
ScholarBERT-XL_1 Model
This is the ScholarBERT-XL_1 variant of the ScholarBERT model family.
The model is pretrained on a large collection of scientific research articles (2.2B tokens).
This is a cased (case-sensitive) model. The tokenizer will not convert all inputs to lower-case by default.
The model has a total of 770M parameters.
Model Architecture
| Hyperparameter | Value |
|---|---|
| Layers | 36 |
| Hidden Size | 1280 |
| Attention Heads | 20 |
| Total Parameters | 770M |
Training Dataset
The vocab and the model are pertrained on 1% of the PRD scientific literature dataset.
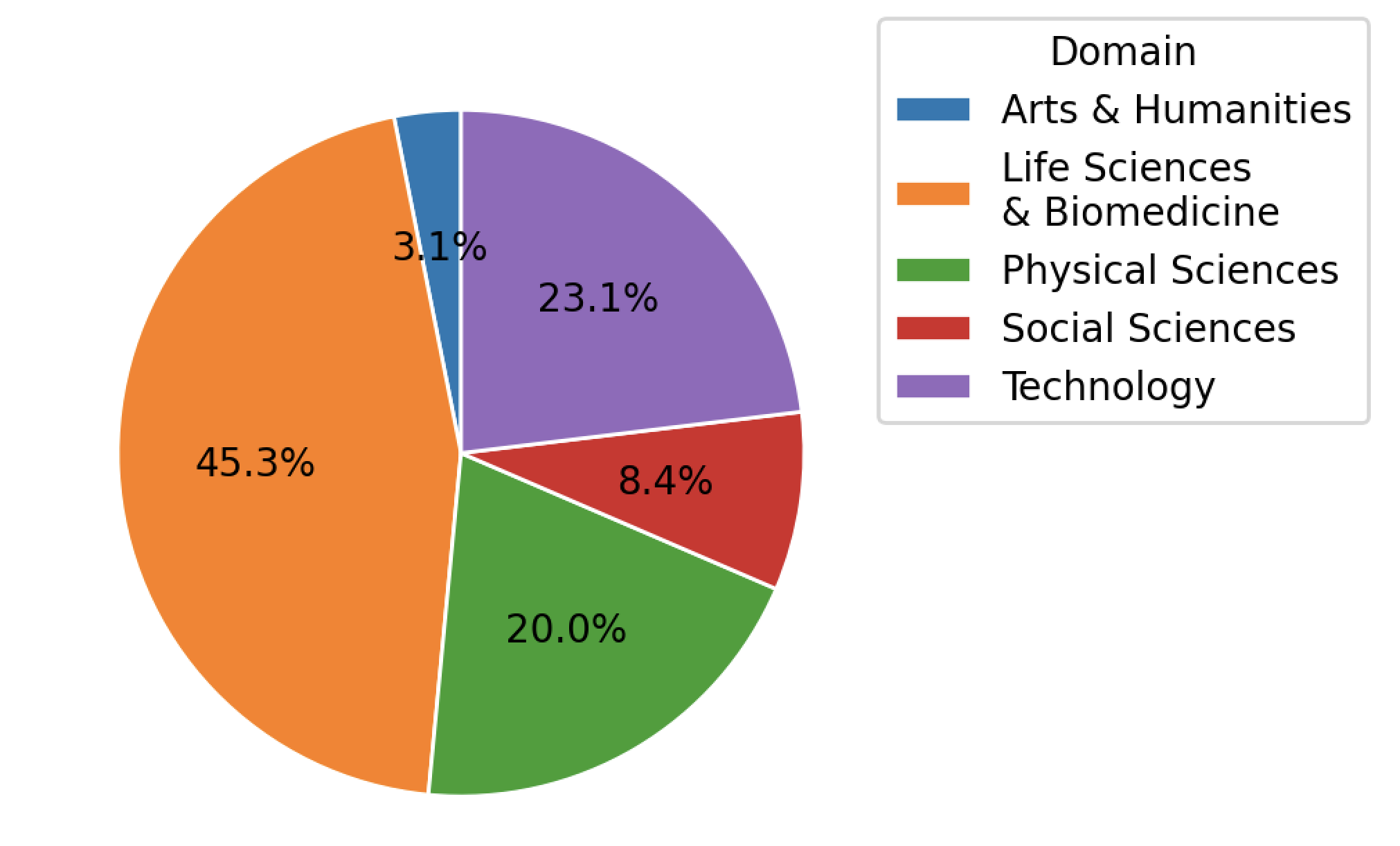
The PRD dataset is provided by Public.Resource.Org, Inc. (“Public Resource”), a nonprofit organization based in California. This dataset was constructed from a corpus of journal article files, from which We successfully extracted text from 75,496,055 articles from 178,928 journals. The articles span across Arts & Humanities, Life Sciences & Biomedicine, Physical Sciences, Social Sciences, and Technology. The distribution of articles is shown below.
BibTeX entry and citation info
If using this model, please cite this paper:
@misc{hong2023diminishing,
title={The Diminishing Returns of Masked Language Models to Science},
author={Zhi Hong and Aswathy Ajith and Gregory Pauloski and Eamon Duede and Kyle Chard and Ian Foster},
year={2023},
eprint={2205.11342},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
- Downloads last month
- 2