
News
[2024-05-16]
Due to certain internal company considerations, we have temporarily removed the model weights.
It will be uploaded again after passing our internal review process.
Please temporarily access this model via API: https://platform.sensenova.cn/doc?path=/chat/Embeddings/Embeddings.md
There is a temporary problem with the API of this page. Please access it temporarily in the following way:
import requests
url = "http://103.237.28.72:8006/v1/qd"
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
data = {
"inputs": ['hello,world']
}
response = requests.post(url, json=data, headers=headers)
print(response.json())
[2024-05-14]
We have currently release our model weights, training code, and tech report. Discussions are welcome.
For training code, please refer to our github
For training details, please refer to our tech-report
[2024-04-22]
piccolo-large-zh-v2 currently ranks first on the C-MTEB list, leading the previous BERT model by about 1.9 points.
Piccolo-large-zh-v2
piccolo-large-zh-v2 is a Chinese embedding model developed by the general model group from SenseTime Research. This upgraded version of Piccolo aims to prioritize general downstream fine-tuning methods. Piccolo2 primarily leverages an efficient multi-task hybrid loss training approach, effectively harnessing textual data and labels from diverse downstream tasks. In addition, Piccolo2 scales up the embedding dimension and uses MRL training to support more flexible vector dimensions.
💡 Model Hightlights
The main feature of piccolo2 is that it uses a multi-task hybrid loss during training.
For retrieval/sorting tasks, we use the standard InfoNCE with in-batch-negative:

For sts/pair classification tasks, we use cosent loss, which is proved to be better for data with more fine-grained labels(e.g. score values ):
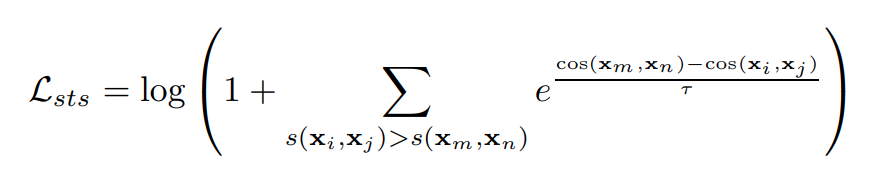
For classification/clustering tasks, by treating text and its semantic labels as positive and negative pairs, we convert the dataset into the format of triples. And then we use InfoNCE to optimize it. However, it’s important to stress that in-batch negatives are no longer used due to the fact that it can easily lead to conflict training targets:
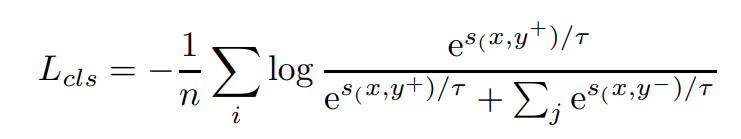
📃 Experiments and Results
Piccolo2 primarily focuses on the downstream general finetune paradigm. Our open source model uses stella-v3.5 as initialization and trained about 2500 steps on 32 GPUS. For more implementation details, please refer to our technical report.
| Model Name | Model Size (GB) | Dimension | Sequence Length | Classification (9) | Clustering (4) | Pair Classification (2) | Reranking (4) | Retrieval (8) | STS (8) | Average (35) |
|---|---|---|---|---|---|---|---|---|---|---|
| piccolo-large-zh-v2 | 1.21 | 1792 | 512 | 74.59 | 62.17 | 90.24 | 70 | 74.36 | 63.5 | 70.95 |
| gte-Qwen1.5-7B-instruct | 26.45 | 32768 | 4096 | 73.35 | 67.08 | 88.52 | 66.38 | 70.62 | 62.32 | 69.56 |
| acge-text-embedding | 1.21 | 1792 | 512 | 72.75 | 58.7 | 87.84 | 67.98 | 72.93 | 62.09 | 69.07 |
🔨 Usage
The piccolo model can be easily accessed in the sentence-transformer package:
# for s2s/s2p dataset, you can use piccolo as below
from sklearn.preprocessing import normalize
from sentence_transformers import SentenceTransformer
sentences = ["数据1", "数据2"]
matryoshka_dim=1792 # support 256, 512, 768, 1024, 1280, 1536, 1792
model = SentenceTransformer('sensenova/piccolo-large-zh-v2')
embeddings_1 = model.encode(sentences, normalize_embeddings=False)
embeddings_2 = model.encode(sentences, normalize_embeddings=False)
embeddings_1 = normalize(embeddings_1[..., :matryoshka_dim], norm="l2", axis=1)
embeddings_2 = normalize(embeddings_2[..., :matryoshka_dim], norm="l2", axis=1)
similarity = embeddings_1 @ embeddings_2.T
🤗 Model List
| Model | Language | Description | prompt |
|---|---|---|---|
| sensenova/piccolo-large-zh-v2 | Chinese | version2: finetuning with multi-task hybrid loss training | None |
| sensenova/piccolo-large-zh | Chinese | version1: pretrain under 400 million chinese text pair | '查询'/'结果' |
| sensenova/piccolo-base-zh | Chinese | version1: pretrain under 400 million chinese text pair | '查询'/'结果' |
Citation
If you find our tech report, models or code helpful, please cite our report or give a star on github or huggingface!
@misc{2405.06932,
Author = {Junqin Huang and Zhongjie Hu and Zihao Jing and Mengya Gao and Yichao Wu},
Title = {Piccolo2: General Text Embedding with Multi-task Hybrid Loss Training},
Year = {2024},
Eprint = {arXiv:2405.06932},
}
- Downloads last month
- 402
Space using sensenova/piccolo-large-zh-v2 1
Evaluation results
- cos_sim_pearson on MTEB AFQMCvalidation set self-reported56.761
- cos_sim_spearman on MTEB AFQMCvalidation set self-reported61.493
- euclidean_pearson on MTEB AFQMCvalidation set self-reported59.145
- euclidean_spearman on MTEB AFQMCvalidation set self-reported60.636
- manhattan_pearson on MTEB AFQMCvalidation set self-reported59.147
- manhattan_spearman on MTEB AFQMCvalidation set self-reported60.635
- cos_sim_pearson on MTEB ATECtest set self-reported56.217
- cos_sim_spearman on MTEB ATECtest set self-reported59.198
- euclidean_pearson on MTEB ATECtest set self-reported62.378
- euclidean_spearman on MTEB ATECtest set self-reported58.794