
Chinese Text Correction Model
中文文本纠错模型chinese-text-correction-1.5b:用于拼写纠错、语法纠错
shibing624/chinese-text-correction-1.5b evaluate test data:
The overall performance of CSC test:
| input_text | predict_text |
|---|---|
| 文本纠错:\n少先队员因该为老人让坐。 | 少先队员应该为老人让座。 |
Models
| Name | Base Model | Download |
|---|---|---|
| chinese-text-correction-1.5b | Qwen/Qwen2.5-1.5B-Instruct | 🤗 Hugging Face |
| chinese-text-correction-1.5b-lora | Qwen/Qwen2.5-1.5B-Instruct | 🤗 Hugging Face |
| chinese-text-correction-7b | Qwen/Qwen2.5-7B-Instruct | 🤗 Hugging Face |
| chinese-text-correction-7b-lora | Qwen/Qwen2.5-7B-Instruct | 🤗 Hugging Face |
评估结果
- 评估指标:F1
- CSC(Chinese Spelling Correction): 拼写纠错模型,表示模型可以处理音似、形似、语法等长度对齐的错误纠正
- CTC(CHinese Text Correction): 文本纠错模型,表示模型支持拼写、语法等长度对齐的错误纠正,还可以处理多字、少字等长度不对齐的错误纠正
- GPU:Tesla V100,显存 32 GB
| Model Name | Model Link | Base Model | Avg | SIGHAN-2015 | EC-LAW | MCSC | GPU/CPU | QPS |
|---|---|---|---|---|---|---|---|---|
| Kenlm-CSC | shibing624/chinese-kenlm-klm | kenlm | 0.3409 | 0.3147 | 0.3763 | 0.3317 | CPU | 9 |
| Mengzi-T5-CSC | shibing624/mengzi-t5-base-chinese-correction | mengzi-t5-base | 0.3984 | 0.7758 | 0.3156 | 0.1039 | GPU | 214 |
| ERNIE-CSC | PaddleNLP/ernie-csc | PaddlePaddle/ernie-1.0-base-zh | 0.4353 | 0.8383 | 0.3357 | 0.1318 | GPU | 114 |
| MacBERT-CSC | shibing624/macbert4csc-base-chinese | hfl/chinese-macbert-base | 0.3993 | 0.8314 | 0.1610 | 0.2055 | GPU | 224 |
| ChatGLM3-6B-CSC | shibing624/chatglm3-6b-csc-chinese-lora | THUDM/chatglm3-6b | 0.4538 | 0.6572 | 0.4369 | 0.2672 | GPU | 3 |
| Qwen2.5-1.5B-CTC | shibing624/chinese-text-correction-1.5b | Qwen/Qwen2.5-1.5B-Instruct | 0.6802 | 0.3032 | 0.7846 | 0.9529 | GPU | 6 |
| Qwen2.5-7B-CTC | shibing624/chinese-text-correction-7b | Qwen/Qwen2.5-7B-Instruct | 0.8225 | 0.4917 | 0.9798 | 0.9959 | GPU | 3 |
Usage (pycorrector)
本项目开源在pycorrector项目:pycorrector,可支持大模型微调后用于文本纠错,通过如下命令调用:
Install package:
pip install -U pycorrector
from pycorrector.gpt.gpt_corrector import GptCorrector
if __name__ == '__main__':
error_sentences = [
'真麻烦你了。希望你们好好的跳无',
'少先队员因该为老人让坐',
'机七学习是人工智能领遇最能体现智能的一个分知',
'一只小鱼船浮在平净的河面上',
'我的家乡是有明的渔米之乡',
]
m = GptCorrector("shibing624/chinese-text-correction-1.5b")
batch_res = m.correct_batch(error_sentences)
for i in batch_res:
print(i)
print()
Usage (HuggingFace Transformers)
Without pycorrector, you can use the model like this:
First, you pass your input through the transformer model, then you get the generated sentence.
Install package:
pip install transformers
# pip install transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "shibing624/chinese-text-correction-1.5b"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint).to(device)
input_content = "文本纠错:\n少先队员因该为老人让坐。"
messages = [{"role": "user", "content": input_content}]
input_text=tokenizer.apply_chat_template(messages, tokenize=False)
print(input_text)
inputs = tokenizer.encode(input_text, return_tensors="pt").to(device)
outputs = model.generate(inputs, max_new_tokens=1024, temperature=0, do_sample=False, repetition_penalty=1.08)
print(tokenizer.decode(outputs[0]))
output:
少先队员应该为老人让座。
模型文件组成:
shibing624/chinese-text-correction-1.5b
|-- added_tokens.json
|-- config.json
|-- generation_config.json
|-- merges.txt
|-- model.safetensors
|-- model.safetensors.index.json
|-- README.md
|-- special_tokens_map.json
|-- tokenizer_config.json
|-- tokenizer.json
`-- vocab.json
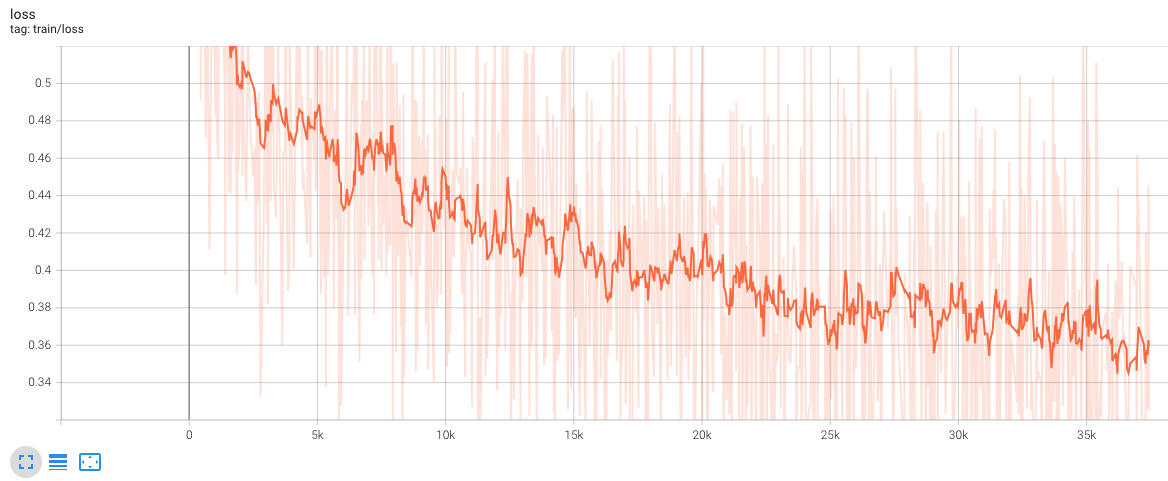
训练参数:
- num_epochs: 8
- batch_size: 4
- steps: 36000
- eval_loss: 0.14
- base model: Qwen/Qwen2.5-1.5B-Instruct
- train data: shibing624/chinese_text_correction
- train time: 9 days 8 hours
- eval_loss:

- train_loss:
训练数据集
中文纠错数据集
如果需要训练Qwen的纠错模型,请参考https://github.com/shibing624/pycorrector 或者 https://github.com/shibing624/MedicalGPT
Citation
@software{pycorrector,
author = {Xu Ming},
title = {pycorrector: Implementation of language model finetune},
year = {2024},
url = {https://github.com/shibing624/pycorrector},
}
- Downloads last month
- 1,510
This model does not have enough activity to be deployed to Inference API (serverless) yet. Increase its social
visibility and check back later, or deploy to Inference Endpoints (dedicated)
instead.