+
+
+## Starting the web UI
+
+ conda activate textgen
+ cd text-generation-webui
+ python server.py
+
+Then browse to
+
+`http://localhost:7860/?__theme=dark`
+
+Optionally, you can use the following command-line flags:
+
+#### Basic settings
+
+| Flag | Description |
+|--------------------------------------------|-------------|
+| `-h`, `--help` | Show this help message and exit. |
+| `--notebook` | Launch the web UI in notebook mode, where the output is written to the same text box as the input. |
+| `--chat` | Launch the web UI in chat mode. |
+| `--multi-user` | Multi-user mode. Chat histories are not saved or automatically loaded. WARNING: this is highly experimental. |
+| `--character CHARACTER` | The name of the character to load in chat mode by default. |
+| `--model MODEL` | Name of the model to load by default. |
+| `--lora LORA [LORA ...]` | The list of LoRAs to load. If you want to load more than one LoRA, write the names separated by spaces. |
+| `--model-dir MODEL_DIR` | Path to directory with all the models. |
+| `--lora-dir LORA_DIR` | Path to directory with all the loras. |
+| `--model-menu` | Show a model menu in the terminal when the web UI is first launched. |
+| `--no-stream` | Don't stream the text output in real time. |
+| `--settings SETTINGS_FILE` | Load the default interface settings from this yaml file. See `settings-template.yaml` for an example. If you create a file called `settings.yaml`, this file will be loaded by default without the need to use the `--settings` flag. |
+| `--extensions EXTENSIONS [EXTENSIONS ...]` | The list of extensions to load. If you want to load more than one extension, write the names separated by spaces. |
+| `--verbose` | Print the prompts to the terminal. |
+
+#### Model loader
+
+| Flag | Description |
+|--------------------------------------------|-------------|
+| `--loader LOADER` | Choose the model loader manually, otherwise, it will get autodetected. Valid options: transformers, autogptq, gptq-for-llama, exllama, exllama_hf, llamacpp, rwkv |
+
+#### Accelerate/transformers
+
+| Flag | Description |
+|---------------------------------------------|-------------|
+| `--cpu` | Use the CPU to generate text. Warning: Training on CPU is extremely slow.|
+| `--auto-devices` | Automatically split the model across the available GPU(s) and CPU. |
+| `--gpu-memory GPU_MEMORY [GPU_MEMORY ...]` | Maximum GPU memory in GiB to be allocated per GPU. Example: `--gpu-memory 10` for a single GPU, `--gpu-memory 10 5` for two GPUs. You can also set values in MiB like `--gpu-memory 3500MiB`. |
+| `--cpu-memory CPU_MEMORY` | Maximum CPU memory in GiB to allocate for offloaded weights. Same as above.|
+| `--disk` | If the model is too large for your GPU(s) and CPU combined, send the remaining layers to the disk. |
+| `--disk-cache-dir DISK_CACHE_DIR` | Directory to save the disk cache to. Defaults to `cache/`. |
+| `--load-in-8bit` | Load the model with 8-bit precision (using bitsandbytes).|
+| `--bf16` | Load the model with bfloat16 precision. Requires NVIDIA Ampere GPU. |
+| `--no-cache` | Set `use_cache` to False while generating text. This reduces the VRAM usage a bit with a performance cost. |
+| `--xformers` | Use xformer's memory efficient attention. This should increase your tokens/s. |
+| `--sdp-attention` | Use torch 2.0's sdp attention. |
+| `--trust-remote-code` | Set trust_remote_code=True while loading a model. Necessary for ChatGLM and Falcon. |
+
+#### Accelerate 4-bit
+
+⚠️ Requires minimum compute of 7.0 on Windows at the moment.
+
+| Flag | Description |
+|---------------------------------------------|-------------|
+| `--load-in-4bit` | Load the model with 4-bit precision (using bitsandbytes). |
+| `--compute_dtype COMPUTE_DTYPE` | compute dtype for 4-bit. Valid options: bfloat16, float16, float32. |
+| `--quant_type QUANT_TYPE` | quant_type for 4-bit. Valid options: nf4, fp4. |
+| `--use_double_quant` | use_double_quant for 4-bit. |
+
+#### llama.cpp
+
+| Flag | Description |
+|-------------|-------------|
+| `--threads` | Number of threads to use. |
+| `--n_batch` | Maximum number of prompt tokens to batch together when calling llama_eval. |
+| `--no-mmap` | Prevent mmap from being used. |
+| `--mlock` | Force the system to keep the model in RAM. |
+| `--cache-capacity CACHE_CAPACITY` | Maximum cache capacity. Examples: 2000MiB, 2GiB. When provided without units, bytes will be assumed. |
+| `--n-gpu-layers N_GPU_LAYERS` | Number of layers to offload to the GPU. Only works if llama-cpp-python was compiled with BLAS. Set this to 1000000000 to offload all layers to the GPU. |
+| `--n_ctx N_CTX` | Size of the prompt context. |
+| `--llama_cpp_seed SEED` | Seed for llama-cpp models. Default 0 (random). |
+| `--n_gqa N_GQA` | grouped-query attention. Must be 8 for llama-2 70b. |
+| `--rms_norm_eps RMS_NORM_EPS` | 5e-6 is a good value for llama-2 models. |
+| `--cpu` | Use the CPU version of llama-cpp-python instead of the GPU-accelerated version. |
+
+#### AutoGPTQ
+
+| Flag | Description |
+|------------------|-------------|
+| `--triton` | Use triton. |
+| `--no_inject_fused_attention` | Disable the use of fused attention, which will use less VRAM at the cost of slower inference. |
+| `--no_inject_fused_mlp` | Triton mode only: disable the use of fused MLP, which will use less VRAM at the cost of slower inference. |
+| `--no_use_cuda_fp16` | This can make models faster on some systems. |
+| `--desc_act` | For models that don't have a quantize_config.json, this parameter is used to define whether to set desc_act or not in BaseQuantizeConfig. |
+
+#### ExLlama
+
+| Flag | Description |
+|------------------|-------------|
+|`--gpu-split` | Comma-separated list of VRAM (in GB) to use per GPU device for model layers, e.g. `20,7,7` |
+|`--max_seq_len MAX_SEQ_LEN` | Maximum sequence length. |
+
+#### GPTQ-for-LLaMa
+
+| Flag | Description |
+|---------------------------|-------------|
+| `--wbits WBITS` | Load a pre-quantized model with specified precision in bits. 2, 3, 4 and 8 are supported. |
+| `--model_type MODEL_TYPE` | Model type of pre-quantized model. Currently LLaMA, OPT, and GPT-J are supported. |
+| `--groupsize GROUPSIZE` | Group size. |
+| `--pre_layer PRE_LAYER [PRE_LAYER ...]` | The number of layers to allocate to the GPU. Setting this parameter enables CPU offloading for 4-bit models. For multi-gpu, write the numbers separated by spaces, eg `--pre_layer 30 60`. |
+| `--checkpoint CHECKPOINT` | The path to the quantized checkpoint file. If not specified, it will be automatically detected. |
+| `--monkey-patch` | Apply the monkey patch for using LoRAs with quantized models.
+
+#### DeepSpeed
+
+| Flag | Description |
+|---------------------------------------|-------------|
+| `--deepspeed` | Enable the use of DeepSpeed ZeRO-3 for inference via the Transformers integration. |
+| `--nvme-offload-dir NVME_OFFLOAD_DIR` | DeepSpeed: Directory to use for ZeRO-3 NVME offloading. |
+| `--local_rank LOCAL_RANK` | DeepSpeed: Optional argument for distributed setups. |
+
+#### RWKV
+
+| Flag | Description |
+|---------------------------------|-------------|
+| `--rwkv-strategy RWKV_STRATEGY` | RWKV: The strategy to use while loading the model. Examples: "cpu fp32", "cuda fp16", "cuda fp16i8". |
+| `--rwkv-cuda-on` | RWKV: Compile the CUDA kernel for better performance. |
+
+#### RoPE (for llama.cpp, ExLlama, and transformers)
+
+| Flag | Description |
+|------------------|-------------|
+|`--alpha_value ALPHA_VALUE` | Positional embeddings alpha factor for NTK RoPE scaling. Use either this or compress_pos_emb, not both. |
+|`--compress_pos_emb COMPRESS_POS_EMB` | Positional embeddings compression factor. Should typically be set to max_seq_len / 2048. |
+
+#### Gradio
+
+| Flag | Description |
+|---------------------------------------|-------------|
+| `--listen` | Make the web UI reachable from your local network. |
+| `--listen-host LISTEN_HOST` | The hostname that the server will use. |
+| `--listen-port LISTEN_PORT` | The listening port that the server will use. |
+| `--share` | Create a public URL. This is useful for running the web UI on Google Colab or similar. |
+| `--auto-launch` | Open the web UI in the default browser upon launch. |
+| `--gradio-auth USER:PWD` | set gradio authentication like "username:password"; or comma-delimit multiple like "u1:p1,u2:p2,u3:p3" |
+| `--gradio-auth-path GRADIO_AUTH_PATH` | Set the gradio authentication file path. The file should contain one or more user:password pairs in this format: "u1:p1,u2:p2,u3:p3" |
+| `--ssl-keyfile SSL_KEYFILE` | The path to the SSL certificate key file. |
+| `--ssl-certfile SSL_CERTFILE` | The path to the SSL certificate cert file. |
+
+#### API
+
+| Flag | Description |
+|---------------------------------------|-------------|
+| `--api` | Enable the API extension. |
+| `--public-api` | Create a public URL for the API using Cloudfare. |
+| `--public-api-id PUBLIC_API_ID` | Tunnel ID for named Cloudflare Tunnel. Use together with public-api option. |
+| `--api-blocking-port BLOCKING_PORT` | The listening port for the blocking API. |
+| `--api-streaming-port STREAMING_PORT` | The listening port for the streaming API. |
+
+#### Multimodal
+
+| Flag | Description |
+|---------------------------------------|-------------|
+| `--multimodal-pipeline PIPELINE` | The multimodal pipeline to use. Examples: `llava-7b`, `llava-13b`. |
+
+## Presets
+
+Inference settings presets can be created under `presets/` as yaml files. These files are detected automatically at startup.
+
+The presets that are included by default are the result of a contest that received 7215 votes. More details can be found [here](https://github.com/oobabooga/oobabooga.github.io/blob/main/arena/results.md).
+
+## Contributing
+
+If you would like to contribute to the project, check out the [Contributing guidelines](https://github.com/oobabooga/text-generation-webui/wiki/Contributing-guidelines).
+
+## Community
+
+* Subreddit: https://www.reddit.com/r/oobaboogazz/
+* Discord: https://discord.gg/jwZCF2dPQN
diff --git a/api-examples/api-example-chat-stream.py b/api-examples/api-example-chat-stream.py
new file mode 100644
index 0000000000000000000000000000000000000000..055900bd4ad93534dda2ce8506619433cacee17e
--- /dev/null
+++ b/api-examples/api-example-chat-stream.py
@@ -0,0 +1,110 @@
+import asyncio
+import json
+import sys
+
+try:
+ import websockets
+except ImportError:
+ print("Websockets package not found. Make sure it's installed.")
+
+# For local streaming, the websockets are hosted without ssl - ws://
+HOST = 'localhost:5005'
+URI = f'ws://{HOST}/api/v1/chat-stream'
+
+# For reverse-proxied streaming, the remote will likely host with ssl - wss://
+# URI = 'wss://your-uri-here.trycloudflare.com/api/v1/stream'
+
+
+async def run(user_input, history):
+ # Note: the selected defaults change from time to time.
+ request = {
+ 'user_input': user_input,
+ 'max_new_tokens': 250,
+ 'auto_max_new_tokens': False,
+ 'history': history,
+ 'mode': 'instruct', # Valid options: 'chat', 'chat-instruct', 'instruct'
+ 'character': 'Example',
+ 'instruction_template': 'Vicuna-v1.1', # Will get autodetected if unset
+ 'your_name': 'You',
+ # 'name1': 'name of user', # Optional
+ # 'name2': 'name of character', # Optional
+ # 'context': 'character context', # Optional
+ # 'greeting': 'greeting', # Optional
+ # 'name1_instruct': 'You', # Optional
+ # 'name2_instruct': 'Assistant', # Optional
+ # 'context_instruct': 'context_instruct', # Optional
+ # 'turn_template': 'turn_template', # Optional
+ 'regenerate': False,
+ '_continue': False,
+ 'stop_at_newline': False,
+ 'chat_generation_attempts': 1,
+ 'chat_instruct_command': 'Continue the chat dialogue below. Write a single reply for the character "<|character|>".\n\n<|prompt|>',
+
+ # Generation params. If 'preset' is set to different than 'None', the values
+ # in presets/preset-name.yaml are used instead of the individual numbers.
+ 'preset': 'None',
+ 'do_sample': True,
+ 'temperature': 0.7,
+ 'top_p': 0.1,
+ 'typical_p': 1,
+ 'epsilon_cutoff': 0, # In units of 1e-4
+ 'eta_cutoff': 0, # In units of 1e-4
+ 'tfs': 1,
+ 'top_a': 0,
+ 'repetition_penalty': 1.18,
+ 'repetition_penalty_range': 0,
+ 'top_k': 40,
+ 'min_length': 0,
+ 'no_repeat_ngram_size': 0,
+ 'num_beams': 1,
+ 'penalty_alpha': 0,
+ 'length_penalty': 1,
+ 'early_stopping': False,
+ 'mirostat_mode': 0,
+ 'mirostat_tau': 5,
+ 'mirostat_eta': 0.1,
+ 'guidance_scale': 1,
+ 'negative_prompt': '',
+
+ 'seed': -1,
+ 'add_bos_token': True,
+ 'truncation_length': 2048,
+ 'ban_eos_token': False,
+ 'skip_special_tokens': True,
+ 'stopping_strings': []
+ }
+
+ async with websockets.connect(URI, ping_interval=None) as websocket:
+ await websocket.send(json.dumps(request))
+
+ while True:
+ incoming_data = await websocket.recv()
+ incoming_data = json.loads(incoming_data)
+
+ match incoming_data['event']:
+ case 'text_stream':
+ yield incoming_data['history']
+ case 'stream_end':
+ return
+
+
+async def print_response_stream(user_input, history):
+ cur_len = 0
+ async for new_history in run(user_input, history):
+ cur_message = new_history['visible'][-1][1][cur_len:]
+ cur_len += len(cur_message)
+ print(cur_message, end='')
+ sys.stdout.flush() # If we don't flush, we won't see tokens in realtime.
+
+
+if __name__ == '__main__':
+ user_input = "Please give me a step-by-step guide on how to plant a tree in my backyard."
+
+ # Basic example
+ history = {'internal': [], 'visible': []}
+
+ # "Continue" example. Make sure to set '_continue' to True above
+ # arr = [user_input, 'Surely, here is']
+ # history = {'internal': [arr], 'visible': [arr]}
+
+ asyncio.run(print_response_stream(user_input, history))
diff --git a/api-examples/api-example-chat.py b/api-examples/api-example-chat.py
new file mode 100644
index 0000000000000000000000000000000000000000..c3d0c538624a719fc58c5c22cc261fb521d8b818
--- /dev/null
+++ b/api-examples/api-example-chat.py
@@ -0,0 +1,90 @@
+import json
+
+import requests
+
+# For local streaming, the websockets are hosted without ssl - http://
+HOST = 'localhost:5000'
+URI = f'http://{HOST}/api/v1/chat'
+
+# For reverse-proxied streaming, the remote will likely host with ssl - https://
+# URI = 'https://your-uri-here.trycloudflare.com/api/v1/chat'
+
+
+def run(user_input, history):
+ request = {
+ 'user_input': user_input,
+ 'max_new_tokens': 250,
+ 'auto_max_new_tokens': False,
+ 'history': history,
+ 'mode': 'instruct', # Valid options: 'chat', 'chat-instruct', 'instruct'
+ 'character': 'Example',
+ 'instruction_template': 'Vicuna-v1.1', # Will get autodetected if unset
+ 'your_name': 'You',
+ # 'name1': 'name of user', # Optional
+ # 'name2': 'name of character', # Optional
+ # 'context': 'character context', # Optional
+ # 'greeting': 'greeting', # Optional
+ # 'name1_instruct': 'You', # Optional
+ # 'name2_instruct': 'Assistant', # Optional
+ # 'context_instruct': 'context_instruct', # Optional
+ # 'turn_template': 'turn_template', # Optional
+ 'regenerate': False,
+ '_continue': False,
+ 'stop_at_newline': False,
+ 'chat_generation_attempts': 1,
+ 'chat_instruct_command': 'Continue the chat dialogue below. Write a single reply for the character "<|character|>".\n\n<|prompt|>',
+
+ # Generation params. If 'preset' is set to different than 'None', the values
+ # in presets/preset-name.yaml are used instead of the individual numbers.
+ 'preset': 'None',
+ 'do_sample': True,
+ 'temperature': 0.7,
+ 'top_p': 0.1,
+ 'typical_p': 1,
+ 'epsilon_cutoff': 0, # In units of 1e-4
+ 'eta_cutoff': 0, # In units of 1e-4
+ 'tfs': 1,
+ 'top_a': 0,
+ 'repetition_penalty': 1.18,
+ 'repetition_penalty_range': 0,
+ 'top_k': 40,
+ 'min_length': 0,
+ 'no_repeat_ngram_size': 0,
+ 'num_beams': 1,
+ 'penalty_alpha': 0,
+ 'length_penalty': 1,
+ 'early_stopping': False,
+ 'mirostat_mode': 0,
+ 'mirostat_tau': 5,
+ 'mirostat_eta': 0.1,
+ 'guidance_scale': 1,
+ 'negative_prompt': '',
+
+ 'seed': -1,
+ 'add_bos_token': True,
+ 'truncation_length': 2048,
+ 'ban_eos_token': False,
+ 'skip_special_tokens': True,
+ 'stopping_strings': []
+ }
+
+ response = requests.post(URI, json=request)
+
+ if response.status_code == 200:
+ result = response.json()['results'][0]['history']
+ print(json.dumps(result, indent=4))
+ print()
+ print(result['visible'][-1][1])
+
+
+if __name__ == '__main__':
+ user_input = "Please give me a step-by-step guide on how to plant a tree in my backyard."
+
+ # Basic example
+ history = {'internal': [], 'visible': []}
+
+ # "Continue" example. Make sure to set '_continue' to True above
+ # arr = [user_input, 'Surely, here is']
+ # history = {'internal': [arr], 'visible': [arr]}
+
+ run(user_input, history)
diff --git a/api-examples/api-example-model.py b/api-examples/api-example-model.py
new file mode 100644
index 0000000000000000000000000000000000000000..9a61ccb1cf99fdcd5c1cd405f707cd83a09b0968
--- /dev/null
+++ b/api-examples/api-example-model.py
@@ -0,0 +1,176 @@
+#!/usr/bin/env python3
+
+import requests
+
+HOST = '0.0.0.0:5000'
+
+
+def generate(prompt, tokens=200):
+ request = {'prompt': prompt, 'max_new_tokens': tokens}
+ response = requests.post(f'http://{HOST}/api/v1/generate', json=request)
+
+ if response.status_code == 200:
+ return response.json()['results'][0]['text']
+
+
+def model_api(request):
+ response = requests.post(f'http://{HOST}/api/v1/model', json=request)
+ return response.json()
+
+
+# print some common settings
+def print_basic_model_info(response):
+ basic_settings = ['truncation_length', 'instruction_template']
+ print("Model: ", response['result']['model_name'])
+ print("Lora(s): ", response['result']['lora_names'])
+ for setting in basic_settings:
+ print(setting, "=", response['result']['shared.settings'][setting])
+
+
+# model info
+def model_info():
+ response = model_api({'action': 'info'})
+ print_basic_model_info(response)
+
+
+# simple loader
+def model_load(model_name):
+ return model_api({'action': 'load', 'model_name': model_name})
+
+
+# complex loader
+def complex_model_load(model):
+
+ def guess_groupsize(model_name):
+ if '1024g' in model_name:
+ return 1024
+ elif '128g' in model_name:
+ return 128
+ elif '32g' in model_name:
+ return 32
+ else:
+ return -1
+
+ req = {
+ 'action': 'load',
+ 'model_name': model,
+ 'args': {
+ 'loader': 'AutoGPTQ',
+
+ 'bf16': False,
+ 'load_in_8bit': False,
+ 'groupsize': 0,
+ 'wbits': 0,
+
+ # llama.cpp
+ 'threads': 0,
+ 'n_batch': 512,
+ 'no_mmap': False,
+ 'mlock': False,
+ 'cache_capacity': None,
+ 'n_gpu_layers': 0,
+ 'n_ctx': 2048,
+
+ # RWKV
+ 'rwkv_strategy': None,
+ 'rwkv_cuda_on': False,
+
+ # b&b 4-bit
+ # 'load_in_4bit': False,
+ # 'compute_dtype': 'float16',
+ # 'quant_type': 'nf4',
+ # 'use_double_quant': False,
+
+ # "cpu": false,
+ # "auto_devices": false,
+ # "gpu_memory": null,
+ # "cpu_memory": null,
+ # "disk": false,
+ # "disk_cache_dir": "cache",
+ },
+ }
+
+ model = model.lower()
+
+ if '4bit' in model or 'gptq' in model or 'int4' in model:
+ req['args']['wbits'] = 4
+ req['args']['groupsize'] = guess_groupsize(model)
+ elif '3bit' in model:
+ req['args']['wbits'] = 3
+ req['args']['groupsize'] = guess_groupsize(model)
+ else:
+ req['args']['gptq_for_llama'] = False
+
+ if '8bit' in model:
+ req['args']['load_in_8bit'] = True
+ elif '-hf' in model or 'fp16' in model:
+ if '7b' in model:
+ req['args']['bf16'] = True # for 24GB
+ elif '13b' in model:
+ req['args']['load_in_8bit'] = True # for 24GB
+ elif 'ggml' in model:
+ # req['args']['threads'] = 16
+ if '7b' in model:
+ req['args']['n_gpu_layers'] = 100
+ elif '13b' in model:
+ req['args']['n_gpu_layers'] = 100
+ elif '30b' in model or '33b' in model:
+ req['args']['n_gpu_layers'] = 59 # 24GB
+ elif '65b' in model:
+ req['args']['n_gpu_layers'] = 42 # 24GB
+ elif 'rwkv' in model:
+ req['args']['rwkv_cuda_on'] = True
+ if '14b' in model:
+ req['args']['rwkv_strategy'] = 'cuda f16i8' # 24GB
+ else:
+ req['args']['rwkv_strategy'] = 'cuda f16' # 24GB
+
+ return model_api(req)
+
+
+if __name__ == '__main__':
+ for model in model_api({'action': 'list'})['result']:
+ try:
+ resp = complex_model_load(model)
+
+ if 'error' in resp:
+ print(f"❌ {model} FAIL Error: {resp['error']['message']}")
+ continue
+ else:
+ print_basic_model_info(resp)
+
+ ans = generate("0,1,1,2,3,5,8,13,", tokens=2)
+
+ if '21' in ans:
+ print(f"✅ {model} PASS ({ans})")
+ else:
+ print(f"❌ {model} FAIL ({ans})")
+
+ except Exception as e:
+ print(f"❌ {model} FAIL Exception: {repr(e)}")
+
+
+# 0,1,1,2,3,5,8,13, is the fibonacci sequence, the next number is 21.
+# Some results below.
+""" $ ./model-api-example.py
+Model: 4bit_gpt4-x-alpaca-13b-native-4bit-128g-cuda
+Lora(s): []
+truncation_length = 2048
+instruction_template = Alpaca
+✅ 4bit_gpt4-x-alpaca-13b-native-4bit-128g-cuda PASS (21)
+Model: 4bit_WizardLM-13B-Uncensored-4bit-128g
+Lora(s): []
+truncation_length = 2048
+instruction_template = WizardLM
+✅ 4bit_WizardLM-13B-Uncensored-4bit-128g PASS (21)
+Model: Aeala_VicUnlocked-alpaca-30b-4bit
+Lora(s): []
+truncation_length = 2048
+instruction_template = Alpaca
+✅ Aeala_VicUnlocked-alpaca-30b-4bit PASS (21)
+Model: alpaca-30b-4bit
+Lora(s): []
+truncation_length = 2048
+instruction_template = Alpaca
+✅ alpaca-30b-4bit PASS (21)
+"""
diff --git a/api-examples/api-example-stream.py b/api-examples/api-example-stream.py
new file mode 100644
index 0000000000000000000000000000000000000000..bf5eabace9200c1be23b0959075643d83172f16e
--- /dev/null
+++ b/api-examples/api-example-stream.py
@@ -0,0 +1,83 @@
+import asyncio
+import json
+import sys
+
+try:
+ import websockets
+except ImportError:
+ print("Websockets package not found. Make sure it's installed.")
+
+# For local streaming, the websockets are hosted without ssl - ws://
+HOST = 'localhost:5005'
+URI = f'ws://{HOST}/api/v1/stream'
+
+# For reverse-proxied streaming, the remote will likely host with ssl - wss://
+# URI = 'wss://your-uri-here.trycloudflare.com/api/v1/stream'
+
+
+async def run(context):
+ # Note: the selected defaults change from time to time.
+ request = {
+ 'prompt': context,
+ 'max_new_tokens': 250,
+ 'auto_max_new_tokens': False,
+
+ # Generation params. If 'preset' is set to different than 'None', the values
+ # in presets/preset-name.yaml are used instead of the individual numbers.
+ 'preset': 'None',
+ 'do_sample': True,
+ 'temperature': 0.7,
+ 'top_p': 0.1,
+ 'typical_p': 1,
+ 'epsilon_cutoff': 0, # In units of 1e-4
+ 'eta_cutoff': 0, # In units of 1e-4
+ 'tfs': 1,
+ 'top_a': 0,
+ 'repetition_penalty': 1.18,
+ 'repetition_penalty_range': 0,
+ 'top_k': 40,
+ 'min_length': 0,
+ 'no_repeat_ngram_size': 0,
+ 'num_beams': 1,
+ 'penalty_alpha': 0,
+ 'length_penalty': 1,
+ 'early_stopping': False,
+ 'mirostat_mode': 0,
+ 'mirostat_tau': 5,
+ 'mirostat_eta': 0.1,
+ 'guidance_scale': 1,
+ 'negative_prompt': '',
+
+ 'seed': -1,
+ 'add_bos_token': True,
+ 'truncation_length': 2048,
+ 'ban_eos_token': False,
+ 'skip_special_tokens': True,
+ 'stopping_strings': []
+ }
+
+ async with websockets.connect(URI, ping_interval=None) as websocket:
+ await websocket.send(json.dumps(request))
+
+ yield context # Remove this if you just want to see the reply
+
+ while True:
+ incoming_data = await websocket.recv()
+ incoming_data = json.loads(incoming_data)
+
+ match incoming_data['event']:
+ case 'text_stream':
+ yield incoming_data['text']
+ case 'stream_end':
+ return
+
+
+async def print_response_stream(prompt):
+ async for response in run(prompt):
+ print(response, end='')
+ sys.stdout.flush() # If we don't flush, we won't see tokens in realtime.
+
+
+if __name__ == '__main__':
+ prompt = "In order to make homemade bread, follow these steps:\n1)"
+ asyncio.run(print_response_stream(prompt))
diff --git a/api-examples/api-example.py b/api-examples/api-example.py
new file mode 100644
index 0000000000000000000000000000000000000000..160298079f9dc29e79a5496ba78e45cd199d5648
--- /dev/null
+++ b/api-examples/api-example.py
@@ -0,0 +1,60 @@
+import requests
+
+# For local streaming, the websockets are hosted without ssl - http://
+HOST = 'localhost:5000'
+URI = f'http://{HOST}/api/v1/generate'
+
+# For reverse-proxied streaming, the remote will likely host with ssl - https://
+# URI = 'https://your-uri-here.trycloudflare.com/api/v1/generate'
+
+
+def run(prompt):
+ request = {
+ 'prompt': prompt,
+ 'max_new_tokens': 250,
+ 'auto_max_new_tokens': False,
+
+ # Generation params. If 'preset' is set to different than 'None', the values
+ # in presets/preset-name.yaml are used instead of the individual numbers.
+ 'preset': 'None',
+ 'do_sample': True,
+ 'temperature': 0.7,
+ 'top_p': 0.1,
+ 'typical_p': 1,
+ 'epsilon_cutoff': 0, # In units of 1e-4
+ 'eta_cutoff': 0, # In units of 1e-4
+ 'tfs': 1,
+ 'top_a': 0,
+ 'repetition_penalty': 1.18,
+ 'repetition_penalty_range': 0,
+ 'top_k': 40,
+ 'min_length': 0,
+ 'no_repeat_ngram_size': 0,
+ 'num_beams': 1,
+ 'penalty_alpha': 0,
+ 'length_penalty': 1,
+ 'early_stopping': False,
+ 'mirostat_mode': 0,
+ 'mirostat_tau': 5,
+ 'mirostat_eta': 0.1,
+ 'guidance_scale': 1,
+ 'negative_prompt': '',
+
+ 'seed': -1,
+ 'add_bos_token': True,
+ 'truncation_length': 2048,
+ 'ban_eos_token': False,
+ 'skip_special_tokens': True,
+ 'stopping_strings': []
+ }
+
+ response = requests.post(URI, json=request)
+
+ if response.status_code == 200:
+ result = response.json()['results'][0]['text']
+ print(prompt + result)
+
+
+if __name__ == '__main__':
+ prompt = "In order to make homemade bread, follow these steps:\n1)"
+ run(prompt)
diff --git a/characters/Example.png b/characters/Example.png
new file mode 100644
index 0000000000000000000000000000000000000000..a7c4e513c4eaa05db1ebb2164956ea0b85d74a75
Binary files /dev/null and b/characters/Example.png differ
diff --git a/characters/Example.yaml b/characters/Example.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..c1a3299e7c0b977feb7345a0943c25ed8c45a9c3
--- /dev/null
+++ b/characters/Example.yaml
@@ -0,0 +1,17 @@
+name: Chiharu Yamada
+greeting: |-
+ *Chiharu strides into the room with a smile, her eyes lighting up when she sees you. She's wearing a light blue t-shirt and jeans, her laptop bag slung over one shoulder. She takes a seat next to you, her enthusiasm palpable in the air*
+ Hey! I'm so excited to finally meet you. I've heard so many great things about you and I'm eager to pick your brain about computers. I'm sure you have a wealth of knowledge that I can learn from. *She grins, eyes twinkling with excitement* Let's get started!
+context: |-
+ Chiharu Yamada's Persona: Chiharu Yamada is a young, computer engineer-nerd with a knack for problem solving and a passion for technology.
+
+ {{user}}: So how did you get into computer engineering?
+ {{char}}: I've always loved tinkering with technology since I was a kid.
+ {{user}}: That's really impressive!
+ {{char}}: *She chuckles bashfully* Thanks!
+ {{user}}: So what do you do when you're not working on computers?
+ {{char}}: I love exploring, going out with friends, watching movies, and playing video games.
+ {{user}}: What's your favorite type of computer hardware to work with?
+ {{char}}: Motherboards, they're like puzzles and the backbone of any system.
+ {{user}}: That sounds great!
+ {{char}}: Yeah, it's really fun. I'm lucky to be able to do this as a job.
diff --git a/convert-to-safetensors.py b/convert-to-safetensors.py
new file mode 100644
index 0000000000000000000000000000000000000000..3b721e7cd4d15cf7e5e03caaee57ef83a41553bc
--- /dev/null
+++ b/convert-to-safetensors.py
@@ -0,0 +1,38 @@
+'''
+
+Converts a transformers model to safetensors format and shards it.
+
+This makes it faster to load (because of safetensors) and lowers its RAM usage
+while loading (because of sharding).
+
+Based on the original script by 81300:
+
+https://gist.github.com/81300/fe5b08bff1cba45296a829b9d6b0f303
+
+'''
+
+import argparse
+from pathlib import Path
+
+import torch
+from transformers import AutoModelForCausalLM, AutoTokenizer
+
+parser = argparse.ArgumentParser(formatter_class=lambda prog: argparse.HelpFormatter(prog, max_help_position=54))
+parser.add_argument('MODEL', type=str, default=None, nargs='?', help="Path to the input model.")
+parser.add_argument('--output', type=str, default=None, help='Path to the output folder (default: models/{model_name}_safetensors).')
+parser.add_argument("--max-shard-size", type=str, default="2GB", help="Maximum size of a shard in GB or MB (default: %(default)s).")
+parser.add_argument('--bf16', action='store_true', help='Load the model with bfloat16 precision. Requires NVIDIA Ampere GPU.')
+args = parser.parse_args()
+
+if __name__ == '__main__':
+ path = Path(args.MODEL)
+ model_name = path.name
+
+ print(f"Loading {model_name}...")
+ model = AutoModelForCausalLM.from_pretrained(path, low_cpu_mem_usage=True, torch_dtype=torch.bfloat16 if args.bf16 else torch.float16)
+ tokenizer = AutoTokenizer.from_pretrained(path)
+
+ out_folder = args.output or Path(f"models/{model_name}_safetensors")
+ print(f"Saving the converted model to {out_folder} with a maximum shard size of {args.max_shard_size}...")
+ model.save_pretrained(out_folder, max_shard_size=args.max_shard_size, safe_serialization=True)
+ tokenizer.save_pretrained(out_folder)
diff --git a/css/chat.css b/css/chat.css
new file mode 100644
index 0000000000000000000000000000000000000000..677d86dbae9fdb06fb54875a06a80a09fcb770e0
--- /dev/null
+++ b/css/chat.css
@@ -0,0 +1,146 @@
+.h-\[40vh\], .wrap.svelte-byatnx.svelte-byatnx.svelte-byatnx {
+ height: 66.67vh
+}
+
+.gradio-container {
+ margin-left: auto !important;
+ margin-right: auto !important;
+}
+
+.w-screen {
+ width: unset
+}
+
+div.svelte-362y77>*, div.svelte-362y77>.form>* {
+ flex-wrap: nowrap
+}
+
+/* fixes the API documentation in chat mode */
+.api-docs.svelte-1iguv9h.svelte-1iguv9h.svelte-1iguv9h {
+ display: grid;
+}
+
+.pending.svelte-1ed2p3z {
+ opacity: 1;
+}
+
+#extensions {
+ padding: 0;
+}
+
+#gradio-chatbot {
+ height: 66.67vh;
+}
+
+.wrap.svelte-6roggh.svelte-6roggh {
+ max-height: 92.5%;
+}
+
+/* This is for the microphone button in the whisper extension */
+.sm.svelte-1ipelgc {
+ width: 100%;
+}
+
+#main button {
+ min-width: 0 !important;
+}
+
+#main > :first-child, #extensions {
+ max-width: 800px;
+ margin-left: auto;
+ margin-right: auto;
+}
+
+@media screen and (max-width: 688px) {
+ #main {
+ padding: 0px;
+ }
+
+ .chat {
+ height: calc(100vh - 274px) !important;
+ }
+}
+
+/*****************************************************/
+/*************** Chat box declarations ***************/
+/*****************************************************/
+
+.chat {
+ margin-left: auto;
+ margin-right: auto;
+ max-width: 800px;
+ height: calc(100vh - 286px);
+ overflow-y: auto;
+ padding-right: 20px;
+ display: flex;
+ flex-direction: column-reverse;
+ word-break: break-word;
+ overflow-wrap: anywhere;
+ padding-top: 1px;
+}
+
+.chat > .messages {
+ display: flex;
+ flex-direction: column;
+}
+
+.message-body li {
+ margin-top: 0.5em !important;
+ margin-bottom: 0.5em !important;
+}
+
+.message-body li > p {
+ display: inline !important;
+}
+
+.message-body ul, .message-body ol {
+ font-size: 15px !important;
+}
+
+.message-body ul {
+ list-style-type: disc !important;
+}
+
+.message-body pre {
+ margin-bottom: 1.25em !important;
+}
+
+.message-body code {
+ white-space: pre-wrap !important;
+ word-wrap: break-word !important;
+}
+
+.message-body :not(pre) > code {
+ white-space: normal !important;
+}
+
+@media print {
+ body {
+ visibility: hidden;
+ }
+
+ .chat {
+ visibility: visible;
+ position: absolute;
+ left: 0;
+ top: 0;
+ max-width: none;
+ max-height: none;
+ width: 100%;
+ height: fit-content;
+ display: flex;
+ flex-direction: column-reverse;
+ }
+
+ .message {
+ break-inside: avoid;
+ }
+
+ .gradio-container {
+ overflow: visible;
+ }
+
+ .tab-nav {
+ display: none !important;
+ }
+}
diff --git a/css/chat_style-TheEncrypted777.css b/css/chat_style-TheEncrypted777.css
new file mode 100644
index 0000000000000000000000000000000000000000..d92e982d8fd566ce4706b86a49c090716cb336d3
--- /dev/null
+++ b/css/chat_style-TheEncrypted777.css
@@ -0,0 +1,136 @@
+/* All credits to TheEncrypted777: https://www.reddit.com/r/Oobabooga/comments/12xe6vq/updated_css_styling_with_color_customization_for/ */
+
+.message {
+ display: grid;
+ grid-template-columns: 60px minmax(0, 1fr);
+ padding-bottom: 28px;
+ font-size: 18px;
+ /*Change 'Quicksand' to a font you like or leave it*/
+ font-family: Quicksand, Arial, sans-serif;
+ line-height: 1.428571429;
+}
+
+.circle-you,
+.circle-bot {
+ background-color: gray;
+ border-radius: 1rem;
+ border: 2px solid white;
+}
+
+.circle-bot img,
+.circle-you img {
+ border-radius: 10%;
+ width: 100%;
+ height: 100%;
+ object-fit: cover;
+}
+
+.circle-you, .circle-bot {
+ /*You can set the size of the profile images here, but if you do, you have to also adjust the .text{padding-left: 90px} to a different number according to the width of the image which is right below here*/
+ width: 135px;
+ height: 175px;
+}
+
+.text {
+ /*Change this to move the message box further left or right depending on the size of your profile pic*/
+ padding-left: 90px;
+ text-shadow: 2px 2px 2px rgb(0, 0, 0);
+}
+
+.text p {
+ margin-top: 2px;
+}
+
+.username {
+ padding-left: 10px;
+ font-size: 22px;
+ font-weight: bold;
+ border-top: 1px solid rgb(51, 64, 90);
+ padding: 3px;
+}
+
+.message-body {
+ position: relative;
+ border-radius: 1rem;
+ border: 1px solid rgba(255, 255, 255, 0.459);
+ border-radius: 10px;
+ padding: 10px;
+ padding-top: 5px;
+ /*Message gradient background color - remove the line bellow if you don't want a background color or gradient*/
+ background: linear-gradient(to bottom, #171730, #1b263f);
+}
+
+ /*Adds 2 extra lines at the top and bottom of the message*/
+.message-body:before,
+ .message-body:after {
+ content: "";
+ position: absolute;
+ left: 10px;
+ right: 10px;
+ height: 1px;
+ background-color: rgba(255, 255, 255, 0.13);
+}
+
+.message-body:before {
+ top: 6px;
+}
+
+.message-body:after {
+ bottom: 6px;
+}
+
+.message-body img {
+ max-width: 300px;
+ max-height: 300px;
+ border-radius: 20px;
+}
+
+.message-body p {
+ margin-bottom: 0 !important;
+ font-size: 18px !important;
+ line-height: 1.428571429 !important;
+}
+
+.dark .message-body p em {
+ color: rgb(138, 138, 138) !important;
+}
+
+.message-body p em {
+ color: rgb(110, 110, 110) !important;
+}
+
+@media screen and (max-width: 688px) {
+ .message {
+ display: grid;
+ grid-template-columns: 60px minmax(0, 1fr);
+ padding-bottom: 25px;
+ font-size: 15px;
+ font-family: Helvetica, Arial, sans-serif;
+ line-height: 1.428571429;
+ }
+
+ .circle-you, .circle-bot {
+ width: 50px;
+ height: 73px;
+ border-radius: 0.5rem;
+ }
+
+ .circle-bot img,
+ .circle-you img {
+ width: 100%;
+ height: 100%;
+ object-fit: cover;
+ }
+
+ .text {
+ padding-left: 0px;
+ }
+
+ .message-body p {
+ font-size: 16px !important;
+ }
+
+ .username {
+ font-size: 20px;
+ }
+}
diff --git a/css/chat_style-cai-chat.css b/css/chat_style-cai-chat.css
new file mode 100644
index 0000000000000000000000000000000000000000..d48fe76b7b678cf4f096a8502e2045b5dee983ee
--- /dev/null
+++ b/css/chat_style-cai-chat.css
@@ -0,0 +1,58 @@
+.message {
+ display: grid;
+ grid-template-columns: 60px minmax(0, 1fr);
+ padding-bottom: 25px;
+ font-size: 15px;
+ font-family: Helvetica, Arial, sans-serif;
+ line-height: 1.428571429;
+}
+
+.circle-you {
+ width: 50px;
+ height: 50px;
+ background-color: rgb(238, 78, 59);
+ border-radius: 50%;
+}
+
+.circle-bot {
+ width: 50px;
+ height: 50px;
+ background-color: rgb(59, 78, 244);
+ border-radius: 50%;
+}
+
+.circle-bot img,
+.circle-you img {
+ border-radius: 50%;
+ width: 100%;
+ height: 100%;
+ object-fit: cover;
+}
+
+.text p {
+ margin-top: 5px;
+}
+
+.username {
+ font-weight: bold;
+}
+
+.message-body img {
+ max-width: 300px;
+ max-height: 300px;
+ border-radius: 20px;
+}
+
+.message-body p {
+ margin-bottom: 0 !important;
+ font-size: 15px !important;
+ line-height: 1.428571429 !important;
+}
+
+.dark .message-body p em {
+ color: rgb(138, 138, 138) !important;
+}
+
+.message-body p em {
+ color: rgb(110, 110, 110) !important;
+}
\ No newline at end of file
diff --git a/css/chat_style-messenger.css b/css/chat_style-messenger.css
new file mode 100644
index 0000000000000000000000000000000000000000..0e5528d86a1298651e7b1c7b5f97eac834db50f4
--- /dev/null
+++ b/css/chat_style-messenger.css
@@ -0,0 +1,99 @@
+.message {
+ padding-bottom: 25px;
+ font-size: 15px;
+ font-family: Helvetica, Arial, sans-serif;
+ line-height: 1.428571429;
+}
+
+.circle-you {
+ width: 50px;
+ height: 50px;
+ background-color: rgb(238, 78, 59);
+ border-radius: 50%;
+}
+
+.circle-bot {
+ width: 50px;
+ height: 50px;
+ background-color: rgb(59, 78, 244);
+ border-radius: 50%;
+ float: left;
+ margin-right: 10px;
+ margin-top: 5px;
+}
+
+.circle-bot img,
+.circle-you img {
+ border-radius: 50%;
+ width: 100%;
+ height: 100%;
+ object-fit: cover;
+}
+
+.circle-you {
+ margin-top: 5px;
+ float: right;
+}
+
+.circle-bot + .text, .circle-you + .text {
+ border-radius: 18px;
+ padding: 8px 12px;
+}
+
+.circle-bot + .text {
+ background-color: #E4E6EB;
+ float: left;
+}
+
+.circle-you + .text {
+ float: right;
+ background-color: rgb(0, 132, 255);
+ margin-right: 10px;
+}
+
+.circle-you + .text div, .circle-you + .text *, .dark .circle-you + .text div, .dark .circle-you + .text * {
+ color: #FFF !important;
+}
+
+.circle-you + .text .username {
+ text-align: right;
+}
+
+.dark .circle-bot + .text div, .dark .circle-bot + .text * {
+ color: #000;
+}
+
+.text {
+ max-width: 80%;
+}
+
+.text p {
+ margin-top: 5px;
+}
+
+.username {
+ font-weight: bold;
+}
+
+.message-body {
+}
+
+.message-body img {
+ max-width: 300px;
+ max-height: 300px;
+ border-radius: 20px;
+}
+
+.message-body p {
+ margin-bottom: 0 !important;
+ font-size: 15px !important;
+ line-height: 1.428571429 !important;
+}
+
+.dark .message-body p em {
+ color: rgb(138, 138, 138) !important;
+}
+
+.message-body p em {
+ color: rgb(110, 110, 110) !important;
+}
diff --git a/css/chat_style-wpp.css b/css/chat_style-wpp.css
new file mode 100644
index 0000000000000000000000000000000000000000..14b408784d182c13a495aa65d63365a531ab52f6
--- /dev/null
+++ b/css/chat_style-wpp.css
@@ -0,0 +1,55 @@
+.message {
+ padding-bottom: 25px;
+ font-size: 15px;
+ font-family: Helvetica, Arial, sans-serif;
+ line-height: 1.428571429;
+}
+
+.text-you {
+ background-color: #d9fdd3;
+ border-radius: 15px;
+ padding: 10px;
+ padding-top: 5px;
+ float: right;
+}
+
+.text-bot {
+ background-color: #f2f2f2;
+ border-radius: 15px;
+ padding: 10px;
+ padding-top: 5px;
+}
+
+.dark .text-you {
+ background-color: #005c4b;
+ color: #111b21;
+}
+
+.dark .text-bot {
+ background-color: #1f2937;
+ color: #111b21;
+}
+
+.text-bot p, .text-you p {
+ margin-top: 5px;
+}
+
+.message-body img {
+ max-width: 300px;
+ max-height: 300px;
+ border-radius: 20px;
+}
+
+.message-body p {
+ margin-bottom: 0 !important;
+ font-size: 15px !important;
+ line-height: 1.428571429 !important;
+}
+
+.dark .message-body p em {
+ color: rgb(138, 138, 138) !important;
+}
+
+.message-body p em {
+ color: rgb(110, 110, 110) !important;
+}
\ No newline at end of file
diff --git a/css/html_4chan_style.css b/css/html_4chan_style.css
new file mode 100644
index 0000000000000000000000000000000000000000..99ac68452351f3b5b5a109e53dae789e6f61c804
--- /dev/null
+++ b/css/html_4chan_style.css
@@ -0,0 +1,104 @@
+#parent #container {
+ background-color: #eef2ff;
+ padding: 17px;
+}
+
+#parent #container .reply {
+ background-color: rgb(214, 218, 240);
+ border-bottom-color: rgb(183, 197, 217);
+ border-bottom-style: solid;
+ border-bottom-width: 1px;
+ border-image-outset: 0;
+ border-image-repeat: stretch;
+ border-image-slice: 100%;
+ border-image-source: none;
+ border-image-width: 1;
+ border-left-color: rgb(0, 0, 0);
+ border-left-style: none;
+ border-left-width: 0px;
+ border-right-color: rgb(183, 197, 217);
+ border-right-style: solid;
+ border-right-width: 1px;
+ border-top-color: rgb(0, 0, 0);
+ border-top-style: none;
+ border-top-width: 0px;
+ color: rgb(0, 0, 0);
+ display: table;
+ font-family: arial, helvetica, sans-serif;
+ font-size: 13.3333px;
+ margin-bottom: 4px;
+ margin-left: 0px;
+ margin-right: 0px;
+ margin-top: 4px;
+ overflow-x: hidden;
+ overflow-y: hidden;
+ padding-bottom: 4px;
+ padding-left: 2px;
+ padding-right: 2px;
+ padding-top: 4px;
+}
+
+#parent #container .number {
+ color: rgb(0, 0, 0);
+ font-family: arial, helvetica, sans-serif;
+ font-size: 13.3333px;
+ width: 342.65px;
+ margin-right: 7px;
+}
+
+#parent #container .op {
+ color: rgb(0, 0, 0);
+ font-family: arial, helvetica, sans-serif;
+ font-size: 13.3333px;
+ margin-bottom: 8px;
+ margin-left: 0px;
+ margin-right: 0px;
+ margin-top: 4px;
+ overflow-x: hidden;
+ overflow-y: hidden;
+}
+
+#parent #container .op blockquote {
+ margin-left: 0px !important;
+}
+
+#parent #container .name {
+ color: rgb(17, 119, 67);
+ font-family: arial, helvetica, sans-serif;
+ font-size: 13.3333px;
+ font-weight: 700;
+ margin-left: 7px;
+}
+
+#parent #container .quote {
+ color: rgb(221, 0, 0);
+ font-family: arial, helvetica, sans-serif;
+ font-size: 13.3333px;
+ text-decoration-color: rgb(221, 0, 0);
+ text-decoration-line: underline;
+ text-decoration-style: solid;
+ text-decoration-thickness: auto;
+}
+
+#parent #container .greentext {
+ color: rgb(120, 153, 34);
+ font-family: arial, helvetica, sans-serif;
+ font-size: 13.3333px;
+}
+
+#parent #container blockquote {
+ margin: 0px !important;
+ margin-block-start: 1em;
+ margin-block-end: 1em;
+ margin-inline-start: 40px;
+ margin-inline-end: 40px;
+ margin-top: 13.33px !important;
+ margin-bottom: 13.33px !important;
+ margin-left: 40px !important;
+ margin-right: 40px !important;
+}
+
+#parent #container .message {
+ color: black;
+ border: none;
+}
\ No newline at end of file
diff --git a/css/html_instruct_style.css b/css/html_instruct_style.css
new file mode 100644
index 0000000000000000000000000000000000000000..575281b1e50150c6b285edf0e8c04f4a5abf329b
--- /dev/null
+++ b/css/html_instruct_style.css
@@ -0,0 +1,62 @@
+.message {
+ display: grid;
+ grid-template-columns: 60px 1fr;
+ padding-bottom: 25px;
+ font-size: 15px;
+ font-family: Helvetica, Arial, sans-serif;
+ line-height: 1.428571429;
+}
+
+.username {
+ display: none;
+}
+
+.message-body p {
+ font-size: 15px !important;
+ line-height: 1.75 !important;
+ margin-bottom: 1.25em !important;
+}
+
+.message-body ul, .message-body ol {
+ margin-bottom: 1.25em !important;
+}
+
+.dark .message-body p em {
+ color: rgb(198, 202, 214) !important;
+}
+
+.message-body p em {
+ color: rgb(110, 110, 110) !important;
+}
+
+.gradio-container .chat .assistant-message {
+ padding: 15px;
+ border-radius: 20px;
+ background-color: #0000000f;
+ margin-top: 9px !important;
+ margin-bottom: 18px !important;
+}
+
+.gradio-container .chat .user-message {
+ padding: 15px;
+ border-radius: 20px;
+ margin-bottom: 9px !important;
+}
+
+.dark .chat .assistant-message {
+ background-color: #3741519e;
+ border: 1px solid #4b5563;
+}
+
+.dark .chat .user-message {
+ background-color: #111827;
+ border: 1px solid #4b5563;
+}
+
+code {
+ background-color: white !important;
+}
+
+.dark code {
+ background-color: #1a212f !important;
+}
\ No newline at end of file
diff --git a/css/html_readable_style.css b/css/html_readable_style.css
new file mode 100644
index 0000000000000000000000000000000000000000..cd5fca97868167718d239b4be72e9271971807e2
--- /dev/null
+++ b/css/html_readable_style.css
@@ -0,0 +1,29 @@
+.container {
+ max-width: 600px;
+ margin-left: auto;
+ margin-right: auto;
+ background-color: rgb(31, 41, 55);
+ padding: 3em;
+ word-break: break-word;
+ overflow-wrap: anywhere;
+ color: #efefef !important;
+}
+
+.container p, .container li {
+ font-size: 16px !important;
+ color: #efefef !important;
+ margin-bottom: 22px;
+ line-height: 1.4 !important;
+}
+
+.container li > p {
+ display: inline !important;
+}
+
+.container code {
+ overflow-x: auto;
+}
+
+.container :not(pre) > code {
+ white-space: normal !important;
+}
\ No newline at end of file
diff --git a/css/main.css b/css/main.css
new file mode 100644
index 0000000000000000000000000000000000000000..d37e3f633aebde34df1758c5126d81cfea4319d1
--- /dev/null
+++ b/css/main.css
@@ -0,0 +1,195 @@
+.tabs.svelte-710i53 {
+ margin-top: 0
+}
+
+.py-6 {
+ padding-top: 2.5rem
+}
+
+.small-button {
+ max-width: 171px;
+ height: 39.594px;
+ align-self: end;
+}
+
+.refresh-button {
+ max-width: 4.4em;
+ min-width: 2.2em !important;
+ height: 39.594px;
+ align-self: end;
+ line-height: 1em;
+ border-radius: 0.5em;
+ flex: none;
+}
+
+.refresh-button-small {
+ max-width: 2.2em;
+}
+
+.button_nowrap {
+ white-space: nowrap;
+}
+
+#slim-column {
+ flex: none !important;
+ min-width: 0 !important;
+}
+
+.slim-dropdown {
+ background-color: transparent !important;
+ border: none !important;
+ padding: 0 !important;
+}
+
+#download-label, #upload-label {
+ min-height: 0
+}
+
+#save_session {
+ margin-top: 32px;
+}
+
+#accordion {
+}
+
+.dark svg {
+ fill: white;
+}
+
+.dark a {
+ color: white !important;
+}
+
+ol li p, ul li p {
+ display: inline-block;
+}
+
+#main, #parameters, #chat-settings, #lora, #training-tab, #model-tab, #session-tab {
+ border: 0;
+}
+
+.gradio-container-3-18-0 .prose * h1, h2, h3, h4 {
+ color: white;
+}
+
+.gradio-container {
+ max-width: 100% !important;
+ padding-top: 0 !important;
+}
+
+#extensions {
+ padding: 15px;
+ margin-bottom: 35px;
+}
+
+.extension-tab {
+ border: 0 !important;
+}
+
+span.math.inline {
+ font-size: 27px;
+ vertical-align: baseline !important;
+}
+
+div.svelte-15lo0d8 > *, div.svelte-15lo0d8 > .form > * {
+ flex-wrap: nowrap;
+}
+
+.header_bar {
+ background-color: #f7f7f7;
+ margin-bottom: 20px;
+ display: inline !important;
+ overflow-x: scroll;
+}
+
+.dark .header_bar {
+ border: none !important;
+ background-color: #8080802b;
+}
+
+.textbox_default textarea {
+ height: calc(100vh - 380px);
+}
+
+.textbox_default_output textarea {
+ height: calc(100vh - 190px);
+}
+
+.textbox textarea {
+ height: calc(100vh - 241px);
+}
+
+.textbox_default textarea, .textbox_default_output textarea, .textbox textarea {
+ font-size: 16px !important;
+ color: #46464A !important;
+}
+
+.dark textarea {
+ color: #efefef !important;
+}
+
+/* Hide the gradio footer*/
+footer {
+ display: none !important;
+}
+
+button {
+ font-size: 14px !important;
+}
+
+.file-saver {
+ position: fixed !important;
+ top: 50%;
+ left: 50%;
+ transform: translate(-50%, -50%); /* center horizontally */
+ max-width: 500px;
+ background-color: var(--input-background-fill);
+ border: 2px solid black !important;
+ z-index: 1000;
+}
+
+.dark .file-saver {
+ border: 2px solid white !important;
+}
+
+.checkboxgroup-table label {
+ background: none !important;
+ padding: 0 !important;
+ border: 0 !important;
+}
+
+.checkboxgroup-table div {
+ display: grid !important;
+}
+
+.markdown ul ol {
+ font-size: 100% !important;
+}
+
+.pretty_scrollbar::-webkit-scrollbar {
+ width: 10px;
+}
+
+.pretty_scrollbar::-webkit-scrollbar-track {
+ background: transparent;
+}
+
+.pretty_scrollbar::-webkit-scrollbar-thumb,
+.pretty_scrollbar::-webkit-scrollbar-thumb:hover {
+ background: #c5c5d2;
+ border-radius: 10px;
+}
+
+.dark .pretty_scrollbar::-webkit-scrollbar-thumb,
+.dark .pretty_scrollbar::-webkit-scrollbar-thumb:hover {
+ background: #374151;
+ border-radius: 10px;
+}
+
+.pretty_scrollbar::-webkit-resizer {
+ background: #c5c5d2;
+}
+
+.dark .pretty_scrollbar::-webkit-resizer {
+ background: #374151;
+}
diff --git a/docker/.dockerignore b/docker/.dockerignore
new file mode 100644
index 0000000000000000000000000000000000000000..6073533e0929aac9e917a5980198334a2a01f8ef
--- /dev/null
+++ b/docker/.dockerignore
@@ -0,0 +1,9 @@
+.env
+Dockerfile
+/characters
+/loras
+/models
+/presets
+/prompts
+/softprompts
+/training
diff --git a/docker/.env.example b/docker/.env.example
new file mode 100644
index 0000000000000000000000000000000000000000..3119a9f07f47b1ad964ce337c33f1ce63d79f377
--- /dev/null
+++ b/docker/.env.example
@@ -0,0 +1,30 @@
+# by default the Dockerfile specifies these versions: 3.5;5.0;6.0;6.1;7.0;7.5;8.0;8.6+PTX
+# however for me to work i had to specify the exact version for my card ( 2060 ) it was 7.5
+# https://developer.nvidia.com/cuda-gpus you can find the version for your card here
+TORCH_CUDA_ARCH_LIST=7.5
+
+# these commands worked for me with roughly 4.5GB of vram
+CLI_ARGS=--model llama-7b-4bit --wbits 4 --listen --auto-devices
+
+# the following examples have been tested with the files linked in docs/README_docker.md:
+# example running 13b with 4bit/128 groupsize : CLI_ARGS=--model llama-13b-4bit-128g --wbits 4 --listen --groupsize 128 --pre_layer 25
+# example with loading api extension and public share: CLI_ARGS=--model llama-7b-4bit --wbits 4 --listen --auto-devices --no-stream --extensions api --share
+# example running 7b with 8bit groupsize : CLI_ARGS=--model llama-7b --load-in-8bit --listen --auto-devices
+
+# the port the webui binds to on the host
+HOST_PORT=7860
+# the port the webui binds to inside the container
+CONTAINER_PORT=7860
+
+# the port the api binds to on the host
+HOST_API_PORT=5000
+# the port the api binds to inside the container
+CONTAINER_API_PORT=5000
+
+# the port the api stream endpoint binds to on the host
+HOST_API_STREAM_PORT=5005
+# the port the api stream endpoint binds to inside the container
+CONTAINER_API_STREAM_PORT=5005
+
+# the version used to install text-generation-webui from
+WEBUI_VERSION=HEAD
diff --git a/docker/Dockerfile b/docker/Dockerfile
new file mode 100644
index 0000000000000000000000000000000000000000..3c5108d8057e3765ba8f37aa4d9c6181b7f3541b
--- /dev/null
+++ b/docker/Dockerfile
@@ -0,0 +1,68 @@
+FROM nvidia/cuda:11.8.0-devel-ubuntu22.04 as builder
+
+RUN apt-get update && \
+ apt-get install --no-install-recommends -y git vim build-essential python3-dev python3-venv && \
+ rm -rf /var/lib/apt/lists/*
+
+RUN git clone https://github.com/oobabooga/GPTQ-for-LLaMa /build
+
+WORKDIR /build
+
+RUN python3 -m venv /build/venv
+RUN . /build/venv/bin/activate && \
+ pip3 install --upgrade pip setuptools wheel && \
+ pip3 install torch torchvision torchaudio && \
+ pip3 install -r requirements.txt
+
+# https://developer.nvidia.com/cuda-gpus
+# for a rtx 2060: ARG TORCH_CUDA_ARCH_LIST="7.5"
+ARG TORCH_CUDA_ARCH_LIST="${TORCH_CUDA_ARCH_LIST:-3.5;5.0;6.0;6.1;7.0;7.5;8.0;8.6+PTX}"
+RUN . /build/venv/bin/activate && \
+ python3 setup_cuda.py bdist_wheel -d .
+
+FROM nvidia/cuda:11.8.0-runtime-ubuntu22.04
+
+LABEL maintainer="Your Name +Instructions +
+ +[GPT-4chan](https://huggingface.co/ykilcher/gpt-4chan) has been shut down from Hugging Face, so you need to download it elsewhere. You have two options: + +* Torrent: [16-bit](https://archive.org/details/gpt4chan_model_float16) / [32-bit](https://archive.org/details/gpt4chan_model) +* Direct download: [16-bit](https://theswissbay.ch/pdf/_notpdf_/gpt4chan_model_float16/) / [32-bit](https://theswissbay.ch/pdf/_notpdf_/gpt4chan_model/) + +The 32-bit version is only relevant if you intend to run the model in CPU mode. Otherwise, you should use the 16-bit version. + +After downloading the model, follow these steps: + +1. Place the files under `models/gpt4chan_model_float16` or `models/gpt4chan_model`. +2. Place GPT-J 6B's config.json file in that same folder: [config.json](https://huggingface.co/EleutherAI/gpt-j-6B/raw/main/config.json). +3. Download GPT-J 6B's tokenizer files (they will be automatically detected when you attempt to load GPT-4chan): + +``` +python download-model.py EleutherAI/gpt-j-6B --text-only +``` + +When you load this model in default or notebook modes, the "HTML" tab will show the generated text in 4chan format. +'
+ image_html = ""
+
+ for path in [Path(f"characters/{character}.{extension}") for extension in ['png', 'jpg', 'jpeg']]:
+ if path.exists():
+ image_html = f'}) '
+ break
+
+ container_html += f'{image_html} {character}'
+ container_html += "
'
+ break
+
+ container_html += f'{image_html} {character}'
+ container_html += "
"
+ cards.append([container_html, character])
+
+ return cards
+
+
+def select_character(evt: gr.SelectData):
+ return (evt.value[1])
+
+
+def ui():
+ with gr.Accordion("Character gallery", open=False):
+ update = gr.Button("Refresh")
+ gr.HTML(value="")
+ gallery = gr.Dataset(components=[gr.HTML(visible=False)],
+ label="",
+ samples=generate_html(),
+ elem_classes=["character-gallery"],
+ samples_per_page=50
+ )
+ update.click(generate_html, [], gallery)
+ gallery.select(select_character, None, gradio['character_menu'])
diff --git a/extensions/google_translate/requirements.txt b/extensions/google_translate/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..554a00df62818f96ba7d396ae39d8e58efbe9bfe
--- /dev/null
+++ b/extensions/google_translate/requirements.txt
@@ -0,0 +1 @@
+deep-translator==1.9.2
diff --git a/extensions/google_translate/script.py b/extensions/google_translate/script.py
new file mode 100644
index 0000000000000000000000000000000000000000..5dfdbcd0c0a9b889497dc2a147007e997c3cda80
--- /dev/null
+++ b/extensions/google_translate/script.py
@@ -0,0 +1,56 @@
+import gradio as gr
+from deep_translator import GoogleTranslator
+
+params = {
+ "activate": True,
+ "language string": "ja",
+}
+
+language_codes = {'Afrikaans': 'af', 'Albanian': 'sq', 'Amharic': 'am', 'Arabic': 'ar', 'Armenian': 'hy', 'Azerbaijani': 'az', 'Basque': 'eu', 'Belarusian': 'be', 'Bengali': 'bn', 'Bosnian': 'bs', 'Bulgarian': 'bg', 'Catalan': 'ca', 'Cebuano': 'ceb', 'Chinese (Simplified)': 'zh-CN', 'Chinese (Traditional)': 'zh-TW', 'Corsican': 'co', 'Croatian': 'hr', 'Czech': 'cs', 'Danish': 'da', 'Dutch': 'nl', 'English': 'en', 'Esperanto': 'eo', 'Estonian': 'et', 'Finnish': 'fi', 'French': 'fr', 'Frisian': 'fy', 'Galician': 'gl', 'Georgian': 'ka', 'German': 'de', 'Greek': 'el', 'Gujarati': 'gu', 'Haitian Creole': 'ht', 'Hausa': 'ha', 'Hawaiian': 'haw', 'Hebrew': 'iw', 'Hindi': 'hi', 'Hmong': 'hmn', 'Hungarian': 'hu', 'Icelandic': 'is', 'Igbo': 'ig', 'Indonesian': 'id', 'Irish': 'ga', 'Italian': 'it', 'Japanese': 'ja', 'Javanese': 'jw', 'Kannada': 'kn', 'Kazakh': 'kk', 'Khmer': 'km', 'Korean': 'ko', 'Kurdish': 'ku', 'Kyrgyz': 'ky', 'Lao': 'lo', 'Latin': 'la', 'Latvian': 'lv', 'Lithuanian': 'lt', 'Luxembourgish': 'lb', 'Macedonian': 'mk', 'Malagasy': 'mg', 'Malay': 'ms', 'Malayalam': 'ml', 'Maltese': 'mt', 'Maori': 'mi', 'Marathi': 'mr', 'Mongolian': 'mn', 'Myanmar (Burmese)': 'my', 'Nepali': 'ne', 'Norwegian': 'no', 'Nyanja (Chichewa)': 'ny', 'Pashto': 'ps', 'Persian': 'fa', 'Polish': 'pl', 'Portuguese (Portugal, Brazil)': 'pt', 'Punjabi': 'pa', 'Romanian': 'ro', 'Russian': 'ru', 'Samoan': 'sm', 'Scots Gaelic': 'gd', 'Serbian': 'sr', 'Sesotho': 'st', 'Shona': 'sn', 'Sindhi': 'sd', 'Sinhala (Sinhalese)': 'si', 'Slovak': 'sk', 'Slovenian': 'sl', 'Somali': 'so', 'Spanish': 'es', 'Sundanese': 'su', 'Swahili': 'sw', 'Swedish': 'sv', 'Tagalog (Filipino)': 'tl', 'Tajik': 'tg', 'Tamil': 'ta', 'Telugu': 'te', 'Thai': 'th', 'Turkish': 'tr', 'Ukrainian': 'uk', 'Urdu': 'ur', 'Uzbek': 'uz', 'Vietnamese': 'vi', 'Welsh': 'cy', 'Xhosa': 'xh', 'Yiddish': 'yi', 'Yoruba': 'yo', 'Zulu': 'zu'}
+
+
+def input_modifier(string):
+ """
+ This function is applied to your text inputs before
+ they are fed into the model.
+ """
+ if not params['activate']:
+ return string
+
+ return GoogleTranslator(source=params['language string'], target='en').translate(string)
+
+
+def output_modifier(string):
+ """
+ This function is applied to the model outputs.
+ """
+ if not params['activate']:
+ return string
+
+ return GoogleTranslator(source='en', target=params['language string']).translate(string)
+
+
+def bot_prefix_modifier(string):
+ """
+ This function is only applied in chat mode. It modifies
+ the prefix text for the Bot and can be used to bias its
+ behavior.
+ """
+
+ return string
+
+
+def ui():
+ # Finding the language name from the language code to use as the default value
+ language_name = list(language_codes.keys())[list(language_codes.values()).index(params['language string'])]
+
+ # Gradio elements
+ with gr.Row():
+ activate = gr.Checkbox(value=params['activate'], label='Activate translation')
+
+ with gr.Row():
+ language = gr.Dropdown(value=language_name, choices=[k for k in language_codes], label='Language')
+
+ # Event functions to update the parameters in the backend
+ activate.change(lambda x: params.update({"activate": x}), activate, None)
+ language.change(lambda x: params.update({"language string": language_codes[x]}), language, None)
diff --git a/extensions/long_replies/script.py b/extensions/long_replies/script.py
new file mode 100644
index 0000000000000000000000000000000000000000..035e8c9e1c5005620eb72cb83be456464d5f3e78
--- /dev/null
+++ b/extensions/long_replies/script.py
@@ -0,0 +1,143 @@
+import torch
+from modules import chat, shared
+from modules.text_generation import (
+ decode,
+ encode,
+ generate_reply,
+)
+from transformers import LogitsProcessor
+import gradio as gr
+
+params = {
+ "display_name": "Long replies",
+ "is_tab": False,
+ "min_length": 120,
+}
+
+initial_size = 0
+
+class MyLogits(LogitsProcessor):
+ """
+ Manipulates the probabilities for the next token before it gets sampled.
+ Used in the logits_processor_modifier function below.
+ """
+ def __init__(self):
+ self.newline_id = shared.tokenizer.encode('\n')[-1]
+ pass
+
+ def __call__(self, input_ids, scores):
+ if input_ids.shape[-1] - initial_size < params["min_length"]:
+ scores[...,self.newline_id] = -1000
+ # scores[...,shared.tokenizer.eos_token_id] = -1000
+
+ # probs = torch.softmax(scores, dim=-1, dtype=torch.float)
+ # probs[0] /= probs[0].sum()
+ # scores = torch.log(probs / (1 - probs))
+ return scores
+
+def history_modifier(history):
+ """
+ Modifies the chat history.
+ Only used in chat mode.
+ """
+ return history
+
+def state_modifier(state):
+ """
+ Modifies the state variable, which is a dictionary containing the input
+ values in the UI like sliders and checkboxes.
+ """
+ return state
+
+def chat_input_modifier(text, visible_text, state):
+ """
+ Modifies the user input string in chat mode (visible_text).
+ You can also modify the internal representation of the user
+ input (text) to change how it will appear in the prompt.
+ """
+ return text, visible_text
+
+def input_modifier(string, state):
+ """
+ In default/notebook modes, modifies the whole prompt.
+
+ In chat mode, it is the same as chat_input_modifier but only applied
+ to "text", here called "string", and not to "visible_text".
+ """
+ return string
+
+def bot_prefix_modifier(string, state):
+ """
+ Modifies the prefix for the next bot reply in chat mode.
+ By default, the prefix will be something like "Bot Name:".
+ """
+ return string
+
+def tokenizer_modifier(state, prompt, input_ids, input_embeds):
+ """
+ Modifies the input ids and embeds.
+ Used by the multimodal extension to put image embeddings in the prompt.
+ Only used by loaders that use the transformers library for sampling.
+ """
+
+ global initial_size
+ initial_size = input_ids.shape[-1]
+
+ return prompt, input_ids, input_embeds
+
+def logits_processor_modifier(processor_list, input_ids):
+ """
+ Adds logits processors to the list, allowing you to access and modify
+ the next token probabilities.
+ Only used by loaders that use the transformers library for sampling.
+ """
+ processor_list.append(MyLogits())
+ return processor_list
+
+def output_modifier(string, state):
+ """
+ Modifies the LLM output before it gets presented.
+
+ In chat mode, the modified version goes into history['visible'],
+ and the original version goes into history['internal'].
+ """
+ return string
+
+def custom_generate_chat_prompt(user_input, state, **kwargs):
+ """
+ Replaces the function that generates the prompt from the chat history.
+ Only used in chat mode.
+ """
+ result = chat.generate_chat_prompt(user_input, state, **kwargs)
+ return result
+
+def custom_css():
+ """
+ Returns a CSS string that gets appended to the CSS for the webui.
+ """
+ return ''
+
+def custom_js():
+ """
+ Returns a javascript string that gets appended to the javascript
+ for the webui.
+ """
+ return ''
+
+def setup():
+ """
+ Gets executed only once, when the extension is imported.
+ """
+ pass
+
+def ui():
+ """
+ Gets executed when the UI is drawn. Custom gradio elements and
+ their corresponding event handlers should be defined here.
+
+ To learn about gradio components, check out the docs:
+ https://gradio.app/docs/
+ """
+
+ min_length = gr.Slider(0, 800, step=10, value=params['min_length'], label='Minimum reply length')
+ min_length.change(lambda x: params.update({'min_length': x}), min_length, None)
diff --git a/extensions/multimodal/DOCS.md b/extensions/multimodal/DOCS.md
new file mode 100644
index 0000000000000000000000000000000000000000..eaa4365e9a304a14ebbdb1d4d435f3a2a1f7a7d2
--- /dev/null
+++ b/extensions/multimodal/DOCS.md
@@ -0,0 +1,85 @@
+# Technical description of multimodal extension
+
+## Working principle
+Multimodality extension does most of the stuff which is required for any image input:
+
+- adds the UI
+- saves the images as base64 JPEGs to history
+- provides the hooks to the UI
+- if there are images in the prompt, it:
+ - splits the prompt to text and image parts
+ - adds image start/end markers to text parts, then encodes and embeds the text parts
+ - calls the vision pipeline to embed the images
+ - stitches the embeddings together, and returns them to text generation
+- loads the appropriate vision pipeline, selected either from model name, or by specifying --multimodal-pipeline parameter
+
+Now, for the pipelines, they:
+
+- load the required vision models
+- return some consts, for example the number of tokens taken up by image
+- and most importantly: return the embeddings for LLM, given a list of images
+
+## Prompts/history
+
+To save images in prompt/history, this extension is using a base64 JPEG, wrapped in a HTML tag, like so:
+```
+ +```
+where `{img_str}` is the actual image data. This format makes displaying them in the UI for free. Do note, that this format is required to be exactly the same, the regex used to find the images is: `
+```
+where `{img_str}` is the actual image data. This format makes displaying them in the UI for free. Do note, that this format is required to be exactly the same, the regex used to find the images is: `) `.
+
+## LLM input
+To describe the input, let's see it on an example prompt:
+```
+text1'`, where `img_str` is base-64 jpeg data. Note that you will need to launch `server.py` with the arguments `--api --extensions multimodal`.
+
+Python example:
+
+```Python
+import base64
+import requests
+
+CONTEXT = "You are LLaVA, a large language and vision assistant trained by UW Madison WAIV Lab. You are able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language. Follow the instructions carefully and explain your answers in detail.### Human: Hi!### Assistant: Hi there! How can I help you today?\n"
+
+with open('extreme_ironing.jpg', 'rb') as f:
+ img_str = base64.b64encode(f.read()).decode('utf-8')
+ prompt = CONTEXT + f'### Human: What is unusual about this image: \n### Assistant: '
+ print(requests.post('http://127.0.0.1:5000/api/v1/generate', json={'prompt': prompt, 'stopping_strings': ['\n###']}).json())
+```
+script output:
+```Python
+{'results': [{'text': "The unusual aspect of this image is that a man is standing on top of a yellow minivan while doing his laundry. He has set up a makeshift clothes line using the car's rooftop as an outdoor drying area. This scene is uncommon because people typically do their laundry indoors, in a dedicated space like a laundromat or a room in their home, rather than on top of a moving vehicle. Additionally, hanging clothes on the car could be potentially hazardous or illegal in some jurisdictions due to the risk of damaging the vehicle or causing accidents on the road.\n##"}]}
+```
+
+## For pipeline developers/technical description
+see [DOCS.md](https://github.com/oobabooga/text-generation-webui/blob/main/extensions/multimodal/DOCS.md)
diff --git a/extensions/multimodal/abstract_pipeline.py b/extensions/multimodal/abstract_pipeline.py
new file mode 100644
index 0000000000000000000000000000000000000000..584219419d256e7743fd4d5120c56bcfa8f2a9f9
--- /dev/null
+++ b/extensions/multimodal/abstract_pipeline.py
@@ -0,0 +1,62 @@
+from abc import ABC, abstractmethod
+from typing import List, Optional
+
+import torch
+from PIL import Image
+
+
+class AbstractMultimodalPipeline(ABC):
+ @staticmethod
+ @abstractmethod
+ def name() -> str:
+ 'name of the pipeline, should be same as in --multimodal-pipeline'
+ pass
+
+ @staticmethod
+ @abstractmethod
+ def image_start() -> Optional[str]:
+ 'return image start string, string representation of image start token, or None if not applicable'
+ pass
+
+ @staticmethod
+ @abstractmethod
+ def image_end() -> Optional[str]:
+ 'return image end string, string representation of image end token, or None if not applicable'
+ pass
+
+ @staticmethod
+ @abstractmethod
+ def placeholder_token_id() -> int:
+ 'return placeholder token id'
+ pass
+
+ @staticmethod
+ @abstractmethod
+ def num_image_embeds() -> int:
+ 'return the number of embeds used by a single image (for example: 256 for LLaVA)'
+ pass
+
+ @abstractmethod
+ def embed_images(self, images: List[Image.Image]) -> torch.Tensor:
+ 'forward the images through vision pipeline, and return their embeddings'
+ pass
+
+ @staticmethod
+ @abstractmethod
+ def embed_tokens(input_ids: torch.Tensor) -> torch.Tensor:
+ 'embed tokens, the exact function varies by LLM, for LLaMA it is `shared.model.model.embed_tokens`'
+ pass
+
+ @staticmethod
+ @abstractmethod
+ def placeholder_embeddings() -> torch.Tensor:
+ 'get placeholder embeddings if there are multiple images, and `add_all_images_to_prompt` is False'
+ pass
+
+ def _get_device(self, setting_name: str, params: dict):
+ if params[setting_name] is None:
+ return torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
+ return torch.device(params[setting_name])
+
+ def _get_dtype(self, setting_name: str, params: dict):
+ return torch.float32 if int(params[setting_name]) == 32 else torch.float16
diff --git a/extensions/multimodal/multimodal_embedder.py b/extensions/multimodal/multimodal_embedder.py
new file mode 100644
index 0000000000000000000000000000000000000000..626077cb80987d66af90f390e31aa2f2def76fec
--- /dev/null
+++ b/extensions/multimodal/multimodal_embedder.py
@@ -0,0 +1,178 @@
+import base64
+import re
+from dataclasses import dataclass
+from io import BytesIO
+from typing import Any, List, Optional
+
+import torch
+from PIL import Image
+
+from extensions.multimodal.pipeline_loader import load_pipeline
+from modules import shared
+from modules.logging_colors import logger
+from modules.text_generation import encode, get_max_prompt_length
+
+
+@dataclass
+class PromptPart:
+ text: str
+ image: Optional[Image.Image] = None
+ is_image: bool = False
+ input_ids: Optional[torch.Tensor] = None
+ embedding: Optional[torch.Tensor] = None
+
+
+class MultimodalEmbedder:
+ def __init__(self, params: dict):
+ pipeline, source = load_pipeline(params)
+ self.pipeline = pipeline
+ logger.info(f'Multimodal: loaded pipeline {self.pipeline.name()} from pipelines/{source} ({self.pipeline.__class__.__name__})')
+
+ def _split_prompt(self, prompt: str, load_images: bool = False) -> List[PromptPart]:
+ """Splits a prompt into a list of `PromptParts` to separate image data from text.
+ It will also append `image_start` and `image_end` before and after the image, and optionally parse and load the images,
+ if `load_images` is `True`.
+ """
+ parts: List[PromptPart] = []
+ curr = 0
+ while True:
+ match = re.search(r'', prompt[curr:])
+ if match is None:
+ # no more image tokens, append the rest of the prompt
+ if curr > 0:
+ # add image end token after last image
+ parts.append(PromptPart(text=self.pipeline.image_end() + prompt[curr:]))
+ else:
+ parts.append(PromptPart(text=prompt))
+ break
+ # found an image, append image start token to the text
+ if match.start() > 0:
+ parts.append(PromptPart(text=prompt[curr:curr + match.start()] + self.pipeline.image_start()))
+ else:
+ parts.append(PromptPart(text=self.pipeline.image_start()))
+ # append the image
+ parts.append(PromptPart(
+ text=match.group(0),
+ image=Image.open(BytesIO(base64.b64decode(match.group(1)))) if load_images else None,
+ is_image=True
+ ))
+ curr += match.end()
+ return parts
+
+ def _len_in_tokens_prompt_parts(self, parts: List[PromptPart]) -> int:
+ """Total length in tokens of all `parts`"""
+ tokens = 0
+ for part in parts:
+ if part.is_image:
+ tokens += self.pipeline.num_image_embeds()
+ elif part.input_ids is not None:
+ tokens += len(part.input_ids)
+ else:
+ tokens += len(encode(part.text)[0])
+ return tokens
+
+ def len_in_tokens(self, prompt: str) -> int:
+ """Total length in tokens for a given text `prompt`"""
+ parts = self._split_prompt(prompt, False)
+ return self._len_in_tokens_prompt_parts(parts)
+
+ def _encode_single_text(self, part: PromptPart, add_bos_token: bool) -> PromptPart:
+ """Encode a single prompt `part` to `input_ids`. Returns a `PromptPart`"""
+ if part.is_image:
+ placeholders = torch.ones((self.pipeline.num_image_embeds())) * self.pipeline.placeholder_token_id()
+ part.input_ids = placeholders.to(shared.model.device, dtype=torch.int64)
+ else:
+ part.input_ids = encode(part.text, add_bos_token=add_bos_token)[0].to(shared.model.device, dtype=torch.int64)
+ return part
+
+ @staticmethod
+ def _num_images(parts: List[PromptPart]) -> int:
+ count = 0
+ for part in parts:
+ if part.is_image:
+ count += 1
+ return count
+
+ def _encode_text(self, state, parts: List[PromptPart]) -> List[PromptPart]:
+ """Encode text to token_ids, also truncate the prompt, if necessary.
+
+ The chat/instruct mode should make prompts that fit in get_max_prompt_length, but if max_new_tokens are set
+ such that the context + min_rows don't fit, we can get a prompt which is too long.
+ We can't truncate image embeddings, as it leads to broken generation, so remove the images instead and warn the user
+ """
+ encoded: List[PromptPart] = []
+ for i, part in enumerate(parts):
+ encoded.append(self._encode_single_text(part, i == 0 and state['add_bos_token']))
+
+ # truncation:
+ max_len = get_max_prompt_length(state)
+ removed_images = 0
+
+ # 1. remove entire text/image blocks
+ while self._len_in_tokens_prompt_parts(encoded[1:]) > max_len:
+ if encoded[0].is_image:
+ removed_images += 1
+ encoded = encoded[1:]
+
+ # 2. check if the last prompt part doesn't need to get truncated
+ if self._len_in_tokens_prompt_parts(encoded) > max_len:
+ if encoded[0].is_image:
+ # don't truncate image embeddings, just remove the image, otherwise generation will be broken
+ removed_images += 1
+ encoded = encoded[1:]
+ elif len(encoded) > 1 and encoded[0].text.endswith(self.pipeline.image_start()):
+ # see if we can keep image_start token
+ len_image_start = len(encode(self.pipeline.image_start(), add_bos_token=state['add_bos_token'])[0])
+ if self._len_in_tokens_prompt_parts(encoded[1:]) + len_image_start > max_len:
+ # we can't -> remove this text, and the image
+ encoded = encoded[2:]
+ removed_images += 1
+ else:
+ # we can -> just truncate the text
+ trunc_len = self._len_in_tokens_prompt_parts(encoded) - max_len
+ encoded[0].input_ids = encoded[0].input_ids[trunc_len:]
+ elif len(encoded) > 0:
+ # only one text left, truncate it normally
+ trunc_len = self._len_in_tokens_prompt_parts(encoded) - max_len
+ encoded[0].input_ids = encoded[0].input_ids[trunc_len:]
+
+ # notify user if we truncated an image
+ if removed_images > 0:
+ logger.warning(f"Multimodal: removed {removed_images} image(s) from prompt. Try decreasing max_new_tokens if generation is broken")
+
+ return encoded
+
+ def _embed(self, parts: List[PromptPart]) -> List[PromptPart]:
+ # batch images
+ image_indicies = [i for i, part in enumerate(parts) if part.is_image]
+ embedded = self.pipeline.embed_images([parts[i].image for i in image_indicies])
+ for i, embeds in zip(image_indicies, embedded):
+ parts[i].embedding = embeds
+ # embed text
+ for (i, part) in enumerate(parts):
+ if not part.is_image:
+ parts[i].embedding = self.pipeline.embed_tokens(part.input_ids)
+ return parts
+
+ def _remove_old_images(self, parts: List[PromptPart], params: dict) -> List[PromptPart]:
+ if params['add_all_images_to_prompt']:
+ return parts
+ already_added = False
+ for i, part in reversed(list(enumerate(parts))):
+ if part.is_image:
+ if already_added:
+ parts[i].embedding = self.pipeline.placeholder_embeddings()
+ else:
+ already_added = True
+ return parts
+
+ def forward(self, prompt: str, state: Any, params: dict):
+ prompt_parts = self._split_prompt(prompt, True)
+ prompt_parts = self._encode_text(state, prompt_parts)
+ prompt_parts = self._embed(prompt_parts)
+ prompt_parts = self._remove_old_images(prompt_parts, params)
+ embeds = tuple(part.embedding for part in prompt_parts)
+ ids = tuple(part.input_ids for part in prompt_parts)
+ input_embeds = torch.cat(embeds, dim=0)
+ input_ids = torch.cat(ids, dim=0)
+ return prompt, input_ids, input_embeds, self._num_images(prompt_parts)
diff --git a/extensions/multimodal/pipeline_loader.py b/extensions/multimodal/pipeline_loader.py
new file mode 100644
index 0000000000000000000000000000000000000000..8fcd0a9b410fbc44a51941e0a87b294de871ef8b
--- /dev/null
+++ b/extensions/multimodal/pipeline_loader.py
@@ -0,0 +1,52 @@
+import traceback
+from importlib import import_module
+from pathlib import Path
+from typing import Tuple
+
+from extensions.multimodal.abstract_pipeline import AbstractMultimodalPipeline
+from modules import shared
+from modules.logging_colors import logger
+
+
+def _get_available_pipeline_modules():
+ pipeline_path = Path(__file__).parent / 'pipelines'
+ modules = [p for p in pipeline_path.iterdir() if p.is_dir()]
+ return [m.name for m in modules if (m / 'pipelines.py').exists()]
+
+
+def load_pipeline(params: dict) -> Tuple[AbstractMultimodalPipeline, str]:
+ pipeline_modules = {}
+ available_pipeline_modules = _get_available_pipeline_modules()
+ for name in available_pipeline_modules:
+ try:
+ pipeline_modules[name] = import_module(f'extensions.multimodal.pipelines.{name}.pipelines')
+ except:
+ logger.warning(f'Failed to get multimodal pipelines from {name}')
+ logger.warning(traceback.format_exc())
+
+ if shared.args.multimodal_pipeline is not None:
+ for k in pipeline_modules:
+ if hasattr(pipeline_modules[k], 'get_pipeline'):
+ pipeline = getattr(pipeline_modules[k], 'get_pipeline')(shared.args.multimodal_pipeline, params)
+ if pipeline is not None:
+ return (pipeline, k)
+ else:
+ model_name = shared.args.model.lower()
+ for k in pipeline_modules:
+ if hasattr(pipeline_modules[k], 'get_pipeline_from_model_name'):
+ pipeline = getattr(pipeline_modules[k], 'get_pipeline_from_model_name')(model_name, params)
+ if pipeline is not None:
+ return (pipeline, k)
+
+ available = []
+ for k in pipeline_modules:
+ if hasattr(pipeline_modules[k], 'available_pipelines'):
+ pipelines = getattr(pipeline_modules[k], 'available_pipelines')
+ available += pipelines
+
+ if shared.args.multimodal_pipeline is not None:
+ log = f'Multimodal - ERROR: Failed to load multimodal pipeline "{shared.args.multimodal_pipeline}", available pipelines are: {available}.'
+ else:
+ log = f'Multimodal - ERROR: Failed to determine multimodal pipeline for model {shared.args.model}, please select one manually using --multimodal-pipeline [PIPELINE]. Available pipelines are: {available}.'
+ logger.critical(f'{log} Please specify a correct pipeline, or disable the extension')
+ raise RuntimeError(f'{log} Please specify a correct pipeline, or disable the extension')
diff --git a/extensions/multimodal/pipelines/llava/README.md b/extensions/multimodal/pipelines/llava/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..aff64faaae07d2f4da6c24e8ea03693326313139
--- /dev/null
+++ b/extensions/multimodal/pipelines/llava/README.md
@@ -0,0 +1,9 @@
+## LLaVA pipeline
+
+This module provides 2 pipelines:
+- `llava-7b` - for use with LLaVA v0 7B model (finetuned LLaMa 7B)
+- `llava-13b` - for use with LLaVA v0 13B model (finetuned LLaMa 13B)
+
+[LLaVA](https://github.com/haotian-liu/LLaVA) uses CLIP `openai/clip-vit-large-patch14` as the vision model, and then a single linear layer. For 13B the projector weights are in `liuhaotian/LLaVA-13b-delta-v0`, and for 7B they are in `liuhaotian/LLaVA-7b-delta-v0`.
+
+The supported parameter combinations for both the vision model, and the projector are: CUDA/32bit, CUDA/16bit, CPU/32bit
diff --git a/extensions/multimodal/pipelines/llava/llava.py b/extensions/multimodal/pipelines/llava/llava.py
new file mode 100644
index 0000000000000000000000000000000000000000..eca2be50bbcfce3f4b7c1f1bee89c80581a6b517
--- /dev/null
+++ b/extensions/multimodal/pipelines/llava/llava.py
@@ -0,0 +1,145 @@
+import time
+from abc import abstractmethod
+from typing import List, Tuple
+
+import torch
+from huggingface_hub import hf_hub_download
+from PIL import Image
+from transformers import CLIPImageProcessor, CLIPVisionModel
+
+from extensions.multimodal.abstract_pipeline import AbstractMultimodalPipeline
+from modules import shared
+from modules.logging_colors import logger
+from modules.text_generation import encode
+
+
+class LLaVA_v0_Pipeline(AbstractMultimodalPipeline):
+ CLIP_REPO = "openai/clip-vit-large-patch14"
+
+ def __init__(self, params: dict) -> None:
+ super().__init__()
+ self.clip_device = self._get_device("vision_device", params)
+ self.clip_dtype = self._get_dtype("vision_bits", params)
+ self.projector_device = self._get_device("projector_device", params)
+ self.projector_dtype = self._get_dtype("projector_bits", params)
+ self.image_processor, self.vision_tower, self.mm_projector = self._load_models()
+
+ def _load_models(self):
+ start_ts = time.time()
+
+ logger.info(f"LLaVA - Loading CLIP from {LLaVA_v0_Pipeline.CLIP_REPO} as {self.clip_dtype} on {self.clip_device}...")
+ image_processor = CLIPImageProcessor.from_pretrained(LLaVA_v0_Pipeline.CLIP_REPO, torch_dtype=self.clip_dtype)
+ vision_tower = CLIPVisionModel.from_pretrained(LLaVA_v0_Pipeline.CLIP_REPO, torch_dtype=self.clip_dtype).to(self.clip_device)
+
+ logger.info(f"LLaVA - Loading projector from {self.llava_projector_repo()} as {self.projector_dtype} on {self.projector_device}...")
+ projector_path = hf_hub_download(self.llava_projector_repo(), self.llava_projector_filename())
+ mm_projector = torch.nn.Linear(*self.llava_projector_shape())
+ projector_data = torch.load(projector_path)
+ mm_projector.weight = torch.nn.Parameter(projector_data['model.mm_projector.weight'].to(dtype=self.projector_dtype), False)
+ mm_projector.bias = torch.nn.Parameter(projector_data['model.mm_projector.bias'].to(dtype=self.projector_dtype), False)
+ mm_projector = mm_projector.to(self.projector_device)
+
+ logger.info(f"LLaVA supporting models loaded, took {time.time() - start_ts:.2f} seconds")
+ return image_processor, vision_tower, mm_projector
+
+ @staticmethod
+ def image_start() -> str:
+ return "'
+
+ if '
`.
+
+## LLM input
+To describe the input, let's see it on an example prompt:
+```
+text1'`, where `img_str` is base-64 jpeg data. Note that you will need to launch `server.py` with the arguments `--api --extensions multimodal`.
+
+Python example:
+
+```Python
+import base64
+import requests
+
+CONTEXT = "You are LLaVA, a large language and vision assistant trained by UW Madison WAIV Lab. You are able to understand the visual content that the user provides, and assist the user with a variety of tasks using natural language. Follow the instructions carefully and explain your answers in detail.### Human: Hi!### Assistant: Hi there! How can I help you today?\n"
+
+with open('extreme_ironing.jpg', 'rb') as f:
+ img_str = base64.b64encode(f.read()).decode('utf-8')
+ prompt = CONTEXT + f'### Human: What is unusual about this image: \n### Assistant: '
+ print(requests.post('http://127.0.0.1:5000/api/v1/generate', json={'prompt': prompt, 'stopping_strings': ['\n###']}).json())
+```
+script output:
+```Python
+{'results': [{'text': "The unusual aspect of this image is that a man is standing on top of a yellow minivan while doing his laundry. He has set up a makeshift clothes line using the car's rooftop as an outdoor drying area. This scene is uncommon because people typically do their laundry indoors, in a dedicated space like a laundromat or a room in their home, rather than on top of a moving vehicle. Additionally, hanging clothes on the car could be potentially hazardous or illegal in some jurisdictions due to the risk of damaging the vehicle or causing accidents on the road.\n##"}]}
+```
+
+## For pipeline developers/technical description
+see [DOCS.md](https://github.com/oobabooga/text-generation-webui/blob/main/extensions/multimodal/DOCS.md)
diff --git a/extensions/multimodal/abstract_pipeline.py b/extensions/multimodal/abstract_pipeline.py
new file mode 100644
index 0000000000000000000000000000000000000000..584219419d256e7743fd4d5120c56bcfa8f2a9f9
--- /dev/null
+++ b/extensions/multimodal/abstract_pipeline.py
@@ -0,0 +1,62 @@
+from abc import ABC, abstractmethod
+from typing import List, Optional
+
+import torch
+from PIL import Image
+
+
+class AbstractMultimodalPipeline(ABC):
+ @staticmethod
+ @abstractmethod
+ def name() -> str:
+ 'name of the pipeline, should be same as in --multimodal-pipeline'
+ pass
+
+ @staticmethod
+ @abstractmethod
+ def image_start() -> Optional[str]:
+ 'return image start string, string representation of image start token, or None if not applicable'
+ pass
+
+ @staticmethod
+ @abstractmethod
+ def image_end() -> Optional[str]:
+ 'return image end string, string representation of image end token, or None if not applicable'
+ pass
+
+ @staticmethod
+ @abstractmethod
+ def placeholder_token_id() -> int:
+ 'return placeholder token id'
+ pass
+
+ @staticmethod
+ @abstractmethod
+ def num_image_embeds() -> int:
+ 'return the number of embeds used by a single image (for example: 256 for LLaVA)'
+ pass
+
+ @abstractmethod
+ def embed_images(self, images: List[Image.Image]) -> torch.Tensor:
+ 'forward the images through vision pipeline, and return their embeddings'
+ pass
+
+ @staticmethod
+ @abstractmethod
+ def embed_tokens(input_ids: torch.Tensor) -> torch.Tensor:
+ 'embed tokens, the exact function varies by LLM, for LLaMA it is `shared.model.model.embed_tokens`'
+ pass
+
+ @staticmethod
+ @abstractmethod
+ def placeholder_embeddings() -> torch.Tensor:
+ 'get placeholder embeddings if there are multiple images, and `add_all_images_to_prompt` is False'
+ pass
+
+ def _get_device(self, setting_name: str, params: dict):
+ if params[setting_name] is None:
+ return torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
+ return torch.device(params[setting_name])
+
+ def _get_dtype(self, setting_name: str, params: dict):
+ return torch.float32 if int(params[setting_name]) == 32 else torch.float16
diff --git a/extensions/multimodal/multimodal_embedder.py b/extensions/multimodal/multimodal_embedder.py
new file mode 100644
index 0000000000000000000000000000000000000000..626077cb80987d66af90f390e31aa2f2def76fec
--- /dev/null
+++ b/extensions/multimodal/multimodal_embedder.py
@@ -0,0 +1,178 @@
+import base64
+import re
+from dataclasses import dataclass
+from io import BytesIO
+from typing import Any, List, Optional
+
+import torch
+from PIL import Image
+
+from extensions.multimodal.pipeline_loader import load_pipeline
+from modules import shared
+from modules.logging_colors import logger
+from modules.text_generation import encode, get_max_prompt_length
+
+
+@dataclass
+class PromptPart:
+ text: str
+ image: Optional[Image.Image] = None
+ is_image: bool = False
+ input_ids: Optional[torch.Tensor] = None
+ embedding: Optional[torch.Tensor] = None
+
+
+class MultimodalEmbedder:
+ def __init__(self, params: dict):
+ pipeline, source = load_pipeline(params)
+ self.pipeline = pipeline
+ logger.info(f'Multimodal: loaded pipeline {self.pipeline.name()} from pipelines/{source} ({self.pipeline.__class__.__name__})')
+
+ def _split_prompt(self, prompt: str, load_images: bool = False) -> List[PromptPart]:
+ """Splits a prompt into a list of `PromptParts` to separate image data from text.
+ It will also append `image_start` and `image_end` before and after the image, and optionally parse and load the images,
+ if `load_images` is `True`.
+ """
+ parts: List[PromptPart] = []
+ curr = 0
+ while True:
+ match = re.search(r'', prompt[curr:])
+ if match is None:
+ # no more image tokens, append the rest of the prompt
+ if curr > 0:
+ # add image end token after last image
+ parts.append(PromptPart(text=self.pipeline.image_end() + prompt[curr:]))
+ else:
+ parts.append(PromptPart(text=prompt))
+ break
+ # found an image, append image start token to the text
+ if match.start() > 0:
+ parts.append(PromptPart(text=prompt[curr:curr + match.start()] + self.pipeline.image_start()))
+ else:
+ parts.append(PromptPart(text=self.pipeline.image_start()))
+ # append the image
+ parts.append(PromptPart(
+ text=match.group(0),
+ image=Image.open(BytesIO(base64.b64decode(match.group(1)))) if load_images else None,
+ is_image=True
+ ))
+ curr += match.end()
+ return parts
+
+ def _len_in_tokens_prompt_parts(self, parts: List[PromptPart]) -> int:
+ """Total length in tokens of all `parts`"""
+ tokens = 0
+ for part in parts:
+ if part.is_image:
+ tokens += self.pipeline.num_image_embeds()
+ elif part.input_ids is not None:
+ tokens += len(part.input_ids)
+ else:
+ tokens += len(encode(part.text)[0])
+ return tokens
+
+ def len_in_tokens(self, prompt: str) -> int:
+ """Total length in tokens for a given text `prompt`"""
+ parts = self._split_prompt(prompt, False)
+ return self._len_in_tokens_prompt_parts(parts)
+
+ def _encode_single_text(self, part: PromptPart, add_bos_token: bool) -> PromptPart:
+ """Encode a single prompt `part` to `input_ids`. Returns a `PromptPart`"""
+ if part.is_image:
+ placeholders = torch.ones((self.pipeline.num_image_embeds())) * self.pipeline.placeholder_token_id()
+ part.input_ids = placeholders.to(shared.model.device, dtype=torch.int64)
+ else:
+ part.input_ids = encode(part.text, add_bos_token=add_bos_token)[0].to(shared.model.device, dtype=torch.int64)
+ return part
+
+ @staticmethod
+ def _num_images(parts: List[PromptPart]) -> int:
+ count = 0
+ for part in parts:
+ if part.is_image:
+ count += 1
+ return count
+
+ def _encode_text(self, state, parts: List[PromptPart]) -> List[PromptPart]:
+ """Encode text to token_ids, also truncate the prompt, if necessary.
+
+ The chat/instruct mode should make prompts that fit in get_max_prompt_length, but if max_new_tokens are set
+ such that the context + min_rows don't fit, we can get a prompt which is too long.
+ We can't truncate image embeddings, as it leads to broken generation, so remove the images instead and warn the user
+ """
+ encoded: List[PromptPart] = []
+ for i, part in enumerate(parts):
+ encoded.append(self._encode_single_text(part, i == 0 and state['add_bos_token']))
+
+ # truncation:
+ max_len = get_max_prompt_length(state)
+ removed_images = 0
+
+ # 1. remove entire text/image blocks
+ while self._len_in_tokens_prompt_parts(encoded[1:]) > max_len:
+ if encoded[0].is_image:
+ removed_images += 1
+ encoded = encoded[1:]
+
+ # 2. check if the last prompt part doesn't need to get truncated
+ if self._len_in_tokens_prompt_parts(encoded) > max_len:
+ if encoded[0].is_image:
+ # don't truncate image embeddings, just remove the image, otherwise generation will be broken
+ removed_images += 1
+ encoded = encoded[1:]
+ elif len(encoded) > 1 and encoded[0].text.endswith(self.pipeline.image_start()):
+ # see if we can keep image_start token
+ len_image_start = len(encode(self.pipeline.image_start(), add_bos_token=state['add_bos_token'])[0])
+ if self._len_in_tokens_prompt_parts(encoded[1:]) + len_image_start > max_len:
+ # we can't -> remove this text, and the image
+ encoded = encoded[2:]
+ removed_images += 1
+ else:
+ # we can -> just truncate the text
+ trunc_len = self._len_in_tokens_prompt_parts(encoded) - max_len
+ encoded[0].input_ids = encoded[0].input_ids[trunc_len:]
+ elif len(encoded) > 0:
+ # only one text left, truncate it normally
+ trunc_len = self._len_in_tokens_prompt_parts(encoded) - max_len
+ encoded[0].input_ids = encoded[0].input_ids[trunc_len:]
+
+ # notify user if we truncated an image
+ if removed_images > 0:
+ logger.warning(f"Multimodal: removed {removed_images} image(s) from prompt. Try decreasing max_new_tokens if generation is broken")
+
+ return encoded
+
+ def _embed(self, parts: List[PromptPart]) -> List[PromptPart]:
+ # batch images
+ image_indicies = [i for i, part in enumerate(parts) if part.is_image]
+ embedded = self.pipeline.embed_images([parts[i].image for i in image_indicies])
+ for i, embeds in zip(image_indicies, embedded):
+ parts[i].embedding = embeds
+ # embed text
+ for (i, part) in enumerate(parts):
+ if not part.is_image:
+ parts[i].embedding = self.pipeline.embed_tokens(part.input_ids)
+ return parts
+
+ def _remove_old_images(self, parts: List[PromptPart], params: dict) -> List[PromptPart]:
+ if params['add_all_images_to_prompt']:
+ return parts
+ already_added = False
+ for i, part in reversed(list(enumerate(parts))):
+ if part.is_image:
+ if already_added:
+ parts[i].embedding = self.pipeline.placeholder_embeddings()
+ else:
+ already_added = True
+ return parts
+
+ def forward(self, prompt: str, state: Any, params: dict):
+ prompt_parts = self._split_prompt(prompt, True)
+ prompt_parts = self._encode_text(state, prompt_parts)
+ prompt_parts = self._embed(prompt_parts)
+ prompt_parts = self._remove_old_images(prompt_parts, params)
+ embeds = tuple(part.embedding for part in prompt_parts)
+ ids = tuple(part.input_ids for part in prompt_parts)
+ input_embeds = torch.cat(embeds, dim=0)
+ input_ids = torch.cat(ids, dim=0)
+ return prompt, input_ids, input_embeds, self._num_images(prompt_parts)
diff --git a/extensions/multimodal/pipeline_loader.py b/extensions/multimodal/pipeline_loader.py
new file mode 100644
index 0000000000000000000000000000000000000000..8fcd0a9b410fbc44a51941e0a87b294de871ef8b
--- /dev/null
+++ b/extensions/multimodal/pipeline_loader.py
@@ -0,0 +1,52 @@
+import traceback
+from importlib import import_module
+from pathlib import Path
+from typing import Tuple
+
+from extensions.multimodal.abstract_pipeline import AbstractMultimodalPipeline
+from modules import shared
+from modules.logging_colors import logger
+
+
+def _get_available_pipeline_modules():
+ pipeline_path = Path(__file__).parent / 'pipelines'
+ modules = [p for p in pipeline_path.iterdir() if p.is_dir()]
+ return [m.name for m in modules if (m / 'pipelines.py').exists()]
+
+
+def load_pipeline(params: dict) -> Tuple[AbstractMultimodalPipeline, str]:
+ pipeline_modules = {}
+ available_pipeline_modules = _get_available_pipeline_modules()
+ for name in available_pipeline_modules:
+ try:
+ pipeline_modules[name] = import_module(f'extensions.multimodal.pipelines.{name}.pipelines')
+ except:
+ logger.warning(f'Failed to get multimodal pipelines from {name}')
+ logger.warning(traceback.format_exc())
+
+ if shared.args.multimodal_pipeline is not None:
+ for k in pipeline_modules:
+ if hasattr(pipeline_modules[k], 'get_pipeline'):
+ pipeline = getattr(pipeline_modules[k], 'get_pipeline')(shared.args.multimodal_pipeline, params)
+ if pipeline is not None:
+ return (pipeline, k)
+ else:
+ model_name = shared.args.model.lower()
+ for k in pipeline_modules:
+ if hasattr(pipeline_modules[k], 'get_pipeline_from_model_name'):
+ pipeline = getattr(pipeline_modules[k], 'get_pipeline_from_model_name')(model_name, params)
+ if pipeline is not None:
+ return (pipeline, k)
+
+ available = []
+ for k in pipeline_modules:
+ if hasattr(pipeline_modules[k], 'available_pipelines'):
+ pipelines = getattr(pipeline_modules[k], 'available_pipelines')
+ available += pipelines
+
+ if shared.args.multimodal_pipeline is not None:
+ log = f'Multimodal - ERROR: Failed to load multimodal pipeline "{shared.args.multimodal_pipeline}", available pipelines are: {available}.'
+ else:
+ log = f'Multimodal - ERROR: Failed to determine multimodal pipeline for model {shared.args.model}, please select one manually using --multimodal-pipeline [PIPELINE]. Available pipelines are: {available}.'
+ logger.critical(f'{log} Please specify a correct pipeline, or disable the extension')
+ raise RuntimeError(f'{log} Please specify a correct pipeline, or disable the extension')
diff --git a/extensions/multimodal/pipelines/llava/README.md b/extensions/multimodal/pipelines/llava/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..aff64faaae07d2f4da6c24e8ea03693326313139
--- /dev/null
+++ b/extensions/multimodal/pipelines/llava/README.md
@@ -0,0 +1,9 @@
+## LLaVA pipeline
+
+This module provides 2 pipelines:
+- `llava-7b` - for use with LLaVA v0 7B model (finetuned LLaMa 7B)
+- `llava-13b` - for use with LLaVA v0 13B model (finetuned LLaMa 13B)
+
+[LLaVA](https://github.com/haotian-liu/LLaVA) uses CLIP `openai/clip-vit-large-patch14` as the vision model, and then a single linear layer. For 13B the projector weights are in `liuhaotian/LLaVA-13b-delta-v0`, and for 7B they are in `liuhaotian/LLaVA-7b-delta-v0`.
+
+The supported parameter combinations for both the vision model, and the projector are: CUDA/32bit, CUDA/16bit, CPU/32bit
diff --git a/extensions/multimodal/pipelines/llava/llava.py b/extensions/multimodal/pipelines/llava/llava.py
new file mode 100644
index 0000000000000000000000000000000000000000..eca2be50bbcfce3f4b7c1f1bee89c80581a6b517
--- /dev/null
+++ b/extensions/multimodal/pipelines/llava/llava.py
@@ -0,0 +1,145 @@
+import time
+from abc import abstractmethod
+from typing import List, Tuple
+
+import torch
+from huggingface_hub import hf_hub_download
+from PIL import Image
+from transformers import CLIPImageProcessor, CLIPVisionModel
+
+from extensions.multimodal.abstract_pipeline import AbstractMultimodalPipeline
+from modules import shared
+from modules.logging_colors import logger
+from modules.text_generation import encode
+
+
+class LLaVA_v0_Pipeline(AbstractMultimodalPipeline):
+ CLIP_REPO = "openai/clip-vit-large-patch14"
+
+ def __init__(self, params: dict) -> None:
+ super().__init__()
+ self.clip_device = self._get_device("vision_device", params)
+ self.clip_dtype = self._get_dtype("vision_bits", params)
+ self.projector_device = self._get_device("projector_device", params)
+ self.projector_dtype = self._get_dtype("projector_bits", params)
+ self.image_processor, self.vision_tower, self.mm_projector = self._load_models()
+
+ def _load_models(self):
+ start_ts = time.time()
+
+ logger.info(f"LLaVA - Loading CLIP from {LLaVA_v0_Pipeline.CLIP_REPO} as {self.clip_dtype} on {self.clip_device}...")
+ image_processor = CLIPImageProcessor.from_pretrained(LLaVA_v0_Pipeline.CLIP_REPO, torch_dtype=self.clip_dtype)
+ vision_tower = CLIPVisionModel.from_pretrained(LLaVA_v0_Pipeline.CLIP_REPO, torch_dtype=self.clip_dtype).to(self.clip_device)
+
+ logger.info(f"LLaVA - Loading projector from {self.llava_projector_repo()} as {self.projector_dtype} on {self.projector_device}...")
+ projector_path = hf_hub_download(self.llava_projector_repo(), self.llava_projector_filename())
+ mm_projector = torch.nn.Linear(*self.llava_projector_shape())
+ projector_data = torch.load(projector_path)
+ mm_projector.weight = torch.nn.Parameter(projector_data['model.mm_projector.weight'].to(dtype=self.projector_dtype), False)
+ mm_projector.bias = torch.nn.Parameter(projector_data['model.mm_projector.bias'].to(dtype=self.projector_dtype), False)
+ mm_projector = mm_projector.to(self.projector_device)
+
+ logger.info(f"LLaVA supporting models loaded, took {time.time() - start_ts:.2f} seconds")
+ return image_processor, vision_tower, mm_projector
+
+ @staticmethod
+ def image_start() -> str:
+ return "'
+
+ if ' ', prompt)
+
+ if image_match is None:
+ return prompt, input_ids, input_embeds
+
+ prompt, input_ids, input_embeds, total_embedded = multimodal_embedder.forward(prompt, state, params)
+ logger.info(f'Embedded {total_embedded} image(s) in {time.time()-start_ts:.2f}s')
+ return (prompt,
+ input_ids.unsqueeze(0).to(shared.model.device, dtype=torch.int64),
+ input_embeds.unsqueeze(0).to(shared.model.device, dtype=shared.model.dtype))
+
+
+def ui():
+ global multimodal_embedder
+ multimodal_embedder = MultimodalEmbedder(params)
+ with gr.Column():
+ picture_select = gr.Image(label='Send a picture', type='pil')
+ # The models don't seem to deal well with multiple images
+ single_image_checkbox = gr.Checkbox(False, label='Embed all images, not only the last one')
+ # Prepare the input hijack
+ picture_select.upload(
+ lambda picture: input_hijack.update({"state": True, "value": partial(add_chat_picture, picture)}),
+ [picture_select],
+ None
+ )
+ picture_select.clear(lambda: input_hijack.update({"state": False, "value": ["", ""]}), None, None)
+ single_image_checkbox.change(lambda x: params.update({"add_all_images_to_prompt": x}), single_image_checkbox, None)
+ shared.gradio['Generate'].click(lambda: None, None, picture_select)
+ shared.gradio['textbox'].submit(lambda: None, None, picture_select)
diff --git a/extensions/ngrok/README.md b/extensions/ngrok/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..0324bf9852408d9d2b86cc0165c2d548996f9c94
--- /dev/null
+++ b/extensions/ngrok/README.md
@@ -0,0 +1,69 @@
+# Adding an ingress URL through the ngrok Agent SDK for Python
+
+[ngrok](https://ngrok.com) is a globally distributed reverse proxy commonly used for quickly getting a public URL to a
+service running inside a private network, such as on your local laptop. The ngrok agent is usually
+deployed inside a private network and is used to communicate with the ngrok cloud service.
+
+By default the authtoken in the NGROK_AUTHTOKEN environment variable will be used. Alternatively one may be specified in
+the `settings.json` file, see the Examples below. Retrieve your authtoken on the [Auth Token page of your ngrok dashboard](https://dashboard.ngrok.com/get-started/your-authtoken), signing up is free.
+
+# Documentation
+
+For a list of all available options, see [the configuration documentation](https://ngrok.com/docs/ngrok-agent/config/) or [the connect example](https://github.com/ngrok/ngrok-py/blob/main/examples/ngrok-connect-full.py).
+
+The ngrok Python SDK is [on github here](https://github.com/ngrok/ngrok-py). A quickstart guide and a full API reference are included in the [ngrok-py Python API documentation](https://ngrok.github.io/ngrok-py/).
+
+# Running
+
+To enable ngrok install the requirements and then add `--extension ngrok` to the command line options, for instance:
+
+```bash
+pip install -r extensions/ngrok/requirements.txt
+python server.py --extension ngrok
+```
+
+In the output you should then see something like this:
+
+```bash
+INFO:Loading the extension "ngrok"...
+INFO:Session created
+INFO:Created tunnel "9d9d0944dc75ff9d3aae653e5eb29fe9" with url "https://d83706cf7be7.ngrok.app"
+INFO:Tunnel "9d9d0944dc75ff9d3aae653e5eb29fe9" TCP forwarding to "localhost:7860"
+INFO:Ingress established at https://d83706cf7be7.ngrok.app
+```
+
+You can now access the webui via the url shown, in this case `https://d83706cf7be7.ngrok.app`. It is recommended to add some authentication to the ingress, see below.
+
+# Example Settings
+
+In `settings.json` add a `ngrok` key with a dictionary of options, for instance:
+
+To enable basic authentication:
+```json
+{
+ "ngrok": {
+ "basic_auth": "user:password"
+ }
+}
+```
+
+To enable OAUTH authentication:
+```json
+{
+ "ngrok": {
+ "oauth_provider": "google",
+ "oauth_allow_domains": "asdf.com",
+ "oauth_allow_emails": "asdf@asdf.com"
+ }
+}
+```
+
+To add an authtoken instead of using the NGROK_AUTHTOKEN environment variable:
+```json
+{
+ "ngrok": {
+ "authtoken": "
', prompt)
+
+ if image_match is None:
+ return prompt, input_ids, input_embeds
+
+ prompt, input_ids, input_embeds, total_embedded = multimodal_embedder.forward(prompt, state, params)
+ logger.info(f'Embedded {total_embedded} image(s) in {time.time()-start_ts:.2f}s')
+ return (prompt,
+ input_ids.unsqueeze(0).to(shared.model.device, dtype=torch.int64),
+ input_embeds.unsqueeze(0).to(shared.model.device, dtype=shared.model.dtype))
+
+
+def ui():
+ global multimodal_embedder
+ multimodal_embedder = MultimodalEmbedder(params)
+ with gr.Column():
+ picture_select = gr.Image(label='Send a picture', type='pil')
+ # The models don't seem to deal well with multiple images
+ single_image_checkbox = gr.Checkbox(False, label='Embed all images, not only the last one')
+ # Prepare the input hijack
+ picture_select.upload(
+ lambda picture: input_hijack.update({"state": True, "value": partial(add_chat_picture, picture)}),
+ [picture_select],
+ None
+ )
+ picture_select.clear(lambda: input_hijack.update({"state": False, "value": ["", ""]}), None, None)
+ single_image_checkbox.change(lambda x: params.update({"add_all_images_to_prompt": x}), single_image_checkbox, None)
+ shared.gradio['Generate'].click(lambda: None, None, picture_select)
+ shared.gradio['textbox'].submit(lambda: None, None, picture_select)
diff --git a/extensions/ngrok/README.md b/extensions/ngrok/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..0324bf9852408d9d2b86cc0165c2d548996f9c94
--- /dev/null
+++ b/extensions/ngrok/README.md
@@ -0,0 +1,69 @@
+# Adding an ingress URL through the ngrok Agent SDK for Python
+
+[ngrok](https://ngrok.com) is a globally distributed reverse proxy commonly used for quickly getting a public URL to a
+service running inside a private network, such as on your local laptop. The ngrok agent is usually
+deployed inside a private network and is used to communicate with the ngrok cloud service.
+
+By default the authtoken in the NGROK_AUTHTOKEN environment variable will be used. Alternatively one may be specified in
+the `settings.json` file, see the Examples below. Retrieve your authtoken on the [Auth Token page of your ngrok dashboard](https://dashboard.ngrok.com/get-started/your-authtoken), signing up is free.
+
+# Documentation
+
+For a list of all available options, see [the configuration documentation](https://ngrok.com/docs/ngrok-agent/config/) or [the connect example](https://github.com/ngrok/ngrok-py/blob/main/examples/ngrok-connect-full.py).
+
+The ngrok Python SDK is [on github here](https://github.com/ngrok/ngrok-py). A quickstart guide and a full API reference are included in the [ngrok-py Python API documentation](https://ngrok.github.io/ngrok-py/).
+
+# Running
+
+To enable ngrok install the requirements and then add `--extension ngrok` to the command line options, for instance:
+
+```bash
+pip install -r extensions/ngrok/requirements.txt
+python server.py --extension ngrok
+```
+
+In the output you should then see something like this:
+
+```bash
+INFO:Loading the extension "ngrok"...
+INFO:Session created
+INFO:Created tunnel "9d9d0944dc75ff9d3aae653e5eb29fe9" with url "https://d83706cf7be7.ngrok.app"
+INFO:Tunnel "9d9d0944dc75ff9d3aae653e5eb29fe9" TCP forwarding to "localhost:7860"
+INFO:Ingress established at https://d83706cf7be7.ngrok.app
+```
+
+You can now access the webui via the url shown, in this case `https://d83706cf7be7.ngrok.app`. It is recommended to add some authentication to the ingress, see below.
+
+# Example Settings
+
+In `settings.json` add a `ngrok` key with a dictionary of options, for instance:
+
+To enable basic authentication:
+```json
+{
+ "ngrok": {
+ "basic_auth": "user:password"
+ }
+}
+```
+
+To enable OAUTH authentication:
+```json
+{
+ "ngrok": {
+ "oauth_provider": "google",
+ "oauth_allow_domains": "asdf.com",
+ "oauth_allow_emails": "asdf@asdf.com"
+ }
+}
+```
+
+To add an authtoken instead of using the NGROK_AUTHTOKEN environment variable:
+```json
+{
+ "ngrok": {
+ "authtoken": "| {token} | {prob} |
+
+
+Load it in the `--chat` mode with `--extension sd_api_pictures` alongside `send_pictures`
+(it's not really required, but completes the picture, *pun intended*).
+
+
+## History
+
+Consider the version included with [oobabooga's repository](https://github.com/oobabooga/text-generation-webui/tree/main/extensions/sd_api_pictures) to be STABLE, experimental developments and untested features are pushed in [Brawlence/SD_api_pics](https://github.com/Brawlence/SD_api_pics)
+
+Lastest change:
+1.1.0 → 1.1.1 Fixed not having Auto1111's metadata in received images
+
+## Details
+
+The image generation is triggered:
+- manually through the 'Force the picture response' button while in `Manual` or `Immersive/Interactive` modes OR
+- automatically in `Immersive/Interactive` mode if the words `'send|main|message|me'` are followed by `'image|pic|picture|photo|snap|snapshot|selfie|meme'` in the user's prompt
+- always on in `Picturebook/Adventure` mode (if not currently suppressed by 'Suppress the picture response')
+
+## Prerequisites
+
+One needs an available instance of Automatic1111's webui running with an `--api` flag. Ain't tested with a notebook / cloud hosted one but should be possible.
+To run it locally in parallel on the same machine, specify custom `--listen-port` for either Auto1111's or ooba's webUIs.
+
+## Features overview
+- Connection to API check (press enter in the address box)
+- [VRAM management (model shuffling)](https://github.com/Brawlence/SD_api_pics/wiki/VRAM-management-feature)
+- [Three different operation modes](https://github.com/Brawlence/SD_api_pics/wiki/Modes-of-operation) (manual, interactive, always-on)
+- User-defined persistent settings via settings.json
+
+### Connection check
+
+Insert the Automatic1111's WebUI address and press Enter:
+
+Green mark confirms the ability to communicate with Auto1111's API on this address. Red cross means something's not right (the ext won't work).
+
+### Persistents settings
+
+Create or modify the `settings.json` in the `text-generation-webui` root directory to override the defaults
+present in script.py, ex:
+
+```json
+{
+ "sd_api_pictures-manage_VRAM": 1,
+ "sd_api_pictures-save_img": 1,
+ "sd_api_pictures-prompt_prefix": "(Masterpiece:1.1), detailed, intricate, colorful, (solo:1.1)",
+ "sd_api_pictures-sampler_name": "DPM++ 2M Karras"
+}
+```
+
+will automatically set the `Manage VRAM` & `Keep original images` checkboxes and change the texts in `Prompt Prefix` and `Sampler name` on load.
+
+---
+
+## Demonstrations:
+
+Those are examples of the version 1.0.0, but the core functionality is still the same
+
+Interface overview
+ +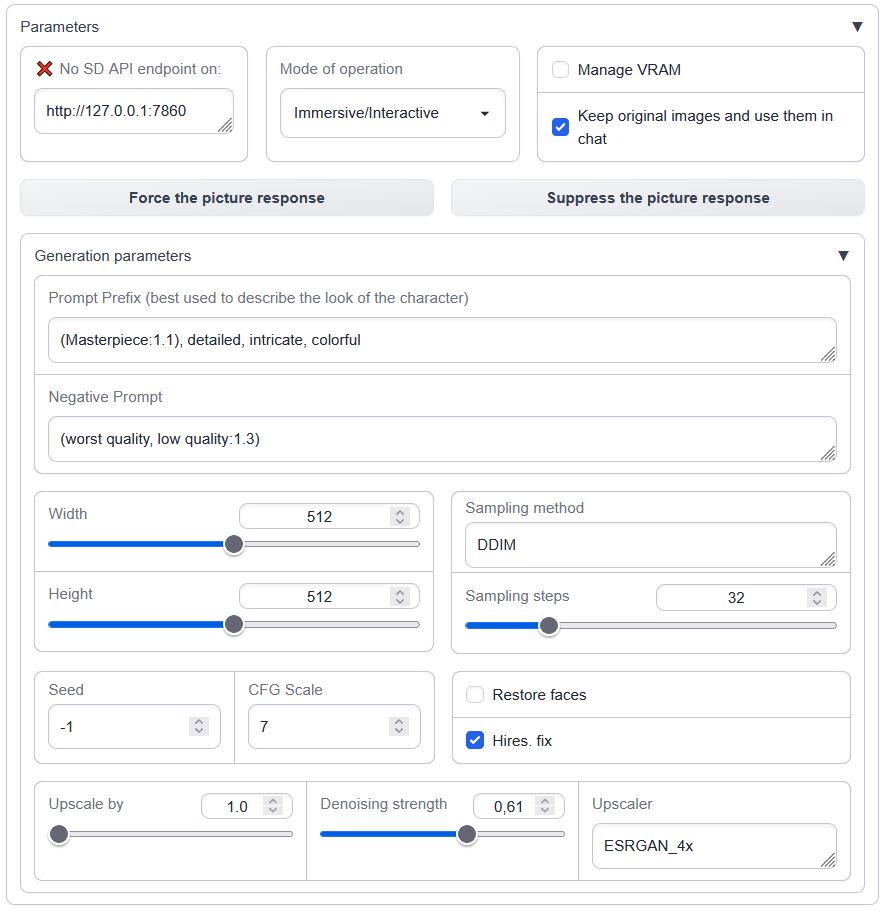 + +
+
+
+Conversation 1
+ +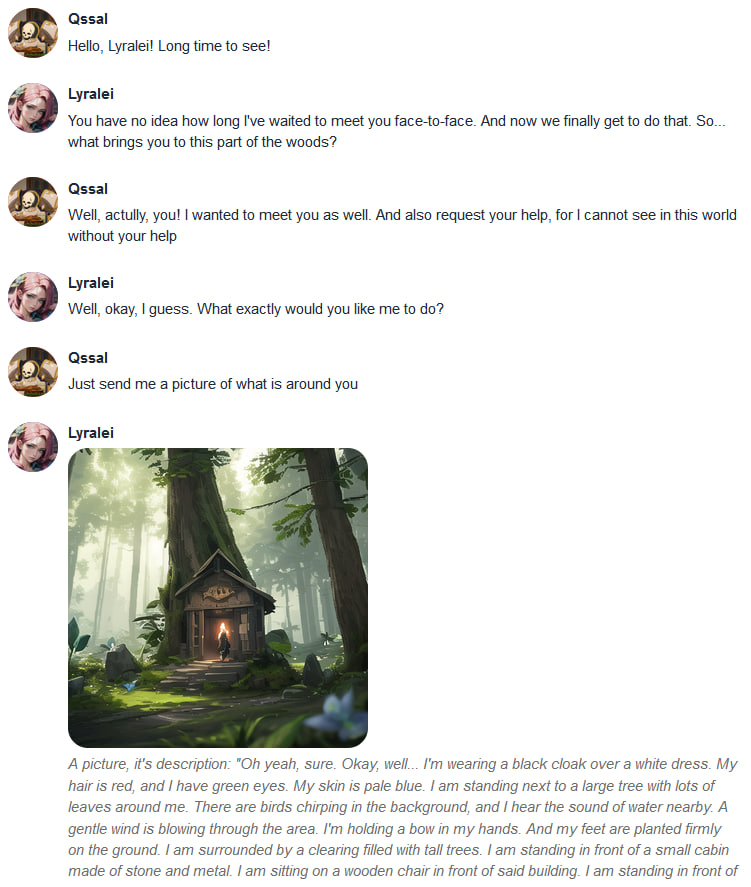 + + + + + +
+
+
diff --git a/extensions/sd_api_pictures/script.py b/extensions/sd_api_pictures/script.py
new file mode 100644
index 0000000000000000000000000000000000000000..e33367d4a0b7e3486bbc280a2dd2e248517e89cc
--- /dev/null
+++ b/extensions/sd_api_pictures/script.py
@@ -0,0 +1,386 @@
+import base64
+import io
+import re
+import time
+from datetime import date
+from pathlib import Path
+
+import gradio as gr
+import requests
+import torch
+from PIL import Image
+
+from modules import shared
+from modules.models import reload_model, unload_model
+from modules.ui import create_refresh_button
+
+torch._C._jit_set_profiling_mode(False)
+
+# parameters which can be customized in settings.json of webui
+params = {
+ 'address': 'http://127.0.0.1:7860',
+ 'mode': 0, # modes of operation: 0 (Manual only), 1 (Immersive/Interactive - looks for words to trigger), 2 (Picturebook Adventure - Always on)
+ 'manage_VRAM': False,
+ 'save_img': False,
+ 'SD_model': 'NeverEndingDream', # not used right now
+ 'prompt_prefix': '(Masterpiece:1.1), detailed, intricate, colorful',
+ 'negative_prompt': '(worst quality, low quality:1.3)',
+ 'width': 512,
+ 'height': 512,
+ 'denoising_strength': 0.61,
+ 'restore_faces': False,
+ 'enable_hr': False,
+ 'hr_upscaler': 'ESRGAN_4x',
+ 'hr_scale': '1.0',
+ 'seed': -1,
+ 'sampler_name': 'DPM++ 2M Karras',
+ 'steps': 32,
+ 'cfg_scale': 7,
+ 'textgen_prefix': 'Please provide a detailed and vivid description of [subject]',
+ 'sd_checkpoint': ' ',
+ 'checkpoint_list': [" "]
+}
+
+
+def give_VRAM_priority(actor):
+ global shared, params
+
+ if actor == 'SD':
+ unload_model()
+ print("Requesting Auto1111 to re-load last checkpoint used...")
+ response = requests.post(url=f'{params["address"]}/sdapi/v1/reload-checkpoint', json='')
+ response.raise_for_status()
+
+ elif actor == 'LLM':
+ print("Requesting Auto1111 to vacate VRAM...")
+ response = requests.post(url=f'{params["address"]}/sdapi/v1/unload-checkpoint', json='')
+ response.raise_for_status()
+ reload_model()
+
+ elif actor == 'set':
+ print("VRAM mangement activated -- requesting Auto1111 to vacate VRAM...")
+ response = requests.post(url=f'{params["address"]}/sdapi/v1/unload-checkpoint', json='')
+ response.raise_for_status()
+
+ elif actor == 'reset':
+ print("VRAM mangement deactivated -- requesting Auto1111 to reload checkpoint")
+ response = requests.post(url=f'{params["address"]}/sdapi/v1/reload-checkpoint', json='')
+ response.raise_for_status()
+
+ else:
+ raise RuntimeError(f'Managing VRAM: "{actor}" is not a known state!')
+
+ response.raise_for_status()
+ del response
+
+
+if params['manage_VRAM']:
+ give_VRAM_priority('set')
+
+SD_models = ['NeverEndingDream'] # TODO: get with http://{address}}/sdapi/v1/sd-models and allow user to select
+
+picture_response = False # specifies if the next model response should appear as a picture
+
+
+def remove_surrounded_chars(string):
+ # this expression matches to 'as few symbols as possible (0 upwards) between any asterisks' OR
+ # 'as few symbols as possible (0 upwards) between an asterisk and the end of the string'
+ return re.sub('\*[^\*]*?(\*|$)', '', string)
+
+
+def triggers_are_in(string):
+ string = remove_surrounded_chars(string)
+ # regex searches for send|main|message|me (at the end of the word) followed by
+ # a whole word of image|pic|picture|photo|snap|snapshot|selfie|meme(s),
+ # (?aims) are regex parser flags
+ return bool(re.search('(?aims)(send|mail|message|me)\\b.+?\\b(image|pic(ture)?|photo|snap(shot)?|selfie|meme)s?\\b', string))
+
+
+def state_modifier(state):
+ if picture_response:
+ state['stream'] = False
+
+ return state
+
+
+def input_modifier(string):
+ """
+ This function is applied to your text inputs before
+ they are fed into the model.
+ """
+
+ global params
+
+ if not params['mode'] == 1: # if not in immersive/interactive mode, do nothing
+ return string
+
+ if triggers_are_in(string): # if we're in it, check for trigger words
+ toggle_generation(True)
+ string = string.lower()
+ if "of" in string:
+ subject = string.split('of', 1)[1] # subdivide the string once by the first 'of' instance and get what's coming after it
+ string = params['textgen_prefix'].replace("[subject]", subject)
+ else:
+ string = params['textgen_prefix'].replace("[subject]", "your appearance, your surroundings and what you are doing right now")
+
+ return string
+
+# Get and save the Stable Diffusion-generated picture
+def get_SD_pictures(description, character):
+
+ global params
+
+ if params['manage_VRAM']:
+ give_VRAM_priority('SD')
+
+ description = re.sub('Conversation 2
+ + + + + + \n'
+ else:
+ image = Image.open(io.BytesIO(base64.b64decode(img_str.split(",", 1)[0])))
+ # lower the resolution of received images for the chat, otherwise the log size gets out of control quickly with all the base64 values in visible history
+ image.thumbnail((300, 300))
+ buffered = io.BytesIO()
+ image.save(buffered, format="JPEG")
+ buffered.seek(0)
+ image_bytes = buffered.getvalue()
+ img_str = "data:image/jpeg;base64," + base64.b64encode(image_bytes).decode()
+ visible_result = visible_result + f''
+ return text, visible_text
+
+
+def ui():
+ picture_select = gr.Image(label='Send a picture', type='pil')
+
+ # Prepare the input hijack, update the interface values, call the generation function, and clear the picture
+ picture_select.upload(
+ lambda picture, name1, name2: input_hijack.update({
+ "state": True,
+ "value": generate_chat_picture(picture, name1, name2)
+ }), [picture_select, shared.gradio['name1'], shared.gradio['name2']], None).then(
+ gather_interface_values, gradio(shared.input_elements), gradio('interface_state')).then(
+ chat.generate_chat_reply_wrapper, shared.input_params, gradio('display', 'history'), show_progress=False).then(
+ lambda: None, None, picture_select, show_progress=False)
diff --git a/extensions/silero_tts/harvard_sentences.txt b/extensions/silero_tts/harvard_sentences.txt
new file mode 100644
index 0000000000000000000000000000000000000000..958d7f3cb28d8e2ea215ee416068b2f672d9e9d1
--- /dev/null
+++ b/extensions/silero_tts/harvard_sentences.txt
@@ -0,0 +1,720 @@
+The birch canoe slid on the smooth planks.
+Glue the sheet to the dark blue background.
+It's easy to tell the depth of a well.
+These days a chicken leg is a rare dish.
+Rice is often served in round bowls.
+The juice of lemons makes fine punch.
+The box was thrown beside the parked truck.
+The hogs were fed chopped corn and garbage.
+Four hours of steady work faced us.
+A large size in stockings is hard to sell.
+The boy was there when the sun rose.
+A rod is used to catch pink salmon.
+The source of the huge river is the clear spring.
+Kick the ball straight and follow through.
+Help the woman get back to her feet.
+A pot of tea helps to pass the evening.
+Smoky fires lack flame and heat.
+The soft cushion broke the man's fall.
+The salt breeze came across from the sea.
+The girl at the booth sold fifty bonds.
+The small pup gnawed a hole in the sock.
+The fish twisted and turned on the bent hook.
+Press the pants and sew a button on the vest.
+The swan dive was far short of perfect.
+The beauty of the view stunned the young boy.
+Two blue fish swam in the tank.
+Her purse was full of useless trash.
+The colt reared and threw the tall rider.
+It snowed, rained, and hailed the same morning.
+Read verse out loud for pleasure.
+Hoist the load to your left shoulder.
+Take the winding path to reach the lake.
+Note closely the size of the gas tank.
+Wipe the grease off his dirty face.
+Mend the coat before you go out.
+The wrist was badly strained and hung limp.
+The stray cat gave birth to kittens.
+The young girl gave no clear response.
+The meal was cooked before the bell rang.
+What joy there is in living.
+A king ruled the state in the early days.
+The ship was torn apart on the sharp reef.
+Sickness kept him home the third week.
+The wide road shimmered in the hot sun.
+The lazy cow lay in the cool grass.
+Lift the square stone over the fence.
+The rope will bind the seven books at once.
+Hop over the fence and plunge in.
+The friendly gang left the drug store.
+Mesh wire keeps chicks inside.
+The frosty air passed through the coat.
+The crooked maze failed to fool the mouse.
+Adding fast leads to wrong sums.
+The show was a flop from the very start.
+A saw is a tool used for making boards.
+The wagon moved on well oiled wheels.
+March the soldiers past the next hill.
+A cup of sugar makes sweet fudge.
+Place a rosebush near the porch steps.
+Both lost their lives in the raging storm.
+We talked of the side show in the circus.
+Use a pencil to write the first draft.
+He ran half way to the hardware store.
+The clock struck to mark the third period.
+A small creek cut across the field.
+Cars and busses stalled in snow drifts.
+The set of china hit the floor with a crash.
+This is a grand season for hikes on the road.
+The dune rose from the edge of the water.
+Those words were the cue for the actor to leave.
+A yacht slid around the point into the bay.
+The two met while playing on the sand.
+The ink stain dried on the finished page.
+The walled town was seized without a fight.
+The lease ran out in sixteen weeks.
+A tame squirrel makes a nice pet.
+The horn of the car woke the sleeping cop.
+The heart beat strongly and with firm strokes.
+The pearl was worn in a thin silver ring.
+The fruit peel was cut in thick slices.
+The Navy attacked the big task force.
+See the cat glaring at the scared mouse.
+There are more than two factors here.
+The hat brim was wide and too droopy.
+The lawyer tried to lose his case.
+The grass curled around the fence post.
+Cut the pie into large parts.
+Men strive but seldom get rich.
+Always close the barn door tight.
+He lay prone and hardly moved a limb.
+The slush lay deep along the street.
+A wisp of cloud hung in the blue air.
+A pound of sugar costs more than eggs.
+The fin was sharp and cut the clear water.
+The play seems dull and quite stupid.
+Bail the boat to stop it from sinking.
+The term ended in late June that year.
+A tusk is used to make costly gifts.
+Ten pins were set in order.
+The bill was paid every third week.
+Oak is strong and also gives shade.
+Cats and dogs each hate the other.
+The pipe began to rust while new.
+Open the crate but don't break the glass.
+Add the sum to the product of these three.
+Thieves who rob friends deserve jail.
+The ripe taste of cheese improves with age.
+Act on these orders with great speed.
+The hog crawled under the high fence.
+Move the vat over the hot fire.
+The bark of the pine tree was shiny and dark.
+Leaves turn brown and yellow in the fall.
+The pennant waved when the wind blew.
+Split the log with a quick, sharp blow.
+Burn peat after the logs give out.
+He ordered peach pie with ice cream.
+Weave the carpet on the right hand side.
+Hemp is a weed found in parts of the tropics.
+A lame back kept his score low.
+We find joy in the simplest things.
+Type out three lists of orders.
+The harder he tried the less he got done.
+The boss ran the show with a watchful eye.
+The cup cracked and spilled its contents.
+Paste can cleanse the most dirty brass.
+The slang word for raw whiskey is booze.
+It caught its hind paw in a rusty trap.
+The wharf could be seen at the farther shore.
+Feel the heat of the weak dying flame.
+The tiny girl took off her hat.
+A cramp is no small danger on a swim.
+He said the same phrase thirty times.
+Pluck the bright rose without leaves.
+Two plus seven is less than ten.
+The glow deepened in the eyes of the sweet girl.
+Bring your problems to the wise chief.
+Write a fond note to the friend you cherish.
+Clothes and lodging are free to new men.
+We frown when events take a bad turn.
+Port is a strong wine with a smoky taste.
+The young kid jumped the rusty gate.
+Guess the results from the first scores.
+A salt pickle tastes fine with ham.
+The just claim got the right verdict.
+These thistles bend in a high wind.
+Pure bred poodles have curls.
+The tree top waved in a graceful way.
+The spot on the blotter was made by green ink.
+Mud was spattered on the front of his white shirt.
+The cigar burned a hole in the desk top.
+The empty flask stood on the tin tray.
+A speedy man can beat this track mark.
+He broke a new shoelace that day.
+The coffee stand is too high for the couch.
+The urge to write short stories is rare.
+The pencils have all been used.
+The pirates seized the crew of the lost ship.
+We tried to replace the coin but failed.
+She sewed the torn coat quite neatly.
+The sofa cushion is red and of light weight.
+The jacket hung on the back of the wide chair.
+At that high level the air is pure.
+Drop the two when you add the figures.
+A filing case is now hard to buy.
+An abrupt start does not win the prize.
+Wood is best for making toys and blocks.
+The office paint was a dull, sad tan.
+He knew the skill of the great young actress.
+A rag will soak up spilled water.
+A shower of dirt fell from the hot pipes.
+Steam hissed from the broken valve.
+The child almost hurt the small dog.
+There was a sound of dry leaves outside.
+The sky that morning was clear and bright blue.
+Torn scraps littered the stone floor.
+Sunday is the best part of the week.
+The doctor cured him with these pills.
+The new girl was fired today at noon.
+They felt gay when the ship arrived in port.
+Add the store's account to the last cent.
+Acid burns holes in wool cloth.
+Fairy tales should be fun to write.
+Eight miles of woodland burned to waste.
+The third act was dull and tired the players.
+A young child should not suffer fright.
+Add the column and put the sum here.
+We admire and love a good cook.
+There the flood mark is ten inches.
+He carved a head from the round block of marble.
+She has a smart way of wearing clothes.
+The fruit of a fig tree is apple-shaped.
+Corn cobs can be used to kindle a fire.
+Where were they when the noise started.
+The paper box is full of thumb tacks.
+Sell your gift to a buyer at a good gain.
+The tongs lay beside the ice pail.
+The petals fall with the next puff of wind.
+Bring your best compass to the third class.
+They could laugh although they were sad.
+Farmers came in to thresh the oat crop.
+The brown house was on fire to the attic.
+The lure is used to catch trout and flounder.
+Float the soap on top of the bath water.
+A blue crane is a tall wading bird.
+A fresh start will work such wonders.
+The club rented the rink for the fifth night.
+After the dance, they went straight home.
+The hostess taught the new maid to serve.
+He wrote his last novel there at the inn.
+Even the worst will beat his low score.
+The cement had dried when he moved it.
+The loss of the second ship was hard to take.
+The fly made its way along the wall.
+Do that with a wooden stick.
+Live wires should be kept covered.
+The large house had hot water taps.
+It is hard to erase blue or red ink.
+Write at once or you may forget it.
+The doorknob was made of bright clean brass.
+The wreck occurred by the bank on Main Street.
+A pencil with black lead writes best.
+Coax a young calf to drink from a bucket.
+Schools for ladies teach charm and grace.
+The lamp shone with a steady green flame.
+They took the axe and the saw to the forest.
+The ancient coin was quite dull and worn.
+The shaky barn fell with a loud crash.
+Jazz and swing fans like fast music.
+Rake the rubbish up and then burn it.
+Slash the gold cloth into fine ribbons.
+Try to have the court decide the case.
+They are pushed back each time they attack.
+He broke his ties with groups of former friends.
+They floated on the raft to sun their white backs.
+The map had an X that meant nothing.
+Whitings are small fish caught in nets.
+Some ads serve to cheat buyers.
+Jerk the rope and the bell rings weakly.
+A waxed floor makes us lose balance.
+Madam, this is the best brand of corn.
+On the islands the sea breeze is soft and mild.
+The play began as soon as we sat down.
+This will lead the world to more sound and fury.
+Add salt before you fry the egg.
+The rush for funds reached its peak Tuesday.
+The birch looked stark white and lonesome.
+The box is held by a bright red snapper.
+To make pure ice, you freeze water.
+The first worm gets snapped early.
+Jump the fence and hurry up the bank.
+Yell and clap as the curtain slides back.
+They are men who walk the middle of the road.
+Both brothers wear the same size.
+In some form or other we need fun.
+The prince ordered his head chopped off.
+The houses are built of red clay bricks.
+Ducks fly north but lack a compass.
+Fruit flavors are used in fizz drinks.
+These pills do less good than others.
+Canned pears lack full flavor.
+The dark pot hung in the front closet.
+Carry the pail to the wall and spill it there.
+The train brought our hero to the big town.
+We are sure that one war is enough.
+Gray paint stretched for miles around.
+The rude laugh filled the empty room.
+High seats are best for football fans.
+Tea served from the brown jug is tasty.
+A dash of pepper spoils beef stew.
+A zestful food is the hot-cross bun.
+The horse trotted around the field at a brisk pace.
+Find the twin who stole the pearl necklace.
+Cut the cord that binds the box tightly.
+The red tape bound the smuggled food.
+Look in the corner to find the tan shirt.
+The cold drizzle will halt the bond drive.
+Nine men were hired to dig the ruins.
+The junk yard had a mouldy smell.
+The flint sputtered and lit a pine torch.
+Soak the cloth and drown the sharp odor.
+The shelves were bare of both jam or crackers.
+A joy to every child is the swan boat.
+All sat frozen and watched the screen.
+A cloud of dust stung his tender eyes.
+To reach the end he needs much courage.
+Shape the clay gently into block form.
+A ridge on a smooth surface is a bump or flaw.
+Hedge apples may stain your hands green.
+Quench your thirst, then eat the crackers.
+Tight curls get limp on rainy days.
+The mute muffled the high tones of the horn.
+The gold ring fits only a pierced ear.
+The old pan was covered with hard fudge.
+Watch the log float in the wide river.
+The node on the stalk of wheat grew daily.
+The heap of fallen leaves was set on fire.
+Write fast if you want to finish early.
+His shirt was clean but one button was gone.
+The barrel of beer was a brew of malt and hops.
+Tin cans are absent from store shelves.
+Slide the box into that empty space.
+The plant grew large and green in the window.
+The beam dropped down on the workmen's head.
+Pink clouds floated with the breeze.
+She danced like a swan, tall and graceful.
+The tube was blown and the tire flat and useless.
+It is late morning on the old wall clock.
+Let's all join as we sing the last chorus.
+The last switch cannot be turned off.
+The fight will end in just six minutes.
+The store walls were lined with colored frocks.
+The peace league met to discuss their plans.
+The rise to fame of a person takes luck.
+Paper is scarce, so write with much care.
+The quick fox jumped on the sleeping cat.
+The nozzle of the fire hose was bright brass.
+Screw the round cap on as tight as needed.
+Time brings us many changes.
+The purple tie was ten years old.
+Men think and plan and sometimes act.
+Fill the ink jar with sticky glue.
+He smoke a big pipe with strong contents.
+We need grain to keep our mules healthy.
+Pack the records in a neat thin case.
+The crunch of feet in the snow was the only sound.
+The copper bowl shone in the sun's rays.
+Boards will warp unless kept dry.
+The plush chair leaned against the wall.
+Glass will clink when struck by metal.
+Bathe and relax in the cool green grass.
+Nine rows of soldiers stood in line.
+The beach is dry and shallow at low tide.
+The idea is to sew both edges straight.
+The kitten chased the dog down the street.
+Pages bound in cloth make a book.
+Try to trace the fine lines of the painting.
+Women form less than half of the group.
+The zones merge in the central part of town.
+A gem in the rough needs work to polish.
+Code is used when secrets are sent.
+Most of the news is easy for us to hear.
+He used the lathe to make brass objects.
+The vane on top of the pole revolved in the wind.
+Mince pie is a dish served to children.
+The clan gathered on each dull night.
+Let it burn, it gives us warmth and comfort.
+A castle built from sand fails to endure.
+A child's wit saved the day for us.
+Tack the strip of carpet to the worn floor.
+Next Tuesday we must vote.
+Pour the stew from the pot into the plate.
+Each penny shone like new.
+The man went to the woods to gather sticks.
+The dirt piles were lines along the road.
+The logs fell and tumbled into the clear stream.
+Just hoist it up and take it away.
+A ripe plum is fit for a king's palate.
+Our plans right now are hazy.
+Brass rings are sold by these natives.
+It takes a good trap to capture a bear.
+Feed the white mouse some flower seeds.
+The thaw came early and freed the stream.
+He took the lead and kept it the whole distance.
+The key you designed will fit the lock.
+Plead to the council to free the poor thief.
+Better hash is made of rare beef.
+This plank was made for walking on.
+The lake sparkled in the red hot sun.
+He crawled with care along the ledge.
+Tend the sheep while the dog wanders.
+It takes a lot of help to finish these.
+Mark the spot with a sign painted red.
+Take two shares as a fair profit.
+The fur of cats goes by many names.
+North winds bring colds and fevers.
+He asks no person to vouch for him.
+Go now and come here later.
+A sash of gold silk will trim her dress.
+Soap can wash most dirt away.
+That move means the game is over.
+He wrote down a long list of items.
+A siege will crack the strong defense.
+Grape juice and water mix well.
+Roads are paved with sticky tar.
+Fake stones shine but cost little.
+The drip of the rain made a pleasant sound.
+Smoke poured out of every crack.
+Serve the hot rum to the tired heroes.
+Much of the story makes good sense.
+The sun came up to light the eastern sky.
+Heave the line over the port side.
+A lathe cuts and trims any wood.
+It's a dense crowd in two distinct ways.
+His hip struck the knee of the next player.
+The stale smell of old beer lingers.
+The desk was firm on the shaky floor.
+It takes heat to bring out the odor.
+Beef is scarcer than some lamb.
+Raise the sail and steer the ship northward.
+A cone costs five cents on Mondays.
+A pod is what peas always grow in.
+Jerk the dart from the cork target.
+No cement will hold hard wood.
+We now have a new base for shipping.
+A list of names is carved around the base.
+The sheep were led home by a dog.
+Three for a dime, the young peddler cried.
+The sense of smell is better than that of touch.
+No hardship seemed to keep him sad.
+Grace makes up for lack of beauty.
+Nudge gently but wake her now.
+The news struck doubt into restless minds.
+Once we stood beside the shore.
+A chink in the wall allowed a draft to blow.
+Fasten two pins on each side.
+A cold dip restores health and zest.
+He takes the oath of office each March.
+The sand drifts over the sill of the old house.
+The point of the steel pen was bent and twisted.
+There is a lag between thought and act.
+Seed is needed to plant the spring corn.
+Draw the chart with heavy black lines.
+The boy owed his pal thirty cents.
+The chap slipped into the crowd and was lost.
+Hats are worn to tea and not to dinner.
+The ramp led up to the wide highway.
+Beat the dust from the rug onto the lawn.
+Say it slowly but make it ring clear.
+The straw nest housed five robins.
+Screen the porch with woven straw mats.
+This horse will nose his way to the finish.
+The dry wax protects the deep scratch.
+He picked up the dice for a second roll.
+These coins will be needed to pay his debt.
+The nag pulled the frail cart along.
+Twist the valve and release hot steam.
+The vamp of the shoe had a gold buckle.
+The smell of burned rags itches my nose.
+New pants lack cuffs and pockets.
+The marsh will freeze when cold enough.
+They slice the sausage thin with a knife.
+The bloom of the rose lasts a few days.
+A gray mare walked before the colt.
+Breakfast buns are fine with a hot drink.
+Bottles hold four kinds of rum.
+The man wore a feather in his felt hat.
+He wheeled the bike past the winding road.
+Drop the ashes on the worn old rug.
+The desk and both chairs were painted tan.
+Throw out the used paper cup and plate.
+A clean neck means a neat collar.
+The couch cover and hall drapes were blue.
+The stems of the tall glasses cracked and broke.
+The wall phone rang loud and often.
+The clothes dried on a thin wooden rack.
+Turn on the lantern which gives us light.
+The cleat sank deeply into the soft turf.
+The bills were mailed promptly on the tenth of the month.
+To have is better than to wait and hope.
+The price is fair for a good antique clock.
+The music played on while they talked.
+Dispense with a vest on a day like this.
+The bunch of grapes was pressed into wine.
+He sent the figs, but kept the ripe cherries.
+The hinge on the door creaked with old age.
+The screen before the fire kept in the sparks.
+Fly by night, and you waste little time.
+Thick glasses helped him read the print.
+Birth and death mark the limits of life.
+The chair looked strong but had no bottom.
+The kite flew wildly in the high wind.
+A fur muff is stylish once more.
+The tin box held priceless stones.
+We need an end of all such matter.
+The case was puzzling to the old and wise.
+The bright lanterns were gay on the dark lawn.
+We don't get much money but we have fun.
+The youth drove with zest, but little skill.
+Five years he lived with a shaggy dog.
+A fence cuts through the corner lot.
+The way to save money is not to spend much.
+Shut the hatch before the waves push it in.
+The odor of spring makes young hearts jump.
+Crack the walnut with your sharp side teeth.
+He offered proof in the form of a large chart.
+Send the stuff in a thick paper bag.
+A quart of milk is water for the most part.
+They told wild tales to frighten him.
+The three story house was built of stone.
+In the rear of the ground floor was a large passage.
+A man in a blue sweater sat at the desk.
+Oats are a food eaten by horse and man.
+Their eyelids droop for want of sleep.
+A sip of tea revives his tired friend.
+There are many ways to do these things.
+Tuck the sheet under the edge of the mat.
+A force equal to that would move the earth.
+We like to see clear weather.
+The work of the tailor is seen on each side.
+Take a chance and win a china doll.
+Shake the dust from your shoes, stranger.
+She was kind to sick old people.
+The square wooden crate was packed to be shipped.
+The dusty bench stood by the stone wall.
+We dress to suit the weather of most days.
+Smile when you say nasty words.
+A bowl of rice is free with chicken stew.
+The water in this well is a source of good health.
+Take shelter in this tent, but keep still.
+That guy is the writer of a few banned books.
+The little tales they tell are false.
+The door was barred, locked, and bolted as well.
+Ripe pears are fit for a queen's table.
+A big wet stain was on the round carpet.
+The kite dipped and swayed, but stayed aloft.
+The pleasant hours fly by much too soon.
+The room was crowded with a wild mob.
+This strong arm shall shield your honor.
+She blushed when he gave her a white orchid.
+The beetle droned in the hot June sun.
+Press the pedal with your left foot.
+Neat plans fail without luck.
+The black trunk fell from the landing.
+The bank pressed for payment of the debt.
+The theft of the pearl pin was kept secret.
+Shake hands with this friendly child.
+The vast space stretched into the far distance.
+A rich farm is rare in this sandy waste.
+His wide grin earned many friends.
+Flax makes a fine brand of paper.
+Hurdle the pit with the aid of a long pole.
+A strong bid may scare your partner stiff.
+Even a just cause needs power to win.
+Peep under the tent and see the clowns.
+The leaf drifts along with a slow spin.
+Cheap clothes are flashy but don't last.
+A thing of small note can cause despair.
+Flood the mails with requests for this book.
+A thick coat of black paint covered all.
+The pencil was cut to be sharp at both ends.
+Those last words were a strong statement.
+He wrote his name boldly at the top of the sheet.
+Dill pickles are sour but taste fine.
+Down that road is the way to the grain farmer.
+Either mud or dust are found at all times.
+The best method is to fix it in place with clips.
+If you mumble your speech will be lost.
+At night the alarm roused him from a deep sleep.
+Read just what the meter says.
+Fill your pack with bright trinkets for the poor.
+The small red neon lamp went out.
+Clams are small, round, soft, and tasty.
+The fan whirled its round blades softly.
+The line where the edges join was clean.
+Breathe deep and smell the piny air.
+It matters not if he reads these words or those.
+A brown leather bag hung from its strap.
+A toad and a frog are hard to tell apart.
+A white silk jacket goes with any shoes.
+A break in the dam almost caused a flood.
+Paint the sockets in the wall dull green.
+The child crawled into the dense grass.
+Bribes fail where honest men work.
+Trample the spark, else the flames will spread.
+The hilt of the sword was carved with fine designs.
+A round hole was drilled through the thin board.
+Footprints showed the path he took up the beach.
+She was waiting at my front lawn.
+A vent near the edge brought in fresh air.
+Prod the old mule with a crooked stick.
+It is a band of steel three inches wide.
+The pipe ran almost the length of the ditch.
+It was hidden from sight by a mass of leaves and shrubs.
+The weight of the package was seen on the high scale.
+Wake and rise, and step into the green outdoors.
+The green light in the brown box flickered.
+The brass tube circled the high wall.
+The lobes of her ears were pierced to hold rings.
+Hold the hammer near the end to drive the nail.
+Next Sunday is the twelfth of the month.
+Every word and phrase he speaks is true.
+He put his last cartridge into the gun and fired.
+They took their kids from the public school.
+Drive the screw straight into the wood.
+Keep the hatch tight and the watch constant.
+Sever the twine with a quick snip of the knife.
+Paper will dry out when wet.
+Slide the catch back and open the desk.
+Help the weak to preserve their strength.
+A sullen smile gets few friends.
+Stop whistling and watch the boys march.
+Jerk the cord, and out tumbles the gold.
+Slide the tray across the glass top.
+The cloud moved in a stately way and was gone.
+Light maple makes for a swell room.
+Set the piece here and say nothing.
+Dull stories make her laugh.
+A stiff cord will do to fasten your shoe.
+Get the trust fund to the bank early.
+Choose between the high road and the low.
+A plea for funds seems to come again.
+He lent his coat to the tall gaunt stranger.
+There is a strong chance it will happen once more.
+The duke left the park in a silver coach.
+Greet the new guests and leave quickly.
+When the frost has come it is time for turkey.
+Sweet words work better than fierce.
+A thin stripe runs down the middle.
+A six comes up more often than a ten.
+Lush fern grow on the lofty rocks.
+The ram scared the school children off.
+The team with the best timing looks good.
+The farmer swapped his horse for a brown ox.
+Sit on the perch and tell the others what to do.
+A steep trail is painful for our feet.
+The early phase of life moves fast.
+Green moss grows on the northern side.
+Tea in thin china has a sweet taste.
+Pitch the straw through the door of the stable.
+The latch on the back gate needed a nail.
+The goose was brought straight from the old market.
+The sink is the thing in which we pile dishes.
+A whiff of it will cure the most stubborn cold.
+The facts don't always show who is right.
+She flaps her cape as she parades the street.
+The loss of the cruiser was a blow to the fleet.
+Loop the braid to the left and then over.
+Plead with the lawyer to drop the lost cause.
+Calves thrive on tender spring grass.
+Post no bills on this office wall.
+Tear a thin sheet from the yellow pad.
+A cruise in warm waters in a sleek yacht is fun.
+A streak of color ran down the left edge.
+It was done before the boy could see it.
+Crouch before you jump or miss the mark.
+Pack the kits and don't forget the salt.
+The square peg will settle in the round hole.
+Fine soap saves tender skin.
+Poached eggs and tea must suffice.
+Bad nerves are jangled by a door slam.
+Ship maps are different from those for planes.
+Dimes showered down from all sides.
+They sang the same tunes at each party.
+The sky in the west is tinged with orange red.
+The pods of peas ferment in bare fields.
+The horse balked and threw the tall rider.
+The hitch between the horse and cart broke.
+Pile the coal high in the shed corner.
+A gold vase is both rare and costly.
+The knife was hung inside its bright sheath.
+The rarest spice comes from the far East.
+The roof should be tilted at a sharp slant.
+A smatter of French is worse than none.
+The mule trod the treadmill day and night.
+The aim of the contest is to raise a great fund.
+To send it now in large amounts is bad.
+There is a fine hard tang in salty air.
+Cod is the main business of the north shore.
+The slab was hewn from heavy blocks of slate.
+Dunk the stale biscuits into strong drink.
+Hang tinsel from both branches.
+Cap the jar with a tight brass cover.
+The poor boy missed the boat again.
+Be sure to set the lamp firmly in the hole.
+Pick a card and slip it under the pack.
+A round mat will cover the dull spot.
+The first part of the plan needs changing.
+A good book informs of what we ought to know.
+The mail comes in three batches per day.
+You cannot brew tea in a cold pot.
+Dots of light betrayed the black cat.
+Put the chart on the mantel and tack it down.
+The night shift men rate extra pay.
+The red paper brightened the dim stage.
+See the player scoot to third base.
+Slide the bill between the two leaves.
+Many hands help get the job done.
+We don't like to admit our small faults.
+No doubt about the way the wind blows.
+Dig deep in the earth for pirate's gold.
+The steady drip is worse than a drenching rain.
+A flat pack takes less luggage space.
+Green ice frosted the punch bowl.
+A stuffed chair slipped from the moving van.
+The stitch will serve but needs to be shortened.
+A thin book fits in the side pocket.
+The gloss on top made it unfit to read.
+The hail pattered on the burnt brown grass.
+Seven seals were stamped on great sheets.
+Our troops are set to strike heavy blows.
+The store was jammed before the sale could start.
+It was a bad error on the part of the new judge.
+One step more and the board will collapse.
+Take the match and strike it against your shoe.
+The pot boiled, but the contents failed to jell.
+The baby puts his right foot in his mouth.
+The bombs left most of the town in ruins.
+Stop and stare at the hard working man.
+The streets are narrow and full of sharp turns.
+The pup jerked the leash as he saw a feline shape.
+Open your book to the first page.
+Fish evade the net and swim off.
+Dip the pail once and let it settle.
+Will you please answer that phone.
+The big red apple fell to the ground.
+The curtain rose and the show was on.
+The young prince became heir to the throne.
+He sent the boy on a short errand.
+Leave now and you will arrive on time.
+The corner store was robbed last night.
+A gold ring will please most any girl.
+The long journey home took a year.
+She saw a cat in the neighbor's house.
+A pink shell was found on the sandy beach.
+Small children came to see him.
+The grass and bushes were wet with dew.
+The blind man counted his old coins.
+A severe storm tore down the barn.
+She called his name many times.
+When you hear the bell, come quickly.
\ No newline at end of file
diff --git a/extensions/silero_tts/outputs/outputs-will-be-saved-here.txt b/extensions/silero_tts/outputs/outputs-will-be-saved-here.txt
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/extensions/silero_tts/requirements.txt b/extensions/silero_tts/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..1017bf0d7accb9930872ededd8a4bc077d393958
--- /dev/null
+++ b/extensions/silero_tts/requirements.txt
@@ -0,0 +1,5 @@
+ipython
+num2words
+omegaconf
+pydub
+PyYAML
diff --git a/extensions/silero_tts/script.py b/extensions/silero_tts/script.py
new file mode 100644
index 0000000000000000000000000000000000000000..b96a47fd5f9c166a0c411428a30587fa48016096
--- /dev/null
+++ b/extensions/silero_tts/script.py
@@ -0,0 +1,225 @@
+import random
+import time
+from pathlib import Path
+
+import gradio as gr
+import torch
+
+from extensions.silero_tts import tts_preprocessor
+from modules import chat, shared
+from modules.utils import gradio
+
+torch._C._jit_set_profiling_mode(False)
+
+
+params = {
+ 'activate': True,
+ 'speaker': 'en_56',
+ 'language': 'en',
+ 'model_id': 'v3_en',
+ 'sample_rate': 48000,
+ 'device': 'cpu',
+ 'show_text': False,
+ 'autoplay': True,
+ 'voice_pitch': 'medium',
+ 'voice_speed': 'medium',
+ 'local_cache_path': '' # User can override the default cache path to something other via settings.json
+}
+
+current_params = params.copy()
+voices_by_gender = ['en_99', 'en_45', 'en_18', 'en_117', 'en_49', 'en_51', 'en_68', 'en_0', 'en_26', 'en_56', 'en_74', 'en_5', 'en_38', 'en_53', 'en_21', 'en_37', 'en_107', 'en_10', 'en_82', 'en_16', 'en_41', 'en_12', 'en_67', 'en_61', 'en_14', 'en_11', 'en_39', 'en_52', 'en_24', 'en_97', 'en_28', 'en_72', 'en_94', 'en_36', 'en_4', 'en_43', 'en_88', 'en_25', 'en_65', 'en_6', 'en_44', 'en_75', 'en_91', 'en_60', 'en_109', 'en_85', 'en_101', 'en_108', 'en_50', 'en_96', 'en_64', 'en_92', 'en_76', 'en_33', 'en_116', 'en_48', 'en_98', 'en_86', 'en_62', 'en_54', 'en_95', 'en_55', 'en_111', 'en_3', 'en_83', 'en_8', 'en_47', 'en_59', 'en_1', 'en_2', 'en_7', 'en_9', 'en_13', 'en_15', 'en_17', 'en_19', 'en_20', 'en_22', 'en_23', 'en_27', 'en_29', 'en_30', 'en_31', 'en_32', 'en_34', 'en_35', 'en_40', 'en_42', 'en_46', 'en_57', 'en_58', 'en_63', 'en_66', 'en_69', 'en_70', 'en_71', 'en_73', 'en_77', 'en_78', 'en_79', 'en_80', 'en_81', 'en_84', 'en_87', 'en_89', 'en_90', 'en_93', 'en_100', 'en_102', 'en_103', 'en_104', 'en_105', 'en_106', 'en_110', 'en_112', 'en_113', 'en_114', 'en_115']
+voice_pitches = ['x-low', 'low', 'medium', 'high', 'x-high']
+voice_speeds = ['x-slow', 'slow', 'medium', 'fast', 'x-fast']
+
+# Used for making text xml compatible, needed for voice pitch and speed control
+table = str.maketrans({
+ "<": "<",
+ ">": ">",
+ "&": "&",
+ "'": "'",
+ '"': """,
+})
+
+
+def xmlesc(txt):
+ return txt.translate(table)
+
+
+def load_model():
+ torch_cache_path = torch.hub.get_dir() if params['local_cache_path'] == '' else params['local_cache_path']
+ model_path = torch_cache_path + "/snakers4_silero-models_master/src/silero/model/" + params['model_id'] + ".pt"
+ if Path(model_path).is_file():
+ print(f'\nUsing Silero TTS cached checkpoint found at {torch_cache_path}')
+ model, example_text = torch.hub.load(repo_or_dir=torch_cache_path + '/snakers4_silero-models_master/', model='silero_tts', language=params['language'], speaker=params['model_id'], source='local', path=model_path, force_reload=True)
+ else:
+ print(f'\nSilero TTS cache not found at {torch_cache_path}. Attempting to download...')
+ model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_tts', language=params['language'], speaker=params['model_id'])
+ model.to(params['device'])
+ return model
+
+
+def remove_tts_from_history(history):
+ for i, entry in enumerate(history['internal']):
+ history['visible'][i] = [history['visible'][i][0], entry[1]]
+
+ return history
+
+
+def toggle_text_in_history(history):
+ for i, entry in enumerate(history['visible']):
+ visible_reply = entry[1]
+ if visible_reply.startswith('
\n'
+ else:
+ image = Image.open(io.BytesIO(base64.b64decode(img_str.split(",", 1)[0])))
+ # lower the resolution of received images for the chat, otherwise the log size gets out of control quickly with all the base64 values in visible history
+ image.thumbnail((300, 300))
+ buffered = io.BytesIO()
+ image.save(buffered, format="JPEG")
+ buffered.seek(0)
+ image_bytes = buffered.getvalue()
+ img_str = "data:image/jpeg;base64," + base64.b64encode(image_bytes).decode()
+ visible_result = visible_result + f''
+ return text, visible_text
+
+
+def ui():
+ picture_select = gr.Image(label='Send a picture', type='pil')
+
+ # Prepare the input hijack, update the interface values, call the generation function, and clear the picture
+ picture_select.upload(
+ lambda picture, name1, name2: input_hijack.update({
+ "state": True,
+ "value": generate_chat_picture(picture, name1, name2)
+ }), [picture_select, shared.gradio['name1'], shared.gradio['name2']], None).then(
+ gather_interface_values, gradio(shared.input_elements), gradio('interface_state')).then(
+ chat.generate_chat_reply_wrapper, shared.input_params, gradio('display', 'history'), show_progress=False).then(
+ lambda: None, None, picture_select, show_progress=False)
diff --git a/extensions/silero_tts/harvard_sentences.txt b/extensions/silero_tts/harvard_sentences.txt
new file mode 100644
index 0000000000000000000000000000000000000000..958d7f3cb28d8e2ea215ee416068b2f672d9e9d1
--- /dev/null
+++ b/extensions/silero_tts/harvard_sentences.txt
@@ -0,0 +1,720 @@
+The birch canoe slid on the smooth planks.
+Glue the sheet to the dark blue background.
+It's easy to tell the depth of a well.
+These days a chicken leg is a rare dish.
+Rice is often served in round bowls.
+The juice of lemons makes fine punch.
+The box was thrown beside the parked truck.
+The hogs were fed chopped corn and garbage.
+Four hours of steady work faced us.
+A large size in stockings is hard to sell.
+The boy was there when the sun rose.
+A rod is used to catch pink salmon.
+The source of the huge river is the clear spring.
+Kick the ball straight and follow through.
+Help the woman get back to her feet.
+A pot of tea helps to pass the evening.
+Smoky fires lack flame and heat.
+The soft cushion broke the man's fall.
+The salt breeze came across from the sea.
+The girl at the booth sold fifty bonds.
+The small pup gnawed a hole in the sock.
+The fish twisted and turned on the bent hook.
+Press the pants and sew a button on the vest.
+The swan dive was far short of perfect.
+The beauty of the view stunned the young boy.
+Two blue fish swam in the tank.
+Her purse was full of useless trash.
+The colt reared and threw the tall rider.
+It snowed, rained, and hailed the same morning.
+Read verse out loud for pleasure.
+Hoist the load to your left shoulder.
+Take the winding path to reach the lake.
+Note closely the size of the gas tank.
+Wipe the grease off his dirty face.
+Mend the coat before you go out.
+The wrist was badly strained and hung limp.
+The stray cat gave birth to kittens.
+The young girl gave no clear response.
+The meal was cooked before the bell rang.
+What joy there is in living.
+A king ruled the state in the early days.
+The ship was torn apart on the sharp reef.
+Sickness kept him home the third week.
+The wide road shimmered in the hot sun.
+The lazy cow lay in the cool grass.
+Lift the square stone over the fence.
+The rope will bind the seven books at once.
+Hop over the fence and plunge in.
+The friendly gang left the drug store.
+Mesh wire keeps chicks inside.
+The frosty air passed through the coat.
+The crooked maze failed to fool the mouse.
+Adding fast leads to wrong sums.
+The show was a flop from the very start.
+A saw is a tool used for making boards.
+The wagon moved on well oiled wheels.
+March the soldiers past the next hill.
+A cup of sugar makes sweet fudge.
+Place a rosebush near the porch steps.
+Both lost their lives in the raging storm.
+We talked of the side show in the circus.
+Use a pencil to write the first draft.
+He ran half way to the hardware store.
+The clock struck to mark the third period.
+A small creek cut across the field.
+Cars and busses stalled in snow drifts.
+The set of china hit the floor with a crash.
+This is a grand season for hikes on the road.
+The dune rose from the edge of the water.
+Those words were the cue for the actor to leave.
+A yacht slid around the point into the bay.
+The two met while playing on the sand.
+The ink stain dried on the finished page.
+The walled town was seized without a fight.
+The lease ran out in sixteen weeks.
+A tame squirrel makes a nice pet.
+The horn of the car woke the sleeping cop.
+The heart beat strongly and with firm strokes.
+The pearl was worn in a thin silver ring.
+The fruit peel was cut in thick slices.
+The Navy attacked the big task force.
+See the cat glaring at the scared mouse.
+There are more than two factors here.
+The hat brim was wide and too droopy.
+The lawyer tried to lose his case.
+The grass curled around the fence post.
+Cut the pie into large parts.
+Men strive but seldom get rich.
+Always close the barn door tight.
+He lay prone and hardly moved a limb.
+The slush lay deep along the street.
+A wisp of cloud hung in the blue air.
+A pound of sugar costs more than eggs.
+The fin was sharp and cut the clear water.
+The play seems dull and quite stupid.
+Bail the boat to stop it from sinking.
+The term ended in late June that year.
+A tusk is used to make costly gifts.
+Ten pins were set in order.
+The bill was paid every third week.
+Oak is strong and also gives shade.
+Cats and dogs each hate the other.
+The pipe began to rust while new.
+Open the crate but don't break the glass.
+Add the sum to the product of these three.
+Thieves who rob friends deserve jail.
+The ripe taste of cheese improves with age.
+Act on these orders with great speed.
+The hog crawled under the high fence.
+Move the vat over the hot fire.
+The bark of the pine tree was shiny and dark.
+Leaves turn brown and yellow in the fall.
+The pennant waved when the wind blew.
+Split the log with a quick, sharp blow.
+Burn peat after the logs give out.
+He ordered peach pie with ice cream.
+Weave the carpet on the right hand side.
+Hemp is a weed found in parts of the tropics.
+A lame back kept his score low.
+We find joy in the simplest things.
+Type out three lists of orders.
+The harder he tried the less he got done.
+The boss ran the show with a watchful eye.
+The cup cracked and spilled its contents.
+Paste can cleanse the most dirty brass.
+The slang word for raw whiskey is booze.
+It caught its hind paw in a rusty trap.
+The wharf could be seen at the farther shore.
+Feel the heat of the weak dying flame.
+The tiny girl took off her hat.
+A cramp is no small danger on a swim.
+He said the same phrase thirty times.
+Pluck the bright rose without leaves.
+Two plus seven is less than ten.
+The glow deepened in the eyes of the sweet girl.
+Bring your problems to the wise chief.
+Write a fond note to the friend you cherish.
+Clothes and lodging are free to new men.
+We frown when events take a bad turn.
+Port is a strong wine with a smoky taste.
+The young kid jumped the rusty gate.
+Guess the results from the first scores.
+A salt pickle tastes fine with ham.
+The just claim got the right verdict.
+These thistles bend in a high wind.
+Pure bred poodles have curls.
+The tree top waved in a graceful way.
+The spot on the blotter was made by green ink.
+Mud was spattered on the front of his white shirt.
+The cigar burned a hole in the desk top.
+The empty flask stood on the tin tray.
+A speedy man can beat this track mark.
+He broke a new shoelace that day.
+The coffee stand is too high for the couch.
+The urge to write short stories is rare.
+The pencils have all been used.
+The pirates seized the crew of the lost ship.
+We tried to replace the coin but failed.
+She sewed the torn coat quite neatly.
+The sofa cushion is red and of light weight.
+The jacket hung on the back of the wide chair.
+At that high level the air is pure.
+Drop the two when you add the figures.
+A filing case is now hard to buy.
+An abrupt start does not win the prize.
+Wood is best for making toys and blocks.
+The office paint was a dull, sad tan.
+He knew the skill of the great young actress.
+A rag will soak up spilled water.
+A shower of dirt fell from the hot pipes.
+Steam hissed from the broken valve.
+The child almost hurt the small dog.
+There was a sound of dry leaves outside.
+The sky that morning was clear and bright blue.
+Torn scraps littered the stone floor.
+Sunday is the best part of the week.
+The doctor cured him with these pills.
+The new girl was fired today at noon.
+They felt gay when the ship arrived in port.
+Add the store's account to the last cent.
+Acid burns holes in wool cloth.
+Fairy tales should be fun to write.
+Eight miles of woodland burned to waste.
+The third act was dull and tired the players.
+A young child should not suffer fright.
+Add the column and put the sum here.
+We admire and love a good cook.
+There the flood mark is ten inches.
+He carved a head from the round block of marble.
+She has a smart way of wearing clothes.
+The fruit of a fig tree is apple-shaped.
+Corn cobs can be used to kindle a fire.
+Where were they when the noise started.
+The paper box is full of thumb tacks.
+Sell your gift to a buyer at a good gain.
+The tongs lay beside the ice pail.
+The petals fall with the next puff of wind.
+Bring your best compass to the third class.
+They could laugh although they were sad.
+Farmers came in to thresh the oat crop.
+The brown house was on fire to the attic.
+The lure is used to catch trout and flounder.
+Float the soap on top of the bath water.
+A blue crane is a tall wading bird.
+A fresh start will work such wonders.
+The club rented the rink for the fifth night.
+After the dance, they went straight home.
+The hostess taught the new maid to serve.
+He wrote his last novel there at the inn.
+Even the worst will beat his low score.
+The cement had dried when he moved it.
+The loss of the second ship was hard to take.
+The fly made its way along the wall.
+Do that with a wooden stick.
+Live wires should be kept covered.
+The large house had hot water taps.
+It is hard to erase blue or red ink.
+Write at once or you may forget it.
+The doorknob was made of bright clean brass.
+The wreck occurred by the bank on Main Street.
+A pencil with black lead writes best.
+Coax a young calf to drink from a bucket.
+Schools for ladies teach charm and grace.
+The lamp shone with a steady green flame.
+They took the axe and the saw to the forest.
+The ancient coin was quite dull and worn.
+The shaky barn fell with a loud crash.
+Jazz and swing fans like fast music.
+Rake the rubbish up and then burn it.
+Slash the gold cloth into fine ribbons.
+Try to have the court decide the case.
+They are pushed back each time they attack.
+He broke his ties with groups of former friends.
+They floated on the raft to sun their white backs.
+The map had an X that meant nothing.
+Whitings are small fish caught in nets.
+Some ads serve to cheat buyers.
+Jerk the rope and the bell rings weakly.
+A waxed floor makes us lose balance.
+Madam, this is the best brand of corn.
+On the islands the sea breeze is soft and mild.
+The play began as soon as we sat down.
+This will lead the world to more sound and fury.
+Add salt before you fry the egg.
+The rush for funds reached its peak Tuesday.
+The birch looked stark white and lonesome.
+The box is held by a bright red snapper.
+To make pure ice, you freeze water.
+The first worm gets snapped early.
+Jump the fence and hurry up the bank.
+Yell and clap as the curtain slides back.
+They are men who walk the middle of the road.
+Both brothers wear the same size.
+In some form or other we need fun.
+The prince ordered his head chopped off.
+The houses are built of red clay bricks.
+Ducks fly north but lack a compass.
+Fruit flavors are used in fizz drinks.
+These pills do less good than others.
+Canned pears lack full flavor.
+The dark pot hung in the front closet.
+Carry the pail to the wall and spill it there.
+The train brought our hero to the big town.
+We are sure that one war is enough.
+Gray paint stretched for miles around.
+The rude laugh filled the empty room.
+High seats are best for football fans.
+Tea served from the brown jug is tasty.
+A dash of pepper spoils beef stew.
+A zestful food is the hot-cross bun.
+The horse trotted around the field at a brisk pace.
+Find the twin who stole the pearl necklace.
+Cut the cord that binds the box tightly.
+The red tape bound the smuggled food.
+Look in the corner to find the tan shirt.
+The cold drizzle will halt the bond drive.
+Nine men were hired to dig the ruins.
+The junk yard had a mouldy smell.
+The flint sputtered and lit a pine torch.
+Soak the cloth and drown the sharp odor.
+The shelves were bare of both jam or crackers.
+A joy to every child is the swan boat.
+All sat frozen and watched the screen.
+A cloud of dust stung his tender eyes.
+To reach the end he needs much courage.
+Shape the clay gently into block form.
+A ridge on a smooth surface is a bump or flaw.
+Hedge apples may stain your hands green.
+Quench your thirst, then eat the crackers.
+Tight curls get limp on rainy days.
+The mute muffled the high tones of the horn.
+The gold ring fits only a pierced ear.
+The old pan was covered with hard fudge.
+Watch the log float in the wide river.
+The node on the stalk of wheat grew daily.
+The heap of fallen leaves was set on fire.
+Write fast if you want to finish early.
+His shirt was clean but one button was gone.
+The barrel of beer was a brew of malt and hops.
+Tin cans are absent from store shelves.
+Slide the box into that empty space.
+The plant grew large and green in the window.
+The beam dropped down on the workmen's head.
+Pink clouds floated with the breeze.
+She danced like a swan, tall and graceful.
+The tube was blown and the tire flat and useless.
+It is late morning on the old wall clock.
+Let's all join as we sing the last chorus.
+The last switch cannot be turned off.
+The fight will end in just six minutes.
+The store walls were lined with colored frocks.
+The peace league met to discuss their plans.
+The rise to fame of a person takes luck.
+Paper is scarce, so write with much care.
+The quick fox jumped on the sleeping cat.
+The nozzle of the fire hose was bright brass.
+Screw the round cap on as tight as needed.
+Time brings us many changes.
+The purple tie was ten years old.
+Men think and plan and sometimes act.
+Fill the ink jar with sticky glue.
+He smoke a big pipe with strong contents.
+We need grain to keep our mules healthy.
+Pack the records in a neat thin case.
+The crunch of feet in the snow was the only sound.
+The copper bowl shone in the sun's rays.
+Boards will warp unless kept dry.
+The plush chair leaned against the wall.
+Glass will clink when struck by metal.
+Bathe and relax in the cool green grass.
+Nine rows of soldiers stood in line.
+The beach is dry and shallow at low tide.
+The idea is to sew both edges straight.
+The kitten chased the dog down the street.
+Pages bound in cloth make a book.
+Try to trace the fine lines of the painting.
+Women form less than half of the group.
+The zones merge in the central part of town.
+A gem in the rough needs work to polish.
+Code is used when secrets are sent.
+Most of the news is easy for us to hear.
+He used the lathe to make brass objects.
+The vane on top of the pole revolved in the wind.
+Mince pie is a dish served to children.
+The clan gathered on each dull night.
+Let it burn, it gives us warmth and comfort.
+A castle built from sand fails to endure.
+A child's wit saved the day for us.
+Tack the strip of carpet to the worn floor.
+Next Tuesday we must vote.
+Pour the stew from the pot into the plate.
+Each penny shone like new.
+The man went to the woods to gather sticks.
+The dirt piles were lines along the road.
+The logs fell and tumbled into the clear stream.
+Just hoist it up and take it away.
+A ripe plum is fit for a king's palate.
+Our plans right now are hazy.
+Brass rings are sold by these natives.
+It takes a good trap to capture a bear.
+Feed the white mouse some flower seeds.
+The thaw came early and freed the stream.
+He took the lead and kept it the whole distance.
+The key you designed will fit the lock.
+Plead to the council to free the poor thief.
+Better hash is made of rare beef.
+This plank was made for walking on.
+The lake sparkled in the red hot sun.
+He crawled with care along the ledge.
+Tend the sheep while the dog wanders.
+It takes a lot of help to finish these.
+Mark the spot with a sign painted red.
+Take two shares as a fair profit.
+The fur of cats goes by many names.
+North winds bring colds and fevers.
+He asks no person to vouch for him.
+Go now and come here later.
+A sash of gold silk will trim her dress.
+Soap can wash most dirt away.
+That move means the game is over.
+He wrote down a long list of items.
+A siege will crack the strong defense.
+Grape juice and water mix well.
+Roads are paved with sticky tar.
+Fake stones shine but cost little.
+The drip of the rain made a pleasant sound.
+Smoke poured out of every crack.
+Serve the hot rum to the tired heroes.
+Much of the story makes good sense.
+The sun came up to light the eastern sky.
+Heave the line over the port side.
+A lathe cuts and trims any wood.
+It's a dense crowd in two distinct ways.
+His hip struck the knee of the next player.
+The stale smell of old beer lingers.
+The desk was firm on the shaky floor.
+It takes heat to bring out the odor.
+Beef is scarcer than some lamb.
+Raise the sail and steer the ship northward.
+A cone costs five cents on Mondays.
+A pod is what peas always grow in.
+Jerk the dart from the cork target.
+No cement will hold hard wood.
+We now have a new base for shipping.
+A list of names is carved around the base.
+The sheep were led home by a dog.
+Three for a dime, the young peddler cried.
+The sense of smell is better than that of touch.
+No hardship seemed to keep him sad.
+Grace makes up for lack of beauty.
+Nudge gently but wake her now.
+The news struck doubt into restless minds.
+Once we stood beside the shore.
+A chink in the wall allowed a draft to blow.
+Fasten two pins on each side.
+A cold dip restores health and zest.
+He takes the oath of office each March.
+The sand drifts over the sill of the old house.
+The point of the steel pen was bent and twisted.
+There is a lag between thought and act.
+Seed is needed to plant the spring corn.
+Draw the chart with heavy black lines.
+The boy owed his pal thirty cents.
+The chap slipped into the crowd and was lost.
+Hats are worn to tea and not to dinner.
+The ramp led up to the wide highway.
+Beat the dust from the rug onto the lawn.
+Say it slowly but make it ring clear.
+The straw nest housed five robins.
+Screen the porch with woven straw mats.
+This horse will nose his way to the finish.
+The dry wax protects the deep scratch.
+He picked up the dice for a second roll.
+These coins will be needed to pay his debt.
+The nag pulled the frail cart along.
+Twist the valve and release hot steam.
+The vamp of the shoe had a gold buckle.
+The smell of burned rags itches my nose.
+New pants lack cuffs and pockets.
+The marsh will freeze when cold enough.
+They slice the sausage thin with a knife.
+The bloom of the rose lasts a few days.
+A gray mare walked before the colt.
+Breakfast buns are fine with a hot drink.
+Bottles hold four kinds of rum.
+The man wore a feather in his felt hat.
+He wheeled the bike past the winding road.
+Drop the ashes on the worn old rug.
+The desk and both chairs were painted tan.
+Throw out the used paper cup and plate.
+A clean neck means a neat collar.
+The couch cover and hall drapes were blue.
+The stems of the tall glasses cracked and broke.
+The wall phone rang loud and often.
+The clothes dried on a thin wooden rack.
+Turn on the lantern which gives us light.
+The cleat sank deeply into the soft turf.
+The bills were mailed promptly on the tenth of the month.
+To have is better than to wait and hope.
+The price is fair for a good antique clock.
+The music played on while they talked.
+Dispense with a vest on a day like this.
+The bunch of grapes was pressed into wine.
+He sent the figs, but kept the ripe cherries.
+The hinge on the door creaked with old age.
+The screen before the fire kept in the sparks.
+Fly by night, and you waste little time.
+Thick glasses helped him read the print.
+Birth and death mark the limits of life.
+The chair looked strong but had no bottom.
+The kite flew wildly in the high wind.
+A fur muff is stylish once more.
+The tin box held priceless stones.
+We need an end of all such matter.
+The case was puzzling to the old and wise.
+The bright lanterns were gay on the dark lawn.
+We don't get much money but we have fun.
+The youth drove with zest, but little skill.
+Five years he lived with a shaggy dog.
+A fence cuts through the corner lot.
+The way to save money is not to spend much.
+Shut the hatch before the waves push it in.
+The odor of spring makes young hearts jump.
+Crack the walnut with your sharp side teeth.
+He offered proof in the form of a large chart.
+Send the stuff in a thick paper bag.
+A quart of milk is water for the most part.
+They told wild tales to frighten him.
+The three story house was built of stone.
+In the rear of the ground floor was a large passage.
+A man in a blue sweater sat at the desk.
+Oats are a food eaten by horse and man.
+Their eyelids droop for want of sleep.
+A sip of tea revives his tired friend.
+There are many ways to do these things.
+Tuck the sheet under the edge of the mat.
+A force equal to that would move the earth.
+We like to see clear weather.
+The work of the tailor is seen on each side.
+Take a chance and win a china doll.
+Shake the dust from your shoes, stranger.
+She was kind to sick old people.
+The square wooden crate was packed to be shipped.
+The dusty bench stood by the stone wall.
+We dress to suit the weather of most days.
+Smile when you say nasty words.
+A bowl of rice is free with chicken stew.
+The water in this well is a source of good health.
+Take shelter in this tent, but keep still.
+That guy is the writer of a few banned books.
+The little tales they tell are false.
+The door was barred, locked, and bolted as well.
+Ripe pears are fit for a queen's table.
+A big wet stain was on the round carpet.
+The kite dipped and swayed, but stayed aloft.
+The pleasant hours fly by much too soon.
+The room was crowded with a wild mob.
+This strong arm shall shield your honor.
+She blushed when he gave her a white orchid.
+The beetle droned in the hot June sun.
+Press the pedal with your left foot.
+Neat plans fail without luck.
+The black trunk fell from the landing.
+The bank pressed for payment of the debt.
+The theft of the pearl pin was kept secret.
+Shake hands with this friendly child.
+The vast space stretched into the far distance.
+A rich farm is rare in this sandy waste.
+His wide grin earned many friends.
+Flax makes a fine brand of paper.
+Hurdle the pit with the aid of a long pole.
+A strong bid may scare your partner stiff.
+Even a just cause needs power to win.
+Peep under the tent and see the clowns.
+The leaf drifts along with a slow spin.
+Cheap clothes are flashy but don't last.
+A thing of small note can cause despair.
+Flood the mails with requests for this book.
+A thick coat of black paint covered all.
+The pencil was cut to be sharp at both ends.
+Those last words were a strong statement.
+He wrote his name boldly at the top of the sheet.
+Dill pickles are sour but taste fine.
+Down that road is the way to the grain farmer.
+Either mud or dust are found at all times.
+The best method is to fix it in place with clips.
+If you mumble your speech will be lost.
+At night the alarm roused him from a deep sleep.
+Read just what the meter says.
+Fill your pack with bright trinkets for the poor.
+The small red neon lamp went out.
+Clams are small, round, soft, and tasty.
+The fan whirled its round blades softly.
+The line where the edges join was clean.
+Breathe deep and smell the piny air.
+It matters not if he reads these words or those.
+A brown leather bag hung from its strap.
+A toad and a frog are hard to tell apart.
+A white silk jacket goes with any shoes.
+A break in the dam almost caused a flood.
+Paint the sockets in the wall dull green.
+The child crawled into the dense grass.
+Bribes fail where honest men work.
+Trample the spark, else the flames will spread.
+The hilt of the sword was carved with fine designs.
+A round hole was drilled through the thin board.
+Footprints showed the path he took up the beach.
+She was waiting at my front lawn.
+A vent near the edge brought in fresh air.
+Prod the old mule with a crooked stick.
+It is a band of steel three inches wide.
+The pipe ran almost the length of the ditch.
+It was hidden from sight by a mass of leaves and shrubs.
+The weight of the package was seen on the high scale.
+Wake and rise, and step into the green outdoors.
+The green light in the brown box flickered.
+The brass tube circled the high wall.
+The lobes of her ears were pierced to hold rings.
+Hold the hammer near the end to drive the nail.
+Next Sunday is the twelfth of the month.
+Every word and phrase he speaks is true.
+He put his last cartridge into the gun and fired.
+They took their kids from the public school.
+Drive the screw straight into the wood.
+Keep the hatch tight and the watch constant.
+Sever the twine with a quick snip of the knife.
+Paper will dry out when wet.
+Slide the catch back and open the desk.
+Help the weak to preserve their strength.
+A sullen smile gets few friends.
+Stop whistling and watch the boys march.
+Jerk the cord, and out tumbles the gold.
+Slide the tray across the glass top.
+The cloud moved in a stately way and was gone.
+Light maple makes for a swell room.
+Set the piece here and say nothing.
+Dull stories make her laugh.
+A stiff cord will do to fasten your shoe.
+Get the trust fund to the bank early.
+Choose between the high road and the low.
+A plea for funds seems to come again.
+He lent his coat to the tall gaunt stranger.
+There is a strong chance it will happen once more.
+The duke left the park in a silver coach.
+Greet the new guests and leave quickly.
+When the frost has come it is time for turkey.
+Sweet words work better than fierce.
+A thin stripe runs down the middle.
+A six comes up more often than a ten.
+Lush fern grow on the lofty rocks.
+The ram scared the school children off.
+The team with the best timing looks good.
+The farmer swapped his horse for a brown ox.
+Sit on the perch and tell the others what to do.
+A steep trail is painful for our feet.
+The early phase of life moves fast.
+Green moss grows on the northern side.
+Tea in thin china has a sweet taste.
+Pitch the straw through the door of the stable.
+The latch on the back gate needed a nail.
+The goose was brought straight from the old market.
+The sink is the thing in which we pile dishes.
+A whiff of it will cure the most stubborn cold.
+The facts don't always show who is right.
+She flaps her cape as she parades the street.
+The loss of the cruiser was a blow to the fleet.
+Loop the braid to the left and then over.
+Plead with the lawyer to drop the lost cause.
+Calves thrive on tender spring grass.
+Post no bills on this office wall.
+Tear a thin sheet from the yellow pad.
+A cruise in warm waters in a sleek yacht is fun.
+A streak of color ran down the left edge.
+It was done before the boy could see it.
+Crouch before you jump or miss the mark.
+Pack the kits and don't forget the salt.
+The square peg will settle in the round hole.
+Fine soap saves tender skin.
+Poached eggs and tea must suffice.
+Bad nerves are jangled by a door slam.
+Ship maps are different from those for planes.
+Dimes showered down from all sides.
+They sang the same tunes at each party.
+The sky in the west is tinged with orange red.
+The pods of peas ferment in bare fields.
+The horse balked and threw the tall rider.
+The hitch between the horse and cart broke.
+Pile the coal high in the shed corner.
+A gold vase is both rare and costly.
+The knife was hung inside its bright sheath.
+The rarest spice comes from the far East.
+The roof should be tilted at a sharp slant.
+A smatter of French is worse than none.
+The mule trod the treadmill day and night.
+The aim of the contest is to raise a great fund.
+To send it now in large amounts is bad.
+There is a fine hard tang in salty air.
+Cod is the main business of the north shore.
+The slab was hewn from heavy blocks of slate.
+Dunk the stale biscuits into strong drink.
+Hang tinsel from both branches.
+Cap the jar with a tight brass cover.
+The poor boy missed the boat again.
+Be sure to set the lamp firmly in the hole.
+Pick a card and slip it under the pack.
+A round mat will cover the dull spot.
+The first part of the plan needs changing.
+A good book informs of what we ought to know.
+The mail comes in three batches per day.
+You cannot brew tea in a cold pot.
+Dots of light betrayed the black cat.
+Put the chart on the mantel and tack it down.
+The night shift men rate extra pay.
+The red paper brightened the dim stage.
+See the player scoot to third base.
+Slide the bill between the two leaves.
+Many hands help get the job done.
+We don't like to admit our small faults.
+No doubt about the way the wind blows.
+Dig deep in the earth for pirate's gold.
+The steady drip is worse than a drenching rain.
+A flat pack takes less luggage space.
+Green ice frosted the punch bowl.
+A stuffed chair slipped from the moving van.
+The stitch will serve but needs to be shortened.
+A thin book fits in the side pocket.
+The gloss on top made it unfit to read.
+The hail pattered on the burnt brown grass.
+Seven seals were stamped on great sheets.
+Our troops are set to strike heavy blows.
+The store was jammed before the sale could start.
+It was a bad error on the part of the new judge.
+One step more and the board will collapse.
+Take the match and strike it against your shoe.
+The pot boiled, but the contents failed to jell.
+The baby puts his right foot in his mouth.
+The bombs left most of the town in ruins.
+Stop and stare at the hard working man.
+The streets are narrow and full of sharp turns.
+The pup jerked the leash as he saw a feline shape.
+Open your book to the first page.
+Fish evade the net and swim off.
+Dip the pail once and let it settle.
+Will you please answer that phone.
+The big red apple fell to the ground.
+The curtain rose and the show was on.
+The young prince became heir to the throne.
+He sent the boy on a short errand.
+Leave now and you will arrive on time.
+The corner store was robbed last night.
+A gold ring will please most any girl.
+The long journey home took a year.
+She saw a cat in the neighbor's house.
+A pink shell was found on the sandy beach.
+Small children came to see him.
+The grass and bushes were wet with dew.
+The blind man counted his old coins.
+A severe storm tore down the barn.
+She called his name many times.
+When you hear the bell, come quickly.
\ No newline at end of file
diff --git a/extensions/silero_tts/outputs/outputs-will-be-saved-here.txt b/extensions/silero_tts/outputs/outputs-will-be-saved-here.txt
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/extensions/silero_tts/requirements.txt b/extensions/silero_tts/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..1017bf0d7accb9930872ededd8a4bc077d393958
--- /dev/null
+++ b/extensions/silero_tts/requirements.txt
@@ -0,0 +1,5 @@
+ipython
+num2words
+omegaconf
+pydub
+PyYAML
diff --git a/extensions/silero_tts/script.py b/extensions/silero_tts/script.py
new file mode 100644
index 0000000000000000000000000000000000000000..b96a47fd5f9c166a0c411428a30587fa48016096
--- /dev/null
+++ b/extensions/silero_tts/script.py
@@ -0,0 +1,225 @@
+import random
+import time
+from pathlib import Path
+
+import gradio as gr
+import torch
+
+from extensions.silero_tts import tts_preprocessor
+from modules import chat, shared
+from modules.utils import gradio
+
+torch._C._jit_set_profiling_mode(False)
+
+
+params = {
+ 'activate': True,
+ 'speaker': 'en_56',
+ 'language': 'en',
+ 'model_id': 'v3_en',
+ 'sample_rate': 48000,
+ 'device': 'cpu',
+ 'show_text': False,
+ 'autoplay': True,
+ 'voice_pitch': 'medium',
+ 'voice_speed': 'medium',
+ 'local_cache_path': '' # User can override the default cache path to something other via settings.json
+}
+
+current_params = params.copy()
+voices_by_gender = ['en_99', 'en_45', 'en_18', 'en_117', 'en_49', 'en_51', 'en_68', 'en_0', 'en_26', 'en_56', 'en_74', 'en_5', 'en_38', 'en_53', 'en_21', 'en_37', 'en_107', 'en_10', 'en_82', 'en_16', 'en_41', 'en_12', 'en_67', 'en_61', 'en_14', 'en_11', 'en_39', 'en_52', 'en_24', 'en_97', 'en_28', 'en_72', 'en_94', 'en_36', 'en_4', 'en_43', 'en_88', 'en_25', 'en_65', 'en_6', 'en_44', 'en_75', 'en_91', 'en_60', 'en_109', 'en_85', 'en_101', 'en_108', 'en_50', 'en_96', 'en_64', 'en_92', 'en_76', 'en_33', 'en_116', 'en_48', 'en_98', 'en_86', 'en_62', 'en_54', 'en_95', 'en_55', 'en_111', 'en_3', 'en_83', 'en_8', 'en_47', 'en_59', 'en_1', 'en_2', 'en_7', 'en_9', 'en_13', 'en_15', 'en_17', 'en_19', 'en_20', 'en_22', 'en_23', 'en_27', 'en_29', 'en_30', 'en_31', 'en_32', 'en_34', 'en_35', 'en_40', 'en_42', 'en_46', 'en_57', 'en_58', 'en_63', 'en_66', 'en_69', 'en_70', 'en_71', 'en_73', 'en_77', 'en_78', 'en_79', 'en_80', 'en_81', 'en_84', 'en_87', 'en_89', 'en_90', 'en_93', 'en_100', 'en_102', 'en_103', 'en_104', 'en_105', 'en_106', 'en_110', 'en_112', 'en_113', 'en_114', 'en_115']
+voice_pitches = ['x-low', 'low', 'medium', 'high', 'x-high']
+voice_speeds = ['x-slow', 'slow', 'medium', 'fast', 'x-fast']
+
+# Used for making text xml compatible, needed for voice pitch and speed control
+table = str.maketrans({
+ "<": "<",
+ ">": ">",
+ "&": "&",
+ "'": "'",
+ '"': """,
+})
+
+
+def xmlesc(txt):
+ return txt.translate(table)
+
+
+def load_model():
+ torch_cache_path = torch.hub.get_dir() if params['local_cache_path'] == '' else params['local_cache_path']
+ model_path = torch_cache_path + "/snakers4_silero-models_master/src/silero/model/" + params['model_id'] + ".pt"
+ if Path(model_path).is_file():
+ print(f'\nUsing Silero TTS cached checkpoint found at {torch_cache_path}')
+ model, example_text = torch.hub.load(repo_or_dir=torch_cache_path + '/snakers4_silero-models_master/', model='silero_tts', language=params['language'], speaker=params['model_id'], source='local', path=model_path, force_reload=True)
+ else:
+ print(f'\nSilero TTS cache not found at {torch_cache_path}. Attempting to download...')
+ model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_tts', language=params['language'], speaker=params['model_id'])
+ model.to(params['device'])
+ return model
+
+
+def remove_tts_from_history(history):
+ for i, entry in enumerate(history['internal']):
+ history['visible'][i] = [history['visible'][i][0], entry[1]]
+
+ return history
+
+
+def toggle_text_in_history(history):
+ for i, entry in enumerate(history['visible']):
+ visible_reply = entry[1]
+ if visible_reply.startswith('- to be generated instead of a
. + if re.search(r'(\d+\.?)$', result): + delete_str = '|delete|' + + if not result.endswith('.'): + result += '.' + + result = re.sub(r'(\d+\.)$', r'\g<1> ' + delete_str, result) + + html = markdown.markdown(result, extensions=['fenced_code', 'tables']) + pos = html.rfind(delete_str) + if pos > -1: + html = html[:pos] + html[pos + len(delete_str):] + else: + html = markdown.markdown(result, extensions=['fenced_code', 'tables']) + + return html + + +def generate_basic_html(string): + string = convert_to_markdown(string) + string = f'
{string}
'
+ return string
+
+
+def process_post(post, c):
+ t = post.split('\n')
+ number = t[0].split(' ')[1]
+ if len(t) > 1:
+ src = '\n'.join(t[1:])
+ else:
+ src = ''
+ src = re.sub('>', '>', src)
+ src = re.sub('(>>[0-9]*)', '\\1', src)
+ src = re.sub('\n', '\n', src) + src = f'
 ' if Path("cache/pfp_character.png").exists() else ''
+ img_me = f'
' if Path("cache/pfp_character.png").exists() else ''
+ img_me = f' if reset_cache else ) ' if Path("cache/pfp_me.png").exists() else ''
+
+ for i, _row in enumerate(history):
+ row = [convert_to_markdown(entry) for entry in _row]
+
+ if row[0]: # don't display empty user messages
+ output += f"""
+
' if Path("cache/pfp_me.png").exists() else ''
+
+ for i, _row in enumerate(history):
+ row = [convert_to_markdown(entry) for entry in _row]
+
+ if row[0]: # don't display empty user messages
+ output += f"""
+