

Commit
•
08b9a5d
1
Parent(s):
247e00a
first commit
Browse files- README.md +59 -0
- arch.jpg +0 -0
- config.json +64 -0
- model.safetensors +3 -0
- preprocessor_config.json +23 -0
- processor_config.json +9 -0
- special_tokens_map.json +4 -0
- teaser.png +0 -0
- tokenizer.json +0 -0
- tokenizer_config.json +0 -0
README.md
CHANGED
|
@@ -1,3 +1,62 @@
|
|
| 1 |
---
|
| 2 |
license: mit
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
license: mit
|
| 3 |
+
license_name: deepseek
|
| 4 |
+
license_link: LICENSE
|
| 5 |
+
pipeline_tag: any-to-any
|
| 6 |
+
tags:
|
| 7 |
+
- muiltimodal
|
| 8 |
+
- text-to-image
|
| 9 |
+
- unified-model
|
| 10 |
---
|
| 11 |
+
|
| 12 |
+
## 1. Introduction
|
| 13 |
+
|
| 14 |
+
Janus is a novel autoregressive framework that unifies multimodal understanding and generation.
|
| 15 |
+
It addresses the limitations of previous approaches by decoupling visual encoding into separate pathways, while still utilizing a single, unified transformer architecture for processing. The decoupling not only alleviates the conflict between the visual encoder’s roles in understanding and generation, but also enhances the framework’s flexibility.
|
| 16 |
+
Janus surpasses previous unified model and matches or exceeds the performance of task-specific models.
|
| 17 |
+
The simplicity, high flexibility, and effectiveness of Janus make it a strong candidate for next-generation unified multimodal models.
|
| 18 |
+
|
| 19 |
+
[Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation](https://arxiv.org/abs/2410.13848)
|
| 20 |
+
|
| 21 |
+
[**Github Repository**](https://github.com/deepseek-ai/Janus)
|
| 22 |
+
|
| 23 |
+
<div align="center">
|
| 24 |
+
<img alt="image" src="teaser.png" style="width:90%;">
|
| 25 |
+
</div>
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
### 2. Model Summary
|
| 29 |
+
|
| 30 |
+
Janus is a unified understanding and generation MLLM, which decouples visual encoding for multimodal understanding and generation.
|
| 31 |
+
Janus is constructed based on the DeepSeek-LLM-1.3b-base which is trained on an approximate corpus of 500B text tokens.
|
| 32 |
+
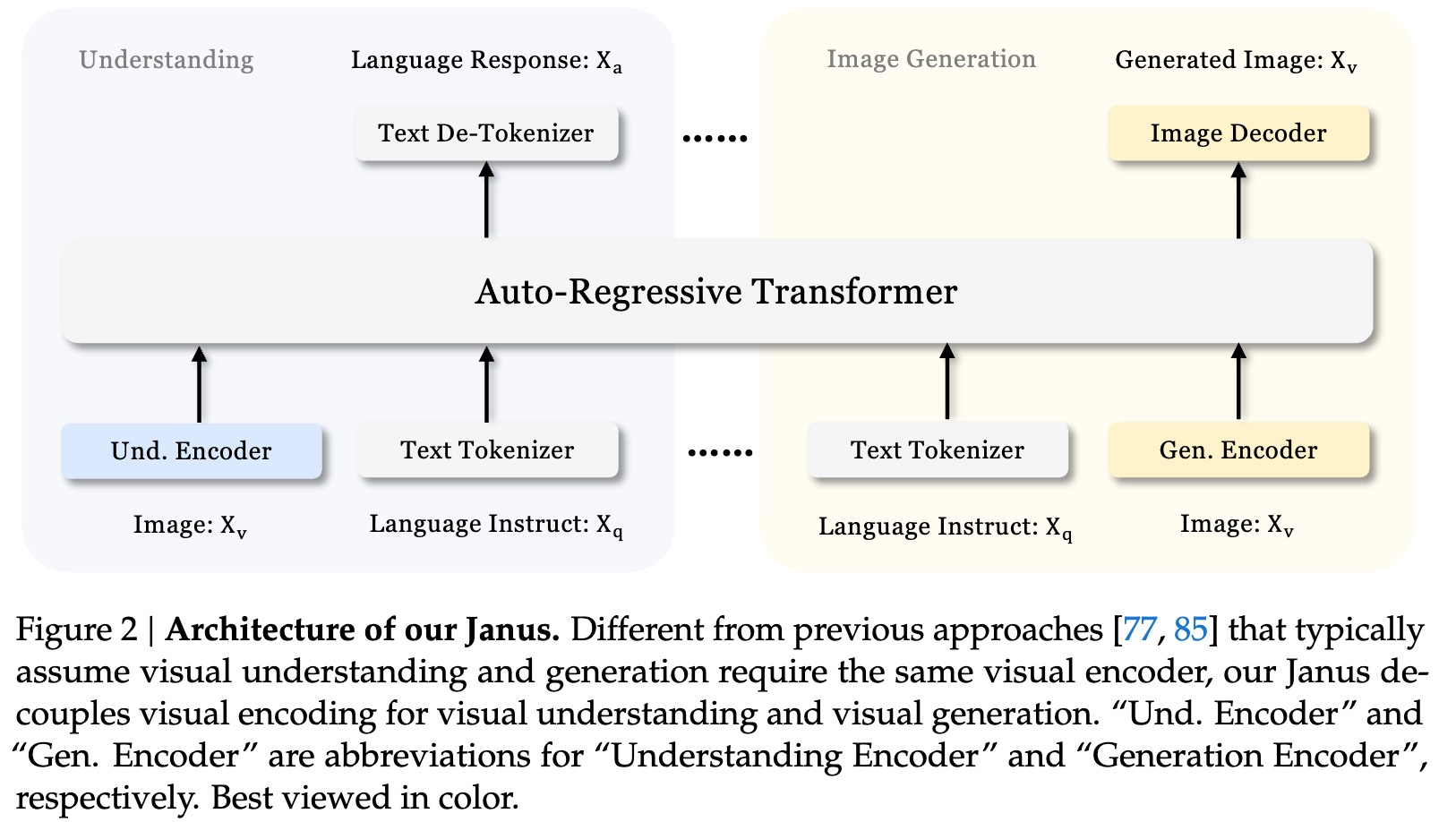
For multimodal understanding, it uses the [SigLIP-L](https://huggingface.co/timm/ViT-L-16-SigLIP-384) as the vision encoder, which supports 384 x 384 image input. For image generation, Janus uses the tokenizer from [here](https://github.com/FoundationVision/LlamaGen) with a downsample rate of 16.
|
| 33 |
+
|
| 34 |
+
<div align="center">
|
| 35 |
+
<img alt="image" src="arch.jpg" style="width:90%;">
|
| 36 |
+
</div>
|
| 37 |
+
|
| 38 |
+
## 3. Quick Start
|
| 39 |
+
|
| 40 |
+
Please refer to [**Github Repository**](https://github.com/deepseek-ai/Janus)
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
## 4. License
|
| 44 |
+
|
| 45 |
+
This code repository is licensed under [the MIT License](https://github.com/deepseek-ai/DeepSeek-LLM/blob/HEAD/LICENSE-CODE). The use of Janus models is subject to [DeepSeek Model License](https://github.com/deepseek-ai/DeepSeek-LLM/blob/HEAD/LICENSE-MODEL).
|
| 46 |
+
## 5. Citation
|
| 47 |
+
|
| 48 |
+
```
|
| 49 |
+
@misc{wu2024janus,
|
| 50 |
+
title={Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation},
|
| 51 |
+
author={Chengyue Wu and Xiaokang Chen and Zhiyu Wu and Yiyang Ma and Xingchao Liu and Zizheng Pan and Wen Liu and Zhenda Xie and Xingkai Yu and Chong Ruan and Ping Luo},
|
| 52 |
+
year={2024},
|
| 53 |
+
eprint={2410.13848},
|
| 54 |
+
archivePrefix={arXiv},
|
| 55 |
+
primaryClass={cs.CV},
|
| 56 |
+
url={https://arxiv.org/abs/2410.13848},
|
| 57 |
+
}
|
| 58 |
+
```
|
| 59 |
+
|
| 60 |
+
## 6. Contact
|
| 61 |
+
|
| 62 |
+
If you have any questions, please raise an issue or contact us at [[email protected]](mailto:[email protected]).
|
arch.jpg
ADDED
|
config.json
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"aligner_config": {
|
| 3 |
+
"cls": "MlpProjector",
|
| 4 |
+
"model_type": "aligner",
|
| 5 |
+
"params": {
|
| 6 |
+
"depth": 2,
|
| 7 |
+
"input_dim": 1024,
|
| 8 |
+
"n_embed": 2048,
|
| 9 |
+
"projector_type": "mlp_gelu"
|
| 10 |
+
}
|
| 11 |
+
},
|
| 12 |
+
"gen_aligner_config": {
|
| 13 |
+
"cls": "MlpProjector",
|
| 14 |
+
"model_type": "gen_aligner",
|
| 15 |
+
"params": {
|
| 16 |
+
"depth": 2,
|
| 17 |
+
"input_dim": 8,
|
| 18 |
+
"n_embed": 2048,
|
| 19 |
+
"projector_type": "mlp_gelu"
|
| 20 |
+
}
|
| 21 |
+
},
|
| 22 |
+
"gen_head_config": {
|
| 23 |
+
"cls": "vision_head",
|
| 24 |
+
"model_type": "gen_head",
|
| 25 |
+
"params": {
|
| 26 |
+
"image_token_embed": 2048,
|
| 27 |
+
"image_token_size": 16384,
|
| 28 |
+
"n_embed": 2048
|
| 29 |
+
}
|
| 30 |
+
},
|
| 31 |
+
"gen_vision_config": {
|
| 32 |
+
"cls": "VQ-16",
|
| 33 |
+
"model_type": "gen_vision",
|
| 34 |
+
"params": {
|
| 35 |
+
"image_token_size": 16384,
|
| 36 |
+
"n_embed": 8
|
| 37 |
+
}
|
| 38 |
+
},
|
| 39 |
+
"language_config": {
|
| 40 |
+
"hidden_size": 2048,
|
| 41 |
+
"intermediate_size": 5632,
|
| 42 |
+
"max_position_embeddings": 16384,
|
| 43 |
+
"model_type": "llama",
|
| 44 |
+
"num_attention_heads": 16,
|
| 45 |
+
"num_hidden_layers": 24,
|
| 46 |
+
"num_key_value_heads": 16,
|
| 47 |
+
"torch_dtype": "bfloat16",
|
| 48 |
+
"vocab_size": 102400,
|
| 49 |
+
"_attn_implementation": "flash_attention_2"
|
| 50 |
+
},
|
| 51 |
+
"model_type": "multi_modality",
|
| 52 |
+
"torch_dtype": "bfloat16",
|
| 53 |
+
"transformers_version": "4.38.2",
|
| 54 |
+
"vision_config": {
|
| 55 |
+
"cls": "CLIPVisionTower",
|
| 56 |
+
"model_type": "vision",
|
| 57 |
+
"params": {
|
| 58 |
+
"image_size": 384,
|
| 59 |
+
"model_name": "siglip_large_patch16_384",
|
| 60 |
+
"select_feature": "same",
|
| 61 |
+
"select_layer": -1
|
| 62 |
+
}
|
| 63 |
+
}
|
| 64 |
+
}
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6e49e46b89583b401f957b1ada267c9d5656e3a463672cdf5ba80bc771974175
|
| 3 |
+
size 4178706382
|
preprocessor_config.json
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"background_color": [
|
| 3 |
+
127,
|
| 4 |
+
127,
|
| 5 |
+
127
|
| 6 |
+
],
|
| 7 |
+
"do_normalize": false,
|
| 8 |
+
"image_mean": [
|
| 9 |
+
0.5,
|
| 10 |
+
0.5,
|
| 11 |
+
0.5
|
| 12 |
+
],
|
| 13 |
+
"image_processor_type": "VLMImageProcessor",
|
| 14 |
+
"image_size": 384,
|
| 15 |
+
"image_std": [
|
| 16 |
+
0.5,
|
| 17 |
+
0.5,
|
| 18 |
+
0.5
|
| 19 |
+
],
|
| 20 |
+
"min_size": 14,
|
| 21 |
+
"processor_class": "VLChatProcessor",
|
| 22 |
+
"rescale_factor": 0.00392156862745098
|
| 23 |
+
}
|
processor_config.json
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_special_token": false,
|
| 3 |
+
"ignore_id": -100,
|
| 4 |
+
"image_tag": "<image_placeholder>",
|
| 5 |
+
"mask_prompt": true,
|
| 6 |
+
"num_image_tokens": 576,
|
| 7 |
+
"processor_class": "VLChatProcessor",
|
| 8 |
+
"sft_format": "deepseek"
|
| 9 |
+
}
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": "<|begin▁of▁sentence|>",
|
| 3 |
+
"eos_token": "<|end▁of▁sentence|>"
|
| 4 |
+
}
|
teaser.png
ADDED

|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|