
url
stringlengths 58
61
| repository_url
stringclasses 1
value | labels_url
stringlengths 72
75
| comments_url
stringlengths 67
70
| events_url
stringlengths 65
68
| html_url
stringlengths 46
51
| id
int64 599M
1.83B
| node_id
stringlengths 18
32
| number
int64 1
6.09k
| title
stringlengths 1
290
| labels
list | state
stringclasses 2
values | locked
bool 1
class | milestone
dict | comments
int64 0
54
| created_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| closed_at
stringlengths 20
20
⌀ | active_lock_reason
null | body
stringlengths 0
228k
⌀ | reactions
dict | timeline_url
stringlengths 67
70
| performed_via_github_app
null | state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict | is_pull_request
bool 2
classes | comments_text
sequence |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/2771 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2771/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2771/comments | https://api.github.com/repos/huggingface/datasets/issues/2771/events | https://github.com/huggingface/datasets/pull/2771 | 963,257,036 | MDExOlB1bGxSZXF1ZXN0NzA1OTExMDMw | 2,771 | [WIP][Common Voice 7] Add common voice 7.0 | [] | closed | false | null | 2 | 2021-08-07T16:01:10Z | 2021-12-06T23:24:02Z | 2021-12-06T23:24:02Z | null | This PR allows to load the new common voice dataset manually as explained when doing:
```python
from datasets import load_dataset
ds = load_dataset("./datasets/datasets/common_voice_7", "ab")
```
=>
```
Please follow the manual download instructions:
You need to manually the dataset from `https://commonvoice.mozilla.org/en/datasets`.
Make sure you choose the version `Common Voice Corpus 7.0`.
Choose a language of your choice and find the corresponding language-id, *e.g.*, `Abkhaz` with language-id `ab`. The following language-ids are available:
['ab', 'ar', 'as', 'az', 'ba', 'bas', 'be', 'bg', 'br', 'ca', 'cnh', 'cs', 'cv', 'cy', 'de', 'dv', 'el', 'en', 'eo', 'es', 'et', 'eu', 'fa', 'fi', 'fr', 'fy-NL', 'ga-IE', 'gl', 'gn', 'ha', 'hi', 'hsb', 'hu', 'hy-AM', 'ia', 'id', 'it', 'ja', 'ka', 'kab', 'kk', 'kmr', 'ky', 'lg', 'lt', 'lv', 'mn', 'mt', 'nl', 'or', 'pa-IN', 'pl', 'pt', 'rm-sursilv', 'rm-vallader', 'ro', 'ru', 'rw', 'sah', 'sk', 'sl', 'sr', 'sv-SE', 'ta', 'th', 'tr', 'tt', 'ug', 'uk', 'ur', 'uz', 'vi', 'vot', 'zh-CN', 'zh-HK', 'zh-TW']
Next, you will have to enter your email address to download the dataset in the `tar.gz` format. Save the file under <path-to-file>.
The file should then be extracted with: ``tar -xvzf <path-to-file>`` which will extract a folder called ``cv-corpus-7.0-2021-07-21``.
The dataset can then be loaded with `datasets.load_dataset("common_voice", <language-id>, data_dir="<path-to-'cv-corpus-7.0-2021-07-21'-folder>", ignore_verifications=True).
```
Having followed those instructions one can then download the data as follows:
```python
from datasets import load_dataset
ds = load_dataset("./datasets/datasets/common_voice_7", "ab", data_dir="./cv-corpus-7.0-2021-07-21/", ignore_verifications=True)
```
## TODO
- [ ] Discuss naming. Is the name ok here "common_voice_7"? The dataset script differs only really in one point from `common_voice.py` in that all the metadata is different (more hours etc...) and that it has to use manual data dir for now
- [ ] Ideally we should get a bundled download link. For `common_voice.py` there is a bundled download link: `https://voice-prod-bundler-ee1969a6ce8178826482b88e843c335139bd3fb4.s3.amazonaws.com/cv-corpus-6.1-2020-12-11/{}.tar.gz` that allows one to directly download the data. However such a link is missing for Common Voice 7. I guess we should try to contact common voice about it and ask whether we could host the data or help otherwise somehow. See: https://github.com/common-voice/common-voice-bundler/issues/15 cc @yjernite
- [ ] I did not compute the dataset.json and it would mean that I'd have to download 76 datasets totalling around 1TB manually before running the checksum command. This just takes too much time. For now the user will have to add a `ignore_verifications=True` to download the data. This step would also be much easier if we could get a bundled link
- [ ] Add dummy data | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2771/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2771/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2771.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2771",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/2771.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2771"
} | true | [
"Hi ! I think the name `common_voice_7` is fine :)\r\nMoreover if the dataset_infos.json is missing I'm pretty sure you don't need to specify `ignore_verifications=True`",
"Hi, how about to add a new parameter \"version\" in the function load_dataset, something like: \r\n`load_dataset(\"common_voice\", \"lg\", version=\"7.0\") `\r\nThis is to avoid creating a new common_voice_? dataset (with almost the same code) every time \r\nMozilla updates their Common Voice dataset.\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/5603 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5603/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5603/comments | https://api.github.com/repos/huggingface/datasets/issues/5603/events | https://github.com/huggingface/datasets/pull/5603 | 1,607,143,509 | PR_kwDODunzps5LJZzG | 5,603 | Don't compute checksums if not necessary in `datasets-cli test` | [] | closed | false | null | 3 | 2023-03-02T16:42:39Z | 2023-03-03T15:45:32Z | 2023-03-03T15:38:28Z | null | we only need them if there exists a `dataset_infos.json` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5603/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5603/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5603.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5603",
"merged_at": "2023-03-03T15:38:28Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5603.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5603"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.008550 / 0.011353 (-0.002803) | 0.004476 / 0.011008 (-0.006532) | 0.100902 / 0.038508 (0.062394) | 0.029684 / 0.023109 (0.006575) | 0.308081 / 0.275898 (0.032183) | 0.363435 / 0.323480 (0.039955) | 0.006987 / 0.007986 (-0.000999) | 0.003401 / 0.004328 (-0.000927) | 0.078218 / 0.004250 (0.073967) | 0.036657 / 0.037052 (-0.000395) | 0.319670 / 0.258489 (0.061181) | 0.349952 / 0.293841 (0.056111) | 0.033416 / 0.128546 (-0.095130) | 0.011511 / 0.075646 (-0.064135) | 0.323888 / 0.419271 (-0.095384) | 0.042429 / 0.043533 (-0.001104) | 0.307310 / 0.255139 (0.052171) | 0.329459 / 0.283200 (0.046259) | 0.085209 / 0.141683 (-0.056474) | 1.475893 / 1.452155 (0.023739) | 1.502782 / 1.492716 (0.010065) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.200137 / 0.018006 (0.182131) | 0.411269 / 0.000490 (0.410780) | 0.000415 / 0.000200 (0.000215) | 0.000061 / 0.000054 (0.000006) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.022626 / 0.037411 (-0.014785) | 0.097045 / 0.014526 (0.082519) | 0.102955 / 0.176557 (-0.073602) | 0.148411 / 0.737135 (-0.588725) | 0.107238 / 0.296338 (-0.189100) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.421683 / 0.215209 (0.206474) | 4.203031 / 2.077655 (2.125376) | 1.908232 / 1.504120 (0.404112) | 1.698867 / 1.541195 (0.157672) | 1.743561 / 1.468490 (0.275071) | 0.693199 / 4.584777 (-3.891578) | 3.361022 / 3.745712 (-0.384690) | 2.989610 / 5.269862 (-2.280251) | 1.533036 / 4.565676 (-3.032641) | 0.082675 / 0.424275 (-0.341601) | 0.012419 / 0.007607 (0.004812) | 0.531543 / 0.226044 (0.305499) | 5.330595 / 2.268929 (3.061666) | 2.347519 / 55.444624 (-53.097105) | 1.975672 / 6.876477 (-4.900804) | 2.039541 / 2.142072 (-0.102532) | 0.810281 / 4.805227 (-3.994946) | 0.148917 / 6.500664 (-6.351747) | 0.065441 / 0.075469 (-0.010028) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.266213 / 1.841788 (-0.575574) | 13.628106 / 8.074308 (5.553798) | 13.852191 / 10.191392 (3.660799) | 0.149004 / 0.680424 (-0.531420) | 0.028549 / 0.534201 (-0.505652) | 0.399824 / 0.579283 (-0.179459) | 0.401231 / 0.434364 (-0.033133) | 0.473251 / 0.540337 (-0.067086) | 0.561094 / 1.386936 (-0.825842) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006669 / 0.011353 (-0.004684) | 0.004477 / 0.011008 (-0.006532) | 0.077514 / 0.038508 (0.039006) | 0.027489 / 0.023109 (0.004380) | 0.341935 / 0.275898 (0.066037) | 0.377392 / 0.323480 (0.053912) | 0.004947 / 0.007986 (-0.003039) | 0.004600 / 0.004328 (0.000271) | 0.075938 / 0.004250 (0.071687) | 0.039586 / 0.037052 (0.002534) | 0.344966 / 0.258489 (0.086477) | 0.392181 / 0.293841 (0.098340) | 0.031838 / 0.128546 (-0.096708) | 0.011572 / 0.075646 (-0.064075) | 0.085811 / 0.419271 (-0.333461) | 0.042250 / 0.043533 (-0.001283) | 0.345605 / 0.255139 (0.090466) | 0.367814 / 0.283200 (0.084615) | 0.090683 / 0.141683 (-0.051000) | 1.483168 / 1.452155 (0.031014) | 1.559724 / 1.492716 (0.067008) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.235655 / 0.018006 (0.217649) | 0.399016 / 0.000490 (0.398527) | 0.003096 / 0.000200 (0.002896) | 0.000077 / 0.000054 (0.000022) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024454 / 0.037411 (-0.012957) | 0.100710 / 0.014526 (0.086185) | 0.107950 / 0.176557 (-0.068606) | 0.161560 / 0.737135 (-0.575576) | 0.111840 / 0.296338 (-0.184498) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.441362 / 0.215209 (0.226153) | 4.428105 / 2.077655 (2.350450) | 2.074501 / 1.504120 (0.570381) | 1.866672 / 1.541195 (0.325477) | 1.928266 / 1.468490 (0.459776) | 0.703561 / 4.584777 (-3.881216) | 3.396537 / 3.745712 (-0.349175) | 3.047369 / 5.269862 (-2.222492) | 1.595133 / 4.565676 (-2.970543) | 0.084028 / 0.424275 (-0.340247) | 0.012349 / 0.007607 (0.004741) | 0.539354 / 0.226044 (0.313310) | 5.401535 / 2.268929 (3.132606) | 2.499874 / 55.444624 (-52.944750) | 2.161406 / 6.876477 (-4.715071) | 2.197385 / 2.142072 (0.055313) | 0.810864 / 4.805227 (-3.994363) | 0.152277 / 6.500664 (-6.348387) | 0.067266 / 0.075469 (-0.008203) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.280900 / 1.841788 (-0.560887) | 13.815731 / 8.074308 (5.741423) | 13.007438 / 10.191392 (2.816046) | 0.129711 / 0.680424 (-0.550713) | 0.016852 / 0.534201 (-0.517349) | 0.380775 / 0.579283 (-0.198508) | 0.384143 / 0.434364 (-0.050221) | 0.459954 / 0.540337 (-0.080383) | 0.549335 / 1.386936 (-0.837601) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009570 / 0.011353 (-0.001783) | 0.005219 / 0.011008 (-0.005789) | 0.098472 / 0.038508 (0.059964) | 0.035429 / 0.023109 (0.012320) | 0.303086 / 0.275898 (0.027188) | 0.365926 / 0.323480 (0.042446) | 0.008797 / 0.007986 (0.000811) | 0.004220 / 0.004328 (-0.000108) | 0.076670 / 0.004250 (0.072419) | 0.045596 / 0.037052 (0.008543) | 0.309476 / 0.258489 (0.050987) | 0.343958 / 0.293841 (0.050117) | 0.038741 / 0.128546 (-0.089805) | 0.011990 / 0.075646 (-0.063657) | 0.332326 / 0.419271 (-0.086945) | 0.048897 / 0.043533 (0.005364) | 0.296002 / 0.255139 (0.040863) | 0.322048 / 0.283200 (0.038849) | 0.104403 / 0.141683 (-0.037280) | 1.461777 / 1.452155 (0.009622) | 1.516362 / 1.492716 (0.023645) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.201565 / 0.018006 (0.183559) | 0.435781 / 0.000490 (0.435291) | 0.004215 / 0.000200 (0.004015) | 0.000282 / 0.000054 (0.000227) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.027272 / 0.037411 (-0.010139) | 0.106157 / 0.014526 (0.091631) | 0.116948 / 0.176557 (-0.059609) | 0.160404 / 0.737135 (-0.576731) | 0.122518 / 0.296338 (-0.173820) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.397721 / 0.215209 (0.182512) | 3.966433 / 2.077655 (1.888778) | 1.755410 / 1.504120 (0.251290) | 1.566480 / 1.541195 (0.025285) | 1.623684 / 1.468490 (0.155194) | 0.696820 / 4.584777 (-3.887957) | 3.750437 / 3.745712 (0.004725) | 2.105875 / 5.269862 (-3.163986) | 1.442026 / 4.565676 (-3.123650) | 0.085026 / 0.424275 (-0.339249) | 0.012239 / 0.007607 (0.004632) | 0.502613 / 0.226044 (0.276569) | 5.049016 / 2.268929 (2.780087) | 2.314499 / 55.444624 (-53.130126) | 1.967943 / 6.876477 (-4.908534) | 2.033507 / 2.142072 (-0.108565) | 0.861908 / 4.805227 (-3.943319) | 0.167784 / 6.500664 (-6.332880) | 0.063022 / 0.075469 (-0.012447) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.210434 / 1.841788 (-0.631353) | 14.979319 / 8.074308 (6.905011) | 14.095263 / 10.191392 (3.903871) | 0.174203 / 0.680424 (-0.506221) | 0.028547 / 0.534201 (-0.505654) | 0.442509 / 0.579283 (-0.136774) | 0.445811 / 0.434364 (0.011447) | 0.531313 / 0.540337 (-0.009024) | 0.636541 / 1.386936 (-0.750395) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007341 / 0.011353 (-0.004012) | 0.005197 / 0.011008 (-0.005811) | 0.075413 / 0.038508 (0.036905) | 0.033261 / 0.023109 (0.010152) | 0.339596 / 0.275898 (0.063698) | 0.376051 / 0.323480 (0.052571) | 0.005827 / 0.007986 (-0.002159) | 0.005473 / 0.004328 (0.001144) | 0.074851 / 0.004250 (0.070600) | 0.049059 / 0.037052 (0.012007) | 0.357182 / 0.258489 (0.098693) | 0.384589 / 0.293841 (0.090748) | 0.037122 / 0.128546 (-0.091424) | 0.012298 / 0.075646 (-0.063348) | 0.088191 / 0.419271 (-0.331081) | 0.052002 / 0.043533 (0.008469) | 0.343216 / 0.255139 (0.088077) | 0.364534 / 0.283200 (0.081334) | 0.105462 / 0.141683 (-0.036221) | 1.486717 / 1.452155 (0.034562) | 1.584725 / 1.492716 (0.092009) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.199210 / 0.018006 (0.181203) | 0.439069 / 0.000490 (0.438580) | 0.000436 / 0.000200 (0.000236) | 0.000059 / 0.000054 (0.000005) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.029931 / 0.037411 (-0.007480) | 0.109564 / 0.014526 (0.095038) | 0.122284 / 0.176557 (-0.054273) | 0.170819 / 0.737135 (-0.566317) | 0.125886 / 0.296338 (-0.170452) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.422724 / 0.215209 (0.207515) | 4.210304 / 2.077655 (2.132650) | 2.001481 / 1.504120 (0.497361) | 1.810818 / 1.541195 (0.269623) | 1.901367 / 1.468490 (0.432877) | 0.686004 / 4.584777 (-3.898773) | 3.768850 / 3.745712 (0.023138) | 2.079501 / 5.269862 (-3.190360) | 1.326970 / 4.565676 (-3.238706) | 0.085991 / 0.424275 (-0.338284) | 0.012298 / 0.007607 (0.004690) | 0.526878 / 0.226044 (0.300833) | 5.267241 / 2.268929 (2.998312) | 2.451781 / 55.444624 (-52.992843) | 2.109143 / 6.876477 (-4.767333) | 2.185426 / 2.142072 (0.043353) | 0.830165 / 4.805227 (-3.975063) | 0.166167 / 6.500664 (-6.334497) | 0.064077 / 0.075469 (-0.011392) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.270430 / 1.841788 (-0.571358) | 14.844852 / 8.074308 (6.770544) | 13.196672 / 10.191392 (3.005280) | 0.162853 / 0.680424 (-0.517571) | 0.017727 / 0.534201 (-0.516474) | 0.424803 / 0.579283 (-0.154480) | 0.439970 / 0.434364 (0.005606) | 0.530691 / 0.540337 (-0.009647) | 0.630474 / 1.386936 (-0.756462) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/5111 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5111/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5111/comments | https://api.github.com/repos/huggingface/datasets/issues/5111/events | https://github.com/huggingface/datasets/issues/5111 | 1,408,143,170 | I_kwDODunzps5T7o9C | 5,111 | map and filter not working properly in multiprocessing with the new release 2.6.0 | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 14 | 2022-10-13T17:00:55Z | 2022-10-17T08:26:59Z | 2022-10-14T14:59:59Z | null | ## Describe the bug
When mapping is used on a dataset with more than one process, there is a weird behavior when trying to use `filter` , it's like only the samples from one worker are retrieved, one needs to specify the same `num_proc` in filter for it to work properly. This doesn't happen with `datasets` version 2.5.2
In the code below the data is filtered differently when we increase `num_proc` used in `map` although the datsets before and after mapping have identical elements.
## Steps to reproduce the bug
```python
import datasets
from datasets import load_dataset
def preprocess(example):
return example
ds = load_dataset("codeparrot/codeparrot-clean-valid", split="train").select([i for i in range(10)])
ds1 = ds.map(preprocess, num_proc=2)
ds2 = ds.map(preprocess)
# the datasets elements are the same
for i in range(len(ds1)):
assert ds1[i]==ds2[i]
print(f'Target column before filtering {ds1["autogenerated"]}')
print(f'Target column before filtering {ds2["autogenerated"]}')
print(f"datasets version {datasets.__version__}")
ds_filtered_1 = ds1.filter(lambda x: not x["autogenerated"])
ds_filtered_2 = ds2.filter(lambda x: not x["autogenerated"])
# all elements in Target column are false so they should all be kept, but for ds2 only the first 5=num_samples/num_proc are kept
print(ds_filtered_1)
print(ds_filtered_2)
```
```
Target column before filtering [False, False, False, False, False, False, False, False, False, False]
Target column before filtering [False, False, False, False, False, False, False, False, False, False]
Dataset({
features: ['repo_name', 'path', 'copies', 'size', 'content', 'license', 'hash', 'line_mean', 'line_max', 'alpha_frac', 'autogenerated'],
num_rows: 5
})
Dataset({
features: ['repo_name', 'path', 'copies', 'size', 'content', 'license', 'hash', 'line_mean', 'line_max', 'alpha_frac', 'autogenerated'],
num_rows: 10
})
```
## Expected results
Increasing `num_proc` in mapping shouldn't alter filtering. With the previous version 2.5.2 this doesn't happen
## Actual results
Filtering doesn't work properly when we increase `num_proc` in mapping but not when calling `filter`
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.6.0
- Platform: Linux-4.19.0-22-cloud-amd64-x86_64-with-glibc2.28
- Python version: 3.9.13
- PyArrow version: 8.0.0
- Pandas version: 1.4.2 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5111/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5111/timeline | null | completed | null | null | false | [
"Same bug exists with `num_proc=1` on colab. `3.7.14 (default, Sep 8 2022, 00:06:44) [GCC 7.5.0]` ",
"Thanks for reporting, @loubnabnl and for the additional information, @PartiallyTyped.\r\n\r\nHowever, I'm not able to reproduce this issue, neither locally nor on Colab:\r\n```\r\nDataset({\r\n features: ['repo_name', 'path', 'copies', 'size', 'content', 'license', 'hash', 'line_mean', 'line_max', 'alpha_frac', 'autogenerated'],\r\n num_rows: 10\r\n})\r\nDataset({\r\n features: ['repo_name', 'path', 'copies', 'size', 'content', 'license', 'hash', 'line_mean', 'line_max', 'alpha_frac', 'autogenerated'],\r\n num_rows: 10\r\n})\r\n```\r\nCC: @huggingface/datasets can anybody reproduce this?",
"This is the minimum reproducible example. I ran this on the premium instances of colab.\r\n\r\n```\r\n# !pip install datasets\r\nimport datasets\r\nfrom datasets import load_dataset\r\nds = load_dataset(\"copenlu/answerable_tydiqa\").filter(\"english\".__eq__, input_columns=\"language\")\r\nassert all(map(\"english\".__eq__, ds[\"train\"][\"language\"]))\r\n```\r\n\r\nIn my case, the number of samples is correct, however, the samples selected when indexing are wrong.\r\n\r\n```python\r\nDatasetDict({\r\n validation: Dataset({\r\n features: ['question_text', 'document_title', 'language', 'annotations', 'document_plaintext', 'document_url'],\r\n num_rows: 990\r\n })\r\n train: Dataset({\r\n features: ['question_text', 'document_title', 'language', 'annotations', 'document_plaintext', 'document_url'],\r\n num_rows: 7389\r\n })\r\n})\r\n```\r\n\r\nThe number of rows is indeed correct, and i have checked it with a version that works.",
"I can reproduce the issue on my mac too \r\n```\r\n- `datasets` version: 2.6.0\r\n- Platform: macOS-12.2.1-arm64-arm-64bit\r\n- Python version: 3.9.13\r\n- PyArrow version: 9.0.0\r\n- Pandas version: 1.4.3\r\n```\r\nBut not on Colab with python 3.7, maybe related to python version? (didn't manage to install python 3.9)\r\n```\r\n- `datasets` version: 2.6.0\r\n- Platform: Linux-5.10.133+-x86_64-with-Ubuntu-18.04-bionic\r\n- Python version: 3.7.14\r\n- PyArrow version: 9.0.0\r\n- Pandas version: 1.3.5\r\n```",
"I have the same issue, here's a simple notebook to reproduce: https://colab.research.google.com/drive/1Lvo9fg5DSpGUUgXW5JAutZ0bFsR-WV--?usp=sharing\r\n\r\n\r\n\r\n",
"I think there are 2 different issues here:\r\n- the one reported by @loubnabnl is related to multiprocessing in map and then filter; we should reproduce it first: I have tried with Python version 3.9.7 and I can't reproduce it either; maybe it is related to the version of PyArrow? To be checked.\r\n- the issue reported by @PartiallyTyped is related just to \"filter\" (without multiprocessing) and I can reproduce it.",
"Could you create another issue for the @PartiallyTyped one please ?\r\n\r\nRegarding the OP issue, I also tried on colab or locally on py3.7 or py3.10 but didn't reproduce",
"I have created another issue for the one reported by @PartiallyTyped: \r\n- #5112 ",
"I managed to reproduce your issue @loubnabnl on colab by upgrading pyarrow to 9.0.0 instead of 6.0.1",
"I managed to have a _super_ minimal reproducible example:\r\n```python\r\n\r\nfrom datasets import Dataset, concatenate_datasets\r\n\r\nds = concatenate_datasets([Dataset.from_dict({\"a\": [i]}) for i in range(10)])\r\nds2 = ds.map(lambda _: {}, batched=True)\r\nassert list(ds2) == list(ds)\r\n```\r\n(filter uses a batched `map` under the hood)",
"> the one reported by @loubnabnl is related to multiprocessing in map and then filter; we should reproduce it first: I have tried with Python version 3.9.7 and I can't reproduce it either; maybe it is related to the version of PyArrow? To be checked.\r\n\r\nSo finally it was related to PyArrow version! :+1: ",
"Doing a patch release asap :)",
"Did the patch release yesterday, lmk if you still have issues",
"It works now, thanks!\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/2344 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2344/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2344/comments | https://api.github.com/repos/huggingface/datasets/issues/2344/events | https://github.com/huggingface/datasets/issues/2344 | 885,331,505 | MDU6SXNzdWU4ODUzMzE1MDU= | 2,344 | Is there a way to join multiple datasets in one? | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | 2 | 2021-05-10T23:16:10Z | 2022-10-05T17:27:05Z | null | null | **Is your feature request related to a problem? Please describe.**
I need to join 2 datasets, one that is in the hub and another I've created from my files. Is there an easy way to join these 2?
**Describe the solution you'd like**
Id like to join them with a merge or join method, just like pandas dataframes.
**Additional context**
If you want to extend an existing dataset with more data, for example for training a language model, you need that functionality. I've not found it in the documentation. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2344/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2344/timeline | null | null | null | null | false | [
"Hi ! We don't have `join`/`merge` on a certain column as in pandas.\r\nMaybe you can just use the [concatenate_datasets](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=concatenate#datasets.concatenate_datasets) function.\r\n",
"Hi! You can use `datasets_sql` for that now. As of recently, PyArrow also supports querying tables via Substrait, so I think we can start adding these methods to the API soon."
] |
https://api.github.com/repos/huggingface/datasets/issues/3848 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3848/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3848/comments | https://api.github.com/repos/huggingface/datasets/issues/3848/events | https://github.com/huggingface/datasets/issues/3848 | 1,162,076,902 | I_kwDODunzps5FQ-Lm | 3,848 | NonMatchingChecksumError when checksum is None | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 7 | 2022-03-08T00:24:12Z | 2022-03-15T14:37:26Z | 2022-03-15T12:28:23Z | null | I ran into the following error when adding a new dataset:
```bash
expected_checksums = {'https://adversarialglue.github.io/dataset/dev.zip': {'checksum': None, 'num_bytes': 40662}}
recorded_checksums = {'https://adversarialglue.github.io/dataset/dev.zip': {'checksum': 'efb4cbd3aa4a87bfaffc310ae951981cc0a36c6c71c6425dd74e5b55f2f325c9', 'num_bytes': 40662}}
verification_name = 'dataset source files'
def verify_checksums(expected_checksums: Optional[dict], recorded_checksums: dict, verification_name=None):
if expected_checksums is None:
logger.info("Unable to verify checksums.")
return
if len(set(expected_checksums) - set(recorded_checksums)) > 0:
raise ExpectedMoreDownloadedFiles(str(set(expected_checksums) - set(recorded_checksums)))
if len(set(recorded_checksums) - set(expected_checksums)) > 0:
raise UnexpectedDownloadedFile(str(set(recorded_checksums) - set(expected_checksums)))
bad_urls = [url for url in expected_checksums if expected_checksums[url] != recorded_checksums[url]]
for_verification_name = " for " + verification_name if verification_name is not None else ""
if len(bad_urls) > 0:
error_msg = "Checksums didn't match" + for_verification_name + ":\n"
> raise NonMatchingChecksumError(error_msg + str(bad_urls))
E datasets.utils.info_utils.NonMatchingChecksumError: Checksums didn't match for dataset source files:
E ['https://adversarialglue.github.io/dataset/dev.zip']
src/datasets/utils/info_utils.py:40: NonMatchingChecksumError
```
## Expected results
The dataset downloads correctly, and there is no error.
## Actual results
Datasets library is looking for a checksum of None, and it gets a non-None checksum, and throws an error. This is clearly a bug. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3848/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3848/timeline | null | completed | null | null | false | [
"Hi @jxmorris12, thanks for reporting.\r\n\r\nThe objective of `verify_checksums` is to check that both checksums are equal. Therefore if one is None and the other is non-None, they are not equal, and the function accordingly raises a NonMatchingChecksumError. That behavior is expected.\r\n\r\nThe question is: how did you generate the expected checksum? Normally, it should not be None. To properly generate it (it is contained in the `dataset_infos.json` file), you should have runned: https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md\r\n```shell\r\ndatasets-cli test <your-dataset-folder> --save_infos --all_configs\r\n```\r\n\r\nOn the other hand, you should take into account that the generation of this file is NOT mandatory for personal/community datasets (we only require it for \"canonical\" datasets, i.e., datasets added to our library GitHub repository: https://github.com/huggingface/datasets/tree/master/datasets). Therefore, other option would be just to delete the `dataset_infos.json` file. If that file is not present, the function `verify_checksums` is not executed.\r\n\r\nFinally, you can circumvent the `verify_checksums` function by passing `ignore_verifications=True` to `load_dataset`:\r\n```python\r\nload_dataset(..., ignore_verifications=True)\r\n``` ",
"Thanks @albertvillanova!\r\n\r\nThat's fine. I did run that command when I was adding a new dataset. Maybe because the command crashed in the middle, the checksum wasn't stored properly. I don't know where the bug is happening. But either (i) `verify_checksums` should properly handle this edge case, where the passed checksum is None or (ii) the `datasets-cli test` shouldn't generate a corrupted dataset_infos.json file.\r\n\r\nJust a more high-level thing, I was trying to follow the instructions for adding a dataset in the CONTRIBUTING.md, so if running that command isn't even necessary, that should probably be mentioned in the document, right? But that's somewhat of a moot point, since something isn't working quite right internally if I was able to get into this corrupted state in the first place, just by following those instructions.",
"Hi @jxmorris12,\r\n\r\nDefinitely, your `dataset_infos.json` was corrupted (and wrongly contains expected None checksum). \r\n\r\nWhile we further investigate how this can happen and fix it, feel free to delete your `dataset_infos.json` file and recreate it with:\r\n```shell\r\ndatasets-cli test <your-dataset-folder> --save_infos --all_configs\r\n```\r\n\r\nAlso note that `verify_checksum` is working as expected: if it receives a None and and a non-None checksums as input pair, it must raise an exception: they are not equal. That is not a bug.",
"At a higher level, also note that we are preparing the release of `datasets` version 2.0, and some docs are being updated...\r\n\r\nIn order to add a dataset, I think the most updated instructions are in our official documentation pages: https://huggingface.co/docs/datasets/share",
"Thanks for the info. Maybe you can update the contributing.md if it's not up-to-date.",
"Hi @jxmorris12, we have discovered the bug why `None` checksums wrongly appeared when generating the `dataset_infos.json` file:\r\n- #3892\r\n\r\nThe fix will be accessible once this PR merged. And we are planning to do our 2.0 release today.\r\n\r\nWe are also working on updating all our docs for our release today.",
"Thanks @albertvillanova - congrats on the release!"
] |
https://api.github.com/repos/huggingface/datasets/issues/3716 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3716/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3716/comments | https://api.github.com/repos/huggingface/datasets/issues/3716/events | https://github.com/huggingface/datasets/issues/3716 | 1,136,831,092 | I_kwDODunzps5Dwqp0 | 3,716 | `FaissIndex` to support multiple GPU and `custom_index` | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 2 | 2022-02-14T06:21:43Z | 2022-03-07T16:28:56Z | 2022-03-07T16:28:56Z | null | **Is your feature request related to a problem? Please describe.**
Currently, because `device` is of the type `int | None`, to leverage `faiss-gpu`'s multi-gpu support, you need to create a `custom_index`. However, if using a `custom_index` created by e.g. `faiss.index_cpu_to_all_gpus`, then `FaissIndex.save` does not work properly because it checks the device id (which is an int, so no multiple GPUs).
**Describe the solution you'd like**
I would like `FaissIndex` to support multiple GPUs, by passing in a list to `add_faiss_index`.
**Describe alternatives you've considered**
Alternatively, I would like it to at least provide a warning cause it wasn't the behavior that I expected.
**Additional context**
Relavent source code here:
https://github.com/huggingface/datasets/blob/6ed6ac9448311930557810383d2cfd4fe6aae269/src/datasets/search.py#L340-L349
Device management needs changing to support multiple GPUs, probably by `isinstance` calls.
I can provide a PR if you like :)
Thanks for reading!
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3716/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3716/timeline | null | completed | null | null | false | [
"Hi @rentruewang, thansk for reporting and for your PR!!! We should definitely support this. ",
"@albertvillanova Great! :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/5958 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5958/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5958/comments | https://api.github.com/repos/huggingface/datasets/issues/5958/events | https://github.com/huggingface/datasets/pull/5958 | 1,757,265,971 | PR_kwDODunzps5TA3__ | 5,958 | set dev version | [] | closed | false | null | 3 | 2023-06-14T16:26:34Z | 2023-06-14T16:34:55Z | 2023-06-14T16:26:51Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5958/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5958/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5958.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5958",
"merged_at": "2023-06-14T16:26:51Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5958.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5958"
} | true | [
"The docs for this PR live [here](https://huggingface.co/docs/datasets/pr_5958). All of your documentation changes will be reflected on that endpoint.",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006232 / 0.011353 (-0.005121) | 0.003788 / 0.011008 (-0.007220) | 0.100014 / 0.038508 (0.061506) | 0.036488 / 0.023109 (0.013379) | 0.306255 / 0.275898 (0.030357) | 0.363337 / 0.323480 (0.039857) | 0.004765 / 0.007986 (-0.003221) | 0.002935 / 0.004328 (-0.001394) | 0.078897 / 0.004250 (0.074647) | 0.052221 / 0.037052 (0.015169) | 0.315169 / 0.258489 (0.056680) | 0.353050 / 0.293841 (0.059209) | 0.029059 / 0.128546 (-0.099488) | 0.008599 / 0.075646 (-0.067047) | 0.318770 / 0.419271 (-0.100502) | 0.046631 / 0.043533 (0.003098) | 0.303728 / 0.255139 (0.048589) | 0.332379 / 0.283200 (0.049180) | 0.021164 / 0.141683 (-0.120519) | 1.576963 / 1.452155 (0.124808) | 1.629575 / 1.492716 (0.136859) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.204246 / 0.018006 (0.186240) | 0.426600 / 0.000490 (0.426110) | 0.004336 / 0.000200 (0.004136) | 0.000082 / 0.000054 (0.000027) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.024039 / 0.037411 (-0.013372) | 0.098240 / 0.014526 (0.083715) | 0.108889 / 0.176557 (-0.067668) | 0.170827 / 0.737135 (-0.566308) | 0.111288 / 0.296338 (-0.185051) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.418103 / 0.215209 (0.202894) | 4.190759 / 2.077655 (2.113104) | 1.875978 / 1.504120 (0.371858) | 1.679198 / 1.541195 (0.138003) | 1.737965 / 1.468490 (0.269474) | 0.556660 / 4.584777 (-4.028117) | 3.413800 / 3.745712 (-0.331912) | 3.004999 / 5.269862 (-2.264862) | 1.464030 / 4.565676 (-3.101647) | 0.067338 / 0.424275 (-0.356937) | 0.011486 / 0.007607 (0.003879) | 0.522589 / 0.226044 (0.296544) | 5.214653 / 2.268929 (2.945724) | 2.316903 / 55.444624 (-53.127722) | 1.991941 / 6.876477 (-4.884536) | 2.110601 / 2.142072 (-0.031471) | 0.665400 / 4.805227 (-4.139828) | 0.135755 / 6.500664 (-6.364910) | 0.065980 / 0.075469 (-0.009489) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.197269 / 1.841788 (-0.644519) | 14.085205 / 8.074308 (6.010897) | 14.083360 / 10.191392 (3.891968) | 0.148054 / 0.680424 (-0.532369) | 0.016548 / 0.534201 (-0.517653) | 0.371538 / 0.579283 (-0.207745) | 0.391068 / 0.434364 (-0.043296) | 0.430589 / 0.540337 (-0.109748) | 0.529319 / 1.386936 (-0.857617) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.006214 / 0.011353 (-0.005138) | 0.003846 / 0.011008 (-0.007162) | 0.078559 / 0.038508 (0.040051) | 0.037855 / 0.023109 (0.014745) | 0.437479 / 0.275898 (0.161581) | 0.497588 / 0.323480 (0.174108) | 0.003491 / 0.007986 (-0.004494) | 0.003900 / 0.004328 (-0.000428) | 0.078443 / 0.004250 (0.074193) | 0.048019 / 0.037052 (0.010967) | 0.452076 / 0.258489 (0.193587) | 0.494597 / 0.293841 (0.200756) | 0.028127 / 0.128546 (-0.100419) | 0.008549 / 0.075646 (-0.067098) | 0.082977 / 0.419271 (-0.336295) | 0.043133 / 0.043533 (-0.000400) | 0.441342 / 0.255139 (0.186203) | 0.464339 / 0.283200 (0.181139) | 0.020110 / 0.141683 (-0.121573) | 1.485181 / 1.452155 (0.033026) | 1.532019 / 1.492716 (0.039302) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.228014 / 0.018006 (0.210007) | 0.416887 / 0.000490 (0.416397) | 0.001133 / 0.000200 (0.000933) | 0.000108 / 0.000054 (0.000053) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026452 / 0.037411 (-0.010960) | 0.104328 / 0.014526 (0.089802) | 0.110045 / 0.176557 (-0.066511) | 0.164725 / 0.737135 (-0.572410) | 0.116348 / 0.296338 (-0.179990) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.483502 / 0.215209 (0.268293) | 4.829814 / 2.077655 (2.752159) | 2.505271 / 1.504120 (1.001151) | 2.305819 / 1.541195 (0.764624) | 2.348633 / 1.468490 (0.880143) | 0.562316 / 4.584777 (-4.022461) | 3.426425 / 3.745712 (-0.319287) | 1.737934 / 5.269862 (-3.531927) | 1.042616 / 4.565676 (-3.523061) | 0.068088 / 0.424275 (-0.356187) | 0.011735 / 0.007607 (0.004128) | 0.586339 / 0.226044 (0.360295) | 5.861283 / 2.268929 (3.592354) | 2.953956 / 55.444624 (-52.490668) | 2.626611 / 6.876477 (-4.249865) | 2.687978 / 2.142072 (0.545906) | 0.672748 / 4.805227 (-4.132479) | 0.137231 / 6.500664 (-6.363433) | 0.068149 / 0.075469 (-0.007320) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.323139 / 1.841788 (-0.518649) | 14.503102 / 8.074308 (6.428794) | 14.092102 / 10.191392 (3.900710) | 0.165395 / 0.680424 (-0.515028) | 0.016898 / 0.534201 (-0.517303) | 0.366905 / 0.579283 (-0.212378) | 0.396671 / 0.434364 (-0.037692) | 0.421831 / 0.540337 (-0.118506) | 0.514075 / 1.386936 (-0.872861) |\n\n</details>\n</details>\n\n\n",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==8.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007778 / 0.011353 (-0.003575) | 0.004624 / 0.011008 (-0.006384) | 0.123426 / 0.038508 (0.084918) | 0.052209 / 0.023109 (0.029100) | 0.341084 / 0.275898 (0.065186) | 0.421905 / 0.323480 (0.098425) | 0.005768 / 0.007986 (-0.002217) | 0.003647 / 0.004328 (-0.000682) | 0.085569 / 0.004250 (0.081319) | 0.070473 / 0.037052 (0.033421) | 0.356626 / 0.258489 (0.098136) | 0.407413 / 0.293841 (0.113572) | 0.038800 / 0.128546 (-0.089746) | 0.010289 / 0.075646 (-0.065357) | 0.462707 / 0.419271 (0.043436) | 0.060390 / 0.043533 (0.016858) | 0.349805 / 0.255139 (0.094666) | 0.355288 / 0.283200 (0.072088) | 0.025364 / 0.141683 (-0.116318) | 1.745720 / 1.452155 (0.293565) | 1.852764 / 1.492716 (0.360048) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.290582 / 0.018006 (0.272576) | 0.480044 / 0.000490 (0.479554) | 0.007658 / 0.000200 (0.007458) | 0.000100 / 0.000054 (0.000046) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.031529 / 0.037411 (-0.005882) | 0.130441 / 0.014526 (0.115915) | 0.147653 / 0.176557 (-0.028904) | 0.215935 / 0.737135 (-0.521200) | 0.149871 / 0.296338 (-0.146467) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.461662 / 0.215209 (0.246453) | 4.570353 / 2.077655 (2.492698) | 2.104416 / 1.504120 (0.600297) | 1.936974 / 1.541195 (0.395779) | 2.139167 / 1.468490 (0.670677) | 0.645100 / 4.584777 (-3.939677) | 4.361536 / 3.745712 (0.615824) | 2.155960 / 5.269862 (-3.113902) | 1.207854 / 4.565676 (-3.357822) | 0.080162 / 0.424275 (-0.344113) | 0.014265 / 0.007607 (0.006658) | 0.606294 / 0.226044 (0.380250) | 5.928093 / 2.268929 (3.659165) | 2.701811 / 55.444624 (-52.742813) | 2.344490 / 6.876477 (-4.531987) | 2.435997 / 2.142072 (0.293925) | 0.761020 / 4.805227 (-4.044207) | 0.165860 / 6.500664 (-6.334804) | 0.075666 / 0.075469 (0.000197) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.427318 / 1.841788 (-0.414469) | 17.327468 / 8.074308 (9.253160) | 15.323065 / 10.191392 (5.131673) | 0.178518 / 0.680424 (-0.501905) | 0.020888 / 0.534201 (-0.513313) | 0.497891 / 0.579283 (-0.081393) | 0.487717 / 0.434364 (0.053353) | 0.581430 / 0.540337 (0.041093) | 0.703430 / 1.386936 (-0.683506) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007954 / 0.011353 (-0.003399) | 0.004442 / 0.011008 (-0.006566) | 0.090950 / 0.038508 (0.052442) | 0.054282 / 0.023109 (0.031173) | 0.424474 / 0.275898 (0.148576) | 0.531770 / 0.323480 (0.208290) | 0.004492 / 0.007986 (-0.003493) | 0.004745 / 0.004328 (0.000416) | 0.088213 / 0.004250 (0.083962) | 0.063967 / 0.037052 (0.026914) | 0.454256 / 0.258489 (0.195767) | 0.502870 / 0.293841 (0.209029) | 0.038203 / 0.128546 (-0.090343) | 0.010327 / 0.075646 (-0.065319) | 0.097809 / 0.419271 (-0.321463) | 0.062136 / 0.043533 (0.018604) | 0.426148 / 0.255139 (0.171009) | 0.467812 / 0.283200 (0.184612) | 0.029148 / 0.141683 (-0.112535) | 1.762307 / 1.452155 (0.310152) | 1.814238 / 1.492716 (0.321521) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.195676 / 0.018006 (0.177670) | 0.475382 / 0.000490 (0.474892) | 0.003070 / 0.000200 (0.002870) | 0.000112 / 0.000054 (0.000057) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.033945 / 0.037411 (-0.003466) | 0.134666 / 0.014526 (0.120140) | 0.147585 / 0.176557 (-0.028971) | 0.209472 / 0.737135 (-0.527664) | 0.154471 / 0.296338 (-0.141867) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.518132 / 0.215209 (0.302923) | 5.103423 / 2.077655 (3.025768) | 2.565207 / 1.504120 (1.061087) | 2.389454 / 1.541195 (0.848259) | 2.391706 / 1.468490 (0.923216) | 0.606463 / 4.584777 (-3.978314) | 4.392227 / 3.745712 (0.646515) | 2.067121 / 5.269862 (-3.202741) | 1.217551 / 4.565676 (-3.348125) | 0.074304 / 0.424275 (-0.349971) | 0.013418 / 0.007607 (0.005811) | 0.623327 / 0.226044 (0.397282) | 6.340233 / 2.268929 (4.071304) | 3.153948 / 55.444624 (-52.290677) | 2.824548 / 6.876477 (-4.051929) | 2.938402 / 2.142072 (0.796329) | 0.774305 / 4.805227 (-4.030922) | 0.170681 / 6.500664 (-6.329983) | 0.075895 / 0.075469 (0.000426) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.473491 / 1.841788 (-0.368296) | 17.372294 / 8.074308 (9.297986) | 15.550201 / 10.191392 (5.358809) | 0.191402 / 0.680424 (-0.489022) | 0.021401 / 0.534201 (-0.512800) | 0.484377 / 0.579283 (-0.094906) | 0.488844 / 0.434364 (0.054480) | 0.563336 / 0.540337 (0.022999) | 0.694210 / 1.386936 (-0.692726) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/4845 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4845/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4845/comments | https://api.github.com/repos/huggingface/datasets/issues/4845/events | https://github.com/huggingface/datasets/pull/4845 | 1,337,928,283 | PR_kwDODunzps49IOjf | 4,845 | Mark CI tests as xfail if Hub HTTP error | [] | closed | false | null | 1 | 2022-08-13T10:45:11Z | 2022-08-23T04:57:12Z | 2022-08-23T04:42:26Z | null | In order to make testing more robust (and avoid merges to master with red tests), we could mark tests as xfailed (instead of failed) when the Hub raises some temporary HTTP errors.
This PR:
- marks tests as xfailed only if the Hub raises a 500 error for:
- test_upstream_hub
- makes pytest report the xfailed/xpassed tests.
More tests could also be marked if needed.
Examples of CI failures due to temporary Hub HTTP errors:
- FAILED tests/test_upstream_hub.py::TestPushToHub::test_push_dataset_dict_to_hub_multiple_files
- https://github.com/huggingface/datasets/runs/7806855399?check_suite_focus=true
`requests.exceptions.HTTPError: 500 Server Error: Internal Server Error for url: https://hub-ci.huggingface.co/api/datasets/__DUMMY_TRANSFORMERS_USER__/test-16603108028233/commit/main (Request ID: aZeAQ5yLktoGHQYBcJ3zo)`
- FAILED tests/test_upstream_hub.py::TestPushToHub::test_push_dataset_dict_to_hub_no_token
- https://github.com/huggingface/datasets/runs/7840022996?check_suite_focus=true
`requests.exceptions.HTTPError: 500 Server Error: Internal Server Error for url: https://s3.us-east-1.amazonaws.com/lfs-staging.huggingface.co/repos/81/e3/81e3b831fa9bf23190ec041f26ef7ff6d6b71c1a937b8ec1ef1f1f05b508c089/caae596caa179cf45e7c9ac0c6d9a9cb0fe2d305291bfbb2d8b648ae26ed38b6?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Content-Sha256=UNSIGNED-PAYLOAD&X-Amz-Credential=AKIA4N7VTDGOZQA2IKWK%2F20220815%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20220815T144713Z&X-Amz-Expires=900&X-Amz-Signature=5ddddfe8ef2b0601e80ab41c78a4d77d921942b0d8160bcab40ff894095e6823&X-Amz-SignedHeaders=host&x-id=PutObject`
- FAILED tests/test_upstream_hub.py::TestPushToHub::test_push_dataset_dict_to_hub_private
- https://github.com/huggingface/datasets/runs/7835921082?check_suite_focus=true
`requests.exceptions.HTTPError: 500 Server Error: Internal Server Error for url: https://hub-ci.huggingface.co/api/repos/create (Request ID: gL_1I7i2dii9leBhlZen-) - Internal Error - We're working hard to fix that as soon as possible!`
- FAILED tests/test_upstream_hub.py::TestPushToHub::test_push_dataset_to_hub_custom_features_image_list
- https://github.com/huggingface/datasets/runs/7835920900?check_suite_focus=true
- This is not 500, but 404:
`requests.exceptions.HTTPError: 404 Client Error: Not Found for url: [https://hub-ci.huggingface.co/datasets/__DUMMY_TRANSFORMERS_USER__/test-16605586458339.git/info/lfs/objects](https://hub-ci.huggingface.co/datasets/__DUMMY_TRANSFORMERS_USER__/test-16605586458339.git/info/lfs/objects/batch)`
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4845/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4845/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4845.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4845",
"merged_at": "2022-08-23T04:42:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4845.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4845"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/241 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/241/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/241/comments | https://api.github.com/repos/huggingface/datasets/issues/241/events | https://github.com/huggingface/datasets/pull/241 | 631,703,079 | MDExOlB1bGxSZXF1ZXN0NDI4NTQwMDM0 | 241 | Fix empty cache dir | [] | closed | false | null | 2 | 2020-06-05T15:45:22Z | 2020-06-08T08:35:33Z | 2020-06-08T08:35:31Z | null | If the cache dir of a dataset is empty, the dataset fails to load and throws a FileNotFounfError. We could end up with empty cache dir because there was a line in the code that created the cache dir without using a temp dir. Using a temp dir is useful as it gets renamed to the real cache dir only if the full process is successful.
So I removed this bad line, and I also reordered things a bit to make sure that we always use a temp dir. I also added warning if we still end up with empty cache dirs in the future.
This should fix #239
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/241/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/241/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/241.diff",
"html_url": "https://github.com/huggingface/datasets/pull/241",
"merged_at": "2020-06-08T08:35:31Z",
"patch_url": "https://github.com/huggingface/datasets/pull/241.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/241"
} | true | [
"Looks great! Will this change force all cached datasets to be redownloaded? But even if it does, it shoud not be a big problem, I think",
"> Looks great! Will this change force all cached datasets to be redownloaded? But even if it does, it shoud not be a big problem, I think\r\n\r\nNo it shouldn't force to redownload"
] |
https://api.github.com/repos/huggingface/datasets/issues/681 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/681/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/681/comments | https://api.github.com/repos/huggingface/datasets/issues/681/events | https://github.com/huggingface/datasets/pull/681 | 710,075,721 | MDExOlB1bGxSZXF1ZXN0NDkzOTkwMjEz | 681 | Adding missing @property (+2 small flake8 fixes). | [] | closed | false | null | 0 | 2020-09-28T08:53:53Z | 2020-09-28T10:26:13Z | 2020-09-28T10:26:09Z | null | Fixes #678 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/681/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/681/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/681.diff",
"html_url": "https://github.com/huggingface/datasets/pull/681",
"merged_at": "2020-09-28T10:26:09Z",
"patch_url": "https://github.com/huggingface/datasets/pull/681.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/681"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/412 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/412/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/412/comments | https://api.github.com/repos/huggingface/datasets/issues/412/events | https://github.com/huggingface/datasets/issues/412 | 660,047,139 | MDU6SXNzdWU2NjAwNDcxMzk= | 412 | Unable to load XTREME dataset from disk | [] | closed | false | null | 3 | 2020-07-18T09:55:00Z | 2020-07-21T08:15:44Z | 2020-07-21T08:15:44Z | null | Hi 🤗 team!
## Description of the problem
Following the [docs](https://huggingface.co/nlp/loading_datasets.html?highlight=xtreme#manually-downloading-files) I'm trying to load the `PAN-X.fr` dataset from the [XTREME](https://github.com/google-research/xtreme) benchmark.
I have manually downloaded the `AmazonPhotos.zip` file from [here](https://www.amazon.com/clouddrive/share/d3KGCRCIYwhKJF0H3eWA26hjg2ZCRhjpEQtDL70FSBN?_encoding=UTF8&%2AVersion%2A=1&%2Aentries%2A=0&mgh=1) and am running into a `FileNotFoundError` when I point to the location of the dataset.
As far as I can tell, the problem is that `AmazonPhotos.zip` decompresses to `panx_dataset` and `load_dataset()` is not looking in the correct path:
```
# path where load_dataset is looking for fr.tar.gz
/root/.cache/huggingface/datasets/9b8c4f1578e45cb2539332c79738beb3b54afbcd842b079cabfd79e3ed6704f6/
# path where it actually exists
/root/.cache/huggingface/datasets/9b8c4f1578e45cb2539332c79738beb3b54afbcd842b079cabfd79e3ed6704f6/panx_dataset/
```
## Steps to reproduce the problem
1. Manually download the XTREME benchmark from [here](https://www.amazon.com/clouddrive/share/d3KGCRCIYwhKJF0H3eWA26hjg2ZCRhjpEQtDL70FSBN?_encoding=UTF8&%2AVersion%2A=1&%2Aentries%2A=0&mgh=1)
2. Run the following code snippet
```python
from nlp import load_dataset
# AmazonPhotos.zip is in the root of the folder
dataset = load_dataset("xtreme", "PAN-X.fr", data_dir='./')
```
3. Here is the stack trace
```
---------------------------------------------------------------------------
FileNotFoundError Traceback (most recent call last)
<ipython-input-4-26786bb5fa93> in <module>
----> 1 dataset = load_dataset("xtreme", "PAN-X.fr", data_dir='./')
/usr/local/lib/python3.6/dist-packages/nlp/load.py in load_dataset(path, name, version, data_dir, data_files, split, cache_dir, download_config, download_mode, ignore_verifications, save_infos, **config_kwargs)
522 download_mode=download_mode,
523 ignore_verifications=ignore_verifications,
--> 524 save_infos=save_infos,
525 )
526
/usr/local/lib/python3.6/dist-packages/nlp/builder.py in download_and_prepare(self, download_config, download_mode, ignore_verifications, save_infos, try_from_hf_gcs, dl_manager, **download_and_prepare_kwargs)
430 verify_infos = not save_infos and not ignore_verifications
431 self._download_and_prepare(
--> 432 dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs
433 )
434 # Sync info
/usr/local/lib/python3.6/dist-packages/nlp/builder.py in _download_and_prepare(self, dl_manager, verify_infos, **prepare_split_kwargs)
464 split_dict = SplitDict(dataset_name=self.name)
465 split_generators_kwargs = self._make_split_generators_kwargs(prepare_split_kwargs)
--> 466 split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
467 # Checksums verification
468 if verify_infos:
/usr/local/lib/python3.6/dist-packages/nlp/datasets/xtreme/b8c2ed3583a7a7ac60b503576dfed3271ac86757628897e945bd329c43b8a746/xtreme.py in _split_generators(self, dl_manager)
725 panx_dl_dir = dl_manager.extract(panx_path)
726 lang = self.config.name.split(".")[1]
--> 727 lang_folder = dl_manager.extract(os.path.join(panx_dl_dir, lang + ".tar.gz"))
728 return [
729 nlp.SplitGenerator(
/usr/local/lib/python3.6/dist-packages/nlp/utils/download_manager.py in extract(self, path_or_paths)
196 """
197 return map_nested(
--> 198 lambda path: cached_path(path, extract_compressed_file=True, force_extract=False), path_or_paths,
199 )
200
/usr/local/lib/python3.6/dist-packages/nlp/utils/py_utils.py in map_nested(function, data_struct, dict_only, map_tuple)
170 return tuple(mapped)
171 # Singleton
--> 172 return function(data_struct)
173
174
/usr/local/lib/python3.6/dist-packages/nlp/utils/download_manager.py in <lambda>(path)
196 """
197 return map_nested(
--> 198 lambda path: cached_path(path, extract_compressed_file=True, force_extract=False), path_or_paths,
199 )
200
/usr/local/lib/python3.6/dist-packages/nlp/utils/file_utils.py in cached_path(url_or_filename, download_config, **download_kwargs)
203 elif urlparse(url_or_filename).scheme == "":
204 # File, but it doesn't exist.
--> 205 raise FileNotFoundError("Local file {} doesn't exist".format(url_or_filename))
206 else:
207 # Something unknown
FileNotFoundError: Local file /root/.cache/huggingface/datasets/9b8c4f1578e45cb2539332c79738beb3b54afbcd842b079cabfd79e3ed6704f6/fr.tar.gz doesn't exist
```
## OS and hardware
```
- `nlp` version: 0.3.0
- Platform: Linux-4.15.0-72-generic-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.6.9
- PyTorch version (GPU?): 1.4.0 (True)
- Tensorflow version (GPU?): 2.1.0 (True)
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/412/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/412/timeline | null | completed | null | null | false | [
"Hi @lewtun, you have to provide the full path to the downloaded file for example `/home/lewtum/..`",
"I was able to repro. Opening a PR to fix that.\r\nThanks for reporting this issue !",
"Thanks for the rapid fix @lhoestq!"
] |
https://api.github.com/repos/huggingface/datasets/issues/4528 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4528/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4528/comments | https://api.github.com/repos/huggingface/datasets/issues/4528/events | https://github.com/huggingface/datasets/issues/4528 | 1,276,679,155 | I_kwDODunzps5MGJPz | 4,528 | Memory leak when iterating a Dataset | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 5 | 2022-06-20T10:03:14Z | 2022-09-12T08:51:39Z | 2022-09-12T08:51:39Z | null | e## Describe the bug
It seems that memory never gets freed after iterating a `Dataset` (using `.map()` or a simple `for` loop)
## Steps to reproduce the bug
```python
import gc
import logging
import time
import pyarrow
from datasets import load_dataset
from tqdm import trange
import os, psutil
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
process = psutil.Process(os.getpid())
print(process.memory_info().rss) # output: 633507840 bytes
corpus = load_dataset("BeIR/msmarco", 'corpus', keep_in_memory=False, streaming=False)['corpus'] # or "BeIR/trec-covid" for a smaller dataset
print(process.memory_info().rss) # output: 698601472 bytes
logger.info("Applying method to all examples in all splits")
for i in trange(0, len(corpus), 1000):
batch = corpus[i:i+1000]
data = pyarrow.total_allocated_bytes()
if data > 0:
logger.info(f"{i}/{len(corpus)}: {data}")
print(process.memory_info().rss) # output: 3788247040 bytes
del batch
gc.collect()
print(process.memory_info().rss) # output: 3788247040 bytes
logger.info("Done...")
time.sleep(100)
```
## Expected results
Limited memory usage, and memory to be freed after processing
## Actual results
Memory leak

You can see how the memory allocation keeps increasing until it reaches a steady state when we hit the `time.sleep(100)`, which showcases that even the garbage collector couldn't free the allocated memory
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.3.2
- Platform: Linux-5.4.0-90-generic-x86_64-with-glibc2.31
- Python version: 3.9.7
- PyArrow version: 8.0.0
- Pandas version: 1.4.2
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4528/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4528/timeline | null | completed | null | null | false | [
"Is someone assigned to this issue?",
"The same issue is being debugged here: https://github.com/huggingface/datasets/issues/4883\r\n",
"Here is a modified repro example that makes it easier to see the leak:\r\n\r\n```\r\n$ cat ds2.py\r\nimport gc, sys\r\nimport time\r\nfrom datasets import load_dataset\r\nimport os, psutil\r\n\r\nprocess = psutil.Process(os.getpid())\r\n\r\nprint(process.memory_info().rss/2**20)\r\n\r\ncorpus = load_dataset(\"BeIR/msmarco\", 'corpus', keep_in_memory=False, streaming=False)['corpus']\r\ncorpus = corpus.select(range(200000))\r\n\r\nprint(process.memory_info().rss/2**20)\r\n\r\nbatch = None\r\n\r\nmem_before_start = psutil.Process(os.getpid()).memory_info().rss / 2**20\r\n\r\nstep = 20000\r\nfor i in range(0, 10*step, step):\r\n mem_before = psutil.Process(os.getpid()).memory_info().rss / 2**20\r\n batch = corpus[i:i+step]\r\n import objgraph\r\n #objgraph.show_refs([batch])\r\n #objgraph.show_refs([corpus])\r\n #sys.exit()\r\n gc.collect()\r\n\r\n mem_after = psutil.Process(os.getpid()).memory_info().rss / 2**20\r\n print(f\"{i:6d} {mem_after - mem_before:12.4f} {mem_after - mem_before_start:12.4f}\")\r\n\r\n```\r\n\r\nLet's run:\r\n\r\n```\r\n$ python ds2.py\r\n 0 36.5391 36.5391\r\n 20000 10.4609 47.0000\r\n 40000 5.9766 52.9766\r\n 60000 7.8906 60.8672\r\n 80000 6.0586 66.9258\r\n100000 8.4453 75.3711\r\n120000 6.7422 82.1133\r\n140000 8.5664 90.6797\r\n160000 5.7344 96.4141\r\n180000 8.3398 104.7539\r\n```\r\n\r\nYou can see the last column of total RSS memory keeps on growing in MBs. The mid column is by how much it was grown during a single iteration of the repro script (20000 items)",
"@NouamaneTazi, please check my analysis here https://github.com/huggingface/datasets/issues/4883#issuecomment-1242599722 so if you agree with my research this Issue can be closed as well.\r\n\r\nI also made a suggestion at how to proceed to hunt for a real leak here https://github.com/huggingface/datasets/issues/4883#issuecomment-1242600626\r\n\r\nyou may find this one to be useful as well https://github.com/huggingface/datasets/issues/4883#issuecomment-1242597966",
"Amazing job! Thanks for taking time to debug this 🤗\r\n\r\nFor my side, I tried to do some more research as well, but to no avail. https://github.com/huggingface/datasets/issues/4883#issuecomment-1243415957"
] |
https://api.github.com/repos/huggingface/datasets/issues/2442 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2442/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2442/comments | https://api.github.com/repos/huggingface/datasets/issues/2442/events | https://github.com/huggingface/datasets/pull/2442 | 909,677,029 | MDExOlB1bGxSZXF1ZXN0NjYwMjE1ODY1 | 2,442 | add english language tags for ~100 datasets | [] | closed | false | null | 1 | 2021-06-02T16:24:56Z | 2021-06-04T09:51:40Z | 2021-06-04T09:51:39Z | null | As discussed on Slack, I have manually checked for ~100 datasets that they have at least one subset in English. This information was missing so adding into the READMEs.
Note that I didn't check all the subsets so it's possible that some of the datasets have subsets in other languages than English... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2442/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2442/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2442.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2442",
"merged_at": "2021-06-04T09:51:39Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2442.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2442"
} | true | [
"Fixing the tags of all the datasets is out of scope for this PR so I'm merging even though the CI fails because of the missing tags"
] |
https://api.github.com/repos/huggingface/datasets/issues/2505 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2505/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2505/comments | https://api.github.com/repos/huggingface/datasets/issues/2505/events | https://github.com/huggingface/datasets/pull/2505 | 921,234,797 | MDExOlB1bGxSZXF1ZXN0NjcwMjY2NjQy | 2,505 | Make numpy arrow extractor faster | [] | closed | false | null | 5 | 2021-06-15T10:11:32Z | 2021-06-28T09:53:39Z | 2021-06-28T09:53:38Z | null | I changed the NumpyArrowExtractor to call directly to_numpy and see if it can lead to speed-ups as discussed in https://github.com/huggingface/datasets/issues/2498
This could make the numpy/torch/tf/jax formatting faster | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 2,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2505/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2505/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2505.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2505",
"merged_at": "2021-06-28T09:53:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2505.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2505"
} | true | [
"Looks like we have a nice speed up in some benchmarks. For example:\r\n- `read_formatted numpy 5000`: 4.584777 sec -> 0.487113 sec\r\n- `read_formatted torch 5000`: 4.565676 sec -> 1.289514 sec",
"Can we convert this draft to PR @lhoestq ?",
"Ready for review ! cc @vblagoje",
"@lhoestq I tried the branch and it works for me. Although performance trace now shows a speedup, the overall pre-training speed up is minimal. But that's on my plate to explore further. ",
"Thanks for investigating @vblagoje \r\n\r\n@albertvillanova , do you have any comments on this PR ? Otherwise I think we can merge it"
] |
https://api.github.com/repos/huggingface/datasets/issues/4374 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4374/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4374/comments | https://api.github.com/repos/huggingface/datasets/issues/4374/events | https://github.com/huggingface/datasets/issues/4374 | 1,241,860,535 | I_kwDODunzps5KBUm3 | 4,374 | extremely slow processing when using a custom dataset | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "d876e3",
"default": true,
"description": "Further information is requested",
"id": 1935892912,
"name": "question",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/question"
}
] | closed | false | null | 2 | 2022-05-19T14:18:05Z | 2023-07-25T15:07:17Z | 2023-07-25T15:07:16Z | null | ## processing a custom dataset loaded as .txt file is extremely slow, compared to a dataset of similar volume from the hub
I have a large .txt file of 22 GB which i load into HF dataset
`lang_dataset = datasets.load_dataset("text", data_files="hi.txt")`
further i use a pre-processing function to clean the dataset
`lang_dataset["train"] = lang_dataset["train"].map(
remove_non_indic_sentences, num_proc=12, batched=True, remove_columns=lang_dataset['train'].column_names), batch_size=64)`
the following processing takes astronomical time to process, while hoging all the ram.
similar dataset of same size that's available in the huggingface hub works completely fine. which runs the same processing function and has the same amount of data.
`lang_dataset = datasets.load_dataset("oscar-corpus/OSCAR-2109", "hi", use_auth_token=True)`
the hours predicted to preprocess are as follows:
huggingface hub dataset: 6.5 hrs
custom loaded dataset: 7000 hrs
note: both the datasets are almost actually same, just provided by different sources with has +/- some samples, only one is hosted on the HF hub and the other is downloaded in a text format.
## Steps to reproduce the bug
```
import datasets
import psutil
import sys
import glob
from fastcore.utils import listify
import re
import gc
def remove_non_indic_sentences(example):
tmp_ls = []
eng_regex = r'[. a-zA-Z0-9ÖÄÅöäå _.,!"\'\/$]*'
for e in listify(example['text']):
matches = re.findall(eng_regex, e)
for match in (str(match).strip() for match in matches if match not in [""," ", " ", ",", " ,", ", ", " , "]):
if len(list(match.split(" "))) > 2:
e = re.sub(match," ",e,count=1)
tmp_ls.append(e)
gc.collect()
example['clean_text'] = tmp_ls
return example
lang_dataset = datasets.load_dataset("text", data_files="hi.txt")
lang_dataset["train"] = lang_dataset["train"].map(
remove_non_indic_sentences, num_proc=12, batched=True, remove_columns=lang_dataset['train'].column_names), batch_size=64)
## same thing work much faster when loading similar dataset from hub
lang_dataset = datasets.load_dataset("oscar-corpus/OSCAR-2109", "hi", split="train", use_auth_token=True)
lang_dataset["train"] = lang_dataset["train"].map(
remove_non_indic_sentences, num_proc=12, batched=True, remove_columns=lang_dataset['train'].column_names), batch_size=64)
```
## Actual results
similar dataset of same size that's available in the huggingface hub works completely fine. which runs the same processing function and has the same amount of data.
`lang_dataset = datasets.load_dataset("oscar-corpus/OSCAR-2109", "hi", use_auth_token=True)
**the hours predicted to preprocess are as follows:**
huggingface hub dataset: 6.5 hrs
custom loaded dataset: 7000 hrs
**i even tried the following:**
- sharding the large 22gb text files into smaller files and loading
- saving the file to disk and then loading
- using lesser num_proc
- using smaller batch size
- processing without batches ie : without `batched=True`
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.2.2.dev0
- Platform: Ubuntu 20.04 LTS
- Python version: 3.9.7
- PyArrow version:8.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4374/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4374/timeline | null | completed | null | null | false | [
"Hi !\r\n\r\nMy guess is that some examples in your dataset are bigger than your RAM, and therefore loading them in RAM to pass them to `remove_non_indic_sentences` takes forever because it might use SWAP memory.\r\n\r\nMaybe several examples in your dataset are grouped together, can you check `len(lang_dataset[\"train\"])` and `lang_dataset[\"train\"].data.nbytes` of both datasets please ? It can also be helpful to check the distribution of lengths of each examples in your dataset.",
"Closing due to inactivity"
] |
https://api.github.com/repos/huggingface/datasets/issues/1280 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1280/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1280/comments | https://api.github.com/repos/huggingface/datasets/issues/1280/events | https://github.com/huggingface/datasets/pull/1280 | 759,151,028 | MDExOlB1bGxSZXF1ZXN0NTM0MTk2MDc0 | 1,280 | disaster response messages dataset | [] | closed | false | null | 2 | 2020-12-08T07:27:16Z | 2020-12-09T16:21:57Z | 2020-12-09T16:21:57Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1280/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1280/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1280.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1280",
"merged_at": "2020-12-09T16:21:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1280.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1280"
} | true | [
"I have added the Readme.md as well, the PR is ready for review. \r\n\r\nThank you ",
"Hi @lhoestq I have updated the code and files. Please if you could check once.\r\n\r\nThank you"
] |
|
https://api.github.com/repos/huggingface/datasets/issues/1758 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1758/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1758/comments | https://api.github.com/repos/huggingface/datasets/issues/1758/events | https://github.com/huggingface/datasets/issues/1758 | 790,626,116 | MDU6SXNzdWU3OTA2MjYxMTY= | 1,758 | dataset.search() (elastic) cannot reliably retrieve search results | [] | closed | false | null | 2 | 2021-01-21T02:26:37Z | 2021-01-22T00:25:50Z | 2021-01-22T00:25:50Z | null | I am trying to use elastic search to retrieve the indices of items in the dataset in their precise order, given shuffled training indices.
The problem I have is that I cannot retrieve reliable results with my data on my first search. I have to run the search **twice** to get the right answer.
I am indexing data that looks like the following from the HF SQuAD 2.0 data set:
```
['57318658e6313a140071d02b',
'56f7165e3d8e2e1400e3733a',
'570e2f6e0b85d914000d7d21',
'5727e58aff5b5019007d97d0',
'5a3b5a503ff257001ab8441f',
'57262fab271a42140099d725']
```
To reproduce the issue, try:
```
from datasets import load_dataset, load_metric
from transformers import BertTokenizerFast, BertForQuestionAnswering
from elasticsearch import Elasticsearch
import numpy as np
import collections
from tqdm.auto import tqdm
import torch
# from https://colab.research.google.com/github/huggingface/notebooks/blob/master/examples/question_answering.ipynb#scrollTo=941LPhDWeYv-
tokenizer = BertTokenizerFast.from_pretrained('bert-base-uncased')
max_length = 384 # The maximum length of a feature (question and context)
doc_stride = 128 # The authorized overlap between two part of the context when splitting it is needed.
pad_on_right = tokenizer.padding_side == "right"
squad_v2 = True
# from https://colab.research.google.com/github/huggingface/notebooks/blob/master/examples/question_answering.ipynb#scrollTo=941LPhDWeYv-
def prepare_validation_features(examples):
# Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
# in one example possible giving several features when a context is long, each of those features having a
# context that overlaps a bit the context of the previous feature.
tokenized_examples = tokenizer(
examples["question" if pad_on_right else "context"],
examples["context" if pad_on_right else "question"],
truncation="only_second" if pad_on_right else "only_first",
max_length=max_length,
stride=doc_stride,
return_overflowing_tokens=True,
return_offsets_mapping=True,
padding="max_length",
)
# Since one example might give us several features if it has a long context, we need a map from a feature to
# its corresponding example. This key gives us just that.
sample_mapping = tokenized_examples.pop("overflow_to_sample_mapping")
# We keep the example_id that gave us this feature and we will store the offset mappings.
tokenized_examples["example_id"] = []
for i in range(len(tokenized_examples["input_ids"])):
# Grab the sequence corresponding to that example (to know what is the context and what is the question).
sequence_ids = tokenized_examples.sequence_ids(i)
context_index = 1 if pad_on_right else 0
# One example can give several spans, this is the index of the example containing this span of text.
sample_index = sample_mapping[i]
tokenized_examples["example_id"].append(examples["id"][sample_index])
# Set to None the offset_mapping that are not part of the context so it's easy to determine if a token
# position is part of the context or not.
tokenized_examples["offset_mapping"][i] = [
(list(o) if sequence_ids[k] == context_index else None)
for k, o in enumerate(tokenized_examples["offset_mapping"][i])
]
return tokenized_examples
# build base examples, features set of training data
shuffled_idx = pd.read_csv('https://raw.githubusercontent.com/afogarty85/temp/main/idx.csv')['idx'].to_list()
examples = load_dataset("squad_v2").shuffle(seed=1)['train']
features = load_dataset("squad_v2").shuffle(seed=1)['train'].map(
prepare_validation_features,
batched=True,
remove_columns=['answers', 'context', 'id', 'question', 'title'])
# reorder features by the training process
features = features.select(indices=shuffled_idx)
# get the example ids to match with the "example" data; get unique entries
id_list = list(dict.fromkeys(features['example_id']))
# now search for their index positions in the examples data set; load elastic search
es = Elasticsearch([{'host': 'localhost'}]).ping()
# add an index to the id column for the examples
examples.add_elasticsearch_index(column='id')
# retrieve the example index
example_idx_k1 = [examples.search(index_name='id', query=i, k=1).indices for i in id_list]
example_idx_k1 = [item for sublist in example_idx_k1 for item in sublist]
example_idx_k2 = [examples.search(index_name='id', query=i, k=3).indices for i in id_list]
example_idx_k2 = [item for sublist in example_idx_k2 for item in sublist]
len(example_idx_k1) # should be 130319
len(example_idx_k2) # should be 130319
#trial 1 lengths:
# k=1: 130314
# k=3: 130319
# trial 2:
# just run k=3 first: 130310
# try k=1 after k=3: 130319
```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1758/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1758/timeline | null | completed | null | null | false | [
"Hi !\r\nI tried your code on my side and I was able to workaround this issue by waiting a few seconds before querying the index.\r\nMaybe this is because the index is not updated yet on the ElasticSearch side ?",
"Thanks for the feedback! I added a 30 second \"sleep\" and that seemed to work well!"
] |
https://api.github.com/repos/huggingface/datasets/issues/922 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/922/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/922/comments | https://api.github.com/repos/huggingface/datasets/issues/922/events | https://github.com/huggingface/datasets/pull/922 | 753,559,130 | MDExOlB1bGxSZXF1ZXN0NTI5NjEzOTA4 | 922 | Add XOR QA Dataset | [] | closed | false | null | 4 | 2020-11-30T15:10:54Z | 2020-12-02T03:12:21Z | 2020-12-02T03:12:21Z | null | Added XOR Question Answering Dataset. The link to the dataset can be found [here](https://nlp.cs.washington.edu/xorqa/)
- [x] Followed the instructions in CONTRIBUTING.md
- [x] Ran the tests successfully
- [x] Created the dummy data | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/922/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/922/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/922.diff",
"html_url": "https://github.com/huggingface/datasets/pull/922",
"merged_at": "2020-12-02T03:12:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/922.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/922"
} | true | [
"Hi @sumanthd17 \r\n\r\nLooks like a good start! You will also need to add a Dataset card, following the instructions given [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md#manually-tag-the-dataset-and-write-the-dataset-card)",
"I followed the instructions mentioned there but my dataset isn't showing up in the dropdown list. Am I missing something here? @yjernite ",
"> I followed the instructions mentioned there but my dataset isn't showing up in the dropdown list. Am I missing something here? @yjernite\r\n\r\nThe best way is to run the tagging app locally and provide it the location to the `dataset_infos.json` after you've run the CLI:\r\nhttps://github.com/huggingface/datasets-tagging\r\n",
"This is a really good data card!!\r\n\r\nSmall changes to make it even better:\r\n- Tags: the dataset has both \"original\" data and data that is \"extended\" from a source dataset: TydiQA - you should choose both options in the tagging apps\r\n- The language and annotation creator tags are off: the language here is the questions: I understand it's a mix of crowd-sourced and expert-generated? Is there any machine translation involved? The annotations are the span selections: is that crowd-sourced?\r\n- Personal and sensitive information: there should be a statement there, even if only to say that none could be found or that it only mentions public figures"
] |
https://api.github.com/repos/huggingface/datasets/issues/1252 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1252/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1252/comments | https://api.github.com/repos/huggingface/datasets/issues/1252/events | https://github.com/huggingface/datasets/pull/1252 | 758,511,388 | MDExOlB1bGxSZXF1ZXN0NTMzNjczMDcx | 1,252 | Add Naver sentiment movie corpus | [] | closed | false | null | 0 | 2020-12-07T13:33:45Z | 2020-12-08T14:32:33Z | 2020-12-08T14:21:37Z | null | Supersedes #1168
> This PR adds the [Naver sentiment movie corpus](https://github.com/e9t/nsmc), a dataset containing Korean movie reviews from Naver, the most commonly used search engine in Korea. This dataset is often used to benchmark models on Korean NLP tasks, as seen in [this paper](https://www.aclweb.org/anthology/2020.lrec-1.199.pdf). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1252/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1252/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1252.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1252",
"merged_at": "2020-12-08T14:21:37Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1252.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1252"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/2560 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2560/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2560/comments | https://api.github.com/repos/huggingface/datasets/issues/2560/events | https://github.com/huggingface/datasets/pull/2560 | 932,143,634 | MDExOlB1bGxSZXF1ZXN0Njc5NTMyODk4 | 2,560 | fix Dataset.map when num_procs > num rows | [] | closed | false | null | 3 | 2021-06-29T02:24:11Z | 2021-06-29T15:00:18Z | 2021-06-29T14:53:31Z | null | closes #2470
## Testing notes
To run updated tests:
```sh
pytest tests/test_arrow_dataset.py -k "BaseDatasetTest and test_map_multiprocessing" -s
```
With Python code (to view warning):
```python
from datasets import Dataset
dataset = Dataset.from_dict({"x": ["sample"]})
print(len(dataset))
dataset.map(lambda x: x, num_proc=10)
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2560/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2560/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2560.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2560",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/2560.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2560"
} | true | [
"Hi ! Thanks for fixing this :)\r\n\r\nLooks like you have tons of changes due to code formatting.\r\nWe're using `black` for this, with a custom line length. To run our code formatting, you just need to run\r\n```\r\nmake style\r\n```\r\n\r\nThen for the windows error in the CI, I'm looking into it. It's probably just a file that isn't properly closed",
"CI is all green now ! Thanks :)\r\n\r\nThere are still many code formatting changes in your PR - probably due to the first commit you did.\r\nTo avoid conflicts with future PRs it would be nice to only have the changes related to the `num_proc` warning, and not have all those code formatting changes,\r\n\r\nCould you try remove those code formatting changes ?\r\n\r\nIf it's easier for you, you can make a new branch from `master` if needed",
"Thanks, @lhoestq! Apologies for the half-baked commits yesterday! I wasn’t able to step back in to resolve those CI issues until this morning.\r\n\r\nAlso, I’m surprised that `make style` isn’t resolving the formatting changes. I’m a bit stumped on that, so I’m going to re-apply on a new branch and open a PR as you suggested."
] |
https://api.github.com/repos/huggingface/datasets/issues/622 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/622/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/622/comments | https://api.github.com/repos/huggingface/datasets/issues/622/events | https://github.com/huggingface/datasets/issues/622 | 700,225,826 | MDU6SXNzdWU3MDAyMjU4MjY= | 622 | load_dataset for text files not working | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | null | 41 | 2020-09-12T12:49:28Z | 2020-10-28T11:07:31Z | 2020-10-28T11:07:30Z | null | Trying the following snippet, I get different problems on Linux and Windows.
```python
dataset = load_dataset("text", data_files="data.txt")
# or
dataset = load_dataset("text", data_files=["data.txt"])
```
(ps [This example](https://huggingface.co/docs/datasets/loading_datasets.html#json-files) shows that you can use a string as input for data_files, but the signature is `Union[Dict, List]`.)
The problem on Linux is that the script crashes with a CSV error (even though it isn't a CSV file). On Windows the script just seems to freeze or get stuck after loading the config file.
Linux stack trace:
```
PyTorch version 1.6.0+cu101 available.
Checking /home/bram/.cache/huggingface/datasets/b1d50a0e74da9a7b9822cea8ff4e4f217dd892e09eb14f6274a2169e5436e2ea.30c25842cda32b0540d88b7195147decf9671ee442f4bc2fb6ad74016852978e.py for additional imports.
Found main folder for dataset https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text/text.py at /home/bram/.cache/huggingface/modules/datasets_modules/datasets/text
Found specific version folder for dataset https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text/text.py at /home/bram/.cache/huggingface/modules/datasets_modules/datasets/text/7e13bc0fa76783d4ef197f079dc8acfe54c3efda980f2c9adfab046ede2f0ff7
Found script file from https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text/text.py to /home/bram/.cache/huggingface/modules/datasets_modules/datasets/text/7e13bc0fa76783d4ef197f079dc8acfe54c3efda980f2c9adfab046ede2f0ff7/text.py
Couldn't find dataset infos file at https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text/dataset_infos.json
Found metadata file for dataset https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text/text.py at /home/bram/.cache/huggingface/modules/datasets_modules/datasets/text/7e13bc0fa76783d4ef197f079dc8acfe54c3efda980f2c9adfab046ede2f0ff7/text.json
Using custom data configuration default
Generating dataset text (/home/bram/.cache/huggingface/datasets/text/default-0907112cc6cd2a38/0.0.0/7e13bc0fa76783d4ef197f079dc8acfe54c3efda980f2c9adfab046ede2f0ff7)
Downloading and preparing dataset text/default-0907112cc6cd2a38 (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /home/bram/.cache/huggingface/datasets/text/default-0907112cc6cd2a38/0.0.0/7e13bc0fa76783d4ef197f079dc8acfe54c3efda980f2c9adfab046ede2f0ff7...
Dataset not on Hf google storage. Downloading and preparing it from source
Downloading took 0.0 min
Checksum Computation took 0.0 min
Unable to verify checksums.
Generating split train
Traceback (most recent call last):
File "/home/bram/Python/projects/dutch-simplification/utils.py", line 45, in prepare_data
dataset = load_dataset("text", data_files=dataset_f)
File "/home/bram/.local/share/virtualenvs/dutch-simplification-NcpPZtDF/lib/python3.8/site-packages/datasets/load.py", line 608, in load_dataset
builder_instance.download_and_prepare(
File "/home/bram/.local/share/virtualenvs/dutch-simplification-NcpPZtDF/lib/python3.8/site-packages/datasets/builder.py", line 468, in download_and_prepare
self._download_and_prepare(
File "/home/bram/.local/share/virtualenvs/dutch-simplification-NcpPZtDF/lib/python3.8/site-packages/datasets/builder.py", line 546, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/bram/.local/share/virtualenvs/dutch-simplification-NcpPZtDF/lib/python3.8/site-packages/datasets/builder.py", line 888, in _prepare_split
for key, table in utils.tqdm(generator, unit=" tables", leave=False, disable=not_verbose):
File "/home/bram/.local/share/virtualenvs/dutch-simplification-NcpPZtDF/lib/python3.8/site-packages/tqdm/std.py", line 1130, in __iter__
for obj in iterable:
File "/home/bram/.cache/huggingface/modules/datasets_modules/datasets/text/7e13bc0fa76783d4ef197f079dc8acfe54c3efda980f2c9adfab046ede2f0ff7/text.py", line 100, in _generate_tables
pa_table = pac.read_csv(
File "pyarrow/_csv.pyx", line 714, in pyarrow._csv.read_csv
File "pyarrow/error.pxi", line 122, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 84, in pyarrow.lib.check_status
pyarrow.lib.ArrowInvalid: CSV parse error: Expected 1 columns, got 2
```
Windows just seems to get stuck. Even with a tiny dataset of 10 lines, it has been stuck for 15 minutes already at this message:
```
Checking C:\Users\bramv\.cache\huggingface\datasets\b1d50a0e74da9a7b9822cea8ff4e4f217dd892e09eb14f6274a2169e5436e2ea.30c25842cda32b0540d88b7195147decf9671ee442f4bc2fb6ad74016852978e.py for additional imports.
Found main folder for dataset https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text/text.py at C:\Users\bramv\.cache\huggingface\modules\datasets_modules\datasets\text
Found specific version folder for dataset https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text/text.py at C:\Users\bramv\.cache\huggingface\modules\datasets_modules\datasets\text\7e13bc0fa76783d4ef197f079dc8acfe54c3efda980f2c9adfab046ede2f0ff7
Found script file from https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text/text.py to C:\Users\bramv\.cache\huggingface\modules\datasets_modules\datasets\text\7e13bc0fa76783d4ef197f079dc8acfe54c3efda980f2c9adfab046ede2f0ff7\text.py
Couldn't find dataset infos file at https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text\dataset_infos.json
Found metadata file for dataset https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text/text.py at C:\Users\bramv\.cache\huggingface\modules\datasets_modules\datasets\text\7e13bc0fa76783d4ef197f079dc8acfe54c3efda980f2c9adfab046ede2f0ff7\text.json
Using custom data configuration default
```
| {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/622/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/622/timeline | null | completed | null | null | false | [
"Can you give us more information on your os and pip environments (pip list)?",
"@thomwolf Sure. I'll try downgrading to 3.7 now even though Arrow say they support >=3.5.\r\n\r\nLinux (Ubuntu 18.04) - Python 3.8\r\n======================\r\nPackage - Version\r\n---------------------\r\ncertifi 2020.6.20\r\nchardet 3.0.4\r\nclick 7.1.2\r\ndatasets 1.0.1\r\ndill 0.3.2\r\nfasttext 0.9.2\r\nfilelock 3.0.12\r\nfuture 0.18.2\r\nidna 2.10\r\njoblib 0.16.0\r\nnltk 3.5\r\nnumpy 1.19.1\r\npackaging 20.4\r\npandas 1.1.2\r\npip 20.0.2\r\nprotobuf 3.13.0\r\npyarrow 1.0.1\r\npybind11 2.5.0\r\npyparsing 2.4.7\r\npython-dateutil 2.8.1\r\npytz 2020.1\r\nregex 2020.7.14\r\nrequests 2.24.0\r\nsacremoses 0.0.43\r\nscikit-learn 0.23.2\r\nscipy 1.5.2\r\nsentence-transformers 0.3.6\r\nsentencepiece 0.1.91\r\nsetuptools 46.1.3\r\nsix 1.15.0\r\nstanza 1.1.1\r\nthreadpoolctl 2.1.0\r\ntokenizers 0.8.1rc2\r\ntorch 1.6.0+cu101\r\ntqdm 4.48.2\r\ntransformers 3.1.0\r\nurllib3 1.25.10\r\nwheel 0.34.2\r\nxxhash 2.0.0\r\n\r\nWindows 10 - Python 3.8\r\n================\r\nPackage - Version\r\n----------------------------\r\ncertifi 2020.6.20\r\nchardet 3.0.4\r\nclick 7.1.2\r\ndatasets 1.0.1\r\ndill 0.3.2\r\nfasttext 0.9.2\r\nfilelock 3.0.12\r\nfuture 0.18.2\r\nidna 2.10\r\njoblib 0.16.0\r\nnlp 0.4.0\r\nnltk 3.5\r\nnumpy 1.19.1\r\npackaging 20.4\r\npandas 1.1.1\r\npip 20.0.2\r\nprotobuf 3.13.0\r\npyarrow 1.0.1\r\npybind11 2.5.0\r\npyparsing 2.4.7\r\npython-dateutil 2.8.1\r\npytz 2020.1\r\nregex 2020.7.14\r\nrequests 2.24.0\r\nsacremoses 0.0.43\r\nscikit-learn 0.23.2\r\nscipy 1.5.2\r\nsentence-transformers 0.3.5.1\r\nsentencepiece 0.1.91\r\nsetuptools 46.1.3\r\nsix 1.15.0\r\nstanza 1.1.1\r\nthreadpoolctl 2.1.0\r\ntokenizers 0.8.1rc1\r\ntorch 1.6.0+cu101\r\ntqdm 4.48.2\r\ntransformers 3.0.2\r\nurllib3 1.25.10\r\nwheel 0.34.2\r\nxxhash 2.0.0",
"Downgrading to 3.7 does not help. Here is a dummy text file:\r\n\r\n```text\r\nVerzekering weigert vaker te betalen\r\nBedrijven van verzekeringen erkennen steeds minder arbeidsongevallen .\r\nIn 2012 weigerden de bedrijven te betalen voor 21.055 ongevallen op het werk .\r\nDat is 11,8 % van alle ongevallen op het werk .\r\nNog nooit weigerden verzekeraars zoveel zaken .\r\nIn 2012 hadden 135.118 mensen een ongeval op het werk .\r\nDat zijn elke werkdag 530 mensen .\r\nBij die ongevallen stierven 67 mensen .\r\nBijna 12.000 hebben een handicap na het ongeval .\r\nGeen echt arbeidsongeval Bedrijven moeten een verzekering hebben voor hun werknemers .\r\n```\r\n\r\nA temporary work around for the \"text\" type, is\r\n\r\n```python\r\ndataset = Dataset.from_dict({\"text\": Path(dataset_f).read_text().splitlines()})\r\n```",
"\r\n\r\neven i am facing the same issue.",
"@banunitte Please do not post screenshots in the future but copy-paste your code and the errors. That allows others to copy-and-paste your code and test it. You may also want to provide the Python version that you are using.",
"I have the exact same problem in Windows 10, Python 3.8.\r\n",
"I have the same problem on Linux of the script crashing with a CSV error. This may be caused by 'CRLF', when changed 'CRLF' to 'LF', the problem solved.",
"I pushed a fix for `pyarrow.lib.ArrowInvalid: CSV parse error`. Let me know if you still have this issue.\r\n\r\nNot sure about the windows one yet",
"To complete what @lhoestq is saying, I think that to use the new version of the `text` processing script (which is on master right now) you need to either specify the version of the script to be the `master` one or to install the lib from source (in which case it uses the `master` version of the script by default):\r\n```python\r\ndataset = load_dataset('text', script_version='master', data_files=XXX)\r\n```\r\nWe do versioning by default, i.e. your version of the dataset lib will use the script with the same version by default (i.e. only the `1.0.1` version of the script if you have the PyPI version `1.0.1` of the lib).",
"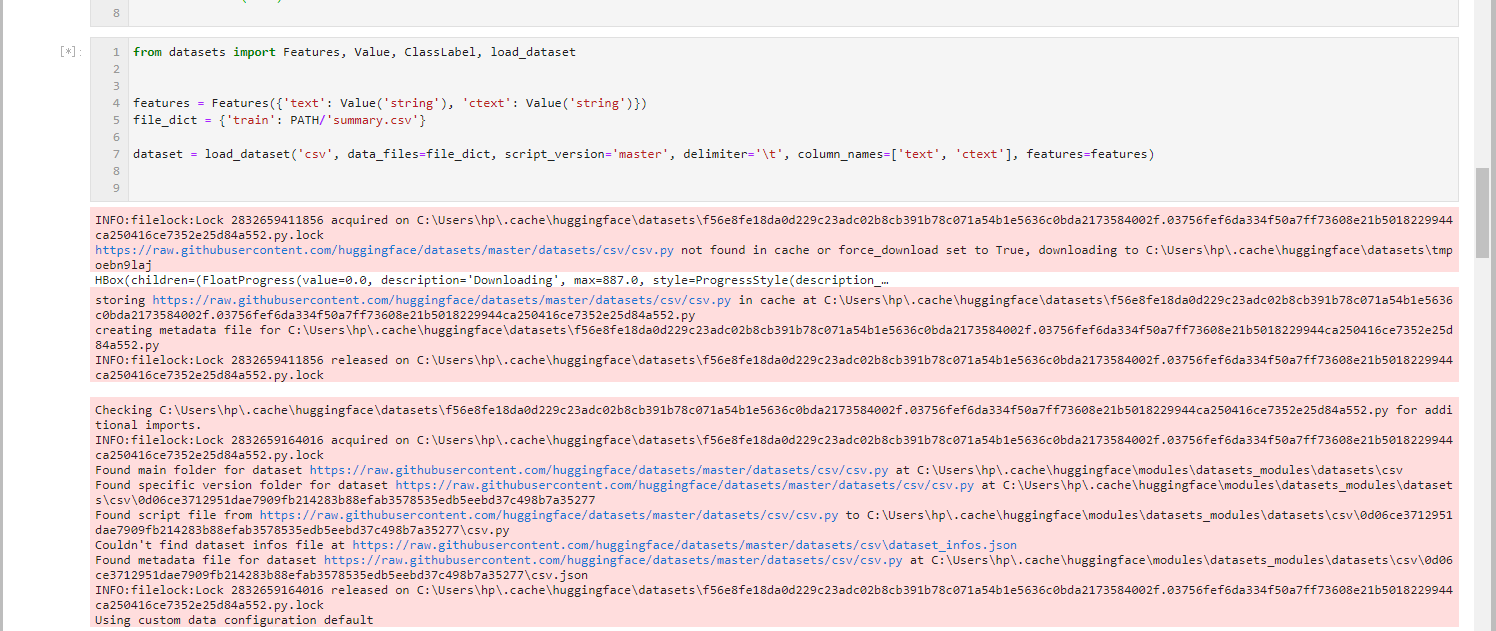\r\nwin10, py3.6\r\n\r\n\r\n```\r\nfrom datasets import Features, Value, ClassLabel, load_dataset\r\n\r\n\r\nfeatures = Features({'text': Value('string'), 'ctext': Value('string')})\r\nfile_dict = {'train': PATH/'summary.csv'}\r\n\r\ndataset = load_dataset('csv', data_files=file_dict, script_version='master', delimiter='\\t', column_names=['text', 'ctext'], features=features)\r\n```",
"```python\r\nTraceback` (most recent call last):\r\n File \"main.py\", line 281, in <module>\r\n main()\r\n File \"main.py\", line 190, in main\r\n train_data, test_data = data_factory(\r\n File \"main.py\", line 129, in data_factory\r\n train_data = load_dataset('text', \r\n File \"/home/me/Downloads/datasets/src/datasets/load.py\", line 608, in load_dataset\r\n builder_instance.download_and_prepare(\r\n File \"/home/me/Downloads/datasets/src/datasets/builder.py\", line 468, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/home/me/Downloads/datasets/src/datasets/builder.py\", line 546, in _download_and_prepare\r\n self._prepare_split(split_generator, **prepare_split_kwargs)\r\n File \"/home/me/Downloads/datasets/src/datasets/builder.py\", line 888, in _prepare_split\r\n for key, table in utils.tqdm(generator, unit=\" tables\", leave=False, disable=not_verbose):\r\n File \"/home/me/.local/lib/python3.8/site-packages/tqdm/std.py\", line 1130, in __iter__\r\n for obj in iterable:\r\n File \"/home/me/.cache/huggingface/modules/datasets_modules/datasets/text/512f465342e4f4cd07a8791428a629c043bb89d55ad7817cbf7fcc649178b014/text.py\", line 103, in _generate_tables\r\n pa_table = pac.read_csv(\r\n File \"pyarrow/_csv.pyx\", line 617, in pyarrow._csv.read_csv\r\n File \"pyarrow/error.pxi\", line 123, in pyarrow.lib.pyarrow_internal_check_status\r\n File \"pyarrow/error.pxi\", line 85, in pyarrow.lib.check_status\r\npyarrow.lib.ArrowInvalid: CSV parse error: Expected 1 columns, got 2\r\n```\r\n\r\nUnfortunately i am still getting this issue on Linux. I installed datasets from source and specified script_version to master.\r\n\r\n",
"> \r\n> win10, py3.6\r\n> \r\n> ```\r\n> from datasets import Features, Value, ClassLabel, load_dataset\r\n> \r\n> \r\n> features = Features({'text': Value('string'), 'ctext': Value('string')})\r\n> file_dict = {'train': PATH/'summary.csv'}\r\n> \r\n> dataset = load_dataset('csv', data_files=file_dict, script_version='master', delimiter='\\t', column_names=['text', 'ctext'], features=features)\r\n> ```\r\n\r\nSince #644 it should now work on windows @ScottishFold007 \r\n\r\n> Trying the following snippet, I get different problems on Linux and Windows.\r\n> \r\n> ```python\r\n> dataset = load_dataset(\"text\", data_files=\"data.txt\")\r\n> # or \r\n> dataset = load_dataset(\"text\", data_files=[\"data.txt\"])\r\n> ```\r\n>\r\n> Windows just seems to get stuck. Even with a tiny dataset of 10 lines, it has been stuck for 15 minutes already at this message:\r\n> \r\n> ```\r\n> Checking C:\\Users\\bramv\\.cache\\huggingface\\datasets\\b1d50a0e74da9a7b9822cea8ff4e4f217dd892e09eb14f6274a2169e5436e2ea.30c25842cda32b0540d88b7195147decf9671ee442f4bc2fb6ad74016852978e.py for additional imports.\r\n> Found main folder for dataset https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text/text.py at C:\\Users\\bramv\\.cache\\huggingface\\modules\\datasets_modules\\datasets\\text\r\n> Found specific version folder for dataset https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text/text.py at C:\\Users\\bramv\\.cache\\huggingface\\modules\\datasets_modules\\datasets\\text\\7e13bc0fa76783d4ef197f079dc8acfe54c3efda980f2c9adfab046ede2f0ff7\r\n> Found script file from https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text/text.py to C:\\Users\\bramv\\.cache\\huggingface\\modules\\datasets_modules\\datasets\\text\\7e13bc0fa76783d4ef197f079dc8acfe54c3efda980f2c9adfab046ede2f0ff7\\text.py\r\n> Couldn't find dataset infos file at https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text\\dataset_infos.json\r\n> Found metadata file for dataset https://raw.githubusercontent.com/huggingface/datasets/1.0.1/datasets/text/text.py at C:\\Users\\bramv\\.cache\\huggingface\\modules\\datasets_modules\\datasets\\text\\7e13bc0fa76783d4ef197f079dc8acfe54c3efda980f2c9adfab046ede2f0ff7\\text.json\r\n> Using custom data configuration default\r\n> ```\r\n\r\nSame for you @BramVanroy .\r\n\r\nNot sure about the one on linux though",
"> To complete what @lhoestq is saying, I think that to use the new version of the `text` processing script (which is on master right now) you need to either specify the version of the script to be the `master` one or to install the lib from source (in which case it uses the `master` version of the script by default):\r\n> \r\n> ```python\r\n> dataset = load_dataset('text', script_version='master', data_files=XXX)\r\n> ```\r\n> \r\n> We do versioning by default, i.e. your version of the dataset lib will use the script with the same version by default (i.e. only the `1.0.1` version of the script if you have the PyPI version `1.0.1` of the lib).\r\n\r\nLinux here:\r\n\r\nI was using the 0.4.0 nlp library load_dataset to load a text dataset of 9-10Gb without collapsing the RAM memory. However, today I got the csv error message mentioned in this issue. After installing the new (datasets) library from source and specifying the script_verson = 'master' I'm still having this same error message. Furthermore, I cannot use the dictionary \"trick\" to load the dataset since the system kills the process due to a RAM out of memory problem. Is there any other solution to this error? Thank you in advance. ",
"Hi @raruidol \r\nTo fix the RAM issue you'll need to shard your text files into smaller files (see https://github.com/huggingface/datasets/issues/610#issuecomment-691672919 for example)\r\n\r\nI'm not sure why you're having the csv error on linux.\r\nDo you think you could to to reproduce it on google colab for example ?\r\nOr send me a dummy .txt file that reproduces the issue ?",
"@lhoestq \r\n\r\nThe crash message shows up when loading the dataset:\r\n```\r\nprint('Loading corpus...') \r\nfiles = glob.glob('corpora/shards/*') \r\n-> dataset = load_dataset('text', script_version='master', data_files=files) \r\nprint('Corpus loaded.')\r\n```\r\nAnd this is the exact message:\r\n```\r\nTraceback (most recent call last):\r\n File \"run_language_modeling.py\", line 27, in <module>\r\n dataset = load_dataset('text', script_version='master', data_files=files)\r\n File \"/home/jupyter-raruidol/DebatAnalyser/env/lib/python3.7/site-packages/datasets/load.py\", line 611, in load_dataset\r\n ignore_verifications=ignore_verifications,\r\n File \"/home/jupyter-raruidol/DebatAnalyser/env/lib/python3.7/site-packages/datasets/builder.py\", line 471, in download_and_prepare\r\n dl_manager=dl_manager, verify_infos=verify_infos, **download_and_prepare_kwargs\r\n File \"/home/jupyter-raruidol/DebatAnalyser/env/lib/python3.7/site-packages/datasets/builder.py\", line 548, in _download_and_prepare\r\n self._prepare_split(split_generator, **prepare_split_kwargs)\r\n File \"/home/jupyter-raruidol/DebatAnalyser/env/lib/python3.7/site-packages/datasets/builder.py\", line 892, in _prepare_split\r\n for key, table in utils.tqdm(generator, unit=\" tables\", leave=False, disable=not_verbose):\r\n File \"/home/jupyter-raruidol/DebatAnalyser/env/lib/python3.7/site-packages/tqdm/std.py\", line 1130, in __iter__\r\n for obj in iterable:\r\n File \"/home/jupyter-raruidol/.cache/huggingface/modules/datasets_modules/datasets/text/512f465342e4f4cd07a8791428a629c043bb89d55ad7817cbf7fcc649178b014/text.py\", line 107, in _generate_tables\r\n convert_options=self.config.convert_options,\r\n File \"pyarrow/_csv.pyx\", line 714, in pyarrow._csv.read_csv\r\n File \"pyarrow/error.pxi\", line 122, in pyarrow.lib.pyarrow_internal_check_status\r\n File \"pyarrow/error.pxi\", line 84, in pyarrow.lib.check_status\r\npyarrow.lib.ArrowInvalid: CSV parse error: Expected 1 columns, got 2\r\n```\r\n\r\nAnd these are the pip packages I have atm and their versions:\r\n\r\n```\r\nPackage Version Location \r\n--------------- --------- -------------------------------------------------------------\r\ncertifi 2020.6.20 \r\nchardet 3.0.4 \r\nclick 7.1.2 \r\ndatasets 1.0.2 \r\ndill 0.3.2 \r\nfilelock 3.0.12 \r\nfuture 0.18.2 \r\nidna 2.10 \r\njoblib 0.16.0 \r\nnumpy 1.19.1 \r\npackaging 20.4 \r\npandas 1.1.1 \r\npip 19.0.3 \r\npyarrow 1.0.1 \r\npyparsing 2.4.7 \r\npython-dateutil 2.8.1 \r\npytz 2020.1 \r\nregex 2020.7.14 \r\nrequests 2.24.0 \r\nsacremoses 0.0.43 \r\nsentencepiece 0.1.91 \r\nsetuptools 40.8.0 \r\nsix 1.15.0 \r\ntokenizers 0.8.1rc2 \r\ntorch 1.6.0 \r\ntqdm 4.48.2 \r\ntransformers 3.0.2 /home/jupyter-raruidol/DebatAnalyser/env/src/transformers/src\r\n```\r\n\r\n\r\n",
"I tested on google colab which is also linux using this code:\r\n\r\n- first download an arbitrary text file\r\n```bash\r\nwget https://raw.githubusercontent.com/abisee/cnn-dailymail/master/url_lists/all_train.txt\r\n```\r\n- then run\r\n```python\r\nfrom datasets import load_dataset\r\n\r\nd = load_dataset(\"text\", data_files=\"all_train.txt\", script_version='master')\r\n```\r\nAnd I don't get this issue.\r\n\r\n\\> Could you test on your side if these lines work @raruidol ?\r\n\r\nalso cc @Skyy93 as it seems you have the same issue\r\n\r\nIf it works:\r\nIt could mean that the issue could come from unexpected patterns in the files you want to use.\r\nIn that case we should find a way to handle them.\r\n\r\nAnd if it doesn't work:\r\nIt could mean that it comes from the way pyarrow reads text files on linux.\r\nIn that case we should report it to pyarrow and find a workaround in the meantime\r\n\r\nEither way it should help to find where this bug comes from and fix it :)\r\n\r\nThank you in advance !",
"Update: also tested the above code in a docker container from [jupyter/minimal-notebook](https://hub.docker.com/r/jupyter/minimal-notebook/) (based on ubuntu) and still not able to reproduce",
"It looks like with your text input file works without any problem. I have been doing some experiments this morning with my input files and I'm almost certain that the crash is caused by some unexpected pattern in the files. However, I've not been able to spot the main cause of it. What I find strange is that this same corpus was being loaded by the nlp 0.4.0 library without any problem... Where can I find the code where you structure the input text data in order to use it with pyarrow?",
"Under the hood it does\r\n```python\r\nimport pyarrow as pa\r\nimport pyarrow.csv\r\n\r\n# Use csv reader from Pyarrow with one column for text files\r\n\r\n# To force the one-column setting, we set an arbitrary character\r\n# that is not in text files as delimiter, such as \\b or \\v.\r\n# The bell character, \\b, was used to make beeps back in the days\r\nparse_options = pa.csv.ParseOptions( \r\n delimiter=\"\\b\", \r\n quote_char=False, \r\n double_quote=False, \r\n escape_char=False, \r\n newlines_in_values=False, \r\n ignore_empty_lines=False, \r\n)\r\n\r\nread_options= pa.csv.ReadOptions(use_threads=True, column_names=[\"text\"])\r\n\r\npa_table = pa.csv.read_csv(\"all_train.txt\", read_options=read_options, parse_options=parse_options)\r\n```\r\n\r\nNote that we changed the parse options with datasets 1.0\r\nIn particular the delimiter used to be `\\r` but this delimiter doesn't work on windows.",
"Could you try with `\\a` instead of `\\b` ? It looks like the bell character is \\a in python and not \\b",
"I was just exploring if the crash was happening in every shard or not, and which shards were generating the error message. With \\b I got the following list of shards crashing:\r\n\r\n```\r\nErrors on files: ['corpora/shards/shard_0069', 'corpora/shards/shard_0043', 'corpora/shards/shard_0014', 'corpora/shards/shard_0032', 'corpora/shards/shard_0088', 'corpora/shards/shard_0018', 'corpora/shards/shard_0073', 'corpora/shards/shard_0079', 'corpora/shards/shard_0038', 'corpora/shards/shard_0041', 'corpora/shards/shard_0007', 'corpora/shards/shard_0004', 'corpora/shards/shard_0102', 'corpora/shards/shard_0096', 'corpora/shards/shard_0030', 'corpora/shards/shard_0076', 'corpora/shards/shard_0067', 'corpora/shards/shard_0052', 'corpora/shards/shard_0026', 'corpora/shards/shard_0024', 'corpora/shards/shard_0064', 'corpora/shards/shard_0044', 'corpora/shards/shard_0013', 'corpora/shards/shard_0062', 'corpora/shards/shard_0057', 'corpora/shards/shard_0097', 'corpora/shards/shard_0094', 'corpora/shards/shard_0078', 'corpora/shards/shard_0075', 'corpora/shards/shard_0039', 'corpora/shards/shard_0077', 'corpora/shards/shard_0021', 'corpora/shards/shard_0040', 'corpora/shards/shard_0009', 'corpora/shards/shard_0023', 'corpora/shards/shard_0095', 'corpora/shards/shard_0107', 'corpora/shards/shard_0063', 'corpora/shards/shard_0086', 'corpora/shards/shard_0047', 'corpora/shards/shard_0089', 'corpora/shards/shard_0037', 'corpora/shards/shard_0101', 'corpora/shards/shard_0093', 'corpora/shards/shard_0082', 'corpora/shards/shard_0091', 'corpora/shards/shard_0065', 'corpora/shards/shard_0020', 'corpora/shards/shard_0070', 'corpora/shards/shard_0008', 'corpora/shards/shard_0058', 'corpora/shards/shard_0060', 'corpora/shards/shard_0022', 'corpora/shards/shard_0059', 'corpora/shards/shard_0100', 'corpora/shards/shard_0027', 'corpora/shards/shard_0072', 'corpora/shards/shard_0098', 'corpora/shards/shard_0019', 'corpora/shards/shard_0066', 'corpora/shards/shard_0042', 'corpora/shards/shard_0053']\r\n```\r\n\r\nI also tried with \\a and the list decreased but there were still several crashes:\r\n\r\n```\r\nErrors on files: ['corpora/shards/shard_0069', 'corpora/shards/shard_0055', 'corpora/shards/shard_0043', 'corpora/shards/shard_0014', 'corpora/shards/shard_0073', 'corpora/shards/shard_0025', 'corpora/shards/shard_0068', 'corpora/shards/shard_0102', 'corpora/shards/shard_0096', 'corpora/shards/shard_0076', 'corpora/shards/shard_0067', 'corpora/shards/shard_0026', 'corpora/shards/shard_0024', 'corpora/shards/shard_0044', 'corpora/shards/shard_0087', 'corpora/shards/shard_0092', 'corpora/shards/shard_0074', 'corpora/shards/shard_0094', 'corpora/shards/shard_0078', 'corpora/shards/shard_0039', 'corpora/shards/shard_0077', 'corpora/shards/shard_0040', 'corpora/shards/shard_0009', 'corpora/shards/shard_0107', 'corpora/shards/shard_0063', 'corpora/shards/shard_0103', 'corpora/shards/shard_0047', 'corpora/shards/shard_0033', 'corpora/shards/shard_0089', 'corpora/shards/shard_0037', 'corpora/shards/shard_0082', 'corpora/shards/shard_0071', 'corpora/shards/shard_0091', 'corpora/shards/shard_0065', 'corpora/shards/shard_0070', 'corpora/shards/shard_0058', 'corpora/shards/shard_0081', 'corpora/shards/shard_0060', 'corpora/shards/shard_0002', 'corpora/shards/shard_0059', 'corpora/shards/shard_0027', 'corpora/shards/shard_0072', 'corpora/shards/shard_0098', 'corpora/shards/shard_0019', 'corpora/shards/shard_0045', 'corpora/shards/shard_0036', 'corpora/shards/shard_0066', 'corpora/shards/shard_0053']\r\n```\r\n\r\nWhich means that it is quite possible that the assumption of that some unexpected pattern in the files is causing the crashes is true. If I am able to reach any conclusion I will post It here asap.",
"Hmmm I was expecting it to work with \\a, not sure why they appear in your text files though",
"Hi @lhoestq, is there any input length restriction which was not before the update of the nlp library?",
"No we never set any input length restriction on our side (maybe arrow but I don't think so)",
"@lhoestq Can you ever be certain that a delimiter character is not present in a plain text file? In other formats (e.g. CSV) , rules are set of what is allowed and what isn't so that it actually constitutes a CSV file. In a text file you basically have \"anything goes\", so I don't think you can ever be entirely sure that the chosen delimiter does not exist in the text file, or am I wrong? \r\n\r\nIf I understand correctly you choose a delimiter that we hope does not exist in the file, so that when the CSV parser starts splitting into columns, it will only ever create one column? Why can't we use a newline character though?",
"Okay, I have splitted the crashing shards into individual sentences and some examples of the inputs that are causing the crashes are the following ones:\r\n\r\n\r\n_4. DE L’ORGANITZACIÓ ESTAMENTAL A L’ORGANITZACIÓ EN CLASSES A mesura que es desenvolupava un sistema econòmic capitalista i naixia una classe burgesa cada vegada més preparada per a substituir els dirigents de les velles monarquies absolutistes, es qüestionava l’abundància de béns amortitzats, que com s’ha dit estaven fora del mercat i no pagaven tributs, pels perjudicis que ocasionaven a les finances públiques i a l’economia en general. Aquest estat d’opinió revolucionari va desembocar en un conjunt de mesures pràctiques de caràcter liberal. D’una banda, les que intentaven desposseir les mans mortes del domini de béns acumulats, procés que acostumem a denominar desamortització, i que no és més que la nacionalització i venda d’aquests béns eclesiàstics o civils en subhasta pública al millor postor. D’altra banda, les que redimien o reduïen els censos i delmes o aixecaven les prohibicions de venda, és a dir, les vinculacions. La desamortització, que va afectar béns dels ordes religiosos, dels pobles i d’algunes corporacions civils, no va ser un camí fàcil, perquè costava i costa trobar algú que sigui indiferent a la pèrdua de béns, drets i privilegis. I té una gran transcendència, va privar els antics estaments de les Espanyes, clero i pobles —la noblesa en queda al marge—, de la força econòmica que els donaven bona part de les seves terres i, en última instància, va preparar el terreny per a la substitució de la vella societat estamental per la nova societat classista. En aquesta societat, en teoria, les agrupacions socials són obertes, no tenen cap estatut jurídic privilegiat i estan definides per la possessió o no d’uns béns econòmics que són lliurement alienables. A les Espanyes la transformació va afectar poc l’aristocràcia latifundista, allà on n’hi havia. Aquesta situació va afavorir, en part, la persistència de la vella cultura de la societat estamental en determinats ambients, i això ha influït decisivament en la manca de democràcia que caracteritza la majoria de règims polítics que s’han anat succeint. Una manera de pensar que sempre sura en un moment o altre, i que de fet no acaba de desaparèixer del tot. 5. INICI DE LA DESAMORTITZACIÓ A LES ESPANYES Durant el segle xviii, dins d’aquesta visió lliberal, va agafar força en alguns cercles de les Espanyes el corrent d’opinió contrari a les mans mortes. Durant el regnat de Carles III, s’arbitraren les primeres mesures desamortitzadores proposades per alguns ministres il·lustrats. Aquestes disposicions foren modestes i poc eficaces, no van aturar l’acumulació de terres per part dels estaments que constituïen les mans mortes i varen afectar principalment béns dels pobles. L’Església no va ser tocada, excepte en el cas de 110_\r\n\r\n_la revolució liberal, perquè, encara que havia perdut els seus drets jurisdiccionals, havia conservat la majoria de terres i fins i tot les havia incrementat amb d’altres que procedien de la desamortització. En la nova situació, les mans mortes del bosc públic eren l’Estat, que no cerca mai l’autofinançament de les despeses de gestió; els diners que manquin ja els posarà l’Estat. 9. DEFENSA I INTENTS DE RECUPERACIÓ DELS BÉNS COMUNALS DESAMORTITZATS El procés de centralització no era senzill, perquè, d’una banda, la nova organització apartava de la gestió moltes corporacions locals i molts veïns que l’havien portada des de l’edat mitjana, i, de l’altra, era difícil de coordinar la nova silvicultura amb moltes pràctiques forestals i drets tradicionals, com la pastura, fer llenya o tallar un arbre aquí i un altre allà quan tenia el gruix suficient, les pràctiques que s’havien fet sempre. Les primeres passes de la nova organització centralitzada varen tenir moltes dificultats en aquells indrets en què els terrenys municipals i comunals tenien un paper important en l’economia local. La desobediència a determinades normes imposades varen prendre formes diferents. Algunes institucions, com, per exemple, la Diputació de Lleida, varen retardar la tramitació d’alguns expedients i varen evitar la venda de béns municipals. Molts pobles permeteren deixar que els veïns continuessin amb les seves pràctiques tradicionals, d’altres varen boicotejar les subhastes d’aprofitaments. L’Estat va reaccionar encomanant a la Guàrdia Civil el compliment de les noves directrius. Imposar el nou règim va costar a l’Administració un grapat d’anys, però de mica en mica, amb molta, molta guarderia i gens de negociació, ho va aconseguir. La nova gestió estatal dels béns municipals va deixar, com hem comentat, molta gent sense uns recursos necessaris per a la supervivència, sobre tot en àrees on predominaven les grans propietats, i on els pagesos sense terra treballaven de jornalers temporers. Això va afavorir que, a bona part de les Espanyes, les primeres lluites camperoles de la segona meitat del segle xix defensessin la recuperació dels comunals desamortitzats; per a molts aquella expropiació i venda dirigida pels governs monàrquics era la causa de molta misèria. D’altres, més radicalitzats, varen entendre que l’eliminació de la propietat col·lectiva i la gestió estatal dels boscos no desamortitzats suposava una usurpació pura i dura. En les zones més afectades per la desamortització això va donar lloc a un imaginari centrat en la defensa del comunal. La Segona República va arribar en una conjuntura econòmica de crisi, generada pel crac del 1929. Al camp, aquesta situació va produir una forta caiguda dels preus dels productes agraris i un increment important de l’atur. QUADERNS AGRARIS 42 (juny 2017), p. 105-126_\r\n\r\nI think that the main difference between the crashing samples and the rest is their length. Therefore, couldn't the length be causing the message errors? I hope with these samples you can identify what is causing the crashes considering that the 0.4.0 nlp library was loading them properly.",
"So we're using the csv reader to read text files because arrow doesn't have a text reader.\r\nTo workaround the fact that text files are just csv with one column, we want to set a delimiter that doesn't appear in text files.\r\nUntil now I thought that it would do the job but unfortunately it looks like even characters like \\a appear in text files.\r\n\r\nSo we have to option:\r\n- find another delimiter that does the job (maybe `\\x1b` esc or `\\x18` cancel)\r\n- don't use the csv reader from arrow but the text reader from pandas instead (or any other reader). The only important thing is that it must be fast (arrow's reader has a nice and fast multithreaded for csv that we're using now but hopefully we can find an alternative)\r\n\r\n\r\n\r\n> @lhoestq Can you ever be certain that a delimiter character is not present in a plain text file? In other formats (e.g. CSV) , rules are set of what is allowed and what isn't so that it actually constitutes a CSV file. In a text file you basically have \"anything goes\", so I don't think you can ever be entirely sure that the chosen delimiter does not exist in the text file, or am I wrong?\r\n\r\nAs long as the text file follows some encoding it wouldn't make sense to have characters such as the bell character. However I agree it can happen.\r\n\r\n> If I understand correctly you choose a delimiter that we hope does not exist in the file, so that when the CSV parser starts splitting into columns, it will only ever create one column? Why can't we use a newline character though?\r\n\r\nExactly. Arrow doesn't allow the newline character unfortunately.",
"> Okay, I have splitted the crashing shards into individual sentences and some examples of the inputs that are causing the crashes are the following ones\r\n\r\nThanks for digging into it !\r\n\r\nCharacters like \\a or \\b are not shown when printing the text, so as it is I can't tell if it contains unexpected characters.\r\nMaybe could could open the file in python and check if `\"\\b\" in open(\"path/to/file\", \"r\").read()` ?\r\n\r\n> I think that the main difference between the crashing samples and the rest is their length. Therefore, couldn't the length be causing the message errors? I hope with these samples you can identify what is causing the crashes considering that the 0.4.0 nlp library was loading them properly.\r\n\r\nTo check that you could try to run \r\n\r\n```python\r\nimport pyarrow as pa\r\nimport pyarrow.csv\r\n\r\nopen(\"dummy.txt\", \"w\").write(((\"a\" * 10_000) + \"\\n\") * 4) # 4 lines of 10 000 'a'\r\n\r\nparse_options = pa.csv.ParseOptions( \r\n delimiter=\"\\b\", \r\n quote_char=False, \r\n double_quote=False, \r\n escape_char=False, \r\n newlines_in_values=False, \r\n ignore_empty_lines=False, \r\n)\r\n\r\nread_options= pa.csv.ReadOptions(use_threads=True, column_names=[\"text\"])\r\n\r\npa_table = pa.csv.read_csv(\"dummy.txt\", read_options=read_options, parse_options=parse_options)\r\n```\r\n\r\non my side it runs without error though",
"That's true, It was my error printing the text that way. Maybe as a workaround, I can force all my input samples to have \"\\b\" at the end?",
"> That's true, It was my error printing the text that way. Maybe as a workaround, I can force all my input samples to have \"\\b\" at the end?\r\n\r\nI don't think it would work since we only want one column, and \"\\b\" is set to be the delimiter between two columns, so it will raise the same issue again. Pyarrow would think that there is more than one column if the delimiter is found somewhere.\r\n\r\nAnyway, I I'll work on a new text reader if we don't find the right workaround about this delimiter issue."
] |
https://api.github.com/repos/huggingface/datasets/issues/4547 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4547/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4547/comments | https://api.github.com/repos/huggingface/datasets/issues/4547/events | https://github.com/huggingface/datasets/pull/4547 | 1,282,160,517 | PR_kwDODunzps46Ot5u | 4,547 | [CI] Fix some warnings | [] | closed | false | null | 4 | 2022-06-23T10:10:49Z | 2022-06-28T14:10:57Z | 2022-06-28T13:59:54Z | null | There are some warnings in the CI that are annoying, I tried to remove most of them | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4547/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4547/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4547.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4547",
"merged_at": "2022-06-28T13:59:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4547.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4547"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"There is a CI failure only related to the missing content of the universal_dependencies dataset card, we can ignore this failure in this PR",
"good catch, I thought I resolved them all sorry",
"Alright it should be good now"
] |
https://api.github.com/repos/huggingface/datasets/issues/1282 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1282/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1282/comments | https://api.github.com/repos/huggingface/datasets/issues/1282/events | https://github.com/huggingface/datasets/pull/1282 | 759,208,335 | MDExOlB1bGxSZXF1ZXN0NTM0MjQ4NzI5 | 1,282 | add thaiqa_squad | [] | closed | false | null | 0 | 2020-12-08T08:14:38Z | 2020-12-08T18:36:18Z | 2020-12-08T18:36:18Z | null | Example format is a little different from SQuAD since `thaiqa` always have one answer per question so I added a check to convert answers to lists if they are not already one to future-proof additional questions that might have multiple answers.
`thaiqa_squad` is an open-domain, extractive question answering dataset (4,000 questions in `train` and 74 questions in `dev`) in [SQuAD](https://rajpurkar.github.io/SQuAD-explorer/) format, originally created by [NECTEC](https://www.nectec.or.th/en/) from Wikipedia articles and adapted to [SQuAD](https://rajpurkar.github.io/SQuAD-explorer/) format by [PyThaiNLP](https://github.com/PyThaiNLP/). | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1282/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1282/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1282.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1282",
"merged_at": "2020-12-08T18:36:18Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1282.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1282"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5365 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5365/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5365/comments | https://api.github.com/repos/huggingface/datasets/issues/5365/events | https://github.com/huggingface/datasets/pull/5365 | 1,498,422,466 | PR_kwDODunzps5Fi6ZD | 5,365 | fix: image array should support other formats than uint8 | [] | closed | false | null | 4 | 2022-12-15T13:17:50Z | 2023-01-26T18:46:45Z | 2023-01-26T18:39:36Z | null | Currently images that are provided as ndarrays, but not in `uint8` format are going to loose data. Namely, for example in a depth image where the data is in float32 format, the type-casting to uint8 will basically make the whole image blank.
`PIL.Image.fromarray` [does support mode `F`](https://pillow.readthedocs.io/en/stable/handbook/concepts.html#concept-modes).
although maybe some further metadata could be supplied via the [Image](https://huggingface.co/docs/datasets/v2.7.1/en/package_reference/main_classes#datasets.Image) object. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5365/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5365/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5365.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5365",
"merged_at": "2023-01-26T18:39:36Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5365.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5365"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Hi, thanks for working on this! \r\n\r\nI agree that the current type-casting (always cast to `np.uint8` as Tensorflow Datasets does) is a bit too harsh. However, not all dtypes are supported in `Image.fromarray` (e.g. np.int64), so we need to treat these with special care (e.g. downcast to the closest supported dtype, maybe with warnings to let the user know what's happening).\r\n\r\nPS: To avoid the CI failures, we need to handle two more instances of the cast to `np.uint8` (both are in the `image.py` file).",
"I've made some changes to the PR.\r\n\r\nNow the encoding procedure behaves as follows:\r\n* for multi-channel arrays: if their dtype is `int`/`uint`, cast to np.uint8 (the only supported dtype for multi-channel arrays), throw an error otherwise\r\n* if the array dtype is of valid kind (\"u\", \"i\", \"f\", ...):\r\n * don't do anything if Pillow natively supports it\r\n * otherwise, downcast until it becomes compatible with Pillow\r\n* raise an error if nothing from above is true",
"<details>\n<summary>Show benchmarks</summary>\n\nPyArrow==6.0.0\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.009537 / 0.011353 (-0.001816) | 0.004946 / 0.011008 (-0.006062) | 0.100552 / 0.038508 (0.062043) | 0.035119 / 0.023109 (0.012009) | 0.295989 / 0.275898 (0.020091) | 0.361326 / 0.323480 (0.037846) | 0.007608 / 0.007986 (-0.000378) | 0.004151 / 0.004328 (-0.000177) | 0.077301 / 0.004250 (0.073050) | 0.042921 / 0.037052 (0.005869) | 0.304804 / 0.258489 (0.046315) | 0.345934 / 0.293841 (0.052093) | 0.038987 / 0.128546 (-0.089559) | 0.012055 / 0.075646 (-0.063591) | 0.334035 / 0.419271 (-0.085236) | 0.052679 / 0.043533 (0.009146) | 0.291700 / 0.255139 (0.036561) | 0.335423 / 0.283200 (0.052223) | 0.107002 / 0.141683 (-0.034680) | 1.516780 / 1.452155 (0.064625) | 1.514137 / 1.492716 (0.021420) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.014719 / 0.018006 (-0.003287) | 0.545251 / 0.000490 (0.544761) | 0.004719 / 0.000200 (0.004519) | 0.000275 / 0.000054 (0.000220) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.026633 / 0.037411 (-0.010779) | 0.106911 / 0.014526 (0.092385) | 0.120258 / 0.176557 (-0.056299) | 0.156196 / 0.737135 (-0.580940) | 0.123132 / 0.296338 (-0.173207) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.398018 / 0.215209 (0.182809) | 3.973992 / 2.077655 (1.896337) | 1.776436 / 1.504120 (0.272316) | 1.579036 / 1.541195 (0.037841) | 1.643345 / 1.468490 (0.174855) | 0.692408 / 4.584777 (-3.892369) | 3.757243 / 3.745712 (0.011531) | 3.226212 / 5.269862 (-2.043649) | 1.797845 / 4.565676 (-2.767831) | 0.085878 / 0.424275 (-0.338398) | 0.012451 / 0.007607 (0.004844) | 0.509755 / 0.226044 (0.283711) | 5.029035 / 2.268929 (2.760107) | 2.255507 / 55.444624 (-53.189117) | 1.892868 / 6.876477 (-4.983609) | 1.900017 / 2.142072 (-0.242055) | 0.853965 / 4.805227 (-3.951263) | 0.167268 / 6.500664 (-6.333396) | 0.062796 / 0.075469 (-0.012673) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.183361 / 1.841788 (-0.658427) | 15.103797 / 8.074308 (7.029489) | 14.112931 / 10.191392 (3.921539) | 0.167234 / 0.680424 (-0.513190) | 0.029487 / 0.534201 (-0.504713) | 0.444121 / 0.579283 (-0.135162) | 0.437821 / 0.434364 (0.003457) | 0.544900 / 0.540337 (0.004562) | 0.642142 / 1.386936 (-0.744794) |\n\n</details>\nPyArrow==latest\n\n<details>\n<summary>Show updated benchmarks!</summary>\n\n### Benchmark: benchmark_array_xd.json\n\n| metric | read_batch_formatted_as_numpy after write_array2d | read_batch_formatted_as_numpy after write_flattened_sequence | read_batch_formatted_as_numpy after write_nested_sequence | read_batch_unformated after write_array2d | read_batch_unformated after write_flattened_sequence | read_batch_unformated after write_nested_sequence | read_col_formatted_as_numpy after write_array2d | read_col_formatted_as_numpy after write_flattened_sequence | read_col_formatted_as_numpy after write_nested_sequence | read_col_unformated after write_array2d | read_col_unformated after write_flattened_sequence | read_col_unformated after write_nested_sequence | read_formatted_as_numpy after write_array2d | read_formatted_as_numpy after write_flattened_sequence | read_formatted_as_numpy after write_nested_sequence | read_unformated after write_array2d | read_unformated after write_flattened_sequence | read_unformated after write_nested_sequence | write_array2d | write_flattened_sequence | write_nested_sequence |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.007078 / 0.011353 (-0.004275) | 0.004983 / 0.011008 (-0.006026) | 0.097106 / 0.038508 (0.058598) | 0.033747 / 0.023109 (0.010637) | 0.382030 / 0.275898 (0.106132) | 0.410193 / 0.323480 (0.086713) | 0.006658 / 0.007986 (-0.001327) | 0.005358 / 0.004328 (0.001029) | 0.073878 / 0.004250 (0.069628) | 0.049292 / 0.037052 (0.012240) | 0.384053 / 0.258489 (0.125564) | 0.427826 / 0.293841 (0.133985) | 0.036780 / 0.128546 (-0.091766) | 0.012469 / 0.075646 (-0.063178) | 0.332989 / 0.419271 (-0.086283) | 0.059531 / 0.043533 (0.015998) | 0.378431 / 0.255139 (0.123292) | 0.402672 / 0.283200 (0.119473) | 0.110782 / 0.141683 (-0.030901) | 1.484570 / 1.452155 (0.032416) | 1.608081 / 1.492716 (0.115365) |\n\n### Benchmark: benchmark_getitem\\_100B.json\n\n| metric | get_batch_of\\_1024\\_random_rows | get_batch_of\\_1024\\_rows | get_first_row | get_last_row |\n|--------|---|---|---|---|\n| new / old (diff) | 0.232356 / 0.018006 (0.214350) | 0.545648 / 0.000490 (0.545158) | 0.003113 / 0.000200 (0.002913) | 0.000089 / 0.000054 (0.000035) |\n\n### Benchmark: benchmark_indices_mapping.json\n\n| metric | select | shard | shuffle | sort | train_test_split |\n|--------|---|---|---|---|---|\n| new / old (diff) | 0.028138 / 0.037411 (-0.009273) | 0.110786 / 0.014526 (0.096260) | 0.123615 / 0.176557 (-0.052941) | 0.165773 / 0.737135 (-0.571362) | 0.126401 / 0.296338 (-0.169937) |\n\n### Benchmark: benchmark_iterating.json\n\n| metric | read 5000 | read 50000 | read_batch 50000 10 | read_batch 50000 100 | read_batch 50000 1000 | read_formatted numpy 5000 | read_formatted pandas 5000 | read_formatted tensorflow 5000 | read_formatted torch 5000 | read_formatted_batch numpy 5000 10 | read_formatted_batch numpy 5000 1000 | shuffled read 5000 | shuffled read 50000 | shuffled read_batch 50000 10 | shuffled read_batch 50000 100 | shuffled read_batch 50000 1000 | shuffled read_formatted numpy 5000 | shuffled read_formatted_batch numpy 5000 10 | shuffled read_formatted_batch numpy 5000 1000 |\n|--------|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 0.440518 / 0.215209 (0.225309) | 4.393821 / 2.077655 (2.316166) | 2.295479 / 1.504120 (0.791359) | 2.116679 / 1.541195 (0.575485) | 2.215561 / 1.468490 (0.747071) | 0.722343 / 4.584777 (-3.862434) | 3.783360 / 3.745712 (0.037647) | 3.302242 / 5.269862 (-1.967620) | 1.681535 / 4.565676 (-2.884142) | 0.085738 / 0.424275 (-0.338537) | 0.012373 / 0.007607 (0.004766) | 0.540499 / 0.226044 (0.314455) | 5.384915 / 2.268929 (3.115986) | 2.766346 / 55.444624 (-52.678279) | 2.451994 / 6.876477 (-4.424483) | 2.505720 / 2.142072 (0.363647) | 0.833006 / 4.805227 (-3.972221) | 0.168206 / 6.500664 (-6.332458) | 0.064971 / 0.075469 (-0.010498) |\n\n### Benchmark: benchmark_map_filter.json\n\n| metric | filter | map fast-tokenizer batched | map identity | map identity batched | map no-op batched | map no-op batched numpy | map no-op batched pandas | map no-op batched pytorch | map no-op batched tensorflow |\n|--------|---|---|---|---|---|---|---|---|---|\n| new / old (diff) | 1.253499 / 1.841788 (-0.588289) | 15.381840 / 8.074308 (7.307532) | 13.519493 / 10.191392 (3.328101) | 0.165559 / 0.680424 (-0.514865) | 0.017682 / 0.534201 (-0.516519) | 0.422248 / 0.579283 (-0.157035) | 0.422750 / 0.434364 (-0.011614) | 0.524546 / 0.540337 (-0.015792) | 0.626956 / 1.386936 (-0.759980) |\n\n</details>\n</details>\n\n\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/4185 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4185/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4185/comments | https://api.github.com/repos/huggingface/datasets/issues/4185/events | https://github.com/huggingface/datasets/issues/4185 | 1,209,429,743 | I_kwDODunzps5IFm7v | 4,185 | Librispeech documentation, clarification on format | [] | open | false | null | 8 | 2022-04-20T09:35:55Z | 2022-04-21T11:00:53Z | null | null | https://github.com/huggingface/datasets/blob/cd3ce34ab1604118351e1978d26402de57188901/datasets/librispeech_asr/librispeech_asr.py#L53
> Note that in order to limit the required storage for preparing this dataset, the audio
> is stored in the .flac format and is not converted to a float32 array. To convert, the audio
> file to a float32 array, please make use of the `.map()` function as follows:
>
> ```python
> import soundfile as sf
> def map_to_array(batch):
> speech_array, _ = sf.read(batch["file"])
> batch["speech"] = speech_array
> return batch
> dataset = dataset.map(map_to_array, remove_columns=["file"])
> ```
Is this still true?
In my case, `ds["train.100"]` returns:
```
Dataset({
features: ['file', 'audio', 'text', 'speaker_id', 'chapter_id', 'id'],
num_rows: 28539
})
```
and taking the first instance yields:
```
{'file': '374-180298-0000.flac',
'audio': {'path': '374-180298-0000.flac',
'array': array([ 7.01904297e-04, 7.32421875e-04, 7.32421875e-04, ...,
-2.74658203e-04, -1.83105469e-04, -3.05175781e-05]),
'sampling_rate': 16000},
'text': 'CHAPTER SIXTEEN I MIGHT HAVE TOLD YOU OF THE BEGINNING OF THIS LIAISON IN A FEW LINES BUT I WANTED YOU TO SEE EVERY STEP BY WHICH WE CAME I TO AGREE TO WHATEVER MARGUERITE WISHED',
'speaker_id': 374,
'chapter_id': 180298,
'id': '374-180298-0000'}
```
The `audio` `array` seems to be already decoded. So such convert/decode code as mentioned in the doc is wrong?
But I wonder, is it actually stored as flac on disk, and the decoding is done on-the-fly? Or was it decoded already during the preparation and is stored as raw samples on disk?
Note that I also used `datasets.load_dataset("librispeech_asr", "clean").save_to_disk(...)` and then `datasets.load_from_disk(...)` in this example. Does this change anything on how it is stored on disk?
A small related question: Actually I would prefer to even store it as mp3 or ogg on disk. Is this easy to convert? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4185/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4185/timeline | null | null | null | null | false | [
"(@patrickvonplaten )",
"Also cc @lhoestq here",
"The documentation in the code is definitely outdated - thanks for letting me know, I'll remove it in https://github.com/huggingface/datasets/pull/4184 .\r\n\r\nYou're exactly right `audio` `array` already decodes the audio file to the correct waveform. This is done on the fly, which is also why one should **not** do `ds[\"audio\"][\"array\"][0]` as this will decode all dataset samples, but instead `ds[0][\"audio\"][\"array\"]` see: https://huggingface.co/docs/datasets/audio_process#audio-datasets\r\n\r\n",
"So, again to clarify: On disk, only the raw flac file content is stored? Is this also the case after `save_to_disk`?\r\n\r\nAnd is it simple to also store it re-encoded as ogg or mp3 instead?\r\n",
"Hey, \r\n\r\nSorry yeah I was just about to look into this! We actually had an outdated version of Librispeech ASR that didn't save any files, but instead converted the audio files to a byte string, then was then decoded on-the-fly. This however is not very user-friendly so we recently decided to instead show the full path of the audio files with the `path` parameter.\r\n\r\nI'm currently changing this for Librispeech here: https://github.com/huggingface/datasets/pull/4184 .\r\nYou should be able to see the audio file in the original `flac` format under `path` then. I don't think it's a good idea to convert to MP3 out-of-the-box, but we could maybe think about some kind of convert function for audio datasets cc @lhoestq ? ",
"> I don't think it's a good idea to convert to MP3 out-of-the-box, but we could maybe think about some kind of convert function for audio datasets cc @lhoestq ?\r\n\r\nSure, I would expect that `load_dataset(\"librispeech_asr\")` would give you the original (not re-encoded) data (flac or already decoded). So such re-encoding logic would be some separate generic function. So I could do sth like `dataset.reencode_as_ogg(**ogg_encode_opts).save_to_disk(...)` or so.\r\n",
"A follow-up question: I wonder whether a Parquet dataset is maybe more what we actually want to have? (Following also my comment here: https://github.com/huggingface/datasets/pull/4184#issuecomment-1105045491.) Because I think we actually would prefer to embed the data content in the dataset.\r\n\r\nSo, instead of `save_to_disk`/`load_from_disk`, we would use `to_parquet`,`from_parquet`? Is there any downside? Are arrow files more efficient?\r\n\r\nRelated is also the doc update in #4193.\r\n",
"`save_to_disk` saves the dataset as an Arrow file, which is the format we use to load a dataset using memory mapping. This way the dataset does not fill your RAM, but is read from your disk instead.\r\n\r\nTherefore you can directly reload a dataset saved with `save_to_disk` using `load_from_disk`.\r\n\r\nParquet files are used for cold storage: to use memory mapping on a Parquet dataset, you first have to convert it to Arrow. We use Parquet to reduce the I/O when pushing/downloading data from the Hugging face Hub. When you load a Parquet file from the Hub, it is converted to Arrow on the fly during the download."
] |
https://api.github.com/repos/huggingface/datasets/issues/3754 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3754/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3754/comments | https://api.github.com/repos/huggingface/datasets/issues/3754/events | https://github.com/huggingface/datasets/issues/3754 | 1,142,886,536 | I_kwDODunzps5EHxCI | 3,754 | Overflowing indices in `select` | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 2 | 2022-02-18T11:30:52Z | 2022-02-18T11:38:23Z | 2022-02-18T11:38:23Z | null | ## Describe the bug
The `Dataset.select` function seems to accept indices that are larger than the dataset size and seems to effectively use `index %len(ds)`.
## Steps to reproduce the bug
```python
from datasets import Dataset
ds = Dataset.from_dict({"test": [1,2,3]})
ds = ds.select(range(5))
print(ds)
print()
print(ds["test"])
```
Result:
```python
Dataset({
features: ['test'],
num_rows: 5
})
[1, 2, 3, 1, 2]
```
This behaviour is not documented and can lead to unexpected behaviour when for example taking a sample larger than the dataset and thus creating a lot of duplicates.
## Expected results
It think this should throw an error or at least a very big warning:
```python
IndexError: Invalid key: 5 is out of bounds for size 3
```
## Environment info
- `datasets` version: 1.18.3
- Platform: macOS-12.0.1-x86_64-i386-64bit
- Python version: 3.9.10
- PyArrow version: 7.0.0 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3754/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3754/timeline | null | completed | null | null | false | [
"Fixed on master (see https://github.com/huggingface/datasets/pull/3719).",
"Awesome, I did not find that one! Thanks."
] |
https://api.github.com/repos/huggingface/datasets/issues/4045 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4045/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4045/comments | https://api.github.com/repos/huggingface/datasets/issues/4045/events | https://github.com/huggingface/datasets/pull/4045 | 1,183,661,091 | PR_kwDODunzps41KtfV | 4,045 | Fix CLI dummy data generation | [] | closed | false | null | 1 | 2022-03-28T16:09:15Z | 2022-03-31T15:04:12Z | 2022-03-31T14:59:06Z | null | PR:
- #3868
broke the CLI dummy data generation.
Fix #4044. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4045/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4045/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4045.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4045",
"merged_at": "2022-03-31T14:59:06Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4045.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4045"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5130 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5130/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5130/comments | https://api.github.com/repos/huggingface/datasets/issues/5130/events | https://github.com/huggingface/datasets/pull/5130 | 1,413,435,000 | PR_kwDODunzps5BBxXX | 5,130 | Avoid extra cast in `class_encode_column` | [] | closed | false | null | 1 | 2022-10-18T15:31:24Z | 2022-10-19T11:53:02Z | 2022-10-19T11:50:46Z | null | Pass the updated features to `map` to avoid the `cast` in `class_encode_column`. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5130/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5130/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5130.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5130",
"merged_at": "2022-10-19T11:50:46Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5130.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5130"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/2027 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2027/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2027/comments | https://api.github.com/repos/huggingface/datasets/issues/2027/events | https://github.com/huggingface/datasets/pull/2027 | 828,490,444 | MDExOlB1bGxSZXF1ZXN0NTkwMjkzNDA1 | 2,027 | Update format columns in Dataset.rename_columns | [] | closed | false | null | 0 | 2021-03-10T23:50:59Z | 2021-03-11T14:38:40Z | 2021-03-11T14:38:40Z | null | Fixes #2026 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2027/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2027/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2027.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2027",
"merged_at": "2021-03-11T14:38:40Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2027.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2027"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3104 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3104/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3104/comments | https://api.github.com/repos/huggingface/datasets/issues/3104/events | https://github.com/huggingface/datasets/issues/3104 | 1,029,080,412 | I_kwDODunzps49VoVc | 3,104 | Missing Zenodo 1.13.3 release | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 1 | 2021-10-18T12:57:18Z | 2021-10-22T13:22:25Z | 2021-10-22T13:22:24Z | null | After `datasets` 1.13.3 release, this does not appear in Zenodo releases: https://zenodo.org/record/5570305
TODO:
- [x] Contact Zenodo support
- [x] Check it is fixed | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3104/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3104/timeline | null | completed | null | null | false | [
"Zenodo has fixed on their side the 1.13.3 release: https://zenodo.org/record/5589150"
] |
https://api.github.com/repos/huggingface/datasets/issues/455 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/455/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/455/comments | https://api.github.com/repos/huggingface/datasets/issues/455/events | https://github.com/huggingface/datasets/pull/455 | 668,037,965 | MDExOlB1bGxSZXF1ZXN0NDU4NTk4NTUw | 455 | Add bleurt | [] | closed | false | null | 4 | 2020-07-29T18:08:32Z | 2020-07-31T13:56:14Z | 2020-07-31T13:56:14Z | null | This PR adds the BLEURT metric to the library.
The BLEURT `Metric` downloads a TF checkpoint corresponding to its `config_name` at creation (in the `_info` function). Default is set to `bleurt-base-128`.
Note that the default in the original package is `bleurt-tiny-128`, but they throw a warning and recommend using `bleurt-base-128` instead. I think it's safer to have our users have a functioning metric when they call the default behavior, we'll address discrepancies in the issues/discussions if it comes up.
In addition to the BLEURT file, `load.py` was changed so we can ask users to pip install the required packages from git when they have a `setup.py` but are not on PyPL
cc @ankparikh @tsellam | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/455/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/455/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/455.diff",
"html_url": "https://github.com/huggingface/datasets/pull/455",
"merged_at": "2020-07-31T13:56:14Z",
"patch_url": "https://github.com/huggingface/datasets/pull/455.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/455"
} | true | [
"Sorry one nit: Could we use named arguments for the call to BLEURT?\r\n\r\ni.e. \r\n scores = self.scorer.score(references=references, candidates=predictions)\r\n\r\n(i.e. so it is less bug prone)\r\n",
"Following up on Ankur's comment---we are going to drop support for\npositional (not named) arguments in the future releases because it seems to\ncause bugs and confusion. I hope it doesn't create too much of a mess.\n\nLe jeu. 30 juil. 2020 à 10:44, ankparikh <[email protected]> a\nécrit :\n\n> Sorry one nit: Could we use named arguments for the call to BLEURT?\n>\n> i.e.\n> scores = self.scorer.score(references=references, candidates=predictions)\n>\n> (i.e. so it is less bug prone)\n>\n> —\n> You are receiving this because you were mentioned.\n> Reply to this email directly, view it on GitHub\n> <https://github.com/huggingface/nlp/pull/455#issuecomment-666414514>, or\n> unsubscribe\n> <https://github.com/notifications/unsubscribe-auth/ABTMRNGAN2PMECS5K4DIHJDR6GBMLANCNFSM4PL323FA>\n> .\n>\n",
"> Following up on Ankur's comment---we are going to drop support for positional (not named) arguments in the future releases because it seems to cause bugs and confusion. I hope it doesn't create too much of a mess. Le jeu. 30 juil. 2020 à 10:44, ankparikh <[email protected]> a écrit :\r\n> […](#)\r\n> Sorry one nit: Could we use named arguments for the call to BLEURT? i.e. scores = self.scorer.score(references=references, candidates=predictions) (i.e. so it is less bug prone) — You are receiving this because you were mentioned. Reply to this email directly, view it on GitHub <[#455 (comment)](https://github.com/huggingface/nlp/pull/455#issuecomment-666414514)>, or unsubscribe <https://github.com/notifications/unsubscribe-auth/ABTMRNGAN2PMECS5K4DIHJDR6GBMLANCNFSM4PL323FA> .\r\n\r\nChanged @ankparikh @tsellam, thanks for taking a look!",
"We should avoid positional arguments in metrics on our side as well. It's a dangerous source of errors indeed."
] |
https://api.github.com/repos/huggingface/datasets/issues/4668 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4668/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4668/comments | https://api.github.com/repos/huggingface/datasets/issues/4668/events | https://github.com/huggingface/datasets/issues/4668 | 1,299,735,893 | I_kwDODunzps5NeGVV | 4,668 | Dataset Viewer issue for hungnm/multilingual-amazon-review-sentiment-processed | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | 1 | 2022-07-09T18:04:13Z | 2022-07-11T07:47:47Z | 2022-07-11T07:47:47Z | null | ### Link
https://huggingface.co/hungnm/multilingual-amazon-review-sentiment
### Description
_No response_
### Owner
Yes | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4668/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4668/timeline | null | completed | null | null | false | [
"It seems like a private dataset. The viewer is currently not supported on the private datasets."
] |
https://api.github.com/repos/huggingface/datasets/issues/3622 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3622/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3622/comments | https://api.github.com/repos/huggingface/datasets/issues/3622/events | https://github.com/huggingface/datasets/issues/3622 | 1,112,831,661 | I_kwDODunzps5CVHat | 3,622 | Extend support for streaming datasets that use os.path.relpath | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 0 | 2022-01-24T15:58:23Z | 2022-02-04T14:03:54Z | 2022-02-04T14:03:54Z | null | Extend support for streaming datasets that use `os.path.relpath`.
This feature will also be useful to yield the relative path of audio or image files.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3622/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3622/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/1413 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1413/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1413/comments | https://api.github.com/repos/huggingface/datasets/issues/1413/events | https://github.com/huggingface/datasets/pull/1413 | 760,615,090 | MDExOlB1bGxSZXF1ZXN0NTM1NDE4MDY2 | 1,413 | Add OffComBR | [] | closed | false | null | 3 | 2020-12-09T19:38:08Z | 2020-12-14T18:06:45Z | 2020-12-14T16:51:10Z | null | Add [OffComBR](https://github.com/rogersdepelle/OffComBR) from [Offensive Comments in the Brazilian Web: a dataset and baseline results](https://sol.sbc.org.br/index.php/brasnam/article/view/3260/3222) paper.
But I'm having a hard time generating dummy data since the original dataset extion is `.arff` and the [_create_dummy_data function](https://github.com/huggingface/datasets/blob/a4aeaf911240057286a01bff1b1d75a89aedd57b/src/datasets/commands/dummy_data.py#L185) doesn't allow it. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1413/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1413/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1413.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1413",
"merged_at": "2020-12-14T16:51:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1413.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1413"
} | true | [
"Hello @hugoabonizio, thanks for the contribution.\r\nRegarding the fake data, you can generate it manually.\r\nRunning the `python datasets-cli dummy_data datasets/offcombr` should give you instructions on how to manually create the dummy data.\r\nFor reference, here is a spec for `.arff` files : https://www.cs.waikato.ac.nz/ml/weka/arff.html",
"@lhoestq again the failing tests doesn't seem to be related",
"merging since the CI is fixed on master"
] |
https://api.github.com/repos/huggingface/datasets/issues/4100 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4100/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4100/comments | https://api.github.com/repos/huggingface/datasets/issues/4100/events | https://github.com/huggingface/datasets/pull/4100 | 1,193,393,959 | PR_kwDODunzps41q4ce | 4,100 | Improve RedCaps dataset card | [] | closed | false | null | 2 | 2022-04-05T15:57:14Z | 2022-04-13T14:08:54Z | 2022-04-13T14:02:26Z | null | This PR modifies the RedCaps card to:
* fix the formatting of the Point of Contact fields on the Hub
* speed up the image fetching logic (aligns it with the [img2dataset](https://github.com/rom1504/img2dataset) tool) and make it more robust (return None if **any** exception is thrown) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4100/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4100/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4100.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4100",
"merged_at": "2022-04-13T14:02:26Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4100.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4100"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I find this preprocessing a bit too specific to add it as a method to `datasets` as it's only useful in the context of CV (and we support multiple modalities). However, I agree it would be great to move this code to another lib to avoid code duplication. Maybe we should create a package with preprocessing functions/transforms for this purpose?"
] |
https://api.github.com/repos/huggingface/datasets/issues/1722 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1722/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1722/comments | https://api.github.com/repos/huggingface/datasets/issues/1722/events | https://github.com/huggingface/datasets/pull/1722 | 783,921,679 | MDExOlB1bGxSZXF1ZXN0NTUzMTk3MTg4 | 1,722 | Added unfiltered versions of the Wiki-Auto training data for the GEM simplification task. | [] | closed | false | null | 1 | 2021-01-12T05:26:04Z | 2021-01-12T18:14:53Z | 2021-01-12T17:35:57Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1722/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1722/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1722.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1722",
"merged_at": "2021-01-12T17:35:57Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1722.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1722"
} | true | [
"The current version of Wiki-Auto dataset contains a filtered version of the aligned dataset. The commit adds unfiltered versions of the data that can be useful the GEM task participants."
] |
|
https://api.github.com/repos/huggingface/datasets/issues/3580 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3580/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3580/comments | https://api.github.com/repos/huggingface/datasets/issues/3580/events | https://github.com/huggingface/datasets/issues/3580 | 1,104,663,242 | I_kwDODunzps5B19LK | 3,580 | Bug in wiki bio load | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | null | 4 | 2022-01-15T10:04:33Z | 2022-01-31T08:38:09Z | 2022-01-31T08:38:09Z | null |
wiki_bio is failing to load because of a failing drive link . Can someone fix this ?
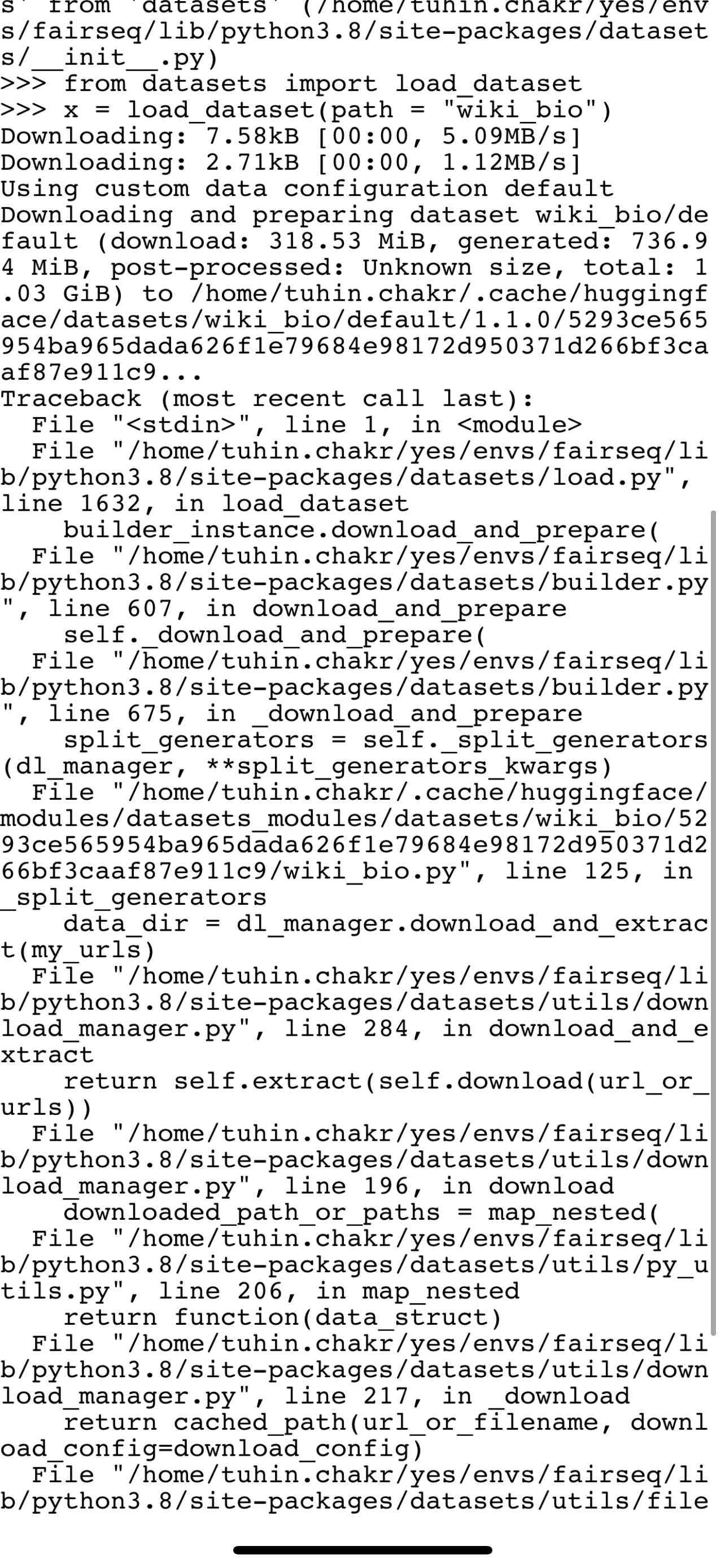
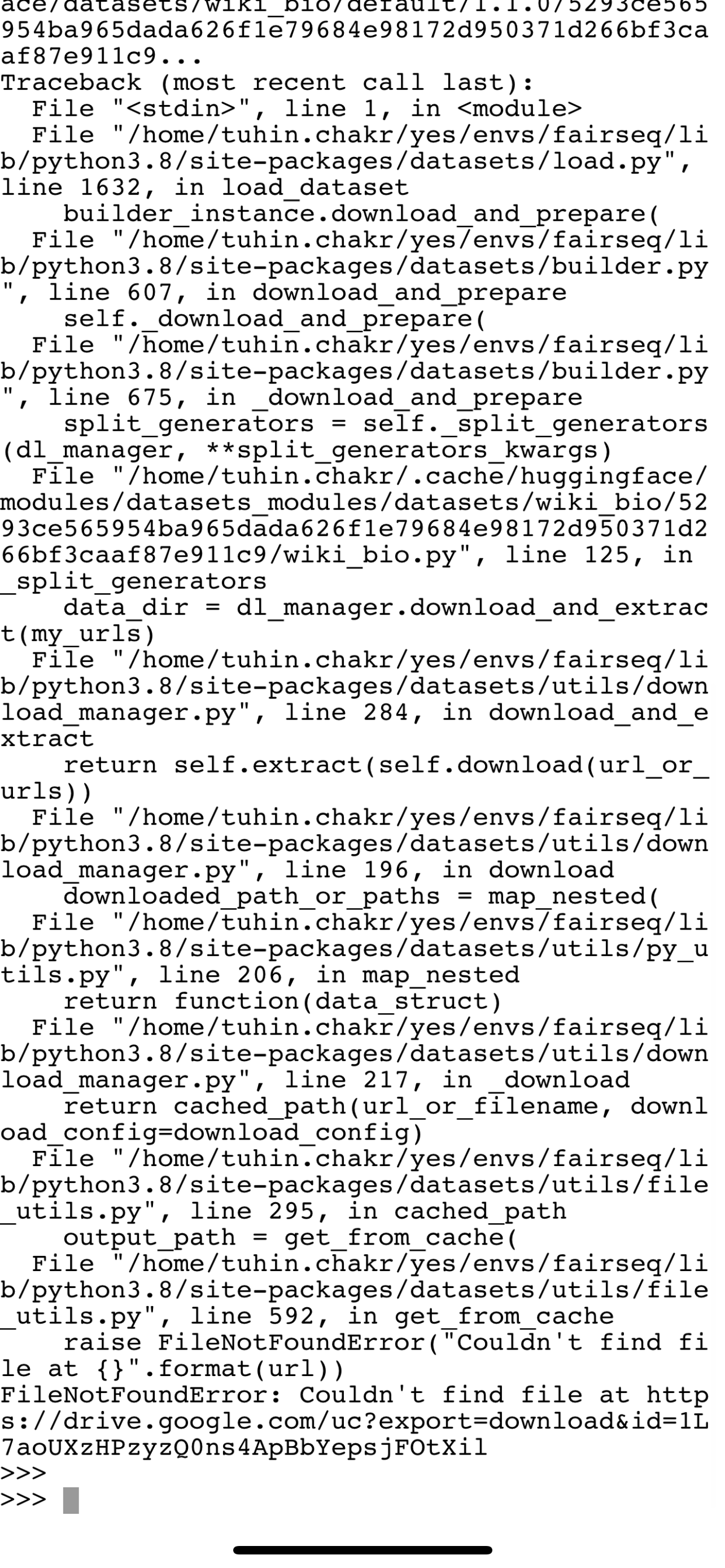
a | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3580/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3580/timeline | null | completed | null | null | false | [
"+1, here's the error I got: \r\n\r\n```\r\n>>> from datasets import load_dataset\r\n>>>\r\n>>> load_dataset(\"wiki_bio\")\r\nDownloading: 7.58kB [00:00, 4.42MB/s]\r\nDownloading: 2.71kB [00:00, 1.30MB/s]\r\nUsing custom data configuration default\r\nDownloading and preparing dataset wiki_bio/default (download: 318.53 MiB, generated: 736.94 MiB, post-processed: Unknown size, total: 1.03 GiB) to /home/jxm3/.cache/huggingface/datasets/wiki_bio/default/1.1.0/5293ce565954ba965dada626f1e79684e98172d950371d266bf3caaf87e911c9...\r\nTraceback (most recent call last):\r\n File \"<stdin>\", line 1, in <module>\r\n File \"/home/jxm3/.conda/envs/torch/lib/python3.9/site-packages/datasets/load.py\", line 1694, in load_dataset\r\n builder_instance.download_and_prepare(\r\n File \"/home/jxm3/.conda/envs/torch/lib/python3.9/site-packages/datasets/builder.py\", line 595, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/home/jxm3/.conda/envs/torch/lib/python3.9/site-packages/datasets/builder.py\", line 662, in _download_and_prepare\r\n split_generators = self._split_generators(dl_manager, **split_generators_kwargs)\r\n File \"/home/jxm3/.cache/huggingface/modules/datasets_modules/datasets/wiki_bio/5293ce565954ba965dada626f1e79684e98172d950371d266bf3caaf87e911c9/wiki_bio.py\", line 125, in _split_generators\r\n data_dir = dl_manager.download_and_extract(my_urls)\r\n File \"/home/jxm3/.conda/envs/torch/lib/python3.9/site-packages/datasets/utils/download_manager.py\", line 308, in download_and_extract\r\n return self.extract(self.download(url_or_urls))\r\n File \"/home/jxm3/.conda/envs/torch/lib/python3.9/site-packages/datasets/utils/download_manager.py\", line 196, in download\r\n downloaded_path_or_paths = map_nested(\r\n File \"/home/jxm3/.conda/envs/torch/lib/python3.9/site-packages/datasets/utils/py_utils.py\", line 251, in map_nested\r\n return function(data_struct)\r\n File \"/home/jxm3/.conda/envs/torch/lib/python3.9/site-packages/datasets/utils/download_manager.py\", line 217, in _download\r\n return cached_path(url_or_filename, download_config=download_config)\r\n File \"/home/jxm3/.conda/envs/torch/lib/python3.9/site-packages/datasets/utils/file_utils.py\", line 298, in cached_path\r\n output_path = get_from_cache(\r\n File \"/home/jxm3/.conda/envs/torch/lib/python3.9/site-packages/datasets/utils/file_utils.py\", line 612, in get_from_cache\r\n raise FileNotFoundError(f\"Couldn't find file at {url}\")\r\nFileNotFoundError: Couldn't find file at https://drive.google.com/uc?export=download&id=1L7aoUXzHPzyzQ0ns4ApBbYepsjFOtXil\r\n>>>\r\n```\r\n",
"@alejandrocros and @lhoestq - you added the wiki_bio dataset in #1173. It doesn't work anymore. Can you take a look at this?",
"And if something is wrong with Google Drive, you could try to download (and collate and unzip) from here: https://github.com/DavidGrangier/wikipedia-biography-dataset",
"Hi ! Thanks for reporting. I've downloaded the data and concatenated them into a zip file available here: https://huggingface.co/datasets/wiki_bio/tree/main/data\r\n\r\nI guess we can update the dataset script to use this zip file now :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/4181 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4181/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4181/comments | https://api.github.com/repos/huggingface/datasets/issues/4181/events | https://github.com/huggingface/datasets/issues/4181 | 1,208,194,805 | I_kwDODunzps5IA5b1 | 4,181 | Support streaming FLEURS dataset | [
{
"color": "2edb81",
"default": false,
"description": "A bug in a dataset script provided in the library",
"id": 2067388877,
"name": "dataset bug",
"node_id": "MDU6TGFiZWwyMDY3Mzg4ODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20bug"
}
] | closed | false | null | 9 | 2022-04-19T11:09:56Z | 2022-07-25T11:44:02Z | 2022-07-25T11:44:02Z | null | ## Dataset viewer issue for '*name of the dataset*'
https://huggingface.co/datasets/google/fleurs
```
Status code: 400
Exception: NotImplementedError
Message: Extraction protocol for TAR archives like 'https://storage.googleapis.com/xtreme_translations/FLEURS/af_za.tar.gz' is not implemented in streaming mode. Please use `dl_manager.iter_archive` instead.
```
Am I the one who added this dataset ? Yes
Can I fix this somehow in the script? @lhoestq @severo
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4181/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4181/timeline | null | completed | null | null | false | [
"Yes, you just have to use `dl_manager.iter_archive` instead of `dl_manager.download_and_extract`.\r\n\r\nThat's because `download_and_extract` doesn't support TAR archives in streaming mode.",
"Tried to make it streamable, but I don't think it's really possible. @lhoestq @polinaeterna maybe you guys can check: \r\nhttps://huggingface.co/datasets/google/fleurs/commit/dcf80160cd77977490a8d32b370c027107f2407b \r\n\r\nreal quick. \r\n\r\nI think the problem is that we cannot ensure that the metadata file is found before the audio. Or is this possible somehow @lhoestq ? ",
"@patrickvonplaten I think the metadata file should be found first because the audio files are contained in a folder next to the metadata files (just as in common voice), so the metadata files should be \"on top of the list\" as they are closer to the root in the directories hierarchy ",
"@patrickvonplaten but apparently it doesn't... I don't really know why.",
"Yeah! Any ideas what could be the reason here? cc @lhoestq ?",
"The order of the files is determined when the TAR archive is created, depending on the commands the creator ran.\r\nIf the metadata file is not at the beginning of the file, that makes streaming completely inefficient. In this case the TAR archive needs to be recreated in an appropriate order.",
"Actually we could maybe just host the metadata file ourselves and then stream the audio data only. Don't think that this would be a problem for the FLEURS authors (I can ask them :-)) ",
"I made a PR to their repo to support streaming (by uploading the metadata file to the Hub). See:\r\n- https://huggingface.co/datasets/google/fleurs/discussions/4",
"I'm closing this issue as the PR above has been merged."
] |
https://api.github.com/repos/huggingface/datasets/issues/5963 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5963/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5963/comments | https://api.github.com/repos/huggingface/datasets/issues/5963/events | https://github.com/huggingface/datasets/issues/5963 | 1,762,774,457 | I_kwDODunzps5pEc25 | 5,963 | Got an error _pickle.PicklingError use Dataset.from_spark. | [] | closed | false | null | 5 | 2023-06-19T05:30:35Z | 2023-07-24T11:55:46Z | 2023-07-24T11:55:46Z | null | python 3.9.2
Got an error _pickle.PicklingError use Dataset.from_spark.
Did the dataset import load data from spark dataframe using multi-node Spark cluster
df = spark.read.parquet(args.input_data).repartition(50)
ds = Dataset.from_spark(df, keep_in_memory=True,
cache_dir="/pnc-data/data/nuplan/t5_spark/cache_data")
ds.save_to_disk(args.output_data)
Error :
_pickle.PicklingError: Could not serialize object: RuntimeError: It appears that you are attempting to reference SparkContext from a broadcast variable, action, or transforma
tion. SparkContext can only be used on the driver, not in code that it run on workers. For more information, see SPARK-5063.
23/06/16 21:17:20 WARN ExecutorPodsWatchSnapshotSource: Kubernetes client has been closed (this is expected if the application is shutting down.)
_Originally posted by @yanzia12138 in https://github.com/huggingface/datasets/issues/5701#issuecomment-1594674306_
W
Traceback (most recent call last):
File "/home/work/main.py", line 100, in <module>
run(args)
File "/home/work/main.py", line 80, in run
ds = Dataset.from_spark(df1, keep_in_memory=True,
File "/home/work/.local/lib/python3.9/site-packages/datasets/arrow_dataset.py", line 1281, in from_spark
return SparkDatasetReader(
File "/home/work/.local/lib/python3.9/site-packages/datasets/io/spark.py", line 53, in read
self.builder.download_and_prepare(
File "/home/work/.local/lib/python3.9/site-packages/datasets/builder.py", line 909, in download_and_prepare
self._download_and_prepare(
File "/home/work/.local/lib/python3.9/site-packages/datasets/builder.py", line 1004, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/work/.local/lib/python3.9/site-packages/datasets/packaged_modules/spark/spark.py", line 254, in _prepare_split
self._validate_cache_dir()
File "/home/work/.local/lib/python3.9/site-packages/datasets/packaged_modules/spark/spark.py", line 122, in _validate_cache_dir
self._spark.sparkContext.parallelize(range(1), 1).mapPartitions(create_cache_and_write_probe).collect()
File "/home/work/.local/lib/python3.9/site-packages/pyspark/rdd.py", line 950, in collect
sock_info = self.ctx._jvm.PythonRDD.collectAndServe(self._jrdd.rdd())
File "/home/work/.local/lib/python3.9/site-packages/pyspark/rdd.py", line 2951, in _jrdd
wrapped_func = _wrap_function(self.ctx, self.func, self._prev_jrdd_deserializer,
File "/home/work/.local/lib/python3.9/site-packages/pyspark/rdd.py", line 2830, in _wrap_function
pickled_command, broadcast_vars, env, includes = _prepare_for_python_RDD(sc, command)
File "/home/work/.local/lib/python3.9/site-packages/pyspark/rdd.py", line 2816, in _prepare_for_python_RDD
pickled_command = ser.dumps(command)
File "/home/work/.local/lib/python3.9/site-packages/pyspark/serializers.py", line 447, in dumps
raise pickle.PicklingError(msg)
_pickle.PicklingError: Could not serialize object: RuntimeError: It appears that you are attempting to reference SparkContext from a broadcast variable, action, or transformation. S
parkContext can only be used on the driver, not in code that it run on workers. For more information, see SPARK-5063.
23/06/19 13:51:21 WARN ExecutorPodsWatchSnapshotSource: Kubernetes client has been closed (this is expected if the application is shutting down.)
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5963/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5963/timeline | null | completed | null | null | false | [
"i got error using method from_spark when using multi-node Spark cluster. seems could only use \"from_spark\" in local?",
"@lhoestq ",
"cc @maddiedawson it looks like there an issue with `_validate_cache_dir` ?\r\n\r\nIt looks like the function passed to mapPartitions has a reference to the Spark dataset builder, and therefore contains the SparkContext itself.\r\n\r\nI think it can be fixed by defining `create_cache_and_write_probe` outside the Spark dataset builder, and pass a `partial(create_cache_and_write_probe, cache_dir=self._cache_dir)` to `mapPartitions`",
"Just saw this; thanks for flagging! Your proposed solution sounds good. I can prepare a PR",
"@maddiedawson can you show me the demo ,so i can test in local .before your PR"
] |
https://api.github.com/repos/huggingface/datasets/issues/5129 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5129/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5129/comments | https://api.github.com/repos/huggingface/datasets/issues/5129/events | https://github.com/huggingface/datasets/issues/5129 | 1,413,031,664 | I_kwDODunzps5UOSbw | 5,129 | unexpected `cast` or `class_encode_column` result after `rename_column` | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 4 | 2022-10-18T11:15:24Z | 2022-10-19T03:02:26Z | 2022-10-19T03:02:26Z | null | ## Describe the bug
When invoke `cast` or `class_encode_column` to a colunm renamed by `rename_column` , it will convert all the variables in this column into one variable. I also run this script in version 2.5.2, this bug does not appear. So I switched to the older version.
## Steps to reproduce the bug
```python
from datasets import load_dataset
dataset = load_dataset("amazon_reviews_multi", "en")
data = dataset['train']
data = data.remove_columns(
[
"review_id",
"product_id",
"reviewer_id",
"review_title",
"language",
"product_category",
]
)
data = data.rename_column("review_body", "text")
data1 = data.class_encode_column("stars")
print(set(data1.data.columns[0]))
# output: {<pyarrow.Int64Scalar: 4>, <pyarrow.Int64Scalar: 2>, <pyarrow.Int64Scalar: 3>, <pyarrow.Int64Scalar: 0>, <pyarrow.Int64Scalar: 1>}
data = data.rename_column("stars", "label")
print(set(data.data.columns[0]))
# output: {<pyarrow.Int32Scalar: 5>, <pyarrow.Int32Scalar: 4>, <pyarrow.Int32Scalar: 1>, <pyarrow.Int32Scalar: 3>, <pyarrow.Int32Scalar: 2>}
data2 = data.class_encode_column("label")
print(set(data2.data.columns[0]))
# output: {<pyarrow.Int64Scalar: 0>}
```
## Expected results
the last print should be:
{<pyarrow.Int64Scalar: 4>, <pyarrow.Int64Scalar: 2>, <pyarrow.Int64Scalar: 3>, <pyarrow.Int64Scalar: 0>, <pyarrow.Int64Scalar: 1>}
## Actual results
but it output:
{<pyarrow.Int64Scalar: 0>}
## Environment info
- `datasets` version: 2.6.1
- Platform: macOS-12.5.1-arm64-arm-64bit
- Python version: 3.10.6
- PyArrow version: 9.0.0
- Pandas version: 1.5.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5129/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5129/timeline | null | completed | null | null | false | [
"Hi! Unfortunately, I can't reproduce this issue locally (in Python 3.7/3.10) or in Colab. I would assume this is due to a bug we fixed in the latest release, but your version is up-to-date, so I'm not sure if there is something we can do to help...",
"Hi, 方子东. I tried running the code with exact the same configuration (both datasets 2.5.2 and 2.6.1, python, pyarrow, pandas), but on Linux. The results seem to be the expected `{<pyarrow.Int64Scalar: 4>, <pyarrow.Int64Scalar: 2>, <pyarrow.Int64Scalar: 3>, <pyarrow.Int64Scalar: 0>, <pyarrow.Int64Scalar: 1>}`.\r\nI don't have a Mac device. I can't verify whether this is a M1 chip-specific problem.",
"I've just tested the code on my M1 Mac, and it behaves as expected.",
"> Hi! Unfortunately, I can't reproduce this issue locally (in Python 3.7/3.10) or in Colab. I would assume this is due to a bug we fixed in the latest release, but your version is up-to-date, so I'm not sure if there is something we can do to help...\r\n\r\nThank you for your attention and feel sorry to take your time. Since this is a bug of old version, I think mybe my problem is because `cast` operation directaly used cached data generated by older verion of `datasets`. I tried to deleted the cached data and I got expected result.\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/4736 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4736/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4736/comments | https://api.github.com/repos/huggingface/datasets/issues/4736/events | https://github.com/huggingface/datasets/issues/4736 | 1,314,931,996 | I_kwDODunzps5OYEUc | 4,736 | Dataset Viewer issue for deepklarity/huggingface-spaces-dataset | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | 1 | 2022-07-22T12:14:18Z | 2022-07-22T13:46:38Z | 2022-07-22T13:46:38Z | null | ### Link
https://huggingface.co/datasets/deepklarity/huggingface-spaces-dataset/viewer/deepklarity--huggingface-spaces-dataset/train
### Description
Hi Team,
I'm getting the following error on a uploaded dataset. I'm getting the same status for a couple of hours now. The dataset size is `<1MB` and the format is csv, so I'm not sure if it's supposed to take this much time or not.
```
Status code: 400
Exception: Status400Error
Message: The split is being processed. Retry later.
```
Is there any explicit step to be taken to get the viewer to work?
### Owner
Yes | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4736/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4736/timeline | null | completed | null | null | false | [
"Thanks for reporting. You're right, workers were under-provisioned due to a manual error, and the job queue was full. It's fixed now."
] |
https://api.github.com/repos/huggingface/datasets/issues/3738 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3738/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3738/comments | https://api.github.com/repos/huggingface/datasets/issues/3738/events | https://github.com/huggingface/datasets/issues/3738 | 1,140,164,253 | I_kwDODunzps5D9Yad | 3,738 | For data-only datasets, streaming and non-streaming don't behave the same | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | 9 | 2022-02-16T15:20:57Z | 2022-02-21T14:24:55Z | null | null | See https://huggingface.co/datasets/huggingface/transformers-metadata: it only contains two JSON files.
In streaming mode, the files are concatenated, and thus the rows might be dictionaries with different keys:
```python
import datasets as ds
iterable_dataset = ds.load_dataset("huggingface/transformers-metadata", split="train", streaming=True);
rows = list(iterable_dataset.take(100))
rows[0]
# {'model_type': 'albert', 'pytorch': True, 'tensorflow': True, 'flax': True, 'processor': 'AutoTokenizer'}
rows[99]
# {'model_class': 'BartModel', 'pipeline_tag': 'feature-extraction', 'auto_class': 'AutoModel'}
```
In normal mode, an exception is thrown:
```python
import datasets as ds
dataset = ds.load_dataset("huggingface/transformers-metadata", split="train");
```
```
ValueError: Couldn't cast
model_class: string
pipeline_tag: string
auto_class: string
to
{'model_type': Value(dtype='string', id=None), 'pytorch': Value(dtype='bool', id=None), 'tensorflow': Value(dtype='bool', id=None), 'flax': Value(dtype='bool', id=None), 'processor': Value(dtype='string', id=None)}
because column names don't match
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3738/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3738/timeline | null | null | null | null | false | [
"Note that we might change the heuristic and create a different config per file, at least in that case.",
"Hi @severo, thanks for reporting.\r\n\r\nYes, this happens because when non-streaming, a cast of all data is done in order to \"concatenate\" it all into a single dataset (thus the error), while this casting is not done while yielding item by item in streaming mode.\r\n\r\nMaybe in streaming mode we should keep the schema (inferred from the first item) and throw an exception if a subsequent item does not conform to the inferred schema?",
"Why do we want to concatenate the files? Is it the expected behavior for most datasets that lack a script and dataset info?",
"These files are two different dataset configurations since they don't share the same schema.\r\n\r\nIMO the streaming mode should fail in this case, as @albertvillanova said.\r\n\r\nThere is one challenge though: inferring the schema from the first example is not robust enough in the general case - especially if some fields are nullable. I guess we can at least make sure that no new columns are added",
"OK. So, if we make the streaming also fail, the dataset https://huggingface.co/datasets/huggingface/transformers-metadata will never be [viewable](https://github.com/huggingface/datasets-preview-backend/issues/144) (be it using streaming or fallback to downloading the files), right?\r\n",
"Yes, until we have a way for the user to specify explicitly that those two files are different configurations.\r\n\r\nWe can maybe have some rule to detect this automatically, maybe checking the first line of each file ? That would mean that for dataset of 10,000+ files we would have to verify every single one of them just to know if there is one ore more configurations, so I'm not sure if this is a good idea",
"i think requiring the user to specify that those two files are different configurations is in that case perfectly reasonable.\r\n\r\n(Maybe at some point we could however detect this type of case and prompt them to define a config mapping etc)",
"OK, so, before closing the issue, what do you think should be done?\r\n\r\n> Maybe in streaming mode we should keep the schema (inferred from the first item) and throw an exception if a subsequent item does not conform to the inferred schema?\r\n\r\nor nothing?",
"We should at least raise an error if a new sample has column names that are missing, or if it has extra columns. No need to check for the type for now.\r\n\r\nI'm in favor of having an error especially because we want to avoid silent issues as much as possible - i.e. when something goes wrong (when schemas don't match or some data are missing) and no errors/warnings are raised.\r\n\r\nConsistency between streaming and non-streaming is also important."
] |
https://api.github.com/repos/huggingface/datasets/issues/1611 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1611/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1611/comments | https://api.github.com/repos/huggingface/datasets/issues/1611/events | https://github.com/huggingface/datasets/issues/1611 | 771,486,456 | MDU6SXNzdWU3NzE0ODY0NTY= | 1,611 | shuffle with torch generator | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 8 | 2020-12-20T00:57:14Z | 2022-06-01T15:30:13Z | 2022-06-01T15:30:13Z | null | Hi
I need to shuffle mutliple large datasets with `generator = torch.Generator()` for a distributed sampler which needs to make sure datasets are consistent across different cores, for this, this is really necessary for me to use torch generator, based on documentation this generator is not supported with datasets, I really need to make shuffle work with this generator and I was wondering what I can do about this issue, thanks for your help
@lhoestq | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1611/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1611/timeline | null | completed | null | null | false | [
"Is there a way one can convert the two generator? not sure overall what alternatives I could have to shuffle the datasets with a torch generator, thanks ",
"@lhoestq let me please expalin in more details, maybe you could help me suggesting an alternative to solve the issue for now, I have multiple large datasets using huggingface library, then I need to define a distributed sampler on top of it, for this I need to shard the datasets and give each shard to each core, but before sharding I need to shuffle the dataset, if you are familiar with distributed sampler in pytorch, this needs to be done based on seed+epoch generator to make it consistent across the cores they do it through defining a torch generator, I was wondering if you could tell me how I can shuffle the data for now, I am unfortunately blocked by this and have a limited time left, and I greatly appreciate your help on this. thanks ",
"@lhoestq Is there a way I could shuffle the datasets from this library with a custom defined shuffle function? thanks for your help on this. ",
"Right now the shuffle method only accepts the `seed` (optional int) or `generator` (optional `np.random.Generator`) parameters.\r\n\r\nHere is a suggestion to shuffle the data using your own shuffle method using `select`.\r\n`select` can be used to re-order the dataset samples or simply pick a few ones if you want.\r\nIt's what is used under the hood when you call `dataset.shuffle`.\r\n\r\nTo use `select` you must have the list of re-ordered indices of your samples.\r\n\r\nLet's say you have a `shuffle` methods that you want to use. Then you can first build your shuffled list of indices:\r\n```python\r\nshuffled_indices = shuffle(range(len(dataset)))\r\n```\r\n\r\nThen you can shuffle your dataset using the shuffled indices with \r\n```python\r\nshuffled_dataset = dataset.select(shuffled_indices)\r\n```\r\n\r\nHope that helps",
"thank you @lhoestq thank you very much for responding to my question, this greatly helped me and remove the blocking for continuing my work, thanks. ",
"@lhoestq could you confirm the method proposed does not bring the whole data into memory? thanks ",
"Yes the dataset is not loaded into memory",
"great. thanks a lot."
] |
https://api.github.com/repos/huggingface/datasets/issues/4055 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4055/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4055/comments | https://api.github.com/repos/huggingface/datasets/issues/4055/events | https://github.com/huggingface/datasets/pull/4055 | 1,184,976,292 | PR_kwDODunzps41PGF1 | 4,055 | [DO NOT MERGE] Test doc-builder | [] | closed | false | null | 2 | 2022-03-29T14:39:02Z | 2022-03-30T12:31:14Z | 2022-03-30T12:25:52Z | null | This is a test PR to ensure the changes in https://github.com/huggingface/doc-builder/pull/164 don't break anything in `datasets` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4055/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4055/timeline | null | null | true | {
"diff_url": "https://github.com/huggingface/datasets/pull/4055.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4055",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/4055.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4055"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"Docs built successfully, so closing this."
] |
https://api.github.com/repos/huggingface/datasets/issues/1537 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1537/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1537/comments | https://api.github.com/repos/huggingface/datasets/issues/1537/events | https://github.com/huggingface/datasets/pull/1537 | 765,095,210 | MDExOlB1bGxSZXF1ZXN0NTM4ODY1NzIz | 1,537 | added ohsumed | [] | closed | false | null | 0 | 2020-12-13T06:58:23Z | 2020-12-17T18:28:16Z | 2020-12-17T18:28:16Z | null | UPDATE2: PR passed all tests. Now waiting for review.
UPDATE: pushed a new version. cross fingers that it should complete all the tests! :)
If it passes all tests then it's not a draft version.
This is a draft version | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1537/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1537/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1537.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1537",
"merged_at": "2020-12-17T18:28:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1537.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1537"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4371 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4371/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4371/comments | https://api.github.com/repos/huggingface/datasets/issues/4371/events | https://github.com/huggingface/datasets/pull/4371 | 1,241,500,906 | PR_kwDODunzps44GzSZ | 4,371 | Add missing language tags for udhr dataset | [] | closed | false | null | 1 | 2022-05-19T09:34:10Z | 2022-06-08T12:03:24Z | 2022-05-20T09:43:10Z | null | Related to #4362. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4371/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4371/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4371.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4371",
"merged_at": "2022-05-20T09:43:10Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4371.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4371"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/3317 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3317/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3317/comments | https://api.github.com/repos/huggingface/datasets/issues/3317/events | https://github.com/huggingface/datasets/issues/3317 | 1,062,284,447 | I_kwDODunzps4_USyf | 3,317 | Add desc parameter to Dataset filter method | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 4 | 2021-11-24T11:01:36Z | 2022-01-05T18:31:24Z | 2022-01-05T18:31:24Z | null | **Is your feature request related to a problem? Please describe.**
As I was filtering very large datasets I noticed the filter method doesn't have the desc parameter which is available in the map method. Why don't we add a desc parameter to the filter method both for consistency and it's nice to give some feedback to users during long operations on Datasets?
**Describe the solution you'd like**
Add desc parameter to Dataset filter method
**Describe alternatives you've considered**
N/A
**Additional context**
N/A
| {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3317/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3317/timeline | null | completed | null | null | false | [
"Hi,\r\n\r\n`Dataset.map` allows more generic transforms compared to `Dataset.filter`, which purpose is very specific (to filter examples based on a condition). That's why I don't think we need the `desc` parameter there for consistency. #3196 has added descriptions to the `Dataset` methods that call `.map` internally, but not for the `filter` method, so we should do that.\r\n\r\nDo you have a description in mind? Maybe `\"Filtering the dataset\"` or `\"Filtering the indices\"`? If yes, feel free to open a PR.",
"I'm personally ok with adding the `desc` parameter actually. Let's say you have different filters, it can be nice to differentiate between the different filters when they're running no ?",
"@mariosasko the use case is filtering of a dataset prior to tokenization and subsequent training. As the dataset is huge it's just a matter of giving a user (model trainer) some feedback on what's going on. Otherwise, feedback is given for all steps in training preparation and not for filtering and the filtering in my use case lasts about 4-5 minutes. And yes, if there are more filtering stages, as @lhoestq pointed out, it would be nice to give some feedback. I thought desc is there already and got confused when I got the script error. ",
"I don't have a strong opinion on that, so having `desc` as a parameter is also OK."
] |
https://api.github.com/repos/huggingface/datasets/issues/342 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/342/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/342/comments | https://api.github.com/repos/huggingface/datasets/issues/342/events | https://github.com/huggingface/datasets/issues/342 | 651,333,194 | MDU6SXNzdWU2NTEzMzMxOTQ= | 342 | Features should be updated when `map()` changes schema | [] | closed | false | null | 1 | 2020-07-06T08:03:23Z | 2020-07-23T10:15:16Z | 2020-07-23T10:15:16Z | null | `dataset.map()` can change the schema and column names.
We should update the features in this case (with what is possible to infer). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/342/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/342/timeline | null | completed | null | null | false | [
"`dataset.column_names` are being updated but `dataset.features` aren't indeed..."
] |
https://api.github.com/repos/huggingface/datasets/issues/1871 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1871/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1871/comments | https://api.github.com/repos/huggingface/datasets/issues/1871/events | https://github.com/huggingface/datasets/pull/1871 | 807,697,671 | MDExOlB1bGxSZXF1ZXN0NTcyODk5Nzgz | 1,871 | Add newspop dataset | [] | closed | false | null | 1 | 2021-02-13T07:31:23Z | 2021-03-08T10:12:45Z | 2021-03-08T10:12:45Z | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1871/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1871/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1871.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1871",
"merged_at": "2021-03-08T10:12:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1871.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1871"
} | true | [
"Thanks for the changes :)\r\nmerging"
] |
|
https://api.github.com/repos/huggingface/datasets/issues/4386 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4386/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4386/comments | https://api.github.com/repos/huggingface/datasets/issues/4386/events | https://github.com/huggingface/datasets/issues/4386 | 1,243,965,532 | I_kwDODunzps5KJWhc | 4,386 | Bug for wiki_auto_asset_turk from GEM | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 7 | 2022-05-21T12:31:30Z | 2022-05-24T05:55:52Z | 2022-05-23T10:29:55Z | null | ## Describe the bug
The script of wiki_auto_asset_turk for GEM may be out of date.
## Steps to reproduce the bug
```python
import datasets
datasets.load_dataset('gem', 'wiki_auto_asset_turk')
```
## Actual results
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/tangtianyi/miniconda3/lib/python3.8/site-packages/datasets/load.py", line 1731, in load_dataset
builder_instance.download_and_prepare(
File "/home/tangtianyi/miniconda3/lib/python3.8/site-packages/datasets/builder.py", line 640, in download_and_prepare
self._download_and_prepare(
File "/home/tangtianyi/miniconda3/lib/python3.8/site-packages/datasets/builder.py", line 1158, in _download_and_prepare
super()._download_and_prepare(dl_manager, verify_infos, check_duplicate_keys=verify_infos)
File "/home/tangtianyi/miniconda3/lib/python3.8/site-packages/datasets/builder.py", line 707, in _download_and_prepare
split_generators = self._split_generators(dl_manager, **split_generators_kwargs)
File "/home/tangtianyi/.cache/huggingface/modules/datasets_modules/datasets/gem/982a54473b12c6a6e40d4356e025fb7172a5bb2065e655e2c1af51f2b3cf4ca1/gem.py", line 538, in _split_generators
dl_dir = dl_manager.download_and_extract(_URLs[self.config.name])
File "/home/tangtianyi/miniconda3/lib/python3.8/site-packages/datasets/utils/download_manager.py", line 416, in download_and_extract
return self.extract(self.download(url_or_urls))
File "/home/tangtianyi/miniconda3/lib/python3.8/site-packages/datasets/utils/download_manager.py", line 294, in download
downloaded_path_or_paths = map_nested(
File "/home/tangtianyi/miniconda3/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 351, in map_nested
mapped = [
File "/home/tangtianyi/miniconda3/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 352, in <listcomp>
_single_map_nested((function, obj, types, None, True, None))
File "/home/tangtianyi/miniconda3/lib/python3.8/site-packages/datasets/utils/py_utils.py", line 288, in _single_map_nested
return function(data_struct)
File "/home/tangtianyi/miniconda3/lib/python3.8/site-packages/datasets/utils/download_manager.py", line 320, in _download
return cached_path(url_or_filename, download_config=download_config)
File "/home/tangtianyi/miniconda3/lib/python3.8/site-packages/datasets/utils/file_utils.py", line 234, in cached_path
output_path = get_from_cache(
File "/home/tangtianyi/miniconda3/lib/python3.8/site-packages/datasets/utils/file_utils.py", line 579, in get_from_cache
raise FileNotFoundError(f"Couldn't find file at {url}")
FileNotFoundError: Couldn't find file at https://github.com/facebookresearch/asset/raw/master/dataset/asset.test.orig
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4386/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4386/timeline | null | completed | null | null | false | [
"Thanks for reporting, @StevenTang1998.\r\n\r\nI'm looking into it. ",
"Hi @StevenTang1998,\r\n\r\nWe have fixed the issue:\r\n- #4389\r\n\r\nThe fix will be available in our next `datasets` library release. In the meantime, you can incorporate that fix by installing `datasets` from our GitHub repo:\r\n```\r\npip install git+https://github.com/huggingface/datasets#egg=datasets\r\n```",
"Thanks for your reply!!\r\nAnd the totto dataset has the same problem. The url should be change to [https://storage.googleapis.com/totto-public/totto_data.zip](https://storage.googleapis.com/totto-public/totto_data.zip).",
"Hi again @StevenTang1998,\r\n\r\nI don't see any problem when loading `totto` dataset:\r\n```python\r\nIn [4]: import datasets\r\n ...: ds = datasets.load_dataset(\"totto\")\r\nDownloading builder script: 5.58kB [00:00, 5.33MB/s] \r\nDownloading metadata: 2.78kB [00:00, 2.96MB/s] \r\nUsing custom data configuration default\r\nDownloading and preparing dataset totto/default (download: 179.03 MiB, generated: 706.59 MiB, post-processed: Unknown size, total: 885.62 MiB) to .../.cache/huggingface/datasets/totto/default/1.0.0/263c85871e5451bc892c65ca0306c0629eb7beb161e0eb998f56231562335dd2...\r\nDownloading data: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 188M/188M [00:32<00:00, 5.77MB/s]\r\nDataset totto downloaded and prepared to .../.cache/huggingface/datasets/totto/default/1.0.0/263c85871e5451bc892c65ca0306c0629eb7beb161e0eb998f56231562335dd2. Subsequent calls will reuse this data.\r\n100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 147.95it/s]\r\n\r\nIn [5]: ds\r\nOut[5]: \r\nDatasetDict({\r\n train: Dataset({\r\n features: ['id', 'table_page_title', 'table_webpage_url', 'table_section_title', 'table_section_text', 'table', 'highlighted_cells', 'example_id', 'sentence_annotations', 'overlap_subset'],\r\n num_rows: 120761\r\n })\r\n validation: Dataset({\r\n features: ['id', 'table_page_title', 'table_webpage_url', 'table_section_title', 'table_section_text', 'table', 'highlighted_cells', 'example_id', 'sentence_annotations', 'overlap_subset'],\r\n num_rows: 7700\r\n })\r\n test: Dataset({\r\n features: ['id', 'table_page_title', 'table_webpage_url', 'table_section_title', 'table_section_text', 'table', 'highlighted_cells', 'example_id', 'sentence_annotations', 'overlap_subset'],\r\n num_rows: 7700\r\n })\r\n})\r\n```",
"Sorry, I didn't express it clearly. It's the totto dataset from gem.\r\ndatasets.load_dataset('gem', 'totto')\r\n",
"@StevenTang1998 fixed in:\r\n- #4396",
"Thanks!!"
] |
https://api.github.com/repos/huggingface/datasets/issues/2259 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2259/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2259/comments | https://api.github.com/repos/huggingface/datasets/issues/2259/events | https://github.com/huggingface/datasets/pull/2259 | 866,880,092 | MDExOlB1bGxSZXF1ZXN0NjIyNjc2ODA0 | 2,259 | Add support for Split.ALL | [] | closed | false | null | 1 | 2021-04-25T01:45:42Z | 2021-06-28T08:21:27Z | 2021-06-28T08:21:27Z | null | The title says it all. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2259/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2259/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2259.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2259",
"merged_at": "2021-06-28T08:21:27Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2259.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2259"
} | true | [
"Honestly, I think we should fix some other issues in Split API before this change. E. g. currently the following will not work, even though it should:\r\n```python\r\nimport datasets\r\ndatasets.load_dataset(\"sst\", split=datasets.Split.TRAIN+datasets.Split.TEST) # AssertionError\r\n```\r\n\r\nEDIT:\r\nActually, think it's OK to merge this PR because the fix will not touch this PR's code."
] |
https://api.github.com/repos/huggingface/datasets/issues/330 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/330/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/330/comments | https://api.github.com/repos/huggingface/datasets/issues/330/events | https://github.com/huggingface/datasets/pull/330 | 648,525,720 | MDExOlB1bGxSZXF1ZXN0NDQyMzIxMjEw | 330 | Doc red | [] | closed | false | null | 0 | 2020-06-30T22:05:31Z | 2020-07-06T12:10:39Z | 2020-07-05T12:27:29Z | null | Adding [DocRED](https://github.com/thunlp/DocRED) - a relation extraction dataset which tests document-level RE. A few implementation notes:
- There are 2 separate versions of the training set - *annotated* and *distant*. Instead of `nlp.Split.Train` I've used the splits `"train_annotated"` and `"train_distant"` to reflect this.
- As well as the relation id, the full relation name is mapped from `rel_info.json`
- I renamed the 'h', 'r', 't' keys to 'head', 'relation' and 'tail' to make them more readable.
- Used the fix from #319 to allow nested sequences of dicts. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/330/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/330/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/330.diff",
"html_url": "https://github.com/huggingface/datasets/pull/330",
"merged_at": "2020-07-05T12:27:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/330.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/330"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4281 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4281/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4281/comments | https://api.github.com/repos/huggingface/datasets/issues/4281/events | https://github.com/huggingface/datasets/pull/4281 | 1,225,556,939 | PR_kwDODunzps43TNBm | 4,281 | Remove a copy-paste sentence in dataset cards | [] | closed | false | null | 2 | 2022-05-04T15:41:55Z | 2022-05-06T08:38:03Z | 2022-05-04T18:33:16Z | null | Remove the following copy-paste sentence from dataset cards:
```
We show detailed information for up to 5 configurations of the dataset.
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4281/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4281/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4281.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4281",
"merged_at": "2022-05-04T18:33:16Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4281.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4281"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"The non-passing tests have nothing to do with this PR."
] |
https://api.github.com/repos/huggingface/datasets/issues/654 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/654/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/654/comments | https://api.github.com/repos/huggingface/datasets/issues/654/events | https://github.com/huggingface/datasets/pull/654 | 705,511,058 | MDExOlB1bGxSZXF1ZXN0NDkwMjI1Nzk3 | 654 | Allow empty inputs in metrics | [] | closed | false | null | 0 | 2020-09-21T11:26:36Z | 2020-10-06T03:51:48Z | 2020-09-21T16:13:38Z | null | There was an arrow error when trying to compute a metric with empty inputs. The error was occurring when reading the arrow file, before calling metric._compute. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/654/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/654/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/654.diff",
"html_url": "https://github.com/huggingface/datasets/pull/654",
"merged_at": "2020-09-21T16:13:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/654.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/654"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/977 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/977/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/977/comments | https://api.github.com/repos/huggingface/datasets/issues/977/events | https://github.com/huggingface/datasets/pull/977 | 754,839,594 | MDExOlB1bGxSZXF1ZXN0NTMwNjY2ODg3 | 977 | Add ROPES dataset | [] | closed | false | null | 0 | 2020-12-02T00:52:10Z | 2020-12-02T10:58:36Z | 2020-12-02T10:58:35Z | null | ROPES dataset
Reasoning over paragraph effects in situations - testing a system's ability to apply knowledge from a passage of text to a new situation. The task is framed into a reading comprehension task following squad-style extractive qa.
One thing to note: labels of the test set are hidden (leaderboard submission) so I encoded that as an empty list (ropes.py:L125) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/977/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/977/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/977.diff",
"html_url": "https://github.com/huggingface/datasets/pull/977",
"merged_at": "2020-12-02T10:58:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/977.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/977"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3613 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3613/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3613/comments | https://api.github.com/repos/huggingface/datasets/issues/3613/events | https://github.com/huggingface/datasets/issues/3613 | 1,110,684,015 | I_kwDODunzps5CM7Fv | 3,613 | Files not updating in dataset viewer | [
{
"color": "E5583E",
"default": false,
"description": "Related to the dataset viewer on huggingface.co",
"id": 3470211881,
"name": "dataset-viewer",
"node_id": "LA_kwDODunzps7O1zsp",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset-viewer"
}
] | closed | false | null | 2 | 2022-01-21T16:47:20Z | 2022-01-22T08:13:13Z | 2022-01-22T08:13:13Z | null | ## Dataset viewer issue for '*name of the dataset*'
**Link:**
Some examples:
* https://huggingface.co/datasets/abidlabs/crowdsourced-speech4
* https://huggingface.co/datasets/abidlabs/test-audio-13
*short description of the issue*
It seems that the dataset viewer is reading a cached version of the dataset and it is not updating to reflect new files that are added to the dataset. I get this error:
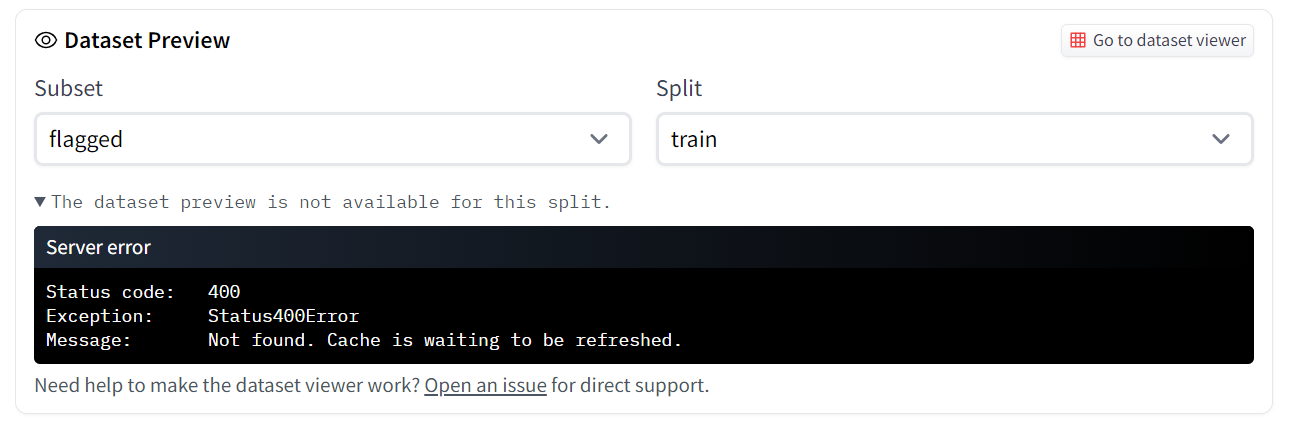
Am I the one who added this dataset? Yes | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3613/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3613/timeline | null | completed | null | null | false | [
"Yes. The jobs queue is full right now, following an upgrade... Back to normality in the next hours hopefully. I'll look at your datasets to be sure the dataset viewer works as expected on them.",
"Should have been fixed now."
] |
https://api.github.com/repos/huggingface/datasets/issues/6022 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/6022/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/6022/comments | https://api.github.com/repos/huggingface/datasets/issues/6022/events | https://github.com/huggingface/datasets/issues/6022 | 1,800,092,589 | I_kwDODunzps5rSzut | 6,022 | Batch map raises TypeError: '>=' not supported between instances of 'NoneType' and 'int' | [] | closed | false | null | 1 | 2023-07-12T03:20:17Z | 2023-07-12T16:18:06Z | 2023-07-12T16:18:05Z | null | ### Describe the bug
When mapping some datasets with `batched=True`, datasets may raise an exeception:
```python
Traceback (most recent call last):
File "/Users/codingl2k1/Work/datasets/venv/lib/python3.11/site-packages/multiprocess/pool.py", line 125, in worker
result = (True, func(*args, **kwds))
^^^^^^^^^^^^^^^^^^^
File "/Users/codingl2k1/Work/datasets/src/datasets/utils/py_utils.py", line 1328, in _write_generator_to_queue
for i, result in enumerate(func(**kwargs)):
File "/Users/codingl2k1/Work/datasets/src/datasets/arrow_dataset.py", line 3483, in _map_single
writer.write_batch(batch)
File "/Users/codingl2k1/Work/datasets/src/datasets/arrow_writer.py", line 549, in write_batch
array = cast_array_to_feature(col_values, col_type) if col_type is not None else col_values
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/codingl2k1/Work/datasets/src/datasets/table.py", line 1831, in wrapper
return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/codingl2k1/Work/datasets/src/datasets/table.py", line 1831, in <listcomp>
return pa.chunked_array([func(chunk, *args, **kwargs) for chunk in array.chunks])
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/codingl2k1/Work/datasets/src/datasets/table.py", line 2063, in cast_array_to_feature
return feature.cast_storage(array)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/codingl2k1/Work/datasets/src/datasets/features/features.py", line 1098, in cast_storage
if min_max["max"] >= self.num_classes:
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: '>=' not supported between instances of 'NoneType' and 'int'
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/Users/codingl2k1/Work/datasets/t1.py", line 33, in <module>
ds = ds.map(transforms, num_proc=14, batched=True, batch_size=5)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/codingl2k1/Work/datasets/src/datasets/dataset_dict.py", line 850, in map
{
File "/Users/codingl2k1/Work/datasets/src/datasets/dataset_dict.py", line 851, in <dictcomp>
k: dataset.map(
^^^^^^^^^^^^
File "/Users/codingl2k1/Work/datasets/src/datasets/arrow_dataset.py", line 577, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/codingl2k1/Work/datasets/src/datasets/arrow_dataset.py", line 542, in wrapper
out: Union["Dataset", "DatasetDict"] = func(self, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/codingl2k1/Work/datasets/src/datasets/arrow_dataset.py", line 3179, in map
for rank, done, content in iflatmap_unordered(
File "/Users/codingl2k1/Work/datasets/src/datasets/utils/py_utils.py", line 1368, in iflatmap_unordered
[async_result.get(timeout=0.05) for async_result in async_results]
File "/Users/codingl2k1/Work/datasets/src/datasets/utils/py_utils.py", line 1368, in <listcomp>
[async_result.get(timeout=0.05) for async_result in async_results]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Users/codingl2k1/Work/datasets/venv/lib/python3.11/site-packages/multiprocess/pool.py", line 774, in get
raise self._value
TypeError: '>=' not supported between instances of 'NoneType' and 'int'
```
### Steps to reproduce the bug
1. Checkout the latest main of datasets.
2. Run the code:
```python
from datasets import load_dataset
def transforms(examples):
# examples["pixel_values"] = [image.convert("RGB").resize((100, 100)) for image in examples["image"]]
return examples
ds = load_dataset("scene_parse_150")
ds = ds.map(transforms, num_proc=14, batched=True, batch_size=5)
print(ds)
```
### Expected behavior
map without exception.
### Environment info
Datasets: https://github.com/huggingface/datasets/commit/b8067c0262073891180869f700ebef5ac3dc5cce
Python: 3.11.4
System: Macos | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/6022/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/6022/timeline | null | completed | null | null | false | [
"Thanks for reporting! I've opened a PR with a fix."
] |
https://api.github.com/repos/huggingface/datasets/issues/1928 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1928/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1928/comments | https://api.github.com/repos/huggingface/datasets/issues/1928/events | https://github.com/huggingface/datasets/pull/1928 | 813,793,434 | MDExOlB1bGxSZXF1ZXN0NTc3ODgyMDM4 | 1,928 | Updating old cards | [] | closed | false | null | 0 | 2021-02-22T19:26:04Z | 2021-02-23T18:19:25Z | 2021-02-23T18:19:25Z | null | Updated the cards for [Allocine](https://github.com/mcmillanmajora/datasets/tree/updating-old-cards/datasets/allocine), [CNN/DailyMail](https://github.com/mcmillanmajora/datasets/tree/updating-old-cards/datasets/cnn_dailymail), and [SNLI](https://github.com/mcmillanmajora/datasets/tree/updating-old-cards/datasets/snli). For the most part, the information was just rearranged or rephrased, but the social impact statements are new. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1928/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1928/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1928.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1928",
"merged_at": "2021-02-23T18:19:25Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1928.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1928"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/202 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/202/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/202/comments | https://api.github.com/repos/huggingface/datasets/issues/202/events | https://github.com/huggingface/datasets/issues/202 | 625,493,983 | MDU6SXNzdWU2MjU0OTM5ODM= | 202 | Mistaken `_KWARGS_DESCRIPTION` for XNLI metric | [] | closed | false | null | 1 | 2020-05-27T08:34:42Z | 2020-05-28T13:22:36Z | 2020-05-28T13:22:36Z | null | Hi!
The [`_KWARGS_DESCRIPTION`](https://github.com/huggingface/nlp/blob/7d0fa58641f3f462fb2861dcdd6ce7f0da3f6a56/metrics/xnli/xnli.py#L45) for the XNLI metric uses `Args` and `Returns` text from [BLEU](https://github.com/huggingface/nlp/blob/7d0fa58641f3f462fb2861dcdd6ce7f0da3f6a56/metrics/bleu/bleu.py#L58) metric:
```
_KWARGS_DESCRIPTION = """
Computes XNLI score which is just simple accuracy.
Args:
predictions: list of translations to score.
Each translation should be tokenized into a list of tokens.
references: list of lists of references for each translation.
Each reference should be tokenized into a list of tokens.
max_order: Maximum n-gram order to use when computing BLEU score.
smooth: Whether or not to apply Lin et al. 2004 smoothing.
Returns:
'bleu': bleu score,
'precisions': geometric mean of n-gram precisions,
'brevity_penalty': brevity penalty,
'length_ratio': ratio of lengths,
'translation_length': translation_length,
'reference_length': reference_length
"""
```
But it should be something like:
```
_KWARGS_DESCRIPTION = """
Computes XNLI score which is just simple accuracy.
Args:
predictions: Predicted labels.
references: Ground truth labels.
Returns:
'accuracy': accuracy
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/202/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/202/timeline | null | completed | null | null | false | [
"Indeed, good catch ! thanks\r\nFixing it right now"
] |
https://api.github.com/repos/huggingface/datasets/issues/2193 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2193/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2193/comments | https://api.github.com/repos/huggingface/datasets/issues/2193/events | https://github.com/huggingface/datasets/issues/2193 | 853,725,707 | MDU6SXNzdWU4NTM3MjU3MDc= | 2,193 | Filtering/mapping on one column is very slow | [
{
"color": "d876e3",
"default": true,
"description": "Further information is requested",
"id": 1935892912,
"name": "question",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEy",
"url": "https://api.github.com/repos/huggingface/datasets/labels/question"
}
] | closed | false | null | 12 | 2021-04-08T18:16:14Z | 2021-04-26T16:13:59Z | 2021-04-26T16:13:59Z | null | I'm currently using the `wikipedia` dataset— I'm tokenizing the articles with the `tokenizers` library using `map()` and also adding a new `num_tokens` column to the dataset as part of that map operation.
I want to be able to _filter_ the dataset based on this `num_tokens` column, but even when I specify `input_columns=['num_tokens']`, it seems that the entirety of each row is loaded into memory, which makes the operation take much longer than it should. Indeed, `filter` currently just calls `map`, and I found that in `_map_single` on lines 1690-1704 of `arrow_dataset.py`, the method is just grabbing slices of _all the rows_ of the dataset and then passing only the specified columns to the map function. It seems that, when the user passes a value for `input_columns`, the `map` function should create a temporary pyarrow table by selecting just those columns, and then get slices from that table. Or something like that— I'm not very familiar with the pyarrow API.
I know that in the meantime I can sort of get around this by simply only returning the rows that match my filter criterion from the tokenizing function I pass to `map()`, but I actually _also_ want to map on just the `num_tokens` column in order to compute batches with a roughly uniform number of tokens per batch. I would also ideally like to be able to change my minimum and maximum article lengths without having to re-tokenize the entire dataset.
PS: This is definitely not a "dataset request." I'm realizing that I don't actually know how to remove labels from my own issues on other people's repos, if that is even possible. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2193/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2193/timeline | null | completed | null | null | false | [
"Hi ! Yes we are working on making `filter` significantly faster. You can look at related PRs here: #2060 #2178 \r\n\r\nI think you can expect to have the fast version of `filter` available next week.\r\n\r\nWe'll make it only select one column, and we'll also make the overall filtering operation way faster by avoiding many arrow<->python conversions especially during writing.\r\n\r\nI'll let you know how it goes !",
"@lhoestq Thanks for the response— it's great to hear that we'll be getting a much faster `filter` method soon. However, my use case does also involve using `map` over a single column in order to pre-compute roughly uniformly sized batches, and right now that is also very slow. Is there any plan to make `map` faster for single column operations?\r\n\r\nIf that's not a priority for the maintainers right now, I could try my hand at adding the feature, but I can't guarantee I would do a good job given my lack of familiarity with pyarrow.",
"Currently the optimal setup for single-column computations is probably to do something like\r\n```python\r\nresult = dataset.map(f, input_columns=\"my_col\", remove_columns=dataset.column_names)\r\n```\r\nThis has two advantages:\r\n- input_columns=\"my_col\" allows to only read the column \"my_col\"\r\n- remove_columns=dataset.column_names makes `map` only keep the output of your function `f`, and it drops the other columns of the dataset instead of keeping them.\r\n\r\nLet me know if it improves speed on your side.\r\n\r\nYou can also get more speed by using `batched=True` and setting `num_proc=` for multiprocessing",
"Hi @lhoestq ,\r\n\r\nI'm hijacking this issue, because I'm currently trying to do the approach you recommend:\r\n\r\n> Currently the optimal setup for single-column computations is probably to do something like\r\n> \r\n> ```python\r\n> result = dataset.map(f, input_columns=\"my_col\", remove_columns=dataset.column_names)\r\n> ```\r\n\r\nHere is my code: (see edit, in which I added a simplified version\r\n\r\n```\r\nThis is the error:\r\n```bash\r\npyarrow.lib.ArrowInvalid: Column 1 named tokens expected length 8964 but got length 1000\r\n```\r\nI wonder why this error occurs, when I delete every column? Can you give me a hint?\r\n\r\n### Edit:\r\nI preprocessed my dataset before (using map with the features argument) and saved it to disk. May this be part of the error? I can iterate over the\r\ncomplete dataset and print every sample before calling map. There seems to be no other problem with the dataset.\r\n\r\nI tried to simplify the code that crashes:\r\n\r\n```python\r\n# works\r\nlog.debug(dataset.column_names)\r\nlog.debug(dataset)\r\nfor i, sample in enumerate(dataset):\r\n log.debug(i, sample)\r\n\r\n# crashes\r\ncounted_dataset = dataset.map(\r\n lambda x: {\"a\": list(range(20))},\r\n input_columns=column,\r\n remove_columns=dataset.column_names,\r\n load_from_cache_file=False,\r\n num_proc=num_workers,\r\n batched=True,\r\n)\r\n```\r\n\r\n```\r\npyarrow.lib.ArrowInvalid: Column 1 named tokens expected length 20 but got length 1000\r\n```\r\n\r\nEdit2: \r\n\r\nMay this be a problem with a schema I set when preprocessing the dataset before? I tried to add the `features` argument to the function and then I get a new error:\r\n\r\n```python\r\n# crashes\r\ncounted_dataset = dataset.map(\r\n lambda x: {\"a\": list(range(20))},\r\n input_columns=column,\r\n remove_columns=dataset.column_names,\r\n load_from_cache_file=False,\r\n num_proc=num_workers,\r\n batched=True,\r\n features=datasets.Features(\r\n {\r\n \"a\": datasets.Sequence(datasets.Value(\"int32\"))\r\n }\r\n )\r\n)\r\n```\r\n\r\n```\r\n File \"env/lib/python3.8/site-packages/datasets/arrow_dataset.py\", line 1704, in _map_single\r\n writer.write_batch(batch)\r\n File \"env/lib/python3.8/site-packages/datasets/arrow_writer.py\", line 312, in write_batch\r\n col_type = schema.field(col).type if schema is not None else None\r\n File \"pyarrow/types.pxi\", line 1341, in pyarrow.lib.Schema.field\r\nKeyError: 'Column tokens does not exist in schema'\r\n```",
"Hi ! Can you open a separate issue for that ?\r\nAlso if you could provide a google colab or a sample code to reproduce this issue that would be helpful.\r\nOn my side I was not able to reproduce this error.",
"@lhoestq Sorry I'm just responding now. I'm currently using your recommendation for the map on a single column, and I've gotten it to be fast enough to sort of work for my use case by just setting `num_proc=10`, although it's still quite slow. It's clear that it is still loading the entirety of each row into memory and then discarding everything except the selected column, instead of exploiting the columnar data format to only load the selected column.\r\n\r\nMy code is like this:\r\n```\r\n self.dataset = self.dataset.sort('num_tokens')\r\n batch_dataset = self.dataset.map(\r\n\tcompute_uniform_sized_batches,\r\n\tbatched=True, batch_size=10_000, num_proc=10, input_columns=['num_tokens'],\r\n\tremove_columns=get_columns_all_equal(self.dataset),\r\n\twith_indices=True,\r\n\tfn_kwargs=dict(max_size=tokens_per_batch)\r\n)\r\nself.batches = {\r\n\tname: list(zip(split['start'], split['length']))\r\n\tfor name, split in batch_dataset.items()\r\n}\r\n```\r\nI find that the processes with higher IDs take significantly longer to complete, presumably because the dataset is sorted by article length and they're loading the entire article text into memory, instead of just the 'num_tokens' column.\r\n\r\nI should note that my batching procedure would work best if I just used `batch_size=None` and loaded the whole column into memory at once, but I found that this was intolerably slow and gave me no progress information, so I'm using the less than ideal `batch_size=10_000`.",
"Hi @norabelrose ! I'm glad you managed to make this work on your side.\r\nRegarding memory usage, you can try to drop the columns that you don't want to use for your `map` for now.\r\n\r\nIn the future we'll try to find a way to not load unnecessary columns in memory in `map`. Currently the way it works is that it gets the batch as a python dict, then it updates it using the output of your mapping function, and finally it removes columns from `remove_columns`. Therefore for a moment some columns are loaded in memory even if you remove them or don't use them for your mapping function.\r\n\r\nIt would be nice to have a way to optimize memory for cases such as yours !",
"@lhoestq After looking through the source code, it looks like the following solution has at least some chance of working:\r\n- refactor `Dataset.map()` so that the `input_columns` parameter is implemented by using the `self.formatted_as()` context manager with `columns=input_columns`\r\n- change `Dataset._getitem()` so that it passes `self._data.drop(drop_columns)` to the `query_table()` function whenever `format_columns` is non-None and `output_all_columns` is False, instead of `self._data` itself",
"Looks like a great direction :)\r\nNote that `query_table` doesn't bring data into memory. Only `format_table` does.\r\nAlso the dataset may already have a format with `columns=` already defined so we would need to define the formatted `input_dataset` like:\r\n```python\r\n# before the `map` main for loop\r\ninput_columns = input_columns if input_columns is not None else self.column_names\r\nif not self._output_all_columns:\r\n columns = [col for col in input_columns if self._format_columns is None or col in self._format_columns]\r\n input_dataset = self.with_format(\r\n type=self._format_type,\r\n columns=columns\r\n )\r\nelse:\r\n # in this case we could find a way to filter both format_columns and unformatted columns eventually\r\n input_dataset = self\r\n# then input_dataset can be used in the main for loop of `map`\r\n```\r\n\r\nEDIT: oh and regarding streaming format versus file format for arrow, we plan to start using the file format #1933 at one point (though I'm not sure if it would improve performance)",
"Good to know about `query_table` not bringing anything into memory. I was under the impression that it did because a while back I looked at my `map` operation in pdb and it looked like it was spending forever in line 93 of formatting.py, `return pa.concat_tables(....)`, although that was before the `fast_slice` interpolation search was implemented, so it may have had more to do with the slow ChunkedArray slice implementation than anything else.\r\n\r\nIf `query_table` is I/O free then the fix may be as simple as just adding this to line 1779 of arrow_dataset.py:\r\n```python\r\n# Only load the columns we actually need\r\nif input_columns:\r\n stack.enter_context(self.formatted_as(\r\n self._format_type,\r\n columns=input_columns,\r\n output_all_columns=False,\r\n **self._format_kwargs\r\n ))\r\n```\r\nIt's not clear to me why the `[col for col in input_columns if self._format_columns is None or col in self._format_columns]` check would be necessary— it seems like either `input_columns` should simply temporarily override the `_format_columns` within the `map` operation, or we should throw an error if there are any conflicts. Currently it doesn't look like this case is checked for at all within `map`, but maybe I'm just missing it.",
"`query_table` simply slices/concatenates parts of the table. The actual data inside the table is not brought in memory.\r\nAlso I'm more in favor of declaring `input_dataset = self.with_format(...)` since `formatted_as` may update the dataset fingerprint of `self`, which is not expected when someone runs `map`.\r\n\r\n> It's not clear to me why the [col for col in input_columns if self._format_columns is None or col in self._format_columns] check would be necessary— it seems like either input_columns should simply temporarily override the _format_columns within the map operation, or we should throw an error if there are any conflicts. Currently it doesn't look like this case is checked for at all within map, but maybe I'm just missing it.\r\n\r\nActually yes we can just use input_columns. And we do need to add a check to make sure there are not conflicts or this could lead to confusing errors.",
"That sounds good to me! I just submitted a PR (#2246) implementing your approach. I also changed how `_query_table` handles Iterable keys since it still seemed like `pa.concat_tables` was taking a long time to create the table for each batch. Now my whole `map()` operation takes 1 min 46 seconds where it used to take somewhere on the order of 10 minutes."
] |
https://api.github.com/repos/huggingface/datasets/issues/2249 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2249/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2249/comments | https://api.github.com/repos/huggingface/datasets/issues/2249/events | https://github.com/huggingface/datasets/pull/2249 | 865,257,826 | MDExOlB1bGxSZXF1ZXN0NjIxMzU1MzE3 | 2,249 | Allow downloading/processing/caching only specific splits | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | {
"closed_at": null,
"closed_issues": 2,
"created_at": "2021-07-21T15:34:56Z",
"creator": {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",
"gists_url": "https://api.github.com/users/albertvillanova/gists{/gist_id}",
"gravatar_id": "",
"html_url": "https://github.com/albertvillanova",
"id": 8515462,
"login": "albertvillanova",
"node_id": "MDQ6VXNlcjg1MTU0NjI=",
"organizations_url": "https://api.github.com/users/albertvillanova/orgs",
"received_events_url": "https://api.github.com/users/albertvillanova/received_events",
"repos_url": "https://api.github.com/users/albertvillanova/repos",
"site_admin": false,
"starred_url": "https://api.github.com/users/albertvillanova/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/albertvillanova/subscriptions",
"type": "User",
"url": "https://api.github.com/users/albertvillanova"
},
"description": "Next minor release",
"due_on": "2021-08-30T07:00:00Z",
"html_url": "https://github.com/huggingface/datasets/milestone/8",
"id": 6968069,
"labels_url": "https://api.github.com/repos/huggingface/datasets/milestones/8/labels",
"node_id": "MI_kwDODunzps4AalMF",
"number": 8,
"open_issues": 4,
"state": "open",
"title": "1.12",
"updated_at": "2021-10-13T10:26:33Z",
"url": "https://api.github.com/repos/huggingface/datasets/milestones/8"
} | 2 | 2021-04-22T17:51:44Z | 2022-07-06T15:19:48Z | null | null | Allow downloading/processing/caching only specific splits without downloading/processing/caching the other splits.
This PR implements two steps to handle only specific splits:
- it allows processing/caching only specific splits into Arrow files
- for some simple cases, it allows downloading only specific splits (which is more intricate as it depends on the user-defined method `_split_generators`)
This PR makes several assumptions:
- `DownloadConfig` contains the configuration settings for downloading
- the parameter `split` passed to `load_dataset` is just a parameter for loading (from cache), not for downloading | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2249/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2249/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2249.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2249",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/2249.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2249"
} | true | [
"> If you pass a dictionary like this:\r\n> \r\n> ```\r\n> {\"main_metadata\": url_to_main_data,\r\n> \"secondary_metadata\": url_to_sec_data,\r\n> \"train\": url_train_data,\r\n> \"test\": url_test_data}\r\n> ```\r\n> \r\n> then only the train or test keys will be kept, which I feel not intuitive.\r\n> \r\n> For example if the users asks to load the \"train\" split, then the main and secondary metadata won't be downloaded.\r\n> You can fix that by keeping all the keys except the splits to ignore\r\n\r\nHi @lhoestq, I have been thinking about this and I think it is worth that we discuss about it.\r\n\r\nWhen I created this PR, my first idea was to create a \"hack\" inside the download manager that will be able to filter some split(s) without touching any dataset script. Of course, the download manager does not know about splits logic, and thus this trick would only work for some very specific datasets: only the ones containing that pass a dict to the download manager containing only the keys \"train\", \"validation\", \"test\" (or the one passed by the user for advanced users knowing they can do it), e.g. the `natural_questions` dataset (which was one of the targets).\r\n\r\nThe big inconvenient of this approach is that it is not applicable to many datasets (or worse, it should be constantly tweaked to cope with exceptional cases). One exceptional case is the one you pointed out. But I see others:\r\n- the split keys can be different: train, test, dev, val, validation, eval,...\r\n- in `hope_edi` dataset, the split keys are: TRAIN_DOWNLOAD_URL, VALIDATION_DOWNLOAD_URL\r\n- in `few_rel` dataset, the split keys are: train_wiki, val_nyt, val_pubmed,..., pid2name\r\n- in `curiosity_dialogs`, the split keys are: train, val, test, test_zero; this means that for every split we pass, we will also get test_zero\r\n- in `deal_or_no_dialog`, each of the splits URL is passed separately to the download manager, so all splits would be always downloaded\r\n- etc.\r\n\r\nThen after discussing, another idea emerged: pass a `split` parameter to `_split_generators`, which know about the splits logic, so that it can handle which splits are passed to the download manager. This approach is more accurate and can be tweaked so that it works with all the datasets we want. The only inconvenient is that then for every target dataset, we must modify its corresponding `_split_generators` script method.\r\n\r\nMy point is that I don't think it is a good idea to implement both approaches. They could even interfere with each other! \r\n\r\nIf you agree, I would implement ONLY the second one, which is simpler, more consistent and stable and will avoid future problems.",
"Hi @albertvillanova !\r\nYup I agree with you, implementing the 2nd approach seems to be the right solution"
] |
https://api.github.com/repos/huggingface/datasets/issues/2913 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2913/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2913/comments | https://api.github.com/repos/huggingface/datasets/issues/2913/events | https://github.com/huggingface/datasets/issues/2913 | 996,436,368 | I_kwDODunzps47ZGmQ | 2,913 | timit_asr dataset only includes one text phrase | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 2 | 2021-09-14T21:06:07Z | 2021-09-15T08:05:19Z | 2021-09-15T08:05:18Z | null | ## Describe the bug
The dataset 'timit_asr' only includes one text phrase. It only includes the transcription "Would such an act of refusal be useful?" multiple times rather than different phrases.
## Steps to reproduce the bug
Note: I am following the tutorial https://huggingface.co/blog/fine-tune-wav2vec2-english
1. Install the dataset and other packages
```python
!pip install datasets>=1.5.0
!pip install transformers==4.4.0
!pip install soundfile
!pip install jiwer
```
2. Load the dataset
```python
from datasets import load_dataset, load_metric
timit = load_dataset("timit_asr")
```
3. Remove columns that we don't want
```python
timit = timit.remove_columns(["phonetic_detail", "word_detail", "dialect_region", "id", "sentence_type", "speaker_id"])
```
4. Write a short function to display some random samples of the dataset.
```python
from datasets import ClassLabel
import random
import pandas as pd
from IPython.display import display, HTML
def show_random_elements(dataset, num_examples=10):
assert num_examples <= len(dataset), "Can't pick more elements than there are in the dataset."
picks = []
for _ in range(num_examples):
pick = random.randint(0, len(dataset)-1)
while pick in picks:
pick = random.randint(0, len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
display(HTML(df.to_html()))
show_random_elements(timit["train"].remove_columns(["file"]))
```
## Expected results
10 random different transcription phrases.
## Actual results
10 of the same transcription phrase "Would such an act of refusal be useful?"
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.4.1
- Platform: macOS-10.15.7-x86_64-i386-64bit
- Python version: 3.8.5
- PyArrow version: not listed
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2913/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2913/timeline | null | completed | null | null | false | [
"Hi @margotwagner, \r\nThis bug was fixed in #1995. Upgrading the datasets should work (min v1.8.0 ideally)",
"Hi @margotwagner,\r\n\r\nYes, as @bhavitvyamalik has commented, this bug was fixed in `datasets` version 1.5.0. You need to update it, as your current version is 1.4.1:\r\n> Environment info\r\n> - `datasets` version: 1.4.1"
] |
https://api.github.com/repos/huggingface/datasets/issues/1214 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1214/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1214/comments | https://api.github.com/repos/huggingface/datasets/issues/1214/events | https://github.com/huggingface/datasets/pull/1214 | 758,002,786 | MDExOlB1bGxSZXF1ZXN0NTMzMjUyNTgx | 1,214 | adding medical-questions-pairs dataset | [] | closed | false | null | 0 | 2020-12-06T19:30:12Z | 2020-12-09T14:42:53Z | 2020-12-09T14:42:53Z | null | This dataset consists of 3048 similar and dissimilar medical question pairs hand-generated and labeled by Curai's doctors.
Dataset : https://github.com/curai/medical-question-pair-dataset
Paper : https://drive.google.com/file/d/1CHPGBXkvZuZc8hpr46HeHU6U6jnVze-s/view | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1214/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1214/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1214.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1214",
"merged_at": "2020-12-09T14:42:53Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1214.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1214"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4158 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4158/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4158/comments | https://api.github.com/repos/huggingface/datasets/issues/4158/events | https://github.com/huggingface/datasets/pull/4158 | 1,202,376,843 | PR_kwDODunzps42ITg3 | 4,158 | Add AUC ROC Metric | [] | closed | false | null | 1 | 2022-04-12T20:53:28Z | 2022-04-26T19:41:50Z | 2022-04-26T19:35:22Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4158/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4158/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4158.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4158",
"merged_at": "2022-04-26T19:35:22Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4158.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4158"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/101 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/101/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/101/comments | https://api.github.com/repos/huggingface/datasets/issues/101/events | https://github.com/huggingface/datasets/pull/101 | 618,111,651 | MDExOlB1bGxSZXF1ZXN0NDE3ODk5OTQ2 | 101 | [Reddit] add reddit | [] | closed | false | null | 0 | 2020-05-14T10:25:02Z | 2020-05-14T10:27:25Z | 2020-05-14T10:27:24Z | null | - Everything worked fine @mariamabarham. Made my computer nearly crash, but all seems to be working :-) | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/101/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/101/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/101.diff",
"html_url": "https://github.com/huggingface/datasets/pull/101",
"merged_at": "2020-05-14T10:27:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/101.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/101"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1736 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1736/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1736/comments | https://api.github.com/repos/huggingface/datasets/issues/1736/events | https://github.com/huggingface/datasets/pull/1736 | 785,433,854 | MDExOlB1bGxSZXF1ZXN0NTU0NDYyNjYw | 1,736 | Adjust BrWaC dataset features name | [] | closed | false | null | 0 | 2021-01-13T20:39:04Z | 2021-01-14T10:29:38Z | 2021-01-14T10:29:38Z | null | I added this dataset some days ago, and today I used it to train some models and realized that the names of the features aren't so good.
Looking at the current features hierarchy, we have "paragraphs" with a list of "sentences" with a list of "sentences?!". But the actual hierarchy is a "text" with a list of "paragraphs" with a list of "sentences".
I confused myself trying to use the dataset with these names. So I think it's better to change it. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1736/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1736/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1736.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1736",
"merged_at": "2021-01-14T10:29:38Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1736.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1736"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1952 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1952/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1952/comments | https://api.github.com/repos/huggingface/datasets/issues/1952/events | https://github.com/huggingface/datasets/pull/1952 | 817,428,160 | MDExOlB1bGxSZXF1ZXN0NTgwOTIyNjQw | 1,952 | Handle timeouts | [] | closed | false | null | 4 | 2021-02-26T15:02:07Z | 2021-03-01T14:29:24Z | 2021-03-01T14:29:24Z | null | As noticed in https://github.com/huggingface/datasets/issues/1939, timeouts were not properly handled when loading a dataset.
This caused the connection to hang indefinitely when working in a firewalled environment cc @stas00
I added a default timeout, and included an option to our offline environment for tests to be able to simulate both connection errors and timeout errors (previously it was simulating connection errors only).
Now networks calls don't hang indefinitely.
The default timeout is set to 10sec (we might reduce it). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1952/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1952/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1952.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1952",
"merged_at": "2021-03-01T14:29:24Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1952.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1952"
} | true | [
"I never said the calls were hanging indefinitely, what we need is quite different - in the firewalled env with a network, there should be no network calls or they should fail instantly.\r\n\r\nTo make this work I suppose on top of this PR we need:\r\n1. `DATASETS_OFFLINE` env var to force set timeout to 0 globally (or to 0.0001 if 0 has a special meaning of no timeout)\r\n2. `DATASETS_OFFLINE` should guard against failing network calls and not fail the program if it has all the data it needs locally.\r\n\r\nBottom line - if the logic wants to check online if the local file matches online dataset name, let it go wild, but it should fail instantly, recover and use the local file - if one is specified explicitly or cache if there is one. And only if neither was found only then assert.\r\n\r\nI hope this makes sense and is doable.\r\n\r\nI have started on the same approach for transformers https://github.com/huggingface/transformers/pull/10407\r\n\r\nThank you, @lhoestq ",
"Yes that was the first step to add DATASETS_OFFLINE :)\r\n\r\nWith this PR, if a request times out (which couldn't happen before because no time out was set), it falls back on the local files with no error.\r\n\r\nAs you said, setting the timeout to something like 1e-16 makes the requests fail instantly, which is one step forward. One last thing left is to disable request retries and everything will be instant !",
"Ah, fantastic. Thank you for elucidating that this PR is part of a bigger master plan! ",
"Merging this one, then I'll open a new PR for the `DATASETS_OFFLINE` env var :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/1289 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1289/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1289/comments | https://api.github.com/repos/huggingface/datasets/issues/1289/events | https://github.com/huggingface/datasets/pull/1289 | 759,333,684 | MDExOlB1bGxSZXF1ZXN0NTM0MzU2ODUw | 1,289 | Jigsaw toxicity classification dataset added | [] | closed | false | null | 0 | 2020-12-08T10:38:51Z | 2020-12-08T15:17:48Z | 2020-12-08T15:17:48Z | null | The dataset requires manually downloading data from Kaggle. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1289/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1289/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1289.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1289",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1289.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1289"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5869 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5869/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5869/comments | https://api.github.com/repos/huggingface/datasets/issues/5869/events | https://github.com/huggingface/datasets/issues/5869 | 1,711,990,003 | I_kwDODunzps5mCuTz | 5,869 | Image Encoding Issue when submitting a Parquet Dataset | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 16 | 2023-05-16T09:42:58Z | 2023-06-16T12:48:38Z | 2023-06-16T09:30:48Z | null | ### Describe the bug
Hello,
I'd like to report an issue related to pushing a dataset represented as a Parquet file to a dataset repository using Dask. Here are the details:
We attempted to load an example dataset in Parquet format from the Hugging Face (HF) filesystem using Dask with the following code snippet:
```
import dask.dataframe as dd
df = dd.read_parquet("hf://datasets/lambdalabs/pokemon-blip-captions",index=False)
```
In this dataset, the "image" column is represented as a dictionary/struct with the format:
```
df = df.compute()
df["image"].iloc[0].keys()
-> dict_keys(['bytes', 'path'])
```
I think this is the format encoded by the [`Image`](https://huggingface.co/docs/datasets/v2.0.0/en/package_reference/main_classes#datasets.Image) feature extractor from datasets to format suitable for Arrow.
The next step was to push the dataset to a repository that I created:
```
dd.to_parquet(dask_df, path = "hf://datasets/philippemo/dummy_dataset/data")
```
However, after pushing the dataset using Dask, the "image" column is now represented as the encoded dictionary `(['bytes', 'path'])`, and the images are not properly visualized. You can find the dataset here: [Link to the problematic dataset](https://huggingface.co/datasets/philippemo/dummy_dataset).
It's worth noting that both the original dataset and the one submitted with Dask have the same schema with minor alterations related to metadata:
**[ Schema of original dummy example.](https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions/blob/main/data/train-00000-of-00001-566cc9b19d7203f8.parquet)**
```
image: struct<bytes: binary, path: null>
child 0, bytes: binary
child 1, path: null
text: string
```
**[ Schema of pushed dataset with dask](https://huggingface.co/datasets/philippemo/dummy_dataset/blob/main/data/part.0.parquet)**
```
image: struct<bytes: binary, path: null>
child 0, bytes: binary
child 1, path: null
text: string
```
This issue seems to be related to an encoding type that occurs when pushing a model to the hub. Normally, models should be represented as an HF dataset before pushing, but we are working with an example where we need to push large datasets using Dask.
Could you please provide clarification on how to resolve this issue?
Thank you!
### Reproduction
To get the schema I downloaded the parquet files and used pyarrow.parquet to read the schema
```
import pyarrow.parquet
pyarrow.parquet.read_schema(<path_to_parquet>, memory_map=True)
```
### Logs
_No response_
### System info
```shell
- huggingface_hub version: 0.14.1
- Platform: Linux-5.19.0-41-generic-x86_64-with-glibc2.35
- Python version: 3.10.6
- Running in iPython ?: No
- Running in notebook ?: No
- Running in Google Colab ?: No
- Token path ?: /home/philippe/.cache/huggingface/token
- Has saved token ?: True
- Who am I ?: philippemo
- Configured git credential helpers: cache
- FastAI: N/A
- Tensorflow: N/A
- Torch: N/A
- Jinja2: 3.1.2
- Graphviz: N/A
- Pydot: N/A
- Pillow: 9.4.0
- hf_transfer: N/A
- gradio: N/A
- ENDPOINT: https://huggingface.co
- HUGGINGFACE_HUB_CACHE: /home/philippe/.cache/huggingface/hub
- HUGGINGFACE_ASSETS_CACHE: /home/philippe/.cache/huggingface/assets
- HF_TOKEN_PATH: /home/philippe/.cache/huggingface/token
- HF_HUB_OFFLINE: False
- HF_HUB_DISABLE_TELEMETRY: False
- HF_HUB_DISABLE_PROGRESS_BARS: None
- HF_HUB_DISABLE_SYMLINKS_WARNING: False
- HF_HUB_DISABLE_EXPERIMENTAL_WARNING: False
- HF_HUB_DISABLE_IMPLICIT_TOKEN: False
- HF_HUB_ENABLE_HF_TRANSFER: False
```
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5869/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5869/timeline | null | completed | null | null | false | [
"Hi @PhilippeMoussalli thanks for opening a detailed issue. It seems the issue is more related to the `datasets` library so I'll ping @lhoestq @mariosasko on this one :) \n\n(edit: also can one of you move the issue to the datasets repo? Thanks in advance 🙏)",
"Hi ! The `Image()` info is stored in the **schema metadata**. More precisely there should be a \"huggingface\" field in the schema metadata that contains the `datasets` feature type of each column.\r\n\r\nTo fix your issue, you can use the same schema as the original Parquet files to write the new ones. You can also get the schema with metadata from a `Features` object, e.g.\r\n\r\n```python\r\nfrom datasets import Features, Image, Value\r\n\r\nfeatures = Features({\"image\": Image(), \"text\": Value(\"string\")})\r\nschema = features.arrow_schema\r\nprint(schema.metadata)\r\n# {b'huggingface': b'{\"info\": {\"features\": {\"image\": {\"_type\": \"Image\"}, \"text\": {\"dtype\": \"string\", \"_type\": \"Value\"}}}}'}\r\n```",
"It appears that the parquet files at `hf://datasets/lambdalabs/pokemon-blip-captions` don't have this metadata, and it is defined in the dataset_infos.json instead (legacy).\r\n\r\nYou can get the right schema with the HF metadata this way:\r\n\r\n```python\r\nfrom datasets import load_dataset_builder\r\n\r\nfeatures = load_dataset_builder(\"lambdalabs/pokemon-blip-captions\").info.features\r\nschema = features.arrow_schema\r\n```",
"Btw in the future we might add support for an dedicated Image extension type in Arrow so that you won't need to add the schema metadata anymore ;)",
"Thanks @Wauplin @lhoestq for the quick reply :)! \r\n\r\nI tried your approach by passing the huggingface schema to the dask writer \r\n\r\n```\r\nfrom datasets import Features, Image, Value\r\ndf = dd.read_parquet(f\"hf://datasets/lambdalabs/pokemon-blip-captions\",index=False)\r\nfeatures = Features({\"image\": Image(), \"text\": Value(\"string\")})\r\nschema = features.arrow_schema\r\ndd.to_parquet(df, path = \"hf://datasets/philippemo/dummy_dataset/data\", schema=schema)\r\n```\r\nAt first it didn't work as I was not able to visualize the images, so then I manually added the `dataset_infos.json` from the example dataset and it worked :)\r\n\r\nHowever, It's not very ideal since there are some metadata in that file that need to be computed in order to load the data properly such as `num_of_bytes` and `num_examples` which might be unknown in my use case. \r\n\r\n\r\n\r\nDo you have any pointers there? you mentioned that `datasets_info.json` will be deprecated/legacy. Could you point me to some example image datasets on the hub that are stored as parquet and don't have the `datasets_info.json`?\r\n\r\n",
"You don't need the dataset_infos.json file as long as you have the schema with HF metadata ;)\r\nI could also check that it works fine myself on the git revision without the dataset_infos.json file.\r\n\r\nWhat made you think it didn't work ?",
"> You don't need the dataset_infos.json file as long as you have the schema with HF metadata ;) I could also check that it works fine myself on the git revision without the dataset_infos.json file.\r\n> \r\n> What made you think it didn't work ?\r\n\r\nThose are two identical dataset repos where both were pushed with dask with the specified schema you mentioned above. I then uploaded the `dataset_infos.json` manually taken from the original example dataset into one of them. \r\n\r\n* **With schema**: https://huggingface.co/datasets/philippemo/dummy_dataset_with_schema\r\n* **Without schema**: https://huggingface.co/datasets/philippemo/dummy_dataset_without_schema\r\n\r\nYou can see that in the examples without schema the images fail to render properly. When loaded with `datasets` they return an dict and not a Pillow Image ",
"I see ! I think it's a bug on our side - it should work without the metadata - let me investigate",
"Alright, it's fixed: https://huggingface.co/datasets/philippemo/dummy_dataset_without_schema\r\n\r\nIt shows the image correctly now - even without the extra metadata :)",
"Thanks @lhoestq! \r\nI tested pushing a dataset again without the metadata and it works perfectly! \r\nI appreciate the help",
"Hi @lhoestq, \r\n\r\nI'v tried pushing another dataset again and I think the issue reappeared again: \r\n\r\n```\r\ndf = dd.read_parquet(f\"hf://datasets/lambdalabs/pokemon-blip-captions\")\r\nfeatures = datasets.Features({\"image\": datasets.Image(), \"text\": datasets.Value(\"string\")})\r\nschema = features.arrow_schema\r\ndd.to_parquet(df, path = \"hf://datasets/philippemo/dummy_dataset_without_schema_12_06/data\", schema=schema)\r\n```\r\n\r\nHere is the dataset: \r\n https://huggingface.co/datasets/philippemo/dummy_dataset_without_schema_12_06\r\nThe one that was working 2 weeks ago still seems to be intact though, it might be that It rendered properly when it was initially submitted and after this something was reverted from your side:\r\nhttps://huggingface.co/datasets/philippemo/dummy_dataset_without_schema\r\n\r\nIt's weird because nothing really changed from the implementation, might be another issue in the hub backend. Do you have any pointers on how to resolve this? ",
"We're doing some changes in the way we're handling image parquet datasets right now. We'll include the fix from https://github.com/huggingface/datasets/pull/5921 in the new datasets-server version in the coming days",
"alright thanks for the update :), would that be part of the new release of datasets or is it something separate? if so, where can I track it? ",
"Once the new version of `datasets` is released (tomorrow probably) we'll open an issue on https://github.com/huggingface/datasets-server to update to this version :)",
"Alright we did the update :) This is fixed for good now",
"Yes thanks 🎉🎉🎉"
] |
https://api.github.com/repos/huggingface/datasets/issues/4262 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4262/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4262/comments | https://api.github.com/repos/huggingface/datasets/issues/4262/events | https://github.com/huggingface/datasets/pull/4262 | 1,222,130,749 | PR_kwDODunzps43IOye | 4,262 | Add YAML tags to Dataset Card rotten tomatoes | [] | closed | false | null | 1 | 2022-05-01T11:59:08Z | 2022-05-03T14:27:33Z | 2022-05-03T14:20:35Z | null | The dataset card for the rotten tomatoes / MR movie review dataset had some missing YAML tags. Hopefully, this also improves the visibility of this dataset now that paperswithcode and huggingface link to eachother. | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4262/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4262/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4262.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4262",
"merged_at": "2022-05-03T14:20:35Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4262.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4262"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/5981 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5981/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5981/comments | https://api.github.com/repos/huggingface/datasets/issues/5981/events | https://github.com/huggingface/datasets/issues/5981 | 1,770,310,087 | I_kwDODunzps5phMnH | 5,981 | Only two cores are getting used in sagemaker with pytorch 3.10 kernel | [] | closed | false | null | 3 | 2023-06-22T19:57:31Z | 2023-07-24T11:54:52Z | 2023-07-24T11:54:52Z | null | ### Describe the bug
When using the newer pytorch 3.10 kernel, only 2 cores are being used by huggingface filter and map functions. The Pytorch 3.9 kernel would use as many cores as specified in the num_proc field.
We have solved this in our own code by placing the following snippet in the code that is called inside subprocesses:
```os.sched_setaffinity(0, {i for i in range(1000)})```
The problem, as near as we can tell, us that once upon a time, cpu affinity was set using a bitmask ("0xfffff" and the like), and affinity recently changed to a list of processors rather than to using the mask. As such, only processors 1 and 17 are shown to be working in htop.

When running functions via `map`, the above resetting of affinity works to spread across the cores. When using `filter`, however, only two cores are active.
### Steps to reproduce the bug
Repro steps:
1. Create an aws sagemaker instance
2. use the pytorch 3_10 kernel
3. Load a dataset
4. run a filter operation
5. watch as only 2 cores are used when num_proc > 2
6. run a map operation
7. watch as only 2 cores are used when num_proc > 2
8. run a map operation with processor affinity reset inside the function called via map
9. Watch as all cores run
### Expected behavior
All specified cores are used via the num_proc argument.
### Environment info
AWS sagemaker with the following init script run in the terminal after instance creation:
conda init bash
bash
conda activate pytorch_p310
pip install Wand PyPDF pytesseract datasets seqeval pdfplumber transformers pymupdf sentencepiece timm donut-python accelerate optimum xgboost
python -m pip install 'git+https://github.com/facebookresearch/detectron2.git'
sudo yum -y install htop
sudo yum -y update
sudo yum -y install wget libstdc++ autoconf automake libtool autoconf-archive pkg-config gcc gcc-c++ make libjpeg-devel libpng-devel libtiff-devel zlib-devel | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5981/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5981/timeline | null | completed | null | null | false | [
"I think it's more likely that this issue is related to PyTorch than Datasets, as PyTorch (on import) registers functions to execute when forking a process. Maybe this is the culprit: https://github.com/pytorch/pytorch/issues/99625",
"From reading that ticket, it may be down in mkl? Is it worth hotfixing in the meantime, with the express intention of turning it off? I know that's a horribly crufty solution, but it's also deeply frustrating to be limited to 2 cores for operations as simple as filtration.",
"This is too specific and unrelated to `datasets`, so this shouldn't be fixed here."
] |
https://api.github.com/repos/huggingface/datasets/issues/2790 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2790/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2790/comments | https://api.github.com/repos/huggingface/datasets/issues/2790/events | https://github.com/huggingface/datasets/pull/2790 | 967,772,181 | MDExOlB1bGxSZXF1ZXN0NzA5OTI3NjM2 | 2,790 | Fix typo in test_dataset_common | [] | closed | false | null | 0 | 2021-08-12T01:10:29Z | 2021-08-12T11:31:29Z | 2021-08-12T11:31:29Z | null | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2790/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2790/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2790.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2790",
"merged_at": "2021-08-12T11:31:29Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2790.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2790"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/5322 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5322/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5322/comments | https://api.github.com/repos/huggingface/datasets/issues/5322/events | https://github.com/huggingface/datasets/pull/5322 | 1,471,502,162 | PR_kwDODunzps5EEeQP | 5,322 | Raise error for `.tar` archives in the same way as for `.tar.gz` and `.tgz` in `_get_extraction_protocol` | [] | closed | false | null | 1 | 2022-12-01T15:19:28Z | 2022-12-14T16:37:16Z | 2022-12-14T16:33:30Z | null | Currently `download_and_extract` doesn't throw an error when it is used with files with `.tar` extension in streaming mode because `_get_extraction_protocol` doesn't do it (like it does for `tar.gz` and `tgz`). `_get_extraction_protocol` returns formatted url as if we support tar protocol but we don't.
That means that in dataset scripts `.tar` files would be attempted to load and fail during examples generation (after `download_and_extract` execution). So this PR raises error for `tar` files too.
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5322/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5322/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5322.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5322",
"merged_at": "2022-12-14T16:33:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5322.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5322"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/2968 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2968/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2968/comments | https://api.github.com/repos/huggingface/datasets/issues/2968/events | https://github.com/huggingface/datasets/issues/2968 | 1,007,209,488 | I_kwDODunzps48CMwQ | 2,968 | `DatasetDict` cannot be exported to parquet if the splits have different features | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 9 | 2021-09-25T22:18:39Z | 2021-10-07T22:47:42Z | 2021-10-07T22:47:26Z | null | ## Describe the bug
I'm trying to use parquet as a means of serialization for both `Dataset` and `DatasetDict` objects. Using `to_parquet` alongside `from_parquet` or `load_dataset` for a `Dataset` works perfectly.
For `DatasetDict`, I use `to_parquet` on each split to save the parquet files in individual folders representing individual splits. This works too, as long as the splits have identical features. If a split has different features to neighboring splits, then loading the dataset will fail: a single schema is used to load both splits, resulting in a failure to load the second parquet file.
## Steps to reproduce the bug
The following works as expected:
```python
from datasets import load_dataset
ds = load_dataset("lhoestq/custom_squad")
ds['train'].to_parquet("./ds/train/split.parquet")
ds['validation'].to_parquet("./ds/validation/split.parquet")
brand_new_dataset = load_dataset("ds")
```
Modifying a single split to add a new feature ends up in a crash:
```python
from datasets import load_dataset
ds = load_dataset("lhoestq/custom_squad")
def identical_answers(e):
e['identical_answers'] = len(set(e['answers']['text'])) == 1
return e
ds['validation'] = ds['validation'].map(identical_answers)
ds['train'].to_parquet("./ds/train/split.parquet")
ds['validation'].to_parquet("./ds/validation/split.parquet")
brand_new_dataset = load_dataset("ds")
```
```
File "/home/lysandre/.config/JetBrains/PyCharm2021.2/scratches/datasets/upload_dataset.py", line 26, in <module>
brand_new_dataset = load_dataset("ds")
File "/home/lysandre/Workspaces/Python/datasets/src/datasets/load.py", line 1151, in load_dataset
builder_instance.download_and_prepare(
File "/home/lysandre/Workspaces/Python/datasets/src/datasets/builder.py", line 642, in download_and_prepare
self._download_and_prepare(
File "/home/lysandre/Workspaces/Python/datasets/src/datasets/builder.py", line 732, in _download_and_prepare
self._prepare_split(split_generator, **prepare_split_kwargs)
File "/home/lysandre/Workspaces/Python/datasets/src/datasets/builder.py", line 1194, in _prepare_split
writer.write_table(table)
File "/home/lysandre/Workspaces/Python/datasets/src/datasets/arrow_writer.py", line 428, in write_table
pa_table = pa.Table.from_arrays([pa_table[name] for name in self._schema.names], schema=self._schema)
File "/home/lysandre/Workspaces/Python/datasets/src/datasets/arrow_writer.py", line 428, in <listcomp>
pa_table = pa.Table.from_arrays([pa_table[name] for name in self._schema.names], schema=self._schema)
File "pyarrow/table.pxi", line 1257, in pyarrow.lib.Table.__getitem__
File "pyarrow/table.pxi", line 1833, in pyarrow.lib.Table.column
File "pyarrow/table.pxi", line 1808, in pyarrow.lib.Table._ensure_integer_index
KeyError: 'Field "identical_answers" does not exist in table schema'
```
It does work, however, to use the `save_to_disk` and `load_from_disk` methods:
```py
from datasets import load_from_disk
ds = load_dataset("lhoestq/custom_squad")
def identical_answers(e):
e['identical_answers'] = len(set(e['answers']['text'])) == 1
return e
ds['validation'] = ds['validation'].map(identical_answers)
ds.save_to_disk("local_path")
brand_new_dataset = load_from_disk("local_path")
```
## Expected results
The saving works correctly - but the loading fails. I would expect either an error when saving or an error-less instantiation of the dataset through the parquet files.
If it's helpful, I've traced a possible patch to the `write_table` method here:
https://github.com/huggingface/datasets/blob/26ff41aa3a642e46489db9e95be1e9a8c4e64bea/src/datasets/arrow_writer.py#L424-L425
The writer is built only if the parquet writer is `None`, but I expect we would want to build a new writer as the table schema has changed. Furthermore, it relies on having the property `update_features` set to `True` in order to update the features:
https://github.com/huggingface/datasets/blob/26ff41aa3a642e46489db9e95be1e9a8c4e64bea/src/datasets/arrow_writer.py#L254-L255
but the `ArrowWriter` is instantiated without that option in the `_prepare_split` method of the `ArrowBasedBuilder`:
https://github.com/huggingface/datasets/blob/26ff41aa3a642e46489db9e95be1e9a8c4e64bea/src/datasets/builder.py#L1190
Updating these two parts to recreate a schema on each split results in an error that is, unfortunately, out of my expertise:
```
File "/home/lysandre/.config/JetBrains/PyCharm2021.2/scratches/datasets/upload_dataset.py", line 27, in <module>
brand_new_dataset = load_dataset("ds")
File "/home/lysandre/Workspaces/Python/datasets/src/datasets/load.py", line 1163, in load_dataset
ds = builder_instance.as_dataset(split=split, ignore_verifications=ignore_verifications, in_memory=keep_in_memory)
File "/home/lysandre/Workspaces/Python/datasets/src/datasets/builder.py", line 819, in as_dataset
datasets = utils.map_nested(
File "/home/lysandre/Workspaces/Python/datasets/src/datasets/utils/py_utils.py", line 207, in map_nested
mapped = [
File "/home/lysandre/Workspaces/Python/datasets/src/datasets/utils/py_utils.py", line 208, in <listcomp>
_single_map_nested((function, obj, types, None, True))
File "/home/lysandre/Workspaces/Python/datasets/src/datasets/utils/py_utils.py", line 143, in _single_map_nested
return function(data_struct)
File "/home/lysandre/Workspaces/Python/datasets/src/datasets/builder.py", line 850, in _build_single_dataset
ds = self._as_dataset(
File "/home/lysandre/Workspaces/Python/datasets/src/datasets/builder.py", line 920, in _as_dataset
dataset_kwargs = ArrowReader(self._cache_dir, self.info).read(
File "/home/lysandre/Workspaces/Python/datasets/src/datasets/arrow_reader.py", line 217, in read
return self.read_files(files=files, original_instructions=instructions, in_memory=in_memory)
File "/home/lysandre/Workspaces/Python/datasets/src/datasets/arrow_reader.py", line 238, in read_files
pa_table = self._read_files(files, in_memory=in_memory)
File "/home/lysandre/Workspaces/Python/datasets/src/datasets/arrow_reader.py", line 173, in _read_files
pa_table: Table = self._get_table_from_filename(f_dict, in_memory=in_memory)
File "/home/lysandre/Workspaces/Python/datasets/src/datasets/arrow_reader.py", line 308, in _get_table_from_filename
table = ArrowReader.read_table(filename, in_memory=in_memory)
File "/home/lysandre/Workspaces/Python/datasets/src/datasets/arrow_reader.py", line 327, in read_table
return table_cls.from_file(filename)
File "/home/lysandre/Workspaces/Python/datasets/src/datasets/table.py", line 458, in from_file
table = _memory_mapped_arrow_table_from_file(filename)
File "/home/lysandre/Workspaces/Python/datasets/src/datasets/table.py", line 45, in _memory_mapped_arrow_table_from_file
pa_table = opened_stream.read_all()
File "pyarrow/ipc.pxi", line 563, in pyarrow.lib.RecordBatchReader.read_all
File "pyarrow/error.pxi", line 114, in pyarrow.lib.check_status
OSError: Header-type of flatbuffer-encoded Message is not RecordBatch.
```
## Environment info
- `datasets` version: 1.12.2.dev0
- Platform: Linux-5.14.7-arch1-1-x86_64-with-glibc2.33
- Python version: 3.9.7
- PyArrow version: 5.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2968/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2968/timeline | null | completed | null | null | false | [
"This is because you have to specify which split corresponds to what file:\r\n```python\r\ndata_files = {\"train\": \"train/split.parquet\", \"validation\": \"validation/split.parquet\"}\r\nbrand_new_dataset_2 = load_dataset(\"ds\", data_files=data_files)\r\n```\r\n\r\nOtherwise it tries to concatenate the two splits, and it fails because they don't have the same features.\r\n\r\nIt works with save_to_disk/load_from_disk because it also stores json files that contain the information about which files goes into which split",
"Wonderful, thanks for the help!",
"I may be mistaken but I think the following doesn't work either:\r\n\r\n```python\r\nfrom datasets import load_dataset\r\n\r\nds = load_dataset(\"lhoestq/custom_squad\")\r\n\r\n\r\ndef identical_answers(e):\r\n e['identical_answers'] = len(set(e['answers']['text'])) == 1\r\n return e\r\n\r\n\r\nds['validation'] = ds['validation'].map(identical_answers)\r\nds['train'].to_parquet(\"./ds/train/split.parquet\")\r\nds['validation'].to_parquet(\"./ds/validation/split.parquet\")\r\n\r\ndata_files = {\"train\": \"train/split.parquet\", \"validation\": \"validation/split.parquet\"}\r\nbrand_new_dataset_2 = load_dataset(\"ds\", data_files=data_files)\r\n```",
"It works on my side as soon as the directories named `ds/train` and `ds/validation` exist (otherwise it returns a FileNotFoundError). What error are you getting ?",
"Also we may introduce a default mapping for the data files:\r\n```python\r\n{\r\n \"train\": [\"*train*\"],\r\n \"test\": [\"*test*\"],\r\n \"validation\": [\"*dev*\", \"valid\"],\r\n}\r\n```\r\nthis way if you name your files according to the splits you won't have to specify the data_files parameter. What do you think ?\r\n\r\nI moved this discussion to #3027 ",
"I'm getting the following error:\r\n\r\n```\r\nDownloading and preparing dataset custom_squad/plain_text to /home/lysandre/.cache/huggingface/datasets/lhoestq___custom_squad)/plain_text/1.0.0/397916d1ae99584877e0fb4f5b8b6f01e66fcbbeff4d178afb30c933a8d0d93a...\r\n100%|██████████| 2/2 [00:00<00:00, 7760.04it/s]\r\n100%|██████████| 2/2 [00:00<00:00, 2020.38it/s]\r\n 0%| | 0/2 [00:00<?, ?it/s]Traceback (most recent call last):\r\n File \"<input>\", line 1, in <module>\r\n File \"/opt/pycharm-professional/plugins/python/helpers/pydev/_pydev_bundle/pydev_umd.py\", line 198, in runfile\r\n pydev_imports.execfile(filename, global_vars, local_vars) # execute the script\r\n File \"/opt/pycharm-professional/plugins/python/helpers/pydev/_pydev_imps/_pydev_execfile.py\", line 18, in execfile\r\n exec(compile(contents+\"\\n\", file, 'exec'), glob, loc)\r\n File \"/home/lysandre/.config/JetBrains/PyCharm2021.2/scratches/datasets/upload_dataset.py\", line 12, in <module>\r\n ds = load_dataset(\"lhoestq/custom_squad\")\r\n File \"/home/lysandre/Workspaces/Python/datasets/src/datasets/load.py\", line 1207, in load_dataset\r\n ds = builder_instance.as_dataset(split=split, ignore_verifications=ignore_verifications, in_memory=keep_in_memory)\r\n File \"/home/lysandre/Workspaces/Python/datasets/src/datasets/builder.py\", line 823, in as_dataset\r\n datasets = utils.map_nested(\r\n File \"/home/lysandre/Workspaces/Python/datasets/src/datasets/utils/py_utils.py\", line 207, in map_nested\r\n mapped = [\r\n File \"/home/lysandre/Workspaces/Python/datasets/src/datasets/utils/py_utils.py\", line 208, in <listcomp>\r\n _single_map_nested((function, obj, types, None, True))\r\n File \"/home/lysandre/Workspaces/Python/datasets/src/datasets/utils/py_utils.py\", line 143, in _single_map_nested\r\n return function(data_struct)\r\n File \"/home/lysandre/Workspaces/Python/datasets/src/datasets/builder.py\", line 854, in _build_single_dataset\r\n ds = self._as_dataset(\r\n File \"/home/lysandre/Workspaces/Python/datasets/src/datasets/builder.py\", line 924, in _as_dataset\r\n dataset_kwargs = ArrowReader(self._cache_dir, self.info).read(\r\n File \"/home/lysandre/Workspaces/Python/datasets/src/datasets/arrow_reader.py\", line 217, in read\r\n return self.read_files(files=files, original_instructions=instructions, in_memory=in_memory)\r\n File \"/home/lysandre/Workspaces/Python/datasets/src/datasets/arrow_reader.py\", line 238, in read_files\r\n pa_table = self._read_files(files, in_memory=in_memory)\r\n File \"/home/lysandre/Workspaces/Python/datasets/src/datasets/arrow_reader.py\", line 173, in _read_files\r\n pa_table: Table = self._get_table_from_filename(f_dict, in_memory=in_memory)\r\n File \"/home/lysandre/Workspaces/Python/datasets/src/datasets/arrow_reader.py\", line 308, in _get_table_from_filename\r\n table = ArrowReader.read_table(filename, in_memory=in_memory)\r\n File \"/home/lysandre/Workspaces/Python/datasets/src/datasets/arrow_reader.py\", line 327, in read_table\r\n return table_cls.from_file(filename)\r\n File \"/home/lysandre/Workspaces/Python/datasets/src/datasets/table.py\", line 458, in from_file\r\n table = _memory_mapped_arrow_table_from_file(filename)\r\n File \"/home/lysandre/Workspaces/Python/datasets/src/datasets/table.py\", line 45, in _memory_mapped_arrow_table_from_file\r\n pa_table = opened_stream.read_all()\r\n File \"pyarrow/ipc.pxi\", line 563, in pyarrow.lib.RecordBatchReader.read_all\r\n File \"pyarrow/error.pxi\", line 114, in pyarrow.lib.check_status\r\nOSError: Header-type of flatbuffer-encoded Message is not RecordBatch.\r\n```\r\n\r\nTried on current master, after updating latest dependencies and obtained the same result",
"The proposal in #3027 sounds good to me!",
"I just tried again on colab by installing `datasets` from source with pyarrow 3.0.0 and didn't get any error.\r\n\r\nYou error seems to happen when doing\r\n```python\r\nds = load_dataset(\"lhoestq/custom_squad\")\r\n```\r\n\r\nMore specifically it fails when trying to read the arrow file that just got generated. I haven't issues like this before. Can you make sure you have a recent version of `pyarrow` ? Maybe it was an old version that wrote the arrow file and some header was missing.",
"Thank you for your pointer! This seems to have been linked to Python 3.9.7: it works flawlessly with Python 3.8.6. This can be closed, thanks a lot for your help."
] |
https://api.github.com/repos/huggingface/datasets/issues/3813 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3813/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3813/comments | https://api.github.com/repos/huggingface/datasets/issues/3813/events | https://github.com/huggingface/datasets/issues/3813 | 1,158,474,859 | I_kwDODunzps5FDOxr | 3,813 | Add MetaShift dataset | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
},
{
"color": "bfdadc",
"default": false,
"description": "Vision datasets",
"id": 3608941089,
"name": "vision",
"node_id": "LA_kwDODunzps7XHBIh",
"url": "https://api.github.com/repos/huggingface/datasets/labels/vision"
}
] | closed | false | null | 7 | 2022-03-03T14:26:45Z | 2022-04-10T13:39:59Z | 2022-04-10T13:39:59Z | null | ## Adding a Dataset
- **Name:** MetaShift
- **Description:** collection of 12,868 sets of natural images across 410 classes-
- **Paper:** https://arxiv.org/abs/2202.06523v1
- **Data:** https://github.com/weixin-liang/metashift
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3813/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3813/timeline | null | completed | null | null | false | [
"I would like to take this up and give it a shot. Any image specific - dataset guidelines to keep in mind ? Thank you.",
"#self-assign",
"I've started working on adding this dataset. I require some inputs on the following : \r\n\r\nRef for the initial draft [here](https://github.com/dnaveenr/datasets/blob/add_metashift_dataset/datasets/metashift/metashift.py)\r\n1. The dataset does not have a typical - train/test/val split. What do we do for the _split_generators() function ? How do we go about this ?\r\n2. This dataset builds on the Visual Genome dataset, using a metadata file. The dataset is generated using generate_full_MetaShift.py script. By default, the authors choose to generate the dataset only for a SELECTED_CLASSES. The following script is used : \r\nCode : https://github.com/Weixin-Liang/MetaShift/blob/main/dataset/generate_full_MetaShift.py \r\nInfo : https://metashift.readthedocs.io/en/latest/sub_pages/download_MetaShift.html#generate-the-full-metashift-dataset\r\nCan I just copy over the required functions into the metashift.py to generate the dataset ?\r\n3. How do we complete the _generate_examples for this dataset ?\r\n\r\nThe user has the ability to use default selected classes, get the complete dataset or add more specific additional classes. I think config would be a good option here.\r\n\r\nInputs, suggestions would be helpful. Thank you.",
"I think @mariosasko and @lhoestq should be able to help here 😄 ",
"Hi ! Thanks for adding this dataset :) Let me answer your questions:\r\n\r\n1. in this case you can put everything in the \"train\" split\r\n2. Yes you can copy the script (provided you also include the MIT license of the code in the file header for example). Though we ideally try to not create new directories nor files when generating dataset, so if possible this script should be adapted to not create the file structure they mentioned, but instead yield the images one by one in `_generate_examples`. Let me know if you think this is feasible\r\n3. see point 2 haha\r\n\r\n> The user has the ability to use default selected classes, get the complete dataset or add more specific additional classes. I think config would be a good option here.\r\n\r\nYup ! We can also define a `selected_classes` parameter such that users can do\r\n```python\r\nload_dataset(\"metashift\", selected_classes=[\"cat\", \"dog\", ...])\r\n```",
"Great. This is helpful. Thanks @lhoestq .\r\nRegarding Point 2, I'll try using yield instead of creating the directories and see if its feasible. selected_classes config sounds good.",
"Closed via #3900 "
] |
https://api.github.com/repos/huggingface/datasets/issues/5258 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5258/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5258/comments | https://api.github.com/repos/huggingface/datasets/issues/5258/events | https://github.com/huggingface/datasets/issues/5258 | 1,453,516,636 | I_kwDODunzps5Woudc | 5,258 | Restore order of split names in dataset_info for canonical datasets | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | 3 | 2022-11-17T15:13:15Z | 2023-02-16T09:49:05Z | 2022-11-19T06:51:37Z | null | After a bulk edit of canonical datasets to create the YAML `dataset_info` metadata, the split names were accidentally sorted alphabetically. See for example:
- https://huggingface.co/datasets/bc2gm_corpus/commit/2384629484401ecf4bb77cd808816719c424e57c
Note that this order is the one appearing in the preview of the datasets.
I'm making a bulk edit to align the order of the splits appearing in the metadata info with the order appearing in the loading script.
Related to:
- #5202 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5258/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5258/timeline | null | completed | null | null | false | [
"The bulk edit is running...\r\n\r\nSee for example: \r\n- A single config: https://huggingface.co/datasets/acronym_identification/discussions/2\r\n- Multiple configs: https://huggingface.co/datasets/babi_qa/discussions/1",
"TODO: Add \"dataset_info\" YAML metadata to:\r\n- [x] \"chr_en\" has no metadata JSON file, nor \"dataset_info\" YAML tag in its card\r\n - Fixing PR: https://huggingface.co/datasets/chr_en/discussions/1 \r\n- [x] \"conll2000\" has no metadata JSON file, but it has \"dataset_info\" YAML tag in its card\r\n- [x] \"crime_and_punish\" has no metadata JSON file, but it has \"dataset_info\" YAML tag in its card\r\n- [x] \"dart\" has no metadata JSON file, but it has \"dataset_info\" YAML tag in its card\r\n- [x] \"iwslt2017\" has no metadata JSON file, but it has \"dataset_info\" YAML tag in its card\r\n- [ ] \"mc4\" has no metadata JSON file, nor \"dataset_info\" YAML tag in its card\r\n- [ ] \"the_pile\" has no metadata JSON file, nor \"dataset_info\" YAML tag in its card\r\n- [ ] \"timit_asr\" has no metadata JSON file, nor \"dataset_info\" YAML tag in its card",
"The bulk edit is finished."
] |
https://api.github.com/repos/huggingface/datasets/issues/1006 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1006/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1006/comments | https://api.github.com/repos/huggingface/datasets/issues/1006/events | https://github.com/huggingface/datasets/pull/1006 | 755,362,766 | MDExOlB1bGxSZXF1ZXN0NTMxMDg3NTIy | 1,006 | add yahoo_answers_topics | [] | closed | false | null | 1 | 2020-12-02T15:16:13Z | 2020-12-03T16:44:38Z | 2020-12-02T18:01:32Z | null | This PR adds yahoo answers topic classification dataset.
More info:
https://github.com/LC-John/Yahoo-Answers-Topic-Classification-Dataset
cc @joeddav, @yjernite | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1006/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1006/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1006.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1006",
"merged_at": "2020-12-02T18:01:32Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1006.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1006"
} | true | [
"feel free to merge/ping me to merge if there're no more changes to do"
] |
https://api.github.com/repos/huggingface/datasets/issues/2421 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2421/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2421/comments | https://api.github.com/repos/huggingface/datasets/issues/2421/events | https://github.com/huggingface/datasets/pull/2421 | 905,549,756 | MDExOlB1bGxSZXF1ZXN0NjU2NjIwMTM3 | 2,421 | doc: fix typo HF_MAX_IN_MEMORY_DATASET_SIZE_IN_BYTES | [] | closed | false | null | 0 | 2021-05-28T14:52:10Z | 2021-06-04T09:52:45Z | 2021-06-04T09:52:45Z | null | MAX_MEMORY_DATASET_SIZE_IN_BYTES should be HF_MAX_MEMORY_DATASET_SIZE_IN_BYTES | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2421/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2421/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2421.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2421",
"merged_at": "2021-06-04T09:52:45Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2421.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2421"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4889 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4889/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4889/comments | https://api.github.com/repos/huggingface/datasets/issues/4889/events | https://github.com/huggingface/datasets/issues/4889 | 1,349,758,525 | I_kwDODunzps5Qc649 | 4,889 | torchaudio 11.0 yields different results than torchaudio 12.1 when loading MP3 | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 5 | 2022-08-24T16:54:43Z | 2023-03-02T15:33:05Z | 2023-03-02T15:33:04Z | null | ## Describe the bug
When loading Common Voice with torchaudio 0.11.0 the results are different to 0.12.1 which leads to problems in transformers see: https://github.com/huggingface/transformers/pull/18749
## Steps to reproduce the bug
If you run the following code once with `torchaudio==0.11.0+cu102` and `torchaudio==0.12.1+cu102` you can see that the tensors differ. This is a pretty big breaking change and makes some integration tests fail in Transformers.
```python
#!/usr/bin/env python3
from datasets import load_dataset
import datasets
import numpy as np
import torch
import torchaudio
print("torch vesion", torch.__version__)
print("torchaudio vesion", torchaudio.__version__)
save_audio = True
load_audios = False
if save_audio:
ds = load_dataset("common_voice", "en", split="train", streaming=True)
ds = ds.cast_column("audio", datasets.Audio(sampling_rate=16_000))
ds_iter = iter(ds)
sample = next(ds_iter)
np.save(f"audio_sample_{torch.__version__}", sample["audio"]["array"])
print(sample["audio"]["array"])
if load_audios:
array_torch_11 = np.load("/home/patrick/audio_sample_1.11.0+cu102.npy")
print("Array 11 Shape", array_torch_11.shape)
print("Array 11 abs sum", np.sum(np.abs(array_torch_11)))
array_torch_12 = np.load("/home/patrick/audio_sample_1.12.1+cu102.npy")
print("Array 12 Shape", array_torch_12.shape)
print("Array 12 abs sum", np.sum(np.abs(array_torch_12)))
```
Having saved the tensors the print output yields:
```
torch vesion 1.12.1+cu102
torchaudio vesion 0.12.1+cu102
Array 11 Shape (122880,)
Array 11 abs sum 1396.4988
Array 12 Shape (123264,)
Array 12 abs sum 1396.5193
```
## Expected results
torchaudio 11.0 and 12.1 should yield same results.
## Actual results
See above.
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 2.1.1.dev0
- Platform: Linux-5.18.10-76051810-generic-x86_64-with-glibc2.34
- Python version: 3.9.7
- PyArrow version: 6.0.1
- Pandas version: 1.4.2
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4889/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4889/timeline | null | completed | null | null | false | [
"Maybe we can just pass this along to torchaudio @lhoestq @albertvillanova ? It be great if you could investigate if the errors lies in datasets or in torchaudio.",
"torchaudio did a change in [0.12](https://github.com/pytorch/audio/releases/tag/v0.12.0) on MP3 decoding (which affects common voice):\r\n> MP3 decoding is now handled by FFmpeg in sox_io backend. (https://github.com/pytorch/audio/pull/2419, https://github.com/pytorch/audio/pull/2428)\r\n> - FFmpeg is now used as fallback in sox_io backend, and now MP3 decoding is handled by FFmpeg. To load MP3 audio with torchaudio.load, please install a compatible version of FFmpeg (Version 4 when using an official binary distribution).\r\n> - Note that, whereas the previous MP3 decoding scheme pads the output audio, the new scheme does not. As a consequence, the new version returns shorter audio tensors.",
"Do we have a solution for this now? Should we just upgrade to `torchaudio 0.12.0` then? ",
"`datasets` supports `torchaudio` 0.12 if you have an environment that supports reading MP3 with `torchaudio`, i.e. if you have `ffmpeg>=4`",
"Closing as we no longer use `torchaudio` for decoding."
] |
https://api.github.com/repos/huggingface/datasets/issues/4259 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4259/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4259/comments | https://api.github.com/repos/huggingface/datasets/issues/4259/events | https://github.com/huggingface/datasets/pull/4259 | 1,221,768,025 | PR_kwDODunzps43HHGc | 4,259 | Fix bug in choices labels in openbookqa dataset | [] | closed | false | null | 1 | 2022-04-30T07:41:39Z | 2022-05-04T06:31:31Z | 2022-05-03T15:14:21Z | null | This PR fixes the Bug in the openbookqa dataset as mentioned in this issue #3550.
Fix #3550.
cc. @lhoestq @mariosasko | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4259/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4259/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4259.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4259",
"merged_at": "2022-05-03T15:14:21Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4259.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4259"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._"
] |
https://api.github.com/repos/huggingface/datasets/issues/109 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/109/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/109/comments | https://api.github.com/repos/huggingface/datasets/issues/109/events | https://github.com/huggingface/datasets/pull/109 | 618,508,359 | MDExOlB1bGxSZXF1ZXN0NDE4MjI0MDYw | 109 | [Reclor] fix reclor | [] | closed | false | null | 0 | 2020-05-14T20:16:26Z | 2020-05-14T20:19:09Z | 2020-05-14T20:19:08Z | null | - That's probably one me. Could have made the manual data test more flexible. @mariamabarham | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/109/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/109/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/109.diff",
"html_url": "https://github.com/huggingface/datasets/pull/109",
"merged_at": "2020-05-14T20:19:08Z",
"patch_url": "https://github.com/huggingface/datasets/pull/109.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/109"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/1564 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1564/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1564/comments | https://api.github.com/repos/huggingface/datasets/issues/1564/events | https://github.com/huggingface/datasets/pull/1564 | 766,266,609 | MDExOlB1bGxSZXF1ZXN0NTM5MzQzMjAy | 1,564 | added saudinewsnet | [] | closed | false | null | 9 | 2020-12-14T10:35:09Z | 2020-12-22T09:51:04Z | 2020-12-22T09:51:04Z | null | I'm having issues in creating the dummy data. I'm still investigating how to fix it. I'll close the PR if I couldn't find a solution | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1564/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1564/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1564.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1564",
"merged_at": "2020-12-22T09:51:04Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1564.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1564"
} | true | [
"Hi @abdulelahsm - This is an interesting dataset! But there are multiple issues with the PR. Some of them are listed below: \r\n- default builder config is not defined. There should be atleast one builder config \r\n- URL is incorrectly constructed so the data files are not being downloaded \r\n- dataset_info.json file was not created\r\n\r\nPlease have a look at some existing merged datasets to get a reference on building the data loader. If you are still stuck, reach out. \r\n",
"@skyprince999 I totally agree. Thx for the feedback!",
"Hi @abdulelahsm ! Thanks for adding this one :) \r\nyou don't actually have to add builder configurations if you don't need them. It's fine as it is now\r\n\r\nAnd as @skyprince999 noticed, the current URLs don't work. to download files.\r\nYou can use this one for example for the first batch instead:\r\nhttps://github.com/parallelfold/SaudiNewsNet/raw/master/dataset/2015-07-21.zip\r\n\r\nFeel free to ping me if you have questions or if you're ready for a review :) ",
"@lhoestq Hey, I tried using the first batch instead, the data was downloaded but I got this error, not sure why it can't find the path?\r\n\r\nfor content, I ran ``` \"./datasets/saudinewsnet/test.py\"```\r\n\r\nwhich is a local test I'm running for the dataset, it contains the following code\r\n\r\n```\r\nfrom datasets import load_dataset\r\n\r\ndata = load_dataset(\"./datasets/saudinewsnet\", split= \"train\")\r\n\r\nprint(data)\r\n\r\nprint(data[1])\r\n```\r\n\r\nthis is the error I got \r\n\r\n```\r\n2020-12-18 21:45:39.403908: W tensorflow/stream_executor/platform/default/dso_loader.cc:59] Could not load dynamic library 'libcudart.so.10.1'; dlerror: libcudart.so.10.1: cannot open shared object file: No such file or directory\r\n2020-12-18 21:45:39.403953: I tensorflow/stream_executor/cuda/cudart_stub.cc:29] Ignore above cudart dlerror if you do not have a GPU set up on your machine.\r\nUsing custom data configuration default\r\nDownloading and preparing dataset saudi_news_net/default (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /home/mesfas/.cache/huggingface/datasets/saudi_news_net/default/0.0.0/62ece5ef0a991415352d4b1efac681d75b5b3404064fd4f6a1d659499dab18f4...\r\nDownloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3.42M/3.42M [00:03<00:00, 1.03MB/s]\r\nTraceback (most recent call last):\r\n File \"/home/mesfas/opensource/datasets/src/datasets/builder.py\", line 604, in _download_and_prepare\r\n self._prepare_split(split_generator, **prepare_split_kwargs)\r\n File \"/home/mesfas/opensource/datasets/src/datasets/builder.py\", line 902, in _prepare_split\r\n for key, record in utils.tqdm(\r\n File \"/home/mesfas/environments/ar_res_reviews/lib/python3.8/site-packages/tqdm/std.py\", line 1133, in __iter__\r\n for obj in iterable:\r\n File \"/home/mesfas/.cache/huggingface/modules/datasets_modules/datasets/saudinewsnet/62ece5ef0a991415352d4b1efac681d75b5b3404064fd4f6a1d659499dab18f4/saudinewsnet.py\", line 108, in _generate_examples\r\n with open(filepath, encoding=\"utf-8\").read() as f:\r\nIsADirectoryError: [Errno 21] Is a directory: '/home/mesfas/.cache/huggingface/datasets/downloads/extracted/314fd983aa07d3dada9429911a805270c3285f48759d3584a1343c2d86260765'\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"./datasets/saudinewsnet/test.py\", line 3, in <module>\r\n data = load_dataset(\"./datasets/saudinewsnet\", split= \"train\")\r\n File \"/home/mesfas/opensource/datasets/src/datasets/load.py\", line 607, in load_dataset\r\n builder_instance.download_and_prepare(\r\n File \"/home/mesfas/opensource/datasets/src/datasets/builder.py\", line 526, in download_and_prepare\r\n self._download_and_prepare(\r\n File \"/home/mesfas/opensource/datasets/src/datasets/builder.py\", line 606, in _download_and_prepare\r\n raise OSError(\r\nOSError: Cannot find data file. \r\nOriginal error:\r\n[Errno 21] Is a directory: '/home/mesfas/.cache/huggingface/datasets/downloads/extracted/314fd983aa07d3dada9429911a805270c3285f48759d3584a1343c2d86260765'\r\n```\r\n\r\n\r\nthis is the split code \r\n\r\n```\r\n def _split_generators(self, dl_manager):\r\n \"\"\"Returns SplitGenerators.\"\"\"\r\n my_urls = _URL\r\n datadir = dl_manager.download_and_extract(my_urls)\r\n return [\r\n datasets.SplitGenerator(\r\n name=datasets.Split.TRAIN,\r\n # These kwargs will be passed to _generate_examples\r\n gen_kwargs={\r\n \"filepath\": datadir,\r\n \"split\": \"train\"\r\n },\r\n ),\r\n ]\r\n```\r\nand this is how I'm generating the examples\r\n\r\n```\r\n def _generate_examples(self, filepath, split):\r\n \r\n #logging.info(\"generating examples from = %s\", filepath)\r\n with open(filepath, encoding=\"utf-8\") as f:\r\n articles = json.load(f)\r\n for article in articles:\r\n title = article.get(\"title\", \"\").strip()\r\n source = article.get(\"source\", \"\").strip()\r\n date = article.get(\"date_extracted\", \"\").strip()\r\n link = article.get(\"url\", \"\").strip()\r\n author = article.get(\"author\", \"\").strip()\r\n content = article.get(\"content\", \"\").strip()\r\n\r\n yield id_, {\r\n \"title\": title,\r\n \"source\": source,\r\n \"date\": date,\r\n \"link\": link,\r\n \"author\": author,\r\n \"content\": content\r\n }\r\n```",
"What's `_URL` ?\r\n\r\nIt looks like you are downloading an archive.\r\nTherefore you may need to get to the file path using `filepath = os.path.join(datadir, \"actual_file_name_inside_the_downloaded_archive\")`",
"@lhoestq you were 100% right. Thank you. All fixed",
"@lhoestq ping!",
"@lhoestq added the remaining 17 batches and modified the readme.md to reflect that + resolved the camel case comment",
"merging since the CI is fixed on master"
] |
https://api.github.com/repos/huggingface/datasets/issues/1026 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1026/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1026/comments | https://api.github.com/repos/huggingface/datasets/issues/1026/events | https://github.com/huggingface/datasets/issues/1026 | 755,689,195 | MDU6SXNzdWU3NTU2ODkxOTU= | 1,026 | Lío o | [] | closed | false | null | 0 | 2020-12-02T23:32:25Z | 2020-12-03T16:42:47Z | 2020-12-03T16:42:47Z | null | ````l`````````
```
O
```
`````
Ño
```
````
``` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1026/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1026/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/5666 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5666/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5666/comments | https://api.github.com/repos/huggingface/datasets/issues/5666/events | https://github.com/huggingface/datasets/issues/5666 | 1,637,675,062 | I_kwDODunzps5hnPA2 | 5,666 | Support tensorflow 2.12.0 in CI | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | 0 | 2023-03-23T14:37:51Z | 2023-03-23T16:14:54Z | 2023-03-23T16:14:54Z | null | Once we find out the root cause of:
- #5663
we should revert the temporary pin on tensorflow introduced by:
- #5664 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5666/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5666/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/1831 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1831/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1831/comments | https://api.github.com/repos/huggingface/datasets/issues/1831/events | https://github.com/huggingface/datasets/issues/1831 | 802,868,854 | MDU6SXNzdWU4MDI4Njg4NTQ= | 1,831 | Some question about raw dataset download info in the project . | [] | closed | false | null | 4 | 2021-02-07T05:33:36Z | 2021-02-25T14:10:18Z | 2021-02-25T14:10:18Z | null | Hi , i review the code in
https://github.com/huggingface/datasets/blob/master/datasets/conll2003/conll2003.py
in the _split_generators function is the truly logic of download raw datasets with dl_manager
and use Conll2003 cls by use import_main_class in load_dataset function
My question is that , with this logic it seems that i can not have the raw dataset download location
in variable in downloaded_files in _split_generators.
If someone also want use huggingface datasets as raw dataset downloader,
how can he retrieve the raw dataset download path from attributes in
datasets.dataset_dict.DatasetDict ? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1831/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1831/timeline | null | completed | null | null | false | [
"Hi ! The `dl_manager` is a `DownloadManager` object and is responsible for downloading the raw data files.\r\nIt is used by dataset builders in their `_split_generators` method to download the raw data files that are necessary to build the datasets splits.\r\n\r\nThe `Conll2003` class is a dataset builder, and so you can download all the raw data files by calling `_split_generators` with a download manager:\r\n```python\r\nfrom datasets import DownloadManager\r\nfrom datasets.load import import_main_class\r\n\r\nconll2003_builder = import_main_class(...)\r\n\r\ndl_manager = DownloadManager()\r\nsplis_generators = conll2003_builder._split_generators(dl_manager)\r\n```\r\n\r\nThen you can see what files have been downloaded with\r\n```python\r\ndl_manager.get_recorded_sizes_checksums()\r\n```\r\nIt returns a dictionary with the format {url: {num_bytes: int, checksum: str}}\r\n\r\nThen you can get the actual location of the downloaded files with\r\n```python\r\nfrom datasets import cached_path\r\n\r\nlocal_path_to_downloaded_file = cached_path(url)\r\n```\r\n\r\n------------------\r\n\r\nNote that you can also get the urls from the Dataset object:\r\n```python\r\nfrom datasets import load_dataset\r\n\r\nconll2003 = load_dataset(\"conll2003\")\r\nprint(conll2003[\"train\"].download_checksums)\r\n```\r\nIt returns the same dictionary with the format {url: {num_bytes: int, checksum: str}}",
"I am afraid that there is not a very straightforward way to get that location.\r\n\r\nAnother option, from _split_generators would be to use:\r\n- `dl_manager._download_config.cache_dir` to get the directory where all the raw downloaded files are:\r\n ```python\r\n download_dir = dl_manager._download_config.cache_dir\r\n ```\r\n- the function `datasets.utils.file_utils.hash_url_to_filename` to get the filenames of the raw downloaded files:\r\n ```python\r\n filenames = [hash_url_to_filename(url) for url in urls_to_download.values()]\r\n ```\r\nTherefore the complete path to the raw downloaded files would be the join of both:\r\n```python\r\ndownloaded_paths = [os.path.join(download_dir, filename) for filename in filenames]\r\n```\r\n\r\nMaybe it would be interesting to make these paths accessible more easily. I could work on this. What do you think, @lhoestq ?",
"Sure it would be nice to have an easier access to these paths !\r\nThe dataset builder could have a method to return those, what do you think ?\r\nFeel free to work on this @albertvillanova , it would be a nice addition :) \r\n\r\nYour suggestion does work as well @albertvillanova if you complete it by specifying `etag=` to `hash_url_to_filename`.\r\n\r\nThe ETag is obtained by a HEAD request and is used to know if the file on the remote host has changed. Therefore if a file is updated on the remote host, then the hash returned by `hash_url_to_filename` is different.",
"Once #1846 will be merged, the paths to the raw downloaded files will be accessible as:\r\n```python\r\nbuilder_instance.dl_manager.downloaded_paths\r\n``` "
] |
https://api.github.com/repos/huggingface/datasets/issues/1635 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1635/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1635/comments | https://api.github.com/repos/huggingface/datasets/issues/1635/events | https://github.com/huggingface/datasets/issues/1635 | 774,524,492 | MDU6SXNzdWU3NzQ1MjQ0OTI= | 1,635 | Persian Abstractive/Extractive Text Summarization | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | null | 0 | 2020-12-24T17:47:12Z | 2021-01-04T15:11:04Z | 2021-01-04T15:11:04Z | null | Assembling datasets tailored to different tasks and languages is a precious target. This would be great to have this dataset included.
## Adding a Dataset
- **Name:** *pn-summary*
- **Description:** *A well-structured summarization dataset for the Persian language consists of 93,207 records. It is prepared for Abstractive/Extractive tasks (like cnn_dailymail for English). It can also be used in other scopes like Text Generation, Title Generation, and News Category Classification.*
- **Paper:** *https://arxiv.org/abs/2012.11204*
- **Data:** *https://github.com/hooshvare/pn-summary/#download*
- **Motivation:** *It is the first Persian abstractive/extractive Text summarization dataset (like cnn_dailymail for English)!*
Instructions to add a new dataset can be found [here](https://github.com/huggingface/datasets/blob/master/ADD_NEW_DATASET.md).
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1635/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1635/timeline | null | completed | null | null | false | [] |
https://api.github.com/repos/huggingface/datasets/issues/2942 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2942/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2942/comments | https://api.github.com/repos/huggingface/datasets/issues/2942/events | https://github.com/huggingface/datasets/pull/2942 | 1,000,309,765 | PR_kwDODunzps4r7tY6 | 2,942 | Add SEDE dataset | [] | closed | false | null | 4 | 2021-09-19T13:11:24Z | 2021-09-24T10:39:55Z | 2021-09-24T10:39:54Z | null | This PR adds the SEDE dataset for the task of realistic Text-to-SQL, following the instructions of how to add a database and a dataset card.
Please see our paper for more details: https://arxiv.org/abs/2106.05006 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2942/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2942/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2942.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2942",
"merged_at": "2021-09-24T10:39:54Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2942.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2942"
} | true | [
"Thanks @albertvillanova for your great suggestions! I just pushed a new commit with the necessary fixes. For some reason, the test `test_metric_common` failed for `meteor` metric, which doesn't have any connection to this PR, so I'm trying to rebase and see if it helps.",
"Hi @Hazoom,\r\n\r\nYou were right: the non-passing test had nothing to do with this PR.\r\n\r\nUnfortunately, you did a git rebase (instead of a git merge), which is not recommended once you have already opened a pull request because you mess up your pull request history. You can see that your pull request now contains:\r\n- your commits repeated two times\r\n- and commits which are not yours from the master branch\r\n\r\nIf you would like to clean your pull request, please make:\r\n```\r\ngit reset --hard 587b93a\r\ngit fetch upstream master\r\ngit merge upstream/master\r\ngit push --force origin sede\r\n```",
"> Hi @Hazoom,\r\n> \r\n> You were right: the non-passing test had nothing to do with this PR.\r\n> \r\n> Unfortunately, you did a git rebase (instead of a git merge), which is not recommended once you have already opened a pull request because you mess up your pull request history. You can see that your pull request now contains:\r\n> \r\n> * your commits repeated two times\r\n> * and commits which are not yours from the master branch\r\n> \r\n> If you would like to clean your pull request, please make:\r\n> \r\n> ```\r\n> git reset --hard 587b93a\r\n> git fetch upstream master\r\n> git merge upstream/master\r\n> git push --force origin sede\r\n> ```\r\n\r\nThanks @albertvillanova ",
"> Nice! Just one final request before approving your pull request:\r\n> \r\n> As you have updated the \"QuerySetId\" field data type, the size of the dataset is smaller now. You should regenerate the metadata. Please run:\r\n> \r\n> ```\r\n> rm datasets/sede/dataset_infos.json\r\n> datasets-cli test datasets/sede --save_infos --all_configs\r\n> ```\r\n\r\n@albertvillanova Good catch, just fixed it."
] |
https://api.github.com/repos/huggingface/datasets/issues/1521 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1521/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1521/comments | https://api.github.com/repos/huggingface/datasets/issues/1521/events | https://github.com/huggingface/datasets/pull/1521 | 764,320,841 | MDExOlB1bGxSZXF1ZXN0NTM4NDQzOTgz | 1,521 | Atomic | [] | closed | false | null | 1 | 2020-12-12T20:18:08Z | 2020-12-12T22:56:48Z | 2020-12-12T22:56:48Z | null | This is the ATOMIC common sense dataset. More info can be found here:
* README.md still to be created. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1521/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1521/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1521.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1521",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/1521.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1521"
} | true | [
"I had to create a new PR to fix git errors. See: https://github.com/huggingface/datasets/pull/1525\r\n\r\nI'm closing this PR. "
] |
https://api.github.com/repos/huggingface/datasets/issues/542 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/542/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/542/comments | https://api.github.com/repos/huggingface/datasets/issues/542/events | https://github.com/huggingface/datasets/pull/542 | 688,555,036 | MDExOlB1bGxSZXF1ZXN0NDc1NzkyNTY0 | 542 | Add TensorFlow example | [] | closed | false | null | 0 | 2020-08-29T15:39:27Z | 2020-08-31T09:49:20Z | 2020-08-31T09:49:19Z | null | Update the Quick Tour documentation in order to add the TensorFlow equivalent source code for the classification example. Now it is possible to select either the code in PyTorch or in TensorFlow in the Quick tour. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/542/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/542/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/542.diff",
"html_url": "https://github.com/huggingface/datasets/pull/542",
"merged_at": "2020-08-31T09:49:19Z",
"patch_url": "https://github.com/huggingface/datasets/pull/542.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/542"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/4385 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4385/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4385/comments | https://api.github.com/repos/huggingface/datasets/issues/4385/events | https://github.com/huggingface/datasets/pull/4385 | 1,243,921,287 | PR_kwDODunzps44OwXF | 4,385 | Test dill | [] | closed | false | null | 4 | 2022-05-21T08:57:43Z | 2022-05-25T08:30:13Z | 2022-05-25T08:21:48Z | null | Regression test for future releases of `dill`.
Related to #4379. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4385/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4385/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4385.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4385",
"merged_at": "2022-05-25T08:21:48Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4385.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4385"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I should point out that the hash will be the same if computed twice with the same code on the same version of dill (after adding huggingface's code that removes line numbers and file names, and sorts globals.) My changes in dill 0.3.5 and ones that I will make in 0.3.6 will result in different pickles than the ones dill 0.3.4 was making. This should still be fine for caching.",
"Just some comments @lhoestq:\r\n\r\nThe best practice for testing is to have a `test_<filename>.py` for each `<filename>.py`. Therefore in order to have the filenames aligned, I would propose:\r\n- either renaming `fingerprint.py` to `caching.py`\r\n- or renaming `test_caching.py` to `test_fingerprint.py`\r\n\r\nOn the other hand, my idea when implementing this test was not to test all the functionalities of the `Hasher`, but just to have a regression test that fails if dill version is > 0.3.4 and the pin in our `setup.py` is not present. Just recall that we had no failing test in our CI when the issue with dill was found on `transformers`.\r\n\r\nThe objective of this PR is just to have a regression test for that case: I tested and I got `AttributeError: module 'dill._dill' has no attribute 'stack'`\r\n\r\nFor this regression test, I took into account this comment by @gugarosa: https://github.com/huggingface/datasets/issues/4379#issuecomment-1133131825\r\n\r\nThere is no equivalent test in `test_caching.py` because our CI did not fail before pinning dill.",
"Ok I see, renaming it to `test_fingerprint.py` sounds like a good idea :)"
] |
https://api.github.com/repos/huggingface/datasets/issues/1436 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1436/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1436/comments | https://api.github.com/repos/huggingface/datasets/issues/1436/events | https://github.com/huggingface/datasets/pull/1436 | 760,873,132 | MDExOlB1bGxSZXF1ZXN0NTM1NjI1MDM0 | 1,436 | add ALT | [] | closed | false | null | 1 | 2020-12-10T04:17:21Z | 2020-12-13T16:14:18Z | 2020-12-11T15:52:41Z | null | ALT dataset -- https://www2.nict.go.jp/astrec-att/member/mutiyama/ALT/ | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 2,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1436/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1436/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1436.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1436",
"merged_at": "2020-12-11T15:52:41Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1436.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1436"
} | true | [
"The errors in de CI are fixed on master so it's fine"
] |
https://api.github.com/repos/huggingface/datasets/issues/2690 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2690/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2690/comments | https://api.github.com/repos/huggingface/datasets/issues/2690/events | https://github.com/huggingface/datasets/pull/2690 | 949,574,500 | MDExOlB1bGxSZXF1ZXN0Njk0MjU5MDc1 | 2,690 | Docs details | [] | closed | false | null | 1 | 2021-07-21T10:43:14Z | 2021-07-27T18:40:54Z | 2021-07-27T18:40:54Z | null | Some comments here:
- the code samples assume the expected libraries have already been installed. Maybe add a section at start, or add it to every code sample. Something like `pip install datasets transformers torch 'datasets[streaming]'` (maybe just link to https://huggingface.co/docs/datasets/installation.html + a one-liner that installs all the requirements / alternatively a requirements.txt file)
- "If you’d like to play with the examples, you must install it from source." in https://huggingface.co/docs/datasets/installation.html: it's not clear to me what this means (what are these "examples"?)
- in https://huggingface.co/docs/datasets/loading_datasets.html: "or AWS bucket if it’s not already stored in the library". It's the only place in the doc (aside from the docstring https://huggingface.co/docs/datasets/package_reference/loading_methods.html?highlight=aws bucket#datasets.list_datasets) where the "AWS bucket" is mentioned. It's not easy to understand what this means. Maybe explain more, and link to https://s3.amazonaws.com/datasets.huggingface.co and/or https://huggingface.co/docs/datasets/filesystems.html.
- example in https://huggingface.co/docs/datasets/loading_datasets.html#manually-downloading-files is obsoleted by https://github.com/huggingface/datasets/pull/2326. Also: see https://github.com/huggingface/datasets/issues/2691 for a bug on this specific dataset.
- in https://huggingface.co/docs/datasets/loading_datasets.html#manually-downloading-files the doc says "After you’ve downloaded the files, you can point to the folder hosting them locally with the data_dir argument as follows:", but the following example does not show how to use `data_dir`
- in https://huggingface.co/docs/datasets/loading_datasets.html#csv-files, it would be nice to have an URL to the csv loader reference (but I'm not sure there is one in the API reference). This comment applies in many places in the doc: I would want the API reference to contain doc for all the code/functions/classes... and I would want a lot more links inside the doc pointing to the API entries.
- in the API reference (docstrings) I would prefer "SOURCE" to link to github instead of a copy of the code inside the docs site (eg. https://github.com/huggingface/datasets/blob/master/src/datasets/load.py#L711 instead of https://huggingface.co/docs/datasets/_modules/datasets/load.html#load_dataset)
- it seems like not all the API is exposed in the doc. For example, there is no doc for [`disable_progress_bar`](https://github.com/huggingface/datasets/search?q=disable_progress_bar), see https://huggingface.co/docs/datasets/search.html?q=disable_progress_bar, even if the code contains docstrings. Does it mean that the function is not officially supported? (otherwise, maybe it also deserves a mention in https://huggingface.co/docs/datasets/package_reference/logging_methods.html)
- in https://huggingface.co/docs/datasets/loading_datasets.html?highlight=most%20efficient%20format%20have%20json%20files%20consisting%20multiple%20json%20objects#json-files, "The most efficient format is to have JSON files consisting of multiple JSON objects, one per line, representing individual data rows:", maybe link to https://en.wikipedia.org/wiki/JSON_streaming#Line-delimited_JSON and give it a name ("line-delimited JSON"? "JSON Lines" as in https://huggingface.co/docs/datasets/processing.html#exporting-a-dataset-to-csv-json-parquet-or-to-python-objects ?)
- in https://huggingface.co/docs/datasets/loading_datasets.html, for the local files sections, it would be nice to provide sample csv / json / text files to download, so that it's easier for the reader to try to load them (instead: they won't try)
- the doc explains how to shard a dataset, but does not explain why and when a dataset should be sharded (I have no idea... for [parallelizing](https://huggingface.co/docs/datasets/processing.html#multiprocessing)?). It does neither give an idea of the number of shards a dataset typically should have and why.
- the code example in https://huggingface.co/docs/datasets/processing.html#mapping-in-a-distributed-setting does not work, because `training_args` has not been defined before in the doc. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2690/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2690/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/2690.diff",
"html_url": "https://github.com/huggingface/datasets/pull/2690",
"merged_at": "2021-07-27T18:40:53Z",
"patch_url": "https://github.com/huggingface/datasets/pull/2690.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/2690"
} | true | [
"Thanks for all the comments and for the corrections in the docs !\r\n\r\nAbout all the points you mentioned:\r\n\r\n> * the code samples assume the expected libraries have already been installed. Maybe add a section at start, or add it to every code sample. Something like `pip install datasets transformers torch 'datasets[streaming]'` (maybe just link to https://huggingface.co/docs/datasets/installation.html + a one-liner that installs all the requirements / alternatively a requirements.txt file)\r\n\r\nYes good idea\r\n\r\n> * \"If you’d like to play with the examples, you must install it from source.\" in https://huggingface.co/docs/datasets/installation.html: it's not clear to me what this means (what are these \"examples\"?)\r\n\r\nIt refers to examples scripts inside the git repository of the library, see the `examples` folder in the `transformers` repo.\r\nWe don't have examples yet in the git repo of `datasets` as in transformers. So currently there are no examples. Maybe we can just remove this sentence from the docs for now\r\n\r\n> * in https://huggingface.co/docs/datasets/loading_datasets.html: \"or AWS bucket if it’s not already stored in the library\". It's the only place in the doc (aside from the docstring https://huggingface.co/docs/datasets/package_reference/loading_methods.html?highlight=aws bucket#datasets.list_datasets) where the \"AWS bucket\" is mentioned. It's not easy to understand what this means. Maybe explain more, and link to https://s3.amazonaws.com/datasets.huggingface.co and/or https://huggingface.co/docs/datasets/filesystems.html.\r\n\r\nThis is outdated and must be replaced by\r\n```\r\nor from the Hugging Face Hub if it’s not already stored in the library\r\n```\r\n\r\n> * example in https://huggingface.co/docs/datasets/loading_datasets.html#manually-downloading-files is obsoleted by [Enable auto-download for PAN-X / Wikiann domain in XTREME #2326](https://github.com/huggingface/datasets/pull/2326). Also: see [xtreme / pan-x cannot be downloaded #2691](https://github.com/huggingface/datasets/issues/2691) for a bug on this specific dataset.\r\n\r\nWe can replace the `XTREME` `PANX` dataste by `matinf` instead for example\r\n\r\n> * in https://huggingface.co/docs/datasets/loading_datasets.html#manually-downloading-files the doc says \"After you’ve downloaded the files, you can point to the folder hosting them locally with the data_dir argument as follows:\", but the following example does not show how to use `data_dir`\r\n\r\nLet's add `data_dir=\"path/to/your/downloaded/data\"` for example\r\n\r\n> * in https://huggingface.co/docs/datasets/loading_datasets.html#csv-files, it would be nice to have an URL to the csv loader reference (but I'm not sure there is one in the API reference). This comment applies in many places in the doc: I would want the API reference to contain doc for all the code/functions/classes... and I would want a lot more links inside the doc pointing to the API entries.\r\n\r\nCurrently there's no documentation for the CSV loader config. Maybe we can add the docstrings to the `CsvConfig` class to explain the parameters and how it works, and then redirect to the doc of this class in this section of the documentation.\r\n\r\n> * in the API reference (docstrings) I would prefer \"SOURCE\" to link to github instead of a copy of the code inside the docs site (eg. https://github.com/huggingface/datasets/blob/master/src/datasets/load.py#L711 instead of https://huggingface.co/docs/datasets/_modules/datasets/load.html#load_dataset)\r\n\r\nThis is the same as in `transformers`, not sure if this is a big issue\r\n\r\n> * it seems like not all the API is exposed in the doc. For example, there is no doc for [`disable_progress_bar`](https://github.com/huggingface/datasets/search?q=disable_progress_bar), see https://huggingface.co/docs/datasets/search.html?q=disable_progress_bar, even if the code contains docstrings. Does it mean that the function is not officially supported? (otherwise, maybe it also deserves a mention in https://huggingface.co/docs/datasets/package_reference/logging_methods.html)\r\n\r\nThe function `disable_progress_bar` should definitely be in the docs, thanks. We can add it to the logging methods\r\n\r\n> * in https://huggingface.co/docs/datasets/loading_datasets.html?highlight=most%20efficient%20format%20have%20json%20files%20consisting%20multiple%20json%20objects#json-files, \"The most efficient format is to have JSON files consisting of multiple JSON objects, one per line, representing individual data rows:\", maybe link to https://en.wikipedia.org/wiki/JSON_streaming#Line-delimited_JSON and give it a name (\"line-delimited JSON\"? \"JSON Lines\" as in https://huggingface.co/docs/datasets/processing.html#exporting-a-dataset-to-csv-json-parquet-or-to-python-objects ?)\r\n\r\nYes good idea !\r\n\r\n> * in https://huggingface.co/docs/datasets/loading_datasets.html, for the local files sections, it would be nice to provide sample csv / json / text files to download, so that it's easier for the reader to try to load them (instead: they won't try)\r\n\r\nSure why not. Moreover the csv loader now supports remote files so you could just run the code pass an an URL to the sample csv file.\r\n\r\n> * the doc explains how to shard a dataset, but does not explain why and when a dataset should be sharded (I have no idea... for [parallelizing](https://huggingface.co/docs/datasets/processing.html#multiprocessing)?). It does neither give an idea of the number of shards a dataset typically should have and why.\r\n\r\nThis can be used for distributed processing or just to use a percentage of the data. We can definitely give example of use cases\r\n\r\n> * the code example in https://huggingface.co/docs/datasets/processing.html#mapping-in-a-distributed-setting does not work, because `training_args` has not been defined before in the doc.\r\n\r\n`training_args` comes from `transformers`, it's a practical way to define all your arguments to train a model. Maybe we can just import it from `transformers` and use it with the default values\r\n\r\n"
] |
https://api.github.com/repos/huggingface/datasets/issues/2727 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/2727/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/2727/comments | https://api.github.com/repos/huggingface/datasets/issues/2727/events | https://github.com/huggingface/datasets/issues/2727 | 955,812,149 | MDU6SXNzdWU5NTU4MTIxNDk= | 2,727 | Error in loading the Arabic Billion Words Corpus | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | 2 | 2021-07-29T12:53:09Z | 2021-07-30T13:03:55Z | 2021-07-30T13:03:55Z | null | ## Describe the bug
I get `IndexError: list index out of range` when trying to load the `Techreen` and `Almustaqbal` configs of the dataset.
## Steps to reproduce the bug
```python
load_dataset("arabic_billion_words", "Techreen")
load_dataset("arabic_billion_words", "Almustaqbal")
```
## Expected results
The datasets load succefully.
## Actual results
```python
_extract_tags(self, sample, tag)
139 if len(out) > 0:
140 break
--> 141 return out[0]
142
143 def _clean_text(self, text):
IndexError: list index out of range
```
## Environment info
<!-- You can run the command `datasets-cli env` and copy-and-paste its output below. -->
- `datasets` version: 1.10.2
- Platform: Ubuntu 18.04.5 LTS
- Python version: 3.7.11
- PyArrow version: 3.0.0
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/2727/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/2727/timeline | null | completed | null | null | false | [
"I modified the dataset loading script to catch the `IndexError` and inspect the records at which the error is happening, and I found this:\r\nFor the `Techreen` config, the error happens in 36 records when trying to find the `Text` or `Dateline` tags. All these 36 records look something like:\r\n```\r\n<Techreen>\r\n <ID>TRN_ARB_0248167</ID>\r\n <URL>http://tishreen.news.sy/tishreen/public/read/248240</URL>\r\n <Headline>Removed, because the original articles was in English</Headline>\r\n</Techreen>\r\n```\r\n\r\nand all the 288 faulty records in the `Almustaqbal` config look like:\r\n```\r\n<Almustaqbal>\r\n <ID>MTL_ARB_0028398</ID>\r\n \r\n <URL>http://www.almustaqbal.com/v4/article.aspx?type=NP&ArticleID=179015</URL>\r\n <Headline> Removed because it is not available in the original site</Headline>\r\n</Almustaqbal>\r\n```\r\n\r\nso the error is happening because the articles were removed and so the associated records lack the `Text` tag.\r\n\r\nIn this case, I think we just need to catch the `IndexError` and ignore (pass) it.\r\n",
"Thanks @M-Salti for reporting this issue and for your investigation.\r\n\r\nIndeed, those `IndexError` should be catched and the corresponding record should be ignored.\r\n\r\nI'm opening a Pull Request to fix it."
] |
https://api.github.com/repos/huggingface/datasets/issues/4503 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/4503/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/4503/comments | https://api.github.com/repos/huggingface/datasets/issues/4503/events | https://github.com/huggingface/datasets/pull/4503 | 1,272,367,055 | PR_kwDODunzps45twLR | 4,503 | Refactor and add metadata to fever dataset | [] | closed | false | null | 5 | 2022-06-15T14:59:47Z | 2022-07-06T11:54:15Z | 2022-07-06T11:41:30Z | null | Related to: #4452 and #3792. | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/4503/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/4503/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/4503.diff",
"html_url": "https://github.com/huggingface/datasets/pull/4503",
"merged_at": "2022-07-06T11:41:30Z",
"patch_url": "https://github.com/huggingface/datasets/pull/4503.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/4503"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"But this is somehow fever v3 dataset (see this link https://fever.ai/ under the dropdown menu called Datasets). Our fever dataset already contains v1 and v2 configs. Then, I added this as if v3 config (but named feverous instead of v3 to align with the original naming by data owners).",
"In any case, if you really think this should be a new dataset, then I would propose to create it on the Hub instead, as \"fever/feverous\".",
"> In any case, if you really think this should be a new dataset, then I would propose to create it on the Hub instead, as \"fever/feverous\".\r\n\r\nYea makes sense ! thanks :) let's push more datasets on the hub rather than on github from now on",
"I have added \"feverous\" dataset to the Hub: https://huggingface.co/datasets/fever/feverous\r\n\r\nI change the name of this PR accordingly, as now it only:\r\n- Refactors code and include for both Fever v1.0 and v2.0 specific:\r\n - Descriptions\r\n - Citations\r\n - Homepages\r\n- Updates documentation card aligned with above:\r\n - It was missing v2.0 description and citation.\r\n- Update metadata JSON"
] |
https://api.github.com/repos/huggingface/datasets/issues/1183 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/1183/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/1183/comments | https://api.github.com/repos/huggingface/datasets/issues/1183/events | https://github.com/huggingface/datasets/pull/1183 | 757,806,570 | MDExOlB1bGxSZXF1ZXN0NTMzMTEwOTY4 | 1,183 | add mkb dataset | [] | closed | false | null | 3 | 2020-12-05T23:44:33Z | 2020-12-09T09:38:50Z | 2020-12-09T09:38:50Z | null | This PR will add Mann Ki Baat dataset (parallel data for Indian languages). | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/1183/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/1183/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/1183.diff",
"html_url": "https://github.com/huggingface/datasets/pull/1183",
"merged_at": "2020-12-09T09:38:50Z",
"patch_url": "https://github.com/huggingface/datasets/pull/1183.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/1183"
} | true | [
"Could you update the languages tags before we merge @VasudevGupta7 ?",
"done.",
"thanks !"
] |
https://api.github.com/repos/huggingface/datasets/issues/777 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/777/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/777/comments | https://api.github.com/repos/huggingface/datasets/issues/777/events | https://github.com/huggingface/datasets/pull/777 | 732,376,648 | MDExOlB1bGxSZXF1ZXN0NTEyMzI2ODM2 | 777 | Better error message for uninitialized metric | [] | closed | false | null | 0 | 2020-10-29T14:42:50Z | 2020-10-29T15:18:26Z | 2020-10-29T15:18:24Z | null | When calling `metric.compute()` without having called `metric.add` or `metric.add_batch` at least once, the error was quite cryptic. I added a better error message
Fix #729 | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/777/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/777/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/777.diff",
"html_url": "https://github.com/huggingface/datasets/pull/777",
"merged_at": "2020-10-29T15:18:23Z",
"patch_url": "https://github.com/huggingface/datasets/pull/777.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/777"
} | true | [] |
https://api.github.com/repos/huggingface/datasets/issues/3595 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/3595/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/3595/comments | https://api.github.com/repos/huggingface/datasets/issues/3595/events | https://github.com/huggingface/datasets/pull/3595 | 1,107,260,527 | PR_kwDODunzps4xOIxH | 3,595 | Add ImageNet toy datasets from fastai | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | null | 1 | 2022-01-18T19:03:35Z | 2022-09-30T14:39:35Z | 2022-09-30T14:39:35Z | null | Adds the ImageNet toy datasets from FastAI: Imagenette, Imagewoof and Imagewang.
TODOs:
* [ ] add dummy data
* [ ] add dataset card
* [ ] generate `dataset_info.json` | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/3595/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/3595/timeline | null | null | true | {
"diff_url": "https://github.com/huggingface/datasets/pull/3595.diff",
"html_url": "https://github.com/huggingface/datasets/pull/3595",
"merged_at": null,
"patch_url": "https://github.com/huggingface/datasets/pull/3595.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/3595"
} | true | [
"Thanks for your contribution, @mariosasko. Are you still interested in adding this dataset?\r\n\r\nWe are removing the dataset scripts from this GitHub repo and moving them to the Hugging Face Hub: https://huggingface.co/datasets\r\n\r\nWe would suggest you create this dataset there. Please, feel free to tell us if you need some help."
] |
https://api.github.com/repos/huggingface/datasets/issues/5305 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5305/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5305/comments | https://api.github.com/repos/huggingface/datasets/issues/5305/events | https://github.com/huggingface/datasets/issues/5305 | 1,465,627,826 | I_kwDODunzps5XW7Sy | 5,305 | Dataset joelito/mc4_legal does not work with multiple files | [] | closed | false | null | 2 | 2022-11-28T00:16:16Z | 2022-11-28T07:22:42Z | 2022-11-28T07:22:42Z | null | ### Describe the bug
The dataset https://huggingface.co/datasets/joelito/mc4_legal works for languages like bg with a single data file, but not for languages with multiple files like de. It shows zero rows for the de dataset.
joelniklaus@Joels-MacBook-Pro ~/N/P/C/L/p/m/mc4_legal (main) [1]> python test_mc4_legal.py (debug)
Found cached dataset mc4_legal (/Users/joelniklaus/.cache/huggingface/datasets/mc4_legal/de/0.0.0/fb6952a097180f8c936e2a7605525ff670354a344fc1a2c70107684d3f7cb02f)
Dataset({
features: ['index', 'url', 'timestamp', 'matches', 'text'],
num_rows: 0
})
joelniklaus@Joels-MacBook-Pro ~/N/P/C/L/p/m/mc4_legal (main)> python test_mc4_legal.py (debug)
Downloading and preparing dataset mc4_legal/bg to /Users/joelniklaus/.cache/huggingface/datasets/mc4_legal/bg/0.0.0/fb6952a097180f8c936e2a7605525ff670354a344fc1a2c70107684d3f7cb02f...
Downloading data files: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1240.55it/s]
Dataset mc4_legal downloaded and prepared to /Users/joelniklaus/.cache/huggingface/datasets/mc4_legal/bg/0.0.0/fb6952a097180f8c936e2a7605525ff670354a344fc1a2c70107684d3f7cb02f. Subsequent calls will reuse this data.
Dataset({
features: ['index', 'url', 'timestamp', 'matches', 'text'],
num_rows: 204
})
### Steps to reproduce the bug
import datasets
from datasets import load_dataset, get_dataset_config_names
language = "bg"
test = load_dataset("joelito/mc4_legal", language, split='train')
### Expected behavior
It should display the correct number of rows for the de dataset which should be a large number (thousands or more).
### Environment info
Package Version
------------------------ --------------
absl-py 1.3.0
aiohttp 3.8.1
aiosignal 1.2.0
astunparse 1.6.3
async-timeout 4.0.2
attrs 22.1.0
beautifulsoup4 4.11.1
blinker 1.4
blis 0.7.8
Bottleneck 1.3.4
brotlipy 0.7.0
cachetools 5.2.0
catalogue 2.0.7
certifi 2022.5.18.1
cffi 1.15.1
chardet 4.0.0
charset-normalizer 2.1.0
click 8.0.4
conllu 4.5.2
cryptography 38.0.1
cymem 2.0.6
datasets 2.6.1
dill 0.3.5.1
docker-pycreds 0.4.0
fasttext 0.9.2
fasttext-langdetect 1.0.3
filelock 3.0.12
flatbuffers 20210226132247
frozenlist 1.3.0
fsspec 2022.5.0
gast 0.4.0
gcloud 0.18.3
gitdb 4.0.9
GitPython 3.1.27
google-auth 2.9.0
google-auth-oauthlib 0.4.6
google-pasta 0.2.0
googleapis-common-protos 1.57.0
grpcio 1.47.0
h5py 3.7.0
httplib2 0.21.0
huggingface-hub 0.8.1
idna 3.4
importlib-metadata 4.12.0
Jinja2 3.1.2
joblib 1.0.1
keras 2.9.0
Keras-Preprocessing 1.1.2
langcodes 3.3.0
lxml 4.9.1
Markdown 3.3.7
MarkupSafe 2.1.1
mkl-fft 1.3.1
mkl-random 1.2.2
mkl-service 2.4.0
multidict 6.0.2
multiprocess 0.70.13
murmurhash 1.0.7
numexpr 2.8.1
numpy 1.22.3
oauth2client 4.1.3
oauthlib 3.2.1
opt-einsum 3.3.0
packaging 21.3
pandas 1.4.2
pathtools 0.1.2
pathy 0.6.1
pip 21.1.2
preshed 3.0.6
promise 2.3
protobuf 4.21.9
psutil 5.9.1
pyarrow 8.0.0
pyasn1 0.4.8
pyasn1-modules 0.2.8
pybind11 2.9.2
pycountry 22.3.5
pycparser 2.21
pydantic 1.8.2
PyJWT 2.4.0
pylzma 0.5.0
pyOpenSSL 22.0.0
pyparsing 3.0.4
PySocks 1.7.1
python-dateutil 2.8.2
pytz 2021.3
PyYAML 6.0
regex 2021.4.4
requests 2.28.1
requests-oauthlib 1.3.1
responses 0.18.0
rsa 4.8
sacremoses 0.0.45
scikit-learn 1.1.1
scipy 1.8.1
sentencepiece 0.1.96
sentry-sdk 1.6.0
setproctitle 1.2.3
setuptools 65.5.0
shortuuid 1.0.9
six 1.16.0
smart-open 5.2.1
smmap 5.0.0
soupsieve 2.3.2.post1
spacy 3.3.1
spacy-legacy 3.0.9
spacy-loggers 1.0.2
srsly 2.4.3
tabulate 0.8.9
tensorboard 2.9.1
tensorboard-data-server 0.6.1
tensorboard-plugin-wit 1.8.1
tensorflow 2.9.1
tensorflow-estimator 2.9.0
termcolor 2.1.0
thinc 8.0.17
threadpoolctl 3.1.0
tokenizers 0.12.1
torch 1.13.0
tqdm 4.64.0
transformers 4.20.1
typer 0.4.1
typing-extensions 4.3.0
Unidecode 1.3.6
urllib3 1.26.12
wandb 0.12.20
wasabi 0.9.1
web-anno-tsv 0.0.1
Werkzeug 2.1.2
wget 3.2
wheel 0.35.1
wrapt 1.14.1
xxhash 3.0.0
yarl 1.8.1
zipp 3.8.0
Python 3.8.10
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5305/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5305/timeline | null | completed | null | null | false | [
"Thanks for reporting @JoelNiklaus.\r\n\r\nPlease note that since we moved all dataset loading scripts to the Hub, the issues and pull requests relative to specific datasets are directly handled on the Hub, in their Community tab. I'm transferring this issue there: https://huggingface.co/datasets/joelito/mc4_legal/discussions\r\n\r\nI am also having a look at the bug in your script.",
"Issue transferred to: https://huggingface.co/datasets/joelito/mc4_legal/discussions/1"
] |
https://api.github.com/repos/huggingface/datasets/issues/5030 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5030/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5030/comments | https://api.github.com/repos/huggingface/datasets/issues/5030/events | https://github.com/huggingface/datasets/pull/5030 | 1,388,061,340 | PR_kwDODunzps4_tfBO | 5,030 | Fast dataset iter | [] | closed | false | null | 2 | 2022-09-27T16:44:51Z | 2022-09-29T15:50:44Z | 2022-09-29T15:48:17Z | null | Use `pa.Table.to_reader` to make iteration over examples/batches faster in `Dataset.{__iter__, map}`
TODO:
* [x] benchmarking (the only benchmark for now - iterating over (single) examples of `bookcorpus` (75 mil examples) in Colab is approx. 2.3x faster)
* [x] check if iterating over bigger chunks + slicing to fetch individual examples in `_iter` yields better performance
| {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5030/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5030/timeline | null | null | false | {
"diff_url": "https://github.com/huggingface/datasets/pull/5030.diff",
"html_url": "https://github.com/huggingface/datasets/pull/5030",
"merged_at": "2022-09-29T15:48:17Z",
"patch_url": "https://github.com/huggingface/datasets/pull/5030.patch",
"url": "https://api.github.com/repos/huggingface/datasets/pulls/5030"
} | true | [
"_The documentation is not available anymore as the PR was closed or merged._",
"I ran some benchmarks (focused on the data fetching part of `__iter__`) and it seems like the combination `table.to_reader(batch_size)` + `RecordBatch.slice` performs the best ([script](https://gist.github.com/mariosasko/0248288a2e3a7556873969717c1fe52b) with the results). I think we can choose (implicit) `batch_size=10` in the final implementation to avoid having problems with fetching large examples."
] |
https://api.github.com/repos/huggingface/datasets/issues/227 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/227/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/227/comments | https://api.github.com/repos/huggingface/datasets/issues/227/events | https://github.com/huggingface/datasets/issues/227 | 629,845,704 | MDU6SXNzdWU2Mjk4NDU3MDQ= | 227 | Should we still have to force to install apache_beam to download wikipedia ? | [] | closed | false | null | 3 | 2020-06-03T09:33:20Z | 2020-06-03T15:25:41Z | 2020-06-03T15:25:41Z | null | Hi, first thanks to @lhoestq 's revolutionary work, I successfully downloaded processed wikipedia according to the doc. 😍😍😍
But at the first try, it tell me to install `apache_beam` and `mwparserfromhell`, which I thought wouldn't be used according to #204 , it was kind of confusing me at that time.
Maybe we should not force users to install these ? Or we just add them to`nlp`'s dependency ? | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/227/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/227/timeline | null | completed | null | null | false | [
"Thanks for your message 😊 \r\nIndeed users shouldn't have to install those dependencies",
"Got it, feel free to close this issue when you think it’s resolved.",
"It should be good now :)"
] |