

QuantFactory/Bielik-7B-Instruct-v0.1-GGUF
This is quantized version of speakleash/Bielik-7B-Instruct-v0.1 created using llama.cpp
Original Model Card

Bielik-7B-Instruct-v0.1
The Bielik-7B-Instruct-v0.1 is an instruct fine-tuned version of the Bielik-7B-v0.1. Forementioned model stands as a testament to the unique collaboration between the open-science/open-souce project SpeakLeash and the High Performance Computing (HPC) center: ACK Cyfronet AGH. Developed and trained on Polish text corpora, which has been cherry-picked and processed by the SpeakLeash team, this endeavor leverages Polish large-scale computing infrastructure, specifically within the PLGrid environment, and more precisely, the HPC centers: ACK Cyfronet AGH. The creation and training of the Bielik-7B-Instruct-v0.1 was propelled by the support of computational grant number PLG/2024/016951, conducted on the Athena and Helios supercomputer, enabling the use of cutting-edge technology and computational resources essential for large-scale machine learning processes. As a result, the model exhibits an exceptional ability to understand and process the Polish language, providing accurate responses and performing a variety of linguistic tasks with high precision.
We have prepared quantized versions of the model as well as MLX format.
🎥 Demo: https://huggingface.co/spaces/speakleash/Bielik-7B-Instruct-v0.1
🗣️ Chat Arena*: https://arena.speakleash.org.pl/
*Chat Arena is a platform for testing and comparing different AI language models, allowing users to evaluate their performance and quality.
Model
The SpeakLeash team is working on their own set of instructions in Polish, which is continuously being expanded and refined by annotators. A portion of these instructions, which had been manually verified and corrected, has been utilized for training purposes. Moreover, due to the limited availability of high-quality instructions in Polish, publicly accessible collections of instructions in English were used - OpenHermes-2.5 and orca-math-word-problems-200k, which accounted for half of the instructions used in training. The instructions varied in quality, leading to a deterioration in model’s performance. To counteract this while still allowing ourselves to utilize forementioned datasets,several improvements were introduced:
- Weighted tokens level loss - a strategy inspired by offline reinforcement learning and C-RLFT
- Adaptive learning rate inspired by the study on Learning Rates as a Function of Batch Size
- Masked user instructions
Bielik-7B-Instruct-v0.1 has been trained with the use of an original open source framework called ALLaMo implemented by Krzysztof Ociepa. This framework allows users to train language models with architecture similar to LLaMA and Mistral in fast and efficient way.
Model description:
- Developed by: SpeakLeash
- Language: Polish
- Model type: causal decoder-only
- Finetuned from: Bielik-7B-v0.1
- License: CC BY NC 4.0 (non-commercial use)
- Model ref: speakleash:e38140bea0d48f1218540800bbc67e89
Training
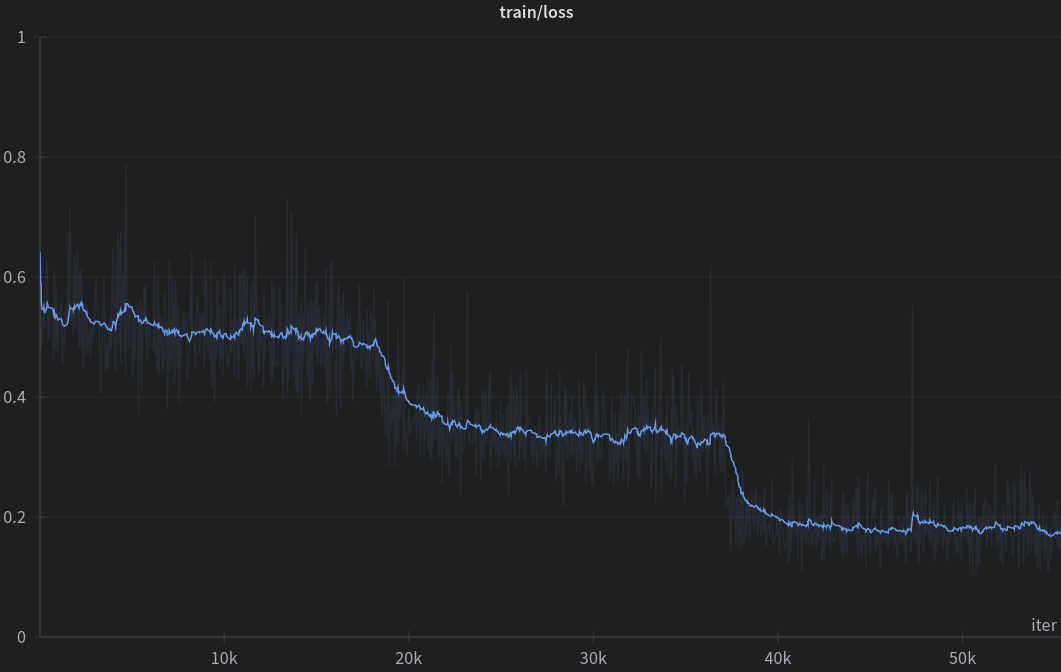

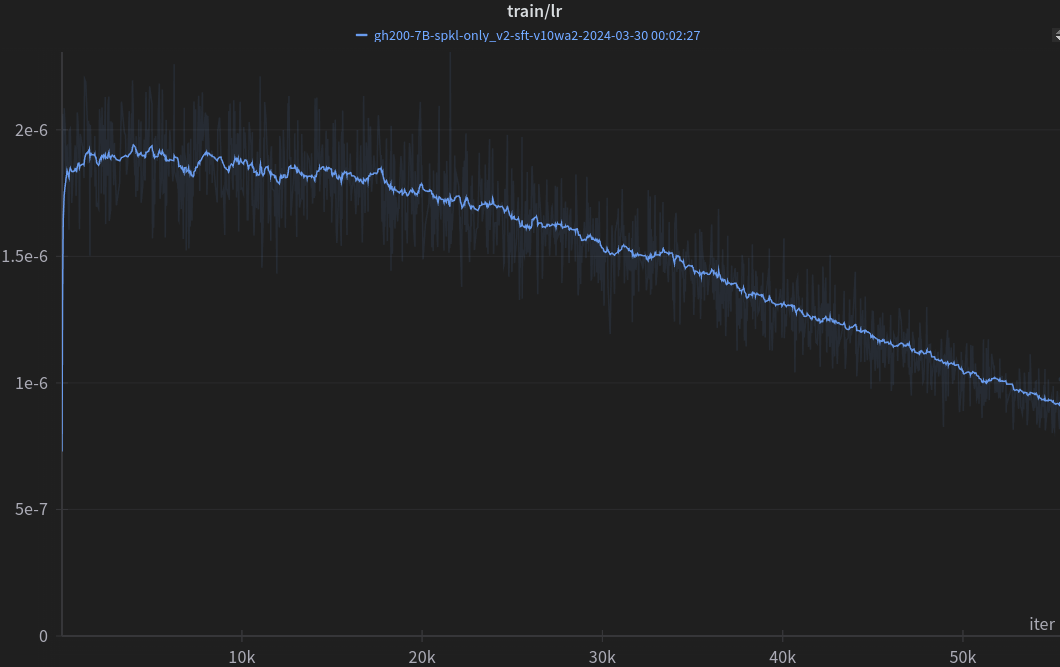
Training hyperparameters:
| Hyperparameter | Value |
|---|---|
| Context length | 4096 |
| Micro Batch Size | 1 |
| Batch Size | up to 4194304 |
| Learning Rate (cosine, adaptive) | 7e-6 -> 6e-7 |
| Warmup Iterations | 50 |
| All Iterations | 55440 |
| Optimizer | AdamW |
| β1, β2 | 0.9, 0.95 |
| Adam_eps | 1e−8 |
| Weight Decay | 0.05 |
| Grad Clip | 1.0 |
| Precision | bfloat16 (mixed) |
Quant and MLX versions:
We know that some people want to explore smaller models or don't have the resources to run a full model. Therefore, we have prepared quantized versions of the Bielik-7B-Instruct-v0.1 model. We are also mindful of Apple Silicon.
Quantized versions (for non-GPU / weaker GPU):
- https://huggingface.co/speakleash/Bielik-7B-Instruct-v0.1-GGUF
- https://huggingface.co/speakleash/Bielik-7B-Instruct-v0.1-GPTQ
- https://huggingface.co/speakleash/Bielik-7B-Instruct-v0.1-AWQ
- https://huggingface.co/speakleash/Bielik-7B-Instruct-v0.1-EXL2
- https://huggingface.co/speakleash/Bielik-7B-Instruct-v0.1-3bit-HQQ
For Apple Silicon:
Instruction format
In order to leverage instruction fine-tuning, your prompt should be surrounded by [INST] and [/INST] tokens. The very first instruction should start with the beginning of a sentence token. The generated completion will be finished by the end-of-sentence token.
E.g.
prompt = "<s>[INST] Jakie mamy pory roku? [/INST]"
completion = "W Polsce mamy 4 pory roku: wiosna, lato, jesień i zima.</s>"
This format is available as a chat template via the apply_chat_template() method:
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model_name = "speakleash/Bielik-7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16)
messages = [
{"role": "system", "content": "Odpowiadaj krótko, precyzyjnie i wyłącznie w języku polskim."},
{"role": "user", "content": "Jakie mamy pory roku w Polsce?"},
{"role": "assistant", "content": "W Polsce mamy 4 pory roku: wiosna, lato, jesień i zima."},
{"role": "user", "content": "Która jest najcieplejsza?"}
]
input_ids = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = input_ids.to(device)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
If for some reason you are unable to use tokenizer.apply_chat_template, the following code will enable you to generate a correct prompt:
def chat_template(message, history, system_prompt):
prompt_builder = ["<s>[INST] "]
if system_prompt:
prompt_builder.append(f"<<SYS>>\n{system_prompt}\n<</SYS>>\n\n")
for human, assistant in history:
prompt_builder.append(f"{human} [/INST] {assistant}</s>[INST] ")
prompt_builder.append(f"{message} [/INST]")
return ''.join(prompt_builder)
system_prompt = "Odpowiadaj krótko, precyzyjnie i wyłącznie w języku polskim."
history = [
("Jakie mamy pory roku w Polsce?", "W Polsce mamy 4 pory roku: wiosna, lato, jesień i zima.")
]
message = "Która jest najcieplejsza?"
prompt = chat_template(message, history, system_prompt)
Evaluation
Models have been evaluated on Open PL LLM Leaderboard 5-shot. The benchmark evaluates models in NLP tasks like sentiment analysis, categorization, text classification but does not test chatting skills. Here are presented:
- Average - average score among all tasks normalized by baseline scores
- Reranking - reranking task, commonly used in RAG
- Reader (Generator) - open book question answering task, commonly used in RAG
- Perplexity (lower is better) - as a bonus, does not correlate with other scores and should not be used for model comparison
As of April 3, 2024, the following table showcases the current scores of pretrained and continuously pretrained models according to the Open PL LLM Leaderboard, evaluated in a 5-shot setting:
| Average | RAG Reranking | RAG Reader | Perplexity | |
|---|---|---|---|---|
| 7B parameters models: | ||||
| Baseline (majority class) | 0.00 | 53.36 | - | - |
| Voicelab/trurl-2-7b | 18.85 | 60.67 | 77.19 | 1098.88 |
| meta-llama/Llama-2-7b-chat-hf | 21.04 | 54.65 | 72.93 | 4018.74 |
| mistralai/Mistral-7B-Instruct-v0.1 | 26.42 | 56.35 | 73.68 | 6909.94 |
| szymonrucinski/Curie-7B-v1 | 26.72 | 55.58 | 85.19 | 389.17 |
| HuggingFaceH4/zephyr-7b-beta | 33.15 | 71.65 | 71.27 | 3613.14 |
| HuggingFaceH4/zephyr-7b-alpha | 33.97 | 71.47 | 73.35 | 4464.45 |
| internlm/internlm2-chat-7b-sft | 36.97 | 73.22 | 69.96 | 4269.63 |
| internlm/internlm2-chat-7b | 37.64 | 72.29 | 71.17 | 3892.50 |
| Bielik-7B-Instruct-v0.1 | 39.28 | 61.89 | 86.00 | 277.92 |
| mistralai/Mistral-7B-Instruct-v0.2 | 40.29 | 72.58 | 79.39 | 2088.08 |
| teknium/OpenHermes-2.5-Mistral-7B | 42.64 | 70.63 | 80.25 | 1463.00 |
| openchat/openchat-3.5-1210 | 44.17 | 71.76 | 82.15 | 1923.83 |
| speakleash/mistral_7B-v2/spkl-all_sft_v2/e1_base/spkl-all_2e6-e1_70c70cc6 (experimental) | 45.44 | 71.27 | 91.50 | 279.24 |
| Nexusflow/Starling-LM-7B-beta | 45.69 | 74.58 | 81.22 | 1161.54 |
| openchat/openchat-3.5-0106 | 47.32 | 74.71 | 83.60 | 1106.56 |
| berkeley-nest/Starling-LM-7B-alpha | 47.46 | 75.73 | 82.86 | 1438.04 |
| Models with different sizes: | ||||
| Azurro/APT3-1B-Instruct-v1 (1B) | -13.80 | 52.11 | 12.23 | 739.09 |
| Voicelab/trurl-2-13b-academic (13B) | 29.45 | 68.19 | 79.88 | 733.91 |
| upstage/SOLAR-10.7B-Instruct-v1.0 (10.7B) | 46.07 | 76.93 | 82.86 | 789.58 |
| 7B parameters pretrained and continously pretrained models: | ||||
| OPI-PG/Qra-7b | 11.13 | 54.40 | 75.25 | 203.36 |
| meta-llama/Llama-2-7b-hf | 12.73 | 54.02 | 77.92 | 850.45 |
| internlm/internlm2-base-7b | 20.68 | 52.39 | 69.85 | 3110.92 |
| Bielik-7B-v0.1 | 29.38 | 62.13 | 88.39 | 123.31 |
| mistralai/Mistral-7B-v0.1 | 30.67 | 60.35 | 85.39 | 857.32 |
| internlm/internlm2-7b | 33.03 | 69.39 | 73.63 | 5498.23 |
| alpindale/Mistral-7B-v0.2-hf | 33.05 | 60.23 | 85.21 | 932.60 |
| speakleash/mistral-apt3-7B/spi-e0_hf (experimental) | 35.50 | 62.14 | 87.48 | 132.78 |
SpeakLeash models have one of the best scores in the RAG Reader task.
We have managed to increase Average score by almost 9 pp. in comparison to Mistral-7B-v0.1.
In our subjective evaluations of chatting skills SpeakLeash models perform better than other models with higher Average scores.
The results in the above table were obtained without utilizing instruction templates for instructional models, instead treating them like base models. This approach could skew the results, as instructional models are optimized with specific instructions in mind.
Limitations and Biases
Bielik-7B-Instruct-v0.1 is a quick demonstration that the base model can be easily fine-tuned to achieve compelling and promising performance. It does not have any moderation mechanisms. We're looking forward to engaging with the community in ways to make the model respect guardrails, allowing for deployment in environments requiring moderated outputs.
Bielik-7B-Instruct-v0.1 can produce factually incorrect output, and should not be relied on to produce factually accurate data. Bielik-7B-Instruct-v0.1 was trained on various public datasets. While great efforts have been taken to clear the training data, it is possible that this model can generate lewd, false, biased or otherwise offensive outputs.
License
Because of an unclear legal situation, we have decided to publish the model under CC BY NC 4.0 license - it allows for non-commercial use. The model can be used for scientific purposes and privately, as long as the license conditions are met.
Citation
Please cite this model using the following format:
@misc{Bielik7Bv01,
title = {Introducing Bielik-7B-Instruct-v0.1: Instruct Polish Language Model},
author = {Ociepa, Krzysztof and Flis, Łukasz and Wróbel, Krzysztof and Kondracki, Sebastian and {SpeakLeash Team} and {Cyfronet Team}},
year = {2024},
url = {https://huggingface.co/speakleash/Bielik-7B-Instruct-v0.1},
note = {Accessed: 2024-04-01}, % change this date
urldate = {2024-04-01} % change this date
}
Responsible for training the model
- Krzysztof OciepaSpeakLeash - team leadership, conceptualizing, data preparation, process optimization and oversight of training
- Łukasz FlisCyfronet AGH - coordinating and supervising the training
- Krzysztof WróbelSpeakLeash - benchmarks
- Sebastian KondrackiSpeakLeash - coordinating and preparation of instructions
- Maria FilipkowskaSpeakLeash - preparation of instructions
- Paweł KiszczakSpeakLeash - preparation of instructions
- Adrian GwoździejSpeakLeash - data quality and instructions cleaning
- Igor CiuciuraSpeakLeash - instructions cleaning
- Jacek ChwiłaSpeakLeash - instructions cleaning
- Remigiusz KinasSpeakLeash - providing quantized models
- Szymon BaczyńskiSpeakLeash - providing quantized models
The model could not have been created without the commitment and work of the entire SpeakLeash team, whose contribution is invaluable. Thanks to the hard work of many individuals, it was possible to gather a large amount of content in Polish and establish collaboration between the open-science SpeakLeash project and the HPC center: ACK Cyfronet AGH. Individuals who contributed to the creation of the model through their commitment to the open-science SpeakLeash project: Grzegorz Urbanowicz, Paweł Cyrta, Jan Maria Kowalski, Karol Jezierski, Kamil Nonckiewicz, Izabela Babis, Nina Babis, Waldemar Boszko, and many other wonderful researchers and enthusiasts of the AI world.
Members of the ACK Cyfronet AGH team providing valuable support and expertise: Szymon Mazurek.
Contact Us
If you have any questions or suggestions, please use the discussion tab. If you want to contact us directly, join our Discord SpeakLeash.
- Downloads last month
- 301