Spaces:
Runtime error

Runtime error
Li Zhaoxu
commited on
Commit
•
122057f
1
Parent(s):
a82e0ab
init
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- app.py +152 -0
- environment.yml +183 -0
- eval_configs/benchmark_evaluation.yaml +60 -0
- eval_configs/tinygptv_stage1_2_3_eval.yaml +24 -0
- eval_configs/tinygptv_stage4_eval.yaml +24 -0
- examples/TinyGPT-V-ST.png +0 -0
- examples/Training_S.png +0 -0
- examples/result.png +0 -0
- minigpt4/__init__.py +31 -0
- minigpt4/__pycache__/__init__.cpython-39.pyc +0 -0
- minigpt4/common/__init__.py +0 -0
- minigpt4/common/__pycache__/__init__.cpython-39.pyc +0 -0
- minigpt4/common/__pycache__/config.cpython-39.pyc +0 -0
- minigpt4/common/__pycache__/dist_utils.cpython-39.pyc +0 -0
- minigpt4/common/__pycache__/logger.cpython-39.pyc +0 -0
- minigpt4/common/__pycache__/registry.cpython-39.pyc +0 -0
- minigpt4/common/__pycache__/utils.cpython-39.pyc +0 -0
- minigpt4/common/config.py +496 -0
- minigpt4/common/dist_utils.py +140 -0
- minigpt4/common/eval_utils.py +76 -0
- minigpt4/common/gradcam.py +24 -0
- minigpt4/common/logger.py +195 -0
- minigpt4/common/optims.py +119 -0
- minigpt4/common/registry.py +329 -0
- minigpt4/common/utils.py +424 -0
- minigpt4/common/vqa_tools/VQA/PythonEvaluationTools/vqaEvalDemo.py +89 -0
- minigpt4/common/vqa_tools/VQA/PythonEvaluationTools/vqaEvaluation/__init__.py +1 -0
- minigpt4/common/vqa_tools/VQA/PythonEvaluationTools/vqaEvaluation/vqaEval.py +192 -0
- minigpt4/common/vqa_tools/VQA/PythonHelperTools/vqaDemo.py +73 -0
- minigpt4/common/vqa_tools/VQA/PythonHelperTools/vqaTools/__init__.py +1 -0
- minigpt4/common/vqa_tools/VQA/PythonHelperTools/vqaTools/vqa.py +179 -0
- minigpt4/common/vqa_tools/VQA/QuestionTypes/abstract_v002_question_types.txt +81 -0
- minigpt4/common/vqa_tools/VQA/QuestionTypes/mscoco_question_types.txt +65 -0
- minigpt4/common/vqa_tools/VQA/README.md +80 -0
- minigpt4/common/vqa_tools/VQA/license.txt +30 -0
- minigpt4/common/vqa_tools/__init__.py +8 -0
- minigpt4/common/vqa_tools/vqa.py +211 -0
- minigpt4/common/vqa_tools/vqa_eval.py +324 -0
- minigpt4/configs/datasets/aokvqa/defaults.yaml +20 -0
- minigpt4/configs/datasets/cc_sbu/align.yaml +5 -0
- minigpt4/configs/datasets/cc_sbu/defaults.yaml +5 -0
- minigpt4/configs/datasets/coco/caption.yaml +21 -0
- minigpt4/configs/datasets/coco/defaults_vqa.yaml +24 -0
- minigpt4/configs/datasets/coco_bbox/invrefcoco.yaml +8 -0
- minigpt4/configs/datasets/coco_bbox/invrefcocog.yaml +8 -0
- minigpt4/configs/datasets/coco_bbox/invrefcocop.yaml +8 -0
- minigpt4/configs/datasets/coco_bbox/refcoco.yaml +8 -0
- minigpt4/configs/datasets/coco_bbox/refcocog.yaml +8 -0
- minigpt4/configs/datasets/coco_bbox/refcocop.yaml +8 -0
- minigpt4/configs/datasets/flickr/caption_to_phrase.yaml +6 -0
app.py
ADDED
|
@@ -0,0 +1,152 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import os
|
| 3 |
+
import random
|
| 4 |
+
|
| 5 |
+
import numpy as np
|
| 6 |
+
import torch
|
| 7 |
+
import gradio as gr
|
| 8 |
+
|
| 9 |
+
from minigpt4.common.config import Config
|
| 10 |
+
from minigpt4.common.dist_utils import get_rank
|
| 11 |
+
from minigpt4.common.registry import registry
|
| 12 |
+
from minigpt4.conversation.conversation import Chat, CONV_VISION
|
| 13 |
+
|
| 14 |
+
# imports modules for registration
|
| 15 |
+
from minigpt4.datasets.builders import *
|
| 16 |
+
from minigpt4.models import *
|
| 17 |
+
from minigpt4.processors import *
|
| 18 |
+
from minigpt4.runners import *
|
| 19 |
+
from minigpt4.tasks import *
|
| 20 |
+
|
| 21 |
+
def parse_args():
|
| 22 |
+
parser = argparse.ArgumentParser(description="Demo")
|
| 23 |
+
parser.add_argument("--cfg-path", type=str, default='eval_configs/tinygptv_stage1_2_3_eval.yaml', help="path to configuration file.")
|
| 24 |
+
parser.add_argument(
|
| 25 |
+
"--options",
|
| 26 |
+
nargs="+",
|
| 27 |
+
help="override some settings in the used config, the key-value pair "
|
| 28 |
+
"in xxx=yyy format will be merged into config file (deprecate), "
|
| 29 |
+
"change to --cfg-options instead.",
|
| 30 |
+
)
|
| 31 |
+
args = parser.parse_args()
|
| 32 |
+
return args
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def setup_seeds(config):
|
| 36 |
+
seed = config.run_cfg.seed + get_rank()
|
| 37 |
+
|
| 38 |
+
random.seed(seed)
|
| 39 |
+
np.random.seed(seed)
|
| 40 |
+
torch.manual_seed(seed)
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
# ========================================
|
| 44 |
+
# Model Initialization
|
| 45 |
+
# ========================================
|
| 46 |
+
|
| 47 |
+
SHARED_UI_WARNING = f'''### [NOTE] It is possible that you are waiting in a lengthy queue.
|
| 48 |
+
|
| 49 |
+
You can duplicate and use it with a paid private GPU.
|
| 50 |
+
|
| 51 |
+
<a class="duplicate-button" style="display:inline-block" target="_blank" href="https://huggingface.co/spaces/Vision-CAIR/minigpt4?duplicate=true"><img style="margin-top:0;margin-bottom:0" src="https://huggingface.co/datasets/huggingface/badges/raw/main/duplicate-this-space-xl-dark.svg" alt="Duplicate Space"></a>
|
| 52 |
+
|
| 53 |
+
Alternatively, you can also use the demo on our [project page](https://minigpt-4.github.io).
|
| 54 |
+
'''
|
| 55 |
+
|
| 56 |
+
print('Initializing Chat')
|
| 57 |
+
cfg = Config(parse_args())
|
| 58 |
+
|
| 59 |
+
model_config = cfg.model_cfg
|
| 60 |
+
model_cls = registry.get_model_class(model_config.arch)
|
| 61 |
+
model = model_cls.from_config(model_config).to('cpu')
|
| 62 |
+
|
| 63 |
+
vis_processor_cfg = cfg.datasets_cfg.cc_sbu_align.vis_processor.train
|
| 64 |
+
vis_processor = registry.get_processor_class(vis_processor_cfg.name).from_config(vis_processor_cfg)
|
| 65 |
+
chat = Chat(model, vis_processor,device='cpu')
|
| 66 |
+
print('Initialization Finished')
|
| 67 |
+
|
| 68 |
+
# ========================================
|
| 69 |
+
# Gradio Setting
|
| 70 |
+
# ========================================
|
| 71 |
+
|
| 72 |
+
def gradio_reset(chat_state, img_list):
|
| 73 |
+
if chat_state is not None:
|
| 74 |
+
chat_state.messages = []
|
| 75 |
+
if img_list is not None:
|
| 76 |
+
img_list = []
|
| 77 |
+
return None, gr.update(value=None, interactive=True), gr.update(placeholder='Please upload your image first', interactive=False), gr.update(value="Upload & Start Chat", interactive=True), chat_state, img_list
|
| 78 |
+
|
| 79 |
+
def upload_img(gr_img, text_input, chat_state):
|
| 80 |
+
if gr_img is None:
|
| 81 |
+
return None, None, gr.update(interactive=True), chat_state, None
|
| 82 |
+
chat_state = CONV_VISION.copy()
|
| 83 |
+
img_list = []
|
| 84 |
+
llm_message = chat.upload_img(gr_img, chat_state, img_list)
|
| 85 |
+
|
| 86 |
+
return gr.update(interactive=False), gr.update(interactive=True, placeholder='Type and press Enter'), gr.update(value="Start Chatting", interactive=False), chat_state, img_list
|
| 87 |
+
|
| 88 |
+
def gradio_ask(user_message, chatbot, chat_state):
|
| 89 |
+
if len(user_message) == 0:
|
| 90 |
+
return gr.update(interactive=True, placeholder='Input should not be empty!'), chatbot, chat_state
|
| 91 |
+
chat.ask(user_message, chat_state)
|
| 92 |
+
chatbot = chatbot + [[user_message, None]]
|
| 93 |
+
return '', chatbot, chat_state
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def gradio_answer(chatbot, chat_state, img_list, num_beams, temperature):
|
| 97 |
+
llm_message = chat.answer(conv=chat_state, img_list=img_list, max_new_tokens=300, num_beams=1, temperature=temperature, max_length=2000)[0]
|
| 98 |
+
chatbot[-1][1] = llm_message
|
| 99 |
+
return chatbot, chat_state, img_list
|
| 100 |
+
|
| 101 |
+
title = """<h1 align="center">Demo of TinyGPT-V</h1>"""
|
| 102 |
+
description = """<h3>This is the demo of TinyGPT-V. Upload your images and start chatting!</h3>"""
|
| 103 |
+
article = """<div style='display:flex; gap: 0.25rem; '><a href='https://github.com/DLYuanGod/TinyGPT-V'><img src='https://img.shields.io/badge/Github-Code-blue'></a><a href='https://arxiv.org/abs/2312.16862'><img src='https://img.shields.io/badge/Paper-PDF-red'></a></div>
|
| 104 |
+
"""
|
| 105 |
+
|
| 106 |
+
#TODO show examples below
|
| 107 |
+
|
| 108 |
+
with gr.Blocks() as demo:
|
| 109 |
+
gr.Markdown(title)
|
| 110 |
+
|
| 111 |
+
gr.Markdown(description)
|
| 112 |
+
gr.Markdown(article)
|
| 113 |
+
|
| 114 |
+
with gr.Row():
|
| 115 |
+
with gr.Column(scale=0.5):
|
| 116 |
+
image = gr.Image(type="pil")
|
| 117 |
+
upload_button = gr.Button(value="Upload & Start Chat", interactive=True, variant="primary")
|
| 118 |
+
clear = gr.Button("Restart")
|
| 119 |
+
|
| 120 |
+
num_beams = gr.Slider(
|
| 121 |
+
minimum=1,
|
| 122 |
+
maximum=5,
|
| 123 |
+
value=1,
|
| 124 |
+
step=1,
|
| 125 |
+
interactive=True,
|
| 126 |
+
label="beam search numbers)",
|
| 127 |
+
)
|
| 128 |
+
|
| 129 |
+
temperature = gr.Slider(
|
| 130 |
+
minimum=0.1,
|
| 131 |
+
maximum=2.0,
|
| 132 |
+
value=1.0,
|
| 133 |
+
step=0.1,
|
| 134 |
+
interactive=True,
|
| 135 |
+
label="Temperature",
|
| 136 |
+
)
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
with gr.Column():
|
| 140 |
+
chat_state = gr.State()
|
| 141 |
+
img_list = gr.State()
|
| 142 |
+
chatbot = gr.Chatbot(label='TinyGPT-V')
|
| 143 |
+
text_input = gr.Textbox(label='User', placeholder='Please upload your image first', interactive=False)
|
| 144 |
+
|
| 145 |
+
upload_button.click(upload_img, [image, text_input, chat_state], [image, text_input, upload_button, chat_state, img_list])
|
| 146 |
+
|
| 147 |
+
text_input.submit(gradio_ask, [text_input, chatbot, chat_state], [text_input, chatbot, chat_state]).then(
|
| 148 |
+
gradio_answer, [chatbot, chat_state, img_list, num_beams, temperature], [chatbot, chat_state, img_list]
|
| 149 |
+
)
|
| 150 |
+
clear.click(gradio_reset, [chat_state, img_list], [chatbot, image, text_input, upload_button, chat_state, img_list], queue=False)
|
| 151 |
+
|
| 152 |
+
demo.launch(enable_queue=True)
|
environment.yml
ADDED
|
@@ -0,0 +1,183 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: tinygptv-demo
|
| 2 |
+
channels:
|
| 3 |
+
- defaults
|
| 4 |
+
|
| 5 |
+
dependencies:
|
| 6 |
+
- _libgcc_mutex=0.1=main
|
| 7 |
+
- _openmp_mutex=5.1=1_gnu
|
| 8 |
+
- ca-certificates=2023.08.22=h06a4308_0
|
| 9 |
+
- cudatoolkit=11.8.0=h6a678d5_0
|
| 10 |
+
- ld_impl_linux-64=2.38=h1181459_1
|
| 11 |
+
- libffi=3.4.4=h6a678d5_0
|
| 12 |
+
- libgcc-ng=11.2.0=h1234567_1
|
| 13 |
+
- libgomp=11.2.0=h1234567_1
|
| 14 |
+
- libstdcxx-ng=11.2.0=h1234567_1
|
| 15 |
+
- ncurses=6.4=h6a678d5_0
|
| 16 |
+
- openssl=3.0.12=h7f8727e_0
|
| 17 |
+
- pip=23.3.1=py39h06a4308_0
|
| 18 |
+
- python=3.9.18=h955ad1f_0
|
| 19 |
+
- readline=8.2=h5eee18b_0
|
| 20 |
+
- setuptools=68.2.2=py39h06a4308_0
|
| 21 |
+
- sqlite=3.41.2=h5eee18b_0
|
| 22 |
+
- tk=8.6.12=h1ccaba5_0
|
| 23 |
+
- wheel=0.41.2=py39h06a4308_0
|
| 24 |
+
- xz=5.4.5=h5eee18b_0
|
| 25 |
+
- zlib=1.2.13=h5eee18b_0
|
| 26 |
+
- pip:
|
| 27 |
+
- accelerate==0.20.3
|
| 28 |
+
- aiofiles==23.2.1
|
| 29 |
+
- aiohttp==3.9.1
|
| 30 |
+
- aiosignal==1.3.1
|
| 31 |
+
- altair==5.2.0
|
| 32 |
+
- annotated-types==0.6.0
|
| 33 |
+
- antlr4-python3-runtime==4.9.3
|
| 34 |
+
- anyio==3.7.1
|
| 35 |
+
- appdirs==1.4.4
|
| 36 |
+
- asttokens==2.4.1
|
| 37 |
+
- async-timeout==4.0.3
|
| 38 |
+
- attrs==23.1.0
|
| 39 |
+
- bitsandbytes==0.37.0
|
| 40 |
+
- braceexpand==0.1.7
|
| 41 |
+
- certifi==2023.11.17
|
| 42 |
+
- charset-normalizer==3.3.2
|
| 43 |
+
- click==8.1.7
|
| 44 |
+
- cmake==3.28.1
|
| 45 |
+
- comm==0.2.0
|
| 46 |
+
- contourpy==1.2.0
|
| 47 |
+
- cycler==0.12.1
|
| 48 |
+
- datasets==2.15.0
|
| 49 |
+
- debugpy==1.8.0
|
| 50 |
+
- decorator==5.1.1
|
| 51 |
+
- decord==0.6.0
|
| 52 |
+
- dill==0.3.7
|
| 53 |
+
- docker-pycreds==0.4.0
|
| 54 |
+
- einops==0.7.0
|
| 55 |
+
- exceptiongroup==1.2.0
|
| 56 |
+
- executing==2.0.1
|
| 57 |
+
- fastapi==0.105.0
|
| 58 |
+
- ffmpy==0.3.1
|
| 59 |
+
- filelock==3.13.1
|
| 60 |
+
- fonttools==4.46.0
|
| 61 |
+
- frozenlist==1.4.1
|
| 62 |
+
- fsspec==2023.10.0
|
| 63 |
+
- gitdb==4.0.11
|
| 64 |
+
- gitpython==3.1.40
|
| 65 |
+
- gradio==3.47.1
|
| 66 |
+
- gradio-client==0.6.0
|
| 67 |
+
- h11==0.14.0
|
| 68 |
+
- httpcore==1.0.2
|
| 69 |
+
- httpx==0.25.2
|
| 70 |
+
- huggingface-hub==0.19.4
|
| 71 |
+
- idna==3.6
|
| 72 |
+
- imageio==2.33.1
|
| 73 |
+
- importlib-metadata==7.0.0
|
| 74 |
+
- importlib-resources==6.1.1
|
| 75 |
+
- iopath==0.1.10
|
| 76 |
+
- ipykernel==6.27.1
|
| 77 |
+
- ipython==8.18.1
|
| 78 |
+
- jedi==0.19.1
|
| 79 |
+
- jinja2==3.1.2
|
| 80 |
+
- joblib==1.3.2
|
| 81 |
+
- jsonschema==4.20.0
|
| 82 |
+
- jsonschema-specifications==2023.11.2
|
| 83 |
+
- jupyter-client==8.6.0
|
| 84 |
+
- jupyter-core==5.5.1
|
| 85 |
+
- kiwisolver==1.4.5
|
| 86 |
+
- lazy-loader==0.3
|
| 87 |
+
- lit==17.0.6
|
| 88 |
+
- markupsafe==2.1.3
|
| 89 |
+
- matplotlib==3.7.0
|
| 90 |
+
- matplotlib-inline==0.1.6
|
| 91 |
+
- mpmath==1.3.0
|
| 92 |
+
- multidict==6.0.4
|
| 93 |
+
- multiprocess==0.70.15
|
| 94 |
+
- nest-asyncio==1.5.8
|
| 95 |
+
- networkx==3.2.1
|
| 96 |
+
- nltk==3.8.1
|
| 97 |
+
- numpy==1.26.2
|
| 98 |
+
- nvidia-cublas-cu11==11.10.3.66
|
| 99 |
+
- nvidia-cuda-cupti-cu11==11.7.101
|
| 100 |
+
- nvidia-cuda-nvrtc-cu11==11.7.99
|
| 101 |
+
- nvidia-cuda-runtime-cu11==11.7.99
|
| 102 |
+
- nvidia-cudnn-cu11==8.5.0.96
|
| 103 |
+
- nvidia-cufft-cu11==10.9.0.58
|
| 104 |
+
- nvidia-curand-cu11==10.2.10.91
|
| 105 |
+
- nvidia-cusolver-cu11==11.4.0.1
|
| 106 |
+
- nvidia-cusparse-cu11==11.7.4.91
|
| 107 |
+
- nvidia-nccl-cu11==2.14.3
|
| 108 |
+
- nvidia-nvtx-cu11==11.7.91
|
| 109 |
+
- omegaconf==2.3.0
|
| 110 |
+
- opencv-python==4.7.0.72
|
| 111 |
+
- orjson==3.9.10
|
| 112 |
+
- packaging==23.2
|
| 113 |
+
- pandas==2.1.4
|
| 114 |
+
- parso==0.8.3
|
| 115 |
+
- peft==0.2.0
|
| 116 |
+
- pexpect==4.9.0
|
| 117 |
+
- pillow==10.1.0
|
| 118 |
+
- platformdirs==4.1.0
|
| 119 |
+
- portalocker==2.8.2
|
| 120 |
+
- progressbar2==4.3.0
|
| 121 |
+
- prompt-toolkit==3.0.43
|
| 122 |
+
- protobuf==4.25.1
|
| 123 |
+
- psutil==5.9.4
|
| 124 |
+
- ptyprocess==0.7.0
|
| 125 |
+
- pure-eval==0.2.2
|
| 126 |
+
- pyarrow==14.0.2
|
| 127 |
+
- pyarrow-hotfix==0.6
|
| 128 |
+
- pydantic==2.5.2
|
| 129 |
+
- pydantic-core==2.14.5
|
| 130 |
+
- pydub==0.25.1
|
| 131 |
+
- pygments==2.17.2
|
| 132 |
+
- pyparsing==3.1.1
|
| 133 |
+
- python-dateutil==2.8.2
|
| 134 |
+
- python-multipart==0.0.6
|
| 135 |
+
- python-utils==3.8.1
|
| 136 |
+
- pytz==2023.3.post1
|
| 137 |
+
- pyyaml==6.0
|
| 138 |
+
- pyzmq==25.1.2
|
| 139 |
+
- referencing==0.32.0
|
| 140 |
+
- regex==2022.10.31
|
| 141 |
+
- requests==2.31.0
|
| 142 |
+
- rpds-py==0.15.2
|
| 143 |
+
- safetensors==0.4.1
|
| 144 |
+
- scikit-image==0.22.0
|
| 145 |
+
- scikit-learn==1.3.2
|
| 146 |
+
- scipy==1.11.4
|
| 147 |
+
- semantic-version==2.10.0
|
| 148 |
+
- sentence-transformers==2.2.2
|
| 149 |
+
- sentencepiece==0.1.99
|
| 150 |
+
- sentry-sdk==1.39.1
|
| 151 |
+
- setproctitle==1.3.3
|
| 152 |
+
- six==1.16.0
|
| 153 |
+
- smmap==5.0.1
|
| 154 |
+
- sniffio==1.3.0
|
| 155 |
+
- stack-data==0.6.3
|
| 156 |
+
- starlette==0.27.0
|
| 157 |
+
- sympy==1.12
|
| 158 |
+
- threadpoolctl==3.2.0
|
| 159 |
+
- tifffile==2023.12.9
|
| 160 |
+
- timm==0.6.13
|
| 161 |
+
- tokenizers==0.15.0
|
| 162 |
+
- toolz==0.12.0
|
| 163 |
+
- torch==2.0.0
|
| 164 |
+
- torchaudio==2.0.1
|
| 165 |
+
- torchvision==0.15.1
|
| 166 |
+
- tornado==6.4
|
| 167 |
+
- tqdm==4.64.1
|
| 168 |
+
- traitlets==5.14.0
|
| 169 |
+
- transformers==4.36.2
|
| 170 |
+
- triton==2.0.0
|
| 171 |
+
- typing-extensions==4.9.0
|
| 172 |
+
- tzdata==2023.3
|
| 173 |
+
- urllib3==2.1.0
|
| 174 |
+
- uvicorn==0.24.0.post1
|
| 175 |
+
- visual-genome==1.1.1
|
| 176 |
+
- wandb==0.16.1
|
| 177 |
+
- wcwidth==0.2.12
|
| 178 |
+
- webdataset==0.2.48
|
| 179 |
+
- websockets==11.0.3
|
| 180 |
+
- xxhash==3.4.1
|
| 181 |
+
- yarl==1.9.4
|
| 182 |
+
- zipp==3.17.0
|
| 183 |
+
|
eval_configs/benchmark_evaluation.yaml
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
arch: minigpt_v2
|
| 3 |
+
model_type: pretrain
|
| 4 |
+
max_txt_len: 500
|
| 5 |
+
end_sym: "###"
|
| 6 |
+
low_resource: False
|
| 7 |
+
prompt_template: 'Instruct: {} /n Output: '
|
| 8 |
+
llama_model: ""
|
| 9 |
+
ckpt: ""
|
| 10 |
+
lora_r: 64
|
| 11 |
+
lora_alpha: 16
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
datasets:
|
| 16 |
+
cc_sbu_align:
|
| 17 |
+
vis_processor:
|
| 18 |
+
train:
|
| 19 |
+
name: "blip2_image_eval"
|
| 20 |
+
image_size: 448
|
| 21 |
+
text_processor:
|
| 22 |
+
train:
|
| 23 |
+
name: "blip_caption"
|
| 24 |
+
|
| 25 |
+
evaluation_datasets:
|
| 26 |
+
gqa:
|
| 27 |
+
eval_file_path: /root/autodl-tmp/evaluation/gqa/annotations/testdev_balanced_questions.json
|
| 28 |
+
img_path: /root/autodl-tmp/evaluation/gqa/images
|
| 29 |
+
max_new_tokens: 20
|
| 30 |
+
batch_size: 10
|
| 31 |
+
vizwiz:
|
| 32 |
+
eval_file_path: /root/autodl-tmp/evaluation/vizwiz/val.json
|
| 33 |
+
img_path: /root/autodl-tmp/evaluation/vizwiz/val
|
| 34 |
+
max_new_tokens: 20
|
| 35 |
+
batch_size: 10
|
| 36 |
+
iconvqa:
|
| 37 |
+
eval_file_path: /root/autodl-tmp/evaluation/iconqa/iconqa_data/problems.json
|
| 38 |
+
img_path: /root/autodl-tmp/evaluation/iconqa/iconqa_data/iconqa
|
| 39 |
+
max_new_tokens: 20
|
| 40 |
+
batch_size: 1
|
| 41 |
+
vsr:
|
| 42 |
+
eval_file_path: /root/autodl-tmp/evaluation/vsr/dev.jsonl
|
| 43 |
+
img_path: /root/autodl-tmp/coco2017/train
|
| 44 |
+
max_new_tokens: 20
|
| 45 |
+
batch_size: 10
|
| 46 |
+
hm:
|
| 47 |
+
eval_file_path: /root/autodl-tmp/evaluation/Hateful_Memes/data/dev.jsonl
|
| 48 |
+
img_path: /root/autodl-tmp/evaluation/Hateful_Memes/data
|
| 49 |
+
max_new_tokens: 20
|
| 50 |
+
batch_size: 10
|
| 51 |
+
|
| 52 |
+
run:
|
| 53 |
+
task: image_text_pretrain
|
| 54 |
+
name: minigptv2_evaluation
|
| 55 |
+
save_path: /root/MiniGPT-4/save_evalution
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
|
eval_configs/tinygptv_stage1_2_3_eval.yaml
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
arch: minigpt4
|
| 3 |
+
model_type: pretrain_vicuna0
|
| 4 |
+
max_txt_len: 160
|
| 5 |
+
bos_token_id: "###"
|
| 6 |
+
low_resource: False
|
| 7 |
+
prompt_template: '###Human: {} ###Assistant: '
|
| 8 |
+
ckpt: 'TinyGPT-V_for_Stage3.pth'
|
| 9 |
+
lora_r: 64
|
| 10 |
+
lora_alpha: 16
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
datasets:
|
| 14 |
+
cc_sbu_align:
|
| 15 |
+
vis_processor:
|
| 16 |
+
train:
|
| 17 |
+
name: "blip2_image_eval"
|
| 18 |
+
image_size: 224
|
| 19 |
+
text_processor:
|
| 20 |
+
train:
|
| 21 |
+
name: "blip_caption"
|
| 22 |
+
|
| 23 |
+
run:
|
| 24 |
+
task: image_text_pretrain
|
eval_configs/tinygptv_stage4_eval.yaml
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
arch: minigpt_v2
|
| 3 |
+
model_type: pretrain
|
| 4 |
+
max_txt_len: 500
|
| 5 |
+
bos_token_id: "###"
|
| 6 |
+
low_resource: False
|
| 7 |
+
prompt_template: 'Instruct: {} /n Output: '
|
| 8 |
+
ckpt: "/home/li0007xu/LLM/TinyGPT-V/TinyGPT-V_for_Stage4.pth"
|
| 9 |
+
lora_r: 64
|
| 10 |
+
lora_alpha: 16
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
datasets:
|
| 14 |
+
cc_sbu_align:
|
| 15 |
+
vis_processor:
|
| 16 |
+
train:
|
| 17 |
+
name: "blip2_image_eval"
|
| 18 |
+
image_size: 448
|
| 19 |
+
text_processor:
|
| 20 |
+
train:
|
| 21 |
+
name: "blip_caption"
|
| 22 |
+
|
| 23 |
+
run:
|
| 24 |
+
task: image_text_pretrain
|
examples/TinyGPT-V-ST.png
ADDED

|
examples/Training_S.png
ADDED

|
examples/result.png
ADDED
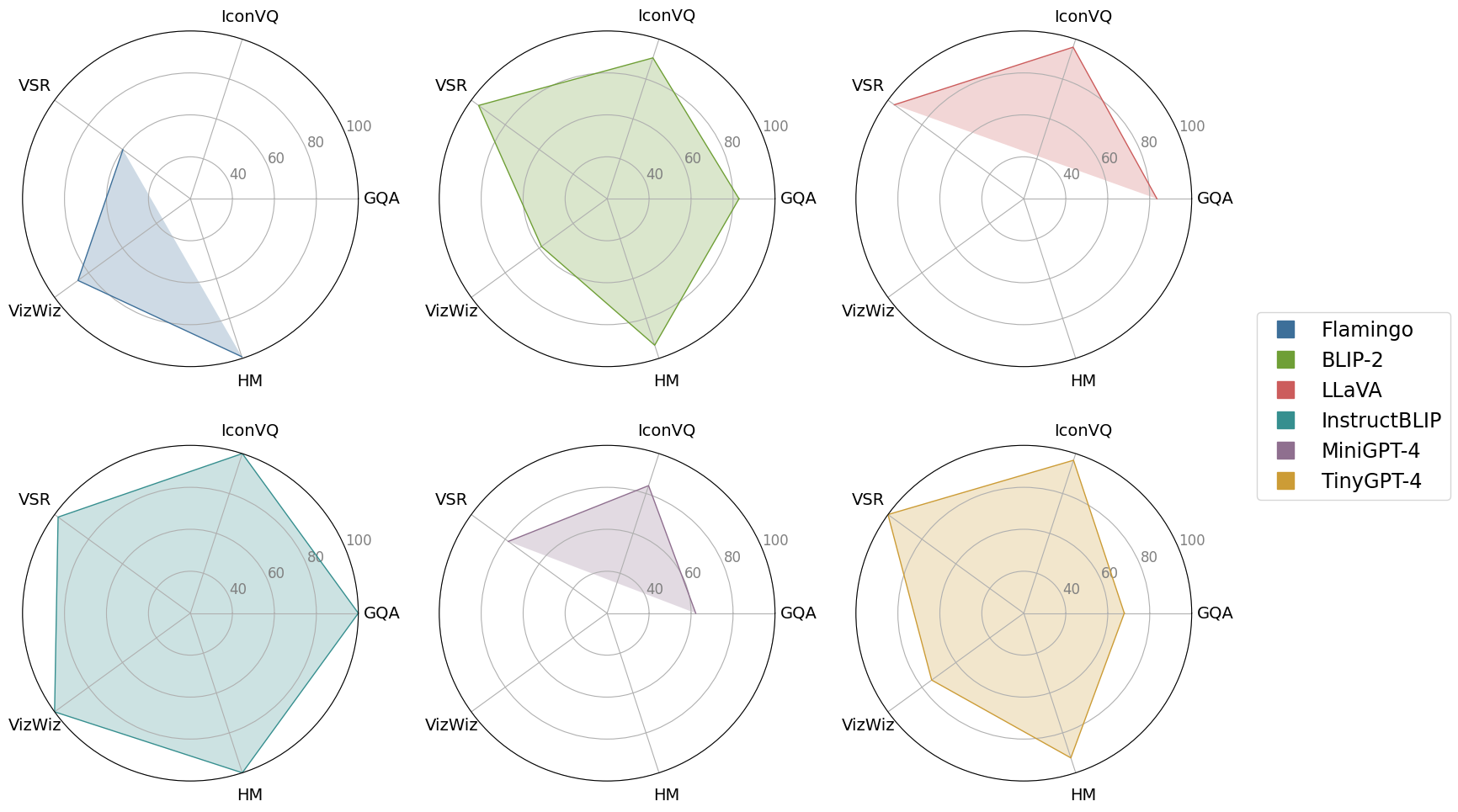
|
minigpt4/__init__.py
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE_Lavis file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import os
|
| 9 |
+
import sys
|
| 10 |
+
|
| 11 |
+
from omegaconf import OmegaConf
|
| 12 |
+
|
| 13 |
+
from minigpt4.common.registry import registry
|
| 14 |
+
|
| 15 |
+
from minigpt4.datasets.builders import *
|
| 16 |
+
from minigpt4.models import *
|
| 17 |
+
from minigpt4.processors import *
|
| 18 |
+
from minigpt4.tasks import *
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
root_dir = os.path.dirname(os.path.abspath(__file__))
|
| 22 |
+
default_cfg = OmegaConf.load(os.path.join(root_dir, "configs/default.yaml"))
|
| 23 |
+
|
| 24 |
+
registry.register_path("library_root", root_dir)
|
| 25 |
+
repo_root = os.path.join(root_dir, "..")
|
| 26 |
+
registry.register_path("repo_root", repo_root)
|
| 27 |
+
cache_root = os.path.join(repo_root, default_cfg.env.cache_root)
|
| 28 |
+
registry.register_path("cache_root", cache_root)
|
| 29 |
+
|
| 30 |
+
registry.register("MAX_INT", sys.maxsize)
|
| 31 |
+
registry.register("SPLIT_NAMES", ["train", "val", "test"])
|
minigpt4/__pycache__/__init__.cpython-39.pyc
ADDED
|
Binary file (1.01 kB). View file
|
|
|
minigpt4/common/__init__.py
ADDED
|
File without changes
|
minigpt4/common/__pycache__/__init__.cpython-39.pyc
ADDED
|
Binary file (143 Bytes). View file
|
|
|
minigpt4/common/__pycache__/config.cpython-39.pyc
ADDED
|
Binary file (12.6 kB). View file
|
|
|
minigpt4/common/__pycache__/dist_utils.cpython-39.pyc
ADDED
|
Binary file (3.79 kB). View file
|
|
|
minigpt4/common/__pycache__/logger.cpython-39.pyc
ADDED
|
Binary file (6.4 kB). View file
|
|
|
minigpt4/common/__pycache__/registry.cpython-39.pyc
ADDED
|
Binary file (9 kB). View file
|
|
|
minigpt4/common/__pycache__/utils.cpython-39.pyc
ADDED
|
Binary file (12.6 kB). View file
|
|
|
minigpt4/common/config.py
ADDED
|
@@ -0,0 +1,496 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE_Lavis file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import logging
|
| 9 |
+
import json
|
| 10 |
+
from typing import Dict
|
| 11 |
+
|
| 12 |
+
from omegaconf import OmegaConf
|
| 13 |
+
from minigpt4.common.registry import registry
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class Config:
|
| 17 |
+
def __init__(self, args):
|
| 18 |
+
self.config = {}
|
| 19 |
+
|
| 20 |
+
self.args = args
|
| 21 |
+
|
| 22 |
+
# Register the config and configuration for setup
|
| 23 |
+
registry.register("configuration", self)
|
| 24 |
+
|
| 25 |
+
user_config = self._build_opt_list(self.args.options)
|
| 26 |
+
|
| 27 |
+
config = OmegaConf.load(self.args.cfg_path)
|
| 28 |
+
|
| 29 |
+
runner_config = self.build_runner_config(config)
|
| 30 |
+
model_config = self.build_model_config(config, **user_config)
|
| 31 |
+
dataset_config = self.build_dataset_config(config)
|
| 32 |
+
evaluation_dataset_config = self.build_evaluation_dataset_config(config)
|
| 33 |
+
|
| 34 |
+
# Validate the user-provided runner configuration
|
| 35 |
+
# model and dataset configuration are supposed to be validated by the respective classes
|
| 36 |
+
# [TODO] validate the model/dataset configuration
|
| 37 |
+
# self._validate_runner_config(runner_config)
|
| 38 |
+
|
| 39 |
+
# Override the default configuration with user options.
|
| 40 |
+
self.config = OmegaConf.merge(
|
| 41 |
+
runner_config, model_config, dataset_config,evaluation_dataset_config, user_config
|
| 42 |
+
)
|
| 43 |
+
|
| 44 |
+
def _validate_runner_config(self, runner_config):
|
| 45 |
+
"""
|
| 46 |
+
This method validates the configuration, such that
|
| 47 |
+
1) all the user specified options are valid;
|
| 48 |
+
2) no type mismatches between the user specified options and the config.
|
| 49 |
+
"""
|
| 50 |
+
runner_config_validator = create_runner_config_validator()
|
| 51 |
+
runner_config_validator.validate(runner_config)
|
| 52 |
+
|
| 53 |
+
def _build_opt_list(self, opts):
|
| 54 |
+
opts_dot_list = self._convert_to_dot_list(opts)
|
| 55 |
+
return OmegaConf.from_dotlist(opts_dot_list)
|
| 56 |
+
|
| 57 |
+
@staticmethod
|
| 58 |
+
def build_model_config(config, **kwargs):
|
| 59 |
+
model = config.get("model", None)
|
| 60 |
+
assert model is not None, "Missing model configuration file."
|
| 61 |
+
|
| 62 |
+
model_cls = registry.get_model_class(model.arch)
|
| 63 |
+
assert model_cls is not None, f"Model '{model.arch}' has not been registered."
|
| 64 |
+
|
| 65 |
+
model_type = kwargs.get("model.model_type", None)
|
| 66 |
+
if not model_type:
|
| 67 |
+
model_type = model.get("model_type", None)
|
| 68 |
+
# else use the model type selected by user.
|
| 69 |
+
|
| 70 |
+
assert model_type is not None, "Missing model_type."
|
| 71 |
+
|
| 72 |
+
model_config_path = model_cls.default_config_path(model_type=model_type)
|
| 73 |
+
|
| 74 |
+
model_config = OmegaConf.create()
|
| 75 |
+
# hierarchy override, customized config > default config
|
| 76 |
+
model_config = OmegaConf.merge(
|
| 77 |
+
model_config,
|
| 78 |
+
OmegaConf.load(model_config_path),
|
| 79 |
+
{"model": config["model"]},
|
| 80 |
+
)
|
| 81 |
+
|
| 82 |
+
return model_config
|
| 83 |
+
|
| 84 |
+
@staticmethod
|
| 85 |
+
def build_runner_config(config):
|
| 86 |
+
return {"run": config.run}
|
| 87 |
+
|
| 88 |
+
@staticmethod
|
| 89 |
+
def build_dataset_config(config):
|
| 90 |
+
datasets = config.get("datasets", None)
|
| 91 |
+
if datasets is None:
|
| 92 |
+
raise KeyError(
|
| 93 |
+
"Expecting 'datasets' as the root key for dataset configuration."
|
| 94 |
+
)
|
| 95 |
+
|
| 96 |
+
dataset_config = OmegaConf.create()
|
| 97 |
+
|
| 98 |
+
for dataset_name in datasets:
|
| 99 |
+
builder_cls = registry.get_builder_class(dataset_name)
|
| 100 |
+
|
| 101 |
+
dataset_config_type = datasets[dataset_name].get("type", "default")
|
| 102 |
+
dataset_config_path = builder_cls.default_config_path(
|
| 103 |
+
type=dataset_config_type
|
| 104 |
+
)
|
| 105 |
+
|
| 106 |
+
# hierarchy override, customized config > default config
|
| 107 |
+
dataset_config = OmegaConf.merge(
|
| 108 |
+
dataset_config,
|
| 109 |
+
OmegaConf.load(dataset_config_path),
|
| 110 |
+
{"datasets": {dataset_name: config["datasets"][dataset_name]}},
|
| 111 |
+
)
|
| 112 |
+
|
| 113 |
+
return dataset_config
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
@staticmethod
|
| 117 |
+
def build_evaluation_dataset_config(config):
|
| 118 |
+
datasets = config.get("evaluation_datasets", None)
|
| 119 |
+
# if datasets is None:
|
| 120 |
+
# raise KeyError(
|
| 121 |
+
# "Expecting 'datasets' as the root key for dataset configuration."
|
| 122 |
+
# )
|
| 123 |
+
|
| 124 |
+
dataset_config = OmegaConf.create()
|
| 125 |
+
|
| 126 |
+
if datasets is not None:
|
| 127 |
+
for dataset_name in datasets:
|
| 128 |
+
builder_cls = registry.get_builder_class(dataset_name)
|
| 129 |
+
|
| 130 |
+
# hierarchy override, customized config > default config
|
| 131 |
+
dataset_config = OmegaConf.merge(
|
| 132 |
+
dataset_config,
|
| 133 |
+
{"evaluation_datasets": {dataset_name: config["evaluation_datasets"][dataset_name]}},
|
| 134 |
+
)
|
| 135 |
+
|
| 136 |
+
return dataset_config
|
| 137 |
+
|
| 138 |
+
def _convert_to_dot_list(self, opts):
|
| 139 |
+
if opts is None:
|
| 140 |
+
opts = []
|
| 141 |
+
|
| 142 |
+
if len(opts) == 0:
|
| 143 |
+
return opts
|
| 144 |
+
|
| 145 |
+
has_equal = opts[0].find("=") != -1
|
| 146 |
+
|
| 147 |
+
if has_equal:
|
| 148 |
+
return opts
|
| 149 |
+
|
| 150 |
+
return [(opt + "=" + value) for opt, value in zip(opts[0::2], opts[1::2])]
|
| 151 |
+
|
| 152 |
+
def get_config(self):
|
| 153 |
+
return self.config
|
| 154 |
+
|
| 155 |
+
@property
|
| 156 |
+
def run_cfg(self):
|
| 157 |
+
return self.config.run
|
| 158 |
+
|
| 159 |
+
@property
|
| 160 |
+
def datasets_cfg(self):
|
| 161 |
+
return self.config.datasets
|
| 162 |
+
|
| 163 |
+
@property
|
| 164 |
+
def evaluation_datasets_cfg(self):
|
| 165 |
+
return self.config.evaluation_datasets
|
| 166 |
+
|
| 167 |
+
@property
|
| 168 |
+
def model_cfg(self):
|
| 169 |
+
return self.config.model
|
| 170 |
+
|
| 171 |
+
def pretty_print(self):
|
| 172 |
+
logging.info("\n===== Running Parameters =====")
|
| 173 |
+
logging.info(self._convert_node_to_json(self.config.run))
|
| 174 |
+
|
| 175 |
+
logging.info("\n====== Dataset Attributes ======")
|
| 176 |
+
datasets = self.config.datasets
|
| 177 |
+
|
| 178 |
+
for dataset in datasets:
|
| 179 |
+
if dataset in self.config.datasets:
|
| 180 |
+
logging.info(f"\n======== {dataset} =======")
|
| 181 |
+
dataset_config = self.config.datasets[dataset]
|
| 182 |
+
logging.info(self._convert_node_to_json(dataset_config))
|
| 183 |
+
else:
|
| 184 |
+
logging.warning(f"No dataset named '{dataset}' in config. Skipping")
|
| 185 |
+
|
| 186 |
+
logging.info(f"\n====== Model Attributes ======")
|
| 187 |
+
logging.info(self._convert_node_to_json(self.config.model))
|
| 188 |
+
|
| 189 |
+
def _convert_node_to_json(self, node):
|
| 190 |
+
container = OmegaConf.to_container(node, resolve=True)
|
| 191 |
+
return json.dumps(container, indent=4, sort_keys=True)
|
| 192 |
+
|
| 193 |
+
def to_dict(self):
|
| 194 |
+
return OmegaConf.to_container(self.config)
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
def node_to_dict(node):
|
| 198 |
+
return OmegaConf.to_container(node)
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
class ConfigValidator:
|
| 202 |
+
"""
|
| 203 |
+
This is a preliminary implementation to centralize and validate the configuration.
|
| 204 |
+
May be altered in the future.
|
| 205 |
+
|
| 206 |
+
A helper class to validate configurations from yaml file.
|
| 207 |
+
|
| 208 |
+
This serves the following purposes:
|
| 209 |
+
1. Ensure all the options in the yaml are defined, raise error if not.
|
| 210 |
+
2. when type mismatches are found, the validator will raise an error.
|
| 211 |
+
3. a central place to store and display helpful messages for supported configurations.
|
| 212 |
+
|
| 213 |
+
"""
|
| 214 |
+
|
| 215 |
+
class _Argument:
|
| 216 |
+
def __init__(self, name, choices=None, type=None, help=None):
|
| 217 |
+
self.name = name
|
| 218 |
+
self.val = None
|
| 219 |
+
self.choices = choices
|
| 220 |
+
self.type = type
|
| 221 |
+
self.help = help
|
| 222 |
+
|
| 223 |
+
def __str__(self):
|
| 224 |
+
s = f"{self.name}={self.val}"
|
| 225 |
+
if self.type is not None:
|
| 226 |
+
s += f", ({self.type})"
|
| 227 |
+
if self.choices is not None:
|
| 228 |
+
s += f", choices: {self.choices}"
|
| 229 |
+
if self.help is not None:
|
| 230 |
+
s += f", ({self.help})"
|
| 231 |
+
return s
|
| 232 |
+
|
| 233 |
+
def __init__(self, description):
|
| 234 |
+
self.description = description
|
| 235 |
+
|
| 236 |
+
self.arguments = dict()
|
| 237 |
+
|
| 238 |
+
self.parsed_args = None
|
| 239 |
+
|
| 240 |
+
def __getitem__(self, key):
|
| 241 |
+
assert self.parsed_args is not None, "No arguments parsed yet."
|
| 242 |
+
|
| 243 |
+
return self.parsed_args[key]
|
| 244 |
+
|
| 245 |
+
def __str__(self) -> str:
|
| 246 |
+
return self.format_help()
|
| 247 |
+
|
| 248 |
+
def add_argument(self, *args, **kwargs):
|
| 249 |
+
"""
|
| 250 |
+
Assume the first argument is the name of the argument.
|
| 251 |
+
"""
|
| 252 |
+
self.arguments[args[0]] = self._Argument(*args, **kwargs)
|
| 253 |
+
|
| 254 |
+
def validate(self, config=None):
|
| 255 |
+
"""
|
| 256 |
+
Convert yaml config (dict-like) to list, required by argparse.
|
| 257 |
+
"""
|
| 258 |
+
for k, v in config.items():
|
| 259 |
+
assert (
|
| 260 |
+
k in self.arguments
|
| 261 |
+
), f"""{k} is not a valid argument. Support arguments are {self.format_arguments()}."""
|
| 262 |
+
|
| 263 |
+
if self.arguments[k].type is not None:
|
| 264 |
+
try:
|
| 265 |
+
self.arguments[k].val = self.arguments[k].type(v)
|
| 266 |
+
except ValueError:
|
| 267 |
+
raise ValueError(f"{k} is not a valid {self.arguments[k].type}.")
|
| 268 |
+
|
| 269 |
+
if self.arguments[k].choices is not None:
|
| 270 |
+
assert (
|
| 271 |
+
v in self.arguments[k].choices
|
| 272 |
+
), f"""{k} must be one of {self.arguments[k].choices}."""
|
| 273 |
+
|
| 274 |
+
return config
|
| 275 |
+
|
| 276 |
+
def format_arguments(self):
|
| 277 |
+
return str([f"{k}" for k in sorted(self.arguments.keys())])
|
| 278 |
+
|
| 279 |
+
def format_help(self):
|
| 280 |
+
# description + key-value pair string for each argument
|
| 281 |
+
help_msg = str(self.description)
|
| 282 |
+
return help_msg + ", available arguments: " + self.format_arguments()
|
| 283 |
+
|
| 284 |
+
def print_help(self):
|
| 285 |
+
# display help message
|
| 286 |
+
print(self.format_help())
|
| 287 |
+
|
| 288 |
+
|
| 289 |
+
def create_runner_config_validator():
|
| 290 |
+
validator = ConfigValidator(description="Runner configurations")
|
| 291 |
+
|
| 292 |
+
validator.add_argument(
|
| 293 |
+
"runner",
|
| 294 |
+
type=str,
|
| 295 |
+
choices=["runner_base", "runner_iter"],
|
| 296 |
+
help="""Runner to use. The "runner_base" uses epoch-based training while iter-based
|
| 297 |
+
runner runs based on iters. Default: runner_base""",
|
| 298 |
+
)
|
| 299 |
+
# add argumetns for training dataset ratios
|
| 300 |
+
validator.add_argument(
|
| 301 |
+
"train_dataset_ratios",
|
| 302 |
+
type=Dict[str, float],
|
| 303 |
+
help="""Ratios of training dataset. This is used in iteration-based runner.
|
| 304 |
+
Do not support for epoch-based runner because how to define an epoch becomes tricky.
|
| 305 |
+
Default: None""",
|
| 306 |
+
)
|
| 307 |
+
validator.add_argument(
|
| 308 |
+
"max_iters",
|
| 309 |
+
type=float,
|
| 310 |
+
help="Maximum number of iterations to run.",
|
| 311 |
+
)
|
| 312 |
+
validator.add_argument(
|
| 313 |
+
"max_epoch",
|
| 314 |
+
type=int,
|
| 315 |
+
help="Maximum number of epochs to run.",
|
| 316 |
+
)
|
| 317 |
+
# add arguments for iters_per_inner_epoch
|
| 318 |
+
validator.add_argument(
|
| 319 |
+
"iters_per_inner_epoch",
|
| 320 |
+
type=float,
|
| 321 |
+
help="Number of iterations per inner epoch. This is required when runner is runner_iter.",
|
| 322 |
+
)
|
| 323 |
+
lr_scheds_choices = registry.list_lr_schedulers()
|
| 324 |
+
validator.add_argument(
|
| 325 |
+
"lr_sched",
|
| 326 |
+
type=str,
|
| 327 |
+
choices=lr_scheds_choices,
|
| 328 |
+
help="Learning rate scheduler to use, from {}".format(lr_scheds_choices),
|
| 329 |
+
)
|
| 330 |
+
task_choices = registry.list_tasks()
|
| 331 |
+
validator.add_argument(
|
| 332 |
+
"task",
|
| 333 |
+
type=str,
|
| 334 |
+
choices=task_choices,
|
| 335 |
+
help="Task to use, from {}".format(task_choices),
|
| 336 |
+
)
|
| 337 |
+
# add arguments for init_lr
|
| 338 |
+
validator.add_argument(
|
| 339 |
+
"init_lr",
|
| 340 |
+
type=float,
|
| 341 |
+
help="Initial learning rate. This will be the learning rate after warmup and before decay.",
|
| 342 |
+
)
|
| 343 |
+
# add arguments for min_lr
|
| 344 |
+
validator.add_argument(
|
| 345 |
+
"min_lr",
|
| 346 |
+
type=float,
|
| 347 |
+
help="Minimum learning rate (after decay).",
|
| 348 |
+
)
|
| 349 |
+
# add arguments for warmup_lr
|
| 350 |
+
validator.add_argument(
|
| 351 |
+
"warmup_lr",
|
| 352 |
+
type=float,
|
| 353 |
+
help="Starting learning rate for warmup.",
|
| 354 |
+
)
|
| 355 |
+
# add arguments for learning rate decay rate
|
| 356 |
+
validator.add_argument(
|
| 357 |
+
"lr_decay_rate",
|
| 358 |
+
type=float,
|
| 359 |
+
help="Learning rate decay rate. Required if using a decaying learning rate scheduler.",
|
| 360 |
+
)
|
| 361 |
+
# add arguments for weight decay
|
| 362 |
+
validator.add_argument(
|
| 363 |
+
"weight_decay",
|
| 364 |
+
type=float,
|
| 365 |
+
help="Weight decay rate.",
|
| 366 |
+
)
|
| 367 |
+
# add arguments for training batch size
|
| 368 |
+
validator.add_argument(
|
| 369 |
+
"batch_size_train",
|
| 370 |
+
type=int,
|
| 371 |
+
help="Training batch size.",
|
| 372 |
+
)
|
| 373 |
+
# add arguments for evaluation batch size
|
| 374 |
+
validator.add_argument(
|
| 375 |
+
"batch_size_eval",
|
| 376 |
+
type=int,
|
| 377 |
+
help="Evaluation batch size, including validation and testing.",
|
| 378 |
+
)
|
| 379 |
+
# add arguments for number of workers for data loading
|
| 380 |
+
validator.add_argument(
|
| 381 |
+
"num_workers",
|
| 382 |
+
help="Number of workers for data loading.",
|
| 383 |
+
)
|
| 384 |
+
# add arguments for warm up steps
|
| 385 |
+
validator.add_argument(
|
| 386 |
+
"warmup_steps",
|
| 387 |
+
type=int,
|
| 388 |
+
help="Number of warmup steps. Required if a warmup schedule is used.",
|
| 389 |
+
)
|
| 390 |
+
# add arguments for random seed
|
| 391 |
+
validator.add_argument(
|
| 392 |
+
"seed",
|
| 393 |
+
type=int,
|
| 394 |
+
help="Random seed.",
|
| 395 |
+
)
|
| 396 |
+
# add arguments for output directory
|
| 397 |
+
validator.add_argument(
|
| 398 |
+
"output_dir",
|
| 399 |
+
type=str,
|
| 400 |
+
help="Output directory to save checkpoints and logs.",
|
| 401 |
+
)
|
| 402 |
+
# add arguments for whether only use evaluation
|
| 403 |
+
validator.add_argument(
|
| 404 |
+
"evaluate",
|
| 405 |
+
help="Whether to only evaluate the model. If true, training will not be performed.",
|
| 406 |
+
)
|
| 407 |
+
# add arguments for splits used for training, e.g. ["train", "val"]
|
| 408 |
+
validator.add_argument(
|
| 409 |
+
"train_splits",
|
| 410 |
+
type=list,
|
| 411 |
+
help="Splits to use for training.",
|
| 412 |
+
)
|
| 413 |
+
# add arguments for splits used for validation, e.g. ["val"]
|
| 414 |
+
validator.add_argument(
|
| 415 |
+
"valid_splits",
|
| 416 |
+
type=list,
|
| 417 |
+
help="Splits to use for validation. If not provided, will skip the validation.",
|
| 418 |
+
)
|
| 419 |
+
# add arguments for splits used for testing, e.g. ["test"]
|
| 420 |
+
validator.add_argument(
|
| 421 |
+
"test_splits",
|
| 422 |
+
type=list,
|
| 423 |
+
help="Splits to use for testing. If not provided, will skip the testing.",
|
| 424 |
+
)
|
| 425 |
+
# add arguments for accumulating gradient for iterations
|
| 426 |
+
validator.add_argument(
|
| 427 |
+
"accum_grad_iters",
|
| 428 |
+
type=int,
|
| 429 |
+
help="Number of iterations to accumulate gradient for.",
|
| 430 |
+
)
|
| 431 |
+
|
| 432 |
+
# ====== distributed training ======
|
| 433 |
+
validator.add_argument(
|
| 434 |
+
"device",
|
| 435 |
+
type=str,
|
| 436 |
+
choices=["cpu", "cuda"],
|
| 437 |
+
help="Device to use. Support 'cuda' or 'cpu' as for now.",
|
| 438 |
+
)
|
| 439 |
+
validator.add_argument(
|
| 440 |
+
"world_size",
|
| 441 |
+
type=int,
|
| 442 |
+
help="Number of processes participating in the job.",
|
| 443 |
+
)
|
| 444 |
+
validator.add_argument("dist_url", type=str)
|
| 445 |
+
validator.add_argument("distributed", type=bool)
|
| 446 |
+
# add arguments to opt using distributed sampler during evaluation or not
|
| 447 |
+
validator.add_argument(
|
| 448 |
+
"use_dist_eval_sampler",
|
| 449 |
+
type=bool,
|
| 450 |
+
help="Whether to use distributed sampler during evaluation or not.",
|
| 451 |
+
)
|
| 452 |
+
|
| 453 |
+
# ====== task specific ======
|
| 454 |
+
# generation task specific arguments
|
| 455 |
+
# add arguments for maximal length of text output
|
| 456 |
+
validator.add_argument(
|
| 457 |
+
"max_len",
|
| 458 |
+
type=int,
|
| 459 |
+
help="Maximal length of text output.",
|
| 460 |
+
)
|
| 461 |
+
# add arguments for minimal length of text output
|
| 462 |
+
validator.add_argument(
|
| 463 |
+
"min_len",
|
| 464 |
+
type=int,
|
| 465 |
+
help="Minimal length of text output.",
|
| 466 |
+
)
|
| 467 |
+
# add arguments number of beams
|
| 468 |
+
validator.add_argument(
|
| 469 |
+
"num_beams",
|
| 470 |
+
type=int,
|
| 471 |
+
help="Number of beams used for beam search.",
|
| 472 |
+
)
|
| 473 |
+
|
| 474 |
+
# vqa task specific arguments
|
| 475 |
+
# add arguments for number of answer candidates
|
| 476 |
+
validator.add_argument(
|
| 477 |
+
"num_ans_candidates",
|
| 478 |
+
type=int,
|
| 479 |
+
help="""For ALBEF and BLIP, these models first rank answers according to likelihood to select answer candidates.""",
|
| 480 |
+
)
|
| 481 |
+
# add arguments for inference method
|
| 482 |
+
validator.add_argument(
|
| 483 |
+
"inference_method",
|
| 484 |
+
type=str,
|
| 485 |
+
choices=["genearte", "rank"],
|
| 486 |
+
help="""Inference method to use for question answering. If rank, requires a answer list.""",
|
| 487 |
+
)
|
| 488 |
+
|
| 489 |
+
# ====== model specific ======
|
| 490 |
+
validator.add_argument(
|
| 491 |
+
"k_test",
|
| 492 |
+
type=int,
|
| 493 |
+
help="Number of top k most similar samples from ITC/VTC selection to be tested.",
|
| 494 |
+
)
|
| 495 |
+
|
| 496 |
+
return validator
|
minigpt4/common/dist_utils.py
ADDED
|
@@ -0,0 +1,140 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE_Lavis file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import datetime
|
| 9 |
+
import functools
|
| 10 |
+
import os
|
| 11 |
+
|
| 12 |
+
import torch
|
| 13 |
+
import torch.distributed as dist
|
| 14 |
+
import timm.models.hub as timm_hub
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def setup_for_distributed(is_master):
|
| 18 |
+
"""
|
| 19 |
+
This function disables printing when not in master process
|
| 20 |
+
"""
|
| 21 |
+
import builtins as __builtin__
|
| 22 |
+
|
| 23 |
+
builtin_print = __builtin__.print
|
| 24 |
+
|
| 25 |
+
def print(*args, **kwargs):
|
| 26 |
+
force = kwargs.pop("force", False)
|
| 27 |
+
if is_master or force:
|
| 28 |
+
builtin_print(*args, **kwargs)
|
| 29 |
+
|
| 30 |
+
__builtin__.print = print
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def is_dist_avail_and_initialized():
|
| 34 |
+
if not dist.is_available():
|
| 35 |
+
return False
|
| 36 |
+
if not dist.is_initialized():
|
| 37 |
+
return False
|
| 38 |
+
return True
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def get_world_size():
|
| 42 |
+
if not is_dist_avail_and_initialized():
|
| 43 |
+
return 1
|
| 44 |
+
return dist.get_world_size()
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def get_rank():
|
| 48 |
+
if not is_dist_avail_and_initialized():
|
| 49 |
+
return 0
|
| 50 |
+
return dist.get_rank()
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def is_main_process():
|
| 54 |
+
return get_rank() == 0
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def init_distributed_mode(args):
|
| 58 |
+
if args.distributed is False:
|
| 59 |
+
print("Not using distributed mode")
|
| 60 |
+
return
|
| 61 |
+
elif "RANK" in os.environ and "WORLD_SIZE" in os.environ:
|
| 62 |
+
args.rank = int(os.environ["RANK"])
|
| 63 |
+
args.world_size = int(os.environ["WORLD_SIZE"])
|
| 64 |
+
args.gpu = int(os.environ["LOCAL_RANK"])
|
| 65 |
+
elif "SLURM_PROCID" in os.environ:
|
| 66 |
+
args.rank = int(os.environ["SLURM_PROCID"])
|
| 67 |
+
args.gpu = args.rank % torch.cuda.device_count()
|
| 68 |
+
else:
|
| 69 |
+
print("Not using distributed mode")
|
| 70 |
+
args.distributed = False
|
| 71 |
+
return
|
| 72 |
+
|
| 73 |
+
args.distributed = True
|
| 74 |
+
|
| 75 |
+
torch.cuda.set_device(args.gpu)
|
| 76 |
+
args.dist_backend = "nccl"
|
| 77 |
+
print(
|
| 78 |
+
"| distributed init (rank {}, world {}): {}".format(
|
| 79 |
+
args.rank, args.world_size, args.dist_url
|
| 80 |
+
),
|
| 81 |
+
flush=True,
|
| 82 |
+
)
|
| 83 |
+
torch.distributed.init_process_group(
|
| 84 |
+
backend=args.dist_backend,
|
| 85 |
+
init_method=args.dist_url,
|
| 86 |
+
world_size=args.world_size,
|
| 87 |
+
rank=args.rank,
|
| 88 |
+
timeout=datetime.timedelta(
|
| 89 |
+
days=365
|
| 90 |
+
), # allow auto-downloading and de-compressing
|
| 91 |
+
)
|
| 92 |
+
torch.distributed.barrier()
|
| 93 |
+
setup_for_distributed(args.rank == 0)
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def get_dist_info():
|
| 97 |
+
if torch.__version__ < "1.0":
|
| 98 |
+
initialized = dist._initialized
|
| 99 |
+
else:
|
| 100 |
+
initialized = dist.is_initialized()
|
| 101 |
+
if initialized:
|
| 102 |
+
rank = dist.get_rank()
|
| 103 |
+
world_size = dist.get_world_size()
|
| 104 |
+
else: # non-distributed training
|
| 105 |
+
rank = 0
|
| 106 |
+
world_size = 1
|
| 107 |
+
return rank, world_size
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def main_process(func):
|
| 111 |
+
@functools.wraps(func)
|
| 112 |
+
def wrapper(*args, **kwargs):
|
| 113 |
+
rank, _ = get_dist_info()
|
| 114 |
+
if rank == 0:
|
| 115 |
+
return func(*args, **kwargs)
|
| 116 |
+
|
| 117 |
+
return wrapper
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
def download_cached_file(url, check_hash=True, progress=False):
|
| 121 |
+
"""
|
| 122 |
+
Download a file from a URL and cache it locally. If the file already exists, it is not downloaded again.
|
| 123 |
+
If distributed, only the main process downloads the file, and the other processes wait for the file to be downloaded.
|
| 124 |
+
"""
|
| 125 |
+
|
| 126 |
+
def get_cached_file_path():
|
| 127 |
+
# a hack to sync the file path across processes
|
| 128 |
+
parts = torch.hub.urlparse(url)
|
| 129 |
+
filename = os.path.basename(parts.path)
|
| 130 |
+
cached_file = os.path.join(timm_hub.get_cache_dir(), filename)
|
| 131 |
+
|
| 132 |
+
return cached_file
|
| 133 |
+
|
| 134 |
+
if is_main_process():
|
| 135 |
+
timm_hub.download_cached_file(url, check_hash, progress)
|
| 136 |
+
|
| 137 |
+
if is_dist_avail_and_initialized():
|
| 138 |
+
dist.barrier()
|
| 139 |
+
|
| 140 |
+
return get_cached_file_path()
|
minigpt4/common/eval_utils.py
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import numpy as np
|
| 3 |
+
from nltk.translate.bleu_score import sentence_bleu
|
| 4 |
+
|
| 5 |
+
from minigpt4.common.registry import registry
|
| 6 |
+
from minigpt4.common.config import Config
|
| 7 |
+
|
| 8 |
+
# imports modules for registration
|
| 9 |
+
from minigpt4.datasets.builders import *
|
| 10 |
+
from minigpt4.models import *
|
| 11 |
+
from minigpt4.processors import *
|
| 12 |
+
from minigpt4.runners import *
|
| 13 |
+
from minigpt4.tasks import *
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def eval_parser():
|
| 18 |
+
parser = argparse.ArgumentParser(description="Demo")
|
| 19 |
+
parser.add_argument("--cfg-path", required=True, help="path to configuration file.")
|
| 20 |
+
parser.add_argument("--name", type=str, default='A2', help="evaluation name")
|
| 21 |
+
parser.add_argument("--ckpt", type=str, help="path to configuration file.")
|
| 22 |
+
parser.add_argument("--eval_opt", type=str, default='all', help="path to configuration file.")
|
| 23 |
+
parser.add_argument("--max_new_tokens", type=int, default=10, help="max number of generated tokens")
|
| 24 |
+
parser.add_argument("--batch_size", type=int, default=32)
|
| 25 |
+
parser.add_argument("--lora_r", type=int, default=64, help="lora rank of the model")
|
| 26 |
+
parser.add_argument("--lora_alpha", type=int, default=16, help="lora alpha")
|
| 27 |
+
parser.add_argument(
|
| 28 |
+
"--options",
|
| 29 |
+
nargs="+",
|
| 30 |
+
help="override some settings in the used config, the key-value pair "
|
| 31 |
+
"in xxx=yyy format will be merged into config file (deprecate), "
|
| 32 |
+
"change to --cfg-options instead.",
|
| 33 |
+
)
|
| 34 |
+
return parser
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
def prepare_texts(texts, conv_temp):
|
| 38 |
+
convs = [conv_temp.copy() for _ in range(len(texts))]
|
| 39 |
+
[conv.append_message(
|
| 40 |
+
conv.roles[0], '<Img><ImageHere></Img> {}'.format(text)) for conv, text in zip(convs, texts)]
|
| 41 |
+
[conv.append_message(conv.roles[1], None) for conv in convs]
|
| 42 |
+
texts = [conv.get_prompt() for conv in convs]
|
| 43 |
+
return texts
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def init_model(args):
|
| 47 |
+
print('Initialization Model')
|
| 48 |
+
cfg = Config(args)
|
| 49 |
+
# cfg.model_cfg.ckpt = args.ckpt
|
| 50 |
+
# cfg.model_cfg.lora_r = args.lora_r
|
| 51 |
+
# cfg.model_cfg.lora_alpha = args.lora_alpha
|
| 52 |
+
|
| 53 |
+
model_config = cfg.model_cfg
|
| 54 |
+
model_cls = registry.get_model_class(model_config.arch)
|
| 55 |
+
model = model_cls.from_config(model_config).to('cuda:0')
|
| 56 |
+
|
| 57 |
+
# import pudb; pudb.set_trace()
|
| 58 |
+
key = list(cfg.datasets_cfg.keys())[0]
|
| 59 |
+
vis_processor_cfg = cfg.datasets_cfg.get(key).vis_processor.train
|
| 60 |
+
vis_processor = registry.get_processor_class(vis_processor_cfg.name).from_config(vis_processor_cfg)
|
| 61 |
+
print('Initialization Finished')
|
| 62 |
+
return model, vis_processor
|
| 63 |
+
|
| 64 |
+
def computeIoU(bbox1, bbox2):
|
| 65 |
+
x1, y1, x2, y2 = bbox1
|
| 66 |
+
x3, y3, x4, y4 = bbox2
|
| 67 |
+
intersection_x1 = max(x1, x3)
|
| 68 |
+
intersection_y1 = max(y1, y3)
|
| 69 |
+
intersection_x2 = min(x2, x4)
|
| 70 |
+
intersection_y2 = min(y2, y4)
|
| 71 |
+
intersection_area = max(0, intersection_x2 - intersection_x1 + 1) * max(0, intersection_y2 - intersection_y1 + 1)
|
| 72 |
+
bbox1_area = (x2 - x1 + 1) * (y2 - y1 + 1)
|
| 73 |
+
bbox2_area = (x4 - x3 + 1) * (y4 - y3 + 1)
|
| 74 |
+
union_area = bbox1_area + bbox2_area - intersection_area
|
| 75 |
+
iou = intersection_area / union_area
|
| 76 |
+
return iou
|
minigpt4/common/gradcam.py
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
from matplotlib import pyplot as plt
|
| 3 |
+
from scipy.ndimage import filters
|
| 4 |
+
from skimage import transform as skimage_transform
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def getAttMap(img, attMap, blur=True, overlap=True):
|
| 8 |
+
attMap -= attMap.min()
|
| 9 |
+
if attMap.max() > 0:
|
| 10 |
+
attMap /= attMap.max()
|
| 11 |
+
attMap = skimage_transform.resize(attMap, (img.shape[:2]), order=3, mode="constant")
|
| 12 |
+
if blur:
|
| 13 |
+
attMap = filters.gaussian_filter(attMap, 0.02 * max(img.shape[:2]))
|
| 14 |
+
attMap -= attMap.min()
|
| 15 |
+
attMap /= attMap.max()
|
| 16 |
+
cmap = plt.get_cmap("jet")
|
| 17 |
+
attMapV = cmap(attMap)
|
| 18 |
+
attMapV = np.delete(attMapV, 3, 2)
|
| 19 |
+
if overlap:
|
| 20 |
+
attMap = (
|
| 21 |
+
1 * (1 - attMap**0.7).reshape(attMap.shape + (1,)) * img
|
| 22 |
+
+ (attMap**0.7).reshape(attMap.shape + (1,)) * attMapV
|
| 23 |
+
)
|
| 24 |
+
return attMap
|
minigpt4/common/logger.py
ADDED
|
@@ -0,0 +1,195 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE_Lavis file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import datetime
|
| 9 |
+
import logging
|
| 10 |
+
import time
|
| 11 |
+
from collections import defaultdict, deque
|
| 12 |
+
|
| 13 |
+
import torch
|
| 14 |
+
import torch.distributed as dist
|
| 15 |
+
|
| 16 |
+
from minigpt4.common import dist_utils
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class SmoothedValue(object):
|
| 20 |
+
"""Track a series of values and provide access to smoothed values over a
|
| 21 |
+
window or the global series average.
|
| 22 |
+
"""
|
| 23 |
+
|
| 24 |
+
def __init__(self, window_size=20, fmt=None):
|
| 25 |
+
if fmt is None:
|
| 26 |
+
fmt = "{median:.4f} ({global_avg:.4f})"
|
| 27 |
+
self.deque = deque(maxlen=window_size)
|
| 28 |
+
self.total = 0.0
|
| 29 |
+
self.count = 0
|
| 30 |
+
self.fmt = fmt
|
| 31 |
+
|
| 32 |
+
def update(self, value, n=1):
|
| 33 |
+
self.deque.append(value)
|
| 34 |
+
self.count += n
|
| 35 |
+
self.total += value * n
|
| 36 |
+
|
| 37 |
+
def synchronize_between_processes(self):
|
| 38 |
+
"""
|
| 39 |
+
Warning: does not synchronize the deque!
|
| 40 |
+
"""
|
| 41 |
+
if not dist_utils.is_dist_avail_and_initialized():
|
| 42 |
+
return
|
| 43 |
+
t = torch.tensor([self.count, self.total], dtype=torch.float64, device="cuda")
|
| 44 |
+
dist.barrier()
|
| 45 |
+
dist.all_reduce(t)
|
| 46 |
+
t = t.tolist()
|
| 47 |
+
self.count = int(t[0])
|
| 48 |
+
self.total = t[1]
|
| 49 |
+
|
| 50 |
+
@property
|
| 51 |
+
def median(self):
|
| 52 |
+
d = torch.tensor(list(self.deque))
|
| 53 |
+
return d.median().item()
|
| 54 |
+
|
| 55 |
+
@property
|
| 56 |
+
def avg(self):
|
| 57 |
+
d = torch.tensor(list(self.deque), dtype=torch.float32)
|
| 58 |
+
return d.mean().item()
|
| 59 |
+
|
| 60 |
+
@property
|
| 61 |
+
def global_avg(self):
|
| 62 |
+
return self.total / self.count
|
| 63 |
+
|
| 64 |
+
@property
|
| 65 |
+
def max(self):
|
| 66 |
+
return max(self.deque)
|
| 67 |
+
|
| 68 |
+
@property
|
| 69 |
+
def value(self):
|
| 70 |
+
return self.deque[-1]
|
| 71 |
+
|
| 72 |
+
def __str__(self):
|
| 73 |
+
return self.fmt.format(
|
| 74 |
+
median=self.median,
|
| 75 |
+
avg=self.avg,
|
| 76 |
+
global_avg=self.global_avg,
|
| 77 |
+
max=self.max,
|
| 78 |
+
value=self.value,
|
| 79 |
+
)
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
class MetricLogger(object):
|
| 83 |
+
def __init__(self, delimiter="\t"):
|
| 84 |
+
self.meters = defaultdict(SmoothedValue)
|
| 85 |
+
self.delimiter = delimiter
|
| 86 |
+
|
| 87 |
+
def update(self, **kwargs):
|
| 88 |
+
for k, v in kwargs.items():
|
| 89 |
+
if isinstance(v, torch.Tensor):
|
| 90 |
+
v = v.item()
|
| 91 |
+
assert isinstance(v, (float, int))
|
| 92 |
+
self.meters[k].update(v)
|
| 93 |
+
|
| 94 |
+
def __getattr__(self, attr):
|
| 95 |
+
if attr in self.meters:
|
| 96 |
+
return self.meters[attr]
|
| 97 |
+
if attr in self.__dict__:
|
| 98 |
+
return self.__dict__[attr]
|
| 99 |
+
raise AttributeError(
|
| 100 |
+
"'{}' object has no attribute '{}'".format(type(self).__name__, attr)
|
| 101 |
+
)
|
| 102 |
+
|
| 103 |
+
def __str__(self):
|
| 104 |
+
loss_str = []
|
| 105 |
+
for name, meter in self.meters.items():
|
| 106 |
+
loss_str.append("{}: {}".format(name, str(meter)))
|
| 107 |
+
return self.delimiter.join(loss_str)
|
| 108 |
+
|
| 109 |
+
def global_avg(self):
|
| 110 |
+
loss_str = []
|
| 111 |
+
for name, meter in self.meters.items():
|
| 112 |
+
loss_str.append("{}: {:.4f}".format(name, meter.global_avg))
|
| 113 |
+
return self.delimiter.join(loss_str)
|
| 114 |
+
|
| 115 |
+
def synchronize_between_processes(self):
|
| 116 |
+
for meter in self.meters.values():
|
| 117 |
+
meter.synchronize_between_processes()
|
| 118 |
+
|
| 119 |
+
def add_meter(self, name, meter):
|
| 120 |
+
self.meters[name] = meter
|
| 121 |
+
|
| 122 |
+
def log_every(self, iterable, print_freq, header=None):
|
| 123 |
+
i = 0
|
| 124 |
+
if not header:
|
| 125 |
+
header = ""
|
| 126 |
+
start_time = time.time()
|
| 127 |
+
end = time.time()
|
| 128 |
+
iter_time = SmoothedValue(fmt="{avg:.4f}")
|
| 129 |
+
data_time = SmoothedValue(fmt="{avg:.4f}")
|
| 130 |
+
space_fmt = ":" + str(len(str(len(iterable)))) + "d"
|
| 131 |
+
log_msg = [
|
| 132 |
+
header,
|
| 133 |
+
"[{0" + space_fmt + "}/{1}]",
|
| 134 |
+
"eta: {eta}",
|
| 135 |
+
"{meters}",
|
| 136 |
+
"time: {time}",
|
| 137 |
+
"data: {data}",
|
| 138 |
+
]
|
| 139 |
+
if torch.cuda.is_available():
|
| 140 |
+
log_msg.append("max mem: {memory:.0f}")
|
| 141 |
+
log_msg = self.delimiter.join(log_msg)
|
| 142 |
+
MB = 1024.0 * 1024.0
|
| 143 |
+
for obj in iterable:
|
| 144 |
+
data_time.update(time.time() - end)
|
| 145 |
+
yield obj
|
| 146 |
+
iter_time.update(time.time() - end)
|
| 147 |
+
if i % print_freq == 0 or i == len(iterable) - 1:
|
| 148 |
+
eta_seconds = iter_time.global_avg * (len(iterable) - i)
|
| 149 |
+
eta_string = str(datetime.timedelta(seconds=int(eta_seconds)))
|
| 150 |
+
if torch.cuda.is_available():
|
| 151 |
+
print(
|
| 152 |
+
log_msg.format(
|
| 153 |
+
i,
|
| 154 |
+
len(iterable),
|
| 155 |
+
eta=eta_string,
|
| 156 |
+
meters=str(self),
|
| 157 |
+
time=str(iter_time),
|
| 158 |
+
data=str(data_time),
|
| 159 |
+
memory=torch.cuda.max_memory_allocated() / MB,
|
| 160 |
+
)
|
| 161 |
+
)
|
| 162 |
+
else:
|
| 163 |
+
print(
|
| 164 |
+
log_msg.format(
|
| 165 |
+
i,
|
| 166 |
+
len(iterable),
|
| 167 |
+
eta=eta_string,
|
| 168 |
+
meters=str(self),
|
| 169 |
+
time=str(iter_time),
|
| 170 |
+
data=str(data_time),
|
| 171 |
+
)
|
| 172 |
+
)
|
| 173 |
+
i += 1
|
| 174 |
+
end = time.time()
|
| 175 |
+
total_time = time.time() - start_time
|
| 176 |
+
total_time_str = str(datetime.timedelta(seconds=int(total_time)))
|
| 177 |
+
print(
|
| 178 |
+
"{} Total time: {} ({:.4f} s / it)".format(
|
| 179 |
+
header, total_time_str, total_time / len(iterable)
|
| 180 |
+
)
|
| 181 |
+
)
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
class AttrDict(dict):
|
| 185 |
+
def __init__(self, *args, **kwargs):
|
| 186 |
+
super(AttrDict, self).__init__(*args, **kwargs)
|
| 187 |
+
self.__dict__ = self
|
| 188 |
+
|
| 189 |
+
|
| 190 |
+
def setup_logger():
|
| 191 |
+
logging.basicConfig(
|
| 192 |
+
level=logging.INFO if dist_utils.is_main_process() else logging.WARN,
|
| 193 |
+
format="%(asctime)s [%(levelname)s] %(message)s",
|
| 194 |
+
handlers=[logging.StreamHandler()],
|
| 195 |
+
)
|
minigpt4/common/optims.py
ADDED
|
@@ -0,0 +1,119 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE_Lavis file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import math
|
| 9 |
+
|
| 10 |
+
from minigpt4.common.registry import registry
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
@registry.register_lr_scheduler("linear_warmup_step_lr")
|
| 14 |
+
class LinearWarmupStepLRScheduler:
|
| 15 |
+
def __init__(
|
| 16 |
+
self,
|
| 17 |
+
optimizer,
|
| 18 |
+
max_epoch,
|
| 19 |
+
min_lr,
|
| 20 |
+
init_lr,
|
| 21 |
+
decay_rate=1,
|
| 22 |
+
warmup_start_lr=-1,
|
| 23 |
+
warmup_steps=0,
|
| 24 |
+
**kwargs
|
| 25 |
+
):
|
| 26 |
+
self.optimizer = optimizer
|
| 27 |
+
|
| 28 |
+
self.max_epoch = max_epoch
|
| 29 |
+
self.min_lr = min_lr
|
| 30 |
+
|
| 31 |
+
self.decay_rate = decay_rate
|
| 32 |
+
|
| 33 |
+
self.init_lr = init_lr
|
| 34 |
+
self.warmup_steps = warmup_steps
|
| 35 |
+
self.warmup_start_lr = warmup_start_lr if warmup_start_lr >= 0 else init_lr
|
| 36 |
+
|
| 37 |
+
def step(self, cur_epoch, cur_step):
|
| 38 |
+
if cur_epoch == 0:
|
| 39 |
+
warmup_lr_schedule(
|
| 40 |
+
step=cur_step,
|
| 41 |
+
optimizer=self.optimizer,
|
| 42 |
+
max_step=self.warmup_steps,
|
| 43 |
+
init_lr=self.warmup_start_lr,
|
| 44 |
+
max_lr=self.init_lr,
|
| 45 |
+
)
|
| 46 |
+
else:
|
| 47 |
+
step_lr_schedule(
|
| 48 |
+
epoch=cur_epoch,
|
| 49 |
+
optimizer=self.optimizer,
|
| 50 |
+
init_lr=self.init_lr,
|
| 51 |
+
min_lr=self.min_lr,
|
| 52 |
+
decay_rate=self.decay_rate,
|
| 53 |
+
)
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
@registry.register_lr_scheduler("linear_warmup_cosine_lr")
|
| 57 |
+
class LinearWarmupCosineLRScheduler:
|
| 58 |
+
def __init__(
|
| 59 |
+
self,
|
| 60 |
+
optimizer,
|
| 61 |
+
max_epoch,
|
| 62 |
+
iters_per_epoch,
|
| 63 |
+
min_lr,
|
| 64 |
+
init_lr,
|
| 65 |
+
warmup_steps=0,
|
| 66 |
+
warmup_start_lr=-1,
|
| 67 |
+
**kwargs
|
| 68 |
+
):
|
| 69 |
+
self.optimizer = optimizer
|
| 70 |
+
|
| 71 |
+
self.max_epoch = max_epoch
|
| 72 |
+
self.iters_per_epoch = iters_per_epoch
|
| 73 |
+
self.min_lr = min_lr
|
| 74 |
+
|
| 75 |
+
self.init_lr = init_lr
|
| 76 |
+
self.warmup_steps = warmup_steps
|
| 77 |
+
self.warmup_start_lr = warmup_start_lr if warmup_start_lr >= 0 else init_lr
|
| 78 |
+
|
| 79 |
+
def step(self, cur_epoch, cur_step):
|
| 80 |
+
total_cur_step = cur_epoch * self.iters_per_epoch + cur_step
|
| 81 |
+
if total_cur_step < self.warmup_steps:
|
| 82 |
+
warmup_lr_schedule(
|
| 83 |
+
step=cur_step,
|
| 84 |
+
optimizer=self.optimizer,
|
| 85 |
+
max_step=self.warmup_steps,
|
| 86 |
+
init_lr=self.warmup_start_lr,
|
| 87 |
+
max_lr=self.init_lr,
|
| 88 |
+
)
|
| 89 |
+
else:
|
| 90 |
+
cosine_lr_schedule(
|
| 91 |
+
epoch=total_cur_step,
|
| 92 |
+
optimizer=self.optimizer,
|
| 93 |
+
max_epoch=self.max_epoch * self.iters_per_epoch,
|
| 94 |
+
init_lr=self.init_lr,
|
| 95 |
+
min_lr=self.min_lr,
|
| 96 |
+
)
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
def cosine_lr_schedule(optimizer, epoch, max_epoch, init_lr, min_lr):
|
| 100 |
+
"""Decay the learning rate"""
|
| 101 |
+
lr = (init_lr - min_lr) * 0.5 * (
|
| 102 |
+
1.0 + math.cos(math.pi * epoch / max_epoch)
|
| 103 |
+
) + min_lr
|
| 104 |
+
for param_group in optimizer.param_groups:
|
| 105 |
+
param_group["lr"] = lr
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
def warmup_lr_schedule(optimizer, step, max_step, init_lr, max_lr):
|
| 109 |
+
"""Warmup the learning rate"""
|
| 110 |
+
lr = min(max_lr, init_lr + (max_lr - init_lr) * step / max(max_step, 1))
|
| 111 |
+
for param_group in optimizer.param_groups:
|
| 112 |
+
param_group["lr"] = lr
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
def step_lr_schedule(optimizer, epoch, init_lr, min_lr, decay_rate):
|
| 116 |
+
"""Decay the learning rate"""
|
| 117 |
+
lr = max(min_lr, init_lr * (decay_rate**epoch))
|
| 118 |
+
for param_group in optimizer.param_groups:
|
| 119 |
+
param_group["lr"] = lr
|
minigpt4/common/registry.py
ADDED
|
@@ -0,0 +1,329 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE_Lavis file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class Registry:
|
| 10 |
+
mapping = {
|
| 11 |
+
"builder_name_mapping": {},
|
| 12 |
+
"task_name_mapping": {},
|
| 13 |
+
"processor_name_mapping": {},
|
| 14 |
+
"model_name_mapping": {},
|
| 15 |
+
"lr_scheduler_name_mapping": {},
|
| 16 |
+
"runner_name_mapping": {},
|
| 17 |
+
"state": {},
|
| 18 |
+
"paths": {},
|
| 19 |
+
}
|
| 20 |
+
|
| 21 |
+
@classmethod
|
| 22 |
+
def register_builder(cls, name):
|
| 23 |
+
r"""Register a dataset builder to registry with key 'name'
|
| 24 |
+
|
| 25 |
+
Args:
|
| 26 |
+
name: Key with which the builder will be registered.
|
| 27 |
+
|
| 28 |
+
Usage:
|
| 29 |
+
|
| 30 |
+
from minigpt4.common.registry import registry
|
| 31 |
+
from minigpt4.datasets.base_dataset_builder import BaseDatasetBuilder
|
| 32 |
+
"""
|
| 33 |
+
|
| 34 |
+
def wrap(builder_cls):
|
| 35 |
+
from minigpt4.datasets.builders.base_dataset_builder import BaseDatasetBuilder
|
| 36 |
+
|
| 37 |
+
assert issubclass(
|
| 38 |
+
builder_cls, BaseDatasetBuilder
|
| 39 |
+
), "All builders must inherit BaseDatasetBuilder class, found {}".format(
|
| 40 |
+
builder_cls
|
| 41 |
+
)
|
| 42 |
+
if name in cls.mapping["builder_name_mapping"]:
|
| 43 |
+
raise KeyError(
|
| 44 |
+
"Name '{}' already registered for {}.".format(
|
| 45 |
+
name, cls.mapping["builder_name_mapping"][name]
|
| 46 |
+
)
|
| 47 |
+
)
|
| 48 |
+
cls.mapping["builder_name_mapping"][name] = builder_cls
|
| 49 |
+
return builder_cls
|
| 50 |
+
|
| 51 |
+
return wrap
|
| 52 |
+
|
| 53 |
+
@classmethod
|
| 54 |
+
def register_task(cls, name):
|
| 55 |
+
r"""Register a task to registry with key 'name'
|
| 56 |
+
|
| 57 |
+
Args:
|
| 58 |
+
name: Key with which the task will be registered.
|
| 59 |
+
|
| 60 |
+
Usage:
|
| 61 |
+
|
| 62 |
+
from minigpt4.common.registry import registry
|
| 63 |
+
"""
|
| 64 |
+
|
| 65 |
+
def wrap(task_cls):
|
| 66 |
+
from minigpt4.tasks.base_task import BaseTask
|
| 67 |
+
|
| 68 |
+
assert issubclass(
|
| 69 |
+
task_cls, BaseTask
|
| 70 |
+
), "All tasks must inherit BaseTask class"
|
| 71 |
+
if name in cls.mapping["task_name_mapping"]:
|
| 72 |
+
raise KeyError(
|
| 73 |
+
"Name '{}' already registered for {}.".format(
|
| 74 |
+
name, cls.mapping["task_name_mapping"][name]
|
| 75 |
+
)
|
| 76 |
+
)
|
| 77 |
+
cls.mapping["task_name_mapping"][name] = task_cls
|
| 78 |
+
return task_cls
|
| 79 |
+
|
| 80 |
+
return wrap
|
| 81 |
+
|
| 82 |
+
@classmethod
|
| 83 |
+
def register_model(cls, name):
|
| 84 |
+
r"""Register a task to registry with key 'name'
|
| 85 |
+
|
| 86 |
+
Args:
|
| 87 |
+
name: Key with which the task will be registered.
|
| 88 |
+
|
| 89 |
+
Usage:
|
| 90 |
+
|
| 91 |
+
from minigpt4.common.registry import registry
|
| 92 |
+
"""
|
| 93 |
+
|
| 94 |
+
def wrap(model_cls):
|
| 95 |
+
from minigpt4.models import BaseModel
|
| 96 |
+
|
| 97 |
+
assert issubclass(
|
| 98 |
+
model_cls, BaseModel
|
| 99 |
+
), "All models must inherit BaseModel class"
|
| 100 |
+
if name in cls.mapping["model_name_mapping"]:
|
| 101 |
+
raise KeyError(
|
| 102 |
+
"Name '{}' already registered for {}.".format(
|
| 103 |
+
name, cls.mapping["model_name_mapping"][name]
|
| 104 |
+
)
|
| 105 |
+
)
|
| 106 |
+
cls.mapping["model_name_mapping"][name] = model_cls
|
| 107 |
+
return model_cls
|
| 108 |
+
|
| 109 |
+
return wrap
|
| 110 |
+
|
| 111 |
+
@classmethod
|
| 112 |
+
def register_processor(cls, name):
|
| 113 |
+
r"""Register a processor to registry with key 'name'
|
| 114 |
+
|
| 115 |
+
Args:
|
| 116 |
+
name: Key with which the task will be registered.
|
| 117 |
+
|
| 118 |
+
Usage:
|
| 119 |
+
|
| 120 |
+
from minigpt4.common.registry import registry
|
| 121 |
+
"""
|
| 122 |
+
|
| 123 |
+
def wrap(processor_cls):
|
| 124 |
+
from minigpt4.processors import BaseProcessor
|
| 125 |
+
|
| 126 |
+
assert issubclass(
|
| 127 |
+
processor_cls, BaseProcessor
|
| 128 |
+
), "All processors must inherit BaseProcessor class"
|
| 129 |
+
if name in cls.mapping["processor_name_mapping"]:
|
| 130 |
+
raise KeyError(
|
| 131 |
+
"Name '{}' already registered for {}.".format(
|
| 132 |
+
name, cls.mapping["processor_name_mapping"][name]
|
| 133 |
+
)
|
| 134 |
+
)
|
| 135 |
+
cls.mapping["processor_name_mapping"][name] = processor_cls
|
| 136 |
+
return processor_cls
|
| 137 |
+
|
| 138 |
+
return wrap
|
| 139 |
+
|
| 140 |
+
@classmethod
|
| 141 |
+
def register_lr_scheduler(cls, name):
|
| 142 |
+
r"""Register a model to registry with key 'name'
|
| 143 |
+
|
| 144 |
+
Args:
|
| 145 |
+
name: Key with which the task will be registered.
|
| 146 |
+
|
| 147 |
+
Usage:
|
| 148 |
+
|
| 149 |
+
from minigpt4.common.registry import registry
|
| 150 |
+
"""
|
| 151 |
+
|
| 152 |
+
def wrap(lr_sched_cls):
|
| 153 |
+
if name in cls.mapping["lr_scheduler_name_mapping"]:
|
| 154 |
+
raise KeyError(
|
| 155 |
+
"Name '{}' already registered for {}.".format(
|
| 156 |
+
name, cls.mapping["lr_scheduler_name_mapping"][name]
|
| 157 |
+
)
|
| 158 |
+
)
|
| 159 |
+
cls.mapping["lr_scheduler_name_mapping"][name] = lr_sched_cls
|
| 160 |
+
return lr_sched_cls
|
| 161 |
+
|
| 162 |
+
return wrap
|
| 163 |
+
|
| 164 |
+
@classmethod
|
| 165 |
+
def register_runner(cls, name):
|
| 166 |
+
r"""Register a model to registry with key 'name'
|
| 167 |
+
|
| 168 |
+
Args:
|
| 169 |
+
name: Key with which the task will be registered.
|
| 170 |
+
|
| 171 |
+
Usage:
|
| 172 |
+
|
| 173 |
+
from minigpt4.common.registry import registry
|
| 174 |
+
"""
|
| 175 |
+
|
| 176 |
+
def wrap(runner_cls):
|
| 177 |
+
if name in cls.mapping["runner_name_mapping"]:
|
| 178 |
+
raise KeyError(
|
| 179 |
+
"Name '{}' already registered for {}.".format(
|
| 180 |
+
name, cls.mapping["runner_name_mapping"][name]
|
| 181 |
+
)
|
| 182 |
+
)
|
| 183 |
+
cls.mapping["runner_name_mapping"][name] = runner_cls
|
| 184 |
+
return runner_cls
|
| 185 |
+
|
| 186 |
+
return wrap
|
| 187 |
+
|
| 188 |
+
@classmethod
|
| 189 |
+
def register_path(cls, name, path):
|
| 190 |
+
r"""Register a path to registry with key 'name'
|
| 191 |
+
|
| 192 |
+
Args:
|
| 193 |
+
name: Key with which the path will be registered.
|
| 194 |
+
|
| 195 |
+
Usage:
|
| 196 |
+
|
| 197 |
+
from minigpt4.common.registry import registry
|
| 198 |
+
"""
|
| 199 |
+
assert isinstance(path, str), "All path must be str."
|
| 200 |
+
if name in cls.mapping["paths"]:
|
| 201 |
+
raise KeyError("Name '{}' already registered.".format(name))
|
| 202 |
+
cls.mapping["paths"][name] = path
|
| 203 |
+
|
| 204 |
+
@classmethod
|
| 205 |
+
def register(cls, name, obj):
|
| 206 |
+
r"""Register an item to registry with key 'name'
|
| 207 |
+
|
| 208 |
+
Args:
|
| 209 |
+
name: Key with which the item will be registered.
|
| 210 |
+
|
| 211 |
+
Usage::
|
| 212 |
+
|
| 213 |
+
from minigpt4.common.registry import registry
|
| 214 |
+
|
| 215 |
+
registry.register("config", {})
|
| 216 |
+
"""
|
| 217 |
+
path = name.split(".")
|
| 218 |
+
current = cls.mapping["state"]
|
| 219 |
+
|
| 220 |
+
for part in path[:-1]:
|
| 221 |
+
if part not in current:
|
| 222 |
+
current[part] = {}
|
| 223 |
+
current = current[part]
|
| 224 |
+
|
| 225 |
+
current[path[-1]] = obj
|
| 226 |
+
|
| 227 |
+
# @classmethod
|
| 228 |
+
# def get_trainer_class(cls, name):
|
| 229 |
+
# return cls.mapping["trainer_name_mapping"].get(name, None)
|
| 230 |
+
|
| 231 |
+
@classmethod
|
| 232 |
+
def get_builder_class(cls, name):
|
| 233 |
+
return cls.mapping["builder_name_mapping"].get(name, None)
|
| 234 |
+
|
| 235 |
+
@classmethod
|
| 236 |
+
def get_model_class(cls, name):
|
| 237 |
+
return cls.mapping["model_name_mapping"].get(name, None)
|
| 238 |
+
|
| 239 |
+
@classmethod
|
| 240 |
+
def get_task_class(cls, name):
|
| 241 |
+
return cls.mapping["task_name_mapping"].get(name, None)
|
| 242 |
+
|
| 243 |
+
@classmethod
|
| 244 |
+
def get_processor_class(cls, name):
|
| 245 |
+
return cls.mapping["processor_name_mapping"].get(name, None)
|
| 246 |
+
|
| 247 |
+
@classmethod
|
| 248 |
+
def get_lr_scheduler_class(cls, name):
|
| 249 |
+
return cls.mapping["lr_scheduler_name_mapping"].get(name, None)
|
| 250 |
+
|
| 251 |
+
@classmethod
|
| 252 |
+
def get_runner_class(cls, name):
|
| 253 |
+
return cls.mapping["runner_name_mapping"].get(name, None)
|
| 254 |
+
|
| 255 |
+
@classmethod
|
| 256 |
+
def list_runners(cls):
|
| 257 |
+
return sorted(cls.mapping["runner_name_mapping"].keys())
|
| 258 |
+
|
| 259 |
+
@classmethod
|
| 260 |
+
def list_models(cls):
|
| 261 |
+
return sorted(cls.mapping["model_name_mapping"].keys())
|
| 262 |
+
|
| 263 |
+
@classmethod
|
| 264 |
+
def list_tasks(cls):
|
| 265 |
+
return sorted(cls.mapping["task_name_mapping"].keys())
|
| 266 |
+
|
| 267 |
+
@classmethod
|
| 268 |
+
def list_processors(cls):
|
| 269 |
+
return sorted(cls.mapping["processor_name_mapping"].keys())
|
| 270 |
+
|
| 271 |
+
@classmethod
|
| 272 |
+
def list_lr_schedulers(cls):
|
| 273 |
+
return sorted(cls.mapping["lr_scheduler_name_mapping"].keys())
|
| 274 |
+
|
| 275 |
+
@classmethod
|
| 276 |
+
def list_datasets(cls):
|
| 277 |
+
return sorted(cls.mapping["builder_name_mapping"].keys())
|
| 278 |
+
|
| 279 |
+
@classmethod
|
| 280 |
+
def get_path(cls, name):
|
| 281 |
+
return cls.mapping["paths"].get(name, None)
|
| 282 |
+
|
| 283 |
+
@classmethod
|
| 284 |
+
def get(cls, name, default=None, no_warning=False):
|
| 285 |
+
r"""Get an item from registry with key 'name'
|
| 286 |
+
|
| 287 |
+
Args:
|
| 288 |
+
name (string): Key whose value needs to be retrieved.
|
| 289 |
+
default: If passed and key is not in registry, default value will
|
| 290 |
+
be returned with a warning. Default: None
|
| 291 |
+
no_warning (bool): If passed as True, warning when key doesn't exist
|
| 292 |
+
will not be generated. Useful for MMF's
|
| 293 |
+
internal operations. Default: False
|
| 294 |
+
"""
|
| 295 |
+
original_name = name
|
| 296 |
+
name = name.split(".")
|
| 297 |
+
value = cls.mapping["state"]
|
| 298 |
+
for subname in name:
|
| 299 |
+
value = value.get(subname, default)
|
| 300 |
+
if value is default:
|
| 301 |
+
break
|
| 302 |
+
|
| 303 |
+
if (
|
| 304 |
+
"writer" in cls.mapping["state"]
|
| 305 |
+
and value == default
|
| 306 |
+
and no_warning is False
|
| 307 |
+
):
|
| 308 |
+
cls.mapping["state"]["writer"].warning(
|
| 309 |
+
"Key {} is not present in registry, returning default value "
|
| 310 |
+
"of {}".format(original_name, default)
|
| 311 |
+
)
|
| 312 |
+
return value
|
| 313 |
+
|
| 314 |
+
@classmethod
|
| 315 |
+
def unregister(cls, name):
|
| 316 |
+
r"""Remove an item from registry with key 'name'
|
| 317 |
+
|
| 318 |
+
Args:
|
| 319 |
+
name: Key which needs to be removed.
|
| 320 |
+
Usage::
|
| 321 |
+
|
| 322 |
+
from mmf.common.registry import registry
|
| 323 |
+
|
| 324 |
+
config = registry.unregister("config")
|
| 325 |
+
"""
|
| 326 |
+
return cls.mapping["state"].pop(name, None)
|
| 327 |
+
|
| 328 |
+
|
| 329 |
+
registry = Registry()
|
minigpt4/common/utils.py
ADDED
|
@@ -0,0 +1,424 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE_Lavis file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import io
|
| 9 |
+
import json
|
| 10 |
+
import logging
|
| 11 |
+
import os
|
| 12 |
+
import pickle
|
| 13 |
+
import re
|
| 14 |
+
import shutil
|
| 15 |
+
import urllib
|
| 16 |
+
import urllib.error
|
| 17 |
+
import urllib.request
|
| 18 |
+
from typing import Optional
|
| 19 |
+
from urllib.parse import urlparse
|
| 20 |
+
|
| 21 |
+
import numpy as np
|
| 22 |
+
import pandas as pd
|
| 23 |
+
import yaml
|
| 24 |
+
from iopath.common.download import download
|
| 25 |
+
from iopath.common.file_io import file_lock, g_pathmgr
|
| 26 |
+
from minigpt4.common.registry import registry
|
| 27 |
+
from torch.utils.model_zoo import tqdm
|
| 28 |
+
from torchvision.datasets.utils import (
|
| 29 |
+
check_integrity,
|
| 30 |
+
download_file_from_google_drive,
|
| 31 |
+
extract_archive,
|
| 32 |
+
)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def now():
|
| 36 |
+
from datetime import datetime
|
| 37 |
+
|
| 38 |
+
return datetime.now().strftime("%Y%m%d%H%M")[:-1]
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def is_url(url_or_filename):
|
| 42 |
+
parsed = urlparse(url_or_filename)
|
| 43 |
+
return parsed.scheme in ("http", "https")
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def get_cache_path(rel_path):
|
| 47 |
+
return os.path.expanduser(os.path.join(registry.get_path("cache_root"), rel_path))
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def get_abs_path(rel_path):
|
| 51 |
+
return os.path.join(registry.get_path("library_root"), rel_path)
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def load_json(filename):
|
| 55 |
+
with open(filename, "r") as f:
|
| 56 |
+
return json.load(f)
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
# The following are adapted from torchvision and vissl
|
| 60 |
+
# torchvision: https://github.com/pytorch/vision
|
| 61 |
+
# vissl: https://github.com/facebookresearch/vissl/blob/main/vissl/utils/download.py
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def makedir(dir_path):
|
| 65 |
+
"""
|
| 66 |
+
Create the directory if it does not exist.
|
| 67 |
+
"""
|
| 68 |
+
is_success = False
|
| 69 |
+
try:
|
| 70 |
+
if not g_pathmgr.exists(dir_path):
|
| 71 |
+
g_pathmgr.mkdirs(dir_path)
|
| 72 |
+
is_success = True
|
| 73 |
+
except BaseException:
|
| 74 |
+
print(f"Error creating directory: {dir_path}")
|
| 75 |
+
return is_success
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def get_redirected_url(url: str):
|
| 79 |
+
"""
|
| 80 |
+
Given a URL, returns the URL it redirects to or the
|
| 81 |
+
original URL in case of no indirection
|
| 82 |
+
"""
|
| 83 |
+
import requests
|
| 84 |
+
|
| 85 |
+
with requests.Session() as session:
|
| 86 |
+
with session.get(url, stream=True, allow_redirects=True) as response:
|
| 87 |
+
if response.history:
|
| 88 |
+
return response.url
|
| 89 |
+
else:
|
| 90 |
+
return url
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
def to_google_drive_download_url(view_url: str) -> str:
|
| 94 |
+
"""
|
| 95 |
+
Utility function to transform a view URL of google drive
|
| 96 |
+
to a download URL for google drive
|
| 97 |
+
Example input:
|
| 98 |
+
https://drive.google.com/file/d/137RyRjvTBkBiIfeYBNZBtViDHQ6_Ewsp/view
|
| 99 |
+
Example output:
|
| 100 |
+
https://drive.google.com/uc?export=download&id=137RyRjvTBkBiIfeYBNZBtViDHQ6_Ewsp
|
| 101 |
+
"""
|
| 102 |
+
splits = view_url.split("/")
|
| 103 |
+
assert splits[-1] == "view"
|
| 104 |
+
file_id = splits[-2]
|
| 105 |
+
return f"https://drive.google.com/uc?export=download&id={file_id}"
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
def download_google_drive_url(url: str, output_path: str, output_file_name: str):
|
| 109 |
+
"""
|
| 110 |
+
Download a file from google drive
|
| 111 |
+
Downloading an URL from google drive requires confirmation when
|
| 112 |
+
the file of the size is too big (google drive notifies that
|
| 113 |
+
anti-viral checks cannot be performed on such files)
|
| 114 |
+
"""
|
| 115 |
+
import requests
|
| 116 |
+
|
| 117 |
+
with requests.Session() as session:
|
| 118 |
+
|
| 119 |
+
# First get the confirmation token and append it to the URL
|
| 120 |
+
with session.get(url, stream=True, allow_redirects=True) as response:
|
| 121 |
+
for k, v in response.cookies.items():
|
| 122 |
+
if k.startswith("download_warning"):
|
| 123 |
+
url = url + "&confirm=" + v
|
| 124 |
+
|
| 125 |
+
# Then download the content of the file
|
| 126 |
+
with session.get(url, stream=True, verify=True) as response:
|
| 127 |
+
makedir(output_path)
|
| 128 |
+
path = os.path.join(output_path, output_file_name)
|
| 129 |
+
total_size = int(response.headers.get("Content-length", 0))
|
| 130 |
+
with open(path, "wb") as file:
|
| 131 |
+
from tqdm import tqdm
|
| 132 |
+
|
| 133 |
+
with tqdm(total=total_size) as progress_bar:
|
| 134 |
+
for block in response.iter_content(
|
| 135 |
+
chunk_size=io.DEFAULT_BUFFER_SIZE
|
| 136 |
+
):
|
| 137 |
+
file.write(block)
|
| 138 |
+
progress_bar.update(len(block))
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
def _get_google_drive_file_id(url: str) -> Optional[str]:
|
| 142 |
+
parts = urlparse(url)
|
| 143 |
+
|
| 144 |
+
if re.match(r"(drive|docs)[.]google[.]com", parts.netloc) is None:
|
| 145 |
+
return None
|
| 146 |
+
|
| 147 |
+
match = re.match(r"/file/d/(?P<id>[^/]*)", parts.path)
|
| 148 |
+
if match is None:
|
| 149 |
+
return None
|
| 150 |
+
|
| 151 |
+
return match.group("id")
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
def _urlretrieve(url: str, filename: str, chunk_size: int = 1024) -> None:
|
| 155 |
+
with open(filename, "wb") as fh:
|
| 156 |
+
with urllib.request.urlopen(
|
| 157 |
+
urllib.request.Request(url, headers={"User-Agent": "vissl"})
|
| 158 |
+
) as response:
|
| 159 |
+
with tqdm(total=response.length) as pbar:
|
| 160 |
+
for chunk in iter(lambda: response.read(chunk_size), ""):
|
| 161 |
+
if not chunk:
|
| 162 |
+
break
|
| 163 |
+
pbar.update(chunk_size)
|
| 164 |
+
fh.write(chunk)
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
def download_url(
|
| 168 |
+
url: str,
|
| 169 |
+
root: str,
|
| 170 |
+
filename: Optional[str] = None,
|
| 171 |
+
md5: Optional[str] = None,
|
| 172 |
+
) -> None:
|
| 173 |
+
"""Download a file from a url and place it in root.
|
| 174 |
+
Args:
|
| 175 |
+
url (str): URL to download file from
|
| 176 |
+
root (str): Directory to place downloaded file in
|
| 177 |
+
filename (str, optional): Name to save the file under.
|
| 178 |
+
If None, use the basename of the URL.
|
| 179 |
+
md5 (str, optional): MD5 checksum of the download. If None, do not check
|
| 180 |
+
"""
|
| 181 |
+
root = os.path.expanduser(root)
|
| 182 |
+
if not filename:
|
| 183 |
+
filename = os.path.basename(url)
|
| 184 |
+
fpath = os.path.join(root, filename)
|
| 185 |
+
|
| 186 |
+
makedir(root)
|
| 187 |
+
|
| 188 |
+
# check if file is already present locally
|
| 189 |
+
if check_integrity(fpath, md5):
|
| 190 |
+
print("Using downloaded and verified file: " + fpath)
|
| 191 |
+
return
|
| 192 |
+
|
| 193 |
+
# expand redirect chain if needed
|
| 194 |
+
url = get_redirected_url(url)
|
| 195 |
+
|
| 196 |
+
# check if file is located on Google Drive
|
| 197 |
+
file_id = _get_google_drive_file_id(url)
|
| 198 |
+
if file_id is not None:
|
| 199 |
+
return download_file_from_google_drive(file_id, root, filename, md5)
|
| 200 |
+
|
| 201 |
+
# download the file
|
| 202 |
+
try:
|
| 203 |
+
print("Downloading " + url + " to " + fpath)
|
| 204 |
+
_urlretrieve(url, fpath)
|
| 205 |
+
except (urllib.error.URLError, IOError) as e: # type: ignore[attr-defined]
|
| 206 |
+
if url[:5] == "https":
|
| 207 |
+
url = url.replace("https:", "http:")
|
| 208 |
+
print(
|
| 209 |
+
"Failed download. Trying https -> http instead."
|
| 210 |
+
" Downloading " + url + " to " + fpath
|
| 211 |
+
)
|
| 212 |
+
_urlretrieve(url, fpath)
|
| 213 |
+
else:
|
| 214 |
+
raise e
|
| 215 |
+
|
| 216 |
+
# check integrity of downloaded file
|
| 217 |
+
if not check_integrity(fpath, md5):
|
| 218 |
+
raise RuntimeError("File not found or corrupted.")
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
def download_and_extract_archive(
|
| 222 |
+
url: str,
|
| 223 |
+
download_root: str,
|
| 224 |
+
extract_root: Optional[str] = None,
|
| 225 |
+
filename: Optional[str] = None,
|
| 226 |
+
md5: Optional[str] = None,
|
| 227 |
+
remove_finished: bool = False,
|
| 228 |
+
) -> None:
|
| 229 |
+
download_root = os.path.expanduser(download_root)
|
| 230 |
+
if extract_root is None:
|
| 231 |
+
extract_root = download_root
|
| 232 |
+
if not filename:
|
| 233 |
+
filename = os.path.basename(url)
|
| 234 |
+
|
| 235 |
+
download_url(url, download_root, filename, md5)
|
| 236 |
+
|
| 237 |
+
archive = os.path.join(download_root, filename)
|
| 238 |
+
print("Extracting {} to {}".format(archive, extract_root))
|
| 239 |
+
extract_archive(archive, extract_root, remove_finished)
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
def cache_url(url: str, cache_dir: str) -> str:
|
| 243 |
+
"""
|
| 244 |
+
This implementation downloads the remote resource and caches it locally.
|
| 245 |
+
The resource will only be downloaded if not previously requested.
|
| 246 |
+
"""
|
| 247 |
+
parsed_url = urlparse(url)
|
| 248 |
+
dirname = os.path.join(cache_dir, os.path.dirname(parsed_url.path.lstrip("/")))
|
| 249 |
+
makedir(dirname)
|
| 250 |
+
filename = url.split("/")[-1]
|
| 251 |
+
cached = os.path.join(dirname, filename)
|
| 252 |
+
with file_lock(cached):
|
| 253 |
+
if not os.path.isfile(cached):
|
| 254 |
+
logging.info(f"Downloading {url} to {cached} ...")
|
| 255 |
+
cached = download(url, dirname, filename=filename)
|
| 256 |
+
logging.info(f"URL {url} cached in {cached}")
|
| 257 |
+
return cached
|
| 258 |
+
|
| 259 |
+
|
| 260 |
+
# TODO (prigoyal): convert this into RAII-style API
|
| 261 |
+
def create_file_symlink(file1, file2):
|
| 262 |
+
"""
|
| 263 |
+
Simply create the symlinks for a given file1 to file2.
|
| 264 |
+
Useful during model checkpointing to symlinks to the
|
| 265 |
+
latest successful checkpoint.
|
| 266 |
+
"""
|
| 267 |
+
try:
|
| 268 |
+
if g_pathmgr.exists(file2):
|
| 269 |
+
g_pathmgr.rm(file2)
|
| 270 |
+
g_pathmgr.symlink(file1, file2)
|
| 271 |
+
except Exception as e:
|
| 272 |
+
logging.info(f"Could NOT create symlink. Error: {e}")
|
| 273 |
+
|
| 274 |
+
|
| 275 |
+
def save_file(data, filename, append_to_json=True, verbose=True):
|
| 276 |
+
"""
|
| 277 |
+
Common i/o utility to handle saving data to various file formats.
|
| 278 |
+
Supported:
|
| 279 |
+
.pkl, .pickle, .npy, .json
|
| 280 |
+
Specifically for .json, users have the option to either append (default)
|
| 281 |
+
or rewrite by passing in Boolean value to append_to_json.
|
| 282 |
+
"""
|
| 283 |
+
if verbose:
|
| 284 |
+
logging.info(f"Saving data to file: {filename}")
|
| 285 |
+
file_ext = os.path.splitext(filename)[1]
|
| 286 |
+
if file_ext in [".pkl", ".pickle"]:
|
| 287 |
+
with g_pathmgr.open(filename, "wb") as fopen:
|
| 288 |
+
pickle.dump(data, fopen, pickle.HIGHEST_PROTOCOL)
|
| 289 |
+
elif file_ext == ".npy":
|
| 290 |
+
with g_pathmgr.open(filename, "wb") as fopen:
|
| 291 |
+
np.save(fopen, data)
|
| 292 |
+
elif file_ext == ".json":
|
| 293 |
+
if append_to_json:
|
| 294 |
+
with g_pathmgr.open(filename, "a") as fopen:
|
| 295 |
+
fopen.write(json.dumps(data, sort_keys=True) + "\n")
|
| 296 |
+
fopen.flush()
|
| 297 |
+
else:
|
| 298 |
+
with g_pathmgr.open(filename, "w") as fopen:
|
| 299 |
+
fopen.write(json.dumps(data, sort_keys=True) + "\n")
|
| 300 |
+
fopen.flush()
|
| 301 |
+
elif file_ext == ".yaml":
|
| 302 |
+
with g_pathmgr.open(filename, "w") as fopen:
|
| 303 |
+
dump = yaml.dump(data)
|
| 304 |
+
fopen.write(dump)
|
| 305 |
+
fopen.flush()
|
| 306 |
+
else:
|
| 307 |
+
raise Exception(f"Saving {file_ext} is not supported yet")
|
| 308 |
+
|
| 309 |
+
if verbose:
|
| 310 |
+
logging.info(f"Saved data to file: {filename}")
|
| 311 |
+
|
| 312 |
+
|
| 313 |
+
def load_file(filename, mmap_mode=None, verbose=True, allow_pickle=False):
|
| 314 |
+
"""
|
| 315 |
+
Common i/o utility to handle loading data from various file formats.
|
| 316 |
+
Supported:
|
| 317 |
+
.pkl, .pickle, .npy, .json
|
| 318 |
+
For the npy files, we support reading the files in mmap_mode.
|
| 319 |
+
If the mmap_mode of reading is not successful, we load data without the
|
| 320 |
+
mmap_mode.
|
| 321 |
+
"""
|
| 322 |
+
if verbose:
|
| 323 |
+
logging.info(f"Loading data from file: {filename}")
|
| 324 |
+
|
| 325 |
+
file_ext = os.path.splitext(filename)[1]
|
| 326 |
+
if file_ext == ".txt":
|
| 327 |
+
with g_pathmgr.open(filename, "r") as fopen:
|
| 328 |
+
data = fopen.readlines()
|
| 329 |
+
elif file_ext in [".pkl", ".pickle"]:
|
| 330 |
+
with g_pathmgr.open(filename, "rb") as fopen:
|
| 331 |
+
data = pickle.load(fopen, encoding="latin1")
|
| 332 |
+
elif file_ext == ".npy":
|
| 333 |
+
if mmap_mode:
|
| 334 |
+
try:
|
| 335 |
+
with g_pathmgr.open(filename, "rb") as fopen:
|
| 336 |
+
data = np.load(
|
| 337 |
+
fopen,
|
| 338 |
+
allow_pickle=allow_pickle,
|
| 339 |
+
encoding="latin1",
|
| 340 |
+
mmap_mode=mmap_mode,
|
| 341 |
+
)
|
| 342 |
+
except ValueError as e:
|
| 343 |
+
logging.info(
|
| 344 |
+
f"Could not mmap {filename}: {e}. Trying without g_pathmgr"
|
| 345 |
+
)
|
| 346 |
+
data = np.load(
|
| 347 |
+
filename,
|
| 348 |
+
allow_pickle=allow_pickle,
|
| 349 |
+
encoding="latin1",
|
| 350 |
+
mmap_mode=mmap_mode,
|
| 351 |
+
)
|
| 352 |
+
logging.info("Successfully loaded without g_pathmgr")
|
| 353 |
+
except Exception:
|
| 354 |
+
logging.info("Could not mmap without g_pathmgr. Trying without mmap")
|
| 355 |
+
with g_pathmgr.open(filename, "rb") as fopen:
|
| 356 |
+
data = np.load(fopen, allow_pickle=allow_pickle, encoding="latin1")
|
| 357 |
+
else:
|
| 358 |
+
with g_pathmgr.open(filename, "rb") as fopen:
|
| 359 |
+
data = np.load(fopen, allow_pickle=allow_pickle, encoding="latin1")
|
| 360 |
+
elif file_ext == ".json":
|
| 361 |
+
with g_pathmgr.open(filename, "r") as fopen:
|
| 362 |
+
data = json.load(fopen)
|
| 363 |
+
elif file_ext == ".yaml":
|
| 364 |
+
with g_pathmgr.open(filename, "r") as fopen:
|
| 365 |
+
data = yaml.load(fopen, Loader=yaml.FullLoader)
|
| 366 |
+
elif file_ext == ".csv":
|
| 367 |
+
with g_pathmgr.open(filename, "r") as fopen:
|
| 368 |
+
data = pd.read_csv(fopen)
|
| 369 |
+
else:
|
| 370 |
+
raise Exception(f"Reading from {file_ext} is not supported yet")
|
| 371 |
+
return data
|
| 372 |
+
|
| 373 |
+
|
| 374 |
+
def abspath(resource_path: str):
|
| 375 |
+
"""
|
| 376 |
+
Make a path absolute, but take into account prefixes like
|
| 377 |
+
"http://" or "manifold://"
|
| 378 |
+
"""
|
| 379 |
+
regex = re.compile(r"^\w+://")
|
| 380 |
+
if regex.match(resource_path) is None:
|
| 381 |
+
return os.path.abspath(resource_path)
|
| 382 |
+
else:
|
| 383 |
+
return resource_path
|
| 384 |
+
|
| 385 |
+
|
| 386 |
+
def makedir(dir_path):
|
| 387 |
+
"""
|
| 388 |
+
Create the directory if it does not exist.
|
| 389 |
+
"""
|
| 390 |
+
is_success = False
|
| 391 |
+
try:
|
| 392 |
+
if not g_pathmgr.exists(dir_path):
|
| 393 |
+
g_pathmgr.mkdirs(dir_path)
|
| 394 |
+
is_success = True
|
| 395 |
+
except BaseException:
|
| 396 |
+
logging.info(f"Error creating directory: {dir_path}")
|
| 397 |
+
return is_success
|
| 398 |
+
|
| 399 |
+
|
| 400 |
+
def is_url(input_url):
|
| 401 |
+
"""
|
| 402 |
+
Check if an input string is a url. look for http(s):// and ignoring the case
|
| 403 |
+
"""
|
| 404 |
+
is_url = re.match(r"^(?:http)s?://", input_url, re.IGNORECASE) is not None
|
| 405 |
+
return is_url
|
| 406 |
+
|
| 407 |
+
|
| 408 |
+
def cleanup_dir(dir):
|
| 409 |
+
"""
|
| 410 |
+
Utility for deleting a directory. Useful for cleaning the storage space
|
| 411 |
+
that contains various training artifacts like checkpoints, data etc.
|
| 412 |
+
"""
|
| 413 |
+
if os.path.exists(dir):
|
| 414 |
+
logging.info(f"Deleting directory: {dir}")
|
| 415 |
+
shutil.rmtree(dir)
|
| 416 |
+
logging.info(f"Deleted contents of directory: {dir}")
|
| 417 |
+
|
| 418 |
+
|
| 419 |
+
def get_file_size(filename):
|
| 420 |
+
"""
|
| 421 |
+
Given a file, get the size of file in MB
|
| 422 |
+
"""
|
| 423 |
+
size_in_mb = os.path.getsize(filename) / float(1024**2)
|
| 424 |
+
return size_in_mb
|
minigpt4/common/vqa_tools/VQA/PythonEvaluationTools/vqaEvalDemo.py
ADDED
|
@@ -0,0 +1,89 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding: utf-8
|
| 2 |
+
|
| 3 |
+
import sys
|
| 4 |
+
dataDir = '../../VQA'
|
| 5 |
+
sys.path.insert(0, '%s/PythonHelperTools/vqaTools' %(dataDir))
|
| 6 |
+
from vqa import VQA
|
| 7 |
+
from vqaEvaluation.vqaEval import VQAEval
|
| 8 |
+
import matplotlib.pyplot as plt
|
| 9 |
+
import skimage.io as io
|
| 10 |
+
import json
|
| 11 |
+
import random
|
| 12 |
+
import os
|
| 13 |
+
|
| 14 |
+
# set up file names and paths
|
| 15 |
+
versionType ='v2_' # this should be '' when using VQA v2.0 dataset
|
| 16 |
+
taskType ='OpenEnded' # 'OpenEnded' only for v2.0. 'OpenEnded' or 'MultipleChoice' for v1.0
|
| 17 |
+
dataType ='mscoco' # 'mscoco' only for v1.0. 'mscoco' for real and 'abstract_v002' for abstract for v1.0.
|
| 18 |
+
dataSubType ='train2014'
|
| 19 |
+
annFile ='%s/Annotations/%s%s_%s_annotations.json'%(dataDir, versionType, dataType, dataSubType)
|
| 20 |
+
quesFile ='%s/Questions/%s%s_%s_%s_questions.json'%(dataDir, versionType, taskType, dataType, dataSubType)
|
| 21 |
+
imgDir ='%s/Images/%s/%s/' %(dataDir, dataType, dataSubType)
|
| 22 |
+
resultType ='fake'
|
| 23 |
+
fileTypes = ['results', 'accuracy', 'evalQA', 'evalQuesType', 'evalAnsType']
|
| 24 |
+
|
| 25 |
+
# An example result json file has been provided in './Results' folder.
|
| 26 |
+
|
| 27 |
+
[resFile, accuracyFile, evalQAFile, evalQuesTypeFile, evalAnsTypeFile] = ['%s/Results/%s%s_%s_%s_%s_%s.json'%(dataDir, versionType, taskType, dataType, dataSubType, \
|
| 28 |
+
resultType, fileType) for fileType in fileTypes]
|
| 29 |
+
|
| 30 |
+
# create vqa object and vqaRes object
|
| 31 |
+
vqa = VQA(annFile, quesFile)
|
| 32 |
+
vqaRes = vqa.loadRes(resFile, quesFile)
|
| 33 |
+
|
| 34 |
+
# create vqaEval object by taking vqa and vqaRes
|
| 35 |
+
vqaEval = VQAEval(vqa, vqaRes, n=2) #n is precision of accuracy (number of places after decimal), default is 2
|
| 36 |
+
|
| 37 |
+
# evaluate results
|
| 38 |
+
"""
|
| 39 |
+
If you have a list of question ids on which you would like to evaluate your results, pass it as a list to below function
|
| 40 |
+
By default it uses all the question ids in annotation file
|
| 41 |
+
"""
|
| 42 |
+
vqaEval.evaluate()
|
| 43 |
+
|
| 44 |
+
# print accuracies
|
| 45 |
+
print "\n"
|
| 46 |
+
print "Overall Accuracy is: %.02f\n" %(vqaEval.accuracy['overall'])
|
| 47 |
+
print "Per Question Type Accuracy is the following:"
|
| 48 |
+
for quesType in vqaEval.accuracy['perQuestionType']:
|
| 49 |
+
print "%s : %.02f" %(quesType, vqaEval.accuracy['perQuestionType'][quesType])
|
| 50 |
+
print "\n"
|
| 51 |
+
print "Per Answer Type Accuracy is the following:"
|
| 52 |
+
for ansType in vqaEval.accuracy['perAnswerType']:
|
| 53 |
+
print "%s : %.02f" %(ansType, vqaEval.accuracy['perAnswerType'][ansType])
|
| 54 |
+
print "\n"
|
| 55 |
+
# demo how to use evalQA to retrieve low score result
|
| 56 |
+
evals = [quesId for quesId in vqaEval.evalQA if vqaEval.evalQA[quesId]<35] #35 is per question percentage accuracy
|
| 57 |
+
if len(evals) > 0:
|
| 58 |
+
print 'ground truth answers'
|
| 59 |
+
randomEval = random.choice(evals)
|
| 60 |
+
randomAnn = vqa.loadQA(randomEval)
|
| 61 |
+
vqa.showQA(randomAnn)
|
| 62 |
+
|
| 63 |
+
print '\n'
|
| 64 |
+
print 'generated answer (accuracy %.02f)'%(vqaEval.evalQA[randomEval])
|
| 65 |
+
ann = vqaRes.loadQA(randomEval)[0]
|
| 66 |
+
print "Answer: %s\n" %(ann['answer'])
|
| 67 |
+
|
| 68 |
+
imgId = randomAnn[0]['image_id']
|
| 69 |
+
imgFilename = 'COCO_' + dataSubType + '_'+ str(imgId).zfill(12) + '.jpg'
|
| 70 |
+
if os.path.isfile(imgDir + imgFilename):
|
| 71 |
+
I = io.imread(imgDir + imgFilename)
|
| 72 |
+
plt.imshow(I)
|
| 73 |
+
plt.axis('off')
|
| 74 |
+
plt.show()
|
| 75 |
+
|
| 76 |
+
# plot accuracy for various question types
|
| 77 |
+
plt.bar(range(len(vqaEval.accuracy['perQuestionType'])), vqaEval.accuracy['perQuestionType'].values(), align='center')
|
| 78 |
+
plt.xticks(range(len(vqaEval.accuracy['perQuestionType'])), vqaEval.accuracy['perQuestionType'].keys(), rotation='0',fontsize=10)
|
| 79 |
+
plt.title('Per Question Type Accuracy', fontsize=10)
|
| 80 |
+
plt.xlabel('Question Types', fontsize=10)
|
| 81 |
+
plt.ylabel('Accuracy', fontsize=10)
|
| 82 |
+
plt.show()
|
| 83 |
+
|
| 84 |
+
# save evaluation results to ./Results folder
|
| 85 |
+
json.dump(vqaEval.accuracy, open(accuracyFile, 'w'))
|
| 86 |
+
json.dump(vqaEval.evalQA, open(evalQAFile, 'w'))
|
| 87 |
+
json.dump(vqaEval.evalQuesType, open(evalQuesTypeFile, 'w'))
|
| 88 |
+
json.dump(vqaEval.evalAnsType, open(evalAnsTypeFile, 'w'))
|
| 89 |
+
|
minigpt4/common/vqa_tools/VQA/PythonEvaluationTools/vqaEvaluation/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
author='aagrawal'
|
minigpt4/common/vqa_tools/VQA/PythonEvaluationTools/vqaEvaluation/vqaEval.py
ADDED
|
@@ -0,0 +1,192 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
|
| 3 |
+
__author__='aagrawal'
|
| 4 |
+
|
| 5 |
+
import re
|
| 6 |
+
# This code is based on the code written by Tsung-Yi Lin for MSCOCO Python API available at the following link:
|
| 7 |
+
# (https://github.com/tylin/coco-caption/blob/master/pycocoevalcap/eval.py).
|
| 8 |
+
import sys
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class VQAEval:
|
| 12 |
+
def __init__(self, vqa, vqaRes, n=2):
|
| 13 |
+
self.n = n
|
| 14 |
+
self.accuracy = {}
|
| 15 |
+
self.evalQA = {}
|
| 16 |
+
self.evalQuesType = {}
|
| 17 |
+
self.evalAnsType = {}
|
| 18 |
+
self.vqa = vqa
|
| 19 |
+
self.vqaRes = vqaRes
|
| 20 |
+
self.params = {'question_id': vqa.getQuesIds()}
|
| 21 |
+
self.contractions = {"aint": "ain't", "arent": "aren't", "cant": "can't", "couldve": "could've", "couldnt": "couldn't", \
|
| 22 |
+
"couldn'tve": "couldn't've", "couldnt've": "couldn't've", "didnt": "didn't", "doesnt": "doesn't", "dont": "don't", "hadnt": "hadn't", \
|
| 23 |
+
"hadnt've": "hadn't've", "hadn'tve": "hadn't've", "hasnt": "hasn't", "havent": "haven't", "hed": "he'd", "hed've": "he'd've", \
|
| 24 |
+
"he'dve": "he'd've", "hes": "he's", "howd": "how'd", "howll": "how'll", "hows": "how's", "Id've": "I'd've", "I'dve": "I'd've", \
|
| 25 |
+
"Im": "I'm", "Ive": "I've", "isnt": "isn't", "itd": "it'd", "itd've": "it'd've", "it'dve": "it'd've", "itll": "it'll", "let's": "let's", \
|
| 26 |
+
"maam": "ma'am", "mightnt": "mightn't", "mightnt've": "mightn't've", "mightn'tve": "mightn't've", "mightve": "might've", \
|
| 27 |
+
"mustnt": "mustn't", "mustve": "must've", "neednt": "needn't", "notve": "not've", "oclock": "o'clock", "oughtnt": "oughtn't", \
|
| 28 |
+
"ow's'at": "'ow's'at", "'ows'at": "'ow's'at", "'ow'sat": "'ow's'at", "shant": "shan't", "shed've": "she'd've", "she'dve": "she'd've", \
|
| 29 |
+
"she's": "she's", "shouldve": "should've", "shouldnt": "shouldn't", "shouldnt've": "shouldn't've", "shouldn'tve": "shouldn't've", \
|
| 30 |
+
"somebody'd": "somebodyd", "somebodyd've": "somebody'd've", "somebody'dve": "somebody'd've", "somebodyll": "somebody'll", \
|
| 31 |
+
"somebodys": "somebody's", "someoned": "someone'd", "someoned've": "someone'd've", "someone'dve": "someone'd've", \
|
| 32 |
+
"someonell": "someone'll", "someones": "someone's", "somethingd": "something'd", "somethingd've": "something'd've", \
|
| 33 |
+
"something'dve": "something'd've", "somethingll": "something'll", "thats": "that's", "thered": "there'd", "thered've": "there'd've", \
|
| 34 |
+
"there'dve": "there'd've", "therere": "there're", "theres": "there's", "theyd": "they'd", "theyd've": "they'd've", \
|
| 35 |
+
"they'dve": "they'd've", "theyll": "they'll", "theyre": "they're", "theyve": "they've", "twas": "'twas", "wasnt": "wasn't", \
|
| 36 |
+
"wed've": "we'd've", "we'dve": "we'd've", "weve": "we've", "werent": "weren't", "whatll": "what'll", "whatre": "what're", \
|
| 37 |
+
"whats": "what's", "whatve": "what've", "whens": "when's", "whered": "where'd", "wheres": "where's", "whereve": "where've", \
|
| 38 |
+
"whod": "who'd", "whod've": "who'd've", "who'dve": "who'd've", "wholl": "who'll", "whos": "who's", "whove": "who've", "whyll": "why'll", \
|
| 39 |
+
"whyre": "why're", "whys": "why's", "wont": "won't", "wouldve": "would've", "wouldnt": "wouldn't", "wouldnt've": "wouldn't've", \
|
| 40 |
+
"wouldn'tve": "wouldn't've", "yall": "y'all", "yall'll": "y'all'll", "y'allll": "y'all'll", "yall'd've": "y'all'd've", \
|
| 41 |
+
"y'alld've": "y'all'd've", "y'all'dve": "y'all'd've", "youd": "you'd", "youd've": "you'd've", "you'dve": "you'd've", \
|
| 42 |
+
"youll": "you'll", "youre": "you're", "youve": "you've"}
|
| 43 |
+
self.manualMap = { 'none': '0',
|
| 44 |
+
'zero': '0',
|
| 45 |
+
'one': '1',
|
| 46 |
+
'two': '2',
|
| 47 |
+
'three': '3',
|
| 48 |
+
'four': '4',
|
| 49 |
+
'five': '5',
|
| 50 |
+
'six': '6',
|
| 51 |
+
'seven': '7',
|
| 52 |
+
'eight': '8',
|
| 53 |
+
'nine': '9',
|
| 54 |
+
'ten': '10'
|
| 55 |
+
}
|
| 56 |
+
self.articles = ['a',
|
| 57 |
+
'an',
|
| 58 |
+
'the'
|
| 59 |
+
]
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
self.periodStrip = re.compile("(?!<=\d)(\.)(?!\d)")
|
| 63 |
+
self.commaStrip = re.compile("(\d)(\,)(\d)")
|
| 64 |
+
self.punct = [';', r"/", '[', ']', '"', '{', '}',
|
| 65 |
+
'(', ')', '=', '+', '\\', '_', '-',
|
| 66 |
+
'>', '<', '@', '`', ',', '?', '!']
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
def evaluate(self, quesIds=None):
|
| 70 |
+
if quesIds == None:
|
| 71 |
+
quesIds = [quesId for quesId in self.params['question_id']]
|
| 72 |
+
gts = {}
|
| 73 |
+
res = {}
|
| 74 |
+
for quesId in quesIds:
|
| 75 |
+
gts[quesId] = self.vqa.qa[quesId]
|
| 76 |
+
res[quesId] = self.vqaRes.qa[quesId]
|
| 77 |
+
|
| 78 |
+
# =================================================
|
| 79 |
+
# Compute accuracy
|
| 80 |
+
# =================================================
|
| 81 |
+
accQA = []
|
| 82 |
+
accQuesType = {}
|
| 83 |
+
accAnsType = {}
|
| 84 |
+
# print "computing accuracy"
|
| 85 |
+
step = 0
|
| 86 |
+
for quesId in quesIds:
|
| 87 |
+
for ansDic in gts[quesId]['answers']:
|
| 88 |
+
ansDic['answer'] = ansDic['answer'].replace('\n', ' ')
|
| 89 |
+
ansDic['answer'] = ansDic['answer'].replace('\t', ' ')
|
| 90 |
+
ansDic['answer'] = ansDic['answer'].strip()
|
| 91 |
+
resAns = res[quesId]['answer']
|
| 92 |
+
resAns = resAns.replace('\n', ' ')
|
| 93 |
+
resAns = resAns.replace('\t', ' ')
|
| 94 |
+
resAns = resAns.strip()
|
| 95 |
+
gtAcc = []
|
| 96 |
+
gtAnswers = [ans['answer'] for ans in gts[quesId]['answers']]
|
| 97 |
+
|
| 98 |
+
if len(set(gtAnswers)) > 1:
|
| 99 |
+
for ansDic in gts[quesId]['answers']:
|
| 100 |
+
ansDic['answer'] = self.processPunctuation(ansDic['answer'])
|
| 101 |
+
ansDic['answer'] = self.processDigitArticle(ansDic['answer'])
|
| 102 |
+
resAns = self.processPunctuation(resAns)
|
| 103 |
+
resAns = self.processDigitArticle(resAns)
|
| 104 |
+
|
| 105 |
+
for gtAnsDatum in gts[quesId]['answers']:
|
| 106 |
+
otherGTAns = [item for item in gts[quesId]['answers'] if item!=gtAnsDatum]
|
| 107 |
+
matchingAns = [item for item in otherGTAns if item['answer'].lower()==resAns.lower()]
|
| 108 |
+
acc = min(1, float(len(matchingAns))/3)
|
| 109 |
+
gtAcc.append(acc)
|
| 110 |
+
quesType = gts[quesId]['question_type']
|
| 111 |
+
ansType = gts[quesId]['answer_type']
|
| 112 |
+
avgGTAcc = float(sum(gtAcc))/len(gtAcc)
|
| 113 |
+
accQA.append(avgGTAcc)
|
| 114 |
+
if quesType not in accQuesType:
|
| 115 |
+
accQuesType[quesType] = []
|
| 116 |
+
accQuesType[quesType].append(avgGTAcc)
|
| 117 |
+
if ansType not in accAnsType:
|
| 118 |
+
accAnsType[ansType] = []
|
| 119 |
+
accAnsType[ansType].append(avgGTAcc)
|
| 120 |
+
self.setEvalQA(quesId, avgGTAcc)
|
| 121 |
+
self.setEvalQuesType(quesId, quesType, avgGTAcc)
|
| 122 |
+
self.setEvalAnsType(quesId, ansType, avgGTAcc)
|
| 123 |
+
if step%100 == 0:
|
| 124 |
+
self.updateProgress(step/float(len(quesIds)))
|
| 125 |
+
step = step + 1
|
| 126 |
+
|
| 127 |
+
self.setAccuracy(accQA, accQuesType, accAnsType)
|
| 128 |
+
# print "Done computing accuracy"
|
| 129 |
+
|
| 130 |
+
def processPunctuation(self, inText):
|
| 131 |
+
outText = inText
|
| 132 |
+
for p in self.punct:
|
| 133 |
+
if (p + ' ' in inText or ' ' + p in inText) or (re.search(self.commaStrip, inText) != None):
|
| 134 |
+
outText = outText.replace(p, '')
|
| 135 |
+
else:
|
| 136 |
+
outText = outText.replace(p, ' ')
|
| 137 |
+
outText = self.periodStrip.sub("",
|
| 138 |
+
outText,
|
| 139 |
+
re.UNICODE)
|
| 140 |
+
return outText
|
| 141 |
+
|
| 142 |
+
def processDigitArticle(self, inText):
|
| 143 |
+
outText = []
|
| 144 |
+
tempText = inText.lower().split()
|
| 145 |
+
for word in tempText:
|
| 146 |
+
word = self.manualMap.setdefault(word, word)
|
| 147 |
+
if word not in self.articles:
|
| 148 |
+
outText.append(word)
|
| 149 |
+
else:
|
| 150 |
+
pass
|
| 151 |
+
for wordId, word in enumerate(outText):
|
| 152 |
+
if word in self.contractions:
|
| 153 |
+
outText[wordId] = self.contractions[word]
|
| 154 |
+
outText = ' '.join(outText)
|
| 155 |
+
return outText
|
| 156 |
+
|
| 157 |
+
def setAccuracy(self, accQA, accQuesType, accAnsType):
|
| 158 |
+
self.accuracy['overall'] = round(100*float(sum(accQA))/len(accQA), self.n)
|
| 159 |
+
self.accuracy['perQuestionType'] = {quesType: round(100*float(sum(accQuesType[quesType]))/len(accQuesType[quesType]), self.n) for quesType in accQuesType}
|
| 160 |
+
self.accuracy['perAnswerType'] = {ansType: round(100*float(sum(accAnsType[ansType]))/len(accAnsType[ansType]), self.n) for ansType in accAnsType}
|
| 161 |
+
|
| 162 |
+
def setEvalQA(self, quesId, acc):
|
| 163 |
+
self.evalQA[quesId] = round(100*acc, self.n)
|
| 164 |
+
|
| 165 |
+
def setEvalQuesType(self, quesId, quesType, acc):
|
| 166 |
+
if quesType not in self.evalQuesType:
|
| 167 |
+
self.evalQuesType[quesType] = {}
|
| 168 |
+
self.evalQuesType[quesType][quesId] = round(100*acc, self.n)
|
| 169 |
+
|
| 170 |
+
def setEvalAnsType(self, quesId, ansType, acc):
|
| 171 |
+
if ansType not in self.evalAnsType:
|
| 172 |
+
self.evalAnsType[ansType] = {}
|
| 173 |
+
self.evalAnsType[ansType][quesId] = round(100*acc, self.n)
|
| 174 |
+
|
| 175 |
+
def updateProgress(self, progress):
|
| 176 |
+
barLength = 20
|
| 177 |
+
status = ""
|
| 178 |
+
if isinstance(progress, int):
|
| 179 |
+
progress = float(progress)
|
| 180 |
+
if not isinstance(progress, float):
|
| 181 |
+
progress = 0
|
| 182 |
+
status = "error: progress var must be float\r\n"
|
| 183 |
+
if progress < 0:
|
| 184 |
+
progress = 0
|
| 185 |
+
status = "Halt...\r\n"
|
| 186 |
+
if progress >= 1:
|
| 187 |
+
progress = 1
|
| 188 |
+
status = "Done...\r\n"
|
| 189 |
+
block = int(round(barLength*progress))
|
| 190 |
+
text = "\rFinshed Percent: [{0}] {1}% {2}".format( "#"*block + "-"*(barLength-block), int(progress*100), status)
|
| 191 |
+
sys.stdout.write(text)
|
| 192 |
+
sys.stdout.flush()
|
minigpt4/common/vqa_tools/VQA/PythonHelperTools/vqaDemo.py
ADDED
|
@@ -0,0 +1,73 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding: utf-8
|
| 2 |
+
|
| 3 |
+
from vqaTools.vqa import VQA
|
| 4 |
+
import random
|
| 5 |
+
import skimage.io as io
|
| 6 |
+
import matplotlib.pyplot as plt
|
| 7 |
+
import os
|
| 8 |
+
|
| 9 |
+
dataDir ='../../VQA'
|
| 10 |
+
versionType ='v2_' # this should be '' when using VQA v2.0 dataset
|
| 11 |
+
taskType ='OpenEnded' # 'OpenEnded' only for v2.0. 'OpenEnded' or 'MultipleChoice' for v1.0
|
| 12 |
+
dataType ='mscoco' # 'mscoco' only for v1.0. 'mscoco' for real and 'abstract_v002' for abstract for v1.0.
|
| 13 |
+
dataSubType ='train2014'
|
| 14 |
+
annFile ='%s/Annotations/%s%s_%s_annotations.json'%(dataDir, versionType, dataType, dataSubType)
|
| 15 |
+
quesFile ='%s/Questions/%s%s_%s_%s_questions.json'%(dataDir, versionType, taskType, dataType, dataSubType)
|
| 16 |
+
imgDir = '%s/Images/%s/%s/' %(dataDir, dataType, dataSubType)
|
| 17 |
+
|
| 18 |
+
# initialize VQA api for QA annotations
|
| 19 |
+
vqa=VQA(annFile, quesFile)
|
| 20 |
+
|
| 21 |
+
# load and display QA annotations for given question types
|
| 22 |
+
"""
|
| 23 |
+
All possible quesTypes for abstract and mscoco has been provided in respective text files in ../QuestionTypes/ folder.
|
| 24 |
+
"""
|
| 25 |
+
annIds = vqa.getQuesIds(quesTypes='how many');
|
| 26 |
+
anns = vqa.loadQA(annIds)
|
| 27 |
+
randomAnn = random.choice(anns)
|
| 28 |
+
vqa.showQA([randomAnn])
|
| 29 |
+
imgId = randomAnn['image_id']
|
| 30 |
+
imgFilename = 'COCO_' + dataSubType + '_'+ str(imgId).zfill(12) + '.jpg'
|
| 31 |
+
if os.path.isfile(imgDir + imgFilename):
|
| 32 |
+
I = io.imread(imgDir + imgFilename)
|
| 33 |
+
plt.imshow(I)
|
| 34 |
+
plt.axis('off')
|
| 35 |
+
plt.show()
|
| 36 |
+
|
| 37 |
+
# load and display QA annotations for given answer types
|
| 38 |
+
"""
|
| 39 |
+
ansTypes can be one of the following
|
| 40 |
+
yes/no
|
| 41 |
+
number
|
| 42 |
+
other
|
| 43 |
+
"""
|
| 44 |
+
annIds = vqa.getQuesIds(ansTypes='yes/no');
|
| 45 |
+
anns = vqa.loadQA(annIds)
|
| 46 |
+
randomAnn = random.choice(anns)
|
| 47 |
+
vqa.showQA([randomAnn])
|
| 48 |
+
imgId = randomAnn['image_id']
|
| 49 |
+
imgFilename = 'COCO_' + dataSubType + '_'+ str(imgId).zfill(12) + '.jpg'
|
| 50 |
+
if os.path.isfile(imgDir + imgFilename):
|
| 51 |
+
I = io.imread(imgDir + imgFilename)
|
| 52 |
+
plt.imshow(I)
|
| 53 |
+
plt.axis('off')
|
| 54 |
+
plt.show()
|
| 55 |
+
|
| 56 |
+
# load and display QA annotations for given images
|
| 57 |
+
"""
|
| 58 |
+
Usage: vqa.getImgIds(quesIds=[], quesTypes=[], ansTypes=[])
|
| 59 |
+
Above method can be used to retrieve imageIds for given question Ids or given question types or given answer types.
|
| 60 |
+
"""
|
| 61 |
+
ids = vqa.getImgIds()
|
| 62 |
+
annIds = vqa.getQuesIds(imgIds=random.sample(ids,5));
|
| 63 |
+
anns = vqa.loadQA(annIds)
|
| 64 |
+
randomAnn = random.choice(anns)
|
| 65 |
+
vqa.showQA([randomAnn])
|
| 66 |
+
imgId = randomAnn['image_id']
|
| 67 |
+
imgFilename = 'COCO_' + dataSubType + '_'+ str(imgId).zfill(12) + '.jpg'
|
| 68 |
+
if os.path.isfile(imgDir + imgFilename):
|
| 69 |
+
I = io.imread(imgDir + imgFilename)
|
| 70 |
+
plt.imshow(I)
|
| 71 |
+
plt.axis('off')
|
| 72 |
+
plt.show()
|
| 73 |
+
|
minigpt4/common/vqa_tools/VQA/PythonHelperTools/vqaTools/__init__.py
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
__author__ = 'aagrawal'
|
minigpt4/common/vqa_tools/VQA/PythonHelperTools/vqaTools/vqa.py
ADDED
|
@@ -0,0 +1,179 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
__author__ = 'aagrawal'
|
| 2 |
+
__version__ = '0.9'
|
| 3 |
+
|
| 4 |
+
# Interface for accessing the VQA dataset.
|
| 5 |
+
|
| 6 |
+
# This code is based on the code written by Tsung-Yi Lin for MSCOCO Python API available at the following link:
|
| 7 |
+
# (https://github.com/pdollar/coco/blob/master/PythonAPI/pycocotools/coco.py).
|
| 8 |
+
|
| 9 |
+
# The following functions are defined:
|
| 10 |
+
# VQA - VQA class that loads VQA annotation file and prepares data structures.
|
| 11 |
+
# getQuesIds - Get question ids that satisfy given filter conditions.
|
| 12 |
+
# getImgIds - Get image ids that satisfy given filter conditions.
|
| 13 |
+
# loadQA - Load questions and answers with the specified question ids.
|
| 14 |
+
# showQA - Display the specified questions and answers.
|
| 15 |
+
# loadRes - Load result file and create result object.
|
| 16 |
+
|
| 17 |
+
# Help on each function can be accessed by: "help(COCO.function)"
|
| 18 |
+
|
| 19 |
+
import json
|
| 20 |
+
import datetime
|
| 21 |
+
import copy
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
class VQA:
|
| 25 |
+
def __init__(self, annotation_file=None, question_file=None):
|
| 26 |
+
"""
|
| 27 |
+
Constructor of VQA helper class for reading and visualizing questions and answers.
|
| 28 |
+
:param annotation_file (str): location of VQA annotation file
|
| 29 |
+
:return:
|
| 30 |
+
"""
|
| 31 |
+
# load dataset
|
| 32 |
+
self.dataset = {}
|
| 33 |
+
self.questions = {}
|
| 34 |
+
self.qa = {}
|
| 35 |
+
self.qqa = {}
|
| 36 |
+
self.imgToQA = {}
|
| 37 |
+
if not annotation_file == None and not question_file == None:
|
| 38 |
+
# print 'loading VQA annotations and questions into memory...'
|
| 39 |
+
time_t = datetime.datetime.utcnow()
|
| 40 |
+
dataset = json.load(open(annotation_file, 'r'))
|
| 41 |
+
questions = json.load(open(question_file, 'r'))
|
| 42 |
+
# print datetime.datetime.utcnow() - time_t
|
| 43 |
+
self.dataset = dataset
|
| 44 |
+
self.questions = questions
|
| 45 |
+
self.createIndex()
|
| 46 |
+
|
| 47 |
+
def createIndex(self):
|
| 48 |
+
imgToQA = {ann['image_id']: [] for ann in self.dataset['annotations']}
|
| 49 |
+
qa = {ann['question_id']: [] for ann in self.dataset['annotations']}
|
| 50 |
+
qqa = {ann['question_id']: [] for ann in self.dataset['annotations']}
|
| 51 |
+
for ann in self.dataset['annotations']:
|
| 52 |
+
imgToQA[ann['image_id']] += [ann]
|
| 53 |
+
qa[ann['question_id']] = ann
|
| 54 |
+
for ques in self.questions['questions']:
|
| 55 |
+
qqa[ques['question_id']] = ques
|
| 56 |
+
# print 'index created!'
|
| 57 |
+
|
| 58 |
+
# create class members
|
| 59 |
+
self.qa = qa
|
| 60 |
+
self.qqa = qqa
|
| 61 |
+
self.imgToQA = imgToQA
|
| 62 |
+
|
| 63 |
+
def info(self):
|
| 64 |
+
"""
|
| 65 |
+
Print information about the VQA annotation file.
|
| 66 |
+
:return:
|
| 67 |
+
"""
|
| 68 |
+
|
| 69 |
+
# for key, value in self.datset['info'].items():
|
| 70 |
+
# print '%s: %s'%(key, value)
|
| 71 |
+
|
| 72 |
+
def getQuesIds(self, imgIds=[], quesTypes=[], ansTypes=[]):
|
| 73 |
+
"""
|
| 74 |
+
Get question ids that satisfy given filter conditions. default skips that filter
|
| 75 |
+
:param imgIds (int array) : get question ids for given imgs
|
| 76 |
+
quesTypes (str array) : get question ids for given question types
|
| 77 |
+
ansTypes (str array) : get question ids for given answer types
|
| 78 |
+
:return: ids (int array) : integer array of question ids
|
| 79 |
+
"""
|
| 80 |
+
imgIds = imgIds if type(imgIds) == list else [imgIds]
|
| 81 |
+
quesTypes = quesTypes if type(quesTypes) == list else [quesTypes]
|
| 82 |
+
ansTypes = ansTypes if type(ansTypes) == list else [ansTypes]
|
| 83 |
+
|
| 84 |
+
if len(imgIds) == len(quesTypes) == len(ansTypes) == 0:
|
| 85 |
+
anns = self.dataset['annotations']
|
| 86 |
+
else:
|
| 87 |
+
if not len(imgIds) == 0:
|
| 88 |
+
anns = sum([self.imgToQA[imgId] for imgId in imgIds if imgId in self.imgToQA], [])
|
| 89 |
+
else:
|
| 90 |
+
anns = self.dataset['annotations']
|
| 91 |
+
anns = anns if len(quesTypes) == 0 else [ann for ann in anns if ann['question_type'] in quesTypes]
|
| 92 |
+
anns = anns if len(ansTypes) == 0 else [ann for ann in anns if ann['answer_type'] in ansTypes]
|
| 93 |
+
ids = [ann['question_id'] for ann in anns]
|
| 94 |
+
return ids
|
| 95 |
+
|
| 96 |
+
def getImgIds(self, quesIds=[], quesTypes=[], ansTypes=[]):
|
| 97 |
+
"""
|
| 98 |
+
Get image ids that satisfy given filter conditions. default skips that filter
|
| 99 |
+
:param quesIds (int array) : get image ids for given question ids
|
| 100 |
+
quesTypes (str array) : get image ids for given question types
|
| 101 |
+
ansTypes (str array) : get image ids for given answer types
|
| 102 |
+
:return: ids (int array) : integer array of image ids
|
| 103 |
+
"""
|
| 104 |
+
quesIds = quesIds if type(quesIds) == list else [quesIds]
|
| 105 |
+
quesTypes = quesTypes if type(quesTypes) == list else [quesTypes]
|
| 106 |
+
ansTypes = ansTypes if type(ansTypes) == list else [ansTypes]
|
| 107 |
+
|
| 108 |
+
if len(quesIds) == len(quesTypes) == len(ansTypes) == 0:
|
| 109 |
+
anns = self.dataset['annotations']
|
| 110 |
+
else:
|
| 111 |
+
if not len(quesIds) == 0:
|
| 112 |
+
anns = sum([self.qa[quesId] for quesId in quesIds if quesId in self.qa], [])
|
| 113 |
+
else:
|
| 114 |
+
anns = self.dataset['annotations']
|
| 115 |
+
anns = anns if len(quesTypes) == 0 else [ann for ann in anns if ann['question_type'] in quesTypes]
|
| 116 |
+
anns = anns if len(ansTypes) == 0 else [ann for ann in anns if ann['answer_type'] in ansTypes]
|
| 117 |
+
ids = [ann['image_id'] for ann in anns]
|
| 118 |
+
return ids
|
| 119 |
+
|
| 120 |
+
def loadQA(self, ids=[]):
|
| 121 |
+
"""
|
| 122 |
+
Load questions and answers with the specified question ids.
|
| 123 |
+
:param ids (int array) : integer ids specifying question ids
|
| 124 |
+
:return: qa (object array) : loaded qa objects
|
| 125 |
+
"""
|
| 126 |
+
if type(ids) == list:
|
| 127 |
+
return [self.qa[id] for id in ids]
|
| 128 |
+
elif type(ids) == int:
|
| 129 |
+
return [self.qa[ids]]
|
| 130 |
+
|
| 131 |
+
def showQA(self, anns):
|
| 132 |
+
"""
|
| 133 |
+
Display the specified annotations.
|
| 134 |
+
:param anns (array of object): annotations to display
|
| 135 |
+
:return: None
|
| 136 |
+
"""
|
| 137 |
+
if len(anns) == 0:
|
| 138 |
+
return 0
|
| 139 |
+
for ann in anns:
|
| 140 |
+
quesId = ann['question_id']
|
| 141 |
+
print("Question: %s" % (self.qqa[quesId]['question']))
|
| 142 |
+
for ans in ann['answers']:
|
| 143 |
+
print("Answer %d: %s" % (ans['answer_id'], ans['answer']))
|
| 144 |
+
|
| 145 |
+
def loadRes(self, resFile, quesFile):
|
| 146 |
+
"""
|
| 147 |
+
Load result file and return a result object.
|
| 148 |
+
:param resFile (str) : file name of result file
|
| 149 |
+
:return: res (obj) : result api object
|
| 150 |
+
"""
|
| 151 |
+
res = VQA()
|
| 152 |
+
res.questions = json.load(open(quesFile))
|
| 153 |
+
res.dataset['info'] = copy.deepcopy(self.questions['info'])
|
| 154 |
+
res.dataset['task_type'] = copy.deepcopy(self.questions['task_type'])
|
| 155 |
+
res.dataset['data_type'] = copy.deepcopy(self.questions['data_type'])
|
| 156 |
+
res.dataset['data_subtype'] = copy.deepcopy(self.questions['data_subtype'])
|
| 157 |
+
res.dataset['license'] = copy.deepcopy(self.questions['license'])
|
| 158 |
+
|
| 159 |
+
# print 'Loading and preparing results... '
|
| 160 |
+
time_t = datetime.datetime.utcnow()
|
| 161 |
+
anns = json.load(open(resFile))
|
| 162 |
+
assert type(anns) == list, 'results is not an array of objects'
|
| 163 |
+
annsQuesIds = [ann['question_id'] for ann in anns]
|
| 164 |
+
assert set(annsQuesIds) == set(self.getQuesIds()), \
|
| 165 |
+
'Results do not correspond to current VQA set. Either the results do not have predictions for all question ids in annotation file or there is atleast one question id that does not belong to the question ids in the annotation file.'
|
| 166 |
+
for ann in anns:
|
| 167 |
+
quesId = ann['question_id']
|
| 168 |
+
if res.dataset['task_type'] == 'Multiple Choice':
|
| 169 |
+
assert ann['answer'] in self.qqa[quesId][
|
| 170 |
+
'multiple_choices'], 'predicted answer is not one of the multiple choices'
|
| 171 |
+
qaAnn = self.qa[quesId]
|
| 172 |
+
ann['image_id'] = qaAnn['image_id']
|
| 173 |
+
ann['question_type'] = qaAnn['question_type']
|
| 174 |
+
ann['answer_type'] = qaAnn['answer_type']
|
| 175 |
+
# print 'DONE (t=%0.2fs)'%((datetime.datetime.utcnow() - time_t).total_seconds())
|
| 176 |
+
|
| 177 |
+
res.dataset['annotations'] = anns
|
| 178 |
+
res.createIndex()
|
| 179 |
+
return res
|
minigpt4/common/vqa_tools/VQA/QuestionTypes/abstract_v002_question_types.txt
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
how many
|
| 2 |
+
what color is the
|
| 3 |
+
is the
|
| 4 |
+
where is the
|
| 5 |
+
what
|
| 6 |
+
what is
|
| 7 |
+
are the
|
| 8 |
+
what is the
|
| 9 |
+
is there a
|
| 10 |
+
does the
|
| 11 |
+
is the woman
|
| 12 |
+
is the man
|
| 13 |
+
what is on the
|
| 14 |
+
is it
|
| 15 |
+
is the girl
|
| 16 |
+
is the boy
|
| 17 |
+
is the dog
|
| 18 |
+
are they
|
| 19 |
+
who is
|
| 20 |
+
what kind of
|
| 21 |
+
what color are the
|
| 22 |
+
what is in the
|
| 23 |
+
what is the man
|
| 24 |
+
is there
|
| 25 |
+
what is the woman
|
| 26 |
+
what are the
|
| 27 |
+
what is the boy
|
| 28 |
+
are there
|
| 29 |
+
what is the girl
|
| 30 |
+
is this
|
| 31 |
+
how
|
| 32 |
+
which
|
| 33 |
+
how many people are
|
| 34 |
+
is the cat
|
| 35 |
+
why is the
|
| 36 |
+
are
|
| 37 |
+
will the
|
| 38 |
+
what type of
|
| 39 |
+
what is the dog
|
| 40 |
+
do
|
| 41 |
+
is she
|
| 42 |
+
does
|
| 43 |
+
do the
|
| 44 |
+
is
|
| 45 |
+
is the baby
|
| 46 |
+
are there any
|
| 47 |
+
is the lady
|
| 48 |
+
can
|
| 49 |
+
what animal is
|
| 50 |
+
where are the
|
| 51 |
+
is the sun
|
| 52 |
+
what are they
|
| 53 |
+
did the
|
| 54 |
+
what is the cat
|
| 55 |
+
what is the lady
|
| 56 |
+
how many clouds are
|
| 57 |
+
is that
|
| 58 |
+
is the little girl
|
| 59 |
+
is he
|
| 60 |
+
are these
|
| 61 |
+
how many trees are
|
| 62 |
+
how many pillows
|
| 63 |
+
are the people
|
| 64 |
+
why
|
| 65 |
+
is the young
|
| 66 |
+
how many windows are
|
| 67 |
+
is this a
|
| 68 |
+
what is the little
|
| 69 |
+
is the tv
|
| 70 |
+
how many animals are
|
| 71 |
+
who
|
| 72 |
+
how many pictures
|
| 73 |
+
how many plants are
|
| 74 |
+
how many birds are
|
| 75 |
+
what color is
|
| 76 |
+
what is the baby
|
| 77 |
+
is anyone
|
| 78 |
+
what color
|
| 79 |
+
how many bushes
|
| 80 |
+
is the old man
|
| 81 |
+
none of the above
|
minigpt4/common/vqa_tools/VQA/QuestionTypes/mscoco_question_types.txt
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
how many
|
| 2 |
+
is the
|
| 3 |
+
what
|
| 4 |
+
what color is the
|
| 5 |
+
what is the
|
| 6 |
+
is this
|
| 7 |
+
is this a
|
| 8 |
+
what is
|
| 9 |
+
are the
|
| 10 |
+
what kind of
|
| 11 |
+
is there a
|
| 12 |
+
what type of
|
| 13 |
+
is it
|
| 14 |
+
what are the
|
| 15 |
+
where is the
|
| 16 |
+
is there
|
| 17 |
+
does the
|
| 18 |
+
what color are the
|
| 19 |
+
are these
|
| 20 |
+
are there
|
| 21 |
+
which
|
| 22 |
+
is
|
| 23 |
+
what is the man
|
| 24 |
+
is the man
|
| 25 |
+
are
|
| 26 |
+
how
|
| 27 |
+
does this
|
| 28 |
+
what is on the
|
| 29 |
+
what does the
|
| 30 |
+
how many people are
|
| 31 |
+
what is in the
|
| 32 |
+
what is this
|
| 33 |
+
do
|
| 34 |
+
what are
|
| 35 |
+
are they
|
| 36 |
+
what time
|
| 37 |
+
what sport is
|
| 38 |
+
are there any
|
| 39 |
+
is he
|
| 40 |
+
what color is
|
| 41 |
+
why
|
| 42 |
+
where are the
|
| 43 |
+
what color
|
| 44 |
+
who is
|
| 45 |
+
what animal is
|
| 46 |
+
is the woman
|
| 47 |
+
is this an
|
| 48 |
+
do you
|
| 49 |
+
how many people are in
|
| 50 |
+
what room is
|
| 51 |
+
has
|
| 52 |
+
is this person
|
| 53 |
+
what is the woman
|
| 54 |
+
can you
|
| 55 |
+
why is the
|
| 56 |
+
is the person
|
| 57 |
+
what is the color of the
|
| 58 |
+
what is the person
|
| 59 |
+
could
|
| 60 |
+
was
|
| 61 |
+
is that a
|
| 62 |
+
what number is
|
| 63 |
+
what is the name
|
| 64 |
+
what brand
|
| 65 |
+
none of the above
|
minigpt4/common/vqa_tools/VQA/README.md
ADDED
|
@@ -0,0 +1,80 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Python API and Evaluation Code for v2.0 and v1.0 releases of the VQA dataset.
|
| 2 |
+
===================
|
| 3 |
+
## VQA v2.0 release ##
|
| 4 |
+
This release consists of
|
| 5 |
+
- Real
|
| 6 |
+
- 82,783 MS COCO training images, 40,504 MS COCO validation images and 81,434 MS COCO testing images (images are obtained from [MS COCO website] (http://mscoco.org/dataset/#download))
|
| 7 |
+
- 443,757 questions for training, 214,354 questions for validation and 447,793 questions for testing
|
| 8 |
+
- 4,437,570 answers for training and 2,143,540 answers for validation (10 per question)
|
| 9 |
+
|
| 10 |
+
There is only one type of task
|
| 11 |
+
- Open-ended task
|
| 12 |
+
|
| 13 |
+
## VQA v1.0 release ##
|
| 14 |
+
This release consists of
|
| 15 |
+
- Real
|
| 16 |
+
- 82,783 MS COCO training images, 40,504 MS COCO validation images and 81,434 MS COCO testing images (images are obtained from [MS COCO website] (http://mscoco.org/dataset/#download))
|
| 17 |
+
- 248,349 questions for training, 121,512 questions for validation and 244,302 questions for testing (3 per image)
|
| 18 |
+
- 2,483,490 answers for training and 1,215,120 answers for validation (10 per question)
|
| 19 |
+
- Abstract
|
| 20 |
+
- 20,000 training images, 10,000 validation images and 20,000 MS COCO testing images
|
| 21 |
+
- 60,000 questions for training, 30,000 questions for validation and 60,000 questions for testing (3 per image)
|
| 22 |
+
- 600,000 answers for training and 300,000 answers for validation (10 per question)
|
| 23 |
+
|
| 24 |
+
There are two types of tasks
|
| 25 |
+
- Open-ended task
|
| 26 |
+
- Multiple-choice task (18 choices per question)
|
| 27 |
+
|
| 28 |
+
## Requirements ##
|
| 29 |
+
- python 2.7
|
| 30 |
+
- scikit-image (visit [this page](http://scikit-image.org/docs/dev/install.html) for installation)
|
| 31 |
+
- matplotlib (visit [this page](http://matplotlib.org/users/installing.html) for installation)
|
| 32 |
+
|
| 33 |
+
## Files ##
|
| 34 |
+
./Questions
|
| 35 |
+
- For v2.0, download the question files from the [VQA download page](http://www.visualqa.org/download.html), extract them and place in this folder.
|
| 36 |
+
- For v1.0, both real and abstract, question files can be found on the [VQA v1 download page](http://www.visualqa.org/vqa_v1_download.html).
|
| 37 |
+
- Question files from Beta v0.9 release (123,287 MSCOCO train and val images, 369,861 questions, 3,698,610 answers) can be found below
|
| 38 |
+
- [training question files](http://visualqa.org/data/mscoco/prev_rel/Beta_v0.9/Questions_Train_mscoco.zip)
|
| 39 |
+
- [validation question files](http://visualqa.org/data/mscoco/prev_rel/Beta_v0.9/Questions_Val_mscoco.zip)
|
| 40 |
+
- Question files from Beta v0.1 release (10k MSCOCO images, 30k questions, 300k answers) can be found [here](http://visualqa.org/data/mscoco/prev_rel/Beta_v0.1/Questions_Train_mscoco.zip).
|
| 41 |
+
|
| 42 |
+
./Annotations
|
| 43 |
+
- For v2.0, download the annotations files from the [VQA download page](http://www.visualqa.org/download.html), extract them and place in this folder.
|
| 44 |
+
- For v1.0, for both real and abstract, annotation files can be found on the [VQA v1 download page](http://www.visualqa.org/vqa_v1_download.html).
|
| 45 |
+
- Annotation files from Beta v0.9 release (123,287 MSCOCO train and val images, 369,861 questions, 3,698,610 answers) can be found below
|
| 46 |
+
- [training annotation files](http://visualqa.org/data/mscoco/prev_rel/Beta_v0.9/Annotations_Train_mscoco.zip)
|
| 47 |
+
- [validation annotation files](http://visualqa.org/data/mscoco/prev_rel/Beta_v0.9/Annotations_Val_mscoco.zip)
|
| 48 |
+
- Annotation files from Beta v0.1 release (10k MSCOCO images, 30k questions, 300k answers) can be found [here](http://visualqa.org/data/mscoco/prev_rel/Beta_v0.1/Annotations_Train_mscoco.zip).
|
| 49 |
+
|
| 50 |
+
./Images
|
| 51 |
+
- For real, create a directory with name mscoco inside this directory. For each of train, val and test, create directories with names train2014, val2014 and test2015 respectively inside mscoco directory, download respective images from [MS COCO website](http://mscoco.org/dataset/#download) and place them in respective folders.
|
| 52 |
+
- For abstract, create a directory with name abstract_v002 inside this directory. For each of train, val and test, create directories with names train2015, val2015 and test2015 respectively inside abstract_v002 directory, download respective images from [VQA download page](http://www.visualqa.org/download.html) and place them in respective folders.
|
| 53 |
+
|
| 54 |
+
./PythonHelperTools
|
| 55 |
+
- This directory contains the Python API to read and visualize the VQA dataset
|
| 56 |
+
- vqaDemo.py (demo script)
|
| 57 |
+
- vqaTools (API to read and visualize data)
|
| 58 |
+
|
| 59 |
+
./PythonEvaluationTools
|
| 60 |
+
- This directory contains the Python evaluation code
|
| 61 |
+
- vqaEvalDemo.py (evaluation demo script)
|
| 62 |
+
- vqaEvaluation (evaluation code)
|
| 63 |
+
|
| 64 |
+
./Results
|
| 65 |
+
- OpenEnded_mscoco_train2014_fake_results.json (an example of a fake results file for v1.0 to run the demo)
|
| 66 |
+
- Visit [VQA evaluation page] (http://visualqa.org/evaluation) for more details.
|
| 67 |
+
|
| 68 |
+
./QuestionTypes
|
| 69 |
+
- This directory contains the following lists of question types for both real and abstract questions (question types are unchanged from v1.0 to v2.0). In a list, if there are question types of length n+k and length n with the same first n words, then the question type of length n does not include questions that belong to the question type of length n+k.
|
| 70 |
+
- mscoco_question_types.txt
|
| 71 |
+
- abstract_v002_question_types.txt
|
| 72 |
+
|
| 73 |
+
## References ##
|
| 74 |
+
- [VQA: Visual Question Answering](http://visualqa.org/)
|
| 75 |
+
- [Microsoft COCO](http://mscoco.org/)
|
| 76 |
+
|
| 77 |
+
## Developers ##
|
| 78 |
+
- Aishwarya Agrawal (Virginia Tech)
|
| 79 |
+
- Code for API is based on [MSCOCO API code](https://github.com/pdollar/coco).
|
| 80 |
+
- The format of the code for evaluation is based on [MSCOCO evaluation code](https://github.com/tylin/coco-caption).
|
minigpt4/common/vqa_tools/VQA/license.txt
ADDED
|
@@ -0,0 +1,30 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Copyright (c) 2014, Aishwarya Agrawal
|
| 2 |
+
All rights reserved.
|
| 3 |
+
|
| 4 |
+
Redistribution and use in source and binary forms, with or without
|
| 5 |
+
modification, are permitted provided that the following conditions are met:
|
| 6 |
+
|
| 7 |
+
1. Redistributions of source code must retain the above copyright notice, this
|
| 8 |
+
list of conditions and the following disclaimer.
|
| 9 |
+
2. Redistributions in binary form must reproduce the above copyright notice,
|
| 10 |
+
this list of conditions and the following disclaimer in the documentation
|
| 11 |
+
and/or other materials provided with the distribution.
|
| 12 |
+
|
| 13 |
+
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
|
| 14 |
+
AND
|
| 15 |
+
ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED
|
| 16 |
+
WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
|
| 17 |
+
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE
|
| 18 |
+
FOR
|
| 19 |
+
ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES
|
| 20 |
+
(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;
|
| 21 |
+
LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND
|
| 22 |
+
ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
|
| 23 |
+
(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
|
| 24 |
+
SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
| 25 |
+
|
| 26 |
+
The views and conclusions contained in the software and documentation are
|
| 27 |
+
those
|
| 28 |
+
of the authors and should not be interpreted as representing official
|
| 29 |
+
policies,
|
| 30 |
+
either expressed or implied, of the FreeBSD Project.
|
minigpt4/common/vqa_tools/__init__.py
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
__author__ = "aagrawal"
|
minigpt4/common/vqa_tools/vqa.py
ADDED
|
@@ -0,0 +1,211 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
__author__ = "aagrawal"
|
| 9 |
+
__version__ = "0.9"
|
| 10 |
+
|
| 11 |
+
# Interface for accessing the VQA dataset.
|
| 12 |
+
|
| 13 |
+
# This code is based on the code written by Tsung-Yi Lin for MSCOCO Python API available at the following link:
|
| 14 |
+
# (https://github.com/pdollar/coco/blob/master/PythonAPI/pycocotools/coco.py).
|
| 15 |
+
|
| 16 |
+
# The following functions are defined:
|
| 17 |
+
# VQA - VQA class that loads VQA annotation file and prepares data structures.
|
| 18 |
+
# getQuesIds - Get question ids that satisfy given filter conditions.
|
| 19 |
+
# getImgIds - Get image ids that satisfy given filter conditions.
|
| 20 |
+
# loadQA - Load questions and answers with the specified question ids.
|
| 21 |
+
# showQA - Display the specified questions and answers.
|
| 22 |
+
# loadRes - Load result file and create result object.
|
| 23 |
+
|
| 24 |
+
# Help on each function can be accessed by: "help(COCO.function)"
|
| 25 |
+
|
| 26 |
+
import json
|
| 27 |
+
import datetime
|
| 28 |
+
import copy
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
class VQA:
|
| 32 |
+
def __init__(self, annotation_file=None, question_file=None):
|
| 33 |
+
"""
|
| 34 |
+
Constructor of VQA helper class for reading and visualizing questions and answers.
|
| 35 |
+
:param annotation_file (str): location of VQA annotation file
|
| 36 |
+
:return:
|
| 37 |
+
"""
|
| 38 |
+
# load dataset
|
| 39 |
+
self.dataset = {}
|
| 40 |
+
self.questions = {}
|
| 41 |
+
self.qa = {}
|
| 42 |
+
self.qqa = {}
|
| 43 |
+
self.imgToQA = {}
|
| 44 |
+
if not annotation_file == None and not question_file == None:
|
| 45 |
+
print("loading VQA annotations and questions into memory...")
|
| 46 |
+
time_t = datetime.datetime.utcnow()
|
| 47 |
+
dataset = json.load(open(annotation_file, "r"))
|
| 48 |
+
questions = json.load(open(question_file, "r"))
|
| 49 |
+
self.dataset = dataset
|
| 50 |
+
self.questions = questions
|
| 51 |
+
self.createIndex()
|
| 52 |
+
|
| 53 |
+
def createIndex(self):
|
| 54 |
+
# create index
|
| 55 |
+
print("creating index...")
|
| 56 |
+
imgToQA = {ann["image_id"]: [] for ann in self.dataset["annotations"]}
|
| 57 |
+
qa = {ann["question_id"]: [] for ann in self.dataset["annotations"]}
|
| 58 |
+
qqa = {ann["question_id"]: [] for ann in self.dataset["annotations"]}
|
| 59 |
+
for ann in self.dataset["annotations"]:
|
| 60 |
+
imgToQA[ann["image_id"]] += [ann]
|
| 61 |
+
qa[ann["question_id"]] = ann
|
| 62 |
+
for ques in self.questions["questions"]:
|
| 63 |
+
qqa[ques["question_id"]] = ques
|
| 64 |
+
print("index created!")
|
| 65 |
+
|
| 66 |
+
# create class members
|
| 67 |
+
self.qa = qa
|
| 68 |
+
self.qqa = qqa
|
| 69 |
+
self.imgToQA = imgToQA
|
| 70 |
+
|
| 71 |
+
def info(self):
|
| 72 |
+
"""
|
| 73 |
+
Print information about the VQA annotation file.
|
| 74 |
+
:return:
|
| 75 |
+
"""
|
| 76 |
+
for key, value in self.datset["info"].items():
|
| 77 |
+
print("%s: %s" % (key, value))
|
| 78 |
+
|
| 79 |
+
def getQuesIds(self, imgIds=[], quesTypes=[], ansTypes=[]):
|
| 80 |
+
"""
|
| 81 |
+
Get question ids that satisfy given filter conditions. default skips that filter
|
| 82 |
+
:param imgIds (int array) : get question ids for given imgs
|
| 83 |
+
quesTypes (str array) : get question ids for given question types
|
| 84 |
+
ansTypes (str array) : get question ids for given answer types
|
| 85 |
+
:return: ids (int array) : integer array of question ids
|
| 86 |
+
"""
|
| 87 |
+
imgIds = imgIds if type(imgIds) == list else [imgIds]
|
| 88 |
+
quesTypes = quesTypes if type(quesTypes) == list else [quesTypes]
|
| 89 |
+
ansTypes = ansTypes if type(ansTypes) == list else [ansTypes]
|
| 90 |
+
|
| 91 |
+
if len(imgIds) == len(quesTypes) == len(ansTypes) == 0:
|
| 92 |
+
anns = self.dataset["annotations"]
|
| 93 |
+
else:
|
| 94 |
+
if not len(imgIds) == 0:
|
| 95 |
+
anns = sum(
|
| 96 |
+
[self.imgToQA[imgId] for imgId in imgIds if imgId in self.imgToQA],
|
| 97 |
+
[],
|
| 98 |
+
)
|
| 99 |
+
else:
|
| 100 |
+
anns = self.dataset["annotations"]
|
| 101 |
+
anns = (
|
| 102 |
+
anns
|
| 103 |
+
if len(quesTypes) == 0
|
| 104 |
+
else [ann for ann in anns if ann["question_type"] in quesTypes]
|
| 105 |
+
)
|
| 106 |
+
anns = (
|
| 107 |
+
anns
|
| 108 |
+
if len(ansTypes) == 0
|
| 109 |
+
else [ann for ann in anns if ann["answer_type"] in ansTypes]
|
| 110 |
+
)
|
| 111 |
+
ids = [ann["question_id"] for ann in anns]
|
| 112 |
+
return ids
|
| 113 |
+
|
| 114 |
+
def getImgIds(self, quesIds=[], quesTypes=[], ansTypes=[]):
|
| 115 |
+
"""
|
| 116 |
+
Get image ids that satisfy given filter conditions. default skips that filter
|
| 117 |
+
:param quesIds (int array) : get image ids for given question ids
|
| 118 |
+
quesTypes (str array) : get image ids for given question types
|
| 119 |
+
ansTypes (str array) : get image ids for given answer types
|
| 120 |
+
:return: ids (int array) : integer array of image ids
|
| 121 |
+
"""
|
| 122 |
+
quesIds = quesIds if type(quesIds) == list else [quesIds]
|
| 123 |
+
quesTypes = quesTypes if type(quesTypes) == list else [quesTypes]
|
| 124 |
+
ansTypes = ansTypes if type(ansTypes) == list else [ansTypes]
|
| 125 |
+
|
| 126 |
+
if len(quesIds) == len(quesTypes) == len(ansTypes) == 0:
|
| 127 |
+
anns = self.dataset["annotations"]
|
| 128 |
+
else:
|
| 129 |
+
if not len(quesIds) == 0:
|
| 130 |
+
anns = sum(
|
| 131 |
+
[self.qa[quesId] for quesId in quesIds if quesId in self.qa], []
|
| 132 |
+
)
|
| 133 |
+
else:
|
| 134 |
+
anns = self.dataset["annotations"]
|
| 135 |
+
anns = (
|
| 136 |
+
anns
|
| 137 |
+
if len(quesTypes) == 0
|
| 138 |
+
else [ann for ann in anns if ann["question_type"] in quesTypes]
|
| 139 |
+
)
|
| 140 |
+
anns = (
|
| 141 |
+
anns
|
| 142 |
+
if len(ansTypes) == 0
|
| 143 |
+
else [ann for ann in anns if ann["answer_type"] in ansTypes]
|
| 144 |
+
)
|
| 145 |
+
ids = [ann["image_id"] for ann in anns]
|
| 146 |
+
return ids
|
| 147 |
+
|
| 148 |
+
def loadQA(self, ids=[]):
|
| 149 |
+
"""
|
| 150 |
+
Load questions and answers with the specified question ids.
|
| 151 |
+
:param ids (int array) : integer ids specifying question ids
|
| 152 |
+
:return: qa (object array) : loaded qa objects
|
| 153 |
+
"""
|
| 154 |
+
if type(ids) == list:
|
| 155 |
+
return [self.qa[id] for id in ids]
|
| 156 |
+
elif type(ids) == int:
|
| 157 |
+
return [self.qa[ids]]
|
| 158 |
+
|
| 159 |
+
def showQA(self, anns):
|
| 160 |
+
"""
|
| 161 |
+
Display the specified annotations.
|
| 162 |
+
:param anns (array of object): annotations to display
|
| 163 |
+
:return: None
|
| 164 |
+
"""
|
| 165 |
+
if len(anns) == 0:
|
| 166 |
+
return 0
|
| 167 |
+
for ann in anns:
|
| 168 |
+
quesId = ann["question_id"]
|
| 169 |
+
print("Question: %s" % (self.qqa[quesId]["question"]))
|
| 170 |
+
for ans in ann["answers"]:
|
| 171 |
+
print("Answer %d: %s" % (ans["answer_id"], ans["answer"]))
|
| 172 |
+
|
| 173 |
+
def loadRes(self, resFile, quesFile):
|
| 174 |
+
"""
|
| 175 |
+
Load result file and return a result object.
|
| 176 |
+
:param resFile (str) : file name of result file
|
| 177 |
+
:return: res (obj) : result api object
|
| 178 |
+
"""
|
| 179 |
+
res = VQA()
|
| 180 |
+
res.questions = json.load(open(quesFile))
|
| 181 |
+
res.dataset["info"] = copy.deepcopy(self.questions["info"])
|
| 182 |
+
res.dataset["task_type"] = copy.deepcopy(self.questions["task_type"])
|
| 183 |
+
res.dataset["data_type"] = copy.deepcopy(self.questions["data_type"])
|
| 184 |
+
res.dataset["data_subtype"] = copy.deepcopy(self.questions["data_subtype"])
|
| 185 |
+
res.dataset["license"] = copy.deepcopy(self.questions["license"])
|
| 186 |
+
|
| 187 |
+
print("Loading and preparing results... ")
|
| 188 |
+
time_t = datetime.datetime.utcnow()
|
| 189 |
+
anns = json.load(open(resFile))
|
| 190 |
+
assert type(anns) == list, "results is not an array of objects"
|
| 191 |
+
annsQuesIds = [ann["question_id"] for ann in anns]
|
| 192 |
+
assert set(annsQuesIds) == set(
|
| 193 |
+
self.getQuesIds()
|
| 194 |
+
), "Results do not correspond to current VQA set. Either the results do not have predictions for all question ids in annotation file or there is atleast one question id that does not belong to the question ids in the annotation file."
|
| 195 |
+
for ann in anns:
|
| 196 |
+
quesId = ann["question_id"]
|
| 197 |
+
if res.dataset["task_type"] == "Multiple Choice":
|
| 198 |
+
assert (
|
| 199 |
+
ann["answer"] in self.qqa[quesId]["multiple_choices"]
|
| 200 |
+
), "predicted answer is not one of the multiple choices"
|
| 201 |
+
qaAnn = self.qa[quesId]
|
| 202 |
+
ann["image_id"] = qaAnn["image_id"]
|
| 203 |
+
ann["question_type"] = qaAnn["question_type"]
|
| 204 |
+
ann["answer_type"] = qaAnn["answer_type"]
|
| 205 |
+
print(
|
| 206 |
+
"DONE (t=%0.2fs)" % ((datetime.datetime.utcnow() - time_t).total_seconds())
|
| 207 |
+
)
|
| 208 |
+
|
| 209 |
+
res.dataset["annotations"] = anns
|
| 210 |
+
res.createIndex()
|
| 211 |
+
return res
|
minigpt4/common/vqa_tools/vqa_eval.py
ADDED
|
@@ -0,0 +1,324 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
# coding=utf-8
|
| 9 |
+
|
| 10 |
+
__author__ = "aagrawal"
|
| 11 |
+
|
| 12 |
+
# This code is based on the code written by Tsung-Yi Lin for MSCOCO Python API available at the following link:
|
| 13 |
+
# (https://github.com/tylin/coco-caption/blob/master/pycocoevalcap/eval.py).
|
| 14 |
+
import sys
|
| 15 |
+
import re
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class VQAEval:
|
| 19 |
+
def __init__(self, vqa=None, vqaRes=None, n=2):
|
| 20 |
+
self.n = n
|
| 21 |
+
self.accuracy = {}
|
| 22 |
+
self.evalQA = {}
|
| 23 |
+
self.evalQuesType = {}
|
| 24 |
+
self.evalAnsType = {}
|
| 25 |
+
self.vqa = vqa
|
| 26 |
+
self.vqaRes = vqaRes
|
| 27 |
+
if vqa is not None:
|
| 28 |
+
self.params = {"question_id": vqa.getQuesIds()}
|
| 29 |
+
self.contractions = {
|
| 30 |
+
"aint": "ain't",
|
| 31 |
+
"arent": "aren't",
|
| 32 |
+
"cant": "can't",
|
| 33 |
+
"couldve": "could've",
|
| 34 |
+
"couldnt": "couldn't",
|
| 35 |
+
"couldn'tve": "couldn't've",
|
| 36 |
+
"couldnt've": "couldn't've",
|
| 37 |
+
"didnt": "didn't",
|
| 38 |
+
"doesnt": "doesn't",
|
| 39 |
+
"dont": "don't",
|
| 40 |
+
"hadnt": "hadn't",
|
| 41 |
+
"hadnt've": "hadn't've",
|
| 42 |
+
"hadn'tve": "hadn't've",
|
| 43 |
+
"hasnt": "hasn't",
|
| 44 |
+
"havent": "haven't",
|
| 45 |
+
"hed": "he'd",
|
| 46 |
+
"hed've": "he'd've",
|
| 47 |
+
"he'dve": "he'd've",
|
| 48 |
+
"hes": "he's",
|
| 49 |
+
"howd": "how'd",
|
| 50 |
+
"howll": "how'll",
|
| 51 |
+
"hows": "how's",
|
| 52 |
+
"Id've": "I'd've",
|
| 53 |
+
"I'dve": "I'd've",
|
| 54 |
+
"Im": "I'm",
|
| 55 |
+
"Ive": "I've",
|
| 56 |
+
"isnt": "isn't",
|
| 57 |
+
"itd": "it'd",
|
| 58 |
+
"itd've": "it'd've",
|
| 59 |
+
"it'dve": "it'd've",
|
| 60 |
+
"itll": "it'll",
|
| 61 |
+
"let's": "let's",
|
| 62 |
+
"maam": "ma'am",
|
| 63 |
+
"mightnt": "mightn't",
|
| 64 |
+
"mightnt've": "mightn't've",
|
| 65 |
+
"mightn'tve": "mightn't've",
|
| 66 |
+
"mightve": "might've",
|
| 67 |
+
"mustnt": "mustn't",
|
| 68 |
+
"mustve": "must've",
|
| 69 |
+
"neednt": "needn't",
|
| 70 |
+
"notve": "not've",
|
| 71 |
+
"oclock": "o'clock",
|
| 72 |
+
"oughtnt": "oughtn't",
|
| 73 |
+
"ow's'at": "'ow's'at",
|
| 74 |
+
"'ows'at": "'ow's'at",
|
| 75 |
+
"'ow'sat": "'ow's'at",
|
| 76 |
+
"shant": "shan't",
|
| 77 |
+
"shed've": "she'd've",
|
| 78 |
+
"she'dve": "she'd've",
|
| 79 |
+
"she's": "she's",
|
| 80 |
+
"shouldve": "should've",
|
| 81 |
+
"shouldnt": "shouldn't",
|
| 82 |
+
"shouldnt've": "shouldn't've",
|
| 83 |
+
"shouldn'tve": "shouldn't've",
|
| 84 |
+
"somebody'd": "somebodyd",
|
| 85 |
+
"somebodyd've": "somebody'd've",
|
| 86 |
+
"somebody'dve": "somebody'd've",
|
| 87 |
+
"somebodyll": "somebody'll",
|
| 88 |
+
"somebodys": "somebody's",
|
| 89 |
+
"someoned": "someone'd",
|
| 90 |
+
"someoned've": "someone'd've",
|
| 91 |
+
"someone'dve": "someone'd've",
|
| 92 |
+
"someonell": "someone'll",
|
| 93 |
+
"someones": "someone's",
|
| 94 |
+
"somethingd": "something'd",
|
| 95 |
+
"somethingd've": "something'd've",
|
| 96 |
+
"something'dve": "something'd've",
|
| 97 |
+
"somethingll": "something'll",
|
| 98 |
+
"thats": "that's",
|
| 99 |
+
"thered": "there'd",
|
| 100 |
+
"thered've": "there'd've",
|
| 101 |
+
"there'dve": "there'd've",
|
| 102 |
+
"therere": "there're",
|
| 103 |
+
"theres": "there's",
|
| 104 |
+
"theyd": "they'd",
|
| 105 |
+
"theyd've": "they'd've",
|
| 106 |
+
"they'dve": "they'd've",
|
| 107 |
+
"theyll": "they'll",
|
| 108 |
+
"theyre": "they're",
|
| 109 |
+
"theyve": "they've",
|
| 110 |
+
"twas": "'twas",
|
| 111 |
+
"wasnt": "wasn't",
|
| 112 |
+
"wed've": "we'd've",
|
| 113 |
+
"we'dve": "we'd've",
|
| 114 |
+
"weve": "we've",
|
| 115 |
+
"werent": "weren't",
|
| 116 |
+
"whatll": "what'll",
|
| 117 |
+
"whatre": "what're",
|
| 118 |
+
"whats": "what's",
|
| 119 |
+
"whatve": "what've",
|
| 120 |
+
"whens": "when's",
|
| 121 |
+
"whered": "where'd",
|
| 122 |
+
"wheres": "where's",
|
| 123 |
+
"whereve": "where've",
|
| 124 |
+
"whod": "who'd",
|
| 125 |
+
"whod've": "who'd've",
|
| 126 |
+
"who'dve": "who'd've",
|
| 127 |
+
"wholl": "who'll",
|
| 128 |
+
"whos": "who's",
|
| 129 |
+
"whove": "who've",
|
| 130 |
+
"whyll": "why'll",
|
| 131 |
+
"whyre": "why're",
|
| 132 |
+
"whys": "why's",
|
| 133 |
+
"wont": "won't",
|
| 134 |
+
"wouldve": "would've",
|
| 135 |
+
"wouldnt": "wouldn't",
|
| 136 |
+
"wouldnt've": "wouldn't've",
|
| 137 |
+
"wouldn'tve": "wouldn't've",
|
| 138 |
+
"yall": "y'all",
|
| 139 |
+
"yall'll": "y'all'll",
|
| 140 |
+
"y'allll": "y'all'll",
|
| 141 |
+
"yall'd've": "y'all'd've",
|
| 142 |
+
"y'alld've": "y'all'd've",
|
| 143 |
+
"y'all'dve": "y'all'd've",
|
| 144 |
+
"youd": "you'd",
|
| 145 |
+
"youd've": "you'd've",
|
| 146 |
+
"you'dve": "you'd've",
|
| 147 |
+
"youll": "you'll",
|
| 148 |
+
"youre": "you're",
|
| 149 |
+
"youve": "you've",
|
| 150 |
+
}
|
| 151 |
+
self.manualMap = {
|
| 152 |
+
"none": "0",
|
| 153 |
+
"zero": "0",
|
| 154 |
+
"one": "1",
|
| 155 |
+
"two": "2",
|
| 156 |
+
"three": "3",
|
| 157 |
+
"four": "4",
|
| 158 |
+
"five": "5",
|
| 159 |
+
"six": "6",
|
| 160 |
+
"seven": "7",
|
| 161 |
+
"eight": "8",
|
| 162 |
+
"nine": "9",
|
| 163 |
+
"ten": "10",
|
| 164 |
+
}
|
| 165 |
+
self.articles = ["a", "an", "the"]
|
| 166 |
+
|
| 167 |
+
self.periodStrip = re.compile("(?!<=\d)(\.)(?!\d)")
|
| 168 |
+
self.commaStrip = re.compile("(\d)(,)(\d)")
|
| 169 |
+
self.punct = [
|
| 170 |
+
";",
|
| 171 |
+
r"/",
|
| 172 |
+
"[",
|
| 173 |
+
"]",
|
| 174 |
+
'"',
|
| 175 |
+
"{",
|
| 176 |
+
"}",
|
| 177 |
+
"(",
|
| 178 |
+
")",
|
| 179 |
+
"=",
|
| 180 |
+
"+",
|
| 181 |
+
"\\",
|
| 182 |
+
"_",
|
| 183 |
+
"-",
|
| 184 |
+
">",
|
| 185 |
+
"<",
|
| 186 |
+
"@",
|
| 187 |
+
"`",
|
| 188 |
+
",",
|
| 189 |
+
"?",
|
| 190 |
+
"!",
|
| 191 |
+
]
|
| 192 |
+
|
| 193 |
+
def evaluate(self, quesIds=None):
|
| 194 |
+
if quesIds == None:
|
| 195 |
+
quesIds = [quesId for quesId in self.params["question_id"]]
|
| 196 |
+
gts = {}
|
| 197 |
+
res = {}
|
| 198 |
+
for quesId in quesIds:
|
| 199 |
+
gts[quesId] = self.vqa.qa[quesId]
|
| 200 |
+
res[quesId] = self.vqaRes.qa[quesId]
|
| 201 |
+
|
| 202 |
+
# =================================================
|
| 203 |
+
# Compute accuracy
|
| 204 |
+
# =================================================
|
| 205 |
+
accQA = []
|
| 206 |
+
accQuesType = {}
|
| 207 |
+
accAnsType = {}
|
| 208 |
+
print("computing accuracy")
|
| 209 |
+
step = 0
|
| 210 |
+
for quesId in quesIds:
|
| 211 |
+
resAns = res[quesId]["answer"]
|
| 212 |
+
resAns = resAns.replace("\n", " ")
|
| 213 |
+
resAns = resAns.replace("\t", " ")
|
| 214 |
+
resAns = resAns.strip()
|
| 215 |
+
resAns = self.processPunctuation(resAns)
|
| 216 |
+
resAns = self.processDigitArticle(resAns)
|
| 217 |
+
gtAcc = []
|
| 218 |
+
gtAnswers = [ans["answer"] for ans in gts[quesId]["answers"]]
|
| 219 |
+
if len(set(gtAnswers)) > 1:
|
| 220 |
+
for ansDic in gts[quesId]["answers"]:
|
| 221 |
+
ansDic["answer"] = self.processPunctuation(ansDic["answer"])
|
| 222 |
+
for gtAnsDatum in gts[quesId]["answers"]:
|
| 223 |
+
otherGTAns = [
|
| 224 |
+
item for item in gts[quesId]["answers"] if item != gtAnsDatum
|
| 225 |
+
]
|
| 226 |
+
matchingAns = [item for item in otherGTAns if item["answer"] == resAns]
|
| 227 |
+
acc = min(1, float(len(matchingAns)) / 3)
|
| 228 |
+
gtAcc.append(acc)
|
| 229 |
+
quesType = gts[quesId]["question_type"]
|
| 230 |
+
ansType = gts[quesId]["answer_type"]
|
| 231 |
+
avgGTAcc = float(sum(gtAcc)) / len(gtAcc)
|
| 232 |
+
accQA.append(avgGTAcc)
|
| 233 |
+
if quesType not in accQuesType:
|
| 234 |
+
accQuesType[quesType] = []
|
| 235 |
+
accQuesType[quesType].append(avgGTAcc)
|
| 236 |
+
if ansType not in accAnsType:
|
| 237 |
+
accAnsType[ansType] = []
|
| 238 |
+
accAnsType[ansType].append(avgGTAcc)
|
| 239 |
+
self.setEvalQA(quesId, avgGTAcc)
|
| 240 |
+
self.setEvalQuesType(quesId, quesType, avgGTAcc)
|
| 241 |
+
self.setEvalAnsType(quesId, ansType, avgGTAcc)
|
| 242 |
+
if step % 100 == 0:
|
| 243 |
+
self.updateProgress(step / float(len(quesIds)))
|
| 244 |
+
step = step + 1
|
| 245 |
+
|
| 246 |
+
self.setAccuracy(accQA, accQuesType, accAnsType)
|
| 247 |
+
print("Done computing accuracy")
|
| 248 |
+
|
| 249 |
+
def processPunctuation(self, inText):
|
| 250 |
+
outText = inText
|
| 251 |
+
for p in self.punct:
|
| 252 |
+
if (p + " " in inText or " " + p in inText) or (
|
| 253 |
+
re.search(self.commaStrip, inText) != None
|
| 254 |
+
):
|
| 255 |
+
outText = outText.replace(p, "")
|
| 256 |
+
else:
|
| 257 |
+
outText = outText.replace(p, " ")
|
| 258 |
+
outText = self.periodStrip.sub("", outText, re.UNICODE)
|
| 259 |
+
return outText
|
| 260 |
+
|
| 261 |
+
def processDigitArticle(self, inText):
|
| 262 |
+
outText = []
|
| 263 |
+
tempText = inText.lower().split()
|
| 264 |
+
for word in tempText:
|
| 265 |
+
word = self.manualMap.setdefault(word, word)
|
| 266 |
+
if word not in self.articles:
|
| 267 |
+
outText.append(word)
|
| 268 |
+
else:
|
| 269 |
+
pass
|
| 270 |
+
for wordId, word in enumerate(outText):
|
| 271 |
+
if word in self.contractions:
|
| 272 |
+
outText[wordId] = self.contractions[word]
|
| 273 |
+
outText = " ".join(outText)
|
| 274 |
+
return outText
|
| 275 |
+
|
| 276 |
+
def setAccuracy(self, accQA, accQuesType, accAnsType):
|
| 277 |
+
self.accuracy["overall"] = round(100 * float(sum(accQA)) / len(accQA), self.n)
|
| 278 |
+
self.accuracy["perQuestionType"] = {
|
| 279 |
+
quesType: round(
|
| 280 |
+
100 * float(sum(accQuesType[quesType])) / len(accQuesType[quesType]),
|
| 281 |
+
self.n,
|
| 282 |
+
)
|
| 283 |
+
for quesType in accQuesType
|
| 284 |
+
}
|
| 285 |
+
self.accuracy["perAnswerType"] = {
|
| 286 |
+
ansType: round(
|
| 287 |
+
100 * float(sum(accAnsType[ansType])) / len(accAnsType[ansType]), self.n
|
| 288 |
+
)
|
| 289 |
+
for ansType in accAnsType
|
| 290 |
+
}
|
| 291 |
+
|
| 292 |
+
def setEvalQA(self, quesId, acc):
|
| 293 |
+
self.evalQA[quesId] = round(100 * acc, self.n)
|
| 294 |
+
|
| 295 |
+
def setEvalQuesType(self, quesId, quesType, acc):
|
| 296 |
+
if quesType not in self.evalQuesType:
|
| 297 |
+
self.evalQuesType[quesType] = {}
|
| 298 |
+
self.evalQuesType[quesType][quesId] = round(100 * acc, self.n)
|
| 299 |
+
|
| 300 |
+
def setEvalAnsType(self, quesId, ansType, acc):
|
| 301 |
+
if ansType not in self.evalAnsType:
|
| 302 |
+
self.evalAnsType[ansType] = {}
|
| 303 |
+
self.evalAnsType[ansType][quesId] = round(100 * acc, self.n)
|
| 304 |
+
|
| 305 |
+
def updateProgress(self, progress):
|
| 306 |
+
barLength = 20
|
| 307 |
+
status = ""
|
| 308 |
+
if isinstance(progress, int):
|
| 309 |
+
progress = float(progress)
|
| 310 |
+
if not isinstance(progress, float):
|
| 311 |
+
progress = 0
|
| 312 |
+
status = "error: progress var must be float\r\n"
|
| 313 |
+
if progress < 0:
|
| 314 |
+
progress = 0
|
| 315 |
+
status = "Halt...\r\n"
|
| 316 |
+
if progress >= 1:
|
| 317 |
+
progress = 1
|
| 318 |
+
status = "Done...\r\n"
|
| 319 |
+
block = int(round(barLength * progress))
|
| 320 |
+
text = "\rFinshed Percent: [{0}] {1}% {2}".format(
|
| 321 |
+
"#" * block + "-" * (barLength - block), int(progress * 100), status
|
| 322 |
+
)
|
| 323 |
+
sys.stdout.write(text)
|
| 324 |
+
sys.stdout.flush()
|
minigpt4/configs/datasets/aokvqa/defaults.yaml
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2022, salesforce.com, inc.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
# SPDX-License-Identifier: BSD-3-Clause
|
| 4 |
+
# For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 5 |
+
|
| 6 |
+
datasets:
|
| 7 |
+
aok_vqa:
|
| 8 |
+
# data_dir: ${env.data_dir}/datasets
|
| 9 |
+
data_type: images # [images|videos|features]
|
| 10 |
+
|
| 11 |
+
build_info:
|
| 12 |
+
# Be careful not to append minus sign (-) before split to avoid itemizing
|
| 13 |
+
annotations:
|
| 14 |
+
train:
|
| 15 |
+
url:
|
| 16 |
+
- https://storage.googleapis.com/sfr-vision-language-research/LAVIS/datasets/aokvqa/aokvqa_v1p0_train.json
|
| 17 |
+
storage:
|
| 18 |
+
- /root/autodl-tmp/minigpt/aokvqa/aokvqa_v1p0_train.json
|
| 19 |
+
images:
|
| 20 |
+
storage: /root/autodl-tmp
|
minigpt4/configs/datasets/cc_sbu/align.yaml
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
datasets:
|
| 2 |
+
cc_sbu_align:
|
| 3 |
+
data_type: images
|
| 4 |
+
build_info:
|
| 5 |
+
storage: /root/autodl-tmp/cc_sbu_align
|
minigpt4/configs/datasets/cc_sbu/defaults.yaml
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
datasets:
|
| 2 |
+
cc_sbu:
|
| 3 |
+
data_type: images
|
| 4 |
+
build_info:
|
| 5 |
+
storage: /root/autodl-tmp/cc_sbu/cc_sbu_dataset/{00000..01255}.tar
|
minigpt4/configs/datasets/coco/caption.yaml
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2022, salesforce.com, inc.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
# SPDX-License-Identifier: BSD-3-Clause
|
| 4 |
+
# For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 5 |
+
|
| 6 |
+
datasets:
|
| 7 |
+
coco_caption: # name of the dataset builder
|
| 8 |
+
# dataset_card: dataset_card/coco_caption.md
|
| 9 |
+
# data_dir: ${env.data_dir}/datasets
|
| 10 |
+
data_type: images # [images|videos|features]
|
| 11 |
+
|
| 12 |
+
build_info:
|
| 13 |
+
# Be careful not to append minus sign (-) before split to avoid itemizing
|
| 14 |
+
annotations:
|
| 15 |
+
train:
|
| 16 |
+
url: https://storage.googleapis.com/sfr-vision-language-research/datasets/coco_karpathy_train.json
|
| 17 |
+
md5: aa31ac474cf6250ebb81d18348a07ed8
|
| 18 |
+
storage: /root/autodl-tmp/coco_karpathy_train.json
|
| 19 |
+
images:
|
| 20 |
+
storage: /root/autodl-tmp
|
| 21 |
+
|
minigpt4/configs/datasets/coco/defaults_vqa.yaml
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2022, salesforce.com, inc.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
# SPDX-License-Identifier: BSD-3-Clause
|
| 4 |
+
# For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 5 |
+
|
| 6 |
+
datasets:
|
| 7 |
+
coco_vqa:
|
| 8 |
+
# data_dir: ${env.data_dir}/datasets
|
| 9 |
+
data_type: images # [images|videos|features]
|
| 10 |
+
|
| 11 |
+
build_info:
|
| 12 |
+
|
| 13 |
+
annotations:
|
| 14 |
+
train:
|
| 15 |
+
url:
|
| 16 |
+
- https://storage.googleapis.com/sfr-vision-language-research/LAVIS/datasets/vqav2/vqa_train.json
|
| 17 |
+
- https://storage.googleapis.com/sfr-vision-language-research/LAVIS/datasets/vqav2/vqa_val.json
|
| 18 |
+
storage:
|
| 19 |
+
- /root/autodl-tmp/minigpt/cocovqa/vqa_train.json
|
| 20 |
+
- /root/autodl-tmp/minigpt/cocovqa/vqa_val.json
|
| 21 |
+
images:
|
| 22 |
+
storage: /root/autodl-tmp
|
| 23 |
+
|
| 24 |
+
|
minigpt4/configs/datasets/coco_bbox/invrefcoco.yaml
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
datasets:
|
| 2 |
+
invrefcoco:
|
| 3 |
+
data_type: images
|
| 4 |
+
build_info:
|
| 5 |
+
image_path: /root/autodl-tmp/train
|
| 6 |
+
ann_path: /root/autodl-tmp/minigpt/coco
|
| 7 |
+
dataset: invrefcoco
|
| 8 |
+
splitBy: unc
|
minigpt4/configs/datasets/coco_bbox/invrefcocog.yaml
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
datasets:
|
| 2 |
+
invrefcocog:
|
| 3 |
+
data_type: images
|
| 4 |
+
build_info:
|
| 5 |
+
image_path: /root/autodl-tmp/train
|
| 6 |
+
ann_path: /root/autodl-tmp/minigpt/coco
|
| 7 |
+
dataset: invrefcocog
|
| 8 |
+
splitBy: umd
|
minigpt4/configs/datasets/coco_bbox/invrefcocop.yaml
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
datasets:
|
| 2 |
+
invrefcocop:
|
| 3 |
+
data_type: images
|
| 4 |
+
build_info:
|
| 5 |
+
image_path: /root/autodl-tmp/train
|
| 6 |
+
ann_path: /root/autodl-tmp/minigpt/coco
|
| 7 |
+
dataset: invrefcoco+
|
| 8 |
+
splitBy: unc
|
minigpt4/configs/datasets/coco_bbox/refcoco.yaml
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
datasets:
|
| 2 |
+
refcoco:
|
| 3 |
+
data_type: images
|
| 4 |
+
build_info:
|
| 5 |
+
image_path: /root/autodl-tmp/train
|
| 6 |
+
ann_path: /root/autodl-tmp/minigpt/coco
|
| 7 |
+
dataset: refcoco
|
| 8 |
+
splitBy: unc
|
minigpt4/configs/datasets/coco_bbox/refcocog.yaml
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
datasets:
|
| 2 |
+
refcocog:
|
| 3 |
+
data_type: images
|
| 4 |
+
build_info:
|
| 5 |
+
image_path: /root/autodl-tmp/train
|
| 6 |
+
ann_path: /root/autodl-tmp/minigpt/coco
|
| 7 |
+
dataset: refcocog
|
| 8 |
+
splitBy: umd
|
minigpt4/configs/datasets/coco_bbox/refcocop.yaml
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
datasets:
|
| 2 |
+
refcocop:
|
| 3 |
+
data_type: images
|
| 4 |
+
build_info:
|
| 5 |
+
image_path: /root/autodl-tmp/train
|
| 6 |
+
ann_path: /root/autodl-tmp/minigpt/coco
|
| 7 |
+
dataset: refcoco+
|
| 8 |
+
splitBy: unc
|
minigpt4/configs/datasets/flickr/caption_to_phrase.yaml
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
datasets:
|
| 2 |
+
flickr_CaptionToPhrase:
|
| 3 |
+
data_type: images
|
| 4 |
+
build_info:
|
| 5 |
+
image_path: /root/autodl-tmp/filtered_flickr/filtered_flickr/images
|
| 6 |
+
ann_path: /root/autodl-tmp/filtered_flickr/filtered_flickr/captiontobbox.json
|