

metadata
license: mit
language:
- en
tags:
- mteb
- sparse
- sparsity
- quantized
- onnx
- embeddings
- int8
- deepsparse
model-index:
- name: bge-base-en-v1.5-quant
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 76.16417910447761
- type: ap
value: 39.62965026785565
- type: f1
value: 70.30041589476463
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 92.95087500000001
- type: ap
value: 89.92451248271642
- type: f1
value: 92.94162732408543
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 48.214
- type: f1
value: 47.57084372829096
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 48.499816497755646
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 42.006939120636034
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 62.390343953329875
- type: mrr
value: 75.69922613551422
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 89.03408553833623
- type: cos_sim_spearman
value: 86.71221676053791
- type: euclidean_pearson
value: 87.81477796215844
- type: euclidean_spearman
value: 87.28994076774481
- type: manhattan_pearson
value: 87.76204756059836
- type: manhattan_spearman
value: 87.1971675695072
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 86.35064935064935
- type: f1
value: 86.32782396028989
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 39.299558776859485
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 35.64603198816062
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 51.269999999999996
- type: f1
value: 45.9714399031315
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 89.7204
- type: ap
value: 85.70238397381907
- type: f1
value: 89.70961232185473
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.95120839033288
- type: f1
value: 93.70348712248138
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 75.25763793889648
- type: f1
value: 57.59583082574482
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 75.16476126429052
- type: f1
value: 73.29287381030854
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 78.9340954942838
- type: f1
value: 79.04036413238218
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 32.80025982143821
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 30.956464446009623
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 31.886626060290734
- type: mrr
value: 32.99813843700759
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 55.693914682185365
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 62.32723620518647
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 84.70275347034692
- type: cos_sim_spearman
value: 80.06126639668393
- type: euclidean_pearson
value: 82.18370726102707
- type: euclidean_spearman
value: 80.05483013524909
- type: manhattan_pearson
value: 82.11962032129463
- type: manhattan_spearman
value: 79.97174232961949
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 86.08210281025868
- type: cos_sim_spearman
value: 77.75002826042643
- type: euclidean_pearson
value: 83.06487161944293
- type: euclidean_spearman
value: 78.0677956304104
- type: manhattan_pearson
value: 83.04321232787379
- type: manhattan_spearman
value: 78.09582483148635
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 84.64353592106988
- type: cos_sim_spearman
value: 86.07934653140616
- type: euclidean_pearson
value: 85.21820182954883
- type: euclidean_spearman
value: 86.18828773665395
- type: manhattan_pearson
value: 85.12075207905364
- type: manhattan_spearman
value: 86.12061116344299
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 84.33571296969136
- type: cos_sim_spearman
value: 82.8868213429789
- type: euclidean_pearson
value: 83.65476643152161
- type: euclidean_spearman
value: 82.76439753890263
- type: manhattan_pearson
value: 83.63348951033883
- type: manhattan_spearman
value: 82.76176495070241
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 87.6337321089215
- type: cos_sim_spearman
value: 88.54453531860615
- type: euclidean_pearson
value: 87.68754116644199
- type: euclidean_spearman
value: 88.22610830299979
- type: manhattan_pearson
value: 87.62214887890859
- type: manhattan_spearman
value: 88.14766677391091
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 83.89742747806514
- type: cos_sim_spearman
value: 85.76282302560992
- type: euclidean_pearson
value: 84.83917251074928
- type: euclidean_spearman
value: 85.74354740775905
- type: manhattan_pearson
value: 84.91190952448616
- type: manhattan_spearman
value: 85.82001542154245
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.70974342036347
- type: cos_sim_spearman
value: 87.82200371351459
- type: euclidean_pearson
value: 88.04095125600278
- type: euclidean_spearman
value: 87.5069523002544
- type: manhattan_pearson
value: 88.03247709799281
- type: manhattan_spearman
value: 87.43433979175654
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 65.0349727703108
- type: cos_sim_spearman
value: 65.46090125254047
- type: euclidean_pearson
value: 66.75349075443432
- type: euclidean_spearman
value: 65.57576680702924
- type: manhattan_pearson
value: 66.72598998285412
- type: manhattan_spearman
value: 65.63446184311414
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 85.18026134463653
- type: cos_sim_spearman
value: 86.79430055943524
- type: euclidean_pearson
value: 86.2668626122386
- type: euclidean_spearman
value: 86.72288498504841
- type: manhattan_pearson
value: 86.28615540445857
- type: manhattan_spearman
value: 86.7110630606802
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 87.05335415919195
- type: mrr
value: 96.27455968142243
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.84653465346534
- type: cos_sim_ap
value: 96.38115549823692
- type: cos_sim_f1
value: 92.15983813859383
- type: cos_sim_precision
value: 93.24462640736951
- type: cos_sim_recall
value: 91.10000000000001
- type: dot_accuracy
value: 99.81782178217821
- type: dot_ap
value: 95.65732630933346
- type: dot_f1
value: 90.68825910931176
- type: dot_precision
value: 91.80327868852459
- type: dot_recall
value: 89.60000000000001
- type: euclidean_accuracy
value: 99.84653465346534
- type: euclidean_ap
value: 96.34134720479366
- type: euclidean_f1
value: 92.1756688541141
- type: euclidean_precision
value: 93.06829765545362
- type: euclidean_recall
value: 91.3
- type: manhattan_accuracy
value: 99.84356435643565
- type: manhattan_ap
value: 96.38165573090185
- type: manhattan_f1
value: 92.07622868605819
- type: manhattan_precision
value: 92.35412474849095
- type: manhattan_recall
value: 91.8
- type: max_accuracy
value: 99.84653465346534
- type: max_ap
value: 96.38165573090185
- type: max_f1
value: 92.1756688541141
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 64.81205738681385
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 34.083934029129445
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 54.447346270481376
- type: mrr
value: 55.382382119514475
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 72.123
- type: ap
value: 14.396060207954983
- type: f1
value: 55.24344377812756
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 59.67176004527447
- type: f1
value: 59.97320225890037
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 49.50190094208029
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 86.70799308577219
- type: cos_sim_ap
value: 76.40980707197174
- type: cos_sim_f1
value: 70.64264849074976
- type: cos_sim_precision
value: 65.56710347943967
- type: cos_sim_recall
value: 76.56992084432717
- type: dot_accuracy
value: 85.75430649102938
- type: dot_ap
value: 72.68783978286282
- type: dot_f1
value: 67.56951102588687
- type: dot_precision
value: 61.90162494510321
- type: dot_recall
value: 74.37994722955145
- type: euclidean_accuracy
value: 86.70799308577219
- type: euclidean_ap
value: 76.43046769325314
- type: euclidean_f1
value: 70.84852905421832
- type: euclidean_precision
value: 65.68981064021641
- type: euclidean_recall
value: 76.88654353562005
- type: manhattan_accuracy
value: 86.70203254455504
- type: manhattan_ap
value: 76.39254562413156
- type: manhattan_f1
value: 70.86557059961316
- type: manhattan_precision
value: 65.39491298527443
- type: manhattan_recall
value: 77.33509234828496
- type: max_accuracy
value: 86.70799308577219
- type: max_ap
value: 76.43046769325314
- type: max_f1
value: 70.86557059961316
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.92381728567548
- type: cos_sim_ap
value: 85.92532857788025
- type: cos_sim_f1
value: 78.11970128792525
- type: cos_sim_precision
value: 73.49806530445998
- type: cos_sim_recall
value: 83.3615645210964
- type: dot_accuracy
value: 88.28540381107618
- type: dot_ap
value: 84.42890126108796
- type: dot_f1
value: 76.98401162790698
- type: dot_precision
value: 72.89430222956234
- type: dot_recall
value: 81.55990144748999
- type: euclidean_accuracy
value: 88.95874568246207
- type: euclidean_ap
value: 85.88338025133037
- type: euclidean_f1
value: 78.14740888593184
- type: euclidean_precision
value: 75.15285084601166
- type: euclidean_recall
value: 81.3905143209116
- type: manhattan_accuracy
value: 88.92769821865176
- type: manhattan_ap
value: 85.84824183217555
- type: manhattan_f1
value: 77.9830582736965
- type: manhattan_precision
value: 74.15972222222223
- type: manhattan_recall
value: 82.22205112411457
- type: max_accuracy
value: 88.95874568246207
- type: max_ap
value: 85.92532857788025
- type: max_f1
value: 78.14740888593184
bge-base-en-v1.5-quant
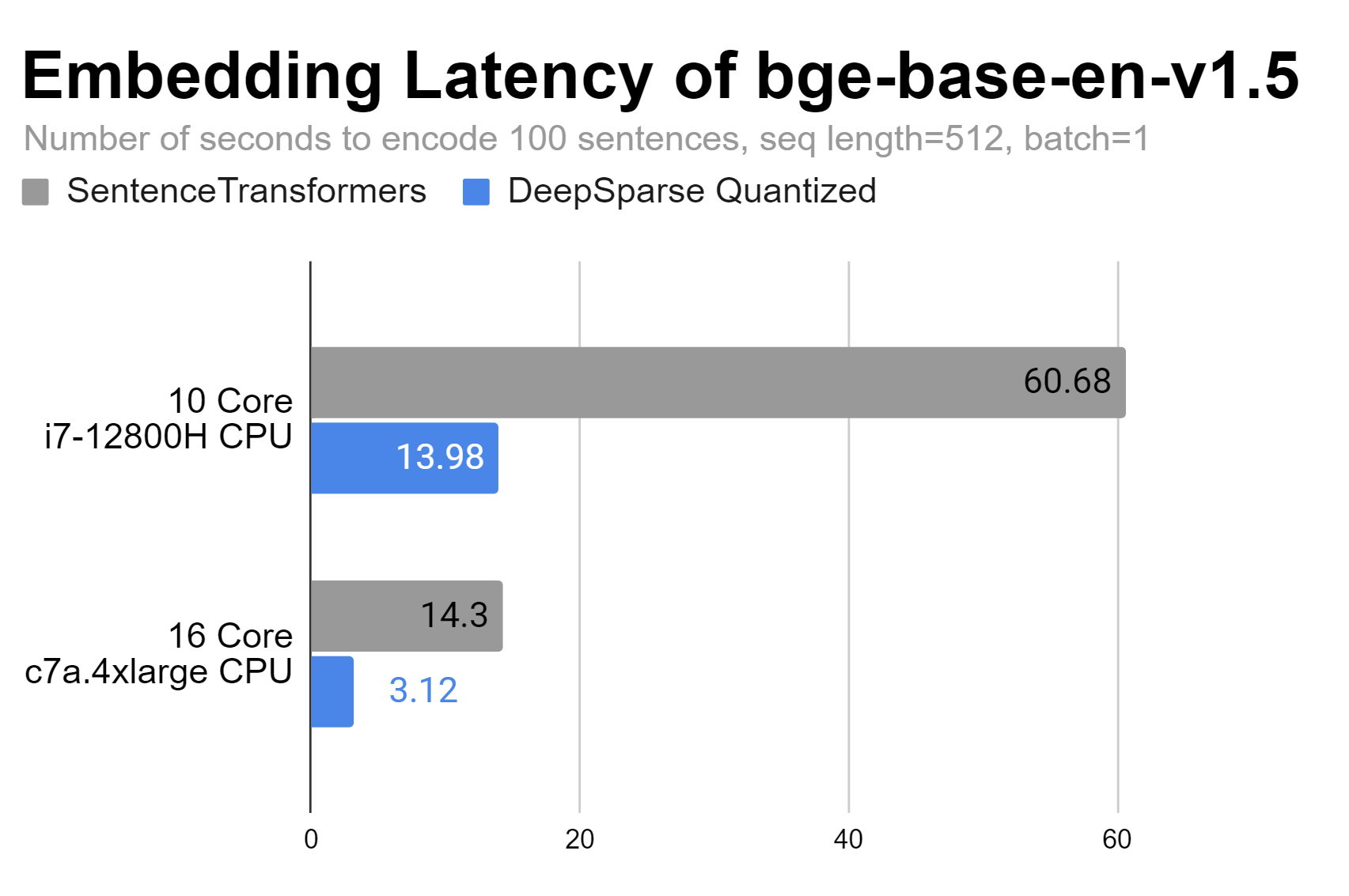
DeepSparse is able to improve latency performance on a 10 core laptop and a 16 core AWS instance by up to 4.5X.
Usage
This is the quantized (INT8) ONNX variant of the bge-base-en-v1.5 embeddings model accelerated with Sparsify for quantization and DeepSparseSentenceTransformers for inference.
pip install -U deepsparse-nightly[sentence_transformers]
from deepsparse.sentence_transformers import DeepSparseSentenceTransformer
model = DeepSparseSentenceTransformer('neuralmagic/bge-base-en-v1.5-quant', export=False)
# Our sentences we like to encode
sentences = ['This framework generates embeddings for each input sentence',
'Sentences are passed as a list of string.',
'The quick brown fox jumps over the lazy dog.']
# Sentences are encoded by calling model.encode()
embeddings = model.encode(sentences)
# Print the embeddings
for sentence, embedding in zip(sentences, embeddings):
print("Sentence:", sentence)
print("Embedding:", embedding.shape)
print("")
For general questions on these models and sparsification methods, reach out to the engineering team on our community Slack.