
license: apache-2.0
tags:
- CLIP
- LLM2CLIP
pipeline_tag: zero-shot-classification
LLM2CLIP: Extending the Capability Boundaries of CLIP through Large Language Models
Weiquan Huang1*, Aoqi Wu1*, Yifan Yang2†, Xufang Luo2, Yuqing Yang2, Liang Hu1, Qi Dai2, Xiyang Dai2, Dongdong Chen2, Chong Luo2, Lili Qiu21Tongji Universiy, 2Microsoft Corporation
*Equal contribution
† Corresponding to: [email protected]
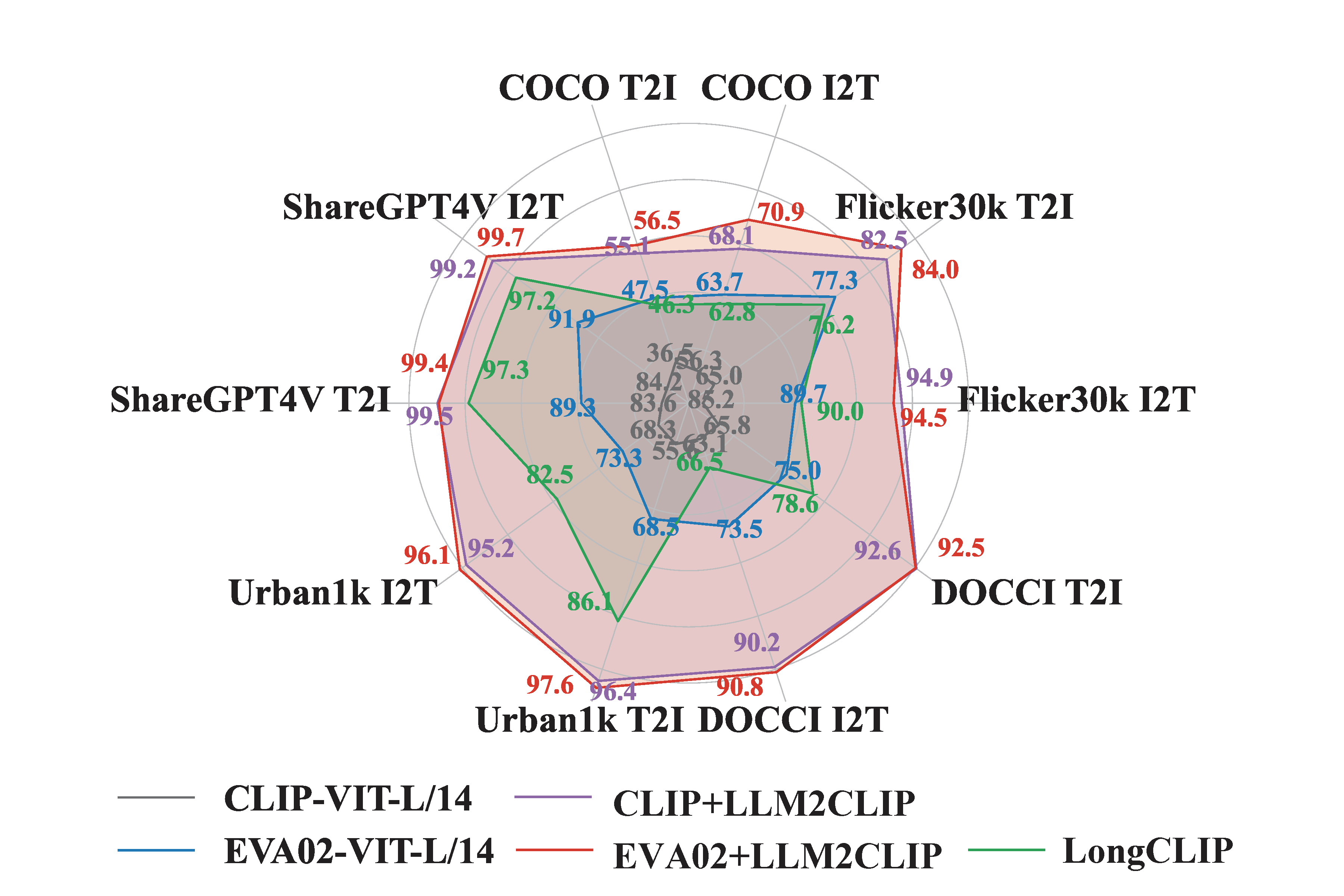
In this paper, we propose LLM2CLIP, a novel approach that embraces the power of LLMs to unlock CLIP’s potential. By fine-tuning the LLM in the caption space with contrastive learning, we extract its textual capabilities into the output embeddings, significantly improving the output layer’s textual discriminability. We then design an efficient training process where the fine-tuned LLM acts as a powerful teacher for CLIP’s visual encoder. Thanks to the LLM’s presence, we can now incorporate longer and more complex captions without being restricted by vanilla CLIP text encoder’s context window and ability limitations. Our experiments demonstrate that this approach brings substantial improvements in cross-modal tasks. Our method directly boosted the performance of the previously SOTA EVA02 model by 16.5% on both long-text and short-text retrieval tasks, transforming a CLIP model trained solely on English data into a state-of-the-art cross-lingual model. Moreover, when integrated into mul- timodal training with models like Llava 1.5, it consistently outperformed CLIP across nearly all benchmarks, demonstrating comprehensive performance improvements.
LLM2CLIP performance
Model Details
- Model Type: vision foundation model, feature backbone
- Pretrain Dataset: CC3M, CC12M, YFCC15M and Recap-DataComp-1B(30M subset)
Usage
Huggingface Version
Image Embeddings
from PIL import Image
from transformers import AutoModel
from transformers import CLIPImageProcessor
import torch
image_path = "CLIP.png"
model_name_or_path = "LLM2CLIP-Openai-L-14-336" # or /path/to/local/LLM2CLIP-Openai-L-14-336
processor = CLIPImageProcessor.from_pretrained("openai/clip-vit-large-patch14-336")
model = AutoModel.from_pretrained(
model_name_or_path,
torch_dtype=torch.float16,
trust_remote_code=True).to('cuda').eval()
image = Image.open(image_path)
input_pixels = processor(images=image, return_tensors="pt").pixel_values.to('cuda')
with torch.no_grad(), torch.cuda.amp.autocast():
outputs = model.get_image_features(input_pixels)
Retrieval
from PIL import Image
from transformers import AutoModel, AutoConfig, AutoTokenizer
from transformers import CLIPImageProcessor
import torch
from llm2vec import LLM2Vec
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
processor = CLIPImageProcessor.from_pretrained("openai/clip-vit-large-patch14-336")
model_name_or_path = "microsoft/LLM2CLIP-Openai-L-14-336" # or /path/to/local/LLM2CLIP-Openai-L-14-336
model = AutoModel.from_pretrained(
model_name_or_path,
torch_dtype=torch.bfloat16,
trust_remote_code=True).to('cuda').eval()
llm_model_name = 'microsoft/LLM2CLIP-Llama-3-8B-Instruct-CC-Finetuned'
config = AutoConfig.from_pretrained(
llm_model_name, trust_remote_code=True
)
llm_model = AutoModel.from_pretrained(llm_model_name, torch_dtype=torch.bfloat16, config=config, trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(llm_model_name)
llm_model.config._name_or_path = 'meta-llama/Meta-Llama-3-8B-Instruct' # Workaround for LLM2VEC
l2v = LLM2Vec(llm_model, tokenizer, pooling_mode="mean", max_length=512, doc_max_length=512)
captions = ["a diagram", "a dog", "a cat"]
image_path = "CLIP.png"
image = Image.open(image_path)
input_pixels = processor(images=image, return_tensors="pt").pixel_values.to('cuda')
text_features = l2v.encode(captions, convert_to_tensor=True).to('cuda')
with torch.no_grad(), torch.cuda.amp.autocast():
image_features = model.get_image_features(input_pixels)
text_features = model.get_text_features(text_features)
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
print("Label probs:", text_probs)
BibTeX & Citation
@misc{huang2024llm2clippowerfullanguagemodel,
title={LLM2CLIP: Powerful Language Model Unlock Richer Visual Representation},
author={Weiquan Huang and Aoqi Wu and Yifan Yang and Xufang Luo and Yuqing Yang and Liang Hu and Qi Dai and Xiyang Dai and Dongdong Chen and Chong Luo and Lili Qiu},
year={2024},
eprint={2411.04997},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2411.04997},
}