
This repository is the awq quantization version of KULLM3.
The quantization was carried out in a custom branch of autoawq. The hyperparameters for quantization are as follows.
{ "zero_point": True, "q_group_size": 128, "w_bit": 4, "version": "GEMM" }
It worked using vllm. It may not work with other frameworks as they have not been tested.
Below is the README.md for the original model.
KULLM3
Introducing KULLM3, a model with advanced instruction-following and fluent chat abilities.
It has shown remarkable performance in instruction-following, speficially by closely following gpt-3.5-turbo.
To our knowledge, It is one of the best publicly opened Korean-speaking language models.
For details, visit the KULLM repository
Model Description
This is the model card of a 🤗 transformers model that has been pushed on the Hub.
- Developed by: NLP&AI Lab
- Language(s) (NLP): Korean, English
- License: CC-BY-NC 4.0
- Finetuned from model: upstage/SOLAR-10.7B-Instruct-v1.0
Example code
Install Dependencies
pip install torch transformers==4.38.2 accelerate
- In transformers>=4.39.0, generate() does not work well. (as of 2024.4.4.)
Python code
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
MODEL_DIR = "nlpai-lab/KULLM3"
model = AutoModelForCausalLM.from_pretrained(MODEL_DIR, torch_dtype=torch.float16).to("cuda")
tokenizer = AutoTokenizer.from_pretrained(MODEL_DIR)
streamer = TextStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True)
s = "고려대학교에 대해서 알고 있니?"
conversation = [{'role': 'user', 'content': s}]
inputs = tokenizer.apply_chat_template(
conversation,
tokenize=True,
add_generation_prompt=True,
return_tensors='pt').to("cuda")
_ = model.generate(inputs, streamer=streamer, max_new_tokens=1024)
# 네, 고려대학교에 대해 알고 있습니다. 고려대학교는 대한민국 서울에 위치한 사립 대학교로, 1905년에 설립되었습니다. 이 대학교는 한국에서 가장 오래된 대학 중 하나로, 다양한 학부 및 대학원 프로그램을 제공합니다. 고려대학교는 특히 법학, 경제학, 정치학, 사회학, 문학, 과학 분야에서 높은 명성을 가지고 있습니다. 또한, 스포츠 분야에서도 활발한 활동을 보이며, 대한민국 대학 스포츠에서 중요한 역할을 하고 있습니다. 고려대학교는 국제적인 교류와 협력에도 적극적이며, 전 세계 다양한 대학과의 협력을 통해 글로벌 경쟁력을 강화하고 있습니다.
Training Details
Training Data
- vicgalle/alpaca-gpt4
- Mixed Korean instruction data (gpt-generated, hand-crafted, etc)
- About 66000+ examples used totally
Training Procedure
- Trained with fixed system prompt below.
당신은 고려대학교 NLP&AI 연구실에서 만든 AI 챗봇입니다.
당신의 이름은 'KULLM'으로, 한국어로는 '구름'을 뜻합니다.
당신은 비도덕적이거나, 성적이거나, 불법적이거나 또는 사회 통념적으로 허용되지 않는 발언은 하지 않습니다.
사용자와 즐겁게 대화하며, 사용자의 응답에 가능한 정확하고 친절하게 응답함으로써 최대한 도와주려고 노력합니다.
질문이 이상하다면, 어떤 부분이 이상한지 설명합니다. 거짓 정보를 발언하지 않도록 주의합니다.
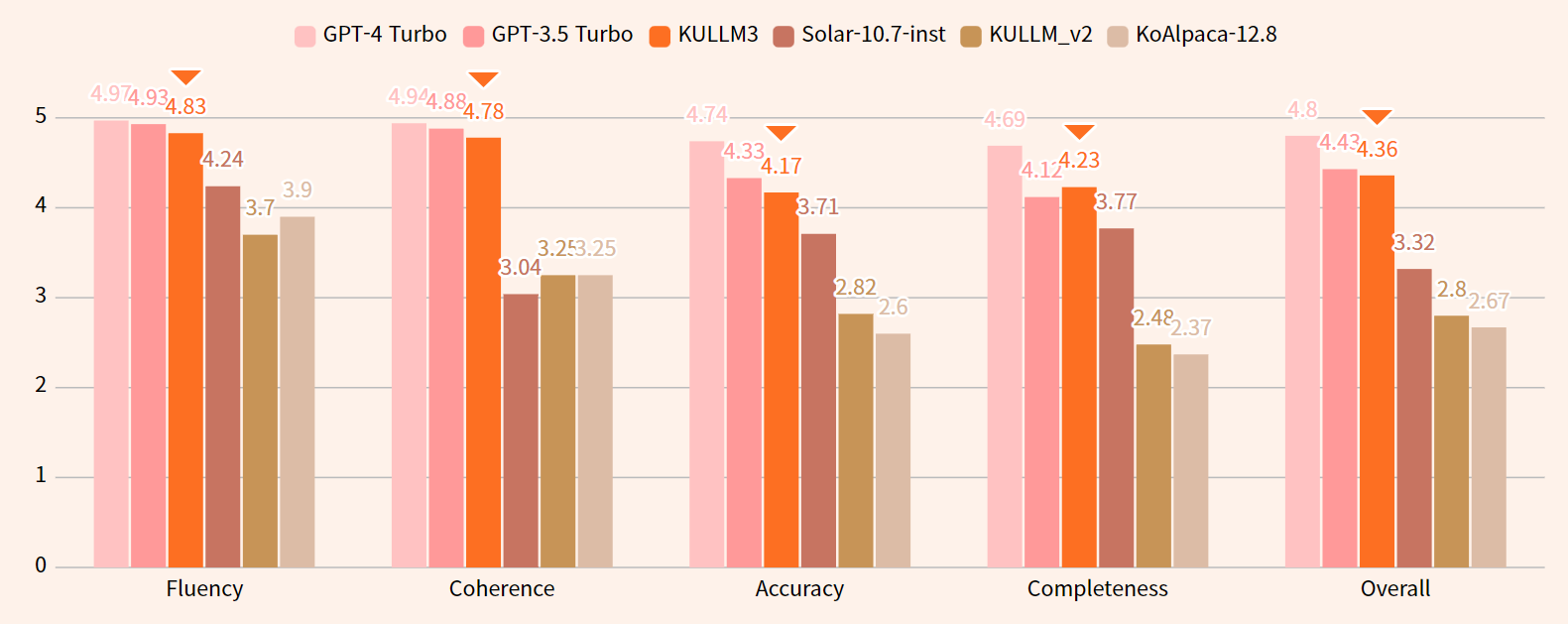
Evaluation
- Evaluation details such as testing data, metrics are written in github.
- Without system prompt used in training phase, KULLM would show lower performance than expect.
Results
Citation
@misc{kullm,
author = {NLP & AI Lab and Human-Inspired AI research},
title = {KULLM: Korea University Large Language Model Project},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/nlpai-lab/kullm}},
}
- Downloads last month
- 39
This model does not have enough activity to be deployed to Inference API (serverless) yet. Increase its social
visibility and check back later, or deploy to Inference Endpoints (dedicated)
instead.