Spaces:
Runtime error

Runtime error
Matthijs Hollemans
commited on
Commit
•
0ecd9fb
1
Parent(s):
e2a288e
add app
Browse files- .gitattributes +1 -0
- .gitignore +4 -0
- LICENSE +21 -0
- app.py +261 -0
- checkpoints/image2reverb_f22.ckpt +3 -0
- checkpoints/mono_odom_640x192/depth.pth +3 -0
- checkpoints/mono_odom_640x192/encoder.pth +3 -0
- checkpoints/mono_odom_640x192/pose.pth +3 -0
- checkpoints/mono_odom_640x192/pose_encoder.pth +3 -0
- checkpoints/mono_odom_640x192/poses.npy +3 -0
- examples/input.0c3f5013.png +0 -0
- examples/input.2238dc21.png +0 -0
- examples/input.321eef38.png +0 -0
- examples/input.4d280b40.png +0 -0
- examples/input.4e2f71f6.png +0 -0
- examples/input.5416407f.png +0 -0
- examples/input.67bc502e.png +0 -0
- examples/input.98773b90.png +0 -0
- examples/input.ac61500f.png +0 -0
- examples/input.c9ee9d49.png +0 -0
- image2reverb/dataset.py +96 -0
- image2reverb/layers.py +88 -0
- image2reverb/mel.py +20 -0
- image2reverb/model.py +207 -0
- image2reverb/networks.py +344 -0
- image2reverb/stft.py +23 -0
- image2reverb/util.py +167 -0
- model.jpg +0 -0
- requirements.txt +6 -0
.gitattributes
CHANGED
|
@@ -28,6 +28,7 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 28 |
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 29 |
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 30 |
*.wasm filter=lfs diff=lfs merge=lfs -text
|
|
|
|
| 31 |
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
|
|
|
| 28 |
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 29 |
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 30 |
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wav filter=lfs diff=lfs merge=lfs -text
|
| 32 |
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.pyc
|
| 2 |
+
__pycache__/
|
| 3 |
+
.DS_Store
|
| 4 |
+
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2020
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
app.py
ADDED
|
@@ -0,0 +1,261 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Hacked together using the code from https://github.com/nikhilsinghmus/image2reverb
|
| 2 |
+
|
| 3 |
+
import os, types
|
| 4 |
+
import numpy as np
|
| 5 |
+
import gradio as gr
|
| 6 |
+
import soundfile as sf
|
| 7 |
+
import scipy
|
| 8 |
+
import librosa.display
|
| 9 |
+
from PIL import Image
|
| 10 |
+
|
| 11 |
+
import matplotlib
|
| 12 |
+
matplotlib.use("Agg")
|
| 13 |
+
import matplotlib.pyplot as plt
|
| 14 |
+
|
| 15 |
+
import torch
|
| 16 |
+
from torch.utils.data import Dataset
|
| 17 |
+
import torchvision.transforms as transforms
|
| 18 |
+
from pytorch_lightning import Trainer
|
| 19 |
+
|
| 20 |
+
from image2reverb.model import Image2Reverb
|
| 21 |
+
from image2reverb.stft import STFT
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
predicted_ir = None
|
| 25 |
+
predicted_spectrogram = None
|
| 26 |
+
predicted_depthmap = None
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def test_step(self, batch, batch_idx):
|
| 30 |
+
spec, label, paths = batch
|
| 31 |
+
examples = [os.path.splitext(os.path.basename(s))[0] for _, s in zip(*paths)]
|
| 32 |
+
|
| 33 |
+
f, img = self.enc.forward(label)
|
| 34 |
+
|
| 35 |
+
shape = (
|
| 36 |
+
f.shape[0],
|
| 37 |
+
(self._latent_dimension - f.shape[1]) if f.shape[1] < self._latent_dimension else f.shape[1],
|
| 38 |
+
f.shape[2],
|
| 39 |
+
f.shape[3]
|
| 40 |
+
)
|
| 41 |
+
z = torch.cat((f, torch.randn(shape, device=model.device)), 1)
|
| 42 |
+
|
| 43 |
+
fake_spec = self.g(z)
|
| 44 |
+
|
| 45 |
+
stft = STFT()
|
| 46 |
+
y_f = [stft.inverse(s.squeeze()) for s in fake_spec]
|
| 47 |
+
|
| 48 |
+
# TODO: bit hacky
|
| 49 |
+
global predicted_ir, predicted_spectrogram, predicted_depthmap
|
| 50 |
+
predicted_ir = y_f[0]
|
| 51 |
+
|
| 52 |
+
s = fake_spec.squeeze().cpu().numpy()
|
| 53 |
+
predicted_spectrogram = np.exp((((s + 1) * 0.5) * 19.5) - 17.5) - 1e-8
|
| 54 |
+
|
| 55 |
+
img = (img + 1) * 0.5
|
| 56 |
+
predicted_depthmap = img.cpu().squeeze().permute(1, 2, 0)[:,:,-1].squeeze().numpy()
|
| 57 |
+
|
| 58 |
+
return {"test_audio": y_f, "test_examples": examples}
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def test_epoch_end(self, outputs):
|
| 62 |
+
if not self.test_callback:
|
| 63 |
+
return
|
| 64 |
+
|
| 65 |
+
examples = []
|
| 66 |
+
audio = []
|
| 67 |
+
|
| 68 |
+
for output in outputs:
|
| 69 |
+
for i in range(len(output["test_examples"])):
|
| 70 |
+
audio.append(output["test_audio"][i])
|
| 71 |
+
examples.append(output["test_examples"][i])
|
| 72 |
+
|
| 73 |
+
self.test_callback(examples, audio)
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
checkpoint_path = "./checkpoints/image2reverb_f22.ckpt"
|
| 77 |
+
encoder_path = None
|
| 78 |
+
depthmodel_path = "./checkpoints/mono_odom_640x192"
|
| 79 |
+
constant_depth = None
|
| 80 |
+
latent_dimension = 512
|
| 81 |
+
|
| 82 |
+
model = Image2Reverb(encoder_path, depthmodel_path)
|
| 83 |
+
m = torch.load(checkpoint_path, map_location=model.device)
|
| 84 |
+
model.load_state_dict(m["state_dict"])
|
| 85 |
+
|
| 86 |
+
model.test_step = types.MethodType(test_step, model)
|
| 87 |
+
model.test_epoch_end = types.MethodType(test_epoch_end, model)
|
| 88 |
+
|
| 89 |
+
image_transforms = transforms.Compose([
|
| 90 |
+
transforms.Resize([224, 224], transforms.functional.InterpolationMode.BICUBIC),
|
| 91 |
+
transforms.ToTensor(),
|
| 92 |
+
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
|
| 93 |
+
])
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
class Image2ReverbDemoDataset(Dataset):
|
| 97 |
+
def __init__(self, image):
|
| 98 |
+
self.image = Image.fromarray(image)
|
| 99 |
+
self.stft = STFT()
|
| 100 |
+
|
| 101 |
+
def __getitem__(self, index):
|
| 102 |
+
img_tensor = image_transforms(self.image.convert("RGB"))
|
| 103 |
+
return torch.zeros(1, int(5.94 * 22050)), img_tensor, ("", "")
|
| 104 |
+
|
| 105 |
+
def __len__(self):
|
| 106 |
+
return 1
|
| 107 |
+
|
| 108 |
+
def name(self):
|
| 109 |
+
return "Image2ReverbDemo"
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
def convolve(audio, reverb):
|
| 113 |
+
# convolve audio with reverb
|
| 114 |
+
wet_audio = np.concatenate((audio, np.zeros(reverb.shape)))
|
| 115 |
+
wet_audio = scipy.signal.oaconvolve(wet_audio, reverb, "full")[:len(wet_audio)]
|
| 116 |
+
|
| 117 |
+
# normalize audio to roughly -1 dB peak and remove DC offset
|
| 118 |
+
wet_audio /= np.max(np.abs(wet_audio))
|
| 119 |
+
wet_audio -= np.mean(wet_audio)
|
| 120 |
+
wet_audio *= 0.9
|
| 121 |
+
return wet_audio
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
def predict(image, audio):
|
| 125 |
+
# image = numpy (height, width, channels)
|
| 126 |
+
# audio = tuple (sample_rate, frames) or (sample_rate, (frames, channels))
|
| 127 |
+
|
| 128 |
+
test_set = Image2ReverbDemoDataset(image)
|
| 129 |
+
test_loader = torch.utils.data.DataLoader(test_set, num_workers=0, batch_size=1)
|
| 130 |
+
trainer = Trainer(limit_test_batches=1)
|
| 131 |
+
trainer.test(model, test_loader, verbose=True)
|
| 132 |
+
|
| 133 |
+
# depthmap output
|
| 134 |
+
depthmap_fig = plt.figure()
|
| 135 |
+
plt.imshow(predicted_depthmap)
|
| 136 |
+
plt.close()
|
| 137 |
+
|
| 138 |
+
# spectrogram output
|
| 139 |
+
spectrogram_fig = plt.figure()
|
| 140 |
+
librosa.display.specshow(predicted_spectrogram, sr=22050, x_axis="time", y_axis="hz")
|
| 141 |
+
plt.close()
|
| 142 |
+
|
| 143 |
+
# plot the IR as a waveform
|
| 144 |
+
waveform_fig = plt.figure()
|
| 145 |
+
librosa.display.waveshow(predicted_ir, sr=22050, alpha=0.5)
|
| 146 |
+
plt.close()
|
| 147 |
+
|
| 148 |
+
# output audio as 16-bit signed integer
|
| 149 |
+
ir = (22050, (predicted_ir * 32767).astype(np.int16))
|
| 150 |
+
|
| 151 |
+
sample_rate, original_audio = audio
|
| 152 |
+
|
| 153 |
+
# incoming audio is 16-bit signed integer, convert to float and normalize
|
| 154 |
+
original_audio = original_audio.astype(np.float32) / 32768.0
|
| 155 |
+
original_audio /= np.max(np.abs(original_audio))
|
| 156 |
+
|
| 157 |
+
# resample reverb to sample_rate first, also normalize
|
| 158 |
+
reverb = predicted_ir.copy()
|
| 159 |
+
reverb = scipy.signal.resample_poly(reverb, up=sample_rate, down=22050)
|
| 160 |
+
reverb /= np.max(np.abs(reverb))
|
| 161 |
+
|
| 162 |
+
# stereo?
|
| 163 |
+
if len(original_audio.shape) > 1:
|
| 164 |
+
wet_left = convolve(original_audio[:, 0], reverb)
|
| 165 |
+
wet_right = convolve(original_audio[:, 1], reverb)
|
| 166 |
+
wet_audio = np.concatenate([wet_left[:, None], wet_right[:, None]], axis=1)
|
| 167 |
+
else:
|
| 168 |
+
wet_audio = convolve(original_audio, reverb)
|
| 169 |
+
|
| 170 |
+
# 50% dry-wet mix
|
| 171 |
+
mixed_audio = wet_audio * 0.5
|
| 172 |
+
mixed_audio[:len(original_audio), ...] += original_audio * 0.9 * 0.5
|
| 173 |
+
|
| 174 |
+
# convert back to 16-bit signed integer
|
| 175 |
+
wet_audio = (wet_audio * 32767).astype(np.int16)
|
| 176 |
+
mixed_audio = (mixed_audio * 32767).astype(np.int16)
|
| 177 |
+
|
| 178 |
+
convolved_audio_100 = (sample_rate, wet_audio)
|
| 179 |
+
convolved_audio_50 = (sample_rate, mixed_audio)
|
| 180 |
+
|
| 181 |
+
return depthmap_fig, spectrogram_fig, waveform_fig, ir, convolved_audio_100, convolved_audio_50
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
title = "Image2Reverb: Cross-Modal Reverb Impulse Response Synthesis"
|
| 185 |
+
|
| 186 |
+
description = """
|
| 187 |
+
<b>Image2Reverb</b> predicts the acoustic reverberation of a given environment from a 2D image. <a href="https://arxiv.org/abs/2103.14201">Read the paper</a>
|
| 188 |
+
|
| 189 |
+
How to use: Choose an image of a room or other environment and an audio file.
|
| 190 |
+
The model will predict what the reverb of the room sounds like and applies this to the audio file.
|
| 191 |
+
|
| 192 |
+
First, the image is resized to 224×224. The monodepth model is used to predict a depthmap, which is added as an
|
| 193 |
+
additional channel to the image input. A ResNet-based encoder then converts the image into features, and
|
| 194 |
+
finally a GAN predicts the spectrogram of the reverb's impulse response.
|
| 195 |
+
|
| 196 |
+
<center><img src="file/model.jpg" width="870" height="297" alt="model architecture"></center>
|
| 197 |
+
|
| 198 |
+
The predicted impulse response is mono 22050 kHz. It is upsampled to the sampling rate of the audio
|
| 199 |
+
file and applied to both channels if the audio is stereo.
|
| 200 |
+
Generating the impulse response involves a certain amount of randomness, making it sound a little
|
| 201 |
+
different every time you try it.
|
| 202 |
+
"""
|
| 203 |
+
|
| 204 |
+
article = """
|
| 205 |
+
<div style='margin:20px auto;'>
|
| 206 |
+
|
| 207 |
+
<p>Based on original work by Nikhil Singh, Jeff Mentch, Jerry Ng, Matthew Beveridge, Iddo Drori.
|
| 208 |
+
<a href="https://web.media.mit.edu/~nsingh1/image2reverb/">Project Page</a> |
|
| 209 |
+
<a href="https://arxiv.org/abs/2103.14201">Paper</a> |
|
| 210 |
+
<a href="https://github.com/nikhilsinghmus/image2reverb">GitHub</a></p>
|
| 211 |
+
|
| 212 |
+
<pre>
|
| 213 |
+
@InProceedings{Singh_2021_ICCV,
|
| 214 |
+
author = {Singh, Nikhil and Mentch, Jeff and Ng, Jerry and Beveridge, Matthew and Drori, Iddo},
|
| 215 |
+
title = {Image2Reverb: Cross-Modal Reverb Impulse Response Synthesis},
|
| 216 |
+
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
|
| 217 |
+
month = {October},
|
| 218 |
+
year = {2021},
|
| 219 |
+
pages = {286-295}
|
| 220 |
+
}
|
| 221 |
+
</pre>
|
| 222 |
+
|
| 223 |
+
<p>🌠 Example images from <a href="https://web.media.mit.edu/~nsingh1/image2reverb/">the original project page</a>.</p>
|
| 224 |
+
|
| 225 |
+
<p>🎶 Example sound from <a href="https://freesound.org/people/ashesanddreams/sounds/610414/">Ashes and Dreams @ freesound.org</a> (CC BY 4.0 license). This is a mono 48 kHz recording that has no reverb on it.</p>
|
| 226 |
+
|
| 227 |
+
</div>
|
| 228 |
+
"""
|
| 229 |
+
|
| 230 |
+
audio_example = "examples/ashesanddreams.wav"
|
| 231 |
+
|
| 232 |
+
examples = [
|
| 233 |
+
["examples/input.4e2f71f6.png", audio_example],
|
| 234 |
+
["examples/input.321eef38.png", audio_example],
|
| 235 |
+
["examples/input.2238dc21.png", audio_example],
|
| 236 |
+
["examples/input.4d280b40.png", audio_example],
|
| 237 |
+
["examples/input.0c3f5013.png", audio_example],
|
| 238 |
+
["examples/input.98773b90.png", audio_example],
|
| 239 |
+
["examples/input.ac61500f.png", audio_example],
|
| 240 |
+
["examples/input.5416407f.png", audio_example],
|
| 241 |
+
]
|
| 242 |
+
|
| 243 |
+
gr.Interface(
|
| 244 |
+
fn=predict,
|
| 245 |
+
inputs=[
|
| 246 |
+
gr.inputs.Image(label="Upload Image"),
|
| 247 |
+
gr.inputs.Audio(label="Upload Audio", source="upload"),
|
| 248 |
+
],
|
| 249 |
+
outputs=[
|
| 250 |
+
gr.Plot(label="Depthmap"),
|
| 251 |
+
gr.Plot(label="Impulse Response Spectrogram"),
|
| 252 |
+
gr.Plot(label="Impulse Response Waveform"),
|
| 253 |
+
gr.outputs.Audio(label="Impulse Response"),
|
| 254 |
+
gr.outputs.Audio(label="Output Audio (100% Wet)"),
|
| 255 |
+
gr.outputs.Audio(label="Output Audio (50% Dry, 50% Wet)"),
|
| 256 |
+
],
|
| 257 |
+
title=title,
|
| 258 |
+
description=description,
|
| 259 |
+
article=article,
|
| 260 |
+
examples=examples,
|
| 261 |
+
).launch()
|
checkpoints/image2reverb_f22.ckpt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d61422e95dc963e258b68536dc8135633a999c3a85a5a80925878ff75ca092e3
|
| 3 |
+
size 687498725
|
checkpoints/mono_odom_640x192/depth.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3a2f542e274a5b0567e3118bc16aea4c2f44ba09df4a08a6c3a47d6d98285b72
|
| 3 |
+
size 12617260
|
checkpoints/mono_odom_640x192/encoder.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:acbf2534608f06be40eecd5026c505ebd0c1d9442fe5864abba1b5d90bff2e3e
|
| 3 |
+
size 46819013
|
checkpoints/mono_odom_640x192/pose.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b4da0fe66fc1f781a05d8c4778f33ffa1851c219cb7fd561328479f5b439707e
|
| 3 |
+
size 5259718
|
checkpoints/mono_odom_640x192/pose_encoder.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:df8659ecf4363335c13ffc4510ff34556715c7f6435707622c3641a7fe055eb2
|
| 3 |
+
size 46856589
|
checkpoints/mono_odom_640x192/poses.npy
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:71a413ff381d4a58345e9152e0ca8d0b45a71e550df7730633a8cf7693edcced
|
| 3 |
+
size 76928
|
examples/input.0c3f5013.png
ADDED

|
examples/input.2238dc21.png
ADDED

|
examples/input.321eef38.png
ADDED

|
examples/input.4d280b40.png
ADDED

|
examples/input.4e2f71f6.png
ADDED

|
examples/input.5416407f.png
ADDED

|
examples/input.67bc502e.png
ADDED

|
examples/input.98773b90.png
ADDED

|
examples/input.ac61500f.png
ADDED

|
examples/input.c9ee9d49.png
ADDED

|
image2reverb/dataset.py
ADDED
|
@@ -0,0 +1,96 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import soundfile
|
| 3 |
+
import torch
|
| 4 |
+
import torchvision.transforms as transforms
|
| 5 |
+
from torch.utils.data import Dataset
|
| 6 |
+
from PIL import Image
|
| 7 |
+
from .stft import STFT
|
| 8 |
+
from .mel import LogMel
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
F_EXTENSIONS = [
|
| 12 |
+
".jpg", ".JPG", ".jpeg", ".JPEG",
|
| 13 |
+
".png", ".PNG", ".ppm", ".PPM", ".bmp", ".BMP", ".tiff", ".wav", ".WAV", ".aif", ".aiff", ".AIF", ".AIFF"
|
| 14 |
+
]
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def is_image_audio_file(filename):
|
| 18 |
+
return any(filename.endswith(extension) for extension in F_EXTENSIONS)
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def make_dataset(dir, extensions=F_EXTENSIONS):
|
| 22 |
+
images = []
|
| 23 |
+
assert os.path.isdir(dir), "%s is not a valid directory." % dir
|
| 24 |
+
|
| 25 |
+
for root, _, fnames in sorted(os.walk(dir)):
|
| 26 |
+
for fname in fnames:
|
| 27 |
+
if is_image_audio_file(fname):
|
| 28 |
+
path = os.path.join(root, fname)
|
| 29 |
+
images.append(path)
|
| 30 |
+
|
| 31 |
+
return images
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
class Image2ReverbDataset(Dataset):
|
| 35 |
+
def __init__(self, dataroot, phase="train", spec="stft"):
|
| 36 |
+
self.root = dataroot
|
| 37 |
+
self.stft = LogMel() if spec == "mel" else STFT()
|
| 38 |
+
|
| 39 |
+
### input A (images)
|
| 40 |
+
dir_A = "_A"
|
| 41 |
+
self.dir_A = os.path.join(self.root, phase + dir_A)
|
| 42 |
+
self.A_paths = sorted(make_dataset(self.dir_A))
|
| 43 |
+
|
| 44 |
+
### input B (audio)
|
| 45 |
+
dir_B = "_B"
|
| 46 |
+
self.dir_B = os.path.join(self.root, phase + dir_B)
|
| 47 |
+
self.B_paths = sorted(make_dataset(self.dir_B))
|
| 48 |
+
|
| 49 |
+
def __getitem__(self, index):
|
| 50 |
+
if index > len(self):
|
| 51 |
+
return None
|
| 52 |
+
### input A (images)
|
| 53 |
+
A_path = self.A_paths[index]
|
| 54 |
+
A = Image.open(A_path)
|
| 55 |
+
t = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
|
| 56 |
+
A_tensor = t(A.convert("RGB"))
|
| 57 |
+
|
| 58 |
+
### input B (audio)
|
| 59 |
+
B_path = self.B_paths[index]
|
| 60 |
+
B, _ = soundfile.read(B_path)
|
| 61 |
+
B_spec = self.stft.transform(B)
|
| 62 |
+
|
| 63 |
+
return B_spec, A_tensor, (B_path, A_path)
|
| 64 |
+
|
| 65 |
+
def __len__(self):
|
| 66 |
+
return len(self.A_paths)
|
| 67 |
+
|
| 68 |
+
def name(self):
|
| 69 |
+
return "Image2Reverb"
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
class Image2ReverbDemoDataset(Dataset):
|
| 73 |
+
def __init__(self, image_paths):
|
| 74 |
+
if isinstance(image_paths, str) and os.path.isdir(image_paths):
|
| 75 |
+
self.paths = sorted(make_dataset(image_paths, [".jpg", ".JPG", ".jpeg", ".JPEG", ".png", ".PNG", ".ppm", ".PPM", ".bmp", ".BMP", ".tiff"]))
|
| 76 |
+
else:
|
| 77 |
+
self.paths = sorted(image_paths)
|
| 78 |
+
|
| 79 |
+
self.stft = STFT()
|
| 80 |
+
|
| 81 |
+
def __getitem__(self, index):
|
| 82 |
+
if index > len(self):
|
| 83 |
+
return None
|
| 84 |
+
### input A (images)
|
| 85 |
+
path = self.paths[index]
|
| 86 |
+
img = Image.open(path)
|
| 87 |
+
t = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
|
| 88 |
+
img_tensor = t(img.convert("RGB"))
|
| 89 |
+
|
| 90 |
+
return torch.zeros(1, int(5.94 * 22050)), img_tensor, ("", path)
|
| 91 |
+
|
| 92 |
+
def __len__(self):
|
| 93 |
+
return len(self.paths)
|
| 94 |
+
|
| 95 |
+
def name(self):
|
| 96 |
+
return "Image2ReverbDemo"
|
image2reverb/layers.py
ADDED
|
@@ -0,0 +1,88 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torch.nn.functional as F
|
| 4 |
+
from torch.nn.init import kaiming_normal_, calculate_gain
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class PixelWiseNormLayer(nn.Module):
|
| 8 |
+
"""PixelNorm layer. Implementation is from https://github.com/shanexn/pytorch-pggan."""
|
| 9 |
+
def __init__(self):
|
| 10 |
+
super().__init__()
|
| 11 |
+
|
| 12 |
+
def forward(self, x):
|
| 13 |
+
return x/torch.sqrt(torch.mean(x ** 2, dim=1, keepdim=True) + 1e-8)
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class MiniBatchAverageLayer(nn.Module):
|
| 17 |
+
"""Minibatch stat concatenation layer. Implementation is from https://github.com/shanexn/pytorch-pggan."""
|
| 18 |
+
def __init__(self, offset=1e-8):
|
| 19 |
+
super().__init__()
|
| 20 |
+
self.offset = offset
|
| 21 |
+
|
| 22 |
+
def forward(self, x):
|
| 23 |
+
stddev = torch.sqrt(torch.mean((x - torch.mean(x, dim=0, keepdim=True))**2, dim=0, keepdim=True) + self.offset)
|
| 24 |
+
inject_shape = list(x.size())[:]
|
| 25 |
+
inject_shape[1] = 1
|
| 26 |
+
inject = torch.mean(stddev, dim=1, keepdim=True)
|
| 27 |
+
inject = inject.expand(inject_shape)
|
| 28 |
+
return torch.cat((x, inject), dim=1)
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
class EqualizedLearningRateLayer(nn.Module):
|
| 32 |
+
"""Applies equalized learning rate to the preceding layer. Implementation is from https://github.com/shanexn/pytorch-pggan."""
|
| 33 |
+
def __init__(self, layer):
|
| 34 |
+
super().__init__()
|
| 35 |
+
self.layer_ = layer
|
| 36 |
+
|
| 37 |
+
kaiming_normal_(self.layer_.weight, a=calculate_gain("conv2d"))
|
| 38 |
+
self.layer_norm_constant_ = (torch.mean(self.layer_.weight.data ** 2)) ** 0.5
|
| 39 |
+
self.layer_.weight.data.copy_(self.layer_.weight.data / self.layer_norm_constant_)
|
| 40 |
+
|
| 41 |
+
self.bias_ = self.layer_.bias if self.layer_.bias else None
|
| 42 |
+
self.layer_.bias = None
|
| 43 |
+
|
| 44 |
+
def forward(self, x):
|
| 45 |
+
self.layer_norm_constant_ = self.layer_norm_constant_.type(torch.cuda.FloatTensor if torch.cuda.is_available() else torch.Tensor)
|
| 46 |
+
x = self.layer_norm_constant_ * x
|
| 47 |
+
if self.bias_ is not None:
|
| 48 |
+
x += self.bias.view(1, self.bias.size()[0], 1, 1)
|
| 49 |
+
return x
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
class ConvBlock(nn.Module):
|
| 53 |
+
"""Layer to perform a convolution followed by ELU
|
| 54 |
+
"""
|
| 55 |
+
def __init__(self, in_channels, out_channels):
|
| 56 |
+
super(ConvBlock, self).__init__()
|
| 57 |
+
|
| 58 |
+
self.conv = Conv3x3(in_channels, out_channels)
|
| 59 |
+
self.nonlin = nn.ELU(inplace=True)
|
| 60 |
+
|
| 61 |
+
def forward(self, x):
|
| 62 |
+
out = self.conv(x)
|
| 63 |
+
out = self.nonlin(out)
|
| 64 |
+
return out
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
class Conv3x3(nn.Module):
|
| 68 |
+
"""Layer to pad and convolve input
|
| 69 |
+
"""
|
| 70 |
+
def __init__(self, in_channels, out_channels, use_refl=True):
|
| 71 |
+
super(Conv3x3, self).__init__()
|
| 72 |
+
|
| 73 |
+
if use_refl:
|
| 74 |
+
self.pad = nn.ReflectionPad2d(1)
|
| 75 |
+
else:
|
| 76 |
+
self.pad = nn.ZeroPad2d(1)
|
| 77 |
+
self.conv = nn.Conv2d(int(in_channels), int(out_channels), 3)
|
| 78 |
+
|
| 79 |
+
def forward(self, x):
|
| 80 |
+
out = self.pad(x)
|
| 81 |
+
out = self.conv(out)
|
| 82 |
+
return out
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
def upsample(x):
|
| 86 |
+
"""Upsample input tensor by a factor of 2
|
| 87 |
+
"""
|
| 88 |
+
return F.interpolate(x, scale_factor=2, mode="nearest")
|
image2reverb/mel.py
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy
|
| 2 |
+
import torch
|
| 3 |
+
import librosa
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class LogMel(torch.nn.Module):
|
| 7 |
+
def __init__(self):
|
| 8 |
+
super().__init__()
|
| 9 |
+
self._eps = 1e-8
|
| 10 |
+
|
| 11 |
+
def transform(self, audio):
|
| 12 |
+
m = librosa.feature.melspectrogram(audio/numpy.abs(audio).max())
|
| 13 |
+
m = numpy.log(m + self._eps)
|
| 14 |
+
return torch.Tensor(((m - m.mean()) / m.std()) * 0.8).unsqueeze(0)
|
| 15 |
+
|
| 16 |
+
def inverse(self, spec):
|
| 17 |
+
s = spec.cpu().detach().numpy()
|
| 18 |
+
s = numpy.exp((s * 5) - 15.96) - self._eps # Empirical mean and standard deviation over test set
|
| 19 |
+
y = librosa.feature.inverse.mel_to_audio(s) # Reconstruct audio
|
| 20 |
+
return y/numpy.abs(y).max()
|
image2reverb/model.py
ADDED
|
@@ -0,0 +1,207 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import json
|
| 3 |
+
import numpy
|
| 4 |
+
import torch
|
| 5 |
+
from torch import nn
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
import pytorch_lightning as pl
|
| 8 |
+
import torchvision
|
| 9 |
+
import pyroomacoustics
|
| 10 |
+
from .networks import Encoder, Generator, Discriminator
|
| 11 |
+
from .stft import STFT
|
| 12 |
+
from .mel import LogMel
|
| 13 |
+
from .util import compare_t60
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
# Hyperparameters
|
| 17 |
+
G_LR = 4e-4
|
| 18 |
+
D_LR = 2e-4
|
| 19 |
+
ENC_LR = 1e-5
|
| 20 |
+
ADAM_BETA = (0.0, 0.99)
|
| 21 |
+
ADAM_EPS = 1e-8
|
| 22 |
+
LAMBDA = 100
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
class Image2Reverb(pl.LightningModule):
|
| 26 |
+
def __init__(self, encoder_path, depthmodel_path, latent_dimension=512, spec="stft", d_threshold=0.2, t60p=True, constant_depth = None, test_callback=None):
|
| 27 |
+
super().__init__()
|
| 28 |
+
self._latent_dimension = latent_dimension
|
| 29 |
+
self._d_threshold = d_threshold
|
| 30 |
+
self.constant_depth = constant_depth
|
| 31 |
+
self.t60p = t60p
|
| 32 |
+
self.confidence = {}
|
| 33 |
+
self.tau = 50
|
| 34 |
+
self.test_callback = test_callback
|
| 35 |
+
self._opt = (d_threshold != None) and (d_threshold > 0) and (d_threshold < 1)
|
| 36 |
+
self.enc = Encoder(encoder_path, depthmodel_path, constant_depth=self.constant_depth, device=self.device)
|
| 37 |
+
self.g = Generator(latent_dimension, spec == "mel")
|
| 38 |
+
self.d = Discriminator(365, spec == "mel")
|
| 39 |
+
self.validation_inputs = []
|
| 40 |
+
self.stft_type = spec
|
| 41 |
+
|
| 42 |
+
def forward(self, x):
|
| 43 |
+
f = self.enc.forward(x)[0]
|
| 44 |
+
z = torch.cat((f, torch.randn((f.shape[0], (self._latent_dimension - f.shape[1]) if f.shape[1] < self._latent_dimension else f.shape[1], f.shape[2], f.shape[3]), device=self.device)), 1)
|
| 45 |
+
return self.g(z)
|
| 46 |
+
|
| 47 |
+
def training_step(self, batch, batch_idx, optimizer_idx):
|
| 48 |
+
opts = None
|
| 49 |
+
if self._opt:
|
| 50 |
+
opts = self.optimizers()
|
| 51 |
+
|
| 52 |
+
spec, label, p = batch
|
| 53 |
+
spec.requires_grad = True # For the backward pass, seems necessary for now
|
| 54 |
+
|
| 55 |
+
# Forward passes through models
|
| 56 |
+
f = self.enc.forward(label)[0]
|
| 57 |
+
z = torch.cat((f, torch.randn((f.shape[0], (self._latent_dimension - f.shape[1]) if f.shape[1] < self._latent_dimension else f.shape[1], f.shape[2], f.shape[3]), device=self.device)), 1)
|
| 58 |
+
fake_spec = self.g(z)
|
| 59 |
+
d_fake = self.d(fake_spec.detach(), f)
|
| 60 |
+
d_real = self.d(spec, f)
|
| 61 |
+
|
| 62 |
+
# Train Generator or Encoder
|
| 63 |
+
if optimizer_idx == 0 or optimizer_idx == 1:
|
| 64 |
+
d_fake2 = self.d(fake_spec.detach(), f)
|
| 65 |
+
G_loss1 = F.mse_loss(d_fake2, torch.ones(d_fake2.shape, device=self.device))
|
| 66 |
+
G_loss2 = F.l1_loss(fake_spec, spec)
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
G_loss = G_loss1 + (LAMBDA * G_loss2)
|
| 70 |
+
if self.t60p:
|
| 71 |
+
t60_err = torch.Tensor([compare_t60(torch.exp(a).sum(-2).squeeze(), torch.exp(b).sum(-2).squeeze()) for a, b in zip(spec, fake_spec)]).to(self.device).mean()
|
| 72 |
+
G_loss += t60_err
|
| 73 |
+
self.log("t60", t60_err, on_step=True, on_epoch=True, prog_bar=True)
|
| 74 |
+
|
| 75 |
+
if self._opt:
|
| 76 |
+
self.manual_backward(G_loss, self.opts[optimizer_idx])
|
| 77 |
+
opts[optimizer_idx].step()
|
| 78 |
+
opts[optimizer_idx].zero_grad()
|
| 79 |
+
|
| 80 |
+
self.log("G", G_loss, on_step=True, on_epoch=True, prog_bar=True)
|
| 81 |
+
|
| 82 |
+
return G_loss
|
| 83 |
+
else: # Train Discriminator
|
| 84 |
+
l_fakeD = F.mse_loss(d_fake, torch.zeros(d_fake.shape, device=self.device))
|
| 85 |
+
l_realD = F.mse_loss(d_real, torch.ones(d_real.shape, device=self.device))
|
| 86 |
+
D_loss = (l_realD + l_fakeD)
|
| 87 |
+
|
| 88 |
+
if self._opt and (D_loss > self._d_threshold):
|
| 89 |
+
self.manual_backward(D_loss, self.opts[optimizer_idx])
|
| 90 |
+
opts[optimizer_idx].step()
|
| 91 |
+
opts[optimizer_idx].zero_grad()
|
| 92 |
+
|
| 93 |
+
self.log("D", D_loss, on_step=True, on_epoch=True, prog_bar=True)
|
| 94 |
+
|
| 95 |
+
return D_loss
|
| 96 |
+
|
| 97 |
+
def configure_optimizers(self):
|
| 98 |
+
g_optim = torch.optim.Adam(self.g.parameters(), lr=G_LR, betas=ADAM_BETA, eps=ADAM_EPS)
|
| 99 |
+
d_optim = torch.optim.Adam(self.d.parameters(), lr=D_LR, betas=ADAM_BETA, eps=ADAM_EPS)
|
| 100 |
+
enc_optim = torch.optim.Adam(self.enc.parameters(), lr=ENC_LR, betas=ADAM_BETA, eps=ADAM_EPS)
|
| 101 |
+
return [enc_optim, g_optim, d_optim], []
|
| 102 |
+
|
| 103 |
+
def validation_step(self, batch, batch_idx):
|
| 104 |
+
spec, label, paths = batch
|
| 105 |
+
examples = [os.path.basename(s[:s.rfind("_")]) for s, _ in zip(*paths)]
|
| 106 |
+
|
| 107 |
+
# Forward passes through models
|
| 108 |
+
f = self.enc.forward(label)[0]
|
| 109 |
+
z = torch.cat((f, torch.randn((f.shape[0], (self._latent_dimension - f.shape[1]) if f.shape[1] < self._latent_dimension else f.shape[1], f.shape[2], f.shape[3]), device=self.device)), 1)
|
| 110 |
+
fake_spec = self.g(z)
|
| 111 |
+
|
| 112 |
+
# Get audio
|
| 113 |
+
stft = LogMel() if self.stft_type == "mel" else STFT()
|
| 114 |
+
y_r = [stft.inverse(s.squeeze()) for s in spec]
|
| 115 |
+
y_f = [stft.inverse(s.squeeze()) for s in fake_spec]
|
| 116 |
+
|
| 117 |
+
# RT60 error (in percentages)
|
| 118 |
+
val_pct = 1
|
| 119 |
+
try:
|
| 120 |
+
f = lambda x : pyroomacoustics.experimental.rt60.measure_rt60(x, 22050)
|
| 121 |
+
t60_r = [f(y) for y in y_r if len(y)]
|
| 122 |
+
t60_f = [f(y) for y in y_f if len(y)]
|
| 123 |
+
val_pct = numpy.mean([((t_b - t_a)/t_a) for t_a, t_b in zip(t60_r, t60_f)])
|
| 124 |
+
except:
|
| 125 |
+
pass
|
| 126 |
+
|
| 127 |
+
return {"val_t60err": val_pct, "val_spec": fake_spec, "val_audio": torch.Tensor(y_f), "val_img": label, "val_examples": examples}
|
| 128 |
+
|
| 129 |
+
def validation_epoch_end(self, outputs):
|
| 130 |
+
if not len(outputs):
|
| 131 |
+
return
|
| 132 |
+
# Log mean T60 errors (in percentages)
|
| 133 |
+
val_t60errmean = torch.Tensor(numpy.array([output["val_t60err"] for output in outputs])).mean()
|
| 134 |
+
self.log("val_t60err", val_t60errmean, on_epoch=True, prog_bar=True)
|
| 135 |
+
|
| 136 |
+
# Log generated spectrogram images
|
| 137 |
+
grid = torchvision.utils.make_grid([torch.flip(x, [0]) for y in [output["val_spec"] for output in outputs] for x in y])
|
| 138 |
+
self.logger.experiment.add_image("generated_spectrograms", grid, self.current_epoch)
|
| 139 |
+
|
| 140 |
+
# Log model input images
|
| 141 |
+
grid = torchvision.utils.make_grid([x for y in [output["val_img"] for output in outputs] for x in y])
|
| 142 |
+
self.logger.experiment.add_image("input_images_with_depthmaps", grid, self.current_epoch)
|
| 143 |
+
|
| 144 |
+
# Log generated audio examples
|
| 145 |
+
for output in outputs:
|
| 146 |
+
for example, audio in zip(output["val_examples"], output["val_audio"]):
|
| 147 |
+
y = audio
|
| 148 |
+
self.logger.experiment.add_audio("generated_audio_%s" % example, y, self.current_epoch, sample_rate=22050)
|
| 149 |
+
|
| 150 |
+
def test_step(self, batch, batch_idx):
|
| 151 |
+
spec, label, paths = batch
|
| 152 |
+
examples = [os.path.basename(s[:s.rfind("_")]) for s, _ in zip(*paths)]
|
| 153 |
+
|
| 154 |
+
# Forward passes through models
|
| 155 |
+
f, img = self.enc.forward(label)
|
| 156 |
+
img = (img + 1) * 0.5
|
| 157 |
+
z = torch.cat((f, torch.randn((f.shape[0], (self._latent_dimension - f.shape[1]) if f.shape[1] < self._latent_dimension else f.shape[1], f.shape[2], f.shape[3]), device=self.device)), 1)
|
| 158 |
+
fake_spec = self.g(z)
|
| 159 |
+
|
| 160 |
+
# Get audio
|
| 161 |
+
stft = LogMel() if self.stft_type == "mel" else STFT()
|
| 162 |
+
y_r = [stft.inverse(s.squeeze()) for s in spec]
|
| 163 |
+
y_f = [stft.inverse(s.squeeze()) for s in fake_spec]
|
| 164 |
+
|
| 165 |
+
# RT60 error (in percentages)
|
| 166 |
+
val_pct = 1
|
| 167 |
+
f = lambda x : pyroomacoustics.experimental.rt60.measure_rt60(x, 22050)
|
| 168 |
+
val_pct = []
|
| 169 |
+
for y_real, y_fake in zip(y_r, y_f):
|
| 170 |
+
try:
|
| 171 |
+
t_a = f(y_real)
|
| 172 |
+
t_b = f(y_fake)
|
| 173 |
+
val_pct.append((t_b - t_a)/t_a)
|
| 174 |
+
except:
|
| 175 |
+
val_pct.append(numpy.nan)
|
| 176 |
+
|
| 177 |
+
return {"test_t60err": val_pct, "test_spec": fake_spec, "test_audio": y_f, "test_img": img, "test_examples": examples}
|
| 178 |
+
|
| 179 |
+
def test_epoch_end(self, outputs):
|
| 180 |
+
if not self.test_callback:
|
| 181 |
+
return
|
| 182 |
+
|
| 183 |
+
examples = []
|
| 184 |
+
t60 = []
|
| 185 |
+
spec_images = []
|
| 186 |
+
audio = []
|
| 187 |
+
input_images = []
|
| 188 |
+
input_depthmaps = []
|
| 189 |
+
|
| 190 |
+
for output in outputs:
|
| 191 |
+
for i in range(len(output["test_examples"])):
|
| 192 |
+
img = output["test_img"][i]
|
| 193 |
+
if img.shape[0] == 3:
|
| 194 |
+
rgb = img
|
| 195 |
+
img = torch.cat((rgb, torch.zeros((1, rgb.shape[1], rgb.shape[2]), device=self.device)), 0)
|
| 196 |
+
t60.append(output["test_t60err"][i])
|
| 197 |
+
spec_images.append(output["test_spec"][i].cpu().squeeze().detach().numpy())
|
| 198 |
+
audio.append(output["test_audio"][i])
|
| 199 |
+
input_images.append(img.cpu().squeeze().permute(1, 2, 0)[:,:,:-1].detach().numpy())
|
| 200 |
+
input_depthmaps.append(img.cpu().squeeze().permute(1, 2, 0)[:,:,-1].squeeze().detach().numpy())
|
| 201 |
+
examples.append(output["test_examples"][i])
|
| 202 |
+
|
| 203 |
+
self.test_callback(examples, t60, spec_images, audio, input_images, input_depthmaps)
|
| 204 |
+
|
| 205 |
+
@property
|
| 206 |
+
def automatic_optimization(self) -> bool:
|
| 207 |
+
return not self._opt
|
image2reverb/networks.py
ADDED
|
@@ -0,0 +1,344 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import numpy
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
import torchvision.models as models
|
| 6 |
+
import torch.utils.model_zoo as model_zoo
|
| 7 |
+
from collections import OrderedDict
|
| 8 |
+
from .layers import PixelWiseNormLayer, MiniBatchAverageLayer, EqualizedLearningRateLayer, Conv3x3, ConvBlock, upsample
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class Encoder(nn.Module):
|
| 12 |
+
"""Load encoder from pre-trained ResNet50 (places365 CNNs) model. Link: http://places2.csail.mit.edu/models_places365/resnet50_places365.pth.tar"""
|
| 13 |
+
def __init__(self, model_weights, depth_model, constant_depth=None, device="cuda", train_enc=True):
|
| 14 |
+
super().__init__()
|
| 15 |
+
self.device = device
|
| 16 |
+
self._constant_depth = constant_depth
|
| 17 |
+
self.model = models.resnet50(num_classes=365)
|
| 18 |
+
|
| 19 |
+
if model_weights:
|
| 20 |
+
c = torch.load(model_weights, map_location=self.device)
|
| 21 |
+
state_dict = {k.replace("module.", ""): v for k, v in c["state_dict"].items()}
|
| 22 |
+
self.model.load_state_dict(state_dict)
|
| 23 |
+
|
| 24 |
+
self._has_depth = False
|
| 25 |
+
if depth_model:
|
| 26 |
+
f = self.model.conv1.weight
|
| 27 |
+
self.model.conv1.weight = torch.nn.Parameter(torch.cat((f, torch.randn(64, 1, 7, 7)), 1))
|
| 28 |
+
self.model.to(self.device)
|
| 29 |
+
|
| 30 |
+
encoder_path = os.path.join(depth_model, "encoder.pth")
|
| 31 |
+
depth_decoder_path = os.path.join(depth_model, "depth.pth")
|
| 32 |
+
self.depth_encoder = ResnetEncoder(18, False)
|
| 33 |
+
loaded_dict_enc = torch.load(encoder_path, map_location=self.device)
|
| 34 |
+
|
| 35 |
+
self.feed_height = loaded_dict_enc["height"]
|
| 36 |
+
self.feed_width = loaded_dict_enc["width"]
|
| 37 |
+
filtered_dict_enc = {k: v for k, v in loaded_dict_enc.items() if k in self.depth_encoder.state_dict()}
|
| 38 |
+
self.depth_encoder.load_state_dict(filtered_dict_enc)
|
| 39 |
+
self.depth_encoder.to(self.device)
|
| 40 |
+
self.depth_encoder.eval()
|
| 41 |
+
|
| 42 |
+
self.depth_decoder = DepthDecoder(num_ch_enc=self.depth_encoder.num_ch_enc, scales=range(4))
|
| 43 |
+
loaded_dict = torch.load(depth_decoder_path, map_location=self.device)
|
| 44 |
+
self.depth_decoder.load_state_dict(loaded_dict, strict=False)
|
| 45 |
+
self.depth_decoder.to(self.device)
|
| 46 |
+
self.depth_decoder.eval()
|
| 47 |
+
|
| 48 |
+
self._has_depth = True
|
| 49 |
+
|
| 50 |
+
if train_enc:
|
| 51 |
+
self.model.train()
|
| 52 |
+
|
| 53 |
+
def forward(self, x):
|
| 54 |
+
if self._has_depth:
|
| 55 |
+
d = torch.full((x.shape[0], 1, x.shape[2], x.shape[3]), self._constant_depth, device=x.device) if self._constant_depth is not None else list(self.depth_decoder(self.depth_encoder(x)).values())[-1]
|
| 56 |
+
x = torch.cat((x, d), 1)
|
| 57 |
+
return self.model.forward(x).unsqueeze(-1).unsqueeze(-1), x
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
class Generator(nn.Module):
|
| 61 |
+
"""Build non-progressive variant of GANSynth generator."""
|
| 62 |
+
def __init__(self, latent_size=512, mel_spec=False): # Encoder output should contain 2048 values
|
| 63 |
+
super().__init__()
|
| 64 |
+
self.latent_size = latent_size
|
| 65 |
+
self._mel_spec = mel_spec
|
| 66 |
+
self.build_model()
|
| 67 |
+
|
| 68 |
+
def forward(self, x):
|
| 69 |
+
return self.model(x)
|
| 70 |
+
|
| 71 |
+
def build_model(self):
|
| 72 |
+
model = []
|
| 73 |
+
# Input block
|
| 74 |
+
if self._mel_spec:
|
| 75 |
+
model.append(nn.Conv2d(self.latent_size, 256, kernel_size=(4, 2), stride=1, padding=2, bias=False))
|
| 76 |
+
else:
|
| 77 |
+
model.append(nn.Conv2d(self.latent_size, 256, kernel_size=8, stride=1, padding=7, bias=False)) # Modified to k=8, p=7 for our image dimensions (i.e. 512x512)
|
| 78 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 79 |
+
model.append(nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1, bias=False))
|
| 80 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 81 |
+
model.append(nn.LeakyReLU(negative_slope=0.2))
|
| 82 |
+
model.append(PixelWiseNormLayer())
|
| 83 |
+
model.append(nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1, bias=False))
|
| 84 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 85 |
+
model.append(nn.LeakyReLU(negative_slope=0.2))
|
| 86 |
+
model.append(PixelWiseNormLayer())
|
| 87 |
+
model.append(nn.Upsample(scale_factor=2, mode="nearest"))
|
| 88 |
+
|
| 89 |
+
model.append(nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1, bias=False))
|
| 90 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 91 |
+
model.append(nn.LeakyReLU(negative_slope=0.2))
|
| 92 |
+
model.append(PixelWiseNormLayer())
|
| 93 |
+
model.append(nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1, bias=False))
|
| 94 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 95 |
+
model.append(nn.LeakyReLU(negative_slope=0.2))
|
| 96 |
+
model.append(PixelWiseNormLayer())
|
| 97 |
+
model.append(nn.Upsample(scale_factor=2, mode="nearest"))
|
| 98 |
+
|
| 99 |
+
model.append(nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1, bias=False))
|
| 100 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 101 |
+
model.append(nn.LeakyReLU(negative_slope=0.2))
|
| 102 |
+
model.append(PixelWiseNormLayer())
|
| 103 |
+
model.append(nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1, bias=False))
|
| 104 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 105 |
+
model.append(nn.LeakyReLU(negative_slope=0.2))
|
| 106 |
+
model.append(PixelWiseNormLayer())
|
| 107 |
+
model.append(nn.Upsample(scale_factor=2, mode="nearest"))
|
| 108 |
+
|
| 109 |
+
model.append(nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1, bias=False))
|
| 110 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 111 |
+
model.append(nn.LeakyReLU(negative_slope=0.2))
|
| 112 |
+
model.append(PixelWiseNormLayer())
|
| 113 |
+
model.append(nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1, bias=False))
|
| 114 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 115 |
+
model.append(nn.LeakyReLU(negative_slope=0.2))
|
| 116 |
+
model.append(PixelWiseNormLayer())
|
| 117 |
+
model.append(nn.Upsample(scale_factor=2, mode="nearest"))
|
| 118 |
+
|
| 119 |
+
model.append(nn.Conv2d(256, 128, kernel_size=3, stride=1, padding=1, bias=False))
|
| 120 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 121 |
+
model.append(nn.LeakyReLU(negative_slope=0.2))
|
| 122 |
+
model.append(PixelWiseNormLayer())
|
| 123 |
+
model.append(nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1, bias=False))
|
| 124 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 125 |
+
model.append(nn.LeakyReLU(negative_slope=0.2))
|
| 126 |
+
model.append(PixelWiseNormLayer())
|
| 127 |
+
model.append(nn.Upsample(scale_factor=2, mode="nearest"))
|
| 128 |
+
|
| 129 |
+
model.append(nn.Conv2d(128, 64, kernel_size=3, stride=1, padding=1, bias=False))
|
| 130 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 131 |
+
model.append(nn.LeakyReLU(negative_slope=0.2))
|
| 132 |
+
model.append(PixelWiseNormLayer())
|
| 133 |
+
model.append(nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1, bias=False))
|
| 134 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 135 |
+
model.append(nn.LeakyReLU(negative_slope=0.2))
|
| 136 |
+
model.append(PixelWiseNormLayer())
|
| 137 |
+
model.append(nn.Upsample(scale_factor=2, mode="nearest"))
|
| 138 |
+
|
| 139 |
+
model.append(nn.Conv2d(64, 32, kernel_size=3, stride=1, padding=1, bias=False))
|
| 140 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 141 |
+
model.append(nn.LeakyReLU(negative_slope=0.2))
|
| 142 |
+
model.append(PixelWiseNormLayer())
|
| 143 |
+
model.append(nn.Conv2d(32, 32, kernel_size=3, stride=1, padding=1, bias=False))
|
| 144 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 145 |
+
model.append(nn.LeakyReLU(negative_slope=0.2))
|
| 146 |
+
model.append(PixelWiseNormLayer())
|
| 147 |
+
|
| 148 |
+
model.append(nn.Conv2d(32, 1, kernel_size=1, stride=1, padding=0, bias=False))
|
| 149 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 150 |
+
model.append(nn.Tanh())
|
| 151 |
+
self.model = nn.Sequential(*model)
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
class Discriminator(nn.Module):
|
| 155 |
+
def __init__(self, label_size=365, mel_spec=False):
|
| 156 |
+
super().__init__()
|
| 157 |
+
self._label_size = 365
|
| 158 |
+
self._mel_spec = mel_spec
|
| 159 |
+
self.build_model()
|
| 160 |
+
|
| 161 |
+
def forward(self, x, l):
|
| 162 |
+
d = self.model(x)
|
| 163 |
+
if self._mel_spec:
|
| 164 |
+
s = list(l.squeeze().shape)
|
| 165 |
+
s[-1] = 19
|
| 166 |
+
z = torch.cat((l.squeeze(), torch.zeros(s).type_as(x)), -1).reshape(d.shape[0], -1, 2, 4)
|
| 167 |
+
else:
|
| 168 |
+
s = list(l.squeeze().shape)
|
| 169 |
+
s[-1] = 512 - s[-1]
|
| 170 |
+
z = torch.cat((l.squeeze(), torch.zeros(s).type_as(x)), -1).reshape(d.shape[0], -1, 8, 8)
|
| 171 |
+
k = torch.cat((d, z), 1)
|
| 172 |
+
return self.output(k)
|
| 173 |
+
|
| 174 |
+
def build_model(self):
|
| 175 |
+
model = []
|
| 176 |
+
model.append(nn.Conv2d(1, 32, kernel_size=1, stride=1, padding=0, bias=False))
|
| 177 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 178 |
+
model.append(nn.Conv2d(32, 32, kernel_size=3, stride=1, padding=1, bias=False))
|
| 179 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 180 |
+
model.append(nn.LeakyReLU(negative_slope=0.2))
|
| 181 |
+
model.append(nn.Conv2d(32, 32, kernel_size=3, stride=1, padding=1, bias=False))
|
| 182 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 183 |
+
model.append(nn.LeakyReLU(negative_slope=0.2))
|
| 184 |
+
model.append(nn.AvgPool2d(kernel_size=2, stride=2, ceil_mode=False, count_include_pad=False))
|
| 185 |
+
|
| 186 |
+
model.append(nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1, bias=False))
|
| 187 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 188 |
+
model.append(nn.LeakyReLU(negative_slope=0.2))
|
| 189 |
+
model.append(nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1, bias=False))
|
| 190 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 191 |
+
model.append(nn.LeakyReLU(negative_slope=0.2))
|
| 192 |
+
model.append(nn.AvgPool2d(kernel_size=2, stride=2, ceil_mode=False, count_include_pad=False))
|
| 193 |
+
|
| 194 |
+
model.append(nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1, bias=False))
|
| 195 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 196 |
+
model.append(nn.LeakyReLU(negative_slope=0.2))
|
| 197 |
+
model.append(nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1, bias=False))
|
| 198 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 199 |
+
model.append(nn.LeakyReLU(negative_slope=0.2))
|
| 200 |
+
model.append(nn.AvgPool2d(kernel_size=2, stride=2, ceil_mode=False, count_include_pad=False))
|
| 201 |
+
|
| 202 |
+
model.append(nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1, bias=False))
|
| 203 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 204 |
+
model.append(nn.LeakyReLU(negative_slope=0.2))
|
| 205 |
+
model.append(nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1, bias=False))
|
| 206 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 207 |
+
model.append(nn.LeakyReLU(negative_slope=0.2))
|
| 208 |
+
model.append(nn.AvgPool2d(kernel_size=2, stride=2, ceil_mode=False, count_include_pad=False))
|
| 209 |
+
|
| 210 |
+
model.append(nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1, bias=False))
|
| 211 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 212 |
+
model.append(nn.LeakyReLU(negative_slope=0.2))
|
| 213 |
+
model.append(nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1, bias=False))
|
| 214 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 215 |
+
model.append(nn.LeakyReLU(negative_slope=0.2))
|
| 216 |
+
model.append(nn.AvgPool2d(kernel_size=2, stride=2, ceil_mode=False, count_include_pad=False))
|
| 217 |
+
|
| 218 |
+
model.append(nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1, bias=False))
|
| 219 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 220 |
+
model.append(nn.LeakyReLU(negative_slope=0.2))
|
| 221 |
+
model.append(nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1, bias=False))
|
| 222 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 223 |
+
model.append(nn.LeakyReLU(negative_slope=0.2))
|
| 224 |
+
model.append(nn.AvgPool2d(kernel_size=2, stride=2, ceil_mode=False, count_include_pad=False))
|
| 225 |
+
|
| 226 |
+
model.append(MiniBatchAverageLayer())
|
| 227 |
+
model.append(nn.Conv2d(257, 256, kernel_size=3, stride=1, padding=1, bias=False))
|
| 228 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 229 |
+
model.append(nn.LeakyReLU(negative_slope=0.2))
|
| 230 |
+
model.append(nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1, bias=False))
|
| 231 |
+
model.append(EqualizedLearningRateLayer(model[-1]))
|
| 232 |
+
model.append(nn.LeakyReLU(negative_slope=0.2))
|
| 233 |
+
|
| 234 |
+
output = [] # After the label concatenation
|
| 235 |
+
if self._mel_spec:
|
| 236 |
+
output.append(nn.Conv2d(304, 256, kernel_size=1, stride=1, padding=0, bias=False))
|
| 237 |
+
else:
|
| 238 |
+
output.append(nn.Conv2d(264, 256, kernel_size=1, stride=1, padding=0, bias=False))
|
| 239 |
+
|
| 240 |
+
output.append(nn.Conv2d(256, 1, kernel_size=1, stride=1, padding=0, bias=False))
|
| 241 |
+
|
| 242 |
+
# model.append(nn.Sigmoid()) # Output probability (in [0, 1])
|
| 243 |
+
self.model = nn.Sequential(*model)
|
| 244 |
+
self.output = nn.Sequential(*output)
|
| 245 |
+
|
| 246 |
+
|
| 247 |
+
class ResnetEncoder(nn.Module):
|
| 248 |
+
"""Pytorch module for a resnet encoder
|
| 249 |
+
"""
|
| 250 |
+
def __init__(self, num_layers, pretrained, num_input_images=1):
|
| 251 |
+
super(ResnetEncoder, self).__init__()
|
| 252 |
+
|
| 253 |
+
self.num_ch_enc = numpy.array([64, 64, 128, 256, 512])
|
| 254 |
+
|
| 255 |
+
resnets = {18: models.resnet18,
|
| 256 |
+
34: models.resnet34,
|
| 257 |
+
50: models.resnet50,
|
| 258 |
+
101: models.resnet101,
|
| 259 |
+
152: models.resnet152}
|
| 260 |
+
|
| 261 |
+
if num_layers not in resnets:
|
| 262 |
+
raise ValueError("{} is not a valid number of resnet layers".format(num_layers))
|
| 263 |
+
|
| 264 |
+
if num_input_images > 1:
|
| 265 |
+
self.encoder = resnet_multiimage_input(num_layers, pretrained, num_input_images)
|
| 266 |
+
else:
|
| 267 |
+
self.encoder = resnets[num_layers](pretrained)
|
| 268 |
+
|
| 269 |
+
if num_layers > 34:
|
| 270 |
+
self.num_ch_enc[1:] *= 4
|
| 271 |
+
|
| 272 |
+
def forward(self, input_image):
|
| 273 |
+
self.features = []
|
| 274 |
+
x = (input_image - 0.45) / 0.225
|
| 275 |
+
x = self.encoder.conv1(x)
|
| 276 |
+
x = self.encoder.bn1(x)
|
| 277 |
+
self.features.append(self.encoder.relu(x))
|
| 278 |
+
self.features.append(self.encoder.layer1(self.encoder.maxpool(self.features[-1])))
|
| 279 |
+
self.features.append(self.encoder.layer2(self.features[-1]))
|
| 280 |
+
self.features.append(self.encoder.layer3(self.features[-1]))
|
| 281 |
+
self.features.append(self.encoder.layer4(self.features[-1]))
|
| 282 |
+
|
| 283 |
+
return self.features
|
| 284 |
+
|
| 285 |
+
|
| 286 |
+
|
| 287 |
+
class DepthDecoder(nn.Module):
|
| 288 |
+
def __init__(self, num_ch_enc, scales=range(4), num_output_channels=1, use_skips=True):
|
| 289 |
+
super(DepthDecoder, self).__init__()
|
| 290 |
+
|
| 291 |
+
self.num_output_channels = num_output_channels
|
| 292 |
+
self.use_skips = use_skips
|
| 293 |
+
self.upsample_mode = "nearest"
|
| 294 |
+
self.scales = scales
|
| 295 |
+
|
| 296 |
+
self.num_ch_enc = num_ch_enc
|
| 297 |
+
self.num_ch_dec = numpy.array([16, 32, 64, 128, 256])
|
| 298 |
+
|
| 299 |
+
# decoder
|
| 300 |
+
self.convs = OrderedDict()
|
| 301 |
+
for i in range(4, -1, -1):
|
| 302 |
+
# upconv_0
|
| 303 |
+
num_ch_in = self.num_ch_enc[-1] if i == 4 else self.num_ch_dec[i + 1]
|
| 304 |
+
num_ch_out = self.num_ch_dec[i]
|
| 305 |
+
# self.convs[("upconv", i, 0)] = ConvBlock(num_ch_in, num_ch_out)
|
| 306 |
+
setattr(self, "upconv_{}_0".format(i), ConvBlock(num_ch_in, num_ch_out))
|
| 307 |
+
|
| 308 |
+
# upconv_1
|
| 309 |
+
num_ch_in = self.num_ch_dec[i]
|
| 310 |
+
if self.use_skips and i > 0:
|
| 311 |
+
num_ch_in += self.num_ch_enc[i - 1]
|
| 312 |
+
num_ch_out = self.num_ch_dec[i]
|
| 313 |
+
# self.convs[("upconv", i, 1)] = ConvBlock(num_ch_in, num_ch_out)
|
| 314 |
+
setattr(self, "upconv_{}_1".format(i), ConvBlock(num_ch_in, num_ch_out))
|
| 315 |
+
|
| 316 |
+
for s in self.scales:
|
| 317 |
+
# self.convs[("dispconv", s)] = Conv3x3(self.num_ch_dec[s], self.num_output_channels)
|
| 318 |
+
setattr(self, "disp_{}".format(s), Conv3x3(self.num_ch_dec[s], self.num_output_channels))
|
| 319 |
+
|
| 320 |
+
self.decoder = nn.ModuleList(
|
| 321 |
+
[x for y in [[getattr(self, "upconv_{}_0".format(i)), getattr(self, "upconv_{}_1".format(i))] for i in range(4, -1, -1)] for x in y] +
|
| 322 |
+
[getattr(self, "disp_{}".format(s)) for s in self.scales]
|
| 323 |
+
)
|
| 324 |
+
self.sigmoid = nn.Sigmoid()
|
| 325 |
+
|
| 326 |
+
def forward(self, input_features):
|
| 327 |
+
outputs = {}
|
| 328 |
+
|
| 329 |
+
# decoder
|
| 330 |
+
x = input_features[-1]
|
| 331 |
+
for i in range(4, -1, -1):
|
| 332 |
+
# x = self.convs[("upconv", i, 0)](x)
|
| 333 |
+
x = getattr(self, "upconv_{}_0".format(i))(x)
|
| 334 |
+
x = [upsample(x)]
|
| 335 |
+
if self.use_skips and i > 0:
|
| 336 |
+
x += [input_features[i - 1]]
|
| 337 |
+
x = torch.cat(x, 1)
|
| 338 |
+
# x = self.convs[("upconv", i, 1)](x)
|
| 339 |
+
x = getattr(self, "upconv_{}_1".format(i))(x)
|
| 340 |
+
if i in self.scales:
|
| 341 |
+
outputs[("disp", i)] = self.sigmoid(getattr(self, "disp_{}".format(i))(x))
|
| 342 |
+
# setattr(self, "outputs_disp_{}".format(i), self.sigmoid(getattr(self, "disp_{}".format(i))(x)))
|
| 343 |
+
|
| 344 |
+
return outputs
|
image2reverb/stft.py
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy
|
| 2 |
+
import torch
|
| 3 |
+
import librosa
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class STFT(torch.nn.Module):
|
| 7 |
+
def __init__(self):
|
| 8 |
+
super().__init__()
|
| 9 |
+
self._eps = 1e-8
|
| 10 |
+
|
| 11 |
+
def transform(self, audio):
|
| 12 |
+
m = numpy.abs(librosa.stft(audio/numpy.abs(audio).max(), 1024, 256))[:-1,:]
|
| 13 |
+
m = numpy.log(m + self._eps)
|
| 14 |
+
m = (((m - m.min())/(m.max() - m.min()) * 2) - 1)
|
| 15 |
+
return (torch.FloatTensor if torch.cuda.is_available() else torch.Tensor)(m * 0.8).unsqueeze(0)
|
| 16 |
+
|
| 17 |
+
def inverse(self, spec):
|
| 18 |
+
s = spec.cpu().detach().numpy()
|
| 19 |
+
s = numpy.exp((((s + 1) * 0.5) * 19.5) - 17.5) - self._eps # Empirical (average) min and max over test set
|
| 20 |
+
rp = numpy.random.uniform(-numpy.pi, numpy.pi, s.shape)
|
| 21 |
+
f = s * (numpy.cos(rp) + (1.j * numpy.sin(rp)))
|
| 22 |
+
y = librosa.istft(f) # Reconstruct audio
|
| 23 |
+
return y/numpy.abs(y).max()
|
image2reverb/util.py
ADDED
|
@@ -0,0 +1,167 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import math
|
| 3 |
+
import numpy
|
| 4 |
+
import torch
|
| 5 |
+
import torch.fft
|
| 6 |
+
from PIL import Image
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def compare_t60(a, b, sr=86):
|
| 10 |
+
try:
|
| 11 |
+
a = a.detach().clone().abs()
|
| 12 |
+
b = b.detach().clone().abs()
|
| 13 |
+
a = (a - a.min())/(a.max() - a.min())
|
| 14 |
+
b = (b - b.min())/(b.max() - b.min())
|
| 15 |
+
t_a = estimate_t60(a, sr)
|
| 16 |
+
t_b = estimate_t60(b, sr)
|
| 17 |
+
return abs((t_b - t_a)/t_a) * 100
|
| 18 |
+
except Exception as error:
|
| 19 |
+
return 100
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def estimate_t60(audio, sr):
|
| 23 |
+
fs = float(sr)
|
| 24 |
+
audio = audio.detach().clone()
|
| 25 |
+
|
| 26 |
+
decay_db = 20
|
| 27 |
+
|
| 28 |
+
# The power of the impulse response in dB
|
| 29 |
+
power = audio ** 2
|
| 30 |
+
energy = torch.flip(torch.cumsum(torch.flip(power, [0]), 0), [0]) # Integration according to Schroeder
|
| 31 |
+
|
| 32 |
+
# remove the possibly all zero tail
|
| 33 |
+
i_nz = torch.max(torch.where(energy > 0)[0])
|
| 34 |
+
n = energy[:i_nz]
|
| 35 |
+
db = 10 * torch.log10(n)
|
| 36 |
+
db = db - db[0]
|
| 37 |
+
|
| 38 |
+
# -5 dB headroom
|
| 39 |
+
i_5db = torch.min(torch.where(-5 - db > 0)[0])
|
| 40 |
+
e_5db = db[i_5db]
|
| 41 |
+
t_5db = i_5db / fs
|
| 42 |
+
|
| 43 |
+
# after decay
|
| 44 |
+
i_decay = torch.min(torch.where(-5 - decay_db - db > 0)[0])
|
| 45 |
+
t_decay = i_decay / fs
|
| 46 |
+
|
| 47 |
+
# compute the decay time
|
| 48 |
+
decay_time = t_decay - t_5db
|
| 49 |
+
est_rt60 = (60 / decay_db) * decay_time
|
| 50 |
+
|
| 51 |
+
return est_rt60
|
| 52 |
+
|
| 53 |
+
def hilbert(x): #hilbert transform
|
| 54 |
+
N = x.shape[1]
|
| 55 |
+
Xf = torch.fft.fft(x, n=None, dim=-1)
|
| 56 |
+
h = torch.zeros(N)
|
| 57 |
+
if N % 2 == 0:
|
| 58 |
+
h[0] = h[N//2] = 1
|
| 59 |
+
h[1:N//2] = 2
|
| 60 |
+
else:
|
| 61 |
+
h[0] = 1
|
| 62 |
+
h[1:(N + 1)//2] = 2
|
| 63 |
+
x = torch.fft.ifft(Xf * h)
|
| 64 |
+
return x
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
def spectral_centroid(x): #calculate the spectral centroid "brightness" of an audio input
|
| 68 |
+
Xf = torch.abs(torch.fft.fft(x,n=None,dim=-1)) #take fft and abs of x
|
| 69 |
+
norm_Xf = Xf / sum(sum(Xf)) # like probability mass function
|
| 70 |
+
norm_freqs = torch.linspace(0, 1, Xf.shape[1])
|
| 71 |
+
spectral_centroid = sum(sum(norm_freqs * norm_Xf))
|
| 72 |
+
return spectral_centroid
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
# Converts a Tensor into a Numpy array
|
| 76 |
+
# |imtype|: the desired type of the converted numpy array
|
| 77 |
+
def tensor2im(image_tensor, imtype=numpy.uint8, normalize=True):
|
| 78 |
+
if isinstance(image_tensor, list):
|
| 79 |
+
image_numpy = []
|
| 80 |
+
for i in range(len(image_tensor)):
|
| 81 |
+
image_numpy.append(tensor2im(image_tensor[i], imtype, normalize))
|
| 82 |
+
return image_numpy
|
| 83 |
+
image_numpy = image_tensor.cpu().float().numpy()
|
| 84 |
+
if normalize:
|
| 85 |
+
image_numpy = (numpy.transpose(image_numpy, (1, 2, 0)) + 1) / 2.0 * 255.0
|
| 86 |
+
else:
|
| 87 |
+
image_numpy = numpy.transpose(image_numpy, (1, 2, 0)) * 255.0
|
| 88 |
+
image_numpy = numpy.clip(image_numpy, 0, 255)
|
| 89 |
+
if image_numpy.shape[2] == 1 or image_numpy.shape[2] > 3:
|
| 90 |
+
image_numpy = image_numpy[:,:,0]
|
| 91 |
+
return image_numpy.astype(imtype)
|
| 92 |
+
|
| 93 |
+
# Converts a one-hot tensor into a colorful label map
|
| 94 |
+
def tensor2label(label_tensor, n_label, imtype=numpy.uint8):
|
| 95 |
+
if n_label == 0:
|
| 96 |
+
return tensor2im(label_tensor, imtype)
|
| 97 |
+
label_tensor = label_tensor.cpu().float()
|
| 98 |
+
if label_tensor.size()[0] > 1:
|
| 99 |
+
label_tensor = label_tensor.max(0, keepdim=True)[1]
|
| 100 |
+
label_tensor = Colorize(n_label)(label_tensor)
|
| 101 |
+
label_numpy = numpy.transpose(label_tensor.numpy(), (1, 2, 0))
|
| 102 |
+
return label_numpy.astype(imtype)
|
| 103 |
+
|
| 104 |
+
def save_image(image_numpy, image_path):
|
| 105 |
+
image_pil = Image.fromarray(image_numpy)
|
| 106 |
+
image_pil.save(image_path)
|
| 107 |
+
|
| 108 |
+
def mkdirs(paths):
|
| 109 |
+
if isinstance(paths, list) and not isinstance(paths, str):
|
| 110 |
+
for path in paths:
|
| 111 |
+
mkdir(path)
|
| 112 |
+
else:
|
| 113 |
+
mkdir(paths)
|
| 114 |
+
|
| 115 |
+
def mkdir(path):
|
| 116 |
+
if not os.path.exists(path):
|
| 117 |
+
os.makedirs(path)
|
| 118 |
+
|
| 119 |
+
###############################################################################
|
| 120 |
+
# Code from
|
| 121 |
+
# https://github.com/ycszen/pytorch-seg/blob/master/transform.py
|
| 122 |
+
# Modified so it complies with the Citscape label map colors
|
| 123 |
+
###############################################################################
|
| 124 |
+
def uint82bin(n, count=8):
|
| 125 |
+
"""returns the binary of integer n, count refers to amount of bits"""
|
| 126 |
+
return ''.join([str((n >> y) & 1) for y in range(count-1, -1, -1)])
|
| 127 |
+
|
| 128 |
+
def labelcolormap(N):
|
| 129 |
+
if N == 35: # cityscape
|
| 130 |
+
cmap = numpy.array([( 0, 0, 0), ( 0, 0, 0), ( 0, 0, 0), ( 0, 0, 0), ( 0, 0, 0), (111, 74, 0), ( 81, 0, 81),
|
| 131 |
+
(128, 64,128), (244, 35,232), (250,170,160), (230,150,140), ( 70, 70, 70), (102,102,156), (190,153,153),
|
| 132 |
+
(180,165,180), (150,100,100), (150,120, 90), (153,153,153), (153,153,153), (250,170, 30), (220,220, 0),
|
| 133 |
+
(107,142, 35), (152,251,152), ( 70,130,180), (220, 20, 60), (255, 0, 0), ( 0, 0,142), ( 0, 0, 70),
|
| 134 |
+
( 0, 60,100), ( 0, 0, 90), ( 0, 0,110), ( 0, 80,100), ( 0, 0,230), (119, 11, 32), ( 0, 0,142)],
|
| 135 |
+
dtype=numpy.uint8)
|
| 136 |
+
else:
|
| 137 |
+
cmap = numpy.zeros((N, 3), dtype=numpy.uint8)
|
| 138 |
+
for i in range(N):
|
| 139 |
+
r, g, b = 0, 0, 0
|
| 140 |
+
id = i
|
| 141 |
+
for j in range(7):
|
| 142 |
+
str_id = uint82bin(id)
|
| 143 |
+
r = r ^ (numpy.uint8(str_id[-1]) << (7-j))
|
| 144 |
+
g = g ^ (numpy.uint8(str_id[-2]) << (7-j))
|
| 145 |
+
b = b ^ (numpy.uint8(str_id[-3]) << (7-j))
|
| 146 |
+
id = id >> 3
|
| 147 |
+
cmap[i, 0] = r
|
| 148 |
+
cmap[i, 1] = g
|
| 149 |
+
cmap[i, 2] = b
|
| 150 |
+
return cmap
|
| 151 |
+
|
| 152 |
+
class Colorize(object):
|
| 153 |
+
def __init__(self, n=35):
|
| 154 |
+
self.cmap = labelcolormap(n)
|
| 155 |
+
self.cmap = torch.from_numpy(self.cmap[:n])
|
| 156 |
+
|
| 157 |
+
def __call__(self, gray_image):
|
| 158 |
+
size = gray_image.size()
|
| 159 |
+
color_image = torch.ByteTensor(3, size[1], size[2]).fill_(0)
|
| 160 |
+
|
| 161 |
+
for label in range(0, len(self.cmap)):
|
| 162 |
+
mask = (label == gray_image[0]).cpu()
|
| 163 |
+
color_image[0][mask] = self.cmap[label][0]
|
| 164 |
+
color_image[1][mask] = self.cmap[label][1]
|
| 165 |
+
color_image[2][mask] = self.cmap[label][2]
|
| 166 |
+
|
| 167 |
+
return color_image
|
model.jpg
ADDED
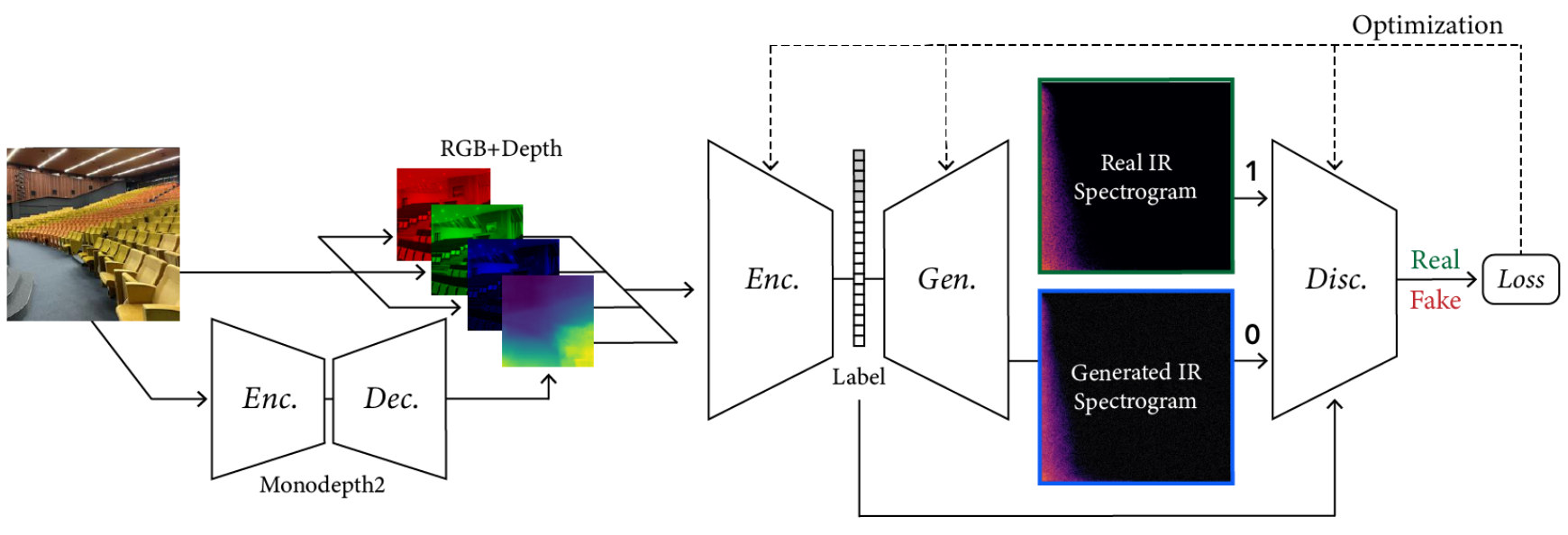
|
requirements.txt
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
torch
|
| 2 |
+
torchvision
|
| 3 |
+
pytorch_lightning
|
| 4 |
+
pyroomacoustics
|
| 5 |
+
soundfile
|
| 6 |
+
librosa
|