Fine-tuning MMS Adapter Models for Multi-Lingual ASR







New (06/2023): This blog post is strongly inspired by "Fine-tuning XLS-R on Multi-Lingual ASR" and can be seen as an improved version of it.
Wav2Vec2 is a pretrained model for Automatic Speech Recognition (ASR) and was released in September 2020 by Alexei Baevski, Michael Auli, and Alex Conneau. Soon after the strong performance of Wav2Vec2 was demonstrated on one of the most popular English datasets for ASR, called LibriSpeech, Facebook AI presented two multi-lingual versions of Wav2Vec2, called XLSR and XLM-R, capable of recognising speech in up to 128 languages. XLSR stands for cross-lingual speech representations and refers to the model's ability to learn speech representations that are useful across multiple languages.
Meta AI's most recent release, Massive Multilingual Speech (MMS) by Vineel Pratap, Andros Tjandra, Bowen Shi, et al. takes multi-lingual speech representations to a new level. Over 1,100 spoken languages can be identified, transcribed and generated with the various language identification, speech recognition, and text-to-speech checkpoints released.
In this blog post, we show how MMS's Adapter training achieves astonishingly low word error rates after just 10-20 minutes of fine-tuning.
For low-resource languages, we strongly recommend using MMS' Adapter training as opposed to fine-tuning the whole model as is done in "Fine-tuning XLS-R on Multi-Lingual ASR".
In our experiments, MMS' Adapter training is both more memory efficient, more robust and yields better performance for low-resource languages. For medium to high resource languages it can still be advantegous to fine-tune the whole checkpoint instead of using Adapter layers though.
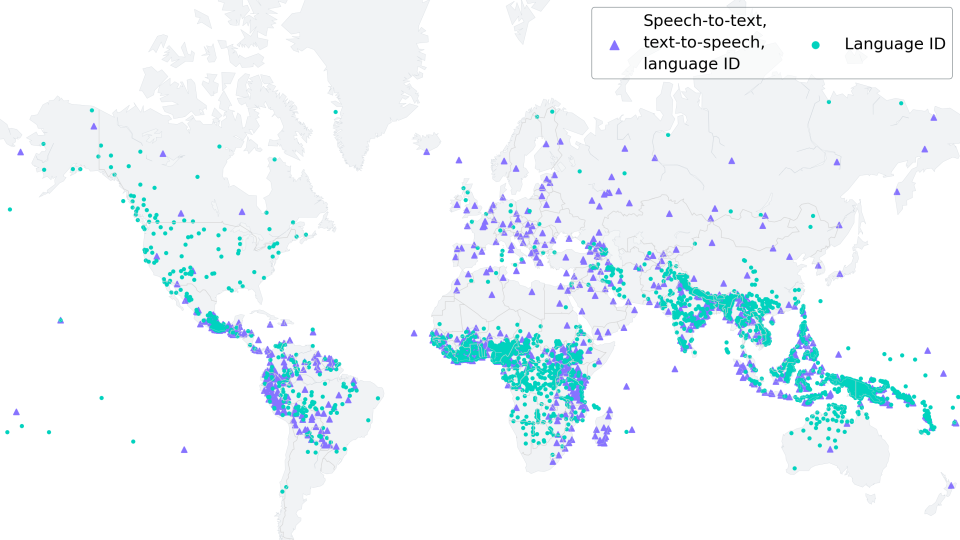
Preserving the world's language diversity
According to https://www.ethnologue.com/ around 3000, or 40% of all "living" languages, are endangered due to fewer and fewer native speakers. This trend will only continue in an increasingly globalized world.
MMS is capable of transcribing many languages which are endangered, such as Ari or Kaivi. In the future, MMS can play a vital role in keeping languages alive by helping the remaining speakers to create written records and communicating in their native tongue.
To adapt to 1000+ different vocabularies, MMS uses of Adapters - a training method where only a small fraction of model weights are trained.
Adapter layers act like linguistic bridges, enabling the model to leverage knowledge from one language when deciphering another.
Fine-tuning MMS
MMS unsupervised checkpoints were pre-trained on more than half a million hours of audio in over 1,400 languages, ranging from 300 million to one billion parameters.
You can find the pretrained-only checkpoints on the 🤗 Hub for model sizes of 300 million parameters (300M) and one billion parameters (1B):
Note: If you want to fine-tune the base models, you can do so in the exact same way as shown in "Fine-tuning XLS-R on Multi-Lingual ASR".
Similar to BERT's masked language modeling objective, MMS learns contextualized speech representations by randomly masking feature vectors before passing them to a transformer network during self-supervised pre-training.
For ASR, the pretrained MMS-1B checkpoint was further fine-tuned in a supervised fashion on 1000+ languages with a joint vocabulary output layer. As a final step, the joint vocabulary output layer was thrown away and language-specific adapter layers were kept instead. Each adapter layer contains just ~2.5M weights, consisting of small linear projection layers for each attention block as well as a language-specific vocabulary output layer.
Three MMS checkpoints fine-tuned for speech recognition (ASR) have been released. They include 102, 1107, and 1162 adapter weights respectively (one for each language):
You can see that the base models are saved (as usual) as a model.safetensors file, but in addition these repositories have many adapter weights stored in the repository, e.g. under the name adapter.fra.safetensors for French.
The Hugging Face docs explain very well how such checkpoints can be used for inference, so in this blog post we will instead focus on learning how we can efficiently train highly performant adapter models based on any of the released ASR checkpoints.
Training adaptive weights
In machine learning, adapters are a method used to fine-tune pre-trained models while keeping the original model parameters unchanged. They do this by inserting small, trainable modules, called adapter layers, between the pre-existing layers of the model, which then adapt the model to a specific task without requiring extensive retraining.
Adapters have a long history in speech recognition and especially speaker recognition. In speaker recognition, adapters have been effectively used to tweak pre-existing models to recognize individual speaker idiosyncrasies, as highlighted in Gales and Woodland's (1996) and Miao et al.'s (2014) work. This approach not only greatly reduces computational requirements compared to training the full model, but also allows for better and more flexible speaker-specific adjustments.
The work done in MMS leverages this idea of adapters for speech recognition across different languages. A small number of adapter weights are fine-tuned to grasp unique phonetic and grammatical traits of each target language. Thereby, MMS enables a single large base model (e.g., the mms-1b-all checkpoint) and 1000+ small adapter layers (2.5M weights each for mms-1b-all) to comprehend and transcribe multiple languages. This dramatically reduces the computational demand of developing distinct models for each language.
Great! Now that we understood the motivation and theory, let's look into fine-tuning adapter weights for mms-1b-all 🔥
Notebook Setup
As done previously in the "Fine-tuning XLS-R on Multi-Lingual ASR" blog post, we fine-tune the model on the low resource ASR dataset of Common Voice that contains only ca. 4h of validated training data.
Just like Wav2Vec2 or XLS-R, MMS is fine-tuned using Connectionist Temporal Classification (CTC), which is an algorithm that is used to train neural networks for sequence-to-sequence problems, such as ASR and handwriting recognition.
For more details on the CTC algorithm, I highly recommend reading the well-written blog post Sequence Modeling with CTC (2017) by Awni Hannun.
Before we start, let's install datasets and transformers. Also, we need torchaudio to load audio files and jiwer to evaluate our fine-tuned model using the word error rate (WER) metric .
%%capture
!pip install --upgrade pip
!pip install datasets[audio]
!pip install evaluate
!pip install git+https://github.com/huggingface/transformers.git
!pip install jiwer
!pip install accelerate
We strongly suggest to upload your training checkpoints directly to the 🤗 Hub while training. The Hub repositories have version control built in, so you can be sure that no model checkpoint is lost during training.
To do so you have to store your authentication token from the Hugging Face website (sign up here if you haven't already!)
from huggingface_hub import notebook_login
notebook_login()
Prepare Data, Tokenizer, Feature Extractor
ASR models transcribe speech to text, which means that we both need a feature extractor that processes the speech signal to the model's input format, e.g. a feature vector, and a tokenizer that processes the model's output format to text.
In 🤗 Transformers, the MMS model is thus accompanied by both a feature extractor, called Wav2Vec2FeatureExtractor, and a tokenizer, called Wav2Vec2CTCTokenizer.
Let's start by creating the tokenizer to decode the predicted output classes to the output transcription.
Create Wav2Vec2CTCTokenizer
Fine-tuned MMS models, such as mms-1b-all already have a tokenizer accompanying the model checkpoint. However since we want to fine-tune the model on specific low-resource data of a certain language, it is recommended to fully remove the tokenizer and vocabulary output layer, and simply create new ones based on the training data itself.
Wav2Vec2-like models fine-tuned on CTC transcribe an audio file with a single forward pass by first processing the audio input into a sequence of processed context representations and then using the final vocabulary output layer to classify each context representation to a character that represents the transcription.
The output size of this layer corresponds to the number of tokens in the vocabulary, which we will extract from the labeled dataset used for fine-tuning. So in the first step, we will take a look at the chosen dataset of Common Voice and define a vocabulary based on the transcriptions.
For this notebook, we will use Common Voice's 6.1 dataset for Turkish. Turkish corresponds to the language code "tr".
Great, now we can use 🤗 Datasets' simple API to download the data. The dataset name is "mozilla-foundation/common_voice_6_1", the configuration name corresponds to the language code, which is "tr" in our case.
Note: Before being able to download the dataset, you have to access it by logging into your Hugging Face account, going on the dataset repo page and clicking on "Agree and Access repository"
Common Voice has many different splits including invalidated, which refers to data that was not rated as "clean enough" to be considered useful. In this notebook, we will only make use of the splits "train", "validation" and "test".
Because the Turkish dataset is so small, we will merge both the validation and training data into a training dataset and only use the test data for validation.
from datasets import load_dataset, load_metric, Audio
common_voice_train = load_dataset("mozilla-foundation/common_voice_6_1", "tr", split="train+validation", use_auth_token=True)
common_voice_test = load_dataset("mozilla-foundation/common_voice_6_1", "tr", split="test", use_auth_token=True)
Many ASR datasets only provide the target text ('sentence') for each audio array ('audio') and file ('path'). Common Voice actually provides much more information about each audio file, such as the 'accent', etc. Keeping the notebook as general as possible, we only consider the transcribed text for fine-tuning.
common_voice_train = common_voice_train.remove_columns(["accent", "age", "client_id", "down_votes", "gender", "locale", "segment", "up_votes"])
common_voice_test = common_voice_test.remove_columns(["accent", "age", "client_id", "down_votes", "gender", "locale", "segment", "up_votes"])
Let's write a short function to display some random samples of the dataset and run it a couple of times to get a feeling for the transcriptions.
from datasets import ClassLabel
import random
import pandas as pd
from IPython.display import display, HTML
def show_random_elements(dataset, num_examples=10):
assert num_examples <= len(dataset), "Can't pick more elements than there are in the dataset."
picks = []
for _ in range(num_examples):
pick = random.randint(0, len(dataset)-1)
while pick in picks:
pick = random.randint(0, len(dataset)-1)
picks.append(pick)
df = pd.DataFrame(dataset[picks])
display(HTML(df.to_html()))
show_random_elements(common_voice_train.remove_columns(["path", "audio"]), num_examples=10)
Oylar teker teker elle sayılacak.
Son olaylar endişe seviyesini yükseltti.
Tek bir kart hepsinin kapılarını açıyor.
Blogcular da tam bundan bahsetmek istiyor.
Bu Aralık iki bin onda oldu.
Fiyatın altmış altı milyon avro olduğu bildirildi.
Ardından da silahlı çatışmalar çıktı.
"Romanya'da kurumlar gelir vergisi oranı yüzde on altı."
Bu konuda neden bu kadar az şey söylendiğini açıklayabilir misiniz?
Alright! The transcriptions look fairly clean. Having translated the transcribed sentences, it seems that the language corresponds more to written-out text than noisy dialogue. This makes sense considering that Common Voice is a crowd-sourced read speech corpus.
We can see that the transcriptions contain some special characters, such as ,.?!;:. Without a language model, it is much harder to classify speech chunks to such special characters because they don't really correspond to a characteristic sound unit. E.g., the letter "s" has a more or less clear sound, whereas the special character "." does not.
Also in order to understand the meaning of a speech signal, it is usually not necessary to include special characters in the transcription.
Let's simply remove all characters that don't contribute to the meaning of a word and cannot really be represented by an acoustic sound and normalize the text.
import re
chars_to_remove_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\']'
def remove_special_characters(batch):
batch["sentence"] = re.sub(chars_to_remove_regex, '', batch["sentence"]).lower()
return batch
common_voice_train = common_voice_train.map(remove_special_characters)
common_voice_test = common_voice_test.map(remove_special_characters)
Let's look at the processed text labels again.
show_random_elements(common_voice_train.remove_columns(["path","audio"]))
i̇kinci tur müzakereler eylül ayında başlayacak
jani ve babası bu düşüncelerinde yalnız değil
onurun gözlerindeki büyü
bandiç oyların yüzde kırk sekiz virgül elli dördünü topladı
bu imkansız
bu konu açık değildir
cinayet kamuoyunu şiddetle sarstı
kentin sokakları iki metre su altında kaldı
muhalefet partileri hükümete karşı ciddi bir mücadele ortaya koyabiliyorlar mı
festivale tüm dünyadan elli film katılıyor
Good! This looks better. We have removed most special characters from transcriptions and normalized them to lower-case only.
Before finalizing the pre-processing, it is always advantageous to consult a native speaker of the target language to see whether the text can be further simplified.
For this blog post, Merve was kind enough to take a quick look and noted that "hatted" characters - like â - aren't really used anymore in Turkish and can be replaced by their "un-hatted" equivalent, e.g. a.
This means that we should replace a sentence like "yargı sistemi hâlâ sağlıksız" to "yargı sistemi hala sağlıksız".
Let's write another short mapping function to further simplify the text labels. Remember - the simpler the text labels, the easier it is for the model to learn to predict those labels.
def replace_hatted_characters(batch):
batch["sentence"] = re.sub('[â]', 'a', batch["sentence"])
batch["sentence"] = re.sub('[î]', 'i', batch["sentence"])
batch["sentence"] = re.sub('[ô]', 'o', batch["sentence"])
batch["sentence"] = re.sub('[û]', 'u', batch["sentence"])
return batch
common_voice_train = common_voice_train.map(replace_hatted_characters)
common_voice_test = common_voice_test.map(replace_hatted_characters)
In CTC, it is common to classify speech chunks into letters, so we will do the same here. Let's extract all distinct letters of the training and test data and build our vocabulary from this set of letters.
We write a mapping function that concatenates all transcriptions into one long transcription and then transforms the string into a set of chars.
It is important to pass the argument batched=True to the map(...) function so that the mapping function has access to all transcriptions at once.
def extract_all_chars(batch):
all_text = " ".join(batch["sentence"])
vocab = list(set(all_text))
return {"vocab": [vocab], "all_text": [all_text]}
vocab_train = common_voice_train.map(extract_all_chars, batched=True, batch_size=-1, keep_in_memory=True, remove_columns=common_voice_train.column_names)
vocab_test = common_voice_test.map(extract_all_chars, batched=True, batch_size=-1, keep_in_memory=True, remove_columns=common_voice_test.column_names)
Now, we create the union of all distinct letters in the training dataset and test dataset and convert the resulting list into an enumerated dictionary.
vocab_list = list(set(vocab_train["vocab"][0]) | set(vocab_test["vocab"][0]))
vocab_dict = {v: k for k, v in enumerate(sorted(vocab_list))}
vocab_dict
{' ': 0,
'a': 1,
'b': 2,
'c': 3,
'd': 4,
'e': 5,
'f': 6,
'g': 7,
'h': 8,
'i': 9,
'j': 10,
'k': 11,
'l': 12,
'm': 13,
'n': 14,
'o': 15,
'p': 16,
'q': 17,
'r': 18,
's': 19,
't': 20,
'u': 21,
'v': 22,
'w': 23,
'x': 24,
'y': 25,
'z': 26,
'ç': 27,
'ë': 28,
'ö': 29,
'ü': 30,
'ğ': 31,
'ı': 32,
'ş': 33,
'̇': 34}
Cool, we see that all letters of the alphabet occur in the dataset (which is not really surprising) and we also extracted the special characters "" and '. Note that we did not exclude those special characters because the model has to learn to predict when a word is finished, otherwise predictions would always be a sequence of letters that would make it impossible to separate words from each other.
One should always keep in mind that pre-processing is a very important step before training your model. E.g., we don't want our model to differentiate between a and A just because we forgot to normalize the data. The difference between a and A does not depend on the "sound" of the letter at all, but more on grammatical rules - e.g. use a capitalized letter at the beginning of the sentence. So it is sensible to remove the difference between capitalized and non-capitalized letters so that the model has an easier time learning to transcribe speech.
To make it clearer that " " has its own token class, we give it a more visible character |. In addition, we also add an "unknown" token so that the model can later deal with characters not encountered in Common Voice's training set.
vocab_dict["|"] = vocab_dict[" "]
del vocab_dict[" "]
Finally, we also add a padding token that corresponds to CTC's "blank token". The "blank token" is a core component of the CTC algorithm. For more information, please take a look at the "Alignment" section here.
vocab_dict["[UNK]"] = len(vocab_dict)
vocab_dict["[PAD]"] = len(vocab_dict)
len(vocab_dict)
37
Cool, now our vocabulary is complete and consists of 37 tokens, which means that the linear layer that we will add on top of the pretrained MMS checkpoint as part of the adapter weights will have an output dimension of 37.
Since a single MMS checkpoint can provide customized weights for multiple languages, the tokenizer can also consist of multiple vocabularies. Therefore, we need to nest our vocab_dict to potentially add more languages to the vocabulary in the future. The dictionary should be nested with the name that is used for the adapter weights and that is saved in the tokenizer config under the name target_lang.
Let's use the ISO-639-3 language codes like the original mms-1b-all checkpoint.
target_lang = "tur"
Let's define an empty dictionary to which we can append the just created vocabulary
new_vocab_dict = {target_lang: vocab_dict}
Note: In case you want to use this notebook to add a new adapter layer to an existing model repo make sure to not create an empty, new vocab dict, but instead re-use one that already exists. To do so you should uncomment the following cells and replace "patrickvonplaten/wav2vec2-large-mms-1b-turkish-colab" with a model repo id to which you want to add your adapter weights.
# from transformers import Wav2Vec2CTCTokenizer
# mms_adapter_repo = "patrickvonplaten/wav2vec2-large-mms-1b-turkish-colab" # make sure to replace this path with a repo to which you want to add your new adapter weights
# tokenizer = Wav2Vec2CTCTokenizer.from_pretrained(mms_adapter_repo)
# new_vocab = tokenizer.vocab
# new_vocab[target_lang] = vocab_dict
Let's now save the vocabulary as a json file.
import json
with open('vocab.json', 'w') as vocab_file:
json.dump(new_vocab_dict, vocab_file)
In a final step, we use the json file to load the vocabulary into an instance of the Wav2Vec2CTCTokenizer class.
from transformers import Wav2Vec2CTCTokenizer
tokenizer = Wav2Vec2CTCTokenizer.from_pretrained("./", unk_token="[UNK]", pad_token="[PAD]", word_delimiter_token="|", target_lang=target_lang)
If one wants to re-use the just created tokenizer with the fine-tuned model of this notebook, it is strongly advised to upload the tokenizer to the 🤗 Hub. Let's call the repo to which we will upload the files
"wav2vec2-large-mms-1b-turkish-colab":
repo_name = "wav2vec2-large-mms-1b-turkish-colab"
and upload the tokenizer to the 🤗 Hub.
tokenizer.push_to_hub(repo_name)
CommitInfo(commit_url='https://huggingface.co/patrickvonplaten/wav2vec2-large-mms-1b-turkish-colab/commit/48cccbfd6059aa6ce655e9d94b8358ba39536cb7', commit_message='Upload tokenizer', commit_description='', oid='48cccbfd6059aa6ce655e9d94b8358ba39536cb7', pr_url=None, pr_revision=None, pr_num=None)
Great, you can see the just created repository under https://huggingface.co/<your-username>/wav2vec2-large-mms-1b-tr-colab
Create Wav2Vec2FeatureExtractor
Speech is a continuous signal and to be treated by computers, it first has to be discretized, which is usually called sampling. The sampling rate hereby plays an important role in that it defines how many data points of the speech signal are measured per second. Therefore, sampling with a higher sampling rate results in a better approximation of the real speech signal but also necessitates more values per second.
A pretrained checkpoint expects its input data to have been sampled more or less from the same distribution as the data it was trained on. The same speech signals sampled at two different rates have a very different distribution, e.g., doubling the sampling rate results in twice as many data points. Thus, before fine-tuning a pretrained checkpoint of an ASR model, it is crucial to verify that the sampling rate of the data that was used to pretrain the model matches the sampling rate of the dataset used to fine-tune the model.
A Wav2Vec2FeatureExtractor object requires the following parameters to be instantiated:
feature_size: Speech models take a sequence of feature vectors as an input. While the length of this sequence obviously varies, the feature size should not. In the case of Wav2Vec2, the feature size is 1 because the model was trained on the raw speech signal .sampling_rate: The sampling rate at which the model is trained on.padding_value: For batched inference, shorter inputs need to be padded with a specific valuedo_normalize: Whether the input should be zero-mean-unit-variance normalized or not. Usually, speech models perform better when normalizing the inputreturn_attention_mask: Whether the model should make use of anattention_maskfor batched inference. In general, XLS-R models checkpoints should always use theattention_mask.
from transformers import Wav2Vec2FeatureExtractor
feature_extractor = Wav2Vec2FeatureExtractor(feature_size=1, sampling_rate=16000, padding_value=0.0, do_normalize=True, return_attention_mask=True)
Great, MMS's feature extraction pipeline is thereby fully defined!
For improved user-friendliness, the feature extractor and tokenizer are wrapped into a single Wav2Vec2Processor class so that one only needs a model and processor object.
from transformers import Wav2Vec2Processor
processor = Wav2Vec2Processor(feature_extractor=feature_extractor, tokenizer=tokenizer)
Next, we can prepare the dataset.
Preprocess Data
So far, we have not looked at the actual values of the speech signal but just the transcription. In addition to sentence, our datasets include two more column names path and audio. path states the absolute path of the audio file and audio represent already loaded audio data. MMS expects the input in the format of a 1-dimensional array of 16 kHz. This means that the audio file has to be loaded and resampled.
Thankfully, datasets does this automatically when the column name is audio. Let's try it out.
common_voice_train[0]["audio"]
{'path': '/root/.cache/huggingface/datasets/downloads/extracted/71ba9bd154da9d8c769b736301417178729d2b87b9e00cda59f6450f742ed778/cv-corpus-6.1-2020-12-11/tr/clips/common_voice_tr_17346025.mp3',
'array': array([ 0.00000000e+00, -2.98378618e-13, -1.59835903e-13, ...,
-2.01663317e-12, -1.87991593e-12, -1.17969588e-12]),
'sampling_rate': 48000}
In the example above we can see that the audio data is loaded with a sampling rate of 48kHz whereas the model expects 16kHz, as we saw. We can set the audio feature to the correct sampling rate by making use of cast_column:
common_voice_train = common_voice_train.cast_column("audio", Audio(sampling_rate=16_000))
common_voice_test = common_voice_test.cast_column("audio", Audio(sampling_rate=16_000))
Let's take a look at "audio" again.
common_voice_train[0]["audio"]
{'path': '/root/.cache/huggingface/datasets/downloads/extracted/71ba9bd154da9d8c769b736301417178729d2b87b9e00cda59f6450f742ed778/cv-corpus-6.1-2020-12-11/tr/clips/common_voice_tr_17346025.mp3',
'array': array([ 9.09494702e-13, -6.13908924e-12, -1.09139364e-11, ...,
1.81898940e-12, 4.54747351e-13, 3.63797881e-12]),
'sampling_rate': 16000}
This seemed to have worked! Let's do a final check that the data is correctly prepared, by printing the shape of the speech input, its transcription, and the corresponding sampling rate.
rand_int = random.randint(0, len(common_voice_train)-1)
print("Target text:", common_voice_train[rand_int]["sentence"])
print("Input array shape:", common_voice_train[rand_int]["audio"]["array"].shape)
print("Sampling rate:", common_voice_train[rand_int]["audio"]["sampling_rate"])
Target text: bağış anlaşması bir ağustosta imzalandı
Input array shape: (70656,)
Sampling rate: 16000
Good! Everything looks fine - the data is a 1-dimensional array, the sampling rate always corresponds to 16kHz, and the target text is normalized.
Finally, we can leverage Wav2Vec2Processor to process the data to the format expected by Wav2Vec2ForCTC for training. To do so let's make use of Dataset's map(...) function.
First, we load and resample the audio data, simply by calling batch["audio"].
Second, we extract the input_values from the loaded audio file. In our case, the Wav2Vec2Processor only normalizes the data. For other speech models, however, this step can include more complex feature extraction, such as Log-Mel feature extraction.
Third, we encode the transcriptions to label ids.
Note: This mapping function is a good example of how the Wav2Vec2Processor class should be used. In "normal" context, calling processor(...) is redirected to Wav2Vec2FeatureExtractor's call method. When wrapping the processor into the as_target_processor context, however, the same method is redirected to Wav2Vec2CTCTokenizer's call method.
For more information please check the docs.
def prepare_dataset(batch):
audio = batch["audio"]
# batched output is "un-batched"
batch["input_values"] = processor(audio["array"], sampling_rate=audio["sampling_rate"]).input_values[0]
batch["input_length"] = len(batch["input_values"])
batch["labels"] = processor(text=batch["sentence"]).input_ids
return batch
Let's apply the data preparation function to all examples.
common_voice_train = common_voice_train.map(prepare_dataset, remove_columns=common_voice_train.column_names)
common_voice_test = common_voice_test.map(prepare_dataset, remove_columns=common_voice_test.column_names)
Note: datasets automatically takes care of audio loading and resampling. If you wish to implement your own costumized data loading/sampling, feel free to just make use of the "path" column instead and disregard the "audio" column.
Awesome, now we are ready to start training!
Training
The data is processed so that we are ready to start setting up the training pipeline. We will make use of 🤗's Trainer for which we essentially need to do the following:
Define a data collator. In contrast to most NLP models, MMS has a much larger input length than output length. E.g., a sample of input length 50000 has an output length of no more than 100. Given the large input sizes, it is much more efficient to pad the training batches dynamically meaning that all training samples should only be padded to the longest sample in their batch and not the overall longest sample. Therefore, fine-tuning MMS requires a special padding data collator, which we will define below
Evaluation metric. During training, the model should be evaluated on the word error rate. We should define a
compute_metricsfunction accordinglyLoad a pretrained checkpoint. We need to load a pretrained checkpoint and configure it correctly for training.
Define the training configuration.
After having fine-tuned the model, we will correctly evaluate it on the test data and verify that it has indeed learned to correctly transcribe speech.
Set-up Trainer
Let's start by defining the data collator. The code for the data collator was copied from this example.
Without going into too many details, in contrast to the common data collators, this data collator treats the input_values and labels differently and thus applies two separate padding functions on them (again making use of MMS processor's context manager). This is necessary because, in speech recognition, input and output are of different modalities so they should not be treated by the same padding function.
Analogous to the common data collators, the padding tokens in the labels with -100 so that those tokens are not taken into account when computing the loss.
import torch
from dataclasses import dataclass, field
from typing import Any, Dict, List, Optional, Union
@dataclass
class DataCollatorCTCWithPadding:
"""
Data collator that will dynamically pad the inputs received.
Args:
processor (:class:`~transformers.Wav2Vec2Processor`)
The processor used for proccessing the data.
padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
among:
* :obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
sequence if provided).
* :obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the
maximum acceptable input length for the model if that argument is not provided.
* :obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
different lengths).
"""
processor: Wav2Vec2Processor
padding: Union[bool, str] = True
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# split inputs and labels since they have to be of different lenghts and need
# different padding methods
input_features = [{"input_values": feature["input_values"]} for feature in features]
label_features = [{"input_ids": feature["labels"]} for feature in features]
batch = self.processor.pad(
input_features,
padding=self.padding,
return_tensors="pt",
)
labels_batch = self.processor.pad(
labels=label_features,
padding=self.padding,
return_tensors="pt",
)
# replace padding with -100 to ignore loss correctly
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
batch["labels"] = labels
return batch
data_collator = DataCollatorCTCWithPadding(processor=processor, padding=True)
Next, the evaluation metric is defined. As mentioned earlier, the predominant metric in ASR is the word error rate (WER), hence we will use it in this notebook as well.
from evaluate import load
wer_metric = load("wer")
The model will return a sequence of logit vectors: with and .
A logit vector contains the log-odds for each word in the vocabulary we defined earlier, thus config.vocab_size. We are interested in the most likely prediction of the model and thus take the argmax(...) of the logits. Also, we transform the encoded labels back to the original string by replacing -100 with the pad_token_id and decoding the ids while making sure that consecutive tokens are not grouped to the same token in CTC style .
def compute_metrics(pred):
pred_logits = pred.predictions
pred_ids = np.argmax(pred_logits, axis=-1)
pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
pred_str = processor.batch_decode(pred_ids)
# we do not want to group tokens when computing the metrics
label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
wer = wer_metric.compute(predictions=pred_str, references=label_str)
return {"wer": wer}
Now, we can load the pretrained checkpoint of mms-1b-all. The tokenizer's pad_token_id must be to define the model's pad_token_id or in the case of Wav2Vec2ForCTC also CTC's blank token .
Since, we're only training a small subset of weights, the model is not prone to overfitting. Therefore, we make sure to disable all dropout layers.
Note: When using this notebook to train MMS on another language of Common Voice those hyper-parameter settings might not work very well. Feel free to adapt those depending on your use case.
from transformers import Wav2Vec2ForCTC
model = Wav2Vec2ForCTC.from_pretrained(
"facebook/mms-1b-all",
attention_dropout=0.0,
hidden_dropout=0.0,
feat_proj_dropout=0.0,
layerdrop=0.0,
ctc_loss_reduction="mean",
pad_token_id=processor.tokenizer.pad_token_id,
vocab_size=len(processor.tokenizer),
ignore_mismatched_sizes=True,
)
Some weights of Wav2Vec2ForCTC were not initialized from the model checkpoint at facebook/mms-1b-all and are newly initialized because the shapes did not match:
- lm_head.bias: found shape torch.Size([154]) in the checkpoint and torch.Size([39]) in the model instantiated
- lm_head.weight: found shape torch.Size([154, 1280]) in the checkpoint and torch.Size([39, 1280]) in the model instantiated
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Note: It is expected that some weights are newly initialized. Those weights correspond to the newly initialized vocabulary output layer.
We now want to make sure that only the adapter weights will be trained and that the rest of the model stays frozen.
First, we re-initialize all the adapter weights which can be done with the handy init_adapter_layers method. It is also possible to not re-initilize the adapter weights and continue fine-tuning, but in this case one should make sure to load fitting adapter weights via the load_adapter(...) method before training. Often the vocabulary still will not match the custom training data very well though, so it's usually easier to just re-initialize all adapter layers so that they can be easily fine-tuned.
model.init_adapter_layers()
Next, we freeze all weights, but the adapter layers.
model.freeze_base_model()
adapter_weights = model._get_adapters()
for param in adapter_weights.values():
param.requires_grad = True
In a final step, we define all parameters related to training. To give more explanation on some of the parameters:
group_by_lengthmakes training more efficient by grouping training samples of similar input length into one batch. This can significantly speed up training time by heavily reducing the overall number of useless padding tokens that are passed through the modellearning_ratewas chosen to be 1e-3 which is a common default value for training with Adam. Other learning rates might work equally well.
For more explanations on other parameters, one can take a look at the docs. To save GPU memory, we enable PyTorch's gradient checkpointing and also set the loss reduction to "mean". MMS adapter fine-tuning converges extremely fast to very good performance, so even for a dataset as small as 4h we will only train for 4 epochs. During training, a checkpoint will be uploaded asynchronously to the hub every 200 training steps. It allows you to also play around with the demo widget even while your model is still training.
Note: If one does not want to upload the model checkpoints to the hub, simply set push_to_hub=False.
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir=repo_name,
group_by_length=True,
per_device_train_batch_size=32,
evaluation_strategy="steps",
num_train_epochs=4,
gradient_checkpointing=True,
fp16=True,
save_steps=200,
eval_steps=100,
logging_steps=100,
learning_rate=1e-3,
warmup_steps=100,
save_total_limit=2,
push_to_hub=True,
)
Now, all instances can be passed to Trainer and we are ready to start training!
from transformers import Trainer
trainer = Trainer(
model=model,
data_collator=data_collator,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=common_voice_train,
eval_dataset=common_voice_test,
tokenizer=processor.feature_extractor,
)
To allow models to become independent of the speaker rate, in CTC, consecutive tokens that are identical are simply grouped as a single token. However, the encoded labels should not be grouped when decoding since they don't correspond to the predicted tokens of the model, which is why the group_tokens=False parameter has to be passed. If we wouldn't pass this parameter a word like "hello" would incorrectly be encoded, and decoded as "helo".
The blank token allows the model to predict a word, such as "hello" by forcing it to insert the blank token between the two l's. A CTC-conform prediction of "hello" of our model would be [PAD] [PAD] "h" "e" "e" "l" "l" [PAD] "l" "o" "o" [PAD].
Training
Training should take less than 30 minutes depending on the GPU used.
trainer.train()
| Training Loss | Training Steps | Validation Loss | Wer |
|---|---|---|---|
| 4.905 | 100 | 0.215 | 0.280 |
| 0.290 | 200 | 0.167 | 0.232 |
| 0.2659 | 300 | 0.161 | 0.229 |
| 0.2398 | 400 | 0.156 | 0.223 |
The training loss and validation WER go down nicely.
We see that fine-tuning adapter layers of mms-1b-all for just 100 steps outperforms fine-tuning the whole xls-r-300m checkpoint shown here already by a large margin.
From the official paper and this quick comparison it becomes clear that mms-1b-all has a much higher capability of transfering knowledge to a low-resource language and should be preferred over xls-r-300m. In addition, training is also more memory-efficient as only a small subset of layers are trained.
The adapter weights will be uploaded as part of the model checkpoint, but we also want to make sure to save them separately so that they can easily be off- and onloaded.
Let's save all the adapter layers into the training output dir so that it can be correctly uploaded to the Hub.
from safetensors.torch import save_file as safe_save_file
from transformers.models.wav2vec2.modeling_wav2vec2 import WAV2VEC2_ADAPTER_SAFE_FILE
import os
adapter_file = WAV2VEC2_ADAPTER_SAFE_FILE.format(target_lang)
adapter_file = os.path.join(training_args.output_dir, adapter_file)
safe_save_file(model._get_adapters(), adapter_file, metadata={"format": "pt"})
Finally, you can upload the result of the training to the 🤗 Hub.
trainer.push_to_hub()
One of the main advantages of adapter weights training is that the "base" model which makes up roughly 99% of the model weights is kept unchanged and only a small 2.5M adapter checkpoint has to be shared in order to use the trained checkpoint.
This makes it extremely simple to train additional adapter layers and add them to your repository.
You can do so very easily by simply re-running this script and changing the language you would like to train on to a different one, e.g. swe for Swedish. In addition, you should make sure that the vocabulary does not get completely overwritten but that the new language vocabulary is appended to the existing one as stated above in the commented out cells.
To demonstrate how different adapter layers can be loaded, I have trained and uploaded also an adapter layer for Swedish under the iso language code swe as you can see here
You can load the fine-tuned checkpoint as usual by using from_pretrained(...), but you should make sure to also add a target_lang="<your-lang-code>" to the method so that the correct adapter is loaded. You should also set the target language correctly for your tokenizer.
Let's see how we can load the Turkish checkpoint first.
model_id = "patrickvonplaten/wav2vec2-large-mms-1b-turkish-colab"
model = Wav2Vec2ForCTC.from_pretrained(model_id, target_lang="tur").to("cuda")
processor = Wav2Vec2Processor.from_pretrained(model_id)
processor.tokenizer.set_target_lang("tur")
Let's check that the model can correctly transcribe Turkish
from datasets import Audio
common_voice_test_tr = load_dataset("mozilla-foundation/common_voice_6_1", "tr", data_dir="./cv-corpus-6.1-2020-12-11", split="test", use_auth_token=True)
common_voice_test_tr = common_voice_test_tr.cast_column("audio", Audio(sampling_rate=16_000))
Let's process the audio, run a forward pass and predict the ids
input_dict = processor(common_voice_test_tr[0]["audio"]["array"], sampling_rate=16_000, return_tensors="pt", padding=True)
logits = model(input_dict.input_values.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)[0]
Finally, we can decode the example.
print("Prediction:")
print(processor.decode(pred_ids))
print("\nReference:")
print(common_voice_test_tr[0]["sentence"].lower())
Output:
Prediction:
pekçoğuda roman toplumundan geliyor
Reference:
pek çoğu da roman toplumundan geliyor.
This looks like it's almost exactly right, just two empty spaces should have been added in the first word.
Now it is very simple to change the adapter to Swedish by calling model.load_adapter(...) and by changing the tokenizer to Swedish as well.
model.load_adapter("swe")
processor.tokenizer.set_target_lang("swe")
We again load the Swedish test set from common voice
common_voice_test_swe = load_dataset("mozilla-foundation/common_voice_6_1", "sv-SE", data_dir="./cv-corpus-6.1-2020-12-11", split="test", use_auth_token=True)
common_voice_test_swe = common_voice_test_swe.cast_column("audio", Audio(sampling_rate=16_000))
and transcribe a sample:
input_dict = processor(common_voice_test_swe[0]["audio"]["array"], sampling_rate=16_000, return_tensors="pt", padding=True)
logits = model(input_dict.input_values.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)[0]
print("Prediction:")
print(processor.decode(pred_ids))
print("\nReference:")
print(common_voice_test_swe[0]["sentence"].lower())
Output:
Prediction:
jag lämnade grovjobbet åt honom
Reference:
jag lämnade grovjobbet åt honom.
Great, this looks like a perfect transcription!
We've shown in this blog post how MMS Adapter Weights fine-tuning not only gives state-of-the-art performance on low-resource languages, but also significantly speeds up training time and allows to easily build a collection of customized adapter weights.
Related posts and additional links are listed here:





