
Llama-3-8B-Instruct-80K-QLoRA-Merged
We extend the context length of Llama-3-8B-Instruct to 80K using QLoRA and 3.5K long-context training data synthesized from GPT-4. The entire training cycle is super efficient, which takes 8 hours on a 8xA800 (80G) machine. Yet, the resulted model achieves remarkable performance on a series of downstream long-context evaluation benchmarks.
NOTE: This repo contains the quantized model of namespace-Pt/Llama-3-8B-Instruct-80K-QLoRA-Merged. The quantization is conducted with llama.cpp (Q4_K_M and Q8_0).
All the following evaluation results are based on the UNQUANTIZED MODEL. They can be reproduced following instructions here. However, after quantization, you may observe quality degradation.
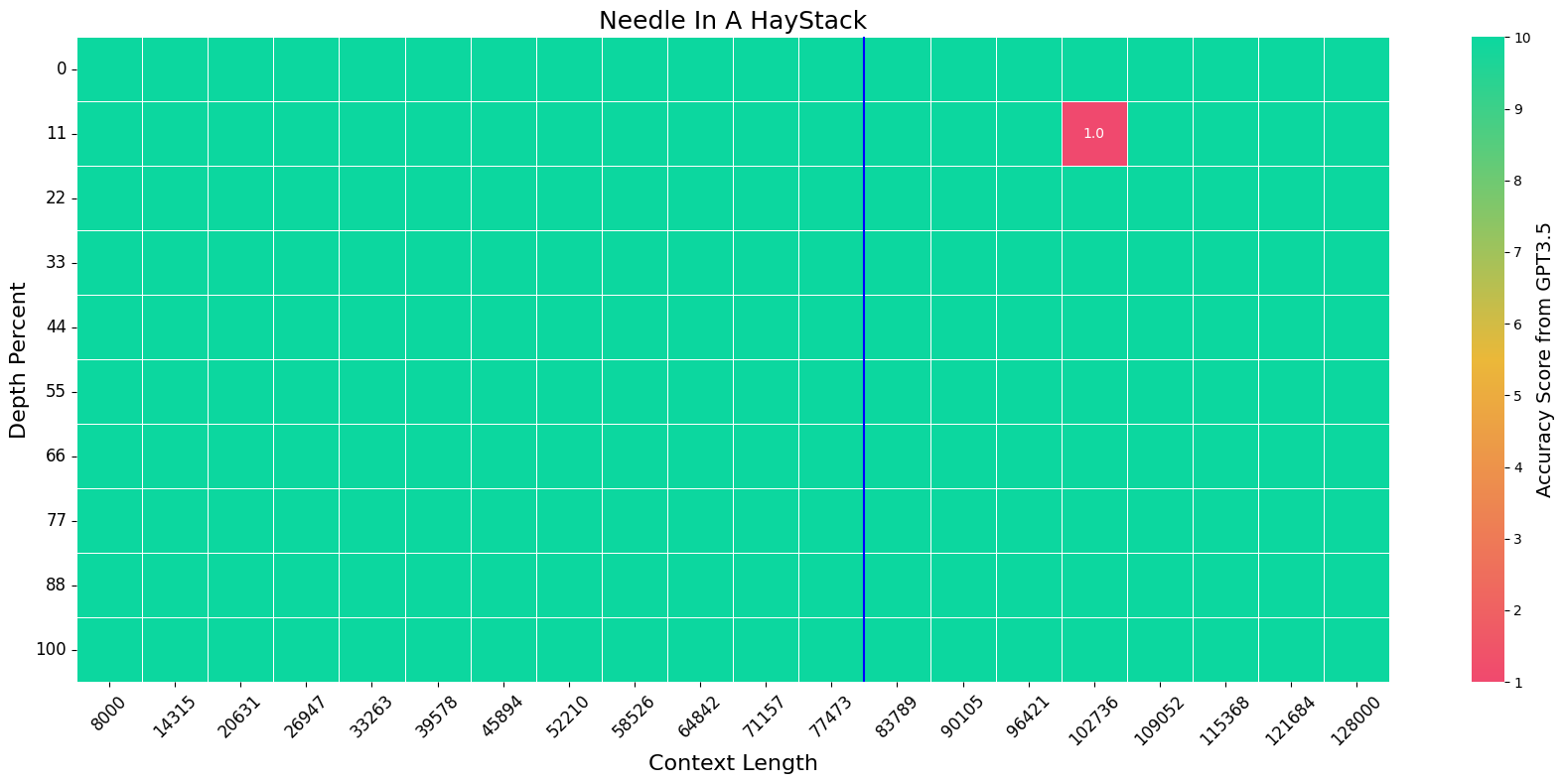
Needle in a Haystack
We evaluate the model on the Needle-In-A-HayStack task using the official setting. The blue vertical line indicates the training context length, i.e. 80K.
LongBench
We evaluate the model on LongBench using 32K context length and the official prompt template. For meta-llama/Meta-Llama-3-8B-Instruct, we use 8K context length.
| Model | Single-Doc QA | Multi-Doc QA | Summarization | Few-Shot Learning | Synthetic | Code | Avg |
|---|---|---|---|---|---|---|---|
| meta-llama/Meta-Llama-3-8B-Instruct | 37.33 | 36.04 | 26.83 | 69.56 | 37.75 | 53.24 | 43.20 |
| gradientai/Llama-3-8B-Instruct-262k | 37.29 | 31.20 | 26.18 | 67.25 | 44.25 | 62.71 | 43.73 |
| Llama-3-8B-Instruct-80K-QLoRA-Merged | 43.57 | 43.07 | 28.93 | 69.15 | 48.50 | 51.95 | 47.19 |
InfiniteBench
We evaluate the model on InfiniteBench using 80K context length and the official prompt template. The results of GPT-4 is copied from the paper. For meta-llama/Meta-Llama-3-8B-Instruct, we use 8K context length.
| Model | LongBookQA Eng | LongBookSum Eng |
|---|---|---|
| GPT-4 | 22.22 | 14.73 |
| meta-llama/Meta-Llama-3-8B-Instruct | 7.00 | 16.40 |
| gradientai/Llama-3-8B-Instruct-262k | 20.30 | 10.34 |
| Llama-3-8B-Instruct-80K-QLoRA-Merged | 30.92 | 14.73 |
Topic Retrieval
We evaluate the model on Topic Retrieval task with [5,10,15,20,25,30,40,50,60,70] topics.

MMLU
We evaluate the model's zero-shot performance on MMLU benchmark as a reflection of its short-context capability.
| Model | STEM | Social Sciences | Humanities | Others | Avg |
|---|---|---|---|---|---|
| Llama-2-7B-Chat | 35.92 | 54.37 | 51.74 | 51.42 | 47.22 |
| Mistral-7B-v0.2-Instruct | 48.79 | 69.95 | 64.99 | 61.64 | 60.10 |
| meta-llama/Meta-Llama-3-8B-Instruct | 53.87 | 75.66 | 69.44 | 69.75 | 65.91 |
| gradientai/Llama-3-8B-Instruct-262k | 52.10 | 73.26 | 67.15 | 69.80 | 64.34 |
| Llama-3-8B-Instruct-80K-QLoRA-Merged | 53.10 | 73.24 | 67.32 | 68.79 | 64.44 |
Environment
llama_cpp
torch==2.1.2
transformers==4.39.3
Usage
huggingface-cli download namespace-Pt/Llama-3-8B-Instruct-80K-QLoRA-Merged-GGUF --local-dir . --local-dir-use-symlinks False
In python,
from llama_cpp import Llama
llm = Llama(
model_path="./Llama-3-8B-Instruct-80K-QLoRA-Merged-Q4_K_M.gguf", # path to GGUF file
n_ctx=81920,
n_threads=96,
n_gpu_layers=32,
)
with open("./data/needle.txt") as f:
text = f.read()
inputs = f"{text}\n\nWhat is the best thing to do in San Francisco?"
print(
llm.create_chat_completion(
messages = [
{
"role": "user",
"content": inputs
}
],
temperature=0,
max_tokens=50
)
)
# The best thing to do in San Francisco is sitting in Helmer Dolores Park on a sunny day, eating a double cheeseburger with ketchup, and watching kids playing around.
- Downloads last month
- 18