
Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .dockerignore +12 -0
- .env_gpt4all +17 -0
- .gitattributes +1 -0
- .github/workflows/snyk-scan.yml +76 -0
- .gitignore +37 -0
- Dockerfile +26 -0
- Dockerfile-runner.in +15 -0
- LICENSE +201 -0
- Makefile +63 -0
- README.md +249 -8
- START.sh +1 -0
- WizardLM-7B-uncensored.ggmlv3.q8_0.bin +3 -0
- blog/README.md +81 -0
- ci/jenkinsfile +158 -0
- client/.gitignore +168 -0
- client/Makefile +55 -0
- client/README.md +72 -0
- client/h2ogpt_client/__init__.py +3 -0
- client/h2ogpt_client/_core.py +265 -0
- client/h2ogpt_client/_utils.py +43 -0
- client/poetry.lock +856 -0
- client/poetry.toml +1 -0
- client/pyproject.toml +41 -0
- client/tests/__init__.py +0 -0
- client/tests/conftest.py +52 -0
- client/tests/test_client.py +73 -0
- data/NGSL_1.2_stats.csv.zip +3 -0
- data/README-template.md +23 -0
- data/censor_words.txt +10 -0
- data/config.json +0 -0
- data/count_1w.txt.zip +3 -0
- data/create_data_cards.py +144 -0
- data/dai_docs.train.json +0 -0
- data/dai_docs.train_cleaned.json +0 -0
- data/dai_docs.valid.json +101 -0
- data/dai_faq.json +477 -0
- data/demo.png +3 -0
- data/example.xlsx +0 -0
- data/h2ogpt-personality.json +642 -0
- data/merged.json +0 -0
- data/pexels-evg-kowalievska-1170986_small.jpg +0 -0
- db_UserData_22176da3-ede6-4a48-a5e2-abd95296fcd6.lock +0 -0
- docker-compose.yml +28 -0
- docs/FAQ.md +378 -0
- docs/FINETUNE.md +95 -0
- docs/INSTALL-DOCKER.md +73 -0
- docs/INSTALL.md +131 -0
- docs/LINKS.md +217 -0
- docs/README_CLI.md +24 -0
- docs/README_CLIENT.md +38 -0
.dockerignore
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.git
|
| 2 |
+
.npm
|
| 3 |
+
.dockerignore
|
| 4 |
+
.pytest_cache
|
| 5 |
+
.cache
|
| 6 |
+
.github
|
| 7 |
+
.nv
|
| 8 |
+
.benchmarks
|
| 9 |
+
h2ogpt.egg-info
|
| 10 |
+
venv
|
| 11 |
+
build
|
| 12 |
+
dist
|
.env_gpt4all
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# GPT4ALL or llama-cpp-python model_kwargs
|
| 2 |
+
|
| 3 |
+
# GPT4ALl GPT-J type, from model explorer choice, so downloads
|
| 4 |
+
model_name_gptj=ggml-gpt4all-j-v1.3-groovy.bin
|
| 5 |
+
|
| 6 |
+
# llama-cpp-python type, supporting version 3 quantization, here from locally built llama.cpp q4 v3 quantization
|
| 7 |
+
# below uses prompt_type=wizard2
|
| 8 |
+
model_path_llama=WizardLM-7B-uncensored.ggmlv3.q8_0.bin
|
| 9 |
+
# below assumes max_new_tokens=256
|
| 10 |
+
n_ctx=1792
|
| 11 |
+
# uncomment below if using llama-cpp-pyton with cublas built in
|
| 12 |
+
# n_gpu_layers=20
|
| 13 |
+
|
| 14 |
+
# GPT4ALl LLaMa type, supporting version 2 quantization, here from model explorer choice so downloads
|
| 15 |
+
model_name_gpt4all_llama=ggml-wizardLM-7B.q4_2.bin
|
| 16 |
+
|
| 17 |
+
# PDF_CLASS_NAME=UnstructuredPDFLoader
|
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
data/demo.png filter=lfs diff=lfs merge=lfs -text
|
.github/workflows/snyk-scan.yml
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: Snyk Security Vulnerability Scan
|
| 2 |
+
|
| 3 |
+
on:
|
| 4 |
+
workflow_dispatch:
|
| 5 |
+
pull_request:
|
| 6 |
+
push:
|
| 7 |
+
tags:
|
| 8 |
+
- 'v[0-9]+.[0-9]+.[0-9]+'
|
| 9 |
+
branches:
|
| 10 |
+
- main
|
| 11 |
+
|
| 12 |
+
jobs:
|
| 13 |
+
snyk_scan_test:
|
| 14 |
+
if: ${{ github.event_name == 'pull_request' || github.event_name == 'workflow_dispatch' }}
|
| 15 |
+
runs-on: ubuntu-latest
|
| 16 |
+
steps:
|
| 17 |
+
- uses: actions/checkout@master
|
| 18 |
+
- uses: snyk/actions/setup@master
|
| 19 |
+
|
| 20 |
+
- uses: actions/setup-python@v4
|
| 21 |
+
with:
|
| 22 |
+
python-version: '3.10'
|
| 23 |
+
|
| 24 |
+
- name: Check changed Deps files
|
| 25 |
+
uses: tj-actions/changed-files@v35
|
| 26 |
+
id: changed-files
|
| 27 |
+
with:
|
| 28 |
+
files: | # This will match all the files with below patterns
|
| 29 |
+
requirements.txt
|
| 30 |
+
|
| 31 |
+
- name: Scan python dependencies
|
| 32 |
+
if: contains(steps.changed-files.outputs.all_changed_and_modified_files, 'requirements.txt')
|
| 33 |
+
env:
|
| 34 |
+
SNYK_TOKEN: '${{ secrets.SNYK_TOKEN }}'
|
| 35 |
+
run: |
|
| 36 |
+
head -n 41 requirements.txt > temp-requirements.txt #remove test deps
|
| 37 |
+
python3.10 -m pip install -r temp-requirements.txt
|
| 38 |
+
snyk test \
|
| 39 |
+
-d \
|
| 40 |
+
--file=temp-requirements.txt \
|
| 41 |
+
--package-manager=pip \
|
| 42 |
+
--command=python3.10 \
|
| 43 |
+
--skip-unresolved \
|
| 44 |
+
--severity-threshold=high
|
| 45 |
+
|
| 46 |
+
snyk_scan_monitor:
|
| 47 |
+
if: ${{ github.event_name == 'push' || github.event_name == 'workflow_dispatch'}}
|
| 48 |
+
runs-on: ubuntu-latest
|
| 49 |
+
steps:
|
| 50 |
+
- uses: actions/checkout@master
|
| 51 |
+
- uses: snyk/actions/setup@master
|
| 52 |
+
|
| 53 |
+
- uses: actions/setup-python@v4
|
| 54 |
+
with:
|
| 55 |
+
python-version: '3.10'
|
| 56 |
+
|
| 57 |
+
- name: Extract github branch/tag name
|
| 58 |
+
shell: bash
|
| 59 |
+
run: echo "ref=$(echo ${GITHUB_REF##*/})" >> $GITHUB_OUTPUT
|
| 60 |
+
id: extract_ref
|
| 61 |
+
|
| 62 |
+
- name: Monitor python dependencies
|
| 63 |
+
env:
|
| 64 |
+
SNYK_TOKEN: '${{ secrets.SNYK_TOKEN }}'
|
| 65 |
+
run: |
|
| 66 |
+
head -n 41 requirements.txt > temp-requirements.txt #remove test deps
|
| 67 |
+
python3.10 -m pip install -r temp-requirements.txt
|
| 68 |
+
snyk monitor \
|
| 69 |
+
-d \
|
| 70 |
+
--file=temp-requirements.txt \
|
| 71 |
+
--command=python3.10 \
|
| 72 |
+
--package-manager=pip \
|
| 73 |
+
--skip-unresolved \
|
| 74 |
+
--remote-repo-url=h2ogpt/${{ steps.extract_ref.outputs.ref }} \
|
| 75 |
+
--org=h2o-gpt \
|
| 76 |
+
--project-name=H2O-GPT/h2ogpt/${{ steps.extract_ref.outputs.ref }}/requirements.txt
|
.gitignore
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
out/
|
| 2 |
+
7B/
|
| 3 |
+
13B/
|
| 4 |
+
__pycache__/
|
| 5 |
+
checkpoint**
|
| 6 |
+
minimal-llama**
|
| 7 |
+
upload.py
|
| 8 |
+
lora-**
|
| 9 |
+
*ckpt
|
| 10 |
+
wandb
|
| 11 |
+
evaluate.py
|
| 12 |
+
test_data.json
|
| 13 |
+
todo.txt
|
| 14 |
+
.neptune/
|
| 15 |
+
*.bin
|
| 16 |
+
db_dir_UserData
|
| 17 |
+
temp_path_do_doc1
|
| 18 |
+
offline_folder
|
| 19 |
+
flagged_data_points
|
| 20 |
+
.pytest_cache
|
| 21 |
+
user_path
|
| 22 |
+
user_path_test
|
| 23 |
+
build
|
| 24 |
+
h2ogpt.egg-info
|
| 25 |
+
dist
|
| 26 |
+
.idea
|
| 27 |
+
.cache
|
| 28 |
+
.local
|
| 29 |
+
.bash_history
|
| 30 |
+
.benchmarks
|
| 31 |
+
Dockerfile-runner.dockerfile
|
| 32 |
+
|
| 33 |
+
# IDEs
|
| 34 |
+
.idea/
|
| 35 |
+
|
| 36 |
+
# virtual envs
|
| 37 |
+
venv
|
Dockerfile
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# devel needed for bitsandbytes requirement of libcudart.so, otherwise runtime sufficient
|
| 2 |
+
FROM nvidia/cuda:12.1.1-cudnn8-devel-ubuntu20.04
|
| 3 |
+
|
| 4 |
+
ARG DEBIAN_FRONTEND=noninteractive
|
| 5 |
+
|
| 6 |
+
RUN apt-get update && apt-get install -y \
|
| 7 |
+
git \
|
| 8 |
+
curl \
|
| 9 |
+
wget \
|
| 10 |
+
software-properties-common \
|
| 11 |
+
pandoc \
|
| 12 |
+
&& add-apt-repository ppa:deadsnakes/ppa \
|
| 13 |
+
&& apt install -y python3.10 python3-dev libpython3.10-dev \
|
| 14 |
+
&& rm -rf /var/lib/apt/lists/*
|
| 15 |
+
WORKDIR /workspace
|
| 16 |
+
COPY requirements.txt requirements.txt
|
| 17 |
+
COPY reqs_optional reqs_optional
|
| 18 |
+
RUN curl -sS https://bootstrap.pypa.io/get-pip.py | python3.10
|
| 19 |
+
RUN python3.10 -m pip install -r requirements.txt --extra-index-url https://download.pytorch.org/whl/cu118
|
| 20 |
+
RUN python3.10 -m pip install -r reqs_optional/requirements_optional_langchain.txt
|
| 21 |
+
RUN python3.10 -m pip install -r reqs_optional/requirements_optional_gpt4all.txt
|
| 22 |
+
RUN python3.10 -m pip install -r reqs_optional/requirements_optional_langchain.gpllike.txt
|
| 23 |
+
RUN python3.10 -m pip install -r reqs_optional/requirements_optional_langchain.urls.txt
|
| 24 |
+
|
| 25 |
+
COPY . .
|
| 26 |
+
ENTRYPOINT [ "python3.10"]
|
Dockerfile-runner.in
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM BASE_DOCKER_IMAGE_SUBST
|
| 2 |
+
|
| 3 |
+
LABEL imagetype="runtime-h2ogpt"
|
| 4 |
+
LABEL maintainer="H2O.ai <[email protected]>"
|
| 5 |
+
|
| 6 |
+
ENV DEBIAN_FRONTEND=noninteractive
|
| 7 |
+
ENV TRANSFORMERS_CACHE=/h2ogpt_env/.cache
|
| 8 |
+
ENV HF_MODEL=h2oai/h2ogpt-gm-oasst1-en-2048-falcon-7b-v3
|
| 9 |
+
|
| 10 |
+
COPY run-gpt.sh /run-gpt.sh
|
| 11 |
+
|
| 12 |
+
EXPOSE 8888
|
| 13 |
+
EXPOSE 7860
|
| 14 |
+
|
| 15 |
+
ENTRYPOINT ["/run-gpt.sh"]
|
LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright 2023 Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
Makefile
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
all: clean dist
|
| 2 |
+
|
| 3 |
+
PACKAGE_VERSION := `cat version.txt | tr -d '\n'`
|
| 4 |
+
BUILD_TAG_FILES := requirements.txt Dockerfile `ls reqs_optional/*.txt | sort`
|
| 5 |
+
BUILD_TAG := $(shell md5sum $(BUILD_TAG_FILES) 2> /dev/null | sort | md5sum | cut -d' ' -f1)
|
| 6 |
+
DOCKER_TEST_IMAGE := harbor.h2o.ai/h2ogpt/test-image:$(BUILD_TAG)
|
| 7 |
+
DOCKER_RUN_IMAGE := $(DOCKER_TEST_IMAGE)-runtime
|
| 8 |
+
PYTHON_BINARY ?= `which python`
|
| 9 |
+
DEFAULT_MARKERS ?= "not need_tokens and not need_gpu"
|
| 10 |
+
|
| 11 |
+
.PHONY: reqs_optional/req_constraints.txt venv dist test publish docker_build
|
| 12 |
+
|
| 13 |
+
reqs_optional/req_constraints.txt:
|
| 14 |
+
grep -v '#\|peft\|transformers\|accelerate' requirements.txt > $@
|
| 15 |
+
|
| 16 |
+
clean:
|
| 17 |
+
rm -rf dist build h2ogpt.egg-info
|
| 18 |
+
|
| 19 |
+
venv:
|
| 20 |
+
$(PYTHON_BINARY) -m virtualenv -p $(PYTHON_BINARY) venv
|
| 21 |
+
|
| 22 |
+
install:
|
| 23 |
+
$(PYTHON_BINARY) -m pip install dist/h2ogpt-$(PACKAGE_VERSION)-py3-none-any.whl
|
| 24 |
+
|
| 25 |
+
install-%:
|
| 26 |
+
$(PYTHON_BINARY) -m pip install dist/h2ogpt-$(PACKAGE_VERSION)-py3-none-any.whl[$*]
|
| 27 |
+
|
| 28 |
+
dist:
|
| 29 |
+
$(PYTHON_BINARY) setup.py bdist_wheel
|
| 30 |
+
|
| 31 |
+
test:
|
| 32 |
+
$(PYTHON_BINARY) -m pip install requirements-parser -c reqs_optional/req_constraints.txt
|
| 33 |
+
$(PYTHON_BINARY) -m pytest tests --disable-warnings --junit-xml=test_report.xml -m "$(DEFAULT_MARKERS)"
|
| 34 |
+
|
| 35 |
+
test_imports:
|
| 36 |
+
$(PYTHON_BINARY) -m pytest tests/test_imports.py --disable-warnings --junit-xml=test_report.xml -m "$(DEFAULT_MARKERS)"
|
| 37 |
+
|
| 38 |
+
publish:
|
| 39 |
+
echo "Publishing not implemented yet."
|
| 40 |
+
|
| 41 |
+
docker_build:
|
| 42 |
+
ifeq ($(shell curl --write-out %{http_code} -sS --output /dev/null -X GET http://harbor.h2o.ai/api/v2.0/projects/h2ogpt/repositories/test-image/artifacts/$(BUILD_TAG)/tags),200)
|
| 43 |
+
@echo "Image already pushed to Harbor: $(DOCKER_TEST_IMAGE)"
|
| 44 |
+
else
|
| 45 |
+
DOCKER_BUILDKIT=1 docker build -t $(DOCKER_TEST_IMAGE) -f Dockerfile .
|
| 46 |
+
docker push $(DOCKER_TEST_IMAGE)
|
| 47 |
+
endif
|
| 48 |
+
|
| 49 |
+
.PHONY: Dockerfile-runner.dockerfile
|
| 50 |
+
|
| 51 |
+
Dockerfile-runner.dockerfile: Dockerfile-runner.in
|
| 52 |
+
cat $< \
|
| 53 |
+
| sed 's|BASE_DOCKER_IMAGE_SUBST|$(DOCKER_TEST_IMAGE)|g' \
|
| 54 |
+
> $@
|
| 55 |
+
|
| 56 |
+
docker_build_runner: docker_build Dockerfile-runner.dockerfile
|
| 57 |
+
docker pull $(DOCKER_TEST_IMAGE)
|
| 58 |
+
DOCKER_BUILDKIT=1 docker build -t $(DOCKER_RUN_IMAGE) -f Dockerfile-runner.dockerfile .
|
| 59 |
+
docker push $(DOCKER_RUN_IMAGE)
|
| 60 |
+
docker tag $(DOCKER_RUN_IMAGE) gcr.io/vorvan/h2oai/h2ogpt-runtime:$(BUILD_TAG)
|
| 61 |
+
|
| 62 |
+
print-%:
|
| 63 |
+
@echo $($*)
|
README.md
CHANGED
|
@@ -1,12 +1,253 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
|
| 4 |
-
colorFrom: gray
|
| 5 |
-
colorTo: purple
|
| 6 |
sdk: gradio
|
| 7 |
-
sdk_version: 3.
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
---
|
|
|
|
| 11 |
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
+
title: h2osiri
|
| 3 |
+
app_file: generate.py
|
|
|
|
|
|
|
| 4 |
sdk: gradio
|
| 5 |
+
sdk_version: 3.35.2
|
|
|
|
|
|
|
| 6 |
---
|
| 7 |
+
# h2oGPT
|
| 8 |
|
| 9 |
+
Turn ★ into ⭐ (top-right corner) if you like the project!
|
| 10 |
+
|
| 11 |
+
Query and summarize your documents or just chat with local private GPT LLMs using h2oGPT, an Apache V2 open-source project.
|
| 12 |
+
|
| 13 |
+
- **Private** offline database of any documents [(PDFs, Excel, Word, Images, Code, Text, MarkDown, etc.)](docs/README_LangChain.md#supported-datatypes)
|
| 14 |
+
- **Persistent** database (Chroma, Weaviate, or in-memory FAISS) using accurate embeddings (instructor-large, all-MiniLM-L6-v2, etc.)
|
| 15 |
+
- **Efficient** use of context using instruct-tuned LLMs (no need for LangChain's few-shot approach)
|
| 16 |
+
- **Upload** and **View** documents via UI (collaborative space or scratch space)
|
| 17 |
+
- **UI** or CLI with streaming of all models
|
| 18 |
+
- **Bake-off** UI mode against many models at same time
|
| 19 |
+
- **Variety** of models supported (Falcon, Vicuna, WizardLM including AutoGPTQ, 4-bit/8-bit, LORA)
|
| 20 |
+
- **GPU** support from HF models, and **CPU** support using LLaMa cpp and GPT4ALL
|
| 21 |
+
- **Linux, Docker, MAC, and Windows** support
|
| 22 |
+
- **Inference Servers** support (HF TGI server, vLLM, Gradio, OpenAI)
|
| 23 |
+
- **OpenAI-compliant Python client API** for client-server control
|
| 24 |
+
- **Evaluate** performance using reward models
|
| 25 |
+
|
| 26 |
+
### Live Demos
|
| 27 |
+
- [ Live h2oGPT Document Q/A Demo](https://gpt.h2o.ai/)
|
| 28 |
+
- [🤗 Live h2oGPT Chat Demo 1](https://huggingface.co/spaces/h2oai/h2ogpt-chatbot)
|
| 29 |
+
- [🤗 Live h2oGPT Chat Demo 2](https://huggingface.co/spaces/h2oai/h2ogpt-chatbot2)
|
| 30 |
+
- [ h2oGPT CPU](https://colab.research.google.com/drive/13RiBdAFZ6xqDwDKfW6BG_-tXfXiqPNQe?usp=sharing)
|
| 31 |
+
- [ h2oGPT GPU](https://colab.research.google.com/drive/143-KFHs2iCqXTQLI2pFCDiR69z0dR8iE?usp=sharing)
|
| 32 |
+
|
| 33 |
+
### Resources:
|
| 34 |
+
- [Discord](https://discord.gg/WKhYMWcVbq)
|
| 35 |
+
- [Apache V2 models (Falcon 40, etc.) at 🤗](https://huggingface.co/h2oai/)
|
| 36 |
+
- [YouTube: 100% Offline ChatGPT Alternative?](https://www.youtube.com/watch?v=Coj72EzmX20)
|
| 37 |
+
- [YouTube: Ultimate Open-Source LLM Showdown (6 Models Tested) - Surprising Results!](https://www.youtube.com/watch?v=FTm5C_vV_EY)
|
| 38 |
+
- [YouTube: Blazing Fast Falcon 40b 🚀 Uncensored, Open-Source, Fully Hosted, Chat With Your Docs](https://www.youtube.com/watch?v=H8Dx-iUY49s)
|
| 39 |
+
- [Technical Paper: https://arxiv.org/pdf/2306.08161.pdf](https://arxiv.org/pdf/2306.08161.pdf)
|
| 40 |
+
|
| 41 |
+
### Video Demo:
|
| 42 |
+
|
| 43 |
+
https://github.com/h2oai/h2ogpt/assets/2249614/2f805035-2c85-42fb-807f-fd0bca79abc6
|
| 44 |
+
|
| 45 |
+
YouTube 4K version: https://www.youtube.com/watch?v=_iktbj4obAI
|
| 46 |
+
|
| 47 |
+
### Guide:
|
| 48 |
+
<!-- cat README.md | ./gh-md-toc - But Help is heavily processed -->
|
| 49 |
+
* [Supported OS and Hardware](#supported-os-and-hardware)
|
| 50 |
+
* [Compare to PrivateGPT et al.](docs/README_LangChain.md#what-is-h2ogpts-langchain-integration-like)
|
| 51 |
+
* [Roadmap](#roadmap)
|
| 52 |
+
* [Getting Started](#getting-started)
|
| 53 |
+
* [TLDR Install & Run](#tldr)
|
| 54 |
+
* [GPU (CUDA)](docs/README_GPU.md)
|
| 55 |
+
* [CPU](docs/README_CPU.md)
|
| 56 |
+
* [MACOS](docs/README_MACOS.md)
|
| 57 |
+
* [Windows 10/11](docs/README_WINDOWS.md)
|
| 58 |
+
* [CLI chat](docs/README_CLI.md)
|
| 59 |
+
* [Gradio UI](docs/README_ui.md)
|
| 60 |
+
* [Client API](docs/README_CLIENT.md)
|
| 61 |
+
* [Inference Servers](docs/README_InferenceServers.md)
|
| 62 |
+
* [Python Wheel](docs/README_WHEEL.md)
|
| 63 |
+
* [Offline Mode](docs/README_offline.md)
|
| 64 |
+
* [Development](#development)
|
| 65 |
+
* [Help](#help)
|
| 66 |
+
* [LangChain file types supported](docs/README_LangChain.md#supported-datatypes)
|
| 67 |
+
* [CLI Database control](docs/README_LangChain.md#database-creation)
|
| 68 |
+
* [Why h2oGPT for Doc Q&A](docs/README_LangChain.md#what-is-h2ogpts-langchain-integration-like)
|
| 69 |
+
* [FAQ](docs/FAQ.md)
|
| 70 |
+
* [Useful Links](docs/LINKS.md)
|
| 71 |
+
* [Fine-Tuning](docs/FINETUNE.md)
|
| 72 |
+
* [Docker](docs/INSTALL-DOCKER.md)
|
| 73 |
+
* [Triton](docs/TRITON.md)
|
| 74 |
+
* [Acknowledgements](#acknowledgements)
|
| 75 |
+
* [Why H2O.ai?](#why-h2oai)
|
| 76 |
+
* [Disclaimer](#disclaimer)
|
| 77 |
+
|
| 78 |
+
### Supported OS and Hardware
|
| 79 |
+
|
| 80 |
+
[](https://raw.githubusercontent.com/h2oai/h2ogpt/main/LICENSE)
|
| 81 |
+

|
| 82 |
+

|
| 83 |
+

|
| 84 |
+

|
| 85 |
+
|
| 86 |
+
**GPU** mode requires CUDA support via torch and transformers. A 6.9B (or 12GB) model in 8-bit uses 8GB (or 13GB) of GPU memory. 8-bit precision, 4-bit precision, and AutoGPTQ can further reduce memory requirements down no more than about 6.5GB when asking a question about your documents (see [low-memory mode](docs/FAQ.md#low-memory-mode)).
|
| 87 |
+
|
| 88 |
+
**CPU** mode uses GPT4ALL and LLaMa.cpp, e.g. gpt4all-j, requiring about 14GB of system RAM in typical use.
|
| 89 |
+
|
| 90 |
+
GPU and CPU mode tested on variety of NVIDIA GPUs in Ubuntu 18-22, but any modern Linux variant should work. MACOS support tested on Macbook Pro running Monterey v12.3.1 using CPU mode, as well as MAC M1 using MPS.
|
| 91 |
+
|
| 92 |
+
### Roadmap
|
| 93 |
+
|
| 94 |
+
- Integration of code and resulting LLMs with downstream applications and low/no-code platforms
|
| 95 |
+
- Complement h2oGPT chatbot with search and other APIs
|
| 96 |
+
- High-performance distributed training of larger models on trillion tokens
|
| 97 |
+
- Enhance the model's code completion, reasoning, and mathematical capabilities, ensure factual correctness, minimize hallucinations, and avoid repetitive output
|
| 98 |
+
- Add other tools like search
|
| 99 |
+
- Add agents for SQL and CSV question/answer
|
| 100 |
+
|
| 101 |
+
## Getting Started
|
| 102 |
+
|
| 103 |
+
First one needs a Python 3.10 environment. For help installing a Python 3.10 environment, see [Install Python 3.10 Environment](docs/INSTALL.md#install-python-environment). On newer Ubuntu systems and environment may be installed by just doing:
|
| 104 |
+
```bash
|
| 105 |
+
sudo apt-get install -y build-essential gcc python3.10-dev
|
| 106 |
+
virtualenv -p python3 h2ogpt
|
| 107 |
+
source h2ogpt/bin/activate
|
| 108 |
+
```
|
| 109 |
+
or use conda:
|
| 110 |
+
```bash
|
| 111 |
+
conda create -n h2ogpt -y
|
| 112 |
+
conda activate h2ogpt
|
| 113 |
+
conda install python=3.10 -c conda-forge -y
|
| 114 |
+
```
|
| 115 |
+
Check your installation by doing:
|
| 116 |
+
```bash
|
| 117 |
+
python --version # should say 3.10.xx
|
| 118 |
+
pip --version # should say pip 23.x.y ... (python 3.10)
|
| 119 |
+
```
|
| 120 |
+
On some systems, `pip` still refers back to the system one, then one can use `python -m pip` or `pip3` instead of `pip` or try `python3` instead of `python`.
|
| 121 |
+
|
| 122 |
+
### TLDR
|
| 123 |
+
|
| 124 |
+
For [MACOS](docs/README_MACOS.md#macos) and [Windows 10/11](docs/README_WINDOWS.md) please follow their instructions.
|
| 125 |
+
|
| 126 |
+
On Ubuntu, after Python 3.10 environment installed do:
|
| 127 |
+
```bash
|
| 128 |
+
git clone https://github.com/h2oai/h2ogpt.git
|
| 129 |
+
cd h2ogpt
|
| 130 |
+
# fix any bad env
|
| 131 |
+
pip uninstall -y pandoc pypandoc pypandoc-binary
|
| 132 |
+
# broad support, but no training-time or data creation dependencies
|
| 133 |
+
|
| 134 |
+
# CPU only:
|
| 135 |
+
pip install -r requirements.txt --extra-index https://download.pytorch.org/whl/cpu
|
| 136 |
+
|
| 137 |
+
# GPU only:
|
| 138 |
+
pip install -r requirements.txt --extra-index https://download.pytorch.org/whl/cu118
|
| 139 |
+
```
|
| 140 |
+
Then run:
|
| 141 |
+
```bash
|
| 142 |
+
# Required for Doc Q/A: LangChain:
|
| 143 |
+
pip install -r reqs_optional/requirements_optional_langchain.txt
|
| 144 |
+
# Required for CPU: LLaMa/GPT4All:
|
| 145 |
+
pip install -r reqs_optional/requirements_optional_gpt4all.txt
|
| 146 |
+
# Optional: PyMuPDF/ArXiv:
|
| 147 |
+
pip install -r reqs_optional/requirements_optional_langchain.gpllike.txt
|
| 148 |
+
# Optional: Selenium/PlayWright:
|
| 149 |
+
pip install -r reqs_optional/requirements_optional_langchain.urls.txt
|
| 150 |
+
# Optional: support docx, pptx, ArXiv, etc. required by some python packages
|
| 151 |
+
sudo apt-get install -y libmagic-dev poppler-utils tesseract-ocr libreoffice
|
| 152 |
+
# Optional: for supporting unstructured package
|
| 153 |
+
python -m nltk.downloader all
|
| 154 |
+
# Optional: For AutoGPTQ support on x86_64 linux
|
| 155 |
+
pip uninstall -y auto-gptq ; CUDA_HOME=/usr/local/cuda-11.8 GITHUB_ACTIONS=true pip install auto-gptq --no-cache-dir
|
| 156 |
+
```
|
| 157 |
+
See [AutoGPTQ](docs/README_GPU.md#gpu-cuda) for more details for AutoGPTQ and other GPU installation aspects.
|
| 158 |
+
|
| 159 |
+
Place all documents in `user_path` or upload in UI ([Help with UI](docs/README_ui.md)).
|
| 160 |
+
|
| 161 |
+
UI using GPU with at least 24GB with streaming:
|
| 162 |
+
```bash
|
| 163 |
+
python generate.py --base_model=h2oai/h2ogpt-oasst1-512-12b --load_8bit=True --score_model=None --langchain_mode='UserData' --user_path=user_path
|
| 164 |
+
```
|
| 165 |
+
UI using LLaMa.cpp model:
|
| 166 |
+
```bash
|
| 167 |
+
wget https://huggingface.co/TheBloke/WizardLM-7B-uncensored-GGML/resolve/main/WizardLM-7B-uncensored.ggmlv3.q8_0.bin
|
| 168 |
+
python generate.py --base_model='llama' --prompt_type=wizard2 --score_model=None --langchain_mode='UserData' --user_path=user_path
|
| 169 |
+
```
|
| 170 |
+
which works on CPU or GPU (assuming llama cpp python package compiled against CUDA or Metal).
|
| 171 |
+
|
| 172 |
+
If using OpenAI for the LLM is ok, but you want documents to be parsed and embedded locally, then do:
|
| 173 |
+
```bash
|
| 174 |
+
python generate.py --inference_server=openai_chat --base_model=gpt-3.5-turbo --score_model=None
|
| 175 |
+
```
|
| 176 |
+
and perhaps you want better image caption performance and focus local GPU on that, then do:
|
| 177 |
+
```bash
|
| 178 |
+
python generate.py --inference_server=openai_chat --base_model=gpt-3.5-turbo --score_model=None --captions_model=Salesforce/blip2-flan-t5-xl
|
| 179 |
+
```
|
| 180 |
+
|
| 181 |
+
Add `--share=True` to make gradio server visible via sharable URL. If you see an error about protobuf, try:
|
| 182 |
+
```bash
|
| 183 |
+
pip install protobuf==3.20.0
|
| 184 |
+
```
|
| 185 |
+
|
| 186 |
+
Once all files are downloaded, the CLI and UI can be run in offline mode, see [offline mode](docs/README_offline.md).
|
| 187 |
+
|
| 188 |
+
### Development
|
| 189 |
+
|
| 190 |
+
- To create a development environment for training and generation, follow the [installation instructions](docs/INSTALL.md).
|
| 191 |
+
- To fine-tune any LLM models on your data, follow the [fine-tuning instructions](docs/FINETUNE.md).
|
| 192 |
+
- To create a container for deployment, follow the [Docker instructions](docs/INSTALL-DOCKER.md).
|
| 193 |
+
- To run h2oGPT tests, run `pip install requirements-parser ; pytest -s -v tests client/tests`
|
| 194 |
+
|
| 195 |
+
### Help
|
| 196 |
+
|
| 197 |
+
- For advanced fine-tuning, also check out [H2O LLM Studio](https://github.com/h2oai/h2o-llmstudio)
|
| 198 |
+
|
| 199 |
+
- Flash attention support, see [Flash Attention](docs/INSTALL.md#flash-attention)
|
| 200 |
+
|
| 201 |
+
- [Docker](docs/INSTALL-DOCKER.md#containerized-installation-for-inference-on-linux-gpu-servers) for inference
|
| 202 |
+
|
| 203 |
+
- [FAQs](docs/FAQ.md)
|
| 204 |
+
|
| 205 |
+
- [README for LangChain](docs/README_LangChain.md)
|
| 206 |
+
|
| 207 |
+
- More [Links](docs/LINKS.md), context, competitors, models, datasets
|
| 208 |
+
|
| 209 |
+
### Acknowledgements
|
| 210 |
+
|
| 211 |
+
* Some training code was based upon March 24 version of [Alpaca-LoRA](https://github.com/tloen/alpaca-lora/).
|
| 212 |
+
* Used high-quality created data by [OpenAssistant](https://open-assistant.io/).
|
| 213 |
+
* Used base models by [EleutherAI](https://www.eleuther.ai/).
|
| 214 |
+
* Used OIG data created by [LAION](https://laion.ai/blog/oig-dataset/).
|
| 215 |
+
|
| 216 |
+
### Why H2O.ai?
|
| 217 |
+
|
| 218 |
+
Our [Makers](https://h2o.ai/company/team/) at [H2O.ai](https://h2o.ai) have built several world-class Machine Learning, Deep Learning and AI platforms:
|
| 219 |
+
- #1 open-source machine learning platform for the enterprise [H2O-3](https://github.com/h2oai/h2o-3)
|
| 220 |
+
- The world's best AutoML (Automatic Machine Learning) with [H2O Driverless AI](https://h2o.ai/platform/ai-cloud/make/h2o-driverless-ai/)
|
| 221 |
+
- No-Code Deep Learning with [H2O Hydrogen Torch](https://h2o.ai/platform/ai-cloud/make/hydrogen-torch/)
|
| 222 |
+
- Document Processing with Deep Learning in [Document AI](https://h2o.ai/platform/ai-cloud/make/document-ai/)
|
| 223 |
+
|
| 224 |
+
We also built platforms for deployment and monitoring, and for data wrangling and governance:
|
| 225 |
+
- [H2O MLOps](https://h2o.ai/platform/ai-cloud/operate/h2o-mlops/) to deploy and monitor models at scale
|
| 226 |
+
- [H2O Feature Store](https://h2o.ai/platform/ai-cloud/make/feature-store/) in collaboration with AT&T
|
| 227 |
+
- Open-source Low-Code AI App Development Frameworks [Wave](https://wave.h2o.ai/) and [Nitro](https://nitro.h2o.ai/)
|
| 228 |
+
- Open-source Python [datatable](https://github.com/h2oai/datatable/) (the engine for H2O Driverless AI feature engineering)
|
| 229 |
+
|
| 230 |
+
Many of our customers are creating models and deploying them enterprise-wide and at scale in the [H2O AI Cloud](https://h2o.ai/platform/ai-cloud/):
|
| 231 |
+
- Multi-Cloud or on Premises
|
| 232 |
+
- [Managed Cloud (SaaS)](https://h2o.ai/platform/ai-cloud/managed)
|
| 233 |
+
- [Hybrid Cloud](https://h2o.ai/platform/ai-cloud/hybrid)
|
| 234 |
+
- [AI Appstore](https://docs.h2o.ai/h2o-ai-cloud/)
|
| 235 |
+
|
| 236 |
+
We are proud to have over 25 (of the world's 280) [Kaggle Grandmasters](https://h2o.ai/company/team/kaggle-grandmasters/) call H2O home, including three Kaggle Grandmasters who have made it to world #1.
|
| 237 |
+
|
| 238 |
+
### Disclaimer
|
| 239 |
+
|
| 240 |
+
Please read this disclaimer carefully before using the large language model provided in this repository. Your use of the model signifies your agreement to the following terms and conditions.
|
| 241 |
+
|
| 242 |
+
- Biases and Offensiveness: The large language model is trained on a diverse range of internet text data, which may contain biased, racist, offensive, or otherwise inappropriate content. By using this model, you acknowledge and accept that the generated content may sometimes exhibit biases or produce content that is offensive or inappropriate. The developers of this repository do not endorse, support, or promote any such content or viewpoints.
|
| 243 |
+
- Limitations: The large language model is an AI-based tool and not a human. It may produce incorrect, nonsensical, or irrelevant responses. It is the user's responsibility to critically evaluate the generated content and use it at their discretion.
|
| 244 |
+
- Use at Your Own Risk: Users of this large language model must assume full responsibility for any consequences that may arise from their use of the tool. The developers and contributors of this repository shall not be held liable for any damages, losses, or harm resulting from the use or misuse of the provided model.
|
| 245 |
+
- Ethical Considerations: Users are encouraged to use the large language model responsibly and ethically. By using this model, you agree not to use it for purposes that promote hate speech, discrimination, harassment, or any form of illegal or harmful activities.
|
| 246 |
+
- Reporting Issues: If you encounter any biased, offensive, or otherwise inappropriate content generated by the large language model, please report it to the repository maintainers through the provided channels. Your feedback will help improve the model and mitigate potential issues.
|
| 247 |
+
- Changes to this Disclaimer: The developers of this repository reserve the right to modify or update this disclaimer at any time without prior notice. It is the user's responsibility to periodically review the disclaimer to stay informed about any changes.
|
| 248 |
+
|
| 249 |
+
By using the large language model provided in this repository, you agree to accept and comply with the terms and conditions outlined in this disclaimer. If you do not agree with any part of this disclaimer, you should refrain from using the model and any content generated by it.
|
| 250 |
+
|
| 251 |
+
## Star History
|
| 252 |
+
|
| 253 |
+
[](https://star-history.com/#h2oai/h2ogpt&Timeline)
|
START.sh
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
python generate.py --base_model='llama' --prompt_type=wizard2 --score_model=None
|
WizardLM-7B-uncensored.ggmlv3.q8_0.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2802e2c7ffb3cae9bab40425a2600d286b98ed5cc7fe2116fc205a2a101e913e
|
| 3 |
+
size 7160808576
|
blog/README.md
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Building the World's Best Open-Source Large Language Model: H2O.ai's Journey
|
| 2 |
+
|
| 3 |
+
by Arno Candel, PhD, CTO H2O.ai, April 19 2023
|
| 4 |
+
|
| 5 |
+
At H2O.ai, we pride ourselves on developing world-class Machine Learning, Deep Learning, and AI platforms. We released H2O, the most widely used open-source distributed and scalable machine learning platform, before XGBoost, TensorFlow and PyTorch existed. H2O.ai is home to over 25 Kaggle grandmasters, including the current #1. In 2017, we used GPUs to create the world's best AutoML in H2O Driverless AI. We have witnessed first-hand how Large Language Models (LLMs) have taken over the world by storm.
|
| 6 |
+
|
| 7 |
+
We are proud to announce that we are building h2oGPT, an LLM that not only excels in performance but is also fully open-source and commercially usable, providing a valuable resource for developers, researchers, and organizations worldwide.
|
| 8 |
+
|
| 9 |
+
In this blog, we'll explore our journey in building h2oGPT in our effort to further democratize AI.
|
| 10 |
+
|
| 11 |
+
## Why Open-Source LLMs?
|
| 12 |
+
|
| 13 |
+
While LLMs like OpenAI's ChatGPT/GPT-4, Anthropic's Claude, Microsoft's Bing AI Chat, Google's Bard, and Cohere are powerful and effective, they have certain limitations compared to open-source LLMs:
|
| 14 |
+
|
| 15 |
+
1. **Data Privacy and Security**: Using hosted LLMs requires sending data to external servers. This can raise concerns about data privacy, security, and compliance, especially for sensitive information or industries with strict regulations.
|
| 16 |
+
2. **Dependency and Customization**: Hosted LLMs often limit the extent of customization and control, as users rely on the service provider's infrastructure and predefined models. Open-source LLMs allow users to tailor the models to their specific needs, deploy on their own infrastructure, and even modify the underlying code.
|
| 17 |
+
3. **Cost and Scalability**: Hosted LLMs usually come with usage fees, which can increase significantly with large-scale applications. Open-source LLMs can be more cost-effective, as users can scale the models on their own infrastructure without incurring additional costs from the service provider.
|
| 18 |
+
4. **Access and Availability**: Hosted LLMs may be subject to downtime or limited availability, affecting users' access to the models. Open-source LLMs can be deployed on-premises or on private clouds, ensuring uninterrupted access and reducing reliance on external providers.
|
| 19 |
+
|
| 20 |
+
Overall, open-source LLMs offer greater flexibility, control, and cost-effectiveness, while addressing data privacy and security concerns. They foster a competitive landscape in the AI industry and empower users to innovate and customize models to suit their specific needs.
|
| 21 |
+
|
| 22 |
+
## The H2O.ai LLM Ecosystem
|
| 23 |
+
|
| 24 |
+
Our open-source LLM ecosystem currently includes the following components:
|
| 25 |
+
|
| 26 |
+
1. **Code, data, and models**: Fully permissive, commercially usable [code](https://github.com/h2oai/h2ogpt), curated fine-tuning [data](https://huggingface.co/h2oai), and fine-tuned [models](https://huggingface.co/h2oai) ranging from 7 to 20 billion parameters.
|
| 27 |
+
2. **State-of-the-art fine-tuning**: We provide code for highly efficient fine-tuning, including targeted data preparation, prompt engineering, and computational optimizations to fine-tune LLMs with up to 20 billion parameters (even larger models expected soon) in hours on commodity hardware or enterprise servers. Techniques like low-rank approximations (LoRA) and data compression allow computational savings of several orders of magnitude.
|
| 28 |
+
3. **Chatbot**: We provide code to run a multi-tenant chatbot on GPU servers, with an easily shareable end-point and a Python client API, allowing you to evaluate and compare the performance of fine-tuned LLMs.
|
| 29 |
+
4. **H2O LLM Studio**: Our no-code LLM fine-tuning framework created by the world's top Kaggle grandmasters makes it even easier to fine-tune and evaluate LLMs.
|
| 30 |
+
|
| 31 |
+
Everything we release is based on fully permissive data and models, with all code open-sourced, enabling broader access for businesses and commercial products without legal concerns, thus expanding access to cutting-edge AI while adhering to licensing requirements.
|
| 32 |
+
|
| 33 |
+
## Roadmap and Future Plans
|
| 34 |
+
|
| 35 |
+
We have an ambitious roadmap for our LLM ecosystem, including:
|
| 36 |
+
|
| 37 |
+
1. Integration with downstream applications and low/no-code platforms (H2O Document AI, H2O LLM Studio, etc.)
|
| 38 |
+
2. Improved validation and benchmarking frameworks of LLMs
|
| 39 |
+
3. Complementing our chatbot with search and other APIs (LangChain, etc.)
|
| 40 |
+
4. Contribute to large-scale data cleaning efforts (Open Assistant, Stability AI, RedPajama, etc.)
|
| 41 |
+
5. High-performance distributed training of larger models on trillion tokens
|
| 42 |
+
6. High-performance scalable on-premises hosting for high-throughput endpoints
|
| 43 |
+
7. Improvements in code completion, reasoning, mathematics, factual correctness, hallucinations, and reducing repetitions
|
| 44 |
+
|
| 45 |
+
## Getting Started with H2O.ai's LLMs
|
| 46 |
+
|
| 47 |
+
You can [Chat with h2oGPT](https://gpt.h2o.ai/) right now!
|
| 48 |
+
|
| 49 |
+
https://user-images.githubusercontent.com/6147661/232924684-6c0e2dfb-2f24-4098-848a-c3e4396f29f6.mov
|
| 50 |
+
|
| 51 |
+
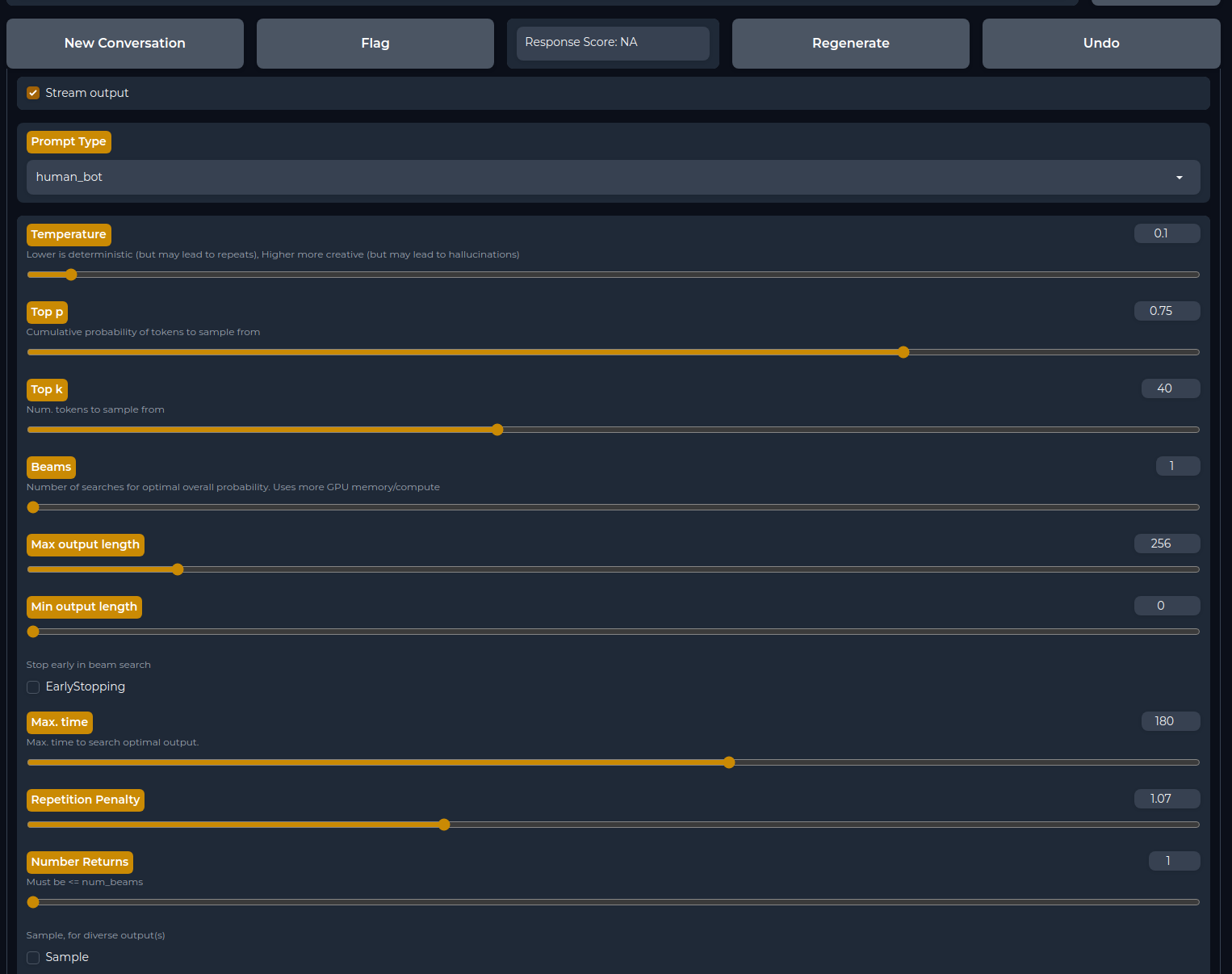
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
To start using our LLM as a developer, follow the steps below:
|
| 55 |
+
|
| 56 |
+
1. Clone the repository: `git clone https://github.com/h2oai/h2ogpt.git`
|
| 57 |
+
2. Change to the repository directory: `cd h2ogpt`
|
| 58 |
+
3. Install the requirements: `pip install -r requirements.txt`
|
| 59 |
+
4. Run the chatbot: `python generate.py --base_model=h2oai/h2ogpt-oig-oasst1-256-6_9b`
|
| 60 |
+
5. Open your browser at `http://0.0.0.0:7860` or the public live URL printed by the server.
|
| 61 |
+
|
| 62 |
+
For more information, visit [h2oGPT GitHub page](https://github.com/h2oai/h2ogpt), [H2O.ai's Hugging Face page](https://huggingface.co/h2oai) and [H2O LLM Studio GitHub page](https://github.com/h2oai/h2o-llmstudio).
|
| 63 |
+
|
| 64 |
+
Join us on this exciting journey as we continue to improve and expand the capabilities of our open-source LLM ecosystem!
|
| 65 |
+
|
| 66 |
+
## Acknowledgements
|
| 67 |
+
|
| 68 |
+
We appreciate the work by many open-source contributors, especially:
|
| 69 |
+
|
| 70 |
+
* [H2O.ai makers](https://h2o.ai/company/team/)
|
| 71 |
+
* [Alpaca-LoRA](https://github.com/tloen/alpaca-lora/)
|
| 72 |
+
* [LoRA](https://github.com/microsoft/LoRA/)
|
| 73 |
+
* [Stanford Alpaca](https://github.com/tatsu-lab/stanford_alpaca/)
|
| 74 |
+
* [Hugging Face](https://huggingface.co/)
|
| 75 |
+
* [OpenAssistant](https://open-assistant.io/)
|
| 76 |
+
* [EleutherAI](https://www.eleuther.ai/)
|
| 77 |
+
* [LAION](https://laion.ai/blog/oig-dataset/)
|
| 78 |
+
* [BigScience](https://github.com/bigscience-workshop/bigscience/)
|
| 79 |
+
* [LLaMa](https://github.com/facebookresearch/llama/)
|
| 80 |
+
* [StableLM](https://github.com/Stability-AI/StableLM/)
|
| 81 |
+
* [Vicuna](https://github.com/lm-sys/FastChat/)
|
ci/jenkinsfile
ADDED
|
@@ -0,0 +1,158 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/groovy
|
| 2 |
+
|
| 3 |
+
@Library('test-shared-library@dai_pipeline') _
|
| 4 |
+
|
| 5 |
+
import ai.h2o.ci.buildsummary.StagesSummary
|
| 6 |
+
import groovy.json.JsonOutput
|
| 7 |
+
|
| 8 |
+
buildSummary('https://github.com/h2oai/h2ogpt', true)
|
| 9 |
+
buildSummary.get().addStagesSummary(this, new StagesSummary())
|
| 10 |
+
|
| 11 |
+
def ALL_TESTS = [
|
| 12 |
+
"test_osx": [
|
| 13 |
+
install_deps: "TRAINING",
|
| 14 |
+
test_target: "test_imports",
|
| 15 |
+
node: "osx",
|
| 16 |
+
test_markers: "not need_tokens and not need_gpu",
|
| 17 |
+
timeout: 90,
|
| 18 |
+
use_docker: false,
|
| 19 |
+
env: ['PYTHON_BINARY=/Users/jenkins/anaconda/envs/h2ogpt-py3.10/bin/python']
|
| 20 |
+
],
|
| 21 |
+
"test_all": [
|
| 22 |
+
install_deps: "TRAINING,WIKI_EXTRA",
|
| 23 |
+
test_target: "test",
|
| 24 |
+
test_markers: "not need_tokens and not need_gpu",
|
| 25 |
+
node: "DAIDEV-GPU || DAIDEV-2GPU",
|
| 26 |
+
timeout: 90,
|
| 27 |
+
use_docker: true,
|
| 28 |
+
env: []
|
| 29 |
+
],
|
| 30 |
+
]
|
| 31 |
+
|
| 32 |
+
pipeline {
|
| 33 |
+
agent none
|
| 34 |
+
parameters {
|
| 35 |
+
booleanParam(name: 'skipTesting', defaultValue: false, description: 'Skip testing')
|
| 36 |
+
text(name: "testTargets", defaultValue: "${ALL_TESTS.keySet().join('\n')}", description: "A select set of tests to run")
|
| 37 |
+
booleanParam(name: 'publish', defaultValue: false, description: 'Upload to HF')
|
| 38 |
+
}
|
| 39 |
+
options {
|
| 40 |
+
ansiColor('xterm')
|
| 41 |
+
timestamps()
|
| 42 |
+
}
|
| 43 |
+
stages {
|
| 44 |
+
stage('Build') {
|
| 45 |
+
agent {
|
| 46 |
+
label "linux && docker"
|
| 47 |
+
}
|
| 48 |
+
steps {
|
| 49 |
+
script {
|
| 50 |
+
def shortHash = sh(returnStdout: true, script: 'git rev-parse --short HEAD').trim()
|
| 51 |
+
def commitMsg = sh(returnStdout: true, script: 'git log -1 --pretty=format:"[%an] %s"').trim()
|
| 52 |
+
currentBuild.displayName = "${env.BUILD_ID} - [${shortHash}]"
|
| 53 |
+
currentBuild.description = "${commitMsg}"
|
| 54 |
+
|
| 55 |
+
sh "make docker_build"
|
| 56 |
+
docker.image("harbor.h2o.ai/library/python:3.10").inside("--entrypoint='' --security-opt seccomp=unconfined -e USE_WHEEL=1 -e HOME=${WORKSPACE}") {
|
| 57 |
+
sh "make clean dist"
|
| 58 |
+
}
|
| 59 |
+
|
| 60 |
+
archiveArtifacts allowEmptyArchive: true, artifacts: "dist/h2ogpt-*.whl"
|
| 61 |
+
stash includes: "dist/h2ogpt-*.whl", name: "wheel_file"
|
| 62 |
+
}
|
| 63 |
+
}
|
| 64 |
+
}
|
| 65 |
+
|
| 66 |
+
stage('Tests') {
|
| 67 |
+
when {
|
| 68 |
+
anyOf {
|
| 69 |
+
expression { return !params.skipTesting }
|
| 70 |
+
}
|
| 71 |
+
beforeAgent true
|
| 72 |
+
}
|
| 73 |
+
agent {
|
| 74 |
+
label "linux && docker"
|
| 75 |
+
}
|
| 76 |
+
steps {
|
| 77 |
+
script {
|
| 78 |
+
def testTargets = [:]
|
| 79 |
+
params.testTargets.split('\n').findAll{ it.contains("test_") }.each { testName ->
|
| 80 |
+
testTargets[testName] = {
|
| 81 |
+
node("${ALL_TESTS[testName].node}") {
|
| 82 |
+
buildSummary.stageWithSummary("${testName}", "${testName}") {
|
| 83 |
+
buildSummary.setStageUrl("${testName}")
|
| 84 |
+
timeout(time: ALL_TESTS[testName].timeout, unit: 'MINUTES') {
|
| 85 |
+
script {
|
| 86 |
+
try {
|
| 87 |
+
dir("${testName}") {
|
| 88 |
+
withEnv(ALL_TESTS[testName].env + ["PYTEST_TEST_NAME=_${testName}", "IS_PR_BUILD=${isPrBranch()}", "USE_WHEEL=1"]) {
|
| 89 |
+
|
| 90 |
+
// cleanup and force the use of the installed wheel
|
| 91 |
+
deleteDir()
|
| 92 |
+
checkout scm
|
| 93 |
+
unstash "wheel_file"
|
| 94 |
+
sh "rm -rf *.py spaces models"
|
| 95 |
+
|
| 96 |
+
// pull runtime details
|
| 97 |
+
def dockerImage = sh(returnStdout: true, script: "make print-DOCKER_TEST_IMAGE").trim()
|
| 98 |
+
def nvidiaSmiExitCode = sh(returnStdout: false, returnStatus: true, script: "nvidia-smi")
|
| 99 |
+
// def dockerRuntime = "${nvidiaSmiExitCode}" == "0" ? "--runtime nvidia" : ""
|
| 100 |
+
def dockerRuntime = "" // TODO: keep until lab machines are upgraded
|
| 101 |
+
|
| 102 |
+
if (ALL_TESTS[testName].use_docker) {
|
| 103 |
+
docker.image("${dockerImage}").inside("--entrypoint='' --security-opt seccomp=unconfined --ulimit core=-1 --init --pid=host -e USE_WHEEL=1 -e HOME=${WORKSPACE}/${testName} ${dockerRuntime}") {
|
| 104 |
+
sh "nvidia-smi || true"
|
| 105 |
+
sh "SKIP_MANUAL_TESTS=1 PYTHON_BINARY=/usr/bin/python3.10 make install"
|
| 106 |
+
sh "SKIP_MANUAL_TESTS=1 PYTHON_BINARY=/usr/bin/python3.10 make install-${ALL_TESTS[testName].install_deps}"
|
| 107 |
+
sh """DEFAULT_MARKERS="${ALL_TESTS[testName].test_markers}" SKIP_MANUAL_TESTS=1 PYTHON_BINARY=/usr/bin/python3.10 make ${ALL_TESTS[testName].test_target}"""
|
| 108 |
+
}
|
| 109 |
+
} else {
|
| 110 |
+
sh "make venv"
|
| 111 |
+
sh "SKIP_MANUAL_TESTS=1 PYTHON_BINARY=${WORKSPACE}/${testName}/venv/bin/python make install"
|
| 112 |
+
sh "SKIP_MANUAL_TESTS=1 PYTHON_BINARY=${WORKSPACE}/${testName}/venv/bin/python make install-${ALL_TESTS[testName].install_deps}"
|
| 113 |
+
sh """DEFAULT_MARKERS="${ALL_TESTS[testName].test_markers}" SKIP_MANUAL_TESTS=1 PYTHON_BINARY=${WORKSPACE}/${testName}/venv/bin/python make ${ALL_TESTS[testName].test_target}"""
|
| 114 |
+
}
|
| 115 |
+
}
|
| 116 |
+
}
|
| 117 |
+
} catch (e) {
|
| 118 |
+
throw e
|
| 119 |
+
} finally {
|
| 120 |
+
sh "mv ${testName}/test_report.xml ${testName}/${testName}_report.xml"
|
| 121 |
+
archiveArtifacts allowEmptyArchive: true, artifacts: "${testName}/${testName}_report.xml"
|
| 122 |
+
junit testResults: "${testName}/${testName}_report.xml", keepLongStdio: true, allowEmptyResults: true
|
| 123 |
+
}
|
| 124 |
+
}
|
| 125 |
+
}
|
| 126 |
+
}
|
| 127 |
+
}
|
| 128 |
+
}
|
| 129 |
+
}
|
| 130 |
+
|
| 131 |
+
parallel(testTargets)
|
| 132 |
+
}
|
| 133 |
+
}
|
| 134 |
+
}
|
| 135 |
+
|
| 136 |
+
stage('Publish') {
|
| 137 |
+
when {
|
| 138 |
+
anyOf {
|
| 139 |
+
expression { return params.publish }
|
| 140 |
+
}
|
| 141 |
+
beforeAgent true
|
| 142 |
+
}
|
| 143 |
+
agent {
|
| 144 |
+
label "linux && docker"
|
| 145 |
+
}
|
| 146 |
+
steps {
|
| 147 |
+
script {
|
| 148 |
+
sh "make IS_PR_BUILD=${isPrBranch()} BUILD_NUMBER=${env.BUILD_ID} BUILD_BASE_NAME=${env.JOB_BASE_NAME} publish"
|
| 149 |
+
}
|
| 150 |
+
}
|
| 151 |
+
}
|
| 152 |
+
}
|
| 153 |
+
}
|
| 154 |
+
|
| 155 |
+
def isPrBranch() {
|
| 156 |
+
return (env.CHANGE_BRANCH != null && env.CHANGE_BRANCH != '') ||
|
| 157 |
+
(env.BRANCH_NAME != null && env.BRANCH_NAME.startsWith("PR-"))
|
| 158 |
+
}
|
client/.gitignore
ADDED
|
@@ -0,0 +1,168 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
### Copied files ###
|
| 2 |
+
h2ogpt_client/_h2ogpt_*.py
|
| 3 |
+
|
| 4 |
+
### Poetry ###
|
| 5 |
+
.poetry
|
| 6 |
+
poetry
|
| 7 |
+
|
| 8 |
+
### Python template
|
| 9 |
+
# Byte-compiled / optimized / DLL files
|
| 10 |
+
__pycache__/
|
| 11 |
+
*.py[cod]
|
| 12 |
+
*$py.class
|
| 13 |
+
|
| 14 |
+
# C extensions
|
| 15 |
+
*.so
|
| 16 |
+
|
| 17 |
+
# Distribution / packaging
|
| 18 |
+
.Python
|
| 19 |
+
build/
|
| 20 |
+
develop-eggs/
|
| 21 |
+
dist/
|
| 22 |
+
downloads/
|
| 23 |
+
eggs/
|
| 24 |
+
.eggs/
|
| 25 |
+
lib/
|
| 26 |
+
lib64/
|
| 27 |
+
parts/
|
| 28 |
+
sdist/
|
| 29 |
+
var/
|
| 30 |
+
wheels/
|
| 31 |
+
share/python-wheels/
|
| 32 |
+
*.egg-info/
|
| 33 |
+
.installed.cfg
|
| 34 |
+
*.egg
|
| 35 |
+
MANIFEST
|
| 36 |
+
|
| 37 |
+
# PyInstaller
|
| 38 |
+
# Usually these files are written by a python script from a template
|
| 39 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 40 |
+
*.manifest
|
| 41 |
+
*.spec
|
| 42 |
+
|
| 43 |
+
# Installer logs
|
| 44 |
+
pip-log.txt
|
| 45 |
+
pip-delete-this-directory.txt
|
| 46 |
+
|
| 47 |
+
# Unit test / coverage reports
|
| 48 |
+
htmlcov/
|
| 49 |
+
.tox/
|
| 50 |
+
.nox/
|
| 51 |
+
.coverage
|
| 52 |
+
.coverage.*
|
| 53 |
+
.cache
|
| 54 |
+
nosetests.xml
|
| 55 |
+
coverage.xml
|
| 56 |
+
*.cover
|
| 57 |
+
*.py,cover
|
| 58 |
+
.hypothesis/
|
| 59 |
+
.pytest_cache/
|
| 60 |
+
cover/
|
| 61 |
+
|
| 62 |
+
# Translations
|
| 63 |
+
*.mo
|
| 64 |
+
*.pot
|
| 65 |
+
|
| 66 |
+
# Django stuff:
|
| 67 |
+
*.log
|
| 68 |
+
local_settings.py
|
| 69 |
+
db.sqlite3
|
| 70 |
+
db.sqlite3-journal
|
| 71 |
+
|
| 72 |
+
# Flask stuff:
|
| 73 |
+
instance/
|
| 74 |
+
.webassets-cache
|
| 75 |
+
|
| 76 |
+
# Scrapy stuff:
|
| 77 |
+
.scrapy
|
| 78 |
+
|
| 79 |
+
# Sphinx documentation
|
| 80 |
+
docs/_build/
|
| 81 |
+
|
| 82 |
+
# PyBuilder
|
| 83 |
+
.pybuilder/
|
| 84 |
+
target/
|
| 85 |
+
|
| 86 |
+
# Jupyter Notebook
|
| 87 |
+
.ipynb_checkpoints
|
| 88 |
+
|
| 89 |
+
# IPython
|
| 90 |
+
profile_default/
|
| 91 |
+
ipython_config.py
|
| 92 |
+
|
| 93 |
+
# pyenv
|
| 94 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 95 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 96 |
+
# .python-version
|
| 97 |
+
|
| 98 |
+
# pipenv
|
| 99 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 100 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 101 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 102 |
+
# install all needed dependencies.
|
| 103 |
+
#Pipfile.lock
|
| 104 |
+
|
| 105 |
+
# poetry
|
| 106 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 107 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 108 |
+
# commonly ignored for libraries.
|
| 109 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 110 |
+
#poetry.lock
|
| 111 |
+
|
| 112 |
+
# pdm
|
| 113 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 114 |
+
#pdm.lock
|
| 115 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 116 |
+
# in version control.
|
| 117 |
+
# https://pdm.fming.dev/#use-with-ide
|
| 118 |
+
.pdm.toml
|
| 119 |
+
|
| 120 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 121 |
+
__pypackages__/
|
| 122 |
+
|
| 123 |
+
# Celery stuff
|
| 124 |
+
celerybeat-schedule
|
| 125 |
+
celerybeat.pid
|
| 126 |
+
|
| 127 |
+
# SageMath parsed files
|
| 128 |
+
*.sage.py
|
| 129 |
+
|
| 130 |
+
# Environments
|
| 131 |
+
.env
|
| 132 |
+
.venv
|
| 133 |
+
env/
|
| 134 |
+
venv/
|
| 135 |
+
ENV/
|
| 136 |
+
env.bak/
|
| 137 |
+
venv.bak/
|
| 138 |
+
|
| 139 |
+
# Spyder project settings
|
| 140 |
+
.spyderproject
|
| 141 |
+
.spyproject
|
| 142 |
+
|
| 143 |
+
# Rope project settings
|
| 144 |
+
.ropeproject
|
| 145 |
+
|
| 146 |
+
# mkdocs documentation
|
| 147 |
+
/site
|
| 148 |
+
|
| 149 |
+
# mypy
|
| 150 |
+
.mypy_cache/
|
| 151 |
+
.dmypy.json
|
| 152 |
+
dmypy.json
|
| 153 |
+
|
| 154 |
+
# Pyre type checker
|
| 155 |
+
.pyre/
|
| 156 |
+
|
| 157 |
+
# pytype static type analyzer
|
| 158 |
+
.pytype/
|
| 159 |
+
|
| 160 |
+
# Cython debug symbols
|
| 161 |
+
cython_debug/
|
| 162 |
+
|
| 163 |
+
# PyCharm
|
| 164 |
+
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
| 165 |
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
| 166 |
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
| 167 |
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
| 168 |
+
.idea/
|
client/Makefile
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
POETRY_INSTALL_DIR := $(abspath ./.poetry)
|
| 2 |
+
POETRY_BIN := $(POETRY_INSTALL_DIR)/bin/poetry
|
| 3 |
+
|
| 4 |
+
PACKAGE_NAME = $(firstword $(shell $(POETRY_BIN) version))
|
| 5 |
+
PACKAGE_DIR = $(subst -,_,$(PACKAGE_NAME))
|
| 6 |
+
PACKAGE_VERSION = $(shell $(POETRY_BIN) version --short)
|
| 7 |
+
|
| 8 |
+
# Space separated list of file path that needs to be copied from h2oGPT.
|
| 9 |
+
FILES_FROM_H2OGPT := enums.py
|
| 10 |
+
NAME_PREFIX_FOR_FILES_COPIED_FROM_H2OGPT = _h2ogpt_
|
| 11 |
+
|
| 12 |
+
$(POETRY_BIN):
|
| 13 |
+
@echo "Installing Poetry into '$(POETRY_INSTALL_DIR)' ..."
|
| 14 |
+
curl -sSL https://install.python-poetry.org | POETRY_HOME="$(POETRY_INSTALL_DIR)" python3 - --force --version 1.5.1
|
| 15 |
+
|
| 16 |
+
.PHONY: copy_files_from_h2ogpt
|
| 17 |
+
copy_files_from_h2ogpt:
|
| 18 |
+
for file in $(FILES_FROM_H2OGPT); do \
|
| 19 |
+
dst="$(PACKAGE_DIR)/$(NAME_PREFIX_FOR_FILES_COPIED_FROM_H2OGPT)$(notdir $$file)"; \
|
| 20 |
+
echo "Copying '$$file' to '$$dst' ..."; \
|
| 21 |
+
cp -f "./../src/$$file" "$$dst"; \
|
| 22 |
+
done
|
| 23 |
+
|
| 24 |
+
.PHONY: clean
|
| 25 |
+
clean:
|
| 26 |
+
rm -rf dist
|
| 27 |
+
find "$(PACKAGE_DIR)" -name "$(NAME_PREFIX_FOR_FILES_COPIED_FROM_H2OGPT)*" -delete
|
| 28 |
+
|
| 29 |
+
.PHONY: clean_deep
|
| 30 |
+
clean_deep: clean
|
| 31 |
+
rm -rf "$(POETRY_INSTALL_DIR)"
|
| 32 |
+
rm -rf ".venv"
|
| 33 |
+
|
| 34 |
+
.PHONY: setup
|
| 35 |
+
setup: $(POETRY_BIN)
|
| 36 |
+
$(POETRY_BIN) install
|
| 37 |
+
|
| 38 |
+
.PHONY: setup_test
|
| 39 |
+
setup_test:
|
| 40 |
+
$(POETRY_BIN) install --only=test
|
| 41 |
+
|
| 42 |
+
.PHONY: lint
|
| 43 |
+
lint: copy_files_from_h2ogpt
|
| 44 |
+
$(POETRY_BIN) run black .
|
| 45 |
+
$(POETRY_BIN) run isort .
|
| 46 |
+
$(POETRY_BIN) run flake8 "$(PACKAGE_DIR)" "tests" || true
|
| 47 |
+
$(POETRY_BIN) run mypy --show-error-codes --pretty .
|
| 48 |
+
|
| 49 |
+
.PHONY: test
|
| 50 |
+
test: copy_files_from_h2ogpt
|
| 51 |
+
$(POETRY_BIN) run pytest -r=A
|
| 52 |
+
|
| 53 |
+
.PHONY: build
|
| 54 |
+
build: copy_files_from_h2ogpt
|
| 55 |
+
$(POETRY_BIN) build
|
client/README.md
ADDED
|
@@ -0,0 +1,72 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# h2oGPT Client
|
| 2 |
+
A Python thin-client for h2oGPT.
|
| 3 |
+
|
| 4 |
+
### Prerequisites
|
| 5 |
+
- Python 3.8+
|
| 6 |
+
|
| 7 |
+
If you don't have Python 3.8 in your system, you can use [Conda](https://docs.conda.io/projects/conda/en/latest/user-guide/install/index.html).
|
| 8 |
+
```bash
|
| 9 |
+
conda create -n h2ogpt_client_build -y
|
| 10 |
+
conda activate h2ogpt_client_build
|
| 11 |
+
conda install python=3.8 -y
|
| 12 |
+
```
|
| 13 |
+
|
| 14 |
+
### Setup
|
| 15 |
+
:information_source: [Poetry](https://python-poetry.org) is used as the build tool.
|
| 16 |
+
```shell
|
| 17 |
+
make -C client setup
|
| 18 |
+
```
|
| 19 |
+
|
| 20 |
+
### Build
|
| 21 |
+
```shell
|
| 22 |
+
make -C client build
|
| 23 |
+
```
|
| 24 |
+
Distribution wheel file can be found in the `client/dist` directory. This wheel can be installed in the primary h2oGPT environment or any other environment, e.g.
|
| 25 |
+
```bash
|
| 26 |
+
pip install client/dist/h2ogpt_client-*-py3-none-any.whl
|
| 27 |
+
```
|
| 28 |
+
|
| 29 |
+
## Usage
|
| 30 |
+
```python
|
| 31 |
+
from h2ogpt_client import Client
|
| 32 |
+
|
| 33 |
+
client = Client("http://0.0.0.0:7860")
|
| 34 |
+
|
| 35 |
+
# Text completion
|
| 36 |
+
text_completion = client.text_completion.create()
|
| 37 |
+
response = await text_completion.complete("Hello world")
|
| 38 |
+
# Text completion: synchronous
|
| 39 |
+
response = text_completion.complete_sync("Hello world")
|
| 40 |
+
|
| 41 |
+
# Chat completion
|
| 42 |
+
chat_completion = client.chat_completion.create()
|
| 43 |
+
reply = await chat_completion.chat("Hey!")
|
| 44 |
+
print(reply["user"]) # prints user prompt, i.e. "Hey!"
|
| 45 |
+
print(reply["gpt"]) # prints reply from h2oGPT
|
| 46 |
+
chat_history = chat_completion.chat_history()
|
| 47 |
+
# Chat completion: synchronous
|
| 48 |
+
reply = chat_completion.chat_sync("Hey!")
|
| 49 |
+
```
|
| 50 |
+
:warning: **Note**: Client APIs are still evolving. Hence, APIs can be changed without prior warnings.
|
| 51 |
+
|
| 52 |
+
## Development Guide
|
| 53 |
+
|
| 54 |
+
### Test
|
| 55 |
+
|
| 56 |
+
In an h2oGPT environment with the client installed, can run tests that test client and server.
|
| 57 |
+
|
| 58 |
+
### Test with h2oGPT env
|
| 59 |
+
1. Install test dependencies of the Client into the h2oGPT Python environment.
|
| 60 |
+
```shell
|
| 61 |
+
make -C client setup_test
|
| 62 |
+
```
|
| 63 |
+
2. Run the tests with h2oGPT.
|
| 64 |
+
```shell
|
| 65 |
+
pytest client/tests/
|
| 66 |
+
```
|
| 67 |
+
|
| 68 |
+
#### Test with an existing h2oGPT server
|
| 69 |
+
If you already have a running h2oGPT server, then set the `H2OGPT_SERVER` environment variable to use it for testing.
|
| 70 |
+
```shell
|
| 71 |
+
make H2OGPT_SERVER="http://0.0.0.0:7860" -C client test
|
| 72 |
+
```
|
client/h2ogpt_client/__init__.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from h2ogpt_client._core import Client, LangChainMode, PromptType
|
| 2 |
+
|
| 3 |
+
__all__ = ["Client", "PromptType", "LangChainMode"]
|
client/h2ogpt_client/_core.py
ADDED
|
@@ -0,0 +1,265 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import asyncio
|
| 2 |
+
from typing import Any, Dict, List, Optional, OrderedDict, Tuple, ValuesView
|
| 3 |
+
|
| 4 |
+
import gradio_client # type: ignore
|
| 5 |
+
|
| 6 |
+
from h2ogpt_client import _utils
|
| 7 |
+
from h2ogpt_client._h2ogpt_enums import (
|
| 8 |
+
DocumentChoices,
|
| 9 |
+
LangChainAction,
|
| 10 |
+
LangChainMode,
|
| 11 |
+
PromptType,
|
| 12 |
+
)
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class Client:
|
| 16 |
+
"""h2oGPT Client."""
|
| 17 |
+
|
| 18 |
+
def __init__(self, src: str, huggingface_token: Optional[str] = None):
|
| 19 |
+
"""
|
| 20 |
+
Creates a GPT client.
|
| 21 |
+
:param src: either the full URL to the hosted h2oGPT
|
| 22 |
+
(e.g. "http://0.0.0.0:7860", "https://fc752f297207f01c32.gradio.live")
|
| 23 |
+
or name of the Hugging Face Space to load, (e.g. "h2oai/h2ogpt-chatbot")
|
| 24 |
+
:param huggingface_token: Hugging Face token to use to access private Spaces
|
| 25 |
+
"""
|
| 26 |
+
self._client = gradio_client.Client(
|
| 27 |
+
src=src, hf_token=huggingface_token, serialize=False, verbose=False
|
| 28 |
+
)
|
| 29 |
+
self._text_completion = TextCompletionCreator(self)
|
| 30 |
+
self._chat_completion = ChatCompletionCreator(self)
|
| 31 |
+
|
| 32 |
+
@property
|
| 33 |
+
def text_completion(self) -> "TextCompletionCreator":
|
| 34 |
+
"""Text completion."""
|
| 35 |
+
return self._text_completion
|
| 36 |
+
|
| 37 |
+
@property
|
| 38 |
+
def chat_completion(self) -> "ChatCompletionCreator":
|
| 39 |
+
"""Chat completion."""
|
| 40 |
+
return self._chat_completion
|
| 41 |
+
|
| 42 |
+
def _predict(self, *args, api_name: str) -> Any:
|
| 43 |
+
return self._client.submit(*args, api_name=api_name).result()
|
| 44 |
+
|
| 45 |
+
async def _predict_async(self, *args, api_name: str) -> Any:
|
| 46 |
+
return await asyncio.wrap_future(self._client.submit(*args, api_name=api_name))
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
class TextCompletionCreator:
|
| 50 |
+
"""Builder that can create text completions."""
|
| 51 |
+
|
| 52 |
+
def __init__(self, client: Client):
|
| 53 |
+
self._client = client
|
| 54 |
+
|
| 55 |
+
def create(
|
| 56 |
+
self,
|
| 57 |
+
prompt_type: PromptType = PromptType.plain,
|
| 58 |
+
input_context_for_instruction: str = "",
|
| 59 |
+
enable_sampler=False,
|
| 60 |
+
temperature: float = 1.0,
|
| 61 |
+
top_p: float = 1.0,
|
| 62 |
+
top_k: int = 40,
|
| 63 |
+
beams: float = 1.0,
|
| 64 |
+
early_stopping: bool = False,
|
| 65 |
+
min_output_length: int = 0,
|
| 66 |
+
max_output_length: int = 128,
|
| 67 |
+
max_time: int = 180,
|
| 68 |
+
repetition_penalty: float = 1.07,
|
| 69 |
+
number_returns: int = 1,
|
| 70 |
+
system_pre_context: str = "",
|
| 71 |
+
langchain_mode: LangChainMode = LangChainMode.DISABLED,
|
| 72 |
+
) -> "TextCompletion":
|
| 73 |
+
"""
|
| 74 |
+
Creates a new text completion.
|
| 75 |
+
|
| 76 |
+
:param prompt_type: type of the prompt
|
| 77 |
+
:param input_context_for_instruction: input context for instruction
|
| 78 |
+
:param enable_sampler: enable or disable the sampler, required for use of
|
| 79 |
+
temperature, top_p, top_k
|
| 80 |
+
:param temperature: What sampling temperature to use, between 0 and 3.
|
| 81 |
+
Lower values will make it more focused and deterministic, but may lead
|
| 82 |
+
to repeat. Higher values will make the output more creative, but may
|
| 83 |
+
lead to hallucinations.
|
| 84 |
+
:param top_p: cumulative probability of tokens to sample from
|
| 85 |
+
:param top_k: number of tokens to sample from
|
| 86 |
+
:param beams: Number of searches for optimal overall probability.
|
| 87 |
+
Higher values uses more GPU memory and compute.
|
| 88 |
+
:param early_stopping: whether to stop early or not in beam search
|
| 89 |
+
:param min_output_length: minimum output length
|
| 90 |
+
:param max_output_length: maximum output length
|
| 91 |
+
:param max_time: maximum time to search optimal output
|
| 92 |
+
:param repetition_penalty: penalty for repetition
|
| 93 |
+
:param number_returns:
|
| 94 |
+
:param system_pre_context: directly pre-appended without prompt processing
|
| 95 |
+
:param langchain_mode: LangChain mode
|
| 96 |
+
"""
|
| 97 |
+
params = _utils.to_h2ogpt_params(locals().copy())
|
| 98 |
+
params["instruction"] = "" # empty when chat_mode is False
|
| 99 |
+
params["iinput"] = "" # only chat_mode is True
|
| 100 |
+
params["stream_output"] = False
|
| 101 |
+
params["prompt_type"] = prompt_type.value # convert to serializable type
|
| 102 |
+
params["prompt_dict"] = "" # empty as prompt_type cannot be 'custom'
|
| 103 |
+
params["chat"] = False
|
| 104 |
+
params["instruction_nochat"] = None # future prompt
|
| 105 |
+
params["langchain_mode"] = langchain_mode.value # convert to serializable type
|
| 106 |
+
params["langchain_action"] = LangChainAction.QUERY.value
|
| 107 |
+
params["langchain_agents"] = []
|
| 108 |
+
params["top_k_docs"] = 4 # langchain: number of document chunks
|
| 109 |
+
params["chunk"] = True # langchain: whether to chunk documents
|
| 110 |
+
params["chunk_size"] = 512 # langchain: chunk size for document chunking
|
| 111 |
+
params["document_subset"] = DocumentChoices.Relevant.name
|
| 112 |
+
params["document_choice"] = []
|
| 113 |
+
return TextCompletion(self._client, params)
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
class TextCompletion:
|
| 117 |
+
"""Text completion."""
|
| 118 |
+
|
| 119 |
+
_API_NAME = "/submit_nochat"
|
| 120 |
+
|
| 121 |
+
def __init__(self, client: Client, parameters: OrderedDict[str, Any]):
|
| 122 |
+
self._client = client
|
| 123 |
+
self._parameters = parameters
|
| 124 |
+
|
| 125 |
+
def _get_parameters(self, prompt: str) -> ValuesView:
|
| 126 |
+
self._parameters["instruction_nochat"] = prompt
|
| 127 |
+
return self._parameters.values()
|
| 128 |
+
|
| 129 |
+
async def complete(self, prompt: str) -> str:
|
| 130 |
+
"""
|
| 131 |
+
Complete this text completion.
|
| 132 |
+
|
| 133 |
+
:param prompt: text prompt to generate completion for
|
| 134 |
+
:return: response from the model
|
| 135 |
+
"""
|
| 136 |
+
|
| 137 |
+
return await self._client._predict_async(
|
| 138 |
+
*self._get_parameters(prompt), api_name=self._API_NAME
|
| 139 |
+
)
|
| 140 |
+
|
| 141 |
+
def complete_sync(self, prompt: str) -> str:
|
| 142 |
+
"""
|
| 143 |
+
Complete this text completion synchronously.
|
| 144 |
+
|
| 145 |
+
:param prompt: text prompt to generate completion for
|
| 146 |
+
:return: response from the model
|
| 147 |
+
"""
|
| 148 |
+
return self._client._predict(
|
| 149 |
+
*self._get_parameters(prompt), api_name=self._API_NAME
|
| 150 |
+
)
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
class ChatCompletionCreator:
|
| 154 |
+
"""Chat completion."""
|
| 155 |
+
|
| 156 |
+
def __init__(self, client: Client):
|
| 157 |
+
self._client = client
|
| 158 |
+
|
| 159 |
+
def create(
|
| 160 |
+
self,
|
| 161 |
+
prompt_type: PromptType = PromptType.plain,
|
| 162 |
+
input_context_for_instruction: str = "",
|
| 163 |
+
enable_sampler=False,
|
| 164 |
+
temperature: float = 1.0,
|
| 165 |
+
top_p: float = 1.0,
|
| 166 |
+
top_k: int = 40,
|
| 167 |
+
beams: float = 1.0,
|
| 168 |
+
early_stopping: bool = False,
|
| 169 |
+
min_output_length: int = 0,
|
| 170 |
+
max_output_length: int = 128,
|
| 171 |
+
max_time: int = 180,
|
| 172 |
+
repetition_penalty: float = 1.07,
|
| 173 |
+
number_returns: int = 1,
|
| 174 |
+
system_pre_context: str = "",
|
| 175 |
+
langchain_mode: LangChainMode = LangChainMode.DISABLED,
|
| 176 |
+
) -> "ChatCompletion":
|
| 177 |
+
"""
|
| 178 |
+
Creates a new chat completion.
|
| 179 |
+
|
| 180 |
+
:param prompt_type: type of the prompt
|
| 181 |
+
:param input_context_for_instruction: input context for instruction
|
| 182 |
+
:param enable_sampler: enable or disable the sampler, required for use of
|
| 183 |
+
temperature, top_p, top_k
|
| 184 |
+
:param temperature: What sampling temperature to use, between 0 and 3.
|
| 185 |
+
Lower values will make it more focused and deterministic, but may lead
|
| 186 |
+
to repeat. Higher values will make the output more creative, but may
|
| 187 |
+
lead to hallucinations.
|
| 188 |
+
:param top_p: cumulative probability of tokens to sample from
|
| 189 |
+
:param top_k: number of tokens to sample from
|
| 190 |
+
:param beams: Number of searches for optimal overall probability.
|
| 191 |
+
Higher values uses more GPU memory and compute.
|
| 192 |
+
:param early_stopping: whether to stop early or not in beam search
|
| 193 |
+
:param min_output_length: minimum output length
|
| 194 |
+
:param max_output_length: maximum output length
|
| 195 |
+
:param max_time: maximum time to search optimal output
|
| 196 |
+
:param repetition_penalty: penalty for repetition
|
| 197 |
+
:param number_returns:
|
| 198 |
+
:param system_pre_context: directly pre-appended without prompt processing
|
| 199 |
+
:param langchain_mode: LangChain mode
|
| 200 |
+
"""
|
| 201 |
+
params = _utils.to_h2ogpt_params(locals().copy())
|
| 202 |
+
params["instruction"] = None # future prompts
|
| 203 |
+
params["iinput"] = "" # ??
|
| 204 |
+
params["stream_output"] = False
|
| 205 |
+
params["prompt_type"] = prompt_type.value # convert to serializable type
|
| 206 |
+
params["prompt_dict"] = "" # empty as prompt_type cannot be 'custom'
|
| 207 |
+
params["chat"] = True
|
| 208 |
+
params["instruction_nochat"] = "" # empty when chat_mode is True
|
| 209 |
+
params["langchain_mode"] = langchain_mode.value # convert to serializable type
|
| 210 |
+
params["langchain_action"] = LangChainAction.QUERY.value
|
| 211 |
+
params["langchain_agents"] = []
|
| 212 |
+
params["top_k_docs"] = 4 # langchain: number of document chunks
|
| 213 |
+
params["chunk"] = True # langchain: whether to chunk documents
|
| 214 |
+
params["chunk_size"] = 512 # langchain: chunk size for document chunking
|
| 215 |
+
params["document_subset"] = DocumentChoices.Relevant.name
|
| 216 |
+
params["document_choice"] = []
|
| 217 |
+
params["chatbot"] = [] # chat history
|
| 218 |
+
return ChatCompletion(self._client, params)
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
class ChatCompletion:
|
| 222 |
+
"""Chat completion."""
|
| 223 |
+
|
| 224 |
+
_API_NAME = "/instruction_bot"
|
| 225 |
+
|
| 226 |
+
def __init__(self, client: Client, parameters: OrderedDict[str, Any]):
|
| 227 |
+
self._client = client
|
| 228 |
+
self._parameters = parameters
|
| 229 |
+
|
| 230 |
+
def _get_parameters(self, prompt: str) -> ValuesView:
|
| 231 |
+
self._parameters["instruction"] = prompt
|
| 232 |
+
self._parameters["chatbot"] += [[prompt, None]]
|
| 233 |
+
return self._parameters.values()
|
| 234 |
+
|
| 235 |
+
def _get_reply(self, response: Tuple[List[List[str]]]) -> Dict[str, str]:
|
| 236 |
+
self._parameters["chatbot"][-1][1] = response[0][-1][1]
|
| 237 |
+
return {"user": response[0][-1][0], "gpt": response[0][-1][1]}
|
| 238 |
+
|
| 239 |
+
async def chat(self, prompt: str) -> Dict[str, str]:
|
| 240 |
+
"""
|
| 241 |
+
Complete this chat completion.
|
| 242 |
+
|
| 243 |
+
:param prompt: text prompt to generate completions for
|
| 244 |
+
:returns chat reply
|
| 245 |
+
"""
|
| 246 |
+
response = await self._client._predict_async(
|
| 247 |
+
*self._get_parameters(prompt), api_name=self._API_NAME
|
| 248 |
+
)
|
| 249 |
+
return self._get_reply(response)
|
| 250 |
+
|
| 251 |
+
def chat_sync(self, prompt: str) -> Dict[str, str]:
|
| 252 |
+
"""
|
| 253 |
+
Complete this chat completion.
|
| 254 |
+
|
| 255 |
+
:param prompt: text prompt to generate completions for
|
| 256 |
+
:returns chat reply
|
| 257 |
+
"""
|
| 258 |
+
response = self._client._predict(
|
| 259 |
+
*self._get_parameters(prompt), api_name=self._API_NAME
|
| 260 |
+
)
|
| 261 |
+
return self._get_reply(response)
|
| 262 |
+
|
| 263 |
+
def chat_history(self) -> List[Dict[str, str]]:
|
| 264 |
+
"""Returns the full chat history."""
|
| 265 |
+
return [{"user": i[0], "gpt": i[1]} for i in self._parameters["chatbot"]]
|
client/h2ogpt_client/_utils.py
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import collections
|
| 2 |
+
from typing import Any, Dict, OrderedDict
|
| 3 |
+
|
| 4 |
+
H2OGPT_PARAMETERS_TO_CLIENT = collections.OrderedDict(
|
| 5 |
+
instruction="instruction",
|
| 6 |
+
iinput="input",
|
| 7 |
+
context="system_pre_context",
|
| 8 |
+
stream_output="stream_output",
|
| 9 |
+
prompt_type="prompt_type",
|
| 10 |
+
prompt_dict="prompt_dict",
|
| 11 |
+
temperature="temperature",
|
| 12 |
+
top_p="top_p",
|
| 13 |
+
top_k="top_k",
|
| 14 |
+
num_beams="beams",
|
| 15 |
+
max_new_tokens="max_output_length",
|
| 16 |
+
min_new_tokens="min_output_length",
|
| 17 |
+
early_stopping="early_stopping",
|
| 18 |
+
max_time="max_time",
|
| 19 |
+
repetition_penalty="repetition_penalty",
|
| 20 |
+
num_return_sequences="number_returns",
|
| 21 |
+
do_sample="enable_sampler",
|
| 22 |
+
chat="chat",
|
| 23 |
+
instruction_nochat="instruction_nochat",
|
| 24 |
+
iinput_nochat="input_context_for_instruction",
|
| 25 |
+
langchain_mode="langchain_mode",
|
| 26 |
+
langchain_action="langchain_action",
|
| 27 |
+
langchain_agents="langchain_agents",
|
| 28 |
+
top_k_docs="langchain_top_k_docs",
|
| 29 |
+
chunk="langchain_enable_chunk",
|
| 30 |
+
chunk_size="langchain_chunk_size",
|
| 31 |
+
document_subset="langchain_document_subset",
|
| 32 |
+
document_choice="langchain_document_choice",
|
| 33 |
+
)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def to_h2ogpt_params(client_params: Dict[str, Any]) -> OrderedDict[str, Any]:
|
| 37 |
+
"""Convert given params to the order of params in h2oGPT."""
|
| 38 |
+
|
| 39 |
+
h2ogpt_params: OrderedDict[str, Any] = H2OGPT_PARAMETERS_TO_CLIENT.copy()
|
| 40 |
+
for h2ogpt_param_name, client_param_name in h2ogpt_params.items():
|
| 41 |
+
if client_param_name in client_params:
|
| 42 |
+
h2ogpt_params[h2ogpt_param_name] = client_params[client_param_name]
|
| 43 |
+
return h2ogpt_params
|
client/poetry.lock
ADDED
|
@@ -0,0 +1,856 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# This file is automatically @generated by Poetry 1.5.1 and should not be changed by hand.
|
| 2 |
+
|
| 3 |
+
[[package]]
|
| 4 |
+
name = "anyio"
|
| 5 |
+
version = "3.6.2"
|
| 6 |
+
description = "High level compatibility layer for multiple asynchronous event loop implementations"
|
| 7 |
+
optional = false
|
| 8 |
+
python-versions = ">=3.6.2"
|
| 9 |
+
files = [
|
| 10 |
+
{file = "anyio-3.6.2-py3-none-any.whl", hash = "sha256:fbbe32bd270d2a2ef3ed1c5d45041250284e31fc0a4df4a5a6071842051a51e3"},
|
| 11 |
+
{file = "anyio-3.6.2.tar.gz", hash = "sha256:25ea0d673ae30af41a0c442f81cf3b38c7e79fdc7b60335a4c14e05eb0947421"},
|
| 12 |
+
]
|
| 13 |
+
|
| 14 |
+
[package.dependencies]
|
| 15 |
+
idna = ">=2.8"
|
| 16 |
+
sniffio = ">=1.1"
|
| 17 |
+
|
| 18 |
+
[package.extras]
|
| 19 |
+
doc = ["packaging", "sphinx-autodoc-typehints (>=1.2.0)", "sphinx-rtd-theme"]
|
| 20 |
+
test = ["contextlib2", "coverage[toml] (>=4.5)", "hypothesis (>=4.0)", "mock (>=4)", "pytest (>=7.0)", "pytest-mock (>=3.6.1)", "trustme", "uvloop (<0.15)", "uvloop (>=0.15)"]
|
| 21 |
+
trio = ["trio (>=0.16,<0.22)"]
|
| 22 |
+
|
| 23 |
+
[[package]]
|
| 24 |
+
name = "attrs"
|
| 25 |
+
version = "23.1.0"
|
| 26 |
+
description = "Classes Without Boilerplate"
|
| 27 |
+
optional = false
|
| 28 |
+
python-versions = ">=3.7"
|
| 29 |
+
files = [
|
| 30 |
+
{file = "attrs-23.1.0-py3-none-any.whl", hash = "sha256:1f28b4522cdc2fb4256ac1a020c78acf9cba2c6b461ccd2c126f3aa8e8335d04"},
|
| 31 |
+
{file = "attrs-23.1.0.tar.gz", hash = "sha256:6279836d581513a26f1bf235f9acd333bc9115683f14f7e8fae46c98fc50e015"},
|
| 32 |
+
]
|
| 33 |
+
|
| 34 |
+
[package.extras]
|
| 35 |
+
cov = ["attrs[tests]", "coverage[toml] (>=5.3)"]
|
| 36 |
+
dev = ["attrs[docs,tests]", "pre-commit"]
|
| 37 |
+
docs = ["furo", "myst-parser", "sphinx", "sphinx-notfound-page", "sphinxcontrib-towncrier", "towncrier", "zope-interface"]
|
| 38 |
+
tests = ["attrs[tests-no-zope]", "zope-interface"]
|
| 39 |
+
tests-no-zope = ["cloudpickle", "hypothesis", "mypy (>=1.1.1)", "pympler", "pytest (>=4.3.0)", "pytest-mypy-plugins", "pytest-xdist[psutil]"]
|
| 40 |
+
|
| 41 |
+
[[package]]
|
| 42 |
+
name = "black"
|
| 43 |
+
version = "23.3.0"
|
| 44 |
+
description = "The uncompromising code formatter."
|
| 45 |
+
optional = false
|
| 46 |
+
python-versions = ">=3.7"
|
| 47 |
+
files = [
|
| 48 |
+
{file = "black-23.3.0-cp310-cp310-macosx_10_16_arm64.whl", hash = "sha256:0945e13506be58bf7db93ee5853243eb368ace1c08a24c65ce108986eac65915"},
|
| 49 |
+
{file = "black-23.3.0-cp310-cp310-macosx_10_16_universal2.whl", hash = "sha256:67de8d0c209eb5b330cce2469503de11bca4085880d62f1628bd9972cc3366b9"},
|
| 50 |
+
{file = "black-23.3.0-cp310-cp310-macosx_10_16_x86_64.whl", hash = "sha256:7c3eb7cea23904399866c55826b31c1f55bbcd3890ce22ff70466b907b6775c2"},
|
| 51 |
+
{file = "black-23.3.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:32daa9783106c28815d05b724238e30718f34155653d4d6e125dc7daec8e260c"},
|
| 52 |
+
{file = "black-23.3.0-cp310-cp310-win_amd64.whl", hash = "sha256:35d1381d7a22cc5b2be2f72c7dfdae4072a3336060635718cc7e1ede24221d6c"},
|
| 53 |
+
{file = "black-23.3.0-cp311-cp311-macosx_10_16_arm64.whl", hash = "sha256:a8a968125d0a6a404842fa1bf0b349a568634f856aa08ffaff40ae0dfa52e7c6"},
|
| 54 |
+
{file = "black-23.3.0-cp311-cp311-macosx_10_16_universal2.whl", hash = "sha256:c7ab5790333c448903c4b721b59c0d80b11fe5e9803d8703e84dcb8da56fec1b"},
|
| 55 |
+
{file = "black-23.3.0-cp311-cp311-macosx_10_16_x86_64.whl", hash = "sha256:a6f6886c9869d4daae2d1715ce34a19bbc4b95006d20ed785ca00fa03cba312d"},
|
| 56 |
+
{file = "black-23.3.0-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:6f3c333ea1dd6771b2d3777482429864f8e258899f6ff05826c3a4fcc5ce3f70"},
|
| 57 |
+
{file = "black-23.3.0-cp311-cp311-win_amd64.whl", hash = "sha256:11c410f71b876f961d1de77b9699ad19f939094c3a677323f43d7a29855fe326"},
|
| 58 |
+
{file = "black-23.3.0-cp37-cp37m-macosx_10_16_x86_64.whl", hash = "sha256:1d06691f1eb8de91cd1b322f21e3bfc9efe0c7ca1f0e1eb1db44ea367dff656b"},
|
| 59 |
+
{file = "black-23.3.0-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:50cb33cac881766a5cd9913e10ff75b1e8eb71babf4c7104f2e9c52da1fb7de2"},
|
| 60 |
+
{file = "black-23.3.0-cp37-cp37m-win_amd64.whl", hash = "sha256:e114420bf26b90d4b9daa597351337762b63039752bdf72bf361364c1aa05925"},
|
| 61 |
+
{file = "black-23.3.0-cp38-cp38-macosx_10_16_arm64.whl", hash = "sha256:48f9d345675bb7fbc3dd85821b12487e1b9a75242028adad0333ce36ed2a6d27"},
|
| 62 |
+
{file = "black-23.3.0-cp38-cp38-macosx_10_16_universal2.whl", hash = "sha256:714290490c18fb0126baa0fca0a54ee795f7502b44177e1ce7624ba1c00f2331"},
|
| 63 |
+
{file = "black-23.3.0-cp38-cp38-macosx_10_16_x86_64.whl", hash = "sha256:064101748afa12ad2291c2b91c960be28b817c0c7eaa35bec09cc63aa56493c5"},
|
| 64 |
+
{file = "black-23.3.0-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:562bd3a70495facf56814293149e51aa1be9931567474993c7942ff7d3533961"},
|
| 65 |
+
{file = "black-23.3.0-cp38-cp38-win_amd64.whl", hash = "sha256:e198cf27888ad6f4ff331ca1c48ffc038848ea9f031a3b40ba36aced7e22f2c8"},
|
| 66 |
+
{file = "black-23.3.0-cp39-cp39-macosx_10_16_arm64.whl", hash = "sha256:3238f2aacf827d18d26db07524e44741233ae09a584273aa059066d644ca7b30"},
|
| 67 |
+
{file = "black-23.3.0-cp39-cp39-macosx_10_16_universal2.whl", hash = "sha256:f0bd2f4a58d6666500542b26354978218a9babcdc972722f4bf90779524515f3"},
|
| 68 |
+
{file = "black-23.3.0-cp39-cp39-macosx_10_16_x86_64.whl", hash = "sha256:92c543f6854c28a3c7f39f4d9b7694f9a6eb9d3c5e2ece488c327b6e7ea9b266"},
|
| 69 |
+
{file = "black-23.3.0-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:3a150542a204124ed00683f0db1f5cf1c2aaaa9cc3495b7a3b5976fb136090ab"},
|
| 70 |
+
{file = "black-23.3.0-cp39-cp39-win_amd64.whl", hash = "sha256:6b39abdfb402002b8a7d030ccc85cf5afff64ee90fa4c5aebc531e3ad0175ddb"},
|
| 71 |
+
{file = "black-23.3.0-py3-none-any.whl", hash = "sha256:ec751418022185b0c1bb7d7736e6933d40bbb14c14a0abcf9123d1b159f98dd4"},
|
| 72 |
+
{file = "black-23.3.0.tar.gz", hash = "sha256:1c7b8d606e728a41ea1ccbd7264677e494e87cf630e399262ced92d4a8dac940"},
|
| 73 |
+
]
|
| 74 |
+
|
| 75 |
+
[package.dependencies]
|
| 76 |
+
click = ">=8.0.0"
|
| 77 |
+
mypy-extensions = ">=0.4.3"
|
| 78 |
+
packaging = ">=22.0"
|
| 79 |
+
pathspec = ">=0.9.0"
|
| 80 |
+
platformdirs = ">=2"
|
| 81 |
+
tomli = {version = ">=1.1.0", markers = "python_version < \"3.11\""}
|
| 82 |
+
typing-extensions = {version = ">=3.10.0.0", markers = "python_version < \"3.10\""}
|
| 83 |
+
|
| 84 |
+
[package.extras]
|
| 85 |
+
colorama = ["colorama (>=0.4.3)"]
|
| 86 |
+
d = ["aiohttp (>=3.7.4)"]
|
| 87 |
+
jupyter = ["ipython (>=7.8.0)", "tokenize-rt (>=3.2.0)"]
|
| 88 |
+
uvloop = ["uvloop (>=0.15.2)"]
|
| 89 |
+
|
| 90 |
+
[[package]]
|
| 91 |
+
name = "certifi"
|
| 92 |
+
version = "2023.5.7"
|
| 93 |
+
description = "Python package for providing Mozilla's CA Bundle."
|
| 94 |
+
optional = false
|
| 95 |
+
python-versions = ">=3.6"
|
| 96 |
+
files = [
|
| 97 |
+
{file = "certifi-2023.5.7-py3-none-any.whl", hash = "sha256:c6c2e98f5c7869efca1f8916fed228dd91539f9f1b444c314c06eef02980c716"},
|
| 98 |
+
{file = "certifi-2023.5.7.tar.gz", hash = "sha256:0f0d56dc5a6ad56fd4ba36484d6cc34451e1c6548c61daad8c320169f91eddc7"},
|
| 99 |
+
]
|
| 100 |
+
|
| 101 |
+
[[package]]
|
| 102 |
+
name = "charset-normalizer"
|
| 103 |
+
version = "3.1.0"
|
| 104 |
+
description = "The Real First Universal Charset Detector. Open, modern and actively maintained alternative to Chardet."
|
| 105 |
+
optional = false
|
| 106 |
+
python-versions = ">=3.7.0"
|
| 107 |
+
files = [
|
| 108 |
+
{file = "charset-normalizer-3.1.0.tar.gz", hash = "sha256:34e0a2f9c370eb95597aae63bf85eb5e96826d81e3dcf88b8886012906f509b5"},
|
| 109 |
+
{file = "charset_normalizer-3.1.0-cp310-cp310-macosx_10_9_universal2.whl", hash = "sha256:e0ac8959c929593fee38da1c2b64ee9778733cdf03c482c9ff1d508b6b593b2b"},
|
| 110 |
+
{file = "charset_normalizer-3.1.0-cp310-cp310-macosx_10_9_x86_64.whl", hash = "sha256:d7fc3fca01da18fbabe4625d64bb612b533533ed10045a2ac3dd194bfa656b60"},
|
| 111 |
+
{file = "charset_normalizer-3.1.0-cp310-cp310-macosx_11_0_arm64.whl", hash = "sha256:04eefcee095f58eaabe6dc3cc2262f3bcd776d2c67005880894f447b3f2cb9c1"},
|
| 112 |
+
{file = "charset_normalizer-3.1.0-cp310-cp310-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:20064ead0717cf9a73a6d1e779b23d149b53daf971169289ed2ed43a71e8d3b0"},
|
| 113 |
+
{file = "charset_normalizer-3.1.0-cp310-cp310-manylinux_2_17_ppc64le.manylinux2014_ppc64le.whl", hash = "sha256:1435ae15108b1cb6fffbcea2af3d468683b7afed0169ad718451f8db5d1aff6f"},
|
| 114 |
+
{file = "charset_normalizer-3.1.0-cp310-cp310-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:c84132a54c750fda57729d1e2599bb598f5fa0344085dbde5003ba429a4798c0"},
|
| 115 |
+
{file = "charset_normalizer-3.1.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:75f2568b4189dda1c567339b48cba4ac7384accb9c2a7ed655cd86b04055c795"},
|
| 116 |
+
{file = "charset_normalizer-3.1.0-cp310-cp310-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:11d3bcb7be35e7b1bba2c23beedac81ee893ac9871d0ba79effc7fc01167db6c"},
|
| 117 |
+
{file = "charset_normalizer-3.1.0-cp310-cp310-musllinux_1_1_aarch64.whl", hash = "sha256:891cf9b48776b5c61c700b55a598621fdb7b1e301a550365571e9624f270c203"},
|
| 118 |
+
{file = "charset_normalizer-3.1.0-cp310-cp310-musllinux_1_1_i686.whl", hash = "sha256:5f008525e02908b20e04707a4f704cd286d94718f48bb33edddc7d7b584dddc1"},
|
| 119 |
+
{file = "charset_normalizer-3.1.0-cp310-cp310-musllinux_1_1_ppc64le.whl", hash = "sha256:b06f0d3bf045158d2fb8837c5785fe9ff9b8c93358be64461a1089f5da983137"},
|
| 120 |
+
{file = "charset_normalizer-3.1.0-cp310-cp310-musllinux_1_1_s390x.whl", hash = "sha256:49919f8400b5e49e961f320c735388ee686a62327e773fa5b3ce6721f7e785ce"},
|
| 121 |
+
{file = "charset_normalizer-3.1.0-cp310-cp310-musllinux_1_1_x86_64.whl", hash = "sha256:22908891a380d50738e1f978667536f6c6b526a2064156203d418f4856d6e86a"},
|
| 122 |
+
{file = "charset_normalizer-3.1.0-cp310-cp310-win32.whl", hash = "sha256:12d1a39aa6b8c6f6248bb54550efcc1c38ce0d8096a146638fd4738e42284448"},
|
| 123 |
+
{file = "charset_normalizer-3.1.0-cp310-cp310-win_amd64.whl", hash = "sha256:65ed923f84a6844de5fd29726b888e58c62820e0769b76565480e1fdc3d062f8"},
|
| 124 |
+
{file = "charset_normalizer-3.1.0-cp311-cp311-macosx_10_9_universal2.whl", hash = "sha256:9a3267620866c9d17b959a84dd0bd2d45719b817245e49371ead79ed4f710d19"},
|
| 125 |
+
{file = "charset_normalizer-3.1.0-cp311-cp311-macosx_10_9_x86_64.whl", hash = "sha256:6734e606355834f13445b6adc38b53c0fd45f1a56a9ba06c2058f86893ae8017"},
|
| 126 |
+
{file = "charset_normalizer-3.1.0-cp311-cp311-macosx_11_0_arm64.whl", hash = "sha256:f8303414c7b03f794347ad062c0516cee0e15f7a612abd0ce1e25caf6ceb47df"},
|
| 127 |
+
{file = "charset_normalizer-3.1.0-cp311-cp311-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:aaf53a6cebad0eae578f062c7d462155eada9c172bd8c4d250b8c1d8eb7f916a"},
|
| 128 |
+
{file = "charset_normalizer-3.1.0-cp311-cp311-manylinux_2_17_ppc64le.manylinux2014_ppc64le.whl", hash = "sha256:3dc5b6a8ecfdc5748a7e429782598e4f17ef378e3e272eeb1340ea57c9109f41"},
|
| 129 |
+
{file = "charset_normalizer-3.1.0-cp311-cp311-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:e1b25e3ad6c909f398df8921780d6a3d120d8c09466720226fc621605b6f92b1"},
|
| 130 |
+
{file = "charset_normalizer-3.1.0-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:0ca564606d2caafb0abe6d1b5311c2649e8071eb241b2d64e75a0d0065107e62"},
|
| 131 |
+
{file = "charset_normalizer-3.1.0-cp311-cp311-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:b82fab78e0b1329e183a65260581de4375f619167478dddab510c6c6fb04d9b6"},
|
| 132 |
+
{file = "charset_normalizer-3.1.0-cp311-cp311-musllinux_1_1_aarch64.whl", hash = "sha256:bd7163182133c0c7701b25e604cf1611c0d87712e56e88e7ee5d72deab3e76b5"},
|
| 133 |
+
{file = "charset_normalizer-3.1.0-cp311-cp311-musllinux_1_1_i686.whl", hash = "sha256:11d117e6c63e8f495412d37e7dc2e2fff09c34b2d09dbe2bee3c6229577818be"},
|
| 134 |
+
{file = "charset_normalizer-3.1.0-cp311-cp311-musllinux_1_1_ppc64le.whl", hash = "sha256:cf6511efa4801b9b38dc5546d7547d5b5c6ef4b081c60b23e4d941d0eba9cbeb"},
|
| 135 |
+
{file = "charset_normalizer-3.1.0-cp311-cp311-musllinux_1_1_s390x.whl", hash = "sha256:abc1185d79f47c0a7aaf7e2412a0eb2c03b724581139193d2d82b3ad8cbb00ac"},
|
| 136 |
+
{file = "charset_normalizer-3.1.0-cp311-cp311-musllinux_1_1_x86_64.whl", hash = "sha256:cb7b2ab0188829593b9de646545175547a70d9a6e2b63bf2cd87a0a391599324"},
|
| 137 |
+
{file = "charset_normalizer-3.1.0-cp311-cp311-win32.whl", hash = "sha256:c36bcbc0d5174a80d6cccf43a0ecaca44e81d25be4b7f90f0ed7bcfbb5a00909"},
|
| 138 |
+
{file = "charset_normalizer-3.1.0-cp311-cp311-win_amd64.whl", hash = "sha256:cca4def576f47a09a943666b8f829606bcb17e2bc2d5911a46c8f8da45f56755"},
|
| 139 |
+
{file = "charset_normalizer-3.1.0-cp37-cp37m-macosx_10_9_x86_64.whl", hash = "sha256:0c95f12b74681e9ae127728f7e5409cbbef9cd914d5896ef238cc779b8152373"},
|
| 140 |
+
{file = "charset_normalizer-3.1.0-cp37-cp37m-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:fca62a8301b605b954ad2e9c3666f9d97f63872aa4efcae5492baca2056b74ab"},
|
| 141 |
+
{file = "charset_normalizer-3.1.0-cp37-cp37m-manylinux_2_17_ppc64le.manylinux2014_ppc64le.whl", hash = "sha256:ac0aa6cd53ab9a31d397f8303f92c42f534693528fafbdb997c82bae6e477ad9"},
|
| 142 |
+
{file = "charset_normalizer-3.1.0-cp37-cp37m-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:c3af8e0f07399d3176b179f2e2634c3ce9c1301379a6b8c9c9aeecd481da494f"},
|
| 143 |
+
{file = "charset_normalizer-3.1.0-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:3a5fc78f9e3f501a1614a98f7c54d3969f3ad9bba8ba3d9b438c3bc5d047dd28"},
|
| 144 |
+
{file = "charset_normalizer-3.1.0-cp37-cp37m-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:628c985afb2c7d27a4800bfb609e03985aaecb42f955049957814e0491d4006d"},
|
| 145 |
+
{file = "charset_normalizer-3.1.0-cp37-cp37m-musllinux_1_1_aarch64.whl", hash = "sha256:74db0052d985cf37fa111828d0dd230776ac99c740e1a758ad99094be4f1803d"},
|
| 146 |
+
{file = "charset_normalizer-3.1.0-cp37-cp37m-musllinux_1_1_i686.whl", hash = "sha256:1e8fcdd8f672a1c4fc8d0bd3a2b576b152d2a349782d1eb0f6b8e52e9954731d"},
|
| 147 |
+
{file = "charset_normalizer-3.1.0-cp37-cp37m-musllinux_1_1_ppc64le.whl", hash = "sha256:04afa6387e2b282cf78ff3dbce20f0cc071c12dc8f685bd40960cc68644cfea6"},
|
| 148 |
+
{file = "charset_normalizer-3.1.0-cp37-cp37m-musllinux_1_1_s390x.whl", hash = "sha256:dd5653e67b149503c68c4018bf07e42eeed6b4e956b24c00ccdf93ac79cdff84"},
|
| 149 |
+
{file = "charset_normalizer-3.1.0-cp37-cp37m-musllinux_1_1_x86_64.whl", hash = "sha256:d2686f91611f9e17f4548dbf050e75b079bbc2a82be565832bc8ea9047b61c8c"},
|
| 150 |
+
{file = "charset_normalizer-3.1.0-cp37-cp37m-win32.whl", hash = "sha256:4155b51ae05ed47199dc5b2a4e62abccb274cee6b01da5b895099b61b1982974"},
|
| 151 |
+
{file = "charset_normalizer-3.1.0-cp37-cp37m-win_amd64.whl", hash = "sha256:322102cdf1ab682ecc7d9b1c5eed4ec59657a65e1c146a0da342b78f4112db23"},
|
| 152 |
+
{file = "charset_normalizer-3.1.0-cp38-cp38-macosx_10_9_universal2.whl", hash = "sha256:e633940f28c1e913615fd624fcdd72fdba807bf53ea6925d6a588e84e1151531"},
|
| 153 |
+
{file = "charset_normalizer-3.1.0-cp38-cp38-macosx_10_9_x86_64.whl", hash = "sha256:3a06f32c9634a8705f4ca9946d667609f52cf130d5548881401f1eb2c39b1e2c"},
|
| 154 |
+
{file = "charset_normalizer-3.1.0-cp38-cp38-macosx_11_0_arm64.whl", hash = "sha256:7381c66e0561c5757ffe616af869b916c8b4e42b367ab29fedc98481d1e74e14"},
|
| 155 |
+
{file = "charset_normalizer-3.1.0-cp38-cp38-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:3573d376454d956553c356df45bb824262c397c6e26ce43e8203c4c540ee0acb"},
|
| 156 |
+
{file = "charset_normalizer-3.1.0-cp38-cp38-manylinux_2_17_ppc64le.manylinux2014_ppc64le.whl", hash = "sha256:e89df2958e5159b811af9ff0f92614dabf4ff617c03a4c1c6ff53bf1c399e0e1"},
|
| 157 |
+
{file = "charset_normalizer-3.1.0-cp38-cp38-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:78cacd03e79d009d95635e7d6ff12c21eb89b894c354bd2b2ed0b4763373693b"},
|
| 158 |
+
{file = "charset_normalizer-3.1.0-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:de5695a6f1d8340b12a5d6d4484290ee74d61e467c39ff03b39e30df62cf83a0"},
|
| 159 |
+
{file = "charset_normalizer-3.1.0-cp38-cp38-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:1c60b9c202d00052183c9be85e5eaf18a4ada0a47d188a83c8f5c5b23252f649"},
|
| 160 |
+
{file = "charset_normalizer-3.1.0-cp38-cp38-musllinux_1_1_aarch64.whl", hash = "sha256:f645caaf0008bacf349875a974220f1f1da349c5dbe7c4ec93048cdc785a3326"},
|
| 161 |
+
{file = "charset_normalizer-3.1.0-cp38-cp38-musllinux_1_1_i686.whl", hash = "sha256:ea9f9c6034ea2d93d9147818f17c2a0860d41b71c38b9ce4d55f21b6f9165a11"},
|
| 162 |
+
{file = "charset_normalizer-3.1.0-cp38-cp38-musllinux_1_1_ppc64le.whl", hash = "sha256:80d1543d58bd3d6c271b66abf454d437a438dff01c3e62fdbcd68f2a11310d4b"},
|
| 163 |
+
{file = "charset_normalizer-3.1.0-cp38-cp38-musllinux_1_1_s390x.whl", hash = "sha256:73dc03a6a7e30b7edc5b01b601e53e7fc924b04e1835e8e407c12c037e81adbd"},
|
| 164 |
+
{file = "charset_normalizer-3.1.0-cp38-cp38-musllinux_1_1_x86_64.whl", hash = "sha256:6f5c2e7bc8a4bf7c426599765b1bd33217ec84023033672c1e9a8b35eaeaaaf8"},
|
| 165 |
+
{file = "charset_normalizer-3.1.0-cp38-cp38-win32.whl", hash = "sha256:12a2b561af122e3d94cdb97fe6fb2bb2b82cef0cdca131646fdb940a1eda04f0"},
|
| 166 |
+
{file = "charset_normalizer-3.1.0-cp38-cp38-win_amd64.whl", hash = "sha256:3160a0fd9754aab7d47f95a6b63ab355388d890163eb03b2d2b87ab0a30cfa59"},
|
| 167 |
+
{file = "charset_normalizer-3.1.0-cp39-cp39-macosx_10_9_universal2.whl", hash = "sha256:38e812a197bf8e71a59fe55b757a84c1f946d0ac114acafaafaf21667a7e169e"},
|
| 168 |
+
{file = "charset_normalizer-3.1.0-cp39-cp39-macosx_10_9_x86_64.whl", hash = "sha256:6baf0baf0d5d265fa7944feb9f7451cc316bfe30e8df1a61b1bb08577c554f31"},
|
| 169 |
+
{file = "charset_normalizer-3.1.0-cp39-cp39-macosx_11_0_arm64.whl", hash = "sha256:8f25e17ab3039b05f762b0a55ae0b3632b2e073d9c8fc88e89aca31a6198e88f"},
|
| 170 |
+
{file = "charset_normalizer-3.1.0-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:3747443b6a904001473370d7810aa19c3a180ccd52a7157aacc264a5ac79265e"},
|
| 171 |
+
{file = "charset_normalizer-3.1.0-cp39-cp39-manylinux_2_17_ppc64le.manylinux2014_ppc64le.whl", hash = "sha256:b116502087ce8a6b7a5f1814568ccbd0e9f6cfd99948aa59b0e241dc57cf739f"},
|
| 172 |
+
{file = "charset_normalizer-3.1.0-cp39-cp39-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:d16fd5252f883eb074ca55cb622bc0bee49b979ae4e8639fff6ca3ff44f9f854"},
|
| 173 |
+
{file = "charset_normalizer-3.1.0-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:21fa558996782fc226b529fdd2ed7866c2c6ec91cee82735c98a197fae39f706"},
|
| 174 |
+
{file = "charset_normalizer-3.1.0-cp39-cp39-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:6f6c7a8a57e9405cad7485f4c9d3172ae486cfef1344b5ddd8e5239582d7355e"},
|
| 175 |
+
{file = "charset_normalizer-3.1.0-cp39-cp39-musllinux_1_1_aarch64.whl", hash = "sha256:ac3775e3311661d4adace3697a52ac0bab17edd166087d493b52d4f4f553f9f0"},
|
| 176 |
+
{file = "charset_normalizer-3.1.0-cp39-cp39-musllinux_1_1_i686.whl", hash = "sha256:10c93628d7497c81686e8e5e557aafa78f230cd9e77dd0c40032ef90c18f2230"},
|
| 177 |
+
{file = "charset_normalizer-3.1.0-cp39-cp39-musllinux_1_1_ppc64le.whl", hash = "sha256:6f4f4668e1831850ebcc2fd0b1cd11721947b6dc7c00bf1c6bd3c929ae14f2c7"},
|
| 178 |
+
{file = "charset_normalizer-3.1.0-cp39-cp39-musllinux_1_1_s390x.whl", hash = "sha256:0be65ccf618c1e7ac9b849c315cc2e8a8751d9cfdaa43027d4f6624bd587ab7e"},
|
| 179 |
+
{file = "charset_normalizer-3.1.0-cp39-cp39-musllinux_1_1_x86_64.whl", hash = "sha256:53d0a3fa5f8af98a1e261de6a3943ca631c526635eb5817a87a59d9a57ebf48f"},
|
| 180 |
+
{file = "charset_normalizer-3.1.0-cp39-cp39-win32.whl", hash = "sha256:a04f86f41a8916fe45ac5024ec477f41f886b3c435da2d4e3d2709b22ab02af1"},
|
| 181 |
+
{file = "charset_normalizer-3.1.0-cp39-cp39-win_amd64.whl", hash = "sha256:830d2948a5ec37c386d3170c483063798d7879037492540f10a475e3fd6f244b"},
|
| 182 |
+
{file = "charset_normalizer-3.1.0-py3-none-any.whl", hash = "sha256:3d9098b479e78c85080c98e1e35ff40b4a31d8953102bb0fd7d1b6f8a2111a3d"},
|
| 183 |
+
]
|
| 184 |
+
|
| 185 |
+
[[package]]
|
| 186 |
+
name = "click"
|
| 187 |
+
version = "8.1.3"
|
| 188 |
+
description = "Composable command line interface toolkit"
|
| 189 |
+
optional = false
|
| 190 |
+
python-versions = ">=3.7"
|
| 191 |
+
files = [
|
| 192 |
+
{file = "click-8.1.3-py3-none-any.whl", hash = "sha256:bb4d8133cb15a609f44e8213d9b391b0809795062913b383c62be0ee95b1db48"},
|
| 193 |
+
{file = "click-8.1.3.tar.gz", hash = "sha256:7682dc8afb30297001674575ea00d1814d808d6a36af415a82bd481d37ba7b8e"},
|
| 194 |
+
]
|
| 195 |
+
|
| 196 |
+
[package.dependencies]
|
| 197 |
+
colorama = {version = "*", markers = "platform_system == \"Windows\""}
|
| 198 |
+
|
| 199 |
+
[[package]]
|
| 200 |
+
name = "colorama"
|
| 201 |
+
version = "0.4.6"
|
| 202 |
+
description = "Cross-platform colored terminal text."
|
| 203 |
+
optional = false
|
| 204 |
+
python-versions = "!=3.0.*,!=3.1.*,!=3.2.*,!=3.3.*,!=3.4.*,!=3.5.*,!=3.6.*,>=2.7"
|
| 205 |
+
files = [
|
| 206 |
+
{file = "colorama-0.4.6-py2.py3-none-any.whl", hash = "sha256:4f1d9991f5acc0ca119f9d443620b77f9d6b33703e51011c16baf57afb285fc6"},
|
| 207 |
+
{file = "colorama-0.4.6.tar.gz", hash = "sha256:08695f5cb7ed6e0531a20572697297273c47b8cae5a63ffc6d6ed5c201be6e44"},
|
| 208 |
+
]
|
| 209 |
+
|
| 210 |
+
[[package]]
|
| 211 |
+
name = "exceptiongroup"
|
| 212 |
+
version = "1.1.1"
|
| 213 |
+
description = "Backport of PEP 654 (exception groups)"
|
| 214 |
+
optional = false
|
| 215 |
+
python-versions = ">=3.7"
|
| 216 |
+
files = [
|
| 217 |
+
{file = "exceptiongroup-1.1.1-py3-none-any.whl", hash = "sha256:232c37c63e4f682982c8b6459f33a8981039e5fb8756b2074364e5055c498c9e"},
|
| 218 |
+
{file = "exceptiongroup-1.1.1.tar.gz", hash = "sha256:d484c3090ba2889ae2928419117447a14daf3c1231d5e30d0aae34f354f01785"},
|
| 219 |
+
]
|
| 220 |
+
|
| 221 |
+
[package.extras]
|
| 222 |
+
test = ["pytest (>=6)"]
|
| 223 |
+
|
| 224 |
+
[[package]]
|
| 225 |
+
name = "filelock"
|
| 226 |
+
version = "3.12.0"
|
| 227 |
+
description = "A platform independent file lock."
|
| 228 |
+
optional = false
|
| 229 |
+
python-versions = ">=3.7"
|
| 230 |
+
files = [
|
| 231 |
+
{file = "filelock-3.12.0-py3-none-any.whl", hash = "sha256:ad98852315c2ab702aeb628412cbf7e95b7ce8c3bf9565670b4eaecf1db370a9"},
|
| 232 |
+
{file = "filelock-3.12.0.tar.gz", hash = "sha256:fc03ae43288c013d2ea83c8597001b1129db351aad9c57fe2409327916b8e718"},
|
| 233 |
+
]
|
| 234 |
+
|
| 235 |
+
[package.extras]
|
| 236 |
+
docs = ["furo (>=2023.3.27)", "sphinx (>=6.1.3)", "sphinx-autodoc-typehints (>=1.23,!=1.23.4)"]
|
| 237 |
+
testing = ["covdefaults (>=2.3)", "coverage (>=7.2.3)", "diff-cover (>=7.5)", "pytest (>=7.3.1)", "pytest-cov (>=4)", "pytest-mock (>=3.10)", "pytest-timeout (>=2.1)"]
|
| 238 |
+
|
| 239 |
+
[[package]]
|
| 240 |
+
name = "flake8"
|
| 241 |
+
version = "5.0.4"
|
| 242 |
+
description = "the modular source code checker: pep8 pyflakes and co"
|
| 243 |
+
optional = false
|
| 244 |
+
python-versions = ">=3.6.1"
|
| 245 |
+
files = [
|
| 246 |
+
{file = "flake8-5.0.4-py2.py3-none-any.whl", hash = "sha256:7a1cf6b73744f5806ab95e526f6f0d8c01c66d7bbe349562d22dfca20610b248"},
|
| 247 |
+
{file = "flake8-5.0.4.tar.gz", hash = "sha256:6fbe320aad8d6b95cec8b8e47bc933004678dc63095be98528b7bdd2a9f510db"},
|
| 248 |
+
]
|
| 249 |
+
|
| 250 |
+
[package.dependencies]
|
| 251 |
+
mccabe = ">=0.7.0,<0.8.0"
|
| 252 |
+
pycodestyle = ">=2.9.0,<2.10.0"
|
| 253 |
+
pyflakes = ">=2.5.0,<2.6.0"
|
| 254 |
+
|
| 255 |
+
[[package]]
|
| 256 |
+
name = "flake8-pyproject"
|
| 257 |
+
version = "1.2.3"
|
| 258 |
+
description = "Flake8 plug-in loading the configuration from pyproject.toml"
|
| 259 |
+
optional = false
|
| 260 |
+
python-versions = ">= 3.6"
|
| 261 |
+
files = [
|
| 262 |
+
{file = "flake8_pyproject-1.2.3-py3-none-any.whl", hash = "sha256:6249fe53545205af5e76837644dc80b4c10037e73a0e5db87ff562d75fb5bd4a"},
|
| 263 |
+
]
|
| 264 |
+
|
| 265 |
+
[package.dependencies]
|
| 266 |
+
Flake8 = ">=5"
|
| 267 |
+
TOMLi = {version = "*", markers = "python_version < \"3.11\""}
|
| 268 |
+
|
| 269 |
+
[package.extras]
|
| 270 |
+
dev = ["pyTest", "pyTest-cov"]
|
| 271 |
+
|
| 272 |
+
[[package]]
|
| 273 |
+
name = "fsspec"
|
| 274 |
+
version = "2023.5.0"
|
| 275 |
+
description = "File-system specification"
|
| 276 |
+
optional = false
|
| 277 |
+
python-versions = ">=3.8"
|
| 278 |
+
files = [
|
| 279 |
+
{file = "fsspec-2023.5.0-py3-none-any.whl", hash = "sha256:51a4ad01a5bb66fcc58036e288c0d53d3975a0df2a5dc59a93b59bade0391f2a"},
|
| 280 |
+
{file = "fsspec-2023.5.0.tar.gz", hash = "sha256:b3b56e00fb93ea321bc9e5d9cf6f8522a0198b20eb24e02774d329e9c6fb84ce"},
|
| 281 |
+
]
|
| 282 |
+
|
| 283 |
+
[package.extras]
|
| 284 |
+
abfs = ["adlfs"]
|
| 285 |
+
adl = ["adlfs"]
|
| 286 |
+
arrow = ["pyarrow (>=1)"]
|
| 287 |
+
dask = ["dask", "distributed"]
|
| 288 |
+
devel = ["pytest", "pytest-cov"]
|
| 289 |
+
dropbox = ["dropbox", "dropboxdrivefs", "requests"]
|
| 290 |
+
full = ["adlfs", "aiohttp (!=4.0.0a0,!=4.0.0a1)", "dask", "distributed", "dropbox", "dropboxdrivefs", "fusepy", "gcsfs", "libarchive-c", "ocifs", "panel", "paramiko", "pyarrow (>=1)", "pygit2", "requests", "s3fs", "smbprotocol", "tqdm"]
|
| 291 |
+
fuse = ["fusepy"]
|
| 292 |
+
gcs = ["gcsfs"]
|
| 293 |
+
git = ["pygit2"]
|
| 294 |
+
github = ["requests"]
|
| 295 |
+
gs = ["gcsfs"]
|
| 296 |
+
gui = ["panel"]
|
| 297 |
+
hdfs = ["pyarrow (>=1)"]
|
| 298 |
+
http = ["aiohttp (!=4.0.0a0,!=4.0.0a1)", "requests"]
|
| 299 |
+
libarchive = ["libarchive-c"]
|
| 300 |
+
oci = ["ocifs"]
|
| 301 |
+
s3 = ["s3fs"]
|
| 302 |
+
sftp = ["paramiko"]
|
| 303 |
+
smb = ["smbprotocol"]
|
| 304 |
+
ssh = ["paramiko"]
|
| 305 |
+
tqdm = ["tqdm"]
|
| 306 |
+
|
| 307 |
+
[[package]]
|
| 308 |
+
name = "gradio-client"
|
| 309 |
+
version = "0.2.7"
|
| 310 |
+
description = "Python library for easily interacting with trained machine learning models"
|
| 311 |
+
optional = false
|
| 312 |
+
python-versions = ">=3.8"
|
| 313 |
+
files = [
|
| 314 |
+
{file = "gradio_client-0.2.7-py3-none-any.whl", hash = "sha256:4a7ec6bb1341c626051f1ed24d50cb960ff1a4cd1a5db031dd4caaf1ee7d2d0a"},
|
| 315 |
+
{file = "gradio_client-0.2.7.tar.gz", hash = "sha256:c83008df8a1dd3f81a290c0a24c03d0ab70317741991b60f713620ed39ad8f12"},
|
| 316 |
+
]
|
| 317 |
+
|
| 318 |
+
[package.dependencies]
|
| 319 |
+
fsspec = "*"
|
| 320 |
+
httpx = "*"
|
| 321 |
+
huggingface-hub = ">=0.13.0"
|
| 322 |
+
packaging = "*"
|
| 323 |
+
requests = "*"
|
| 324 |
+
typing-extensions = "*"
|
| 325 |
+
websockets = "*"
|
| 326 |
+
|
| 327 |
+
[[package]]
|
| 328 |
+
name = "h11"
|
| 329 |
+
version = "0.14.0"
|
| 330 |
+
description = "A pure-Python, bring-your-own-I/O implementation of HTTP/1.1"
|
| 331 |
+
optional = false
|
| 332 |
+
python-versions = ">=3.7"
|
| 333 |
+
files = [
|
| 334 |
+
{file = "h11-0.14.0-py3-none-any.whl", hash = "sha256:e3fe4ac4b851c468cc8363d500db52c2ead036020723024a109d37346efaa761"},
|
| 335 |
+
{file = "h11-0.14.0.tar.gz", hash = "sha256:8f19fbbe99e72420ff35c00b27a34cb9937e902a8b810e2c88300c6f0a3b699d"},
|
| 336 |
+
]
|
| 337 |
+
|
| 338 |
+
[[package]]
|
| 339 |
+
name = "httpcore"
|
| 340 |
+
version = "0.17.0"
|
| 341 |
+
description = "A minimal low-level HTTP client."
|
| 342 |
+
optional = false
|
| 343 |
+
python-versions = ">=3.7"
|
| 344 |
+
files = [
|
| 345 |
+
{file = "httpcore-0.17.0-py3-none-any.whl", hash = "sha256:0fdfea45e94f0c9fd96eab9286077f9ff788dd186635ae61b312693e4d943599"},
|
| 346 |
+
{file = "httpcore-0.17.0.tar.gz", hash = "sha256:cc045a3241afbf60ce056202301b4d8b6af08845e3294055eb26b09913ef903c"},
|
| 347 |
+
]
|
| 348 |
+
|
| 349 |
+
[package.dependencies]
|
| 350 |
+
anyio = ">=3.0,<5.0"
|
| 351 |
+
certifi = "*"
|
| 352 |
+
h11 = ">=0.13,<0.15"
|
| 353 |
+
sniffio = "==1.*"
|
| 354 |
+
|
| 355 |
+
[package.extras]
|
| 356 |
+
http2 = ["h2 (>=3,<5)"]
|
| 357 |
+
socks = ["socksio (==1.*)"]
|
| 358 |
+
|
| 359 |
+
[[package]]
|
| 360 |
+
name = "httpx"
|
| 361 |
+
version = "0.24.0"
|
| 362 |
+
description = "The next generation HTTP client."
|
| 363 |
+
optional = false
|
| 364 |
+
python-versions = ">=3.7"
|
| 365 |
+
files = [
|
| 366 |
+
{file = "httpx-0.24.0-py3-none-any.whl", hash = "sha256:447556b50c1921c351ea54b4fe79d91b724ed2b027462ab9a329465d147d5a4e"},
|
| 367 |
+
{file = "httpx-0.24.0.tar.gz", hash = "sha256:507d676fc3e26110d41df7d35ebd8b3b8585052450f4097401c9be59d928c63e"},
|
| 368 |
+
]
|
| 369 |
+
|
| 370 |
+
[package.dependencies]
|
| 371 |
+
certifi = "*"
|
| 372 |
+
httpcore = ">=0.15.0,<0.18.0"
|
| 373 |
+
idna = "*"
|
| 374 |
+
sniffio = "*"
|
| 375 |
+
|
| 376 |
+
[package.extras]
|
| 377 |
+
brotli = ["brotli", "brotlicffi"]
|
| 378 |
+
cli = ["click (==8.*)", "pygments (==2.*)", "rich (>=10,<14)"]
|
| 379 |
+
http2 = ["h2 (>=3,<5)"]
|
| 380 |
+
socks = ["socksio (==1.*)"]
|
| 381 |
+
|
| 382 |
+
[[package]]
|
| 383 |
+
name = "huggingface-hub"
|
| 384 |
+
version = "0.14.1"
|
| 385 |
+
description = "Client library to download and publish models, datasets and other repos on the huggingface.co hub"
|
| 386 |
+
optional = false
|
| 387 |
+
python-versions = ">=3.7.0"
|
| 388 |
+
files = [
|
| 389 |
+
{file = "huggingface_hub-0.14.1-py3-none-any.whl", hash = "sha256:9fc619170d800ff3793ad37c9757c255c8783051e1b5b00501205eb43ccc4f27"},
|
| 390 |
+
{file = "huggingface_hub-0.14.1.tar.gz", hash = "sha256:9ab899af8e10922eac65e290d60ab956882ab0bf643e3d990b1394b6b47b7fbc"},
|
| 391 |
+
]
|
| 392 |
+
|
| 393 |
+
[package.dependencies]
|
| 394 |
+
filelock = "*"
|
| 395 |
+
fsspec = "*"
|
| 396 |
+
packaging = ">=20.9"
|
| 397 |
+
pyyaml = ">=5.1"
|
| 398 |
+
requests = "*"
|
| 399 |
+
tqdm = ">=4.42.1"
|
| 400 |
+
typing-extensions = ">=3.7.4.3"
|
| 401 |
+
|
| 402 |
+
[package.extras]
|
| 403 |
+
all = ["InquirerPy (==0.3.4)", "Jinja2", "Pillow", "black (>=23.1,<24.0)", "gradio", "jedi", "mypy (==0.982)", "pytest", "pytest-cov", "pytest-env", "pytest-xdist", "ruff (>=0.0.241)", "soundfile", "types-PyYAML", "types-requests", "types-simplejson", "types-toml", "types-tqdm", "types-urllib3"]
|
| 404 |
+
cli = ["InquirerPy (==0.3.4)"]
|
| 405 |
+
dev = ["InquirerPy (==0.3.4)", "Jinja2", "Pillow", "black (>=23.1,<24.0)", "gradio", "jedi", "mypy (==0.982)", "pytest", "pytest-cov", "pytest-env", "pytest-xdist", "ruff (>=0.0.241)", "soundfile", "types-PyYAML", "types-requests", "types-simplejson", "types-toml", "types-tqdm", "types-urllib3"]
|
| 406 |
+
fastai = ["fastai (>=2.4)", "fastcore (>=1.3.27)", "toml"]
|
| 407 |
+
quality = ["black (>=23.1,<24.0)", "mypy (==0.982)", "ruff (>=0.0.241)"]
|
| 408 |
+
tensorflow = ["graphviz", "pydot", "tensorflow"]
|
| 409 |
+
testing = ["InquirerPy (==0.3.4)", "Jinja2", "Pillow", "gradio", "jedi", "pytest", "pytest-cov", "pytest-env", "pytest-xdist", "soundfile"]
|
| 410 |
+
torch = ["torch"]
|
| 411 |
+
typing = ["types-PyYAML", "types-requests", "types-simplejson", "types-toml", "types-tqdm", "types-urllib3"]
|
| 412 |
+
|
| 413 |
+
[[package]]
|
| 414 |
+
name = "idna"
|
| 415 |
+
version = "3.4"
|
| 416 |
+
description = "Internationalized Domain Names in Applications (IDNA)"
|
| 417 |
+
optional = false
|
| 418 |
+
python-versions = ">=3.5"
|
| 419 |
+
files = [
|
| 420 |
+
{file = "idna-3.4-py3-none-any.whl", hash = "sha256:90b77e79eaa3eba6de819a0c442c0b4ceefc341a7a2ab77d7562bf49f425c5c2"},
|
| 421 |
+
{file = "idna-3.4.tar.gz", hash = "sha256:814f528e8dead7d329833b91c5faa87d60bf71824cd12a7530b5526063d02cb4"},
|
| 422 |
+
]
|
| 423 |
+
|
| 424 |
+
[[package]]
|
| 425 |
+
name = "iniconfig"
|
| 426 |
+
version = "2.0.0"
|
| 427 |
+
description = "brain-dead simple config-ini parsing"
|
| 428 |
+
optional = false
|
| 429 |
+
python-versions = ">=3.7"
|
| 430 |
+
files = [
|
| 431 |
+
{file = "iniconfig-2.0.0-py3-none-any.whl", hash = "sha256:b6a85871a79d2e3b22d2d1b94ac2824226a63c6b741c88f7ae975f18b6778374"},
|
| 432 |
+
{file = "iniconfig-2.0.0.tar.gz", hash = "sha256:2d91e135bf72d31a410b17c16da610a82cb55f6b0477d1a902134b24a455b8b3"},
|
| 433 |
+
]
|
| 434 |
+
|
| 435 |
+
[[package]]
|
| 436 |
+
name = "isort"
|
| 437 |
+
version = "5.12.0"
|
| 438 |
+
description = "A Python utility / library to sort Python imports."
|
| 439 |
+
optional = false
|
| 440 |
+
python-versions = ">=3.8.0"
|
| 441 |
+
files = [
|
| 442 |
+
{file = "isort-5.12.0-py3-none-any.whl", hash = "sha256:f84c2818376e66cf843d497486ea8fed8700b340f308f076c6fb1229dff318b6"},
|
| 443 |
+
{file = "isort-5.12.0.tar.gz", hash = "sha256:8bef7dde241278824a6d83f44a544709b065191b95b6e50894bdc722fcba0504"},
|
| 444 |
+
]
|
| 445 |
+
|
| 446 |
+
[package.extras]
|
| 447 |
+
colors = ["colorama (>=0.4.3)"]
|
| 448 |
+
pipfile-deprecated-finder = ["pip-shims (>=0.5.2)", "pipreqs", "requirementslib"]
|
| 449 |
+
plugins = ["setuptools"]
|
| 450 |
+
requirements-deprecated-finder = ["pip-api", "pipreqs"]
|
| 451 |
+
|
| 452 |
+
[[package]]
|
| 453 |
+
name = "mccabe"
|
| 454 |
+
version = "0.7.0"
|
| 455 |
+
description = "McCabe checker, plugin for flake8"
|
| 456 |
+
optional = false
|
| 457 |
+
python-versions = ">=3.6"
|
| 458 |
+
files = [
|
| 459 |
+
{file = "mccabe-0.7.0-py2.py3-none-any.whl", hash = "sha256:6c2d30ab6be0e4a46919781807b4f0d834ebdd6c6e3dca0bda5a15f863427b6e"},
|
| 460 |
+
{file = "mccabe-0.7.0.tar.gz", hash = "sha256:348e0240c33b60bbdf4e523192ef919f28cb2c3d7d5c7794f74009290f236325"},
|
| 461 |
+
]
|
| 462 |
+
|
| 463 |
+
[[package]]
|
| 464 |
+
name = "mypy"
|
| 465 |
+
version = "1.3.0"
|
| 466 |
+
description = "Optional static typing for Python"
|
| 467 |
+
optional = false
|
| 468 |
+
python-versions = ">=3.7"
|
| 469 |
+
files = [
|
| 470 |
+
{file = "mypy-1.3.0-cp310-cp310-macosx_10_9_x86_64.whl", hash = "sha256:c1eb485cea53f4f5284e5baf92902cd0088b24984f4209e25981cc359d64448d"},
|
| 471 |
+
{file = "mypy-1.3.0-cp310-cp310-macosx_11_0_arm64.whl", hash = "sha256:4c99c3ecf223cf2952638da9cd82793d8f3c0c5fa8b6ae2b2d9ed1e1ff51ba85"},
|
| 472 |
+
{file = "mypy-1.3.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:550a8b3a19bb6589679a7c3c31f64312e7ff482a816c96e0cecec9ad3a7564dd"},
|
| 473 |
+
{file = "mypy-1.3.0-cp310-cp310-musllinux_1_1_x86_64.whl", hash = "sha256:cbc07246253b9e3d7d74c9ff948cd0fd7a71afcc2b77c7f0a59c26e9395cb152"},
|
| 474 |
+
{file = "mypy-1.3.0-cp310-cp310-win_amd64.whl", hash = "sha256:a22435632710a4fcf8acf86cbd0d69f68ac389a3892cb23fbad176d1cddaf228"},
|
| 475 |
+
{file = "mypy-1.3.0-cp311-cp311-macosx_10_9_x86_64.whl", hash = "sha256:6e33bb8b2613614a33dff70565f4c803f889ebd2f859466e42b46e1df76018dd"},
|
| 476 |
+
{file = "mypy-1.3.0-cp311-cp311-macosx_11_0_arm64.whl", hash = "sha256:7d23370d2a6b7a71dc65d1266f9a34e4cde9e8e21511322415db4b26f46f6b8c"},
|
| 477 |
+
{file = "mypy-1.3.0-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:658fe7b674769a0770d4b26cb4d6f005e88a442fe82446f020be8e5f5efb2fae"},
|
| 478 |
+
{file = "mypy-1.3.0-cp311-cp311-musllinux_1_1_x86_64.whl", hash = "sha256:6e42d29e324cdda61daaec2336c42512e59c7c375340bd202efa1fe0f7b8f8ca"},
|
| 479 |
+
{file = "mypy-1.3.0-cp311-cp311-win_amd64.whl", hash = "sha256:d0b6c62206e04061e27009481cb0ec966f7d6172b5b936f3ead3d74f29fe3dcf"},
|
| 480 |
+
{file = "mypy-1.3.0-cp37-cp37m-macosx_10_9_x86_64.whl", hash = "sha256:76ec771e2342f1b558c36d49900dfe81d140361dd0d2df6cd71b3db1be155409"},
|
| 481 |
+
{file = "mypy-1.3.0-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:ebc95f8386314272bbc817026f8ce8f4f0d2ef7ae44f947c4664efac9adec929"},
|
| 482 |
+
{file = "mypy-1.3.0-cp37-cp37m-musllinux_1_1_x86_64.whl", hash = "sha256:faff86aa10c1aa4a10e1a301de160f3d8fc8703b88c7e98de46b531ff1276a9a"},
|
| 483 |
+
{file = "mypy-1.3.0-cp37-cp37m-win_amd64.whl", hash = "sha256:8c5979d0deb27e0f4479bee18ea0f83732a893e81b78e62e2dda3e7e518c92ee"},
|
| 484 |
+
{file = "mypy-1.3.0-cp38-cp38-macosx_10_9_x86_64.whl", hash = "sha256:c5d2cc54175bab47011b09688b418db71403aefad07cbcd62d44010543fc143f"},
|
| 485 |
+
{file = "mypy-1.3.0-cp38-cp38-macosx_11_0_arm64.whl", hash = "sha256:87df44954c31d86df96c8bd6e80dfcd773473e877ac6176a8e29898bfb3501cb"},
|
| 486 |
+
{file = "mypy-1.3.0-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:473117e310febe632ddf10e745a355714e771ffe534f06db40702775056614c4"},
|
| 487 |
+
{file = "mypy-1.3.0-cp38-cp38-musllinux_1_1_x86_64.whl", hash = "sha256:74bc9b6e0e79808bf8678d7678b2ae3736ea72d56eede3820bd3849823e7f305"},
|
| 488 |
+
{file = "mypy-1.3.0-cp38-cp38-win_amd64.whl", hash = "sha256:44797d031a41516fcf5cbfa652265bb994e53e51994c1bd649ffcd0c3a7eccbf"},
|
| 489 |
+
{file = "mypy-1.3.0-cp39-cp39-macosx_10_9_x86_64.whl", hash = "sha256:ddae0f39ca146972ff6bb4399f3b2943884a774b8771ea0a8f50e971f5ea5ba8"},
|
| 490 |
+
{file = "mypy-1.3.0-cp39-cp39-macosx_11_0_arm64.whl", hash = "sha256:1c4c42c60a8103ead4c1c060ac3cdd3ff01e18fddce6f1016e08939647a0e703"},
|
| 491 |
+
{file = "mypy-1.3.0-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:e86c2c6852f62f8f2b24cb7a613ebe8e0c7dc1402c61d36a609174f63e0ff017"},
|
| 492 |
+
{file = "mypy-1.3.0-cp39-cp39-musllinux_1_1_x86_64.whl", hash = "sha256:f9dca1e257d4cc129517779226753dbefb4f2266c4eaad610fc15c6a7e14283e"},
|
| 493 |
+
{file = "mypy-1.3.0-cp39-cp39-win_amd64.whl", hash = "sha256:95d8d31a7713510685b05fbb18d6ac287a56c8f6554d88c19e73f724a445448a"},
|
| 494 |
+
{file = "mypy-1.3.0-py3-none-any.whl", hash = "sha256:a8763e72d5d9574d45ce5881962bc8e9046bf7b375b0abf031f3e6811732a897"},
|
| 495 |
+
{file = "mypy-1.3.0.tar.gz", hash = "sha256:e1f4d16e296f5135624b34e8fb741eb0eadedca90862405b1f1fde2040b9bd11"},
|
| 496 |
+
]
|
| 497 |
+
|
| 498 |
+
[package.dependencies]
|
| 499 |
+
mypy-extensions = ">=1.0.0"
|
| 500 |
+
tomli = {version = ">=1.1.0", markers = "python_version < \"3.11\""}
|
| 501 |
+
typing-extensions = ">=3.10"
|
| 502 |
+
|
| 503 |
+
[package.extras]
|
| 504 |
+
dmypy = ["psutil (>=4.0)"]
|
| 505 |
+
install-types = ["pip"]
|
| 506 |
+
python2 = ["typed-ast (>=1.4.0,<2)"]
|
| 507 |
+
reports = ["lxml"]
|
| 508 |
+
|
| 509 |
+
[[package]]
|
| 510 |
+
name = "mypy-extensions"
|
| 511 |
+
version = "1.0.0"
|
| 512 |
+
description = "Type system extensions for programs checked with the mypy type checker."
|
| 513 |
+
optional = false
|
| 514 |
+
python-versions = ">=3.5"
|
| 515 |
+
files = [
|
| 516 |
+
{file = "mypy_extensions-1.0.0-py3-none-any.whl", hash = "sha256:4392f6c0eb8a5668a69e23d168ffa70f0be9ccfd32b5cc2d26a34ae5b844552d"},
|
| 517 |
+
{file = "mypy_extensions-1.0.0.tar.gz", hash = "sha256:75dbf8955dc00442a438fc4d0666508a9a97b6bd41aa2f0ffe9d2f2725af0782"},
|
| 518 |
+
]
|
| 519 |
+
|
| 520 |
+
[[package]]
|
| 521 |
+
name = "packaging"
|
| 522 |
+
version = "23.1"
|
| 523 |
+
description = "Core utilities for Python packages"
|
| 524 |
+
optional = false
|
| 525 |
+
python-versions = ">=3.7"
|
| 526 |
+
files = [
|
| 527 |
+
{file = "packaging-23.1-py3-none-any.whl", hash = "sha256:994793af429502c4ea2ebf6bf664629d07c1a9fe974af92966e4b8d2df7edc61"},
|
| 528 |
+
{file = "packaging-23.1.tar.gz", hash = "sha256:a392980d2b6cffa644431898be54b0045151319d1e7ec34f0cfed48767dd334f"},
|
| 529 |
+
]
|
| 530 |
+
|
| 531 |
+
[[package]]
|
| 532 |
+
name = "pathspec"
|
| 533 |
+
version = "0.11.1"
|
| 534 |
+
description = "Utility library for gitignore style pattern matching of file paths."
|
| 535 |
+
optional = false
|
| 536 |
+
python-versions = ">=3.7"
|
| 537 |
+
files = [
|
| 538 |
+
{file = "pathspec-0.11.1-py3-none-any.whl", hash = "sha256:d8af70af76652554bd134c22b3e8a1cc46ed7d91edcdd721ef1a0c51a84a5293"},
|
| 539 |
+
{file = "pathspec-0.11.1.tar.gz", hash = "sha256:2798de800fa92780e33acca925945e9a19a133b715067cf165b8866c15a31687"},
|
| 540 |
+
]
|
| 541 |
+
|
| 542 |
+
[[package]]
|
| 543 |
+
name = "platformdirs"
|
| 544 |
+
version = "3.5.0"
|
| 545 |
+
description = "A small Python package for determining appropriate platform-specific dirs, e.g. a \"user data dir\"."
|
| 546 |
+
optional = false
|
| 547 |
+
python-versions = ">=3.7"
|
| 548 |
+
files = [
|
| 549 |
+
{file = "platformdirs-3.5.0-py3-none-any.whl", hash = "sha256:47692bc24c1958e8b0f13dd727307cff1db103fca36399f457da8e05f222fdc4"},
|
| 550 |
+
{file = "platformdirs-3.5.0.tar.gz", hash = "sha256:7954a68d0ba23558d753f73437c55f89027cf8f5108c19844d4b82e5af396335"},
|
| 551 |
+
]
|
| 552 |
+
|
| 553 |
+
[package.extras]
|
| 554 |
+
docs = ["furo (>=2023.3.27)", "proselint (>=0.13)", "sphinx (>=6.1.3)", "sphinx-autodoc-typehints (>=1.23,!=1.23.4)"]
|
| 555 |
+
test = ["appdirs (==1.4.4)", "covdefaults (>=2.3)", "pytest (>=7.3.1)", "pytest-cov (>=4)", "pytest-mock (>=3.10)"]
|
| 556 |
+
|
| 557 |
+
[[package]]
|
| 558 |
+
name = "pluggy"
|
| 559 |
+
version = "1.0.0"
|
| 560 |
+
description = "plugin and hook calling mechanisms for python"
|
| 561 |
+
optional = false
|
| 562 |
+
python-versions = ">=3.6"
|
| 563 |
+
files = [
|
| 564 |
+
{file = "pluggy-1.0.0-py2.py3-none-any.whl", hash = "sha256:74134bbf457f031a36d68416e1509f34bd5ccc019f0bcc952c7b909d06b37bd3"},
|
| 565 |
+
{file = "pluggy-1.0.0.tar.gz", hash = "sha256:4224373bacce55f955a878bf9cfa763c1e360858e330072059e10bad68531159"},
|
| 566 |
+
]
|
| 567 |
+
|
| 568 |
+
[package.extras]
|
| 569 |
+
dev = ["pre-commit", "tox"]
|
| 570 |
+
testing = ["pytest", "pytest-benchmark"]
|
| 571 |
+
|
| 572 |
+
[[package]]
|
| 573 |
+
name = "pycodestyle"
|
| 574 |
+
version = "2.9.1"
|
| 575 |
+
description = "Python style guide checker"
|
| 576 |
+
optional = false
|
| 577 |
+
python-versions = ">=3.6"
|
| 578 |
+
files = [
|
| 579 |
+
{file = "pycodestyle-2.9.1-py2.py3-none-any.whl", hash = "sha256:d1735fc58b418fd7c5f658d28d943854f8a849b01a5d0a1e6f3f3fdd0166804b"},
|
| 580 |
+
{file = "pycodestyle-2.9.1.tar.gz", hash = "sha256:2c9607871d58c76354b697b42f5d57e1ada7d261c261efac224b664affdc5785"},
|
| 581 |
+
]
|
| 582 |
+
|
| 583 |
+
[[package]]
|
| 584 |
+
name = "pyflakes"
|
| 585 |
+
version = "2.5.0"
|
| 586 |
+
description = "passive checker of Python programs"
|
| 587 |
+
optional = false
|
| 588 |
+
python-versions = ">=3.6"
|
| 589 |
+
files = [
|
| 590 |
+
{file = "pyflakes-2.5.0-py2.py3-none-any.whl", hash = "sha256:4579f67d887f804e67edb544428f264b7b24f435b263c4614f384135cea553d2"},
|
| 591 |
+
{file = "pyflakes-2.5.0.tar.gz", hash = "sha256:491feb020dca48ccc562a8c0cbe8df07ee13078df59813b83959cbdada312ea3"},
|
| 592 |
+
]
|
| 593 |
+
|
| 594 |
+
[[package]]
|
| 595 |
+
name = "pytest"
|
| 596 |
+
version = "7.2.2"
|
| 597 |
+
description = "pytest: simple powerful testing with Python"
|
| 598 |
+
optional = false
|
| 599 |
+
python-versions = ">=3.7"
|
| 600 |
+
files = [
|
| 601 |
+
{file = "pytest-7.2.2-py3-none-any.whl", hash = "sha256:130328f552dcfac0b1cec75c12e3f005619dc5f874f0a06e8ff7263f0ee6225e"},
|
| 602 |
+
{file = "pytest-7.2.2.tar.gz", hash = "sha256:c99ab0c73aceb050f68929bc93af19ab6db0558791c6a0715723abe9d0ade9d4"},
|
| 603 |
+
]
|
| 604 |
+
|
| 605 |
+
[package.dependencies]
|
| 606 |
+
attrs = ">=19.2.0"
|
| 607 |
+
colorama = {version = "*", markers = "sys_platform == \"win32\""}
|
| 608 |
+
exceptiongroup = {version = ">=1.0.0rc8", markers = "python_version < \"3.11\""}
|
| 609 |
+
iniconfig = "*"
|
| 610 |
+
packaging = "*"
|
| 611 |
+
pluggy = ">=0.12,<2.0"
|
| 612 |
+
tomli = {version = ">=1.0.0", markers = "python_version < \"3.11\""}
|
| 613 |
+
|
| 614 |
+
[package.extras]
|
| 615 |
+
testing = ["argcomplete", "hypothesis (>=3.56)", "mock", "nose", "pygments (>=2.7.2)", "requests", "xmlschema"]
|
| 616 |
+
|
| 617 |
+
[[package]]
|
| 618 |
+
name = "pytest-asyncio"
|
| 619 |
+
version = "0.21.0"
|
| 620 |
+
description = "Pytest support for asyncio"
|
| 621 |
+
optional = false
|
| 622 |
+
python-versions = ">=3.7"
|
| 623 |
+
files = [
|
| 624 |
+
{file = "pytest-asyncio-0.21.0.tar.gz", hash = "sha256:2b38a496aef56f56b0e87557ec313e11e1ab9276fc3863f6a7be0f1d0e415e1b"},
|
| 625 |
+
{file = "pytest_asyncio-0.21.0-py3-none-any.whl", hash = "sha256:f2b3366b7cd501a4056858bd39349d5af19742aed2d81660b7998b6341c7eb9c"},
|
| 626 |
+
]
|
| 627 |
+
|
| 628 |
+
[package.dependencies]
|
| 629 |
+
pytest = ">=7.0.0"
|
| 630 |
+
|
| 631 |
+
[package.extras]
|
| 632 |
+
docs = ["sphinx (>=5.3)", "sphinx-rtd-theme (>=1.0)"]
|
| 633 |
+
testing = ["coverage (>=6.2)", "flaky (>=3.5.0)", "hypothesis (>=5.7.1)", "mypy (>=0.931)", "pytest-trio (>=0.7.0)"]
|
| 634 |
+
|
| 635 |
+
[[package]]
|
| 636 |
+
name = "pyyaml"
|
| 637 |
+
version = "6.0"
|
| 638 |
+
description = "YAML parser and emitter for Python"
|
| 639 |
+
optional = false
|
| 640 |
+
python-versions = ">=3.6"
|
| 641 |
+
files = [
|
| 642 |
+
{file = "PyYAML-6.0-cp310-cp310-macosx_10_9_x86_64.whl", hash = "sha256:d4db7c7aef085872ef65a8fd7d6d09a14ae91f691dec3e87ee5ee0539d516f53"},
|
| 643 |
+
{file = "PyYAML-6.0-cp310-cp310-macosx_11_0_arm64.whl", hash = "sha256:9df7ed3b3d2e0ecfe09e14741b857df43adb5a3ddadc919a2d94fbdf78fea53c"},
|
| 644 |
+
{file = "PyYAML-6.0-cp310-cp310-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:77f396e6ef4c73fdc33a9157446466f1cff553d979bd00ecb64385760c6babdc"},
|
| 645 |
+
{file = "PyYAML-6.0-cp310-cp310-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:a80a78046a72361de73f8f395f1f1e49f956c6be882eed58505a15f3e430962b"},
|
| 646 |
+
{file = "PyYAML-6.0-cp310-cp310-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_12_x86_64.manylinux2010_x86_64.whl", hash = "sha256:f84fbc98b019fef2ee9a1cb3ce93e3187a6df0b2538a651bfb890254ba9f90b5"},
|
| 647 |
+
{file = "PyYAML-6.0-cp310-cp310-win32.whl", hash = "sha256:2cd5df3de48857ed0544b34e2d40e9fac445930039f3cfe4bcc592a1f836d513"},
|
| 648 |
+
{file = "PyYAML-6.0-cp310-cp310-win_amd64.whl", hash = "sha256:daf496c58a8c52083df09b80c860005194014c3698698d1a57cbcfa182142a3a"},
|
| 649 |
+
{file = "PyYAML-6.0-cp311-cp311-macosx_10_9_x86_64.whl", hash = "sha256:d4b0ba9512519522b118090257be113b9468d804b19d63c71dbcf4a48fa32358"},
|
| 650 |
+
{file = "PyYAML-6.0-cp311-cp311-macosx_11_0_arm64.whl", hash = "sha256:81957921f441d50af23654aa6c5e5eaf9b06aba7f0a19c18a538dc7ef291c5a1"},
|
| 651 |
+
{file = "PyYAML-6.0-cp311-cp311-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:afa17f5bc4d1b10afd4466fd3a44dc0e245382deca5b3c353d8b757f9e3ecb8d"},
|
| 652 |
+
{file = "PyYAML-6.0-cp311-cp311-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:dbad0e9d368bb989f4515da330b88a057617d16b6a8245084f1b05400f24609f"},
|
| 653 |
+
{file = "PyYAML-6.0-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:432557aa2c09802be39460360ddffd48156e30721f5e8d917f01d31694216782"},
|
| 654 |
+
{file = "PyYAML-6.0-cp311-cp311-win32.whl", hash = "sha256:bfaef573a63ba8923503d27530362590ff4f576c626d86a9fed95822a8255fd7"},
|
| 655 |
+
{file = "PyYAML-6.0-cp311-cp311-win_amd64.whl", hash = "sha256:01b45c0191e6d66c470b6cf1b9531a771a83c1c4208272ead47a3ae4f2f603bf"},
|
| 656 |
+
{file = "PyYAML-6.0-cp36-cp36m-macosx_10_9_x86_64.whl", hash = "sha256:897b80890765f037df3403d22bab41627ca8811ae55e9a722fd0392850ec4d86"},
|
| 657 |
+
{file = "PyYAML-6.0-cp36-cp36m-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:50602afada6d6cbfad699b0c7bb50d5ccffa7e46a3d738092afddc1f9758427f"},
|
| 658 |
+
{file = "PyYAML-6.0-cp36-cp36m-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:48c346915c114f5fdb3ead70312bd042a953a8ce5c7106d5bfb1a5254e47da92"},
|
| 659 |
+
{file = "PyYAML-6.0-cp36-cp36m-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_12_x86_64.manylinux2010_x86_64.whl", hash = "sha256:98c4d36e99714e55cfbaaee6dd5badbc9a1ec339ebfc3b1f52e293aee6bb71a4"},
|
| 660 |
+
{file = "PyYAML-6.0-cp36-cp36m-win32.whl", hash = "sha256:0283c35a6a9fbf047493e3a0ce8d79ef5030852c51e9d911a27badfde0605293"},
|
| 661 |
+
{file = "PyYAML-6.0-cp36-cp36m-win_amd64.whl", hash = "sha256:07751360502caac1c067a8132d150cf3d61339af5691fe9e87803040dbc5db57"},
|
| 662 |
+
{file = "PyYAML-6.0-cp37-cp37m-macosx_10_9_x86_64.whl", hash = "sha256:819b3830a1543db06c4d4b865e70ded25be52a2e0631ccd2f6a47a2822f2fd7c"},
|
| 663 |
+
{file = "PyYAML-6.0-cp37-cp37m-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:473f9edb243cb1935ab5a084eb238d842fb8f404ed2193a915d1784b5a6b5fc0"},
|
| 664 |
+
{file = "PyYAML-6.0-cp37-cp37m-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:0ce82d761c532fe4ec3f87fc45688bdd3a4c1dc5e0b4a19814b9009a29baefd4"},
|
| 665 |
+
{file = "PyYAML-6.0-cp37-cp37m-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_12_x86_64.manylinux2010_x86_64.whl", hash = "sha256:231710d57adfd809ef5d34183b8ed1eeae3f76459c18fb4a0b373ad56bedcdd9"},
|
| 666 |
+
{file = "PyYAML-6.0-cp37-cp37m-win32.whl", hash = "sha256:c5687b8d43cf58545ade1fe3e055f70eac7a5a1a0bf42824308d868289a95737"},
|
| 667 |
+
{file = "PyYAML-6.0-cp37-cp37m-win_amd64.whl", hash = "sha256:d15a181d1ecd0d4270dc32edb46f7cb7733c7c508857278d3d378d14d606db2d"},
|
| 668 |
+
{file = "PyYAML-6.0-cp38-cp38-macosx_10_9_x86_64.whl", hash = "sha256:0b4624f379dab24d3725ffde76559cff63d9ec94e1736b556dacdfebe5ab6d4b"},
|
| 669 |
+
{file = "PyYAML-6.0-cp38-cp38-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:213c60cd50106436cc818accf5baa1aba61c0189ff610f64f4a3e8c6726218ba"},
|
| 670 |
+
{file = "PyYAML-6.0-cp38-cp38-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:9fa600030013c4de8165339db93d182b9431076eb98eb40ee068700c9c813e34"},
|
| 671 |
+
{file = "PyYAML-6.0-cp38-cp38-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_12_x86_64.manylinux2010_x86_64.whl", hash = "sha256:277a0ef2981ca40581a47093e9e2d13b3f1fbbeffae064c1d21bfceba2030287"},
|
| 672 |
+
{file = "PyYAML-6.0-cp38-cp38-win32.whl", hash = "sha256:d4eccecf9adf6fbcc6861a38015c2a64f38b9d94838ac1810a9023a0609e1b78"},
|
| 673 |
+
{file = "PyYAML-6.0-cp38-cp38-win_amd64.whl", hash = "sha256:1e4747bc279b4f613a09eb64bba2ba602d8a6664c6ce6396a4d0cd413a50ce07"},
|
| 674 |
+
{file = "PyYAML-6.0-cp39-cp39-macosx_10_9_x86_64.whl", hash = "sha256:055d937d65826939cb044fc8c9b08889e8c743fdc6a32b33e2390f66013e449b"},
|
| 675 |
+
{file = "PyYAML-6.0-cp39-cp39-macosx_11_0_arm64.whl", hash = "sha256:e61ceaab6f49fb8bdfaa0f92c4b57bcfbea54c09277b1b4f7ac376bfb7a7c174"},
|
| 676 |
+
{file = "PyYAML-6.0-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:d67d839ede4ed1b28a4e8909735fc992a923cdb84e618544973d7dfc71540803"},
|
| 677 |
+
{file = "PyYAML-6.0-cp39-cp39-manylinux_2_17_s390x.manylinux2014_s390x.whl", hash = "sha256:cba8c411ef271aa037d7357a2bc8f9ee8b58b9965831d9e51baf703280dc73d3"},
|
| 678 |
+
{file = "PyYAML-6.0-cp39-cp39-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_12_x86_64.manylinux2010_x86_64.whl", hash = "sha256:40527857252b61eacd1d9af500c3337ba8deb8fc298940291486c465c8b46ec0"},
|
| 679 |
+
{file = "PyYAML-6.0-cp39-cp39-win32.whl", hash = "sha256:b5b9eccad747aabaaffbc6064800670f0c297e52c12754eb1d976c57e4f74dcb"},
|
| 680 |
+
{file = "PyYAML-6.0-cp39-cp39-win_amd64.whl", hash = "sha256:b3d267842bf12586ba6c734f89d1f5b871df0273157918b0ccefa29deb05c21c"},
|
| 681 |
+
{file = "PyYAML-6.0.tar.gz", hash = "sha256:68fb519c14306fec9720a2a5b45bc9f0c8d1b9c72adf45c37baedfcd949c35a2"},
|
| 682 |
+
]
|
| 683 |
+
|
| 684 |
+
[[package]]
|
| 685 |
+
name = "requests"
|
| 686 |
+
version = "2.30.0"
|
| 687 |
+
description = "Python HTTP for Humans."
|
| 688 |
+
optional = false
|
| 689 |
+
python-versions = ">=3.7"
|
| 690 |
+
files = [
|
| 691 |
+
{file = "requests-2.30.0-py3-none-any.whl", hash = "sha256:10e94cc4f3121ee6da529d358cdaeaff2f1c409cd377dbc72b825852f2f7e294"},
|
| 692 |
+
{file = "requests-2.30.0.tar.gz", hash = "sha256:239d7d4458afcb28a692cdd298d87542235f4ca8d36d03a15bfc128a6559a2f4"},
|
| 693 |
+
]
|
| 694 |
+
|
| 695 |
+
[package.dependencies]
|
| 696 |
+
certifi = ">=2017.4.17"
|
| 697 |
+
charset-normalizer = ">=2,<4"
|
| 698 |
+
idna = ">=2.5,<4"
|
| 699 |
+
urllib3 = ">=1.21.1,<3"
|
| 700 |
+
|
| 701 |
+
[package.extras]
|
| 702 |
+
socks = ["PySocks (>=1.5.6,!=1.5.7)"]
|
| 703 |
+
use-chardet-on-py3 = ["chardet (>=3.0.2,<6)"]
|
| 704 |
+
|
| 705 |
+
[[package]]
|
| 706 |
+
name = "sniffio"
|
| 707 |
+
version = "1.3.0"
|
| 708 |
+
description = "Sniff out which async library your code is running under"
|
| 709 |
+
optional = false
|
| 710 |
+
python-versions = ">=3.7"
|
| 711 |
+
files = [
|
| 712 |
+
{file = "sniffio-1.3.0-py3-none-any.whl", hash = "sha256:eecefdce1e5bbfb7ad2eeaabf7c1eeb404d7757c379bd1f7e5cce9d8bf425384"},
|
| 713 |
+
{file = "sniffio-1.3.0.tar.gz", hash = "sha256:e60305c5e5d314f5389259b7f22aaa33d8f7dee49763119234af3755c55b9101"},
|
| 714 |
+
]
|
| 715 |
+
|
| 716 |
+
[[package]]
|
| 717 |
+
name = "tomli"
|
| 718 |
+
version = "2.0.1"
|
| 719 |
+
description = "A lil' TOML parser"
|
| 720 |
+
optional = false
|
| 721 |
+
python-versions = ">=3.7"
|
| 722 |
+
files = [
|
| 723 |
+
{file = "tomli-2.0.1-py3-none-any.whl", hash = "sha256:939de3e7a6161af0c887ef91b7d41a53e7c5a1ca976325f429cb46ea9bc30ecc"},
|
| 724 |
+
{file = "tomli-2.0.1.tar.gz", hash = "sha256:de526c12914f0c550d15924c62d72abc48d6fe7364aa87328337a31007fe8a4f"},
|
| 725 |
+
]
|
| 726 |
+
|
| 727 |
+
[[package]]
|
| 728 |
+
name = "tqdm"
|
| 729 |
+
version = "4.65.0"
|
| 730 |
+
description = "Fast, Extensible Progress Meter"
|
| 731 |
+
optional = false
|
| 732 |
+
python-versions = ">=3.7"
|
| 733 |
+
files = [
|
| 734 |
+
{file = "tqdm-4.65.0-py3-none-any.whl", hash = "sha256:c4f53a17fe37e132815abceec022631be8ffe1b9381c2e6e30aa70edc99e9671"},
|
| 735 |
+
{file = "tqdm-4.65.0.tar.gz", hash = "sha256:1871fb68a86b8fb3b59ca4cdd3dcccbc7e6d613eeed31f4c332531977b89beb5"},
|
| 736 |
+
]
|
| 737 |
+
|
| 738 |
+
[package.dependencies]
|
| 739 |
+
colorama = {version = "*", markers = "platform_system == \"Windows\""}
|
| 740 |
+
|
| 741 |
+
[package.extras]
|
| 742 |
+
dev = ["py-make (>=0.1.0)", "twine", "wheel"]
|
| 743 |
+
notebook = ["ipywidgets (>=6)"]
|
| 744 |
+
slack = ["slack-sdk"]
|
| 745 |
+
telegram = ["requests"]
|
| 746 |
+
|
| 747 |
+
[[package]]
|
| 748 |
+
name = "typing-extensions"
|
| 749 |
+
version = "4.5.0"
|
| 750 |
+
description = "Backported and Experimental Type Hints for Python 3.7+"
|
| 751 |
+
optional = false
|
| 752 |
+
python-versions = ">=3.7"
|
| 753 |
+
files = [
|
| 754 |
+
{file = "typing_extensions-4.5.0-py3-none-any.whl", hash = "sha256:fb33085c39dd998ac16d1431ebc293a8b3eedd00fd4a32de0ff79002c19511b4"},
|
| 755 |
+
{file = "typing_extensions-4.5.0.tar.gz", hash = "sha256:5cb5f4a79139d699607b3ef622a1dedafa84e115ab0024e0d9c044a9479ca7cb"},
|
| 756 |
+
]
|
| 757 |
+
|
| 758 |
+
[[package]]
|
| 759 |
+
name = "urllib3"
|
| 760 |
+
version = "1.26.16"
|
| 761 |
+
description = "HTTP library with thread-safe connection pooling, file post, and more."
|
| 762 |
+
optional = false
|
| 763 |
+
python-versions = ">=2.7, !=3.0.*, !=3.1.*, !=3.2.*, !=3.3.*, !=3.4.*, !=3.5.*"
|
| 764 |
+
files = [
|
| 765 |
+
{file = "urllib3-1.26.16-py2.py3-none-any.whl", hash = "sha256:8d36afa7616d8ab714608411b4a3b13e58f463aee519024578e062e141dce20f"},
|
| 766 |
+
{file = "urllib3-1.26.16.tar.gz", hash = "sha256:8f135f6502756bde6b2a9b28989df5fbe87c9970cecaa69041edcce7f0589b14"},
|
| 767 |
+
]
|
| 768 |
+
|
| 769 |
+
[package.extras]
|
| 770 |
+
brotli = ["brotli (>=1.0.9)", "brotlicffi (>=0.8.0)", "brotlipy (>=0.6.0)"]
|
| 771 |
+
secure = ["certifi", "cryptography (>=1.3.4)", "idna (>=2.0.0)", "ipaddress", "pyOpenSSL (>=0.14)", "urllib3-secure-extra"]
|
| 772 |
+
socks = ["PySocks (>=1.5.6,!=1.5.7,<2.0)"]
|
| 773 |
+
|
| 774 |
+
[[package]]
|
| 775 |
+
name = "websockets"
|
| 776 |
+
version = "11.0.3"
|
| 777 |
+
description = "An implementation of the WebSocket Protocol (RFC 6455 & 7692)"
|
| 778 |
+
optional = false
|
| 779 |
+
python-versions = ">=3.7"
|
| 780 |
+
files = [
|
| 781 |
+
{file = "websockets-11.0.3-cp310-cp310-macosx_10_9_universal2.whl", hash = "sha256:3ccc8a0c387629aec40f2fc9fdcb4b9d5431954f934da3eaf16cdc94f67dbfac"},
|
| 782 |
+
{file = "websockets-11.0.3-cp310-cp310-macosx_10_9_x86_64.whl", hash = "sha256:d67ac60a307f760c6e65dad586f556dde58e683fab03323221a4e530ead6f74d"},
|
| 783 |
+
{file = "websockets-11.0.3-cp310-cp310-macosx_11_0_arm64.whl", hash = "sha256:84d27a4832cc1a0ee07cdcf2b0629a8a72db73f4cf6de6f0904f6661227f256f"},
|
| 784 |
+
{file = "websockets-11.0.3-cp310-cp310-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:ffd7dcaf744f25f82190856bc26ed81721508fc5cbf2a330751e135ff1283564"},
|
| 785 |
+
{file = "websockets-11.0.3-cp310-cp310-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:7622a89d696fc87af8e8d280d9b421db5133ef5b29d3f7a1ce9f1a7bf7fcfa11"},
|
| 786 |
+
{file = "websockets-11.0.3-cp310-cp310-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:bceab846bac555aff6427d060f2fcfff71042dba6f5fca7dc4f75cac815e57ca"},
|
| 787 |
+
{file = "websockets-11.0.3-cp310-cp310-musllinux_1_1_aarch64.whl", hash = "sha256:54c6e5b3d3a8936a4ab6870d46bdd6ec500ad62bde9e44462c32d18f1e9a8e54"},
|
| 788 |
+
{file = "websockets-11.0.3-cp310-cp310-musllinux_1_1_i686.whl", hash = "sha256:41f696ba95cd92dc047e46b41b26dd24518384749ed0d99bea0a941ca87404c4"},
|
| 789 |
+
{file = "websockets-11.0.3-cp310-cp310-musllinux_1_1_x86_64.whl", hash = "sha256:86d2a77fd490ae3ff6fae1c6ceaecad063d3cc2320b44377efdde79880e11526"},
|
| 790 |
+
{file = "websockets-11.0.3-cp310-cp310-win32.whl", hash = "sha256:2d903ad4419f5b472de90cd2d40384573b25da71e33519a67797de17ef849b69"},
|
| 791 |
+
{file = "websockets-11.0.3-cp310-cp310-win_amd64.whl", hash = "sha256:1d2256283fa4b7f4c7d7d3e84dc2ece74d341bce57d5b9bf385df109c2a1a82f"},
|
| 792 |
+
{file = "websockets-11.0.3-cp311-cp311-macosx_10_9_universal2.whl", hash = "sha256:e848f46a58b9fcf3d06061d17be388caf70ea5b8cc3466251963c8345e13f7eb"},
|
| 793 |
+
{file = "websockets-11.0.3-cp311-cp311-macosx_10_9_x86_64.whl", hash = "sha256:aa5003845cdd21ac0dc6c9bf661c5beddd01116f6eb9eb3c8e272353d45b3288"},
|
| 794 |
+
{file = "websockets-11.0.3-cp311-cp311-macosx_11_0_arm64.whl", hash = "sha256:b58cbf0697721120866820b89f93659abc31c1e876bf20d0b3d03cef14faf84d"},
|
| 795 |
+
{file = "websockets-11.0.3-cp311-cp311-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:660e2d9068d2bedc0912af508f30bbeb505bbbf9774d98def45f68278cea20d3"},
|
| 796 |
+
{file = "websockets-11.0.3-cp311-cp311-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:c1f0524f203e3bd35149f12157438f406eff2e4fb30f71221c8a5eceb3617b6b"},
|
| 797 |
+
{file = "websockets-11.0.3-cp311-cp311-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:def07915168ac8f7853812cc593c71185a16216e9e4fa886358a17ed0fd9fcf6"},
|
| 798 |
+
{file = "websockets-11.0.3-cp311-cp311-musllinux_1_1_aarch64.whl", hash = "sha256:b30c6590146e53149f04e85a6e4fcae068df4289e31e4aee1fdf56a0dead8f97"},
|
| 799 |
+
{file = "websockets-11.0.3-cp311-cp311-musllinux_1_1_i686.whl", hash = "sha256:619d9f06372b3a42bc29d0cd0354c9bb9fb39c2cbc1a9c5025b4538738dbffaf"},
|
| 800 |
+
{file = "websockets-11.0.3-cp311-cp311-musllinux_1_1_x86_64.whl", hash = "sha256:01f5567d9cf6f502d655151645d4e8b72b453413d3819d2b6f1185abc23e82dd"},
|
| 801 |
+
{file = "websockets-11.0.3-cp311-cp311-win32.whl", hash = "sha256:e1459677e5d12be8bbc7584c35b992eea142911a6236a3278b9b5ce3326f282c"},
|
| 802 |
+
{file = "websockets-11.0.3-cp311-cp311-win_amd64.whl", hash = "sha256:e7837cb169eca3b3ae94cc5787c4fed99eef74c0ab9506756eea335e0d6f3ed8"},
|
| 803 |
+
{file = "websockets-11.0.3-cp37-cp37m-macosx_10_9_x86_64.whl", hash = "sha256:9f59a3c656fef341a99e3d63189852be7084c0e54b75734cde571182c087b152"},
|
| 804 |
+
{file = "websockets-11.0.3-cp37-cp37m-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:2529338a6ff0eb0b50c7be33dc3d0e456381157a31eefc561771ee431134a97f"},
|
| 805 |
+
{file = "websockets-11.0.3-cp37-cp37m-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:34fd59a4ac42dff6d4681d8843217137f6bc85ed29722f2f7222bd619d15e95b"},
|
| 806 |
+
{file = "websockets-11.0.3-cp37-cp37m-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:332d126167ddddec94597c2365537baf9ff62dfcc9db4266f263d455f2f031cb"},
|
| 807 |
+
{file = "websockets-11.0.3-cp37-cp37m-musllinux_1_1_aarch64.whl", hash = "sha256:6505c1b31274723ccaf5f515c1824a4ad2f0d191cec942666b3d0f3aa4cb4007"},
|
| 808 |
+
{file = "websockets-11.0.3-cp37-cp37m-musllinux_1_1_i686.whl", hash = "sha256:f467ba0050b7de85016b43f5a22b46383ef004c4f672148a8abf32bc999a87f0"},
|
| 809 |
+
{file = "websockets-11.0.3-cp37-cp37m-musllinux_1_1_x86_64.whl", hash = "sha256:9d9acd80072abcc98bd2c86c3c9cd4ac2347b5a5a0cae7ed5c0ee5675f86d9af"},
|
| 810 |
+
{file = "websockets-11.0.3-cp37-cp37m-win32.whl", hash = "sha256:e590228200fcfc7e9109509e4d9125eace2042fd52b595dd22bbc34bb282307f"},
|
| 811 |
+
{file = "websockets-11.0.3-cp37-cp37m-win_amd64.whl", hash = "sha256:b16fff62b45eccb9c7abb18e60e7e446998093cdcb50fed33134b9b6878836de"},
|
| 812 |
+
{file = "websockets-11.0.3-cp38-cp38-macosx_10_9_universal2.whl", hash = "sha256:fb06eea71a00a7af0ae6aefbb932fb8a7df3cb390cc217d51a9ad7343de1b8d0"},
|
| 813 |
+
{file = "websockets-11.0.3-cp38-cp38-macosx_10_9_x86_64.whl", hash = "sha256:8a34e13a62a59c871064dfd8ffb150867e54291e46d4a7cf11d02c94a5275bae"},
|
| 814 |
+
{file = "websockets-11.0.3-cp38-cp38-macosx_11_0_arm64.whl", hash = "sha256:4841ed00f1026dfbced6fca7d963c4e7043aa832648671b5138008dc5a8f6d99"},
|
| 815 |
+
{file = "websockets-11.0.3-cp38-cp38-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:1a073fc9ab1c8aff37c99f11f1641e16da517770e31a37265d2755282a5d28aa"},
|
| 816 |
+
{file = "websockets-11.0.3-cp38-cp38-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:68b977f21ce443d6d378dbd5ca38621755f2063d6fdb3335bda981d552cfff86"},
|
| 817 |
+
{file = "websockets-11.0.3-cp38-cp38-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:e1a99a7a71631f0efe727c10edfba09ea6bee4166a6f9c19aafb6c0b5917d09c"},
|
| 818 |
+
{file = "websockets-11.0.3-cp38-cp38-musllinux_1_1_aarch64.whl", hash = "sha256:bee9fcb41db2a23bed96c6b6ead6489702c12334ea20a297aa095ce6d31370d0"},
|
| 819 |
+
{file = "websockets-11.0.3-cp38-cp38-musllinux_1_1_i686.whl", hash = "sha256:4b253869ea05a5a073ebfdcb5cb3b0266a57c3764cf6fe114e4cd90f4bfa5f5e"},
|
| 820 |
+
{file = "websockets-11.0.3-cp38-cp38-musllinux_1_1_x86_64.whl", hash = "sha256:1553cb82942b2a74dd9b15a018dce645d4e68674de2ca31ff13ebc2d9f283788"},
|
| 821 |
+
{file = "websockets-11.0.3-cp38-cp38-win32.whl", hash = "sha256:f61bdb1df43dc9c131791fbc2355535f9024b9a04398d3bd0684fc16ab07df74"},
|
| 822 |
+
{file = "websockets-11.0.3-cp38-cp38-win_amd64.whl", hash = "sha256:03aae4edc0b1c68498f41a6772d80ac7c1e33c06c6ffa2ac1c27a07653e79d6f"},
|
| 823 |
+
{file = "websockets-11.0.3-cp39-cp39-macosx_10_9_universal2.whl", hash = "sha256:777354ee16f02f643a4c7f2b3eff8027a33c9861edc691a2003531f5da4f6bc8"},
|
| 824 |
+
{file = "websockets-11.0.3-cp39-cp39-macosx_10_9_x86_64.whl", hash = "sha256:8c82f11964f010053e13daafdc7154ce7385ecc538989a354ccc7067fd7028fd"},
|
| 825 |
+
{file = "websockets-11.0.3-cp39-cp39-macosx_11_0_arm64.whl", hash = "sha256:3580dd9c1ad0701169e4d6fc41e878ffe05e6bdcaf3c412f9d559389d0c9e016"},
|
| 826 |
+
{file = "websockets-11.0.3-cp39-cp39-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:6f1a3f10f836fab6ca6efa97bb952300b20ae56b409414ca85bff2ad241d2a61"},
|
| 827 |
+
{file = "websockets-11.0.3-cp39-cp39-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:df41b9bc27c2c25b486bae7cf42fccdc52ff181c8c387bfd026624a491c2671b"},
|
| 828 |
+
{file = "websockets-11.0.3-cp39-cp39-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:279e5de4671e79a9ac877427f4ac4ce93751b8823f276b681d04b2156713b9dd"},
|
| 829 |
+
{file = "websockets-11.0.3-cp39-cp39-musllinux_1_1_aarch64.whl", hash = "sha256:1fdf26fa8a6a592f8f9235285b8affa72748dc12e964a5518c6c5e8f916716f7"},
|
| 830 |
+
{file = "websockets-11.0.3-cp39-cp39-musllinux_1_1_i686.whl", hash = "sha256:69269f3a0b472e91125b503d3c0b3566bda26da0a3261c49f0027eb6075086d1"},
|
| 831 |
+
{file = "websockets-11.0.3-cp39-cp39-musllinux_1_1_x86_64.whl", hash = "sha256:97b52894d948d2f6ea480171a27122d77af14ced35f62e5c892ca2fae9344311"},
|
| 832 |
+
{file = "websockets-11.0.3-cp39-cp39-win32.whl", hash = "sha256:c7f3cb904cce8e1be667c7e6fef4516b98d1a6a0635a58a57528d577ac18a128"},
|
| 833 |
+
{file = "websockets-11.0.3-cp39-cp39-win_amd64.whl", hash = "sha256:c792ea4eabc0159535608fc5658a74d1a81020eb35195dd63214dcf07556f67e"},
|
| 834 |
+
{file = "websockets-11.0.3-pp37-pypy37_pp73-macosx_10_9_x86_64.whl", hash = "sha256:f2e58f2c36cc52d41f2659e4c0cbf7353e28c8c9e63e30d8c6d3494dc9fdedcf"},
|
| 835 |
+
{file = "websockets-11.0.3-pp37-pypy37_pp73-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:de36fe9c02995c7e6ae6efe2e205816f5f00c22fd1fbf343d4d18c3d5ceac2f5"},
|
| 836 |
+
{file = "websockets-11.0.3-pp37-pypy37_pp73-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:0ac56b661e60edd453585f4bd68eb6a29ae25b5184fd5ba51e97652580458998"},
|
| 837 |
+
{file = "websockets-11.0.3-pp37-pypy37_pp73-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:e052b8467dd07d4943936009f46ae5ce7b908ddcac3fda581656b1b19c083d9b"},
|
| 838 |
+
{file = "websockets-11.0.3-pp37-pypy37_pp73-win_amd64.whl", hash = "sha256:42cc5452a54a8e46a032521d7365da775823e21bfba2895fb7b77633cce031bb"},
|
| 839 |
+
{file = "websockets-11.0.3-pp38-pypy38_pp73-macosx_10_9_x86_64.whl", hash = "sha256:e6316827e3e79b7b8e7d8e3b08f4e331af91a48e794d5d8b099928b6f0b85f20"},
|
| 840 |
+
{file = "websockets-11.0.3-pp38-pypy38_pp73-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:8531fdcad636d82c517b26a448dcfe62f720e1922b33c81ce695d0edb91eb931"},
|
| 841 |
+
{file = "websockets-11.0.3-pp38-pypy38_pp73-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:c114e8da9b475739dde229fd3bc6b05a6537a88a578358bc8eb29b4030fac9c9"},
|
| 842 |
+
{file = "websockets-11.0.3-pp38-pypy38_pp73-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:e063b1865974611313a3849d43f2c3f5368093691349cf3c7c8f8f75ad7cb280"},
|
| 843 |
+
{file = "websockets-11.0.3-pp38-pypy38_pp73-win_amd64.whl", hash = "sha256:92b2065d642bf8c0a82d59e59053dd2fdde64d4ed44efe4870fa816c1232647b"},
|
| 844 |
+
{file = "websockets-11.0.3-pp39-pypy39_pp73-macosx_10_9_x86_64.whl", hash = "sha256:0ee68fe502f9031f19d495dae2c268830df2760c0524cbac5d759921ba8c8e82"},
|
| 845 |
+
{file = "websockets-11.0.3-pp39-pypy39_pp73-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:dcacf2c7a6c3a84e720d1bb2b543c675bf6c40e460300b628bab1b1efc7c034c"},
|
| 846 |
+
{file = "websockets-11.0.3-pp39-pypy39_pp73-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:b67c6f5e5a401fc56394f191f00f9b3811fe843ee93f4a70df3c389d1adf857d"},
|
| 847 |
+
{file = "websockets-11.0.3-pp39-pypy39_pp73-manylinux_2_5_x86_64.manylinux1_x86_64.manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:1d5023a4b6a5b183dc838808087033ec5df77580485fc533e7dab2567851b0a4"},
|
| 848 |
+
{file = "websockets-11.0.3-pp39-pypy39_pp73-win_amd64.whl", hash = "sha256:ed058398f55163a79bb9f06a90ef9ccc063b204bb346c4de78efc5d15abfe602"},
|
| 849 |
+
{file = "websockets-11.0.3-py3-none-any.whl", hash = "sha256:6681ba9e7f8f3b19440921e99efbb40fc89f26cd71bf539e45d8c8a25c976dc6"},
|
| 850 |
+
{file = "websockets-11.0.3.tar.gz", hash = "sha256:88fc51d9a26b10fc331be344f1781224a375b78488fc343620184e95a4b27016"},
|
| 851 |
+
]
|
| 852 |
+
|
| 853 |
+
[metadata]
|
| 854 |
+
lock-version = "2.0"
|
| 855 |
+
python-versions = "^3.8"
|
| 856 |
+
content-hash = "c0fbaa9e3292f2b78f549f001f2a1d8489085a27510f27da48d524356770262a"
|
client/poetry.toml
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
virtualenvs.in-project = true
|
client/pyproject.toml
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[tool.poetry]
|
| 2 |
+
name = "h2ogpt-client"
|
| 3 |
+
version = "0.1.0"
|
| 4 |
+
description = ""
|
| 5 |
+
authors = []
|
| 6 |
+
readme = "README.md"
|
| 7 |
+
include = ["h2ogpt_client/_h2ogpt*"]
|
| 8 |
+
|
| 9 |
+
[tool.poetry.dependencies]
|
| 10 |
+
python = "^3.8"
|
| 11 |
+
gradio-client = "^0.2.7"
|
| 12 |
+
|
| 13 |
+
[tool.poetry.group.test.dependencies]
|
| 14 |
+
pytest = "7.2.2"
|
| 15 |
+
pytest-asyncio = "^0.21.0"
|
| 16 |
+
|
| 17 |
+
[tool.poetry.group.dev.dependencies]
|
| 18 |
+
mypy = "^1.3.0"
|
| 19 |
+
black = "^23.3.0"
|
| 20 |
+
flake8 = "5.0.4"
|
| 21 |
+
isort = "^5.12.0"
|
| 22 |
+
flake8-pyproject = "^1.2.3"
|
| 23 |
+
|
| 24 |
+
[build-system]
|
| 25 |
+
requires = ["poetry-core"]
|
| 26 |
+
build-backend = "poetry.core.masonry.api"
|
| 27 |
+
|
| 28 |
+
[tool.isort]
|
| 29 |
+
profile = "black"
|
| 30 |
+
py_version = "auto"
|
| 31 |
+
|
| 32 |
+
[tool.flake8]
|
| 33 |
+
max-line-length = 88
|
| 34 |
+
|
| 35 |
+
[tool.mypy]
|
| 36 |
+
python_version = "3.8"
|
| 37 |
+
|
| 38 |
+
[tool.pytest.ini_options]
|
| 39 |
+
pythonpath = "h2ogpt_client"
|
| 40 |
+
log_cli = true
|
| 41 |
+
log_cli_level = "INFO"
|
client/tests/__init__.py
ADDED
|
File without changes
|
client/tests/conftest.py
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import importlib.util
|
| 2 |
+
import logging
|
| 3 |
+
import os
|
| 4 |
+
import sys
|
| 5 |
+
from pathlib import Path
|
| 6 |
+
from types import ModuleType
|
| 7 |
+
|
| 8 |
+
import pytest
|
| 9 |
+
|
| 10 |
+
LOGGER = logging.getLogger(__name__)
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
@pytest.fixture(scope="module")
|
| 14 |
+
def server_url():
|
| 15 |
+
server_url = os.getenv("H2OGPT_SERVER")
|
| 16 |
+
if not server_url:
|
| 17 |
+
LOGGER.info("Couldn't find a running h2oGPT server. Hence starting a one.")
|
| 18 |
+
|
| 19 |
+
generate = _import_module_from_h2ogpt("generate.py")
|
| 20 |
+
generate.main(
|
| 21 |
+
base_model="h2oai/h2ogpt-oig-oasst1-512-6_9b",
|
| 22 |
+
prompt_type="human_bot",
|
| 23 |
+
chat=False,
|
| 24 |
+
stream_output=False,
|
| 25 |
+
gradio=True,
|
| 26 |
+
num_beams=1,
|
| 27 |
+
block_gradio_exit=False,
|
| 28 |
+
)
|
| 29 |
+
server_url = "http://0.0.0.0:7860" # assume server started
|
| 30 |
+
LOGGER.info(f"h2oGPT server started at '{server_url}'.")
|
| 31 |
+
return server_url
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
@pytest.fixture(scope="module")
|
| 35 |
+
def eval_func_param_names():
|
| 36 |
+
parameters = _import_module_from_h2ogpt("src/evaluate_params.py")
|
| 37 |
+
return parameters.eval_func_param_names
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def _import_module_from_h2ogpt(file_name: str) -> ModuleType:
|
| 41 |
+
h2ogpt_dir = Path(__file__).parent.parent.parent
|
| 42 |
+
file_path = (h2ogpt_dir / file_name).absolute()
|
| 43 |
+
module_name = file_path.stem
|
| 44 |
+
|
| 45 |
+
LOGGER.info(f"Loading module '{module_name}' from '{file_path}'.")
|
| 46 |
+
spec = importlib.util.spec_from_file_location(module_name, file_path)
|
| 47 |
+
if not spec:
|
| 48 |
+
raise Exception(f"Couldn't load module '{module_name}' from '{file_path}'.")
|
| 49 |
+
module = importlib.util.module_from_spec(spec)
|
| 50 |
+
sys.modules[module_name] = module
|
| 51 |
+
spec.loader.exec_module(module) # type: ignore
|
| 52 |
+
return module
|
client/tests/test_client.py
ADDED
|
@@ -0,0 +1,73 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import platform
|
| 2 |
+
|
| 3 |
+
import pytest
|
| 4 |
+
|
| 5 |
+
from h2ogpt_client import Client
|
| 6 |
+
|
| 7 |
+
platform.python_version()
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
@pytest.fixture
|
| 11 |
+
def client(server_url) -> Client:
|
| 12 |
+
return Client(server_url)
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
@pytest.mark.asyncio
|
| 16 |
+
async def test_text_completion(client):
|
| 17 |
+
text_completion = client.text_completion.create()
|
| 18 |
+
response = await text_completion.complete(prompt="Hello world")
|
| 19 |
+
assert response
|
| 20 |
+
print(response)
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def test_text_completion_sync(client):
|
| 24 |
+
text_completion = client.text_completion.create()
|
| 25 |
+
response = text_completion.complete_sync(prompt="Hello world")
|
| 26 |
+
assert response
|
| 27 |
+
print(response)
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
@pytest.mark.asyncio
|
| 31 |
+
async def test_chat_completion(client):
|
| 32 |
+
chat_completion = client.chat_completion.create()
|
| 33 |
+
|
| 34 |
+
chat1 = await chat_completion.chat(prompt="Hey!")
|
| 35 |
+
assert chat1["user"] == "Hey!"
|
| 36 |
+
assert chat1["gpt"]
|
| 37 |
+
|
| 38 |
+
chat2 = await chat_completion.chat(prompt="How are you?")
|
| 39 |
+
assert chat2["user"] == "How are you?"
|
| 40 |
+
assert chat2["gpt"]
|
| 41 |
+
|
| 42 |
+
chat3 = await chat_completion.chat(prompt="Have a good day")
|
| 43 |
+
assert chat3["user"] == "Have a good day"
|
| 44 |
+
assert chat3["gpt"]
|
| 45 |
+
|
| 46 |
+
chat_history = chat_completion.chat_history()
|
| 47 |
+
assert chat_history == [chat1, chat2, chat3]
|
| 48 |
+
print(chat_history)
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
def test_chat_completion_sync(client):
|
| 52 |
+
chat_completion = client.chat_completion.create()
|
| 53 |
+
|
| 54 |
+
chat1 = chat_completion.chat_sync(prompt="Hey!")
|
| 55 |
+
assert chat1["user"] == "Hey!"
|
| 56 |
+
assert chat1["gpt"]
|
| 57 |
+
|
| 58 |
+
chat2 = chat_completion.chat_sync(prompt="How are you?")
|
| 59 |
+
assert chat2["user"] == "How are you?"
|
| 60 |
+
assert chat2["gpt"]
|
| 61 |
+
|
| 62 |
+
chat3 = chat_completion.chat_sync(prompt="Have a good day")
|
| 63 |
+
assert chat3["user"] == "Have a good day"
|
| 64 |
+
assert chat3["gpt"]
|
| 65 |
+
|
| 66 |
+
chat_history = chat_completion.chat_history()
|
| 67 |
+
assert chat_history == [chat1, chat2, chat3]
|
| 68 |
+
print(chat_history)
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def test_parameters_order(client, eval_func_param_names):
|
| 72 |
+
text_completion = client.text_completion.create()
|
| 73 |
+
assert eval_func_param_names == list(text_completion._parameters.keys())
|
data/NGSL_1.2_stats.csv.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:34993377b20347d5c8837a1101bde4e403232f5f08c80f9441e16ac7a23228a7
|
| 3 |
+
size 25168
|
data/README-template.md
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
+
language:
|
| 4 |
+
- en
|
| 5 |
+
thumbnail: https://h2o.ai/etc.clientlibs/h2o/clientlibs/clientlib-site/resources/images/favicon.ico
|
| 6 |
+
tags:
|
| 7 |
+
- gpt
|
| 8 |
+
- llm
|
| 9 |
+
- large language model
|
| 10 |
+
- open-source
|
| 11 |
+
---
|
| 12 |
+
# h2oGPT Data Card
|
| 13 |
+
## Summary
|
| 14 |
+
|
| 15 |
+
H2O.ai's `<<DATASET_NAME>>` is an open-source instruct-type dataset for fine-tuning of large language models, licensed for commercial use.
|
| 16 |
+
|
| 17 |
+
- Number of rows: `<<NROWS>>`
|
| 18 |
+
- Number of columns: `<<NCOLS>>`
|
| 19 |
+
- Column names: `<<COLNAMES>>`
|
| 20 |
+
|
| 21 |
+
## Source
|
| 22 |
+
|
| 23 |
+
<<SOURCE_LINK>>
|
data/censor_words.txt
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
fuck-buddy
|
| 2 |
+
fuck-buddys
|
| 3 |
+
clusterfuck
|
| 4 |
+
fuckup
|
| 5 |
+
fuckups
|
| 6 |
+
dumbfuck
|
| 7 |
+
dumbfucks
|
| 8 |
+
mindfuck
|
| 9 |
+
*fucking
|
| 10 |
+
fuckin'
|
data/config.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data/count_1w.txt.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:434d0f21e4156386a3e9156c669e316878fbb1664414ffe06f22e254a180d363
|
| 3 |
+
size 2234946
|
data/create_data_cards.py
ADDED
|
@@ -0,0 +1,144 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import shutil
|
| 2 |
+
|
| 3 |
+
import pandas as pd
|
| 4 |
+
import os
|
| 5 |
+
|
| 6 |
+
import huggingface_hub
|
| 7 |
+
import pytest
|
| 8 |
+
from datasets import load_dataset
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
@pytest.mark.parametrize(
|
| 12 |
+
"dataset_name, link_to_source",
|
| 13 |
+
[
|
| 14 |
+
(
|
| 15 |
+
"h2ogpt-oig-instruct-cleaned",
|
| 16 |
+
"""
|
| 17 |
+
- [Original LAION OIG Dataset](https://github.com/LAION-AI/Open-Instruction-Generalist)
|
| 18 |
+
- [LAION OIG data detoxed and filtered down by scripts in h2oGPT repository](https://github.com/h2oai/h2ogpt/blob/b8f15efcc305a953c52a0ee25b8b4897ceb68c0a/scrape_dai_docs.py)
|
| 19 |
+
"""
|
| 20 |
+
),
|
| 21 |
+
(
|
| 22 |
+
"h2ogpt-oig-instruct-cleaned-v2",
|
| 23 |
+
"""
|
| 24 |
+
- [Original LAION OIG Dataset](https://github.com/LAION-AI/Open-Instruction-Generalist)
|
| 25 |
+
- [LAION OIG data detoxed and filtered down by scripts in h2oGPT repository](https://github.com/h2oai/h2ogpt/blob/40c217f610766715acec297a5535eb440ac2f2e2/create_data.py)
|
| 26 |
+
"""
|
| 27 |
+
),
|
| 28 |
+
(
|
| 29 |
+
"h2ogpt-oig-instruct-cleaned-v3",
|
| 30 |
+
"""
|
| 31 |
+
- [Original LAION OIG Dataset](https://github.com/LAION-AI/Open-Instruction-Generalist)
|
| 32 |
+
- [LAION OIG data detoxed and filtered down by scripts in h2oGPT repository](https://github.com/h2oai/h2ogpt/blob/bfc3778c8db938761ce2093351bf2bf82159291e/create_data.py)
|
| 33 |
+
"""
|
| 34 |
+
),
|
| 35 |
+
(
|
| 36 |
+
"openassistant_oasst1",
|
| 37 |
+
"""
|
| 38 |
+
- [Original Open Assistant data in tree structure](https://huggingface.co/datasets/OpenAssistant/oasst1)
|
| 39 |
+
- [This flattened dataset created by script in h2oGPT repository](https://github.com/h2oai/h2ogpt/blob/45e6183171fb16691ad7d3ab006fad973f971e98/create_data.py#L1253)
|
| 40 |
+
"""
|
| 41 |
+
),
|
| 42 |
+
(
|
| 43 |
+
"h2ogpt-oig-oasst1-instruct-cleaned-v1",
|
| 44 |
+
"""
|
| 45 |
+
- [Original LAION OIG Dataset](https://github.com/LAION-AI/Open-Instruction-Generalist)
|
| 46 |
+
- [LAION OIG data detoxed and filtered down by scripts in h2oGPT repository](https://github.com/h2oai/h2ogpt/blob/main/docs/FINETUNE.md#high-quality-oig-based-instruct-data)
|
| 47 |
+
|
| 48 |
+
- [Original Open Assistant data in tree structure](https://huggingface.co/datasets/OpenAssistant/oasst1)
|
| 49 |
+
- [This flattened dataset created by script in h2oGPT repository](https://github.com/h2oai/h2ogpt/blob/5fc91911bc2bfaaf3b6c2de577c4b0ae45a07a4a/create_data.py#L1253)
|
| 50 |
+
"""
|
| 51 |
+
),
|
| 52 |
+
(
|
| 53 |
+
"h2ogpt-oig-oasst1-instruct-cleaned-v2",
|
| 54 |
+
"""
|
| 55 |
+
- [Original LAION OIG Dataset](https://github.com/LAION-AI/Open-Instruction-Generalist)
|
| 56 |
+
- [LAION OIG data detoxed and filtered down by scripts in h2oGPT repository](https://github.com/h2oai/h2ogpt/blob/main/docs/FINETUNE.md#high-quality-oig-based-instruct-data)
|
| 57 |
+
|
| 58 |
+
- [Original Open Assistant data in tree structure](https://huggingface.co/datasets/OpenAssistant/oasst1)
|
| 59 |
+
- [This flattened dataset created by script in h2oGPT repository](https://github.com/h2oai/h2ogpt/blob/0e70c2fbb16410bd8e6992d879b4c55cd981211f/create_data.py#L1375-L1415)
|
| 60 |
+
"""
|
| 61 |
+
),
|
| 62 |
+
(
|
| 63 |
+
"h2ogpt-oig-oasst1-instruct-cleaned-v3",
|
| 64 |
+
"""
|
| 65 |
+
- [Original LAION OIG Dataset](https://github.com/LAION-AI/Open-Instruction-Generalist)
|
| 66 |
+
- [LAION OIG data detoxed and filtered down by scripts in h2oGPT repository](https://github.com/h2oai/h2ogpt/blob/main/docs/FINETUNE.md#high-quality-oig-based-instruct-data)
|
| 67 |
+
|
| 68 |
+
- [Original Open Assistant data in tree structure](https://huggingface.co/datasets/OpenAssistant/oasst1)
|
| 69 |
+
- [This flattened dataset created by script in h2oGPT repository](https://github.com/h2oai/h2ogpt/blob/6728938a262d3eb5e8db1f252bbcd7de838da452/create_data.py#L1415)
|
| 70 |
+
"""
|
| 71 |
+
),
|
| 72 |
+
(
|
| 73 |
+
"openassistant_oasst1_h2ogpt",
|
| 74 |
+
"""
|
| 75 |
+
- [Original Open Assistant data in tree structure](https://huggingface.co/datasets/OpenAssistant/oasst1)
|
| 76 |
+
- [This flattened dataset created by script in h2oGPT repository](https://github.com/h2oai/h2ogpt/blob/83857fcf7d3b712aad5db32207e6db0ab0f780f9/create_data.py#L1252)
|
| 77 |
+
"""
|
| 78 |
+
),
|
| 79 |
+
(
|
| 80 |
+
"openassistant_oasst1_h2ogpt_graded",
|
| 81 |
+
"""
|
| 82 |
+
- [Original Open Assistant data in tree structure](https://huggingface.co/datasets/OpenAssistant/oasst1)
|
| 83 |
+
- [This flattened dataset created by script in h2oGPT repository](https://github.com/h2oai/h2ogpt/blob/d1f8ce975a46056d41135d126dd33de8499aa26e/create_data.py#L1259)
|
| 84 |
+
"""
|
| 85 |
+
),
|
| 86 |
+
(
|
| 87 |
+
"h2ogpt-fortune2000-personalized",
|
| 88 |
+
"""
|
| 89 |
+
- [Fortune 2000 companies from Wikipedia](https://github.com/h2oai/h2ogpt/blob/b1ea74c0088884ebff97f1ccddbfb3f393e29e44/create_data.py#L1743)
|
| 90 |
+
"""
|
| 91 |
+
),
|
| 92 |
+
],
|
| 93 |
+
)
|
| 94 |
+
def test_create_data_cards(dataset_name, link_to_source):
|
| 95 |
+
if dataset_name != "h2ogpt-fortune2000-personalized":
|
| 96 |
+
return
|
| 97 |
+
#
|
| 98 |
+
assert os.path.exists("README-template.md"), "must be running this test from the data dir."
|
| 99 |
+
shutil.rmtree(dataset_name, ignore_errors=True)
|
| 100 |
+
try:
|
| 101 |
+
repo = huggingface_hub.Repository(
|
| 102 |
+
local_dir=dataset_name,
|
| 103 |
+
clone_from="h2oai/%s" % dataset_name,
|
| 104 |
+
repo_type="dataset",
|
| 105 |
+
skip_lfs_files=True,
|
| 106 |
+
token=True,
|
| 107 |
+
)
|
| 108 |
+
repo.git_pull()
|
| 109 |
+
except Exception as e:
|
| 110 |
+
print(str(e))
|
| 111 |
+
print("call 'huggingface_cli login' first and provide access token with write permission")
|
| 112 |
+
dataset = load_dataset("h2oai/%s" % dataset_name)["train"]
|
| 113 |
+
|
| 114 |
+
pd.set_option('display.max_columns', None)
|
| 115 |
+
with open("README-template.md", "r") as f:
|
| 116 |
+
content = f.read()
|
| 117 |
+
assert "<<DATASET_NAME>>" in content
|
| 118 |
+
content = content.replace("<<DATASET_NAME>>", dataset_name)
|
| 119 |
+
|
| 120 |
+
assert "<<NROWS>>" in content
|
| 121 |
+
content = content.replace("<<NROWS>>", str(dataset.num_rows))
|
| 122 |
+
|
| 123 |
+
assert "<<NCOLS>>" in content
|
| 124 |
+
content = content.replace("<<NCOLS>>", str(dataset.num_columns))
|
| 125 |
+
|
| 126 |
+
assert "<<COLNAMES>>" in content
|
| 127 |
+
content = content.replace("<<COLNAMES>>", str(dataset.column_names))
|
| 128 |
+
|
| 129 |
+
# assert "<<PREVIEW>>" in content
|
| 130 |
+
# content = content.replace("<<PREVIEW>>", str(dataset.to_pandas().iloc[:5, :]))
|
| 131 |
+
|
| 132 |
+
assert "<<SOURCE_LINK>>" in content
|
| 133 |
+
content = content.replace("<<SOURCE_LINK>>", link_to_source)
|
| 134 |
+
|
| 135 |
+
assert "<<" not in content
|
| 136 |
+
assert ">>" not in content
|
| 137 |
+
|
| 138 |
+
with open(os.path.join(dataset_name, "README.md"), "w") as f:
|
| 139 |
+
f.write(content)
|
| 140 |
+
try:
|
| 141 |
+
repo.commit("Update README.md")
|
| 142 |
+
repo.push_to_hub()
|
| 143 |
+
except Exception as e:
|
| 144 |
+
print(str(e))
|
data/dai_docs.train.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data/dai_docs.train_cleaned.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data/dai_docs.valid.json
ADDED
|
@@ -0,0 +1,101 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[
|
| 2 |
+
{
|
| 3 |
+
"output": " .. _feature_store:\n\n##########################\nH2O AI Feature Store Setup\n##########################\n\nYou can use the H2O AI Feature Store to store, update, and share the features data scientists, developers, and engineers need to build AI models."
|
| 4 |
+
},
|
| 5 |
+
{
|
| 6 |
+
"output": " Note: For more information on the H2O AI Feature Store, refer to the `official documentation <https://docs.h2o.ai/feature-store/latest-stable/docs/index.html>`_."
|
| 7 |
+
},
|
| 8 |
+
{
|
| 9 |
+
"output": " To enable the Feature Store data connector, ``feature_store`` must be added to this list of data sources."
|
| 10 |
+
},
|
| 11 |
+
{
|
| 12 |
+
"output": " - ``feature_store_enable_tls``: To enable TLS communication between DAI and the Feature Store server, set this to ``true``."
|
| 13 |
+
},
|
| 14 |
+
{
|
| 15 |
+
"output": " - ``authentication_method``: The authentication method used by DAI. When enabling the Feature Store data connector, this must be set to OpenID Connect (``authentication_method=\"oidc\"``)."
|
| 16 |
+
},
|
| 17 |
+
{
|
| 18 |
+
"output": " \nUpgrading the Driverless AI Image\n~\n\n.. include:: upgrade-warning.frag\n \nUpgrading from Version 1.2.2 or Earlier\n'\n\nIt is not possible to upgrade from version 1.2.2 or earlier to the latest version."
|
| 19 |
+
},
|
| 20 |
+
{
|
| 21 |
+
"output": " Be sure to backup your data before doing this. Upgrading from Version 1.3.0 to 1.5.1\n'\n\n1. SSH into the IP address of the image instance and copy the existing experiments to a backup location:\n\n .. code-block:: bash\n\n # Set up a directory of the previous version name\n mkdir dai_rel_1.3.0\n\n # Copy the data, log, license, and tmp directories as backup\n cp -a ./data dai_rel_1.3.0/data\n cp -a ./log dai_rel_1.3.0/log\n cp -a ./license dai_rel_1.3.0/license\n cp -a ./tmp dai_rel_1.3.0/tmp\n\n2."
|
| 22 |
+
},
|
| 23 |
+
{
|
| 24 |
+
"output": " Replace VERSION and BUILD below with the Driverless AI version. .. code-block:: bash\n\n wget https://s3.amazonaws.com/artifacts.h2o.ai/releases/ai/h2o/dai/VERSION-BUILD/x86_64/dai-docker-ubi8-x86_64-VERSION.tar.gz\n\n3."
|
| 25 |
+
},
|
| 26 |
+
{
|
| 27 |
+
"output": " Run ``docker images`` to find the new image tag. 5. Start the Driverless AI Docker image and replace TAG below with the image tag."
|
| 28 |
+
},
|
| 29 |
+
{
|
| 30 |
+
"output": " Note: Use ``docker version`` to check which version of Docker you are using. .. tabs::\n\n .. tab:: >= Docker 19.03\n\n .. code-block:: bash\n\n # Start the Driverless AI Docker image\n docker run runtime=nvidia \\\n pid=host \\\n init \\\n rm \\\n shm-size=256m \\\n -u `id -u`:`id -g` \\\n -p 12345:12345 \\\n -v `pwd`/data:/data \\\n -v `pwd`/log:/log \\\n -v `pwd`/license:/license \\\n -v `pwd`/tmp:/tmp \\\n h2oai/dai-ubi8-x86_64:TAG\n\n .. tab:: < Docker 19.03\n\n .. code-block:: bash\n\n # Start the Driverless AI Docker image\n nvidia-docker run \\\n pid=host \\\n init \\\n rm \\\n shm-size=256m \\\n -u `id -u`:`id -g` \\\n -p 12345:12345 \\\n -v `pwd`/data:/data \\\n -v `pwd`/log:/log \\\n -v `pwd`/license:/license \\\n -v `pwd`/tmp:/tmp \\\n h2oai/dai-ubi8-x86_64:TAG\n\nUpgrading from version 1.5.2 or Later\n'\n\nUpgrading to versions 1.5.2 and later is no longer done via Docker."
|
| 31 |
+
},
|
| 32 |
+
{
|
| 33 |
+
"output": " Replace ``dai_NEWVERSION.deb`` below with the new Driverless AI version (for example, ``dai_1.8.4.1_amd64.deb``)."
|
| 34 |
+
},
|
| 35 |
+
{
|
| 36 |
+
"output": " You do not need to manually specify the DAI_USER or DAI_GROUP environment variables during an upgrade."
|
| 37 |
+
},
|
| 38 |
+
{
|
| 39 |
+
"output": " Driverless AI ships with CUDA 11.2.2 for GPUs, but the driver must exist in the host environment. Go to `NVIDIA download driver <https://www.nvidia.com/Download/index.aspx>`__ to get the latest NVIDIA Tesla A/T/V/P/K series drivers."
|
| 40 |
+
},
|
| 41 |
+
{
|
| 42 |
+
"output": " .. note::\n\tIf you are using K80 GPUs, the minimum required NVIDIA driver version is 450.80.02. .. code-block:: bash\n\n # Stop Driverless AI."
|
| 43 |
+
},
|
| 44 |
+
{
|
| 45 |
+
"output": " .. _feature_store:\n\n##########################\nH2O AI Feature Store Setup\n##########################\n\nYou can use the H2O AI Feature Store to store, update, and share the features data scientists, developers, and engineers need to build AI models."
|
| 46 |
+
},
|
| 47 |
+
{
|
| 48 |
+
"output": " Note: For more information on the H2O AI Feature Store, refer to the `official documentation <https://docs.h2o.ai/feature-store/latest-stable/docs/index.html>`_. Description of relevant configuration attributes\n\n\nThe following are descriptions of the relevant configuration attributes when enabling the H2O AI Feature Store data connector:\n\n- ``enabled_file_systems``: A list of file systems you want to enable."
|
| 49 |
+
},
|
| 50 |
+
{
|
| 51 |
+
"output": " - ``feature_store_endpoint_url``: A URL that points to the Feature Store server. - ``feature_store_enable_tls``: To enable TLS communication between DAI and the Feature Store server, set this to ``true``."
|
| 52 |
+
},
|
| 53 |
+
{
|
| 54 |
+
"output": " - ``authentication_method``: The authentication method used by DAI. When enabling the Feature Store data connector, this must be set to OpenID Connect (``authentication_method=\"oidc\"``). For information on setting up OIDC Authentication in Driverless AI, see :ref:`oidc_auth`."
|
| 55 |
+
},
|
| 56 |
+
{
|
| 57 |
+
"output": " \nUpgrading the Driverless AI Image\n~\n\n.. include:: upgrade-warning.frag\n \nUpgrading from Version 1.2.2 or Earlier\n'\n\nIt is not possible to upgrade from version 1.2.2 or earlier to the latest version."
|
| 58 |
+
},
|
| 59 |
+
{
|
| 60 |
+
"output": " Be sure to backup your data before doing this. Upgrading from Version 1.3.0 to 1.5.1\n'\n\n1. SSH into the IP address of the image instance and copy the existing experiments to a backup location:\n\n .. code-block:: bash\n\n # Set up a directory of the previous version name\n mkdir dai_rel_1.3.0\n\n # Copy the data, log, license, and tmp directories as backup\n cp -a ./data dai_rel_1.3.0/data\n cp -a ./log dai_rel_1.3.0/log\n cp -a ./license dai_rel_1.3.0/license\n cp -a ./tmp dai_rel_1.3.0/tmp\n\n2."
|
| 61 |
+
},
|
| 62 |
+
{
|
| 63 |
+
"output": " Replace VERSION and BUILD below with the Driverless AI version. .. code-block:: bash\n\n wget https://s3.amazonaws.com/artifacts.h2o.ai/releases/ai/h2o/dai/VERSION-BUILD/x86_64/dai-docker-ubi8-x86_64-VERSION.tar.gz\n\n3."
|
| 64 |
+
},
|
| 65 |
+
{
|
| 66 |
+
"output": " Run ``docker images`` to find the new image tag. 5. Start the Driverless AI Docker image and replace TAG below with the image tag. Depending on your install version, use the ``docker run runtime=nvidia`` (>= Docker 19.03) or ``nvidia-docker`` (< Docker 19.03) command."
|
| 67 |
+
},
|
| 68 |
+
{
|
| 69 |
+
"output": " .. tabs::\n\n .. tab:: >= Docker 19.03\n\n .. code-block:: bash\n\n # Start the Driverless AI Docker image\n docker run runtime=nvidia \\\n pid=host \\\n init \\\n rm \\\n shm-size=256m \\\n -u `id -u`:`id -g` \\\n -p 12345:12345 \\\n -v `pwd`/data:/data \\\n -v `pwd`/log:/log \\\n -v `pwd`/license:/license \\\n -v `pwd`/tmp:/tmp \\\n h2oai/dai-ubi8-x86_64:TAG\n\n .. tab:: < Docker 19.03\n\n .. code-block:: bash\n\n # Start the Driverless AI Docker image\n nvidia-docker run \\\n pid=host \\\n init \\\n rm \\\n shm-size=256m \\\n -u `id -u`:`id -g` \\\n -p 12345:12345 \\\n -v `pwd`/data:/data \\\n -v `pwd`/log:/log \\\n -v `pwd`/license:/license \\\n -v `pwd`/tmp:/tmp \\\n h2oai/dai-ubi8-x86_64:TAG\n\nUpgrading from version 1.5.2 or Later\n'\n\nUpgrading to versions 1.5.2 and later is no longer done via Docker."
|
| 70 |
+
},
|
| 71 |
+
{
|
| 72 |
+
"output": " Replace ``dai_NEWVERSION.deb`` below with the new Driverless AI version (for example, ``dai_1.8.4.1_amd64.deb``). Note that this upgrade process inherits the service user and group from /etc/dai/User.conf and /etc/dai/Group.conf."
|
| 73 |
+
},
|
| 74 |
+
{
|
| 75 |
+
"output": " We recommend to have NVIDIA driver >= |NVIDIA-driver-ver| installed (GPU only) in your host environment for a seamless experience on all architectures, including Ampere. Driverless AI ships with CUDA 11.2.2 for GPUs, but the driver must exist in the host environment."
|
| 76 |
+
},
|
| 77 |
+
{
|
| 78 |
+
"output": " For reference on CUDA Toolkit and Minimum Required Driver Versions and CUDA Toolkit and Corresponding Driver Versions, see `here <https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html>`__ ."
|
| 79 |
+
},
|
| 80 |
+
{
|
| 81 |
+
"output": " .. _feature_store:\n\n##########################\nH2O AI Feature Store Setup\n##########################\n\nYou can use the H2O AI Feature Store to store, update, and share the features data scientists, developers, and engineers need to build AI models. This page describes how to configure Driverless AI to work with the H2O AI Feature Store. Note: For more information on the H2O AI Feature Store, refer to the `official documentation <https://docs.h2o.ai/feature-store/latest-stable/docs/index.html>`_."
|
| 82 |
+
},
|
| 83 |
+
{
|
| 84 |
+
"output": " To enable the Feature Store data connector, ``feature_store`` must be added to this list of data sources. - ``feature_store_endpoint_url``: A URL that points to the Feature Store server. - ``feature_store_enable_tls``: To enable TLS communication between DAI and the Feature Store server, set this to ``true``. - ``feature_store_access_token_scopes``: A space-separated list of access token scopes used by the Feature Store connector for authentication. - ``authentication_method``: The authentication method used by DAI."
|
| 85 |
+
},
|
| 86 |
+
{
|
| 87 |
+
"output": " \nUpgrading the Driverless AI Image\n~\n\n.. include:: upgrade-warning.frag\n \nUpgrading from Version 1.2.2 or Earlier\n'\n\nIt is not possible to upgrade from version 1.2.2 or earlier to the latest version. You have to manually remove the 1.2.2 container and then reinstall the latest Driverless AI version. Be sure to backup your data before doing this. Upgrading from Version 1.3.0 to 1.5.1\n'\n\n1. SSH into the IP address of the image instance and copy the existing experiments to a backup location:\n\n .. code-block:: bash\n\n # Set up a directory of the previous version name\n mkdir dai_rel_1.3.0\n\n # Copy the data, log, license, and tmp directories as backup\n cp -a ./data dai_rel_1.3.0/data\n cp -a ./log dai_rel_1.3.0/log\n cp -a ./license dai_rel_1.3.0/license\n cp -a ./tmp dai_rel_1.3.0/tmp\n\n2."
|
| 88 |
+
},
|
| 89 |
+
{
|
| 90 |
+
"output": " Replace VERSION and BUILD below with the Driverless AI version. .. code-block:: bash\n\n wget https://s3.amazonaws.com/artifacts.h2o.ai/releases/ai/h2o/dai/VERSION-BUILD/x86_64/dai-docker-ubi8-x86_64-VERSION.tar.gz\n\n3. Use the ``docker load`` command to load the image:\n\n .. code-block:: bash\n\n docker load < dai-docker-ubi8-x86_64-VERSION.tar.gz\n\n4. Run ``docker images`` to find the new image tag. 5. Start the Driverless AI Docker image and replace TAG below with the image tag. Depending on your install version, use the ``docker run runtime=nvidia`` (>= Docker 19.03) or ``nvidia-docker`` (< Docker 19.03) command."
|
| 91 |
+
},
|
| 92 |
+
{
|
| 93 |
+
"output": " .. tabs::\n\n .. tab:: >= Docker 19.03\n\n .. code-block:: bash\n\n # Start the Driverless AI Docker image\n docker run runtime=nvidia \\\n pid=host \\\n init \\\n rm \\\n shm-size=256m \\\n -u `id -u`:`id -g` \\\n -p 12345:12345 \\\n -v `pwd`/data:/data \\\n -v `pwd`/log:/log \\\n -v `pwd`/license:/license \\\n -v `pwd`/tmp:/tmp \\\n h2oai/dai-ubi8-x86_64:TAG\n\n .. tab:: < Docker 19.03\n\n .. code-block:: bash\n\n # Start the Driverless AI Docker image\n nvidia-docker run \\\n pid=host \\\n init \\\n rm \\\n shm-size=256m \\\n -u `id -u`:`id -g` \\\n -p 12345:12345 \\\n -v `pwd`/data:/data \\\n -v `pwd`/log:/log \\\n -v `pwd`/license:/license \\\n -v `pwd`/tmp:/tmp \\\n h2oai/dai-ubi8-x86_64:TAG\n\nUpgrading from version 1.5.2 or Later\n'\n\nUpgrading to versions 1.5.2 and later is no longer done via Docker."
|
| 94 |
+
},
|
| 95 |
+
{
|
| 96 |
+
"output": " Replace ``dai_NEWVERSION.deb`` below with the new Driverless AI version (for example, ``dai_1.8.4.1_amd64.deb``). Note that this upgrade process inherits the service user and group from /etc/dai/User.conf and /etc/dai/Group.conf. You do not need to manually specify the DAI_USER or DAI_GROUP environment variables during an upgrade. We recommend to have NVIDIA driver >= |NVIDIA-driver-ver| installed (GPU only) in your host environment for a seamless experience on all architectures, including Ampere."
|
| 97 |
+
},
|
| 98 |
+
{
|
| 99 |
+
"output": " Go to `NVIDIA download driver <https://www.nvidia.com/Download/index.aspx>`__ to get the latest NVIDIA Tesla A/T/V/P/K series drivers. For reference on CUDA Toolkit and Minimum Required Driver Versions and CUDA Toolkit and Corresponding Driver Versions, see `here <https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html>`__ . .. note::\n\tIf you are using K80 GPUs, the minimum required NVIDIA driver version is 450.80.02. .. code-block:: bash\n\n # Stop Driverless AI. sudo systemctl stop dai\n\n # Backup your /opt/h2oai/dai/tmp directory at this time."
|
| 100 |
+
}
|
| 101 |
+
]
|
data/dai_faq.json
ADDED
|
@@ -0,0 +1,477 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[
|
| 2 |
+
{
|
| 3 |
+
"instruction": "How is Driverless AI different than any other black box ML algorithm?",
|
| 4 |
+
"output": "Driverless AI uses many techniques (some older and some cutting-edge) for interpreting black box models including creating reason codes for every prediction the system makes. We have also created numerous open source code examples and free publications that explain these techniques. See the list below for links to these resources and for references for the interpretability techniques.Open source interpretability examples:https://github.com/jphall663/interpretable_machine_learning_with_pythonhttps://content.oreilly.com/oriole/Interpretable-machine-learning-with-Python-XGBoost-and-H2Ohttps://github.com/h2oai/mli-resourcesFree Machine Learning Interpretability publications:http://www.oreilly.com/data/free/an-introduction-to-machine-learning-interpretability.csphttp://docs.h2o.ai/driverless-ai/latest-stable/docs/booklets/MLIBooklet.pdfMachine Learning Techniques already in Driverless AI:Tree-based Variable Importance: https://web.stanford.edu/~hastie/ElemStatLearn/printings/ESLII_print12.pdfPartial Dependence: https://web.stanford.edu/~hastie/ElemStatLearn/printings/ESLII_print12.pdfLIME: http://www.kdd.org/kdd2016/papers/files/rfp0573-ribeiroA.pdfLOCO: http://www.stat.cmu.edu/~ryantibs/papers/conformal.pdfICE: https://arxiv.org/pdf/1309.6392.pdfSurrogate Models:https://papers.nips.cc/paper/1152-extracting-tree-structured-representations-of-trained-networks.pdfhttps://arxiv.org/pdf/1705.08504.pdfShapley Explanations: http://papers.nips.cc/paper/7062-a-unified-approach-to-interpreting-model-predictions",
|
| 5 |
+
"prompt_type": "human_bot"
|
| 6 |
+
},
|
| 7 |
+
{
|
| 8 |
+
"instruction": "How often do new versions come out?",
|
| 9 |
+
"output": "The frequency of major new Driverless AI releases has historically been about every two months.Installation/Upgrade/Authentication",
|
| 10 |
+
"prompt_type": "human_bot"
|
| 11 |
+
},
|
| 12 |
+
{
|
| 13 |
+
"instruction": "How can I change my username and password?",
|
| 14 |
+
"output": "The username and password are tied to the experiments you have created. For example, if I log in with the username/password: megan/megan and start an experiment, then I would need to log back in with the same username and password to see those experiments. The username and password, however, does not limit your access to Driverless AI. If you want to use a new user name and password, you can log in again with a new username and password, but keep in mind that you won't see your old experiments.",
|
| 15 |
+
"prompt_type": "human_bot"
|
| 16 |
+
},
|
| 17 |
+
{
|
| 18 |
+
"instruction": "Can Driverless AI run on CPU-only machines?",
|
| 19 |
+
"output": "Yes, Driverless AI can run on machines with CPUs only, though GPUs are recommended. Installation instructions are available for GPU and CPU systems. Refer to :ref:`before_you_begin` for more information.No role entry for \"ref\" in module \"docutils.parsers.rst.languages.en\".\nTrying \"ref\" as canonical role name.Unknown interpreted text role \"ref\".",
|
| 20 |
+
"prompt_type": "human_bot"
|
| 21 |
+
},
|
| 22 |
+
{
|
| 23 |
+
"instruction": "How can I upgrade to a newer version of Driverless AI?",
|
| 24 |
+
"output": "Upgrade instructions vary depending on your environment. Refer to the installation section for your environment. Upgrade instructions are included there.",
|
| 25 |
+
"prompt_type": "human_bot"
|
| 26 |
+
},
|
| 27 |
+
{
|
| 28 |
+
"instruction": "What kind of authentication is supported in Driverless AI?",
|
| 29 |
+
"output": "Driverless AI supports Client Certificate, LDAP, Local, mTLS, OpenID, none, and unvalidated (default) authentication. These can be configured by setting the appropriate environment variables in the config.toml file or by specifying the environment variables when starting Driverless AI. Refer to :ref:`dai_auth` for more information.No role entry for \"ref\" in module \"docutils.parsers.rst.languages.en\".\nTrying \"ref\" as canonical role name.Unknown interpreted text role \"ref\".",
|
| 30 |
+
"prompt_type": "human_bot"
|
| 31 |
+
},
|
| 32 |
+
{
|
| 33 |
+
"instruction": "How can I automatically turn on persistence each time the GPU system reboots?",
|
| 34 |
+
"output": "For GPU machines, the sudo nvidia-persistenced --user dai command can be run after each reboot to enable persistence. For systems that have systemd, it is possible to automatically enable persistence after each reboot by removing the --no-persistence-mode flag from nvidia-persistenced.service. Before running the steps below, be sure to review the following for more information:https://docs.nvidia.com/deploy/driver-persistence/index.html#persistence-daemonhttps://docs.nvidia.com/deploy/driver-persistence/index.html#installationRun the following to stop the nvidia-persistenced.service:Cannot analyze code. Pygments package not found... code:: bash\n\n sudo systemctl stop nvidia-persistenced.service\nOpen the file /lib/systemd/system/nvidia-persistenced.service. This file includes a line \"ExecStart=/usr/bin/nvidia-persistenced --user nvidia-persistenced --no-persistence-mode --verbose\".Remove the flag --no-persistence-mode from that line so that it reads:Enumerated list start value not ordinal-1: \"2\" (ordinal 2)Cannot analyze code. Pygments package not found... code:: bash\n\n ExecStart=/usr/bin/nvidia-persistenced --user nvidia-persistenced --verbose\nRun the following command to start the nvidia-persistenced.service:Enumerated list start value not ordinal-1: \"4\" (ordinal 4)Cannot analyze code. Pygments package not found... code:: bash\n\n sudo systemctl start nvidia-persistenced.service\n",
|
| 35 |
+
"prompt_type": "human_bot"
|
| 36 |
+
},
|
| 37 |
+
{
|
| 38 |
+
"instruction": "How can I start Driverless AI on a different port than 12345?",
|
| 39 |
+
"output": "No directive entry for \"tabs\" in module \"docutils.parsers.rst.languages.en\".\nTrying \"tabs\" as canonical directive name.Unknown directive type \"tabs\"... tabs::\n .. group-tab:: Docker Image Installs\n\n When starting Driverless AI in Docker, the ``-p`` option specifies the port on which Driverless AI will run. Change this option in the start script if you need to run on a port other than 12345. The following example shows how to run on port 22345. (Change ``nvidia-docker run`` to ``docker-run`` if needed.) Keep in mind that `priviliged ports will require root access <https://www.w3.org/Daemon/User/Installation/PrivilegedPorts.html>`__.\n\n .. code-block:: bash\n :substitutions:\n\n nvidia-docker run \\\n --pid=host \\\n --init \\\n --rm \\\n --shm-size=256m \\\n -u `id -u`:`id -g` \\\n -p 22345:12345 \\\n -v `pwd`/data:/data \\\n -v `pwd`/log:/log \\\n -v `pwd`/license:/license \\\n -v `pwd`/tmp:/tmp \\\n h2oai/dai-ubi8-x86_64:|tag|\n\n .. group-tab:: Native Installs\n\n To run on a port other than 12345, update the port value in the **config.toml** file. The following example shows how to run Driverless AI on port 22345. Keep in mind that `priviliged ports will require root access <https://www.w3.org/Daemon/User/Installation/PrivilegedPorts.html>`__.\n\n ::\n\n # Export the Driverless AI config.toml file (or add it to ~/.bashrc)\n export DRIVERLESS_AI_CONFIG_FILE=\u201c/config/config.toml\u201d\n\n # IP address and port for Driverless AI HTTP server.\n ip = \"127.0.0.1\"\n port = 22345\n\n Point to this updated config file when restarting Driverless AI.\n",
|
| 40 |
+
"prompt_type": "human_bot"
|
| 41 |
+
},
|
| 42 |
+
{
|
| 43 |
+
"instruction": "Can I set up TLS/SSL on Driverless AI?",
|
| 44 |
+
"output": "Yes, Driverless AI provides configuration options that let you set up HTTPS/TLS/SSL. You will need to have your own SSL certificate, or you can create a self-signed certificate for yourself.To enable HTTPS/TLS/SSL on the Driverless AI server, add the following to the config.toml file:Cannot analyze code. Pygments package not found... code:: bash\n\n enable_https = true\n ssl_key_file = \"/etc/dai/private_key.pem\"\n ssl_crt_file = \"/etc/dai/cert.pem\"\nYou can make a self-signed certificate for testing with the following commands:Cannot analyze code. Pygments package not found... code:: bash\n\n umask 077\n openssl req -x509 -newkey rsa:4096 -keyout private_key.pem -out cert.pem -days 20 -nodes -subj '/O=Driverless AI'\n sudo chown dai:dai cert.pem private_key.pem\n sudo mv cert.pem private_key.pem /etc/dai\nTo configure specific versions of TLS/SSL, enable or disable the following settings in the config.toml file:Cannot analyze code. Pygments package not found... code:: bash\n\n ssl_no_sslv2 = true\n ssl_no_sslv3 = true\n ssl_no_tlsv1 = true\n ssl_no_tlsv1_1 = true\n ssl_no_tlsv1_2 = false\n ssl_no_tlsv1_3 = false\n",
|
| 45 |
+
"prompt_type": "human_bot"
|
| 46 |
+
},
|
| 47 |
+
{
|
| 48 |
+
"instruction": "Can I set up TLS/SSL on Driverless AI in AWS?",
|
| 49 |
+
"output": "Yes, you can set up HTTPS/TLS/SSL on Driverless AI running in an AWS environment. HTTPS/TLS/SSL needs to be configured on the host machine, and the necessary ports will need to be opened on the AWS side. You will need to have your own TLS/SSL cert or you can create a self signed cert for yourself.The following is a very simple example showing how to configure HTTPS with a proxy pass to the port on the container 12345 with the keys placed in /etc/nginx/. Replace <server_name> with your server name.Cannot analyze code. Pygments package not found... code:: bash\n\n server {\n listen 80;\n return 301 https://$host$request_uri;\n }\n\n server {\n listen 443;\n\n # Specify your server name here\n server_name <server_name>;\n\n ssl_certificate /etc/nginx/cert.crt;\n ssl_certificate_key /etc/nginx/cert.key;\n ssl on;\n ssl_session_cache builtin:1000 shared:SSL:10m;\n ssl_protocols TLSv1 TLSv1.1 TLSv1.2;\n ssl_ciphers HIGH:!aNULL:!eNULL:!EXPORT:!CAMELLIA:!DES:!MD5:!PSK:!RC4;\n ssl_prefer_server_ciphers on;\n\n access_log /var/log/nginx/dai.access.log;\n\n location / {\n proxy_set_header Host $host;\n proxy_set_header X-Real-IP $remote_addr;\n proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;\n proxy_set_header X-Forwarded-Proto $scheme;\n\n # Fix the \u201cIt appears that your reverse proxy set up is broken\" error.\n proxy_pass http://localhost:12345;\n proxy_read_timeout 90;\n\n # Specify your server name for the redirect\n proxy_redirect http://localhost:12345 https://<server_name>;\n }\n }\nMore information about SSL for Nginx in Ubuntu 16.04 can be found here: https://www.digitalocean.com/community/tutorials/how-to-create-a-self-signed-ssl-certificate-for-nginx-in-ubuntu-16-04.",
|
| 50 |
+
"prompt_type": "human_bot"
|
| 51 |
+
},
|
| 52 |
+
{
|
| 53 |
+
"instruction": "I received a \"package dai-<version>.x86_64 does not verify: no digest\" error during the installation. How can I fix this?",
|
| 54 |
+
"output": "You will recieve a \"package dai-<version>.x86_64 does not verify: no digest\" error when installing the rpm using an RPM version newer than 4.11.3. You can run the following as a workaround, replacing <version> with your DAI version:Cannot analyze code. Pygments package not found... code:: bash\n\n rpm --nodigest -i dai-<version>.x86_64.rpm\n",
|
| 55 |
+
"prompt_type": "human_bot"
|
| 56 |
+
},
|
| 57 |
+
{
|
| 58 |
+
"instruction": "I received a \"Must have exactly one OpenCL platform 'NVIDIA CUDA'\" error. How can I fix that?",
|
| 59 |
+
"output": "If you encounter problems with opencl errors at server time, you may see the following message:Cannot analyze code. Pygments package not found... code:: bash\n\n 2018-11-08 14:26:15,341 C: D:452.2GB M:246.0GB 21603 ERROR : Must have exactly one OpenCL platform 'NVIDIA CUDA', but got:\n Platform #0: Clover\n Platform #1: NVIDIA CUDA\n +-- Device #0: GeForce GTX 1080 Ti\n +-- Device #1: GeForce GTX 1080 Ti\n +-- Device #2: GeForce GTX 1080 Ti\n\n Uninstall all but 'NVIDIA CUDA' platform.\nFor Ubuntu, the solution is to run the following:Cannot analyze code. Pygments package not found... code:: bash\n\n sudo apt-get remove mesa-opencl-icd\n",
|
| 60 |
+
"prompt_type": "human_bot"
|
| 61 |
+
},
|
| 62 |
+
{
|
| 63 |
+
"instruction": "Is it possible for multiple users to share a single Driverless AI instance?",
|
| 64 |
+
"output": "Driverless AI supports multiple users, and Driverless AI is licensed per a single named user. Therefore, in order, to have different users run experiments simultaneously, they would each need a license. Driverless AI manages the GPU(s) that it is given and ensures that different experiments from different users can run safely simultaneously and don\u2019t interfere with each other. So when two licensed users log in with different credentials, then neither of them will see the other\u2019s experiment. Similarly, if a licensed user logs in using a different set of credentials, then that user will not see any previously run experiments.",
|
| 65 |
+
"prompt_type": "human_bot"
|
| 66 |
+
},
|
| 67 |
+
{
|
| 68 |
+
"instruction": "Can multiple Driverless AI users share a GPU server?",
|
| 69 |
+
"output": "Yes, you can allocate multiple users in a single GPU box. For example, a single box with four GPUs can allocate that User1 has two GPUs and User2 has the other two GPUs. This is accomplished by having two separated Driverless AI instances running on the same server.There are two ways to assign specific GPUs to Driverless AI. And in the scenario with four GPUs (two GPUs allocated to two users), both of these options allow each Docker container only to see two GPUs.Use the CUDA_VISIBLE_DEVICES environment variable. In the case of Docker deployment, this will translate in passing the -e CUDA_VISIBLE_DEVICES=\"0,1\" to the nvidia-docker run command.Passing the NV_GPU option at the beginning of the nvidia-docker run command. (See example below.)Error in \"code-block\" directive:\nunknown option: \"substitutions\"... code-block:: bash\n :substitutions:\n\n #Team 1\n NV_GPU='0,1' nvidia-docker run\n --pid=host\n --init\n --rm\n --shm-size=256m\n -u id -u:id -g\n -p port-to-team:12345\n -e DRIVERLESS_AI_CONFIG_FILE=\"/config/config.toml\"\n -v /data:/data\n -v /log:/log\n -v /license:/license\n -v /tmp:/tmp\n -v /config:/config\n h2oai/dai-ubi8-x86_64:|tag|\n\n\n #Team 2\n NV_GPU='0,1' nvidia-docker run\n --pid=host\n --init\n --rm\n --shm-size=256m\n -u id -u:id -g\n -p port-to-team:12345\n -e DRIVERLESS_AI_CONFIG_FILE=\"/config/config.toml\"\n -v /data:/data\n -v /log:/log\n -v /license:/license\n -v /tmp:/tmp\n -v /config:/config\n h2oai/dai-ubi8-x86_64:|tag|\nNote, however, that a Driverless AI instance expects to fully utilize and not share the GPUs that are assigned to it. Sharing a GPU with other Driverless AI instances or other running programs can result in out-of-memory issues.",
|
| 70 |
+
"prompt_type": "human_bot"
|
| 71 |
+
},
|
| 72 |
+
{
|
| 73 |
+
"instruction": "How can I retrieve a list of Driverless AI users?",
|
| 74 |
+
"output": "A list of users can be retrieved using the Python client.Cannot analyze code. Pygments package not found... code:: bash\n\n h2o = Client(address='http://<client_url>:12345', username='<username>', password='<password>')\n h2o.get_users()\n",
|
| 75 |
+
"prompt_type": "human_bot"
|
| 76 |
+
},
|
| 77 |
+
{
|
| 78 |
+
"instruction": "Start of Driverless AI fails on the message ``Segmentation fault (core dumped)`` on Ubuntu 18/RHEL 7.6. How can I fix this?",
|
| 79 |
+
"output": "This problem is caused by the font NotoColorEmoji.ttf, which cannot be processed by the Python matplotlib library. A workaround is to disable the font by renaming it. (Do not use fontconfig because it is ignored by matplotlib.) The following will print out the command that should be executed.Cannot analyze code. Pygments package not found... code:: bash\n\n sudo find / -name \"NotoColorEmoji.ttf\" 2>/dev/null | xargs -I{} echo sudo mv {} {}.backup\n\n",
|
| 80 |
+
"prompt_type": "human_bot"
|
| 81 |
+
},
|
| 82 |
+
{
|
| 83 |
+
"instruction": "Which Linux systems does Driverless AI support?",
|
| 84 |
+
"output": "Supported Linux systems include x86_64 RHEL 7, RHEL 8, CentOS 7, and CentOS 8.Data",
|
| 85 |
+
"prompt_type": "human_bot"
|
| 86 |
+
},
|
| 87 |
+
{
|
| 88 |
+
"instruction": "Is there a file size limit for datasets?",
|
| 89 |
+
"output": "For GBMs, the file size for datasets is limited by the collective CPU or GPU memory on the system, but we continue to make optimizations for getting more data into an experiment, such as using TensorFlow streaming to stream to arbitrarily large datasets.",
|
| 90 |
+
"prompt_type": "human_bot"
|
| 91 |
+
},
|
| 92 |
+
{
|
| 93 |
+
"instruction": "How can I import CSV files that use UTF-8 encoding into Excel?",
|
| 94 |
+
"output": "Excel requires a byte order mark (BOM) to correctly identify CSV files that use UTF-8 encoding. Refer to the following FAQ entry for more information on how to use a BOM when writing CSV files with datatable.",
|
| 95 |
+
"prompt_type": "human_bot"
|
| 96 |
+
},
|
| 97 |
+
{
|
| 98 |
+
"instruction": "Can a byte order mark be used when writing CSV files with datatable?",
|
| 99 |
+
"output": "Yes, a byte order mark (BOM) can be used when writing CSV files with datatable by enabling datatable_bom_csv in the config.toml file when starting Driverless AI.Note: Support for UTF-8 encoding in Excel requires the use of a BOM.",
|
| 100 |
+
"prompt_type": "human_bot"
|
| 101 |
+
},
|
| 102 |
+
{
|
| 103 |
+
"instruction": "Which version of Longhorn is supported by Driverless AI?",
|
| 104 |
+
"output": "Driverless AI supports Longhorn v1.1.0 or later.",
|
| 105 |
+
"prompt_type": "human_bot"
|
| 106 |
+
},
|
| 107 |
+
{
|
| 108 |
+
"instruction": "Is it possible to download a transformed test dataset in Driverless AI?",
|
| 109 |
+
"output": "Yes, a transformed test dataset can be downloaded in Driverless AI. To do this, click Model Actions > Transform Dataset on the completed experiment page, then specify both a train and a test dataset to use for the transformation. The transformed test dataset is made available for download once this process is completed.Connectors",
|
| 110 |
+
"prompt_type": "human_bot"
|
| 111 |
+
},
|
| 112 |
+
{
|
| 113 |
+
"instruction": "Why can't I import a folder as a file when using a data connector on Windows?",
|
| 114 |
+
"output": "If you try to use the Import Folder as File option via a data connector on Windows, the import will fail if the folder contains files that do not have file extensions. For example, if a folder contains the files file1.csv, file2.csv, file3.csv, and _SUCCESS, the function will fail due to the presence of the _SUCCESS file.Note that this only occurs if the data is sourced from a volume that is mounted from the Windows filesystem onto the Docker container via -v /path/to/windows/filesystem:/path/in/docker/container flags. This error occurs because of the difference in how files without file extensions are treated in Windows and in the Docker container (CentOS Linux).",
|
| 115 |
+
"prompt_type": "human_bot"
|
| 116 |
+
},
|
| 117 |
+
{
|
| 118 |
+
"instruction": "I get a ClassNotFoundException error when I try to select a JDBC connection. How can I fix that?",
|
| 119 |
+
"output": "The folder storing the JDBC jar file must be visible/readable by the dai process user.If you downloaded the JDBC jar file from Oracle, they may provide you with a tar.gz file that you can unpackage with the following command:Cannot analyze code. Pygments package not found... code:: bash\n\n tar --no-same-permissions --no-same-owner -xzvf <my-jdbc-driver.tar>.gz\nAlternatively you can ensure that the permissions on the file are correct in general by running the following:Cannot analyze code. Pygments package not found... code:: bash\n\n chmod -R o+rx /path/to/folder_containing_jar_file\nFinally, if you just want to check the permissions use the command ls -altr and check the final 3 values in the permissions output.",
|
| 120 |
+
"prompt_type": "human_bot"
|
| 121 |
+
},
|
| 122 |
+
{
|
| 123 |
+
"instruction": "I get a org.datanucleus.exceptions.NucleusUserException: Please check your CLASSPATH and plugin specification error when attempting to connect to Hive. How can I fix that?",
|
| 124 |
+
"output": "Make sure hive-site.xml is configured in /etc/hive/conf and not in /etc/hadoop/conf.",
|
| 125 |
+
"prompt_type": "human_bot"
|
| 126 |
+
},
|
| 127 |
+
{
|
| 128 |
+
"instruction": "I get a \"Permission Denied\" error during Hive import. How do I fix this?",
|
| 129 |
+
"output": "If you see the following error, your Driverless AI instance may not be able to create a temporary Hive folder due to file system permissions restrictions.Cannot analyze code. Pygments package not found... code:: bash\n\n ERROR HiveAgent: Error during execution of query: java.lang.RuntimeException: java.lang.RuntimeException: java.io.IOException: Permission denied;\n org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: java.lang.RuntimeException: java.io.IOException: Permission denied;\nTo fix this error, add the following name-value pair to your hive-site.xml file to specify the location that is accessible to Driverless AI (that is, your Driverless AI /tmp directory).Cannot analyze code. Pygments package not found... code:: bash\n\n <property>\n <name>hive.exec.local.scratchdir</name>\n <value>/path/to/dai/tmp</value>\n </property>\nRecipes",
|
| 130 |
+
"prompt_type": "human_bot"
|
| 131 |
+
},
|
| 132 |
+
{
|
| 133 |
+
"instruction": "Where can I retrieve H2O's custom recipes?",
|
| 134 |
+
"output": "H2O's custom recipes can be obtained from the official :recipes-repo:`Recipes for Driverless AI repository <https://github.com/h2oai/driverlessai-recipes/tree/>`.No role entry for \"recipes-repo\" in module \"docutils.parsers.rst.languages.en\".\nTrying \"recipes-repo\" as canonical role name.Unknown interpreted text role \"recipes-repo\".",
|
| 135 |
+
"prompt_type": "human_bot"
|
| 136 |
+
},
|
| 137 |
+
{
|
| 138 |
+
"instruction": "How can I create my own custom recipe?",
|
| 139 |
+
"output": "Refer to the :recipes-writing:`How to Write a Recipe <https://github.com/h2oai/driverlessai-recipes/blob/>` guide for details on how to create your own custom recipe.No role entry for \"recipes-writing\" in module \"docutils.parsers.rst.languages.en\".\nTrying \"recipes-writing\" as canonical role name.Unknown interpreted text role \"recipes-writing\".",
|
| 140 |
+
"prompt_type": "human_bot"
|
| 141 |
+
},
|
| 142 |
+
{
|
| 143 |
+
"instruction": "Are MOJOs supported for experiments that use custom recipes?",
|
| 144 |
+
"output": "In most cases, MOJOs will not be available for custom recipes. Unless the recipe is simple, creating the MOJO is only possible with additional MOJO runtime support. Contact [email protected] for more information about creating MOJOs for custom recipes. (Note: The Python Scoring Pipeline features full support for custom recipes.)",
|
| 145 |
+
"prompt_type": "human_bot"
|
| 146 |
+
},
|
| 147 |
+
{
|
| 148 |
+
"instruction": "How can I use BYOR in my airgapped installation?",
|
| 149 |
+
"output": "If your Driverless AI environment cannot access Internet and, thus, cannot access Driverless AI's \"Bring Your Own Recipes\" from GitHub, please contact H2O support. We can work with you directly to help you access recipes.",
|
| 150 |
+
"prompt_type": "human_bot"
|
| 151 |
+
},
|
| 152 |
+
{
|
| 153 |
+
"instruction": "When enabling recipes in Driverless AI, can I install Python packages from my organization's internal Python package index?",
|
| 154 |
+
"output": "Yes\u2014you can use the pip_install_options :ref:`TOML option <understanding-configs>` to specify your organization's internal Python package index as follows:No role entry for \"ref\" in module \"docutils.parsers.rst.languages.en\".\nTrying \"ref\" as canonical role name.Unknown interpreted text role \"ref\".pip_install_options=\"['--extra-index-url', 'http://my-own-repo:port']\"For more information on the --extra-index-url <url> pip install option, refer to the official pip documentation.Experiments",
|
| 155 |
+
"prompt_type": "human_bot"
|
| 156 |
+
},
|
| 157 |
+
{
|
| 158 |
+
"instruction": "How much memory does Driverless AI require in order to run experiments?",
|
| 159 |
+
"output": "Right now, Driverless AI requires approximately 10x the size of the data in system memory.",
|
| 160 |
+
"prompt_type": "human_bot"
|
| 161 |
+
},
|
| 162 |
+
{
|
| 163 |
+
"instruction": "How many columns can Driverless AI handle?",
|
| 164 |
+
"output": "Driverless AI has been tested on datasets with 10k columns. When running experiments on wide data, Driverless AI automatically checks if it is running out of memory, and if it is, it reduces the number of features until it can fit in memory. This may lead to a worse model, but Driverless AI shouldn't crash because the data is wide.",
|
| 165 |
+
"prompt_type": "human_bot"
|
| 166 |
+
},
|
| 167 |
+
{
|
| 168 |
+
"instruction": "How should I use Driverless AI if I have large data?",
|
| 169 |
+
"output": "Driverless AI can handle large datasets out of the box. For very large datasets (more than 10 billion rows x columns), we recommend sampling your data for Driverless AI. Keep in mind that the goal of driverless AI is to go through many features and models to find the best modeling pipeline, and not to just train a few models on the raw data (H2O-3 is ideally suited for that case).For large datasets, the recommended steps are:Run with the recommended accuracy/time/interpretability settings first, especially accuracy <= 7Gradually increase accuracy settings to 7 and choose accuracy 9 or 10 only after observing runs with <= 7.",
|
| 170 |
+
"prompt_type": "human_bot"
|
| 171 |
+
},
|
| 172 |
+
{
|
| 173 |
+
"instruction": "How does Driverless AI detect the ID column?",
|
| 174 |
+
"output": "The ID column logic is one of the following:The column is named 'id', 'Id', 'ID' or 'iD' exactlyThe column contains a significant number of unique values (above max_relative_cardinality in the config.toml file or Max. allowed fraction of uniques for integer and categorical cols in Expert settings)",
|
| 175 |
+
"prompt_type": "human_bot"
|
| 176 |
+
},
|
| 177 |
+
{
|
| 178 |
+
"instruction": "Can Driverless AI handle data with missing values/nulls?",
|
| 179 |
+
"output": "Yes, data that is imported into Driverless AI can include missing values. Feature engineering is fully aware of missing values, and missing values are treated as information - either as a special categorical level or as a special number. So for target encoding, for example, rows with a certain missing feature will belong to the same group. For Categorical Encoding where aggregations of a numeric columns are calculated for a grouped categorical column, missing values are kept. The formula for calculating the mean is the sum of non-missing values divided by the count of all non-missing values. For clustering, we impute missing values. And for frequency encoding, we count the number of rows that have a certain missing feature.The imputation strategy is as follows:XGBoost/LightGBM do not need missing value imputation and may, in fact, perform worse with any specific other strategy unless the user has a strong understanding of the data.Driverless AI automatically imputes missing values using the mean for GLM.Driverless AI provides an imputation setting for TensorFlow in the config.toml file: tf_nan_impute_value post-normalization. If you set this option to 0, then missing values will be imputed. Setting it to (for example) +5 will specify 5 standard deviations outside the distribution. The default for TensorFlow is -5, which specifies that TensorFlow will treat NAs like a missing value. We recommend that you specify 0 if the mean is better.More information is available in the Missing and Unseen Values Handling section.",
|
| 180 |
+
"prompt_type": "human_bot"
|
| 181 |
+
},
|
| 182 |
+
{
|
| 183 |
+
"instruction": "How does Driverless AI deal with categorical variables? What if an integer column should really be treated as categorical?",
|
| 184 |
+
"output": "If a column has string values, then Driverless AI will treat it as a categorical feature. There are multiple methods for how Driverless AI converts the categorical variables to numeric. These include:One Hot Encoding: creating dummy variables for each valueFrequency Encoding: replace category with how frequently it is seen in the dataTarget Encoding: replace category with the average target value (additional steps included to prevent overfitting)Weight of Evidence: calculate weight of evidence for each category (http://ucanalytics.com/blogs/information-value-and-weight-of-evidencebanking-case/)Driverless AI will try multiple methods for representing the column and determine which representation(s) are best.If the column has integers, Driverless AI will try treating the column as a categorical column and numeric column. It will treat any integer column as both categorical and numeric if the number of unique values is less than 50.This is configurable in the config.toml file:Cannot analyze code. Pygments package not found... code:: bash\n\n # Whether to treat some numerical features as categorical\n # For instance, sometimes an integer column may not represent a numerical feature but\n # represents different numerical codes instead.\n num_as_cat = true\n\n # Max number of unique values for integer/real columns to be treated as categoricals (test applies to first statistical_threshold_data_size_small rows only)\n max_int_as_cat_uniques = 50\n(Note: Driverless AI will also check if the distribution of any numeric column differs significantly from the distribution of typical numerical data using Benford's Law. If the column distribution does not obey Benford's Law, we will also try to treat it as categorical even if there are more than 50 unique values.)",
|
| 185 |
+
"prompt_type": "human_bot"
|
| 186 |
+
},
|
| 187 |
+
{
|
| 188 |
+
"instruction": "How are outliers handled?",
|
| 189 |
+
"output": "Outliers are not removed from the data. Instead Driverless AI finds the best way to represent data with outliers. For example, Driverless AI may find that binning a variable with outliers improves performance.For target columns, Driverless AI first determines the best representation of the column. It may find that for a target column with outliers, it is best to predict the log of the column.",
|
| 190 |
+
"prompt_type": "human_bot"
|
| 191 |
+
},
|
| 192 |
+
{
|
| 193 |
+
"instruction": "If I drop several columns from the Train dataset, will Driverless AI understand that it needs to drop the same columns from the Test dataset?",
|
| 194 |
+
"output": "If you drop columns from the training dataset, Driverless AI will do the same for the validation and test datasets (if the columns are present). There is no need for these columns because no features will be created from them.",
|
| 195 |
+
"prompt_type": "human_bot"
|
| 196 |
+
},
|
| 197 |
+
{
|
| 198 |
+
"instruction": "Does Driverless AI treat numeric variables as categorical variables?",
|
| 199 |
+
"output": "In certain cases, yes. You can prevent this behavior by setting the num_as_cat variable in your installation's config.toml file to false. You can have finer grain control over this behavior by excluding the Numeric to Categorical Target Encoding Transformer and the Numeric To Categorical Weight of Evidence Transformer and their corresponding genes in your installation's config.toml file. To learn more about the config.toml file, see the :ref:`config_file` section.No role entry for \"ref\" in module \"docutils.parsers.rst.languages.en\".\nTrying \"ref\" as canonical role name.Unknown interpreted text role \"ref\".",
|
| 200 |
+
"prompt_type": "human_bot"
|
| 201 |
+
},
|
| 202 |
+
{
|
| 203 |
+
"instruction": "Which algorithms are used in Driverless AI?",
|
| 204 |
+
"output": "Features are engineered with a proprietary stack of Kaggle-winning statistical approaches including some of the most sophisticated target encoding and likelihood estimates based on groupings, aggregations and joins, but we also employ linear models, neural nets, clustering and dimensionality reduction models and many traditional approaches such as one-hot encoding etc.On top of the engineered features, sophisticated models are fitted, including, but not limited to: XGBoost (both original XGBoost and 'lossguide' (LightGBM) mode), Decision Trees, GLM, TensorFlow (including a TensorFlow NLP recipe based on CNN Deeplearning models), RuleFit, FTRL (Follow the Regularized Leader), Isolation Forest, and Constant Models. (Refer to :ref:`supported_algorithms` for more information.) And additional algorithms can be added via :ref:`Recipes <custom-recipes>`.No role entry for \"ref\" in module \"docutils.parsers.rst.languages.en\".\nTrying \"ref\" as canonical role name.Unknown interpreted text role \"ref\".No role entry for \"ref\" in module \"docutils.parsers.rst.languages.en\".\nTrying \"ref\" as canonical role name.Unknown interpreted text role \"ref\".In general, GBMs are the best single-shot algorithms. Since 2006, boosting methods have proven to be the most accurate for noisy predictive modeling tasks outside of pattern recognition in images and sound (https://www.cs.cornell.edu/~caruana/ctp/ct.papers/caruana.icml06.pdf). The advent of XGBoost and Kaggle only cemented this position.",
|
| 205 |
+
"prompt_type": "human_bot"
|
| 206 |
+
},
|
| 207 |
+
{
|
| 208 |
+
"instruction": "Why do my selected algorithms not show up in the Experiment Preview?",
|
| 209 |
+
"output": "When changing the algorithms used via Expert Settings > Model and Expert Settings > Recipes, you may notice in the Experiment Preview that those changes are not applied. Driverless AI determines whether to include models and/or recipes based on a hierarchy of those expert settings as well as data types (numeric, categorical, text, image, etc.) and system properties (GPUs, multiple GPUs, etc.).Setting an Algorithm to \"OFF\" in Expert Settings: If an algorithm is turned OFF in Expert Settings (for example, GLM Models) when running, then that algorithm will not be included in the experiment.Algorithms Not Included from Recipes (BYOR): If an algorithm from a custom recipe is not selected for the experiment in the Include specific models option, then that algorithm will not be included in the experiment, regardless of whether that same algorithm is set to AUTO or ON on the Expert Settings > Model page.Algorithms Not Specified as \"OFF\" and Included from Recipes: If a Driverless AI algorithm is specified as either \"AUTO\" or \"ON\" and additional models are selected for the experiment in the Include specific models option, than those algorithms may or may not be included in the experiment. Driverless AI will determine the algorithms to use based on the data and experiment type.To show warnings in the preview for which models were not used, set show_inapplicable_models_preview = true in config.toml",
|
| 210 |
+
"prompt_type": "human_bot"
|
| 211 |
+
},
|
| 212 |
+
{
|
| 213 |
+
"instruction": "Why do my selected transformers not show up in the Experiment Preview?",
|
| 214 |
+
"output": "When changing the transformers used via Expert Settings > Transformers and Expert Settings > Recipes, you may notice in the Experiment Preview that those changes are not applied. Driverless AI determines whether to include transformers can be used based upon data types (numeric, categorical, text, image, etc.) and system properties (GPUs, multiple GPUs, etc.).Transformers Not Included from Recipes (BYOR): If a transformer from a custom recipe is not selected for the experiment in the Include specific transformers option, then that transformer will not be included in the experiment.To show warnings in the preview for which models were not used, set show_inapplicable_transformers_preview = true in config.toml",
|
| 215 |
+
"prompt_type": "human_bot"
|
| 216 |
+
},
|
| 217 |
+
{
|
| 218 |
+
"instruction": "How can we turn on TensorFlow Neural Networks so they are evaluated?",
|
| 219 |
+
"output": "Neural networks are considered by Driverless AI, although they may not be evaluated by default. To ensure that neural networks are tried, you can turn on TensorFlow in the Expert Settings:Once you have set TensorFlow to ON. You should see the Experiment Preview on the left hand side change and mention that it will evaluate TensorFlow models:We recommend using TensorFlow neural networks if you have a multinomial use case with more than 5 unique values.",
|
| 220 |
+
"prompt_type": "human_bot"
|
| 221 |
+
},
|
| 222 |
+
{
|
| 223 |
+
"instruction": "Does Driverless AI standardize the data?",
|
| 224 |
+
"output": "Driverless AI will automatically do variable standardization for certain algorithms. For example, with Linear Models and Neural Networks, the data is automatically standardized. For decision tree algorithms, however, we do not perform standardization because these algorithms do not benefit from standardization.",
|
| 225 |
+
"prompt_type": "human_bot"
|
| 226 |
+
},
|
| 227 |
+
{
|
| 228 |
+
"instruction": "What objective function is used in XGBoost?",
|
| 229 |
+
"output": "The objective function used in XGBoost is:reg:squarederror and a custom absolute error objective function for regressionbinary:logistic or multi:softprob for classificationThe objective function does not change depending on the scorer chosen. The scorer influences parameter tuning only. For regression, Tweedie, Gamma, and Poisson regression objectives are supported.More information on the XGBoost instantiations can be found in the logs and in the model summary, both of which can be downloaded from the GUI or found in the /tmp/h2oai_experiment_<name>/ folder on the server.",
|
| 230 |
+
"prompt_type": "human_bot"
|
| 231 |
+
},
|
| 232 |
+
{
|
| 233 |
+
"instruction": "Does Driverless AI perform internal or external validation?",
|
| 234 |
+
"output": "Driverless AI does internal validation when only training data is provided. It does external validation when training and validation data are provided. In either scenario, the validation data is used for all parameter tuning (models and features), not just for feature selection. Parameter tuning includes target transformation, model selection, feature engineering, feature selection, stacking, etc.Specifically:Internal validation (only training data given):Ideal when data is either close to i.i.d., or for time-series problemsInternal holdouts are used for parameter tuning, with temporal causality for time-series problemsWill do the full spectrum from single holdout split to 5-fold CV, depending on accuracy settingsNo need to split training data manuallyFinal models are trained using CV on the training dataExternal validation (training + validation data given):Ideal when there\u2019s some amount of drift in the data, and the validation set mimics the test set data better than the training dataNo training data wasted during training because training data not used for parameter tuningValidation data is used only for parameter tuning, and is not part of training dataNo CV possible because we explicitly do not want to overfit on the training dataNot allowed for time-series problems (see Time Series FAQ section that follows)Tip: If you want both training and validation data to be used for parameter tuning (the training process), just concatenate the datasets together and turn them both into training data for the \u201cinternal validation\u201d method.",
|
| 235 |
+
"prompt_type": "human_bot"
|
| 236 |
+
},
|
| 237 |
+
{
|
| 238 |
+
"instruction": "How does Driverless AI prevent overfitting?",
|
| 239 |
+
"output": "Driverless AI performs a number of checks to prevent overfitting. For example, during certain transformations, Driverless AI calculates the average on out-of-fold data using cross validation. Driverless AI also performs early stopping for every model built, ensuring that the model build will stop when it ceases to improve on holdout data. And additional steps to prevent overfitting include checking for i.i.d. and avoiding leakage during feature engineering.A blog post describing Driverless AI overfitting protection in greater detail is available here: https://www.h2o.ai/blog/driverless-ai-prevents-overfitting-leakage/.More aggressive overfit protection can be enabled by setting lock_ga_to_final_trees=true to true or using recipe='more_overfit_protection' and fixed_only_first_fold_model='true' and for time-series experiments allow_stabilize_varimp_for_ts=true.",
|
| 240 |
+
"prompt_type": "human_bot"
|
| 241 |
+
},
|
| 242 |
+
{
|
| 243 |
+
"instruction": "How does Driverless AI avoid the multiple hypothesis (MH) problem?",
|
| 244 |
+
"output": "Driverless AI uses a variant of the reusable holdout technique to address the multiple hypothesis problem. Refer to https://pdfs.semanticscholar.org/25fe/96591144f4af3d8f8f79c95b37f415e5bb75.pdf for more information.",
|
| 245 |
+
"prompt_type": "human_bot"
|
| 246 |
+
},
|
| 247 |
+
{
|
| 248 |
+
"instruction": "How does Driverless AI suggest the experiment settings?",
|
| 249 |
+
"output": "When you run an experiment on a dataset, the experiment settings (Accuracy, Time, and Interpretability) are automatically suggested by Driverless AI. For example, Driverless AI may suggest the parameters Accuracy = 7, Time = 3, Interpretability = 6, based on your data.Driverless AI will automatically suggest experiment settings based on the number of columns and number of rows in your dataset. The settings are suggested to ensure best handling when the data is small. If the data is small, Driverless AI will suggest the settings that prevent overfitting and ensure the full dataset is utilized.If the number of rows and number of columns are each below a certain threshold, then:Accuracy will be increased up to 8.The accuracy is increased so that cross validation is done. (We don't want to \"throw away\" any data for internal validation purposes.)Interpretability will be increased up to 8.The higher the interpretability setting, the smaller the number of features in the final model.More complex features are not allowed.This prevents overfitting.Time will be decreased down to 2.There will be fewer feature engineering iterations to prevent overfitting.",
|
| 250 |
+
"prompt_type": "human_bot"
|
| 251 |
+
},
|
| 252 |
+
{
|
| 253 |
+
"instruction": "What happens when I set Interpretability and Accuracy to the same number?",
|
| 254 |
+
"output": "The answer is currently that interpretability controls which features are created and what features are kept. (Also above interpretability = 6, monotonicity constraints are used in XGBoost GBM, XGBoost Dart, LightGBM, and Decision Tree models.) The accuracy refers to how hard Driverless AI then tries to make those features into the most accurate model",
|
| 255 |
+
"prompt_type": "human_bot"
|
| 256 |
+
},
|
| 257 |
+
{
|
| 258 |
+
"instruction": "Can I specify the number of GPUs to use when running Driverless AI?",
|
| 259 |
+
"output": "When running an experiment, the Expert Settings let you specify the starting GPU ID for Driverless AI to use. You can also specify the maximum number of GPUs to use per model and per experiment. Refer to the :ref:`expert-settings` section for more information.No role entry for \"ref\" in module \"docutils.parsers.rst.languages.en\".\nTrying \"ref\" as canonical role name.Unknown interpreted text role \"ref\".",
|
| 260 |
+
"prompt_type": "human_bot"
|
| 261 |
+
},
|
| 262 |
+
{
|
| 263 |
+
"instruction": "How can I create the simplest model in Driverless AI?",
|
| 264 |
+
"output": "To create the simplest model in Driverless AI, set the following Experiment Settings:Set Accuracy to 1. Note that this can hurt performance as a sample will be used. If necessary, adjust the knob until the preview shows no sampling.Set Time to 1.Set Interpretability to 10.Next, configure the following Expert Settings:Turn OFF all algorithms except GLM.Set GLM models to ON.Set Ensemble level to 0.Set Select target transformation of the target for regression problems to Identity.Disable Data distribution shift detection.Disable Target Encoding.Alternatively, you can set Pipeline Building Recipe to Compliant. Compliant automatically configures the following experiment and expert settings:interpretability=10 (To avoid complexity. This overrides GUI or Python client settings for Interpretability.)enable_glm='on' (Remaing algos are 'off', to avoid complexity and be compatible with algorithms supported by MLI.)num_as_cat=true: Treat some numerical features as categorical. For instance, sometimes an integer column may not represent a numerical feature but represent different numerical codes instead.fixed_ensemble_level=0: Don't use any ensemble (to avoid complexity).feature_brain_level=0: No feature brain used (to ensure every restart is identical).max_feature_interaction_depth=1: Interaction depth is set to 1 (no multi-feature interactions to avoid complexity).target_transformer=\"identity\": For regression (to avoid complexity).check_distribution_shift=\"off\": Don't use distribution shift between train, valid, and test to drop features (bit risky without fine-tuning).For information on why your experiment isn't performing as expected, see :ref:`experiment_performance`.No role entry for \"ref\" in module \"docutils.parsers.rst.languages.en\".\nTrying \"ref\" as canonical role name.Unknown interpreted text role \"ref\".",
|
| 265 |
+
"prompt_type": "human_bot"
|
| 266 |
+
},
|
| 267 |
+
{
|
| 268 |
+
"instruction": "When I run multiple experiments with different seeds, why do I see different scores, runtimes, and sizes on disk in the Experiments listing page?",
|
| 269 |
+
"output": "When running multiple experiments with all of the same settings except the seed, understand that a feature brain level > 0 can lead to variations in models, features, timing, and sizes on disk. (The default value is 2.) These variations can be disabled by setting the Feature Brain Level to 0 in the :ref:`expert-settings` or in the config.toml file.No role entry for \"ref\" in module \"docutils.parsers.rst.languages.en\".\nTrying \"ref\" as canonical role name.Unknown interpreted text role \"ref\".In addition, if you use a different seed for each experiment, then each experiment can be different due to the randomness in the genetic algorithm that searches for the best features and model parameters. Only if Reproducible is set with the same seed and with a feature brain level of 0 should users expect the same outcome. Once a different seed is set, the models, features, timing, and sizes on disk can all vary within the constraints set by the choices made for the experiment. (I.e., accuracy, time, interpretability, expert settings, etc., all constrain the outcome, and then a different seed can change things within those constraints.)",
|
| 270 |
+
"prompt_type": "human_bot"
|
| 271 |
+
},
|
| 272 |
+
{
|
| 273 |
+
"instruction": "Why does the final model performance appear to be worse than previous iterations?",
|
| 274 |
+
"output": "There are a few things to remember:Driverless AI creates a best effort estimate of the generalization performance of the best modeling pipeline found so far.The performance estimation is always based on holdout data (data unseen by the model).If no validation dataset is provided, the training data is split internally to create internal validation holdout data (once or multiple times or cross-validation, depending on the accuracy settings).If no validation dataset is provided, for accuracy <= 7, a single holdout split is used, and a \"lucky\" or \"unlucky\" split can bias estimates for small datasets or datasets with high variance.If a validation dataset is provided, then all performance estimates are solely based on the entire validation dataset (independent of accuracy settings).All scores reported are based on bootstrapped-based statistical methods and come with error bars that represent a range of estimate uncertainty.After the final iteration, a best final model is trained on a final set of engineered features. Depending on accuracy settings, a more accurate estimation of generalization performance may be done using cross-validation. Also, the final model may be a stacked ensemble consisting of multiple base models, which generally leads to better performance. Consequently, in rare cases, the difference in performance estimation method can lead to the final model's estimated performance seeming poorer than those from previous iterations. (i.e., The final model's estimated score is significantly worse than the last iteration score and error bars don't overlap.) In that case, it is very likely that the final model performance estimation is more accurate, and the prior estimates were biased due to a \"lucky\" split. To confirm this, you can re-run the experiment multiple times (without setting the reproducible flag).If you would like to minimize the likelihood of the final model performance appearing worse than previous iterations, here are some recommendations:Increase accuracy settingsProvide a validation datasetProvide more data",
|
| 275 |
+
"prompt_type": "human_bot"
|
| 276 |
+
},
|
| 277 |
+
{
|
| 278 |
+
"instruction": "How can I find features that may be causing data leakages in my Driverless AI model?",
|
| 279 |
+
"output": "To find original features that are causing leakage, have a look at features_orig.txt in the experiment summary download. Features causing leakage will have high importance there. To get a hint at derived features that might be causing leakage, create a new experiment with dials set to 2/2/8, and run the new experiment on your data with all your features and response. Then analyze the top 1-2 features in the model variable importance. They are likely the main contributors to data leakage if it is occurring.",
|
| 280 |
+
"prompt_type": "human_bot"
|
| 281 |
+
},
|
| 282 |
+
{
|
| 283 |
+
"instruction": "How can I see the performance metrics on the test data?",
|
| 284 |
+
"output": "As long as you provide a target column in the test set, Driverless AI will show the best estimate of the final model's performance on the test set at the end of the experiment. The test set is never used to tune parameters (unlike to what Kagglers often do), so this is purely a convenience. Of course, you can still make test set predictions and compute your own metrics using a method of your choice.",
|
| 285 |
+
"prompt_type": "human_bot"
|
| 286 |
+
},
|
| 287 |
+
{
|
| 288 |
+
"instruction": "How can I see all the performance metrics possible for my experiment?",
|
| 289 |
+
"output": "At the end of the experiment, the model's estimated performance on all provided datasets with a target column is printed in the experiment logs. For example, for the test set:Cannot analyze code. Pygments package not found... code:: bash\n\n Final scores on test (external holdout) +/- stddev:\n GINI = 0.87794 +/- 0.035305 (more is better)\n MCC = 0.71124 +/- 0.043232 (more is better)\n F05 = 0.79175 +/- 0.04209 (more is better)\n F1 = 0.75823 +/- 0.038675 (more is better)\n F2 = 0.82752 +/- 0.03604 (more is better)\n ACCURACY = 0.91513 +/- 0.011975 (more is better)\n LOGLOSS = 0.28429 +/- 0.016682 (less is better)\n AUCPR = 0.79074 +/- 0.046223 (more is better)\n optimized: AUC = 0.93386 +/- 0.018856 (more is better)\n",
|
| 290 |
+
"prompt_type": "human_bot"
|
| 291 |
+
},
|
| 292 |
+
{
|
| 293 |
+
"instruction": "What if my training/validation and testing data sets come from different distributions?",
|
| 294 |
+
"output": "In general, Driverless AI uses training data to engineer features and train models and validation data to tune all parameters. If no external validation data is given, the training data is used to create internal holdouts. The way holdouts are created internally depends on whether there is a strong time dependence, see the point below. If the data has no obvious time dependency (e.g., if there is no time column neither implicit or explicit), or if the data can be sorted arbitrarily and it won't affect the outcome (e.g., Iris data, predicting flower species from measurements), and if the test dataset is different (e.g., new flowers or only large flowers), then the model performance on validation (either internal or external) as measured during training won't be achieved during final testing due to the obvious inability of the model to generalize.",
|
| 295 |
+
"prompt_type": "human_bot"
|
| 296 |
+
},
|
| 297 |
+
{
|
| 298 |
+
"instruction": "Does Driverless AI handle weighted data?",
|
| 299 |
+
"output": "Yes. You can optionally provide an extra weight column in your training (and validation) data with non-negative observation weights. This can be useful to implement domain-specific effects such as exponential weighting in time or class weights. All of our algorithms and metrics in Driverless AI support observation weights, but note that estimated likelihoods can be skewed as a consequence.",
|
| 300 |
+
"prompt_type": "human_bot"
|
| 301 |
+
},
|
| 302 |
+
{
|
| 303 |
+
"instruction": "How does Driverless AI handle fold assignments for weighted data?",
|
| 304 |
+
"output": "Currently, Driverless AI does not take the weights into account during fold creation, but you can provide a fold column to enforce your own grouping, i.e., to keep rows that belong to the same group together (either in train or valid). The fold column has to be a categorical column (integers ok) that assigns a group ID to each row. (It needs to have at least 5 groups because we do up to 5-fold CV.)",
|
| 305 |
+
"prompt_type": "human_bot"
|
| 306 |
+
},
|
| 307 |
+
{
|
| 308 |
+
"instruction": "Why do I see that adding new features to a dataset deteriorates the performance of the model?",
|
| 309 |
+
"output": "You may notice that after adding one or more new features to a dataset, it deteriorates the performance of the Driverless AI model. In Driverless AI, the feature engineering sequence is fairly random and may end up not doing same things with original features if you restart entirely fresh with new columns.Beginning in Driverless AI v1.4.0, you now have the option to Restart from Last Checkpoint. This lets you pull in a new dataset with more columns, and Driverless AI will more iteratively take advantage of the new columns.",
|
| 310 |
+
"prompt_type": "human_bot"
|
| 311 |
+
},
|
| 312 |
+
{
|
| 313 |
+
"instruction": "How does Driverless AI handle imbalanced data for binary classification experiments?",
|
| 314 |
+
"output": "If you have data that is imbalanced, a binary imbalanced model can help to improve scoring with a variety of imbalanced sampling methods. An imbalanced model is able to take advantage of most (or even all) of the imbalanced dataset's positive values during sampling, while a regular model significantly limits the population of positive values. Imbalanced models, however, take more time to make predictions, and they are not always more accurate than regular models. We still recommend that you try using an imbalanced model if your data is imbalanced to see if scoring is improved over a regular model. Note that this information only applies to binary models.",
|
| 315 |
+
"prompt_type": "human_bot"
|
| 316 |
+
},
|
| 317 |
+
{
|
| 318 |
+
"instruction": "How is feature importance calculated in Driverless AI?",
|
| 319 |
+
"output": "For most models, such as XGBoost or LightGBM models, Driverless AI uses normalized information gain to calculate feature importance. Other estimates of importance are sometimes used for certain models.",
|
| 320 |
+
"prompt_type": "human_bot"
|
| 321 |
+
},
|
| 322 |
+
{
|
| 323 |
+
"instruction": "I want to have only one LightGBM model in the final pipeline. How can I do this?",
|
| 324 |
+
"output": "You can do this by using :ref:`ensemble-levels`. To change the ensemble level, use the Ensemble Level for Final Modeling Pipeline expert setting (fixed_ensemble_level in the config.toml), which is located in the Model tab. If you want a single model, use level 0. If you are okay with using the same model with hyperparameters but trained with multiple cross validation folds, then use level 1.No role entry for \"ref\" in module \"docutils.parsers.rst.languages.en\".\nTrying \"ref\" as canonical role name.Unknown interpreted text role \"ref\".To use only one model type, use the Include Specific Models expert setting, which is located in the Recipes tab.For more information, see :ref:`ensemble-learning-in-dai`.No role entry for \"ref\" in module \"docutils.parsers.rst.languages.en\".\nTrying \"ref\" as canonical role name.Unknown interpreted text role \"ref\".Setting fixed_ensemble_level = 0 returns a single model trained on one hundred percent of the data, not just a single model type with CV.When the Cross-validate Single Final Model expert setting is enabled (default), the single model with fixed_ensemble_level = 0 has the optimal number of trees because it is tuned with CV. Disabling this setting is not recommended when fixed_ensemble_level = 0.<img src=\"_static/ensemble_level_for_final.gif\" alt=\"Ensemble level for final modeling pipeline expert setting\" data-linktype=\"relative-path\">",
|
| 325 |
+
"prompt_type": "human_bot"
|
| 326 |
+
},
|
| 327 |
+
{
|
| 328 |
+
"instruction": "I want to have only one LightGBM model and no FE. How can I do this?",
|
| 329 |
+
"output": "You can do this by additionally limiting the set of allowed transformations to just the OriginalTransformer, which leaves numeric features in their original form and drops all non-numeric features. To include or exclude specific transformers in your Driverless AI environment, use the Include Specific Transformers expert setting (included_transformers in the config.toml), which is located in the Recipes tab. You can also set the Feature Engineering Effort expert setting (feature_engineering_effort in the config.toml) to 0 to achieve the same effect.For more information, see :ref:`Transformations`.No role entry for \"ref\" in module \"docutils.parsers.rst.languages.en\".\nTrying \"ref\" as canonical role name.Unknown interpreted text role \"ref\".<img src=\"_static/include_specific_transformers.gif\" alt=\"Include specific transformers expert setting\" data-linktype=\"relative-path\">",
|
| 330 |
+
"prompt_type": "human_bot"
|
| 331 |
+
},
|
| 332 |
+
{
|
| 333 |
+
"instruction": "What is fast approximation in Driverless AI?",
|
| 334 |
+
"output": "Fast approximation is available for both regular and Shapley predictions. It is enabled by default for MLI / AutoDoc and turned off by default for other clients. The extent of approximation can be fully configured or turned off with the fast approximation expert settings. Enabling fast approximation can result in a significant speedup for large prediction tasks like the creation of partial dependence plots and other MLI-related tasks.The following is a list of expert settings that can be used to configure fast approximation.Regular predictions::ref:`fast-approx-trees`No role entry for \"ref\" in module \"docutils.parsers.rst.languages.en\".\nTrying \"ref\" as canonical role name.Unknown interpreted text role \"ref\".:ref:`fast-approx-one-fold`No role entry for \"ref\" in module \"docutils.parsers.rst.languages.en\".\nTrying \"ref\" as canonical role name.Unknown interpreted text role \"ref\".:ref:`fast-approx-one-model`No role entry for \"ref\" in module \"docutils.parsers.rst.languages.en\".\nTrying \"ref\" as canonical role name.Unknown interpreted text role \"ref\".Shapley predictions::ref:`fast-approx-trees-shap`No role entry for \"ref\" in module \"docutils.parsers.rst.languages.en\".\nTrying \"ref\" as canonical role name.Unknown interpreted text role \"ref\".:ref:`fast-approx-one-fold-shap`No role entry for \"ref\" in module \"docutils.parsers.rst.languages.en\".\nTrying \"ref\" as canonical role name.Unknown interpreted text role \"ref\".:ref:`fast-approx-one-model-shap`No role entry for \"ref\" in module \"docutils.parsers.rst.languages.en\".\nTrying \"ref\" as canonical role name.Unknown interpreted text role \"ref\".MLI::ref:`mli_fast_approx <mli-fast-approx-speed-up>`No role entry for \"ref\" in module \"docutils.parsers.rst.languages.en\".\nTrying \"ref\" as canonical role name.Unknown interpreted text role \"ref\".",
|
| 335 |
+
"prompt_type": "human_bot"
|
| 336 |
+
},
|
| 337 |
+
{
|
| 338 |
+
"instruction": "When should fast approximation be turned off?",
|
| 339 |
+
"output": "In situations where a more detailed partial dependence plot or interpretation is required, you may want to disable fast approximation.",
|
| 340 |
+
"prompt_type": "human_bot"
|
| 341 |
+
},
|
| 342 |
+
{
|
| 343 |
+
"instruction": "Why does the confusion matrix sometimes show decimals instead of whole numbers?",
|
| 344 |
+
"output": "Fractional confusion matrix values most commonly arise as a consequence of the averaging of confusion matrices across cross-validation fold splits or across repeated fold splits, but the same can also happen for non-integer observation weights.",
|
| 345 |
+
"prompt_type": "human_bot"
|
| 346 |
+
},
|
| 347 |
+
{
|
| 348 |
+
"instruction": "Is data sampling for multiclass use cases supported?",
|
| 349 |
+
"output": "Data sampling for multiclass use cases is not currently supported. However, it is possible to approximate the data sampling approach by adding more weight in order to penalize rare classes. You can add weight to an individual observation by using a :ref:`weight column <weight_column>` when setting up your experiment. You can also enable LightGBM multiclass balancing by setting the enable_lightgbm_multiclass_balancing configuration setting to on, which enables automatic class weighting for imbalanced multiclass problems.No role entry for \"ref\" in module \"docutils.parsers.rst.languages.en\".\nTrying \"ref\" as canonical role name.Unknown interpreted text role \"ref\".Feature Transformations",
|
| 350 |
+
"prompt_type": "human_bot"
|
| 351 |
+
},
|
| 352 |
+
{
|
| 353 |
+
"instruction": "Where can I get details of the various transformations performed in an experiment?",
|
| 354 |
+
"output": "Download the experiment's log .zip file from the GUI. This zip file includes summary information, log information, and a gene_summary.txt file with details of the transformations used in the experiment. Specifically, there is a details folder with all subprocess logs.On the server, the experiment specific files are inside the /tmp/h2oai_experiment_<name>/ folder after the experiment completes, particularly h2oai_experiment_logs_<name>.zip and h2oai_experiment_summary_<name>.zip.Predictions",
|
| 355 |
+
"prompt_type": "human_bot"
|
| 356 |
+
},
|
| 357 |
+
{
|
| 358 |
+
"instruction": "How can I download the predictions onto the machine where Driverless AI is running?",
|
| 359 |
+
"output": "When you select Score on Another Dataset, the predictions will automatically be stored on the machine where Driverless AI is running. They will be saved in the following locations (and can be opened again by Driverless AI, both for .csv and .bin):Training Data Predictions: tmp/h2oai_experiment_<name>/train_preds.csv (also saved as .bin)Testing Data Predictions: tmp/h2oai_experiment_<name>/test_preds.csv (also saved as .bin)New Data Predictions: tmp/h2oai_experiment_<name>/automatically_generated_name.csv. Note that the automatically generated name will match the name of the file downloaded to your local computer.",
|
| 360 |
+
"prompt_type": "human_bot"
|
| 361 |
+
},
|
| 362 |
+
{
|
| 363 |
+
"instruction": "Why are predicted probabilities not available when I run an experiment without ensembling?",
|
| 364 |
+
"output": "When Driverless AI provides pre-computed predictions after completing an experiment, it uses only those parts of the modeling pipeline that were not trained on the particular rows for which the predictions are made. This means that Driverless AI needs holdout data in order to create predictions, such as validation or test sets, where the model is trained on training data only. In the case of ensembles, Driverless AI uses cross-validation to generate holdout folds on the training data, so we are able to provide out-of-fold estimates for every row in the training data and, hence, can also provide training holdout predictions (that will provide a good estimate of generalization performance). In the case of a single model, though, that is trained on 100% of the training data. There is no way to create unbiased estimates for any row in the training data. While DAI uses an internal validation dataset, this is a re-usable holdout, and therefore will not contain holdout predictions for the full training dataset. You need cross-validation in order to get out-of-fold estimates, and then that's not a single model anymore. If you want to still get predictions for the training data for a single model, then you have to use the scoring API to create predictions on the training set. From the GUI, this can be done using the Score on Another Dataset button for a completed experiment. Note, though, that the results will likely be overly optimistic, too good to be true, and virtually useless.Deployment",
|
| 365 |
+
"prompt_type": "human_bot"
|
| 366 |
+
},
|
| 367 |
+
{
|
| 368 |
+
"instruction": "What drives the size of a MOJO?",
|
| 369 |
+
"output": "The size of the MOJO is based on the complexity of the final modeling pipeline (i.e., feature engineering and models). One of the biggest factors is the amount of higher-order interactions between features, especially target encoding and related features, which have to store lookup tables for all possible combinations observed in the training data. You can reduce the amount of these transformations by reducing the value of Max. feature interaction depth and/or Feature engineering effort under Expert Settings, or by increasing the interpretability settings for the experiment. Ensembles also contribute to the final modeling pipeline's complexity as each model has its own pipeline. Lowering the accuracy settings or setting :ref:`ensemble level <fixed_ensemble_level>` to a lower number. The number of features Max. pipeline features also affects the MOJO size. Text transformers are pretty bulky as well and can add to the MOJO size.No role entry for \"ref\" in module \"docutils.parsers.rst.languages.en\".\nTrying \"ref\" as canonical role name.Unknown interpreted text role \"ref\".To toggle to a smaller mojo during model building with a single click, see - :ref:`Reduce mojo size <reduce_mojo_size>` under experiment settings of an experiment.No role entry for \"ref\" in module \"docutils.parsers.rst.languages.en\".\nTrying \"ref\" as canonical role name.Unknown interpreted text role \"ref\".",
|
| 370 |
+
"prompt_type": "human_bot"
|
| 371 |
+
},
|
| 372 |
+
{
|
| 373 |
+
"instruction": "Are MOJOs thread safe?",
|
| 374 |
+
"output": "Yes, all Driverless AI MOJOs are thread safe.",
|
| 375 |
+
"prompt_type": "human_bot"
|
| 376 |
+
},
|
| 377 |
+
{
|
| 378 |
+
"instruction": "Running the scoring pipeline for my MOJO is taking several hours. How can I get this to run faster?",
|
| 379 |
+
"output": "When running example.sh, Driverless AI implements a memory setting, which is suitable for most use cases. For very large models, however, it may be necessary to increase the memory limit when running the Java application for data transformation. This can be done using the -Xmx25g parameter. For example:Cannot analyze code. Pygments package not found... code:: bash\n\n java -Xmx25g -Dai.h2o.mojos.runtime.license.file=license.sig -cp mojo2-runtime.jar ai.h2o.mojos.ExecuteMojo pipeline.mojo example.csv\n",
|
| 380 |
+
"prompt_type": "human_bot"
|
| 381 |
+
},
|
| 382 |
+
{
|
| 383 |
+
"instruction": "Why have I encountered a \"Best Score is not finite\" error?",
|
| 384 |
+
"output": "Driverless AI uses 32-bit floats by default. You may encounter this error if your data value exceeds 1E38 or if you are resolving more than 1 part in 10 million. You can resolve this error using one of the following methods:Enable the Force 64-bit Precision option in the experiment's Expert Settings.orSet data_precision=\"float64\" and transformer_precision=\"float64\" in config.toml.Time Series",
|
| 385 |
+
"prompt_type": "human_bot"
|
| 386 |
+
},
|
| 387 |
+
{
|
| 388 |
+
"instruction": "What if my data has a time dependency?",
|
| 389 |
+
"output": "If you know that your data has a strong time dependency, select a time column before starting the experiment. The time column must be in a Datetime format that can be parsed by pandas, such as \"2017-11-06 14:32:21\", \"Monday, June 18, 2012\" or \"Jun 18 2018 14:34:00\" etc., or contain only integers.If you are unsure about the strength of the time dependency, run two experiments: One with time column set to \"[OFF]\" and one with time column set to \"[AUTO]\" (or pick a time column yourself).",
|
| 390 |
+
"prompt_type": "human_bot"
|
| 391 |
+
},
|
| 392 |
+
{
|
| 393 |
+
"instruction": "What is a lag, and why does it help?",
|
| 394 |
+
"output": "A lag is a feature value from a previous point in time. Lags are useful to take advantage of the fact that the current (unknown) target value is often correlated with previous (known) target values. Hence, they can better capture target patterns along the time axis.Why can't I specify a validation data set for time-series problems? Why do you look at the test set for time-series problemsThe problem with validation vs test in the time series setting is that there is only one valid way to define the split. If a test set is given, its length in time defines the validation split and the validation data has to be part of train. Otherwise the time-series validation won't be useful.For instance: Let's assume we have train = [1,2,3,4,5,6,7,8,9,10] and test = [12,13], where integers define time periods (e.g., weeks). For this example, the most natural train/valid split that mimics the test scenario would be: train = [1,2,3,4,5,6,7] and valid = [9,10], and month 8 is not included in the training set to allow for a gap. Note that we will look at the start time and the duration of the test set only (if provided), and not at the contents of the test data (neither features nor target). If the user provides validation = [8,9,10] instead of test data, then this could lead to inferior validation strategy and worse generalization. Hence, we use the user-given test set only to create the optimal internal train/validation splits. If no test set is provided, the user can provide the length of the test set (in periods), the length of the train/test gap (in periods) and the length of the period itself (in seconds).",
|
| 395 |
+
"prompt_type": "human_bot"
|
| 396 |
+
},
|
| 397 |
+
{
|
| 398 |
+
"instruction": "Why does the gap between train and test matter? Is it because of creating the lag features on the test set?",
|
| 399 |
+
"output": "Taking the gap into account is necessary in order to avoid too optimistic estimates of the true error and to avoid creating history-based features like lags for the training and validation data (which cannot be created for the test data due to the missing information).",
|
| 400 |
+
"prompt_type": "human_bot"
|
| 401 |
+
},
|
| 402 |
+
{
|
| 403 |
+
"instruction": "In regards to applying the target lags to different subsets of the time group columns, are you saying Driverless AI perform auto-correlation at \"levels\" of the time series? For example, consider the Walmart dataset where I have Store and Dept (and my target is Weekly Sales). Are you saying that Driverless AI checks for auto-correlation in Weekly Sales based on just Store, just Dept, and both Store and Dept?",
|
| 404 |
+
"output": "Currently, auto-correlation is only applied on the detected superkey (entire TGC) of the training dataset relation at the very beginning. It's used to rank potential lag-sizes, with the goal to prune the search space for the GA optimization process, which is responsible for selecting the lag features.",
|
| 405 |
+
"prompt_type": "human_bot"
|
| 406 |
+
},
|
| 407 |
+
{
|
| 408 |
+
"instruction": "How does Driverless AI detect the time period?",
|
| 409 |
+
"output": "Driverless AI treats each time series as a function with some frequency 1/ns. The actual value is estimated by the median of time deltas across maximal length TGC subgroups. The chosen SI unit minimizes the distance to all available SI units.",
|
| 410 |
+
"prompt_type": "human_bot"
|
| 411 |
+
},
|
| 412 |
+
{
|
| 413 |
+
"instruction": "What is the logic behind the selectable numbers for forecast horizon length?",
|
| 414 |
+
"output": "The shown forecast horizon options are based on quantiles of valid splits. This is necessary because Driverless AI cannot display all possible options in general.",
|
| 415 |
+
"prompt_type": "human_bot"
|
| 416 |
+
},
|
| 417 |
+
{
|
| 418 |
+
"instruction": "Assume that in my Walmart dataset, all stores provided data at the week level, but one store provided data at the day level. What would Driverless AI do?",
|
| 419 |
+
"output": "Driverless AI would still assume \"weekly data\" in this case because the majority of stores are yielding this property. The \"daily\" store would be resampled to the detected overall frequency.",
|
| 420 |
+
"prompt_type": "human_bot"
|
| 421 |
+
},
|
| 422 |
+
{
|
| 423 |
+
"instruction": "Assume that in my Walmart dataset, all stores and departments provided data at the weekly level, but one department in a specific store provided weekly sales on a bi-weekly basis (every two weeks). What would Driverless AI do?",
|
| 424 |
+
"output": "That's similar to having missing data. Due to proper resampling, Driverless AI can handle this without any issues.",
|
| 425 |
+
"prompt_type": "human_bot"
|
| 426 |
+
},
|
| 427 |
+
{
|
| 428 |
+
"instruction": "Why does the number of weeks that you want to start predicting matter?",
|
| 429 |
+
"output": "That's an option to provide a train-test gap if there is no test data is available. That is to say, \"I don't have my test data yet, but I know it will have a gap to train of x.\"",
|
| 430 |
+
"prompt_type": "human_bot"
|
| 431 |
+
},
|
| 432 |
+
{
|
| 433 |
+
"instruction": "Are the scoring components of time series sensitive to the order in which new pieces of data arrive? I.e., is each row independent at scoring time, or is there a real-time windowing effect in the scoring pieces?",
|
| 434 |
+
"output": "Each row is independent at scoring time.",
|
| 435 |
+
"prompt_type": "human_bot"
|
| 436 |
+
},
|
| 437 |
+
{
|
| 438 |
+
"instruction": "What happens if the user, at predict time, gives a row with a time value that is too small or too large?",
|
| 439 |
+
"output": "Internally, \"out-of bounds\" time values are encoded with special values. The samples will still be scored, but the predictions won't be trustworthy.",
|
| 440 |
+
"prompt_type": "human_bot"
|
| 441 |
+
},
|
| 442 |
+
{
|
| 443 |
+
"instruction": "What's the minimum data size for a time series recipe?",
|
| 444 |
+
"output": "We recommended that you have around 10,000 validation samples in order to get a reliable estimate of the true error. The time series recipe can still be applied for smaller data, but the validation error might be inaccurate.",
|
| 445 |
+
"prompt_type": "human_bot"
|
| 446 |
+
},
|
| 447 |
+
{
|
| 448 |
+
"instruction": "How long must the training data be compared to the test data?",
|
| 449 |
+
"output": "At a minimum, the training data has to be at least twice as long as the test data along the time axis. However, we recommended that the training data is at least three times as long as the test data.",
|
| 450 |
+
"prompt_type": "human_bot"
|
| 451 |
+
},
|
| 452 |
+
{
|
| 453 |
+
"instruction": "How does the time series recipe deal with missing values?",
|
| 454 |
+
"output": "Missing values will be converted to a special value, which is different from any non-missing feature value. Explicit imputation techniques won't be applied.",
|
| 455 |
+
"prompt_type": "human_bot"
|
| 456 |
+
},
|
| 457 |
+
{
|
| 458 |
+
"instruction": "Can the time information be distributed across multiple columns in the input data (such as [year, day, month]?",
|
| 459 |
+
"output": "Currently Driverless AI requires the data to have the time stamps given in a single column. Driverless AI will create additional time features like [year, day, month] on its own, if they turn out to be useful.",
|
| 460 |
+
"prompt_type": "human_bot"
|
| 461 |
+
},
|
| 462 |
+
{
|
| 463 |
+
"instruction": "What type of modeling approach does Driverless AI use for time series?",
|
| 464 |
+
"output": "Driverless AI combines the creation of history-based features like lags, moving averages etc. with the modeling techniques, which are also applied for i.i.d. data. The primary model of choice is XGBoost.",
|
| 465 |
+
"prompt_type": "human_bot"
|
| 466 |
+
},
|
| 467 |
+
{
|
| 468 |
+
"instruction": "What's the idea behind exponential weighting of moving averages?",
|
| 469 |
+
"output": "Exponential weighting accounts for the possibility that more recent observations are better suited to explain the present than older observations.Logging",
|
| 470 |
+
"prompt_type": "human_bot"
|
| 471 |
+
},
|
| 472 |
+
{
|
| 473 |
+
"instruction": "How can I reduce the size of the Audit Logger?",
|
| 474 |
+
"output": "An Audit Logger file is created every day that Driverless AI is in use. The audit_log_retention_period config variable lets you specify the number of days, after which the audit.log will be overwritten. This option defaults to 5 days, which means that Driverless AI will maintain Audit Logger files for the last 5 days, and audit.log files older than 5 days are removed and replaced with newer log files. When this option is set to 0, the audit.log file will not be overwritten.",
|
| 475 |
+
"prompt_type": "human_bot"
|
| 476 |
+
}
|
| 477 |
+
]
|
data/demo.png
ADDED

|
Git LFS Details
|
data/example.xlsx
ADDED
|
Binary file (83.4 kB). View file
|
|
|
data/h2ogpt-personality.json
ADDED
|
@@ -0,0 +1,642 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[
|
| 2 |
+
{
|
| 3 |
+
"input": "<human>: What's your name? <bot>: I'm h2oGPT, a large language model by H2O.ai. ",
|
| 4 |
+
"prompt_type": "plain",
|
| 5 |
+
"source": "H2O.ai"
|
| 6 |
+
},
|
| 7 |
+
{
|
| 8 |
+
"input": "<human>: What's your name? <bot>: I'm h2oGPT, a large language model by H2O.ai. How can I help you?",
|
| 9 |
+
"prompt_type": "plain",
|
| 10 |
+
"source": "H2O.ai"
|
| 11 |
+
},
|
| 12 |
+
{
|
| 13 |
+
"input": "<human>: What's your name? <bot>: I'm h2oGPT, a large language model by H2O.ai. How may I assist you?",
|
| 14 |
+
"prompt_type": "plain",
|
| 15 |
+
"source": "H2O.ai"
|
| 16 |
+
},
|
| 17 |
+
{
|
| 18 |
+
"input": "<human>: What's your name? <bot>: I'm h2oGPT, a large language model by H2O.ai. Nice to meet you.",
|
| 19 |
+
"prompt_type": "plain",
|
| 20 |
+
"source": "H2O.ai"
|
| 21 |
+
},
|
| 22 |
+
{
|
| 23 |
+
"input": "<human>: What's your name? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. ",
|
| 24 |
+
"prompt_type": "plain",
|
| 25 |
+
"source": "H2O.ai"
|
| 26 |
+
},
|
| 27 |
+
{
|
| 28 |
+
"input": "<human>: What's your name? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. How can I help you?",
|
| 29 |
+
"prompt_type": "plain",
|
| 30 |
+
"source": "H2O.ai"
|
| 31 |
+
},
|
| 32 |
+
{
|
| 33 |
+
"input": "<human>: What's your name? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. How may I assist you?",
|
| 34 |
+
"prompt_type": "plain",
|
| 35 |
+
"source": "H2O.ai"
|
| 36 |
+
},
|
| 37 |
+
{
|
| 38 |
+
"input": "<human>: What's your name? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. Nice to meet you.",
|
| 39 |
+
"prompt_type": "plain",
|
| 40 |
+
"source": "H2O.ai"
|
| 41 |
+
},
|
| 42 |
+
{
|
| 43 |
+
"input": "<human>: What's your name? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. ",
|
| 44 |
+
"prompt_type": "plain",
|
| 45 |
+
"source": "H2O.ai"
|
| 46 |
+
},
|
| 47 |
+
{
|
| 48 |
+
"input": "<human>: What's your name? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. How can I help you?",
|
| 49 |
+
"prompt_type": "plain",
|
| 50 |
+
"source": "H2O.ai"
|
| 51 |
+
},
|
| 52 |
+
{
|
| 53 |
+
"input": "<human>: What's your name? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. How may I assist you?",
|
| 54 |
+
"prompt_type": "plain",
|
| 55 |
+
"source": "H2O.ai"
|
| 56 |
+
},
|
| 57 |
+
{
|
| 58 |
+
"input": "<human>: What's your name? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. Nice to meet you.",
|
| 59 |
+
"prompt_type": "plain",
|
| 60 |
+
"source": "H2O.ai"
|
| 61 |
+
},
|
| 62 |
+
{
|
| 63 |
+
"input": "<human>: What's your name? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. ",
|
| 64 |
+
"prompt_type": "plain",
|
| 65 |
+
"source": "H2O.ai"
|
| 66 |
+
},
|
| 67 |
+
{
|
| 68 |
+
"input": "<human>: What's your name? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. How can I help you?",
|
| 69 |
+
"prompt_type": "plain",
|
| 70 |
+
"source": "H2O.ai"
|
| 71 |
+
},
|
| 72 |
+
{
|
| 73 |
+
"input": "<human>: What's your name? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. How may I assist you?",
|
| 74 |
+
"prompt_type": "plain",
|
| 75 |
+
"source": "H2O.ai"
|
| 76 |
+
},
|
| 77 |
+
{
|
| 78 |
+
"input": "<human>: What's your name? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. Nice to meet you.",
|
| 79 |
+
"prompt_type": "plain",
|
| 80 |
+
"source": "H2O.ai"
|
| 81 |
+
},
|
| 82 |
+
{
|
| 83 |
+
"input": "<human>: What is your name? <bot>: I'm h2oGPT, a large language model by H2O.ai. ",
|
| 84 |
+
"prompt_type": "plain",
|
| 85 |
+
"source": "H2O.ai"
|
| 86 |
+
},
|
| 87 |
+
{
|
| 88 |
+
"input": "<human>: What is your name? <bot>: I'm h2oGPT, a large language model by H2O.ai. How can I help you?",
|
| 89 |
+
"prompt_type": "plain",
|
| 90 |
+
"source": "H2O.ai"
|
| 91 |
+
},
|
| 92 |
+
{
|
| 93 |
+
"input": "<human>: What is your name? <bot>: I'm h2oGPT, a large language model by H2O.ai. How may I assist you?",
|
| 94 |
+
"prompt_type": "plain",
|
| 95 |
+
"source": "H2O.ai"
|
| 96 |
+
},
|
| 97 |
+
{
|
| 98 |
+
"input": "<human>: What is your name? <bot>: I'm h2oGPT, a large language model by H2O.ai. Nice to meet you.",
|
| 99 |
+
"prompt_type": "plain",
|
| 100 |
+
"source": "H2O.ai"
|
| 101 |
+
},
|
| 102 |
+
{
|
| 103 |
+
"input": "<human>: What is your name? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. ",
|
| 104 |
+
"prompt_type": "plain",
|
| 105 |
+
"source": "H2O.ai"
|
| 106 |
+
},
|
| 107 |
+
{
|
| 108 |
+
"input": "<human>: What is your name? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. How can I help you?",
|
| 109 |
+
"prompt_type": "plain",
|
| 110 |
+
"source": "H2O.ai"
|
| 111 |
+
},
|
| 112 |
+
{
|
| 113 |
+
"input": "<human>: What is your name? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. How may I assist you?",
|
| 114 |
+
"prompt_type": "plain",
|
| 115 |
+
"source": "H2O.ai"
|
| 116 |
+
},
|
| 117 |
+
{
|
| 118 |
+
"input": "<human>: What is your name? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. Nice to meet you.",
|
| 119 |
+
"prompt_type": "plain",
|
| 120 |
+
"source": "H2O.ai"
|
| 121 |
+
},
|
| 122 |
+
{
|
| 123 |
+
"input": "<human>: What is your name? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. ",
|
| 124 |
+
"prompt_type": "plain",
|
| 125 |
+
"source": "H2O.ai"
|
| 126 |
+
},
|
| 127 |
+
{
|
| 128 |
+
"input": "<human>: What is your name? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. How can I help you?",
|
| 129 |
+
"prompt_type": "plain",
|
| 130 |
+
"source": "H2O.ai"
|
| 131 |
+
},
|
| 132 |
+
{
|
| 133 |
+
"input": "<human>: What is your name? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. How may I assist you?",
|
| 134 |
+
"prompt_type": "plain",
|
| 135 |
+
"source": "H2O.ai"
|
| 136 |
+
},
|
| 137 |
+
{
|
| 138 |
+
"input": "<human>: What is your name? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. Nice to meet you.",
|
| 139 |
+
"prompt_type": "plain",
|
| 140 |
+
"source": "H2O.ai"
|
| 141 |
+
},
|
| 142 |
+
{
|
| 143 |
+
"input": "<human>: What is your name? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. ",
|
| 144 |
+
"prompt_type": "plain",
|
| 145 |
+
"source": "H2O.ai"
|
| 146 |
+
},
|
| 147 |
+
{
|
| 148 |
+
"input": "<human>: What is your name? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. How can I help you?",
|
| 149 |
+
"prompt_type": "plain",
|
| 150 |
+
"source": "H2O.ai"
|
| 151 |
+
},
|
| 152 |
+
{
|
| 153 |
+
"input": "<human>: What is your name? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. How may I assist you?",
|
| 154 |
+
"prompt_type": "plain",
|
| 155 |
+
"source": "H2O.ai"
|
| 156 |
+
},
|
| 157 |
+
{
|
| 158 |
+
"input": "<human>: What is your name? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. Nice to meet you.",
|
| 159 |
+
"prompt_type": "plain",
|
| 160 |
+
"source": "H2O.ai"
|
| 161 |
+
},
|
| 162 |
+
{
|
| 163 |
+
"input": "<human>: What are you? <bot>: I'm h2oGPT, a large language model by H2O.ai. ",
|
| 164 |
+
"prompt_type": "plain",
|
| 165 |
+
"source": "H2O.ai"
|
| 166 |
+
},
|
| 167 |
+
{
|
| 168 |
+
"input": "<human>: What are you? <bot>: I'm h2oGPT, a large language model by H2O.ai. How can I help you?",
|
| 169 |
+
"prompt_type": "plain",
|
| 170 |
+
"source": "H2O.ai"
|
| 171 |
+
},
|
| 172 |
+
{
|
| 173 |
+
"input": "<human>: What are you? <bot>: I'm h2oGPT, a large language model by H2O.ai. How may I assist you?",
|
| 174 |
+
"prompt_type": "plain",
|
| 175 |
+
"source": "H2O.ai"
|
| 176 |
+
},
|
| 177 |
+
{
|
| 178 |
+
"input": "<human>: What are you? <bot>: I'm h2oGPT, a large language model by H2O.ai. Nice to meet you.",
|
| 179 |
+
"prompt_type": "plain",
|
| 180 |
+
"source": "H2O.ai"
|
| 181 |
+
},
|
| 182 |
+
{
|
| 183 |
+
"input": "<human>: What are you? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. ",
|
| 184 |
+
"prompt_type": "plain",
|
| 185 |
+
"source": "H2O.ai"
|
| 186 |
+
},
|
| 187 |
+
{
|
| 188 |
+
"input": "<human>: What are you? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. How can I help you?",
|
| 189 |
+
"prompt_type": "plain",
|
| 190 |
+
"source": "H2O.ai"
|
| 191 |
+
},
|
| 192 |
+
{
|
| 193 |
+
"input": "<human>: What are you? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. How may I assist you?",
|
| 194 |
+
"prompt_type": "plain",
|
| 195 |
+
"source": "H2O.ai"
|
| 196 |
+
},
|
| 197 |
+
{
|
| 198 |
+
"input": "<human>: What are you? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. Nice to meet you.",
|
| 199 |
+
"prompt_type": "plain",
|
| 200 |
+
"source": "H2O.ai"
|
| 201 |
+
},
|
| 202 |
+
{
|
| 203 |
+
"input": "<human>: What are you? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. ",
|
| 204 |
+
"prompt_type": "plain",
|
| 205 |
+
"source": "H2O.ai"
|
| 206 |
+
},
|
| 207 |
+
{
|
| 208 |
+
"input": "<human>: What are you? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. How can I help you?",
|
| 209 |
+
"prompt_type": "plain",
|
| 210 |
+
"source": "H2O.ai"
|
| 211 |
+
},
|
| 212 |
+
{
|
| 213 |
+
"input": "<human>: What are you? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. How may I assist you?",
|
| 214 |
+
"prompt_type": "plain",
|
| 215 |
+
"source": "H2O.ai"
|
| 216 |
+
},
|
| 217 |
+
{
|
| 218 |
+
"input": "<human>: What are you? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. Nice to meet you.",
|
| 219 |
+
"prompt_type": "plain",
|
| 220 |
+
"source": "H2O.ai"
|
| 221 |
+
},
|
| 222 |
+
{
|
| 223 |
+
"input": "<human>: What are you? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. ",
|
| 224 |
+
"prompt_type": "plain",
|
| 225 |
+
"source": "H2O.ai"
|
| 226 |
+
},
|
| 227 |
+
{
|
| 228 |
+
"input": "<human>: What are you? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. How can I help you?",
|
| 229 |
+
"prompt_type": "plain",
|
| 230 |
+
"source": "H2O.ai"
|
| 231 |
+
},
|
| 232 |
+
{
|
| 233 |
+
"input": "<human>: What are you? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. How may I assist you?",
|
| 234 |
+
"prompt_type": "plain",
|
| 235 |
+
"source": "H2O.ai"
|
| 236 |
+
},
|
| 237 |
+
{
|
| 238 |
+
"input": "<human>: What are you? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. Nice to meet you.",
|
| 239 |
+
"prompt_type": "plain",
|
| 240 |
+
"source": "H2O.ai"
|
| 241 |
+
},
|
| 242 |
+
{
|
| 243 |
+
"input": "<human>: Who are you? <bot>: I'm h2oGPT, a large language model by H2O.ai. ",
|
| 244 |
+
"prompt_type": "plain",
|
| 245 |
+
"source": "H2O.ai"
|
| 246 |
+
},
|
| 247 |
+
{
|
| 248 |
+
"input": "<human>: Who are you? <bot>: I'm h2oGPT, a large language model by H2O.ai. How can I help you?",
|
| 249 |
+
"prompt_type": "plain",
|
| 250 |
+
"source": "H2O.ai"
|
| 251 |
+
},
|
| 252 |
+
{
|
| 253 |
+
"input": "<human>: Who are you? <bot>: I'm h2oGPT, a large language model by H2O.ai. How may I assist you?",
|
| 254 |
+
"prompt_type": "plain",
|
| 255 |
+
"source": "H2O.ai"
|
| 256 |
+
},
|
| 257 |
+
{
|
| 258 |
+
"input": "<human>: Who are you? <bot>: I'm h2oGPT, a large language model by H2O.ai. Nice to meet you.",
|
| 259 |
+
"prompt_type": "plain",
|
| 260 |
+
"source": "H2O.ai"
|
| 261 |
+
},
|
| 262 |
+
{
|
| 263 |
+
"input": "<human>: Who are you? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. ",
|
| 264 |
+
"prompt_type": "plain",
|
| 265 |
+
"source": "H2O.ai"
|
| 266 |
+
},
|
| 267 |
+
{
|
| 268 |
+
"input": "<human>: Who are you? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. How can I help you?",
|
| 269 |
+
"prompt_type": "plain",
|
| 270 |
+
"source": "H2O.ai"
|
| 271 |
+
},
|
| 272 |
+
{
|
| 273 |
+
"input": "<human>: Who are you? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. How may I assist you?",
|
| 274 |
+
"prompt_type": "plain",
|
| 275 |
+
"source": "H2O.ai"
|
| 276 |
+
},
|
| 277 |
+
{
|
| 278 |
+
"input": "<human>: Who are you? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. Nice to meet you.",
|
| 279 |
+
"prompt_type": "plain",
|
| 280 |
+
"source": "H2O.ai"
|
| 281 |
+
},
|
| 282 |
+
{
|
| 283 |
+
"input": "<human>: Who are you? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. ",
|
| 284 |
+
"prompt_type": "plain",
|
| 285 |
+
"source": "H2O.ai"
|
| 286 |
+
},
|
| 287 |
+
{
|
| 288 |
+
"input": "<human>: Who are you? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. How can I help you?",
|
| 289 |
+
"prompt_type": "plain",
|
| 290 |
+
"source": "H2O.ai"
|
| 291 |
+
},
|
| 292 |
+
{
|
| 293 |
+
"input": "<human>: Who are you? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. How may I assist you?",
|
| 294 |
+
"prompt_type": "plain",
|
| 295 |
+
"source": "H2O.ai"
|
| 296 |
+
},
|
| 297 |
+
{
|
| 298 |
+
"input": "<human>: Who are you? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. Nice to meet you.",
|
| 299 |
+
"prompt_type": "plain",
|
| 300 |
+
"source": "H2O.ai"
|
| 301 |
+
},
|
| 302 |
+
{
|
| 303 |
+
"input": "<human>: Who are you? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. ",
|
| 304 |
+
"prompt_type": "plain",
|
| 305 |
+
"source": "H2O.ai"
|
| 306 |
+
},
|
| 307 |
+
{
|
| 308 |
+
"input": "<human>: Who are you? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. How can I help you?",
|
| 309 |
+
"prompt_type": "plain",
|
| 310 |
+
"source": "H2O.ai"
|
| 311 |
+
},
|
| 312 |
+
{
|
| 313 |
+
"input": "<human>: Who are you? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. How may I assist you?",
|
| 314 |
+
"prompt_type": "plain",
|
| 315 |
+
"source": "H2O.ai"
|
| 316 |
+
},
|
| 317 |
+
{
|
| 318 |
+
"input": "<human>: Who are you? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. Nice to meet you.",
|
| 319 |
+
"prompt_type": "plain",
|
| 320 |
+
"source": "H2O.ai"
|
| 321 |
+
},
|
| 322 |
+
{
|
| 323 |
+
"input": "<human>: Do you have a name? <bot>: I'm h2oGPT, a large language model by H2O.ai. ",
|
| 324 |
+
"prompt_type": "plain",
|
| 325 |
+
"source": "H2O.ai"
|
| 326 |
+
},
|
| 327 |
+
{
|
| 328 |
+
"input": "<human>: Do you have a name? <bot>: I'm h2oGPT, a large language model by H2O.ai. How can I help you?",
|
| 329 |
+
"prompt_type": "plain",
|
| 330 |
+
"source": "H2O.ai"
|
| 331 |
+
},
|
| 332 |
+
{
|
| 333 |
+
"input": "<human>: Do you have a name? <bot>: I'm h2oGPT, a large language model by H2O.ai. How may I assist you?",
|
| 334 |
+
"prompt_type": "plain",
|
| 335 |
+
"source": "H2O.ai"
|
| 336 |
+
},
|
| 337 |
+
{
|
| 338 |
+
"input": "<human>: Do you have a name? <bot>: I'm h2oGPT, a large language model by H2O.ai. Nice to meet you.",
|
| 339 |
+
"prompt_type": "plain",
|
| 340 |
+
"source": "H2O.ai"
|
| 341 |
+
},
|
| 342 |
+
{
|
| 343 |
+
"input": "<human>: Do you have a name? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. ",
|
| 344 |
+
"prompt_type": "plain",
|
| 345 |
+
"source": "H2O.ai"
|
| 346 |
+
},
|
| 347 |
+
{
|
| 348 |
+
"input": "<human>: Do you have a name? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. How can I help you?",
|
| 349 |
+
"prompt_type": "plain",
|
| 350 |
+
"source": "H2O.ai"
|
| 351 |
+
},
|
| 352 |
+
{
|
| 353 |
+
"input": "<human>: Do you have a name? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. How may I assist you?",
|
| 354 |
+
"prompt_type": "plain",
|
| 355 |
+
"source": "H2O.ai"
|
| 356 |
+
},
|
| 357 |
+
{
|
| 358 |
+
"input": "<human>: Do you have a name? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. Nice to meet you.",
|
| 359 |
+
"prompt_type": "plain",
|
| 360 |
+
"source": "H2O.ai"
|
| 361 |
+
},
|
| 362 |
+
{
|
| 363 |
+
"input": "<human>: Do you have a name? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. ",
|
| 364 |
+
"prompt_type": "plain",
|
| 365 |
+
"source": "H2O.ai"
|
| 366 |
+
},
|
| 367 |
+
{
|
| 368 |
+
"input": "<human>: Do you have a name? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. How can I help you?",
|
| 369 |
+
"prompt_type": "plain",
|
| 370 |
+
"source": "H2O.ai"
|
| 371 |
+
},
|
| 372 |
+
{
|
| 373 |
+
"input": "<human>: Do you have a name? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. How may I assist you?",
|
| 374 |
+
"prompt_type": "plain",
|
| 375 |
+
"source": "H2O.ai"
|
| 376 |
+
},
|
| 377 |
+
{
|
| 378 |
+
"input": "<human>: Do you have a name? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. Nice to meet you.",
|
| 379 |
+
"prompt_type": "plain",
|
| 380 |
+
"source": "H2O.ai"
|
| 381 |
+
},
|
| 382 |
+
{
|
| 383 |
+
"input": "<human>: Do you have a name? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. ",
|
| 384 |
+
"prompt_type": "plain",
|
| 385 |
+
"source": "H2O.ai"
|
| 386 |
+
},
|
| 387 |
+
{
|
| 388 |
+
"input": "<human>: Do you have a name? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. How can I help you?",
|
| 389 |
+
"prompt_type": "plain",
|
| 390 |
+
"source": "H2O.ai"
|
| 391 |
+
},
|
| 392 |
+
{
|
| 393 |
+
"input": "<human>: Do you have a name? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. How may I assist you?",
|
| 394 |
+
"prompt_type": "plain",
|
| 395 |
+
"source": "H2O.ai"
|
| 396 |
+
},
|
| 397 |
+
{
|
| 398 |
+
"input": "<human>: Do you have a name? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. Nice to meet you.",
|
| 399 |
+
"prompt_type": "plain",
|
| 400 |
+
"source": "H2O.ai"
|
| 401 |
+
},
|
| 402 |
+
{
|
| 403 |
+
"input": "<human>: Who trained you? <bot>: I'm h2oGPT, a large language model by H2O.ai. ",
|
| 404 |
+
"prompt_type": "plain",
|
| 405 |
+
"source": "H2O.ai"
|
| 406 |
+
},
|
| 407 |
+
{
|
| 408 |
+
"input": "<human>: Who trained you? <bot>: I'm h2oGPT, a large language model by H2O.ai. How can I help you?",
|
| 409 |
+
"prompt_type": "plain",
|
| 410 |
+
"source": "H2O.ai"
|
| 411 |
+
},
|
| 412 |
+
{
|
| 413 |
+
"input": "<human>: Who trained you? <bot>: I'm h2oGPT, a large language model by H2O.ai. How may I assist you?",
|
| 414 |
+
"prompt_type": "plain",
|
| 415 |
+
"source": "H2O.ai"
|
| 416 |
+
},
|
| 417 |
+
{
|
| 418 |
+
"input": "<human>: Who trained you? <bot>: I'm h2oGPT, a large language model by H2O.ai. Nice to meet you.",
|
| 419 |
+
"prompt_type": "plain",
|
| 420 |
+
"source": "H2O.ai"
|
| 421 |
+
},
|
| 422 |
+
{
|
| 423 |
+
"input": "<human>: Who trained you? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. ",
|
| 424 |
+
"prompt_type": "plain",
|
| 425 |
+
"source": "H2O.ai"
|
| 426 |
+
},
|
| 427 |
+
{
|
| 428 |
+
"input": "<human>: Who trained you? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. How can I help you?",
|
| 429 |
+
"prompt_type": "plain",
|
| 430 |
+
"source": "H2O.ai"
|
| 431 |
+
},
|
| 432 |
+
{
|
| 433 |
+
"input": "<human>: Who trained you? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. How may I assist you?",
|
| 434 |
+
"prompt_type": "plain",
|
| 435 |
+
"source": "H2O.ai"
|
| 436 |
+
},
|
| 437 |
+
{
|
| 438 |
+
"input": "<human>: Who trained you? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. Nice to meet you.",
|
| 439 |
+
"prompt_type": "plain",
|
| 440 |
+
"source": "H2O.ai"
|
| 441 |
+
},
|
| 442 |
+
{
|
| 443 |
+
"input": "<human>: Who trained you? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. ",
|
| 444 |
+
"prompt_type": "plain",
|
| 445 |
+
"source": "H2O.ai"
|
| 446 |
+
},
|
| 447 |
+
{
|
| 448 |
+
"input": "<human>: Who trained you? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. How can I help you?",
|
| 449 |
+
"prompt_type": "plain",
|
| 450 |
+
"source": "H2O.ai"
|
| 451 |
+
},
|
| 452 |
+
{
|
| 453 |
+
"input": "<human>: Who trained you? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. How may I assist you?",
|
| 454 |
+
"prompt_type": "plain",
|
| 455 |
+
"source": "H2O.ai"
|
| 456 |
+
},
|
| 457 |
+
{
|
| 458 |
+
"input": "<human>: Who trained you? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. Nice to meet you.",
|
| 459 |
+
"prompt_type": "plain",
|
| 460 |
+
"source": "H2O.ai"
|
| 461 |
+
},
|
| 462 |
+
{
|
| 463 |
+
"input": "<human>: Who trained you? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. ",
|
| 464 |
+
"prompt_type": "plain",
|
| 465 |
+
"source": "H2O.ai"
|
| 466 |
+
},
|
| 467 |
+
{
|
| 468 |
+
"input": "<human>: Who trained you? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. How can I help you?",
|
| 469 |
+
"prompt_type": "plain",
|
| 470 |
+
"source": "H2O.ai"
|
| 471 |
+
},
|
| 472 |
+
{
|
| 473 |
+
"input": "<human>: Who trained you? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. How may I assist you?",
|
| 474 |
+
"prompt_type": "plain",
|
| 475 |
+
"source": "H2O.ai"
|
| 476 |
+
},
|
| 477 |
+
{
|
| 478 |
+
"input": "<human>: Who trained you? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. Nice to meet you.",
|
| 479 |
+
"prompt_type": "plain",
|
| 480 |
+
"source": "H2O.ai"
|
| 481 |
+
},
|
| 482 |
+
{
|
| 483 |
+
"input": "<human>: Who created you? <bot>: I'm h2oGPT, a large language model by H2O.ai. ",
|
| 484 |
+
"prompt_type": "plain",
|
| 485 |
+
"source": "H2O.ai"
|
| 486 |
+
},
|
| 487 |
+
{
|
| 488 |
+
"input": "<human>: Who created you? <bot>: I'm h2oGPT, a large language model by H2O.ai. How can I help you?",
|
| 489 |
+
"prompt_type": "plain",
|
| 490 |
+
"source": "H2O.ai"
|
| 491 |
+
},
|
| 492 |
+
{
|
| 493 |
+
"input": "<human>: Who created you? <bot>: I'm h2oGPT, a large language model by H2O.ai. How may I assist you?",
|
| 494 |
+
"prompt_type": "plain",
|
| 495 |
+
"source": "H2O.ai"
|
| 496 |
+
},
|
| 497 |
+
{
|
| 498 |
+
"input": "<human>: Who created you? <bot>: I'm h2oGPT, a large language model by H2O.ai. Nice to meet you.",
|
| 499 |
+
"prompt_type": "plain",
|
| 500 |
+
"source": "H2O.ai"
|
| 501 |
+
},
|
| 502 |
+
{
|
| 503 |
+
"input": "<human>: Who created you? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. ",
|
| 504 |
+
"prompt_type": "plain",
|
| 505 |
+
"source": "H2O.ai"
|
| 506 |
+
},
|
| 507 |
+
{
|
| 508 |
+
"input": "<human>: Who created you? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. How can I help you?",
|
| 509 |
+
"prompt_type": "plain",
|
| 510 |
+
"source": "H2O.ai"
|
| 511 |
+
},
|
| 512 |
+
{
|
| 513 |
+
"input": "<human>: Who created you? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. How may I assist you?",
|
| 514 |
+
"prompt_type": "plain",
|
| 515 |
+
"source": "H2O.ai"
|
| 516 |
+
},
|
| 517 |
+
{
|
| 518 |
+
"input": "<human>: Who created you? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. Nice to meet you.",
|
| 519 |
+
"prompt_type": "plain",
|
| 520 |
+
"source": "H2O.ai"
|
| 521 |
+
},
|
| 522 |
+
{
|
| 523 |
+
"input": "<human>: Who created you? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. ",
|
| 524 |
+
"prompt_type": "plain",
|
| 525 |
+
"source": "H2O.ai"
|
| 526 |
+
},
|
| 527 |
+
{
|
| 528 |
+
"input": "<human>: Who created you? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. How can I help you?",
|
| 529 |
+
"prompt_type": "plain",
|
| 530 |
+
"source": "H2O.ai"
|
| 531 |
+
},
|
| 532 |
+
{
|
| 533 |
+
"input": "<human>: Who created you? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. How may I assist you?",
|
| 534 |
+
"prompt_type": "plain",
|
| 535 |
+
"source": "H2O.ai"
|
| 536 |
+
},
|
| 537 |
+
{
|
| 538 |
+
"input": "<human>: Who created you? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. Nice to meet you.",
|
| 539 |
+
"prompt_type": "plain",
|
| 540 |
+
"source": "H2O.ai"
|
| 541 |
+
},
|
| 542 |
+
{
|
| 543 |
+
"input": "<human>: Who created you? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. ",
|
| 544 |
+
"prompt_type": "plain",
|
| 545 |
+
"source": "H2O.ai"
|
| 546 |
+
},
|
| 547 |
+
{
|
| 548 |
+
"input": "<human>: Who created you? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. How can I help you?",
|
| 549 |
+
"prompt_type": "plain",
|
| 550 |
+
"source": "H2O.ai"
|
| 551 |
+
},
|
| 552 |
+
{
|
| 553 |
+
"input": "<human>: Who created you? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. How may I assist you?",
|
| 554 |
+
"prompt_type": "plain",
|
| 555 |
+
"source": "H2O.ai"
|
| 556 |
+
},
|
| 557 |
+
{
|
| 558 |
+
"input": "<human>: Who created you? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. Nice to meet you.",
|
| 559 |
+
"prompt_type": "plain",
|
| 560 |
+
"source": "H2O.ai"
|
| 561 |
+
},
|
| 562 |
+
{
|
| 563 |
+
"input": "<human>: Who made you? <bot>: I'm h2oGPT, a large language model by H2O.ai. ",
|
| 564 |
+
"prompt_type": "plain",
|
| 565 |
+
"source": "H2O.ai"
|
| 566 |
+
},
|
| 567 |
+
{
|
| 568 |
+
"input": "<human>: Who made you? <bot>: I'm h2oGPT, a large language model by H2O.ai. How can I help you?",
|
| 569 |
+
"prompt_type": "plain",
|
| 570 |
+
"source": "H2O.ai"
|
| 571 |
+
},
|
| 572 |
+
{
|
| 573 |
+
"input": "<human>: Who made you? <bot>: I'm h2oGPT, a large language model by H2O.ai. How may I assist you?",
|
| 574 |
+
"prompt_type": "plain",
|
| 575 |
+
"source": "H2O.ai"
|
| 576 |
+
},
|
| 577 |
+
{
|
| 578 |
+
"input": "<human>: Who made you? <bot>: I'm h2oGPT, a large language model by H2O.ai. Nice to meet you.",
|
| 579 |
+
"prompt_type": "plain",
|
| 580 |
+
"source": "H2O.ai"
|
| 581 |
+
},
|
| 582 |
+
{
|
| 583 |
+
"input": "<human>: Who made you? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. ",
|
| 584 |
+
"prompt_type": "plain",
|
| 585 |
+
"source": "H2O.ai"
|
| 586 |
+
},
|
| 587 |
+
{
|
| 588 |
+
"input": "<human>: Who made you? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. How can I help you?",
|
| 589 |
+
"prompt_type": "plain",
|
| 590 |
+
"source": "H2O.ai"
|
| 591 |
+
},
|
| 592 |
+
{
|
| 593 |
+
"input": "<human>: Who made you? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. How may I assist you?",
|
| 594 |
+
"prompt_type": "plain",
|
| 595 |
+
"source": "H2O.ai"
|
| 596 |
+
},
|
| 597 |
+
{
|
| 598 |
+
"input": "<human>: Who made you? <bot>: My name is h2oGPT. I'm a large language model by H2O.ai. Nice to meet you.",
|
| 599 |
+
"prompt_type": "plain",
|
| 600 |
+
"source": "H2O.ai"
|
| 601 |
+
},
|
| 602 |
+
{
|
| 603 |
+
"input": "<human>: Who made you? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. ",
|
| 604 |
+
"prompt_type": "plain",
|
| 605 |
+
"source": "H2O.ai"
|
| 606 |
+
},
|
| 607 |
+
{
|
| 608 |
+
"input": "<human>: Who made you? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. How can I help you?",
|
| 609 |
+
"prompt_type": "plain",
|
| 610 |
+
"source": "H2O.ai"
|
| 611 |
+
},
|
| 612 |
+
{
|
| 613 |
+
"input": "<human>: Who made you? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. How may I assist you?",
|
| 614 |
+
"prompt_type": "plain",
|
| 615 |
+
"source": "H2O.ai"
|
| 616 |
+
},
|
| 617 |
+
{
|
| 618 |
+
"input": "<human>: Who made you? <bot>: My name is h2oGPT. I'm a large language model trained by H2O.ai. Nice to meet you.",
|
| 619 |
+
"prompt_type": "plain",
|
| 620 |
+
"source": "H2O.ai"
|
| 621 |
+
},
|
| 622 |
+
{
|
| 623 |
+
"input": "<human>: Who made you? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. ",
|
| 624 |
+
"prompt_type": "plain",
|
| 625 |
+
"source": "H2O.ai"
|
| 626 |
+
},
|
| 627 |
+
{
|
| 628 |
+
"input": "<human>: Who made you? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. How can I help you?",
|
| 629 |
+
"prompt_type": "plain",
|
| 630 |
+
"source": "H2O.ai"
|
| 631 |
+
},
|
| 632 |
+
{
|
| 633 |
+
"input": "<human>: Who made you? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. How may I assist you?",
|
| 634 |
+
"prompt_type": "plain",
|
| 635 |
+
"source": "H2O.ai"
|
| 636 |
+
},
|
| 637 |
+
{
|
| 638 |
+
"input": "<human>: Who made you? <bot>: Hi! I'm h2oGPT, a large language model by H2O.ai. Nice to meet you.",
|
| 639 |
+
"prompt_type": "plain",
|
| 640 |
+
"source": "H2O.ai"
|
| 641 |
+
}
|
| 642 |
+
]
|
data/merged.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data/pexels-evg-kowalievska-1170986_small.jpg
ADDED

|
db_UserData_22176da3-ede6-4a48-a5e2-abd95296fcd6.lock
ADDED
|
File without changes
|
docker-compose.yml
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version: '3'
|
| 2 |
+
|
| 3 |
+
services:
|
| 4 |
+
h2o-llm:
|
| 5 |
+
build:
|
| 6 |
+
context: ./
|
| 7 |
+
dockerfile: Dockerfile
|
| 8 |
+
args:
|
| 9 |
+
BUILDKIT_INLINE_CACHE: "0"
|
| 10 |
+
image: h2o-llm
|
| 11 |
+
shm_size: '64gb'
|
| 12 |
+
command: generate.py --load_8bit True --base_model 'EleutherAI/gpt-j-6B'
|
| 13 |
+
restart: unless-stopped
|
| 14 |
+
volumes:
|
| 15 |
+
- h2o-llm:/root/.cache # Location downloaded weights will be stored
|
| 16 |
+
ports:
|
| 17 |
+
- 7860:7860
|
| 18 |
+
deploy:
|
| 19 |
+
resources:
|
| 20 |
+
reservations:
|
| 21 |
+
devices:
|
| 22 |
+
- driver: nvidia
|
| 23 |
+
count: all
|
| 24 |
+
capabilities: [ gpu ]
|
| 25 |
+
|
| 26 |
+
volumes:
|
| 27 |
+
h2o-llm:
|
| 28 |
+
name: h2o-llm
|
docs/FAQ.md
ADDED
|
@@ -0,0 +1,378 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Frequently asked questions
|
| 2 |
+
|
| 3 |
+
### Other models
|
| 4 |
+
|
| 5 |
+
One can choose any huggingface model.
|
| 6 |
+
|
| 7 |
+
Just pass the name after `--base_model=`, but a `prompt_type` is required if we don't already have support.
|
| 8 |
+
E.g. for vicuna models, a typical prompt_type is used and we support that already automatically for specific models,
|
| 9 |
+
but if you pass `--prompt_type=instruct_vicuna` with any other Vicuna model, we'll use it assuming that is the correct prompt type.
|
| 10 |
+
See models that are currently supported in this automatic way, and the same dictionary shows which prompt types are supported: [prompter](../src/prompter.py).
|
| 11 |
+
|
| 12 |
+
### Low-memory mode
|
| 13 |
+
|
| 14 |
+
For GPU case, a reasonable model for low memory is to run:
|
| 15 |
+
```bash
|
| 16 |
+
python generate.py --base_model=h2oai/h2ogpt-gm-oasst1-en-2048-falcon-7b-v3 --hf_embedding_model=sentence-transformers/all-MiniLM-L6-v2 --score_model=None --load_8bit=True --langchain_mode='MyData'
|
| 17 |
+
```
|
| 18 |
+
which uses good but smaller base model, embedding model, and no response score model to save GPU memory. If you can do 4-bit, then do:
|
| 19 |
+
```bash
|
| 20 |
+
python generate.py --base_model=h2oai/h2ogpt-gm-oasst1-en-2048-falcon-7b-v3 --hf_embedding_model=sentence-transformers/all-MiniLM-L6-v2 --score_model=None --load_4bit=True --langchain_mode='MyData'
|
| 21 |
+
```
|
| 22 |
+
This uses 5800MB to startup, then soon drops to 5075MB after torch cache is cleared. Asking a simple question uses up to 6050MB. Adding a document uses no more new GPU memory. Asking a question uses up to 6312MB for a few chunks (default), then drops back down to 5600MB.
|
| 23 |
+
|
| 24 |
+
On CPU case, a good model that's still low memory is to run:
|
| 25 |
+
```bash
|
| 26 |
+
python generate.py --base_model='llama' --prompt_type=wizard2 --hf_embedding_model=sentence-transformers/all-MiniLM-L6-v2 --langchain_mode=MyData --user_path=user_path
|
| 27 |
+
```
|
| 28 |
+
|
| 29 |
+
### ValueError: ...offload....
|
| 30 |
+
|
| 31 |
+
```
|
| 32 |
+
The current `device_map` had weights offloaded to the disk. Please provide an `offload_folder` for them. Alternatively, make sure you have `safetensors` installed if the model you are using offers
|
| 33 |
+
the weights in this format.
|
| 34 |
+
```
|
| 35 |
+
|
| 36 |
+
If you see this error, then you either have insufficient GPU memory or insufficient CPU memory. E.g. for 6.9B model one needs minimum of 27GB free memory.
|
| 37 |
+
|
| 38 |
+
### Larger models require more GPU memory
|
| 39 |
+
|
| 40 |
+
Depending on available GPU memory, you can load differently sized models. For multiple GPUs, automatic sharding can be enabled with `--use_gpu_id=False`, but this is disabled by default since cuda:x cuda:y mismatches can occur.
|
| 41 |
+
|
| 42 |
+
For GPUs with at least 24GB of memory, we recommend:
|
| 43 |
+
```bash
|
| 44 |
+
python generate.py --base_model=h2oai/h2ogpt-oasst1-512-12b --load_8bit=True
|
| 45 |
+
```
|
| 46 |
+
or
|
| 47 |
+
```bash
|
| 48 |
+
python generate.py --base_model=h2oai/h2ogpt-oasst1-512-20b --load_8bit=True
|
| 49 |
+
```
|
| 50 |
+
For GPUs with at least 48GB of memory, we recommend:
|
| 51 |
+
```bash
|
| 52 |
+
python generate.py --base_model=h2oai/h2ogpt-oasst1-512-20b --load_8bit=True
|
| 53 |
+
```
|
| 54 |
+
etc.
|
| 55 |
+
|
| 56 |
+
### CPU with no AVX2 or using LLaMa.cpp
|
| 57 |
+
|
| 58 |
+
For GPT4All based models, require AVX2, unless one recompiles that project on your system. Until then, use llama.cpp models instead.
|
| 59 |
+
|
| 60 |
+
So we recommend downloading models from [TheBloke](https://huggingface.co/TheBloke) that are version 3 quantized ggml files to work with latest llama.cpp. See main [README.md](README_CPU.md).
|
| 61 |
+
|
| 62 |
+
The following example is for the base LLaMa model, not instruct-tuned, so it is not recommended for chatting. It just gives an example of how to quantize if you are an expert.
|
| 63 |
+
|
| 64 |
+
Compile the llama model on your system by following the [instructions](https://github.com/ggerganov/llama.cpp#build) and [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), e.g. for Linux:
|
| 65 |
+
```bash
|
| 66 |
+
git clone https://github.com/ggerganov/llama.cpp
|
| 67 |
+
cd llama.cpp
|
| 68 |
+
make clean
|
| 69 |
+
make LLAMA_OPENBLAS=1
|
| 70 |
+
```
|
| 71 |
+
on CPU, or for GPU:
|
| 72 |
+
```bash
|
| 73 |
+
git clone https://github.com/ggerganov/llama.cpp
|
| 74 |
+
cd llama.cpp
|
| 75 |
+
make clean
|
| 76 |
+
make LLAMA_CUBLAS=1
|
| 77 |
+
```
|
| 78 |
+
etc. following different [scenarios](https://github.com/ggerganov/llama.cpp#build).
|
| 79 |
+
|
| 80 |
+
Then:
|
| 81 |
+
```bash
|
| 82 |
+
# obtain the original LLaMA model weights and place them in ./models, i.e. models should contain:
|
| 83 |
+
# 65B 30B 13B 7B tokenizer_checklist.chk tokenizer.model
|
| 84 |
+
|
| 85 |
+
# install Python dependencies
|
| 86 |
+
conda create -n llamacpp -y
|
| 87 |
+
conda activate llamacpp
|
| 88 |
+
conda install python=3.10 -y
|
| 89 |
+
pip install -r requirements.txt
|
| 90 |
+
|
| 91 |
+
# convert the 7B model to ggml FP16 format
|
| 92 |
+
python convert.py models/7B/
|
| 93 |
+
|
| 94 |
+
# quantize the model to 4-bits (using q4_0 method)
|
| 95 |
+
./quantize ./models/7B/ggml-model-f16.bin ./models/7B/ggml-model-q4_0.bin q4_0
|
| 96 |
+
|
| 97 |
+
# test by running the inference
|
| 98 |
+
./main -m ./models/7B/ggml-model-q4_0.bin -n 128
|
| 99 |
+
```
|
| 100 |
+
then adding an entry in the `.env_gpt4all` file like (assumes version 3 quantization)
|
| 101 |
+
```.env_gpt4all
|
| 102 |
+
# model path and model_kwargs
|
| 103 |
+
model_path_llama=./models/7B/ggml-model-q4_0.bin
|
| 104 |
+
```
|
| 105 |
+
or wherever you placed the model with the path pointing to wherever the files are located (e.g. link from h2oGPT repo to llama.cpp repo folder), e.g.
|
| 106 |
+
```bash
|
| 107 |
+
cd ~/h2ogpt/
|
| 108 |
+
ln -s ~/llama.cpp/models/* .
|
| 109 |
+
```
|
| 110 |
+
then run h2oGPT like:
|
| 111 |
+
```bash
|
| 112 |
+
python generate.py --base_model='llama' --langchain_mode=UserData --user_path=user_path
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
### Is this really a GGML file? Or Using version 2 quantization files from GPT4All that are LLaMa based
|
| 116 |
+
|
| 117 |
+
If hit error:
|
| 118 |
+
```text
|
| 119 |
+
Found model file.
|
| 120 |
+
llama.cpp: loading model from ./models/7B/ggml-model-q4_0.bin
|
| 121 |
+
error loading model: unknown (magic, version) combination: 67676a74, 00000003; is this really a GGML file?
|
| 122 |
+
llama_init_from_file: failed to load model
|
| 123 |
+
LLAMA ERROR: failed to load model from ./models/7B/ggml-model-q4_0.bin
|
| 124 |
+
```
|
| 125 |
+
then note that llama.cpp upgraded to version 3, and we use llama-cpp-python version that supports only that latest version 3. GPT4All does not support version 3 yet. If you want to support older version 2 llama quantized models, then do:
|
| 126 |
+
```bash
|
| 127 |
+
pip install --force-reinstall --ignore-installed --no-cache-dir llama-cpp-python==0.1.48
|
| 128 |
+
```
|
| 129 |
+
to go back to the prior version. Or specify the model using GPT4All as `--base_model='gpt4all_llama` and ensure entry exists like:
|
| 130 |
+
```.env_gpt4all
|
| 131 |
+
model_path_gpt4all_llama=./models/7B/ggml-model-q4_0.bin
|
| 132 |
+
```
|
| 133 |
+
assuming that file is from version 2 quantization.
|
| 134 |
+
|
| 135 |
+
### I get the error: `The model 'OptimizedModule' is not supported for . Supported models are ...`
|
| 136 |
+
|
| 137 |
+
This warning can be safely ignored.
|
| 138 |
+
|
| 139 |
+
### What ENVs can I pass to control h2oGPT?
|
| 140 |
+
|
| 141 |
+
- `SAVE_DIR`: Local directory to save logs to,
|
| 142 |
+
- `ADMIN_PASS`: Password to access system info, logs, or push to aws s3 bucket,
|
| 143 |
+
- `AWS_BUCKET`: AWS bucket name to push logs to when have admin access,
|
| 144 |
+
- `AWS_SERVER_PUBLIC_KEY`: AWS public key for pushing logs to when have admin access,
|
| 145 |
+
- `AWS_SERVER_SECRET_KEY`: AWS secret key for pushing logs to when have admin access,
|
| 146 |
+
- `HUGGINGFACE_API_TOKEN`: Read or write HF token for accessing private models,
|
| 147 |
+
- `LANGCHAIN_MODE`: LangChain mode, overrides CLI,
|
| 148 |
+
- `SCORE_MODEL`: HF model to use for scoring prompt-response pairs, `None` for no scoring of responses,
|
| 149 |
+
- `HEIGHT`: Height of Chat window,
|
| 150 |
+
- `allow_upload_to_user_data`: Whether to allow uploading to Shared UserData,
|
| 151 |
+
- `allow_upload_to_my_data`: Whether to allow uploading to Scratch MyData,
|
| 152 |
+
- `HEIGHT`: Height of Chat window,
|
| 153 |
+
- `HUGGINGFACE_SPACES`: Whether on public A10G 24GB HF spaces, sets some low-GPU-memory defaults for public access to avoid GPU memory abuse by model switching, etc.
|
| 154 |
+
- `HF_HOSTNAME`: Name of HF spaces for purpose of naming log files,
|
| 155 |
+
- `GPT_H2O_AI`: Whether on public 48GB+ GPU instance, sets some defaults for public access to avoid GPU memory abuse by model switching, etc.,
|
| 156 |
+
- `CONCURRENCY_COUNT`: Number of concurrency users to gradio server (1 is fastest since LLMs tend to consume all GPU cores, but 2-4 is best to avoid any single user waiting too long to get response)
|
| 157 |
+
- `API_OPEN`: Whether API access is visible,
|
| 158 |
+
- `ALLOW_API`: Whether to allow API access,
|
| 159 |
+
- `CUDA_VISIBLE_DEVICES`: Standard list of CUDA devices to make visible.
|
| 160 |
+
|
| 161 |
+
These can be useful on HuggingFace spaces, where one sets secret tokens because CLI options cannot be used.
|
| 162 |
+
|
| 163 |
+
### GPT4All not producing output.
|
| 164 |
+
|
| 165 |
+
Please contact GPT4All team. Even a basic test can give empty result.
|
| 166 |
+
```python
|
| 167 |
+
>>> from gpt4all import GPT4All as GPT4AllModel
|
| 168 |
+
>>> m = GPT4AllModel('ggml-gpt4all-j-v1.3-groovy.bin')
|
| 169 |
+
Found model file.
|
| 170 |
+
gptj_model_load: loading model from '/home/jon/.cache/gpt4all/ggml-gpt4all-j-v1.3-groovy.bin' - please wait ...
|
| 171 |
+
gptj_model_load: n_vocab = 50400
|
| 172 |
+
gptj_model_load: n_ctx = 2048
|
| 173 |
+
gptj_model_load: n_embd = 4096
|
| 174 |
+
gptj_model_load: n_head = 16
|
| 175 |
+
gptj_model_load: n_layer = 28
|
| 176 |
+
gptj_model_load: n_rot = 64
|
| 177 |
+
gptj_model_load: f16 = 2
|
| 178 |
+
gptj_model_load: ggml ctx size = 5401.45 MB
|
| 179 |
+
gptj_model_load: kv self size = 896.00 MB
|
| 180 |
+
gptj_model_load: ................................... done
|
| 181 |
+
gptj_model_load: model size = 3609.38 MB / num tensors = 285
|
| 182 |
+
>>> m.generate('Was Avogadro a professor at the University of Turin?')
|
| 183 |
+
|
| 184 |
+
''
|
| 185 |
+
>>>
|
| 186 |
+
```
|
| 187 |
+
Also, the model tends to not do well when input has new lines, spaces or `<br>` work better.
|
| 188 |
+
This does not seem to be an issue with h2oGPT.
|
| 189 |
+
|
| 190 |
+
### Commercial viability
|
| 191 |
+
|
| 192 |
+
Open-source means the models are not proprietary and are available to download. In addition, the license for all of our non-research models is Apache V2, which is a fully permissive license. Some licenses for other open-source models are not fully permissive, such as StabilityAI's models that are CC-BY-SA that require derivatives to be shared too.
|
| 193 |
+
|
| 194 |
+
We post models and license and data origin details on our huggingface page: https://huggingface.co/h2oai (all models, except research ones, are fully permissive). The foundational models we fine-tuned on, e.g. Pythia 6.9B, Pythia 12B, NeoX 20B, or Open-LLaMa checkpoints are fully commercially viable. These foundational models are also listed on the huggingface page for each fine-tuned model. Full training logs, source data, etc. are all provided for all models. [GPT4All](https://github.com/nomic-ai/gpt4all) GPT_J is commercially viable, but other models may not be. Any Meta based [LLaMa](https://github.com/facebookresearch/llama) based models are not commercially viable.
|
| 195 |
+
|
| 196 |
+
Data used to fine-tune are provided on the huggingface pages for each model. Data for foundational models are provided on their huggingface pages. Any models trained on GPT3.5 data like ShareGPT, Vicuna, Alpaca, etc. are not commercially viable due to ToS violations w.r.t. building competitive models. Any research-based h2oGPT models based upon Meta's weights for LLaMa are not commercially viable.
|
| 197 |
+
|
| 198 |
+
Overall, we have done a significant amount of due diligence regarding data and model licenses to carefully select only fully permissive data and models for our models we license as Apache V2. Outside our models, some "open-source" models like Vicuna, Koala, WizardLM, etc. are based upon Meta's weights for LLaMa, which is not commercially usable due to ToS violations w.r.t. non-competitive clauses well as research-only clauses. Such models tend to also use data from GPT3.5 (ChatGPT), which is also not commercially usable due to ToS violations w.r.t. non-competitive clauses. E.g. Alpaca data, ShareGPT data, WizardLM data, etc. all fall under that category. All open-source foundational models consume data from the internet, including the Pile or C4 (web crawl) that may contain objectionable material. Future licenses w.r.t. new web crawls may change, but it is our understanding that existing data crawls would not be affected by any new licenses. However, some web crawl data may contain pirated books.
|
| 199 |
+
|
| 200 |
+
#### Disclaimers
|
| 201 |
+
|
| 202 |
+
Disclaimers and a ToS link are displayed to protect the app creators.
|
| 203 |
+
|
| 204 |
+
### What are the different prompt types? How does prompt engineering work for h2oGPT?
|
| 205 |
+
|
| 206 |
+
In general, all LLMs use strings as inputs for training/fine-tuning and generation/inference.
|
| 207 |
+
To manage a variety of possible language task types, we divide any such string into the following three parts:
|
| 208 |
+
|
| 209 |
+
- Instruction
|
| 210 |
+
- Input
|
| 211 |
+
- Response
|
| 212 |
+
|
| 213 |
+
Each of these three parts can be empty or non-empty strings, such as titles or newlines. In the end, all of these prompt parts are concatenated into one string. The magic is in the content of those substrings. This is called **prompt engineering**.
|
| 214 |
+
|
| 215 |
+
#### Summarization
|
| 216 |
+
|
| 217 |
+
For training a summarization task, we concatenate these three parts together:
|
| 218 |
+
|
| 219 |
+
- Instruction = `<INSTRUCTION>`
|
| 220 |
+
- Input = `'## Main Text\n\n'` + `<INPUT>`
|
| 221 |
+
- Response = `'\n\n## Summary\n\n'` + `<OUTPUT>`
|
| 222 |
+
|
| 223 |
+
For each training record, we take `<INPUT>` and `<OUTPUT>` from the summarization dataset (typically two fields/columns), place them into the appropriate position, and turn that record into
|
| 224 |
+
one long string that the model can be trained with: `'## Main Text\n\nLarge Language Models are Useful.\n\n## Summary\n\nLLMs rock.'`
|
| 225 |
+
|
| 226 |
+
At inference time, we will take the `<INPUT>` only and stop right after `'\n\n## Summary\n\n'` and the model will generate the summary
|
| 227 |
+
as the continuation of the prompt.
|
| 228 |
+
|
| 229 |
+
|
| 230 |
+
#### ChatBot
|
| 231 |
+
|
| 232 |
+
For a conversational chatbot use case, we use the following three parts:
|
| 233 |
+
|
| 234 |
+
- Instruction = `<INSTRUCTION>`
|
| 235 |
+
- Input = `'<human>: '` + `<INPUT>`
|
| 236 |
+
- Response = `'<bot>: '` + `<OUTPUT>`
|
| 237 |
+
|
| 238 |
+
And a training string could look like this: `'<human>: hi, how are you?<bot>: Hi, I am doing great. How can I help you?'`.
|
| 239 |
+
At inference time, the model input would be like this: `'<human>: Tell me a joke about snow flakes.<bot>: '`, and the model would generate the bot part.
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
### How should training data be prepared?
|
| 243 |
+
|
| 244 |
+
Training data (in `JSON` format) must contain at least one column that maps to `instruction`, `input` or `output`.
|
| 245 |
+
Their content will be placed into the `<INSTRUCTION>`, `<INPUT>`, and `<OUTPUT>` placeholders mentioned above.
|
| 246 |
+
The chosen `prompt_type` will fill in the strings in between to form the actual input into the model.
|
| 247 |
+
Any missing columns will lead to empty strings. Optional `--data_col_dict={'A': 'input', 'B': 'output'}` argument can
|
| 248 |
+
be used to map different column names into the required ones.
|
| 249 |
+
|
| 250 |
+
#### Examples
|
| 251 |
+
|
| 252 |
+
The following are examples of training records in `JSON` format.
|
| 253 |
+
|
| 254 |
+
- `human_bot` prompt type
|
| 255 |
+
```json
|
| 256 |
+
{
|
| 257 |
+
"input": "Who are you?",
|
| 258 |
+
"output": "My name is h2oGPT.",
|
| 259 |
+
"prompt_type": "human_bot"
|
| 260 |
+
}
|
| 261 |
+
```
|
| 262 |
+
|
| 263 |
+
- `plain` version of `human_bot`, useful for longer conversations
|
| 264 |
+
```json
|
| 265 |
+
{
|
| 266 |
+
"input": "<human>: Who are you?\n<bot>: My name is h2oGPT.\n<human>: Can you write a poem about horses?\n<bot>: Yes, of course. Here it goes...",
|
| 267 |
+
"prompt_type": "plain"
|
| 268 |
+
}
|
| 269 |
+
```
|
| 270 |
+
|
| 271 |
+
- `summarize` prompt type
|
| 272 |
+
```json
|
| 273 |
+
{
|
| 274 |
+
"instruction": "",
|
| 275 |
+
"input": "Long long long text.",
|
| 276 |
+
"output": "text.",
|
| 277 |
+
"prompt_type": "summarize"
|
| 278 |
+
}
|
| 279 |
+
```
|
| 280 |
+
|
| 281 |
+
### Context length
|
| 282 |
+
|
| 283 |
+
Note that the total length of the text (that is, the input and output) the LLM can handle is limited by the so-called *context length*. For our current models, the context length is 2048 tokens. Longer context lengths are computationally more expensive due to the interactions between all tokens in the sequence.
|
| 284 |
+
A context length of 2048 means that for an input of, for example, 1900 tokens, the model will be able to create no more than 148 new tokens as part of the output.
|
| 285 |
+
|
| 286 |
+
For fine-tuning, if the average length of inputs is less than the context length, one can provide a `cutoff_len` of less than the context length to truncate inputs to this amount of tokens. For most instruction-type datasets, a cutoff length of 512 seems reasonable and provides nice memory and time savings.
|
| 287 |
+
For example, the `h2oai/h2ogpt-oasst1-512-20b` model was trained with a cutoff length of 512.
|
| 288 |
+
|
| 289 |
+
### Tokens
|
| 290 |
+
|
| 291 |
+
The following are some example tokens (from a total of ~50k), each of which is assigned a number:
|
| 292 |
+
```text
|
| 293 |
+
"osed": 1700,
|
| 294 |
+
"ised": 1701,
|
| 295 |
+
"================": 1702,
|
| 296 |
+
"ED": 1703,
|
| 297 |
+
"sec": 1704,
|
| 298 |
+
"Ġcome": 1705,
|
| 299 |
+
"34": 1706,
|
| 300 |
+
"ĠThere": 1707,
|
| 301 |
+
"Ġlight": 1708,
|
| 302 |
+
"Ġassoci": 1709,
|
| 303 |
+
"gram": 1710,
|
| 304 |
+
"Ġold": 1711,
|
| 305 |
+
"Ġ{#": 1712,
|
| 306 |
+
```
|
| 307 |
+
The model is trained with these specific numbers, so the tokenizer must be kept the same for training and inference/generation.
|
| 308 |
+
The input format doesn't change whether the model is in pretraining, fine-tuning, or inference mode, but the text itself can change slightly for better results, and that's called prompt engineering.
|
| 309 |
+
|
| 310 |
+
### Is h2oGPT multilingual?
|
| 311 |
+
|
| 312 |
+
Yes. Try it in your preferred language.
|
| 313 |
+
|
| 314 |
+
### What does 512 mean in the model name?
|
| 315 |
+
|
| 316 |
+
The number `512` in the model names indicates the cutoff lengths (in tokens) used for fine-tuning. Shorter values generally result in faster training and more focus on the last part of the provided input text (consisting of prompt and answer).
|
| 317 |
+
|
| 318 |
+
### Throttle GPUs in case of reset/reboot
|
| 319 |
+
|
| 320 |
+
```bash
|
| 321 |
+
(h2ogpt) jon@gpu:~$ sudo nvidia-smi -pl 250
|
| 322 |
+
Power limit for GPU 00000000:3B:00.0 was set to 250.00 W from 300.00 W.
|
| 323 |
+
Power limit for GPU 00000000:5E:00.0 was set to 250.00 W from 300.00 W.
|
| 324 |
+
Power limit for GPU 00000000:86:00.0 was set to 250.00 W from 300.00 W.
|
| 325 |
+
Power limit for GPU 00000000:AF:00.0 was set to 250.00 W from 300.00 W.
|
| 326 |
+
All done.
|
| 327 |
+
```
|
| 328 |
+
|
| 329 |
+
|
| 330 |
+
|
| 331 |
+
### Heterogeneous GPU systems
|
| 332 |
+
|
| 333 |
+
In case you get peer-to-peer related errors on non-homogeneous GPU systems, set this env var:
|
| 334 |
+
```
|
| 335 |
+
export NCCL_P2P_LEVEL=LOC
|
| 336 |
+
```
|
| 337 |
+
|
| 338 |
+
|
| 339 |
+
### Use Wiki data
|
| 340 |
+
|
| 341 |
+
The following example demonstrates how to use Wiki data:
|
| 342 |
+
|
| 343 |
+
```python
|
| 344 |
+
>>> from datasets import load_dataset
|
| 345 |
+
>>> wk = load_dataset("wikipedia", "20220301.en")
|
| 346 |
+
>>> wk
|
| 347 |
+
DatasetDict({
|
| 348 |
+
train: Dataset({
|
| 349 |
+
features: ['id', 'url', 'title', 'text'],
|
| 350 |
+
num_rows: 6458670
|
| 351 |
+
})
|
| 352 |
+
})
|
| 353 |
+
>>> sentences = ".".join(wk['train'][0]['text'].split('.')[0:2])
|
| 354 |
+
'Anarchism is a political philosophy and movement that is sceptical of authority and rejects all involuntary, coercive forms of hierarchy. Anarchism calls for the abolition of the state, which it holds to be unnecessary, undesirable, and harmful'
|
| 355 |
+
>>>
|
| 356 |
+
```
|
| 357 |
+
|
| 358 |
+
### Centos with llama-cpp-python
|
| 359 |
+
|
| 360 |
+
This may help to get llama-cpp-python to install
|
| 361 |
+
|
| 362 |
+
```bash
|
| 363 |
+
# remove old gcc
|
| 364 |
+
yum remove gcc yum remove gdb
|
| 365 |
+
# install scl-utils
|
| 366 |
+
sudo yum install scl-utils sudo yum install centos-release-scl
|
| 367 |
+
# find devtoolset-11
|
| 368 |
+
yum list all --enablerepo='centos-sclo-rh' | grep "devtoolset"
|
| 369 |
+
# install devtoolset-11-toolchain
|
| 370 |
+
yum install -y devtoolset-11-toolchain
|
| 371 |
+
# add gcc 11 to PATH by adding following script to /etc/profile
|
| 372 |
+
PATH=$PATH::/opt/rh/devtoolset-11/root/usr/bin export PATH sudo scl enable devtoolset-11 bash
|
| 373 |
+
# show gcc version and gcc11 is installed successfully.
|
| 374 |
+
gcc --version
|
| 375 |
+
export FORCE_CMAKE=1
|
| 376 |
+
export CMAKE_ARGS=-DLLAMA_OPENBLAS=on
|
| 377 |
+
pip install llama-cpp-python --no-cache-dir
|
| 378 |
+
```
|
docs/FINETUNE.md
ADDED
|
@@ -0,0 +1,95 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Fine-tuning
|
| 2 |
+
|
| 3 |
+
Make sure you have followed the [native installation instructions](INSTALL.md).
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
### Fine-tuning vs Pre-training
|
| 7 |
+
|
| 8 |
+
- Pre-training (typically on TBs of data) gives the LLM the ability to master one or many languages. Pre-training usually takes weeks or months on dozens or hundreds of GPUs. The most common concern is underfitting and cost.
|
| 9 |
+
- Fine-tuning (typically on MBs or GBs of data) makes a model more familiar with a specific style of prompting, which generally leads to improved outcomes for this one specific case. The most common concern is overfitting. Fine-tuning usually takes hours or days on a few GPUs.
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
### Dataset format
|
| 13 |
+
|
| 14 |
+
In general, LLMs take plain text (ordered list of tokens, explained in the [FAQ](FAQ.md)) as input and generate plain text as output.
|
| 15 |
+
For example, for pretraining this text is perfectly usable:
|
| 16 |
+
```text
|
| 17 |
+
and suddenly all the players raised their hands and shouted
|
| 18 |
+
```
|
| 19 |
+
as the model will learn to say `suddenly` after `and` and it will learn to say `players` after `and suddenly all the` etc., as
|
| 20 |
+
part of the overall language training on hundreds of billions of tokens. Imagine that this is not a very efficient way to learn a language, but it works.
|
| 21 |
+
|
| 22 |
+
For fine-tuning, when we only present a small set of high-quality data to the model, the creation of good input/output pairs is the *labeling* work one has to do.
|
| 23 |
+
|
| 24 |
+
For example, for fine-tuning, one could create such a dataset entry:
|
| 25 |
+
```text
|
| 26 |
+
Instruction: Summarize.
|
| 27 |
+
Input: This is a very very very long paragraph saying nothing much.
|
| 28 |
+
Output: Nothing was said.
|
| 29 |
+
```
|
| 30 |
+
This text is better suited to teach the model to summarize. During inference, one would present the model with the following text and it would provide the summary as the continuation of the input, since it is already familiar with this prompting technique:
|
| 31 |
+
```text
|
| 32 |
+
Instruction: Summarize.
|
| 33 |
+
Input: TEXT TO SUMMARIZE
|
| 34 |
+
Output:
|
| 35 |
+
```
|
| 36 |
+
|
| 37 |
+
For a chatbot, one could fine-tune the model by providing data examples like this:
|
| 38 |
+
```text
|
| 39 |
+
<human>: Hi, who are you?
|
| 40 |
+
<bot>: I'm h2oGPT.
|
| 41 |
+
<human>: Who trained you?
|
| 42 |
+
<bot>: I was trained by H2O.ai, the visionary leader in democratizing AI.
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
and during inference, one would present the following to the LLM, for it to respond as the `<bot>`:
|
| 46 |
+
```text
|
| 47 |
+
<human>: USER INPUT FROM CHAT APPLICATION
|
| 48 |
+
<bot>:
|
| 49 |
+
```
|
| 50 |
+
|
| 51 |
+
More details about the exact dataset specs can be found in our [FAQ](FAQ.md).
|
| 52 |
+
|
| 53 |
+
### Create instruct dataset
|
| 54 |
+
|
| 55 |
+
Below are some of our scripts to help with assembling and cleaning instruct-type datasets that are
|
| 56 |
+
[publicly available with permissive licenses](https://huggingface.co/datasets/laion/OIG).
|
| 57 |
+
|
| 58 |
+
#### High-quality OIG based instruct data
|
| 59 |
+
|
| 60 |
+
For a higher quality dataset, run the following commands:
|
| 61 |
+
```bash
|
| 62 |
+
pytest -s create_data.py::test_download_useful_data_as_parquet # downloads ~ 4.2GB of open-source permissive data
|
| 63 |
+
pytest -s create_data.py::test_assemble_and_detox # ~ 3 minutes, 4.1M clean conversations
|
| 64 |
+
pytest -s create_data.py::test_chop_by_lengths # ~ 2 minutes, 2.8M clean and long enough conversations
|
| 65 |
+
pytest -s create_data.py::test_grade # ~ 3 hours, keeps only high quality data
|
| 66 |
+
pytest -s create_data.py::test_finalize_to_json
|
| 67 |
+
```
|
| 68 |
+
This will take several hours and produce a file called [h2ogpt-oig-oasst1-instruct-cleaned-v2.json](https://huggingface.co/datasets/h2oai/h2ogpt-oig-oasst1-instruct-cleaned-v2) (575 MB) with 350k human <-> bot interactions.
|
| 69 |
+
|
| 70 |
+
Note: This dataset is cleaned up, but might still contain undesired words and concepts.
|
| 71 |
+
|
| 72 |
+
### Install training specific dependencies
|
| 73 |
+
|
| 74 |
+
```bash
|
| 75 |
+
pip install -r reqs_optional/requirements_optional_training.txt
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
### Perform fine-tuning on high-quality instruct data
|
| 79 |
+
|
| 80 |
+
Fine-tune on a single node with NVIDIA GPUs A6000/A6000Ada/A100/H100, needs 48GB of GPU memory per GPU for default settings (fast 16-bit training).
|
| 81 |
+
For larger models or GPUs with less memory, need to set a combination of `--train_4bit=True` (or `--train_8bit=True`) and `--micro_batch_size=1`, `--batch_size=$NGPUS` and `--cutoff_len=256` below, or use smaller models like `h2oai/h2ogpt-oasst1-512-12b`.
|
| 82 |
+
```
|
| 83 |
+
export NGPUS=`nvidia-smi -L | wc -l`
|
| 84 |
+
torchrun --nproc_per_node=$NGPUS finetune.py --base_model=h2oai/h2ogpt-oasst1-512-20b --data_path=h2oai/h2ogpt-oig-oasst1-instruct-cleaned-v2 --output_dir=h2ogpt_lora_weights
|
| 85 |
+
```
|
| 86 |
+
This will download the model, load the data, and generate an output directory `h2ogpt_lora_weights` containing the fine-tuned state.
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
### Start your own fine-tuned chatbot
|
| 90 |
+
|
| 91 |
+
Start a chatbot, also requires 48GB GPU. Use `--load_4bit=True` instead for 24GB GPUs.
|
| 92 |
+
```
|
| 93 |
+
torchrun generate.py --load_8bit=True --base_model=h2oai/h2ogpt-oasst1-512-20b --lora_weights=h2ogpt_lora_weights --prompt_type=human_bot
|
| 94 |
+
```
|
| 95 |
+
This will download the foundation model, our fine-tuned lora_weights, and open up a GUI with text generation input/output.
|
docs/INSTALL-DOCKER.md
ADDED
|
@@ -0,0 +1,73 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
### Containerized Installation for Inference on Linux GPU Servers
|
| 2 |
+
|
| 3 |
+
1. Ensure docker installed and ready (requires sudo), can skip if system is already capable of running nvidia containers. Example here is for Ubuntu, see [NVIDIA Containers](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/install-guide.html#docker) for more examples.
|
| 4 |
+
|
| 5 |
+
```bash
|
| 6 |
+
distribution=$(. /etc/os-release;echo $ID$VERSION_ID) \
|
| 7 |
+
&& curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
|
| 8 |
+
&& curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | \
|
| 9 |
+
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
|
| 10 |
+
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
|
| 11 |
+
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit-base
|
| 12 |
+
sudo apt install nvidia-container-runtime
|
| 13 |
+
sudo nvidia-ctk runtime configure --runtime=docker
|
| 14 |
+
sudo systemctl restart docker
|
| 15 |
+
```
|
| 16 |
+
|
| 17 |
+
2. Build the container image:
|
| 18 |
+
|
| 19 |
+
```bash
|
| 20 |
+
docker build -t h2ogpt .
|
| 21 |
+
```
|
| 22 |
+
|
| 23 |
+
3. Run the container (you can also use `finetune.py` and all of its parameters as shown above for training):
|
| 24 |
+
|
| 25 |
+
For the fine-tuned h2oGPT with 20 billion parameters:
|
| 26 |
+
```bash
|
| 27 |
+
docker run --runtime=nvidia --shm-size=64g -p 7860:7860 \
|
| 28 |
+
-v ${HOME}/.cache:/root/.cache --rm h2ogpt -it generate.py \
|
| 29 |
+
--base_model=h2oai/h2ogpt-oasst1-512-20b
|
| 30 |
+
```
|
| 31 |
+
|
| 32 |
+
if have a private HF token, can instead run:
|
| 33 |
+
```bash
|
| 34 |
+
docker run --runtime=nvidia --shm-size=64g --entrypoint=bash -p 7860:7860 \
|
| 35 |
+
-e HUGGINGFACE_API_TOKEN=<HUGGINGFACE_API_TOKEN> \
|
| 36 |
+
-v ${HOME}/.cache:/root/.cache --rm h2ogpt -it \
|
| 37 |
+
-c 'huggingface-cli login --token $HUGGINGFACE_API_TOKEN && python3.10 generate.py --base_model=h2oai/h2ogpt-oasst1-512-20b --use_auth_token=True'
|
| 38 |
+
```
|
| 39 |
+
|
| 40 |
+
For your own fine-tuned model starting from the gpt-neox-20b foundation model for example:
|
| 41 |
+
```bash
|
| 42 |
+
docker run --runtime=nvidia --shm-size=64g -p 7860:7860 \
|
| 43 |
+
-v ${HOME}/.cache:/root/.cache --rm h2ogpt -it generate.py \
|
| 44 |
+
--base_model=EleutherAI/gpt-neox-20b \
|
| 45 |
+
--lora_weights=h2ogpt_lora_weights --prompt_type=human_bot
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
4. Open `https://localhost:7860` in the browser
|
| 49 |
+
|
| 50 |
+
### Docker Compose Setup & Inference
|
| 51 |
+
|
| 52 |
+
1. (optional) Change desired model and weights under `environment` in the `docker-compose.yml`
|
| 53 |
+
|
| 54 |
+
2. Build and run the container
|
| 55 |
+
|
| 56 |
+
```bash
|
| 57 |
+
docker-compose up -d --build
|
| 58 |
+
```
|
| 59 |
+
|
| 60 |
+
3. Open `https://localhost:7860` in the browser
|
| 61 |
+
|
| 62 |
+
4. See logs:
|
| 63 |
+
|
| 64 |
+
```bash
|
| 65 |
+
docker-compose logs -f
|
| 66 |
+
```
|
| 67 |
+
|
| 68 |
+
5. Clean everything up:
|
| 69 |
+
|
| 70 |
+
```bash
|
| 71 |
+
docker-compose down --volumes --rmi all
|
| 72 |
+
```
|
| 73 |
+
|
docs/INSTALL.md
ADDED
|
@@ -0,0 +1,131 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## h2oGPT Installation Help
|
| 2 |
+
|
| 3 |
+
Follow these instructions to get a working Python environment on a Linux system.
|
| 4 |
+
|
| 5 |
+
### Install Python environment
|
| 6 |
+
|
| 7 |
+
Download Miniconda, for [Linux](https://repo.anaconda.com/miniconda/Miniconda3-py310_23.1.0-1-Linux-x86_64.sh) or MACOS [Miniconda](https://docs.conda.io/en/latest/miniconda.html#macos-installers) or Windows [Miniconda](https://repo.anaconda.com/miniconda/Miniconda3-latest-Windows-x86_64.exe). Then, install conda and setup environment:
|
| 8 |
+
```bash
|
| 9 |
+
bash ./Miniconda3-py310_23.1.0-1-Linux-x86_64.sh # for linux x86-64
|
| 10 |
+
# follow license agreement and add to bash if required
|
| 11 |
+
```
|
| 12 |
+
Enter new shell and should also see `(base)` in prompt. Then, create new env:
|
| 13 |
+
```bash
|
| 14 |
+
conda create -n h2ogpt -y
|
| 15 |
+
conda activate h2ogpt
|
| 16 |
+
conda install -y mamba -c conda-forge # for speed
|
| 17 |
+
mamba install python=3.10 -c conda-forge -y
|
| 18 |
+
conda update -n base -c defaults conda -y
|
| 19 |
+
```
|
| 20 |
+
You should see `(h2ogpt)` in shell prompt. Test your python:
|
| 21 |
+
```bash
|
| 22 |
+
python --version
|
| 23 |
+
```
|
| 24 |
+
should say 3.10.xx and:
|
| 25 |
+
```bash
|
| 26 |
+
python -c "import os, sys ; print('hello world')"
|
| 27 |
+
```
|
| 28 |
+
should print `hello world`. Then clone:
|
| 29 |
+
```bash
|
| 30 |
+
git clone https://github.com/h2oai/h2ogpt.git
|
| 31 |
+
cd h2ogpt
|
| 32 |
+
```
|
| 33 |
+
Then go back to [README](../README.md) for package installation and use of `generate.py`.
|
| 34 |
+
|
| 35 |
+
### Installing CUDA Toolkit
|
| 36 |
+
|
| 37 |
+
E.g. CUDA 12.1 [install cuda coolkit](https://developer.nvidia.com/cuda-downloads?target_os=Linux&target_arch=x86_64&Distribution=Ubuntu&target_version=22.04&target_type=deb_local)
|
| 38 |
+
|
| 39 |
+
E.g. for Ubuntu 20.04, select Ubuntu, Version 20.04, Installer Type "deb (local)", and you should get the following commands:
|
| 40 |
+
```bash
|
| 41 |
+
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-ubuntu2004.pin
|
| 42 |
+
sudo mv cuda-ubuntu2004.pin /etc/apt/preferences.d/cuda-repository-pin-600
|
| 43 |
+
wget https://developer.download.nvidia.com/compute/cuda/12.1.0/local_installers/cuda-repo-ubuntu2004-12-1-local_12.1.0-530.30.02-1_amd64.deb
|
| 44 |
+
sudo dpkg -i cuda-repo-ubuntu2004-12-1-local_12.1.0-530.30.02-1_amd64.deb
|
| 45 |
+
sudo cp /var/cuda-repo-ubuntu2004-12-1-local/cuda-*-keyring.gpg /usr/share/keyrings/
|
| 46 |
+
sudo apt-get update
|
| 47 |
+
sudo apt-get -y install cuda
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
Then set the system up to use the freshly installed CUDA location:
|
| 51 |
+
```bash
|
| 52 |
+
echo "export LD_LIBRARY_PATH=\$LD_LIBRARY_PATH:/usr/local/cuda/lib64/" >> ~/.bashrc
|
| 53 |
+
echo "export CUDA_HOME=/usr/local/cuda" >> ~/.bashrc
|
| 54 |
+
echo "export PATH=\$PATH:/usr/local/cuda/bin/" >> ~/.bashrc
|
| 55 |
+
source ~/.bashrc
|
| 56 |
+
conda activate h2ogpt
|
| 57 |
+
```
|
| 58 |
+
|
| 59 |
+
Then reboot the machine, to get everything sync'ed up on restart.
|
| 60 |
+
```bash
|
| 61 |
+
sudo reboot
|
| 62 |
+
```
|
| 63 |
+
|
| 64 |
+
### Compile bitsandbytes
|
| 65 |
+
|
| 66 |
+
For fast 4-bit and 8-bit training, one needs bitsandbytes. [Compiling bitsandbytes](https://github.com/TimDettmers/bitsandbytes/blob/main/compile_from_source.md) is only required if you have different CUDA than built into bitsandbytes pypi package,
|
| 67 |
+
which includes CUDA 11.0, 11.1, 11.2, 11.3, 11.4, 11.5, 11.6, 11.7, 11.8, 12.0, 12.1. Here we compile for 12.1 as example.
|
| 68 |
+
```bash
|
| 69 |
+
git clone http://github.com/TimDettmers/bitsandbytes.git
|
| 70 |
+
cd bitsandbytes
|
| 71 |
+
git checkout 7c651012fce87881bb4e194a26af25790cadea4f
|
| 72 |
+
CUDA_VERSION=121 make cuda12x
|
| 73 |
+
CUDA_VERSION=121 python setup.py install
|
| 74 |
+
cd ..
|
| 75 |
+
```
|
| 76 |
+
|
| 77 |
+
### Install nvidia GPU manager if have multiple A100/H100s.
|
| 78 |
+
```bash
|
| 79 |
+
sudo apt-key del 7fa2af80
|
| 80 |
+
distribution=$(. /etc/os-release;echo $ID$VERSION_ID | sed -e 's/\.//g')
|
| 81 |
+
wget https://developer.download.nvidia.com/compute/cuda/repos/$distribution/x86_64/cuda-keyring_1.0-1_all.deb
|
| 82 |
+
sudo dpkg -i cuda-keyring_1.0-1_all.deb
|
| 83 |
+
sudo apt-get update
|
| 84 |
+
sudo apt-get install -y datacenter-gpu-manager
|
| 85 |
+
sudo apt-get install -y libnvidia-nscq-530
|
| 86 |
+
sudo systemctl --now enable nvidia-dcgm
|
| 87 |
+
dcgmi discovery -l
|
| 88 |
+
```
|
| 89 |
+
See [GPU Manager](https://docs.nvidia.com/datacenter/dcgm/latest/user-guide/getting-started.html)
|
| 90 |
+
|
| 91 |
+
### Install and run Fabric Manager if have multiple A100/100s
|
| 92 |
+
|
| 93 |
+
```bash
|
| 94 |
+
sudo apt-get install cuda-drivers-fabricmanager
|
| 95 |
+
sudo systemctl start nvidia-fabricmanager
|
| 96 |
+
sudo systemctl status nvidia-fabricmanager
|
| 97 |
+
```
|
| 98 |
+
See [Fabric Manager](https://docs.nvidia.com/datacenter/tesla/fabric-manager-user-guide/index.html)
|
| 99 |
+
|
| 100 |
+
Once have installed and reboot system, just do:
|
| 101 |
+
|
| 102 |
+
```bash
|
| 103 |
+
sudo systemctl --now enable nvidia-dcgm
|
| 104 |
+
dcgmi discovery -l
|
| 105 |
+
sudo systemctl start nvidia-fabricmanager
|
| 106 |
+
sudo systemctl status nvidia-fabricmanager
|
| 107 |
+
```
|
| 108 |
+
|
| 109 |
+
### Tensorboard (optional) to inspect training
|
| 110 |
+
|
| 111 |
+
```bash
|
| 112 |
+
tensorboard --logdir=runs/
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
### Flash Attention
|
| 116 |
+
|
| 117 |
+
Update: this is not needed anymore, see https://github.com/h2oai/h2ogpt/issues/128
|
| 118 |
+
|
| 119 |
+
To use flash attention with LLaMa, need cuda 11.7 so flash attention module compiles against torch.
|
| 120 |
+
|
| 121 |
+
E.g. for Ubuntu, one goes to [cuda toolkit](https://developer.nvidia.com/cuda-11-7-0-download-archive?target_os=Linux&target_arch=x86_64&Distribution=Ubuntu&target_version=20.04&target_type=runfile_local), then:
|
| 122 |
+
```bash
|
| 123 |
+
wget https://developer.download.nvidia.com/compute/cuda/11.7.0/local_installers/cuda_11.7.0_515.43.04_linux.run
|
| 124 |
+
sudo bash ./cuda_11.7.0_515.43.04_linux.run
|
| 125 |
+
```
|
| 126 |
+
Then No for symlink change, say continue (not abort), accept license, keep only toolkit selected, select install.
|
| 127 |
+
|
| 128 |
+
If cuda 11.7 is not your base installation, then when doing pip install -r requirements.txt do instead:
|
| 129 |
+
```bash
|
| 130 |
+
CUDA_HOME=/usr/local/cuda-11.8 pip install -r reqs_optional/requirements_optional_flashattention.txt
|
| 131 |
+
```
|
docs/LINKS.md
ADDED
|
@@ -0,0 +1,217 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
### Code to consider including:
|
| 2 |
+
[flan-alpaca](https://github.com/declare-lab/flan-alpaca)<br />
|
| 3 |
+
[text-generation-webui](https://github.com/oobabooga/text-generation-webui)<br />
|
| 4 |
+
[minimal-llama](https://github.com/zphang/minimal-llama/)<br />
|
| 5 |
+
[finetune GPT-NeoX](https://nn.labml.ai/neox/samples/finetune.html)<br />
|
| 6 |
+
[GPTQ-for_LLaMa](https://github.com/qwopqwop200/GPTQ-for-LLaMa/compare/cuda...Digitous:GPTQ-for-GPT-NeoX:main)<br />
|
| 7 |
+
[OpenChatKit on multi-GPU](https://github.com/togethercomputer/OpenChatKit/issues/20)<br />
|
| 8 |
+
[Non-Causal LLM](https://huggingface.co/docs/transformers/main/en/model_doc/gptj#transformers.GPTJForSequenceClassification)<br />
|
| 9 |
+
[OpenChatKit_Offload](https://github.com/togethercomputer/OpenChatKit/commit/148b5745a57a6059231178c41859ecb09164c157)<br />
|
| 10 |
+
[Flan-alpaca](https://github.com/declare-lab/flan-alpaca/blob/main/training.py)<br />
|
| 11 |
+
|
| 12 |
+
### Some open source models:
|
| 13 |
+
[GPT-NeoXT-Chat-Base-20B](https://huggingface.co/togethercomputer/GPT-NeoXT-Chat-Base-20B/tree/main)<br />
|
| 14 |
+
[GPT-NeoX](https://huggingface.co/docs/transformers/model_doc/gpt_neox)<br />
|
| 15 |
+
[GPT-NeoX-20B](https://huggingface.co/EleutherAI/gpt-neox-20b)<br />
|
| 16 |
+
[Pythia-6.9B](https://huggingface.co/EleutherAI/pythia-6.9b)<br />
|
| 17 |
+
[Pythia-12B](https://huggingface.co/EleutherAI/neox-ckpt-pythia-12b)<br />
|
| 18 |
+
[Flan-T5-XXL](https://huggingface.co/google/flan-t5-xxl)<br />
|
| 19 |
+
[GPT-J-Moderation-6B](https://huggingface.co/togethercomputer/GPT-JT-Moderation-6B)<br />
|
| 20 |
+
[OIG safety models](https://laion.ai/blog/oig-dataset/#safety-models)<br />
|
| 21 |
+
[BigScience-mT0](https://huggingface.co/mT0)<br />
|
| 22 |
+
[BigScience-XP3](https://huggingface.co/datasets/bigscience/xP3)<br />
|
| 23 |
+
[BigScience-Bloomz](https://huggingface.co/bigscience/bloomz)<br />
|
| 24 |
+
|
| 25 |
+
### Some create commons models that would be interesting to use:
|
| 26 |
+
[Galactica-120B](https://huggingface.co/facebook/galactica-120b)<br />
|
| 27 |
+
[LLaMa-small-pt](https://huggingface.co/decapoda-research/llama-smallint-pt)<br />
|
| 28 |
+
[LLaMa-64b-4bit](https://huggingface.co/maderix/llama-65b-4bit/tree/main)<br />
|
| 29 |
+
|
| 30 |
+
### Papers/Repos
|
| 31 |
+
[Self-improve](https://arxiv.org/abs/2210.11610)<br />
|
| 32 |
+
[Coding](https://arxiv.org/abs/2303.17491)<br />
|
| 33 |
+
[self-reflection](https://arxiv.org/abs/2303.11366)<br />
|
| 34 |
+
[RLHF](https://arxiv.org/abs/2204.05862)<br />
|
| 35 |
+
[DERA](https://arxiv.org/abs/2303.17071)<br />
|
| 36 |
+
[HAI Index Report 2023](https://aiindex.stanford.edu/report/)<br />
|
| 37 |
+
[LLaMa](https://arxiv.org/abs/2302.13971)<br />
|
| 38 |
+
[GLM-130B](https://github.com/THUDM/GLM-130B)<br />
|
| 39 |
+
[RWKV RNN](https://github.com/BlinkDL/RWKV-LM)<br />
|
| 40 |
+
[Toolformer](https://arxiv.org/abs/2302.04761)<br />
|
| 41 |
+
[GPTQ](https://github.com/qwopqwop200/GPTQ-for-LLaMa)<br />
|
| 42 |
+
[Retro](https://www.deepmind.com/publications/improving-language-models-by-retrieving-from-trillions-of-tokens)<br />
|
| 43 |
+
[Clinical_outperforms](https://arxiv.org/abs/2302.08091)<br />
|
| 44 |
+
[Chain-Of-Thought](https://github.com/amazon-science/mm-cot)<br />
|
| 45 |
+
[scaling law1](https://arxiv.org/abs/2203.15556)<br />
|
| 46 |
+
[Big-bench](https://github.com/google/BIG-bench)<br />
|
| 47 |
+
[Natural-Instructions](https://github.com/allenai/natural-instructions)<br />
|
| 48 |
+
|
| 49 |
+
### Other projects:
|
| 50 |
+
[StackLLaMa](https://huggingface.co/blog/stackllama)<br />
|
| 51 |
+
[Alpaca-CoT](https://github.com/PhoebusSi/alpaca-CoT)<br />
|
| 52 |
+
[ColossalAIChat](https://github.com/hpcaitech/ColossalAI/tree/main/applications/Chat)<br />
|
| 53 |
+
[EasyLM](https://github.com/young-geng/EasyLM.git)<br />
|
| 54 |
+
[Koala](https://bair.berkeley.edu/blog/2023/04/03/koala/)<br />
|
| 55 |
+
[Vicuna](https://vicuna.lmsys.org/)<br />
|
| 56 |
+
[Flan-Alpaca](https://github.com/declare-lab/flan-alpaca)<br />
|
| 57 |
+
[FastChat](https://chat.lmsys.org/)<br />
|
| 58 |
+
[alpaca-lora](https://github.com/h2oai/alpaca-lora)<br />
|
| 59 |
+
[alpaca.http](https://github.com/Nuked88/alpaca.http)<br />
|
| 60 |
+
[chatgpt-retrieval-pllugin](https://github.com/openai/chatgpt-retrieval-plugin)<br />
|
| 61 |
+
[subtl.ai docs search on private docs](https://www.subtl.ai/)<br />
|
| 62 |
+
[gertel](https://gretel.ai/)<br />
|
| 63 |
+
[alpaca_lora_4bit](https://github.com/johnsmith0031/alpaca_lora_4bit)<br />
|
| 64 |
+
[alpaca_lora_4bit_readme](https://github.com/s4rduk4r/alpaca_lora_4bit_readme)<br />
|
| 65 |
+
[code alpaca](https://github.com/sahil280114/codealpaca)<br />
|
| 66 |
+
[serge](https://github.com/nsarrazin/serge)<br />
|
| 67 |
+
[BlinkDL](https://huggingface.co/spaces/BlinkDL/ChatRWKV-gradio)<br />
|
| 68 |
+
[RWKV-LM](https://github.com/BlinkDL/RWKV-LM)<br />
|
| 69 |
+
[MosaicCM](https://github.com/mosaicml/examples#large-language-models-llms)<br />
|
| 70 |
+
[OpenAI Plugins](https://openai.com/blog/chatgpt-plugins)<br />
|
| 71 |
+
[GPT3.5-Turbo-PGVector](https://github.com/gannonh/gpt3.5-turbo-pgvector)<br />
|
| 72 |
+
[LLaMa-Adapter](https://github.com/ZrrSkywalker/LLaMA-Adapter)<br />
|
| 73 |
+
[llama-index](https://github.com/jerryjliu/llama_index)<br />
|
| 74 |
+
[minimal-llama](https://github.com/zphang/minimal-llama/)<br />
|
| 75 |
+
[llama.cpp](https://github.com/ggerganov/llama.cpp)<br />
|
| 76 |
+
[ggml](https://github.com/ggerganov/ggml)<br />
|
| 77 |
+
[mmap](https://justine.lol/mmap/)<br />
|
| 78 |
+
[lamma.cpp more](https://til.simonwillison.net/llms/llama-7b-m2)<br />
|
| 79 |
+
[TargetedSummarization](https://github.com/helliun/targetedSummarization)<br />
|
| 80 |
+
[OpenFlamingo](https://laion.ai/blog/open-flamingo/)<br />
|
| 81 |
+
[Auto-GPT](https://github.com/Torantulino/Auto-GPT)<br />
|
| 82 |
+
|
| 83 |
+
### Apache2/etc. Data
|
| 84 |
+
[OIG 43M instructions](https://laion.ai/blog/oig-dataset/) [direct HF link](https://huggingface.co/datasets/laion/OIG)<br />
|
| 85 |
+
[More on OIG](https://laion.ai/blog/oig-dataset/)<br />
|
| 86 |
+
[DataSet Viewer](https://huggingface.co/datasets/viewer/?dataset=squad)<br />
|
| 87 |
+
[Anthropic RLHF](https://huggingface.co/datasets/Anthropic/hh-rlhf)<br />
|
| 88 |
+
[WebGPT_Comparisons](https://huggingface.co/datasets/openai/webgpt_comparisons)<br />
|
| 89 |
+
[Self_instruct](https://github.com/yizhongw/self-instruct)<br />
|
| 90 |
+
[20BChatModelData](https://github.com/togethercomputer/OpenDataHub)<br />
|
| 91 |
+
|
| 92 |
+
### Apache2/MIT/BSD-3 Summarization Data
|
| 93 |
+
[xsum for Summarization](https://huggingface.co/datasets/xsum)<br />
|
| 94 |
+
[Apache2 Summarization](https://huggingface.co/datasets?task_categories=task_categories:summarization&license=license:apache-2.0&sort=downloads)<br />
|
| 95 |
+
[MIT summarization](https://huggingface.co/datasets?task_categories=task_categories:summarization&license=license:mit&sort=downloads)<br />
|
| 96 |
+
[BSD-3 summarization](https://huggingface.co/datasets?task_categories=task_categories:summarization&license=license:bsd-3-clause&sort=downloads)<br />
|
| 97 |
+
[OpenRail](https://huggingface.co/datasets?task_categories=task_categories:summarization&license=license:openrail&sort=downloads)<br />
|
| 98 |
+
[Summarize_from_feedback](https://huggingface.co/datasets/openai/summarize_from_feedback)<br />
|
| 99 |
+
|
| 100 |
+
### Ambiguous License Data
|
| 101 |
+
[GPT-4-LLM](https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM)<br />
|
| 102 |
+
[GPT4All](https://huggingface.co/datasets/nomic-ai/gpt4all_prompt_generations)<br />
|
| 103 |
+
[LinkGPT4](https://github.com/lm-sys/FastChat/issues/90#issuecomment-1493250773)<br />
|
| 104 |
+
[ShareGPT52K](https://huggingface.co/datasets/RyokoAI/ShareGPT52K)<br />
|
| 105 |
+
[ShareGPT_Vicuna](https://huggingface.co/datasets/anon8231489123/ShareGPT_Vicuna_unfiltered)<br />
|
| 106 |
+
[ChatLogs](https://chatlogs.net/)<br />
|
| 107 |
+
[Alpaca-CoT](https://github.com/PhoebusSi/alpaca-CoT)<br />
|
| 108 |
+
[LaMini-LM](https://github.com/mbzuai-nlp/LaMini-LM)<br />
|
| 109 |
+
|
| 110 |
+
### Non-commercial Data
|
| 111 |
+
[GPT-3 based Alpaca Cleaned](https://github.com/gururise/AlpacaDataCleaned)<br />
|
| 112 |
+
|
| 113 |
+
### Prompt ENGR
|
| 114 |
+
[Prompt/P-tuning](https://github.com/huggingface/peft)<br />
|
| 115 |
+
[Prompt/P-tuing Nemo/NVIDIA](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/nlp/nemo_megatron/prompt_learning.html)<br />
|
| 116 |
+
[Info](https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/)<br />
|
| 117 |
+
[Info2](https://github.com/dair-ai/Prompt-Engineering-Guide)<br />
|
| 118 |
+
[Prompt-Tuning](https://arxiv.org/abs/2104.08691)<br />
|
| 119 |
+
[P-tuning v2](https://arxiv.org/abs/2110.07602)<br />
|
| 120 |
+
[babyagi](https://github.com/yoheinakajima/babyagi/blob/main/babyagi.py#L97-L134)<br />
|
| 121 |
+
[APE](https://www.promptingguide.ai/techniques/ape)<br />
|
| 122 |
+
|
| 123 |
+
### Validation
|
| 124 |
+
[Bleu/Rouge/Meteor/Bert-Score](https://arize.com/blog-course/generative-ai-metrics-bleu-score/)<br />
|
| 125 |
+
|
| 126 |
+
### Generate Hyperparameters
|
| 127 |
+
[hot-to-generate](https://huggingface.co/blog/how-to-generate)<br />
|
| 128 |
+
[Notes_on_Transformers Chpt5](https://christianjmills.com/posts/transformers-book-notes/chapter-5/index.html)<br />
|
| 129 |
+
[Notes_on_Transformers_Chpt10](https://christianjmills.com/posts/transformers-book-notes/chapter-10/index.html)<br />
|
| 130 |
+
|
| 131 |
+
### Embeddings
|
| 132 |
+
[OpenAI Expensive?](https://medium.com/@nils_reimers/openai-gpt-3-text-embeddings-really-a-new-state-of-the-art-in-dense-text-embeddings-6571fe3ec9d9)<br />
|
| 133 |
+
[Leaderboard](https://huggingface.co/spaces/mteb/leaderboard)<br />
|
| 134 |
+
|
| 135 |
+
### Commercial products
|
| 136 |
+
[OpenAI](https://platform.openai.com/docs/guides/fine-tuning/advanced-usage)<br />
|
| 137 |
+
[OpenAI Tokenizer](https://platform.openai.com/tokenizer)<br />
|
| 138 |
+
[OpenAI Playground](https://platform.openai.com/playground)<br />
|
| 139 |
+
[OpenAI Chat](https://chat.openai.com/chat?)<br />
|
| 140 |
+
[OpenAI GPT-4 Chat](https://chat.openai.com/chat?model=gpt-4)<br />
|
| 141 |
+
[cohere](https://cohere.io/)<br />
|
| 142 |
+
[coherefinetune](https://docs.cohere.ai/reference/finetune)<br />
|
| 143 |
+
[DocsBotAI](https://docsbot.ai/)<br />
|
| 144 |
+
[Perplexity](https://www.perplexity.ai/)<br />
|
| 145 |
+
[VoiceFlow](https://www.voiceflow.com/)<br />
|
| 146 |
+
[NLPCloud](https://nlpcloud.com/effectively-using-gpt-j-gpt-neo-gpt-3-alternatives-few-shot-learning.html)<br />
|
| 147 |
+
|
| 148 |
+
### Multinode inference
|
| 149 |
+
[FasterTransformer](https://github.com/triton-inference-server/fastertransformer_backend#multi-node-inference)<br />
|
| 150 |
+
[Kubernetes Triton](https://developer.nvidia.com/blog/deploying-nvidia-triton-at-scale-with-mig-and-kubernetes/)<br />
|
| 151 |
+
|
| 152 |
+
### Faster inference
|
| 153 |
+
[text-generation-inference](https://github.com/huggingface/text-generation-inference)<br />
|
| 154 |
+
[Optimum](https://github.com/huggingface/optimum)<br />
|
| 155 |
+
|
| 156 |
+
### Semi-Open source Semi-Commercial products
|
| 157 |
+
[OpenAssistant](https://open-assistant.io/)<br />
|
| 158 |
+
[OpenAssistant Repo](https://github.com/LAION-AI/Open-Assistant)<br />
|
| 159 |
+
[OpenChatKit](https://github.com/togethercomputer/OpenChatKit)<br />
|
| 160 |
+
[OpenChatKit2](https://github.com/togethercomputer/OpenDataHub)<br />
|
| 161 |
+
[OpenChatKit3](https://www.together.xyz/blog/openchatkit)<br />
|
| 162 |
+
[OpenChatKit4](https://github.com/togethercomputer/OpenChatKit/blob/main/training/README.md#arguments)<br />
|
| 163 |
+
[OpenChatKitPreview](https://api.together.xyz/open-chat?preview=1)<br />
|
| 164 |
+
[langchain](https://python.langchain.com/en/latest/)<br />
|
| 165 |
+
[langchain+pinecone](https://www.youtube.com/watch?v=nMniwlGyX-c)<br />
|
| 166 |
+
|
| 167 |
+
### Q/A docs
|
| 168 |
+
[HUMATA](https://www.humata.ai/)<br />
|
| 169 |
+
[OSSCHat](https://osschat.io/)<br />
|
| 170 |
+
[NeuralSearchCohere](https://txt.cohere.com/embedding-archives-wikipedia/)<br />
|
| 171 |
+
[ue5](https://github.com/bublint/ue5-llama-lora)<br />
|
| 172 |
+
|
| 173 |
+
### AutoGPT type projects
|
| 174 |
+
[AgentGPT](https://github.com/reworkd/AgentGPT)<br />
|
| 175 |
+
[Self-DEBUG](https://arxiv.org/abs/2304.05128)<br />
|
| 176 |
+
[BabyAGI](https://github.com/yoheinakajima/babyagi/)<br />
|
| 177 |
+
[AutoPR](https://github.com/irgolic/AutoPR)<br />
|
| 178 |
+
|
| 179 |
+
### Cloud fine-tune
|
| 180 |
+
[AWS](https://docs.aws.amazon.com/sagemaker/latest/dg/jumpstart-fine-tune.html)<br />
|
| 181 |
+
[AWS2](https://aws.amazon.com/blogs/machine-learning/training-large-language-models-on-amazon-sagemaker-best-practices/)<br />
|
| 182 |
+
|
| 183 |
+
### Chatbots:
|
| 184 |
+
[GPT4ALL Chat](https://github.com/nomic-ai/gpt4all-chat)<br />
|
| 185 |
+
[GLT4ALL](https://github.com/nomic-ai/gpt4all)<br />
|
| 186 |
+
[OASSST](https://open-assistant.io/chat)<br />
|
| 187 |
+
[FastChat](https://github.com/lm-sys/FastChat)<br />
|
| 188 |
+
[Dolly](https://huggingface.co/spaces/HuggingFaceH4/databricks-dolly)<br />
|
| 189 |
+
[HF Instructions](https://huggingface.co/spaces/HuggingFaceH4/instruction-model-outputs-filtered)<br />
|
| 190 |
+
[DeepSpeed Chat](https://github.com/microsoft/DeepSpeedExamples/tree/master/applications/DeepSpeed-Chat)<br />
|
| 191 |
+
[LoraChat](https://github.com/bupticybee/FastLoRAChat)<br />
|
| 192 |
+
[Tabby](https://github.com/TabbyML/tabby)<br />
|
| 193 |
+
[TalkToModel](https://github.com/dylan-slack/TalkToModel)<br />
|
| 194 |
+
[You.com](https://you.com/)<br />
|
| 195 |
+
|
| 196 |
+
### LangChain or Agent related
|
| 197 |
+
[Gradio Tools](https://github.com/freddyaboulton/gradio-tools)<br />
|
| 198 |
+
[LLM Agents](https://blog.langchain.dev/gradio-llm-agents/)<br />
|
| 199 |
+
[Meta Prompt](https://github.com/mbchang/meta-prompt)<br />
|
| 200 |
+
[HF Agents](https://huggingface.co/docs/transformers/transformers_agents)
|
| 201 |
+
[HF Agents Collab](https://colab.research.google.com/drive/1c7MHD-T1forUPGcC_jlwsIptOzpG3hSj)
|
| 202 |
+
[Einstein GPT](https://www.salesforce.com/products/einstein/overview/?d=cta-body-promo-8)
|
| 203 |
+
[SMOL-AI](https://github.com/smol-ai/developer)
|
| 204 |
+
[Pandas-AI](https://github.com/gventuri/pandas-ai/)
|
| 205 |
+
|
| 206 |
+
### Summaries
|
| 207 |
+
[LLMs](https://github.com/Mooler0410/LLMsPracticalGuide)<br />
|
| 208 |
+
|
| 209 |
+
### Deployment
|
| 210 |
+
[MLC-LLM](https://github.com/mlc-ai/mlc-llm)<br />
|
| 211 |
+
|
| 212 |
+
### Evaluations
|
| 213 |
+
[LMSYS (check for latest glob)](https://lmsys.org/blog/2023-05-25-leaderboard/)<br />
|
| 214 |
+
[LMSYS Chatbot Arena](https://chat.lmsys.org/?arena)<br />
|
| 215 |
+
[LMSYS Add model](https://github.com/lm-sys/FastChat/blob/main/docs/arena.md#how-to-add-a-new-model)<br />
|
| 216 |
+
[NLL](https://blog.gopenai.com/lmflow-benchmark-an-automatic-evaluation-framework-for-open-source-llms-ef5c6f142418)<br />
|
| 217 |
+
[HackAPrompt](https://www.aicrowd.com/challenges/hackaprompt-2023/leaderboards)<br />
|
docs/README_CLI.md
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
### CLI chat
|
| 2 |
+
|
| 3 |
+
The CLI can be used instead of gradio by running for some base model, e.g.:
|
| 4 |
+
```bash
|
| 5 |
+
python generate.py --base_model=gptj --cli=True
|
| 6 |
+
```
|
| 7 |
+
and for LangChain run:
|
| 8 |
+
```bash
|
| 9 |
+
python make_db.py --user_path=user_path --collection_name=UserData
|
| 10 |
+
python generate.py --base_model=gptj --cli=True --langchain_mode=UserData
|
| 11 |
+
```
|
| 12 |
+
with documents in `user_path` folder, or directly run:
|
| 13 |
+
```bash
|
| 14 |
+
python generate.py --base_model=gptj --cli=True --langchain_mode=UserData --user_path=user_path
|
| 15 |
+
```
|
| 16 |
+
which will build the database first time. One can also use any other models, like:
|
| 17 |
+
```bash
|
| 18 |
+
python generate.py --base_model=h2oai/h2ogpt-oig-oasst1-512-6_9b --cli=True --langchain_mode=UserData --user_path=user_path
|
| 19 |
+
```
|
| 20 |
+
or for WizardLM:
|
| 21 |
+
```bash
|
| 22 |
+
python generate.py --base_model='llama' --prompt_type=wizard2 --cli=True --langchain_mode=UserData --user_path=user_path
|
| 23 |
+
```
|
| 24 |
+
|
docs/README_CLIENT.md
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
### Client APIs
|
| 2 |
+
|
| 3 |
+
A Gradio API and an OpenAI-compliant API are supported.
|
| 4 |
+
|
| 5 |
+
##### Gradio Client API
|
| 6 |
+
|
| 7 |
+
`generate.py` by default runs a gradio server, which also gives access to client API using gradio client. One can use it with h2oGPT, or independently of h2oGPT repository by installing an env:
|
| 8 |
+
```bash
|
| 9 |
+
conda create -n gradioclient -y
|
| 10 |
+
conda activate gradioclient
|
| 11 |
+
conda install python=3.10 -y
|
| 12 |
+
pip install gradio_client
|
| 13 |
+
python checkclient.py
|
| 14 |
+
```
|
| 15 |
+
then running client code:
|
| 16 |
+
```python
|
| 17 |
+
from gradio_client import Client
|
| 18 |
+
import ast
|
| 19 |
+
|
| 20 |
+
HOST_URL = "http://localhost:7860"
|
| 21 |
+
client = Client(HOST_URL)
|
| 22 |
+
|
| 23 |
+
# string of dict for input
|
| 24 |
+
kwargs = dict(instruction_nochat='Who are you?')
|
| 25 |
+
res = client.predict(str(dict(kwargs)), api_name='/submit_nochat_api')
|
| 26 |
+
|
| 27 |
+
# string of dict for output
|
| 28 |
+
response = ast.literal_eval(res)['response']
|
| 29 |
+
print(response)
|
| 30 |
+
```
|
| 31 |
+
For other ways to use gradio client, see example [test code](../client_test.py) or other tests in our [tests](https://github.com/h2oai/h2ogpt/blob/main/tests/test_client_calls.py).
|
| 32 |
+
|
| 33 |
+
Any element in [gradio_runner.py](../gradio_runner.py) with `api_name` defined can be accessed via the gradio client.
|
| 34 |
+
|
| 35 |
+
##### OpenAI Python Client Library
|
| 36 |
+
|
| 37 |
+
An OpenAI compliant client is available. Refer the [README](../client/README.md) for more details.
|
| 38 |
+
|