
Gengzigang
commited on
Commit
•
dc88ad3
1
Parent(s):
3e16209
update
Browse files- README.md +5 -5
- convert_evaclip_pytorch_to_hf.py +0 -193
- teaser.png +0 -0
README.md
CHANGED
|
@@ -3,12 +3,12 @@ license: apache-2.0
|
|
| 3 |
---
|
| 4 |
<div align="center">
|
| 5 |
|
| 6 |
-
<h2><a href="
|
| 7 |
Weiquan Huang<sup>1*</sup>, Aoqi Wu<sup>1*</sup>, Yifan Yang<sup>2†</sup>, Xufang Luo<sup>2</sup>, Yuqing Yang<sup>2</sup>, Liang Hu<sup>1</sup>, Qi Dai<sup>2</sup>, Xiyang Dai<sup>2</sup>, Dongdong Chen<sup>2</sup>, Chong Luo<sup>2</sup>, Lili Qiu<sup>2</sup>
|
| 8 |
|
| 9 |
<sup>1</sup>Tongji Universiy, <sup>2</sup>Microsoft Corporation <br><sup>*</sup>Equal contribution <br><sup>†</sup> Corresponding to: [email protected]
|
| 10 |
|
| 11 |
-
<p><a rel="nofollow" href="">[📂 GitHub]</a> <a rel="nofollow" href="">[🆕 Blog]</a> <a rel="nofollow" href="
|
| 12 |
</div>
|
| 13 |
|
| 14 |
|
|
@@ -17,7 +17,7 @@ In this paper, we propose LLM2CLIP, a novel approach that embraces the power of
|
|
| 17 |
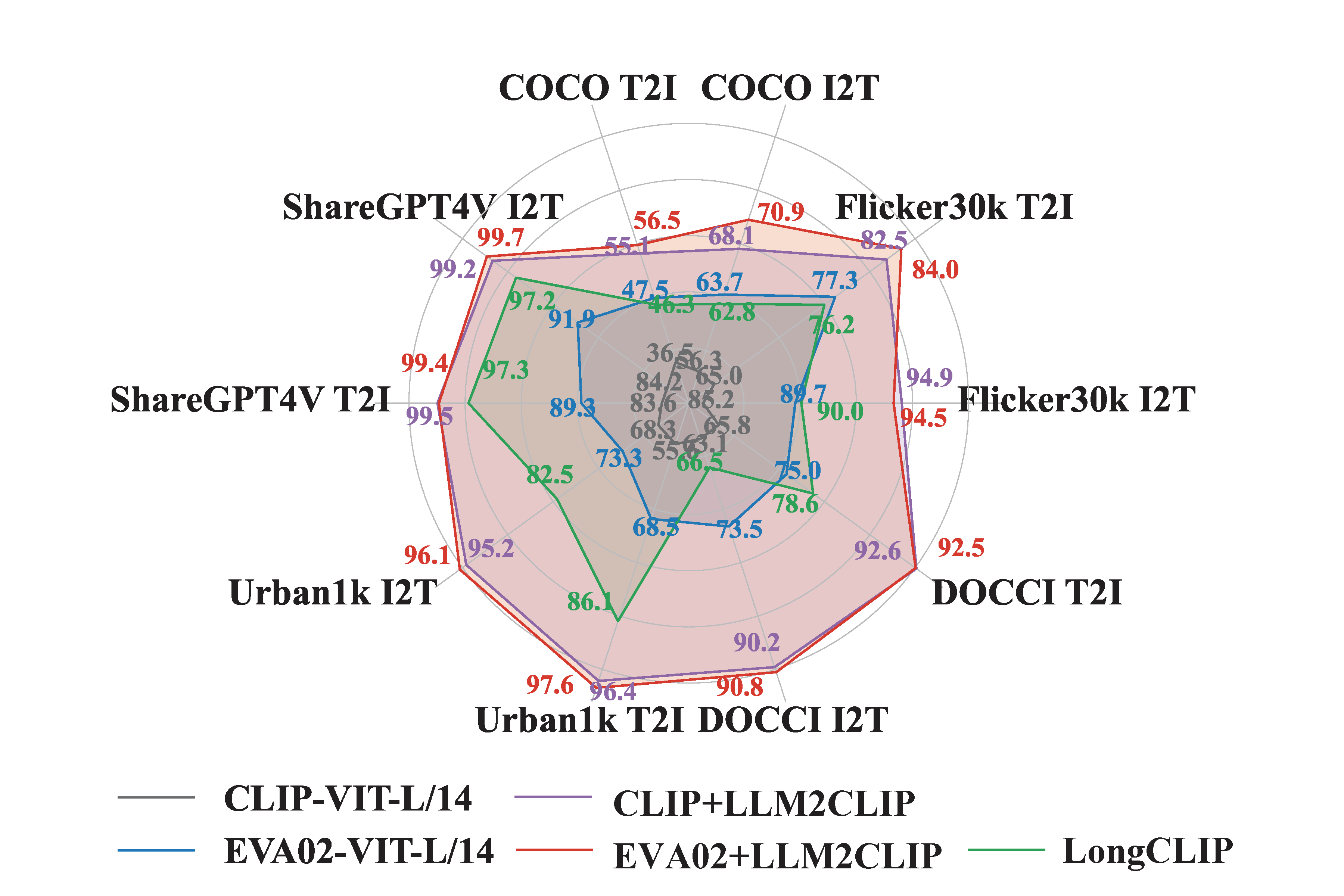
## LLM2CLIP performance
|
| 18 |
|
| 19 |
<div align="center">
|
| 20 |
-
<img src="teaser.png" alt="summary_tab" width="
|
| 21 |
</div>
|
| 22 |
**It's important to note that all results presented in the paper are evaluated using PyTorch weights. There may be differences in performance when using Hugging Face (hf) models.**
|
| 23 |
|
|
@@ -39,7 +39,7 @@ image_path = "CLIP.png"
|
|
| 39 |
model_name_or_path = "LLM2CLIP-EVA02-L-14-336" # or /path/to/local/LLM2CLIP-EVA02-L-14-336
|
| 40 |
image_size = 336
|
| 41 |
|
| 42 |
-
processor = CLIPImageProcessor.from_pretrained("openai/clip-vit-large-patch14
|
| 43 |
model = AutoModel.from_pretrained(
|
| 44 |
model_name_or_path,
|
| 45 |
torch_dtype=torch.float16,
|
|
@@ -52,4 +52,4 @@ with torch.no_grad(), torch.cuda.amp.autocast():
|
|
| 52 |
outputs = model.get_image_features(input_pixels)
|
| 53 |
```
|
| 54 |
|
| 55 |
-
## BibTeX & Citation
|
|
|
|
| 3 |
---
|
| 4 |
<div align="center">
|
| 5 |
|
| 6 |
+
<h2><a href="">LLM2CLIP: Extending the Capability Boundaries of CLIP through Large Language Models</a></h2>
|
| 7 |
Weiquan Huang<sup>1*</sup>, Aoqi Wu<sup>1*</sup>, Yifan Yang<sup>2†</sup>, Xufang Luo<sup>2</sup>, Yuqing Yang<sup>2</sup>, Liang Hu<sup>1</sup>, Qi Dai<sup>2</sup>, Xiyang Dai<sup>2</sup>, Dongdong Chen<sup>2</sup>, Chong Luo<sup>2</sup>, Lili Qiu<sup>2</sup>
|
| 8 |
|
| 9 |
<sup>1</sup>Tongji Universiy, <sup>2</sup>Microsoft Corporation <br><sup>*</sup>Equal contribution <br><sup>†</sup> Corresponding to: [email protected]
|
| 10 |
|
| 11 |
+
<p><a rel="nofollow" href="https://github.com/microsoft/LLM2CLIP">[📂 GitHub]</a> <a rel="nofollow" href="https://microsoft.github.io/LLM2CLIP/">[🆕 Blog]</a> <a rel="nofollow" href="">[📜 LLM2CLIP]</a>
|
| 12 |
</div>
|
| 13 |
|
| 14 |
|
|
|
|
| 17 |
## LLM2CLIP performance
|
| 18 |
|
| 19 |
<div align="center">
|
| 20 |
+
<img src="teaser.png" alt="summary_tab" width="85%">
|
| 21 |
</div>
|
| 22 |
**It's important to note that all results presented in the paper are evaluated using PyTorch weights. There may be differences in performance when using Hugging Face (hf) models.**
|
| 23 |
|
|
|
|
| 39 |
model_name_or_path = "LLM2CLIP-EVA02-L-14-336" # or /path/to/local/LLM2CLIP-EVA02-L-14-336
|
| 40 |
image_size = 336
|
| 41 |
|
| 42 |
+
processor = CLIPImageProcessor.from_pretrained("openai/clip-vit-large-patch14")
|
| 43 |
model = AutoModel.from_pretrained(
|
| 44 |
model_name_or_path,
|
| 45 |
torch_dtype=torch.float16,
|
|
|
|
| 52 |
outputs = model.get_image_features(input_pixels)
|
| 53 |
```
|
| 54 |
|
| 55 |
+
## BibTeX & Citation
|
convert_evaclip_pytorch_to_hf.py
DELETED
|
@@ -1,193 +0,0 @@
|
|
| 1 |
-
# coding=utf-8
|
| 2 |
-
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
|
| 3 |
-
#
|
| 4 |
-
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
-
# you may not use this file except in compliance with the License.
|
| 6 |
-
# You may obtain a copy of the License at
|
| 7 |
-
#
|
| 8 |
-
# http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
-
#
|
| 10 |
-
# Unless required by applicable law or agreed to in writing, software
|
| 11 |
-
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
-
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
-
# See the License for the specific language governing permissions and
|
| 14 |
-
# limitations under the License.
|
| 15 |
-
|
| 16 |
-
# Part of the code was taken from:
|
| 17 |
-
# https://github.com/huggingface/transformers/blob/main/src/transformers/models/clap/convert_clap_original_pytorch_to_hf.py
|
| 18 |
-
|
| 19 |
-
import argparse
|
| 20 |
-
|
| 21 |
-
import torch
|
| 22 |
-
from PIL import Image
|
| 23 |
-
from transformers import AutoModel, AutoConfig
|
| 24 |
-
from transformers import CLIPImageProcessor, pipeline, CLIPTokenizer
|
| 25 |
-
from configuration_evaclip import EvaCLIPConfig
|
| 26 |
-
from modeling_evaclip import EvaCLIPModel
|
| 27 |
-
|
| 28 |
-
|
| 29 |
-
KEYS_TO_MODIFY_MAPPING = {
|
| 30 |
-
"cls_token":"embeddings.class_embedding",
|
| 31 |
-
"pos_embed":"embeddings.position_embedding.weight",
|
| 32 |
-
"patch_embed.proj":"embeddings.patch_embedding",
|
| 33 |
-
".positional_embedding":".embeddings.position_embedding.weight",
|
| 34 |
-
".token_embedding":".embeddings.token_embedding",
|
| 35 |
-
# "text.text_projection":"text_projection.weight",
|
| 36 |
-
"mlp.c_fc":"mlp.fc1",
|
| 37 |
-
"mlp.c_proj":"mlp.fc2",
|
| 38 |
-
"mlp.w1":"mlp.fc1",
|
| 39 |
-
"mlp.w2":"mlp.fc2",
|
| 40 |
-
"mlp.w3":"mlp.fc3",
|
| 41 |
-
".proj.":".out_proj.",
|
| 42 |
-
# "q_bias":"q_proj.bias",
|
| 43 |
-
# "v_bias":"v_proj.bias",
|
| 44 |
-
"out.":"out_proj.",
|
| 45 |
-
"norm1":"layer_norm1",
|
| 46 |
-
"norm2":"layer_norm2",
|
| 47 |
-
"ln_1":"layer_norm1",
|
| 48 |
-
"ln_2":"layer_norm2",
|
| 49 |
-
".attn":".self_attn",
|
| 50 |
-
"norm.":"post_layernorm.",
|
| 51 |
-
"ln_final":"final_layer_norm",
|
| 52 |
-
"visual.blocks":"vision_model.encoder.layers",
|
| 53 |
-
# "text.transformer.resblocks":"text_model.encoder.layers",
|
| 54 |
-
"visual.head":"visual_projection",
|
| 55 |
-
"visual.":"vision_model.",
|
| 56 |
-
# "text.":"text_model.",
|
| 57 |
-
|
| 58 |
-
}
|
| 59 |
-
|
| 60 |
-
def rename_state_dict(state_dict):
|
| 61 |
-
model_state_dict = {}
|
| 62 |
-
|
| 63 |
-
for key, value in state_dict.items():
|
| 64 |
-
# check if any key needs to be modified
|
| 65 |
-
for key_to_modify, new_key in KEYS_TO_MODIFY_MAPPING.items():
|
| 66 |
-
if key_to_modify in key:
|
| 67 |
-
key = key.replace(key_to_modify, new_key)
|
| 68 |
-
if "text_projection" in key:
|
| 69 |
-
model_state_dict[key] = value.T
|
| 70 |
-
elif "attn.qkv" in key:
|
| 71 |
-
# split qkv into query key and value
|
| 72 |
-
mixed_qkv = value
|
| 73 |
-
qkv_dim = mixed_qkv.size(0) // 3
|
| 74 |
-
|
| 75 |
-
query_layer = mixed_qkv[:qkv_dim]
|
| 76 |
-
key_layer = mixed_qkv[qkv_dim : qkv_dim * 2]
|
| 77 |
-
value_layer = mixed_qkv[qkv_dim * 2 :]
|
| 78 |
-
|
| 79 |
-
model_state_dict[key.replace("qkv", "q_proj")] = query_layer
|
| 80 |
-
model_state_dict[key.replace("qkv", "k_proj")] = key_layer
|
| 81 |
-
model_state_dict[key.replace("qkv", "v_proj")] = value_layer
|
| 82 |
-
|
| 83 |
-
elif "attn.in_proj" in key:
|
| 84 |
-
# split qkv into query key and value
|
| 85 |
-
mixed_qkv = value
|
| 86 |
-
qkv_dim = mixed_qkv.size(0) // 3
|
| 87 |
-
|
| 88 |
-
query_layer = mixed_qkv[:qkv_dim]
|
| 89 |
-
key_layer = mixed_qkv[qkv_dim : qkv_dim * 2]
|
| 90 |
-
value_layer = mixed_qkv[qkv_dim * 2 :]
|
| 91 |
-
|
| 92 |
-
model_state_dict[key.replace("in_proj_", "q_proj.")] = query_layer
|
| 93 |
-
model_state_dict[key.replace("in_proj_", "k_proj.")] = key_layer
|
| 94 |
-
model_state_dict[key.replace("in_proj_", "v_proj.")] = value_layer
|
| 95 |
-
|
| 96 |
-
elif "class_embedding" in key:
|
| 97 |
-
model_state_dict[key] = value[0,0,:]
|
| 98 |
-
elif "vision_model.embeddings.position_embedding" in key:
|
| 99 |
-
model_state_dict[key] = value[0,:,:]
|
| 100 |
-
|
| 101 |
-
else:
|
| 102 |
-
model_state_dict[key] = value
|
| 103 |
-
|
| 104 |
-
return model_state_dict
|
| 105 |
-
|
| 106 |
-
# This requires having a clone of https://github.com/baaivision/EVA/tree/master/EVA-CLIP as well as the right conda env
|
| 107 |
-
# Part of the code is copied from https://github.com/baaivision/EVA/blob/master/EVA-CLIP/README.md "Usage" section
|
| 108 |
-
def getevaclip(checkpoint_path, input_pixels, captions):
|
| 109 |
-
from eva_clip import create_model_and_transforms, get_tokenizer
|
| 110 |
-
model_name = "EVA02-CLIP-bigE-14-plus"
|
| 111 |
-
model, _, _ = create_model_and_transforms(model_name, checkpoint_path, force_custom_clip=True)
|
| 112 |
-
tokenizer = get_tokenizer(model_name)
|
| 113 |
-
text = tokenizer(captions)
|
| 114 |
-
|
| 115 |
-
with torch.no_grad():
|
| 116 |
-
text_features = model.encode_text(text)
|
| 117 |
-
image_features = model.encode_image(input_pixels)
|
| 118 |
-
image_features_normed = image_features / image_features.norm(dim=-1, keepdim=True)
|
| 119 |
-
text_features_normed = text_features / text_features.norm(dim=-1, keepdim=True)
|
| 120 |
-
|
| 121 |
-
label_probs = (100.0 * image_features_normed @ text_features_normed.T).softmax(dim=-1)
|
| 122 |
-
|
| 123 |
-
return label_probs
|
| 124 |
-
|
| 125 |
-
def save_model_and_config(pytorch_dump_folder_path, hf_model, transformers_config):
|
| 126 |
-
hf_model.save_pretrained(pytorch_dump_folder_path, safe_serialization=False)
|
| 127 |
-
transformers_config.save_pretrained(pytorch_dump_folder_path)
|
| 128 |
-
|
| 129 |
-
def check_loaded_model(pytorch_dump_folder_path, processor, image):
|
| 130 |
-
# hf_config = AutoConfig.from_pretrained(pytorch_dump_folder_path, trust_remote_code=True)
|
| 131 |
-
# hf_model = AutoModel.from_pretrained(pytorch_dump_folder_path, config=hf_config, trust_remote_code=True)
|
| 132 |
-
hf_model = AutoModel.from_pretrained(pytorch_dump_folder_path, trust_remote_code=True)
|
| 133 |
-
|
| 134 |
-
processor = CLIPImageProcessor.from_pretrained("openai/clip-vit-large-patch14-336")
|
| 135 |
-
image_path = 'LLM2CLIP-EVA02-L-14-336/CLIP.png'
|
| 136 |
-
image = Image.open(image_path)
|
| 137 |
-
input_pixels = processor(images=image, return_tensors="pt").pixel_values
|
| 138 |
-
with torch.no_grad():
|
| 139 |
-
image_features = hf_model.get_image_features(input_pixels)
|
| 140 |
-
print(image_features.shape)
|
| 141 |
-
|
| 142 |
-
|
| 143 |
-
# detector = pipeline(model=hf_model, task="zero-shot-image-classification", tokenizer = tokenizer, image_processor=processor)
|
| 144 |
-
# detector_probs = detector(image, candidate_labels=captions)
|
| 145 |
-
# print(f"text_probs loaded hf_model using pipeline: {detector_probs}")
|
| 146 |
-
|
| 147 |
-
def convert_evaclip_checkpoint(checkpoint_path, pytorch_dump_folder_path, config_path, image_path, save=False):
|
| 148 |
-
processor = CLIPImageProcessor.from_pretrained("openai/clip-vit-large-patch14-336")
|
| 149 |
-
image = Image.open(image_path)
|
| 150 |
-
input_pixels = processor( images=image, return_tensors="pt", padding=True).pixel_values
|
| 151 |
-
|
| 152 |
-
# This requires having a clone of https://github.com/baaivision/EVA/tree/master/EVA-CLIP as well as the right conda env
|
| 153 |
-
# original_evaclip_probs = getevaclip(checkpoint_path, input_pixels, captions)
|
| 154 |
-
# print(f"original_evaclip label probs: {original_evaclip_probs}")
|
| 155 |
-
|
| 156 |
-
transformers_config = EvaCLIPConfig.from_pretrained(config_path)
|
| 157 |
-
hf_model = EvaCLIPModel(transformers_config)
|
| 158 |
-
pt_model_state_dict = torch.load(checkpoint_path)['module']
|
| 159 |
-
state_dict = rename_state_dict(pt_model_state_dict)
|
| 160 |
-
|
| 161 |
-
hf_model.load_state_dict(state_dict, strict=False)
|
| 162 |
-
|
| 163 |
-
with torch.no_grad():
|
| 164 |
-
image_features = hf_model.get_image_features(input_pixels)
|
| 165 |
-
# text_features = hf_model.get_text_features(input_ids)
|
| 166 |
-
image_features /= image_features.norm(dim=-1, keepdim=True)
|
| 167 |
-
# text_features /= text_features.norm(dim=-1, keepdim=True)
|
| 168 |
-
|
| 169 |
-
print(image_features.shape)
|
| 170 |
-
# label_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
|
| 171 |
-
# print(f"hf_model label probs: {label_probs}")
|
| 172 |
-
|
| 173 |
-
if save:
|
| 174 |
-
save_model_and_config(pytorch_dump_folder_path, hf_model, transformers_config)
|
| 175 |
-
|
| 176 |
-
check_loaded_model(pytorch_dump_folder_path, processor, image)
|
| 177 |
-
|
| 178 |
-
# hf_model.push_to_hub("ORGANIZATION_NAME/EVA02_CLIP_E_psz14_plus_s9B")
|
| 179 |
-
|
| 180 |
-
|
| 181 |
-
|
| 182 |
-
|
| 183 |
-
if __name__ == "__main__":
|
| 184 |
-
parser = argparse.ArgumentParser()
|
| 185 |
-
parser.add_argument("--pytorch_dump_folder_path", default="LLM2CLIP-EVA02-L-14-336" ,type=str, help="Path to the output PyTorch model.")
|
| 186 |
-
parser.add_argument("--checkpoint_path", default="model_states.pt", type=str, help="Path to checkpoint" )
|
| 187 |
-
parser.add_argument("--config_path", default='LLM2CLIP-EVA02-L-14-336', type=str, help="Path to hf config.json of model to convert")
|
| 188 |
-
parser.add_argument("--image_path", default='LLM2CLIP-EVA02-L-14-336/CLIP.png', type=str, help="Path to image")
|
| 189 |
-
parser.add_argument("--save", default=False, type=str, help="Path to image")
|
| 190 |
-
|
| 191 |
-
args = parser.parse_args()
|
| 192 |
-
|
| 193 |
-
convert_evaclip_checkpoint(args.checkpoint_path, args.pytorch_dump_folder_path, args.config_path, args.image_path, args.save)
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
teaser.png
CHANGED

|
|