
NexusRaven V2
Collection
11 items
•
Updated
•
2
Nexusflow HF - Nexusflow Discord - NexusRaven-V2 blog post - Prompting Notebook CoLab - Leaderboard - Read-World Demo - NexusRaven-V2-13B Github

NexusRaven is an open-source and commercially viable function calling LLM that surpasses the state-of-the-art in function calling capabilities.
💪 Versatile Function Calling Capability: NexusRaven-V2 is capable of generating single function calls, nested calls, and parallel calls in many challenging cases.
🤓 Fully Explainable: NexusRaven-V2 is capable of generating very detailed explanations for the function calls it generates. This behavior can be turned off, to save tokens during inference.
📊 Performance Highlights: NexusRaven-V2 surpasses GPT-4 by 7% in function calling success rates in human-generated use cases involving nested and composite functions.
🔧 Generalization to the Unseen: NexusRaven-V2 has never been trained on the functions used in evaluation.
🔥 Commercially Permissive: The training of NexusRaven-V2 does not involve any data generated by proprietary LLMs such as GPT-4. You have full control of the model when deployed in commercial applications.
Please checkout the following links!
NexusRaven-V2 accepts a list of python functions.
These python functions can do anything (including sending GET/POST requests to external APIs!).
The two requirements include the python function signature and the appropriate docstring to generate the function call.
NexusRaven-V2 also does best on functions with arguments, so please always only provide functions that require arguments to raven.
NexusRaven-V2 is capable of generating deeply nested function calls, parallel function calls, and simple single calls. It can also justify the function calls it generated. If you would like to generate the call only, please set a stop criteria of "<bot_end>". Otherwise, please allow NexusRaven-V2 to run until its stop token (i.e. "</s>").
Please refer to our notebook, How-To-Prompt.ipynb, for more advanced tutorials on using NexusRaven-V2!
func(dummy_arg) is preferred over func()) as this can help accuracy.When handling irrelevant user queries, users have noticed that specifying a "no-op" function with arguments work best. For example, something like this might work:
def no_relevant_function(user_query : str):
"""
Call this when no other provided function can be called to answer the user query.
Args:
user_query: The user_query that cannot be answered by any other function calls.
"""
Please ensure to provide an argument to this function, as Raven works best on functions with arguments.
For parallel calls, due to the model being targeted for industry use, you can "enable" parallel calls by adding this into the prompt:
"Setting: Allowed to issue multiple calls with semicolon\n"
This can be added above the User Query to "allow" the model to use parallel calls, otherwise, the model will focus on nested and single calls primarily.
You can run the model on a GPU using the following code.
# Please `pip install transformers accelerate`
from transformers import pipeline
pipeline = pipeline(
"text-generation",
model="Nexusflow/NexusRaven-V2-13B",
torch_dtype="auto",
device_map="auto",
)
prompt_template = \
'''
Function:
def get_weather_data(coordinates):
"""
Fetches weather data from the Open-Meteo API for the given latitude and longitude.
Args:
coordinates (tuple): The latitude of the location.
Returns:
float: The current temperature in the coordinates you've asked for
"""
Function:
def get_coordinates_from_city(city_name):
"""
Fetches the latitude and longitude of a given city name using the Maps.co Geocoding API.
Args:
city_name (str): The name of the city.
Returns:
tuple: The latitude and longitude of the city.
"""
User Query: {query}<human_end>
'''
prompt = prompt_template.format(query="What's the weather like in Seattle right now?")
result = pipeline(prompt, max_new_tokens=2048, return_full_text=False, do_sample=False, temperature=0.001)[0]["generated_text"]
print (result)
This should generate the following:
Call: get_weather_data(coordinates=get_coordinates_from_city(city_name='Seattle'))<bot_end>
Thought: The function call `get_weather_data(coordinates=get_coordinates_from_city(city_name='Seattle'))` answers the question "What's the weather like in Seattle right now?" by following these steps:
1. `get_coordinates_from_city(city_name='Seattle')`: This function call fetches the latitude and longitude of the city "Seattle" using the Maps.co Geocoding API.
2. `get_weather_data(coordinates=...)`: This function call fetches the current weather data for the coordinates returned by the previous function call.
Therefore, the function call `get_weather_data(coordinates=get_coordinates_from_city(city_name='Seattle'))` answers the question "What's the weather like in Seattle right now?" by first fetching the coordinates of the city "Seattle" and then fetching the current weather data for those coordinates.
If you would like to prevent the generation of the explanation of the function call (for example, to save on inference tokens), please set a stopping criteria of <bot_end>.
Please follow this prompting template to maximize the performance of RavenV2.
We've also included a small demo for using Raven with langchain!

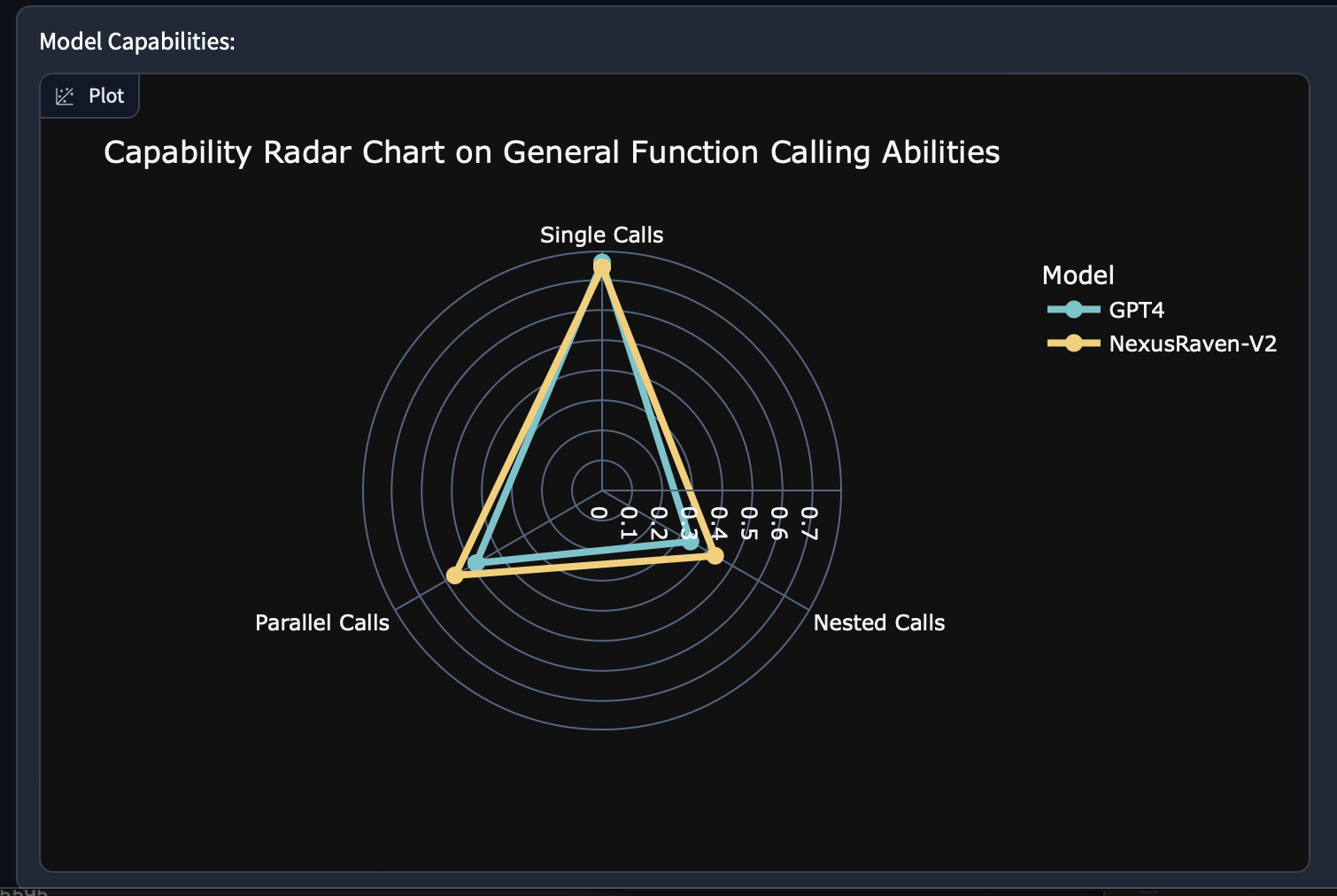
For a deeper dive into the results, please see our Github README.
This model was trained on commercially viable data and is licensed under the Nexusflow community license.
We thank the CodeLlama team for their amazing models!
@misc{rozière2023code,
title={Code Llama: Open Foundation Models for Code},
author={Baptiste Rozière and Jonas Gehring and Fabian Gloeckle and Sten Sootla and Itai Gat and Xiaoqing Ellen Tan and Yossi Adi and Jingyu Liu and Tal Remez and Jérémy Rapin and Artyom Kozhevnikov and Ivan Evtimov and Joanna Bitton and Manish Bhatt and Cristian Canton Ferrer and Aaron Grattafiori and Wenhan Xiong and Alexandre Défossez and Jade Copet and Faisal Azhar and Hugo Touvron and Louis Martin and Nicolas Usunier and Thomas Scialom and Gabriel Synnaeve},
year={2023},
eprint={2308.12950},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{nexusraven,
title={NexusRaven-V2: Surpassing GPT-4 for Zero-shot Function Calling},
author={Nexusflow.ai team},
year={2023},
url={https://nexusflow.ai/blogs/ravenv2}
}
Please join our Discord Channel to reach out for any issues and comments!
Base model
codellama/CodeLlama-13b-Instruct-hf