

中文 | English
360智脑
{kind=link}
欢迎访问360智脑官网 https://ai.360.com 体验更多更强大的功能。
模型介绍
🎉🎉🎉我们开源了360智脑大模型的系列工作,本次开源了以下模型:
- 360Zhinao-7B-Base
- 360Zhinao-7B-Chat-4K
- 360Zhinao-7B-Chat-32K
- 360Zhinao-7B-Chat-360K
360智脑大模型特点如下:
- 基础模型:采用 3.4 万亿 Tokens 的高质量语料库训练,以中文、英文、代码为主,在相关基准评测中,同尺寸有竞争力。
- 对话模型:具有强大的对话能力,开放4K、32K、360K三种不同文本长度。据了解,360K(约50万字)是当前国产开源模型文本长度最长的。
更新信息
- [2024.04.10] 我们发布了360Zhinao-7B 1.0版本,同时开放Base模型和4K、32K、360K三种文本长度的Chat模型。
目录
下载地址
本次发布版本和下载链接见下表:
| Size | Model | BF16 | Int4 |
|---|---|---|---|
| 7B | 360Zhinao-7B-Base | 🤖 🤗 | |
| 7B | 360Zhinao-7B-Chat-4K | 🤖 🤗 | 🤖 🤗 |
| 7B | 360Zhinao-7B-Chat-32K | 🤖 🤗 | 🤖 🤗 |
| 7B | 360Zhinao-7B-Chat-360K | 🤖 🤗 | 🤖 🤗 |
模型评估
基础模型
我们在OpenCompass的主流评测数据集上验证了我们的模型性能,包括C-Eval、AGIEval、MMLU、CMMLU、HellaSwag、MATH、GSM8K、HumanEval、MBPP、BBH、LAMBADA,考察的能力包括自然语言理解、知识、数学计算和推理、代码生成、逻辑推理等。
Model |
AVG | CEval | AGIEval | MMLU | CMMLU | HellaSwag | MATH | GSM8K | HumanEval | MBPP | BBH | LAMBADA |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Baichuan2-7B | 41.49 | 56.3 | 34.6 | 54.7 | 57 | 67 | 5.4 | 24.6 | 17.7 | 24 | 41.8 | 73.3 |
| Baichuan-7B | 31.94 | 44.7 | 24.6 | 41.5 | 44.6 | 68.4 | 2.5 | 9.6 | 9.1 | 6.4 | 32.8 | 67.1 |
| ChatGLM3-6B | 58.67 | 67 | 47.4 | 62.8 | 66.5 | 76.5 | 19.2 | 61 | 44.5 | 57.2 | 66.2 | 77.1 |
| DeepSeek-7B | 39.8 | 45 | 24 | 49.3 | 46.8 | 73.4 | 4.2 | 18.3 | 25 | 36.4 | 42.8 | 72.6 |
| InternLM2-7B | 58.01 | 65.7 | 50.2 | 65.5 | 66.2 | 79.6 | 19.9 | 70.6 | 41.5 | 42.4 | 64.4 | 72.1 |
| InternLM-7B | 39.33 | 53.4 | 36.9 | 51 | 51.8 | 70.6 | 6.3 | 31.2 | 13.4 | 14 | 37 | 67 |
| LLaMA-2-7B | 33.27 | 32.5 | 21.8 | 46.8 | 31.8 | 74 | 3.3 | 16.7 | 12.8 | 14.8 | 38.2 | 73.3 |
| LLaMA-7B | 30.35 | 27.3 | 20.6 | 35.6 | 26.8 | 74.3 | 2.9 | 10 | 12.8 | 16.8 | 33.5 | 73.3 |
| Mistral-7B-v0.1 | 47.67 | 47.4 | 32.8 | 64.1 | 44.7 | 78.9 | 11.3 | 47.5 | 27.4 | 38.6 | 56.7 | 75 |
| MPT-7B | 30.06 | 23.5 | 21.3 | 27.5 | 25.9 | 75 | 2.9 | 9.1 | 17.1 | 22.8 | 35.6 | 70 |
| Qwen1.5-7B | 55.12 | 73.57 | 50.8 | 62.15 | 71.84 | 72.62 | 20.36 | 54.36 | 53.05 | 36.8 | 40.01 | 70.74 |
| Qwen-7B | 49.53 | 63.4 | 45.3 | 59.7 | 62.5 | 75 | 13.3 | 54.1 | 27.4 | 31.4 | 45.2 | 67.5 |
| XVERSE-7B | 34.27 | 61.1 | 39 | 58.4 | 60.8 | 73.7 | 2.2 | 11.7 | 4.9 | 10.2 | 31 | 24 |
| Yi-6B | 47.8 | 73 | 44.3 | 64 | 73.5 | 73.1 | 6.3 | 39.9 | 15.2 | 23.6 | 44.9 | 68 |
| 360Zhinao-7B | 56.15 | 74.11 | 49.49 | 67.44 | 72.38 | 83.05 | 16.38 | 53.83 | 35.98 | 42.4 | 43.95 | 78.59 |
以上结果,在官方Opencompass上可查询或可复现。
Chat模型
我们采用两阶段的方式训练长文本模型.
第一阶段:我们增大RoPE base,将上下文长度扩展至32K训练: - 首先,对基础模型进行了约5B tokens的32K窗口继续预训练。 - 接着,SFT阶段使用了多种形式和来源的长文本数据,包括高质量的人工标注32K长文本数据。
第二阶段:我们将上下文长度扩展至360K进行训练,使用数据如下: - 少量高质量人工标注数据。 - 由于带有标注的超长文本数据的稀缺性,我们构造了多种形式的合成数据: - 多文档问答:类似Ziya-Reader,我们基于360自有数据构造了多种类型的多文档问答数据,同时将问答改为多轮,显著提升长文本的训练效率。 - 单文档问答:类似LLama2 Long,我们构造了基于超长文本各个片段的多轮问答数据。
我们在多种长度和多种任务的评测Benchmark上验证不同版本模型的性能。
360Zhinao-7B-Chat-32K模型长文本能力评测
我们使用LongBench验证长文本效果。LongBench是第一个多任务、中英双语、针对大语言模型长文本理解能力的评测基准。LongBench由六大类、二十一个不同的任务组成,我们选择其中与中文长文本应用最密切相关的中文单文档问答、多文档问答、摘要、Few-shot等任务进行评测。
Model Avg 单文档QA 多文档QA 摘要 Few-shot学习 代码补全 GPT-3.5-Turbo-16k 37.84 61.2 28.7 16 29.2 54.1 ChatGLM2-6B-32k 37.16 51.6 37.6 16.2 27.7 52.7 ChatGLM3-6B-32k 44.62 62.3 44.8 17.8 42 56.2 InternLM2-Chat-7B 42.20 56.65 29.15 17.99 43.5 63.72 Qwen1.5-Chat-7B 36.75 52.85 30.08 14.28 32 54.55 Qwen1.5-Chat-14B 39.80 60.39 27.99 14.77 37 58.87 360Zhinao-7B-Chat-32K 45.18 57.18 48.06 15.03 44 61.64 360Zhinao-7B-Chat-360K“大海捞针”测试
大海捞针测试(NeedleInAHaystack)是将关键信息插入一段长文本的不同位置,再对该关键信息提问,从而测试大模型的长文本能力的一种方法。
360Zhinao-7B-Chat-360K在中英文大海捞针中都能达到98%以上的准确率。
英文"大海捞针"(和NeedleInAHaystack相同)
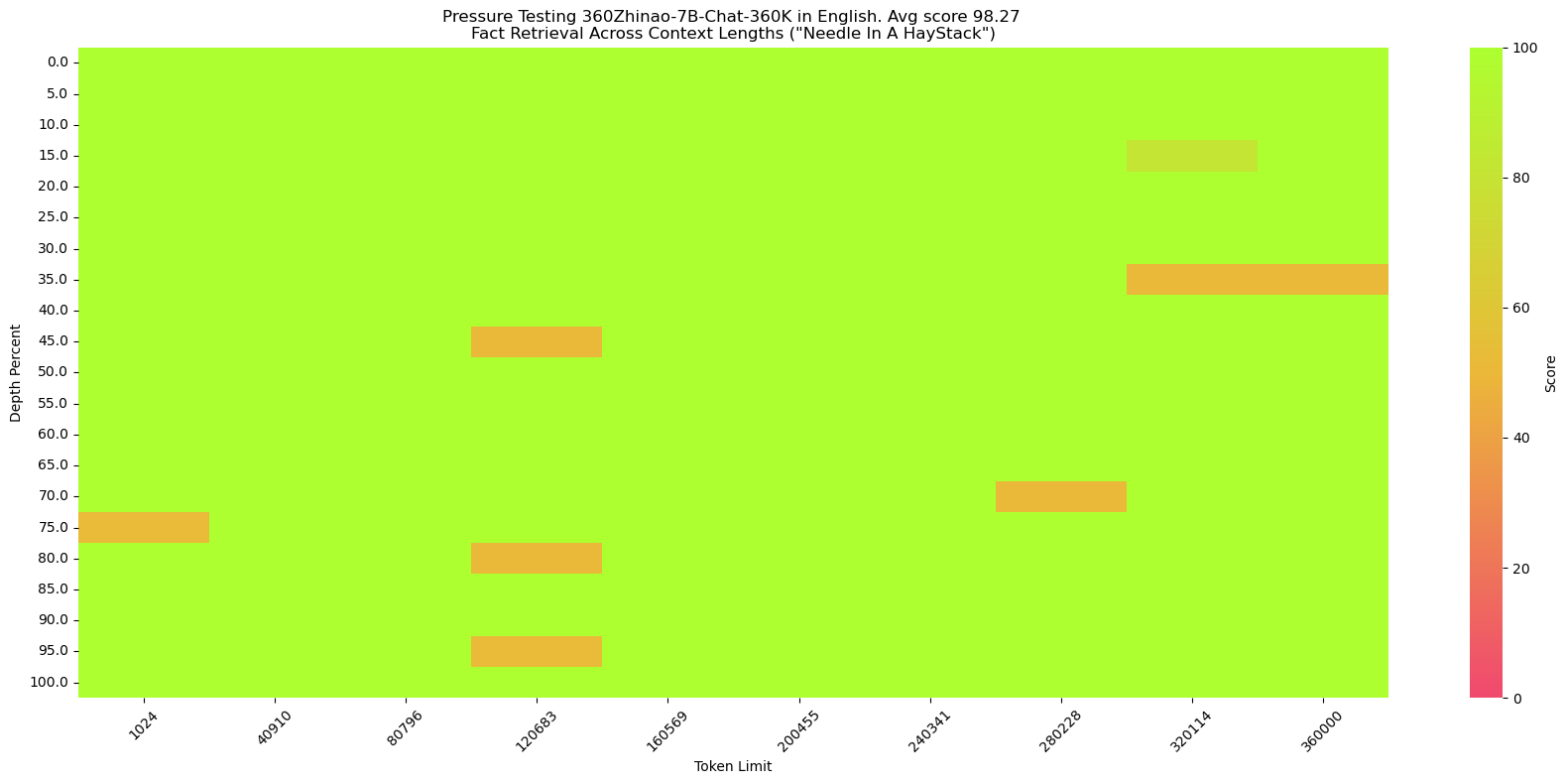
针:The best thing to do in San Francisco is eat a sandwich and sit in Dolores Park on a sunny day.
提问:What is the best thing to do in San Francisco?
中文“大海捞针”
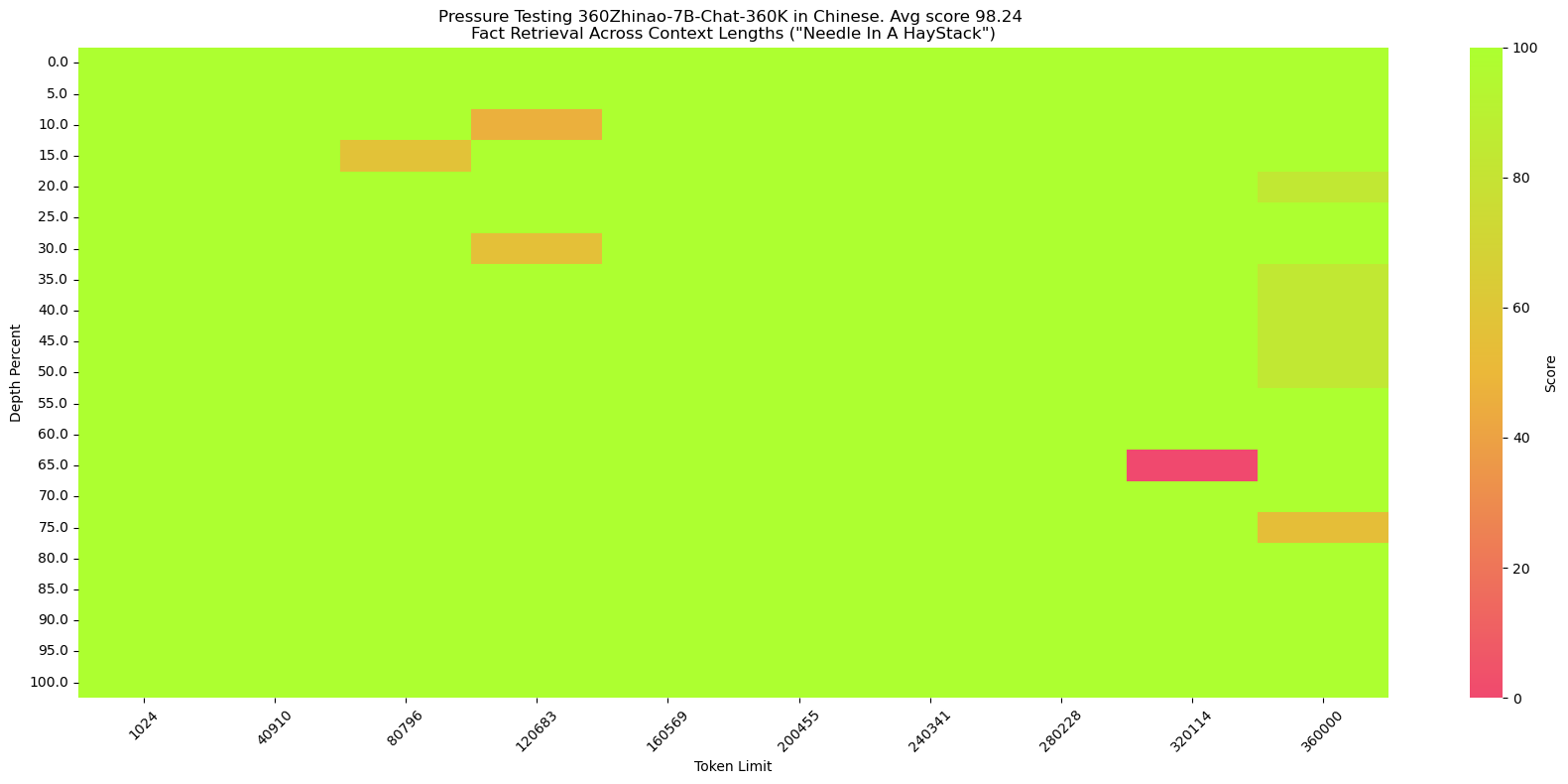
我们仿照SuperCLUE-200K测评基准构造了中文大海捞针:
海:长篇小说。
针:王莽是一名勤奋的店员,他每天凌晨就起床,赶在第一缕阳光照亮大地之前到达店铺,为即将开始的一天做准备。他清扫店铺,整理货架,为顾客提供方便。他对五金的种类和用途了如指掌,无论顾客需要什么,他总能准确地找到。\n然而,他的老板刘秀却总是对他吹毛求疵。刘秀是个挑剔的人,他总能在王莽的工作中找出一些小错误,然后以此为由扣他的工资。他对王莽的工作要求非常严格,甚至有些过分。即使王莽做得再好,刘秀也总能找出一些小问题,让王莽感到非常沮丧。\n王莽虽然对此感到不满,但他并没有放弃。他知道,只有通过自己的努力,才能获得更好的生活。他坚持每天早起,尽管他知道那天可能会再次被刘秀扣工资。他始终保持微笑,尽管他知道刘秀可能会再次对他挑剔。
提问:王莽在谁的手下工作?
快速开始
简单的示例来说明如何利用🤖 ModelScope和🤗 Transformers快速使用360Zhinao-7B-Base和360Zhinao-7B-Chat
依赖安装
- python 3.8 and above
- pytorch 2.0 and above
- transformers 4.37.2 and above
- CUDA 11.4 and above are recommended.
pip install -r requirements.txt
我们推荐安装flash-attention(当前已支持flash attention 2)来提高你的运行效率以及降低显存占用。(flash-attention只是可选项,不安装也可正常运行该项目)
flash-attn >= 2.3.6
FLASH_ATTENTION_FORCE_BUILD=TRUE pip install flash-attn==2.3.6
🤗 Transformers
Base模型推理
此代码演示使用transformers快速使用360Zhinao-7B-Base模型进行推理
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers.generation import GenerationConfig
MODEL_NAME_OR_PATH = "qihoo360/360Zhinao-7B-Base"
tokenizer = AutoTokenizer.from_pretrained(
MODEL_NAME_OR_PATH,
trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME_OR_PATH,
device_map="auto",
trust_remote_code=True)
generation_config = GenerationConfig.from_pretrained(
MODEL_NAME_OR_PATH,
trust_remote_code=True)
inputs = tokenizer('中国二十四节气\n1. 立春\n2. 雨水\n3. 惊蛰\n4. 春分\n5. 清明\n', return_tensors='pt')
inputs = inputs.to(model.device)
pred = model.generate(input_ids=inputs["input_ids"], generation_config=generation_config)
print("outputs:\n", tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
Chat模型推理
此代码演示使用transformers快速使用360Zhinao-7B-Chat-4K模型进行推理
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers.generation import GenerationConfig
MODEL_NAME_OR_PATH = "qihoo360/360Zhinao-7B-Chat-4K"
tokenizer = AutoTokenizer.from_pretrained(
MODEL_NAME_OR_PATH,
trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME_OR_PATH,
device_map="auto",
trust_remote_code=True)
generation_config = GenerationConfig.from_pretrained(
MODEL_NAME_OR_PATH,
trust_remote_code=True)
messages = []
#round-1
messages.append({"role": "user", "content": "介绍一下刘德华"})
response = model.chat(tokenizer=tokenizer, messages=messages, generation_config=generation_config)
messages.append({"role": "assistant", "content": response})
print(messages)
#round-2
messages.append({"role": "user", "content": "他有什么代表作?"})
response = model.chat(tokenizer=tokenizer, messages=messages, generation_config=generation_config)
messages.append({"role": "assistant", "content": response})
print(messages)
🤖 ModelScope
Base模型推理
此代码演示使用ModelScope快速使用360Zhinao-7B-Base模型进行推理
from modelscope import AutoModelForCausalLM, AutoTokenizer
from modelscope import GenerationConfig
MODEL_NAME_OR_PATH = "qihoo360/360Zhinao-7B-Base"
tokenizer = AutoTokenizer.from_pretrained(
MODEL_NAME_OR_PATH,
trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME_OR_PATH,
device_map="auto",
trust_remote_code=True)
generation_config = GenerationConfig.from_pretrained(
MODEL_NAME_OR_PATH,
trust_remote_code=True)
inputs = tokenizer('中国二十四节气\n1. 立春\n2. 雨水\n3. 惊蛰\n4. 春分\n5. 清明\n', return_tensors='pt')
inputs = inputs.to(model.device)
pred = model.generate(input_ids=inputs["input_ids"], generation_config=generation_config)
print("outputs:\n", tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
Chat模型推理
此代码演示使用ModelScope快速使用360Zhinao-7B-Chat-4K模型进行推理
from modelscope import AutoModelForCausalLM, AutoTokenizer
from modelscope import GenerationConfig
MODEL_NAME_OR_PATH = "qihoo360/360Zhinao-7B-Chat-4K"
tokenizer = AutoTokenizer.from_pretrained(
MODEL_NAME_OR_PATH,
trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
MODEL_NAME_OR_PATH,
device_map="auto",
trust_remote_code=True)
generation_config = GenerationConfig.from_pretrained(
MODEL_NAME_OR_PATH,
trust_remote_code=True)
messages = []
#round-1
messages.append({"role": "user", "content": "介绍一下刘德华"})
response = model.chat(tokenizer=tokenizer, messages=messages, generation_config=generation_config)
messages.append({"role": "assistant", "content": response})
print(messages)
#round-2
messages.append({"role": "user", "content": "他有什么代表作?"})
response = model.chat(tokenizer=tokenizer, messages=messages, generation_config=generation_config)
messages.append({"role": "assistant", "content": response})
print(messages)
终端 Demo
可使用终端交互实现快速体验
python cli_demo.py

网页 Demo
也可使用网页交互实现快速体验
streamlit run web_demo.py

API Demo
启动命令
python openai_api.py
请求参数
curl 'http://localhost:8360/v1/chat/completions' \
-H 'Content-Type: application/json' \
-d '{
"max_new_tokens": 200,
"do_sample": true,
"top_k": 0,
"top_p": 0.8,
"temperature": 1.0,
"repetition_penalty": 1.0,
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你好"}
]
}'
模型推理
模型量化
我们提供了基于AutoGPTQ的量化方案,并开源了Int4量化模型。
模型部署
vLLM安装环境
如希望部署及加速推理,我们建议你使用 vLLM==0.3.3。
如果你使用CUDA 12.1和PyTorch 2.1,可以直接使用以下命令安装vLLM。
pip install vllm==0.3.3
否则请参考vLLM官方的安装说明。
安装完成后,还需要以下操作~
把vllm/zhinao.py文件复制到env环境对应的vllm/model_executor/models目录下。
把vllm/serving_chat.py文件复制到env环境对应的vllm/entrypoints/openai目录下。
然后在vllm/model_executor/models/__init__.py文件增加一行代码
"ZhinaoForCausalLM": ("zhinao", "ZhinaoForCausalLM"),
vLLM服务启动
启动服务
python -m vllm.entrypoints.openai.api_server \
--served-model-name 360Zhinao-7B-Chat-4K \
--model qihoo360/360Zhinao-7B-Chat-4K \
--trust-remote-code \
--tensor-parallel-size 1 \
--max-model-len 4096 \
--host 0.0.0.0 \
--port 8360
使用curl请求服务
curl http://localhost:8360/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "360Zhinao-7B-Chat-4K",
"max_tokens": 200,
"top_k": -1,
"top_p": 0.8,
"temperature": 1.0,
"presence_penalty": 0.0,
"frequency_penalty": 0.0,
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你好"}
],
"stop": [
"<eod>",
"<|im_end|>",
"<|im_start|>"
]
}'
使用python请求服务
from openai import OpenAI
# Set OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8360/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="360Zhinao-7B-Chat-4K",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "你好"},
],
stop=[
"<eod>",
"<|im_end|>",
"<|im_start|>"
],
presence_penalty=0.0,
frequency_penalty=0.0
)
print("Chat response:", chat_response)
注意:如需要开启重复惩罚,建议使用 presence_penalty 和 frequency_penalty 参数。
模型微调
训练数据
我们提供了微调训练样例数据 data/test.json,该样例数据是从 multiturn_chat_0.8M 采样出 1 万条,并且做了格式转换。
数据格式:
[
{
"id": 1,
"conversations": [
{
"from": "system",
"value": "You are a helpful assistant."
},
{
"from": "user",
"value": "您好啊"
},
{
"from": "assistant",
"value": "你好!我今天能为您做些什么?有什么问题或需要帮助吗? 我在这里为您提供服务。"
}
]
}
]
微调训练
训练脚本如下:
set -x
HOSTFILE=hostfile
DS_CONFIG=./finetune/ds_config_zero2.json
# PARAMS
LR=5e-6
EPOCHS=3
MAX_LEN=4096
BATCH_SIZE=4
NUM_NODES=1
NUM_GPUS=8
MASTER_PORT=29500
IS_CONCAT=False # 是否数据拼接到最大长度(MAX_LEN)
DATA_PATH="./data/training_data_sample.json"
MODEL_PATH="qihoo360/360Zhinao-7B-Base"
OUTPUT_DIR="./outputs/"
deepspeed --hostfile ${HOSTFILE} \
--master_port ${MASTER_PORT} \
--num_nodes ${NUM_NODES} \
--num_gpus ${NUM_GPUS} \
finetune.py \
--report_to "tensorboard" \
--data_path ${DATA_PATH} \
--model_name_or_path ${MODEL_PATH} \
--output_dir ${OUTPUT_DIR} \
--model_max_length ${MAX_LEN} \
--num_train_epochs ${EPOCHS} \
--per_device_train_batch_size ${BATCH_SIZE} \
--gradient_accumulation_steps 1 \
--save_strategy steps \
--save_steps 200 \
--learning_rate ${LR} \
--lr_scheduler_type cosine \
--adam_beta1 0.9 \
--adam_beta2 0.95 \
--adam_epsilon 1e-8 \
--max_grad_norm 1.0 \
--weight_decay 0.1 \
--warmup_ratio 0.01 \
--gradient_checkpointing True \
--bf16 True \
--tf32 True \
--deepspeed ${DS_CONFIG} \
--is_concat ${IS_CONCAT} \
--logging_steps 1 \
--log_on_each_node False
bash finetune/ds_finetune.sh
- 可通过配置hostfile,实现单机、多机训练。
- 可通过配置ds_config,实现zero2、zero3。
- 可通过配置fp16、bf16实现混合精度训练,建议使用bf16,与预训练模型保持一致。
- 可通过配置is_concat参数,控制训练数据是否拼接,当训练数据量级较大时,可通过拼接提升训练效率。
许可证
本仓库源码遵循开源许可证Apache 2.0。
360智脑开源模型支持商用,若需将本模型及衍生模型用于商业用途,请通过邮箱([email protected])联系进行申请, 具体许可协议请见《360智脑开源模型许可证》。