
Update README.md
Browse files
README.md
CHANGED
|
@@ -1,17 +1,16 @@
|
|
| 1 |
---
|
| 2 |
-
license:
|
| 3 |
tags:
|
| 4 |
- text-to-image
|
| 5 |
---
|
| 6 |
-
###
|
| 7 |
-
####
|
| 8 |
-
This
|
| 9 |
-
|
| 10 |
|
| 11 |
-
|
| 12 |
-
And you can run your new concept via `diffusers`: [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb), [Spaces with the Public Concepts loaded](https://huggingface.co/spaces/sd-dreambooth-library/stable-diffusion-dreambooth-concepts)
|
| 13 |
|
| 14 |
-
Here are the images used for training this concept:
|
| 15 |

|
| 16 |

|
| 17 |

|
|
@@ -26,5 +25,4 @@ Here are the images used for training this concept:
|
|
| 26 |

|
| 27 |
|
| 28 |

|
| 29 |
-

|
| 30 |
-
|
|
|
|
| 1 |
---
|
| 2 |
+
license: apache-2.0
|
| 3 |
tags:
|
| 4 |
- text-to-image
|
| 5 |
---
|
| 6 |
+
### Tessa on Stable Diffusion v1.5 via Dreambooth
|
| 7 |
+
####
|
| 8 |
+
This is a Stable Diffusion (v1.5) model fine-tuned on the concept of my dog, Tessa, usiung the Dreambooth method: https://dreambooth.github.io/
|
| 9 |
+
To use the model, try modifying the basic prompt: \"**a photo of \<tessa\> dog**\".
|
| 10 |
|
| 11 |
+
The model was fine-tuned for 1200 steps with a learning rate of 2e-6, using 15 images of Tessa and 500 class regularization images. The class images were generated in advance by Stable Diffusion v1.5 using the prompt "Photo of a dog".
|
|
|
|
| 12 |
|
| 13 |
+
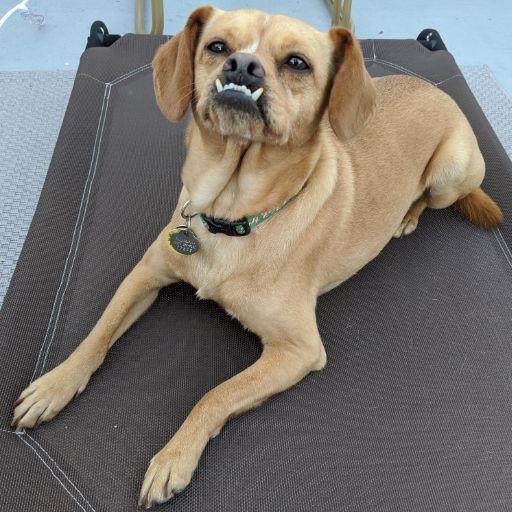
Here are the images of Tessa used for training this concept:
|
| 14 |

|
| 15 |

|
| 16 |

|
|
|
|
| 25 |

|
| 26 |

|
| 27 |

|
| 28 |
+

|
|
|