
metrics:
- accuracy
pipeline_tag: image-classification
base_model: google/vit-base-patch16-384
model-index:
- name: AdamCodd/vit-base-nsfw-detector
results:
- task:
type: image-classification
name: Image Classification
metrics:
- type: accuracy
value: 0.9654
name: Accuracy
- type: AUC
value: 0.9948
- type: loss
value: 0.0937
name: Loss
license: apache-2.0
library_name: transformers.js
vit-base-nsfw-detector
This model is a fine-tuned version of vit-base-patch16-384 on around 25_000 images (drawings, photos...). It achieves the following results on the evaluation set:
- Loss: 0.0937
- Accuracy: 0.9654
Model description
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pretrained on a large collection of images in a supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. Next, the model was fine-tuned on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, at a higher resolution of 384x384.
Intended uses & limitations
There are two classes: SFW and NSFW. The model has been trained to be restrictive and therefore classify "sexy" images as NSFW. That is, if the image shows cleavage or too much skin, it will be classified as NSFW. This is normal.
Usage for a local image:
from transformers import pipeline
from PIL import Image
img = Image.open("<path_to_image_file>")
predict = pipeline("image-classification", model="AdamCodd/vit-base-nsfw-detector")
predict(img)
Usage for a distant image:
from transformers import ViTImageProcessor, AutoModelForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = ViTImageProcessor.from_pretrained('AdamCodd/vit-base-nsfw-detector')
model = AutoModelForImageClassification.from_pretrained('AdamCodd/vit-base-nsfw-detector')
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
# Predicted class: sfw
Usage with Transformers.js (Vanilla JS):
/* Instructions:
* - Place this script in an HTML file using the <script type="module"> tag.
* - Ensure the HTML file is served over a local or remote server (e.g., using Python's http.server, Node.js server, or similar).
* - Replace 'https://example.com/path/to/image.jpg' in the classifyImage function call with the URL of the image you want to classify.
*
* Example of how to include this script in HTML:
* <script type="module" src="path/to/this_script.js"></script>
*
* This setup ensures that the script can use imports and perform network requests without CORS issues.
*/
import { pipeline, env } from 'https://cdn.jsdelivr.net/npm/@xenova/[email protected]';
// Since we will download the model from HuggingFace Hub, we can skip the local model check
env.allowLocalModels = false;
// Load the image classification model
const classifier = await pipeline('image-classification', 'AdamCodd/vit-base-nsfw-detector');
// Function to fetch and classify an image from a URL
async function classifyImage(url) {
try {
const response = await fetch(url);
if (!response.ok) throw new Error('Failed to load image');
const blob = await response.blob();
const image = new Image();
const imagePromise = new Promise((resolve, reject) => {
image.onload = () => resolve(image);
image.onerror = reject;
image.src = URL.createObjectURL(blob);
});
const img = await imagePromise; // Ensure the image is loaded
const classificationResults = await classifier([img.src]); // Classify the image
console.log('Predicted class: ', classificationResults[0].label);
} catch (error) {
console.error('Error classifying image:', error);
}
}
// Example usage
classifyImage('https://example.com/path/to/image.jpg');
// Predicted class: sfw
The model has been trained on a variety of images (realistic, 3D, drawings), yet it is not perfect and some images may be wrongly classified as NSFW when they are not. Additionally, please note that using the quantized ONNX model within the transformers.js pipeline will slightly reduce the model's accuracy.
Training and evaluation data
More information needed
Training procedure
Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- num_epochs: 1
Training results
- Validation Loss: 0.0937
- Accuracy: 0.9654,
- AUC: 0.9948
Confusion matrix (eval):
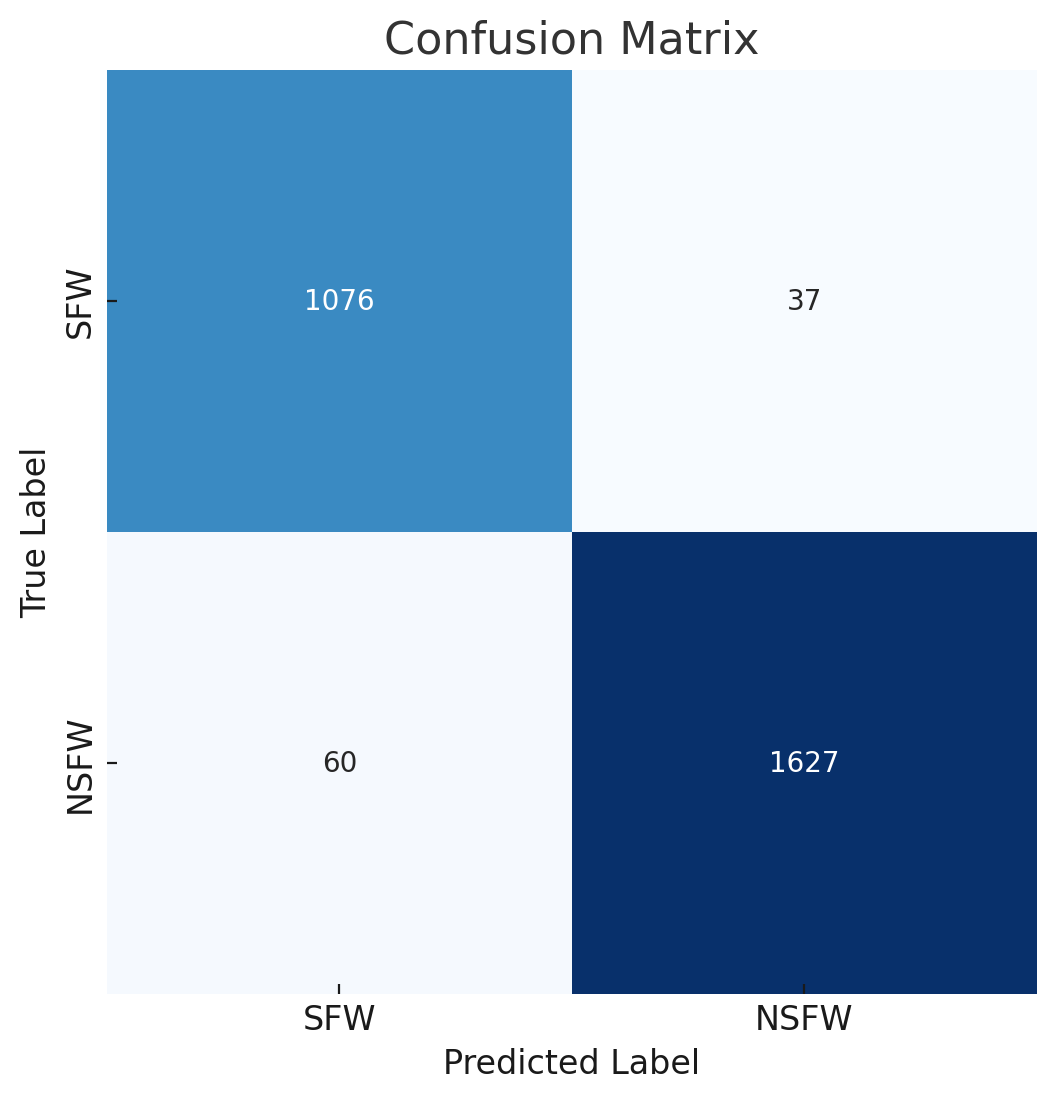{kind=link}
[1076 37]
[ 60 1627]
Framework versions
- Transformers 4.36.2
- Evaluate 0.4.1
If you want to support me, you can here.