
file_path
stringlengths 50
101
| content
stringlengths 743
26.4k
|
|---|---|
C:\Gradio Guides\1 Getting Started\01_quickstart.md |
# Quickstart
Gradio is an open-source Python package that allows you to quickly **build** a demo or web application for your machine learning model, API, or any arbitary Python function. You can then **share** a link to your demo or web application in just a few seconds using Gradio's built-in sharing features. *No JavaScript, CSS, or web hosting experience needed!*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/gradio-guides/lcm-screenshot-3.gif" style="padding-bottom: 10px">
It just takes a few lines of Python to create a demo like the one above, so let's get started 💫
## Installation
**Prerequisite**: Gradio requires [Python 3.8 or higher](https://www.python.org/downloads/)
We recommend installing Gradio using `pip`, which is included by default in Python. Run this in your terminal or command prompt:
```bash
pip install gradio
```
Tip: it is best to install Gradio in a virtual environment. Detailed installation instructions for all common operating systems <a href="https://www.gradio.app/main/guides/installing-gradio-in-a-virtual-environment">are provided here</a>.
## Building Your First Demo
You can run Gradio in your favorite code editor, Jupyter notebook, Google Colab, or anywhere else you write Python. Let's write your first Gradio app:
$code_hello_world_4
Tip: We shorten the imported name from <code>gradio</code> to <code>gr</code> for better readability of code. This is a widely adopted convention that you should follow so that anyone working with your code can easily understand it.
Now, run your code. If you've written the Python code in a file named, for example, `app.py`, then you would run `python app.py` from the terminal.
The demo below will open in a browser on [http://localhost:7860](http://localhost:7860) if running from a file. If you are running within a notebook, the demo will appear embedded within the notebook.
$demo_hello_world_4
Type your name in the textbox on the left, drag the slider, and then press the Submit button. You should see a friendly greeting on the right.
Tip: When developing locally, you can run your Gradio app in <strong>hot reload mode</strong>, which automatically reloads the Gradio app whenever you make changes to the file. To do this, simply type in <code>gradio</code> before the name of the file instead of <code>python</code>. In the example above, you would type: `gradio app.py` in your terminal. Learn more about hot reloading in the <a href="https://www.gradio.app/guides/developing-faster-with-reload-mode">Hot Reloading Guide</a>.
**Understanding the `Interface` Class**
You'll notice that in order to make your first demo, you created an instance of the `gr.Interface` class. The `Interface` class is designed to create demos for machine learning models which accept one or more inputs, and return one or more outputs.
The `Interface` class has three core arguments:
- `fn`: the function to wrap a user interface (UI) around
- `inputs`: the Gradio component(s) to use for the input. The number of components should match the number of arguments in your function.
- `outputs`: the Gradio component(s) to use for the output. The number of components should match the number of return values from your function.
The `fn` argument is very flexible -- you can pass *any* Python function that you want to wrap with a UI. In the example above, we saw a relatively simple function, but the function could be anything from a music generator to a tax calculator to the prediction function of a pretrained machine learning model.
The `inputs` and `outputs` arguments take one or more Gradio components. As we'll see, Gradio includes more than [30 built-in components](https://www.gradio.app/docs/gradio/components) (such as the `gr.Textbox()`, `gr.Image()`, and `gr.HTML()` components) that are designed for machine learning applications.
Tip: For the `inputs` and `outputs` arguments, you can pass in the name of these components as a string (`"textbox"`) or an instance of the class (`gr.Textbox()`).
If your function accepts more than one argument, as is the case above, pass a list of input components to `inputs`, with each input component corresponding to one of the arguments of the function, in order. The same holds true if your function returns more than one value: simply pass in a list of components to `outputs`. This flexibility makes the `Interface` class a very powerful way to create demos.
We'll dive deeper into the `gr.Interface` on our series on [building Interfaces](https://www.gradio.app/main/guides/the-interface-class).
## Sharing Your Demo
What good is a beautiful demo if you can't share it? Gradio lets you easily share a machine learning demo without having to worry about the hassle of hosting on a web server. Simply set `share=True` in `launch()`, and a publicly accessible URL will be created for your demo. Let's revisit our example demo, but change the last line as follows:
```python
import gradio as gr
def greet(name):
return "Hello " + name + "!"
demo = gr.Interface(fn=greet, inputs="textbox", outputs="textbox")
demo.launch(share=True) # Share your demo with just 1 extra parameter 🚀
```
When you run this code, a public URL will be generated for your demo in a matter of seconds, something like:
👉 `https://a23dsf231adb.gradio.live`
Now, anyone around the world can try your Gradio demo from their browser, while the machine learning model and all computation continues to run locally on your computer.
To learn more about sharing your demo, read our dedicated guide on [sharing your Gradio application](https://www.gradio.app/guides/sharing-your-app).
## Core Gradio Classes
So far, we've been discussing the `Interface` class, which is a high-level class that lets to build demos quickly with Gradio. But what else does Gradio include?aaa
### Chatbots with `gr.ChatInterface`
Gradio includes another high-level class, `gr.ChatInterface`, which is specifically designed to create Chatbot UIs. Similar to `Interface`, you supply a function and Gradio creates a fully working Chatbot UI. If you're interested in creating a chatbot, you can jump straight to [our dedicated guide on `gr.ChatInterface`](https://www.gradio.app/guides/creating-a-chatbot-fast).
### Custom Demos with `gr.Blocks`
Gradio also offers a low-level approach for designing web apps with more flexible layouts and data flows with the `gr.Blocks` class. Blocks allows you to do things like control where components appear on the page, handle complex data flows (e.g. outputs can serve as inputs to other functions), and update properties/visibility of components based on user interaction — still all in Python.
You can build very custom and complex applications using `gr.Blocks()`. For example, the popular image generation [Automatic1111 Web UI](https://github.com/AUTOMATIC1111/stable-diffusion-webui) is built using Gradio Blocks. We dive deeper into the `gr.Blocks` on our series on [building with Blocks](https://www.gradio.app/guides/blocks-and-event-listeners).
### The Gradio Python & JavaScript Ecosystem
That's the gist of the core `gradio` Python library, but Gradio is actually so much more! Its an entire ecosystem of Python and JavaScript libraries that let you build machine learning applications, or query them programmatically, in Python or JavaScript. Here are other related parts of the Gradio ecosystem:
* [Gradio Python Client](https://www.gradio.app/guides/getting-started-with-the-python-client) (`gradio_client`): query any Gradio app programmatically in Python.
* [Gradio JavaScript Client](https://www.gradio.app/guides/getting-started-with-the-js-client) (`@gradio/client`): query any Gradio app programmatically in JavaScript.
* [Gradio-Lite](https://www.gradio.app/guides/gradio-lite) (`@gradio/lite`): write Gradio apps in Python that run entirely in the browser (no server needed!), thanks to Pyodide.
* [Hugging Face Spaces](https://huggingface.co/spaces): the most popular place to host Gradio applications — for free!
## What's Next?
Keep learning about Gradio sequentially using the Gradio Guides, which include explanations as well as example code and embedded interactive demos. Next up: [let's dive deeper into the Interface class](https://www.gradio.app/guides/the-interface-class).
Or, if you already know the basics and are looking for something specific, you can search the more [technical API documentation](https://www.gradio.app/docs/).
|
C:\Gradio Guides\1 Getting Started\02_key-features.md |
# Key Features
Let's go through some of the key features of Gradio. This guide is intended to be a high-level overview of various things that you should be aware of as you build your demo. Where appropriate, we link to more detailed guides on specific topics.
1. [Components](#components)
2. [Queuing](#queuing)
3. [Streaming outputs](#streaming-outputs)
4. [Streaming inputs](#streaming-inputs)
5. [Alert modals](#alert-modals)
6. [Styling](#styling)
7. [Progress bars](#progress-bars)
8. [Batch functions](#batch-functions)
## Components
Gradio includes more than 30 pre-built components (as well as many user-built _custom components_) that can be used as inputs or outputs in your demo with a single line of code. These components correspond to common data types in machine learning and data science, e.g. the `gr.Image` component is designed to handle input or output images, the `gr.Label` component displays classification labels and probabilities, the `gr.Plot` component displays various kinds of plots, and so on.
Each component includes various constructor attributes that control the properties of the component. For example, you can control the number of lines in a `gr.Textbox` using the `lines` argument (which takes a positive integer) in its constructor. Or you can control the way that a user can provide an image in the `gr.Image` component using the `sources` parameter (which takes a list like `["webcam", "upload"]`).
**Static and Interactive Components**
Every component has a _static_ version that is designed to *display* data, and most components also have an _interactive_ version designed to let users input or modify the data. Typically, you don't need to think about this distinction, because when you build a Gradio demo, Gradio automatically figures out whether the component should be static or interactive based on whether it is being used as an input or output. However, you can set this manually using the `interactive` argument that every component supports.
**Preprocessing and Postprocessing**
When a component is used as an input, Gradio automatically handles the _preprocessing_ needed to convert the data from a type sent by the user's browser (such as an uploaded image) to a form that can be accepted by your function (such as a `numpy` array).
Similarly, when a component is used as an output, Gradio automatically handles the _postprocessing_ needed to convert the data from what is returned by your function (such as a list of image paths) to a form that can be displayed in the user's browser (a gallery of images).
Consider an example demo with three input components (`gr.Textbox`, `gr.Number`, and `gr.Image`) and two outputs (`gr.Number` and `gr.Gallery`) that serve as a UI for your image-to-image generation model. Below is a diagram of what our preprocessing will send to the model and what our postprocessing will require from it.

In this image, the following preprocessing steps happen to send the data from the browser to your function:
* The text in the textbox is converted to a Python `str` (essentially no preprocessing)
* The number in the number input is converted to a Python `int` (essentially no preprocessing)
* Most importantly, ihe image supplied by the user is converted to a `numpy.array` representation of the RGB values in the image
Images are converted to NumPy arrays because they are a common format for machine learning workflows. You can control the _preprocessing_ using the component's parameters when constructing the component. For example, if you instantiate the `Image` component with the following parameters, it will preprocess the image to the `PIL` format instead:
```py
img = gr.Image(type="pil")
```
Postprocessing is even simpler! Gradio automatically recognizes the format of the returned data (e.g. does the user's function return a `numpy` array or a `str` filepath for the `gr.Image` component?) and postprocesses it appropriately into a format that can be displayed by the browser.
So in the image above, the following postprocessing steps happen to send the data returned from a user's function to the browser:
* The `float` is displayed as a number and displayed directly to the user
* The list of string filepaths (`list[str]`) is interpreted as a list of image filepaths and displayed as a gallery in the browser
Take a look at the [Docs](https://gradio.app/docs) to see all the parameters for each Gradio component.
## Queuing
Every Gradio app comes with a built-in queuing system that can scale to thousands of concurrent users. You can configure the queue by using `queue()` method which is supported by the `gr.Interface`, `gr.Blocks`, and `gr.ChatInterface` classes.
For example, you can control the number of requests processed at a single time by setting the `default_concurrency_limit` parameter of `queue()`, e.g.
```python
demo = gr.Interface(...).queue(default_concurrency_limit=5)
demo.launch()
```
This limits the number of requests processed for this event listener at a single time to 5. By default, the `default_concurrency_limit` is actually set to `1`, which means that when many users are using your app, only a single user's request will be processed at a time. This is because many machine learning functions consume a significant amount of memory and so it is only suitable to have a single user using the demo at a time. However, you can change this parameter in your demo easily.
See the [docs on queueing](https://gradio.app/docs/gradio/interface#interface-queue) for more details on configuring the queuing parameters.
## Streaming outputs
In some cases, you may want to stream a sequence of outputs rather than show a single output at once. For example, you might have an image generation model and you want to show the image that is generated at each step, leading up to the final image. Or you might have a chatbot which streams its response one token at a time instead of returning it all at once.
In such cases, you can supply a **generator** function into Gradio instead of a regular function. Creating generators in Python is very simple: instead of a single `return` value, a function should `yield` a series of values instead. Usually the `yield` statement is put in some kind of loop. Here's an example of an generator that simply counts up to a given number:
```python
def my_generator(x):
for i in range(x):
yield i
```
You supply a generator into Gradio the same way as you would a regular function. For example, here's a a (fake) image generation model that generates noise for several steps before outputting an image using the `gr.Interface` class:
$code_fake_diffusion
$demo_fake_diffusion
Note that we've added a `time.sleep(1)` in the iterator to create an artificial pause between steps so that you are able to observe the steps of the iterator (in a real image generation model, this probably wouldn't be necessary).
## Streaming inputs
Similarly, Gradio can handle streaming inputs, e.g. a live audio stream that can gets transcribed to text in real time, or an image generation model that reruns every time a user types a letter in a textbox. This is covered in more details in our guide on building [reactive Interfaces](/guides/reactive-interfaces).
## Alert modals
You may wish to raise alerts to the user. To do so, raise a `gr.Error("custom message")` to display an error message. You can also issue `gr.Warning("message")` and `gr.Info("message")` by having them as standalone lines in your function, which will immediately display modals while continuing the execution of your function. Queueing needs to be enabled for this to work.
Note below how the `gr.Error` has to be raised, while the `gr.Warning` and `gr.Info` are single lines.
```python
def start_process(name):
gr.Info("Starting process")
if name is None:
gr.Warning("Name is empty")
...
if success == False:
raise gr.Error("Process failed")
```
## Styling
Gradio themes are the easiest way to customize the look and feel of your app. You can choose from a variety of themes, or create your own. To do so, pass the `theme=` kwarg to the `Interface` constructor. For example:
```python
demo = gr.Interface(..., theme=gr.themes.Monochrome())
```
Gradio comes with a set of prebuilt themes which you can load from `gr.themes.*`. You can extend these themes or create your own themes from scratch - see the [theming guide](https://gradio.app/guides/theming-guide) for more details.
For additional styling ability, you can pass any CSS (as well as custom JavaScript) to your Gradio application. This is discussed in more detail in our [custom JS and CSS guide](/guides/custom-CSS-and-JS).
## Progress bars
Gradio supports the ability to create custom Progress Bars so that you have customizability and control over the progress update that you show to the user. In order to enable this, simply add an argument to your method that has a default value of a `gr.Progress` instance. Then you can update the progress levels by calling this instance directly with a float between 0 and 1, or using the `tqdm()` method of the `Progress` instance to track progress over an iterable, as shown below.
$code_progress_simple
$demo_progress_simple
If you use the `tqdm` library, you can even report progress updates automatically from any `tqdm.tqdm` that already exists within your function by setting the default argument as `gr.Progress(track_tqdm=True)`!
## Batch functions
Gradio supports the ability to pass _batch_ functions. Batch functions are just
functions which take in a list of inputs and return a list of predictions.
For example, here is a batched function that takes in two lists of inputs (a list of
words and a list of ints), and returns a list of trimmed words as output:
```py
import time
def trim_words(words, lens):
trimmed_words = []
time.sleep(5)
for w, l in zip(words, lens):
trimmed_words.append(w[:int(l)])
return [trimmed_words]
```
The advantage of using batched functions is that if you enable queuing, the Gradio server can automatically _batch_ incoming requests and process them in parallel,
potentially speeding up your demo. Here's what the Gradio code looks like (notice the `batch=True` and `max_batch_size=16`)
With the `gr.Interface` class:
```python
demo = gr.Interface(
fn=trim_words,
inputs=["textbox", "number"],
outputs=["output"],
batch=True,
max_batch_size=16
)
demo.launch()
```
With the `gr.Blocks` class:
```py
import gradio as gr
with gr.Blocks() as demo:
with gr.Row():
word = gr.Textbox(label="word")
leng = gr.Number(label="leng")
output = gr.Textbox(label="Output")
with gr.Row():
run = gr.Button()
event = run.click(trim_words, [word, leng], output, batch=True, max_batch_size=16)
demo.launch()
```
In the example above, 16 requests could be processed in parallel (for a total inference time of 5 seconds), instead of each request being processed separately (for a total
inference time of 80 seconds). Many Hugging Face `transformers` and `diffusers` models work very naturally with Gradio's batch mode: here's [an example demo using diffusers to
generate images in batches](https://github.com/gradio-app/gradio/blob/main/demo/diffusers_with_batching/run.py)
|
C:\Gradio Guides\2 Building Interfaces\00_the-interface-class.md |
# The `Interface` class
As mentioned in the [Quickstart](/main/guides/quickstart), the `gr.Interface` class is a high-level abstraction in Gradio that allows you to quickly create a demo for any Python function simply by specifying the input types and the output types. Revisiting our first demo:
$code_hello_world_4
We see that the `Interface` class is initialized with three required parameters:
- `fn`: the function to wrap a user interface (UI) around
- `inputs`: which Gradio component(s) to use for the input. The number of components should match the number of arguments in your function.
- `outputs`: which Gradio component(s) to use for the output. The number of components should match the number of return values from your function.
In this Guide, we'll dive into `gr.Interface` and the various ways it can be customized, but before we do that, let's get a better understanding of Gradio components.
## Gradio Components
Gradio includes more than 30 pre-built components (as well as many [community-built _custom components_](https://www.gradio.app/custom-components/gallery)) that can be used as inputs or outputs in your demo. These components correspond to common data types in machine learning and data science, e.g. the `gr.Image` component is designed to handle input or output images, the `gr.Label` component displays classification labels and probabilities, the `gr.Plot` component displays various kinds of plots, and so on.
**Static and Interactive Components**
Every component has a _static_ version that is designed to *display* data, and most components also have an _interactive_ version designed to let users input or modify the data. Typically, you don't need to think about this distinction, because when you build a Gradio demo, Gradio automatically figures out whether the component should be static or interactive based on whether it is being used as an input or output. However, you can set this manually using the `interactive` argument that every component supports.
**Preprocessing and Postprocessing**
When a component is used as an input, Gradio automatically handles the _preprocessing_ needed to convert the data from a type sent by the user's browser (such as an uploaded image) to a form that can be accepted by your function (such as a `numpy` array).
Similarly, when a component is used as an output, Gradio automatically handles the _postprocessing_ needed to convert the data from what is returned by your function (such as a list of image paths) to a form that can be displayed in the user's browser (a gallery of images).
## Components Attributes
We used the default versions of the `gr.Textbox` and `gr.Slider`, but what if you want to change how the UI components look or behave?
Let's say you want to customize the slider to have values from 1 to 10, with a default of 2. And you wanted to customize the output text field — you want it to be larger and have a label.
If you use the actual classes for `gr.Textbox` and `gr.Slider` instead of the string shortcuts, you have access to much more customizability through component attributes.
$code_hello_world_2
$demo_hello_world_2
## Multiple Input and Output Components
Suppose you had a more complex function, with multiple outputs as well. In the example below, we define a function that takes a string, boolean, and number, and returns a string and number.
$code_hello_world_3
$demo_hello_world_3
Just as each component in the `inputs` list corresponds to one of the parameters of the function, in order, each component in the `outputs` list corresponds to one of the values returned by the function, in order.
## An Image Example
Gradio supports many types of components, such as `Image`, `DataFrame`, `Video`, or `Label`. Let's try an image-to-image function to get a feel for these!
$code_sepia_filter
$demo_sepia_filter
When using the `Image` component as input, your function will receive a NumPy array with the shape `(height, width, 3)`, where the last dimension represents the RGB values. We'll return an image as well in the form of a NumPy array.
As mentioned above, Gradio handles the preprocessing and postprocessing to convert images to NumPy arrays and vice versa. You can also control the preprocessing performed with the `type=` keyword argument. For example, if you wanted your function to take a file path to an image instead of a NumPy array, the input `Image` component could be written as:
```python
gr.Image(type="filepath", shape=...)
```
You can read more about the built-in Gradio components and how to customize them in the [Gradio docs](https://gradio.app/docs).
## Example Inputs
You can provide example data that a user can easily load into `Interface`. This can be helpful to demonstrate the types of inputs the model expects, as well as to provide a way to explore your dataset in conjunction with your model. To load example data, you can provide a **nested list** to the `examples=` keyword argument of the Interface constructor. Each sublist within the outer list represents a data sample, and each element within the sublist represents an input for each input component. The format of example data for each component is specified in the [Docs](https://gradio.app/docs#components).
$code_calculator
$demo_calculator
You can load a large dataset into the examples to browse and interact with the dataset through Gradio. The examples will be automatically paginated (you can configure this through the `examples_per_page` argument of `Interface`).
Continue learning about examples in the [More On Examples](https://gradio.app/guides/more-on-examples) guide.
## Descriptive Content
In the previous example, you may have noticed the `title=` and `description=` keyword arguments in the `Interface` constructor that helps users understand your app.
There are three arguments in the `Interface` constructor to specify where this content should go:
- `title`: which accepts text and can display it at the very top of interface, and also becomes the page title.
- `description`: which accepts text, markdown or HTML and places it right under the title.
- `article`: which also accepts text, markdown or HTML and places it below the interface.

Note: if you're using the `Blocks` class, you can insert text, markdown, or HTML anywhere in your application using the `gr.Markdown(...)` or `gr.HTML(...)` components.
Another useful keyword argument is `label=`, which is present in every `Component`. This modifies the label text at the top of each `Component`. You can also add the `info=` keyword argument to form elements like `Textbox` or `Radio` to provide further information on their usage.
```python
gr.Number(label='Age', info='In years, must be greater than 0')
```
## Additional Inputs within an Accordion
If your prediction function takes many inputs, you may want to hide some of them within a collapsed accordion to avoid cluttering the UI. The `Interface` class takes an `additional_inputs` argument which is similar to `inputs` but any input components included here are not visible by default. The user must click on the accordion to show these components. The additional inputs are passed into the prediction function, in order, after the standard inputs.
You can customize the appearance of the accordion by using the optional `additional_inputs_accordion` argument, which accepts a string (in which case, it becomes the label of the accordion), or an instance of the `gr.Accordion()` class (e.g. this lets you control whether the accordion is open or closed by default).
Here's an example:
$code_interface_with_additional_inputs
$demo_interface_with_additional_inputs
|
C:\Gradio Guides\2 Building Interfaces\01_more-on-examples.md |
# More on Examples
In the [previous Guide](/main/guides/the-interface-class), we discussed how to provide example inputs for your demo to make it easier for users to try it out. Here, we dive into more details.
## Providing Examples
Adding examples to an Interface is as easy as providing a list of lists to the `examples`
keyword argument.
Each sublist is a data sample, where each element corresponds to an input of the prediction function.
The inputs must be ordered in the same order as the prediction function expects them.
If your interface only has one input component, then you can provide your examples as a regular list instead of a list of lists.
### Loading Examples from a Directory
You can also specify a path to a directory containing your examples. If your Interface takes only a single file-type input, e.g. an image classifier, you can simply pass a directory filepath to the `examples=` argument, and the `Interface` will load the images in the directory as examples.
In the case of multiple inputs, this directory must
contain a log.csv file with the example values.
In the context of the calculator demo, we can set `examples='/demo/calculator/examples'` and in that directory we include the following `log.csv` file:
```csv
num,operation,num2
5,"add",3
4,"divide",2
5,"multiply",3
```
This can be helpful when browsing flagged data. Simply point to the flagged directory and the `Interface` will load the examples from the flagged data.
### Providing Partial Examples
Sometimes your app has many input components, but you would only like to provide examples for a subset of them. In order to exclude some inputs from the examples, pass `None` for all data samples corresponding to those particular components.
## Caching examples
You may wish to provide some cached examples of your model for users to quickly try out, in case your model takes a while to run normally.
If `cache_examples=True`, your Gradio app will run all of the examples and save the outputs when you call the `launch()` method. This data will be saved in a directory called `gradio_cached_examples` in your working directory by default. You can also set this directory with the `GRADIO_EXAMPLES_CACHE` environment variable, which can be either an absolute path or a relative path to your working directory.
Whenever a user clicks on an example, the output will automatically be populated in the app now, using data from this cached directory instead of actually running the function. This is useful so users can quickly try out your model without adding any load!
Alternatively, you can set `cache_examples="lazy"`. This means that each particular example will only get cached after it is first used (by any user) in the Gradio app. This is helpful if your prediction function is long-running and you do not want to wait a long time for your Gradio app to start.
Keep in mind once the cache is generated, it will not be updated automatically in future launches. If the examples or function logic change, delete the cache folder to clear the cache and rebuild it with another `launch()`.
|
C:\Gradio Guides\2 Building Interfaces\02_flagging.md |
# Flagging
You may have noticed the "Flag" button that appears by default in your `Interface`. When a user using your demo sees input with interesting output, such as erroneous or unexpected model behaviour, they can flag the input for you to review. Within the directory provided by the `flagging_dir=` argument to the `Interface` constructor, a CSV file will log the flagged inputs. If the interface involves file data, such as for Image and Audio components, folders will be created to store those flagged data as well.
For example, with the calculator interface shown above, we would have the flagged data stored in the flagged directory shown below:
```directory
+-- calculator.py
+-- flagged/
| +-- logs.csv
```
_flagged/logs.csv_
```csv
num1,operation,num2,Output
5,add,7,12
6,subtract,1.5,4.5
```
With the sepia interface shown earlier, we would have the flagged data stored in the flagged directory shown below:
```directory
+-- sepia.py
+-- flagged/
| +-- logs.csv
| +-- im/
| | +-- 0.png
| | +-- 1.png
| +-- Output/
| | +-- 0.png
| | +-- 1.png
```
_flagged/logs.csv_
```csv
im,Output
im/0.png,Output/0.png
im/1.png,Output/1.png
```
If you wish for the user to provide a reason for flagging, you can pass a list of strings to the `flagging_options` argument of Interface. Users will have to select one of the strings when flagging, which will be saved as an additional column to the CSV.
|
C:\Gradio Guides\2 Building Interfaces\03_interface-state.md |
# Interface State
So far, we've assumed that your demos are *stateless*: that they do not persist information beyond a single function call. What if you want to modify the behavior of your demo based on previous interactions with the demo? There are two approaches in Gradio: *global state* and *session state*.
## Global State
If the state is something that should be accessible to all function calls and all users, you can create a variable outside the function call and access it inside the function. For example, you may load a large model outside the function and use it inside the function so that every function call does not need to reload the model.
$code_score_tracker
In the code above, the `scores` array is shared between all users. If multiple users are accessing this demo, their scores will all be added to the same list, and the returned top 3 scores will be collected from this shared reference.
## Session State
Another type of data persistence Gradio supports is session state, where data persists across multiple submits within a page session. However, data is _not_ shared between different users of your model. To store data in a session state, you need to do three things:
1. Pass in an extra parameter into your function, which represents the state of the interface.
2. At the end of the function, return the updated value of the state as an extra return value.
3. Add the `'state'` input and `'state'` output components when creating your `Interface`
Here's a simple app to illustrate session state - this app simply stores users previous submissions and displays them back to the user:
$code_interface_state
$demo_interface_state
Notice how the state persists across submits within each page, but if you load this demo in another tab (or refresh the page), the demos will not share chat history. Here, we could not store the submission history in a global variable, otherwise the submission history would then get jumbled between different users.
The initial value of the `State` is `None` by default. If you pass a parameter to the `value` argument of `gr.State()`, it is used as the default value of the state instead.
Note: the `Interface` class only supports a single session state variable (though it can be a list with multiple elements). For more complex use cases, you can use Blocks, [which supports multiple `State` variables](/guides/state-in-blocks/). Alternatively, if you are building a chatbot that maintains user state, consider using the `ChatInterface` abstraction, [which manages state automatically](/guides/creating-a-chatbot-fast).
|
C:\Gradio Guides\2 Building Interfaces\04_reactive-interfaces.md |
# Reactive Interfaces
Finally, we cover how to get Gradio demos to refresh automatically or continuously stream data.
## Live Interfaces
You can make interfaces automatically refresh by setting `live=True` in the interface. Now the interface will recalculate as soon as the user input changes.
$code_calculator_live
$demo_calculator_live
Note there is no submit button, because the interface resubmits automatically on change.
## Streaming Components
Some components have a "streaming" mode, such as `Audio` component in microphone mode, or the `Image` component in webcam mode. Streaming means data is sent continuously to the backend and the `Interface` function is continuously being rerun.
The difference between `gr.Audio(source='microphone')` and `gr.Audio(source='microphone', streaming=True)`, when both are used in `gr.Interface(live=True)`, is that the first `Component` will automatically submit data and run the `Interface` function when the user stops recording, whereas the second `Component` will continuously send data and run the `Interface` function _during_ recording.
Here is example code of streaming images from the webcam.
$code_stream_frames
Streaming can also be done in an output component. A `gr.Audio(streaming=True)` output component can take a stream of audio data yielded piece-wise by a generator function and combines them into a single audio file.
$code_stream_audio_out
For a more detailed example, see our guide on performing [automatic speech recognition](/guides/real-time-speech-recognition) with Gradio.
|
C:\Gradio Guides\2 Building Interfaces\05_four-kinds-of-interfaces.md |
# The 4 Kinds of Gradio Interfaces
So far, we've always assumed that in order to build an Gradio demo, you need both inputs and outputs. But this isn't always the case for machine learning demos: for example, _unconditional image generation models_ don't take any input but produce an image as the output.
It turns out that the `gradio.Interface` class can actually handle 4 different kinds of demos:
1. **Standard demos**: which have both separate inputs and outputs (e.g. an image classifier or speech-to-text model)
2. **Output-only demos**: which don't take any input but produce on output (e.g. an unconditional image generation model)
3. **Input-only demos**: which don't produce any output but do take in some sort of input (e.g. a demo that saves images that you upload to a persistent external database)
4. **Unified demos**: which have both input and output components, but the input and output components _are the same_. This means that the output produced overrides the input (e.g. a text autocomplete model)
Depending on the kind of demo, the user interface (UI) looks slightly different:

Let's see how to build each kind of demo using the `Interface` class, along with examples:
## Standard demos
To create a demo that has both the input and the output components, you simply need to set the values of the `inputs` and `outputs` parameter in `Interface()`. Here's an example demo of a simple image filter:
$code_sepia_filter
$demo_sepia_filter
## Output-only demos
What about demos that only contain outputs? In order to build such a demo, you simply set the value of the `inputs` parameter in `Interface()` to `None`. Here's an example demo of a mock image generation model:
$code_fake_gan_no_input
$demo_fake_gan_no_input
## Input-only demos
Similarly, to create a demo that only contains inputs, set the value of `outputs` parameter in `Interface()` to be `None`. Here's an example demo that saves any uploaded image to disk:
$code_save_file_no_output
$demo_save_file_no_output
## Unified demos
A demo that has a single component as both the input and the output. It can simply be created by setting the values of the `inputs` and `outputs` parameter as the same component. Here's an example demo of a text generation model:
$code_unified_demo_text_generation
$demo_unified_demo_text_generation
|
C:\Gradio Guides\3 Additional Features\01_queuing.md |
# Queuing
Every Gradio app comes with a built-in queuing system that can scale to thousands of concurrent users. You can configure the queue by using `queue()` method which is supported by the `gr.Interface`, `gr.Blocks`, and `gr.ChatInterface` classes.
For example, you can control the number of requests processed at a single time by setting the `default_concurrency_limit` parameter of `queue()`, e.g.
```python
demo = gr.Interface(...).queue(default_concurrency_limit=5)
demo.launch()
```
This limits the number of requests processed for this event listener at a single time to 5. By default, the `default_concurrency_limit` is actually set to `1`, which means that when many users are using your app, only a single user's request will be processed at a time. This is because many machine learning functions consume a significant amount of memory and so it is only suitable to have a single user using the demo at a time. However, you can change this parameter in your demo easily.
See the [docs on queueing](/docs/gradio/interface#interface-queue) for more details on configuring the queuing parameters.
You can see analytics on the number and status of all requests processed by the queue by visiting the `/monitoring` endpoint of your app. This endpoint will print a secret URL to your console that links to the full analytics dashboard. |
C:\Gradio Guides\3 Additional Features\02_streaming-outputs.md |
# Streaming outputs
In some cases, you may want to stream a sequence of outputs rather than show a single output at once. For example, you might have an image generation model and you want to show the image that is generated at each step, leading up to the final image. Or you might have a chatbot which streams its response one token at a time instead of returning it all at once.
In such cases, you can supply a **generator** function into Gradio instead of a regular function. Creating generators in Python is very simple: instead of a single `return` value, a function should `yield` a series of values instead. Usually the `yield` statement is put in some kind of loop. Here's an example of an generator that simply counts up to a given number:
```python
def my_generator(x):
for i in range(x):
yield i
```
You supply a generator into Gradio the same way as you would a regular function. For example, here's a a (fake) image generation model that generates noise for several steps before outputting an image using the `gr.Interface` class:
$code_fake_diffusion
$demo_fake_diffusion
Note that we've added a `time.sleep(1)` in the iterator to create an artificial pause between steps so that you are able to observe the steps of the iterator (in a real image generation model, this probably wouldn't be necessary).
Similarly, Gradio can handle streaming inputs, e.g. an image generation model that reruns every time a user types a letter in a textbox. This is covered in more details in our guide on building [reactive Interfaces](/guides/reactive-interfaces).
|
C:\Gradio Guides\3 Additional Features\03_alerts.md |
# Alerts
You may wish to display alerts to the user. To do so, raise a `gr.Error("custom message")` in your function to halt the execution of your function and display an error message to the user.
Alternatively, can issue `gr.Warning("custom message")` or `gr.Info("custom message")` by having them as standalone lines in your function, which will immediately display modals while continuing the execution of your function. The only difference between `gr.Info()` and `gr.Warning()` is the color of the alert.
```python
def start_process(name):
gr.Info("Starting process")
if name is None:
gr.Warning("Name is empty")
...
if success == False:
raise gr.Error("Process failed")
```
Tip: Note that `gr.Error()` is an exception that has to be raised, while `gr.Warning()` and `gr.Info()` are functions that are called directly.
|
C:\Gradio Guides\3 Additional Features\04_styling.md |
# Styling
Gradio themes are the easiest way to customize the look and feel of your app. You can choose from a variety of themes, or create your own. To do so, pass the `theme=` kwarg to the `Interface` constructor. For example:
```python
demo = gr.Interface(..., theme=gr.themes.Monochrome())
```
Gradio comes with a set of prebuilt themes which you can load from `gr.themes.*`. You can extend these themes or create your own themes from scratch - see the [theming guide](https://gradio.app/guides/theming-guide) for more details.
For additional styling ability, you can pass any CSS (as well as custom JavaScript) to your Gradio application. This is discussed in more detail in our [custom JS and CSS guide](/guides/custom-CSS-and-JS).
|
C:\Gradio Guides\3 Additional Features\05_progress-bars.md |
# Progress Bars
Gradio supports the ability to create custom Progress Bars so that you have customizability and control over the progress update that you show to the user. In order to enable this, simply add an argument to your method that has a default value of a `gr.Progress` instance. Then you can update the progress levels by calling this instance directly with a float between 0 and 1, or using the `tqdm()` method of the `Progress` instance to track progress over an iterable, as shown below.
$code_progress_simple
$demo_progress_simple
If you use the `tqdm` library, you can even report progress updates automatically from any `tqdm.tqdm` that already exists within your function by setting the default argument as `gr.Progress(track_tqdm=True)`!
|
C:\Gradio Guides\3 Additional Features\06_batch-functions.md |
# Batch functions
Gradio supports the ability to pass _batch_ functions. Batch functions are just
functions which take in a list of inputs and return a list of predictions.
For example, here is a batched function that takes in two lists of inputs (a list of
words and a list of ints), and returns a list of trimmed words as output:
```py
import time
def trim_words(words, lens):
trimmed_words = []
time.sleep(5)
for w, l in zip(words, lens):
trimmed_words.append(w[:int(l)])
return [trimmed_words]
```
The advantage of using batched functions is that if you enable queuing, the Gradio server can automatically _batch_ incoming requests and process them in parallel,
potentially speeding up your demo. Here's what the Gradio code looks like (notice the `batch=True` and `max_batch_size=16`)
With the `gr.Interface` class:
```python
demo = gr.Interface(
fn=trim_words,
inputs=["textbox", "number"],
outputs=["output"],
batch=True,
max_batch_size=16
)
demo.launch()
```
With the `gr.Blocks` class:
```py
import gradio as gr
with gr.Blocks() as demo:
with gr.Row():
word = gr.Textbox(label="word")
leng = gr.Number(label="leng")
output = gr.Textbox(label="Output")
with gr.Row():
run = gr.Button()
event = run.click(trim_words, [word, leng], output, batch=True, max_batch_size=16)
demo.launch()
```
In the example above, 16 requests could be processed in parallel (for a total inference time of 5 seconds), instead of each request being processed separately (for a total
inference time of 80 seconds). Many Hugging Face `transformers` and `diffusers` models work very naturally with Gradio's batch mode: here's [an example demo using diffusers to
generate images in batches](https://github.com/gradio-app/gradio/blob/main/demo/diffusers_with_batching/run.py)
|
C:\Gradio Guides\3 Additional Features\07_resource-cleanup.md |
# Resource Cleanup
Your Gradio application may create resources during its lifetime.
Examples of resources are `gr.State` variables, any variables you create and explicitly hold in memory, or files you save to disk.
Over time, these resources can use up all of your server's RAM or disk space and crash your application.
Gradio provides some tools for you to clean up the resources created by your app:
1. Automatic deletion of `gr.State` variables.
2. Automatic cache cleanup with the `delete_cache` parameter.
2. The `Blocks.unload` event.
Let's take a look at each of them individually.
## Automatic deletion of `gr.State`
When a user closes their browser tab, Gradio will automatically delete any `gr.State` variables associated with that user session after 60 minutes. If the user connects again within those 60 minutes, no state will be deleted.
You can control the deletion behavior further with the following two parameters of `gr.State`:
1. `delete_callback` - An arbitrary function that will be called when the variable is deleted. This function must take the state value as input. This function is useful for deleting variables from GPU memory.
2. `time_to_live` - The number of seconds the state should be stored for after it is created or updated. This will delete variables before the session is closed, so it's useful for clearing state for potentially long running sessions.
## Automatic cache cleanup via `delete_cache`
Your Gradio application will save uploaded and generated files to a special directory called the cache directory. Gradio uses a hashing scheme to ensure that duplicate files are not saved to the cache but over time the size of the cache will grow (especially if your app goes viral 😉).
Gradio can periodically clean up the cache for you if you specify the `delete_cache` parameter of `gr.Blocks()`, `gr.Interface()`, or `gr.ChatInterface()`.
This parameter is a tuple of the form `[frequency, age]` both expressed in number of seconds.
Every `frequency` seconds, the temporary files created by this Blocks instance will be deleted if more than `age` seconds have passed since the file was created.
For example, setting this to (86400, 86400) will delete temporary files every day if they are older than a day old.
Additionally, the cache will be deleted entirely when the server restarts.
## The `unload` event
Additionally, Gradio now includes a `Blocks.unload()` event, allowing you to run arbitrary cleanup functions when users disconnect (this does not have a 60 minute delay).
Unlike other gradio events, this event does not accept inputs or outptus.
You can think of the `unload` event as the opposite of the `load` event.
## Putting it all together
The following demo uses all of these features. When a user visits the page, a special unique directory is created for that user.
As the user interacts with the app, images are saved to disk in that special directory.
When the user closes the page, the images created in that session are deleted via the `unload` event.
The state and files in the cache are cleaned up automatically as well.
$code_state_cleanup
$demo_state_cleanup |
C:\Gradio Guides\3 Additional Features\08_environment-variables.md |
# Environment Variables
Environment variables in Gradio provide a way to customize your applications and launch settings without changing the codebase. In this guide, we'll explore the key environment variables supported in Gradio and how to set them.
## Key Environment Variables
### 1. `GRADIO_SERVER_PORT`
- **Description**: Specifies the port on which the Gradio app will run.
- **Default**: `7860`
- **Example**:
```bash
export GRADIO_SERVER_PORT=8000
```
### 2. `GRADIO_SERVER_NAME`
- **Description**: Defines the host name for the Gradio server. To make Gradio accessible from any IP address, set this to `"0.0.0.0"`
- **Default**: `"127.0.0.1"`
- **Example**:
```bash
export GRADIO_SERVER_NAME="0.0.0.0"
```
### 3. `GRADIO_ANALYTICS_ENABLED`
- **Description**: Whether Gradio should provide
- **Default**: `"True"`
- **Options**: `"True"`, `"False"`
- **Example**:
```sh
export GRADIO_ANALYTICS_ENABLED="True"
```
### 4. `GRADIO_DEBUG`
- **Description**: Enables or disables debug mode in Gradio. If debug mode is enabled, the main thread does not terminate allowing error messages to be printed in environments such as Google Colab.
- **Default**: `0`
- **Example**:
```sh
export GRADIO_DEBUG=1
```
### 5. `GRADIO_ALLOW_FLAGGING`
- **Description**: Controls whether users can flag inputs/outputs in the Gradio interface. See [the Guide on flagging](/guides/using-flagging) for more details.
- **Default**: `"manual"`
- **Options**: `"never"`, `"manual"`, `"auto"`
- **Example**:
```sh
export GRADIO_ALLOW_FLAGGING="never"
```
### 6. `GRADIO_TEMP_DIR`
- **Description**: Specifies the directory where temporary files created by Gradio are stored.
- **Default**: System default temporary directory
- **Example**:
```sh
export GRADIO_TEMP_DIR="/path/to/temp"
```
### 7. `GRADIO_ROOT_PATH`
- **Description**: Sets the root path for the Gradio application. Useful if running Gradio [behind a reverse proxy](/guides/running-gradio-on-your-web-server-with-nginx).
- **Default**: `""`
- **Example**:
```sh
export GRADIO_ROOT_PATH="/myapp"
```
### 8. `GRADIO_SHARE`
- **Description**: Enables or disables sharing the Gradio app.
- **Default**: `"False"`
- **Options**: `"True"`, `"False"`
- **Example**:
```sh
export GRADIO_SHARE="True"
```
### 9. `GRADIO_ALLOWED_PATHS`
- **Description**: Sets a list of complete filepaths or parent directories that gradio is allowed to serve. Must be absolute paths. Warning: if you provide directories, any files in these directories or their subdirectories are accessible to all users of your app. Multiple items can be specified by separating items with commas.
- **Default**: `""`
- **Example**:
```sh
export GRADIO_ALLOWED_PATHS="/mnt/sda1,/mnt/sda2"
```
### 10. `GRADIO_BLOCKED_PATHS`
- **Description**: Sets a list of complete filepaths or parent directories that gradio is not allowed to serve (i.e. users of your app are not allowed to access). Must be absolute paths. Warning: takes precedence over `allowed_paths` and all other directories exposed by Gradio by default. Multiple items can be specified by separating items with commas.
- **Default**: `""`
- **Example**:
```sh
export GRADIO_BLOCKED_PATHS="/users/x/gradio_app/admin,/users/x/gradio_app/keys"
```
## How to Set Environment Variables
To set environment variables in your terminal, use the `export` command followed by the variable name and its value. For example:
```sh
export GRADIO_SERVER_PORT=8000
```
If you're using a `.env` file to manage your environment variables, you can add them like this:
```sh
GRADIO_SERVER_PORT=8000
GRADIO_SERVER_NAME="localhost"
```
Then, use a tool like `dotenv` to load these variables when running your application.
|
C:\Gradio Guides\3 Additional Features\09_sharing-your-app.md |
# Sharing Your App
In this Guide, we dive more deeply into the various aspects of sharing a Gradio app with others. We will cover:
1. [Sharing demos with the share parameter](#sharing-demos)
2. [Hosting on HF Spaces](#hosting-on-hf-spaces)
3. [Embedding hosted spaces](#embedding-hosted-spaces)
4. [Using the API page](#api-page)
5. [Accessing network requests](#accessing-the-network-request-directly)
6. [Mounting within FastAPI](#mounting-within-another-fast-api-app)
7. [Authentication](#authentication)
8. [Security and file access](#security-and-file-access)
9. [Analytics](#analytics)
## Sharing Demos
Gradio demos can be easily shared publicly by setting `share=True` in the `launch()` method. Like this:
```python
import gradio as gr
def greet(name):
return "Hello " + name + "!"
demo = gr.Interface(fn=greet, inputs="textbox", outputs="textbox")
demo.launch(share=True) # Share your demo with just 1 extra parameter 🚀
```
This generates a public, shareable link that you can send to anybody! When you send this link, the user on the other side can try out the model in their browser. Because the processing happens on your device (as long as your device stays on), you don't have to worry about any packaging any dependencies.

A share link usually looks something like this: **https://07ff8706ab.gradio.live**. Although the link is served through the Gradio Share Servers, these servers are only a proxy for your local server, and do not store any data sent through your app. Share links expire after 72 hours. (it is [also possible to set up your own Share Server](https://github.com/huggingface/frp/) on your own cloud server to overcome this restriction.)
Tip: Keep in mind that share links are publicly accessible, meaning that anyone can use your model for prediction! Therefore, make sure not to expose any sensitive information through the functions you write, or allow any critical changes to occur on your device. Or you can [add authentication to your Gradio app](#authentication) as discussed below.
Note that by default, `share=False`, which means that your server is only running locally. (This is the default, except in Google Colab notebooks, where share links are automatically created). As an alternative to using share links, you can use use [SSH port-forwarding](https://www.ssh.com/ssh/tunneling/example) to share your local server with specific users.
## Hosting on HF Spaces
If you'd like to have a permanent link to your Gradio demo on the internet, use Hugging Face Spaces. [Hugging Face Spaces](http://huggingface.co/spaces/) provides the infrastructure to permanently host your machine learning model for free!
After you have [created a free Hugging Face account](https://huggingface.co/join), you have two methods to deploy your Gradio app to Hugging Face Spaces:
1. From terminal: run `gradio deploy` in your app directory. The CLI will gather some basic metadata and then launch your app. To update your space, you can re-run this command or enable the Github Actions option to automatically update the Spaces on `git push`.
2. From your browser: Drag and drop a folder containing your Gradio model and all related files [here](https://huggingface.co/new-space). See [this guide how to host on Hugging Face Spaces](https://huggingface.co/blog/gradio-spaces) for more information, or watch the embedded video:
<video autoplay muted loop>
<source src="https://github.com/gradio-app/gradio/blob/main/guides/assets/hf_demo.mp4?raw=true" type="video/mp4" />
</video>
## Embedding Hosted Spaces
Once you have hosted your app on Hugging Face Spaces (or on your own server), you may want to embed the demo on a different website, such as your blog or your portfolio. Embedding an interactive demo allows people to try out the machine learning model that you have built, without needing to download or install anything — right in their browser! The best part is that you can embed interactive demos even in static websites, such as GitHub pages.
There are two ways to embed your Gradio demos. You can find quick links to both options directly on the Hugging Face Space page, in the "Embed this Space" dropdown option:

### Embedding with Web Components
Web components typically offer a better experience to users than IFrames. Web components load lazily, meaning that they won't slow down the loading time of your website, and they automatically adjust their height based on the size of the Gradio app.
To embed with Web Components:
1. Import the gradio JS library into into your site by adding the script below in your site (replace {GRADIO_VERSION} in the URL with the library version of Gradio you are using).
```html
<script
type="module"
src="https://gradio.s3-us-west-2.amazonaws.com/{GRADIO_VERSION}/gradio.js"
></script>
```
2. Add
```html
<gradio-app src="https://$your_space_host.hf.space"></gradio-app>
```
element where you want to place the app. Set the `src=` attribute to your Space's embed URL, which you can find in the "Embed this Space" button. For example:
```html
<gradio-app
src="https://abidlabs-pytorch-image-classifier.hf.space"
></gradio-app>
```
<script>
fetch("https://pypi.org/pypi/gradio/json"
).then(r => r.json()
).then(obj => {
let v = obj.info.version;
content = document.querySelector('.prose');
content.innerHTML = content.innerHTML.replaceAll("{GRADIO_VERSION}", v);
});
</script>
You can see examples of how web components look <a href="https://www.gradio.app">on the Gradio landing page</a>.
You can also customize the appearance and behavior of your web component with attributes that you pass into the `<gradio-app>` tag:
- `src`: as we've seen, the `src` attributes links to the URL of the hosted Gradio demo that you would like to embed
- `space`: an optional shorthand if your Gradio demo is hosted on Hugging Face Space. Accepts a `username/space_name` instead of a full URL. Example: `gradio/Echocardiogram-Segmentation`. If this attribute attribute is provided, then `src` does not need to be provided.
- `control_page_title`: a boolean designating whether the html title of the page should be set to the title of the Gradio app (by default `"false"`)
- `initial_height`: the initial height of the web component while it is loading the Gradio app, (by default `"300px"`). Note that the final height is set based on the size of the Gradio app.
- `container`: whether to show the border frame and information about where the Space is hosted (by default `"true"`)
- `info`: whether to show just the information about where the Space is hosted underneath the embedded app (by default `"true"`)
- `autoscroll`: whether to autoscroll to the output when prediction has finished (by default `"false"`)
- `eager`: whether to load the Gradio app as soon as the page loads (by default `"false"`)
- `theme_mode`: whether to use the `dark`, `light`, or default `system` theme mode (by default `"system"`)
- `render`: an event that is triggered once the embedded space has finished rendering.
Here's an example of how to use these attributes to create a Gradio app that does not lazy load and has an initial height of 0px.
```html
<gradio-app
space="gradio/Echocardiogram-Segmentation"
eager="true"
initial_height="0px"
></gradio-app>
```
Here's another example of how to use the `render` event. An event listener is used to capture the `render` event and will call the `handleLoadComplete()` function once rendering is complete.
```html
<script>
function handleLoadComplete() {
console.log("Embedded space has finished rendering");
}
const gradioApp = document.querySelector("gradio-app");
gradioApp.addEventListener("render", handleLoadComplete);
</script>
```
_Note: While Gradio's CSS will never impact the embedding page, the embedding page can affect the style of the embedded Gradio app. Make sure that any CSS in the parent page isn't so general that it could also apply to the embedded Gradio app and cause the styling to break. Element selectors such as `header { ... }` and `footer { ... }` will be the most likely to cause issues._
### Embedding with IFrames
To embed with IFrames instead (if you cannot add javascript to your website, for example), add this element:
```html
<iframe src="https://$your_space_host.hf.space"></iframe>
```
Again, you can find the `src=` attribute to your Space's embed URL, which you can find in the "Embed this Space" button.
Note: if you use IFrames, you'll probably want to add a fixed `height` attribute and set `style="border:0;"` to remove the boreder. In addition, if your app requires permissions such as access to the webcam or the microphone, you'll need to provide that as well using the `allow` attribute.
## API Page
You can use almost any Gradio app as an API! In the footer of a Gradio app [like this one](https://huggingface.co/spaces/gradio/hello_world), you'll see a "Use via API" link.

This is a page that lists the endpoints that can be used to query the Gradio app, via our supported clients: either [the Python client](https://gradio.app/guides/getting-started-with-the-python-client/), or [the JavaScript client](https://gradio.app/guides/getting-started-with-the-js-client/). For each endpoint, Gradio automatically generates the parameters and their types, as well as example inputs, like this.

The endpoints are automatically created when you launch a Gradio `Interface`. If you are using Gradio `Blocks`, you can also set up a Gradio API page, though we recommend that you explicitly name each event listener, such as
```python
btn.click(add, [num1, num2], output, api_name="addition")
```
This will add and document the endpoint `/api/addition/` to the automatically generated API page. Otherwise, your API endpoints will appear as "unnamed" endpoints.
## Accessing the Network Request Directly
When a user makes a prediction to your app, you may need the underlying network request, in order to get the request headers (e.g. for advanced authentication), log the client's IP address, getting the query parameters, or for other reasons. Gradio supports this in a similar manner to FastAPI: simply add a function parameter whose type hint is `gr.Request` and Gradio will pass in the network request as that parameter. Here is an example:
```python
import gradio as gr
def echo(text, request: gr.Request):
if request:
print("Request headers dictionary:", request.headers)
print("IP address:", request.client.host)
print("Query parameters:", dict(request.query_params))
return text
io = gr.Interface(echo, "textbox", "textbox").launch()
```
Note: if your function is called directly instead of through the UI (this happens, for
example, when examples are cached, or when the Gradio app is called via API), then `request` will be `None`.
You should handle this case explicitly to ensure that your app does not throw any errors. That is why
we have the explicit check `if request`.
## Mounting Within Another FastAPI App
In some cases, you might have an existing FastAPI app, and you'd like to add a path for a Gradio demo.
You can easily do this with `gradio.mount_gradio_app()`.
Here's a complete example:
$code_custom_path
Note that this approach also allows you run your Gradio apps on custom paths (`http://localhost:8000/gradio` in the example above).
## Authentication
### Password-protected app
You may wish to put an authentication page in front of your app to limit who can open your app. With the `auth=` keyword argument in the `launch()` method, you can provide a tuple with a username and password, or a list of acceptable username/password tuples; Here's an example that provides password-based authentication for a single user named "admin":
```python
demo.launch(auth=("admin", "pass1234"))
```
For more complex authentication handling, you can even pass a function that takes a username and password as arguments, and returns `True` to allow access, `False` otherwise.
Here's an example of a function that accepts any login where the username and password are the same:
```python
def same_auth(username, password):
return username == password
demo.launch(auth=same_auth)
```
If you have multiple users, you may wish to customize the content that is shown depending on the user that is logged in. You can retrieve the logged in user by [accessing the network request directly](#accessing-the-network-request-directly) as discussed above, and then reading the `.username` attribute of the request. Here's an example:
```python
import gradio as gr
def update_message(request: gr.Request):
return f"Welcome, {request.username}"
with gr.Blocks() as demo:
m = gr.Markdown()
demo.load(update_message, None, m)
demo.launch(auth=[("Abubakar", "Abubakar"), ("Ali", "Ali")])
```
Note: For authentication to work properly, third party cookies must be enabled in your browser. This is not the case by default for Safari or for Chrome Incognito Mode.
If users visit the `/logout` page of your Gradio app, they will automatically be logged out and session cookies deleted. This allows you to add logout functionality to your Gradio app as well. Let's update the previous example to include a log out button:
```python
import gradio as gr
def update_message(request: gr.Request):
return f"Welcome, {request.username}"
with gr.Blocks() as demo:
m = gr.Markdown()
logout_button = gr.Button("Logout", link="/logout")
demo.load(update_message, None, m)
demo.launch(auth=[("Pete", "Pete"), ("Dawood", "Dawood")])
```
Note: Gradio's built-in authentication provides a straightforward and basic layer of access control but does not offer robust security features for applications that require stringent access controls (e.g. multi-factor authentication, rate limiting, or automatic lockout policies).
### OAuth (Login via Hugging Face)
Gradio natively supports OAuth login via Hugging Face. In other words, you can easily add a _"Sign in with Hugging Face"_ button to your demo, which allows you to get a user's HF username as well as other information from their HF profile. Check out [this Space](https://huggingface.co/spaces/Wauplin/gradio-oauth-demo) for a live demo.
To enable OAuth, you must set `hf_oauth: true` as a Space metadata in your README.md file. This will register your Space
as an OAuth application on Hugging Face. Next, you can use `gr.LoginButton` to add a login button to
your Gradio app. Once a user is logged in with their HF account, you can retrieve their profile by adding a parameter of type
`gr.OAuthProfile` to any Gradio function. The user profile will be automatically injected as a parameter value. If you want
to perform actions on behalf of the user (e.g. list user's private repos, create repo, etc.), you can retrieve the user
token by adding a parameter of type `gr.OAuthToken`. You must define which scopes you will use in your Space metadata
(see [documentation](https://huggingface.co/docs/hub/spaces-oauth#scopes) for more details).
Here is a short example:
```py
import gradio as gr
from huggingface_hub import whoami
def hello(profile: gr.OAuthProfile | None) -> str:
if profile is None:
return "I don't know you."
return f"Hello {profile.name}"
def list_organizations(oauth_token: gr.OAuthToken | None) -> str:
if oauth_token is None:
return "Please log in to list organizations."
org_names = [org["name"] for org in whoami(oauth_token.token)["orgs"]]
return f"You belong to {', '.join(org_names)}."
with gr.Blocks() as demo:
gr.LoginButton()
m1 = gr.Markdown()
m2 = gr.Markdown()
demo.load(hello, inputs=None, outputs=m1)
demo.load(list_organizations, inputs=None, outputs=m2)
demo.launch()
```
When the user clicks on the login button, they get redirected in a new page to authorize your Space.
<center>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/gradio-guides/oauth_sign_in.png" style="width:300px; max-width:80%">
</center>
Users can revoke access to their profile at any time in their [settings](https://huggingface.co/settings/connected-applications).
As seen above, OAuth features are available only when your app runs in a Space. However, you often need to test your app
locally before deploying it. To test OAuth features locally, your machine must be logged in to Hugging Face. Please run `huggingface-cli login` or set `HF_TOKEN` as environment variable with one of your access token. You can generate a new token in your settings page (https://huggingface.co/settings/tokens). Then, clicking on the `gr.LoginButton` will login your local Hugging Face profile, allowing you to debug your app with your Hugging Face account before deploying it to a Space.
### OAuth (with external providers)
It is also possible to authenticate with external OAuth providers (e.g. Google OAuth) in your Gradio apps. To do this, first mount your Gradio app within a FastAPI app ([as discussed above](#mounting-within-another-fast-api-app)). Then, you must write an *authentication function*, which gets the user's username from the OAuth provider and returns it. This function should be passed to the `auth_dependency` parameter in `gr.mount_gradio_app`.
Similar to [FastAPI dependency functions](https://fastapi.tiangolo.com/tutorial/dependencies/), the function specified by `auth_dependency` will run before any Gradio-related route in your FastAPI app. The function should accept a single parameter: the FastAPI `Request` and return either a string (representing a user's username) or `None`. If a string is returned, the user will be able to access the Gradio-related routes in your FastAPI app.
First, let's show a simplistic example to illustrate the `auth_dependency` parameter:
```python
from fastapi import FastAPI, Request
import gradio as gr
app = FastAPI()
def get_user(request: Request):
return request.headers.get("user")
demo = gr.Interface(lambda s: f"Hello {s}!", "textbox", "textbox")
app = gr.mount_gradio_app(app, demo, path="/demo", auth_dependency=get_user)
if __name__ == '__main__':
uvicorn.run(app)
```
In this example, only requests that include a "user" header will be allowed to access the Gradio app. Of course, this does not add much security, since any user can add this header in their request.
Here's a more complete example showing how to add Google OAuth to a Gradio app (assuming you've already created OAuth Credentials on the [Google Developer Console](https://console.cloud.google.com/project)):
```python
import os
from authlib.integrations.starlette_client import OAuth, OAuthError
from fastapi import FastAPI, Depends, Request
from starlette.config import Config
from starlette.responses import RedirectResponse
from starlette.middleware.sessions import SessionMiddleware
import uvicorn
import gradio as gr
app = FastAPI()
# Replace these with your own OAuth settings
GOOGLE_CLIENT_ID = "..."
GOOGLE_CLIENT_SECRET = "..."
SECRET_KEY = "..."
config_data = {'GOOGLE_CLIENT_ID': GOOGLE_CLIENT_ID, 'GOOGLE_CLIENT_SECRET': GOOGLE_CLIENT_SECRET}
starlette_config = Config(environ=config_data)
oauth = OAuth(starlette_config)
oauth.register(
name='google',
server_metadata_url='https://accounts.google.com/.well-known/openid-configuration',
client_kwargs={'scope': 'openid email profile'},
)
SECRET_KEY = os.environ.get('SECRET_KEY') or "a_very_secret_key"
app.add_middleware(SessionMiddleware, secret_key=SECRET_KEY)
# Dependency to get the current user
def get_user(request: Request):
user = request.session.get('user')
if user:
return user['name']
return None
@app.get('/')
def public(user: dict = Depends(get_user)):
if user:
return RedirectResponse(url='/gradio')
else:
return RedirectResponse(url='/login-demo')
@app.route('/logout')
async def logout(request: Request):
request.session.pop('user', None)
return RedirectResponse(url='/')
@app.route('/login')
async def login(request: Request):
redirect_uri = request.url_for('auth')
# If your app is running on https, you should ensure that the
# `redirect_uri` is https, e.g. uncomment the following lines:
#
# from urllib.parse import urlparse, urlunparse
# redirect_uri = urlunparse(urlparse(str(redirect_uri))._replace(scheme='https'))
return await oauth.google.authorize_redirect(request, redirect_uri)
@app.route('/auth')
async def auth(request: Request):
try:
access_token = await oauth.google.authorize_access_token(request)
except OAuthError:
return RedirectResponse(url='/')
request.session['user'] = dict(access_token)["userinfo"]
return RedirectResponse(url='/')
with gr.Blocks() as login_demo:
gr.Button("Login", link="/login")
app = gr.mount_gradio_app(app, login_demo, path="/login-demo")
def greet(request: gr.Request):
return f"Welcome to Gradio, {request.username}"
with gr.Blocks() as main_demo:
m = gr.Markdown("Welcome to Gradio!")
gr.Button("Logout", link="/logout")
main_demo.load(greet, None, m)
app = gr.mount_gradio_app(app, main_demo, path="/gradio", auth_dependency=get_user)
if __name__ == '__main__':
uvicorn.run(app)
```
There are actually two separate Gradio apps in this example! One that simply displays a log in button (this demo is accessible to any user), while the other main demo is only accessible to users that are logged in. You can try this example out on [this Space](https://huggingface.co/spaces/gradio/oauth-example).
## Security and File Access
Sharing your Gradio app with others (by hosting it on Spaces, on your own server, or through temporary share links) **exposes** certain files on the host machine to users of your Gradio app.
In particular, Gradio apps ALLOW users to access to four kinds of files:
- **Temporary files created by Gradio.** These are files that are created by Gradio as part of running your prediction function. For example, if your prediction function returns a video file, then Gradio will save that video to a temporary cache on your device and then send the path to the file to the front end. You can customize the location of temporary cache files created by Gradio by setting the environment variable `GRADIO_TEMP_DIR` to an absolute path, such as `/home/usr/scripts/project/temp/`. You can delete the files created by your app when it shuts down with the `delete_cache` parameter of `gradio.Blocks`, `gradio.Interface`, and `gradio.ChatInterface`. This parameter is a tuple of integers of the form `[frequency, age]` where `frequency` is how often to delete files and `age` is the time in seconds since the file was last modified.
- **Cached examples created by Gradio.** These are files that are created by Gradio as part of caching examples for faster runtimes, if you set `cache_examples=True` or `cache_examples="lazy"` in `gr.Interface()`, `gr.ChatInterface()` or in `gr.Examples()`. By default, these files are saved in the `gradio_cached_examples/` subdirectory within your app's working directory. You can customize the location of cached example files created by Gradio by setting the environment variable `GRADIO_EXAMPLES_CACHE` to an absolute path or a path relative to your working directory.
- **Files that you explicitly allow via the `allowed_paths` parameter in `launch()`**. This parameter allows you to pass in a list of additional directories or exact filepaths you'd like to allow users to have access to. (By default, this parameter is an empty list).
- **Static files that you explicitly set via the `gr.set_static_paths` function**. This parameter allows you to pass in a list of directories or filenames that will be considered static. This means that they will not be copied to the cache and will be served directly from your computer. This can help save disk space and reduce the time your app takes to launch but be mindful of possible security implications.
Gradio DOES NOT ALLOW access to:
- **Files that you explicitly block via the `blocked_paths` parameter in `launch()`**. You can pass in a list of additional directories or exact filepaths to the `blocked_paths` parameter in `launch()`. This parameter takes precedence over the files that Gradio exposes by default or by the `allowed_paths`.
- **Any other paths on the host machine**. Users should NOT be able to access other arbitrary paths on the host.
Sharing your Gradio application will also allow users to upload files to your computer or server. You can set a maximum file size for uploads to prevent abuse and to preserve disk space. You can do this with the `max_file_size` parameter of `.launch`. For example, the following two code snippets limit file uploads to 5 megabytes per file.
```python
import gradio as gr
demo = gr.Interface(lambda x: x, "image", "image")
demo.launch(max_file_size="5mb")
# or
demo.launch(max_file_size=5 * gr.FileSize.MB)
```
Please make sure you are running the latest version of `gradio` for these security settings to apply.
## Analytics
By default, Gradio collects certain analytics to help us better understand the usage of the `gradio` library. This includes the following information:
* What environment the Gradio app is running on (e.g. Colab Notebook, Hugging Face Spaces)
* What input/output components are being used in the Gradio app
* Whether the Gradio app is utilizing certain advanced features, such as `auth` or `show_error`
* The IP address which is used solely to measure the number of unique developers using Gradio
* The version of Gradio that is running
No information is collected from _users_ of your Gradio app. If you'd like to diable analytics altogether, you can do so by setting the `analytics_enabled` parameter to `False` in `gr.Blocks`, `gr.Interface`, or `gr.ChatInterface`. Or, you can set the GRADIO_ANALYTICS_ENABLED environment variable to `"False"` to apply this to all Gradio apps created across your system.
*Note*: this reflects the analytics policy as of `gradio>=4.32.0`.
|
C:\Gradio Guides\4 Building with Blocks\01_blocks-and-event-listeners.md |
# Blocks and Event Listeners
We briefly descirbed the Blocks class in the [Quickstart](/main/guides/quickstart#custom-demos-with-gr-blocks) as a way to build custom demos. Let's dive deeper.
## Blocks Structure
Take a look at the demo below.
$code_hello_blocks
$demo_hello_blocks
- First, note the `with gr.Blocks() as demo:` clause. The Blocks app code will be contained within this clause.
- Next come the Components. These are the same Components used in `Interface`. However, instead of being passed to some constructor, Components are automatically added to the Blocks as they are created within the `with` clause.
- Finally, the `click()` event listener. Event listeners define the data flow within the app. In the example above, the listener ties the two Textboxes together. The Textbox `name` acts as the input and Textbox `output` acts as the output to the `greet` method. This dataflow is triggered when the Button `greet_btn` is clicked. Like an Interface, an event listener can take multiple inputs or outputs.
You can also attach event listeners using decorators - skip the `fn` argument and assign `inputs` and `outputs` directly:
$code_hello_blocks_decorator
## Event Listeners and Interactivity
In the example above, you'll notice that you are able to edit Textbox `name`, but not Textbox `output`. This is because any Component that acts as an input to an event listener is made interactive. However, since Textbox `output` acts only as an output, Gradio determines that it should not be made interactive. You can override the default behavior and directly configure the interactivity of a Component with the boolean `interactive` keyword argument.
```python
output = gr.Textbox(label="Output", interactive=True)
```
_Note_: What happens if a Gradio component is neither an input nor an output? If a component is constructed with a default value, then it is presumed to be displaying content and is rendered non-interactive. Otherwise, it is rendered interactive. Again, this behavior can be overridden by specifying a value for the `interactive` argument.
## Types of Event Listeners
Take a look at the demo below:
$code_blocks_hello
$demo_blocks_hello
Instead of being triggered by a click, the `welcome` function is triggered by typing in the Textbox `inp`. This is due to the `change()` event listener. Different Components support different event listeners. For example, the `Video` Component supports a `play()` event listener, triggered when a user presses play. See the [Docs](http://gradio.app/docs#components) for the event listeners for each Component.
## Multiple Data Flows
A Blocks app is not limited to a single data flow the way Interfaces are. Take a look at the demo below:
$code_reversible_flow
$demo_reversible_flow
Note that `num1` can act as input to `num2`, and also vice-versa! As your apps get more complex, you will have many data flows connecting various Components.
Here's an example of a "multi-step" demo, where the output of one model (a speech-to-text model) gets fed into the next model (a sentiment classifier).
$code_blocks_speech_text_sentiment
$demo_blocks_speech_text_sentiment
## Function Input List vs Dict
The event listeners you've seen so far have a single input component. If you'd like to have multiple input components pass data to the function, you have two options on how the function can accept input component values:
1. as a list of arguments, or
2. as a single dictionary of values, keyed by the component
Let's see an example of each:
$code_calculator_list_and_dict
Both `add()` and `sub()` take `a` and `b` as inputs. However, the syntax is different between these listeners.
1. To the `add_btn` listener, we pass the inputs as a list. The function `add()` takes each of these inputs as arguments. The value of `a` maps to the argument `num1`, and the value of `b` maps to the argument `num2`.
2. To the `sub_btn` listener, we pass the inputs as a set (note the curly brackets!). The function `sub()` takes a single dictionary argument `data`, where the keys are the input components, and the values are the values of those components.
It is a matter of preference which syntax you prefer! For functions with many input components, option 2 may be easier to manage.
$demo_calculator_list_and_dict
## Function Return List vs Dict
Similarly, you may return values for multiple output components either as:
1. a list of values, or
2. a dictionary keyed by the component
Let's first see an example of (1), where we set the values of two output components by returning two values:
```python
with gr.Blocks() as demo:
food_box = gr.Number(value=10, label="Food Count")
status_box = gr.Textbox()
def eat(food):
if food > 0:
return food - 1, "full"
else:
return 0, "hungry"
gr.Button("EAT").click(
fn=eat,
inputs=food_box,
outputs=[food_box, status_box]
)
```
Above, each return statement returns two values corresponding to `food_box` and `status_box`, respectively.
Instead of returning a list of values corresponding to each output component in order, you can also return a dictionary, with the key corresponding to the output component and the value as the new value. This also allows you to skip updating some output components.
```python
with gr.Blocks() as demo:
food_box = gr.Number(value=10, label="Food Count")
status_box = gr.Textbox()
def eat(food):
if food > 0:
return {food_box: food - 1, status_box: "full"}
else:
return {status_box: "hungry"}
gr.Button("EAT").click(
fn=eat,
inputs=food_box,
outputs=[food_box, status_box]
)
```
Notice how when there is no food, we only update the `status_box` element. We skipped updating the `food_box` component.
Dictionary returns are helpful when an event listener affects many components on return, or conditionally affects outputs and not others.
Keep in mind that with dictionary returns, we still need to specify the possible outputs in the event listener.
## Updating Component Configurations
The return value of an event listener function is usually the updated value of the corresponding output Component. Sometimes we want to update the configuration of the Component as well, such as the visibility. In this case, we return a new Component, setting the properties we want to change.
$code_blocks_essay_simple
$demo_blocks_essay_simple
See how we can configure the Textbox itself through a new `gr.Textbox()` method. The `value=` argument can still be used to update the value along with Component configuration. Any arguments we do not set will use their previous values.
## Examples
Just like with `gr.Interface`, you can also add examples for your functions when you are working with `gr.Blocks`. In this case, instantiate a `gr.Examples` similar to how you would instantiate any other component. The constructor of `gr.Examples` takes two required arguments:
* `examples`: a nested list of examples, in which the outer list consists of examples and each inner list consists of an input corresponding to each input component
* `inputs`: the component or list of components that should be populated when the examples are clicked
You can also set `cache_examples=True` similar to `gr.Interface`, in which case two additional arguments must be provided:
* `outputs`: the component or list of components corresponding to the output of the examples
* `fn`: the function to run to generate the outputs corresponding to the examples
Here's an example showing how to use `gr.Examples` in a `gr.Blocks` app:
$code_calculator_blocks
**Note**: In Gradio 4.0 or later, when you click on examples, not only does the value of the input component update to the example value, but the component's configuration also reverts to the properties with which you constructed the component. This ensures that the examples are compatible with the component even if its configuration has been changed.
## Running Events Consecutively
You can also run events consecutively by using the `then` method of an event listener. This will run an event after the previous event has finished running. This is useful for running events that update components in multiple steps.
For example, in the chatbot example below, we first update the chatbot with the user message immediately, and then update the chatbot with the computer response after a simulated delay.
$code_chatbot_consecutive
$demo_chatbot_consecutive
The `.then()` method of an event listener executes the subsequent event regardless of whether the previous event raised any errors. If you'd like to only run subsequent events if the previous event executed successfully, use the `.success()` method, which takes the same arguments as `.then()`.
## Running Events Continuously
You can run events on a fixed schedule using `gr.Timer()` object. This will run the event when the timer's `tick` event fires. See the code below:
```python
with gr.Blocks as demo:
timer = gr.Timer(5)
textbox = gr.Textbox()
textbox2 = gr.Textbox()
timer.tick(set_textbox_fn, textbox, textbox2)
```
This can also be used directly with a Component's `every=` parameter as such:
```python
with gr.Blocks as demo:
timer = gr.Timer(5)
textbox = gr.Textbox()
textbox2 = gr.Textbox(set_textbox_fn, inputs=[textbox], every=timer)
```
Here is an example of a demo that print the current timestamp, and also prints random numbers regularly!
$code_timer
$demo_timer
## Gathering Event Data
You can gather specific data about an event by adding the associated event data class as a type hint to an argument in the event listener function.
For example, event data for `.select()` can be type hinted by a `gradio.SelectData` argument. This event is triggered when a user selects some part of the triggering component, and the event data includes information about what the user specifically selected. If a user selected a specific word in a `Textbox`, a specific image in a `Gallery`, or a specific cell in a `DataFrame`, the event data argument would contain information about the specific selection.
In the 2 player tic-tac-toe demo below, a user can select a cell in the `DataFrame` to make a move. The event data argument contains information about the specific cell that was selected. We can first check to see if the cell is empty, and then update the cell with the user's move.
$code_tictactoe
$demo_tictactoe
## Binding Multiple Triggers to a Function
Often times, you may want to bind multiple triggers to the same function. For example, you may want to allow a user to click a submit button, or press enter to submit a form. You can do this using the `gr.on` method and passing a list of triggers to the `trigger`.
$code_on_listener_basic
$demo_on_listener_basic
You can use decorator syntax as well:
$code_on_listener_decorator
You can use `gr.on` to create "live" events by binding to the `change` event of components that implement it. If you do not specify any triggers, the function will automatically bind to all `change` event of all input components that include a `change` event (for example `gr.Textbox` has a `change` event whereas `gr.Button` does not).
$code_on_listener_live
$demo_on_listener_live
You can follow `gr.on` with `.then`, just like any regular event listener. This handy method should save you from having to write a lot of repetitive code!
## Binding a Component Value Directly to a Function of Other Components
If you want to set a Component's value to always be a function of the value of other Components, you can use the following shorthand:
```python
with gr.Blocks() as demo:
num1 = gr.Number()
num2 = gr.Number()
product = gr.Number(lambda a, b: a * b, inputs=[num1, num2])
```
This functionally the same as:
```python
with gr.Blocks() as demo:
num1 = gr.Number()
num2 = gr.Number()
product = gr.Number()
gr.on(
[num1.change, num2.change, demo.load],
lambda a, b: a * b,
inputs=[num1, num2],
outputs=product
)
```
|
C:\Gradio Guides\4 Building with Blocks\02_controlling-layout.md |
# Controlling Layout
By default, Components in Blocks are arranged vertically. Let's take a look at how we can rearrange Components. Under the hood, this layout structure uses the [flexbox model of web development](https://developer.mozilla.org/en-US/docs/Web/CSS/CSS_Flexible_Box_Layout/Basic_Concepts_of_Flexbox).
## Rows
Elements within a `with gr.Row` clause will all be displayed horizontally. For example, to display two Buttons side by side:
```python
with gr.Blocks() as demo:
with gr.Row():
btn1 = gr.Button("Button 1")
btn2 = gr.Button("Button 2")
```
To make every element in a Row have the same height, use the `equal_height` argument of the `style` method.
```python
with gr.Blocks() as demo:
with gr.Row(equal_height=True):
textbox = gr.Textbox()
btn2 = gr.Button("Button 2")
```
The widths of elements in a Row can be controlled via a combination of `scale` and `min_width` arguments that are present in every Component.
- `scale` is an integer that defines how an element will take up space in a Row. If scale is set to `0`, the element will not expand to take up space. If scale is set to `1` or greater, the element will expand. Multiple elements in a row will expand proportional to their scale. Below, `btn2` will expand twice as much as `btn1`, while `btn0` will not expand at all:
```python
with gr.Blocks() as demo:
with gr.Row():
btn0 = gr.Button("Button 0", scale=0)
btn1 = gr.Button("Button 1", scale=1)
btn2 = gr.Button("Button 2", scale=2)
```
- `min_width` will set the minimum width the element will take. The Row will wrap if there isn't sufficient space to satisfy all `min_width` values.
Learn more about Rows in the [docs](https://gradio.app/docs/row).
## Columns and Nesting
Components within a Column will be placed vertically atop each other. Since the vertical layout is the default layout for Blocks apps anyway, to be useful, Columns are usually nested within Rows. For example:
$code_rows_and_columns
$demo_rows_and_columns
See how the first column has two Textboxes arranged vertically. The second column has an Image and Button arranged vertically. Notice how the relative widths of the two columns is set by the `scale` parameter. The column with twice the `scale` value takes up twice the width.
Learn more about Columns in the [docs](https://gradio.app/docs/column).
# Dimensions
You can control the height and width of various components, where the parameters are available. These parameters accept either a number (interpreted as pixels) or a string. Using a string allows the direct application of any CSS unit to the encapsulating Block element, catering to more specific design requirements. When omitted, Gradio uses default dimensions suited for most use cases.
Below is an example illustrating the use of viewport width (vw):
```python
import gradio as gr
with gr.Blocks() as demo:
im = gr.ImageEditor(
width="50vw",
)
demo.launch()
```
When using percentage values for dimensions, you may want to define a parent component with an absolute unit (e.g. `px` or `vw`). This approach ensures that child components with relative dimensions are sized appropriately:
```python
import gradio as gr
css = """
.container {
height: 100vh;
}
"""
with gr.Blocks(css=css) as demo:
with gr.Column(elem_classes=["container"]):
name = gr.Chatbot(value=[["1", "2"]], height="70%")
demo.launch()
```
In this example, the Column layout component is given a height of 100% of the viewport height (100vh), and the Chatbot component inside it takes up 70% of the Column's height.
You can apply any valid CSS unit for these parameters. For a comprehensive list of CSS units, refer to [this guide](https://www.w3schools.com/cssref/css_units.php). We recommend you always consider responsiveness and test your interfaces on various screen sizes to ensure a consistent user experience.
## Tabs and Accordions
You can also create Tabs using the `with gr.Tab('tab_name'):` clause. Any component created inside of a `with gr.Tab('tab_name'):` context appears in that tab. Consecutive Tab clauses are grouped together so that a single tab can be selected at one time, and only the components within that Tab's context are shown.
For example:
$code_blocks_flipper
$demo_blocks_flipper
Also note the `gr.Accordion('label')` in this example. The Accordion is a layout that can be toggled open or closed. Like `Tabs`, it is a layout element that can selectively hide or show content. Any components that are defined inside of a `with gr.Accordion('label'):` will be hidden or shown when the accordion's toggle icon is clicked.
Learn more about [Tabs](https://gradio.app/docs/tab) and [Accordions](https://gradio.app/docs/accordion) in the docs.
## Visibility
Both Components and Layout elements have a `visible` argument that can set initially and also updated. Setting `gr.Column(visible=...)` on a Column can be used to show or hide a set of Components.
$code_blocks_form
$demo_blocks_form
## Variable Number of Outputs
By adjusting the visibility of components in a dynamic way, it is possible to create
demos with Gradio that support a _variable numbers of outputs_. Here's a very simple example
where the number of output textboxes is controlled by an input slider:
$code_variable_outputs
$demo_variable_outputs
## Defining and Rendering Components Separately
In some cases, you might want to define components before you actually render them in your UI. For instance, you might want to show an examples section using `gr.Examples` above the corresponding `gr.Textbox` input. Since `gr.Examples` requires as a parameter the input component object, you will need to first define the input component, but then render it later, after you have defined the `gr.Examples` object.
The solution to this is to define the `gr.Textbox` outside of the `gr.Blocks()` scope and use the component's `.render()` method wherever you'd like it placed in the UI.
Here's a full code example:
```python
input_textbox = gr.Textbox()
with gr.Blocks() as demo:
gr.Examples(["hello", "bonjour", "merhaba"], input_textbox)
input_textbox.render()
```
|
C:\Gradio Guides\4 Building with Blocks\03_state-in-blocks.md |
# State in Blocks
We covered [State in Interfaces](https://gradio.app/interface-state), this guide takes a look at state in Blocks, which works mostly the same.
## Global State
Global state in Blocks works the same as in Interface. Any variable created outside a function call is a reference shared between all users.
## Session State
Gradio supports session **state**, where data persists across multiple submits within a page session, in Blocks apps as well. To reiterate, session data is _not_ shared between different users of your model. To store data in a session state, you need to do three things:
1. Create a `gr.State()` object. If there is a default value to this stateful object, pass that into the constructor.
2. In the event listener, put the `State` object as an input and output.
3. In the event listener function, add the variable to the input parameters and the return value.
Let's take a look at a game of hangman.
$code_hangman
$demo_hangman
Let's see how we do each of the 3 steps listed above in this game:
1. We store the used letters in `used_letters_var`. In the constructor of `State`, we set the initial value of this to `[]`, an empty list.
2. In `btn.click()`, we have a reference to `used_letters_var` in both the inputs and outputs.
3. In `guess_letter`, we pass the value of this `State` to `used_letters`, and then return an updated value of this `State` in the return statement.
With more complex apps, you will likely have many State variables storing session state in a single Blocks app.
Learn more about `State` in the [docs](https://gradio.app/docs/state).
|
C:\Gradio Guides\4 Building with Blocks\04_dynamic-apps-with-render-decorator.md |
# Dynamic Apps with the Render Decorator
The components and event listeners you define in a Blocks so far have been fixed - once the demo was launched, new components and listeners could not be added, and existing one could not be removed.
The `@gr.render` decorator introduces the ability to dynamically change this. Let's take a look.
## Dynamic Number of Components
In the example below, we will create a variable number of Textboxes. When the user edits the input Textbox, we create a Textbox for each letter in the input. Try it out below:
$code_render_split_simple
$demo_render_split_simple
See how we can now create a variable number of Textboxes using our custom logic - in this case, a simple `for` loop. The `@gr.render` decorator enables this with the following steps:
1. Create a function and attach the @gr.render decorator to it.
2. Add the input components to the `inputs=` argument of @gr.render, and create a corresponding argument in your function for each component. This function will automatically re-run on any change to a component.
3. Add all components inside the function that you want to render based on the inputs.
Now whenever the inputs change, the function re-runs, and replaces the components created from the previous function run with the latest run. Pretty straightforward! Let's add a little more complexity to this app:
$code_render_split
$demo_render_split
By default, `@gr.render` re-runs are triggered by the `.load` listener to the app and the `.change` listener to any input component provided. We can override this by explicitly setting the triggers in the decorator, as we have in this app to only trigger on `input_text.submit` instead.
If you are setting custom triggers, and you also want an automatic render at the start of the app, make sure to add `demo.load` to your list of triggers.
## Dynamic Event Listeners
If you're creating components, you probably want to attach event listeners to them as well. Let's take a look at an example that takes in a variable number of Textbox as input, and merges all the text into a single box.
$code_render_merge_simple
$demo_render_merge_simple
Let's take a look at what's happening here:
1. The state variable `text_count` is keeping track of the number of Textboxes to create. By clicking on the Add button, we increase `text_count` which triggers the render decorator.
2. Note that in every single Textbox we create in the render function, we explicitly set a `key=` argument. This key allows us to preserve the value of this Component between re-renders. If you type in a value in a textbox, and then click the Add button, all the Textboxes re-render, but their values aren't cleared because the `key=` maintains the the value of a Component across a render.
3. We've stored the Textboxes created in a list, and provide this list as input to the merge button event listener. Note that **all event listeners that use Components created inside a render function must also be defined inside that render function**. The event listener can still reference Components outside the render function, as we do here by referencing `merge_btn` and `output` which are both defined outside the render function.
Just as with Components, whenever a function re-renders, the event listeners created from the previous render are cleared and the new event listeners from the latest run are attached.
This allows us to create highly customizable and complex interactions!
## Putting it Together
Let's look at two examples that use all the features above. First, try out the to-do list app below:
$code_todo_list
$demo_todo_list
Note that almost the entire app is inside a single `gr.render` that reacts to the tasks `gr.State` variable. This variable is a nested list, which presents some complexity. If you design a `gr.render` to react to a list or dict structure, ensure you do the following:
1. Any event listener that modifies a state variable in a manner that should trigger a re-render must set the state variable as an output. This lets Gradio know to check if the variable has changed behind the scenes.
2. In a `gr.render`, if a variable in a loop is used inside an event listener function, that variable should be "frozen" via setting it to itself as a default argument in the function header. See how we have `task=task` in both `mark_done` and `delete`. This freezes the variable to its "loop-time" value.
Let's take a look at one last example that uses everything we learned. Below is an audio mixer. Provide multiple audio tracks and mix them together.
$code_audio_mixer
$demo_audio_mixer
Two things to not in this app:
1. Here we provide `key=` to all the components! We need to do this so that if we add another track after setting the values for an existing track, our input values to the existing track do not get reset on re-render.
2. When there are lots of components of different types and arbitrary counts passed to an event listener, it is easier to use the set and dictionary notation for inputs rather than list notation. Above, we make one large set of all the input `gr.Audio` and `gr.Slider` components when we pass the inputs to the `merge` function. In the function body we query the component values as a dict.
The `gr.render` expands gradio capabilities extensively - see what you can make out of it!
|
C:\Gradio Guides\4 Building with Blocks\05_custom-CSS-and-JS.md |
# Customizing your demo with CSS and Javascript
Gradio allows you to customize your demo in several ways. You can customize the layout of your demo, add custom HTML, and add custom theming as well. This tutorial will go beyond that and walk you through how to add custom CSS and JavaScript code to your demo in order to add custom styling, animations, custom UI functionality, analytics, and more.
## Adding custom CSS to your demo
Gradio themes are the easiest way to customize the look and feel of your app. You can choose from a variety of themes, or create your own. To do so, pass the `theme=` kwarg to the `Blocks` constructor. For example:
```python
with gr.Blocks(theme=gr.themes.Glass()):
...
```
Gradio comes with a set of prebuilt themes which you can load from `gr.themes.*`. You can extend these themes or create your own themes from scratch - see the [Theming guide](/guides/theming-guide) for more details.
For additional styling ability, you can pass any CSS to your app using the `css=` kwarg. You can either the filepath to a CSS file, or a string of CSS code.
**Warning**: The use of query selectors in custom JS and CSS is _not_ guaranteed to work across Gradio versions as the Gradio HTML DOM may change. We recommend using query selectors sparingly.
The base class for the Gradio app is `gradio-container`, so here's an example that changes the background color of the Gradio app:
```python
with gr.Blocks(css=".gradio-container {background-color: red}") as demo:
...
```
If you'd like to reference external files in your css, preface the file path (which can be a relative or absolute path) with `"file="`, for example:
```python
with gr.Blocks(css=".gradio-container {background: url('file=clouds.jpg')}") as demo:
...
```
Note: By default, files in the host machine are not accessible to users running the Gradio app. As a result, you should make sure that any referenced files (such as `clouds.jpg` here) are either URLs or allowed via the `allow_list` parameter in `launch()`. Read more in our [section on Security and File Access](/guides/sharing-your-app#security-and-file-access).
## The `elem_id` and `elem_classes` Arguments
You can `elem_id` to add an HTML element `id` to any component, and `elem_classes` to add a class or list of classes. This will allow you to select elements more easily with CSS. This approach is also more likely to be stable across Gradio versions as built-in class names or ids may change (however, as mentioned in the warning above, we cannot guarantee complete compatibility between Gradio versions if you use custom CSS as the DOM elements may themselves change).
```python
css = """
#warning {background-color: #FFCCCB}
.feedback textarea {font-size: 24px !important}
"""
with gr.Blocks(css=css) as demo:
box1 = gr.Textbox(value="Good Job", elem_classes="feedback")
box2 = gr.Textbox(value="Failure", elem_id="warning", elem_classes="feedback")
```
The CSS `#warning` ruleset will only target the second Textbox, while the `.feedback` ruleset will target both. Note that when targeting classes, you might need to put the `!important` selector to override the default Gradio styles.
## Adding custom JavaScript to your demo
There are 3 ways to add javascript code to your Gradio demo:
1. You can add JavaScript code as a string or as a filepath to the `js` parameter of the `Blocks` or `Interface` initializer. This will run the JavaScript code when the demo is first loaded.
Below is an example of adding custom js to show an animated welcome message when the demo first loads.
$code_blocks_js_load
$demo_blocks_js_load
Note: You can also supply your custom js code as a file path. For example, if you have a file called `custom.js` in the same directory as your Python script, you can add it to your demo like so: `with gr.Blocks(js="custom.js") as demo:`. Same goes for `Interface` (ex: `gr.Interface(..., js="custom.js")`).
2. When using `Blocks` and event listeners, events have a `js` argument that can take a JavaScript function as a string and treat it just like a Python event listener function. You can pass both a JavaScript function and a Python function (in which case the JavaScript function is run first) or only Javascript (and set the Python `fn` to `None`). Take a look at the code below:
$code_blocks_js_methods
$demo_blocks_js_methods
3. Lastly, you can add JavaScript code to the `head` param of the `Blocks` initializer. This will add the code to the head of the HTML document. For example, you can add Google Analytics to your demo like so:
```python
head = f"""
<script async src="https://www.googletagmanager.com/gtag/js?id={google_analytics_tracking_id}"></script>
<script>
window.dataLayer = window.dataLayer || [];
function gtag(){{dataLayer.push(arguments);}}
gtag('js', new Date());
gtag('config', '{google_analytics_tracking_id}');
</script>
"""
with gr.Blocks(head=head) as demo:
...demo code...
```
The `head` parameter accepts any HTML tags you would normally insert into the `<head>` of a page. For example, you can also include `<meta>` tags to `head`.
Note that injecting custom HTML can affect browser behavior and compatibility (e.g. keyboard shortcuts). You should test your interface across different browsers and be mindful of how scripts may interact with browser defaults.
Here's an example where pressing `Shift + s` triggers the `click` event of a specific `Button` component if the browser focus is _not_ on an input component (e.g. `Textbox` component):
```python
import gradio as gr
shortcut_js = """
<script>
function shortcuts(e) {
var event = document.all ? window.event : e;
switch (e.target.tagName.toLowerCase()) {
case "input":
case "textarea":
break;
default:
if (e.key.toLowerCase() == "s" && e.shiftKey) {
document.getElementById("my_btn").click();
}
}
}
document.addEventListener('keypress', shortcuts, false);
</script>
"""
with gr.Blocks(head=shortcut_js) as demo:
action_button = gr.Button(value="Name", elem_id="my_btn")
textbox = gr.Textbox()
action_button.click(lambda : "button pressed", None, textbox)
demo.launch()
```
|
C:\Gradio Guides\4 Building with Blocks\06_using-blocks-like-functions.md |
# Using Gradio Blocks Like Functions
Tags: TRANSLATION, HUB, SPACES
**Prerequisite**: This Guide builds on the Blocks Introduction. Make sure to [read that guide first](https://gradio.app/blocks-and-event-listeners).
## Introduction
Did you know that apart from being a full-stack machine learning demo, a Gradio Blocks app is also a regular-old python function!?
This means that if you have a gradio Blocks (or Interface) app called `demo`, you can use `demo` like you would any python function.
So doing something like `output = demo("Hello", "friend")` will run the first event defined in `demo` on the inputs "Hello" and "friend" and store it
in the variable `output`.
If I put you to sleep 🥱, please bear with me! By using apps like functions, you can seamlessly compose Gradio apps.
The following section will show how.
## Treating Blocks like functions
Let's say we have the following demo that translates english text to german text.
$code_english_translator
I already went ahead and hosted it in Hugging Face spaces at [gradio/english_translator](https://huggingface.co/spaces/gradio/english_translator).
You can see the demo below as well:
$demo_english_translator
Now, let's say you have an app that generates english text, but you wanted to additionally generate german text.
You could either:
1. Copy the source code of my english-to-german translation and paste it in your app.
2. Load my english-to-german translation in your app and treat it like a normal python function.
Option 1 technically always works, but it often introduces unwanted complexity.
Option 2 lets you borrow the functionality you want without tightly coupling our apps.
All you have to do is call the `Blocks.load` class method in your source file.
After that, you can use my translation app like a regular python function!
The following code snippet and demo shows how to use `Blocks.load`.
Note that the variable `english_translator` is my english to german app, but its used in `generate_text` like a regular function.
$code_generate_english_german
$demo_generate_english_german
## How to control which function in the app to use
If the app you are loading defines more than one function, you can specify which function to use
with the `fn_index` and `api_name` parameters.
In the code for our english to german demo, you'll see the following line:
```python
translate_btn.click(translate, inputs=english, outputs=german, api_name="translate-to-german")
```
The `api_name` gives this function a unique name in our app. You can use this name to tell gradio which
function in the upstream space you want to use:
```python
english_generator(text, api_name="translate-to-german")[0]["generated_text"]
```
You can also use the `fn_index` parameter.
Imagine my app also defined an english to spanish translation function.
In order to use it in our text generation app, we would use the following code:
```python
english_generator(text, fn_index=1)[0]["generated_text"]
```
Functions in gradio spaces are zero-indexed, so since the spanish translator would be the second function in my space,
you would use index 1.
## Parting Remarks
We showed how treating a Blocks app like a regular python helps you compose functionality across different apps.
Any Blocks app can be treated like a function, but a powerful pattern is to `load` an app hosted on
[Hugging Face Spaces](https://huggingface.co/spaces) prior to treating it like a function in your own app.
You can also load models hosted on the [Hugging Face Model Hub](https://huggingface.co/models) - see the [Using Hugging Face Integrations](/using_hugging_face_integrations) guide for an example.
### Happy building! ⚒️
|
C:\Gradio Guides\5 Chatbots\01_creating-a-chatbot-fast.md |
# How to Create a Chatbot with Gradio
Tags: NLP, TEXT, CHAT
## Introduction
Chatbots are a popular application of large language models. Using `gradio`, you can easily build a demo of your chatbot model and share that with your users, or try it yourself using an intuitive chatbot UI.
This tutorial uses `gr.ChatInterface()`, which is a high-level abstraction that allows you to create your chatbot UI fast, often with a single line of code. The chatbot interface that we create will look something like this:
$demo_chatinterface_streaming_echo
We'll start with a couple of simple examples, and then show how to use `gr.ChatInterface()` with real language models from several popular APIs and libraries, including `langchain`, `openai`, and Hugging Face.
**Prerequisites**: please make sure you are using the **latest version** version of Gradio:
```bash
$ pip install --upgrade gradio
```
## Defining a chat function
When working with `gr.ChatInterface()`, the first thing you should do is define your chat function. Your chat function should take two arguments: `message` and then `history` (the arguments can be named anything, but must be in this order).
- `message`: a `str` representing the user's input.
- `history`: a `list` of `list` representing the conversations up until that point. Each inner list consists of two `str` representing a pair: `[user input, bot response]`.
Your function should return a single string response, which is the bot's response to the particular user input `message`. Your function can take into account the `history` of messages, as well as the current message.
Let's take a look at a few examples.
## Example: a chatbot that responds yes or no
Let's write a chat function that responds `Yes` or `No` randomly.
Here's our chat function:
```python
import random
def random_response(message, history):
return random.choice(["Yes", "No"])
```
Now, we can plug this into `gr.ChatInterface()` and call the `.launch()` method to create the web interface:
```python
import gradio as gr
gr.ChatInterface(random_response).launch()
```
That's it! Here's our running demo, try it out:
$demo_chatinterface_random_response
## Another example using the user's input and history
Of course, the previous example was very simplistic, it didn't even take user input or the previous history into account! Here's another simple example showing how to incorporate a user's input as well as the history.
```python
import random
import gradio as gr
def alternatingly_agree(message, history):
if len(history) % 2 == 0:
return f"Yes, I do think that '{message}'"
else:
return "I don't think so"
gr.ChatInterface(alternatingly_agree).launch()
```
## Streaming chatbots
In your chat function, you can use `yield` to generate a sequence of partial responses, each replacing the previous ones. This way, you'll end up with a streaming chatbot. It's that simple!
```python
import time
import gradio as gr
def slow_echo(message, history):
for i in range(len(message)):
time.sleep(0.3)
yield "You typed: " + message[: i+1]
gr.ChatInterface(slow_echo).launch()
```
Tip: While the response is streaming, the "Submit" button turns into a "Stop" button that can be used to stop the generator function. You can customize the appearance and behavior of the "Stop" button using the `stop_btn` parameter.
## Customizing your chatbot
If you're familiar with Gradio's `Interface` class, the `gr.ChatInterface` includes many of the same arguments that you can use to customize the look and feel of your Chatbot. For example, you can:
- add a title and description above your chatbot using `title` and `description` arguments.
- add a theme or custom css using `theme` and `css` arguments respectively.
- add `examples` and even enable `cache_examples`, which make it easier for users to try it out .
- You can change the text or disable each of the buttons that appear in the chatbot interface: `submit_btn`, `retry_btn`, `undo_btn`, `clear_btn`.
If you want to customize the `gr.Chatbot` or `gr.Textbox` that compose the `ChatInterface`, then you can pass in your own chatbot or textbox as well. Here's an example of how we can use these parameters:
```python
import gradio as gr
def yes_man(message, history):
if message.endswith("?"):
return "Yes"
else:
return "Ask me anything!"
gr.ChatInterface(
yes_man,
chatbot=gr.Chatbot(height=300),
textbox=gr.Textbox(placeholder="Ask me a yes or no question", container=False, scale=7),
title="Yes Man",
description="Ask Yes Man any question",
theme="soft",
examples=["Hello", "Am I cool?", "Are tomatoes vegetables?"],
cache_examples=True,
retry_btn=None,
undo_btn="Delete Previous",
clear_btn="Clear",
).launch()
```
In particular, if you'd like to add a "placeholder" for your chat interface, which appears before the user has started chatting, you can do so using the `placeholder` argument of `gr.Chatbot`, which accepts Markdown or HTML.
```python
gr.ChatInterface(
yes_man,
chatbot=gr.Chatbot(placeholder="<strong>Your Personal Yes-Man</strong><br>Ask Me Anything"),
...
```
The placeholder appears vertically and horizontally centered in the chatbot.
## Add Multimodal Capability to your chatbot
You may want to add multimodal capability to your chatbot. For example, you may want users to be able to easily upload images or files to your chatbot and ask questions about it. You can make your chatbot "multimodal" by passing in a single parameter (`multimodal=True`) to the `gr.ChatInterface` class.
```python
import gradio as gr
import time
def count_files(message, history):
num_files = len(message["files"])
return f"You uploaded {num_files} files"
demo = gr.ChatInterface(fn=count_files, examples=[{"text": "Hello", "files": []}], title="Echo Bot", multimodal=True)
demo.launch()
```
When `multimodal=True`, the signature of `fn` changes slightly. The first parameter of your function should accept a dictionary consisting of the submitted text and uploaded files that looks like this: `{"text": "user input", "file": ["file_path1", "file_path2", ...]}`. Similarly, any examples you provide should be in a dictionary of this form. Your function should still return a single `str` message.
Tip: If you'd like to customize the UI/UX of the textbox for your multimodal chatbot, you should pass in an instance of `gr.MultimodalTextbox` to the `textbox` argument of `ChatInterface` instead of an instance of `gr.Textbox`.
## Additional Inputs
You may want to add additional parameters to your chatbot and expose them to your users through the Chatbot UI. For example, suppose you want to add a textbox for a system prompt, or a slider that sets the number of tokens in the chatbot's response. The `ChatInterface` class supports an `additional_inputs` parameter which can be used to add additional input components.
The `additional_inputs` parameters accepts a component or a list of components. You can pass the component instances directly, or use their string shortcuts (e.g. `"textbox"` instead of `gr.Textbox()`). If you pass in component instances, and they have _not_ already been rendered, then the components will appear underneath the chatbot (and any examples) within a `gr.Accordion()`. You can set the label of this accordion using the `additional_inputs_accordion_name` parameter.
Here's a complete example:
$code_chatinterface_system_prompt
If the components you pass into the `additional_inputs` have already been rendered in a parent `gr.Blocks()`, then they will _not_ be re-rendered in the accordion. This provides flexibility in deciding where to lay out the input components. In the example below, we position the `gr.Textbox()` on top of the Chatbot UI, while keeping the slider underneath.
```python
import gradio as gr
import time
def echo(message, history, system_prompt, tokens):
response = f"System prompt: {system_prompt}\n Message: {message}."
for i in range(min(len(response), int(tokens))):
time.sleep(0.05)
yield response[: i+1]
with gr.Blocks() as demo:
system_prompt = gr.Textbox("You are helpful AI.", label="System Prompt")
slider = gr.Slider(10, 100, render=False)
gr.ChatInterface(
echo, additional_inputs=[system_prompt, slider]
)
demo.launch()
```
If you need to create something even more custom, then its best to construct the chatbot UI using the low-level `gr.Blocks()` API. We have [a dedicated guide for that here](/guides/creating-a-custom-chatbot-with-blocks).
## Using Gradio Components inside the Chatbot
The `Chatbot` component supports using many of the core Gradio components (such as `gr.Image`, `gr.Plot`, `gr.Audio`, and `gr.HTML`) inside of the chatbot. Simply return one of these components from your function to use it with `gr.ChatInterface`. Here's an example:
```py
import gradio as gr
def fake(message, history):
if message.strip():
return gr.Audio("https://github.com/gradio-app/gradio/raw/main/test/test_files/audio_sample.wav")
else:
return "Please provide the name of an artist"
gr.ChatInterface(
fake,
textbox=gr.Textbox(placeholder="Which artist's music do you want to listen to?", scale=7),
chatbot=gr.Chatbot(placeholder="Play music by any artist!"),
).launch()
```
## Using your chatbot via an API
Once you've built your Gradio chatbot and are hosting it on [Hugging Face Spaces](https://hf.space) or somewhere else, then you can query it with a simple API at the `/chat` endpoint. The endpoint just expects the user's message (and potentially additional inputs if you have set any using the `additional_inputs` parameter), and will return the response, internally keeping track of the messages sent so far.
[](https://github.com/gradio-app/gradio/assets/1778297/7b10d6db-6476-4e2e-bebd-ecda802c3b8f)
To use the endpoint, you should use either the [Gradio Python Client](/guides/getting-started-with-the-python-client) or the [Gradio JS client](/guides/getting-started-with-the-js-client).
## A `langchain` example
Now, let's actually use the `gr.ChatInterface` with some real large language models. We'll start by using `langchain` on top of `openai` to build a general-purpose streaming chatbot application in 19 lines of code. You'll need to have an OpenAI key for this example (keep reading for the free, open-source equivalent!)
```python
from langchain.chat_models import ChatOpenAI
from langchain.schema import AIMessage, HumanMessage
import openai
import gradio as gr
os.environ["OPENAI_API_KEY"] = "sk-..." # Replace with your key
llm = ChatOpenAI(temperature=1.0, model='gpt-3.5-turbo-0613')
def predict(message, history):
history_langchain_format = []
for human, ai in history:
history_langchain_format.append(HumanMessage(content=human))
history_langchain_format.append(AIMessage(content=ai))
history_langchain_format.append(HumanMessage(content=message))
gpt_response = llm(history_langchain_format)
return gpt_response.content
gr.ChatInterface(predict).launch()
```
## A streaming example using `openai`
Of course, we could also use the `openai` library directy. Here a similar example, but this time with streaming results as well:
```python
from openai import OpenAI
import gradio as gr
api_key = "sk-..." # Replace with your key
client = OpenAI(api_key=api_key)
def predict(message, history):
history_openai_format = []
for human, assistant in history:
history_openai_format.append({"role": "user", "content": human })
history_openai_format.append({"role": "assistant", "content":assistant})
history_openai_format.append({"role": "user", "content": message})
response = client.chat.completions.create(model='gpt-3.5-turbo',
messages= history_openai_format,
temperature=1.0,
stream=True)
partial_message = ""
for chunk in response:
if chunk.choices[0].delta.content is not None:
partial_message = partial_message + chunk.choices[0].delta.content
yield partial_message
gr.ChatInterface(predict).launch()
```
**Handling Concurrent Users with Threads**
The example above works if you have a single user — or if you have multiple users, since it passes the entire history of the conversation each time there is a new message from a user.
However, the `openai` library also provides higher-level abstractions that manage conversation history for you, e.g. the [Threads abstraction](https://platform.openai.com/docs/assistants/how-it-works/managing-threads-and-messages). If you use these abstractions, you will need to create a separate thread for each user session. Here's a partial example of how you can do that, by accessing the `session_hash` within your `predict()` function:
```py
import openai
import gradio as gr
client = openai.OpenAI(api_key = os.getenv("OPENAI_API_KEY"))
threads = {}
def predict(message, history, request: gr.Request):
if request.session_hash in threads:
thread = threads[request.session_hash]
else:
threads[request.session_hash] = client.beta.threads.create()
message = client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content=message)
...
gr.ChatInterface(predict).launch()
```
## Example using a local, open-source LLM with Hugging Face
Of course, in many cases you want to run a chatbot locally. Here's the equivalent example using Together's RedePajama model, from Hugging Face (this requires you to have a GPU with CUDA).
```python
import gradio as gr
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, StoppingCriteria, StoppingCriteriaList, TextIteratorStreamer
from threading import Thread
tokenizer = AutoTokenizer.from_pretrained("togethercomputer/RedPajama-INCITE-Chat-3B-v1")
model = AutoModelForCausalLM.from_pretrained("togethercomputer/RedPajama-INCITE-Chat-3B-v1", torch_dtype=torch.float16)
model = model.to('cuda:0')
class StopOnTokens(StoppingCriteria):
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor, **kwargs) -> bool:
stop_ids = [29, 0]
for stop_id in stop_ids:
if input_ids[0][-1] == stop_id:
return True
return False
def predict(message, history):
history_transformer_format = history + [[message, ""]]
stop = StopOnTokens()
messages = "".join(["".join(["\n<human>:"+item[0], "\n<bot>:"+item[1]])
for item in history_transformer_format])
model_inputs = tokenizer([messages], return_tensors="pt").to("cuda")
streamer = TextIteratorStreamer(tokenizer, timeout=10., skip_prompt=True, skip_special_tokens=True)
generate_kwargs = dict(
model_inputs,
streamer=streamer,
max_new_tokens=1024,
do_sample=True,
top_p=0.95,
top_k=1000,
temperature=1.0,
num_beams=1,
stopping_criteria=StoppingCriteriaList([stop])
)
t = Thread(target=model.generate, kwargs=generate_kwargs)
t.start()
partial_message = ""
for new_token in streamer:
if new_token != '<':
partial_message += new_token
yield partial_message
gr.ChatInterface(predict).launch()
```
With those examples, you should be all set to create your own Gradio Chatbot demos soon! For building even more custom Chatbot applications, check out [a dedicated guide](/guides/creating-a-custom-chatbot-with-blocks) using the low-level `gr.Blocks()` API.
|
C:\Gradio Guides\5 Chatbots\02_creating-a-custom-chatbot-with-blocks.md |
# How to Create a Custom Chatbot with Gradio Blocks
Tags: NLP, TEXT, CHAT
Related spaces: https://huggingface.co/spaces/gradio/chatbot_streaming, https://huggingface.co/spaces/project-baize/Baize-7B,
## Introduction
**Important Note**: if you are getting started, we recommend using the `gr.ChatInterface` to create chatbots -- its a high-level abstraction that makes it possible to create beautiful chatbot applications fast, often with a single line of code. [Read more about it here](/guides/creating-a-chatbot-fast).
This tutorial will show how to make chatbot UIs from scratch with Gradio's low-level Blocks API. This will give you full control over your Chatbot UI. You'll start by first creating a a simple chatbot to display text, a second one to stream text responses, and finally a chatbot that can handle media files as well. The chatbot interface that we create will look something like this:
$demo_chatbot_streaming
**Prerequisite**: We'll be using the `gradio.Blocks` class to build our Chatbot demo.
You can [read the Guide to Blocks first](https://gradio.app/blocks-and-event-listeners) if you are not already familiar with it. Also please make sure you are using the **latest version** version of Gradio: `pip install --upgrade gradio`.
## A Simple Chatbot Demo
Let's start with recreating the simple demo above. As you may have noticed, our bot simply randomly responds "How are you?", "I love you", or "I'm very hungry" to any input. Here's the code to create this with Gradio:
$code_chatbot_simple
There are three Gradio components here:
- A `Chatbot`, whose value stores the entire history of the conversation, as a list of response pairs between the user and bot.
- A `Textbox` where the user can type their message, and then hit enter/submit to trigger the chatbot response
- A `ClearButton` button to clear the Textbox and entire Chatbot history
We have a single function, `respond()`, which takes in the entire history of the chatbot, appends a random message, waits 1 second, and then returns the updated chat history. The `respond()` function also clears the textbox when it returns.
Of course, in practice, you would replace `respond()` with your own more complex function, which might call a pretrained model or an API, to generate a response.
$demo_chatbot_simple
## Add Streaming to your Chatbot
There are several ways we can improve the user experience of the chatbot above. First, we can stream responses so the user doesn't have to wait as long for a message to be generated. Second, we can have the user message appear immediately in the chat history, while the chatbot's response is being generated. Here's the code to achieve that:
$code_chatbot_streaming
You'll notice that when a user submits their message, we now _chain_ three event events with `.then()`:
1. The first method `user()` updates the chatbot with the user message and clears the input field. This method also makes the input field non interactive so that the user can't send another message while the chatbot is responding. Because we want this to happen instantly, we set `queue=False`, which would skip any queue had it been enabled. The chatbot's history is appended with `(user_message, None)`, the `None` signifying that the bot has not responded.
2. The second method, `bot()` updates the chatbot history with the bot's response. Instead of creating a new message, we just replace the previously-created `None` message with the bot's response. Finally, we construct the message character by character and `yield` the intermediate outputs as they are being constructed. Gradio automatically turns any function with the `yield` keyword [into a streaming output interface](/guides/key-features/#iterative-outputs).
3. The third method makes the input field interactive again so that users can send another message to the bot.
Of course, in practice, you would replace `bot()` with your own more complex function, which might call a pretrained model or an API, to generate a response.
Finally, we enable queuing by running `demo.queue()`, which is required for streaming intermediate outputs. You can try the improved chatbot by scrolling to the demo at the top of this page.
## Liking / Disliking Chat Messages
Once you've created your `gr.Chatbot`, you can add the ability for users to like or dislike messages. This can be useful if you would like users to vote on a bot's responses or flag inappropriate results.
To add this functionality to your Chatbot, simply attach a `.like()` event to your Chatbot. A chatbot that has the `.like()` event will automatically feature a thumbs-up icon and a thumbs-down icon next to every bot message.
The `.like()` method requires you to pass in a function that is called when a user clicks on these icons. In your function, you should have an argument whose type is `gr.LikeData`. Gradio will automatically supply the parameter to this argument with an object that contains information about the liked or disliked message. Here's a simplistic example of how you can have users like or dislike chat messages:
```py
import gradio as gr
def greet(history, input):
return history + [(input, "Hello, " + input)]
def vote(data: gr.LikeData):
if data.liked:
print("You upvoted this response: " + data.value["value"])
else:
print("You downvoted this response: " + data.value["value"])
with gr.Blocks() as demo:
chatbot = gr.Chatbot()
textbox = gr.Textbox()
textbox.submit(greet, [chatbot, textbox], [chatbot])
chatbot.like(vote, None, None) # Adding this line causes the like/dislike icons to appear in your chatbot
demo.launch()
```
## Adding Markdown, Images, Audio, or Videos
The `gr.Chatbot` component supports a subset of markdown including bold, italics, and code. For example, we could write a function that responds to a user's message, with a bold **That's cool!**, like this:
```py
def bot(history):
response = "**That's cool!**"
history[-1][1] = response
return history
```
In addition, it can handle media files, such as images, audio, and video. You can use the `MultimodalTextbox` component to easily upload all types of media files to your chatbot. To pass in a media file, we must pass in the file as a tuple of two strings, like this: `(filepath, alt_text)`. The `alt_text` is optional, so you can also just pass in a tuple with a single element `(filepath,)`, like this:
```python
def add_message(history, message):
for x in message["files"]:
history.append(((x["path"],), None))
if message["text"] is not None:
history.append((message["text"], None))
return history, gr.MultimodalTextbox(value=None, interactive=False, file_types=["image"])
```
Putting this together, we can create a _multimodal_ chatbot with a multimodal textbox for a user to submit text and media files. The rest of the code looks pretty much the same as before:
$code_chatbot_multimodal
$demo_chatbot_multimodal
And you're done! That's all the code you need to build an interface for your chatbot model. Finally, we'll end our Guide with some links to Chatbots that are running on Spaces so that you can get an idea of what else is possible:
- [project-baize/Baize-7B](https://huggingface.co/spaces/project-baize/Baize-7B): A stylized chatbot that allows you to stop generation as well as regenerate responses.
- [MAGAer13/mPLUG-Owl](https://huggingface.co/spaces/MAGAer13/mPLUG-Owl): A multimodal chatbot that allows you to upvote and downvote responses.
|
C:\Gradio Guides\5 Chatbots\03_creating-a-discord-bot-from-a-gradio-app.md |
# 🚀 Creating Discord Bots from Gradio Apps 🚀
Tags: NLP, TEXT, CHAT
We're excited to announce that Gradio can now automatically create a discord bot from a deployed app! 🤖
Discord is a popular communication platform that allows users to chat and interact with each other in real-time. By turning your Gradio app into a Discord bot, you can bring cutting edge AI to your discord server and give your community a whole new way to interact.
## 💻 How does it work? 💻
With `gradio_client` version `0.3.0`, any gradio `ChatInterface` app on the internet can automatically be deployed as a discord bot via the `deploy_discord` method of the `Client` class.
Technically, any gradio app that exposes an api route that takes in a single string and outputs a single string can be deployed to discord. In this guide, we will focus on `gr.ChatInterface` as those apps naturally lend themselves to discord's chat functionality.
## 🛠️ Requirements 🛠️
Make sure you have the latest `gradio_client` and `gradio` versions installed.
```bash
pip install gradio_client>=0.3.0 gradio>=3.38.0
```
Also, make sure you have a [Hugging Face account](https://huggingface.co/) and a [write access token](https://huggingface.co/docs/hub/security-tokens).
⚠️ Tip ⚠️: Make sure you login to the Hugging Face Hub by running `huggingface-cli login`. This will let you skip passing your token in all subsequent commands in this guide.
## 🏃♀️ Quickstart 🏃♀️
### Step 1: Implementing our chatbot
Let's build a very simple Chatbot using `ChatInterface` that simply repeats the user message. Write the following code into an `app.py`
```python
import gradio as gr
def slow_echo(message, history):
return message
demo = gr.ChatInterface(slow_echo).queue().launch()
```
### Step 2: Deploying our App
In order to create a discord bot for our app, it must be accessible over the internet. In this guide, we will use the `gradio deploy` command to deploy our chatbot to Hugging Face spaces from the command line. Run the following command.
```bash
gradio deploy --title echo-chatbot --app-file app.py
```
This command will ask you some questions, e.g. requested hardware, requirements, but the default values will suffice for this guide.
Note the URL of the space that was created. Mine is https://huggingface.co/spaces/freddyaboulton/echo-chatbot
### Step 3: Creating a Discord Bot
Turning our space into a discord bot is also a one-liner thanks to the `gradio deploy-discord`. Run the following command:
```bash
gradio deploy-discord --src freddyaboulton/echo-chatbot
```
❗️ Advanced ❗️: If you already have a discord bot token you can pass it to the `deploy-discord` command. Don't worry, if you don't have one yet!
```bash
gradio deploy-discord --src freddyaboulton/echo-chatbot --discord-bot-token <token>
```
Note the URL that gets printed out to the console. Mine is https://huggingface.co/spaces/freddyaboulton/echo-chatbot-gradio-discord-bot
### Step 4: Getting a Discord Bot Token
If you didn't have a discord bot token for step 3, go to the URL that got printed in the console and follow the instructions there.
Once you obtain a token, run the command again but this time pass in the token:
```bash
gradio deploy-discord --src freddyaboulton/echo-chatbot --discord-bot-token <token>
```
### Step 5: Add the bot to your server
Visit the space of your discord bot. You should see "Add this bot to your server by clicking this link:" followed by a URL. Go to that URL and add the bot to your server!
### Step 6: Use your bot!
By default the bot can be called by starting a message with `/chat`, e.g. `/chat <your prompt here>`.
⚠️ Tip ⚠️: If either of the deployed spaces goes to sleep, the bot will stop working. By default, spaces go to sleep after 48 hours of inactivity. You can upgrade the hardware of your space to prevent it from going to sleep. See this [guide](https://huggingface.co/docs/hub/spaces-gpus#using-gpu-spaces) for more information.
<img src="https://gradio-builds.s3.amazonaws.com/demo-files/discordbots/guide/echo_slash.gif">
### Using the `gradio_client.Client` Class
You can also create a discord bot from a deployed gradio app with python.
```python
import gradio_client as grc
grc.Client("freddyaboulton/echo-chatbot").deploy_discord()
```
## 🦾 Using State of The Art LLMs 🦾
We have created an organization on Hugging Face called [gradio-discord-bots](https://huggingface.co/gradio-discord-bots) containing several template spaces that explain how to deploy state of the art LLMs powered by gradio as discord bots.
The easiest way to get started is by deploying Meta's Llama 2 LLM with 70 billion parameter. Simply go to this [space](https://huggingface.co/spaces/gradio-discord-bots/Llama-2-70b-chat-hf) and follow the instructions.
The deployment can be done in one line! 🤯
```python
import gradio_client as grc
grc.Client("ysharma/Explore_llamav2_with_TGI").deploy_discord(to_id="llama2-70b-discord-bot")
```
## 🦜 Additional LLMs 🦜
In addition to Meta's 70 billion Llama 2 model, we have prepared template spaces for the following LLMs and deployment options:
- [gpt-3.5-turbo](https://huggingface.co/spaces/gradio-discord-bots/gpt-35-turbo), powered by openai. Required OpenAI key.
- [falcon-7b-instruct](https://huggingface.co/spaces/gradio-discord-bots/falcon-7b-instruct) powered by Hugging Face Inference Endpoints.
- [Llama-2-13b-chat-hf](https://huggingface.co/spaces/gradio-discord-bots/Llama-2-13b-chat-hf) powered by Hugging Face Inference Endpoints.
- [Llama-2-13b-chat-hf](https://huggingface.co/spaces/gradio-discord-bots/llama-2-13b-chat-transformers) powered by Hugging Face transformers.
To deploy any of these models to discord, simply follow the instructions in the linked space for that model.
## Deploying non-chat gradio apps to discord
As mentioned above, you don't need a `gr.ChatInterface` if you want to deploy your gradio app to discord. All that's needed is an api route that takes in a single string and outputs a single string.
The following code will deploy a space that translates english to german as a discord bot.
```python
import gradio_client as grc
client = grc.Client("freddyaboulton/english-to-german")
client.deploy_discord(api_names=['german'])
```
## Conclusion
That's it for this guide! We're really excited about this feature. Tag [@Gradio](https://twitter.com/Gradio) on twitter and show us how your discord community interacts with your discord bots.
|
C:\Gradio Guides\6 Custom Components\01_custom-components-in-five-minutes.md |
# Custom Components in 5 minutes
Gradio 4.0 introduces Custom Components -- the ability for developers to create their own custom components and use them in Gradio apps.
You can publish your components as Python packages so that other users can use them as well.
Users will be able to use all of Gradio's existing functions, such as `gr.Blocks`, `gr.Interface`, API usage, themes, etc. with Custom Components.
This guide will cover how to get started making custom components.
## Installation
You will need to have:
* Python 3.8+ (<a href="https://www.python.org/downloads/" target="_blank">install here</a>)
* pip 21.3+ (`python -m pip install --upgrade pip`)
* Node.js v16.14+ (<a href="https://nodejs.dev/en/download/package-manager/" target="_blank">install here</a>)
* npm 9+ (<a href="https://docs.npmjs.com/downloading-and-installing-node-js-and-npm/" target="_blank">install here</a>)
* Gradio 4.0+ (`pip install --upgrade gradio`)
## The Workflow
The Custom Components workflow consists of 4 steps: create, dev, build, and publish.
1. create: creates a template for you to start developing a custom component.
2. dev: launches a development server with a sample app & hot reloading allowing you to easily develop your custom component
3. build: builds a python package containing to your custom component's Python and JavaScript code -- this makes things official!
4. publish: uploads your package to [PyPi](https://pypi.org/) and/or a sample app to [HuggingFace Spaces](https://hf.co/spaces).
Each of these steps is done via the Custom Component CLI. You can invoke it with `gradio cc` or `gradio component`
Tip: Run `gradio cc --help` to get a help menu of all available commands. There are some commands that are not covered in this guide. You can also append `--help` to any command name to bring up a help page for that command, e.g. `gradio cc create --help`.
## 1. create
Bootstrap a new template by running the following in any working directory:
```bash
gradio cc create MyComponent --template SimpleTextbox
```
Instead of `MyComponent`, give your component any name.
Instead of `SimpleTextbox`, you can use any Gradio component as a template. `SimpleTextbox` is actually a special component that a stripped-down version of the `Textbox` component that makes it particularly useful when creating your first custom component.
Some other components that are good if you are starting out: `SimpleDropdown`, `SimpleImage`, or `File`.
Tip: Run `gradio cc show` to get a list of available component templates.
The `create` command will:
1. Create a directory with your component's name in lowercase with the following structure:
```directory
- backend/ <- The python code for your custom component
- frontend/ <- The javascript code for your custom component
- demo/ <- A sample app using your custom component. Modify this to develop your component!
- pyproject.toml <- Used to build the package and specify package metadata.
```
2. Install the component in development mode
Each of the directories will have the code you need to get started developing!
## 2. dev
Once you have created your new component, you can start a development server by `entering the directory` and running
```bash
gradio cc dev
```
You'll see several lines that are printed to the console.
The most important one is the one that says:
> Frontend Server (Go here): http://localhost:7861/
The port number might be different for you.
Click on that link to launch the demo app in hot reload mode.
Now, you can start making changes to the backend and frontend you'll see the results reflected live in the sample app!
We'll go through a real example in a later guide.
Tip: You don't have to run dev mode from your custom component directory. The first argument to `dev` mode is the path to the directory. By default it uses the current directory.
## 3. build
Once you are satisfied with your custom component's implementation, you can `build` it to use it outside of the development server.
From your component directory, run:
```bash
gradio cc build
```
This will create a `tar.gz` and `.whl` file in a `dist/` subdirectory.
If you or anyone installs that `.whl` file (`pip install <path-to-whl>`) they will be able to use your custom component in any gradio app!
The `build` command will also generate documentation for your custom component. This takes the form of an interactive space and a static `README.md`. You can disable this by passing `--no-generate-docs`. You can read more about the documentation generator in [the dedicated guide](https://gradio.app/guides/documenting-custom-components).
## 4. publish
Right now, your package is only available on a `.whl` file on your computer.
You can share that file with the world with the `publish` command!
Simply run the following command from your component directory:
```bash
gradio cc publish
```
This will guide you through the following process:
1. Upload your distribution files to PyPi. This is optional. If you decide to upload to PyPi, you will need a PyPI username and password. You can get one [here](https://pypi.org/account/register/).
2. Upload a demo of your component to hugging face spaces. This is also optional.
Here is an example of what publishing looks like:
<video autoplay muted loop>
<source src="https://gradio-builds.s3.amazonaws.com/assets/text_with_attachments_publish.mov" type="video/mp4" />
</video>
## Conclusion
Now that you know the high-level workflow of creating custom components, you can go in depth in the next guides!
After reading the guides, check out this [collection](https://huggingface.co/collections/gradio/custom-components-65497a761c5192d981710b12) of custom components on the HuggingFace Hub so you can learn from other's code.
Tip: If you want to start off from someone else's custom component see this [guide](./frequently-asked-questions#do-i-always-need-to-start-my-component-from-scratch).
|
C:\Gradio Guides\6 Custom Components\02_key-component-concepts.md |
# Gradio Components: The Key Concepts
In this section, we discuss a few important concepts when it comes to components in Gradio.
It's important to understand these concepts when developing your own component.
Otherwise, your component may behave very different to other Gradio components!
Tip: You can skip this section if you are familiar with the internals of the Gradio library, such as each component's preprocess and postprocess methods.
## Interactive vs Static
Every component in Gradio comes in a `static` variant, and most come in an `interactive` version as well.
The `static` version is used when a component is displaying a value, and the user can **NOT** change that value by interacting with it.
The `interactive` version is used when the user is able to change the value by interacting with the Gradio UI.
Let's see some examples:
```python
import gradio as gr
with gr.Blocks() as demo:
gr.Textbox(value="Hello", interactive=True)
gr.Textbox(value="Hello", interactive=False)
demo.launch()
```
This will display two textboxes.
The only difference: you'll be able to edit the value of the Gradio component on top, and you won't be able to edit the variant on the bottom (i.e. the textbox will be disabled).
Perhaps a more interesting example is with the `Image` component:
```python
import gradio as gr
with gr.Blocks() as demo:
gr.Image(interactive=True)
gr.Image(interactive=False)
demo.launch()
```
The interactive version of the component is much more complex -- you can upload images or snap a picture from your webcam -- while the static version can only be used to display images.
Not every component has a distinct interactive version. For example, the `gr.AnnotatedImage` only appears as a static version since there's no way to interactively change the value of the annotations or the image.
### What you need to remember
* Gradio will use the interactive version (if available) of a component if that component is used as the **input** to any event; otherwise, the static version will be used.
* When you design custom components, you **must** accept the boolean interactive keyword in the constructor of your Python class. In the frontend, you **may** accept the `interactive` property, a `bool` which represents whether the component should be static or interactive. If you do not use this property in the frontend, the component will appear the same in interactive or static mode.
## The value and how it is preprocessed/postprocessed
The most important attribute of a component is its `value`.
Every component has a `value`.
The value that is typically set by the user in the frontend (if the component is interactive) or displayed to the user (if it is static).
It is also this value that is sent to the backend function when a user triggers an event, or returned by the user's function e.g. at the end of a prediction.
So this value is passed around quite a bit, but sometimes the format of the value needs to change between the frontend and backend.
Take a look at this example:
```python
import numpy as np
import gradio as gr
def sepia(input_img):
sepia_filter = np.array([
[0.393, 0.769, 0.189],
[0.349, 0.686, 0.168],
[0.272, 0.534, 0.131]
])
sepia_img = input_img.dot(sepia_filter.T)
sepia_img /= sepia_img.max()
return sepia_img
demo = gr.Interface(sepia, gr.Image(shape=(200, 200)), "image")
demo.launch()
```
This will create a Gradio app which has an `Image` component as the input and the output.
In the frontend, the Image component will actually **upload** the file to the server and send the **filepath** but this is converted to a `numpy` array before it is sent to a user's function.
Conversely, when the user returns a `numpy` array from their function, the numpy array is converted to a file so that it can be sent to the frontend and displayed by the `Image` component.
Tip: By default, the `Image` component sends numpy arrays to the python function because it is a common choice for machine learning engineers, though the Image component also supports other formats using the `type` parameter. Read the `Image` docs [here](https://www.gradio.app/docs/image) to learn more.
Each component does two conversions:
1. `preprocess`: Converts the `value` from the format sent by the frontend to the format expected by the python function. This usually involves going from a web-friendly **JSON** structure to a **python-native** data structure, like a `numpy` array or `PIL` image. The `Audio`, `Image` components are good examples of `preprocess` methods.
2. `postprocess`: Converts the value returned by the python function to the format expected by the frontend. This usually involves going from a **python-native** data-structure, like a `PIL` image to a **JSON** structure.
### What you need to remember
* Every component must implement `preprocess` and `postprocess` methods. In the rare event that no conversion needs to happen, simply return the value as-is. `Textbox` and `Number` are examples of this.
* As a component author, **YOU** control the format of the data displayed in the frontend as well as the format of the data someone using your component will receive. Think of an ergonomic data-structure a **python** developer will find intuitive, and control the conversion from a **Web-friendly JSON** data structure (and vice-versa) with `preprocess` and `postprocess.`
## The "Example Version" of a Component
Gradio apps support providing example inputs -- and these are very useful in helping users get started using your Gradio app.
In `gr.Interface`, you can provide examples using the `examples` keyword, and in `Blocks`, you can provide examples using the special `gr.Examples` component.
At the bottom of this screenshot, we show a miniature example image of a cheetah that, when clicked, will populate the same image in the input Image component:
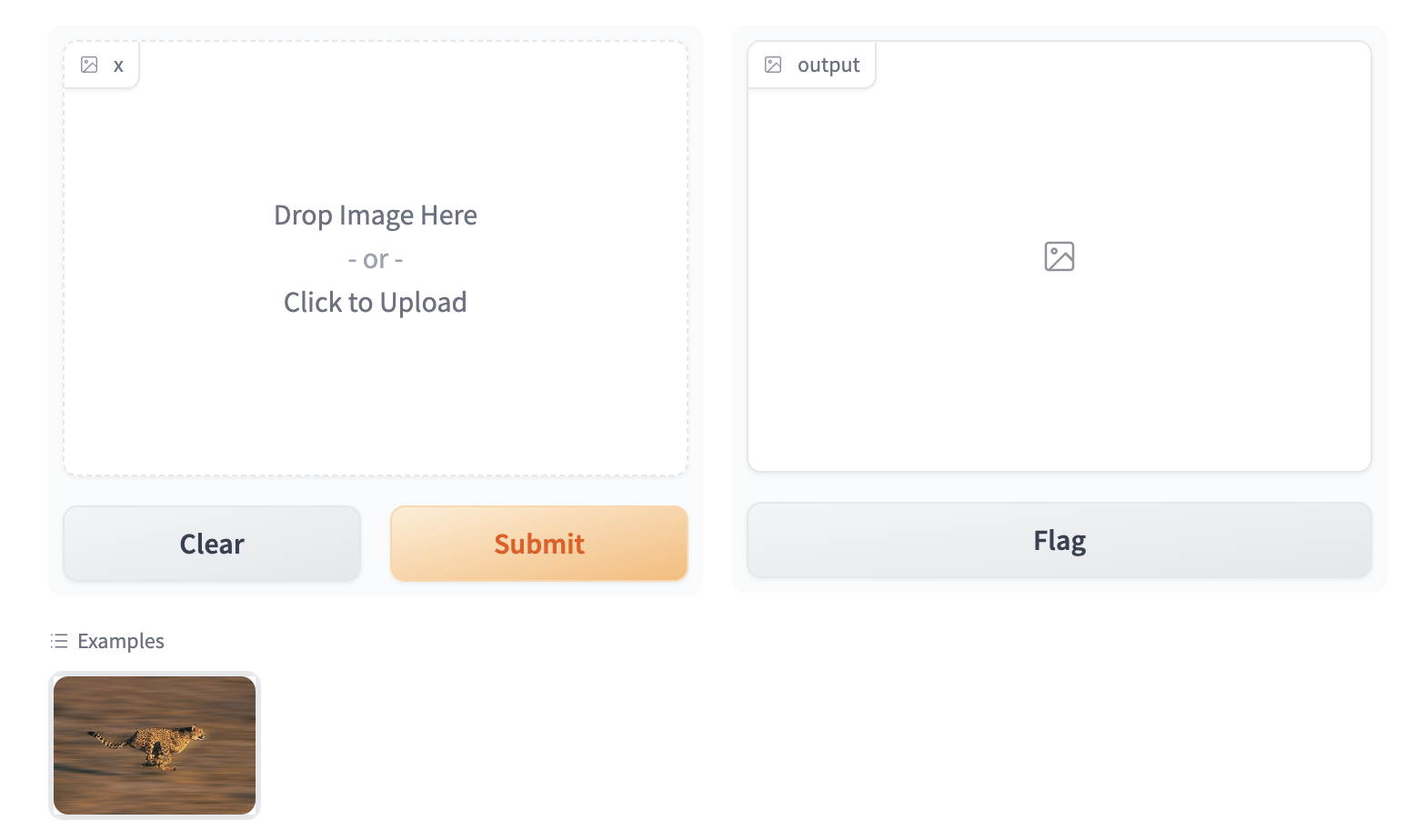
To enable the example view, you must have the following two files in the top of the `frontend` directory:
* `Example.svelte`: this corresponds to the "example version" of your component
* `Index.svelte`: this corresponds to the "regular version"
In the backend, you typically don't need to do anything. The user-provided example `value` is processed using the same `.postprocess()` method described earlier. If you'd like to do process the data differently (for example, if the `.postprocess()` method is computationally expensive), then you can write your own `.process_example()` method for your custom component, which will be used instead.
The `Example.svelte` file and `process_example()` method will be covered in greater depth in the dedicated [frontend](./frontend) and [backend](./backend) guides respectively.
### What you need to remember
* If you expect your component to be used as input, it is important to define an "Example" view.
* If you don't, Gradio will use a default one but it won't be as informative as it can be!
## Conclusion
Now that you know the most important pieces to remember about Gradio components, you can start to design and build your own! |
C:\Gradio Guides\6 Custom Components\03_configuration.md |
# Configuring Your Custom Component
The custom components workflow focuses on [convention over configuration](https://en.wikipedia.org/wiki/Convention_over_configuration) to reduce the number of decisions you as a developer need to make when developing your custom component.
That being said, you can still configure some aspects of the custom component package and directory.
This guide will cover how.
## The Package Name
By default, all custom component packages are called `gradio_<component-name>` where `component-name` is the name of the component's python class in lowercase.
As an example, let's walkthrough changing the name of a component from `gradio_mytextbox` to `supertextbox`.
1. Modify the `name` in the `pyproject.toml` file.
```bash
[project]
name = "supertextbox"
```
2. Change all occurrences of `gradio_<component-name>` in `pyproject.toml` to `<component-name>`
```bash
[tool.hatch.build]
artifacts = ["/backend/supertextbox/templates", "*.pyi"]
[tool.hatch.build.targets.wheel]
packages = ["/backend/supertextbox"]
```
3. Rename the `gradio_<component-name>` directory in `backend/` to `<component-name>`
```bash
mv backend/gradio_mytextbox backend/supertextbox
```
Tip: Remember to change the import statement in `demo/app.py`!
## Top Level Python Exports
By default, only the custom component python class is a top level export.
This means that when users type `from gradio_<component-name> import ...`, the only class that will be available is the custom component class.
To add more classes as top level exports, modify the `__all__` property in `__init__.py`
```python
from .mytextbox import MyTextbox
from .mytextbox import AdditionalClass, additional_function
__all__ = ['MyTextbox', 'AdditionalClass', 'additional_function']
```
## Python Dependencies
You can add python dependencies by modifying the `dependencies` key in `pyproject.toml`
```bash
dependencies = ["gradio", "numpy", "PIL"]
```
Tip: Remember to run `gradio cc install` when you add dependencies!
## Javascript Dependencies
You can add JavaScript dependencies by modifying the `"dependencies"` key in `frontend/package.json`
```json
"dependencies": {
"@gradio/atoms": "0.2.0-beta.4",
"@gradio/statustracker": "0.3.0-beta.6",
"@gradio/utils": "0.2.0-beta.4",
"your-npm-package": "<version>"
}
```
## Directory Structure
By default, the CLI will place the Python code in `backend` and the JavaScript code in `frontend`.
It is not recommended to change this structure since it makes it easy for a potential contributor to look at your source code and know where everything is.
However, if you did want to this is what you would have to do:
1. Place the Python code in the subdirectory of your choosing. Remember to modify the `[tool.hatch.build]` `[tool.hatch.build.targets.wheel]` in the `pyproject.toml` to match!
2. Place the JavaScript code in the subdirectory of your choosing.
2. Add the `FRONTEND_DIR` property on the component python class. It must be the relative path from the file where the class is defined to the location of the JavaScript directory.
```python
class SuperTextbox(Component):
FRONTEND_DIR = "../../frontend/"
```
The JavaScript and Python directories must be under the same common directory!
## Conclusion
Sticking to the defaults will make it easy for others to understand and contribute to your custom component.
After all, the beauty of open source is that anyone can help improve your code!
But if you ever need to deviate from the defaults, you know how! |
C:\Gradio Guides\6 Custom Components\04_backend.md |
# The Backend 🐍
This guide will cover everything you need to know to implement your custom component's backend processing.
## Which Class to Inherit From
All components inherit from one of three classes `Component`, `FormComponent`, or `BlockContext`.
You need to inherit from one so that your component behaves like all other gradio components.
When you start from a template with `gradio cc create --template`, you don't need to worry about which one to choose since the template uses the correct one.
For completeness, and in the event that you need to make your own component from scratch, we explain what each class is for.
* `FormComponent`: Use this when you want your component to be grouped together in the same `Form` layout with other `FormComponents`. The `Slider`, `Textbox`, and `Number` components are all `FormComponents`.
* `BlockContext`: Use this when you want to place other components "inside" your component. This enabled `with MyComponent() as component:` syntax.
* `Component`: Use this for all other cases.
Tip: If your component supports streaming output, inherit from the `StreamingOutput` class.
Tip: If you inherit from `BlockContext`, you also need to set the metaclass to be `ComponentMeta`. See example below.
```python
from gradio.blocks import BlockContext
from gradio.component_meta import ComponentMeta
@document()
class Row(BlockContext, metaclass=ComponentMeta):
pass
```
## The methods you need to implement
When you inherit from any of these classes, the following methods must be implemented.
Otherwise the Python interpreter will raise an error when you instantiate your component!
### `preprocess` and `postprocess`
Explained in the [Key Concepts](./key-component-concepts#the-value-and-how-it-is-preprocessed-postprocessed) guide.
They handle the conversion from the data sent by the frontend to the format expected by the python function.
```python
def preprocess(self, x: Any) -> Any:
"""
Convert from the web-friendly (typically JSON) value in the frontend to the format expected by the python function.
"""
return x
def postprocess(self, y):
"""
Convert from the data returned by the python function to the web-friendly (typically JSON) value expected by the frontend.
"""
return y
```
### `process_example`
Takes in the original Python value and returns the modified value that should be displayed in the examples preview in the app.
If not provided, the `.postprocess()` method is used instead. Let's look at the following example from the `SimpleDropdown` component.
```python
def process_example(self, input_data):
return next((c[0] for c in self.choices if c[1] == input_data), None)
```
Since `self.choices` is a list of tuples corresponding to (`display_name`, `value`), this converts the value that a user provides to the display value (or if the value is not present in `self.choices`, it is converted to `None`).
### `api_info`
A JSON-schema representation of the value that the `preprocess` expects.
This powers api usage via the gradio clients.
You do **not** need to implement this yourself if you components specifies a `data_model`.
The `data_model` in the following section.
```python
def api_info(self) -> dict[str, list[str]]:
"""
A JSON-schema representation of the value that the `preprocess` expects and the `postprocess` returns.
"""
pass
```
### `example_payload`
An example payload for your component, e.g. something that can be passed into the `.preprocess()` method
of your component. The example input is displayed in the `View API` page of a Gradio app that uses your custom component.
Must be JSON-serializable. If your component expects a file, it is best to use a publicly accessible URL.
```python
def example_payload(self) -> Any:
"""
The example inputs for this component for API usage. Must be JSON-serializable.
"""
pass
```
### `example_value`
An example value for your component, e.g. something that can be passed into the `.postprocess()` method
of your component. This is used as the example value in the default app that is created in custom component development.
```python
def example_payload(self) -> Any:
"""
The example inputs for this component for API usage. Must be JSON-serializable.
"""
pass
```
### `flag`
Write the component's value to a format that can be stored in the `csv` or `json` file used for flagging.
You do **not** need to implement this yourself if you components specifies a `data_model`.
The `data_model` in the following section.
```python
def flag(self, x: Any | GradioDataModel, flag_dir: str | Path = "") -> str:
pass
```
### `read_from_flag`
Convert from the format stored in the `csv` or `json` file used for flagging to the component's python `value`.
You do **not** need to implement this yourself if you components specifies a `data_model`.
The `data_model` in the following section.
```python
def read_from_flag(
self,
x: Any,
) -> GradioDataModel | Any:
"""
Convert the data from the csv or jsonl file into the component state.
"""
return x
```
## The `data_model`
The `data_model` is how you define the expected data format your component's value will be stored in the frontend.
It specifies the data format your `preprocess` method expects and the format the `postprocess` method returns.
It is not necessary to define a `data_model` for your component but it greatly simplifies the process of creating a custom component.
If you define a custom component you only need to implement four methods - `preprocess`, `postprocess`, `example_payload`, and `example_value`!
You define a `data_model` by defining a [pydantic model](https://docs.pydantic.dev/latest/concepts/models/#basic-model-usage) that inherits from either `GradioModel` or `GradioRootModel`.
This is best explained with an example. Let's look at the core `Video` component, which stores the video data as a JSON object with two keys `video` and `subtitles` which point to separate files.
```python
from gradio.data_classes import FileData, GradioModel
class VideoData(GradioModel):
video: FileData
subtitles: Optional[FileData] = None
class Video(Component):
data_model = VideoData
```
By adding these four lines of code, your component automatically implements the methods needed for API usage, the flagging methods, and example caching methods!
It also has the added benefit of self-documenting your code.
Anyone who reads your component code will know exactly the data it expects.
Tip: If your component expects files to be uploaded from the frontend, your must use the `FileData` model! It will be explained in the following section.
Tip: Read the pydantic docs [here](https://docs.pydantic.dev/latest/concepts/models/#basic-model-usage).
The difference between a `GradioModel` and a `GradioRootModel` is that the `RootModel` will not serialize the data to a dictionary.
For example, the `Names` model will serialize the data to `{'names': ['freddy', 'pete']}` whereas the `NamesRoot` model will serialize it to `['freddy', 'pete']`.
```python
from typing import List
class Names(GradioModel):
names: List[str]
class NamesRoot(GradioRootModel):
root: List[str]
```
Even if your component does not expect a "complex" JSON data structure it can be beneficial to define a `GradioRootModel` so that you don't have to worry about implementing the API and flagging methods.
Tip: Use classes from the Python typing library to type your models. e.g. `List` instead of `list`.
## Handling Files
If your component expects uploaded files as input, or returns saved files to the frontend, you **MUST** use the `FileData` to type the files in your `data_model`.
When you use the `FileData`:
* Gradio knows that it should allow serving this file to the frontend. Gradio automatically blocks requests to serve arbitrary files in the computer running the server.
* Gradio will automatically place the file in a cache so that duplicate copies of the file don't get saved.
* The client libraries will automatically know that they should upload input files prior to sending the request. They will also automatically download files.
If you do not use the `FileData`, your component will not work as expected!
## Adding Event Triggers To Your Component
The events triggers for your component are defined in the `EVENTS` class attribute.
This is a list that contains the string names of the events.
Adding an event to this list will automatically add a method with that same name to your component!
You can import the `Events` enum from `gradio.events` to access commonly used events in the core gradio components.
For example, the following code will define `text_submit`, `file_upload` and `change` methods in the `MyComponent` class.
```python
from gradio.events import Events
from gradio.components import FormComponent
class MyComponent(FormComponent):
EVENTS = [
"text_submit",
"file_upload",
Events.change
]
```
Tip: Don't forget to also handle these events in the JavaScript code!
## Conclusion
|
C:\Gradio Guides\6 Custom Components\05_frontend.md |
# The Frontend 🌐⭐️
This guide will cover everything you need to know to implement your custom component's frontend.
Tip: Gradio components use Svelte. Writing Svelte is fun! If you're not familiar with it, we recommend checking out their interactive [guide](https://learn.svelte.dev/tutorial/welcome-to-svelte).
## The directory structure
The frontend code should have, at minimum, three files:
* `Index.svelte`: This is the main export and where your component's layout and logic should live.
* `Example.svelte`: This is where the example view of the component is defined.
Feel free to add additional files and subdirectories.
If you want to export any additional modules, remember to modify the `package.json` file
```json
"exports": {
".": "./Index.svelte",
"./example": "./Example.svelte",
"./package.json": "./package.json"
},
```
## The Index.svelte file
Your component should expose the following props that will be passed down from the parent Gradio application.
```typescript
import type { LoadingStatus } from "@gradio/statustracker";
import type { Gradio } from "@gradio/utils";
export let gradio: Gradio<{
event_1: never;
event_2: never;
}>;
export let elem_id = "";
export let elem_classes: string[] = [];
export let scale: number | null = null;
export let min_width: number | undefined = undefined;
export let loading_status: LoadingStatus | undefined = undefined;
export let mode: "static" | "interactive";
```
* `elem_id` and `elem_classes` allow Gradio app developers to target your component with custom CSS and JavaScript from the Python `Blocks` class.
* `scale` and `min_width` allow Gradio app developers to control how much space your component takes up in the UI.
* `loading_status` is used to display a loading status over the component when it is the output of an event.
* `mode` is how the parent Gradio app tells your component whether the `interactive` or `static` version should be displayed.
* `gradio`: The `gradio` object is created by the parent Gradio app. It stores some application-level configuration that will be useful in your component, like internationalization. You must use it to dispatch events from your component.
A minimal `Index.svelte` file would look like:
```svelte
<script lang="ts">
import type { LoadingStatus } from "@gradio/statustracker";
import { Block } from "@gradio/atoms";
import { StatusTracker } from "@gradio/statustracker";
import type { Gradio } from "@gradio/utils";
export let gradio: Gradio<{
event_1: never;
event_2: never;
}>;
export let value = "";
export let elem_id = "";
export let elem_classes: string[] = [];
export let scale: number | null = null;
export let min_width: number | undefined = undefined;
export let loading_status: LoadingStatus | undefined = undefined;
export let mode: "static" | "interactive";
</script>
<Block
visible={true}
{elem_id}
{elem_classes}
{scale}
{min_width}
allow_overflow={false}
padding={true}
>
{#if loading_status}
<StatusTracker
autoscroll={gradio.autoscroll}
i18n={gradio.i18n}
{...loading_status}
/>
{/if}
<p>{value}</p>
</Block>
```
## The Example.svelte file
The `Example.svelte` file should expose the following props:
```typescript
export let value: string;
export let type: "gallery" | "table";
export let selected = false;
export let index: number;
```
* `value`: The example value that should be displayed.
* `type`: This is a variable that can be either `"gallery"` or `"table"` depending on how the examples are displayed. The `"gallery"` form is used when the examples correspond to a single input component, while the `"table"` form is used when a user has multiple input components, and the examples need to populate all of them.
* `selected`: You can also adjust how the examples are displayed if a user "selects" a particular example by using the selected variable.
* `index`: The current index of the selected value.
* Any additional props your "non-example" component takes!
This is the `Example.svelte` file for the code `Radio` component:
```svelte
<script lang="ts">
export let value: string;
export let type: "gallery" | "table";
export let selected = false;
</script>
<div
class:table={type === "table"}
class:gallery={type === "gallery"}
class:selected
>
{value}
</div>
<style>
.gallery {
padding: var(--size-1) var(--size-2);
}
</style>
```
## Handling Files
If your component deals with files, these files **should** be uploaded to the backend server.
The `@gradio/client` npm package provides the `upload` and `prepare_files` utility functions to help you do this.
The `prepare_files` function will convert the browser's `File` datatype to gradio's internal `FileData` type.
You should use the `FileData` data in your component to keep track of uploaded files.
The `upload` function will upload an array of `FileData` values to the server.
Here's an example of loading files from an `<input>` element when its value changes.
```svelte
<script lang="ts">
import { upload, prepare_files, type FileData } from "@gradio/client";
export let root;
export let value;
let uploaded_files;
async function handle_upload(file_data: FileData[]): Promise<void> {
await tick();
uploaded_files = await upload(file_data, root);
}
async function loadFiles(files: FileList): Promise<void> {
let _files: File[] = Array.from(files);
if (!files.length) {
return;
}
if (file_count === "single") {
_files = [files[0]];
}
let file_data = await prepare_files(_files);
await handle_upload(file_data);
}
async function loadFilesFromUpload(e: Event): Promise<void> {
const target = e.target;
if (!target.files) return;
await loadFiles(target.files);
}
</script>
<input
type="file"
on:change={loadFilesFromUpload}
multiple={true}
/>
```
The component exposes a prop named `root`.
This is passed down by the parent gradio app and it represents the base url that the files will be uploaded to and fetched from.
For WASM support, you should get the upload function from the `Context` and pass that as the third parameter of the `upload` function.
```typescript
<script lang="ts">
import { getContext } from "svelte";
const upload_fn = getContext<typeof upload_files>("upload_files");
async function handle_upload(file_data: FileData[]): Promise<void> {
await tick();
await upload(file_data, root, upload_fn);
}
</script>
```
## Leveraging Existing Gradio Components
Most of Gradio's frontend components are published on [npm](https://www.npmjs.com/), the javascript package repository.
This means that you can use them to save yourself time while incorporating common patterns in your component, like uploading files.
For example, the `@gradio/upload` package has `Upload` and `ModifyUpload` components for properly uploading files to the Gradio server.
Here is how you can use them to create a user interface to upload and display PDF files.
```svelte
<script>
import { type FileData, Upload, ModifyUpload } from "@gradio/upload";
import { Empty, UploadText, BlockLabel } from "@gradio/atoms";
</script>
<BlockLabel Icon={File} label={label || "PDF"} />
{#if value === null && interactive}
<Upload
filetype="application/pdf"
on:load={handle_load}
{root}
>
<UploadText type="file" i18n={gradio.i18n} />
</Upload>
{:else if value !== null}
{#if interactive}
<ModifyUpload i18n={gradio.i18n} on:clear={handle_clear}/>
{/if}
<iframe title={value.orig_name || "PDF"} src={value.data} height="{height}px" width="100%"></iframe>
{:else}
<Empty size="large"> <File/> </Empty>
{/if}
```
You can also combine existing Gradio components to create entirely unique experiences.
Like rendering a gallery of chatbot conversations.
The possibilities are endless, please read the documentation on our javascript packages [here](https://gradio.app/main/docs/js).
We'll be adding more packages and documentation over the coming weeks!
## Matching Gradio Core's Design System
You can explore our component library via Storybook. You'll be able to interact with our components and see them in their various states.
For those interested in design customization, we provide the CSS variables consisting of our color palette, radii, spacing, and the icons we use - so you can easily match up your custom component with the style of our core components. This Storybook will be regularly updated with any new additions or changes.
[Storybook Link](https://gradio.app/main/docs/js/storybook)
## Custom configuration
If you want to make use of the vast vite ecosystem, you can use the `gradio.config.js` file to configure your component's build process. This allows you to make use of tools like tailwindcss, mdsvex, and more.
Currently, it is possible to configure the following:
Vite options:
- `plugins`: A list of vite plugins to use.
Svelte options:
- `preprocess`: A list of svelte preprocessors to use.
- `extensions`: A list of file extensions to compile to `.svelte` files.
- `build.target`: The target to build for, this may be necessary to support newer javascript features. See the [esbuild docs](https://esbuild.github.io/api/#target) for more information.
The `gradio.config.js` file should be placed in the root of your component's `frontend` directory. A default config file is created for you when you create a new component. But you can also create your own config file, if one doesn't exist, and use it to customize your component's build process.
### Example for a Vite plugin
Custom components can use Vite plugins to customize the build process. Check out the [Vite Docs](https://vitejs.dev/guide/using-plugins.html) for more information.
Here we configure [TailwindCSS](https://tailwindcss.com), a utility-first CSS framework. Setup is easiest using the version 4 prerelease.
```
npm install tailwindcss@next @tailwindcss/vite@next
```
In `gradio.config.js`:
```typescript
import tailwindcss from "@tailwindcss/vite";
export default {
plugins: [tailwindcss()]
};
```
Then create a `style.css` file with the following content:
```css
@import "tailwindcss";
```
Import this file into `Index.svelte`. Note, that you need to import the css file containing `@import` and cannot just use a `<style>` tag and use `@import` there.
```svelte
<script lang="ts">
[...]
import "./style.css";
[...]
</script>
```
### Example for Svelte options
In `gradio.config.js` you can also specify a some Svelte options to apply to the Svelte compilation. In this example we will add support for [`mdsvex`](https://mdsvex.pngwn.io), a Markdown preprocessor for Svelte.
In order to do this we will need to add a [Svelte Preprocessor](https://svelte.dev/docs/svelte-compiler#preprocess) to the `svelte` object in `gradio.config.js` and configure the [`extensions`](https://github.com/sveltejs/vite-plugin-svelte/blob/HEAD/docs/config.md#config-file) field. Other options are not currently supported.
First, install the `mdsvex` plugin:
```bash
npm install mdsvex
```
Then add the following to `gradio.config.js`:
```typescript
import { mdsvex } from "mdsvex";
export default {
svelte: {
preprocess: [
mdsvex()
],
extensions: [".svelte", ".svx"]
}
};
```
Now we can create `mdsvex` documents in our component's `frontend` directory and they will be compiled to `.svelte` files.
```md
<!-- HelloWorld.svx -->
<script lang="ts">
import { Block } from "@gradio/atoms";
export let title = "Hello World";
</script>
<Block label="Hello World">
# {title}
This is a markdown file.
</Block>
```
We can then use the `HelloWorld.svx` file in our components:
```svelte
<script lang="ts">
import HelloWorld from "./HelloWorld.svx";
</script>
<HelloWorld />
```
## Conclusion
You now how to create delightful frontends for your components!
|
C:\Gradio Guides\6 Custom Components\06_frequently-asked-questions.md |
# Frequently Asked Questions
## What do I need to install before using Custom Components?
Before using Custom Components, make sure you have Python 3.8+, Node.js v16.14+, npm 9+, and Gradio 4.0+ installed.
## What templates can I use to create my custom component?
Run `gradio cc show` to see the list of built-in templates.
You can also start off from other's custom components!
Simply `git clone` their repository and make your modifications.
## What is the development server?
When you run `gradio cc dev`, a development server will load and run a Gradio app of your choosing.
This is like when you run `python <app-file>.py`, however the `gradio` command will hot reload so you can instantly see your changes.
## The development server didn't work for me
**1. Check your terminal and browser console**
Make sure there are no syntax errors or other obvious problems in your code. Exceptions triggered from python will be displayed in the terminal. Exceptions from javascript will be displayed in the browser console and/or the terminal.
**2. Are you developing on Windows?**
Chrome on Windows will block the local compiled svelte files for security reasons. We recommend developing your custom component in the windows subsystem for linux (WSL) while the team looks at this issue.
**3. Inspect the window.__GRADIO_CC__ variable**
In the browser console, print the `window.__GRADIO__CC` variable (just type it into the console). If it is an empty object, that means
that the CLI could not find your custom component source code. Typically, this happens when the custom component is installed in a different virtual environment than the one used to run the dev command. Please use the `--python-path` and `gradio-path` CLI arguments to specify the path of the python and gradio executables for the environment your component is installed in. For example, if you are using a virtualenv located at `/Users/mary/venv`, pass in `/Users/mary/bin/python` and `/Users/mary/bin/gradio` respectively.
If the `window.__GRADIO__CC` variable is not empty (see below for an example), then the dev server should be working correctly.

**4. Make sure you are using a virtual environment**
It is highly recommended you use a virtual environment to prevent conflicts with other python dependencies installed in your system.
## Do I always need to start my component from scratch?
No! You can start off from an existing gradio component as a template, see the [five minute guide](./custom-components-in-five-minutes).
You can also start from an existing custom component if you'd like to tweak it further. Once you find the source code of a custom component you like, clone the code to your computer and run `gradio cc install`. Then you can run the development server to make changes.If you run into any issues, contact the author of the component by opening an issue in their repository. The [gallery](https://www.gradio.app/custom-components/gallery) is a good place to look for published components. For example, to start from the [PDF component](https://www.gradio.app/custom-components/gallery?id=freddyaboulton%2Fgradio_pdf), clone the space with `git clone https://huggingface.co/spaces/freddyaboulton/gradio_pdf`, `cd` into the `src` directory, and run `gradio cc install`.
## Do I need to host my custom component on HuggingFace Spaces?
You can develop and build your custom component without hosting or connecting to HuggingFace.
If you would like to share your component with the gradio community, it is recommended to publish your package to PyPi and host a demo on HuggingFace so that anyone can install it or try it out.
## What methods are mandatory for implementing a custom component in Gradio?
You must implement the `preprocess`, `postprocess`, `example_payload`, and `example_value` methods. If your component does not use a data model, you must also define the `api_info`, `flag`, and `read_from_flag` methods. Read more in the [backend guide](./backend).
## What is the purpose of a `data_model` in Gradio custom components?
A `data_model` defines the expected data format for your component, simplifying the component development process and self-documenting your code. It streamlines API usage and example caching.
## Why is it important to use `FileData` for components dealing with file uploads?
Utilizing `FileData` is crucial for components that expect file uploads. It ensures secure file handling, automatic caching, and streamlined client library functionality.
## How can I add event triggers to my custom Gradio component?
You can define event triggers in the `EVENTS` class attribute by listing the desired event names, which automatically adds corresponding methods to your component.
## Can I implement a custom Gradio component without defining a `data_model`?
Yes, it is possible to create custom components without a `data_model`, but you are going to have to manually implement `api_info`, `flag`, and `read_from_flag` methods.
## Are there sample custom components I can learn from?
We have prepared this [collection](https://huggingface.co/collections/gradio/custom-components-65497a761c5192d981710b12) of custom components on the HuggingFace Hub that you can use to get started!
## How can I find custom components created by the Gradio community?
We're working on creating a gallery to make it really easy to discover new custom components.
In the meantime, you can search for HuggingFace Spaces that are tagged as a `gradio-custom-component` [here](https://huggingface.co/search/full-text?q=gradio-custom-component&type=space) |
C:\Gradio Guides\6 Custom Components\07_pdf-component-example.md |
# Case Study: A Component to Display PDFs
Let's work through an example of building a custom gradio component for displaying PDF files.
This component will come in handy for showcasing [document question answering](https://huggingface.co/models?pipeline_tag=document-question-answering&sort=trending) models, which typically work on PDF input.
This is a sneak preview of what our finished component will look like:
## Step 0: Prerequisites
Make sure you have gradio 4.0 installed as well as node 18+.
As of the time of publication, the latest release is 4.1.1.
Also, please read the [Five Minute Tour](./custom-components-in-five-minutes) of custom components and the [Key Concepts](./key-component-concepts) guide before starting.
## Step 1: Creating the custom component
Navigate to a directory of your choosing and run the following command:
```bash
gradio cc create PDF
```
Tip: You should change the name of the component.
Some of the screenshots assume the component is called `PDF` but the concepts are the same!
This will create a subdirectory called `pdf` in your current working directory.
There are three main subdirectories in `pdf`: `frontend`, `backend`, and `demo`.
If you open `pdf` in your code editor, it will look like this:
Tip: For this demo we are not templating off a current gradio component. But you can see the list of available templates with `gradio cc show` and then pass the template name to the `--template` option, e.g. `gradio cc create <Name> --template <foo>`
## Step 2: Frontend - modify javascript dependencies
We're going to use the [pdfjs](https://mozilla.github.io/pdf.js/) javascript library to display the pdfs in the frontend.
Let's start off by adding it to our frontend project's dependencies, as well as adding a couple of other projects we'll need.
From within the `frontend` directory, run `npm install @gradio/client @gradio/upload @gradio/icons @gradio/button` and `npm install --save-dev [email protected]`.
Also, let's uninstall the `@zerodevx/svelte-json-view` dependency by running `npm uninstall @zerodevx/svelte-json-view`.
The complete `package.json` should look like this:
```json
{
"name": "gradio_pdf",
"version": "0.2.0",
"description": "Gradio component for displaying PDFs",
"type": "module",
"author": "",
"license": "ISC",
"private": false,
"main_changeset": true,
"exports": {
".": "./Index.svelte",
"./example": "./Example.svelte",
"./package.json": "./package.json"
},
"devDependencies": {
"pdfjs-dist": "3.11.174"
},
"dependencies": {
"@gradio/atoms": "0.2.0",
"@gradio/statustracker": "0.3.0",
"@gradio/utils": "0.2.0",
"@gradio/client": "0.7.1",
"@gradio/upload": "0.3.2",
"@gradio/icons": "0.2.0",
"@gradio/button": "0.2.3",
"pdfjs-dist": "3.11.174"
}
}
```
Tip: Running `npm install` will install the latest version of the package available. You can install a specific version with `npm install package@<version>`. You can find all of the gradio javascript package documentation [here](https://www.gradio.app/main/docs/js). It is recommended you use the same versions as me as the API can change.
Navigate to `Index.svelte` and delete mentions of `JSONView`
```ts
import { JsonView } from "@zerodevx/svelte-json-view";
```
```svelte
<JsonView json={value} />
```
## Step 3: Frontend - Launching the Dev Server
Run the `dev` command to launch the development server.
This will open the demo in `demo/app.py` in an environment where changes to the `frontend` and `backend` directories will reflect instantaneously in the launched app.
After launching the dev server, you should see a link printed to your console that says `Frontend Server (Go here): ... `.
You should see the following:

Its not impressive yet but we're ready to start coding!
## Step 4: Frontend - The basic skeleton
We're going to start off by first writing the skeleton of our frontend and then adding the pdf rendering logic.
Add the following imports and expose the following properties to the top of your file in the `<script>` tag.
You may get some warnings from your code editor that some props are not used.
That's ok.
```ts
import { tick } from "svelte";
import type { Gradio } from "@gradio/utils";
import { Block, BlockLabel } from "@gradio/atoms";
import { File } from "@gradio/icons";
import { StatusTracker } from "@gradio/statustracker";
import type { LoadingStatus } from "@gradio/statustracker";
import type { FileData } from "@gradio/client";
import { Upload, ModifyUpload } from "@gradio/upload";
export let elem_id = "";
export let elem_classes: string[] = [];
export let visible = true;
export let value: FileData | null = null;
export let container = true;
export let scale: number | null = null;
export let root: string;
export let height: number | null = 500;
export let label: string;
export let proxy_url: string;
export let min_width: number | undefined = undefined;
export let loading_status: LoadingStatus;
export let gradio: Gradio<{
change: never;
upload: never;
}>;
let _value = value;
let old_value = _value;
```
Tip: The `gradio`` object passed in here contains some metadata about the application as well as some utility methods. One of these utilities is a dispatch method. We want to dispatch change and upload events whenever our PDF is changed or updated. This line provides type hints that these are the only events we will be dispatching.
We want our frontend component to let users upload a PDF document if there isn't one already loaded.
If it is loaded, we want to display it underneath a "clear" button that lets our users upload a new document.
We're going to use the `Upload` and `ModifyUpload` components that come with the `@gradio/upload` package to do this.
Underneath the `</script>` tag, delete all the current code and add the following:
```svelte
<Block {visible} {elem_id} {elem_classes} {container} {scale} {min_width}>
{#if loading_status}
<StatusTracker
autoscroll={gradio.autoscroll}
i18n={gradio.i18n}
{...loading_status}
/>
{/if}
<BlockLabel
show_label={label !== null}
Icon={File}
float={value === null}
label={label || "File"}
/>
{#if _value}
<ModifyUpload i18n={gradio.i18n} absolute />
{:else}
<Upload
filetype={"application/pdf"}
file_count="single"
{root}
>
Upload your PDF
</Upload>
{/if}
</Block>
```
You should see the following when you navigate to your app after saving your current changes:

## Step 5: Frontend - Nicer Upload Text
The `Upload your PDF` text looks a bit small and barebones.
Lets customize it!
Create a new file called `PdfUploadText.svelte` and copy the following code.
Its creating a new div to display our "upload text" with some custom styling.
Tip: Notice that we're leveraging Gradio core's existing css variables here: `var(--size-60)` and `var(--body-text-color-subdued)`. This allows our component to work nicely in light mode and dark mode, as well as with Gradio's built-in themes.
```svelte
<script lang="ts">
import { Upload as UploadIcon } from "@gradio/icons";
export let hovered = false;
</script>
<div class="wrap">
<span class="icon-wrap" class:hovered><UploadIcon /> </span>
Drop PDF
<span class="or">- or -</span>
Click to Upload
</div>
<style>
.wrap {
display: flex;
flex-direction: column;
justify-content: center;
align-items: center;
min-height: var(--size-60);
color: var(--block-label-text-color);
line-height: var(--line-md);
height: 100%;
padding-top: var(--size-3);
}
.or {
color: var(--body-text-color-subdued);
display: flex;
}
.icon-wrap {
width: 30px;
margin-bottom: var(--spacing-lg);
}
@media (--screen-md) {
.wrap {
font-size: var(--text-lg);
}
}
.hovered {
color: var(--color-accent);
}
</style>
```
Now import `PdfUploadText.svelte` in your `<script>` and pass it to the `Upload` component!
```svelte
import PdfUploadText from "./PdfUploadText.svelte";
...
<Upload
filetype={"application/pdf"}
file_count="single"
{root}
>
<PdfUploadText />
</Upload>
```
After saving your code, the frontend should now look like this:
## Step 6: PDF Rendering logic
This is the most advanced javascript part.
It took me a while to figure it out!
Do not worry if you have trouble, the important thing is to not be discouraged 💪
Ask for help in the gradio [discord](https://discord.gg/hugging-face-879548962464493619) if you need and ask for help.
With that out of the way, let's start off by importing `pdfjs` and loading the code of the pdf worker from the mozilla cdn.
```ts
import pdfjsLib from "pdfjs-dist";
...
pdfjsLib.GlobalWorkerOptions.workerSrc = "https://cdn.bootcss.com/pdf.js/3.11.174/pdf.worker.js";
```
Also create the following variables:
```ts
let pdfDoc;
let numPages = 1;
let currentPage = 1;
let canvasRef;
```
Now, we will use `pdfjs` to render a given page of the PDF onto an `html` document.
Add the following code to `Index.svelte`:
```ts
async function get_doc(value: FileData) {
const loadingTask = pdfjsLib.getDocument(value.url);
pdfDoc = await loadingTask.promise;
numPages = pdfDoc.numPages;
render_page();
}
function render_page() {
// Render a specific page of the PDF onto the canvas
pdfDoc.getPage(currentPage).then(page => {
const ctx = canvasRef.getContext('2d')
ctx.clearRect(0, 0, canvasRef.width, canvasRef.height);
let viewport = page.getViewport({ scale: 1 });
let scale = height / viewport.height;
viewport = page.getViewport({ scale: scale });
const renderContext = {
canvasContext: ctx,
viewport,
};
canvasRef.width = viewport.width;
canvasRef.height = viewport.height;
page.render(renderContext);
});
}
// If the value changes, render the PDF of the currentPage
$: if(JSON.stringify(old_value) != JSON.stringify(_value)) {
if (_value){
get_doc(_value);
}
old_value = _value;
gradio.dispatch("change");
}
```
Tip: The `$:` syntax in svelte is how you declare statements to be reactive. Whenever any of the inputs of the statement change, svelte will automatically re-run that statement.
Now place the `canvas` underneath the `ModifyUpload` component:
```svelte
<div class="pdf-canvas" style="height: {height}px">
<canvas bind:this={canvasRef}></canvas>
</div>
```
And add the following styles to the `<style>` tag:
```svelte
<style>
.pdf-canvas {
display: flex;
justify-content: center;
align-items: center;
}
</style>
```
## Step 7: Handling The File Upload And Clear
Now for the fun part - actually rendering the PDF when the file is uploaded!
Add the following functions to the `<script>` tag:
```ts
async function handle_clear() {
_value = null;
await tick();
gradio.dispatch("change");
}
async function handle_upload({detail}: CustomEvent<FileData>): Promise<void> {
value = detail;
await tick();
gradio.dispatch("change");
gradio.dispatch("upload");
}
```
Tip: The `gradio.dispatch` method is actually what is triggering the `change` or `upload` events in the backend. For every event defined in the component's backend, we will explain how to do this in Step 9, there must be at least one `gradio.dispatch("<event-name>")` call. These are called `gradio` events and they can be listended from the entire Gradio application. You can dispatch a built-in `svelte` event with the `dispatch` function. These events can only be listened to from the component's direct parent. Learn about svelte events from the [official documentation](https://learn.svelte.dev/tutorial/component-events).
Now we will run these functions whenever the `Upload` component uploads a file and whenever the `ModifyUpload` component clears the current file. The `<Upload>` component dispatches a `load` event with a payload of type `FileData` corresponding to the uploaded file. The `on:load` syntax tells `Svelte` to automatically run this function in response to the event.
```svelte
<ModifyUpload i18n={gradio.i18n} on:clear={handle_clear} absolute />
...
<Upload
on:load={handle_upload}
filetype={"application/pdf"}
file_count="single"
{root}
>
<PdfUploadText/>
</Upload>
```
Congratulations! You have a working pdf uploader!
## Step 8: Adding buttons to navigate pages
If a user uploads a PDF document with multiple pages, they will only be able to see the first one.
Let's add some buttons to help them navigate the page.
We will use the `BaseButton` from `@gradio/button` so that they look like regular Gradio buttons.
Import the `BaseButton` and add the following functions that will render the next and previous page of the PDF.
```ts
import { BaseButton } from "@gradio/button";
...
function next_page() {
if (currentPage >= numPages) {
return;
}
currentPage++;
render_page();
}
function prev_page() {
if (currentPage == 1) {
return;
}
currentPage--;
render_page();
}
```
Now we will add them underneath the canvas in a separate `<div>`
```svelte
...
<ModifyUpload i18n={gradio.i18n} on:clear={handle_clear} absolute />
<div class="pdf-canvas" style="height: {height}px">
<canvas bind:this={canvasRef}></canvas>
</div>
<div class="button-row">
<BaseButton on:click={prev_page}>
⬅️
</BaseButton>
<span class="page-count"> {currentPage} / {numPages} </span>
<BaseButton on:click={next_page}>
➡️
</BaseButton>
</div>
...
<style>
.button-row {
display: flex;
flex-direction: row;
width: 100%;
justify-content: center;
align-items: center;
}
.page-count {
margin: 0 10px;
font-family: var(--font-mono);
}
```
Congratulations! The frontend is almost complete 🎉
## Step 8.5: The Example view
We're going to want users of our component to get a preview of the PDF if its used as an `example` in a `gr.Interface` or `gr.Examples`.
To do so, we're going to add some of the pdf rendering logic in `Index.svelte` to `Example.svelte`.
```svelte
<script lang="ts">
export let value: string;
export let type: "gallery" | "table";
export let selected = false;
import pdfjsLib from "pdfjs-dist";
pdfjsLib.GlobalWorkerOptions.workerSrc = "https://cdn.bootcss.com/pdf.js/3.11.174/pdf.worker.js";
let pdfDoc;
let canvasRef;
async function get_doc(url: string) {
const loadingTask = pdfjsLib.getDocument(url);
pdfDoc = await loadingTask.promise;
renderPage();
}
function renderPage() {
// Render a specific page of the PDF onto the canvas
pdfDoc.getPage(1).then(page => {
const ctx = canvasRef.getContext('2d')
ctx.clearRect(0, 0, canvasRef.width, canvasRef.height);
const viewport = page.getViewport({ scale: 0.2 });
const renderContext = {
canvasContext: ctx,
viewport
};
canvasRef.width = viewport.width;
canvasRef.height = viewport.height;
page.render(renderContext);
});
}
$: get_doc(value);
</script>
<div
class:table={type === "table"}
class:gallery={type === "gallery"}
class:selected
style="justify-content: center; align-items: center; display: flex; flex-direction: column;"
>
<canvas bind:this={canvasRef}></canvas>
</div>
<style>
.gallery {
padding: var(--size-1) var(--size-2);
}
</style>
```
Tip: Exercise for the reader - reduce the code duplication between `Index.svelte` and `Example.svelte` 😊
You will not be able to render examples until we make some changes to the backend code in the next step!
## Step 9: The backend
The backend changes needed are smaller.
We're almost done!
What we're going to do is:
* Add `change` and `upload` events to our component.
* Add a `height` property to let users control the height of the PDF.
* Set the `data_model` of our component to be `FileData`. This is so that Gradio can automatically cache and safely serve any files that are processed by our component.
* Modify the `preprocess` method to return a string corresponding to the path of our uploaded PDF.
* Modify the `postprocess` to turn a path to a PDF created in an event handler to a `FileData`.
When all is said an done, your component's backend code should look like this:
```python
from __future__ import annotations
from typing import Any, Callable, TYPE_CHECKING
from gradio.components.base import Component
from gradio.data_classes import FileData
from gradio import processing_utils
if TYPE_CHECKING:
from gradio.components import Timer
class PDF(Component):
EVENTS = ["change", "upload"]
data_model = FileData
def __init__(self, value: Any = None, *,
height: int | None = None,
label: str | None = None, info: str | None = None,
show_label: bool | None = None,
container: bool = True,
scale: int | None = None,
min_width: int | None = None,
interactive: bool | None = None,
visible: bool = True,
elem_id: str | None = None,
elem_classes: list[str] | str | None = None,
render: bool = True,
load_fn: Callable[..., Any] | None = None,
every: Timer | float | None = None):
super().__init__(value, label=label, info=info,
show_label=show_label, container=container,
scale=scale, min_width=min_width,
interactive=interactive, visible=visible,
elem_id=elem_id, elem_classes=elem_classes,
render=render, load_fn=load_fn, every=every)
self.height = height
def preprocess(self, payload: FileData) -> str:
return payload.path
def postprocess(self, value: str | None) -> FileData:
if not value:
return None
return FileData(path=value)
def example_payload(self):
return "https://gradio-builds.s3.amazonaws.com/assets/pdf-guide/fw9.pdf"
def example_value(self):
return "https://gradio-builds.s3.amazonaws.com/assets/pdf-guide/fw9.pdf"
```
## Step 10: Add a demo and publish!
To test our backend code, let's add a more complex demo that performs Document Question and Answering with huggingface transformers.
In our `demo` directory, create a `requirements.txt` file with the following packages
```
torch
transformers
pdf2image
pytesseract
```
Tip: Remember to install these yourself and restart the dev server! You may need to install extra non-python dependencies for `pdf2image`. See [here](https://pypi.org/project/pdf2image/). Feel free to write your own demo if you have trouble.
```python
import gradio as gr
from gradio_pdf import PDF
from pdf2image import convert_from_path
from transformers import pipeline
from pathlib import Path
dir_ = Path(__file__).parent
p = pipeline(
"document-question-answering",
model="impira/layoutlm-document-qa",
)
def qa(question: str, doc: str) -> str:
img = convert_from_path(doc)[0]
output = p(img, question)
return sorted(output, key=lambda x: x["score"], reverse=True)[0]['answer']
demo = gr.Interface(
qa,
[gr.Textbox(label="Question"), PDF(label="Document")],
gr.Textbox(),
)
demo.launch()
```
See our demo in action below!
<video autoplay muted loop>
<source src="https://gradio-builds.s3.amazonaws.com/assets/pdf-guide/PDFDemo.mov" type="video/mp4" />
</video>
Finally lets build our component with `gradio cc build` and publish it with the `gradio cc publish` command!
This will guide you through the process of uploading your component to [PyPi](https://pypi.org/) and [HuggingFace Spaces](https://huggingface.co/spaces).
Tip: You may need to add the following lines to the `Dockerfile` of your HuggingFace Space.
```Dockerfile
RUN mkdir -p /tmp/cache/
RUN chmod a+rwx -R /tmp/cache/
RUN apt-get update && apt-get install -y poppler-utils tesseract-ocr
ENV TRANSFORMERS_CACHE=/tmp/cache/
```
## Conclusion
In order to use our new component in **any** gradio 4.0 app, simply install it with pip, e.g. `pip install gradio-pdf`. Then you can use it like the built-in `gr.File()` component (except that it will only accept and display PDF files).
Here is a simple demo with the Blocks api:
```python
import gradio as gr
from gradio_pdf import PDF
with gr.Blocks() as demo:
pdf = PDF(label="Upload a PDF", interactive=True)
name = gr.Textbox()
pdf.upload(lambda f: f, pdf, name)
demo.launch()
```
I hope you enjoyed this tutorial!
The complete source code for our component is [here](https://huggingface.co/spaces/freddyaboulton/gradio_pdf/tree/main/src).
Please don't hesitate to reach out to the gradio community on the [HuggingFace Discord](https://discord.gg/hugging-face-879548962464493619) if you get stuck.
|
C:\Gradio Guides\6 Custom Components\08_multimodal-chatbot-part1.md |
# Build a Custom Multimodal Chatbot - Part 1
This is the first in a two part series where we build a custom Multimodal Chatbot component.
In part 1, we will modify the Gradio Chatbot component to display text and media files (video, audio, image) in the same message.
In part 2, we will build a custom Textbox component that will be able to send multimodal messages (text and media files) to the chatbot.
You can follow along with the author of this post as he implements the chatbot component in the following YouTube video!
<iframe width="560" height="315" src="https://www.youtube.com/embed/IVJkOHTBPn0?si=bs-sBv43X-RVA8ly" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe>
Here's a preview of what our multimodal chatbot component will look like:
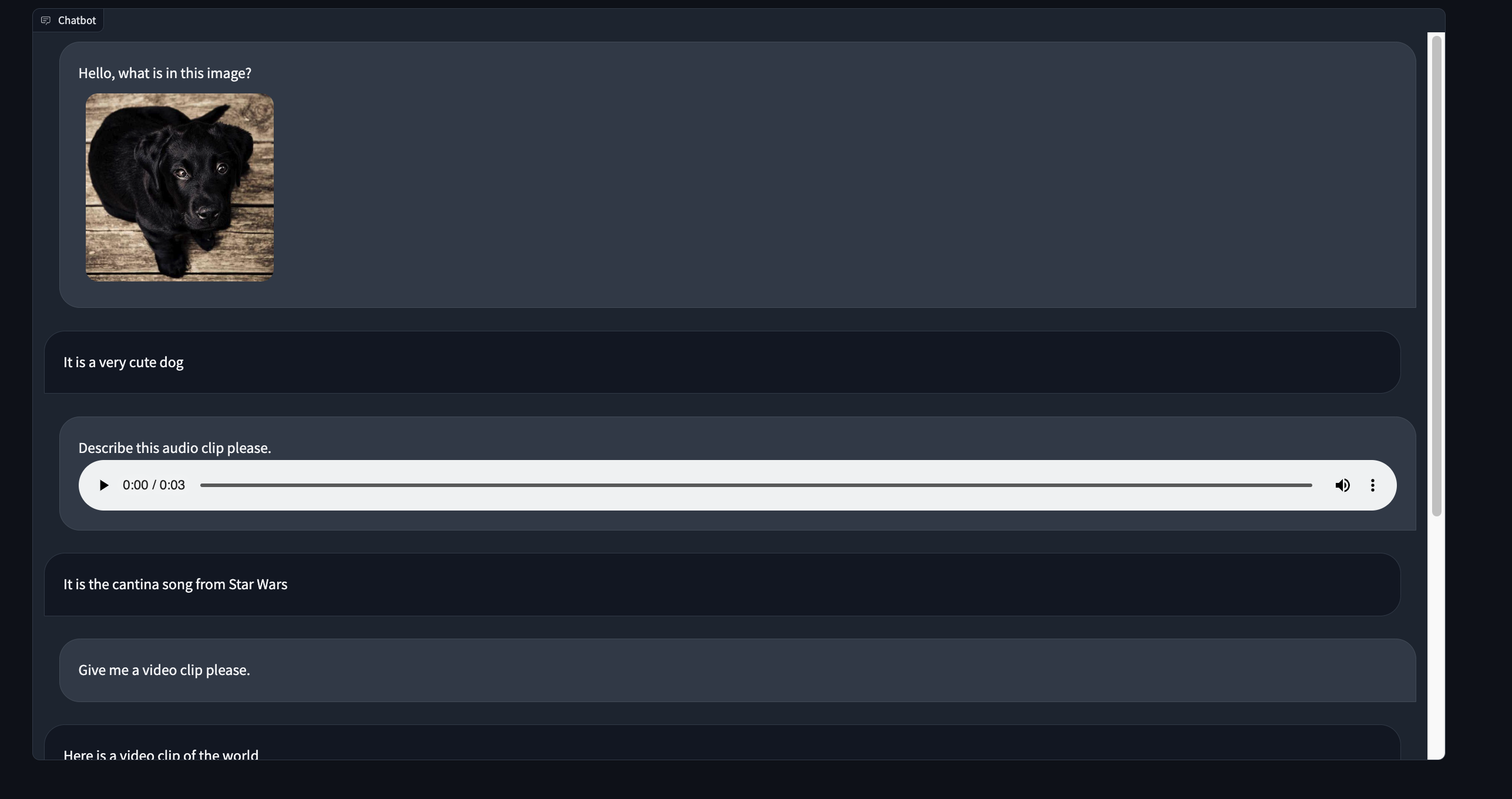
## Part 1 - Creating our project
For this demo we will be tweaking the existing Gradio `Chatbot` component to display text and media files in the same message.
Let's create a new custom component directory by templating off of the `Chatbot` component source code.
```bash
gradio cc create MultimodalChatbot --template Chatbot
```
And we're ready to go!
Tip: Make sure to modify the `Author` key in the `pyproject.toml` file.
## Part 2a - The backend data_model
Open up the `multimodalchatbot.py` file in your favorite code editor and let's get started modifying the backend of our component.
The first thing we will do is create the `data_model` of our component.
The `data_model` is the data format that your python component will receive and send to the javascript client running the UI.
You can read more about the `data_model` in the [backend guide](./backend).
For our component, each chatbot message will consist of two keys: a `text` key that displays the text message and an optional list of media files that can be displayed underneath the text.
Import the `FileData` and `GradioModel` classes from `gradio.data_classes` and modify the existing `ChatbotData` class to look like the following:
```python
class FileMessage(GradioModel):
file: FileData
alt_text: Optional[str] = None
class MultimodalMessage(GradioModel):
text: Optional[str] = None
files: Optional[List[FileMessage]] = None
class ChatbotData(GradioRootModel):
root: List[Tuple[Optional[MultimodalMessage], Optional[MultimodalMessage]]]
class MultimodalChatbot(Component):
...
data_model = ChatbotData
```
Tip: The `data_model`s are implemented using `Pydantic V2`. Read the documentation [here](https://docs.pydantic.dev/latest/).
We've done the hardest part already!
## Part 2b - The pre and postprocess methods
For the `preprocess` method, we will keep it simple and pass a list of `MultimodalMessage`s to the python functions that use this component as input.
This will let users of our component access the chatbot data with `.text` and `.files` attributes.
This is a design choice that you can modify in your implementation!
We can return the list of messages with the `root` property of the `ChatbotData` like so:
```python
def preprocess(
self,
payload: ChatbotData | None,
) -> List[MultimodalMessage] | None:
if payload is None:
return payload
return payload.root
```
Tip: Learn about the reasoning behind the `preprocess` and `postprocess` methods in the [key concepts guide](./key-component-concepts)
In the `postprocess` method we will coerce each message returned by the python function to be a `MultimodalMessage` class.
We will also clean up any indentation in the `text` field so that it can be properly displayed as markdown in the frontend.
We can leave the `postprocess` method as is and modify the `_postprocess_chat_messages`
```python
def _postprocess_chat_messages(
self, chat_message: MultimodalMessage | dict | None
) -> MultimodalMessage | None:
if chat_message is None:
return None
if isinstance(chat_message, dict):
chat_message = MultimodalMessage(**chat_message)
chat_message.text = inspect.cleandoc(chat_message.text or "")
for file_ in chat_message.files:
file_.file.mime_type = client_utils.get_mimetype(file_.file.path)
return chat_message
```
Before we wrap up with the backend code, let's modify the `example_value` and `example_payload` method to return a valid dictionary representation of the `ChatbotData`:
```python
def example_value(self) -> Any:
return [[{"text": "Hello!", "files": []}, None]]
def example_payload(self) -> Any:
return [[{"text": "Hello!", "files": []}, None]]
```
Congrats - the backend is complete!
## Part 3a - The Index.svelte file
The frontend for the `Chatbot` component is divided into two parts - the `Index.svelte` file and the `shared/Chatbot.svelte` file.
The `Index.svelte` file applies some processing to the data received from the server and then delegates the rendering of the conversation to the `shared/Chatbot.svelte` file.
First we will modify the `Index.svelte` file to apply processing to the new data type the backend will return.
Let's begin by porting our custom types from our python `data_model` to typescript.
Open `frontend/shared/utils.ts` and add the following type definitions at the top of the file:
```ts
export type FileMessage = {
file: FileData;
alt_text?: string;
};
export type MultimodalMessage = {
text: string;
files?: FileMessage[];
}
```
Now let's import them in `Index.svelte` and modify the type annotations for `value` and `_value`.
```ts
import type { FileMessage, MultimodalMessage } from "./shared/utils";
export let value: [
MultimodalMessage | null,
MultimodalMessage | null
][] = [];
let _value: [
MultimodalMessage | null,
MultimodalMessage | null
][];
```
We need to normalize each message to make sure each file has a proper URL to fetch its contents from.
We also need to format any embedded file links in the `text` key.
Let's add a `process_message` utility function and apply it whenever the `value` changes.
```ts
function process_message(msg: MultimodalMessage | null): MultimodalMessage | null {
if (msg === null) {
return msg;
}
msg.text = redirect_src_url(msg.text);
msg.files = msg.files.map(normalize_messages);
return msg;
}
$: _value = value
? value.map(([user_msg, bot_msg]) => [
process_message(user_msg),
process_message(bot_msg)
])
: [];
```
## Part 3b - the Chatbot.svelte file
Let's begin similarly to the `Index.svelte` file and let's first modify the type annotations.
Import `Mulimodal` message at the top of the `<script>` section and use it to type the `value` and `old_value` variables.
```ts
import type { MultimodalMessage } from "./utils";
export let value:
| [
MultimodalMessage | null,
MultimodalMessage | null
][]
| null;
let old_value:
| [
MultimodalMessage | null,
MultimodalMessage | null
][]
| null = null;
```
We also need to modify the `handle_select` and `handle_like` functions:
```ts
function handle_select(
i: number,
j: number,
message: MultimodalMessage | null
): void {
dispatch("select", {
index: [i, j],
value: message
});
}
function handle_like(
i: number,
j: number,
message: MultimodalMessage | null,
liked: boolean
): void {
dispatch("like", {
index: [i, j],
value: message,
liked: liked
});
}
```
Now for the fun part, actually rendering the text and files in the same message!
You should see some code like the following that determines whether a file or a markdown message should be displayed depending on the type of the message:
```svelte
{#if typeof message === "string"}
<Markdown
{message}
{latex_delimiters}
{sanitize_html}
{render_markdown}
{line_breaks}
on:load={scroll}
/>
{:else if message !== null && message.file?.mime_type?.includes("audio")}
<audio
data-testid="chatbot-audio"
controls
preload="metadata"
...
```
We will modify this code to always display the text message and then loop through the files and display all of them that are present:
```svelte
<Markdown
message={message.text}
{latex_delimiters}
{sanitize_html}
{render_markdown}
{line_breaks}
on:load={scroll}
/>
{#each message.files as file, k}
{#if file !== null && file.file.mime_type?.includes("audio")}
<audio
data-testid="chatbot-audio"
controls
preload="metadata"
src={file.file?.url}
title={file.alt_text}
on:play
on:pause
on:ended
/>
{:else if message !== null && file.file?.mime_type?.includes("video")}
<video
data-testid="chatbot-video"
controls
src={file.file?.url}
title={file.alt_text}
preload="auto"
on:play
on:pause
on:ended
>
<track kind="captions" />
</video>
{:else if message !== null && file.file?.mime_type?.includes("image")}
<img
data-testid="chatbot-image"
src={file.file?.url}
alt={file.alt_text}
/>
{:else if message !== null && file.file?.url !== null}
<a
data-testid="chatbot-file"
href={file.file?.url}
target="_blank"
download={window.__is_colab__
? null
: file.file?.orig_name || file.file?.path}
>
{file.file?.orig_name || file.file?.path}
</a>
{:else if pending_message && j === 1}
<Pending {layout} />
{/if}
{/each}
```
We did it! 🎉
## Part 4 - The demo
For this tutorial, let's keep the demo simple and just display a static conversation between a hypothetical user and a bot.
This demo will show how both the user and the bot can send files.
In part 2 of this tutorial series we will build a fully functional chatbot demo!
The demo code will look like the following:
```python
import gradio as gr
from gradio_multimodalchatbot import MultimodalChatbot
from gradio.data_classes import FileData
user_msg1 = {"text": "Hello, what is in this image?",
"files": [{"file": FileData(path="https://gradio-builds.s3.amazonaws.com/diffusion_image/cute_dog.jpg")}]
}
bot_msg1 = {"text": "It is a very cute dog",
"files": []}
user_msg2 = {"text": "Describe this audio clip please.",
"files": [{"file": FileData(path="cantina.wav")}]}
bot_msg2 = {"text": "It is the cantina song from Star Wars",
"files": []}
user_msg3 = {"text": "Give me a video clip please.",
"files": []}
bot_msg3 = {"text": "Here is a video clip of the world",
"files": [{"file": FileData(path="world.mp4")},
{"file": FileData(path="cantina.wav")}]}
conversation = [[user_msg1, bot_msg1], [user_msg2, bot_msg2], [user_msg3, bot_msg3]]
with gr.Blocks() as demo:
MultimodalChatbot(value=conversation, height=800)
demo.launch()
```
Tip: Change the filepaths so that they correspond to files on your machine. Also, if you are running in development mode, make sure the files are located in the top level of your custom component directory.
## Part 5 - Deploying and Conclusion
Let's build and deploy our demo with `gradio cc build` and `gradio cc deploy`!
You can check out our component deployed to [HuggingFace Spaces](https://huggingface.co/spaces/freddyaboulton/gradio_multimodalchatbot) and all of the source code is available [here](https://huggingface.co/spaces/freddyaboulton/gradio_multimodalchatbot/tree/main/src).
See you in the next installment of this series! |
C:\Gradio Guides\6 Custom Components\09_documenting-custom-components.md |
# Documenting Custom Components
In 4.15, we added a new `gradio cc docs` command to the Gradio CLI to generate rich documentation for your custom component. This command will generate documentation for users automatically, but to get the most out of it, you need to do a few things.
## How do I use it?
The documentation will be generated when running `gradio cc build`. You can pass the `--no-generate-docs` argument to turn off this behaviour.
There is also a standalone `docs` command that allows for greater customisation. If you are running this command manually it should be run _after_ the `version` in your `pyproject.toml` has been bumped but before building the component.
All arguments are optional.
```bash
gradio cc docs
path # The directory of the custom component.
--demo-dir # Path to the demo directory.
--demo-name # Name of the demo file
--space-url # URL of the Hugging Face Space to link to
--generate-space # create a documentation space.
--no-generate-space # do not create a documentation space
--readme-path # Path to the README.md file.
--generate-readme # create a REAMDE.md file
--no-generate-readme # do not create a README.md file
--suppress-demo-check # suppress validation checks and warnings
```
## What gets generated?
The `gradio cc docs` command will generate an interactive Gradio app and a static README file with various features. You can see an example here:
- [Gradio app deployed on Hugging Face Spaces]()
- [README.md rendered by GitHub]()
The README.md and space both have the following features:
- A description.
- Installation instructions.
- A fully functioning code snippet.
- Optional links to PyPi, GitHub, and Hugging Face Spaces.
- API documentation including:
- An argument table for component initialisation showing types, defaults, and descriptions.
- A description of how the component affects the user's predict function.
- A table of events and their descriptions.
- Any additional interfaces or classes that may be used during initialisation or in the pre- or post- processors.
Additionally, the Gradio includes:
- A live demo.
- A richer, interactive version of the parameter tables.
- Nicer styling!
## What do I need to do?
The documentation generator uses existing standards to extract the necessary information, namely Type Hints and Docstrings. There are no Gradio-specific APIs for documentation, so following best practices will generally yield the best results.
If you already use type hints and docstrings in your component source code, you don't need to do much to benefit from this feature, but there are some details that you should be aware of.
### Python version
To get the best documentation experience, you need to use Python `3.10` or greater when generating documentation. This is because some introspection features used to generate the documentation were only added in `3.10`.
### Type hints
Python type hints are used extensively to provide helpful information for users.
<details>
<summary> What are type hints?</summary>
If you need to become more familiar with type hints in Python, they are a simple way to express what Python types are expected for arguments and return values of functions and methods. They provide a helpful in-editor experience, aid in maintenance, and integrate with various other tools. These types can be simple primitives, like `list` `str` `bool`; they could be more compound types like `list[str]`, `str | None` or `tuple[str, float | int]`; or they can be more complex types using utility classed like [`TypedDict`](https://peps.python.org/pep-0589/#abstract).
[Read more about type hints in Python.](https://realpython.com/lessons/type-hinting/)
</details>
#### What do I need to add hints to?
You do not need to add type hints to every part of your code. For the documentation to work correctly, you will need to add type hints to the following component methods:
- `__init__` parameters should be typed.
- `postprocess` parameters and return value should be typed.
- `preprocess` parameters and return value should be typed.
If you are using `gradio cc create`, these types should already exist, but you may need to tweak them based on any changes you make.
##### `__init__`
Here, you only need to type the parameters. If you have cloned a template with `gradio` cc create`, these should already be in place. You will only need to add new hints for anything you have added or changed:
```py
def __init__(
self,
value: str | None = None,
*,
sources: Literal["upload", "microphone"] = "upload,
every: Timer | float | None = None,
...
):
...
```
##### `preprocess` and `postprocess`
The `preprocess` and `postprocess` methods determine the value passed to the user function and the value that needs to be returned.
Even if the design of your component is primarily as an input or an output, it is worth adding type hints to both the input parameters and the return values because Gradio has no way of limiting how components can be used.
In this case, we specifically care about:
- The return type of `preprocess`.
- The input type of `postprocess`.
```py
def preprocess(
self, payload: FileData | None # input is optional
) -> tuple[int, str] | str | None:
# user function input is the preprocess return ▲
# user function output is the postprocess input ▼
def postprocess(
self, value: tuple[int, str] | None
) -> FileData | bytes | None: # return is optional
...
```
### Docstrings
Docstrings are also used extensively to extract more meaningful, human-readable descriptions of certain parts of the API.
<details>
<summary> What are docstrings?</summary>
If you need to become more familiar with docstrings in Python, they are a way to annotate parts of your code with human-readable decisions and explanations. They offer a rich in-editor experience like type hints, but unlike type hints, they don't have any specific syntax requirements. They are simple strings and can take almost any form. The only requirement is where they appear. Docstrings should be "a string literal that occurs as the first statement in a module, function, class, or method definition".
[Read more about Python docstrings.](https://peps.python.org/pep-0257/#what-is-a-docstring)
</details>
While docstrings don't have any syntax requirements, we need a particular structure for documentation purposes.
As with type hint, the specific information we care about is as follows:
- `__init__` parameter docstrings.
- `preprocess` return docstrings.
- `postprocess` input parameter docstrings.
Everything else is optional.
Docstrings should always take this format to be picked up by the documentation generator:
#### Classes
```py
"""
A description of the class.
This can span multiple lines and can _contain_ *markdown*.
"""
```
#### Methods and functions
Markdown in these descriptions will not be converted into formatted text.
```py
"""
Parameters:
param_one: A description for this parameter.
param_two: A description for this parameter.
Returns:
A description for this return value.
"""
```
### Events
In custom components, events are expressed as a list stored on the `events` field of the component class. While we do not need types for events, we _do_ need a human-readable description so users can understand the behaviour of the event.
To facilitate this, we must create the event in a specific way.
There are two ways to add events to a custom component.
#### Built-in events
Gradio comes with a variety of built-in events that may be enough for your component. If you are using built-in events, you do not need to do anything as they already have descriptions we can extract:
```py
from gradio.events import Events
class ParamViewer(Component):
...
EVENTS = [
Events.change,
Events.upload,
]
```
#### Custom events
You can define a custom event if the built-in events are unsuitable for your use case. This is a straightforward process, but you must create the event in this way for docstrings to work correctly:
```py
from gradio.events import Events, EventListener
class ParamViewer(Component):
...
EVENTS = [
Events.change,
EventListener(
"bingbong",
doc="This listener is triggered when the user does a bingbong."
)
]
```
### Demo
The `demo/app.py`, often used for developing the component, generates the live demo and code snippet. The only strict rule here is that the `demo.launch()` command must be contained with a `__name__ == "__main__"` conditional as below:
```py
if __name__ == "__main__":
demo.launch()
```
The documentation generator will scan for such a clause and error if absent. If you are _not_ launching the demo inside the `demo/app.py`, then you can pass `--suppress-demo-check` to turn off this check.
#### Demo recommendations
Although there are no additional rules, there are some best practices you should bear in mind to get the best experience from the documentation generator.
These are only guidelines, and every situation is unique, but they are sound principles to remember.
##### Keep the demo compact
Compact demos look better and make it easier for users to understand what the demo does. Try to remove as many extraneous UI elements as possible to focus the users' attention on the core use case.
Sometimes, it might make sense to have a `demo/app.py` just for the docs and an additional, more complex app for your testing purposes. You can also create other spaces, showcasing more complex examples and linking to them from the main class docstring or the `pyproject.toml` description.
#### Keep the code concise
The 'getting started' snippet utilises the demo code, which should be as short as possible to keep users engaged and avoid confusion.
It isn't the job of the sample snippet to demonstrate the whole API; this snippet should be the shortest path to success for a new user. It should be easy to type or copy-paste and easy to understand. Explanatory comments should be brief and to the point.
#### Avoid external dependencies
As mentioned above, users should be able to copy-paste a snippet and have a fully working app. Try to avoid third-party library dependencies to facilitate this.
You should carefully consider any examples; avoiding examples that require additional files or that make assumptions about the environment is generally a good idea.
#### Ensure the `demo` directory is self-contained
Only the `demo` directory will be uploaded to Hugging Face spaces in certain instances, as the component will be installed via PyPi if possible. It is essential that this directory is self-contained and any files needed for the correct running of the demo are present.
### Additional URLs
The documentation generator will generate a few buttons, providing helpful information and links to users. They are obtained automatically in some cases, but some need to be explicitly included in the `pyproject.yaml`.
- PyPi Version and link - This is generated automatically.
- GitHub Repository - This is populated via the `pyproject.toml`'s `project.urls.repository`.
- Hugging Face Space - This is populated via the `pyproject.toml`'s `project.urls.space`.
An example `pyproject.toml` urls section might look like this:
```toml
[project.urls]
repository = "https://github.com/user/repo-name"
space = "https://huggingface.co/spaces/user/space-name"
``` |
C:\Gradio Guides\7 Tabular Data Science and Plots\01_connecting-to-a-database.md |
# Connecting to a Database
Related spaces: https://huggingface.co/spaces/gradio/chicago-bikeshare-dashboard
Tags: TABULAR, PLOTS
## Introduction
This guide explains how you can use Gradio to connect your app to a database. We will be
connecting to a PostgreSQL database hosted on AWS but gradio is completely agnostic to the type of
database you are connecting to and where it's hosted. So as long as you can write python code to connect
to your data, you can display it in a web UI with gradio 💪
## Overview
We will be analyzing bike share data from Chicago. The data is hosted on kaggle [here](https://www.kaggle.com/datasets/evangower/cyclistic-bike-share?select=202203-divvy-tripdata.csv).
Our goal is to create a dashboard that will enable our business stakeholders to answer the following questions:
1. Are electric bikes more popular than regular bikes?
2. What are the top 5 most popular departure bike stations?
At the end of this guide, we will have a functioning application that looks like this:
<gradio-app space="gradio/chicago-bikeshare-dashboard"> </gradio-app>
## Step 1 - Creating your database
We will be storing our data on a PostgreSQL hosted on Amazon's RDS service. Create an AWS account if you don't already have one
and create a PostgreSQL database on the free tier.
**Important**: If you plan to host this demo on HuggingFace Spaces, make sure database is on port **8080**. Spaces will
block all outgoing connections unless they are made to port 80, 443, or 8080 as noted [here](https://huggingface.co/docs/hub/spaces-overview#networking).
RDS will not let you create a postgreSQL instance on ports 80 or 443.
Once your database is created, download the dataset from Kaggle and upload it to your database.
For the sake of this demo, we will only upload March 2022 data.
## Step 2.a - Write your ETL code
We will be querying our database for the total count of rides split by the type of bicycle (electric, standard, or docked).
We will also query for the total count of rides that depart from each station and take the top 5.
We will then take the result of our queries and visualize them in with matplotlib.
We will use the pandas [read_sql](https://pandas.pydata.org/docs/reference/api/pandas.read_sql.html)
method to connect to the database. This requires the `psycopg2` library to be installed.
In order to connect to our database, we will specify the database username, password, and host as environment variables.
This will make our app more secure by avoiding storing sensitive information as plain text in our application files.
```python
import os
import pandas as pd
import matplotlib.pyplot as plt
DB_USER = os.getenv("DB_USER")
DB_PASSWORD = os.getenv("DB_PASSWORD")
DB_HOST = os.getenv("DB_HOST")
PORT = 8080
DB_NAME = "bikeshare"
connection_string = f"postgresql://{DB_USER}:{DB_PASSWORD}@{DB_HOST}?port={PORT}&dbname={DB_NAME}"
def get_count_ride_type():
df = pd.read_sql(
"""
SELECT COUNT(ride_id) as n, rideable_type
FROM rides
GROUP BY rideable_type
ORDER BY n DESC
""",
con=connection_string
)
fig_m, ax = plt.subplots()
ax.bar(x=df['rideable_type'], height=df['n'])
ax.set_title("Number of rides by bycycle type")
ax.set_ylabel("Number of Rides")
ax.set_xlabel("Bicycle Type")
return fig_m
def get_most_popular_stations():
df = pd.read_sql(
"""
SELECT COUNT(ride_id) as n, MAX(start_station_name) as station
FROM RIDES
WHERE start_station_name is NOT NULL
GROUP BY start_station_id
ORDER BY n DESC
LIMIT 5
""",
con=connection_string
)
fig_m, ax = plt.subplots()
ax.bar(x=df['station'], height=df['n'])
ax.set_title("Most popular stations")
ax.set_ylabel("Number of Rides")
ax.set_xlabel("Station Name")
ax.set_xticklabels(
df['station'], rotation=45, ha="right", rotation_mode="anchor"
)
ax.tick_params(axis="x", labelsize=8)
fig_m.tight_layout()
return fig_m
```
If you were to run our script locally, you could pass in your credentials as environment variables like so
```bash
DB_USER='username' DB_PASSWORD='password' DB_HOST='host' python app.py
```
## Step 2.c - Write your gradio app
We will display or matplotlib plots in two separate `gr.Plot` components displayed side by side using `gr.Row()`.
Because we have wrapped our function to fetch the data in a `demo.load()` event trigger,
our demo will fetch the latest data **dynamically** from the database each time the web page loads. 🪄
```python
import gradio as gr
with gr.Blocks() as demo:
with gr.Row():
bike_type = gr.Plot()
station = gr.Plot()
demo.load(get_count_ride_type, inputs=None, outputs=bike_type)
demo.load(get_most_popular_stations, inputs=None, outputs=station)
demo.launch()
```
## Step 3 - Deployment
If you run the code above, your app will start running locally.
You can even get a temporary shareable link by passing the `share=True` parameter to `launch`.
But what if you want to a permanent deployment solution?
Let's deploy our Gradio app to the free HuggingFace Spaces platform.
If you haven't used Spaces before, follow the previous guide [here](/using_hugging_face_integrations).
You will have to add the `DB_USER`, `DB_PASSWORD`, and `DB_HOST` variables as "Repo Secrets". You can do this in the "Settings" tab.

## Conclusion
Congratulations! You know how to connect your gradio app to a database hosted on the cloud! ☁️
Our dashboard is now running on [Spaces](https://huggingface.co/spaces/gradio/chicago-bikeshare-dashboard).
The complete code is [here](https://huggingface.co/spaces/gradio/chicago-bikeshare-dashboard/blob/main/app.py)
As you can see, gradio gives you the power to connect to your data wherever it lives and display however you want! 🔥
|
C:\Gradio Guides\7 Tabular Data Science and Plots\creating-a-dashboard-from-bigquery-data.md |
# Creating a Real-Time Dashboard from BigQuery Data
Tags: TABULAR, DASHBOARD, PLOTS
[Google BigQuery](https://cloud.google.com/bigquery) is a cloud-based service for processing very large data sets. It is a serverless and highly scalable data warehousing solution that enables users to analyze data [using SQL-like queries](https://www.oreilly.com/library/view/google-bigquery-the/9781492044451/ch01.html).
In this tutorial, we will show you how to query a BigQuery dataset in Python and display the data in a dashboard that updates in real time using `gradio`. The dashboard will look like this:
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/gradio-guides/bigquery-dashboard.gif">
We'll cover the following steps in this Guide:
1. Setting up your BigQuery credentials
2. Using the BigQuery client
3. Building the real-time dashboard (in just _7 lines of Python_)
We'll be working with the [New York Times' COVID dataset](https://www.nytimes.com/interactive/2021/us/covid-cases.html) that is available as a public dataset on BigQuery. The dataset, named `covid19_nyt.us_counties` contains the latest information about the number of confirmed cases and deaths from COVID across US counties.
**Prerequisites**: This Guide uses [Gradio Blocks](/guides/quickstart/#blocks-more-flexibility-and-control), so make your are familiar with the Blocks class.
## Setting up your BigQuery Credentials
To use Gradio with BigQuery, you will need to obtain your BigQuery credentials and use them with the [BigQuery Python client](https://pypi.org/project/google-cloud-bigquery/). If you already have BigQuery credentials (as a `.json` file), you can skip this section. If not, you can do this for free in just a couple of minutes.
1. First, log in to your Google Cloud account and go to the Google Cloud Console (https://console.cloud.google.com/)
2. In the Cloud Console, click on the hamburger menu in the top-left corner and select "APIs & Services" from the menu. If you do not have an existing project, you will need to create one.
3. Then, click the "+ Enabled APIs & services" button, which allows you to enable specific services for your project. Search for "BigQuery API", click on it, and click the "Enable" button. If you see the "Manage" button, then the BigQuery is already enabled, and you're all set.
4. In the APIs & Services menu, click on the "Credentials" tab and then click on the "Create credentials" button.
5. In the "Create credentials" dialog, select "Service account key" as the type of credentials to create, and give it a name. Also grant the service account permissions by giving it a role such as "BigQuery User", which will allow you to run queries.
6. After selecting the service account, select the "JSON" key type and then click on the "Create" button. This will download the JSON key file containing your credentials to your computer. It will look something like this:
```json
{
"type": "service_account",
"project_id": "your project",
"private_key_id": "your private key id",
"private_key": "private key",
"client_email": "email",
"client_id": "client id",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://accounts.google.com/o/oauth2/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/email_id"
}
```
## Using the BigQuery Client
Once you have the credentials, you will need to use the BigQuery Python client to authenticate using your credentials. To do this, you will need to install the BigQuery Python client by running the following command in the terminal:
```bash
pip install google-cloud-bigquery[pandas]
```
You'll notice that we've installed the pandas add-on, which will be helpful for processing the BigQuery dataset as a pandas dataframe. Once the client is installed, you can authenticate using your credentials by running the following code:
```py
from google.cloud import bigquery
client = bigquery.Client.from_service_account_json("path/to/key.json")
```
With your credentials authenticated, you can now use the BigQuery Python client to interact with your BigQuery datasets.
Here is an example of a function which queries the `covid19_nyt.us_counties` dataset in BigQuery to show the top 20 counties with the most confirmed cases as of the current day:
```py
import numpy as np
QUERY = (
'SELECT * FROM `bigquery-public-data.covid19_nyt.us_counties` '
'ORDER BY date DESC,confirmed_cases DESC '
'LIMIT 20')
def run_query():
query_job = client.query(QUERY)
query_result = query_job.result()
df = query_result.to_dataframe()
# Select a subset of columns
df = df[["confirmed_cases", "deaths", "county", "state_name"]]
# Convert numeric columns to standard numpy types
df = df.astype({"deaths": np.int64, "confirmed_cases": np.int64})
return df
```
## Building the Real-Time Dashboard
Once you have a function to query the data, you can use the `gr.DataFrame` component from the Gradio library to display the results in a tabular format. This is a useful way to inspect the data and make sure that it has been queried correctly.
Here is an example of how to use the `gr.DataFrame` component to display the results. By passing in the `run_query` function to `gr.DataFrame`, we instruct Gradio to run the function as soon as the page loads and show the results. In addition, you also pass in the keyword `every` to tell the dashboard to refresh every hour (60\*60 seconds).
```py
import gradio as gr
with gr.Blocks() as demo:
gr.DataFrame(run_query, every=gr.Timer(60*60))
demo.launch()
```
Perhaps you'd like to add a visualization to our dashboard. You can use the `gr.ScatterPlot()` component to visualize the data in a scatter plot. This allows you to see the relationship between different variables such as case count and case deaths in the dataset and can be useful for exploring the data and gaining insights. Again, we can do this in real-time
by passing in the `every` parameter.
Here is a complete example showing how to use the `gr.ScatterPlot` to visualize in addition to displaying data with the `gr.DataFrame`
```py
import gradio as gr
with gr.Blocks() as demo:
gr.Markdown("# 💉 Covid Dashboard (Updated Hourly)")
with gr.Row():
gr.DataFrame(run_query, every=gr.Timer(60*60))
gr.ScatterPlot(run_query, every=gr.Timer(60*60), x="confirmed_cases",
y="deaths", tooltip="county", width=500, height=500)
demo.queue().launch() # Run the demo with queuing enabled
```
|
C:\Gradio Guides\7 Tabular Data Science and Plots\creating-a-dashboard-from-supabase-data.md |
# Create a Dashboard from Supabase Data
Tags: TABULAR, DASHBOARD, PLOTS
[Supabase](https://supabase.com/) is a cloud-based open-source backend that provides a PostgreSQL database, authentication, and other useful features for building web and mobile applications. In this tutorial, you will learn how to read data from Supabase and plot it in **real-time** on a Gradio Dashboard.
**Prerequisites:** To start, you will need a free Supabase account, which you can sign up for here: [https://app.supabase.com/](https://app.supabase.com/)
In this end-to-end guide, you will learn how to:
- Create tables in Supabase
- Write data to Supabase using the Supabase Python Client
- Visualize the data in a real-time dashboard using Gradio
If you already have data on Supabase that you'd like to visualize in a dashboard, you can skip the first two sections and go directly to [visualizing the data](#visualize-the-data-in-a-real-time-gradio-dashboard)!
## Create a table in Supabase
First of all, we need some data to visualize. Following this [excellent guide](https://supabase.com/blog/loading-data-supabase-python), we'll create fake commerce data and put it in Supabase.
1\. Start by creating a new project in Supabase. Once you're logged in, click the "New Project" button
2\. Give your project a name and database password. You can also choose a pricing plan (for our purposes, the Free Tier is sufficient!)
3\. You'll be presented with your API keys while the database spins up (can take up to 2 minutes).
4\. Click on "Table Editor" (the table icon) in the left pane to create a new table. We'll create a single table called `Product`, with the following schema:
<center>
<table>
<tr><td>product_id</td><td>int8</td></tr>
<tr><td>inventory_count</td><td>int8</td></tr>
<tr><td>price</td><td>float8</td></tr>
<tr><td>product_name</td><td>varchar</td></tr>
</table>
</center>
5\. Click Save to save the table schema.
Our table is now ready!
## Write data to Supabase
The next step is to write data to a Supabase dataset. We will use the Supabase Python library to do this.
6\. Install `supabase` by running the following command in your terminal:
```bash
pip install supabase
```
7\. Get your project URL and API key. Click the Settings (gear icon) on the left pane and click 'API'. The URL is listed in the Project URL box, while the API key is listed in Project API keys (with the tags `service_role`, `secret`)
8\. Now, run the following Python script to write some fake data to the table (note you have to put the values of `SUPABASE_URL` and `SUPABASE_SECRET_KEY` from step 7):
```python
import supabase
# Initialize the Supabase client
client = supabase.create_client('SUPABASE_URL', 'SUPABASE_SECRET_KEY')
# Define the data to write
import random
main_list = []
for i in range(10):
value = {'product_id': i,
'product_name': f"Item {i}",
'inventory_count': random.randint(1, 100),
'price': random.random()*100
}
main_list.append(value)
# Write the data to the table
data = client.table('Product').insert(main_list).execute()
```
Return to your Supabase dashboard and refresh the page, you should now see 10 rows populated in the `Product` table!
## Visualize the Data in a Real-Time Gradio Dashboard
Finally, we will read the data from the Supabase dataset using the same `supabase` Python library and create a realtime dashboard using `gradio`.
Note: We repeat certain steps in this section (like creating the Supabase client) in case you did not go through the previous sections. As described in Step 7, you will need the project URL and API Key for your database.
9\. Write a function that loads the data from the `Product` table and returns it as a pandas Dataframe:
```python
import supabase
import pandas as pd
client = supabase.create_client('SUPABASE_URL', 'SUPABASE_SECRET_KEY')
def read_data():
response = client.table('Product').select("*").execute()
df = pd.DataFrame(response.data)
return df
```
10\. Create a small Gradio Dashboard with 2 Barplots that plots the prices and inventories of all of the items every minute and updates in real-time:
```python
import gradio as gr
with gr.Blocks() as dashboard:
with gr.Row():
gr.BarPlot(read_data, x="product_id", y="price", title="Prices", every=gr.Timer(60))
gr.BarPlot(read_data, x="product_id", y="inventory_count", title="Inventory", every=gr.Timer(60))
dashboard.queue().launch()
```
Notice that by passing in a function to `gr.BarPlot()`, we have the BarPlot query the database as soon as the web app loads (and then again every 60 seconds because of the `every` parameter). Your final dashboard should look something like this:
<gradio-app space="abidlabs/supabase"></gradio-app>
## Conclusion
That's it! In this tutorial, you learned how to write data to a Supabase dataset, and then read that data and plot the results as bar plots. If you update the data in the Supabase database, you'll notice that the Gradio dashboard will update within a minute.
Try adding more plots and visualizations to this example (or with a different dataset) to build a more complex dashboard!
|
C:\Gradio Guides\7 Tabular Data Science and Plots\creating-a-realtime-dashboard-from-google-sheets.md |
# Creating a Real-Time Dashboard from Google Sheets
Tags: TABULAR, DASHBOARD, PLOTS
[Google Sheets](https://www.google.com/sheets/about/) are an easy way to store tabular data in the form of spreadsheets. With Gradio and pandas, it's easy to read data from public or private Google Sheets and then display the data or plot it. In this blog post, we'll build a small _real-time_ dashboard, one that updates when the data in the Google Sheets updates.
Building the dashboard itself will just be 9 lines of Python code using Gradio, and our final dashboard will look like this:
<gradio-app space="gradio/line-plot"></gradio-app>
**Prerequisites**: This Guide uses [Gradio Blocks](/guides/quickstart/#blocks-more-flexibility-and-control), so make you are familiar with the Blocks class.
The process is a little different depending on if you are working with a publicly accessible or a private Google Sheet. We'll cover both, so let's get started!
## Public Google Sheets
Building a dashboard from a public Google Sheet is very easy, thanks to the [`pandas` library](https://pandas.pydata.org/):
1\. Get the URL of the Google Sheets that you want to use. To do this, simply go to the Google Sheets, click on the "Share" button in the top-right corner, and then click on the "Get shareable link" button. This will give you a URL that looks something like this:
```html
https://docs.google.com/spreadsheets/d/1UoKzzRzOCt-FXLLqDKLbryEKEgllGAQUEJ5qtmmQwpU/edit#gid=0
```
2\. Now, let's modify this URL and then use it to read the data from the Google Sheets into a Pandas DataFrame. (In the code below, replace the `URL` variable with the URL of your public Google Sheet):
```python
import pandas as pd
URL = "https://docs.google.com/spreadsheets/d/1UoKzzRzOCt-FXLLqDKLbryEKEgllGAQUEJ5qtmmQwpU/edit#gid=0"
csv_url = URL.replace('/edit#gid=', '/export?format=csv&gid=')
def get_data():
return pd.read_csv(csv_url)
```
3\. The data query is a function, which means that it's easy to display it real-time using the `gr.DataFrame` component, or plot it real-time using the `gr.LinePlot` component (of course, depending on the data, a different plot may be appropriate). To do this, just pass the function into the respective components, and set the `every` parameter based on how frequently (in seconds) you would like the component to refresh. Here's the Gradio code:
```python
import gradio as gr
with gr.Blocks() as demo:
gr.Markdown("# 📈 Real-Time Line Plot")
with gr.Row():
with gr.Column():
gr.DataFrame(get_data, every=gr.Timer(5))
with gr.Column():
gr.LinePlot(get_data, every=gr.Timer(5), x="Date", y="Sales", y_title="Sales ($ millions)", overlay_point=True, width=500, height=500)
demo.queue().launch() # Run the demo with queuing enabled
```
And that's it! You have a dashboard that refreshes every 5 seconds, pulling the data from your Google Sheet.
## Private Google Sheets
For private Google Sheets, the process requires a little more work, but not that much! The key difference is that now, you must authenticate yourself to authorize access to the private Google Sheets.
### Authentication
To authenticate yourself, obtain credentials from Google Cloud. Here's [how to set up google cloud credentials](https://developers.google.com/workspace/guides/create-credentials):
1\. First, log in to your Google Cloud account and go to the Google Cloud Console (https://console.cloud.google.com/)
2\. In the Cloud Console, click on the hamburger menu in the top-left corner and select "APIs & Services" from the menu. If you do not have an existing project, you will need to create one.
3\. Then, click the "+ Enabled APIs & services" button, which allows you to enable specific services for your project. Search for "Google Sheets API", click on it, and click the "Enable" button. If you see the "Manage" button, then Google Sheets is already enabled, and you're all set.
4\. In the APIs & Services menu, click on the "Credentials" tab and then click on the "Create credentials" button.
5\. In the "Create credentials" dialog, select "Service account key" as the type of credentials to create, and give it a name. **Note down the email of the service account**
6\. After selecting the service account, select the "JSON" key type and then click on the "Create" button. This will download the JSON key file containing your credentials to your computer. It will look something like this:
```json
{
"type": "service_account",
"project_id": "your project",
"private_key_id": "your private key id",
"private_key": "private key",
"client_email": "email",
"client_id": "client id",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://accounts.google.com/o/oauth2/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/email_id"
}
```
### Querying
Once you have the credentials `.json` file, you can use the following steps to query your Google Sheet:
1\. Click on the "Share" button in the top-right corner of the Google Sheet. Share the Google Sheets with the email address of the service from Step 5 of authentication subsection (this step is important!). Then click on the "Get shareable link" button. This will give you a URL that looks something like this:
```html
https://docs.google.com/spreadsheets/d/1UoKzzRzOCt-FXLLqDKLbryEKEgllGAQUEJ5qtmmQwpU/edit#gid=0
```
2\. Install the [`gspread` library](https://docs.gspread.org/en/v5.7.0/), which makes it easy to work with the [Google Sheets API](https://developers.google.com/sheets/api/guides/concepts) in Python by running in the terminal: `pip install gspread`
3\. Write a function to load the data from the Google Sheet, like this (replace the `URL` variable with the URL of your private Google Sheet):
```python
import gspread
import pandas as pd
# Authenticate with Google and get the sheet
URL = 'https://docs.google.com/spreadsheets/d/1_91Vps76SKOdDQ8cFxZQdgjTJiz23375sAT7vPvaj4k/edit#gid=0'
gc = gspread.service_account("path/to/key.json")
sh = gc.open_by_url(URL)
worksheet = sh.sheet1
def get_data():
values = worksheet.get_all_values()
df = pd.DataFrame(values[1:], columns=values[0])
return df
```
4\. The data query is a function, which means that it's easy to display it real-time using the `gr.DataFrame` component, or plot it real-time using the `gr.LinePlot` component (of course, depending on the data, a different plot may be appropriate). To do this, we just pass the function into the respective components, and set the `every` parameter based on how frequently (in seconds) we would like the component to refresh. Here's the Gradio code:
```python
import gradio as gr
with gr.Blocks() as demo:
gr.Markdown("# 📈 Real-Time Line Plot")
with gr.Row():
with gr.Column():
gr.DataFrame(get_data, every=gr.Timer(5))
with gr.Column():
gr.LinePlot(get_data, every=gr.Timer(5), x="Date", y="Sales", y_title="Sales ($ millions)", overlay_point=True, width=500, height=500)
demo.queue().launch() # Run the demo with queuing enabled
```
You now have a Dashboard that refreshes every 5 seconds, pulling the data from your Google Sheet.
## Conclusion
And that's all there is to it! With just a few lines of code, you can use `gradio` and other libraries to read data from a public or private Google Sheet and then display and plot the data in a real-time dashboard.
|
C:\Gradio Guides\7 Tabular Data Science and Plots\plot-component-for-maps.md |
# How to Use the Plot Component for Maps
Tags: PLOTS, MAPS
## Introduction
This guide explains how you can use Gradio to plot geographical data on a map using the `gradio.Plot` component. The Gradio `Plot` component works with Matplotlib, Bokeh and Plotly. Plotly is what we will be working with in this guide. Plotly allows developers to easily create all sorts of maps with their geographical data. Take a look [here](https://plotly.com/python/maps/) for some examples.
## Overview
We will be using the New York City Airbnb dataset, which is hosted on kaggle [here](https://www.kaggle.com/datasets/dgomonov/new-york-city-airbnb-open-data). I've uploaded it to the Hugging Face Hub as a dataset [here](https://huggingface.co/datasets/gradio/NYC-Airbnb-Open-Data) for easier use and download. Using this data we will plot Airbnb locations on a map output and allow filtering based on price and location. Below is the demo that we will be building. ⚡️
$demo_map_airbnb
## Step 1 - Loading CSV data 💾
Let's start by loading the Airbnb NYC data from the Hugging Face Hub.
```python
from datasets import load_dataset
dataset = load_dataset("gradio/NYC-Airbnb-Open-Data", split="train")
df = dataset.to_pandas()
def filter_map(min_price, max_price, boroughs):
new_df = df[(df['neighbourhood_group'].isin(boroughs)) &
(df['price'] > min_price) & (df['price'] < max_price)]
names = new_df["name"].tolist()
prices = new_df["price"].tolist()
text_list = [(names[i], prices[i]) for i in range(0, len(names))]
```
In the code above, we first load the csv data into a pandas dataframe. Let's begin by defining a function that we will use as the prediction function for the gradio app. This function will accept the minimum price and maximum price range as well as the list of boroughs to filter the resulting map. We can use the passed in values (`min_price`, `max_price`, and list of `boroughs`) to filter the dataframe and create `new_df`. Next we will create `text_list` of the names and prices of each Airbnb to use as labels on the map.
## Step 2 - Map Figure 🌐
Plotly makes it easy to work with maps. Let's take a look below how we can create a map figure.
```python
import plotly.graph_objects as go
fig = go.Figure(go.Scattermapbox(
customdata=text_list,
lat=new_df['latitude'].tolist(),
lon=new_df['longitude'].tolist(),
mode='markers',
marker=go.scattermapbox.Marker(
size=6
),
hoverinfo="text",
hovertemplate='<b>Name</b>: %{customdata[0]}<br><b>Price</b>: $%{customdata[1]}'
))
fig.update_layout(
mapbox_style="open-street-map",
hovermode='closest',
mapbox=dict(
bearing=0,
center=go.layout.mapbox.Center(
lat=40.67,
lon=-73.90
),
pitch=0,
zoom=9
),
)
```
Above, we create a scatter plot on mapbox by passing it our list of latitudes and longitudes to plot markers. We also pass in our custom data of names and prices for additional info to appear on every marker we hover over. Next we use `update_layout` to specify other map settings such as zoom, and centering.
More info [here](https://plotly.com/python/scattermapbox/) on scatter plots using Mapbox and Plotly.
## Step 3 - Gradio App ⚡️
We will use two `gr.Number` components and a `gr.CheckboxGroup` to allow users of our app to specify price ranges and borough locations. We will then use the `gr.Plot` component as an output for our Plotly + Mapbox map we created earlier.
```python
with gr.Blocks() as demo:
with gr.Column():
with gr.Row():
min_price = gr.Number(value=250, label="Minimum Price")
max_price = gr.Number(value=1000, label="Maximum Price")
boroughs = gr.CheckboxGroup(choices=["Queens", "Brooklyn", "Manhattan", "Bronx", "Staten Island"], value=["Queens", "Brooklyn"], label="Select Boroughs:")
btn = gr.Button(value="Update Filter")
map = gr.Plot()
demo.load(filter_map, [min_price, max_price, boroughs], map)
btn.click(filter_map, [min_price, max_price, boroughs], map)
```
We layout these components using the `gr.Column` and `gr.Row` and we'll also add event triggers for when the demo first loads and when our "Update Filter" button is clicked in order to trigger the map to update with our new filters.
This is what the full demo code looks like:
$code_map_airbnb
## Step 4 - Deployment 🤗
If you run the code above, your app will start running locally.
You can even get a temporary shareable link by passing the `share=True` parameter to `launch`.
But what if you want to a permanent deployment solution?
Let's deploy our Gradio app to the free HuggingFace Spaces platform.
If you haven't used Spaces before, follow the previous guide [here](/using_hugging_face_integrations).
## Conclusion 🎉
And you're all done! That's all the code you need to build a map demo.
Here's a link to the demo [Map demo](https://huggingface.co/spaces/gradio/map_airbnb) and [complete code](https://huggingface.co/spaces/gradio/map_airbnb/blob/main/run.py) (on Hugging Face Spaces)
|
C:\Gradio Guides\7 Tabular Data Science and Plots\styling-the-gradio-dataframe.md |
# How to Style the Gradio Dataframe
Tags: DATAFRAME, STYLE, COLOR
## Introduction
Data visualization is a crucial aspect of data analysis and machine learning. The Gradio `DataFrame` component is a popular way to display tabular data (particularly data in the form of a `pandas` `DataFrame` object) within a web application.
This post will explore the recent enhancements in Gradio that allow users to integrate the styling options of pandas, e.g. adding colors to the DataFrame component, or setting the display precision of numbers.

Let's dive in!
**Prerequisites**: We'll be using the `gradio.Blocks` class in our examples.
You can [read the Guide to Blocks first](https://gradio.app/blocks-and-event-listeners) if you are not already familiar with it. Also please make sure you are using the **latest version** version of Gradio: `pip install --upgrade gradio`.
## Overview
The Gradio `DataFrame` component now supports values of the type `Styler` from the `pandas` class. This allows us to reuse the rich existing API and documentation of the `Styler` class instead of inventing a new style format on our own. Here's a complete example of how it looks:
```python
import pandas as pd
import gradio as gr
# Creating a sample dataframe
df = pd.DataFrame({
"A" : [14, 4, 5, 4, 1],
"B" : [5, 2, 54, 3, 2],
"C" : [20, 20, 7, 3, 8],
"D" : [14, 3, 6, 2, 6],
"E" : [23, 45, 64, 32, 23]
})
# Applying style to highlight the maximum value in each row
styler = df.style.highlight_max(color = 'lightgreen', axis = 0)
# Displaying the styled dataframe in Gradio
with gr.Blocks() as demo:
gr.DataFrame(styler)
demo.launch()
```
The Styler class can be used to apply conditional formatting and styling to dataframes, making them more visually appealing and interpretable. You can highlight certain values, apply gradients, or even use custom CSS to style the DataFrame. The Styler object is applied to a DataFrame and it returns a new object with the relevant styling properties, which can then be previewed directly, or rendered dynamically in a Gradio interface.
To read more about the Styler object, read the official `pandas` documentation at: https://pandas.pydata.org/docs/user_guide/style.html
Below, we'll explore a few examples:
## Highlighting Cells
Ok, so let's revisit the previous example. We start by creating a `pd.DataFrame` object and then highlight the highest value in each row with a light green color:
```python
import pandas as pd
# Creating a sample dataframe
df = pd.DataFrame({
"A" : [14, 4, 5, 4, 1],
"B" : [5, 2, 54, 3, 2],
"C" : [20, 20, 7, 3, 8],
"D" : [14, 3, 6, 2, 6],
"E" : [23, 45, 64, 32, 23]
})
# Applying style to highlight the maximum value in each row
styler = df.style.highlight_max(color = 'lightgreen', axis = 0)
```
Now, we simply pass this object into the Gradio `DataFrame` and we can visualize our colorful table of data in 4 lines of python:
```python
import gradio as gr
with gr.Blocks() as demo:
gr.Dataframe(styler)
demo.launch()
```
Here's how it looks:

## Font Colors
Apart from highlighting cells, you might want to color specific text within the cells. Here's how you can change text colors for certain columns:
```python
import pandas as pd
import gradio as gr
# Creating a sample dataframe
df = pd.DataFrame({
"A" : [14, 4, 5, 4, 1],
"B" : [5, 2, 54, 3, 2],
"C" : [20, 20, 7, 3, 8],
"D" : [14, 3, 6, 2, 6],
"E" : [23, 45, 64, 32, 23]
})
# Function to apply text color
def highlight_cols(x):
df = x.copy()
df.loc[:, :] = 'color: purple'
df[['B', 'C', 'E']] = 'color: green'
return df
# Applying the style function
s = df.style.apply(highlight_cols, axis = None)
# Displaying the styled dataframe in Gradio
with gr.Blocks() as demo:
gr.DataFrame(s)
demo.launch()
```
In this script, we define a custom function highlight_cols that changes the text color to purple for all cells, but overrides this for columns B, C, and E with green. Here's how it looks:

## Display Precision
Sometimes, the data you are dealing with might have long floating numbers, and you may want to display only a fixed number of decimals for simplicity. The pandas Styler object allows you to format the precision of numbers displayed. Here's how you can do this:
```python
import pandas as pd
import gradio as gr
# Creating a sample dataframe with floating numbers
df = pd.DataFrame({
"A" : [14.12345, 4.23456, 5.34567, 4.45678, 1.56789],
"B" : [5.67891, 2.78912, 54.89123, 3.91234, 2.12345],
# ... other columns
})
# Setting the precision of numbers to 2 decimal places
s = df.style.format("{:.2f}")
# Displaying the styled dataframe in Gradio
with gr.Blocks() as demo:
gr.DataFrame(s)
demo.launch()
```
In this script, the format method of the Styler object is used to set the precision of numbers to two decimal places. Much cleaner now:

## Note about Interactivity
One thing to keep in mind is that the gradio `DataFrame` component only accepts `Styler` objects when it is non-interactive (i.e. in "static" mode). If the `DataFrame` component is interactive, then the styling information is ignored and instead the raw table values are shown instead.
The `DataFrame` component is by default non-interactive, unless it is used as an input to an event. In which case, you can force the component to be non-interactive by setting the `interactive` prop like this:
```python
c = gr.DataFrame(styler, interactive=False)
```
## Conclusion 🎉
This is just a taste of what's possible using the `gradio.DataFrame` component with the `Styler` class from `pandas`. Try it out and let us know what you think! |
C:\Gradio Guides\7 Tabular Data Science and Plots\using-gradio-for-tabular-workflows.md |
# Using Gradio for Tabular Data Science Workflows
Related spaces: https://huggingface.co/spaces/scikit-learn/gradio-skops-integration, https://huggingface.co/spaces/scikit-learn/tabular-playground, https://huggingface.co/spaces/merve/gradio-analysis-dashboard
## Introduction
Tabular data science is the most widely used domain of machine learning, with problems ranging from customer segmentation to churn prediction. Throughout various stages of the tabular data science workflow, communicating your work to stakeholders or clients can be cumbersome; which prevents data scientists from focusing on what matters, such as data analysis and model building. Data scientists can end up spending hours building a dashboard that takes in dataframe and returning plots, or returning a prediction or plot of clusters in a dataset. In this guide, we'll go through how to use `gradio` to improve your data science workflows. We will also talk about how to use `gradio` and [skops](https://skops.readthedocs.io/en/stable/) to build interfaces with only one line of code!
### Prerequisites
Make sure you have the `gradio` Python package already [installed](/getting_started).
## Let's Create a Simple Interface!
We will take a look at how we can create a simple UI that predicts failures based on product information.
```python
import gradio as gr
import pandas as pd
import joblib
import datasets
inputs = [gr.Dataframe(row_count = (2, "dynamic"), col_count=(4,"dynamic"), label="Input Data", interactive=1)]
outputs = [gr.Dataframe(row_count = (2, "dynamic"), col_count=(1, "fixed"), label="Predictions", headers=["Failures"])]
model = joblib.load("model.pkl")
# we will give our dataframe as example
df = datasets.load_dataset("merve/supersoaker-failures")
df = df["train"].to_pandas()
def infer(input_dataframe):
return pd.DataFrame(model.predict(input_dataframe))
gr.Interface(fn = infer, inputs = inputs, outputs = outputs, examples = [[df.head(2)]]).launch()
```
Let's break down above code.
- `fn`: the inference function that takes input dataframe and returns predictions.
- `inputs`: the component we take our input with. We define our input as dataframe with 2 rows and 4 columns, which initially will look like an empty dataframe with the aforementioned shape. When the `row_count` is set to `dynamic`, you don't have to rely on the dataset you're inputting to pre-defined component.
- `outputs`: The dataframe component that stores outputs. This UI can take single or multiple samples to infer, and returns 0 or 1 for each sample in one column, so we give `row_count` as 2 and `col_count` as 1 above. `headers` is a list made of header names for dataframe.
- `examples`: You can either pass the input by dragging and dropping a CSV file, or a pandas DataFrame through examples, which headers will be automatically taken by the interface.
We will now create an example for a minimal data visualization dashboard. You can find a more comprehensive version in the related Spaces.
<gradio-app space="gradio/tabular-playground"></gradio-app>
```python
import gradio as gr
import pandas as pd
import datasets
import seaborn as sns
import matplotlib.pyplot as plt
df = datasets.load_dataset("merve/supersoaker-failures")
df = df["train"].to_pandas()
df.dropna(axis=0, inplace=True)
def plot(df):
plt.scatter(df.measurement_13, df.measurement_15, c = df.loading,alpha=0.5)
plt.savefig("scatter.png")
df['failure'].value_counts().plot(kind='bar')
plt.savefig("bar.png")
sns.heatmap(df.select_dtypes(include="number").corr())
plt.savefig("corr.png")
plots = ["corr.png","scatter.png", "bar.png"]
return plots
inputs = [gr.Dataframe(label="Supersoaker Production Data")]
outputs = [gr.Gallery(label="Profiling Dashboard", columns=(1,3))]
gr.Interface(plot, inputs=inputs, outputs=outputs, examples=[df.head(100)], title="Supersoaker Failures Analysis Dashboard").launch()
```
<gradio-app space="gradio/gradio-analysis-dashboard-minimal"></gradio-app>
We will use the same dataset we used to train our model, but we will make a dashboard to visualize it this time.
- `fn`: The function that will create plots based on data.
- `inputs`: We use the same `Dataframe` component we used above.
- `outputs`: The `Gallery` component is used to keep our visualizations.
- `examples`: We will have the dataset itself as the example.
## Easily load tabular data interfaces with one line of code using skops
`skops` is a library built on top of `huggingface_hub` and `sklearn`. With the recent `gradio` integration of `skops`, you can build tabular data interfaces with one line of code!
```python
import gradio as gr
# title and description are optional
title = "Supersoaker Defective Product Prediction"
description = "This model predicts Supersoaker production line failures. Drag and drop any slice from dataset or edit values as you wish in below dataframe component."
gr.load("huggingface/scikit-learn/tabular-playground", title=title, description=description).launch()
```
<gradio-app space="gradio/gradio-skops-integration"></gradio-app>
`sklearn` models pushed to Hugging Face Hub using `skops` include a `config.json` file that contains an example input with column names, the task being solved (that can either be `tabular-classification` or `tabular-regression`). From the task type, `gradio` constructs the `Interface` and consumes column names and the example input to build it. You can [refer to skops documentation on hosting models on Hub](https://skops.readthedocs.io/en/latest/auto_examples/plot_hf_hub.html#sphx-glr-auto-examples-plot-hf-hub-py) to learn how to push your models to Hub using `skops`.
|
C:\Gradio Guides\8 Gradio Clients and Lite\01_getting-started-with-the-python-client.md |
# Getting Started with the Gradio Python client
Tags: CLIENT, API, SPACES
The Gradio Python client makes it very easy to use any Gradio app as an API. As an example, consider this [Hugging Face Space that transcribes audio files](https://huggingface.co/spaces/abidlabs/whisper) that are recorded from the microphone.

Using the `gradio_client` library, we can easily use the Gradio as an API to transcribe audio files programmatically.
Here's the entire code to do it:
```python
from gradio_client import Client, file
client = Client("abidlabs/whisper")
client.predict(
audio=file("audio_sample.wav")
)
>> "This is a test of the whisper speech recognition model."
```
The Gradio client works with any hosted Gradio app! Although the Client is mostly used with apps hosted on [Hugging Face Spaces](https://hf.space), your app can be hosted anywhere, such as your own server.
**Prerequisites**: To use the Gradio client, you do _not_ need to know the `gradio` library in great detail. However, it is helpful to have general familiarity with Gradio's concepts of input and output components.
## Installation
If you already have a recent version of `gradio`, then the `gradio_client` is included as a dependency. But note that this documentation reflects the latest version of the `gradio_client`, so upgrade if you're not sure!
The lightweight `gradio_client` package can be installed from pip (or pip3) and is tested to work with **Python versions 3.9 or higher**:
```bash
$ pip install --upgrade gradio_client
```
## Connecting to a Gradio App on Hugging Face Spaces
Start by connecting instantiating a `Client` object and connecting it to a Gradio app that is running on Hugging Face Spaces.
```python
from gradio_client import Client
client = Client("abidlabs/en2fr") # a Space that translates from English to French
```
You can also connect to private Spaces by passing in your HF token with the `hf_token` parameter. You can get your HF token here: https://huggingface.co/settings/tokens
```python
from gradio_client import Client
client = Client("abidlabs/my-private-space", hf_token="...")
```
## Duplicating a Space for private use
While you can use any public Space as an API, you may get rate limited by Hugging Face if you make too many requests. For unlimited usage of a Space, simply duplicate the Space to create a private Space,
and then use it to make as many requests as you'd like!
The `gradio_client` includes a class method: `Client.duplicate()` to make this process simple (you'll need to pass in your [Hugging Face token](https://huggingface.co/settings/tokens) or be logged in using the Hugging Face CLI):
```python
import os
from gradio_client import Client, file
HF_TOKEN = os.environ.get("HF_TOKEN")
client = Client.duplicate("abidlabs/whisper", hf_token=HF_TOKEN)
client.predict(file("audio_sample.wav"))
>> "This is a test of the whisper speech recognition model."
```
If you have previously duplicated a Space, re-running `duplicate()` will _not_ create a new Space. Instead, the Client will attach to the previously-created Space. So it is safe to re-run the `Client.duplicate()` method multiple times.
**Note:** if the original Space uses GPUs, your private Space will as well, and your Hugging Face account will get billed based on the price of the GPU. To minimize charges, your Space will automatically go to sleep after 1 hour of inactivity. You can also set the hardware using the `hardware` parameter of `duplicate()`.
## Connecting a general Gradio app
If your app is running somewhere else, just provide the full URL instead, including the "http://" or "https://". Here's an example of making predictions to a Gradio app that is running on a share URL:
```python
from gradio_client import Client
client = Client("https://bec81a83-5b5c-471e.gradio.live")
```
## Connecting to a Gradio app with auth
If the Gradio application you are connecting to [requires a username and password](/guides/sharing-your-app#authentication), then provide them as a tuple to the `auth` argument of the `Client` class:
```python
from gradio_client import Client
Client(
space_name,
auth=[username, password]
)
```
## Inspecting the API endpoints
Once you have connected to a Gradio app, you can view the APIs that are available to you by calling the `Client.view_api()` method. For the Whisper Space, we see the following:
```bash
Client.predict() Usage Info
---------------------------
Named API endpoints: 1
- predict(audio, api_name="/predict") -> output
Parameters:
- [Audio] audio: filepath (required)
Returns:
- [Textbox] output: str
```
We see that we have 1 API endpoint in this space, and shows us how to use the API endpoint to make a prediction: we should call the `.predict()` method (which we will explore below), providing a parameter `input_audio` of type `str`, which is a `filepath or URL`.
We should also provide the `api_name='/predict'` argument to the `predict()` method. Although this isn't necessary if a Gradio app has only 1 named endpoint, it does allow us to call different endpoints in a single app if they are available.
## The "View API" Page
As an alternative to running the `.view_api()` method, you can click on the "Use via API" link in the footer of the Gradio app, which shows us the same information, along with example usage.

The View API page also includes an "API Recorder" that lets you interact with the Gradio UI normally and converts your interactions into the corresponding code to run with the Python Client.
## Making a prediction
The simplest way to make a prediction is simply to call the `.predict()` function with the appropriate arguments:
```python
from gradio_client import Client
client = Client("abidlabs/en2fr", api_name='/predict')
client.predict("Hello")
>> Bonjour
```
If there are multiple parameters, then you should pass them as separate arguments to `.predict()`, like this:
```python
from gradio_client import Client
client = Client("gradio/calculator")
client.predict(4, "add", 5)
>> 9.0
```
It is recommended to provide key-word arguments instead of positional arguments:
```python
from gradio_client import Client
client = Client("gradio/calculator")
client.predict(num1=4, operation="add", num2=5)
>> 9.0
```
This allows you to take advantage of default arguments. For example, this Space includes the default value for the Slider component so you do not need to provide it when accessing it with the client.
```python
from gradio_client import Client
client = Client("abidlabs/image_generator")
client.predict(text="an astronaut riding a camel")
```
The default value is the initial value of the corresponding Gradio component. If the component does not have an initial value, but if the corresponding argument in the predict function has a default value of `None`, then that parameter is also optional in the client. Of course, if you'd like to override it, you can include it as well:
```python
from gradio_client import Client
client = Client("abidlabs/image_generator")
client.predict(text="an astronaut riding a camel", steps=25)
```
For providing files or URLs as inputs, you should pass in the filepath or URL to the file enclosed within `gradio_client.file()`. This takes care of uploading the file to the Gradio server and ensures that the file is preprocessed correctly:
```python
from gradio_client import Client, file
client = Client("abidlabs/whisper")
client.predict(
audio=file("https://audio-samples.github.io/samples/mp3/blizzard_unconditional/sample-0.mp3")
)
>> "My thought I have nobody by a beauty and will as you poured. Mr. Rochester is serve in that so don't find simpus, and devoted abode, to at might in a r—"
```
## Running jobs asynchronously
Oe should note that `.predict()` is a _blocking_ operation as it waits for the operation to complete before returning the prediction.
In many cases, you may be better off letting the job run in the background until you need the results of the prediction. You can do this by creating a `Job` instance using the `.submit()` method, and then later calling `.result()` on the job to get the result. For example:
```python
from gradio_client import Client
client = Client(space="abidlabs/en2fr")
job = client.submit("Hello", api_name="/predict") # This is not blocking
# Do something else
job.result() # This is blocking
>> Bonjour
```
## Adding callbacks
Alternatively, one can add one or more callbacks to perform actions after the job has completed running, like this:
```python
from gradio_client import Client
def print_result(x):
print("The translated result is: {x}")
client = Client(space="abidlabs/en2fr")
job = client.submit("Hello", api_name="/predict", result_callbacks=[print_result])
# Do something else
>> The translated result is: Bonjour
```
## Status
The `Job` object also allows you to get the status of the running job by calling the `.status()` method. This returns a `StatusUpdate` object with the following attributes: `code` (the status code, one of a set of defined strings representing the status. See the `utils.Status` class), `rank` (the current position of this job in the queue), `queue_size` (the total queue size), `eta` (estimated time this job will complete), `success` (a boolean representing whether the job completed successfully), and `time` (the time that the status was generated).
```py
from gradio_client import Client
client = Client(src="gradio/calculator")
job = client.submit(5, "add", 4, api_name="/predict")
job.status()
>> <Status.STARTING: 'STARTING'>
```
_Note_: The `Job` class also has a `.done()` instance method which returns a boolean indicating whether the job has completed.
## Cancelling Jobs
The `Job` class also has a `.cancel()` instance method that cancels jobs that have been queued but not started. For example, if you run:
```py
client = Client("abidlabs/whisper")
job1 = client.submit(file("audio_sample1.wav"))
job2 = client.submit(file("audio_sample2.wav"))
job1.cancel() # will return False, assuming the job has started
job2.cancel() # will return True, indicating that the job has been canceled
```
If the first job has started processing, then it will not be canceled. If the second job
has not yet started, it will be successfully canceled and removed from the queue.
## Generator Endpoints
Some Gradio API endpoints do not return a single value, rather they return a series of values. You can get the series of values that have been returned at any time from such a generator endpoint by running `job.outputs()`:
```py
from gradio_client import Client
client = Client(src="gradio/count_generator")
job = client.submit(3, api_name="/count")
while not job.done():
time.sleep(0.1)
job.outputs()
>> ['0', '1', '2']
```
Note that running `job.result()` on a generator endpoint only gives you the _first_ value returned by the endpoint.
The `Job` object is also iterable, which means you can use it to display the results of a generator function as they are returned from the endpoint. Here's the equivalent example using the `Job` as a generator:
```py
from gradio_client import Client
client = Client(src="gradio/count_generator")
job = client.submit(3, api_name="/count")
for o in job:
print(o)
>> 0
>> 1
>> 2
```
You can also cancel jobs that that have iterative outputs, in which case the job will finish as soon as the current iteration finishes running.
```py
from gradio_client import Client
import time
client = Client("abidlabs/test-yield")
job = client.submit("abcdef")
time.sleep(3)
job.cancel() # job cancels after 2 iterations
```
## Demos with Session State
Gradio demos can include [session state](https://www.gradio.app/guides/state-in-blocks), which provides a way for demos to persist information from user interactions within a page session.
For example, consider the following demo, which maintains a list of words that a user has submitted in a `gr.State` component. When a user submits a new word, it is added to the state, and the number of previous occurrences of that word is displayed:
```python
import gradio as gr
def count(word, list_of_words):
return list_of_words.count(word), list_of_words + [word]
with gr.Blocks() as demo:
words = gr.State([])
textbox = gr.Textbox()
number = gr.Number()
textbox.submit(count, inputs=[textbox, words], outputs=[number, words])
demo.launch()
```
If you were to connect this this Gradio app using the Python Client, you would notice that the API information only shows a single input and output:
```csv
Client.predict() Usage Info
---------------------------
Named API endpoints: 1
- predict(word, api_name="/count") -> value_31
Parameters:
- [Textbox] word: str (required)
Returns:
- [Number] value_31: float
```
That is because the Python client handles state automatically for you -- as you make a series of requests, the returned state from one request is stored internally and automatically supplied for the subsequent request. If you'd like to reset the state, you can do that by calling `Client.reset_session()`. |
C:\Gradio Guides\8 Gradio Clients and Lite\02_getting-started-with-the-js-client.md |
# Getting Started with the Gradio JavaScript Client
Tags: CLIENT, API, SPACES
The Gradio JavaScript Client makes it very easy to use any Gradio app as an API. As an example, consider this [Hugging Face Space that transcribes audio files](https://huggingface.co/spaces/abidlabs/whisper) that are recorded from the microphone.

Using the `@gradio/client` library, we can easily use the Gradio as an API to transcribe audio files programmatically.
Here's the entire code to do it:
```js
import { Client } from "@gradio/client";
const response = await fetch(
"https://github.com/audio-samples/audio-samples.github.io/raw/master/samples/wav/ted_speakers/SalmanKhan/sample-1.wav"
);
const audio_file = await response.blob();
const app = await Client.connect("abidlabs/whisper");
const transcription = await app.predict("/predict", [audio_file]);
console.log(transcription.data);
// [ "I said the same phrase 30 times." ]
```
The Gradio Client works with any hosted Gradio app, whether it be an image generator, a text summarizer, a stateful chatbot, a tax calculator, or anything else! The Gradio Client is mostly used with apps hosted on [Hugging Face Spaces](https://hf.space), but your app can be hosted anywhere, such as your own server.
**Prequisites**: To use the Gradio client, you do _not_ need to know the `gradio` library in great detail. However, it is helpful to have general familiarity with Gradio's concepts of input and output components.
## Installation via npm
Install the @gradio/client package to interact with Gradio APIs using Node.js version >=18.0.0 or in browser-based projects. Use npm or any compatible package manager:
```bash
npm i @gradio/client
```
This command adds @gradio/client to your project dependencies, allowing you to import it in your JavaScript or TypeScript files.
## Installation via CDN
For quick addition to your web project, you can use the jsDelivr CDN to load the latest version of @gradio/client directly into your HTML:
```bash
<script src="https://cdn.jsdelivr.net/npm/@gradio/client/dist/index.min.js"></script>
```
Be sure to add this to the `<head>` of your HTML. This will install the latest version but we advise hardcoding the version in production. You can find all available versions [here](https://www.jsdelivr.com/package/npm/@gradio/client). This approach is ideal for experimental or prototying purposes, though has some limitations.
## Connecting to a running Gradio App
Start by connecting instantiating a `client` instance and connecting it to a Gradio app that is running on Hugging Face Spaces or generally anywhere on the web.
## Connecting to a Hugging Face Space
```js
import { Client } from "@gradio/client";
const app = Client.connect("abidlabs/en2fr"); // a Space that translates from English to French
```
You can also connect to private Spaces by passing in your HF token with the `hf_token` property of the options parameter. You can get your HF token here: https://huggingface.co/settings/tokens
```js
import { Client } from "@gradio/client";
const app = Client.connect("abidlabs/my-private-space", { hf_token="hf_..." })
```
## Duplicating a Space for private use
While you can use any public Space as an API, you may get rate limited by Hugging Face if you make too many requests. For unlimited usage of a Space, simply duplicate the Space to create a private Space, and then use it to make as many requests as you'd like! You'll need to pass in your [Hugging Face token](https://huggingface.co/settings/tokens)).
`Client.duplicate` is almost identical to `Client.connect`, the only difference is under the hood:
```js
import { Client } from "@gradio/client";
const response = await fetch(
"https://audio-samples.github.io/samples/mp3/blizzard_unconditional/sample-0.mp3"
);
const audio_file = await response.blob();
const app = await Client.duplicate("abidlabs/whisper", { hf_token: "hf_..." });
const transcription = await app.predict("/predict", [audio_file]);
```
If you have previously duplicated a Space, re-running `Client.duplicate` will _not_ create a new Space. Instead, the client will attach to the previously-created Space. So it is safe to re-run the `Client.duplicate` method multiple times with the same space.
**Note:** if the original Space uses GPUs, your private Space will as well, and your Hugging Face account will get billed based on the price of the GPU. To minimize charges, your Space will automatically go to sleep after 5 minutes of inactivity. You can also set the hardware using the `hardware` and `timeout` properties of `duplicate`'s options object like this:
```js
import { Client } from "@gradio/client";
const app = await Client.duplicate("abidlabs/whisper", {
hf_token: "hf_...",
timeout: 60,
hardware: "a10g-small"
});
```
## Connecting a general Gradio app
If your app is running somewhere else, just provide the full URL instead, including the "http://" or "https://". Here's an example of making predictions to a Gradio app that is running on a share URL:
```js
import { Client } from "@gradio/client";
const app = Client.connect("https://bec81a83-5b5c-471e.gradio.live");
```
## Connecting to a Gradio app with auth
If the Gradio application you are connecting to [requires a username and password](/guides/sharing-your-app#authentication), then provide them as a tuple to the `auth` argument of the `Client` class:
```js
import { Client } from "@gradio/client";
Client.connect(
space_name,
{ auth: [username, password] }
)
```
## Inspecting the API endpoints
Once you have connected to a Gradio app, you can view the APIs that are available to you by calling the `Client`'s `view_api` method.
For the Whisper Space, we can do this:
```js
import { Client } from "@gradio/client";
const app = await Client.connect("abidlabs/whisper");
const app_info = await app.view_api();
console.log(app_info);
```
And we will see the following:
```json
{
"named_endpoints": {
"/predict": {
"parameters": [
{
"label": "text",
"component": "Textbox",
"type": "string"
}
],
"returns": [
{
"label": "output",
"component": "Textbox",
"type": "string"
}
]
}
},
"unnamed_endpoints": {}
}
```
This shows us that we have 1 API endpoint in this space, and shows us how to use the API endpoint to make a prediction: we should call the `.predict()` method (which we will explore below), providing a parameter `input_audio` of type `string`, which is a url to a file.
We should also provide the `api_name='/predict'` argument to the `predict()` method. Although this isn't necessary if a Gradio app has only 1 named endpoint, it does allow us to call different endpoints in a single app if they are available. If an app has unnamed API endpoints, these can also be displayed by running `.view_api(all_endpoints=True)`.
## The "View API" Page
As an alternative to running the `.view_api()` method, you can click on the "Use via API" link in the footer of the Gradio app, which shows us the same information, along with example usage.

The View API page also includes an "API Recorder" that lets you interact with the Gradio UI normally and converts your interactions into the corresponding code to run with the JS Client.
## Making a prediction
The simplest way to make a prediction is simply to call the `.predict()` method with the appropriate arguments:
```js
import { Client } from "@gradio/client";
const app = await Client.connect("abidlabs/en2fr");
const result = await app.predict("/predict", ["Hello"]);
```
If there are multiple parameters, then you should pass them as an array to `.predict()`, like this:
```js
import { Client } from "@gradio/client";
const app = await Client.connect("gradio/calculator");
const result = await app.predict("/predict", [4, "add", 5]);
```
For certain inputs, such as images, you should pass in a `Buffer`, `Blob` or `File` depending on what is most convenient. In node, this would be a `Buffer` or `Blob`; in a browser environment, this would be a `Blob` or `File`.
```js
import { Client } from "@gradio/client";
const response = await fetch(
"https://audio-samples.github.io/samples/mp3/blizzard_unconditional/sample-0.mp3"
);
const audio_file = await response.blob();
const app = await Client.connect("abidlabs/whisper");
const result = await app.predict("/predict", [audio_file]);
```
## Using events
If the API you are working with can return results over time, or you wish to access information about the status of a job, you can use the iterable interface for more flexibility. This is especially useful for iterative endpoints or generator endpoints that will produce a series of values over time as discreet responses.
```js
import { Client } from "@gradio/client";
function log_result(payload) {
const {
data: [translation]
} = payload;
console.log(`The translated result is: ${translation}`);
}
const app = await Client.connect("abidlabs/en2fr");
const job = app.submit("/predict", ["Hello"]);
for await (const message of job) {
log_result(message);
}
```
## Status
The event interface also allows you to get the status of the running job by instantiating the client with the `events` options passing `status` and `data` as an array:
```ts
import { Client } from "@gradio/client";
const app = await Client.connect("abidlabs/en2fr", {
events: ["status", "data"]
});
```
This ensures that status messages are also reported to the client.
`status`es are returned as an object with the following attributes: `status` (a human readbale status of the current job, `"pending" | "generating" | "complete" | "error"`), `code` (the detailed gradio code for the job), `position` (the current position of this job in the queue), `queue_size` (the total queue size), `eta` (estimated time this job will complete), `success` (a boolean representing whether the job completed successfully), and `time` ( as `Date` object detailing the time that the status was generated).
```js
import { Client } from "@gradio/client";
function log_status(status) {
console.log(
`The current status for this job is: ${JSON.stringify(status, null, 2)}.`
);
}
const app = await Client.connect("abidlabs/en2fr", {
events: ["status", "data"]
});
const job = app.submit("/predict", ["Hello"]);
for await (const message of job) {
if (message.type === "status") {
log_status(message);
}
}
```
## Cancelling Jobs
The job instance also has a `.cancel()` method that cancels jobs that have been queued but not started. For example, if you run:
```js
import { Client } from "@gradio/client";
const app = await Client.connect("abidlabs/en2fr");
const job_one = app.submit("/predict", ["Hello"]);
const job_two = app.submit("/predict", ["Friends"]);
job_one.cancel();
job_two.cancel();
```
If the first job has started processing, then it will not be canceled but the client will no longer listen for updates (throwing away the job). If the second job has not yet started, it will be successfully canceled and removed from the queue.
## Generator Endpoints
Some Gradio API endpoints do not return a single value, rather they return a series of values. You can listen for these values in real time using the iterable interface:
```js
import { Client } from "@gradio/client";
const app = await Client.connect("gradio/count_generator");
const job = app.submit(0, [9]);
for await (const message of job) {
console.log(message.data);
}
```
This will log out the values as they are generated by the endpoint.
You can also cancel jobs that that have iterative outputs, in which case the job will finish immediately.
```js
import { Client } from "@gradio/client";
const app = await Client.connect("gradio/count_generator");
const job = app.submit(0, [9]);
for await (const message of job) {
console.log(message.data);
}
setTimeout(() => {
job.cancel();
}, 3000);
```
|
C:\Gradio Guides\8 Gradio Clients and Lite\03_querying-gradio-apps-with-curl.md |
# Querying Gradio Apps with Curl
Tags: CURL, API, SPACES
It is possible to use any Gradio app as an API using cURL, the command-line tool that is pre-installed on many operating systems. This is particularly useful if you are trying to query a Gradio app from an environment other than Python or Javascript (since specialized Gradio clients exist for both [Python](/guides/getting-started-with-the-python-client) and [Javascript](/guides/getting-started-with-the-js-client)).
As an example, consider this Gradio demo that translates text from English to French: https://abidlabs-en2fr.hf.space/.
Using `curl`, we can translate text programmatically.
Here's the code to do it:
```bash
$ curl -X POST https://abidlabs-en2fr.hf.space/call/predict -H "Content-Type: application/json" -d '{
"data": ["Hello, my friend."]
}'
>> {"event_id": $EVENT_ID}
```
```bash
$ curl -N https://abidlabs-en2fr.hf.space/call/predict/$EVENT_ID
>> event: complete
>> data: ["Bonjour, mon ami."]
```
Note: making a prediction and getting a result requires two `curl` requests: a `POST` and a `GET`. The `POST` request returns an `EVENT_ID` and prints it to the console, which is used in the second `GET` request to fetch the results. You can combine these into a single command using `awk` and `read` to parse the results of the first command and pipe into the second, like this:
```bash
$ curl -X POST https://abidlabs-en2fr.hf.space/call/predict -H "Content-Type: application/json" -d '{
"data": ["Hello, my friend."]
}' \
| awk -F'"' '{ print $4}' \
| read EVENT_ID; curl -N https://abidlabs-en2fr.hf.space/call/predict/$EVENT_ID
>> event: complete
>> data: ["Bonjour, mon ami."]
```
In the rest of this Guide, we'll explain these two steps in more detail and provide additional examples of querying Gradio apps with `curl`.
**Prerequisites**: For this Guide, you do _not_ need to know how to build Gradio apps in great detail. However, it is helpful to have general familiarity with Gradio's concepts of input and output components.
## Installation
You generally don't need to install cURL, as it comes pre-installed on many operating systems. Run:
```bash
curl --version
```
to confirm that `curl` is installed. If it is not already installed, you can install it by visiting https://curl.se/download.html.
## Step 0: Get the URL for your Gradio App
To query a Gradio app, you'll need its full URL. This is usually just the URL that the Gradio app is hosted on, for example: https://bec81a83-5b5c-471e.gradio.live
**Hugging Face Spaces**
However, if you are querying a Gradio on Hugging Face Spaces, you will need to use the URL of the embedded Gradio app, not the URL of the Space webpage. For example:
```bash
❌ Space URL: https://huggingface.co/spaces/abidlabs/en2fr
✅ Gradio app URL: https://abidlabs-en2fr.hf.space/
```
You can get the Gradio app URL by clicking the "view API" link at the bottom of the page. Or, you can right-click on the page and then click on "View Frame Source" or the equivalent in your browser to view the URL of the embedded Gradio app.
While you can use any public Space as an API, you may get rate limited by Hugging Face if you make too many requests. For unlimited usage of a Space, simply duplicate the Space to create a private Space,
and then use it to make as many requests as you'd like!
Note: to query private Spaces, you will need to pass in your Hugging Face (HF) token. You can get your HF token here: https://huggingface.co/settings/tokens. In this case, you will need to include an additional header in both of your `curl` calls that we'll discuss below:
```bash
-H "Authorization: Bearer $HF_TOKEN"
```
Now, we are ready to make the two `curl` requests.
## Step 1: Make a Prediction (POST)
The first of the two `curl` requests is `POST` request that submits the input payload to the Gradio app.
The syntax of the `POST` request is as follows:
```bash
$ curl -X POST $URL/call/$API_NAME -H "Content-Type: application/json" -d '{
"data": $PAYLOAD
}'
```
Here:
* `$URL` is the URL of the Gradio app as obtained in Step 0
* `$API_NAME` is the name of the API endpoint for the event that you are running. You can get the API endpoint names by clicking the "view API" link at the bottom of the page.
* `$PAYLOAD` is a valid JSON data list containing the input payload, one element for each input component.
When you make this `POST` request successfully, you will get an event id that is printed to the terminal in this format:
```bash
>> {"event_id": $EVENT_ID}
```
This `EVENT_ID` will be needed in the subsequent `curl` request to fetch the results of the prediction.
Here are some examples of how to make the `POST` request
**Basic Example**
Revisiting the example at the beginning of the page, here is how to make the `POST` request for a simple Gradio application that takes in a single input text component:
```bash
$ curl -X POST https://abidlabs-en2fr.hf.space/call/predict -H "Content-Type: application/json" -d '{
"data": ["Hello, my friend."]
}'
```
**Multiple Input Components**
This [Gradio demo](https://huggingface.co/spaces/gradio/hello_world_3) accepts three inputs: a string corresponding to the `gr.Textbox`, a boolean value corresponding to the `gr.Checkbox`, and a numerical value corresponding to the `gr.Slider`. Here is the `POST` request:
```bash
curl -X POST https://gradio-hello-world-3.hf.space/call/predict -H "Content-Type: application/json" -d '{
"data": ["Hello", true, 5]
}'
```
**Private Spaces**
As mentioned earlier, if you are making a request to a private Space, you will need to pass in a [Hugging Face token](https://huggingface.co/settings/tokens) that has read access to the Space. The request will look like this:
```bash
$ curl -X POST https://private-space.hf.space/call/predict -H "Content-Type: application/json" -H "Authorization: Bearer $HF_TOKEN" -d '{
"data": ["Hello, my friend."]
}'
```
**Files**
If you are using `curl` to query a Gradio application that requires file inputs, the files *need* to be provided as URLs, and The URL needs to be enclosed in a dictionary in this format:
```bash
{"path": $URL}
```
Here is an example `POST` request:
```bash
$ curl -X POST https://gradio-image-mod.hf.space/call/predict -H "Content-Type: application/json" -d '{
"data": [{"path": "https://raw.githubusercontent.com/gradio-app/gradio/main/test/test_files/bus.png"}]
}'
```
**Stateful Demos**
If your Gradio demo [persists user state](/guides/interface-state) across multiple interactions (e.g. is a chatbot), you can pass in a `session_hash` alongside the `data`. Requests with the same `session_hash` are assumed to be part of the same user session. Here's how that might look:
```bash
# These two requests will share a session
curl -X POST https://gradio-chatinterface-random-response.hf.space/call/chat -H "Content-Type: application/json" -d '{
"data": ["Are you sentient?"],
"session_hash": "randomsequence1234"
}'
curl -X POST https://gradio-chatinterface-random-response.hf.space/call/chat -H "Content-Type: application/json" -d '{
"data": ["Really?"],
"session_hash": "randomsequence1234"
}'
# This request will be treated as a new session
curl -X POST https://gradio-chatinterface-random-response.hf.space/call/chat -H "Content-Type: application/json" -d '{
"data": ["Are you sentient?"],
"session_hash": "newsequence5678"
}'
```
## Step 2: GET the result
Once you have received the `EVENT_ID` corresponding to your prediction, you can stream the results. Gradio stores these results in a least-recently-used cache in the Gradio app. By default, the cache can store 2,000 results (across all users and endpoints of the app).
To stream the results for your prediction, make a `GET` request with the following syntax:
```bash
$ curl -N $URL/call/$API_NAME/$EVENT_ID
```
Tip: If you are fetching results from a private Space, include a header with your HF token like this: `-H "Authorization: Bearer $HF_TOKEN"` in the `GET` request.
This should produce a stream of responses in this format:
```bash
event: ...
data: ...
event: ...
data: ...
...
```
Here: `event` can be one of the following:
* `generating`: indicating an intermediate result
* `complete`: indicating that the prediction is complete and the final result
* `error`: indicating that the prediction was not completed successfully
* `heartbeat`: sent every 15 seconds to keep the request alive
The `data` is in the same format as the input payload: valid JSON data list containing the output result, one element for each output component.
Here are some examples of what results you should expect if a request is completed successfully:
**Basic Example**
Revisiting the example at the beginning of the page, we would expect the result to look like this:
```bash
event: complete
data: ["Bonjour, mon ami."]
```
**Multiple Outputs**
If your endpoint returns multiple values, they will appear as elements of the `data` list:
```bash
event: complete
data: ["Good morning Hello. It is 5 degrees today", -15.0]
```
**Streaming Example**
If your Gradio app [streams a sequence of values](/guides/streaming-outputs), then they will be streamed directly to your terminal, like this:
```bash
event: generating
data: ["Hello, w!"]
event: generating
data: ["Hello, wo!"]
event: generating
data: ["Hello, wor!"]
event: generating
data: ["Hello, worl!"]
event: generating
data: ["Hello, world!"]
event: complete
data: ["Hello, world!"]
```
**File Example**
If your Gradio app returns a file, the file will be represented as a dictionary in this format (including potentially some additional keys):
```python
{
"orig_name": "example.jpg",
"path": "/path/in/server.jpg",
"url": "https:/example.com/example.jpg",
"meta": {"_type": "gradio.FileData"}
}
```
In your terminal, it may appear like this:
```bash
event: complete
data: [{"path": "/tmp/gradio/359933dc8d6cfe1b022f35e2c639e6e42c97a003/image.webp", "url": "https://gradio-image-mod.hf.space/c/file=/tmp/gradio/359933dc8d6cfe1b022f35e2c639e6e42c97a003/image.webp", "size": null, "orig_name": "image.webp", "mime_type": null, "is_stream": false, "meta": {"_type": "gradio.FileData"}}]
```
## Authentication
What if your Gradio application has [authentication enabled](/guides/sharing-your-app#authentication)? In that case, you'll need to make an additional `POST` request with cURL to authenticate yourself before you make any queries. Here are the complete steps:
First, login with a `POST` request supplying a valid username and password:
```bash
curl -X POST $URL/login \
-d "username=$USERNAME&password=$PASSWORD" \
-c cookies.txt
```
If the credentials are correct, you'll get `{"success":true}` in response and the cookies will be saved in `cookies.txt`.
Next, you'll need to include these cookies when you make the original `POST` request, like this:
```bash
$ curl -X POST $URL/call/$API_NAME -b cookies.txt -H "Content-Type: application/json" -d '{
"data": $PAYLOAD
}'
```
Finally, you'll need to `GET` the results, again supplying the cookies from the file:
```bash
curl -N $URL/call/$API_NAME/$EVENT_ID -b cookies.txt
```
|
C:\Gradio Guides\8 Gradio Clients and Lite\04_gradio-and-llm-agents.md |
# Gradio & LLM Agents 🤝
Large Language Models (LLMs) are very impressive but they can be made even more powerful if we could give them skills to accomplish specialized tasks.
The [gradio_tools](https://github.com/freddyaboulton/gradio-tools) library can turn any [Gradio](https://github.com/gradio-app/gradio) application into a [tool](https://python.langchain.com/en/latest/modules/agents/tools.html) that an [agent](https://docs.langchain.com/docs/components/agents/agent) can use to complete its task. For example, an LLM could use a Gradio tool to transcribe a voice recording it finds online and then summarize it for you. Or it could use a different Gradio tool to apply OCR to a document on your Google Drive and then answer questions about it.
This guide will show how you can use `gradio_tools` to grant your LLM Agent access to the cutting edge Gradio applications hosted in the world. Although `gradio_tools` are compatible with more than one agent framework, we will focus on [Langchain Agents](https://docs.langchain.com/docs/components/agents/) in this guide.
## Some background
### What are agents?
A [LangChain agent](https://docs.langchain.com/docs/components/agents/agent) is a Large Language Model (LLM) that takes user input and reports an output based on using one of many tools at its disposal.
### What is Gradio?
[Gradio](https://github.com/gradio-app/gradio) is the defacto standard framework for building Machine Learning Web Applications and sharing them with the world - all with just python! 🐍
## gradio_tools - An end-to-end example
To get started with `gradio_tools`, all you need to do is import and initialize your tools and pass them to the langchain agent!
In the following example, we import the `StableDiffusionPromptGeneratorTool` to create a good prompt for stable diffusion, the
`StableDiffusionTool` to create an image with our improved prompt, the `ImageCaptioningTool` to caption the generated image, and
the `TextToVideoTool` to create a video from a prompt.
We then tell our agent to create an image of a dog riding a skateboard, but to please improve our prompt ahead of time. We also ask
it to caption the generated image and create a video for it. The agent can decide which tool to use without us explicitly telling it.
```python
import os
if not os.getenv("OPENAI_API_KEY"):
raise ValueError("OPENAI_API_KEY must be set")
from langchain.agents import initialize_agent
from langchain.llms import OpenAI
from gradio_tools import (StableDiffusionTool, ImageCaptioningTool, StableDiffusionPromptGeneratorTool,
TextToVideoTool)
from langchain.memory import ConversationBufferMemory
llm = OpenAI(temperature=0)
memory = ConversationBufferMemory(memory_key="chat_history")
tools = [StableDiffusionTool().langchain, ImageCaptioningTool().langchain,
StableDiffusionPromptGeneratorTool().langchain, TextToVideoTool().langchain]
agent = initialize_agent(tools, llm, memory=memory, agent="conversational-react-description", verbose=True)
output = agent.run(input=("Please create a photo of a dog riding a skateboard "
"but improve my prompt prior to using an image generator."
"Please caption the generated image and create a video for it using the improved prompt."))
```
You'll note that we are using some pre-built tools that come with `gradio_tools`. Please see this [doc](https://github.com/freddyaboulton/gradio-tools#gradio-tools-gradio--llm-agents) for a complete list of the tools that come with `gradio_tools`.
If you would like to use a tool that's not currently in `gradio_tools`, it is very easy to add your own. That's what the next section will cover.
## gradio_tools - creating your own tool
The core abstraction is the `GradioTool`, which lets you define a new tool for your LLM as long as you implement a standard interface:
```python
class GradioTool(BaseTool):
def __init__(self, name: str, description: str, src: str) -> None:
@abstractmethod
def create_job(self, query: str) -> Job:
pass
@abstractmethod
def postprocess(self, output: Tuple[Any] | Any) -> str:
pass
```
The requirements are:
1. The name for your tool
2. The description for your tool. This is crucial! Agents decide which tool to use based on their description. Be precise and be sure to include example of what the input and the output of the tool should look like.
3. The url or space id, e.g. `freddyaboulton/calculator`, of the Gradio application. Based on this value, `gradio_tool` will create a [gradio client](https://github.com/gradio-app/gradio/blob/main/client/python/README.md) instance to query the upstream application via API. Be sure to click the link and learn more about the gradio client library if you are not familiar with it.
4. create_job - Given a string, this method should parse that string and return a job from the client. Most times, this is as simple as passing the string to the `submit` function of the client. More info on creating jobs [here](https://github.com/gradio-app/gradio/blob/main/client/python/README.md#making-a-prediction)
5. postprocess - Given the result of the job, convert it to a string the LLM can display to the user.
6. _Optional_ - Some libraries, e.g. [MiniChain](https://github.com/srush/MiniChain/tree/main), may need some info about the underlying gradio input and output types used by the tool. By default, this will return gr.Textbox() but
if you'd like to provide more accurate info, implement the `_block_input(self, gr)` and `_block_output(self, gr)` methods of the tool. The `gr` variable is the gradio module (the result of `import gradio as gr`). It will be
automatically imported by the `GradiTool` parent class and passed to the `_block_input` and `_block_output` methods.
And that's it!
Once you have created your tool, open a pull request to the `gradio_tools` repo! We welcome all contributions.
## Example tool - Stable Diffusion
Here is the code for the StableDiffusion tool as an example:
```python
from gradio_tool import GradioTool
import os
class StableDiffusionTool(GradioTool):
"""Tool for calling stable diffusion from llm"""
def __init__(
self,
name="StableDiffusion",
description=(
"An image generator. Use this to generate images based on "
"text input. Input should be a description of what the image should "
"look like. The output will be a path to an image file."
),
src="gradio-client-demos/stable-diffusion",
hf_token=None,
) -> None:
super().__init__(name, description, src, hf_token)
def create_job(self, query: str) -> Job:
return self.client.submit(query, "", 9, fn_index=1)
def postprocess(self, output: str) -> str:
return [os.path.join(output, i) for i in os.listdir(output) if not i.endswith("json")][0]
def _block_input(self, gr) -> "gr.components.Component":
return gr.Textbox()
def _block_output(self, gr) -> "gr.components.Component":
return gr.Image()
```
Some notes on this implementation:
1. All instances of `GradioTool` have an attribute called `client` that is a pointed to the underlying [gradio client](https://github.com/gradio-app/gradio/tree/main/client/python#gradio_client-use-a-gradio-app-as-an-api----in-3-lines-of-python). That is what you should use
in the `create_job` method.
2. `create_job` just passes the query string to the `submit` function of the client with some other parameters hardcoded, i.e. the negative prompt string and the guidance scale. We could modify our tool to also accept these values from the input string in a subsequent version.
3. The `postprocess` method simply returns the first image from the gallery of images created by the stable diffusion space. We use the `os` module to get the full path of the image.
## Conclusion
You now know how to extend the abilities of your LLM with the 1000s of gradio spaces running in the wild!
Again, we welcome any contributions to the [gradio_tools](https://github.com/freddyaboulton/gradio-tools) library.
We're excited to see the tools you all build!
|
C:\Gradio Guides\8 Gradio Clients and Lite\05_gradio-lite.md |
# Gradio-Lite: Serverless Gradio Running Entirely in Your Browser
Tags: SERVERLESS, BROWSER, PYODIDE
Gradio is a popular Python library for creating interactive machine learning apps. Traditionally, Gradio applications have relied on server-side infrastructure to run, which can be a hurdle for developers who need to host their applications.
Enter Gradio-lite (`@gradio/lite`): a library that leverages [Pyodide](https://pyodide.org/en/stable/) to bring Gradio directly to your browser. In this blog post, we'll explore what `@gradio/lite` is, go over example code, and discuss the benefits it offers for running Gradio applications.
## What is `@gradio/lite`?
`@gradio/lite` is a JavaScript library that enables you to run Gradio applications directly within your web browser. It achieves this by utilizing Pyodide, a Python runtime for WebAssembly, which allows Python code to be executed in the browser environment. With `@gradio/lite`, you can **write regular Python code for your Gradio applications**, and they will **run seamlessly in the browser** without the need for server-side infrastructure.
## Getting Started
Let's build a "Hello World" Gradio app in `@gradio/lite`
### 1. Import JS and CSS
Start by creating a new HTML file, if you don't have one already. Importing the JavaScript and CSS corresponding to the `@gradio/lite` package by using the following code:
```html
<html>
<head>
<script type="module" crossorigin src="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.js"></script>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.css" />
</head>
</html>
```
Note that you should generally use the latest version of `@gradio/lite` that is available. You can see the [versions available here](https://www.jsdelivr.com/package/npm/@gradio/lite?tab=files).
### 2. Create the `<gradio-lite>` tags
Somewhere in the body of your HTML page (wherever you'd like the Gradio app to be rendered), create opening and closing `<gradio-lite>` tags.
```html
<html>
<head>
<script type="module" crossorigin src="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.js"></script>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.css" />
</head>
<body>
<gradio-lite>
</gradio-lite>
</body>
</html>
```
Note: you can add the `theme` attribute to the `<gradio-lite>` tag to force the theme to be dark or light (by default, it respects the system theme). E.g.
```html
<gradio-lite theme="dark">
...
</gradio-lite>
```
### 3. Write your Gradio app inside of the tags
Now, write your Gradio app as you would normally, in Python! Keep in mind that since this is Python, whitespace and indentations matter.
```html
<html>
<head>
<script type="module" crossorigin src="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.js"></script>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.css" />
</head>
<body>
<gradio-lite>
import gradio as gr
def greet(name):
return "Hello, " + name + "!"
gr.Interface(greet, "textbox", "textbox").launch()
</gradio-lite>
</body>
</html>
```
And that's it! You should now be able to open your HTML page in the browser and see the Gradio app rendered! Note that it may take a little while for the Gradio app to load initially since Pyodide can take a while to install in your browser.
**Note on debugging**: to see any errors in your Gradio-lite application, open the inspector in your web browser. All errors (including Python errors) will be printed there.
## More Examples: Adding Additional Files and Requirements
What if you want to create a Gradio app that spans multiple files? Or that has custom Python requirements? Both are possible with `@gradio/lite`!
### Multiple Files
Adding multiple files within a `@gradio/lite` app is very straightforward: use the `<gradio-file>` tag. You can have as many `<gradio-file>` tags as you want, but each one needs to have a `name` attribute and the entry point to your Gradio app should have the `entrypoint` attribute.
Here's an example:
```html
<gradio-lite>
<gradio-file name="app.py" entrypoint>
import gradio as gr
from utils import add
demo = gr.Interface(fn=add, inputs=["number", "number"], outputs="number")
demo.launch()
</gradio-file>
<gradio-file name="utils.py" >
def add(a, b):
return a + b
</gradio-file>
</gradio-lite>
```
### Additional Requirements
If your Gradio app has additional requirements, it is usually possible to [install them in the browser using micropip](https://pyodide.org/en/stable/usage/loading-packages.html#loading-packages). We've created a wrapper to make this paticularly convenient: simply list your requirements in the same syntax as a `requirements.txt` and enclose them with `<gradio-requirements>` tags.
Here, we install `transformers_js_py` to run a text classification model directly in the browser!
```html
<gradio-lite>
<gradio-requirements>
transformers_js_py
</gradio-requirements>
<gradio-file name="app.py" entrypoint>
from transformers_js import import_transformers_js
import gradio as gr
transformers = await import_transformers_js()
pipeline = transformers.pipeline
pipe = await pipeline('sentiment-analysis')
async def classify(text):
return await pipe(text)
demo = gr.Interface(classify, "textbox", "json")
demo.launch()
</gradio-file>
</gradio-lite>
```
**Try it out**: You can see this example running in [this Hugging Face Static Space](https://huggingface.co/spaces/abidlabs/gradio-lite-classify), which lets you host static (serverless) web applications for free. Visit the page and you'll be able to run a machine learning model without internet access!
### SharedWorker mode
By default, Gradio-Lite executes Python code in a [Web Worker](https://developer.mozilla.org/en-US/docs/Web/API/Web_Workers_API) with [Pyodide](https://pyodide.org/) runtime, and each Gradio-Lite app has its own worker.
It has some benefits such as environment isolation.
However, when there are many Gradio-Lite apps in the same page, it may cause performance issues such as high memory usage because each app has its own worker and Pyodide runtime.
In such cases, you can use the **SharedWorker mode** to share a single Pyodide runtime in a [SharedWorker](https://developer.mozilla.org/en-US/docs/Web/API/SharedWorker) among multiple Gradio-Lite apps. To enable the SharedWorker mode, set the `shared-worker` attribute to the `<gradio-lite>` tag.
```html
<!-- These two Gradio-Lite apps share a single worker -->
<gradio-lite shared-worker>
import gradio as gr
# ...
</gradio-lite>
<gradio-lite shared-worker>
import gradio as gr
# ...
</gradio-lite>
```
When using the SharedWorker mode, you should be aware of the following points:
* The apps share the same Python environment, which means that they can access the same modules and objects. If, for example, one app makes changes to some modules, the changes will be visible to other apps.
* The file system is shared among the apps, while each app's files are mounted in each home directory, so each app can access the files of other apps.
### Code and Demo Playground
If you'd like to see the code side-by-side with the demo just pass in the `playground` attribute to the gradio-lite element. This will create an interactive playground that allows you to change the code and update the demo! If you're using playground, you can also set layout to either 'vertical' or 'horizontal' which will determine if the code editor and preview are side-by-side or on top of each other (by default it's reposnsive with the width of the page).
```html
<gradio-lite playground layout="horizontal">
import gradio as gr
gr.Interface(fn=lambda x: x,
inputs=gr.Textbox(),
outputs=gr.Textbox()
).launch()
</gradio-lite>
```
## Benefits of Using `@gradio/lite`
### 1. Serverless Deployment
The primary advantage of @gradio/lite is that it eliminates the need for server infrastructure. This simplifies deployment, reduces server-related costs, and makes it easier to share your Gradio applications with others.
### 2. Low Latency
By running in the browser, @gradio/lite offers low-latency interactions for users. There's no need for data to travel to and from a server, resulting in faster responses and a smoother user experience.
### 3. Privacy and Security
Since all processing occurs within the user's browser, `@gradio/lite` enhances privacy and security. User data remains on their device, providing peace of mind regarding data handling.
### Limitations
* Currently, the biggest limitation in using `@gradio/lite` is that your Gradio apps will generally take more time (usually 5-15 seconds) to load initially in the browser. This is because the browser needs to load the Pyodide runtime before it can render Python code.
* Not every Python package is supported by Pyodide. While `gradio` and many other popular packages (including `numpy`, `scikit-learn`, and `transformers-js`) can be installed in Pyodide, if your app has many dependencies, its worth checking whether whether the dependencies are included in Pyodide, or can be [installed with `micropip`](https://micropip.pyodide.org/en/v0.2.2/project/api.html#micropip.install).
## Try it out!
You can immediately try out `@gradio/lite` by copying and pasting this code in a local `index.html` file and opening it with your browser:
```html
<html>
<head>
<script type="module" crossorigin src="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.js"></script>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.css" />
</head>
<body>
<gradio-lite>
import gradio as gr
def greet(name):
return "Hello, " + name + "!"
gr.Interface(greet, "textbox", "textbox").launch()
</gradio-lite>
</body>
</html>
```
We've also created a playground on the Gradio website that allows you to interactively edit code and see the results immediately!
Playground: https://www.gradio.app/playground
|
C:\Gradio Guides\8 Gradio Clients and Lite\06_gradio-lite-and-transformers-js.md |
# Building Serverless Machine Learning Apps with Gradio-Lite and Transformers.js
Tags: SERVERLESS, BROWSER, PYODIDE, TRANSFORMERS
Gradio and [Transformers](https://huggingface.co/docs/transformers/index) are a powerful combination for building machine learning apps with a web interface. Both libraries have serverless versions that can run entirely in the browser: [Gradio-Lite](./gradio-lite) and [Transformers.js](https://huggingface.co/docs/transformers.js/index).
In this document, we will introduce how to create a serverless machine learning application using Gradio-Lite and Transformers.js.
You will just write Python code within a static HTML file and host it without setting up a server-side Python runtime.
## Libraries Used
### Gradio-Lite
Gradio-Lite is the serverless version of Gradio, allowing you to build serverless web UI applications by embedding Python code within HTML. For a detailed introduction to Gradio-Lite itself, please read [this Guide](./gradio-lite).
### Transformers.js and Transformers.js.py
Transformers.js is the JavaScript version of the Transformers library that allows you to run machine learning models entirely in the browser.
Since Transformers.js is a JavaScript library, it cannot be directly used from the Python code of Gradio-Lite applications. To address this, we use a wrapper library called [Transformers.js.py](https://github.com/whitphx/transformers.js.py).
The name Transformers.js.py may sound unusual, but it represents the necessary technology stack for using Transformers.js from Python code within a browser environment. The regular Transformers library is not compatible with browser environments.
## Sample Code
Here's an example of how to use Gradio-Lite and Transformers.js together.
Please create an HTML file and paste the following code:
```html
<html>
<head>
<script type="module" crossorigin src="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.js"></script>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.css" />
</head>
<body>
<gradio-lite>
import gradio as gr
from transformers_js_py import pipeline
pipe = await pipeline('sentiment-analysis')
demo = gr.Interface.from_pipeline(pipe)
demo.launch()
<gradio-requirements>
transformers-js-py
</gradio-requirements>
</gradio-lite>
</body>
</html>
```
Here is a running example of the code above (after the app has loaded, you could disconnect your Internet connection and the app will still work since its running entirely in your browser):
<gradio-lite shared-worker>
import gradio as gr
from transformers_js_py import pipeline
<!-- --->
pipe = await pipeline('sentiment-analysis')
<!-- --->
demo = gr.Interface.from_pipeline(pipe)
<!-- --->
demo.launch()
<gradio-requirements>
transformers-js-py
</gradio-requirements>
</gradio-lite>
And you you can open your HTML file in a browser to see the Gradio app running!
The Python code inside the `<gradio-lite>` tag is the Gradio application code. For more details on this part, please refer to [this article](./gradio-lite).
The `<gradio-requirements>` tag is used to specify packages to be installed in addition to Gradio-Lite and its dependencies. In this case, we are using Transformers.js.py (`transformers-js-py`), so it is specified here.
Let's break down the code:
`pipe = await pipeline('sentiment-analysis')` creates a Transformers.js pipeline.
In this example, we create a sentiment analysis pipeline.
For more information on the available pipeline types and usage, please refer to the [Transformers.js documentation](https://huggingface.co/docs/transformers.js/index).
`demo = gr.Interface.from_pipeline(pipe)` creates a Gradio app instance. By passing the Transformers.js.py pipeline to `gr.Interface.from_pipeline()`, we can create an interface that utilizes that pipeline with predefined input and output components.
Finally, `demo.launch()` launches the created app.
## Customizing the Model or Pipeline
You can modify the line `pipe = await pipeline('sentiment-analysis')` in the sample above to try different models or tasks.
For example, if you change it to `pipe = await pipeline('sentiment-analysis', 'Xenova/bert-base-multilingual-uncased-sentiment')`, you can test the same sentiment analysis task but with a different model. The second argument of the `pipeline` function specifies the model name.
If it's not specified like in the first example, the default model is used. For more details on these specs, refer to the [Transformers.js documentation](https://huggingface.co/docs/transformers.js/index).
<gradio-lite shared-worker>
import gradio as gr
from transformers_js_py import pipeline
<!-- --->
pipe = await pipeline('sentiment-analysis', 'Xenova/bert-base-multilingual-uncased-sentiment')
<!-- --->
demo = gr.Interface.from_pipeline(pipe)
<!-- --->
demo.launch()
<gradio-requirements>
transformers-js-py
</gradio-requirements>
</gradio-lite>
As another example, changing it to `pipe = await pipeline('image-classification')` creates a pipeline for image classification instead of sentiment analysis.
In this case, the interface created with `demo = gr.Interface.from_pipeline(pipe)` will have a UI for uploading an image and displaying the classification result. The `gr.Interface.from_pipeline` function automatically creates an appropriate UI based on the type of pipeline.
<gradio-lite shared-worker>
import gradio as gr
from transformers_js_py import pipeline
<!-- --->
pipe = await pipeline('image-classification')
<!-- --->
demo = gr.Interface.from_pipeline(pipe)
<!-- --->
demo.launch()
<gradio-requirements>
transformers-js-py
</gradio-requirements>
</gradio-lite>
<br>
**Note**: If you use an audio pipeline, such as `automatic-speech-recognition`, you will need to put `transformers-js-py[audio]` in your `<gradio-requirements>` as there are additional requirements needed to process audio files.
## Customizing the UI
Instead of using `gr.Interface.from_pipeline()`, you can define the user interface using Gradio's regular API.
Here's an example where the Python code inside the `<gradio-lite>` tag has been modified from the previous sample:
```html
<html>
<head>
<script type="module" crossorigin src="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.js"></script>
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/@gradio/lite/dist/lite.css" />
</head>
<body>
<gradio-lite>
import gradio as gr
from transformers_js_py import pipeline
pipe = await pipeline('sentiment-analysis')
async def fn(text):
result = await pipe(text)
return result
demo = gr.Interface(
fn=fn,
inputs=gr.Textbox(),
outputs=gr.JSON(),
)
demo.launch()
<gradio-requirements>
transformers-js-py
</gradio-requirements>
</gradio-lite>
</body>
</html>
```
In this example, we modified the code to construct the Gradio user interface manually so that we could output the result as JSON.
<gradio-lite shared-worker>
import gradio as gr
from transformers_js_py import pipeline
<!-- --->
pipe = await pipeline('sentiment-analysis')
<!-- --->
async def fn(text):
result = await pipe(text)
return result
<!-- --->
demo = gr.Interface(
fn=fn,
inputs=gr.Textbox(),
outputs=gr.JSON(),
)
<!-- --->
demo.launch()
<gradio-requirements>
transformers-js-py
</gradio-requirements>
</gradio-lite>
## Conclusion
By combining Gradio-Lite and Transformers.js (and Transformers.js.py), you can create serverless machine learning applications that run entirely in the browser.
Gradio-Lite provides a convenient method to create an interface for a given Transformers.js pipeline, `gr.Interface.from_pipeline()`.
This method automatically constructs the interface based on the pipeline's task type.
Alternatively, you can define the interface manually using Gradio's regular API, as shown in the second example.
By using these libraries, you can build and deploy machine learning applications without the need for server-side Python setup or external dependencies.
|
C:\Gradio Guides\8 Gradio Clients and Lite\07_fastapi-app-with-the-gradio-client.md |
# Building a Web App with the Gradio Python Client
Tags: CLIENT, API, WEB APP
In this blog post, we will demonstrate how to use the `gradio_client` [Python library](getting-started-with-the-python-client/), which enables developers to make requests to a Gradio app programmatically, by creating an end-to-end example web app using FastAPI. The web app we will be building is called "Acapellify," and it will allow users to upload video files as input and return a version of that video without instrumental music. It will also display a gallery of generated videos.
**Prerequisites**
Before we begin, make sure you are running Python 3.9 or later, and have the following libraries installed:
- `gradio_client`
- `fastapi`
- `uvicorn`
You can install these libraries from `pip`:
```bash
$ pip install gradio_client fastapi uvicorn
```
You will also need to have ffmpeg installed. You can check to see if you already have ffmpeg by running in your terminal:
```bash
$ ffmpeg version
```
Otherwise, install ffmpeg [by following these instructions](https://www.hostinger.com/tutorials/how-to-install-ffmpeg).
## Step 1: Write the Video Processing Function
Let's start with what seems like the most complex bit -- using machine learning to remove the music from a video.
Luckily for us, there's an existing Space we can use to make this process easier: [https://huggingface.co/spaces/abidlabs/music-separation](https://huggingface.co/spaces/abidlabs/music-separation). This Space takes an audio file and produces two separate audio files: one with the instrumental music and one with all other sounds in the original clip. Perfect to use with our client!
Open a new Python file, say `main.py`, and start by importing the `Client` class from `gradio_client` and connecting it to this Space:
```py
from gradio_client import Client
client = Client("abidlabs/music-separation")
def acapellify(audio_path):
result = client.predict(audio_path, api_name="/predict")
return result[0]
```
That's all the code that's needed -- notice that the API endpoints returns two audio files (one without the music, and one with just the music) in a list, and so we just return the first element of the list.
---
**Note**: since this is a public Space, there might be other users using this Space as well, which might result in a slow experience. You can duplicate this Space with your own [Hugging Face token](https://huggingface.co/settings/tokens) and create a private Space that only you have will have access to and bypass the queue. To do that, simply replace the first two lines above with:
```py
from gradio_client import Client
client = Client.duplicate("abidlabs/music-separation", hf_token=YOUR_HF_TOKEN)
```
Everything else remains the same!
---
Now, of course, we are working with video files, so we first need to extract the audio from the video files. For this, we will be using the `ffmpeg` library, which does a lot of heavy lifting when it comes to working with audio and video files. The most common way to use `ffmpeg` is through the command line, which we'll call via Python's `subprocess` module:
Our video processing workflow will consist of three steps:
1. First, we start by taking in a video filepath and extracting the audio using `ffmpeg`.
2. Then, we pass in the audio file through the `acapellify()` function above.
3. Finally, we combine the new audio with the original video to produce a final acapellified video.
Here's the complete code in Python, which you can add to your `main.py` file:
```python
import subprocess
def process_video(video_path):
old_audio = os.path.basename(video_path).split(".")[0] + ".m4a"
subprocess.run(['ffmpeg', '-y', '-i', video_path, '-vn', '-acodec', 'copy', old_audio])
new_audio = acapellify(old_audio)
new_video = f"acap_{video_path}"
subprocess.call(['ffmpeg', '-y', '-i', video_path, '-i', new_audio, '-map', '0:v', '-map', '1:a', '-c:v', 'copy', '-c:a', 'aac', '-strict', 'experimental', f"static/{new_video}"])
return new_video
```
You can read up on [ffmpeg documentation](https://ffmpeg.org/ffmpeg.html) if you'd like to understand all of the command line parameters, as they are beyond the scope of this tutorial.
## Step 2: Create a FastAPI app (Backend Routes)
Next up, we'll create a simple FastAPI app. If you haven't used FastAPI before, check out [the great FastAPI docs](https://fastapi.tiangolo.com/). Otherwise, this basic template, which we add to `main.py`, will look pretty familiar:
```python
import os
from fastapi import FastAPI, File, UploadFile, Request
from fastapi.responses import HTMLResponse, RedirectResponse
from fastapi.staticfiles import StaticFiles
from fastapi.templating import Jinja2Templates
app = FastAPI()
os.makedirs("static", exist_ok=True)
app.mount("/static", StaticFiles(directory="static"), name="static")
templates = Jinja2Templates(directory="templates")
videos = []
@app.get("/", response_class=HTMLResponse)
async def home(request: Request):
return templates.TemplateResponse(
"home.html", {"request": request, "videos": videos})
@app.post("/uploadvideo/")
async def upload_video(video: UploadFile = File(...)):
video_path = video.filename
with open(video_path, "wb+") as fp:
fp.write(video.file.read())
new_video = process_video(video.filename)
videos.append(new_video)
return RedirectResponse(url='/', status_code=303)
```
In this example, the FastAPI app has two routes: `/` and `/uploadvideo/`.
The `/` route returns an HTML template that displays a gallery of all uploaded videos.
The `/uploadvideo/` route accepts a `POST` request with an `UploadFile` object, which represents the uploaded video file. The video file is "acapellified" via the `process_video()` method, and the output video is stored in a list which stores all of the uploaded videos in memory.
Note that this is a very basic example and if this were a production app, you will need to add more logic to handle file storage, user authentication, and security considerations.
## Step 3: Create a FastAPI app (Frontend Template)
Finally, we create the frontend of our web application. First, we create a folder called `templates` in the same directory as `main.py`. We then create a template, `home.html` inside the `templates` folder. Here is the resulting file structure:
```csv
├── main.py
├── templates
│ └── home.html
```
Write the following as the contents of `home.html`:
```html
<!DOCTYPE html> <html> <head> <title>Video Gallery</title>
<style> body { font-family: sans-serif; margin: 0; padding: 0;
background-color: #f5f5f5; } h1 { text-align: center; margin-top: 30px;
margin-bottom: 20px; } .gallery { display: flex; flex-wrap: wrap;
justify-content: center; gap: 20px; padding: 20px; } .video { border: 2px solid
#ccc; box-shadow: 0px 0px 10px rgba(0, 0, 0, 0.2); border-radius: 5px; overflow:
hidden; width: 300px; margin-bottom: 20px; } .video video { width: 100%; height:
200px; } .video p { text-align: center; margin: 10px 0; } form { margin-top:
20px; text-align: center; } input[type="file"] { display: none; } .upload-btn {
display: inline-block; background-color: #3498db; color: #fff; padding: 10px
20px; font-size: 16px; border: none; border-radius: 5px; cursor: pointer; }
.upload-btn:hover { background-color: #2980b9; } .file-name { margin-left: 10px;
} </style> </head> <body> <h1>Video Gallery</h1> {% if videos %}
<div class="gallery"> {% for video in videos %} <div class="video">
<video controls> <source src="{{ url_for('static', path=video) }}"
type="video/mp4"> Your browser does not support the video tag. </video>
<p>{{ video }}</p> </div> {% endfor %} </div> {% else %} <p>No
videos uploaded yet.</p> {% endif %} <form action="/uploadvideo/"
method="post" enctype="multipart/form-data"> <label for="video-upload"
class="upload-btn">Choose video file</label> <input type="file"
name="video" id="video-upload"> <span class="file-name"></span> <button
type="submit" class="upload-btn">Upload</button> </form> <script> //
Display selected file name in the form const fileUpload =
document.getElementById("video-upload"); const fileName =
document.querySelector(".file-name"); fileUpload.addEventListener("change", (e)
=> { fileName.textContent = e.target.files[0].name; }); </script> </body>
</html>
```
## Step 4: Run your FastAPI app
Finally, we are ready to run our FastAPI app, powered by the Gradio Python Client!
Open up a terminal and navigate to the directory containing `main.py`. Then run the following command in the terminal:
```bash
$ uvicorn main:app
```
You should see an output that looks like this:
```csv
Loaded as API: https://abidlabs-music-separation.hf.space ✔
INFO: Started server process [1360]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
```
And that's it! Start uploading videos and you'll get some "acapellified" videos in response (might take seconds to minutes to process depending on the length of your videos). Here's how the UI looks after uploading two videos:

If you'd like to learn more about how to use the Gradio Python Client in your projects, [read the dedicated Guide](/guides/getting-started-with-the-python-client/).
|
C:\Gradio Guides\9 Other Tutorials\01_using-hugging-face-integrations.md |
# Using Hugging Face Integrations
Related spaces: https://huggingface.co/spaces/gradio/en2es
Tags: HUB, SPACES, EMBED
Contributed by <a href="https://huggingface.co/osanseviero">Omar Sanseviero</a> 🦙
## Introduction
The Hugging Face Hub is a central platform that has hundreds of thousands of [models](https://huggingface.co/models), [datasets](https://huggingface.co/datasets) and [demos](https://huggingface.co/spaces) (also known as Spaces).
Gradio has multiple features that make it extremely easy to leverage existing models and Spaces on the Hub. This guide walks through these features.
## Demos with the Hugging Face Inference Endpoints
Hugging Face has a service called [Serverless Inference Endpoints](https://huggingface.co/docs/api-inference/index), which allows you to send HTTP requests to models on the Hub. The API includes a generous free tier, and you can switch to [dedicated Inference Endpoints](https://huggingface.co/inference-endpoints/dedicated) when you want to use it in production. Gradio integrates directly with Serverless Inference Endpoints so that you can create a demo simply by specifying a model's name (e.g. `Helsinki-NLP/opus-mt-en-es`), like this:
```python
import gradio as gr
demo = gr.load("Helsinki-NLP/opus-mt-en-es", src="models")
demo.launch()
```
For any Hugging Face model supported in Inference Endpoints, Gradio automatically infers the expected input and output and make the underlying server calls, so you don't have to worry about defining the prediction function.
Notice that we just put specify the model name and state that the `src` should be `models` (Hugging Face's Model Hub). There is no need to install any dependencies (except `gradio`) since you are not loading the model on your computer.
You might notice that the first inference takes a little bit longer. This happens since the Inference Endpoints is loading the model in the server. You get some benefits afterward:
- The inference will be much faster.
- The server caches your requests.
- You get built-in automatic scaling.
## Hosting your Gradio demos on Spaces
[Hugging Face Spaces](https://hf.co/spaces) allows anyone to host their Gradio demos freely, and uploading your Gradio demos take a couple of minutes. You can head to [hf.co/new-space](https://huggingface.co/new-space), select the Gradio SDK, create an `app.py` file, and voila! You have a demo you can share with anyone else. To learn more, read [this guide how to host on Hugging Face Spaces using the website](https://huggingface.co/blog/gradio-spaces).
Alternatively, you can create a Space programmatically, making use of the [huggingface_hub client library](https://huggingface.co/docs/huggingface_hub/index) library. Here's an example:
```python
from huggingface_hub import (
create_repo,
get_full_repo_name,
upload_file,
)
create_repo(name=target_space_name, token=hf_token, repo_type="space", space_sdk="gradio")
repo_name = get_full_repo_name(model_id=target_space_name, token=hf_token)
file_url = upload_file(
path_or_fileobj="file.txt",
path_in_repo="app.py",
repo_id=repo_name,
repo_type="space",
token=hf_token,
)
```
Here, `create_repo` creates a gradio repo with the target name under a specific account using that account's Write Token. `repo_name` gets the full repo name of the related repo. Finally `upload_file` uploads a file inside the repo with the name `app.py`.
## Loading demos from Spaces
You can also use and remix existing Gradio demos on Hugging Face Spaces. For example, you could take two existing Gradio demos on Spaces and put them as separate tabs and create a new demo. You can run this new demo locally, or upload it to Spaces, allowing endless possibilities to remix and create new demos!
Here's an example that does exactly that:
```python
import gradio as gr
with gr.Blocks() as demo:
with gr.Tab("Translate to Spanish"):
gr.load("gradio/en2es", src="spaces")
with gr.Tab("Translate to French"):
gr.load("abidlabs/en2fr", src="spaces")
demo.launch()
```
Notice that we use `gr.load()`, the same method we used to load models using Inference Endpoints. However, here we specify that the `src` is `spaces` (Hugging Face Spaces).
Note: loading a Space in this way may result in slight differences from the original Space. In particular, any attributes that apply to the entire Blocks, such as the theme or custom CSS/JS, will not be loaded. You can copy these properties from the Space you are loading into your own `Blocks` object.
## Demos with the `Pipeline` in `transformers`
Hugging Face's popular `transformers` library has a very easy-to-use abstraction, [`pipeline()`](https://huggingface.co/docs/transformers/v4.16.2/en/main_classes/pipelines#transformers.pipeline) that handles most of the complex code to offer a simple API for common tasks. By specifying the task and an (optional) model, you can build a demo around an existing model with few lines of Python:
```python
import gradio as gr
from transformers import pipeline
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-en-es")
def predict(text):
return pipe(text)[0]["translation_text"]
demo = gr.Interface(
fn=predict,
inputs='text',
outputs='text',
)
demo.launch()
```
But `gradio` actually makes it even easier to convert a `pipeline` to a demo, simply by using the `gradio.Interface.from_pipeline` methods, which skips the need to specify the input and output components:
```python
from transformers import pipeline
import gradio as gr
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-en-es")
demo = gr.Interface.from_pipeline(pipe)
demo.launch()
```
The previous code produces the following interface, which you can try right here in your browser:
<gradio-app space="gradio/en2es"></gradio-app>
## Recap
That's it! Let's recap the various ways Gradio and Hugging Face work together:
1. You can build a demo around Inference Endpoints without having to load the model, by using `gr.load()`.
2. You host your Gradio demo on Hugging Face Spaces, either using the GUI or entirely in Python.
3. You can load demos from Hugging Face Spaces to remix and create new Gradio demos using `gr.load()`.
4. You can convert a `transformers` pipeline into a Gradio demo using `from_pipeline()`.
🤗
|
C:\Gradio Guides\9 Other Tutorials\create-your-own-friends-with-a-gan.md |
# Create Your Own Friends with a GAN
Related spaces: https://huggingface.co/spaces/NimaBoscarino/cryptopunks, https://huggingface.co/spaces/nateraw/cryptopunks-generator
Tags: GAN, IMAGE, HUB
Contributed by <a href="https://huggingface.co/NimaBoscarino">Nima Boscarino</a> and <a href="https://huggingface.co/nateraw">Nate Raw</a>
## Introduction
It seems that cryptocurrencies, [NFTs](https://www.nytimes.com/interactive/2022/03/18/technology/nft-guide.html), and the web3 movement are all the rage these days! Digital assets are being listed on marketplaces for astounding amounts of money, and just about every celebrity is debuting their own NFT collection. While your crypto assets [may be taxable, such as in Canada](https://www.canada.ca/en/revenue-agency/programs/about-canada-revenue-agency-cra/compliance/digital-currency/cryptocurrency-guide.html), today we'll explore some fun and tax-free ways to generate your own assortment of procedurally generated [CryptoPunks](https://www.larvalabs.com/cryptopunks).
Generative Adversarial Networks, often known just as _GANs_, are a specific class of deep-learning models that are designed to learn from an input dataset to create (_generate!_) new material that is convincingly similar to elements of the original training set. Famously, the website [thispersondoesnotexist.com](https://thispersondoesnotexist.com/) went viral with lifelike, yet synthetic, images of people generated with a model called StyleGAN2. GANs have gained traction in the machine learning world, and are now being used to generate all sorts of images, text, and even [music](https://salu133445.github.io/musegan/)!
Today we'll briefly look at the high-level intuition behind GANs, and then we'll build a small demo around a pre-trained GAN to see what all the fuss is about. Here's a [peek](https://nimaboscarino-cryptopunks.hf.space) at what we're going to be putting together.
### Prerequisites
Make sure you have the `gradio` Python package already [installed](/getting_started). To use the pretrained model, also install `torch` and `torchvision`.
## GANs: a very brief introduction
Originally proposed in [Goodfellow et al. 2014](https://arxiv.org/abs/1406.2661), GANs are made up of neural networks which compete with the intention of outsmarting each other. One network, known as the _generator_, is responsible for generating images. The other network, the _discriminator_, receives an image at a time from the generator along with a **real** image from the training data set. The discriminator then has to guess: which image is the fake?
The generator is constantly training to create images which are trickier for the discriminator to identify, while the discriminator raises the bar for the generator every time it correctly detects a fake. As the networks engage in this competitive (_adversarial!_) relationship, the images that get generated improve to the point where they become indistinguishable to human eyes!
For a more in-depth look at GANs, you can take a look at [this excellent post on Analytics Vidhya](https://www.analyticsvidhya.com/blog/2021/06/a-detailed-explanation-of-gan-with-implementation-using-tensorflow-and-keras/) or this [PyTorch tutorial](https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html). For now, though, we'll dive into a demo!
## Step 1 — Create the Generator model
To generate new images with a GAN, you only need the generator model. There are many different architectures that the generator could use, but for this demo we'll use a pretrained GAN generator model with the following architecture:
```python
from torch import nn
class Generator(nn.Module):
# Refer to the link below for explanations about nc, nz, and ngf
# https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html#inputs
def __init__(self, nc=4, nz=100, ngf=64):
super(Generator, self).__init__()
self.network = nn.Sequential(
nn.ConvTranspose2d(nz, ngf * 4, 3, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
nn.ConvTranspose2d(ngf * 4, ngf * 2, 3, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 0, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
nn.ConvTranspose2d(ngf, nc, 4, 2, 1, bias=False),
nn.Tanh(),
)
def forward(self, input):
output = self.network(input)
return output
```
We're taking the generator from [this repo by @teddykoker](https://github.com/teddykoker/cryptopunks-gan/blob/main/train.py#L90), where you can also see the original discriminator model structure.
After instantiating the model, we'll load in the weights from the Hugging Face Hub, stored at [nateraw/cryptopunks-gan](https://huggingface.co/nateraw/cryptopunks-gan):
```python
from huggingface_hub import hf_hub_download
import torch
model = Generator()
weights_path = hf_hub_download('nateraw/cryptopunks-gan', 'generator.pth')
model.load_state_dict(torch.load(weights_path, map_location=torch.device('cpu'))) # Use 'cuda' if you have a GPU available
```
## Step 2 — Defining a `predict` function
The `predict` function is the key to making Gradio work! Whatever inputs we choose through the Gradio interface will get passed through our `predict` function, which should operate on the inputs and generate outputs that we can display with Gradio output components. For GANs it's common to pass random noise into our model as the input, so we'll generate a tensor of random numbers and pass that through the model. We can then use `torchvision`'s `save_image` function to save the output of the model as a `png` file, and return the file name:
```python
from torchvision.utils import save_image
def predict(seed):
num_punks = 4
torch.manual_seed(seed)
z = torch.randn(num_punks, 100, 1, 1)
punks = model(z)
save_image(punks, "punks.png", normalize=True)
return 'punks.png'
```
We're giving our `predict` function a `seed` parameter, so that we can fix the random tensor generation with a seed. We'll then be able to reproduce punks if we want to see them again by passing in the same seed.
_Note!_ Our model needs an input tensor of dimensions 100x1x1 to do a single inference, or (BatchSize)x100x1x1 for generating a batch of images. In this demo we'll start by generating 4 punks at a time.
## Step 3 — Creating a Gradio interface
At this point you can even run the code you have with `predict(<SOME_NUMBER>)`, and you'll find your freshly generated punks in your file system at `./punks.png`. To make a truly interactive demo, though, we'll build out a simple interface with Gradio. Our goals here are to:
- Set a slider input so users can choose the "seed" value
- Use an image component for our output to showcase the generated punks
- Use our `predict()` to take the seed and generate the images
With `gr.Interface()`, we can define all of that with a single function call:
```python
import gradio as gr
gr.Interface(
predict,
inputs=[
gr.Slider(0, 1000, label='Seed', default=42),
],
outputs="image",
).launch()
```
## Step 4 — Even more punks!
Generating 4 punks at a time is a good start, but maybe we'd like to control how many we want to make each time. Adding more inputs to our Gradio interface is as simple as adding another item to the `inputs` list that we pass to `gr.Interface`:
```python
gr.Interface(
predict,
inputs=[
gr.Slider(0, 1000, label='Seed', default=42),
gr.Slider(4, 64, label='Number of Punks', step=1, default=10), # Adding another slider!
],
outputs="image",
).launch()
```
The new input will be passed to our `predict()` function, so we have to make some changes to that function to accept a new parameter:
```python
def predict(seed, num_punks):
torch.manual_seed(seed)
z = torch.randn(num_punks, 100, 1, 1)
punks = model(z)
save_image(punks, "punks.png", normalize=True)
return 'punks.png'
```
When you relaunch your interface, you should see a second slider that'll let you control the number of punks!
## Step 5 - Polishing it up
Your Gradio app is pretty much good to go, but you can add a few extra things to really make it ready for the spotlight ✨
We can add some examples that users can easily try out by adding this to the `gr.Interface`:
```python
gr.Interface(
# ...
# keep everything as it is, and then add
examples=[[123, 15], [42, 29], [456, 8], [1337, 35]],
).launch(cache_examples=True) # cache_examples is optional
```
The `examples` parameter takes a list of lists, where each item in the sublists is ordered in the same order that we've listed the `inputs`. So in our case, `[seed, num_punks]`. Give it a try!
You can also try adding a `title`, `description`, and `article` to the `gr.Interface`. Each of those parameters accepts a string, so try it out and see what happens 👀 `article` will also accept HTML, as [explored in a previous guide](/guides/key-features/#descriptive-content)!
When you're all done, you may end up with something like [this](https://nimaboscarino-cryptopunks.hf.space).
For reference, here is our full code:
```python
import torch
from torch import nn
from huggingface_hub import hf_hub_download
from torchvision.utils import save_image
import gradio as gr
class Generator(nn.Module):
# Refer to the link below for explanations about nc, nz, and ngf
# https://pytorch.org/tutorials/beginner/dcgan_faces_tutorial.html#inputs
def __init__(self, nc=4, nz=100, ngf=64):
super(Generator, self).__init__()
self.network = nn.Sequential(
nn.ConvTranspose2d(nz, ngf * 4, 3, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
nn.ConvTranspose2d(ngf * 4, ngf * 2, 3, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 0, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
nn.ConvTranspose2d(ngf, nc, 4, 2, 1, bias=False),
nn.Tanh(),
)
def forward(self, input):
output = self.network(input)
return output
model = Generator()
weights_path = hf_hub_download('nateraw/cryptopunks-gan', 'generator.pth')
model.load_state_dict(torch.load(weights_path, map_location=torch.device('cpu'))) # Use 'cuda' if you have a GPU available
def predict(seed, num_punks):
torch.manual_seed(seed)
z = torch.randn(num_punks, 100, 1, 1)
punks = model(z)
save_image(punks, "punks.png", normalize=True)
return 'punks.png'
gr.Interface(
predict,
inputs=[
gr.Slider(0, 1000, label='Seed', default=42),
gr.Slider(4, 64, label='Number of Punks', step=1, default=10),
],
outputs="image",
examples=[[123, 15], [42, 29], [456, 8], [1337, 35]],
).launch(cache_examples=True)
```
---
Congratulations! You've built out your very own GAN-powered CryptoPunks generator, with a fancy Gradio interface that makes it easy for anyone to use. Now you can [scour the Hub for more GANs](https://huggingface.co/models?other=gan) (or train your own) and continue making even more awesome demos 🤗
|
C:\Gradio Guides\9 Other Tutorials\deploying-gradio-with-docker.md |
# Deploying a Gradio app with Docker
Tags: DEPLOYMENT, DOCKER
### Introduction
Gradio is a powerful and intuitive Python library designed for creating web apps that showcase machine learning models. These web apps can be run locally, or [deployed on Hugging Face Spaces ](https://huggingface.co/spaces)for free. Or, you can deploy them on your servers in Docker containers. Dockerizing Gradio apps offers several benefits:
- **Consistency**: Docker ensures that your Gradio app runs the same way, irrespective of where it is deployed, by packaging the application and its environment together.
- **Portability**: Containers can be easily moved across different systems or cloud environments.
- **Scalability**: Docker works well with orchestration systems like Kubernetes, allowing your app to scale up or down based on demand.
## How to Dockerize a Gradio App
Let's go through a simple example to understand how to containerize a Gradio app using Docker.
#### Step 1: Create Your Gradio App
First, we need a simple Gradio app. Let's create a Python file named `app.py` with the following content:
```python
import gradio as gr
def greet(name):
return f"Hello {name}!"
iface = gr.Interface(fn=greet, inputs="text", outputs="text").launch()
```
This app creates a simple interface that greets the user by name.
#### Step 2: Create a Dockerfile
Next, we'll create a Dockerfile to specify how our app should be built and run in a Docker container. Create a file named `Dockerfile` in the same directory as your app with the following content:
```dockerfile
FROM python:3.8-slim
WORKDIR /usr/src/app
COPY . .
RUN pip install --no-cache-dir gradio
EXPOSE 7860
ENV GRADIO_SERVER_NAME="0.0.0.0"
CMD ["python", "app.py"]
```
This Dockerfile performs the following steps:
- Starts from a Python 3.8 slim image.
- Sets the working directory and copies the app into the container.
- Installs Gradio (you should install all other requirements as well).
- Exposes port 7860 (Gradio's default port).
- Sets the `GRADIO_SERVER_NAME` environment variable to ensure Gradio listens on all network interfaces.
- Specifies the command to run the app.
#### Step 3: Build and Run Your Docker Container
With the Dockerfile in place, you can build and run your container:
```bash
docker build -t gradio-app .
docker run -p 7860:7860 gradio-app
```
Your Gradio app should now be accessible at `http://localhost:7860`.
## Important Considerations
When running Gradio applications in Docker, there are a few important things to keep in mind:
#### Running the Gradio app on `"0.0.0.0"` and exposing port 7860
In the Docker environment, setting `GRADIO_SERVER_NAME="0.0.0.0"` as an environment variable (or directly in your Gradio app's `launch()` function) is crucial for allowing connections from outside the container. And the `EXPOSE 7860` directive in the Dockerfile tells Docker to expose Gradio's default port on the container to enable external access to the Gradio app.
#### Enable Stickiness for Multiple Replicas
When deploying Gradio apps with multiple replicas, such as on AWS ECS, it's important to enable stickiness with `sessionAffinity: ClientIP`. This ensures that all requests from the same user are routed to the same instance. This is important because Gradio's communication protocol requires multiple separate connections from the frontend to the backend in order for events to be processed correctly. (If you use Terraform, you'll want to add a [stickiness block](https://registry.terraform.io/providers/hashicorp/aws/3.14.1/docs/resources/lb_target_group#stickiness) into your target group definition.)
#### Deploying Behind a Proxy
If you're deploying your Gradio app behind a proxy, like Nginx, it's essential to configure the proxy correctly. Gradio provides a [Guide that walks through the necessary steps](https://www.gradio.app/guides/running-gradio-on-your-web-server-with-nginx). This setup ensures your app is accessible and performs well in production environments.
|
C:\Gradio Guides\9 Other Tutorials\developing-faster-with-reload-mode.md |
# Developing Faster with Auto-Reloading
**Prerequisite**: This Guide requires you to know about Blocks. Make sure to [read the Guide to Blocks first](https://gradio.app/blocks-and-event-listeners).
This guide covers auto reloading, reloading in a Python IDE, and using gradio with Jupyter Notebooks.
## Why Auto-Reloading?
When you are building a Gradio demo, particularly out of Blocks, you may find it cumbersome to keep re-running your code to test your changes.
To make it faster and more convenient to write your code, we've made it easier to "reload" your Gradio apps instantly when you are developing in a **Python IDE** (like VS Code, Sublime Text, PyCharm, or so on) or generally running your Python code from the terminal. We've also developed an analogous "magic command" that allows you to re-run cells faster if you use **Jupyter Notebooks** (or any similar environment like Colab).
This short Guide will cover both of these methods, so no matter how you write Python, you'll leave knowing how to build Gradio apps faster.
## Python IDE Reload 🔥
If you are building Gradio Blocks using a Python IDE, your file of code (let's name it `run.py`) might look something like this:
```python
import gradio as gr
with gr.Blocks() as demo:
gr.Markdown("# Greetings from Gradio!")
inp = gr.Textbox(placeholder="What is your name?")
out = gr.Textbox()
inp.change(fn=lambda x: f"Welcome, {x}!",
inputs=inp,
outputs=out)
if __name__ == "__main__":
demo.launch()
```
The problem is that anytime that you want to make a change to your layout, events, or components, you have to close and rerun your app by writing `python run.py`.
Instead of doing this, you can run your code in **reload mode** by changing 1 word: `python` to `gradio`:
In the terminal, run `gradio run.py`. That's it!
Now, you'll see that after you'll see something like this:
```bash
Watching: '/Users/freddy/sources/gradio/gradio', '/Users/freddy/sources/gradio/demo/'
Running on local URL: http://127.0.0.1:7860
```
The important part here is the line that says `Watching...` What's happening here is that Gradio will be observing the directory where `run.py` file lives, and if the file changes, it will automatically rerun the file for you. So you can focus on writing your code, and your Gradio demo will refresh automatically 🥳
Tip: the `gradio` command does not detect the parameters passed to the `launch()` methods because the `launch()` method is never called in reload mode. For example, setting `auth`, or `show_error` in `launch()` will not be reflected in the app.
There is one important thing to keep in mind when using the reload mode: Gradio specifically looks for a Gradio Blocks/Interface demo called `demo` in your code. If you have named your demo something else, you will need to pass in the name of your demo as the 2nd parameter in your code. So if your `run.py` file looked like this:
```python
import gradio as gr
with gr.Blocks() as my_demo:
gr.Markdown("# Greetings from Gradio!")
inp = gr.Textbox(placeholder="What is your name?")
out = gr.Textbox()
inp.change(fn=lambda x: f"Welcome, {x}!",
inputs=inp,
outputs=out)
if __name__ == "__main__":
my_demo.launch()
```
Then you would launch it in reload mode like this: `gradio run.py --demo-name=my_demo`.
By default, the Gradio use UTF-8 encoding for scripts. **For reload mode**, If you are using encoding formats other than UTF-8 (such as cp1252), make sure you've done like this:
1. Configure encoding declaration of python script, for example: `# -*- coding: cp1252 -*-`
2. Confirm that your code editor has identified that encoding format.
3. Run like this: `gradio run.py --encoding cp1252`
🔥 If your application accepts command line arguments, you can pass them in as well. Here's an example:
```python
import gradio as gr
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--name", type=str, default="User")
args, unknown = parser.parse_known_args()
with gr.Blocks() as demo:
gr.Markdown(f"# Greetings {args.name}!")
inp = gr.Textbox()
out = gr.Textbox()
inp.change(fn=lambda x: x, inputs=inp, outputs=out)
if __name__ == "__main__":
demo.launch()
```
Which you could run like this: `gradio run.py --name Gretel`
As a small aside, this auto-reloading happens if you change your `run.py` source code or the Gradio source code. Meaning that this can be useful if you decide to [contribute to Gradio itself](https://github.com/gradio-app/gradio/blob/main/CONTRIBUTING.md) ✅
## Controlling the Reload 🎛️
By default, reload mode will re-run your entire script for every change you make.
But there are some cases where this is not desirable.
For example, loading a machine learning model should probably only happen once to save time. There are also some Python libraries that use C or Rust extensions that throw errors when they are reloaded, like `numpy` and `tiktoken`.
In these situations, you can place code that you do not want to be re-run inside an `if gr.NO_RELOAD:` codeblock. Here's an example of how you can use it to only load a transformers model once during the development process.
Tip: The value of `gr.NO_RELOAD` is `True`. So you don't have to change your script when you are done developing and want to run it in production. Simply run the file with `python` instead of `gradio`.
```python
import gradio as gr
if gr.NO_RELOAD:
from transformers import pipeline
pipe = pipeline("text-classification", model="cardiffnlp/twitter-roberta-base-sentiment-latest")
demo = gr.Interface(lambda s: pipe(s), gr.Textbox(), gr.Label())
if __name__ == "__main__":
demo.launch()
```
## Jupyter Notebook Magic 🔮
What about if you use Jupyter Notebooks (or Colab Notebooks, etc.) to develop code? We got something for you too!
We've developed a **magic command** that will create and run a Blocks demo for you. To use this, load the gradio extension at the top of your notebook:
`%load_ext gradio`
Then, in the cell that you are developing your Gradio demo, simply write the magic command **`%%blocks`** at the top, and then write the layout and components like you would normally:
```py
%%blocks
import gradio as gr
with gr.Blocks() as demo:
gr.Markdown(f"# Greetings {args.name}!")
inp = gr.Textbox()
out = gr.Textbox()
inp.change(fn=lambda x: x, inputs=inp, outputs=out)
```
Notice that:
- You do not need to launch your demo — Gradio does that for you automatically!
- Every time you rerun the cell, Gradio will re-render your app on the same port and using the same underlying web server. This means you'll see your changes _much, much faster_ than if you were rerunning the cell normally.
Here's what it looks like in a jupyter notebook:
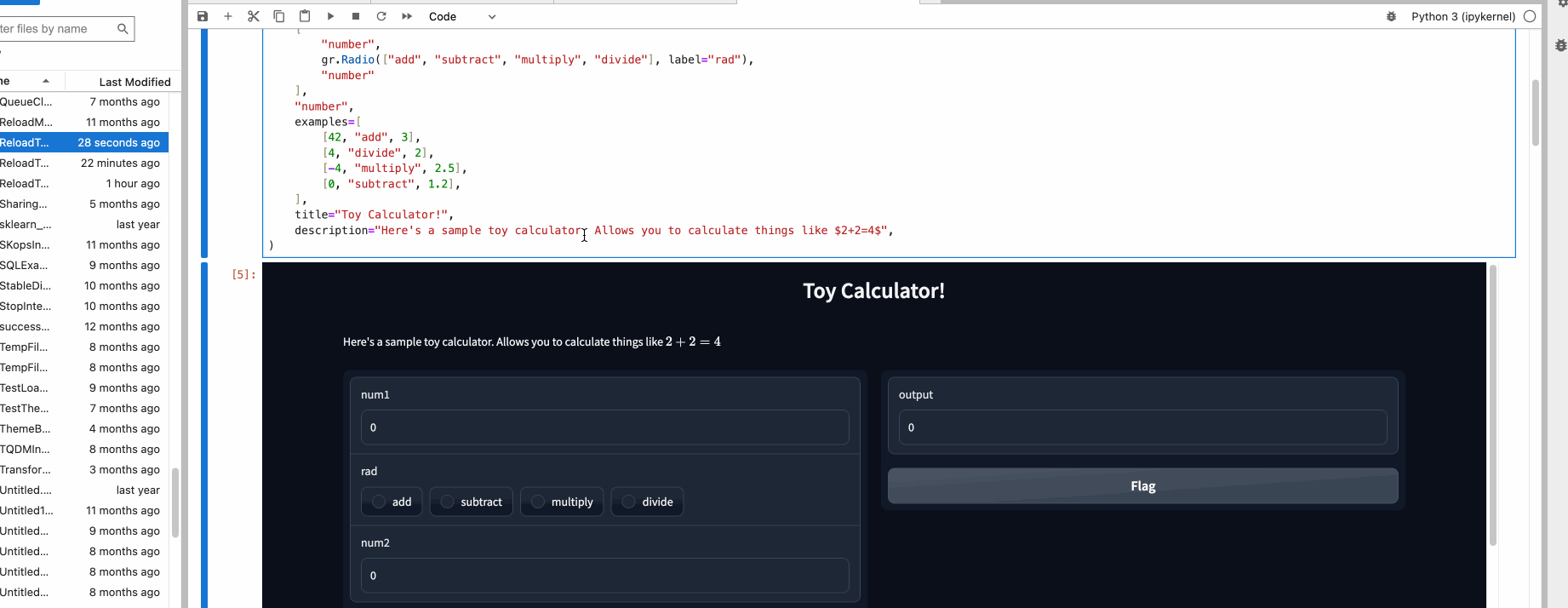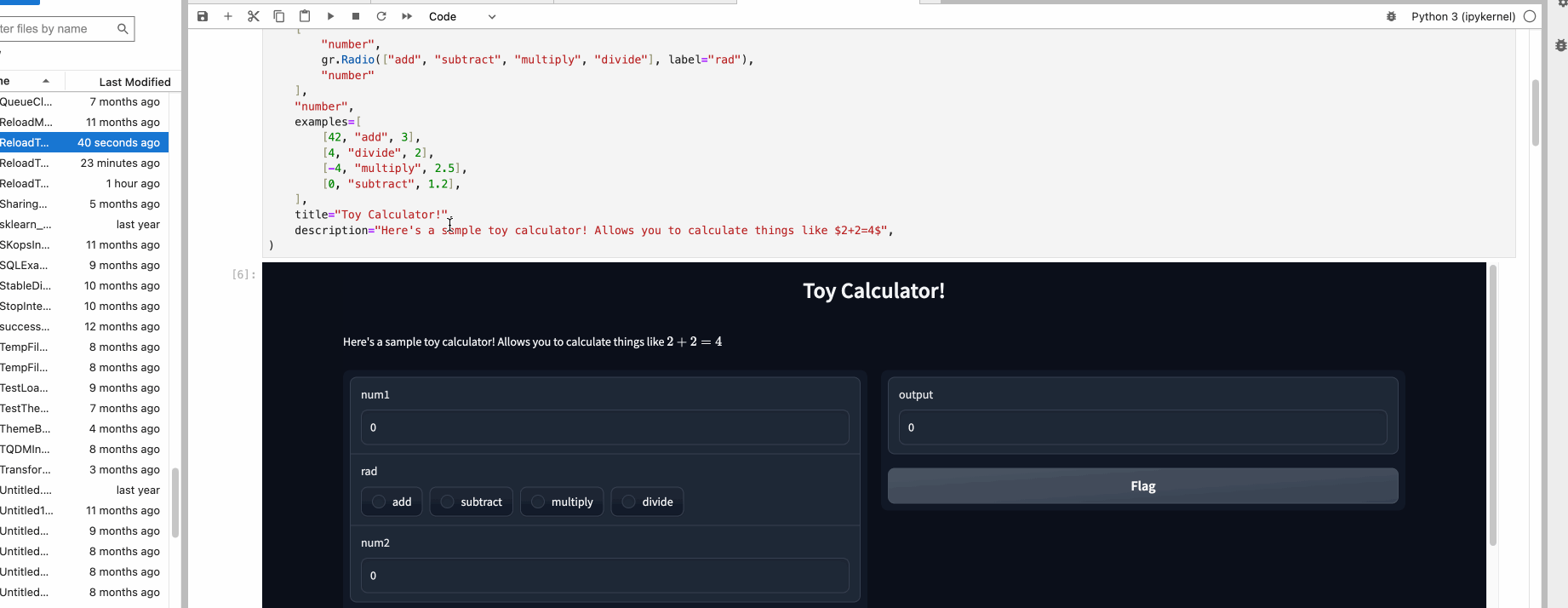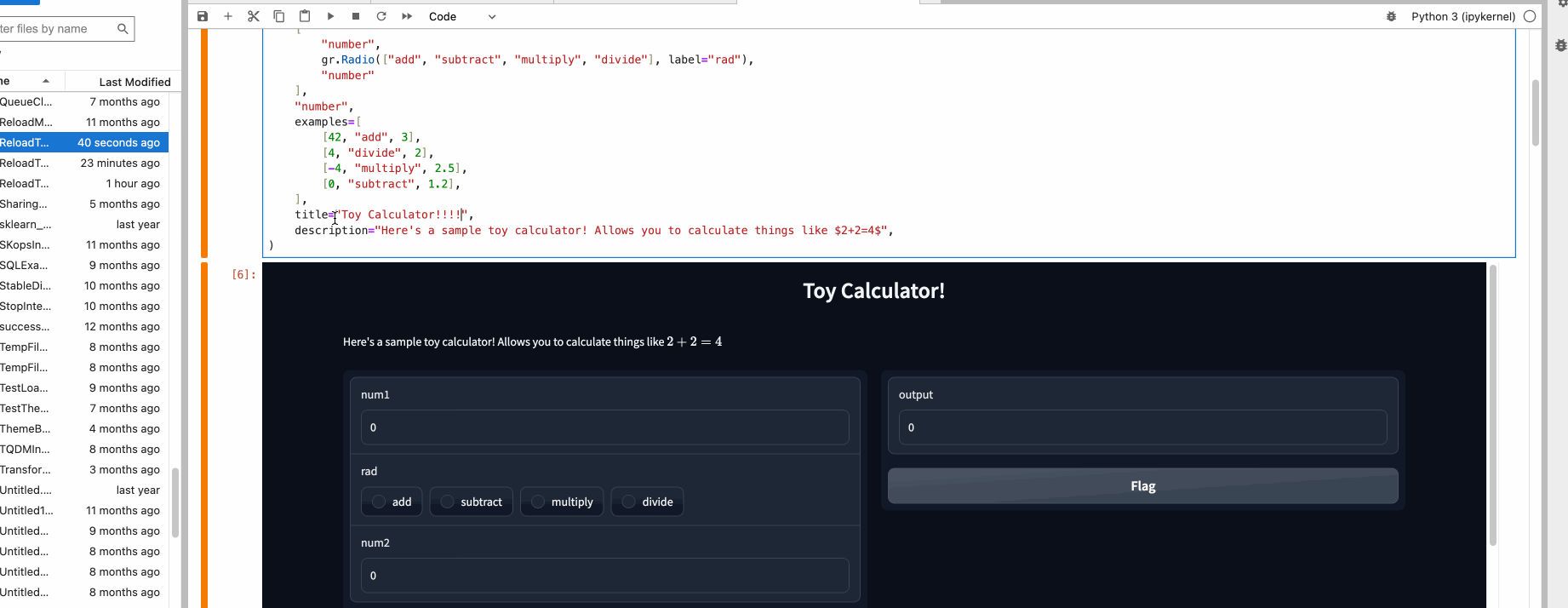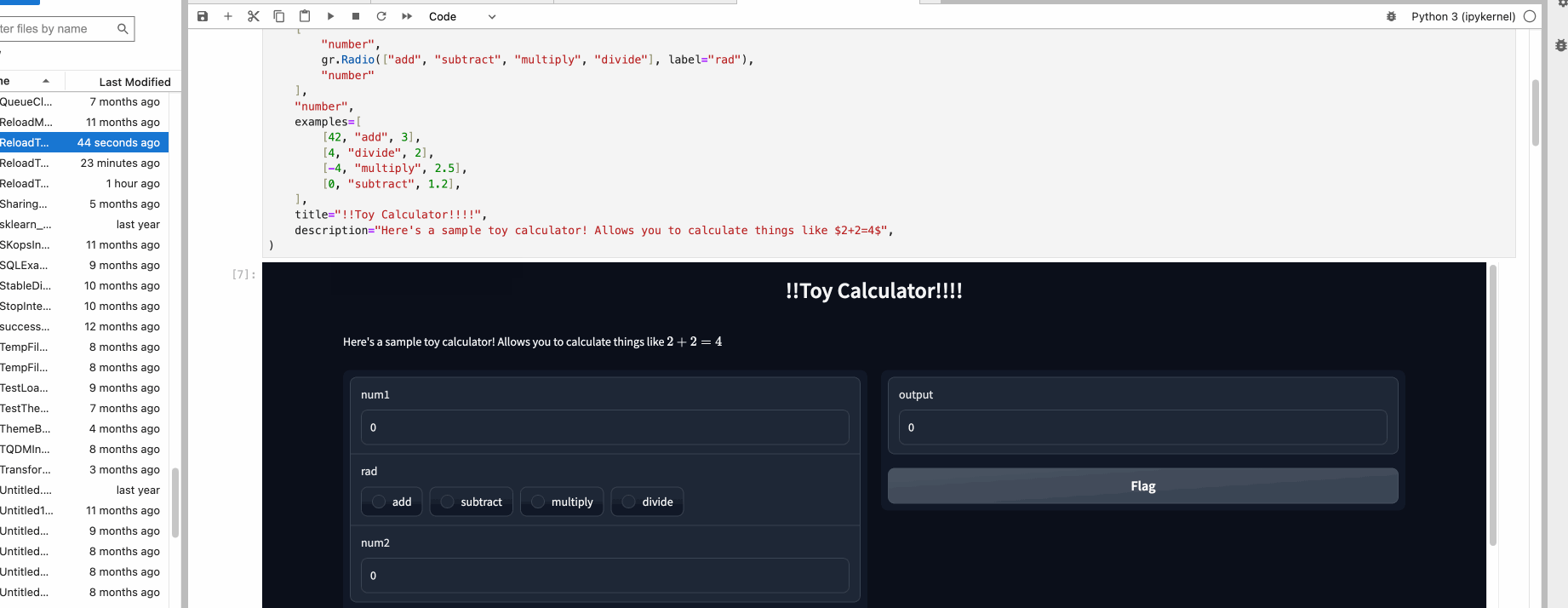
🪄 This works in colab notebooks too! [Here's a colab notebook](https://colab.research.google.com/drive/1zAuWoiTIb3O2oitbtVb2_ekv1K6ggtC1?usp=sharing) where you can see the Blocks magic in action. Try making some changes and re-running the cell with the Gradio code!
The Notebook Magic is now the author's preferred way of building Gradio demos. Regardless of how you write Python code, we hope either of these methods will give you a much better development experience using Gradio.
---
## Next Steps
Now that you know how to develop quickly using Gradio, start building your own!
If you are looking for inspiration, try exploring demos other people have built with Gradio, [browse public Hugging Face Spaces](http://hf.space/) 🤗
|
C:\Gradio Guides\9 Other Tutorials\Gradio-and-Comet.md |
# Using Gradio and Comet
Tags: COMET, SPACES
Contributed by the Comet team
## Introduction
In this guide we will demonstrate some of the ways you can use Gradio with Comet. We will cover the basics of using Comet with Gradio and show you some of the ways that you can leverage Gradio's advanced features such as [Embedding with iFrames](https://www.gradio.app/guides/sharing-your-app/#embedding-with-iframes) and [State](https://www.gradio.app/docs/#state) to build some amazing model evaluation workflows.
Here is a list of the topics covered in this guide.
1. Logging Gradio UI's to your Comet Experiments
2. Embedding Gradio Applications directly into your Comet Projects
3. Embedding Hugging Face Spaces directly into your Comet Projects
4. Logging Model Inferences from your Gradio Application to Comet
## What is Comet?
[Comet](https://www.comet.com?utm_source=gradio&utm_medium=referral&utm_campaign=gradio-integration&utm_content=gradio-docs) is an MLOps Platform that is designed to help Data Scientists and Teams build better models faster! Comet provides tooling to Track, Explain, Manage, and Monitor your models in a single place! It works with Jupyter Notebooks and Scripts and most importantly it's 100% free!
## Setup
First, install the dependencies needed to run these examples
```shell
pip install comet_ml torch torchvision transformers gradio shap requests Pillow
```
Next, you will need to [sign up for a Comet Account](https://www.comet.com/signup?utm_source=gradio&utm_medium=referral&utm_campaign=gradio-integration&utm_content=gradio-docs). Once you have your account set up, [grab your API Key](https://www.comet.com/docs/v2/guides/getting-started/quickstart/#get-an-api-key?utm_source=gradio&utm_medium=referral&utm_campaign=gradio-integration&utm_content=gradio-docs) and configure your Comet credentials
If you're running these examples as a script, you can either export your credentials as environment variables
```shell
export COMET_API_KEY="<Your API Key>"
export COMET_WORKSPACE="<Your Workspace Name>"
export COMET_PROJECT_NAME="<Your Project Name>"
```
or set them in a `.comet.config` file in your working directory. You file should be formatted in the following way.
```shell
[comet]
api_key=<Your API Key>
workspace=<Your Workspace Name>
project_name=<Your Project Name>
```
If you are using the provided Colab Notebooks to run these examples, please run the cell with the following snippet before starting the Gradio UI. Running this cell allows you to interactively add your API key to the notebook.
```python
import comet_ml
comet_ml.init()
```
## 1. Logging Gradio UI's to your Comet Experiments
[](https://colab.research.google.com/github/comet-ml/comet-examples/blob/master/integrations/model-evaluation/gradio/notebooks/Gradio_and_Comet.ipynb)
In this example, we will go over how to log your Gradio Applications to Comet and interact with them using the Gradio Custom Panel.
Let's start by building a simple Image Classification example using `resnet18`.
```python
import comet_ml
import requests
import torch
from PIL import Image
from torchvision import transforms
torch.hub.download_url_to_file("https://github.com/pytorch/hub/raw/master/images/dog.jpg", "dog.jpg")
if torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
model = torch.hub.load("pytorch/vision:v0.6.0", "resnet18", pretrained=True).eval()
model = model.to(device)
# Download human-readable labels for ImageNet.
response = requests.get("https://git.io/JJkYN")
labels = response.text.split("\n")
def predict(inp):
inp = Image.fromarray(inp.astype("uint8"), "RGB")
inp = transforms.ToTensor()(inp).unsqueeze(0)
with torch.no_grad():
prediction = torch.nn.functional.softmax(model(inp.to(device))[0], dim=0)
return {labels[i]: float(prediction[i]) for i in range(1000)}
inputs = gr.Image()
outputs = gr.Label(num_top_classes=3)
io = gr.Interface(
fn=predict, inputs=inputs, outputs=outputs, examples=["dog.jpg"]
)
io.launch(inline=False, share=True)
experiment = comet_ml.Experiment()
experiment.add_tag("image-classifier")
io.integrate(comet_ml=experiment)
```
The last line in this snippet will log the URL of the Gradio Application to your Comet Experiment. You can find the URL in the Text Tab of your Experiment.
<video width="560" height="315" controls>
<source src="https://user-images.githubusercontent.com/7529846/214328034-09369d4d-8b94-4c4a-aa3c-25e3ed8394c4.mp4"></source>
</video>
Add the Gradio Panel to your Experiment to interact with your application.
<video width="560" height="315" controls>
<source src="https://user-images.githubusercontent.com/7529846/214328194-95987f83-c180-4929-9bed-c8a0d3563ed7.mp4"></source>
</video>
## 2. Embedding Gradio Applications directly into your Comet Projects
<iframe width="560" height="315" src="https://www.youtube.com/embed/KZnpH7msPq0?start=9" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe>
If you are permanently hosting your Gradio application, you can embed the UI using the Gradio Panel Extended custom Panel.
Go to your Comet Project page, and head over to the Panels tab. Click the `+ Add` button to bring up the Panels search page.
<img width="560" alt="adding-panels" src="https://user-images.githubusercontent.com/7529846/214329314-70a3ff3d-27fb-408c-a4d1-4b58892a3854.jpeg">
Next, search for Gradio Panel Extended in the Public Panels section and click `Add`.
<img width="560" alt="gradio-panel-extended" src="https://user-images.githubusercontent.com/7529846/214325577-43226119-0292-46be-a62a-0c7a80646ebb.png">
Once you have added your Panel, click `Edit` to access to the Panel Options page and paste in the URL of your Gradio application.
<img width="560" alt="Edit-Gradio-Panel-URL" src="https://user-images.githubusercontent.com/7529846/214334843-870fe726-0aa1-4b21-bbc6-0c48f56c48d8.png">
## 3. Embedding Hugging Face Spaces directly into your Comet Projects
<iframe width="560" height="315" src="https://www.youtube.com/embed/KZnpH7msPq0?start=107" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe>
You can also embed Gradio Applications that are hosted on Hugging Faces Spaces into your Comet Projects using the Hugging Face Spaces Panel.
Go to your Comet Project page, and head over to the Panels tab. Click the `+ Add` button to bring up the Panels search page. Next, search for the Hugging Face Spaces Panel in the Public Panels section and click `Add`.
<img width="560" height="315" alt="huggingface-spaces-panel" src="https://user-images.githubusercontent.com/7529846/214325606-99aa3af3-b284-4026-b423-d3d238797e12.png">
Once you have added your Panel, click Edit to access to the Panel Options page and paste in the path of your Hugging Face Space e.g. `pytorch/ResNet`
<img width="560" height="315" alt="Edit-HF-Space" src="https://user-images.githubusercontent.com/7529846/214335868-c6f25dee-13db-4388-bcf5-65194f850b02.png">
## 4. Logging Model Inferences to Comet
<iframe width="560" height="315" src="https://www.youtube.com/embed/KZnpH7msPq0?start=176" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture; web-share" allowfullscreen></iframe>
[](https://colab.research.google.com/github/comet-ml/comet-examples/blob/master/integrations/model-evaluation/gradio/notebooks/Logging_Model_Inferences_with_Comet_and_Gradio.ipynb)
In the previous examples, we demonstrated the various ways in which you can interact with a Gradio application through the Comet UI. Additionally, you can also log model inferences, such as SHAP plots, from your Gradio application to Comet.
In the following snippet, we're going to log inferences from a Text Generation model. We can persist an Experiment across multiple inference calls using Gradio's [State](https://www.gradio.app/docs/#state) object. This will allow you to log multiple inferences from a model to a single Experiment.
```python
import comet_ml
import gradio as gr
import shap
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
if torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
MODEL_NAME = "gpt2"
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME)
# set model decoder to true
model.config.is_decoder = True
# set text-generation params under task_specific_params
model.config.task_specific_params["text-generation"] = {
"do_sample": True,
"max_length": 50,
"temperature": 0.7,
"top_k": 50,
"no_repeat_ngram_size": 2,
}
model = model.to(device)
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
explainer = shap.Explainer(model, tokenizer)
def start_experiment():
"""Returns an APIExperiment object that is thread safe
and can be used to log inferences to a single Experiment
"""
try:
api = comet_ml.API()
workspace = api.get_default_workspace()
project_name = comet_ml.config.get_config()["comet.project_name"]
experiment = comet_ml.APIExperiment(
workspace=workspace, project_name=project_name
)
experiment.log_other("Created from", "gradio-inference")
message = f"Started Experiment: [{experiment.name}]({experiment.url})"
return (experiment, message)
except Exception as e:
return None, None
def predict(text, state, message):
experiment = state
shap_values = explainer([text])
plot = shap.plots.text(shap_values, display=False)
if experiment is not None:
experiment.log_other("message", message)
experiment.log_html(plot)
return plot
with gr.Blocks() as demo:
start_experiment_btn = gr.Button("Start New Experiment")
experiment_status = gr.Markdown()
# Log a message to the Experiment to provide more context
experiment_message = gr.Textbox(label="Experiment Message")
experiment = gr.State()
input_text = gr.Textbox(label="Input Text", lines=5, interactive=True)
submit_btn = gr.Button("Submit")
output = gr.HTML(interactive=True)
start_experiment_btn.click(
start_experiment, outputs=[experiment, experiment_status]
)
submit_btn.click(
predict, inputs=[input_text, experiment, experiment_message], outputs=[output]
)
```
Inferences from this snippet will be saved in the HTML tab of your experiment.
<video width="560" height="315" controls>
<source src="https://user-images.githubusercontent.com/7529846/214328610-466e5c81-4814-49b9-887c-065aca14dd30.mp4"></source>
</video>
## Conclusion
We hope you found this guide useful and that it provides some inspiration to help you build awesome model evaluation workflows with Comet and Gradio.
## How to contribute Gradio demos on HF spaces on the Comet organization
- Create an account on Hugging Face [here](https://huggingface.co/join).
- Add Gradio Demo under your username, see this [course](https://huggingface.co/course/chapter9/4?fw=pt) for setting up Gradio Demo on Hugging Face.
- Request to join the Comet organization [here](https://huggingface.co/Comet).
## Additional Resources
- [Comet Documentation](https://www.comet.com/docs/v2/?utm_source=gradio&utm_medium=referral&utm_campaign=gradio-integration&utm_content=gradio-docs)
|
C:\Gradio Guides\9 Other Tutorials\Gradio-and-ONNX-on-Hugging-Face.md |
# Gradio and ONNX on Hugging Face
Related spaces: https://huggingface.co/spaces/onnx/EfficientNet-Lite4
Tags: ONNX, SPACES
Contributed by Gradio and the <a href="https://onnx.ai/">ONNX</a> team
## Introduction
In this Guide, we'll walk you through:
- Introduction of ONNX, ONNX model zoo, Gradio, and Hugging Face Spaces
- How to setup a Gradio demo for EfficientNet-Lite4
- How to contribute your own Gradio demos for the ONNX organization on Hugging Face
Here's an [example](https://onnx-efficientnet-lite4.hf.space/) of an ONNX model.
## What is the ONNX Model Zoo?
Open Neural Network Exchange ([ONNX](https://onnx.ai/)) is an open standard format for representing machine learning models. ONNX is supported by a community of partners who have implemented it in many frameworks and tools. For example, if you have trained a model in TensorFlow or PyTorch, you can convert it to ONNX easily, and from there run it on a variety of devices using an engine/compiler like ONNX Runtime.
The [ONNX Model Zoo](https://github.com/onnx/models) is a collection of pre-trained, state-of-the-art models in the ONNX format contributed by community members. Accompanying each model are Jupyter notebooks for model training and running inference with the trained model. The notebooks are written in Python and include links to the training dataset as well as references to the original paper that describes the model architecture.
## What are Hugging Face Spaces & Gradio?
### Gradio
Gradio lets users demo their machine learning models as a web app all in python code. Gradio wraps a python function into a user interface and the demos can be launched inside jupyter notebooks, colab notebooks, as well as embedded in your own website and hosted on Hugging Face Spaces for free.
Get started [here](https://gradio.app/getting_started)
### Hugging Face Spaces
Hugging Face Spaces is a free hosting option for Gradio demos. Spaces comes with 3 SDK options: Gradio, Streamlit and Static HTML demos. Spaces can be public or private and the workflow is similar to github repos. There are over 2000+ spaces currently on Hugging Face. Learn more about spaces [here](https://huggingface.co/spaces/launch).
### Hugging Face Models
Hugging Face Model Hub also supports ONNX models and ONNX models can be filtered through the [ONNX tag](https://huggingface.co/models?library=onnx&sort=downloads)
## How did Hugging Face help the ONNX Model Zoo?
There are a lot of Jupyter notebooks in the ONNX Model Zoo for users to test models. Previously, users needed to download the models themselves and run those notebooks locally for testing. With Hugging Face, the testing process can be much simpler and more user-friendly. Users can easily try certain ONNX Model Zoo model on Hugging Face Spaces and run a quick demo powered by Gradio with ONNX Runtime, all on cloud without downloading anything locally. Note, there are various runtimes for ONNX, e.g., [ONNX Runtime](https://github.com/microsoft/onnxruntime), [MXNet](https://github.com/apache/incubator-mxnet).
## What is the role of ONNX Runtime?
ONNX Runtime is a cross-platform inference and training machine-learning accelerator. It makes live Gradio demos with ONNX Model Zoo model on Hugging Face possible.
ONNX Runtime inference can enable faster customer experiences and lower costs, supporting models from deep learning frameworks such as PyTorch and TensorFlow/Keras as well as classical machine learning libraries such as scikit-learn, LightGBM, XGBoost, etc. ONNX Runtime is compatible with different hardware, drivers, and operating systems, and provides optimal performance by leveraging hardware accelerators where applicable alongside graph optimizations and transforms. For more information please see the [official website](https://onnxruntime.ai/).
## Setting up a Gradio Demo for EfficientNet-Lite4
EfficientNet-Lite 4 is the largest variant and most accurate of the set of EfficientNet-Lite models. It is an integer-only quantized model that produces the highest accuracy of all of the EfficientNet models. It achieves 80.4% ImageNet top-1 accuracy, while still running in real-time (e.g. 30ms/image) on a Pixel 4 CPU. To learn more read the [model card](https://github.com/onnx/models/tree/main/vision/classification/efficientnet-lite4)
Here we walk through setting up a example demo for EfficientNet-Lite4 using Gradio
First we import our dependencies and download and load the efficientnet-lite4 model from the onnx model zoo. Then load the labels from the labels_map.txt file. We then setup our preprocessing functions, load the model for inference, and setup the inference function. Finally, the inference function is wrapped into a gradio interface for a user to interact with. See the full code below.
```python
import numpy as np
import math
import matplotlib.pyplot as plt
import cv2
import json
import gradio as gr
from huggingface_hub import hf_hub_download
from onnx import hub
import onnxruntime as ort
# loads ONNX model from ONNX Model Zoo
model = hub.load("efficientnet-lite4")
# loads the labels text file
labels = json.load(open("labels_map.txt", "r"))
# sets image file dimensions to 224x224 by resizing and cropping image from center
def pre_process_edgetpu(img, dims):
output_height, output_width, _ = dims
img = resize_with_aspectratio(img, output_height, output_width, inter_pol=cv2.INTER_LINEAR)
img = center_crop(img, output_height, output_width)
img = np.asarray(img, dtype='float32')
# converts jpg pixel value from [0 - 255] to float array [-1.0 - 1.0]
img -= [127.0, 127.0, 127.0]
img /= [128.0, 128.0, 128.0]
return img
# resizes the image with a proportional scale
def resize_with_aspectratio(img, out_height, out_width, scale=87.5, inter_pol=cv2.INTER_LINEAR):
height, width, _ = img.shape
new_height = int(100. * out_height / scale)
new_width = int(100. * out_width / scale)
if height > width:
w = new_width
h = int(new_height * height / width)
else:
h = new_height
w = int(new_width * width / height)
img = cv2.resize(img, (w, h), interpolation=inter_pol)
return img
# crops the image around the center based on given height and width
def center_crop(img, out_height, out_width):
height, width, _ = img.shape
left = int((width - out_width) / 2)
right = int((width + out_width) / 2)
top = int((height - out_height) / 2)
bottom = int((height + out_height) / 2)
img = img[top:bottom, left:right]
return img
sess = ort.InferenceSession(model)
def inference(img):
img = cv2.imread(img)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = pre_process_edgetpu(img, (224, 224, 3))
img_batch = np.expand_dims(img, axis=0)
results = sess.run(["Softmax:0"], {"images:0": img_batch})[0]
result = reversed(results[0].argsort()[-5:])
resultdic = {}
for r in result:
resultdic[labels[str(r)]] = float(results[0][r])
return resultdic
title = "EfficientNet-Lite4"
description = "EfficientNet-Lite 4 is the largest variant and most accurate of the set of EfficientNet-Lite model. It is an integer-only quantized model that produces the highest accuracy of all of the EfficientNet models. It achieves 80.4% ImageNet top-1 accuracy, while still running in real-time (e.g. 30ms/image) on a Pixel 4 CPU."
examples = [['catonnx.jpg']]
gr.Interface(inference, gr.Image(type="filepath"), "label", title=title, description=description, examples=examples).launch()
```
## How to contribute Gradio demos on HF spaces using ONNX models
- Add model to the [onnx model zoo](https://github.com/onnx/models/blob/main/.github/PULL_REQUEST_TEMPLATE.md)
- Create an account on Hugging Face [here](https://huggingface.co/join).
- See list of models left to add to ONNX organization, please refer to the table with the [Models list](https://github.com/onnx/models#models)
- Add Gradio Demo under your username, see this [blog post](https://huggingface.co/blog/gradio-spaces) for setting up Gradio Demo on Hugging Face.
- Request to join ONNX Organization [here](https://huggingface.co/onnx).
- Once approved transfer model from your username to ONNX organization
- Add a badge for model in model table, see examples in [Models list](https://github.com/onnx/models#models)
|
C:\Gradio Guides\9 Other Tutorials\Gradio-and-Wandb-Integration.md |
# Gradio and W&B Integration
Related spaces: https://huggingface.co/spaces/akhaliq/JoJoGAN
Tags: WANDB, SPACES
Contributed by Gradio team
## Introduction
In this Guide, we'll walk you through:
- Introduction of Gradio, and Hugging Face Spaces, and Wandb
- How to setup a Gradio demo using the Wandb integration for JoJoGAN
- How to contribute your own Gradio demos after tracking your experiments on wandb to the Wandb organization on Hugging Face
## What is Wandb?
Weights and Biases (W&B) allows data scientists and machine learning scientists to track their machine learning experiments at every stage, from training to production. Any metric can be aggregated over samples and shown in panels in a customizable and searchable dashboard, like below:
<img alt="Screen Shot 2022-08-01 at 5 54 59 PM" src="https://user-images.githubusercontent.com/81195143/182252755-4a0e1ca8-fd25-40ff-8c91-c9da38aaa9ec.png">
## What are Hugging Face Spaces & Gradio?
### Gradio
Gradio lets users demo their machine learning models as a web app, all in a few lines of Python. Gradio wraps any Python function (such as a machine learning model's inference function) into a user interface and the demos can be launched inside jupyter notebooks, colab notebooks, as well as embedded in your own website and hosted on Hugging Face Spaces for free.
Get started [here](https://gradio.app/getting_started)
### Hugging Face Spaces
Hugging Face Spaces is a free hosting option for Gradio demos. Spaces comes with 3 SDK options: Gradio, Streamlit and Static HTML demos. Spaces can be public or private and the workflow is similar to github repos. There are over 2000+ spaces currently on Hugging Face. Learn more about spaces [here](https://huggingface.co/spaces/launch).
## Setting up a Gradio Demo for JoJoGAN
Now, let's walk you through how to do this on your own. We'll make the assumption that you're new to W&B and Gradio for the purposes of this tutorial.
Let's get started!
1. Create a W&B account
Follow [these quick instructions](https://app.wandb.ai/login) to create your free account if you don’t have one already. It shouldn't take more than a couple minutes. Once you're done (or if you've already got an account), next, we'll run a quick colab.
2. Open Colab Install Gradio and W&B
We'll be following along with the colab provided in the JoJoGAN repo with some minor modifications to use Wandb and Gradio more effectively.
[](https://colab.research.google.com/github/mchong6/JoJoGAN/blob/main/stylize.ipynb)
Install Gradio and Wandb at the top:
```sh
pip install gradio wandb
```
3. Finetune StyleGAN and W&B experiment tracking
This next step will open a W&B dashboard to track your experiments and a gradio panel showing pretrained models to choose from a drop down menu from a Gradio Demo hosted on Huggingface Spaces. Here's the code you need for that:
```python
alpha = 1.0
alpha = 1-alpha
preserve_color = True
num_iter = 100
log_interval = 50
samples = []
column_names = ["Reference (y)", "Style Code(w)", "Real Face Image(x)"]
wandb.init(project="JoJoGAN")
config = wandb.config
config.num_iter = num_iter
config.preserve_color = preserve_color
wandb.log(
{"Style reference": [wandb.Image(transforms.ToPILImage()(target_im))]},
step=0)
# load discriminator for perceptual loss
discriminator = Discriminator(1024, 2).eval().to(device)
ckpt = torch.load('models/stylegan2-ffhq-config-f.pt', map_location=lambda storage, loc: storage)
discriminator.load_state_dict(ckpt["d"], strict=False)
# reset generator
del generator
generator = deepcopy(original_generator)
g_optim = optim.Adam(generator.parameters(), lr=2e-3, betas=(0, 0.99))
# Which layers to swap for generating a family of plausible real images -> fake image
if preserve_color:
id_swap = [9,11,15,16,17]
else:
id_swap = list(range(7, generator.n_latent))
for idx in tqdm(range(num_iter)):
mean_w = generator.get_latent(torch.randn([latents.size(0), latent_dim]).to(device)).unsqueeze(1).repeat(1, generator.n_latent, 1)
in_latent = latents.clone()
in_latent[:, id_swap] = alpha*latents[:, id_swap] + (1-alpha)*mean_w[:, id_swap]
img = generator(in_latent, input_is_latent=True)
with torch.no_grad():
real_feat = discriminator(targets)
fake_feat = discriminator(img)
loss = sum([F.l1_loss(a, b) for a, b in zip(fake_feat, real_feat)])/len(fake_feat)
wandb.log({"loss": loss}, step=idx)
if idx % log_interval == 0:
generator.eval()
my_sample = generator(my_w, input_is_latent=True)
generator.train()
my_sample = transforms.ToPILImage()(utils.make_grid(my_sample, normalize=True, range=(-1, 1)))
wandb.log(
{"Current stylization": [wandb.Image(my_sample)]},
step=idx)
table_data = [
wandb.Image(transforms.ToPILImage()(target_im)),
wandb.Image(img),
wandb.Image(my_sample),
]
samples.append(table_data)
g_optim.zero_grad()
loss.backward()
g_optim.step()
out_table = wandb.Table(data=samples, columns=column_names)
wandb.log({"Current Samples": out_table})
```
4. Save, Download, and Load Model
Here's how to save and download your model.
```python
from PIL import Image
import torch
torch.backends.cudnn.benchmark = True
from torchvision import transforms, utils
from util import *
import math
import random
import numpy as np
from torch import nn, autograd, optim
from torch.nn import functional as F
from tqdm import tqdm
import lpips
from model import *
from e4e_projection import projection as e4e_projection
from copy import deepcopy
import imageio
import os
import sys
import torchvision.transforms as transforms
from argparse import Namespace
from e4e.models.psp import pSp
from util import *
from huggingface_hub import hf_hub_download
from google.colab import files
torch.save({"g": generator.state_dict()}, "your-model-name.pt")
files.download('your-model-name.pt')
latent_dim = 512
device="cuda"
model_path_s = hf_hub_download(repo_id="akhaliq/jojogan-stylegan2-ffhq-config-f", filename="stylegan2-ffhq-config-f.pt")
original_generator = Generator(1024, latent_dim, 8, 2).to(device)
ckpt = torch.load(model_path_s, map_location=lambda storage, loc: storage)
original_generator.load_state_dict(ckpt["g_ema"], strict=False)
mean_latent = original_generator.mean_latent(10000)
generator = deepcopy(original_generator)
ckpt = torch.load("/content/JoJoGAN/your-model-name.pt", map_location=lambda storage, loc: storage)
generator.load_state_dict(ckpt["g"], strict=False)
generator.eval()
plt.rcParams['figure.dpi'] = 150
transform = transforms.Compose(
[
transforms.Resize((1024, 1024)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]
)
def inference(img):
img.save('out.jpg')
aligned_face = align_face('out.jpg')
my_w = e4e_projection(aligned_face, "out.pt", device).unsqueeze(0)
with torch.no_grad():
my_sample = generator(my_w, input_is_latent=True)
npimage = my_sample[0].cpu().permute(1, 2, 0).detach().numpy()
imageio.imwrite('filename.jpeg', npimage)
return 'filename.jpeg'
````
5. Build a Gradio Demo
```python
import gradio as gr
title = "JoJoGAN"
description = "Gradio Demo for JoJoGAN: One Shot Face Stylization. To use it, simply upload your image, or click one of the examples to load them. Read more at the links below."
demo = gr.Interface(
inference,
gr.Image(type="pil"),
gr.Image(type="file"),
title=title,
description=description
)
demo.launch(share=True)
```
6. Integrate Gradio into your W&B Dashboard
The last step—integrating your Gradio demo with your W&B dashboard—is just one extra line:
```python
demo.integrate(wandb=wandb)
```
Once you call integrate, a demo will be created and you can integrate it into your dashboard or report.
Outside of W&B with Web components, using the `gradio-app` tags, anyone can embed Gradio demos on HF spaces directly into their blogs, websites, documentation, etc.:
```html
<gradio-app space="akhaliq/JoJoGAN"> </gradio-app>
```
7. (Optional) Embed W&B plots in your Gradio App
It's also possible to embed W&B plots within Gradio apps. To do so, you can create a W&B Report of your plots and
embed them within your Gradio app within a `gr.HTML` block.
The Report will need to be public and you will need to wrap the URL within an iFrame like this:
```python
import gradio as gr
def wandb_report(url):
iframe = f'<iframe src={url} style="border:none;height:1024px;width:100%">'
return gr.HTML(iframe)
with gr.Blocks() as demo:
report_url = 'https://wandb.ai/_scott/pytorch-sweeps-demo/reports/loss-22-10-07-16-00-17---VmlldzoyNzU2NzAx'
report = wandb_report(report_url)
demo.launch(share=True)
```
## Conclusion
We hope you enjoyed this brief demo of embedding a Gradio demo to a W&B report! Thanks for making it to the end. To recap:
- Only one single reference image is needed for fine-tuning JoJoGAN which usually takes about 1 minute on a GPU in colab. After training, style can be applied to any input image. Read more in the paper.
- W&B tracks experiments with just a few lines of code added to a colab and you can visualize, sort, and understand your experiments in a single, centralized dashboard.
- Gradio, meanwhile, demos the model in a user friendly interface to share anywhere on the web.
## How to contribute Gradio demos on HF spaces on the Wandb organization
- Create an account on Hugging Face [here](https://huggingface.co/join).
- Add Gradio Demo under your username, see this [course](https://huggingface.co/course/chapter9/4?fw=pt) for setting up Gradio Demo on Hugging Face.
- Request to join wandb organization [here](https://huggingface.co/wandb).
- Once approved transfer model from your username to Wandb organization
|
C:\Gradio Guides\9 Other Tutorials\how-to-use-3D-model-component.md |
# How to Use the 3D Model Component
Related spaces: https://huggingface.co/spaces/gradio/Model3D, https://huggingface.co/spaces/gradio/PIFu-Clothed-Human-Digitization, https://huggingface.co/spaces/gradio/dpt-depth-estimation-3d-obj
Tags: VISION, IMAGE
## Introduction
3D models are becoming more popular in machine learning and make for some of the most fun demos to experiment with. Using `gradio`, you can easily build a demo of your 3D image model and share it with anyone. The Gradio 3D Model component accepts 3 file types including: _.obj_, _.glb_, & _.gltf_.
This guide will show you how to build a demo for your 3D image model in a few lines of code; like the one below. Play around with 3D object by clicking around, dragging and zooming:
<gradio-app space="gradio/Model3D"> </gradio-app>
### Prerequisites
Make sure you have the `gradio` Python package already [installed](https://gradio.app/guides/quickstart).
## Taking a Look at the Code
Let's take a look at how to create the minimal interface above. The prediction function in this case will just return the original 3D model mesh, but you can change this function to run inference on your machine learning model. We'll take a look at more complex examples below.
```python
import gradio as gr
import os
def load_mesh(mesh_file_name):
return mesh_file_name
demo = gr.Interface(
fn=load_mesh,
inputs=gr.Model3D(),
outputs=gr.Model3D(
clear_color=[0.0, 0.0, 0.0, 0.0], label="3D Model"),
examples=[
[os.path.join(os.path.dirname(__file__), "files/Bunny.obj")],
[os.path.join(os.path.dirname(__file__), "files/Duck.glb")],
[os.path.join(os.path.dirname(__file__), "files/Fox.gltf")],
[os.path.join(os.path.dirname(__file__), "files/face.obj")],
],
)
if __name__ == "__main__":
demo.launch()
```
Let's break down the code above:
`load_mesh`: This is our 'prediction' function and for simplicity, this function will take in the 3D model mesh and return it.
Creating the Interface:
- `fn`: the prediction function that is used when the user clicks submit. In our case this is the `load_mesh` function.
- `inputs`: create a model3D input component. The input expects an uploaded file as a {str} filepath.
- `outputs`: create a model3D output component. The output component also expects a file as a {str} filepath.
- `clear_color`: this is the background color of the 3D model canvas. Expects RGBa values.
- `label`: the label that appears on the top left of the component.
- `examples`: list of 3D model files. The 3D model component can accept _.obj_, _.glb_, & _.gltf_ file types.
- `cache_examples`: saves the predicted output for the examples, to save time on inference.
## Exploring a more complex Model3D Demo:
Below is a demo that uses the DPT model to predict the depth of an image and then uses 3D Point Cloud to create a 3D object. Take a look at the [app.py](https://huggingface.co/spaces/gradio/dpt-depth-estimation-3d-obj/blob/main/app.py) file for a peek into the code and the model prediction function.
<gradio-app space="gradio/dpt-depth-estimation-3d-obj"> </gradio-app>
---
And you're done! That's all the code you need to build an interface for your Model3D model. Here are some references that you may find useful:
- Gradio's ["Getting Started" guide](https://gradio.app/getting_started/)
- The first [3D Model Demo](https://huggingface.co/spaces/gradio/Model3D) and [complete code](https://huggingface.co/spaces/gradio/Model3D/tree/main) (on Hugging Face Spaces)
|
C:\Gradio Guides\9 Other Tutorials\image-classification-in-pytorch.md |
# Image Classification in PyTorch
Related spaces: https://huggingface.co/spaces/abidlabs/pytorch-image-classifier, https://huggingface.co/spaces/pytorch/ResNet, https://huggingface.co/spaces/pytorch/ResNext, https://huggingface.co/spaces/pytorch/SqueezeNet
Tags: VISION, RESNET, PYTORCH
## Introduction
Image classification is a central task in computer vision. Building better classifiers to classify what object is present in a picture is an active area of research, as it has applications stretching from autonomous vehicles to medical imaging.
Such models are perfect to use with Gradio's _image_ input component, so in this tutorial we will build a web demo to classify images using Gradio. We will be able to build the whole web application in Python, and it will look like the demo on the bottom of the page.
Let's get started!
### Prerequisites
Make sure you have the `gradio` Python package already [installed](/getting_started). We will be using a pretrained image classification model, so you should also have `torch` installed.
## Step 1 — Setting up the Image Classification Model
First, we will need an image classification model. For this tutorial, we will use a pretrained Resnet-18 model, as it is easily downloadable from [PyTorch Hub](https://pytorch.org/hub/pytorch_vision_resnet/). You can use a different pretrained model or train your own.
```python
import torch
model = torch.hub.load('pytorch/vision:v0.6.0', 'resnet18', pretrained=True).eval()
```
Because we will be using the model for inference, we have called the `.eval()` method.
## Step 2 — Defining a `predict` function
Next, we will need to define a function that takes in the _user input_, which in this case is an image, and returns the prediction. The prediction should be returned as a dictionary whose keys are class name and values are confidence probabilities. We will load the class names from this [text file](https://git.io/JJkYN).
In the case of our pretrained model, it will look like this:
```python
import requests
from PIL import Image
from torchvision import transforms
# Download human-readable labels for ImageNet.
response = requests.get("https://git.io/JJkYN")
labels = response.text.split("\n")
def predict(inp):
inp = transforms.ToTensor()(inp).unsqueeze(0)
with torch.no_grad():
prediction = torch.nn.functional.softmax(model(inp)[0], dim=0)
confidences = {labels[i]: float(prediction[i]) for i in range(1000)}
return confidences
```
Let's break this down. The function takes one parameter:
- `inp`: the input image as a `PIL` image
Then, the function converts the image to a PIL Image and then eventually a PyTorch `tensor`, passes it through the model, and returns:
- `confidences`: the predictions, as a dictionary whose keys are class labels and whose values are confidence probabilities
## Step 3 — Creating a Gradio Interface
Now that we have our predictive function set up, we can create a Gradio Interface around it.
In this case, the input component is a drag-and-drop image component. To create this input, we use `Image(type="pil")` which creates the component and handles the preprocessing to convert that to a `PIL` image.
The output component will be a `Label`, which displays the top labels in a nice form. Since we don't want to show all 1,000 class labels, we will customize it to show only the top 3 images by constructing it as `Label(num_top_classes=3)`.
Finally, we'll add one more parameter, the `examples`, which allows us to prepopulate our interfaces with a few predefined examples. The code for Gradio looks like this:
```python
import gradio as gr
gr.Interface(fn=predict,
inputs=gr.Image(type="pil"),
outputs=gr.Label(num_top_classes=3),
examples=["lion.jpg", "cheetah.jpg"]).launch()
```
This produces the following interface, which you can try right here in your browser (try uploading your own examples!):
<gradio-app space="gradio/pytorch-image-classifier">
---
And you're done! That's all the code you need to build a web demo for an image classifier. If you'd like to share with others, try setting `share=True` when you `launch()` the Interface!
|
C:\Gradio Guides\9 Other Tutorials\image-classification-in-tensorflow.md |
# Image Classification in TensorFlow and Keras
Related spaces: https://huggingface.co/spaces/abidlabs/keras-image-classifier
Tags: VISION, MOBILENET, TENSORFLOW
## Introduction
Image classification is a central task in computer vision. Building better classifiers to classify what object is present in a picture is an active area of research, as it has applications stretching from traffic control systems to satellite imaging.
Such models are perfect to use with Gradio's _image_ input component, so in this tutorial we will build a web demo to classify images using Gradio. We will be able to build the whole web application in Python, and it will look like the demo on the bottom of the page.
Let's get started!
### Prerequisites
Make sure you have the `gradio` Python package already [installed](/getting_started). We will be using a pretrained Keras image classification model, so you should also have `tensorflow` installed.
## Step 1 — Setting up the Image Classification Model
First, we will need an image classification model. For this tutorial, we will use a pretrained Mobile Net model, as it is easily downloadable from [Keras](https://keras.io/api/applications/mobilenet/). You can use a different pretrained model or train your own.
```python
import tensorflow as tf
inception_net = tf.keras.applications.MobileNetV2()
```
This line automatically downloads the MobileNet model and weights using the Keras library.
## Step 2 — Defining a `predict` function
Next, we will need to define a function that takes in the _user input_, which in this case is an image, and returns the prediction. The prediction should be returned as a dictionary whose keys are class name and values are confidence probabilities. We will load the class names from this [text file](https://git.io/JJkYN).
In the case of our pretrained model, it will look like this:
```python
import requests
# Download human-readable labels for ImageNet.
response = requests.get("https://git.io/JJkYN")
labels = response.text.split("\n")
def classify_image(inp):
inp = inp.reshape((-1, 224, 224, 3))
inp = tf.keras.applications.mobilenet_v2.preprocess_input(inp)
prediction = inception_net.predict(inp).flatten()
confidences = {labels[i]: float(prediction[i]) for i in range(1000)}
return confidences
```
Let's break this down. The function takes one parameter:
- `inp`: the input image as a `numpy` array
Then, the function adds a batch dimension, passes it through the model, and returns:
- `confidences`: the predictions, as a dictionary whose keys are class labels and whose values are confidence probabilities
## Step 3 — Creating a Gradio Interface
Now that we have our predictive function set up, we can create a Gradio Interface around it.
In this case, the input component is a drag-and-drop image component. To create this input, we can use the `"gradio.inputs.Image"` class, which creates the component and handles the preprocessing to convert that to a numpy array. We will instantiate the class with a parameter that automatically preprocesses the input image to be 224 pixels by 224 pixels, which is the size that MobileNet expects.
The output component will be a `"label"`, which displays the top labels in a nice form. Since we don't want to show all 1,000 class labels, we will customize it to show only the top 3 images.
Finally, we'll add one more parameter, the `examples`, which allows us to prepopulate our interfaces with a few predefined examples. The code for Gradio looks like this:
```python
import gradio as gr
gr.Interface(fn=classify_image,
inputs=gr.Image(shape=(224, 224)),
outputs=gr.Label(num_top_classes=3),
examples=["banana.jpg", "car.jpg"]).launch()
```
This produces the following interface, which you can try right here in your browser (try uploading your own examples!):
<gradio-app space="gradio/keras-image-classifier">
---
And you're done! That's all the code you need to build a web demo for an image classifier. If you'd like to share with others, try setting `share=True` when you `launch()` the Interface!
|
C:\Gradio Guides\9 Other Tutorials\image-classification-with-vision-transformers.md |
# Image Classification with Vision Transformers
Related spaces: https://huggingface.co/spaces/abidlabs/vision-transformer
Tags: VISION, TRANSFORMERS, HUB
## Introduction
Image classification is a central task in computer vision. Building better classifiers to classify what object is present in a picture is an active area of research, as it has applications stretching from facial recognition to manufacturing quality control.
State-of-the-art image classifiers are based on the _transformers_ architectures, originally popularized for NLP tasks. Such architectures are typically called vision transformers (ViT). Such models are perfect to use with Gradio's _image_ input component, so in this tutorial we will build a web demo to classify images using Gradio. We will be able to build the whole web application in a **single line of Python**, and it will look like the demo on the bottom of the page.
Let's get started!
### Prerequisites
Make sure you have the `gradio` Python package already [installed](/getting_started).
## Step 1 — Choosing a Vision Image Classification Model
First, we will need an image classification model. For this tutorial, we will use a model from the [Hugging Face Model Hub](https://huggingface.co/models?pipeline_tag=image-classification). The Hub contains thousands of models covering dozens of different machine learning tasks.
Expand the Tasks category on the left sidebar and select "Image Classification" as our task of interest. You will then see all of the models on the Hub that are designed to classify images.
At the time of writing, the most popular one is `google/vit-base-patch16-224`, which has been trained on ImageNet images at a resolution of 224x224 pixels. We will use this model for our demo.
## Step 2 — Loading the Vision Transformer Model with Gradio
When using a model from the Hugging Face Hub, we do not need to define the input or output components for the demo. Similarly, we do not need to be concerned with the details of preprocessing or postprocessing.
All of these are automatically inferred from the model tags.
Besides the import statement, it only takes a single line of Python to load and launch the demo.
We use the `gr.Interface.load()` method and pass in the path to the model including the `huggingface/` to designate that it is from the Hugging Face Hub.
```python
import gradio as gr
gr.Interface.load(
"huggingface/google/vit-base-patch16-224",
examples=["alligator.jpg", "laptop.jpg"]).launch()
```
Notice that we have added one more parameter, the `examples`, which allows us to prepopulate our interfaces with a few predefined examples.
This produces the following interface, which you can try right here in your browser. When you input an image, it is automatically preprocessed and sent to the Hugging Face Hub API, where it is passed through the model and returned as a human-interpretable prediction. Try uploading your own image!
<gradio-app space="gradio/vision-transformer">
---
And you're done! In one line of code, you have built a web demo for an image classifier. If you'd like to share with others, try setting `share=True` when you `launch()` the Interface!
|
C:\Gradio Guides\9 Other Tutorials\installing-gradio-in-a-virtual-environment.md |
# Installing Gradio in a Virtual Environment
Tags: INSTALLATION
In this guide, we will describe step-by-step how to install `gradio` within a virtual environment. This guide will cover both Windows and MacOS/Linux systems.
## Virtual Environments
A virtual environment in Python is a self-contained directory that holds a Python installation for a particular version of Python, along with a number of additional packages. This environment is isolated from the main Python installation and other virtual environments. Each environment can have its own independent set of installed Python packages, which allows you to maintain different versions of libraries for different projects without conflicts.
Using virtual environments ensures that you can work on multiple Python projects on the same machine without any conflicts. This is particularly useful when different projects require different versions of the same library. It also simplifies dependency management and enhances reproducibility, as you can easily share the requirements of your project with others.
## Installing Gradio on Windows
To install Gradio on a Windows system in a virtual environment, follow these steps:
1. **Install Python**: Ensure you have Python 3.8 or higher installed. You can download it from [python.org](https://www.python.org/). You can verify the installation by running `python --version` or `python3 --version` in Command Prompt.
2. **Create a Virtual Environment**:
Open Command Prompt and navigate to your project directory. Then create a virtual environment using the following command:
```bash
python -m venv gradio-env
```
This command creates a new directory `gradio-env` in your project folder, containing a fresh Python installation.
3. **Activate the Virtual Environment**:
To activate the virtual environment, run:
```bash
.\gradio-env\Scripts\activate
```
Your command prompt should now indicate that you are working inside `gradio-env`. Note: you can choose a different name than `gradio-env` for your virtual environment in this step.
4. **Install Gradio**:
Now, you can install Gradio using pip:
```bash
pip install gradio
```
5. **Verification**:
To verify the installation, run `python` and then type:
```python
import gradio as gr
print(gr.__version__)
```
This will display the installed version of Gradio.
## Installing Gradio on MacOS/Linux
The installation steps on MacOS and Linux are similar to Windows but with some differences in commands.
1. **Install Python**:
Python usually comes pre-installed on MacOS and most Linux distributions. You can verify the installation by running `python --version` in the terminal (note that depending on how Python is installed, you might have to use `python3` instead of `python` throughout these steps).
Ensure you have Python 3.8 or higher installed. If you do not have it installed, you can download it from [python.org](https://www.python.org/).
2. **Create a Virtual Environment**:
Open Terminal and navigate to your project directory. Then create a virtual environment using:
```bash
python -m venv gradio-env
```
Note: you can choose a different name than `gradio-env` for your virtual environment in this step.
3. **Activate the Virtual Environment**:
To activate the virtual environment on MacOS/Linux, use:
```bash
source gradio-env/bin/activate
```
4. **Install Gradio**:
With the virtual environment activated, install Gradio using pip:
```bash
pip install gradio
```
5. **Verification**:
To verify the installation, run `python` and then type:
```python
import gradio as gr
print(gr.__version__)
```
This will display the installed version of Gradio.
By following these steps, you can successfully install Gradio in a virtual environment on your operating system, ensuring a clean and managed workspace for your Python projects. |
C:\Gradio Guides\9 Other Tutorials\named-entity-recognition.md |
# Named-Entity Recognition
Related spaces: https://huggingface.co/spaces/rajistics/biobert_ner_demo, https://huggingface.co/spaces/abidlabs/ner, https://huggingface.co/spaces/rajistics/Financial_Analyst_AI
Tags: NER, TEXT, HIGHLIGHT
## Introduction
Named-entity recognition (NER), also known as token classification or text tagging, is the task of taking a sentence and classifying every word (or "token") into different categories, such as names of people or names of locations, or different parts of speech.
For example, given the sentence:
> Does Chicago have any Pakistani restaurants?
A named-entity recognition algorithm may identify:
- "Chicago" as a **location**
- "Pakistani" as an **ethnicity**
and so on.
Using `gradio` (specifically the `HighlightedText` component), you can easily build a web demo of your NER model and share that with the rest of your team.
Here is an example of a demo that you'll be able to build:
$demo_ner_pipeline
This tutorial will show how to take a pretrained NER model and deploy it with a Gradio interface. We will show two different ways to use the `HighlightedText` component -- depending on your NER model, either of these two ways may be easier to learn!
### Prerequisites
Make sure you have the `gradio` Python package already [installed](/getting_started). You will also need a pretrained named-entity recognition model. You can use your own, while in this tutorial, we will use one from the `transformers` library.
### Approach 1: List of Entity Dictionaries
Many named-entity recognition models output a list of dictionaries. Each dictionary consists of an _entity_, a "start" index, and an "end" index. This is, for example, how NER models in the `transformers` library operate:
```py
from transformers import pipeline
ner_pipeline = pipeline("ner")
ner_pipeline("Does Chicago have any Pakistani restaurants")
```
Output:
```bash
[{'entity': 'I-LOC',
'score': 0.9988978,
'index': 2,
'word': 'Chicago',
'start': 5,
'end': 12},
{'entity': 'I-MISC',
'score': 0.9958592,
'index': 5,
'word': 'Pakistani',
'start': 22,
'end': 31}]
```
If you have such a model, it is very easy to hook it up to Gradio's `HighlightedText` component. All you need to do is pass in this **list of entities**, along with the **original text** to the model, together as dictionary, with the keys being `"entities"` and `"text"` respectively.
Here is a complete example:
$code_ner_pipeline
$demo_ner_pipeline
### Approach 2: List of Tuples
An alternative way to pass data into the `HighlightedText` component is a list of tuples. The first element of each tuple should be the word or words that are being classified into a particular entity. The second element should be the entity label (or `None` if they should be unlabeled). The `HighlightedText` component automatically strings together the words and labels to display the entities.
In some cases, this can be easier than the first approach. Here is a demo showing this approach using Spacy's parts-of-speech tagger:
$code_text_analysis
$demo_text_analysis
---
And you're done! That's all you need to know to build a web-based GUI for your NER model.
Fun tip: you can share your NER demo instantly with others simply by setting `share=True` in `launch()`.
|
C:\Gradio Guides\9 Other Tutorials\real-time-speech-recognition.md |
# Real Time Speech Recognition
Tags: ASR, SPEECH, STREAMING
## Introduction
Automatic speech recognition (ASR), the conversion of spoken speech to text, is a very important and thriving area of machine learning. ASR algorithms run on practically every smartphone, and are becoming increasingly embedded in professional workflows, such as digital assistants for nurses and doctors. Because ASR algorithms are designed to be used directly by customers and end users, it is important to validate that they are behaving as expected when confronted with a wide variety of speech patterns (different accents, pitches, and background audio conditions).
Using `gradio`, you can easily build a demo of your ASR model and share that with a testing team, or test it yourself by speaking through the microphone on your device.
This tutorial will show how to take a pretrained speech-to-text model and deploy it with a Gradio interface. We will start with a **_full-context_** model, in which the user speaks the entire audio before the prediction runs. Then we will adapt the demo to make it **_streaming_**, meaning that the audio model will convert speech as you speak.
### Prerequisites
Make sure you have the `gradio` Python package already [installed](/getting_started). You will also need a pretrained speech recognition model. In this tutorial, we will build demos from 2 ASR libraries:
- Transformers (for this, `pip install transformers` and `pip install torch`)
Make sure you have at least one of these installed so that you can follow along the tutorial. You will also need `ffmpeg` [installed on your system](https://www.ffmpeg.org/download.html), if you do not already have it, to process files from the microphone.
Here's how to build a real time speech recognition (ASR) app:
1. [Set up the Transformers ASR Model](#1-set-up-the-transformers-asr-model)
2. [Create a Full-Context ASR Demo with Transformers](#2-create-a-full-context-asr-demo-with-transformers)
3. [Create a Streaming ASR Demo with Transformers](#3-create-a-streaming-asr-demo-with-transformers)
## 1. Set up the Transformers ASR Model
First, you will need to have an ASR model that you have either trained yourself or you will need to download a pretrained model. In this tutorial, we will start by using a pretrained ASR model from the model, `whisper`.
Here is the code to load `whisper` from Hugging Face `transformers`.
```python
from transformers import pipeline
p = pipeline("automatic-speech-recognition", model="openai/whisper-base.en")
```
That's it!
## 2. Create a Full-Context ASR Demo with Transformers
We will start by creating a _full-context_ ASR demo, in which the user speaks the full audio before using the ASR model to run inference. This is very easy with Gradio -- we simply create a function around the `pipeline` object above.
We will use `gradio`'s built in `Audio` component, configured to take input from the user's microphone and return a filepath for the recorded audio. The output component will be a plain `Textbox`.
$code_asr
$demo_asr
The `transcribe` function takes a single parameter, `audio`, which is a numpy array of the audio the user recorded. The `pipeline` object expects this in float32 format, so we convert it first to float32, and then extract the transcribed text.
## 3. Create a Streaming ASR Demo with Transformers
To make this a *streaming* demo, we need to make these changes:
1. Set `streaming=True` in the `Audio` component
2. Set `live=True` in the `Interface`
3. Add a `state` to the interface to store the recorded audio of a user
Take a look below.
$code_stream_asr
Notice now we have a state variable now, because we need to track all the audio history. `transcribe` gets called whenever there is a new small chunk of audio, but we also need to keep track of all the audio that has been spoken so far in state.
As the interface runs, the `transcribe` function gets called, with a record of all the previously spoken audio in `stream`, as well as the new chunk of audio as `new_chunk`. We return the new full audio so that can be stored back in state, and we also return the transcription.
Here we naively append the audio together and simply call the `transcriber` object on the entire audio. You can imagine more efficient ways of handling this, such as re-processing only the last 5 seconds of audio whenever a new chunk of audio received.
$demo_stream_asr
Now the ASR model will run inference as you speak! |
C:\Gradio Guides\9 Other Tutorials\running-background-tasks.md |
# Running Background Tasks
Related spaces: https://huggingface.co/spaces/freddyaboulton/gradio-google-forms
Tags: TASKS, SCHEDULED, TABULAR, DATA
## Introduction
This guide explains how you can run background tasks from your gradio app.
Background tasks are operations that you'd like to perform outside the request-response
lifecycle of your app either once or on a periodic schedule.
Examples of background tasks include periodically synchronizing data to an external database or
sending a report of model predictions via email.
## Overview
We will be creating a simple "Google-forms-style" application to gather feedback from users of the gradio library.
We will use a local sqlite database to store our data, but we will periodically synchronize the state of the database
with a [HuggingFace Dataset](https://huggingface.co/datasets) so that our user reviews are always backed up.
The synchronization will happen in a background task running every 60 seconds.
At the end of the demo, you'll have a fully working application like this one:
<gradio-app space="freddyaboulton/gradio-google-forms"> </gradio-app>
## Step 1 - Write your database logic 💾
Our application will store the name of the reviewer, their rating of gradio on a scale of 1 to 5, as well as
any comments they want to share about the library. Let's write some code that creates a database table to
store this data. We'll also write some functions to insert a review into that table and fetch the latest 10 reviews.
We're going to use the `sqlite3` library to connect to our sqlite database but gradio will work with any library.
The code will look like this:
```python
DB_FILE = "./reviews.db"
db = sqlite3.connect(DB_FILE)
# Create table if it doesn't already exist
try:
db.execute("SELECT * FROM reviews").fetchall()
db.close()
except sqlite3.OperationalError:
db.execute(
'''
CREATE TABLE reviews (id INTEGER PRIMARY KEY AUTOINCREMENT NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP NOT NULL,
name TEXT, review INTEGER, comments TEXT)
''')
db.commit()
db.close()
def get_latest_reviews(db: sqlite3.Connection):
reviews = db.execute("SELECT * FROM reviews ORDER BY id DESC limit 10").fetchall()
total_reviews = db.execute("Select COUNT(id) from reviews").fetchone()[0]
reviews = pd.DataFrame(reviews, columns=["id", "date_created", "name", "review", "comments"])
return reviews, total_reviews
def add_review(name: str, review: int, comments: str):
db = sqlite3.connect(DB_FILE)
cursor = db.cursor()
cursor.execute("INSERT INTO reviews(name, review, comments) VALUES(?,?,?)", [name, review, comments])
db.commit()
reviews, total_reviews = get_latest_reviews(db)
db.close()
return reviews, total_reviews
```
Let's also write a function to load the latest reviews when the gradio application loads:
```python
def load_data():
db = sqlite3.connect(DB_FILE)
reviews, total_reviews = get_latest_reviews(db)
db.close()
return reviews, total_reviews
```
## Step 2 - Create a gradio app ⚡
Now that we have our database logic defined, we can use gradio create a dynamic web page to ask our users for feedback!
```python
with gr.Blocks() as demo:
with gr.Row():
with gr.Column():
name = gr.Textbox(label="Name", placeholder="What is your name?")
review = gr.Radio(label="How satisfied are you with using gradio?", choices=[1, 2, 3, 4, 5])
comments = gr.Textbox(label="Comments", lines=10, placeholder="Do you have any feedback on gradio?")
submit = gr.Button(value="Submit Feedback")
with gr.Column():
data = gr.Dataframe(label="Most recently created 10 rows")
count = gr.Number(label="Total number of reviews")
submit.click(add_review, [name, review, comments], [data, count])
demo.load(load_data, None, [data, count])
```
## Step 3 - Synchronize with HuggingFace Datasets 🤗
We could call `demo.launch()` after step 2 and have a fully functioning application. However,
our data would be stored locally on our machine. If the sqlite file were accidentally deleted, we'd lose all of our reviews!
Let's back up our data to a dataset on the HuggingFace hub.
Create a dataset [here](https://huggingface.co/datasets) before proceeding.
Now at the **top** of our script, we'll use the [huggingface hub client library](https://huggingface.co/docs/huggingface_hub/index)
to connect to our dataset and pull the latest backup.
```python
TOKEN = os.environ.get('HUB_TOKEN')
repo = huggingface_hub.Repository(
local_dir="data",
repo_type="dataset",
clone_from="<name-of-your-dataset>",
use_auth_token=TOKEN
)
repo.git_pull()
shutil.copyfile("./data/reviews.db", DB_FILE)
```
Note that you'll have to get an access token from the "Settings" tab of your HuggingFace for the above code to work.
In the script, the token is securely accessed via an environment variable.

Now we will create a background task to synch our local database to the dataset hub every 60 seconds.
We will use the [AdvancedPythonScheduler](https://apscheduler.readthedocs.io/en/3.x/) to handle the scheduling.
However, this is not the only task scheduling library available. Feel free to use whatever you are comfortable with.
The function to back up our data will look like this:
```python
from apscheduler.schedulers.background import BackgroundScheduler
def backup_db():
shutil.copyfile(DB_FILE, "./data/reviews.db")
db = sqlite3.connect(DB_FILE)
reviews = db.execute("SELECT * FROM reviews").fetchall()
pd.DataFrame(reviews).to_csv("./data/reviews.csv", index=False)
print("updating db")
repo.push_to_hub(blocking=False, commit_message=f"Updating data at {datetime.datetime.now()}")
scheduler = BackgroundScheduler()
scheduler.add_job(func=backup_db, trigger="interval", seconds=60)
scheduler.start()
```
## Step 4 (Bonus) - Deployment to HuggingFace Spaces
You can use the HuggingFace [Spaces](https://huggingface.co/spaces) platform to deploy this application for free ✨
If you haven't used Spaces before, follow the previous guide [here](/using_hugging_face_integrations).
You will have to use the `HUB_TOKEN` environment variable as a secret in the Guides.
## Conclusion
Congratulations! You know how to run background tasks from your gradio app on a schedule ⏲️.
Checkout the application running on Spaces [here](https://huggingface.co/spaces/freddyaboulton/gradio-google-forms).
The complete code is [here](https://huggingface.co/spaces/freddyaboulton/gradio-google-forms/blob/main/app.py)
|
C:\Gradio Guides\9 Other Tutorials\running-gradio-on-your-web-server-with-nginx.md |
# Running a Gradio App on your Web Server with Nginx
Tags: DEPLOYMENT, WEB SERVER, NGINX
## Introduction
Gradio is a Python library that allows you to quickly create customizable web apps for your machine learning models and data processing pipelines. Gradio apps can be deployed on [Hugging Face Spaces](https://hf.space) for free.
In some cases though, you might want to deploy a Gradio app on your own web server. You might already be using [Nginx](https://www.nginx.com/), a highly performant web server, to serve your website (say `https://www.example.com`), and you want to attach Gradio to a specific subpath on your website (e.g. `https://www.example.com/gradio-demo`).
In this Guide, we will guide you through the process of running a Gradio app behind Nginx on your own web server to achieve this.
**Prerequisites**
1. A Linux web server with [Nginx installed](https://www.nginx.com/blog/setting-up-nginx/) and [Gradio installed](/quickstart)
2. A working Gradio app saved as a python file on your web server
## Editing your Nginx configuration file
1. Start by editing the Nginx configuration file on your web server. By default, this is located at: `/etc/nginx/nginx.conf`
In the `http` block, add the following line to include server block configurations from a separate file:
```bash
include /etc/nginx/sites-enabled/*;
```
2. Create a new file in the `/etc/nginx/sites-available` directory (create the directory if it does not already exist), using a filename that represents your app, for example: `sudo nano /etc/nginx/sites-available/my_gradio_app`
3. Paste the following into your file editor:
```bash
server {
listen 80;
server_name example.com www.example.com; # Change this to your domain name
location /gradio-demo/ { # Change this if you'd like to server your Gradio app on a different path
proxy_pass http://127.0.0.1:7860/; # Change this if your Gradio app will be running on a different port
proxy_buffering off;
proxy_redirect off;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_set_header Host $host;
proxy_set_header X-Forwarded-Host $host;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
```
Tip: Setting the `X-Forwarded-Host` and `X-Forwarded-Proto` headers is important as Gradio uses these, in conjunction with the `root_path` parameter discussed below, to construct the public URL that your app is being served on. Gradio uses the public URL to fetch various static assets. If these headers are not set, your Gradio app may load in a broken state.
*Note:* The `$host` variable does not include the host port. If you are serving your Gradio application on a raw IP address and port, you should use the `$http_host` variable instead, in these lines:
```bash
proxy_set_header Host $host;
proxy_set_header X-Forwarded-Host $host;
```
## Run your Gradio app on your web server
1. Before you launch your Gradio app, you'll need to set the `root_path` to be the same as the subpath that you specified in your nginx configuration. This is necessary for Gradio to run on any subpath besides the root of the domain.
*Note:* Instead of a subpath, you can also provide a complete URL for `root_path` (beginning with `http` or `https`) in which case the `root_path` is treated as an absolute URL instead of a URL suffix (but in this case, you'll need to update the `root_path` if the domain changes).
Here's a simple example of a Gradio app with a custom `root_path` corresponding to the Nginx configuration above.
```python
import gradio as gr
import time
def test(x):
time.sleep(4)
return x
gr.Interface(test, "textbox", "textbox").queue().launch(root_path="/gradio-demo")
```
2. Start a `tmux` session by typing `tmux` and pressing enter (optional)
It's recommended that you run your Gradio app in a `tmux` session so that you can keep it running in the background easily
3. Then, start your Gradio app. Simply type in `python` followed by the name of your Gradio python file. By default, your app will run on `localhost:7860`, but if it starts on a different port, you will need to update the nginx configuration file above.
## Restart Nginx
1. If you are in a tmux session, exit by typing CTRL+B (or CMD+B), followed by the "D" key.
2. Finally, restart nginx by running `sudo systemctl restart nginx`.
And that's it! If you visit `https://example.com/gradio-demo` on your browser, you should see your Gradio app running there
|
C:\Gradio Guides\9 Other Tutorials\setting-up-a-demo-for-maximum-performance.md |
# Setting Up a Demo for Maximum Performance
Tags: CONCURRENCY, LATENCY, PERFORMANCE
Let's say that your Gradio demo goes _viral_ on social media -- you have lots of users trying it out simultaneously, and you want to provide your users with the best possible experience or, in other words, minimize the amount of time that each user has to wait in the queue to see their prediction.
How can you configure your Gradio demo to handle the most traffic? In this Guide, we dive into some of the parameters of Gradio's `.queue()` method as well as some other related parameters, and discuss how to set these parameters in a way that allows you to serve lots of users simultaneously with minimal latency.
This is an advanced guide, so make sure you know the basics of Gradio already, such as [how to create and launch a Gradio Interface](https://gradio.app/guides/quickstart/). Most of the information in this Guide is relevant whether you are hosting your demo on [Hugging Face Spaces](https://hf.space) or on your own server.
## Overview of Gradio's Queueing System
By default, every Gradio demo includes a built-in queuing system that scales to thousands of requests. When a user of your app submits a request (i.e. submits an input to your function), Gradio adds the request to the queue, and requests are processed in order, generally speaking (this is not exactly true, as discussed below). When the user's request has finished processing, the Gradio server returns the result back to the user using server-side events (SSE). The SSE protocol has several advantages over simply using HTTP POST requests:
(1) They do not time out -- most browsers raise a timeout error if they do not get a response to a POST request after a short period of time (e.g. 1 min). This can be a problem if your inference function takes longer than 1 minute to run or if many people are trying out your demo at the same time, resulting in increased latency.
(2) They allow the server to send multiple updates to the frontend. This means, for example, that the server can send a real-time ETA of how long your prediction will take to complete.
To configure the queue, simply call the `.queue()` method before launching an `Interface`, `TabbedInterface`, `ChatInterface` or any `Blocks`. Here's an example:
```py
import gradio as gr
app = gr.Interface(lambda x:x, "image", "image")
app.queue() # <-- Sets up a queue with default parameters
app.launch()
```
**How Requests are Processed from the Queue**
When a Gradio server is launched, a pool of threads is used to execute requests from the queue. By default, the maximum size of this thread pool is `40` (which is the default inherited from FastAPI, on which the Gradio server is based). However, this does *not* mean that 40 requests are always processed in parallel from the queue.
Instead, Gradio uses a **single-function-single-worker** model by default. This means that each worker thread is only assigned a single function from among all of the functions that could be part of your Gradio app. This ensures that you do not see, for example, out-of-memory errors, due to multiple workers calling a machine learning model at the same time. Suppose you have 3 functions in your Gradio app: A, B, and C. And you see the following sequence of 7 requests come in from users using your app:
```
1 2 3 4 5 6 7
-------------
A B A A C B A
```
Initially, 3 workers will get dispatched to handle requests 1, 2, and 5 (corresponding to functions: A, B, C). As soon as any of these workers finish, they will start processing the next function in the queue of the same function type, e.g. the worker that finished processing request 1 will start processing request 3, and so on.
If you want to change this behavior, there are several parameters that can be used to configure the queue and help reduce latency. Let's go through them one-by-one.
### The `default_concurrency_limit` parameter in `queue()`
The first parameter we will explore is the `default_concurrency_limit` parameter in `queue()`. This controls how many workers can execute the same event. By default, this is set to `1`, but you can set it to a higher integer: `2`, `10`, or even `None` (in the last case, there is no limit besides the total number of available workers).
This is useful, for example, if your Gradio app does not call any resource-intensive functions. If your app only queries external APIs, then you can set the `default_concurrency_limit` much higher. Increasing this parameter can **linearly multiply the capacity of your server to handle requests**.
So why not set this parameter much higher all the time? Keep in mind that since requests are processed in parallel, each request will consume memory to store the data and weights for processing. This means that you might get out-of-memory errors if you increase the `default_concurrency_limit` too high. You may also start to get diminishing returns if the `default_concurrency_limit` is too high because of costs of switching between different worker threads.
**Recommendation**: Increase the `default_concurrency_limit` parameter as high as you can while you continue to see performance gains or until you hit memory limits on your machine. You can [read about Hugging Face Spaces machine specs here](https://huggingface.co/docs/hub/spaces-overview).
### The `concurrency_limit` parameter in events
You can also set the number of requests that can be processed in parallel for each event individually. These take priority over the `default_concurrency_limit` parameter described previously.
To do this, set the `concurrency_limit` parameter of any event listener, e.g. `btn.click(..., concurrency_limit=20)` or in the `Interface` or `ChatInterface` classes: e.g. `gr.Interface(..., concurrency_limit=20)`. By default, this parameter is set to the global `default_concurrency_limit`.
### The `max_threads` parameter in `launch()`
If your demo uses non-async functions, e.g. `def` instead of `async def`, they will be run in a threadpool. This threadpool has a size of 40 meaning that only 40 threads can be created to run your non-async functions. If you are running into this limit, you can increase the threadpool size with `max_threads`. The default value is 40.
Tip: You should use async functions whenever possible to increase the number of concurrent requests your app can handle. Quick functions that are not CPU-bound are good candidates to be written as `async`. This [guide](https://fastapi.tiangolo.com/async/) is a good primer on the concept.
### The `max_size` parameter in `queue()`
A more blunt way to reduce the wait times is simply to prevent too many people from joining the queue in the first place. You can set the maximum number of requests that the queue processes using the `max_size` parameter of `queue()`. If a request arrives when the queue is already of the maximum size, it will not be allowed to join the queue and instead, the user will receive an error saying that the queue is full and to try again. By default, `max_size=None`, meaning that there is no limit to the number of users that can join the queue.
Paradoxically, setting a `max_size` can often improve user experience because it prevents users from being dissuaded by very long queue wait times. Users who are more interested and invested in your demo will keep trying to join the queue, and will be able to get their results faster.
**Recommendation**: For a better user experience, set a `max_size` that is reasonable given your expectations of how long users might be willing to wait for a prediction.
### The `max_batch_size` parameter in events
Another way to increase the parallelism of your Gradio demo is to write your function so that it can accept **batches** of inputs. Most deep learning models can process batches of samples more efficiently than processing individual samples.
If you write your function to process a batch of samples, Gradio will automatically batch incoming requests together and pass them into your function as a batch of samples. You need to set `batch` to `True` (by default it is `False`) and set a `max_batch_size` (by default it is `4`) based on the maximum number of samples your function is able to handle. These two parameters can be passed into `gr.Interface()` or to an event in Blocks such as `.click()`.
While setting a batch is conceptually similar to having workers process requests in parallel, it is often _faster_ than setting the `concurrency_count` for deep learning models. The downside is that you might need to adapt your function a little bit to accept batches of samples instead of individual samples.
Here's an example of a function that does _not_ accept a batch of inputs -- it processes a single input at a time:
```py
import time
def trim_words(word, length):
return word[:int(length)]
```
Here's the same function rewritten to take in a batch of samples:
```py
import time
def trim_words(words, lengths):
trimmed_words = []
for w, l in zip(words, lengths):
trimmed_words.append(w[:int(l)])
return [trimmed_words]
```
The second function can be used with `batch=True` and an appropriate `max_batch_size` parameter.
**Recommendation**: If possible, write your function to accept batches of samples, and then set `batch` to `True` and the `max_batch_size` as high as possible based on your machine's memory limits.
## Upgrading your Hardware (GPUs, TPUs, etc.)
If you have done everything above, and your demo is still not fast enough, you can upgrade the hardware that your model is running on. Changing the model from running on CPUs to running on GPUs will usually provide a 10x-50x increase in inference time for deep learning models.
It is particularly straightforward to upgrade your Hardware on Hugging Face Spaces. Simply click on the "Settings" tab in your Space and choose the Space Hardware you'd like.

While you might need to adapt portions of your machine learning inference code to run on a GPU (here's a [handy guide](https://cnvrg.io/pytorch-cuda/) if you are using PyTorch), Gradio is completely agnostic to the choice of hardware and will work completely fine if you use it with CPUs, GPUs, TPUs, or any other hardware!
Note: your GPU memory is different than your CPU memory, so if you upgrade your hardware,
you might need to adjust the value of the `default_concurrency_limit` parameter described above.
## Conclusion
Congratulations! You know how to set up a Gradio demo for maximum performance. Good luck on your next viral demo!
|
C:\Gradio Guides\9 Other Tutorials\theming-guide.md |
# Theming
Tags: THEMES
## Introduction
Gradio features a built-in theming engine that lets you customize the look and feel of your app. You can choose from a variety of themes, or create your own. To do so, pass the `theme=` kwarg to the `Blocks` or `Interface` constructor. For example:
```python
with gr.Blocks(theme=gr.themes.Soft()) as demo:
...
```
<div class="wrapper">
<iframe
src="https://gradio-theme-soft.hf.space?__theme=light"
frameborder="0"
></iframe>
</div>
Gradio comes with a set of prebuilt themes which you can load from `gr.themes.*`. These are:
- `gr.themes.Base()`
- `gr.themes.Default()`
- `gr.themes.Glass()`
- `gr.themes.Monochrome()`
- `gr.themes.Soft()`
Each of these themes set values for hundreds of CSS variables. You can use prebuilt themes as a starting point for your own custom themes, or you can create your own themes from scratch. Let's take a look at each approach.
## Using the Theme Builder
The easiest way to build a theme is using the Theme Builder. To launch the Theme Builder locally, run the following code:
```python
import gradio as gr
gr.themes.builder()
```
$demo_theme_builder
You can use the Theme Builder running on Spaces above, though it runs much faster when you launch it locally via `gr.themes.builder()`.
As you edit the values in the Theme Builder, the app will preview updates in real time. You can download the code to generate the theme you've created so you can use it in any Gradio app.
In the rest of the guide, we will cover building themes programmatically.
## Extending Themes via the Constructor
Although each theme has hundreds of CSS variables, the values for most these variables are drawn from 8 core variables which can be set through the constructor of each prebuilt theme. Modifying these 8 arguments allows you to quickly change the look and feel of your app.
### Core Colors
The first 3 constructor arguments set the colors of the theme and are `gradio.themes.Color` objects. Internally, these Color objects hold brightness values for the palette of a single hue, ranging from 50, 100, 200..., 800, 900, 950. Other CSS variables are derived from these 3 colors.
The 3 color constructor arguments are:
- `primary_hue`: This is the color draws attention in your theme. In the default theme, this is set to `gradio.themes.colors.orange`.
- `secondary_hue`: This is the color that is used for secondary elements in your theme. In the default theme, this is set to `gradio.themes.colors.blue`.
- `neutral_hue`: This is the color that is used for text and other neutral elements in your theme. In the default theme, this is set to `gradio.themes.colors.gray`.
You could modify these values using their string shortcuts, such as
```python
with gr.Blocks(theme=gr.themes.Default(primary_hue="red", secondary_hue="pink")) as demo:
...
```
or you could use the `Color` objects directly, like this:
```python
with gr.Blocks(theme=gr.themes.Default(primary_hue=gr.themes.colors.red, secondary_hue=gr.themes.colors.pink)) as demo:
...
```
<div class="wrapper">
<iframe
src="https://gradio-theme-extended-step-1.hf.space?__theme=light"
frameborder="0"
></iframe>
</div>
Predefined colors are:
- `slate`
- `gray`
- `zinc`
- `neutral`
- `stone`
- `red`
- `orange`
- `amber`
- `yellow`
- `lime`
- `green`
- `emerald`
- `teal`
- `cyan`
- `sky`
- `blue`
- `indigo`
- `violet`
- `purple`
- `fuchsia`
- `pink`
- `rose`
You could also create your own custom `Color` objects and pass them in.
### Core Sizing
The next 3 constructor arguments set the sizing of the theme and are `gradio.themes.Size` objects. Internally, these Size objects hold pixel size values that range from `xxs` to `xxl`. Other CSS variables are derived from these 3 sizes.
- `spacing_size`: This sets the padding within and spacing between elements. In the default theme, this is set to `gradio.themes.sizes.spacing_md`.
- `radius_size`: This sets the roundedness of corners of elements. In the default theme, this is set to `gradio.themes.sizes.radius_md`.
- `text_size`: This sets the font size of text. In the default theme, this is set to `gradio.themes.sizes.text_md`.
You could modify these values using their string shortcuts, such as
```python
with gr.Blocks(theme=gr.themes.Default(spacing_size="sm", radius_size="none")) as demo:
...
```
or you could use the `Size` objects directly, like this:
```python
with gr.Blocks(theme=gr.themes.Default(spacing_size=gr.themes.sizes.spacing_sm, radius_size=gr.themes.sizes.radius_none)) as demo:
...
```
<div class="wrapper">
<iframe
src="https://gradio-theme-extended-step-2.hf.space?__theme=light"
frameborder="0"
></iframe>
</div>
The predefined size objects are:
- `radius_none`
- `radius_sm`
- `radius_md`
- `radius_lg`
- `spacing_sm`
- `spacing_md`
- `spacing_lg`
- `text_sm`
- `text_md`
- `text_lg`
You could also create your own custom `Size` objects and pass them in.
### Core Fonts
The final 2 constructor arguments set the fonts of the theme. You can pass a list of fonts to each of these arguments to specify fallbacks. If you provide a string, it will be loaded as a system font. If you provide a `gradio.themes.GoogleFont`, the font will be loaded from Google Fonts.
- `font`: This sets the primary font of the theme. In the default theme, this is set to `gradio.themes.GoogleFont("Source Sans Pro")`.
- `font_mono`: This sets the monospace font of the theme. In the default theme, this is set to `gradio.themes.GoogleFont("IBM Plex Mono")`.
You could modify these values such as the following:
```python
with gr.Blocks(theme=gr.themes.Default(font=[gr.themes.GoogleFont("Inconsolata"), "Arial", "sans-serif"])) as demo:
...
```
<div class="wrapper">
<iframe
src="https://gradio-theme-extended-step-3.hf.space?__theme=light"
frameborder="0"
></iframe>
</div>
## Extending Themes via `.set()`
You can also modify the values of CSS variables after the theme has been loaded. To do so, use the `.set()` method of the theme object to get access to the CSS variables. For example:
```python
theme = gr.themes.Default(primary_hue="blue").set(
loader_color="#FF0000",
slider_color="#FF0000",
)
with gr.Blocks(theme=theme) as demo:
...
```
In the example above, we've set the `loader_color` and `slider_color` variables to `#FF0000`, despite the overall `primary_color` using the blue color palette. You can set any CSS variable that is defined in the theme in this manner.
Your IDE type hinting should help you navigate these variables. Since there are so many CSS variables, let's take a look at how these variables are named and organized.
### CSS Variable Naming Conventions
CSS variable names can get quite long, like `button_primary_background_fill_hover_dark`! However they follow a common naming convention that makes it easy to understand what they do and to find the variable you're looking for. Separated by underscores, the variable name is made up of:
1. The target element, such as `button`, `slider`, or `block`.
2. The target element type or sub-element, such as `button_primary`, or `block_label`.
3. The property, such as `button_primary_background_fill`, or `block_label_border_width`.
4. Any relevant state, such as `button_primary_background_fill_hover`.
5. If the value is different in dark mode, the suffix `_dark`. For example, `input_border_color_focus_dark`.
Of course, many CSS variable names are shorter than this, such as `table_border_color`, or `input_shadow`.
### CSS Variable Organization
Though there are hundreds of CSS variables, they do not all have to have individual values. They draw their values by referencing a set of core variables and referencing each other. This allows us to only have to modify a few variables to change the look and feel of the entire theme, while also getting finer control of individual elements that we may want to modify.
#### Referencing Core Variables
To reference one of the core constructor variables, precede the variable name with an asterisk. To reference a core color, use the `*primary_`, `*secondary_`, or `*neutral_` prefix, followed by the brightness value. For example:
```python
theme = gr.themes.Default(primary_hue="blue").set(
button_primary_background_fill="*primary_200",
button_primary_background_fill_hover="*primary_300",
)
```
In the example above, we've set the `button_primary_background_fill` and `button_primary_background_fill_hover` variables to `*primary_200` and `*primary_300`. These variables will be set to the 200 and 300 brightness values of the blue primary color palette, respectively.
Similarly, to reference a core size, use the `*spacing_`, `*radius_`, or `*text_` prefix, followed by the size value. For example:
```python
theme = gr.themes.Default(radius_size="md").set(
button_primary_border_radius="*radius_xl",
)
```
In the example above, we've set the `button_primary_border_radius` variable to `*radius_xl`. This variable will be set to the `xl` setting of the medium radius size range.
#### Referencing Other Variables
Variables can also reference each other. For example, look at the example below:
```python
theme = gr.themes.Default().set(
button_primary_background_fill="#FF0000",
button_primary_background_fill_hover="#FF0000",
button_primary_border="#FF0000",
)
```
Having to set these values to a common color is a bit tedious. Instead, we can reference the `button_primary_background_fill` variable in the `button_primary_background_fill_hover` and `button_primary_border` variables, using a `*` prefix.
```python
theme = gr.themes.Default().set(
button_primary_background_fill="#FF0000",
button_primary_background_fill_hover="*button_primary_background_fill",
button_primary_border="*button_primary_background_fill",
)
```
Now, if we change the `button_primary_background_fill` variable, the `button_primary_background_fill_hover` and `button_primary_border` variables will automatically update as well.
This is particularly useful if you intend to share your theme - it makes it easy to modify the theme without having to change every variable.
Note that dark mode variables automatically reference each other. For example:
```python
theme = gr.themes.Default().set(
button_primary_background_fill="#FF0000",
button_primary_background_fill_dark="#AAAAAA",
button_primary_border="*button_primary_background_fill",
button_primary_border_dark="*button_primary_background_fill_dark",
)
```
`button_primary_border_dark` will draw its value from `button_primary_background_fill_dark`, because dark mode always draw from the dark version of the variable.
## Creating a Full Theme
Let's say you want to create a theme from scratch! We'll go through it step by step - you can also see the source of prebuilt themes in the gradio source repo for reference - [here's the source](https://github.com/gradio-app/gradio/blob/main/gradio/themes/monochrome.py) for the Monochrome theme.
Our new theme class will inherit from `gradio.themes.Base`, a theme that sets a lot of convenient defaults. Let's make a simple demo that creates a dummy theme called Seafoam, and make a simple app that uses it.
$code_theme_new_step_1
<div class="wrapper">
<iframe
src="https://gradio-theme-new-step-1.hf.space?__theme=light"
frameborder="0"
></iframe>
</div>
The Base theme is very barebones, and uses `gr.themes.Blue` as it primary color - you'll note the primary button and the loading animation are both blue as a result. Let's change the defaults core arguments of our app. We'll overwrite the constructor and pass new defaults for the core constructor arguments.
We'll use `gr.themes.Emerald` as our primary color, and set secondary and neutral hues to `gr.themes.Blue`. We'll make our text larger using `text_lg`. We'll use `Quicksand` as our default font, loaded from Google Fonts.
$code_theme_new_step_2
<div class="wrapper">
<iframe
src="https://gradio-theme-new-step-2.hf.space?__theme=light"
frameborder="0"
></iframe>
</div>
See how the primary button and the loading animation are now green? These CSS variables are tied to the `primary_hue` variable.
Let's modify the theme a bit more directly. We'll call the `set()` method to overwrite CSS variable values explicitly. We can use any CSS logic, and reference our core constructor arguments using the `*` prefix.
$code_theme_new_step_3
<div class="wrapper">
<iframe
src="https://gradio-theme-new-step-3.hf.space?__theme=light"
frameborder="0"
></iframe>
</div>
Look how fun our theme looks now! With just a few variable changes, our theme looks completely different.
You may find it helpful to explore the [source code of the other prebuilt themes](https://github.com/gradio-app/gradio/blob/main/gradio/themes) to see how they modified the base theme. You can also find your browser's Inspector useful to select elements from the UI and see what CSS variables are being used in the styles panel.
## Sharing Themes
Once you have created a theme, you can upload it to the HuggingFace Hub to let others view it, use it, and build off of it!
### Uploading a Theme
There are two ways to upload a theme, via the theme class instance or the command line. We will cover both of them with the previously created `seafoam` theme.
- Via the class instance
Each theme instance has a method called `push_to_hub` we can use to upload a theme to the HuggingFace hub.
```python
seafoam.push_to_hub(repo_name="seafoam",
version="0.0.1",
hf_token="<token>")
```
- Via the command line
First save the theme to disk
```python
seafoam.dump(filename="seafoam.json")
```
Then use the `upload_theme` command:
```bash
upload_theme\
"seafoam.json"\
"seafoam"\
--version "0.0.1"\
--hf_token "<token>"
```
In order to upload a theme, you must have a HuggingFace account and pass your [Access Token](https://huggingface.co/docs/huggingface_hub/quick-start#login)
as the `hf_token` argument. However, if you log in via the [HuggingFace command line](https://huggingface.co/docs/huggingface_hub/quick-start#login) (which comes installed with `gradio`),
you can omit the `hf_token` argument.
The `version` argument lets you specify a valid [semantic version](https://www.geeksforgeeks.org/introduction-semantic-versioning/) string for your theme.
That way your users are able to specify which version of your theme they want to use in their apps. This also lets you publish updates to your theme without worrying
about changing how previously created apps look. The `version` argument is optional. If omitted, the next patch version is automatically applied.
### Theme Previews
By calling `push_to_hub` or `upload_theme`, the theme assets will be stored in a [HuggingFace space](https://huggingface.co/docs/hub/spaces-overview).
The theme preview for our seafoam theme is here: [seafoam preview](https://huggingface.co/spaces/gradio/seafoam).
<div class="wrapper">
<iframe
src="https://gradio-seafoam.hf.space?__theme=light"
frameborder="0"
></iframe>
</div>
### Discovering Themes
The [Theme Gallery](https://huggingface.co/spaces/gradio/theme-gallery) shows all the public gradio themes. After publishing your theme,
it will automatically show up in the theme gallery after a couple of minutes.
You can sort the themes by the number of likes on the space and from most to least recently created as well as toggling themes between light and dark mode.
<div class="wrapper">
<iframe
src="https://gradio-theme-gallery.static.hf.space"
frameborder="0"
></iframe>
</div>
### Downloading
To use a theme from the hub, use the `from_hub` method on the `ThemeClass` and pass it to your app:
```python
my_theme = gr.Theme.from_hub("gradio/seafoam")
with gr.Blocks(theme=my_theme) as demo:
....
```
You can also pass the theme string directly to `Blocks` or `Interface` (`gr.Blocks(theme="gradio/seafoam")`)
You can pin your app to an upstream theme version by using semantic versioning expressions.
For example, the following would ensure the theme we load from the `seafoam` repo was between versions `0.0.1` and `0.1.0`:
```python
with gr.Blocks(theme="gradio/seafoam@>=0.0.1,<0.1.0") as demo:
....
```
Enjoy creating your own themes! If you make one you're proud of, please share it with the world by uploading it to the hub!
If you tag us on [Twitter](https://twitter.com/gradio) we can give your theme a shout out!
<style>
.wrapper {
position: relative;
padding-bottom: 56.25%;
padding-top: 25px;
height: 0;
}
.wrapper iframe {
position: absolute;
top: 0;
left: 0;
width: 100%;
height: 100%;
}
</style>
|
C:\Gradio Guides\9 Other Tutorials\using-flagging.md |
# Using Flagging
Related spaces: https://huggingface.co/spaces/gradio/calculator-flagging-crowdsourced, https://huggingface.co/spaces/gradio/calculator-flagging-options, https://huggingface.co/spaces/gradio/calculator-flag-basic
Tags: FLAGGING, DATA
## Introduction
When you demo a machine learning model, you might want to collect data from users who try the model, particularly data points in which the model is not behaving as expected. Capturing these "hard" data points is valuable because it allows you to improve your machine learning model and make it more reliable and robust.
Gradio simplifies the collection of this data by including a **Flag** button with every `Interface`. This allows a user or tester to easily send data back to the machine where the demo is running. In this Guide, we discuss more about how to use the flagging feature, both with `gradio.Interface` as well as with `gradio.Blocks`.
## The **Flag** button in `gradio.Interface`
Flagging with Gradio's `Interface` is especially easy. By default, underneath the output components, there is a button marked **Flag**. When a user testing your model sees input with interesting output, they can click the flag button to send the input and output data back to the machine where the demo is running. The sample is saved to a CSV log file (by default). If the demo involves images, audio, video, or other types of files, these are saved separately in a parallel directory and the paths to these files are saved in the CSV file.
There are [four parameters](https://gradio.app/docs/interface#initialization) in `gradio.Interface` that control how flagging works. We will go over them in greater detail.
- `allow_flagging`: this parameter can be set to either `"manual"` (default), `"auto"`, or `"never"`.
- `manual`: users will see a button to flag, and samples are only flagged when the button is clicked.
- `auto`: users will not see a button to flag, but every sample will be flagged automatically.
- `never`: users will not see a button to flag, and no sample will be flagged.
- `flagging_options`: this parameter can be either `None` (default) or a list of strings.
- If `None`, then the user simply clicks on the **Flag** button and no additional options are shown.
- If a list of strings are provided, then the user sees several buttons, corresponding to each of the strings that are provided. For example, if the value of this parameter is `["Incorrect", "Ambiguous"]`, then buttons labeled **Flag as Incorrect** and **Flag as Ambiguous** appear. This only applies if `allow_flagging` is `"manual"`.
- The chosen option is then logged along with the input and output.
- `flagging_dir`: this parameter takes a string.
- It represents what to name the directory where flagged data is stored.
- `flagging_callback`: this parameter takes an instance of a subclass of the `FlaggingCallback` class
- Using this parameter allows you to write custom code that gets run when the flag button is clicked
- By default, this is set to an instance of `gr.CSVLogger`
- One example is setting it to an instance of `gr.HuggingFaceDatasetSaver` which can allow you to pipe any flagged data into a HuggingFace Dataset. (See more below.)
## What happens to flagged data?
Within the directory provided by the `flagging_dir` argument, a CSV file will log the flagged data.
Here's an example: The code below creates the calculator interface embedded below it:
```python
import gradio as gr
def calculator(num1, operation, num2):
if operation == "add":
return num1 + num2
elif operation == "subtract":
return num1 - num2
elif operation == "multiply":
return num1 * num2
elif operation == "divide":
return num1 / num2
iface = gr.Interface(
calculator,
["number", gr.Radio(["add", "subtract", "multiply", "divide"]), "number"],
"number",
allow_flagging="manual"
)
iface.launch()
```
<gradio-app space="gradio/calculator-flag-basic/"></gradio-app>
When you click the flag button above, the directory where the interface was launched will include a new flagged subfolder, with a csv file inside it. This csv file includes all the data that was flagged.
```directory
+-- flagged/
| +-- logs.csv
```
_flagged/logs.csv_
```csv
num1,operation,num2,Output,timestamp
5,add,7,12,2022-01-31 11:40:51.093412
6,subtract,1.5,4.5,2022-01-31 03:25:32.023542
```
If the interface involves file data, such as for Image and Audio components, folders will be created to store those flagged data as well. For example an `image` input to `image` output interface will create the following structure.
```directory
+-- flagged/
| +-- logs.csv
| +-- image/
| | +-- 0.png
| | +-- 1.png
| +-- Output/
| | +-- 0.png
| | +-- 1.png
```
_flagged/logs.csv_
```csv
im,Output timestamp
im/0.png,Output/0.png,2022-02-04 19:49:58.026963
im/1.png,Output/1.png,2022-02-02 10:40:51.093412
```
If you wish for the user to provide a reason for flagging, you can pass a list of strings to the `flagging_options` argument of Interface. Users will have to select one of these choices when flagging, and the option will be saved as an additional column to the CSV.
If we go back to the calculator example, the following code will create the interface embedded below it.
```python
iface = gr.Interface(
calculator,
["number", gr.Radio(["add", "subtract", "multiply", "divide"]), "number"],
"number",
allow_flagging="manual",
flagging_options=["wrong sign", "off by one", "other"]
)
iface.launch()
```
<gradio-app space="gradio/calculator-flagging-options/"></gradio-app>
When users click the flag button, the csv file will now include a column indicating the selected option.
_flagged/logs.csv_
```csv
num1,operation,num2,Output,flag,timestamp
5,add,7,-12,wrong sign,2022-02-04 11:40:51.093412
6,subtract,1.5,3.5,off by one,2022-02-04 11:42:32.062512
```
## The HuggingFaceDatasetSaver Callback
Sometimes, saving the data to a local CSV file doesn't make sense. For example, on Hugging Face
Spaces, developers typically don't have access to the underlying ephemeral machine hosting the Gradio
demo. That's why, by default, flagging is turned off in Hugging Face Space. However,
you may want to do something else with the flagged data.
We've made this super easy with the `flagging_callback` parameter.
For example, below we're going to pipe flagged data from our calculator example into a Hugging Face Dataset, e.g. so that we can build a "crowd-sourced" dataset:
```python
import os
HF_TOKEN = os.getenv('HF_TOKEN')
hf_writer = gr.HuggingFaceDatasetSaver(HF_TOKEN, "crowdsourced-calculator-demo")
iface = gr.Interface(
calculator,
["number", gr.Radio(["add", "subtract", "multiply", "divide"]), "number"],
"number",
description="Check out the crowd-sourced dataset at: [https://huggingface.co/datasets/aliabd/crowdsourced-calculator-demo](https://huggingface.co/datasets/aliabd/crowdsourced-calculator-demo)",
allow_flagging="manual",
flagging_options=["wrong sign", "off by one", "other"],
flagging_callback=hf_writer
)
iface.launch()
```
Notice that we define our own
instance of `gradio.HuggingFaceDatasetSaver` using our Hugging Face token and
the name of a dataset we'd like to save samples to. In addition, we also set `allow_flagging="manual"`
because on Hugging Face Spaces, `allow_flagging` is set to `"never"` by default. Here's our demo:
<gradio-app space="gradio/calculator-flagging-crowdsourced/"></gradio-app>
You can now see all the examples flagged above in this [public Hugging Face dataset](https://huggingface.co/datasets/aliabd/crowdsourced-calculator-demo).
We created the `gradio.HuggingFaceDatasetSaver` class, but you can pass your own custom class as long as it inherits from `FLaggingCallback` defined in [this file](https://github.com/gradio-app/gradio/blob/master/gradio/flagging.py). If you create a cool callback, contribute it to the repo!
## Flagging with Blocks
What about if you are using `gradio.Blocks`? On one hand, you have even more flexibility
with Blocks -- you can write whatever Python code you want to run when a button is clicked,
and assign that using the built-in events in Blocks.
At the same time, you might want to use an existing `FlaggingCallback` to avoid writing extra code.
This requires two steps:
1. You have to run your callback's `.setup()` somewhere in the code prior to the
first time you flag data
2. When the flagging button is clicked, then you trigger the callback's `.flag()` method,
making sure to collect the arguments correctly and disabling the typical preprocessing.
Here is an example with an image sepia filter Blocks demo that lets you flag
data using the default `CSVLogger`:
$code_blocks_flag
$demo_blocks_flag
## Privacy
Important Note: please make sure your users understand when the data they submit is being saved, and what you plan on doing with it. This is especially important when you use `allow_flagging=auto` (when all of the data submitted through the demo is being flagged)
### That's all! Happy building :)
|
C:\Gradio Guides\9 Other Tutorials\wrapping-layouts.md |
# Wrapping Layouts
Tags: LAYOUTS
## Introduction
Gradio features [blocks](https://www.gradio.app/docs/blocks) to easily layout applications. To use this feature, you need to stack or nest layout components and create a hierarchy with them. This isn't difficult to implement and maintain for small projects, but after the project gets more complex, this component hierarchy becomes difficult to maintain and reuse.
In this guide, we are going to explore how we can wrap the layout classes to create more maintainable and easy-to-read applications without sacrificing flexibility.
## Example
We are going to follow the implementation from this Huggingface Space example:
<gradio-app
space="WoWoWoWololo/wrapping-layouts">
</gradio-app>
## Implementation
The wrapping utility has two important classes. The first one is the ```LayoutBase``` class and the other one is the ```Application``` class.
We are going to look at the ```render``` and ```attach_event``` functions of them for brevity. You can look at the full implementation from [the example code](https://huggingface.co/spaces/WoWoWoWololo/wrapping-layouts/blob/main/app.py).
So let's start with the ```LayoutBase``` class.
### LayoutBase Class
1. Render Function
Let's look at the ```render``` function in the ```LayoutBase``` class:
```python
# other LayoutBase implementations
def render(self) -> None:
with self.main_layout:
for renderable in self.renderables:
renderable.render()
self.main_layout.render()
```
This is a little confusing at first but if you consider the default implementation you can understand it easily.
Let's look at an example:
In the default implementation, this is what we're doing:
```python
with Row():
left_textbox = Textbox(value="left_textbox")
right_textbox = Textbox(value="right_textbox")
```
Now, pay attention to the Textbox variables. These variables' ```render``` parameter is true by default. So as we use the ```with``` syntax and create these variables, they are calling the ```render``` function under the ```with``` syntax.
We know the render function is called in the constructor with the implementation from the ```gradio.blocks.Block``` class:
```python
class Block:
# constructor parameters are omitted for brevity
def __init__(self, ...):
# other assign functions
if render:
self.render()
```
So our implementation looks like this:
```python
# self.main_layout -> Row()
with self.main_layout:
left_textbox.render()
right_textbox.render()
```
What this means is by calling the components' render functions under the ```with``` syntax, we are actually simulating the default implementation.
So now let's consider two nested ```with```s to see how the outer one works. For this, let's expand our example with the ```Tab``` component:
```python
with Tab():
with Row():
first_textbox = Textbox(value="first_textbox")
second_textbox = Textbox(value="second_textbox")
```
Pay attention to the Row and Tab components this time. We have created the Textbox variables above and added them to Row with the ```with``` syntax. Now we need to add the Row component to the Tab component. You can see that the Row component is created with default parameters, so its render parameter is true, that's why the render function is going to be executed under the Tab component's ```with``` syntax.
To mimic this implementation, we need to call the ```render``` function of the ```main_layout``` variable after the ```with``` syntax of the ```main_layout``` variable.
So the implementation looks like this:
```python
with tab_main_layout:
with row_main_layout:
first_textbox.render()
second_textbox.render()
row_main_layout.render()
tab_main_layout.render()
```
The default implementation and our implementation are the same, but we are using the render function ourselves. So it requires a little work.
Now, let's take a look at the ```attach_event``` function.
2. Attach Event Function
The function is left as not implemented because it is specific to the class, so each class has to implement its `attach_event` function.
```python
# other LayoutBase implementations
def attach_event(self, block_dict: Dict[str, Block]) -> None:
raise NotImplementedError
```
Check out the ```block_dict``` variable in the ```Application``` class's ```attach_event``` function.
### Application Class
1. Render Function
```python
# other Application implementations
def _render(self):
with self.app:
for child in self.children:
child.render()
self.app.render()
```
From the explanation of the ```LayoutBase``` class's ```render``` function, we can understand the ```child.render``` part.
So let's look at the bottom part, why are we calling the ```app``` variable's ```render``` function? It's important to call this function because if we look at the implementation in the ```gradio.blocks.Blocks``` class, we can see that it is adding the components and event functions into the root component. To put it another way, it is creating and structuring the gradio application.
2. Attach Event Function
Let's see how we can attach events to components:
```python
# other Application implementations
def _attach_event(self):
block_dict: Dict[str, Block] = {}
for child in self.children:
block_dict.update(child.global_children_dict)
with self.app:
for child in self.children:
try:
child.attach_event(block_dict=block_dict)
except NotImplementedError:
print(f"{child.name}'s attach_event is not implemented")
```
You can see why the ```global_children_list``` is used in the ```LayoutBase``` class from the example code. With this, all the components in the application are gathered into one dictionary, so the component can access all the components with their names.
The ```with``` syntax is used here again to attach events to components. If we look at the ```__exit__``` function in the ```gradio.blocks.Blocks``` class, we can see that it is calling the ```attach_load_events``` function which is used for setting event triggers to components. So we have to use the ```with``` syntax to trigger the ```__exit__``` function.
Of course, we can call ```attach_load_events``` without using the ```with``` syntax, but the function needs a ```Context.root_block```, and it is set in the ```__enter__``` function. So we used the ```with``` syntax here rather than calling the function ourselves.
## Conclusion
In this guide, we saw
- How we can wrap the layouts
- How components are rendered
- How we can structure our application with wrapped layout classes
Because the classes used in this guide are used for demonstration purposes, they may still not be totally optimized or modular. But that would make the guide much longer!
I hope this guide helps you gain another view of the layout classes and gives you an idea about how you can use them for your needs. See the full implementation of our example [here](https://huggingface.co/spaces/WoWoWoWololo/wrapping-layouts/blob/main/app.py).
|