttpConnector.java
│ ├── HttpHeader.java
│ ├── HttpProcessor.java
│ ├── HttpRequest.java
│ ├── HttpRequestFacade.java
│ ├── HttpRequestLine.java 拆出来一个单独的类代表 request 的第一行,包括请求类型,URI,协议等信息
│ ├── HttpResponse.java
│ ├── HttpResponseFacade.java
│ ├── LocalStrings.properties
│ ├── LocalStrings_es.properties
│ ├── LocalStrings_ja.properties
│ └── SocketInputStream.java
└── startup
└── Bootstrap.java 启动类,实例化 HttpConnector 并调用 start() 方法
```
Bootstrap.java 为启动类,内容很简单,就是 new 一个 connector, 然后执行 start 方法,让 connector 常驻。
connector 下的类可以分为五类
* connect 及该类的辅助类(HttpConnector + HttpProcessor)
* 代表 Http Request 的类(HttpRequest)及其辅助类
* 代表 Http Response 的类(HttpResponse)及其辅助类
* Facade 类(HttpRequestFacade + HttpResponseFacade)
* Constant 常量类
类关系图
{% plantuml %}
HttpConnector "1"-"1" HttpProcessor
HttpProcessor "uses".up.> StringManager
HttpProcessor "uses".up.> SocketInputStream
HttpProcessor "uses".up.> HttpHeader
HttpProcessor "uses".up.> HttpRequestLine
HttpProcessor "1"*.down."1" ServletProcessor
HttpProcessor "1"*.down."1" StaticResourceProcessor
ServletProcessor "uses".down.> HttpRequest
ServletProcessor "uses".down.> HttpResponse
StaticResourceProcessor "uses".down.> HttpRequest
StaticResourceProcessor "uses".down.> HttpResponse
{% endplantuml %}
和 ex02 比,这里将 HttpServer 拆成了 HttpConnector 和 HttpProcessor 两个类。HttpConnector 等待 request, HttpProcessor 负责 request/response 的生成和处理。
为了提高 connector 的效率,设计的时候将 request 中的 parse 的行为尽可能的延后了(比如有些 servlet 根本不需要 request 中的参数,这样 parse 就显得很多余,白白浪费了时间)。
### The Connector
HttpConnector 表示 connector 的实体类,他负责创建 server socket 并等待 Http request 的到来。HttpConnector 实现 runnable 接口,当 start() 被调用时,HttpConnector 被创建并运行。
connector 运行时会做如下几件事情
* 等待 HTTP requests
* 为每个 request 创建 HttpProcessor
* 调用 processor 的 process 方法
HttpProcessor 的 process 方法在拿到 socket 后,会做如下事情
* Create an HttpRequest/HttpResponse object
* Parse request first line and headers, populate to HttpRequest object
* Pass HttpRequest, HttpResponse to Processor(servlet process/static processor)
#### Create an HttpRequest Object
HttpRequest 的继承关系图如下
{% plantuml %}
skinparam linetype ortho
interface javax.servlet.http.HttpServletRequest
HttpRequestFacade .up.|> javax.servlet.http.HttpServletRequest
HttpRequest .up.|> javax.servlet.http.HttpServletRequest
interface javax.servlet.ServletInputStream
RequestStream .up.|> javax.servlet.ServletInputStream
RequestStream "1"-*"1" HttpRequest
{% endplantuml %}
本章的 HttpRequest 实现的很多方法都留空了,下一章会有具体实现。但是 header,cookies 等主要属性的提取已经实现了。由于 HttpRequst 的解析比较复杂,下面会分几个小节介绍
#### Reading the Socket's input Stream
SocketInputStream 的实现是直接从 Tomcat 4 的实现中 copy 过来的,他负责解析从 socket 中获取的 inputStream。
#### Parsing the Request Line
processor 中处理 socket 的过程如下
{% plantuml %}
(*) --> "init request, response"
--> "parse request line"
--> "parse headers"
if "uri contains '/servlet/'" then
--> [Yes] "init ServletProcessor"
--> "invoke process()"
else
--> [No] "init StaticProessor"
--> "invoke process()"
endif
--> (*)
{% endplantuml %}
request line 就是 inputStream 中的第一行内容,下面是示例
> GET /myApp/ModernServlet?userName=tarzan&password=pwd HTTP/1.1
各部分称谓如下
* GET - method
* /myApp/ModernServlet - URI
* userName=tarzan&password=pwd - query string
* parameters - userName/tarzan;password/pwd 成对出现
servlet/JSP 程序中通过 JsessionId 指代 session。 session 标识符通常通过 cookies 存储,如果客户端没有 enable cookie 还需要将它 append 到 URL 中
HttpProcessor 的 process 方法会将上面提到的对象从 inputStream 中提取出来并塞到对应的对象中
```java
private void parseRequest(SocketInputStream input, OutputStream output) throws IOException, ServletException {
// Parse the incoming request line
input.readRequestLine(requestLine);
String method = new String(requestLine.method, 0, requestLine.methodEnd);
String uri = null;
String protocol = new String(requestLine.protocol, 0,
requestLine.protocolEnd);
// Validate the incoming request line
if (method.length() < 1) {
throw new ServletException("Missing HTTP request method");
} else if (requestLine.uriEnd < 1) {
throw new ServletException("Missing HTTP request URI");
}
// Parse any query parameters out of the request URI
int question = requestLine.indexOf("?");
if (question >= 0) {
request.setQueryString(new String(requestLine.uri, question + 1,
requestLine.uriEnd - question - 1));
uri = new String(requestLine.uri, 0, question);
} else {
request.setQueryString(null);
uri = new String(requestLine.uri, 0, requestLine.uriEnd);
}
// Checking for an absolute URI (with the HTTP protocol)
if (!uri.startsWith("/")) {
int pos = uri.indexOf("://");
// Parsing out protocol and host name
if (pos != -1) {
pos = uri.indexOf('/', pos + 3);
if (pos == -1) {
uri = "";
} else {
uri = uri.substring(pos);
}
}
}
// Parse any requested session ID out of the request URI
String match = ";jsessionid=";
int semicolon = uri.indexOf(match);
if (semicolon >= 0) {
String rest = uri.substring(semicolon + match.length());
int semicolon2 = rest.indexOf(';');
if (semicolon2 >= 0) {
request.setRequestedSessionId(rest.substring(0, semicolon2));
rest = rest.substring(semicolon2);
} else {
request.setRequestedSessionId(rest);
rest = "";
}
request.setRequestedSessionURL(true);
uri = uri.substring(0, semicolon) + rest;
} else {
request.setRequestedSessionId(null);
request.setRequestedSessionURL(false);
}
// Normalize URI (using String operations at the moment)
String normalizedUri = normalize(uri);
// Set the corresponding request properties
((HttpRequest) request).setMethod(method);
request.setProtocol(protocol);
if (normalizedUri != null) {
((HttpRequest) request).setRequestURI(normalizedUri);
} else {
((HttpRequest) request).setRequestURI(uri);
}
if (normalizedUri == null) {
throw new ServletException("Invalid URI: " + uri + "'");
}
}
```
UML 图示如下
{% plantuml %}
(*) --> "populate to HttpRequestLine obj"
if "requestLine contains '?'" then
--> [true] "request.setQueryString() + init uri"
--> "absolute uri check"
else
--> "init uri"
endif
--> "absolute uri check"
if "uri contains jsession" then
--> [true] "parse + reqeust.setReqeustedSessionId() + set flag"
--> "normalize uri"
else
--> "set flag"
endif
--> "normalize uri"
--> (*)
{% endplantuml %}
Request line 的类实现为 HttpRequestLine, 它的实现比较有意思,它为这个类中的各个部分声明了一个存储的 char 数组,并标识了结束地址 `char[] method, int methodEnd`
{% plantuml %}
Class HttpRequestLine {
+char[] method;
+int methodEnd;
+char[] uri;
+int uriEnd;
+char[] protocol;
+int protocolEnd;
+HttpRequestLine();
+HttpRequestLine(method, methodEnd, uri, uriEnd, protocol, protocolEnd);
}
{% endplantuml %}
我们通过处理 SocketInputStream 可以得到 request line 的信息用以填充 HttpRequestLine,主要涉及的方法
* readRequestLine(HttpRequestLine) 填充 line 对象的方法入口
* fill() 使用 buffer 的方式读取输入流中的内容,这个过程中会初始化 pos 和 count 的值。pos 表示当前位置,count 表示流中内容长度
* read() 放回 pos 位置上的内容
SocketInputStream 的 read() 方法有一个很有意思的处理方式
```java
/**
* Read byte.
*/
public int read()
throws IOException {
if (pos >= count) {
fill();
if (pos >= count)
return -1;
}
return buf[pos++] & 0xff;
}
```
可以看到最后的处理方式是返回 `buf[n] & 0xff` 0xff 即 0000 0000 0000 1111 做与操作可以将前面的值置零
readRequestLine 中用了三个 while 循环通过判断空格和行结束符将首行的信息提取出来。很雷同的还有一个叫 readHeader() 的方法处理解析 request 中的 headers.
#### Parsing Headers
request 的 header 部分由 HttpHeader 这个类表示。将在第四章介绍具体实现,目前只需要了解一下几点
* 可以使用无参数构造器创建实例
* 通过调用 readHeader 方法 SocketInputStream 中的 header 部分解析并填充进指定的 HttpHeader 对象
* 通过 String name = new String(header.name, 0, header.nameEnd) 拿到 header 的 name, 同理获取 value
由于一个 request 中可能包含多个 header,所以通过 while 循环解析,解析完后通过 addHeader 塞入 request 中
```java
private void parseHeaders(SocketInputStream input) throws IOException, ServletException {
while (true) {
HttpHeader header = new HttpHeader();
;
// Read the next header
input.readHeader(header);
if (header.nameEnd == 0) {
if (header.valueEnd == 0) {
return;
} else {
throw new ServletException(
sm.getString("httpProcessor.parseHeaders.colon"));
}
}
String name = new String(header.name, 0, header.nameEnd);
String value = new String(header.value, 0, header.valueEnd);
request.addHeader(name, value);
// do something for some headers, ignore others.
if (name.equals("cookie")) {
Cookie cookies[] = RequestUtil.parseCookieHeader(value);
for (int i = 0; i < cookies.length; i++) {
if (cookies[i].getName().equals("jsessionid")) {
// Override anything requested in the URL
if (!request.isRequestedSessionIdFromCookie()) {
// Accept only the first session id cookie
request.setRequestedSessionId(cookies[i].getValue());
request.setRequestedSessionCookie(true);
request.setRequestedSessionURL(false);
}
}
request.addCookie(cookies[i]);
}
} else if (name.equals("content-length")) {
int n = -1;
try {
n = Integer.parseInt(value);
} catch (Exception e) {
throw new ServletException(
sm.getString("httpProcessor.parseHeaders.contentLength"));
}
request.setContentLength(n);
} else if (name.equals("content-type")) {
request.setContentType(value);
}
} // end while
}
```
#### Parsing Cookies
随便访问了一下网页,下面是一个 cookie 的例子
```
txtcookie: fontstyle=null; loginMethodCookieKey=PWD; bizxThemeId=lightGrayPlacematBlueAccentNoTexture; route=133abdfd8b5240fdc3330810e535ae4c79433a08; zsessionid=45641c6c-9dff-4d67-8893-b0764636ee1f; JSESSIONID=D8477F13FD4A9257B98731F666694D91.mo-bce0c171c
```
在前面的 parseHeaders 方法中,处理 cookie 的部分,通过 RequestUtil.parseCookieHeader(value) 解析 cookie
```java
/**
* Parse a cookie header into an array of cookies according to RFC 2109.
*
* @param header Value of an HTTP "Cookie" header
*/
public static Cookie[] parseCookieHeader(String header) {
if ((header == null) || (header.length() < 1))
return (new Cookie[0]);
ArrayList cookies = new ArrayList();
while (header.length() > 0) {
int semicolon = header.indexOf(';');
if (semicolon < 0)
semicolon = header.length();
if (semicolon == 0)
break;
String token = header.substring(0, semicolon);
if (semicolon < header.length())
header = header.substring(semicolon + 1);
else
header = "";
try {
int equals = token.indexOf('=');
if (equals > 0) {
String name = token.substring(0, equals).trim();
String value = token.substring(equals+1).trim();
cookies.add(new Cookie(name, value));
}
} catch (Throwable e) {
;
}
}
return ((Cookie[]) cookies.toArray(new Cookie[cookies.size()]));
}
```
#### Obtaining Parameters
解析 parameter 的动作放在 HttpRequest 的 parseParameters 方法中。在调用 parameter 相关的方法,比如 getParameterMap, getParameterNames 等时,会先调用 parseParameters 方法解析他,而且只需要解析一次即可,再次调用时,使用之前解析的结果。
```java
/**
* Parse the parameters of this request, if it has not already occurred.
* If parameters are present in both the query string and the request
* content, they are merged.
*/
protected void parseParameters() {
if (parsed)
return;
ParameterMap results = parameters;
if (results == null)
results = new ParameterMap();
results.setLocked(false);
String encoding = getCharacterEncoding();
if (encoding == null)
encoding = "ISO-8859-1";
// Parse any parameters specified in the query string
String queryString = getQueryString();
try {
RequestUtil.parseParameters(results, queryString, encoding);
}
catch (UnsupportedEncodingException e) {
;
}
// Parse any parameters specified in the input stream
String contentType = getContentType();
if (contentType == null)
contentType = "";
int semicolon = contentType.indexOf(';');
if (semicolon >= 0) {
contentType = contentType.substring(0, semicolon).trim();
}
else {
contentType = contentType.trim();
}
if ("POST".equals(getMethod()) && (getContentLength() > 0)
&& "application/x-www-form-urlencoded".equals(contentType)) {
try {
int max = getContentLength();
int len = 0;
byte buf[] = new byte[getContentLength()];
ServletInputStream is = getInputStream();
while (len < max) {
int next = is.read(buf, len, max - len);
if (next < 0 ) {
break;
}
len += next;
}
is.close();
if (len < max) {
throw new RuntimeException("Content length mismatch");
}
RequestUtil.parseParameters(results, buf, encoding);
}
catch (UnsupportedEncodingException ue) {
;
}
catch (IOException e) {
throw new RuntimeException("Content read fail");
}
}
// Store the final results
results.setLocked(true);
parsed = true;
parameters = results;
}
```
在 GET 类型的 request 中,所有的 parameter 都是存在 URL 中的,在POST 类型的 request,parameter 是存在 body 中的。解析的 parameter 会存在特殊的 Map 中,这个 map 不允许改变存放的 parameter 的值。对应的实现是 org.apache.catalina.util.ParameterMap. 看了一下具体的实现类代码,其实就是一个 HashMap, 最大的特点是他新加了一个 locked 的 boolean 属性,在增删改的时候都会先检查一下这个 flag 如果此时 flag 为 false 则抛异常。
```java
public final class ParameterMap extends HashMap {
// ...
private boolean locked = false;
// ...
public void clear() {
if (locked)
throw new IllegalStateException(sm.getString("parameterMap.locked"));
super.clear();
}
// ...
}
```
### Creating a HttpResponse Object
HttpReponse 类图
{% plantuml %}
skinparam linetype ortho
Interface javax.servlet.http.HttpServletResponse
Interface javax.servlet.ServletOutputStream
Interface java.io.PrintWriter
javax.servlet.http.HttpServletResponse <|.. HttpResponseFacade
javax.servlet.http.HttpServletResponse <|.. HttpResponse
javax.servlet.ServletOutputStream <|.. ResponseStream
java.io.PrintWriter <|.. ResponseWriter
HttpResponse "1"*-l->"1" ResponseStream
HttpResponse "uses"-r-> ResponseWriter
{% endplantuml %}
通过设置 PrintWriter 的 auto flush 功能,之前打印的 behavior 才修复了,不然只会打印第一句话。为了了解这里说的东西,你需要查一下 Writer 相关的知识点。
## 问题
> server 启动后访问 URL 抛异常 `Exception in thread "Thread-0" java.util.MissingResourceException: Can't find bundle for base name com.jzheng.connector.http.LocalStrings, locale en_US`
查看了一下编译后的 target 文件加,其中咩有 properties 文件,怀疑是一些类型的文件编译时没有同步过去,试着在 pom 中添加以前项目中用过的 build 代码,问题解决
```xml
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
<!-- 在 build 的时候将工程中的配置文件也一并 copy 到编译文件中,即 target 文件夹下 -->
<resources>
<resource>
<directory>src/main/resources</directory>
<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
</resource>
<resource>
<directory>src/main/java</directory>
<includes>
<include>**/*.properties</include>
<include>**/*.xml</include>
</includes>
<filtering>true</filtering>
</resource>
</resources>
</build>
``` | 18,332 | MIT |
---
title: "iOS Block 相关梳理"
date: 2020-12-15 22:11:36 +0530
author: taoye
categories: [iOS, 2020年复现总结]
tags: [iOS, block]
---
### 预览图

### block 有哪几种类型
共5种,,iOS上基本只有3种
* _NSConcreteGlobalBlock 数据区, 全局定义的block,比如typedef void(^block)(int a);、新创建的block内部没有引用外部变量的在全局区
* _NSConcreteStackBlock 栈区, 初始化的block、 rac下 被赋值后,都会变成malloc
* _NSConcreteMallocBlock 堆区, 属性、copy过的,block有引用外部变量的 都是
### block 的结构 (Clang后的对应)
```
// Values for Block_layout->flags to describe block objects
enum {
BLOCK_DEALLOCATING = (0x0001), // runtime
BLOCK_REFCOUNT_MASK = (0xfffe), // runtime
BLOCK_NEEDS_FREE = (1 << 24), // runtime
BLOCK_HAS_COPY_DISPOSE = (1 << 25), // compiler
BLOCK_HAS_CTOR = (1 << 26), // compiler: helpers have C++ code
BLOCK_IS_GC = (1 << 27), // runtime
BLOCK_IS_GLOBAL = (1 << 28), // compiler
BLOCK_USE_STRET = (1 << 29), // compiler: undefined if !BLOCK_HAS_SIGNATURE
BLOCK_HAS_SIGNATURE = (1 << 30), // compiler
BLOCK_HAS_EXTENDED_LAYOUT=(1 << 31) // compiler
};
#define BLOCK_DESCRIPTOR_1 1
struct Block_descriptor_1 {
uintptr_t reserved;
uintptr_t size;
};
#define BLOCK_DESCRIPTOR_2 1
struct Block_descriptor_2 {
// requires BLOCK_HAS_COPY_DISPOSE
void (*copy)(void *dst, const void *src);
void (*dispose)(const void *);
};
#define BLOCK_DESCRIPTOR_3 1
struct Block_descriptor_3 {
// requires BLOCK_HAS_SIGNATURE
const char *signature;
const char *layout; // contents depend on BLOCK_HAS_EXTENDED_LAYOUT
};
struct Block_layout {
void *isa;
volatile int32_t flags; // contains ref count
int32_t reserved;
void (*invoke)(void *, ...);
struct Block_descriptor_1 *descriptor;
// imported variables
};
```
1. block也有isa指针
2. block也有引用计数
3. block的invoke是C语言的匿名函数,也可以理解为函 数指针,指向block的实际执行体
4. Block_descriptor有三个,分别包含了不同的信息
5. block的flags里边会存储block的信息,包含引用计数、是否有签名BLOCK_HAS_SIGNATURE等。
6. block的签名很关键,没有签名则无法使用NSInvocation来执行。
将block的descriptor合并后,转换以后的结构如下,比如Aspects里,对block进行invoke调用(hook)
```
// Block internals.
typedef NS_OPTIONS(int, AspectBlockFlags) {
AspectBlockFlagsHasCopyDisposeHelpers = (1 << 25),
AspectBlockFlagsHasSignature = (1 << 30)
};
typedef struct _AspectBlock {
__unused Class isa;
AspectBlockFlags flags;
__unused int reserved;
void (__unused *invoke)(struct _AspectBlock *block, ...);
struct {
unsigned long int reserved;
unsigned long int size;
// requires AspectBlockFlagsHasCopyDisposeHelpers
void (*copy)(void *dst, const void *src);
void (*dispose)(const void *);
// requires AspectBlockFlagsHasSignature
const char *signature;
const char *layout;
} *descriptor;
// imported variables
} *AspectBlockRef;
- (void)testBlock {
void(^block1)(void) = ^{
NSLog(@"block1");
};
block1();
/// block的源码结构:
struct _AspectBlock *myBlock = (__bridge struct _AspectBlock *)block1;
myBlock->invoke(myBlock); // 输出block1
}
```
### 获取block的签名
获取到block的底层结构,根据flags 做&操作,然后再进行内存偏移。
代码如下:
```
static struct Block_descriptor_3 * _Block_descriptor_3(struct Block_layout *aBlock)
{
if (! (aBlock->flags & BLOCK_HAS_SIGNATURE)) return NULL;
uint8_t *desc = (uint8_t *)aBlock->descriptor;
desc += sizeof(struct Block_descriptor_1);
if (aBlock->flags & BLOCK_HAS_COPY_DISPOSE) {
desc += sizeof(struct Block_descriptor_2);
}
return (struct Block_descriptor_3 *)desc;
}
// Checks for a valid signature, not merely the BLOCK_HAS_SIGNATURE bit.
BLOCK_EXPORT
bool _Block_has_signature(void *aBlock) {
return _Block_signature(aBlock) ? true : false;
}
BLOCK_EXPORT
const char * _Block_signature(void *aBlock)
{
struct Block_descriptor_3 *desc3 = _Block_descriptor_3(aBlock);
if (!desc3) return NULL;
return desc3->signature;
}
/// 测试
- (void)testBlock {
void(^block1)(void) = ^{
NSLog(@"block1");
};
/// 如何通过NSInvocation来执行一个block,关键就在于获取block的方法签名
NSMethodSignature *sign = [self blockSignature:block1];
NSInvocation *invocation = [NSInvocation invocationWithMethodSignature:sign];
invocation.target = block1;
[invocation invoke]; // 输出block1
}
- (NSMethodSignature *)blockSignature:(id)block {
const char *sign = _Block_signature((__bridge void *)block);
return [NSMethodSignature signatureWithObjCTypes:sign];
}
```
#### block捕获(多次嵌套情况)
1. static 全局变量 存在 __DATA下,存在全局存储区,该地址在程序运行过程中一直不会改变,所以能访问最新值
2. const 存在__Text下
3.
2. 局部变量 auto变量(普通变量) - 值传递。 被static修饰后,指针传递,
3. 全局变量 - 直接访问

#### block copy 引用外部对象时的过程
如果是对象类型,则转成block后desc对象里会多两个函数指针(即desc2),copy、dispose两个函数指针,时机如下图

MRC下 栈block 不会对持有对象的对象进行copy

#### block copy到堆或释放的过程
Block_copy
```
void *_Block_copy(const void *arg) {
//1、
struct Block_layout *aBlock;
if (!arg) return NULL;
//2、
// The following would be better done as a switch statement
aBlock = (struct Block_layout *)arg;
//3、
if (aBlock->flags & BLOCK_NEEDS_FREE) {
// latches on high
latching_incr_int(&aBlock->flags);
return aBlock;
}
//4、
else if (aBlock->flags & BLOCK_IS_GLOBAL) {
return aBlock;
}
else {
//5、
// Its a stack block. Make a copy.
struct Block_layout *result = malloc(aBlock->descriptor->size);
if (!result) return NULL;
//6、
memmove(result, aBlock, aBlock->descriptor->size); // bitcopy first
// reset refcount
//7、
result->flags &= ~(BLOCK_REFCOUNT_MASK|BLOCK_DEALLOCATING); // XXX not needed
result->flags |= BLOCK_NEEDS_FREE | 2; // logical refcount 1
//8、
_Block_call_copy_helper(result, aBlock);
// Set isa last so memory analysis tools see a fully-initialized object.
//9、
result->isa = _NSConcreteMallocBlock;
return result;
}
}
static int32_t latching_incr_int(volatile int32_t *where) {
while (1) {
int32_t old_value = *where;
if ((old_value & BLOCK_REFCOUNT_MASK) == BLOCK_REFCOUNT_MASK) {
return BLOCK_REFCOUNT_MASK;
}
if (OSAtomicCompareAndSwapInt(old_value, old_value+2, where)) {
return old_value+2;
}
}
}
static void _Block_call_copy_helper(void *result, struct Block_layout *aBlock)
{
struct Block_descriptor_2 *desc = _Block_descriptor_2(aBlock);
if (!desc) return;
(*desc->copy)(result, aBlock); // do fixup
}
static struct Block_descriptor_2 * _Block_descriptor_2(struct Block_layout *aBlock)
{
if (! (aBlock->flags & BLOCK_HAS_COPY_DISPOSE)) return NULL;
uint8_t *desc = (uint8_t *)aBlock->descriptor;
desc += sizeof(struct Block_descriptor_1);
return (struct Block_descriptor_2 *)desc;
}
/*
1、先声明一个Block_layout结构体类型的指针,如果传入的Block为NULL就直接返回。
2、如果Block有值就强转成Block_layout的指针类型。
3、如果Block的flags表明该Block为堆Block时,就对其引用计数递增,然后返回原Block。latching_incr_int这个函数进行了一次死循环,如果flags含有BLOCK_REFCOUNT_MASK证明其引用计数达到最大,直接返回,需要三万多个指针指向,正常情况下不会出现。随后做一次原子性判断其值当前是否被其他线程改动,如果被改动就进入下一次循环直到改动结束后赋值。OSAtomicCompareAndSwapInt的作用就是在where取值与old_value相同时,将old_value+2赋给where。 注:Block的引用计数以flags的后16位代表,以 2为单位,每次递增2,1被BLOCK_DEALLOCATING正在释放占用。
4、如果Block为全局Block就不做其他处理直接返回。
5、该else中就是栈Block了,按原Block的内存大小分配一块相同大小的内存,如果失败就返回NULL。
6、memmove()用于复制位元,将aBlock的所有信息copy到result的位置上。
7、将新Block的引用计数置零。BLOCK_REFCOUNT_MASK|BLOCK_DEALLOCATING就是0xffff,~(0xffff)就是0x0000,result->flags与0x0000与等就将result->flags的后16位置零。然后将新Block标识为堆Block并将其引用计数置为2。
8、如果有copy_dispose助手,就执行Block的保存的copy函数,就是上面的__main_block_copy_0。在_Block_descriptor_2函数中,用BLOCK_HAS_COPY_DISPOSE来判断是否有Block_descriptor_2,且取Block的Block_descriptor_2时,因为有无是编译器确定的,在Block结构体中并无保留,所以需要使用指针相加的方式来确定其指针位置。有就执行,没有就return掉。
9、将堆Block的isa指针置为_NSConcreteMallocBlock,返回新Block,end。
*/
```
release
Block_release 调用 _Block_release
```
void _Block_release(const void *arg) {
//1、
struct Block_layout *aBlock = (struct Block_layout *)arg;
if (!aBlock) return;
//2、
if (aBlock->flags & BLOCK_IS_GLOBAL) return;
//3、
if (! (aBlock->flags & BLOCK_NEEDS_FREE)) return;
//4、
if (latching_decr_int_should_deallocate(&aBlock->flags)) {
//5、
_Block_call_dispose_helper(aBlock);
//6、
_Block_destructInstance(aBlock);
//7、
free(aBlock);
}
}
static bool latching_decr_int_should_deallocate(volatile int32_t *where) {
while (1) {
int32_t old_value = *where;
if ((old_value & BLOCK_REFCOUNT_MASK) == BLOCK_REFCOUNT_MASK) {
return false; // latched high
}
if ((old_value & BLOCK_REFCOUNT_MASK) == 0) {
return false; // underflow, latch low
}
int32_t new_value = old_value - 2;
bool result = false;
if ((old_value & (BLOCK_REFCOUNT_MASK|BLOCK_DEALLOCATING)) == 2) {
new_value = old_value - 1;
result = true;
}
if (OSAtomicCompareAndSwapInt(old_value, new_value, where)) {
return result;
}
}
}
static void _Block_call_dispose_helper(struct Block_layout *aBlock)
{
struct Block_descriptor_2 *desc = _Block_descriptor_2(aBlock);
if (!desc) return;
(*desc->dispose)(aBlock);
}
static void _Block_destructInstance_default(const void *aBlock __unused) {}
static void (*_Block_destructInstance) (const void *aBlock) = _Block_destructInstance_default;
/*
1、将入参arg强转成(struct Block_layout *)类型,如果入参为NULL则直接返回。
2、如果入参为全局Block则返回不做处理。
3、如果入参不为堆Block则返回不做处理。
4、判断aBlock的引用计数是否需要释放内存。与copy同样的,latching_decr_int_should_deallocate也做了一次循环和原子性判断保证原子性。如果该block的引用计数过高(0xfffe)或者过低(0)返回false不做处理。如果其引用计数为2,则将其引用计数-1即BLOCK_DEALLOCATING标明正在释放,返回true,如果大于2则将其引用计数-2并返回false。
5、如果步骤4标明了该block需要被释放,就进入步骤5。如果aBlock含有copy_dispose助手就执行aBlock中的dispose函数,与copy中的对应不再多做解释。
6、_Block_destructInstance默认没做其他操作,可见源码。
7、最后一步释放掉aBlock,end。
*/
```
```
捕获外部变量对象时候执行的方法。真正retain还是用的arc
_Block_object_assign
_Block_object_dispose
_Block_byref_release(__Block引用生成的block)
如果是嵌套block
_Block_release(object)
普通捕获对象,交给arc
```
#### __block的作用和结构
* 在block内访问外部变量都是复制进去的,即:写操作不对原变量生效
使用__block标记的变量,会在block内部生成一个结构体,该结构体内创建一个一样的对象,然后进行值传递或指针传递, 这个结构体如下
block内部修改的值,其实就是修改的这个结构体里面的, (里面的和外面被__Block表示的是同一个)

如果引用是对象类型, 结构体里会多上两个函数指针, copy和dispose, 如下:
```
struct __Block_byref_array_1 {
void *__isa;
__Block_byref_array_1 *__forwarding;
int __flags;
int __size;
void (*__Block_byref_id_object_copy)(void*, void*);
void (*__Block_byref_id_object_dispose)(void*);
NSMutableArray *array;
};
```
#### __forwarding指针的作用
结构体中有一个__forwarding指针,初始化时此指针指向转换后变量本身
此后代码中涉及到原变量的地方,都会转换成新变量->__forwarding->原变量同类型变量
1. 在使用__block变量时经转换后,其实都是通过其__forwarding来访问的
2. block中修改了__block变量,block外修改亦有效,其实这也是__forwarding的功效
#### block怎么持有对象
FBRetainCycleDetector源码
```
- (NSSet *)allRetainedObjects {
NSMutableArray *results = [[[super allRetainedObjects] allObjects] mutableCopy];
__attribute__((objc_precise_lifetime)) id anObject = self.object;
void *blockObjectReference = (__bridge void *)anObject;
NSArray *allRetainedReferences = FBGetBlockStrongReferences(blockObjectReference);
for (id object in allRetainedReferences) {
FBObjectiveCGraphElement *element = FBWrapObjectGraphElement(self, object, self.configuration);
if (element) {
[results addObject:element];
}
}
return [NSSet setWithArray:results];
}
NSArray *FBGetBlockStrongReferences(void *block) {
if (!FBObjectIsBlock(block)) {
return nil;
}
NSMutableArray *results = [NSMutableArray new];
void **blockReference = block;
NSIndexSet *strongLayout = _GetBlockStrongLayout(block);
[strongLayout enumerateIndexesUsingBlock:^(NSUInteger idx, BOOL *stop) {
void **reference = &blockReference[idx];
if (reference && (*reference)) {
id object = (id)(*reference);
if (object) {
[results addObject:object];
}
}
}];
return [results autorelease];
}
FBGetBlockStrongReferences 是对另一个私有函数 _GetBlockStrongLayout 的封装,也是实现最有意思的部分。
static NSIndexSet *_GetBlockStrongLayout(void *block) {
struct BlockLiteral *blockLiteral = block;
// 如果 block 有 Cpp 的构造器/析构器,说明它持有的对象很有可能没有按照指针大小对齐,我们很难检测到所有的对象
// 如果 block 没有 dispose 函数,说明它无法 retain 对象,也就是说我们也没有办法测试其强引用了哪些对象
if ((blockLiteral->flags & BLOCK_HAS_CTOR)
|| !(blockLiteral->flags & BLOCK_HAS_COPY_DISPOSE)) {
return nil;
}
...
/*
1. 从 BlockDescriptor 取出 dispose_helper 以及 size(block 持有的所有对象的大小)
2. 通过 (blockLiteral->descriptor->size + ptrSize - 1) / ptrSize 向上取整,获取 block 持有的指针的数量
3. 初始化两个包含 elements 个 FBBlockStrongRelationDetector 实例的数组,其中第一个数组用于传入 dispose_helper,第二个数组用于检测 _strong 是否被标记为 YES
4. 在自动释放池中执行 dispose_helper(obj),释放 block 持有的对象
/*
void (*dispose_helper)(void *src) = blockLiteral->descriptor->dispose_helper;
const size_t ptrSize = sizeof(void *);
const size_t elements = (blockLiteral->descriptor->size + ptrSize - 1) / ptrSize;
void *obj[elements];
void *detectors[elements];
for (size_t i = 0; i < elements; ++i) {
FBBlockStrongRelationDetector *detector = [FBBlockStrongRelationDetector new];
obj[i] = detectors[i] = detector;
}
@autoreleasepool {
dispose_helper(obj);
}
...
// 因为 dispose_helper 只会调用 release 方法,但是这并不会导致我们的 FBBlockStrongRelationDetector 实例被释放掉,反而会标记 _strong 属性,在这里我们只需要判断这个属性的真假,将对应索引加入数组,最后再调用 trueRelease 真正的释放对象。
NSMutableIndexSet *layout = [NSMutableIndexSet indexSet];
for (size_t i = 0; i < elements; ++i) {
FBBlockStrongRelationDetector *detector = (FBBlockStrongRelationDetector *)(detectors[i]);
if (detector.isStrong) {
[layout addIndex:i];
}
[detector trueRelease];
}
return layout;
}
```
实验代码如下
```
NSObject *firstObject = [NSObject new];
__attribute__((objc_precise_lifetime)) NSObject *object = [NSObject new];
__weak NSObject *secondObject = object;
NSObject *thirdObject = [NSObject new];
__unused void (^block)() = ^{
__unused NSObject *first = firstObject;
__unused NSObject *second = secondObject;
__unused NSObject *third = thirdObject;
};
```

首先打印 block 变量的大小,因为 block 变量其实只是一个指向结构体的指针,所以大小为 8,而结构体的大小为 32;
以 block 的地址为基址,偏移 32,得到一个指针
使用 $3[0] $3[1] $3[2] 依次打印地址为 0x1001023b0 0x1001023b8 0x1001023c0 的内容,可以发现它们就是 block 捕获的全部引用,前两个是强引用,最后的是弱引用
这可以得出一个结论:block 将其捕获的引用存放在结构体的下面
block 对持有的对象的布局的顺序依然是强引用在前、弱引用在后,我们不妨做一个假设:block 会将强引用的对象排放在弱引用对象的前面
第二个需要介绍的是 dispose_helper,这是 BlockDescriptor 结构体中的一个指针:
```
struct BlockDescriptor {
unsigned long int reserved; // NULL
unsigned long int size;
// optional helper functions
void (*copy_helper)(void *dst, void *src); // IFF (1<<25)
void (*dispose_helper)(void *src); // IFF (1<<25)
const char *signature; // IFF (1<<30)
};
```
上面的结构体中有两个函数指针,copy_helper 用于 block 的拷贝,dispose_helper 用于 block 的 dispose 也就是 block 在析构的时候会调用这个函数指针,销毁自己持有的对象,而这个原理也是区别强弱引用的关键,因为在 dispose_helper 会对强引用发送 release 消息,对弱引用不会做任何的处理。
私有方法 _GetBlockStrongLayout 进行分析 ,见上面代码
如果 block 有 Cpp 的构造器/析构器,说明它持有的对象很有可能没有按照指针大小对齐,我们很难检测到所有的对象
如果 block 没有 dispose 函数,说明它无法 retain 对象,也就是说我们也没有办法测试其强引用了哪些对象
然后看上述代码_GetBlockStrongLayout的备注
> 参考文档:https://github.com/draveness/analyze/blob/master/contents/FBRetainCycleDetector/iOS%20%E4%B8%AD%E7%9A%84%20block%20%E6%98%AF%E5%A6%82%E4%BD%95%E6%8C%81%E6%9C%89%E5%AF%B9%E8%B1%A1%E7%9A%84.md
#### block hook的实现
见上述的获取签名
#### 如何获取block参数的个数和类型 | 15,801 | MIT |
---
title: 配置令牌 - Azure Active Directory B2C | Microsoft Docs
description: 了解如何在 Azure Active Directory B2C 中配置令牌生存期和兼容性设置。
services: active-directory-b2c
author: mmacy
manager: celestedg
ms.service: active-directory
ms.workload: identity
ms.topic: conceptual
origin.date: 04/16/2019
ms.date: 10/24/2019
ms.author: v-junlch
ms.subservice: B2C
ms.openlocfilehash: 5fe5567a7f2ca8840700c9fdd2849379a5b2cbba
ms.sourcegitcommit: 817faf4e8d15ca212a2f802593d92c4952516ef4
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 10/24/2019
ms.locfileid: "72847117"
---
# <a name="configure-tokens-in-azure-active-directory-b2c"></a>在 Azure Active Directory B2C 中配置令牌
本文介绍如何在 Azure Active Directory B2C (Azure AD B2C) 中配置[令牌的生存期和兼容性](active-directory-b2c-reference-tokens.md)。
## <a name="prerequisites"></a>先决条件
[创建用户流](tutorial-create-user-flows.md),以便用户能够注册并登录应用程序。
## <a name="configure-token-lifetime"></a>配置令牌生存期
可以在任何用户流上配置令牌生存期。
1. 登录到 [Azure 门户](https://portal.azure.cn)。
2. 请确保使用的是包含 Azure AD B2C 租户的目录。 选择顶部菜单中的“目录 + 订阅”筛选器,然后选择包含 Azure AD B2C 租户的目录 。
3. 选择 Azure 门户左上角的“所有服务”,然后搜索并选择“Azure AD B2C” 。
4. 选择“用户流(策略)” 。
5. 打开之前创建的用户流。
6. 选择“属性” 。
7. 在“令牌生存期” 下,调整以下属性以满足应用程序的需要:

8. 单击“保存” 。
## <a name="configure-token-compatibility"></a>配置令牌兼容性
1. 选择“用户流(策略)” 。
2. 打开之前创建的用户流。
3. 选择“属性” 。
4. 在“令牌兼容性设置” 下,调整以下属性以满足应用程序的需要:

5. 单击“保存” 。
## <a name="next-steps"></a>后续步骤
详细了解如何[使用访问令牌](active-directory-b2c-access-tokens.md)。
<!-- Update_Description: wording update --> | 1,652 | CC-BY-4.0 |
---
title: 托管磁盘的增量快照
description: 了解托管磁盘的增量快照,包括如何使用 CLI 和 Azure 资源管理器创建增量快照。
author: Johnnytechn
ms.service: virtual-machines-linux
ms.topic: how-to
origin.date: 03/13/2020
ms.date: 06/17/2020
ms.author: v-johya
ms.subservice: disks
ms.openlocfilehash: 1e73700b78edc08dcbe9f60fb1acc89618dedafa
ms.sourcegitcommit: 1c01c98a2a42a7555d756569101a85e3245732fd
ms.translationtype: HT
ms.contentlocale: zh-CN
ms.lasthandoff: 06/19/2020
ms.locfileid: "85097231"
---
<!--Verified successfully by PG team-->
# <a name="create-an-incremental-snapshot-for-managed-disks---cli"></a>为托管磁盘创建增量快照 - CLI
[!INCLUDE [virtual-machines-disks-incremental-snapshot-cli](../../../includes/virtual-machines-disks-incremental-snapshot-cli.md)]
<!-- Update_Description: new article about disks incremental snapshots -->
<!--NEW.date: 06/15/2020--> | 823 | CC-BY-4.0 |
---
layout: post
title: English Learning(基礎英文口語二十六句! (日常生活中最常用的英語 #55))
categories: English
description: 基礎英文口語二十六句! (日常生活中最常用的英語 #55)
keywords: English Speaking
---
<!-- START doctoc generated TOC please keep comment here to allow auto update -->
<!-- DON'T EDIT THIS SECTION, INSTEAD RE-RUN doctoc TO UPDATE -->
- [基礎英文口語二十六句! (日常生活中最常用的英語 #55)](#%E5%9F%BA%E7%A4%8E%E8%8B%B1%E6%96%87%E5%8F%A3%E8%AA%9E%E4%BA%8C%E5%8D%81%E5%85%AD%E5%8F%A5-%E6%97%A5%E5%B8%B8%E7%94%9F%E6%B4%BB%E4%B8%AD%E6%9C%80%E5%B8%B8%E7%94%A8%E7%9A%84%E8%8B%B1%E8%AA%9E-55)
- [中文](#%E4%B8%AD%E6%96%87)
- [English](#english)
<!-- END doctoc generated TOC please keep comment here to allow auto update -->
# 基礎英文口語二十六句! (日常生活中最常用的英語 #55)
## 中文
1. 有什么进展了吗?
2. 事情没有按照计划进行
3. 这件事情很有挑战性
4. 我没有想到这件事情会有这么复杂
5. 没有任何线索
6. 我们走投无路了
7. 这没什么大不了的
8. 我们从不同的角度看这件事情吧
9. 我们就往好的方面看吧
10. 你在享受你现在的工作吗?
11. 我想,我生来就是为了做这份工作
12. 我一开始学习就忘记时间
13. 我完全把时间忘掉了
14. 你在开玩笑吧?
15. 我没有理由要骗你
16. 听起来有道理
17. 你确定你能做到这件事吗?
18. 在这方面我可是个专家
19. 就交给我吧
20. 我这方面的经验不太多
21. 不过,我会做到我力所能及的地方
22. 你是个做事有条不紊的人
23. 我第一次看到你的时候就知道这个
24. 请你告诉我,秘密是什么?
25. 你最好安排工作的优先顺序
26. 你最好按照事情的轻重缓急去做事
## English
1. Has there been any progress?
2. Things didn't work out as planned.
3. It's quite challenging.
4. I didn't expect it would be this complicated.
5. There is no lead any more.
6. We are stuck in a dead end.
7. It's not a big deal.
8. Let's look at this from another angle.
9. Let's look on the bright side.
10. Are you enjoying what you are doing now?
11. I think I was born to do this job.
12. I lose track of time, once I start to study.
13. I've completely lost track of time.
14. You've got to be kidding me.
15. I have no reason to lie to you.
16. That sounds about right.
17. Are you sure you can do this job?
18. That's right up my alley.
19. Just leave it to me.
20. I don't have much experience in this field.
21. But I'll do as much as I can.
22. You are a very organized person.
23. I knew it the very first time I saw you.
24. Please tell me, what's the secret?
25. You'd better prioritize your tasks.
26. You'd better do things in order of priority. | 2,092 | MIT |
---
title: 1 React 入门开篇
date: 2020-11-01
categories:
- 前端
tags:
- React
- 入门指南
---
这个系列是 React.js 框架的使用,目的是能使用 React 开发开发常见的 Web 应用。
<!-- more -->
## 1. React 内容概述
我们将分为如下几个部分来详细讲解 React 的使用:
1. React 基础,包括
- 使用 create-react-app 创建项目
- JSX与模板语法
- diff 算法更新过程
- setState 数据更新
4. React 组件化开发,包括 props 传值和组件间通信
3. React 生命周期
6. 组件开发之如何设计一个类似 Ant Design 的 form 表单
8. React Router
## 2. 学习资料
React 的参考资料主要是 [React 的官方文档](https://react.docschina.org/docs/getting-started.html)。与 React 相比 React 提供的 api 更接近原生 JS,没有额外的过多语法,所以看上一边文档,就差不多了。 | 544 | MIT |
---
layout : post
titile : Json解析数字
tags : C Json
---
# Json 解析数字
## 初探重构
在讨论解析数字之前,我们再补充 TDD 中的一个步骤──重构(refactoring)。根据[1],重构是一个这样的过程:
> 在不改变代码外在行为的情况下,对代码作出修改,以改进程序的内部结构。
在 TDD 的过程中,我们的目标是编写代码去通过测试。但由于这个目标的引导性太强,我们可能会忽略正确性以外的软件品质。在通过测试之后,代码的正确性得以保证,我们就应该审视现时的代码,看看有没有地方可以改进,而同时能维持测试顺利通过。我们可以安心地做各种修改,因为我们有单元测试,可以判断代码在修改后是否影响原来的行为。
那么,哪里要作出修改?Beck 和 Fowler([1] 第 3 章)认为程序员要培养一种判断能力,找出程序中的坏味道。例如,在第一单元的练习中,可能大部分人都会复制 lept_parse_null() 的代码,作一些修改,成为 lept_parse_true() 和lept_parse_false()。如果我们再审视这 3 个函数,它们非常相似。这违反编程中常说的 DRY(don't repeat yourself)原则。本单元的第一个练习题,就是尝试合并这 3 个函数。
另外,我们也可能发现,单元测试代码也有很重复的代码,例如 test_parse_invalid_value() 中我们每次测试一个不合法的 JSON 值,都有 4 行相似的代码。我们可以把它用宏的方式把它们简化:
```c
#define TEST_ERROR(error, json)\
do {\
lept_value v;\
v.type = LEPT_FALSE;\
EXPECT_EQ_INT(error, lept_parse(&v, json));\
EXPECT_EQ_INT(LEPT_NULL, lept_get_type(&v));\
} while(0)
static void test_parse_expect_value() {
TEST_ERROR(LEPT_PARSE_EXPECT_VALUE, "");
TEST_ERROR(LEPT_PARSE_EXPECT_VALUE, " ");
}
```
# 2. JSON 数字语法
回归正题,本单元的重点在于解析 JSON number 类型。我们先看看它的语法:
```text
number = [ "-" ] int [ frac ] [ exp ]
int = "0" / digit1-9 *digit
frac = "." 1*digit
exp = ("e" / "E") ["-" / "+"] 1*digit
```
number 是以十进制表示,它主要由 4 部分顺序组成:负号、整数、小数、指数。只有整数是必需部分。注意和直觉可能不同的是,正号是不合法的。
整数部分如果是 0 开始,只能是单个 0;而由 1-9 开始的话,可以加任意数量的数字(0-9)。也就是说,0123 不是一个合法的 JSON 数字。
小数部分比较直观,就是小数点后是一或多个数字(0-9)。
JSON 可使用科学记数法,指数部分由大写 E 或小写 e 开始,然后可有正负号,之后是一或多个数字(0-9)。
JSON 标准 [ECMA-404](https://link.zhihu.com/?target=http%3A//www.ecma-international.org/publications/files/ECMA-ST/ECMA-404.pdf) 采用图的形式表示语法,也可以更直观地看到解析时可能经过的路径:
上一单元的 null、false、true 在解析后,我们只需把它们存储为类型。但对于数字,我们要考虑怎么存储解析后的结果。
# 3. 数字表示方式
从 JSON 数字的语法,我们可能直观地会认为它应该表示为一个浮点数(floating point number),因为它带有小数和指数部分。然而,标准中并没有限制数字的范围或精度。为简单起见,leptjson 选择以双精度浮点数(C 中的 double 类型)来存储 JSON 数字。
我们为 lept_value 添加成员:
```c
typedef struct {
double n;
lept_type type;
}lept_value;
```
仅当 type == LEPT_NUMBER 时,n 才表示 JSON 数字的数值。所以获取该值的 API 是这么实现的:
```c
double lept_get_number(const lept_value* v) {
assert(v != NULL && v->type == LEPT_NUMBER);
return v->n;
}
```
使用者应确保类型正确,才调用此 API。我们继续使用断言来保证。
# 4. 单元测试
我们定义了 API 之后,按照 TDD,我们可以先写一些单元测试。这次我们使用多行的宏的减少重复代码:
```c
#define TEST_NUMBER(expect, json)\
do {\
lept_value v;\
EXPECT_EQ_INT(LEPT_PARSE_OK, lept_parse(&v, json));\
EXPECT_EQ_INT(LEPT_NUMBER, lept_get_type(&v));\
EXPECT_EQ_DOUBLE(expect, lept_get_number(&v));\
} while(0)
static void test_parse_number() {
TEST_NUMBER(0.0, "0");
TEST_NUMBER(0.0, "-0");
TEST_NUMBER(0.0, "-0.0");
TEST_NUMBER(1.0, "1");
TEST_NUMBER(-1.0, "-1");
TEST_NUMBER(1.5, "1.5");
TEST_NUMBER(-1.5, "-1.5");
TEST_NUMBER(3.1416, "3.1416");
TEST_NUMBER(1E10, "1E10");
TEST_NUMBER(1e10, "1e10");
TEST_NUMBER(1E+10, "1E+10");
TEST_NUMBER(1E-10, "1E-10");
TEST_NUMBER(-1E10, "-1E10");
TEST_NUMBER(-1e10, "-1e10");
TEST_NUMBER(-1E+10, "-1E+10");
TEST_NUMBER(-1E-10, "-1E-10");
TEST_NUMBER(1.234E+10, "1.234E+10");
TEST_NUMBER(1.234E-10, "1.234E-10");
TEST_NUMBER(0.0, "1e-10000"); /* must underflow */
}
```
以上这些都是很基本的测试用例,也可供调试用。大部分情况下,测试案例不能穷举所有可能性。因此,除了加入一些典型的用例,我们也常会使用一些边界值,例如最大值等。练习中会让同学找一些边界值作为用例。
除了这些合法的 JSON,我们也要写一些不合语法的用例:
```abap
static void test_parse_invalid_value() {
/* ... */
/* invalid number */
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "+0");
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "+1");
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, ".123"); /* at least one digit before '.' */
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "1."); /* at least one digit after '.' */
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "INF");
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "inf");
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "NAN");
TEST_ERROR(LEPT_PARSE_INVALID_VALUE, "nan");
}
```
# 5. 十进制转换至二进制
我们需要把十进制的数字转换成二进制的 double。这并不是容易的事情 [2]。为了简单起见,leptjson 将使用标准库的[strtod()](https://link.zhihu.com/?target=http%3A//en.cppreference.com/w/c/string/byte/strtof) 来进行转换。strtod() 可转换 JSON 所要求的格式,但问题是,一些 JSON 不容许的格式,strtod() 也可转换,所以我们需要自行做格式校验。
```c
#include <stdlib.h> /* NULL, strtod() */
static int lept_parse_number(lept_context* c, lept_value* v) {
char* end;
/* \TODO validate number */
v->n = strtod(c->json, &end);
if (c->json == end)
return LEPT_PARSE_INVALID_VALUE;
c->json = end;
v->type = LEPT_NUMBER;
return LEPT_PARSE_OK;
}
```
加入了 number 后,value 的语法变成:
```text
value = null / false / true / number
```
记得在第一单元中,我们说可以用一个字符就能得知 value 是什么类型,有 11 个字符可判断 number:
- 0-9/- ➔ number
但是,由于我们在 lept_parse_number() 内部将会校验输入是否正确的值,我们可以简单地把余下的情况都交给lept_parse_number():
```c
static int lept_parse_value(lept_context* c, lept_value* v) {
switch (*c->json) {
case 't': return lept_parse_true(c, v);
case 'f': return lept_parse_false(c, v);
case 'n': return lept_parse_null(c, v);
default: return lept_parse_number(c, v);
case '\0': return LEPT_PARSE_EXPECT_VALUE;
}
}
```
## 1. 重构合并
由于 true / false / null 的字符数量不一样,这个答案以 for 循环作比较,直至 '\0'。
```c
static int lept_parse_literal(lept_context* c, lept_value* v,
const char* literal, lept_type type)
{
size_t i;
EXPECT(c, literal[0]);
for (i = 0; literal[i + 1]; i++)
if (c->json[i] != literal[i + 1])
return LEPT_PARSE_INVALID_VALUE;
c->json += i;
v->type = type;
return LEPT_PARSE_OK;
}
static int lept_parse_value(lept_context* c, lept_value* v) {
switch (*c->json) {
case 't': return lept_parse_literal(c, v, "true", LEPT_TRUE);
case 'f': return lept_parse_literal(c, v, "false", LEPT_FALSE);
case 'n': return lept_parse_literal(c, v, "null", LEPT_NULL);
/* ... */
}
}
```
注意在 C 语言中,数组长度、索引值最好使用 size_t 类型,而不是 int 或 unsigned。
你也可以直接传送长度参数 4、5、4,只要能通过测试就行了。
## 2. 边界值测试
这问题其实涉及一些浮点数类型的细节,例如 IEEE-754 浮点数中,有所谓的 normal 和 subnormal 值,这里暂时不展开讨论了。以下是我加入的一些边界值,可能和同学的不完全一样。
```c
/* the smallest number > 1 */
TEST_NUMBER(1.0000000000000002, "1.0000000000000002");
/* minimum denormal */
TEST_NUMBER( 4.9406564584124654e-324, "4.9406564584124654e-324");
TEST_NUMBER(-4.9406564584124654e-324, "-4.9406564584124654e-324");
/* Max subnormal double */
TEST_NUMBER( 2.2250738585072009e-308, "2.2250738585072009e-308");
TEST_NUMBER(-2.2250738585072009e-308, "-2.2250738585072009e-308");
/* Min normal positive double */
TEST_NUMBER( 2.2250738585072014e-308, "2.2250738585072014e-308");
TEST_NUMBER(-2.2250738585072014e-308, "-2.2250738585072014e-308");
/* Max double */
TEST_NUMBER( 1.7976931348623157e+308, "1.7976931348623157e+308");
TEST_NUMBER(-1.7976931348623157e+308, "-1.7976931348623157e+308");
```
另外,这些加入的测试用例,正常的 strtod() 都能通过。所以不能做到测试失败、修改实现、测试成功的 TDD 步骤。
有一些 JSON 解析器不使用 strtod() 而自行转换,例如在校验的同时,记录负号、尾数(整数和小数)和指数,然后 naive 地计算:
```c
int negative = 0;
int64_t mantissa = 0;
int exp = 0;
/* 解析... 并存储 negative, mantissa, exp */
v->n = (negative ? -mantissa : mantissa) * pow(10.0, exp);
```
这种做法会有精度问题。实现正确的答案是很复杂的,RapidJSON 的初期版本也是 naive 的,后来 RapidJSON 就内部实现了三种算法(使用 kParseFullPrecision 选项开启),最后一种算法用到了大整数(高精度计算)。有兴趣的同学也可以先尝试做一个 naive 版本,不使用 strtod()。之后可再参考 Google 的 [double-conversion](https://link.zhihu.com/?target=https%3A//github.com/google/double-conversion) 开源项目及相关论文。
## 3. 校验数字
这条题目是本单元的重点,考验同学是否能把语法手写为校验规则。我详细说明。
首先,如同 lept_parse_whitespace(),我们使用一个指针 p 来表示当前的解析字符位置。这样做有两个好处,一是代码更简单,二是在某些编译器下性能更好(因为不能确定 c 会否被改变,从而每次更改 c->json 都要做一次间接访问)。如果校验成功,才把 p 赋值至 c->json。
```c
static int lept_parse_number(lept_context* c, lept_value* v) {
const char* p = c->json;
/* 负号 ... */
/* 整数 ... */
/* 小数 ... */
/* 指数 ... */
v->n = strtod(c->json, NULL);
v->type = LEPT_NUMBER;
c->json = p;
return LEPT_PARSE_OK;
}
```
我们把语法再看一遍:
```text
number = [ "-" ] int [ frac ] [ exp ]
int = "0" / digit1-9 *digit
frac = "." 1*digit
exp = ("e" / "E") ["-" / "+"] 1*digit
```
负号最简单,有的话跳过便行:
```c
if (*p == '-') p++;
```
整数部分有两种合法情况,一是单个 0,否则是一个 1-9 再加上任意数量的 digit。对于第一种情况,我们像负数般跳过便行。对于第二种情况,第一个字符必须为 1-9,如果否定的就是不合法的,可立即返回错误码。然后,有多少个 digit 就跳过多少个。
```c
if (*p == '0') p++;
else {
if (!ISDIGIT1TO9(*p)) return LEPT_PARSE_INVALID_VALUE;
for (p++; ISDIGIT(*p); p++);
}
```
如果出现小数点,我们跳过该小数点,然后检查它至少应有一个 digit,不是 digit 就返回错误码。跳过首个 digit,我们再检查有没有 digit,有多少个跳过多少个。这里用了 for 循环技巧来做这件事。
```c
if (*p == '.') {
p++;
if (!ISDIGIT(*p)) return LEPT_PARSE_INVALID_VALUE;
for (p++; ISDIGIT(*p); p++);
}
```
最后,如果出现大小写 e,就表示有指数部分。跳过那个 e 之后,可以有一个正或负号,有的话就跳过。然后和小数的逻辑是一样的。
```c
if (*p == 'e' || *p == 'E') {
p++;
if (*p == '+' || *p == '-') p++;
if (!ISDIGIT(*p)) return LEPT_PARSE_INVALID_VALUE;
for (p++; ISDIGIT(*p); p++);
}
```
这里用了 18 行代码去做这个校验。当中把一些 if 用一行来排版,而没用采用传统两行缩进风格,我个人认为在不影响阅读时可以这样弹性处理。当然那些 for 也可分拆成三行:
```c
p++;
while (ISDIGIT(*p))
p++;
```
## 4. 数字过大的处理
最后这题纯粹是阅读理解题。
```c
#include <errno.h> /* errno, ERANGE */
#include <math.h> /* HUGE_VAL */
static int lept_parse_number(lept_context* c, lept_value* v) {
/* ... */
errno = 0;
v->n = strtod(c->json, NULL);
if (errno == ERANGE && (v->n == HUGE_VAL || v->n == -HUGE_VAL))
return LEPT_PARSE_NUMBER_TOO_BIG;
/* ... */
}
``` | 9,775 | MIT |
---
layout: post
title: "Android 使用 so 文件存储私密数据,并增加签名防盗机制"
excerpt: "使用 .so 文件来存储 APP 静态私密数据,并且增加身份验证,防止 .so 被恶意调用"
date: 2018-11-18
categories:
- Android NDK
tags:
- AndroidStudio NDK
- NDK
- JNI
---
-------------------
## 0x00 实际项目中引出的一些需求问题
> 有时你需要在客户端存放一些保密的数据,比如某些授权 Key ,如果直接写在 Java 中,会很容易被反编译看到,那么我们可以把这些数据存在 so 文件中,来增加反编译难度,并且增加 APP 签名防盗机制来防止别人盗用 so 文件。
-------------------
## 0x01 一些准备工作
- 配置 NDK 开发环境,看这里 → [Android Studio NDK 开发安装配置](https://rockycoder.cn/android%20ndk/2018/01/18/Android-Studio-JNI-Exercise.html)
- 有必要的了解一下 NDK 开发基础(此例子使用的是 CMake)、最好学习一下 C/C++ 基础,不然代码看起来很费劲
-------------------
## 0x02 编写配置文件、Java、C/C++ 代码
1、新建 JNIKey.class 并声明 native 方法
```
public class JNIKey {
static {
System.loadLibrary("Key");
}
/**
* 初始化并判断当前 APP 是否为合法应用,只需调用一次
*
* @return 返回 true 则初始化成功并当前 APP 为合法应用
*/
public static native boolean init();
/**
* 获取 Key
*
* @return return key
*/
public static native String getKey();
}
```
2、Build → Rebuild Project 生成 class 文件,生成目录一般在如下目录
```
JNIKey\build\intermediates\javac\debug\compileDebugJavaWithJavac\classes\me\key\protection\
```
3、根据生成的 class 文件生成 .h 文件,进入 Terminal 命令窗口输入以下命令
```
javah -d jni -classpath D:\Android\Workspace\JNIKeyProtection\Key\build\intermediates\javac\debug\compileDebugJavaWithJavac\classes me.key.protection.JNIKey
```
> 注意路径不要写错了,生成的 .h 文件里包含自动生成的一些方法,方法名称一一应对 Java native 方法,如果在 .cpp 代码里用的是动态注册的方式,这步可以忽略不做,因为动态注册方法名可以随便写,具体看 .cpp 里的代码
4、在 src\main 目录下新建 cpp 目录,新建 Key.cpp 文件在这里编写 C++ 代码,.cpp 表示 C++ 文件, .c 表示 C 文件

5、在 Module 根目录下新建 CmakeLists.txt 文件,配置 JNI 相关参数
```
# 指定编译器版本
cmake_minimum_required(VERSION 3.4.1)
# 存放生成 so 库的目录
# set(CMAKE_LIBRARY_OUTPUT_DIRECTORY ${PROJECT_SOURCE_DIR}/libs/${ANDROID_ABI})
# 配置 so 库信息
add_library(
# 生成的 so 库名称,此处生成的 so 文件名称是libKey.so
Key
# STATIC:静态库,是目标文件的归档文件,在链接其它目标的时候使用
# SHARED:动态库,会被动态链接,在运行时被加载
# MODULE:模块库,是不会被链接到其它目标中的插件,但是可能会在运行时使用dlopen-系列的函数动态链接
SHARED
# 资源文件,可以多个,资源路径是相对路径,相对于本CMakeLists.txt所在目录
src/main/cpp/Key.cpp)
# 依赖 NDK 中的 log 日志库
find_library(
log-lib
log)
# 关联 log 库到本地库。如果你本地的库(DecryptKey)想要调用log库的方法,那么就需要配置这个属性
target_link_libraries(
# 目标库
Key
# 依赖库
${log-lib})
```
> 注意是 Module 根目录,不是 Project 根目录
6、修改对应 Module 的 build.gradle 文件添加配置参数
- defaultConfig 标签里添加如下配置
```
externalNativeBuild {
cmake {
cppFlags "-frtti -fexceptions"
}
}
// 平台架构支持
ndk {
abiFilters 'arm64-v8a', 'armeabi', 'armeabi-v7a', 'x86', 'x86_64'
}
```
- android 标签里添加如下配置
```
externalNativeBuild {
cmake {
path "CMakeLists.txt"
}
}
```
7、在 cpp 文件夹下新建 Key.cpp 文件里面放 c++ 代码
> 完整代码 → [Key.cpp](https://github.com/RockyQu/JNIKeyProtection/blob/master/JNIKey/src/main/cpp/Key.cpp)
-------------------
## 0x03 调用生成的 .so 文件
- 默认 .so 文件生成目录,复制出来放到 libs 目录下,即可使用
```
{项目目录}\JNIKey\build\intermediates\cmake\debug\obj\
```
- 你可以对生成的库文件封装一个 Jar 包,这样 .so 就不必放在特定的包下,Jar 包的生成必须要 Module 里,默认 Jar 包生成目录
```
{项目目录}\JNIKey\build\intermediates\intermediate-jars\debug\classes.jar
```
-------------------
## 0x04 完整开源项目 → [JNIKeyProtection](https://github.com/RockyQu/JNIKeyProtection) | 3,330 | Apache-2.0 |
> [简体中文](README.zh-CN.md) | [English](README.md)
> ### 背景
> 经常会使用到的token令牌解决方案
> 一次会生成两面令牌
>
> 一个是临时令牌 `token` ,用于当前使用,一般时间为 `1+` 天。
> 此令牌可以在 `1+` 天内随意使用
>
> 一个是长时间令牌 `extend` ,用于保持登录,一般时间为 `7+` 天
> 此令牌可以让用户在 `7+` 天内,当临时令牌过期后,用于刷新临时令牌
> 当此令牌过期后,最好要求用户重新登录
>
> 所以我们专门设计了这个 `token` 令牌方案
##### 在我的想法当中是这样的:<br/>
1. 用户登录注册时, 生成令牌 `Tokenizer`<br/>
2. 在临时令牌时间内 `Token`, 将用户可以直接使用临时令牌请求接口<br/>
3. 临时令牌过期后, 自动使用 `Extend` 请求刷新 `Token` <br/>
##### 生成令牌 `generate`
```php
/** 只需要引入即可 */
$app = new \NiceYuv\Tokenizer();
/** generate 值为 string */
$resp = $app->generate('1');
/** 生成令牌 返回值 */
^ NiceYuv\TokenizerDto {#15 ▼
+token: "qiC77BlTQZGkk61Bk1NOcX+zYzzF/73J2i3Nh/O2Z2FtdA83tsCoALd6+F7ftGofgrAXlIGKfFD3o2KlhxziD+yEfr8KS78V"
+extend: "qiC77BlTQZGK6roRwTJcVlc0b58w7HlzumffGveAMg2v8jFxklOCaBJVuzVAdY+kJPaRZVM0k+cyN9/uCKZhVIbPUgX36K8SwI6eVW8O7NZBlhnJrxqEWA=="
+login_date: DateTime @1641541496 {#58 ▼
date: 2022-01-07 15:44:56.908481 Asia/Shanghai (+08:00)
}
+expire_date: DateTime @1641800696 {#2 ▼
date: 2022-01-10 15:44:56.908440 Asia/Shanghai (+08:00)
}
}
// OR
null
```
##### 验证临时令牌 `verify`
```php
$app = new \NiceYuv\Tokenizer();
$resp = $app->generate('1');
$data = $app->verify($resp->token);
/** 验证临时令牌 返回值 */
^ NiceYuv\TokenDto {#90 ▼
+id: "1"
+refresh: null
+platform: "web"
+expireTime: DateTime @1641547514 {#99 ▼
date: 2022-01-07 17:25:14.0 +08:00
}
}
// OR
null
```
##### 刷新临时令牌 `refreshToken`
- 需要将 `way` 设定为 `true`, 才可以返回 `ExtendToken`
- 调用后 `refreshToken` 会刷新 `token`
- `注意` `注意` `注意`
- 传入的 `extend`不会刷新
```php
$app = new \NiceYuv\Tokenizer();
$app->setWay(true);
$resp = $app->generate('1');
$data = $app->refreshToken($resp->extend);
/**
* 刷新临时令牌 返回值
*/
^ NiceYuv\TokenizerDto {#34 ▼
+token: "qiC77BlTQZGkk61Bk1NOcX+zYzzF/73J2i3Nh/O2Z2FtdA83tsCoALd6+F7ftGofgrAXlIGKfFCL+az9o02XyeyEfr8KS78V"
+extend: "qiC77BlTQZGK6roRwTJcVlc0b58w7HlzumffGveAMg2v8jFxklOCaBJVuzVAdY+kJPaRZVM0k+cyN9/uCKZhVIbPUgX36K8SJALMiFMrUwtBlhnJrxqEWA=="
+login_date: DateTime @1641541631 {#146 ▼
date: 2022-01-07 15:47:11.492178 Asia/Shanghai (+08:00)
}
+expire_date: DateTime @1641800831 {#80 ▼
date: 2022-01-10 15:47:11.491920 Asia/Shanghai (+08:00)
}
}
// OR
null
```
##### 刷新延长令牌 `refreshExtend`
- 需要将 `way` 设定为 `true`, 才可以返回 `ExtendToken`
- 需要将 `refresh` 设定为 `true`, 才会允许刷新 `ExtendToken`
```php
$app = new \NiceYuv\Tokenizer();
$app->setWay(true);
$app->setRefresh(true);
$resp = $app->generate('1');
$refresh = $app->refreshExtend($resp->extend);
/**
* 刷新延期令牌 返回值
*/
^ NiceYuv\TokenizerDto {#91 ▼
+token: "qiC77BlTQZGkk61Bk1NOcX+zYzzF/73J2i3Nh/O2Z2FtdA83tsCoALd6+F7ftGofgrAXlIGKfFD8y1M69PzOMuyEfr8KS78V"
+extend: "qiC77BlTQZGK6roRwTJcVlc0b58w7HlzumffGveAMg2v8jFxklOCaBJVuzVAdY+kJPaRZVM0k+cyN9/uCKZhVIbPUgX36K8ShGcwqFr2dtxBlhnJrxqEWA=="
+login_date: DateTime @1641541659 {#237 ▼
date: 2022-01-07 15:47:39.956036 Asia/Shanghai (+08:00)
}
+expire_date: DateTime @1641800859 {#185 ▼
date: 2022-01-10 15:47:39.955783 Asia/Shanghai (+08:00)
}
}
OR
null
```
##### 有几个参数需要注意
```php
/**
* 是否生成长久令牌, 默认 (false)
* 当设置为 (true) 时, 则 `token` 允许被刷新
*/
private bool $way = false;
/** 是否允许 `extend` 被刷新, 默认 (false) */
private bool $refresh = false;
/** 临时令牌可用时间, 默认 (+1天) */
private string $expireDate = "+1 day";
/** 延长令牌可用时间, 默认 (+7天) */
private string $extendDate = '+7 day';
/** 设置内部服务器时区 */
private string $dateTimeZone = 'Asia/Shanghai';
/** 加密串 */
private string $secret = '8a8b57b12684504f511e85ad5073d1b2b430d143a';
```
##### 你可以这样设置主要参数
```php
$app = new \NiceYuv\Tokenizer();
$app->setWay(true);
$app->setRefresh(true);
$app->setExpireDate('+3 day');
$app->setExtendDate('+15 day');
$app->setSecret('8a8b57b12684504f511e85ad5073d1b2b430d143a');
$app->setDateTimeZone('Asia/Shanghai');
/** Tokenizer 示例 */
^ NiceYuv\Tokenizer {#3 ▼
-way: true
-refresh: true
-expireDate: "+3 day"
-extendDate: "+7 day"
-dateTimeZone: "Asia/Shanghai"
-secret: "8a8b57b12684504f511e85ad5073d1b2b430d143a"
}
```
#### 下面是两个用到的 `Dto` 需要注意
##### TokenizerDto
```php
class TokenizerDto
{
public string $token;
public string $extend;
public DateTime $login_date;
public DateTime $expire_date;
}
```
##### TokenDto
```php
class TokenDto
{
public string $id;
public ?bool $refresh = null;
public string $platform;
public DateTime $expireTime;
}
``` | 4,379 | MIT |
# 如何在 React 中使用(单纯的 React 应用,非 Taro 应用)
### 在 React 应用中使用需要在如下文件中添加代码
```bash
yarn add @tarojs/taro @tarojs/components @antmjs/vantui
yarn add @antmjs/babel-preset --dev
```
- index.html
```html
<head>
<script>
!(function (n) {
function e() {
var e = n.document.documentElement,
t = e.getBoundingClientRect().width
e.style.fontSize =
t >= 640 ? '40px' : t <= 320 ? '20px' : (t / 320) * 20 + 'px'
}
n.addEventListener('resize', function () {
e()
}),
e()
})(window)
</script>
</head>
```
- src/index.js (入口文件)
```js
import { init } from '@antmjs/vantui'
import { defineCustomElements, applyPolyfills } from '@tarojs/components/loader'
init()
applyPolyfills().then(function () {
defineCustomElements(window)
})
```
- webpack.config.js
```js
{
resolve: {
mainFields: [
'main:h5',
'browser',
'module',
'jsnext:main',
'main',
],
alias: {
// 默认@tarojs/components要指向dist-h5/react,而loader和taro-components.css只要直接指向@tarojs/components就行
// 理论上还有优化的空间,慢慢来,持续迭代
'@tarojs/components/dist/taro-components/taro-components.css': path.resolve(process.cwd(), './node_modules/@tarojs/components/dist/taro-components/taro-components.css'),
'@tarojs/components/loader': path.resolve(process.cwd(), './node_modules/@tarojs/components/loader'),
'@tarojs/components': path.resolve(process.cwd(), './node_modules/@tarojs/components/dist-h5/react'),
react: path.resolve(process.cwd(), './node_modules/react'),
'react-dom': path.resolve(process.cwd(), './node_modules/react-dom'),
},
},
module: {
rules: [
{
// 这里其实可以在自己的webpack内配置,核心就是匹配到test的部分不触发polyfill,仅仅更新下语法就行,否则会报错
test: /node_modules[\\/]@tarojs(.+?)\.[tj]sx?$/i,
loader: require.resolve('babel-loader'),
options: {
presets: [
[
'@antmjs/babel-preset',
{
presets: {
env: {
debug: false,
/**
* false: 不处理polyfill,自己手动引入【全量】
* usage: 按需加载 polyfill,且不需要手动引入【按需】
* entry: 必须手动引入,但会根据设置的目标环境全量导入【按环境全量】
* 注:在 Babel 7.4.0 之后的版本,Babel官方明确建议了不再使用 @babel/polyfill ,建议使用 core-js/stable 和 regenerator-runtime/runtime。本包已经安装了core-js、@babel/plugin-transform-runtime和@babel/runtime,所以选择false或者entry选项的只需要在主文件顶部引入core-js即可
*/
useBuiltIns: false,
corejs: false,
modules: false, // 对es6的模块文件不做转译,以便使用tree shaking、sideEffects等
},
react: {
runtime: 'automatic',
},
typescript: {
isTSX: true,
jsxPragma: 'React',
allExtensions: true,
allowNamespaces: true,
},
},
decorators: {
legacy: false,
decoratorsBeforeExport: false,
},
classProperties: {
loose: false,
},
runtime: {
absoluteRuntime: path.dirname(
require.resolve(
'@babel/runtime-corejs3/package.json',
),
),
version: require('@babel/runtime-corejs3/package.json')
.version,
corejs: false,
helpers: true, // 使用到@babel/runtime
regenerator: true, // 使用到@babel/runtime
useESModules: false,
},
exclude: [/@babel[/|\\\\]runtime/, /core-js/],
},
],
],
},
},
{
// 可以参考Taro的自适应方案
test: /\.less$/
use: [
// 这里展示的是组件核心需要的loader,其他loader请自行添加
{
loader: require.resolve('postcss-loader'),
options: {
ident: 'postcss',
plugins: () => [
require('postcss-pxtransform')({
platform: 'h5',
designWidth: 750,
})
]
}
}
]
}
]
},
plugins: [
// 为了使移动H5和Taro小程序保持同一套组件,原因在介绍有说明,所以这里需要把Taro内置的一些插件属性给加进来
new webpack.DefinePlugin({
ENABLE_INNER_HTML: true,
ENABLE_ADJACENT_HTML: true,
ENABLE_TEMPLATE_CONTENT: true,
ENABLE_CLONE_NODE: true,
ENABLE_SIZE_APIS: false,
}),
new webpack.EnvironmentPlugin({
LIBRARY_ENV: 'react',
TARO_ENV: 'h5',
}),
// const VantUIPlugin = require('@antmjs/plugin-vantui')
// 如果用的就是750,则不需要添加该插件了
new VantUIPlugin({
designWidth: 750,
deviceRatio: {
640: 2.34 / 2,
750: 1,
828: 1.81 / 2,
},
}),
],
}
```
```bash
TARO_ENV=h5 yarn start
```
> 愉快的玩耍吧! | 5,027 | MIT |
---
layout: post
title: Spring Core And MVC
categories: [spring]
keywords: java, spring
---
## AOP
AOP( Aspect-OrientedProgramming, 面向方面编程), 可以说是OOP(Object-Oriented Programing,面向对象编程)
的补充和完善。OOP引入封装、继承和多态性等概念来建立一种对象层次结构用以模拟公共行为的一个集合。
当我们需要为分散的对象引入公共行为的时候,OOP则显得无能为力。也就是说,OOP允许你定义从上到下的关系,但并不适合定义从左到右的关系。
例如日志功能。日志代码往往水平地散布在所有对象层次中,而与它所散布到的对象的核心功能毫无关系。对于其他类型的代码,如安全性、异常处理和透明的持续性也是如此。这种散布在各处的无关的代码被称为横切(cross-cutting)代码,在OOP设计中,它导致了大量代码的重复,而不利于各个模块的重用。
而AOP技术则恰恰相反,它利用一种称为“横切”的技术,剖解开封装的对象内部,并将那些影响了多个类的公共行为封装到
一个可重用模块,并将其名为“Aspect”,即方面。所谓“方面”,简单地说,就是将那些与业务无关,却为业务模块所共
同调用的逻辑或责任封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可操作性和可维护性。
AOP代表的是一个横向的关系,如果说“对象”是一个空心的圆柱体,其中封装的是对象的属性和行为;那么面向方面编程的方法,
就仿佛一把利刃,将这些空心圆柱体剖开,以获得其内部的消息。而剖开的切面,也就是所谓的“方面”了。然后它又以巧夺天
功的妙手将这些剖开的切面复原,不留痕迹。
使用“横切”技术,AOP把软件系统分为两个部分:核心关注点和横切关注点。业务处理的主要流程是核心关注点,
与之关系不大的部分是横切关注点。横切关注点的一个特点是,他们经常发生在核心关注点的多处,而各处都基本相似。
比如权限认证、日志、事务处理。Aop 的作用在于分离系统中的各种关注点,将核心关注点和横切关注点分离开来。
正如Avanade公司的高级方案构架师Adam Magee所说,AOP的核心思想就是“将应用程序中的商业逻辑同对其提供支持的通
用服务进行分离。”
实现AOP的技术,主要分为两大类:一是采用动态代理技术,利用截取消息的方式,对该消息进行装饰,以取代原有对象行为的
执行;二是采用静态织入的方式,引入特定的语法创建“方面”,从而使得编译器可以在编译期间织入有关“方面”的代码。

### Spring AOP代理对象的生成
Spring提供了两种方式来生成代理对象: JDKProxy和Cglib,具体使用哪种方式生成由AopProxyFactory根据
AdvisedSupport 对象的配置来决定。默认的策略是如果目标类是接口,则使用 JDK 动态代理技术,否则使用 Cglib 来生成代理。
下面我们来研究一下Spring如何使用JDK来生成代理对象,具体的生成代码放在 **JdkDynamicAopProxy** 这个类中,
直接上相关代码:
```java
/**
* <li>获取代理类要实现的接口,除了Advised对象中配置的,还会加上SpringProxy, Advised(opaque=false)
* <li>检查上面得到的接口中有没有定义 equals或者hashcode的接口
* <li>调用Proxy.newProxyInstance创建代理对象
*/
public Object getProxy(ClassLoader classLoader) {
if (logger.isDebugEnabled()) {
logger.debug("Creating JDK dynamic proxy: target source is " +this.advised.getTargetSource());
}
Class[] proxiedInterfaces =AopProxyUtils.completeProxiedInterfaces(this.advised);
findDefinedEqualsAndHashCodeMethods(proxiedInterfaces);
return Proxy.newProxyInstance(classLoader, proxiedInterfaces, this);
}
```
我们知道 InvocationHandler 是JDK动态代理的核心,生成的代理对象的方法调用都会委托到 InvocationHandler.invoke() 方法。
而通过 JdkDynamicAopProxy 的签名我们可以看到这个类其实也实现了 InvocationHandler,下面我们就通过分析这个类中实现的 invoke() 方法来具体看
下 Spring AOP 是如何织入切面的
```java
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
MethodInvocation invocation = null;
Object oldProxy = null;
boolean setProxyContext = false;
TargetSource targetSource = this.advised.targetSource;
Class targetClass = null;
Object target = null;
try {
//eqauls()方法,具目标对象未实现此方法
if (!this.equalsDefined && AopUtils.isEqualsMethod(method)){
return (equals(args[0])? Boolean.TRUE : Boolean.FALSE);
}
//hashCode()方法,具目标对象未实现此方法
if (!this.hashCodeDefined && AopUtils.isHashCodeMethod(method)){
return newInteger(hashCode());
}
//Advised接口或者其父接口中定义的方法,直接反射调用,不应用通知
if (!this.advised.opaque &&method.getDeclaringClass().isInterface()
&&method.getDeclaringClass().isAssignableFrom(Advised.class)) {
// Service invocations onProxyConfig with the proxy config...
return AopUtils.invokeJoinpointUsingReflection(this.advised,method, args);
}
Object retVal = null;
if (this.advised.exposeProxy) {
// Make invocation available ifnecessary.
oldProxy = AopContext.setCurrentProxy(proxy);
setProxyContext = true;
}
//获得目标对象的类
target = targetSource.getTarget();
if (target != null) {
targetClass = target.getClass();
}
//获取可以应用到此方法上的Interceptor列表
List chain = this.advised.getInterceptorsAndDynamicInterceptionAdvice(method,targetClass);
//如果没有可以应用到此方法的通知(Interceptor),此直接反射调用 method.invoke(target, args)
if (chain.isEmpty()) {
retVal = AopUtils.invokeJoinpointUsingReflection(target,method, args);
} else {
//创建MethodInvocation
invocation = newReflectiveMethodInvocation(proxy, target, method, args, targetClass, chain);
retVal = invocation.proceed();
}
// Massage return value if necessary.
if (retVal != null && retVal == target &&method.getReturnType().isInstance(proxy)
&&!RawTargetAccess.class.isAssignableFrom(method.getDeclaringClass())) {
// Special case: it returned"this" and the return type of the method
// is type-compatible. Notethat we can't help if the target sets
// a reference to itself inanother returned object.
retVal = proxy;
}
return retVal;
} finally {
if (target != null && !targetSource.isStatic()) {
// Must have come fromTargetSource.
targetSource.releaseTarget(target);
}
if (setProxyContext) {
// Restore old proxy.
AopContext.setCurrentProxy(oldProxy);
}
}
}
```
主流程可以简述为:获取可以应用到此方法上的通知链(Interceptor Chain),如果有, 则应用通知,并执行joinpoint; 如果没有,则直接反射执行joinpoint。
而这里的关键是通知链是如何获取的以及它又是如何执行的,下面逐一分析下。
首先,从上面的代码可以看到,通知链是通过cAdvised.getInterceptorsAndDynamicInterceptionAdvice()c这个方法来获取的, 我们来看下这个方法的实现:
```java
public List<Object> getInterceptorsAndDynamicInterceptionAdvice(Method method, Class targetClass) {
MethodCacheKeycacheKey = new MethodCacheKey(method);
List<Object>cached = this.methodCache.get(cacheKey);
if(cached == null) {
cached= this.advisorChainFactory.getInterceptorsAndDynamicInterceptionAdvice(
this,method, targetClass);
this.methodCache.put(cacheKey,cached);
}
returncached;
}
```
可以看到实际的获取工作其实是由AdvisorChainFactory. getInterceptorsAndDynamicInterceptionAdvice()这个方法来完成的,获取到的结果会被缓存。
下面来分析下这个方法的实现:
```java
/**
* 从提供的配置实例config中获取advisor列表,遍历处理这些advisor.如果是IntroductionAdvisor,
* 则判断此Advisor能否应用到目标类targetClass上.如果是PointcutAdvisor,则判断
* 此Advisor能否应用到目标方法method上.将满足条件的Advisor通过AdvisorAdaptor转化成Interceptor列表返回.
*/
publicList getInterceptorsAndDynamicInterceptionAdvice(Advised config, Methodmethod, Class targetClass) {
// This is somewhat tricky... we have to process introductions first,
// but we need to preserve order in the ultimate list.
List interceptorList = new ArrayList(config.getAdvisors().length);
//查看是否包含IntroductionAdvisor
boolean hasIntroductions = hasMatchingIntroductions(config,targetClass);
//这里实际上注册一系列AdvisorAdapter,用于将Advisor转化成MethodInterceptor
AdvisorAdapterRegistry registry = GlobalAdvisorAdapterRegistry.getInstance();
Advisor[] advisors = config.getAdvisors();
for (int i = 0; i <advisors.length; i++) {
Advisor advisor = advisors[i];
if (advisor instanceof PointcutAdvisor) {
// Add it conditionally.
PointcutAdvisor pointcutAdvisor= (PointcutAdvisor) advisor;
if(config.isPreFiltered() ||pointcutAdvisor.getPointcut().getClassFilter().matches(targetClass)) {
//TODO: 这个地方这两个方法的位置可以互换下
//将Advisor转化成Interceptor
MethodInterceptor[]interceptors = registry.getInterceptors(advisor);
//检查当前advisor的pointcut是否可以匹配当前方法
MethodMatcher mm =pointcutAdvisor.getPointcut().getMethodMatcher();
if (MethodMatchers.matches(mm,method, targetClass, hasIntroductions)) {
if(mm.isRuntime()) {
// Creating a newobject instance in the getInterceptors() method
// isn't a problemas we normally cache created chains.
for (intj = 0; j < interceptors.length; j++) {
interceptorList.add(new InterceptorAndDynamicMethodMatcher(interceptors[j],mm));
}
} else {
interceptorList.addAll(Arrays.asList(interceptors));
}
}
}
} else if (advisor instanceof IntroductionAdvisor){
IntroductionAdvisor ia =(IntroductionAdvisor) advisor;
if(config.isPreFiltered() || ia.getClassFilter().matches(targetClass)) {
Interceptor[] interceptors= registry.getInterceptors(advisor);
interceptorList.addAll(Arrays.asList(interceptors));
}
} else {
Interceptor[] interceptors =registry.getInterceptors(advisor);
interceptorList.addAll(Arrays.asList(interceptors));
}
}
return interceptorList;
}
```
从这段代码可以看出,如果得到的拦截器链为空,则直接反射调用目标方法,否则创建MethodInvocation,调用其proceed方法,触发拦截器链的执行,来看下具体代码
这个方法执行完成后,Advised中配置能够应用到连接点或者目标类的Advisor全部被转化成了MethodInterceptor.
```java
if (chain.isEmpty()) {
retVal = AopUtils.invokeJoinpointUsingReflection(target,method, args);
} else {
//创建MethodInvocation
invocation = newReflectiveMethodInvocation(proxy, target, method, args, targetClass, chain);
retVal = invocation.proceed();
}
```
从这段代码可以看出,如果得到的拦截器链为空,则直接反射调用目标方法,否则创建MethodInvocation,调用其proceed方法,触发拦截器链的执行,来看下具体代码
```java
public Object proceed() throws Throwable {
// We start with an index of -1and increment early.
if (this.currentInterceptorIndex == this.interceptorsAndDynamicMethodMatchers.size()- 1) {
//如果Interceptor执行完了,则执行joinPoint
return invokeJoinpoint();
}
Object interceptorOrInterceptionAdvice =
this.interceptorsAndDynamicMethodMatchers.get(++this.currentInterceptorIndex);
//如果要动态匹配joinPoint
if (interceptorOrInterceptionAdvice instanceof InterceptorAndDynamicMethodMatcher){
// Evaluate dynamic method matcher here: static part will already have
// been evaluated and found to match.
InterceptorAndDynamicMethodMatcher dm =
(InterceptorAndDynamicMethodMatcher)interceptorOrInterceptionAdvice;
//动态匹配:运行时参数是否满足匹配条件
if (dm.methodMatcher.matches(this.method, this.targetClass,this.arguments)) {
//执行当前Intercetpor
returndm.interceptor.invoke(this);
}
else {
//动态匹配失败时,略过当前Intercetpor,调用下一个Interceptor
return proceed();
}
}
else {
// It's an interceptor, so we just invoke it: The pointcutwill have
// been evaluated statically before this object was constructed.
//执行当前Intercetpor
return ((MethodInterceptor) interceptorOrInterceptionAdvice).invoke(this);
}
}
```
## Spring MVC
### 指定 Spring mvc 的入口程序 (web.xml)
```xml
<servlet>
<servlet-name> dispatcher </servlet-name>
<servlet-class> org.springframework.web.servlet.DispatcherServlet </servlet-class>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name> dispatcher </servlet-name>
<url-pattern> /** </url-pattern>
</servlet-mapping>
```
DispatcherServlet 是核心分派器, 是 Spring MVC 最重要的类之一, 之后我们会对其单独展开分析
### 编写 Spring mvc 的核心配置文件 ([servlet-name]-servlet.xml)
xml 中前面的 beans 就不写了
```xml
<!-- Enables the Spring MVC @Controller programming model -->
<mvc:annotation-driven />
<context:component-scan base-package="com.abc" />
<bean class = "org.springframework.web.servlet.view.InternalResourceViewResolver">
<property name = "prefix" value = "/" />
<property name = "suffix" value = ".jsp" />
</bean>
```
用于配置 view 的位置以及扫描范围
### 编写 Controller 代码
```java
@Controller
@RequestMapping
public class UserController {
@RequestMapping("login")
public ModelAndView login(String name, String password) {
return new ModelAndView("success");
}
}
```
### 核心分派器
Servlet 本质上是一个 Java 类, 通过 servlet 接口定义的 HttpServletRequest 对象,
我们可以处理整个请求生命周期的数据, 通过 HttpServletResponse 对象, 我们可以处理 Http 响应行为。
```java
try
mappedHandler = getHandler(processRequest, false);
if(mappedHandler == null || mappedHandler.getHandelr() == null)
noHandlerFound(processRequest, response)
return;
HandlerAdapter ha = getHandlerAdapter(mappedHandler.getHandler())
mv = ha.handle(processedRequest, response, mappedHandler.getHandler())
catch (ModelAndViewDefinitionException)
mv = ex.getModelAndView
catch (Exception)
Object handler = (mappedHandler != null ? mappedHandler.getHandler() : null)
mv = processHandlerException(processedRequest, response, handler, ex);
errorView = (mv != null)
```
HandlerMapping 与其子类:(需要举例子)
**BeanNameUrlHandlerMapping:** 根据 spring 容器中的 bean 的定义来指定请求映射关系
**SimpleUrlHandlerMapping:** 直接指定 URL 与 Controller 的映射关系, 其中 URL 支持 Ant 风格
**DefaultAnnotationHandlerMapping:** 支持通过直接扫描 Controller 类中的 Annotation 来确定
请求映射关系
**RequestMappingHandlerMapping** 通过扫描 Controller 类中的 Annotation 来确定请求映射关系的另一个实现类
## 原理

## 基础
### 注解
**@Autowired**
示例1, autowire 参数, 并根据名字过滤, 这两个注解可以替换为 Resource(name="redBean")
```java
// 产生一个 Bean
@Qualifier("redBean")
class Red implements Color { // Class code here }
or
<bean id="redBean" class="com.mycompany.movies.Red"/>
@Autowire
@Qualifier("redBean")
public void setColor(Color color) {
this.color = color;
}
```
autowire 成员变量
```
@Controller // defines that this class is a spring bean
@RequestMapping("/users")
public class SomeController {
// tells the application context to inject an instance of UserService here
@Autowired private UserService userService;
```
## 实现
### 常用接口
```java
interface HandlerMapping
HandlerExecutionChain getHandler(HttpServletRequest request) throws Exception;
class HandlerExecutionChain
private final Object handler;
private HandlerInterceptor[] interceptors;
applyPreHandle(HttpServletRequest request, HttpServletResponse response)
applyPostHandle(HttpServletRequest request, HttpServletResponse response, ModelAndView mv)
triggerAfterCompletion(HttpServletRequest request, HttpServletResponse response, Exception ex)
interface HandlerInterceptor
preHandle(HttpServletRequest request, HttpServletResponse response, Object handler)
postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView)
void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex)
interface HandlerAdapter
boolean supports(Object handler);
ModelAndView handle(HttpServletRequest request, HttpServletResponse response, Object handler)
```
## Spring mvc 的设计原则
### Open for extension closed for modification
**使用 final 关键字来限定核心组件的核心方法**
Some methods in the core classes of spring web mvc are marked as final. This has
not been done arbitrarily, but specifically with the principle in mind.
HandlerAdapter 实现类 RequestMappingHandlerAdapter 中, 核心方法 `handleInternal` 就被定义为 final
**大量使用 private 方法** | 15,523 | MIT |
---
title: MySQL -- 主从切换
date: 2019-02-27 01:10:39
categories:
- Storage
- MySQL
tags:
- Storage
- MySQL
---
## 一主多从
<img src="https://mysql-1253868755.cos.ap-guangzhou.myqcloud.com/mysql-master-multi-slave.png" width=500/>
<!-- more -->
1. 虚线箭头为**主从关系**,`A`和`A'`互为主从,`B`、`C`、`D`指向主库`A`
2. 一主多从的设置,一般用于**读写分离**,主库负责**所有的写入**和**一部分读**,其它读请求由从库分担
## 主库故障切换
`A'`成为新的主库,`B`、`C`、`D`指向主库`A'`
<img src="https://mysql-1253868755.cos.ap-guangzhou.myqcloud.com/mysql-master-crash-switch.png" width=500/>
## 基于位点的切换
`B`原先是`A`的从库,本地记录的也是`A`的位点,但**相同的日志**,`A`的位点与`A'`的位点是**不同**的
```sql
-- 节点B设置为节点A'的从库
CHANGE MASTER TO
MASTER_HOST=$host_name
MASTER_PORT=$port
MASTER_USER=$user_name
MASTER_PASSWORD=$password
MASTER_LOG_FILE=$master_log_name
MASTER_LOG_POS=$master_log_pos
```
### 寻找位点
1. _**很难精确,只能大概获取一个位置**_
2. 由于在切换过程中**不能丢数据**,在寻找位点的时候,总是找一个**稍微往前的位点**,跳过那些已经在`B`执行过的事务
#### 常规步骤
1. 等待新主库`A'`将所有`relaylog`全部执行完
2. 在`A'`上执行`SHOW MASTER STATUS`,得到`A'`上最新的`File`和`Position`
3. 获取原主库`A`发生故障的时刻`T`
4. 使用`mysqlbinlog`解析`A'`的`File`,得到时刻`T`的位点
```sql
-- end_log_pos=123,表示在时刻T,A'写入新binlog的位置,作为B的CHANGE MASTER TO命令的MASTER_LOG_POS参数
$ mysqlbinlog /var/lib/mysql/slave-bin.000009 --start-datetime='2019-02-26 17:44:00' --stop-datetime='2019-02-26 17:45:00' | grep end_log_pos
#190226 17:42:01 server id 2 end_log_pos 123 CRC32 0x5b852e9b Start: binlog v 4, server v 5.7.25-log created 190226 17:42:01 at startup
```
#### 位点不精确
1. 假设在时刻`T`,原主库`A`已经执行完成了一个`INSERT`语句,插入一行记录`R`
- 并且已经将`binlog`传给`A'`和B,然后原主库`A`掉电
2. 在`B`上,由于已经同步了`binlog`,`R`这一行是已经存在的
3. 在新主库`A'`上,`R`这一行也是存在的,日志写在了`123`这个位置之后
4. 在`B`上执行`CHANGE MASTER TO`,执行`A'`的`File`文件的`123`位置
- 就会把插入`R`这一行数据的`binlog`又同步到`B`去执行
- `B`的同步线程会报**重复主键**错误,然后停止同步
##### 跳过错误
方式1:主动跳过一个事务,需要**持续观察**,每次碰到这些错误,就执行一次跳过命令
```sql
SET GLOBAL sql_slave_skip_counter=1;
START SLAVE;
```
方式1:设置`slave_skip_errors=1032,1062`,`1032`错误是删除数据时**找不到行**,`1062`错误是插入数据时报**唯一键冲突**
在**主从切换过程**中,直接跳过`1032`和`1062`是**无损**的,等主从间的同步关系建立完成后,需要将`slave_skip_errors`恢复为`OFF`
```sql
mysql> SHOW VARIABLES LIKE '%slave_skip_errors%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| slave_skip_errors | OFF |
+-------------------+-------+
```
## 基于GTID的切换
1. GTID: Global Transaction Identifier,**全局事务ID**
2. 在事务**提交**时生成,是事务的唯一标识,组成`GTID = server_uuid:gno`
- `server_uuid`是实例第一次**启动**时自动生成的,是一个**全局唯一** 的值
- `gno`是一个整数,初始值为`1`,每次**提交事务**时分配,`+1`
3. 官方定义:`GTID = source_id:transaction_id`
- `source_id`即`server_uuid`
- `transaction_id`容易造成误解
- `transaction_id`一般指事务ID,是在事务**执行过程**中分配的,即使事务**回滚**了,事务ID也会**递增**
- 而`gno`只有在事务**提交**时才会分配,因此`GTID`往往是**连续**的
4. 开启`GTID`模式,添加启动参数`gtid_mode=ON`和`enforce_gtid_consistency=ON`
5. 在`GTID`模式下,每个事务都会跟一个`GTID`一一对应,生成`GTID`的方式由参数`gtid_next`(Session)控制
6. 每个MySQL实例都维护了一个`GTID`集合,用于表示:_**实例执行过的所有事务**_
### gtid_next
1. `gtid_next=AUTOMATIC`,MySQL会将`server_uuid:gno`分配给该事务
- 记录`binlog`时,会先记录一行`SET @@SESSION.GTID_NEXT=server_uuid:gno`,将该`GTID`加入到本实例的`GTID`集合
2. `gtid_next=UUID:NUMBER`,通过`SET @@SESSION.GTID_NEXT=current_gtid`执行
- 如果`current_gtid`已经**存在**于实例的`GTID`集合中,那么接下来执行的这个事务会直接被系统**忽略**
- 如果`current_gtid`并**没有存在**于实例的`GTID`集合中,那么接下来执行的这个事务会被分配为`current_gtid`
- `current_gtid`只能给**一个事务**使用,如果执行下一个事务,需要把`gtid_next`设置成另一个`GTID`或者`AUTOMATIC`
```sql
-- gtid_next=AUTOMATIC
mysql> SHOW BINLOG EVENTS IN 'master-bin.000003';
+-------------------+-----+----------------+-----------+-------------+--------------------------------------------------------------------------------------------------------------------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+-------------------+-----+----------------+-----------+-------------+--------------------------------------------------------------------------------------------------------------------------------------------+
| master-bin.000003 | 4 | Format_desc | 1 | 123 | Server ver: 5.7.25-log, Binlog ver: 4 |
| master-bin.000003 | 123 | Previous_gtids | 1 | 194 | b8502fe3-3b4a-11e9-9562-0242ac110002:1-5 |
| master-bin.000003 | 194 | Gtid | 1 | 259 | SET @@SESSION.GTID_NEXT= 'b8502fe3-3b4a-11e9-9562-0242ac110002:6' |
| master-bin.000003 | 259 | Query | 1 | 484 | GRANT REPLICATION SLAVE ON *.* TO 'replication'@'%' IDENTIFIED WITH 'mysql_native_password' AS '*6BB4837EB74329105EE4568DDA7DC67ED2CA2AD9' |
| master-bin.000003 | 484 | Gtid | 1 | 549 | SET @@SESSION.GTID_NEXT= 'b8502fe3-3b4a-11e9-9562-0242ac110002:7' |
| master-bin.000003 | 549 | Query | 1 | 643 | CREATE DATABASE test |
+-------------------+-----+----------------+-----------+-------------+--------------------------------------------------------------------------------------------------------------------------------------------+
```
### 表初始化
```sql
CREATE TABLE `t` (
`id` INT(11) NOT NULL,
`c` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
INSERT INTO t VALUES (1,1);
```
#### 对应的binlog
```sql
mysql> SHOW MASTER STATUS;
+-------------------+----------+--------------+------------------+-------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-------------------+----------+--------------+------------------+-------------------------------------------+
| master-bin.000004 | 877 | | | b8502fe3-3b4a-11e9-9562-0242ac110002:1-12 |
+-------------------+----------+--------------+------------------+-------------------------------------------+
mysql> SHOW BINLOG EVENTS IN 'master-bin.000004';
+-------------------+-----+----------------+-----------+-------------+--------------------------------------------------------------------+
| Log_name | Pos | Event_type | Server_id | End_log_pos | Info |
+-------------------+-----+----------------+-----------+-------------+--------------------------------------------------------------------+
| master-bin.000004 | 4 | Format_desc | 1 | 123 | Server ver: 5.7.25-log, Binlog ver: 4 |
| master-bin.000004 | 123 | Previous_gtids | 1 | 194 | b8502fe3-3b4a-11e9-9562-0242ac110002:1-9 |
| master-bin.000004 | 194 | Gtid | 1 | 259 | SET @@SESSION.GTID_NEXT= 'b8502fe3-3b4a-11e9-9562-0242ac110002:10' |
| master-bin.000004 | 259 | Query | 1 | 373 | use `test`; DROP TABLE `t` /* generated by server */ |
| master-bin.000004 | 373 | Gtid | 1 | 438 | SET @@SESSION.GTID_NEXT= 'b8502fe3-3b4a-11e9-9562-0242ac110002:11' |
| master-bin.000004 | 438 | Query | 1 | 620 | use `test`; CREATE TABLE `t` (
`id` INT(11) NOT NULL,
`c` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB |
| master-bin.000004 | 620 | Gtid | 1 | 685 | SET @@SESSION.GTID_NEXT= 'b8502fe3-3b4a-11e9-9562-0242ac110002:12' |
| master-bin.000004 | 685 | Query | 1 | 757 | BEGIN |
| master-bin.000004 | 757 | Table_map | 1 | 802 | table_id: 109 (test.t) |
| master-bin.000004 | 802 | Write_rows | 1 | 846 | table_id: 109 flags: STMT_END_F |
| master-bin.000004 | 846 | Xid | 1 | 877 | COMMIT /* xid=27 */ |
+-------------------+-----+----------------+-----------+-------------+--------------------------------------------------------------------+
```
1. 事务`BEGIN`之前有一条`SET @@SESSION.GTID_NEXT`
2. 如果实例X有从库Z,那么将`CREATE TABLE`和`INSERT`语句的`binlog`同步到从库Z执行
- 执行事务之前,会先执行两个`SET`命令,这样两个`GTID`就会被加入到从库Z的`GTID`集合
#### 主键冲突
1. 如果实例X是实例Y的从库,之前实例Y上执行`INSERT INTO t VALUES (1,1)`
- 对应的`GTID`为`aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee:12`
- 实例X需要同步该事务过来执行,会报**主键冲突**的错误,实例X的同步线程停止,处理方法如下
```sql
-- 实例X提交一个空事务,将该GTID加到实例X的GTID集合中
SET gtid_next='aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee:12';
BEGIN;
COMMIT;
-- 实例X的Executed_Gtid_Set已经包含了aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee:12
mysql> SHOW MASTER STATUS;
+-------------------+----------+--------------+------------------+------------------------------------------------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+-------------------+----------+--------------+------------------+------------------------------------------------------------------------------------+
| master-bin.000004 | 1087 | | | aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee:12,b8502fe3-3b4a-11e9-9562-0242ac110002:1-12 |
+-------------------+----------+--------------+------------------+------------------------------------------------------------------------------------+
-- 恢复GTID的默认分配行为
SET gtid_next=AUTOMATIC;
-- 实例X还是会继续执行实例Y传过来的事务
-- 但由于实例X的GTID集合已经包含了aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee:12,因此实例X会直接跳过该事务
START SLAVE;
```
### 主从切换
```
CHANGE MASTER TO
MASTER_HOST=$host_name
MASTER_PORT=$port
MASTER_USER=$user_name
MASTER_PASSWORD=$password
master_auto_position=1
```
1. `master_auto_position=1`:主从关系使用的是`GTID`协议,不再需要指定`MASTER_LOG_FILE`和`MASTER_LOG_POS`
2. 实例`A'`的`GTID`集合记为`set_a`,实例`B`的`GTID`集合记为`set_b`
3. 实例`B`执行`START SLAVE`,取`binlog`的逻辑如下
#### START SLAVE
1. 实例`B`指定新主库`A'`,基于**主从协议**建立连接
2. 实例`B`把`set_b`发送给`A'`
3. 实例`A'`计算出`seb_a`和`set_b`的`GTID`差集(存在于`set_a`,但不存在于`set_b`的`GTID`集合)
- 判断实例`A'`本地是否包含了**差集需要的所有`binlog`事务**
- 如果**没有全部包含**,说明实例`A'`已经把实例`B`所需要的`binlog`删除掉了,直接返回错误
- 如果**全部包含**,实例`A'`从自己的`binlog`文件里面,找到第1个不在`set_b`的事务,发送给实例`B`
- 然后从该事务开始,往后读文件,按顺序读取`binlog`,发给实例`B`去执行
#### 位点 VS GTID
1. 基于`GTID`的主从关系里面,系统认为只要**建立了主从关系**,就必须保证**主库发给从库的日志是完整**的
2. 如果实例`B`需要的日志已经不存在了,那么实例`A'`就拒绝将日志发送给实例`B`
3. 基于**位点**的协议,是由**从库决定**的,从库指定哪个位点,主库就发送什么位点,不做**日志完整性**的判断
4. 基于`GTID`的协议,主从切换**不再需要找位点**,而找位点的工作在实例`A'`内部**自动完成**
#### 日志格式
1. 切换前
- 实例`B`的`GTID`集合:`server_uuid_of_A:1-N`
2. 新主库`A'`自己生成的`binlog`对应的`GTID`集合:`server_uuid_of_A':1-M`
3. 切换后
- 实例`B`的`GTID`集合:`server_uuid_of_A:1-N,server_uuid_of_A':1-M`
## 参考资料
《MySQL实战45讲》
<!-- indicate-the-source --> | 11,135 | MIT |
# Vuex 操作vuex
## Vuex 操作vuex使用方法
```
/**
* @description: 获取vuex的state中变量
* @param {string} name 变量名
*/
this.$store.state.version
```
```
/**
* @description: 修改vuex的state中变量
* @param {string} name 变量名
* @param {string} value 变量值
*/
this.$uct.vuex("version", "0.0.2");
```
## Vuex 操作vuex案例
```vue
<template>
<view class="getLoc">
<uct-nav>
<view slot="center">Vuex 操作</view>
</uct-nav>
<view>当前版本:{{$store.state.version}}</view>
<uct-button class="mt40"
@click="setVersion"
text="更改版本"></uct-button>
</view>
</template>
<script>
export default {
methods: {
setVersion() {
this.$uct.vuex("version", "0.0.2");
},
},
};
</script>
``` | 707 | MIT |
---
layout: post
title: phpredis扩展调用 redis的scan方法报错
date: 2017-06-29 21:30:00 +0800
categories: redis
tag: 随笔
---
* content
{:toc}
官方文档的例子如下:
{% highlight php %}
<?php
/* Without enabling Redis::SCAN_RETRY (default condition) */
$it = NULL;
do {
// Scan for some keys
$arr_keys = $redis->scan($it);
// Redis may return empty results, so protect against that
if ($arr_keys !== FALSE) {
foreach($arr_keys as $str_key) {
echo "Here is a key: $str_key\n";
}
}
} while ($it > 0);
echo "No more keys to scan!\n";
/* With Redis::SCAN_RETRY enabled */
$redis->setOption(Redis::OPT_SCAN, Redis::SCAN_RETRY);
$it = NULL;
/* phpredis will retry the SCAN command if empty results are returned from the
server, so no empty results check is required. */
while ($arr_keys = $redis->scan($it)) {
foreach ($arr_keys as $str_key) {
echo "Here is a key: $str_key\n";
}
}
echo "No more keys to scan!\n";
?>
{% endhighlight php %}
运行后会发现报了下面的错误:
{% highlight php %}
Warning: Parameter 1 to Redis::scan() expected to be a reference, value given
{% endhighlight php %}
scan的第一个参数必须是个引用传值
解决方案如下(代码只列出了主要部分,不是完整代码):
{% highlight php %}
<?php
$iterator = null;
$arguments = array(&$iterator,'match_str*',100);
$redis->setOption(Redis::OPT_SCAN, Redis::SCAN_RETRY);
do{
#bug 问题
#$res = $redis->scan($iterator,'match_str*',100);
$res = call_user_func_array(array($redis, 'scan'), $arguments);
foreach($res as $value) {
$this->del($value);
echo $value." 已删除\n";
}
} while($iterator >0);
?>
{% endhighlight php %} | 1,707 | MIT |
---
title: Docker アプリケーションの外側のループ DevOps ワークフローの手順を実行します。
description: DevOps ワークフローの「外側のループ」手順を説明します
author: CESARDELATORRE
ms.author: wiwagn
ms.date: 02/15/2019
ms.openlocfilehash: 7043f34557651c3e8e79baf263bd0bcefd5a847a
ms.sourcegitcommit: bd28ff1e312eaba9718c4f7ea272c2d4781a7cac
ms.translationtype: MT
ms.contentlocale: ja-JP
ms.lasthandoff: 02/26/2019
ms.locfileid: "56836410"
---
# <a name="steps-in-the-outer-loop-devops-workflow-for-a-docker-application"></a>Docker アプリケーションの外側のループ DevOps ワークフローの手順を実行します。
図 5-1 は、DevOps の外側のループのワークフローを構成する手順の説明、エンド ツー エンドの図を表示します。

**図 5-1**します。 Microsoft ツールと Docker アプリケーション DevOps 外側のループのワークフロー
次に、それぞれの手順を詳しく見ていきましょう。
## <a name="step-1-inner-loop-development-workflow"></a>手順 1: 内部ループ開発ワークフロー
この手順は、第 4 章で詳しく説明を要約すると、ここでは、外側のループ開始位置となる、開発者が CI パイプラインのアクションの開始 (Git) のようなソース コントロール管理システムにコードをプッシュする時点。
## <a name="step-2-source-code-control-integration-and-management-with-azure-devops-services-and-git"></a>手順 2: ソース コード管理の統合と Azure DevOps サービスと Git による管理
この手順では、チームのさまざまな開発者から、すべてのコードの統合されたバージョンを収集するバージョン管理システムに用意する必要があります。
アプリケーションを Docker イメージを送信する必要がありますいないを強調するために重要な場合でも、ソース コード管理 (SCC) とソース コード管理には、習慣にほとんどの開発者、DevOps ライフで Docker アプリケーションを作成するときのサイクルと思われる場合があります、直接、グローバル Docker レジストリに (Azure Container Registry や Docker Hub) など、開発者のマシンから。 反対に、グローバル ビルドまたはソース コード リポジトリ (Git) などに基づく CI パイプラインで、統合されることは、ソース コードのみにリリースされ、運用環境に展開する Docker イメージを作成する必要があります。
独自のマシン内でテストするときに、それらにより、開発者によって生成される、ローカルのイメージを使用だけください。 その理由は DevOps パイプラインを SCC コードからアクティブ化することが重要です。
Azure DevOps サービスと Team Foundation Server は、Git と Team Foundation バージョン管理をサポートします。 それらの間を選択し、エンド ツー エンドの Microsoft エクスペリエンスを使用できます。 ただし、管理することもできます (GitHub、Git リポジトリをオンプレミス、または Subversion) ような外部リポジトリでは、コードとそれに接続し、DevOps の CI パイプラインの開始点としてコードを取得できます。
## <a name="step-3-build-ci-integrate-and-test-with-azure-devops-services-and-docker"></a>手順 3: ビルド、CI、統合、および Azure DevOps を使用してテスト サービスと Docker
CI が最新のソフトウェアのテストおよび配信のための標準として登場しました。 Docker ソリューションでは、開発および運用チーム間での問題を明確に分離を維持します。 Docker イメージの不変性により、どのような開発、CI、テストおよび運用環境で実行が間に反復可能なデプロイ。 Docker エンジン開発者向けのノート パソコンに展開し、テスト インフラストラクチャは、環境間で、コンテナーを移植性。
この時点で、送信された正しいコードにバージョン管理システムがある必要があります、*サービスを構築*コードを選択し、グローバル ビルドとテストを実行します。
(CI、ビルド、テスト) この手順の内部ワークフローとは、ビルド サーバー (Azure DevOps サービス)、Docker エンジンと Docker レジストリをコード リポジトリ (Git など) から成る CI パイプラインを作成する方法。
できますサービスを使用する Azure DevOps の基盤として、アプリケーションを構築および、CI のパイプラインを設定するため、組み込みの「アイテム」を公開するため"アーティファクト リポジトリに、"については、次の手順で説明します。
Docker を使用して、展開は、「最終的な成果物」ときに展開するのには、アプリケーションやサービスを使用した Docker イメージ内に埋め込まれます。 これらのイメージのプッシュまたは発行を*Docker レジストリ*(Azure Container Registry で使用できるはまたはの公式の基本イメージの一般的な使用の Docker Hub レジストリなどのパブリック 1 などのプライベート リポジトリ)。
基本的な概念を次に示します。CI パイプラインは、Git などのソース コード管理リポジトリにコミットしてから開始されます。 図 5-2 に示すように、コミットは、Docker コンテナー内のビルド ジョブを実行し、そのジョブが正常に完了すると、Docker レジストリに Docker イメージをプッシュする DevOps サービスを Azure になります。

**図 5-2** CI で必要な手順
Docker と Azure DevOps サービスの基本的な CI ワークフロー手順を次に示します。
1. 開発者は、ソース コード管理リポジトリ (Git または Azure DevOps Services、GitHub など) にコミットをプッシュします。
2. Azure DevOps Services または Git を使用している場合は、CI ビルドは、Azure DevOps サービスのチェック ボックスを選択するだけであることを意味します。 (GitHub) などの外部の SCC を使用している場合、`webhook`更新プログラムの DevOps サービスを Azure に通知または Git と GitHub にプッシュされます。
3. Azure DevOps サービスは、イメージだけでなく、アプリケーションとテストのコードを記述する Dockerfile を含む、SCC リポジトリをプルします。
4. Azure DevOps サービスは、Docker イメージをビルドおよびビルド番号のラベルします。
5. Azure DevOps サービスは、プロビジョニング済みの Docker ホスト内の Docker コンテナーをインスタンス化し、適切なテストを実行します。
6. 「試みられたビルド」がわかるように、イメージが最初にわかりやすい名前を付け、テストが成功した場合は、(のように"/1.0.0"またはその他の任意のラベル)、(Docker Hub、Azure Container Registry、DTR など)、Docker レジストリにプッシュし、
### <a name="implementing-the-ci-pipeline-with-azure-devops-services-and-the-docker-extension-for-azure-devops-services"></a>Azure DevOps サービス用の Azure DevOps サービスと Docker 拡張機能を使用して、CI パイプラインの実装
Visual Studio の Azure DevOps サービスには、ビルド (&)、CI/CD パイプラインを Docker イメージを作成、認証済みの Docker レジストリに Docker イメージをプッシュ、または実行する Docker イメージ、によって提供されるその他の操作を実行に使用できるリリース テンプレートが含まれています。Docker CLI。 また、ビルド、プッシュ、およびマルチ コンテナー Docker アプリケーションを実行または図 5-3 に示すように Docker Compose CLI によって提供されるその他の操作を実行に使用できる Docker Compose のタスクを追加します。

**図 5-3** ビルド & リリース テンプレートと関連するタスクを含む Azure DevOps サービスで Docker CI パイプラインです。
これらのテンプレートとタスクを使用するにはビルド/テストおよびデプロイする CI/CD アーティファクトを作成する Azure Service Fabric、Azure Kubernetes サービス、および類似のサービスです。
これらの Visual Studio Team Services タスクとビルドを Linux Docker ホスト/VM Azure でプロビジョニングし、(Azure Container Registry、Docker Hub、プライベート Docker DTR、またはその他の任意の Docker レジストリ)、優先の Docker レジストリの Docker の CI パイプラインをアセンブルできます、非常に一貫した方法です。
***要件:***
- Azure DevOps サービス、またはオンプレミス インストールの場合、Team Foundation Server 2015 Update 3 またはそれ以降。
- Docker バイナリを含む Azure DevOps サービス エージェント。
これらのエージェントのいずれかを作成する簡単な方法では、Docker を使用して、Azure DevOps サービス エージェントの Docker イメージに基づくコンテナーを実行します。
> [!情報] をクリックし、Azure DevOps サービスの Docker CI のアセンブリについての詳細はパイプラインし、チュートリアルの表示を読み取り、これらのサイトを参照してください。
>
> - Docker コンテナーとして、Visual Studio Team Services (今すぐ Azure DevOps サービス) エージェントを実行します \。
> [*https://hub.docker.com/r/microsoft/vsts-agent/*](https://hub.docker.com/r/microsoft/vsts-agent/)
>
> - Azure DevOps サービスを使用した .NET Core Linux Docker イメージを構築します \。
> [*https://blogs.msdn.microsoft.com/stevelasker/2016/06/13/building-net-core-linux-docker-images-with-visual-studio-team-services/*](https://blogs.msdn.microsoft.com/stevelasker/2016/06/13/building-net-core-linux-docker-images-with-visual-studio-team-services/)
>
> - Docker サポートし、マシンを構築する Linux ベースの Visual Studio チーム サービスの構築: \
> [*http://donovanbrown.com/post/2016/06/03/Building-a-Linux-Based-Visual-Studio-Team-Service-Build-Machine-with-Docker-Support*](http://donovanbrown.com/post/2016/06/03/Building-a-Linux-Based-Visual-Studio-Team-Service-Build-Machine-with-Docker-Support)
### <a name="integrate-test-and-validate-multi-container-docker-applications"></a>統合、テスト、およびマルチ コンテナー Docker アプリケーションの検証
通常、1 つのコンテナーではなく、複数のコンテナーの Docker アプリケーションのほとんどがで構成されます。 良い例は、マイクロ サービスごとに 1 つのコンテナーが、マイクロ サービス指向アプリケーションです。 ただし、マイクロ サービス アプローチのパターンに厳密に従うと、なくては Docker アプリケーションは、複数のコンテナーまたはサービスの構成は可能性の高い。
そのため、CI パイプラインでアプリケーション コンテナーをビルドした後も必要があります、展開、統合、およびすべての統合の Docker ホスト内で、またはさらには、コンテナーがテスト クラスターには、そのコンテナー全体のアプリケーションをテストするには分散されます。
1 つのホストを使用している場合は、docker などの Docker コマンドを使用することができます-ビルドしてデプロイをテストし、1 つの VM で Docker 環境を検証関連のコンテナーを作成します。 しかし、DC/OS、Kubernetes、Docker Swarm などをオーケストレーター クラスタを使用する場合は別のメカニズムまたはオーケストレーターで、選択したクラスター/スケジューラによって、コンテナーをデプロイする必要があります。
次に、Docker コンテナーに対して実行できるテストの種類をいくつか示します。
- Docker コンテナー用の単体テスト
- 相互に関連するアプリケーションやマイクロ サービスのグループのテスト
- 運用環境と「カナリア」のリリースでのテストします。
重要な点は、統合と機能テストを実行するときに、コンテナーの外部からそれらのテストを実行する必要があります。 テストは含まれているまたはコンテナーが必要がありますが、運用環境にデプロイするものとまったく同じように静的なイメージに基づいているために、展開する場合は、コンテナーで実行できません。
実用的なオプションでは、いくつかのクラスター (クラスター、クラスターのステージング、および運用環境のクラスターのテスト) を含むなどのシナリオより高度なテスト時に、さまざまなクラスターでテストできますのでをレジストリにイメージを発行することです。
### <a name="push-the-custom-application-docker-image-into-your-global-docker-registry"></a>グローバルな Docker レジストリをカスタム アプリケーションの Docker イメージをプッシュします。
Docker イメージをテストおよび検証した後にタグ付けし、Docker レジストリに公開します。 Docker レジストリは重要な部分を Docker アプリケーションのライフ サイクルの QA および実稼動環境にデプロイするのには、カスタム テスト (「試みられたイメージ」とも呼ばれます) を格納する中央の場所です。
方法、ソース コード管理リポジトリ (Git など) に格納されているアプリケーション コードは、「普遍の情報源」と同様に、Docker レジストリは、「ソース実のところの」、QA 環境または運用環境にデプロイするには、バイナリのアプリケーションやビットです。
通常、Azure コンテナー レジストリまたは Docker Trusted Registry のように、オンプレミスのレジストリまたは (制限付きのアクセス権を持つパブリック クラウドのレジストリで、カスタム イメージのプライベート リポジトリをプライベート リポジトリのいずれかがする可能性があります。Docker Hub)、この最後の場合、コードがオープン ソースの場合でも、ベンダーのセキュリティを信頼する必要があります。 どちらの方法を使用するメソッドはのようなに基づいて、`docker push`コマンド、図 5-4 に示すようにします。

**図 5-4** カスタム イメージを Docker レジストリに発行
Azure Container Registry、Amazon Web Services Container Registry、Google Container Registry、Quay レジストリなどのクラウド ベンダーからの Docker レジストリの複数のサービス提供しています。
Docker タスクを使用して、定義したサービスのイメージのセットをプッシュすることができます、`docker-compose.yml`ファイル (Azure Container Registry) などの認証済みの Docker レジストリに、複数のタグと図 5-5 に示すようにします。

**図 5-5** Azure DevOps サービスを使用して Docker レジストリにカスタム イメージを発行する
> [!情報] Azure Container Registry の詳細については、次を参照してください。<https://aka.ms/azurecontainerregistry>します。
## <a name="step-4-cd-deploy"></a>手順 4: CD、展開
Docker イメージの不変性により、反復可能な展開に何が開発、CI、テストし、運用環境で実行します。 所持している複数の環境に展開したり、Docker レジストリ (プライベートまたはパブリック) で公開されているアプリケーションの Docker イメージを作成したら、(運用、QA、ステージングなど) Azure DevOps サービスを使用して、CD パイプラインからパイプラインのタスクまたは Azure DevOps サービス リリース管理されます。
ただし、この時点でに依存する展開する Docker アプリケーションの種類。 簡単なアプリケーション (構成と展開の観点から)、モノリシックのように、いくつかのコンテナーやサービスを構成するアプリケーションと展開をいくつかのサーバーまたは Vm を展開するとは異なるような複雑なアプリケーションを展開します。ハイパー スケール機能を備えたマイクロ サービス指向アプリケーションです。 これら 2 つのシナリオは、次のセクションについて説明します。
### <a name="deploying-composed-docker-applications-to-multiple-docker-environments"></a>複数の Docker 環境への Docker アプリケーションの展開で構成されています
最初に、複雑なシナリオを見てみましょう。 単純で Docker ホスト (Vm またはサーバー) 環境を 1 つまたは複数の環境に展開する (品質保証、ステージング、および運用)。 このシナリオで内部的には、CD パイプラインできますを使用して docker-図 5-6 に示すようにコンテナーやサービス、その関連する一連の Docker アプリケーションを展開する (Azure DevOps サービス展開タスク) から作成します。

**図 5-6**します。 単純な Docker ホスト環境のレジストリにアプリケーション コンテナーのデプロイ
図 5-7 は、タスクの追加 ダイアログ ボックスの Docker Compose をクリックして、Azure DevOps サービスを使用して、QA/テスト環境にビルド、CI を接続する方法を示しています。 ただし、ステージング環境または運用環境を展開する場合は、通常使用する Release Management の機能が複数の環境を処理 (などの QA、ステージング、および運用)。 Azure DevOps サービスを使用して単一の Docker ホストにデプロイする場合は"Docker Compose"タスク (を呼び出すことは、`docker-compose up`内部的にはコマンド)。 Azure Container Service にデプロイする場合は、以下のセクションで説明したように、Docker デプロイ タスクを使用します。

**図 5-7** Azure DevOps サービス パイプラインで Docker Compose のタスクを追加します。
Azure DevOps サービスで、リリースを作成するときに、一連の入力の成果物がかかります。 これらの成果物が意図されていない変更可能なリリースの有効期間のすべての環境で。 コンテナーを導入するときに、入力の成果物を展開する、レジストリ内のイメージを識別します。 これらのイメージの識別方法に応じてする保証はありません、最も明白なケースが参照すると、リリースの全期間にわたって同じまま`myimage:latest`から、`docker-compose`ファイル。
Azure DevOps サービス テンプレートが表示ダイジェストとなる特定のレジストリのイメージが含まれているビルド成果物を生成する機能と同じイメージのバイナリを一意に識別することが保証されます。 これらは実際に、リリースへの入力として使用します。
### <a name="managing-releases-to-docker-environments-by-using-azure-devops-services-release-management"></a>Azure DevOps Services Release Management を使用して Docker 環境にリリースを管理します。
Azure DevOps サービス テンプレートを新しいイメージをビルド、Docker レジストリに発行して、Linux または Windows のホストで実行してのコマンドを使用します`docker-compose`Azure DevOps などのアプリケーションが全体として複数のコンテナーをデプロイするには。図 5-8 に示すように複数の環境用リリース管理機能をサービスします。

**図 5-8**. Azure DevOps サービス Release Management から Azure DevOps サービスの Docker Compose のタスクを構成します。
ただし、図 5-6 に示すように、図 5-8 の実装のシナリオは、単純なものにしてください (単一の Docker ホストと Vm への展開は、および 1 つのコンテナーまたはイメージごとのインスタンス) と、おそらく、開発またはテスト sce に対してのみ使用する必要がありますnarios します。 高可用性 (HA) と管理が容易なスケーラビリティが複数のノード、サーバー、Vm、および「インテリジェントなフェールオーバー」の間で負荷分散をするほとんどのエンタープライズ運用環境シナリオで、サーバーまたはノードが失敗した場合、そのサービスとコンテナー別のホスト サーバーまたは VM に移動されます。 その場合は、クラスターのコンテナー、オーケストレーター、およびスケジューラなどのより高度なテクノロジ必要があります。 したがって、これらのクラスターにデプロイする方法は、高度なシナリオを処理することで、[次へ] のセクションで説明します。
### <a name="deploying-docker-applications-to-docker-clusters"></a>Docker クラスターへの Docker アプリケーションの展開
分散アプリケーションの性質も分散されるコンピューティング リソースが必要です。 運用規模の機能には、高いスケーラビリティとプールされたリソースに基づく、高可用性を提供する機能をクラスタ リングにする必要があります。
コンテナーを CLI ツールまたは web UI からこれらのクラスターに手動でデプロイできますが、その種のスポット展開のテストに手動の作業を予約する必要があります。 またはスケール アウトや監視などの管理のため。
CD の観点と Azure DevOps サービスから具体的には、タスクを実行できます特別に作成された展開から、Azure DevOps サービス リリース管理環境をコンテナーに分散クラスターにコンテナー化されたアプリケーションを展開します。図 5-9 に示すようには、サービスです。

**図 5-9** 分散アプリケーションをコンテナー サービスを展開します。
最初を特定のクラスターやオーケストレーターに展開する場合は従来使用して特定の展開スクリプトと各オーケストレーター (Kubernetes およびさまざまな展開メカニズムがある Service Fabric) メカニズムではなく、単純です使いやすい`docker-compose`に基づいてツール、`docker-compose.yml`定義ファイル。 ただし、図 5-10 に示すように、Azure DevOps サービスの Docker デプロイ タスクに協力してくれたするようになりましたデプロイこともできますサポートされているオーケストレーターを使い慣れたを使用するだけで`docker-compose.yml`ツールが「変換」を実行するためのファイル (、から`docker-compose.yml`をオーケストレーターで必要な形式のファイル)。

**図 5-10** RM 環境への Docker デプロイ タスクの追加
図 5-11 は、Docker の展開タスクを編集し、対象の型 (Azure Container Service DC/OS、ここでは)、Docker Compose ファイル、および (Azure Container Registry や Docker Hub) などの Docker レジストリ接続を指定する方法について説明します。 これは、すぐに使用できるカスタム Docker イメージとして、クラスター内のコンテナー デプロイを取得するタスク。

**図 5-11** Docker デプロイ タスクの定義を展開する Azure Container Service DC/OS に
> [!詳細情報] に関する Azure DevOps サービスと Docker の CD パイプラインを次を参照してください。 <https://azure.microsoft.com/services/devops/pipelines>
## <a name="step-5-run-and-manage"></a>手順 5: 実行し、管理
エンタープライズ運用レベルは、し、それ自体のと操作の種類のための主要なサブジェクトと、ユーザーがこの領域の大きなスコープとそのレベル (IT 運用) にとって、全体を次に充てることが実行されていると、アプリケーションを管理するためこれを説明する章です。
## <a name="step-6-monitor-and-diagnose"></a>手順 6: 監視し、診断
このトピックでは、次についても説明、タスクの一部として章実稼働システムでその IT を実行しますただしが、アプリケーションが頻繁に改善するために、開発チームにこの手順で得られた知見をフィードする必要がありますを強調表示に重要です。 そのポイントの表示からもの一部では、DevOps タスクと操作によって実行が一般的ですが IT です。
監視と診断は、DevOps の領域内の 100% の場合にのみは、監視のプロセスとまたはベータ版のテスト環境に対して、開発チームによって実行された分析です。 これは、ロード テストを実行するか、ベータ版またはベータ テスト担当者が新しいバージョンを試みている、QA 環境を監視します。
>[!div class="step-by-step"]
>[前へ](index.md)
>[次へ](create-ci-cd-pipelines-azure-devops-services-aspnetcore-kubernetes.md) | 13,612 | CC-BY-4.0 |
# 工厂模式(Factory)
[参考地址](https://segmentfault.com/a/1190000007473294)
## 概念
- 是我们最常用的实例化对象的模式
- 是用工厂方法代替*new*操作的一种模式
## 优点
- 如修改实例化的类名时,只需修改该工厂方法的内容即可,不需逐一寻找代码中具体实例化的地方(*new*处)修改了。为系统结构提供**灵活的动态扩展机制,减少了耦合**。
## 细分
- [简单工厂模式](#简单工厂模式)
- [工厂方法模式](#工厂方法模式)
- [抽象工厂模式](#抽象工厂模式)
### 简单工厂模式
- 又称静态工厂方法模式,通过一个静态方法来创建对象
- 代码示例
<?php
/* 定义人类的接口 */
interface People {
function say();
}
class Man implements People {
function say() {
echo "Man";
}
}
class Women implements People {
function say() {
echo "Women";
}
}
/* 工厂类 */
class SimpleFactory {
// 静态方法-创建对象
static function createMan(){
return new Man();
}
static function createWomen(){
return new Women();
}
}
//调用
$man = SimpleFactory::createMan();
$man->say(); // 输出 Man
$women = SimpleFactory::createWomen();
$women->say(); // 输出 Women
### 工厂方法模式
- 定义**一个**用于创建对象的接口,让子类决定哪个类实例化
- 可以解决简单工厂模式中的**[开放封闭原则](../principle/OCP.md)**问题
- 代码示例:
<?php
/* 定义人类的接口 */
interface People {
function say();
}
class Man implements People {
function say(){echo "Man";}
}
class Women implements People {
function say(){echo "Women";}
}
/* 将对象的创建抽象成一个接口 */
interface CreatePeople {
function create();
}
class FactoryMan implements CreatePeople {
function create() {
return new Man();
}
}
class FactoryWomen implements CreatePeople {
function create() {
return new Women();
}
}
/*调用*/
$manFactory = new FactoryMan();
$man = $manFactory->create();
$man->say();
$womenFactory = new FactoryWomen();
$women = $womenFactory->create();
$women->say();
## 抽象工厂模式
- 提供一个创建**一系列**相关或相互依赖对象的接口
- 和工厂方法的区别是:一系列(多个),而工厂方法只有一个
- 代码示例:
<?php
interface People {
function say();
}
class OneMan implements People {
function say(){ echo "OneMan"; }
}
class TwoMan implements People {
function say(){ echo "TwoMan"; }
}
class OneWomen implements People {
function say(){ echo "OneWomen"; }
}
class TwoWomen implements People {
function say(){ echo "TwoWomen"; }
}
/* 定义一个创建一系列对象的接口,含有多个工厂方法 */
interface CreatePeople {
function createOne();
function createTwo();
}
class FactoryMan implements CreatePeople {
function createOne(){
return new OneMan();
}
function createTwo(){
return new TwoMan();
}
}
class FactoryWomen implements CreatePeople {
function createOne(){
return new OneWomen();
}
function createTwo(){
return new TwoWomen();
}
}
/* 调用 */
$manFactory = new FactoryMan();
$oneMan = $manFactory->createOne();
$oneMan->say();
$twoMan = $manFactory->createTwo();
$twoMan->say();
$womenFactory = new FactoryWomen();
$oneWomen = $womenFactory->createOne();
$oneWomen->say();
$twoWomen = $womenFactory->createTwo();
$twoWomen->say();
## 区别
- 简单工厂模式(静态方法工厂模式): 用来生成同一等级结构中的固定产品(不能增加新的产品)
- 工厂方法模式: 用来生成同一等级的任意产品(支持添加任意产品)
- 抽象工厂模式: 用来生产不同产品种类的全部产品(不能增加新的产品,支持增加产品种类)
## 适用范围
- 简单工厂模式:工厂类负责创建的对象较少,操作时只需知道传入工厂类的参数即可,对于如何创建对象过程不用关心。
- 工厂方法模式:满足以下条件时,可以考虑使用工厂方法模式
- 当一个类不知道它所必须创建对象的类时
- 一个类希望由子类来指定它所创建的对象时
- 当类将创建对象的职责委托给多个帮助子类中的某一个,并且你希望将哪一个帮助子类是代理者这一信息局部化时
- 抽象工厂模式:满足以下条件时,可以考虑使用抽象工厂模式
- 系统不依赖于产品类实例如何被创建,组合和表达的细节。
- 系统的产品有多于一个的产品族,而系统只消费其中某一族的产品
- 同属于同一个产品族是在一起使用的。这一约束必须在系统的设计中体现出来。
- 系统提供一个产品类的库,所有产品以同样的接口出现,从而使客户端不依赖于实现
以上几种,归根结底,都是将重复的东西提取出来,以方便整体解耦和复用,修改时方便。可根据具体需求而选择使用。 | 3,921 | MIT |
# 頁面佈局(Layouts)

## Avoid positioning properties 要避開座標屬性
Components should be made in a way that they're reusable in different contexts. Avoid putting these properties in components:<br>
建立出來的元件必須是可以在不同地方重複使用的,因此我們要避免使用到以下的屬性。
* Positioning (`position`, `top`, `left`, `right`, `bottom`)
* 座標相關 (`position`, `top`, `left`, `right`, `bottom`)
* Floats (`float`, `clear`)
* 浮動相關 (`float`, `clear`)
* Margins (`margin`)
* 邊距相關 (`margin`)
* Dimensions (`width`, `height`)
* 尺寸相關 (`width`, `height`)
## Fixed dimensions 固定尺寸
Exception to these would be elements that have fixed width/heights, such as avatars and logos.
當然有些例外的情況是需要固定的長寬,像是 替身(avatar) 或是標誌(logo)。
## Define positioning in parents 在父節點定義位置
If you need to define these, try to define them in whatever context they will be in. In this example below, notice that the widths and floats are applied on the *list* component, not the component itself. <br>
如果你需要定義上述的屬性,試著定義他們在任何區塊都是一樣的。例如下面的範例,要注意到寬度及浮動的屬性是設定在 *list* 元件,而不是元件本身。
```css
.article-list {
& {
@include clearfix;
}
> .article-card {
width: 33.3%;
float: left;
}
}
.article-card {
& { /* ... */ }
> .image { /* ... */ }
> .title { /* ... */ }
> .category { /* ... */ }
}
```
How do you apply margins outside a layout? Try it with Helpers.
如何在頁面佈局外使用邊距,試試 Helpers 吧。
[Continue 繼續 →](helpers.md)
<!-- {p:.pull-box} --> | 1,446 | MIT |
# async函数
------
| 标题 | 内容 |
| --- | --- |
| async的引入 | `AsyncFunction`构造函数, `Generator` |
| async的含义 | async函数是什么? |
| async的特点 | 内置执行器, 更好的语义, 更广的适用性, 返回值是`Promise` |
| async的实现原理 | `Generator`函数, 自动执行器 |
------
## async的引入
- ES2017标准引入了` async `函数,使得异步操作变得更加方便。也可以说是`Generator`的语法糖。
### (了解)AsyncFunction构造函数
- `AsyncFunction`构造函数用来创建新的**异步函数**对象,JavaScript中每个异步函数都是`AsyncFunction`的对象。
```javascript
async function asyncFunction(){}
asyncFunction.constructor
// AsyncFunction() { [native code] }
```
- **注意**: `AsyncFunction`并不是全局对象,需要通过下面的方法来获取:
```javascript
Object.getPrototypeOf(async function(){}).constructor
// AsyncFunction() { [native code] }
```
#### AsyncFunction语法
```javascript
new AsyncFunction([arg1[, arg2[, ...argN]],] functionBody)
```
#### AsyncFunction参数
- `arg1, arg2, ... argN`: 函数的参数名,它们是符合`JavaScript`标示符规范的一个或多个用逗号隔开的字符串。例如`x, theValue`或`a, b`。
- `functionBody`: 一段字符串形式的`JavaScript`语句,这些语句组成了新函数的定义。
```javascript
function resolveAfter2Seconds(x) {
return new Promise(resolve => {
setTimeout(() => {
resolve(x);
}, 2000);
});
}
var AsyncFunction = Object.getPrototypeOf(async function(){}).constructor;
var a = new AsyncFunction('a',
'b',
'return await resolveAfter2Seconds(a) + await resolveAfter2Seconds(b);');
a(10, 20).then(v => {
console.log(v); // 4 秒后打印 30
});
```
- 执行` AsyncFunction `构造函数的时候,会创建一个**异步函数**对象。但是这种方式不如先用**异步函数表达式**定义一个异步函数,然后再调用其来创建**异步函数**对象来的高效,因为第二种方式中**异步函数是与其他代码一起被解释器解析**的,而第一种方式的**函数体是单独解析**的。
- 传递给` AsyncFunction `构造函数的**所有参数**,都会成为**新函数中的变量**,**变量的名称和定义顺序与各参数相同**。
- **注意**: 使用` AsyncFunction `构造函数创建的**异步函数**并不会在**当前上下文中创建闭包**,其**作用域始终是全局**的。因此运行的时候只能访问**它们自己的本地变量**和**全局变量**,但**不能访问构造函数被调用的那个作用域中的变量**。这是它与` eval `不同的地方(`eval`函数最好永远也不要使用)。
```javascript
/**
* @description 自己的本地变量和全局变量
*/
function resolveAfter2Seconds(x) {
return new Promise(resolve => {
setTimeout(() => {
resolve(x);
}, 2000);
})
}
var c = 1;
var AsyncFunction = Object.getPrototypeOf(async function(){}).constructor;
var a = new AsyncFunction('a', 'b', 'c', 'return await resolveAfter2Seconds(a) + await resolveAfter2Seconds(b) + await resolveAfter2Seconds(c);');
a(10, 20, c).then(v => {
console.log(v);
})
```
```javascript
/**
* @description 建议: 永远不要使用eval
*/
function test() {
var x = 2, y = 4;
console.log(eval('x + y')); // 直接调用,使用本地作用域,结果是 6
var geval = eval; // 等价于在全局作用域调用
console.log(geval('x + y')); // 间接调用,使用全局作用域,throws ReferenceError 因为`x`未定义
(0, eval)('x + y'); // 另一个间接调用的例子
}
```
- 调用` AsyncFunction `构造函数时可以省略` new `,其效果是一样的。
------
### async函数
- async函数是使用`async`关键字声明的函数。async函数是AsyncFunction构造函数的实例,并且其中允许使用`await`关键字。
- async和await关键字让我们可以用一种更简洁的方式写出基于`Promise`的异步行为,而无需刻意地链式调用`promise`。
```javascript
function resolveAfter2Seconds() {
return new Promise(resolve => {
setTimeout(() => {
resolve('resolved');
}, 2000);
});
}
async function asyncCall() {
console.log('calling');
const result = await resolveAfter2Seconds();
console.log(result);
}
aysncCall();// 先输出calling 2秒之后输出resolved
```
#### async函数的语法
```javascript
async function name([param[, param[, ... param]]]) {
statements
}
```
#### async函数的参数
- `name`: 函数名称。
- `param`: 要传递给函数的参数的名称。
- `statements`: 包含函数主体的表达式。可以使用`await`机制。
#### 返回值
- 一个`Promise`, 这个`promise`要么会通过一个由`async`函数返回的值被解决, 要么会通过一个从`async`函数中抛出的(或其中没有被捕获到的)异常被拒绝。
```javascript
async function foo() {
return 1
}
// 等价于
function foo() {
return Promise.resolve(1)
}
```
```javascript
async function foo() {
await 1
}
// 等价于
function foo() {
return Promise.resolve(1).then(() => undefined)
}
```
------
## async的含义
- async函数的函数体可以被看作是由**0个**或者**多个**await表达式分割开来的。从**第一行代码**直到(并包括)**第一个await表达式**(如果有的话)都是**同步运行**的。这样的话,一个**不含await表达式的async函数是会同步运行**的。然而, 如果**函数体内有一个await表达式**, async函数就一定会**异步执行**。
```javascript
// promise链不是一次就构建好的,相反,promise链是分阶段构造的,因此在处理异步函数时必须注意对错误函数的处理
async function foo() {
const result1 = await new Promise((resolve) => setTimeout(() => resolve('1')))
const result2 = await new Promise((resolve) => setTimeout(() => resolve('2')))
}
foo()
```
- 上面的执行顺序:
- 1. foo函数的第一行将会同步执行, await将会等待promise的结束。然后暂停通过foo的进程, 并将控制权交还给调用foo的函数。
- 2. 一段时间后, 当第一个promise完结的时候, 控制权将重新回到foo函数内。示例中将会`1`(promise状态为fulfilled)作为结果返回给await表达式的左边即`result1`。接下来函数会继续进行, 到达第二个await区域, 此时foo函数的进程将再次被暂停。
- 3. 一段时间后, 同样当第二个promise完结的时候, `result2`将被赋值为`2`, 之后函数将会正常同步执行, 将默认返回`undefined`。
```javascript
// 在promise链上配置了.catch处理程序,将抛出未处理的promise错误。这是因为p2返回的结果不会被await处理
async function foo() {
const p1 = new Promise((resolve) => setTimeout(() => resolve('1'), 1000))
const p2 = new Promise((_,reject) => setTimeout(() => reject('2'), 500))
const results = [await p1, await p2] // 不推荐使用这种方式,请使用 Promise.all或者Promise.allSettled
}
foo().catch(() => {}) // 捕捉所有的错误...
```
```javascript
// 函数声明
async function foo() {};
// 函数表达式
const foo = async function () {};
// 对象的方法
let obj = { async foo() {} };
obj.foo().then(...)
// Class的方法
class Storage {
constructor() {
this.cachePromise = caches.open('avatars');
}
async getAvatar(name) {
const cache = await this.cachePromise;
return cache.match(`/avatars/${name}.jpg`);
}
}
const storage = new Storage();
storage.getAvatar('jack').then(...);
// 箭头函数
const foo = async () => {};
```
-----
## async的特点
### 内置执行器
- `Generator `函数的执行必须靠执行器,所以才有了`co`模块,而async函数**自带执行器**。也就是说,async函数的执行,与普通函数一模一样,只要一行。
```javascript
const asyncFunction = async function () {
const f1 = await 1
const f2 = await 2
console.log(f1.toString());
console.log(f2.toString());
};
asyncFunction();
// 1
// 2
```
- 上面的代码调用了`asyncFunction`函数, 然后它就会自动执行, 输出最后结果。这完全不像`Generator`函数, 需要调用`next`方法,或者使用`co`模块, 才能真正执行, 得到最后结果。
```javascript
var gen = function* () {
var f1 = yield 1
var f2 = yield 2
console.log(f1.toString())
console.log(f2.toString())
}
var co = require('co'); // Generatir直接执行需要使用co模块
co(gen).then(function() {
console.log('Generator 函数执行完成');
});
// 1
// 2
// Generator 函数执行完成
```
### 更好的语义
- `async`和`await`, 比起**星号**和`yield`, 语义更清楚了。`async`表示函数里有异步操作, `await`表示紧跟在后面的表达式需要等待结果。
```javascript
const asyncFunction = async function() {
const f1 = await 1 // 紧跟在后面的表达式需要等待结果
const f2 = await 2
console.log(f1.toString())
console.log(f2.toString())
}
```
```javascript
const genFunction = function* () {
const f1 = yield 1
const f2 = yield 2
console.log(f1.toString())
console.log(f2.toString())
}
```
### 更广的实用型
- `co`模块约定, `yield`命令后面只能是**Thunk函数**或者**Promise对象**, 而`async`函数的`await`命令后面, 可以是**Promise对象**和**原始类型的值**(**数值**、**字符串**和**布尔值**, 但这时会自动转成**立即resolved的Promise对象**)。
```javascript
```
### 返回值是Promise
- `async`函数的返回值是**Promise对象**, 这比`Generator`函数的返回值是`Iterator`对象方便多了。你可以用`then`方法指定下一步的操作。
```javascript
function getStockSymbol(name) {
const symbolName = Symbol(name)
return symbolName
}
function getStockUser(symbol) {
return symbol
}
async function getUserByName(name) {
const symbol = await getStockSymbol(name);
const stockUser = await getStockUser(symbol);
console.log('stockUser', stockUser)
return stockUser;
}
getUserByName('JackDan').then(function (result) {
console.log(result)
})
```
- 进一步说, `async`函数完全可以看作多个异步操作, 包装成的一个**Promise对象**, 而`await`命令就是内部`then`命令的语法糖。
```javascript
function timeout(ms) {
return new Promise((resolve) => {
setTimeout(resolve, ms);
});
}
async function asyncPrint(value, ms) {
await timeout(ms)
console.log(value)
}
asyncPrint('hello world', 5000);
// 间隔5秒 输出hello world
```
- 由于`async`函数返回的是` Promise `对象,可以作为`await`命令的参数。
```javascript
async function timeout(ms) {
await new Promise((resolve) => {
setTimeout(resolve, ms);
});
}
async function asyncPrint(value, ms) {
await timeout(ms);
console.log(value);
}
asyncPrint('hello world', 3000);
// 间隔3秒 输出hello world
```
------
## async的实现原理
- async函数的实现原理, 就是将`Generator`函数和**自动执行器**, 包装在一个函数里。
```javascript
async function asyncFunction() {
// ...
}
// 等同于
function asyncFunction(args) {
return spawn(function* () {
// ...
})
}
function spawn(genFunction) {
// 返回一个Promise对象, async返回的也是Promise对象
return new Promise(function(resolve, reject) {
const _gen = genFunction();
function step(nextFunction) {
let _next;
try {
_next = nextFunction();
} catch(e) {
return reject(e);
}
if(_next.done) {
return resolve(_next.value);
}
Promise.resolve(_next.value).then(function(v) {
step(function() { return _gen.next(v); });
}, function(e) {
step(function() { return _gen.throw(e); });
})
}
step(function() { return _gen.next(undefined); });
})
}
```
------
## 来个示例
```javascript
var resolveAfter2Seconds = function () {
console.log("starting slow promise");
return new Promise((resolve) => {
setTimeout(function() {
resolve('slow');
console.log("slow promise is done");
}, 20000);
});
};
var resolveAfter1Seconds = function () {
console.log("starting fast promise");
return new Promise((resolve) => {
setTimeout(function() {
resolve('fast');
console.log("fast promise is done");
}, 1000);
});
};
var parallel = async function() {
console.log('==PARALLEL with await Promise.all==');
await Promise.all([
(async() => console.log(await resolveAfter2Seconds()))(),
(async() => console.log(await resolveAfter1Seconds()))()
]);
}
setTimeout(parallel, 10000);
```
```javascript
var resolveAfter2Seconds = function () {
console.log("starting slow promise");
return new Promise((resolve) => {
resolve('slow');
console.log("slow promise is done")
}, 2000);
}
var resolveAfter1Seconds = function () {
console.log("starting fast promise");
return new Promise((resolve) => {
resolve('fast');
console.log("fast promise is done");
}, 1000);
}
var sequentialStart = async function() {
console.log('==SEQUENTIAL START==');
// 1. Execution gets here almost instantly
const slow = await resolveAfter2Seconds();
console.log(slow); // 2. this runs 2 seconds after 1.
const fast = await resolveAfter1Second();
console.log(fast); // 3. this runs 3 seconds after 1.
}
```
```javascript
var resolveAfter2Seconds = function () {
console.log("starting slow promise");
return new Promise((resolve) => {
resolve('slow');
console.log("slow promise is done")
}, 2000);
}
var resolveAfter1Seconds = function () {
console.log("starting fast promise");
return new Promise((resolve) => {
resolve('fast');
console.log("fast promise is done");
}, 1000);
}
var concurrentStart = async function() {
console.log('==CONCURRENT START with await==');
const slow = resolveAfter2Seconds(); // starts timer immediately
const fast = resolveAfter1Second(); // starts timer immediately
// 1. Execution gets here almost instantly
console.log(await slow); // 2. this runs 2 seconds after 1.
console.log(await fast); // 3. this runs 2 seconds after 1., immediately after 2., since fast is already resolved
}
```
------
> JackDan Thinking
> https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Statements/async_function
> https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/AsyncFunction | 11,288 | MIT |
<properties
pageTitle="Logic Apps とは"
description="App Service Logic Apps ついてさらに詳しく説明します"
authors="kevinlam1"
manager="dwrede"
editor=""
services="app-service\logic"
documentationCenter=""/>
<tags
ms.service="app-service-logic"
ms.workload="na"
ms.tgt_pltfrm="na"
ms.devlang="na"
ms.topic="hero-article"
ms.date="04/07/2016"
ms.author="klam"/>
#Logic Apps とは
| クイック リファレンス |
| --------------- |
| [Logic Apps の定義言語](https://msdn.microsoft.com/library/azure/mt643789.aspx) |
| [Logic Apps コネクターのドキュメント](../connectors/apis-list.md) |
| [Logic Apps フォーラム](https://social.msdn.microsoft.com/Forums/en-US/home?forum=azurelogicapps) |
Azure App Service は、Web アプリ、モバイル アプリ、統合アプリの作成を容易にする、開発者向けの完全に管理された PaaS (サービスとしてのプラットフォーム) です。Logic Apps はこのスイートの一部であり、技術系ユーザーや開発者が、使いやすいビジュアル デザイナーを使用してビジネス プロセスの実行とワークフローを自動化できます。
特に、Logic Apps を組み込みの[マネージ API][managedapis] と組み合わせることで、扱いが難しい統合シナリオも簡単に解決できるようになります。

既に説明したように、Logic Apps を使うと、ビジネス プロセスを自動化できます。いくつかの例を次に示します。
* SQL DB の新しいレコードを自動的にレプリケートし、フロント デスクにメールを送信できます。
* ネガティブなツイートを自動的に検出し、スラック チャネルに送信できます。
こうしたシナリオはすべてビジュアル デザイナーで、コードを 1 行も記述することなく構成できます。[ロジック アプリの構築を今すぐ開始][create]しましょう。
## なぜ Logic Apps か
開発者は Logic Apps を使用することで、トリガーで開始され、一連のステップを実行するワークフローを設計できます。各ステップでは、認証とベスト プラクティス (チェックポイント処理や永続的な実行など) に確実に対処しながら、API を呼び出します。
ビジネス プロセスの自動化 (ネガティブなツイートを検出して組織内のスラック チャネルに送信する、SQL の新しい顧客レコードが到着したら、そのレコードを CRM システムにレプリケートするなど) が必要な場合、Logic Apps を使用すると、クラウドからオンプレミスに異なるデータ ソースを簡単に統合できます。[マネージ API][managedapis] について確認して何かひらめいたら、[作業を開始][create]して実際に何ができるか確かめましょう。
さらに、[BizTalk マネージ API][biztalk] では、[ルール エンジン][rules]や[取引先管理][tpm]など、数多くの機能を利用して統合シナリオを拡張することができます。
- **使いやすいデザイン ツール** - Logic Apps は、ブラウザーで全体を設計することができます。トリガーで開始 - 単純なスケジュールから会社についてのツイートが表示される各タイミングまで。次に、豊富なコネクタのギャラリーを使用して必要な数のアクションを調整します。
- **SaaS を簡単に構成** - 簡単に説明できるような構成タスクでさえ、コードとして実装するには困難が伴います。Logic Apps を使用すれば異なるシステムへの接続も簡単です。Facebook や Twitter アカウントのアクティビティに基づいて CRM ソフトウェアにタスクを作成しようとしていますか? クラウド マーケティング ソリューションをオンプレミスの請求書作成システムに接続しようとしていますか? Logic Apps は、これらの問題にソリューションを提供する、最も迅速で信頼できる手段です。
- **テンプレートからすばやく開始** - 作業開始を手助けするため、一般的なソリューションを速やかに作成できる[テンプレート ギャラリー][templates]が用意されています。高度な BizTalk ソリューションから単純な SaaS 接続まであるうえ、単なる 'お遊び用' のものも用意しています。Logic Apps の能力を理解するには、このギャラリーが一番の近道です。
- **組み込みの拡張機能** - 必要な API が見つかりませんか? Logic Apps は、API Apps と連携するように設計されています。独自の API アプリを作成してカスタム API として簡単に使用できます。自分だけの新しいアプリを作成するか、Marketplace で共有して収益化してください。
- **真の統合能力** - 手軽に始めて必要に応じて拡張できます。Logic Apps は、Microsoft の業界屈指の統合ソリューション、BizTalk の能力を統合担当者が簡単に利用して必要なソリューションを構築できるようにしています。[Logic Apps で提供される BizTalk の機能][biztalk]について、詳細を確認してください。
## Logic Apps の概念
Logic Apps の機能を構成する主な要素とは次のとおりです。
- **ワークフロー** - Logic Apps では、ビジネス プロセスを一連の手順やワークフローとしてグラフィカルにモデル化できます。
- **マネージ API** - ロジック アプリにはデータとサービスへのアクセスが必要です。マネージ API は、データへの接続とデータの操作を補助するために、特別に作成されます。現時点で使用できる API の一覧については、「[Logic Apps で使用するコネクタと API Apps の一覧][managedapis]」をご覧ください。
- **トリガー** - 一部のマネージ API は、トリガーとしても動作します。トリガーは、電子メールや Azure のストレージ アカウントの変更の到着などの特定のイベントに基づいて、ワークフローの新しいインスタンスを開始します。
- **アクション** - ワークフローにおけるトリガーの後の各ステップは、アクションと呼ばれます。通常、各アクションはマネージ API アプリまたはカスタム API アプリでの操作にマップされます。
- **BizTalk** - Logic Apps には、高度な統合シナリオ向けに Biztalk の機能が含まれています。Biztalk は、マイクロソフトの業界屈指の統合プラットフォームです。BizTalk API Apps により、Logic Apps ワークフローに検証、変換、ルールなどを簡単に含めることができます。詳細については、[BizTalk API Apps とは何か][biztalk]を説明しているページを参照してください。
## Getting Started (概要)
- Logic Apps の使用を開始するには、[ロジック アプリの作成][create]に関するページのチュートリアルに従ってください。
- [一般的な例とシナリオを確認する](app-service-logic-examples-and-scenarios.md)
- [Logic Apps を使用してビジネス プロセスを自動化する](http://channel9.msdn.com/Events/Build/2016/T694)
- [Logic Apps を使用してシステムを統合する方法を説明する](http://channel9.msdn.com/Events/Build/2016/P462)
- Azure App Service プラットフォームの詳細については、[Azure App Service][appservice] に関するページを参照してください。
[biztalk]: app-service-logic-what-are-biztalk-api-apps.md
[appservice]: ../app-service/app-service-value-prop-what-is.md
[create]: app-service-logic-create-a-logic-app.md
[managedapis]: ../connectors/apis-list.md
[tpm]: app-service-logic-create-a-trading-partner-agreement.md
[rules]: app-service-logic-use-biztalk-rules.md
[templates]: app-service-logic-use-logic-app-templates.md
<!---HONumber=AcomDC_0601_2016--> | 4,266 | CC-BY-3.0 |
# centos7安装loki及promtail
> 系统版本centos7.6
>
> loki版本0.4.0
>
> promtail版本0.4.0
## 下载loki、promtail
```shell
wget https://github.com/grafana/loki/releases/download/v0.4.0/loki-linux-amd64.gz
wget https://github.com/grafana/loki/releases/download/v0.4.0/promtail-linux-amd64.gz
```
## 解压
> 解压并移动位置
```shell
#loki
mkdir /usr/local/loki
gunzip loki-linux-amd64.gz
chmod +x loki-linux-amd64
mv loki-linux-amd64 loki
mv loki /usr/local/loki
#promt
mkdir /usr/local/promtail
gunzip promtail-linux-amd64.gz
chmod +x promtail-linux-amd64
mv promtail-linux-amd64 promtail
mv promtail /usr/local/promtail
```
## 配置loki
```shell
cd /usr/local/loki
vim loki-local-config.yaml
# 写入以下内容
auth_enabled: false
server:
http_listen_port: 3100
ingester:
lifecycler:
address: 127.0.0.1
ring:
kvstore:
store: inmemory
replication_factor: 1
final_sleep: 0s
chunk_idle_period: 5m
chunk_retain_period: 30s
max_transfer_retries: 1
schema_config:
configs:
- from: 2018-04-15
store: boltdb
object_store: filesystem
schema: v9
index:
prefix: index_
period: 168h
storage_config:
boltdb:
directory: /tmp/loki/index
filesystem:
directory: /tmp/loki/chunks
limits_config:
enforce_metric_name: false
reject_old_samples: true
reject_old_samples_max_age: 168h
chunk_store_config:
max_look_back_period: 0
table_manager:
chunk_tables_provisioning:
inactive_read_throughput: 0
inactive_write_throughput: 0
provisioned_read_throughput: 0
provisioned_write_throughput: 0
index_tables_provisioning:
inactive_read_throughput: 0
inactive_write_throughput: 0
provisioned_read_throughput: 0
provisioned_write_throughput: 0
retention_deletes_enabled: false
retention_period: 0
```
## 静态配置promtail
```shell
cd /usr/local/promtail
vim promtail-local-config.yaml
# 写入以下内容
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml
clients:
- url: http://localhost:3100/loki/api/v1/push
scrape_configs:
- job_name: system
static_configs:
- targets:
- localhost
labels:
job: varlogs
__path__: /var/log/*
```
## 基于文件的服务发现配置promtail
> 和静态配置promtail二选一即可
```shell
cd /usr/local/promtail/
vim promtail-local-config.yaml
#写入一下内容
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml
clients:
- url: http://localhost:3100/loki/api/v1/push
scrape_configs:
- job_name: order
file_sd_configs:
- files:
- /usr/local/promtail/config/*.yaml
refresh_interval: 5s #更新的间隔 默认是5m
```
```shell
#创建存放配置的目录
mkdir config
vim ./config/ceshi.yaml
#写入一下内容
- targets:
- localhost
labels:
job: varlogs
__path__: /var/log/*
```
## 启动
- loki
```shell
cd /usr/local/loki
./loki -config.file=loki-local-config.yaml
```
- promtail
```shell
cd /usr/local/promtail
./promtail -config.file=promtail-local-config.yaml
```
## 配置系统服务
- loki
```shell
vim /etc/systemd/system/loki.service
# 写入以下内容
[Unit]
Description=loki
Wants=network-online.target
After=network-online.target
[Service]
Restart=on-failure
ExecStart=/usr/local/loki/loki --config.file=/usr/local/loki/loki-local-config.yaml
[Install]
WantedBy=multi-user.target
```
- promtail
```shell
vim /etc/systemd/system/promtail.service
#写入以下内容
[Unit]
Description=promtail
Wants=network-online.target
After=network-online.target
[Service]
Restart=on-failure
ExecStart=/usr/local/promtail/promtail --config.file=/usr/local/promtail/promtail-local-config.yaml
[Install]
WantedBy=multi-user.target
```
配置好均需要执行以下命令
```shell
systemctl daemon-reload
```
## 相关启动、停止命令
```shell
systemctl start loki.service
systemctl status loki.service
systemctl stop loki.service
systemctl restart loki.service
systemctl start promtail.service
systemctl status promtail.service
systemctl restart promtail.service
systemctl stop promtail.service
```
至此 loki和promtail安装完成 ,后续可以加入grafana中。 | 3,977 | MIT |
---
layout: post
title: P3 Hadoop运行模式
categories: hadoop
keywords: hadoop
---
官方网站:[http://hadoop.apache.org/](http://hadoop.apache.org/)
hadoop运行模式包括:本地模式、伪分布式模式、完全分布式模式
1. 本地模式:单机运行,生产环境不用
2. 伪分布模式:单机运行,但是具备Hadoop集群的所有功能,一台服务器模拟一个分布式环境。个别缺钱的公司用来测试,生产环境不用。
3. 完全分布式模式:多台服务器组成分布式环境。生产环境使用
## scp 传输文件
把hadoop102上安装好的jdk,hadoop上传到hadoop103,hadoop104上,可用后面面的分发脚本
```shell
# scp
$ scp -r /opt/module/jdk1.8.0_181/ [email protected]:/opt/module/
# rsync 不创建文件夹,-a 归档拷贝 -v 显示复制过程
$ rsync -av /opt/module/hadoop-3.1.3/ [email protected]:/opt/module/
```
## 分发脚本
把文件配置到`$PATH`中,用户`/home/hqq/bin`已经配置到`$PATH`中
```shell
[hqq@hadoop102 ~]$ echo $PATH
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/hqq/.local/bin:/home/hqq/bin:/opt/module/jdk1.8.0_181/bin:/opt/module/hadoop-3.1.3/bin:/opt/module/hadoop-3.1.3/sbin
```
切换成当前用户目录下
```shell
[hqq@hadoop102 ~]$ pwd
/home/hqq
# 如果没有bin目录,则创建bin目录
[hqq@hadoop102 ~]$ mkdir bin
[hqq@hadoop102 ~]$ cd bin
```
创建脚本xsync
```shell
[hqq@hadoop102 bin]$ vim xsync
```
脚本内容如下:
```shell
#!/bin/bash
# 判断参数是否足够
if [ $# -lt 1 ]
then
echo Not Enounh Arguement!
exit;
fi
# 遍历所有的机器
for host in hadoop102 hadoop103 hadoop104
do
echo ============ $host ============
for file in $@
do
# 判断文件是否存在
if [ -e $file ]
then
# 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
# 获取当前目录的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
```
给xsync添加可执行权限并同步
```shell
[hqq@hadoop102 bin]$ chmod 777 xsync
# 同步
[hqq@hadoop102 ~]$ xsync bin/
# 因为xsync是在自己家目录下,添加sudo,使用绝对路径
[hqq@hadoop102 ~]$ sudo ./bin/xsync /etc/profile.d/my_env.sh
# 同步jdk, hadoop
[hqq@hadoop102 ~]$ sudo ./bin/xsync /opt/module/jdk1.8.0_181/
[hqq@hadoop102 ~]$ sudo ./bin/xsync /opt/module/hadoop-3.1.3/
# 最后登录相应的主机,使配置生效
[hqq@hadoop103 ~]$ source /etc/profile
[hqq@hadoop104 ~]$ source /etc/profile
```
## ssh免密登录
首选要在自己服务器上创建一对密钥:公钥,私钥。

```shell
# 生成一对密钥 id_rsa 私钥 id_rsa.pub 公钥 authorized_keys 存放授权过的无密登录服务公钥
$ ssh-keygen -t rsa
# 上传到另主机上
$ ssh-copy-id hadoop103
```
查看用户目录下隐藏文件
```shell
[hqq@hadoop102 ~]$ ll -al
[hqq@hadoop102 ~]$ cd .ssh
[hqq@hadoop102 .ssh]$ ssh-keygen -t rsa
[hqq@hadoop102 .ssh]$ ls
id_rsa id_rsa.pub known_hosts
# 把公钥拷贝到hadoop103,hadoop104上
[hqq@hadoop102 .ssh]$ ssh-copy-id hadoop103
# 切换root用户,也可配root用户免密登录hadoop103,hadoop104
[root@hadoop102 .ssh]# ssh-keygen -t rsa
[root@hadoop102 .ssh]# ssh-copy-id hadoop103
```
## 集群配置
### 集群部署规划
NameNode和SecondaryNameNode不要安装在同一台服务器
ResourceManager也很**消耗内存**,不要和NameNode、SecondaryNameNode配置在同一台机器上
| | hadoop102 | hadoop103 | hadoop104 |
| ---- | ---- | ---- | ---- |
| hdfs | NameNode <br>DataNode | DataNode | SecondaryNameNode <br>DataNode |
| yarn | NodeManager | ResourceManager <br>NodeManager | NodeManager |
### 配置文件说明
Hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值。
#### 1. 默认配置文件
| 要获取的默认文件 | 文件存放在hadoop的jar包中的位置 |
|----- | ----- |
| core-default.xml | hadoop-common-3.1.3.jar/core-default.xml |
| hdfs-default.xml | hadoop-hdfs-3.1.3.jar/hdfs-default.xml |
| yarm-default.xml | hadoop-yarn-common-3.1.3.jar/yarn-default.xml |
| mapred-default.xml | hadoop-mapreduce-client-core-3.1.3.jar/mapred-default.xml |
文件地址
[https://hadoop.apache.org/docs/r3.3.1/](https://hadoop.apache.org/docs/r3.3.1/)
#### 2. 自定义配置文件
**core-site.xml** 、**hdfs-site.xml**、**yarn-site.xml**、**mapred-site.xml** 四个配置文件存放在`$HADOOP_HOME/etc/hadoop`这个路径上。
#### 3. 配置集群
##### 1. 核心配置文件
配置core-site.xml
```
[hqq@hadoop102 ~]$ cd $HADOOP_HOME/etc/hadoop
[hqq@hadoop102 hadoop]$ vim core-site.xml
```
内容如下
```xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<!-- 指定NameNode的地址 -->
<name>fs.defaultFS</name>
<!-- 9000 或 9820 -->
<value>hdfs://hadoop102:8020</value>
</property>
<property>
<!-- 数据存储目录 -->
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<property>
<!-- 配置hdfs网页登录使用的静态用户为hqq -->
<name>hadoop.http.staticuser.user</name>
<value>hqq</value>
</property>
</configuration>
```
##### 2. HDFS配置文件
配置hdfs-site.xml
```
[hqq@hadoop102 hadoop]$ vim hdfs-site.xml
```
内容如下
```xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web端访问地址 -->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop102:9870</value>
</property>
<property>
<!-- 2nn web端访问地址 -->
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop104:9868</value>
</property>
</configuration>
```
##### 3. YARN配置文件
配置yarn-site.xml
```
[hqq@hadoop102 hadoop]$ vim yarn-site.xml
```
内容如下
```xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop103</value>
</property>
<property>
<!-- 指定MR走shuffle -->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 环境变量的继承 HADOOP_MAPRED_HOME -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
```
##### 4. MapReduce配置文件
配置mapred-site.xml
```
[hqq@hadoop102 hadoop]$ vim mapred-site.xml
```
内容如下
```xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定MapReduce程序运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
```
##### 5. workers配置文件
配置workers
```shell
[hqq@hadoop102 hadoop]$ vim workers
# 分发下
[hqq@hadoop102 hadoop]$ xsync workers
```
添加如下
hadoop102
hadoop103
hadoop104
#### 4. 在集群上分发配置好的Hadoop配置文件
```shell
[hqq@hadoop102 hadoop]$ xsync /opt/module/hadoop-3.1.3/etc/hadoop/
```
去103和104上查看文件分发的情况
```shell
$ cat /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml
```
### 启动集群
如果是第一次启动,需要在hadoop102节点格式化NameNode
注意:格式化NameNode,会产生新的集群id,导致NameNode和DataNode的集群id不一致,集群找不到已往数据,如果集群在运行过程中报错,需要重新格式化NameNode的话,一定要先停止NameNode和DataNode进程,并删除所有机器的data和logs目录,然后进行格式化。
```shell
[hqq@hadoop102 hadoop-3.1.3]$ pwd
/opt/module/hadoop-3.1.3
[hqq@hadoop102 hadoop-3.1.3]$ hdfs namenode -format
```
启动HDFS
```
[hqq@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
```
在配置的ResourceManager的节点(Hadoop103)启动yarn
```
[hqq@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
```
如果出现`Permission denied (publickey,gssapi-keyex,gssapi-with-mic)`,刚修改下ssh免密登录hadoop103
```
$ jps
```
web端查看hdfs的NameNode
>1. 浏览器输入:https://hadoop102:9870
>2. 查看HDFS上存储的数据信息
web端查看YARN的ResourceManager
>1. 浏览器输入:https://hadoop103:8088
>2. 查看YARN上运行的job信息
### 集群基本测试
上传文件到集群
```shell
[hqq@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /wcinput
# 上传文件
[hqq@hadoop102 hadoop-3.1.3]$ hadoop fs -put ~/a.txt /wcinput
# 查看yarn运行状态
[hqq@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wcinput /wcoutput
```
### 配置历史服务器
为了查看程序的历史运行情况
#### 1. 配置mapred-site.xml
```shell
$ vim mapred-site.xml
```
文件添加如下
```xml
<!-- 历史服务器地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
```
#### 2. 分发配置
```shell
[hqq@hadoop102 hadoop]$ xsync $HADOOP_HOME/etc/hadoop/mapred-site.xml
# 在hadoop103上重新启动yarn,如果已经启动先停止
[hqq@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
```
#### 3. 在hadoop102启动历史服务器
```
[hqq@hadoop102 hadoop-3.1.3]$ bin/mapred --daemon start historyserver
# 查看有JobHistoryServer进程么
$ jps
```
测试
```shell
[hqq@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /input
[hqq@hadoop102 hadoop-3.1.3]$ hadoop fs -put ~/wcinput/word.txt /input
```
查看JobHistory
[http://hadoop102:19888/jobhistory](http://hadoop102:19888/jobhistory)
### 配置日志的聚集
日志聚集功能可以方便的查看到程序运行详情,方便开发调试。
注意:**开启日志聚集功能,需要重新启动NodeManager、ResourceManager、HistoryServer**
开启日志聚集功能步聚如下:
配置yarn-site.xml
```
$ vim yarn-site.xml
```
添加如下配置:
```xml
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
```
分发配置
```shell
$ xsync yarn-site.xml
```
重启history,yarn
```shell
$ mapred --daemon stop historyserver
# 重启之前要先关闭yarn
[hqq@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
[hqq@hadoop102 hadoop-3.1.3]$ mapred --daemon start historyserver
```
## 常用命令
启动停止hdfs,yarn
```shell
start-dfs.sh stop-dfs.sh
start-yarn.sh stop-yarn.sh
```
各个服务组件一启动停止
```shell
hdfs --daemon start/stop namenode/datanode/secondarynamenode
yarn --daemon start/stop resourcemanager/nodemanager
```
另外
```shell
#启动所有
$ sbin/start-all.sh
#关闭所有
$ sbin/stop-all.sh
#常看端口
$ netstat -tlpn
```
## hadoop集群启动脚本
在用户bin/目录下创建myhadoop.sh
```shell
#!/bin/bash
# 判断参数是否足够
if [ $# -lt 1 ]
then
echo Not Enounh Arguement!
exit;
fi
case $1 in
"start")
echo "============ 启动 hadoop 集群 ============"
echo " 启动 hdfs "
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " 启动 yarn "
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " 启动 historyserver "
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo "============ 关闭 hadoop 集群 ============"
echo " 关闭 historyserver "
ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " 关闭 yarn "
ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " 关闭 hdfs "
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
```
chmod 777 myhadoop.sh
查看所有服务器运行状态,编写脚本jpsall
```shell
#!/bin/bash
for host in hadoop102 hadoop103 hadoop104
do
echo ============ $host ============
ssh $host jps
done
```
## 常用端口
| 端口名称 | Hadoop2.x | Hadoop3.x |
| ---------- | ---------- | ---------- |
| NameNode内部通信 | 8020,9000 | 8020,9000,9820 |
| NameNode Http url | 50070 | 9870 |
| MapReduce查看地执行任务 | 8088 | 8088 |
| 历史服务器通信 | 19888 | 19888 | | 10,688 | MIT |
# Bootstrap-Honoka-Rails
[engilish](README.md)/[japanese](README_ja.md)
[Honoka](https://github.com/windyakin/Honoka) は日本語も美しく表示できる Bootstrap テーマです。
bootstrap-honoka-rails は [Honoka](https://github.com/windyakin/Honoka) や [Umi](https://ysakasin.github.io/Umi/) や [Nico](https://nico.kubosho.com/) や [Rin](https://rinhoshizo.la/) を Rails 上に簡単にインストールできます。
## Installation
gemfile に下記記載します。
```ruby
gem 'bootstrap-honoka-rails' , '~>4.4.1' # or '~> 3.3.7'
```
そして下記コマンドでインストール :
$ bundle
又は gemに直接インストールします:
$ gem install bootstrap-honoka-rails
## Usage
application.cssに `*= require _honoka` を追加します。<br>
bootstrap3の場合は `*= _bootstrap-sprockets`. も追加します。
app/assets/stylesheets/application.css
```css
/*
*= require _bootstrap-sprockets # 追加行 ※ v3 のみ
*= require _honoka # 追加行
*= require_self
*/
```
次にapplication.jsに下記を追加しましょう。 <br>
```js
`//= require popper` // * bootstrap ver4 以降
`//= require bootstrap-sprockets`
```
app/assets/javascripts/application.js
```js
//= require jquery2
//= require rails-ujs
//= require activestorage
//= require popper # add line ※ ver4 以降
//= require bootstrap-sprockets # 追加行
//= require turbolinks
//= require_tree .
```
インストール後、上記を application.css と application.js に追加すれば OK です。<br>
注意点として `bootstrap-sprockets` を読み込むと思いますが、その場合 `bootstrap.min` は読み込む必要がありません。<br>
何故なら Dropdown が正しく動作しない可能性がある為です。 <br>
詳細は[こちら](https://github.com/twbs/bootstrap-sass/issues/714)をご確認ください。<br>
※production 環境で動作することを確認済み。 サンプルアプリは 'test/dummy' ディレクトリ内 にあります。
---
[特定のバージョン](VERSIONS.md)では "Nico"と "Umi" と "Rin" も対応しています。
app/assets/stylesheets/application.css
```css
*= require _umi # 追加行
*= require_self
```
or
```css
*= require _nico # 追加行
*= require_self
```
or
```css
*= require _rin # 追加行
*= require_self
```
Honoka Nico Umi Rin の対応 Ver は[VERSIONS.md](VERSIONS.md)をご確認ください。
## Notice
bootstrap-honoka-rails は bootstrap 又は bootstrap-sass を内部的に使っています。
## License
本gemは[MITライセンス]((https://opensource.org/licenses/MIT))の条件の下でオープンソースとして利用可能です。
## Supported bootstrap themes
#### [Honoka](http://honokak.osaka/)
Source URL ... [https://github.com/windyakin/Honoka](https://github.com/windyakin/Honoka)
> The MIT License (MIT)
>
> Copyright (c) 2015 windyakin
[License View All](https://github.com/windyakin/Honoka/blob/master/LICENSE)
#### [Umi](https://ysakasin.github.io/Umi/)
Source URL ... [https://github.com/ysakasin/Umi](https://github.com/ysakasin/Umi)
> The MIT License (MIT)
>
> Copyright (c) 2015 ysakasin
[License View All](https://github.com/ysakasin/Umi/blob/master/LICENSE)
#### [Nico](https://nico.kubosho.com/)
Source URL ... [https://github.com/kubosho/Nico](https://github.com/kubosho/Nico)
> The MIT License (MIT)
>
> Copyright (c) 2015 windyakin, kubosho
[License View All](https://github.com/kubosho/Nico/blob/master/LICENSE)
#### [Rin](https://rinhoshizo.la/)
Source URL ... [https://github.com/raryosu/Rin](https://github.com/raryosu/Rin)
> The MIT License (MIT)
>
> Copyright (c) 2016 Hagihara Ryosuke
[License View All](https://github.com/raryosu/Rin/blob/master/LICENSE) | 3,079 | MIT |
---
title: Common Data Service のエンティティおよびメタデータ | MicrosoftDocs
description: Common Data Service のエンティティとメタデータについて
ms.custom: ''
ms.date: 05/30/2018
ms.reviewer: ''
ms.service: powerapps
ms.suite: ''
ms.tgt_pltfrm: ''
ms.topic: article
applies_to:
- Dynamics 365 (online)
- Dynamics 365 Version 9.x
- powerapps
author: Mattp123
ms.assetid: 88b18946-474c-4c94-8e4c-27532f930757
caps.latest.revision: 28
ms.author: matp
manager: kvivek
search.audienceType:
- maker
search.app:
- PowerApps
- D365CE
---
# <a name="entities-and-metadata-in-common-data-service"></a>Common Data Service のエンティティおよびメタデータについて
Common Data Service はアプリケーションのデータ モデルをすばやく簡単に作成できるように設計されています。 通常、このトピックで紹介されるメタデータの詳細の一部について懸念する必要はありません。 しかし、Common Data Service を使うアプリの作業方法および可能な情報の評価方法について深い理解をもとめるなら、Common Data Service で使用されるメタデータに関して本質的に理解できる可能性があります。
*メタデータ* はデータに関するデータを意味します。 環境で使用するデータの定義の編集がかなり容易になるので、Common Data Service はユーザーに柔軟なプラットフォームを提供します。 Common Data Serviceで、メタデータはエンティティ コレクションです。 エンティティは、データベースに保存されているデータの種類について説明します。 各エンティティはデータベース テーブルに対応して、エンティティ内の各フィールド (属性) はテーブル内の列を表します。 エンティティ メタデータは、作成できるレコードの種類と、それらのレコードに対して実行できるアクションの種類を制御するものです。 エンティティ、フィールドおよびエンティティの関連付けを作成または編集するためにカスタマイズ ツールを使用する場合は、このメタデータを編集します。
自分の環境内のデータとやり取りするために使用するさまざまなクライアントは、カスタマイズするメタデータによって異なり、エンティティ メタデータの変更に応じて変化します。 しかし、これらのクライアントも他のデータに依存して、表示するビジュアル要素、適用するユーザー定義ロジック、およびセキュリティの適用方法を制御します。 このシステム データもエンティティ内に格納されますが、エンティティ自体はカスタマイズに使用できません。
Common Data Service で既定に含まれる標準エンティティ、属性およびエンティティの関連付けについては、[エンティティの参照](/powerapps/developer/common-data-service/reference/about-entity-reference) を確認してください。
> [!TIP]
> メタデータを編集できるデザイナーは、メタデータにあるすべての詳細を表示できません。 システムにあるメタデータ プロパティとすべてのエンティティを表示できるように、**メタデータ ブラウザ**というモデル駆動型のアプリをインストールできます。 詳細: [環境に適切なメタデータ ブラウザ](https://docs.microsoft.com/dynamics365/customer-engagement/developer/browse-your-metadata) を参照してください。
<a name="BKMK_CreateNewOrUseExistingMetadata"></a>
## <a name="create-new-metadata-or-use-existing-metadata"></a>メタデータの新規作成、または既存のメタデータの使用か。
Common Data Service にはコアの業務アプリケーション機能をサポートする多くの標準エンティティが用意されています。 たとえば、顧客と潜在顧客に関するデータは、取引先企業または取引先担当者エンティティを使用して保存されるようになっています。
これらの各エンティティには、 システムが各エンティティについて保存が必要と考える共通データを表す複数のフィールドも含まれています。
ほとんどの組織の場合、提供された目的に合わせて、標準エンティティおよび属性を使用する方が利点があります。
ソリューションをインストールすると、ソリューション開発者が標準エンティティや属性を活用することが期待できます。 システム エンティティまたは属性に取って代わる新しいユーザー定義エンティティを作成することで、使用可能なソリューションが組織に対して機能しない可能性があります。
このような理由から、提供する標準エンティティ、フィールドおよびエンティティの関連付けは、お客様の組織にとって意味のあるときに検索して使用することをお勧めします。 これらが意味を成さず、またニーズに合うように編集できない場合は、新しいエンティティ、フィールドまたはエンティティの関連付けの作成が必須かどうかを評価する必要があります。
<!-- Can we say this yet?
> [!NOTE]
> The [Common Data Model](/powerapps/common-data-model/overview) will provide a capability to add additional standard entities.
-->
組織で使用する用語に一致するように表示名を変更できることに留意してください。 たとえば、ユーザーが、取引先企業エンティティの表示名を*企業*に、または取引先担当者エンティティの表示名を*個人*に変更することはよくあることです。 これは、エンティティの動作を変更することなく、エンティティまたは属性に対して実行できます。 エンティティの名前変更の詳細については、「[エンティティの名前の変更](edit-entities.md#change-the-name-of-an-entity)」を参照してください。
標準エンティティ、フィールドまたはエンティティの関連付けを削除できません。 これらはシステム ソリューションの一部とみなされ、すべての組織でその使用が予定されています。 標準エンティティを非表示にする場合は、組織のセキュリティ ロール特権を変更して、そのエンティティの読み取り特権を削除します。 これにより、アプリケーションのほとんどからそのエンティティが削除されます。 不要なシステム フィールドがある場合は、使用するフォームやビューからそのフィールドを削除します。 フィールドおよびエンティティの関連付け定義の**検索可能**値を変更して、高度な検索で表示されないようにします。
<a name="BKMK_LimitationsOnMetadata"></a>
## <a name="limitations-on-creating-metadata-items"></a>メタデータ アイテムの作成の制限
作成できるエンティティの数に制限があります。 **[設定](../model-driven-apps/advanced-navigation.md#settings)** > **管理** > **使用中のリソース**ページにて、その最大数に関する情報を参照できます。 ユーザー定義エンティティがさらに必要な場合は、テクニカル サポートまでお問い合わせください。 この上限は調整できます。
各エンティティには、作成できるフィールドの数に上限があります。 この制限は、データベース テーブルの行に保存できるデータの量に対する技術的な制約に基づいています。 それぞれの種類のフィールドが使用できる容量は異なるので、特定の数を提供することは困難です。 上限は、エンティティのすべてのフィールドで使用される合計容量に基づいて決まります。
ほとんどのユーザーは制限に到達するほどユーザー定義フィールドを作成しませんが、エンティティに数百ものユーザー定義フィールドを追加するようになった場合は、これが最善の設計であるかどうかを検討する必要があります。 追加予定のすべてのフィールドが、そのエンティティのレコードのプロパティを記述していますか。 組織を使用しているユーザーが、そのような多数のフィールドのあるフォームを扱うことができる本当にお考えですか。 フォームに追加するフィールドの数によって、レコードが編集されるたびに転送する必要のあるデータの量が増加し、システムのパフォーマンスに影響を与えます。 エンティティにユーザー定義フィールドを追加する際は、これらの要因を考慮してください。
オプション セット フィールドは、フォームのドロップダウン コントロール、または高度な検索使用時の候補リスト コントロールに表示される、オプション セットを提供します。 お客様の環境はオプション セット内で数千のオプションをサポートできますが、これを上限と考えない方がいいでしょう。 使いやすさの調査から、ドロップダウン コントロールが多数のオプションを提供するシステムの使用で、ユーザーが困難に遭遇していることが示されています。 データのカテゴリの定義には、オプション セット フィールドを使用してください。 データの個別のアイテムを実際に表すカテゴリを選択するために、オプション セット フィールドを使用しないでください。 たとえば、備品の種類の数百の製造元のそれぞれを格納するオプション セット フィールドを維持するのではなく、各製造元への参照を格納するエンティティの作成を検討し、オプション セットの代わりに検索フィールドを使用してください。
## <a name="next-steps"></a>次のステップ
[エンティティ (レコードの種類) の作成または編集](create-edit-entities.md)<br />
[エンティティ間の関連付けの作成および編集](create-edit-entity-relationships.md) | 4,714 | CC-BY-4.0 |
---
title: LeetCode Notes - 7
date: 2017-03-09 19:35:26
categories: LeetCode
tags: [LeetCode,Programing,Algorithm]
keywords: LeetCode
toc: true
---
* [LeetCode](https://leetcode.com)
* 本文包括 [LeetCode - 492. Construct the Rectangle](https://leetcode.com/problems/construct-the-rectangle/?tab=Description),[LeetCode - 133. Clone Graph](https://leetcode.com/problems/clone-graph/?tab=Description), [LeetCode - 452. Minimum Number of Arrows to Burst Balloons](https://leetcode.com/problems/minimum-number-of-arrows-to-burst-balloons/?tab=Description), [LeetCode - 435. Non-overlapping Intervals](https://leetcode.com/problems/non-overlapping-intervals/?tab=Description) 和 [LeetCode - 138. Copy List with Random Pointer](https://leetcode.com/problems/copy-list-with-random-pointer/?tab=Description)5道题目,每道题目均给出了分析过程以及C++,JAVA,JavaScript代码实现。
<!--more-->
## Construct the Rectangle(492)
### Description
* [LeetCode - 492. Construct the Rectangle](https://leetcode.com/problems/construct-the-rectangle/?tab=Description)
* For a web developer, it is very important to know how to design a web page's size. So, given a specific rectangular web page’s area, your job by now is to design a rectangular web page, whose length L and width W satisfy the following requirements:
- The area of the rectangular web page you designed must equal to the given target area.
- The width W should not be larger than the length L, which means L >= W.
- The difference between length L and width W should be as small as possible.
* You need to output the length L and the width W of the web page you designed in sequence.
* Example
```
Input: 4
Output: [2, 2]
Explanation: The target area is 4, and all the possible ways to construct it are [1,4], [2,2], [4,1]. But according to requirement 2, [1,4] is illegal; according to requirement 3, [4,1] is not optimal compared to [2,2]. So the length L is 2, and the width W is 2.
```
* Note
- The given area won't exceed 10,000,000 and is a positive integer
- The web page's width and length you designed must be positive integers.
### Analysis
* 思路1
若L和W相差最小,则L和W应该在`sqrt(num)`的附近。
### Slove
#### Method 1: C++
* 方法1:参照思路1。 (Cost 6ms.Beats 32.88%)
```cpp
class Solution {
public:
vector<int> constructRectangle(int area) {
vector<int> res(2);
res[1] = (int)sqrt(area); // w
while(area%res[1]){
res[1]--;
}
res[0]=area/res[1]; //L
return res;
}
};
```
* 方法2:参照思路1。计算`sqrt()`耗时较大,采用循环代替。 (Cost 3ms.Beats 37.03%)
```cpp
class Solution {
public:
vector<int> constructRectangle(int area) {
if (area <= 0) return vector<int> {};
vector<int> res;
int w = area;
for (int i = 1; i * i <= area; ++i) {
if (area % i == 0) w = i;
}
return vector<int> {area / w, w};
}
};
```
#### Method 2: JavaScript
* 方法1:参照思路1。 (Cost 239ms.Beats 18.71%)
```javascript
/**
* @param {number} area
* @return {number[]}
*/
var constructRectangle = function(area) {
var res= [];
res[0] = Math.ceil(Math.sqrt(area));
while((area%res[0])){
res[0]++; //L
}
res[1] = area/res[0];
return res;
};
```
#### Method 3: Java
原理同C++,此处不再赘述。
## Clone Graph(133)
### Description
* [LeetCode - 133. Clone Graph](https://leetcode.com/problems/clone-graph/?tab=Description)
* Clone an undirected graph. Each node in the graph contains a `label` and a list of its `neighbors`.
* OJ's undirected graph serialization:
Nodes are labeled uniquely.
We use `#` as a separator for each node, and `,` as a separator for node label and each neighbor of the node.
As an example, consider the serialized graph `{0,1,2#1,2#2,2}`.
The graph has a total of three nodes, and therefore contains three parts as separated by `#`.
* First node is labeled as 0. Connect node 0 to both nodes 1 and 2.
* Second node is labeled as 1. Connect node 1 to node 2.
* Third node is labeled as 2. Connect node 2 to node 2 (itself), thus forming a self-cycle.
Visually, the graph looks like the following
```
1
/ \
/ \
0 --- 2
/ \
\_/
```
* Tags: Depth-first Search, Graph
### Analysis
* 思路1:DFS
- 首先,这道题目不能直接返回node。因为需要克隆,也就意味着要为所有的节点新分配空间。
- 其次,分析节点的元素,包括`label`和`neighbors`两项。这意味着完成一个节点需要克隆一个`int`和一个`vector<UndirectedGraphNode *>`。
- 根据参数中的node提取出其label值,然后用构造方法生成一个节点,这样就完成了一个节点的生成。
- 然后,根据参数中的node提取其neighbors中的元素。只需要把这些元素加入刚生成的节点中,便完成了第一个节点的克隆。
- 再次,neighbor元素怎么生成呢?同样需要克隆。这样我们就可以总结出递归的思路。
- 最后,由于克隆要求每个节点只能有一个备份(其实也只能做到一个备份),所以,对于已经有开辟空间的节点,我们只需要返回已经存在的节点即可。那怎么做到不重复呢?HashMap!只要我们为每个节点开辟一个空间的时候把这个空间指针保存在HashMap中,便可以通过查找HashMap来确定当前要克隆的节点是否已经存在,不存在再新开辟空间。
### Slove
#### Method 1: C++
* 方法1:参照思路1,采用DFS。 (Cost 29ms. Beats 69.29%)
```cpp
class Solution {
public:
UndirectedGraphNode *cloneGraph(UndirectedGraphNode *node) {
//labeled uniquely so label can be used as the key of map
map<int, UndirectedGraphNode *> hashTable;
return clone(node, hashTable);
}
UndirectedGraphNode * clone(UndirectedGraphNode *node, map<int, UndirectedGraphNode *> & hashTable){
if(node == NULL){
return NULL;
}
//表明这个节点已经创建了,所以没有必要重复创建,只要把已经创建的节点返回即可
if(hashTable.find(node->label) != hashTable.end()){
return hashTable[node->label];
}
//如果没有创建参数中节点,则创建,并添加到hashtable中
UndirectedGraphNode * result = new UndirectedGraphNode(node->label);
hashTable[node->label] = result;
//clone所有的邻节点,并添加到刚clone好的节点的第二个元素vector中
for(int i=0; i<node->neighbors.size();i++){
UndirectedGraphNode * newnode = clone(node->neighbors[i], hashTable);
result->neighbors.push_back(newnode);
}
return hashTable[node->label];
//或 return result;
}
};
```
* 方法2:同方法1,在算法上进行优化。 (Cost 29ms. Beats 69.29%)
```cpp
class Solution {
public:
unordered_map<UndirectedGraphNode*, UndirectedGraphNode*> hash;
UndirectedGraphNode *cloneGraph(UndirectedGraphNode *node) {
if (!node) return node;
if(hash.find(node) == hash.end()) { //未找到
hash[node] = new UndirectedGraphNode(node -> label);
for (auto x : node -> neighbors) {
(hash[node] -> neighbors).push_back( cloneGraph(x) );
}
}
return hash[node]; //若找到,直接返回
}
};
```
#### Method 2: JavaScript
原理同C++,此处不再赘述。
#### Method 3: Java
原理同C++,此处不再赘述。
## Minimum Number of Arrows to Burst Balloons(452)
### Description
* [LeetCode - 452. Minimum Number of Arrows to Burst Balloons](https://leetcode.com/problems/minimum-number-of-arrows-to-burst-balloons/?tab=Description)
* There are a number of spherical balloons spread in two-dimensional space. For each balloon, provided input is the start and end coordinates of the horizontal diameter. Since it's horizontal, y-coordinates don't matter and hence the x-coordinates of start and end of the diameter suffice. Start is always smaller than end. There will be at most 104 balloons.
* An arrow can be shot up exactly vertically from different points along the x-axis. A balloon with `xstart` and `xend` bursts by an arrow shot at x if xstart ≤ x ≤ xend. There is no limit to the number of arrows that can be shot. An arrow once shot keeps travelling up infinitely. The problem is to find the minimum number of arrows that must be shot to burst all balloons.
* Example:
```
Input: [[10,16], [2,8], [1,6], [7,12]]
Output: 2
Explanation:
One way is to shoot one arrow for example at x = 6 (bursting the balloons [2,8] and [1,6]) and another arrow at x = 11 (bursting the other two balloons).
```
* Tags: Greedy
### Analysis
* 思路1 (排序+贪婪算法,子问题的最优解就是全局最优解)
- 首先对数据进行排序,按照`pair`的第1个数字(气球起点坐标)升序排序;若相同,则按照第2个数字(气球终点坐标)升序排序。
- 将打枪的位置设定在第1个气球的终点坐标处,标记为`end`值。
- 若下一个气球的起点坐标小于end值,则修改end为当前end值和下一个气球的终点坐标中的较小值,即`end = min(end,points[i].second)`。
- 若下一个气球的起点坐标大于end值,则需要重新打一枪,更新end值为下一个气球的终点坐标值。
### Slove
#### Method 1: C++
* 方法1:参照思路1。 (Cost 85ms.Beats 97.42%)
```cpp
class Solution {
public:
int findMinArrowShots(vector<pair<int, int>>& points) {
if(points.empty()){
return 0;
}
int res = 0;
int size = points.size();
//数组排序
sort(points.begin(),points.end());
//贪婪算法
int end = points[0].second; // 第1枪
res++;
for(int i=1;i<size;i++){
if(end >= points[i].first){
end = min(end,points[i].second); //修正打枪的位置
}
else{
end = points[i].second; //更新end值
res++;
}
}
return res;
}
};
```
#### Method 2: JavaScript
* 方法1:参照思路1。 (Cost 179ms.Beats 100.00%)
注意JavaScript中数组的`sort()`方法是默认按照ASCII排序的。此种排序下,`10`是小于`2`的。因此,需要自己指定排序函数。
```javascript
/**
* @param {number[][]} points
* @return {number}
*/
var findMinArrowShots = function(points) {
var res;
var length = points.length;
if(length === 0){
return 0;
}
points.sort(function(a,b){
if(a[0] === b[0]){
return a[1]-b[1];
}
else{
return a[0]-b[0];
}
});
var end = points[0][1]; //第1枪
res = 1;
for(var i=1;i<length;i++){
if(points[i][0]<= end){
//修正end值
end = Math.min(end,points[i][1]);
}
else{
res++;
end = points[i][1]; //下一枪位置
}
}
return res;
};
```
#### Method 3: Java
原理同C++,此处不再赘述。
## Non-overlapping Intervals(435)
### Description
* [LeetCode - 435. Non-overlapping Intervals](https://leetcode.com/problems/non-overlapping-intervals/?tab=Description)
* Given a collection of intervals, find the minimum number of intervals you need to remove to make the rest of the intervals non-overlapping.
* You may assume the interval's end point is always bigger than its start point.
* Intervals like [1,2] and [2,3] have borders "touching" but they don't overlap each other.
* Example 1
```
Input: [ [1,2], [2,3], [3,4], [1,3] ]
Output: 1
Explanation: [1,3] can be removed and the rest of intervals are non-overlapping.
```
* Example 2:
```
Input: [ [1,2], [1,2], [1,2] ]
Output: 2
Explanation: You need to remove two [1,2] to make the rest of intervals non-overlapping.
```
* Example 3
```
Input: [ [1,2], [2,3] ]
Output: 0
Explanation: You don't need to remove any of the intervals since they're already non-overlapping.
```
* Tags: Greedy
### Analysis
* 思路1(排序+贪婪算法)
- 思路同[LeetCode - 452. Minimum Number of Arrows to Burst Balloons](https://leetcode.com/problems/minimum-number-of-arrows-to-burst-balloons/?tab=Description)中的思路1。
- 首先对数据进行升序排序。排序时若调用`sort()`方法记得指定比较函数。
- 遍历数组,采用贪婪算法思想,每次若要删除数据,都删除跨度最大的数据。
- 指定一个end标志值,初始值为第1个数组的结束坐标。若end值小于下一个数组的起点坐标,则将end值更新为end和下一个数组终点坐标中的较小值,删除最大值对应的数组(贪婪思想)。若end值大于下一个数组的起点坐标,则更新end值为下一个数组的终点坐标。
### Slove
#### Method 1: C++
* 方法1:参照思路1。 (Cost 9ms. Beasts 56.29%)
```cpp
/**
* Definition for an interval.
* struct Interval {
* int start;
* int end;
* Interval() : start(0), end(0) {}
* Interval(int s, int e) : start(s), end(e) {}
* };
*/
class Solution {
public:
int eraseOverlapIntervals(vector<Interval>& intervals) {
int size = intervals.size();
//匿名函数表达式
auto comp = [](const Interval& i1, const Interval& i2) {
if(i1.start == i2.start){
return i1.start < i2.start;
}
else{
return i1.start < i2.start;
}
};
sort(intervals.begin(), intervals.end(), comp);
int res = 0, pre = 0;
for (int i = 1; i < size; i++) {
if (intervals[i].start < intervals[pre].end) {
res++;
if (intervals[i].end < intervals[pre].end) {
pre = i;
}
}
else {
pre = i;
}
}
return res;
}
};
```
需要注意的是,`sort()`方法中的比较函数采用了[匿名函数表达式(lambda表达式)](https://zh.wikipedia.org/wiki/%E5%8C%BF%E5%90%8D%E5%87%BD%E6%95%B0#C.2B.2B)。
C++中不允许嵌套定义函数(但允许匿名函数在某个函数内定义),只允许嵌套调用函数。因此,比较函数不能定义在`eraseOverlapIntervals`函数体内。比较函数不能是类的成员函数。因此,可以考虑将比较函数定义为匿名比较函数。匿名函数允许定义在某个函数体内。
> 比较函数不能是类的成员函数。 ——[C++ 定义实用比较函数注意点](http://www.sigmainfy.com/blog/c-compare-functions-notes.html)
#### Method 2: JavaScript
* 方法1:参照思路1。 (Cost 138ms. Beasts 34.38%)
```javascript
/**
* Definition for an interval.
* function Interval(start, end) {
* this.start = start;
* this.end = end;
* }
*/
/**
* @param {Interval[]} intervals
* @return {number}
*/
var eraseOverlapIntervals = function(intervals) {
var size = intervals.length;
if(size === 0){
return 0;
}
intervals.sort(function(a,b){
if(a.start === b.start){
return a.end - b.end;
}
else{
return a.start - b.start;
}
});
var res = 0;
var pre = 0;
var end = intervals[0].end;
for (var i = 1; i < size; i++) {
if (intervals[i].start < end) {
if (intervals[i].end < end) {
end = intervals[i].end;
}
res++;
}
else {
end = intervals[i].end;
}
}
return res;
};
```
> JavaScript中数组排序为`myArr.sort(compareFunction)`。其中,`compareFunction(a,b)`根据返回值大于0或小于0的数字。例如,`return a-b;`。若值小于0,则将a排在b之前。
>
> C++中数组排序为`sort(myArr,myArr+length,compareFunction)`。其中,`compareFunction(a,b)`根据返回值为布尔值,例如,`return a<b;`。若值为真,则a排在b之前。
#### Method 3: Java
原理同C++,此处不再赘述。
## Copy List with Random Pointers(138)
### Description
* [LeetCode - 138. Copy List with Random Pointer](https://leetcode.com/problems/copy-list-with-random-pointer/?tab=Description)
* A linked list is given such that each node contains an additional random pointer which could point to any node in the list or null.
* Return a deep copy of the list.
### Analysis
* 参考资料
- [LeetCode 138 - Copy List with Random Pointer - 博客](http://yuanhsh.iteye.com/blog/2185974)
* 思路1
- 解决思路同[LeetCode - 133. Clone Graph](https://leetcode.com/problems/clone-graph/?tab=Description)中的C++实现中的方法2。
- 创建一个哈希表,若该链表已经存在,则直接返回;若不存在,则新建一个链表节点,并函数递归实现对`label`,`next`和`random`的复制。
* 思路2
- 参考:[Copy List with Random Pointer 复制带有随机指针的链表](http://blog.csdn.net/tmylzq187/article/details/50913211)
- Step 1:复制节点,并将拷贝后的节点放到原节点的后面。
- Step 2:更新所有拷贝节点的random节点:`h.next.random = h.random.next`
- 将原链表与复制链表断开。
<div align="center">
<img src="http://ol3kbaay9.bkt.clouddn.com/leetcode-138-2.png" />
</div>


### Slove
#### Method 1: C++
* 方法1:参考思路1,函数递归实现。 (Cost 65ms. Beasts 40.64%)
```cpp
/**
* Definition for singly-linked list with a random pointer.
* struct RandomListNode {
* int label;
* RandomListNode *next, *random;
* RandomListNode(int x) : label(x), next(NULL), random(NULL) {}
* };
*/
class Solution {
public:
unordered_map<RandomListNode *, RandomListNode*> hashTable;
RandomListNode *copyRandomList(RandomListNode *head) {
if (head == NULL) {
return NULL;
}
if (hashTable.find(head) == hashTable.end()) {
hashTable[head] = new RandomListNode(head->label); //创建新节点
hashTable[head]->next = copyRandomList(head->next);
hashTable[head]->random = copyRandomList(head->random);
}
return hashTable[head]; //若已经存在,则直接返回
}
};
```
* 方法2:参考思路2。 (Cost 43ms. Beasts 98.45%)
```cpp
/**
* Definition for singly-linked list with a random pointer.
* struct RandomListNode {
* int label;
* RandomListNode *next, *random;
* RandomListNode(int x) : label(x), next(NULL), random(NULL) {}
* };
*/
class Solution {
public:
RandomListNode *copyRandomList(RandomListNode *head) {
if (head == NULL) return NULL;
RandomListNode* current = NULL;
RandomListNode* head_preserve = head;
// step1 create add new node into original list
while (head != NULL) {
current = new RandomListNode(head->label);
current->next = head->next;
head->next = current;
head = head->next->next;
}
//step 2 populate random pointer of new list
head = head_preserve;
while (head != NULL) {
current = head->next;
if (head->random != NULL) {
current->random = head->random->next;
}
head = head->next->next;
}
// step3 seperate old list and new list
head = head_preserve;
head_preserve = head->next;
while (head != NULL) {
current = head->next;
head->next = head->next->next;
head = head->next;
if (head != NULL)
current->next = head->next;
}
return head_preserve;
}
};
```
#### Method 2: JavaScript
原理同C++,此处不再赘述。
#### Method 3: Java
* 方法1:参考思路2。 (Cost 2ms. Beasts 72.6%)
```java
/**
* Definition for singly-linked list with a random pointer.
* class RandomListNode {
* int label;
* RandomListNode next, random;
* RandomListNode(int x) { this.label = x; }
* };
*/
public class Solution {
public RandomListNode copyRandomList(RandomListNode head) {
if(head == null) return null;
RandomListNode h = head;
while(h != null) {
RandomListNode copy = new RandomListNode(h.label);
RandomListNode next = h.next;
h.next = copy;
copy.next = next;
h = next;
}
h = head;
while(h != null) {
if(h.random != null)
h.next.random = h.random.next;
h = h.next.next;
}
h = head;
RandomListNode newHead = h.next;
while(h != null) {
RandomListNode copy = h.next;
h.next = copy.next;
h = h.next;
copy.next = h != null ? h.next : null;
}
return newHead;
}
}
```
## 反馈与建议
- 邮箱:<[email protected]>
- 微信:[@脱缰的哈士奇(ab1203940926)](http://ojx8u3g1z.bkt.clouddn.com/wechat-id.jpg)
- 微博:[@脱缰的哈士](http://weibo.com/2329754491/profile) | 17,753 | Apache-2.0 |
<div align="center" style="margin-top: 10px">
<a href="http://hiprint.io/">
<img width="100" height="100" src="http://hiprint.io/Content/assets/hi.png">
</a>
<a href="https://cn.vuejs.org/">
<img width="100" height="100" src="https://cn.vuejs.org/images/logo.svg">
</a>
</div>
[![npm][npm]][npm-url]
[![node][node]][node-url]


# vue-plugin-hiprint <a href="http://hiprint.io/docs/start">hiprint官方文档</a>
> hiprint for vue2.0
## 配套直接打印客户端(win/mac/linux)
### <a href="https://gitee.com/CcSimple/electron-hiprint">gitee</a> <a href="https://gitee.com/CcSimple/electron-hiprint"> github</a>
<div align="center">

</div>
## 参与/预览 <a href="https://ccsimple.gitee.io/vue-plugin-hiprint/">demo</a>
```console
git clone https://github.com/CcSimple/vue-plugin-hiprint.git
// or
git clone https://gitee.com/CcSimple/vue-plugin-hiprint.git
// init
cd vue-plugin-hiprint
npm i
// 调试预览
npm run serve
// 打包
npm run build
```
## demo调试(显示打印iframe)
```javascript
// 快速显示/隐藏 打印iframe 方便调试  ̄□ ̄||
// 在浏览器控制台输入:
// 显示打印页面
$('#app').css('display','block');
$('#hiwprint_iframe').css('visibility','hidden');
$('#hiwprint_iframe').css('width','100%');
$('#hiwprint_iframe').css('height','251.09mm'); // 这里替换个实际高度才能显示完
// 显示vue页面
$('#app').css('display','block');
$('#hiwprint_iframe').css('visibility','hidden');
```
## 安装
```console
npm install vue-plugin-hiprint
```
## 全局使用
```javascript
// main.js中 引入安装
import {hiPrintPlugin} from 'vue-plugin-hiprint'
Vue.use(hiPrintPlugin, '$pluginName')
// 然后使用
this.$pluginName
// 例如
this.$pluginName.init();
var hiprintTemplate = new this.$pluginName.PrintTemplate();
var panel = hiprintTemplate.addPrintPanel({ width: 100, height: 130, paperFooter: 340, paperHeader: 10 });
//文本
panel.addPrintText({ options: { width: 140, height: 15, top: 20, left: 20, title: 'hiprint插件手动添加text', textAlign: 'center' } });
//条形码
panel.addPrintText({ options: { width: 140, height: 35, top: 40, left: 20, title: '123456', textType: 'barcode' } });
//二维码
panel.addPrintText({ options: { width: 35, height: 35, top: 40, left: 165, title: '123456', textType: 'qrcode' } });
//长文本
panel.addPrintLongText({ options: { width: 180, height: 35, top: 90, left: 20, title: '长文本:hiprint是一个很好的webjs打印,浏览器在的地方他都可以运行' } });
//表格
panel.addPrintTable({ options: { width: 252, height: 35, top: 130, left: 20, content: $('#testTable').html() } });
//Html
panel.addPrintHtml({ options: { width: 140, height: 35, top: 180, left: 20, content:'' } });
//竖线//不设置宽度
panel.addPrintVline({ options: { height: 35, top: 230, left: 20 } });
//横线 //不设置高度
panel.addPrintHline({ options: { width: 140, top: 245, left: 120 } });
//矩形
panel.addPrintRect({ options: { width: 35, height: 35, top: 230, left: 60 } });
//打印
hiprintTemplate.print({});
//直接打印,需要安装客户端
hiprintTemplate.print2({});
```
## 自定义设计 (详情查看demo目录)
```javascript
import {hiprint,defaultElementTypeProvider} from 'vue-plugin-hiprint'
hiprint.init({
providers: [new defaultElementTypeProvider()]
})
hiprint.PrintElementTypeManager.buildByHtml($('.ep-draggable-item'));
hiprintTemplate = new hiprint.PrintTemplate({
template: {},
settingContainer: '#PrintElementOptionSetting',
paginationContainer: '.hiprint-printPagination'
});
hiprintTemplate.design('#hiprint-printTemplate');
```
## 常见问题
> design时怎么修改默认图片?
```vue
<!-- 组件内, 显示的图片-->
<style lang="less" scoped>
/deep/ .hiprint-printElement-image-content {
img {
content: url("~@/assets/logo.png");
}
}
</style>
<!-- App.vue 拖拽时显示的图片-->
<!-- 不要 scoped, 拖拽时是添加到 html body内的-->
<style lang="less">
.hiprint-printElement-image-content {
img {
content: url("~@/assets/logo.png");
}
}
</style>
```
> print/print2 打印回调
```javascript
// 浏览器预览打印
hiprintTemplate.print(this.printData, {}, {
callback: () => {
console.log('浏览器打印窗口已打开')
}
})
// 直接打印
hiprintTemplate.print2(printData, {printer: '打印机名称', title: '打印标题'})
hiprintTemplate.on('printSuccess', function (data) {
console.log('打印完成')
})
hiprintTemplate.on('printError', function (data) {
console.log('打印失败')
})
```
> 打印重叠 / 样式问题
```javascript
// 开发时默认用的Ant Design Vue, 所有其他ui框架没有测试过
// 自0.0.13起, 可自定义样式处理
hiprintTemplate.print(this.printData, {}, {
styleHandler: () => {
let css = ''
// xxxxx
return css
}
})
// 直接打印
hiprintTemplate.print2(this.printData, {
styleHandler: () => {
let css = ''
// xxxxx
return css
}
})
```
> 修改默认配置 / 显示/隐藏元素设置参数
```javascript
// 0.0.13, 新增setConfig方法
// 还原配置
hiprint.setConfig()
// 替换配置
hiprint.setConfig({
movingDistance: 2.5,
text:{
supportOptions: [
{
name: 'styler',
hidden: true
},
{
name: 'formatter',
hidden: true
},
]
}
})
```
## 交流群
<div align="center">

</div>
若过期 加我 备注加群
## 演示/截个图咯~
<div align="center">


</div>
## 状态/调整/优化
- [x] `vue 插件` 发布npm包,方便直接使用
- [x] `Ant Design Vue demo` 默认拖拽设计、自定义设计、队列打印
- [x] `优化删除元素功能` 支持 backSpace/delete 按键删除
- [x] `优化拖动功能` fix 元素拖出窗口外的问题
- [x] `优化框选功能` fix 原只能从上往下框选问题
- [x] `支持修改默认直接打印主机` window.hiwebSocket.setHost("xxx:17521")
- [x] `print优化调整` 支持设置callback 见demo的preview.vue
- [x] `table/tableCustom优化调整` 支持设置options.fields 双击选择字段,
- [x] `table优化调整` 支持设置isEnableInsertColumn/isEnableDeleteColumn等参数,支持插入/删除列
- [x] `table/tableCustom优化调整` 支持设置options.tableHeaderRepeat/tableFooterRepeat 表头/表脚显示模式
- [x] `table优化调整` 支持设置 不显示表头
- [x] `条形码优化调整` fix 条码格式错误的问题(EAN-13、ITF、UPC等)
- [x] `字段名优化调整` 元素的字段名(field) 支持嵌套(eg: a.b.c.d)
- [x] `新增支持不分页(小票打印)` 可设置不分页 table、longText处理
- [x] `新增支持复制/粘贴` 支持 基本元素的ctrl+c/v(复制/粘贴)
### 咳咳..
第一次写插件(webpack打包这些都不太了解),不合理的地方欢迎指正<a href="https://github.com/CcSimple/vue-plugin-hiprint/issues">issues</a>。
简单的修改了下`hiprint.bundle.js`引入了相关资源,然后`export hiprint,defaultElementTypeProvider`
#### 详见源码<a href="https://github.com/CcSimple/vue-plugin-hiprint">vue-plugin-hiprint</a>
#### 呃呃.. 记录一下处理过程
> webpack 配置
```javascript
{
// 引用本地资源, 一些源码中 require('xxx') 需要处理
resolve: {
alias: {
'vue$': 'vue/dist/vue.esm.js',
'jquery$': path.resolve(__dirname, "./src/hiprint/plugins/jq-3.31.js"),
// 这两个资源在 plugins/jspdf/canvg.min.js 中的需要
'rgbcolor$': path.resolve(__dirname, "./src/hiprint/plugins/jspdf/rgbcolor.js"),
'stackblur-canvas$': path.resolve(__dirname, "./src/hiprint/plugins/jspdf/stackblur-canvas.js"),
}
},
// 全局jQuery问题
plugins: [
new webpack.ProvidePlugin({
jQuery: "jquery",
$: "jquery"
}),
],
// 资源处理
module: {
rules: [
// url-loader 处理 jquery.minicolors.png, 转成base64
{
test: /\.(png|jpg|gif|svg)$/,
loader: 'url-loader',
options: {
name: '[name].[ext]'
}
}
]
}
}
```
[npm]: https://img.shields.io/npm/v/vue-plugin-hiprint.svg
[npm-url]: https://npmjs.com/package/vue-plugin-hiprint
[node]: https://img.shields.io/node/v/vue-plugin-hiprint.svg
[node-url]: https://nodejs.org | 7,079 | MIT |
---
layout: post
Date: 2016-04-05 12:00:00 +0800
title: '微信开发平台本地调式方法'
tags: [wechat, proxy, ssh, netcat, openapi]
last_modified_at: 2016-08-25 15:20:00 +0800
---
```
<WOS> <AE> <ML>
+--------------------+ +------------+ +-----------+
| WeChat Open Server | <=====> | Aliyun ECS | <====> | My Laptop |
+--------------------+ +------------+ +-----------+
```
<!--more-->
### 传统方式
`ML`上开发代码,打包部署到 `AE` 上运行,然后与 `WOS` 联调。
#### 问题
1. `AE` 上开发工具简陋,调试效率低;
2. `ML` 通常在内网没有独立对外 IP,致使 `WOS` 不能直连。
### 改进方式
思路是将 `AE` 作为**透传代理**。 实现方式如下:
#### SSH 远程转发
```
ML> ssh -R '8080:localhost:12306' {AE}
```
在 `ML` 上执行上面的命令连接 `AE`, 将 `AE` 上所有 `8080` 端口的请求转发到 `ML` 的 `12306` 端口上。
> 这里会遇到一个坑,`SSH`默认只会转发所有到`127.0.0.1:8080`的数据。显然这不是我们想要的,然而`Aliyun ECS`上即便修改`GatewayPorts=yes`也无法实现转发来自对外 IP 的数据,故此有了下面的办法。
>
#### NC 本地转发
```
AE> nc --sh-exec "nc localhost 8080" -l 80 --keep-open
```
在 `AE` 上执行上述命令, 实现监听 `80` 端口并将所有数据透传到本地的 `8080` 端口。
The end. | 1,016 | MIT |
---
title : jQuery と JScript を使って IE11 限定で動作するサーバーレス掲示板を作る
created : 2016-07-17
last-modified: 2016-07-17
header-date : true
path:
- /index.html Neo's World
- /blog/index.html Blog
- /blog/2016/index.html 2016年
- /blog/2016/07/index.html 07月
hidden-info:
original-blog: Corredor
---
どこかのプログラミング講師が「なんか最近やたらと DB であれこれデータ管理すること多くない?ファイルの読み書きってのも場合によっては有効なことがあるんだけどなぁ」と言ってたのを思い出して、サーバがない環境でもファイルの読み書きができれば、チャットだとか掲示板とかが作れるんじゃないかと思ってやってみた。
`Scripting.FileSystemObject` でファイルが読み書きできるのを利用して、サーバーレスの掲示板を作ってみる。
## DOM 操作は jQuery・ファイル読み書きは JScript
厳密な区分けが分かっていないが、WSH に分類される処理は JavaScript ではなく、JScript と呼ぶのが適切かと思っている。ただ、いずれにしても HTML に埋め込んでしまえば JavaScript として普通に使えるので、DOM やイベントの操作は jQuery で行いつつ、ファイルの読み書きは先述のとおり `FileSystemObject` を使ってみる。
JavaScript はこんな感じ。
```javascript
// FileSystemObject 用定数
var ForReading = 1;
var ForWriting = 2;
/** BBS のデータファイルのフルパス */
var BbsFile = "C:/BBS/bbs.txt";
/** ファイルの読み込み */
function loadText() {
var fso = new ActiveXObject("Scripting.FileSystemObject");
var bbs = fso.OpenTextFile(BbsFile, ForReading);
return bbs.ReadAll();
}
/** 投稿内容のロード */
function load() {
$("#data").html(loadText());
}
/** 投稿 */
function post(name, msg) {
// 既存の書き込み内容の取得
var data = loadText();
// 投稿内容の生成
var postData = "<dt>" + name + "</dt>"
+ "<dd"> + msg + "</dd>" + "\r\n";
// 投稿内容 → 既存の書き込みの順に出力し直す
var fso = new ActiveXObject("Scripting.FileSystemObject");
var bbs = fso.OpenTextFile(BbsFile, ForWriting);
bbs.Write(postData);
bbs.Write(data);
}
/** jQuery */
$(function() {
// 初回読み込み
load();
// 投稿・再読み込み
$("#post").on("click", function() {
post($("#name").val(), $("#msg").val());
load();
$("#msg").val(""); // メッセージは投稿後空欄にする
});
});
```
これに対応する HTML はこんな感じ。
```html
<h1>BBS</h1>
<p>
<input type="text" id="name" size="10" value="" placeholder="Name">
<input type="text" id="msg" size="50" value="" placeholder="Message">
</p>
<p>
<input type="button" id="post" value="Post">
</p>
<dl id="data">
</dl>
```
つまり、1回の投稿ごとに、`bbs.txt` には以下のような行が出力される。
```html
<dt>Neo</dt><dd>こんにちは!</dd>
```
これを `dl#data` 内に展開してやることで、書き込み内容を表示させるというワケ。
ActiveXObject を使っているので、例によって IE11 限定だが、ローカルでサーバを構築せずに簡単に掲示板っぽいことをするにはコレで十分かな。 | 2,238 | MIT |
# 13.2.4. 查询适配给定范围的最新版本
[![semver-badge]][semver] [![cat-config-badge]][cat-config]
给定一个版本字符串 &str 的列表,查找最新的语义化版本 [`semver::Version`]。[`semver::VersionReq`] 用 [`VersionReq::matches`] 过滤列表,也可以展示语义化版本 `semver` 的预发布参数设置。
```rust,edition2018
{{ #include ../../../examples/development-tools/versioning/examples/semver-latest.rs }}
```
[`semver::Version`]: https://docs.rs/semver/*/semver/struct.Version.html
[`semver::VersionReq`]: https://docs.rs/semver/*/semver/struct.VersionReq.html
[`VersionReq::matches`]: https://docs.rs/semver/*/semver/struct.VersionReq.html#method.matches
{{#include ../../links.md}} | 610 | Apache-2.0 |
---
title: "SpaceVim lang#nim 模块"
description: "该模块为 SpaceVim 提供 Nim 开发支持,包括语法高亮、代码补全、编译运行以及交互式编程等功能。"
lang: zh
---
# [可用模块](../../) >> lang#nim
<!-- vim-markdown-toc GFM -->
- [模块简介](#模块简介)
- [功能特性](#功能特性)
- [启用模块](#启用模块)
- [快捷键](#快捷键)
- [交互式编程](#交互式编程)
- [示例项目](#示例项目)
<!-- vim-markdown-toc -->
## 模块简介
[Nim](https://github.com/nim-lang/Nim) 是一种编译型的系统语言,具有高效的垃圾回收机制,该模块为 SpaceVim 添加了 Nim 语言开发支持。
## 功能特性
- 语法高亮
- 代码补全
- 一键编译运行
## 启用模块
可通过在配置文件内加入如下配置来启用该模块:
```toml
[[layers]]
name = "lang#nim"
```
在使用该模块之前,首先需要确保本地 Nim 环境安装完整,可通过包管理器安装 Nim, 例如:
```sh
sudo pacman -S Nim nimble
```
## 快捷键
| 快捷键 | 功能描述 |
| --------- | ------------------------------------ |
| `SPC l r` | 编译,并运行当前文件 |
| `SPC l e` | 在当前文件范围内,重命名光标下的符号 |
| `SPC l E` | 在整个项目范围内,重命名贯标下的符号 |
### 交互式编程
启动 `nim secret` 交互进程,快捷键为: `SPC l s i`。如果存在可执行命令 `ipython`,
则使用该命令为默认的交互式命令;否则则使用默认的 `python` 命令。可通过设置虚拟环境来修改可执行命令。
将代码传输给 REPL 进程执行:
| 快捷键 | 功能描述 |
| ----------- | ----------------------- |
| `SPC l s b` | 发送整个文件内容至 REPL |
| `SPC l s l` | 发送当前行内容至 REPL |
| `SPC l s s` | 发送已选中的内容至 REPL |
## 示例项目
该项目为使用 SpaceVim 开发 Nim 的示例项目:
<https://github.com/wsdjeg/nim-example> | 1,229 | MIT |
# 利用观察者模式实现多表联合查询的结果缓存的一致性
## 场景说明:
在现实生活中,经常有关联表查询的需求,如果不进行数据缓存,频繁查询数据库对数据库压力很大,如果缓存了又可能导致缓存不一致。
例如:有A/B/C三个表,A依赖B,B依赖C,前端页面上可能会要求显示ABC三张表里的字段信息,如果此时在A表中进行关联查询,并且结果缓存了,那么对B和C的新增修改及删除都可能导致
A表中缓存的数据与数据库中不一致了。
## 解决思路:
因为A表依赖BC表,只要BC表数据变更,就更新A的缓存或者清除A的缓存。
## 实现原理:
ABC的service层实现,都是观察者和被观察者角色,A观察BC,
C更新了数据,则通知B和A各自更新自己的缓存,B更新了数据,则通知A更新或清除A的缓存。
## 重要说明:
本文虽说是观察者模式,其实和真正的观察者模式还是有些区别的,但是其实核心还是观察者的思想原理。
## 代码实现如下:
有两套实现ejpa和embp的,类似的,本文以embp的实现进行说明!
- embp: 1.0.0+
- ejpa: 4.0.0+
### 基础的观察者及被观察者模型:
- 继承BaseObservable,说明自己可以被别人观察,因此需要实现注册观察者及通知观察者的方法;
- 实现BaseObserver说明自己也可以观察别人,别人更新了则需要更新自己的缓存!
```java
/**
* Description: 尝试基于观察者模式的缓存一致性基类service
* 注意,此处就是jdk的java.util.Observable的实现,之所以存在是为了解开java中类不能多继承的死结
* 本类中的泛型参数,其实没有使用到,只是为了子类继承传递的需要而已
* @author dbdu
*/
@Slf4j
public abstract class BaseObservable<M extends BaseMapper<T>, T> extends ServiceImpl<M,T> {
private boolean changed = false;
private Vector<BaseObserver<M, T>> obs;
/**
* Construct an Observable with zero BaseObservers.
*/
public BaseObservable() {
obs = new Vector<>();
}
/**
* Adds an observer to the set of observers for this object, provided
* that it is not the same as some observer already in the set.
* The order in which notifications will be delivered to multiple
* observers is not specified. See the class comment.
*
* @param o an observer to be added.
* @throws NullPointerException if the parameter o is null.
*/
public synchronized void addBaseObserver(BaseObserver<M, T> o) {
if (o == null) {
throw new NullPointerException();
}
if (!obs.contains(o)) {
obs.addElement(o);
}
}
/**
* Deletes an observer from the set of observers of this object.
* Passing <CODE>null</CODE> to this method will have no effect.
*
* @param o the observer to be deleted.
*/
public synchronized void deleteBaseObserver(BaseObserver<M, T> o) {
obs.removeElement(o);
}
/**
* If this object has changed, as indicated by the
* <code>hasChanged</code> method, then notify all of its observers
* and then call the <code>clearChanged</code> method to
* indicate that this object has no longer changed.
* <p>
* Each observer has its <code>update</code> method called with two
* arguments: this observable object and <code>null</code>. In other
* words, this method is equivalent to:
* <blockquote><tt>
* notifyBaseObservers(null)</tt></blockquote>
*/
public void notifyBaseObservers() {
notifyBaseObservers(null);
}
/**
* If this object has changed, as indicated by the
* <code>hasChanged</code> method, then notify all of its observers
* and then call the <code>clearChanged</code> method to indicate
* that this object has no longer changed.
* <p>
* Each observer has its <code>update</code> method called with two
* arguments: this observable object and the <code>arg</code> argument.
*
* @param arg any object.
*/
public void notifyBaseObservers(Object arg) {
/*
* a temporary array buffer, used as a snapshot of the state of
* current BaseObservers.
*/
Object[] arrLocal;
synchronized (this) {
/* We don't want the BaseBaseObserver doing callbacks into
* arbitrary code while holding its own Monitor.
* The code where we extract each Observable from
* the Vector and store the state of the BaseBaseObserver
* needs synchronization, but notifying observers
* does not (should not). The worst result of any
* potential race-condition here is that:
* 1) a newly-added BaseBaseObserver will miss a
* notification in progress
* 2) a recently unregistered BaseBaseObserver will be
* wrongly notified when it doesn't care
*/
if (!changed) {
return;
}
arrLocal = obs.toArray();
clearChanged();
}
for (int i = arrLocal.length - 1; i >= 0; i--) {
((BaseObserver<M, T>) arrLocal[i]).update(this, arg);
}
}
/**
* Clears the observer list so that this object no longer has any observers.
*/
public synchronized void deleteBaseObservers() {
obs.removeAllElements();
}
/**
* Marks this <tt>Observable</tt> object as having been changed; the
* <tt>hasChanged</tt> method will now return <tt>true</tt>.
*/
protected synchronized void setChanged() {
changed = true;
}
/**
* Indicates that this object has no longer changed, or that it has
* already notified all of its observers of its most recent change,
* so that the <tt>hasChanged</tt> method will now return <tt>false</tt>.
* This method is called automatically by the
* <code>notifyBaseObservers</code> methods.
*
*/
protected synchronized void clearChanged() {
changed = false;
}
/**
* Tests if this object has changed.
*
* @return <code>true</code> if and only if the <code>setChanged</code>
* method has been called more recently than the
* <code>clearChanged</code> method on this object;
* <code>false</code> otherwise.
*/
public synchronized boolean hasChanged() {
return changed;
}
/**
* Returns the number of observers of this <tt>Observable</tt> object.
*
* @return the number of observers of this object.
*/
public synchronized int countBaseObservers() {
return obs.size();
}
}
```
```java
/**
* 本类中的泛型参数,其实没有使用到,只是为了子类继承传递的需要而已
* @param <M> mapper
* @param <T> entity
*/
public interface BaseObserver<M extends BaseMapper<T>, T> {
/**
* This method is called whenever the observed object is changed. An
* application calls an <tt>Observable</tt> object's
* <code>notifyObservers</code> method to have all the object's
* observers notified of the change.
*
* @param o the observable object.
* @param arg an argument passed to the <code>notifyObservers</code>
* method.
*/
void update(BaseObservable<M, T> o, Object arg);
}
```
### 基础的服务层实现分别继承和实现接口
```java
public class BaseServiceImpl<T extends BaseEntity<T>, M extends BaseMapper<T>>
extends BaseObservable<M, T>
implements IBaseService<T>, BaseObserver<M, T> {
//// 此处省略了一些其他代码////
// ######################################################################################
// 注意下面的三个方法是是维护多表关联查询结果缓存的一致性的,除非你知道在做什么,否则不要去修改! #
// 三个方法是:registObservers,notifyOthers,update #
// 此处使用了jdk自带的观察者的设计模式。 当前对象既是被观察者,也是观察者! #
// ######################################################################################
/**
* 注册观察者,即哪些组件观察自己,让子类调用此方法实现观察者注册
*/
@Override
public void registObservers(BaseObserver... baseObservers) {
for (BaseObserver baseObserver : baseObservers) {
this.addBaseObserver(baseObserver);
}
}
/**
* 自己的状态改变了,通知所有依赖自己的组件进行缓存清除,
* 通常的增删改的方法都需要调用这个方法,来维持 cache right!
* @param arg 通知观察者时可以传递礼物arg,即数据,如果不需要数据就传递null;
*/
@Override
public void notifyOthers(Object arg) {
//注意在用Java中的Observer模式的时候下面这句话不可少
this.setChanged();
// 然后主动通知, 这里用的是推的方式
this.notifyBaseObservers(arg);
// 如果用拉的方式,这么调用
// this.notifyBaseObservers();
}
/**
* 这是观察别人,别人更新了之后来更新自己的
* 其实此处不需要被观察者的任何数据,只是为了知道被观察者状态变了,自己的相关缓存也就需要清除了,否则不一致
* 例如:观察A对象,但是A对象被删除了,那个自己这边关联查询与A有关的缓存都应该清除
* 子类重写此方法在方法前面加上清除缓存的注解,或者在方法体内具体执行一些清除缓存的代码。
*
* @param o 被观察的对象
* @param arg 传递的数据
*/
@Override
public void update(BaseObservable o, Object arg) {
}
}
```
- 上面观察者可能会收到更新者发送的数据对象arg,为了规范处理,特定义了一个通用的类来表示,如下:
```java
/**
* Description: 这个类是缓存一致性维护时使用,
* 如果B组件需要精细地维护A组件的缓存就需要本类,以便A组件根据本类的信息进行精细化更新自己的缓存数据。
* 当然,如果不需要精细,直接通知A清除A所有缓存。
*
* @Author dbdu
* @Date 2020-09-06
*/
@Setter
@Getter
@NoArgsConstructor
@AllArgsConstructor
public class ObserveData {
/**
* 哪个类更新了,例如:User
* 之所以有这个字段,是因为一个组件可能观察多个其他组件,同过本字段就可以清楚知道谁更新了
*/
private String className;
/**
* 操作的类型是什么,例如:增--1;改--2;删--3
* 参看:OperateTypeEnum
*/
private Integer operType;
/**
* 更新的主键集合是什么,多个主键用分隔符分割,然后解析时使用对应的分隔符即可!
* 建议支持的分隔符:中英文的逗号分号,和中文的顿号!
* String[] keys = data.split(",|;|、|,|;");
*/
private String data;
@Override
public String toString() {
return "ObserveData{" +
"className='" + className + '\'' +
", operType=" + operType +
", data='" + data + '\'' +
'}';
}
}
```
### 启动项目时在这里全局注册相应的观察者,避免每个组件独立注册可能导致的循环引用问题,例如:
```java
package vip.efactory.embp.example.config;
import lombok.AllArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Component;
import vip.efactory.embp.example.service.impl.SysMenuServiceImpl;
import vip.efactory.embp.example.service.impl.SysRoleServiceImpl;
import vip.efactory.embp.example.service.impl.SysUserServiceImpl;
import javax.annotation.PostConstruct;
/**
* Description: 统一处理缓存观察者模式的。避免局部处理的循环引用
*
* @Author dbdu
* @Date 2020-08-24
*/
@AllArgsConstructor
@Component
@Slf4j
public class CacheObserveBeanPostProcessor {
// menu ,user,role组件的缓存处理
SysMenuServiceImpl sysMenuServiceImpl;
SysUserServiceImpl sysUserServiceImpl;
SysRoleServiceImpl sysRoleServiceImpl;
private void init4menu() {
log.info("开始注册menu的观察者...");
sysMenuServiceImpl.registObservers(sysUserServiceImpl, sysRoleServiceImpl);
}
private void init4role() {
log.info("开始注册role的观察者...");
sysRoleServiceImpl.registObservers(sysUserServiceImpl);
}
@PostConstruct
private void initCacheObserve() {
init4menu();
init4role();
}
}
```
在菜单模块调用的更新方法,就会通知用户模块去清除自己的缓存数据:
```java
package vip.efactory.embp.example.service.impl;
// 省略包导入
/**
* 菜单权限表 服务实现类
*/
@Service
@RequiredArgsConstructor
public class SysMenuServiceImpl extends BaseServiceImpl<SysMenu, SysMenuMapper> implements SysMenuService {
// 省略了其他的代码
@Override
@CacheEvict(value = "MENU_DETAILS", allEntries = true)
public Boolean updateMenuById(SysMenu sysMenu) {
boolean ret = this.updateById(sysMenu);
if(ret) {
// 不传递数据
// notifyOthers(null);
// 传递数据
ObserveData data = new ObserveData("SysMenu", OperateTypeEnum.UPDATE.getCode(), sysMenu.getMenuId().toString());
notifyOthers(data);
}
return ret;
}
}
```
上面要不要传递数据,取决于观察者要不要精细地维护自己的缓存,如果不需要就传null就好了
用户模块的服务层实现,重写update方法,以便处理用户模块自己的缓存:
```java
package vip.efactory.embp.example.service.impl;
// 省略包导入
@Slf4j
@Service
@RequiredArgsConstructor
public class SysUserServiceImpl extends BaseServiceImpl<SysUser, SysUserMapper> implements SysUserService {
static final String STATUS_NORMAL = "0";
private final SysMenuService sysMenuService;
private final SysRoleService sysRoleService;
private final SysUserRoleService sysUserRoleService;
// 此处省略了其他代码 //
// 联动清除本地的缓存!
@Override
@CacheEvict(value = "USER_DETAILS",allEntries = true)
public void update(BaseObservable o, Object arg) {
log.info("联动清除user缓存信息.....");
log.info("收到的数据是:" + arg);
}
}
```
以上是使用注解(**@CacheEvict(value = "USER_DETAILS",allEntries = true)**)直接清除用户模块的所有缓存的方式,如果这不是你想要的方式,
可以不用在update方法上加此注解,而是在方法内部利用收到的数据arg进行手动精细维护用户模块的缓存一致性!
或者在方法内部调用该模块特写的缓存处理方法(因为要想精细维护,缓存的key要有很好的规律性,这一点可能不容易),那么可以在特写的方法中:
擦除所有的缓存后,立即拉取最新数据进行缓存。但是,仍然尽量避免在一些高并发的场景下更新数据,有缓存击穿风险。
因为一个系统不可能一直是高并发状态,可以选择在非高并发时更新数据。
## 注意:其实对于多表联合查询的缓存也可以有一些其他的方案:
方式一: 缓存时间很短,例如:缓存2-3分钟,在2-3分钟内可能会有不一致的情况,这种方法适合一些非实时的场景,短暂不一致也没什么要紧的场景;
优点:可以明显提高效率;
缺点:不适合高并发场景,可能导致缓存瞬时击穿,给数据库造成非常大的压力甚至数据库服务器宕机!
方式二: 冗余连表查询的字段,但是这种可能因为冗余会把数据不一致带到数据表里面。
至于采用何种方式,可以根据具体的使用场景来决定!
## 相关源码如下:
ejpa实现:https://github.com/vip-efactory/ejpa
测试及使用:https://github.com/vip-efactory/ejpa-example
embp实现:https://github.com/vip-efactory/embp
测试及使用:https://github.com/vip-efactory/embp-example | 12,492 | Apache-2.0 |
# Arduino講義:Serial Communication (SPI)
## Introduction of SPI
* SPI 全名 Serial Peripheral Interface ,中文叫做序列周邊介面。
* 一種主從式架構的同步資料協定,可以讓多個裝置在短距離互相通訊。
* SPI 裝置之間使用<font color="red">全雙工模式通訊</font>,包含一個<font color="red">主機(master)</font>和一個或<font color="red">多個從機(slave)</font>。
* **SPI** : <font color="red"> 全雙工、串列、同步</font>
* 主要用以連接 ADC、DAC、EEPROM、通訊傳輸 IC...等週邊晶片。
### SPI 接腳名稱及意義
| 接腳名稱 | 腳位 | 說明 |
| -------- | --------|--------|
| MOSI (Master Output,Slave Input)|11| master 數據輸出,slave 數據輸入|
| MISO (Master Input,Slave Output) |12| master 數據輸入,slave 數據輸出|
| SCLK (Serial Clock)|13| 時脈信號,由 master 產生並控制 |
| SS (Slave Selected) |10| LOW(低電位)時表示裝置可以與Master通訊|
* SPI 匯流排:
* 單一主機對單一從機

* 單一主機對複合從機
主機將欲操作之從機選擇線拉低(SS to LOW),再分別透過 MOSI/MISO 啟動數據發送/接收。

#### 傳輸方式
* 當 Master 對 Slave 做 select 之後 (連接到該 slave 的 SS 拉 low), Master 開始送出 clock, 同時 Master 的資料 (MSB, 最高位元), 也由 shift register 推出,以在 MOSI 上維持住它的值,而 Slave 的資料也是在同一時間送到 MISO,說明了 SPI 是一個全雙工同步的訊號系統。

---
## Data Modes
* CPOL
* 寫入1時,時脈閒置時為高準位;寫入0時,時脈閒置時為低準位。
write 1 
write 0 
| CPOL0 | Leading edge | Trailing edge |
| -------- | --------| --------|
| 0 | Rising | Falling |
| 1 | Falling | Rising |
* CPHA
* 決定要在時脈的前緣或後緣取樣
| CPHA0 | Leading edge | Trailing edge |
| -------- | --------| --------|
| 0 | Sample | Setup |
| 1 | Setup | Sample |
### The Table of SPI Modes
| SPI Mode | Conditions | Leading Edge |Trailing Edge|
| -------- | --------| --------|--------|
|0| CPOL=0, CPHA=0 | Sample (Rising) | Setup (Falling)|
|1| CPOL=0, CPHA=1 | Setup (Rising) | Sample (Falling)|
|2| CPOL=1, CPHA=0 | Sample (Falling) | Setup (Rising)|
|3| CPOL=1, CPHA=1 | Setup (Falling) |Sample (Rising)|
:::success
舉例:CPOL =0 表示 clock 原本在 low,CPHA =0 表示資料在第1個 edge 被讀取. 也就是 rising edge 被讀取。其他以此類推。
:::
<!-- * 平常使用 SPI Library 時,SPI Mode 預設值為0,SCLK 為4Mhz。
``` c++=
SPISettings() {
init_AlwaysInline(4000000, MSBFIRST, SPI_MODE0);
}
```
### SPI Transfer Format with CPHA = 0

### SPI Transfer Format with CPHA = 1
 -->
---
### 相關函數
| 函數 | 作用 |
| -------- | -------- |
| SPI.begin()| 初始化 SPI Bus,設置SCK、MOSI和SS為輸出:將SCK和MOSI拉低,將SS拉高|
|SPI.end()|結束 SPI Bus|
|SPI.setBitOrder(order)|設定數據在 SPI Bus 上傳送順序為低位元(`LSBFIRST`)優先或高位元(`MSBFIRST`)優先|
|SPI.setClockDivider(divider)|設定 SPI 時脈的除數(Arduino硬體時脈為16Mhz)|
|SPI.transfer(val)|由 SPI 介面發送並接收 1 個 byte 資料|
---
## LAB1
* 實驗目的 :利用 SPI 進行 Arduino 間通訊
* Arduino UNO 內定 10,11,12,13 為 SPI 通信界面使用
* Pin 10 :SS chip select從設備致能信號,由主設備控制
* Pin 11 : MOSI 主設備數據輸出,從設備數據輸入
* Pin 12 : MISO 主設備數據輸入,從設備數據輸出
* Pin 13 : SCLK ,由主設備產生
* schematic

* Master example

<!--
// #include <SPI.h>
// void setup (void)
// {
// digitalWrite(SS, HIGH); // 確保SS初始狀態為HIGH
// SPI.begin ();
// SPI.setClockDivider(SPI_CLOCK_DIV8); //設定時脈為16/8 = 2 Mhz
// }
// void loop (void)
// {
// char c;
// digitalWrite(SS, LOW); //開始與從機通訊 //SS pin為10
// // 傳送字串
// for (const char * p = "Hello, world!\n" ; c = *p; p++)
// SPI.transfer (c);
// digitalWrite(SS, HIGH); // 關閉與從機的通訊
// delay (1000);
// } -->
* Slave example

<!-- #include <SPI.h>
char buf [100];
volatile byte pos;
volatile bool process_it;
void setup (void)
{
Serial.begin (115200);
SPCR |= bit (SPE); //開啟從機的SPI通訊
pinMode (MISO, OUTPUT); //設定主入從出
pos = 0; // buffer 裡頭為空
process_it = false;
SPI.attachInterrupt(); //啟用中斷函式
}
ISR (SPI_STC_vect) //SPI中斷程序
{
byte c = SPDR; //從SPI Data Register獲取資料(byte)
if (pos < sizeof buf) //若buffer空間足夠就寫入buffer裡頭
{
buf [pos++] = c;
if (c == '\n') // 收到換行字元表示要處理buffer
process_it = true;
}
}
void loop (void) // 等待中斷函式回傳true
{
if (process_it)
{
buf [pos] = 0;
Serial.println (buf);
pos = 0;
process_it = false;
}
}
``` -->
* SPCR

[參考資料](https://www.sparkfun.com/datasheets/Components/SMD/ATMega328.pdf)
* ISR 介紹 [click here](http://programmermagazine.github.io/201407/htm/article1.html)
<!-- :::info
關於中斷函式:[**點我**](http://coopermaa2nd.blogspot.tw/2011/04/attachinterrupt.html)
::: -->
# Arduino講義:計步器
## MPU6050模組
* 這次要練習的是 GY-521 的 Sensor,其核心的晶片是 MPU-6050。
* MPU-6050 是一個內包含<font color="red">三軸陀螺儀</font>以及<font color="red">三軸加速計</font>結合在一起的數位運動處理器(簡稱DMP),以 <font color="red"> I²C </font> 輸出6軸的旋轉矩陣的數位資料。
### GY-521規格
* 核心晶片:MPU-6050 模組(三軸陀螺儀 + 三軸加速度計)
* 供電電源:3-5v(內部低壓差穩壓)
* 通信方式:標準 I²C 通信協議
* 晶片內置 : 16bit AD 轉換器,16位數據輸出
* 陀螺儀範圍:±250 500 1000 2000 °/s
* 加速度範圍:±2 , ±4 , ±8 , ±16g
* MPU6050 晶片座標定義 :
將晶片平放在桌面上,將其表面文字轉至正確角度,此時,以晶片內部中心為原點,水平向右為x軸,水平向上為Y軸,指向天花板為Z軸。

- 三軸加速度計 :
- 加速度計的三軸分量 ACC_X、ACC_Y 和 ACC_Z 均為<font color="red">16位有符號整數</font>,分別表示物件在三個軸向上的加速度,取負值時加速度沿座標軸負向,取正值時沿正向。
- 三個加速度分量均以<font color="red">重力加速度 g 的倍數為單位</font>,能夠表示的加速度範圍,即倍率可以統一設定,有4個可選倍率:2g、4g、8g、16g。
- 以 ACC_X 為例,若<font color="red">倍率設定為 2g (默認)</font>,則意味著 ACC_X 取最小值-32768時,當前加速度為沿 X 軸正方向2倍的重力加速度;若設定為4g,取-32768時表示沿 X 軸正方向4倍的重力加速度,以此類推。顯然,<font color="red">倍率越低精度越好,倍率越高表示的範圍越大</font>,這要根據具體的應用來設定。
- 這三個加速度分量是16位的二進制補碼值,且是有符號的。故而其輸出範圍 -32768~32767。 32767/2 = <font color="red">16384 即加速度計的靈敏度</font>。
* <font color="red"> Q&A </font> 那這個靈敏度怎麼使用呢?我們使用 Serial Port 顯示的一組數據來舉個例子:
- ACC_X=03702 , ACC_Y=12456 , ACC_Z=06268 , G_X=-00023 , G_Y=-00059 , G_Z=00005
- 加速度計 X 軸獲取原始數據位 03702,那麼它對應的加速度數據是:03702/16384 = 0.23g。 g 為加速度的單位,重力加速度定義為1g, 等於9.8米每平方秒。
- 具體的加速度公式 : <font color="red"> 加速度數據 = 加速度軸原始數據/加速度靈敏度</font>。
* 三軸陀螺儀 :
* 繞 X、Y 和 Z 三個座標軸旋轉的角速度分量 GYR_X、GYR_Y 和 GYR_Z 均為16位有符號整數。從原點向旋轉軸方向看去,<font color="red">取正值時為順時針旋轉,取負值時為逆時針旋轉</font>。
* 三個角速度分量均以“度/秒”為單位,能夠表示的角速度範圍,即倍率可統一設定,有4個可選倍率:250度/秒、500度/秒、1000度/秒、2000度/秒。
* 以 GYR_X 為例,若倍率設定為250度/秒,則意味著 GYR_X 取正最大值32768時,當前角速度為順時針250度/秒;若設定為500度/秒,取32768時表示當前角速度為順時針500度/秒。顯然,倍率越低精度越好,倍率越高表示的範圍越大。
* 這三個陀螺儀分量是16位的二進制補碼值,且是有符號的。故而其輸出範圍 -32768~32767。32767/2000 = <font color="red">16.4 即陀螺儀的靈敏度</font>。
### 下載 MPU-6050 library
* MPU-6050 因為是靠 I2C 溝通的,所以是需要到 I2Cdevlib 去找相關的函式庫 library 。
* 但怕各位太辛苦,直接下載此處2個檔案即可 [MPU-6050](https://drive.google.com/open?id=1oLRlk2aqHdkppUU8AvR3iSkq-6myVYdo) 、 [I2Cdev](https://drive.google.com/file/d/1EDCvJBOozDBpI7-4ffF62k8mr7yetxEQ/view?usp=sharing) 。
* 將 MPU-6050 與 I2Cdev 資料夾, 丟進 Arduino 的 libraries 資料夾。
* (Windows 預設路徑是: C:\Program Files (x86)\Arduino\libraries)
### 學習如何讀出 MPU-6050 量測之值
* MPU-6050 腳位 :
| Arduino | MPU-6050 | 備註 |
| -------- | -------- | -------- |
| 3.3-5V | VCC |<font color="red">注意電源不可接錯</font> |
| GND | GND |<font color="red">注意電源不可接錯</font> |
| A5 | SCL |I2C 時脈線|
| A4 | SDA |I2C 數據線|
| 本次不使用 | XDA | |
| 本次不使用 | XCL | |
| 本次不使用 | AD0 | |
| 2 | INT |中斷腳位(本次不使用)|
* 線路接法
* code

## Lab2
### 計步器實作
* 實驗目標 : 利用 MPU-6050 做出簡易計步器之功能
* 實驗要求 : <font color="red">靜止時或輕輕移動時 </font>,計步器數值不會加一,需<font color="red">超過一定幅度</font>數值才會加一。
* 實驗步驟參考 :
<font color="red">! ! 提醒 : 此實驗步驟為只使用三軸加速度之值來進行運算</font>
* Step 1 : 利用講義上面介紹的加速度公式,得量化之加速度數據
* Step 2 : 透過下方公式將加速度數據代入,回推出變化之角度

* Step 3 : 為避免雜訊干擾,需透過前面量測出來之數據來設立閥值進行校準
* Step 4 : 定義怎樣的移動算一步
* 示範影片 :
<iframe width="640" height="360" src="https://www.youtube.com/embed/Y54LS3jHnQk" frameborder="0" allow="autoplay; encrypted-media" allowfullscreen></iframe>
## Lab3
### 計步器實作
* 實驗目標 : 完善你的簡易計步器,為其加上LCD以及清除按鈕
* 實驗要求 : LCD 第一行顯示文字,第二行顯示步數。按下清除開關時,步數歸零。
* 示範影片 :
<iframe width="640" height="360" src="https://www.youtube.com/embed/iNj8Kv7kHRk" frameborder="0" allow="autoplay; encrypted-media" allowfullscreen></iframe>
<!-- ### 加分 LAB SPI -- 接收 slave 端的回饋值
- 實驗目的:SPI用 master 端與 slave 端溝通方式。
- 實驗目標:將 master 端的數值丟入 slave 端進行運算後,slave 端將計算後的數值送回 master 端並於 Serial Monitor 顯示計算結果。
- schematic:

- master:
```c=
#include <SPI.h>
void setup (void)
{
Serial.begin (115200);
Serial.println ();
digitalWrite(SS, HIGH);
SPI.begin ();
SPI.setClockDivider(SPI_CLOCK_DIV8);
}
byte transferAndWait (const byte what) //數值傳送至Slave端
{
byte a = ;
delayMicroseconds (20);
return a;
}
void loop (void)
{
byte a, b, c, d;
digitalWrite(SS, LOW);
/*在此填入加法指令與數值*/
transferAndWait ('a');
transferAndWait (0);
a = transferAndWait (17);
digitalWrite(SS, HIGH);
/*回傳值顯示在Serial Monitor上*/
Serial.println ("Adding results:");
Serial.println (a, DEC);
delay(1000);
digitalWrite(SS, LOW);
/*在此填入減法指令與數值*/
transferAndWait ('s');
transferAndWait (0);
a = transferAndWait (17);
digitalWrite(SS, HIGH);
/*回傳值顯示在Serial Monitor上*/
Serial.println ("Subtracting results:");
Serial.println (a, DEC);
delay (1000);
}
```
- slave:
```c=
volatile byte command = 0;
void setup (void)
{
/*設定主入從出*/
/*啟用slave模式*/
/*啟用中斷*/
}
ISR (SPI_STC_vect) //SPI中斷程序
{
byte c = SPDR;
switch (command)
{
case 0:
command = c; //將暫存器內的資料設給command
SPDR = 0; //清空暫存器
break;
/*收到加法or減法指令並在此進行計算*/
}
}
void loop (void)
{
if (digitalRead (SS) == HIGH) //若SPI通訊關閉,清除目前command
command = 0;
}
``` -->
## 課後問題 (三題)
:::info
* Q1.請簡述 URAT、I2C、SPI三介面之特性與傳輸差異。
* Q2.MPU-6050 的接腳 XDA、XCL、AD0 功能為何?
* Q3.下方為不呼叫 MPU-6050 library 來讀出 MPU-6050 數值之程式,
請為其標上 <font color="red">完整的註解</font>。
```c=
#include<Wire.h>
const int MPU_addr=0x68;
void setup(){
Wire.begin();
Wire.beginTransmission(MPU_addr);
Wire.write(0x6B);
Wire.write(0);
Wire.endTransmission(true);
Serial.begin(38400);
}
void loop(){
Wire.beginTransmission(MPU_addr);
Wire.write(0x3B);
Wire.endTransmission(false);
Wire.requestFrom(MPU_addr,14,true);
AcX=Wire.read()<<8|Wire.read();
AcY=Wire.read()<<8|Wire.read();
AcZ=Wire.read()<<8|Wire.read();
GyX=Wire.read()<<8|Wire.read();
GyY=Wire.read()<<8|Wire.read();
GyZ=Wire.read()<<8|Wire.read();
Serial.print("AcX = "); Serial.print(AcX);
Serial.print(" | AcY = "); Serial.print(AcY);
Serial.print(" | AcZ = "); Serial.print(AcZ);
Serial.print(" | GyX = "); Serial.print(GyX);
Serial.print(" | GyY = "); Serial.print(GyY);
Serial.print(" | GyZ = "); Serial.println(GyZ);
delay(333);
}
```
::: | 11,067 | MIT |
---
title: 同步多个 Azure Kinect DK 设备
description: 本文探讨多设备同步的优势,以及如何设置要同步的设备。
author: tesych
ms.author: tesych
ms.prod: kinect-dk
ms.date: 02/20/2020
ms.topic: article
keywords: azure, kinect, 规格, 硬件, DK, 功能, 深度, 彩色, RGB, IMU, 阵列, 多, 同步
ms.openlocfilehash: 30961152b31a659cb27e91a99d6806490998d18d
ms.sourcegitcommit: d2d1c90ec5218b93abb80b8f3ed49dcf4327f7f4
ms.translationtype: MT
ms.contentlocale: zh-CN
ms.lasthandoff: 12/16/2020
ms.locfileid: "97592273"
---
# <a name="synchronize-multiple-azure-kinect-dk-devices"></a>同步多个 Azure Kinect DK 设备
每个 Azure Kinect DK 设备附带 3.5 毫米同步端口(**输入同步** 和 **输出同步**),可将多个设备链接在一起。 连接设备后,软件可以协调设备之间的触发定时。
本文将介绍如何连接和同步设备。
## <a name="benefits-of-using-multiple-azure-kinect-dk-devices"></a>使用多个 Azure Kinect DK 设备的好处
使用多个 Azure Kinect DK 设备的原因有很多,包括:
- 填补遮挡区域。 尽管 Azure Kinect DK 数据转换生成的是单个图像,但两个相机(深度和 RGB 相机)实际上保持着较小的一段距离。 这种偏移使得遮挡成为可能。 遮挡是指前景对象阻挡了设备上两个相机之一的背景对象的部分视角。 在生成的彩色图像中,前景对象看上去像是在背景对象上投射了一个阴影。
例如,在下图中,左侧相机可看到灰色像素“P2”。 但是,白色的前景对象阻挡了右侧相机的红外光束。 右侧相机无法获取“P2”的数据。

附加的同步设备可以提供遮挡的数据。
- 扫描三维对象。
- 将有效帧速率提升至 30 帧/秒 (FPS) 以上的值。
- 捕获同一场景的多个 4K 彩色图像,所有图像都在曝光中心时间点的 100 微秒 (μs) 内对齐。
- 增大相机的空间覆盖范围。
## <a name="plan-your-multi-device-configuration"></a>规划多设备配置
在开始之前,请务必查看 [Azure Kinect DK 硬件规格](hardware-specification.md)和 [Azure Kinect DK 深度相机](depth-camera.md)。
### <a name="select-a-device-configuration"></a>选择设备配置
可使用以下任一方法来完成设备配置:
- **菊花链配置**。 同步一个主设备以及最多八个从属设备。

- **星形配置**。 同步一个主设备以及最多两个从属设备。

#### <a name="using-an-external-sync-trigger"></a>使用外部同步触发器
在两种配置中,主设备提供从属设备的触发信号。 但是,可将自定义的外部源用于同步触发器。 例如,可以使用此选项同步其他设备的图像捕获信号。 在菊花链配置或星形配置中,外部触发器源将连接到主设备。
外部触发器源的工作方式必须与主设备相同。 它必须提供一个具有以下特征的同步信号:
- 活动程度高
- 脉冲宽度:大于 8μs
- 5V TTL/CMOS
- 最大驱动容量:不小于 8 毫安 (mA)
- 频率支持:精确到 30 FPS、15 FPS 和 5 FPS(彩色相机主 VSYNC 信号的频率)
触发器源必须使用 3.5 毫米音频线将信号传送到主设备的 **输入同步** 端口。 可以使用立体声或单声道音频线。 Azure Kinect DK 会将音频线连接器的所有套管和套环短接到一起,并将其接地。 如下图所示,设备只从连接器尖端接收同步信号。

有关如何使用外部设备的详细信息,请参阅[将 Azure Kinect 录制器与外部同步设备配合使用](record-external-synchronized-units.md)
### <a name="plan-your-camera-settings-and-software-configuration"></a>规划相机设置和软件配置
有关如何设置软件来控制相机以及如何使用图像数据的信息,请参阅 [Azure Kinect 传感器 SDK](about-sensor-sdk.md)。
本部分讨论影响已同步设备(而不是单独的设备)的多种因素。 软件应考虑到这些因素。
#### <a name="exposure-considerations"></a>曝光考虑因素
若要控制每个设备的精确定时,我们建议使用手动曝光设置。 使用自动曝光设置时,每个彩色相机可能会动态更改实际曝光。 由于曝光会影响定时,此类更改很快就会使相机失去同步。
避免在图像捕获循环中重复指定相同的曝光设置。 必要时,请只调用 API 一次。
#### <a name="avoiding-interference-between-multiple-depth-cameras"></a>避免多个深度相机之间产生干扰
如果多个深度相机对重叠的视场成像,每个相机必须对其自身关联的激光成像。 为了防止激光相互干扰,相机捕获应相互偏离 160μs 或以上。
对于每次深度相机捕获,激光会打开 9 次,每次只保持活动状态 125μs。 然后,激光将空闲 14505μs 或 23905μs,具体取决于工作模式。 此行为意味着,偏移量计算的起点为 125μs。
此外,相机时钟与设备固件时钟之差会将最小偏移量增大至 160μs。 若要根据配置计算出更精确的偏移量,请注意所用的深度模式,并参考[深度传感器原始定时表](hardware-specification.md#depth-sensor-raw-timing)。 参考此表中的数据可以使用以下公式计算最小偏移量(每个相机的曝光时间):
> 曝光时间 = (红外脉冲 × 脉冲宽度) + (空闲周期 × 空闲时间)
使用 160μs 偏移量时,最多可以配置 9 个额外的深度相机,以便在每束激光打开时,其他激光保持空闲状态。
在软件中,使用 ```depth_delay_off_color_usec``` 或 ```subordinate_delay_off_master_usec``` 来确保每束红外激光在其自身的 160μs 时限内触发,或者提供不同的视场。
> [!NOTE]
> 实际的脉冲宽度为125us,但我们将160us 为某些机动时间提供。 以 NFOV UNBINNED 为例,每个125us 脉冲后跟 1450us idle。 汇总这些 (9 x 125) + (8 x 1450) ,产生曝光度为 12.8 ms 的曝光时间。 可以交错两个设备的曝光,使第二个相机的第一次脉冲落在第一个相机的第一个空闲期间。 第一个和第二个摄像机之间的延迟可能会小到 125us (脉冲的宽度) 不过,我们建议机动时间160us。 给定的160us,你可以交错最多10个相机的曝光期限。
## <a name="prepare-your-devices-and-other-hardware"></a>准备设备和其他硬件
除了多个 Azure Kinect 深色设备,你可能还需要获取其他主机计算机和其他硬件,以支持你想要生成的配置。 使用此部分中的信息,确保所有设备和硬件都已准备就绪,然后才能开始设置。
### <a name="azure-kinect-dk-devices"></a>Azure Kinect 深色设备
对于要同步的每个 Azure Kinect 深色设备,请执行以下操作:
- 确保设备上已安装最新的固件。 有关如何更新设备的详细信息,请参阅 [更新 Azure KINECT 深色固件](update-device-firmware.md)。
- 卸下设备盖以显示同步端口。
- 记下每个设备的序列号。 稍后将在安装过程中使用此数字。
### <a name="host-computers"></a>主机计算机
通常,每个 Azure Kinect 深色都使用其自己的主计算机。 你可以使用专用的主机控制器,具体取决于你使用设备的方式,以及通过 USB 连接传输的数据量。
请确保每台主机计算机上都安装了 Azure Kinect 传感器 SDK。 有关如何安装传感器 SDK 的详细信息,请参阅 [快速入门:设置 Azure KINECT 深色](set-up-azure-kinect-dk.md)。
#### <a name="linux-computers-usb-memory-on-ubuntu"></a>Linux 计算机: Ubuntu 上的 USB 内存
默认情况下,基于 Linux 的主机计算机仅分配 16 MB 的内核内存来处理 USB 传输。 此量通常足以支持单个 Azure Kinect 深色。 但是,为了支持多个设备,USB 控制器必须具有更多内存。 若要增加内存,请执行以下步骤:
1. 编辑/**etc/默认/grub**。
1. 找到以下行:
```cmd
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash"
```
使用以下行替换它:
```cmd
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash usbcore.usbfs_memory_mb=32"
```
> [!NOTE]
> 这些命令将 USB 内存设置为 32 MB。 这是一个示例设置,默认值为两倍。 根据解决方案的需要,可以设置更大的值。
1. 运行 **sudo 更新-grub**。
1. 重新启动计算机。
### <a name="cables"></a>电缆
若要将设备连接到另一台设备并连接到主机计算机,必须使用 3.5-mm 插头到插头电缆 (也称为 3.5-mm 音频电缆) 。 电缆长度应小于10米,可以是立体声或 mono。
你必须具有的电缆数量取决于你使用的设备数和特定设备配置。 Azure Kinect 深色框不包括电缆。 您必须单独购买它们。
如果在星形配置中连接设备,还必须有一个耳机拆分器。
## <a name="connect-your-devices"></a>连接数据
**连接菊花链配置中的 Azure Kinect 深色设备**
1. 将每个 Azure Kinect 深色连接到 power。
1. 将每个设备连接到其主机。
1. 选择一台设备作为主设备,并将 3.5-mm 音频电缆插入到其 **同步输出** 端口。
1. 将电缆的另一端插入第一个从属设备的 " **同步** 端口" 端口。
1. 若要连接另一台设备,请将另一条电缆插入到第一个从属设备的 **sync out** 端口,并将其插入到下一个设备的 " **同步** 到" 端口。
1. 重复上一步,直到所有设备都已连接。 最后一台设备应该只有一个电缆连接。 其 **同步输出** 端口应为空。
**连接星型配置中的 Azure Kinect 深色设备**
1. 将每个 Azure Kinect 深色连接到 power。
1. 将每个设备连接到其主机。
1. 选择一个设备作为主设备,并将耳机分隔条的一端插入到其 **同步输出** 端口。
1. 将3.5 毫米音频电缆连接到耳机拆分器的 "拆分" 端。
1. 将每个电缆的另一端插入到一个从属设备的 "同步端口" 端口 **中** 。
## <a name="verify-that-the-devices-are-connected-and-communicating"></a>验证设备是否已连接并进行通信
若要验证设备是否已正确连接,请使用 [Azure Kinect 查看器](azure-kinect-viewer.md)。 根据需要重复此过程,以将每个从属设备与主设备结合在一起测试
> [!IMPORTANT]
> 对于此过程,必须了解每个 Azure Kinect 深色的序列号。
1. 打开 Azure Kinect 查看器的两个实例。
1. 在 " **打开设备**" 下,选择要测试的从属设备的序列号。

> [!IMPORTANT]
> 若要在所有设备之间获取精确的图像捕获对齐方式,你必须最后启动主设备。
1. 在 " **外部同步**" 下选择 " **Sub**"。

1. 选择“开始”。
> [!NOTE]
> 由于这是从属设备,因此在设备启动后,Azure Kinect 查看器不会显示图像。 在从属设备从主设备收到同步信号之前,不会显示图像。
1. 启动从属设备后,请使用 Azure Kinect 查看器的其他实例打开主设备。
1. 在 " **外部同步**" 下,选择 " **Master**"。
1. 选择“开始”。
当 Azure kinect 设备的主节点启动时,Azure Kinect 查看器的两个实例都应显示图像。
## <a name="calibrate-the-devices-as-a-synchronized-set"></a>将设备校准为同步集
验证设备是否正确通信后,便可以校准它们以在单个域中生成映像。
在单个设备中,深度和 RGB 相机进行了工厂校准,共同合作。 但是,当多个设备必须一起工作时,必须校准它们,以确定如何将图像从相机的域转换为要用于处理图像的照相机的域。
交叉校准设备有多个选项。 Microsoft 提供 [GitHub 绿色屏幕代码示例](https://github.com/microsoft/Azure-Kinect-Sensor-SDK/tree/develop/examples/green_screen),它使用 OpenCV 方法。 此代码示例的自述文件提供了有关校准设备的更多详细信息和说明。
有关校准的详细信息,请参阅 [使用 Azure Kinect 校准函数](use-calibration-functions.md)。
## <a name="next-steps"></a>后续步骤
设置同步设备后,还可以了解如何使用
> [!div class="nextstepaction"]
> [Azure Kinect 传感器 SDK 录制和播放 API](record-playback-api.md)
## <a name="related-topics"></a>相关主题
- [关于 Azure Kinect 传感器 SDK](about-sensor-sdk.md)
- [Azure Kinect DK 硬件规格](hardware-specification.md)
- [快速入门:设置 Azure Kinect 深色](set-up-azure-kinect-dk.md)
- [更新 Azure Kinect DK 固件](update-device-firmware.md)
- [重置 Azure Kinect DK](reset-azure-kinect-dk.md)
- [Azure Kinect 查看器](azure-kinect-viewer.md) | 7,154 | CC-BY-4.0 |
---
layout: daily
title: option search.caseInsensitive 过滤框是否区分大小写 《不定时一讲》 DataTables中文网
short: option search.caseInsensitive 过滤框是否区分大小写
date: 2016-5-11
group: 2016-5
caption: 《不定时一讲》
categories: manual daily
tags: [不定时一讲]
author: DataTables中文网
banner: http://tse4.mm.bing.net/th?id=OIP.M34f91e39cb7ee45c2708ac9a3a7b7beao0&w=218&h=139&c=7&rs=1&qlt=90&o=4&pid=1.1
---
参数详解连接{% include href/option/Options.html param="search.caseInsensitive" %}
这个参数很简单,在只有英文的情况下使用这个参数可以设置这个参数,Datatables过滤的时候是否区分大小写
默认是区分大小写的,所以如果你不想区分大小写,参考如下代码:
<!--more-->
{% highlight javascript linenos %}
var table = $('#example').DataTable( {
"search": {
//关掉区分大小写过滤
"caseInsensitive": false
}
} );
{% endhighlight %} | 728 | CC0-1.0 |
<!-- PROJECT SHIELDS -->
<!--
*** I'm using markdown "reference style" links for readability.
*** Reference links are enclosed in brackets [ ] instead of parentheses ( ).
*** See the bottom of this document for the declaration of the reference variables
*** for contributors-url, forks-url, etc. This is an optional, concise syntax you may use.
*** https://www.markdownguide.org/basic-syntax/#reference-style-links
-->
[![Contributors][contributors-shield]][contributors-url]
[![Forks][forks-shield]][forks-url]
[![Stargazers][stars-shield]][stars-url]
[![Issues][issues-shield]][issues-url]
[![MIT License][license-shield]][license-url]
[English README.md(英文版 README.md)](https://github.com/DysonMa/PTT-Crawler/blob/master/README.md)
<!-- PROJECT LOGO -->
<br />
<p align="center">
<!-- <a href="https://github.com/othneildrew/Best-README-Template"> -->
<img src="./image/ptt.PNG" alt="Logo" width="80" height="80">
<!-- </a> -->
<h3 align="center">PTT 爬蟲</h3>
<p align="center">
這是一個利用requests, pyquery, pandas, SQLite爬蟲的程式,爬取 PTT 網站並將資料存入SQLite資料庫,並串接至 LINE Notify 通知服務。
</p>
</p>
<!-- TABLE OF CONTENTS -->
<details open="open">
<summary>目錄</summary>
<ol>
<li>
<a href="#about-the-project">關於</a>
<ul>
<li><a href="#built-with">建立的環境與套件</a></li>
</ul>
</li>
<li>
<a href="#getting-started">如何開始</a>
<ul>
<li><a href="#installation">下載</a></li>
</ul>
</li>
<li><a href="#usage">如何使用</a></li>
<li><a href="#license">憑證</a></li>
<li><a href="#contact">聯絡方式</a></li>
<li><a href="#acknowledgements">致謝</a></li>
</ol>
</details>
<!-- ABOUT THE PROJECT -->
## 關於
PTT 是台灣最常使用到的社群(鄉民)網站之一。
因為每天的資訊量太過龐大,難以完全的消化,所以我們可以透過爬蟲的技術來快速地蒐集資料。
之外,將資料存入資料庫將有利於後續的分析,如: 機器學習、深度學習、大眾輿情分析...等等。


### 建立的環境與套件
* [Python](https://www.python.org/)
* [LINE Notify](https://notify-bot.line.me/zh_TW/)
* [SQLite](https://www.sqlite.org/download.html)
* Pandas
* requests
* pyquery
<!-- GETTING STARTED -->
## 如何開始
### 下載
1. Clone the repo
```
git clone https://github.com/DysonMa/PTT-Crawler.git
```
2. 編輯 `config.ini`
`boardlist`: 輸入ptt爬蟲的版名
`deadline`: 設定爬蟲停止的截止日期
`sqlite_path`: SQLite資料庫的存取路徑
`token`: LINE Notification service token
<!-- USAGE EXAMPLES -->
## 如何使用
首先,利用前述提到的必要參數要來創建一個 `config.ini` 檔,這個檔案的路徑必須和 `main.ipynb` 相同。
底下是一個簡單的例子:
* 載入 ptt 套件
```
from ptt.crawler import *
from ptt.schedule import *
```
* 檢查參數是否正確
```
print('config_path:', config_path)
print('deadline:', deadline)
print('boardlist:', boardlist)
print('updatePageNum:', updatePageNum)
print('sqlite_path:', sqlite_path)
```
>config_path: config.ini<br>
deadline: 2020-12-19 00:00:00<br>
boardlist: ['Civil', 'Soft_Job', 'NBA']<br>
updatePageNum: 1<br>
sqlite_path: D:\ptt_test.db<br>
* 依據特定的版名來命名 `website` 這個變數名稱
```
website = get_index('civil')
print(get_weburl(website))
```
https://www.ptt.cc//bbs/civil/index.html
* 利用 **頁數** 來爬取PTT網站
```
df = CrawlingByPage(website, page=2, save=True, update=True)
```


* 利用 **日期時間** 來爬取PTT網站
```
df = CrawlingByDate(website, deadline, save=True, update=True)
```

* 利用 **排程** 來定期爬取PTT網站
```
schedule()
```

Line Notification 通知服務
<img src='/image/line-notification.png' width="250"></img>
<!-- LICENSE -->
## 憑證
Distributed under the MIT License.
<!-- CONTACT -->
## 聯絡方式
Dyson Ma - [Gmail]([email protected])
Project Link: [https://github.com/DysonMa/PTT-Crawler](https://github.com/DysonMa/PTT-Crawler)
<!-- ACKNOWLEDGEMENTS -->
## 致謝
* [Best-README-Template](https://github.com/othneildrew/Best-README-Template)
<!-- MARKDOWN LINKS & IMAGES -->
<!-- https://www.markdownguide.org/basic-syntax/#reference-style-links -->
[contributors-shield]: https://img.shields.io/github/contributors/dysonma/PTT-Crawler?style=for-the-badge
[contributors-url]: https://github.com/DysonMa/PTT-Crawler/graphs/contributors
[forks-shield]: https://img.shields.io/github/forks/dysonma/PTT-Crawler?style=for-the-badge
[forks-url]: https://github.com/DysonMa/PTT-Crawler/network/members
[stars-shield]: https://img.shields.io/github/stars/dysonma/PTT-Crawler?style=for-the-badge
[stars-url]: https://github.com/DysonMa/PTT-Crawler/stargazers
[issues-shield]: https://img.shields.io/github/issues/dysonma/PTT-Crawler?style=for-the-badge
[issues-url]: https://github.com/DysonMa/PTT-Crawler/issues
[license-shield]: https://img.shields.io/github/license/dysonma/PTT-Crawler?style=for-the-badge
[license-url]: https://github.com/DysonMa/PTT-Crawler/blob/master/LICENSE | 4,689 | MIT |