
Sofian Hadiwijaya
commited on
Commit
•
7e9d3a4
1
Parent(s):
42b94b0
add files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +5 -0
- Dockerfile +89 -0
- LICENSE +21 -0
- README.md +8 -8
- app.py +294 -0
- assets/BBOX_SHIFT.md +26 -0
- assets/demo/man/man.png +3 -0
- assets/demo/monalisa/monalisa.png +0 -0
- assets/demo/musk/musk.png +0 -0
- assets/demo/sit/sit.jpeg +0 -0
- assets/demo/sun1/sun.png +0 -0
- assets/demo/sun2/sun.png +0 -0
- assets/demo/video1/video1.png +0 -0
- assets/demo/yongen/yongen.jpeg +0 -0
- assets/figs/landmark_ref.png +0 -0
- assets/figs/musetalk_arc.jpg +0 -0
- configs/inference/test.yaml +10 -0
- data/audio/sun.wav +3 -0
- data/audio/yongen.wav +3 -0
- data/video/sun.mp4 +3 -0
- data/video/yongen.mp4 +3 -0
- entrypoint.sh +11 -0
- install_ffmpeg.sh +70 -0
- musetalk/models/unet.py +47 -0
- musetalk/models/vae.py +148 -0
- musetalk/utils/__init__.py +5 -0
- musetalk/utils/blending.py +59 -0
- musetalk/utils/dwpose/default_runtime.py +54 -0
- musetalk/utils/dwpose/rtmpose-l_8xb32-270e_coco-ubody-wholebody-384x288.py +257 -0
- musetalk/utils/face_detection/README.md +1 -0
- musetalk/utils/face_detection/__init__.py +7 -0
- musetalk/utils/face_detection/api.py +240 -0
- musetalk/utils/face_detection/detection/__init__.py +1 -0
- musetalk/utils/face_detection/detection/core.py +130 -0
- musetalk/utils/face_detection/detection/sfd/__init__.py +1 -0
- musetalk/utils/face_detection/detection/sfd/bbox.py +129 -0
- musetalk/utils/face_detection/detection/sfd/detect.py +114 -0
- musetalk/utils/face_detection/detection/sfd/net_s3fd.py +129 -0
- musetalk/utils/face_detection/detection/sfd/sfd_detector.py +59 -0
- musetalk/utils/face_detection/models.py +261 -0
- musetalk/utils/face_detection/utils.py +313 -0
- musetalk/utils/face_parsing/__init__.py +56 -0
- musetalk/utils/face_parsing/model.py +283 -0
- musetalk/utils/face_parsing/resnet.py +109 -0
- musetalk/utils/preprocessing.py +113 -0
- musetalk/utils/utils.py +61 -0
- musetalk/whisper/audio2feature.py +124 -0
- musetalk/whisper/whisper/__init__.py +116 -0
- musetalk/whisper/whisper/__main__.py +4 -0
- musetalk/whisper/whisper/assets/gpt2/merges.txt +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,8 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
assets/demo/man/man.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
data/audio/sun.wav filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
data/audio/yongen.wav filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
data/video/sun.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
data/video/yongen.mp4 filter=lfs diff=lfs merge=lfs -text
|
Dockerfile
ADDED
|
@@ -0,0 +1,89 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM anchorxia/musev:latest
|
| 2 |
+
|
| 3 |
+
#MAINTAINER 维护者信息
|
| 4 |
+
LABEL MAINTAINER="zkangchen"
|
| 5 |
+
LABEL Email="[email protected]"
|
| 6 |
+
LABEL Description="musev gradio image, from docker pull anchorxia/musev:latest"
|
| 7 |
+
|
| 8 |
+
SHELL ["/bin/bash", "--login", "-c"]
|
| 9 |
+
|
| 10 |
+
# Set up a new user named "user" with user ID 1000
|
| 11 |
+
RUN useradd -m -u 1000 user
|
| 12 |
+
|
| 13 |
+
# Switch to the "user" user
|
| 14 |
+
USER user
|
| 15 |
+
|
| 16 |
+
# Set home to the user's home directory
|
| 17 |
+
ENV HOME=/home/user \
|
| 18 |
+
PATH=/home/user/.local/bin:$PATH
|
| 19 |
+
|
| 20 |
+
# Set the working directory to the user's home directory
|
| 21 |
+
WORKDIR $HOME/app
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
################################################# INSTALLING FFMPEG ##################################################
|
| 25 |
+
# RUN apt-get update ; apt-get install -y git build-essential gcc make yasm autoconf automake cmake libtool checkinstall libmp3lame-dev pkg-config libunwind-dev zlib1g-dev libssl-dev
|
| 26 |
+
|
| 27 |
+
# RUN apt-get update \
|
| 28 |
+
# && apt-get clean \
|
| 29 |
+
# && apt-get install -y --no-install-recommends libc6-dev libgdiplus wget software-properties-common
|
| 30 |
+
|
| 31 |
+
#RUN RUN apt-add-repository ppa:git-core/ppa && apt-get update && apt-get install -y git
|
| 32 |
+
|
| 33 |
+
# RUN wget https://www.ffmpeg.org/releases/ffmpeg-4.0.2.tar.gz
|
| 34 |
+
# RUN tar -xzf ffmpeg-4.0.2.tar.gz; rm -r ffmpeg-4.0.2.tar.gz
|
| 35 |
+
# RUN cd ./ffmpeg-4.0.2; ./configure --enable-gpl --enable-libmp3lame --enable-decoder=mjpeg,png --enable-encoder=png --enable-openssl --enable-nonfree
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
# RUN cd ./ffmpeg-4.0.2; make
|
| 39 |
+
# RUN cd ./ffmpeg-4.0.2; make install
|
| 40 |
+
######################################################################################################################
|
| 41 |
+
|
| 42 |
+
RUN echo "docker start"\
|
| 43 |
+
&& whoami \
|
| 44 |
+
&& which python \
|
| 45 |
+
&& pwd
|
| 46 |
+
|
| 47 |
+
RUN git clone -b main --recursive https://github.com/TMElyralab/MuseTalk.git
|
| 48 |
+
|
| 49 |
+
RUN chmod -R 777 /home/user/app/MuseTalk
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
RUN . /opt/conda/etc/profile.d/conda.sh \
|
| 54 |
+
&& echo "source activate musev" >> ~/.bashrc \
|
| 55 |
+
&& conda activate musev \
|
| 56 |
+
&& conda env list
|
| 57 |
+
# && conda install ffmpeg
|
| 58 |
+
|
| 59 |
+
RUN ffmpeg -codecs
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
WORKDIR /home/user/app/MuseTalk/
|
| 66 |
+
|
| 67 |
+
RUN pip install -r requirements.txt \
|
| 68 |
+
&& pip install --no-cache-dir -U openmim \
|
| 69 |
+
&& mim install mmengine \
|
| 70 |
+
&& mim install "mmcv>=2.0.1" \
|
| 71 |
+
&& mim install "mmdet>=3.1.0" \
|
| 72 |
+
&& mim install "mmpose>=1.1.0"
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
# Add entrypoint script
|
| 76 |
+
#RUN chmod 777 ./entrypoint.sh
|
| 77 |
+
RUN ls -l ./
|
| 78 |
+
|
| 79 |
+
EXPOSE 7860
|
| 80 |
+
|
| 81 |
+
# CMD ["/bin/bash", "-c", "python app.py"]
|
| 82 |
+
CMD ["./install_ffmpeg.sh"]
|
| 83 |
+
CMD ["./entrypoint.sh"]
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2024 TMElyralab
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
CHANGED
|
@@ -1,13 +1,13 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
emoji:
|
| 4 |
-
colorFrom:
|
| 5 |
colorTo: purple
|
| 6 |
-
sdk:
|
| 7 |
-
sdk_version: 4.44.1
|
| 8 |
-
app_file: app.py
|
| 9 |
pinned: false
|
| 10 |
-
license:
|
|
|
|
|
|
|
| 11 |
---
|
| 12 |
|
| 13 |
-
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
| 1 |
---
|
| 2 |
+
title: MuseTalkDemo
|
| 3 |
+
emoji: 🌍
|
| 4 |
+
colorFrom: gray
|
| 5 |
colorTo: purple
|
| 6 |
+
sdk: docker
|
|
|
|
|
|
|
| 7 |
pinned: false
|
| 8 |
+
license: creativeml-openrail-m
|
| 9 |
+
app_file: app.py
|
| 10 |
+
app_port: 7860
|
| 11 |
---
|
| 12 |
|
| 13 |
+
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
app.py
ADDED
|
@@ -0,0 +1,294 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import time
|
| 3 |
+
import pdb
|
| 4 |
+
|
| 5 |
+
import gradio as gr
|
| 6 |
+
import spaces
|
| 7 |
+
import numpy as np
|
| 8 |
+
import sys
|
| 9 |
+
import subprocess
|
| 10 |
+
|
| 11 |
+
from huggingface_hub import snapshot_download
|
| 12 |
+
import requests
|
| 13 |
+
|
| 14 |
+
import argparse
|
| 15 |
+
import os
|
| 16 |
+
from omegaconf import OmegaConf
|
| 17 |
+
import numpy as np
|
| 18 |
+
import cv2
|
| 19 |
+
import torch
|
| 20 |
+
import glob
|
| 21 |
+
import pickle
|
| 22 |
+
from tqdm import tqdm
|
| 23 |
+
import copy
|
| 24 |
+
from argparse import Namespace
|
| 25 |
+
import shutil
|
| 26 |
+
import gdown
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def download_model():
|
| 30 |
+
if not os.path.exists(CheckpointsDir):
|
| 31 |
+
os.makedirs(CheckpointsDir)
|
| 32 |
+
print("Checkpoint Not Downloaded, start downloading...")
|
| 33 |
+
tic = time.time()
|
| 34 |
+
snapshot_download(
|
| 35 |
+
repo_id="TMElyralab/MuseTalk",
|
| 36 |
+
local_dir=CheckpointsDir,
|
| 37 |
+
max_workers=8,
|
| 38 |
+
local_dir_use_symlinks=True,
|
| 39 |
+
)
|
| 40 |
+
# weight
|
| 41 |
+
snapshot_download(
|
| 42 |
+
repo_id="stabilityai/sd-vae-ft-mse",
|
| 43 |
+
local_dir=CheckpointsDir,
|
| 44 |
+
max_workers=8,
|
| 45 |
+
local_dir_use_symlinks=True,
|
| 46 |
+
)
|
| 47 |
+
#dwpose
|
| 48 |
+
snapshot_download(
|
| 49 |
+
repo_id="yzd-v/DWPose",
|
| 50 |
+
local_dir=CheckpointsDir,
|
| 51 |
+
max_workers=8,
|
| 52 |
+
local_dir_use_symlinks=True,
|
| 53 |
+
)
|
| 54 |
+
#vae
|
| 55 |
+
url = "https://openaipublic.azureedge.net/main/whisper/models/65147644a518d12f04e32d6f3b26facc3f8dd46e5390956a9424a650c0ce22b9/tiny.pt"
|
| 56 |
+
response = requests.get(url)
|
| 57 |
+
# 确保请求成功
|
| 58 |
+
if response.status_code == 200:
|
| 59 |
+
# 指定文件保存的位置
|
| 60 |
+
file_path = f"{CheckpointsDir}/whisper/tiny.pt"
|
| 61 |
+
os.makedirs(f"{CheckpointsDir}/whisper/")
|
| 62 |
+
# 将文件内容写入指定位置
|
| 63 |
+
with open(file_path, "wb") as f:
|
| 64 |
+
f.write(response.content)
|
| 65 |
+
else:
|
| 66 |
+
print(f"请求失败,状态码:{response.status_code}")
|
| 67 |
+
#gdown face parse
|
| 68 |
+
url = "https://drive.google.com/uc?id=154JgKpzCPW82qINcVieuPH3fZ2e0P812"
|
| 69 |
+
os.makedirs(f"{CheckpointsDir}/face-parse-bisent/")
|
| 70 |
+
file_path = f"{CheckpointsDir}/face-parse-bisent/79999_iter.pth"
|
| 71 |
+
gdown.download(url, output, quiet=False)
|
| 72 |
+
#resnet
|
| 73 |
+
url = "https://download.pytorch.org/models/resnet18-5c106cde.pth"
|
| 74 |
+
response = requests.get(url)
|
| 75 |
+
# 确保请求成功
|
| 76 |
+
if response.status_code == 200:
|
| 77 |
+
# 指定文件保存的位置
|
| 78 |
+
file_path = f"{CheckpointsDir}/face-parse-bisent/resnet18-5c106cde.pth"
|
| 79 |
+
# 将文件内容写入指定位置
|
| 80 |
+
with open(file_path, "wb") as f:
|
| 81 |
+
f.write(response.content)
|
| 82 |
+
else:
|
| 83 |
+
print(f"请求失败,状态码:{response.status_code}")
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
toc = time.time()
|
| 87 |
+
|
| 88 |
+
print(f"download cost {toc-tic} seconds")
|
| 89 |
+
else:
|
| 90 |
+
print("Already download the model.")
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
download_model() # for huggingface deployment.
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
from musetalk.utils.utils import get_file_type,get_video_fps,datagen
|
| 98 |
+
from musetalk.utils.preprocessing import get_landmark_and_bbox,read_imgs,coord_placeholder
|
| 99 |
+
from musetalk.utils.blending import get_image
|
| 100 |
+
from musetalk.utils.utils import load_all_model
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
ProjectDir = os.path.abspath(os.path.dirname(__file__))
|
| 105 |
+
CheckpointsDir = os.path.join(ProjectDir, "checkpoints")
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
@spaces.GPU(duration=600)
|
| 109 |
+
@torch.no_grad()
|
| 110 |
+
def inference(audio_path,video_path,bbox_shift,progress=gr.Progress(track_tqdm=True)):
|
| 111 |
+
args_dict={"result_dir":'./results', "fps":25, "batch_size":8, "output_vid_name":'', "use_saved_coord":False}#same with inferenece script
|
| 112 |
+
args = Namespace(**args_dict)
|
| 113 |
+
|
| 114 |
+
input_basename = os.path.basename(video_path).split('.')[0]
|
| 115 |
+
audio_basename = os.path.basename(audio_path).split('.')[0]
|
| 116 |
+
output_basename = f"{input_basename}_{audio_basename}"
|
| 117 |
+
result_img_save_path = os.path.join(args.result_dir, output_basename) # related to video & audio inputs
|
| 118 |
+
crop_coord_save_path = os.path.join(result_img_save_path, input_basename+".pkl") # only related to video input
|
| 119 |
+
os.makedirs(result_img_save_path,exist_ok =True)
|
| 120 |
+
|
| 121 |
+
if args.output_vid_name=="":
|
| 122 |
+
output_vid_name = os.path.join(args.result_dir, output_basename+".mp4")
|
| 123 |
+
else:
|
| 124 |
+
output_vid_name = os.path.join(args.result_dir, args.output_vid_name)
|
| 125 |
+
############################################## extract frames from source video ##############################################
|
| 126 |
+
if get_file_type(video_path)=="video":
|
| 127 |
+
save_dir_full = os.path.join(args.result_dir, input_basename)
|
| 128 |
+
os.makedirs(save_dir_full,exist_ok = True)
|
| 129 |
+
cmd = f"ffmpeg -v fatal -i {video_path} -start_number 0 {save_dir_full}/%08d.png"
|
| 130 |
+
os.system(cmd)
|
| 131 |
+
input_img_list = sorted(glob.glob(os.path.join(save_dir_full, '*.[jpJP][pnPN]*[gG]')))
|
| 132 |
+
fps = get_video_fps(video_path)
|
| 133 |
+
else: # input img folder
|
| 134 |
+
input_img_list = glob.glob(os.path.join(video_path, '*.[jpJP][pnPN]*[gG]'))
|
| 135 |
+
input_img_list = sorted(input_img_list, key=lambda x: int(os.path.splitext(os.path.basename(x))[0]))
|
| 136 |
+
fps = args.fps
|
| 137 |
+
#print(input_img_list)
|
| 138 |
+
############################################## extract audio feature ##############################################
|
| 139 |
+
whisper_feature = audio_processor.audio2feat(audio_path)
|
| 140 |
+
whisper_chunks = audio_processor.feature2chunks(feature_array=whisper_feature,fps=fps)
|
| 141 |
+
############################################## preprocess input image ##############################################
|
| 142 |
+
if os.path.exists(crop_coord_save_path) and args.use_saved_coord:
|
| 143 |
+
print("using extracted coordinates")
|
| 144 |
+
with open(crop_coord_save_path,'rb') as f:
|
| 145 |
+
coord_list = pickle.load(f)
|
| 146 |
+
frame_list = read_imgs(input_img_list)
|
| 147 |
+
else:
|
| 148 |
+
print("extracting landmarks...time consuming")
|
| 149 |
+
coord_list, frame_list = get_landmark_and_bbox(input_img_list, bbox_shift)
|
| 150 |
+
with open(crop_coord_save_path, 'wb') as f:
|
| 151 |
+
pickle.dump(coord_list, f)
|
| 152 |
+
|
| 153 |
+
i = 0
|
| 154 |
+
input_latent_list = []
|
| 155 |
+
for bbox, frame in zip(coord_list, frame_list):
|
| 156 |
+
if bbox == coord_placeholder:
|
| 157 |
+
continue
|
| 158 |
+
x1, y1, x2, y2 = bbox
|
| 159 |
+
crop_frame = frame[y1:y2, x1:x2]
|
| 160 |
+
crop_frame = cv2.resize(crop_frame,(256,256),interpolation = cv2.INTER_LANCZOS4)
|
| 161 |
+
latents = vae.get_latents_for_unet(crop_frame)
|
| 162 |
+
input_latent_list.append(latents)
|
| 163 |
+
|
| 164 |
+
# to smooth the first and the last frame
|
| 165 |
+
frame_list_cycle = frame_list + frame_list[::-1]
|
| 166 |
+
coord_list_cycle = coord_list + coord_list[::-1]
|
| 167 |
+
input_latent_list_cycle = input_latent_list + input_latent_list[::-1]
|
| 168 |
+
############################################## inference batch by batch ##############################################
|
| 169 |
+
print("start inference")
|
| 170 |
+
video_num = len(whisper_chunks)
|
| 171 |
+
batch_size = args.batch_size
|
| 172 |
+
gen = datagen(whisper_chunks,input_latent_list_cycle,batch_size)
|
| 173 |
+
res_frame_list = []
|
| 174 |
+
for i, (whisper_batch,latent_batch) in enumerate(tqdm(gen,total=int(np.ceil(float(video_num)/batch_size)))):
|
| 175 |
+
|
| 176 |
+
tensor_list = [torch.FloatTensor(arr) for arr in whisper_batch]
|
| 177 |
+
audio_feature_batch = torch.stack(tensor_list).to(unet.device) # torch, B, 5*N,384
|
| 178 |
+
audio_feature_batch = pe(audio_feature_batch)
|
| 179 |
+
|
| 180 |
+
pred_latents = unet.model(latent_batch, timesteps, encoder_hidden_states=audio_feature_batch).sample
|
| 181 |
+
recon = vae.decode_latents(pred_latents)
|
| 182 |
+
for res_frame in recon:
|
| 183 |
+
res_frame_list.append(res_frame)
|
| 184 |
+
|
| 185 |
+
############################################## pad to full image ##############################################
|
| 186 |
+
print("pad talking image to original video")
|
| 187 |
+
for i, res_frame in enumerate(tqdm(res_frame_list)):
|
| 188 |
+
bbox = coord_list_cycle[i%(len(coord_list_cycle))]
|
| 189 |
+
ori_frame = copy.deepcopy(frame_list_cycle[i%(len(frame_list_cycle))])
|
| 190 |
+
x1, y1, x2, y2 = bbox
|
| 191 |
+
try:
|
| 192 |
+
res_frame = cv2.resize(res_frame.astype(np.uint8),(x2-x1,y2-y1))
|
| 193 |
+
except:
|
| 194 |
+
# print(bbox)
|
| 195 |
+
continue
|
| 196 |
+
|
| 197 |
+
combine_frame = get_image(ori_frame,res_frame,bbox)
|
| 198 |
+
cv2.imwrite(f"{result_img_save_path}/{str(i).zfill(8)}.png",combine_frame)
|
| 199 |
+
|
| 200 |
+
cmd_img2video = f"ffmpeg -y -v fatal -r {fps} -f image2 -i {result_img_save_path}/%08d.png -vcodec libx264 -vf format=rgb24,scale=out_color_matrix=bt709,format=yuv420p -crf 18 temp.mp4"
|
| 201 |
+
print(cmd_img2video)
|
| 202 |
+
os.system(cmd_img2video)
|
| 203 |
+
|
| 204 |
+
cmd_combine_audio = f"ffmpeg -y -v fatal -i {audio_path} -i temp.mp4 {output_vid_name}"
|
| 205 |
+
print(cmd_combine_audio)
|
| 206 |
+
os.system(cmd_combine_audio)
|
| 207 |
+
|
| 208 |
+
os.remove("temp.mp4")
|
| 209 |
+
shutil.rmtree(result_img_save_path)
|
| 210 |
+
print(f"result is save to {output_vid_name}")
|
| 211 |
+
return output_vid_name
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
# load model weights
|
| 216 |
+
audio_processor,vae,unet,pe = load_all_model()
|
| 217 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 218 |
+
timesteps = torch.tensor([0], device=device)
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
|
| 223 |
+
def check_video(video):
|
| 224 |
+
# Define the output video file name
|
| 225 |
+
dir_path, file_name = os.path.split(video)
|
| 226 |
+
if file_name.startswith("outputxxx_"):
|
| 227 |
+
return video
|
| 228 |
+
# Add the output prefix to the file name
|
| 229 |
+
output_file_name = "outputxxx_" + file_name
|
| 230 |
+
|
| 231 |
+
# Combine the directory path and the new file name
|
| 232 |
+
output_video = os.path.join(dir_path, output_file_name)
|
| 233 |
+
|
| 234 |
+
|
| 235 |
+
# Run the ffmpeg command to change the frame rate to 25fps
|
| 236 |
+
command = f"ffmpeg -i {video} -r 25 {output_video} -y"
|
| 237 |
+
subprocess.run(command, shell=True, check=True)
|
| 238 |
+
return output_video
|
| 239 |
+
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
|
| 243 |
+
css = """#input_img {max-width: 1024px !important} #output_vid {max-width: 1024px; max-height: 576px}"""
|
| 244 |
+
|
| 245 |
+
with gr.Blocks(css=css) as demo:
|
| 246 |
+
gr.Markdown(
|
| 247 |
+
"<div align='center'> <h1>MuseTalk: Real-Time High Quality Lip Synchronization with Latent Space Inpainting </span> </h1> \
|
| 248 |
+
<h2 style='font-weight: 450; font-size: 1rem; margin: 0rem'>\
|
| 249 |
+
</br>\
|
| 250 |
+
Yue Zhang <sup>\*</sup>,\
|
| 251 |
+
Minhao Liu<sup>\*</sup>,\
|
| 252 |
+
Zhaokang Chen,\
|
| 253 |
+
Bin Wu<sup>†</sup>,\
|
| 254 |
+
Yingjie He,\
|
| 255 |
+
Chao Zhan,\
|
| 256 |
+
Wenjiang Zhou\
|
| 257 |
+
(<sup>*</sup>Equal Contribution, <sup>†</sup>Corresponding Author, [email protected])\
|
| 258 |
+
Lyra Lab, Tencent Music Entertainment\
|
| 259 |
+
</h2> \
|
| 260 |
+
<a style='font-size:18px;color: #000000' href='https://github.com/TMElyralab/MuseTalk'>[Github Repo]</a>\
|
| 261 |
+
<a style='font-size:18px;color: #000000' href='https://github.com/TMElyralab/MuseTalk'>[Huggingface]</a>\
|
| 262 |
+
<a style='font-size:18px;color: #000000' href=''> [Technical report(Coming Soon)] </a>\
|
| 263 |
+
<a style='font-size:18px;color: #000000' href=''> [Project Page(Coming Soon)] </a> </div>"
|
| 264 |
+
)
|
| 265 |
+
|
| 266 |
+
with gr.Row():
|
| 267 |
+
with gr.Column():
|
| 268 |
+
audio = gr.Audio(label="Driven Audio",type="filepath")
|
| 269 |
+
video = gr.Video(label="Reference Video")
|
| 270 |
+
bbox_shift = gr.Number(label="BBox_shift,[-9,9]", value=-1)
|
| 271 |
+
btn = gr.Button("Generate")
|
| 272 |
+
out1 = gr.Video()
|
| 273 |
+
|
| 274 |
+
video.change(
|
| 275 |
+
fn=check_video, inputs=[video], outputs=[video]
|
| 276 |
+
)
|
| 277 |
+
btn.click(
|
| 278 |
+
fn=inference,
|
| 279 |
+
inputs=[
|
| 280 |
+
audio,
|
| 281 |
+
video,
|
| 282 |
+
bbox_shift,
|
| 283 |
+
],
|
| 284 |
+
outputs=out1,
|
| 285 |
+
)
|
| 286 |
+
|
| 287 |
+
# Set the IP and port
|
| 288 |
+
ip_address = "0.0.0.0" # Replace with your desired IP address
|
| 289 |
+
port_number = 7860 # Replace with your desired port number
|
| 290 |
+
|
| 291 |
+
|
| 292 |
+
demo.queue().launch(
|
| 293 |
+
share=False , debug=True, server_name=ip_address, server_port=port_number
|
| 294 |
+
)
|
assets/BBOX_SHIFT.md
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Why is there a "bbox_shift" parameter?
|
| 2 |
+
When processing training data, we utilize the combination of face detection results (bbox) and facial landmarks to determine the region of the head segmentation box. Specifically, we use the upper bound of the bbox as the upper boundary of the segmentation box, the maximum y value of the facial landmarks coordinates as the lower boundary of the segmentation box, and the minimum and maximum x values of the landmarks coordinates as the left and right boundaries of the segmentation box. By processing the dataset in this way, we can ensure the integrity of the face.
|
| 3 |
+
|
| 4 |
+
However, we have observed that the masked ratio on the face varies across different images due to the varying face shapes of subjects. Furthermore, we found that the upper-bound of the mask mainly lies close to the landmark28, landmark29 and landmark30 landmark points (as shown in Fig.1), which correspond to proportions of 15%, 63%, and 22% in the dataset, respectively.
|
| 5 |
+
|
| 6 |
+
During the inference process, we discover that as the upper-bound of the mask gets closer to the mouth (near landmark30), the audio features contribute more to lip movements. Conversely, as the upper-bound of the mask moves away from the mouth (near landmark28), the audio features contribute more to generating details of facial appearance. Hence, we define this characteristic as a parameter that can adjust the contribution of audio features to generating lip movements, which users can modify according to their specific needs in practical scenarios.
|
| 7 |
+
|
| 8 |
+

|
| 9 |
+
|
| 10 |
+
Fig.1. Facial landmarks
|
| 11 |
+
### Step 0.
|
| 12 |
+
Running with the default configuration to obtain the adjustable value range.
|
| 13 |
+
```
|
| 14 |
+
python -m scripts.inference --inference_config configs/inference/test.yaml
|
| 15 |
+
```
|
| 16 |
+
```
|
| 17 |
+
********************************************bbox_shift parameter adjustment**********************************************************
|
| 18 |
+
Total frame:「838」 Manually adjust range : [ -9~9 ] , the current value: 0
|
| 19 |
+
*************************************************************************************************************************************
|
| 20 |
+
```
|
| 21 |
+
### Step 1.
|
| 22 |
+
Re-run the script within the above range.
|
| 23 |
+
```
|
| 24 |
+
python -m scripts.inference --inference_config configs/inference/test.yaml --bbox_shift xx # where xx is in [-9, 9].
|
| 25 |
+
```
|
| 26 |
+
In our experimental observations, we found that positive values (moving towards the lower half) generally increase mouth openness, while negative values (moving towards the upper half) generally decrease mouth openness. However, it's important to note that this is not an absolute rule, and users may need to adjust the parameter according to their specific needs and the desired effect.
|
assets/demo/man/man.png
ADDED

|
Git LFS Details
|
assets/demo/monalisa/monalisa.png
ADDED

|
assets/demo/musk/musk.png
ADDED

|
assets/demo/sit/sit.jpeg
ADDED

|
assets/demo/sun1/sun.png
ADDED

|
assets/demo/sun2/sun.png
ADDED

|
assets/demo/video1/video1.png
ADDED

|
assets/demo/yongen/yongen.jpeg
ADDED

|
assets/figs/landmark_ref.png
ADDED

|
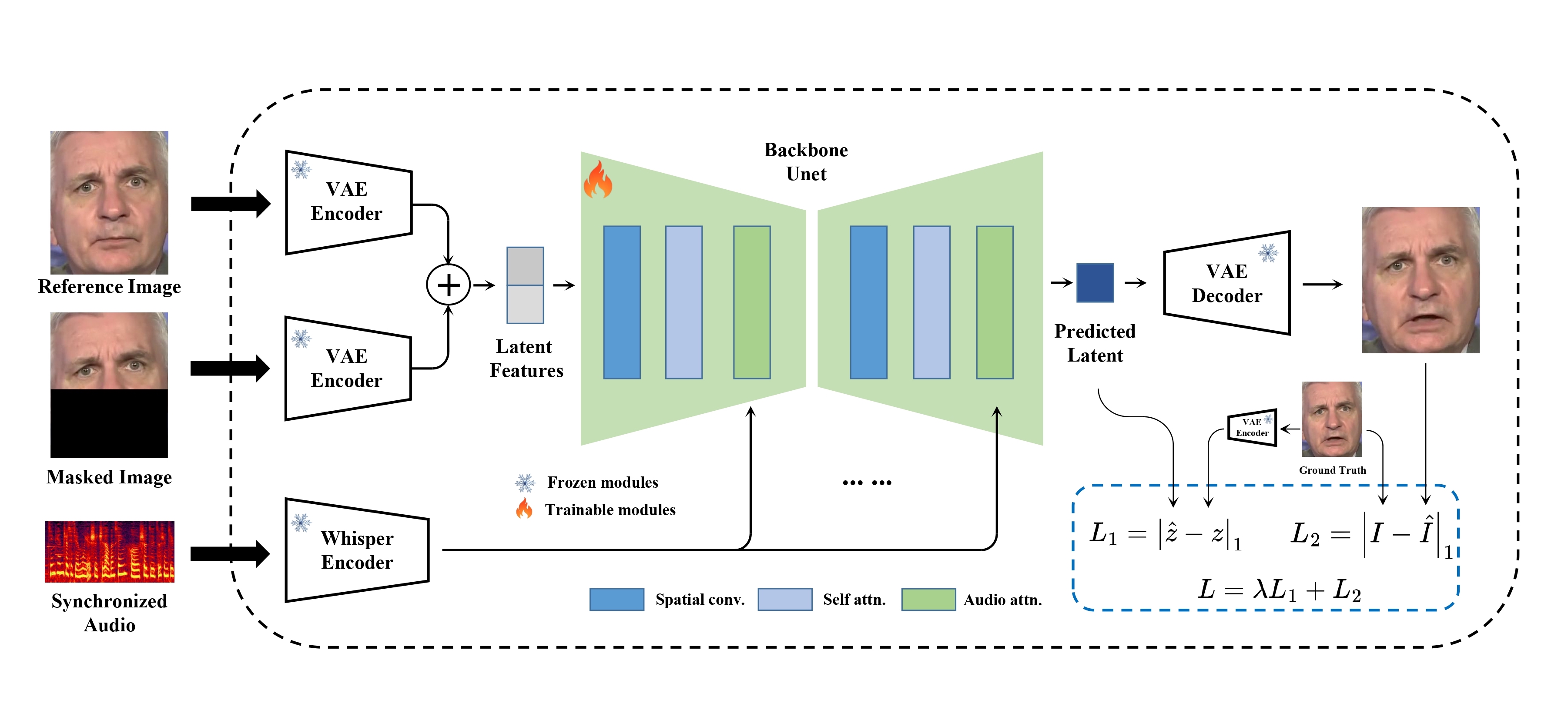
assets/figs/musetalk_arc.jpg
ADDED
|
configs/inference/test.yaml
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
task_0:
|
| 2 |
+
video_path: "data/video/yongen.mp4"
|
| 3 |
+
audio_path: "data/audio/yongen.wav"
|
| 4 |
+
|
| 5 |
+
task_1:
|
| 6 |
+
video_path: "data/video/sun.mp4"
|
| 7 |
+
audio_path: "data/audio/sun.wav"
|
| 8 |
+
bbox_shift: -7
|
| 9 |
+
|
| 10 |
+
|
data/audio/sun.wav
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3f163b0fe2f278504c15cab74cd37b879652749e2a8a69f7848ad32c847d8007
|
| 3 |
+
size 1983572
|
data/audio/yongen.wav
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2b775c363c968428d1d6df4456495e4c11f00e3204d3082e51caff415ec0e2ba
|
| 3 |
+
size 1536078
|
data/video/sun.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9f240982090f4255a7589e3cd67b4219be7820f9eb9a7461fc915eb5f0c8e075
|
| 3 |
+
size 2217973
|
data/video/yongen.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1effa976d410571cd185554779d6d43a6ba636e0e3401385db1d607daa46441f
|
| 3 |
+
size 1870923
|
entrypoint.sh
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
echo "entrypoint.sh"
|
| 4 |
+
whoami
|
| 5 |
+
which python
|
| 6 |
+
echo "pythonpath" $PYTHONPATH
|
| 7 |
+
|
| 8 |
+
source /opt/conda/etc/profile.d/conda.sh
|
| 9 |
+
conda activate musev
|
| 10 |
+
which python
|
| 11 |
+
python app.py
|
install_ffmpeg.sh
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
FFMPEG_PREFIX="$(echo $HOME/local)"
|
| 3 |
+
FFMPEG_SOURCES="$(echo $HOME/ffmpeg_sources)"
|
| 4 |
+
FFMPEG_BINDIR="$(echo $FFMPEG_PREFIX/bin)"
|
| 5 |
+
PATH=$FFMPEG_BINDIR:$PATH
|
| 6 |
+
|
| 7 |
+
mkdir -p $FFMPEG_PREFIX
|
| 8 |
+
mkdir -p $FFMPEG_SOURCES
|
| 9 |
+
|
| 10 |
+
cd $FFMPEG_SOURCES
|
| 11 |
+
wget http://www.tortall.net/projects/yasm/releases/yasm-1.2.0.tar.gz
|
| 12 |
+
tar xzvf yasm-1.2.0.tar.gz
|
| 13 |
+
cd yasm-1.2.0
|
| 14 |
+
./configure --prefix="$FFMPEG_PREFIX" --bindir="$FFMPEG_BINDIR"
|
| 15 |
+
make
|
| 16 |
+
make install
|
| 17 |
+
make distclean
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
cd $FFMPEG_SOURCES
|
| 22 |
+
wget http://download.videolan.org/pub/x264/snapshots/last_x264.tar.bz2
|
| 23 |
+
tar xjvf last_x264.tar.bz2
|
| 24 |
+
cd x264-snapshot*
|
| 25 |
+
./configure --prefix="$FFMPEG_PREFIX" --bindir="$FFMPEG_BINDIR" --enable-static
|
| 26 |
+
make
|
| 27 |
+
make install
|
| 28 |
+
make distclean
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
cd $FFMPEG_SOURCES
|
| 33 |
+
wget -O fdk-aac.tar.gz https://github.com/mstorsjo/fdk-aac/tarball/master
|
| 34 |
+
tar xzvf fdk-aac.tar.gz
|
| 35 |
+
cd mstorsjo-fdk-aac*
|
| 36 |
+
autoreconf -fiv
|
| 37 |
+
./configure --prefix="$FFMPEG_PREFIX" --disable-shared
|
| 38 |
+
make
|
| 39 |
+
make install
|
| 40 |
+
make distclean
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
cd $FFMPEG_SOURCES
|
| 45 |
+
wget http://webm.googlecode.com/files/libvpx-v1.3.0.tar.bz2
|
| 46 |
+
tar xjvf libvpx-v1.3.0.tar.bz2
|
| 47 |
+
cd libvpx-v1.3.0
|
| 48 |
+
./configure --prefix="$FFMPEG_PREFIX" --disable-examples
|
| 49 |
+
make
|
| 50 |
+
make install
|
| 51 |
+
make clean
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
cd $FFMPEG_SOURCES
|
| 56 |
+
wget https://github.com/FFmpeg/FFmpeg/tarball/master -O ffmpeg.tar.gz
|
| 57 |
+
rm -rf FFmpeg-FFmpeg*
|
| 58 |
+
tar -zxvf ffmpeg.tar.gz
|
| 59 |
+
cd FFmpeg-FFmpeg*
|
| 60 |
+
PKG_CONFIG_PATH="$FFMPEG_PREFIX/lib/pkgconfig"
|
| 61 |
+
export PKG_CONFIG_PATH
|
| 62 |
+
./configure --prefix="$FFMPEG_PREFIX" --extra-cflags="-I$FFMPEG_PREFIX/include" \
|
| 63 |
+
--extra-ldflags="-L$FFMPEG_PREFIX/lib" --bindir="$FFMPEG_BINDIR" --extra-libs="-ldl" --enable-gpl \
|
| 64 |
+
--enable-libass --enable-libfdk-aac --enable-libmp3lame --enable-libtheora \
|
| 65 |
+
--enable-libvorbis --enable-libvpx --enable-libx264 --enable-nonfree \
|
| 66 |
+
--enable-libopencore-amrnb --enable-libopencore-amrwb --enable-version3 --enable-libvo-amrwbenc
|
| 67 |
+
make
|
| 68 |
+
make install
|
| 69 |
+
make distclean
|
| 70 |
+
hash -r
|
musetalk/models/unet.py
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import math
|
| 4 |
+
import json
|
| 5 |
+
|
| 6 |
+
from diffusers import UNet2DConditionModel
|
| 7 |
+
import sys
|
| 8 |
+
import time
|
| 9 |
+
import numpy as np
|
| 10 |
+
import os
|
| 11 |
+
|
| 12 |
+
class PositionalEncoding(nn.Module):
|
| 13 |
+
def __init__(self, d_model=384, max_len=5000):
|
| 14 |
+
super(PositionalEncoding, self).__init__()
|
| 15 |
+
pe = torch.zeros(max_len, d_model)
|
| 16 |
+
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
|
| 17 |
+
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
|
| 18 |
+
pe[:, 0::2] = torch.sin(position * div_term)
|
| 19 |
+
pe[:, 1::2] = torch.cos(position * div_term)
|
| 20 |
+
pe = pe.unsqueeze(0)
|
| 21 |
+
self.register_buffer('pe', pe)
|
| 22 |
+
|
| 23 |
+
def forward(self, x):
|
| 24 |
+
b, seq_len, d_model = x.size()
|
| 25 |
+
pe = self.pe[:, :seq_len, :]
|
| 26 |
+
x = x + pe.to(x.device)
|
| 27 |
+
return x
|
| 28 |
+
|
| 29 |
+
class UNet():
|
| 30 |
+
def __init__(self,
|
| 31 |
+
unet_config,
|
| 32 |
+
model_path,
|
| 33 |
+
use_float16=False,
|
| 34 |
+
):
|
| 35 |
+
with open(unet_config, 'r') as f:
|
| 36 |
+
unet_config = json.load(f)
|
| 37 |
+
self.model = UNet2DConditionModel(**unet_config)
|
| 38 |
+
self.pe = PositionalEncoding(d_model=384)
|
| 39 |
+
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 40 |
+
self.weights = torch.load(model_path) if torch.cuda.is_available() else torch.load(model_path, map_location=self.device)
|
| 41 |
+
self.model.load_state_dict(self.weights)
|
| 42 |
+
if use_float16:
|
| 43 |
+
self.model = self.model.half()
|
| 44 |
+
self.model.to(self.device)
|
| 45 |
+
|
| 46 |
+
if __name__ == "__main__":
|
| 47 |
+
unet = UNet()
|
musetalk/models/vae.py
ADDED
|
@@ -0,0 +1,148 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from diffusers import AutoencoderKL
|
| 2 |
+
import torch
|
| 3 |
+
import torchvision.transforms as transforms
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
import cv2
|
| 6 |
+
import numpy as np
|
| 7 |
+
from PIL import Image
|
| 8 |
+
import os
|
| 9 |
+
|
| 10 |
+
class VAE():
|
| 11 |
+
"""
|
| 12 |
+
VAE (Variational Autoencoder) class for image processing.
|
| 13 |
+
"""
|
| 14 |
+
|
| 15 |
+
def __init__(self, model_path="./models/sd-vae-ft-mse/", resized_img=256, use_float16=False):
|
| 16 |
+
"""
|
| 17 |
+
Initialize the VAE instance.
|
| 18 |
+
|
| 19 |
+
:param model_path: Path to the trained model.
|
| 20 |
+
:param resized_img: The size to which images are resized.
|
| 21 |
+
:param use_float16: Whether to use float16 precision.
|
| 22 |
+
"""
|
| 23 |
+
self.model_path = model_path
|
| 24 |
+
self.vae = AutoencoderKL.from_pretrained(self.model_path)
|
| 25 |
+
|
| 26 |
+
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 27 |
+
self.vae.to(self.device)
|
| 28 |
+
|
| 29 |
+
if use_float16:
|
| 30 |
+
self.vae = self.vae.half()
|
| 31 |
+
self._use_float16 = True
|
| 32 |
+
else:
|
| 33 |
+
self._use_float16 = False
|
| 34 |
+
|
| 35 |
+
self.scaling_factor = self.vae.config.scaling_factor
|
| 36 |
+
self.transform = transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
|
| 37 |
+
self._resized_img = resized_img
|
| 38 |
+
self._mask_tensor = self.get_mask_tensor()
|
| 39 |
+
|
| 40 |
+
def get_mask_tensor(self):
|
| 41 |
+
"""
|
| 42 |
+
Creates a mask tensor for image processing.
|
| 43 |
+
:return: A mask tensor.
|
| 44 |
+
"""
|
| 45 |
+
mask_tensor = torch.zeros((self._resized_img,self._resized_img))
|
| 46 |
+
mask_tensor[:self._resized_img//2,:] = 1
|
| 47 |
+
mask_tensor[mask_tensor< 0.5] = 0
|
| 48 |
+
mask_tensor[mask_tensor>= 0.5] = 1
|
| 49 |
+
return mask_tensor
|
| 50 |
+
|
| 51 |
+
def preprocess_img(self,img_name,half_mask=False):
|
| 52 |
+
"""
|
| 53 |
+
Preprocess an image for the VAE.
|
| 54 |
+
|
| 55 |
+
:param img_name: The image file path or a list of image file paths.
|
| 56 |
+
:param half_mask: Whether to apply a half mask to the image.
|
| 57 |
+
:return: A preprocessed image tensor.
|
| 58 |
+
"""
|
| 59 |
+
window = []
|
| 60 |
+
if isinstance(img_name, str):
|
| 61 |
+
window_fnames = [img_name]
|
| 62 |
+
for fname in window_fnames:
|
| 63 |
+
img = cv2.imread(fname)
|
| 64 |
+
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
|
| 65 |
+
img = cv2.resize(img, (self._resized_img, self._resized_img),
|
| 66 |
+
interpolation=cv2.INTER_LANCZOS4)
|
| 67 |
+
window.append(img)
|
| 68 |
+
else:
|
| 69 |
+
img = cv2.cvtColor(img_name, cv2.COLOR_BGR2RGB)
|
| 70 |
+
window.append(img)
|
| 71 |
+
|
| 72 |
+
x = np.asarray(window) / 255.
|
| 73 |
+
x = np.transpose(x, (3, 0, 1, 2))
|
| 74 |
+
x = torch.squeeze(torch.FloatTensor(x))
|
| 75 |
+
if half_mask:
|
| 76 |
+
x = x * (self._mask_tensor>0.5)
|
| 77 |
+
x = self.transform(x)
|
| 78 |
+
|
| 79 |
+
x = x.unsqueeze(0) # [1, 3, 256, 256] torch tensor
|
| 80 |
+
x = x.to(self.vae.device)
|
| 81 |
+
|
| 82 |
+
return x
|
| 83 |
+
|
| 84 |
+
def encode_latents(self,image):
|
| 85 |
+
"""
|
| 86 |
+
Encode an image into latent variables.
|
| 87 |
+
|
| 88 |
+
:param image: The image tensor to encode.
|
| 89 |
+
:return: The encoded latent variables.
|
| 90 |
+
"""
|
| 91 |
+
with torch.no_grad():
|
| 92 |
+
init_latent_dist = self.vae.encode(image.to(self.vae.dtype)).latent_dist
|
| 93 |
+
init_latents = self.scaling_factor * init_latent_dist.sample()
|
| 94 |
+
return init_latents
|
| 95 |
+
|
| 96 |
+
def decode_latents(self, latents):
|
| 97 |
+
"""
|
| 98 |
+
Decode latent variables back into an image.
|
| 99 |
+
:param latents: The latent variables to decode.
|
| 100 |
+
:return: A NumPy array representing the decoded image.
|
| 101 |
+
"""
|
| 102 |
+
latents = (1/ self.scaling_factor) * latents
|
| 103 |
+
image = self.vae.decode(latents.to(self.vae.dtype)).sample
|
| 104 |
+
image = (image / 2 + 0.5).clamp(0, 1)
|
| 105 |
+
image = image.detach().cpu().permute(0, 2, 3, 1).float().numpy()
|
| 106 |
+
image = (image * 255).round().astype("uint8")
|
| 107 |
+
image = image[...,::-1] # RGB to BGR
|
| 108 |
+
return image
|
| 109 |
+
|
| 110 |
+
def get_latents_for_unet(self,img):
|
| 111 |
+
"""
|
| 112 |
+
Prepare latent variables for a U-Net model.
|
| 113 |
+
:param img: The image to process.
|
| 114 |
+
:return: A concatenated tensor of latents for U-Net input.
|
| 115 |
+
"""
|
| 116 |
+
|
| 117 |
+
ref_image = self.preprocess_img(img,half_mask=True) # [1, 3, 256, 256] RGB, torch tensor
|
| 118 |
+
masked_latents = self.encode_latents(ref_image) # [1, 4, 32, 32], torch tensor
|
| 119 |
+
ref_image = self.preprocess_img(img,half_mask=False) # [1, 3, 256, 256] RGB, torch tensor
|
| 120 |
+
ref_latents = self.encode_latents(ref_image) # [1, 4, 32, 32], torch tensor
|
| 121 |
+
latent_model_input = torch.cat([masked_latents, ref_latents], dim=1)
|
| 122 |
+
return latent_model_input
|
| 123 |
+
|
| 124 |
+
if __name__ == "__main__":
|
| 125 |
+
vae_mode_path = "./models/sd-vae-ft-mse/"
|
| 126 |
+
vae = VAE(model_path = vae_mode_path,use_float16=False)
|
| 127 |
+
img_path = "./results/sun001_crop/00000.png"
|
| 128 |
+
|
| 129 |
+
crop_imgs_path = "./results/sun001_crop/"
|
| 130 |
+
latents_out_path = "./results/latents/"
|
| 131 |
+
if not os.path.exists(latents_out_path):
|
| 132 |
+
os.mkdir(latents_out_path)
|
| 133 |
+
|
| 134 |
+
files = os.listdir(crop_imgs_path)
|
| 135 |
+
files.sort()
|
| 136 |
+
files = [file for file in files if file.split(".")[-1] == "png"]
|
| 137 |
+
|
| 138 |
+
for file in files:
|
| 139 |
+
index = file.split(".")[0]
|
| 140 |
+
img_path = crop_imgs_path + file
|
| 141 |
+
latents = vae.get_latents_for_unet(img_path)
|
| 142 |
+
print(img_path,"latents",latents.size())
|
| 143 |
+
#torch.save(latents,os.path.join(latents_out_path,index+".pt"))
|
| 144 |
+
#reload_tensor = torch.load('tensor.pt')
|
| 145 |
+
#print(reload_tensor.size())
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
|
musetalk/utils/__init__.py
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
from os.path import abspath, dirname
|
| 3 |
+
current_dir = dirname(abspath(__file__))
|
| 4 |
+
parent_dir = dirname(current_dir)
|
| 5 |
+
sys.path.append(parent_dir+'/utils')
|
musetalk/utils/blending.py
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from PIL import Image
|
| 2 |
+
import numpy as np
|
| 3 |
+
import cv2
|
| 4 |
+
from face_parsing import FaceParsing
|
| 5 |
+
|
| 6 |
+
fp = FaceParsing()
|
| 7 |
+
|
| 8 |
+
def get_crop_box(box, expand):
|
| 9 |
+
x, y, x1, y1 = box
|
| 10 |
+
x_c, y_c = (x+x1)//2, (y+y1)//2
|
| 11 |
+
w, h = x1-x, y1-y
|
| 12 |
+
s = int(max(w, h)//2*expand)
|
| 13 |
+
crop_box = [x_c-s, y_c-s, x_c+s, y_c+s]
|
| 14 |
+
return crop_box, s
|
| 15 |
+
|
| 16 |
+
def face_seg(image):
|
| 17 |
+
seg_image = fp(image)
|
| 18 |
+
if seg_image is None:
|
| 19 |
+
print("error, no person_segment")
|
| 20 |
+
return None
|
| 21 |
+
|
| 22 |
+
seg_image = seg_image.resize(image.size)
|
| 23 |
+
return seg_image
|
| 24 |
+
|
| 25 |
+
def get_image(image,face,face_box,upper_boundary_ratio = 0.5,expand=1.2):
|
| 26 |
+
#print(image.shape)
|
| 27 |
+
#print(face.shape)
|
| 28 |
+
|
| 29 |
+
body = Image.fromarray(image[:,:,::-1])
|
| 30 |
+
face = Image.fromarray(face[:,:,::-1])
|
| 31 |
+
|
| 32 |
+
x, y, x1, y1 = face_box
|
| 33 |
+
#print(x1-x,y1-y)
|
| 34 |
+
crop_box, s = get_crop_box(face_box, expand)
|
| 35 |
+
x_s, y_s, x_e, y_e = crop_box
|
| 36 |
+
face_position = (x, y)
|
| 37 |
+
|
| 38 |
+
face_large = body.crop(crop_box)
|
| 39 |
+
ori_shape = face_large.size
|
| 40 |
+
|
| 41 |
+
mask_image = face_seg(face_large)
|
| 42 |
+
mask_small = mask_image.crop((x-x_s, y-y_s, x1-x_s, y1-y_s))
|
| 43 |
+
mask_image = Image.new('L', ori_shape, 0)
|
| 44 |
+
mask_image.paste(mask_small, (x-x_s, y-y_s, x1-x_s, y1-y_s))
|
| 45 |
+
|
| 46 |
+
# keep upper_boundary_ratio of talking area
|
| 47 |
+
width, height = mask_image.size
|
| 48 |
+
top_boundary = int(height * upper_boundary_ratio)
|
| 49 |
+
modified_mask_image = Image.new('L', ori_shape, 0)
|
| 50 |
+
modified_mask_image.paste(mask_image.crop((0, top_boundary, width, height)), (0, top_boundary))
|
| 51 |
+
|
| 52 |
+
blur_kernel_size = int(0.1 * ori_shape[0] // 2 * 2) + 1
|
| 53 |
+
mask_array = cv2.GaussianBlur(np.array(modified_mask_image), (blur_kernel_size, blur_kernel_size), 0)
|
| 54 |
+
mask_image = Image.fromarray(mask_array)
|
| 55 |
+
|
| 56 |
+
face_large.paste(face, (x-x_s, y-y_s, x1-x_s, y1-y_s))
|
| 57 |
+
body.paste(face_large, crop_box[:2], mask_image)
|
| 58 |
+
body = np.array(body)
|
| 59 |
+
return body[:,:,::-1]
|
musetalk/utils/dwpose/default_runtime.py
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
default_scope = 'mmpose'
|
| 2 |
+
|
| 3 |
+
# hooks
|
| 4 |
+
default_hooks = dict(
|
| 5 |
+
timer=dict(type='IterTimerHook'),
|
| 6 |
+
logger=dict(type='LoggerHook', interval=50),
|
| 7 |
+
param_scheduler=dict(type='ParamSchedulerHook'),
|
| 8 |
+
checkpoint=dict(type='CheckpointHook', interval=10),
|
| 9 |
+
sampler_seed=dict(type='DistSamplerSeedHook'),
|
| 10 |
+
visualization=dict(type='PoseVisualizationHook', enable=False),
|
| 11 |
+
badcase=dict(
|
| 12 |
+
type='BadCaseAnalysisHook',
|
| 13 |
+
enable=False,
|
| 14 |
+
out_dir='badcase',
|
| 15 |
+
metric_type='loss',
|
| 16 |
+
badcase_thr=5))
|
| 17 |
+
|
| 18 |
+
# custom hooks
|
| 19 |
+
custom_hooks = [
|
| 20 |
+
# Synchronize model buffers such as running_mean and running_var in BN
|
| 21 |
+
# at the end of each epoch
|
| 22 |
+
dict(type='SyncBuffersHook')
|
| 23 |
+
]
|
| 24 |
+
|
| 25 |
+
# multi-processing backend
|
| 26 |
+
env_cfg = dict(
|
| 27 |
+
cudnn_benchmark=False,
|
| 28 |
+
mp_cfg=dict(mp_start_method='fork', opencv_num_threads=0),
|
| 29 |
+
dist_cfg=dict(backend='nccl'),
|
| 30 |
+
)
|
| 31 |
+
|
| 32 |
+
# visualizer
|
| 33 |
+
vis_backends = [
|
| 34 |
+
dict(type='LocalVisBackend'),
|
| 35 |
+
# dict(type='TensorboardVisBackend'),
|
| 36 |
+
# dict(type='WandbVisBackend'),
|
| 37 |
+
]
|
| 38 |
+
visualizer = dict(
|
| 39 |
+
type='PoseLocalVisualizer', vis_backends=vis_backends, name='visualizer')
|
| 40 |
+
|
| 41 |
+
# logger
|
| 42 |
+
log_processor = dict(
|
| 43 |
+
type='LogProcessor', window_size=50, by_epoch=True, num_digits=6)
|
| 44 |
+
log_level = 'INFO'
|
| 45 |
+
load_from = None
|
| 46 |
+
resume = False
|
| 47 |
+
|
| 48 |
+
# file I/O backend
|
| 49 |
+
backend_args = dict(backend='local')
|
| 50 |
+
|
| 51 |
+
# training/validation/testing progress
|
| 52 |
+
train_cfg = dict(by_epoch=True)
|
| 53 |
+
val_cfg = dict()
|
| 54 |
+
test_cfg = dict()
|
musetalk/utils/dwpose/rtmpose-l_8xb32-270e_coco-ubody-wholebody-384x288.py
ADDED
|
@@ -0,0 +1,257 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#_base_ = ['../../../_base_/default_runtime.py']
|
| 2 |
+
_base_ = ['default_runtime.py']
|
| 3 |
+
|
| 4 |
+
# runtime
|
| 5 |
+
max_epochs = 270
|
| 6 |
+
stage2_num_epochs = 30
|
| 7 |
+
base_lr = 4e-3
|
| 8 |
+
train_batch_size = 32
|
| 9 |
+
val_batch_size = 32
|
| 10 |
+
|
| 11 |
+
train_cfg = dict(max_epochs=max_epochs, val_interval=10)
|
| 12 |
+
randomness = dict(seed=21)
|
| 13 |
+
|
| 14 |
+
# optimizer
|
| 15 |
+
optim_wrapper = dict(
|
| 16 |
+
type='OptimWrapper',
|
| 17 |
+
optimizer=dict(type='AdamW', lr=base_lr, weight_decay=0.05),
|
| 18 |
+
paramwise_cfg=dict(
|
| 19 |
+
norm_decay_mult=0, bias_decay_mult=0, bypass_duplicate=True))
|
| 20 |
+
|
| 21 |
+
# learning rate
|
| 22 |
+
param_scheduler = [
|
| 23 |
+
dict(
|
| 24 |
+
type='LinearLR',
|
| 25 |
+
start_factor=1.0e-5,
|
| 26 |
+
by_epoch=False,
|
| 27 |
+
begin=0,
|
| 28 |
+
end=1000),
|
| 29 |
+
dict(
|
| 30 |
+
# use cosine lr from 150 to 300 epoch
|
| 31 |
+
type='CosineAnnealingLR',
|
| 32 |
+
eta_min=base_lr * 0.05,
|
| 33 |
+
begin=max_epochs // 2,
|
| 34 |
+
end=max_epochs,
|
| 35 |
+
T_max=max_epochs // 2,
|
| 36 |
+
by_epoch=True,
|
| 37 |
+
convert_to_iter_based=True),
|
| 38 |
+
]
|
| 39 |
+
|
| 40 |
+
# automatically scaling LR based on the actual training batch size
|
| 41 |
+
auto_scale_lr = dict(base_batch_size=512)
|
| 42 |
+
|
| 43 |
+
# codec settings
|
| 44 |
+
codec = dict(
|
| 45 |
+
type='SimCCLabel',
|
| 46 |
+
input_size=(288, 384),
|
| 47 |
+
sigma=(6., 6.93),
|
| 48 |
+
simcc_split_ratio=2.0,
|
| 49 |
+
normalize=False,
|
| 50 |
+
use_dark=False)
|
| 51 |
+
|
| 52 |
+
# model settings
|
| 53 |
+
model = dict(
|
| 54 |
+
type='TopdownPoseEstimator',
|
| 55 |
+
data_preprocessor=dict(
|
| 56 |
+
type='PoseDataPreprocessor',
|
| 57 |
+
mean=[123.675, 116.28, 103.53],
|
| 58 |
+
std=[58.395, 57.12, 57.375],
|
| 59 |
+
bgr_to_rgb=True),
|
| 60 |
+
backbone=dict(
|
| 61 |
+
_scope_='mmdet',
|
| 62 |
+
type='CSPNeXt',
|
| 63 |
+
arch='P5',
|
| 64 |
+
expand_ratio=0.5,
|
| 65 |
+
deepen_factor=1.,
|
| 66 |
+
widen_factor=1.,
|
| 67 |
+
out_indices=(4, ),
|
| 68 |
+
channel_attention=True,
|
| 69 |
+
norm_cfg=dict(type='SyncBN'),
|
| 70 |
+
act_cfg=dict(type='SiLU'),
|
| 71 |
+
init_cfg=dict(
|
| 72 |
+
type='Pretrained',
|
| 73 |
+
prefix='backbone.',
|
| 74 |
+
checkpoint='https://download.openmmlab.com/mmpose/v1/projects/'
|
| 75 |
+
'rtmpose/cspnext-l_udp-aic-coco_210e-256x192-273b7631_20230130.pth' # noqa: E501
|
| 76 |
+
)),
|
| 77 |
+
head=dict(
|
| 78 |
+
type='RTMCCHead',
|
| 79 |
+
in_channels=1024,
|
| 80 |
+
out_channels=133,
|
| 81 |
+
input_size=codec['input_size'],
|
| 82 |
+
in_featuremap_size=(9, 12),
|
| 83 |
+
simcc_split_ratio=codec['simcc_split_ratio'],
|
| 84 |
+
final_layer_kernel_size=7,
|
| 85 |
+
gau_cfg=dict(
|
| 86 |
+
hidden_dims=256,
|
| 87 |
+
s=128,
|
| 88 |
+
expansion_factor=2,
|
| 89 |
+
dropout_rate=0.,
|
| 90 |
+
drop_path=0.,
|
| 91 |
+
act_fn='SiLU',
|
| 92 |
+
use_rel_bias=False,
|
| 93 |
+
pos_enc=False),
|
| 94 |
+
loss=dict(
|
| 95 |
+
type='KLDiscretLoss',
|
| 96 |
+
use_target_weight=True,
|
| 97 |
+
beta=10.,
|
| 98 |
+
label_softmax=True),
|
| 99 |
+
decoder=codec),
|
| 100 |
+
test_cfg=dict(flip_test=True, ))
|
| 101 |
+
|
| 102 |
+
# base dataset settings
|
| 103 |
+
dataset_type = 'UBody2dDataset'
|
| 104 |
+
data_mode = 'topdown'
|
| 105 |
+
data_root = 'data/UBody/'
|
| 106 |
+
|
| 107 |
+
backend_args = dict(backend='local')
|
| 108 |
+
|
| 109 |
+
scenes = [
|
| 110 |
+
'Magic_show', 'Entertainment', 'ConductMusic', 'Online_class', 'TalkShow',
|
| 111 |
+
'Speech', 'Fitness', 'Interview', 'Olympic', 'TVShow', 'Singing',
|
| 112 |
+
'SignLanguage', 'Movie', 'LiveVlog', 'VideoConference'
|
| 113 |
+
]
|
| 114 |
+
|
| 115 |
+
train_datasets = [
|
| 116 |
+
dict(
|
| 117 |
+
type='CocoWholeBodyDataset',
|
| 118 |
+
data_root='data/coco/',
|
| 119 |
+
data_mode=data_mode,
|
| 120 |
+
ann_file='annotations/coco_wholebody_train_v1.0.json',
|
| 121 |
+
data_prefix=dict(img='train2017/'),
|
| 122 |
+
pipeline=[])
|
| 123 |
+
]
|
| 124 |
+
|
| 125 |
+
for scene in scenes:
|
| 126 |
+
train_dataset = dict(
|
| 127 |
+
type=dataset_type,
|
| 128 |
+
data_root=data_root,
|
| 129 |
+
data_mode=data_mode,
|
| 130 |
+
ann_file=f'annotations/{scene}/train_annotations.json',
|
| 131 |
+
data_prefix=dict(img='images/'),
|
| 132 |
+
pipeline=[],
|
| 133 |
+
sample_interval=10)
|
| 134 |
+
train_datasets.append(train_dataset)
|
| 135 |
+
|
| 136 |
+
# pipelines
|
| 137 |
+
train_pipeline = [
|
| 138 |
+
dict(type='LoadImage', backend_args=backend_args),
|
| 139 |
+
dict(type='GetBBoxCenterScale'),
|
| 140 |
+
dict(type='RandomFlip', direction='horizontal'),
|
| 141 |
+
dict(type='RandomHalfBody'),
|
| 142 |
+
dict(
|
| 143 |
+
type='RandomBBoxTransform', scale_factor=[0.5, 1.5], rotate_factor=90),
|
| 144 |
+
dict(type='TopdownAffine', input_size=codec['input_size']),
|
| 145 |
+
dict(type='mmdet.YOLOXHSVRandomAug'),
|
| 146 |
+
dict(
|
| 147 |
+
type='Albumentation',
|
| 148 |
+
transforms=[
|
| 149 |
+
dict(type='Blur', p=0.1),
|
| 150 |
+
dict(type='MedianBlur', p=0.1),
|
| 151 |
+
dict(
|
| 152 |
+
type='CoarseDropout',
|
| 153 |
+
max_holes=1,
|
| 154 |
+
max_height=0.4,
|
| 155 |
+
max_width=0.4,
|
| 156 |
+
min_holes=1,
|
| 157 |
+
min_height=0.2,
|
| 158 |
+
min_width=0.2,
|
| 159 |
+
p=1.0),
|
| 160 |
+
]),
|
| 161 |
+
dict(type='GenerateTarget', encoder=codec),
|
| 162 |
+
dict(type='PackPoseInputs')
|
| 163 |
+
]
|
| 164 |
+
val_pipeline = [
|
| 165 |
+
dict(type='LoadImage', backend_args=backend_args),
|
| 166 |
+
dict(type='GetBBoxCenterScale'),
|
| 167 |
+
dict(type='TopdownAffine', input_size=codec['input_size']),
|
| 168 |
+
dict(type='PackPoseInputs')
|
| 169 |
+
]
|
| 170 |
+
|
| 171 |
+
train_pipeline_stage2 = [
|
| 172 |
+
dict(type='LoadImage', backend_args=backend_args),
|
| 173 |
+
dict(type='GetBBoxCenterScale'),
|
| 174 |
+
dict(type='RandomFlip', direction='horizontal'),
|
| 175 |
+
dict(type='RandomHalfBody'),
|
| 176 |
+
dict(
|
| 177 |
+
type='RandomBBoxTransform',
|
| 178 |
+
shift_factor=0.,
|
| 179 |
+
scale_factor=[0.5, 1.5],
|
| 180 |
+
rotate_factor=90),
|
| 181 |
+
dict(type='TopdownAffine', input_size=codec['input_size']),
|
| 182 |
+
dict(type='mmdet.YOLOXHSVRandomAug'),
|
| 183 |
+
dict(
|
| 184 |
+
type='Albumentation',
|
| 185 |
+
transforms=[
|
| 186 |
+
dict(type='Blur', p=0.1),
|
| 187 |
+
dict(type='MedianBlur', p=0.1),
|
| 188 |
+
dict(
|
| 189 |
+
type='CoarseDropout',
|
| 190 |
+
max_holes=1,
|
| 191 |
+
max_height=0.4,
|
| 192 |
+
max_width=0.4,
|
| 193 |
+
min_holes=1,
|
| 194 |
+
min_height=0.2,
|
| 195 |
+
min_width=0.2,
|
| 196 |
+
p=0.5),
|
| 197 |
+
]),
|
| 198 |
+
dict(type='GenerateTarget', encoder=codec),
|
| 199 |
+
dict(type='PackPoseInputs')
|
| 200 |
+
]
|
| 201 |
+
|
| 202 |
+
# data loaders
|
| 203 |
+
train_dataloader = dict(
|
| 204 |
+
batch_size=train_batch_size,
|
| 205 |
+
num_workers=10,
|
| 206 |
+
persistent_workers=True,
|
| 207 |
+
sampler=dict(type='DefaultSampler', shuffle=True),
|
| 208 |
+
dataset=dict(
|
| 209 |
+
type='CombinedDataset',
|
| 210 |
+
metainfo=dict(from_file='configs/_base_/datasets/coco_wholebody.py'),
|
| 211 |
+
datasets=train_datasets,
|
| 212 |
+
pipeline=train_pipeline,
|
| 213 |
+
test_mode=False,
|
| 214 |
+
))
|
| 215 |
+
|
| 216 |
+
val_dataloader = dict(
|
| 217 |
+
batch_size=val_batch_size,
|
| 218 |
+
num_workers=10,
|
| 219 |
+
persistent_workers=True,
|
| 220 |
+
drop_last=False,
|
| 221 |
+
sampler=dict(type='DefaultSampler', shuffle=False, round_up=False),
|
| 222 |
+
dataset=dict(
|
| 223 |
+
type='CocoWholeBodyDataset',
|
| 224 |
+
data_root=data_root,
|
| 225 |
+
data_mode=data_mode,
|
| 226 |
+
ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json',
|
| 227 |
+
bbox_file='data/coco/person_detection_results/'
|
| 228 |
+
'COCO_val2017_detections_AP_H_56_person.json',
|
| 229 |
+
data_prefix=dict(img='coco/val2017/'),
|
| 230 |
+
test_mode=True,
|
| 231 |
+
pipeline=val_pipeline,
|
| 232 |
+
))
|
| 233 |
+
test_dataloader = val_dataloader
|
| 234 |
+
|
| 235 |
+
# hooks
|
| 236 |
+
default_hooks = dict(
|
| 237 |
+
checkpoint=dict(
|
| 238 |
+
save_best='coco-wholebody/AP', rule='greater', max_keep_ckpts=1))
|
| 239 |
+
|
| 240 |
+
custom_hooks = [
|
| 241 |
+
dict(
|
| 242 |
+
type='EMAHook',
|
| 243 |
+
ema_type='ExpMomentumEMA',
|
| 244 |
+
momentum=0.0002,
|
| 245 |
+
update_buffers=True,
|
| 246 |
+
priority=49),
|
| 247 |
+
dict(
|
| 248 |
+
type='mmdet.PipelineSwitchHook',
|
| 249 |
+
switch_epoch=max_epochs - stage2_num_epochs,
|
| 250 |
+
switch_pipeline=train_pipeline_stage2)
|
| 251 |
+
]
|
| 252 |
+
|
| 253 |
+
# evaluators
|
| 254 |
+
val_evaluator = dict(
|
| 255 |
+
type='CocoWholeBodyMetric',
|
| 256 |
+
ann_file='data/coco/annotations/coco_wholebody_val_v1.0.json')
|
| 257 |
+
test_evaluator = val_evaluator
|
musetalk/utils/face_detection/README.md
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
The code for Face Detection in this folder has been taken from the wonderful [face_alignment](https://github.com/1adrianb/face-alignment) repository. This has been modified to take batches of faces at a time.
|
musetalk/utils/face_detection/__init__.py
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
|
| 3 |
+
__author__ = """Adrian Bulat"""
|
| 4 |
+
__email__ = '[email protected]'
|
| 5 |
+
__version__ = '1.0.1'
|
| 6 |
+
|
| 7 |
+
from .api import FaceAlignment, LandmarksType, NetworkSize, YOLOv8_face
|
musetalk/utils/face_detection/api.py
ADDED
|
@@ -0,0 +1,240 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from __future__ import print_function
|
| 2 |
+
import os
|
| 3 |
+
import torch
|
| 4 |
+
from torch.utils.model_zoo import load_url
|
| 5 |
+
from enum import Enum
|
| 6 |
+
import numpy as np
|
| 7 |
+
import cv2
|
| 8 |
+
try:
|
| 9 |
+
import urllib.request as request_file
|
| 10 |
+
except BaseException:
|
| 11 |
+
import urllib as request_file
|
| 12 |
+
|
| 13 |
+
from .models import FAN, ResNetDepth
|
| 14 |
+
from .utils import *
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class LandmarksType(Enum):
|
| 18 |
+
"""Enum class defining the type of landmarks to detect.
|
| 19 |
+
|
| 20 |
+
``_2D`` - the detected points ``(x,y)`` are detected in a 2D space and follow the visible contour of the face
|
| 21 |
+
``_2halfD`` - this points represent the projection of the 3D points into 3D
|
| 22 |
+
``_3D`` - detect the points ``(x,y,z)``` in a 3D space
|
| 23 |
+
|
| 24 |
+
"""
|
| 25 |
+
_2D = 1
|
| 26 |
+
_2halfD = 2
|
| 27 |
+
_3D = 3
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
class NetworkSize(Enum):
|
| 31 |
+
# TINY = 1
|
| 32 |
+
# SMALL = 2
|
| 33 |
+
# MEDIUM = 3
|
| 34 |
+
LARGE = 4
|
| 35 |
+
|
| 36 |
+
def __new__(cls, value):
|
| 37 |
+
member = object.__new__(cls)
|
| 38 |
+
member._value_ = value
|
| 39 |
+
return member
|
| 40 |
+
|
| 41 |
+
def __int__(self):
|
| 42 |
+
return self.value
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
class FaceAlignment:
|
| 47 |
+
def __init__(self, landmarks_type, network_size=NetworkSize.LARGE,
|
| 48 |
+
device='cuda', flip_input=False, face_detector='sfd', verbose=False):
|
| 49 |
+
self.device = device
|
| 50 |
+
self.flip_input = flip_input
|
| 51 |
+
self.landmarks_type = landmarks_type
|
| 52 |
+
self.verbose = verbose
|
| 53 |
+
|
| 54 |
+
network_size = int(network_size)
|
| 55 |
+
|
| 56 |
+
if 'cuda' in device:
|
| 57 |
+
torch.backends.cudnn.benchmark = True
|
| 58 |
+
# torch.backends.cuda.matmul.allow_tf32 = False
|
| 59 |
+
# torch.backends.cudnn.benchmark = True
|
| 60 |
+
# torch.backends.cudnn.deterministic = False
|
| 61 |
+
# torch.backends.cudnn.allow_tf32 = True
|
| 62 |
+
print('cuda start')
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
# Get the face detector
|
| 66 |
+
face_detector_module = __import__('face_detection.detection.' + face_detector,
|
| 67 |
+
globals(), locals(), [face_detector], 0)
|
| 68 |
+
|
| 69 |
+
self.face_detector = face_detector_module.FaceDetector(device=device, verbose=verbose)
|
| 70 |
+
|
| 71 |
+
def get_detections_for_batch(self, images):
|
| 72 |
+
images = images[..., ::-1]
|
| 73 |
+
detected_faces = self.face_detector.detect_from_batch(images.copy())
|
| 74 |
+
results = []
|
| 75 |
+
|
| 76 |
+
for i, d in enumerate(detected_faces):
|
| 77 |
+
if len(d) == 0:
|
| 78 |
+
results.append(None)
|
| 79 |
+
continue
|
| 80 |
+
d = d[0]
|
| 81 |
+
d = np.clip(d, 0, None)
|
| 82 |
+
|
| 83 |
+
x1, y1, x2, y2 = map(int, d[:-1])
|
| 84 |
+
results.append((x1, y1, x2, y2))
|
| 85 |
+
|
| 86 |
+
return results
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
class YOLOv8_face:
|
| 90 |
+
def __init__(self, path = 'face_detection/weights/yolov8n-face.onnx', conf_thres=0.2, iou_thres=0.5):
|
| 91 |
+
self.conf_threshold = conf_thres
|
| 92 |
+
self.iou_threshold = iou_thres
|
| 93 |
+
self.class_names = ['face']
|
| 94 |
+
self.num_classes = len(self.class_names)
|
| 95 |
+
# Initialize model
|
| 96 |
+
self.net = cv2.dnn.readNet(path)
|
| 97 |
+
self.input_height = 640
|
| 98 |
+
self.input_width = 640
|
| 99 |
+
self.reg_max = 16
|
| 100 |
+
|
| 101 |
+
self.project = np.arange(self.reg_max)
|
| 102 |
+
self.strides = (8, 16, 32)
|
| 103 |
+
self.feats_hw = [(math.ceil(self.input_height / self.strides[i]), math.ceil(self.input_width / self.strides[i])) for i in range(len(self.strides))]
|
| 104 |
+
self.anchors = self.make_anchors(self.feats_hw)
|
| 105 |
+
|
| 106 |
+
def make_anchors(self, feats_hw, grid_cell_offset=0.5):
|
| 107 |
+
"""Generate anchors from features."""
|
| 108 |
+
anchor_points = {}
|
| 109 |
+
for i, stride in enumerate(self.strides):
|
| 110 |
+
h,w = feats_hw[i]
|
| 111 |
+
x = np.arange(0, w) + grid_cell_offset # shift x
|
| 112 |
+
y = np.arange(0, h) + grid_cell_offset # shift y
|
| 113 |
+
sx, sy = np.meshgrid(x, y)
|
| 114 |
+
# sy, sx = np.meshgrid(y, x)
|
| 115 |
+
anchor_points[stride] = np.stack((sx, sy), axis=-1).reshape(-1, 2)
|
| 116 |
+
return anchor_points
|
| 117 |
+
|
| 118 |
+
def softmax(self, x, axis=1):
|
| 119 |
+
x_exp = np.exp(x)
|
| 120 |
+
# 如果是列向量,则axis=0
|
| 121 |
+
x_sum = np.sum(x_exp, axis=axis, keepdims=True)
|
| 122 |
+
s = x_exp / x_sum
|
| 123 |
+
return s
|
| 124 |
+
|
| 125 |
+
def resize_image(self, srcimg, keep_ratio=True):
|
| 126 |
+
top, left, newh, neww = 0, 0, self.input_width, self.input_height
|
| 127 |
+
if keep_ratio and srcimg.shape[0] != srcimg.shape[1]:
|
| 128 |
+
hw_scale = srcimg.shape[0] / srcimg.shape[1]
|
| 129 |
+
if hw_scale > 1:
|
| 130 |
+
newh, neww = self.input_height, int(self.input_width / hw_scale)
|
| 131 |
+
img = cv2.resize(srcimg, (neww, newh), interpolation=cv2.INTER_AREA)
|
| 132 |
+
left = int((self.input_width - neww) * 0.5)
|
| 133 |
+
img = cv2.copyMakeBorder(img, 0, 0, left, self.input_width - neww - left, cv2.BORDER_CONSTANT,
|
| 134 |
+
value=(0, 0, 0)) # add border
|
| 135 |
+
else:
|
| 136 |
+
newh, neww = int(self.input_height * hw_scale), self.input_width
|
| 137 |
+
img = cv2.resize(srcimg, (neww, newh), interpolation=cv2.INTER_AREA)
|
| 138 |
+
top = int((self.input_height - newh) * 0.5)
|
| 139 |
+
img = cv2.copyMakeBorder(img, top, self.input_height - newh - top, 0, 0, cv2.BORDER_CONSTANT,
|
| 140 |
+
value=(0, 0, 0))
|
| 141 |
+
else:
|
| 142 |
+
img = cv2.resize(srcimg, (self.input_width, self.input_height), interpolation=cv2.INTER_AREA)
|
| 143 |
+
return img, newh, neww, top, left
|
| 144 |
+
|
| 145 |
+
def detect(self, srcimg):
|
| 146 |
+
input_img, newh, neww, padh, padw = self.resize_image(cv2.cvtColor(srcimg, cv2.COLOR_BGR2RGB))
|
| 147 |
+
scale_h, scale_w = srcimg.shape[0]/newh, srcimg.shape[1]/neww
|
| 148 |
+
input_img = input_img.astype(np.float32) / 255.0
|
| 149 |
+
|
| 150 |
+
blob = cv2.dnn.blobFromImage(input_img)
|
| 151 |
+
self.net.setInput(blob)
|
| 152 |
+
outputs = self.net.forward(self.net.getUnconnectedOutLayersNames())
|
| 153 |
+
# if isinstance(outputs, tuple):
|
| 154 |
+
# outputs = list(outputs)
|
| 155 |
+
# if float(cv2.__version__[:3])>=4.7:
|
| 156 |
+
# outputs = [outputs[2], outputs[0], outputs[1]] ###opencv4.7需要这一步,opencv4.5不需要
|
| 157 |
+
# Perform inference on the image
|
| 158 |
+
det_bboxes, det_conf, det_classid, landmarks = self.post_process(outputs, scale_h, scale_w, padh, padw)
|
| 159 |
+
return det_bboxes, det_conf, det_classid, landmarks
|
| 160 |
+
|
| 161 |
+
def post_process(self, preds, scale_h, scale_w, padh, padw):
|
| 162 |
+
bboxes, scores, landmarks = [], [], []
|
| 163 |
+
for i, pred in enumerate(preds):
|
| 164 |
+
stride = int(self.input_height/pred.shape[2])
|
| 165 |
+
pred = pred.transpose((0, 2, 3, 1))
|
| 166 |
+
|
| 167 |
+
box = pred[..., :self.reg_max * 4]
|
| 168 |
+
cls = 1 / (1 + np.exp(-pred[..., self.reg_max * 4:-15])).reshape((-1,1))
|
| 169 |
+
kpts = pred[..., -15:].reshape((-1,15)) ### x1,y1,score1, ..., x5,y5,score5
|
| 170 |
+
|
| 171 |
+
# tmp = box.reshape(self.feats_hw[i][0], self.feats_hw[i][1], 4, self.reg_max)
|
| 172 |
+
tmp = box.reshape(-1, 4, self.reg_max)
|
| 173 |
+
bbox_pred = self.softmax(tmp, axis=-1)
|
| 174 |
+
bbox_pred = np.dot(bbox_pred, self.project).reshape((-1,4))
|
| 175 |
+
|
| 176 |
+
bbox = self.distance2bbox(self.anchors[stride], bbox_pred, max_shape=(self.input_height, self.input_width)) * stride
|
| 177 |
+
kpts[:, 0::3] = (kpts[:, 0::3] * 2.0 + (self.anchors[stride][:, 0].reshape((-1,1)) - 0.5)) * stride
|
| 178 |
+
kpts[:, 1::3] = (kpts[:, 1::3] * 2.0 + (self.anchors[stride][:, 1].reshape((-1,1)) - 0.5)) * stride
|
| 179 |
+
kpts[:, 2::3] = 1 / (1+np.exp(-kpts[:, 2::3]))
|
| 180 |
+
|
| 181 |
+
bbox -= np.array([[padw, padh, padw, padh]]) ###合理使用广播法则
|
| 182 |
+
bbox *= np.array([[scale_w, scale_h, scale_w, scale_h]])
|
| 183 |
+
kpts -= np.tile(np.array([padw, padh, 0]), 5).reshape((1,15))
|
| 184 |
+
kpts *= np.tile(np.array([scale_w, scale_h, 1]), 5).reshape((1,15))
|
| 185 |
+
|
| 186 |
+
bboxes.append(bbox)
|
| 187 |
+
scores.append(cls)
|
| 188 |
+
landmarks.append(kpts)
|
| 189 |
+
|
| 190 |
+
bboxes = np.concatenate(bboxes, axis=0)
|
| 191 |
+
scores = np.concatenate(scores, axis=0)
|
| 192 |
+
landmarks = np.concatenate(landmarks, axis=0)
|
| 193 |
+
|
| 194 |
+
bboxes_wh = bboxes.copy()
|
| 195 |
+
bboxes_wh[:, 2:4] = bboxes[:, 2:4] - bboxes[:, 0:2] ####xywh
|
| 196 |
+
classIds = np.argmax(scores, axis=1)
|
| 197 |
+
confidences = np.max(scores, axis=1) ####max_class_confidence
|
| 198 |
+
|
| 199 |
+
mask = confidences>self.conf_threshold
|
| 200 |
+
bboxes_wh = bboxes_wh[mask] ###合理使用广播法则
|
| 201 |
+
confidences = confidences[mask]
|
| 202 |
+
classIds = classIds[mask]
|
| 203 |
+
landmarks = landmarks[mask]
|
| 204 |
+
|
| 205 |
+
indices = cv2.dnn.NMSBoxes(bboxes_wh.tolist(), confidences.tolist(), self.conf_threshold,
|
| 206 |
+
self.iou_threshold).flatten()
|
| 207 |
+
if len(indices) > 0:
|
| 208 |
+
mlvl_bboxes = bboxes_wh[indices]
|
| 209 |
+
confidences = confidences[indices]
|
| 210 |
+
classIds = classIds[indices]
|
| 211 |
+
landmarks = landmarks[indices]
|
| 212 |
+
return mlvl_bboxes, confidences, classIds, landmarks
|
| 213 |
+
else:
|
| 214 |
+
print('nothing detect')
|
| 215 |
+
return np.array([]), np.array([]), np.array([]), np.array([])
|
| 216 |
+
|
| 217 |
+
def distance2bbox(self, points, distance, max_shape=None):
|
| 218 |
+
x1 = points[:, 0] - distance[:, 0]
|
| 219 |
+
y1 = points[:, 1] - distance[:, 1]
|
| 220 |
+
x2 = points[:, 0] + distance[:, 2]
|
| 221 |
+
y2 = points[:, 1] + distance[:, 3]
|
| 222 |
+
if max_shape is not None:
|
| 223 |
+
x1 = np.clip(x1, 0, max_shape[1])
|
| 224 |
+
y1 = np.clip(y1, 0, max_shape[0])
|
| 225 |
+
x2 = np.clip(x2, 0, max_shape[1])
|
| 226 |
+
y2 = np.clip(y2, 0, max_shape[0])
|
| 227 |
+
return np.stack([x1, y1, x2, y2], axis=-1)
|
| 228 |
+
|
| 229 |
+
def draw_detections(self, image, boxes, scores, kpts):
|
| 230 |
+
for box, score, kp in zip(boxes, scores, kpts):
|
| 231 |
+
x, y, w, h = box.astype(int)
|
| 232 |
+
# Draw rectangle
|
| 233 |
+
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), thickness=3)
|
| 234 |
+
cv2.putText(image, "face:"+str(round(score,2)), (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), thickness=2)
|
| 235 |
+
for i in range(5):
|
| 236 |
+
cv2.circle(image, (int(kp[i * 3]), int(kp[i * 3 + 1])), 4, (0, 255, 0), thickness=-1)
|
| 237 |
+
# cv2.putText(image, str(i), (int(kp[i * 3]), int(kp[i * 3 + 1]) - 10), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 0, 0), thickness=1)
|
| 238 |
+
return image
|
| 239 |
+
|
| 240 |
+
ROOT = os.path.dirname(os.path.abspath(__file__))
|
musetalk/utils/face_detection/detection/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .core import FaceDetector
|
musetalk/utils/face_detection/detection/core.py
ADDED
|
@@ -0,0 +1,130 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import glob
|
| 3 |
+
from tqdm import tqdm
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
import cv2
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class FaceDetector(object):
|
| 10 |
+
"""An abstract class representing a face detector.
|
| 11 |
+
|
| 12 |
+
Any other face detection implementation must subclass it. All subclasses
|
| 13 |
+
must implement ``detect_from_image``, that return a list of detected
|
| 14 |
+
bounding boxes. Optionally, for speed considerations detect from path is
|
| 15 |
+
recommended.
|
| 16 |
+
"""
|
| 17 |
+
|
| 18 |
+
def __init__(self, device, verbose):
|
| 19 |
+
self.device = device
|
| 20 |
+
self.verbose = verbose
|
| 21 |
+
|
| 22 |
+
if verbose:
|
| 23 |
+
if 'cpu' in device:
|
| 24 |
+
logger = logging.getLogger(__name__)
|
| 25 |
+
logger.warning("Detection running on CPU, this may be potentially slow.")
|
| 26 |
+
|
| 27 |
+
if 'cpu' not in device and 'cuda' not in device:
|
| 28 |
+
if verbose:
|
| 29 |
+
logger.error("Expected values for device are: {cpu, cuda} but got: %s", device)
|
| 30 |
+
raise ValueError
|
| 31 |
+
|
| 32 |
+
def detect_from_image(self, tensor_or_path):
|
| 33 |
+
"""Detects faces in a given image.
|
| 34 |
+
|
| 35 |
+
This function detects the faces present in a provided BGR(usually)
|
| 36 |
+
image. The input can be either the image itself or the path to it.
|
| 37 |
+
|
| 38 |
+
Arguments:
|
| 39 |
+
tensor_or_path {numpy.ndarray, torch.tensor or string} -- the path
|
| 40 |
+
to an image or the image itself.
|
| 41 |
+
|
| 42 |
+
Example::
|
| 43 |
+
|
| 44 |
+
>>> path_to_image = 'data/image_01.jpg'
|
| 45 |
+
... detected_faces = detect_from_image(path_to_image)
|
| 46 |
+
[A list of bounding boxes (x1, y1, x2, y2)]
|
| 47 |
+
>>> image = cv2.imread(path_to_image)
|
| 48 |
+
... detected_faces = detect_from_image(image)
|
| 49 |
+
[A list of bounding boxes (x1, y1, x2, y2)]
|
| 50 |
+
|
| 51 |
+
"""
|
| 52 |
+
raise NotImplementedError
|
| 53 |
+
|
| 54 |
+
def detect_from_directory(self, path, extensions=['.jpg', '.png'], recursive=False, show_progress_bar=True):
|
| 55 |
+
"""Detects faces from all the images present in a given directory.
|
| 56 |
+
|
| 57 |
+
Arguments:
|
| 58 |
+
path {string} -- a string containing a path that points to the folder containing the images
|
| 59 |
+
|
| 60 |
+
Keyword Arguments:
|
| 61 |
+
extensions {list} -- list of string containing the extensions to be
|
| 62 |
+
consider in the following format: ``.extension_name`` (default:
|
| 63 |
+
{['.jpg', '.png']}) recursive {bool} -- option wherever to scan the
|
| 64 |
+
folder recursively (default: {False}) show_progress_bar {bool} --
|
| 65 |
+
display a progressbar (default: {True})
|
| 66 |
+
|
| 67 |
+
Example:
|
| 68 |
+
>>> directory = 'data'
|
| 69 |
+
... detected_faces = detect_from_directory(directory)
|
| 70 |
+
{A dictionary of [lists containing bounding boxes(x1, y1, x2, y2)]}
|
| 71 |
+
|
| 72 |
+
"""
|
| 73 |
+
if self.verbose:
|
| 74 |
+
logger = logging.getLogger(__name__)
|
| 75 |
+
|
| 76 |
+
if len(extensions) == 0:
|
| 77 |
+
if self.verbose:
|
| 78 |
+
logger.error("Expected at list one extension, but none was received.")
|
| 79 |
+
raise ValueError
|
| 80 |
+
|
| 81 |
+
if self.verbose:
|
| 82 |
+
logger.info("Constructing the list of images.")
|
| 83 |
+
additional_pattern = '/**/*' if recursive else '/*'
|
| 84 |
+
files = []
|
| 85 |
+
for extension in extensions:
|
| 86 |
+
files.extend(glob.glob(path + additional_pattern + extension, recursive=recursive))
|
| 87 |
+
|
| 88 |
+
if self.verbose:
|
| 89 |
+
logger.info("Finished searching for images. %s images found", len(files))
|
| 90 |
+
logger.info("Preparing to run the detection.")
|
| 91 |
+
|
| 92 |
+
predictions = {}
|
| 93 |
+
for image_path in tqdm(files, disable=not show_progress_bar):
|
| 94 |
+
if self.verbose:
|
| 95 |
+
logger.info("Running the face detector on image: %s", image_path)
|
| 96 |
+
predictions[image_path] = self.detect_from_image(image_path)
|
| 97 |
+
|
| 98 |
+
if self.verbose:
|
| 99 |
+
logger.info("The detector was successfully run on all %s images", len(files))
|
| 100 |
+
|
| 101 |
+
return predictions
|
| 102 |
+
|
| 103 |
+
@property
|
| 104 |
+
def reference_scale(self):
|
| 105 |
+
raise NotImplementedError
|
| 106 |
+
|
| 107 |
+
@property
|
| 108 |
+
def reference_x_shift(self):
|
| 109 |
+
raise NotImplementedError
|
| 110 |
+
|
| 111 |
+
@property
|
| 112 |
+
def reference_y_shift(self):
|
| 113 |
+
raise NotImplementedError
|
| 114 |
+
|
| 115 |
+
@staticmethod
|
| 116 |
+
def tensor_or_path_to_ndarray(tensor_or_path, rgb=True):
|
| 117 |
+
"""Convert path (represented as a string) or torch.tensor to a numpy.ndarray
|
| 118 |
+
|
| 119 |
+
Arguments:
|
| 120 |
+
tensor_or_path {numpy.ndarray, torch.tensor or string} -- path to the image, or the image itself
|
| 121 |
+
"""
|
| 122 |
+
if isinstance(tensor_or_path, str):
|
| 123 |
+
return cv2.imread(tensor_or_path) if not rgb else cv2.imread(tensor_or_path)[..., ::-1]
|
| 124 |
+
elif torch.is_tensor(tensor_or_path):
|
| 125 |
+
# Call cpu in case its coming from cuda
|
| 126 |
+
return tensor_or_path.cpu().numpy()[..., ::-1].copy() if not rgb else tensor_or_path.cpu().numpy()
|
| 127 |
+
elif isinstance(tensor_or_path, np.ndarray):
|
| 128 |
+
return tensor_or_path[..., ::-1].copy() if not rgb else tensor_or_path
|
| 129 |
+
else:
|
| 130 |
+
raise TypeError
|
musetalk/utils/face_detection/detection/sfd/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
from .sfd_detector import SFDDetector as FaceDetector
|
musetalk/utils/face_detection/detection/sfd/bbox.py
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from __future__ import print_function
|
| 2 |
+
import os
|
| 3 |
+
import sys
|
| 4 |
+
import cv2
|
| 5 |
+
import random
|
| 6 |
+
import datetime
|
| 7 |
+
import time
|
| 8 |
+
import math
|
| 9 |
+
import argparse
|
| 10 |
+
import numpy as np
|
| 11 |
+
import torch
|
| 12 |
+
|
| 13 |
+
try:
|
| 14 |
+
from iou import IOU
|
| 15 |
+
except BaseException:
|
| 16 |
+
# IOU cython speedup 10x
|
| 17 |
+
def IOU(ax1, ay1, ax2, ay2, bx1, by1, bx2, by2):
|
| 18 |
+
sa = abs((ax2 - ax1) * (ay2 - ay1))
|
| 19 |
+
sb = abs((bx2 - bx1) * (by2 - by1))
|
| 20 |
+
x1, y1 = max(ax1, bx1), max(ay1, by1)
|
| 21 |
+
x2, y2 = min(ax2, bx2), min(ay2, by2)
|
| 22 |
+
w = x2 - x1
|
| 23 |
+
h = y2 - y1
|
| 24 |
+
if w < 0 or h < 0:
|
| 25 |
+
return 0.0
|
| 26 |
+
else:
|
| 27 |
+
return 1.0 * w * h / (sa + sb - w * h)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def bboxlog(x1, y1, x2, y2, axc, ayc, aww, ahh):
|
| 31 |
+
xc, yc, ww, hh = (x2 + x1) / 2, (y2 + y1) / 2, x2 - x1, y2 - y1
|
| 32 |
+
dx, dy = (xc - axc) / aww, (yc - ayc) / ahh
|
| 33 |
+
dw, dh = math.log(ww / aww), math.log(hh / ahh)
|
| 34 |
+
return dx, dy, dw, dh
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def bboxloginv(dx, dy, dw, dh, axc, ayc, aww, ahh):
|
| 38 |
+
xc, yc = dx * aww + axc, dy * ahh + ayc
|
| 39 |
+
ww, hh = math.exp(dw) * aww, math.exp(dh) * ahh
|
| 40 |
+
x1, x2, y1, y2 = xc - ww / 2, xc + ww / 2, yc - hh / 2, yc + hh / 2
|
| 41 |
+
return x1, y1, x2, y2
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def nms(dets, thresh):
|
| 45 |
+
if 0 == len(dets):
|
| 46 |
+
return []
|
| 47 |
+
x1, y1, x2, y2, scores = dets[:, 0], dets[:, 1], dets[:, 2], dets[:, 3], dets[:, 4]
|
| 48 |
+
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
|
| 49 |
+
order = scores.argsort()[::-1]
|
| 50 |
+
|
| 51 |
+
keep = []
|
| 52 |
+
while order.size > 0:
|
| 53 |
+
i = order[0]
|
| 54 |
+
keep.append(i)
|
| 55 |
+
xx1, yy1 = np.maximum(x1[i], x1[order[1:]]), np.maximum(y1[i], y1[order[1:]])
|
| 56 |
+
xx2, yy2 = np.minimum(x2[i], x2[order[1:]]), np.minimum(y2[i], y2[order[1:]])
|
| 57 |
+
|
| 58 |
+
w, h = np.maximum(0.0, xx2 - xx1 + 1), np.maximum(0.0, yy2 - yy1 + 1)
|
| 59 |
+
ovr = w * h / (areas[i] + areas[order[1:]] - w * h)
|
| 60 |
+
|
| 61 |
+
inds = np.where(ovr <= thresh)[0]
|
| 62 |
+
order = order[inds + 1]
|
| 63 |
+
|
| 64 |
+
return keep
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def encode(matched, priors, variances):
|
| 68 |
+
"""Encode the variances from the priorbox layers into the ground truth boxes
|
| 69 |
+
we have matched (based on jaccard overlap) with the prior boxes.
|
| 70 |
+
Args:
|
| 71 |
+
matched: (tensor) Coords of ground truth for each prior in point-form
|
| 72 |
+
Shape: [num_priors, 4].
|
| 73 |
+
priors: (tensor) Prior boxes in center-offset form
|
| 74 |
+
Shape: [num_priors,4].
|
| 75 |
+
variances: (list[float]) Variances of priorboxes
|
| 76 |
+
Return:
|
| 77 |
+
encoded boxes (tensor), Shape: [num_priors, 4]
|
| 78 |
+
"""
|
| 79 |
+
|
| 80 |
+
# dist b/t match center and prior's center
|
| 81 |
+
g_cxcy = (matched[:, :2] + matched[:, 2:]) / 2 - priors[:, :2]
|
| 82 |
+
# encode variance
|
| 83 |
+
g_cxcy /= (variances[0] * priors[:, 2:])
|
| 84 |
+
# match wh / prior wh
|
| 85 |
+
g_wh = (matched[:, 2:] - matched[:, :2]) / priors[:, 2:]
|
| 86 |
+
g_wh = torch.log(g_wh) / variances[1]
|
| 87 |
+
# return target for smooth_l1_loss
|
| 88 |
+
return torch.cat([g_cxcy, g_wh], 1) # [num_priors,4]
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def decode(loc, priors, variances):
|
| 92 |
+
"""Decode locations from predictions using priors to undo
|
| 93 |
+
the encoding we did for offset regression at train time.
|
| 94 |
+
Args:
|
| 95 |
+
loc (tensor): location predictions for loc layers,
|
| 96 |
+
Shape: [num_priors,4]
|
| 97 |
+
priors (tensor): Prior boxes in center-offset form.
|
| 98 |
+
Shape: [num_priors,4].
|
| 99 |
+
variances: (list[float]) Variances of priorboxes
|
| 100 |
+
Return:
|
| 101 |
+
decoded bounding box predictions
|
| 102 |
+
"""
|
| 103 |
+
|
| 104 |
+
boxes = torch.cat((
|
| 105 |
+
priors[:, :2] + loc[:, :2] * variances[0] * priors[:, 2:],
|
| 106 |
+
priors[:, 2:] * torch.exp(loc[:, 2:] * variances[1])), 1)
|
| 107 |
+
boxes[:, :2] -= boxes[:, 2:] / 2
|
| 108 |
+
boxes[:, 2:] += boxes[:, :2]
|
| 109 |
+
return boxes
|
| 110 |
+
|
| 111 |
+
def batch_decode(loc, priors, variances):
|
| 112 |
+
"""Decode locations from predictions using priors to undo
|
| 113 |
+
the encoding we did for offset regression at train time.
|
| 114 |
+
Args:
|
| 115 |
+
loc (tensor): location predictions for loc layers,
|
| 116 |
+
Shape: [num_priors,4]
|
| 117 |
+
priors (tensor): Prior boxes in center-offset form.
|
| 118 |
+
Shape: [num_priors,4].
|
| 119 |
+
variances: (list[float]) Variances of priorboxes
|
| 120 |
+
Return:
|
| 121 |
+
decoded bounding box predictions
|
| 122 |
+
"""
|
| 123 |
+
|
| 124 |
+
boxes = torch.cat((
|
| 125 |
+
priors[:, :, :2] + loc[:, :, :2] * variances[0] * priors[:, :, 2:],
|
| 126 |
+
priors[:, :, 2:] * torch.exp(loc[:, :, 2:] * variances[1])), 2)
|
| 127 |
+
boxes[:, :, :2] -= boxes[:, :, 2:] / 2
|
| 128 |
+
boxes[:, :, 2:] += boxes[:, :, :2]
|
| 129 |
+
return boxes
|
musetalk/utils/face_detection/detection/sfd/detect.py
ADDED
|
@@ -0,0 +1,114 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn.functional as F
|
| 3 |
+
|
| 4 |
+
import os
|
| 5 |
+
import sys
|
| 6 |
+
import cv2
|
| 7 |
+
import random
|
| 8 |
+
import datetime
|
| 9 |
+
import math
|
| 10 |
+
import argparse
|
| 11 |
+
import numpy as np
|
| 12 |
+
|
| 13 |
+
import scipy.io as sio
|
| 14 |
+
import zipfile
|
| 15 |
+
from .net_s3fd import s3fd
|
| 16 |
+
from .bbox import *
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def detect(net, img, device):
|
| 20 |
+
img = img - np.array([104, 117, 123])
|
| 21 |
+
img = img.transpose(2, 0, 1)
|
| 22 |
+
img = img.reshape((1,) + img.shape)
|
| 23 |
+
|
| 24 |
+
if 'cuda' in device:
|
| 25 |
+
torch.backends.cudnn.benchmark = True
|
| 26 |
+
|
| 27 |
+
img = torch.from_numpy(img).float().to(device)
|
| 28 |
+
BB, CC, HH, WW = img.size()
|
| 29 |
+
with torch.no_grad():
|
| 30 |
+
olist = net(img)
|
| 31 |
+
|
| 32 |
+
bboxlist = []
|
| 33 |
+
for i in range(len(olist) // 2):
|
| 34 |
+
olist[i * 2] = F.softmax(olist[i * 2], dim=1)
|
| 35 |
+
olist = [oelem.data.cpu() for oelem in olist]
|
| 36 |
+
for i in range(len(olist) // 2):
|
| 37 |
+
ocls, oreg = olist[i * 2], olist[i * 2 + 1]
|
| 38 |
+
FB, FC, FH, FW = ocls.size() # feature map size
|
| 39 |
+
stride = 2**(i + 2) # 4,8,16,32,64,128
|
| 40 |
+
anchor = stride * 4
|
| 41 |
+
poss = zip(*np.where(ocls[:, 1, :, :] > 0.05))
|
| 42 |
+
for Iindex, hindex, windex in poss:
|
| 43 |
+
axc, ayc = stride / 2 + windex * stride, stride / 2 + hindex * stride
|
| 44 |
+
score = ocls[0, 1, hindex, windex]
|
| 45 |
+
loc = oreg[0, :, hindex, windex].contiguous().view(1, 4)
|
| 46 |
+
priors = torch.Tensor([[axc / 1.0, ayc / 1.0, stride * 4 / 1.0, stride * 4 / 1.0]])
|
| 47 |
+
variances = [0.1, 0.2]
|
| 48 |
+
box = decode(loc, priors, variances)
|
| 49 |
+
x1, y1, x2, y2 = box[0] * 1.0
|
| 50 |
+
# cv2.rectangle(imgshow,(int(x1),int(y1)),(int(x2),int(y2)),(0,0,255),1)
|
| 51 |
+
bboxlist.append([x1, y1, x2, y2, score])
|
| 52 |
+
bboxlist = np.array(bboxlist)
|
| 53 |
+
if 0 == len(bboxlist):
|
| 54 |
+
bboxlist = np.zeros((1, 5))
|
| 55 |
+
|
| 56 |
+
return bboxlist
|
| 57 |
+
|
| 58 |
+
def batch_detect(net, imgs, device):
|
| 59 |
+
imgs = imgs - np.array([104, 117, 123])
|
| 60 |
+
imgs = imgs.transpose(0, 3, 1, 2)
|
| 61 |
+
|
| 62 |
+
if 'cuda' in device:
|
| 63 |
+
torch.backends.cudnn.benchmark = True
|
| 64 |
+
|
| 65 |
+
imgs = torch.from_numpy(imgs).float().to(device)
|
| 66 |
+
BB, CC, HH, WW = imgs.size()
|
| 67 |
+
with torch.no_grad():
|
| 68 |
+
olist = net(imgs)
|
| 69 |
+
# print(olist)
|
| 70 |
+
|
| 71 |
+
bboxlist = []
|
| 72 |
+
for i in range(len(olist) // 2):
|
| 73 |
+
olist[i * 2] = F.softmax(olist[i * 2], dim=1)
|
| 74 |
+
|
| 75 |
+
olist = [oelem.cpu() for oelem in olist]
|
| 76 |
+
for i in range(len(olist) // 2):
|
| 77 |
+
ocls, oreg = olist[i * 2], olist[i * 2 + 1]
|
| 78 |
+
FB, FC, FH, FW = ocls.size() # feature map size
|
| 79 |
+
stride = 2**(i + 2) # 4,8,16,32,64,128
|
| 80 |
+
anchor = stride * 4
|
| 81 |
+
poss = zip(*np.where(ocls[:, 1, :, :] > 0.05))
|
| 82 |
+
for Iindex, hindex, windex in poss:
|
| 83 |
+
axc, ayc = stride / 2 + windex * stride, stride / 2 + hindex * stride
|
| 84 |
+
score = ocls[:, 1, hindex, windex]
|
| 85 |
+
loc = oreg[:, :, hindex, windex].contiguous().view(BB, 1, 4)
|
| 86 |
+
priors = torch.Tensor([[axc / 1.0, ayc / 1.0, stride * 4 / 1.0, stride * 4 / 1.0]]).view(1, 1, 4)
|
| 87 |
+
variances = [0.1, 0.2]
|
| 88 |
+
box = batch_decode(loc, priors, variances)
|
| 89 |
+
box = box[:, 0] * 1.0
|
| 90 |
+
# cv2.rectangle(imgshow,(int(x1),int(y1)),(int(x2),int(y2)),(0,0,255),1)
|
| 91 |
+
bboxlist.append(torch.cat([box, score.unsqueeze(1)], 1).cpu().numpy())
|
| 92 |
+
bboxlist = np.array(bboxlist)
|
| 93 |
+
if 0 == len(bboxlist):
|
| 94 |
+
bboxlist = np.zeros((1, BB, 5))
|
| 95 |
+
|
| 96 |
+
return bboxlist
|
| 97 |
+
|
| 98 |
+
def flip_detect(net, img, device):
|
| 99 |
+
img = cv2.flip(img, 1)
|
| 100 |
+
b = detect(net, img, device)
|
| 101 |
+
|
| 102 |
+
bboxlist = np.zeros(b.shape)
|
| 103 |
+
bboxlist[:, 0] = img.shape[1] - b[:, 2]
|
| 104 |
+
bboxlist[:, 1] = b[:, 1]
|
| 105 |
+
bboxlist[:, 2] = img.shape[1] - b[:, 0]
|
| 106 |
+
bboxlist[:, 3] = b[:, 3]
|
| 107 |
+
bboxlist[:, 4] = b[:, 4]
|
| 108 |
+
return bboxlist
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
def pts_to_bb(pts):
|
| 112 |
+
min_x, min_y = np.min(pts, axis=0)
|
| 113 |
+
max_x, max_y = np.max(pts, axis=0)
|
| 114 |
+
return np.array([min_x, min_y, max_x, max_y])
|
musetalk/utils/face_detection/detection/sfd/net_s3fd.py
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class L2Norm(nn.Module):
|
| 7 |
+
def __init__(self, n_channels, scale=1.0):
|
| 8 |
+
super(L2Norm, self).__init__()
|
| 9 |
+
self.n_channels = n_channels
|
| 10 |
+
self.scale = scale
|
| 11 |
+
self.eps = 1e-10
|
| 12 |
+
self.weight = nn.Parameter(torch.Tensor(self.n_channels))
|
| 13 |
+
self.weight.data *= 0.0
|
| 14 |
+
self.weight.data += self.scale
|
| 15 |
+
|
| 16 |
+
def forward(self, x):
|
| 17 |
+
norm = x.pow(2).sum(dim=1, keepdim=True).sqrt() + self.eps
|
| 18 |
+
x = x / norm * self.weight.view(1, -1, 1, 1)
|
| 19 |
+
return x
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
class s3fd(nn.Module):
|
| 23 |
+
def __init__(self):
|
| 24 |
+
super(s3fd, self).__init__()
|
| 25 |
+
self.conv1_1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)
|
| 26 |
+
self.conv1_2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1)
|
| 27 |
+
|
| 28 |
+
self.conv2_1 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)
|
| 29 |
+
self.conv2_2 = nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1)
|
| 30 |
+
|
| 31 |
+
self.conv3_1 = nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1)
|
| 32 |
+
self.conv3_2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
|
| 33 |
+
self.conv3_3 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
|
| 34 |
+
|
| 35 |
+
self.conv4_1 = nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1)
|
| 36 |
+
self.conv4_2 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1)
|
| 37 |
+
self.conv4_3 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1)
|
| 38 |
+
|
| 39 |
+
self.conv5_1 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1)
|
| 40 |
+
self.conv5_2 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1)
|
| 41 |
+
self.conv5_3 = nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1)
|
| 42 |
+
|
| 43 |
+
self.fc6 = nn.Conv2d(512, 1024, kernel_size=3, stride=1, padding=3)
|
| 44 |
+
self.fc7 = nn.Conv2d(1024, 1024, kernel_size=1, stride=1, padding=0)
|
| 45 |
+
|
| 46 |
+
self.conv6_1 = nn.Conv2d(1024, 256, kernel_size=1, stride=1, padding=0)
|
| 47 |
+
self.conv6_2 = nn.Conv2d(256, 512, kernel_size=3, stride=2, padding=1)
|
| 48 |
+
|
| 49 |
+
self.conv7_1 = nn.Conv2d(512, 128, kernel_size=1, stride=1, padding=0)
|
| 50 |
+
self.conv7_2 = nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1)
|
| 51 |
+
|
| 52 |
+
self.conv3_3_norm = L2Norm(256, scale=10)
|
| 53 |
+
self.conv4_3_norm = L2Norm(512, scale=8)
|
| 54 |
+
self.conv5_3_norm = L2Norm(512, scale=5)
|
| 55 |
+
|
| 56 |
+
self.conv3_3_norm_mbox_conf = nn.Conv2d(256, 4, kernel_size=3, stride=1, padding=1)
|
| 57 |
+
self.conv3_3_norm_mbox_loc = nn.Conv2d(256, 4, kernel_size=3, stride=1, padding=1)
|
| 58 |
+
self.conv4_3_norm_mbox_conf = nn.Conv2d(512, 2, kernel_size=3, stride=1, padding=1)
|
| 59 |
+
self.conv4_3_norm_mbox_loc = nn.Conv2d(512, 4, kernel_size=3, stride=1, padding=1)
|
| 60 |
+
self.conv5_3_norm_mbox_conf = nn.Conv2d(512, 2, kernel_size=3, stride=1, padding=1)
|
| 61 |
+
self.conv5_3_norm_mbox_loc = nn.Conv2d(512, 4, kernel_size=3, stride=1, padding=1)
|
| 62 |
+
|
| 63 |
+
self.fc7_mbox_conf = nn.Conv2d(1024, 2, kernel_size=3, stride=1, padding=1)
|
| 64 |
+
self.fc7_mbox_loc = nn.Conv2d(1024, 4, kernel_size=3, stride=1, padding=1)
|
| 65 |
+
self.conv6_2_mbox_conf = nn.Conv2d(512, 2, kernel_size=3, stride=1, padding=1)
|
| 66 |
+
self.conv6_2_mbox_loc = nn.Conv2d(512, 4, kernel_size=3, stride=1, padding=1)
|
| 67 |
+
self.conv7_2_mbox_conf = nn.Conv2d(256, 2, kernel_size=3, stride=1, padding=1)
|
| 68 |
+
self.conv7_2_mbox_loc = nn.Conv2d(256, 4, kernel_size=3, stride=1, padding=1)
|
| 69 |
+
|
| 70 |
+
def forward(self, x):
|
| 71 |
+
h = F.relu(self.conv1_1(x))
|
| 72 |
+
h = F.relu(self.conv1_2(h))
|
| 73 |
+
h = F.max_pool2d(h, 2, 2)
|
| 74 |
+
|
| 75 |
+
h = F.relu(self.conv2_1(h))
|
| 76 |
+
h = F.relu(self.conv2_2(h))
|
| 77 |
+
h = F.max_pool2d(h, 2, 2)
|
| 78 |
+
|
| 79 |
+
h = F.relu(self.conv3_1(h))
|
| 80 |
+
h = F.relu(self.conv3_2(h))
|
| 81 |
+
h = F.relu(self.conv3_3(h))
|
| 82 |
+
f3_3 = h
|
| 83 |
+
h = F.max_pool2d(h, 2, 2)
|
| 84 |
+
|
| 85 |
+
h = F.relu(self.conv4_1(h))
|
| 86 |
+
h = F.relu(self.conv4_2(h))
|
| 87 |
+
h = F.relu(self.conv4_3(h))
|
| 88 |
+
f4_3 = h
|
| 89 |
+
h = F.max_pool2d(h, 2, 2)
|
| 90 |
+
|
| 91 |
+
h = F.relu(self.conv5_1(h))
|
| 92 |
+
h = F.relu(self.conv5_2(h))
|
| 93 |
+
h = F.relu(self.conv5_3(h))
|
| 94 |
+
f5_3 = h
|
| 95 |
+
h = F.max_pool2d(h, 2, 2)
|
| 96 |
+
|
| 97 |
+
h = F.relu(self.fc6(h))
|
| 98 |
+
h = F.relu(self.fc7(h))
|
| 99 |
+
ffc7 = h
|
| 100 |
+
h = F.relu(self.conv6_1(h))
|
| 101 |
+
h = F.relu(self.conv6_2(h))
|
| 102 |
+
f6_2 = h
|
| 103 |
+
h = F.relu(self.conv7_1(h))
|
| 104 |
+
h = F.relu(self.conv7_2(h))
|
| 105 |
+
f7_2 = h
|
| 106 |
+
|
| 107 |
+
f3_3 = self.conv3_3_norm(f3_3)
|
| 108 |
+
f4_3 = self.conv4_3_norm(f4_3)
|
| 109 |
+
f5_3 = self.conv5_3_norm(f5_3)
|
| 110 |
+
|
| 111 |
+
cls1 = self.conv3_3_norm_mbox_conf(f3_3)
|
| 112 |
+
reg1 = self.conv3_3_norm_mbox_loc(f3_3)
|
| 113 |
+
cls2 = self.conv4_3_norm_mbox_conf(f4_3)
|
| 114 |
+
reg2 = self.conv4_3_norm_mbox_loc(f4_3)
|
| 115 |
+
cls3 = self.conv5_3_norm_mbox_conf(f5_3)
|
| 116 |
+
reg3 = self.conv5_3_norm_mbox_loc(f5_3)
|
| 117 |
+
cls4 = self.fc7_mbox_conf(ffc7)
|
| 118 |
+
reg4 = self.fc7_mbox_loc(ffc7)
|
| 119 |
+
cls5 = self.conv6_2_mbox_conf(f6_2)
|
| 120 |
+
reg5 = self.conv6_2_mbox_loc(f6_2)
|
| 121 |
+
cls6 = self.conv7_2_mbox_conf(f7_2)
|
| 122 |
+
reg6 = self.conv7_2_mbox_loc(f7_2)
|
| 123 |
+
|
| 124 |
+
# max-out background label
|
| 125 |
+
chunk = torch.chunk(cls1, 4, 1)
|
| 126 |
+
bmax = torch.max(torch.max(chunk[0], chunk[1]), chunk[2])
|
| 127 |
+
cls1 = torch.cat([bmax, chunk[3]], dim=1)
|
| 128 |
+
|
| 129 |
+
return [cls1, reg1, cls2, reg2, cls3, reg3, cls4, reg4, cls5, reg5, cls6, reg6]
|
musetalk/utils/face_detection/detection/sfd/sfd_detector.py
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import cv2
|
| 3 |
+
from torch.utils.model_zoo import load_url
|
| 4 |
+
|
| 5 |
+
from ..core import FaceDetector
|
| 6 |
+
|
| 7 |
+
from .net_s3fd import s3fd
|
| 8 |
+
from .bbox import *
|
| 9 |
+
from .detect import *
|
| 10 |
+
|
| 11 |
+
models_urls = {
|
| 12 |
+
's3fd': 'https://www.adrianbulat.com/downloads/python-fan/s3fd-619a316812.pth',
|
| 13 |
+
}
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class SFDDetector(FaceDetector):
|
| 17 |
+
def __init__(self, device, path_to_detector=os.path.join(os.path.dirname(os.path.abspath(__file__)), 's3fd.pth'), verbose=False):
|
| 18 |
+
super(SFDDetector, self).__init__(device, verbose)
|
| 19 |
+
|
| 20 |
+
# Initialise the face detector
|
| 21 |
+
if not os.path.isfile(path_to_detector):
|
| 22 |
+
model_weights = load_url(models_urls['s3fd'])
|
| 23 |
+
else:
|
| 24 |
+
model_weights = torch.load(path_to_detector)
|
| 25 |
+
|
| 26 |
+
self.face_detector = s3fd()
|
| 27 |
+
self.face_detector.load_state_dict(model_weights)
|
| 28 |
+
self.face_detector.to(device)
|
| 29 |
+
self.face_detector.eval()
|
| 30 |
+
|
| 31 |
+
def detect_from_image(self, tensor_or_path):
|
| 32 |
+
image = self.tensor_or_path_to_ndarray(tensor_or_path)
|
| 33 |
+
|
| 34 |
+
bboxlist = detect(self.face_detector, image, device=self.device)
|
| 35 |
+
keep = nms(bboxlist, 0.3)
|
| 36 |
+
bboxlist = bboxlist[keep, :]
|
| 37 |
+
bboxlist = [x for x in bboxlist if x[-1] > 0.5]
|
| 38 |
+
|
| 39 |
+
return bboxlist
|
| 40 |
+
|
| 41 |
+
def detect_from_batch(self, images):
|
| 42 |
+
bboxlists = batch_detect(self.face_detector, images, device=self.device)
|
| 43 |
+
keeps = [nms(bboxlists[:, i, :], 0.3) for i in range(bboxlists.shape[1])]
|
| 44 |
+
bboxlists = [bboxlists[keep, i, :] for i, keep in enumerate(keeps)]
|
| 45 |
+
bboxlists = [[x for x in bboxlist if x[-1] > 0.5] for bboxlist in bboxlists]
|
| 46 |
+
|
| 47 |
+
return bboxlists
|
| 48 |
+
|
| 49 |
+
@property
|
| 50 |
+
def reference_scale(self):
|
| 51 |
+
return 195
|
| 52 |
+
|
| 53 |
+
@property
|
| 54 |
+
def reference_x_shift(self):
|
| 55 |
+
return 0
|
| 56 |
+
|
| 57 |
+
@property
|
| 58 |
+
def reference_y_shift(self):
|
| 59 |
+
return 0
|
musetalk/utils/face_detection/models.py
ADDED
|
@@ -0,0 +1,261 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
import math
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def conv3x3(in_planes, out_planes, strd=1, padding=1, bias=False):
|
| 8 |
+
"3x3 convolution with padding"
|
| 9 |
+
return nn.Conv2d(in_planes, out_planes, kernel_size=3,
|
| 10 |
+
stride=strd, padding=padding, bias=bias)
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class ConvBlock(nn.Module):
|
| 14 |
+
def __init__(self, in_planes, out_planes):
|
| 15 |
+
super(ConvBlock, self).__init__()
|
| 16 |
+
self.bn1 = nn.BatchNorm2d(in_planes)
|
| 17 |
+
self.conv1 = conv3x3(in_planes, int(out_planes / 2))
|
| 18 |
+
self.bn2 = nn.BatchNorm2d(int(out_planes / 2))
|
| 19 |
+
self.conv2 = conv3x3(int(out_planes / 2), int(out_planes / 4))
|
| 20 |
+
self.bn3 = nn.BatchNorm2d(int(out_planes / 4))
|
| 21 |
+
self.conv3 = conv3x3(int(out_planes / 4), int(out_planes / 4))
|
| 22 |
+
|
| 23 |
+
if in_planes != out_planes:
|
| 24 |
+
self.downsample = nn.Sequential(
|
| 25 |
+
nn.BatchNorm2d(in_planes),
|
| 26 |
+
nn.ReLU(True),
|
| 27 |
+
nn.Conv2d(in_planes, out_planes,
|
| 28 |
+
kernel_size=1, stride=1, bias=False),
|
| 29 |
+
)
|
| 30 |
+
else:
|
| 31 |
+
self.downsample = None
|
| 32 |
+
|
| 33 |
+
def forward(self, x):
|
| 34 |
+
residual = x
|
| 35 |
+
|
| 36 |
+
out1 = self.bn1(x)
|
| 37 |
+
out1 = F.relu(out1, True)
|
| 38 |
+
out1 = self.conv1(out1)
|
| 39 |
+
|
| 40 |
+
out2 = self.bn2(out1)
|
| 41 |
+
out2 = F.relu(out2, True)
|
| 42 |
+
out2 = self.conv2(out2)
|
| 43 |
+
|
| 44 |
+
out3 = self.bn3(out2)
|
| 45 |
+
out3 = F.relu(out3, True)
|
| 46 |
+
out3 = self.conv3(out3)
|
| 47 |
+
|
| 48 |
+
out3 = torch.cat((out1, out2, out3), 1)
|
| 49 |
+
|
| 50 |
+
if self.downsample is not None:
|
| 51 |
+
residual = self.downsample(residual)
|
| 52 |
+
|
| 53 |
+
out3 += residual
|
| 54 |
+
|
| 55 |
+
return out3
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
class Bottleneck(nn.Module):
|
| 59 |
+
|
| 60 |
+
expansion = 4
|
| 61 |
+
|
| 62 |
+
def __init__(self, inplanes, planes, stride=1, downsample=None):
|
| 63 |
+
super(Bottleneck, self).__init__()
|
| 64 |
+
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
|
| 65 |
+
self.bn1 = nn.BatchNorm2d(planes)
|
| 66 |
+
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
|
| 67 |
+
padding=1, bias=False)
|
| 68 |
+
self.bn2 = nn.BatchNorm2d(planes)
|
| 69 |
+
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
|
| 70 |
+
self.bn3 = nn.BatchNorm2d(planes * 4)
|
| 71 |
+
self.relu = nn.ReLU(inplace=True)
|
| 72 |
+
self.downsample = downsample
|
| 73 |
+
self.stride = stride
|
| 74 |
+
|
| 75 |
+
def forward(self, x):
|
| 76 |
+
residual = x
|
| 77 |
+
|
| 78 |
+
out = self.conv1(x)
|
| 79 |
+
out = self.bn1(out)
|
| 80 |
+
out = self.relu(out)
|
| 81 |
+
|
| 82 |
+
out = self.conv2(out)
|
| 83 |
+
out = self.bn2(out)
|
| 84 |
+
out = self.relu(out)
|
| 85 |
+
|
| 86 |
+
out = self.conv3(out)
|
| 87 |
+
out = self.bn3(out)
|
| 88 |
+
|
| 89 |
+
if self.downsample is not None:
|
| 90 |
+
residual = self.downsample(x)
|
| 91 |
+
|
| 92 |
+
out += residual
|
| 93 |
+
out = self.relu(out)
|
| 94 |
+
|
| 95 |
+
return out
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
class HourGlass(nn.Module):
|
| 99 |
+
def __init__(self, num_modules, depth, num_features):
|
| 100 |
+
super(HourGlass, self).__init__()
|
| 101 |
+
self.num_modules = num_modules
|
| 102 |
+
self.depth = depth
|
| 103 |
+
self.features = num_features
|
| 104 |
+
|
| 105 |
+
self._generate_network(self.depth)
|
| 106 |
+
|
| 107 |
+
def _generate_network(self, level):
|
| 108 |
+
self.add_module('b1_' + str(level), ConvBlock(self.features, self.features))
|
| 109 |
+
|
| 110 |
+
self.add_module('b2_' + str(level), ConvBlock(self.features, self.features))
|
| 111 |
+
|
| 112 |
+
if level > 1:
|
| 113 |
+
self._generate_network(level - 1)
|
| 114 |
+
else:
|
| 115 |
+
self.add_module('b2_plus_' + str(level), ConvBlock(self.features, self.features))
|
| 116 |
+
|
| 117 |
+
self.add_module('b3_' + str(level), ConvBlock(self.features, self.features))
|
| 118 |
+
|
| 119 |
+
def _forward(self, level, inp):
|
| 120 |
+
# Upper branch
|
| 121 |
+
up1 = inp
|
| 122 |
+
up1 = self._modules['b1_' + str(level)](up1)
|
| 123 |
+
|
| 124 |
+
# Lower branch
|
| 125 |
+
low1 = F.avg_pool2d(inp, 2, stride=2)
|
| 126 |
+
low1 = self._modules['b2_' + str(level)](low1)
|
| 127 |
+
|
| 128 |
+
if level > 1:
|
| 129 |
+
low2 = self._forward(level - 1, low1)
|
| 130 |
+
else:
|
| 131 |
+
low2 = low1
|
| 132 |
+
low2 = self._modules['b2_plus_' + str(level)](low2)
|
| 133 |
+
|
| 134 |
+
low3 = low2
|
| 135 |
+
low3 = self._modules['b3_' + str(level)](low3)
|
| 136 |
+
|
| 137 |
+
up2 = F.interpolate(low3, scale_factor=2, mode='nearest')
|
| 138 |
+
|
| 139 |
+
return up1 + up2
|
| 140 |
+
|
| 141 |
+
def forward(self, x):
|
| 142 |
+
return self._forward(self.depth, x)
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
class FAN(nn.Module):
|
| 146 |
+
|
| 147 |
+
def __init__(self, num_modules=1):
|
| 148 |
+
super(FAN, self).__init__()
|
| 149 |
+
self.num_modules = num_modules
|
| 150 |
+
|
| 151 |
+
# Base part
|
| 152 |
+
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)
|
| 153 |
+
self.bn1 = nn.BatchNorm2d(64)
|
| 154 |
+
self.conv2 = ConvBlock(64, 128)
|
| 155 |
+
self.conv3 = ConvBlock(128, 128)
|
| 156 |
+
self.conv4 = ConvBlock(128, 256)
|
| 157 |
+
|
| 158 |
+
# Stacking part
|
| 159 |
+
for hg_module in range(self.num_modules):
|
| 160 |
+
self.add_module('m' + str(hg_module), HourGlass(1, 4, 256))
|
| 161 |
+
self.add_module('top_m_' + str(hg_module), ConvBlock(256, 256))
|
| 162 |
+
self.add_module('conv_last' + str(hg_module),
|
| 163 |
+
nn.Conv2d(256, 256, kernel_size=1, stride=1, padding=0))
|
| 164 |
+
self.add_module('bn_end' + str(hg_module), nn.BatchNorm2d(256))
|
| 165 |
+
self.add_module('l' + str(hg_module), nn.Conv2d(256,
|
| 166 |
+
68, kernel_size=1, stride=1, padding=0))
|
| 167 |
+
|
| 168 |
+
if hg_module < self.num_modules - 1:
|
| 169 |
+
self.add_module(
|
| 170 |
+
'bl' + str(hg_module), nn.Conv2d(256, 256, kernel_size=1, stride=1, padding=0))
|
| 171 |
+
self.add_module('al' + str(hg_module), nn.Conv2d(68,
|
| 172 |
+
256, kernel_size=1, stride=1, padding=0))
|
| 173 |
+
|
| 174 |
+
def forward(self, x):
|
| 175 |
+
x = F.relu(self.bn1(self.conv1(x)), True)
|
| 176 |
+
x = F.avg_pool2d(self.conv2(x), 2, stride=2)
|
| 177 |
+
x = self.conv3(x)
|
| 178 |
+
x = self.conv4(x)
|
| 179 |
+
|
| 180 |
+
previous = x
|
| 181 |
+
|
| 182 |
+
outputs = []
|
| 183 |
+
for i in range(self.num_modules):
|
| 184 |
+
hg = self._modules['m' + str(i)](previous)
|
| 185 |
+
|
| 186 |
+
ll = hg
|
| 187 |
+
ll = self._modules['top_m_' + str(i)](ll)
|
| 188 |
+
|
| 189 |
+
ll = F.relu(self._modules['bn_end' + str(i)]
|
| 190 |
+
(self._modules['conv_last' + str(i)](ll)), True)
|
| 191 |
+
|
| 192 |
+
# Predict heatmaps
|
| 193 |
+
tmp_out = self._modules['l' + str(i)](ll)
|
| 194 |
+
outputs.append(tmp_out)
|
| 195 |
+
|
| 196 |
+
if i < self.num_modules - 1:
|
| 197 |
+
ll = self._modules['bl' + str(i)](ll)
|
| 198 |
+
tmp_out_ = self._modules['al' + str(i)](tmp_out)
|
| 199 |
+
previous = previous + ll + tmp_out_
|
| 200 |
+
|
| 201 |
+
return outputs
|
| 202 |
+
|
| 203 |
+
|
| 204 |
+
class ResNetDepth(nn.Module):
|
| 205 |
+
|
| 206 |
+
def __init__(self, block=Bottleneck, layers=[3, 8, 36, 3], num_classes=68):
|
| 207 |
+
self.inplanes = 64
|
| 208 |
+
super(ResNetDepth, self).__init__()
|
| 209 |
+
self.conv1 = nn.Conv2d(3 + 68, 64, kernel_size=7, stride=2, padding=3,
|
| 210 |
+
bias=False)
|
| 211 |
+
self.bn1 = nn.BatchNorm2d(64)
|
| 212 |
+
self.relu = nn.ReLU(inplace=True)
|
| 213 |
+
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
|
| 214 |
+
self.layer1 = self._make_layer(block, 64, layers[0])
|
| 215 |
+
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
|
| 216 |
+
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
|
| 217 |
+
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
|
| 218 |
+
self.avgpool = nn.AvgPool2d(7)
|
| 219 |
+
self.fc = nn.Linear(512 * block.expansion, num_classes)
|
| 220 |
+
|
| 221 |
+
for m in self.modules():
|
| 222 |
+
if isinstance(m, nn.Conv2d):
|
| 223 |
+
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
|
| 224 |
+
m.weight.data.normal_(0, math.sqrt(2. / n))
|
| 225 |
+
elif isinstance(m, nn.BatchNorm2d):
|
| 226 |
+
m.weight.data.fill_(1)
|
| 227 |
+
m.bias.data.zero_()
|
| 228 |
+
|
| 229 |
+
def _make_layer(self, block, planes, blocks, stride=1):
|
| 230 |
+
downsample = None
|
| 231 |
+
if stride != 1 or self.inplanes != planes * block.expansion:
|
| 232 |
+
downsample = nn.Sequential(
|
| 233 |
+
nn.Conv2d(self.inplanes, planes * block.expansion,
|
| 234 |
+
kernel_size=1, stride=stride, bias=False),
|
| 235 |
+
nn.BatchNorm2d(planes * block.expansion),
|
| 236 |
+
)
|
| 237 |
+
|
| 238 |
+
layers = []
|
| 239 |
+
layers.append(block(self.inplanes, planes, stride, downsample))
|
| 240 |
+
self.inplanes = planes * block.expansion
|
| 241 |
+
for i in range(1, blocks):
|
| 242 |
+
layers.append(block(self.inplanes, planes))
|
| 243 |
+
|
| 244 |
+
return nn.Sequential(*layers)
|
| 245 |
+
|
| 246 |
+
def forward(self, x):
|
| 247 |
+
x = self.conv1(x)
|
| 248 |
+
x = self.bn1(x)
|
| 249 |
+
x = self.relu(x)
|
| 250 |
+
x = self.maxpool(x)
|
| 251 |
+
|
| 252 |
+
x = self.layer1(x)
|
| 253 |
+
x = self.layer2(x)
|
| 254 |
+
x = self.layer3(x)
|
| 255 |
+
x = self.layer4(x)
|
| 256 |
+
|
| 257 |
+
x = self.avgpool(x)
|
| 258 |
+
x = x.view(x.size(0), -1)
|
| 259 |
+
x = self.fc(x)
|
| 260 |
+
|
| 261 |
+
return x
|
musetalk/utils/face_detection/utils.py
ADDED
|
@@ -0,0 +1,313 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from __future__ import print_function
|
| 2 |
+
import os
|
| 3 |
+
import sys
|
| 4 |
+
import time
|
| 5 |
+
import torch
|
| 6 |
+
import math
|
| 7 |
+
import numpy as np
|
| 8 |
+
import cv2
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def _gaussian(
|
| 12 |
+
size=3, sigma=0.25, amplitude=1, normalize=False, width=None,
|
| 13 |
+
height=None, sigma_horz=None, sigma_vert=None, mean_horz=0.5,
|
| 14 |
+
mean_vert=0.5):
|
| 15 |
+
# handle some defaults
|
| 16 |
+
if width is None:
|
| 17 |
+
width = size
|
| 18 |
+
if height is None:
|
| 19 |
+
height = size
|
| 20 |
+
if sigma_horz is None:
|
| 21 |
+
sigma_horz = sigma
|
| 22 |
+
if sigma_vert is None:
|
| 23 |
+
sigma_vert = sigma
|
| 24 |
+
center_x = mean_horz * width + 0.5
|
| 25 |
+
center_y = mean_vert * height + 0.5
|
| 26 |
+
gauss = np.empty((height, width), dtype=np.float32)
|
| 27 |
+
# generate kernel
|
| 28 |
+
for i in range(height):
|
| 29 |
+
for j in range(width):
|
| 30 |
+
gauss[i][j] = amplitude * math.exp(-(math.pow((j + 1 - center_x) / (
|
| 31 |
+
sigma_horz * width), 2) / 2.0 + math.pow((i + 1 - center_y) / (sigma_vert * height), 2) / 2.0))
|
| 32 |
+
if normalize:
|
| 33 |
+
gauss = gauss / np.sum(gauss)
|
| 34 |
+
return gauss
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def draw_gaussian(image, point, sigma):
|
| 38 |
+
# Check if the gaussian is inside
|
| 39 |
+
ul = [math.floor(point[0] - 3 * sigma), math.floor(point[1] - 3 * sigma)]
|
| 40 |
+
br = [math.floor(point[0] + 3 * sigma), math.floor(point[1] + 3 * sigma)]
|
| 41 |
+
if (ul[0] > image.shape[1] or ul[1] > image.shape[0] or br[0] < 1 or br[1] < 1):
|
| 42 |
+
return image
|
| 43 |
+
size = 6 * sigma + 1
|
| 44 |
+
g = _gaussian(size)
|
| 45 |
+
g_x = [int(max(1, -ul[0])), int(min(br[0], image.shape[1])) - int(max(1, ul[0])) + int(max(1, -ul[0]))]
|
| 46 |
+
g_y = [int(max(1, -ul[1])), int(min(br[1], image.shape[0])) - int(max(1, ul[1])) + int(max(1, -ul[1]))]
|
| 47 |
+
img_x = [int(max(1, ul[0])), int(min(br[0], image.shape[1]))]
|
| 48 |
+
img_y = [int(max(1, ul[1])), int(min(br[1], image.shape[0]))]
|
| 49 |
+
assert (g_x[0] > 0 and g_y[1] > 0)
|
| 50 |
+
image[img_y[0] - 1:img_y[1], img_x[0] - 1:img_x[1]
|
| 51 |
+
] = image[img_y[0] - 1:img_y[1], img_x[0] - 1:img_x[1]] + g[g_y[0] - 1:g_y[1], g_x[0] - 1:g_x[1]]
|
| 52 |
+
image[image > 1] = 1
|
| 53 |
+
return image
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def transform(point, center, scale, resolution, invert=False):
|
| 57 |
+
"""Generate and affine transformation matrix.
|
| 58 |
+
|
| 59 |
+
Given a set of points, a center, a scale and a targer resolution, the
|
| 60 |
+
function generates and affine transformation matrix. If invert is ``True``
|
| 61 |
+
it will produce the inverse transformation.
|
| 62 |
+
|
| 63 |
+
Arguments:
|
| 64 |
+
point {torch.tensor} -- the input 2D point
|
| 65 |
+
center {torch.tensor or numpy.array} -- the center around which to perform the transformations
|
| 66 |
+
scale {float} -- the scale of the face/object
|
| 67 |
+
resolution {float} -- the output resolution
|
| 68 |
+
|
| 69 |
+
Keyword Arguments:
|
| 70 |
+
invert {bool} -- define wherever the function should produce the direct or the
|
| 71 |
+
inverse transformation matrix (default: {False})
|
| 72 |
+
"""
|
| 73 |
+
_pt = torch.ones(3)
|
| 74 |
+
_pt[0] = point[0]
|
| 75 |
+
_pt[1] = point[1]
|
| 76 |
+
|
| 77 |
+
h = 200.0 * scale
|
| 78 |
+
t = torch.eye(3)
|
| 79 |
+
t[0, 0] = resolution / h
|
| 80 |
+
t[1, 1] = resolution / h
|
| 81 |
+
t[0, 2] = resolution * (-center[0] / h + 0.5)
|
| 82 |
+
t[1, 2] = resolution * (-center[1] / h + 0.5)
|
| 83 |
+
|
| 84 |
+
if invert:
|
| 85 |
+
t = torch.inverse(t)
|
| 86 |
+
|
| 87 |
+
new_point = (torch.matmul(t, _pt))[0:2]
|
| 88 |
+
|
| 89 |
+
return new_point.int()
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
def crop(image, center, scale, resolution=256.0):
|
| 93 |
+
"""Center crops an image or set of heatmaps
|
| 94 |
+
|
| 95 |
+
Arguments:
|
| 96 |
+
image {numpy.array} -- an rgb image
|
| 97 |
+
center {numpy.array} -- the center of the object, usually the same as of the bounding box
|
| 98 |
+
scale {float} -- scale of the face
|
| 99 |
+
|
| 100 |
+
Keyword Arguments:
|
| 101 |
+
resolution {float} -- the size of the output cropped image (default: {256.0})
|
| 102 |
+
|
| 103 |
+
Returns:
|
| 104 |
+
[type] -- [description]
|
| 105 |
+
""" # Crop around the center point
|
| 106 |
+
""" Crops the image around the center. Input is expected to be an np.ndarray """
|
| 107 |
+
ul = transform([1, 1], center, scale, resolution, True)
|
| 108 |
+
br = transform([resolution, resolution], center, scale, resolution, True)
|
| 109 |
+
# pad = math.ceil(torch.norm((ul - br).float()) / 2.0 - (br[0] - ul[0]) / 2.0)
|
| 110 |
+
if image.ndim > 2:
|
| 111 |
+
newDim = np.array([br[1] - ul[1], br[0] - ul[0],
|
| 112 |
+
image.shape[2]], dtype=np.int32)
|
| 113 |
+
newImg = np.zeros(newDim, dtype=np.uint8)
|
| 114 |
+
else:
|
| 115 |
+
newDim = np.array([br[1] - ul[1], br[0] - ul[0]], dtype=np.int)
|
| 116 |
+
newImg = np.zeros(newDim, dtype=np.uint8)
|
| 117 |
+
ht = image.shape[0]
|
| 118 |
+
wd = image.shape[1]
|
| 119 |
+
newX = np.array(
|
| 120 |
+
[max(1, -ul[0] + 1), min(br[0], wd) - ul[0]], dtype=np.int32)
|
| 121 |
+
newY = np.array(
|
| 122 |
+
[max(1, -ul[1] + 1), min(br[1], ht) - ul[1]], dtype=np.int32)
|
| 123 |
+
oldX = np.array([max(1, ul[0] + 1), min(br[0], wd)], dtype=np.int32)
|
| 124 |
+
oldY = np.array([max(1, ul[1] + 1), min(br[1], ht)], dtype=np.int32)
|
| 125 |
+
newImg[newY[0] - 1:newY[1], newX[0] - 1:newX[1]
|
| 126 |
+
] = image[oldY[0] - 1:oldY[1], oldX[0] - 1:oldX[1], :]
|
| 127 |
+
newImg = cv2.resize(newImg, dsize=(int(resolution), int(resolution)),
|
| 128 |
+
interpolation=cv2.INTER_LINEAR)
|
| 129 |
+
return newImg
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
def get_preds_fromhm(hm, center=None, scale=None):
|
| 133 |
+
"""Obtain (x,y) coordinates given a set of N heatmaps. If the center
|
| 134 |
+
and the scale is provided the function will return the points also in
|
| 135 |
+
the original coordinate frame.
|
| 136 |
+
|
| 137 |
+
Arguments:
|
| 138 |
+
hm {torch.tensor} -- the predicted heatmaps, of shape [B, N, W, H]
|
| 139 |
+
|
| 140 |
+
Keyword Arguments:
|
| 141 |
+
center {torch.tensor} -- the center of the bounding box (default: {None})
|
| 142 |
+
scale {float} -- face scale (default: {None})
|
| 143 |
+
"""
|
| 144 |
+
max, idx = torch.max(
|
| 145 |
+
hm.view(hm.size(0), hm.size(1), hm.size(2) * hm.size(3)), 2)
|
| 146 |
+
idx += 1
|
| 147 |
+
preds = idx.view(idx.size(0), idx.size(1), 1).repeat(1, 1, 2).float()
|
| 148 |
+
preds[..., 0].apply_(lambda x: (x - 1) % hm.size(3) + 1)
|
| 149 |
+
preds[..., 1].add_(-1).div_(hm.size(2)).floor_().add_(1)
|
| 150 |
+
|
| 151 |
+
for i in range(preds.size(0)):
|
| 152 |
+
for j in range(preds.size(1)):
|
| 153 |
+
hm_ = hm[i, j, :]
|
| 154 |
+
pX, pY = int(preds[i, j, 0]) - 1, int(preds[i, j, 1]) - 1
|
| 155 |
+
if pX > 0 and pX < 63 and pY > 0 and pY < 63:
|
| 156 |
+
diff = torch.FloatTensor(
|
| 157 |
+
[hm_[pY, pX + 1] - hm_[pY, pX - 1],
|
| 158 |
+
hm_[pY + 1, pX] - hm_[pY - 1, pX]])
|
| 159 |
+
preds[i, j].add_(diff.sign_().mul_(.25))
|
| 160 |
+
|
| 161 |
+
preds.add_(-.5)
|
| 162 |
+
|
| 163 |
+
preds_orig = torch.zeros(preds.size())
|
| 164 |
+
if center is not None and scale is not None:
|
| 165 |
+
for i in range(hm.size(0)):
|
| 166 |
+
for j in range(hm.size(1)):
|
| 167 |
+
preds_orig[i, j] = transform(
|
| 168 |
+
preds[i, j], center, scale, hm.size(2), True)
|
| 169 |
+
|
| 170 |
+
return preds, preds_orig
|
| 171 |
+
|
| 172 |
+
def get_preds_fromhm_batch(hm, centers=None, scales=None):
|
| 173 |
+
"""Obtain (x,y) coordinates given a set of N heatmaps. If the centers
|
| 174 |
+
and the scales is provided the function will return the points also in
|
| 175 |
+
the original coordinate frame.
|
| 176 |
+
|
| 177 |
+
Arguments:
|
| 178 |
+
hm {torch.tensor} -- the predicted heatmaps, of shape [B, N, W, H]
|
| 179 |
+
|
| 180 |
+
Keyword Arguments:
|
| 181 |
+
centers {torch.tensor} -- the centers of the bounding box (default: {None})
|
| 182 |
+
scales {float} -- face scales (default: {None})
|
| 183 |
+
"""
|
| 184 |
+
max, idx = torch.max(
|
| 185 |
+
hm.view(hm.size(0), hm.size(1), hm.size(2) * hm.size(3)), 2)
|
| 186 |
+
idx += 1
|
| 187 |
+
preds = idx.view(idx.size(0), idx.size(1), 1).repeat(1, 1, 2).float()
|
| 188 |
+
preds[..., 0].apply_(lambda x: (x - 1) % hm.size(3) + 1)
|
| 189 |
+
preds[..., 1].add_(-1).div_(hm.size(2)).floor_().add_(1)
|
| 190 |
+
|
| 191 |
+
for i in range(preds.size(0)):
|
| 192 |
+
for j in range(preds.size(1)):
|
| 193 |
+
hm_ = hm[i, j, :]
|
| 194 |
+
pX, pY = int(preds[i, j, 0]) - 1, int(preds[i, j, 1]) - 1
|
| 195 |
+
if pX > 0 and pX < 63 and pY > 0 and pY < 63:
|
| 196 |
+
diff = torch.FloatTensor(
|
| 197 |
+
[hm_[pY, pX + 1] - hm_[pY, pX - 1],
|
| 198 |
+
hm_[pY + 1, pX] - hm_[pY - 1, pX]])
|
| 199 |
+
preds[i, j].add_(diff.sign_().mul_(.25))
|
| 200 |
+
|
| 201 |
+
preds.add_(-.5)
|
| 202 |
+
|
| 203 |
+
preds_orig = torch.zeros(preds.size())
|
| 204 |
+
if centers is not None and scales is not None:
|
| 205 |
+
for i in range(hm.size(0)):
|
| 206 |
+
for j in range(hm.size(1)):
|
| 207 |
+
preds_orig[i, j] = transform(
|
| 208 |
+
preds[i, j], centers[i], scales[i], hm.size(2), True)
|
| 209 |
+
|
| 210 |
+
return preds, preds_orig
|
| 211 |
+
|
| 212 |
+
def shuffle_lr(parts, pairs=None):
|
| 213 |
+
"""Shuffle the points left-right according to the axis of symmetry
|
| 214 |
+
of the object.
|
| 215 |
+
|
| 216 |
+
Arguments:
|
| 217 |
+
parts {torch.tensor} -- a 3D or 4D object containing the
|
| 218 |
+
heatmaps.
|
| 219 |
+
|
| 220 |
+
Keyword Arguments:
|
| 221 |
+
pairs {list of integers} -- [order of the flipped points] (default: {None})
|
| 222 |
+
"""
|
| 223 |
+
if pairs is None:
|
| 224 |
+
pairs = [16, 15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0,
|
| 225 |
+
26, 25, 24, 23, 22, 21, 20, 19, 18, 17, 27, 28, 29, 30, 35,
|
| 226 |
+
34, 33, 32, 31, 45, 44, 43, 42, 47, 46, 39, 38, 37, 36, 41,
|
| 227 |
+
40, 54, 53, 52, 51, 50, 49, 48, 59, 58, 57, 56, 55, 64, 63,
|
| 228 |
+
62, 61, 60, 67, 66, 65]
|
| 229 |
+
if parts.ndimension() == 3:
|
| 230 |
+
parts = parts[pairs, ...]
|
| 231 |
+
else:
|
| 232 |
+
parts = parts[:, pairs, ...]
|
| 233 |
+
|
| 234 |
+
return parts
|
| 235 |
+
|
| 236 |
+
|
| 237 |
+
def flip(tensor, is_label=False):
|
| 238 |
+
"""Flip an image or a set of heatmaps left-right
|
| 239 |
+
|
| 240 |
+
Arguments:
|
| 241 |
+
tensor {numpy.array or torch.tensor} -- [the input image or heatmaps]
|
| 242 |
+
|
| 243 |
+
Keyword Arguments:
|
| 244 |
+
is_label {bool} -- [denote wherever the input is an image or a set of heatmaps ] (default: {False})
|
| 245 |
+
"""
|
| 246 |
+
if not torch.is_tensor(tensor):
|
| 247 |
+
tensor = torch.from_numpy(tensor)
|
| 248 |
+
|
| 249 |
+
if is_label:
|
| 250 |
+
tensor = shuffle_lr(tensor).flip(tensor.ndimension() - 1)
|
| 251 |
+
else:
|
| 252 |
+
tensor = tensor.flip(tensor.ndimension() - 1)
|
| 253 |
+
|
| 254 |
+
return tensor
|
| 255 |
+
|
| 256 |
+
# From pyzolib/paths.py (https://bitbucket.org/pyzo/pyzolib/src/tip/paths.py)
|
| 257 |
+
|
| 258 |
+
|
| 259 |
+
def appdata_dir(appname=None, roaming=False):
|
| 260 |
+
""" appdata_dir(appname=None, roaming=False)
|
| 261 |
+
|
| 262 |
+
Get the path to the application directory, where applications are allowed
|
| 263 |
+
to write user specific files (e.g. configurations). For non-user specific
|
| 264 |
+
data, consider using common_appdata_dir().
|
| 265 |
+
If appname is given, a subdir is appended (and created if necessary).
|
| 266 |
+
If roaming is True, will prefer a roaming directory (Windows Vista/7).
|
| 267 |
+
"""
|
| 268 |
+
|
| 269 |
+
# Define default user directory
|
| 270 |
+
userDir = os.getenv('FACEALIGNMENT_USERDIR', None)
|
| 271 |
+
if userDir is None:
|
| 272 |
+
userDir = os.path.expanduser('~')
|
| 273 |
+
if not os.path.isdir(userDir): # pragma: no cover
|
| 274 |
+
userDir = '/var/tmp' # issue #54
|
| 275 |
+
|
| 276 |
+
# Get system app data dir
|
| 277 |
+
path = None
|
| 278 |
+
if sys.platform.startswith('win'):
|
| 279 |
+
path1, path2 = os.getenv('LOCALAPPDATA'), os.getenv('APPDATA')
|
| 280 |
+
path = (path2 or path1) if roaming else (path1 or path2)
|
| 281 |
+
elif sys.platform.startswith('darwin'):
|
| 282 |
+
path = os.path.join(userDir, 'Library', 'Application Support')
|
| 283 |
+
# On Linux and as fallback
|
| 284 |
+
if not (path and os.path.isdir(path)):
|
| 285 |
+
path = userDir
|
| 286 |
+
|
| 287 |
+
# Maybe we should store things local to the executable (in case of a
|
| 288 |
+
# portable distro or a frozen application that wants to be portable)
|
| 289 |
+
prefix = sys.prefix
|
| 290 |
+
if getattr(sys, 'frozen', None):
|
| 291 |
+
prefix = os.path.abspath(os.path.dirname(sys.executable))
|
| 292 |
+
for reldir in ('settings', '../settings'):
|
| 293 |
+
localpath = os.path.abspath(os.path.join(prefix, reldir))
|
| 294 |
+
if os.path.isdir(localpath): # pragma: no cover
|
| 295 |
+
try:
|
| 296 |
+
open(os.path.join(localpath, 'test.write'), 'wb').close()
|
| 297 |
+
os.remove(os.path.join(localpath, 'test.write'))
|
| 298 |
+
except IOError:
|
| 299 |
+
pass # We cannot write in this directory
|
| 300 |
+
else:
|
| 301 |
+
path = localpath
|
| 302 |
+
break
|
| 303 |
+
|
| 304 |
+
# Get path specific for this app
|
| 305 |
+
if appname:
|
| 306 |
+
if path == userDir:
|
| 307 |
+
appname = '.' + appname.lstrip('.') # Make it a hidden directory
|
| 308 |
+
path = os.path.join(path, appname)
|
| 309 |
+
if not os.path.isdir(path): # pragma: no cover
|
| 310 |
+
os.mkdir(path)
|
| 311 |
+
|
| 312 |
+
# Done
|
| 313 |
+
return path
|
musetalk/utils/face_parsing/__init__.py
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import time
|
| 3 |
+
import os
|
| 4 |
+
import cv2
|
| 5 |
+
import numpy as np
|
| 6 |
+
from PIL import Image
|
| 7 |
+
from .model import BiSeNet
|
| 8 |
+
import torchvision.transforms as transforms
|
| 9 |
+
|
| 10 |
+
class FaceParsing():
|
| 11 |
+
def __init__(self):
|
| 12 |
+
self.net = self.model_init()
|
| 13 |
+
self.preprocess = self.image_preprocess()
|
| 14 |
+
|
| 15 |
+
def model_init(self,
|
| 16 |
+
resnet_path='./models/face-parse-bisent/resnet18-5c106cde.pth',
|
| 17 |
+
model_pth='./models/face-parse-bisent/79999_iter.pth'):
|
| 18 |
+
net = BiSeNet(resnet_path)
|
| 19 |
+
if torch.cuda.is_available():
|
| 20 |
+
net.cuda()
|
| 21 |
+
net.load_state_dict(torch.load(model_pth))
|
| 22 |
+
else:
|
| 23 |
+
net.load_state_dict(torch.load(model_pth, map_location=torch.device('cpu')))
|
| 24 |
+
net.eval()
|
| 25 |
+
return net
|
| 26 |
+
|
| 27 |
+
def image_preprocess(self):
|
| 28 |
+
return transforms.Compose([
|
| 29 |
+
transforms.ToTensor(),
|
| 30 |
+
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),
|
| 31 |
+
])
|
| 32 |
+
|
| 33 |
+
def __call__(self, image, size=(512, 512)):
|
| 34 |
+
if isinstance(image, str):
|
| 35 |
+
image = Image.open(image)
|
| 36 |
+
|
| 37 |
+
width, height = image.size
|
| 38 |
+
with torch.no_grad():
|
| 39 |
+
image = image.resize(size, Image.BILINEAR)
|
| 40 |
+
img = self.preprocess(image)
|
| 41 |
+
if torch.cuda.is_available():
|
| 42 |
+
img = torch.unsqueeze(img, 0).cuda()
|
| 43 |
+
else:
|
| 44 |
+
img = torch.unsqueeze(img, 0)
|
| 45 |
+
out = self.net(img)[0]
|
| 46 |
+
parsing = out.squeeze(0).cpu().numpy().argmax(0)
|
| 47 |
+
parsing[np.where(parsing>13)] = 0
|
| 48 |
+
parsing[np.where(parsing>=1)] = 255
|
| 49 |
+
parsing = Image.fromarray(parsing.astype(np.uint8))
|
| 50 |
+
return parsing
|
| 51 |
+
|
| 52 |
+
if __name__ == "__main__":
|
| 53 |
+
fp = FaceParsing()
|
| 54 |
+
segmap = fp('154_small.png')
|
| 55 |
+
segmap.save('res.png')
|
| 56 |
+
|
musetalk/utils/face_parsing/model.py
ADDED
|
@@ -0,0 +1,283 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/python
|
| 2 |
+
# -*- encoding: utf-8 -*-
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
import torch.nn.functional as F
|
| 8 |
+
import torchvision
|
| 9 |
+
|
| 10 |
+
from .resnet import Resnet18
|
| 11 |
+
# from modules.bn import InPlaceABNSync as BatchNorm2d
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class ConvBNReLU(nn.Module):
|
| 15 |
+
def __init__(self, in_chan, out_chan, ks=3, stride=1, padding=1, *args, **kwargs):
|
| 16 |
+
super(ConvBNReLU, self).__init__()
|
| 17 |
+
self.conv = nn.Conv2d(in_chan,
|
| 18 |
+
out_chan,
|
| 19 |
+
kernel_size = ks,
|
| 20 |
+
stride = stride,
|
| 21 |
+
padding = padding,
|
| 22 |
+
bias = False)
|
| 23 |
+
self.bn = nn.BatchNorm2d(out_chan)
|
| 24 |
+
self.init_weight()
|
| 25 |
+
|
| 26 |
+
def forward(self, x):
|
| 27 |
+
x = self.conv(x)
|
| 28 |
+
x = F.relu(self.bn(x))
|
| 29 |
+
return x
|
| 30 |
+
|
| 31 |
+
def init_weight(self):
|
| 32 |
+
for ly in self.children():
|
| 33 |
+
if isinstance(ly, nn.Conv2d):
|
| 34 |
+
nn.init.kaiming_normal_(ly.weight, a=1)
|
| 35 |
+
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
|
| 36 |
+
|
| 37 |
+
class BiSeNetOutput(nn.Module):
|
| 38 |
+
def __init__(self, in_chan, mid_chan, n_classes, *args, **kwargs):
|
| 39 |
+
super(BiSeNetOutput, self).__init__()
|
| 40 |
+
self.conv = ConvBNReLU(in_chan, mid_chan, ks=3, stride=1, padding=1)
|
| 41 |
+
self.conv_out = nn.Conv2d(mid_chan, n_classes, kernel_size=1, bias=False)
|
| 42 |
+
self.init_weight()
|
| 43 |
+
|
| 44 |
+
def forward(self, x):
|
| 45 |
+
x = self.conv(x)
|
| 46 |
+
x = self.conv_out(x)
|
| 47 |
+
return x
|
| 48 |
+
|
| 49 |
+
def init_weight(self):
|
| 50 |
+
for ly in self.children():
|
| 51 |
+
if isinstance(ly, nn.Conv2d):
|
| 52 |
+
nn.init.kaiming_normal_(ly.weight, a=1)
|
| 53 |
+
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
|
| 54 |
+
|
| 55 |
+
def get_params(self):
|
| 56 |
+
wd_params, nowd_params = [], []
|
| 57 |
+
for name, module in self.named_modules():
|
| 58 |
+
if isinstance(module, nn.Linear) or isinstance(module, nn.Conv2d):
|
| 59 |
+
wd_params.append(module.weight)
|
| 60 |
+
if not module.bias is None:
|
| 61 |
+
nowd_params.append(module.bias)
|
| 62 |
+
elif isinstance(module, nn.BatchNorm2d):
|
| 63 |
+
nowd_params += list(module.parameters())
|
| 64 |
+
return wd_params, nowd_params
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
class AttentionRefinementModule(nn.Module):
|
| 68 |
+
def __init__(self, in_chan, out_chan, *args, **kwargs):
|
| 69 |
+
super(AttentionRefinementModule, self).__init__()
|
| 70 |
+
self.conv = ConvBNReLU(in_chan, out_chan, ks=3, stride=1, padding=1)
|
| 71 |
+
self.conv_atten = nn.Conv2d(out_chan, out_chan, kernel_size= 1, bias=False)
|
| 72 |
+
self.bn_atten = nn.BatchNorm2d(out_chan)
|
| 73 |
+
self.sigmoid_atten = nn.Sigmoid()
|
| 74 |
+
self.init_weight()
|
| 75 |
+
|
| 76 |
+
def forward(self, x):
|
| 77 |
+
feat = self.conv(x)
|
| 78 |
+
atten = F.avg_pool2d(feat, feat.size()[2:])
|
| 79 |
+
atten = self.conv_atten(atten)
|
| 80 |
+
atten = self.bn_atten(atten)
|
| 81 |
+
atten = self.sigmoid_atten(atten)
|
| 82 |
+
out = torch.mul(feat, atten)
|
| 83 |
+
return out
|
| 84 |
+
|
| 85 |
+
def init_weight(self):
|
| 86 |
+
for ly in self.children():
|
| 87 |
+
if isinstance(ly, nn.Conv2d):
|
| 88 |
+
nn.init.kaiming_normal_(ly.weight, a=1)
|
| 89 |
+
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
class ContextPath(nn.Module):
|
| 93 |
+
def __init__(self, resnet_path, *args, **kwargs):
|
| 94 |
+
super(ContextPath, self).__init__()
|
| 95 |
+
self.resnet = Resnet18(resnet_path)
|
| 96 |
+
self.arm16 = AttentionRefinementModule(256, 128)
|
| 97 |
+
self.arm32 = AttentionRefinementModule(512, 128)
|
| 98 |
+
self.conv_head32 = ConvBNReLU(128, 128, ks=3, stride=1, padding=1)
|
| 99 |
+
self.conv_head16 = ConvBNReLU(128, 128, ks=3, stride=1, padding=1)
|
| 100 |
+
self.conv_avg = ConvBNReLU(512, 128, ks=1, stride=1, padding=0)
|
| 101 |
+
|
| 102 |
+
self.init_weight()
|
| 103 |
+
|
| 104 |
+
def forward(self, x):
|
| 105 |
+
H0, W0 = x.size()[2:]
|
| 106 |
+
feat8, feat16, feat32 = self.resnet(x)
|
| 107 |
+
H8, W8 = feat8.size()[2:]
|
| 108 |
+
H16, W16 = feat16.size()[2:]
|
| 109 |
+
H32, W32 = feat32.size()[2:]
|
| 110 |
+
|
| 111 |
+
avg = F.avg_pool2d(feat32, feat32.size()[2:])
|
| 112 |
+
avg = self.conv_avg(avg)
|
| 113 |
+
avg_up = F.interpolate(avg, (H32, W32), mode='nearest')
|
| 114 |
+
|
| 115 |
+
feat32_arm = self.arm32(feat32)
|
| 116 |
+
feat32_sum = feat32_arm + avg_up
|
| 117 |
+
feat32_up = F.interpolate(feat32_sum, (H16, W16), mode='nearest')
|
| 118 |
+
feat32_up = self.conv_head32(feat32_up)
|
| 119 |
+
|
| 120 |
+
feat16_arm = self.arm16(feat16)
|
| 121 |
+
feat16_sum = feat16_arm + feat32_up
|
| 122 |
+
feat16_up = F.interpolate(feat16_sum, (H8, W8), mode='nearest')
|
| 123 |
+
feat16_up = self.conv_head16(feat16_up)
|
| 124 |
+
|
| 125 |
+
return feat8, feat16_up, feat32_up # x8, x8, x16
|
| 126 |
+
|
| 127 |
+
def init_weight(self):
|
| 128 |
+
for ly in self.children():
|
| 129 |
+
if isinstance(ly, nn.Conv2d):
|
| 130 |
+
nn.init.kaiming_normal_(ly.weight, a=1)
|
| 131 |
+
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
|
| 132 |
+
|
| 133 |
+
def get_params(self):
|
| 134 |
+
wd_params, nowd_params = [], []
|
| 135 |
+
for name, module in self.named_modules():
|
| 136 |
+
if isinstance(module, (nn.Linear, nn.Conv2d)):
|
| 137 |
+
wd_params.append(module.weight)
|
| 138 |
+
if not module.bias is None:
|
| 139 |
+
nowd_params.append(module.bias)
|
| 140 |
+
elif isinstance(module, nn.BatchNorm2d):
|
| 141 |
+
nowd_params += list(module.parameters())
|
| 142 |
+
return wd_params, nowd_params
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
### This is not used, since I replace this with the resnet feature with the same size
|
| 146 |
+
class SpatialPath(nn.Module):
|
| 147 |
+
def __init__(self, *args, **kwargs):
|
| 148 |
+
super(SpatialPath, self).__init__()
|
| 149 |
+
self.conv1 = ConvBNReLU(3, 64, ks=7, stride=2, padding=3)
|
| 150 |
+
self.conv2 = ConvBNReLU(64, 64, ks=3, stride=2, padding=1)
|
| 151 |
+
self.conv3 = ConvBNReLU(64, 64, ks=3, stride=2, padding=1)
|
| 152 |
+
self.conv_out = ConvBNReLU(64, 128, ks=1, stride=1, padding=0)
|
| 153 |
+
self.init_weight()
|
| 154 |
+
|
| 155 |
+
def forward(self, x):
|
| 156 |
+
feat = self.conv1(x)
|
| 157 |
+
feat = self.conv2(feat)
|
| 158 |
+
feat = self.conv3(feat)
|
| 159 |
+
feat = self.conv_out(feat)
|
| 160 |
+
return feat
|
| 161 |
+
|
| 162 |
+
def init_weight(self):
|
| 163 |
+
for ly in self.children():
|
| 164 |
+
if isinstance(ly, nn.Conv2d):
|
| 165 |
+
nn.init.kaiming_normal_(ly.weight, a=1)
|
| 166 |
+
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
|
| 167 |
+
|
| 168 |
+
def get_params(self):
|
| 169 |
+
wd_params, nowd_params = [], []
|
| 170 |
+
for name, module in self.named_modules():
|
| 171 |
+
if isinstance(module, nn.Linear) or isinstance(module, nn.Conv2d):
|
| 172 |
+
wd_params.append(module.weight)
|
| 173 |
+
if not module.bias is None:
|
| 174 |
+
nowd_params.append(module.bias)
|
| 175 |
+
elif isinstance(module, nn.BatchNorm2d):
|
| 176 |
+
nowd_params += list(module.parameters())
|
| 177 |
+
return wd_params, nowd_params
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
class FeatureFusionModule(nn.Module):
|
| 181 |
+
def __init__(self, in_chan, out_chan, *args, **kwargs):
|
| 182 |
+
super(FeatureFusionModule, self).__init__()
|
| 183 |
+
self.convblk = ConvBNReLU(in_chan, out_chan, ks=1, stride=1, padding=0)
|
| 184 |
+
self.conv1 = nn.Conv2d(out_chan,
|
| 185 |
+
out_chan//4,
|
| 186 |
+
kernel_size = 1,
|
| 187 |
+
stride = 1,
|
| 188 |
+
padding = 0,
|
| 189 |
+
bias = False)
|
| 190 |
+
self.conv2 = nn.Conv2d(out_chan//4,
|
| 191 |
+
out_chan,
|
| 192 |
+
kernel_size = 1,
|
| 193 |
+
stride = 1,
|
| 194 |
+
padding = 0,
|
| 195 |
+
bias = False)
|
| 196 |
+
self.relu = nn.ReLU(inplace=True)
|
| 197 |
+
self.sigmoid = nn.Sigmoid()
|
| 198 |
+
self.init_weight()
|
| 199 |
+
|
| 200 |
+
def forward(self, fsp, fcp):
|
| 201 |
+
fcat = torch.cat([fsp, fcp], dim=1)
|
| 202 |
+
feat = self.convblk(fcat)
|
| 203 |
+
atten = F.avg_pool2d(feat, feat.size()[2:])
|
| 204 |
+
atten = self.conv1(atten)
|
| 205 |
+
atten = self.relu(atten)
|
| 206 |
+
atten = self.conv2(atten)
|
| 207 |
+
atten = self.sigmoid(atten)
|
| 208 |
+
feat_atten = torch.mul(feat, atten)
|
| 209 |
+
feat_out = feat_atten + feat
|
| 210 |
+
return feat_out
|
| 211 |
+
|
| 212 |
+
def init_weight(self):
|
| 213 |
+
for ly in self.children():
|
| 214 |
+
if isinstance(ly, nn.Conv2d):
|
| 215 |
+
nn.init.kaiming_normal_(ly.weight, a=1)
|
| 216 |
+
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
|
| 217 |
+
|
| 218 |
+
def get_params(self):
|
| 219 |
+
wd_params, nowd_params = [], []
|
| 220 |
+
for name, module in self.named_modules():
|
| 221 |
+
if isinstance(module, nn.Linear) or isinstance(module, nn.Conv2d):
|
| 222 |
+
wd_params.append(module.weight)
|
| 223 |
+
if not module.bias is None:
|
| 224 |
+
nowd_params.append(module.bias)
|
| 225 |
+
elif isinstance(module, nn.BatchNorm2d):
|
| 226 |
+
nowd_params += list(module.parameters())
|
| 227 |
+
return wd_params, nowd_params
|
| 228 |
+
|
| 229 |
+
|
| 230 |
+
class BiSeNet(nn.Module):
|
| 231 |
+
def __init__(self, resnet_path='models/resnet18-5c106cde.pth', n_classes=19, *args, **kwargs):
|
| 232 |
+
super(BiSeNet, self).__init__()
|
| 233 |
+
self.cp = ContextPath(resnet_path)
|
| 234 |
+
## here self.sp is deleted
|
| 235 |
+
self.ffm = FeatureFusionModule(256, 256)
|
| 236 |
+
self.conv_out = BiSeNetOutput(256, 256, n_classes)
|
| 237 |
+
self.conv_out16 = BiSeNetOutput(128, 64, n_classes)
|
| 238 |
+
self.conv_out32 = BiSeNetOutput(128, 64, n_classes)
|
| 239 |
+
self.init_weight()
|
| 240 |
+
|
| 241 |
+
def forward(self, x):
|
| 242 |
+
H, W = x.size()[2:]
|
| 243 |
+
feat_res8, feat_cp8, feat_cp16 = self.cp(x) # here return res3b1 feature
|
| 244 |
+
feat_sp = feat_res8 # use res3b1 feature to replace spatial path feature
|
| 245 |
+
feat_fuse = self.ffm(feat_sp, feat_cp8)
|
| 246 |
+
|
| 247 |
+
feat_out = self.conv_out(feat_fuse)
|
| 248 |
+
feat_out16 = self.conv_out16(feat_cp8)
|
| 249 |
+
feat_out32 = self.conv_out32(feat_cp16)
|
| 250 |
+
|
| 251 |
+
feat_out = F.interpolate(feat_out, (H, W), mode='bilinear', align_corners=True)
|
| 252 |
+
feat_out16 = F.interpolate(feat_out16, (H, W), mode='bilinear', align_corners=True)
|
| 253 |
+
feat_out32 = F.interpolate(feat_out32, (H, W), mode='bilinear', align_corners=True)
|
| 254 |
+
return feat_out, feat_out16, feat_out32
|
| 255 |
+
|
| 256 |
+
def init_weight(self):
|
| 257 |
+
for ly in self.children():
|
| 258 |
+
if isinstance(ly, nn.Conv2d):
|
| 259 |
+
nn.init.kaiming_normal_(ly.weight, a=1)
|
| 260 |
+
if not ly.bias is None: nn.init.constant_(ly.bias, 0)
|
| 261 |
+
|
| 262 |
+
def get_params(self):
|
| 263 |
+
wd_params, nowd_params, lr_mul_wd_params, lr_mul_nowd_params = [], [], [], []
|
| 264 |
+
for name, child in self.named_children():
|
| 265 |
+
child_wd_params, child_nowd_params = child.get_params()
|
| 266 |
+
if isinstance(child, FeatureFusionModule) or isinstance(child, BiSeNetOutput):
|
| 267 |
+
lr_mul_wd_params += child_wd_params
|
| 268 |
+
lr_mul_nowd_params += child_nowd_params
|
| 269 |
+
else:
|
| 270 |
+
wd_params += child_wd_params
|
| 271 |
+
nowd_params += child_nowd_params
|
| 272 |
+
return wd_params, nowd_params, lr_mul_wd_params, lr_mul_nowd_params
|
| 273 |
+
|
| 274 |
+
|
| 275 |
+
if __name__ == "__main__":
|
| 276 |
+
net = BiSeNet(19)
|
| 277 |
+
net.cuda()
|
| 278 |
+
net.eval()
|
| 279 |
+
in_ten = torch.randn(16, 3, 640, 480).cuda()
|
| 280 |
+
out, out16, out32 = net(in_ten)
|
| 281 |
+
print(out.shape)
|
| 282 |
+
|
| 283 |
+
net.get_params()
|
musetalk/utils/face_parsing/resnet.py
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/python
|
| 2 |
+
# -*- encoding: utf-8 -*-
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
import torch.utils.model_zoo as modelzoo
|
| 8 |
+
|
| 9 |
+
# from modules.bn import InPlaceABNSync as BatchNorm2d
|
| 10 |
+
|
| 11 |
+
resnet18_url = 'https://download.pytorch.org/models/resnet18-5c106cde.pth'
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def conv3x3(in_planes, out_planes, stride=1):
|
| 15 |
+
"""3x3 convolution with padding"""
|
| 16 |
+
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
|
| 17 |
+
padding=1, bias=False)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class BasicBlock(nn.Module):
|
| 21 |
+
def __init__(self, in_chan, out_chan, stride=1):
|
| 22 |
+
super(BasicBlock, self).__init__()
|
| 23 |
+
self.conv1 = conv3x3(in_chan, out_chan, stride)
|
| 24 |
+
self.bn1 = nn.BatchNorm2d(out_chan)
|
| 25 |
+
self.conv2 = conv3x3(out_chan, out_chan)
|
| 26 |
+
self.bn2 = nn.BatchNorm2d(out_chan)
|
| 27 |
+
self.relu = nn.ReLU(inplace=True)
|
| 28 |
+
self.downsample = None
|
| 29 |
+
if in_chan != out_chan or stride != 1:
|
| 30 |
+
self.downsample = nn.Sequential(
|
| 31 |
+
nn.Conv2d(in_chan, out_chan,
|
| 32 |
+
kernel_size=1, stride=stride, bias=False),
|
| 33 |
+
nn.BatchNorm2d(out_chan),
|
| 34 |
+
)
|
| 35 |
+
|
| 36 |
+
def forward(self, x):
|
| 37 |
+
residual = self.conv1(x)
|
| 38 |
+
residual = F.relu(self.bn1(residual))
|
| 39 |
+
residual = self.conv2(residual)
|
| 40 |
+
residual = self.bn2(residual)
|
| 41 |
+
|
| 42 |
+
shortcut = x
|
| 43 |
+
if self.downsample is not None:
|
| 44 |
+
shortcut = self.downsample(x)
|
| 45 |
+
|
| 46 |
+
out = shortcut + residual
|
| 47 |
+
out = self.relu(out)
|
| 48 |
+
return out
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def create_layer_basic(in_chan, out_chan, bnum, stride=1):
|
| 52 |
+
layers = [BasicBlock(in_chan, out_chan, stride=stride)]
|
| 53 |
+
for i in range(bnum-1):
|
| 54 |
+
layers.append(BasicBlock(out_chan, out_chan, stride=1))
|
| 55 |
+
return nn.Sequential(*layers)
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
class Resnet18(nn.Module):
|
| 59 |
+
def __init__(self, model_path):
|
| 60 |
+
super(Resnet18, self).__init__()
|
| 61 |
+
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
|
| 62 |
+
bias=False)
|
| 63 |
+
self.bn1 = nn.BatchNorm2d(64)
|
| 64 |
+
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
|
| 65 |
+
self.layer1 = create_layer_basic(64, 64, bnum=2, stride=1)
|
| 66 |
+
self.layer2 = create_layer_basic(64, 128, bnum=2, stride=2)
|
| 67 |
+
self.layer3 = create_layer_basic(128, 256, bnum=2, stride=2)
|
| 68 |
+
self.layer4 = create_layer_basic(256, 512, bnum=2, stride=2)
|
| 69 |
+
self.init_weight(model_path)
|
| 70 |
+
|
| 71 |
+
def forward(self, x):
|
| 72 |
+
x = self.conv1(x)
|
| 73 |
+
x = F.relu(self.bn1(x))
|
| 74 |
+
x = self.maxpool(x)
|
| 75 |
+
|
| 76 |
+
x = self.layer1(x)
|
| 77 |
+
feat8 = self.layer2(x) # 1/8
|
| 78 |
+
feat16 = self.layer3(feat8) # 1/16
|
| 79 |
+
feat32 = self.layer4(feat16) # 1/32
|
| 80 |
+
return feat8, feat16, feat32
|
| 81 |
+
|
| 82 |
+
def init_weight(self, model_path):
|
| 83 |
+
state_dict = torch.load(model_path) #modelzoo.load_url(resnet18_url)
|
| 84 |
+
self_state_dict = self.state_dict()
|
| 85 |
+
for k, v in state_dict.items():
|
| 86 |
+
if 'fc' in k: continue
|
| 87 |
+
self_state_dict.update({k: v})
|
| 88 |
+
self.load_state_dict(self_state_dict)
|
| 89 |
+
|
| 90 |
+
def get_params(self):
|
| 91 |
+
wd_params, nowd_params = [], []
|
| 92 |
+
for name, module in self.named_modules():
|
| 93 |
+
if isinstance(module, (nn.Linear, nn.Conv2d)):
|
| 94 |
+
wd_params.append(module.weight)
|
| 95 |
+
if not module.bias is None:
|
| 96 |
+
nowd_params.append(module.bias)
|
| 97 |
+
elif isinstance(module, nn.BatchNorm2d):
|
| 98 |
+
nowd_params += list(module.parameters())
|
| 99 |
+
return wd_params, nowd_params
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
if __name__ == "__main__":
|
| 103 |
+
net = Resnet18()
|
| 104 |
+
x = torch.randn(16, 3, 224, 224)
|
| 105 |
+
out = net(x)
|
| 106 |
+
print(out[0].size())
|
| 107 |
+
print(out[1].size())
|
| 108 |
+
print(out[2].size())
|
| 109 |
+
net.get_params()
|
musetalk/utils/preprocessing.py
ADDED
|
@@ -0,0 +1,113 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
from face_detection import FaceAlignment,LandmarksType
|
| 3 |
+
from os import listdir, path
|
| 4 |
+
import subprocess
|
| 5 |
+
import numpy as np
|
| 6 |
+
import cv2
|
| 7 |
+
import pickle
|
| 8 |
+
import os
|
| 9 |
+
import json
|
| 10 |
+
from mmpose.apis import inference_topdown, init_model
|
| 11 |
+
from mmpose.structures import merge_data_samples
|
| 12 |
+
import torch
|
| 13 |
+
from tqdm import tqdm
|
| 14 |
+
|
| 15 |
+
# initialize the mmpose model
|
| 16 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 17 |
+
config_file = './musetalk/utils/dwpose/rtmpose-l_8xb32-270e_coco-ubody-wholebody-384x288.py'
|
| 18 |
+
checkpoint_file = './models/dwpose/dw-ll_ucoco_384.pth'
|
| 19 |
+
model = init_model(config_file, checkpoint_file, device=device)
|
| 20 |
+
|
| 21 |
+
# initialize the face detection model
|
| 22 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 23 |
+
fa = FaceAlignment(LandmarksType._2D, flip_input=False,device=device)
|
| 24 |
+
|
| 25 |
+
# maker if the bbox is not sufficient
|
| 26 |
+
coord_placeholder = (0.0,0.0,0.0,0.0)
|
| 27 |
+
|
| 28 |
+
def resize_landmark(landmark, w, h, new_w, new_h):
|
| 29 |
+
w_ratio = new_w / w
|
| 30 |
+
h_ratio = new_h / h
|
| 31 |
+
landmark_norm = landmark / [w, h]
|
| 32 |
+
landmark_resized = landmark_norm * [new_w, new_h]
|
| 33 |
+
return landmark_resized
|
| 34 |
+
|
| 35 |
+
def read_imgs(img_list):
|
| 36 |
+
frames = []
|
| 37 |
+
print('reading images...')
|
| 38 |
+
for img_path in tqdm(img_list):
|
| 39 |
+
frame = cv2.imread(img_path)
|
| 40 |
+
frames.append(frame)
|
| 41 |
+
return frames
|
| 42 |
+
|
| 43 |
+
def get_landmark_and_bbox(img_list,upperbondrange =0):
|
| 44 |
+
frames = read_imgs(img_list)
|
| 45 |
+
batch_size_fa = 1
|
| 46 |
+
batches = [frames[i:i + batch_size_fa] for i in range(0, len(frames), batch_size_fa)]
|
| 47 |
+
coords_list = []
|
| 48 |
+
landmarks = []
|
| 49 |
+
if upperbondrange != 0:
|
| 50 |
+
print('get key_landmark and face bounding boxes with the bbox_shift:',upperbondrange)
|
| 51 |
+
else:
|
| 52 |
+
print('get key_landmark and face bounding boxes with the default value')
|
| 53 |
+
average_range_minus = []
|
| 54 |
+
average_range_plus = []
|
| 55 |
+
for fb in tqdm(batches):
|
| 56 |
+
results = inference_topdown(model, np.asarray(fb)[0])
|
| 57 |
+
results = merge_data_samples(results)
|
| 58 |
+
keypoints = results.pred_instances.keypoints
|
| 59 |
+
face_land_mark= keypoints[0][23:91]
|
| 60 |
+
face_land_mark = face_land_mark.astype(np.int32)
|
| 61 |
+
|
| 62 |
+
# get bounding boxes by face detetion
|
| 63 |
+
bbox = fa.get_detections_for_batch(np.asarray(fb))
|
| 64 |
+
|
| 65 |
+
# adjust the bounding box refer to landmark
|
| 66 |
+
# Add the bounding box to a tuple and append it to the coordinates list
|
| 67 |
+
for j, f in enumerate(bbox):
|
| 68 |
+
if f is None: # no face in the image
|
| 69 |
+
coords_list += [coord_placeholder]
|
| 70 |
+
continue
|
| 71 |
+
|
| 72 |
+
half_face_coord = face_land_mark[29]#np.mean([face_land_mark[28], face_land_mark[29]], axis=0)
|
| 73 |
+
range_minus = (face_land_mark[30]- face_land_mark[29])[1]
|
| 74 |
+
range_plus = (face_land_mark[29]- face_land_mark[28])[1]
|
| 75 |
+
average_range_minus.append(range_minus)
|
| 76 |
+
average_range_plus.append(range_plus)
|
| 77 |
+
if upperbondrange != 0:
|
| 78 |
+
half_face_coord[1] = upperbondrange+half_face_coord[1] #手动调整 + 向下(偏29) - 向上(偏28)
|
| 79 |
+
half_face_dist = np.max(face_land_mark[:,1]) - half_face_coord[1]
|
| 80 |
+
upper_bond = half_face_coord[1]-half_face_dist
|
| 81 |
+
|
| 82 |
+
f_landmark = (np.min(face_land_mark[:, 0]),int(upper_bond),np.max(face_land_mark[:, 0]),np.max(face_land_mark[:,1]))
|
| 83 |
+
x1, y1, x2, y2 = f_landmark
|
| 84 |
+
|
| 85 |
+
if y2-y1<=0 or x2-x1<=0 or x1<0: # if the landmark bbox is not suitable, reuse the bbox
|
| 86 |
+
coords_list += [f]
|
| 87 |
+
w,h = f[2]-f[0], f[3]-f[1]
|
| 88 |
+
print("error bbox:",f)
|
| 89 |
+
else:
|
| 90 |
+
coords_list += [f_landmark]
|
| 91 |
+
|
| 92 |
+
print("********************************************bbox_shift parameter adjustment**********************************************************")
|
| 93 |
+
print(f"Total frame:「{len(frames)}」 Manually adjust range : [ -{int(sum(average_range_minus) / len(average_range_minus))}~{int(sum(average_range_plus) / len(average_range_plus))} ] , the current value: {upperbondrange}")
|
| 94 |
+
print("*************************************************************************************************************************************")
|
| 95 |
+
return coords_list,frames
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
if __name__ == "__main__":
|
| 99 |
+
img_list = ["./results/lyria/00000.png","./results/lyria/00001.png","./results/lyria/00002.png","./results/lyria/00003.png"]
|
| 100 |
+
crop_coord_path = "./coord_face.pkl"
|
| 101 |
+
coords_list,full_frames = get_landmark_and_bbox(img_list)
|
| 102 |
+
with open(crop_coord_path, 'wb') as f:
|
| 103 |
+
pickle.dump(coords_list, f)
|
| 104 |
+
|
| 105 |
+
for bbox, frame in zip(coords_list,full_frames):
|
| 106 |
+
if bbox == coord_placeholder:
|
| 107 |
+
continue
|
| 108 |
+
x1, y1, x2, y2 = bbox
|
| 109 |
+
crop_frame = frame[y1:y2, x1:x2]
|
| 110 |
+
print('Cropped shape', crop_frame.shape)
|
| 111 |
+
|
| 112 |
+
#cv2.imwrite(path.join(save_dir, '{}.png'.format(i)),full_frames[i][0][y1:y2, x1:x2])
|
| 113 |
+
print(coords_list)
|
musetalk/utils/utils.py
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import cv2
|
| 3 |
+
import numpy as np
|
| 4 |
+
import torch
|
| 5 |
+
|
| 6 |
+
ffmpeg_path = os.getenv('FFMPEG_PATH')
|
| 7 |
+
if ffmpeg_path is None:
|
| 8 |
+
print("please download ffmpeg-static and export to FFMPEG_PATH. \nFor example: export FFMPEG_PATH=/musetalk/ffmpeg-4.4-amd64-static")
|
| 9 |
+
elif ffmpeg_path not in os.getenv('PATH'):
|
| 10 |
+
print("add ffmpeg to path")
|
| 11 |
+
os.environ["PATH"] = f"{ffmpeg_path}:{os.environ['PATH']}"
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
from musetalk.whisper.audio2feature import Audio2Feature
|
| 15 |
+
from musetalk.models.vae import VAE
|
| 16 |
+
from musetalk.models.unet import UNet,PositionalEncoding
|
| 17 |
+
|
| 18 |
+
def load_all_model():
|
| 19 |
+
audio_processor = Audio2Feature(model_path="./models/whisper/tiny.pt")
|
| 20 |
+
vae = VAE(model_path = "./models/sd-vae-ft-mse/")
|
| 21 |
+
unet = UNet(unet_config="./models/musetalk/musetalk.json",
|
| 22 |
+
model_path ="./models/musetalk/pytorch_model.bin")
|
| 23 |
+
pe = PositionalEncoding(d_model=384)
|
| 24 |
+
return audio_processor,vae,unet,pe
|
| 25 |
+
|
| 26 |
+
def get_file_type(video_path):
|
| 27 |
+
_, ext = os.path.splitext(video_path)
|
| 28 |
+
|
| 29 |
+
if ext.lower() in ['.jpg', '.jpeg', '.png', '.bmp', '.tif', '.tiff']:
|
| 30 |
+
return 'image'
|
| 31 |
+
elif ext.lower() in ['.avi', '.mp4', '.mov', '.flv', '.mkv']:
|
| 32 |
+
return 'video'
|
| 33 |
+
else:
|
| 34 |
+
return 'unsupported'
|
| 35 |
+
|
| 36 |
+
def get_video_fps(video_path):
|
| 37 |
+
video = cv2.VideoCapture(video_path)
|
| 38 |
+
fps = video.get(cv2.CAP_PROP_FPS)
|
| 39 |
+
video.release()
|
| 40 |
+
return fps
|
| 41 |
+
|
| 42 |
+
def datagen(whisper_chunks,vae_encode_latents,batch_size=8,delay_frame = 0):
|
| 43 |
+
whisper_batch, latent_batch = [], []
|
| 44 |
+
for i, w in enumerate(whisper_chunks):
|
| 45 |
+
idx = (i+delay_frame)%len(vae_encode_latents)
|
| 46 |
+
latent = vae_encode_latents[idx]
|
| 47 |
+
whisper_batch.append(w)
|
| 48 |
+
latent_batch.append(latent)
|
| 49 |
+
|
| 50 |
+
if len(latent_batch) >= batch_size:
|
| 51 |
+
whisper_batch = np.asarray(whisper_batch)
|
| 52 |
+
latent_batch = torch.cat(latent_batch, dim=0)
|
| 53 |
+
yield whisper_batch, latent_batch
|
| 54 |
+
whisper_batch, latent_batch = [], []
|
| 55 |
+
|
| 56 |
+
# the last batch may smaller than batch size
|
| 57 |
+
if len(latent_batch) > 0:
|
| 58 |
+
whisper_batch = np.asarray(whisper_batch)
|
| 59 |
+
latent_batch = torch.cat(latent_batch, dim=0)
|
| 60 |
+
|
| 61 |
+
yield whisper_batch, latent_batch
|
musetalk/whisper/audio2feature.py
ADDED
|
@@ -0,0 +1,124 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from .whisper import load_model
|
| 3 |
+
import soundfile as sf
|
| 4 |
+
import numpy as np
|
| 5 |
+
import time
|
| 6 |
+
import sys
|
| 7 |
+
sys.path.append("..")
|
| 8 |
+
|
| 9 |
+
class Audio2Feature():
|
| 10 |
+
def __init__(self,
|
| 11 |
+
whisper_model_type="tiny",
|
| 12 |
+
model_path="./models/whisper/tiny.pt"):
|
| 13 |
+
self.whisper_model_type = whisper_model_type
|
| 14 |
+
self.model = load_model(model_path) #
|
| 15 |
+
|
| 16 |
+
def get_sliced_feature(self,feature_array, vid_idx, audio_feat_length= [2,2],fps = 25):
|
| 17 |
+
"""
|
| 18 |
+
Get sliced features based on a given index
|
| 19 |
+
:param feature_array:
|
| 20 |
+
:param start_idx: the start index of the feature
|
| 21 |
+
:param audio_feat_length:
|
| 22 |
+
:return:
|
| 23 |
+
"""
|
| 24 |
+
length = len(feature_array)
|
| 25 |
+
selected_feature = []
|
| 26 |
+
selected_idx = []
|
| 27 |
+
|
| 28 |
+
center_idx = int(vid_idx*50/fps)
|
| 29 |
+
left_idx = center_idx-audio_feat_length[0]*2
|
| 30 |
+
right_idx = center_idx + (audio_feat_length[1]+1)*2
|
| 31 |
+
|
| 32 |
+
for idx in range(left_idx,right_idx):
|
| 33 |
+
idx = max(0, idx)
|
| 34 |
+
idx = min(length-1, idx)
|
| 35 |
+
x = feature_array[idx]
|
| 36 |
+
selected_feature.append(x)
|
| 37 |
+
selected_idx.append(idx)
|
| 38 |
+
|
| 39 |
+
selected_feature = np.concatenate(selected_feature, axis=0)
|
| 40 |
+
selected_feature = selected_feature.reshape(-1, 384)# 50*384
|
| 41 |
+
return selected_feature,selected_idx
|
| 42 |
+
|
| 43 |
+
def get_sliced_feature_sparse(self,feature_array, vid_idx, audio_feat_length= [2,2],fps = 25):
|
| 44 |
+
"""
|
| 45 |
+
Get sliced features based on a given index
|
| 46 |
+
:param feature_array:
|
| 47 |
+
:param start_idx: the start index of the feature
|
| 48 |
+
:param audio_feat_length:
|
| 49 |
+
:return:
|
| 50 |
+
"""
|
| 51 |
+
length = len(feature_array)
|
| 52 |
+
selected_feature = []
|
| 53 |
+
selected_idx = []
|
| 54 |
+
|
| 55 |
+
for dt in range(-audio_feat_length[0],audio_feat_length[1]+1):
|
| 56 |
+
left_idx = int((vid_idx+dt)*50/fps)
|
| 57 |
+
if left_idx<1 or left_idx>length-1:
|
| 58 |
+
left_idx = max(0, left_idx)
|
| 59 |
+
left_idx = min(length-1, left_idx)
|
| 60 |
+
|
| 61 |
+
x = feature_array[left_idx]
|
| 62 |
+
x = x[np.newaxis,:,:]
|
| 63 |
+
x = np.repeat(x, 2, axis=0)
|
| 64 |
+
selected_feature.append(x)
|
| 65 |
+
selected_idx.append(left_idx)
|
| 66 |
+
selected_idx.append(left_idx)
|
| 67 |
+
else:
|
| 68 |
+
x = feature_array[left_idx-1:left_idx+1]
|
| 69 |
+
selected_feature.append(x)
|
| 70 |
+
selected_idx.append(left_idx-1)
|
| 71 |
+
selected_idx.append(left_idx)
|
| 72 |
+
selected_feature = np.concatenate(selected_feature, axis=0)
|
| 73 |
+
selected_feature = selected_feature.reshape(-1, 384)# 50*384
|
| 74 |
+
return selected_feature,selected_idx
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
def feature2chunks(self,feature_array,fps,audio_feat_length = [2,2]):
|
| 78 |
+
whisper_chunks = []
|
| 79 |
+
whisper_idx_multiplier = 50./fps
|
| 80 |
+
i = 0
|
| 81 |
+
print(f"video in {fps} FPS, audio idx in 50FPS")
|
| 82 |
+
while 1:
|
| 83 |
+
start_idx = int(i * whisper_idx_multiplier)
|
| 84 |
+
selected_feature,selected_idx = self.get_sliced_feature(feature_array= feature_array,vid_idx = i,audio_feat_length=audio_feat_length,fps=fps)
|
| 85 |
+
#print(f"i:{i},selected_idx {selected_idx}")
|
| 86 |
+
whisper_chunks.append(selected_feature)
|
| 87 |
+
i += 1
|
| 88 |
+
if start_idx>len(feature_array):
|
| 89 |
+
break
|
| 90 |
+
|
| 91 |
+
return whisper_chunks
|
| 92 |
+
|
| 93 |
+
def audio2feat(self,audio_path):
|
| 94 |
+
# get the sample rate of the audio
|
| 95 |
+
result = self.model.transcribe(audio_path)
|
| 96 |
+
embed_list = []
|
| 97 |
+
for emb in result['segments']:
|
| 98 |
+
encoder_embeddings = emb['encoder_embeddings']
|
| 99 |
+
encoder_embeddings = encoder_embeddings.transpose(0,2,1,3)
|
| 100 |
+
encoder_embeddings = encoder_embeddings.squeeze(0)
|
| 101 |
+
start_idx = int(emb['start'])
|
| 102 |
+
end_idx = int(emb['end'])
|
| 103 |
+
emb_end_idx = int((end_idx - start_idx)/2)
|
| 104 |
+
embed_list.append(encoder_embeddings[:emb_end_idx])
|
| 105 |
+
concatenated_array = np.concatenate(embed_list, axis=0)
|
| 106 |
+
return concatenated_array
|
| 107 |
+
|
| 108 |
+
if __name__ == "__main__":
|
| 109 |
+
audio_processor = Audio2Feature(model_path="../../models/whisper/whisper_tiny.pt")
|
| 110 |
+
audio_path = "./test.mp3"
|
| 111 |
+
array = audio_processor.audio2feat(audio_path)
|
| 112 |
+
print(array.shape)
|
| 113 |
+
fps = 25
|
| 114 |
+
whisper_idx_multiplier = 50./fps
|
| 115 |
+
|
| 116 |
+
i = 0
|
| 117 |
+
print(f"video in {fps} FPS, audio idx in 50FPS")
|
| 118 |
+
while 1:
|
| 119 |
+
start_idx = int(i * whisper_idx_multiplier)
|
| 120 |
+
selected_feature,selected_idx = audio_processor.get_sliced_feature(feature_array= array,vid_idx = i,audio_feat_length=[2,2],fps=fps)
|
| 121 |
+
print(f"video idx {i},\t audio idx {selected_idx},\t shape {selected_feature.shape}")
|
| 122 |
+
i += 1
|
| 123 |
+
if start_idx>len(array):
|
| 124 |
+
break
|
musetalk/whisper/whisper/__init__.py
ADDED
|
@@ -0,0 +1,116 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import hashlib
|
| 2 |
+
import io
|
| 3 |
+
import os
|
| 4 |
+
import urllib
|
| 5 |
+
import warnings
|
| 6 |
+
from typing import List, Optional, Union
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
from tqdm import tqdm
|
| 10 |
+
|
| 11 |
+
from .audio import load_audio, log_mel_spectrogram, pad_or_trim
|
| 12 |
+
from .decoding import DecodingOptions, DecodingResult, decode, detect_language
|
| 13 |
+
from .model import Whisper, ModelDimensions
|
| 14 |
+
from .transcribe import transcribe
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
_MODELS = {
|
| 18 |
+
"tiny.en": "https://openaipublic.azureedge.net/main/whisper/models/d3dd57d32accea0b295c96e26691aa14d8822fac7d9d27d5dc00b4ca2826dd03/tiny.en.pt",
|
| 19 |
+
"tiny": "https://openaipublic.azureedge.net/main/whisper/models/65147644a518d12f04e32d6f3b26facc3f8dd46e5390956a9424a650c0ce22b9/tiny.pt",
|
| 20 |
+
"base.en": "https://openaipublic.azureedge.net/main/whisper/models/25a8566e1d0c1e2231d1c762132cd20e0f96a85d16145c3a00adf5d1ac670ead/base.en.pt",
|
| 21 |
+
"base": "https://openaipublic.azureedge.net/main/whisper/models/ed3a0b6b1c0edf879ad9b11b1af5a0e6ab5db9205f891f668f8b0e6c6326e34e/base.pt",
|
| 22 |
+
"small.en": "https://openaipublic.azureedge.net/main/whisper/models/f953ad0fd29cacd07d5a9eda5624af0f6bcf2258be67c92b79389873d91e0872/small.en.pt",
|
| 23 |
+
"small": "https://openaipublic.azureedge.net/main/whisper/models/9ecf779972d90ba49c06d968637d720dd632c55bbf19d441fb42bf17a411e794/small.pt",
|
| 24 |
+
"medium.en": "https://openaipublic.azureedge.net/main/whisper/models/d7440d1dc186f76616474e0ff0b3b6b879abc9d1a4926b7adfa41db2d497ab4f/medium.en.pt",
|
| 25 |
+
"medium": "https://openaipublic.azureedge.net/main/whisper/models/345ae4da62f9b3d59415adc60127b97c714f32e89e936602e85993674d08dcb1/medium.pt",
|
| 26 |
+
"large": "https://openaipublic.azureedge.net/main/whisper/models/e4b87e7e0bf463eb8e6956e646f1e277e901512310def2c24bf0e11bd3c28e9a/large.pt",
|
| 27 |
+
"large-v1": "https://openaipublic.azureedge.net/main/whisper/models/e4b87e7e0bf463eb8e6956e646f1e277e901512310def2c24bf0e11bd3c28e9a/large-v1.pt",
|
| 28 |
+
"large-v2": "https://openaipublic.azureedge.net/main/whisper/models/81f7c96c852ee8fc832187b0132e569d6c3065a3252ed18e56effd0b6a73e524/large-v2.pt",
|
| 29 |
+
"large-v3": "https://openaipublic.azureedge.net/main/whisper/models/e5b1a55b89c1367dacf97e3e19bfd829a01529dbfdeefa8caeb59b3f1b81dadb/large-v3.pt",
|
| 30 |
+
}
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def _download(url: str, root: str, in_memory: bool) -> Union[bytes, str]:
|
| 34 |
+
os.makedirs(root, exist_ok=True)
|
| 35 |
+
|
| 36 |
+
expected_sha256 = url.split("/")[-2]
|
| 37 |
+
download_target = os.path.join(root, os.path.basename(url))
|
| 38 |
+
|
| 39 |
+
if os.path.exists(download_target) and not os.path.isfile(download_target):
|
| 40 |
+
raise RuntimeError(f"{download_target} exists and is not a regular file")
|
| 41 |
+
|
| 42 |
+
if os.path.isfile(download_target):
|
| 43 |
+
model_bytes = open(download_target, "rb").read()
|
| 44 |
+
if hashlib.sha256(model_bytes).hexdigest() == expected_sha256:
|
| 45 |
+
return model_bytes if in_memory else download_target
|
| 46 |
+
else:
|
| 47 |
+
warnings.warn(f"{download_target} exists, but the SHA256 checksum does not match; re-downloading the file")
|
| 48 |
+
|
| 49 |
+
with urllib.request.urlopen(url) as source, open(download_target, "wb") as output:
|
| 50 |
+
with tqdm(total=int(source.info().get("Content-Length")), ncols=80, unit='iB', unit_scale=True, unit_divisor=1024) as loop:
|
| 51 |
+
while True:
|
| 52 |
+
buffer = source.read(8192)
|
| 53 |
+
if not buffer:
|
| 54 |
+
break
|
| 55 |
+
|
| 56 |
+
output.write(buffer)
|
| 57 |
+
loop.update(len(buffer))
|
| 58 |
+
|
| 59 |
+
model_bytes = open(download_target, "rb").read()
|
| 60 |
+
if hashlib.sha256(model_bytes).hexdigest() != expected_sha256:
|
| 61 |
+
raise RuntimeError("Model has been downloaded but the SHA256 checksum does not not match. Please retry loading the model.")
|
| 62 |
+
|
| 63 |
+
return model_bytes if in_memory else download_target
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def available_models() -> List[str]:
|
| 67 |
+
"""Returns the names of available models"""
|
| 68 |
+
return list(_MODELS.keys())
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def load_model(name: str, device: Optional[Union[str, torch.device]] = None, download_root: str = None, in_memory: bool = False) -> Whisper:
|
| 72 |
+
"""
|
| 73 |
+
Load a Whisper ASR model
|
| 74 |
+
|
| 75 |
+
Parameters
|
| 76 |
+
----------
|
| 77 |
+
name : str
|
| 78 |
+
one of the official model names listed by `whisper.available_models()`, or
|
| 79 |
+
path to a model checkpoint containing the model dimensions and the model state_dict.
|
| 80 |
+
device : Union[str, torch.device]
|
| 81 |
+
the PyTorch device to put the model into
|
| 82 |
+
download_root: str
|
| 83 |
+
path to download the model files; by default, it uses "~/.cache/whisper"
|
| 84 |
+
in_memory: bool
|
| 85 |
+
whether to preload the model weights into host memory
|
| 86 |
+
|
| 87 |
+
Returns
|
| 88 |
+
-------
|
| 89 |
+
model : Whisper
|
| 90 |
+
The Whisper ASR model instance
|
| 91 |
+
"""
|
| 92 |
+
|
| 93 |
+
if device is None:
|
| 94 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 95 |
+
if download_root is None:
|
| 96 |
+
download_root = os.getenv(
|
| 97 |
+
"XDG_CACHE_HOME",
|
| 98 |
+
os.path.join(os.path.expanduser("~"), ".cache", "whisper")
|
| 99 |
+
)
|
| 100 |
+
|
| 101 |
+
if name in _MODELS:
|
| 102 |
+
checkpoint_file = _download(_MODELS[name], download_root, in_memory)
|
| 103 |
+
elif os.path.isfile(name):
|
| 104 |
+
checkpoint_file = open(name, "rb").read() if in_memory else name
|
| 105 |
+
else:
|
| 106 |
+
raise RuntimeError(f"Model {name} not found; available models = {available_models()}")
|
| 107 |
+
|
| 108 |
+
with (io.BytesIO(checkpoint_file) if in_memory else open(checkpoint_file, "rb")) as fp:
|
| 109 |
+
checkpoint = torch.load(fp, map_location=device)
|
| 110 |
+
del checkpoint_file
|
| 111 |
+
|
| 112 |
+
dims = ModelDimensions(**checkpoint["dims"])
|
| 113 |
+
model = Whisper(dims)
|
| 114 |
+
model.load_state_dict(checkpoint["model_state_dict"])
|
| 115 |
+
|
| 116 |
+
return model.to(device)
|
musetalk/whisper/whisper/__main__.py
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .transcribe import cli
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
cli()
|
musetalk/whisper/whisper/assets/gpt2/merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|