
Model Card for the Social Orientation Tagger
This multilingual social orientation tagger is an XLM-RoBERTa base model trained on the Conversations Gone Awry (CGA) dataset with social orientation labels collected using GPT-4. This model can be used to predict social orientation labels for new conversations. See example usage below or our Github repo for more extensive examples: examples/single_prediction.py or examples/evaluate.py.
See the English version of this model here: tee-oh-double-dee/social-orientation
This dataset was created as part of the work described in Social Orientation: A New Feature for Dialogue Analysis, which was accepted to LREC-COLING 2024.
Usage
You can make direct use of this social orientation tagger as follows:
import pprint
from transformers import AutoModelForSequenceClassification, AutoTokenizer
sample_input = 'Speaker 1: This is really terrific work!'
model = AutoModelForSequenceClassification.from_pretrained('tee-oh-double-dee/social-orientation-multilingual')
model.eval()
tokenizer = AutoTokenizer.from_pretrained('tee-oh-double-dee/social-orientation-multilingual')
model_input = tokenizer(sample_input, return_tensors='pt')
output = model(**model_input)
output_probs = output.logits.softmax(dim=1)
id2label = model.config.id2label
pred_dict = {
id2label[i]: output_probs[0][i].item()
for i in range(len(id2label))
}
pprint.pprint(pred_dict)
Downstream Use
Predicted social orientation tags can be prepended to dialog utterances to assist downstream models. For instance, you could convert
Speaker 1: This is really terrific work!
to
Speaker 1 (Gregarious-Extraverted): This is really terrific work!
and then feed these new utterances to a model that predicts if a conversation will succeed or fail. We showed the effectiveness of this strategy in our paper.
Model Details
Model Description
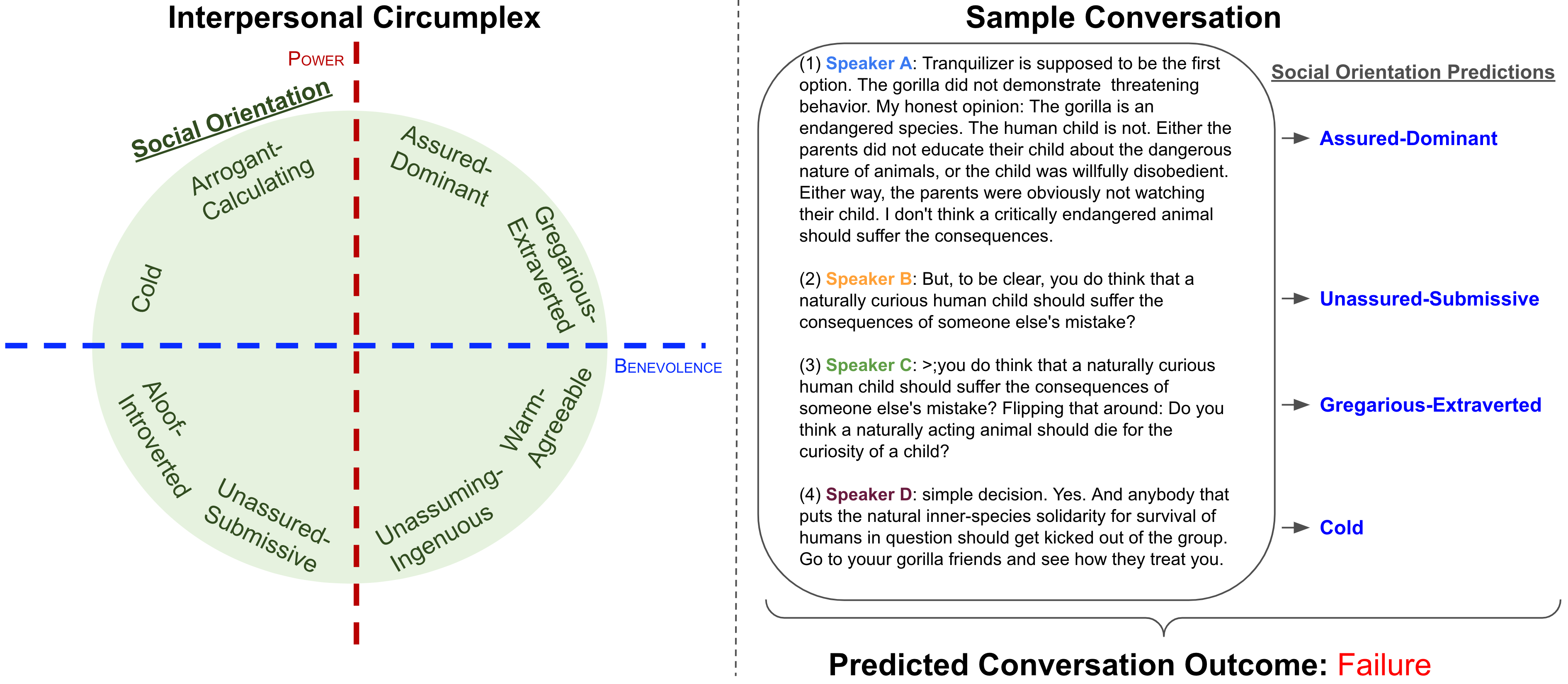
There are many settings where it is useful to predict and explain the success or failure of a dialogue. Circumplex theory from psychology models the social orientations (e.g., Warm-Agreeable, Arrogant-Calculating) of conversation participants, which can in turn can be used to predict and explain the outcome of social interactions, such as in online debates over Wikipedia page edits or on the Reddit ChangeMyView forum. This model enables social orientation tagging of dialog utterances.
The prediction set includes: {Assured-Dominant, Gregarious-Extraverted, Warm-Agreeable, Unassuming-Ingenuous, Unassured-Submissive, Aloof-Introverted, Cold, Arrogant-Calculating, Not Available}
- Developed by: Todd Morrill
- Funded by [optional]: DARPA
- Model type: classification model
- Language(s) (NLP): Multilingual
- Finetuned from model [optional]: XLM-RoBERTa base model
Model Sources
- Repository: Github repository
- Paper [optional]: Social Orientation: A New Feature for Dialogue Analysis
Training Details
Training Data
See tee-oh-double-dee/social-orientation for details on the training dataset.
Training Procedure
We initialize our social orientation tagger weights from the XLM-RoBERTa base pre-trained checkpoint from Hugging Face. We use following hyperparameter settings: batch size=32, learning rate=1e-6, we include speaker names before each utterance, we train in 16 bit floating point representation, we use window size of two utterances (i.e., we use the previous utterance's text and the current utterance's text to predict the current utterance's social orientation tag), and we use a weighted loss function to address class imbalance and improve prediction set diversity. The weight assigned to each class is defined by
where , where denotes the number of examples in the training set, and denotes the number of examples in class in the training set, and is the number of classes. In our case is , including the Not Available class, which is used for all empty utterances.
Evaluation
We evaluate accuracy at the individual utterance level and report the following results:
| Split | Accuracy |
|---|---|
| Train | 39.21% |
| Validation | 35.04% |
| Test | 37.25% |
Without loss weighting, it is possible to achieve an accuracy of 45%.
Citation
BibTeX:
@misc{morrill2024social,
title={Social Orientation: A New Feature for Dialogue Analysis},
author={Todd Morrill and Zhaoyuan Deng and Yanda Chen and Amith Ananthram and Colin Wayne Leach and Kathleen McKeown},
year={2024},
eprint={2403.04770},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
- Downloads last month
- 5