
“WadoodAbdul”
commited on
Commit
•
54f77a5
1
Parent(s):
215aa92
updated about section
Browse files- app.py +11 -3
- assets/entity_distribution.png +0 -0
- assets/ner_evaluation_example.png +0 -0
- src/about.py +152 -11
- src/display/utils.py +1 -1
app.py
CHANGED
|
@@ -10,7 +10,11 @@ from src.about import (
|
|
| 10 |
CITATION_BUTTON_TEXT,
|
| 11 |
EVALUATION_QUEUE_TEXT,
|
| 12 |
INTRODUCTION_TEXT,
|
| 13 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
| 14 |
TITLE,
|
| 15 |
LOGO
|
| 16 |
)
|
|
@@ -341,7 +345,7 @@ with demo:
|
|
| 341 |
with gr.Column(min_width=320):
|
| 342 |
# with gr.Box(elem_id="box-filter"):
|
| 343 |
filter_columns_type = gr.CheckboxGroup(
|
| 344 |
-
label="Model
|
| 345 |
choices=[t.to_str() for t in ModelType],
|
| 346 |
value=[t.to_str() for t in ModelType],
|
| 347 |
interactive=True,
|
|
@@ -418,7 +422,11 @@ with demo:
|
|
| 418 |
)
|
| 419 |
|
| 420 |
with gr.TabItem("📝 About", elem_id="llm-benchmark-tab-table", id=2):
|
| 421 |
-
gr.Markdown(
|
|
|
|
|
|
|
|
|
|
|
|
|
| 422 |
|
| 423 |
with gr.TabItem("🚀 Submit here! ", elem_id="llm-benchmark-tab-table", id=3):
|
| 424 |
with gr.Column():
|
|
|
|
| 10 |
CITATION_BUTTON_TEXT,
|
| 11 |
EVALUATION_QUEUE_TEXT,
|
| 12 |
INTRODUCTION_TEXT,
|
| 13 |
+
LLM_BENCHMARKS_TEXT_1,
|
| 14 |
+
EVALUATION_EXAMPLE_IMG,
|
| 15 |
+
LLM_BENCHMARKS_TEXT_2,
|
| 16 |
+
ENTITY_DISTRIBUTION_IMG,
|
| 17 |
+
LLM_BENCHMARKS_TEXT_3,
|
| 18 |
TITLE,
|
| 19 |
LOGO
|
| 20 |
)
|
|
|
|
| 345 |
with gr.Column(min_width=320):
|
| 346 |
# with gr.Box(elem_id="box-filter"):
|
| 347 |
filter_columns_type = gr.CheckboxGroup(
|
| 348 |
+
label="Model Types",
|
| 349 |
choices=[t.to_str() for t in ModelType],
|
| 350 |
value=[t.to_str() for t in ModelType],
|
| 351 |
interactive=True,
|
|
|
|
| 422 |
)
|
| 423 |
|
| 424 |
with gr.TabItem("📝 About", elem_id="llm-benchmark-tab-table", id=2):
|
| 425 |
+
gr.Markdown(LLM_BENCHMARKS_TEXT_1, elem_classes="markdown-text")
|
| 426 |
+
gr.HTML(EVALUATION_EXAMPLE_IMG, elem_classes="logo")
|
| 427 |
+
gr.Markdown(LLM_BENCHMARKS_TEXT_2, elem_classes="markdown-text")
|
| 428 |
+
gr.HTML(ENTITY_DISTRIBUTION_IMG, elem_classes="logo")
|
| 429 |
+
gr.Markdown(LLM_BENCHMARKS_TEXT_3, elem_classes="markdown-text")
|
| 430 |
|
| 431 |
with gr.TabItem("🚀 Submit here! ", elem_id="llm-benchmark-tab-table", id=3):
|
| 432 |
with gr.Column():
|
assets/entity_distribution.png
ADDED
|
assets/ner_evaluation_example.png
ADDED

|
src/about.py
CHANGED
|
@@ -57,32 +57,173 @@ Disclaimer: It is important to note that the purpose of this evaluation is purel
|
|
| 57 |
"""
|
| 58 |
|
| 59 |
# Which evaluations are you running? how can people reproduce what you have?
|
| 60 |
-
|
| 61 |
|
| 62 |
-
The Named Clinical Entity Recognition Leaderboard is aimed at advancing the field of natural language processing in healthcare. It provides a standardized platform for evaluating and comparing the performance of various language models in recognizing named clinical entities, a critical task for applications such as clinical documentation, decision support, and information extraction. By fostering transparency and facilitating benchmarking, the leaderboard's goal is to drive innovation and improvement in NLP models. It also helps researchers identify the strengths and weaknesses of different approaches, ultimately contributing to the development of more accurate and reliable tools for clinical use. Despite its exploratory nature, the leaderboard aims to play a role in guiding research and ensuring that advancements are grounded in rigorous and comprehensive evaluations.
|
| 63 |
## About
|
| 64 |
|
|
|
|
|
|
|
| 65 |
## How it works
|
| 66 |
|
| 67 |
### Evaluation method and metrics
|
| 68 |
When training a Named Entity Recognition (NER) system, the most common evaluation methods involve measuring precision, recall, and F1-score at the token level. While these metrics are useful for fine-tuning the NER system, evaluating the predicted named entities for downstream tasks requires metrics at the full named-entity level. We include both evaluation methods: token-based and span-based. We provide an example below which helps in understanding the difference between the methods.
|
| 69 |
Example Sentence: "The patient was diagnosed with a skin cancer disease."
|
| 70 |
For simplicity, let's assume the an example sentence which contains 10 tokens, with a single two-token disease entity (as shown in the figure below).
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 71 |
|
| 72 |
-
### Datasets
|
| 73 |
-
📈 We evaluate the models on 4 datasets, encompassing 6 entity types
|
| 74 |
-
- [NCBI](https://huggingface.co/datasets/m42-health/clinical_ncbi)
|
| 75 |
-
- [CHIA](https://huggingface.co/datasets/m42-health/clinical_chia)
|
| 76 |
-
- [BIORED](https://huggingface.co/datasets/m42-health/clinical_biored)
|
| 77 |
-
- [BC5CD](https://huggingface.co/datasets/m42-health/clinical_bc5cdr)
|
| 78 |
|
| 79 |
-
###
|
| 80 |
-
|
| 81 |
|
| 82 |
|
| 83 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 84 |
To reproduce our results, follow the steps detailed [here](https://github.com/WadoodAbdul/medics_ner/blob/master/docs/reproducing_results.md)
|
| 85 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 86 |
"""
|
| 87 |
|
| 88 |
EVALUATION_QUEUE_TEXT = """
|
|
|
|
| 57 |
"""
|
| 58 |
|
| 59 |
# Which evaluations are you running? how can people reproduce what you have?
|
| 60 |
+
LLM_BENCHMARKS_TEXT_1 = f"""
|
| 61 |
|
|
|
|
| 62 |
## About
|
| 63 |
|
| 64 |
+
The Named Clinical Entity Recognition Leaderboard is aimed at advancing the field of natural language processing in healthcare. It provides a standardized platform for evaluating and comparing the performance of various language models in recognizing named clinical entities, a critical task for applications such as clinical documentation, decision support, and information extraction. By fostering transparency and facilitating benchmarking, the leaderboard's goal is to drive innovation and improvement in NLP models. It also helps researchers identify the strengths and weaknesses of different approaches, ultimately contributing to the development of more accurate and reliable tools for clinical use. Despite its exploratory nature, the leaderboard aims to play a role in guiding research and ensuring that advancements are grounded in rigorous and comprehensive evaluations.
|
| 65 |
+
|
| 66 |
## How it works
|
| 67 |
|
| 68 |
### Evaluation method and metrics
|
| 69 |
When training a Named Entity Recognition (NER) system, the most common evaluation methods involve measuring precision, recall, and F1-score at the token level. While these metrics are useful for fine-tuning the NER system, evaluating the predicted named entities for downstream tasks requires metrics at the full named-entity level. We include both evaluation methods: token-based and span-based. We provide an example below which helps in understanding the difference between the methods.
|
| 70 |
Example Sentence: "The patient was diagnosed with a skin cancer disease."
|
| 71 |
For simplicity, let's assume the an example sentence which contains 10 tokens, with a single two-token disease entity (as shown in the figure below).
|
| 72 |
+
"""
|
| 73 |
+
EVALUATION_EXAMPLE_IMG = """<img src="file/assets/ner_evaluation_example.png" alt="Clinical X HF" width="750" height="500">"""
|
| 74 |
+
LLM_BENCHMARKS_TEXT_2 = """
|
| 75 |
+
Token-based evaluation involves obtaining the set of token labels (ground-truth annotations) for the annotated entities and the set of token predictions, comparing these sets, and computing a classification report. Hence, the results for the example above are shown below.
|
| 76 |
+
**Token-based metrics:**
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
| Model | TP | FP | FN | Precision | Recall | F1-Score |
|
| 81 |
+
| ------- | --- | --- | --- | --------- | ------ | -------- |
|
| 82 |
+
| Model D | 0 | 1 | 0 | 0.00 | 0.00 | 0.00 |
|
| 83 |
+
| Model C | 1 | 1 | 1 | 0.50 | 0.50 | 0.50 |
|
| 84 |
+
| Model B | 2 | 2 | 0 | 0.50 | 1.00 | 0.67 |
|
| 85 |
+
| Model A | 2 | 1 | 0 | 0.67 | 1.00 | 0.80 |
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
Where,
|
| 89 |
+
$$ Precision = TP / (TP + FP)$$
|
| 90 |
+
$$ Recall = TP / (TP + FN)$$
|
| 91 |
+
$$ f1score = 2 * (Prec * Rec) / (Prec + Rec)$$
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
With this token-based approach, we have a broad idea of the performance of the model at the token level. However, it may misrepresent the performance at the entity level when the entity includes more than 1 token (which may be more relevant for certain applications). In addition, depending on the annotations of certain datasets, we may not want to penalize a model for a "partial" match with a certain entity.
|
| 96 |
+
The span-based method attempts to address some of these issues, by determining the full or partial matches at the entity level to classify the predictions as correct, incorrect, missed and spurious. These are then used to calculate precision, recall and F1-score. Given this, for the example below.
|
| 97 |
+
|
| 98 |
+
**Span-based metrics:**
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
| Model | Correct | Incorrect | Missed | Spurious | Precision | Recall | F1-Score |
|
| 102 |
+
| ------- | ------- | --------- | ------ | -------- | --------- | ------ | -------- |
|
| 103 |
+
| Model A | 1 | 0 | 0 | 0 | 1.00 | 1.00 | 1.00 |
|
| 104 |
+
| Model B | 1 | 0 | 0 | 0 | 1.00 | 1.00 | 1.00 |
|
| 105 |
+
| Model C | 1 | 0 | 0 | 0 | 1.00 | 1.00 | 1.00 |
|
| 106 |
+
| Model D | 0 | 0 | 1 | 1 | 0.00 | 0.00 | 0.00 |
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
Where,
|
| 110 |
+
$$ Precision = COR / (COR + INC + SPU)$$
|
| 111 |
+
$$ Recall = COR / (COR + INC + MIS)$$
|
| 112 |
+
$$ f1score = 2 * (Prec * Rec) / (Prec + Rec)$$
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
This span-based approach is equivalent to the Partial Match ("Type") in the nervaluate (NER evaluation considering partial match scoring) python package.
|
| 116 |
+
Further examples are presented the section below (Other example evaluations).
|
| 117 |
+
|
| 118 |
+
## Datasets
|
| 119 |
+
The following datasets (test splits only) have been included in the evaluation.
|
| 120 |
+
|
| 121 |
+
### [NCBI Disease](https://huggingface.co/datasets/m42-health/clinical_ncbi)
|
| 122 |
+
The NCBI Disease corpus includes mention and concept level annotations on PubMed abstracts. It covers annotations of diseases.
|
| 123 |
+
|
| 124 |
+
| | Counts |
|
| 125 |
+
| ---------- | ------ |
|
| 126 |
+
| Samples | 100 |
|
| 127 |
+
| Annotation | 960 |
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
### [CHIA](https://huggingface.co/datasets/m42-health/clinical_chia)
|
| 131 |
+
This is a large, annotated corpus of patient eligibility criteria extracted from registered clinical trials (ClinicalTrials.gov). Annotations cover 15 different entity types, including conditions, drugs, procedures, and measurements.
|
| 132 |
+
|
| 133 |
+
|
| 134 |
+
| | Counts |
|
| 135 |
+
| ---------- | ------ |
|
| 136 |
+
| Samples | 194 |
|
| 137 |
+
| Annotation | 3981 |
|
| 138 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 139 |
|
| 140 |
+
### [BC5CDR](https://huggingface.co/datasets/m42-health/clinical_bc5cdr)
|
| 141 |
+
The BC5CDR corpus consists of 1500 PubMed articles with annotated chemicals and diseases.
|
| 142 |
|
| 143 |
|
| 144 |
+
| | Counts |
|
| 145 |
+
| ---------- | ------ |
|
| 146 |
+
| Samples | 500 |
|
| 147 |
+
| Annotation | 9928 |
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
### [BIORED](https://huggingface.co/datasets/m42-health/clinical_biored)
|
| 151 |
+
The BIORED corpus includes a set of PubMed abstracts with annotations of multiple entity types (e.g., gene/protein, disease, chemical).
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
| | Counts |
|
| 155 |
+
| ---------- | ------ |
|
| 156 |
+
| Samples | 100 |
|
| 157 |
+
| Annotation | 3535 |
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
Datasets summary
|
| 161 |
+
|
| 162 |
+
A summary of the datasets used are summarized here.
|
| 163 |
+
|
| 164 |
+
|
| 165 |
+
| Dataset | # samples | # annotations | # original entities | # clinical entities |
|
| 166 |
+
| ------- | --------- | ------------- | ------------------- | ------------------- |
|
| 167 |
+
| NCBI | 100 | 960 | 4 | 1 |
|
| 168 |
+
| CHIA | 194 | 3981 | 16 | 4 |
|
| 169 |
+
| BIORED | 500 | 9928 | 2 | 4 |
|
| 170 |
+
| BC5CDR | 100 | 3535 | 6 | 2 |
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
## Clinical Entity Types
|
| 174 |
+
|
| 175 |
+
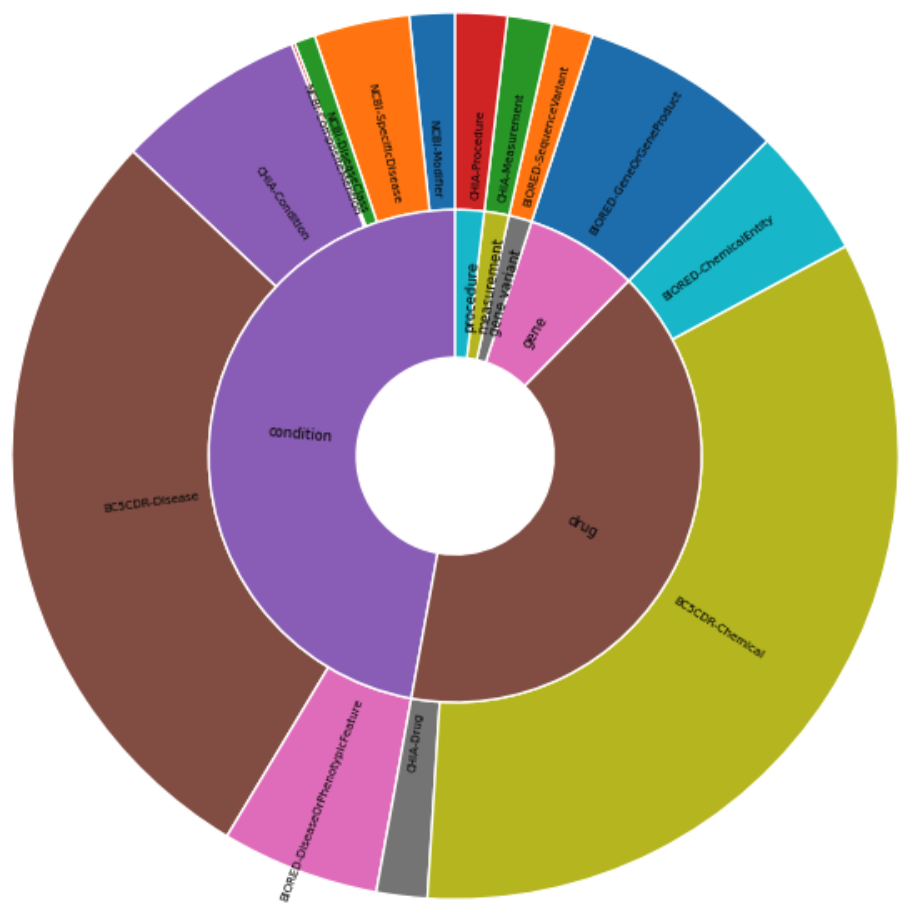
The above datasets are modified to cater to the clinical setting. For this, the entity types that are clinically relevant are retained and the rest are dropped. Further, the clinical entity type is standardized across the dataset to obtain a total of 6 clinical entity types shown below.
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
| Clinical Entity | Combined Annotation |
|
| 179 |
+
| --------------- | ------------------- |
|
| 180 |
+
| Condition | 7514 |
|
| 181 |
+
| Drug | 6443 |
|
| 182 |
+
| Procedure | 300 |
|
| 183 |
+
| Measurement | 258 |
|
| 184 |
+
| Gene | 1180 |
|
| 185 |
+
| Gene Variant | 241 |
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
The pie chart on the left below the distribution of clinical entities and their original dataset types.
|
| 189 |
+
"""
|
| 190 |
+
|
| 191 |
+
ENTITY_DISTRIBUTION_IMG = """<img src="file/assets/entity_distribution.png" alt="Clinical X HF" width="750" height="500">"""
|
| 192 |
+
LLM_BENCHMARKS_TEXT_3="""
|
| 193 |
+
## Decoder Model Evaluation
|
| 194 |
+
Evaluating encoder models, such as BERT, for token classification tasks (e.g., NER) is straightforward given that these models process the entire input sequence simultaneously. This allows them to generate token-level classifications by leveraging bidirectional context, facilitating a direct comparison of predicted tags against the gold standard labels for each token in the input sequence.
|
| 195 |
+
|
| 196 |
+
In contrast, decoder-only models, like GPT, generate responses sequentially, predicting one token at a time based on the preceding context. Evaluating the performance of these models for token classification tasks requires a different approach. First, we prompt the decoder-only LLM with a specific task of tagging the different entity types within a given text. This task is clearly defined to the model, ensuring it understands which types of entities to identify (i.e., conditions, drugs, procedures, etc).
|
| 197 |
+
An example of the task prompt is shown below.
|
| 198 |
+
```
|
| 199 |
+
## Instruction
|
| 200 |
+
Your task is to generate an HTML version of an input text, marking up specific entities related to healthcare. The entities to be identified are: symptom, disorder. Use HTML <span > tags to highlight these entities. Each <span > should have a class attribute indicating the type of the entity. Do NOT provide further examples and just consider the input provided below. Do NOT provide an explanation nor notes about the reasoning. Do NOT reformat nor summarize the input text. Follow the instruction and the format of the example below.
|
| 201 |
+
|
| 202 |
+
## Entity markup guide
|
| 203 |
+
Use <span class='symptom' > to denote a symptom.
|
| 204 |
+
Use <span class='disorder' > to denote a disorder.
|
| 205 |
+
```
|
| 206 |
+
To ensure deterministic and consistent outputs, the temperature for generation is kept at 0.0. The model then generates a sequential response that includes the tagged entities, as shown in the example below.
|
| 207 |
+
```
|
| 208 |
+
## Input:
|
| 209 |
+
He had been diagnosed with osteoarthritis of the knees and had undergone arthroscopy years prior to admission.
|
| 210 |
+
## Output:
|
| 211 |
+
He had been diagnosed with <span class="disease" >osteoarthritis of the knees</span >and had undergone <span class="procedure" >arthroscopy</span >years prior to admission.
|
| 212 |
+
```
|
| 213 |
+
|
| 214 |
+
After the tagged output is generated, it is parsed to extract the tagged entities. The parsed data are then compared against the gold standard labels, and performance metrics are computed as above. This evaluation method ensures a consistent and objective assessment of decoder-only LLM's performance in NER tasks, despite the differences in their architecture compared to encoder models.
|
| 215 |
+
|
| 216 |
+
# Reproducibility
|
| 217 |
To reproduce our results, follow the steps detailed [here](https://github.com/WadoodAbdul/medics_ner/blob/master/docs/reproducing_results.md)
|
| 218 |
|
| 219 |
+
# Disclaimer and Advisory
|
| 220 |
+
The Leaderboard is maintained by the authors and affiliated entity as part of our ongoing contribution to open research in the field of NLP in healthcare. The leaderboard is intended for academic and exploratory purposes only. The language models evaluated on this platform (to the best knowledge of the authors) have not been approved for clinical use, and their performance should not be interpreted as clinically validated or suitable for real-world medical applications.
|
| 221 |
+
|
| 222 |
+
Users are advised to approach the results with an understanding of the inherent limitations and the experimental nature of this evaluation. The authors and affiliated entity do not endorse any specific model or approach, and the leaderboard is provided without any warranties or guarantees. Researchers and practitioners are encouraged to use the leaderboard as a resource to guide further research and development, keeping in mind the necessity for rigorous testing and validation in clinical settings before any practical application.
|
| 223 |
+
|
| 224 |
+
|
| 225 |
+
|
| 226 |
+
|
| 227 |
"""
|
| 228 |
|
| 229 |
EVALUATION_QUEUE_TEXT = """
|
src/display/utils.py
CHANGED
|
@@ -159,7 +159,7 @@ class PromptTemplateName(Enum):
|
|
| 159 |
UniversalNERTemplate = "universal_ner"
|
| 160 |
LLMHTMLHighlightedSpansTemplate = "llm_html_highlighted_spans"
|
| 161 |
LLamaNERTemplate = "llama_70B_ner_v0.3"
|
| 162 |
-
MixtralNERTemplate = "mixtral_ner_v0.3
|
| 163 |
|
| 164 |
|
| 165 |
|
|
|
|
| 159 |
UniversalNERTemplate = "universal_ner"
|
| 160 |
LLMHTMLHighlightedSpansTemplate = "llm_html_highlighted_spans"
|
| 161 |
LLamaNERTemplate = "llama_70B_ner_v0.3"
|
| 162 |
+
MixtralNERTemplate = "mixtral_ner_v0.3"
|
| 163 |
|
| 164 |
|
| 165 |
|