
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 599M
2.14B
| node_id
stringlengths 18
32
| number
int64 1
6.68k
| title
stringlengths 1
290
| user
dict | labels
listlengths 0
4
| state
stringclasses 2
values | locked
bool 1
class | assignee
dict | assignees
listlengths 0
4
| milestone
dict | num_comments
int64 0
70
| created_at
unknown | updated_at
unknown | closed_at
unknown | author_association
stringclasses 3
values | active_lock_reason
float64 | draft
float64 0
1
⌀ | pull_request
dict | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
float64 | state_reason
stringclasses 3
values | __index_level_0__
int64 0
6.65k
| is_pr
bool 2
classes | comments
sequencelengths 0
30
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/50 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/50/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/50/comments | https://api.github.com/repos/huggingface/datasets/issues/50/events | https://github.com/huggingface/datasets/pull/50 | 612,583,126 | MDExOlB1bGxSZXF1ZXN0NDEzNTAwMjE0 | 50 | [Tests] test only for fast test as a default | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [] | closed | false | null | [] | null | 1 | "2020-05-05T12:59:22Z" | "2020-05-05T13:02:18Z" | "2020-05-05T13:02:16Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/50.diff",
"html_url": "https://github.com/huggingface/datasets/pull/50",
"merged_at": "2020-05-05T13:02:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/50.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/50"
} | Test only for one config on circle ci to speed up testing. Add all config test as a slow test.
@mariamabarham @thomwolf | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/50/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/50/timeline | null | null | 6,600 | true | [
"Test failure is not related to change in test file.\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/49 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/49/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/49/comments | https://api.github.com/repos/huggingface/datasets/issues/49/events | https://github.com/huggingface/datasets/pull/49 | 612,545,483 | MDExOlB1bGxSZXF1ZXN0NDEzNDY5ODg0 | 49 | fix flatten nested | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | 0 | "2020-05-05T11:55:13Z" | "2020-05-05T13:59:26Z" | "2020-05-05T13:59:25Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/49.diff",
"html_url": "https://github.com/huggingface/datasets/pull/49",
"merged_at": "2020-05-05T13:59:25Z",
"patch_url": "https://github.com/huggingface/datasets/pull/49.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/49"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/49/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/49/timeline | null | null | 6,601 | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/48 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/48/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/48/comments | https://api.github.com/repos/huggingface/datasets/issues/48/events | https://github.com/huggingface/datasets/pull/48 | 612,504,687 | MDExOlB1bGxSZXF1ZXN0NDEzNDM2MTgz | 48 | [Command Convert] remove tensorflow import | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [] | closed | false | null | [] | null | 0 | "2020-05-05T10:41:00Z" | "2020-05-05T11:13:58Z" | "2020-05-05T11:13:56Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/48.diff",
"html_url": "https://github.com/huggingface/datasets/pull/48",
"merged_at": "2020-05-05T11:13:56Z",
"patch_url": "https://github.com/huggingface/datasets/pull/48.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/48"
} | Remove all tensorflow import statements. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/48/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/48/timeline | null | null | 6,602 | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/47 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/47/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/47/comments | https://api.github.com/repos/huggingface/datasets/issues/47/events | https://github.com/huggingface/datasets/pull/47 | 612,446,493 | MDExOlB1bGxSZXF1ZXN0NDEzMzg5MDc1 | 47 | [PyArrow Feature] fix py arrow bool | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [] | closed | false | null | [] | null | 0 | "2020-05-05T08:56:28Z" | "2020-05-05T10:40:28Z" | "2020-05-05T10:40:27Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/47.diff",
"html_url": "https://github.com/huggingface/datasets/pull/47",
"merged_at": "2020-05-05T10:40:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/47.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/47"
} | To me it seems that `bool` can only be accessed with `bool_` when looking at the pyarrow types: https://arrow.apache.org/docs/python/api/datatypes.html. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/47/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/47/timeline | null | null | 6,603 | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/46 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/46/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/46/comments | https://api.github.com/repos/huggingface/datasets/issues/46/events | https://github.com/huggingface/datasets/pull/46 | 612,398,190 | MDExOlB1bGxSZXF1ZXN0NDEzMzUxNTY0 | 46 | [Features] Strip str key before dict look-up | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [] | closed | false | null | [] | null | 0 | "2020-05-05T07:31:45Z" | "2020-05-05T08:37:45Z" | "2020-05-05T08:37:44Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/46.diff",
"html_url": "https://github.com/huggingface/datasets/pull/46",
"merged_at": "2020-05-05T08:37:44Z",
"patch_url": "https://github.com/huggingface/datasets/pull/46.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/46"
} | The dataset `anli.py` currently fails because it tries to look up a key `1\n` in a dict that only has the key `1`. Added an if statement to strip key if it cannot be found in dict. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/46/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/46/timeline | null | null | 6,604 | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/45 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/45/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/45/comments | https://api.github.com/repos/huggingface/datasets/issues/45/events | https://github.com/huggingface/datasets/pull/45 | 612,386,583 | MDExOlB1bGxSZXF1ZXN0NDEzMzQzMjAy | 45 | [Load] Separate Module kwargs and builder kwargs. | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [] | closed | false | null | [] | null | 0 | "2020-05-05T07:09:54Z" | "2022-10-04T09:32:11Z" | "2020-05-08T09:51:22Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/45.diff",
"html_url": "https://github.com/huggingface/datasets/pull/45",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/45.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/45"
} | Kwargs for the `load_module` fn should be passed with `module_xxxx` to `builder_kwargs` of `load` fn.
This is a follow-up PR of: https://github.com/huggingface/nlp/pull/41 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/45/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/45/timeline | null | null | 6,605 | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/44 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/44/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/44/comments | https://api.github.com/repos/huggingface/datasets/issues/44/events | https://github.com/huggingface/datasets/pull/44 | 611,873,486 | MDExOlB1bGxSZXF1ZXN0NDEyOTUwMzU1 | 44 | [Tests] Fix tests for datasets with no config | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [] | closed | false | null | [] | null | 0 | "2020-05-04T13:25:38Z" | "2020-05-04T13:28:04Z" | "2020-05-04T13:28:03Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/44.diff",
"html_url": "https://github.com/huggingface/datasets/pull/44",
"merged_at": "2020-05-04T13:28:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/44.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/44"
} | Forgot to fix `None` problem for datasets that have no config this in PR: https://github.com/huggingface/nlp/pull/42 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/44/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/44/timeline | null | null | 6,606 | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/43 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/43/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/43/comments | https://api.github.com/repos/huggingface/datasets/issues/43/events | https://github.com/huggingface/datasets/pull/43 | 611,773,279 | MDExOlB1bGxSZXF1ZXN0NDEyODcxNTE5 | 43 | [Checksums] If no configs exist prevent to run over empty list | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [] | closed | false | null | [] | null | 3 | "2020-05-04T10:39:42Z" | "2022-10-04T09:32:02Z" | "2020-05-04T13:18:03Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/43.diff",
"html_url": "https://github.com/huggingface/datasets/pull/43",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/43.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/43"
} | `movie_rationales` e.g. has no configs. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/43/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/43/timeline | null | null | 6,607 | true | [
"Whoops I fixed it directly on master before checking that you have done it in this PR. We may close it",
"Yeah, I saw :-) But I think we should add this as well since some datasets have an empty list of configs and then as the code is now it would fail. \r\n\r\nIn this PR, I just make sure that the code jumps in the correct else if \"there are no configs\" as is the case for some datasets @mariamabarham ",
"Sorry, I thought you meant a different commit . Just saw this one: https://github.com/huggingface/nlp/commit/7c644f284e2303b57612a6e7c904fe13906d893f\r\n.\r\n\r\nAll good then :-) "
] |
https://api.github.com/repos/huggingface/datasets/issues/42 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/42/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/42/comments | https://api.github.com/repos/huggingface/datasets/issues/42/events | https://github.com/huggingface/datasets/pull/42 | 611,754,343 | MDExOlB1bGxSZXF1ZXN0NDEyODU1OTE2 | 42 | [Tests] allow tests for builders without config | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [] | closed | false | null | [] | null | 0 | "2020-05-04T10:06:22Z" | "2020-05-04T13:10:50Z" | "2020-05-04T13:10:48Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/42.diff",
"html_url": "https://github.com/huggingface/datasets/pull/42",
"merged_at": "2020-05-04T13:10:48Z",
"patch_url": "https://github.com/huggingface/datasets/pull/42.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/42"
} | Some dataset scripts have no configs - the tests have to be adapted for this case.
In this case the dummy data will be saved as:
- natural_questions
-> dummy
-> -> 1.0.0 (version num)
-> -> -> dummy_data.zip
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/42/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/42/timeline | null | null | 6,608 | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/41 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/41/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/41/comments | https://api.github.com/repos/huggingface/datasets/issues/41/events | https://github.com/huggingface/datasets/pull/41 | 611,739,219 | MDExOlB1bGxSZXF1ZXN0NDEyODQzNDQy | 41 | [Load module] allow kwargs into load module | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [] | closed | false | null | [] | null | 0 | "2020-05-04T09:42:11Z" | "2020-05-04T19:39:07Z" | "2020-05-04T19:39:06Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/41.diff",
"html_url": "https://github.com/huggingface/datasets/pull/41",
"merged_at": "2020-05-04T19:39:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/41.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/41"
} | Currenly it is not possible to force a re-download of the dataset script.
This simple change allows to pass ``force_reload=True`` as ``builder_kwargs`` in the ``load.py`` function. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/41/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/41/timeline | null | null | 6,609 | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/40 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/40/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/40/comments | https://api.github.com/repos/huggingface/datasets/issues/40/events | https://github.com/huggingface/datasets/pull/40 | 611,721,308 | MDExOlB1bGxSZXF1ZXN0NDEyODI4NzU2 | 40 | Update remote checksums instead of overwrite | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | 0 | "2020-05-04T09:13:14Z" | "2020-05-04T11:51:51Z" | "2020-05-04T11:51:49Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/40.diff",
"html_url": "https://github.com/huggingface/datasets/pull/40",
"merged_at": "2020-05-04T11:51:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/40.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/40"
} | When the user uploads a dataset on S3, checksums are also uploaded with the `--upload_checksums` parameter.
If the user uploads the dataset in several steps, then the remote checksums file was previously overwritten. Now it's going to be updated with the new checksums. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/40/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/40/timeline | null | null | 6,610 | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/39 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/39/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/39/comments | https://api.github.com/repos/huggingface/datasets/issues/39/events | https://github.com/huggingface/datasets/pull/39 | 611,712,135 | MDExOlB1bGxSZXF1ZXN0NDEyODIxNTA4 | 39 | [Test] improve slow testing | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [] | closed | false | null | [] | null | 0 | "2020-05-04T08:58:33Z" | "2020-05-04T08:59:50Z" | "2020-05-04T08:59:49Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/39.diff",
"html_url": "https://github.com/huggingface/datasets/pull/39",
"merged_at": "2020-05-04T08:59:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/39.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/39"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/39/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/39/timeline | null | null | 6,611 | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/38 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/38/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/38/comments | https://api.github.com/repos/huggingface/datasets/issues/38/events | https://github.com/huggingface/datasets/issues/38 | 611,677,656 | MDU6SXNzdWU2MTE2Nzc2NTY= | 38 | [Checksums] Error for some datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
},
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
}
] | null | 3 | "2020-05-04T08:00:16Z" | "2020-05-04T09:48:20Z" | "2020-05-04T09:48:20Z" | MEMBER | null | null | null | The checksums command works very nicely for `squad`. But for `crime_and_punish` and `xnli`,
the same bug happens:
When running:
```
python nlp-cli nlp-cli test xnli --save_checksums
```
leads to:
```
File "nlp-cli", line 33, in <module>
service.run()
File "/home/patrick/python_bin/nlp/commands/test.py", line 61, in run
ignore_checksums=self._ignore_checksums,
File "/home/patrick/python_bin/nlp/builder.py", line 383, in download_and_prepare
self._download_and_prepare(dl_manager=dl_manager, download_config=download_config)
File "/home/patrick/python_bin/nlp/builder.py", line 627, in _download_and_prepare
dl_manager=dl_manager, max_examples_per_split=download_config.max_examples_per_split,
File "/home/patrick/python_bin/nlp/builder.py", line 431, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
File "/home/patrick/python_bin/nlp/datasets/xnli/8bf4185a2da1ef2a523186dd660d9adcf0946189e7fa5942ea31c63c07b68a7f/xnli.py", line 95, in _split_generators
dl_dir = dl_manager.download_and_extract(_DATA_URL)
File "/home/patrick/python_bin/nlp/utils/download_manager.py", line 246, in download_and_extract
return self.extract(self.download(url_or_urls))
File "/home/patrick/python_bin/nlp/utils/download_manager.py", line 186, in download
self._record_sizes_checksums(url_or_urls, downloaded_path_or_paths)
File "/home/patrick/python_bin/nlp/utils/download_manager.py", line 166, in _record_sizes_checksums
self._recorded_sizes_checksums[url] = get_size_checksum(path)
File "/home/patrick/python_bin/nlp/utils/checksums_utils.py", line 81, in get_size_checksum
with open(path, "rb") as f:
TypeError: expected str, bytes or os.PathLike object, not tuple
```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/38/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/38/timeline | null | completed | 6,612 | false | [
"@lhoestq - could you take a look? It's not very urgent though!",
"Fixed with 06882b4\r\n\r\nNow your command works :)\r\nNote that you can also do\r\n```\r\nnlp-cli test datasets/nlp/xnli --save_checksums\r\n```\r\nSo that it will save the checksums directly in the right directory.",
"Awesome!"
] |
https://api.github.com/repos/huggingface/datasets/issues/37 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/37/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/37/comments | https://api.github.com/repos/huggingface/datasets/issues/37/events | https://github.com/huggingface/datasets/pull/37 | 611,670,295 | MDExOlB1bGxSZXF1ZXN0NDEyNzg5MjQ4 | 37 | [Datasets ToDo-List] add datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
},
{
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham"
}
] | null | 8 | "2020-05-04T07:47:39Z" | "2022-10-04T09:32:17Z" | "2020-05-08T13:48:23Z" | MEMBER | null | 1 | {
"diff_url": "https://github.com/huggingface/datasets/pull/37.diff",
"html_url": "https://github.com/huggingface/datasets/pull/37",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/37.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/37"
} | ## Description
This PR acts as a dashboard to see which datasets are added to the library and work.
Cicle-ci should always be green so that we can be sure that newly added datasets are functional.
This PR should not be merged.
## Progress
**For the following datasets the test commands**:
```
RUN_SLOW=1 pytest tests/test_dataset_common.py::DatasetTest::test_load_real_dataset_<your-dataset-name>
```
and
```
RUN_SLOW=1 pytest tests/test_dataset_common.py::DatasetTest::test_load_dataset_all_configs_<your-dataset-name>
```
**passes**.
- [x] Squad
- [x] Sentiment140
- [x] XNLI
- [x] Crime_and_Punish
- [x] movie_rationales
- [x] ai2_arc
- [x] anli
- [x] event2Mind
- [x] Fquad
- [x] blimp
- [x] empathetic_dialogues
- [x] cosmos_qa
- [x] xquad
- [x] blog_authorship_corpus
- [x] SNLI
- [x] break_data
- [x] SQuAD v2
- [x] cfq
- [x] eraser_multi_rc
- [x] Glue
- [x] Tydiqa
- [x] wiki_qa
- [x] wikitext
- [x] winogrande
- [x] wiqa
- [x] esnli
- [x] civil_comments
- [x] commonsense_qa
- [x] com_qa
- [x] coqa
- [x] wiki_split
- [x] cos_e
- [x] xcopa
- [x] quarel
- [x] quartz
- [x] squad_it
- [x] quoref
- [x] squad_pt
- [x] cornell_movie_dialog
- [x] SciQ
- [x] Scifact
- [x] hellaswag
- [x] ted_multi (in translate)
- [x] Aeslc (summarization)
- [x] drop
- [x] gap
- [x] hansard
- [x] opinosis
- [x] MLQA
- [x] math_dataset
## How-To-Add a dataset
**Before adding a dataset make sure that your branch is up to date**:
1. `git checkout add_datasets`
2. `git pull`
**Add a dataset via the `convert_dataset.sh` bash script:**
Running `bash convert_dataset.sh <file/to/tfds/datascript.py>` (*e.g.* `bash convert_dataset.sh ../tensorflow-datasets/tensorflow_datasets/text/movie_rationales.py`) will automatically run all the steps mentioned in **Add a dataset manually** below.
Make sure that you run `convert_dataset.sh` from the root folder of `nlp`.
The conversion script should work almost always for step 1): "convert dataset script from tfds to nlp format" and 2) "create checksum file" and step 3) "make style".
It can also sometimes automatically run step 4) "create the correct dummy data from tfds", but this will only work if a) there is either no config name or only one config name and b) the `tfds testing/test_data/fake_example` is in the correct form.
Nevertheless, the script should always be run in the beginning until an error occurs to be more efficient.
If the conversion script does not work or fails at some step, then you can run the steps manually as follows:
**Add a dataset manually**
Make sure you run all of the following commands from the root of your `nlp` git clone.
Also make sure that you changed to this branch:
```
git checkout add_datasets
```
1) the tfds datascript file should be converted to `nlp` style:
```
python nlp-cli convert --tfds_path <path/to/tensorflow_datasets/text/your_dataset_name>.py --nlp_directory datasets/nlp
```
This will convert the tdfs script and create a folder with the correct name.
2) the checksum file should be added. Use the command:
```
python nlp-cli test datasets/nlp/<your-dataset-folder> --save_checksums --all_configs
```
A checksums.txt file should be created in your folder and the structure should look as follows:
squad/
├── squad.py/
└── urls_checksums/
...........└── checksums.txt
Delete the created `*.lock` file afterward - it should not be uploaded to AWS.
3) run black and isort on your newly added datascript files so that they look nice:
```
make style
```
4) the dummy data should be added. For this it might be useful to take a look into the structure of other examples as shown in the PR here and at `<path/to/tensorflow_datasets/testing/test_data/test_data/fake_examples>` whether the same data can be used.
5) the data can be uploaded to AWS using the command
```
aws s3 cp datasets/nlp/<your-dataset-folder> s3://datasets.huggingface.co/nlp/<your-dataset-folder> --recursive
```
6) check whether all works as expected using:
```
RUN_SLOW=1 pytest tests/test_dataset_common.py::DatasetTest::test_load_real_dataset_<your-dataset-name>
```
and
```
RUN_SLOW=1 pytest tests/test_dataset_common.py::DatasetTest::test_load_dataset_all_configs_<your-dataset-name>
```
7) push to this PR and rerun the circle ci workflow to check whether circle ci stays green.
8) Edit this commend and tick off your newly added dataset :-)
## TODO-list
Maybe we can add a TODO-list here for everybody that feels like adding new datasets so that we will not add the same datasets.
Here a link to available datasets: https://docs.google.com/spreadsheets/d/1zOtEqOrnVQwdgkC4nJrTY6d-Av02u0XFzeKAtBM2fUI/edit#gid=0
Patrick:
- [ ] boolq - *weird download link*
- [ ] c4 - *beam dataset* | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/37/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/37/timeline | null | null | 6,613 | true | [
"Note:\r\n```\r\nnlp-cli test datasets/nlp/<your-dataset-folder> --save_checksums --all_configs\r\n```\r\ndirectly saves the checksums in the right place, and runs for all the dataset configurations.",
"@patrickvonplaten can you provide the add the link to the PR for the dummy data? ",
"https://github.com/huggingface/nlp/pull/15 - But it's probably best to checkout into this branch and look how the dummy data strtucture is for `squad` for example.",
"are lock files supposed to stay ?",
"> are lock files supposed to stay ?\r\n\r\nNot sure! I think the checksum command creates them, so I just uploaded them as well.",
"We can trash the `lock` file, they are dummy file that are only used to avoid concurrent access when the library is run.\r\nYou can read the filelock readme and code, it's a very simple single-file library: https://github.com/benediktschmitt/py-filelock",
"The testing design was slightly changed as explained in https://github.com/huggingface/nlp/pull/51 . \r\nIf creating the dummy folder is too confusing it helps to upload everything else to AWS, then run the test and check the INFO when testing on how to create the dummy folder structure.",
"Closing because we can now work on master"
] |
https://api.github.com/repos/huggingface/datasets/issues/36 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/36/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/36/comments | https://api.github.com/repos/huggingface/datasets/issues/36/events | https://github.com/huggingface/datasets/pull/36 | 611,528,349 | MDExOlB1bGxSZXF1ZXN0NDEyNjgwOTk1 | 36 | Metrics - refactoring, adding support for download and distributed metrics | {
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf"
} | [] | closed | false | null | [] | null | 3 | "2020-05-03T23:00:17Z" | "2020-05-11T08:16:02Z" | "2020-05-11T08:16:00Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/36.diff",
"html_url": "https://github.com/huggingface/datasets/pull/36",
"merged_at": "2020-05-11T08:16:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/36.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/36"
} | Refactoring metrics to have a similar loading API than the datasets and improving the import system.
# Import system
The import system has ben upgraded. There are now three types of imports allowed:
1. `library` imports (identified as "absolute imports")
```python
import seqeval
```
=> we'll test all the imports before running the scripts and if one cannot be imported we'll display an error message like this one:
`ImportError: To be able to use this metric/dataset, you need to install the following dependencies ['seqeval'] using 'pip install seqeval' for instance'`
2. `internal` imports (identified as "relative imports")
```python
import .c4_utils
```
=> we'll assume this point to a file in the same directory/S3-directory as the main script and download this file.
2. `external` imports (identified as "relative imports" with a comment starting with `# From:`)
```python
from .nmt_bleu import compute_bleu # From: https://github.com/tensorflow/nmt/blob/master/nmt/scripts/bleu.py
```
=> we'll assume this point to the URL of a python script (if it's a link to a github file, we'll take the raw file automatically).
=> the script is downloaded and renamed to the import name (here above renamed from `bleu.py` to `nmt_bleu.py`). Renaming the file can be necessary if the distant file has the same name as the dataset/metric processing script. If you forgot to rename the distant script and it has the same name as the dataset/metric, you'll have an explicit error message asking to rename the import anyway.
# Hosting metrics
Metrics are hosted on a S3 bucket like the dataset processing scripts.
# Metrics scripts
Metrics scripts have a lot in common with datasets processing scripts. They also have a `metric.info` including citations, descriptions and links to relevant pages.
Metrics have more documentation to supply to ensure they are used well.
Four examples are already included for reference in [./metrics](./metrics): BLEU, ROUGE, SacreBLEU and SeqEVAL.
# Automatic support for distributed/multi-processing metric computation
We've also added support for automatic distributed/multi-processing metric computation (e.g. when using DistributedDataParallel). We leverage our own dataset format for smart caching in this case.
Here is a quick gist of a standard use of metrics (the simplest usage):
```python
import nlp
bleu_metric = nlp.load_metric('bleu')
# If you only have a single iteration, you can easily compute the score like this
predictions = model(inputs)
score = bleu_metric.compute(predictions, references)
# If you have a loop, you can "add" your predictions and references at each iteration instead of having to save them yourself (the metric object store them efficiently for you)
for batch in dataloader:
model_input, targets = batch
predictions = model(model_inputs)
bleu.add(predictions, targets)
score = bleu_metric.compute() # Compute the score from all the stored predictions/references
```
Here is a quick gist of a use in a distributed torch setup (should work for any python multi-process setup actually). It's pretty much identical to the second example above:
```python
import nlp
# You need to give the total number of parallel python processes (num_process) and the id of each process (process_id)
bleu = nlp.load_metric('bleu', process_id=torch.distributed.get_rank(),b num_process=torch.distributed.get_world_size())
for batch in dataloader:
model_input, targets = batch
predictions = model(model_inputs)
bleu.add(predictions, targets)
score = bleu_metric.compute() # Compute the score on the first node by default (can be set to compute on each node as well)
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/36/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/36/timeline | null | null | 6,614 | true | [
"Ok, this one seems to be ready to merge.",
"> Really cool, I love it! I would just raise a tiny point, the distributive version of the metrics might not work properly with TF because it is a different way to do, why not to add a \"framework\" detection and raise warning when TF is used, saying something like \"not available yet in TF switch to non distributive metric computation\".\r\n> \r\n> What do you think?\r\n\r\nGood point @jplu I'm not sure how you should do distributed metrics evaluation for TF.\r\nThere is only one python script, right?\r\nMaybe it's just the same as in the not-distributed case?",
"I think non-distributed case should work in TF for both cases indeed, but this needs to be tested."
] |
https://api.github.com/repos/huggingface/datasets/issues/35 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/35/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/35/comments | https://api.github.com/repos/huggingface/datasets/issues/35/events | https://github.com/huggingface/datasets/pull/35 | 611,413,731 | MDExOlB1bGxSZXF1ZXN0NDEyNjAyMTc0 | 35 | [Tests] fix typo | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [] | closed | false | null | [] | null | 0 | "2020-05-03T13:23:49Z" | "2020-05-03T13:24:21Z" | "2020-05-03T13:24:20Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/35.diff",
"html_url": "https://github.com/huggingface/datasets/pull/35",
"merged_at": "2020-05-03T13:24:20Z",
"patch_url": "https://github.com/huggingface/datasets/pull/35.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/35"
} | @lhoestq - currently the slow test fail with:
```
_____________________________________________________________________________________ DatasetTest.test_load_real_dataset_xnli _____________________________________________________________________________________
self = <tests.test_dataset_common.DatasetTest testMethod=test_load_real_dataset_xnli>, dataset_name = 'xnli'
@slow
def test_load_real_dataset(self, dataset_name):
with tempfile.TemporaryDirectory() as temp_data_dir:
> dataset = load(dataset_name, data_dir=temp_data_dir)
tests/test_dataset_common.py:153:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
../../python_bin/nlp/load.py:497: in load
dbuilder.download_and_prepare(**download_and_prepare_kwargs)
../../python_bin/nlp/builder.py:383: in download_and_prepare
self._download_and_prepare(dl_manager=dl_manager, download_config=download_config)
../../python_bin/nlp/builder.py:627: in _download_and_prepare
dl_manager=dl_manager, max_examples_per_split=download_config.max_examples_per_split,
../../python_bin/nlp/builder.py:431: in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
../../python_bin/nlp/datasets/xnli/8bf4185a2da1ef2a523186dd660d9adcf0946189e7fa5942ea31c63c07b68a7f/xnli.py:95: in _split_generators
dl_dir = dl_manager.download_and_extract(_DATA_URL)
../../python_bin/nlp/utils/download_manager.py:246: in download_and_extract
return self.extract(self.download(url_or_urls))
../../python_bin/nlp/utils/download_manager.py:186: in download
self._record_sizes_checksums(url_or_urls, downloaded_path_or_paths)
../../python_bin/nlp/utils/download_manager.py:166: in _record_sizes_checksums
self._recorded_sizes_checksums[url] = get_size_checksum(path)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
path = ('', '/tmp/tmpkajlg9yc/downloads/c0f7773c480a3f2d85639d777e0e17e65527460310d80760fd3fc2b2f2960556.c952a63cb17d3d46e412ceb7dbcd656ce2b15cc9ef17f50c28f81c48a7c853b5')
def get_size_checksum(path: str) -> Tuple[int, str]:
"""Compute the file size and the sha256 checksum of a file"""
m = sha256()
> with open(path, "rb") as f:
E TypeError: expected str, bytes or os.PathLike object, not tuple
../../python_bin/nlp/utils/checksums_utils.py:81: TypeError
```
- the checksums probably need to be updated no? And we should also think about how to write a test for the checksums. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/35/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/35/timeline | null | null | 6,615 | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/34 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/34/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/34/comments | https://api.github.com/repos/huggingface/datasets/issues/34/events | https://github.com/huggingface/datasets/pull/34 | 611,385,516 | MDExOlB1bGxSZXF1ZXN0NDEyNTg0OTM0 | 34 | [Tests] add slow tests | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [] | closed | false | null | [] | null | 0 | "2020-05-03T11:01:22Z" | "2020-05-03T12:18:30Z" | "2020-05-03T12:18:29Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/34.diff",
"html_url": "https://github.com/huggingface/datasets/pull/34",
"merged_at": "2020-05-03T12:18:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/34.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/34"
} | This PR adds a slow test that downloads the "real" dataset. The test is decorated as "slow" so that it will not automatically run on circle ci.
Before uploading a dataset, one should test that this test passes, manually by running
```
RUN_SLOW=1 pytest tests/test_dataset_common.py::DatasetTest::test_load_real_dataset_<your-dataset-script-name>
```
This PR should be merged after PR: #33 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/34/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/34/timeline | null | null | 6,616 | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/33 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/33/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/33/comments | https://api.github.com/repos/huggingface/datasets/issues/33/events | https://github.com/huggingface/datasets/pull/33 | 611,052,081 | MDExOlB1bGxSZXF1ZXN0NDEyMzU1ODE0 | 33 | Big cleanup/refactoring for clean serialization | {
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf"
} | [] | closed | false | null | [] | null | 1 | "2020-05-01T23:45:57Z" | "2020-05-03T12:17:34Z" | "2020-05-03T12:17:33Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/33.diff",
"html_url": "https://github.com/huggingface/datasets/pull/33",
"merged_at": "2020-05-03T12:17:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/33.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/33"
} | This PR cleans many base classes to re-build them as `dataclasses`. We can thus use a simple serialization workflow for `DatasetInfo`, including it's `Features` and `SplitDict` based on `dataclasses` `asdict()`.
The resulting code is a lot shorter, can be easily serialized/deserialized, dataset info are human-readable and we can get rid of the `dataclass_json` dependency.
The scripts have breaking changes and the conversion tool is updated.
Example of dataset info in SQuAD script now:
```python
def _info(self):
return nlp.DatasetInfo(
description=_DESCRIPTION,
features=nlp.Features({
"id":
nlp.Value('string'),
"title":
nlp.Value('string'),
"context":
nlp.Value('string'),
"question":
nlp.Value('string'),
"answers":
nlp.Sequence({
"text": nlp.Value('string'),
"answer_start": nlp.Value('int32'),
}),
}),
# No default supervised_keys (as we have to pass both question
# and context as input).
supervised_keys=None,
homepage="https://rajpurkar.github.io/SQuAD-explorer/",
citation=_CITATION,
)
```
Example of serialized dataset info:
```bash
{
"description": "Stanford Question Answering Dataset (SQuAD) is a reading comprehension dataset, consisting of questions posed by crowdworkers on a set of Wikipedia articles, where the answer to every question is a segment of text, or span, from the corresponding reading passage, or the question might be unanswerable.\n",
"citation": "@article{2016arXiv160605250R,\n author = {{Rajpurkar}, Pranav and {Zhang}, Jian and {Lopyrev},\n Konstantin and {Liang}, Percy},\n title = \"{SQuAD: 100,000+ Questions for Machine Comprehension of Text}\",\n journal = {arXiv e-prints},\n year = 2016,\n eid = {arXiv:1606.05250},\n pages = {arXiv:1606.05250},\narchivePrefix = {arXiv},\n eprint = {1606.05250},\n}\n",
"homepage": "https://rajpurkar.github.io/SQuAD-explorer/",
"license": "",
"features": {
"id": {
"dtype": "string",
"_type": "Value"
},
"title": {
"dtype": "string",
"_type": "Value"
},
"context": {
"dtype": "string",
"_type": "Value"
},
"question": {
"dtype": "string",
"_type": "Value"
},
"answers": {
"feature": {
"text": {
"dtype": "string",
"_type": "Value"
},
"answer_start": {
"dtype": "int32",
"_type": "Value"
}
},
"length": -1,
"_type": "Sequence"
}
},
"supervised_keys": null,
"name": "squad",
"version": {
"version_str": "1.0.0",
"description": "New split API (https://tensorflow.org/datasets/splits)",
"nlp_version_to_prepare": null,
"major": 1,
"minor": 0,
"patch": 0
},
"splits": {
"train": {
"name": "train",
"num_bytes": 79426386,
"num_examples": 87599,
"dataset_name": "squad"
},
"validation": {
"name": "validation",
"num_bytes": 10491883,
"num_examples": 10570,
"dataset_name": "squad"
}
},
"size_in_bytes": 0,
"download_size": 35142551,
"download_checksums": []
}
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/33/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/33/timeline | null | null | 6,617 | true | [
"Great! I think when this merged, we can merge sure that Circle Ci stays happy when uploading new datasets. "
] |
https://api.github.com/repos/huggingface/datasets/issues/32 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/32/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/32/comments | https://api.github.com/repos/huggingface/datasets/issues/32/events | https://github.com/huggingface/datasets/pull/32 | 610,715,580 | MDExOlB1bGxSZXF1ZXN0NDEyMTAzMzIx | 32 | Fix map caching notebooks | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | 0 | "2020-05-01T11:55:26Z" | "2020-05-03T12:15:58Z" | "2020-05-03T12:15:57Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/32.diff",
"html_url": "https://github.com/huggingface/datasets/pull/32",
"merged_at": "2020-05-03T12:15:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/32.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/32"
} | Previously, caching results with `.map()` didn't work in notebooks.
To reuse a result, `.map()` serializes the functions with `dill.dumps` and then it hashes it.
The problem is that when using `dill.dumps` to serialize a function, it also saves its origin (filename + line no.) and the origin of all the `globals` this function needs. However for notebooks and shells, the filename looks like \<ipython-input-13-9ed2afe61d25\> and the line no. changes often.
To fix the problem, I added a new dispatch function for code objects that ignore the origin of the code if it comes from a notebook or a python shell.
I tested these cases in a notebook:
- lambda functions
- named functions
- methods
- classmethods
- staticmethods
- classes that implement `__call__`
The caching now works as expected for all of them :)
I also tested the caching in the demo notebook and it works fine ! | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/32/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/32/timeline | null | null | 6,618 | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/31 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/31/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/31/comments | https://api.github.com/repos/huggingface/datasets/issues/31/events | https://github.com/huggingface/datasets/pull/31 | 610,677,641 | MDExOlB1bGxSZXF1ZXN0NDEyMDczNDE4 | 31 | [Circle ci] Install a virtual env before running tests | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [] | closed | false | null | [] | null | 0 | "2020-05-01T10:11:17Z" | "2020-05-01T22:06:16Z" | "2020-05-01T22:06:15Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/31.diff",
"html_url": "https://github.com/huggingface/datasets/pull/31",
"merged_at": "2020-05-01T22:06:15Z",
"patch_url": "https://github.com/huggingface/datasets/pull/31.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/31"
} | Install a virtual env before running tests to not running into sudo issues when dynamically downloading files.
Same number of tests now pass / fail as on my local computer:
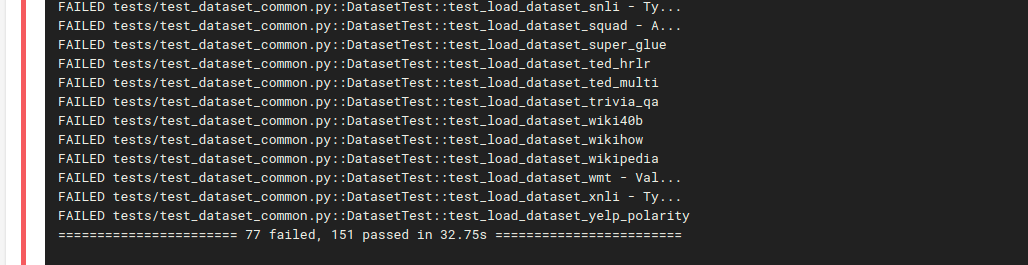
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/31/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/31/timeline | null | null | 6,619 | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/30 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/30/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/30/comments | https://api.github.com/repos/huggingface/datasets/issues/30/events | https://github.com/huggingface/datasets/pull/30 | 610,549,072 | MDExOlB1bGxSZXF1ZXN0NDExOTY4Mzk3 | 30 | add metrics which require download files from github | {
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham"
} | [] | closed | false | null | [] | null | 0 | "2020-05-01T04:13:22Z" | "2022-10-04T09:31:58Z" | "2020-05-11T08:19:54Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/30.diff",
"html_url": "https://github.com/huggingface/datasets/pull/30",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/30.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/30"
} | To download files from github, I copied the `load_dataset_module` and its dependencies (without the builder) in `load.py` to `metrics/metric_utils.py`. I made the following changes:
- copy the needed files in a folder`metric_name`
- delete all other files that are not needed
For metrics that require an external import, I first create a `<metric_name>_imports.py` file which contains all external urls. Then I create a `<metric_name>.py` in which I will load the external files using `<metric_name>_imports.py` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/30/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/30/timeline | null | null | 6,620 | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/29 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/29/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/29/comments | https://api.github.com/repos/huggingface/datasets/issues/29/events | https://github.com/huggingface/datasets/pull/29 | 610,243,997 | MDExOlB1bGxSZXF1ZXN0NDExNzIwODMx | 29 | Hf_api small changes | {
"avatar_url": "https://avatars.githubusercontent.com/u/326577?v=4",
"events_url": "https://api.github.com/users/julien-c/events{/privacy}",
"followers_url": "https://api.github.com/users/julien-c/followers",
"following_url": "https://api.github.com/users/julien-c/following{/other_user}",
"gists_url": "https://api.github.com/users/julien-c/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/julien-c",
"id": 326577,
"login": "julien-c",
"node_id": "MDQ6VXNlcjMyNjU3Nw==",
"organizations_url": "https://api.github.com/users/julien-c/orgs",
"received_events_url": "https://api.github.com/users/julien-c/received_events",
"repos_url": "https://api.github.com/users/julien-c/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/julien-c/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/julien-c/subscriptions",
"type": "User",
"url": "https://api.github.com/users/julien-c"
} | [] | closed | false | null | [] | null | 1 | "2020-04-30T17:06:43Z" | "2020-04-30T19:51:45Z" | "2020-04-30T19:51:44Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/29.diff",
"html_url": "https://github.com/huggingface/datasets/pull/29",
"merged_at": "2020-04-30T19:51:44Z",
"patch_url": "https://github.com/huggingface/datasets/pull/29.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/29"
} | From Patrick:
```python
from nlp import hf_api
api = hf_api.HfApi()
api.dataset_list()
```
works :-) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/29/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/29/timeline | null | null | 6,621 | true | [
"Ok merging! I think it's good now"
] |
https://api.github.com/repos/huggingface/datasets/issues/28 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/28/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/28/comments | https://api.github.com/repos/huggingface/datasets/issues/28/events | https://github.com/huggingface/datasets/pull/28 | 610,241,907 | MDExOlB1bGxSZXF1ZXN0NDExNzE5MTQy | 28 | [Circle ci] Adds circle ci config | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [] | closed | false | null | [] | null | 0 | "2020-04-30T17:03:35Z" | "2020-04-30T19:51:09Z" | "2020-04-30T19:51:08Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/28.diff",
"html_url": "https://github.com/huggingface/datasets/pull/28",
"merged_at": "2020-04-30T19:51:08Z",
"patch_url": "https://github.com/huggingface/datasets/pull/28.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/28"
} | @thomwolf can you take a look and set up circle ci on:
https://app.circleci.com/projects/project-dashboard/github/huggingface
I think for `nlp` only admins can set it up, which I guess is you :-) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/28/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/28/timeline | null | null | 6,622 | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/27 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/27/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/27/comments | https://api.github.com/repos/huggingface/datasets/issues/27/events | https://github.com/huggingface/datasets/pull/27 | 610,230,476 | MDExOlB1bGxSZXF1ZXN0NDExNzA5OTc0 | 27 | [Cleanup] Removes all files in testing except test_dataset_common | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [] | closed | false | null | [] | null | 0 | "2020-04-30T16:45:21Z" | "2020-04-30T17:39:25Z" | "2020-04-30T17:39:23Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/27.diff",
"html_url": "https://github.com/huggingface/datasets/pull/27",
"merged_at": "2020-04-30T17:39:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/27.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/27"
} | As far as I know, all files in `tests` were old `tfds test files` so I removed them. We can still look them up on the other library. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/27/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/27/timeline | null | null | 6,623 | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/26 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/26/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/26/comments | https://api.github.com/repos/huggingface/datasets/issues/26/events | https://github.com/huggingface/datasets/pull/26 | 610,226,047 | MDExOlB1bGxSZXF1ZXN0NDExNzA2NjA2 | 26 | [Tests] Clean tests | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [] | closed | false | null | [] | null | 0 | "2020-04-30T16:38:29Z" | "2020-04-30T20:12:04Z" | "2020-04-30T20:12:03Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/26.diff",
"html_url": "https://github.com/huggingface/datasets/pull/26",
"merged_at": "2020-04-30T20:12:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/26.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/26"
} | the abseil testing library (https://abseil.io/docs/python/quickstart.html) is better than the one I had before, so I decided to switch to that and changed the `setup.py` config file.
Abseil has more support and a cleaner API for parametrized testing I think.
I added a list of all dataset scripts that are currently on AWS, but will replace that once the
API is integrated into this lib.
One can now easily test for just a single function for a single dataset with:
`tests/test_dataset_common.py::DatasetTest::test_load_dataset_wikipedia`
NOTE: This PR is rebased on PR #29 so should be merged after. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/26/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/26/timeline | null | null | 6,624 | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/25 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/25/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/25/comments | https://api.github.com/repos/huggingface/datasets/issues/25/events | https://github.com/huggingface/datasets/pull/25 | 609,708,863 | MDExOlB1bGxSZXF1ZXN0NDExMjQ4Nzg2 | 25 | Add script csv datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.github.com/users/jplu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jplu",
"id": 959590,
"login": "jplu",
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"organizations_url": "https://api.github.com/users/jplu/orgs",
"received_events_url": "https://api.github.com/users/jplu/received_events",
"repos_url": "https://api.github.com/users/jplu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jplu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jplu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jplu"
} | [] | closed | false | null | [] | null | 3 | "2020-04-30T08:28:08Z" | "2022-10-04T09:32:13Z" | "2020-05-07T21:14:49Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/25.diff",
"html_url": "https://github.com/huggingface/datasets/pull/25",
"merged_at": "2020-05-07T21:14:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/25.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/25"
} | This is a PR allowing to create datasets from local CSV files. A usage might be:
```python
import nlp
ds = nlp.load(
path="csv",
name="bbc",
dataset_files={
nlp.Split.TRAIN: ["datasets/dummy_data/csv/train.csv"],
nlp.Split.TEST: [""datasets/dummy_data/csv/test.csv""]
},
csv_kwargs={
"skip_rows": 0,
"delimiter": ",",
"quote_char": "\"",
"header_as_column_names": True
}
)
```
```
Downloading and preparing dataset bbc/1.0.0 (download: Unknown size, generated: Unknown size, total: Unknown size) to /home/jplu/.cache/huggingface/datasets/bbc/1.0.0...
Dataset bbc downloaded and prepared to /home/jplu/.cache/huggingface/datasets/bbc/1.0.0. Subsequent calls will reuse this data.
{'test': Dataset(schema: {'category': 'string', 'text': 'string'}, num_rows: 49), 'train': Dataset(schema: {'category': 'string', 'text': 'string'}, num_rows: 99), 'validation': Dataset(schema: {'category': 'string', 'text': 'string'}, num_rows: 0)}
```
How it is read:
- `path`: the `csv` word means "I want to create a CSV dataset"
- `name`: the name of this dataset is `bbc`
- `dataset_files`: this is a dictionary where each key is the list of files corresponding to the key split.
- `csv_kwargs`: this is the keywords arguments to "explain" how to read the CSV files
* `skip_rows`: number of rows have to be skipped, starting from the beginning of the file
* `delimiter`: which delimiter is used to separate the columns
* `quote_char`: which quote char is used to represent a column where the delimiter appears in one of them
* `header_as_column_names`: will use the first row (header) of the file as name for the features. Otherwise the names will be automatically generated as `f1`, `f2`, etc... Will be applied after the `skip_rows` parameter.
**TODO**: for now the `csv.py` is copied each time we create a new dataset as `ds_name.py`, this behavior will be modified to have only the `csv.py` script copied only once and not for all the CSV datasets. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/25/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/25/timeline | null | null | 6,625 | true | [
"Very interesting thoughts, we should think deeper about all what you raised indeed.",
"Ok here is a proposal for a more general API and workflow.\r\n\r\n# New `ArrowBasedBuilder`\r\n\r\nFor all the formats that can be directly and efficiently loaded by Arrow (CSV, JSON, Parquet, Arrow), we don't really want to have to go through a conversion to python and back to Arrow. This new builder has a `_generate_tables` method to yield `Arrow.Tables` instead of single examples.\r\nThe tables can be directly casted in Arrow so it's not necessary to supply `Features`, they can be deduced from the `Table` column.\r\n\r\n# Central role of the `BuilderConfig` to store all the arguments necessary for the Dataset creation.\r\n \r\n`BuilderConfig` provide a few defaults fields `name`, `version`, `description`, `data_files` and `data_dir` which can be used to store values necessary for the creation of the dataset. It can be freely extended to store additional information (see the example for `CsvConfig`).\r\n\r\nOn the contrary, `DatasetInfo` is designed as an organized and delimited information storage class with predefined fields.\r\n\r\n`DatasetInfo` now store two names:\r\n- `builder_name`: Name of the builder script used to create the dataset\r\n- `config_name`: Name of the configuration used to create the dataset.\r\n\r\n# Refactoring `load()` arguments and all the chain of processing including the `DownloadManager`\r\n\r\n`load()` now accept a selection of arguments which are used to update the `BuilderConfig` and some kwargs which are used to handle the download process.\r\n\r\nSupplying a `BuilderConfig` as `config` will override the config provided in the dataset. Supplying a `str` will get the associated config from the dataset. Default is to fetch the first config of the dataset.\r\n\r\nGiving additional arguments to `load()` will override the arguments in the `BuilderConfig`.\r\n\r\n# CSV script\r\n\r\nThe `csv.py` script is provided as an example, usage is:\r\n```python\r\nbbc = nlp.load('/Users/thomwolf/Documents/GitHub/datasets/datasets/nlp/csv',\r\n name='bbc',\r\n version=\"1.0.1\",\r\n split='train',\r\n data_files={'train': ['/Users/thomwolf/Documents/GitHub/datasets/datasets/dummy_data/csv/test.csv']},\r\n skip_rows=10,\r\n download_mode='force_redownload')\r\n```\r\n\r\n# Checksums\r\n\r\nWe now don't raise an error if the checksum file is not found.\r\n\r\n# `DownloadConfig`\r\n\r\nWe now have a download configuration class to handle all the specific arguments for file caching like proxies, using only local files or user-agents.",
"Ok merging this for now.\r\n\r\nOne general note is that it's a bit hard to handle the `ClassLabel` generally in both `nlp` and `Arrow` since a class label typically need some metadata for the class names. For now, I raise a `NotImplementedError` when an `ArrowBuilder` output a table with a `DictionaryType` is encountered (which could be a simple equivalent for a `ClassLabel` Feature in Arrow tables).\r\n\r\nIn general and if we need this in the future for some Beam Datasets for instance, I think we should use one of the `metadata` fields in the `Arrow` type or table's schema to store the relation with indices and class names.\r\n\r\nSo ping me if you meet Beam datasets which uses `ClassLabels` (cc @lhoestq @patrickvonplaten @mariamabarham)."
] |
https://api.github.com/repos/huggingface/datasets/issues/24 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/24/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/24/comments | https://api.github.com/repos/huggingface/datasets/issues/24/events | https://github.com/huggingface/datasets/pull/24 | 609,064,987 | MDExOlB1bGxSZXF1ZXN0NDEwNzE5MTU0 | 24 | Add checksums | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | 5 | "2020-04-29T13:37:29Z" | "2020-04-30T19:52:50Z" | "2020-04-30T19:52:49Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/24.diff",
"html_url": "https://github.com/huggingface/datasets/pull/24",
"merged_at": "2020-04-30T19:52:49Z",
"patch_url": "https://github.com/huggingface/datasets/pull/24.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/24"
} | ### Checksums files
They are stored next to the dataset script in urls_checksums/checksums.txt.
They are used to check the integrity of the datasets downloaded files.
I kept the same format as tensorflow-datasets.
There is one checksums file for all configs.
### Load a dataset
When you do `load("squad")`, it will also download the checksums file and put it next to the script in nlp/datasets/hash/urls_checksums/checksums.txt.
It also verifies that the downloaded files checksums match the expected ones.
You can ignore checksum tests with `load("squad", ignore_checksums=True)` (under the hood it just adds `ignore_checksums=True` in the `DownloadConfig`)
### Test a dataset
There is a new command `nlp-cli test squad` that runs `download_and_prepare` to see if it runs ok, and that verifies that all the checksums match. Allowed arguments are `--name`, `--all_configs`, `--ignore_checksums` and `--register_checksums`.
### Register checksums
1. If the dataset has external dataset files
The command `nlp-cli test squad --register_checksums --all_configs` runs `download_and_prepare` on all configs to see if it runs ok, and it creates the checksums file.
You can also register one config at a time using `--name` instead ; the checksums file will be completed and not overwritten.
If the script is a local script, the checksum file is moved to urls_checksums/checksums.txt next to the local script, to enable the user to upload both the script and the checksums file afterwards with `nlp-cli upload squad`.
2. If the dataset files are all inside the directory of the dataset script
The user can directly do `nlp-cli upload squad --register_checksums`, as there is no need to download anything.
In this case however, all the dataset must be uploaded at once.
--
PS : it doesn't allow to register checksums for canonical datasets, the file has to be added manually on S3 for now (I guess ?)
Also I feel like we must be sure that this processes would not constrain too much any user from uploading its dataset.
Let me know what you think :) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/24/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/24/timeline | null | null | 6,626 | true | [
"Looks good to me :-) \r\n\r\nJust would prefer to get rid of the `_DYNAMICALLY_IMPORTED_MODULE` attribute and replace it by a `get_imported_module()` function. Maybe there is something I'm not seeing here though - what do you think? ",
"> * I'm not sure I understand the general organization of checksums. I see we have a checksum folder with potentially several checksum files but I also see that checksum files can potentially contain several checksums. Could you explain a bit more how this is organized?\r\n\r\nIt should look like this:\r\nsquad/\r\n├── squad.py/\r\n└── urls_checksums/\r\n...........└── checksums.txt\r\n\r\nIn checksums.txt, the format is one line per (url, size, checksum)\r\n\r\nI don't have a strong opinion between `urls_checksums/checksums.txt` or directly `checksums.txt` (not inside the `urls_checksums` folder), let me know what you think.\r\n\r\n\r\n> * Also regarding your comment on checksum files for \"canonical\" datasets. I understand we can just create these with `nlp-cli test` and then upload them manually to our S3, right?\r\n\r\nYes you're right",
"Update of the commands:\r\n\r\n- nlp-cli test \\<dataset\\> : Run download_and_prepare and verify checksums\r\n * --name \\<name\\> : run only for the name\r\n * --all_configs : run for all configs\r\n * --save_checksums : instead of verifying checksums, compute and save them\r\n * --ignore_checksums : don't do checksums verification\r\n\r\n- nlp-cli upload \\<dataset_folder\\> : Upload a dataset\r\n * --upload_checksums : compute and upload checksums for uploaded files\r\n\r\nTODO:\r\n- don't overwrite checksums files on S3, to let the user upload a dataset in several steps if needed\r\n\r\nQuestion:\r\n- One idea from @patrickvonplaten : shall we upload checksums everytime we upload files ? (and therefore remove the upload_checksums parameter)",
"Ok, ready to merge, then @lhoestq ?",
"Yep :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/23 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/23/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/23/comments | https://api.github.com/repos/huggingface/datasets/issues/23/events | https://github.com/huggingface/datasets/pull/23 | 608,508,706 | MDExOlB1bGxSZXF1ZXN0NDEwMjczOTU2 | 23 | Add metrics | {
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham"
} | [] | closed | false | null | [] | null | 0 | "2020-04-28T18:02:05Z" | "2022-10-04T09:31:56Z" | "2020-05-11T08:19:38Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/23.diff",
"html_url": "https://github.com/huggingface/datasets/pull/23",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/23.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/23"
} | This PR is a draft for adding metrics (sacrebleu and seqeval are added)
use case examples:
`import nlp`
**sacrebleu:**
```
refs = [['The dog bit the man.', 'It was not unexpected.', 'The man bit him first.'],
['The dog had bit the man.', 'No one was surprised.', 'The man had bitten the dog.']]
sys = ['The dog bit the man.', "It wasn't surprising.", 'The man had just bitten him.']
sacrebleu = nlp.load_metrics('sacrebleu')
print(sacrebleu.score)
```
**seqeval:**
```
y_true = [['O', 'O', 'O', 'B-MISC', 'I-MISC', 'I-MISC', 'O'], ['B-PER', 'I-PER', 'O']]
y_pred = [['O', 'O', 'B-MISC', 'I-MISC', 'I-MISC', 'I-MISC', 'O'], ['B-PER', 'I-PER', 'O']]
seqeval = nlp.load_metrics('seqeval')
print(seqeval.accuracy_score(y_true, y_pred)
print(seqeval.f1_score(y_true, y_pred)
```
_examples are taken from the corresponding web page_
your comments and suggestions are more than welcomed
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/23/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/23/timeline | null | null | 6,627 | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/22 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/22/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/22/comments | https://api.github.com/repos/huggingface/datasets/issues/22/events | https://github.com/huggingface/datasets/pull/22 | 608,298,586 | MDExOlB1bGxSZXF1ZXN0NDEwMTAyMjU3 | 22 | adding bleu score code | {
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham"
} | [] | closed | false | null | [] | null | 0 | "2020-04-28T13:00:50Z" | "2020-04-28T17:48:20Z" | "2020-04-28T17:48:08Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/22.diff",
"html_url": "https://github.com/huggingface/datasets/pull/22",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/22.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/22"
} | this PR add the BLEU score metric to the lib. It can be tested by running the following code.
` from nlp.metrics import bleu
hyp1 = "It is a guide to action which ensures that the military always obeys the commands of the party"
ref1a = "It is a guide to action that ensures that the military forces always being under the commands of the party "
ref1b = "It is the guiding principle which guarantees the military force always being under the command of the Party"
ref1c = "It is the practical guide for the army always to heed the directions of the party"
list_of_references = [[ref1a, ref1b, ref1c]]
hypotheses = [hyp1]
bleu = bleu.bleu_score(list_of_references, hypotheses,4, smooth=True)
print(bleu) ` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/22/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/22/timeline | null | null | 6,628 | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/21 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/21/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/21/comments | https://api.github.com/repos/huggingface/datasets/issues/21/events | https://github.com/huggingface/datasets/pull/21 | 607,914,185 | MDExOlB1bGxSZXF1ZXN0NDA5Nzk2MTM4 | 21 | Cleanup Features - Updating convert command - Fix Download manager | {
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf"
} | [] | closed | false | null | [] | null | 2 | "2020-04-27T23:16:55Z" | "2020-05-01T09:29:47Z" | "2020-05-01T09:29:46Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/21.diff",
"html_url": "https://github.com/huggingface/datasets/pull/21",
"merged_at": "2020-05-01T09:29:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/21.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/21"
} | This PR makes a number of changes:
# Updating `Features`
Features are a complex mechanism provided in `tfds` to be able to modify a dataset on-the-fly when serializing to disk and when loading from disk.
We don't really need this because (1) it hides too much from the user and (2) our datatype can be directly mapped to Arrow tables on drive so we usually don't need to change the format before/after serialization.
This PR extracts and refactors these features in a single `features.py` files. It still keep a number of features classes for easy compatibility with tfds, namely the `Sequence`, `Tensor`, `ClassLabel` and `Translation` features.
Some more complex features involving a pre-processing on-the-fly during serialization are kept:
- `ClassLabel` which are able to convert from label strings to integers,
- `Translation`which does some check on the languages.
# Updating the `convert` command
We do a few updates here
- following the simplification of the `features` (cf above), conversion are updated
- we also makes it simpler to convert a single file
- some code need to be fixed manually after conversion (e.g. to remove some encoding processing in former tfds `Text` features. We highlight this code with a "git merge conflict" style syntax for easy manual fixing.
# Fix download manager iterator
You kept me up quite late on Tuesday night with this `os.scandir` change @lhoestq ;-)
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/21/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/21/timeline | null | null | 6,629 | true | [
"For conflicts, I think the mention hint \"This should be modified because it mentions ...\" is missing.",
"Looks great!"
] |
https://api.github.com/repos/huggingface/datasets/issues/20 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/20/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/20/comments | https://api.github.com/repos/huggingface/datasets/issues/20/events | https://github.com/huggingface/datasets/pull/20 | 607,313,557 | MDExOlB1bGxSZXF1ZXN0NDA5MzEyMDI1 | 20 | remove boto3 and promise dependencies | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | 0 | "2020-04-27T07:39:45Z" | "2020-04-27T16:04:17Z" | "2020-04-27T14:15:45Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/20.diff",
"html_url": "https://github.com/huggingface/datasets/pull/20",
"merged_at": "2020-04-27T14:15:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/20.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/20"
} | With the new download manager, we don't need `promise` anymore.
I also removed `boto3` as in [this pr](https://github.com/huggingface/transformers/pull/3968) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/20/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/20/timeline | null | null | 6,630 | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/19 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/19/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/19/comments | https://api.github.com/repos/huggingface/datasets/issues/19/events | https://github.com/huggingface/datasets/pull/19 | 606,400,645 | MDExOlB1bGxSZXF1ZXN0NDA4NjIwMjUw | 19 | Replace tf.constant for TF | {
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.github.com/users/jplu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jplu",
"id": 959590,
"login": "jplu",
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"organizations_url": "https://api.github.com/users/jplu/orgs",
"received_events_url": "https://api.github.com/users/jplu/received_events",
"repos_url": "https://api.github.com/users/jplu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jplu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jplu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jplu"
} | [] | closed | false | null | [] | null | 1 | "2020-04-24T15:32:06Z" | "2020-04-29T09:27:08Z" | "2020-04-25T21:18:45Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/19.diff",
"html_url": "https://github.com/huggingface/datasets/pull/19",
"merged_at": "2020-04-25T21:18:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/19.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/19"
} | Replace simple tf.constant type of Tensor to tf.ragged.constant which allows to have examples of different size in a tf.data.Dataset.
Now the training works with TF. Here the same example than for the PT in collab:
```python
import tensorflow as tf
import nlp
from transformers import BertTokenizerFast, TFBertForQuestionAnswering
# Load our training dataset and tokenizer
train_dataset = nlp.load('squad', split="train[:1%]")
tokenizer = BertTokenizerFast.from_pretrained('bert-base-cased')
def get_correct_alignement(context, answer):
start_idx = answer['answer_start'][0]
text = answer['text'][0]
end_idx = start_idx + len(text)
if context[start_idx:end_idx] == text:
return start_idx, end_idx # When the gold label position is good
elif context[start_idx-1:end_idx-1] == text:
return start_idx-1, end_idx-1 # When the gold label is off by one character
elif context[start_idx-2:end_idx-2] == text:
return start_idx-2, end_idx-2 # When the gold label is off by two character
else:
raise ValueError()
# Tokenize our training dataset
def convert_to_features(example_batch):
# Tokenize contexts and questions (as pairs of inputs)
input_pairs = list(zip(example_batch['context'], example_batch['question']))
encodings = tokenizer.batch_encode_plus(input_pairs, pad_to_max_length=True)
# Compute start and end tokens for labels using Transformers's fast tokenizers alignement methods.
start_positions, end_positions = [], []
for i, (context, answer) in enumerate(zip(example_batch['context'], example_batch['answers'])):
start_idx, end_idx = get_correct_alignement(context, answer)
start_positions.append([encodings.char_to_token(i, start_idx)])
end_positions.append([encodings.char_to_token(i, end_idx-1)])
if start_positions and end_positions:
encodings.update({'start_positions': start_positions,
'end_positions': end_positions})
return encodings
train_dataset = train_dataset.map(convert_to_features, batched=True)
columns = ['input_ids', 'token_type_ids', 'attention_mask', 'start_positions', 'end_positions']
train_dataset.set_format(type='tensorflow', columns=columns)
features = {x: train_dataset[x] for x in columns[:3]}
labels = {"output_1": train_dataset["start_positions"]}
labels["output_2"] = train_dataset["end_positions"]
tfdataset = tf.data.Dataset.from_tensor_slices((features, labels)).batch(8)
model = TFBertForQuestionAnswering.from_pretrained("bert-base-cased")
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(reduction=tf.keras.losses.Reduction.NONE, from_logits=True)
opt = tf.keras.optimizers.Adam(learning_rate=3e-5)
model.compile(optimizer=opt,
loss={'output_1': loss_fn, 'output_2': loss_fn},
loss_weights={'output_1': 1., 'output_2': 1.},
metrics=['accuracy'])
model.fit(tfdataset, epochs=1, steps_per_epoch=3)
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/19/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/19/timeline | null | null | 6,631 | true | [
"Awesome!"
] |
https://api.github.com/repos/huggingface/datasets/issues/18 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/18/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/18/comments | https://api.github.com/repos/huggingface/datasets/issues/18/events | https://github.com/huggingface/datasets/pull/18 | 606,109,196 | MDExOlB1bGxSZXF1ZXN0NDA4Mzg0MTc3 | 18 | Updating caching mechanism - Allow dependency in dataset processing scripts - Fix style and quality in the repo | {
"avatar_url": "https://avatars.githubusercontent.com/u/7353373?v=4",
"events_url": "https://api.github.com/users/thomwolf/events{/privacy}",
"followers_url": "https://api.github.com/users/thomwolf/followers",
"following_url": "https://api.github.com/users/thomwolf/following{/other_user}",
"gists_url": "https://api.github.com/users/thomwolf/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/thomwolf",
"id": 7353373,
"login": "thomwolf",
"node_id": "MDQ6VXNlcjczNTMzNzM=",
"organizations_url": "https://api.github.com/users/thomwolf/orgs",
"received_events_url": "https://api.github.com/users/thomwolf/received_events",
"repos_url": "https://api.github.com/users/thomwolf/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/thomwolf/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomwolf/subscriptions",
"type": "User",
"url": "https://api.github.com/users/thomwolf"
} | [] | closed | false | null | [] | null | 1 | "2020-04-24T07:39:48Z" | "2020-04-29T15:27:28Z" | "2020-04-28T16:06:28Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/18.diff",
"html_url": "https://github.com/huggingface/datasets/pull/18",
"merged_at": "2020-04-28T16:06:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/18.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/18"
} | This PR has a lot of content (might be hard to review, sorry, in particular because I fixed the style in the repo at the same time).
# Style & quality:
You can now install the style and quality tools with `pip install -e .[quality]`. This will install black, the compatible version of sort and flake8.
You can then clean the style and check the quality before merging your PR with:
```bash
make style
make quality
```
# Allow dependencies in dataset processing scripts
We can now allow (some level) of imports in dataset processing scripts (in addition to PyPi imports).
Namely, you can do the two following things:
Import from a relative path to a file in the same folder as the dataset processing script:
```python
import .c4_utils
```
Or import from a relative path to a file in a folder/archive/github repo to which you provide an URL after the import state with `# From: [URL]`:
```python
import .clicr.dataset_code.build_json_dataset # From: https://github.com/clips/clicr
```
In both these cases, after downloading the main dataset processing script, we will identify the location of these dependencies, download them and copy them in the dataset processing script folder.
Note that only direct import in the dataset processing script will be handled.
We don't recursively explore the additional import to download further files.
Also, when we download from an additional directory (in the second case above), we recursively add `__init__.py` to all the sub-folder so you can import from them.
This part is still tested for now. If you've seen datasets which required external utilities, tell me and I can test it.
# Update the cache to have a better local structure
The local structure in the `src/datasets` folder is now: `src/datasets/DATASET_NAME/DATASET_HASH/*`
The hash is computed from the full code of the dataset processing script as well as all the local and downloaded dependencies as mentioned above. This way if you change some code in a utility related to your dataset, a new hash should be computed. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/18/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/18/timeline | null | null | 6,632 | true | [
"LGTM"
] |
https://api.github.com/repos/huggingface/datasets/issues/17 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/17/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/17/comments | https://api.github.com/repos/huggingface/datasets/issues/17/events | https://github.com/huggingface/datasets/pull/17 | 605,753,027 | MDExOlB1bGxSZXF1ZXN0NDA4MDk3NjM0 | 17 | Add Pandas as format type | {
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.github.com/users/jplu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jplu",
"id": 959590,
"login": "jplu",
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"organizations_url": "https://api.github.com/users/jplu/orgs",
"received_events_url": "https://api.github.com/users/jplu/received_events",
"repos_url": "https://api.github.com/users/jplu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jplu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jplu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jplu"
} | [] | closed | false | null | [] | null | 0 | "2020-04-23T18:20:14Z" | "2020-04-27T18:07:50Z" | "2020-04-27T18:07:48Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/17.diff",
"html_url": "https://github.com/huggingface/datasets/pull/17",
"merged_at": "2020-04-27T18:07:48Z",
"patch_url": "https://github.com/huggingface/datasets/pull/17.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/17"
} | As detailed in the title ^^ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/17/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/17/timeline | null | null | 6,633 | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/16 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/16/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/16/comments | https://api.github.com/repos/huggingface/datasets/issues/16/events | https://github.com/huggingface/datasets/pull/16 | 605,661,462 | MDExOlB1bGxSZXF1ZXN0NDA4MDIyMTUz | 16 | create our own DownloadManager | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https://api.github.com/users/lhoestq/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/lhoestq",
"id": 42851186,
"login": "lhoestq",
"node_id": "MDQ6VXNlcjQyODUxMTg2",
"organizations_url": "https://api.github.com/users/lhoestq/orgs",
"received_events_url": "https://api.github.com/users/lhoestq/received_events",
"repos_url": "https://api.github.com/users/lhoestq/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/lhoestq/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lhoestq/subscriptions",
"type": "User",
"url": "https://api.github.com/users/lhoestq"
} | [] | closed | false | null | [] | null | 4 | "2020-04-23T16:08:07Z" | "2021-05-05T18:25:24Z" | "2020-04-25T21:25:10Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/16.diff",
"html_url": "https://github.com/huggingface/datasets/pull/16",
"merged_at": "2020-04-25T21:25:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/16.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/16"
} | I tried to create our own - and way simpler - download manager, by replacing all the complicated stuff with our own `cached_path` solution.
With this implementation, I tried `dataset = nlp.load('squad')` and it seems to work fine.
For the implementation, what I did exactly:
- I copied the old download manager
- I removed all the dependences to the old `download` files
- I replaced all the download + extract calls by calls to `cached_path`
- I removed unused parameters (extract_dir, compute_stats) (maybe compute_stats could be re-added later if we want to compute stats...)
- I left some functions unimplemented for now. We will probably have to implement them because they are used by some datasets scripts (download_kaggle_data, iter_archive) or because we may need them at some point (download_checksums, _record_sizes_checksums)
Let me know if you think that this is going the right direction or if you have remarks.
Note: I didn't write any test yet as I wanted to read your remarks first | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/16/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/16/timeline | null | null | 6,634 | true | [
"Looks great to me! ",
"The new download manager is ready. I removed the old folder and I fixed a few remaining dependencies.\r\nI tested it on squad and a few others from the dataset folder and it works fine.\r\n\r\nThe only impact of these changes is that it breaks the `download_and_prepare` script that was used to register the checksums when we create a dataset, as the checksum logic is not implemented.\r\n\r\nLet me know if you have remarks",
"Ok merged it (a bit fast for you to update the copyright, now I see that. but it's ok, we'll do a pass on these doc/copyright before releasing anyway)",
"Actually two additional things here @lhoestq (I merged too fast sorry, let's make a new PR for additional developments):\r\n- I think we can remove some dependencies now (e.g. `promises`) in setup.py, can you have a look?\r\n- also, I think we can remove the boto3 dependency like here: https://github.com/huggingface/transformers/pull/3968"
] |
https://api.github.com/repos/huggingface/datasets/issues/15 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/15/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/15/comments | https://api.github.com/repos/huggingface/datasets/issues/15/events | https://github.com/huggingface/datasets/pull/15 | 604,906,708 | MDExOlB1bGxSZXF1ZXN0NDA3NDEwOTk3 | 15 | [Tests] General Test Design for all dataset scripts | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [] | closed | false | null | [] | null | 10 | "2020-04-22T16:46:01Z" | "2022-10-04T09:31:54Z" | "2020-04-27T14:48:02Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/15.diff",
"html_url": "https://github.com/huggingface/datasets/pull/15",
"merged_at": "2020-04-27T14:48:02Z",
"patch_url": "https://github.com/huggingface/datasets/pull/15.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/15"
} | The general idea is similar to how testing is done in `transformers`. There is one general `test_dataset_common.py` file which has a `DatasetTesterMixin` class. This class implements all of the logic that can be used in a generic way for all dataset classes. The idea is to keep each individual dataset test file as minimal as possible.
In order to test whether the specific data set class can download the data and generate the examples **without** downloading the actual data all the time, a MockDataLoaderManager class is used which receives a `mock_folder_structure_fn` function from each individual dataset test file that create "fake" data and which returns the same folder structure that would have been created when using the real data downloader. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/15/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/15/timeline | null | null | 6,635 | true | [
"> I think I'm fine with this.\r\n> \r\n> The alternative would be to host a small subset of the dataset on the S3 together with the testing script. But I think having all (test file creation + actual tests) in one file is actually quite convenient.\r\n> \r\n> Good for me!\r\n> \r\n> One question though, will we have to create one test file for each of the 100+ datasets or could we make some automatic conversion from tfds dataset test files?\r\n\r\nI think if we go the way shown in the PR we would have to create one test file for each of the 100+ datasets. \r\n\r\nAs far as I know the tfds test files all rely on the user having created a special download folder structure in `tensorflow-datasets/tensorflow_datasets/testing/test_data/fake_examples`. \r\n\r\nMy hypothesis was: \r\nBecasue, we don't want to work with PRs, no `dataset_script` is going to be in the official repo, so no `dataset_script_test` can be in the repo either. Therefore we can also not have any \"fake\" test folder structure in the repo. \r\n\r\n**BUT:** As you mentioned @thom, we could have a fake data structure on AWS. To add a test the user has to upload multiple small test files when uploading his data set script. \r\n\r\nSo for a cli this could look like:\r\n`python nlp-cli upload <data_set_script> --testfiles <relative path to test file 1> <relative path to test file 2> ...` \r\n\r\nor even easier if the user just creates the dataset folder with the script inside and the testing folder structure, then the API could look like:\r\n\r\n`python nlp-cli upload <path/to/dataset/folder>`\r\n\r\nand the dataset folder would look like\r\n```\r\nsquad\r\n- squad.py\r\n- fake_data # this dir would have to have the exact same structure we get when downloading from the official squad data url\r\n```\r\n\r\nThis way I think we wouldn't even need any test files at all for each dataset script. For special datasets like `c4` or `wikipedia` we could then allow to optionally upload another test script. \r\nWe just assume that this is our downloaded `url` and check all functionality from there. \r\n\r\nThinking a bit more about this solution sounds a) much less work and b) even easier for the user.\r\n\r\nA small problem I see here though:\r\n1) What do we do when the depending on the config name the downloaded folder structure is very different? I think for each dataset config name we should have one test, which could correspond to one \"fake\" folder structure on AWS\r\n\r\n@thomwolf What do you think? I would actually go for this solution instead now.\r\n@mariamabarham You have written many more tfds dataset scripts and tests than I have - what do you think? \r\n\r\n",
"Regarding the tfds tests, I don't really see a point in keeping them because:\r\n\r\n1) If you provide a fake data structure, IMO there is no need for each dataset to have an individual test file because (I think) most datasets have the same functions `_split_generators` and `_generate_examples` for which you can just test the functionality in a common test file. For special functions like these beam / pipeline functionality you probably need an extra test file. But @mariamabarham I think you have seen more than I have here as well \r\n\r\n2) The dataset test design is very much intertwined with the download manager design and contains a lot of code. I would like to seperate the tests into a) tests for downloading in general b) tests for post download data set pre-processing. Since we are going to change the download code anyways quite a lot, my plan was to focus on b) first. ",
"I like the idea of having a fake data folder on S3. I have seen datasets with nested compressed files structures that would be tedious to generate with code. And for users it is probably easier to create a fake data folder by taking a subset of the actual data, and then upload it as you said.",
"> > I think I'm fine with this.\r\n> > The alternative would be to host a small subset of the dataset on the S3 together with the testing script. But I think having all (test file creation + actual tests) in one file is actually quite convenient.\r\n> > Good for me!\r\n> > One question though, will we have to create one test file for each of the 100+ datasets or could we make some automatic conversion from tfds dataset test files?\r\n> \r\n> I think if we go the way shown in the PR we would have to create one test file for each of the 100+ datasets.\r\n> \r\n> As far as I know the tfds test files all rely on the user having created a special download folder structure in `tensorflow-datasets/tensorflow_datasets/testing/test_data/fake_examples`.\r\n> \r\n> My hypothesis was:\r\n> Becasue, we don't want to work with PRs, no `dataset_script` is going to be in the official repo, so no `dataset_script_test` can be in the repo either. Therefore we can also not have any \"fake\" test folder structure in the repo.\r\n> \r\n> **BUT:** As you mentioned @thom, we could have a fake data structure on AWS. To add a test the user has to upload multiple small test files when uploading his data set script.\r\n> \r\n> So for a cli this could look like:\r\n> `python nlp-cli upload <data_set_script> --testfiles <relative path to test file 1> <relative path to test file 2> ...`\r\n> \r\n> or even easier if the user just creates the dataset folder with the script inside and the testing folder structure, then the API could look like:\r\n> \r\n> `python nlp-cli upload <path/to/dataset/folder>`\r\n> \r\n> and the dataset folder would look like\r\n> \r\n> ```\r\n> squad\r\n> - squad.py\r\n> - fake_data # this dir would have to have the exact same structure we get when downloading from the official squad data url\r\n> ```\r\n> \r\n> This way I think we wouldn't even need any test files at all for each dataset script. For special datasets like `c4` or `wikipedia` we could then allow to optionally upload another test script.\r\n> We just assume that this is our downloaded `url` and check all functionality from there.\r\n> \r\n> Thinking a bit more about this solution sounds a) much less work and b) even easier for the user.\r\n> \r\n> A small problem I see here though:\r\n> \r\n> 1. What do we do when the depending on the config name the downloaded folder structure is very different? I think for each dataset config name we should have one test, which could correspond to one \"fake\" folder structure on AWS\r\n> \r\n> @thomwolf What do you think? I would actually go for this solution instead now.\r\n> @mariamabarham You have written many more tfds dataset scripts and tests than I have - what do you think?\r\n\r\nI'm agreed with you just one thing, for some dataset like glue or xtreme you may have multiple datasets in it. so I think a good way is to have one main fake folder and a subdirectory for each dataset inside",
"> Regarding the tfds tests, I don't really see a point in keeping them because:\r\n> \r\n> 1. If you provide a fake data structure, IMO there is no need for each dataset to have an individual test file because (I think) most datasets have the same functions `_split_generators` and `_generate_examples` for which you can just test the functionality in a common test file. For special functions like these beam / pipeline functionality you probably need an extra test file. But @mariamabarham I think you have seen more than I have here as well\r\n> 2. The dataset test design is very much intertwined with the download manager design and contains a lot of code. I would like to seperate the tests into a) tests for downloading in general b) tests for post download data set pre-processing. Since we are going to change the download code anyways quite a lot, my plan was to focus on b) first.\r\n\r\nFor _split_generator, yes. But I'm not sure for _generate_examples because there is lots of things that should be taken into account such as feature names and types, data format (json, jsonl, csv, tsv,..)",
"Sounds good to me!\r\n\r\nWhen testing, we could thus just override the prefix in the URL inside the download manager to have them point to the test directory on our S3.\r\n\r\nCc @lhoestq ",
"Ok, here is a second draft for the testing structure. \r\n\r\nI think the big difficulty here is \"How can you generate tests on the fly from a given dataset name, *e.g.* `squad`\"?\r\n\r\nSo, this morning I did some research on \"parameterized testing\" and pure `unittest` or `pytest` didn't work very well. \r\nI found the lib https://github.com/wolever/parameterized, which works very nicely for our use case I think. \r\n@thomwolf - would it be ok to have a dependence on this lib for `nlp`? It seems like a light-weight lib to me. \r\n\r\nThis lib allows to add a `parameterization` decorator to a `unittest.TestCase` class so that the class can be instantiated for multiple different arguments (which are the dataset names `squad` etc. in our case).\r\n\r\nWhat I like about this lib is that one only has to add the decorator and the each of the parameterized tests are shown, like this: \r\n\r\n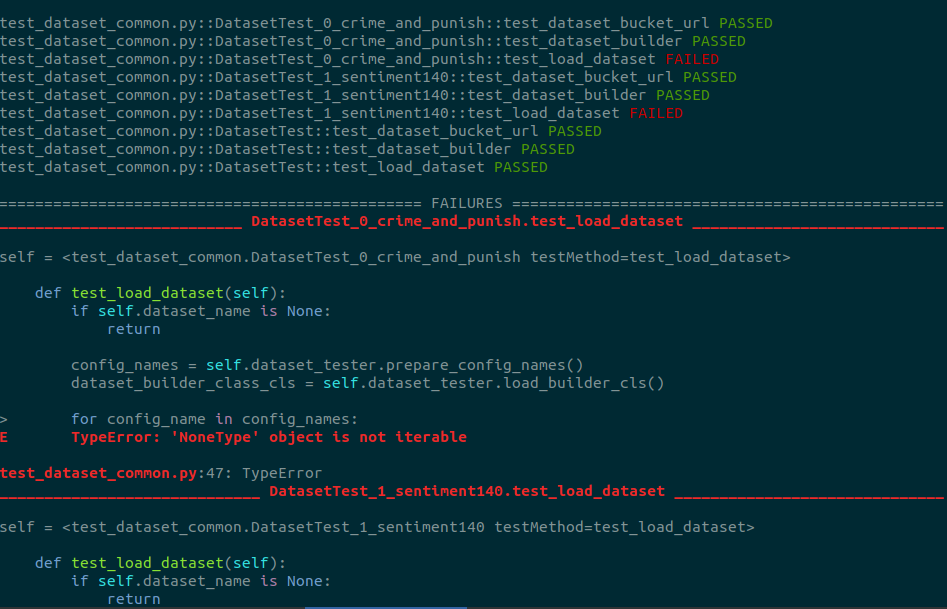\r\n\r\nWith this structure we would only have to upload the dummy data for each dataset and would not require a specific testing file. \r\n\r\nWhat do you think @thomwolf @mariamabarham @lhoestq ?",
"I think this is a nice solution.\r\n\r\nDo you think we could have the `parametrized` dependency in a `[test]` optional installation of `setup.py`? I would really like to keep the dependencies of the standard installation as small as possible. ",
"> I think this is a nice solution.\r\n> \r\n> Do you think we could have the `parametrized` dependency in a `[test]` optional installation of `setup.py`? I would really like to keep the dependencies of the standard installation as small as possible.\r\n\r\nYes definitely!",
"UPDATE: \r\n\r\nThis test design is ready now. I added dummy data to S3 for the dataests: `squad, crime_and_punish, sentiment140` . The structure can be seen on `https://s3.console.aws.amazon.com/s3/buckets/datasets.huggingface.co/nlp/squad/dummy/?region=us-east-1&tab=overview` for `squad`. \r\n\r\nAll dummy data files have to be in .zip format and called `dummy_data.zip`. The zip file should thereby have the exact same folder structure one gets from downloading the \"real\" data url(s). \r\n\r\nTo show how the .zip file looks like for the added datasets, I added the folder `nlp/datasets/dummy_data` in this PR. I think we can leave for the moment so that people can see better how to add dummy data tests and later delete it like `nlp/datasets/nlp`."
] |
https://api.github.com/repos/huggingface/datasets/issues/14 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/14/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/14/comments | https://api.github.com/repos/huggingface/datasets/issues/14/events | https://github.com/huggingface/datasets/pull/14 | 604,761,315 | MDExOlB1bGxSZXF1ZXN0NDA3MjkzNjU5 | 14 | [Download] Only create dir if not already exist | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [] | closed | false | null | [] | null | 0 | "2020-04-22T13:32:51Z" | "2022-10-04T09:31:50Z" | "2020-04-23T08:27:33Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/14.diff",
"html_url": "https://github.com/huggingface/datasets/pull/14",
"merged_at": "2020-04-23T08:27:33Z",
"patch_url": "https://github.com/huggingface/datasets/pull/14.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/14"
} | This was quite annoying to find out :D.
Some datasets have save in the same directory. So we should only create a new directory if it doesn't already exist. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/14/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/14/timeline | null | null | 6,636 | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/13 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/13/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/13/comments | https://api.github.com/repos/huggingface/datasets/issues/13/events | https://github.com/huggingface/datasets/pull/13 | 604,547,951 | MDExOlB1bGxSZXF1ZXN0NDA3MTIxMjkw | 13 | [Make style] | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [] | closed | false | null | [] | null | 3 | "2020-04-22T08:10:06Z" | "2022-10-04T09:31:51Z" | "2020-04-23T13:02:22Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/13.diff",
"html_url": "https://github.com/huggingface/datasets/pull/13",
"merged_at": "2020-04-23T13:02:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/13.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/13"
} | Added Makefile and applied make style to all.
make style runs the following code:
```
style:
black --line-length 119 --target-version py35 src
isort --recursive src
```
It's the same code that is run in `transformers`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/13/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/13/timeline | null | null | 6,637 | true | [
"I think this can be quickly reproduced. \r\nI use `black, version 19.10b0`. \r\n\r\nWhen running: \r\n`black nlp/src/arrow_reader.py` \r\nit gives me: \r\n\r\n```\r\nerror: cannot format /home/patrick/hugging_face/nlp/src/nlp/arrow_reader.py: cannot use --safe with this file; failed to parse source file. AST error message: invalid syntax (<unknown>, line 78)\r\nOh no! 💥 💔 💥\r\n1 file failed to reformat.\r\n```\r\n\r\nThe line in question is: \r\nhttps://github.com/huggingface/nlp/blob/6922a16705e61f9e31a365f2606090b84d49241f/src/nlp/arrow_reader.py#L78\r\n\r\nWhat is weird is that the trainer file in `transformers` has more or less the same syntax and black does not fail there: \r\nhttps://github.com/huggingface/transformers/blob/cb3c2212c79d7ff0a4a4e84c3db48371ecc1c15d/src/transformers/trainer.py#L95\r\n\r\nI googled quite a bit about black & typing hints yesterday and didn't find anything useful. \r\nAny ideas @thomwolf @julien-c @LysandreJik ?",
"> I think this can be quickly reproduced.\r\n> I use `black, version 19.10b0`.\r\n> \r\n> When running:\r\n> `black nlp/src/arrow_reader.py`\r\n> it gives me:\r\n> \r\n> ```\r\n> error: cannot format /home/patrick/hugging_face/nlp/src/nlp/arrow_reader.py: cannot use --safe with this file; failed to parse source file. AST error message: invalid syntax (<unknown>, line 78)\r\n> Oh no! 💥 💔 💥\r\n> 1 file failed to reformat.\r\n> ```\r\n> \r\n> The line in question is:\r\n> https://github.com/huggingface/nlp/blob/6922a16705e61f9e31a365f2606090b84d49241f/src/nlp/arrow_reader.py#L78\r\n> \r\n> What is weird is that the trainer file in `transformers` has more or less the same syntax and black does not fail there:\r\n> https://github.com/huggingface/transformers/blob/cb3c2212c79d7ff0a4a4e84c3db48371ecc1c15d/src/transformers/trainer.py#L95\r\n> \r\n> I googled quite a bit about black & typing hints yesterday and didn't find anything useful.\r\n> Any ideas @thomwolf @julien-c @LysandreJik ?\r\n\r\nOk I found the problem. It was the one Julien mentioned and has nothing to do with this line. Black's error message is a bit misleading here, I guess",
"Ok, just had to remove the python 2 syntax comments `# type`. \r\n\r\nGood to merge for me now @thomwolf "
] |
https://api.github.com/repos/huggingface/datasets/issues/12 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/12/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/12/comments | https://api.github.com/repos/huggingface/datasets/issues/12/events | https://github.com/huggingface/datasets/pull/12 | 604,518,583 | MDExOlB1bGxSZXF1ZXN0NDA3MDk3MzA4 | 12 | [Map Function] add assert statement if map function does not return dict or None | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [] | closed | false | null | [] | null | 3 | "2020-04-22T07:21:24Z" | "2022-10-04T09:31:53Z" | "2020-04-24T06:29:03Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/12.diff",
"html_url": "https://github.com/huggingface/datasets/pull/12",
"merged_at": "2020-04-24T06:29:03Z",
"patch_url": "https://github.com/huggingface/datasets/pull/12.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/12"
} | IMO, if a function is provided that is not a print statement (-> returns variable of type `None`) or a function that updates the datasets (-> returns variable of type `dict`), then a `TypeError` should be raised.
Not sure whether you had cases in mind where the user should do something else @thomwolf , but I think a lot of silent errors can be avoided with this assert statement. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/12/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/12/timeline | null | null | 6,638 | true | [
"Also added to an assert statement that if a dict is returned by function, all values of `dicts` are `lists`",
"Wait to merge until `make style` is set in place.",
"Updated the assert statements. Played around with multiple cases and it should be good now IMO. "
] |
https://api.github.com/repos/huggingface/datasets/issues/11 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/11/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/11/comments | https://api.github.com/repos/huggingface/datasets/issues/11/events | https://github.com/huggingface/datasets/pull/11 | 603,921,624 | MDExOlB1bGxSZXF1ZXN0NDA2NjExODk2 | 11 | [Convert TFDS to HFDS] Extend script to also allow just converting a single file | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [] | closed | false | null | [] | null | 0 | "2020-04-21T11:25:33Z" | "2022-10-04T09:31:46Z" | "2020-04-21T20:47:00Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/11.diff",
"html_url": "https://github.com/huggingface/datasets/pull/11",
"merged_at": "2020-04-21T20:47:00Z",
"patch_url": "https://github.com/huggingface/datasets/pull/11.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/11"
} | Adds another argument to be able to convert only a single file | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/11/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/11/timeline | null | null | 6,639 | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/10 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/10/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/10/comments | https://api.github.com/repos/huggingface/datasets/issues/10/events | https://github.com/huggingface/datasets/pull/10 | 603,909,327 | MDExOlB1bGxSZXF1ZXN0NDA2NjAxNzQ2 | 10 | Name json file "squad.json" instead of "squad.py.json" | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [] | closed | false | null | [] | null | 0 | "2020-04-21T11:04:28Z" | "2022-10-04T09:31:44Z" | "2020-04-21T20:48:06Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/10.diff",
"html_url": "https://github.com/huggingface/datasets/pull/10",
"merged_at": "2020-04-21T20:48:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/10.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/10"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/10/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/10/timeline | null | null | 6,640 | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/9 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/9/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/9/comments | https://api.github.com/repos/huggingface/datasets/issues/9/events | https://github.com/huggingface/datasets/pull/9 | 603,894,874 | MDExOlB1bGxSZXF1ZXN0NDA2NTkwMDQw | 9 | [Clean up] Datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/patrickvonplaten",
"id": 23423619,
"login": "patrickvonplaten",
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"type": "User",
"url": "https://api.github.com/users/patrickvonplaten"
} | [] | closed | false | null | [] | null | 1 | "2020-04-21T10:39:56Z" | "2022-10-04T09:31:42Z" | "2020-04-21T20:49:58Z" | MEMBER | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/9.diff",
"html_url": "https://github.com/huggingface/datasets/pull/9",
"merged_at": "2020-04-21T20:49:58Z",
"patch_url": "https://github.com/huggingface/datasets/pull/9.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/9"
} | Clean up `nlp/datasets` folder.
As I understood, eventually the `nlp/datasets` shall not exist anymore at all.
The folder `nlp/datasets/nlp` is kept for the moment, but won't be needed in the future, since it will live on S3 (actually it already does) at: `https://s3.console.aws.amazon.com/s3/buckets/datasets.huggingface.co/nlp/?region=us-east-1` and the different `dataset downloader scripts will be added to `nlp/src/nlp` when downloaded by the user.
The folder `nlp/datasets/checksums` is kept for now, but won't be needed anymore in the future.
The remaining folders/ files are leftovers from tensorflow-datasets and are not needed. The can be looked up in the private tensorflow-dataset repo. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/9/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/9/timeline | null | null | 6,641 | true | [
"Yes!"
] |
https://api.github.com/repos/huggingface/datasets/issues/8 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/8/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/8/comments | https://api.github.com/repos/huggingface/datasets/issues/8/events | https://github.com/huggingface/datasets/pull/8 | 601,783,243 | MDExOlB1bGxSZXF1ZXN0NDA0OTg0NDUz | 8 | Fix issue 6: error when the citation is missing in the DatasetInfo | {
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.github.com/users/jplu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jplu",
"id": 959590,
"login": "jplu",
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"organizations_url": "https://api.github.com/users/jplu/orgs",
"received_events_url": "https://api.github.com/users/jplu/received_events",
"repos_url": "https://api.github.com/users/jplu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jplu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jplu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jplu"
} | [] | closed | false | null | [] | null | 0 | "2020-04-17T08:04:26Z" | "2020-04-29T09:27:11Z" | "2020-04-20T13:24:12Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/8.diff",
"html_url": "https://github.com/huggingface/datasets/pull/8",
"merged_at": "2020-04-20T13:24:12Z",
"patch_url": "https://github.com/huggingface/datasets/pull/8.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/8"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/8/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/8/timeline | null | null | 6,642 | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/7 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/7/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/7/comments | https://api.github.com/repos/huggingface/datasets/issues/7/events | https://github.com/huggingface/datasets/pull/7 | 601,780,534 | MDExOlB1bGxSZXF1ZXN0NDA0OTgyMzA2 | 7 | Fix issue 5: allow empty datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.github.com/users/jplu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jplu",
"id": 959590,
"login": "jplu",
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"organizations_url": "https://api.github.com/users/jplu/orgs",
"received_events_url": "https://api.github.com/users/jplu/received_events",
"repos_url": "https://api.github.com/users/jplu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jplu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jplu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jplu"
} | [] | closed | false | null | [] | null | 0 | "2020-04-17T07:59:56Z" | "2020-04-29T09:27:13Z" | "2020-04-20T13:23:48Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/7.diff",
"html_url": "https://github.com/huggingface/datasets/pull/7",
"merged_at": "2020-04-20T13:23:47Z",
"patch_url": "https://github.com/huggingface/datasets/pull/7.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/7"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/7/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/7/timeline | null | null | 6,643 | true | [] |
|
https://api.github.com/repos/huggingface/datasets/issues/6 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6/comments | https://api.github.com/repos/huggingface/datasets/issues/6/events | https://github.com/huggingface/datasets/issues/6 | 600,330,836 | MDU6SXNzdWU2MDAzMzA4MzY= | 6 | Error when citation is not given in the DatasetInfo | {
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.github.com/users/jplu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jplu",
"id": 959590,
"login": "jplu",
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"organizations_url": "https://api.github.com/users/jplu/orgs",
"received_events_url": "https://api.github.com/users/jplu/received_events",
"repos_url": "https://api.github.com/users/jplu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jplu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jplu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jplu"
} | [] | closed | false | null | [] | null | 3 | "2020-04-15T14:14:54Z" | "2020-04-29T09:23:22Z" | "2020-04-29T09:23:22Z" | CONTRIBUTOR | null | null | null | The following error is raised when the `citation` parameter is missing when we instantiate a `DatasetInfo`:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/jplu/dev/jplu/datasets/src/nlp/info.py", line 338, in __repr__
citation_pprint = _indent('"""{}"""'.format(self.citation.strip()))
AttributeError: 'NoneType' object has no attribute 'strip'
```
I propose to do the following change in the `info.py` file. The method:
```python
def __repr__(self):
splits_pprint = _indent("\n".join(["{"] + [
" '{}': {},".format(k, split.num_examples)
for k, split in sorted(self.splits.items())
] + ["}"]))
features_pprint = _indent(repr(self.features))
citation_pprint = _indent('"""{}"""'.format(self.citation.strip()))
return INFO_STR.format(
name=self.name,
version=self.version,
description=self.description,
total_num_examples=self.splits.total_num_examples,
features=features_pprint,
splits=splits_pprint,
citation=citation_pprint,
homepage=self.homepage,
supervised_keys=self.supervised_keys,
# Proto add a \n that we strip.
license=str(self.license).strip())
```
Becomes:
```python
def __repr__(self):
splits_pprint = _indent("\n".join(["{"] + [
" '{}': {},".format(k, split.num_examples)
for k, split in sorted(self.splits.items())
] + ["}"]))
features_pprint = _indent(repr(self.features))
## the strip is done only is the citation is given
citation_pprint = self.citation
if self.citation:
citation_pprint = _indent('"""{}"""'.format(self.citation.strip()))
return INFO_STR.format(
name=self.name,
version=self.version,
description=self.description,
total_num_examples=self.splits.total_num_examples,
features=features_pprint,
splits=splits_pprint,
citation=citation_pprint,
homepage=self.homepage,
supervised_keys=self.supervised_keys,
# Proto add a \n that we strip.
license=str(self.license).strip())
```
And now it is ok. @thomwolf are you ok with this fix? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6/timeline | null | completed | 6,644 | false | [
"Yes looks good to me.\r\nNote that we may refactor quite strongly the `info.py` to make it a lot simpler (it's very complicated for basically a dictionary of info I think)",
"No, problem ^^ It might just be a temporary fix :)",
"Fixed."
] |
https://api.github.com/repos/huggingface/datasets/issues/5 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5/comments | https://api.github.com/repos/huggingface/datasets/issues/5/events | https://github.com/huggingface/datasets/issues/5 | 600,295,889 | MDU6SXNzdWU2MDAyOTU4ODk= | 5 | ValueError when a split is empty | {
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.github.com/users/jplu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jplu",
"id": 959590,
"login": "jplu",
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"organizations_url": "https://api.github.com/users/jplu/orgs",
"received_events_url": "https://api.github.com/users/jplu/received_events",
"repos_url": "https://api.github.com/users/jplu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jplu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jplu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jplu"
} | [] | closed | false | null | [] | null | 3 | "2020-04-15T13:25:13Z" | "2020-04-29T09:23:05Z" | "2020-04-29T09:23:05Z" | CONTRIBUTOR | null | null | null | When a split is empty either TEST, VALIDATION or TRAIN I get the following error:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/jplu/dev/jplu/datasets/src/nlp/load.py", line 295, in load
ds = dbuilder.as_dataset(**as_dataset_kwargs)
File "/home/jplu/dev/jplu/datasets/src/nlp/builder.py", line 587, in as_dataset
datasets = utils.map_nested(build_single_dataset, split, map_tuple=True)
File "/home/jplu/dev/jplu/datasets/src/nlp/utils/py_utils.py", line 158, in map_nested
for k, v in data_struct.items()
File "/home/jplu/dev/jplu/datasets/src/nlp/utils/py_utils.py", line 158, in <dictcomp>
for k, v in data_struct.items()
File "/home/jplu/dev/jplu/datasets/src/nlp/utils/py_utils.py", line 172, in map_nested
return function(data_struct)
File "/home/jplu/dev/jplu/datasets/src/nlp/builder.py", line 601, in _build_single_dataset
split=split,
File "/home/jplu/dev/jplu/datasets/src/nlp/builder.py", line 625, in _as_dataset
split_infos=self.info.splits.values(),
File "/home/jplu/dev/jplu/datasets/src/nlp/arrow_reader.py", line 200, in read
return py_utils.map_nested(_read_instruction_to_ds, instructions)
File "/home/jplu/dev/jplu/datasets/src/nlp/utils/py_utils.py", line 172, in map_nested
return function(data_struct)
File "/home/jplu/dev/jplu/datasets/src/nlp/arrow_reader.py", line 191, in _read_instruction_to_ds
file_instructions = make_file_instructions(name, split_infos, instruction)
File "/home/jplu/dev/jplu/datasets/src/nlp/arrow_reader.py", line 104, in make_file_instructions
absolute_instructions=absolute_instructions,
File "/home/jplu/dev/jplu/datasets/src/nlp/arrow_reader.py", line 122, in _make_file_instructions_from_absolutes
'Split empty. This might means that dataset hasn\'t been generated '
ValueError: Split empty. This might means that dataset hasn't been generated yet and info not restored from GCS, or that legacy dataset is used.
```
How to reproduce:
```python
import csv
import nlp
class Bbc(nlp.GeneratorBasedBuilder):
VERSION = nlp.Version("1.0.0")
def __init__(self, **config):
self.train = config.pop("train", None)
self.validation = config.pop("validation", None)
super(Bbc, self).__init__(**config)
def _info(self):
return nlp.DatasetInfo(builder=self, description="bla", features=nlp.features.FeaturesDict({"id": nlp.int32, "text": nlp.string, "label": nlp.string}))
def _split_generators(self, dl_manager):
return [nlp.SplitGenerator(name=nlp.Split.TRAIN, gen_kwargs={"filepath": self.train}),
nlp.SplitGenerator(name=nlp.Split.VALIDATION, gen_kwargs={"filepath": self.validation}),
nlp.SplitGenerator(name=nlp.Split.TEST, gen_kwargs={"filepath": None})]
def _generate_examples(self, filepath):
if not filepath:
return None, {}
with open(filepath) as f:
reader = csv.reader(f, delimiter=',', quotechar="\"")
lines = list(reader)[1:]
for idx, line in enumerate(lines):
yield idx, {"id": idx, "text": line[1], "label": line[0]}
```
```python
import nlp
dataset = nlp.load("bbc", builder_kwargs={"train": "bbc/data/train.csv", "validation": "bbc/data/test.csv"})
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5/timeline | null | completed | 6,645 | false | [
"To fix this I propose to modify only the file `arrow_reader.py` with few updates. First update, the following method:\r\n```python\r\ndef _make_file_instructions_from_absolutes(\r\n name,\r\n name2len,\r\n absolute_instructions,\r\n):\r\n \"\"\"Returns the files instructions from the absolute instructions list.\"\"\"\r\n # For each split, return the files instruction (skip/take)\r\n file_instructions = []\r\n num_examples = 0\r\n for abs_instr in absolute_instructions:\r\n length = name2len[abs_instr.splitname]\r\n if not length:\r\n raise ValueError(\r\n 'Split empty. This might means that dataset hasn\\'t been generated '\r\n 'yet and info not restored from GCS, or that legacy dataset is used.')\r\n filename = filename_for_dataset_split(\r\n dataset_name=name,\r\n split=abs_instr.splitname,\r\n filetype_suffix='arrow')\r\n from_ = 0 if abs_instr.from_ is None else abs_instr.from_\r\n to = length if abs_instr.to is None else abs_instr.to\r\n num_examples += to - from_\r\n single_file_instructions = [{\"filename\": filename, \"skip\": from_, \"take\": to - from_}]\r\n file_instructions.extend(single_file_instructions)\r\n return FileInstructions(\r\n num_examples=num_examples,\r\n file_instructions=file_instructions,\r\n )\r\n```\r\nBecomes:\r\n```python\r\ndef _make_file_instructions_from_absolutes(\r\n name,\r\n name2len,\r\n absolute_instructions,\r\n):\r\n \"\"\"Returns the files instructions from the absolute instructions list.\"\"\"\r\n # For each split, return the files instruction (skip/take)\r\n file_instructions = []\r\n num_examples = 0\r\n for abs_instr in absolute_instructions:\r\n length = name2len[abs_instr.splitname]\r\n ## Delete the if not length and the raise\r\n filename = filename_for_dataset_split(\r\n dataset_name=name,\r\n split=abs_instr.splitname,\r\n filetype_suffix='arrow')\r\n from_ = 0 if abs_instr.from_ is None else abs_instr.from_\r\n to = length if abs_instr.to is None else abs_instr.to\r\n num_examples += to - from_\r\n single_file_instructions = [{\"filename\": filename, \"skip\": from_, \"take\": to - from_}]\r\n file_instructions.extend(single_file_instructions)\r\n return FileInstructions(\r\n num_examples=num_examples,\r\n file_instructions=file_instructions,\r\n )\r\n```\r\n\r\nSecond update the following method:\r\n```python\r\ndef _read_files(files, info):\r\n \"\"\"Returns Dataset for given file instructions.\r\n\r\n Args:\r\n files: List[dict(filename, skip, take)], the files information.\r\n The filenames contain the absolute path, not relative.\r\n skip/take indicates which example read in the file: `ds.slice(skip, take)`\r\n \"\"\"\r\n pa_batches = []\r\n for f_dict in files:\r\n pa_table: pa.Table = _get_dataset_from_filename(f_dict)\r\n pa_batches.extend(pa_table.to_batches())\r\n pa_table = pa.Table.from_batches(pa_batches)\r\n ds = Dataset(arrow_table=pa_table, data_files=files, info=info)\r\n return ds\r\n```\r\nBecomes:\r\n```python\r\ndef _read_files(files, info):\r\n \"\"\"Returns Dataset for given file instructions.\r\n\r\n Args:\r\n files: List[dict(filename, skip, take)], the files information.\r\n The filenames contain the absolute path, not relative.\r\n skip/take indicates which example read in the file: `ds.slice(skip, take)`\r\n \"\"\"\r\n pa_batches = []\r\n for f_dict in files:\r\n pa_table: pa.Table = _get_dataset_from_filename(f_dict)\r\n pa_batches.extend(pa_table.to_batches())\r\n ## we modify the table only if there are some batches\r\n if pa_batches:\r\n pa_table = pa.Table.from_batches(pa_batches)\r\n ds = Dataset(arrow_table=pa_table, data_files=files, info=info)\r\n return ds\r\n```\r\n\r\nWith these two updates it works now. @thomwolf are you ok with this changes?",
"Yes sounds good to me!\r\nDo you want to make a PR? or I can do it as well",
"Fixed."
] |
https://api.github.com/repos/huggingface/datasets/issues/4 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4/comments | https://api.github.com/repos/huggingface/datasets/issues/4/events | https://github.com/huggingface/datasets/issues/4 | 600,185,417 | MDU6SXNzdWU2MDAxODU0MTc= | 4 | [Feature] Keep the list of labels of a dataset as metadata | {
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.github.com/users/jplu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jplu",
"id": 959590,
"login": "jplu",
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"organizations_url": "https://api.github.com/users/jplu/orgs",
"received_events_url": "https://api.github.com/users/jplu/received_events",
"repos_url": "https://api.github.com/users/jplu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jplu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jplu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jplu"
} | [] | closed | false | null | [] | null | 6 | "2020-04-15T10:17:10Z" | "2020-07-08T16:59:46Z" | "2020-05-04T06:11:57Z" | CONTRIBUTOR | null | null | null | It would be useful to keep the list of the labels of a dataset as metadata. Either directly in the `DatasetInfo` or in the Arrow metadata. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4/timeline | null | completed | 6,646 | false | [
"Yes! I see mostly two options for this:\r\n- a `Feature` approach like currently (but we might deprecate features)\r\n- wrapping in a smart way the Dictionary arrays of Arrow: https://arrow.apache.org/docs/python/data.html?highlight=dictionary%20encode#dictionary-arrays",
"I would have a preference for the second bullet point.",
"This should be accessible now as a feature in dataset.info.features (and even have the mapping methods).",
"Perfect! Well done!!",
"Hi,\r\nI hope we could get a better documentation.\r\nIt took me more than 1 hour to found this way to get the label information.",
"Yes we are working on the doc right now, should be in the next release quite soon."
] |
https://api.github.com/repos/huggingface/datasets/issues/3 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3/comments | https://api.github.com/repos/huggingface/datasets/issues/3/events | https://github.com/huggingface/datasets/issues/3 | 600,180,050 | MDU6SXNzdWU2MDAxODAwNTA= | 3 | [Feature] More dataset outputs | {
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.github.com/users/jplu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jplu",
"id": 959590,
"login": "jplu",
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"organizations_url": "https://api.github.com/users/jplu/orgs",
"received_events_url": "https://api.github.com/users/jplu/received_events",
"repos_url": "https://api.github.com/users/jplu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jplu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jplu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jplu"
} | [] | closed | false | null | [] | null | 3 | "2020-04-15T10:08:14Z" | "2020-05-04T06:12:27Z" | "2020-05-04T06:12:27Z" | CONTRIBUTOR | null | null | null | Add the following dataset outputs:
- Spark
- Pandas | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3/timeline | null | completed | 6,647 | false | [
"Yes!\r\n- pandas will be a one-liner in `arrow_dataset`: https://arrow.apache.org/docs/python/generated/pyarrow.Table.html#pyarrow.Table.to_pandas\r\n- for Spark I have no idea. let's investigate that at some point",
"For Spark it looks to be pretty straightforward as well https://spark.apache.org/docs/latest/sql-pyspark-pandas-with-arrow.html but looks to be having a dependency to Spark is necessary, then nevermind we can skip it",
"Now Pandas is available."
] |
https://api.github.com/repos/huggingface/datasets/issues/2 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2/comments | https://api.github.com/repos/huggingface/datasets/issues/2/events | https://github.com/huggingface/datasets/issues/2 | 599,767,671 | MDU6SXNzdWU1OTk3Njc2NzE= | 2 | Issue to read a local dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.github.com/users/jplu/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/jplu",
"id": 959590,
"login": "jplu",
"node_id": "MDQ6VXNlcjk1OTU5MA==",
"organizations_url": "https://api.github.com/users/jplu/orgs",
"received_events_url": "https://api.github.com/users/jplu/received_events",
"repos_url": "https://api.github.com/users/jplu/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/jplu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jplu/subscriptions",
"type": "User",
"url": "https://api.github.com/users/jplu"
} | [] | closed | false | null | [] | null | 5 | "2020-04-14T18:18:51Z" | "2020-05-11T18:55:23Z" | "2020-05-11T18:55:22Z" | CONTRIBUTOR | null | null | null | Hello,
As proposed by @thomwolf, I open an issue to explain what I'm trying to do without success. What I want to do is to create and load a local dataset, the script I have done is the following:
```python
import os
import csv
import nlp
class BbcConfig(nlp.BuilderConfig):
def __init__(self, **kwargs):
super(BbcConfig, self).__init__(**kwargs)
class Bbc(nlp.GeneratorBasedBuilder):
_DIR = "./data"
_DEV_FILE = "test.csv"
_TRAINING_FILE = "train.csv"
BUILDER_CONFIGS = [BbcConfig(name="bbc", version=nlp.Version("1.0.0"))]
def _info(self):
return nlp.DatasetInfo(builder=self, features=nlp.features.FeaturesDict({"id": nlp.string, "text": nlp.string, "label": nlp.string}))
def _split_generators(self, dl_manager):
files = {"train": os.path.join(self._DIR, self._TRAINING_FILE), "dev": os.path.join(self._DIR, self._DEV_FILE)}
return [nlp.SplitGenerator(name=nlp.Split.TRAIN, gen_kwargs={"filepath": files["train"]}),
nlp.SplitGenerator(name=nlp.Split.VALIDATION, gen_kwargs={"filepath": files["dev"]})]
def _generate_examples(self, filepath):
with open(filepath) as f:
reader = csv.reader(f, delimiter=',', quotechar="\"")
lines = list(reader)[1:]
for idx, line in enumerate(lines):
yield idx, {"idx": idx, "text": line[1], "label": line[0]}
```
The dataset is attached to this issue as well:
[data.zip](https://github.com/huggingface/datasets/files/4476928/data.zip)
Now the steps to reproduce what I would like to do:
1. unzip data locally (I know the nlp lib can detect and extract archives but I want to reduce and facilitate the reproduction as much as possible)
2. create the `bbc.py` script as above at the same location than the unziped `data` folder.
Now I try to load the dataset in three different ways and none works, the first one with the name of the dataset like I would do with TFDS:
```python
import nlp
from bbc import Bbc
dataset = nlp.load("bbc")
```
I get:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/opt/anaconda3/envs/transformers/lib/python3.7/site-packages/nlp/load.py", line 280, in load
dbuilder: DatasetBuilder = builder(path, name, data_dir=data_dir, **builder_kwargs)
File "/opt/anaconda3/envs/transformers/lib/python3.7/site-packages/nlp/load.py", line 166, in builder
builder_cls = load_dataset(path, name=name, **builder_kwargs)
File "/opt/anaconda3/envs/transformers/lib/python3.7/site-packages/nlp/load.py", line 88, in load_dataset
local_files_only=local_files_only,
File "/opt/anaconda3/envs/transformers/lib/python3.7/site-packages/nlp/utils/file_utils.py", line 214, in cached_path
if not is_zipfile(output_path) and not tarfile.is_tarfile(output_path):
File "/opt/anaconda3/envs/transformers/lib/python3.7/zipfile.py", line 203, in is_zipfile
with open(filename, "rb") as fp:
TypeError: expected str, bytes or os.PathLike object, not NoneType
```
But @thomwolf told me that no need to import the script, just put the path of it, then I tried three different way to do:
```python
import nlp
dataset = nlp.load("bbc.py")
```
And
```python
import nlp
dataset = nlp.load("./bbc.py")
```
And
```python
import nlp
dataset = nlp.load("/absolute/path/to/bbc.py")
```
These three ways gives me:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/opt/anaconda3/envs/transformers/lib/python3.7/site-packages/nlp/load.py", line 280, in load
dbuilder: DatasetBuilder = builder(path, name, data_dir=data_dir, **builder_kwargs)
File "/opt/anaconda3/envs/transformers/lib/python3.7/site-packages/nlp/load.py", line 166, in builder
builder_cls = load_dataset(path, name=name, **builder_kwargs)
File "/opt/anaconda3/envs/transformers/lib/python3.7/site-packages/nlp/load.py", line 124, in load_dataset
dataset_module = importlib.import_module(module_path)
File "/opt/anaconda3/envs/transformers/lib/python3.7/importlib/__init__.py", line 127, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "<frozen importlib._bootstrap>", line 1006, in _gcd_import
File "<frozen importlib._bootstrap>", line 983, in _find_and_load
File "<frozen importlib._bootstrap>", line 965, in _find_and_load_unlocked
ModuleNotFoundError: No module named 'nlp.datasets.2fd72627d92c328b3e9c4a3bf7ec932c48083caca09230cebe4c618da6e93688.bbc'
```
Any idea of what I'm missing? or I might have spot a bug :) | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2/timeline | null | completed | 6,648 | false | [
"My first bug report ❤️\r\nLooking into this right now!",
"Ok, there are some news, most good than bad :laughing: \r\n\r\nThe dataset script now became:\r\n```python\r\nimport csv\r\n\r\nimport nlp\r\n\r\n\r\nclass Bbc(nlp.GeneratorBasedBuilder):\r\n VERSION = nlp.Version(\"1.0.0\")\r\n\r\n def __init__(self, **config):\r\n self.train = config.pop(\"train\", None)\r\n self.validation = config.pop(\"validation\", None)\r\n super(Bbc, self).__init__(**config)\r\n\r\n def _info(self):\r\n return nlp.DatasetInfo(builder=self, description=\"bla\", features=nlp.features.FeaturesDict({\"id\": nlp.int32, \"text\": nlp.string, \"label\": nlp.string}))\r\n\r\n def _split_generators(self, dl_manager):\r\n return [nlp.SplitGenerator(name=nlp.Split.TRAIN, gen_kwargs={\"filepath\": self.train}),\r\n nlp.SplitGenerator(name=nlp.Split.VALIDATION, gen_kwargs={\"filepath\": self.validation})]\r\n\r\n def _generate_examples(self, filepath):\r\n with open(filepath) as f:\r\n reader = csv.reader(f, delimiter=',', quotechar=\"\\\"\")\r\n lines = list(reader)[1:]\r\n\r\n for idx, line in enumerate(lines):\r\n yield idx, {\"id\": idx, \"text\": line[1], \"label\": line[0]}\r\n\r\n```\r\n\r\nAnd the dataset folder becomes:\r\n```\r\n.\r\n├── bbc\r\n│ ├── bbc.py\r\n│ └── data\r\n│ ├── test.csv\r\n│ └── train.csv\r\n```\r\nI can load the dataset by using the keywords arguments like this:\r\n```python\r\nimport nlp\r\ndataset = nlp.load(\"bbc\", builder_kwargs={\"train\": \"bbc/data/train.csv\", \"validation\": \"bbc/data/test.csv\"})\r\n```\r\n\r\nThat was the good part ^^ Because it took me some time to understand that the script itself is put in cache in `datasets/src/nlp/datasets/some-hash/bbc.py` which is very difficult to discover without checking the source code. It means that doesn't matter the changes you do to your original script it is taken into account. I think instead of doing a hash on the name (I suppose it is the name), a hash on the content of the script itself should be a better solution.\r\n\r\nThen by diving a bit in the code I found the `force_reload` parameter [here](https://github.com/huggingface/datasets/blob/master/src/nlp/load.py#L50) but the call of this `load_dataset` method is done with the `builder_kwargs` as seen [here](https://github.com/huggingface/datasets/blob/master/src/nlp/load.py#L166) which is ok until the call to the builder is done as the builder do not have this `force_reload` parameter. To show as example, the previous load becomes:\r\n```python\r\nimport nlp\r\ndataset = nlp.load(\"bbc\", builder_kwargs={\"train\": \"bbc/data/train.csv\", \"validation\": \"bbc/data/test.csv\", \"force_reload\": True})\r\n```\r\nRaises\r\n```\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/jplu/dev/jplu/datasets/src/nlp/load.py\", line 283, in load\r\n dbuilder: DatasetBuilder = builder(path, name, data_dir=data_dir, **builder_kwargs)\r\n File \"/home/jplu/dev/jplu/datasets/src/nlp/load.py\", line 170, in builder\r\n builder_instance = builder_cls(**builder_kwargs)\r\n File \"/home/jplu/dev/jplu/datasets/src/nlp/datasets/84d638d2a8ca919d1021a554e741766f50679dc6553d5a0612b6094311babd39/bbc.py\", line 12, in __init__\r\n super(Bbc, self).__init__(**config)\r\nTypeError: __init__() got an unexpected keyword argument 'force_reload'\r\n```\r\nSo yes the cache is refreshed with the new script but then raises this error.",
"Ok great, so as discussed today, let's:\r\n- have a main dataset directory inside the lib with sub-directories hashed by the content of the file\r\n- keep a cache for downloading the scripts from S3 for now\r\n- later: add methods to list and clean the local versions of the datasets (and the distant versions on S3 as well)\r\n\r\nSide question: do you often use `builder_kwargs` for other things than supplying file paths? I was thinking about having a more easy to read and remember `data_files` argument maybe.",
"Good plan!\r\n\r\nYes I do use `builder_kwargs` for other things such as:\r\n- dataset name\r\n- properties to know how to properly read a CSV file: do I have to skip the first line in a CSV, which delimiter is used, and the columns ids to use.\r\n- properties to know how to properly read a JSON file: which properties in a JSON object to read",
"Done!"
] |
https://api.github.com/repos/huggingface/datasets/issues/1 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1/comments | https://api.github.com/repos/huggingface/datasets/issues/1/events | https://github.com/huggingface/datasets/pull/1 | 599,457,467 | MDExOlB1bGxSZXF1ZXN0NDAzMDk1NDYw | 1 | changing nlp.bool to nlp.bool_ | {
"avatar_url": "https://avatars.githubusercontent.com/u/38249783?v=4",
"events_url": "https://api.github.com/users/mariamabarham/events{/privacy}",
"followers_url": "https://api.github.com/users/mariamabarham/followers",
"following_url": "https://api.github.com/users/mariamabarham/following{/other_user}",
"gists_url": "https://api.github.com/users/mariamabarham/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/mariamabarham",
"id": 38249783,
"login": "mariamabarham",
"node_id": "MDQ6VXNlcjM4MjQ5Nzgz",
"organizations_url": "https://api.github.com/users/mariamabarham/orgs",
"received_events_url": "https://api.github.com/users/mariamabarham/received_events",
"repos_url": "https://api.github.com/users/mariamabarham/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/mariamabarham/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mariamabarham/subscriptions",
"type": "User",
"url": "https://api.github.com/users/mariamabarham"
} | [] | closed | false | null | [] | null | 0 | "2020-04-14T10:18:02Z" | "2022-10-04T09:31:40Z" | "2020-04-14T12:01:40Z" | CONTRIBUTOR | null | 0 | {
"diff_url": "https://github.com/huggingface/datasets/pull/1.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1",
"merged_at": "2020-04-14T12:01:40Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1"
} | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1/timeline | null | null | 6,649 | true | [] |