Spaces:
No application file

SATO: Stable Text-to-Motion Framework
Wenshuo chen*, Hongru Xiao*, Erhang Zhang*, Lijie Hu, Lei Wang, Mengyuan Liu, Chen Chen

![]()
Existing Challenges
A fundamental challenge inherent in text-to-motion tasks stems from the variability of textual inputs. Even when conveying similar or the same meanings and intentions, texts can exhibit considerable variations in vocabulary and structure due to individual user preferences or linguistic nuances. Despite the considerable advancements made in these models, we find a notable weakness: all of them demonstrate instability in prediction when encountering minor textual perturbations, such as synonym substitutions. In the following demonstration, we showcase the instability of predictions generated by the previous method when presented with different user inputs conveying identical semantic meaning.
| Original text: A man kicks something or someone with his left leg. | |||
|---|---|---|---|
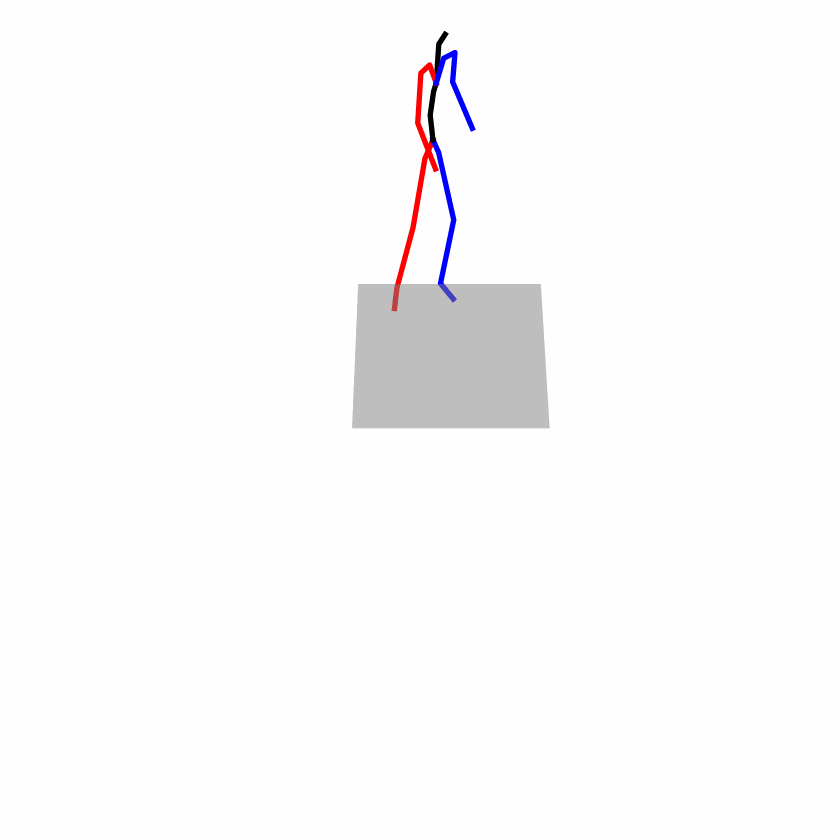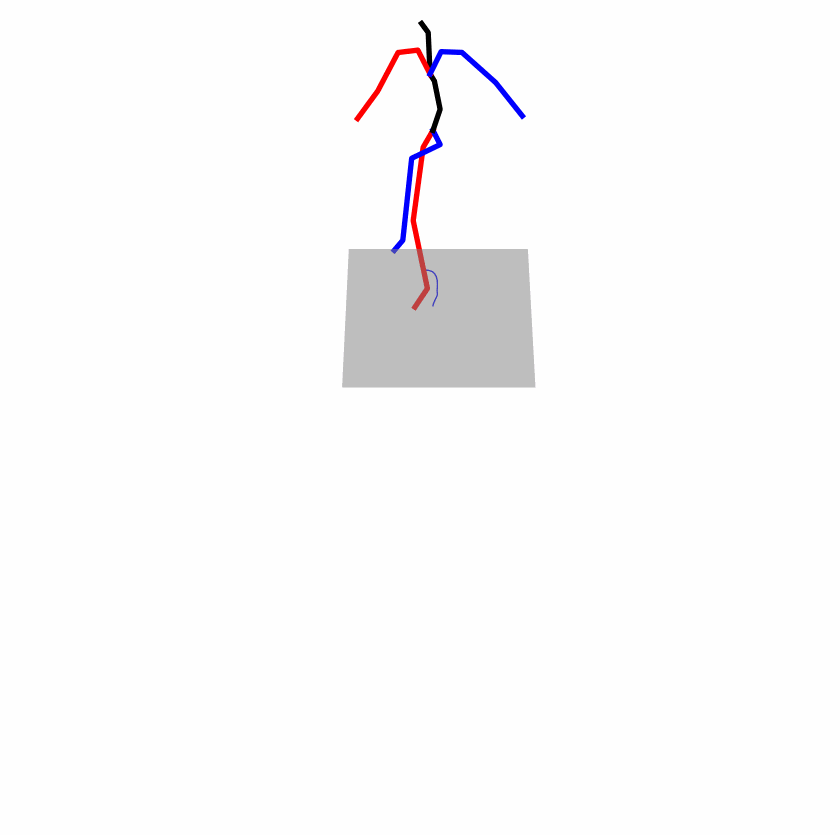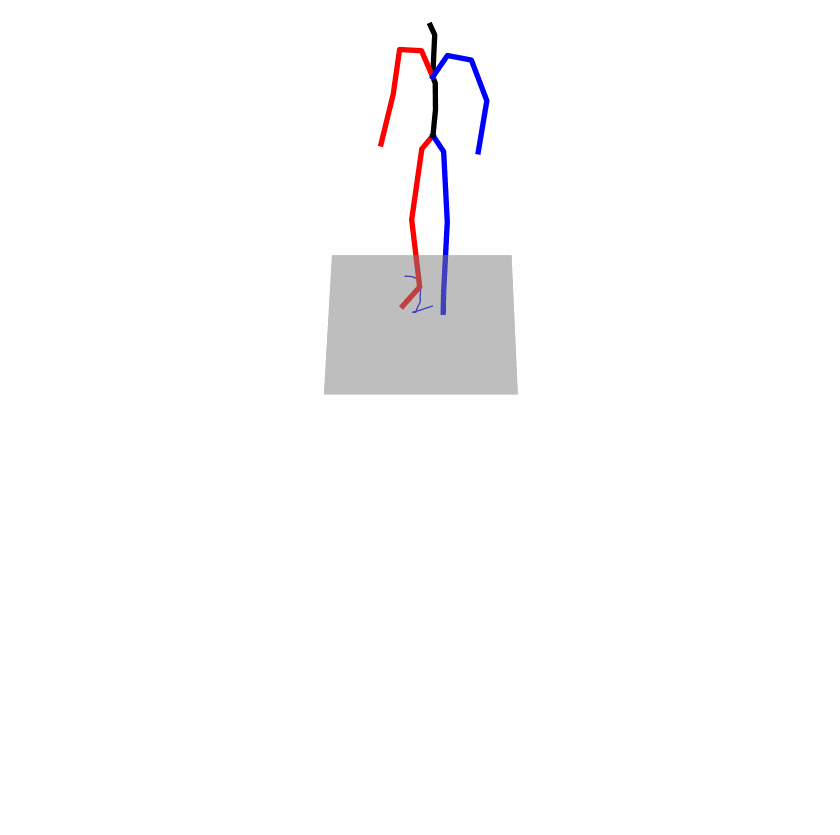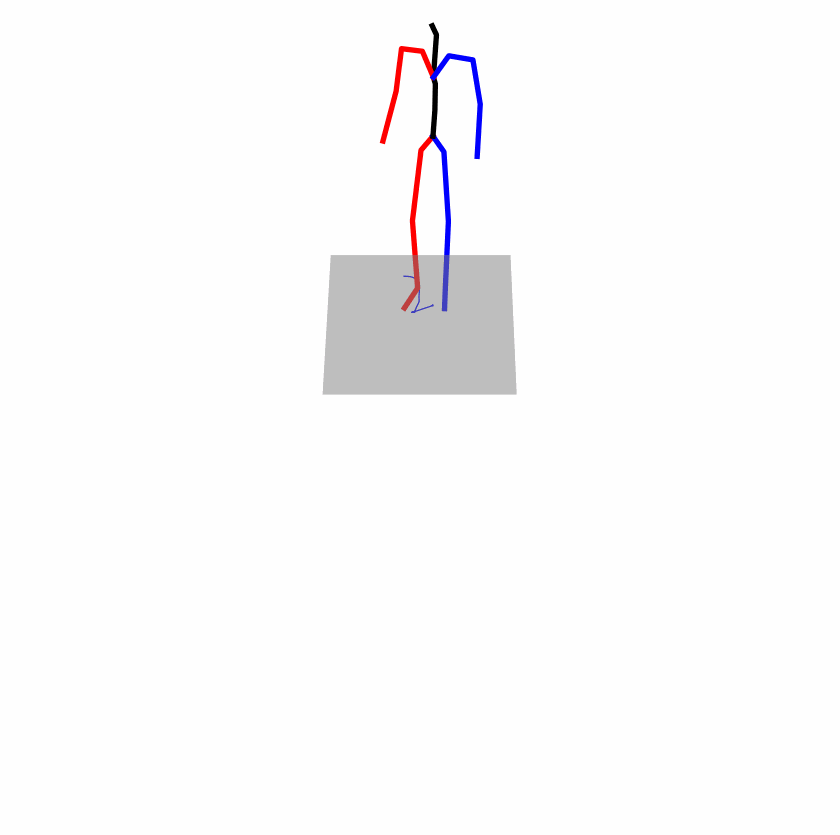 |
 |
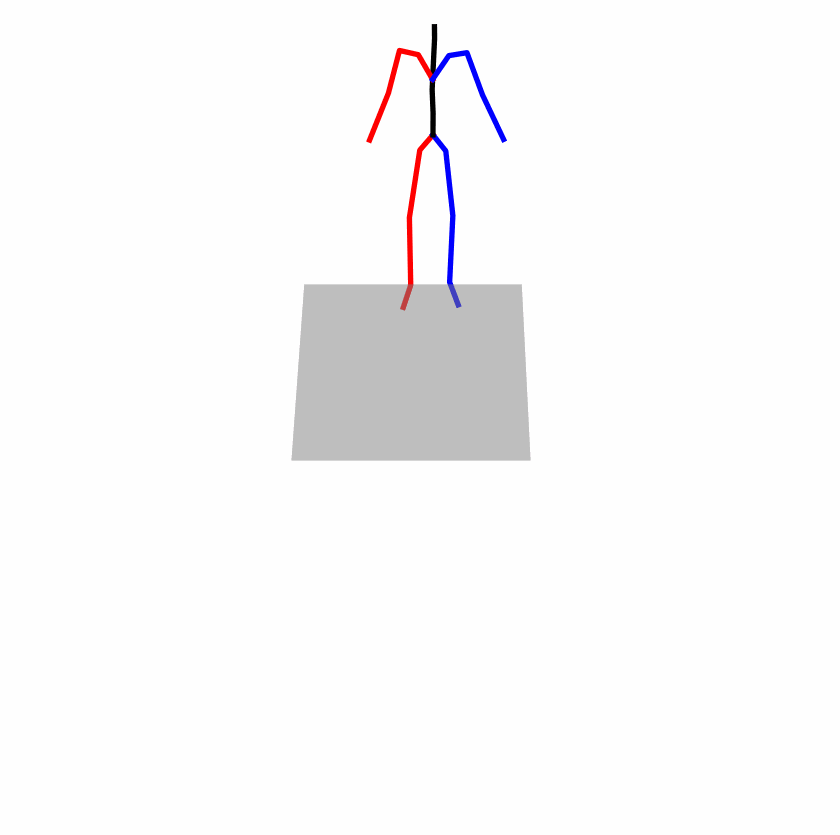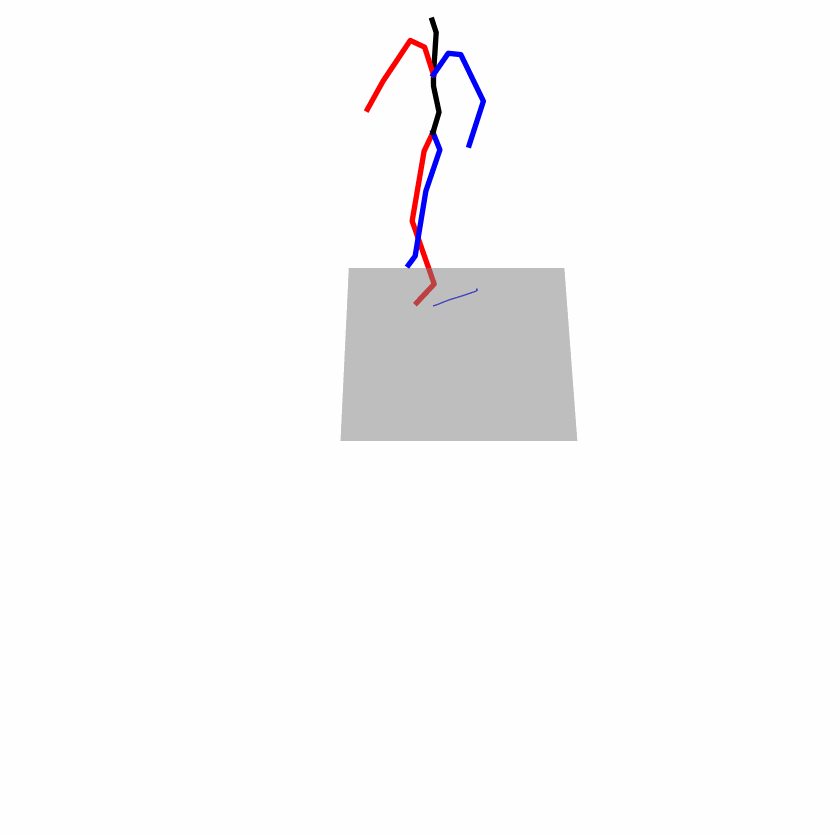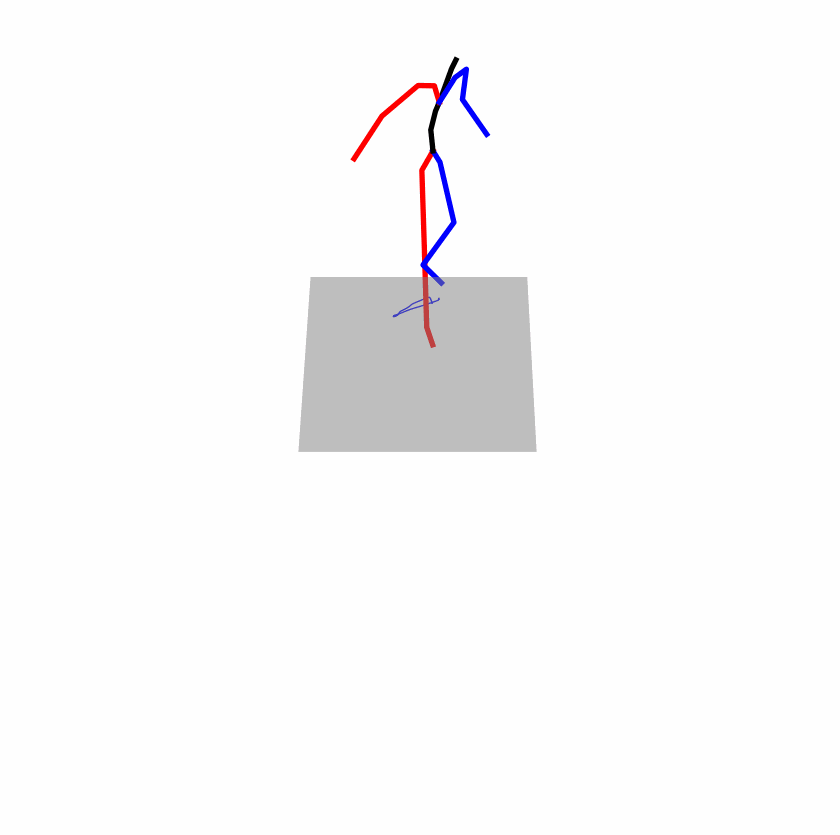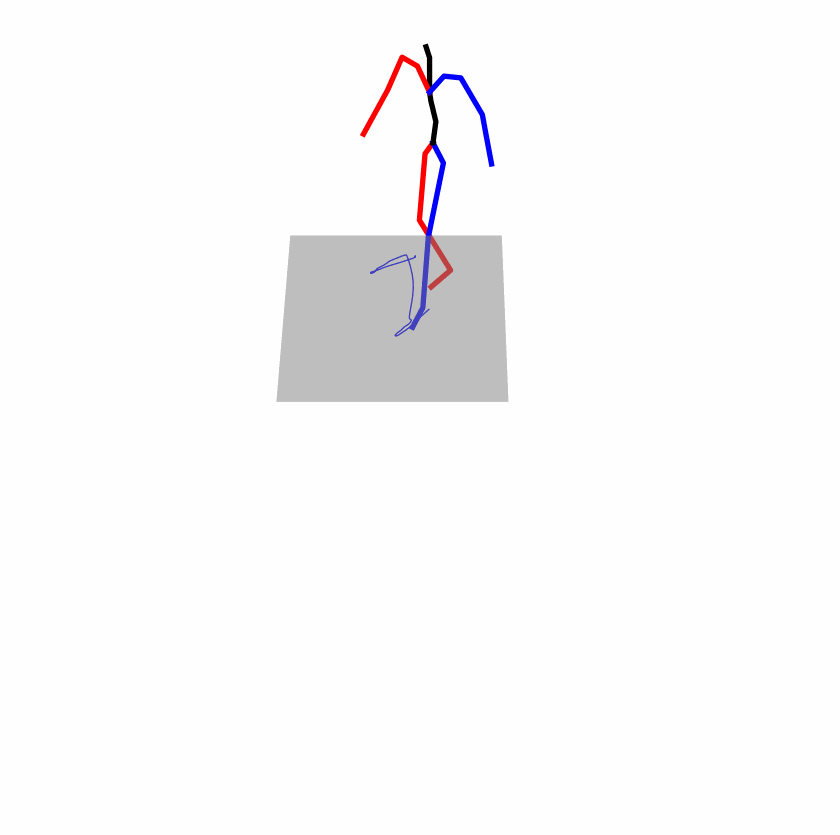 |
|
| Perturbed text: A human boots something or someone with his left leg. | |||
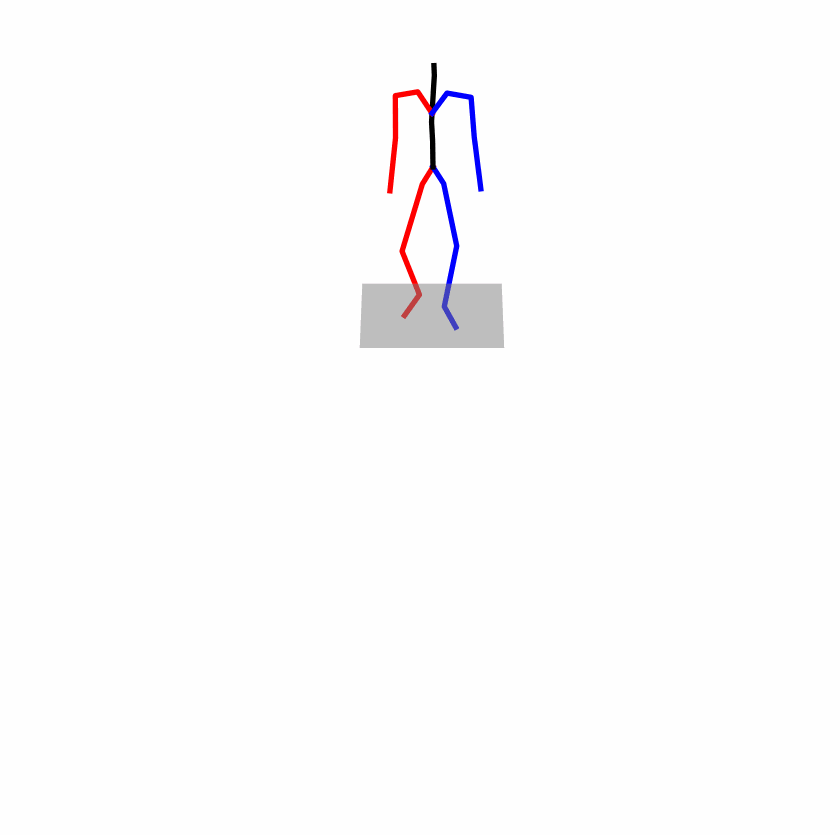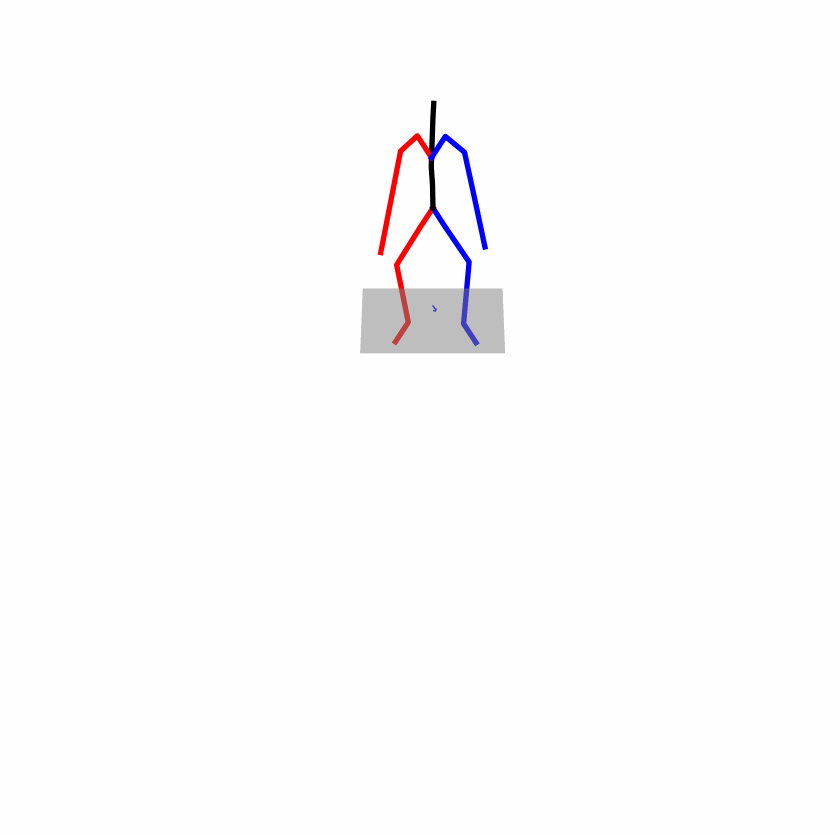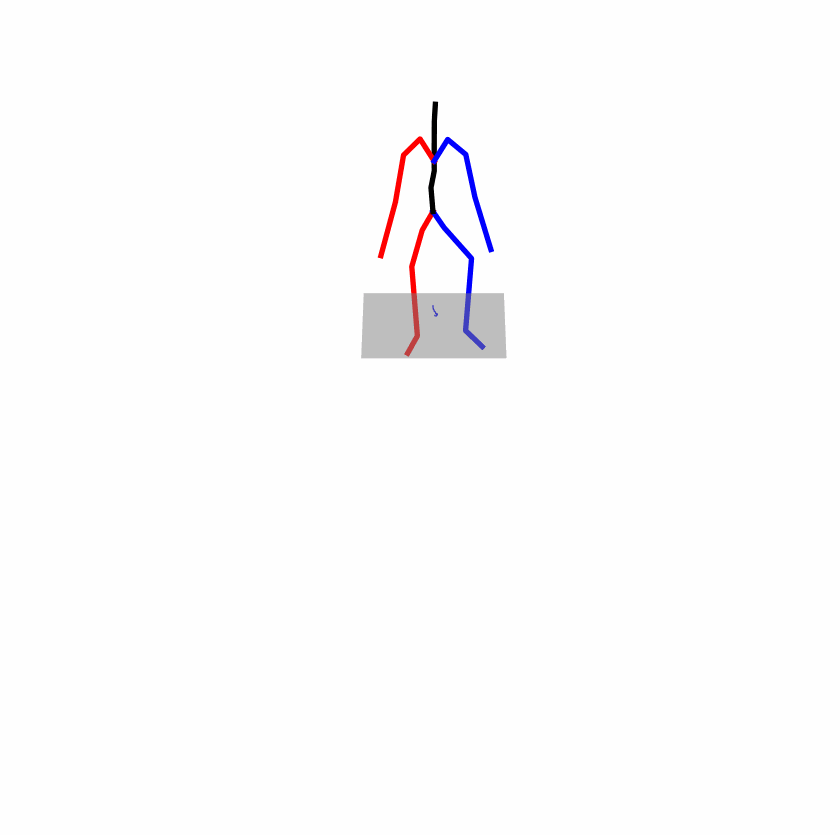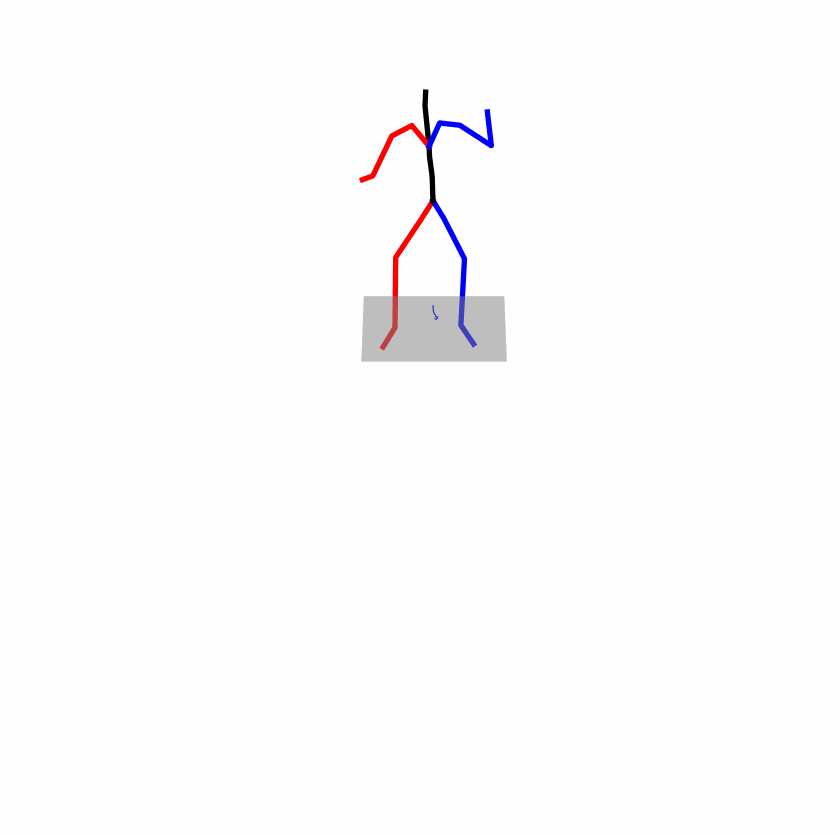 |
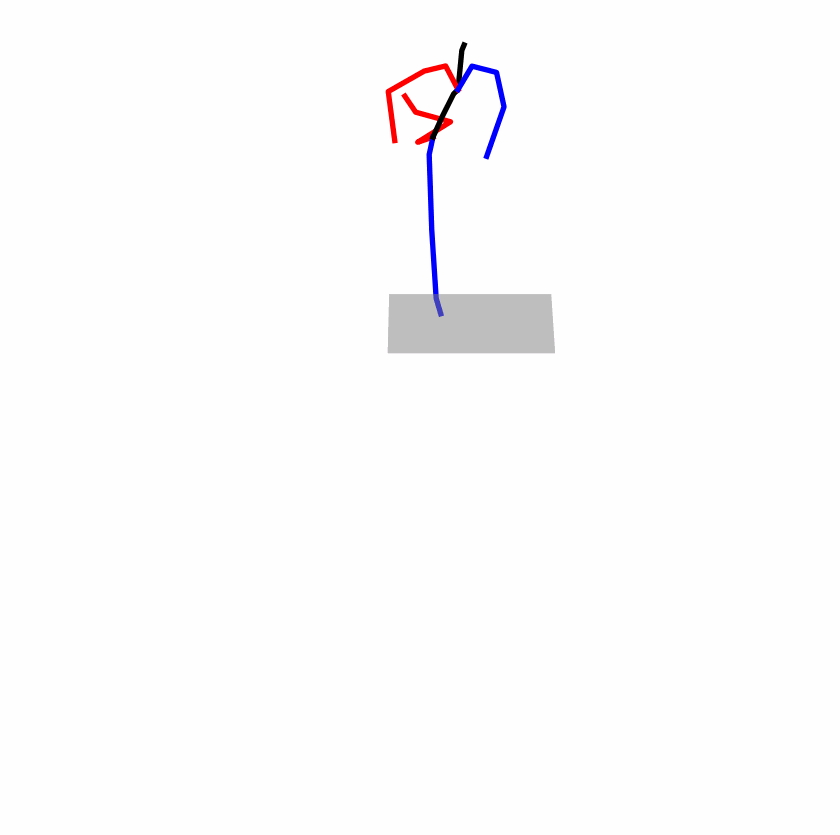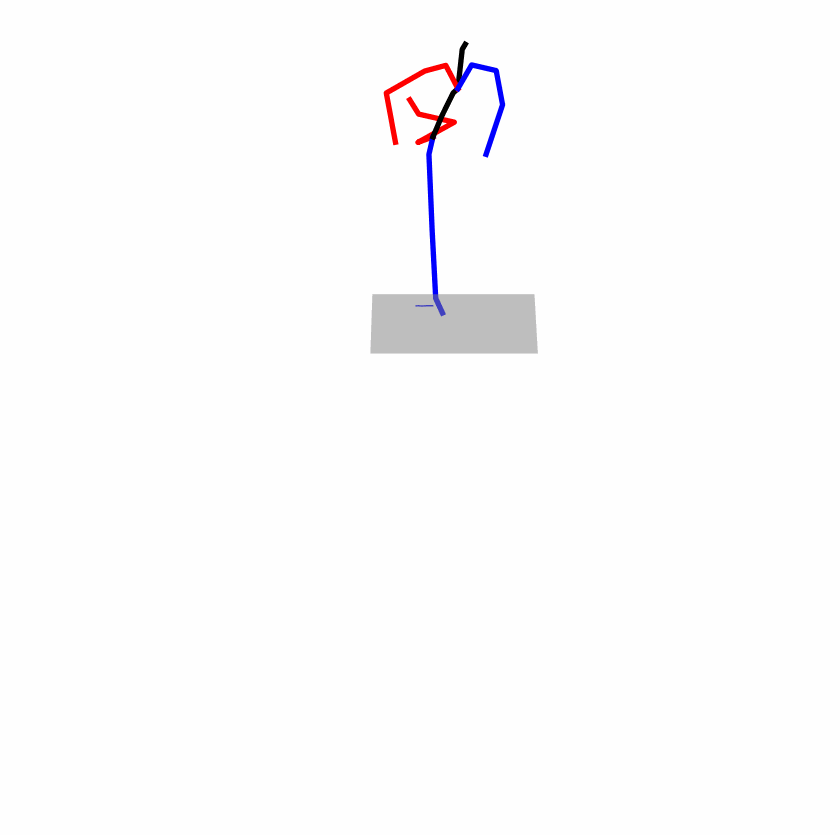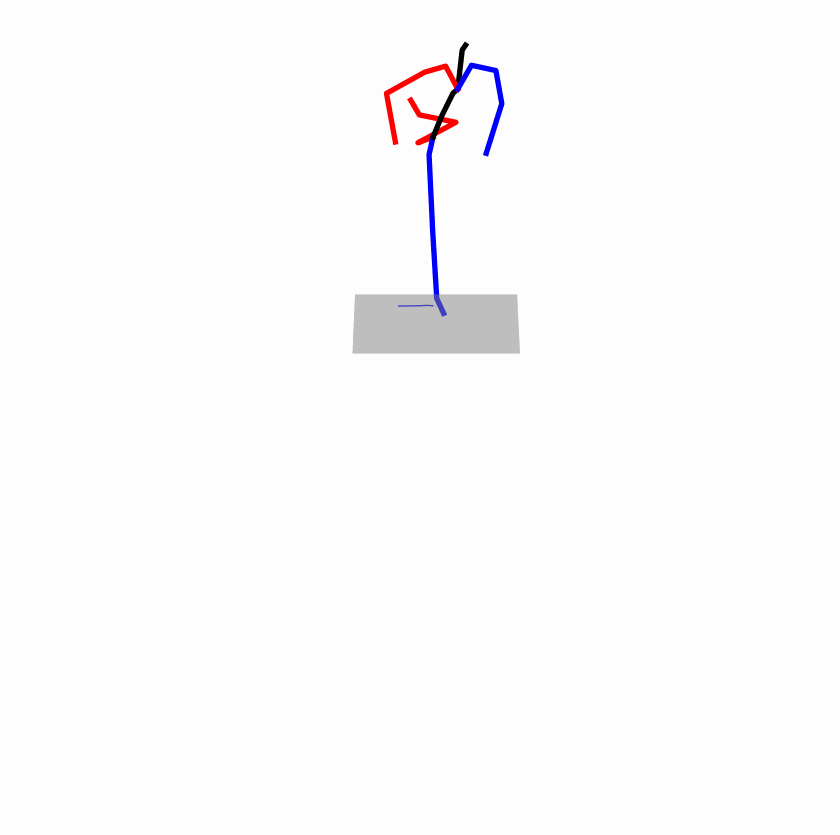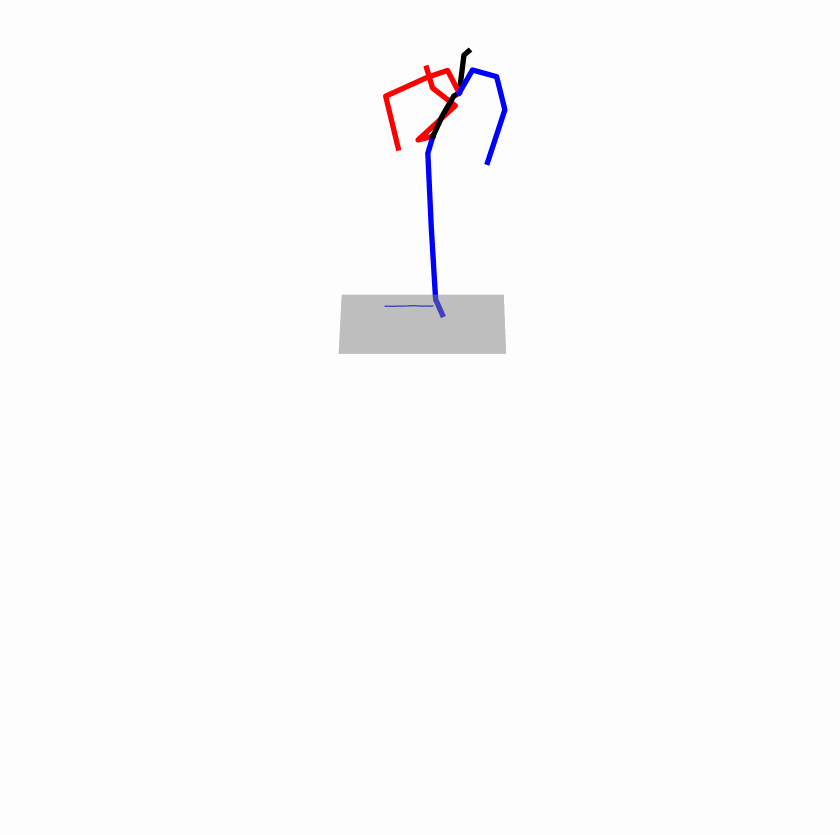 |
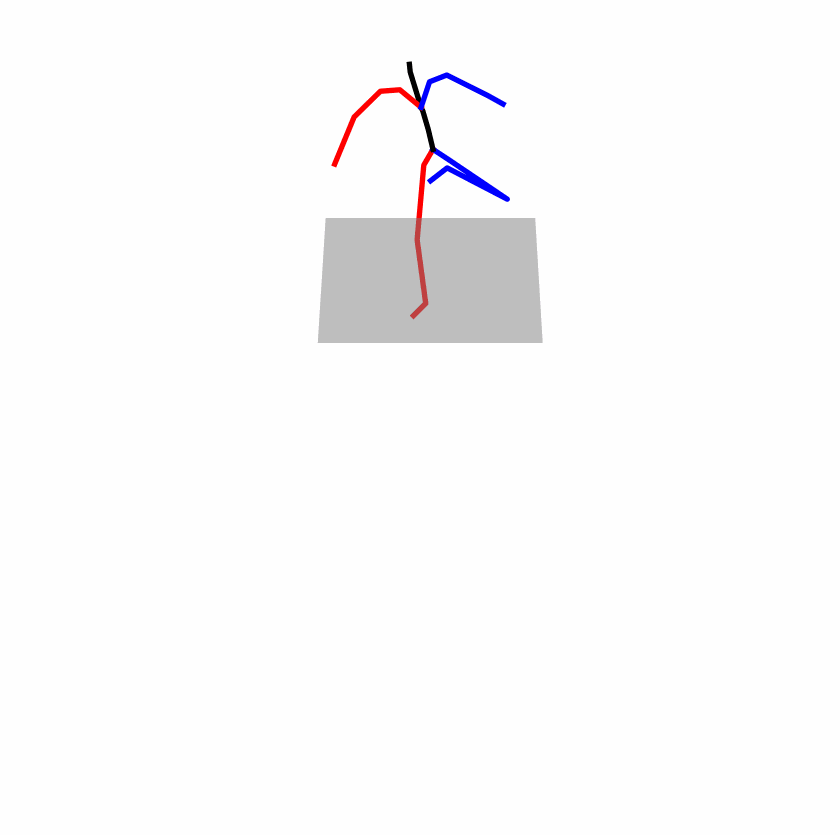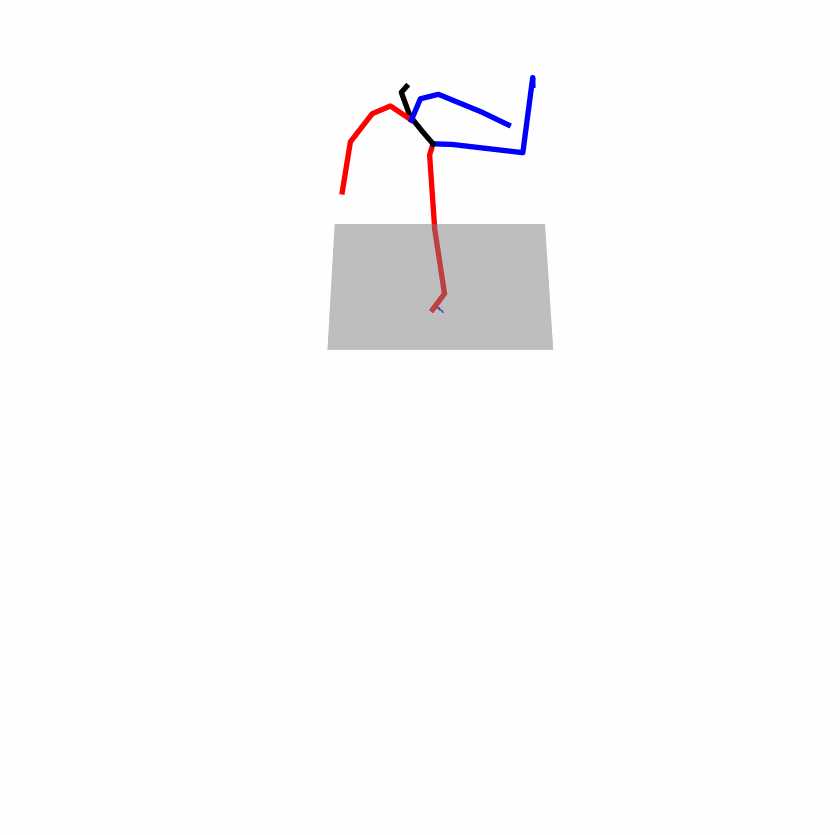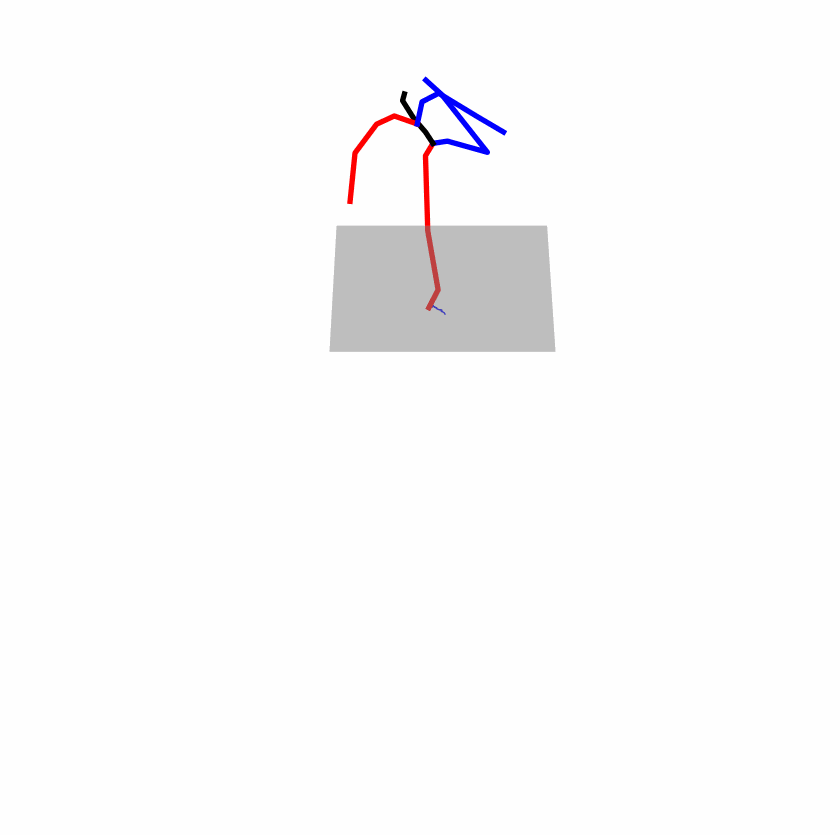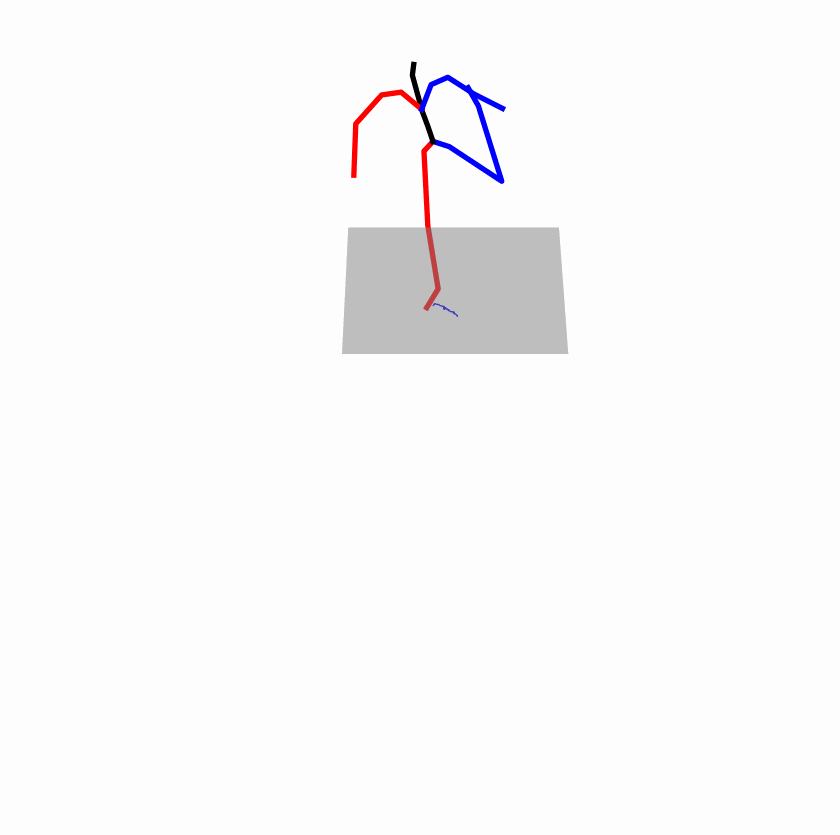 |
|
Motivation
 The model's inconsistent outputs are accompanied by unstable attention patterns. We further elucidate the aforementioned experimental findings: When perturbed text is inputted, the model exhibits unstable attention, often neglecting critical text elements necessary for accurate motion prediction. This instability further complicates the encoding of text into consistent embeddings, leading to a cascade of consecutive temporal motion generation errors.
The model's inconsistent outputs are accompanied by unstable attention patterns. We further elucidate the aforementioned experimental findings: When perturbed text is inputted, the model exhibits unstable attention, often neglecting critical text elements necessary for accurate motion prediction. This instability further complicates the encoding of text into consistent embeddings, leading to a cascade of consecutive temporal motion generation errors.
Our Approach
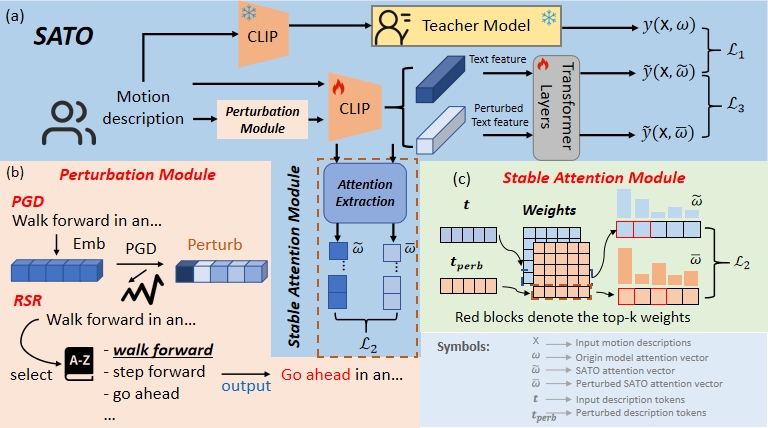
Attention Stability. For the original text input, we can easily observe the model's attention vector for the text. This attention vector reflects the model's attentional ranking of the text, indicating the importance of each word to the text encoder's prediction. We hope a stable attention vector maintains a consistent ranking even after perturbations.
Prediction Robustness. Even with stable attention, we still cannot achieve stable results due to the change in text embeddings when facing perturbations, even with similar attention vectors. This requires us to impose further restrictions on the model's predictions. Specifically, in the face of perturbations, the model's prediction should remain consistent with the original distribution, meaning the model's output should be robust to perturbations.
Balancing Accuracy and Robustness Trade-off. Accuracy and robustness are naturally in a trade-off relationship. Our objective is to bolster stability while minimizing the decline in model accuracy, thereby mitigating catastrophic errors arising from input perturbations. Consequently, we require a mechanism to uphold the model's performance concerning the original input.
Quantitative evaluation on the HumanML3D and KIT-ML.

Visualization
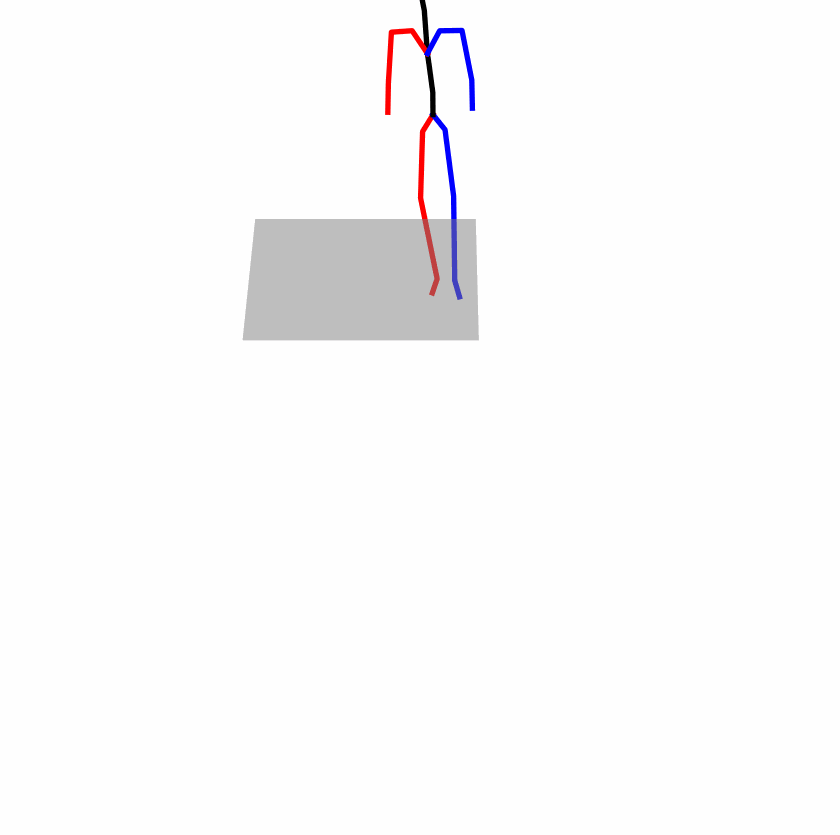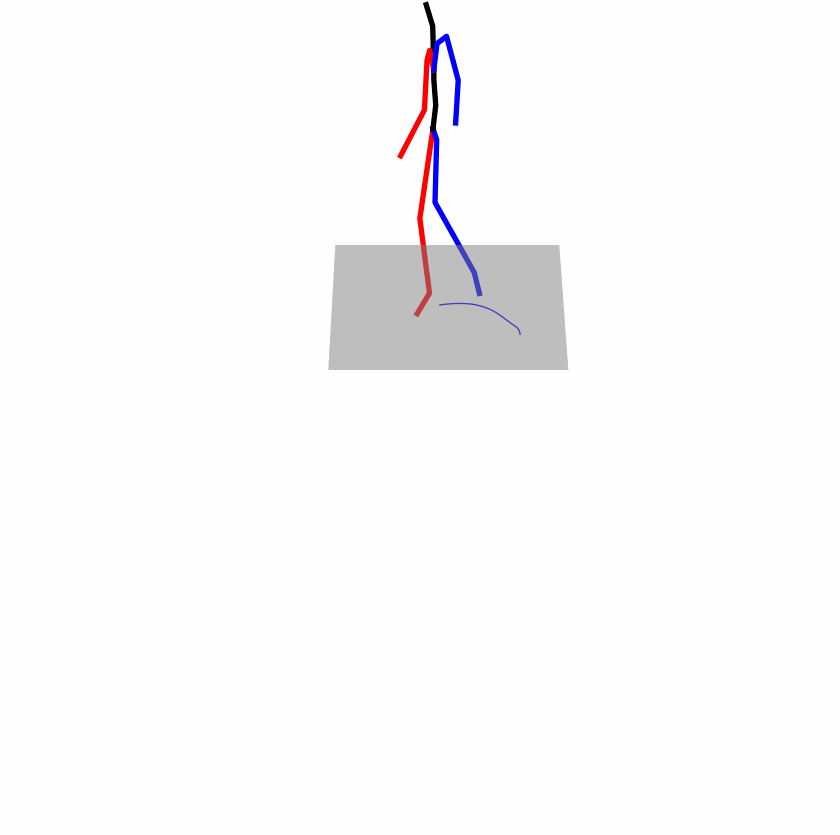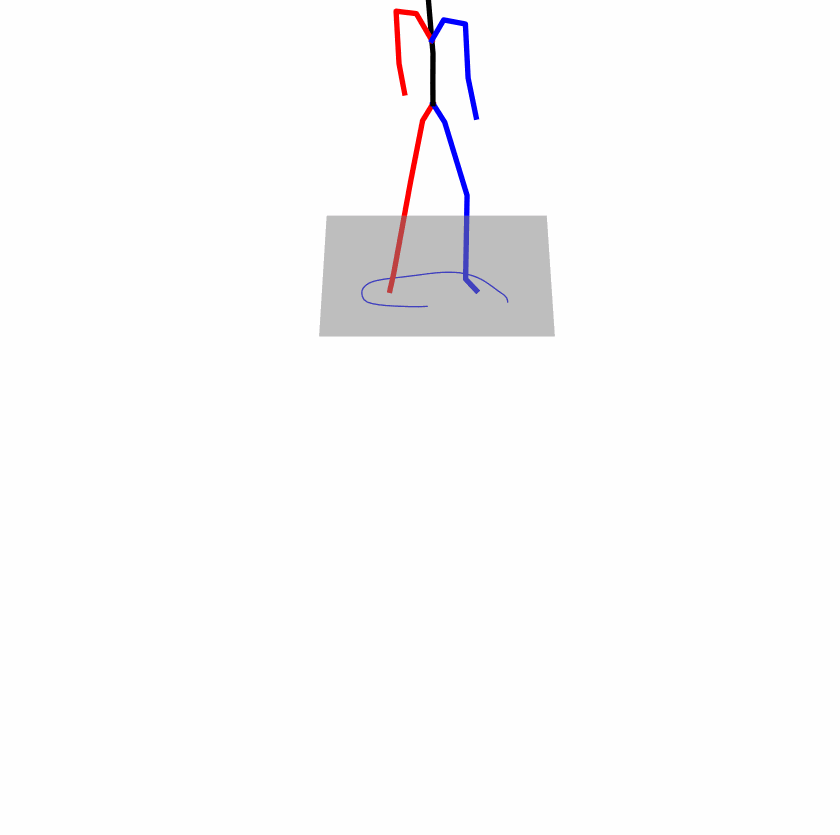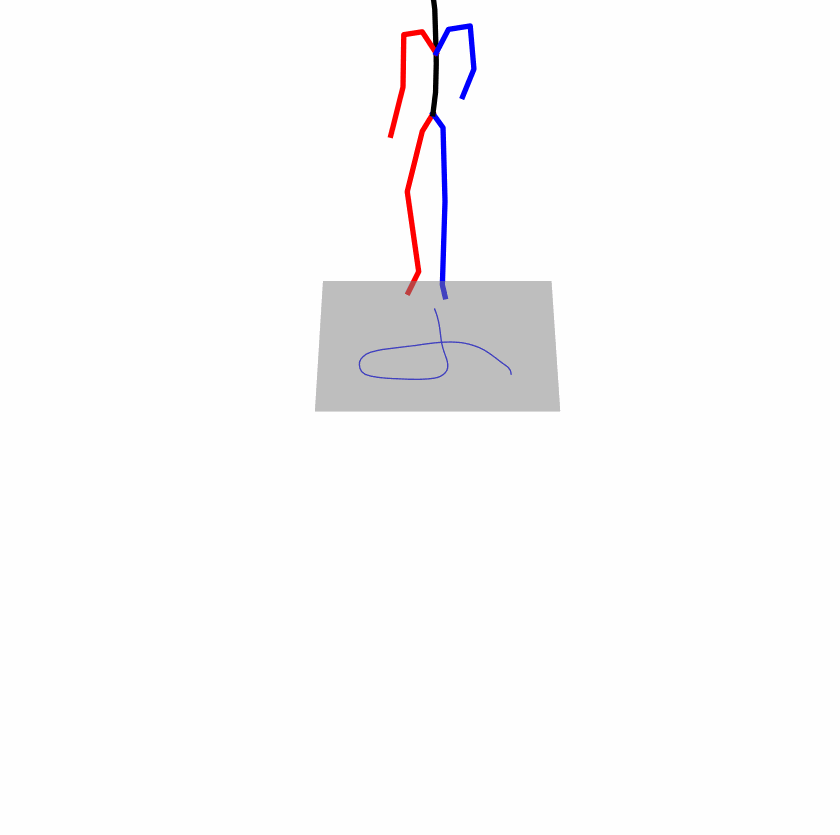
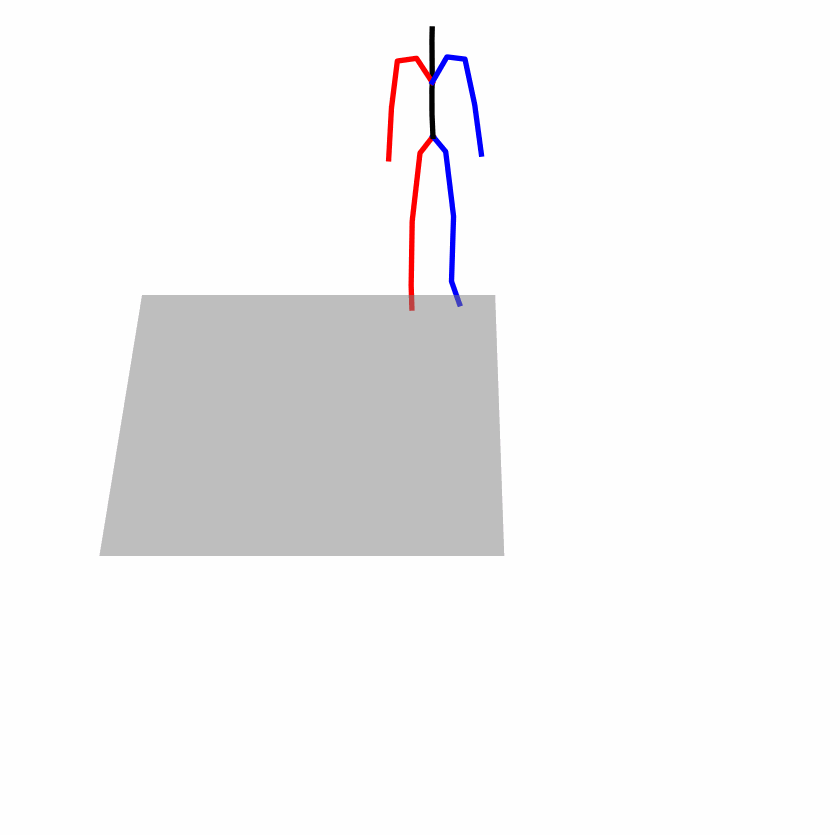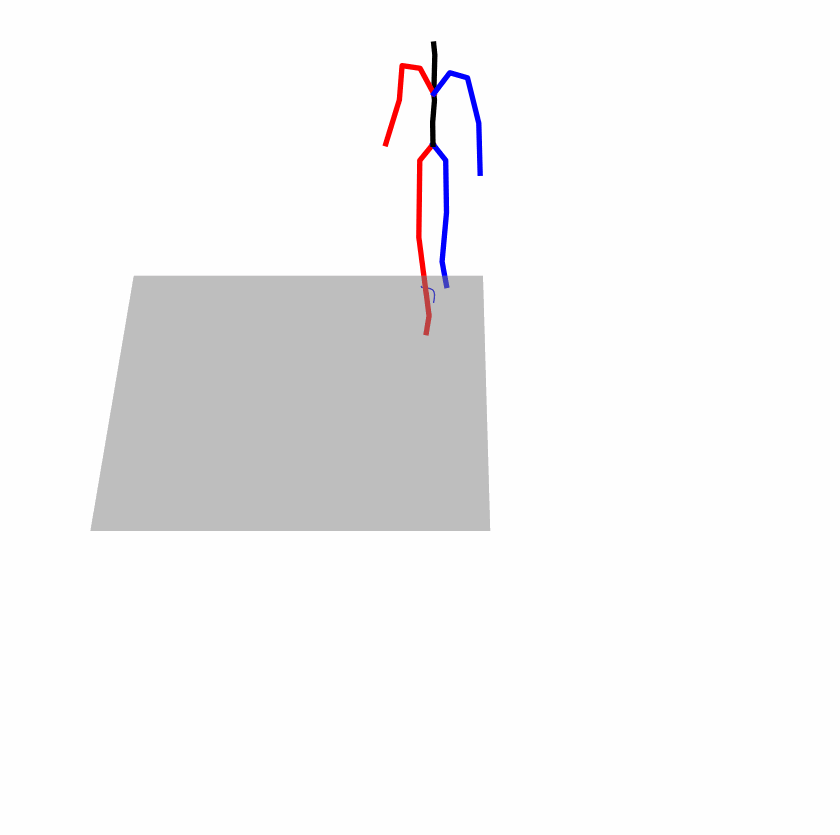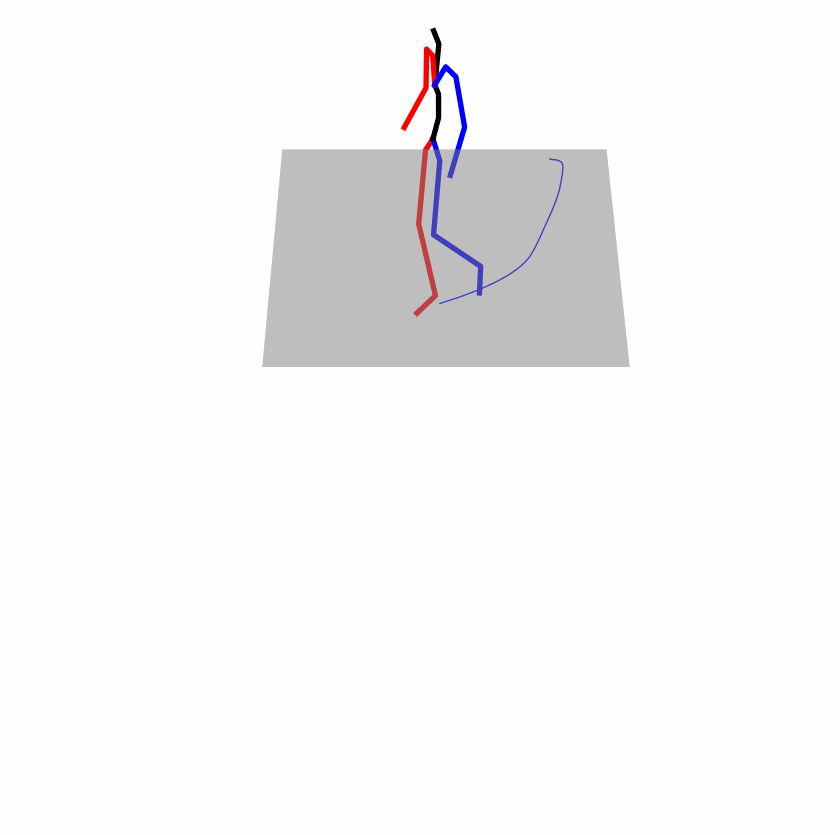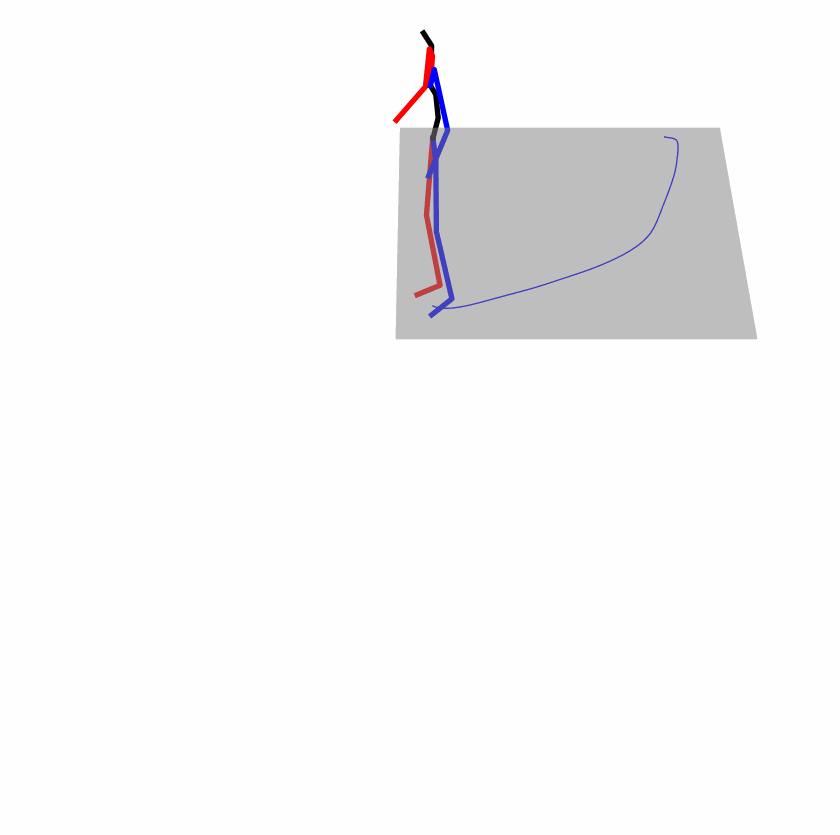
| Original text: person is walking normally in a circle. | |||
|---|---|---|---|
 |
 |
 |
 |
| Perturbed text: human is walking usually in a loop. | |||
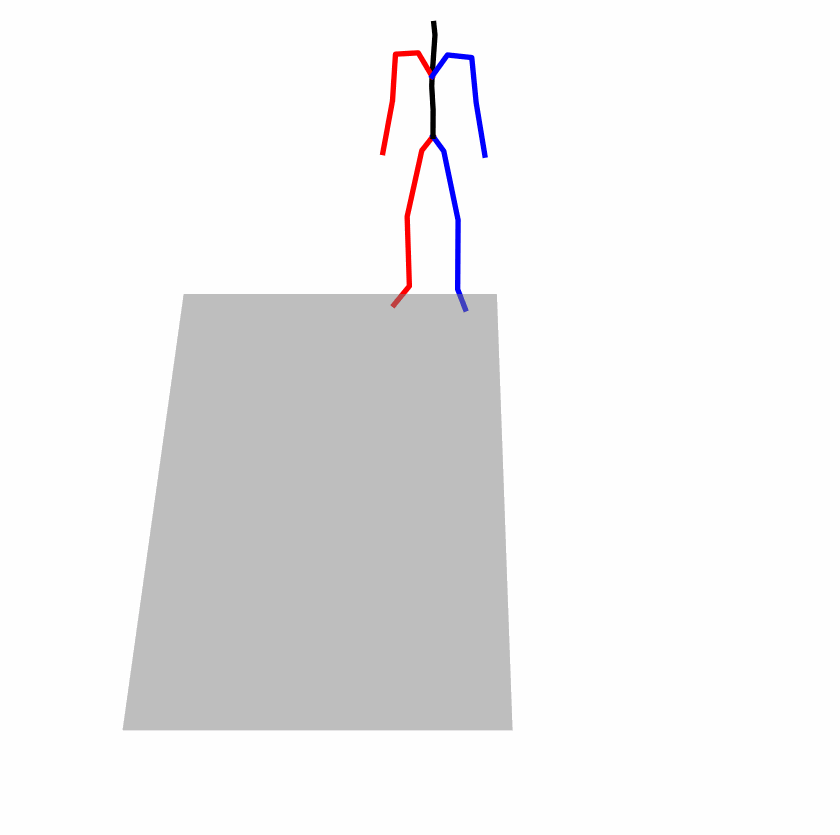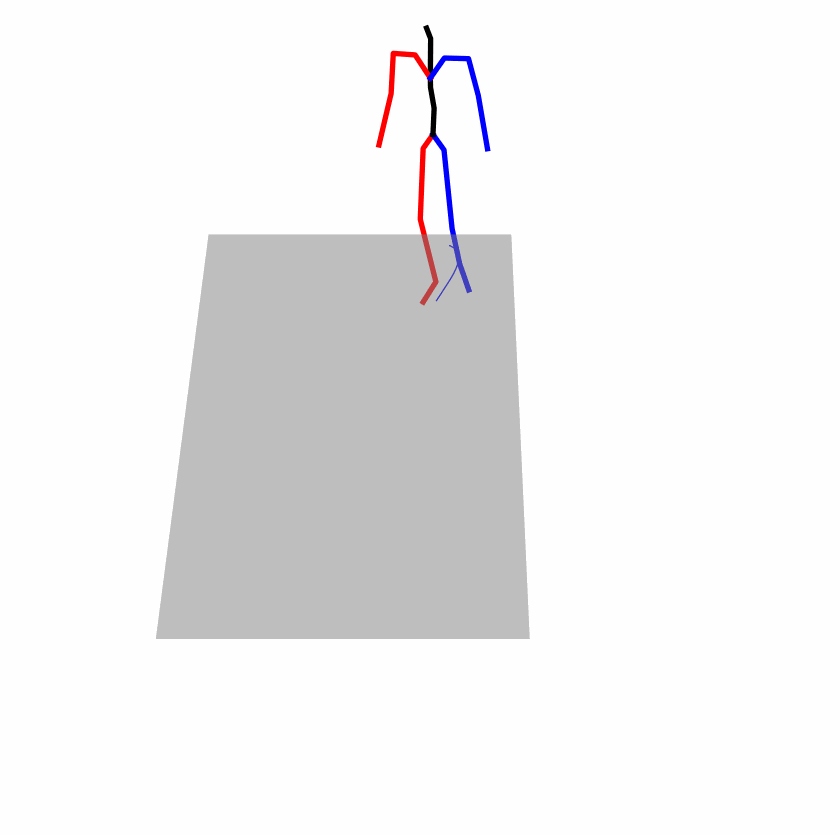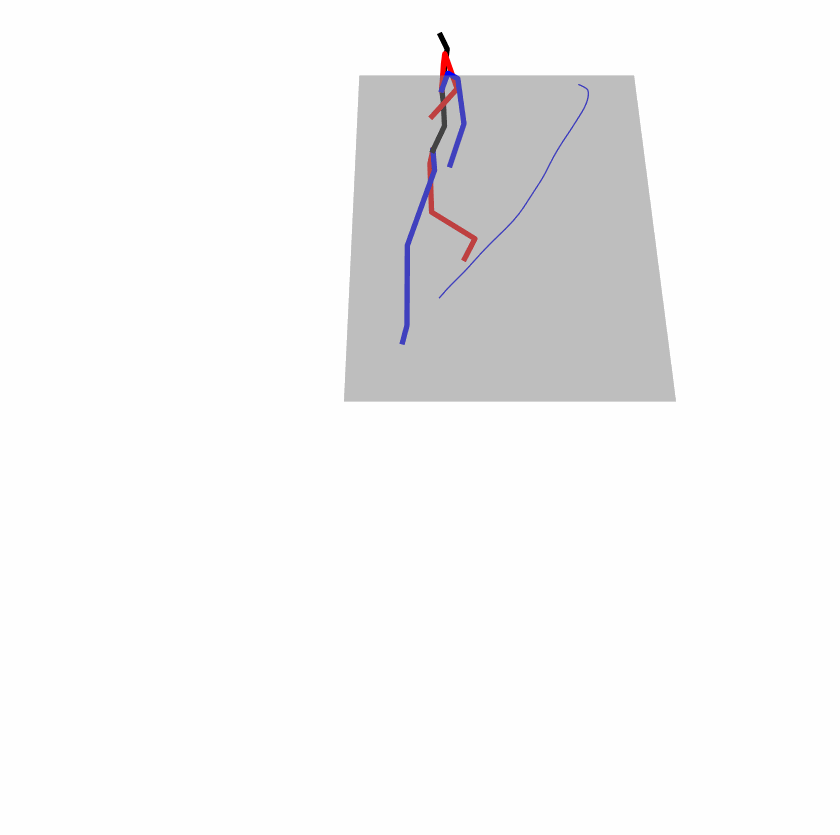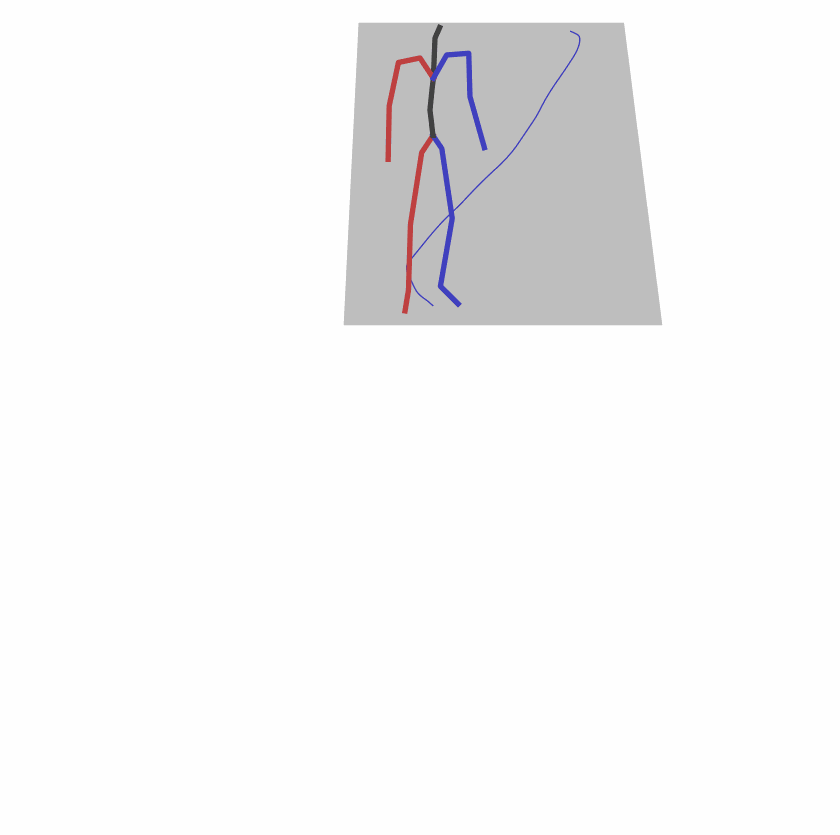 |
 |
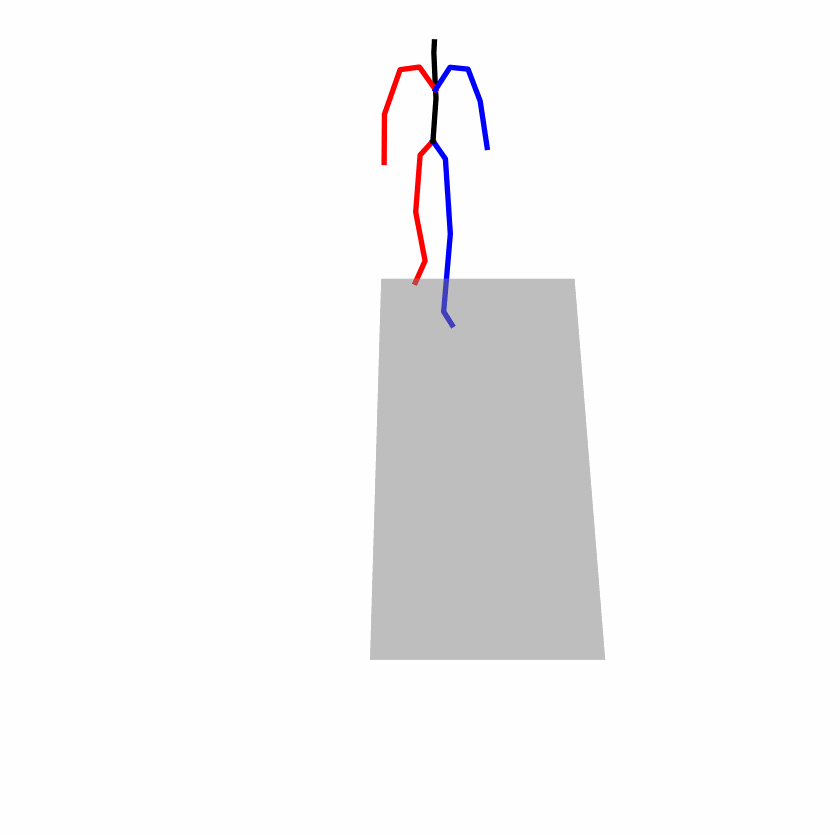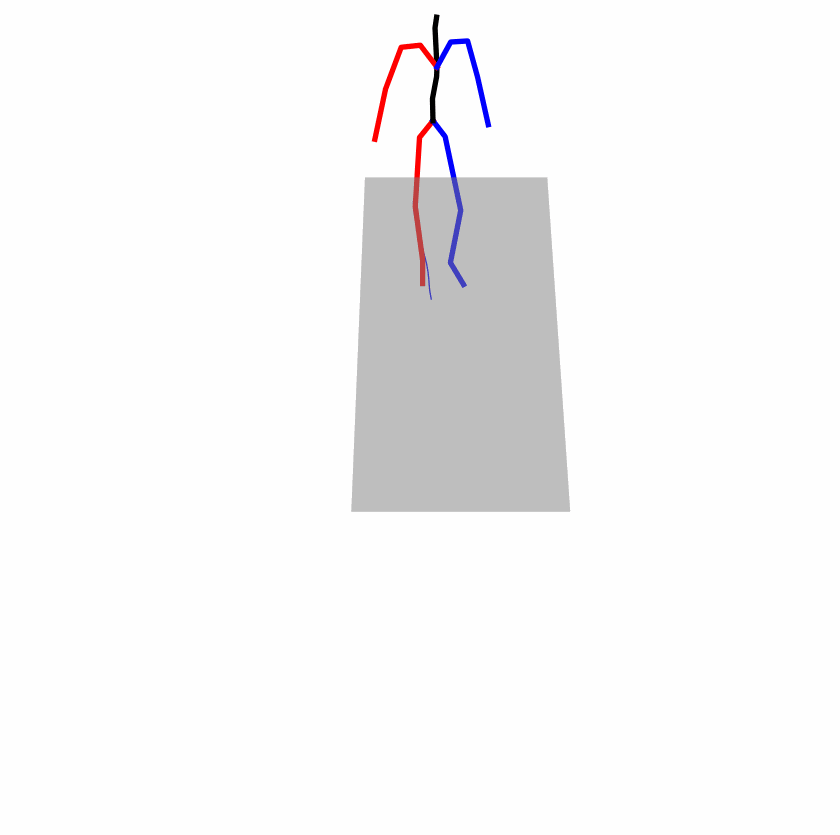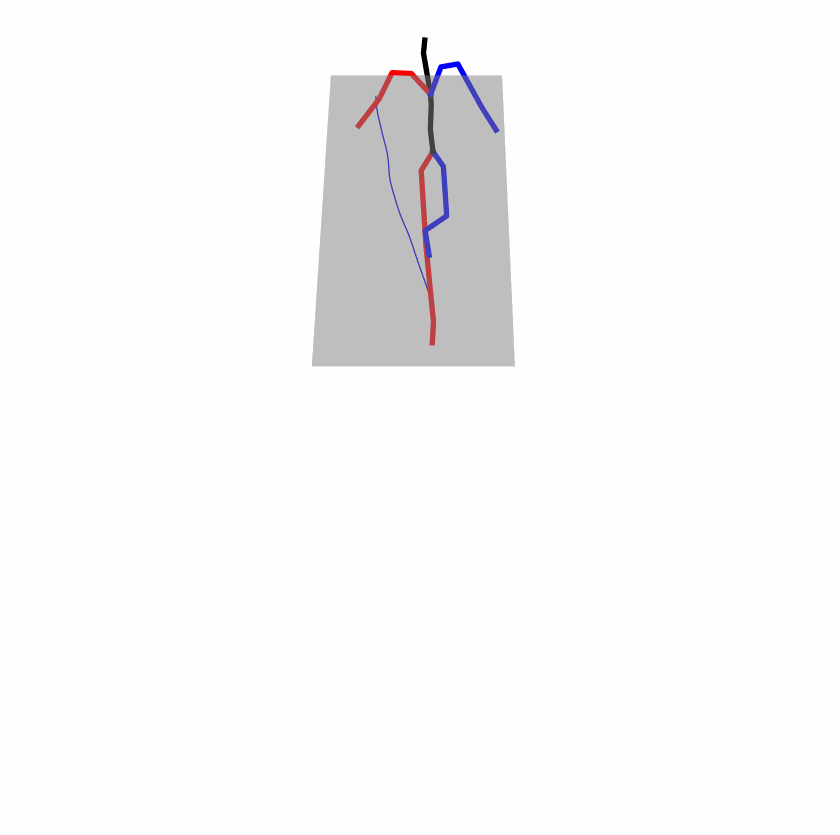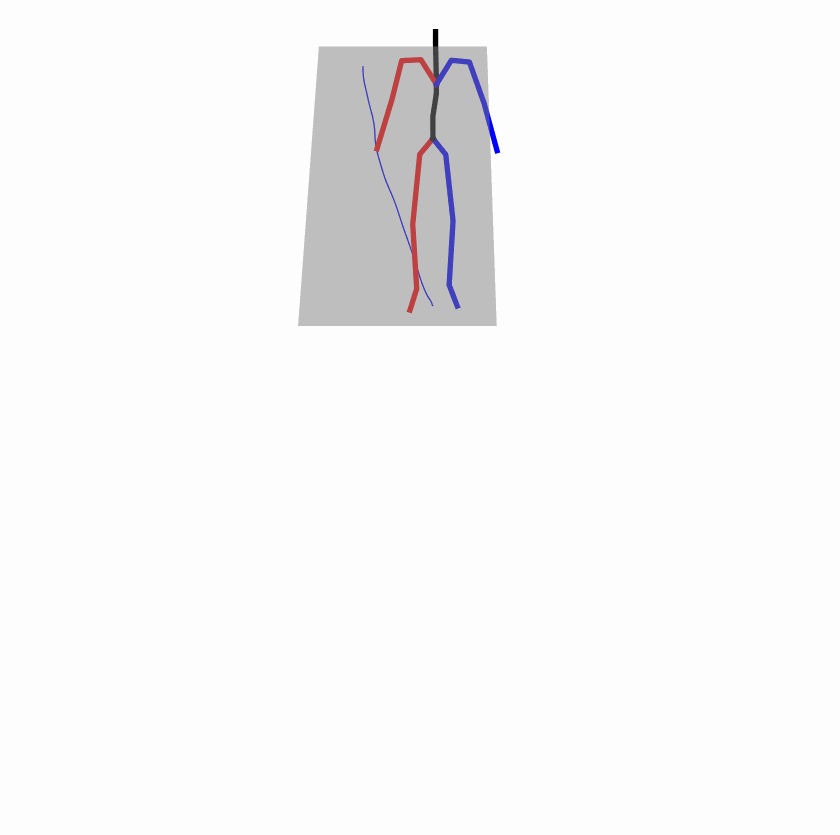 |
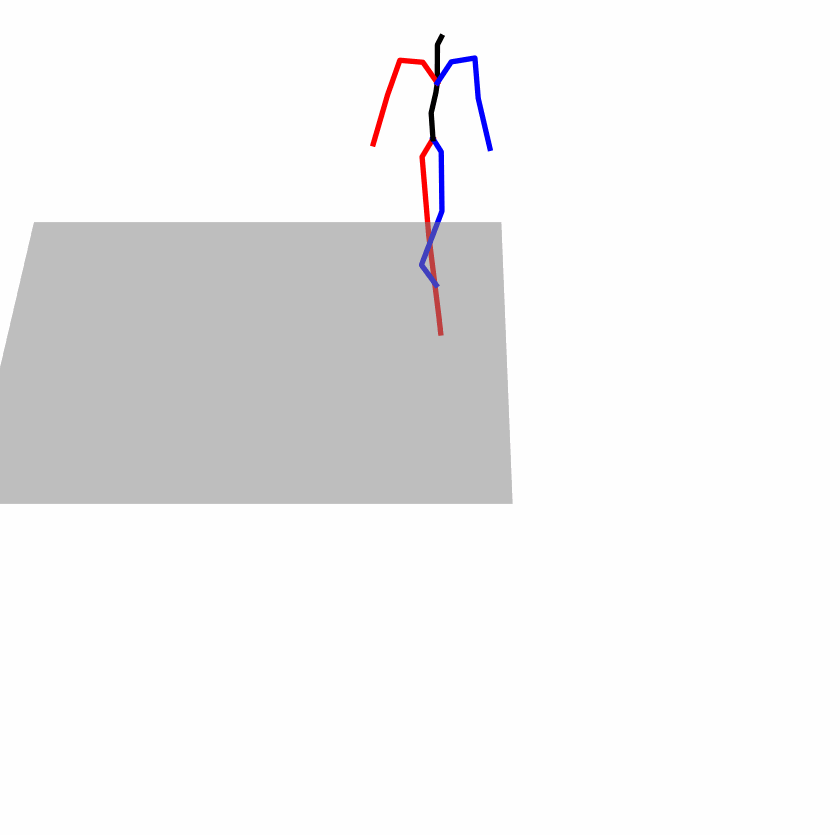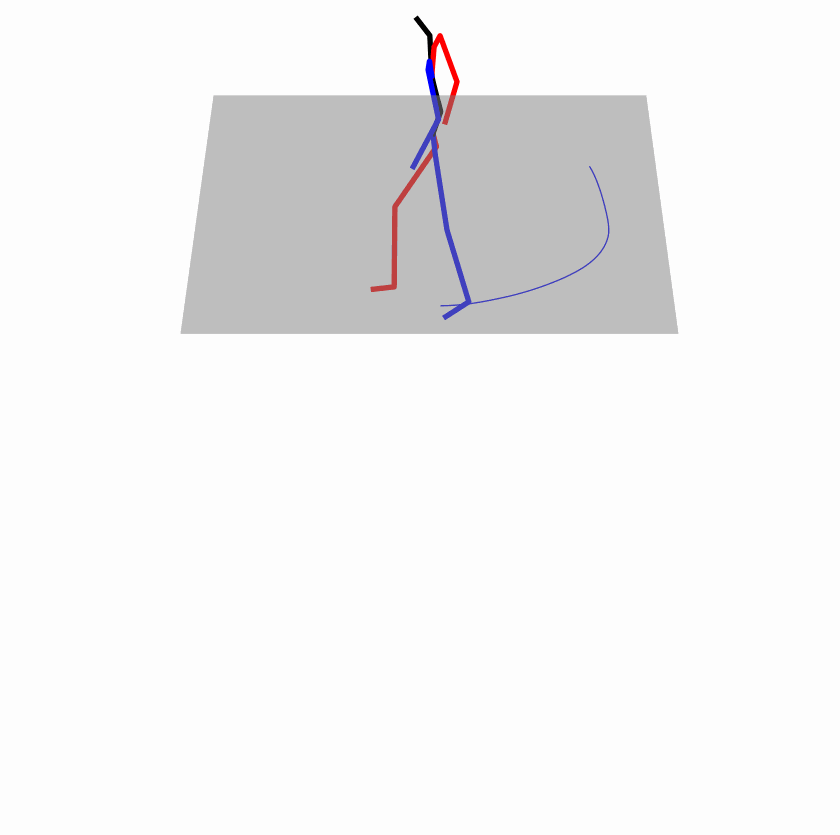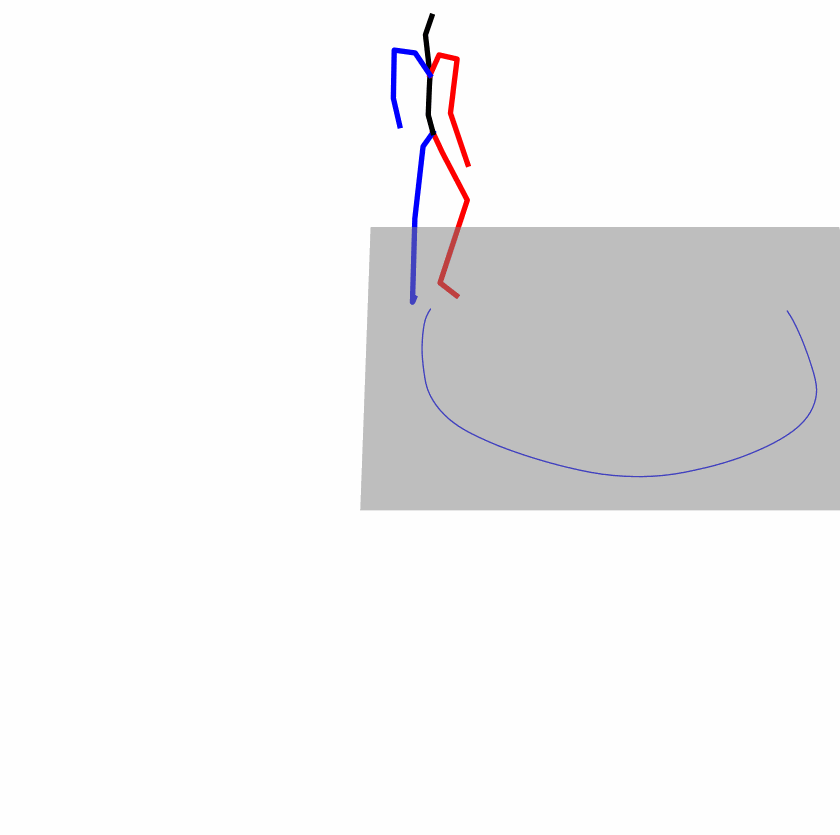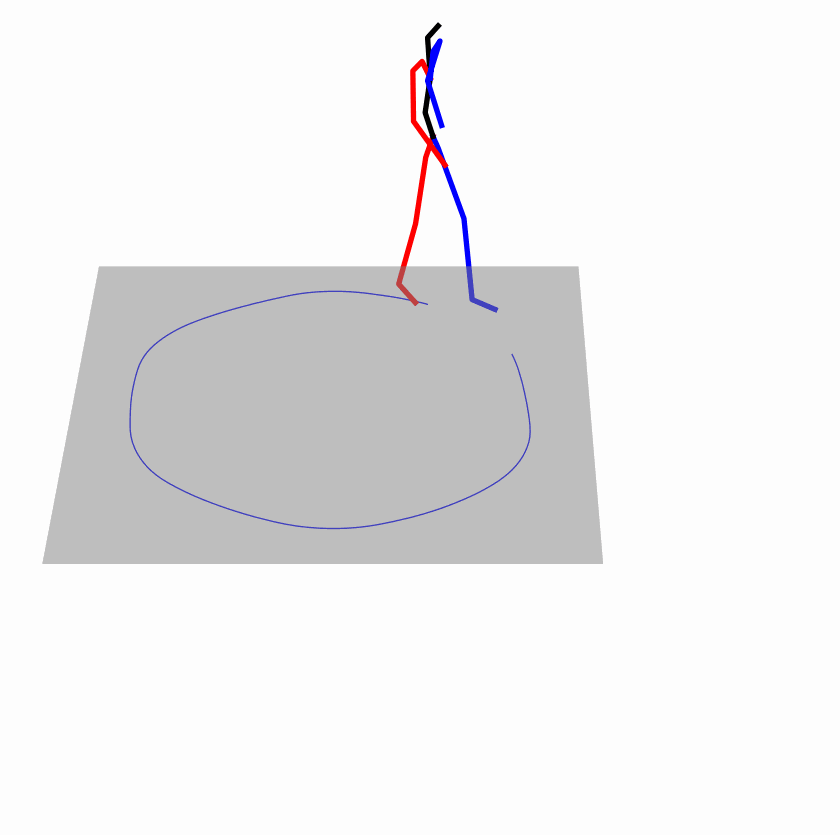 |
Explanation: T2M-GPT, MDM, and MoMask all don't walk in a loop.
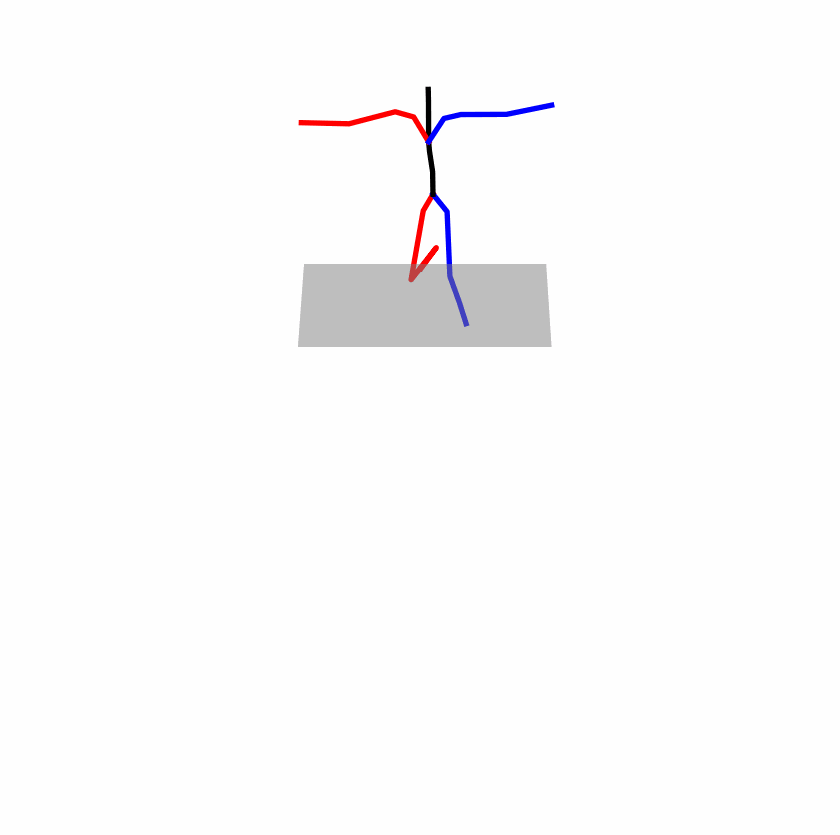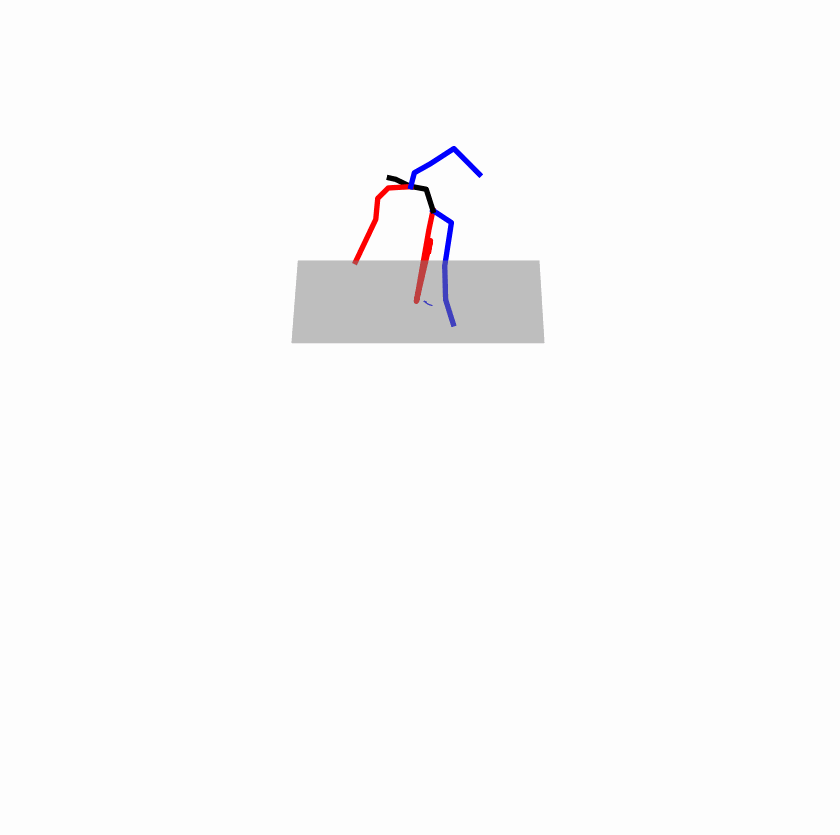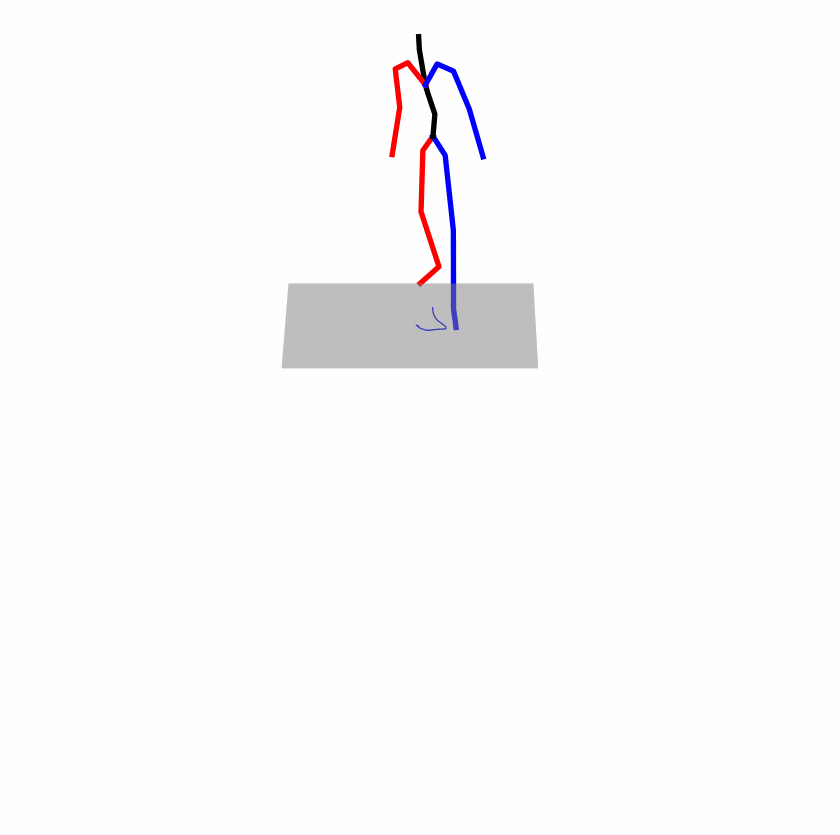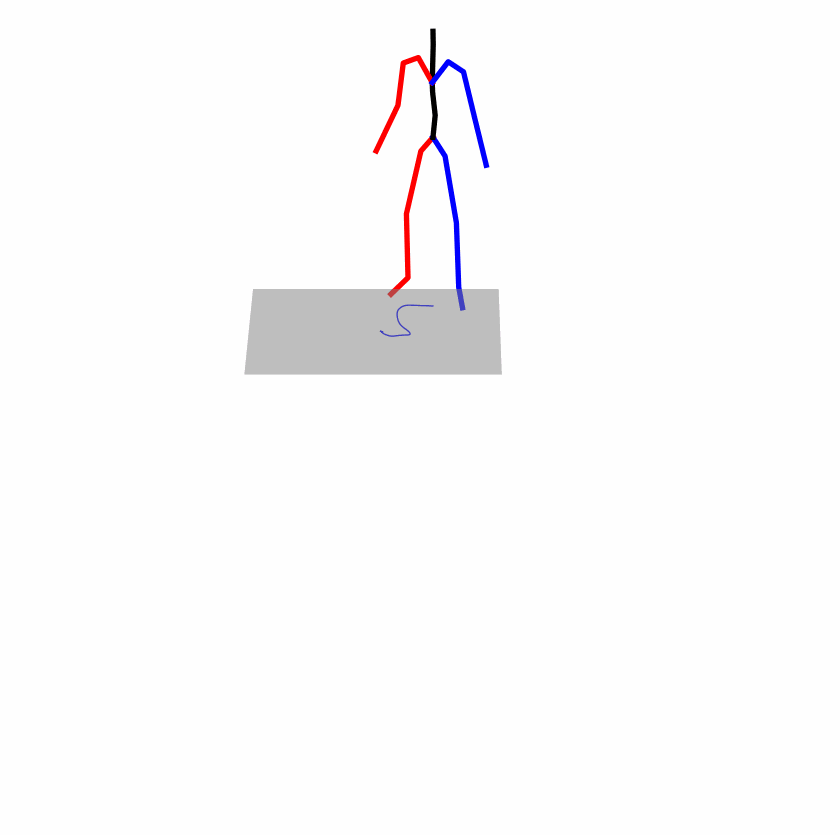
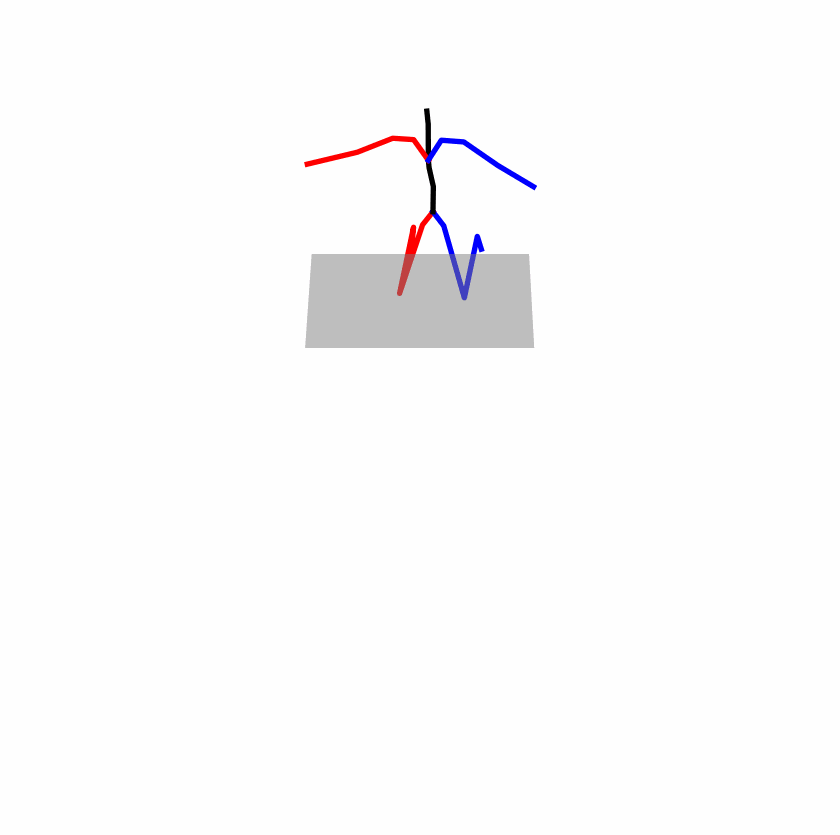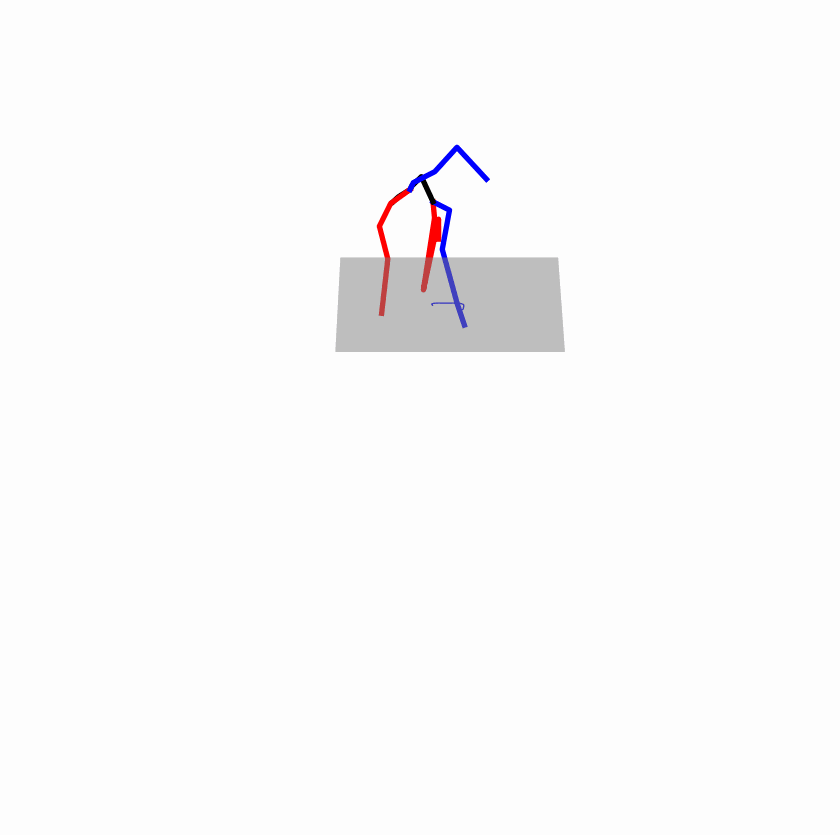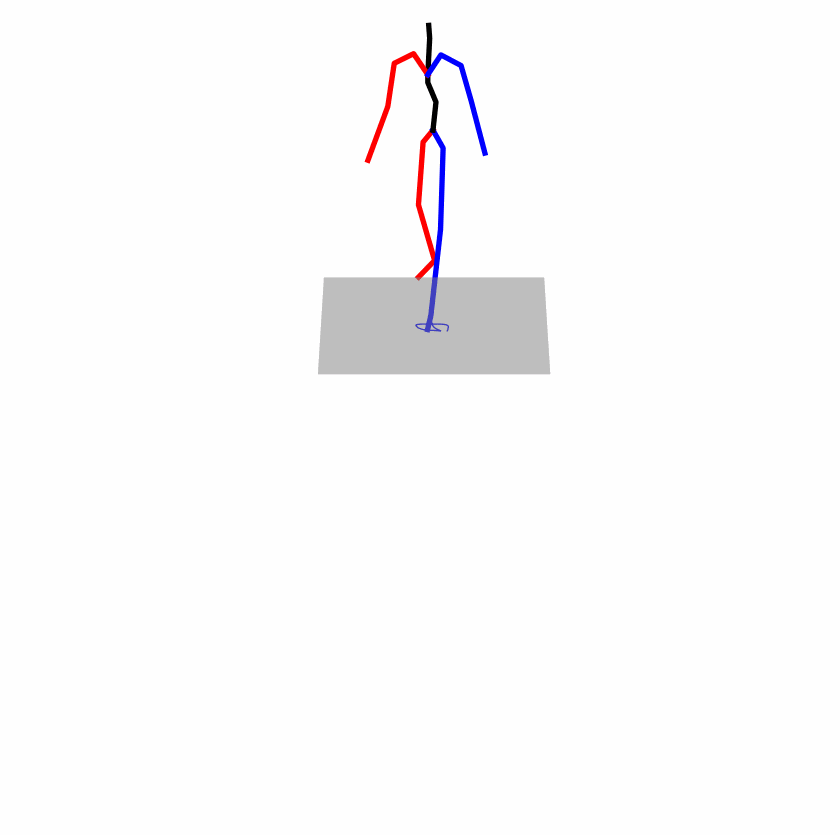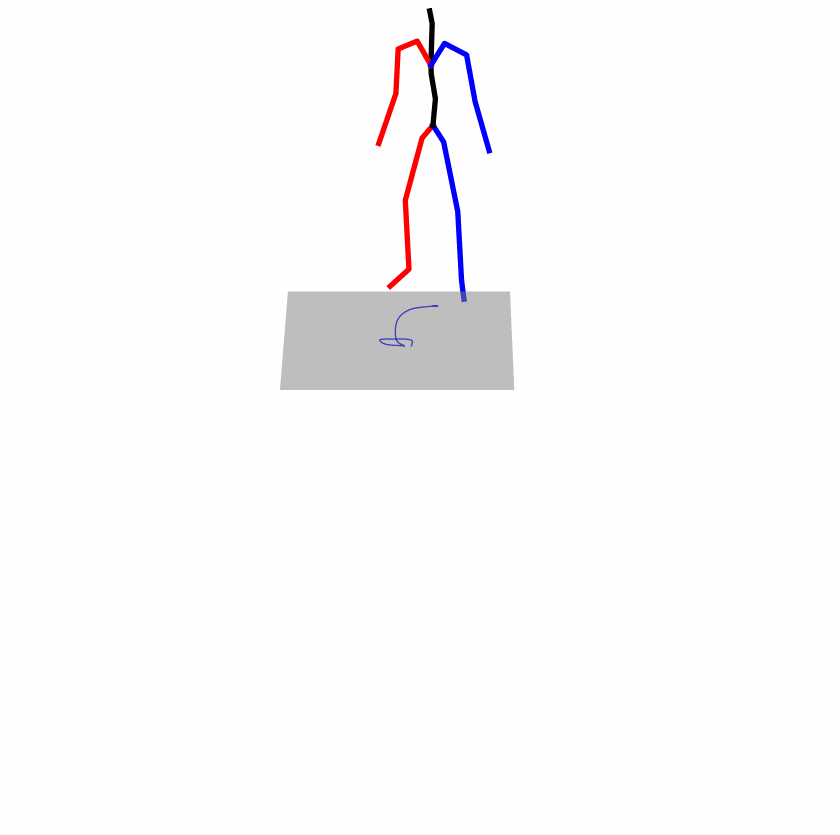
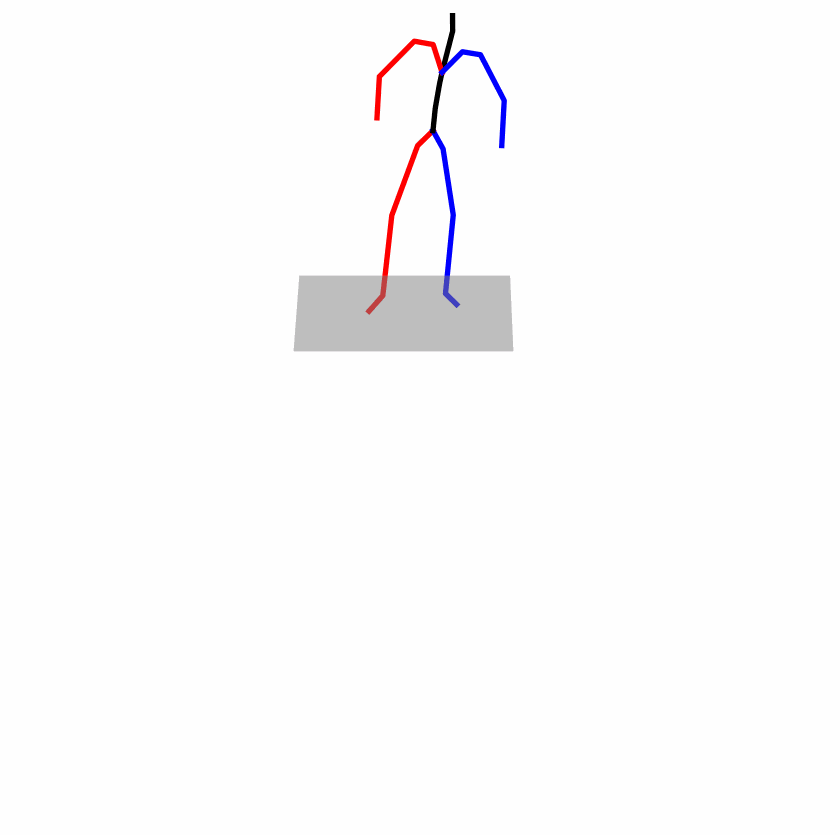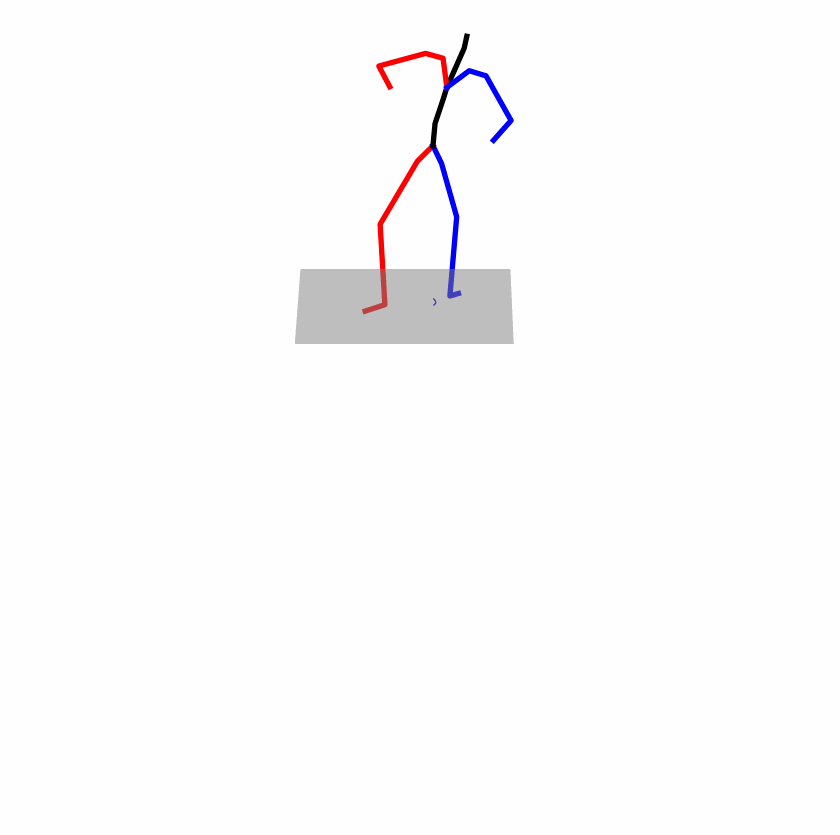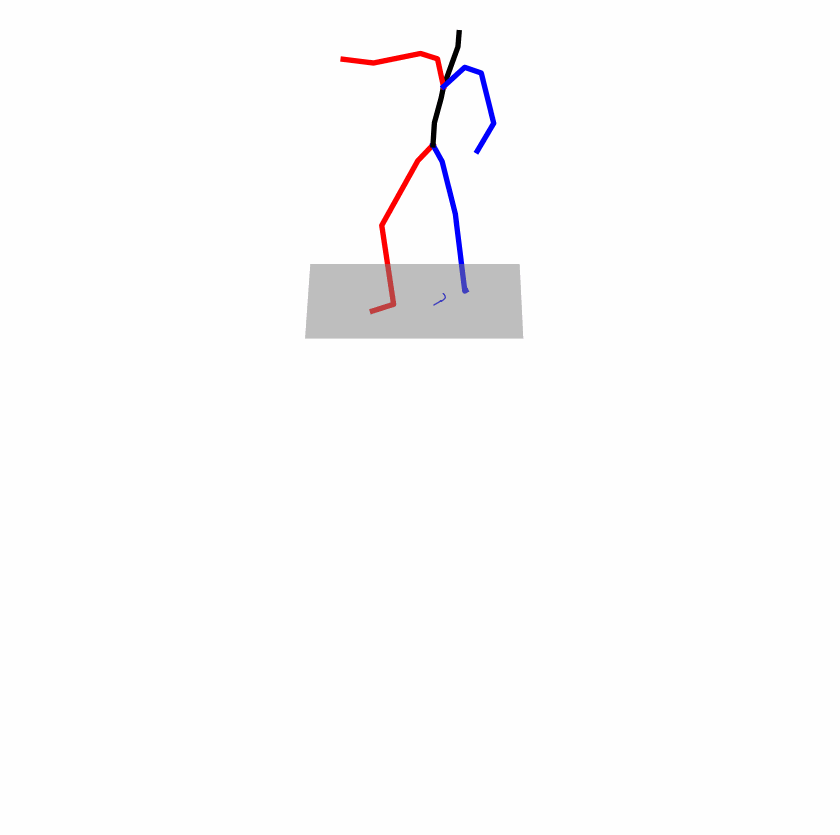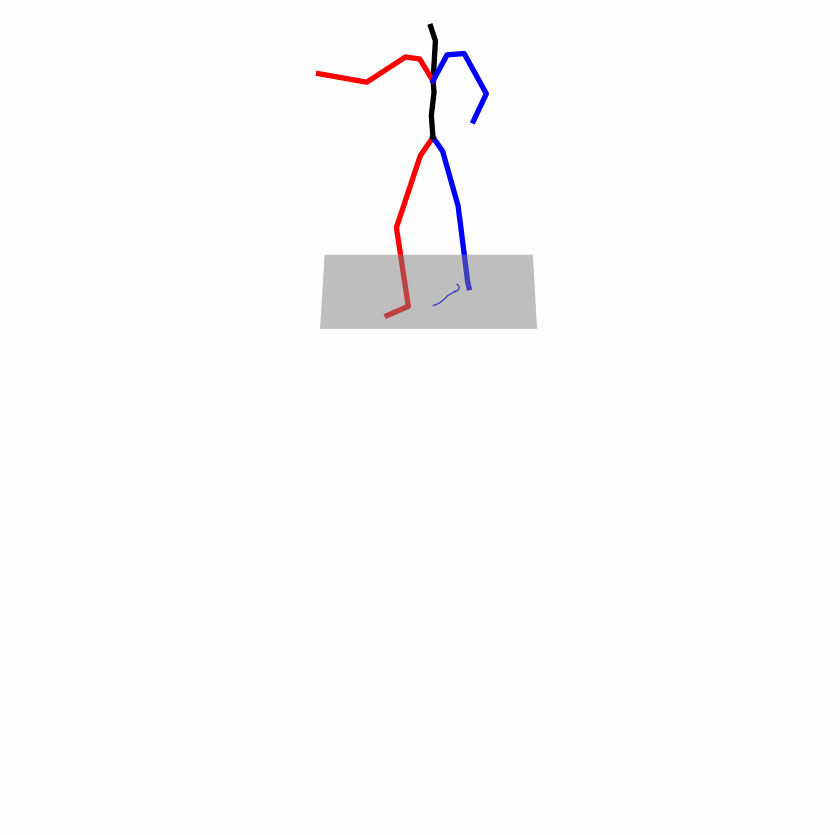
| Original text: a person uses his right arm to help himself to stand up. | |||
|---|---|---|---|
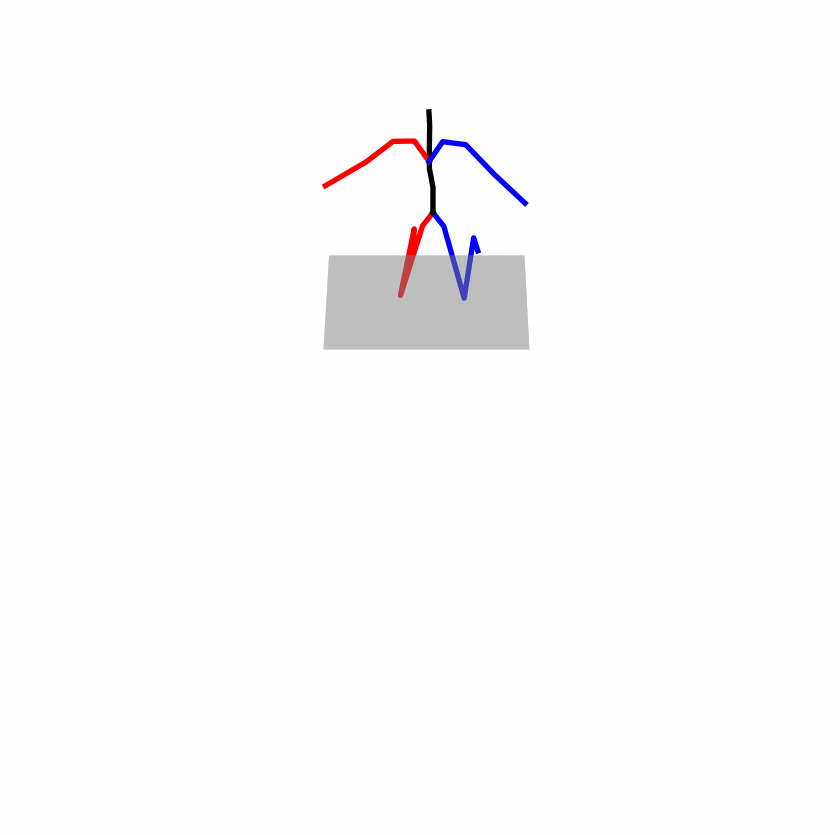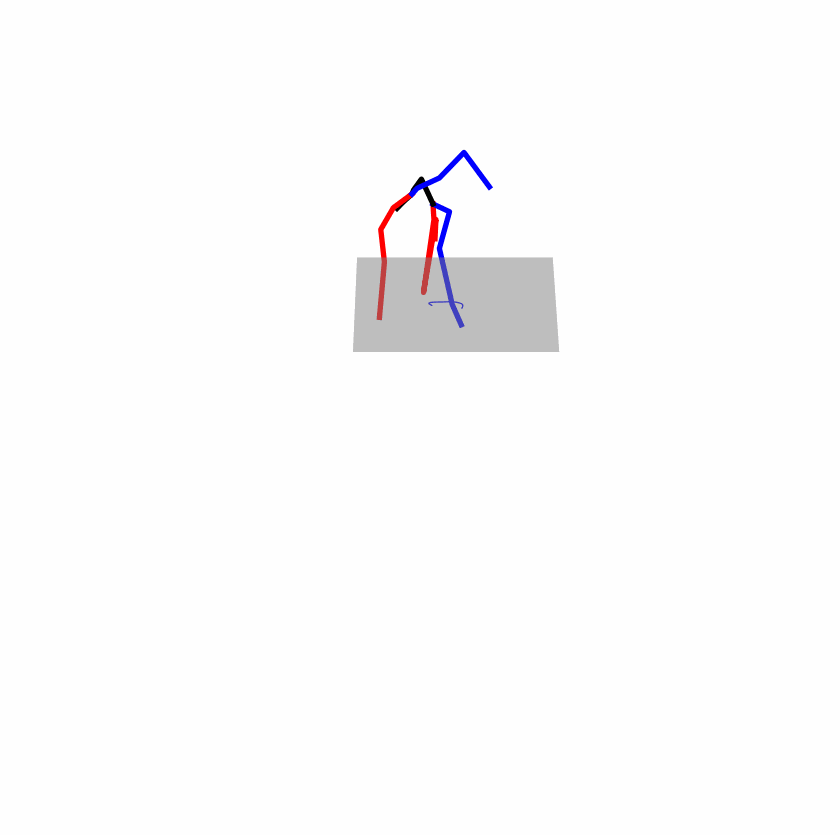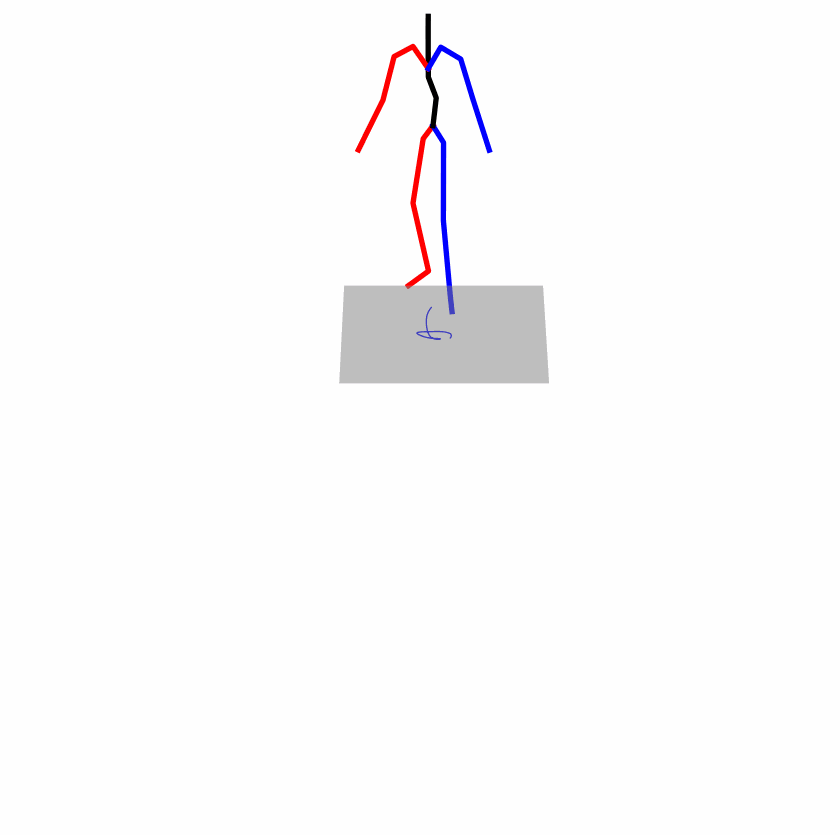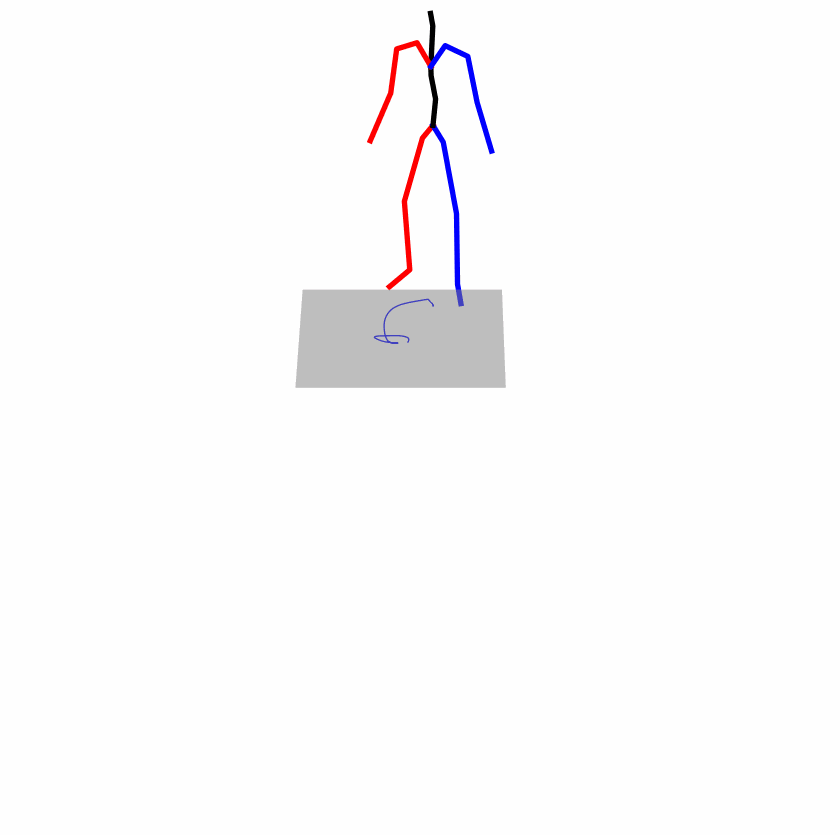 |
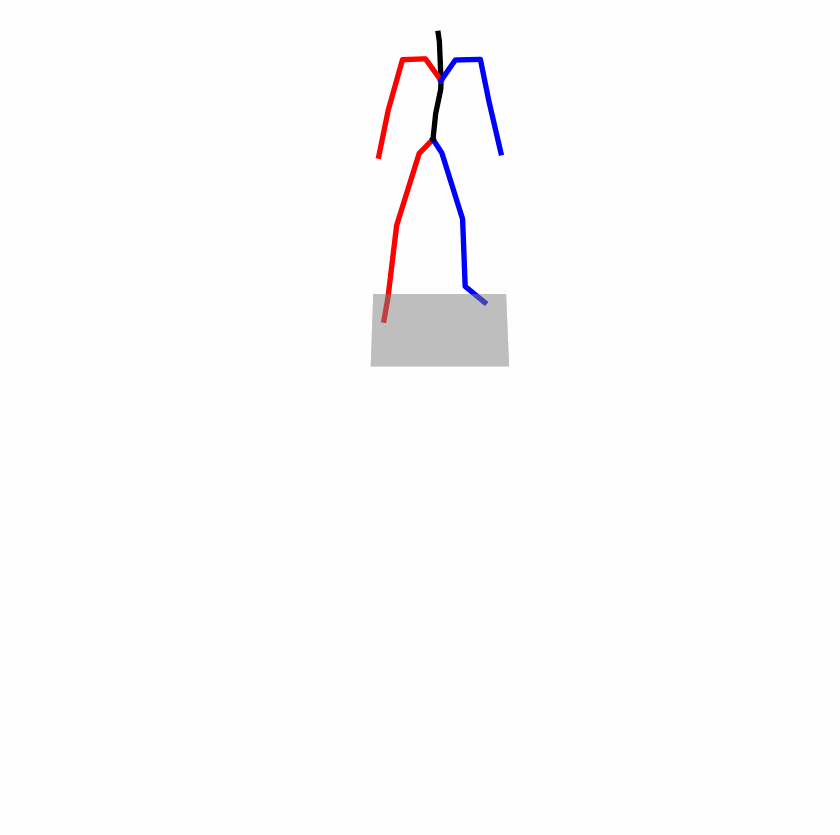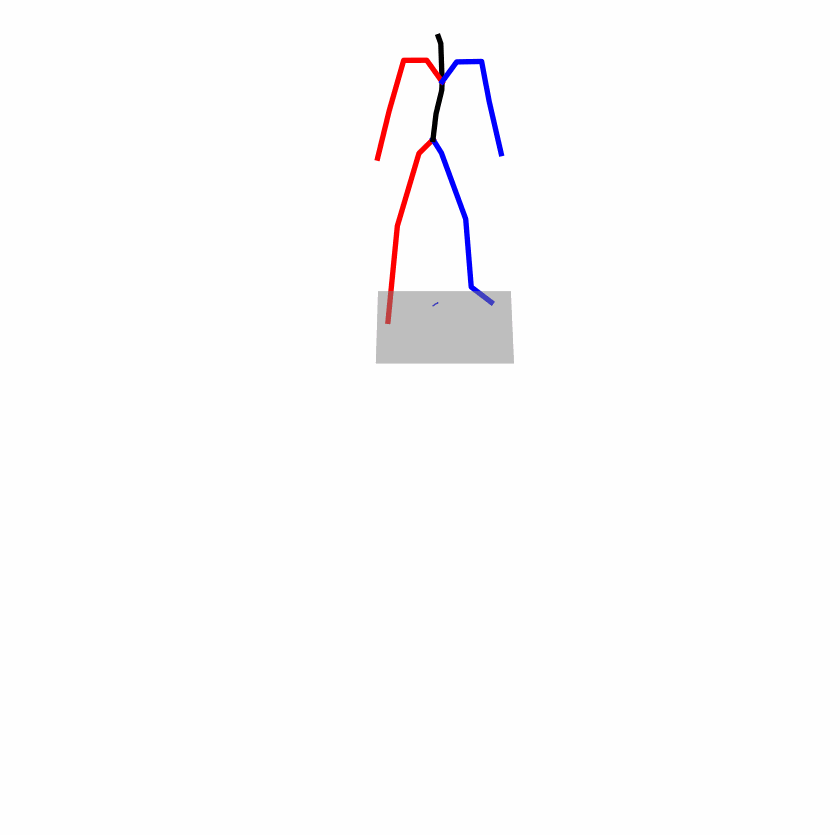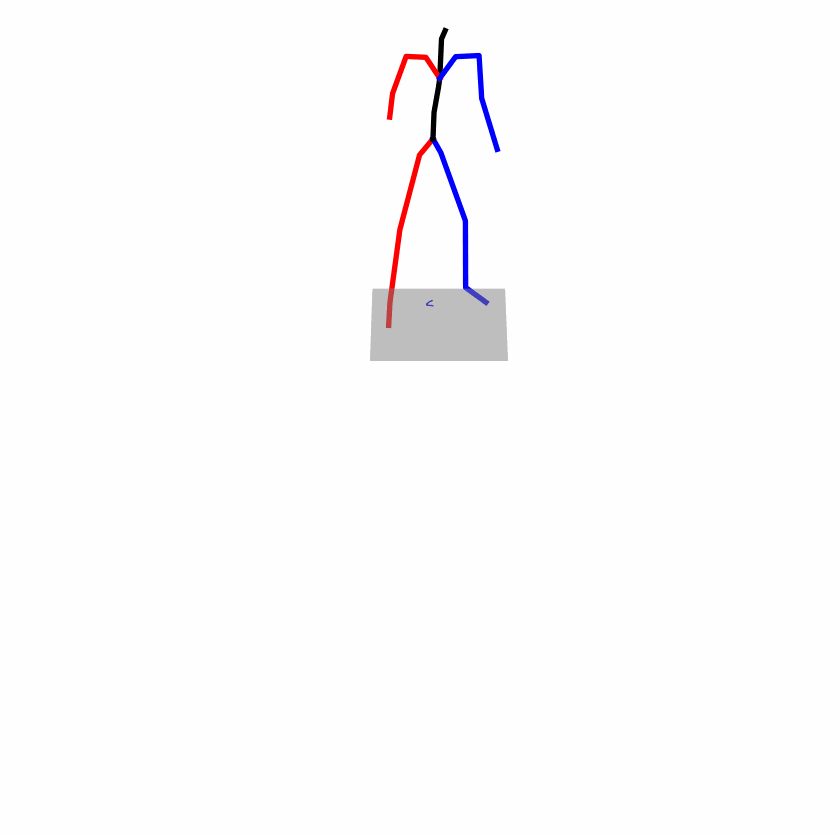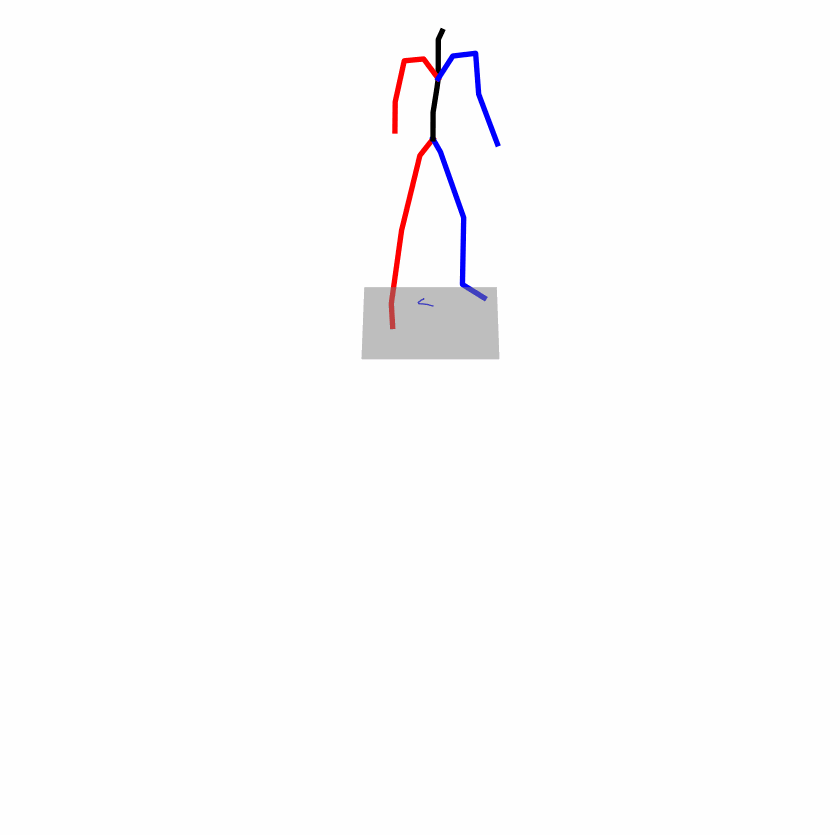 |
 |
 |
| Perturbed text: A human utilizes his right arm to help himself to stand up. | |||
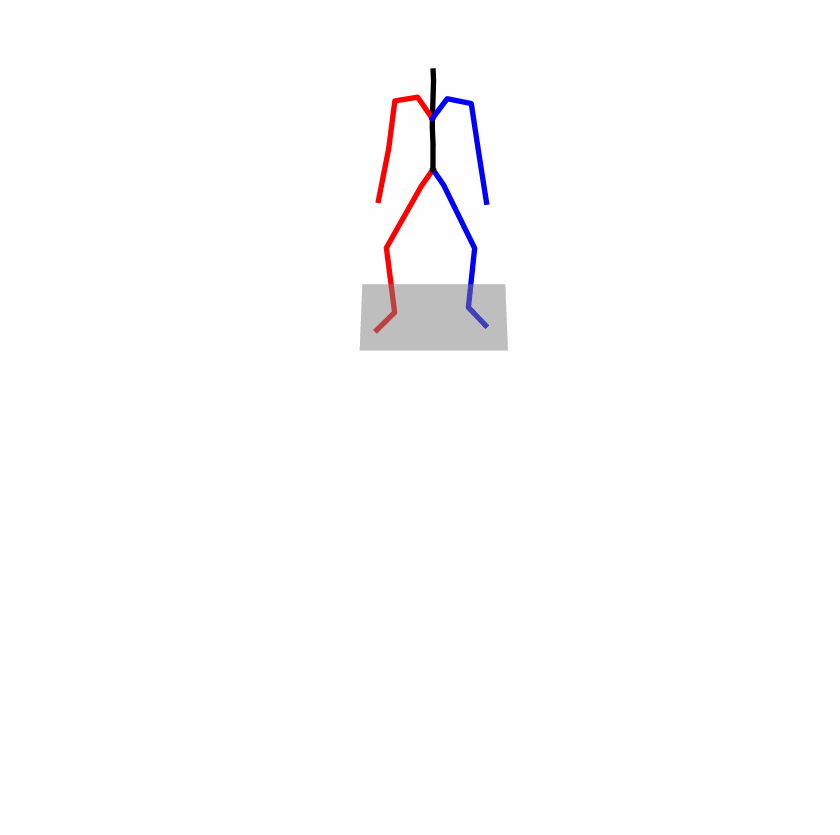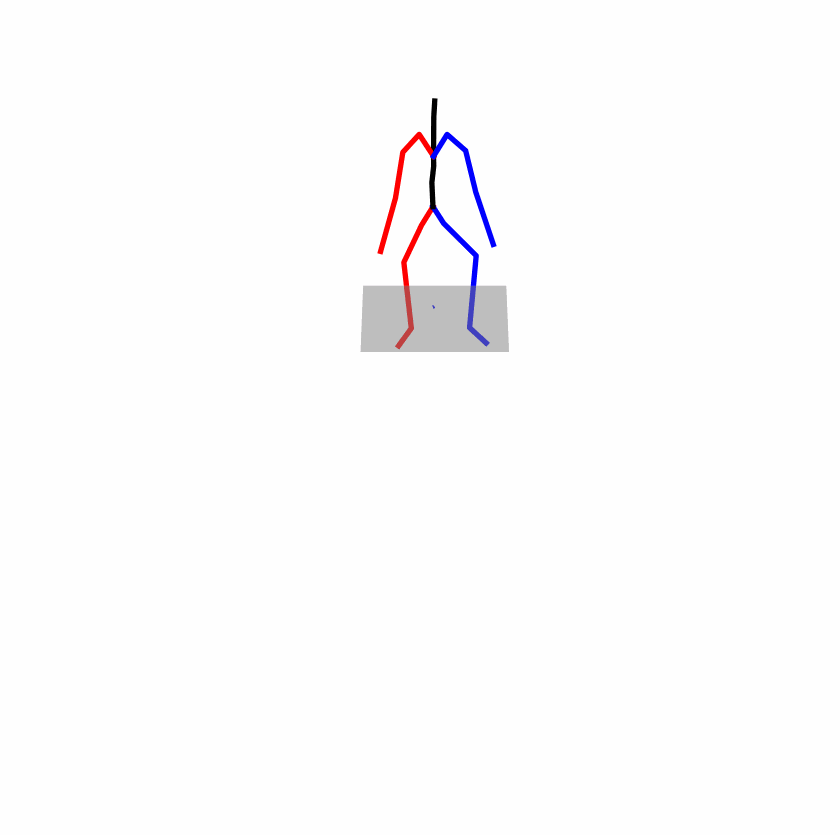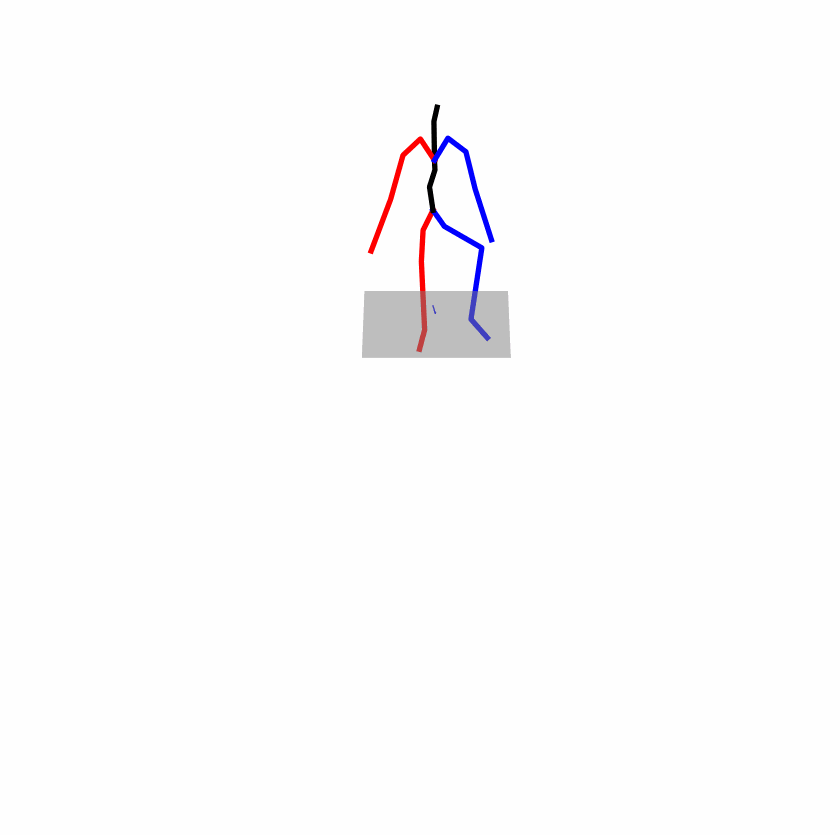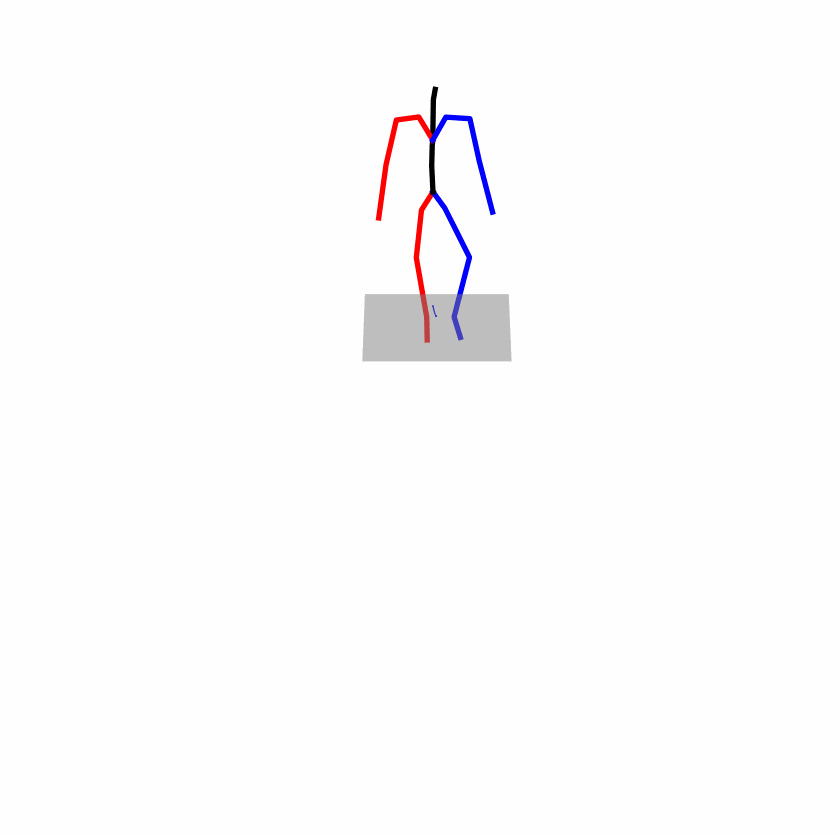 |
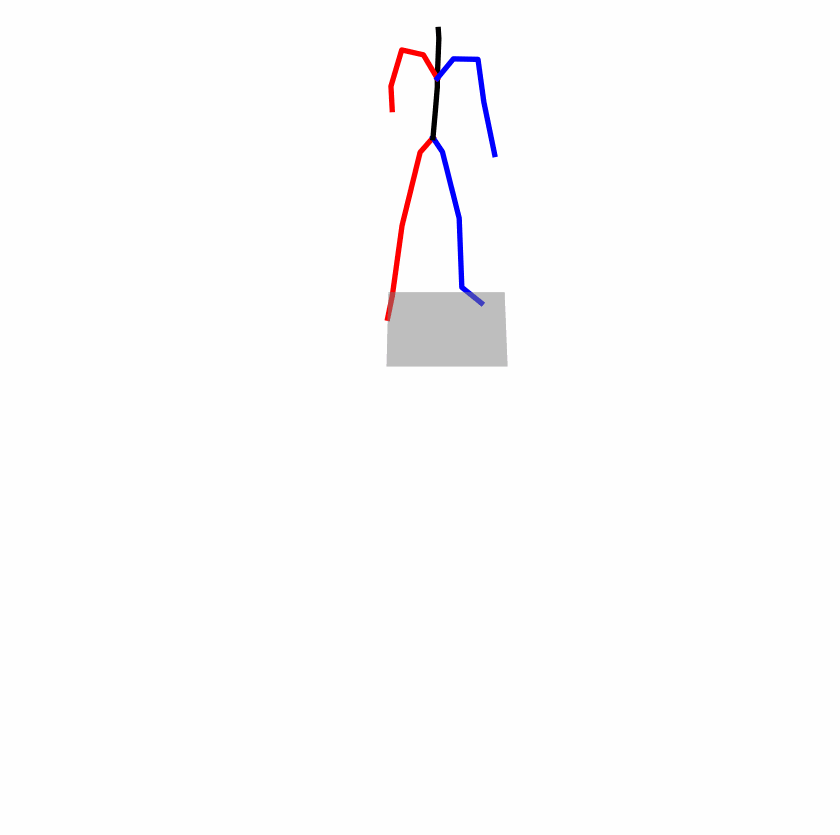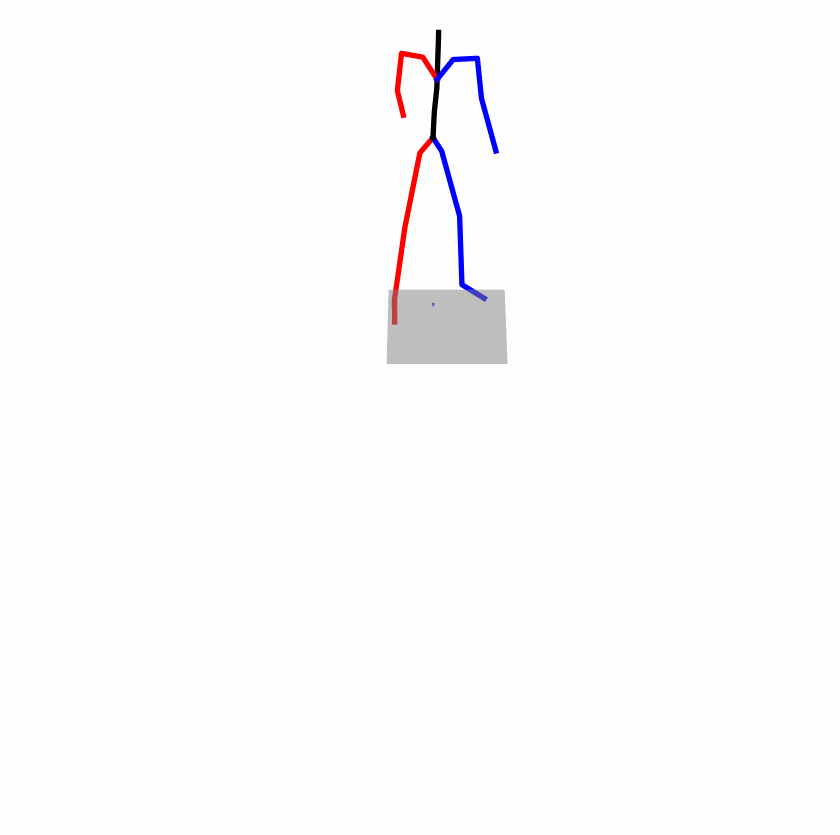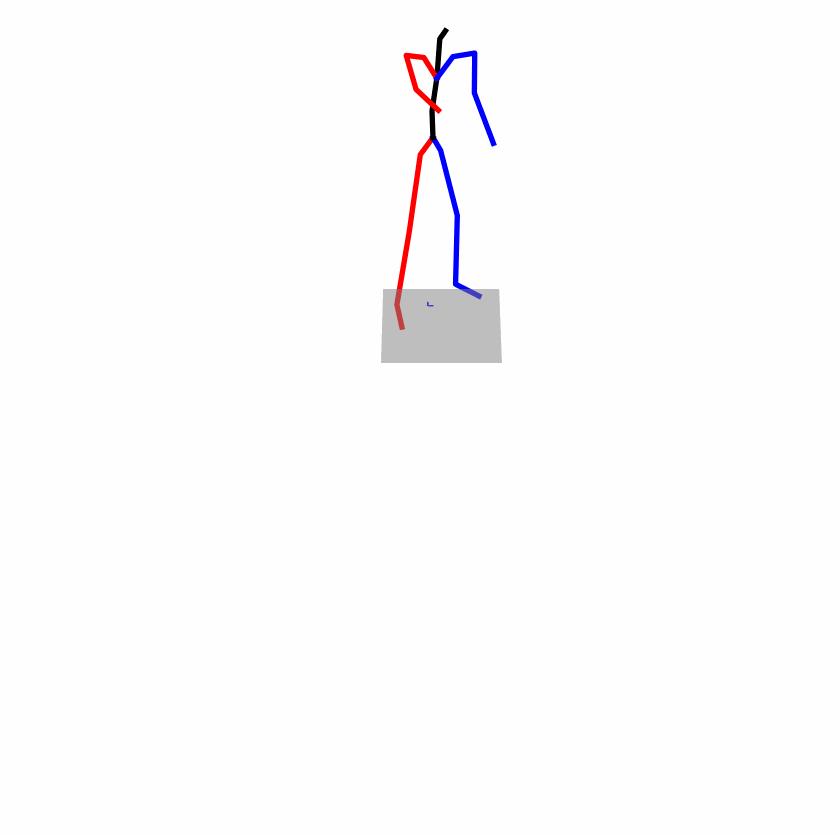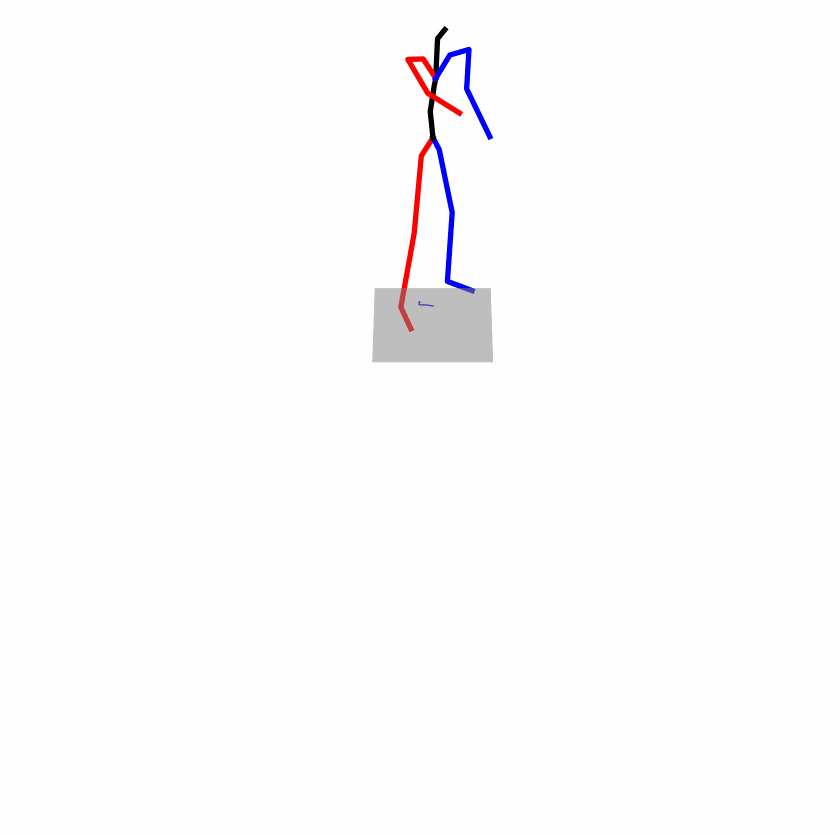 |
 |
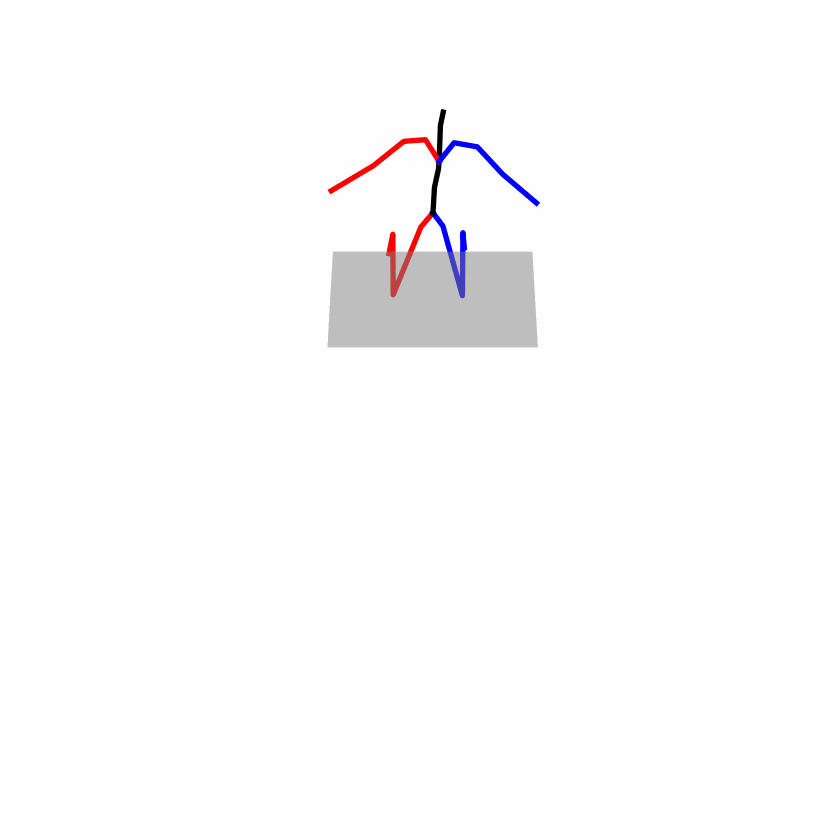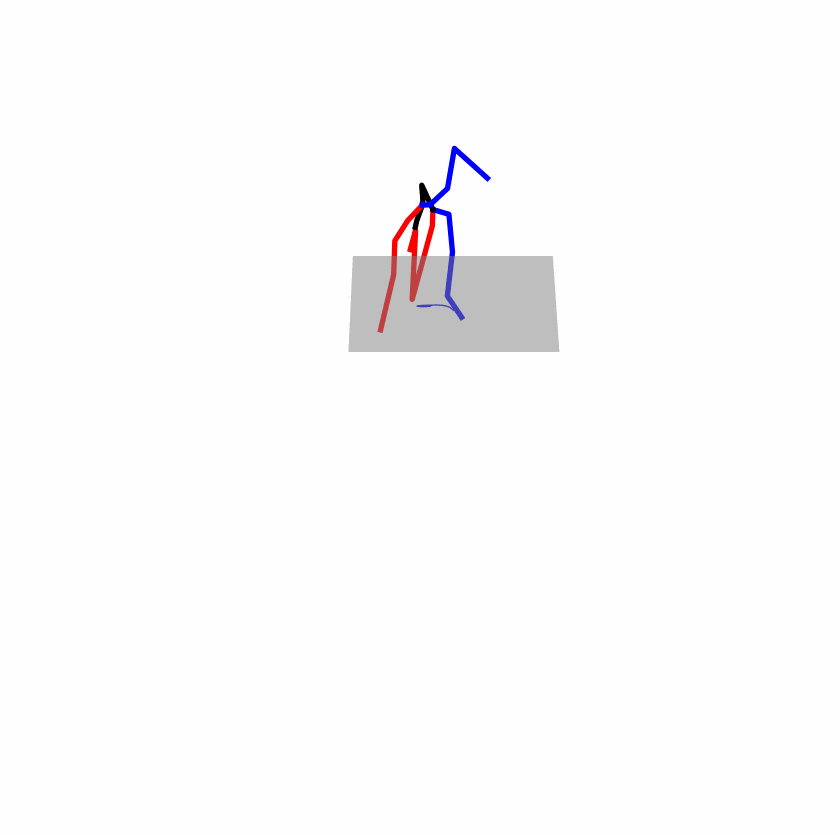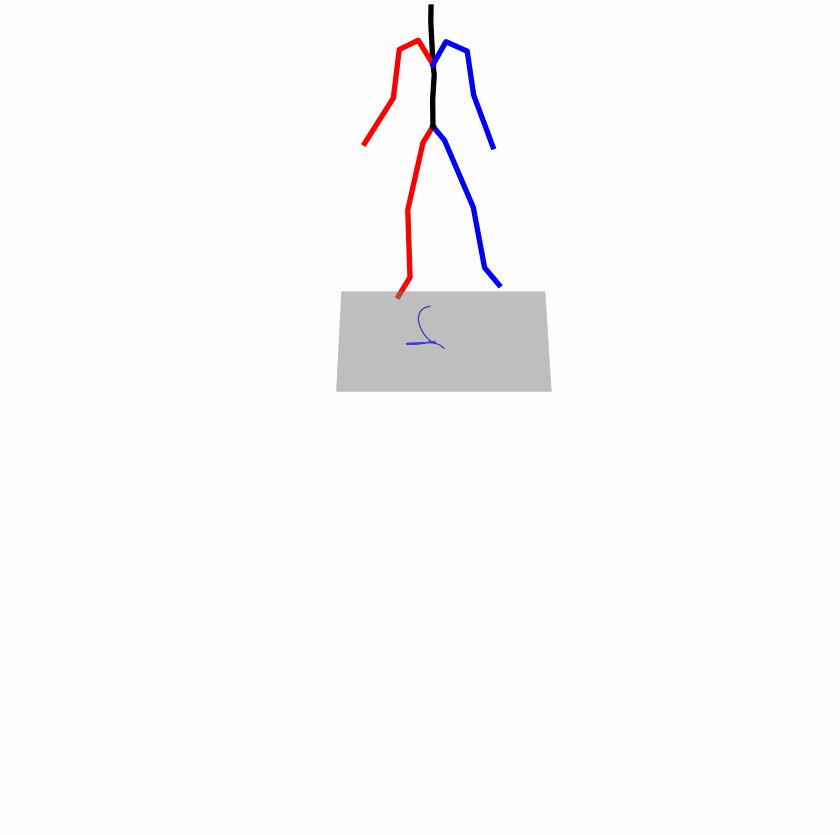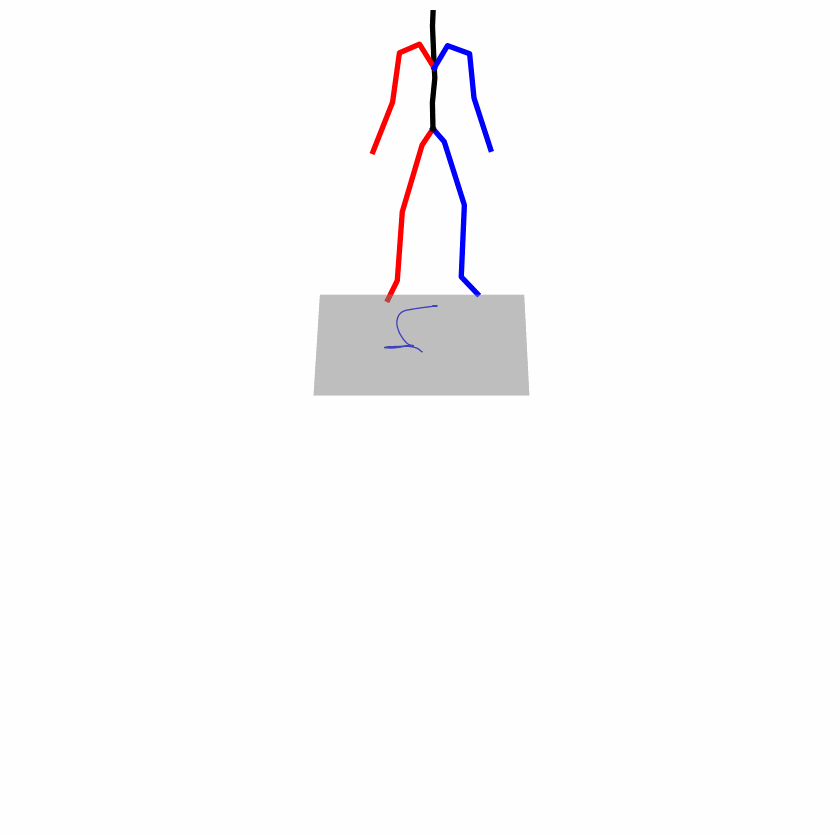 |
Explanation: T2M-GPT, MDM, and MoMask all lack the action of transitioning from squatting to standing up, resulting in a catastrophic error.
How to Use the Code
Setup and Installation
Clone the repository:
git clone https://github.com/sato-team/Stable-Text-to-motion-Framework.git
Create fresh conda environment and install all the dependencies:
conda env create -f environment.yml
conda activate SATO
The code was tested on Python 3.8 and PyTorch 1.8.1.
Dependencies
bash dataset/prepare/download_extractor.sh
bash dataset/prepare/download_glove.sh
Quick Start
A quick reference guide for using our code is provided in quickstart.ipynb.
Datasets
We are using two 3D human motion-language dataset: HumanML3D and KIT-ML. For both datasets, you could find the details as well as download link. We perturbed the input texts based on the two datasets mentioned. You can access the perturbed text dataset through the following link. Take HumanML3D for an example, the dataset structure should look like this:
./dataset/HumanML3D/
├── new_joint_vecs/
├── texts/ # You need to replace the 'texts' folder in the original dataset with the 'texts' folder from our dataset.
├── Mean.npy
├── Std.npy
├── train.txt
├── val.txt
├── test.txt
├── train_val.txt
└── all.txt
Train
We will release the training code soon.
Evaluation
You can download the pretrained models in this link.
python eval_t2m.py --resume-pth pretrained/net_best_fid.pth --clip_path pretrained/clip_best_fid.pth
Acknowledgements
We appreciate helps from :
- Open Source Code:T2M-GPT, MoMask , MDM, etc.
- Hongru Xiao, Erhang Zhang, Lijie Hu, Lei Wang, Mengyuan Liu, Chen Chen for discussions and guidance throughout the project, which has been instrumental to our work.
- Zhen Zhao for project website.
- If you find our work helpful, we would appreciate it if you could give our project a star!
Citing
If you find this code useful for your research, please consider citing the following paper: