

gokaygokay/Florence-2-SD3-Captioner
Image-Text-to-Text
•
Updated
•
6.21k
•
27
The viewer is disabled because this dataset repo requires arbitrary Python code execution. Please consider
removing the
loading script
and relying on
automated data support
(you can use
convert_to_parquet
from the datasets library). If this is not possible, please
open a discussion
for direct help.
Please visit the webpage for all the information about the IIW project, data downloads, visualizations, and much more.

Please reach out to [email protected] for thoughts/feedback/questions/collaborations.
from datasets import load_dataset
# `name` can be one of: IIW-400, DCI_Test, DOCCI_Test, CM_3600, LocNar_Eval
# refer: https://github.com/google/imageinwords/tree/main/datasets
dataset = load_dataset('google/imageinwords', token=None, name="IIW-400", trust_remote_code=True)
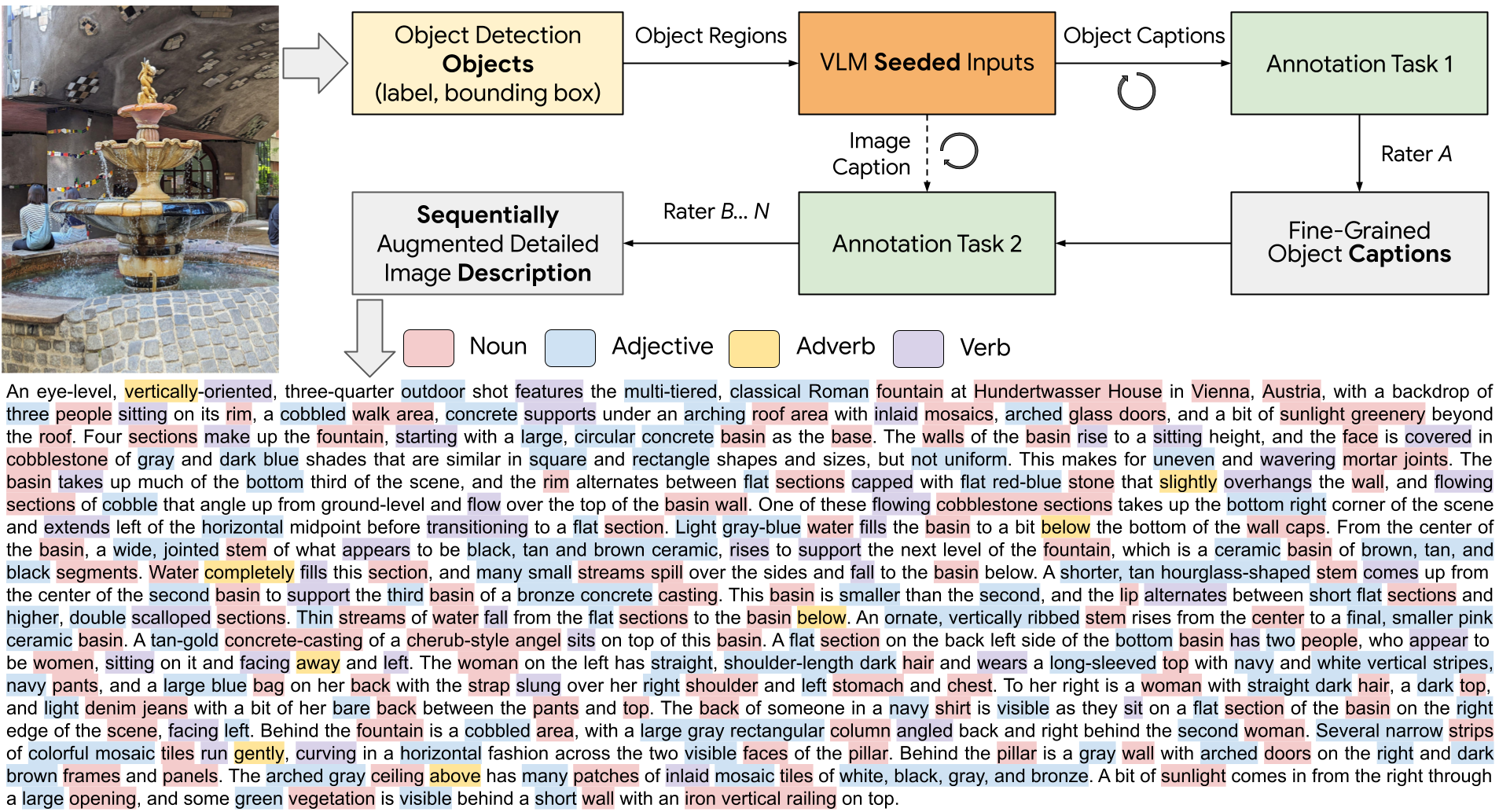
ImageInWords (IIW), a carefully designed human-in-the-loop annotation framework for curating hyper-detailed image descriptions and a new dataset resulting from this process. We validate the framework through evaluations focused on the quality of the dataset and its utility for fine-tuning with considerations for readability, comprehensiveness, specificity, hallucinations, and human-likeness.
This Data Card describes IIW-Benchmark: Eval Datasets, a mixture of human annotated and machine generated data intended to help create and capture rich, hyper-detailed image descriptions.
IIW dataset has two parts: human annotations and model outputs. The main purposes of this dataset are:
Text-to-Image, Image-to-Text, Object Detection
English
For details on the datasets and output keys, please refer to our GitHub data page inside the individual folders.
IIW-400:
image/keyimage/urlIIW: Human generated image descriptionIIW-P5B: Machine generated image descriptioniiw-human-sxs-gpt4v and iiw-human-sxs-iiw-p5b: human SxS metricsDCI_Test:
imageimage/urlex_idIIW: Human authored image descriptionmetrics/Comprehensivenessmetrics/Specificitymetrics/Hallucinationmetrics/First few line(s) as tldrmetrics/Human LikeDOCCI_Test:
imageimage/thumbnail_urlIIW: Human generated image descriptionDOCCI: Image description from DOCCImetrics/Comprehensivenessmetrics/Specificitymetrics/Hallucinationmetrics/First few line(s) as tldrmetrics/Human LikeLocNar_Eval:
image/keyimage/urlIIW-P5B: Machine generated image descriptionCM_3600:
image/keyimage/urlIIW-P5B: Machine generated image descriptionPlease note that all fields are string.
| Dataset | Size |
|---|---|
| IIW-400 | 400 |
| DCI_Test | 112 |
| DOCCI_Test | 100 |
| LocNar_Eval | 1000 |
| CM_3600 | 1000 |
Some text descriptions were written by human annotators and some were generated by machine models. The metrics are all from human SxS.
The images that were used for the descriptions and the machine generated text descriptions are checked (by algorithmic methods and manual inspection) for S/PII, pornographic content, and violence and any we found may contain such information have been filtered. We asked that human annotators use an objective and respectful language for the image descriptions.
CC BY 4.0
@misc{garg2024imageinwords,
title={ImageInWords: Unlocking Hyper-Detailed Image Descriptions},
author={Roopal Garg and Andrea Burns and Burcu Karagol Ayan and Yonatan Bitton and Ceslee Montgomery and Yasumasa Onoe and Andrew Bunner and Ranjay Krishna and Jason Baldridge and Radu Soricut},
year={2024},
eprint={2405.02793},
archivePrefix={arXiv},
primaryClass={cs.CV}
}


