Spaces:
Runtime error

Runtime error
Commit
•
79f9f38
1
Parent(s):
533f061
Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +15 -0
- .gitignore +0 -0
- ASR/FunASR.py +54 -0
- ASR/README.md +77 -0
- ASR/Whisper.py +129 -0
- ASR/__init__.py +4 -0
- ASR/__pycache__/FunASR.cpython-310.pyc +0 -0
- ASR/__pycache__/Whisper.cpython-310.pyc +0 -0
- ASR/__pycache__/__init__.cpython-310.pyc +0 -0
- ASR/requirements_funasr.txt +3 -0
- AutoDL部署.md +215 -0
- GPT_SoVITS/AR/__init__.py +0 -0
- GPT_SoVITS/AR/__pycache__/__init__.cpython-310.pyc +0 -0
- GPT_SoVITS/AR/data/__init__.py +0 -0
- GPT_SoVITS/AR/data/bucket_sampler.py +162 -0
- GPT_SoVITS/AR/data/data_module.py +74 -0
- GPT_SoVITS/AR/data/dataset.py +320 -0
- GPT_SoVITS/AR/models/__init__.py +0 -0
- GPT_SoVITS/AR/models/__pycache__/__init__.cpython-310.pyc +0 -0
- GPT_SoVITS/AR/models/__pycache__/t2s_lightning_module.cpython-310.pyc +0 -0
- GPT_SoVITS/AR/models/__pycache__/t2s_model.cpython-310.pyc +0 -0
- GPT_SoVITS/AR/models/__pycache__/utils.cpython-310.pyc +0 -0
- GPT_SoVITS/AR/models/t2s_lightning_module.py +140 -0
- GPT_SoVITS/AR/models/t2s_lightning_module_onnx.py +106 -0
- GPT_SoVITS/AR/models/t2s_model.py +327 -0
- GPT_SoVITS/AR/models/t2s_model_onnx.py +337 -0
- GPT_SoVITS/AR/models/utils.py +160 -0
- GPT_SoVITS/AR/modules/__init__.py +0 -0
- GPT_SoVITS/AR/modules/__pycache__/__init__.cpython-310.pyc +0 -0
- GPT_SoVITS/AR/modules/__pycache__/activation.cpython-310.pyc +0 -0
- GPT_SoVITS/AR/modules/__pycache__/embedding.cpython-310.pyc +0 -0
- GPT_SoVITS/AR/modules/__pycache__/lr_schedulers.cpython-310.pyc +0 -0
- GPT_SoVITS/AR/modules/__pycache__/optim.cpython-310.pyc +0 -0
- GPT_SoVITS/AR/modules/__pycache__/patched_mha_with_cache.cpython-310.pyc +0 -0
- GPT_SoVITS/AR/modules/__pycache__/scaling.cpython-310.pyc +0 -0
- GPT_SoVITS/AR/modules/__pycache__/transformer.cpython-310.pyc +0 -0
- GPT_SoVITS/AR/modules/activation.py +428 -0
- GPT_SoVITS/AR/modules/activation_onnx.py +178 -0
- GPT_SoVITS/AR/modules/embedding.py +81 -0
- GPT_SoVITS/AR/modules/embedding_onnx.py +63 -0
- GPT_SoVITS/AR/modules/lr_schedulers.py +82 -0
- GPT_SoVITS/AR/modules/optim.py +622 -0
- GPT_SoVITS/AR/modules/patched_mha_with_cache.py +463 -0
- GPT_SoVITS/AR/modules/patched_mha_with_cache_onnx.py +92 -0
- GPT_SoVITS/AR/modules/scaling.py +335 -0
- GPT_SoVITS/AR/modules/transformer.py +378 -0
- GPT_SoVITS/AR/modules/transformer_onnx.py +292 -0
- GPT_SoVITS/AR/text_processing/__init__.py +0 -0
- GPT_SoVITS/AR/text_processing/phonemizer.py +78 -0
- GPT_SoVITS/AR/text_processing/symbols.py +9 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,18 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
examples/source_image/art_16.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
examples/source_image/art_17.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
examples/source_image/art_3.png filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
examples/source_image/art_4.png filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
examples/source_image/art_5.png filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
examples/source_image/art_8.png filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
examples/source_image/art_9.png filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
inputs/boy.png filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
src/flagged/output/tmpo637ce1j0fp0pquk.wav filter=lfs diff=lfs merge=lfs -text
|
| 45 |
+
src/flagged/output/tmpo637ce1ja0w7yqmc.wav filter=lfs diff=lfs merge=lfs -text
|
| 46 |
+
src/flagged/output/tmpo637ce1jd5uwg9n4.wav filter=lfs diff=lfs merge=lfs -text
|
| 47 |
+
src/flagged/output/tmpo637ce1jf0_w0vtj.wav filter=lfs diff=lfs merge=lfs -text
|
| 48 |
+
src/flagged/output/tmpo637ce1jhhf3fjqe.wav filter=lfs diff=lfs merge=lfs -text
|
| 49 |
+
src/flagged/output/tmpo637ce1jrkt2shbg.wav filter=lfs diff=lfs merge=lfs -text
|
| 50 |
+
src/flagged/output/tmpo637ce1jyle9jjlm.wav filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
File without changes
|
ASR/FunASR.py
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
'''
|
| 2 |
+
Reference: https://github.com/alibaba-damo-academy/FunASR
|
| 3 |
+
pip install funasr
|
| 4 |
+
pip install modelscope
|
| 5 |
+
pip install -U rotary_embedding_torch
|
| 6 |
+
'''
|
| 7 |
+
try:
|
| 8 |
+
from funasr import AutoModel
|
| 9 |
+
except:
|
| 10 |
+
print("如果想使用FunASR,请先安装funasr,若使用Whisper,请忽略此条信息")
|
| 11 |
+
import os
|
| 12 |
+
import sys
|
| 13 |
+
sys.path.append('./')
|
| 14 |
+
from src.cost_time import calculate_time
|
| 15 |
+
|
| 16 |
+
class FunASR:
|
| 17 |
+
def __init__(self) -> None:
|
| 18 |
+
# 定义模型的自定义路径
|
| 19 |
+
model_path = "FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch"
|
| 20 |
+
vad_model_path = "FunASR/speech_fsmn_vad_zh-cn-16k-common-pytorch"
|
| 21 |
+
punc_model_path = "FunASR/punc_ct-transformer_zh-cn-common-vocab272727-pytorch"
|
| 22 |
+
|
| 23 |
+
# 检查文件是否存在于 FunASR 目录下
|
| 24 |
+
model_exists = os.path.exists(model_path)
|
| 25 |
+
vad_model_exists = os.path.exists(vad_model_path)
|
| 26 |
+
punc_model_exists = os.path.exists(punc_model_path)
|
| 27 |
+
# Modelscope AutoDownload
|
| 28 |
+
self.model = AutoModel(
|
| 29 |
+
model=model_path if model_exists else "paraformer-zh",
|
| 30 |
+
vad_model=vad_model_path if vad_model_exists else "fsmn-vad",
|
| 31 |
+
punc_model=punc_model_path if punc_model_exists else "ct-punc-c",
|
| 32 |
+
)
|
| 33 |
+
# 自定义路径
|
| 34 |
+
# self.model = AutoModel(model="FunASR/speech_seaco_paraformer_large_asr_nat-zh-cn-16k-common-vocab8404-pytorch", # model_revision="v2.0.4",
|
| 35 |
+
# vad_model="FunASR/speech_fsmn_vad_zh-cn-16k-common-pytorch", # vad_model_revision="v2.0.4",
|
| 36 |
+
# punc_model="FunASR/punc_ct-transformer_zh-cn-common-vocab272727-pytorch", # punc_model_revision="v2.0.4",
|
| 37 |
+
# # spk_model="cam++", spk_model_revision="v2.0.2",
|
| 38 |
+
# )
|
| 39 |
+
@calculate_time
|
| 40 |
+
def transcribe(self, audio_file):
|
| 41 |
+
res = self.model.generate(input=audio_file,
|
| 42 |
+
batch_size_s=300)
|
| 43 |
+
print(res)
|
| 44 |
+
return res[0]['text']
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
if __name__ == "__main__":
|
| 48 |
+
import os
|
| 49 |
+
# 创建ASR对象并进行语音识别
|
| 50 |
+
audio_file = "output.wav" # 音频文件路径
|
| 51 |
+
if not os.path.exists(audio_file):
|
| 52 |
+
os.system('edge-tts --text "hello" --write-media output.wav')
|
| 53 |
+
asr = FunASR()
|
| 54 |
+
print(asr.transcribe(audio_file))
|
ASR/README.md
ADDED
|
@@ -0,0 +1,77 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## ASR 同数字人沟通的桥梁
|
| 2 |
+
|
| 3 |
+
### Whisper OpenAI
|
| 4 |
+
|
| 5 |
+
Whisper 是一个自动语音识别 (ASR) 系统,它使用从网络上收集的 680,000 小时多语言和多任务监督数据进行训练。使用如此庞大且多样化的数据集可以提高对口音、背景噪音和技术语言的鲁棒性。此外,它还支持多种语言的转录,以及将这些语言翻译成英语。
|
| 6 |
+
|
| 7 |
+
使用方法很简单,我们只要安装以下库,后续模型会自动下载
|
| 8 |
+
|
| 9 |
+
```bash
|
| 10 |
+
pip install -U openai-whisper
|
| 11 |
+
```
|
| 12 |
+
|
| 13 |
+
借鉴OpenAI的Whisper实现了ASR的语音识别,具体使用方法参考 [https://github.com/openai/whisper](https://github.com/openai/whisper)
|
| 14 |
+
|
| 15 |
+
```python
|
| 16 |
+
'''
|
| 17 |
+
https://github.com/openai/whisper
|
| 18 |
+
pip install -U openai-whisper
|
| 19 |
+
'''
|
| 20 |
+
import whisper
|
| 21 |
+
|
| 22 |
+
class WhisperASR:
|
| 23 |
+
def __init__(self, model_path):
|
| 24 |
+
self.LANGUAGES = {
|
| 25 |
+
"en": "english",
|
| 26 |
+
"zh": "chinese",
|
| 27 |
+
}
|
| 28 |
+
self.model = whisper.load_model(model_path)
|
| 29 |
+
|
| 30 |
+
def transcribe(self, audio_file):
|
| 31 |
+
result = self.model.transcribe(audio_file)
|
| 32 |
+
return result["text"]
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
### FunASR Alibaba
|
| 38 |
+
|
| 39 |
+
阿里的`FunASR`的语音识别效果也是相当不错,而且时间也是比whisper更快的,更能达到实时的效果,所以也将FunASR添加进去了,在ASR文件夹下的FunASR文件里可以进行体验,参考 [https://github.com/alibaba-damo-academy/FunASR](https://github.com/alibaba-damo-academy/FunASR)
|
| 40 |
+
|
| 41 |
+
需要注意的是,在第一次运行的时候,需要安装以下库。
|
| 42 |
+
|
| 43 |
+
```bash
|
| 44 |
+
pip install funasr
|
| 45 |
+
pip install modelscope
|
| 46 |
+
pip install -U rotary_embedding_torch
|
| 47 |
+
```
|
| 48 |
+
|
| 49 |
+
```python
|
| 50 |
+
'''
|
| 51 |
+
Reference: https://github.com/alibaba-damo-academy/FunASR
|
| 52 |
+
pip install funasr
|
| 53 |
+
pip install modelscope
|
| 54 |
+
pip install -U rotary_embedding_torch
|
| 55 |
+
'''
|
| 56 |
+
try:
|
| 57 |
+
from funasr import AutoModel
|
| 58 |
+
except:
|
| 59 |
+
print("如果想使用FunASR,请先安装funasr,若使用Whisper,请忽略此条信息")
|
| 60 |
+
|
| 61 |
+
class FunASR:
|
| 62 |
+
def __init__(self) -> None:
|
| 63 |
+
self.model = AutoModel(model="paraformer-zh", model_revision="v2.0.4",
|
| 64 |
+
vad_model="fsmn-vad", vad_model_revision="v2.0.4",
|
| 65 |
+
punc_model="ct-punc-c", punc_model_revision="v2.0.4",
|
| 66 |
+
# spk_model="cam++", spk_model_revision="v2.0.2",
|
| 67 |
+
)
|
| 68 |
+
|
| 69 |
+
def transcribe(self, audio_file):
|
| 70 |
+
res = self.model.generate(input=audio_file,
|
| 71 |
+
batch_size_s=300)
|
| 72 |
+
print(res)
|
| 73 |
+
return res[0]['text']
|
| 74 |
+
```
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
|
ASR/Whisper.py
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
'''
|
| 2 |
+
https://github.com/openai/whisper
|
| 3 |
+
pip install -U openai-whisper
|
| 4 |
+
'''
|
| 5 |
+
import whisper
|
| 6 |
+
import sys
|
| 7 |
+
sys.path.append('./')
|
| 8 |
+
from src.cost_time import calculate_time
|
| 9 |
+
|
| 10 |
+
class WhisperASR:
|
| 11 |
+
def __init__(self, model_path):
|
| 12 |
+
self.LANGUAGES = {
|
| 13 |
+
"en": "english",
|
| 14 |
+
"zh": "chinese",
|
| 15 |
+
"de": "german",
|
| 16 |
+
"es": "spanish",
|
| 17 |
+
"ru": "russian",
|
| 18 |
+
"ko": "korean",
|
| 19 |
+
"fr": "french",
|
| 20 |
+
"ja": "japanese",
|
| 21 |
+
"pt": "portuguese",
|
| 22 |
+
"tr": "turkish",
|
| 23 |
+
"pl": "polish",
|
| 24 |
+
"ca": "catalan",
|
| 25 |
+
"nl": "dutch",
|
| 26 |
+
"ar": "arabic",
|
| 27 |
+
"sv": "swedish",
|
| 28 |
+
"it": "italian",
|
| 29 |
+
"id": "indonesian",
|
| 30 |
+
"hi": "hindi",
|
| 31 |
+
"fi": "finnish",
|
| 32 |
+
"vi": "vietnamese",
|
| 33 |
+
"he": "hebrew",
|
| 34 |
+
"uk": "ukrainian",
|
| 35 |
+
"el": "greek",
|
| 36 |
+
"ms": "malay",
|
| 37 |
+
"cs": "czech",
|
| 38 |
+
"ro": "romanian",
|
| 39 |
+
"da": "danish",
|
| 40 |
+
"hu": "hungarian",
|
| 41 |
+
"ta": "tamil",
|
| 42 |
+
"no": "norwegian",
|
| 43 |
+
"th": "thai",
|
| 44 |
+
"ur": "urdu",
|
| 45 |
+
"hr": "croatian",
|
| 46 |
+
"bg": "bulgarian",
|
| 47 |
+
"lt": "lithuanian",
|
| 48 |
+
"la": "latin",
|
| 49 |
+
"mi": "maori",
|
| 50 |
+
"ml": "malayalam",
|
| 51 |
+
"cy": "welsh",
|
| 52 |
+
"sk": "slovak",
|
| 53 |
+
"te": "telugu",
|
| 54 |
+
"fa": "persian",
|
| 55 |
+
"lv": "latvian",
|
| 56 |
+
"bn": "bengali",
|
| 57 |
+
"sr": "serbian",
|
| 58 |
+
"az": "azerbaijani",
|
| 59 |
+
"sl": "slovenian",
|
| 60 |
+
"kn": "kannada",
|
| 61 |
+
"et": "estonian",
|
| 62 |
+
"mk": "macedonian",
|
| 63 |
+
"br": "breton",
|
| 64 |
+
"eu": "basque",
|
| 65 |
+
"is": "icelandic",
|
| 66 |
+
"hy": "armenian",
|
| 67 |
+
"ne": "nepali",
|
| 68 |
+
"mn": "mongolian",
|
| 69 |
+
"bs": "bosnian",
|
| 70 |
+
"kk": "kazakh",
|
| 71 |
+
"sq": "albanian",
|
| 72 |
+
"sw": "swahili",
|
| 73 |
+
"gl": "galician",
|
| 74 |
+
"mr": "marathi",
|
| 75 |
+
"pa": "punjabi",
|
| 76 |
+
"si": "sinhala",
|
| 77 |
+
"km": "khmer",
|
| 78 |
+
"sn": "shona",
|
| 79 |
+
"yo": "yoruba",
|
| 80 |
+
"so": "somali",
|
| 81 |
+
"af": "afrikaans",
|
| 82 |
+
"oc": "occitan",
|
| 83 |
+
"ka": "georgian",
|
| 84 |
+
"be": "belarusian",
|
| 85 |
+
"tg": "tajik",
|
| 86 |
+
"sd": "sindhi",
|
| 87 |
+
"gu": "gujarati",
|
| 88 |
+
"am": "amharic",
|
| 89 |
+
"yi": "yiddish",
|
| 90 |
+
"lo": "lao",
|
| 91 |
+
"uz": "uzbek",
|
| 92 |
+
"fo": "faroese",
|
| 93 |
+
"ht": "haitian creole",
|
| 94 |
+
"ps": "pashto",
|
| 95 |
+
"tk": "turkmen",
|
| 96 |
+
"nn": "nynorsk",
|
| 97 |
+
"mt": "maltese",
|
| 98 |
+
"sa": "sanskrit",
|
| 99 |
+
"lb": "luxembourgish",
|
| 100 |
+
"my": "myanmar",
|
| 101 |
+
"bo": "tibetan",
|
| 102 |
+
"tl": "tagalog",
|
| 103 |
+
"mg": "malagasy",
|
| 104 |
+
"as": "assamese",
|
| 105 |
+
"tt": "tatar",
|
| 106 |
+
"haw": "hawaiian",
|
| 107 |
+
"ln": "lingala",
|
| 108 |
+
"ha": "hausa",
|
| 109 |
+
"ba": "bashkir",
|
| 110 |
+
"jw": "javanese",
|
| 111 |
+
"su": "sundanese",
|
| 112 |
+
}
|
| 113 |
+
self.model = whisper.load_model(model_path)
|
| 114 |
+
|
| 115 |
+
@calculate_time
|
| 116 |
+
def transcribe(self, audio_file):
|
| 117 |
+
result = self.model.transcribe(audio_file)
|
| 118 |
+
return result["text"]
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
if __name__ == "__main__":
|
| 122 |
+
import os
|
| 123 |
+
# 创建ASR对象并进行语音识别
|
| 124 |
+
model_path = "./Whisper/tiny.pt" # 模型路径
|
| 125 |
+
audio_file = "output.wav" # 音频文件路径
|
| 126 |
+
if not os.path.exists(audio_file):
|
| 127 |
+
os.system('edge-tts --text "hello" --write-media output.wav')
|
| 128 |
+
asr = WhisperASR(model_path)
|
| 129 |
+
print(asr.transcribe(audio_file))
|
ASR/__init__.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .Whisper import WhisperASR
|
| 2 |
+
from .FunASR import FunASR
|
| 3 |
+
|
| 4 |
+
__all__ = ['WhisperASR', 'FunASR']
|
ASR/__pycache__/FunASR.cpython-310.pyc
ADDED
|
Binary file (1.77 kB). View file
|
|
|
ASR/__pycache__/Whisper.cpython-310.pyc
ADDED
|
Binary file (3.32 kB). View file
|
|
|
ASR/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (230 Bytes). View file
|
|
|
ASR/requirements_funasr.txt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
funasr
|
| 2 |
+
modelscope
|
| 3 |
+
# rotary_embedding_torch
|
AutoDL部署.md
ADDED
|
@@ -0,0 +1,215 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# 在AutoDL平台部署Linly-Talker (0基础小白超详细教程)
|
| 2 |
+
|
| 3 |
+
<!-- TOC -->
|
| 4 |
+
|
| 5 |
+
- [在AutoDL平台部署Linly-Talker 0基础小白超详细教程](#%E5%9C%A8autodl%E5%B9%B3%E5%8F%B0%E9%83%A8%E7%BD%B2linly-talker-0%E5%9F%BA%E7%A1%80%E5%B0%8F%E7%99%BD%E8%B6%85%E8%AF%A6%E7%BB%86%E6%95%99%E7%A8%8B)
|
| 6 |
+
- [快速上手直接使用镜像以下安装操作全免](#%E5%BF%AB%E9%80%9F%E4%B8%8A%E6%89%8B%E7%9B%B4%E6%8E%A5%E4%BD%BF%E7%94%A8%E9%95%9C%E5%83%8F%E4%BB%A5%E4%B8%8B%E5%AE%89%E8%A3%85%E6%93%8D%E4%BD%9C%E5%85%A8%E5%85%8D)
|
| 7 |
+
- [一、注册AutoDL](#%E4%B8%80%E6%B3%A8%E5%86%8Cautodl)
|
| 8 |
+
- [二、创建实例](#%E4%BA%8C%E5%88%9B%E5%BB%BA%E5%AE%9E%E4%BE%8B)
|
| 9 |
+
- [登录AutoDL,进入算力市场,选择机器](#%E7%99%BB%E5%BD%95autodl%E8%BF%9B%E5%85%A5%E7%AE%97%E5%8A%9B%E5%B8%82%E5%9C%BA%E9%80%89%E6%8B%A9%E6%9C%BA%E5%99%A8)
|
| 10 |
+
- [配置基础镜像](#%E9%85%8D%E7%BD%AE%E5%9F%BA%E7%A1%80%E9%95%9C%E5%83%8F)
|
| 11 |
+
- [无卡模式开机](#%E6%97%A0%E5%8D%A1%E6%A8%A1%E5%BC%8F%E5%BC%80%E6%9C%BA)
|
| 12 |
+
- [三、部署环境](#%E4%B8%89%E9%83%A8%E7%BD%B2%E7%8E%AF%E5%A2%83)
|
| 13 |
+
- [进入终端](#%E8%BF%9B%E5%85%A5%E7%BB%88%E7%AB%AF)
|
| 14 |
+
- [下载代码文件](#%E4%B8%8B%E8%BD%BD%E4%BB%A3%E7%A0%81%E6%96%87%E4%BB%B6)
|
| 15 |
+
- [下载模型文件](#%E4%B8%8B%E8%BD%BD%E6%A8%A1%E5%9E%8B%E6%96%87%E4%BB%B6)
|
| 16 |
+
- [四、Linly-Talker项目](#%E5%9B%9Blinly-talker%E9%A1%B9%E7%9B%AE)
|
| 17 |
+
- [环境安装](#%E7%8E%AF%E5%A2%83%E5%AE%89%E8%A3%85)
|
| 18 |
+
- [端口设置](#%E7%AB%AF%E5%8F%A3%E8%AE%BE%E7%BD%AE)
|
| 19 |
+
- [有卡开机](#%E6%9C%89%E5%8D%A1%E5%BC%80%E6%9C%BA)
|
| 20 |
+
- [运行网页版对话webui](#%E8%BF%90%E8%A1%8C%E7%BD%91%E9%A1%B5%E7%89%88%E5%AF%B9%E8%AF%9Dwebui)
|
| 21 |
+
- [端口映射](#%E7%AB%AF%E5%8F%A3%E6%98%A0%E5%B0%84)
|
| 22 |
+
- [体验Linly-Talker(成功)](#%E4%BD%93%E9%AA%8Clinly-talker%E6%88%90%E5%8A%9F)
|
| 23 |
+
|
| 24 |
+
<!-- /TOC -->
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
## 快速上手直接使用镜像(以下安装操作全免)
|
| 29 |
+
|
| 30 |
+
若使用我设定好的镜像,可以直接运行即可,不需要安装环境,直接运行webui.py或者是app_talk.py即可体验,不需要安装任何环境,可直接跳到4.4即可
|
| 31 |
+
|
| 32 |
+
访问后在自定义设置里面打开端口,默认是6006端口,直接使用运行即可!
|
| 33 |
+
|
| 34 |
+
```bash
|
| 35 |
+
python webui.py
|
| 36 |
+
python app_talk.py
|
| 37 |
+
```
|
| 38 |
+
|
| 39 |
+
环境模型都安装好了,直接使用即可,镜像地址在:[https://www.codewithgpu.com/i/Kedreamix/Linly-Talker/Kedreamix-Linly-Talker](https://www.codewithgpu.com/i/Kedreamix/Linly-Talker/Kedreamix-Linly-Talker),感谢大家的支持
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
## 一、注册AutoDL
|
| 44 |
+
|
| 45 |
+
[AutoDL官网](https://www.autodl.com/home) 注册账户好并充值,自己选择机器,我觉得如果正常跑一下,5元已经够了
|
| 46 |
+
|
| 47 |
+
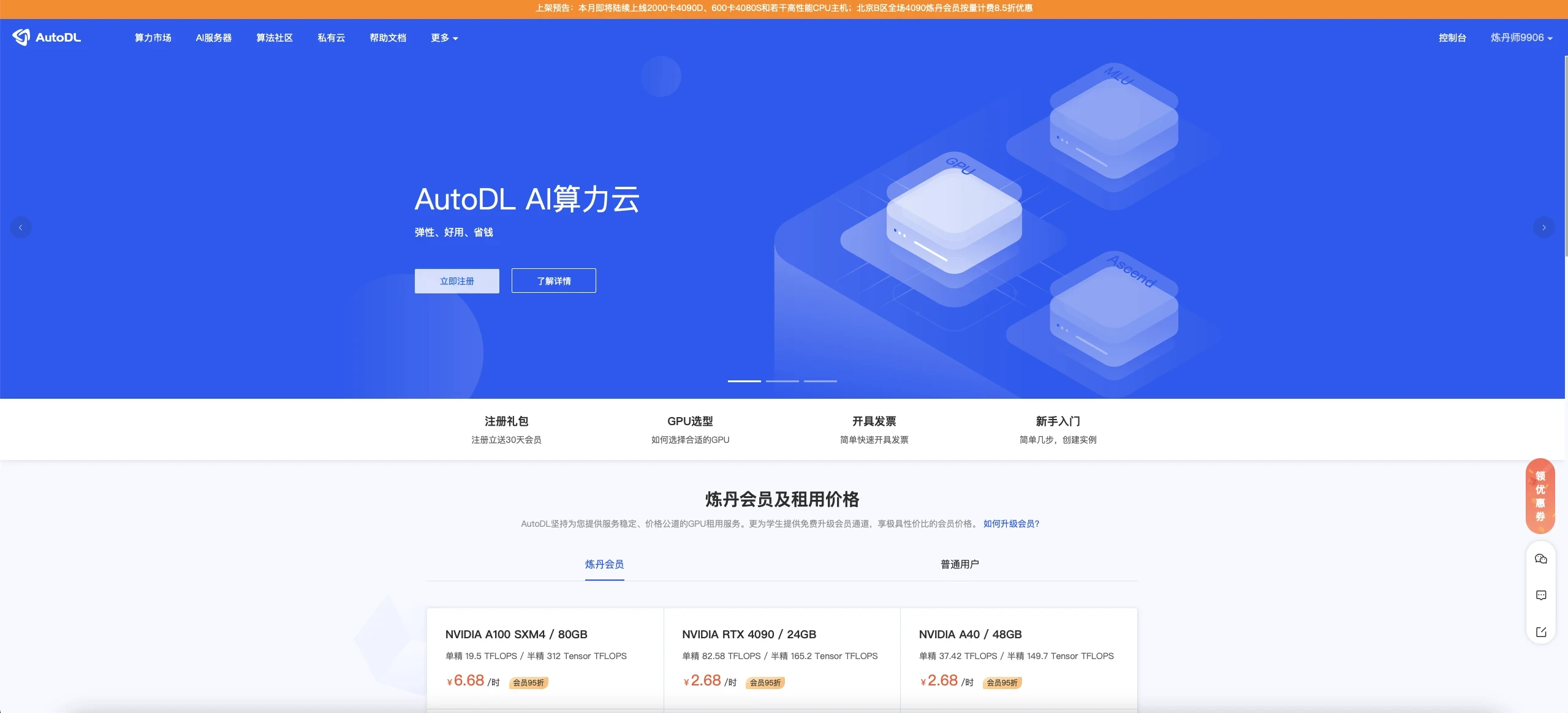
|
| 48 |
+
|
| 49 |
+
## 二、创建实例
|
| 50 |
+
|
| 51 |
+
### 2.1 登录AutoDL,进入算力市场,选择机器
|
| 52 |
+
|
| 53 |
+
这一部分实际上我觉得12g都OK的,无非是速度问题而已
|
| 54 |
+
|
| 55 |
+
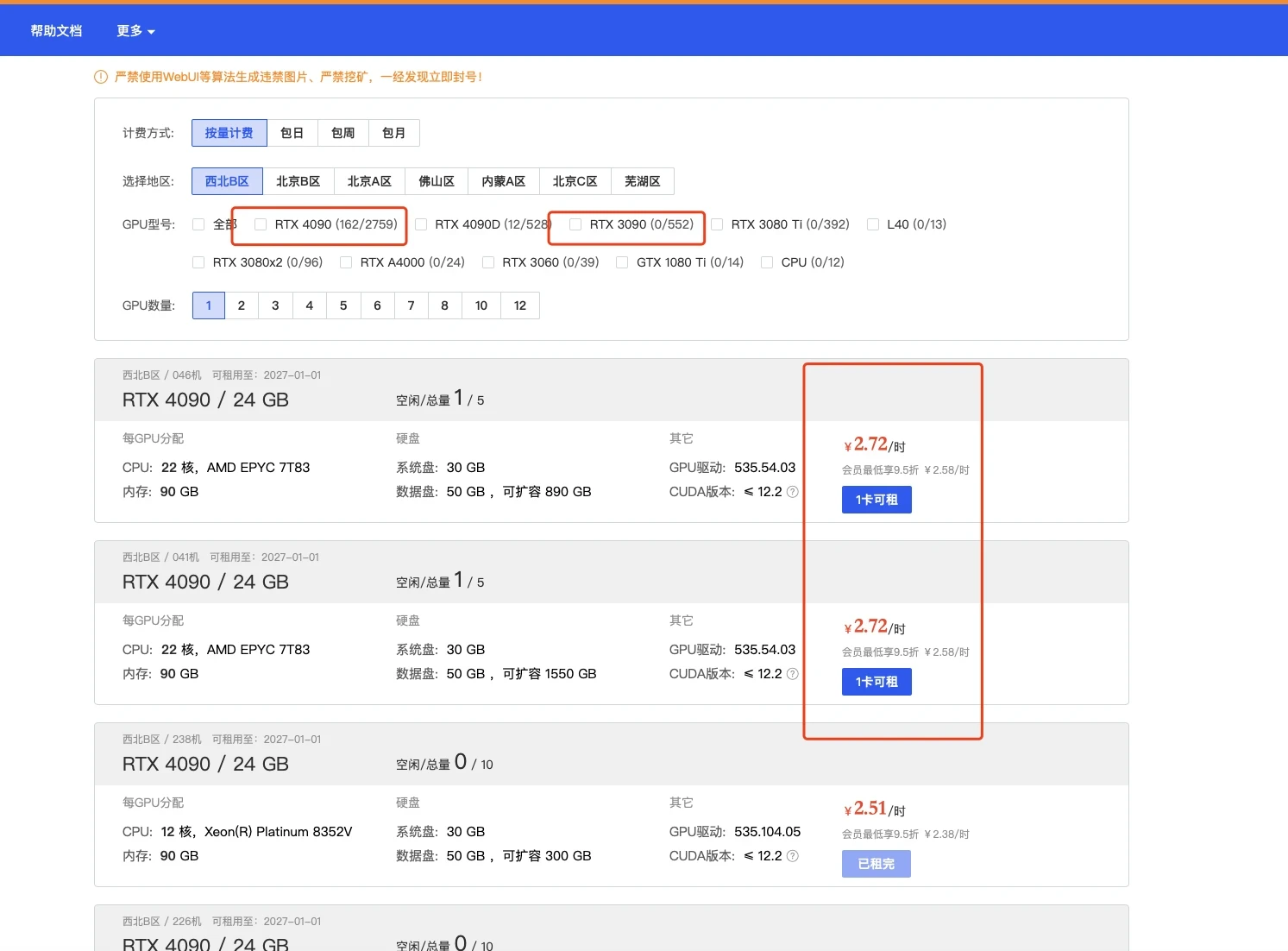
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
### 2.2 配置基础镜像
|
| 60 |
+
|
| 61 |
+
选择镜像,最好选择2.0以上可以体验克隆声音功能,其他无所谓
|
| 62 |
+
|
| 63 |
+
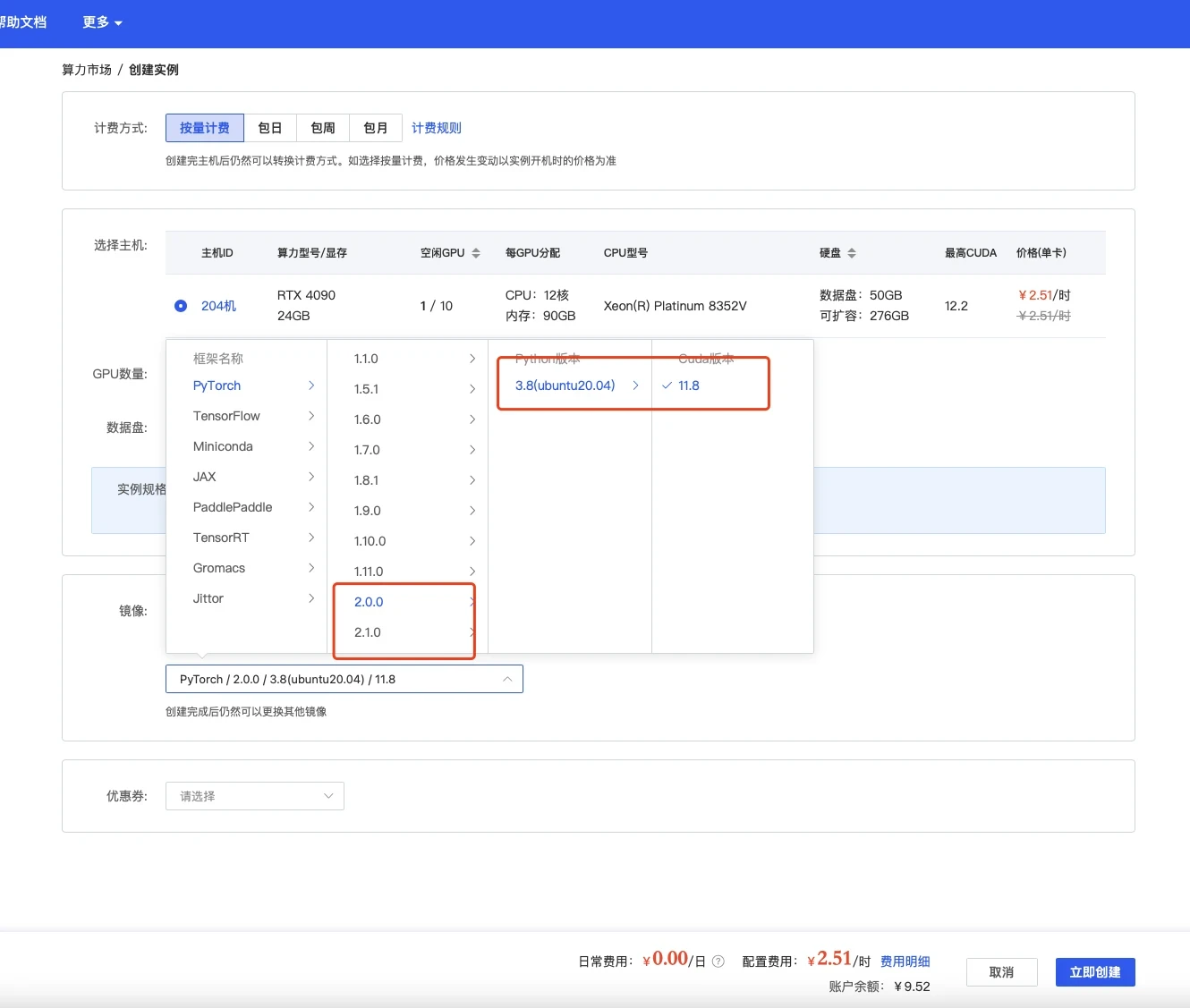
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
### 2.3 无卡模式开机
|
| 68 |
+
|
| 69 |
+
创建成功后为了省钱先关机,然后使用无卡模式开机。
|
| 70 |
+
无卡模式一个小时只需要0.1元,比较适合部署环境。
|
| 71 |
+
|
| 72 |
+
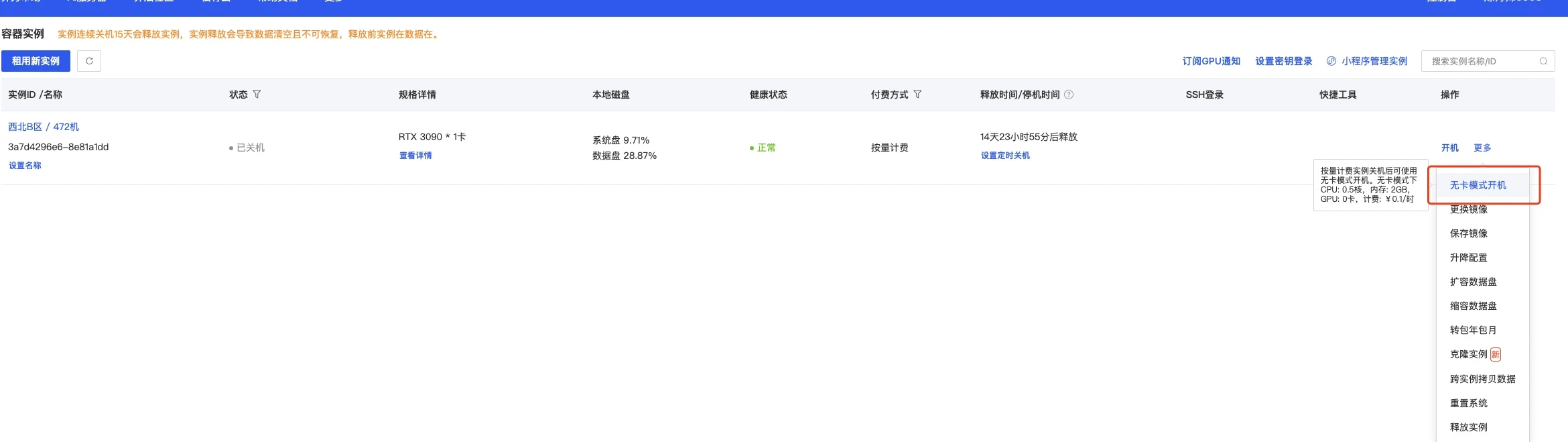
|
| 73 |
+
|
| 74 |
+
## 三、部署环境
|
| 75 |
+
|
| 76 |
+
### 3.1 进入终端
|
| 77 |
+
|
| 78 |
+
打开jupyterLab,进入数据盘(autodl-tmp),打开终端,将Linly-Talker模型下载到数据盘中。
|
| 79 |
+
|
| 80 |
+
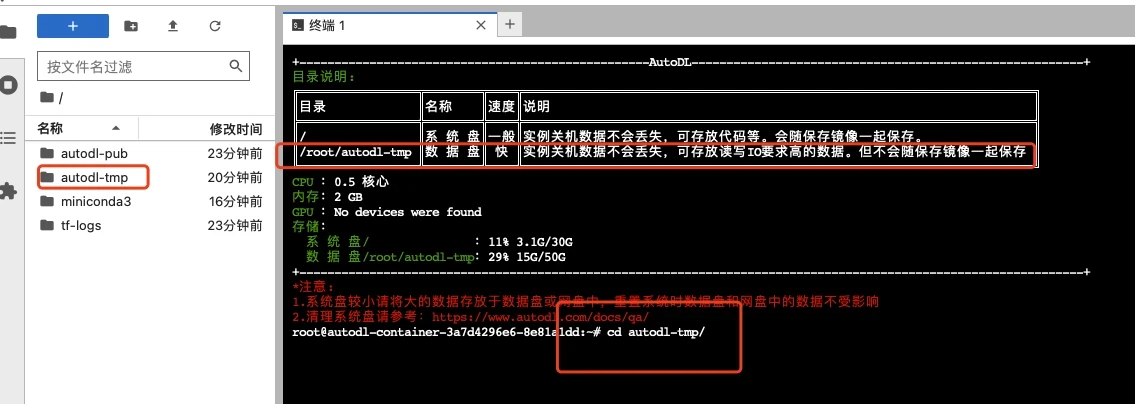
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
### 3.2 下载代码文件
|
| 85 |
+
|
| 86 |
+
根据Github上的说明,使用命令行下载模型文件和代码文件,利用学术加速会快一点
|
| 87 |
+
|
| 88 |
+
```bash
|
| 89 |
+
# 开启学术镜像,更快的clone代码 参考 https://www.autodl.com/docs/network_turbo/
|
| 90 |
+
source /etc/network_turbo
|
| 91 |
+
|
| 92 |
+
cd /root/autodl-tmp/
|
| 93 |
+
# 下载代码
|
| 94 |
+
git clone https://github.com/Kedreamix/Linly-Talker.git --depth 1
|
| 95 |
+
|
| 96 |
+
# 取消学术加速
|
| 97 |
+
unset http_proxy && unset https_proxy
|
| 98 |
+
```
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
### 3.3 下载模型文件
|
| 103 |
+
|
| 104 |
+
我制作一个脚本可以完成下述所有模型的下载,无需用户过多操作。这种方式适合网络稳定的情况,并且特别适合 Linux 用户。对于 Windows 用户,也可以使用 Git 来下载模型。如果网络环境不稳定,用户可以选择使用手动下载方法,或者尝试运行 Shell 脚本来完成下载。脚本具有以下功能。
|
| 105 |
+
|
| 106 |
+
1. **选择下载方式**: 用户可以选择从三种不同的源下载模型:ModelScope、Huggingface 或 Huggingface 镜像站点。
|
| 107 |
+
2. **下载模型**: 根据用户的选择,执行相应的下载命令。
|
| 108 |
+
3. **移动模型文件**: 下载完成后,将模型文件移动到指定的目录。
|
| 109 |
+
4. **错误处理**: 在每一步操作中加入了错误检查,如果操作失败,脚本会输出错误���息并停止执行。
|
| 110 |
+
|
| 111 |
+
选择使用`modelscope`来下载会快一点,不需要开学术加速,记得首先需要先安装modelscope库
|
| 112 |
+
|
| 113 |
+
```sh
|
| 114 |
+
# 下载modelscope
|
| 115 |
+
pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple
|
| 116 |
+
cd /root/autodl-tmp/Linly-Talker
|
| 117 |
+
sh scripts/download_models.sh
|
| 118 |
+
```
|
| 119 |
+
|
| 120 |
+
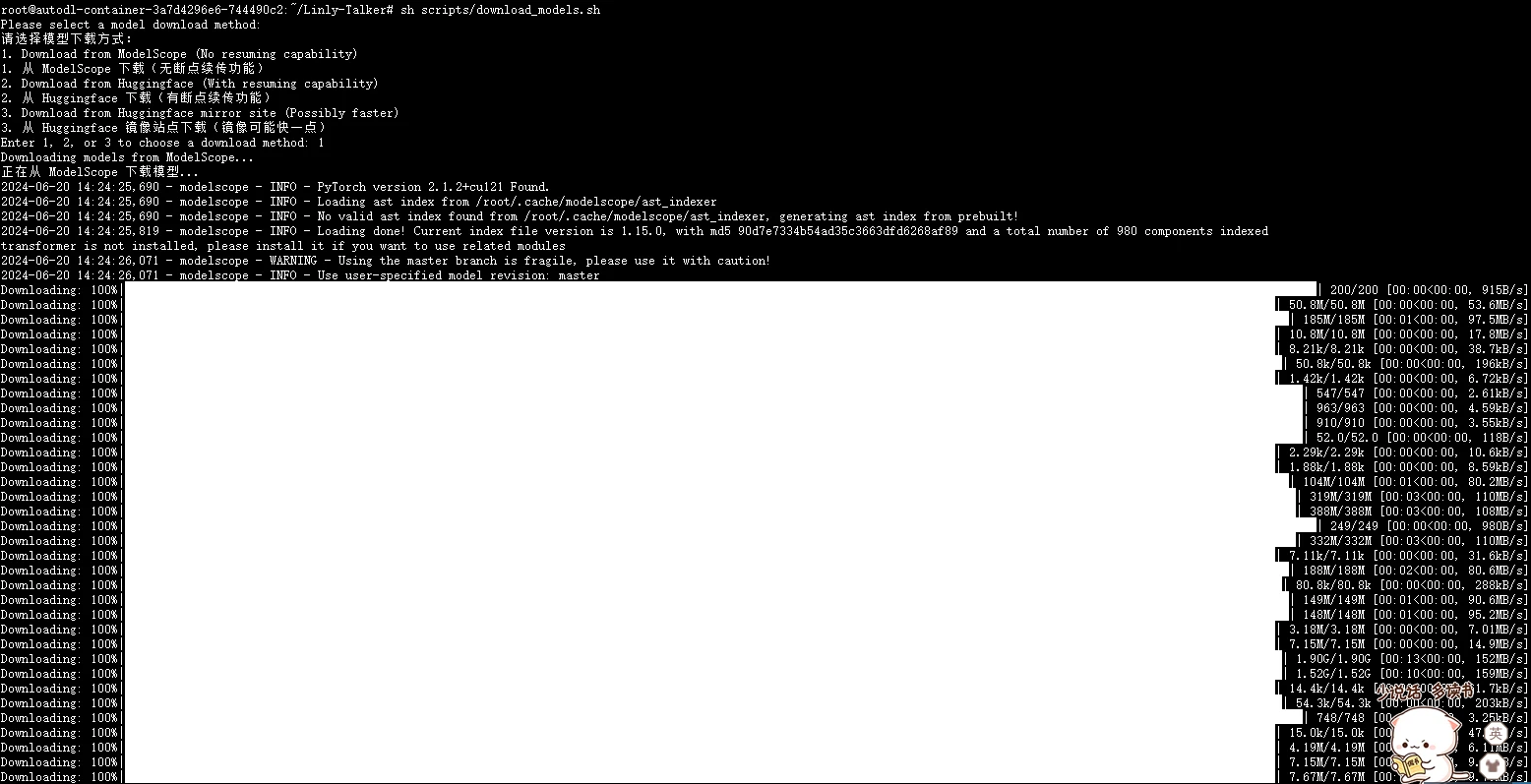
|
| 121 |
+
|
| 122 |
+
等待一段时间下载完以后,脚本会自动移动到对应的目录
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
## 四、Linly-Talker项目
|
| 127 |
+
|
| 128 |
+
### 4.1 环境安装
|
| 129 |
+
|
| 130 |
+
进入代码路径,进行安装环境,由于选了镜像是含有pytorch的,所以只需要进行安装其他依赖即可,可能需要花一定的时间,建议直接使用安装好的镜像
|
| 131 |
+
|
| 132 |
+
```bash
|
| 133 |
+
cd /root/autodl-tmp/Linly-Talker
|
| 134 |
+
|
| 135 |
+
conda install ffmpeg==4.2.2 # ffmpeg==4.2.2
|
| 136 |
+
|
| 137 |
+
# 升级pip
|
| 138 |
+
python -m pip install --upgrade pip
|
| 139 |
+
# 更换 pypi 源加速库的安装
|
| 140 |
+
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
|
| 141 |
+
|
| 142 |
+
pip install tb-nightly -i https://mirrors.aliyun.com/pypi/simple
|
| 143 |
+
pip install -r requirements_webui.txt
|
| 144 |
+
|
| 145 |
+
# 安装有关musetalk依赖
|
| 146 |
+
pip install --no-cache-dir -U openmim
|
| 147 |
+
mim install mmengine
|
| 148 |
+
mim install "mmcv>=2.0.1"
|
| 149 |
+
mim install "mmdet>=3.1.0"
|
| 150 |
+
mim install "mmpose>=1.1.0"
|
| 151 |
+
|
| 152 |
+
# 安装NeRF-based依赖,可能问题较多,可以先放弃
|
| 153 |
+
# 亲测需要有卡开机后再跑这个pytorch3d,需要一定的内存来编译
|
| 154 |
+
pip install "git+https://github.com/facebookresearch/pytorch3d.git"
|
| 155 |
+
|
| 156 |
+
# 若pyaudio出现问题,可安装对应依赖
|
| 157 |
+
sudo apt-get update
|
| 158 |
+
sudo apt-get install libasound-dev portaudio19-dev libportaudio2 libportaudiocpp0
|
| 159 |
+
pip install -r TFG/requirements_nerf.txt
|
| 160 |
+
```
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
|
| 164 |
+
### 4.2 有卡开机
|
| 165 |
+
|
| 166 |
+
进入autodl容器实例界面,执行关机操作,然后进行有卡开机,开机后打开jupyterLab。
|
| 167 |
+
|
| 168 |
+
查看配置
|
| 169 |
+
|
| 170 |
+
```bash
|
| 171 |
+
nvidia-smi
|
| 172 |
+
```
|
| 173 |
+
|
| 174 |
+
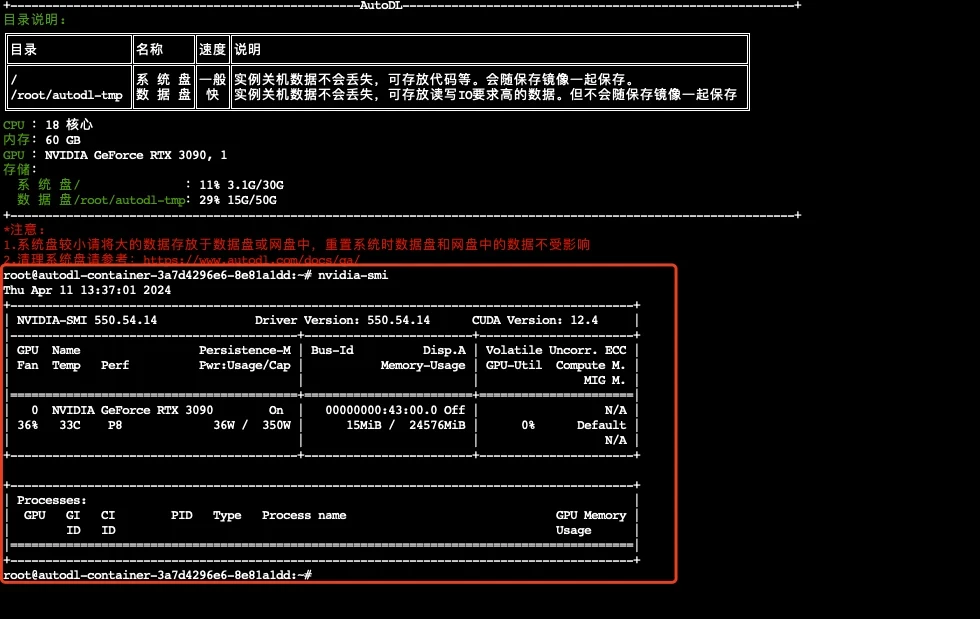
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
### 4.3 运行网页版对话webui
|
| 179 |
+
|
| 180 |
+
需要有卡模式开机,执行下边命令,这里面就跟代码是一模一样的了
|
| 181 |
+
|
| 182 |
+
```bash
|
| 183 |
+
cd /root/autodl-tmp/Linly-Talker
|
| 184 |
+
# 第一次运行可能会下载部分nltk,可以使用一下学术加速
|
| 185 |
+
source /etc/network_turbo
|
| 186 |
+
python webui.py
|
| 187 |
+
```
|
| 188 |
+
|
| 189 |
+
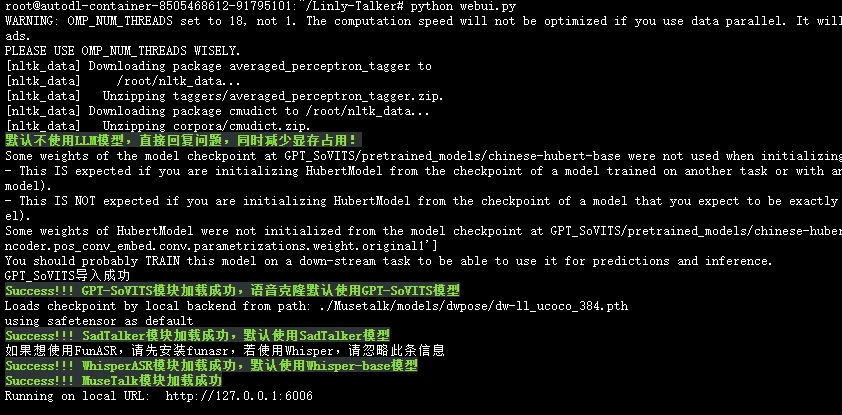
|
| 190 |
+
|
| 191 |
+
### 4.4 端口映射
|
| 192 |
+
|
| 193 |
+
这可以直接打开autodl的自定义服务,默认是6006端口,我们已经设置了,所以直接使用即可
|
| 194 |
+
|
| 195 |
+
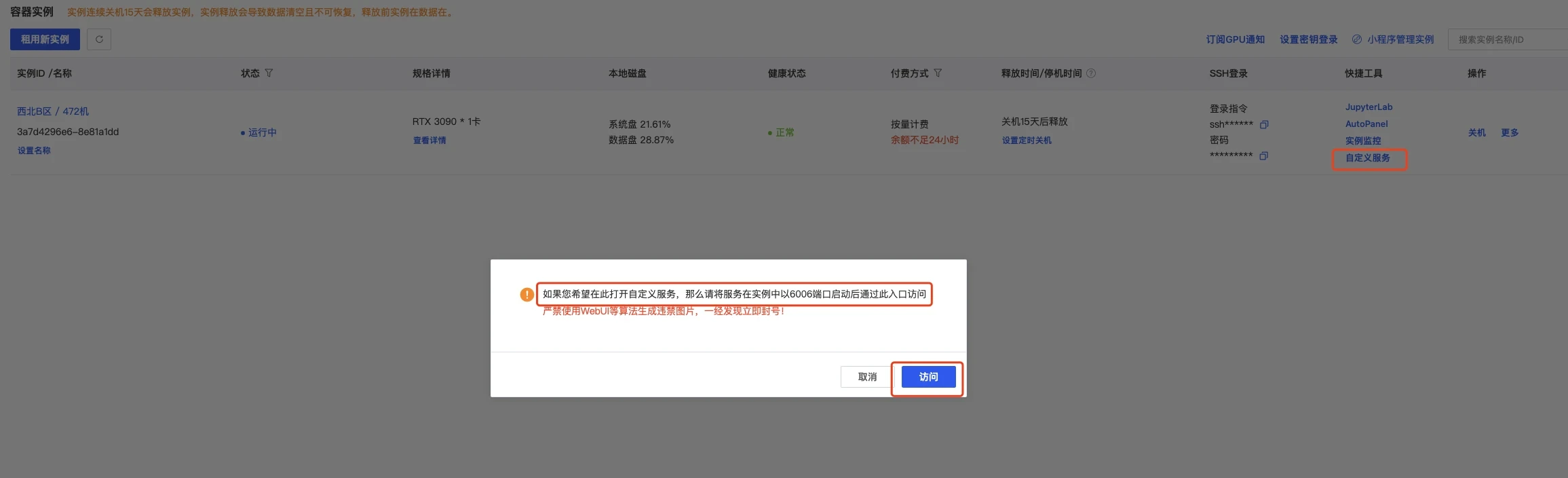
|
| 196 |
+
|
| 197 |
+
另外还有一种端口映射方式,是通过输入ssh账密实现的,步骤是一样的
|
| 198 |
+
|
| 199 |
+
> ssh端口映射工具:windows:[https://autodl-public.ks3-cn-beijing.ksyuncs.com/tool/AutoDL-SSH-Tools.zip](https://autodl-public.ks3-cn-beijing.ksyuncs.com/tool/AutoDL-SSH-Tools.zip)
|
| 200 |
+
|
| 201 |
+
### 4.5 体验Linly-Talker(成功)
|
| 202 |
+
|
| 203 |
+
点开网页,即可正确执行Linly-Talker,这一部分就跟视频一模一样了
|
| 204 |
+
|
| 205 |
+
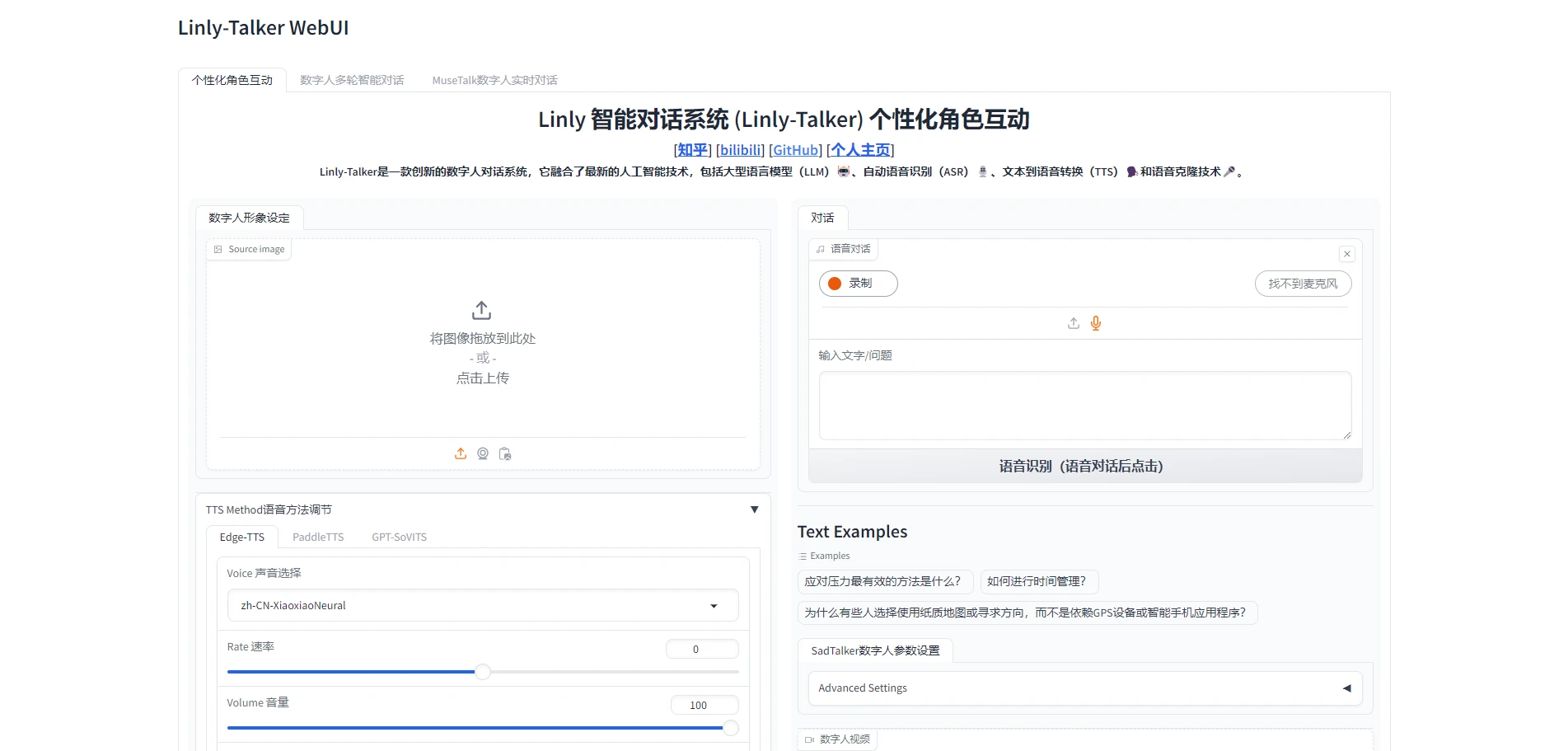
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
|
| 209 |
+
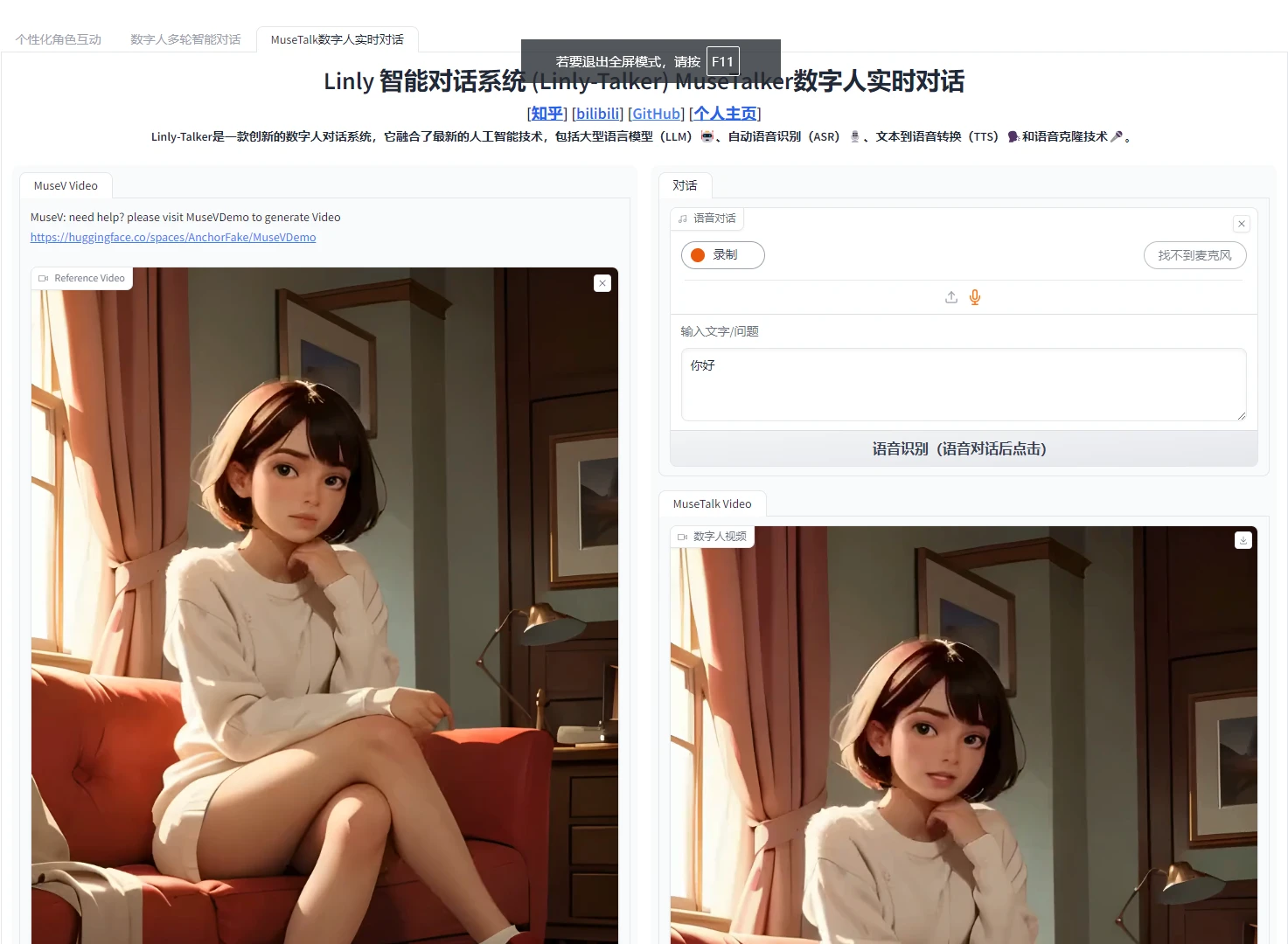
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
|
| 213 |
+
**!!!注意:不用了,一定要去控制台=》容器实例,把镜像实例关机,它是按时收费的,不关机会一直扣费的。**
|
| 214 |
+
|
| 215 |
+
**建议选北京区的,稍微便宜一些。可以晚上部署,网速快,便宜的GPU也充足。白天部署,北京区的GPU容易没有。**
|
GPT_SoVITS/AR/__init__.py
ADDED
|
File without changes
|
GPT_SoVITS/AR/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (140 Bytes). View file
|
|
|
GPT_SoVITS/AR/data/__init__.py
ADDED
|
File without changes
|
GPT_SoVITS/AR/data/bucket_sampler.py
ADDED
|
@@ -0,0 +1,162 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/feng-yufei/shared_debugging_code/blob/main/bucketsampler.py
|
| 2 |
+
import itertools
|
| 3 |
+
import math
|
| 4 |
+
import random
|
| 5 |
+
from random import shuffle
|
| 6 |
+
from typing import Iterator
|
| 7 |
+
from typing import Optional
|
| 8 |
+
from typing import TypeVar
|
| 9 |
+
|
| 10 |
+
import torch
|
| 11 |
+
import torch.distributed as dist
|
| 12 |
+
from torch.utils.data import Dataset
|
| 13 |
+
from torch.utils.data import Sampler
|
| 14 |
+
|
| 15 |
+
__all__ = [
|
| 16 |
+
"DistributedBucketSampler",
|
| 17 |
+
]
|
| 18 |
+
|
| 19 |
+
T_co = TypeVar("T_co", covariant=True)
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
class DistributedBucketSampler(Sampler[T_co]):
|
| 23 |
+
r"""
|
| 24 |
+
sort the dataset wrt. input length
|
| 25 |
+
divide samples into buckets
|
| 26 |
+
sort within buckets
|
| 27 |
+
divide buckets into batches
|
| 28 |
+
sort batches
|
| 29 |
+
"""
|
| 30 |
+
|
| 31 |
+
def __init__(
|
| 32 |
+
self,
|
| 33 |
+
dataset: Dataset,
|
| 34 |
+
num_replicas: Optional[int] = None,
|
| 35 |
+
rank: Optional[int] = None,
|
| 36 |
+
shuffle: bool = True,
|
| 37 |
+
seed: int = 0,
|
| 38 |
+
drop_last: bool = False,
|
| 39 |
+
batch_size: int = 32,
|
| 40 |
+
) -> None:
|
| 41 |
+
if num_replicas is None:
|
| 42 |
+
if not dist.is_available():
|
| 43 |
+
raise RuntimeError("Requires distributed package to be available")
|
| 44 |
+
num_replicas = dist.get_world_size() if torch.cuda.is_available() else 1
|
| 45 |
+
if rank is None:
|
| 46 |
+
if not dist.is_available():
|
| 47 |
+
raise RuntimeError("Requires distributed package to be available")
|
| 48 |
+
rank = dist.get_rank() if torch.cuda.is_available() else 0
|
| 49 |
+
if torch.cuda.is_available():
|
| 50 |
+
torch.cuda.set_device(rank)
|
| 51 |
+
if rank >= num_replicas or rank < 0:
|
| 52 |
+
raise ValueError(
|
| 53 |
+
"Invalid rank {}, rank should be in the interval"
|
| 54 |
+
" [0, {}]".format(rank, num_replicas - 1)
|
| 55 |
+
)
|
| 56 |
+
self.dataset = dataset
|
| 57 |
+
self.num_replicas = num_replicas
|
| 58 |
+
self.rank = rank
|
| 59 |
+
self.epoch = 0
|
| 60 |
+
self.drop_last = drop_last
|
| 61 |
+
# If the dataset length is evenly divisible by # of replicas, then there
|
| 62 |
+
# is no need to drop any data, since the dataset will be split equally.
|
| 63 |
+
if (
|
| 64 |
+
self.drop_last and len(self.dataset) % self.num_replicas != 0
|
| 65 |
+
): # type: ignore[arg-type]
|
| 66 |
+
# Split to nearest available length that is evenly divisible.
|
| 67 |
+
# This is to ensure each rank receives the same amount of data when
|
| 68 |
+
# using this Sampler.
|
| 69 |
+
self.num_samples = math.ceil(
|
| 70 |
+
(len(self.dataset) - self.num_replicas)
|
| 71 |
+
/ self.num_replicas # type: ignore[arg-type]
|
| 72 |
+
)
|
| 73 |
+
else:
|
| 74 |
+
self.num_samples = math.ceil(
|
| 75 |
+
len(self.dataset) / self.num_replicas
|
| 76 |
+
) # type: ignore[arg-type]
|
| 77 |
+
self.total_size = self.num_samples * self.num_replicas
|
| 78 |
+
self.shuffle = shuffle
|
| 79 |
+
self.seed = seed
|
| 80 |
+
self.batch_size = batch_size
|
| 81 |
+
self.id_with_length = self._get_sample_lengths()
|
| 82 |
+
self.id_buckets = self.make_buckets(bucket_width=2.0)
|
| 83 |
+
|
| 84 |
+
def _get_sample_lengths(self):
|
| 85 |
+
id_with_lengths = []
|
| 86 |
+
for i in range(len(self.dataset)):
|
| 87 |
+
id_with_lengths.append((i, self.dataset.get_sample_length(i)))
|
| 88 |
+
id_with_lengths.sort(key=lambda x: x[1])
|
| 89 |
+
return id_with_lengths
|
| 90 |
+
|
| 91 |
+
def make_buckets(self, bucket_width: float = 2.0):
|
| 92 |
+
buckets = []
|
| 93 |
+
cur = []
|
| 94 |
+
max_sec = bucket_width
|
| 95 |
+
for id, sec in self.id_with_length:
|
| 96 |
+
if sec < max_sec:
|
| 97 |
+
cur.append(id)
|
| 98 |
+
else:
|
| 99 |
+
buckets.append(cur)
|
| 100 |
+
cur = [id]
|
| 101 |
+
max_sec += bucket_width
|
| 102 |
+
if len(cur) > 0:
|
| 103 |
+
buckets.append(cur)
|
| 104 |
+
return buckets
|
| 105 |
+
|
| 106 |
+
def __iter__(self) -> Iterator[T_co]:
|
| 107 |
+
if self.shuffle:
|
| 108 |
+
# deterministically shuffle based on epoch and seed
|
| 109 |
+
g = torch.Generator()
|
| 110 |
+
g.manual_seed(self.seed + self.epoch)
|
| 111 |
+
random.seed(self.epoch + self.seed)
|
| 112 |
+
shuffled_bucket = []
|
| 113 |
+
for buc in self.id_buckets:
|
| 114 |
+
buc_copy = buc.copy()
|
| 115 |
+
shuffle(buc_copy)
|
| 116 |
+
shuffled_bucket.append(buc_copy)
|
| 117 |
+
grouped_batch_size = self.batch_size * self.num_replicas
|
| 118 |
+
shuffled_bucket = list(itertools.chain(*shuffled_bucket))
|
| 119 |
+
n_batch = int(math.ceil(len(shuffled_bucket) / grouped_batch_size))
|
| 120 |
+
batches = [
|
| 121 |
+
shuffled_bucket[b * grouped_batch_size : (b + 1) * grouped_batch_size]
|
| 122 |
+
for b in range(n_batch)
|
| 123 |
+
]
|
| 124 |
+
shuffle(batches)
|
| 125 |
+
indices = list(itertools.chain(*batches))
|
| 126 |
+
else:
|
| 127 |
+
# type: ignore[arg-type]
|
| 128 |
+
indices = list(range(len(self.dataset)))
|
| 129 |
+
|
| 130 |
+
if not self.drop_last:
|
| 131 |
+
# add extra samples to make it evenly divisible
|
| 132 |
+
padding_size = self.total_size - len(indices)
|
| 133 |
+
if padding_size <= len(indices):
|
| 134 |
+
indices += indices[:padding_size]
|
| 135 |
+
else:
|
| 136 |
+
indices += (indices * math.ceil(padding_size / len(indices)))[
|
| 137 |
+
:padding_size
|
| 138 |
+
]
|
| 139 |
+
else:
|
| 140 |
+
# remove tail of data to make it evenly divisible.
|
| 141 |
+
indices = indices[: self.total_size]
|
| 142 |
+
assert len(indices) == self.total_size
|
| 143 |
+
|
| 144 |
+
# subsample
|
| 145 |
+
indices = indices[self.rank : self.total_size : self.num_replicas]
|
| 146 |
+
assert len(indices) == self.num_samples
|
| 147 |
+
|
| 148 |
+
return iter(indices)
|
| 149 |
+
|
| 150 |
+
def __len__(self) -> int:
|
| 151 |
+
return self.num_samples
|
| 152 |
+
|
| 153 |
+
def set_epoch(self, epoch: int) -> None:
|
| 154 |
+
r"""
|
| 155 |
+
Sets the epoch for this sampler. When :attr:`shuffle=True`, this ensures all replicas
|
| 156 |
+
use a different random ordering for each epoch. Otherwise, the next iteration of this
|
| 157 |
+
sampler will yield the same ordering.
|
| 158 |
+
|
| 159 |
+
Args:
|
| 160 |
+
epoch (int): Epoch number.
|
| 161 |
+
"""
|
| 162 |
+
self.epoch = epoch
|
GPT_SoVITS/AR/data/data_module.py
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/feng-yufei/shared_debugging_code/blob/main/data_module.py
|
| 2 |
+
from pytorch_lightning import LightningDataModule
|
| 3 |
+
from AR.data.bucket_sampler import DistributedBucketSampler
|
| 4 |
+
from AR.data.dataset import Text2SemanticDataset
|
| 5 |
+
from torch.utils.data import DataLoader
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class Text2SemanticDataModule(LightningDataModule):
|
| 9 |
+
def __init__(
|
| 10 |
+
self,
|
| 11 |
+
config,
|
| 12 |
+
train_semantic_path,
|
| 13 |
+
train_phoneme_path,
|
| 14 |
+
dev_semantic_path=None,
|
| 15 |
+
dev_phoneme_path=None,
|
| 16 |
+
):
|
| 17 |
+
super().__init__()
|
| 18 |
+
self.config = config
|
| 19 |
+
self.train_semantic_path = train_semantic_path
|
| 20 |
+
self.train_phoneme_path = train_phoneme_path
|
| 21 |
+
self.dev_semantic_path = dev_semantic_path
|
| 22 |
+
self.dev_phoneme_path = dev_phoneme_path
|
| 23 |
+
self.num_workers = self.config["data"]["num_workers"]
|
| 24 |
+
|
| 25 |
+
def prepare_data(self):
|
| 26 |
+
pass
|
| 27 |
+
|
| 28 |
+
def setup(self, stage=None, output_logs=False):
|
| 29 |
+
self._train_dataset = Text2SemanticDataset(
|
| 30 |
+
phoneme_path=self.train_phoneme_path,
|
| 31 |
+
semantic_path=self.train_semantic_path,
|
| 32 |
+
max_sec=self.config["data"]["max_sec"],
|
| 33 |
+
pad_val=self.config["data"]["pad_val"],
|
| 34 |
+
)
|
| 35 |
+
self._dev_dataset = self._train_dataset
|
| 36 |
+
# self._dev_dataset = Text2SemanticDataset(
|
| 37 |
+
# phoneme_path=self.dev_phoneme_path,
|
| 38 |
+
# semantic_path=self.dev_semantic_path,
|
| 39 |
+
# max_sample=self.config['data']['max_eval_sample'],
|
| 40 |
+
# max_sec=self.config['data']['max_sec'],
|
| 41 |
+
# pad_val=self.config['data']['pad_val'])
|
| 42 |
+
|
| 43 |
+
def train_dataloader(self):
|
| 44 |
+
batch_size = max(min(self.config["train"]["batch_size"],len(self._train_dataset)//4),1)#防止不保存
|
| 45 |
+
sampler = DistributedBucketSampler(self._train_dataset, batch_size=batch_size)
|
| 46 |
+
return DataLoader(
|
| 47 |
+
self._train_dataset,
|
| 48 |
+
batch_size=batch_size,
|
| 49 |
+
sampler=sampler,
|
| 50 |
+
collate_fn=self._train_dataset.collate,
|
| 51 |
+
num_workers=self.num_workers,
|
| 52 |
+
persistent_workers=True,
|
| 53 |
+
prefetch_factor=16,
|
| 54 |
+
)
|
| 55 |
+
|
| 56 |
+
def val_dataloader(self):
|
| 57 |
+
return DataLoader(
|
| 58 |
+
self._dev_dataset,
|
| 59 |
+
batch_size=1,
|
| 60 |
+
shuffle=False,
|
| 61 |
+
collate_fn=self._train_dataset.collate,
|
| 62 |
+
num_workers=max(self.num_workers, 12),
|
| 63 |
+
persistent_workers=True,
|
| 64 |
+
prefetch_factor=16,
|
| 65 |
+
)
|
| 66 |
+
|
| 67 |
+
# 这个会使用到嘛?
|
| 68 |
+
def test_dataloader(self):
|
| 69 |
+
return DataLoader(
|
| 70 |
+
self._dev_dataset,
|
| 71 |
+
batch_size=1,
|
| 72 |
+
shuffle=False,
|
| 73 |
+
collate_fn=self._train_dataset.collate,
|
| 74 |
+
)
|
GPT_SoVITS/AR/data/dataset.py
ADDED
|
@@ -0,0 +1,320 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/feng-yufei/shared_debugging_code/blob/main/t2s_dataset.py
|
| 2 |
+
import pdb
|
| 3 |
+
import sys
|
| 4 |
+
|
| 5 |
+
# sys.path.append("/data/docker/liujing04/gpt-vits/mq-vits-s1bert_no_bert")
|
| 6 |
+
import traceback, os
|
| 7 |
+
from typing import Dict
|
| 8 |
+
from typing import List
|
| 9 |
+
|
| 10 |
+
import numpy as np
|
| 11 |
+
import pandas as pd
|
| 12 |
+
import torch, json
|
| 13 |
+
from torch.utils.data import DataLoader
|
| 14 |
+
from torch.utils.data import Dataset
|
| 15 |
+
from transformers import AutoTokenizer
|
| 16 |
+
|
| 17 |
+
from text import cleaned_text_to_sequence
|
| 18 |
+
|
| 19 |
+
# from config import exp_dir
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def batch_sequences(sequences: List[np.array], axis: int = 0, pad_value: int = 0):
|
| 23 |
+
seq = sequences[0]
|
| 24 |
+
ndim = seq.ndim
|
| 25 |
+
if axis < 0:
|
| 26 |
+
axis += ndim
|
| 27 |
+
dtype = seq.dtype
|
| 28 |
+
pad_value = dtype.type(pad_value)
|
| 29 |
+
seq_lengths = [seq.shape[axis] for seq in sequences]
|
| 30 |
+
max_length = np.max(seq_lengths)
|
| 31 |
+
|
| 32 |
+
padded_sequences = []
|
| 33 |
+
for seq, length in zip(sequences, seq_lengths):
|
| 34 |
+
padding = (
|
| 35 |
+
[(0, 0)] * axis + [(0, max_length - length)] + [(0, 0)] * (ndim - axis - 1)
|
| 36 |
+
)
|
| 37 |
+
padded_seq = np.pad(seq, padding, mode="constant", constant_values=pad_value)
|
| 38 |
+
padded_sequences.append(padded_seq)
|
| 39 |
+
batch = np.stack(padded_sequences)
|
| 40 |
+
return batch
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
class Text2SemanticDataset(Dataset):
|
| 44 |
+
"""dataset class for text tokens to semantic model training."""
|
| 45 |
+
|
| 46 |
+
def __init__(
|
| 47 |
+
self,
|
| 48 |
+
phoneme_path: str,
|
| 49 |
+
semantic_path: str,
|
| 50 |
+
max_sample: int = None,
|
| 51 |
+
max_sec: int = 100,
|
| 52 |
+
pad_val: int = 1024,
|
| 53 |
+
# min value of phoneme/sec
|
| 54 |
+
min_ps_ratio: int = 3,
|
| 55 |
+
# max value of phoneme/sec
|
| 56 |
+
max_ps_ratio: int = 25,
|
| 57 |
+
) -> None:
|
| 58 |
+
super().__init__()
|
| 59 |
+
|
| 60 |
+
self.semantic_data = pd.read_csv(
|
| 61 |
+
semantic_path, delimiter="\t", encoding="utf-8"
|
| 62 |
+
)
|
| 63 |
+
# get dict
|
| 64 |
+
self.path2 = phoneme_path # "%s/2-name2text.txt"%exp_dir#phoneme_path
|
| 65 |
+
self.path3 = "%s/3-bert" % (
|
| 66 |
+
os.path.basename(phoneme_path)
|
| 67 |
+
) # "%s/3-bert"%exp_dir#bert_dir
|
| 68 |
+
self.path6 = semantic_path # "%s/6-name2semantic.tsv"%exp_dir#semantic_path
|
| 69 |
+
assert os.path.exists(self.path2)
|
| 70 |
+
assert os.path.exists(self.path6)
|
| 71 |
+
self.phoneme_data = {}
|
| 72 |
+
with open(self.path2, "r", encoding="utf8") as f:
|
| 73 |
+
lines = f.read().strip("\n").split("\n")
|
| 74 |
+
|
| 75 |
+
for line in lines:
|
| 76 |
+
tmp = line.split("\t")
|
| 77 |
+
if len(tmp) != 4:
|
| 78 |
+
continue
|
| 79 |
+
self.phoneme_data[tmp[0]] = [tmp[1], tmp[2], tmp[3]]
|
| 80 |
+
|
| 81 |
+
# self.phoneme_data = np.load(phoneme_path, allow_pickle=True).item()
|
| 82 |
+
# pad for semantic tokens
|
| 83 |
+
self.PAD: int = pad_val
|
| 84 |
+
# self.hz = 25
|
| 85 |
+
# with open("/data/docker/liujing04/gpt-vits/mq-vits-s1bert_no_bert/configs/s2.json", "r") as f:data = f.read()
|
| 86 |
+
# data=json.loads(data)["model"]["semantic_frame_rate"]#50hz
|
| 87 |
+
# self.hz=int(data[:-2])#
|
| 88 |
+
self.hz = int(os.environ.get("hz", "25hz")[:-2])
|
| 89 |
+
|
| 90 |
+
# max seconds of semantic token
|
| 91 |
+
self.max_sec = max_sec
|
| 92 |
+
self.min_ps_ratio = min_ps_ratio
|
| 93 |
+
self.max_ps_ratio = max_ps_ratio
|
| 94 |
+
|
| 95 |
+
if max_sample is not None:
|
| 96 |
+
self.semantic_data = self.semantic_data[:max_sample]
|
| 97 |
+
|
| 98 |
+
# {idx: (semantic, phoneme)}
|
| 99 |
+
# semantic list, phoneme list
|
| 100 |
+
self.semantic_phoneme = []
|
| 101 |
+
self.item_names = []
|
| 102 |
+
|
| 103 |
+
self.inited = False
|
| 104 |
+
|
| 105 |
+
if not self.inited:
|
| 106 |
+
# 调用初始化函数
|
| 107 |
+
self.init_batch()
|
| 108 |
+
self.inited = True
|
| 109 |
+
del self.semantic_data
|
| 110 |
+
del self.phoneme_data
|
| 111 |
+
# self.tokenizer = AutoTokenizer.from_pretrained("hfl/chinese-roberta-wwm-ext-large")
|
| 112 |
+
# self.tokenizer = AutoTokenizer.from_pretrained("/data/docker/liujing04/bert-vits2/Bert-VITS2-master20231106/bert/chinese-roberta-wwm-ext-large")
|
| 113 |
+
|
| 114 |
+
def init_batch(self):
|
| 115 |
+
semantic_data_len = len(self.semantic_data)
|
| 116 |
+
phoneme_data_len = len(self.phoneme_data.keys())
|
| 117 |
+
print("semantic_data_len:", semantic_data_len)
|
| 118 |
+
print("phoneme_data_len:", phoneme_data_len)
|
| 119 |
+
print(self.semantic_data)
|
| 120 |
+
idx = 0
|
| 121 |
+
num_not_in = 0
|
| 122 |
+
num_deleted_bigger = 0
|
| 123 |
+
num_deleted_ps = 0
|
| 124 |
+
for i in range(semantic_data_len):
|
| 125 |
+
# 先依次遍历
|
| 126 |
+
# get str
|
| 127 |
+
item_name = self.semantic_data.iloc[i,0]
|
| 128 |
+
# print(self.phoneme_data)
|
| 129 |
+
try:
|
| 130 |
+
phoneme, word2ph, text = self.phoneme_data[item_name]
|
| 131 |
+
except Exception:
|
| 132 |
+
traceback.print_exc()
|
| 133 |
+
# print(f"{item_name} not in self.phoneme_data !")
|
| 134 |
+
num_not_in += 1
|
| 135 |
+
continue
|
| 136 |
+
|
| 137 |
+
semantic_str = self.semantic_data.iloc[i,1]
|
| 138 |
+
# get token list
|
| 139 |
+
semantic_ids = [int(idx) for idx in semantic_str.split(" ")]
|
| 140 |
+
# (T), 是否需要变成 (1, T) -> 不需要,因为需要求 len
|
| 141 |
+
# 过滤掉太长的样本
|
| 142 |
+
if (
|
| 143 |
+
len(semantic_ids) > self.max_sec * self.hz
|
| 144 |
+
): #########1###根据token个数推测总时长过滤时长60s(config里)#40*25=1k
|
| 145 |
+
num_deleted_bigger += 1
|
| 146 |
+
continue
|
| 147 |
+
# (T, ), 这个速度不会很慢,所以可以在一开始就处理,无需在 __getitem__ 里面单个处理####
|
| 148 |
+
phoneme = phoneme.split(" ")
|
| 149 |
+
|
| 150 |
+
try:
|
| 151 |
+
phoneme_ids = cleaned_text_to_sequence(phoneme)
|
| 152 |
+
except:
|
| 153 |
+
traceback.print_exc()
|
| 154 |
+
# print(f"{item_name} not in self.phoneme_data !")
|
| 155 |
+
num_not_in += 1
|
| 156 |
+
continue
|
| 157 |
+
# if len(phoneme_ids) >400:###########2:改为恒定限制为semantic/2.5就行
|
| 158 |
+
if (
|
| 159 |
+
len(phoneme_ids) > self.max_sec * self.hz / 2.5
|
| 160 |
+
): ###########2:改为恒定限制为semantic/2.5就行
|
| 161 |
+
num_deleted_ps += 1
|
| 162 |
+
continue
|
| 163 |
+
# if len(semantic_ids) > 1000:###########3
|
| 164 |
+
# num_deleted_bigger += 1
|
| 165 |
+
# continue
|
| 166 |
+
|
| 167 |
+
ps_ratio = len(phoneme_ids) / (len(semantic_ids) / self.hz)
|
| 168 |
+
|
| 169 |
+
if (
|
| 170 |
+
ps_ratio > self.max_ps_ratio or ps_ratio < self.min_ps_ratio
|
| 171 |
+
): ##########4#3~25#每秒多少个phone
|
| 172 |
+
num_deleted_ps += 1
|
| 173 |
+
# print(item_name)
|
| 174 |
+
continue
|
| 175 |
+
|
| 176 |
+
self.semantic_phoneme.append((semantic_ids, phoneme_ids))
|
| 177 |
+
idx += 1
|
| 178 |
+
self.item_names.append(item_name)
|
| 179 |
+
|
| 180 |
+
min_num = 100 # 20直接不补#30补了也不存ckpt
|
| 181 |
+
leng = len(self.semantic_phoneme)
|
| 182 |
+
if leng < min_num:
|
| 183 |
+
tmp1 = self.semantic_phoneme
|
| 184 |
+
tmp2 = self.item_names
|
| 185 |
+
self.semantic_phoneme = []
|
| 186 |
+
self.item_names = []
|
| 187 |
+
for _ in range(max(2, int(min_num / leng))):
|
| 188 |
+
self.semantic_phoneme += tmp1
|
| 189 |
+
self.item_names += tmp2
|
| 190 |
+
if num_not_in > 0:
|
| 191 |
+
print(f"there are {num_not_in} semantic datas not in phoneme datas")
|
| 192 |
+
if num_deleted_bigger > 0:
|
| 193 |
+
print(
|
| 194 |
+
f"deleted {num_deleted_bigger} audios who's duration are bigger than {self.max_sec} seconds"
|
| 195 |
+
)
|
| 196 |
+
if num_deleted_ps > 0:
|
| 197 |
+
# 4702 for LibriTTS, LirbriTTS 是标注数据, 是否需要筛?=> 需要,有值为 100 的极端值
|
| 198 |
+
print(
|
| 199 |
+
f"deleted {num_deleted_ps} audios who's phoneme/sec are bigger than {self.max_ps_ratio} or smaller than {self.min_ps_ratio}"
|
| 200 |
+
)
|
| 201 |
+
"""
|
| 202 |
+
there are 31 semantic datas not in phoneme datas
|
| 203 |
+
deleted 34 audios who's duration are bigger than 54 seconds
|
| 204 |
+
deleted 3190 audios who's phoneme/sec are bigger than 25 or smaller than 3
|
| 205 |
+
dataset.__len__(): 366463
|
| 206 |
+
|
| 207 |
+
"""
|
| 208 |
+
# 345410 for LibriTTS
|
| 209 |
+
print("dataset.__len__():", self.__len__())
|
| 210 |
+
|
| 211 |
+
def __get_item_names__(self) -> List[str]:
|
| 212 |
+
return self.item_names
|
| 213 |
+
|
| 214 |
+
def __len__(self) -> int:
|
| 215 |
+
return len(self.semantic_phoneme)
|
| 216 |
+
|
| 217 |
+
def __getitem__(self, idx: int) -> Dict:
|
| 218 |
+
semantic_ids, phoneme_ids = self.semantic_phoneme[idx]
|
| 219 |
+
item_name = self.item_names[idx]
|
| 220 |
+
phoneme_ids_len = len(phoneme_ids)
|
| 221 |
+
# semantic tokens target
|
| 222 |
+
semantic_ids_len = len(semantic_ids)
|
| 223 |
+
|
| 224 |
+
flag = 0
|
| 225 |
+
path_bert = "%s/%s.pt" % (self.path3, item_name)
|
| 226 |
+
if os.path.exists(path_bert) == True:
|
| 227 |
+
bert_feature = torch.load(path_bert, map_location="cpu")
|
| 228 |
+
else:
|
| 229 |
+
flag = 1
|
| 230 |
+
if flag == 1:
|
| 231 |
+
# bert_feature=torch.zeros_like(phoneme_ids,dtype=torch.float32)
|
| 232 |
+
bert_feature = None
|
| 233 |
+
else:
|
| 234 |
+
assert bert_feature.shape[-1] == len(phoneme_ids)
|
| 235 |
+
return {
|
| 236 |
+
"idx": idx,
|
| 237 |
+
"phoneme_ids": phoneme_ids,
|
| 238 |
+
"phoneme_ids_len": phoneme_ids_len,
|
| 239 |
+
"semantic_ids": semantic_ids,
|
| 240 |
+
"semantic_ids_len": semantic_ids_len,
|
| 241 |
+
"bert_feature": bert_feature,
|
| 242 |
+
}
|
| 243 |
+
|
| 244 |
+
def get_sample_length(self, idx: int):
|
| 245 |
+
semantic_ids = self.semantic_phoneme[idx][0]
|
| 246 |
+
sec = 1.0 * len(semantic_ids) / self.hz
|
| 247 |
+
return sec
|
| 248 |
+
|
| 249 |
+
def collate(self, examples: List[Dict]) -> Dict:
|
| 250 |
+
sample_index: List[int] = []
|
| 251 |
+
phoneme_ids: List[torch.Tensor] = []
|
| 252 |
+
phoneme_ids_lens: List[int] = []
|
| 253 |
+
semantic_ids: List[torch.Tensor] = []
|
| 254 |
+
semantic_ids_lens: List[int] = []
|
| 255 |
+
# return
|
| 256 |
+
|
| 257 |
+
for item in examples:
|
| 258 |
+
sample_index.append(item["idx"])
|
| 259 |
+
phoneme_ids.append(np.array(item["phoneme_ids"], dtype=np.int64))
|
| 260 |
+
semantic_ids.append(np.array(item["semantic_ids"], dtype=np.int64))
|
| 261 |
+
phoneme_ids_lens.append(item["phoneme_ids_len"])
|
| 262 |
+
semantic_ids_lens.append(item["semantic_ids_len"])
|
| 263 |
+
|
| 264 |
+
# pad 0
|
| 265 |
+
phoneme_ids = batch_sequences(phoneme_ids)
|
| 266 |
+
semantic_ids = batch_sequences(semantic_ids, pad_value=self.PAD)
|
| 267 |
+
|
| 268 |
+
# # convert each batch to torch.tensor
|
| 269 |
+
phoneme_ids = torch.tensor(phoneme_ids)
|
| 270 |
+
semantic_ids = torch.tensor(semantic_ids)
|
| 271 |
+
phoneme_ids_lens = torch.tensor(phoneme_ids_lens)
|
| 272 |
+
semantic_ids_lens = torch.tensor(semantic_ids_lens)
|
| 273 |
+
bert_padded = torch.FloatTensor(len(examples), 1024, max(phoneme_ids_lens))
|
| 274 |
+
bert_padded.zero_()
|
| 275 |
+
|
| 276 |
+
for idx, item in enumerate(examples):
|
| 277 |
+
bert = item["bert_feature"]
|
| 278 |
+
if bert != None:
|
| 279 |
+
bert_padded[idx, :, : bert.shape[-1]] = bert
|
| 280 |
+
|
| 281 |
+
return {
|
| 282 |
+
# List[int]
|
| 283 |
+
"ids": sample_index,
|
| 284 |
+
# torch.Tensor (B, max_phoneme_length)
|
| 285 |
+
"phoneme_ids": phoneme_ids,
|
| 286 |
+
# torch.Tensor (B)
|
| 287 |
+
"phoneme_ids_len": phoneme_ids_lens,
|
| 288 |
+
# torch.Tensor (B, max_semantic_ids_length)
|
| 289 |
+
"semantic_ids": semantic_ids,
|
| 290 |
+
# torch.Tensor (B)
|
| 291 |
+
"semantic_ids_len": semantic_ids_lens,
|
| 292 |
+
# torch.Tensor (B, 1024, max_phoneme_length)
|
| 293 |
+
"bert_feature": bert_padded,
|
| 294 |
+
}
|
| 295 |
+
|
| 296 |
+
|
| 297 |
+
if __name__ == "__main__":
|
| 298 |
+
root_dir = "/data/docker/liujing04/gpt-vits/prepare/dump_mix/"
|
| 299 |
+
dataset = Text2SemanticDataset(
|
| 300 |
+
phoneme_path=root_dir + "phoneme_train.npy",
|
| 301 |
+
semantic_path=root_dir + "semantic_train.tsv",
|
| 302 |
+
)
|
| 303 |
+
|
| 304 |
+
batch_size = 12
|
| 305 |
+
dataloader = DataLoader(
|
| 306 |
+
dataset, batch_size=batch_size, collate_fn=dataset.collate, shuffle=False
|
| 307 |
+
)
|
| 308 |
+
for i, batch in enumerate(dataloader):
|
| 309 |
+
if i % 1000 == 0:
|
| 310 |
+
print(i)
|
| 311 |
+
# if i == 0:
|
| 312 |
+
# print('batch["ids"]:', batch["ids"])
|
| 313 |
+
# print('batch["phoneme_ids"]:', batch["phoneme_ids"],
|
| 314 |
+
# batch["phoneme_ids"].shape)
|
| 315 |
+
# print('batch["phoneme_ids_len"]:', batch["phoneme_ids_len"],
|
| 316 |
+
# batch["phoneme_ids_len"].shape)
|
| 317 |
+
# print('batch["semantic_ids"]:', batch["semantic_ids"],
|
| 318 |
+
# batch["semantic_ids"].shape)
|
| 319 |
+
# print('batch["semantic_ids_len"]:', batch["semantic_ids_len"],
|
| 320 |
+
# batch["semantic_ids_len"].shape)
|
GPT_SoVITS/AR/models/__init__.py
ADDED
|
File without changes
|
GPT_SoVITS/AR/models/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (147 Bytes). View file
|
|
|
GPT_SoVITS/AR/models/__pycache__/t2s_lightning_module.cpython-310.pyc
ADDED
|
Binary file (3.15 kB). View file
|
|
|
GPT_SoVITS/AR/models/__pycache__/t2s_model.cpython-310.pyc
ADDED
|
Binary file (6.83 kB). View file
|
|
|
GPT_SoVITS/AR/models/__pycache__/utils.cpython-310.pyc
ADDED
|
Binary file (4.46 kB). View file
|
|
|
GPT_SoVITS/AR/models/t2s_lightning_module.py
ADDED
|
@@ -0,0 +1,140 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/feng-yufei/shared_debugging_code/blob/main/model/t2s_lightning_module.py
|
| 2 |
+
import os, sys
|
| 3 |
+
|
| 4 |
+
now_dir = os.getcwd()
|
| 5 |
+
sys.path.append(now_dir)
|
| 6 |
+
from typing import Dict
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
from pytorch_lightning import LightningModule
|
| 10 |
+
from AR.models.t2s_model import Text2SemanticDecoder
|
| 11 |
+
from AR.modules.lr_schedulers import WarmupCosineLRSchedule
|
| 12 |
+
from AR.modules.optim import ScaledAdam
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class Text2SemanticLightningModule(LightningModule):
|
| 16 |
+
def __init__(self, config, output_dir, is_train=True):
|
| 17 |
+
super().__init__()
|
| 18 |
+
self.config = config
|
| 19 |
+
self.top_k = 3
|
| 20 |
+
self.model = Text2SemanticDecoder(config=config, top_k=self.top_k)
|
| 21 |
+
pretrained_s1 = config.get("pretrained_s1")
|
| 22 |
+
if pretrained_s1 and is_train:
|
| 23 |
+
# print(self.load_state_dict(torch.load(pretrained_s1,map_location="cpu")["state_dict"]))
|
| 24 |
+
print(
|
| 25 |
+
self.load_state_dict(
|
| 26 |
+
torch.load(pretrained_s1, map_location="cpu")["weight"]
|
| 27 |
+
)
|
| 28 |
+
)
|
| 29 |
+
if is_train:
|
| 30 |
+
self.automatic_optimization = False
|
| 31 |
+
self.save_hyperparameters()
|
| 32 |
+
self.eval_dir = output_dir / "eval"
|
| 33 |
+
self.eval_dir.mkdir(parents=True, exist_ok=True)
|
| 34 |
+
|
| 35 |
+
def training_step(self, batch: Dict, batch_idx: int):
|
| 36 |
+
opt = self.optimizers()
|
| 37 |
+
scheduler = self.lr_schedulers()
|
| 38 |
+
loss, acc = self.model.forward(
|
| 39 |
+
batch["phoneme_ids"],
|
| 40 |
+
batch["phoneme_ids_len"],
|
| 41 |
+
batch["semantic_ids"],
|
| 42 |
+
batch["semantic_ids_len"],
|
| 43 |
+
batch["bert_feature"],
|
| 44 |
+
)
|
| 45 |
+
self.manual_backward(loss)
|
| 46 |
+
if batch_idx > 0 and batch_idx % 4 == 0:
|
| 47 |
+
opt.step()
|
| 48 |
+
opt.zero_grad()
|
| 49 |
+
scheduler.step()
|
| 50 |
+
|
| 51 |
+
self.log(
|
| 52 |
+
"total_loss",
|
| 53 |
+
loss,
|
| 54 |
+
on_step=True,
|
| 55 |
+
on_epoch=True,
|
| 56 |
+
prog_bar=True,
|
| 57 |
+
sync_dist=True,
|
| 58 |
+
)
|
| 59 |
+
self.log(
|
| 60 |
+
"lr",
|
| 61 |
+
scheduler.get_last_lr()[0],
|
| 62 |
+
on_epoch=True,
|
| 63 |
+
prog_bar=True,
|
| 64 |
+
sync_dist=True,
|
| 65 |
+
)
|
| 66 |
+
self.log(
|
| 67 |
+
f"top_{self.top_k}_acc",
|
| 68 |
+
acc,
|
| 69 |
+
on_step=True,
|
| 70 |
+
on_epoch=True,
|
| 71 |
+
prog_bar=True,
|
| 72 |
+
sync_dist=True,
|
| 73 |
+
)
|
| 74 |
+
|
| 75 |
+
def validation_step(self, batch: Dict, batch_idx: int):
|
| 76 |
+
return
|
| 77 |
+
|
| 78 |
+
# # get loss
|
| 79 |
+
# loss, acc = self.model.forward(
|
| 80 |
+
# batch['phoneme_ids'], batch['phoneme_ids_len'],
|
| 81 |
+
# batch['semantic_ids'], batch['semantic_ids_len'],
|
| 82 |
+
# batch['bert_feature']
|
| 83 |
+
# )
|
| 84 |
+
#
|
| 85 |
+
# self.log(
|
| 86 |
+
# "val_total_loss",
|
| 87 |
+
# loss,
|
| 88 |
+
# on_step=True,
|
| 89 |
+
# on_epoch=True,
|
| 90 |
+
# prog_bar=True,
|
| 91 |
+
# sync_dist=True)
|
| 92 |
+
# self.log(
|
| 93 |
+
# f"val_top_{self.top_k}_acc",
|
| 94 |
+
# acc,
|
| 95 |
+
# on_step=True,
|
| 96 |
+
# on_epoch=True,
|
| 97 |
+
# prog_bar=True,
|
| 98 |
+
# sync_dist=True)
|
| 99 |
+
#
|
| 100 |
+
# # get infer output
|
| 101 |
+
# semantic_len = batch['semantic_ids'].size(1)
|
| 102 |
+
# prompt_len = min(int(semantic_len * 0.5), 150)
|
| 103 |
+
# prompt = batch['semantic_ids'][:, :prompt_len]
|
| 104 |
+
# pred_semantic = self.model.infer(batch['phoneme_ids'],
|
| 105 |
+
# batch['phoneme_ids_len'], prompt,
|
| 106 |
+
# batch['bert_feature']
|
| 107 |
+
# )
|
| 108 |
+
# save_name = f'semantic_toks_{batch_idx}.pt'
|
| 109 |
+
# save_path = os.path.join(self.eval_dir, save_name)
|
| 110 |
+
# torch.save(pred_semantic.detach().cpu(), save_path)
|
| 111 |
+
|
| 112 |
+
def configure_optimizers(self):
|
| 113 |
+
model_parameters = self.model.parameters()
|
| 114 |
+
parameters_names = []
|
| 115 |
+
parameters_names.append(
|
| 116 |
+
[name_param_pair[0] for name_param_pair in self.model.named_parameters()]
|
| 117 |
+
)
|
| 118 |
+
lm_opt = ScaledAdam(
|
| 119 |
+
model_parameters,
|
| 120 |
+
lr=0.01,
|
| 121 |
+
betas=(0.9, 0.95),
|
| 122 |
+
clipping_scale=2.0,
|
| 123 |
+
parameters_names=parameters_names,
|
| 124 |
+
show_dominant_parameters=False,
|
| 125 |
+
clipping_update_period=1000,
|
| 126 |
+
)
|
| 127 |
+
|
| 128 |
+
return {
|
| 129 |
+
"optimizer": lm_opt,
|
| 130 |
+
"lr_scheduler": {
|
| 131 |
+
"scheduler": WarmupCosineLRSchedule(
|
| 132 |
+
lm_opt,
|
| 133 |
+
init_lr=self.config["optimizer"]["lr_init"],
|
| 134 |
+
peak_lr=self.config["optimizer"]["lr"],
|
| 135 |
+
end_lr=self.config["optimizer"]["lr_end"],
|
| 136 |
+
warmup_steps=self.config["optimizer"]["warmup_steps"],
|
| 137 |
+
total_steps=self.config["optimizer"]["decay_steps"],
|
| 138 |
+
)
|
| 139 |
+
},
|
| 140 |
+
}
|
GPT_SoVITS/AR/models/t2s_lightning_module_onnx.py
ADDED
|
@@ -0,0 +1,106 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/feng-yufei/shared_debugging_code/blob/main/model/t2s_lightning_module.py
|
| 2 |
+
import os, sys
|
| 3 |
+
|
| 4 |
+
now_dir = os.getcwd()
|
| 5 |
+
sys.path.append(now_dir)
|
| 6 |
+
from typing import Dict
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
from pytorch_lightning import LightningModule
|
| 10 |
+
from AR.models.t2s_model_onnx import Text2SemanticDecoder
|
| 11 |
+
from AR.modules.lr_schedulers import WarmupCosineLRSchedule
|
| 12 |
+
from AR.modules.optim import ScaledAdam
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class Text2SemanticLightningModule(LightningModule):
|
| 16 |
+
def __init__(self, config, output_dir, is_train=True):
|
| 17 |
+
super().__init__()
|
| 18 |
+
self.config = config
|
| 19 |
+
self.top_k = 3
|
| 20 |
+
self.model = Text2SemanticDecoder(config=config, top_k=self.top_k)
|
| 21 |
+
pretrained_s1 = config.get("pretrained_s1")
|
| 22 |
+
if pretrained_s1 and is_train:
|
| 23 |
+
# print(self.load_state_dict(torch.load(pretrained_s1,map_location="cpu")["state_dict"]))
|
| 24 |
+
print(
|
| 25 |
+
self.load_state_dict(
|
| 26 |
+
torch.load(pretrained_s1, map_location="cpu")["weight"]
|
| 27 |
+
)
|
| 28 |
+
)
|
| 29 |
+
if is_train:
|
| 30 |
+
self.automatic_optimization = False
|
| 31 |
+
self.save_hyperparameters()
|
| 32 |
+
self.eval_dir = output_dir / "eval"
|
| 33 |
+
self.eval_dir.mkdir(parents=True, exist_ok=True)
|
| 34 |
+
|
| 35 |
+
def training_step(self, batch: Dict, batch_idx: int):
|
| 36 |
+
opt = self.optimizers()
|
| 37 |
+
scheduler = self.lr_schedulers()
|
| 38 |
+
loss, acc = self.model.forward(
|
| 39 |
+
batch["phoneme_ids"],
|
| 40 |
+
batch["phoneme_ids_len"],
|
| 41 |
+
batch["semantic_ids"],
|
| 42 |
+
batch["semantic_ids_len"],
|
| 43 |
+
batch["bert_feature"],
|
| 44 |
+
)
|
| 45 |
+
self.manual_backward(loss)
|
| 46 |
+
if batch_idx > 0 and batch_idx % 4 == 0:
|
| 47 |
+
opt.step()
|
| 48 |
+
opt.zero_grad()
|
| 49 |
+
scheduler.step()
|
| 50 |
+
|
| 51 |
+
self.log(
|
| 52 |
+
"total_loss",
|
| 53 |
+
loss,
|
| 54 |
+
on_step=True,
|
| 55 |
+
on_epoch=True,
|
| 56 |
+
prog_bar=True,
|
| 57 |
+
sync_dist=True,
|
| 58 |
+
)
|
| 59 |
+
self.log(
|
| 60 |
+
"lr",
|
| 61 |
+
scheduler.get_last_lr()[0],
|
| 62 |
+
on_epoch=True,
|
| 63 |
+
prog_bar=True,
|
| 64 |
+
sync_dist=True,
|
| 65 |
+
)
|
| 66 |
+
self.log(
|
| 67 |
+
f"top_{self.top_k}_acc",
|
| 68 |
+
acc,
|
| 69 |
+
on_step=True,
|
| 70 |
+
on_epoch=True,
|
| 71 |
+
prog_bar=True,
|
| 72 |
+
sync_dist=True,
|
| 73 |
+
)
|
| 74 |
+
|
| 75 |
+
def validation_step(self, batch: Dict, batch_idx: int):
|
| 76 |
+
return
|
| 77 |
+
|
| 78 |
+
def configure_optimizers(self):
|
| 79 |
+
model_parameters = self.model.parameters()
|
| 80 |
+
parameters_names = []
|
| 81 |
+
parameters_names.append(
|
| 82 |
+
[name_param_pair[0] for name_param_pair in self.model.named_parameters()]
|
| 83 |
+
)
|
| 84 |
+
lm_opt = ScaledAdam(
|
| 85 |
+
model_parameters,
|
| 86 |
+
lr=0.01,
|
| 87 |
+
betas=(0.9, 0.95),
|
| 88 |
+
clipping_scale=2.0,
|
| 89 |
+
parameters_names=parameters_names,
|
| 90 |
+
show_dominant_parameters=False,
|
| 91 |
+
clipping_update_period=1000,
|
| 92 |
+
)
|
| 93 |
+
|
| 94 |
+
return {
|
| 95 |
+
"optimizer": lm_opt,
|
| 96 |
+
"lr_scheduler": {
|
| 97 |
+
"scheduler": WarmupCosineLRSchedule(
|
| 98 |
+
lm_opt,
|
| 99 |
+
init_lr=self.config["optimizer"]["lr_init"],
|
| 100 |
+
peak_lr=self.config["optimizer"]["lr"],
|
| 101 |
+
end_lr=self.config["optimizer"]["lr_end"],
|
| 102 |
+
warmup_steps=self.config["optimizer"]["warmup_steps"],
|
| 103 |
+
total_steps=self.config["optimizer"]["decay_steps"],
|
| 104 |
+
)
|
| 105 |
+
},
|
| 106 |
+
}
|
GPT_SoVITS/AR/models/t2s_model.py
ADDED
|
@@ -0,0 +1,327 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/feng-yufei/shared_debugging_code/blob/main/model/t2s_model.py
|
| 2 |
+
import torch
|
| 3 |
+
from tqdm import tqdm
|
| 4 |
+
|
| 5 |
+
from AR.models.utils import make_pad_mask
|
| 6 |
+
from AR.models.utils import (
|
| 7 |
+
topk_sampling,
|
| 8 |
+
sample,
|
| 9 |
+
logits_to_probs,
|
| 10 |
+
multinomial_sample_one_no_sync,
|
| 11 |
+
)
|
| 12 |
+
from AR.modules.embedding import SinePositionalEmbedding
|
| 13 |
+
from AR.modules.embedding import TokenEmbedding
|
| 14 |
+
from AR.modules.transformer import LayerNorm
|
| 15 |
+
from AR.modules.transformer import TransformerEncoder
|
| 16 |
+
from AR.modules.transformer import TransformerEncoderLayer
|
| 17 |
+
from torch import nn
|
| 18 |
+
from torch.nn import functional as F
|
| 19 |
+
from torchmetrics.classification import MulticlassAccuracy
|
| 20 |
+
|
| 21 |
+
default_config = {
|
| 22 |
+
"embedding_dim": 512,
|
| 23 |
+
"hidden_dim": 512,
|
| 24 |
+
"num_head": 8,
|
| 25 |
+
"num_layers": 12,
|
| 26 |
+
"num_codebook": 8,
|
| 27 |
+
"p_dropout": 0.0,
|
| 28 |
+
"vocab_size": 1024 + 1,
|
| 29 |
+
"phoneme_vocab_size": 512,
|
| 30 |
+
"EOS": 1024,
|
| 31 |
+
}
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
class Text2SemanticDecoder(nn.Module):
|
| 35 |
+
def __init__(self, config, norm_first=False, top_k=3):
|
| 36 |
+
super(Text2SemanticDecoder, self).__init__()
|
| 37 |
+
self.model_dim = config["model"]["hidden_dim"]
|
| 38 |
+
self.embedding_dim = config["model"]["embedding_dim"]
|
| 39 |
+
self.num_head = config["model"]["head"]
|
| 40 |
+
self.num_layers = config["model"]["n_layer"]
|
| 41 |
+
self.norm_first = norm_first
|
| 42 |
+
self.vocab_size = config["model"]["vocab_size"]
|
| 43 |
+
self.phoneme_vocab_size = config["model"]["phoneme_vocab_size"]
|
| 44 |
+
self.p_dropout = config["model"]["dropout"]
|
| 45 |
+
self.EOS = config["model"]["EOS"]
|
| 46 |
+
self.norm_first = norm_first
|
| 47 |
+
assert self.EOS == self.vocab_size - 1
|
| 48 |
+
# should be same as num of kmeans bin
|
| 49 |
+
# assert self.EOS == 1024
|
| 50 |
+
self.bert_proj = nn.Linear(1024, self.embedding_dim)
|
| 51 |
+
self.ar_text_embedding = TokenEmbedding(
|
| 52 |
+
self.embedding_dim, self.phoneme_vocab_size, self.p_dropout
|
| 53 |
+
)
|
| 54 |
+
self.ar_text_position = SinePositionalEmbedding(
|
| 55 |
+
self.embedding_dim, dropout=0.1, scale=False, alpha=True
|
| 56 |
+
)
|
| 57 |
+
self.ar_audio_embedding = TokenEmbedding(
|
| 58 |
+
self.embedding_dim, self.vocab_size, self.p_dropout
|
| 59 |
+
)
|
| 60 |
+
self.ar_audio_position = SinePositionalEmbedding(
|
| 61 |
+
self.embedding_dim, dropout=0.1, scale=False, alpha=True
|
| 62 |
+
)
|
| 63 |
+
|
| 64 |
+
self.h = TransformerEncoder(
|
| 65 |
+
TransformerEncoderLayer(
|
| 66 |
+
d_model=self.model_dim,
|
| 67 |
+
nhead=self.num_head,
|
| 68 |
+
dim_feedforward=self.model_dim * 4,
|
| 69 |
+
dropout=0.1,
|
| 70 |
+
batch_first=True,
|
| 71 |
+
norm_first=norm_first,
|
| 72 |
+
),
|
| 73 |
+
num_layers=self.num_layers,
|
| 74 |
+
norm=LayerNorm(self.model_dim) if norm_first else None,
|
| 75 |
+
)
|
| 76 |
+
|
| 77 |
+
self.ar_predict_layer = nn.Linear(self.model_dim, self.vocab_size, bias=False)
|
| 78 |
+
self.loss_fct = nn.CrossEntropyLoss(reduction="sum")
|
| 79 |
+
|
| 80 |
+
self.ar_accuracy_metric = MulticlassAccuracy(
|
| 81 |
+
self.vocab_size,
|
| 82 |
+
top_k=top_k,
|
| 83 |
+
average="micro",
|
| 84 |
+
multidim_average="global",
|
| 85 |
+
ignore_index=self.EOS,
|
| 86 |
+
)
|
| 87 |
+
|
| 88 |
+
def forward(self, x, x_lens, y, y_lens, bert_feature):
|
| 89 |
+
"""
|
| 90 |
+
x: phoneme_ids
|
| 91 |
+
y: semantic_ids
|
| 92 |
+
"""
|
| 93 |
+
x = self.ar_text_embedding(x)
|
| 94 |
+
x = x + self.bert_proj(bert_feature.transpose(1, 2))
|
| 95 |
+
x = self.ar_text_position(x)
|
| 96 |
+
x_mask = make_pad_mask(x_lens)
|
| 97 |
+
|
| 98 |
+
y_mask = make_pad_mask(y_lens)
|
| 99 |
+
y_mask_int = y_mask.type(torch.int64)
|
| 100 |
+
codes = y.type(torch.int64) * (1 - y_mask_int)
|
| 101 |
+
|
| 102 |
+
# Training
|
| 103 |
+
# AR Decoder
|
| 104 |
+
y, targets = self.pad_y_eos(codes, y_mask_int, eos_id=self.EOS)
|
| 105 |
+
x_len = x_lens.max()
|
| 106 |
+
y_len = y_lens.max()
|
| 107 |
+
y_emb = self.ar_audio_embedding(y)
|
| 108 |
+
y_pos = self.ar_audio_position(y_emb)
|
| 109 |
+
|
| 110 |
+
xy_padding_mask = torch.concat([x_mask, y_mask], dim=1)
|
| 111 |
+
ar_xy_padding_mask = xy_padding_mask
|
| 112 |
+
|
| 113 |
+
x_attn_mask = F.pad(
|
| 114 |
+
torch.zeros((x_len, x_len), dtype=torch.bool, device=x.device),
|
| 115 |
+
(0, y_len),
|
| 116 |
+
value=True,
|
| 117 |
+
)
|
| 118 |
+
y_attn_mask = F.pad(
|
| 119 |
+
torch.triu(
|
| 120 |
+
torch.ones(y_len, y_len, dtype=torch.bool, device=x.device),
|
| 121 |
+
diagonal=1,
|
| 122 |
+
),
|
| 123 |
+
(x_len, 0),
|
| 124 |
+
value=False,
|
| 125 |
+
)
|
| 126 |
+
xy_attn_mask = torch.concat([x_attn_mask, y_attn_mask], dim=0)
|
| 127 |
+
bsz, src_len = x.shape[0], x_len + y_len
|
| 128 |
+
_xy_padding_mask = (
|
| 129 |
+
ar_xy_padding_mask.view(bsz, 1, 1, src_len)
|
| 130 |
+
.expand(-1, self.num_head, -1, -1)
|
| 131 |
+
.reshape(bsz * self.num_head, 1, src_len)
|
| 132 |
+
)
|
| 133 |
+
xy_attn_mask = xy_attn_mask.logical_or(_xy_padding_mask)
|
| 134 |
+
new_attn_mask = torch.zeros_like(xy_attn_mask, dtype=x.dtype)
|
| 135 |
+
new_attn_mask.masked_fill_(xy_attn_mask, float("-inf"))
|
| 136 |
+
xy_attn_mask = new_attn_mask
|
| 137 |
+
# x 和完整的 y 一次性输入模型
|
| 138 |
+
xy_pos = torch.concat([x, y_pos], dim=1)
|
| 139 |
+
xy_dec, _ = self.h(
|
| 140 |
+
(xy_pos, None),
|
| 141 |
+
mask=xy_attn_mask,
|
| 142 |
+
)
|
| 143 |
+
logits = self.ar_predict_layer(xy_dec[:, x_len:]).permute(0, 2, 1)
|
| 144 |
+
# loss
|
| 145 |
+
# from feiteng: 每次 duration 越多, 梯度更新也应该更多, 所以用 sum
|
| 146 |
+
loss = F.cross_entropy(logits, targets, reduction="sum")
|
| 147 |
+
acc = self.ar_accuracy_metric(logits.detach(), targets).item()
|
| 148 |
+
return loss, acc
|
| 149 |
+
|
| 150 |
+
# 需要看下这个函数和 forward 的区别以及没有 semantic 的时候 prompts 输入什么
|
| 151 |
+
def infer(
|
| 152 |
+
self,
|
| 153 |
+
x,
|
| 154 |
+
x_lens,
|
| 155 |
+
prompts,
|
| 156 |
+
bert_feature,
|
| 157 |
+
top_k: int = -100,
|
| 158 |
+
early_stop_num: int = -1,
|
| 159 |
+
temperature: float = 1.0,
|
| 160 |
+
):
|
| 161 |
+
x = self.ar_text_embedding(x)
|
| 162 |
+
x = x + self.bert_proj(bert_feature.transpose(1, 2))
|
| 163 |
+
x = self.ar_text_position(x)
|
| 164 |
+
|
| 165 |
+
# AR Decoder
|
| 166 |
+
y = prompts
|
| 167 |
+
prefix_len = y.shape[1]
|
| 168 |
+
x_len = x.shape[1]
|
| 169 |
+
x_attn_mask = torch.zeros((x_len, x_len), dtype=torch.bool)
|
| 170 |
+
stop = False
|
| 171 |
+
for _ in tqdm(range(1500)):
|
| 172 |
+
y_emb = self.ar_audio_embedding(y)
|
| 173 |
+
y_pos = self.ar_audio_position(y_emb)
|
| 174 |
+
# x 和逐渐增长的 y 一起输入给模型
|
| 175 |
+
xy_pos = torch.concat([x, y_pos], dim=1)
|
| 176 |
+
y_len = y.shape[1]
|
| 177 |
+
x_attn_mask_pad = F.pad(
|
| 178 |
+
x_attn_mask,
|
| 179 |
+
(0, y_len),
|
| 180 |
+
value=True,
|
| 181 |
+
)
|
| 182 |
+
y_attn_mask = F.pad(
|
| 183 |
+
torch.triu(torch.ones(y_len, y_len, dtype=torch.bool), diagonal=1),
|
| 184 |
+
(x_len, 0),
|
| 185 |
+
value=False,
|
| 186 |
+
)
|
| 187 |
+
xy_attn_mask = torch.concat([x_attn_mask_pad, y_attn_mask], dim=0).to(
|
| 188 |
+
y.device
|
| 189 |
+
)
|
| 190 |
+
|
| 191 |
+
xy_dec, _ = self.h(
|
| 192 |
+
(xy_pos, None),
|
| 193 |
+
mask=xy_attn_mask,
|
| 194 |
+
)
|
| 195 |
+
logits = self.ar_predict_layer(xy_dec[:, -1])
|
| 196 |
+
samples = topk_sampling(
|
| 197 |
+
logits, top_k=top_k, top_p=1.0, temperature=temperature
|
| 198 |
+
)
|
| 199 |
+
|
| 200 |
+
if early_stop_num != -1 and (y.shape[1] - prefix_len) > early_stop_num:
|
| 201 |
+
print("use early stop num:", early_stop_num)
|
| 202 |
+
stop = True
|
| 203 |
+
|
| 204 |
+
if torch.argmax(logits, dim=-1)[0] == self.EOS or samples[0, 0] == self.EOS:
|
| 205 |
+
# print(torch.argmax(logits, dim=-1)[0] == self.EOS, samples[0, 0] == self.EOS)
|
| 206 |
+
stop = True
|
| 207 |
+
if stop:
|
| 208 |
+
if prompts.shape[1] == y.shape[1]:
|
| 209 |
+
y = torch.concat([y, torch.zeros_like(samples)], dim=1)
|
| 210 |
+
print("bad zero prediction")
|
| 211 |
+
print(f"T2S Decoding EOS [{prefix_len} -> {y.shape[1]}]")
|
| 212 |
+
break
|
| 213 |
+
# 本次生成的 semantic_ids 和之前的 y 构成新的 y
|
| 214 |
+
# print(samples.shape)#[1,1]#第一个1是bs
|
| 215 |
+
# import os
|
| 216 |
+
# os._exit(2333)
|
| 217 |
+
y = torch.concat([y, samples], dim=1)
|
| 218 |
+
return y
|
| 219 |
+
|
| 220 |
+
def pad_y_eos(self, y, y_mask_int, eos_id):
|
| 221 |
+
targets = F.pad(y, (0, 1), value=0) + eos_id * F.pad(
|
| 222 |
+
y_mask_int, (0, 1), value=1
|
| 223 |
+
)
|
| 224 |
+
# 错位
|
| 225 |
+
return targets[:, :-1], targets[:, 1:]
|
| 226 |
+
|
| 227 |
+
def infer_panel(
|
| 228 |
+
self,
|
| 229 |
+
x, #####全部文本token
|
| 230 |
+
x_lens,
|
| 231 |
+
prompts, ####参考音频token
|
| 232 |
+
bert_feature,
|
| 233 |
+
top_k: int = -100,
|
| 234 |
+
early_stop_num: int = -1,
|
| 235 |
+
temperature: float = 1.0,
|
| 236 |
+
):
|
| 237 |
+
x = self.ar_text_embedding(x)
|
| 238 |
+
x = x + self.bert_proj(bert_feature.transpose(1, 2))
|
| 239 |
+
x = self.ar_text_position(x)
|
| 240 |
+
|
| 241 |
+
# AR Decoder
|
| 242 |
+
y = prompts
|
| 243 |
+
prefix_len = y.shape[1]
|
| 244 |
+
x_len = x.shape[1]
|
| 245 |
+
x_attn_mask = torch.zeros((x_len, x_len), dtype=torch.bool)
|
| 246 |
+
stop = False
|
| 247 |
+
# print(1111111,self.num_layers)
|
| 248 |
+
cache = {
|
| 249 |
+
"all_stage": self.num_layers,
|
| 250 |
+
"k": [None] * self.num_layers, ###根据配置自己手写
|
| 251 |
+
"v": [None] * self.num_layers,
|
| 252 |
+
# "xy_pos":None,##y_pos位置编码每次都不一样的没法缓存,每次都要重新拼xy_pos.主要还是写法原因,其实是可以历史统一一样的,但也没啥计算量就不管了
|
| 253 |
+
"y_emb": None, ##只需要对最新的samples求emb,再拼历史的就行
|
| 254 |
+
# "logits":None,###原版就已经只对结尾求再拼接了,不用管
|
| 255 |
+
# "xy_dec":None,###不需要,本来只需要最后一个做logits
|
| 256 |
+
"first_infer": 1,
|
| 257 |
+
"stage": 0,
|
| 258 |
+
}
|
| 259 |
+
for idx in tqdm(range(1500)):
|
| 260 |
+
if cache["first_infer"] == 1:
|
| 261 |
+
y_emb = self.ar_audio_embedding(y)
|
| 262 |
+
else:
|
| 263 |
+
y_emb = torch.cat(
|
| 264 |
+
[cache["y_emb"], self.ar_audio_embedding(y[:, -1:])], 1
|
| 265 |
+
)
|
| 266 |
+
cache["y_emb"] = y_emb
|
| 267 |
+
y_pos = self.ar_audio_position(y_emb)
|
| 268 |
+
# x 和逐渐增长的 y 一起输入给模型
|
| 269 |
+
if cache["first_infer"] == 1:
|
| 270 |
+
xy_pos = torch.concat([x, y_pos], dim=1)
|
| 271 |
+
else:
|
| 272 |
+
xy_pos = y_pos[:, -1:]
|
| 273 |
+
y_len = y_pos.shape[1]
|
| 274 |
+
###以下3个不做缓存
|
| 275 |
+
if cache["first_infer"] == 1:
|
| 276 |
+
x_attn_mask_pad = F.pad(
|
| 277 |
+
x_attn_mask,
|
| 278 |
+
(0, y_len), ###xx的纯0扩展到xx纯0+xy纯1,(x,x+y)
|
| 279 |
+
value=True,
|
| 280 |
+
)
|
| 281 |
+
y_attn_mask = F.pad( ###yy的右上1扩展到左边xy的0,(y,x+y)
|
| 282 |
+
torch.triu(torch.ones(y_len, y_len, dtype=torch.bool), diagonal=1),
|
| 283 |
+
(x_len, 0),
|
| 284 |
+
value=False,
|
| 285 |
+
)
|
| 286 |
+
xy_attn_mask = torch.concat([x_attn_mask_pad, y_attn_mask], dim=0).to(
|
| 287 |
+
y.device
|
| 288 |
+
)
|
| 289 |
+
else:
|
| 290 |
+
###最右边一列(是错的)
|
| 291 |
+
# xy_attn_mask=torch.ones((1, x_len+y_len), dtype=torch.bool,device=xy_pos.device)
|
| 292 |
+
# xy_attn_mask[:,-1]=False
|
| 293 |
+
###最下面一行(是对的)
|
| 294 |
+
xy_attn_mask = torch.zeros(
|
| 295 |
+
(1, x_len + y_len), dtype=torch.bool, device=xy_pos.device
|
| 296 |
+
)
|
| 297 |
+
# pdb.set_trace()
|
| 298 |
+
###缓存重头戏
|
| 299 |
+
# print(1111,xy_pos.shape,xy_attn_mask.shape,x_len,y_len)
|
| 300 |
+
xy_dec, _ = self.h((xy_pos, None), mask=xy_attn_mask, cache=cache)
|
| 301 |
+
logits = self.ar_predict_layer(
|
| 302 |
+
xy_dec[:, -1]
|
| 303 |
+
) ##不用改,如果用了cache的默认就是只有一帧,取最后一帧一样的
|
| 304 |
+
# samples = topk_sampling(logits, top_k=top_k, top_p=1.0, temperature=temperature)
|
| 305 |
+
if(idx==0):###第一次跑不能EOS否则没有了
|
| 306 |
+
logits = logits[:, :-1] ###刨除1024终止符号的概率
|
| 307 |
+
samples = sample(
|
| 308 |
+
logits[0], y, top_k=top_k, top_p=1.0, repetition_penalty=1.35
|
| 309 |
+
)[0].unsqueeze(0)
|
| 310 |
+
if early_stop_num != -1 and (y.shape[1] - prefix_len) > early_stop_num:
|
| 311 |
+
print("use early stop num:", early_stop_num)
|
| 312 |
+
stop = True
|
| 313 |
+
|
| 314 |
+
if torch.argmax(logits, dim=-1)[0] == self.EOS or samples[0, 0] == self.EOS:
|
| 315 |
+
# print(torch.argmax(logits, dim=-1)[0] == self.EOS, samples[0, 0] == self.EOS)
|
| 316 |
+
stop = True
|
| 317 |
+
if stop:
|
| 318 |
+
if prompts.shape[1] == y.shape[1]:
|
| 319 |
+
y = torch.concat([y, torch.zeros_like(samples)], dim=1)
|
| 320 |
+
print("bad zero prediction")
|
| 321 |
+
print(f"T2S Decoding EOS [{prefix_len} -> {y.shape[1]}]")
|
| 322 |
+
break
|
| 323 |
+
# 本次生成的 semantic_ids 和之前的 y 构成新的 y
|
| 324 |
+
# print(samples.shape)#[1,1]#第一个1是bs
|
| 325 |
+
y = torch.concat([y, samples], dim=1)
|
| 326 |
+
cache["first_infer"] = 0
|
| 327 |
+
return y, idx
|
GPT_SoVITS/AR/models/t2s_model_onnx.py
ADDED
|
@@ -0,0 +1,337 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/feng-yufei/shared_debugging_code/blob/main/model/t2s_model.py
|
| 2 |
+
import torch
|
| 3 |
+
from tqdm import tqdm
|
| 4 |
+
|
| 5 |
+
from AR.modules.embedding_onnx import SinePositionalEmbedding
|
| 6 |
+
from AR.modules.embedding_onnx import TokenEmbedding
|
| 7 |
+
from AR.modules.transformer_onnx import LayerNorm
|
| 8 |
+
from AR.modules.transformer_onnx import TransformerEncoder
|
| 9 |
+
from AR.modules.transformer_onnx import TransformerEncoderLayer
|
| 10 |
+
from torch import nn
|
| 11 |
+
from torch.nn import functional as F
|
| 12 |
+
from torchmetrics.classification import MulticlassAccuracy
|
| 13 |
+
|
| 14 |
+
default_config = {
|
| 15 |
+
"embedding_dim": 512,
|
| 16 |
+
"hidden_dim": 512,
|
| 17 |
+
"num_head": 8,
|
| 18 |
+
"num_layers": 12,
|
| 19 |
+
"num_codebook": 8,
|
| 20 |
+
"p_dropout": 0.0,
|
| 21 |
+
"vocab_size": 1024 + 1,
|
| 22 |
+
"phoneme_vocab_size": 512,
|
| 23 |
+
"EOS": 1024,
|
| 24 |
+
}
|
| 25 |
+
|
| 26 |
+
inf_tensor_value = torch.FloatTensor([-float("Inf")]).float()
|
| 27 |
+
|
| 28 |
+
def logits_to_probs(
|
| 29 |
+
logits,
|
| 30 |
+
previous_tokens = None,
|
| 31 |
+
temperature: float = 1.0,
|
| 32 |
+
top_k = None,
|
| 33 |
+
top_p = None,
|
| 34 |
+
repetition_penalty: float = 1.0,
|
| 35 |
+
):
|
| 36 |
+
previous_tokens = previous_tokens.squeeze()
|
| 37 |
+
if previous_tokens is not None and repetition_penalty != 1.0:
|
| 38 |
+
previous_tokens = previous_tokens.long()
|
| 39 |
+
score = torch.gather(logits, dim=0, index=previous_tokens)
|
| 40 |
+
score = torch.where(
|
| 41 |
+
score < 0, score * repetition_penalty, score / repetition_penalty
|
| 42 |
+
)
|
| 43 |
+
logits.scatter_(dim=0, index=previous_tokens, src=score)
|
| 44 |
+
|
| 45 |
+
if top_p is not None and top_p < 1.0:
|
| 46 |
+
sorted_logits, sorted_indices = torch.sort(logits, descending=True)
|
| 47 |
+
cum_probs = torch.cumsum(
|
| 48 |
+
torch.nn.functional.softmax(sorted_logits, dim=-1), dim=-1
|
| 49 |
+
)
|
| 50 |
+
sorted_indices_to_remove = cum_probs > top_p
|
| 51 |
+
sorted_indices_to_remove[0] = False # keep at least one option
|
| 52 |
+
indices_to_remove = sorted_indices_to_remove.scatter(
|
| 53 |
+
dim=0, index=sorted_indices, src=sorted_indices_to_remove
|
| 54 |
+
)
|
| 55 |
+
logits = logits.masked_fill(indices_to_remove, -float("Inf"))
|
| 56 |
+
|
| 57 |
+
logits = logits / max(temperature, 1e-5)
|
| 58 |
+
|
| 59 |
+
if top_k is not None:
|
| 60 |
+
v, _ = torch.topk(logits, min(top_k, logits.size(-1)))
|
| 61 |
+
pivot = v.select(-1, -1).unsqueeze(-1)
|
| 62 |
+
logits = torch.where(logits < pivot, inf_tensor_value, logits)
|
| 63 |
+
|
| 64 |
+
probs = torch.nn.functional.softmax(logits, dim=-1)
|
| 65 |
+
return probs
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def multinomial_sample_one_no_sync(
|
| 69 |
+
probs_sort
|
| 70 |
+
): # Does multinomial sampling without a cuda synchronization
|
| 71 |
+
q = torch.randn_like(probs_sort)
|
| 72 |
+
return torch.argmax(probs_sort / q, dim=-1, keepdim=True).to(dtype=torch.int)
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
def sample(
|
| 76 |
+
logits,
|
| 77 |
+
previous_tokens,
|
| 78 |
+
**sampling_kwargs,
|
| 79 |
+
):
|
| 80 |
+
probs = logits_to_probs(
|
| 81 |
+
logits=logits, previous_tokens=previous_tokens, **sampling_kwargs
|
| 82 |
+
)
|
| 83 |
+
idx_next = multinomial_sample_one_no_sync(probs)
|
| 84 |
+
return idx_next, probs
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
class OnnxEncoder(nn.Module):
|
| 88 |
+
def __init__(self, ar_text_embedding, bert_proj, ar_text_position):
|
| 89 |
+
super().__init__()
|
| 90 |
+
self.ar_text_embedding = ar_text_embedding
|
| 91 |
+
self.bert_proj = bert_proj
|
| 92 |
+
self.ar_text_position = ar_text_position
|
| 93 |
+
|
| 94 |
+
def forward(self, x, bert_feature):
|
| 95 |
+
x = self.ar_text_embedding(x)
|
| 96 |
+
x = x + self.bert_proj(bert_feature.transpose(1, 2))
|
| 97 |
+
return self.ar_text_position(x)
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
class T2SFirstStageDecoder(nn.Module):
|
| 101 |
+
def __init__(self, ar_audio_embedding, ar_audio_position, h, ar_predict_layer, loss_fct, ar_accuracy_metric,
|
| 102 |
+
top_k, early_stop_num, num_layers):
|
| 103 |
+
super().__init__()
|
| 104 |
+
self.ar_audio_embedding = ar_audio_embedding
|
| 105 |
+
self.ar_audio_position = ar_audio_position
|
| 106 |
+
self.h = h
|
| 107 |
+
self.ar_predict_layer = ar_predict_layer
|
| 108 |
+
self.loss_fct = loss_fct
|
| 109 |
+
self.ar_accuracy_metric = ar_accuracy_metric
|
| 110 |
+
self.top_k = top_k
|
| 111 |
+
self.early_stop_num = early_stop_num
|
| 112 |
+
self.num_layers = num_layers
|
| 113 |
+
|
| 114 |
+
def forward(self, x, prompt):
|
| 115 |
+
y = prompt
|
| 116 |
+
x_example = x[:,:,0] * 0.0
|
| 117 |
+
#N, 1, 512
|
| 118 |
+
cache = {
|
| 119 |
+
"all_stage": self.num_layers,
|
| 120 |
+
"k": None,
|
| 121 |
+
"v": None,
|
| 122 |
+
"y_emb": None,
|
| 123 |
+
"first_infer": 1,
|
| 124 |
+
"stage": 0,
|
| 125 |
+
}
|
| 126 |
+
|
| 127 |
+
y_emb = self.ar_audio_embedding(y)
|
| 128 |
+
|
| 129 |
+
cache["y_emb"] = y_emb
|
| 130 |
+
y_pos = self.ar_audio_position(y_emb)
|
| 131 |
+
|
| 132 |
+
xy_pos = torch.concat([x, y_pos], dim=1)
|
| 133 |
+
|
| 134 |
+
y_example = y_pos[:,:,0] * 0.0
|
| 135 |
+
x_attn_mask = torch.matmul(x_example.transpose(0, 1) , x_example).bool()
|
| 136 |
+
y_attn_mask = torch.ones_like(torch.matmul(y_example.transpose(0, 1), y_example), dtype=torch.int64)
|
| 137 |
+
y_attn_mask = torch.cumsum(y_attn_mask, dim=1) - torch.cumsum(
|
| 138 |
+
torch.ones_like(y_example.transpose(0, 1), dtype=torch.int64), dim=0
|
| 139 |
+
)
|
| 140 |
+
y_attn_mask = y_attn_mask > 0
|
| 141 |
+
|
| 142 |
+
x_y_pad = torch.matmul(x_example.transpose(0, 1), y_example).bool()
|
| 143 |
+
y_x_pad = torch.matmul(y_example.transpose(0, 1), x_example).bool()
|
| 144 |
+
x_attn_mask_pad = torch.cat([x_attn_mask, torch.ones_like(x_y_pad)], dim=1)
|
| 145 |
+
y_attn_mask = torch.cat([y_x_pad, y_attn_mask], dim=1)
|
| 146 |
+
xy_attn_mask = torch.concat([x_attn_mask_pad, y_attn_mask], dim=0)
|
| 147 |
+
cache["k"] = torch.matmul(x_attn_mask_pad[0].float().unsqueeze(-1), torch.zeros((1, 512)))\
|
| 148 |
+
.unsqueeze(1).repeat(self.num_layers, 1, 1, 1)
|
| 149 |
+
cache["v"] = torch.matmul(x_attn_mask_pad[0].float().unsqueeze(-1), torch.zeros((1, 512)))\
|
| 150 |
+
.unsqueeze(1).repeat(self.num_layers, 1, 1, 1)
|
| 151 |
+
|
| 152 |
+
xy_dec = self.h(xy_pos, mask=xy_attn_mask, cache=cache)
|
| 153 |
+
logits = self.ar_predict_layer(xy_dec[:, -1])
|
| 154 |
+
samples = sample(logits[0], y, top_k=self.top_k, top_p=1.0, repetition_penalty=1.35)[0].unsqueeze(0)
|
| 155 |
+
|
| 156 |
+
y = torch.concat([y, samples], dim=1)
|
| 157 |
+
|
| 158 |
+
return y, cache["k"], cache["v"], cache["y_emb"], x_example
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
class T2SStageDecoder(nn.Module):
|
| 162 |
+
def __init__(self, ar_audio_embedding, ar_audio_position, h, ar_predict_layer, loss_fct, ar_accuracy_metric,
|
| 163 |
+
top_k, early_stop_num, num_layers):
|
| 164 |
+
super().__init__()
|
| 165 |
+
self.ar_audio_embedding = ar_audio_embedding
|
| 166 |
+
self.ar_audio_position = ar_audio_position
|
| 167 |
+
self.h = h
|
| 168 |
+
self.ar_predict_layer = ar_predict_layer
|
| 169 |
+
self.loss_fct = loss_fct
|
| 170 |
+
self.ar_accuracy_metric = ar_accuracy_metric
|
| 171 |
+
self.top_k = top_k
|
| 172 |
+
self.early_stop_num = early_stop_num
|
| 173 |
+
self.num_layers = num_layers
|
| 174 |
+
|
| 175 |
+
def forward(self, y, k, v, y_emb, x_example):
|
| 176 |
+
cache = {
|
| 177 |
+
"all_stage": self.num_layers,
|
| 178 |
+
"k": torch.nn.functional.pad(k, (0, 0, 0, 0, 0, 1)),
|
| 179 |
+
"v": torch.nn.functional.pad(v, (0, 0, 0, 0, 0, 1)),
|
| 180 |
+
"y_emb": y_emb,
|
| 181 |
+
"first_infer": 0,
|
| 182 |
+
"stage": 0,
|
| 183 |
+
}
|
| 184 |
+
|
| 185 |
+
y_emb = torch.cat(
|
| 186 |
+
[cache["y_emb"], self.ar_audio_embedding(y[:, -1:])], 1
|
| 187 |
+
)
|
| 188 |
+
cache["y_emb"] = y_emb
|
| 189 |
+
y_pos = self.ar_audio_position(y_emb)
|
| 190 |
+
|
| 191 |
+
xy_pos = y_pos[:, -1:]
|
| 192 |
+
|
| 193 |
+
y_example = y_pos[:,:,0] * 0.0
|
| 194 |
+
|
| 195 |
+
xy_attn_mask = torch.cat([x_example, y_example], dim=1)
|
| 196 |
+
xy_attn_mask = torch.zeros_like(xy_attn_mask, dtype=torch.bool)
|
| 197 |
+
|
| 198 |
+
xy_dec = self.h(xy_pos, mask=xy_attn_mask, cache=cache)
|
| 199 |
+
logits = self.ar_predict_layer(xy_dec[:, -1])
|
| 200 |
+
samples = sample(logits[0], y, top_k=self.top_k, top_p=1.0, repetition_penalty=1.35)[0].unsqueeze(0)
|
| 201 |
+
|
| 202 |
+
y = torch.concat([y, samples], dim=1)
|
| 203 |
+
|
| 204 |
+
return y, cache["k"], cache["v"], cache["y_emb"], logits, samples
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
class Text2SemanticDecoder(nn.Module):
|
| 208 |
+
def __init__(self, config, norm_first=False, top_k=3):
|
| 209 |
+
super(Text2SemanticDecoder, self).__init__()
|
| 210 |
+
self.model_dim = config["model"]["hidden_dim"]
|
| 211 |
+
self.embedding_dim = config["model"]["embedding_dim"]
|
| 212 |
+
self.num_head = config["model"]["head"]
|
| 213 |
+
self.num_layers = config["model"]["n_layer"]
|
| 214 |
+
self.norm_first = norm_first
|
| 215 |
+
self.vocab_size = config["model"]["vocab_size"]
|
| 216 |
+
self.phoneme_vocab_size = config["model"]["phoneme_vocab_size"]
|
| 217 |
+
self.p_dropout = float(config["model"]["dropout"])
|
| 218 |
+
self.EOS = config["model"]["EOS"]
|
| 219 |
+
self.norm_first = norm_first
|
| 220 |
+
assert self.EOS == self.vocab_size - 1
|
| 221 |
+
self.bert_proj = nn.Linear(1024, self.embedding_dim)
|
| 222 |
+
self.ar_text_embedding = TokenEmbedding(self.embedding_dim, self.phoneme_vocab_size, self.p_dropout)
|
| 223 |
+
self.ar_text_position = SinePositionalEmbedding(self.embedding_dim, dropout=0.1, scale=False, alpha=True)
|
| 224 |
+
self.ar_audio_embedding = TokenEmbedding(self.embedding_dim, self.vocab_size, self.p_dropout)
|
| 225 |
+
self.ar_audio_position = SinePositionalEmbedding(self.embedding_dim, dropout=0.1, scale=False, alpha=True)
|
| 226 |
+
self.h = TransformerEncoder(
|
| 227 |
+
TransformerEncoderLayer(
|
| 228 |
+
d_model=self.model_dim,
|
| 229 |
+
nhead=self.num_head,
|
| 230 |
+
dim_feedforward=self.model_dim * 4,
|
| 231 |
+
dropout=0.1,
|
| 232 |
+
batch_first=True,
|
| 233 |
+
norm_first=norm_first,
|
| 234 |
+
),
|
| 235 |
+
num_layers=self.num_layers,
|
| 236 |
+
norm=LayerNorm(self.model_dim) if norm_first else None,
|
| 237 |
+
)
|
| 238 |
+
self.ar_predict_layer = nn.Linear(self.model_dim, self.vocab_size, bias=False)
|
| 239 |
+
self.loss_fct = nn.CrossEntropyLoss(reduction="sum")
|
| 240 |
+
self.ar_accuracy_metric = MulticlassAccuracy(
|
| 241 |
+
self.vocab_size,
|
| 242 |
+
top_k=top_k,
|
| 243 |
+
average="micro",
|
| 244 |
+
multidim_average="global",
|
| 245 |
+
ignore_index=self.EOS,
|
| 246 |
+
)
|
| 247 |
+
self.top_k = torch.LongTensor([1])
|
| 248 |
+
self.early_stop_num = torch.LongTensor([-1])
|
| 249 |
+
|
| 250 |
+
def init_onnx(self):
|
| 251 |
+
self.onnx_encoder = OnnxEncoder(self.ar_text_embedding, self.bert_proj, self.ar_text_position)
|
| 252 |
+
self.first_stage_decoder = T2SFirstStageDecoder(self.ar_audio_embedding, self.ar_audio_position, self.h,
|
| 253 |
+
self.ar_predict_layer, self.loss_fct, self.ar_accuracy_metric, self.top_k, self.early_stop_num,
|
| 254 |
+
self.num_layers)
|
| 255 |
+
self.stage_decoder = T2SStageDecoder(self.ar_audio_embedding, self.ar_audio_position, self.h,
|
| 256 |
+
self.ar_predict_layer, self.loss_fct, self.ar_accuracy_metric, self.top_k, self.early_stop_num,
|
| 257 |
+
self.num_layers)
|
| 258 |
+
|
| 259 |
+
def forward(self, x, prompts, bert_feature):
|
| 260 |
+
early_stop_num = self.early_stop_num
|
| 261 |
+
prefix_len = prompts.shape[1]
|
| 262 |
+
|
| 263 |
+
x = self.onnx_encoder(x, bert_feature)
|
| 264 |
+
y, k, v, y_emb, stage, x_example = self.first_stage_decoder(x, prompts)
|
| 265 |
+
|
| 266 |
+
stop = False
|
| 267 |
+
for idx in range(1, 1500):
|
| 268 |
+
enco = self.stage_decoder(y, k, v, y_emb, stage, x_example)
|
| 269 |
+
y, k, v, y_emb, stage, logits, samples = enco
|
| 270 |
+
if early_stop_num != -1 and (y.shape[1] - prefix_len) > early_stop_num:
|
| 271 |
+
stop = True
|
| 272 |
+
if torch.argmax(logits, dim=-1)[0] == self.EOS or samples[0, 0] == self.EOS:
|
| 273 |
+
stop = True
|
| 274 |
+
if stop:
|
| 275 |
+
break
|
| 276 |
+
y[0, -1] = 0
|
| 277 |
+
return y, idx
|
| 278 |
+
|
| 279 |
+
def infer(self, x, prompts, bert_feature):
|
| 280 |
+
top_k = self.top_k
|
| 281 |
+
early_stop_num = self.early_stop_num
|
| 282 |
+
|
| 283 |
+
x = self.onnx_encoder(x, bert_feature)
|
| 284 |
+
|
| 285 |
+
y = prompts
|
| 286 |
+
prefix_len = y.shape[1]
|
| 287 |
+
x_len = x.shape[1]
|
| 288 |
+
x_example = x[:,:,0] * 0.0
|
| 289 |
+
x_attn_mask = torch.matmul(x_example.transpose(0, 1), x_example)
|
| 290 |
+
x_attn_mask = torch.zeros_like(x_attn_mask, dtype=torch.bool)
|
| 291 |
+
|
| 292 |
+
stop = False
|
| 293 |
+
cache = {
|
| 294 |
+
"all_stage": self.num_layers,
|
| 295 |
+
"k": [None] * self.num_layers,
|
| 296 |
+
"v": [None] * self.num_layers,
|
| 297 |
+
"y_emb": None,
|
| 298 |
+
"first_infer": 1,
|
| 299 |
+
"stage": 0,
|
| 300 |
+
}
|
| 301 |
+
for idx in range(1500):
|
| 302 |
+
if cache["first_infer"] == 1:
|
| 303 |
+
y_emb = self.ar_audio_embedding(y)
|
| 304 |
+
else:
|
| 305 |
+
y_emb = torch.cat(
|
| 306 |
+
[cache["y_emb"], self.ar_audio_embedding(y[:, -1:])], 1
|
| 307 |
+
)
|
| 308 |
+
cache["y_emb"] = y_emb
|
| 309 |
+
y_pos = self.ar_audio_position(y_emb)
|
| 310 |
+
if cache["first_infer"] == 1:
|
| 311 |
+
xy_pos = torch.concat([x, y_pos], dim=1)
|
| 312 |
+
else:
|
| 313 |
+
xy_pos = y_pos[:, -1:]
|
| 314 |
+
y_len = y_pos.shape[1]
|
| 315 |
+
if cache["first_infer"] == 1:
|
| 316 |
+
x_attn_mask_pad = F.pad(x_attn_mask, (0, y_len), value=True)
|
| 317 |
+
y_attn_mask = F.pad(
|
| 318 |
+
torch.triu(torch.ones(y_len, y_len, dtype=torch.bool), diagonal=1),
|
| 319 |
+
(x_len, 0), value=False
|
| 320 |
+
)
|
| 321 |
+
xy_attn_mask = torch.concat([x_attn_mask_pad, y_attn_mask], dim=0)
|
| 322 |
+
else:
|
| 323 |
+
xy_attn_mask = torch.zeros((1, x_len + y_len), dtype=torch.bool)
|
| 324 |
+
xy_dec = self.h(xy_pos, mask=xy_attn_mask, cache=cache)
|
| 325 |
+
logits = self.ar_predict_layer(xy_dec[:, -1])
|
| 326 |
+
samples = sample(logits[0], y, top_k=top_k, top_p=1.0, repetition_penalty=1.35)[0].unsqueeze(0)
|
| 327 |
+
if early_stop_num != -1 and (y.shape[1] - prefix_len) > early_stop_num:
|
| 328 |
+
stop = True
|
| 329 |
+
if torch.argmax(logits, dim=-1)[0] == self.EOS or samples[0, 0] == self.EOS:
|
| 330 |
+
stop = True
|
| 331 |
+
if stop:
|
| 332 |
+
if prompts.shape[1] == y.shape[1]:
|
| 333 |
+
y = torch.concat([y, torch.zeros_like(samples)], dim=1)
|
| 334 |
+
break
|
| 335 |
+
y = torch.concat([y, samples], dim=1)
|
| 336 |
+
cache["first_infer"] = 0
|
| 337 |
+
return y, idx
|
GPT_SoVITS/AR/models/utils.py
ADDED
|
@@ -0,0 +1,160 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/feng-yufei/shared_debugging_code/blob/main/model/utils.py\
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def sequence_mask(length, max_length=None):
|
| 7 |
+
if max_length is None:
|
| 8 |
+
max_length = length.max()
|
| 9 |
+
x = torch.arange(max_length, dtype=length.dtype, device=length.device)
|
| 10 |
+
return x.unsqueeze(0) < length.unsqueeze(1)
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def make_pad_mask(lengths: torch.Tensor, max_len: int = 0) -> torch.Tensor:
|
| 14 |
+
"""
|
| 15 |
+
Args:
|
| 16 |
+
lengths:
|
| 17 |
+
A 1-D tensor containing sentence lengths.
|
| 18 |
+
max_len:
|
| 19 |
+
The length of masks.
|
| 20 |
+
Returns:
|
| 21 |
+
Return a 2-D bool tensor, where masked positions
|
| 22 |
+
are filled with `True` and non-masked positions are
|
| 23 |
+
filled with `False`.
|
| 24 |
+
|
| 25 |
+
#>>> lengths = torch.tensor([1, 3, 2, 5])
|
| 26 |
+
#>>> make_pad_mask(lengths)
|
| 27 |
+
tensor([[False, True, True, True, True],
|
| 28 |
+
[False, False, False, True, True],
|
| 29 |
+
[False, False, True, True, True],
|
| 30 |
+
[False, False, False, False, False]])
|
| 31 |
+
"""
|
| 32 |
+
assert lengths.ndim == 1, lengths.ndim
|
| 33 |
+
max_len = max(max_len, lengths.max())
|
| 34 |
+
n = lengths.size(0)
|
| 35 |
+
seq_range = torch.arange(0, max_len, device=lengths.device)
|
| 36 |
+
expaned_lengths = seq_range.unsqueeze(0).expand(n, max_len)
|
| 37 |
+
|
| 38 |
+
return expaned_lengths >= lengths.unsqueeze(-1)
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
# https://github.com/microsoft/unilm/blob/master/xtune/src/transformers/modeling_utils.py
|
| 42 |
+
def top_k_top_p_filtering(
|
| 43 |
+
logits, top_k=0, top_p=1.0, filter_value=-float("Inf"), min_tokens_to_keep=1
|
| 44 |
+
):
|
| 45 |
+
"""Filter a distribution of logits using top-k and/or nucleus (top-p) filtering
|
| 46 |
+
Args:
|
| 47 |
+
logits: logits distribution shape (batch size, vocabulary size)
|
| 48 |
+
if top_k > 0: keep only top k tokens with highest probability (top-k filtering).
|
| 49 |
+
if top_p < 1.0: keep the top tokens with cumulative probability >= top_p (nucleus filtering).
|
| 50 |
+
Nucleus filtering is described in Holtzman et al. (http://arxiv.org/abs/1904.09751)
|
| 51 |
+
Make sure we keep at least min_tokens_to_keep per batch example in the output
|
| 52 |
+
From: https://gist.github.com/thomwolf/1a5a29f6962089e871b94cbd09daf317
|
| 53 |
+
"""
|
| 54 |
+
if top_k > 0:
|
| 55 |
+
top_k = min(max(top_k, min_tokens_to_keep), logits.size(-1)) # Safety check
|
| 56 |
+
# Remove all tokens with a probability less than the last token of the top-k
|
| 57 |
+
indices_to_remove = logits < torch.topk(logits, top_k)[0][..., -1, None]
|
| 58 |
+
logits[indices_to_remove] = filter_value
|
| 59 |
+
|
| 60 |
+
if top_p < 1.0:
|
| 61 |
+
sorted_logits, sorted_indices = torch.sort(logits, descending=True)
|
| 62 |
+
cumulative_probs = torch.cumsum(F.softmax(sorted_logits, dim=-1), dim=-1)
|
| 63 |
+
|
| 64 |
+
# Remove tokens with cumulative probability above the threshold (token with 0 are kept)
|
| 65 |
+
sorted_indices_to_remove = cumulative_probs > top_p
|
| 66 |
+
if min_tokens_to_keep > 1:
|
| 67 |
+
# Keep at least min_tokens_to_keep (set to min_tokens_to_keep-1 because we add the first one below)
|
| 68 |
+
sorted_indices_to_remove[..., :min_tokens_to_keep] = 0
|
| 69 |
+
# Shift the indices to the right to keep also the first token above the threshold
|
| 70 |
+
sorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[..., :-1].clone()
|
| 71 |
+
sorted_indices_to_remove[..., 0] = 0
|
| 72 |
+
|
| 73 |
+
# scatter sorted tensors to original indexing
|
| 74 |
+
indices_to_remove = sorted_indices_to_remove.scatter(
|
| 75 |
+
1, sorted_indices, sorted_indices_to_remove
|
| 76 |
+
)
|
| 77 |
+
logits[indices_to_remove] = filter_value
|
| 78 |
+
return logits
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
def topk_sampling(logits, top_k=10, top_p=1.0, temperature=1.0):
|
| 82 |
+
# temperature: (`optional`) float
|
| 83 |
+
# The value used to module the next token probabilities. Must be strictly positive. Default to 1.0.
|
| 84 |
+
# top_k: (`optional`) int
|
| 85 |
+
# The number of highest probability vocabulary tokens to keep for top-k-filtering. Between 1 and infinity. Default to 50.
|
| 86 |
+
# top_p: (`optional`) float
|
| 87 |
+
# The cumulative probability of parameter highest probability vocabulary tokens to keep for nucleus sampling. Must be between 0 and 1. Default to 1.
|
| 88 |
+
|
| 89 |
+
# Temperature (higher temperature => more likely to sample low probability tokens)
|
| 90 |
+
if temperature != 1.0:
|
| 91 |
+
logits = logits / temperature
|
| 92 |
+
# Top-p/top-k filtering
|
| 93 |
+
logits = top_k_top_p_filtering(logits, top_k=top_k, top_p=top_p)
|
| 94 |
+
# Sample
|
| 95 |
+
token = torch.multinomial(F.softmax(logits, dim=-1), num_samples=1)
|
| 96 |
+
return token
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
from typing import Optional, Tuple
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
def multinomial_sample_one_no_sync(
|
| 103 |
+
probs_sort,
|
| 104 |
+
): # Does multinomial sampling without a cuda synchronization
|
| 105 |
+
q = torch.empty_like(probs_sort).exponential_(1)
|
| 106 |
+
return torch.argmax(probs_sort / q, dim=-1, keepdim=True).to(dtype=torch.int)
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def logits_to_probs(
|
| 110 |
+
logits,
|
| 111 |
+
previous_tokens: Optional[torch.Tensor] = None,
|
| 112 |
+
temperature: float = 1.0,
|
| 113 |
+
top_k: Optional[int] = None,
|
| 114 |
+
top_p: Optional[int] = None,
|
| 115 |
+
repetition_penalty: float = 1.0,
|
| 116 |
+
):
|
| 117 |
+
previous_tokens = previous_tokens.squeeze()
|
| 118 |
+
# print(logits.shape,previous_tokens.shape)
|
| 119 |
+
# pdb.set_trace()
|
| 120 |
+
if previous_tokens is not None and repetition_penalty != 1.0:
|
| 121 |
+
previous_tokens = previous_tokens.long()
|
| 122 |
+
score = torch.gather(logits, dim=0, index=previous_tokens)
|
| 123 |
+
score = torch.where(
|
| 124 |
+
score < 0, score * repetition_penalty, score / repetition_penalty
|
| 125 |
+
)
|
| 126 |
+
logits.scatter_(dim=0, index=previous_tokens, src=score)
|
| 127 |
+
|
| 128 |
+
if top_p is not None and top_p < 1.0:
|
| 129 |
+
sorted_logits, sorted_indices = torch.sort(logits, descending=True)
|
| 130 |
+
cum_probs = torch.cumsum(
|
| 131 |
+
torch.nn.functional.softmax(sorted_logits, dim=-1), dim=-1
|
| 132 |
+
)
|
| 133 |
+
sorted_indices_to_remove = cum_probs > top_p
|
| 134 |
+
sorted_indices_to_remove[0] = False # keep at least one option
|
| 135 |
+
indices_to_remove = sorted_indices_to_remove.scatter(
|
| 136 |
+
dim=0, index=sorted_indices, src=sorted_indices_to_remove
|
| 137 |
+
)
|
| 138 |
+
logits = logits.masked_fill(indices_to_remove, -float("Inf"))
|
| 139 |
+
|
| 140 |
+
logits = logits / max(temperature, 1e-5)
|
| 141 |
+
|
| 142 |
+
if top_k is not None:
|
| 143 |
+
v, _ = torch.topk(logits, min(top_k, logits.size(-1)))
|
| 144 |
+
pivot = v.select(-1, -1).unsqueeze(-1)
|
| 145 |
+
logits = torch.where(logits < pivot, -float("Inf"), logits)
|
| 146 |
+
|
| 147 |
+
probs = torch.nn.functional.softmax(logits, dim=-1)
|
| 148 |
+
return probs
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
def sample(
|
| 152 |
+
logits,
|
| 153 |
+
previous_tokens: Optional[torch.Tensor] = None,
|
| 154 |
+
**sampling_kwargs,
|
| 155 |
+
) -> Tuple[torch.Tensor, torch.Tensor]:
|
| 156 |
+
probs = logits_to_probs(
|
| 157 |
+
logits=logits, previous_tokens=previous_tokens, **sampling_kwargs
|
| 158 |
+
)
|
| 159 |
+
idx_next = multinomial_sample_one_no_sync(probs)
|
| 160 |
+
return idx_next, probs
|
GPT_SoVITS/AR/modules/__init__.py
ADDED
|
File without changes
|
GPT_SoVITS/AR/modules/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (148 Bytes). View file
|
|
|
GPT_SoVITS/AR/modules/__pycache__/activation.cpython-310.pyc
ADDED
|
Binary file (14 kB). View file
|
|
|
GPT_SoVITS/AR/modules/__pycache__/embedding.cpython-310.pyc
ADDED
|
Binary file (3.07 kB). View file
|
|
|
GPT_SoVITS/AR/modules/__pycache__/lr_schedulers.cpython-310.pyc
ADDED
|
Binary file (2.38 kB). View file
|
|
|
GPT_SoVITS/AR/modules/__pycache__/optim.cpython-310.pyc
ADDED
|
Binary file (18.9 kB). View file
|
|
|
GPT_SoVITS/AR/modules/__pycache__/patched_mha_with_cache.cpython-310.pyc
ADDED
|
Binary file (11.3 kB). View file
|
|
|
GPT_SoVITS/AR/modules/__pycache__/scaling.cpython-310.pyc
ADDED
|
Binary file (9.57 kB). View file
|
|
|
GPT_SoVITS/AR/modules/__pycache__/transformer.cpython-310.pyc
ADDED
|
Binary file (9.93 kB). View file
|
|
|
GPT_SoVITS/AR/modules/activation.py
ADDED
|
@@ -0,0 +1,428 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/lifeiteng/vall-e/blob/main/valle/modules/activation.py
|
| 2 |
+
from typing import Optional
|
| 3 |
+
from typing import Tuple
|
| 4 |
+
import torch
|
| 5 |
+
from torch import Tensor
|
| 6 |
+
from torch.nn import Linear
|
| 7 |
+
from torch.nn import Module
|
| 8 |
+
from torch.nn.init import constant_
|
| 9 |
+
from torch.nn.init import xavier_normal_
|
| 10 |
+
from torch.nn.init import xavier_uniform_
|
| 11 |
+
from torch.nn.modules.linear import NonDynamicallyQuantizableLinear
|
| 12 |
+
from torch.nn.parameter import Parameter
|
| 13 |
+
|
| 14 |
+
from torch.nn import functional as F
|
| 15 |
+
from AR.modules.patched_mha_with_cache import multi_head_attention_forward_patched
|
| 16 |
+
|
| 17 |
+
F.multi_head_attention_forward = multi_head_attention_forward_patched
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class MultiheadAttention(Module):
|
| 21 |
+
r"""Allows the model to jointly attend to information
|
| 22 |
+
from different representation subspaces as described in the paper:
|
| 23 |
+
`Attention Is All You Need <https://arxiv.org/abs/1706.03762>`_.
|
| 24 |
+
|
| 25 |
+
Multi-Head Attention is defined as:
|
| 26 |
+
|
| 27 |
+
.. math::
|
| 28 |
+
\text{MultiHead}(Q, K, V) = \text{Concat}(head_1,\dots,head_h)W^O
|
| 29 |
+
|
| 30 |
+
where :math:`head_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V)`.
|
| 31 |
+
|
| 32 |
+
``forward()`` will use a special optimized implementation if all of the following
|
| 33 |
+
conditions are met:
|
| 34 |
+
|
| 35 |
+
- self attention is being computed (i.e., ``query``, ``key``, and ``value`` are the same tensor. This
|
| 36 |
+
restriction will be loosened in the future.)
|
| 37 |
+
- Either autograd is disabled (using ``torch.inference_mode`` or ``torch.no_grad``) or no tensor argument ``requires_grad``
|
| 38 |
+
- training is disabled (using ``.eval()``)
|
| 39 |
+
- dropout is 0
|
| 40 |
+
- ``add_bias_kv`` is ``False``
|
| 41 |
+
- ``add_zero_attn`` is ``False``
|
| 42 |
+
- ``batch_first`` is ``True`` and the input is batched
|
| 43 |
+
- ``kdim`` and ``vdim`` are equal to ``embed_dim``
|
| 44 |
+
- at most one of ``key_padding_mask`` or ``attn_mask`` is passed
|
| 45 |
+
- if a `NestedTensor <https://pytorch.org/docs/stable/nested.html>`_ is passed, neither ``key_padding_mask``
|
| 46 |
+
nor ``attn_mask`` is passed
|
| 47 |
+
|
| 48 |
+
If the optimized implementation is in use, a
|
| 49 |
+
`NestedTensor <https://pytorch.org/docs/stable/nested.html>`_ can be passed for
|
| 50 |
+
``query``/``key``/``value`` to represent padding more efficiently than using a
|
| 51 |
+
padding mask. In this case, a `NestedTensor <https://pytorch.org/docs/stable/nested.html>`_
|
| 52 |
+
will be returned, and an additional speedup proportional to the fraction of the input
|
| 53 |
+
that is padding can be expected.
|
| 54 |
+
|
| 55 |
+
Args:
|
| 56 |
+
embed_dim: Total dimension of the model.
|
| 57 |
+
num_heads: Number of parallel attention heads. Note that ``embed_dim`` will be split
|
| 58 |
+
across ``num_heads`` (i.e. each head will have dimension ``embed_dim // num_heads``).
|
| 59 |
+
dropout: Dropout probability on ``attn_output_weights``. Default: ``0.0`` (no dropout).
|
| 60 |
+
bias: If specified, adds bias to input / output projection layers. Default: ``True``.
|
| 61 |
+
add_bias_kv: If specified, adds bias to the key and value sequences at dim=0. Default: ``False``.
|
| 62 |
+
add_zero_attn: If specified, adds a new batch of zeros to the key and value sequences at dim=1.
|
| 63 |
+
Default: ``False``.
|
| 64 |
+
kdim: Total number of features for keys. Default: ``None`` (uses ``kdim=embed_dim``).
|
| 65 |
+
vdim: Total number of features for values. Default: ``None`` (uses ``vdim=embed_dim``).
|
| 66 |
+
batch_first: If ``True``, then the input and output tensors are provided
|
| 67 |
+
as (batch, seq, feature). Default: ``False`` (seq, batch, feature).
|
| 68 |
+
|
| 69 |
+
Examples::
|
| 70 |
+
|
| 71 |
+
>>> # xdoctest: +SKIP
|
| 72 |
+
>>> multihead_attn = nn.MultiheadAttention(embed_dim, num_heads)
|
| 73 |
+
>>> attn_output, attn_output_weights = multihead_attn(query, key, value)
|
| 74 |
+
|
| 75 |
+
"""
|
| 76 |
+
__constants__ = ["batch_first"]
|
| 77 |
+
bias_k: Optional[torch.Tensor]
|
| 78 |
+
bias_v: Optional[torch.Tensor]
|
| 79 |
+
|
| 80 |
+
def __init__(
|
| 81 |
+
self,
|
| 82 |
+
embed_dim,
|
| 83 |
+
num_heads,
|
| 84 |
+
dropout=0.0,
|
| 85 |
+
bias=True,
|
| 86 |
+
add_bias_kv=False,
|
| 87 |
+
add_zero_attn=False,
|
| 88 |
+
kdim=None,
|
| 89 |
+
vdim=None,
|
| 90 |
+
batch_first=False,
|
| 91 |
+
linear1_cls=Linear,
|
| 92 |
+
linear2_cls=Linear,
|
| 93 |
+
device=None,
|
| 94 |
+
dtype=None,
|
| 95 |
+
) -> None:
|
| 96 |
+
factory_kwargs = {"device": device, "dtype": dtype}
|
| 97 |
+
super(MultiheadAttention, self).__init__()
|
| 98 |
+
self.embed_dim = embed_dim
|
| 99 |
+
self.kdim = kdim if kdim is not None else embed_dim
|
| 100 |
+
self.vdim = vdim if vdim is not None else embed_dim
|
| 101 |
+
self._qkv_same_embed_dim = self.kdim == embed_dim and self.vdim == embed_dim
|
| 102 |
+
|
| 103 |
+
self.num_heads = num_heads
|
| 104 |
+
self.dropout = dropout
|
| 105 |
+
self.batch_first = batch_first
|
| 106 |
+
self.head_dim = embed_dim // num_heads
|
| 107 |
+
assert (
|
| 108 |
+
self.head_dim * num_heads == self.embed_dim
|
| 109 |
+
), "embed_dim must be divisible by num_heads"
|
| 110 |
+
|
| 111 |
+
if add_bias_kv:
|
| 112 |
+
self.bias_k = Parameter(torch.empty((1, 1, embed_dim), **factory_kwargs))
|
| 113 |
+
self.bias_v = Parameter(torch.empty((1, 1, embed_dim), **factory_kwargs))
|
| 114 |
+
else:
|
| 115 |
+
self.bias_k = self.bias_v = None
|
| 116 |
+
|
| 117 |
+
if linear1_cls == Linear:
|
| 118 |
+
if not self._qkv_same_embed_dim:
|
| 119 |
+
self.q_proj_weight = Parameter(
|
| 120 |
+
torch.empty((embed_dim, embed_dim), **factory_kwargs)
|
| 121 |
+
)
|
| 122 |
+
self.k_proj_weight = Parameter(
|
| 123 |
+
torch.empty((embed_dim, self.kdim), **factory_kwargs)
|
| 124 |
+
)
|
| 125 |
+
self.v_proj_weight = Parameter(
|
| 126 |
+
torch.empty((embed_dim, self.vdim), **factory_kwargs)
|
| 127 |
+
)
|
| 128 |
+
self.register_parameter("in_proj_weight", None)
|
| 129 |
+
else:
|
| 130 |
+
self.in_proj_weight = Parameter(
|
| 131 |
+
torch.empty((3 * embed_dim, embed_dim), **factory_kwargs)
|
| 132 |
+
)
|
| 133 |
+
self.register_parameter("q_proj_weight", None)
|
| 134 |
+
self.register_parameter("k_proj_weight", None)
|
| 135 |
+
self.register_parameter("v_proj_weight", None)
|
| 136 |
+
|
| 137 |
+
if bias:
|
| 138 |
+
self.in_proj_bias = Parameter(
|
| 139 |
+
torch.empty(3 * embed_dim, **factory_kwargs)
|
| 140 |
+
)
|
| 141 |
+
else:
|
| 142 |
+
self.register_parameter("in_proj_bias", None)
|
| 143 |
+
self.out_proj = NonDynamicallyQuantizableLinear(
|
| 144 |
+
embed_dim, embed_dim, bias=bias, **factory_kwargs
|
| 145 |
+
)
|
| 146 |
+
|
| 147 |
+
self._reset_parameters()
|
| 148 |
+
else:
|
| 149 |
+
if not self._qkv_same_embed_dim:
|
| 150 |
+
raise NotImplementedError
|
| 151 |
+
else:
|
| 152 |
+
self.in_proj_linear = linear1_cls(
|
| 153 |
+
embed_dim, 3 * embed_dim, bias=bias, **factory_kwargs
|
| 154 |
+
)
|
| 155 |
+
self.in_proj_weight = self.in_proj_linear.weight
|
| 156 |
+
|
| 157 |
+
self.register_parameter("q_proj_weight", None)
|
| 158 |
+
self.register_parameter("k_proj_weight", None)
|
| 159 |
+
self.register_parameter("v_proj_weight", None)
|
| 160 |
+
|
| 161 |
+
if bias:
|
| 162 |
+
self.in_proj_bias = self.in_proj_linear.bias
|
| 163 |
+
else:
|
| 164 |
+
self.register_parameter("in_proj_bias", None)
|
| 165 |
+
|
| 166 |
+
self.out_proj = linear2_cls(
|
| 167 |
+
embed_dim, embed_dim, bias=bias, **factory_kwargs
|
| 168 |
+
)
|
| 169 |
+
|
| 170 |
+
if self.bias_k is not None:
|
| 171 |
+
xavier_normal_(self.bias_k)
|
| 172 |
+
if self.bias_v is not None:
|
| 173 |
+
xavier_normal_(self.bias_v)
|
| 174 |
+
|
| 175 |
+
self.add_zero_attn = add_zero_attn
|
| 176 |
+
|
| 177 |
+
def _reset_parameters(self):
|
| 178 |
+
if self._qkv_same_embed_dim:
|
| 179 |
+
xavier_uniform_(self.in_proj_weight)
|
| 180 |
+
else:
|
| 181 |
+
xavier_uniform_(self.q_proj_weight)
|
| 182 |
+
xavier_uniform_(self.k_proj_weight)
|
| 183 |
+
xavier_uniform_(self.v_proj_weight)
|
| 184 |
+
|
| 185 |
+
if self.in_proj_bias is not None:
|
| 186 |
+
constant_(self.in_proj_bias, 0.0)
|
| 187 |
+
constant_(self.out_proj.bias, 0.0)
|
| 188 |
+
|
| 189 |
+
if self.bias_k is not None:
|
| 190 |
+
xavier_normal_(self.bias_k)
|
| 191 |
+
if self.bias_v is not None:
|
| 192 |
+
xavier_normal_(self.bias_v)
|
| 193 |
+
|
| 194 |
+
def __setstate__(self, state):
|
| 195 |
+
# Support loading old MultiheadAttention checkpoints generated by v1.1.0
|
| 196 |
+
if "_qkv_same_embed_dim" not in state:
|
| 197 |
+
state["_qkv_same_embed_dim"] = True
|
| 198 |
+
|
| 199 |
+
super(MultiheadAttention, self).__setstate__(state)
|
| 200 |
+
|
| 201 |
+
def forward(
|
| 202 |
+
self,
|
| 203 |
+
query: Tensor,
|
| 204 |
+
key: Tensor,
|
| 205 |
+
value: Tensor,
|
| 206 |
+
key_padding_mask: Optional[Tensor] = None,
|
| 207 |
+
need_weights: bool = True,
|
| 208 |
+
attn_mask: Optional[Tensor] = None,
|
| 209 |
+
average_attn_weights: bool = True,
|
| 210 |
+
cache=None,
|
| 211 |
+
) -> Tuple[Tensor, Optional[Tensor]]:
|
| 212 |
+
r"""
|
| 213 |
+
Args:
|
| 214 |
+
query: Query embeddings of shape :math:`(L, E_q)` for unbatched input, :math:`(L, N, E_q)` when ``batch_first=False``
|
| 215 |
+
or :math:`(N, L, E_q)` when ``batch_first=True``, where :math:`L` is the target sequence length,
|
| 216 |
+
:math:`N` is the batch size, and :math:`E_q` is the query embedding dimension ``embed_dim``.
|
| 217 |
+
Queries are compared against key-value pairs to produce the output.
|
| 218 |
+
See "Attention Is All You Need" for more details.
|
| 219 |
+
key: Key embeddings of shape :math:`(S, E_k)` for unbatched input, :math:`(S, N, E_k)` when ``batch_first=False``
|
| 220 |
+
or :math:`(N, S, E_k)` when ``batch_first=True``, where :math:`S` is the source sequence length,
|
| 221 |
+
:math:`N` is the batch size, and :math:`E_k` is the key embedding dimension ``kdim``.
|
| 222 |
+
See "Attention Is All You Need" for more details.
|
| 223 |
+
value: Value embeddings of shape :math:`(S, E_v)` for unbatched input, :math:`(S, N, E_v)` when
|
| 224 |
+
``batch_first=False`` or :math:`(N, S, E_v)` when ``batch_first=True``, where :math:`S` is the source
|
| 225 |
+
sequence length, :math:`N` is the batch size, and :math:`E_v` is the value embedding dimension ``vdim``.
|
| 226 |
+
See "Attention Is All You Need" for more details.
|
| 227 |
+
key_padding_mask: If specified, a mask of shape :math:`(N, S)` indicating which elements within ``key``
|
| 228 |
+
to ignore for the purpose of attention (i.e. treat as "padding"). For unbatched `query`, shape should be :math:`(S)`.
|
| 229 |
+
Binary and byte masks are supported.
|
| 230 |
+
For a binary mask, a ``True`` value indicates that the corresponding ``key`` value will be ignored for
|
| 231 |
+
the purpose of attention. For a float mask, it will be directly added to the corresponding ``key`` value.
|
| 232 |
+
need_weights: If specified, returns ``attn_output_weights`` in addition to ``attn_outputs``.
|
| 233 |
+
Default: ``True``.
|
| 234 |
+
attn_mask: If specified, a 2D or 3D mask preventing attention to certain positions. Must be of shape
|
| 235 |
+
:math:`(L, S)` or :math:`(N\cdot\text{num\_heads}, L, S)`, where :math:`N` is the batch size,
|
| 236 |
+
:math:`L` is the target sequence length, and :math:`S` is the source sequence length. A 2D mask will be
|
| 237 |
+
broadcasted across the batch while a 3D mask allows for a different mask for each entry in the batch.
|
| 238 |
+
Binary, byte, and float masks are supported. For a binary mask, a ``True`` value indicates that the
|
| 239 |
+
corresponding position is not allowed to attend. For a byte mask, a non-zero value indicates that the
|
| 240 |
+
corresponding position is not allowed to attend. For a float mask, the mask values will be added to
|
| 241 |
+
the attention weight.
|
| 242 |
+
average_attn_weights: If true, indicates that the returned ``attn_weights`` should be averaged across
|
| 243 |
+
heads. Otherwise, ``attn_weights`` are provided separately per head. Note that this flag only has an
|
| 244 |
+
effect when ``need_weights=True``. Default: ``True`` (i.e. average weights across heads)
|
| 245 |
+
|
| 246 |
+
Outputs:
|
| 247 |
+
- **attn_output** - Attention outputs of shape :math:`(L, E)` when input is unbatched,
|
| 248 |
+
:math:`(L, N, E)` when ``batch_first=False`` or :math:`(N, L, E)` when ``batch_first=True``,
|
| 249 |
+
where :math:`L` is the target sequence length, :math:`N` is the batch size, and :math:`E` is the
|
| 250 |
+
embedding dimension ``embed_dim``.
|
| 251 |
+
- **attn_output_weights** - Only returned when ``need_weights=True``. If ``average_attn_weights=True``,
|
| 252 |
+
returns attention weights averaged across heads of shape :math:`(L, S)` when input is unbatched or
|
| 253 |
+
:math:`(N, L, S)`, where :math:`N` is the batch size, :math:`L` is the target sequence length, and
|
| 254 |
+
:math:`S` is the source sequence length. If ``average_attn_weights=False``, returns attention weights per
|
| 255 |
+
head of shape :math:`(\text{num\_heads}, L, S)` when input is unbatched or :math:`(N, \text{num\_heads}, L, S)`.
|
| 256 |
+
|
| 257 |
+
.. note::
|
| 258 |
+
`batch_first` argument is ignored for unbatched inputs.
|
| 259 |
+
"""
|
| 260 |
+
is_batched = query.dim() == 3
|
| 261 |
+
if key_padding_mask is not None:
|
| 262 |
+
_kpm_dtype = key_padding_mask.dtype
|
| 263 |
+
if _kpm_dtype != torch.bool and not torch.is_floating_point(
|
| 264 |
+
key_padding_mask
|
| 265 |
+
):
|
| 266 |
+
raise AssertionError(
|
| 267 |
+
"only bool and floating types of key_padding_mask are supported"
|
| 268 |
+
)
|
| 269 |
+
why_not_fast_path = ""
|
| 270 |
+
if not is_batched:
|
| 271 |
+
why_not_fast_path = (
|
| 272 |
+
f"input not batched; expected query.dim() of 3 but got {query.dim()}"
|
| 273 |
+
)
|
| 274 |
+
elif query is not key or key is not value:
|
| 275 |
+
# When lifting this restriction, don't forget to either
|
| 276 |
+
# enforce that the dtypes all match or test cases where
|
| 277 |
+
# they don't!
|
| 278 |
+
why_not_fast_path = "non-self attention was used (query, key, and value are not the same Tensor)"
|
| 279 |
+
elif self.in_proj_bias is not None and query.dtype != self.in_proj_bias.dtype:
|
| 280 |
+
why_not_fast_path = f"dtypes of query ({query.dtype}) and self.in_proj_bias ({self.in_proj_bias.dtype}) don't match"
|
| 281 |
+
elif (
|
| 282 |
+
self.in_proj_weight is not None and query.dtype != self.in_proj_weight.dtype
|
| 283 |
+
):
|
| 284 |
+
# this case will fail anyway, but at least they'll get a useful error message.
|
| 285 |
+
why_not_fast_path = f"dtypes of query ({query.dtype}) and self.in_proj_weight ({self.in_proj_weight.dtype}) don't match"
|
| 286 |
+
elif self.training:
|
| 287 |
+
why_not_fast_path = "training is enabled"
|
| 288 |
+
elif not self.batch_first:
|
| 289 |
+
why_not_fast_path = "batch_first was not True"
|
| 290 |
+
elif self.bias_k is not None:
|
| 291 |
+
why_not_fast_path = "self.bias_k was not None"
|
| 292 |
+
elif self.bias_v is not None:
|
| 293 |
+
why_not_fast_path = "self.bias_v was not None"
|
| 294 |
+
elif self.dropout:
|
| 295 |
+
why_not_fast_path = f"dropout was {self.dropout}, required zero"
|
| 296 |
+
elif self.add_zero_attn:
|
| 297 |
+
why_not_fast_path = "add_zero_attn was enabled"
|
| 298 |
+
elif not self._qkv_same_embed_dim:
|
| 299 |
+
why_not_fast_path = "_qkv_same_embed_dim was not True"
|
| 300 |
+
elif attn_mask is not None:
|
| 301 |
+
why_not_fast_path = "attn_mask was not None"
|
| 302 |
+
elif query.is_nested and key_padding_mask is not None:
|
| 303 |
+
why_not_fast_path = (
|
| 304 |
+
"key_padding_mask is not supported with NestedTensor input"
|
| 305 |
+
)
|
| 306 |
+
elif self.num_heads % 2 == 1:
|
| 307 |
+
why_not_fast_path = "num_heads is odd"
|
| 308 |
+
elif torch.is_autocast_enabled():
|
| 309 |
+
why_not_fast_path = "autocast is enabled"
|
| 310 |
+
|
| 311 |
+
if not why_not_fast_path:
|
| 312 |
+
tensor_args = (
|
| 313 |
+
query,
|
| 314 |
+
key,
|
| 315 |
+
value,
|
| 316 |
+
self.in_proj_weight,
|
| 317 |
+
self.in_proj_bias,
|
| 318 |
+
self.out_proj.weight,
|
| 319 |
+
self.out_proj.bias,
|
| 320 |
+
)
|
| 321 |
+
# We have to use list comprehensions below because TorchScript does not support
|
| 322 |
+
# generator expressions.
|
| 323 |
+
if torch.overrides.has_torch_function(tensor_args):
|
| 324 |
+
why_not_fast_path = "some Tensor argument has_torch_function"
|
| 325 |
+
elif not all(
|
| 326 |
+
[
|
| 327 |
+
(x is None or x.is_cuda or "cpu" in str(x.device))
|
| 328 |
+
for x in tensor_args
|
| 329 |
+
]
|
| 330 |
+
):
|
| 331 |
+
why_not_fast_path = "some Tensor argument is neither CUDA nor CPU"
|
| 332 |
+
elif torch.is_grad_enabled() and any(
|
| 333 |
+
[x is not None and x.requires_grad for x in tensor_args]
|
| 334 |
+
):
|
| 335 |
+
why_not_fast_path = (
|
| 336 |
+
"grad is enabled and at least one of query or the "
|
| 337 |
+
"input/output projection weights or biases requires_grad"
|
| 338 |
+
)
|
| 339 |
+
if not why_not_fast_path:
|
| 340 |
+
return torch._native_multi_head_attention(
|
| 341 |
+
query,
|
| 342 |
+
key,
|
| 343 |
+
value,
|
| 344 |
+
self.embed_dim,
|
| 345 |
+
self.num_heads,
|
| 346 |
+
self.in_proj_weight,
|
| 347 |
+
self.in_proj_bias,
|
| 348 |
+
self.out_proj.weight,
|
| 349 |
+
self.out_proj.bias,
|
| 350 |
+
key_padding_mask if key_padding_mask is not None else attn_mask,
|
| 351 |
+
need_weights,
|
| 352 |
+
average_attn_weights,
|
| 353 |
+
1
|
| 354 |
+
if key_padding_mask is not None
|
| 355 |
+
else 0
|
| 356 |
+
if attn_mask is not None
|
| 357 |
+
else None,
|
| 358 |
+
)
|
| 359 |
+
|
| 360 |
+
any_nested = query.is_nested or key.is_nested or value.is_nested
|
| 361 |
+
assert not any_nested, (
|
| 362 |
+
"MultiheadAttention does not support NestedTensor outside of its fast path. "
|
| 363 |
+
+ f"The fast path was not hit because {why_not_fast_path}"
|
| 364 |
+
)
|
| 365 |
+
|
| 366 |
+
if self.batch_first and is_batched:
|
| 367 |
+
# make sure that the transpose op does not affect the "is" property
|
| 368 |
+
if key is value:
|
| 369 |
+
if query is key:
|
| 370 |
+
query = key = value = query.transpose(1, 0)
|
| 371 |
+
else:
|
| 372 |
+
query, key = [x.transpose(1, 0) for x in (query, key)]
|
| 373 |
+
value = key
|
| 374 |
+
else:
|
| 375 |
+
query, key, value = [x.transpose(1, 0) for x in (query, key, value)]
|
| 376 |
+
|
| 377 |
+
if not self._qkv_same_embed_dim:
|
| 378 |
+
attn_output, attn_output_weights = F.multi_head_attention_forward(
|
| 379 |
+
query,
|
| 380 |
+
key,
|
| 381 |
+
value,
|
| 382 |
+
self.embed_dim,
|
| 383 |
+
self.num_heads,
|
| 384 |
+
self.in_proj_weight,
|
| 385 |
+
self.in_proj_bias,
|
| 386 |
+
self.bias_k,
|
| 387 |
+
self.bias_v,
|
| 388 |
+
self.add_zero_attn,
|
| 389 |
+
self.dropout,
|
| 390 |
+
self.out_proj.weight,
|
| 391 |
+
self.out_proj.bias,
|
| 392 |
+
training=self.training,
|
| 393 |
+
key_padding_mask=key_padding_mask,
|
| 394 |
+
need_weights=need_weights,
|
| 395 |
+
attn_mask=attn_mask,
|
| 396 |
+
use_separate_proj_weight=True,
|
| 397 |
+
q_proj_weight=self.q_proj_weight,
|
| 398 |
+
k_proj_weight=self.k_proj_weight,
|
| 399 |
+
v_proj_weight=self.v_proj_weight,
|
| 400 |
+
average_attn_weights=average_attn_weights,
|
| 401 |
+
cache=cache,
|
| 402 |
+
)
|
| 403 |
+
else:
|
| 404 |
+
attn_output, attn_output_weights = F.multi_head_attention_forward(
|
| 405 |
+
query,
|
| 406 |
+
key,
|
| 407 |
+
value,
|
| 408 |
+
self.embed_dim,
|
| 409 |
+
self.num_heads,
|
| 410 |
+
self.in_proj_weight,
|
| 411 |
+
self.in_proj_bias,
|
| 412 |
+
self.bias_k,
|
| 413 |
+
self.bias_v,
|
| 414 |
+
self.add_zero_attn,
|
| 415 |
+
self.dropout,
|
| 416 |
+
self.out_proj.weight,
|
| 417 |
+
self.out_proj.bias,
|
| 418 |
+
training=self.training,
|
| 419 |
+
key_padding_mask=key_padding_mask,
|
| 420 |
+
need_weights=need_weights,
|
| 421 |
+
attn_mask=attn_mask,
|
| 422 |
+
average_attn_weights=average_attn_weights,
|
| 423 |
+
cache=cache,
|
| 424 |
+
)
|
| 425 |
+
if self.batch_first and is_batched:
|
| 426 |
+
return attn_output.transpose(1, 0), attn_output_weights
|
| 427 |
+
else:
|
| 428 |
+
return attn_output, attn_output_weights
|
GPT_SoVITS/AR/modules/activation_onnx.py
ADDED
|
@@ -0,0 +1,178 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/lifeiteng/vall-e/blob/main/valle/modules/activation.py
|
| 2 |
+
from typing import Optional
|
| 3 |
+
from typing import Tuple
|
| 4 |
+
import torch
|
| 5 |
+
from torch import Tensor
|
| 6 |
+
from torch.nn import Linear
|
| 7 |
+
from torch.nn import Module
|
| 8 |
+
from torch.nn.init import constant_
|
| 9 |
+
from torch.nn.init import xavier_normal_
|
| 10 |
+
from torch.nn.init import xavier_uniform_
|
| 11 |
+
from torch.nn.modules.linear import NonDynamicallyQuantizableLinear
|
| 12 |
+
from torch.nn.parameter import Parameter
|
| 13 |
+
|
| 14 |
+
from torch.nn import functional as F
|
| 15 |
+
from AR.modules.patched_mha_with_cache_onnx import multi_head_attention_forward_patched
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class MultiheadAttention(Module):
|
| 19 |
+
__constants__ = ["batch_first"]
|
| 20 |
+
bias_k: Optional[torch.Tensor]
|
| 21 |
+
bias_v: Optional[torch.Tensor]
|
| 22 |
+
|
| 23 |
+
def __init__(
|
| 24 |
+
self,
|
| 25 |
+
embed_dim,
|
| 26 |
+
num_heads,
|
| 27 |
+
dropout=0.0,
|
| 28 |
+
bias=True,
|
| 29 |
+
add_bias_kv=False,
|
| 30 |
+
add_zero_attn=False,
|
| 31 |
+
kdim=None,
|
| 32 |
+
vdim=None,
|
| 33 |
+
batch_first=False,
|
| 34 |
+
linear1_cls=Linear,
|
| 35 |
+
linear2_cls=Linear,
|
| 36 |
+
device=None,
|
| 37 |
+
dtype=None,
|
| 38 |
+
) -> None:
|
| 39 |
+
factory_kwargs = {"device": device, "dtype": dtype}
|
| 40 |
+
super(MultiheadAttention, self).__init__()
|
| 41 |
+
self.embed_dim = embed_dim
|
| 42 |
+
self.kdim = kdim if kdim is not None else embed_dim
|
| 43 |
+
self.vdim = vdim if vdim is not None else embed_dim
|
| 44 |
+
self._qkv_same_embed_dim = self.kdim == embed_dim and self.vdim == embed_dim
|
| 45 |
+
|
| 46 |
+
self.num_heads = num_heads
|
| 47 |
+
self.dropout = dropout
|
| 48 |
+
self.batch_first = batch_first
|
| 49 |
+
self.head_dim = embed_dim // num_heads
|
| 50 |
+
assert (
|
| 51 |
+
self.head_dim * num_heads == self.embed_dim
|
| 52 |
+
), "embed_dim must be divisible by num_heads"
|
| 53 |
+
|
| 54 |
+
if add_bias_kv:
|
| 55 |
+
self.bias_k = Parameter(torch.empty((1, 1, embed_dim), **factory_kwargs))
|
| 56 |
+
self.bias_v = Parameter(torch.empty((1, 1, embed_dim), **factory_kwargs))
|
| 57 |
+
else:
|
| 58 |
+
self.bias_k = self.bias_v = None
|
| 59 |
+
|
| 60 |
+
if linear1_cls == Linear:
|
| 61 |
+
if not self._qkv_same_embed_dim:
|
| 62 |
+
self.q_proj_weight = Parameter(
|
| 63 |
+
torch.empty((embed_dim, embed_dim), **factory_kwargs)
|
| 64 |
+
)
|
| 65 |
+
self.k_proj_weight = Parameter(
|
| 66 |
+
torch.empty((embed_dim, self.kdim), **factory_kwargs)
|
| 67 |
+
)
|
| 68 |
+
self.v_proj_weight = Parameter(
|
| 69 |
+
torch.empty((embed_dim, self.vdim), **factory_kwargs)
|
| 70 |
+
)
|
| 71 |
+
self.register_parameter("in_proj_weight", None)
|
| 72 |
+
else:
|
| 73 |
+
self.in_proj_weight = Parameter(
|
| 74 |
+
torch.empty((3 * embed_dim, embed_dim), **factory_kwargs)
|
| 75 |
+
)
|
| 76 |
+
self.register_parameter("q_proj_weight", None)
|
| 77 |
+
self.register_parameter("k_proj_weight", None)
|
| 78 |
+
self.register_parameter("v_proj_weight", None)
|
| 79 |
+
|
| 80 |
+
if bias:
|
| 81 |
+
self.in_proj_bias = Parameter(
|
| 82 |
+
torch.empty(3 * embed_dim, **factory_kwargs)
|
| 83 |
+
)
|
| 84 |
+
else:
|
| 85 |
+
self.register_parameter("in_proj_bias", None)
|
| 86 |
+
self.out_proj = NonDynamicallyQuantizableLinear(
|
| 87 |
+
embed_dim, embed_dim, bias=bias, **factory_kwargs
|
| 88 |
+
)
|
| 89 |
+
|
| 90 |
+
self._reset_parameters()
|
| 91 |
+
else:
|
| 92 |
+
if not self._qkv_same_embed_dim:
|
| 93 |
+
raise NotImplementedError
|
| 94 |
+
else:
|
| 95 |
+
self.in_proj_linear = linear1_cls(
|
| 96 |
+
embed_dim, 3 * embed_dim, bias=bias, **factory_kwargs
|
| 97 |
+
)
|
| 98 |
+
self.in_proj_weight = self.in_proj_linear.weight
|
| 99 |
+
|
| 100 |
+
self.register_parameter("q_proj_weight", None)
|
| 101 |
+
self.register_parameter("k_proj_weight", None)
|
| 102 |
+
self.register_parameter("v_proj_weight", None)
|
| 103 |
+
|
| 104 |
+
if bias:
|
| 105 |
+
self.in_proj_bias = self.in_proj_linear.bias
|
| 106 |
+
else:
|
| 107 |
+
self.register_parameter("in_proj_bias", None)
|
| 108 |
+
|
| 109 |
+
self.out_proj = linear2_cls(
|
| 110 |
+
embed_dim, embed_dim, bias=bias, **factory_kwargs
|
| 111 |
+
)
|
| 112 |
+
|
| 113 |
+
if self.bias_k is not None:
|
| 114 |
+
xavier_normal_(self.bias_k)
|
| 115 |
+
if self.bias_v is not None:
|
| 116 |
+
xavier_normal_(self.bias_v)
|
| 117 |
+
|
| 118 |
+
self.add_zero_attn = add_zero_attn
|
| 119 |
+
|
| 120 |
+
def _reset_parameters(self):
|
| 121 |
+
if self._qkv_same_embed_dim:
|
| 122 |
+
xavier_uniform_(self.in_proj_weight)
|
| 123 |
+
else:
|
| 124 |
+
xavier_uniform_(self.q_proj_weight)
|
| 125 |
+
xavier_uniform_(self.k_proj_weight)
|
| 126 |
+
xavier_uniform_(self.v_proj_weight)
|
| 127 |
+
|
| 128 |
+
if self.in_proj_bias is not None:
|
| 129 |
+
constant_(self.in_proj_bias, 0.0)
|
| 130 |
+
constant_(self.out_proj.bias, 0.0)
|
| 131 |
+
|
| 132 |
+
if self.bias_k is not None:
|
| 133 |
+
xavier_normal_(self.bias_k)
|
| 134 |
+
if self.bias_v is not None:
|
| 135 |
+
xavier_normal_(self.bias_v)
|
| 136 |
+
|
| 137 |
+
def __setstate__(self, state):
|
| 138 |
+
# Support loading old MultiheadAttention checkpoints generated by v1.1.0
|
| 139 |
+
if "_qkv_same_embed_dim" not in state:
|
| 140 |
+
state["_qkv_same_embed_dim"] = True
|
| 141 |
+
|
| 142 |
+
super(MultiheadAttention, self).__setstate__(state)
|
| 143 |
+
|
| 144 |
+
def forward(
|
| 145 |
+
self,
|
| 146 |
+
query: Tensor,
|
| 147 |
+
key: Tensor,
|
| 148 |
+
value: Tensor,
|
| 149 |
+
key_padding_mask: Optional[Tensor] = None,
|
| 150 |
+
need_weights: bool = True,
|
| 151 |
+
attn_mask: Optional[Tensor] = None,
|
| 152 |
+
average_attn_weights: bool = True,
|
| 153 |
+
cache=None,
|
| 154 |
+
) -> Tuple[Tensor, Optional[Tensor]]:
|
| 155 |
+
any_nested = query.is_nested or key.is_nested or value.is_nested
|
| 156 |
+
query = key = value = query.transpose(1, 0)
|
| 157 |
+
attn_output = multi_head_attention_forward_patched(
|
| 158 |
+
query,
|
| 159 |
+
key,
|
| 160 |
+
value,
|
| 161 |
+
self.embed_dim,
|
| 162 |
+
self.num_heads,
|
| 163 |
+
self.in_proj_weight,
|
| 164 |
+
self.in_proj_bias,
|
| 165 |
+
self.bias_k,
|
| 166 |
+
self.bias_v,
|
| 167 |
+
self.add_zero_attn,
|
| 168 |
+
self.dropout,
|
| 169 |
+
self.out_proj.weight,
|
| 170 |
+
self.out_proj.bias,
|
| 171 |
+
training=self.training,
|
| 172 |
+
key_padding_mask=key_padding_mask,
|
| 173 |
+
need_weights=need_weights,
|
| 174 |
+
attn_mask=attn_mask,
|
| 175 |
+
average_attn_weights=average_attn_weights,
|
| 176 |
+
cache=cache,
|
| 177 |
+
)
|
| 178 |
+
return attn_output.transpose(1, 0)
|
GPT_SoVITS/AR/modules/embedding.py
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/lifeiteng/vall-e/blob/main/valle/modules/embedding.py
|
| 2 |
+
import math
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from torch import nn
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class TokenEmbedding(nn.Module):
|
| 9 |
+
def __init__(
|
| 10 |
+
self,
|
| 11 |
+
embedding_dim: int,
|
| 12 |
+
vocab_size: int,
|
| 13 |
+
dropout: float = 0.0,
|
| 14 |
+
):
|
| 15 |
+
super().__init__()
|
| 16 |
+
|
| 17 |
+
self.vocab_size = vocab_size
|
| 18 |
+
self.embedding_dim = embedding_dim
|
| 19 |
+
|
| 20 |
+
self.dropout = torch.nn.Dropout(p=dropout)
|
| 21 |
+
self.word_embeddings = nn.Embedding(self.vocab_size, self.embedding_dim)
|
| 22 |
+
|
| 23 |
+
@property
|
| 24 |
+
def weight(self) -> torch.Tensor:
|
| 25 |
+
return self.word_embeddings.weight
|
| 26 |
+
|
| 27 |
+
def embedding(self, index: int) -> torch.Tensor:
|
| 28 |
+
return self.word_embeddings.weight[index : index + 1]
|
| 29 |
+
|
| 30 |
+
def forward(self, x: torch.Tensor):
|
| 31 |
+
x = self.word_embeddings(x)
|
| 32 |
+
x = self.dropout(x)
|
| 33 |
+
return x
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
class SinePositionalEmbedding(nn.Module):
|
| 37 |
+
def __init__(
|
| 38 |
+
self,
|
| 39 |
+
embedding_dim: int,
|
| 40 |
+
dropout: float = 0.0,
|
| 41 |
+
scale: bool = False,
|
| 42 |
+
alpha: bool = False,
|
| 43 |
+
):
|
| 44 |
+
super().__init__()
|
| 45 |
+
self.embedding_dim = embedding_dim
|
| 46 |
+
self.x_scale = math.sqrt(embedding_dim) if scale else 1.0
|
| 47 |
+
self.alpha = nn.Parameter(torch.ones(1), requires_grad=alpha)
|
| 48 |
+
self.dropout = torch.nn.Dropout(p=dropout)
|
| 49 |
+
|
| 50 |
+
self.reverse = False
|
| 51 |
+
self.pe = None
|
| 52 |
+
self.extend_pe(torch.tensor(0.0).expand(1, 4000))
|
| 53 |
+
|
| 54 |
+
def extend_pe(self, x):
|
| 55 |
+
"""Reset the positional encodings."""
|
| 56 |
+
if self.pe is not None:
|
| 57 |
+
if self.pe.size(1) >= x.size(1):
|
| 58 |
+
if self.pe.dtype != x.dtype or self.pe.device != x.device:
|
| 59 |
+
self.pe = self.pe.to(dtype=x.dtype, device=x.device)
|
| 60 |
+
return
|
| 61 |
+
pe = torch.zeros(x.size(1), self.embedding_dim)
|
| 62 |
+
if self.reverse:
|
| 63 |
+
position = torch.arange(
|
| 64 |
+
x.size(1) - 1, -1, -1.0, dtype=torch.float32
|
| 65 |
+
).unsqueeze(1)
|
| 66 |
+
else:
|
| 67 |
+
position = torch.arange(0, x.size(1), dtype=torch.float32).unsqueeze(1)
|
| 68 |
+
div_term = torch.exp(
|
| 69 |
+
torch.arange(0, self.embedding_dim, 2, dtype=torch.float32)
|
| 70 |
+
* -(math.log(10000.0) / self.embedding_dim)
|
| 71 |
+
)
|
| 72 |
+
pe[:, 0::2] = torch.sin(position * div_term)
|
| 73 |
+
pe[:, 1::2] = torch.cos(position * div_term)
|
| 74 |
+
pe = pe.unsqueeze(0)
|
| 75 |
+
self.pe = pe.to(device=x.device, dtype=x.dtype).detach()
|
| 76 |
+
|
| 77 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 78 |
+
self.extend_pe(x)
|
| 79 |
+
output = x.unsqueeze(-1) if x.ndim == 2 else x
|
| 80 |
+
output = output * self.x_scale + self.alpha * self.pe[:, : x.size(1)]
|
| 81 |
+
return self.dropout(output)
|
GPT_SoVITS/AR/modules/embedding_onnx.py
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/lifeiteng/vall-e/blob/main/valle/modules/embedding.py
|
| 2 |
+
import math
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from torch import nn
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class TokenEmbedding(nn.Module):
|
| 9 |
+
def __init__(
|
| 10 |
+
self,
|
| 11 |
+
embedding_dim: int,
|
| 12 |
+
vocab_size: int,
|
| 13 |
+
dropout: float = 0.0,
|
| 14 |
+
):
|
| 15 |
+
super().__init__()
|
| 16 |
+
|
| 17 |
+
self.vocab_size = vocab_size
|
| 18 |
+
self.embedding_dim = embedding_dim
|
| 19 |
+
|
| 20 |
+
self.dropout = torch.nn.Dropout(p=dropout)
|
| 21 |
+
self.word_embeddings = nn.Embedding(self.vocab_size, self.embedding_dim)
|
| 22 |
+
|
| 23 |
+
@property
|
| 24 |
+
def weight(self) -> torch.Tensor:
|
| 25 |
+
return self.word_embeddings.weight
|
| 26 |
+
|
| 27 |
+
def embedding(self, index: int) -> torch.Tensor:
|
| 28 |
+
return self.word_embeddings.weight[index : index + 1]
|
| 29 |
+
|
| 30 |
+
def forward(self, x: torch.Tensor):
|
| 31 |
+
x = self.word_embeddings(x)
|
| 32 |
+
x = self.dropout(x)
|
| 33 |
+
return x
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
class SinePositionalEmbedding(nn.Module):
|
| 37 |
+
def __init__(
|
| 38 |
+
self,
|
| 39 |
+
embedding_dim: int,
|
| 40 |
+
dropout: float = 0.0,
|
| 41 |
+
scale: bool = False,
|
| 42 |
+
alpha: bool = False,
|
| 43 |
+
):
|
| 44 |
+
super().__init__()
|
| 45 |
+
self.embedding_dim = embedding_dim
|
| 46 |
+
self.x_scale = math.sqrt(embedding_dim) if scale else 1.0
|
| 47 |
+
self.alpha = nn.Parameter(torch.ones(1), requires_grad=alpha)
|
| 48 |
+
self.dropout = torch.nn.Dropout(p=dropout)
|
| 49 |
+
self.reverse = False
|
| 50 |
+
self.div_term = torch.exp(torch.arange(0, self.embedding_dim, 2) * -(math.log(10000.0) / self.embedding_dim))
|
| 51 |
+
|
| 52 |
+
def extend_pe(self, x):
|
| 53 |
+
position = torch.cumsum(torch.ones_like(x[:,:,0]), dim=1).transpose(0, 1)
|
| 54 |
+
scpe = (position * self.div_term).unsqueeze(0)
|
| 55 |
+
pe = torch.cat([torch.sin(scpe), torch.cos(scpe)]).permute(1, 2, 0)
|
| 56 |
+
pe = pe.contiguous().view(1, -1, self.embedding_dim)
|
| 57 |
+
return pe
|
| 58 |
+
|
| 59 |
+
def forward(self, x: torch.Tensor) -> torch.Tensor:
|
| 60 |
+
pe = self.extend_pe(x)
|
| 61 |
+
output = x.unsqueeze(-1) if x.ndim == 2 else x
|
| 62 |
+
output = output * self.x_scale + self.alpha * pe
|
| 63 |
+
return self.dropout(output)
|
GPT_SoVITS/AR/modules/lr_schedulers.py
ADDED
|
@@ -0,0 +1,82 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/feng-yufei/shared_debugging_code/blob/main/model/lr_schedulers.py
|
| 2 |
+
import math
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from matplotlib import pyplot as plt
|
| 6 |
+
from torch import nn
|
| 7 |
+
from torch.optim import Adam
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
class WarmupCosineLRSchedule(torch.optim.lr_scheduler._LRScheduler):
|
| 11 |
+
"""
|
| 12 |
+
Implements Warmup learning rate schedule until 'warmup_steps', going from 'init_lr' to 'peak_lr' for multiple optimizers.
|
| 13 |
+
"""
|
| 14 |
+
|
| 15 |
+
def __init__(
|
| 16 |
+
self,
|
| 17 |
+
optimizer,
|
| 18 |
+
init_lr,
|
| 19 |
+
peak_lr,
|
| 20 |
+
end_lr,
|
| 21 |
+
warmup_steps=10000,
|
| 22 |
+
total_steps=400000,
|
| 23 |
+
current_step=0,
|
| 24 |
+
):
|
| 25 |
+
self.init_lr = init_lr
|
| 26 |
+
self.peak_lr = peak_lr
|
| 27 |
+
self.end_lr = end_lr
|
| 28 |
+
self.optimizer = optimizer
|
| 29 |
+
self._warmup_rate = (peak_lr - init_lr) / warmup_steps
|
| 30 |
+
self._decay_rate = (end_lr - peak_lr) / (total_steps - warmup_steps)
|
| 31 |
+
self._current_step = current_step
|
| 32 |
+
self.lr = init_lr
|
| 33 |
+
self.warmup_steps = warmup_steps
|
| 34 |
+
self.total_steps = total_steps
|
| 35 |
+
self._last_lr = [self.lr]
|
| 36 |
+
|
| 37 |
+
def set_lr(self, lr):
|
| 38 |
+
self._last_lr = [g["lr"] for g in self.optimizer.param_groups]
|
| 39 |
+
for g in self.optimizer.param_groups:
|
| 40 |
+
# g['lr'] = lr
|
| 41 |
+
g["lr"] = self.end_lr ###锁定用线性
|
| 42 |
+
|
| 43 |
+
def step(self):
|
| 44 |
+
if self._current_step < self.warmup_steps:
|
| 45 |
+
lr = self.init_lr + self._warmup_rate * self._current_step
|
| 46 |
+
|
| 47 |
+
elif self._current_step > self.total_steps:
|
| 48 |
+
lr = self.end_lr
|
| 49 |
+
|
| 50 |
+
else:
|
| 51 |
+
decay_ratio = (self._current_step - self.warmup_steps) / (
|
| 52 |
+
self.total_steps - self.warmup_steps
|
| 53 |
+
)
|
| 54 |
+
if decay_ratio < 0.0 or decay_ratio > 1.0:
|
| 55 |
+
raise RuntimeError(
|
| 56 |
+
"Decay ratio must be in [0.0, 1.0]. Fix LR scheduler settings."
|
| 57 |
+
)
|
| 58 |
+
coeff = 0.5 * (1.0 + math.cos(math.pi * decay_ratio))
|
| 59 |
+
lr = self.end_lr + coeff * (self.peak_lr - self.end_lr)
|
| 60 |
+
|
| 61 |
+
self.lr = lr = self.end_lr = 0.002 ###锁定用线性###不听话,直接锁定!
|
| 62 |
+
self.set_lr(lr)
|
| 63 |
+
self.lr = lr
|
| 64 |
+
self._current_step += 1
|
| 65 |
+
return self.lr
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
if __name__ == "__main__":
|
| 69 |
+
m = nn.Linear(10, 10)
|
| 70 |
+
opt = Adam(m.parameters(), lr=1e-4)
|
| 71 |
+
s = WarmupCosineLRSchedule(
|
| 72 |
+
opt, 1e-6, 2e-4, 1e-6, warmup_steps=2000, total_steps=20000, current_step=0
|
| 73 |
+
)
|
| 74 |
+
lrs = []
|
| 75 |
+
for i in range(25000):
|
| 76 |
+
s.step()
|
| 77 |
+
lrs.append(s.lr)
|
| 78 |
+
print(s.lr)
|
| 79 |
+
|
| 80 |
+
plt.plot(lrs)
|
| 81 |
+
plt.plot(range(0, 25000), lrs)
|
| 82 |
+
plt.show()
|
GPT_SoVITS/AR/modules/optim.py
ADDED
|
@@ -0,0 +1,622 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2022 Xiaomi Corp. (authors: Daniel Povey)
|
| 2 |
+
#
|
| 3 |
+
# See ../LICENSE for clarification regarding multiple authors
|
| 4 |
+
#
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 6 |
+
# you may not use this file except in compliance with the License.
|
| 7 |
+
# You may obtain a copy of the License at
|
| 8 |
+
#
|
| 9 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 10 |
+
#
|
| 11 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 12 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 13 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 14 |
+
# See the License for the specific language governing permissions and
|
| 15 |
+
# limitations under the License.
|
| 16 |
+
import contextlib
|
| 17 |
+
import logging
|
| 18 |
+
from collections import defaultdict
|
| 19 |
+
from typing import List
|
| 20 |
+
from typing import Tuple
|
| 21 |
+
|
| 22 |
+
import torch
|
| 23 |
+
from torch import Tensor
|
| 24 |
+
from torch.optim import Optimizer
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class BatchedOptimizer(Optimizer):
|
| 28 |
+
"""
|
| 29 |
+
This class adds to class Optimizer the capability to optimize parameters in batches:
|
| 30 |
+
it will stack the parameters and their grads for you so the optimizer can work
|
| 31 |
+
on tensors with an extra leading dimension. This is intended for speed with GPUs,
|
| 32 |
+
as it reduces the number of kernels launched in the optimizer.
|
| 33 |
+
|
| 34 |
+
Args:
|
| 35 |
+
params:
|
| 36 |
+
"""
|
| 37 |
+
|
| 38 |
+
def __init__(self, params, defaults):
|
| 39 |
+
super(BatchedOptimizer, self).__init__(params, defaults)
|
| 40 |
+
|
| 41 |
+
@contextlib.contextmanager
|
| 42 |
+
def batched_params(self, param_group, group_params_names):
|
| 43 |
+
"""
|
| 44 |
+
This function returns (technically, yields) a list of
|
| 45 |
+
of tuples (p, state), where
|
| 46 |
+
p is a `fake` parameter that is stacked (over axis 0) from real parameters
|
| 47 |
+
that share the same shape, and its gradient is also stacked;
|
| 48 |
+
`state` is the state corresponding to this batch of parameters
|
| 49 |
+
(it will be physically located in the "state" for one of the real
|
| 50 |
+
parameters, the last one that has any particular shape and dtype).
|
| 51 |
+
|
| 52 |
+
This function is decorated as a context manager so that it can
|
| 53 |
+
write parameters back to their "real" locations.
|
| 54 |
+
|
| 55 |
+
The idea is, instead of doing:
|
| 56 |
+
<code>
|
| 57 |
+
for p in group["params"]:
|
| 58 |
+
state = self.state[p]
|
| 59 |
+
...
|
| 60 |
+
</code>
|
| 61 |
+
you can do:
|
| 62 |
+
<code>
|
| 63 |
+
with self.batched_params(group["params"]) as batches:
|
| 64 |
+
for p, state, p_names in batches:
|
| 65 |
+
...
|
| 66 |
+
</code>
|
| 67 |
+
|
| 68 |
+
Args:
|
| 69 |
+
group: a parameter group, which is a list of parameters; should be
|
| 70 |
+
one of self.param_groups.
|
| 71 |
+
group_params_names: name for each parameter in group,
|
| 72 |
+
which is List[str].
|
| 73 |
+
"""
|
| 74 |
+
batches = defaultdict(
|
| 75 |
+
list
|
| 76 |
+
) # `batches` maps from tuple (dtype_as_str,*shape) to list of nn.Parameter
|
| 77 |
+
batches_names = defaultdict(
|
| 78 |
+
list
|
| 79 |
+
) # `batches` maps from tuple (dtype_as_str,*shape) to list of str
|
| 80 |
+
|
| 81 |
+
assert len(param_group) == len(group_params_names)
|
| 82 |
+
for p, named_p in zip(param_group, group_params_names):
|
| 83 |
+
key = (str(p.dtype), *p.shape)
|
| 84 |
+
batches[key].append(p)
|
| 85 |
+
batches_names[key].append(named_p)
|
| 86 |
+
|
| 87 |
+
batches_names_keys = list(batches_names.keys())
|
| 88 |
+
sorted_idx = sorted(
|
| 89 |
+
range(len(batches_names)), key=lambda i: batches_names_keys[i])
|
| 90 |
+
batches_names = [
|
| 91 |
+
batches_names[batches_names_keys[idx]] for idx in sorted_idx
|
| 92 |
+
]
|
| 93 |
+
batches = [batches[batches_names_keys[idx]] for idx in sorted_idx]
|
| 94 |
+
|
| 95 |
+
stacked_params_dict = dict()
|
| 96 |
+
|
| 97 |
+
# turn batches into a list, in deterministic order.
|
| 98 |
+
# tuples will contain tuples of (stacked_param, state, stacked_params_names),
|
| 99 |
+
# one for each batch in `batches`.
|
| 100 |
+
tuples = []
|
| 101 |
+
|
| 102 |
+
for batch, batch_names in zip(batches, batches_names):
|
| 103 |
+
p = batch[0]
|
| 104 |
+
# we arbitrarily store the state in the
|
| 105 |
+
# state corresponding to the 1st parameter in the
|
| 106 |
+
# group. class Optimizer will take care of saving/loading state.
|
| 107 |
+
state = self.state[p]
|
| 108 |
+
p_stacked = torch.stack(batch)
|
| 109 |
+
grad = torch.stack([
|
| 110 |
+
torch.zeros_like(p) if p.grad is None else p.grad for p in batch
|
| 111 |
+
])
|
| 112 |
+
p_stacked.grad = grad
|
| 113 |
+
stacked_params_dict[key] = p_stacked
|
| 114 |
+
tuples.append((p_stacked, state, batch_names))
|
| 115 |
+
|
| 116 |
+
yield tuples # <-- calling code will do the actual optimization here!
|
| 117 |
+
|
| 118 |
+
for ((stacked_params, _state, _names), batch) in zip(tuples, batches):
|
| 119 |
+
for i, p in enumerate(batch): # batch is list of Parameter
|
| 120 |
+
p.copy_(stacked_params[i])
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
class ScaledAdam(BatchedOptimizer):
|
| 124 |
+
"""
|
| 125 |
+
Implements 'Scaled Adam', a variant of Adam where we scale each parameter's update
|
| 126 |
+
proportional to the norm of that parameter; and also learn the scale of the parameter,
|
| 127 |
+
in log space, subject to upper and lower limits (as if we had factored each parameter as
|
| 128 |
+
param = underlying_param * log_scale.exp())
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
Args:
|
| 132 |
+
params: The parameters or param_groups to optimize (like other Optimizer subclasses)
|
| 133 |
+
lr: The learning rate. We will typically use a learning rate schedule that starts
|
| 134 |
+
at 0.03 and decreases over time, i.e. much higher than other common
|
| 135 |
+
optimizers.
|
| 136 |
+
clipping_scale: (e.g. 2.0)
|
| 137 |
+
A scale for gradient-clipping: if specified, the normalized gradients
|
| 138 |
+
over the whole model will be clipped to have 2-norm equal to
|
| 139 |
+
`clipping_scale` times the median 2-norm over the most recent period
|
| 140 |
+
of `clipping_update_period` minibatches. By "normalized gradients",
|
| 141 |
+
we mean after multiplying by the rms parameter value for this tensor
|
| 142 |
+
[for non-scalars]; this is appropriate because our update is scaled
|
| 143 |
+
by this quantity.
|
| 144 |
+
betas: beta1,beta2 are momentum constants for regular momentum, and moving sum-sq grad.
|
| 145 |
+
Must satisfy 0 < beta <= beta2 < 1.
|
| 146 |
+
scalar_lr_scale: A scaling factor on the learning rate, that we use to update the
|
| 147 |
+
scale of each parameter tensor and scalar parameters of the mode..
|
| 148 |
+
If each parameter were decomposed
|
| 149 |
+
as p * p_scale.exp(), where (p**2).mean().sqrt() == 1.0, scalar_lr_scale
|
| 150 |
+
would be a the scaling factor on the learning rate of p_scale.
|
| 151 |
+
eps: A general-purpose epsilon to prevent division by zero
|
| 152 |
+
param_min_rms: Minimum root-mean-square value of parameter tensor, for purposes of
|
| 153 |
+
learning the scale on the parameters (we'll constrain the rms of each non-scalar
|
| 154 |
+
parameter tensor to be >= this value)
|
| 155 |
+
param_max_rms: Maximum root-mean-square value of parameter tensor, for purposes of
|
| 156 |
+
learning the scale on the parameters (we'll constrain the rms of each non-scalar
|
| 157 |
+
parameter tensor to be <= this value)
|
| 158 |
+
scalar_max: Maximum absolute value for scalar parameters (applicable if your
|
| 159 |
+
model has any parameters with numel() == 1).
|
| 160 |
+
size_update_period: The periodicity, in steps, with which we update the size (scale)
|
| 161 |
+
of the parameter tensor. This is provided to save a little time
|
| 162 |
+
in the update.
|
| 163 |
+
clipping_update_period: if clipping_scale is specified, this is the period
|
| 164 |
+
"""
|
| 165 |
+
|
| 166 |
+
def __init__(
|
| 167 |
+
self,
|
| 168 |
+
params,
|
| 169 |
+
lr=3e-02,
|
| 170 |
+
clipping_scale=None,
|
| 171 |
+
betas=(0.9, 0.98),
|
| 172 |
+
scalar_lr_scale=0.1,
|
| 173 |
+
eps=1.0e-08,
|
| 174 |
+
param_min_rms=1.0e-05,
|
| 175 |
+
param_max_rms=3.0,
|
| 176 |
+
scalar_max=10.0,
|
| 177 |
+
size_update_period=4,
|
| 178 |
+
clipping_update_period=100,
|
| 179 |
+
parameters_names=None,
|
| 180 |
+
show_dominant_parameters=True, ):
|
| 181 |
+
|
| 182 |
+
assert parameters_names is not None, (
|
| 183 |
+
"Please prepare parameters_names,"
|
| 184 |
+
"which is a List[List[str]]. Each List[str] is for a group"
|
| 185 |
+
"and each str is for a parameter")
|
| 186 |
+
defaults = dict(
|
| 187 |
+
lr=lr,
|
| 188 |
+
clipping_scale=clipping_scale,
|
| 189 |
+
betas=betas,
|
| 190 |
+
scalar_lr_scale=scalar_lr_scale,
|
| 191 |
+
eps=eps,
|
| 192 |
+
param_min_rms=param_min_rms,
|
| 193 |
+
param_max_rms=param_max_rms,
|
| 194 |
+
scalar_max=scalar_max,
|
| 195 |
+
size_update_period=size_update_period,
|
| 196 |
+
clipping_update_period=clipping_update_period, )
|
| 197 |
+
|
| 198 |
+
super(ScaledAdam, self).__init__(params, defaults)
|
| 199 |
+
assert len(self.param_groups) == len(parameters_names)
|
| 200 |
+
self.parameters_names = parameters_names
|
| 201 |
+
self.show_dominant_parameters = show_dominant_parameters
|
| 202 |
+
|
| 203 |
+
def __setstate__(self, state):
|
| 204 |
+
super(ScaledAdam, self).__setstate__(state)
|
| 205 |
+
|
| 206 |
+
@torch.no_grad()
|
| 207 |
+
def step(self, closure=None):
|
| 208 |
+
"""Performs a single optimization step.
|
| 209 |
+
|
| 210 |
+
Arguments:
|
| 211 |
+
closure (callable, optional): A closure that reevaluates the model
|
| 212 |
+
and returns the loss.
|
| 213 |
+
"""
|
| 214 |
+
loss = None
|
| 215 |
+
if closure is not None:
|
| 216 |
+
with torch.enable_grad():
|
| 217 |
+
loss = closure()
|
| 218 |
+
|
| 219 |
+
batch = True
|
| 220 |
+
|
| 221 |
+
for group, group_params_names in zip(self.param_groups,
|
| 222 |
+
self.parameters_names):
|
| 223 |
+
|
| 224 |
+
with self.batched_params(group["params"],
|
| 225 |
+
group_params_names) as batches:
|
| 226 |
+
|
| 227 |
+
# batches is list of pairs (stacked_param, state). stacked_param is like
|
| 228 |
+
# a regular parameter, and will have a .grad, but the 1st dim corresponds to
|
| 229 |
+
# a stacking dim, it is not a real dim.
|
| 230 |
+
|
| 231 |
+
if (len(batches[0][1]) ==
|
| 232 |
+
0): # if len(first state) == 0: not yet initialized
|
| 233 |
+
clipping_scale = 1
|
| 234 |
+
else:
|
| 235 |
+
clipping_scale = self._get_clipping_scale(group, batches)
|
| 236 |
+
|
| 237 |
+
for p, state, _ in batches:
|
| 238 |
+
# Perform optimization step.
|
| 239 |
+
# grad is not going to be None, we handled that when creating the batches.
|
| 240 |
+
grad = p.grad
|
| 241 |
+
if grad.is_sparse:
|
| 242 |
+
raise RuntimeError(
|
| 243 |
+
"ScaledAdam optimizer does not support sparse gradients"
|
| 244 |
+
)
|
| 245 |
+
# State initialization
|
| 246 |
+
if len(state) == 0:
|
| 247 |
+
self._init_state(group, p, state)
|
| 248 |
+
|
| 249 |
+
self._step_one_batch(group, p, state, clipping_scale)
|
| 250 |
+
|
| 251 |
+
return loss
|
| 252 |
+
|
| 253 |
+
def _init_state(self, group: dict, p: Tensor, state: dict):
|
| 254 |
+
"""
|
| 255 |
+
Initializes state dict for parameter 'p'. Assumes that dim 0 of tensor p
|
| 256 |
+
is actually the batch dimension, corresponding to batched-together
|
| 257 |
+
parameters of a given shape.
|
| 258 |
+
|
| 259 |
+
|
| 260 |
+
Args:
|
| 261 |
+
group: Dict to look up configuration values.
|
| 262 |
+
p: The parameter that we are initializing the state for
|
| 263 |
+
state: Dict from string to whatever state we are initializing
|
| 264 |
+
"""
|
| 265 |
+
size_update_period = group["size_update_period"]
|
| 266 |
+
|
| 267 |
+
state["step"] = 0
|
| 268 |
+
|
| 269 |
+
kwargs = {"device": p.device, "dtype": p.dtype}
|
| 270 |
+
|
| 271 |
+
# 'delta' implements conventional momentum. There are
|
| 272 |
+
# several different kinds of update going on, so rather than
|
| 273 |
+
# compute "exp_avg" like in Adam, we store and decay a
|
| 274 |
+
# parameter-change "delta", which combines all forms of
|
| 275 |
+
# update. this is equivalent to how it's done in Adam,
|
| 276 |
+
# except for the first few steps.
|
| 277 |
+
state["delta"] = torch.zeros_like(
|
| 278 |
+
p, memory_format=torch.preserve_format)
|
| 279 |
+
|
| 280 |
+
batch_size = p.shape[0]
|
| 281 |
+
numel = p.numel() // batch_size
|
| 282 |
+
numel = p.numel()
|
| 283 |
+
|
| 284 |
+
if numel > 1:
|
| 285 |
+
# "param_rms" just periodically records the scalar root-mean-square value of
|
| 286 |
+
# the parameter tensor.
|
| 287 |
+
# it has a shape like (batch_size, 1, 1, 1, 1)
|
| 288 |
+
param_rms = (
|
| 289 |
+
(p**2).mean(dim=list(range(1, p.ndim)), keepdim=True).sqrt())
|
| 290 |
+
state["param_rms"] = param_rms
|
| 291 |
+
|
| 292 |
+
state["scale_exp_avg_sq"] = torch.zeros_like(param_rms)
|
| 293 |
+
state["scale_grads"] = torch.zeros(size_update_period,
|
| 294 |
+
*param_rms.shape, **kwargs)
|
| 295 |
+
|
| 296 |
+
# exp_avg_sq is the weighted sum of scaled gradients. as in Adam.
|
| 297 |
+
state["exp_avg_sq"] = torch.zeros_like(
|
| 298 |
+
p, memory_format=torch.preserve_format)
|
| 299 |
+
|
| 300 |
+
def _get_clipping_scale(self,
|
| 301 |
+
group: dict,
|
| 302 |
+
tuples: List[Tuple[Tensor, dict, List[str]]]
|
| 303 |
+
) -> float:
|
| 304 |
+
"""
|
| 305 |
+
Returns a scalar factor <= 1.0 that dictates gradient clipping, i.e. we will scale the gradients
|
| 306 |
+
by this amount before applying the rest of the update.
|
| 307 |
+
|
| 308 |
+
Args:
|
| 309 |
+
group: the parameter group, an item in self.param_groups
|
| 310 |
+
tuples: a list of tuples of (param, state, param_names)
|
| 311 |
+
where param is a batched set of parameters,
|
| 312 |
+
with a .grad (1st dim is batch dim)
|
| 313 |
+
and state is the state-dict where optimization parameters are kept.
|
| 314 |
+
param_names is a List[str] while each str is name for a parameter
|
| 315 |
+
in batched set of parameters "param".
|
| 316 |
+
"""
|
| 317 |
+
assert len(tuples) >= 1
|
| 318 |
+
clipping_scale = group["clipping_scale"]
|
| 319 |
+
(first_p, first_state, _) = tuples[0]
|
| 320 |
+
step = first_state["step"]
|
| 321 |
+
if clipping_scale is None or step == 0:
|
| 322 |
+
# no clipping. return early on step == 0 because the other
|
| 323 |
+
# parameters' state won't have been initialized yet.
|
| 324 |
+
return 1.0
|
| 325 |
+
clipping_update_period = group["clipping_update_period"]
|
| 326 |
+
|
| 327 |
+
tot_sumsq = torch.tensor(0.0, device=first_p.device)
|
| 328 |
+
for (p, state, param_names) in tuples:
|
| 329 |
+
grad = p.grad
|
| 330 |
+
if grad.is_sparse:
|
| 331 |
+
raise RuntimeError(
|
| 332 |
+
"ScaledAdam optimizer does not support sparse gradients")
|
| 333 |
+
if p.numel() == p.shape[0]: # a batch of scalars
|
| 334 |
+
tot_sumsq += (grad**2).sum() # sum() to change shape [1] to []
|
| 335 |
+
else:
|
| 336 |
+
tot_sumsq += ((grad * state["param_rms"])**2).sum()
|
| 337 |
+
|
| 338 |
+
tot_norm = tot_sumsq.sqrt()
|
| 339 |
+
if "model_norms" not in first_state:
|
| 340 |
+
first_state["model_norms"] = torch.zeros(
|
| 341 |
+
clipping_update_period, device=p.device)
|
| 342 |
+
first_state["model_norms"][step % clipping_update_period] = tot_norm
|
| 343 |
+
|
| 344 |
+
if step % clipping_update_period == 0:
|
| 345 |
+
# Print some stats.
|
| 346 |
+
# We don't reach here if step == 0 because we would have returned
|
| 347 |
+
# above.
|
| 348 |
+
sorted_norms = first_state["model_norms"].sort()[0].to("cpu")
|
| 349 |
+
quartiles = []
|
| 350 |
+
for n in range(0, 5):
|
| 351 |
+
index = min(
|
| 352 |
+
clipping_update_period - 1,
|
| 353 |
+
(clipping_update_period // 4) * n, )
|
| 354 |
+
quartiles.append(sorted_norms[index].item())
|
| 355 |
+
|
| 356 |
+
median = quartiles[2]
|
| 357 |
+
threshold = clipping_scale * median
|
| 358 |
+
first_state["model_norm_threshold"] = threshold
|
| 359 |
+
percent_clipped = (first_state["num_clipped"] * 100.0 /
|
| 360 |
+
clipping_update_period
|
| 361 |
+
if "num_clipped" in first_state else 0.0)
|
| 362 |
+
first_state["num_clipped"] = 0
|
| 363 |
+
quartiles = " ".join(["%.3e" % x for x in quartiles])
|
| 364 |
+
logging.info(
|
| 365 |
+
f"Clipping_scale={clipping_scale}, grad-norm quartiles {quartiles}, "
|
| 366 |
+
f"threshold={threshold:.3e}, percent-clipped={percent_clipped:.1f}"
|
| 367 |
+
)
|
| 368 |
+
|
| 369 |
+
if step < clipping_update_period:
|
| 370 |
+
return 1.0 # We have not yet estimated a norm to clip to.
|
| 371 |
+
else:
|
| 372 |
+
try:
|
| 373 |
+
model_norm_threshold = first_state["model_norm_threshold"]
|
| 374 |
+
except KeyError:
|
| 375 |
+
logging.info(
|
| 376 |
+
"Warning: model_norm_threshold not in state: possibly "
|
| 377 |
+
"you changed config when restarting, adding clipping_scale option?"
|
| 378 |
+
)
|
| 379 |
+
return 1.0
|
| 380 |
+
ans = min(1.0, (model_norm_threshold / (tot_norm + 1.0e-20)).item())
|
| 381 |
+
if ans < 1.0:
|
| 382 |
+
first_state["num_clipped"] += 1
|
| 383 |
+
if ans < 0.1:
|
| 384 |
+
logging.warn(
|
| 385 |
+
f"Scaling gradients by {ans}, model_norm_threshold={model_norm_threshold}"
|
| 386 |
+
)
|
| 387 |
+
if self.show_dominant_parameters:
|
| 388 |
+
assert p.shape[0] == len(param_names)
|
| 389 |
+
self._show_gradient_dominating_parameter(tuples, tot_sumsq)
|
| 390 |
+
return ans
|
| 391 |
+
|
| 392 |
+
def _show_gradient_dominating_parameter(
|
| 393 |
+
self, tuples: List[Tuple[Tensor, dict, List[str]]],
|
| 394 |
+
tot_sumsq: Tensor):
|
| 395 |
+
"""
|
| 396 |
+
Show information of parameter wihch dominanting tot_sumsq.
|
| 397 |
+
|
| 398 |
+
Args:
|
| 399 |
+
tuples: a list of tuples of (param, state, param_names)
|
| 400 |
+
where param is a batched set of parameters,
|
| 401 |
+
with a .grad (1st dim is batch dim)
|
| 402 |
+
and state is the state-dict where optimization parameters are kept.
|
| 403 |
+
param_names is a List[str] while each str is name for a parameter
|
| 404 |
+
in batched set of parameters "param".
|
| 405 |
+
tot_sumsq: sumsq of all parameters. Though it's could be calculated
|
| 406 |
+
from tuples, we still pass it to save some time.
|
| 407 |
+
"""
|
| 408 |
+
all_sumsq_orig = {}
|
| 409 |
+
for (p, state, batch_param_names) in tuples:
|
| 410 |
+
# p is a stacked batch parameters.
|
| 411 |
+
batch_grad = p.grad
|
| 412 |
+
if p.numel() == p.shape[0]: # a batch of scalars
|
| 413 |
+
batch_sumsq_orig = batch_grad**2
|
| 414 |
+
# Dummpy values used by following `zip` statement.
|
| 415 |
+
batch_rms_orig = torch.ones(p.shape[0])
|
| 416 |
+
else:
|
| 417 |
+
batch_rms_orig = state["param_rms"]
|
| 418 |
+
batch_sumsq_orig = ((batch_grad * batch_rms_orig)**2).sum(
|
| 419 |
+
dim=list(range(1, batch_grad.ndim)))
|
| 420 |
+
|
| 421 |
+
for name, sumsq_orig, rms, grad in zip(batch_param_names,
|
| 422 |
+
batch_sumsq_orig,
|
| 423 |
+
batch_rms_orig, batch_grad):
|
| 424 |
+
|
| 425 |
+
proportion_orig = sumsq_orig / tot_sumsq
|
| 426 |
+
all_sumsq_orig[name] = (proportion_orig, sumsq_orig, rms, grad)
|
| 427 |
+
|
| 428 |
+
assert torch.isclose(
|
| 429 |
+
sum([value[0] for value in all_sumsq_orig.values()]).cpu(),
|
| 430 |
+
torch.tensor(1.0), )
|
| 431 |
+
sorted_by_proportion = {
|
| 432 |
+
k: v
|
| 433 |
+
for k, v in sorted(
|
| 434 |
+
all_sumsq_orig.items(),
|
| 435 |
+
key=lambda item: item[1][0],
|
| 436 |
+
reverse=True, )
|
| 437 |
+
}
|
| 438 |
+
dominant_param_name = next(iter(sorted_by_proportion))
|
| 439 |
+
(dominant_proportion, dominant_sumsq, dominant_rms,
|
| 440 |
+
dominant_grad, ) = sorted_by_proportion[dominant_param_name]
|
| 441 |
+
logging.info(f"Parameter Dominanting tot_sumsq {dominant_param_name}"
|
| 442 |
+
f" with proportion {dominant_proportion:.2f},"
|
| 443 |
+
f" where dominant_sumsq=(grad_sumsq*orig_rms_sq)"
|
| 444 |
+
f"={dominant_sumsq:.3e},"
|
| 445 |
+
f" grad_sumsq = {(dominant_grad**2).sum():.3e},"
|
| 446 |
+
f" orig_rms_sq={(dominant_rms**2).item():.3e}")
|
| 447 |
+
|
| 448 |
+
def _step_one_batch(self,
|
| 449 |
+
group: dict,
|
| 450 |
+
p: Tensor,
|
| 451 |
+
state: dict,
|
| 452 |
+
clipping_scale: float):
|
| 453 |
+
"""
|
| 454 |
+
Do the step for one parameter, which is actually going to be a batch of
|
| 455 |
+
`real` parameters, with dim 0 as the batch dim.
|
| 456 |
+
Args:
|
| 457 |
+
group: dict to look up configuration values
|
| 458 |
+
p: parameter to update (actually multiple parameters stacked together
|
| 459 |
+
as a batch)
|
| 460 |
+
state: state-dict for p, to look up the optimizer state
|
| 461 |
+
"""
|
| 462 |
+
lr = group["lr"]
|
| 463 |
+
size_update_period = group["size_update_period"]
|
| 464 |
+
beta1 = group["betas"][0]
|
| 465 |
+
|
| 466 |
+
grad = p.grad
|
| 467 |
+
if clipping_scale != 1.0:
|
| 468 |
+
grad = grad * clipping_scale
|
| 469 |
+
step = state["step"]
|
| 470 |
+
delta = state["delta"]
|
| 471 |
+
|
| 472 |
+
delta.mul_(beta1)
|
| 473 |
+
batch_size = p.shape[0]
|
| 474 |
+
numel = p.numel() // batch_size
|
| 475 |
+
if numel > 1:
|
| 476 |
+
# Update the size/scale of p, and set param_rms
|
| 477 |
+
scale_grads = state["scale_grads"]
|
| 478 |
+
scale_grads[step % size_update_period] = (p * grad).sum(
|
| 479 |
+
dim=list(range(1, p.ndim)), keepdim=True)
|
| 480 |
+
if step % size_update_period == size_update_period - 1:
|
| 481 |
+
param_rms = state["param_rms"] # shape: (batch_size, 1, 1, ..)
|
| 482 |
+
param_rms.copy_((p**2)
|
| 483 |
+
.mean(dim=list(range(1, p.ndim)), keepdim=True)
|
| 484 |
+
.sqrt())
|
| 485 |
+
if step > 0:
|
| 486 |
+
# self._size_update() learns the overall scale on the
|
| 487 |
+
# parameter, by shrinking or expanding it.
|
| 488 |
+
self._size_update(group, scale_grads, p, state)
|
| 489 |
+
|
| 490 |
+
if numel == 1:
|
| 491 |
+
# For parameters with 1 element we just use regular Adam.
|
| 492 |
+
# Updates delta.
|
| 493 |
+
self._step_scalar(group, p, state)
|
| 494 |
+
else:
|
| 495 |
+
self._step(group, p, state)
|
| 496 |
+
|
| 497 |
+
state["step"] = step + 1
|
| 498 |
+
|
| 499 |
+
def _size_update(self,
|
| 500 |
+
group: dict,
|
| 501 |
+
scale_grads: Tensor,
|
| 502 |
+
p: Tensor,
|
| 503 |
+
state: dict) -> None:
|
| 504 |
+
"""
|
| 505 |
+
Called only where p.numel() > 1, this updates the scale of the parameter.
|
| 506 |
+
If we imagine: p = underlying_param * scale.exp(), and we are doing
|
| 507 |
+
gradient descent on underlying param and on scale, this function does the update
|
| 508 |
+
on `scale`.
|
| 509 |
+
|
| 510 |
+
Args:
|
| 511 |
+
group: dict to look up configuration values
|
| 512 |
+
scale_grads: a tensor of shape (size_update_period, batch_size, 1, 1,...) containing
|
| 513 |
+
grads w.r.t. the scales.
|
| 514 |
+
p: The parameter to update
|
| 515 |
+
state: The state-dict of p
|
| 516 |
+
"""
|
| 517 |
+
|
| 518 |
+
param_rms = state["param_rms"]
|
| 519 |
+
beta1, beta2 = group["betas"]
|
| 520 |
+
size_lr = group["lr"] * group["scalar_lr_scale"]
|
| 521 |
+
param_min_rms = group["param_min_rms"]
|
| 522 |
+
param_max_rms = group["param_max_rms"]
|
| 523 |
+
eps = group["eps"]
|
| 524 |
+
step = state["step"]
|
| 525 |
+
batch_size = p.shape[0]
|
| 526 |
+
|
| 527 |
+
size_update_period = scale_grads.shape[0]
|
| 528 |
+
# correct beta2 for the size update period: we will have
|
| 529 |
+
# faster decay at this level.
|
| 530 |
+
beta2_corr = beta2**size_update_period
|
| 531 |
+
|
| 532 |
+
scale_exp_avg_sq = state[
|
| 533 |
+
"scale_exp_avg_sq"] # shape: (batch_size, 1, 1, ..)
|
| 534 |
+
scale_exp_avg_sq.mul_(beta2_corr).add_(
|
| 535 |
+
(scale_grads**2).mean(dim=0), # mean over dim `size_update_period`
|
| 536 |
+
alpha=1 - beta2_corr, ) # shape is (batch_size, 1, 1, ...)
|
| 537 |
+
|
| 538 |
+
# The 1st time we reach here is when size_step == 1.
|
| 539 |
+
size_step = (step + 1) // size_update_period
|
| 540 |
+
bias_correction2 = 1 - beta2_corr**size_step
|
| 541 |
+
# we don't bother with bias_correction1; this will help prevent divergence
|
| 542 |
+
# at the start of training.
|
| 543 |
+
|
| 544 |
+
denom = scale_exp_avg_sq.sqrt() + eps
|
| 545 |
+
|
| 546 |
+
scale_step = (-size_lr * (bias_correction2**0.5) *
|
| 547 |
+
scale_grads.sum(dim=0) / denom)
|
| 548 |
+
|
| 549 |
+
is_too_small = param_rms < param_min_rms
|
| 550 |
+
is_too_large = param_rms > param_max_rms
|
| 551 |
+
|
| 552 |
+
# when the param gets too small, just don't shrink it any further.
|
| 553 |
+
scale_step.masked_fill_(is_too_small, 0.0)
|
| 554 |
+
# when it gets too large, stop it from getting any larger.
|
| 555 |
+
scale_step.masked_fill_(is_too_large, -size_lr * size_update_period)
|
| 556 |
+
delta = state["delta"]
|
| 557 |
+
# the factor of (1-beta1) relates to momentum.
|
| 558 |
+
delta.add_(p * scale_step, alpha=(1 - beta1))
|
| 559 |
+
|
| 560 |
+
def _step(self, group: dict, p: Tensor, state: dict):
|
| 561 |
+
"""
|
| 562 |
+
This function does the core update of self.step(), in the case where the members of
|
| 563 |
+
the batch have more than 1 element.
|
| 564 |
+
|
| 565 |
+
Args:
|
| 566 |
+
group: A dict which will be used to look up configuration values
|
| 567 |
+
p: The parameter to be updated
|
| 568 |
+
grad: The grad of p
|
| 569 |
+
state: The state-dict corresponding to parameter p
|
| 570 |
+
|
| 571 |
+
This function modifies p.
|
| 572 |
+
"""
|
| 573 |
+
grad = p.grad
|
| 574 |
+
lr = group["lr"]
|
| 575 |
+
beta1, beta2 = group["betas"]
|
| 576 |
+
eps = group["eps"]
|
| 577 |
+
param_min_rms = group["param_min_rms"]
|
| 578 |
+
step = state["step"]
|
| 579 |
+
|
| 580 |
+
exp_avg_sq = state["exp_avg_sq"]
|
| 581 |
+
exp_avg_sq.mul_(beta2).addcmul_(grad, grad, value=(1 - beta2))
|
| 582 |
+
|
| 583 |
+
this_step = state["step"] - (state["zero_step"]
|
| 584 |
+
if "zero_step" in state else 0)
|
| 585 |
+
bias_correction2 = 1 - beta2**(this_step + 1)
|
| 586 |
+
if bias_correction2 < 0.99:
|
| 587 |
+
# note: not in-place.
|
| 588 |
+
exp_avg_sq = exp_avg_sq * (1.0 / bias_correction2)
|
| 589 |
+
|
| 590 |
+
denom = exp_avg_sq.sqrt()
|
| 591 |
+
denom += eps
|
| 592 |
+
grad = grad / denom
|
| 593 |
+
|
| 594 |
+
alpha = -lr * (1 - beta1) * state["param_rms"].clamp(min=param_min_rms)
|
| 595 |
+
|
| 596 |
+
delta = state["delta"]
|
| 597 |
+
delta.add_(grad * alpha)
|
| 598 |
+
p.add_(delta)
|
| 599 |
+
|
| 600 |
+
def _step_scalar(self, group: dict, p: Tensor, state: dict):
|
| 601 |
+
"""
|
| 602 |
+
A simplified form of the core update for scalar tensors, where we cannot get a good
|
| 603 |
+
estimate of the parameter rms.
|
| 604 |
+
"""
|
| 605 |
+
beta1, beta2 = group["betas"]
|
| 606 |
+
scalar_max = group["scalar_max"]
|
| 607 |
+
eps = group["eps"]
|
| 608 |
+
lr = group["lr"] * group["scalar_lr_scale"]
|
| 609 |
+
grad = p.grad
|
| 610 |
+
|
| 611 |
+
exp_avg_sq = state["exp_avg_sq"] # shape: (batch_size,)
|
| 612 |
+
exp_avg_sq.mul_(beta2).addcmul_(grad, grad, value=1 - beta2)
|
| 613 |
+
|
| 614 |
+
# bias_correction2 is like in Adam. Don't bother with bias_correction1;
|
| 615 |
+
# slower update at the start will help stability anyway.
|
| 616 |
+
bias_correction2 = 1 - beta2**(state["step"] + 1)
|
| 617 |
+
denom = (exp_avg_sq / bias_correction2).sqrt() + eps
|
| 618 |
+
|
| 619 |
+
delta = state["delta"]
|
| 620 |
+
delta.add_(grad / denom, alpha=-lr * (1 - beta1))
|
| 621 |
+
p.clamp_(min=-scalar_max, max=scalar_max)
|
| 622 |
+
p.add_(delta)
|
GPT_SoVITS/AR/modules/patched_mha_with_cache.py
ADDED
|
@@ -0,0 +1,463 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from torch.nn.functional import *
|
| 2 |
+
from torch.nn.functional import (
|
| 3 |
+
_mha_shape_check,
|
| 4 |
+
_canonical_mask,
|
| 5 |
+
_none_or_dtype,
|
| 6 |
+
_in_projection_packed,
|
| 7 |
+
)
|
| 8 |
+
|
| 9 |
+
# import torch
|
| 10 |
+
# Tensor = torch.Tensor
|
| 11 |
+
# from typing import Callable, List, Optional, Tuple, Union
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def multi_head_attention_forward_patched(
|
| 15 |
+
query: Tensor,
|
| 16 |
+
key: Tensor,
|
| 17 |
+
value: Tensor,
|
| 18 |
+
embed_dim_to_check: int,
|
| 19 |
+
num_heads: int,
|
| 20 |
+
in_proj_weight: Optional[Tensor],
|
| 21 |
+
in_proj_bias: Optional[Tensor],
|
| 22 |
+
bias_k: Optional[Tensor],
|
| 23 |
+
bias_v: Optional[Tensor],
|
| 24 |
+
add_zero_attn: bool,
|
| 25 |
+
dropout_p: float,
|
| 26 |
+
out_proj_weight: Tensor,
|
| 27 |
+
out_proj_bias: Optional[Tensor],
|
| 28 |
+
training: bool = True,
|
| 29 |
+
key_padding_mask: Optional[Tensor] = None,
|
| 30 |
+
need_weights: bool = True,
|
| 31 |
+
attn_mask: Optional[Tensor] = None,
|
| 32 |
+
use_separate_proj_weight: bool = False,
|
| 33 |
+
q_proj_weight: Optional[Tensor] = None,
|
| 34 |
+
k_proj_weight: Optional[Tensor] = None,
|
| 35 |
+
v_proj_weight: Optional[Tensor] = None,
|
| 36 |
+
static_k: Optional[Tensor] = None,
|
| 37 |
+
static_v: Optional[Tensor] = None,
|
| 38 |
+
average_attn_weights: bool = True,
|
| 39 |
+
is_causal: bool = False,
|
| 40 |
+
cache=None,
|
| 41 |
+
) -> Tuple[Tensor, Optional[Tensor]]:
|
| 42 |
+
r"""
|
| 43 |
+
Args:
|
| 44 |
+
query, key, value: map a query and a set of key-value pairs to an output.
|
| 45 |
+
See "Attention Is All You Need" for more details.
|
| 46 |
+
embed_dim_to_check: total dimension of the model.
|
| 47 |
+
num_heads: parallel attention heads.
|
| 48 |
+
in_proj_weight, in_proj_bias: input projection weight and bias.
|
| 49 |
+
bias_k, bias_v: bias of the key and value sequences to be added at dim=0.
|
| 50 |
+
add_zero_attn: add a new batch of zeros to the key and
|
| 51 |
+
value sequences at dim=1.
|
| 52 |
+
dropout_p: probability of an element to be zeroed.
|
| 53 |
+
out_proj_weight, out_proj_bias: the output projection weight and bias.
|
| 54 |
+
training: apply dropout if is ``True``.
|
| 55 |
+
key_padding_mask: if provided, specified padding elements in the key will
|
| 56 |
+
be ignored by the attention. This is an binary mask. When the value is True,
|
| 57 |
+
the corresponding value on the attention layer will be filled with -inf.
|
| 58 |
+
need_weights: output attn_output_weights.
|
| 59 |
+
Default: `True`
|
| 60 |
+
Note: `needs_weight` defaults to `True`, but should be set to `False`
|
| 61 |
+
For best performance when attention weights are not nedeeded.
|
| 62 |
+
*Setting needs_weights to `True`
|
| 63 |
+
leads to a significant performance degradation.*
|
| 64 |
+
attn_mask: 2D or 3D mask that prevents attention to certain positions. A 2D mask will be broadcasted for all
|
| 65 |
+
the batches while a 3D mask allows to specify a different mask for the entries of each batch.
|
| 66 |
+
is_causal: If specified, applies a causal mask as attention mask, and ignores
|
| 67 |
+
attn_mask for computing scaled dot product attention.
|
| 68 |
+
Default: ``False``.
|
| 69 |
+
.. warning::
|
| 70 |
+
is_causal is provides a hint that the attn_mask is the
|
| 71 |
+
causal mask.Providing incorrect hints can result in
|
| 72 |
+
incorrect execution, including forward and backward
|
| 73 |
+
compatibility.
|
| 74 |
+
use_separate_proj_weight: the function accept the proj. weights for query, key,
|
| 75 |
+
and value in different forms. If false, in_proj_weight will be used, which is
|
| 76 |
+
a combination of q_proj_weight, k_proj_weight, v_proj_weight.
|
| 77 |
+
q_proj_weight, k_proj_weight, v_proj_weight, in_proj_bias: input projection weight and bias.
|
| 78 |
+
static_k, static_v: static key and value used for attention operators.
|
| 79 |
+
average_attn_weights: If true, indicates that the returned ``attn_weights`` should be averaged across heads.
|
| 80 |
+
Otherwise, ``attn_weights`` are provided separately per head. Note that this flag only has an effect
|
| 81 |
+
when ``need_weights=True.``. Default: True
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
Shape:
|
| 85 |
+
Inputs:
|
| 86 |
+
- query: :math:`(L, E)` or :math:`(L, N, E)` where L is the target sequence length, N is the batch size, E is
|
| 87 |
+
the embedding dimension.
|
| 88 |
+
- key: :math:`(S, E)` or :math:`(S, N, E)`, where S is the source sequence length, N is the batch size, E is
|
| 89 |
+
the embedding dimension.
|
| 90 |
+
- value: :math:`(S, E)` or :math:`(S, N, E)` where S is the source sequence length, N is the batch size, E is
|
| 91 |
+
the embedding dimension.
|
| 92 |
+
- key_padding_mask: :math:`(S)` or :math:`(N, S)` where N is the batch size, S is the source sequence length.
|
| 93 |
+
If a FloatTensor is provided, it will be directly added to the value.
|
| 94 |
+
If a BoolTensor is provided, the positions with the
|
| 95 |
+
value of ``True`` will be ignored while the position with the value of ``False`` will be unchanged.
|
| 96 |
+
- attn_mask: 2D mask :math:`(L, S)` where L is the target sequence length, S is the source sequence length.
|
| 97 |
+
3D mask :math:`(N*num_heads, L, S)` where N is the batch size, L is the target sequence length,
|
| 98 |
+
S is the source sequence length. attn_mask ensures that position i is allowed to attend the unmasked
|
| 99 |
+
positions. If a BoolTensor is provided, positions with ``True``
|
| 100 |
+
are not allowed to attend while ``False`` values will be unchanged. If a FloatTensor
|
| 101 |
+
is provided, it will be added to the attention weight.
|
| 102 |
+
- static_k: :math:`(N*num_heads, S, E/num_heads)`, where S is the source sequence length,
|
| 103 |
+
N is the batch size, E is the embedding dimension. E/num_heads is the head dimension.
|
| 104 |
+
- static_v: :math:`(N*num_heads, S, E/num_heads)`, where S is the source sequence length,
|
| 105 |
+
N is the batch size, E is the embedding dimension. E/num_heads is the head dimension.
|
| 106 |
+
|
| 107 |
+
Outputs:
|
| 108 |
+
- attn_output: :math:`(L, E)` or :math:`(L, N, E)` where L is the target sequence length, N is the batch size,
|
| 109 |
+
E is the embedding dimension.
|
| 110 |
+
- attn_output_weights: Only returned when ``need_weights=True``. If ``average_attn_weights=True``, returns
|
| 111 |
+
attention weights averaged across heads of shape :math:`(L, S)` when input is unbatched or
|
| 112 |
+
:math:`(N, L, S)`, where :math:`N` is the batch size, :math:`L` is the target sequence length, and
|
| 113 |
+
:math:`S` is the source sequence length. If ``average_attn_weights=False``, returns attention weights per
|
| 114 |
+
head of shape :math:`(num_heads, L, S)` when input is unbatched or :math:`(N, num_heads, L, S)`.
|
| 115 |
+
"""
|
| 116 |
+
tens_ops = (
|
| 117 |
+
query,
|
| 118 |
+
key,
|
| 119 |
+
value,
|
| 120 |
+
in_proj_weight,
|
| 121 |
+
in_proj_bias,
|
| 122 |
+
bias_k,
|
| 123 |
+
bias_v,
|
| 124 |
+
out_proj_weight,
|
| 125 |
+
out_proj_bias,
|
| 126 |
+
)
|
| 127 |
+
if has_torch_function(tens_ops):
|
| 128 |
+
return handle_torch_function(
|
| 129 |
+
multi_head_attention_forward,
|
| 130 |
+
tens_ops,
|
| 131 |
+
query,
|
| 132 |
+
key,
|
| 133 |
+
value,
|
| 134 |
+
embed_dim_to_check,
|
| 135 |
+
num_heads,
|
| 136 |
+
in_proj_weight,
|
| 137 |
+
in_proj_bias,
|
| 138 |
+
bias_k,
|
| 139 |
+
bias_v,
|
| 140 |
+
add_zero_attn,
|
| 141 |
+
dropout_p,
|
| 142 |
+
out_proj_weight,
|
| 143 |
+
out_proj_bias,
|
| 144 |
+
training=training,
|
| 145 |
+
key_padding_mask=key_padding_mask,
|
| 146 |
+
need_weights=need_weights,
|
| 147 |
+
attn_mask=attn_mask,
|
| 148 |
+
is_causal=is_causal,
|
| 149 |
+
use_separate_proj_weight=use_separate_proj_weight,
|
| 150 |
+
q_proj_weight=q_proj_weight,
|
| 151 |
+
k_proj_weight=k_proj_weight,
|
| 152 |
+
v_proj_weight=v_proj_weight,
|
| 153 |
+
static_k=static_k,
|
| 154 |
+
static_v=static_v,
|
| 155 |
+
average_attn_weights=average_attn_weights,
|
| 156 |
+
cache=cache,
|
| 157 |
+
)
|
| 158 |
+
|
| 159 |
+
is_batched = _mha_shape_check(
|
| 160 |
+
query, key, value, key_padding_mask, attn_mask, num_heads
|
| 161 |
+
)
|
| 162 |
+
|
| 163 |
+
# For unbatched input, we unsqueeze at the expected batch-dim to pretend that the input
|
| 164 |
+
# is batched, run the computation and before returning squeeze the
|
| 165 |
+
# batch dimension so that the output doesn't carry this temporary batch dimension.
|
| 166 |
+
if not is_batched:
|
| 167 |
+
# unsqueeze if the input is unbatched
|
| 168 |
+
query = query.unsqueeze(1)
|
| 169 |
+
key = key.unsqueeze(1)
|
| 170 |
+
value = value.unsqueeze(1)
|
| 171 |
+
if key_padding_mask is not None:
|
| 172 |
+
key_padding_mask = key_padding_mask.unsqueeze(0)
|
| 173 |
+
|
| 174 |
+
# set up shape vars
|
| 175 |
+
tgt_len, bsz, embed_dim = query.shape
|
| 176 |
+
src_len, _, _ = key.shape
|
| 177 |
+
|
| 178 |
+
key_padding_mask = _canonical_mask(
|
| 179 |
+
mask=key_padding_mask,
|
| 180 |
+
mask_name="key_padding_mask",
|
| 181 |
+
other_type=_none_or_dtype(attn_mask),
|
| 182 |
+
other_name="attn_mask",
|
| 183 |
+
target_type=query.dtype,
|
| 184 |
+
)
|
| 185 |
+
|
| 186 |
+
if is_causal and attn_mask is None:
|
| 187 |
+
raise RuntimeError(
|
| 188 |
+
"Need attn_mask if specifying the is_causal hint. "
|
| 189 |
+
"You may use the Transformer module method "
|
| 190 |
+
"`generate_square_subsequent_mask` to create this mask."
|
| 191 |
+
)
|
| 192 |
+
|
| 193 |
+
if is_causal and key_padding_mask is None and not need_weights:
|
| 194 |
+
# when we have a kpm or need weights, we need attn_mask
|
| 195 |
+
# Otherwise, we use the is_causal hint go as is_causal
|
| 196 |
+
# indicator to SDPA.
|
| 197 |
+
attn_mask = None
|
| 198 |
+
else:
|
| 199 |
+
attn_mask = _canonical_mask(
|
| 200 |
+
mask=attn_mask,
|
| 201 |
+
mask_name="attn_mask",
|
| 202 |
+
other_type=None,
|
| 203 |
+
other_name="",
|
| 204 |
+
target_type=query.dtype,
|
| 205 |
+
check_other=False,
|
| 206 |
+
)
|
| 207 |
+
|
| 208 |
+
if key_padding_mask is not None:
|
| 209 |
+
# We have the attn_mask, and use that to merge kpm into it.
|
| 210 |
+
# Turn off use of is_causal hint, as the merged mask is no
|
| 211 |
+
# longer causal.
|
| 212 |
+
is_causal = False
|
| 213 |
+
|
| 214 |
+
assert (
|
| 215 |
+
embed_dim == embed_dim_to_check
|
| 216 |
+
), f"was expecting embedding dimension of {embed_dim_to_check}, but got {embed_dim}"
|
| 217 |
+
if isinstance(embed_dim, torch.Tensor):
|
| 218 |
+
# embed_dim can be a tensor when JIT tracing
|
| 219 |
+
head_dim = embed_dim.div(num_heads, rounding_mode="trunc")
|
| 220 |
+
else:
|
| 221 |
+
head_dim = embed_dim // num_heads
|
| 222 |
+
assert (
|
| 223 |
+
head_dim * num_heads == embed_dim
|
| 224 |
+
), f"embed_dim {embed_dim} not divisible by num_heads {num_heads}"
|
| 225 |
+
if use_separate_proj_weight:
|
| 226 |
+
# allow MHA to have different embedding dimensions when separate projection weights are used
|
| 227 |
+
assert (
|
| 228 |
+
key.shape[:2] == value.shape[:2]
|
| 229 |
+
), f"key's sequence and batch dims {key.shape[:2]} do not match value's {value.shape[:2]}"
|
| 230 |
+
else:
|
| 231 |
+
assert (
|
| 232 |
+
key.shape == value.shape
|
| 233 |
+
), f"key shape {key.shape} does not match value shape {value.shape}"
|
| 234 |
+
|
| 235 |
+
#
|
| 236 |
+
# compute in-projection
|
| 237 |
+
#
|
| 238 |
+
if not use_separate_proj_weight:
|
| 239 |
+
assert (
|
| 240 |
+
in_proj_weight is not None
|
| 241 |
+
), "use_separate_proj_weight is False but in_proj_weight is None"
|
| 242 |
+
q, k, v = _in_projection_packed(query, key, value, in_proj_weight, in_proj_bias)
|
| 243 |
+
else:
|
| 244 |
+
assert (
|
| 245 |
+
q_proj_weight is not None
|
| 246 |
+
), "use_separate_proj_weight is True but q_proj_weight is None"
|
| 247 |
+
assert (
|
| 248 |
+
k_proj_weight is not None
|
| 249 |
+
), "use_separate_proj_weight is True but k_proj_weight is None"
|
| 250 |
+
assert (
|
| 251 |
+
v_proj_weight is not None
|
| 252 |
+
), "use_separate_proj_weight is True but v_proj_weight is None"
|
| 253 |
+
if in_proj_bias is None:
|
| 254 |
+
b_q = b_k = b_v = None
|
| 255 |
+
else:
|
| 256 |
+
b_q, b_k, b_v = in_proj_bias.chunk(3)
|
| 257 |
+
q, k, v = _in_projection(
|
| 258 |
+
query,
|
| 259 |
+
key,
|
| 260 |
+
value,
|
| 261 |
+
q_proj_weight,
|
| 262 |
+
k_proj_weight,
|
| 263 |
+
v_proj_weight,
|
| 264 |
+
b_q,
|
| 265 |
+
b_k,
|
| 266 |
+
b_v,
|
| 267 |
+
)
|
| 268 |
+
if cache != None:
|
| 269 |
+
if cache["first_infer"] == 1:
|
| 270 |
+
cache["k"][cache["stage"]] = k
|
| 271 |
+
# print(0,cache["k"].shape)
|
| 272 |
+
cache["v"][cache["stage"]] = v
|
| 273 |
+
else: ###12个layer每个都要留自己的cache_kv
|
| 274 |
+
# print(1,cache["k"].shape)
|
| 275 |
+
cache["k"][cache["stage"]] = torch.cat(
|
| 276 |
+
[cache["k"][cache["stage"]], k], 0
|
| 277 |
+
) ##本来时序是1,但是proj的时候可能transpose了所以时序到0维了
|
| 278 |
+
cache["v"][cache["stage"]] = torch.cat([cache["v"][cache["stage"]], v], 0)
|
| 279 |
+
# print(2, cache["k"].shape)
|
| 280 |
+
src_len = cache["k"][cache["stage"]].shape[0]
|
| 281 |
+
k = cache["k"][cache["stage"]]
|
| 282 |
+
v = cache["v"][cache["stage"]]
|
| 283 |
+
# if attn_mask is not None:
|
| 284 |
+
# attn_mask=attn_mask[-1:,]
|
| 285 |
+
# print(attn_mask.shape,attn_mask)
|
| 286 |
+
cache["stage"] = (cache["stage"] + 1) % cache["all_stage"]
|
| 287 |
+
# print(2333,cache)
|
| 288 |
+
# prep attention mask
|
| 289 |
+
|
| 290 |
+
attn_mask = _canonical_mask(
|
| 291 |
+
mask=attn_mask,
|
| 292 |
+
mask_name="attn_mask",
|
| 293 |
+
other_type=None,
|
| 294 |
+
other_name="",
|
| 295 |
+
target_type=q.dtype,
|
| 296 |
+
check_other=False,
|
| 297 |
+
)
|
| 298 |
+
|
| 299 |
+
if attn_mask is not None:
|
| 300 |
+
# ensure attn_mask's dim is 3
|
| 301 |
+
if attn_mask.dim() == 2:
|
| 302 |
+
correct_2d_size = (tgt_len, src_len)
|
| 303 |
+
if attn_mask.shape != correct_2d_size:
|
| 304 |
+
raise RuntimeError(
|
| 305 |
+
f"The shape of the 2D attn_mask is {attn_mask.shape}, but should be {correct_2d_size}."
|
| 306 |
+
)
|
| 307 |
+
attn_mask = attn_mask.unsqueeze(0)
|
| 308 |
+
elif attn_mask.dim() == 3:
|
| 309 |
+
correct_3d_size = (bsz * num_heads, tgt_len, src_len)
|
| 310 |
+
if attn_mask.shape != correct_3d_size:
|
| 311 |
+
raise RuntimeError(
|
| 312 |
+
f"The shape of the 3D attn_mask is {attn_mask.shape}, but should be {correct_3d_size}."
|
| 313 |
+
)
|
| 314 |
+
else:
|
| 315 |
+
raise RuntimeError(
|
| 316 |
+
f"attn_mask's dimension {attn_mask.dim()} is not supported"
|
| 317 |
+
)
|
| 318 |
+
|
| 319 |
+
# add bias along batch dimension (currently second)
|
| 320 |
+
if bias_k is not None and bias_v is not None:
|
| 321 |
+
assert static_k is None, "bias cannot be added to static key."
|
| 322 |
+
assert static_v is None, "bias cannot be added to static value."
|
| 323 |
+
k = torch.cat([k, bias_k.repeat(1, bsz, 1)])
|
| 324 |
+
v = torch.cat([v, bias_v.repeat(1, bsz, 1)])
|
| 325 |
+
if attn_mask is not None:
|
| 326 |
+
attn_mask = pad(attn_mask, (0, 1))
|
| 327 |
+
if key_padding_mask is not None:
|
| 328 |
+
key_padding_mask = pad(key_padding_mask, (0, 1))
|
| 329 |
+
else:
|
| 330 |
+
assert bias_k is None
|
| 331 |
+
assert bias_v is None
|
| 332 |
+
|
| 333 |
+
#
|
| 334 |
+
# reshape q, k, v for multihead attention and make em batch first
|
| 335 |
+
#
|
| 336 |
+
q = q.view(tgt_len, bsz * num_heads, head_dim).transpose(0, 1)
|
| 337 |
+
if static_k is None:
|
| 338 |
+
k = k.view(k.shape[0], bsz * num_heads, head_dim).transpose(0, 1)
|
| 339 |
+
else:
|
| 340 |
+
# TODO finish disentangling control flow so we don't do in-projections when statics are passed
|
| 341 |
+
assert (
|
| 342 |
+
static_k.size(0) == bsz * num_heads
|
| 343 |
+
), f"expecting static_k.size(0) of {bsz * num_heads}, but got {static_k.size(0)}"
|
| 344 |
+
assert (
|
| 345 |
+
static_k.size(2) == head_dim
|
| 346 |
+
), f"expecting static_k.size(2) of {head_dim}, but got {static_k.size(2)}"
|
| 347 |
+
k = static_k
|
| 348 |
+
if static_v is None:
|
| 349 |
+
v = v.view(v.shape[0], bsz * num_heads, head_dim).transpose(0, 1)
|
| 350 |
+
else:
|
| 351 |
+
# TODO finish disentangling control flow so we don't do in-projections when statics are passed
|
| 352 |
+
assert (
|
| 353 |
+
static_v.size(0) == bsz * num_heads
|
| 354 |
+
), f"expecting static_v.size(0) of {bsz * num_heads}, but got {static_v.size(0)}"
|
| 355 |
+
assert (
|
| 356 |
+
static_v.size(2) == head_dim
|
| 357 |
+
), f"expecting static_v.size(2) of {head_dim}, but got {static_v.size(2)}"
|
| 358 |
+
v = static_v
|
| 359 |
+
|
| 360 |
+
# add zero attention along batch dimension (now first)
|
| 361 |
+
if add_zero_attn:
|
| 362 |
+
zero_attn_shape = (bsz * num_heads, 1, head_dim)
|
| 363 |
+
k = torch.cat(
|
| 364 |
+
[k, torch.zeros(zero_attn_shape, dtype=k.dtype, device=k.device)], dim=1
|
| 365 |
+
)
|
| 366 |
+
v = torch.cat(
|
| 367 |
+
[v, torch.zeros(zero_attn_shape, dtype=v.dtype, device=v.device)], dim=1
|
| 368 |
+
)
|
| 369 |
+
if attn_mask is not None:
|
| 370 |
+
attn_mask = pad(attn_mask, (0, 1))
|
| 371 |
+
if key_padding_mask is not None:
|
| 372 |
+
key_padding_mask = pad(key_padding_mask, (0, 1))
|
| 373 |
+
|
| 374 |
+
# update source sequence length after adjustments
|
| 375 |
+
src_len = k.size(1)
|
| 376 |
+
|
| 377 |
+
# merge key padding and attention masks
|
| 378 |
+
if key_padding_mask is not None:
|
| 379 |
+
assert key_padding_mask.shape == (
|
| 380 |
+
bsz,
|
| 381 |
+
src_len,
|
| 382 |
+
), f"expecting key_padding_mask shape of {(bsz, src_len)}, but got {key_padding_mask.shape}"
|
| 383 |
+
key_padding_mask = (
|
| 384 |
+
key_padding_mask.view(bsz, 1, 1, src_len)
|
| 385 |
+
.expand(-1, num_heads, -1, -1)
|
| 386 |
+
.reshape(bsz * num_heads, 1, src_len)
|
| 387 |
+
)
|
| 388 |
+
if attn_mask is None:
|
| 389 |
+
attn_mask = key_padding_mask
|
| 390 |
+
else:
|
| 391 |
+
attn_mask = attn_mask + key_padding_mask
|
| 392 |
+
|
| 393 |
+
# adjust dropout probability
|
| 394 |
+
if not training:
|
| 395 |
+
dropout_p = 0.0
|
| 396 |
+
|
| 397 |
+
#
|
| 398 |
+
# (deep breath) calculate attention and out projection
|
| 399 |
+
#
|
| 400 |
+
|
| 401 |
+
if need_weights:
|
| 402 |
+
B, Nt, E = q.shape
|
| 403 |
+
q_scaled = q / math.sqrt(E)
|
| 404 |
+
|
| 405 |
+
assert not (
|
| 406 |
+
is_causal and attn_mask is None
|
| 407 |
+
), "FIXME: is_causal not implemented for need_weights"
|
| 408 |
+
|
| 409 |
+
if attn_mask is not None:
|
| 410 |
+
attn_output_weights = torch.baddbmm(
|
| 411 |
+
attn_mask, q_scaled, k.transpose(-2, -1)
|
| 412 |
+
)
|
| 413 |
+
else:
|
| 414 |
+
attn_output_weights = torch.bmm(q_scaled, k.transpose(-2, -1))
|
| 415 |
+
attn_output_weights = softmax(attn_output_weights, dim=-1)
|
| 416 |
+
if dropout_p > 0.0:
|
| 417 |
+
attn_output_weights = dropout(attn_output_weights, p=dropout_p)
|
| 418 |
+
|
| 419 |
+
attn_output = torch.bmm(attn_output_weights, v)
|
| 420 |
+
|
| 421 |
+
attn_output = (
|
| 422 |
+
attn_output.transpose(0, 1).contiguous().view(tgt_len * bsz, embed_dim)
|
| 423 |
+
)
|
| 424 |
+
attn_output = linear(attn_output, out_proj_weight, out_proj_bias)
|
| 425 |
+
attn_output = attn_output.view(tgt_len, bsz, attn_output.size(1))
|
| 426 |
+
|
| 427 |
+
# optionally average attention weights over heads
|
| 428 |
+
attn_output_weights = attn_output_weights.view(bsz, num_heads, tgt_len, src_len)
|
| 429 |
+
if average_attn_weights:
|
| 430 |
+
attn_output_weights = attn_output_weights.mean(dim=1)
|
| 431 |
+
|
| 432 |
+
if not is_batched:
|
| 433 |
+
# squeeze the output if input was unbatched
|
| 434 |
+
attn_output = attn_output.squeeze(1)
|
| 435 |
+
attn_output_weights = attn_output_weights.squeeze(0)
|
| 436 |
+
return attn_output, attn_output_weights
|
| 437 |
+
else:
|
| 438 |
+
# attn_mask can be either (L,S) or (N*num_heads, L, S)
|
| 439 |
+
# if attn_mask's shape is (1, L, S) we need to unsqueeze to (1, 1, L, S)
|
| 440 |
+
# in order to match the input for SDPA of (N, num_heads, L, S)
|
| 441 |
+
if attn_mask is not None:
|
| 442 |
+
if attn_mask.size(0) == 1 and attn_mask.dim() == 3:
|
| 443 |
+
attn_mask = attn_mask.unsqueeze(0)
|
| 444 |
+
else:
|
| 445 |
+
attn_mask = attn_mask.view(bsz, num_heads, -1, src_len)
|
| 446 |
+
|
| 447 |
+
q = q.view(bsz, num_heads, tgt_len, head_dim)
|
| 448 |
+
k = k.view(bsz, num_heads, src_len, head_dim)
|
| 449 |
+
v = v.view(bsz, num_heads, src_len, head_dim)
|
| 450 |
+
|
| 451 |
+
attn_output = scaled_dot_product_attention(
|
| 452 |
+
q, k, v, attn_mask, dropout_p, is_causal
|
| 453 |
+
)
|
| 454 |
+
attn_output = (
|
| 455 |
+
attn_output.permute(2, 0, 1, 3).contiguous().view(bsz * tgt_len, embed_dim)
|
| 456 |
+
)
|
| 457 |
+
|
| 458 |
+
attn_output = linear(attn_output, out_proj_weight, out_proj_bias)
|
| 459 |
+
attn_output = attn_output.view(tgt_len, bsz, attn_output.size(1))
|
| 460 |
+
if not is_batched:
|
| 461 |
+
# squeeze the output if input was unbatched
|
| 462 |
+
attn_output = attn_output.squeeze(1)
|
| 463 |
+
return attn_output, None
|
GPT_SoVITS/AR/modules/patched_mha_with_cache_onnx.py
ADDED
|
@@ -0,0 +1,92 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from torch.nn.functional import *
|
| 2 |
+
from torch.nn.functional import (
|
| 3 |
+
_mha_shape_check,
|
| 4 |
+
_canonical_mask,
|
| 5 |
+
_none_or_dtype,
|
| 6 |
+
_in_projection_packed,
|
| 7 |
+
)
|
| 8 |
+
|
| 9 |
+
def multi_head_attention_forward_patched(
|
| 10 |
+
query,
|
| 11 |
+
key,
|
| 12 |
+
value,
|
| 13 |
+
embed_dim_to_check: int,
|
| 14 |
+
num_heads: int,
|
| 15 |
+
in_proj_weight,
|
| 16 |
+
in_proj_bias: Optional[Tensor],
|
| 17 |
+
bias_k: Optional[Tensor],
|
| 18 |
+
bias_v: Optional[Tensor],
|
| 19 |
+
add_zero_attn: bool,
|
| 20 |
+
dropout_p: float,
|
| 21 |
+
out_proj_weight: Tensor,
|
| 22 |
+
out_proj_bias: Optional[Tensor],
|
| 23 |
+
training: bool = True,
|
| 24 |
+
key_padding_mask: Optional[Tensor] = None,
|
| 25 |
+
need_weights: bool = True,
|
| 26 |
+
attn_mask: Optional[Tensor] = None,
|
| 27 |
+
use_separate_proj_weight: bool = False,
|
| 28 |
+
q_proj_weight: Optional[Tensor] = None,
|
| 29 |
+
k_proj_weight: Optional[Tensor] = None,
|
| 30 |
+
v_proj_weight: Optional[Tensor] = None,
|
| 31 |
+
static_k: Optional[Tensor] = None,
|
| 32 |
+
static_v: Optional[Tensor] = None,
|
| 33 |
+
average_attn_weights: bool = True,
|
| 34 |
+
is_causal: bool = False,
|
| 35 |
+
cache=None,
|
| 36 |
+
) -> Tuple[Tensor, Optional[Tensor]]:
|
| 37 |
+
|
| 38 |
+
# set up shape vars
|
| 39 |
+
_, _, embed_dim = query.shape
|
| 40 |
+
attn_mask = _canonical_mask(
|
| 41 |
+
mask=attn_mask,
|
| 42 |
+
mask_name="attn_mask",
|
| 43 |
+
other_type=None,
|
| 44 |
+
other_name="",
|
| 45 |
+
target_type=query.dtype,
|
| 46 |
+
check_other=False,
|
| 47 |
+
)
|
| 48 |
+
head_dim = embed_dim // num_heads
|
| 49 |
+
|
| 50 |
+
proj_qkv = linear(query, in_proj_weight, in_proj_bias)
|
| 51 |
+
proj_qkv = proj_qkv.unflatten(-1, (3, query.size(-1))).unsqueeze(0).transpose(0, -2).squeeze(-2).contiguous()
|
| 52 |
+
q, k, v = proj_qkv[0], proj_qkv[1], proj_qkv[2]
|
| 53 |
+
|
| 54 |
+
if cache["first_infer"] == 1:
|
| 55 |
+
cache["k"][cache["stage"]] = k
|
| 56 |
+
cache["v"][cache["stage"]] = v
|
| 57 |
+
else:
|
| 58 |
+
cache["k"][cache["stage"]] = torch.cat([cache["k"][cache["stage"]][:-1], k], 0)
|
| 59 |
+
cache["v"][cache["stage"]] = torch.cat([cache["v"][cache["stage"]][:-1], v], 0)
|
| 60 |
+
k = cache["k"][cache["stage"]]
|
| 61 |
+
v = cache["v"][cache["stage"]]
|
| 62 |
+
cache["stage"] = (cache["stage"] + 1) % cache["all_stage"]
|
| 63 |
+
|
| 64 |
+
attn_mask = _canonical_mask(
|
| 65 |
+
mask=attn_mask,
|
| 66 |
+
mask_name="attn_mask",
|
| 67 |
+
other_type=None,
|
| 68 |
+
other_name="",
|
| 69 |
+
target_type=q.dtype,
|
| 70 |
+
check_other=False,
|
| 71 |
+
)
|
| 72 |
+
attn_mask = attn_mask.unsqueeze(0)
|
| 73 |
+
|
| 74 |
+
q = q.view(-1, num_heads, head_dim).transpose(0, 1)
|
| 75 |
+
k = k.view(-1, num_heads, head_dim).transpose(0, 1)
|
| 76 |
+
v = v.view(-1, num_heads, head_dim).transpose(0, 1)
|
| 77 |
+
|
| 78 |
+
dropout_p = 0.0
|
| 79 |
+
attn_mask = attn_mask.unsqueeze(0)
|
| 80 |
+
q = q.view(num_heads, -1, head_dim).unsqueeze(0)
|
| 81 |
+
k = k.view(num_heads, -1, head_dim).unsqueeze(0)
|
| 82 |
+
v = v.view(num_heads, -1, head_dim).unsqueeze(0)
|
| 83 |
+
attn_output = scaled_dot_product_attention(
|
| 84 |
+
q, k, v, attn_mask, dropout_p, is_causal
|
| 85 |
+
)
|
| 86 |
+
attn_output = (
|
| 87 |
+
attn_output.permute(2, 0, 1, 3).contiguous().view(-1, embed_dim)
|
| 88 |
+
)
|
| 89 |
+
attn_output = linear(attn_output, out_proj_weight, out_proj_bias)
|
| 90 |
+
attn_output = attn_output.view(-1, 1, attn_output.size(1))
|
| 91 |
+
|
| 92 |
+
return attn_output
|
GPT_SoVITS/AR/modules/scaling.py
ADDED
|
@@ -0,0 +1,335 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright 2022 Xiaomi Corp. (authors: Daniel Povey)
|
| 2 |
+
#
|
| 3 |
+
# See ../../../../LICENSE for clarification regarding multiple authors
|
| 4 |
+
#
|
| 5 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 6 |
+
# you may not use this file except in compliance with the License.
|
| 7 |
+
# You may obtain a copy of the License at
|
| 8 |
+
#
|
| 9 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 10 |
+
#
|
| 11 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 12 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 13 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 14 |
+
# See the License for the specific language governing permissions and
|
| 15 |
+
# limitations under the License.
|
| 16 |
+
import logging
|
| 17 |
+
import math
|
| 18 |
+
import random
|
| 19 |
+
from typing import Optional
|
| 20 |
+
from typing import Tuple
|
| 21 |
+
from typing import Union
|
| 22 |
+
|
| 23 |
+
import torch
|
| 24 |
+
import torch.nn as nn
|
| 25 |
+
from torch import Tensor
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class DoubleSwishFunction(torch.autograd.Function):
|
| 29 |
+
"""
|
| 30 |
+
double_swish(x) = x * torch.sigmoid(x-1)
|
| 31 |
+
This is a definition, originally motivated by its close numerical
|
| 32 |
+
similarity to swish(swish(x)), where swish(x) = x * sigmoid(x).
|
| 33 |
+
|
| 34 |
+
Memory-efficient derivative computation:
|
| 35 |
+
double_swish(x) = x * s, where s(x) = torch.sigmoid(x-1)
|
| 36 |
+
double_swish'(x) = d/dx double_swish(x) = x * s'(x) + x' * s(x) = x * s'(x) + s(x).
|
| 37 |
+
Now, s'(x) = s(x) * (1-s(x)).
|
| 38 |
+
double_swish'(x) = x * s'(x) + s(x).
|
| 39 |
+
= x * s(x) * (1-s(x)) + s(x).
|
| 40 |
+
= double_swish(x) * (1-s(x)) + s(x)
|
| 41 |
+
... so we just need to remember s(x) but not x itself.
|
| 42 |
+
"""
|
| 43 |
+
|
| 44 |
+
@staticmethod
|
| 45 |
+
def forward(ctx, x: Tensor) -> Tensor:
|
| 46 |
+
requires_grad = x.requires_grad
|
| 47 |
+
x_dtype = x.dtype
|
| 48 |
+
if x.dtype == torch.float16:
|
| 49 |
+
x = x.to(torch.float32)
|
| 50 |
+
|
| 51 |
+
s = torch.sigmoid(x - 1.0)
|
| 52 |
+
y = x * s
|
| 53 |
+
|
| 54 |
+
if requires_grad:
|
| 55 |
+
deriv = y * (1 - s) + s
|
| 56 |
+
# notes on derivative of x * sigmoid(x - 1):
|
| 57 |
+
# https://www.wolframalpha.com/input?i=d%2Fdx+%28x+*+sigmoid%28x-1%29%29
|
| 58 |
+
# min \simeq -0.043638. Take floor as -0.043637 so it's a lower bund
|
| 59 |
+
# max \simeq 1.1990. Take ceil to be 1.2 so it's an upper bound.
|
| 60 |
+
# the combination of "+ torch.rand_like(deriv)" and casting to torch.uint8 (which
|
| 61 |
+
# floors), should be expectation-preserving.
|
| 62 |
+
floor = -0.043637
|
| 63 |
+
ceil = 1.2
|
| 64 |
+
d_scaled = (deriv - floor) * (255.0 / (ceil - floor)) + torch.rand_like(
|
| 65 |
+
deriv
|
| 66 |
+
)
|
| 67 |
+
if __name__ == "__main__":
|
| 68 |
+
# for self-testing only.
|
| 69 |
+
assert d_scaled.min() >= 0.0
|
| 70 |
+
assert d_scaled.max() < 256.0
|
| 71 |
+
d_int = d_scaled.to(torch.uint8)
|
| 72 |
+
ctx.save_for_backward(d_int)
|
| 73 |
+
if x.dtype == torch.float16 or torch.is_autocast_enabled():
|
| 74 |
+
y = y.to(torch.float16)
|
| 75 |
+
return y
|
| 76 |
+
|
| 77 |
+
@staticmethod
|
| 78 |
+
def backward(ctx, y_grad: Tensor) -> Tensor:
|
| 79 |
+
(d,) = ctx.saved_tensors
|
| 80 |
+
# the same constants as used in forward pass.
|
| 81 |
+
floor = -0.043637
|
| 82 |
+
ceil = 1.2
|
| 83 |
+
d = d * ((ceil - floor) / 255.0) + floor
|
| 84 |
+
return y_grad * d
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
class DoubleSwish(torch.nn.Module):
|
| 88 |
+
def forward(self, x: Tensor) -> Tensor:
|
| 89 |
+
"""Return double-swish activation function which is an approximation to Swish(Swish(x)),
|
| 90 |
+
that we approximate closely with x * sigmoid(x-1).
|
| 91 |
+
"""
|
| 92 |
+
if torch.jit.is_scripting() or torch.jit.is_tracing():
|
| 93 |
+
return x * torch.sigmoid(x - 1.0)
|
| 94 |
+
return DoubleSwishFunction.apply(x)
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
class ActivationBalancerFunction(torch.autograd.Function):
|
| 98 |
+
@staticmethod
|
| 99 |
+
def forward(
|
| 100 |
+
ctx,
|
| 101 |
+
x: Tensor,
|
| 102 |
+
scale_factor: Tensor,
|
| 103 |
+
sign_factor: Optional[Tensor],
|
| 104 |
+
channel_dim: int,
|
| 105 |
+
) -> Tensor:
|
| 106 |
+
if channel_dim < 0:
|
| 107 |
+
channel_dim += x.ndim
|
| 108 |
+
ctx.channel_dim = channel_dim
|
| 109 |
+
xgt0 = x > 0
|
| 110 |
+
if sign_factor is None:
|
| 111 |
+
ctx.save_for_backward(xgt0, scale_factor)
|
| 112 |
+
else:
|
| 113 |
+
ctx.save_for_backward(xgt0, scale_factor, sign_factor)
|
| 114 |
+
return x
|
| 115 |
+
|
| 116 |
+
@staticmethod
|
| 117 |
+
def backward(ctx, x_grad: Tensor) -> Tuple[Tensor, None, None, None]:
|
| 118 |
+
if len(ctx.saved_tensors) == 3:
|
| 119 |
+
xgt0, scale_factor, sign_factor = ctx.saved_tensors
|
| 120 |
+
for _ in range(ctx.channel_dim, x_grad.ndim - 1):
|
| 121 |
+
scale_factor = scale_factor.unsqueeze(-1)
|
| 122 |
+
sign_factor = sign_factor.unsqueeze(-1)
|
| 123 |
+
factor = sign_factor + scale_factor * (xgt0.to(x_grad.dtype) - 0.5)
|
| 124 |
+
else:
|
| 125 |
+
xgt0, scale_factor = ctx.saved_tensors
|
| 126 |
+
for _ in range(ctx.channel_dim, x_grad.ndim - 1):
|
| 127 |
+
scale_factor = scale_factor.unsqueeze(-1)
|
| 128 |
+
factor = scale_factor * (xgt0.to(x_grad.dtype) - 0.5)
|
| 129 |
+
neg_delta_grad = x_grad.abs() * factor
|
| 130 |
+
return (
|
| 131 |
+
x_grad - neg_delta_grad,
|
| 132 |
+
None,
|
| 133 |
+
None,
|
| 134 |
+
None,
|
| 135 |
+
)
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
def _compute_scale_factor(
|
| 139 |
+
x: Tensor,
|
| 140 |
+
channel_dim: int,
|
| 141 |
+
min_abs: float,
|
| 142 |
+
max_abs: float,
|
| 143 |
+
gain_factor: float,
|
| 144 |
+
max_factor: float,
|
| 145 |
+
) -> Tensor:
|
| 146 |
+
if channel_dim < 0:
|
| 147 |
+
channel_dim += x.ndim
|
| 148 |
+
sum_dims = [d for d in range(x.ndim) if d != channel_dim]
|
| 149 |
+
x_abs_mean = torch.mean(x.abs(), dim=sum_dims).to(torch.float32)
|
| 150 |
+
|
| 151 |
+
if min_abs == 0.0:
|
| 152 |
+
below_threshold = 0.0
|
| 153 |
+
else:
|
| 154 |
+
# below_threshold is 0 if x_abs_mean > min_abs, can be at most max_factor if
|
| 155 |
+
# x_abs)_mean , min_abs.
|
| 156 |
+
below_threshold = ((min_abs - x_abs_mean) * (gain_factor / min_abs)).clamp(
|
| 157 |
+
min=0, max=max_factor
|
| 158 |
+
)
|
| 159 |
+
|
| 160 |
+
above_threshold = ((x_abs_mean - max_abs) * (gain_factor / max_abs)).clamp(
|
| 161 |
+
min=0, max=max_factor
|
| 162 |
+
)
|
| 163 |
+
|
| 164 |
+
return below_threshold - above_threshold
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
def _compute_sign_factor(
|
| 168 |
+
x: Tensor,
|
| 169 |
+
channel_dim: int,
|
| 170 |
+
min_positive: float,
|
| 171 |
+
max_positive: float,
|
| 172 |
+
gain_factor: float,
|
| 173 |
+
max_factor: float,
|
| 174 |
+
) -> Tensor:
|
| 175 |
+
if channel_dim < 0:
|
| 176 |
+
channel_dim += x.ndim
|
| 177 |
+
sum_dims = [d for d in range(x.ndim) if d != channel_dim]
|
| 178 |
+
proportion_positive = torch.mean((x > 0).to(torch.float32), dim=sum_dims)
|
| 179 |
+
if min_positive == 0.0:
|
| 180 |
+
factor1 = 0.0
|
| 181 |
+
else:
|
| 182 |
+
# 0 if proportion_positive >= min_positive, else can be
|
| 183 |
+
# as large as max_factor.
|
| 184 |
+
factor1 = (
|
| 185 |
+
(min_positive - proportion_positive) * (gain_factor / min_positive)
|
| 186 |
+
).clamp_(min=0, max=max_factor)
|
| 187 |
+
|
| 188 |
+
if max_positive == 1.0:
|
| 189 |
+
factor2 = 0.0
|
| 190 |
+
else:
|
| 191 |
+
# 0 if self.proportion_positive <= max_positive, else can be
|
| 192 |
+
# as large as -max_factor.
|
| 193 |
+
factor2 = (
|
| 194 |
+
(proportion_positive - max_positive) * (gain_factor / (1.0 - max_positive))
|
| 195 |
+
).clamp_(min=0, max=max_factor)
|
| 196 |
+
sign_factor = factor1 - factor2
|
| 197 |
+
# require min_positive != 0 or max_positive != 1:
|
| 198 |
+
assert not isinstance(sign_factor, float)
|
| 199 |
+
return sign_factor
|
| 200 |
+
|
| 201 |
+
|
| 202 |
+
class ActivationBalancer(torch.nn.Module):
|
| 203 |
+
"""
|
| 204 |
+
Modifies the backpropped derivatives of a function to try to encourage, for
|
| 205 |
+
each channel, that it is positive at least a proportion `threshold` of the
|
| 206 |
+
time. It does this by multiplying negative derivative values by up to
|
| 207 |
+
(1+max_factor), and positive derivative values by up to (1-max_factor),
|
| 208 |
+
interpolated from 1 at the threshold to those extremal values when none
|
| 209 |
+
of the inputs are positive.
|
| 210 |
+
|
| 211 |
+
Args:
|
| 212 |
+
num_channels: the number of channels
|
| 213 |
+
channel_dim: the dimension/axis corresponding to the channel, e.g.
|
| 214 |
+
-1, 0, 1, 2; will be interpreted as an offset from x.ndim if negative.
|
| 215 |
+
min_positive: the minimum, per channel, of the proportion of the time
|
| 216 |
+
that (x > 0), below which we start to modify the derivatives.
|
| 217 |
+
max_positive: the maximum, per channel, of the proportion of the time
|
| 218 |
+
that (x > 0), above which we start to modify the derivatives.
|
| 219 |
+
max_factor: the maximum factor by which we modify the derivatives for
|
| 220 |
+
either the sign constraint or the magnitude constraint;
|
| 221 |
+
e.g. with max_factor=0.02, the the derivatives would be multiplied by
|
| 222 |
+
values in the range [0.98..1.02].
|
| 223 |
+
sign_gain_factor: determines the 'gain' with which we increase the
|
| 224 |
+
change in gradient once the constraints on min_positive and max_positive
|
| 225 |
+
are violated.
|
| 226 |
+
scale_gain_factor: determines the 'gain' with which we increase the
|
| 227 |
+
change in gradient once the constraints on min_abs and max_abs
|
| 228 |
+
are violated.
|
| 229 |
+
min_abs: the minimum average-absolute-value difference from the mean
|
| 230 |
+
value per channel, which we allow, before we start to modify
|
| 231 |
+
the derivatives to prevent this.
|
| 232 |
+
max_abs: the maximum average-absolute-value difference from the mean
|
| 233 |
+
value per channel, which we allow, before we start to modify
|
| 234 |
+
the derivatives to prevent this.
|
| 235 |
+
min_prob: determines the minimum probability with which we modify the
|
| 236 |
+
gradients for the {min,max}_positive and {min,max}_abs constraints,
|
| 237 |
+
on each forward(). This is done randomly to prevent all layers
|
| 238 |
+
from doing it at the same time. Early in training we may use
|
| 239 |
+
higher probabilities than this; it will decay to this value.
|
| 240 |
+
"""
|
| 241 |
+
|
| 242 |
+
def __init__(
|
| 243 |
+
self,
|
| 244 |
+
num_channels: int,
|
| 245 |
+
channel_dim: int,
|
| 246 |
+
min_positive: float = 0.05,
|
| 247 |
+
max_positive: float = 0.95,
|
| 248 |
+
max_factor: float = 0.04,
|
| 249 |
+
sign_gain_factor: float = 0.01,
|
| 250 |
+
scale_gain_factor: float = 0.02,
|
| 251 |
+
min_abs: float = 0.2,
|
| 252 |
+
max_abs: float = 100.0,
|
| 253 |
+
min_prob: float = 0.1,
|
| 254 |
+
):
|
| 255 |
+
super(ActivationBalancer, self).__init__()
|
| 256 |
+
self.num_channels = num_channels
|
| 257 |
+
self.channel_dim = channel_dim
|
| 258 |
+
self.min_positive = min_positive
|
| 259 |
+
self.max_positive = max_positive
|
| 260 |
+
self.max_factor = max_factor
|
| 261 |
+
self.min_abs = min_abs
|
| 262 |
+
self.max_abs = max_abs
|
| 263 |
+
self.min_prob = min_prob
|
| 264 |
+
self.sign_gain_factor = sign_gain_factor
|
| 265 |
+
self.scale_gain_factor = scale_gain_factor
|
| 266 |
+
|
| 267 |
+
# count measures how many times the forward() function has been called.
|
| 268 |
+
# We occasionally sync this to a tensor called `count`, that exists to
|
| 269 |
+
# make sure it is synced to disk when we load and save the model.
|
| 270 |
+
self.cpu_count = 0
|
| 271 |
+
self.register_buffer("count", torch.tensor(0, dtype=torch.int64))
|
| 272 |
+
|
| 273 |
+
def forward(self, x: Tensor) -> Tensor:
|
| 274 |
+
if torch.jit.is_scripting() or not x.requires_grad or torch.jit.is_tracing():
|
| 275 |
+
return _no_op(x)
|
| 276 |
+
|
| 277 |
+
count = self.cpu_count
|
| 278 |
+
self.cpu_count += 1
|
| 279 |
+
|
| 280 |
+
if random.random() < 0.01:
|
| 281 |
+
# Occasionally sync self.cpu_count with self.count.
|
| 282 |
+
# count affects the decay of 'prob'. don't do this on every iter,
|
| 283 |
+
# because syncing with the GPU is slow.
|
| 284 |
+
self.cpu_count = max(self.cpu_count, self.count.item())
|
| 285 |
+
self.count.fill_(self.cpu_count)
|
| 286 |
+
|
| 287 |
+
# the prob of doing some work exponentially decreases from 0.5 till it hits
|
| 288 |
+
# a floor at min_prob (==0.1, by default)
|
| 289 |
+
prob = max(self.min_prob, 0.5 ** (1 + (count / 4000.0)))
|
| 290 |
+
|
| 291 |
+
if random.random() < prob:
|
| 292 |
+
sign_gain_factor = 0.5
|
| 293 |
+
if self.min_positive != 0.0 or self.max_positive != 1.0:
|
| 294 |
+
sign_factor = _compute_sign_factor(
|
| 295 |
+
x,
|
| 296 |
+
self.channel_dim,
|
| 297 |
+
self.min_positive,
|
| 298 |
+
self.max_positive,
|
| 299 |
+
gain_factor=self.sign_gain_factor / prob,
|
| 300 |
+
max_factor=self.max_factor,
|
| 301 |
+
)
|
| 302 |
+
else:
|
| 303 |
+
sign_factor = None
|
| 304 |
+
|
| 305 |
+
scale_factor = _compute_scale_factor(
|
| 306 |
+
x.detach(),
|
| 307 |
+
self.channel_dim,
|
| 308 |
+
min_abs=self.min_abs,
|
| 309 |
+
max_abs=self.max_abs,
|
| 310 |
+
gain_factor=self.scale_gain_factor / prob,
|
| 311 |
+
max_factor=self.max_factor,
|
| 312 |
+
)
|
| 313 |
+
return ActivationBalancerFunction.apply(
|
| 314 |
+
x,
|
| 315 |
+
scale_factor,
|
| 316 |
+
sign_factor,
|
| 317 |
+
self.channel_dim,
|
| 318 |
+
)
|
| 319 |
+
else:
|
| 320 |
+
return _no_op(x)
|
| 321 |
+
|
| 322 |
+
|
| 323 |
+
def BalancedDoubleSwish(
|
| 324 |
+
d_model, channel_dim=-1, max_abs=10.0, min_prob=0.25
|
| 325 |
+
) -> nn.Sequential:
|
| 326 |
+
"""
|
| 327 |
+
ActivationBalancer -> DoubleSwish
|
| 328 |
+
"""
|
| 329 |
+
balancer = ActivationBalancer(
|
| 330 |
+
d_model, channel_dim=channel_dim, max_abs=max_abs, min_prob=min_prob
|
| 331 |
+
)
|
| 332 |
+
return nn.Sequential(
|
| 333 |
+
balancer,
|
| 334 |
+
DoubleSwish(),
|
| 335 |
+
)
|
GPT_SoVITS/AR/modules/transformer.py
ADDED
|
@@ -0,0 +1,378 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/lifeiteng/vall-e/blob/main/valle/modules/transformer.py
|
| 2 |
+
import copy
|
| 3 |
+
import numbers
|
| 4 |
+
from functools import partial
|
| 5 |
+
from typing import Any
|
| 6 |
+
from typing import Callable
|
| 7 |
+
from typing import List
|
| 8 |
+
from typing import Optional
|
| 9 |
+
from typing import Tuple
|
| 10 |
+
from typing import Union
|
| 11 |
+
|
| 12 |
+
import torch
|
| 13 |
+
from AR.modules.activation import MultiheadAttention
|
| 14 |
+
from AR.modules.scaling import BalancedDoubleSwish
|
| 15 |
+
from torch import nn
|
| 16 |
+
from torch import Tensor
|
| 17 |
+
from torch.nn import functional as F
|
| 18 |
+
|
| 19 |
+
_shape_t = Union[int, List[int], torch.Size]
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
class LayerNorm(nn.Module):
|
| 23 |
+
__constants__ = ["normalized_shape", "eps", "elementwise_affine"]
|
| 24 |
+
normalized_shape: Tuple[int, ...]
|
| 25 |
+
eps: float
|
| 26 |
+
elementwise_affine: bool
|
| 27 |
+
|
| 28 |
+
def __init__(
|
| 29 |
+
self,
|
| 30 |
+
normalized_shape: _shape_t,
|
| 31 |
+
eps: float = 1e-5,
|
| 32 |
+
elementwise_affine: bool = True,
|
| 33 |
+
device=None,
|
| 34 |
+
dtype=None,
|
| 35 |
+
) -> None:
|
| 36 |
+
factory_kwargs = {"device": device, "dtype": dtype}
|
| 37 |
+
super(LayerNorm, self).__init__()
|
| 38 |
+
if isinstance(normalized_shape, numbers.Integral):
|
| 39 |
+
# mypy error: incompatible types in assignment
|
| 40 |
+
normalized_shape = (normalized_shape,) # type: ignore[assignment]
|
| 41 |
+
self.normalized_shape = tuple(normalized_shape) # type: ignore[arg-type]
|
| 42 |
+
self.eps = eps
|
| 43 |
+
self.elementwise_affine = elementwise_affine
|
| 44 |
+
if self.elementwise_affine:
|
| 45 |
+
self.weight = nn.Parameter(
|
| 46 |
+
torch.empty(self.normalized_shape, **factory_kwargs)
|
| 47 |
+
)
|
| 48 |
+
self.bias = nn.Parameter(
|
| 49 |
+
torch.empty(self.normalized_shape, **factory_kwargs)
|
| 50 |
+
)
|
| 51 |
+
else:
|
| 52 |
+
self.register_parameter("weight", None)
|
| 53 |
+
self.register_parameter("bias", None)
|
| 54 |
+
|
| 55 |
+
self.reset_parameters()
|
| 56 |
+
|
| 57 |
+
def reset_parameters(self) -> None:
|
| 58 |
+
if self.elementwise_affine:
|
| 59 |
+
nn.init.ones_(self.weight)
|
| 60 |
+
nn.init.zeros_(self.bias)
|
| 61 |
+
|
| 62 |
+
def forward(self, input: Tensor, embedding: Any = None) -> Tensor:
|
| 63 |
+
if isinstance(input, tuple):
|
| 64 |
+
input, embedding = input
|
| 65 |
+
return (
|
| 66 |
+
F.layer_norm(
|
| 67 |
+
input,
|
| 68 |
+
self.normalized_shape,
|
| 69 |
+
self.weight,
|
| 70 |
+
self.bias,
|
| 71 |
+
self.eps,
|
| 72 |
+
),
|
| 73 |
+
embedding,
|
| 74 |
+
)
|
| 75 |
+
|
| 76 |
+
assert embedding is None
|
| 77 |
+
return F.layer_norm(
|
| 78 |
+
input, self.normalized_shape, self.weight, self.bias, self.eps
|
| 79 |
+
)
|
| 80 |
+
|
| 81 |
+
def extra_repr(self) -> str:
|
| 82 |
+
return (
|
| 83 |
+
"{normalized_shape}, eps={eps}, "
|
| 84 |
+
"elementwise_affine={elementwise_affine}".format(**self.__dict__)
|
| 85 |
+
)
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
class IdentityNorm(nn.Module):
|
| 89 |
+
def __init__(
|
| 90 |
+
self,
|
| 91 |
+
d_model: int,
|
| 92 |
+
eps: float = 1e-5,
|
| 93 |
+
device=None,
|
| 94 |
+
dtype=None,
|
| 95 |
+
) -> None:
|
| 96 |
+
super(IdentityNorm, self).__init__()
|
| 97 |
+
|
| 98 |
+
def forward(self, input: Tensor, embedding: Any = None) -> Tensor:
|
| 99 |
+
if isinstance(input, tuple):
|
| 100 |
+
return input
|
| 101 |
+
|
| 102 |
+
assert embedding is None
|
| 103 |
+
return input
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
class TransformerEncoder(nn.Module):
|
| 107 |
+
r"""TransformerEncoder is a stack of N encoder layers. Users can build the
|
| 108 |
+
BERT(https://arxiv.org/abs/1810.04805) model with corresponding parameters.
|
| 109 |
+
|
| 110 |
+
Args:
|
| 111 |
+
encoder_layer: an instance of the TransformerEncoderLayer() class (required).
|
| 112 |
+
num_layers: the number of sub-encoder-layers in the encoder (required).
|
| 113 |
+
norm: the layer normalization component (optional).
|
| 114 |
+
enable_nested_tensor: if True, input will automatically convert to nested tensor
|
| 115 |
+
(and convert back on output). This will improve the overall performance of
|
| 116 |
+
TransformerEncoder when padding rate is high. Default: ``True`` (enabled).
|
| 117 |
+
|
| 118 |
+
Examples::
|
| 119 |
+
>>> encoder_layer = TransformerEncoderLayer(d_model=512, nhead=8)
|
| 120 |
+
>>> transformer_encoder = TransformerEncoder(encoder_layer, num_layers=6)
|
| 121 |
+
>>> src = torch.rand(10, 32, 512)
|
| 122 |
+
>>> out = transformer_encoder(src)
|
| 123 |
+
"""
|
| 124 |
+
__constants__ = ["norm"]
|
| 125 |
+
|
| 126 |
+
def __init__(self, encoder_layer, num_layers, norm=None):
|
| 127 |
+
super(TransformerEncoder, self).__init__()
|
| 128 |
+
self.layers = _get_clones(encoder_layer, num_layers)
|
| 129 |
+
self.num_layers = num_layers
|
| 130 |
+
self.norm = norm
|
| 131 |
+
|
| 132 |
+
def forward(
|
| 133 |
+
self,
|
| 134 |
+
src: Tensor,
|
| 135 |
+
mask: Optional[Tensor] = None,
|
| 136 |
+
src_key_padding_mask: Optional[Tensor] = None,
|
| 137 |
+
return_layer_states: bool = False,
|
| 138 |
+
cache=None,
|
| 139 |
+
) -> Tensor:
|
| 140 |
+
r"""Pass the input through the encoder layers in turn.
|
| 141 |
+
|
| 142 |
+
Args:
|
| 143 |
+
src: the sequence to the encoder (required).
|
| 144 |
+
mask: the mask for the src sequence (optional).
|
| 145 |
+
src_key_padding_mask: the mask for the src keys per batch (optional).
|
| 146 |
+
return_layer_states: return layers' state (optional).
|
| 147 |
+
|
| 148 |
+
Shape:
|
| 149 |
+
see the docs in Transformer class.
|
| 150 |
+
"""
|
| 151 |
+
if return_layer_states:
|
| 152 |
+
layer_states = [] # layers' output
|
| 153 |
+
output = src
|
| 154 |
+
for mod in self.layers:
|
| 155 |
+
output = mod(
|
| 156 |
+
output,
|
| 157 |
+
src_mask=mask,
|
| 158 |
+
src_key_padding_mask=src_key_padding_mask,
|
| 159 |
+
cache=cache,
|
| 160 |
+
)
|
| 161 |
+
layer_states.append(output[0])
|
| 162 |
+
|
| 163 |
+
if self.norm is not None:
|
| 164 |
+
output = self.norm(output)
|
| 165 |
+
|
| 166 |
+
return layer_states, output
|
| 167 |
+
|
| 168 |
+
output = src
|
| 169 |
+
for mod in self.layers:
|
| 170 |
+
output = mod(
|
| 171 |
+
output,
|
| 172 |
+
src_mask=mask,
|
| 173 |
+
src_key_padding_mask=src_key_padding_mask,
|
| 174 |
+
cache=cache,
|
| 175 |
+
)
|
| 176 |
+
|
| 177 |
+
if self.norm is not None:
|
| 178 |
+
output = self.norm(output)
|
| 179 |
+
|
| 180 |
+
return output
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
class TransformerEncoderLayer(nn.Module):
|
| 184 |
+
__constants__ = ["batch_first", "norm_first"]
|
| 185 |
+
|
| 186 |
+
def __init__(
|
| 187 |
+
self,
|
| 188 |
+
d_model: int,
|
| 189 |
+
nhead: int,
|
| 190 |
+
dim_feedforward: int = 2048,
|
| 191 |
+
dropout: float = 0.1,
|
| 192 |
+
activation: Union[str, Callable[[Tensor], Tensor]] = F.relu,
|
| 193 |
+
batch_first: bool = False,
|
| 194 |
+
norm_first: bool = False,
|
| 195 |
+
device=None,
|
| 196 |
+
dtype=None,
|
| 197 |
+
linear1_self_attention_cls: nn.Module = nn.Linear,
|
| 198 |
+
linear2_self_attention_cls: nn.Module = nn.Linear,
|
| 199 |
+
linear1_feedforward_cls: nn.Module = nn.Linear,
|
| 200 |
+
linear2_feedforward_cls: nn.Module = nn.Linear,
|
| 201 |
+
layer_norm_cls: nn.Module = LayerNorm,
|
| 202 |
+
layer_norm_eps: float = 1e-5,
|
| 203 |
+
adaptive_layer_norm=False,
|
| 204 |
+
) -> None:
|
| 205 |
+
factory_kwargs = {"device": device, "dtype": dtype}
|
| 206 |
+
super(TransformerEncoderLayer, self).__init__()
|
| 207 |
+
# print(233333333333,d_model,nhead)
|
| 208 |
+
# import os
|
| 209 |
+
# os._exit(2333333)
|
| 210 |
+
self.self_attn = MultiheadAttention(
|
| 211 |
+
d_model, # 512 16
|
| 212 |
+
nhead,
|
| 213 |
+
dropout=dropout,
|
| 214 |
+
batch_first=batch_first,
|
| 215 |
+
linear1_cls=linear1_self_attention_cls,
|
| 216 |
+
linear2_cls=linear2_self_attention_cls,
|
| 217 |
+
**factory_kwargs,
|
| 218 |
+
)
|
| 219 |
+
|
| 220 |
+
# Implementation of Feedforward model
|
| 221 |
+
self.linear1 = linear1_feedforward_cls(
|
| 222 |
+
d_model, dim_feedforward, **factory_kwargs
|
| 223 |
+
)
|
| 224 |
+
self.dropout = nn.Dropout(dropout)
|
| 225 |
+
self.linear2 = linear2_feedforward_cls(
|
| 226 |
+
dim_feedforward, d_model, **factory_kwargs
|
| 227 |
+
)
|
| 228 |
+
|
| 229 |
+
self.norm_first = norm_first
|
| 230 |
+
self.dropout1 = nn.Dropout(dropout)
|
| 231 |
+
self.dropout2 = nn.Dropout(dropout)
|
| 232 |
+
|
| 233 |
+
# Legacy string support for activation function.
|
| 234 |
+
if isinstance(activation, str):
|
| 235 |
+
activation = _get_activation_fn(activation)
|
| 236 |
+
elif isinstance(activation, partial):
|
| 237 |
+
activation = activation(d_model)
|
| 238 |
+
elif activation == BalancedDoubleSwish:
|
| 239 |
+
activation = BalancedDoubleSwish(d_model)
|
| 240 |
+
|
| 241 |
+
# # We can't test self.activation in forward() in TorchScript,
|
| 242 |
+
# # so stash some information about it instead.
|
| 243 |
+
# if activation is F.relu or isinstance(activation, torch.nn.ReLU):
|
| 244 |
+
# self.activation_relu_or_gelu = 1
|
| 245 |
+
# elif activation is F.gelu or isinstance(activation, torch.nn.GELU):
|
| 246 |
+
# self.activation_relu_or_gelu = 2
|
| 247 |
+
# else:
|
| 248 |
+
# self.activation_relu_or_gelu = 0
|
| 249 |
+
self.activation = activation
|
| 250 |
+
|
| 251 |
+
norm1 = layer_norm_cls(d_model, eps=layer_norm_eps, **factory_kwargs)
|
| 252 |
+
if layer_norm_cls == IdentityNorm:
|
| 253 |
+
norm2 = BalancedBasicNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
|
| 254 |
+
else:
|
| 255 |
+
norm2 = layer_norm_cls(d_model, eps=layer_norm_eps, **factory_kwargs)
|
| 256 |
+
|
| 257 |
+
if adaptive_layer_norm:
|
| 258 |
+
self.norm1 = AdaptiveLayerNorm(d_model, norm1)
|
| 259 |
+
self.norm2 = AdaptiveLayerNorm(d_model, norm2)
|
| 260 |
+
else:
|
| 261 |
+
self.norm1 = norm1
|
| 262 |
+
self.norm2 = norm2
|
| 263 |
+
|
| 264 |
+
def __setstate__(self, state):
|
| 265 |
+
super(TransformerEncoderLayer, self).__setstate__(state)
|
| 266 |
+
if not hasattr(self, "activation"):
|
| 267 |
+
self.activation = F.relu
|
| 268 |
+
|
| 269 |
+
def forward(
|
| 270 |
+
self,
|
| 271 |
+
src: Tensor,
|
| 272 |
+
src_mask: Optional[Tensor] = None,
|
| 273 |
+
src_key_padding_mask: Optional[Tensor] = None,
|
| 274 |
+
cache=None,
|
| 275 |
+
) -> Tensor:
|
| 276 |
+
r"""Pass the input through the encoder layer.
|
| 277 |
+
|
| 278 |
+
Args:
|
| 279 |
+
src: the sequence to the encoder layer (required).
|
| 280 |
+
src_mask: the mask for the src sequence (optional).
|
| 281 |
+
src_key_padding_mask: the mask for the src keys per batch (optional).
|
| 282 |
+
|
| 283 |
+
Shape:
|
| 284 |
+
see the docs in Transformer class.
|
| 285 |
+
"""
|
| 286 |
+
x, stage_embedding = src, None
|
| 287 |
+
is_src_tuple = False
|
| 288 |
+
if isinstance(src, tuple):
|
| 289 |
+
x, stage_embedding = src
|
| 290 |
+
is_src_tuple = True
|
| 291 |
+
|
| 292 |
+
if src_key_padding_mask is not None:
|
| 293 |
+
_skpm_dtype = src_key_padding_mask.dtype
|
| 294 |
+
if _skpm_dtype != torch.bool and not torch.is_floating_point(
|
| 295 |
+
src_key_padding_mask
|
| 296 |
+
):
|
| 297 |
+
raise AssertionError(
|
| 298 |
+
"only bool and floating types of key_padding_mask are supported"
|
| 299 |
+
)
|
| 300 |
+
|
| 301 |
+
if self.norm_first:
|
| 302 |
+
x = x + self._sa_block(
|
| 303 |
+
self.norm1(x, stage_embedding),
|
| 304 |
+
src_mask,
|
| 305 |
+
src_key_padding_mask,
|
| 306 |
+
cache=cache,
|
| 307 |
+
)
|
| 308 |
+
x = x + self._ff_block(self.norm2(x, stage_embedding))
|
| 309 |
+
else:
|
| 310 |
+
x = self.norm1(
|
| 311 |
+
x + self._sa_block(x, src_mask, src_key_padding_mask, cache=cache),
|
| 312 |
+
stage_embedding,
|
| 313 |
+
)
|
| 314 |
+
x = self.norm2(x + self._ff_block(x), stage_embedding)
|
| 315 |
+
|
| 316 |
+
if is_src_tuple:
|
| 317 |
+
return (x, stage_embedding)
|
| 318 |
+
return x
|
| 319 |
+
|
| 320 |
+
# self-attention block
|
| 321 |
+
def _sa_block(
|
| 322 |
+
self,
|
| 323 |
+
x: Tensor,
|
| 324 |
+
attn_mask: Optional[Tensor],
|
| 325 |
+
key_padding_mask: Optional[Tensor],
|
| 326 |
+
cache=None,
|
| 327 |
+
) -> Tensor:
|
| 328 |
+
# print(x.shape,attn_mask.shape,key_padding_mask)
|
| 329 |
+
# torch.Size([1, 188, 512]) torch.Size([188, 188]) None
|
| 330 |
+
# import os
|
| 331 |
+
# os._exit(23333)
|
| 332 |
+
x = self.self_attn(
|
| 333 |
+
x,
|
| 334 |
+
x,
|
| 335 |
+
x,
|
| 336 |
+
attn_mask=attn_mask,
|
| 337 |
+
key_padding_mask=key_padding_mask,
|
| 338 |
+
need_weights=False,
|
| 339 |
+
cache=cache,
|
| 340 |
+
)[0]
|
| 341 |
+
return self.dropout1(x)
|
| 342 |
+
|
| 343 |
+
# feed forward block
|
| 344 |
+
def _ff_block(self, x: Tensor) -> Tensor:
|
| 345 |
+
x = self.linear2(self.dropout(self.activation(self.linear1(x))))
|
| 346 |
+
return self.dropout2(x)
|
| 347 |
+
|
| 348 |
+
|
| 349 |
+
class AdaptiveLayerNorm(nn.Module):
|
| 350 |
+
r"""Adaptive Layer Normalization"""
|
| 351 |
+
|
| 352 |
+
def __init__(self, d_model, norm) -> None:
|
| 353 |
+
super(AdaptiveLayerNorm, self).__init__()
|
| 354 |
+
self.project_layer = nn.Linear(d_model, 2 * d_model)
|
| 355 |
+
self.norm = norm
|
| 356 |
+
self.d_model = d_model
|
| 357 |
+
self.eps = self.norm.eps
|
| 358 |
+
|
| 359 |
+
def forward(self, input: Tensor, embedding: Tensor = None) -> Tensor:
|
| 360 |
+
if isinstance(input, tuple):
|
| 361 |
+
input, embedding = input
|
| 362 |
+
weight, bias = torch.split(
|
| 363 |
+
self.project_layer(embedding),
|
| 364 |
+
split_size_or_sections=self.d_model,
|
| 365 |
+
dim=-1,
|
| 366 |
+
)
|
| 367 |
+
return (weight * self.norm(input) + bias, embedding)
|
| 368 |
+
|
| 369 |
+
weight, bias = torch.split(
|
| 370 |
+
self.project_layer(embedding),
|
| 371 |
+
split_size_or_sections=self.d_model,
|
| 372 |
+
dim=-1,
|
| 373 |
+
)
|
| 374 |
+
return weight * self.norm(input) + bias
|
| 375 |
+
|
| 376 |
+
|
| 377 |
+
def _get_clones(module, N):
|
| 378 |
+
return nn.ModuleList([copy.deepcopy(module) for i in range(N)])
|
GPT_SoVITS/AR/modules/transformer_onnx.py
ADDED
|
@@ -0,0 +1,292 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/lifeiteng/vall-e/blob/main/valle/modules/transformer.py
|
| 2 |
+
import copy
|
| 3 |
+
import numbers
|
| 4 |
+
from functools import partial
|
| 5 |
+
from typing import Any
|
| 6 |
+
from typing import Callable
|
| 7 |
+
from typing import List
|
| 8 |
+
from typing import Optional
|
| 9 |
+
from typing import Tuple
|
| 10 |
+
from typing import Union
|
| 11 |
+
|
| 12 |
+
import torch
|
| 13 |
+
from AR.modules.activation_onnx import MultiheadAttention
|
| 14 |
+
from AR.modules.scaling import BalancedDoubleSwish
|
| 15 |
+
from torch import nn
|
| 16 |
+
from torch import Tensor
|
| 17 |
+
from torch.nn import functional as F
|
| 18 |
+
|
| 19 |
+
_shape_t = Union[int, List[int], torch.Size]
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
class LayerNorm(nn.Module):
|
| 23 |
+
__constants__ = ["normalized_shape", "eps", "elementwise_affine"]
|
| 24 |
+
normalized_shape: Tuple[int, ...]
|
| 25 |
+
eps: float
|
| 26 |
+
elementwise_affine: bool
|
| 27 |
+
|
| 28 |
+
def __init__(
|
| 29 |
+
self,
|
| 30 |
+
normalized_shape: _shape_t,
|
| 31 |
+
eps: float = 1e-5,
|
| 32 |
+
elementwise_affine: bool = True,
|
| 33 |
+
device=None,
|
| 34 |
+
dtype=None,
|
| 35 |
+
) -> None:
|
| 36 |
+
factory_kwargs = {"device": device, "dtype": dtype}
|
| 37 |
+
super(LayerNorm, self).__init__()
|
| 38 |
+
if isinstance(normalized_shape, numbers.Integral):
|
| 39 |
+
# mypy error: incompatible types in assignment
|
| 40 |
+
normalized_shape = (normalized_shape,) # type: ignore[assignment]
|
| 41 |
+
self.normalized_shape = tuple(normalized_shape) # type: ignore[arg-type]
|
| 42 |
+
self.eps = eps
|
| 43 |
+
self.elementwise_affine = elementwise_affine
|
| 44 |
+
if self.elementwise_affine:
|
| 45 |
+
self.weight = nn.Parameter(
|
| 46 |
+
torch.empty(self.normalized_shape, **factory_kwargs)
|
| 47 |
+
)
|
| 48 |
+
self.bias = nn.Parameter(
|
| 49 |
+
torch.empty(self.normalized_shape, **factory_kwargs)
|
| 50 |
+
)
|
| 51 |
+
else:
|
| 52 |
+
self.register_parameter("weight", None)
|
| 53 |
+
self.register_parameter("bias", None)
|
| 54 |
+
|
| 55 |
+
self.reset_parameters()
|
| 56 |
+
|
| 57 |
+
def reset_parameters(self) -> None:
|
| 58 |
+
if self.elementwise_affine:
|
| 59 |
+
nn.init.ones_(self.weight)
|
| 60 |
+
nn.init.zeros_(self.bias)
|
| 61 |
+
|
| 62 |
+
def forward(self, input: Tensor, embedding: Any = None) -> Tensor:
|
| 63 |
+
if isinstance(input, tuple):
|
| 64 |
+
input, embedding = input
|
| 65 |
+
return (
|
| 66 |
+
F.layer_norm(
|
| 67 |
+
input,
|
| 68 |
+
self.normalized_shape,
|
| 69 |
+
self.weight,
|
| 70 |
+
self.bias,
|
| 71 |
+
self.eps,
|
| 72 |
+
),
|
| 73 |
+
embedding,
|
| 74 |
+
)
|
| 75 |
+
|
| 76 |
+
assert embedding is None
|
| 77 |
+
return F.layer_norm(
|
| 78 |
+
input, self.normalized_shape, self.weight, self.bias, self.eps
|
| 79 |
+
)
|
| 80 |
+
|
| 81 |
+
def extra_repr(self) -> str:
|
| 82 |
+
return (
|
| 83 |
+
"{normalized_shape}, eps={eps}, "
|
| 84 |
+
"elementwise_affine={elementwise_affine}".format(**self.__dict__)
|
| 85 |
+
)
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
class IdentityNorm(nn.Module):
|
| 89 |
+
def __init__(
|
| 90 |
+
self,
|
| 91 |
+
d_model: int,
|
| 92 |
+
eps: float = 1e-5,
|
| 93 |
+
device=None,
|
| 94 |
+
dtype=None,
|
| 95 |
+
) -> None:
|
| 96 |
+
super(IdentityNorm, self).__init__()
|
| 97 |
+
|
| 98 |
+
def forward(self, input: Tensor, embedding: Any = None) -> Tensor:
|
| 99 |
+
if isinstance(input, tuple):
|
| 100 |
+
return input
|
| 101 |
+
|
| 102 |
+
assert embedding is None
|
| 103 |
+
return input
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
class TransformerEncoder(nn.Module):
|
| 107 |
+
r"""TransformerEncoder is a stack of N encoder layers. Users can build the
|
| 108 |
+
BERT(https://arxiv.org/abs/1810.04805) model with corresponding parameters.
|
| 109 |
+
|
| 110 |
+
Args:
|
| 111 |
+
encoder_layer: an instance of the TransformerEncoderLayer() class (required).
|
| 112 |
+
num_layers: the number of sub-encoder-layers in the encoder (required).
|
| 113 |
+
norm: the layer normalization component (optional).
|
| 114 |
+
enable_nested_tensor: if True, input will automatically convert to nested tensor
|
| 115 |
+
(and convert back on output). This will improve the overall performance of
|
| 116 |
+
TransformerEncoder when padding rate is high. Default: ``True`` (enabled).
|
| 117 |
+
|
| 118 |
+
Examples::
|
| 119 |
+
>>> encoder_layer = TransformerEncoderLayer(d_model=512, nhead=8)
|
| 120 |
+
>>> transformer_encoder = TransformerEncoder(encoder_layer, num_layers=6)
|
| 121 |
+
>>> src = torch.rand(10, 32, 512)
|
| 122 |
+
>>> out = transformer_encoder(src)
|
| 123 |
+
"""
|
| 124 |
+
__constants__ = ["norm"]
|
| 125 |
+
|
| 126 |
+
def __init__(self, encoder_layer, num_layers, norm=None):
|
| 127 |
+
super(TransformerEncoder, self).__init__()
|
| 128 |
+
self.layers = _get_clones(encoder_layer, num_layers)
|
| 129 |
+
self.num_layers = num_layers
|
| 130 |
+
self.norm = norm
|
| 131 |
+
|
| 132 |
+
def forward(
|
| 133 |
+
self,
|
| 134 |
+
src: Tensor,
|
| 135 |
+
mask: Optional[Tensor] = None,
|
| 136 |
+
src_key_padding_mask: Optional[Tensor] = None,
|
| 137 |
+
return_layer_states: bool = False,
|
| 138 |
+
cache=None,
|
| 139 |
+
) -> Tensor:
|
| 140 |
+
output = src
|
| 141 |
+
for mod in self.layers:
|
| 142 |
+
output = mod(
|
| 143 |
+
output,
|
| 144 |
+
src_mask=mask,
|
| 145 |
+
src_key_padding_mask=src_key_padding_mask,
|
| 146 |
+
cache=cache,
|
| 147 |
+
)
|
| 148 |
+
|
| 149 |
+
if self.norm is not None:
|
| 150 |
+
output = self.norm(output)
|
| 151 |
+
|
| 152 |
+
return output
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
class TransformerEncoderLayer(nn.Module):
|
| 156 |
+
__constants__ = ["batch_first", "norm_first"]
|
| 157 |
+
def __init__(
|
| 158 |
+
self,
|
| 159 |
+
d_model: int,
|
| 160 |
+
nhead: int,
|
| 161 |
+
dim_feedforward: int = 2048,
|
| 162 |
+
dropout: float = 0.1,
|
| 163 |
+
activation: Union[str, Callable[[Tensor], Tensor]] = F.relu,
|
| 164 |
+
batch_first: bool = False,
|
| 165 |
+
norm_first: bool = False,
|
| 166 |
+
device=None,
|
| 167 |
+
dtype=None,
|
| 168 |
+
linear1_self_attention_cls: nn.Module = nn.Linear,
|
| 169 |
+
linear2_self_attention_cls: nn.Module = nn.Linear,
|
| 170 |
+
linear1_feedforward_cls: nn.Module = nn.Linear,
|
| 171 |
+
linear2_feedforward_cls: nn.Module = nn.Linear,
|
| 172 |
+
layer_norm_cls: nn.Module = LayerNorm,
|
| 173 |
+
layer_norm_eps: float = 1e-5,
|
| 174 |
+
adaptive_layer_norm=False,
|
| 175 |
+
) -> None:
|
| 176 |
+
factory_kwargs = {"device": device, "dtype": dtype}
|
| 177 |
+
super(TransformerEncoderLayer, self).__init__()
|
| 178 |
+
self.self_attn = MultiheadAttention(
|
| 179 |
+
d_model, # 512 16
|
| 180 |
+
nhead,
|
| 181 |
+
dropout=dropout,
|
| 182 |
+
batch_first=batch_first,
|
| 183 |
+
linear1_cls=linear1_self_attention_cls,
|
| 184 |
+
linear2_cls=linear2_self_attention_cls,
|
| 185 |
+
**factory_kwargs,
|
| 186 |
+
)
|
| 187 |
+
self.linear1 = linear1_feedforward_cls(
|
| 188 |
+
d_model, dim_feedforward, **factory_kwargs
|
| 189 |
+
)
|
| 190 |
+
self.dropout = nn.Dropout(dropout)
|
| 191 |
+
self.linear2 = linear2_feedforward_cls(
|
| 192 |
+
dim_feedforward, d_model, **factory_kwargs
|
| 193 |
+
)
|
| 194 |
+
self.norm_first = norm_first
|
| 195 |
+
self.dropout1 = nn.Dropout(dropout)
|
| 196 |
+
self.dropout2 = nn.Dropout(dropout)
|
| 197 |
+
if isinstance(activation, str):
|
| 198 |
+
activation = _get_activation_fn(activation)
|
| 199 |
+
elif isinstance(activation, partial):
|
| 200 |
+
activation = activation(d_model)
|
| 201 |
+
elif activation == BalancedDoubleSwish:
|
| 202 |
+
activation = BalancedDoubleSwish(d_model)
|
| 203 |
+
self.activation = activation
|
| 204 |
+
|
| 205 |
+
norm1 = layer_norm_cls(d_model, eps=layer_norm_eps, **factory_kwargs)
|
| 206 |
+
if layer_norm_cls == IdentityNorm:
|
| 207 |
+
norm2 = BalancedBasicNorm(d_model, eps=layer_norm_eps, **factory_kwargs)
|
| 208 |
+
else:
|
| 209 |
+
norm2 = layer_norm_cls(d_model, eps=layer_norm_eps, **factory_kwargs)
|
| 210 |
+
|
| 211 |
+
if adaptive_layer_norm:
|
| 212 |
+
self.norm1 = AdaptiveLayerNorm(d_model, norm1)
|
| 213 |
+
self.norm2 = AdaptiveLayerNorm(d_model, norm2)
|
| 214 |
+
else:
|
| 215 |
+
self.norm1 = norm1
|
| 216 |
+
self.norm2 = norm2
|
| 217 |
+
|
| 218 |
+
def __setstate__(self, state):
|
| 219 |
+
super(TransformerEncoderLayer, self).__setstate__(state)
|
| 220 |
+
if not hasattr(self, "activation"):
|
| 221 |
+
self.activation = F.relu
|
| 222 |
+
|
| 223 |
+
def forward(
|
| 224 |
+
self,
|
| 225 |
+
src: Tensor,
|
| 226 |
+
src_mask: Optional[Tensor] = None,
|
| 227 |
+
src_key_padding_mask: Optional[Tensor] = None,
|
| 228 |
+
cache=None,
|
| 229 |
+
) -> Tensor:
|
| 230 |
+
x = src
|
| 231 |
+
stage_embedding = None
|
| 232 |
+
x = self.norm1(
|
| 233 |
+
x + self._sa_block(x, src_mask, src_key_padding_mask, cache=cache),
|
| 234 |
+
stage_embedding,
|
| 235 |
+
)
|
| 236 |
+
x = self.norm2(x + self._ff_block(x), stage_embedding)
|
| 237 |
+
|
| 238 |
+
return x
|
| 239 |
+
|
| 240 |
+
def _sa_block(
|
| 241 |
+
self,
|
| 242 |
+
x: Tensor,
|
| 243 |
+
attn_mask: Optional[Tensor],
|
| 244 |
+
key_padding_mask: Optional[Tensor],
|
| 245 |
+
cache=None,
|
| 246 |
+
) -> Tensor:
|
| 247 |
+
x = self.self_attn(
|
| 248 |
+
x,
|
| 249 |
+
x,
|
| 250 |
+
x,
|
| 251 |
+
attn_mask=attn_mask,
|
| 252 |
+
key_padding_mask=key_padding_mask,
|
| 253 |
+
need_weights=False,
|
| 254 |
+
cache=cache,
|
| 255 |
+
)
|
| 256 |
+
return self.dropout1(x)
|
| 257 |
+
|
| 258 |
+
def _ff_block(self, x: Tensor) -> Tensor:
|
| 259 |
+
x = self.linear2(self.dropout(self.activation(self.linear1(x))))
|
| 260 |
+
return self.dropout2(x)
|
| 261 |
+
|
| 262 |
+
|
| 263 |
+
class AdaptiveLayerNorm(nn.Module):
|
| 264 |
+
r"""Adaptive Layer Normalization"""
|
| 265 |
+
|
| 266 |
+
def __init__(self, d_model, norm) -> None:
|
| 267 |
+
super(AdaptiveLayerNorm, self).__init__()
|
| 268 |
+
self.project_layer = nn.Linear(d_model, 2 * d_model)
|
| 269 |
+
self.norm = norm
|
| 270 |
+
self.d_model = d_model
|
| 271 |
+
self.eps = self.norm.eps
|
| 272 |
+
|
| 273 |
+
def forward(self, input: Tensor, embedding: Tensor = None) -> Tensor:
|
| 274 |
+
if isinstance(input, tuple):
|
| 275 |
+
input, embedding = input
|
| 276 |
+
weight, bias = torch.split(
|
| 277 |
+
self.project_layer(embedding),
|
| 278 |
+
split_size_or_sections=self.d_model,
|
| 279 |
+
dim=-1,
|
| 280 |
+
)
|
| 281 |
+
return (weight * self.norm(input) + bias, embedding)
|
| 282 |
+
|
| 283 |
+
weight, bias = torch.split(
|
| 284 |
+
self.project_layer(embedding),
|
| 285 |
+
split_size_or_sections=self.d_model,
|
| 286 |
+
dim=-1,
|
| 287 |
+
)
|
| 288 |
+
return weight * self.norm(input) + bias
|
| 289 |
+
|
| 290 |
+
|
| 291 |
+
def _get_clones(module, N):
|
| 292 |
+
return nn.ModuleList([copy.deepcopy(module) for i in range(N)])
|
GPT_SoVITS/AR/text_processing/__init__.py
ADDED
|
File without changes
|
GPT_SoVITS/AR/text_processing/phonemizer.py
ADDED
|
@@ -0,0 +1,78 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/feng-yufei/shared_debugging_code/blob/main/text_processing/phonemizer.py
|
| 2 |
+
import itertools
|
| 3 |
+
import re
|
| 4 |
+
from typing import Dict
|
| 5 |
+
from typing import List
|
| 6 |
+
|
| 7 |
+
import regex
|
| 8 |
+
from gruut import sentences
|
| 9 |
+
from gruut.const import Sentence
|
| 10 |
+
from gruut.const import Word
|
| 11 |
+
from AR.text_processing.symbols import SYMBOL_TO_ID
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class GruutPhonemizer:
|
| 15 |
+
def __init__(self, language: str):
|
| 16 |
+
self._phonemizer = sentences
|
| 17 |
+
self.lang = language
|
| 18 |
+
self.symbol_to_id = SYMBOL_TO_ID
|
| 19 |
+
self._special_cases_dict: Dict[str] = {
|
| 20 |
+
r"\.\.\.": "... ",
|
| 21 |
+
";": "; ",
|
| 22 |
+
":": ": ",
|
| 23 |
+
",": ", ",
|
| 24 |
+
r"\.": ". ",
|
| 25 |
+
"!": "! ",
|
| 26 |
+
r"\?": "? ",
|
| 27 |
+
"—": "—",
|
| 28 |
+
"…": "… ",
|
| 29 |
+
"«": "«",
|
| 30 |
+
"»": "»",
|
| 31 |
+
}
|
| 32 |
+
self._punctuation_regexp: str = (
|
| 33 |
+
rf"([{''.join(self._special_cases_dict.keys())}])"
|
| 34 |
+
)
|
| 35 |
+
|
| 36 |
+
def _normalize_punctuation(self, text: str) -> str:
|
| 37 |
+
text = regex.sub(rf"\pZ+{self._punctuation_regexp}", r"\1", text)
|
| 38 |
+
text = regex.sub(rf"{self._punctuation_regexp}(\pL)", r"\1 \2", text)
|
| 39 |
+
text = regex.sub(r"\pZ+", r" ", text)
|
| 40 |
+
return text.strip()
|
| 41 |
+
|
| 42 |
+
def _convert_punctuation(self, word: Word) -> str:
|
| 43 |
+
if not word.phonemes:
|
| 44 |
+
return ""
|
| 45 |
+
if word.phonemes[0] in ["‖", "|"]:
|
| 46 |
+
return word.text.strip()
|
| 47 |
+
|
| 48 |
+
phonemes = "".join(word.phonemes)
|
| 49 |
+
# remove modifier characters ˈˌː with regex
|
| 50 |
+
phonemes = re.sub(r"[ˈˌː͡]", "", phonemes)
|
| 51 |
+
return phonemes.strip()
|
| 52 |
+
|
| 53 |
+
def phonemize(self, text: str, espeak: bool = False) -> str:
|
| 54 |
+
text_to_phonemize: str = self._normalize_punctuation(text)
|
| 55 |
+
sents: List[Sentence] = [
|
| 56 |
+
sent
|
| 57 |
+
for sent in self._phonemizer(text_to_phonemize, lang="en-us", espeak=espeak)
|
| 58 |
+
]
|
| 59 |
+
words: List[str] = [
|
| 60 |
+
self._convert_punctuation(word) for word in itertools.chain(*sents)
|
| 61 |
+
]
|
| 62 |
+
return " ".join(words)
|
| 63 |
+
|
| 64 |
+
def transform(self, phonemes):
|
| 65 |
+
# convert phonemes to ids
|
| 66 |
+
# dictionary is in symbols.py
|
| 67 |
+
return [self.symbol_to_id[p] for p in phonemes if p in self.symbol_to_id.keys()]
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
if __name__ == "__main__":
|
| 71 |
+
phonemizer = GruutPhonemizer("en-us")
|
| 72 |
+
# text -> IPA
|
| 73 |
+
phonemes = phonemizer.phonemize("Hello, wor-ld ?")
|
| 74 |
+
print("phonemes:", phonemes)
|
| 75 |
+
print("len(phonemes):", len(phonemes))
|
| 76 |
+
phoneme_ids = phonemizer.transform(phonemes)
|
| 77 |
+
print("phoneme_ids:", phoneme_ids)
|
| 78 |
+
print("len(phoneme_ids):", len(phoneme_ids))
|
GPT_SoVITS/AR/text_processing/symbols.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# modified from https://github.com/feng-yufei/shared_debugging_code/blob/main/text_processing/symbols.py
|
| 2 |
+
PAD = "_"
|
| 3 |
+
PUNCTUATION = ';:,.!?¡¿—…"«»“” '
|
| 4 |
+
LETTERS = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"
|
| 5 |
+
IPA_LETTERS = "ɑɐɒæɓʙβɔɕçɗɖðʤəɘɚɛɜɝɞɟʄɡɠɢʛɦɧħɥʜɨɪʝɭɬɫɮʟɱɯɰŋɳɲɴøɵɸθœɶʘɹɺɾɻʀʁɽʂʃʈʧʉʊʋⱱʌɣɤʍχʎʏʑʐʒʔʡʕʢǀǁǂǃˈˌːˑʼʴʰʱʲʷˠˤ˞↓↑→↗↘'̩'ᵻ"
|
| 6 |
+
SYMBOLS = [PAD] + list(PUNCTUATION) + list(LETTERS) + list(IPA_LETTERS)
|
| 7 |
+
SPACE_ID = SYMBOLS.index(" ")
|
| 8 |
+
SYMBOL_TO_ID = {s: i for i, s in enumerate(SYMBOLS)}
|
| 9 |
+
ID_TO_SYMBOL = {i: s for i, s in enumerate(SYMBOLS)}
|