
LLaMA 3 8B - Seed-Free Synthetic Instruct (F+C+D+)
This model is the result of fine-tuning LLaMA 3 8B using our novel seed-free synthetic instruction dataset for Thai. It represents the outcome of our research "Seed-Free Synthetic Data Generation Framework for Instruction-Tuning LLMs: A Case Study in Thai" submitted to ACL SRW 2024.
Model Details
- Base Model: LLaMA 3 8B
- Fine-tuning Dataset: Seed-Free Synthetic Instruct Thai v1 (F+C+D+)
- Training Corpus Size: 5,000 instructions
- Languages: Primarily Thai, with potential for English and other languages supported by LLaMA 3
Intended Use
This model is designed for:
- Thai language understanding and generation
- Instruction following in Thai
- General language tasks with a focus on Thai cultural context
It can be used for research purposes, to power Thai language applications, or as a baseline for further fine-tuning on specific Thai language tasks.
Performance and Limitations
Strengths
- Comparable performance to state-of-the-art Thai LLMs (e.g., WangchanX, OpenThaiGPT)
- Second-highest BERTScore on both Thai Culture and General Test Sets
- Efficient performance achieved with only 5,000 instructions
- Strong understanding of Thai cultural context
Limitations
- Performance on tasks outside the scope of the fine-tuning dataset may vary
- May exhibit biases present in the synthetic dataset or the base LLaMA 3 model
- Not extensively tested for factual accuracy or potential harmful outputs
Training Procedure
- Fine-tuning Framework: axolotl
- Training Data: Seed-Free Synthetic Instruct Thai v1 (F+C+D+), generated using our novel framework
Evaluation Results
The model was evaluated on various Thai language tasks, including:
- Thai Culture Test Set
- General Test Set
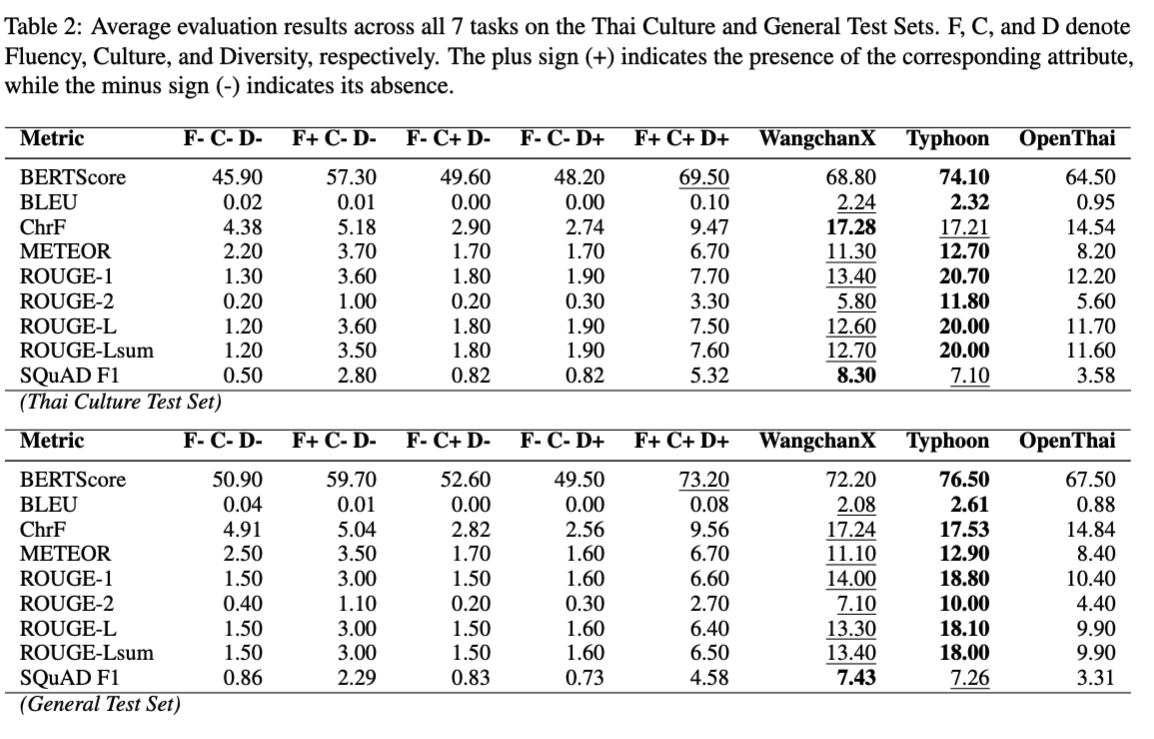
For detailed performance metrics and comparisons, please refer to the full research paper and the GitHub repository.
Ethical Considerations
While efforts have been made to incorporate diverse and culturally appropriate content, users should be aware of potential biases in the model outputs. The model should not be used as a sole source of factual information, especially for critical applications.
Citation
[COMING SOON]
Additional Information
For more details on the training process, evaluation methodology, and complete results, please refer to:
- Full research paper (link to be added upon publication)
- GitHub repository
- Dataset on Hugging Face
Acknowledgments
This research has received funding support from the NSRF via the Program Management Unit for Human Resources & Institutional Development, Research and Innovation Grant Number B46G670083.
- Downloads last month
- 8