

license: cc-by-nc-4.0
datasets:
- chrisociepa/wikipedia-pl-20230401
language:
- pl
library_name: transformers
tags:
- llama
- ALLaMo
inference: false
APT3-500M-Base
Introduction
At Azurro, we consistently place importance on using the Open Source technologies, both while working on the projects and in our everyday lives. We have decided to share a base language model trained by us. We are confident that smaller language models have great potential, and direct access to them for all people that are interested in such models democratizes this significant and dynamically changing field even more.
Statements
Training large language models requires a lot of computing power and it is meant for the major players on the market. However, does it mean that individuals or small companies cannot train language models capable of performing specific tasks? We decided to answer this question and train our own language model from scratch. We have made the following statements:
- we use 1 consumer graphic card
- we train the model only with the Polish corpus
- we use manually selected, high quality texts for training the model.
Why have we made such statements? It is worth noting that training a model requires several times more resources than using it. To put it simply, it can be assumed that it is about 3-4 times more. Therefore, if a model can be run with a graphic card that has 6 GB VRAM, then training this model requires about 24 GB VRAM (this is the minimum value).
Many consumer computers are equipped with good quality graphic cards that can be used for training a model at one’s own home. This is why we have decided to use a top consumer graphic card - Nvidia’s RTX 4090 24GB VRAM.
All the currently available language models have been trained mainly with English corpora with a little bit of other languages, including Polish. The effect is that these models are not the best at dealing with the Polish texts. Even the popular GPT-3.5 model from OpenAI often has issues with correct forms. Therefore we have decided to prepare a model based only on the Polish corpus. An additional advantage of using only the Polish corpus is the size of the model - it is better to focus on one language in the case of smaller models.
It is important to remember that models are as good as the data with which they are trained. Having regard to the small size of the model, we trained it with carefully selected texts. This is why we have not used corpora such as Common Crawl that contain a lot of poor quality data. Our team has prepared a set of sources that then have been processed and used for training the model.
Model
APT3-500M-Base has been trained with the use of an original open source framework called ALLaMo. This framework allows the user to train language models similar to the Meta AI’s LLaMA models quickly and efficiently.
APT3-500M-Base is an autoregressive language model based on the architecture of a transformer. It has been trained with data collected before November 2023.
27 billion tokens have been used for training, and the training dataset (the Polish corpus) has over 20 billion tokens.
A special tokenizer has been prepared and trained for the purpose of training the model.
Model description:
- Developed by: Azurro
- Language: Polish
- Model type: causal decoder-only
- License: CC BY NC 4.0 (non-commercial use)
Model details:
| Hyperparameter | Value |
|---|---|
| Model Parameters | 477M |
| Sequence Length | 1024 |
| Vocabulary Size | 31980 |
| Layers | 32 |
| Heads | 16 |
| d_head | 64 |
| d_model | 1024 |
| Dropout | 0.0 |
| Bias | No |
| Positional Encoding | RoPE |
| Activation Function | SwiGLU |
| Normalizing Function | RMSNorm |
| Intermediate Size | 2816 |
| Norm Epsilon | 1e-06 |
Tokenizer details:
- type: BPE
- special tokens: 8 (
<unk>,<s>,</s>,<pad>,[INST],[/INST],<<SYS>>,<</SYS>>) - alphabet size: 113
- vocabulary size: 31980
Training
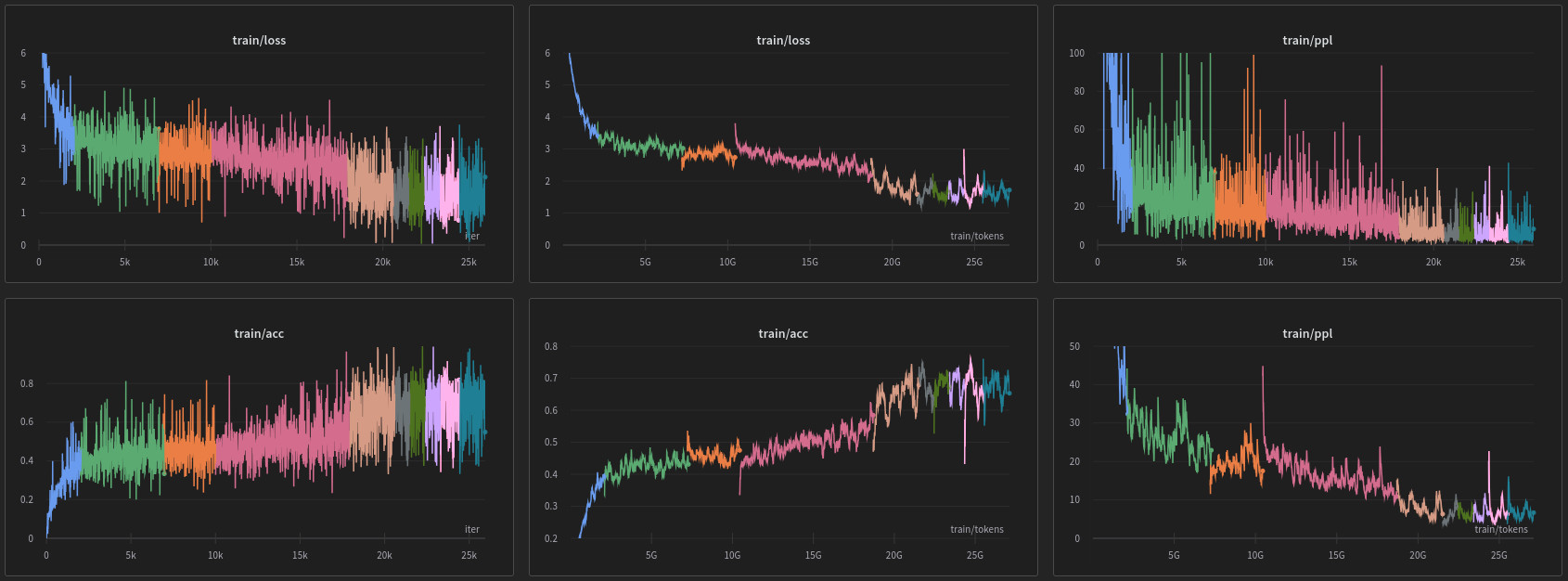
Training hyperparameters:
| Hyperparameter | Value |
|---|---|
| Micro Batch Size | 6 |
| Gradient Accumulation Steps | 170 |
| Batch Size | 1044480 |
| Learning Rate (cosine) | 4e-04 -> 2e-05 |
| Warmup Iterations | 1000 |
| All Iterations | 25900 |
| Optimizer | AdamW |
| β1, β2 | 0.9, 0.95 |
| Adam_eps | 1e−8 |
| Weight Decay | 0.1 |
| Grad Clip | 1.0 |
| Precision | bfloat16 |
Dataset
Collecting a large amount of high quality training data is a great challenge. Over the past years at Azurro, we have done a lot of projects connected with processing Big Data. Therefore, with our extensive experience, we have been able to prepare carefully selected training dataset quickly and efficiently.
Our training dataset contains:
- ebooks 8%
- Polish Wikipedia 4%
- web crawl data 88%
Quickstart
This model can be easily loaded using the AutoModelForCausalLM functionality.
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "Azurro/APT3-500M-Base"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
In order to reduce the memory usage, you can use smaller precision (bfloat16).
import torch
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16)
And then you can use Hugging Face Pipelines to generate text.
import transformers
text = "Najważniejszym celem człowieka na ziemi jest"
pipeline = transformers.pipeline("text-generation", model=model, tokenizer=tokenizer)
sequences = pipeline(max_new_tokens=100, do_sample=True, top_k=50, eos_token_id=tokenizer.eos_token_id, text_inputs=text)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
Limitations and Biases
APT3-500M-Base is not intended for deployment without fine-tuning. It should not be used for human-facing interactions without further guardrails and user consent.
APT3-500M-Base can produce factually incorrect output, and should not be relied on to produce factually accurate information. APT3-500M-Base was trained on various public datasets. While great efforts have been taken to clean the pretraining data, it is possible that this model could generate lewd, biased or otherwise offensive outputs.
License
Because of an unclear legal situation, we have decided to publish the model under CC BY NC 4.0 license - it allows for non-commercial use. The model can be used for scientific purposes and privately, as long as the license conditions are met.
Disclaimer
The license on this model does not constitute legal advice. We are not responsible for the actions of third parties who use this model.
Citation
Please cite this model using the following format:
@online{AzurroAPT3Base500M,
author = {Ociepa, Krzysztof and {Azurro Team}},
title = {Introducing APT3-500M-Base: Polish Language Model},
year = {2023},
url = {https://azurro.pl/apt3-500m-base-en},
note = {Accessed: 2023-11-10}, % change this date
urldate = {2023-11-10} % change this date
}