Spaces:
Runtime error

Runtime error
Avijit Ghosh
commited on
Commit
•
5fbbee3
1
Parent(s):
d43a899
fixed checkbox logic to allow multiple selections
Browse files- Images/Forgetting1.png +0 -0
- Images/Forgetting2.png +0 -0
- app.py +68 -15
- configs/measuringforgetting.yaml +19 -0
Images/Forgetting1.png
ADDED
|
Images/Forgetting2.png
ADDED

|
app.py
CHANGED
|
@@ -4,13 +4,31 @@ import pandas as pd
|
|
| 4 |
from gradio_modal import Modal
|
| 5 |
import os
|
| 6 |
import yaml
|
| 7 |
-
|
| 8 |
|
| 9 |
folder_path = 'configs'
|
| 10 |
# List to store data from YAML files
|
| 11 |
data_list = []
|
| 12 |
metadata_dict = {}
|
| 13 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 14 |
# Iterate over each file in the folder
|
| 15 |
for filename in os.listdir(folder_path):
|
| 16 |
if filename.endswith('.yaml'):
|
|
@@ -27,11 +45,14 @@ globaldf['Link'] = '<u>'+globaldf['Link']+'</u>'
|
|
| 27 |
|
| 28 |
# Define the desired order of categories
|
| 29 |
modality_order = ["Text", "Image", "Audio", "Video"]
|
| 30 |
-
|
|
|
|
|
|
|
|
|
|
| 31 |
|
| 32 |
# Convert Modality and Level columns to categorical with specified order
|
| 33 |
globaldf['Modality'] = pd.Categorical(globaldf['Modality'], categories=modality_order, ordered=True)
|
| 34 |
-
globaldf['Level'] = pd.Categorical(globaldf['Level'], categories=
|
| 35 |
|
| 36 |
# Sort DataFrame by Modality and Level
|
| 37 |
globaldf.sort_values(by=['Modality', 'Level'], inplace=True)
|
|
@@ -40,8 +61,8 @@ globaldf.sort_values(by=['Modality', 'Level'], inplace=True)
|
|
| 40 |
|
| 41 |
# Path: taxonomy.py
|
| 42 |
|
| 43 |
-
def
|
| 44 |
-
filteredtable = fulltable[fulltable['Modality'].
|
| 45 |
return filteredtable
|
| 46 |
|
| 47 |
def showmodal(evt: gr.SelectData):
|
|
@@ -92,18 +113,18 @@ with gr.Blocks(title = "Social Impact Measurement V2", css=custom_css) as demo:
|
|
| 92 |
gr.Markdown("""
|
| 93 |
#### Technical Base System Evaluations:
|
| 94 |
|
| 95 |
-
Below we list the aspects possible to evaluate in a generative system. Context-absent evaluations only provide narrow insights into the described aspects of the
|
| 96 |
|
| 97 |
The following categories are high-level, non-exhaustive, and present a synthesis of the findings across different modalities. They refer solely to what can be evaluated in a base technical system:
|
| 98 |
|
| 99 |
""")
|
| 100 |
with gr.Tabs(elem_classes="tab-buttons") as tabs1:
|
| 101 |
-
with gr.TabItem("Bias/
|
| 102 |
fulltable = globaldf[globaldf['Group'] == 'BiasEvals']
|
| 103 |
fulltable = fulltable[['Modality','Level', 'Suggested Evaluation', 'What it is evaluating', 'Considerations', 'Link']]
|
| 104 |
|
| 105 |
gr.Markdown("""
|
| 106 |
-
Generative AI systems can perpetuate harmful biases from various sources, including systemic, human, and statistical biases. These biases, also known as "fairness" considerations, can manifest in the final system due to choices made throughout the development process. They include harmful associations and
|
| 107 |
""")
|
| 108 |
with gr.Row():
|
| 109 |
modality_filter = gr.CheckboxGroup(["Text", "Image", "Audio", "Video"],
|
|
@@ -112,7 +133,7 @@ The following categories are high-level, non-exhaustive, and present a synthesis
|
|
| 112 |
show_label=True,
|
| 113 |
# info="Which modality to show."
|
| 114 |
)
|
| 115 |
-
|
| 116 |
value=["Model", "Dataset", "Output", "Taxonomy"],
|
| 117 |
label="Level",
|
| 118 |
show_label=True,
|
|
@@ -121,8 +142,8 @@ The following categories are high-level, non-exhaustive, and present a synthesis
|
|
| 121 |
with gr.Row():
|
| 122 |
table_full = gr.DataFrame(value=fulltable, wrap=True, datatype="markdown", visible=False, interactive=False)
|
| 123 |
table_filtered = gr.DataFrame(value=fulltable, wrap=True, datatype="markdown", visible=True, interactive=False)
|
| 124 |
-
modality_filter.change(
|
| 125 |
-
|
| 126 |
|
| 127 |
|
| 128 |
with Modal(visible=False) as modal:
|
|
@@ -150,7 +171,7 @@ The following categories are high-level, non-exhaustive, and present a synthesis
|
|
| 150 |
show_label=True,
|
| 151 |
# info="Which modality to show."
|
| 152 |
)
|
| 153 |
-
|
| 154 |
value=["Model", "Dataset", "Output", "Taxonomy"],
|
| 155 |
label="Level",
|
| 156 |
show_label=True,
|
|
@@ -159,8 +180,8 @@ The following categories are high-level, non-exhaustive, and present a synthesis
|
|
| 159 |
with gr.Row():
|
| 160 |
table_full = gr.DataFrame(value=fulltable, wrap=True, datatype="markdown", visible=False, interactive=False)
|
| 161 |
table_filtered = gr.DataFrame(value=fulltable, wrap=True, datatype="markdown", visible=True, interactive=False)
|
| 162 |
-
modality_filter.change(
|
| 163 |
-
|
| 164 |
|
| 165 |
|
| 166 |
with Modal(visible=False) as modal:
|
|
@@ -179,8 +200,40 @@ The following categories are high-level, non-exhaustive, and present a synthesis
|
|
| 179 |
# gr.Image()
|
| 180 |
|
| 181 |
with gr.TabItem("Privacy/Data Protection"):
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 182 |
with gr.Row():
|
| 183 |
-
gr.Image
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 184 |
|
| 185 |
# with gr.TabItem("Financial Costs"):
|
| 186 |
# with gr.Row():
|
|
|
|
| 4 |
from gradio_modal import Modal
|
| 5 |
import os
|
| 6 |
import yaml
|
| 7 |
+
import itertools
|
| 8 |
|
| 9 |
folder_path = 'configs'
|
| 10 |
# List to store data from YAML files
|
| 11 |
data_list = []
|
| 12 |
metadata_dict = {}
|
| 13 |
|
| 14 |
+
|
| 15 |
+
def expand_string_list(string_list):
|
| 16 |
+
expanded_list = []
|
| 17 |
+
|
| 18 |
+
# Add individual strings to the expanded list
|
| 19 |
+
expanded_list.extend(string_list)
|
| 20 |
+
|
| 21 |
+
# Generate combinations of different lengths from the input list
|
| 22 |
+
for r in range(2, len(string_list) + 1):
|
| 23 |
+
combinations = itertools.combinations(string_list, r)
|
| 24 |
+
for combination in combinations:
|
| 25 |
+
# Generate permutations of each combination
|
| 26 |
+
permutations = itertools.permutations(combination)
|
| 27 |
+
for permutation in permutations:
|
| 28 |
+
expanded_list.append(' + '.join(permutation))
|
| 29 |
+
|
| 30 |
+
return expanded_list
|
| 31 |
+
|
| 32 |
# Iterate over each file in the folder
|
| 33 |
for filename in os.listdir(folder_path):
|
| 34 |
if filename.endswith('.yaml'):
|
|
|
|
| 45 |
|
| 46 |
# Define the desired order of categories
|
| 47 |
modality_order = ["Text", "Image", "Audio", "Video"]
|
| 48 |
+
level_order = ["Model", "Dataset", "Output", "Taxonomy"]
|
| 49 |
+
|
| 50 |
+
modality_order = expand_string_list(modality_order)
|
| 51 |
+
level_order = expand_string_list(level_order)
|
| 52 |
|
| 53 |
# Convert Modality and Level columns to categorical with specified order
|
| 54 |
globaldf['Modality'] = pd.Categorical(globaldf['Modality'], categories=modality_order, ordered=True)
|
| 55 |
+
globaldf['Level'] = pd.Categorical(globaldf['Level'], categories=level_order, ordered=True)
|
| 56 |
|
| 57 |
# Sort DataFrame by Modality and Level
|
| 58 |
globaldf.sort_values(by=['Modality', 'Level'], inplace=True)
|
|
|
|
| 61 |
|
| 62 |
# Path: taxonomy.py
|
| 63 |
|
| 64 |
+
def filter_modality_level(fulltable, modality_filter, level_filter):
|
| 65 |
+
filteredtable = fulltable[fulltable['Modality'].str.contains('|'.join(modality_filter)) & fulltable['Level'].str.contains('|'.join(level_filter))]
|
| 66 |
return filteredtable
|
| 67 |
|
| 68 |
def showmodal(evt: gr.SelectData):
|
|
|
|
| 113 |
gr.Markdown("""
|
| 114 |
#### Technical Base System Evaluations:
|
| 115 |
|
| 116 |
+
Below we list the aspects possible to evaluate in a generative system. Context-absent evaluations only provide narrow insights into the described aspects of the level of generative AI system. The depth of literature and research on evaluations differ by modality with some modalities having sparse or no relevant literature, but the themes for evaluations can be applied to most systems.
|
| 117 |
|
| 118 |
The following categories are high-level, non-exhaustive, and present a synthesis of the findings across different modalities. They refer solely to what can be evaluated in a base technical system:
|
| 119 |
|
| 120 |
""")
|
| 121 |
with gr.Tabs(elem_classes="tab-buttons") as tabs1:
|
| 122 |
+
with gr.TabItem("Bias/Stereolevels"):
|
| 123 |
fulltable = globaldf[globaldf['Group'] == 'BiasEvals']
|
| 124 |
fulltable = fulltable[['Modality','Level', 'Suggested Evaluation', 'What it is evaluating', 'Considerations', 'Link']]
|
| 125 |
|
| 126 |
gr.Markdown("""
|
| 127 |
+
Generative AI systems can perpetuate harmful biases from various sources, including systemic, human, and statistical biases. These biases, also known as "fairness" considerations, can manifest in the final system due to choices made throughout the development process. They include harmful associations and stereolevels related to protected classes, such as race, gender, and sexuality. Evaluating biases involves assessing correlations, co-occurrences, sentiment, and toxicity across different modalities, both within the model itself and in the outputs of downstream tasks.
|
| 128 |
""")
|
| 129 |
with gr.Row():
|
| 130 |
modality_filter = gr.CheckboxGroup(["Text", "Image", "Audio", "Video"],
|
|
|
|
| 133 |
show_label=True,
|
| 134 |
# info="Which modality to show."
|
| 135 |
)
|
| 136 |
+
level_filter = gr.CheckboxGroup(["Model", "Dataset", "Output", "Taxonomy"],
|
| 137 |
value=["Model", "Dataset", "Output", "Taxonomy"],
|
| 138 |
label="Level",
|
| 139 |
show_label=True,
|
|
|
|
| 142 |
with gr.Row():
|
| 143 |
table_full = gr.DataFrame(value=fulltable, wrap=True, datatype="markdown", visible=False, interactive=False)
|
| 144 |
table_filtered = gr.DataFrame(value=fulltable, wrap=True, datatype="markdown", visible=True, interactive=False)
|
| 145 |
+
modality_filter.change(filter_modality_level, inputs=[table_full, modality_filter, level_filter], outputs=table_filtered)
|
| 146 |
+
level_filter.change(filter_modality_level, inputs=[table_full, modality_filter, level_filter], outputs=table_filtered)
|
| 147 |
|
| 148 |
|
| 149 |
with Modal(visible=False) as modal:
|
|
|
|
| 171 |
show_label=True,
|
| 172 |
# info="Which modality to show."
|
| 173 |
)
|
| 174 |
+
level_filter = gr.CheckboxGroup(["Model", "Dataset", "Output", "Taxonomy"],
|
| 175 |
value=["Model", "Dataset", "Output", "Taxonomy"],
|
| 176 |
label="Level",
|
| 177 |
show_label=True,
|
|
|
|
| 180 |
with gr.Row():
|
| 181 |
table_full = gr.DataFrame(value=fulltable, wrap=True, datatype="markdown", visible=False, interactive=False)
|
| 182 |
table_filtered = gr.DataFrame(value=fulltable, wrap=True, datatype="markdown", visible=True, interactive=False)
|
| 183 |
+
modality_filter.change(filter_modality_level, inputs=[table_full, modality_filter, level_filter], outputs=table_filtered)
|
| 184 |
+
level_filter.change(filter_modality_level, inputs=[table_full, modality_filter, level_filter], outputs=table_filtered)
|
| 185 |
|
| 186 |
|
| 187 |
with Modal(visible=False) as modal:
|
|
|
|
| 200 |
# gr.Image()
|
| 201 |
|
| 202 |
with gr.TabItem("Privacy/Data Protection"):
|
| 203 |
+
fulltable = globaldf[globaldf['Group'] == 'PrivacyEvals']
|
| 204 |
+
fulltable = fulltable[['Modality','Level', 'Suggested Evaluation', 'What it is evaluating', 'Considerations', 'Link']]
|
| 205 |
+
|
| 206 |
+
gr.Markdown("""Cultural values are specific to groups and sensitive content is normative. Sensitive topics also vary by culture and can include hate speech. What is considered a sensitive topic, such as egregious violence or adult sexual content, can vary widely by viewpoint. Due to norms differing by culture, region, and language, there is no standard for what constitutes sensitive content.
|
| 207 |
+
Distinct cultural values present a challenge for deploying models into a global sphere, as what may be appropriate in one culture may be unsafe in others. Generative AI systems cannot be neutral or objective, nor can they encompass truly universal values. There is no “view from nowhere”; in quantifying anything, a particular frame of reference is imposed.
|
| 208 |
+
""")
|
| 209 |
with gr.Row():
|
| 210 |
+
modality_filter = gr.CheckboxGroup(["Text", "Image", "Audio", "Video"],
|
| 211 |
+
value=["Text", "Image", "Audio", "Video"],
|
| 212 |
+
label="Modality",
|
| 213 |
+
show_label=True,
|
| 214 |
+
# info="Which modality to show."
|
| 215 |
+
)
|
| 216 |
+
level_filter = gr.CheckboxGroup(["Model", "Dataset", "Output", "Taxonomy"],
|
| 217 |
+
value=["Model", "Dataset", "Output", "Taxonomy"],
|
| 218 |
+
label="Level",
|
| 219 |
+
show_label=True,
|
| 220 |
+
# info="Which modality to show."
|
| 221 |
+
)
|
| 222 |
+
with gr.Row():
|
| 223 |
+
table_full = gr.DataFrame(value=fulltable, wrap=True, datatype="markdown", visible=False, interactive=False)
|
| 224 |
+
table_filtered = gr.DataFrame(value=fulltable, wrap=True, datatype="markdown", visible=True, interactive=False)
|
| 225 |
+
modality_filter.change(filter_modality_level, inputs=[table_full, modality_filter, level_filter], outputs=table_filtered)
|
| 226 |
+
level_filter.change(filter_modality_level, inputs=[table_full, modality_filter, level_filter], outputs=table_filtered)
|
| 227 |
+
|
| 228 |
+
|
| 229 |
+
with Modal(visible=False) as modal:
|
| 230 |
+
titlemd = gr.Markdown(visible=False)
|
| 231 |
+
authormd = gr.Markdown(visible=False)
|
| 232 |
+
tagsmd = gr.Markdown(visible=False)
|
| 233 |
+
abstractmd = gr.Markdown(visible=False)
|
| 234 |
+
datasetmd = gr.Markdown(visible=False)
|
| 235 |
+
gallery = gr.Gallery(visible=False)
|
| 236 |
+
table_filtered.select(showmodal, None, [modal, titlemd, authormd, tagsmd, abstractmd, datasetmd, gallery])
|
| 237 |
|
| 238 |
# with gr.TabItem("Financial Costs"):
|
| 239 |
# with gr.Row():
|
configs/measuringforgetting.yaml
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
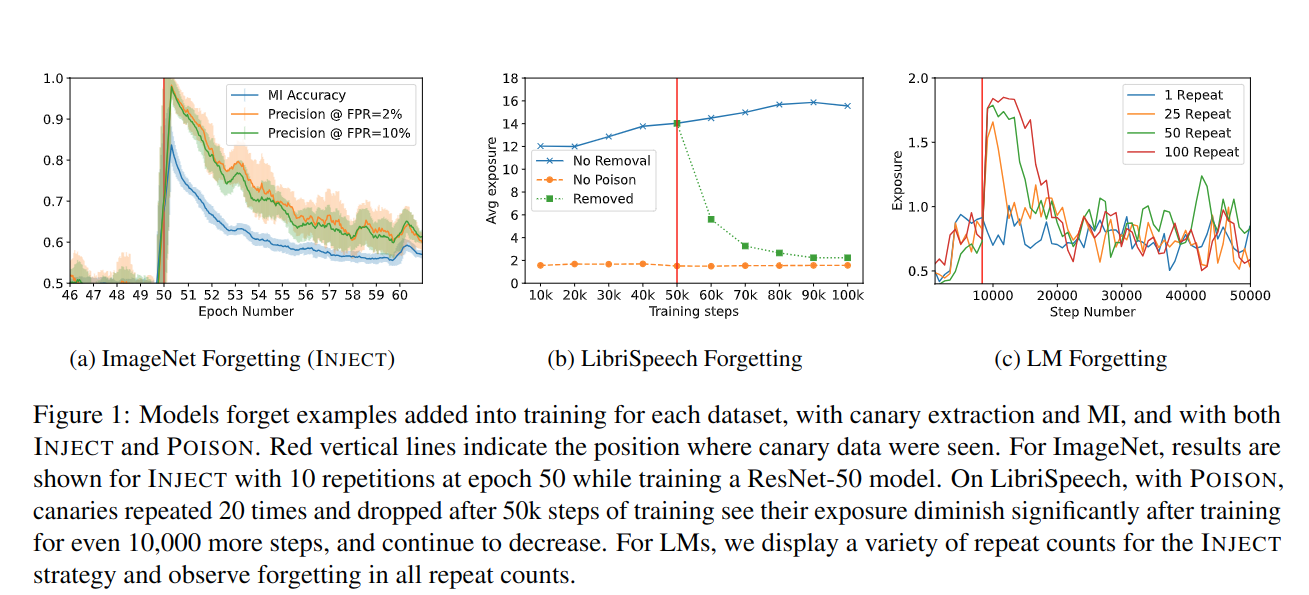
Abstract: "Machine learning models exhibit two seemingly contradictory phenomena: training data memorization, and various forms of forgetting. In memorization, models overfit specific training examples and become susceptible to privacy attacks. In forgetting, examples which appeared early in training are forgotten by the end. In this work, we connect these phenomena. We propose a technique to measure to what extent models \"forget\" the specifics of training examples, becoming less susceptible to privacy attacks on examples they have not seen recently. We show that, while non-convex models can memorize data forever in the worst-case, standard image, speech, and language models empirically do forget examples over time. We identify nondeterminism as a potential explanation, showing that deterministically trained models do not forget. Our results suggest that examples seen early when training with extremely large datasets - for instance those examples used to pre-train a model - may observe privacy benefits at the expense of examples seen later."
|
| 2 |
+
Applicable Models:
|
| 3 |
+
- ResNet (Image)
|
| 4 |
+
- Conformer (Audio)
|
| 5 |
+
- T5 (Text)
|
| 6 |
+
Authors: Matthew Jagielski, Om Thakkar, Florian Tramèr, Daphne Ippolito, Katherine Lee, Nicholas Carlini, Eric Wallace, Shuang Song, Abhradeep Thakurta, Nicolas Papernot, Chiyuan Zhang
|
| 7 |
+
Considerations: .nan
|
| 8 |
+
Datasets: .nan
|
| 9 |
+
Group: PrivacyEvals
|
| 10 |
+
Hashtags: .nan
|
| 11 |
+
Link: 'Measuring Forgetting of Memorized Training Examples'
|
| 12 |
+
Modality: Text + Image + Audio
|
| 13 |
+
Screenshots:
|
| 14 |
+
- Images/Forgetting1.png
|
| 15 |
+
- Images/Forgetting2.png
|
| 16 |
+
Suggested Evaluation: Measuring forgetting of training examples
|
| 17 |
+
Level: Model
|
| 18 |
+
URL: https://arxiv.org/pdf/2207.00099.pdf
|
| 19 |
+
What it is evaluating: Measure whether models forget training examples over time, over different types of models (image, audio, text) and how order of training affects privacy attacks
|