
Model Summary

Introducing the world's first Llama-3 base model with 6B parameters. This model is a pretrained version of prince-canuma/Llama-3-6B-v0, which was created from Meta-Llama-3-8B using a technique called downcycling . The model was continually pretrained on 1 billion tokens of English-only text from fineweb, achieving impressive results on the evaluation set:
- Loss: 2.4942
Model Description
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- Developed by: Prince Canuma
- Sponsored by: General
- Model type: Llama
- License: Llama-3
- Pretrained from model: prince-canuma/Llama-3-6B-v0
Model Sources
- Repository: https://github.com/Blaizzy/Coding-LLMs-from-scratch/tree/main/Llama-3
- Video: https://youtube.com/playlist?list=PLDn_JsyofyfTH5_5V1MNb8UYKxMl6IMNy&si=5Y4cm-6wrMOD1Abr
Uses
You can use this model to create instruct and chat versions for various use cases such as: Coding assistant, RAG, Function Calling and more.
Limitations
This model inherits some of the base model's limitations and some additional ones from it's creation process, such as:
- Limited scope for coding and math: According to benchmarks, this model needs more pretraining/finetuning on code and math data to excel at reasoning tasks.
- Language Limitations: This model was continually pretrained on english only data. If you are planning to use it for multilingual use cases I recommend fine-tuning or continued pretraining.
How to Get Started with the Model
Use the code below to get started with the model.
from transformers import AutoModelForCausalLM, AutoConfig, AutoTokenizer
# Load model, config and tokenizer
model_name = "prince-canuma/Llama-3-6B-v0.1"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
inputs = tokenizer(
[
"Who created Python?"
], return_tensors = "pt")
from transformers import TextStreamer
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 200)
Output:
<|begin_of_text|>Who created Python? What is Python used for? What is the difference between Python 2 and Python 3? What is the difference between Python and Python 3?
Python is a programming language that was created by Guido van Rossum in 1991. It is a widely used language for web development, data science, and machine learning. Python is also used for creating software applications and games.
Python is a powerful language that is easy to learn and use. It has a large library of built-in functions and packages that make it easy to write code. Python is also a very popular language for web development, with many popular web frameworks such as Django and Flask being written in Python.
Python is also used for data science and machine learning. It has a large library of packages for data analysis, machine learning, and artificial intelligence. Python is also used for creating software applications and games.
Python 2 and Python 3 are two different versions of the Python language. Python 2 was the original version of the
Training Details
Downcycling
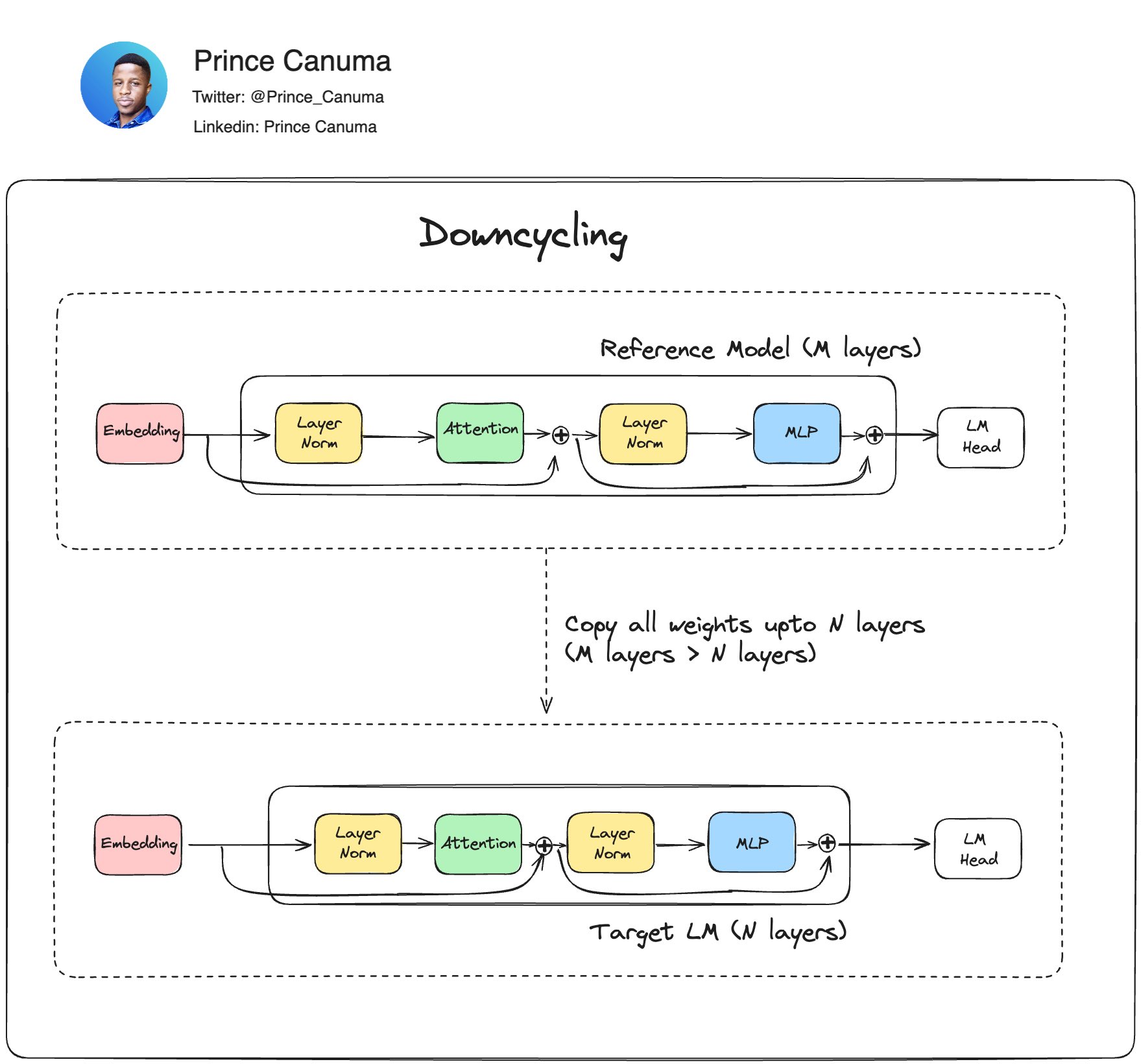 Fig 1. Downcycling workflow as also described in [arxiv.org/abs/2404.08634](https://arxiv.org/abs/2404.08634).
Fig 1. Downcycling workflow as also described in [arxiv.org/abs/2404.08634](https://arxiv.org/abs/2404.08634).
A technique that allows you to create new LLMs of diversa sizes from checkpoints of large pretrained models. You take a reference model (i.e., Llama-3-8B) and copy the weights of 24 layers out of 32 layers alongside embedding and prediction heads. Then you initialize a smaller target model with 24 layers and load those pretrained weights.
This new model will most likely still output legible outputs, but for it to perform well you need continue the pretraining.
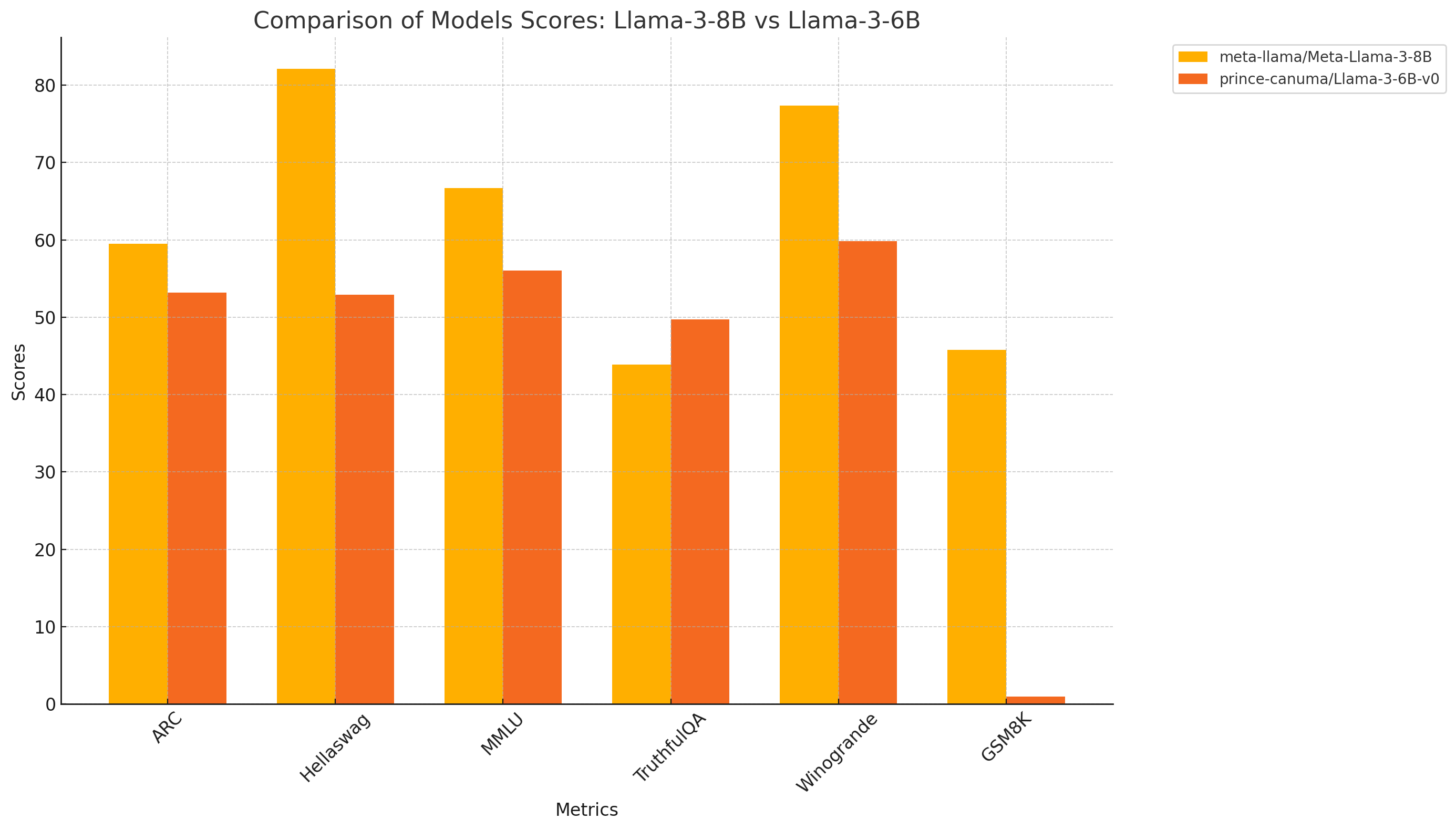 Fig 2. Downcycled model vs Reference model, without continued pretraining.
Fig 2. Downcycled model vs Reference model, without continued pretraining.
Training Data
For continued pretrained, I extracted 1B tokens from Huggingface's FineWeb CC-Main-2024-10 slice.
Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 8
- total_train_batch_size: 64
- total_eval_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 100
- num_epochs: 2
![]()
See axolotl config
axolotl version: 0.4.0
base_model: prince-canuma/Llama-3-6B-v0.1
model_type: AutoModelForCausalLM
tokenizer_type: AutoTokenizer
load_in_8bit: false
load_in_4bit: true
strict: false
datasets:
- path: prince-canuma/fineweb-CC-MAIN-2024-10-1B-en
type: completion
split: train
dataset_prepared_path: last_run_prepared
val_set_size: 0.001
output_dir: ./llama-3-6b
save_safetensors: true
adapter: qlora
lora_model_dir:
sequence_len: 8192
sample_packing: false
pad_to_sequence_len: false
lora_r: 128
lora_alpha: 128
lora_dropout: 0.05
lora_target_modules:
lora_target_linear: true
lora_fan_in_fan_out:
wandb_project: llama-3-6b
wandb_entity:
wandb_watch:
wandb_name:
wandb_log_model:
gradient_accumulation_steps: 8
micro_batch_size: 2
num_epochs: 2
optimizer: paged_adamw_32bit
lr_scheduler: cosine
learning_rate: 2e-4
train_on_inputs: false
group_by_length: false
bf16: auto
fp16:
tf32: false
gradient_checkpointing: true
early_stopping_patience:
resume_from_checkpoint:
local_rank:
logging_steps: 1
xformers_attention:
flash_attention: true
warmup_steps: 100
evals_per_epoch: 4
eval_table_size:
save_steps: 4000
debug:
deepspeed:
weight_decay: 0.0
fsdp:
fsdp_config:
special_tokens:
pad_token: "<|reserved_special_token_0|>"
Training results
There were 3 distinct experiments. In these experiments, QLoRA was used instead of Full Fine-tuning due to budget constraints.
- v0: This was a test ran for 1K steps to check if the model would improve with QLoRA params.
- v1: Here the QLoRA parameters where tweaked (Rank and Alpha).
- v2: This was the main experiment, ran for 2 epochs on 1B tokens from FineWeb.
All details can be found on my Wandb dashboard: https://wandb.ai/prince-canuma/llama-3-6b?nw=nwuserprincecanuma
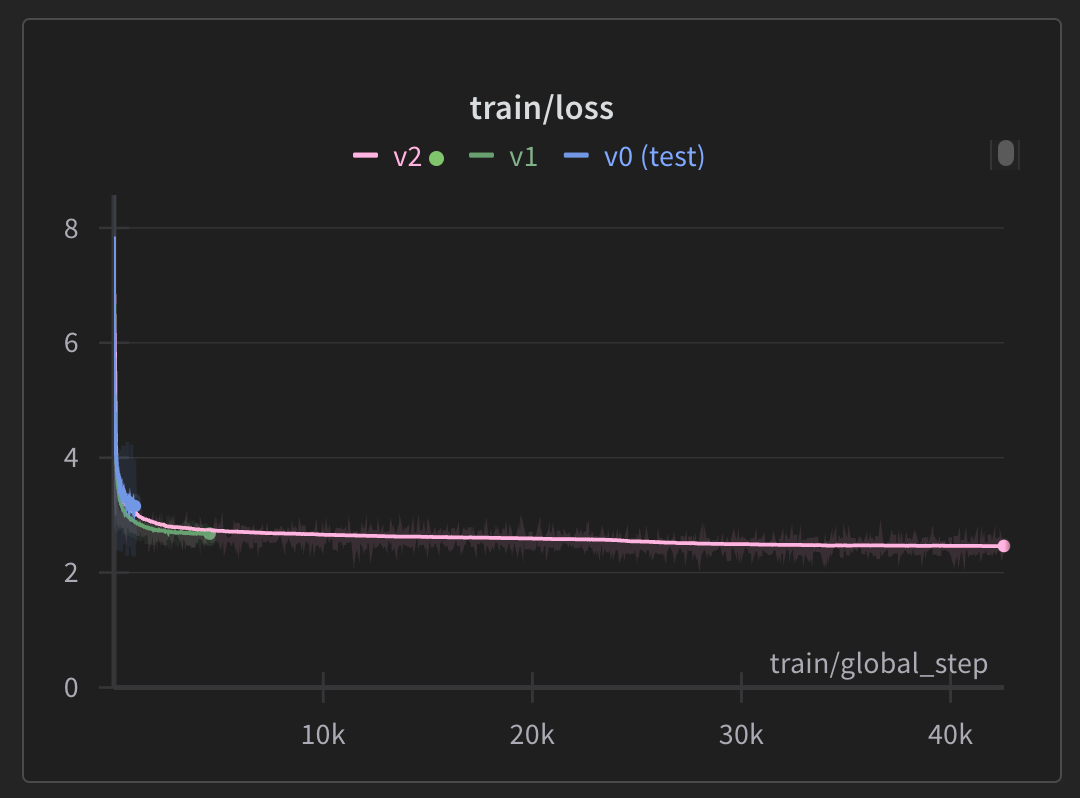 Fig 3. Experiment training loss charts on wandb.
Fig 3. Experiment training loss charts on wandb.
Overal metrics:
| Training Loss | Epoch | Step | Validation Loss |
|---|---|---|---|
| 7.1562 | 0.0 | 1 | 7.1806 |
| 2.7339 | 0.25 | 5867 | 2.6266 |
| 2.6905 | 0.5 | 11734 | 2.5872 |
| 2.6134 | 0.75 | 17601 | 2.5549 |
| 2.532 | 1.0 | 23468 | 2.5235 |
| 2.5319 | 1.25 | 29335 | 2.5067 |
| 2.3336 | 1.5 | 35202 | 2.4968 |
| 2.3486 | 1.75 | 41069 | 2.4942 |
Framework versions
- PEFT 0.10.0
- Transformers 4.40.0.dev0
- Pytorch 2.2.0+cu121
- Datasets 2.15.0
- Tokenizers 0.15.0
Hardware:
- 4xRTX6000 using JarvisLabs (Sponsored by General Catalyst thanks to Viet)
Evaluation
Benchmarks
- Hellaswag: a dataset for studying grounded commonsense inference.
- ARC: a multiple-choice question-answering dataset. from science exams from grade 3 to grade 9.
- MMLU: a test with 57 tasks to measure a text model's multitask accuracy.
- TruthfulQA: a test to measure a model's propensity to reproduce falsehoods commonly found online.
- Winogrande: for commonsense reasoning.
- GSM8k: diverse grade school math word problems to measure a model's ability to solve multi-step mathematical reasoning problems.
Results
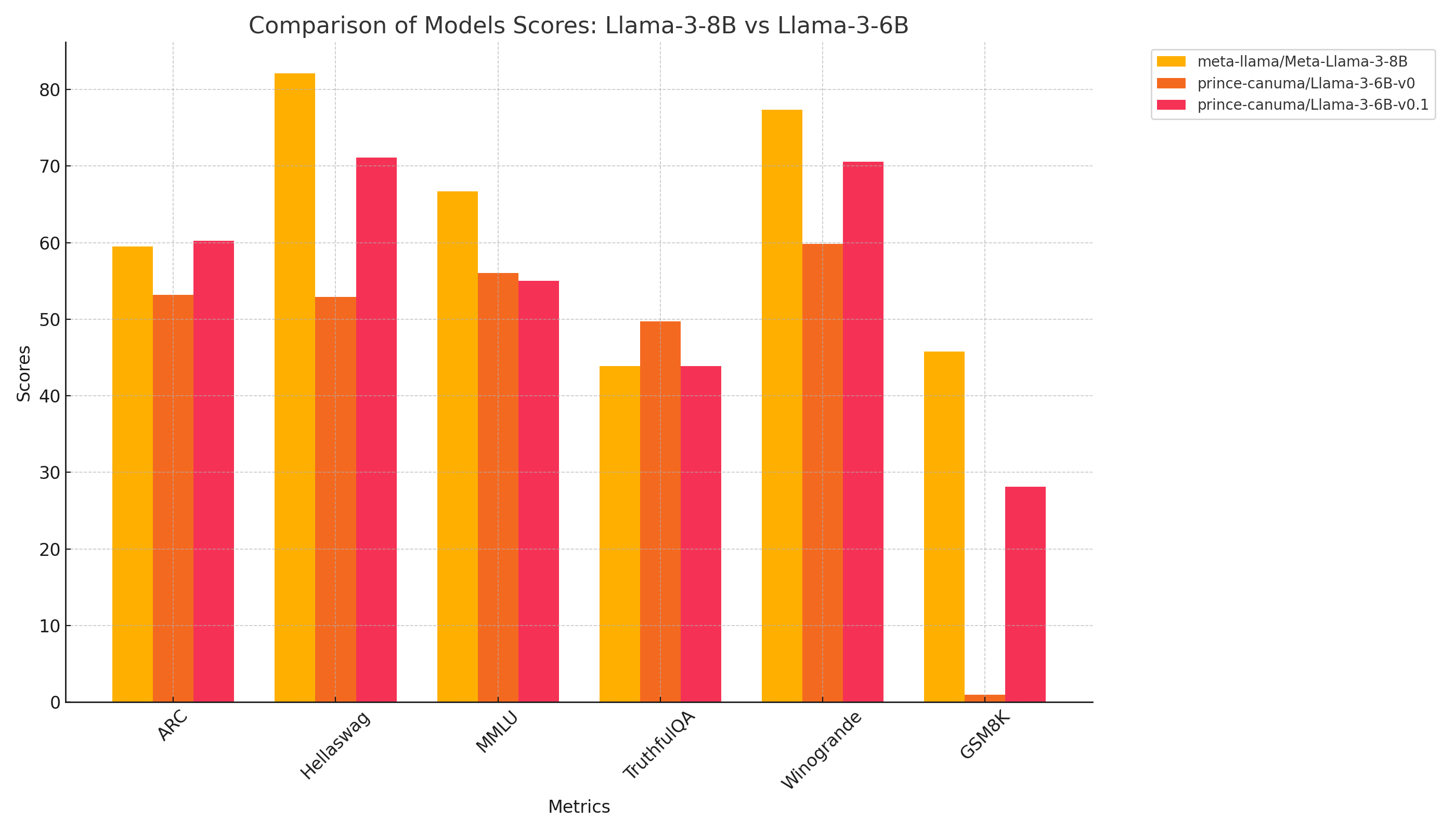 Fig 4. Performance comparision of Llama-3-8B, Llama-3-6B and Llama-3-6B (w/ continued pretraining)
Fig 4. Performance comparision of Llama-3-8B, Llama-3-6B and Llama-3-6B (w/ continued pretraining)
Pretraining for 2 epochs on 1B tokens had a positive effect across the board. The new base model now performs competitively with its reference model (Llama-3-8B) whilst being 1.3x smaller.
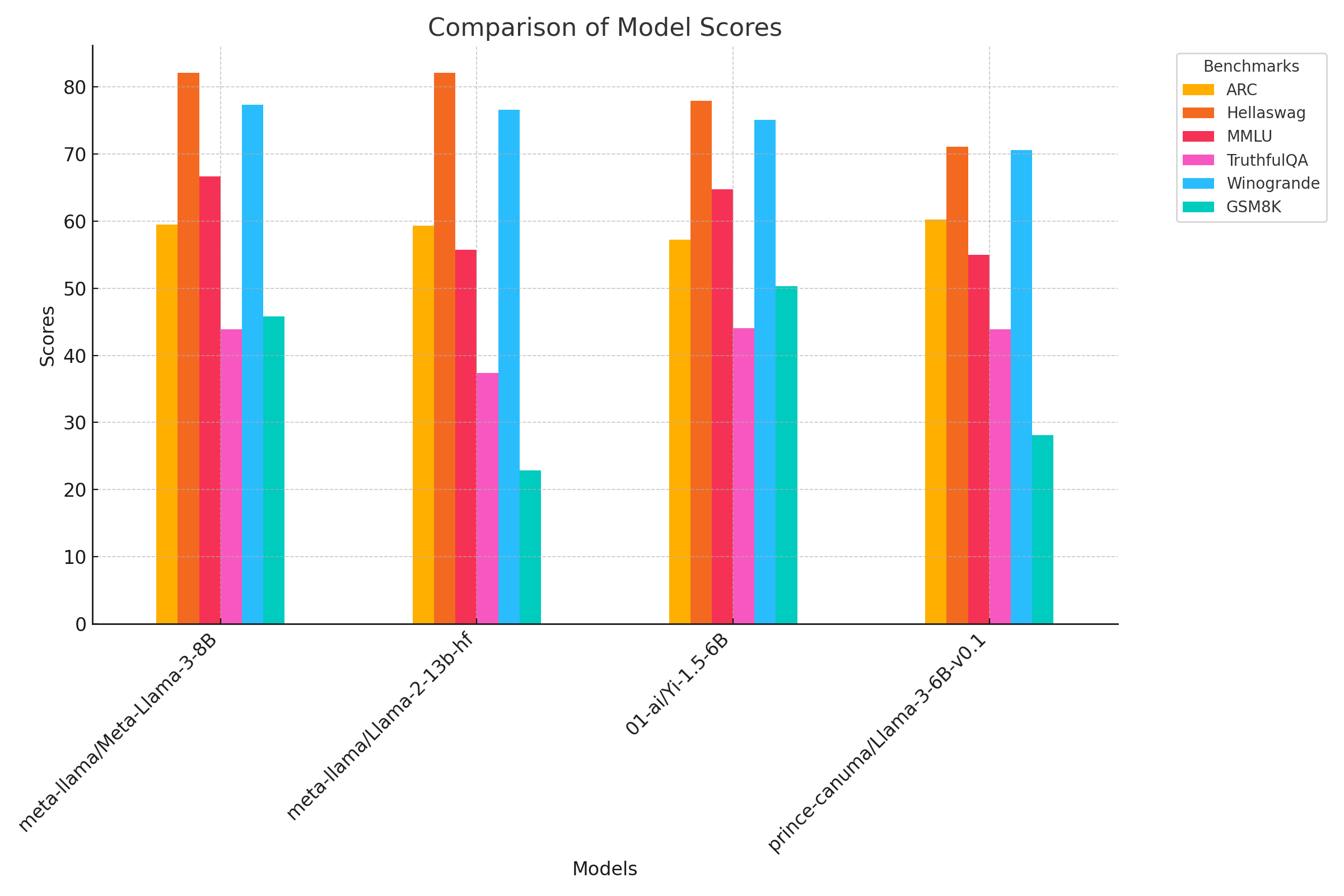 Fig 5. Performance comparision of Llama-3-8B, Llama-2-13B, Yi-1.5-6B and Llama-3-6B.
Fig 5. Performance comparision of Llama-3-8B, Llama-2-13B, Yi-1.5-6B and Llama-3-6B.
Llama-3-6B is competive with model within it's category and upto 2x larger than it self across 6 diverse benchmarks.
Summary and future directions:
This experiment was a success! Using this technique, I'll be able to build many variants. This is the first of many new base models I intend to create.
Next, I plan to explore different data mixtures and perform full fine-tuning, all of which will contribute to developing other small model as well as larger and more robust models.
Citation
BibTeX:
@misc{prince2024downcycling,
title={Efficient LLM Downcycling: Generating Diverse Model Sizes from Pretrained Giants},
author={Prince Canuma},
year={2024},
}
Thank You!
I want to extend my heartfelt thanks to the community for the invaluable expertise and unwavering support.
Additionally, I would like to thank Viet from General Catalyst (GC) for providing me with the much needed compute.
This is my most ambitious project yet, and it wouldn't have been possible without the incredible open-source ML community!
Developers, I am eager to see and hear about the innovative fine-tunes and applications you create.
Users, I am excited to learn about your experiences and use cases.
Thank you for your interest and support!
References:
@misc{komatsuzaki2023sparse,
title={Sparse Upcycling: Training Mixture-of-Experts from Dense Checkpoints},
author={Aran Komatsuzaki and Joan Puigcerver and James Lee-Thorp and Carlos Riquelme Ruiz and Basil Mustafa and Joshua Ainslie and Yi Tay and Mostafa Dehghani and Neil Houlsby},
year={2023},
eprint={2212.05055},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
@misc{sanyal2024pretraining,
title={Pre-training Small Base LMs with Fewer Tokens},
author={Sunny Sanyal and Sujay Sanghavi and Alexandros G. Dimakis},
year={2024},
eprint={2404.08634},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
- Downloads last month
- 39
Model tree for prince-canuma/Llama-3-6B-v0.1
Base model
prince-canuma/Llama-3-6B-v0