
Upload folder using huggingface_hub
Browse files- .gitattributes +9 -0
- README.md +324 -0
- assets/animagine_xl.png +3 -0
- assets/compare_sdxl_lightning.png +3 -0
- assets/controlnet_depth_sdxl.png +3 -0
- assets/inpainting_sdxl.png +3 -0
- assets/ip_adapter.png +3 -0
- assets/styled_lora.png +3 -0
- assets/t2i_sdxl.png +3 -0
- assets/teaser.jpeg +0 -0
- assets/teaser_fig.png +3 -0
- assets/versatility.png +3 -0
- pytorch_lora_weights.safetensors +3 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,12 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
assets/animagine_xl.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
assets/compare_sdxl_lightning.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
assets/controlnet_depth_sdxl.png filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
assets/inpainting_sdxl.png filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
assets/ip_adapter.png filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
assets/styled_lora.png filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
assets/t2i_sdxl.png filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
assets/teaser_fig.png filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
assets/versatility.png filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,324 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
library_name: diffusers
|
| 3 |
+
base_model: stabilityai/stable-diffusion-xl-base-1.0
|
| 4 |
+
tags:
|
| 5 |
+
- lora
|
| 6 |
+
- text-to-image
|
| 7 |
+
license: mit
|
| 8 |
+
inference: false
|
| 9 |
+
---
|
| 10 |
+
|
| 11 |
+
# Trajectory Consistency Distillation
|
| 12 |
+
|
| 13 |
+
[]()
|
| 14 |
+
[](https://mhh0318.github.io/tcd/)
|
| 15 |
+
[](https://github.com/jabir-zheng/TCD)
|
| 16 |
+
[]()
|
| 17 |
+
|
| 18 |
+
Official Repository of the paper: [Trajectory Consistency Distillation]()
|
| 19 |
+
|
| 20 |
+

|
| 21 |
+
|
| 22 |
+
## News
|
| 23 |
+
- (🔥New) 2024/2/28 We provided a demo of TCD on 🤗 Hugging Face Space. Try it out [here]().
|
| 24 |
+
- (🔥New) 2024/2/28 We released our model [TCD-SDXL-Lora]() in 🤗 Hugging Face.
|
| 25 |
+
- (🔥New) 2024/2/28 Please refer to the [Usage](#usage-anchor) for more information with Diffusers Pipeline.
|
| 26 |
+
|
| 27 |
+
## Introduction
|
| 28 |
+
|
| 29 |
+
TCD, inspired by [Consistency Models](https://arxiv.org/abs/2303.01469), is a novel distillation technology that enables the distillation of knowledge from pre-trained diffusion models into a few-step sampler. In this repository, we release the inference code and our model named TCD-SDXL, which is distilled from [SDXL Base 1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0). We provide the LoRA checkpoint in this [repository]().
|
| 30 |
+
|
| 31 |
+
✨TCD has following advantages:
|
| 32 |
+
|
| 33 |
+
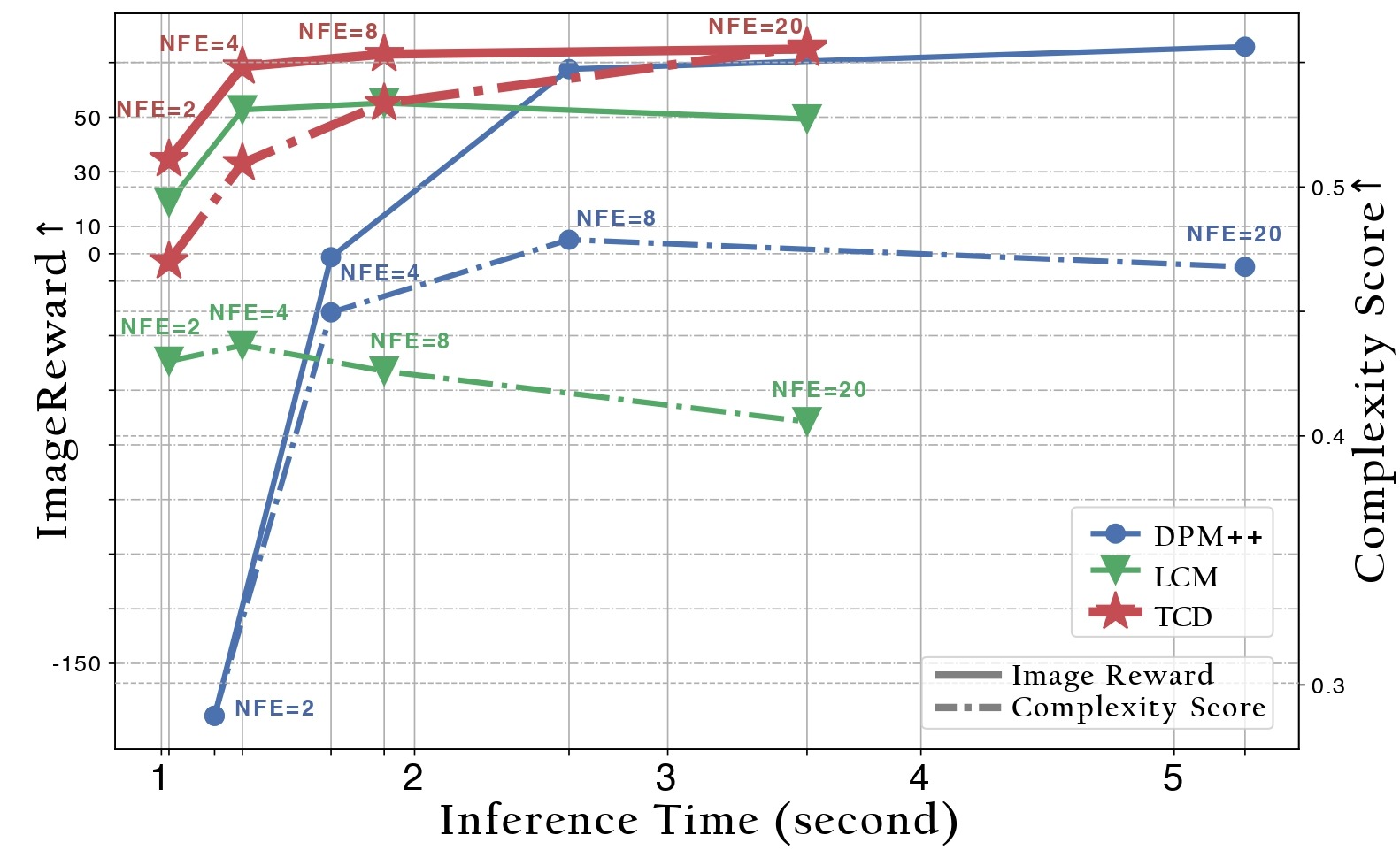
- `High-Quality with Few-Step`: TCD significantly surpasses the previous state-of-the-art few-step text-to-image model [LCM](https://github.com/luosiallen/latent-consistency-model/tree/main) in terms of image quality. Notably, LCM experiences a notable decline in quality at high NFEs. In contrast, _**TCD maintains superior generative quality at high NFEs, even exceeding the performance of DPM-Solver++(2S) with origin SDXL**_.
|
| 34 |
+

|
| 35 |
+
<!-- We observed that the images generated with 8 steps by TCD-SDXL are already highly impressive, even outperforming the original SDXL 50-steps generation results. -->
|
| 36 |
+
- `Versatility`: Integrated with LoRA technology, TCD can be directly applied to various models (including the custom Community Models, styled LoRA, ControlNet, IP-Adapter) that share the same backbone, as demonstrated in the [Usage](#usage-anchor).
|
| 37 |
+

|
| 38 |
+
- `Avoiding Mode Collapse`: TCD achieves few-step generation without the need for adversarial training, thus circumventing mode collapse caused by the GAN objective.
|
| 39 |
+
In contrast to the concurrent work [SDXL-Lightning](https://huggingface.co/ByteDance/SDXL-Lightning), which relies on Adversarial Diffusion Distillation, TCD can synthesize results that are more realistic and slightly more diverse, without the presence of "Janus" artifacts.
|
| 40 |
+

|
| 41 |
+
|
| 42 |
+
For more information, please refer to our paper [Trajectory Consistency Distillation]().
|
| 43 |
+
|
| 44 |
+
<a id="usage-anchor"></a>
|
| 45 |
+
|
| 46 |
+
## Usage
|
| 47 |
+
To run the model yourself, you can leverage the 🧨 Diffusers library.
|
| 48 |
+
```bash
|
| 49 |
+
pip install diffusers transformers accelerate peft
|
| 50 |
+
```
|
| 51 |
+
And then we clone the repo.
|
| 52 |
+
```bash
|
| 53 |
+
git clone https://github.com/jabir-zheng/TCD.git
|
| 54 |
+
cd TCD
|
| 55 |
+
```
|
| 56 |
+
Here, we demonstrate the applicability of our TCD LoRA to various models, including [SDXL](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0), [SDXL Inpainting](https://huggingface.co/diffusers/stable-diffusion-xl-1.0-inpainting-0.1), a community model named [Animagine XL](https://huggingface.co/cagliostrolab/animagine-xl-3.0), a styled LoRA [Papercut](https://huggingface.co/TheLastBen/Papercut_SDXL), pretrained [Depth Controlnet](https://huggingface.co/diffusers/controlnet-depth-sdxl-1.0), and [IP-Adapter](https://github.com/tencent-ailab/IP-Adapter) to accelerate image generation with high quality in 4-8 steps.
|
| 57 |
+
|
| 58 |
+
### Text-to-Image generation
|
| 59 |
+
```py
|
| 60 |
+
import torch
|
| 61 |
+
from diffusers import StableDiffusionXLPipeline
|
| 62 |
+
from scheduling_tcd import TCDScheduler
|
| 63 |
+
|
| 64 |
+
device = "cuda"
|
| 65 |
+
base_model_id = "stabilityai/stable-diffusion-xl-base-1.0"
|
| 66 |
+
tcd_lora_id = ""
|
| 67 |
+
|
| 68 |
+
pipe = StableDiffusionXLPipeline.from_pretrained(base_model_id, torch_dtype=torch.float16, variant="fp16").to(device)
|
| 69 |
+
pipe.scheduler = TCDScheduler.from_config(pipe.scheduler.config)
|
| 70 |
+
|
| 71 |
+
pipe.load_lora_weights(tcd_lora_id)
|
| 72 |
+
pipe.fuse_lora()
|
| 73 |
+
|
| 74 |
+
prompt = "Beautiful woman, bubblegum pink, lemon yellow, minty blue, futuristic, high-detail, epic composition, watercolor."
|
| 75 |
+
|
| 76 |
+
image = pipe(
|
| 77 |
+
prompt=prompt,
|
| 78 |
+
num_inference_steps=4,
|
| 79 |
+
guidance_scale=0,
|
| 80 |
+
# Eta (referred to as `gamma` in the paper) is used to control the stochasticity in every step.
|
| 81 |
+
# A value of 0.3 often yields good results.
|
| 82 |
+
# We recommend using a higher eta when increasing the number of inference steps.
|
| 83 |
+
eta=0.3,
|
| 84 |
+
generator=torch.Generator(device=device).manual_seed(0),
|
| 85 |
+
).images[0]
|
| 86 |
+
```
|
| 87 |
+

|
| 88 |
+
|
| 89 |
+
### Inpainting
|
| 90 |
+
```py
|
| 91 |
+
import torch
|
| 92 |
+
from diffusers import AutoPipelineForInpainting
|
| 93 |
+
from diffusers.utils import load_image, make_image_grid
|
| 94 |
+
from scheduling_tcd import TCDScheduler
|
| 95 |
+
|
| 96 |
+
device = "cuda"
|
| 97 |
+
base_model_id = "diffusers/stable-diffusion-xl-1.0-inpainting-0.1"
|
| 98 |
+
tcd_lora_id = ""
|
| 99 |
+
|
| 100 |
+
pipe = AutoPipelineForInpainting.from_pretrained(base_model_id, torch_dtype=torch.float16, variant="fp16").to(device)
|
| 101 |
+
pipe.scheduler = TCDScheduler.from_config(pipe.scheduler.config)
|
| 102 |
+
|
| 103 |
+
pipe.load_lora_weights(tcd_lora_id)
|
| 104 |
+
pipe.fuse_lora()
|
| 105 |
+
|
| 106 |
+
img_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png"
|
| 107 |
+
mask_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png"
|
| 108 |
+
|
| 109 |
+
init_image = load_image(img_url).resize((1024, 1024))
|
| 110 |
+
mask_image = load_image(mask_url).resize((1024, 1024))
|
| 111 |
+
|
| 112 |
+
prompt = "a tiger sitting on a park bench"
|
| 113 |
+
|
| 114 |
+
image = pipe(
|
| 115 |
+
prompt=prompt,
|
| 116 |
+
image=init_image,
|
| 117 |
+
mask_image=mask_image,
|
| 118 |
+
num_inference_steps=8,
|
| 119 |
+
guidance_scale=0,
|
| 120 |
+
eta=0.3, # Eta (referred to as `gamma` in the paper) is used to control the stochasticity in every step. A value of 0.3 often yields good results.
|
| 121 |
+
strength=0.99, # make sure to use `strength` below 1.0
|
| 122 |
+
generator=torch.Generator(device=device).manual_seed(0),
|
| 123 |
+
).images[0]
|
| 124 |
+
|
| 125 |
+
grid_image = make_image_grid([init_image, mask_image, image], rows=1, cols=3)
|
| 126 |
+
```
|
| 127 |
+

|
| 128 |
+
|
| 129 |
+
### Versatile for Community Models
|
| 130 |
+
```py
|
| 131 |
+
import torch
|
| 132 |
+
from diffusers import StableDiffusionXLPipeline
|
| 133 |
+
from scheduling_tcd import TCDScheduler
|
| 134 |
+
|
| 135 |
+
device = "cuda"
|
| 136 |
+
base_model_id = "cagliostrolab/animagine-xl-3.0"
|
| 137 |
+
tcd_lora_id = ""
|
| 138 |
+
|
| 139 |
+
pipe = StableDiffusionXLPipeline.from_pretrained(base_model_id, torch_dtype=torch.float16, variant="fp16").to(device)
|
| 140 |
+
pipe.scheduler = TCDScheduler.from_config(pipe.scheduler.config)
|
| 141 |
+
|
| 142 |
+
pipe.load_lora_weights(tcd_lora_id)
|
| 143 |
+
pipe.fuse_lora()
|
| 144 |
+
|
| 145 |
+
prompt = "A man, clad in a meticulously tailored military uniform, stands with unwavering resolve. The uniform boasts intricate details, and his eyes gleam with determination. Strands of vibrant, windswept hair peek out from beneath the brim of his cap."
|
| 146 |
+
|
| 147 |
+
image = pipe(
|
| 148 |
+
prompt=prompt,
|
| 149 |
+
num_inference_steps=8,
|
| 150 |
+
guidance_scale=0,
|
| 151 |
+
# Eta (referred to as `gamma` in the paper) is used to control the stochasticity in every step.
|
| 152 |
+
# A value of 0.3 often yields good results.
|
| 153 |
+
# We recommend using a higher eta when increasing the number of inference steps.
|
| 154 |
+
eta=0.3,
|
| 155 |
+
generator=torch.Generator(device=device).manual_seed(0),
|
| 156 |
+
).images[0]
|
| 157 |
+
```
|
| 158 |
+

|
| 159 |
+
|
| 160 |
+
### Combine with styled LoRA
|
| 161 |
+
```py
|
| 162 |
+
import torch
|
| 163 |
+
from diffusers import StableDiffusionXLPipeline
|
| 164 |
+
from scheduling_tcd import TCDScheduler
|
| 165 |
+
|
| 166 |
+
device = "cuda"
|
| 167 |
+
base_model_id = "stabilityai/stable-diffusion-xl-base-1.0"
|
| 168 |
+
tcd_lora_id = ""
|
| 169 |
+
styled_lora_id = "TheLastBen/Papercut_SDXL"
|
| 170 |
+
|
| 171 |
+
pipe = StableDiffusionXLPipeline.from_pretrained(base_model_id, torch_dtype=torch.float16, variant="fp16").to(device)
|
| 172 |
+
pipe.scheduler = TCDScheduler.from_config(pipe.scheduler.config)
|
| 173 |
+
|
| 174 |
+
pipe.load_lora_weights(tcd_lora_id, adapter_name="tcd")
|
| 175 |
+
pipe.load_lora_weights(styled_lora_id, adapter_name="style")
|
| 176 |
+
pipe.set_adapters(["tcd", "style"], adapter_weights=[1.0, 1.0])
|
| 177 |
+
|
| 178 |
+
prompt = "papercut of a winter mountain, snow"
|
| 179 |
+
|
| 180 |
+
image = pipe(
|
| 181 |
+
prompt=prompt,
|
| 182 |
+
num_inference_steps=4,
|
| 183 |
+
guidance_scale=0,
|
| 184 |
+
# Eta (referred to as `gamma` in the paper) is used to control the stochasticity in every step.
|
| 185 |
+
# A value of 0.3 often yields good results.
|
| 186 |
+
# We recommend using a higher eta when increasing the number of inference steps.
|
| 187 |
+
eta=0.3,
|
| 188 |
+
generator=torch.Generator(device=device).manual_seed(0),
|
| 189 |
+
).images[0]
|
| 190 |
+
```
|
| 191 |
+

|
| 192 |
+
|
| 193 |
+
### Compatibility with ControlNet
|
| 194 |
+
```py
|
| 195 |
+
import torch
|
| 196 |
+
import numpy as np
|
| 197 |
+
from PIL import Image
|
| 198 |
+
from transformers import DPTFeatureExtractor, DPTForDepthEstimation
|
| 199 |
+
from diffusers import ControlNetModel, StableDiffusionXLControlNetPipeline
|
| 200 |
+
from diffusers.utils import load_image, make_image_grid
|
| 201 |
+
from scheduling_tcd import TCDScheduler
|
| 202 |
+
|
| 203 |
+
device = "cuda"
|
| 204 |
+
depth_estimator = DPTForDepthEstimation.from_pretrained("Intel/dpt-hybrid-midas").to(device)
|
| 205 |
+
feature_extractor = DPTFeatureExtractor.from_pretrained("Intel/dpt-hybrid-midas")
|
| 206 |
+
|
| 207 |
+
def get_depth_map(image):
|
| 208 |
+
image = feature_extractor(images=image, return_tensors="pt").pixel_values.to(device)
|
| 209 |
+
with torch.no_grad(), torch.autocast(device):
|
| 210 |
+
depth_map = depth_estimator(image).predicted_depth
|
| 211 |
+
|
| 212 |
+
depth_map = torch.nn.functional.interpolate(
|
| 213 |
+
depth_map.unsqueeze(1),
|
| 214 |
+
size=(1024, 1024),
|
| 215 |
+
mode="bicubic",
|
| 216 |
+
align_corners=False,
|
| 217 |
+
)
|
| 218 |
+
depth_min = torch.amin(depth_map, dim=[1, 2, 3], keepdim=True)
|
| 219 |
+
depth_max = torch.amax(depth_map, dim=[1, 2, 3], keepdim=True)
|
| 220 |
+
depth_map = (depth_map - depth_min) / (depth_max - depth_min)
|
| 221 |
+
image = torch.cat([depth_map] * 3, dim=1)
|
| 222 |
+
|
| 223 |
+
image = image.permute(0, 2, 3, 1).cpu().numpy()[0]
|
| 224 |
+
image = Image.fromarray((image * 255.0).clip(0, 255).astype(np.uint8))
|
| 225 |
+
return image
|
| 226 |
+
|
| 227 |
+
base_model_id = "stabilityai/stable-diffusion-xl-base-1.0"
|
| 228 |
+
controlnet_id = "/mnt/CV_teamz/pretrained/controlnet-depth-sdxl-1.0"
|
| 229 |
+
tcd_lora_id = ""
|
| 230 |
+
|
| 231 |
+
controlnet = ControlNetModel.from_pretrained(
|
| 232 |
+
controlnet_id,
|
| 233 |
+
torch_dtype=torch.float16,
|
| 234 |
+
variant="fp16",
|
| 235 |
+
).to(device)
|
| 236 |
+
pipe = StableDiffusionXLControlNetPipeline.from_pretrained(
|
| 237 |
+
base_model_id,
|
| 238 |
+
controlnet=controlnet,
|
| 239 |
+
torch_dtype=torch.float16,
|
| 240 |
+
variant="fp16",
|
| 241 |
+
).to(device)
|
| 242 |
+
pipe.enable_model_cpu_offload()
|
| 243 |
+
|
| 244 |
+
pipe.scheduler = TCDScheduler.from_config(pipe.scheduler.config)
|
| 245 |
+
|
| 246 |
+
pipe.load_lora_weights(tcd_lora_id)
|
| 247 |
+
pipe.fuse_lora()
|
| 248 |
+
|
| 249 |
+
prompt = "stormtrooper lecture, photorealistic"
|
| 250 |
+
|
| 251 |
+
image = load_image("https://huggingface.co/lllyasviel/sd-controlnet-depth/resolve/main/images/stormtrooper.png")
|
| 252 |
+
depth_image = get_depth_map(image)
|
| 253 |
+
|
| 254 |
+
controlnet_conditioning_scale = 0.5 # recommended for good generalization
|
| 255 |
+
|
| 256 |
+
image = pipe(
|
| 257 |
+
prompt,
|
| 258 |
+
image=depth_image,
|
| 259 |
+
num_inference_steps=4,
|
| 260 |
+
guidance_scale=0,
|
| 261 |
+
eta=0.3, # A parameter (referred to as `gamma` in the paper) is used to control the stochasticity in every step. A value of 0.3 often yields good results.
|
| 262 |
+
controlnet_conditioning_scale=controlnet_conditioning_scale,
|
| 263 |
+
generator=torch.Generator(device=device).manual_seed(0),
|
| 264 |
+
).images[0]
|
| 265 |
+
|
| 266 |
+
grid_image = make_image_grid([depth_image, image], rows=1, cols=2)
|
| 267 |
+
```
|
| 268 |
+

|
| 269 |
+
|
| 270 |
+
### Compatibility with IP-Adapter
|
| 271 |
+
Please refer to the official [repository](https://github.com/tencent-ailab/IP-Adapter/tree/main) for instructions on installing dependencies for IP-Adapter.
|
| 272 |
+
```py
|
| 273 |
+
import torch
|
| 274 |
+
from PIL import Image
|
| 275 |
+
from diffusers import StableDiffusionXLPipeline
|
| 276 |
+
from diffusers.utils import make_image_grid
|
| 277 |
+
|
| 278 |
+
from ip_adapter import IPAdapterXL
|
| 279 |
+
from scheduling_tcd import TCDScheduler
|
| 280 |
+
|
| 281 |
+
device = "cuda"
|
| 282 |
+
base_model_path = "stabilityai/stable-diffusion-xl-base-1.0"
|
| 283 |
+
image_encoder_path = "sdxl_models/image_encoder"
|
| 284 |
+
ip_ckpt = "sdxl_models/ip-adapter_sdxl.bin"
|
| 285 |
+
tcd_lora_id = ""
|
| 286 |
+
|
| 287 |
+
pipe = StableDiffusionXLPipeline.from_pretrained(
|
| 288 |
+
base_model_path,
|
| 289 |
+
torch_dtype=torch.float16,
|
| 290 |
+
variant="fp16"
|
| 291 |
+
)
|
| 292 |
+
pipe.scheduler = TCDScheduler.from_config(pipe.scheduler.config)
|
| 293 |
+
|
| 294 |
+
pipe.load_lora_weights(tcd_lora_id)
|
| 295 |
+
pipe.fuse_lora()
|
| 296 |
+
|
| 297 |
+
ip_model = IPAdapterXL(pipe, image_encoder_path, ip_ckpt, device)
|
| 298 |
+
|
| 299 |
+
ref_image = Image.open(f"assets/images/woman.png")
|
| 300 |
+
ref_image.resize((512, 512))
|
| 301 |
+
|
| 302 |
+
prompt = "best quality, high quality, wearing sunglasses"
|
| 303 |
+
|
| 304 |
+
image = ip_model.generate(
|
| 305 |
+
pil_image=ref_image,
|
| 306 |
+
prompt=prompt,
|
| 307 |
+
scale=0.5,
|
| 308 |
+
num_samples=1,
|
| 309 |
+
num_inference_steps=4,
|
| 310 |
+
guidance_scale=0,
|
| 311 |
+
eta=0.3, # A parameter (referred to as `gamma` in the paper) is used to control the stochasticity in every step. A value of 0.3 often yields good results.
|
| 312 |
+
seed=0,
|
| 313 |
+
)[0]
|
| 314 |
+
|
| 315 |
+
grid_image = make_image_grid([ref_image, image], rows=1, cols=2)
|
| 316 |
+
```
|
| 317 |
+

|
| 318 |
+
|
| 319 |
+
## Citation
|
| 320 |
+
```bibtex
|
| 321 |
+
```
|
| 322 |
+
|
| 323 |
+
## Acknowledgments
|
| 324 |
+
This codebase heavily relies on the 🤗[Diffusers](https://github.com/huggingface/diffusers) library and [LCM](https://github.com/luosiallen/latent-consistency-model).
|
assets/animagine_xl.png
ADDED

|
Git LFS Details
|
assets/compare_sdxl_lightning.png
ADDED

|
Git LFS Details
|
assets/controlnet_depth_sdxl.png
ADDED

|
Git LFS Details
|
assets/inpainting_sdxl.png
ADDED

|
Git LFS Details
|
assets/ip_adapter.png
ADDED

|
Git LFS Details
|
assets/styled_lora.png
ADDED

|
Git LFS Details
|
assets/t2i_sdxl.png
ADDED

|
Git LFS Details
|
assets/teaser.jpeg
ADDED
|
assets/teaser_fig.png
ADDED

|
Git LFS Details
|
assets/versatility.png
ADDED

|
Git LFS Details
|
pytorch_lora_weights.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2c777bc60abf41d3eb0fe405d23d73c280a020eea5adf97a82a141592c33feba
|
| 3 |
+
size 393854624
|