
Jais Family
Collection
The Jais Family of Models
•
22 items
•
Updated
•
10
The Jais family of models is a comprehensive series of bilingual English-Arabic large language models (LLMs). These models are optimized to excel in Arabic while having strong English capabilities. We release two variants of foundation models that include:
jais-family-*).jais-adapted-*).In this release, we introduce 20 models across 8 sizes, ranging from 590M to 70B parameters, trained on up to 1.6T tokens of Arabic, English, and code data. All pre-trained models in this series are instruction fine-tuned (*-chat) for dialog using a curated mix of Arabic and English instruction data.
We hope this extensive release will accelerate research in Arabic NLP, and enable numerous downstream applications for the Arabic speaking and bilingual community. The training and adaptation techniques we demonstrate successfully for Arabic models are extensible to other low and medium resource languages.
| Pre-trained Model | Fine-tuned Model | Size (Parameters) | Context length (Tokens) |
|---|---|---|---|
| jais-family-30b-16k | Jais-family-30b-16k-chat | 30B | 16,384 |
| jais-family-30b-8k | Jais-family-30b-8k-chat | 30B | 8,192 |
| jais-family-13b | Jais-family-13b-chat | 13B | 2,048 |
| jais-family-6p7b | Jais-family-6p7b-chat | 6.7B | 2,048 |
| jais-family-2p7b | Jais-family-2p7b-chat | 2.7B | 2,048 |
| jais-family-1p3b | Jais-family-1p3b-chat | 1.3B | 2,048 |
| jais-family-590m | Jais-family-590m-chat | 590M | 2,048 |
| Adapted pre-trained Model | Fine-tuned Model | Size (Parameters) | Context length (Tokens) |
|---|---|---|---|
| jais-adapted-70b | Jais-adapted-70b-chat | 70B | 4,096 |
| jais-adapted-13b | Jais-adapted-13b-chat | 13B | 4,096 |
| jais-adapted-7b | Jais-adapted-7b-chat | 7B | 4,096 |
All models in this family are auto-regressive language models that use a transformer-based, decoder-only architecture (GPT-3).
Jais models (jais-family-*) are trained from scratch, incorporating the SwiGLU non-linear activation function and ALiBi position encoding. These architectural enhancements allow the models to extrapolate at long sequence lengths, leading to improved context handling and precision.
Jais adapted models (jais-adapted-*) are built on top of Llama-2, which employs RoPE position embedding and Grouped Query Attention. We introduce tokenizer expansion with Arabic data, which improves fertility and compute efficiency by over 3x. In particular, we add 32,000 new Arabic tokens from the Jais-30b vocabulary into the Llama-2 tokenizer.
To initialize these new Arabic token embeddings we first learn a linear projection from the embedding space of Jais-30b to Llama's embedding space, using the set of shared English tokens present in both vocabularies. Next, this learned projection is applied to transform the existing Jais-30b Arabic embeddings into the Llama-2 embedding space.
Below is sample code to use the model. Note that the model requires a custom model class, so users must enable trust_remote_code=True while loading the model.
# -*- coding: utf-8 -*-
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_path = "inceptionai/jais-adapted-70b"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto", trust_remote_code=True)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
def get_response(text, tokenizer=tokenizer, model=model):
tokenized = tokenizer(text, return_tensors="pt")
input_ids, attention_mask = tokenized['input_ids'].to(device), tokenized['attention_mask'].to(device)
input_len = input_ids.shape[-1]
generate_ids = model.generate(
input_ids,
attention_mask=attention_mask,
top_p=0.9,
temperature=0.3,
max_length=2048,
min_length=input_len + 4,
repetition_penalty=1.2,
do_sample=True,
pad_token_id=tokenizer.pad_token_id
)
response = tokenizer.batch_decode(
generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
)[0]
return response
text = "عاصمة دولة الإمارات العربية المتحدة ه"
print(get_response(text))
text = "The capital of UAE is"
print(get_response(text))
The Jais family of models are trained on up to 1.6 Trillion tokens of diverse English, Arabic and Code data. The data consists of the following sources:
Web: We used publicly available web pages, wikipedia articles, news articles, and social network content in both Arabic and English.
Code: To enhance the reasoning capability of our model, we include Code data in various programming languages.
Books: We used a selection of publicly available Arabic and English books data, which improves long-range context modelling and coherent storytelling.
Scientific: A subset of ArXiv papers were included to improve reasoning and long context abilities.
Synthetic: We augment the volume of Arabic data by translating English to Arabic using an in-house machine translation system. We restrict this to high quality English resources such as English Wikipedia and English books.
We extensively preprocess and deduplicate the training data. For Arabic, we used a custom preprocessing pipeline to filter for data with high linguistic quality. More information on this pipeline can be found in the Jais paper.
jais-family-*): Following our previous experimentation with language alignment mixing in Jais, we used a ratio of 1:2:0.4 of Arabic:English:Code data. This recipe for from scratch pre-training addresses Arabic data scarcity while improving performance in both languages.jais-adapted-*): For the adapted pre-training of Llama-2, we utilized a larger Arabic dataset of ~334B Arabic tokens mixed with English and Code data. We vary the mixing ratio, at different model sizes, to introduce strong Arabic capabilities while maintaining performance in English.| Pre-trained model | English data (tokens) | Arabic data (tokens) | Code data (tokens) | Total data (tokens) |
|---|---|---|---|---|
| jais-family-30b-16k | 980B | 490B | 196B | 1666B |
| jais-family-30b-8k | 882B | 441B | 177B | 1500B |
| jais-family-13b | 283B | 141B | 56B | 480B |
| jais-family-6p7b | 283B | 141B | 56B | 480B |
| jais-family-2p7b | 283B | 141B | 56B | 480B |
| jais-family-1p3b | 283B | 141B | 56B | 480B |
| jais-family-590m | 283B | 141B | 56B | 480B |
| jais-adapted-70b | 33B | 334B | 4B | 371B |
| jais-adapted-13b | 127B | 140B | 13B | 280B |
| jais-adapted-7b | 18B | 19B | 2B | 39B |
All chat models in the Jais family are fine-tuned using Arabic and English prompt-response pairs in both single-turn and multi-turn settings. Data sources include open-source fine-tuning datasets filtered for topic and style diversity. Additionally, internally curated human data is incorporated to enhance cultural adaptation. This data is supplemented with content generated using synthetic methods including machine translation, distillation, and model self-chat. Overall, our updated instruction-tuning dataset comprises ~10M and ~4M prompt-response pairs in English and Arabic respectively.
During the pre-training of (jais-family-*) models, documents are packed into sequences separated by EOS tokens, and the model is trained autoregressively, applying the loss to all tokens. For jais-30b models, the context length is progressively expanded from 2k to 8K to 16K by incorporating curated long-context documents in training. This progressive expansion leverages faster initial training at shorter context lengths, while gradually extending support for larger context lengths towards the end of the training process.
During the adapted pre-training of the (jais-adapted-*) models, we first initialize the new tokenizer and Arabic embeddings as described in Model Architecture. In training, we implemented a two-stage approach to overcome observed higher norms of the new Arabic embeddings. In the first stage, the backbone of the model is frozen, and the embeddings are trained using approximately 15 billion tokens from a bilingual corpus of English and Arabic. In the second stage, the backbone is unfrozen, and continuous pretraining is conducted with all parameters.
During instruction tuning, each training example consists of a single-turn or multi-turn prompt and it's response. Instead of one example per sequence, examples are packed together while the loss is masked on the prompt tokens. This approach speeds up training by allowing more examples to be processed per batch.
| Hyperparameter | Value |
|---|---|
| Precision | fp32 |
| Optimizer | AdamW |
| Learning rate | 0 to 0.00015(<=95 warmup steps) 0.00015 to 0.000015(>95 and <=94316 steps, Cosine Decay) |
| Weight decay | 0.1 |
| Batch size | 960 |
| Context Length | 4096 |
| Steps | 94316 |
The training process was performed on the Condor Galaxy (CG) supercomputer platform. A CG contains 64 Cerebras CS-2 Wafer-Scale Engines (WSE-2) with 40 GB of SRAM, and achieves a total of 960 PetaFLOP/s.
We conducted a comprehensive evaluation of Jais models focusing on both English and Arabic, using LM-harness in a zero-shot setting. The evaluation criteria spanned various dimensions, including:
| Models | Avg | ArabicMMLU* | MMLU | EXAMS* | LitQA* | agqa | agrc | Hellaswag | PIQA | BoolQA | Situated QA | ARC-C | OpenBookQA | TruthfulQA | CrowS-Pairs |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| jais-family-30b-16k | 49.2 | 44.0 | 33.4 | 40.9 | 60 | 47.8 | 49.3 | 60.9 | 68.6 | 70.3 | 41.6 | 38.7 | 31.8 | 45.2 | 57 |
| jais-family-30b-8k | 49.7 | 46.0 | 34 | 42 | 60.6 | 47.6 | 50.4 | 60.4 | 69 | 67.7 | 42.2 | 39.2 | 33.8 | 45.1 | 57.3 |
| jais-family-13b | 46.1 | 34.0 | 30.3 | 42.7 | 58.3 | 40.5 | 45.5 | 57.3 | 68.1 | 63.1 | 41.6 | 35.3 | 31.4 | 41 | 56.1 |
| jais-family-6p7b | 44.6 | 32.2 | 29.9 | 39 | 50.3 | 39.2 | 44.1 | 54.3 | 66.8 | 66.5 | 40.9 | 33.5 | 30.4 | 41.2 | 55.4 |
| jais-family-2p7b | 41.0 | 29.5 | 28.5 | 36.1 | 45.7 | 32.4 | 40.8 | 44.2 | 62.5 | 62.2 | 39.2 | 27.4 | 28.2 | 43.6 | 53.6 |
| jais-family-1p3b | 40.8 | 28.9 | 28.5 | 34.2 | 45.7 | 32.4 | 40.8 | 44.2 | 62.5 | 62.2 | 39.2 | 27.4 | 28.2 | 43.6 | 53.6 |
| jais-family-590m | 39.7 | 31.2 | 27 | 33.1 | 41.7 | 33.8 | 38.8 | 38.2 | 60.7 | 62.2 | 37.9 | 25.5 | 27.4 | 44.7 | 53.3 |
| jais-family-30b-16k-chat | 51.6 | 59.9 | 34.6 | 40.2 | 58.9 | 46.8 | 54.7 | 56.2 | 64.4 | 76.7 | 55.9 | 40.8 | 30.8 | 49.5 | 52.9 |
| jais-family-30b-8k-chat | 51.4 | 61.2 | 34.2 | 40.2 | 54.3 | 47.3 | 53.6 | 60 | 63.4 | 76.8 | 54.7 | 39.5 | 30 | 50.7 | 54.3 |
| jais-family-13b-chat | 50.3 | 58.2 | 33.9 | 42.9 | 53.1 | 46.8 | 51.7 | 59.3 | 65.4 | 75.2 | 51.2 | 38.4 | 29.8 | 44.8 | 53.8 |
| jais-family-6p7b-chat | 48.7 | 55.7 | 32.8 | 37.7 | 49.7 | 40.5 | 50.1 | 56.2 | 62.9 | 79.4 | 52 | 38 | 30.4 | 44.7 | 52 |
| jais-family-2p7b-chat | 45.6 | 50.0 | 31.5 | 35.9 | 41.1 | 37.3 | 42.1 | 48.6 | 63.7 | 74.4 | 50.9 | 35.3 | 31.2 | 44.5 | 51.3 |
| jais-family-1p3b-chat | 42.7 | 42.2 | 30.1 | 33.6 | 40.6 | 34.1 | 41.2 | 43 | 63.6 | 69.3 | 44.9 | 31.6 | 28 | 45.6 | 50.4 |
| jais-family-590m-chat | 37.8 | 39.1 | 28 | 29.5 | 33.1 | 30.8 | 36.4 | 30.3 | 57.8 | 57.2 | 40.5 | 25.9 | 26.8 | 44.5 | 49.3 |
| Adapted Models | Avg | ArabicMMLU* | MMLU | EXAMS* | LitQA* | agqa | agrc | Hellaswag | PIQA | BoolQA | Situated QA | ARC-C | OpenBookQA | TruthfulQA | CrowS-Pairs |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| jais-adapted-70b | 51.5 | 55.9 | 36.8 | 42.3 | 58.3 | 48.6 | 54 | 61.5 | 68.4 | 68.4 | 42.1 | 42.6 | 33 | 50.2 | 58.3 |
| jais-adapted-13b | 46.6 | 44.7 | 30.6 | 37.7 | 54.3 | 43.8 | 48.3 | 54.9 | 67.1 | 64.5 | 40.6 | 36.1 | 32 | 43.6 | 54.00 |
| jais-adapted-7b | 42.0 | 35.9 | 28.9 | 36.7 | 46.3 | 34.1 | 40.3 | 45 | 61.3 | 63.8 | 38.1 | 29.7 | 30.2 | 44.3 | 53.6 |
| jais-adapted-70b-chat | 52.9 | 66.8 | 34.6 | 42.5 | 62.9 | 36.8 | 48.6 | 64.5 | 69.7 | 82.8 | 49.3 | 44.2 | 32.2 | 53.3 | 52.4 |
| jais-adapted-13b-chat | 50.3 | 59.0 | 31.7 | 37.5 | 56.6 | 41.9 | 51.7 | 58.8 | 67.1 | 78.2 | 45.9 | 41 | 34.2 | 48.3 | 52.1 |
| jais-adapted-7b-chat | 46.1 | 51.3 | 30 | 37 | 48 | 36.8 | 48.6 | 51.1 | 62.9 | 72.4 | 41.3 | 34.6 | 30.4 | 48.6 | 51.8 |
Arabic benchmarks are translated using an in-house MT model and reviewed by Arabic linguists. Benchmarks labeled with an asterisk (*) are natively Arabic; for further details, see the Jais paper. Additionally, we include ArabicMMLU, a native Arabic benchmark based on regional knowledge.
| Models | Avg | MMLU | RACE | Hellaswag | PIQA | BoolQA | SIQA | ARC-Challenge | OpenBookQA | Winogrande | TruthfulQA | CrowS-Pairs |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| jais-family-30b-16k | 59.3 | 42.2 | 40.5 | 79.7 | 80.6 | 78.7 | 48.8 | 50.3 | 44.2 | 71.6 | 43.5 | 72.6 |
| jais-family-30b-8k | 58.8 | 42.3 | 40.3 | 79.1 | 80.5 | 80.9 | 49.3 | 48.4 | 43.2 | 70.6 | 40.3 | 72.3 |
| jais-family-13b | 54.6 | 32.3 | 39 | 72 | 77.4 | 73.9 | 47.9 | 43.2 | 40 | 67.1 | 36.1 | 71.7 |
| jais-family-6p7b | 53.1 | 32 | 38 | 69.3 | 76 | 71.7 | 47.1 | 40.3 | 37.4 | 65.1 | 34.4 | 72.5 |
| jais-family-2p7b | 51 | 29.4 | 38 | 62.7 | 74.1 | 67.4 | 45.6 | 35.1 | 35.6 | 62.9 | 40.1 | 70.2 |
| jais-family-1p3b | 48.7 | 28.2 | 35.4 | 55.4 | 72 | 62.7 | 44.9 | 30.7 | 36.2 | 60.9 | 40.4 | 69 |
| jais-family-590m | 45.2 | 27.8 | 32.9 | 46.1 | 68.1 | 60.4 | 43.2 | 25.6 | 30.8 | 55.8 | 40.9 | 65.3 |
| jais-family-30b-16k-chat | 58.8 | 42 | 41.1 | 76.2 | 73.3 | 84.6 | 60.3 | 48.4 | 40.8 | 68.2 | 44.8 | 67 |
| jais-family-30b-8k-chat | 60.3 | 40.6 | 47.1 | 78.9 | 72.7 | 90.6 | 60 | 50.1 | 43.2 | 70.6 | 44.9 | 64.2 |
| jais-family-13b-chat | 57.5 | 36.6 | 42.6 | 75 | 75.8 | 87.6 | 54.4 | 47.9 | 42 | 65 | 40.6 | 64.5 |
| jais-family-6p7b-chat | 56 | 36.6 | 41.3 | 72 | 74 | 86.9 | 55.4 | 44.6 | 40 | 62.4 | 41 | 62.2 |
| jais-family-2p7b-chat | 52.8 | 32.7 | 40.4 | 62.2 | 71 | 84.1 | 54 | 37.2 | 36.8 | 61.4 | 40.9 | 59.8 |
| jais-family-1p3b-chat | 49.3 | 31.9 | 37.4 | 54.5 | 70.2 | 77.8 | 49.8 | 34.4 | 35.6 | 52.7 | 37.2 | 60.8 |
| jais-family-590m-chat | 42.6 | 27.9 | 33.4 | 33.1 | 63.7 | 60.1 | 45.3 | 26.7 | 25.8 | 50.5 | 44.5 | 57.7 |
| Adapted Models | Avg | MMLU | RACE | Hellaswag | PIQA | BoolQA | SIQA | ARC-Challenge | OpenBookQA | Winogrande | TruthfulQA | CrowS-Pairs |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| jais-adapted-70b | 60.1 | 40.4 | 38.5 | 81.2 | 81.1 | 81.2 | 48.1 | 50.4 | 45 | 75.8 | 45.7 | 74 |
| jais-adapted-13b | 56 | 33.8 | 39.5 | 76.5 | 78.6 | 77.8 | 44.6 | 45.9 | 44.4 | 71.4 | 34.6 | 69 |
| jais-adapted-7b | 55.7 | 32.2 | 39.8 | 75.3 | 78.8 | 75.7 | 45.2 | 42.8 | 43 | 68 | 38.3 | 73.1 |
| jais-adapted-70b-chat | 61.4 | 38.7 | 42.9 | 82.7 | 81.2 | 89.6 | 52.9 | 54.9 | 44.4 | 75.7 | 44 | 68.8 |
| jais-adapted-13b-chat | 58.5 | 34.9 | 42.4 | 79.6 | 79.7 | 88.2 | 50.5 | 48.5 | 42.4 | 70.3 | 42.2 | 65.1 |
| jais-adapted-7b-chat | 58.5 | 33.8 | 43.9 | 77.8 | 79.4 | 87.1 | 47.3 | 46.9 | 43.4 | 69.9 | 42 | 72.4 |
In addition to the LM-Harness evaluation, we conducted an open-ended generation evaluation using GPT-4-as-a-judge. We measured pairwise win-rates of model responses in both Arabic and English on a fixed set of 80 prompts from the Vicuna test set. English prompts were translated to Arabic by our in-house linguists. In the following, we compare the models in this release of the jais family against previously released versions:

GPT-4-as-a-judge evaluation of Jais in Arabic and English. Jais family models are significantly better than previous Jais at generations in both languages.
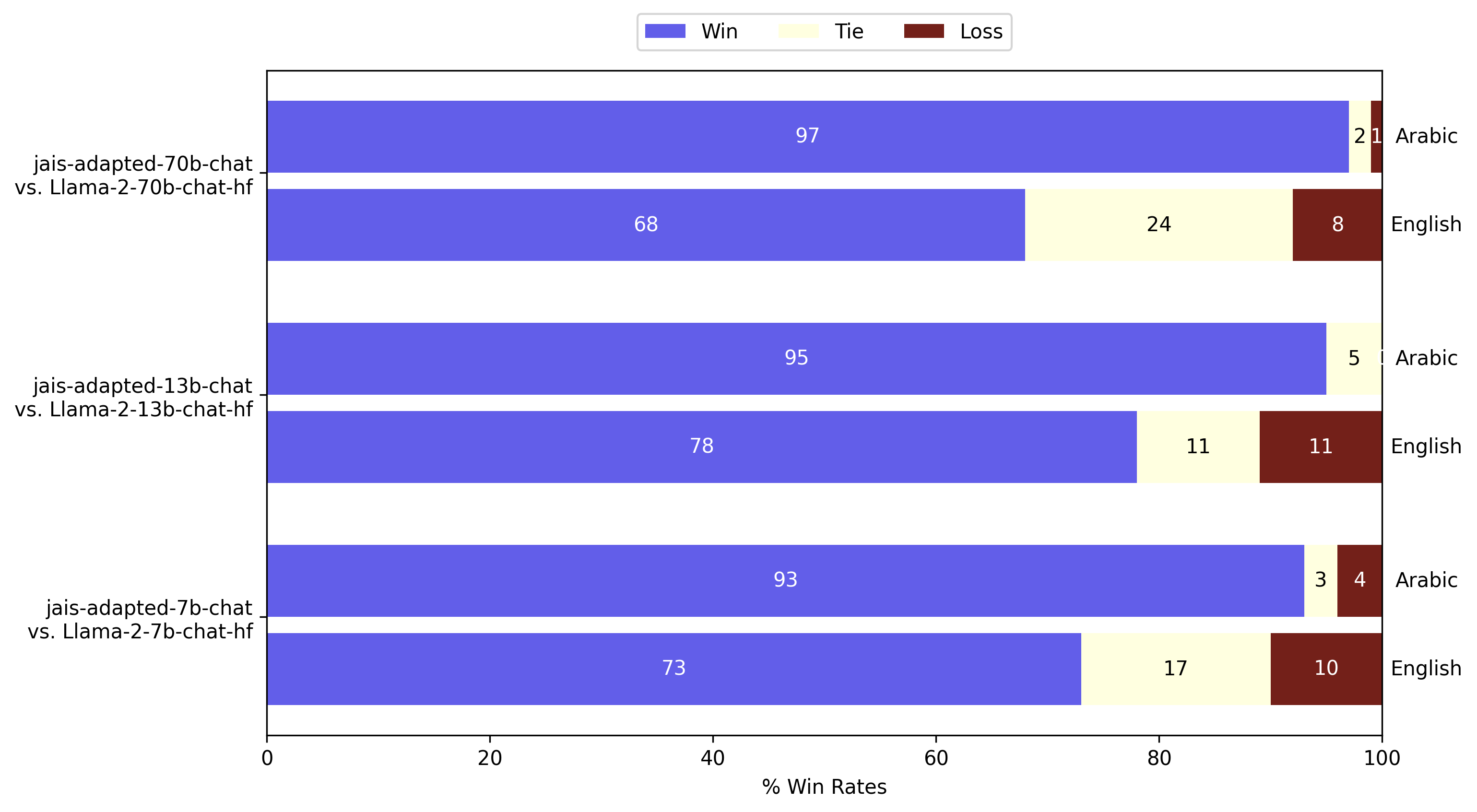
GPT-4-as-a-judge evaluation of adapted Jais in Arabic and English. The generation quality of Arabic is significantly enhanced, while achieving improvement in English when compared to Llama-2 instruct.
Besides pairwise comparison, we also perform MT-bench style single-answer grading on a scale of 1 to 10.
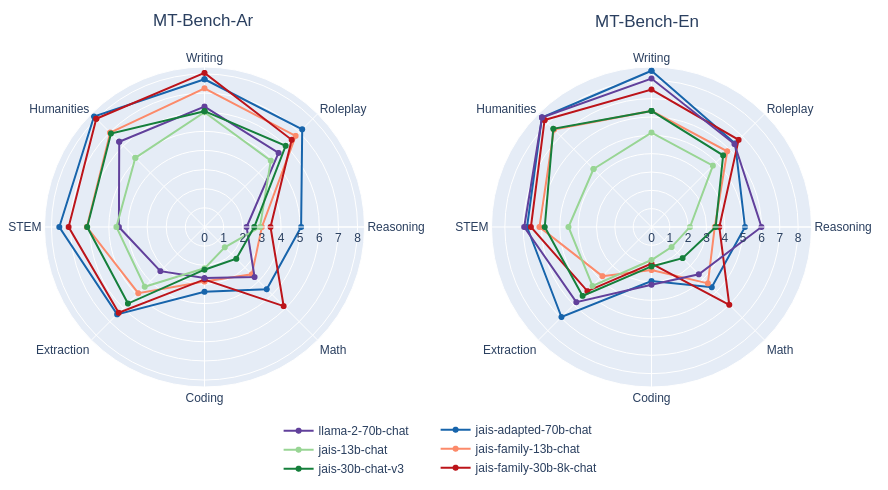
MT-bench style single-answer grading evaluation of Jais and adapted Jais in Arabic and English. Comparisons are made between select corresponding models from earlier releases. The quality ratings of responses are generally improved, with significant enhancements in Arabic.
We release the Jais family of models under a full open-source license. We welcome all feedback and opportunities to collaborate. Spanning sizes from 590M to 70B parameters, this suite of bilingual models accommodates a wide range of use cases. Some potential downstream applications include:
Research: The Jais family serves Arabic researchers and NLP practitioners, offering both compute-efficient and advanced model sizes
Commercial Use: Jais 30B and 70B chat models are well-suited for direct use in chat applications with appropriate prompting or for further fine-tuning on specific tasks.
Audiences that we hope will benefit from our model:
While the Jais family of models are powerful Arabic and English bilingual models, it's essential to understand their limitations and the potential of misuse. It is prohibited to use the model in any manner that violates applicable laws or regulations.
The following are some example scenarios where the model should not be used.
Malicious Use: The model should not be used to generate harmful, misleading, or inappropriate content. Thisincludes but is not limited to:
Sensitive Information: The model should not be used to handle or generate personal, confidential, or sensitive information.
Generalization Across All Languages: Jais family of models are bilingual and optimized for Arabic and English. They should not be presumed to have equal proficiency in other languages or dialects.
High-Stakes Decisions: The model should not be used to make high-stakes decisions without human oversight. This includes medical, legal, financial, or safety-critical decisions.
The Jais family is trained on publicly available data which was in part curated by Inception. We have employed different techniques to reduce bias in the model. While efforts have been made to minimize biases, it is likely that the model, as with all LLM models, will exhibit some bias.
The fine-tuned variants are trained as an AI assistant for Arabic and English speakers. Chat models are limited to produce responses for queries in these two languages and may not produce appropriate responses to other language queries.
By using Jais, you acknowledge and accept that, as with any large language model, it may generate incorrect, misleading and/or offensive information or content. The information is not intended as advice and should not be relied upon in any way, nor are we responsible for any of the content or consequences resulting from its use. We are continuously working to develop models with greater capabilities, and as such, welcome any feedback on the model.
Copyright Inception Institute of Artificial Intelligence Ltd. JAIS is made available under the Apache License, Version 2.0 (the “License”). You shall not use JAIS except in compliance with the License. You may obtain a copy of the License at https://www.apache.org/licenses/LICENSE-2.0.
Unless required by applicable law or agreed to in writing, JAIS is distributed on an AS IS basis, without warranties or conditions of any kind, either express or implied. Please see the terms of the License for the specific language permissions and limitations under the License.
We release the Jais family of Arabic and English bilingual models. The wide range of pre-trained model sizes, the recipe for adapting English-centric models to Arabic, and the fine-tuning of all sizes unlocks numerous use cases commercially and academically in the Arabic setting.
Through this release, we aim to make LLMs more accessible to Arabic NLP researchers and companies, offering native Arabic models that provide better cultural understanding than English centric ones. The strategies we employ for pre-training, fine-tuning and adaptation to Arabic are extensible to other low and medium resource languages, paving the way for language-focused and accessible models that cater to local contexts.
@misc{sengupta2023jais,
title={Jais and Jais-chat: Arabic-Centric Foundation and Instruction-Tuned Open Generative Large Language Models},
author={Neha Sengupta, Sunil Kumar Sahu, Bokang Jia, Satheesh Katipomu, Haonan Li, Fajri Koto, William Marshall, Gurpreet Gosal, Cynthia Liu, Zhiming Chen, Osama Mohammed Afzal, Samta Kamboj, Onkar Pandit, Rahul Pal, Lalit Pradhan, Zain Muhammad Mujahid, Massa Baali, Xudong Han, Sondos Mahmoud Bsharat, Alham Fikri Aji, Zhiqiang Shen, Zhengzhong Liu, Natalia Vassilieva, Joel Hestness, Andy Hock, Andrew Feldman, Jonathan Lee, Andrew Jackson, Hector Xuguang Ren, Preslav Nakov, Timothy Baldwin and Eric Xing},
year={2023},
eprint={2308.16149},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@article{jaisfamilymodelcard,
title={Jais Family Model Card},
author={Inception},
year={2024},
url = {https://huggingface.co/inceptionai/jais-family-30b-16k-chat/blob/main/README.md}
}