
DeBERTa V3 Base for Multilingual Readability Assessment
This is a fine-tuned version of the multilingual DeBERTa model (mdeberta) for assessing text readability across languages.
Model Details
- Architecture: mdeberta-base
- Task: Regression (Readability Assessment)
- Training Data: agentlans/tatoeba-english-translations dataset containing 39 100 English translations
- Input: Text in any of the supported languages by DeBERTa
- Output: Estimated U.S. grade level for text comprehension
- higher values indicate more complex text
Performance
Root mean squared error (RMSE) on 20% held-out validation set: 1.063
Training Data
The model was trained on agentlans/tatoeba-english-translations.
Usage
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
model_name="agentlans/mdeberta-v3-base-readability"
# Put model on GPU or else CPU
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
def readability(text):
"""Processes the text using the model and returns its logits.
In this case, it's reading grade level in years of education
(the higher the number, the harder it is to read the text)."""
inputs = tokenizer(text, return_tensors="pt", truncation=True, padding=True).to(device)
with torch.no_grad():
logits = model(**inputs).logits.squeeze().cpu()
return logits.tolist()
readability("Your text here.")
Results
In this study, 10 English text samples of varying readability were generated and translated into Arabic, Chinese, French, Russian, and Spanish using Google Translate. This resulted in a total of 50 translated samples, which were subsequently analyzed by a trained classifier to predict their readability scores.
The following table presents the 10 original texts along with their translations:
| # | English | French | Spanish | Russian | Chinese | Arabic |
|---|---|---|---|---|---|---|
| 1 | The cat sat on the mat. | Le chat était assis sur le tapis. | El gato se sentó en la alfombra. | Кошка села на коврик. | 猫坐在垫子上。 | جلست القطة على الحصيرة. |
| 2 | She quickly ran to catch the bus. | Elle courut vite pour attraper le bus. | Corrió rápidamente para alcanzar el autobús. | Она быстро побежала, чтобы успеть на автобус. | 她飞快地跑去赶公共汽车。 | وركضت بسرعة لتلحق بالحافلة. |
| 3 | The old house creaked in the strong wind. | La vieille maison craquait sous le vent fort. | La vieja casa crujió con el fuerte viento. | Старый дом скрипел на сильном ветру. | 老房子在强风中吱吱作响。 | صرير البيت القديم في الرياح القوية. |
| 4 | Despite the rain, they enjoyed their picnic in the park. | Malgré la pluie, ils profitèrent de leur pique-nique dans le parc. | A pesar de la lluvia, disfrutaron de su picnic en el parque. | Несмотря на дождь, они наслаждались пикником в парке. | 尽管下着雨,他们还是在公园里享受着野餐。 | على الرغم من المطر، استمتعوا بنزهتهم في الحديقة. |
| 5 | The intricate design of the butterfly's wings fascinated the young scientist. | Le dessin complexe des ailes du papillon fascina le jeune scientifique. | El intrincado diseño de las alas de la mariposa fascinó al joven científico. | Замысловатый дизайн крыльев бабочки очаровал молодого ученого. | 蝴蝶翅膀的复杂设计让这位年轻的科学家着迷。 | أذهل التصميم المعقد لأجنحة الفراشة العالم الشاب. |
| 6 | The company's quarterly report indicated a significant increase in revenue. | Le rapport trimestriel de l'entreprise indiquait une augmentation significative des revenus. | El informe trimestral de la empresa indicó un aumento significativo de los ingresos. | Квартальный отчет компании показал значительный рост доходов. | 该公司的季度报告显示收入大幅增加。 | أشار التقرير ربع السنوي للشركة إلى زيادة كبيرة في الإيرادات. |
| 7 | The philosopher posited that consciousness arises from complex neural interactions. | Le philosophe postulat que la conscience naît d'interactions neuronales complexes. | El filósofo postuló que la conciencia surge de interacciones neuronales complejas. | Философ утверждал, что сознание возникает из сложных нейронных взаимодействий. | 哲学家认为意识源于复杂的神经相互作用。 | افترض الفيلسوف أن الوعي ينشأ من تفاعلات عصبية معقدة. |
| 8 | The quantum entanglement phenomenon challenges our understanding of locality and causality. | Le phénomène d'intrication quantique remet en question notre compréhension de la localité et de la causalité. | El fenómeno del entrelazamiento cuántico desafía nuestra comprensión de la localidad y la causalidad. | Феномен квантовой запутанности бросает вызов нашему пониманию локальности и причинности. | 量子纠缠现象挑战了我们对局部性和因果关系的理解。 | تتحدى ظاهرة التشابك الكمي فهمنا للمحلية والسببية. |
| 9 | The multifaceted approach to urban development necessitates consideration of socioeconomic factors. | L'approche multidimensionnelle du développement urbain nécessite de prendre en compte les facteurs socio-économiques. | El enfoque multifacético del desarrollo urbano requiere la consideración de factores socioeconómicos. | Многогранный подход к городскому развитию требует учета социально-экономических факторов. | 城市发展的多方面方法需要考虑社会经济因素。 | يتطلب النهج المتعدد الأوجه للتطوير الحضري مراعاة العوامل الاجتماعية والاقتصادية. |
| 10 | The esoteric nature of post-structuralist literary theory often obfuscates its practical applications. | La nature ésotérique de la théorie littéraire post-structuraliste obscurcit souvent ses applications pratiques. | La naturaleza esotérica de la teoría literaria posestructuralista a menudo ofusca sus aplicaciones prácticas. | Эзотерическая природа постструктуралистской литературной теории часто затрудняет ее практическое применение. | 后结构主义文学理论的深奥性质常常掩盖其实际应用。 | غالبًا ما تحجب الطبيعة الباطنية لنظرية الأدب ما بعد البنيوية تطبيقاتها العملية. |
The scatterplot below illustrates the predicted readability scores grouped by each text sample. Notably, the prediction scores exhibit low variability across different languages for the same text, indicating a consistent assessment of translation readability regardless of the target language.
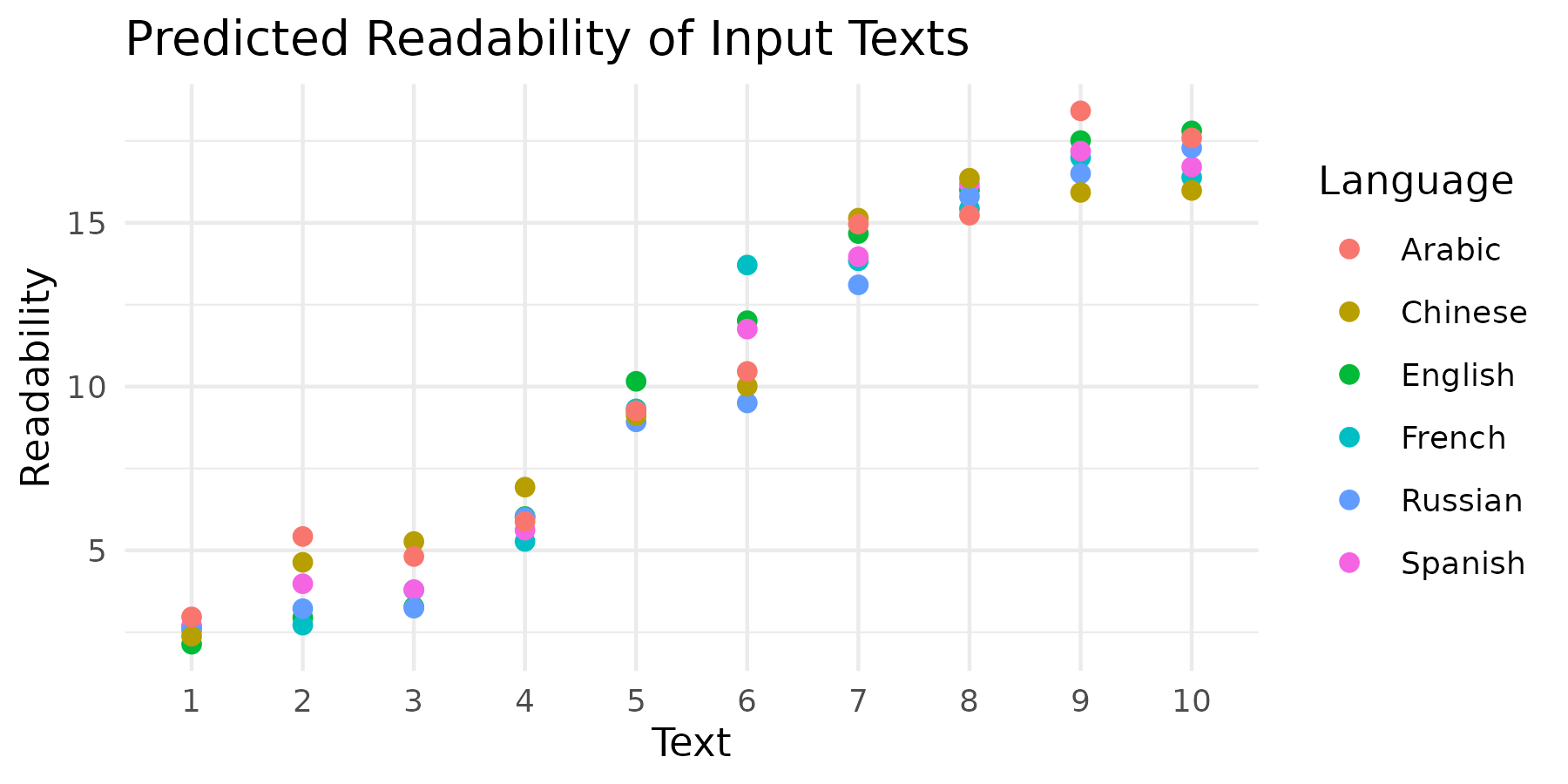
This analysis highlights the effectiveness of using machine learning classifiers in evaluating textual readability across multiple languages.
Limitations
- Performance may vary for texts significantly different from the training data
- Output is based on statistical patterns and may not always align with human judgment
- Readability is assessed purely on textual features, not considering factors like subject familiarity or cultural context
Ethical Considerations
- Should not be used as the sole determinant of text suitability for specific audiences
- Results may reflect biases present in the training data sources
- Care should be taken when using these models in educational or publishing contexts
- Downloads last month
- 16
Model tree for agentlans/mdeberta-v3-base-readability
Base model
microsoft/mdeberta-v3-base