
Dataset Preview
Full Screen Viewer
Full Screen
The full dataset viewer is not available (click to read why). Only showing a preview of the rows.
The dataset generation failed
Error code: DatasetGenerationError
Exception: TypeError
Message: Couldn't cast array of type string to null
Traceback: Traceback (most recent call last):
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/builder.py", line 2011, in _prepare_split_single
writer.write_table(table)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/arrow_writer.py", line 585, in write_table
pa_table = table_cast(pa_table, self._schema)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 2302, in table_cast
return cast_table_to_schema(table, schema)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 2261, in cast_table_to_schema
arrays = [cast_array_to_feature(table[name], feature) for name, feature in features.items()]
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 2261, in <listcomp>
arrays = [cast_array_to_feature(table[name], feature) for name, feature in features.items()]
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 1802, in wrapper
return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 1802, in <listcomp>
return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 2116, in cast_array_to_feature
return array_cast(
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 1804, in wrapper
return func(array, *args, **kwargs)
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/table.py", line 1962, in array_cast
raise TypeError(f"Couldn't cast array of type {_short_str(array.type)} to {_short_str(pa_type)}")
TypeError: Couldn't cast array of type string to null
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/src/services/worker/src/worker/job_runners/config/parquet_and_info.py", line 1524, in compute_config_parquet_and_info_response
parquet_operations, partial, estimated_dataset_info = stream_convert_to_parquet(
File "/src/services/worker/src/worker/job_runners/config/parquet_and_info.py", line 1099, in stream_convert_to_parquet
builder._prepare_split(
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/builder.py", line 1882, in _prepare_split
for job_id, done, content in self._prepare_split_single(
File "/src/services/worker/.venv/lib/python3.9/site-packages/datasets/builder.py", line 2038, in _prepare_split_single
raise DatasetGenerationError("An error occurred while generating the dataset") from e
datasets.exceptions.DatasetGenerationError: An error occurred while generating the datasetNeed help to make the dataset viewer work? Make sure to review how to configure the dataset viewer, and open a discussion for direct support.
url
string | repository_url
string | labels_url
string | comments_url
string | events_url
string | html_url
string | id
int64 | node_id
string | number
int64 | title
string | user
dict | labels
list | state
string | locked
bool | assignee
dict | assignees
list | milestone
null | comments
int64 | created_at
int64 | updated_at
int64 | closed_at
null | author_association
string | active_lock_reason
null | body
string | performed_via_github_app
null | pull_request
null |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/transformers/issues/11046 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11046/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11046/comments | https://api.github.com/repos/huggingface/transformers/issues/11046/events | https://github.com/huggingface/transformers/issues/11046 | 849,568,459 | MDU6SXNzdWU4NDk1Njg0NTk= | 11,046 | Potential incorrect application of layer norm in BlenderbotSmallDecoder | {
"login": "sougata-ub",
"id": 59206549,
"node_id": "MDQ6VXNlcjU5MjA2NTQ5",
"avatar_url": "https://avatars.githubusercontent.com/u/59206549?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sougata-ub",
"html_url": "https://github.com/sougata-ub",
"followers_url": "https://api.github.com/users/sougata-ub/followers",
"following_url": "https://api.github.com/users/sougata-ub/following{/other_user}",
"gists_url": "https://api.github.com/users/sougata-ub/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sougata-ub/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sougata-ub/subscriptions",
"organizations_url": "https://api.github.com/users/sougata-ub/orgs",
"repos_url": "https://api.github.com/users/sougata-ub/repos",
"events_url": "https://api.github.com/users/sougata-ub/events{/privacy}",
"received_events_url": "https://api.github.com/users/sougata-ub/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 1,617,421,052,000 | 1,617,421,052,000 | null | NONE | null | In BlenderbotSmallDecoder, layer norm is applied only on the token embeddings, and not on the hidden_states, whereas in the BlenderbotSmallEncoder, layer norm is applied after adding the input_embeds and positional embeds
BlenderbotSmallEncoder:
`hidden_states = inputs_embeds + embed_pos`
`hidden_states = self.layernorm_embedding(hidden_states)`
BlenderbotSmallDecoder:
`inputs_embeds = self.layernorm_embedding(inputs_embeds)`
`hidden_states = inputs_embeds + positions` | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11045 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11045/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11045/comments | https://api.github.com/repos/huggingface/transformers/issues/11045/events | https://github.com/huggingface/transformers/issues/11045 | 849,544,374 | MDU6SXNzdWU4NDk1NDQzNzQ= | 11,045 | Multi-GPU seq2seq example evaluation significantly slower than legacy example evaluation | {
"login": "PeterAJansen",
"id": 3813268,
"node_id": "MDQ6VXNlcjM4MTMyNjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/3813268?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/PeterAJansen",
"html_url": "https://github.com/PeterAJansen",
"followers_url": "https://api.github.com/users/PeterAJansen/followers",
"following_url": "https://api.github.com/users/PeterAJansen/following{/other_user}",
"gists_url": "https://api.github.com/users/PeterAJansen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/PeterAJansen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PeterAJansen/subscriptions",
"organizations_url": "https://api.github.com/users/PeterAJansen/orgs",
"repos_url": "https://api.github.com/users/PeterAJansen/repos",
"events_url": "https://api.github.com/users/PeterAJansen/events{/privacy}",
"received_events_url": "https://api.github.com/users/PeterAJansen/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 1,617,411,144,000 | 1,617,411,144,000 | null | NONE | null |
### Who can help
@patil-suraj @sgugger
Models:
T5
## Information
I've been doing multi-GPU evaluation for some weeks using a Transformers pull from Feb 12th, just using the example scripts for training/evaluating custom datasets (specifically `run_distributed_eval.py` , though that seq2seq example is now legacy: https://github.com/huggingface/transformers/tree/master/examples/legacy/seq2seq )
Today I grabbed a fresh pull and migrated the data over to the JSON lines format for the new seq2seq example `run_summarization.py` : https://github.com/huggingface/transformers/blob/master/examples/seq2seq/run_summarization.py
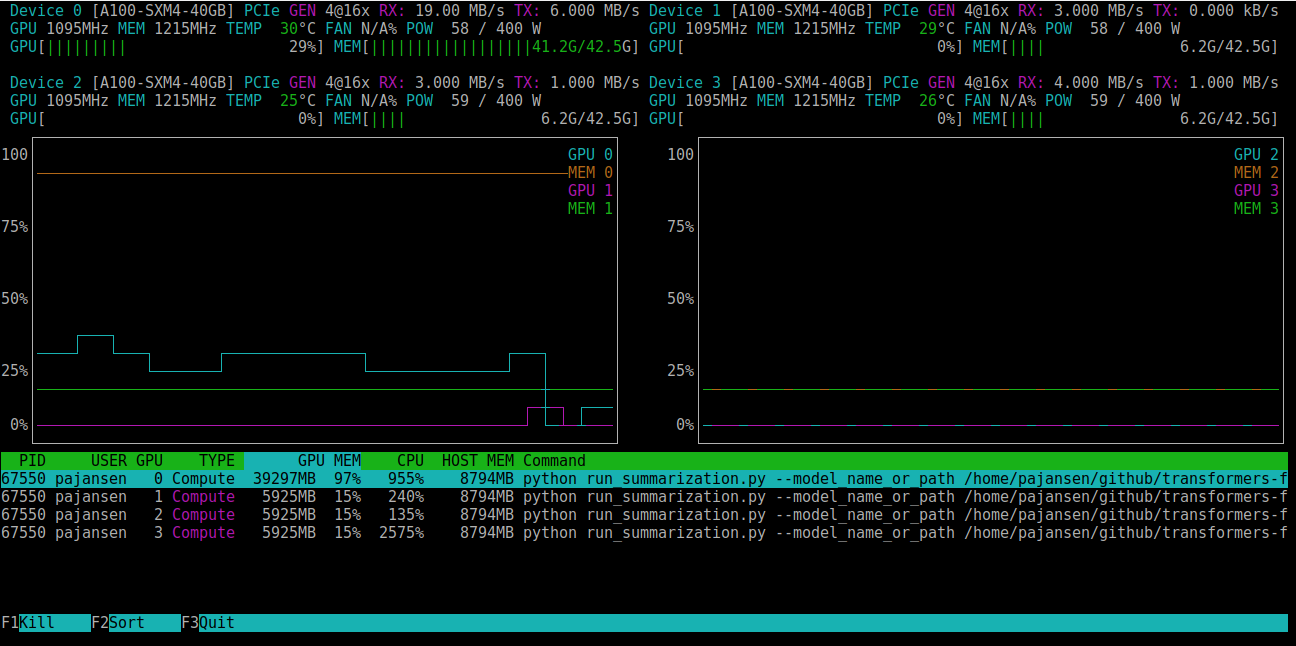
run_summarization.py appears to use all visible GPUs to do the evaluation (great!), but it also appears significantly slower than the old run_distributed_eval.py .
When examining GPU utilization using `nvtop`, it appears that it allocates GPU memory from all devices (much more from device 0), but only uses device 0 for processing:
## Script
In case it's my issue and I'm not invoking it correctly (I know the legacy one required being invoked with `torch.distributed.launch` for multi-GPU evaluation), the runscript I'm using is:
```
#/bin/bash
python run_summarization.py \
--model_name_or_path mymodel-debug1000 \
--do_predict \
--train_file mydata/train.json \
--validation_file mydata/val.json \
--test_file mydata/val.json \
--max_source_length 256 \
--max_target_length 512 \
--num_beams 8 \
--source_prefix "" \
--output_dir tst-debug \
--overwrite_output_dir \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--predict_with_generate
``` | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11044 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11044/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11044/comments | https://api.github.com/repos/huggingface/transformers/issues/11044/events | https://github.com/huggingface/transformers/issues/11044 | 849,529,761 | MDU6SXNzdWU4NDk1Mjk3NjE= | 11,044 | [DeepSpeed] ZeRO stage 3 integration: getting started and issues | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2659267025,
"node_id": "MDU6TGFiZWwyNjU5MjY3MDI1",
"url": "https://api.github.com/repos/huggingface/transformers/labels/DeepSpeed",
"name": "DeepSpeed",
"color": "4D34F7",
"default": false,
"description": ""
}
] | open | false | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
}
] | null | 0 | 1,617,406,842,000 | 1,617,408,018,000 | null | COLLABORATOR | null | **[This is not yet alive, preparing for the release, so please ignore for now]**
The DeepSpeed ZeRO-3 has been integrated into HF `transformers`.
While I tried to write tests for a wide range of situations I'm sure I've missed some scenarios so if you run into any problems please file a separate issue. I'm going to use this issue to track progress on individual ZeRO3 issues.
# Why would you want ZeRO-3
In a few words, while ZeRO-2 was very limited scability-wise - if `model.half()` couldn't fit onto a single gpu, adding more gpus won't have helped so if you had a 24GB GPU you couldn't train a model larger than about 5B params.
Since with ZeRO-3 the model weights are partitioned across multiple GPUs plus offloaded to CPU, the upper limit on model size has increased by about 2 orders of magnitude. That is ZeRO-3 allows you to scale to huge models with Trillions of parameters assuming you have enough GPUs and general RAM to support this. ZeRO-3 can benefit a lot from general RAM if you have it. If not that's OK too. ZeRO-3 combines all your GPUs memory and general RAM into a vast pool of memory.
If you don't have many GPUs but just a single one but have a lot of general RAM ZeRO-3 will allow you to fit larger models.
Of course, if you run in an environment like the free google colab, while you can use run Deepspeed there, you get so little general RAM it's very hard to make something out of nothing. Some users (or some sessions) one gets 12GB of RAM which is impossible to work with - you want at least 24GB instances. Setting is up might be tricky too, please see this notebook for an example:
https://github.com/stas00/porting/blob/master/transformers/deepspeed/DeepSpeed_on_colab_CLI.ipynb
# Getting started
Install the latest deepspeed version:
```
pip install deepspeed
```
You will want to be on a transformers master branch, if you want to run a quick test:
```
git clone https://github.com/huggingface/transformers
cd transformers
BS=4; PYTHONPATH=src USE_TF=0 deepspeed examples/seq2seq/run_translation.py \
--model_name_or_path t5-small --output_dir /tmp/zero3 --overwrite_output_dir --max_train_samples 64 \
--max_val_samples 64 --max_source_length 128 --max_target_length 128 --val_max_target_length 128 \
--do_train --num_train_epochs 1 --per_device_train_batch_size $BS --per_device_eval_batch_size $BS \
--learning_rate 3e-3 --warmup_steps 500 --predict_with_generate --logging_steps 0 --save_steps 0 \
--eval_steps 1 --group_by_length --adafactor --dataset_name wmt16 --dataset_config ro-en --source_lang en \
--target_lang ro --source_prefix "translate English to Romanian: " \
--deepspeed examples/tests/deepspeed/ds_config_zero3.json
```
You will find a very detailed configuration here: https://huggingface.co/transformers/master/main_classes/trainer.html#deepspeed
Your new config file will look like this:
```json
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"zero_optimization": {
"stage": 3,
"cpu_offload": true,
"cpu_offload_params": true,
"cpu_offload_use_pin_memory" : true,
"overlap_comm": true,
"contiguous_gradients": true,
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_prefetch_bucket_size": 0.94e6,
"stage3_param_persistence_threshold": 1e4,
"reduce_bucket_size": 1e6,
"prefetch_bucket_size": 3e6,
"sub_group_size": 1e14,
"stage3_gather_fp16_weights_on_model_save": true
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": 3e-5,
"betas": [0.8, 0.999],
"eps": 1e-8,
"weight_decay": 3e-7
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 3e-5,
"warmup_num_steps": 500
}
},
"steps_per_print": 2000,
"wall_clock_breakdown": false
}
```
So if you were already using ZeRO-2 it's only the `zero_optimization` stage that has changed.
One of the biggest nuances of ZeRO-3 is that the model weights aren't inside `model.state_dict`, as they are spread out through multiple gpus. The Trainer has been modified to support this but you will notice a slow model saving - as it has to consolidate weights from all the gpus. I'm planning to do more performance improvements in the future PRs, but for now let's focus on making things work.
# Issues / Questions
If you have any general questions or something is unclear/missing in the docs please don't hesitate to ask in this thread. But for any bugs or problems please open a new Issue and tag me there. You don't need to tag anybody else. Thank you! | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11043 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11043/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11043/comments | https://api.github.com/repos/huggingface/transformers/issues/11043/events | https://github.com/huggingface/transformers/issues/11043 | 849,499,734 | MDU6SXNzdWU4NDk0OTk3MzQ= | 11,043 | Can't load model to estimater | {
"login": "gwc4github",
"id": 3164663,
"node_id": "MDQ6VXNlcjMxNjQ2NjM=",
"avatar_url": "https://avatars.githubusercontent.com/u/3164663?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gwc4github",
"html_url": "https://github.com/gwc4github",
"followers_url": "https://api.github.com/users/gwc4github/followers",
"following_url": "https://api.github.com/users/gwc4github/following{/other_user}",
"gists_url": "https://api.github.com/users/gwc4github/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gwc4github/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gwc4github/subscriptions",
"organizations_url": "https://api.github.com/users/gwc4github/orgs",
"repos_url": "https://api.github.com/users/gwc4github/repos",
"events_url": "https://api.github.com/users/gwc4github/events{/privacy}",
"received_events_url": "https://api.github.com/users/gwc4github/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 1,617,400,304,000 | 1,617,400,304,000 | null | NONE | null | I was trying to follow the Sagemaker instructions [here](https://docs.aws.amazon.com/sagemaker/latest/dg/deploy-model.html) to load the model I just trained and test an estimation. I get the error message:
NotImplementedError: Creating model with HuggingFace training job is not supported.
Can someone share some sample code to run to do this? Here is the basic thing I am trying to do:
```
from sagemaker.estimator import Estimator
# job which is going to be attached to the estimator
old_training_job_name='huggingface-sdk-extension-2021-04-02-19-10-00-242'
# attach old training job
huggingface_estimator_loaded = Estimator.attach(old_training_job_name)
# get model output s3 from training job
testModel = huggingface_estimator_loaded.model_data
ner_classifier = huggingface_estimator.deploy(initial_instance_count=1, instance_type='ml.m4.xlarge')
```
I also tried some things with .deploy() and endpoints but didn't have any luck there either.
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/11042 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11042/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11042/comments | https://api.github.com/repos/huggingface/transformers/issues/11042/events | https://github.com/huggingface/transformers/issues/11042 | 849,274,362 | MDU6SXNzdWU4NDkyNzQzNjI= | 11,042 | [LXMERT] Unclear what img_tensorize does with color spaces | {
"login": "hivestrung",
"id": 27841209,
"node_id": "MDQ6VXNlcjI3ODQxMjA5",
"avatar_url": "https://avatars.githubusercontent.com/u/27841209?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hivestrung",
"html_url": "https://github.com/hivestrung",
"followers_url": "https://api.github.com/users/hivestrung/followers",
"following_url": "https://api.github.com/users/hivestrung/following{/other_user}",
"gists_url": "https://api.github.com/users/hivestrung/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hivestrung/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hivestrung/subscriptions",
"organizations_url": "https://api.github.com/users/hivestrung/orgs",
"repos_url": "https://api.github.com/users/hivestrung/repos",
"events_url": "https://api.github.com/users/hivestrung/events{/privacy}",
"received_events_url": "https://api.github.com/users/hivestrung/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 1,617,376,377,000 | 1,617,376,507,000 | null | NONE | null | ## Environment info
- `transformers` version: Not using transformers directly, I'm loading a model "unc-nlp/frcnn-vg-finetuned"
- Platform: MacOS
- Python version: 3.8
- PyTorch version (GPU?): 1.6.0, no GPU
- Tensorflow version (GPU?): don't have
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help
@eltoto1219 probably
Models: "LXMERT": "unc-nlp/frcnn-vg-finetuned"
Library: https://github.com/huggingface/transformers/tree/master/examples/research_projects/lxmert
## Information
Model I am using (Bert, XLNet ...): "LXMERT": "unc-nlp/frcnn-vg-finetuned"
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x ] my own task or dataset: (give details below)
## Problem
I don't get what img_tensorize in utils.py is doing with color spaces. I run the following code to load the model.
```
# load models and model components
frcnn_cfg = Config.from_pretrained("unc-nlp/frcnn-vg-finetuned")
frcnn = GeneralizedRCNN.from_pretrained("unc-nlp/frcnn-vg-finetuned", config=frcnn_cfg)
image_preprocess = Preprocess(frcnn_cfg)
```
Turns out that frcnn_cfg.input.format is "BGR" so I wanted to know what exactly is going on? Here is where the image is loaded (utils.img_tensorize)
```
def img_tensorize(im, input_format="RGB"):
assert isinstance(im, str)
if os.path.isfile(im):
img = cv2.imread(im)
else:
img = get_image_from_url(im)
assert img is not None, f"could not connect to: {im}"
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
if input_format == "RGB":
img = img[:, :, ::-1]
return img
```
See, we seem to be converting the images to RGB, then if it's "RGB" format we flip the blue (?) channel? Is the image ever converted to "BGR"?
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/11041 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11041/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11041/comments | https://api.github.com/repos/huggingface/transformers/issues/11041/events | https://github.com/huggingface/transformers/pull/11041 | 849,269,684 | MDExOlB1bGxSZXF1ZXN0NjA4MDcxNjc1 | 11,041 | wav2vec2 converter: create the proper vocab.json while converting fairseq wav2vec2 finetuned model | {
"login": "cceyda",
"id": 15624271,
"node_id": "MDQ6VXNlcjE1NjI0Mjcx",
"avatar_url": "https://avatars.githubusercontent.com/u/15624271?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cceyda",
"html_url": "https://github.com/cceyda",
"followers_url": "https://api.github.com/users/cceyda/followers",
"following_url": "https://api.github.com/users/cceyda/following{/other_user}",
"gists_url": "https://api.github.com/users/cceyda/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cceyda/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cceyda/subscriptions",
"organizations_url": "https://api.github.com/users/cceyda/orgs",
"repos_url": "https://api.github.com/users/cceyda/repos",
"events_url": "https://api.github.com/users/cceyda/events{/privacy}",
"received_events_url": "https://api.github.com/users/cceyda/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 1,617,375,854,000 | 1,617,377,521,000 | null | CONTRIBUTOR | null | # What does this PR do?
While converting a finetuned wav2vec2 model we also need to convert the related dictionary `dict.ltr.txt` to hugging face `vocab.json` format.
If a `dict_path` is specified:
- Creates&saves the necessary vocab.json file
- Modifies config file special token ids and vocab size accordingly
- Creates a processor with the right special tokens and saves the processor `preprocessor_config.json`
## Before submitting
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Did you make sure to update the documentation with your changes? -> not sure if there are any docs related to this.
- [ ] Did you write any new necessary tests? -> not sure if there are tests related to this.
## Who can review?
Models:
- wav2vec2: @patrickvonplaten @LysandreJik
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/11040 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11040/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11040/comments | https://api.github.com/repos/huggingface/transformers/issues/11040/events | https://github.com/huggingface/transformers/issues/11040 | 849,265,615 | MDU6SXNzdWU4NDkyNjU2MTU= | 11,040 | max_length in beam_search() and group_beam_search() does not consider beam_scorer.max_length | {
"login": "GeetDsa",
"id": 13940397,
"node_id": "MDQ6VXNlcjEzOTQwMzk3",
"avatar_url": "https://avatars.githubusercontent.com/u/13940397?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/GeetDsa",
"html_url": "https://github.com/GeetDsa",
"followers_url": "https://api.github.com/users/GeetDsa/followers",
"following_url": "https://api.github.com/users/GeetDsa/following{/other_user}",
"gists_url": "https://api.github.com/users/GeetDsa/gists{/gist_id}",
"starred_url": "https://api.github.com/users/GeetDsa/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/GeetDsa/subscriptions",
"organizations_url": "https://api.github.com/users/GeetDsa/orgs",
"repos_url": "https://api.github.com/users/GeetDsa/repos",
"events_url": "https://api.github.com/users/GeetDsa/events{/privacy}",
"received_events_url": "https://api.github.com/users/GeetDsa/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 1,617,375,392,000 | 1,617,375,452,000 | null | CONTRIBUTOR | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform: 4.3.2
- Python version: 3.8.5
- PyTorch version (GPU?): 1.8.0
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
I am using BART model in particular, but this problem exists for all the other models, using `beam_search()` and `group_beam_search()` for decoding the generated text.
The `max_length` variable set using `BeamSearchScorer` is not used by `beam_search()` or `group_beam_search()` function in `generation_utils.py` script.
Thus using a smaller `max_length` while initializing the object of class, for example:
```
beam_scorer = BeamSearchScorer(
batch_size=1,
max_length=5,
num_beams=num_beams,
device=model.device,
)
```
instead of
```
beam_scorer = BeamSearchScorer(
batch_size=1,
max_length=model.config.max_length,
num_beams=num_beams,
device=model.device,
)
```
in the example given [here](https://huggingface.co/transformers/main_classes/model.html#transformers.generation_utils.GenerationMixin.beam_search)
results in an error:
```
File "temp.py", line 34, in <module>
outputs = model.beam_search(input_ids, beam_scorer, logits_processor=logits_processor, **model_kwargs)
File "<conda_env_dir>/lib/python3.8/site-packages/transformers/generation_utils.py", line 1680, in beam_search
sequence_outputs = beam_scorer.finalize(
File "<conda_env_dir>/lib/python3.8/site-packages/transformers/generation_beam_search.py", line 328, in finalize
decoded[i, : sent_lengths[i]] = hypo
RuntimeError: The expanded size of the tensor (5) must match the existing size (6) at non-singleton dimension 0. Target sizes: [5]. Tensor sizes: [6]
```
The problem arises when using:
* [x] the official example scripts:
- [beam_scorer_example](https://huggingface.co/transformers/main_classes/model.html#transformers.generation_utils.GenerationMixin.beam_search)
* [x] my own modified scripts:
- Also, using `max_length` higher than `model.config.max_length` while initializing object (`beam_scorer`) of type `BeamSearchScorer` does not help in generating longer sequences, as `beam_scorer.max_length` is not used by `beam_search()` or `group_beam_search()`
## To reproduce
Steps to reproduce the behavior:
1. The above mentioned modification in the [example](https://huggingface.co/transformers/main_classes/model.html#transformers.generation_utils.GenerationMixin.beam_search)
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
1. The program to run without any errors when lower `max_length` is set for object of type `BeamSearchScorer`
2. Generate longer length sequences (longer than `model.config.max_length`) when higher `max_length` is set for object of type `BeamSearchScorer`
<!-- A clear and concise description of what you would expect to happen. -->
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/11039 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11039/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11039/comments | https://api.github.com/repos/huggingface/transformers/issues/11039/events | https://github.com/huggingface/transformers/issues/11039 | 849,244,819 | MDU6SXNzdWU4NDkyNDQ4MTk= | 11,039 | Trainer not logging into Tensorboard | {
"login": "thomas-happify",
"id": 66082334,
"node_id": "MDQ6VXNlcjY2MDgyMzM0",
"avatar_url": "https://avatars.githubusercontent.com/u/66082334?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thomas-happify",
"html_url": "https://github.com/thomas-happify",
"followers_url": "https://api.github.com/users/thomas-happify/followers",
"following_url": "https://api.github.com/users/thomas-happify/following{/other_user}",
"gists_url": "https://api.github.com/users/thomas-happify/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thomas-happify/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thomas-happify/subscriptions",
"organizations_url": "https://api.github.com/users/thomas-happify/orgs",
"repos_url": "https://api.github.com/users/thomas-happify/repos",
"events_url": "https://api.github.com/users/thomas-happify/events{/privacy}",
"received_events_url": "https://api.github.com/users/thomas-happify/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 1,617,373,074,000 | 1,617,387,532,000 | null | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.5.0.dev0
- Platform: Ubuntu 18.04.5 LTS (x86_64)
- Python version: 3.7.0
- PyTorch version (GPU?): 1.7.1+cu101
- Tensorflow version (GPU?):
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: Yes
### Who can help
@sgugger
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...): EncoderDecoderModel
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
This is the tensorboard logs
https://tensorboard.dev/experiment/caY7XIGGTbK2Zfr2DTeoJA/#scalars
1. go to the `Text` tab [here](https://tensorboard.dev/experiment/caY7XIGGTbK2Zfr2DTeoJA/#text), you can see that `"logging_first_step": true, "logging_steps": 2`
2. `epoch` graph is showing 75 total steps, but no scalars were logged except for the first_step
<img width="413" alt="Screen Shot 2021-04-02 at 10 14 49 AM" src="https://user-images.githubusercontent.com/66082334/113423326-48c54080-939c-11eb-9c61-b8fde0d62d12.png">
```
[INFO|trainer.py:402] 2021-04-02 10:05:50,085 >> Using amp fp16 backend
[INFO|trainer.py:1013] 2021-04-02 10:05:50,181 >> ***** Running training *****
[INFO|trainer.py:1014] 2021-04-02 10:05:50,182 >> Num examples = 100
[INFO|trainer.py:1015] 2021-04-02 10:05:50,182 >> Num Epochs = 3
[INFO|trainer.py:1016] 2021-04-02 10:05:50,182 >> Instantaneous batch size per device = 1
[INFO|trainer.py:1017] 2021-04-02 10:05:50,182 >> Total train batch size (w. parallel, distributed & accumulation) = 4
[INFO|trainer.py:1018] 2021-04-02 10:05:50,182 >> Gradient Accumulation steps = 1
[INFO|trainer.py:1019] 2021-04-02 10:05:50,182 >> Total optimization steps = 75
{'loss': 13.7546, 'learning_rate': 2.5000000000000002e-08, 'epoch': 0.04}
100%|█████████████████████████████████████████████████████████████████████████████████| 75/75 [01:03<00:00, 1.28it/s][INFO|trainer.py:1196] 2021-04-02 10:06:53,931 >>
Training completed. Do not forget to share your model on huggingface.co/models =)
{'train_runtime': 63.7497, 'train_samples_per_second': 1.176, 'epoch': 3.0}
100%|█████████████████████████████████████████████████████████████████████████████████| 75/75 [01:03<00:00, 1.18it/s]
[INFO|trainer.py:1648] 2021-04-02 10:06:54,265 >> Saving model checkpoint to ./pretrain_decoder/
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
It should log training loss very other `logging_steps` right? or did I misunderstood?
<!-- A clear and concise description of what you would expect to happen. -->
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/11038 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11038/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11038/comments | https://api.github.com/repos/huggingface/transformers/issues/11038/events | https://github.com/huggingface/transformers/issues/11038 | 849,180,384 | MDU6SXNzdWU4NDkxODAzODQ= | 11,038 | DeBERTa xlarge v2 throwing runtime error | {
"login": "roshan-k-patel",
"id": 48667731,
"node_id": "MDQ6VXNlcjQ4NjY3NzMx",
"avatar_url": "https://avatars.githubusercontent.com/u/48667731?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/roshan-k-patel",
"html_url": "https://github.com/roshan-k-patel",
"followers_url": "https://api.github.com/users/roshan-k-patel/followers",
"following_url": "https://api.github.com/users/roshan-k-patel/following{/other_user}",
"gists_url": "https://api.github.com/users/roshan-k-patel/gists{/gist_id}",
"starred_url": "https://api.github.com/users/roshan-k-patel/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/roshan-k-patel/subscriptions",
"organizations_url": "https://api.github.com/users/roshan-k-patel/orgs",
"repos_url": "https://api.github.com/users/roshan-k-patel/repos",
"events_url": "https://api.github.com/users/roshan-k-patel/events{/privacy}",
"received_events_url": "https://api.github.com/users/roshan-k-patel/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 4 | 1,617,365,153,000 | 1,617,372,009,000 | null | NONE | null | - `transformers` version: 4.4.2
- Platform: Linux-3.10.0-1127.el7.x86_64-x86_64-with-redhat-7.8-Maipo
- Python version: 3.6.13
- PyTorch version (GPU?): 1.7.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script: yes
```
RuntimeError: Error(s) in loading state_dict for DebertaForSequenceClassification:
size mismatch for deberta.encoder.rel_embeddings.weight: copying a param with shape torch.Size([512, 1536]) from checkpoint, the shape in current model is torch.Size([1024, 1536]).
```
I've seen a previous post made about this error and i believe it is a known issue. On the thread i found it was mentioned that a fix was due to come out a month ago. Has the fix come out?
[Downloaded from here](https://huggingface.co/microsoft/deberta-v2-xlarge) | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11036 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11036/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11036/comments | https://api.github.com/repos/huggingface/transformers/issues/11036/events | https://github.com/huggingface/transformers/issues/11036 | 848,996,240 | MDU6SXNzdWU4NDg5OTYyNDA= | 11,036 | BertForTokenClassification class ignores long tokens when making predictions | {
"login": "guanqun-yang",
"id": 36497361,
"node_id": "MDQ6VXNlcjM2NDk3MzYx",
"avatar_url": "https://avatars.githubusercontent.com/u/36497361?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/guanqun-yang",
"html_url": "https://github.com/guanqun-yang",
"followers_url": "https://api.github.com/users/guanqun-yang/followers",
"following_url": "https://api.github.com/users/guanqun-yang/following{/other_user}",
"gists_url": "https://api.github.com/users/guanqun-yang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/guanqun-yang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/guanqun-yang/subscriptions",
"organizations_url": "https://api.github.com/users/guanqun-yang/orgs",
"repos_url": "https://api.github.com/users/guanqun-yang/repos",
"events_url": "https://api.github.com/users/guanqun-yang/events{/privacy}",
"received_events_url": "https://api.github.com/users/guanqun-yang/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 1,617,344,535,000 | 1,617,349,504,000 | null | NONE | null | # Goal
I am trying to run the adapted version of `run_ner.py` hosted [here](https://github.com/huggingface/transformers/tree/master/examples/token-classification) (see MWE session for my code) on my custom dataset.
The dataset I am using has some extra-long tokens (mainly URLs). When I obtained the predictions after running `run_ner.py`, I found that some tokens are missing. Concretely, in my experiment, 28970 - 28922 = 68 tokens are missing in the predictions
- Here is the prediction statistics I obtained with `sklearn.metrics.classification_report`
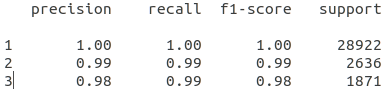
- Here is the statistics of the dataset when I looked at the dataset

I further checked the threshold of token length (in characters) the `BertForTokenClassification` decided to ignore, it turns out that when the length of token is greater or equal to 28, it is ignored

I have searched the documentation to find if there is a parameter I could set to control this behavior but no luck. This made me suspect this might be a undocumented behavior worth noticing for the community.
# Environment info
- `transformers` version: 4.4.2
- Platform: Linux-5.4.0-70-generic-x86_64-with-debian-buster-sid
- Python version: 3.7.0
- PyTorch version (GPU?): 1.7.1 (True)
- Tensorflow version (GPU?): 2.2.0 (True)
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
# Who can help
Model
- albert, bert, xlm: @LysandreJik
Library:
- tokenizers: @LysandreJik
- trainer: @sgugger
# MWE
The following is the main body of code and (anonymized) toy dataset used to show the behavior. After running the code, you will see the following, which shows that **model ignores many tokens when making predictions**.

To reproduce the result, simply copy and paste and dataset into `data.json` and put it in the same directory as the code. Then run the code
## Code
```python
import json
import itertools
import numpy as np
from datasets import load_dataset
from transformers import AutoConfig, AutoTokenizer, AutoModelForTokenClassification
from transformers import DataCollatorForTokenClassification, Trainer, TrainingArguments
from collections import Counter
from sklearn.metrics import classification_report
model_name = "bert-base-uncased"
label_list = ["O", "P", "Q"]
label_to_id = {"O": 0, "P": 1, "Q": 2}
tokenizer = AutoTokenizer.from_pretrained(model_name)
def tokenize_and_align_labels(examples):
padding = False
text_column_name = "tokens"
label_column_name = "tags"
tokenized_inputs = tokenizer(examples[text_column_name], padding=padding, truncation=True, is_split_into_words=True)
labels = list()
for i, label in enumerate(examples[label_column_name]):
word_ids = tokenized_inputs.word_ids(batch_index=i)
previous_word_idx = None
label_ids = list()
for word_idx in word_ids:
if word_idx is None: label_ids.append(-100)
elif word_idx != previous_word_idx: label_ids.append(label_to_id[label[word_idx]])
else: label_ids.append(-100)
previous_word_idx = word_idx
labels.append(label_ids)
tokenized_inputs["labels"] = labels
return tokenized_inputs
training_args = TrainingArguments(output_dir="output/ner",
per_device_train_batch_size=2,
per_device_eval_batch_size=2)
config = AutoConfig.from_pretrained(model_name, num_labels=3)
model = AutoModelForTokenClassification.from_pretrained(model_name, config=config)
data_collator = DataCollatorForTokenClassification(tokenizer, pad_to_multiple_of=None)
datasets = load_dataset("json", data_files={"test": "data.json"})
tokenized_datasets = datasets.map(tokenize_and_align_labels,
batched=True,
num_proc=None,
load_from_cache_file=True)
trainer = Trainer(model=model,
args=training_args,
tokenizer=tokenizer,
train_dataset=None,
eval_dataset=None,
data_collator=data_collator)
predictions, labels, metrics = trainer.predict(tokenized_datasets["test"])
predictions = np.argmax(predictions, axis=2)
y_pred = [[label_list[p] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)]
y_true = [[label_list[l] for (p, l) in zip(prediction, label) if l != -100]
for prediction, label in zip(predictions, labels)]
y_pred_list = list(itertools.chain(*y_pred))
y_true_list = list(itertools.chain(*y_true))
print("predictions...")
metric = classification_report(y_true=y_true_list, y_pred=y_pred_list, target_names=label_list, output_dict=False)
print(metric)
print("statistics of datasets...")
tag_list = list()
with open("data.json", "r") as fp:
for line in fp.readlines():
tag_list.extend(json.loads(line)["tags"])
print(Counter(tag_list))
```
## Dataset
```
{"tokens": ["c", "HdI", "Op", "Ypgdm", "kssA", "gM", "azGFjtgAGDKJwahegGycdUsraeRvx", "Y", "z"], "tags": ["O", "O", "Q", "P", "P", "O", "P", "O", "P"]}
{"tokens": ["HnRCVoBlyYjvWw", "JOQLTMrQSuPnB", "tj", "PjM", "dDMwaNYdwfgh", "kehjfOZa", "GG", "BGbWacckKOTSglSZpFsKssjnkqxuZzStYnFw", "Fu", "FPb", "yGvnkbGOAG", "WXxmmC", "KPD", "qgd", "wqGPK", "ulgmNz", "lDw", "P", "ee", "Rdrk", "mb", "rgZQnJGL", "YgOaUHjxik", "CzacME", "l", "RYFh", "C", "WscGhFK", "vcSldQFcbUdvg", "ijK", "MRD", "hnsPMqA", "tJn", "tkSuD", "sbJINmCL", "A", "XKtvHv", "NbrqNKuGA", "mF", "NDJf", "jcaodNHnUX", "bL", "bwIfI", "j", "mDPxyf", "Jp", "QvVBNmw", "W", "wBYzhr", "mzjxngTtvL", "y", "xZP", "ST", "KUcgzAUJswD", "vLir", "ZGUmN", "k", "kyoqdki", "YSGyV", "gfpy", "E"], "tags": ["O", "O", "O", "Q", "Q", "P", "P", "P", "O", "O", "O", "Q", "Q", "Q", "P", "P", "Q", "O", "O", "Q", "P", "Q", "Q", "P", "Q", "Q", "P", "Q", "O", "P", "Q", "Q", "Q", "P", "O", "P", "O", "O", "P", "P", "O", "Q", "Q", "Q", "Q", "Q", "Q", "P", "O", "Q", "O", "P", "P", "O", "Q", "O", "Q", "P", "Q", "Q", "Q"]}
{"tokens": ["mHjjgX", "pv", "NlnLGhfJOjXQmdKBDoZbMJYbjMUPPpQVqLyj", "QwKjLiAVjZahrYjMsD", "ud", "fOYI", "wZCamIed", "V", "YNDFWpi", "n", "QLaToqF", "V", "P", "KG", "xk", "gHL", "to", "doYsYrgwC", "aP", "wijzV", "aR", "kZxvRsje", "eRSG", "moaijWxPGU", "IrFLx", "s"], "tags": ["Q", "O", "O", "P", "O", "O", "P", "O", "P", "P", "Q", "O", "O", "P", "O", "P", "P", "Q", "O", "Q", "Q", "O", "Q", "P", "Q", "O"]}
{"tokens": ["Tq", "QnBu", "fOvqVK", "NlC", "JIBZwVk", "uL", "ceGY", "YQibS", "EI", "stIoTiWuwDCuLPBbZyVdxThcsjjTrXXbLZbPThg", "T", "plU", "yc", "pOOd", "bJKTECZM", "EcZHhimP", "rlxMVb", "wLj", "MAfob", "gT", "olvMEVNU", "JX", "uvhILBJSnxhrzBeEioHJuH", "j"], "tags": ["Q", "P", "O", "P", "O", "P", "O", "O", "P", "Q", "O", "P", "Q", "O", "P", "Q", "P", "O", "P", "O", "O", "Q", "O", "O"]}
{"tokens": ["FqXSxwtS", "VzFPLNX", "NcTWHoHSv", "Rn", "uCj", "iodTKA", "cHLzTmFnR", "GK", "XqX", "T", "MIseQD", "hoY", "ws", "BFhME", "LDJJDlG", "nKkWW", "diEiWLHCSeAIIruHn", "MpYpfbTXQ", "QD", "ruHxEjF", "BTuuSVsCV", "IfsD", "GrM", "q", "f", "a", "F", "sMGEnatpNHMJBfinEzIzybvhPjKRnbd", "U", "v", "d", "n", "pBzXRQBdRcWphjmLVxmnBNtOJMceisw", "H", "GN", "S", "O", "n", "bICOosUadrGNlfAssbJOcpWJQLcCCKQq", "XliiPNU", "MKkF", "rN", "EBlhwak", "Lbato", "MjiPVtGMjR", "moD", "yTTxFb", "SW", "ossZZ", "gR", "sybT", "tq", "eKo", "mxQfeoi", "DZbe", "k", "uBvzS", "TFwxyIRx", "lXiv", "JrXcwr", "XdSfxLlDZR", "y"], "tags": ["O", "Q", "P", "Q", "P", "Q", "O", "O", "O", "P", "O", "Q", "O", "O", "O", "Q", "O", "Q", "P", "Q", "P", "Q", "O", "P", "O", "O", "O", "O", "Q", "O", "O", "P", "P", "O", "P", "Q", "Q", "Q", "O", "O", "Q", "O", "O", "O", "P", "P", "Q", "Q", "Q", "P", "P", "P", "O", "Q", "P", "O", "O", "O", "Q", "O", "Q", "Q"]}
{"tokens": ["cMpSfp", "IOSq", "wizkn", "oEB", "Ux", "Gmord", "V", "RvkwzjJrkBOMsVEuoLvACZjFYDBrBUEnWkPuqnzY", "cgjplUK", "D", "Auj", "RGLDSSW", "uWRB", "y", "e", "JlTunC", "b", "GqYOtc", "CRXIL", "DOSndEb", "j", "C", "DVe", "Csp", "IjYeptL", "HWtK", "uDIKPJ", "E", "NIOshiUq", "KtD", "CGzcNNg", "Q", "e", "rzyYVX", "ncx", "yhGACxogyADau", "evP", "qbYK", "oigXl", "P"], "tags": ["O", "P", "Q", "P", "P", "P", "P", "O", "O", "O", "O", "Q", "O", "O", "P", "O", "Q", "O", "Q", "P", "O", "O", "P", "O", "O", "P", "Q", "O", "Q", "Q", "P", "O", "O", "Q", "Q", "Q", "O", "O", "Q", "P"]}
{"tokens": ["hyAcXV", "RW", "iO", "e", "eTePUCB", "o", "grVNB", "M", "LX", "CWkrrMHaxHFNu", "JXDPpxS", "g", "iWciIRc", "RyZjwZU", "u", "plcdCecp", "LOWbDCO", "n", "CzAULxOi", "LMPyDWe", "N", "SfZysOoD", "gusPKRp", "R", "DldmjFoHIY", "wXOrbAq", "G", "zuDJFvSXWhgTNTgwoE", "OLFazlp", "B", "cWEZHEBOWss", "PMzyvWG", "q", "gHJEujHPPwHXneHYv", "XZalipR", "T", "JFBaJlhHuFDWLM", "IuutEum", "A", "TNVmvRlQUuD", "HmZsgzC", "X", "szBRrWzUoLAOGsfBohYPDIVLr", "EijeeQw", "R", "xUsvfNrjMNxBCYhg", "cEbAIsG", "F", "MhWZlEDNGBOXJaQuesNfXdydiwxaUST", "URImwm", "yFOKiYpM", "x", "eao", "O", "DsP", "g", "fs", "a", "Mo", "p", "LgA", "q", "r", "siDKIEPOZkyI", "L", "v", "EQTSNTOxrd", "epW", "K", "ziV", "p", "A", "eWra", "U", "hBGCLsYLllrR", "ZfcJg", "g", "c", "P", "oUJUef", "aqWS", "i", "AHs", "F", "St", "T", "TbDMAs", "fIN", "kSup", "c", "BgKBoKtxXFBf", "t", "b", "o", "hKRhT", "U", "N", "m", "pZfQLs", "fLn", "T", "Imx", "H", "nG", "H", "ocVNIs", "kgT", "nZedF", "J", "U", "tcmU", "aSYlJG", "vpA", "Xf", "V", "FdrvDP", "OHcc", "UntG", "YFyy", "NAHr", "m", "opzPb", "icgUoNo", "fWKI", "cI", "ybB", "XQbwSa", "pEDMAJZ", "Ajnqq", "yOLKPAE", "cEACM", "dT", "pau", "OjAT", "UCmZNFHQ", "Vb", "ECpULl", "KaJsF", "GEmg", "o", "kjEc", "gKkvZvj", "gSM", "HCaPbni", "p", "OhYz", "tdTKv", "Oeuresj", "Raqjcr", "Z", "sKCQiSjGWyqvJASuB", "HNiFpp", "i", "HHwkWlygESwwMBL", "GEpb", "R", "SjjRzuPXZEcgNqfgbJGUgAIiMi", "Iwwp", "P", "s", "FGqxybNIPJzVwhL", "G", "nfKb", "qEnHOJl", "kGT", "SLXDAvfwR", "n", "WEso", "puuYI", "nPdUJOJ", "NAVRZp", "e", "gMhFUtVnSZaZAPeBi", "NNQGMQ", "R", "mzIOmvrRVjzVBfS", "Zmtj", "B", "uvwYbcmunUbgoJabBLymVNXCyE", "wpmI", "Z", "fqOjYrLSDtKXbqcBCE", "uDXTCqJ", "L", "L", "IrSpLTyHmyZqJg", "P", "yaWdOfA", "xLMytL", "r", "uJtGGjajlrSAKJXnv", "INXREu", "t", "h", "ndrFkQBGoRkiIHlCp", "f", "NjJxWLK", "kirQOT"], "tags": ["P", "Q", "P", "P", "P", "P", "O", "Q", "P", "O", "O", "P", "P", "P", "P", "O", "Q", "O", "P", "O", "P", "Q", "Q", "O", "Q", "O", "Q", "P", "Q", "P", "Q", "O", "O", "O", "O", "O", "Q", "O", "P", "O", "O", "Q", "O", "O", "P", "Q", "P", "P", "Q", "Q", "P", "O", "O", "O", "Q", "Q", "O", "Q", "Q", "O", "O", "P", "Q", "O", "Q", "P", "Q", "Q", "P", "Q", "Q", "O", "O", "Q", "P", "Q", "O", "O", "Q", "Q", "O", "P", "O", "P", "O", "O", "O", "O", "P", "P", "P", "P", "O", "P", "Q", "O", "Q", "Q", "Q", "P", "P", "O", "O", "P", "O", "Q", "Q", "Q", "P", "O", "P", "O", "O", "Q", "O", "O", "O", "O", "Q", "O", "Q", "O", "O", "P", "Q", "P", "Q", "O", "O", "Q", "O", "P", "P", "Q", "Q", "P", "P", "Q", "Q", "O", "P", "P", "O", "Q", "Q", "Q", "Q", "Q", "Q", "Q", "Q", "Q", "O", "Q", "Q", "Q", "Q", "P", "Q", "P", "P", "O", "Q", "P", "P", "Q", "P", "P", "Q", "Q", "P", "P", "P", "O", "O", "O", "P", "P", "P", "P", "O", "P", "P", "O", "Q", "O", "O", "O", "O", "P", "P", "P", "Q", "O", "O", "Q", "P", "O"]}
{"tokens": ["bJl", "cAsqzlymeBfFnO", "hMigNgVJ", "vD", "esTrrnMJBamvkOvjaLWARywfQiFwRwM", "Is", "Hhp", "lbn", "vnf", "wuWVkO", "Aw", "PnUPcoI", "AJE", "xnixjKF", "uRzEGyaDrRkjLd", "Qqel", "sLc", "ukyjdp", "Cyqn", "o", "fPBJSrC", "FqtzKpK", "Dw", "Vkl", "J", "HnnTKNsVP", "DPiK", "a", "ZUXAQ", "hRIbLv", "WWyWOq", "iyzEziDrS", "th", "VHyIL", "h", "eXFLCs", "xQ", "XandWFa", "W", "hncKOj", "KLdkXOrRyE", "b", "Oy", "mbbElWnm", "NHrDqsE", "nBtVcsPWY", "BdPX", "RX", "VHefpxJdxK", "a", "MRMAY", "iwQs", "hrZETMe", "lL", "E", "dQuLPWnub", "D"], "tags": ["O", "O", "Q", "O", "P", "O", "O", "Q", "P", "P", "Q", "O", "O", "O", "O", "P", "O", "O", "P", "Q", "Q", "P", "O", "O", "P", "O", "Q", "P", "P", "P", "P", "O", "Q", "P", "P", "P", "Q", "O", "O", "Q", "Q", "O", "O", "P", "Q", "O", "Q", "O", "O", "Q", "Q", "Q", "O", "Q", "P", "P", "Q"]}
{"tokens": ["PjUgTUcniaaguyQczGZDlOAxudGEQUpxxTsr", "Rf", "zGC", "cdfOxLl", "vLwEb", "mBbiLKn", "EvhIfT", "KED", "tvc", "deUac", "lHaBcZ", "mWH", "W", "yw", "rjfX", "tH", "eDdqDHyJ", "MaUJzNVJyW", "AhQlsI", "i", "Eilm", "b", "jBZUzcA", "nJsSQzOcjtBoa", "fvR", "Vih", "HGnLEjG", "frT", "eJaEN", "sypBkIMw", "H", "HxwFFg", "QOjNHfklD", "DZ", "KYOWZ", "m", "MogbCy", "Wu", "QhzMXWx", "O", "sMIUQR", "YioflBLuit", "m", "Hv", "gKMaoRXH", "DwsM", "wOeAUwkSlbV", "zTOOv", "GlSZly", "TEz", "t", "fllFm", "VqEcjKZ", "d", "Qj", "jiZQwLFNNccV", "LL", "m", "PRxEnWeJvUhmtuFzZb", "GWYCJs", "RljauRaV", "J"], "tags": ["O", "O", "P", "O", "O", "Q", "P", "O", "P", "O", "Q", "Q", "Q", "P", "P", "Q", "P", "O", "O", "Q", "O", "O", "P", "Q", "P", "P", "P", "O", "P", "P", "O", "O", "Q", "O", "Q", "P", "O", "O", "P", "Q", "Q", "P", "Q", "P", "O", "Q", "O", "P", "O", "O", "O", "Q", "O", "P", "P", "P", "O", "Q", "Q", "P", "Q", "P"]}
{"tokens": ["abX", "gDeEwdSlQFUXFWiWRIie", "emdFvnyR", "GZ", "jSm", "fagyuPSYnS", "qmosLR", "wL", "nLRINCl", "zUSyOZU", "AIO", "eLecAu", "ijzZSCWa", "r", "cmgXSrlFaoD", "ayF", "qfFQPi", "yxrvzDIe", "t", "dIK", "zweNjVRuf", "fmU", "vkIAaH", "hObrzx", "QlXqVW", "uZHCwn", "PeQWgisYg", "WV", "erxvr", "h", "oJivba", "gj", "ucRLQFQ", "z", "PCleg", "y", "Nkf", "oizdKKJ", "fzqexnO", "LSXd", "SdEfZcM", "uuWgbC", "rKKkDwPqWc", "b", "bw", "HNRCHCxUHbmV", "Wh", "qrsekbtnTJitvsENHpARJgKThtgEmXbv", "i"], "tags": ["Q", "P", "P", "P", "O", "P", "Q", "Q", "Q", "O", "Q", "Q", "O", "O", "O", "Q", "Q", "P", "O", "Q", "O", "P", "Q", "Q", "O", "O", "P", "O", "O", "O", "Q", "O", "O", "P", "Q", "O", "Q", "Q", "P", "P", "O", "O", "O", "P", "Q", "O", "O", "P", "P"]}
```
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/11035 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11035/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11035/comments | https://api.github.com/repos/huggingface/transformers/issues/11035/events | https://github.com/huggingface/transformers/issues/11035 | 848,976,468 | MDU6SXNzdWU4NDg5NzY0Njg= | 11,035 | 404 Client Error: Not Found for url: https://huggingface.co/%5CHuggingface-Sentiment-Pipeline/resolve/main/config.json | {
"login": "nithinreddyy",
"id": 56256685,
"node_id": "MDQ6VXNlcjU2MjU2Njg1",
"avatar_url": "https://avatars.githubusercontent.com/u/56256685?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nithinreddyy",
"html_url": "https://github.com/nithinreddyy",
"followers_url": "https://api.github.com/users/nithinreddyy/followers",
"following_url": "https://api.github.com/users/nithinreddyy/following{/other_user}",
"gists_url": "https://api.github.com/users/nithinreddyy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nithinreddyy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nithinreddyy/subscriptions",
"organizations_url": "https://api.github.com/users/nithinreddyy/orgs",
"repos_url": "https://api.github.com/users/nithinreddyy/repos",
"events_url": "https://api.github.com/users/nithinreddyy/events{/privacy}",
"received_events_url": "https://api.github.com/users/nithinreddyy/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 4 | 1,617,341,944,000 | 1,617,369,878,000 | null | NONE | null | I'm trying to use the hugging face sentimet-analysis pipeline. I've downloaded the pipeline using save.pretrained(model). And trying to load the pipeline with the help of below code
```
from transformers import pipeline
model = '\Huggingface-Sentiment-Pipeline'
classifier = pipeline(task='sentiment-analysis', model=model, tokenizer=model, from_pt=True)
```
The Huggingface-Sentiment-Pipeline contains 6 files. I'm mentioning below
```
-> Huggingface-Sentiment-Pipeline
-> config.json
-> modelcard.json
-> pytorch_model.bin
-> special_tokens_map.json
-> tokenizer_config.json
-> vocab.txt
```
The error I'm getting is given below
```
404 Client Error: Not Found for url: https://huggingface.co/%5CHuggingface-Sentiment-Pipeline/resolve/main/config.json
---------------------------------------------------------------------------
HTTPError Traceback (most recent call last)
~\sentiment_pipeline\lib\site-packages\transformers\configuration_utils.py in get_config_dict(cls, pretrained_model_name_or_path, **kwargs)
423 local_files_only=local_files_only,
--> 424 use_auth_token=use_auth_token,
425 )
~\sentiment_pipeline\lib\site-packages\transformers\file_utils.py in cached_path(url_or_filename, cache_dir, force_download, proxies, resume_download, user_agent, extract_compressed_file, force_extract, use_auth_token, local_files_only)
1085 use_auth_token=use_auth_token,
-> 1086 local_files_only=local_files_only,
1087 )
~\sentiment_pipeline\lib\site-packages\transformers\file_utils.py in get_from_cache(url, cache_dir, force_download, proxies, etag_timeout, resume_download, user_agent, use_auth_token, local_files_only)
1215 r = requests.head(url, headers=headers, allow_redirects=False, proxies=proxies, timeout=etag_timeout)
-> 1216 r.raise_for_status()
1217 etag = r.headers.get("X-Linked-Etag") or r.headers.get("ETag")
~\sentiment_pipeline\lib\site-packages\requests\models.py in raise_for_status(self)
942 if http_error_msg:
--> 943 raise HTTPError(http_error_msg, response=self)
944
HTTPError: 404 Client Error: Not Found for url: https://huggingface.co/%5CHuggingface-Sentiment-Pipeline/resolve/main/config.json
During handling of the above exception, another exception occurred:
OSError Traceback (most recent call last)
<ipython-input-7-5074b39a82b6> in <module>
----> 1 classifier = pipeline(task='sentiment-analysis', model=model, tokenizer=model, from_pt=True)
~\sentiment_pipeline\lib\site-packages\transformers\pipelines\__init__.py in pipeline(task, model, config, tokenizer, framework, revision, use_fast, **kwargs)
338 model = get_default_model(targeted_task, framework, task_options)
339
--> 340 framework = framework or get_framework(model)
341
342 task_class, model_class = targeted_task["impl"], targeted_task[framework]
~\sentiment_pipeline\lib\site-packages\transformers\pipelines\base.py in get_framework(model, revision)
64 if isinstance(model, str):
65 if is_torch_available() and not is_tf_available():
---> 66 model = AutoModel.from_pretrained(model, revision=revision)
67 elif is_tf_available() and not is_torch_available():
68 model = TFAutoModel.from_pretrained(model, revision=revision)
~\sentiment_pipeline\lib\site-packages\transformers\models\auto\modeling_auto.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
768 if not isinstance(config, PretrainedConfig):
769 config, kwargs = AutoConfig.from_pretrained(
--> 770 pretrained_model_name_or_path, return_unused_kwargs=True, **kwargs
771 )
772
~\sentiment_pipeline\lib\site-packages\transformers\models\auto\configuration_auto.py in from_pretrained(cls, pretrained_model_name_or_path, **kwargs)
366 {'foo': False}
367 """
--> 368 config_dict, _ = PretrainedConfig.get_config_dict(pretrained_model_name_or_path, **kwargs)
369
370 if "model_type" in config_dict:
~\sentiment_pipeline\lib\site-packages\transformers\configuration_utils.py in get_config_dict(cls, pretrained_model_name_or_path, **kwargs)
434 f"- or '{pretrained_model_name_or_path}' is the correct path to a directory containing a {CONFIG_NAME} file\n\n"
435 )
--> 436 raise EnvironmentError(msg)
437
438 except json.JSONDecodeError:
OSError: Can't load config for '\Huggingface-Sentiment-Pipeline'. Make sure that:
- '\Huggingface-Sentiment-Pipeline' is a correct model identifier listed on 'https://huggingface.co/models'
- or '\Huggingface-Sentiment-Pipeline' is the correct path to a directory containing a config.json file
```
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/11034 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11034/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11034/comments | https://api.github.com/repos/huggingface/transformers/issues/11034/events | https://github.com/huggingface/transformers/issues/11034 | 848,939,310 | MDU6SXNzdWU4NDg5MzkzMTA= | 11,034 | GPT-2 example is broken? | {
"login": "ba305",
"id": 35350330,
"node_id": "MDQ6VXNlcjM1MzUwMzMw",
"avatar_url": "https://avatars.githubusercontent.com/u/35350330?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ba305",
"html_url": "https://github.com/ba305",
"followers_url": "https://api.github.com/users/ba305/followers",
"following_url": "https://api.github.com/users/ba305/following{/other_user}",
"gists_url": "https://api.github.com/users/ba305/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ba305/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ba305/subscriptions",
"organizations_url": "https://api.github.com/users/ba305/orgs",
"repos_url": "https://api.github.com/users/ba305/repos",
"events_url": "https://api.github.com/users/ba305/events{/privacy}",
"received_events_url": "https://api.github.com/users/ba305/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 2 | 1,617,335,800,000 | 1,617,384,338,000 | null | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: I have had this issue with both 4.3.0 and 4.4.2 (and probably other versions as well)
- Python version: 3.7.6
- PyTorch version (GPU?): 1.7.0
- Using GPU in script?: No, I just tested it on the CPU, but it would probably also happen on the GPU
- Using distributed or parallel set-up in script?: No
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
-->
- gpt2: @patrickvonplaten, @LysandreJik
- Documentation: @sgugger
## Information
Model I am using (Bert, XLNet ...): gpt2
The problem arises when using:
* [ x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
## To reproduce
Hello, I am trying to run this example here: https://huggingface.co/transformers/task_summary.html#causal-language-modeling. When I run that code, exactly the same as it is on that page, I get strange/very bad results. Even when I change the input text, it still gives weird results (e.g., predicting empty spaces or strange characters). I also asked my coworker to try it on her computer, and she also got strange results.
I am planning to fine-tune GPT-2 for a different purpose later, but was a bit concerned because I couldn't even get this simple example demo to work. Thanks for your help!
Steps to reproduce the behavior:
1. Just run the exact example code that I linked above
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.--> | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11033 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11033/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11033/comments | https://api.github.com/repos/huggingface/transformers/issues/11033/events | https://github.com/huggingface/transformers/issues/11033 | 848,936,573 | MDU6SXNzdWU4NDg5MzY1NzM= | 11,033 | RuntimeError: The size of tensor a (1024) must match the size of tensor b (1025) at non-singleton dimension 3 | {
"login": "yananchen1989",
"id": 26405281,
"node_id": "MDQ6VXNlcjI2NDA1Mjgx",
"avatar_url": "https://avatars.githubusercontent.com/u/26405281?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yananchen1989",
"html_url": "https://github.com/yananchen1989",
"followers_url": "https://api.github.com/users/yananchen1989/followers",
"following_url": "https://api.github.com/users/yananchen1989/following{/other_user}",
"gists_url": "https://api.github.com/users/yananchen1989/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yananchen1989/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yananchen1989/subscriptions",
"organizations_url": "https://api.github.com/users/yananchen1989/orgs",
"repos_url": "https://api.github.com/users/yananchen1989/repos",
"events_url": "https://api.github.com/users/yananchen1989/events{/privacy}",
"received_events_url": "https://api.github.com/users/yananchen1989/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 1,617,335,157,000 | 1,617,335,157,000 | null | NONE | null | Here I try to use gpt2 to generation the text under the prompt text. I have several datasets, some of them, such as AG_NEWS and POP_NEWS, are made of short sentences while when I use YAHOO_NEWS, consisting of longer sentences, the error came out.
Anything to modify for my codes?
Thanks.
```
from transformers import (
CTRLLMHeadModel,
CTRLTokenizer,
GPT2LMHeadModel,
GPT2Tokenizer,
OpenAIGPTLMHeadModel,
OpenAIGPTTokenizer,
TransfoXLLMHeadModel,
TransfoXLTokenizer,
XLMTokenizer,
XLMWithLMHeadModel,
XLNetLMHeadModel,
XLNetTokenizer,
)
class generation():
def __init__(self, model_name='gpt2',num_return_sequences=1):
self.model_name = model_name
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.MODEL_CLASSES = {
"gpt2": (GPT2LMHeadModel, GPT2Tokenizer),
"ctrl": (CTRLLMHeadModel, CTRLTokenizer),
"openai-gpt": (OpenAIGPTLMHeadModel, OpenAIGPTTokenizer),
"xlnet-base-cased": (XLNetLMHeadModel, XLNetTokenizer),
"transfo-xl": (TransfoXLLMHeadModel, TransfoXLTokenizer),
"xlm": (XLMWithLMHeadModel, XLMTokenizer),
}
self.length = 100
self.k = 0
self.p = 0.9
self.num_return_sequences = num_return_sequences
self.model_class, self.tokenizer_class = self.MODEL_CLASSES[self.model_name]
self.tokenizer = self.tokenizer_class.from_pretrained(self.model_name)
self.model = self.model_class.from_pretrained(self.model_name)
self.model.to(self.device)
if self.model_name == "xlnet-base-cased":
self.p=0.95
self.k=60
self.length = self.adjust_length_to_model(self.length, max_sequence_length=self.model.config.max_position_embeddings)
if self.model_name == 'ctrl':
self.temperature = 0.3
self.repetition_penalty = 1.2
else:
self.temperature = 1.0
self.repetition_penalty = 1.0
def adjust_length_to_model(self, length, max_sequence_length):
if length < 0 and max_sequence_length > 0:
length = max_sequence_length
elif 0 < max_sequence_length < length:
length = max_sequence_length # No generation bigger than model size
elif length < 0:
length = 1000 # avoid infinite loop
return length
def ctrl_label2prefix(self, label):
# https://github.com/salesforce/ctrl/blob/master/control_codes.py
'''
'Pregnancy Christianity Explain Fitness Saving Ask Ass Joke Questions Thoughts Retail
Feminism Writing Atheism Netflix Computing Opinion Alone Funny Gaming Human India Joker Diet
Legal Norman Tip Weight Movies Running Science Horror Confession Finance Politics Scary Support
Technologies Teenage Event Learned Notion Wikipedia Books Extract Confessions Conspiracy Links
Narcissus Relationship Relationships Reviews News Translation multilingual'
'''
return 'News'
if label in ('Sci/Tech', 'tech'):
return 'Technologies'
elif label in ('politics'):
return 'Politics'
elif label in ('Sports', 'sport'):
return 'Fitness'
else:
return 'News'
def augment(self, prompt_text):
if self.model_name == 'ctrl':
prefix = 'News '
else:
prefix = ''
encoded_prompt = self.tokenizer.encode(prefix + prompt_text, add_special_tokens=False, return_tensors="pt")
encoded_prompt = encoded_prompt.to(self.device)
if encoded_prompt.size()[-1] == 0:
input_ids = None
else:
input_ids = encoded_prompt
output_sequences = self.model.generate(
input_ids=input_ids,
max_length= self.length + len(encoded_prompt[0]),
temperature=self.temperature,
top_k=self.k,
top_p=self.p,
repetition_penalty=self.repetition_penalty,
do_sample=True,
num_return_sequences=self.num_return_sequences,
)
# Decode text
text_generated = self.tokenizer.decode(output_sequences[0][len(encoded_prompt[0]):], clean_up_tokenization_spaces=True)
return text_generated
# unit test
'''
augmentor = generation('gpt2')
prompt_text = "Microsoft has said it will replace more than 14 million power cables for its Xbox consoles due to safety concerns."
prompt_text = "Versace art portfolio up for sale The art collection of murdered fashion designer Gianni Versace could fetch \
up to £9m ($17m) when it is auctioned in New York and \
London later this year. <eod> </s> <eos>"
augmentor.augment(prompt_text)
'''
```
ERROR information:
> File "baseline_classifier.py", line 45, in run_benchmark
> ds.df_train['content_aug'] = ds.df_train['content'].map(lambda x: augmentor.augment(x))
> File "/workspace/.conda/miniconda/lib/python3.7/site-packages/pandas/core/series.py", line 3382, in map
> arg, na_action=na_action)
> File "/workspace/.conda/miniconda/lib/python3.7/site-packages/pandas/core/base.py", line 1218, in _map_values
> new_values = map_f(values, mapper)
> File "pandas/_libs/lib.pyx", line 2217, in pandas._libs.lib.map_infer
> File "baseline_classifier.py", line 45, in <lambda>
> ds.df_train['content_aug'] = ds.df_train['content'].map(lambda x: augmentor.augment(x))
> File "/workspace/user-workspace/topic_classification_augmentation/aug_generation.py", line 110, in augment
> num_return_sequences=self.num_return_sequences,
> File "/workspace/.conda/miniconda/lib/python3.7/site-packages/torch/autograd/grad_mode.py", line 15, in decorate_context
> return func(*args, **kwargs)
> File "/workspace/.conda/miniconda/lib/python3.7/site-packages/transformers/generation_utils.py", line 1019, in generate
> **model_kwargs,
> File "/workspace/.conda/miniconda/lib/python3.7/site-packages/transformers/generation_utils.py", line 1486, in sample
> output_hidden_states=output_hidden_states,
> File "/workspace/.conda/miniconda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 550, in __call__
> result = self.forward(*input, **kwargs)
> File "/workspace/.conda/miniconda/lib/python3.7/site-packages/transformers/models/gpt2/modeling_gpt2.py", line 917, in forward
> return_dict=return_dict,
> File "/workspace/.conda/miniconda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 550, in __call__
> result = self.forward(*input, **kwargs)
> File "/workspace/.conda/miniconda/lib/python3.7/site-packages/transformers/models/gpt2/modeling_gpt2.py", line 760, in forward
> output_attentions=output_attentions,
> File "/workspace/.conda/miniconda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 550, in __call__
> result = self.forward(*input, **kwargs)
> File "/workspace/.conda/miniconda/lib/python3.7/site-packages/transformers/models/gpt2/modeling_gpt2.py", line 296, in forward
> output_attentions=output_attentions,
> File "/workspace/.conda/miniconda/lib/python3.7/site-packages/torch/nn/modules/module.py", line 550, in __call__
> result = self.forward(*input, **kwargs)
> File "/workspace/.conda/miniconda/lib/python3.7/site-packages/transformers/models/gpt2/modeling_gpt2.py", line 241, in forward
> attn_outputs = self._attn(query, key, value, attention_mask, head_mask, output_attentions)
> File "/workspace/.conda/miniconda/lib/python3.7/site-packages/transformers/models/gpt2/modeling_gpt2.py", line 176, in _attn
> w = torch.where(mask.bool(), w, self.masked_bias.to(w.dtype))
> RuntimeError: The size of tensor a (1024) must match the size of tensor b (1025) at non-singleton dimension 3 | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11032 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11032/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11032/comments | https://api.github.com/repos/huggingface/transformers/issues/11032/events | https://github.com/huggingface/transformers/issues/11032 | 848,921,982 | MDU6SXNzdWU4NDg5MjE5ODI= | 11,032 | How to get masked word prediction for other languages | {
"login": "AnnaSou",
"id": 43326583,
"node_id": "MDQ6VXNlcjQzMzI2NTgz",
"avatar_url": "https://avatars.githubusercontent.com/u/43326583?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AnnaSou",
"html_url": "https://github.com/AnnaSou",
"followers_url": "https://api.github.com/users/AnnaSou/followers",
"following_url": "https://api.github.com/users/AnnaSou/following{/other_user}",
"gists_url": "https://api.github.com/users/AnnaSou/gists{/gist_id}",
"starred_url": "https://api.github.com/users/AnnaSou/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AnnaSou/subscriptions",
"organizations_url": "https://api.github.com/users/AnnaSou/orgs",
"repos_url": "https://api.github.com/users/AnnaSou/repos",
"events_url": "https://api.github.com/users/AnnaSou/events{/privacy}",
"received_events_url": "https://api.github.com/users/AnnaSou/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 3 | 1,617,332,380,000 | 1,617,418,490,000 | null | NONE | null | Hello,
I trying to get masked words predictions for languages except English with Roberta or XLM Roberta.
```
from transformers import pipeline
nlp = pipeline("fill-mask", model="roberta-base")
template = f"That woman is {nlp.tokenizer.mask_token}."
output = nlp(template)
nlp4 = pipeline("fill-mask", model="roberta-base")
nlp4(f"Женщины работают {nlp4.tokenizer.mask_token}.")
```
The output for English example is quite good, while for Russian one does not make sense at all:
`[{'sequence': 'Женщины работаюта.', 'score': 0.2504434883594513, 'token': 26161, 'token_str': 'а'}, {'sequence': 'Женщины работають.', 'score': 0.24665573239326477, 'token': 47015, 'token_str': 'ь'}, {'sequence': 'Женщины работаюты.', 'score': 0.1454654186964035, 'token': 46800, 'token_str': 'ы'}, {'sequence': 'Женщины работаюте.', 'score': 0.07919821888208389, 'token': 25482, 'token_str': 'е'}, {'sequence': 'Женщины работаюти.', 'score': 0.07401203364133835, 'token': 35328, 'token_str': 'и'}]`
Neither "roberta-base" nor "xlm-roberta-base" work for Russian language example.
Maybe I am doing it wrong, but how would one use masked word prediction for other languages?
Thanks! | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11030 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11030/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11030/comments | https://api.github.com/repos/huggingface/transformers/issues/11030/events | https://github.com/huggingface/transformers/issues/11030 | 848,823,702 | MDU6SXNzdWU4NDg4MjM3MDI= | 11,030 | pipeline.from_pretrained | {
"login": "cronoik",
"id": 18630848,
"node_id": "MDQ6VXNlcjE4NjMwODQ4",
"avatar_url": "https://avatars.githubusercontent.com/u/18630848?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cronoik",
"html_url": "https://github.com/cronoik",
"followers_url": "https://api.github.com/users/cronoik/followers",
"following_url": "https://api.github.com/users/cronoik/following{/other_user}",
"gists_url": "https://api.github.com/users/cronoik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cronoik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cronoik/subscriptions",
"organizations_url": "https://api.github.com/users/cronoik/orgs",
"repos_url": "https://api.github.com/users/cronoik/repos",
"events_url": "https://api.github.com/users/cronoik/events{/privacy}",
"received_events_url": "https://api.github.com/users/cronoik/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 1,617,315,416,000 | 1,617,315,451,000 | null | CONTRIBUTOR | null | # 🚀 Feature request
Nearly everyone who is using the transformers library is aware of the `from_pretrained()` and `save_pretrained()` concept. The [Pipeline class](https://huggingface.co/transformers/main_classes/pipelines.html#parent-class-pipeline) is currently only providing the `save_pretrained()` method which can cause confusion for some users as saving and loading of the pipeline needs to be done like this:
```
from transformers import pipeline
TASK = 'something'
DIRECTORY='something'
classifier = pipeline(TASK)
classifier.save_pretrained(DIRECTORY)
c2 = pipeline(task = TASK, model=DIRECTORY, tokenizer=DIRECTORY)
```
This is probably not that obvious for people who just read the documentation and not the code. I suggest implementing the `from_pretrained()` method for the pipelines to make the library even more intuitive.
## Your contribution
There is actually not much to do since the tokenizer and model are loaded by the corresponding Auto classes. The only information that is missing to construct the saved pipeline with `pipeline.from_pretraind(PATH)` is the task identifier. This information should be stored in a new separate file called `pipeline_config.json`.
I can provide a PR if you think this is a useful enhancement for the library @LysandreJik
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/11029 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11029/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11029/comments | https://api.github.com/repos/huggingface/transformers/issues/11029/events | https://github.com/huggingface/transformers/pull/11029 | 848,798,224 | MDExOlB1bGxSZXF1ZXN0NjA3Njc4Nzg3 | 11,029 | Documentation about loading a fast tokenizer within Transformers | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 1,617,312,168,000 | 1,617,312,168,000 | null | MEMBER | null | This PR does two things:
- Allows to load a fast tokenizer from an instantiated `tokenizers` object
- Adds a page to document how to use these tokenizers within `transformers`
See [here](https://190138-155220641-gh.circle-artifacts.com/0/docs/_build/html/fast_tokenizers.html) for the generated docs | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11028 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11028/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11028/comments | https://api.github.com/repos/huggingface/transformers/issues/11028/events | https://github.com/huggingface/transformers/issues/11028 | 848,769,061 | MDU6SXNzdWU4NDg3NjkwNjE= | 11,028 | Fine Tune GPT-NEO 2.7B | {
"login": "antocapp",
"id": 26765504,
"node_id": "MDQ6VXNlcjI2NzY1NTA0",
"avatar_url": "https://avatars.githubusercontent.com/u/26765504?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/antocapp",
"html_url": "https://github.com/antocapp",
"followers_url": "https://api.github.com/users/antocapp/followers",
"following_url": "https://api.github.com/users/antocapp/following{/other_user}",
"gists_url": "https://api.github.com/users/antocapp/gists{/gist_id}",
"starred_url": "https://api.github.com/users/antocapp/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/antocapp/subscriptions",
"organizations_url": "https://api.github.com/users/antocapp/orgs",
"repos_url": "https://api.github.com/users/antocapp/repos",
"events_url": "https://api.github.com/users/antocapp/events{/privacy}",
"received_events_url": "https://api.github.com/users/antocapp/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 1 | 1,617,309,086,000 | 1,617,312,297,000 | null | NONE | null | Hello to everyone, is there a script to fine tune this new model?
Thanks | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11027 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11027/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11027/comments | https://api.github.com/repos/huggingface/transformers/issues/11027/events | https://github.com/huggingface/transformers/pull/11027 | 848,767,936 | MDExOlB1bGxSZXF1ZXN0NjA3NjUzMTAy | 11,027 | [WIP] Refactor AutoModel classes and add Flax Auto classes | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 1,617,308,974,000 | 1,617,310,405,000 | null | MEMBER | null | # What does this PR do?
This PR refactors the logic behind all the Auto model classes in one function that automatically builds those classes from a template. In passing, it uses this new function to build the auto classes for FLAX (at least the ones that have at least one model implemented). | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11026 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11026/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11026/comments | https://api.github.com/repos/huggingface/transformers/issues/11026/events | https://github.com/huggingface/transformers/pull/11026 | 848,754,983 | MDExOlB1bGxSZXF1ZXN0NjA3NjQyMjM1 | 11,026 | Add `examples/language_modeling/run_clm_no_trainer.py` | {
"login": "hemildesai",
"id": 8195444,
"node_id": "MDQ6VXNlcjgxOTU0NDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/8195444?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hemildesai",
"html_url": "https://github.com/hemildesai",
"followers_url": "https://api.github.com/users/hemildesai/followers",
"following_url": "https://api.github.com/users/hemildesai/following{/other_user}",
"gists_url": "https://api.github.com/users/hemildesai/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hemildesai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hemildesai/subscriptions",
"organizations_url": "https://api.github.com/users/hemildesai/orgs",
"repos_url": "https://api.github.com/users/hemildesai/repos",
"events_url": "https://api.github.com/users/hemildesai/events{/privacy}",
"received_events_url": "https://api.github.com/users/hemildesai/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 1,617,307,709,000 | 1,617,314,068,000 | null | CONTRIBUTOR | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
This PR adds an example of finetuning a Causal Language Model (without using Trainer) to show the functionalities of the new accelerate library.
## Who can review?
@sgugger
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/11024 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11024/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11024/comments | https://api.github.com/repos/huggingface/transformers/issues/11024/events | https://github.com/huggingface/transformers/pull/11024 | 848,717,134 | MDExOlB1bGxSZXF1ZXN0NjA3NjEwNjQ1 | 11,024 | Add a script to check inits are consistent | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 1,617,304,032,000 | 1,617,312,410,000 | null | MEMBER | null | # What does this PR do?
Most inits in the project define the same objects twice (once in `_import_structure` and once in TYPE_CHECKING) to have a fast import so objects are only grabbed when actually needed. The problem is that those two halves have a tendency to diverge as contributors do not always pay attention to have them exactly match.
Well not anymore. Introducing `utils/check_inits.py`. This script will parse all the inits with two halves and return an error with a delightful and informative message telling the user what they did wrong. It is enforced in the CI and added to `make fixup` and `make quality`. | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11023 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11023/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11023/comments | https://api.github.com/repos/huggingface/transformers/issues/11023/events | https://github.com/huggingface/transformers/issues/11023 | 848,680,168 | MDU6SXNzdWU4NDg2ODAxNjg= | 11,023 | Strange ValueError with GPT-2 | {
"login": "AI-Guru",
"id": 32195399,
"node_id": "MDQ6VXNlcjMyMTk1Mzk5",
"avatar_url": "https://avatars.githubusercontent.com/u/32195399?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AI-Guru",
"html_url": "https://github.com/AI-Guru",
"followers_url": "https://api.github.com/users/AI-Guru/followers",
"following_url": "https://api.github.com/users/AI-Guru/following{/other_user}",
"gists_url": "https://api.github.com/users/AI-Guru/gists{/gist_id}",
"starred_url": "https://api.github.com/users/AI-Guru/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AI-Guru/subscriptions",
"organizations_url": "https://api.github.com/users/AI-Guru/orgs",
"repos_url": "https://api.github.com/users/AI-Guru/repos",
"events_url": "https://api.github.com/users/AI-Guru/events{/privacy}",
"received_events_url": "https://api.github.com/users/AI-Guru/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 2 | 1,617,300,552,000 | 1,617,345,060,000 | null | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.4.2
- Platform: macOS-10.15.7-x86_64-i386-64bit
- Python version: 3.8.6
- PyTorch version (GPU?): 1.7.1 (False)
- Tensorflow version (GPU?): 2.4.0 (False)
- Using GPU in script?: No.
- Using distributed or parallel set-up in script?: No.
### Who can help
Models:
- gpt2: @patrickvonplaten, @LysandreJik
## Information
Model I am using (Bert, XLNet ...): GPT-2
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [X] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: (give details below)
## To reproduce
Create and train GPT-2 with 8 heads and batch size 32.
I get an error message when training GPT-2. When number of heads and batch size are the same it works. Looks like a shape check is wronk. See error message below.
```
File "train.py", line 66, in <module>
history = model.fit(
File "/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/keras/engine/training.py", line 1100, in fit
tmp_logs = self.train_function(iterator)
File "/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/eager/def_function.py", line 828, in __call__
result = self._call(*args, **kwds)
File "/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/eager/def_function.py", line 871, in _call
self._initialize(args, kwds, add_initializers_to=initializers)
File "/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/eager/def_function.py", line 725, in _initialize
self._stateful_fn._get_concrete_function_internal_garbage_collected( # pylint: disable=protected-access
File "/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/eager/function.py", line 2969, in _get_concrete_function_internal_garbage_collected
graph_function, _ = self._maybe_define_function(args, kwargs)
File "/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/eager/function.py", line 3361, in _maybe_define_function
graph_function = self._create_graph_function(args, kwargs)
File "/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/eager/function.py", line 3196, in _create_graph_function
func_graph_module.func_graph_from_py_func(
File "/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/framework/func_graph.py", line 990, in func_graph_from_py_func
func_outputs = python_func(*func_args, **func_kwargs)
File "/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/eager/def_function.py", line 634, in wrapped_fn
out = weak_wrapped_fn().__wrapped__(*args, **kwds)
File "/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/framework/func_graph.py", line 977, in wrapper
raise e.ag_error_metadata.to_exception(e)
ValueError: in user code:
/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/keras/engine/training.py:805 train_function *
return step_function(self, iterator)
/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/keras/engine/training.py:795 step_function **
outputs = model.distribute_strategy.run(run_step, args=(data,))
/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/distribute/distribute_lib.py:1259 run
return self._extended.call_for_each_replica(fn, args=args, kwargs=kwargs)
/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/distribute/distribute_lib.py:2730 call_for_each_replica
return self._call_for_each_replica(fn, args, kwargs)
/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/distribute/distribute_lib.py:3417 _call_for_each_replica
return fn(*args, **kwargs)
/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/keras/engine/training.py:788 run_step **
outputs = model.train_step(data)
/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/keras/engine/training.py:758 train_step
self.compiled_metrics.update_state(y, y_pred, sample_weight)
/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/keras/engine/compile_utils.py:408 update_state
metric_obj.update_state(y_t, y_p, sample_weight=mask)
/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/keras/utils/metrics_utils.py:90 decorated
update_op = update_state_fn(*args, **kwargs)
/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/keras/metrics.py:177 update_state_fn
return ag_update_state(*args, **kwargs)
/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/keras/metrics.py:618 update_state **
matches = ag_fn(y_true, y_pred, **self._fn_kwargs)
/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/util/dispatch.py:201 wrapper
return target(*args, **kwargs)
/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/keras/metrics.py:3315 sparse_categorical_accuracy
return math_ops.cast(math_ops.equal(y_true, y_pred), K.floatx())
/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/util/dispatch.py:201 wrapper
return target(*args, **kwargs)
/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/ops/math_ops.py:1679 equal
return gen_math_ops.equal(x, y, name=name)
/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/ops/gen_math_ops.py:3177 equal
_, _, _op, _outputs = _op_def_library._apply_op_helper(
/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/framework/op_def_library.py:748 _apply_op_helper
op = g._create_op_internal(op_type_name, inputs, dtypes=None,
/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/framework/func_graph.py:590 _create_op_internal
return super(FuncGraph, self)._create_op_internal( # pylint: disable=protected-access
/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/framework/ops.py:3528 _create_op_internal
ret = Operation(
/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/framework/ops.py:2015 __init__
self._c_op = _create_c_op(self._graph, node_def, inputs,
/Users/tristanbehrens/Development/python-venvs/tf2-p38/lib/python3.8/site-packages/tensorflow/python/framework/ops.py:1856 _create_c_op
raise ValueError(str(e))
ValueError: Dimensions must be equal, but are 32 and 8 for '{{node Equal_1}} = Equal[T=DT_FLOAT, incompatible_shape_error=true](Cast_6, Cast_7)' with input shapes: [32,301], [2,32,8,301].
```
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/11022 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11022/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11022/comments | https://api.github.com/repos/huggingface/transformers/issues/11022/events | https://github.com/huggingface/transformers/issues/11022 | 848,679,174 | MDU6SXNzdWU4NDg2NzkxNzQ= | 11,022 | cannot import name 'AutoModelForSequenceClassification' from 'transformers' | {
"login": "nithinreddyy",
"id": 56256685,
"node_id": "MDQ6VXNlcjU2MjU2Njg1",
"avatar_url": "https://avatars.githubusercontent.com/u/56256685?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nithinreddyy",
"html_url": "https://github.com/nithinreddyy",
"followers_url": "https://api.github.com/users/nithinreddyy/followers",
"following_url": "https://api.github.com/users/nithinreddyy/following{/other_user}",
"gists_url": "https://api.github.com/users/nithinreddyy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nithinreddyy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nithinreddyy/subscriptions",
"organizations_url": "https://api.github.com/users/nithinreddyy/orgs",
"repos_url": "https://api.github.com/users/nithinreddyy/repos",
"events_url": "https://api.github.com/users/nithinreddyy/events{/privacy}",
"received_events_url": "https://api.github.com/users/nithinreddyy/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 1 | 1,617,300,456,000 | 1,617,315,547,000 | null | NONE | null | ```
from transformers import pipeline
classifier = pipeline('sentiment-analysis') #This code will download the pipeline
classifier('We are very happy to show you the 🤗 Transformers library.')
classifier.save_pretrained('/some/directory')
```
I'm trying to save the model and trying to perform the sentiment-analysis operation offline
```
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
t = AutoTokenizer.from_pretrained('/some/directory')
m = AutoModelForSequenceClassification.from_pretrained('/some/directory')
c2 = pipeline(task = 'sentiment-analysis', model=m, tokenizer=t)
I'm facing import error for jupyter notebook as given below
`**cannot import name 'AutoModelForSequenceClassification' from 'transformers'**`
``` | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11021 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11021/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11021/comments | https://api.github.com/repos/huggingface/transformers/issues/11021/events | https://github.com/huggingface/transformers/issues/11021 | 848,651,434 | MDU6SXNzdWU4NDg2NTE0MzQ= | 11,021 | Module Not found: datasets_modules.datasets.output | {
"login": "ashleylew",
"id": 68515763,
"node_id": "MDQ6VXNlcjY4NTE1NzYz",
"avatar_url": "https://avatars.githubusercontent.com/u/68515763?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ashleylew",
"html_url": "https://github.com/ashleylew",
"followers_url": "https://api.github.com/users/ashleylew/followers",
"following_url": "https://api.github.com/users/ashleylew/following{/other_user}",
"gists_url": "https://api.github.com/users/ashleylew/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ashleylew/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ashleylew/subscriptions",
"organizations_url": "https://api.github.com/users/ashleylew/orgs",
"repos_url": "https://api.github.com/users/ashleylew/repos",
"events_url": "https://api.github.com/users/ashleylew/events{/privacy}",
"received_events_url": "https://api.github.com/users/ashleylew/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 1,617,297,828,000 | 1,617,297,861,000 | null | NONE | null | ## Environment info
- `transformers` version: 4.5.0.dev0
- Platform: Linux-3.10.0-1160.15.2.el7.x86_64-x86_64-with-glibc2.10
- Python version: 3.8.5
- PyTorch version (GPU?): 1.8.1 (False)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: not sure
- Using distributed or parallel set-up in script?: <fill in> ?
### Who can help
@patil-suraj
## Information
Model I am using (Bert, XLNet ...): BART seq2seq
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. "Install from source" method
2. ran this command, where "data/output.jsonl" is my dataset:
```
python examples/seq2seq/run_translation.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--source_lang en \
--target_lang de \
--source_prefix "Translate English to Logical Forms: " \
--dataset_name data/output.jsonl \
--output_dir /tmp/tst-translation \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
3. Got the following error:
```
ModuleNotFoundError: No module named 'datasets_modules.datasets.output'
```
At first it told me that "datasets" was not installed, so I did ```pip install datasets``` and that worked fine. Then I got this error and haven't been able to figure out what it means or how to fix it. | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11020 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11020/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11020/comments | https://api.github.com/repos/huggingface/transformers/issues/11020/events | https://github.com/huggingface/transformers/issues/11020 | 848,566,666 | MDU6SXNzdWU4NDg1NjY2NjY= | 11,020 | Trainer API crashes GPUs | {
"login": "dmitriydligach",
"id": 5121609,
"node_id": "MDQ6VXNlcjUxMjE2MDk=",
"avatar_url": "https://avatars.githubusercontent.com/u/5121609?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dmitriydligach",
"html_url": "https://github.com/dmitriydligach",
"followers_url": "https://api.github.com/users/dmitriydligach/followers",
"following_url": "https://api.github.com/users/dmitriydligach/following{/other_user}",
"gists_url": "https://api.github.com/users/dmitriydligach/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dmitriydligach/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dmitriydligach/subscriptions",
"organizations_url": "https://api.github.com/users/dmitriydligach/orgs",
"repos_url": "https://api.github.com/users/dmitriydligach/repos",
"events_url": "https://api.github.com/users/dmitriydligach/events{/privacy}",
"received_events_url": "https://api.github.com/users/dmitriydligach/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 2 | 1,617,290,704,000 | 1,617,295,389,000 | null | NONE | null | ## Environment info
- `transformers` version: 4.5.0.dev0
- Platform: Ubuntu 20.04.2 LTS
- Python version: Python 3.8.5
- PyTorch version (GPU?): 1.7.1
- Tensorflow version (GPU?): 2.4.1
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: Yes
My scripts that use Trainer API crash GPUs on a Linux server that has 4 Quadro RTX 8000 GPUs (NVIDIA-SMI 460.39, Driver Version: 460.39, CUDA Version: 11.2). In order to understand if this is my problem or not, I installed Huggingface examples as described in
https://huggingface.co/transformers/examples.html.
I then run
python3 examples/seq2seq/run_summarization.py \
> --model_name_or_path t5-large \
> --do_train \
> --do_eval \
> --dataset_name cnn_dailymail \
> --dataset_config "3.0.0" \
> --source_prefix "summarize: " \
> --output_dir /tmp/tst-summarization \
> --per_device_train_batch_size=2 \
> --per_device_eval_batch_size=2 \
> --overwrite_output_dir \
> --predict_with_generate
After this script runs for a few minutes (and I can see that the GPUs are being utilized when I run nvidia-smi), all GPUs crash with the following error:
Traceback (most recent call last):
File "examples/seq2seq/run_summarization.py", line 591, in <module>
main()
File "examples/seq2seq/run_summarization.py", line 529, in main
train_result = trainer.train(resume_from_checkpoint=checkpoint)
File "/home/dima/.local/lib/python3.8/site-packages/transformers/trainer.py", line 1120, in train
tr_loss += self.training_step(model, inputs)
File "/home/dima/.local/lib/python3.8/site-packages/transformers/trainer.py", line 1542, in training_step
loss.backward()
File "/usr/lib/python3/dist-packages/torch/tensor.py", line 221, in backward
torch.autograd.backward(self, gradient, retain_graph, create_graph)
File "/usr/lib/python3/dist-packages/torch/autograd/__init__.py", line 130, in backward
Variable._execution_engine.run_backward(
RuntimeError: CUDA error: unspecified launch failure
When I run nvidia-smi, I get:
Unable to determine the device handle for GPU 0000:40:00.0: Unknown Error
Rebooting the server helps to restore the GPUs, but the same problem happens again if I try to run the example script above.
Please help! :) | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11019 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11019/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11019/comments | https://api.github.com/repos/huggingface/transformers/issues/11019/events | https://github.com/huggingface/transformers/issues/11019 | 848,543,462 | MDU6SXNzdWU4NDg1NDM0NjI= | 11,019 | Enable multiple `eval_dataset` in `Trainer` API | {
"login": "simonschoe",
"id": 53626067,
"node_id": "MDQ6VXNlcjUzNjI2MDY3",
"avatar_url": "https://avatars.githubusercontent.com/u/53626067?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/simonschoe",
"html_url": "https://github.com/simonschoe",
"followers_url": "https://api.github.com/users/simonschoe/followers",
"following_url": "https://api.github.com/users/simonschoe/following{/other_user}",
"gists_url": "https://api.github.com/users/simonschoe/gists{/gist_id}",
"starred_url": "https://api.github.com/users/simonschoe/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/simonschoe/subscriptions",
"organizations_url": "https://api.github.com/users/simonschoe/orgs",
"repos_url": "https://api.github.com/users/simonschoe/repos",
"events_url": "https://api.github.com/users/simonschoe/events{/privacy}",
"received_events_url": "https://api.github.com/users/simonschoe/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2648621985,
"node_id": "MDU6TGFiZWwyNjQ4NjIxOTg1",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Feature%20request",
"name": "Feature request",
"color": "FBCA04",
"default": false,
"description": "Request for a new feature"
}
] | open | false | null | [] | null | 1 | 1,617,289,031,000 | 1,617,298,990,000 | null | NONE | null | # 🚀 Feature request
Allow for two or more (equally long) validation sets to be passed to the `Trainer` API which are evaluated sequentially each `eval_steps`.
## Motivation
You can find my motivation in this [thread](https://discuss.huggingface.co/t/use-trainer-api-with-two-valiation-sets/5212) and the referenced paper. My idea would be to evaluate language model pre-training on an overlapping validation set (coming from the same data distribution as the training set) and a non-overlapping validation set (sampled from future periods or another domain). Ideally, I would like to track and log the validation loss during pre-training for both validation sets. | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11018 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11018/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11018/comments | https://api.github.com/repos/huggingface/transformers/issues/11018/events | https://github.com/huggingface/transformers/issues/11018 | 848,537,240 | MDU6SXNzdWU4NDg1MzcyNDA= | 11,018 | T5 documentation for computing pretraining loss seems to have a mistake | {
"login": "dorost1234",
"id": 79165106,
"node_id": "MDQ6VXNlcjc5MTY1MTA2",
"avatar_url": "https://avatars.githubusercontent.com/u/79165106?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dorost1234",
"html_url": "https://github.com/dorost1234",
"followers_url": "https://api.github.com/users/dorost1234/followers",
"following_url": "https://api.github.com/users/dorost1234/following{/other_user}",
"gists_url": "https://api.github.com/users/dorost1234/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dorost1234/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dorost1234/subscriptions",
"organizations_url": "https://api.github.com/users/dorost1234/orgs",
"repos_url": "https://api.github.com/users/dorost1234/repos",
"events_url": "https://api.github.com/users/dorost1234/events{/privacy}",
"received_events_url": "https://api.github.com/users/dorost1234/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 1,617,288,595,000 | 1,617,297,044,000 | null | NONE | null | Dear @patrickvonplaten
The documentation of T5 for computing loss of pretraining seems to have a mistake, where it talks on the loss formulation:
https://huggingface.co/transformers/model_doc/t5.html?highlight=decoder_input_ids
```
input_ids = tokenizer('The <extra_id_0> walks in <extra_id_1> park', return_tensors='pt').input_ids
labels = tokenizer('<extra_id_0> cute dog <extra_id_1> the <extra_id_2>', return_tensors='pt').input_ids
# the forward function automatically creates the correct decoder_input_ids
loss = model(input_ids=input_ids, labels=labels).loss
```
1) the loss as per mt5 paper "T5 is pre-trained on a masked language modeling “span-corruption” objective, where consecutive spans of input tokens are replaced with a mask token and the model is trained to **reconstruct the masked-out tokens.** "
https://arxiv.org/pdf/2010.11934.pdf
So I believe you need to set the labels of masked tokens in labels to -100 then compute the loss in this example for pretraining.
2) Based on other examples in the repository, I think one need to do shift_right to compute the correct ` decoder_input_ids` before modifying the labels for the loss (before replacing -100 for the masked tokens) and pass it to the model as well, please correct me if mistaken.
I greatly appreciate updating the documentations to show the correct procedure.
thanks. | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11016 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11016/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11016/comments | https://api.github.com/repos/huggingface/transformers/issues/11016/events | https://github.com/huggingface/transformers/issues/11016 | 848,490,060 | MDU6SXNzdWU4NDg0OTAwNjA= | 11,016 | Add new CANINE model | {
"login": "stefan-it",
"id": 20651387,
"node_id": "MDQ6VXNlcjIwNjUxMzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/20651387?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stefan-it",
"html_url": "https://github.com/stefan-it",
"followers_url": "https://api.github.com/users/stefan-it/followers",
"following_url": "https://api.github.com/users/stefan-it/following{/other_user}",
"gists_url": "https://api.github.com/users/stefan-it/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stefan-it/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stefan-it/subscriptions",
"organizations_url": "https://api.github.com/users/stefan-it/orgs",
"repos_url": "https://api.github.com/users/stefan-it/repos",
"events_url": "https://api.github.com/users/stefan-it/events{/privacy}",
"received_events_url": "https://api.github.com/users/stefan-it/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1843244711,
"node_id": "MDU6TGFiZWwxODQzMjQ0NzEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/New%20model",
"name": "New model",
"color": "fbca04",
"default": false,
"description": ""
}
] | open | false | null | [] | null | 0 | 1,617,285,201,000 | 1,617,286,936,000 | null | COLLABORATOR | null | # 🌟 New model addition
## Model description
Google recently proposed a new **C**haracter **A**rchitecture with **N**o tokenization **I**n **N**eural **E**ncoders architecture (CANINE). Not only the title is exciting:
> Pipelined NLP systems have largely been superseded by end-to-end neural modeling, yet nearly all commonly-used models still require an explicit tokenization step. While recent tokenization approaches based on data-derived subword lexicons are less brittle than manually engineered tokenizers, these techniques are not equally suited to all languages, and the use of any fixed vocabulary may limit a model's ability to adapt. In this paper, we present CANINE, a neural encoder that operates directly on character sequences, without explicit tokenization or vocabulary, and a pre-training strategy that operates either directly on characters or optionally uses subwords as a soft inductive bias. To use its finer-grained input effectively and efficiently, CANINE combines downsampling, which reduces the input sequence length, with a deep transformer stack, which encodes context. CANINE outperforms a comparable mBERT model by 2.8 F1 on TyDi QA, a challenging multilingual benchmark, despite having 28% fewer model parameters.
Overview of the architecture:
Paper is available [here](https://arxiv.org/abs/2103.06874).
We heavily need this architecture in Transformers (RIP subword tokenization)!
The first author (Jonathan Clark) said on [Twitter](https://twitter.com/JonClarkSeattle/status/1377505048029134856) that the model and code will be released in April :partying_face:
## Open source status
* [ ] the model implementation is available: soon [here](https://caninemodel.page.link/code)
* [ ] the model weights are available: soon [here](https://caninemodel.page.link/code)
* [x] who are the authors: @jhclark-google (not sure), @dhgarrette, @jwieting (not sure)
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/11014 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11014/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11014/comments | https://api.github.com/repos/huggingface/transformers/issues/11014/events | https://github.com/huggingface/transformers/issues/11014 | 848,375,119 | MDU6SXNzdWU4NDgzNzUxMTk= | 11,014 | OSError: Can't load config for '/content/wav2vec2-large-xlsr-asr-demo'. Make sure that: | {
"login": "Kowsher",
"id": 16461536,
"node_id": "MDQ6VXNlcjE2NDYxNTM2",
"avatar_url": "https://avatars.githubusercontent.com/u/16461536?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Kowsher",
"html_url": "https://github.com/Kowsher",
"followers_url": "https://api.github.com/users/Kowsher/followers",
"following_url": "https://api.github.com/users/Kowsher/following{/other_user}",
"gists_url": "https://api.github.com/users/Kowsher/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Kowsher/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Kowsher/subscriptions",
"organizations_url": "https://api.github.com/users/Kowsher/orgs",
"repos_url": "https://api.github.com/users/Kowsher/repos",
"events_url": "https://api.github.com/users/Kowsher/events{/privacy}",
"received_events_url": "https://api.github.com/users/Kowsher/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 1 | 1,617,275,957,000 | 1,617,295,152,000 | null | NONE | null | I'm using
pip install transformers==4.4.2
After completing the training process of ASR I can not read the trained file from my local storage. Although the path is right. But can read from hugging face
model = Wav2Vec2ForCTC.from_pretrained("/content/wav2vec2-large-xlsr-asr-demo").to("cuda")
The error:
OSError: Can't load config for '/content/wav2vec2-large-xlsr-asr-demo'. Make sure that:
- '/content/wav2vec2-large-xlsr-asr-demo' is a correct model identifier listed on 'https://huggingface.co/models'
- or '/content/wav2vec2-large-xlsr-asr-demo' is the correct path to a directory containing a config.json file | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11013 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11013/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11013/comments | https://api.github.com/repos/huggingface/transformers/issues/11013/events | https://github.com/huggingface/transformers/issues/11013 | 848,349,453 | MDU6SXNzdWU4NDgzNDk0NTM= | 11,013 | use `BaseModelOutput` as common interface for all different `BaseModelOutputWith*`? | {
"login": "JoanFM",
"id": 19825685,
"node_id": "MDQ6VXNlcjE5ODI1Njg1",
"avatar_url": "https://avatars.githubusercontent.com/u/19825685?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/JoanFM",
"html_url": "https://github.com/JoanFM",
"followers_url": "https://api.github.com/users/JoanFM/followers",
"following_url": "https://api.github.com/users/JoanFM/following{/other_user}",
"gists_url": "https://api.github.com/users/JoanFM/gists{/gist_id}",
"starred_url": "https://api.github.com/users/JoanFM/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/JoanFM/subscriptions",
"organizations_url": "https://api.github.com/users/JoanFM/orgs",
"repos_url": "https://api.github.com/users/JoanFM/repos",
"events_url": "https://api.github.com/users/JoanFM/events{/privacy}",
"received_events_url": "https://api.github.com/users/JoanFM/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2648621985,
"node_id": "MDU6TGFiZWwyNjQ4NjIxOTg1",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Feature%20request",
"name": "Feature request",
"color": "FBCA04",
"default": false,
"description": "Request for a new feature"
}
] | open | false | null | [] | null | 0 | 1,617,273,662,000 | 1,617,299,016,000 | null | NONE | null | Hello team,
I have been taking a look at the `different` output models from your models, and I wonder if it would make sense to inherit all the `BaseModelOutputWithPool` and all the other flavours of modeling output, instead of using `ModelOutput`.
https://github.com/huggingface/transformers/blob/c301c26370dfa48f6a6d0408b5bb9eb70ca831b3/src/transformers/modeling_outputs.py#L24
We are trying to build a wrapper around many of the public models hosted on hugging face, and it would be useful to know if we can assume that all the potential `outputs` of the models will contain `hidden_states`. Since now they all only inherit from `ModelOutput` it seems a little confusing.
Am I missing something? Is it not something that can be assumed? | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11012 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11012/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11012/comments | https://api.github.com/repos/huggingface/transformers/issues/11012/events | https://github.com/huggingface/transformers/pull/11012 | 848,275,273 | MDExOlB1bGxSZXF1ZXN0NjA3MjM3OTQ4 | 11,012 | Add multi-class, multi-label and regression to transformers | {
"login": "abhishekkrthakur",
"id": 1183441,
"node_id": "MDQ6VXNlcjExODM0NDE=",
"avatar_url": "https://avatars.githubusercontent.com/u/1183441?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/abhishekkrthakur",
"html_url": "https://github.com/abhishekkrthakur",
"followers_url": "https://api.github.com/users/abhishekkrthakur/followers",
"following_url": "https://api.github.com/users/abhishekkrthakur/following{/other_user}",
"gists_url": "https://api.github.com/users/abhishekkrthakur/gists{/gist_id}",
"starred_url": "https://api.github.com/users/abhishekkrthakur/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abhishekkrthakur/subscriptions",
"organizations_url": "https://api.github.com/users/abhishekkrthakur/orgs",
"repos_url": "https://api.github.com/users/abhishekkrthakur/repos",
"events_url": "https://api.github.com/users/abhishekkrthakur/events{/privacy}",
"received_events_url": "https://api.github.com/users/abhishekkrthakur/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 1,617,268,019,000 | 1,617,368,441,000 | null | MEMBER | null | null | null |
|
https://api.github.com/repos/huggingface/transformers/issues/11050 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11050/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11050/comments | https://api.github.com/repos/huggingface/transformers/issues/11050/events | https://github.com/huggingface/transformers/pull/11050 | 849,866,711 | MDExOlB1bGxSZXF1ZXN0NjA4NTM5Nzgw | 11,050 | accelerate scripts for question answering with no trainer | {
"login": "theainerd",
"id": 15798640,
"node_id": "MDQ6VXNlcjE1Nzk4NjQw",
"avatar_url": "https://avatars.githubusercontent.com/u/15798640?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/theainerd",
"html_url": "https://github.com/theainerd",
"followers_url": "https://api.github.com/users/theainerd/followers",
"following_url": "https://api.github.com/users/theainerd/following{/other_user}",
"gists_url": "https://api.github.com/users/theainerd/gists{/gist_id}",
"starred_url": "https://api.github.com/users/theainerd/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/theainerd/subscriptions",
"organizations_url": "https://api.github.com/users/theainerd/orgs",
"repos_url": "https://api.github.com/users/theainerd/repos",
"events_url": "https://api.github.com/users/theainerd/events{/privacy}",
"received_events_url": "https://api.github.com/users/theainerd/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 1,617,539,967,000 | 1,617,539,967,000 | null | NONE | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
@sgugger
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/11049 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11049/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11049/comments | https://api.github.com/repos/huggingface/transformers/issues/11049/events | https://github.com/huggingface/transformers/pull/11049 | 849,737,172 | MDExOlB1bGxSZXF1ZXN0NjA4NDQyMTM1 | 11,049 | [docs] fix xref to `PreTrainedModel.generate` | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 1,617,482,996,000 | 1,617,483,306,000 | null | COLLABORATOR | null | This PR partially resolves the issue raised in https://github.com/huggingface/transformers/issues/9202
I spent quite some time to try to figure out how to get sphinx to figure out the inheritance so that it could cross-reference inherited methods, but it can't even handle mixins it seems. i.e. it can't resolve: `transformers.PreTrainedModel.generate`
So one has to explicitly specify the fully qualified original method for xref to work :(
Bottom line - if currently you want a cross-reference link to `transformers.PreTrainedModel.generate` or `T5ForConditionalGeneration.generate` to work, you have to use `~transformers.generation_utils.GenerationMixin.generate`
So I did:
```
find . -type d -name ".git" -prune -o -type f -exec perl -pi -e 's|transformers\.\w+\.generate|transformers.generation_utils.GenerationMixin.generate|g' {} \;
```
Fixes: https://github.com/huggingface/transformers/issues/9202
@sgugger | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11048 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11048/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11048/comments | https://api.github.com/repos/huggingface/transformers/issues/11048/events | https://github.com/huggingface/transformers/pull/11048 | 849,734,674 | MDExOlB1bGxSZXF1ZXN0NjA4NDQwMjYz | 11,048 | fix incorrect case for s|Pretrained|PreTrained| | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 1,617,482,010,000 | 1,617,482,010,000 | null | COLLABORATOR | null | This PR fixes incorrect `Pretrained` case for 2 cases:
```
git-replace PretrainedTokenizer PreTrainedTokenizer
git-replace transformers.PretrainedModel transformers.PreTrainedModel
```
there might be other cases to fix, but these stood out.
@sgugger | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11047 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11047/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11047/comments | https://api.github.com/repos/huggingface/transformers/issues/11047/events | https://github.com/huggingface/transformers/issues/11047 | 849,604,791 | MDU6SXNzdWU4NDk2MDQ3OTE= | 11,047 | Use Bert model without pretrained weights | {
"login": "avinashsai",
"id": 22453634,
"node_id": "MDQ6VXNlcjIyNDUzNjM0",
"avatar_url": "https://avatars.githubusercontent.com/u/22453634?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/avinashsai",
"html_url": "https://github.com/avinashsai",
"followers_url": "https://api.github.com/users/avinashsai/followers",
"following_url": "https://api.github.com/users/avinashsai/following{/other_user}",
"gists_url": "https://api.github.com/users/avinashsai/gists{/gist_id}",
"starred_url": "https://api.github.com/users/avinashsai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/avinashsai/subscriptions",
"organizations_url": "https://api.github.com/users/avinashsai/orgs",
"repos_url": "https://api.github.com/users/avinashsai/repos",
"events_url": "https://api.github.com/users/avinashsai/events{/privacy}",
"received_events_url": "https://api.github.com/users/avinashsai/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | null | 2 | 1,617,436,513,000 | 1,617,451,672,000 | null | NONE | null | Hi,
I wanted to train a Bert classifier from scratch without any pretrained weights. It has to be randomly initialized and trained.
Example:
```
bert_base_model = BertForSequenceClassification()
trainer = Trainer(model=bert_base_model,
args=training_args,
train_dataset=train_loader,
eval_dataset=test_loader,
compute_metrics=compute_metrics
)
``` | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11046 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11046/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11046/comments | https://api.github.com/repos/huggingface/transformers/issues/11046/events | https://github.com/huggingface/transformers/issues/11046 | 849,568,459 | MDU6SXNzdWU4NDk1Njg0NTk= | 11,046 | Potential incorrect application of layer norm in BlenderbotSmallDecoder | {
"login": "sougata-ub",
"id": 59206549,
"node_id": "MDQ6VXNlcjU5MjA2NTQ5",
"avatar_url": "https://avatars.githubusercontent.com/u/59206549?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sougata-ub",
"html_url": "https://github.com/sougata-ub",
"followers_url": "https://api.github.com/users/sougata-ub/followers",
"following_url": "https://api.github.com/users/sougata-ub/following{/other_user}",
"gists_url": "https://api.github.com/users/sougata-ub/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sougata-ub/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sougata-ub/subscriptions",
"organizations_url": "https://api.github.com/users/sougata-ub/orgs",
"repos_url": "https://api.github.com/users/sougata-ub/repos",
"events_url": "https://api.github.com/users/sougata-ub/events{/privacy}",
"received_events_url": "https://api.github.com/users/sougata-ub/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 1,617,421,052,000 | 1,617,421,052,000 | null | NONE | null | In BlenderbotSmallDecoder, layer norm is applied only on the token embeddings, and not on the hidden_states, whereas in the BlenderbotSmallEncoder, layer norm is applied after adding the input_embeds and positional embeds
BlenderbotSmallEncoder:
`hidden_states = inputs_embeds + embed_pos`
`hidden_states = self.layernorm_embedding(hidden_states)`
BlenderbotSmallDecoder:
`inputs_embeds = self.layernorm_embedding(inputs_embeds)`
`hidden_states = inputs_embeds + positions` | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11045 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11045/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11045/comments | https://api.github.com/repos/huggingface/transformers/issues/11045/events | https://github.com/huggingface/transformers/issues/11045 | 849,544,374 | MDU6SXNzdWU4NDk1NDQzNzQ= | 11,045 | Multi-GPU seq2seq example evaluation significantly slower than legacy example evaluation | {
"login": "PeterAJansen",
"id": 3813268,
"node_id": "MDQ6VXNlcjM4MTMyNjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/3813268?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/PeterAJansen",
"html_url": "https://github.com/PeterAJansen",
"followers_url": "https://api.github.com/users/PeterAJansen/followers",
"following_url": "https://api.github.com/users/PeterAJansen/following{/other_user}",
"gists_url": "https://api.github.com/users/PeterAJansen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/PeterAJansen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PeterAJansen/subscriptions",
"organizations_url": "https://api.github.com/users/PeterAJansen/orgs",
"repos_url": "https://api.github.com/users/PeterAJansen/repos",
"events_url": "https://api.github.com/users/PeterAJansen/events{/privacy}",
"received_events_url": "https://api.github.com/users/PeterAJansen/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 1,617,411,144,000 | 1,617,411,144,000 | null | NONE | null |
### Who can help
@patil-suraj @sgugger
Models:
T5
## Information
I've been doing multi-GPU evaluation for some weeks using a Transformers pull from Feb 12th, just using the example scripts for training/evaluating custom datasets (specifically `run_distributed_eval.py` , though that seq2seq example is now legacy: https://github.com/huggingface/transformers/tree/master/examples/legacy/seq2seq )
Today I grabbed a fresh pull and migrated the data over to the JSON lines format for the new seq2seq example `run_summarization.py` : https://github.com/huggingface/transformers/blob/master/examples/seq2seq/run_summarization.py
run_summarization.py appears to use all visible GPUs to do the evaluation (great!), but it also appears significantly slower than the old run_distributed_eval.py .
When examining GPU utilization using `nvtop`, it appears that it allocates GPU memory from all devices (much more from device 0), but only uses device 0 for processing:

## Script
In case it's my issue and I'm not invoking it correctly (I know the legacy one required being invoked with `torch.distributed.launch` for multi-GPU evaluation), the runscript I'm using is:
```
#/bin/bash
python run_summarization.py \
--model_name_or_path mymodel-debug1000 \
--do_predict \
--train_file mydata/train.json \
--validation_file mydata/val.json \
--test_file mydata/val.json \
--max_source_length 256 \
--max_target_length 512 \
--num_beams 8 \
--source_prefix "" \
--output_dir tst-debug \
--overwrite_output_dir \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--predict_with_generate
``` | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11044 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11044/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11044/comments | https://api.github.com/repos/huggingface/transformers/issues/11044/events | https://github.com/huggingface/transformers/issues/11044 | 849,529,761 | MDU6SXNzdWU4NDk1Mjk3NjE= | 11,044 | [DeepSpeed] ZeRO stage 3 integration: getting started and issues | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2659267025,
"node_id": "MDU6TGFiZWwyNjU5MjY3MDI1",
"url": "https://api.github.com/repos/huggingface/transformers/labels/DeepSpeed",
"name": "DeepSpeed",
"color": "4D34F7",
"default": false,
"description": ""
}
] | open | false | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
}
] | null | 0 | 1,617,406,842,000 | 1,617,497,735,000 | null | COLLABORATOR | null | **[This is not yet alive, preparing for the release, so please ignore for now]**
While we are waiting for deespeed to make a new release and then merge the PR, you can try `pip install -e .` in these 2 branches:
https://github.com/stas00/DeepSpeed/tree/zero3-everything
https://github.com/stas00/transformers/tree/ds-zero-3
and see if it works for you.
-------------------------------
The DeepSpeed ZeRO-3 has been integrated into HF `transformers`.
While I tried to write tests for a wide range of situations I'm sure I've missed some scenarios so if you run into any problems please file a separate issue. I'm going to use this issue to track progress on individual ZeRO3 issues.
# Why would you want ZeRO-3
In a few words, while ZeRO-2 was very limited scability-wise - if `model.half()` couldn't fit onto a single gpu, adding more gpus won't have helped so if you had a 24GB GPU you couldn't train a model larger than about 5B params.
Since with ZeRO-3 the model weights are partitioned across multiple GPUs plus offloaded to CPU, the upper limit on model size has increased by about 2 orders of magnitude. That is ZeRO-3 allows you to scale to huge models with Trillions of parameters assuming you have enough GPUs and general RAM to support this. ZeRO-3 can benefit a lot from general RAM if you have it. If not that's OK too. ZeRO-3 combines all your GPUs memory and general RAM into a vast pool of memory.
If you don't have many GPUs but just a single one but have a lot of general RAM ZeRO-3 will allow you to fit larger models.
Of course, if you run in an environment like the free google colab, while you can use run Deepspeed there, you get so little general RAM it's very hard to make something out of nothing. Some users (or some sessions) one gets 12GB of RAM which is impossible to work with - you want at least 24GB instances. Setting is up might be tricky too, please see this notebook for an example:
https://github.com/stas00/porting/blob/master/transformers/deepspeed/DeepSpeed_on_colab_CLI.ipynb
# Getting started
Install the latest deepspeed version:
```
pip install deepspeed
```
You will want to be on a transformers master branch, if you want to run a quick test:
```
git clone https://github.com/huggingface/transformers
cd transformers
BS=4; PYTHONPATH=src USE_TF=0 deepspeed examples/seq2seq/run_translation.py \
--model_name_or_path t5-small --output_dir /tmp/zero3 --overwrite_output_dir --max_train_samples 64 \
--max_val_samples 64 --max_source_length 128 --max_target_length 128 --val_max_target_length 128 \
--do_train --num_train_epochs 1 --per_device_train_batch_size $BS --per_device_eval_batch_size $BS \
--learning_rate 3e-3 --warmup_steps 500 --predict_with_generate --logging_steps 0 --save_steps 0 \
--eval_steps 1 --group_by_length --adafactor --dataset_name wmt16 --dataset_config ro-en --source_lang en \
--target_lang ro --source_prefix "translate English to Romanian: " \
--deepspeed examples/tests/deepspeed/ds_config_zero3.json
```
You will find a very detailed configuration here: https://huggingface.co/transformers/master/main_classes/trainer.html#deepspeed
Your new config file will look like this:
```json
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"zero_optimization": {
"stage": 3,
"cpu_offload": true,
"cpu_offload_params": true,
"cpu_offload_use_pin_memory" : true,
"overlap_comm": true,
"contiguous_gradients": true,
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_prefetch_bucket_size": 0.94e6,
"stage3_param_persistence_threshold": 1e4,
"reduce_bucket_size": 1e6,
"prefetch_bucket_size": 3e6,
"sub_group_size": 1e14,
"stage3_gather_fp16_weights_on_model_save": true
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": 3e-5,
"betas": [0.8, 0.999],
"eps": 1e-8,
"weight_decay": 3e-7
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 3e-5,
"warmup_num_steps": 500
}
},
"steps_per_print": 2000,
"wall_clock_breakdown": false
}
```
So if you were already using ZeRO-2 it's only the `zero_optimization` stage that has changed.
One of the biggest nuances of ZeRO-3 is that the model weights aren't inside `model.state_dict`, as they are spread out through multiple gpus. The Trainer has been modified to support this but you will notice a slow model saving - as it has to consolidate weights from all the gpus. I'm planning to do more performance improvements in the future PRs, but for now let's focus on making things work.
# Issues / Questions
If you have any general questions or something is unclear/missing in the docs please don't hesitate to ask in this thread. But for any bugs or problems please open a new Issue and tag me there. You don't need to tag anybody else. Thank you! | null | null |
https://api.github.com/repos/huggingface/transformers/issues/11043 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11043/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11043/comments | https://api.github.com/repos/huggingface/transformers/issues/11043/events | https://github.com/huggingface/transformers/issues/11043 | 849,499,734 | MDU6SXNzdWU4NDk0OTk3MzQ= | 11,043 | Can't load model to estimater | {
"login": "gwc4github",
"id": 3164663,
"node_id": "MDQ6VXNlcjMxNjQ2NjM=",
"avatar_url": "https://avatars.githubusercontent.com/u/3164663?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gwc4github",
"html_url": "https://github.com/gwc4github",
"followers_url": "https://api.github.com/users/gwc4github/followers",
"following_url": "https://api.github.com/users/gwc4github/following{/other_user}",
"gists_url": "https://api.github.com/users/gwc4github/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gwc4github/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gwc4github/subscriptions",
"organizations_url": "https://api.github.com/users/gwc4github/orgs",
"repos_url": "https://api.github.com/users/gwc4github/repos",
"events_url": "https://api.github.com/users/gwc4github/events{/privacy}",
"received_events_url": "https://api.github.com/users/gwc4github/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 1,617,400,304,000 | 1,617,400,304,000 | null | NONE | null | I was trying to follow the Sagemaker instructions [here](https://docs.aws.amazon.com/sagemaker/latest/dg/deploy-model.html) to load the model I just trained and test an estimation. I get the error message:
NotImplementedError: Creating model with HuggingFace training job is not supported.
Can someone share some sample code to run to do this? Here is the basic thing I am trying to do:
```
from sagemaker.estimator import Estimator
# job which is going to be attached to the estimator
old_training_job_name='huggingface-sdk-extension-2021-04-02-19-10-00-242'
# attach old training job
huggingface_estimator_loaded = Estimator.attach(old_training_job_name)
# get model output s3 from training job
testModel = huggingface_estimator_loaded.model_data
ner_classifier = huggingface_estimator.deploy(initial_instance_count=1, instance_type='ml.m4.xlarge')
```
I also tried some things with .deploy() and endpoints but didn't have any luck there either.
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/11042 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11042/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11042/comments | https://api.github.com/repos/huggingface/transformers/issues/11042/events | https://github.com/huggingface/transformers/issues/11042 | 849,274,362 | MDU6SXNzdWU4NDkyNzQzNjI= | 11,042 | [LXMERT] Unclear what img_tensorize does with color spaces | {
"login": "hivestrung",
"id": 27841209,
"node_id": "MDQ6VXNlcjI3ODQxMjA5",
"avatar_url": "https://avatars.githubusercontent.com/u/27841209?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hivestrung",
"html_url": "https://github.com/hivestrung",
"followers_url": "https://api.github.com/users/hivestrung/followers",
"following_url": "https://api.github.com/users/hivestrung/following{/other_user}",
"gists_url": "https://api.github.com/users/hivestrung/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hivestrung/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hivestrung/subscriptions",
"organizations_url": "https://api.github.com/users/hivestrung/orgs",
"repos_url": "https://api.github.com/users/hivestrung/repos",
"events_url": "https://api.github.com/users/hivestrung/events{/privacy}",
"received_events_url": "https://api.github.com/users/hivestrung/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 1,617,376,377,000 | 1,617,376,507,000 | null | NONE | null | ## Environment info
- `transformers` version: Not using transformers directly, I'm loading a model "unc-nlp/frcnn-vg-finetuned"
- Platform: MacOS
- Python version: 3.8
- PyTorch version (GPU?): 1.6.0, no GPU
- Tensorflow version (GPU?): don't have
- Using GPU in script?: no
- Using distributed or parallel set-up in script?: no
### Who can help
@eltoto1219 probably
Models: "LXMERT": "unc-nlp/frcnn-vg-finetuned"
Library: https://github.com/huggingface/transformers/tree/master/examples/research_projects/lxmert
## Information
Model I am using (Bert, XLNet ...): "LXMERT": "unc-nlp/frcnn-vg-finetuned"
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x ] my own task or dataset: (give details below)
## Problem
I don't get what img_tensorize in utils.py is doing with color spaces. I run the following code to load the model.
```
# load models and model components
frcnn_cfg = Config.from_pretrained("unc-nlp/frcnn-vg-finetuned")
frcnn = GeneralizedRCNN.from_pretrained("unc-nlp/frcnn-vg-finetuned", config=frcnn_cfg)
image_preprocess = Preprocess(frcnn_cfg)
```
Turns out that frcnn_cfg.input.format is "BGR" so I wanted to know what exactly is going on? Here is where the image is loaded (utils.img_tensorize)
```
def img_tensorize(im, input_format="RGB"):
assert isinstance(im, str)
if os.path.isfile(im):
img = cv2.imread(im)
else:
img = get_image_from_url(im)
assert img is not None, f"could not connect to: {im}"
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
if input_format == "RGB":
img = img[:, :, ::-1]
return img
```
See, we seem to be converting the images to RGB, then if it's "RGB" format we flip the blue (?) channel? Is the image ever converted to "BGR"?
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/11041 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11041/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11041/comments | https://api.github.com/repos/huggingface/transformers/issues/11041/events | https://github.com/huggingface/transformers/pull/11041 | 849,269,684 | MDExOlB1bGxSZXF1ZXN0NjA4MDcxNjc1 | 11,041 | wav2vec2 converter: create the proper vocab.json while converting fairseq wav2vec2 finetuned model | {
"login": "cceyda",
"id": 15624271,
"node_id": "MDQ6VXNlcjE1NjI0Mjcx",
"avatar_url": "https://avatars.githubusercontent.com/u/15624271?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cceyda",
"html_url": "https://github.com/cceyda",
"followers_url": "https://api.github.com/users/cceyda/followers",
"following_url": "https://api.github.com/users/cceyda/following{/other_user}",
"gists_url": "https://api.github.com/users/cceyda/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cceyda/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cceyda/subscriptions",
"organizations_url": "https://api.github.com/users/cceyda/orgs",
"repos_url": "https://api.github.com/users/cceyda/repos",
"events_url": "https://api.github.com/users/cceyda/events{/privacy}",
"received_events_url": "https://api.github.com/users/cceyda/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 1,617,375,854,000 | 1,617,377,521,000 | null | CONTRIBUTOR | null | # What does this PR do?
While converting a finetuned wav2vec2 model we also need to convert the related dictionary `dict.ltr.txt` to hugging face `vocab.json` format.
If a `dict_path` is specified:
- Creates&saves the necessary vocab.json file
- Modifies config file special token ids and vocab size accordingly
- Creates a processor with the right special tokens and saves the processor `preprocessor_config.json`
## Before submitting
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Did you make sure to update the documentation with your changes? -> not sure if there are any docs related to this.
- [ ] Did you write any new necessary tests? -> not sure if there are tests related to this.
## Who can review?
Models:
- wav2vec2: @patrickvonplaten @LysandreJik
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/11040 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/11040/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/11040/comments | https://api.github.com/repos/huggingface/transformers/issues/11040/events | https://github.com/huggingface/transformers/issues/11040 | 849,265,615 | MDU6SXNzdWU4NDkyNjU2MTU= | 11,040 | max_length in beam_search() and group_beam_search() does not consider beam_scorer.max_length | {
"login": "GeetDsa",
"id": 13940397,
"node_id": "MDQ6VXNlcjEzOTQwMzk3",
"avatar_url": "https://avatars.githubusercontent.com/u/13940397?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/GeetDsa",
"html_url": "https://github.com/GeetDsa",
"followers_url": "https://api.github.com/users/GeetDsa/followers",
"following_url": "https://api.github.com/users/GeetDsa/following{/other_user}",
"gists_url": "https://api.github.com/users/GeetDsa/gists{/gist_id}",
"starred_url": "https://api.github.com/users/GeetDsa/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/GeetDsa/subscriptions",
"organizations_url": "https://api.github.com/users/GeetDsa/orgs",
"repos_url": "https://api.github.com/users/GeetDsa/repos",
"events_url": "https://api.github.com/users/GeetDsa/events{/privacy}",
"received_events_url": "https://api.github.com/users/GeetDsa/received_events",
"type": "User",
"site_admin": false
} | [] | open | false | null | [] | null | 0 | 1,617,375,392,000 | 1,617,375,452,000 | null | CONTRIBUTOR | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform: 4.3.2
- Python version: 3.8.5
- PyTorch version (GPU?): 1.8.0
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @LysandreJik
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
Model hub:
- for issues with a model report at https://discuss.huggingface.co/ and tag the model's creator.
HF projects:
- datasets: [different repo](https://github.com/huggingface/datasets)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
I am using BART model in particular, but this problem exists for all the other models, using `beam_search()` and `group_beam_search()` for decoding the generated text.
The `max_length` variable set using `BeamSearchScorer` is not used by `beam_search()` or `group_beam_search()` function in `generation_utils.py` script.
Thus using a smaller `max_length` while initializing the object of class, for example:
```
beam_scorer = BeamSearchScorer(
batch_size=1,
max_length=5,
num_beams=num_beams,
device=model.device,
)
```
instead of
```
beam_scorer = BeamSearchScorer(
batch_size=1,
max_length=model.config.max_length,
num_beams=num_beams,
device=model.device,
)
```
in the example given [here](https://huggingface.co/transformers/main_classes/model.html#transformers.generation_utils.GenerationMixin.beam_search)
results in an error:
```
File "temp.py", line 34, in <module>
outputs = model.beam_search(input_ids, beam_scorer, logits_processor=logits_processor, **model_kwargs)
File "<conda_env_dir>/lib/python3.8/site-packages/transformers/generation_utils.py", line 1680, in beam_search
sequence_outputs = beam_scorer.finalize(
File "<conda_env_dir>/lib/python3.8/site-packages/transformers/generation_beam_search.py", line 328, in finalize
decoded[i, : sent_lengths[i]] = hypo
RuntimeError: The expanded size of the tensor (5) must match the existing size (6) at non-singleton dimension 0. Target sizes: [5]. Tensor sizes: [6]
```
The problem arises when using:
* [x] the official example scripts:
- [beam_scorer_example](https://huggingface.co/transformers/main_classes/model.html#transformers.generation_utils.GenerationMixin.beam_search)
* [x] my own modified scripts:
- Also, using `max_length` higher than `model.config.max_length` while initializing object (`beam_scorer`) of type `BeamSearchScorer` does not help in generating longer sequences, as `beam_scorer.max_length` is not used by `beam_search()` or `group_beam_search()`
## To reproduce
Steps to reproduce the behavior:
1. The above mentioned modification in the [example](https://huggingface.co/transformers/main_classes/model.html#transformers.generation_utils.GenerationMixin.beam_search)
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
1. The program to run without any errors when lower `max_length` is set for object of type `BeamSearchScorer`
2. Generate longer length sequences (longer than `model.config.max_length`) when higher `max_length` is set for object of type `BeamSearchScorer`
<!-- A clear and concise description of what you would expect to happen. -->
| null | null |
End of preview.
No dataset card yet
New: Create and edit this dataset card directly on the website!
Contribute a Dataset Card- Downloads last month
- 86