
metadata
language:
- en
license: llama3
library_name: transformers
tags:
- axolotl
- finetune
- dpo
- facebook
- meta
- pytorch
- llama
- llama-3
- chatml
base_model: meta-llama/Meta-Llama-3-70B-Instruct
datasets:
- argilla/ultrafeedback-binarized-preferences
pipeline_tag: text-generation
license_name: llama3
license_link: LICENSE
inference: false
model_creator: MaziyarPanahi
quantized_by: MaziyarPanahi
model-index:
- name: calme-2.4-llama3-70b
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 72.61
name: normalized accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=MaziyarPanahi/calme-2.4-llama3-70b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 86.03
name: normalized accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=MaziyarPanahi/calme-2.4-llama3-70b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 80.5
name: accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=MaziyarPanahi/calme-2.4-llama3-70b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 63.26
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=MaziyarPanahi/calme-2.4-llama3-70b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 83.58
name: accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=MaziyarPanahi/calme-2.4-llama3-70b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 87.34
name: accuracy
source:
url: >-
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=MaziyarPanahi/calme-2.4-llama3-70b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: IFEval (0-Shot)
type: HuggingFaceH4/ifeval
args:
num_few_shot: 0
metrics:
- type: inst_level_strict_acc and prompt_level_strict_acc
value: 50.27
name: strict accuracy
source:
url: >-
https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=MaziyarPanahi/calme-2.4-llama3-70b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: BBH (3-Shot)
type: BBH
args:
num_few_shot: 3
metrics:
- type: acc_norm
value: 48.4
name: normalized accuracy
source:
url: >-
https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=MaziyarPanahi/calme-2.4-llama3-70b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MATH Lvl 5 (4-Shot)
type: hendrycks/competition_math
args:
num_few_shot: 4
metrics:
- type: exact_match
value: 22.66
name: exact match
source:
url: >-
https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=MaziyarPanahi/calme-2.4-llama3-70b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GPQA (0-shot)
type: Idavidrein/gpqa
args:
num_few_shot: 0
metrics:
- type: acc_norm
value: 11.97
name: acc_norm
source:
url: >-
https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=MaziyarPanahi/calme-2.4-llama3-70b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MuSR (0-shot)
type: TAUR-Lab/MuSR
args:
num_few_shot: 0
metrics:
- type: acc_norm
value: 13.1
name: acc_norm
source:
url: >-
https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=MaziyarPanahi/calme-2.4-llama3-70b
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU-PRO (5-shot)
type: TIGER-Lab/MMLU-Pro
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 46.71
name: accuracy
source:
url: >-
https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard?query=MaziyarPanahi/calme-2.4-llama3-70b
name: Open LLM Leaderboard

MaziyarPanahi/calme-2.4-llama3-70b
This model is a fine-tune (DPO) of meta-llama/Meta-Llama-3-70B-Instruct model.
⚡ Quantized GGUF
All GGUF models are available here: MaziyarPanahi/calme-2.4-llama3-70b-GGUF
🏆 Open LLM Leaderboard Evaluation Results
Detailed results can be found here
| Metric | Value |
|---|---|
| Avg. | 32.18 |
| IFEval (0-Shot) | 50.27 |
| BBH (3-Shot) | 48.40 |
| MATH Lvl 5 (4-Shot) | 22.66 |
| GPQA (0-shot) | 11.97 |
| MuSR (0-shot) | 13.10 |
| MMLU-PRO (5-shot) | 46.71 |
| Metric | Value |
|---|---|
| Avg. | 78.89 |
| AI2 Reasoning Challenge (25-Shot) | 72.61 |
| HellaSwag (10-Shot) | 86.03 |
| MMLU (5-Shot) | 80.50 |
| TruthfulQA (0-shot) | 63.26 |
| Winogrande (5-shot) | 83.58 |
| GSM8k (5-shot) | 87.34 |
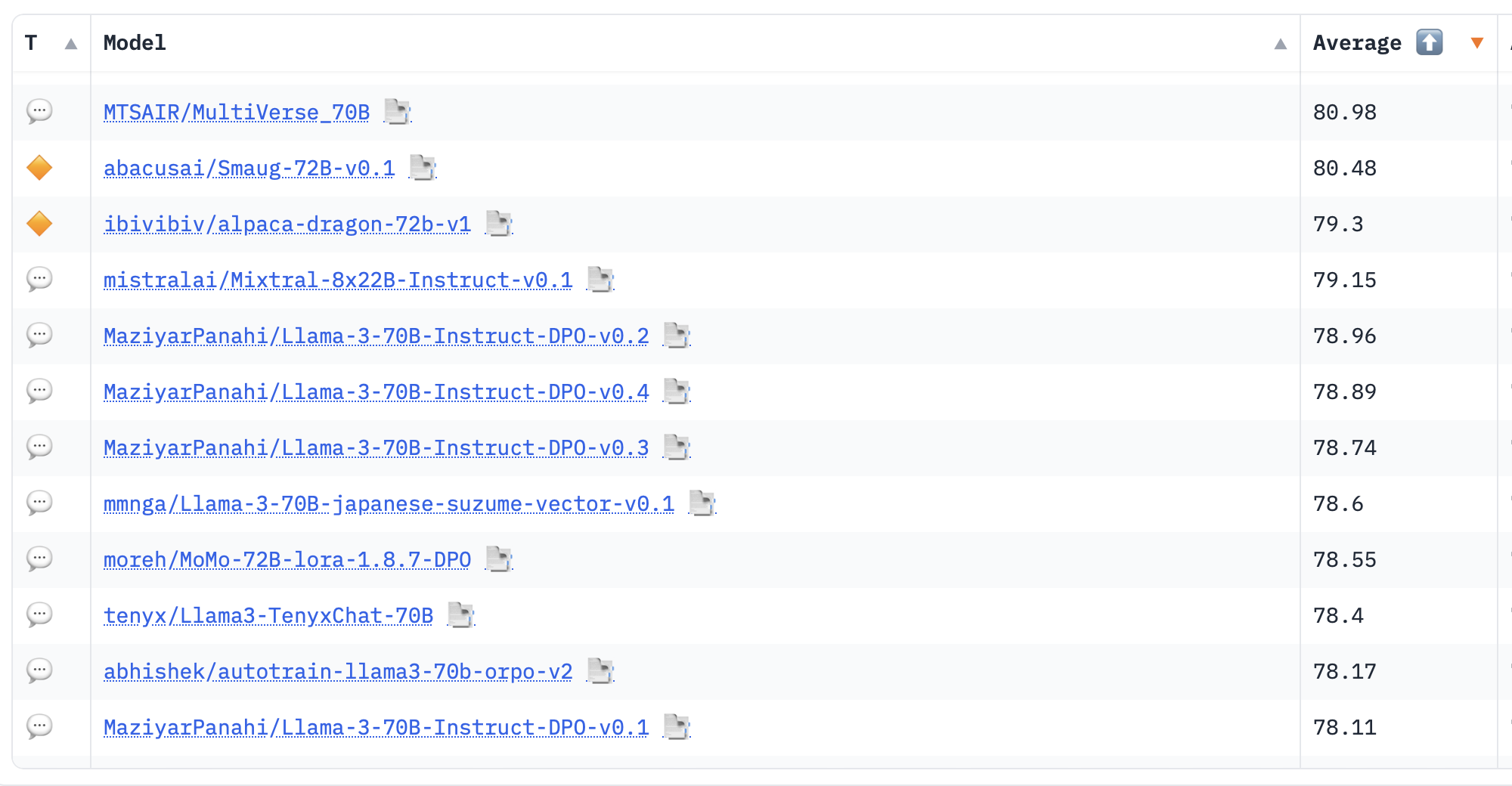
Top 10 models on the Leaderboard
Prompt Template
This model uses ChatML prompt template:
<|im_start|>system
{System}
<|im_end|>
<|im_start|>user
{User}
<|im_end|>
<|im_start|>assistant
{Assistant}
How to use
You can use this model by using MaziyarPanahi/calme-2.4-llama3-70b as the model name in Hugging Face's
transformers library.
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
from transformers import pipeline
import torch
model_id = "MaziyarPanahi/calme-2.4-llama3-70b"
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True,
# attn_implementation="flash_attention_2"
)
tokenizer = AutoTokenizer.from_pretrained(
model_id,
trust_remote_code=True
)
streamer = TextStreamer(tokenizer)
pipeline = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
model_kwargs={"torch_dtype": torch.bfloat16},
streamer=streamer
)
# Then you can use the pipeline to generate text.
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
prompt = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|im_end|>"),
tokenizer.convert_tokens_to_ids("<|eot_id|>") # safer to have this too
]
outputs = pipeline(
prompt,
max_new_tokens=2048,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.95,
)
print(outputs[0]["generated_text"][len(prompt):])
Sample Response
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
describe about pros and cons of docker system.<|im_end|>
<|im_start|>assistant
Here are the pros and cons of the Docker system:
**Pros:**
1. **Lightweight**: Docker containers are lightweight and use fewer resources compared to traditional virtual machines.
2. **Isolation**: Docker provides a high level of isolation between containers, ensuring that each application runs independently without interfering with others.
3. **Portability**: Docker containers are highly portable and can run on any system that supports Docker, without requiring specific dependencies or configurations.
4. **Efficient Use of Resources**: Docker containers can share the same kernel and use fewer resources, making them more efficient than traditional virtual machines.
5. **Fast Deployment**: Docker containers can be spun up quickly, making it ideal for rapid deployment and scaling of applications.
6. **Easy Maintenance**: Docker provides a simple way to manage and update applications, with features like rolling updates and rollbacks.
7. **Security**: Docker provides a secure environment for applications, with features like network isolation and encryption.
8. **Large Ecosystem**: Docker has a large and active ecosystem, with a wide range of tools and plugins available for various tasks.
9. **Version Control**: Docker provides an easy way to manage different versions of an application, with features like version tagging and rollbacks.
10. **Cost-Effective**: Docker can help reduce costs by minimizing the need for virtual machines and reducing the overhead of resource allocation.
**Cons:**
1. **Steep Learning Curve**: Docker has a complex architecture and requires a good understanding of containerization, networking, and storage.
2. **Overhead**: While Docker containers are lightweight, they still require some overhead in terms of resources and management.
3. **Security Risks**: If not properly configured, Docker containers can introduce security risks, such as unauthorized access to the host system.
4. **Limited Support for GUI Applications**: Docker is primarily designed for running command-line applications, and running GUI applications can be challenging.
5. **Networking Complexity**: Docker's networking model can be complex, especially in large-scale deployments.
6. **Storage Complexity**: Docker's storage model can be complex, especially when dealing with persistent data.
7. **Limited Support for Legacy Applications**: Docker is designed for modern, cloud-native applications, and may not be suitable for legacy applications that rely on older technologies.
8. **Dependence on Docker Hub**: Docker relies heavily on Docker Hub, which can be a single point of failure if the hub is down or experiencing issues.
9. **Orchestration Complexity**: Docker provides a built-in orchestration tool, Docker Swarm, but it can be complex to set up and manage.
10. **Vendor Lock-in**: Docker is a proprietary technology, and while it has a large ecosystem, it can be difficult to switch to alternative containerization platforms.
Overall, Docker provides a powerful and flexible way to deploy and manage applications, but it requires careful planning, configuration, and management to ensure optimal performance and security.