Spaces:
Runtime error

A newer version of the Gradio SDK is available:
5.1.0
问题汇总
目录
- 问题汇总
- 一、下载问题
- 二、环境配置问题
- 三、运行问题
- 3.1 文件找不到
- 3.2 FFMPEG问题
- 3.3 路径问题
- 3.4 GFPGANer is not defined
- 3.5 Microsoft Visual C++ 14.0 is required
- 3.6 多个服务器部署
- 3.7 GeminiPro的参数proxy代理设置
- 3.8 项目更新方向
- 3.9 version GLIBCXX_3.4.* not found
- 3.10 Gradio Connection errored out
- 3.11 gr.Error("无克隆环境或者无克隆模型权重,无法克隆声音", e)
- 3.12 OSError: WinError 127 找不到指定的程序
- 3.13 LLM对话步骤出现错误:“对不起,你的请求出错了,请再次尝试。”
- 3.14 启动报错 SadTalker Error: invalid load key, 'v'.
- 3.15 nltk下载出现问题
- 四、使用问题
- 五、功能迭代问题
- 六、交流群问题
一、下载问题
1.1 代码下载
代码可以从Github下载 https://github.com/Kedreamix/Linly-Talker,也可以从Gitee下载 https://gitee.com/kedreamix/Linly-Talker
Github会是最新的代码,Gitee会不定时更新
1.2 权重下载
提供以下四种渠道下载权重,具体可看README
- Baidu (百度云盘) (Password:
linl) - huggingface
- modelscope
- Quark(夸克网盘)
SadTalker的代码可以从 Baidu (百度云盘) (Password: linl) 下载,也可以直接运行shell文件bash scripts/download_models.sh 运行自动下载所有模型,并且移动到对应的目录(比较适用于Linux)。
Wav2Lip的代码模型也可以从One Drive下载,可以只下载第一个或者第二个:
| Model | Description | Link to the model |
|---|---|---|
| Wav2Lip | Highly accurate lip-sync | Link |
| Wav2Lip + GAN | Slightly inferior lip-sync, but better visual quality | Link |
| Expert Discriminator | Weights of the expert discriminator | Link |
| Visual Quality Discriminator | Weights of the visual disc trained in a GAN setup | Link |
GPT-SoVITS的代码模型可以从以下链接下载,具体可看https://github.com/RVC-Boss/GPT-SoVITS/blob/main/docs/cn/README.md#预训练模型
从 GPT-SoVITS Models 下载预训练模型,并将它们放置在 GPT_SoVITS\pretrained_models 中。
中国地区用户可以进入以下链接并点击“下载副本”下载以上两个模型:
以及MuseTalk模型也可以从modelscope中进行下载,建议都使用modelscope下载,国内速度也较快
python scripts/modelscope_download.py
1.3 网络下载
有时候利用代码下载的时候出现网络问题,可能会有网络的问题,比如大模型的huggingface下载,我目前已经加上了Baidu (百度云盘) (Password: linl) ,可以考虑下载到本地以后根据文件夹放置,也可以完成对应的功能。
如果有什么文件下载有问题,也可以提建议给我,我会上传到百度网盘。
1.4 克隆语音 权重
为了保护用户隐私安全,我并未提供克隆语音的权重,因为这可能涉及版权问题,如果大家感兴趣的话,可以尝试使用相同的方法进行训练或者私聊我,感谢大家的理解
一部分克隆语音和参考音频已经放在了Quark(夸克网盘),可自取
二、环境配置问题
2.1 GPU环境
我使用的是Pytorch 2.0+的版本,因为语音克隆模型需要比较高版本的pytorch,具体下载的命令可以根据pytorch官网的命令进行设置 https://pytorch.org/get-started/previous-versions/,建议有时候可以使用anaconda来安装,这样方便管理和安装其他都比较方便
conda create -n linly python=3.10
conda activate linly
# pytorch安装方式1:conda安装
# CUDA 11.7
# conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.7 -c pytorch -c nvidia
# CUDA 11.8
# conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.8 -c pytorch -c nvidia
# pytorch安装方式2:pip 安装
# CUDA 11.7
# pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2
# CUDA 11.8
pip install torch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 --index-url https://download.pytorch.org/whl/cu118
conda install -q ffmpeg # ffmpeg==4.2.2
# 升级pip
python -m pip install --upgrade pip
# 更换 pypi 源加速库的安装
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install tb-nightly -i https://mirrors.aliyun.com/pypi/simple
pip install -r requirements_webui.txt
# 安装有关musetalk依赖
pip install --no-cache-dir -U openmim
mim install mmengine
mim install "mmcv>=2.0.1"
mim install "mmdet>=3.1.0"
mim install "mmpose>=1.1.0"
GPU环境有时候需要配置CUDA,这一部分网上有很多介绍,所以这里我就不多说了。
2.2 CPU环境
可以将GPU替换为CPU,但是这样可能会比较慢,只需要安装pytorch的时候,不安装GPU版本即可,应该也能完成对应的结果,但是可能结果会比较差,因为需要跑大模型等等,所以还是建议GPU环境
2.3 显存问题
暂时以我测试的来说,现在Sadtalker大概默认Batch Size = 1,可以选择是否导入大模型,如果不导入大模型,默认的显存大概占2g,加入SadTalker后大概4~6g,所以大概最低为6~8G显存的电脑都能正常部署,这里面针对的是GPU的环境。
若使用MuseTalk的话会占据比较大的显存,建议需要11G的显存去部署,但是如果上传图片的分辨率比较大,可能还是会出现溢出的问题,这里需要注意一下。
三、运行问题
3.1 文件找不到
如果出现FileNotFound的问题,如果是权重的问题的话,那就回到1.2的问题,重新下载即可,记住看readme目录尾部文件夹结构。
3.2 FFMPEG问题
如果正常运行在最后的生成视频出现ffmpeg的问题,那可能安装ffmpeg出错了,有两种方式。
第一种是使用conda安装ffmpeg,需要ffmpeg>=4.2.2左右
conda install -q ffmpeg # ffmpeg==4.2.2
第二种就是正常安装ffmpeg
# Linux下载
sudo apt install ffmpeg
第三种就是Windows安装ffmpeg
Windows安装下载ffmpeg也是很简单的,我这里给一个链接,大家可以试一下 Windows下安装使用ffmpeg,直接去官网下载即可https://ffmpeg.org/。
3.3 路径问题
如果下载的时候没有放对位置,需要在config.py设置对应的路径,并且可以修改端口的,默认设置为7860,也可以设置其他的端口,只要不被占用即可。
3.4 GFPGANer is not defined
如果在运行的时候出现了这个问题,这是一个增强的模块,这一部分模块如果需要运行,首先要安装gfpgan库即可
pip install gfpgan
3.5 Microsoft Visual C++ 14.0 is required
如果遇到这个问题,是因为window需要一些依赖,可以参考这篇文章解决一下 Microsoft Visual C++ 14.0 is required解决方法

3.6 多个服务器部署
如果有多台服务器,大模型可以考虑放在另一个服务器中进行部署,我写了FastAPI的版本,可以利用部署api的方式来使用模型。
也可以其实先在本地部署,这样每次运行的时候不用一只load大模型,这样也会等待一段时间。
3.7 GeminiPro的参数proxy代理设置
对于GeminiPro的代理设置proxy_url可以传入参数,这个参数我设置是http://127.0.0.1:7890。
因为我用的是clash,所以开的端口是7890,这里面也可以换成自己对应的端口进行设置。
3.8 项目更新方向
如果要加入其他的模型的话和方向的话,可以在对应的文件夹ASR,TTS,THG和LLM中添加对应的算法,也可以向我提建议,我有时间也会进行更新的,欢迎大家向我提供资料。
我会一直保持更新的哈哈,有时候可能要想一些点子做好一点在放上去,也欢迎大家给我提PR,我都会加油的!!!冲冲冲!!!
3.9 version GLIBCXX_3.4.* not found
如果有遇到这样的问题,那可能是一些库的版本的问题,具体可以看,["`GLIBCXX_3.4.32' not found" error at runtime. GCC 13.2.0](https://stackoverflow.com/questions/76974555/glibcxx-3-4-32-not-found-error-at-runtime-gcc-13-2-0)
/lib/libstdc++.so.6: version `GLIBCXX_3.4.32' not found
我这里说一下我发现的问题,大概我发现有两种方式,第一种就是似乎python版本会解决问题,我用3.10居然不会出现错误,3.9出现了错误
第二个解决方法我发现,实际上这个错误是在pyopenjtalk/opencc库的问题,我们可以降低他的版本即可,比如这样的方法
pip install pyopenjtalk==0.3.1
pip install opencc==1.1.1
我们也可以看看自己机器本身含有的GLIBCXX的版本
strings /usr/lib/x86_64-linux-gnu/libstdc++.so.6 | grep GLIBCXX
3.10 Gradio Connection errored out
我还没有遇到这种问题,但是有一些人遇到了,感觉在win上不稳定的多一点,这一部分大家可以提点建议,跟我说一下有没有一些通用的解决方案,因为在网上查找的资料感觉都不是很行
3.11 gr.Error("无克隆环境或者无克隆模型权重,无法克隆声音", e)
这属于功能迭代的问题,也就是克隆环境和克隆模型权重,首先注意按照克隆环境
pip install VITS/requirements.txt
再根据4.2 克隆语音模型替换去修改模型权重即可
3.12 OSError: [WinError 127] 找不到指定的程序
这个错误通常发生在尝试在 Windows 操作系统上运行一个程序或命令时,但是系统找不到指定的可执行文件。一般来说,就是对应库的安装没安装好,可以建议根据出错的库重新安装一遍即可。
3.13 LLM对话步骤出现错误:“对不起,你的请求出错了,请再次尝试。”
大模型兼容出现错误,重新安装对应的库即可解决
pip install transformers==4.32.0 accelerate tiktoken einops scipy transformers_stream_generator==0.0.4 peft deepspeed
3.14 启动报错 SadTalker Error: invalid load key, 'v'.
在启动文件的时候,发现报错,我仔细去找这个问题,最后发现,应该是模型权重的下载有误,特别是关于mapping的两个pth文件有时候下载的时候没有174MB的内存,理论上大小如下。
149M checkpoints/mapping_00109-model.pth.tar
149M checkpoints/mapping_00229-model.pth.tar
所以遇到这个问题,建议重新下载这两个文件即可,提供以下三种渠道下载权重,具体可看README
- Baidu (百度云盘) (Password:
linl) - huggingface
- modelscope
- Quark(夸克网盘)
git lfs clone可能有时候会出bug,那就可以直接下载这两个文件即可,如利用wget下载即可,也可以下载后重新上传到checkpoints
wget -c https://modelscope.cn/api/v1/models/Kedreamix/Linly-Talker/repo?Revision=master&FilePath=checkpoints%2Fmapping_00109-model.pth.tar
wget -c https://modelscope.cn/api/v1/models/Kedreamix/Linly-Talker/repo?Revision=master&FilePath=checkpoints%2Fmapping_00229-model.pth.tar
3.15 nltk下载出现问题
nltk自动下载模型的时候会出现一些网络问题,导致无法使用,所以我们可以自己下载nltk_data来避免下载问题,首先可以查看nltk_data的缓存路径
import nltk
print(nltk.data.path)
找到路径以后,将文件放入缓存路径中,如果之前已经有了一些下载缓存,可以进行替换和覆盖,nltk_data已放在Quark(夸克网盘),分别为corpora和taggers
四、使用问题
4.1 TTS声音是否可以调整
Linly-Talker中内置了几种TTS模型,分别是EdgeTTS和PaddleTTS,EdgeTTS的声音会更好一点,并且选择也会更多一点,具体可以从TTS Method语音方法调节部分来换声音。
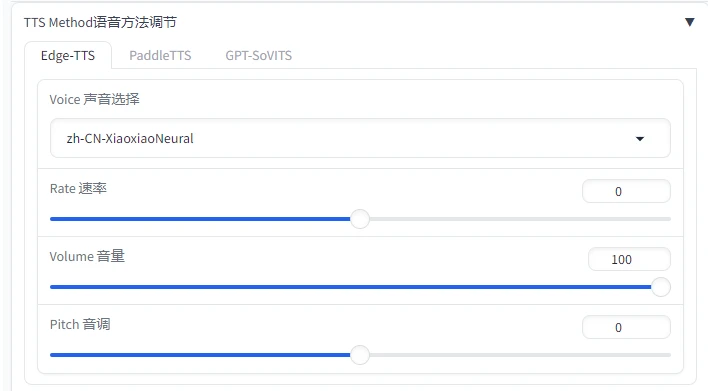
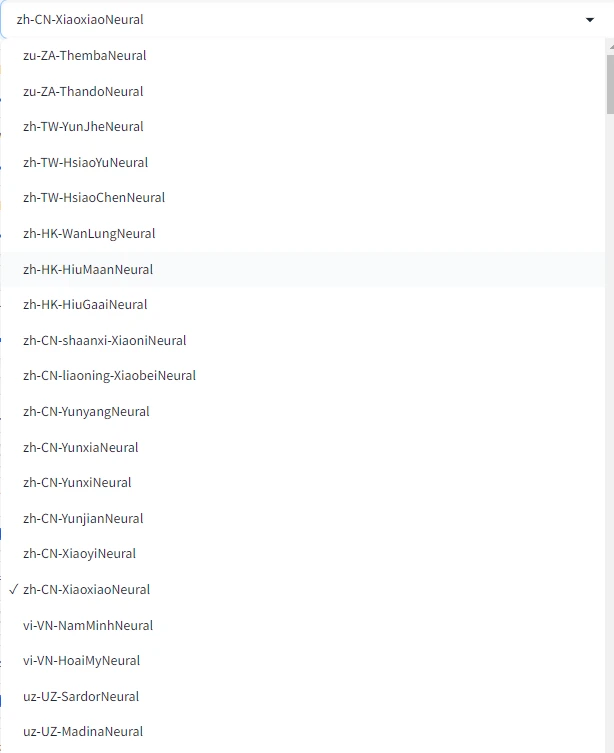
其中有很多声音,包括不同语言的声音,以及台湾的声音等等,在zh-CN开头的声音中,Xiao是女生的声音,Yun是男生的声音
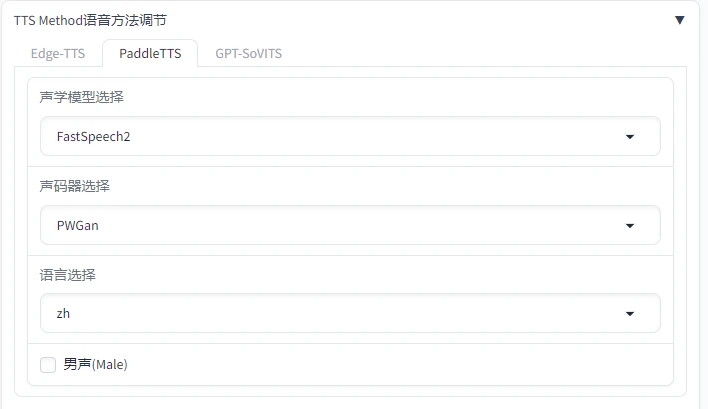
相对而言PaddleTTS的功能选择比较少,可以根据自己的兴趣使用
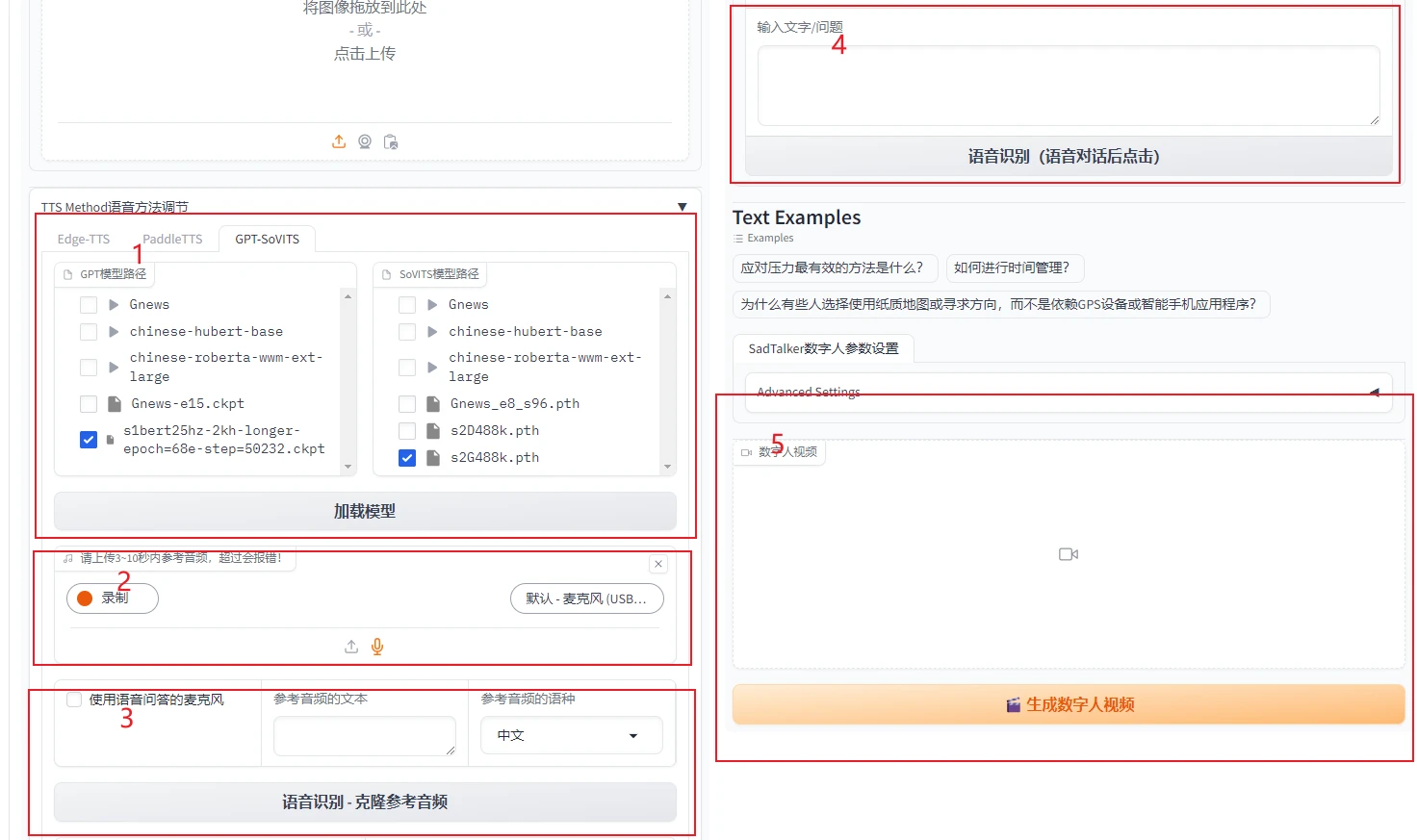
4.2 声音克隆操作
声音克隆可以参考https://github.com/RVC-Boss/GPT-SoVITS的方法进行克隆自己的声音,b站上也有很多教学视频,包括一些公开的权重,我同样也放了一些在夸克网盘上,大家可以自行获取,需要注意的是克隆声音的使用方式
- 加载模型权重
- 上传参考音频
- 识别参考音频文本
- 输入目标文本,也就是输入问题
- 生成克隆后的声音
五、功能迭代问题
5.1 LLM大模型更新
如果要加入新的LLM大模型,可以在LLM文件夹加入选择的大模型
我这里给出一个适用于任何大型语言模型(LLM)的中文类模板。这个模板旨在具有灵活性和易于配置,同时为不同的模型提供一致的交互接口。
from transformers import AutoModelForCausalLM, AutoTokenizer
class LLMTemplate:
def __init__(self, model_name_or_path, mode='offline'):
"""
初始化LLM模板
Args:
model_name_or_path (str): 模型名称或路径
mode (str, optional): 模式,'offline'表示离线模式,'api'表示使用API模式。默认为'offline'。
"""
self.mode = mode
# 模型初始化
self.model, self.tokenizer = self.init_model(model_name_or_path)
self.history = None
def init_model(self, model_name_or_path):
"""
初始化语言模型
Args:
model_name_or_path (str): 模型名称或路径
Returns:
model: 加载的语言模型
tokenizer: 加载的tokenizer
"""
# TODO: 模型加载
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
device_map="auto",
trust_remote_code=True).eval()
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)
return model, tokenizer
def generate(self, prompt, system_prompt=""):
"""
生成对话响应
Args:
prompt (str): 对话的提示
system_prompt (str, optional): 系统提示。默认为""。
Returns:
str: 对话响应
"""
# TODO: 模型预测
# 这一块需要尤其注意,这里的模板是借鉴了HuggingFace上的一些推理模板,需要根据自己的模型进行调整
# 这里的模板主要是为了方便调试,因为模型预测的时候,会有很多不同的输入,所以可以根据自己的模型进行调整
if self.mode != 'api':
try:
response, self.history = self.model.chat(self.tokenizer, prompt, history=self.history, system = system_prompt)
return response
except Exception as e:
print(e)
return "对不起,你的请求出错了,请再次尝试。\nSorry, your request has encountered an error. Please try again.\n"
else:
return self.predict_api(prompt)
def predict_api(self, prompt):
"""
使用API预测对话响应
Args:
prompt (str): 对话的提示
Returns:
str: 对话响应
"""
'''暂时不写api版本,与Linly-api相类似,感兴趣可以实现一下'''
pass
def chat(self, system_prompt, message):
response = self.generate(message, system_prompt)
self.history.append((message, response))
return response, self.history
def clear_history(self):
self.history = []
5.2 克隆语音模型替换
克隆语音模型可以放在GPT_SoVITS/pretrained_models文件夹下,这样在WebUI的界面就可以看到指定模型进行修改了,非常方便

5.3 LLM API的使用问题
我们是可以使用市面上的LLM的API的,需要修改LLM下的文件,我这里以ChatGPT为例,我们可以写完generate函数和chat函数即可,然后再对__init__.py的选择进行修改即可
'''
pip install openai
'''
import os
import openai
class ChatGPT:
def __init__(self, model_path='gpt-3.5-turbo', api_key=None, proxy_url=None, prefix_prompt='请用少于25个字回答以下问题\n\n'):
if proxy_url:
os.environ['https_proxy'] = proxy_url
os.environ['http_proxy'] = proxy_url
openai.api_key = api_key
self.model_path = model_path
self.prefix_prompt = prefix_prompt
self.history = []
def generate(self, message, system_prompt="You are a helpful assistant."):
self.history.append({"role": "user", "content": self.prefix_prompt + message})
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.extend(self.history)
try:
response = openai.ChatCompletion.create(
model=self.model_path,
messages=messages
)
answer = response['choices'][0]['message']['content']
if 'sorry' in answer.lower():
return '对不起,你的请求出错了,请再次尝试。\nSorry, your request has encountered an error. Please try again.\n'
return answer
except Exception as e:
print(e)
return '对不起,你的请求出错了,请再次尝试。\nSorry, your request has encountered an error. Please try again.\n'
def chat(self, system_prompt="You are a helpful assistant.", message=""):
response = self.generate(message, system_prompt)
self.history.append({"role": "assistant", "content": response})
return response, self.history
def clear_history(self):
self.history = []
if __name__ == '__main__':
API_KEY = '******' # 替换为你的API密钥
llm = ChatGPT(model_path='gpt-3.5-turbo', api_key=API_KEY, proxy_url=None)
answer, history = llm.chat(message="如何应对压力?")
print(answer)
from time import sleep
sleep(5) # 模拟对话中的延迟
answer, history = llm.chat(message="能不能更加详细一点呢")
print(answer)
5.4 Linly-Talker效果问题
Linly-Talker的效果当然存在一些问题,后续也会不断的更新和改进,也欢迎大家提出意见,我会努力改善,大家发现的bug也会及时解决和回复的
六、交流群问题
已经搞了一个WeChat,大家可以交流学习
大家有什么想法可以在视频下方留言或者私信我,我都会看的,如果交流群过期了,可以加我wx:pikachu2biubiu
由于交流群人数满200人,所以需要我拉人,所以大家可以加我以后拉群,感谢关注!