


OpenThaiLLM-Prebuilt-7B: Thai & China & English Large Language Model
OpenThaiLLM-Prebuilt-7B is a Thai 🇹🇭 & Chinese 🇨🇳 & English 🇬🇧 large language model with 7 billion parameters, and it is continue pretrain based on Qwen2-7B. It demonstrates competitive performance with llama-3-typhoon-v1.5-8b, and is optimized for application use cases, Retrieval-Augmented Generation (RAG), constrained generation, and reasoning tasks.
Model detail
For release notes, please see our blog.
We do not recommend using base language models for conversations. Instead, you can apply post-training, e.g., SFT, RLHF, continued pretraining, etc., on this model.
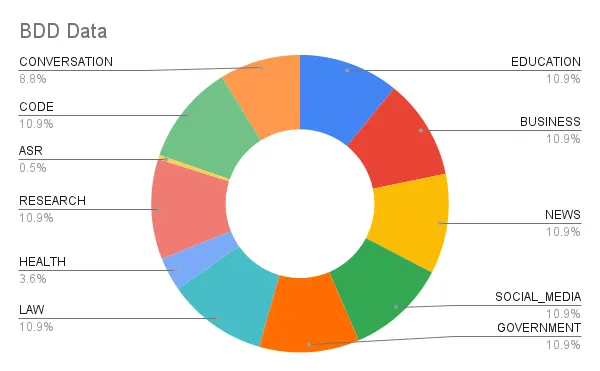
Datasets Ratio
Requirements
The code of Qwen2.5 has been in the latest Hugging face transformers and we advise you to use the latest version of transformers.
With transformers<4.37.0, you will encounter the following error:
KeyError: 'qwen2'
Evaluation Performance
The Model evaluation performance is outperfoms other model that are leading in the top base model performance of Thai NLP community.
| Model | ONET | IC | TGAT | TPAT-1 | A-Level | Average (ThaiExam) | MMLU | M3Exam | M6Exam |
|---|---|---|---|---|---|---|---|---|---|
| OpenthaiLLM-Prebuilt-7B | 0.5493 | 0.6315 | 0.6307 | 0.4655 | 0.37 | 0.5294 | 0.7054 | 0.5705 | 0.596 |
| SeaLLM-v3-7B | 0.4753 | 0.6421 | 0.6153 | 0.3275 | 0.3464 | 0.4813 | 0.7037 | 0.4907 | 0.4625 |
| llama-3-typhoon-v1.5-8B | 0.3765 | 0.3473 | 0.5538 | 0.4137 | 0.2913 | 0.3965 | 0.6451 | 0.4312 | 0.4125 |
| Qwen-2-7B | 0.4814 | 0.621 | 0.6153 | 0.3448 | 0.3385 | 0.4802 | 0.7073 | 0.4949 | 0.4807 |
| Meta-Llama-3.1-8B | 0.3641 | 0.2631 | 0.2769 | 0.3793 | 0.1811 | 0.2929 | 0.6591 | 0.4239 | 0.3583 |
Contributor Contract
LLM Team
Pakawat Phasook ([email protected])
Jessada Pranee ([email protected])
Arnon Saeoung ([email protected])
Kun Kerdthaisong ([email protected])
Kittisak Sukhantharat ([email protected])
Piyawat Chuangkrud ([email protected])
Chaianun Damrongrat ([email protected])
Sarawoot Kongyoung ([email protected])
Audio Team
Pattara Tipaksorn ([email protected])
Wayupuk Sommuang ([email protected])
Oatsada Chatthong ([email protected])
Kwanchiva Thangthai ([email protected])
Vision Team
Thirawarit Pitiphiphat ([email protected])
Peerapas Ngokpon ([email protected])
Theerasit Issaranon ([email protected])
Citation
If you find our work helpful, feel free to give us a cite.
@misc{qwen2.5,
title = {Qwen2.5: A Party of Foundation Models},
url = {https://qwenlm.github.io/blog/qwen2.5/},
author = {Qwen Team},
month = {September},
year = {2024}
}
@article{qwen2,
title={Qwen2 Technical Report},
author={An Yang and Baosong Yang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Zhou and Chengpeng Li and Chengyuan Li and Dayiheng Liu and Fei Huang and Guanting Dong and Haoran Wei and Huan Lin and Jialong Tang and Jialin Wang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Ma and Jin Xu and Jingren Zhou and Jinze Bai and Jinzheng He and Junyang Lin and Kai Dang and Keming Lu and Keqin Chen and Kexin Yang and Mei Li and Mingfeng Xue and Na Ni and Pei Zhang and Peng Wang and Ru Peng and Rui Men and Ruize Gao and Runji Lin and Shijie Wang and Shuai Bai and Sinan Tan and Tianhang Zhu and Tianhao Li and Tianyu Liu and Wenbin Ge and Xiaodong Deng and Xiaohuan Zhou and Xingzhang Ren and Xinyu Zhang and Xipin Wei and Xuancheng Ren and Yang Fan and Yang Yao and Yichang Zhang and Yu Wan and Yunfei Chu and Yuqiong Liu and Zeyu Cui and Zhenru Zhang and Zhihao Fan},
journal={arXiv preprint arXiv:2407.10671},
year={2024}
}
- Downloads last month
- 550