
WIP
AI & ML interests
None defined yet.
Intel and Hugging Face are working together to democratize machine learning, making the latest and greatest models from Hugging Face run fast and efficiently on Intel devices. To make this acceleration accessible to the global AI community, Intel is proud to sponsor the free and accelerated inference of over 80,000 open source models on Hugging Face, powered by Intel Xeon Ice Lake processors in the Hugging Face Inference API. Intel Xeon Ice Lake provides up to 34% acceleration for transformer model inference.
Try it out today on any Hugging Face model, right from the model page, using the Inference Widget!


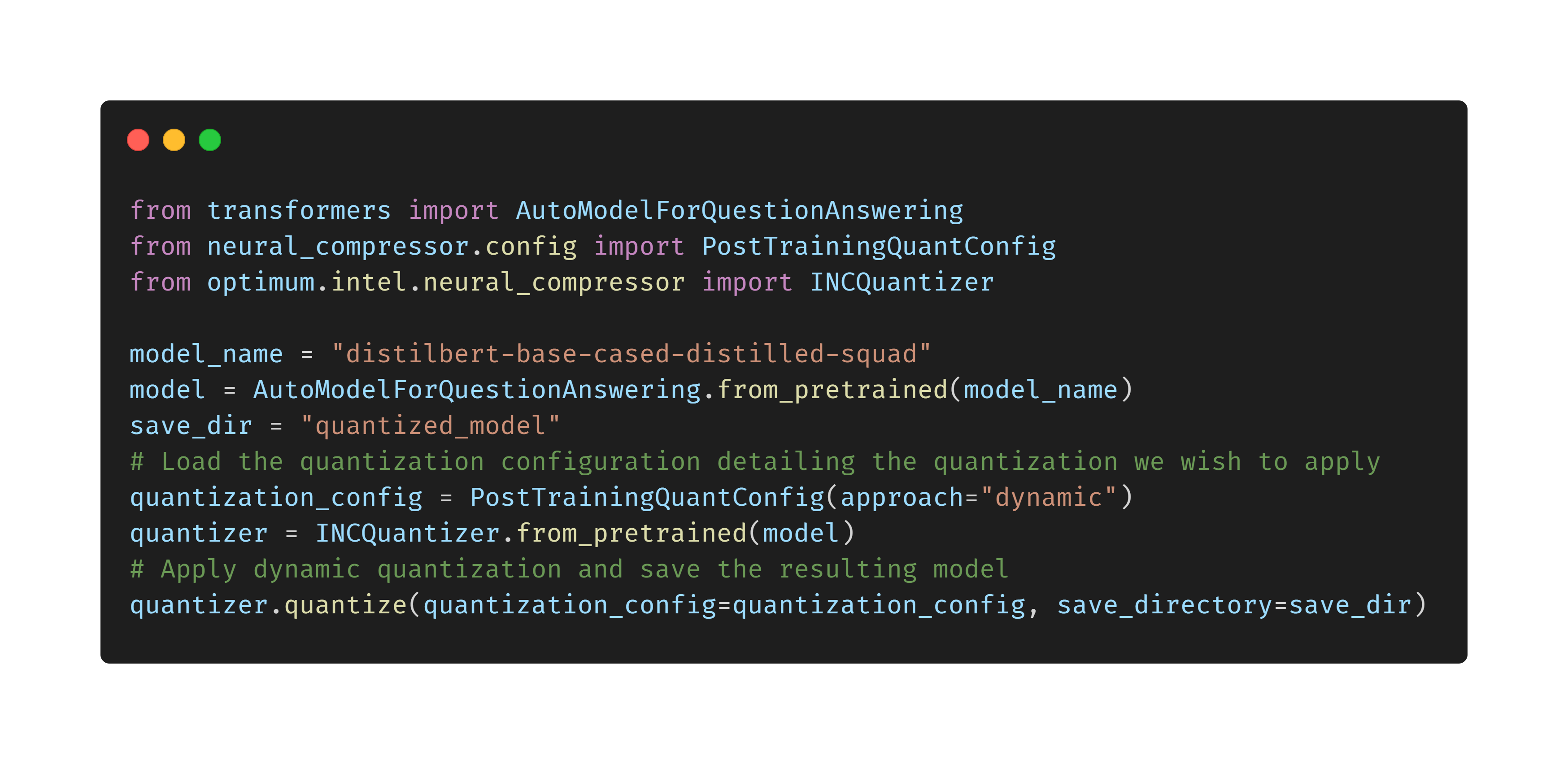
Intel provides a complete foundation for accelerated AI with the Intel Xeon Scalable CPU platform and a wide range of hardware-optimized AI software tools, frameworks, and libraries. With the Optimum-Intel library, Intel and Hugging Face are making it easy for Hugging Face users to get the best performance for their models on Intel Xeon processors, leveraging acceleration libraries including Intel Neural Compressor and OpenVINO.
To learn more about the partnership and Intel AI tools, check out these resources: