Предварительно обученные модели для распознавания речи
В этом разделе мы рассмотрим, как с помощью pipeline() использовать предварительно обученные модели для распознавания речи.
В Разделе 2 мы представили pipeline() как простой способ выполнения задач распознавания речи с предварительной
и последующей обработкой “под капотом” и возможностью быстро экспериментировать с любой предварительно обученной контрольной точкой модели на Hugging Face Hub.
В этом разделе мы углубимся в изучение различных характеристик моделей распознавания речи и рассмотрим, как их можно использовать для решения различных задач.
Как подробно описано в Разделе 3, модели распознавания речи в целом относятся к одной из двух категорий:
- Connectionist Temporal Classification (CTC) или Коннекционистская Временная Классификация: модели состящие только из энкодера, с головой линейного классификатора в вершине модели.
- Sequence-to-sequence (Seq2Seq) или последовательность-в-последовательность: модели включающие в себя как энкодер, так и декодер с механизмом перекрестного внимания между ними (cross-attention).
До 2022 года более популярной из двух архитектур была CTC, а такие модели, работающие только с энкодером, как Wav2Vec2, HuBERT и XLSR, совершили прорыв в парадигме предварительного обучения/дообучения в задачах с речью. Крупные корпорации, такие как Meta и Microsoft, предварительно обучали энкодер на огромных объемах неразмеченных аудиоданных в течение многих дней или недель. Затем пользователи могли взять предварительно обученную контрольную точку и дообучить ее с помощью головы CTC всего на 10 минутах размеченных речевых данных для достижения высоких результатов в последующей задаче распознавания речи.
Однако модели CTC имеют свои недостатки. Присоединение простого линейного слоя к кодирующему устройству дает небольшую и быструю модель в целом, но она может быть подвержена фонетическим ошибкам в написании. Ниже мы продемонстрируем это на примере модели Wav2Vec2.
Анализ моделей CTC
Загрузим небольшой фрагмент набора данных LibriSpeech ASR чтобы продемонстрировать возможности Wav2Vec2 по транскрибации речи:
from datasets import load_dataset
dataset = load_dataset(
"hf-internal-testing/librispeech_asr_dummy", "clean", split="validation"
)
datasetOutput:
Dataset({
features: ['file', 'audio', 'text', 'speaker_id', 'chapter_id', 'id'],
num_rows: 73
})Мы можем выбрать один из 73 аудиообразцов и просмотреть его, а также транскрипцию:
from IPython.display import Audio
sample = dataset[2]
print(sample["text"])
Audio(sample["audio"]["array"], rate=sample["audio"]["sampling_rate"])Output:
HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAS AND ROAST BEEF LOOMING BEFORE US SIMILES DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MINDХорошо! Рождество и запеченная в духовке говядина, звучит здорово! 🎄 Сформировав выборку данных, мы теперь загружаем
дообученную контрольную точку в pipeline(). Для этого мы будем использовать официальную контрольную точку Wav2Vec2 base
дообученную на 100 часах данных LibriSpeech:
from transformers import pipeline
pipe = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-base-100h")Далее мы возьмем пример из набора данных и передадим его исходные данные в конвейер. Поскольку pipeline поглощает любой словарь, который мы ему
передаем (то есть его нельзя использовать повторно), мы будем передавать копию данных. Таким образом, мы можем безопасно повторно использовать один
и тот же аудиообразец в следующих примерах:
pipe(sample["audio"].copy())Output:
{"text": "HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAUS AND ROSE BEEF LOOMING BEFORE US SIMALYIS DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND"}Видно, что модель Wav2Vec2 неплохо справляется с транскрибацией данного образца - на первый взгляд, все выглядит в целом корректно. Давайте поставим целевое значение (target) и прогноз/предсказание модели (prediction) рядом и выделим различия:
Target: HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAS AND ROAST BEEF LOOMING BEFORE US SIMILES DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND
Prediction: HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH **CHRISTMAUS** AND **ROSE** BEEF LOOMING BEFORE US **SIMALYIS** DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MINDСравнивая целевой текст с предсказанной транскрибацией, мы видим, что все слова звучат правильно, но некоторые написаны не совсем точно. Например:
- CHRISTMAUS vs. CHRISTMAS
- ROSE vs. ROAST
- SIMALYIS vs. SIMILES
Это подчеркивает недостаток модели CTC. Модель CTC - это, по сути, “только акустическая” модель: она состоит из энкодера, который формирует представления скрытых состояний из аудиовходов, и линейного слоя, который отображает скрытые состояния в символы:
Это означает, что система практически полностью основывает свое предсказание на акустических данных (фонетических звуках аудиозаписи) и поэтому склонна транскрибировать аудиозапись фонетическим способом (например, CHRISTMAUS). В нем меньше внимания уделяется языковому моделирующему контексту предыдущих и последующих букв, поэтому он склонен к фонетическим ошибкам в написании. Более интеллектуальная модель определила бы, что CHRISTMAUS не является правильным словом в английском словаре, и исправила бы его на CHRISTMAS, когда делала бы свои предсказания. Кроме того, в нашем прогнозировании отсутствуют два важных признака - регистр и пунктуация, что ограничивает полезность транскрибации модели для реальных приложений.
Переход к Seq2Seq
Модели Seq2Seq! Как было описано в Разделе 3, модели Seq2Seq состоят из энкодера и декодера, связанных между собой механизмом перекрестного внимания. Энкодер играет ту же роль, что и раньше, вычисляя представления скрытых состояний аудиовходов, а декодер - роль языковой модели. Декодер обрабатывает всю последовательность представлений скрытых состояний, полученных от энкодера, и формирует соответствующие текстовые транскрипции. Имея глобальный контекст входного аудиосигнала, декодер может использовать контекст языкового моделирования при составлении своих прогнозов, исправляя орфографические ошибки “на лету” и тем самым обходя проблему фонетических прогнозов.
У моделей Seq2Seq есть два недостатка:
- Они изначально медленнее декодируют, поскольку процесс декодирования происходит по одному шагу за раз, а не все сразу
- Они более требовательны к данным, для достижения сходимости им требуется значительно больше обучающих данных
В частности, узким местом в развитии архитектур Seq2Seq для задач с речью является потребность в больших объемах обучающих данных. Размеченные речевые данные труднодоступны, самые большие аннотированные базы данных на тот момент составляли всего 10 000 часов. Все изменилось в 2022 году после выхода Whisper. Whisper - это предварительно обученная модель для распознавания речи, опубликованная в Сентябре 2022 авторами Alec Radford и др. из компании OpenAI. В отличие от предшественников CTC, которые обучались исключительно на неразмеченных аудиоданных, Whisper предварительно обучен на огромном количестве размеченных данных аудиотранскрипции, а именно на 680 000 часов.
Это на порядок больше данных, чем неразмеченные аудиоданные, использованные для обучения Wav2Vec 2.0 (60 000 часов). Более того, 117 000 часов этих данных, предназначенных для предварительного обучения, являются мультиязычными (или “не английскими”) данными. В результате контрольные точки могут быть применены к более чем 96 языкам, многие из которых считаются низкоресурсными, т.е. не имеющими большого корпуса данных, пригодных для обучения.
При масштабировании на 680 000 часов аннотированных данных для предварительного обучения модели Whisper демонстрируют высокую способность к обобщению на многие наборы данных и области. Предварительно обученные контрольные точки достигают результатов, конкурентоспособных с state-of-the-art pipe systems, с коэффициентом ошибок в словах (WER) около 3% на подмножестве чистых тестов LibriSpeech и новым рекордом на TED-LIUM с WER 4,7% (см. табл. 8 Whisper paper).
Особое значение имеет способность Whisper работать с длинными аудиообразцами, устойчивость к входным шумам и возможность предсказывать транскрипцию с использованием падежей и пунктуации. Это делает его перспективным для использования в реальных системах распознавания речи.
В оставшейся части этого раздела будет показано, как использовать предварительно обученные модели Whisper для распознавания речи с помощью 🤗 Transformers. Во многих ситуациях предварительно обученные контрольные точки Whisper обладают высокой производительностью и дают отличные результаты, поэтому мы рекомендуем вам попробовать использовать предварительно обученные контрольные точки в качестве первого шага к решению любой задачи распознавания речи. Благодаря дообучению предварительно обученные контрольные точки могут быть адаптированы для конкретных наборов данных и языков с целью дальнейшего улучшения результатов. Как это сделать, мы продемонстрируем в следующем подразделе, посвященном [дообучению] (fine-tuning).
Контрольные точки модели Whisper доступны в пяти конфигурациях с различными размерами модели. Наименьшие по параметрам четыре модели обучаются либо только на английском, либо на многоязычных данных. Самая большая по параметрам контрольная точка была обучена только на мультиязычных данных. Все девять предварительно обученных контрольных точек доступны на Hugging Face Hub. Контрольные точки приведены в следующей таблице со ссылками на модели на Hugging Face Hub. “VRAM” обозначает объем памяти GPU, необходимый для работы модели с минимальным размером пакета = 1. “Rel Speed” - относительная скорость контрольной точки по сравнению с самой большой моделью. На основе этой информации можно выбрать контрольную точку, наиболее подходящую для вашего оборудования.
| Size | Parameters | VRAM / GB | Rel Speed | English-only | Multilingual |
|---|---|---|---|---|---|
| tiny | 39 M | 1.4 | 32 | ✓ | ✓ |
| base | 74 M | 1.5 | 16 | ✓ | ✓ |
| small | 244 M | 2.3 | 6 | ✓ | ✓ |
| medium | 769 M | 4.2 | 2 | ✓ | ✓ |
| large | 1550 M | 7.5 | 1 | x | ✓ |
Загрузим контрольную точку Whisper Base, которая по размеру сопоставима с контрольной точкой Wav2Vec2, которую
мы использовали ранее. Предваряя наш переход к многоязычному распознаванию речи, загрузим многоязычный вариант базовой контрольной точки. Мы также загрузим
модель на GPU, если он доступен, или на CPU в противном случае. В последствии pipeline() позаботится о перемещении всех входов/выходов с CPU на GPU по мере
необходимости:
import torch
from transformers import pipeline
device = "cuda:0" if torch.cuda.is_available() else "cpu"
pipe = pipeline(
"automatic-speech-recognition", model="openai/whisper-base", device=device
)Отлично! Теперь давайте транскрибируем аудиозапись, как и раньше. Единственное изменение - это передача дополнительного аргумента max_new_tokens, который
указывает модели максимальное количество токенов, которые нужно генерировать при предсказании:
pipe(sample["audio"], max_new_tokens=256)Output:
{'text': ' He tells us that at this festive season of the year, with Christmas and roast beef looming before us, similarly is drawn from eating and its results occur most readily to the mind.'}Достаточно легко! Первое, на что вы обратите внимание, - это наличие как регистра, так и знаков препинания. Это сразу же делает транскрипцию более удобной для чтения по сравнению с транскрипцией из Wav2Vec2, не содержащей ни регистра, ни пунктуации. Давайте поместим транскрипцию рядом с целевой меткой:
Target: HE TELLS US THAT AT THIS FESTIVE SEASON OF THE YEAR WITH CHRISTMAS AND ROAST BEEF LOOMING BEFORE US SIMILES DRAWN FROM EATING AND ITS RESULTS OCCUR MOST READILY TO THE MIND
Prediction: He tells us that at this festive season of the year, with **Christmas** and **roast** beef looming before us, **similarly** is drawn from eating and its results occur most readily to the mind.Whisper проделал большую работу по исправлению фонетических ошибок, которые мы видели в Wav2Vec2 - и Christmas, и roast написаны правильно. Мы видим, что модель все еще испытывает трудности с SIMILES, которое неправильно транскрибируется как similarly, но на этот раз предсказание является правильным словом из английского словаря. Использование контрольной точки Whisper большего размера позволяет еще больше снизить количество ошибок в транскрибированном тексте, но при этом требует больше вычислений и увеличивает время транскрибации.
Нам обещали модель, способную работать с 96 языками, так что оставим пока распознавание английской речи и пойдем по миру 🌎! Набор данных Multilingual LibriSpeech (MLS) представляет собой многоязычный аналог набора данных LibriSpeech, содержащий размеченные аудиоданные на шести языках. Мы загрузим одну образец из испанской части набора данных MLS, используя режим streaming, чтобы не загружать весь набор данных:
dataset = load_dataset(
"facebook/multilingual_librispeech", "spanish", split="validation", streaming=True
)
sample = next(iter(dataset))Снова посмотрим текстовую транскрипцию и прослушаем аудиофрагмент:
print(sample["text"])
Audio(sample["audio"]["array"], rate=sample["audio"]["sampling_rate"])Output:
entonces te delelitarás en jehová y yo te haré subir sobre las alturas de la tierra y te daré á comer la heredad de jacob tu padre porque la boca de jehová lo ha habladoЭто целевой текст, на который мы ориентируемся в нашей транскрипции Whisper. Хотя теперь мы знаем, что, вероятно, можем сделать это лучше, поскольку наша модель будет предсказывать также пунктуацию и регистр, которые в выводе примера отсутствуют. Передадим образец звука в конвейер для получения предсказания текста. Следует отметить, что конвейер потребует словарь аудиовходов, который мы вводим, то есть словарь не может быть использован повторно. Чтобы обойти эту проблему, мы будем передавать копию аудиообразца, что позволит нам повторно использовать тот же самый аудиообразец в последующих примерах кода:
pipe(sample["audio"].copy(), max_new_tokens=256, generate_kwargs={"task": "transcribe"})Output:
{'text': ' Entonces te deleitarás en Jehová y yo te haré subir sobre las alturas de la tierra y te daré a comer la heredad de Jacob tu padre porque la boca de Jehová lo ha hablado.'}Отлично - это очень похоже на наш целевой текст (возможно, даже лучше, поскольку в нем есть пунктуация и регистр!). Обратите внимание, что мы передали
"task" в качестве аргумента генерируемого ключевого слова (generate kwarg). Передача ключу "task" значения "transcribe" заставляет Whisper
выполнять задачу распознавания речи, при которой аудиозапись транскрибируется на том же языке, на котором была произнесена речь. Whisper также
способен выполнять тесно связанную с задачу - перевода речи, когда аудиозапись на испанском языке может быть переведена в текст на английском.
Для этого мы передаем ключу "task" значение "translate":
pipe(sample["audio"], max_new_tokens=256, generate_kwargs={"task": "translate"})Output:
{'text': ' So you will choose in Jehovah and I will raise you on the heights of the earth and I will give you the honor of Jacob to your father because the voice of Jehovah has spoken to you.'}Теперь, когда мы знаем, что можем переключаться между распознаванием речи и ее переводом, мы можем выбирать задачу в зависимости от наших потребностей. Либо мы распознаем звук на языке X в текст на том же языке X (например, испанский звук в испанский текст), либо переводим с любого языка X в текст на английском языке (например, испанский звук в английский текст).
Подробнее о том, как аргумент "task" используется для управления свойствами генерируемого текста, см. в карточке модели
для базовой модели Whisper.
Длинноформатная транскрипция и временные метки
Пока мы были сосредоточены на транскрибации коротких аудиофрагментов длительностью менее 30 секунд. Мы уже упоминали, что одной из привлекательных сторон Whisper является возможность работы с длинными аудиофрагментами. В этой части раздела мы рассмотрим эту задачу!
Создадим длинный аудиофайл путем конкатенации последовательных выборок из набора данных MLS. Поскольку набор данных MLS формируется путем разбиения длинных записей аудиокниг на более короткие сегменты, конкатенация образцов является одним из способов реконструкции более длинных отрывков аудиокниг. Следовательно, результирующий звук должен быть когерентным по всей выборке.
Мы установим целевую длительность звука в 5 минут и прекратим конкатенацию сэмплов, как только достигнем этого значения:
import numpy as np
target_length_in_m = 5
# преобразование из минут в секунды (* 60) в число выборок (* частота дискретизации)
sampling_rate = pipe.feature_extractor.sampling_rate
target_length_in_samples = target_length_in_m * 60 * sampling_rate
# итерируемся по нашему потоковому набору данных, конкатенируя выборки до тех пор, пока мы не достигнем нашей цели
long_audio = []
for sample in dataset:
long_audio.extend(sample["audio"]["array"])
if len(long_audio) > target_length_in_samples:
break
long_audio = np.asarray(long_audio)
# что у нас получилось?
seconds = len(long_audio) / 16000
minutes, seconds = divmod(seconds, 60)
print(f"Length of audio sample is {minutes} minutes {seconds:.2f} seconds")Output:
Length of audio sample is 5.0 minutes 17.22 secondsОтлично! Осталось транскрибировать 5 минут 17 секунд аудиозаписи. При передаче такого длинного аудиофрагмента непосредственно в модель возникают две проблемы:
- Whisper изначально рассчитан на работу с 30-секундными образцами: все, что короче 30 секунд, заполняется тишиной, все, что длиннее 30 секунд, усекается до 30 секунд путем вырезания лишнего звука, поэтому если мы передадим наш звук напрямую, то получим транскрипцию только первых 30 секунд
- Память в сети трансформера зависит от квадрата длины последовательности: удвоение длины входного сигнала увеличивает потребность в памяти в четыре раза, поэтому передача очень длинных аудиофайлов обязательно приведет к ошибке “вне памяти” (out-of-memory)
Длинная транскрибация в 🤗 Transformers осуществляется путем фрагментации (от англ. chunking) входного аудио на более мелкие и управляемые фрагменты. Каждый фрагмент имеет небольшое наложение с предыдущим. Это позволяет нам точно соединять фрагменты на границах, так как мы можем найти наложение между фрагментами и соответствующим образом объединить транскрипции:
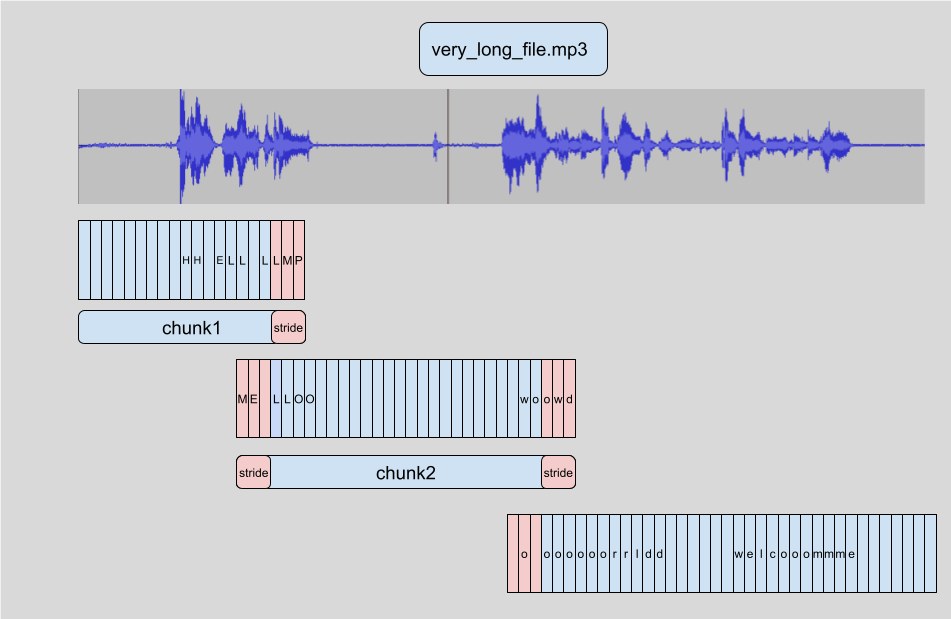
Преимущество фрагментирования аудиообразцов на части заключается в том, что нам не нужен результат транскрибации небольшого фрагмента аудиосигнала для транскрибации последующего фрагмента. Соединение выполняется после того, как мы транскрибировали все фрагменты на границах фрагментов, поэтому не имеет значения, в каком порядке мы их транскрибируем. Алгоритм полностью нестационарный, поэтому мы можем даже обрабатывать фрагмент одновременно с фрагментом! Это позволяет нам пакетировать (от англ. batch) фрагменты и прогонять их через модель параллельно, обеспечивая значительное ускорение вычислений по сравнению с их последовательной транскрибацией. Более подробно о фрагментированни в 🤗 Transformers можно прочитать в посте из блога.
Для активации длинных транскрипций необходимо добавить один дополнительный аргумент при вызове конвейера. Этот аргумент, chunk_length_s,
определяет длину фрагментов в секундах. Для Whisper оптимальной является 30-секундная длина фрагментов, поскольку она соответствует длине
входного сигнала, ожидаемого Whisper.
Чтобы активизировать пакетную обработку, необходимо передать конвейеру аргумент batch_size. Если собрать все это воедино,
то транскрибация длинного аудиообразца с использованием чанкинга и батчинга может быть выполнена следующим образом:
pipe(
long_audio,
max_new_tokens=256,
generate_kwargs={"task": "transcribe"},
chunk_length_s=30,
batch_size=8,
)Output:
{'text': ' Entonces te deleitarás en Jehová, y yo te haré subir sobre las alturas de la tierra, y te daré a comer la
heredad de Jacob tu padre, porque la boca de Jehová lo ha hablado. nosotros curados. Todos nosotros nos descarriamos
como bejas, cada cual se apartó por su camino, mas Jehová cargó en él el pecado de todos nosotros...Мы не будем приводить здесь весь результат, поскольку он довольно длинный (всего 312 слов)! На графическом процессоре V100 с памятью 16 Гбайт выполнение приведенной выше строки займет примерно 3,45 секунды, что весьма неплохо для 317-секундного аудиообразца. На CPU ожидается около 30 секунд.
Whisper также способен предсказывать временные метки на уровне фрагментов для аудиоданных. Эти временные метки указывают на время начала и окончания короткого отрывка аудиозаписи и особенно полезны для выравнивания транскрипции с входным аудиосигналом. Предположим, мы хотим создать субтитры для видео - нам нужны эти временные метки, чтобы знать, какая часть транскрипции соответствует определенному сегменту видео, чтобы отобразить правильную транскрипцию для этого времени.
Активировать предсказание временных меток очень просто, достаточно установить аргумент return_timestamps=True. Временные метки совместимы
с методами фрагментирования и пакетирования, которые мы использовали ранее, поэтому мы можем просто добавить аргумент timestamp к нашему
предыдущему вызову:
pipe(
long_audio,
max_new_tokens=256,
generate_kwargs={"task": "transcribe"},
chunk_length_s=30,
batch_size=8,
return_timestamps=True,
)["chunks"]Output:
[{'timestamp': (0.0, 26.4),
'text': ' Entonces te deleitarás en Jehová, y yo te haré subir sobre las alturas de la tierra, y te daré a comer la heredad de Jacob tu padre, porque la boca de Jehová lo ha hablado. nosotros curados. Todos nosotros nos descarriamos como bejas, cada cual se apartó por su camino,'},
{'timestamp': (26.4, 32.48),
'text': ' mas Jehová cargó en él el pecado de todos nosotros. No es que partas tu pan con el'},
{'timestamp': (32.48, 38.4),
'text': ' hambriento y a los hombres herrantes metas en casa, que cuando vieres al desnudo lo cubras y no'},
...И вуаля! У нас есть предсказанный текст и соответствующие временные метки.
Итоги
Whisper - это сильная предварительно обученная модель для распознавания и перевода речи. По сравнению с Wav2Vec2, он обладает более
высокой точностью транскрибации, при этом выходные данные содержат знаки препинания и регистр. Он может использоваться для транскрибации
речи на английском и 96 других языках, как на коротких аудиофрагментах, так и на более длинных за счет фрагментирования. Эти качества делают
его подходящей моделью для многих задач распознавания речи и перевода без необходимости дообучения. Метод pipeline() обеспечивает простой
способ выполнения выводов в виде однострочных вызовов API с контролем над генерируемыми предсказаниями.
В то время как модель Whisper демонстрирует отличные результаты на многих языках с большим количеством ресурсов, она имеет более низкую точность транскрибации и перевода на языках с малым количеством ресурсов, т.е. на языках с меньшим количеством доступных обучающих данных. Кроме того, существуют различия в результатах работы с разными акцентами и диалектами некоторых языков, включая более низкую точность для носителей разных полов, рас, возрастов и других демографических критериев (например, Whisper paper).
Для повышения производительности при работе с языками, акцентами или диалектами, не имеющими достаточного количества ресурсов, мы можем взять предварительно обученную модель Whisper и обучить ее на небольшом корпусе данных, подобранных соответствующим образом, в процессе, называемом дообучением. Мы покажем, что всего десять часов дополнительных данных позволяют повысить производительность модели Whisper более чем на 100% на языке с низким уровнем ресурсов. В следующей секции мы рассмотрим процесс выбора набора данных для дообучения модели.
< > Update on GitHub