
ALLaVA: Harnessing GPT4V-synthesized Data for A Lite Vision-Language Model
⚡ALLaVA is a project that provides a large-scale GPT4V-synthesized dataset for training LVLMs.⚡
📃 Paper • 🌐 Demo • 👨🏻💻 Github
🤗 ALLaVA-3B-Longer • 🤗 ALLaVA-3B
Benchmark Result
Our model ALLaVA-3B-Longer and ALLaVA-3B achieve competitive results on 12 benchmarks. Bold numbers denote the SOTA performance among 3B-scale models.
| Model | Backbone | Vicuna-80 | MMB | SEEDBench-v1 (img) | MM-Vet | MMMU (val) | MME | TextVQA | GQA | EMT (CIFAR10) | MLLM-Bench | TouchStone | LLaVA (In-the-Wild) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Qwen-VL-Chat | Qwen-7B | - | 60.6 | 65.4 | - | 35.9 | 1487.5 | 61.5 | 57.5 | - | 6.2 | 711.6 | - |
| LLaVA-v1.5-7B | Vicuna-7B | - | 64.3 | - | 31.1 | - | 1510.7 | 58.2 | 62.0 | - | - | 65.4 | |
| LLaVA-v1.5-13B | Vicuna-13B | 22.50 | 67.7 | 68.2 | 35.4 | 36.4 | 1531.3 | 61.3 | 63.3 | 85.0 | 7.4 | 637.7 | 70.7 |
| ShareGPT4V-7B | Vicuna-7B | - | 68.8 | 69.7 | 37.6 | - | 1943.8 | 60.4 | 63.3 | - | - | - | 72.6 |
| TinyGPT-V | Phi2-2.7B | - | - | - | - | - | - | - | 33.6 | - | - | - | - |
| MobileVLM | MobileLLaMA-2.7B | - | 59.6 | - | - | - | 1288.9 | 47.5 | - | - | - | - | - |
| LLaVA-Phi | Phi2-2.7B | - | 59.8 | - | 28.9 | - | 1335.1 | 48.6 | - | - | - | - | - |
| ALLaVA-3B | Phi2-2.7B | 48.8 | 64.0 | 65.2 | 32.2 | 35.3 | 1623.2 | 49.5 | 48.8 | 90.2 | 6.7 | 632.0 | 69.4 |
| ALLaVA-3B-Longer | Phi2-2.7B | 52.5 | 64.6 | 65.6 | 35.5 | 33.2 | 1564.6 | 50.3 | 50.0 | 85.9 | 8.8 | 636.5 | 71.7 |
The detailed information of each benchmark is shown in Table 4 of our technical report.
🏭 Inference
Load from 🤗 (Recommended)
See the example script.
CLI
See here for CLI code snippet.
🏋️♂️ Training
Data
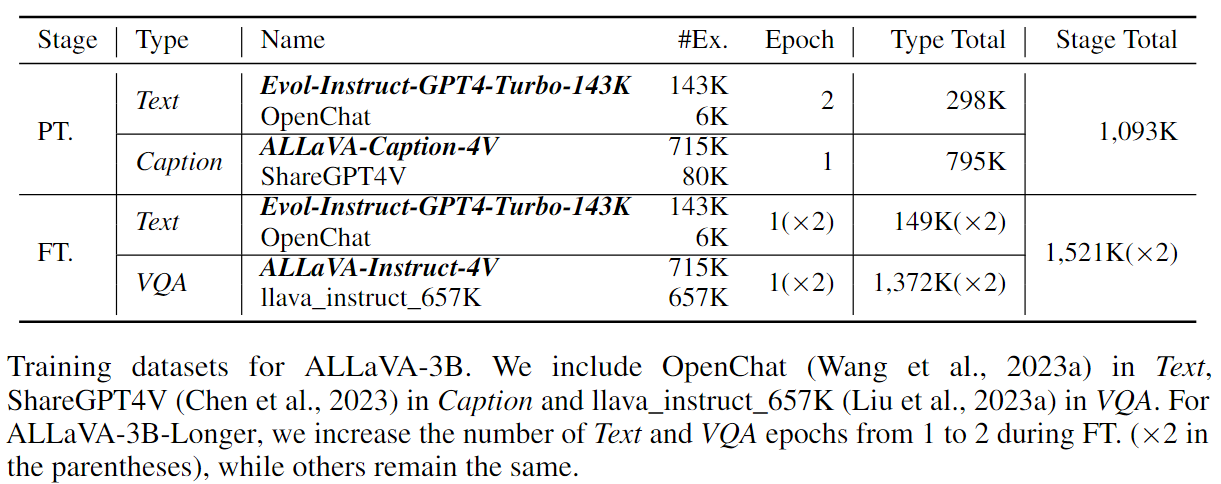
As shown in the table, ALLaVA-3B uses 1M and 1.5M data for PT. and FT., respectively. ALLaVA-3B-Longer trains one more epoch (i.e. 3M in total) for the FT. stage.
Code
The training code is largely based on LLaVA-v1.5. We wholeheartedly express our gratitude for their invaluable contributions to open-sourcing LVLMs.
Cost
We train our models on 8*A800 GPUs. ALLaVA-3B-Longer takes 8.3h for PT and 21.3h for FT. ALLaVA-3B takes 8.3h for PT and 10.6h for FT. These two models share the same PT procedure.
Hyperparameters
| Global Batch Size | ZeRO Stage | Optimizer | Max LR | Min LR | Scheduler | Max length | Weight decay |
|---|---|---|---|---|---|---|---|
| 256 (PT) / 128 (FT) | 1 | AdamW | 2e-5 | 2e-6 | CosineAnnealingWarmRestarts | 2048 | 0 |
The LM backbone, projector are trainable, while the vision encoder is kept frozen. The trainabilities of each module are the same for both stages.
📚 ALLaVA-4V Data
The majority part of training data is ALLaVA-4V. See here to prepare it for training.
🙌 Contributors
Project Leader: Guiming Hardy Chen
Data: Shunian Chen, Junying Chen, Xiangbo Wu
Evaluation: Ruifei Zhang
Deployment: Xiangbo Wu, Zhiyi Zhang
Advising: Zhihong Chen, Benyou Wang
Others: Jianquan Li, Xiang Wan
📝 Citation
If you find our data useful, please consider citing our work! We are FreedomIntelligence from Shenzhen Research Institute of Big Data and The Chinese University of Hong Kong, Shenzhen
@article{chen2024allava,
title={ALLaVA: Harnessing GPT4V-synthesized Data for A Lite Vision-Language Model},
author={Chen, Guiming Hardy and Chen, Shunian and Zhang, Ruifei and Chen, Junying and Wu, Xiangbo and Zhang, Zhiyi and Chen, Zhihong and Li, Jianquan and Wan, Xiang and Wang, Benyou},
journal={arXiv preprint arXiv:2402.11684},
year={2024}
}
- Downloads last month
- 86