
Tele-FLM (FLM-2)
Collection
3 items
•
Updated
•
2
Tele-FLM (aka FLM-2) is a 52B open-sourced multilingual large language model that features a stable, efficient pre-training paradigm and enhanced factual judgement capabilities. Built upon the decoder-only transformer architecture, it has been trained on approximately 2T tokens. Tele-FLM demonstrates superior performances at its scale, and sometimes surpass larger models. In addition to sharing the model weights, we provide the core designs, engineering practices, and training details, anticipating their benefits for both academic and industrial communities.
Although we've made extensive efforts to thoroughly clean and filter the training corpus for the model, due to the open nature of the dataset, the model may still have picked up on some unsafe examples. Consequently, the model may still generate unexpected content, including but not limited to discrimination, bias, or offensive language. We would like to strongly advise users not to spread any unsafe content generated by the model. The project developers cannot be held responsible for any repercussions stemming from the dissemination of harmful information.
Use the code below to get started with Tele-FLM.
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained('CofeAI/Tele-FLM', trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained('CofeAI/Tele-FLM', torch_dtype=torch.bfloat16, low_cpu_mem_usage=True, device_map="auto", trust_remote_code=True)
inputs = tokenizer('Beijing is the capital of China.', return_tensors='pt').to(model.device)
generated = model.generate(**inputs, max_new_tokens=128, repetition_penalty=1.03)
print(tokenizer.decode(generated.cpu()[0], skip_special_tokens=True))
Our training dataset comprises a variety of domains, as detailed in the table below. The total amount of data is roughly 2 trillion, with English and Chinese data in a ratio of about 2:1. In line with the methodology of GPT-4, we collected some instruct data and incorporated it into our pre-training data after removing the test sets of common datasets using the strict n-gram-based method. We deliberately avoid “training on the test set” or any other benchmark-oriented trick.
| Domain | Language | Sampling Prop. | Epochs | Disk Size |
|---|---|---|---|---|
| Webtext | en, zh | 75.21% | 1.0 | 5.9 TB |
| Code | code, zh | 9.81% | 1.0 | 528.1 GB |
| Book | en, zh | 7.17% | 0.8 | 647.6 GB |
| WorldKnowledge | multi, en, zh | 2.87% | 2.5 | 67.5 GB |
| QA | en, zh | 2.12% | 1.0 | 159.2 GB |
| AcademicPaper | en | 0.99% | 1.0 | 54.4 GB |
| Profession-Law | zh | 1.04% | 1.0 | 84.2 GB |
| Profession-Math | math | 0.62% | 2.0 | 6.1 GB |
| Profession-Patent | zh | 0.14% | 1.0 | 10.4 GB |
| Profession-Medical | zh | 0.02% | 1.0 | 1.2 GB |
| ClassicalChinese | zh | 0.02% | 2.5 | 0.5 GB |
We adopt the architecture of FLM-101B as the backbone for Tele-FLM, with several modifications:
Consequently, Tele-FLM is largely compatible with Llama architecturally. To maximize convenience for the community, we made minimal adjustments to Llama's code to adapt it to Tele-FLM and released it as open source.
In the pre-training stage, we employ μP for optimal hyperparameter search. The μP model (Tele-FLM_μP) is architecturally identical to Tele-FLM except for the model width. The architecture of Tele-FLM and Tele-FLM_μP is listed below. For more details of μP, please refer to our technical report and the original Tensor Program papers.
| Models | layer number |
attention heads |
hidden size |
ffn hidden size |
vocab size |
context length |
param size (M) |
|---|---|---|---|---|---|---|---|
| Tele-FLM | 64 | 64 | 8,192 | 21,824 | 80,000 | 4,096 | 52,850 |
| Tele-FLM_μP | 64 | 4 | 512 | 1,344 | 80,000 | 4,096 | 283 |
Due to the smaller size, Tele-FLM_μP allows for significantly more experimental runs within fixed time and resource constraints. We searched seven hyperparameters for pretraining. All the hyperparameters are shown below.
| Searched Hyperparameters | Non-Searched Hyperparameters | |||
|---|---|---|---|---|
| Learning Rate | 1.5e-4 | LR Schedule Type | cosine | |
| Matrix Learning Rate | 1.5e-4 | LR Schedule (tokens) | 2.5T | |
| Minimum Learning Rate | 1.5e-5 | Warmup Step | 2,000 | |
| Standard Deviation | 4e-3 | Clip Grad | 1.0 | |
| Matrix Standard Deviation | 4.242e-3 | Weight Decay | 0.0 | |
| Input Mult | 1.0 | Batch Size (tokens) | 5,505,024 | |
| Output Mult | 3.125e-2 | RoPE Theta | 10,000 |
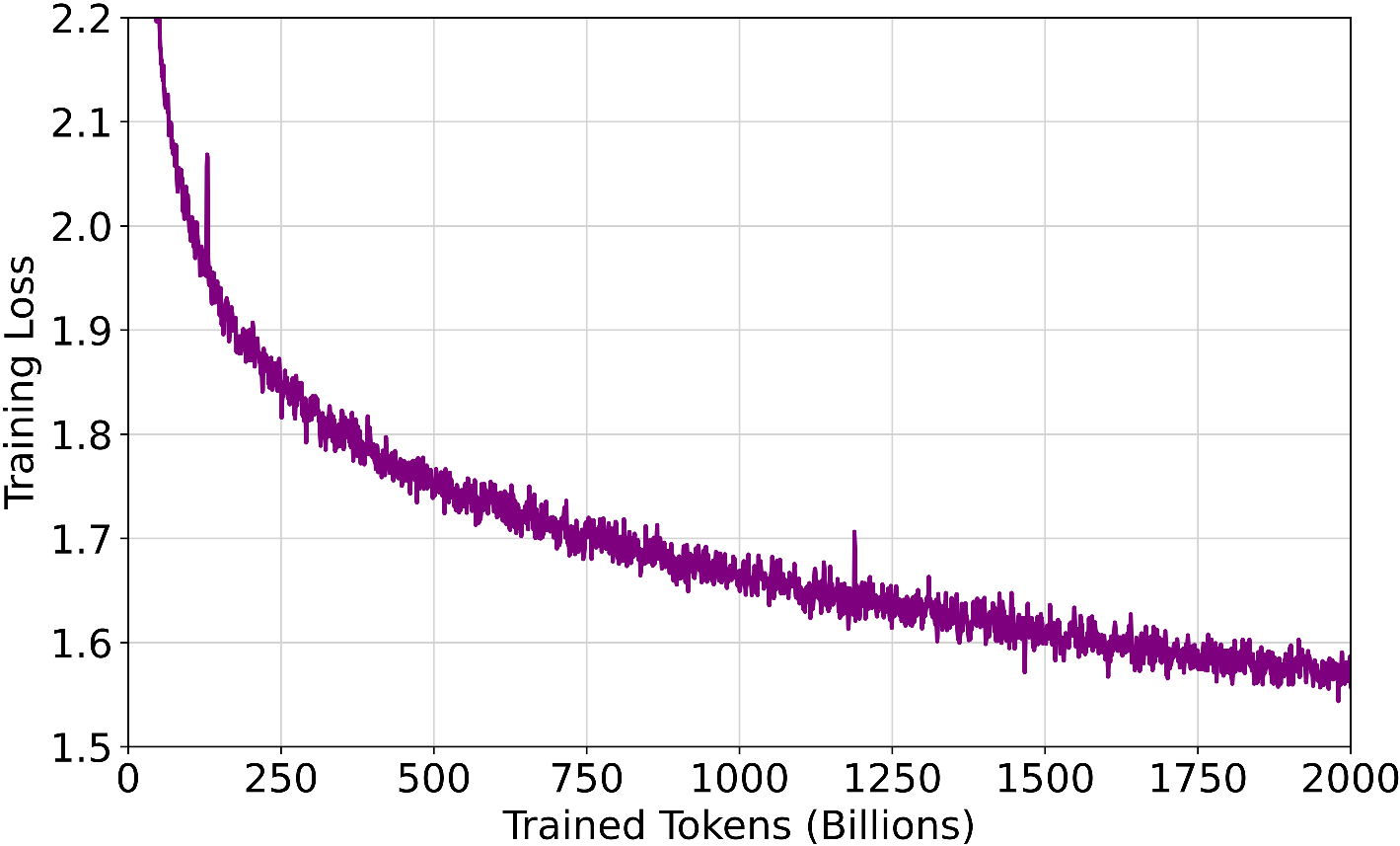
Tele-FLM is trained on a cluster of 112 A800 SXM4 GPU servers, each with 8 NVLink A800 GPUs and 2TB of RAM. The nodes have varied CPU configurations: 96 nodes with Intel 8358 (128x 2.60GHz) CPUs and 16 nodes with AMD 7643 (96x 2.30GHz) CPUs. All nodes are interconnected via InfiniBand (IB). The training process lasted around two months, including downtime due to unexpected factors.
Tele-FLM utilizes 3D parallel training, combining the prevailing methodologies: data parallelism, tensor parallelism, and pipeline parallelism. The parallel training setup for Tele-FLM is configured as follows: tensor parallel=4, pipeline parallel=2, and data parallel=112.
| Model | Average | ARC | HellaSwag | MMLU | TruthfulQA | WinoGrade | GSM8K | HumanEval | BBH |
|---|---|---|---|---|---|---|---|---|---|
| 25-shot | 10-shot | 5-shot | zero-shot | 5-shot | 5-shot | zero-shot | 3-shot | ||
| LLAMA2-70B | 63.39 | 67.32 | 87.33 | 69.83 | 44.92 | 83.74 | 54.06 | 46.95 | 52.94 |
| LLAMA2-13B | 50.29 | 59.39 | 82.13 | 55.77 | 37.38 | 76.64 | 22.82 | 28.66 | 39.52 |
| LLAMA-65B | 56.98 | 63.48 | 86.09 | 63.93 | 43.43 | 82.56 | 37.23 | 33.54 | 45.54 |
| LLAMA-13B | 46.20 | 56.23 | 80.93 | 47.67 | 39.48 | 76.24 | 7.58 | 23.78 | 37.72 |
| Tele-FLM | 56.60 | 59.47 | 82.25 | 64.00 | 43.09 | 79.40 | 45.19 | 34.76 | 44.60 |
| Model | Average | C-Eval | CMMLU | C3 | CHID | CSL |
|---|---|---|---|---|---|---|
| GPT-4 | 76.64 | 69.90 | 71.00 | 95.10 | 82.20 | 65.00 |
| GPT-3.5 | 61.86 | 52.50 | 53.90 | 85.60 | 60.40 | 56.90 |
| Qwen1.5-72B | 80.45 | 83.72 | 83.09 | 81.86 | 91.09 | 62.50 |
| Qwen-72B | 83.00 | 83.30 | 83.60 | 95.80 | 91.10 | 61.20 |
| DeepSeek-67B | 73.46 | 66.90 | 70.40 | 77.80 | 89.10 | 63.10 |
| Tele-FLM | 71.13 | 65.48 | 66.98 | 66.25 | 92.57 | 64.38 |
If you find our work helpful, please consider citing it.
@article{tele-flm-2024,
author = {Xiang Li and Yiqun Yao and Xin Jiang and Xuezhi Fang and Chao Wang and Xinzhang Liu and Zihan Wang and Yu Zhao and Xin Wang and Yuyao Huang and Shuangyong Song and Yongxiang Li and Zheng Zhang and Bo Zhao and Aixin Sun and Yequan Wang and Zhongjiang He and Zhongyuan Wang and Xuelong Li and Tiejun Huang},
title = {Tele-FLM Technical Report},
journal = {CoRR},
volume = {abs/2404.16645},
year = {2024},
url = {https://doi.org/10.48550/arXiv.2404.16645},
doi = {10.48550/ARXIV.2404.16645},
eprinttype = {arXiv},
eprint = {2404.16645},
}