Spaces:
Running


Italian CLIP
With a few tricks, we have been able to fine-tune a competitive Italian CLIP model with only 1.4 million training samples. Our Italian CLIP model is built upon the Italian BERT model provided by dbmdz and the OpenAI vision transformer.
In building this project we kept in mind the following principles:
- Novel Contributions: We created a dataset of ~1.4 million Italian image-text pairs and, to the best of our knowledge, we trained the best Italian CLIP model currently in existence;
- Scientific Validity: Claim are easy, facts are hard. That's why validation is important to assess the real impact of a model. We thoroughly evaluated our models in several tasks and made the validation reproducible for everybody.
- Broader Outlook: We always kept in mind which are the possible usages for this model.
We put our hearts and souls into the project during this week! Not only did we work on a cool project, but we were able to make new friends and and learn a lot from each other to work towards a common goal! Thank you for this amazing opportunity, we hope you will like the results. :heart:
Novel Contributions
The original CLIP model was trained on 400 million image-text pairs; this amount of data is not available for Italian. We indeed worked in a low-resource setting. The only datasets for Italian captioning in the literature are MSCOCO-IT (a translated version of MSCOCO) and WIT. To get competitive results we followed three strategies:
- more and better data;
- better augmentations;
- better training.
More and Better Data
We eventually had to deal with the fact that we do not have the same data that OpenAI had during the training of CLIP. Thus, we tried to add as much data as possible while keeping the data-quality as high as possible.
We considered three main sources of data:
WIT is an image-caption dataset collected from Wikipedia (see, Srinivasan et al., 2021). We focused on the Reference Description captions described in the paper as they are the ones of highest quality. Nonetheless, many of these captions describe ontological knowledge and encyclopedic facts (e.g., Roberto Baggio in 1994). However, this kind of text, without more information, is not useful to learn a good mapping between images and captions. On the other hand, this text is written in Italian and it is of good quality. We cannot just remove short captions as some of those are still good (e.g., "running dog"). Thus, to prevent polluting the data with captions that are not meaningful, we used POS tagging on the text and removed all the captions that were composed for the 80% or more by PROPN (around ~10% of the data). This is a simple solution that allowed us to retain much of the dataset, without introducing noise.
Captions like: *'Dora Riparia', 'Anna Maria Mozzoni', 'Joey Ramone Place', 'Kim Rhodes', 'Ralph George Hawtrey' * have been removed.
MSCOCO-IT. This image-caption dataset comes from the work by Scaiella et al., 2019. The captions comes from the original MSCOCO dataset and have been translated with Microsoft Translator. The 2017 version of the MSCOCO training set contains more than 100K images, for each image more than one caption is available.
Conceptual Captions. This image-caption dataset comes from the work by Sharma et al., 2018. There are more than 3mln image-caption pairs in this dataset and these have been collected from the web. We downloaded the images with the URLs provided by the dataset, but we could not retrieve them all. Eventually, we had to translate the captions to Italian. We have been able to collect a dataset with 700K translated captions.
Better Augmentations
Better Training
After different trials, we realized that the usual way of training this model was not good enough to get good results. We thus modified two different parts of the training pipeline: the optimizer and the training with frozen components.
Optimizer
The standard AdamW didn't seem enough to train the model and thus we opted for a different optimization strategy. We eventually used AdaBelief with AGC and Cosine Annealing. Our implementation is available online here.
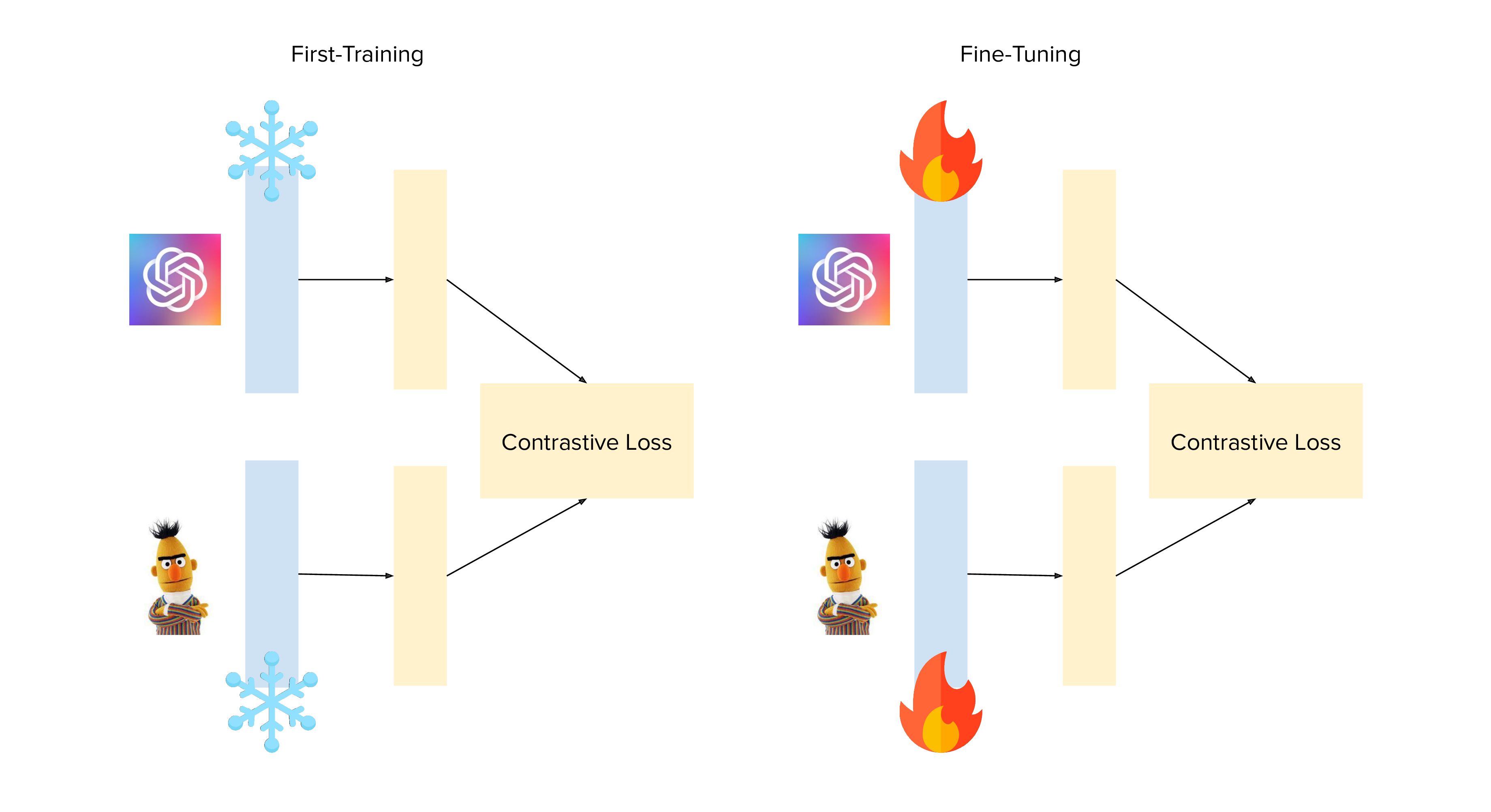
Backbone Freezing
The ViT used by OpenAI was already trained on 400million images and it is the element in our architecture that probably required less training. The same is true for the BERT model we use. Thus, we decided to do a first training with the backbone of our architecture completely frozen, to allow the deeper layer to adapt to the new setting. Eventually, we run a new training, by fine-tuning al the components. This technique allowed us to reach a much better validation loss.
Scientific Validity
Quantitative Evaluation
Those images are definitely cool and interesting, but a model is nothing without validation. To better understand how well our clip-italian model works we run an experimental evaluation. Since this is the first clip-based model in Italian, we used the multilingual CLIP model as a comparison baseline.
mCLIP
The multilingual CLIP (henceforth, mCLIP), is a model introduced by Nils Reimers in his sentence-transformer library. mCLIP is based on a multilingual encoder that was created through multilingual knowledge distillation (see Reimers et al., 2020).
Experiments Replication
We provide two colab notebooks to replicate both experiments.
Tasks
We selected two different tasks:
- image-retrieval
- zero-shot classification
Image Retrieval
This experiment is run against the MSCOCO-IT validation set (that we haven't used in training). Given in input a caption, we search for the most similar image in the MSCOCO-IT validation set. As evaluation metrics we use the MRR.
| MRR | CLIP-Italian | mCLIP |
|---|---|---|
| MRR@1 | 0.3797 | 0.2874 |
| MRR@5 | 0.5039 | 0.3957 |
| MRR@10 | 0.5204 | 0.4129 |
It is true that we used MSCOCO-IT in training, and this might give us an advantage. However the original CLIP model was trained on 400million images (and some of them probably were from MSCOCO).
Colab: Image Retrieval Evaluation
Zero-shot image classification
This experiment replicates the original one run by OpenAI on zero-shot image classification on ImageNet. To do this, we used DeepL to translate the image labels in ImageNet with DeepL. We evaluate the models computing the accuracy.
| Accuracy | CLIP-Italian | mCLIP |
|---|---|---|
| Accuracy@1 | 22.11 | 20.15 |
| Accuracy@5 | 43.69 | 36.57 |
| Accuracy@10 | 52.55 | 42.91 |
| Accuracy@100 | 81.08 | 67.11 |
Colab: ImageNet Zero Shot Evaluation
Our results confirm that CLIP-Italian is very competitive and beats mCLIP on the two different task we have been testing. Note, however, that our results are lower than those shown in the original OpenAI paper (see, Radford et al., 2021). However, considering that our results are in line with those obtained by mCLIP we think that the translated image labels might have had an impact on the final scores.
Qualitative Evaluation
We hereby show some very interesting properties of the model. The first one is its ability to detect colors and the second one is its (partial) counting ability. To our own surprise, many of the answers the model gives make a lot of sense!
Colors
Counting
Broader Outlook
We believe that this model can be useful for many different applications, not only in research settings. Italy has many different collections of photos in digital format. For example, the Istituto Luce Cinecittà is an Italian governative entity that collects photos of Italy since the early 1900 and it is part of the largest movie studios in Europe (Cinecittà).
References
Scaiella, A., Croce, D., & Basili, R. (2019). Large scale datasets for Image and Video Captioning in Italian. IJCoL. Italian Journal of Computational Linguistics, 5(5-2), 49-60.
Sharma, P., Ding, N., Goodman, S., & Soricut, R. (2018, July). Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (pp. 2556-2565).
Srinivasan, K., Raman, K., Chen, J., Bendersky, M., & Najork, M. (2021). WIT: Wikipedia-based image text dataset for multimodal multilingual machine learning. arXiv preprint arXiv:2103.01913.
Reimers, N., & Gurevych, I. (2020, November). Making Monolingual Sentence Embeddings Multilingual Using Knowledge Distillation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) (pp. 4512-4525).
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., & Sutskever, I. (2021). Learning Transferable Visual Models From Natural Language Supervision. ICML.
Other Notes
This readme has been designed using resources from Flaticon.com