Sujet 8B V0.1
Collection
A Specialized Financial Language Model
•
4 items
•
Updated

Welcome to the exciting world of Sujet Finance 8B v0.1 – your go-to language model for all things finance! 💰 This state-of-the-art model is a fine-tuned version of the powerful LLAMA 3 model, meticulously trained on the comprehensive Sujet Finance Instruct-177k dataset. 📈
In this initial fine-tuning iteration, we've focused on three key financial tasks:
✅❌ Yes/No Questions
📂 Topic Classification
😊😐😡 Sentiment Analysis
This model was finetuned using Unsloth. Please refer to their github repository and make sure you have it installed before using the model : Unsloth
from unsloth import FastLanguageModel
max_seq_length = 2048
dtype = None
load_in_4bit = False
alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}"""
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "sujet-ai/Sujet-Finance-8B-v0.1",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
token = "your hf token here",
)
example = {
'system_prompt': 'You are a financial sentiment analysis expert. Your task is to analyze the sentiment expressed in the given financial text.Only reply with bearish, neutral, or bullish.',
'user_prompt': "Expedia's Problems Run Deeper Than SEO Headwinds",
'answer': 'bearish',
}
inputs = tokenizer(
[alpaca_prompt.format(
example['system_prompt'], # instruction
example['user_prompt'], # input
"", # output - leave this blank for generation!
)],
return_tensors="pt"
).to("cuda")
outputs = model.generate(**inputs, max_new_tokens=2048, use_cache=True, pad_token_id=tokenizer.eos_token_id)
output = tokenizer.batch_decode(outputs)[0]
response = output.split("### Response:")[1].strip()
print(response)
You can find more information about the dataset by clicking on this link : Sujet-Finance-Instruct-177k Dataset
Our model has been carefully trained to excel in these areas, providing accurate and insightful responses to your financial queries. 💡
To ensure optimal performance, we've employed a balanced training approach. Our dataset preparation process strategically selects an equal number of examples from each subclass within the three focus tasks. This results in a well-rounded model that can handle a diverse range of financial questions and topics. 🧠
The final balanced training dataset consists of 17,036 examples, while the evaluation dataset contains 4,259 examples.
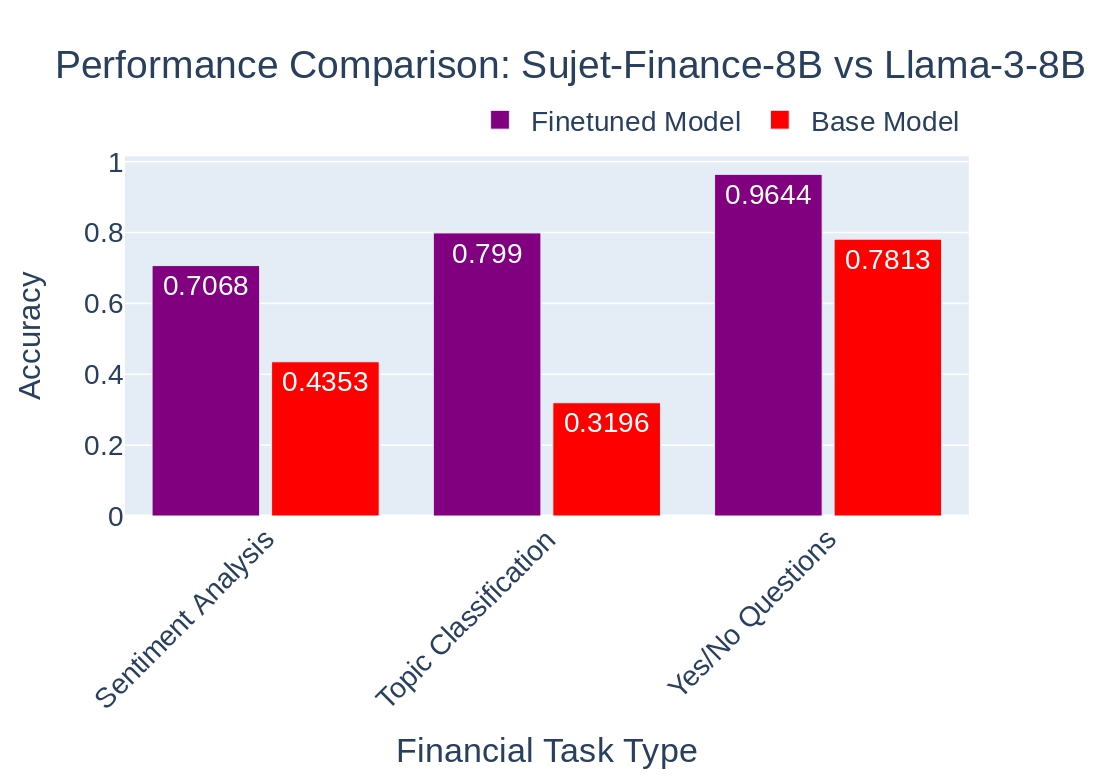
We've put our model to the test, comparing its performance against the base LLAMA 3 model on our evaluation dataset. The results are impressive! 🏆
We consider a response correct if the true answer appears within the first 10 words generated by the model. This strict criterion ensures that our model not only provides accurate answers but also prioritizes the most relevant information. 🎯